PDF_4
Werbung

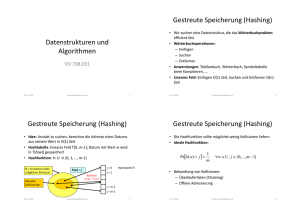
Wiederholung • QuickSort: – Sortieralgorithmus nach Divide-and-Conquer Prinzip (rekursives Zerlegen von Feldern) – Laufzeit hängt von Teilungsindex k ab (ist durch Pivotelement bestimmt) Datenstrukturen und Algorithmen VO 708.031 T(n) = T(k) + T(n-k) + O(n) • Bester Fall: k=n/2 ⇒ T(n) = O(n*log n) • Schlechtester Fall: k=1 ⇒ T(n) = O(n2) • Mittlerer Fall: P(k)=1/(n-1) ⇒ T(n) = O(n*log n) Randomisierte Pivotwahl 19.11.2009 [email protected] 1 Untere Schranke für Sortieren 19.11.2009 [email protected] Untere Schranke für Sortieren • Die bisher betrachteten schnellen Sortieralgorithmen (MergeSort, HeapSort, QuickSort) brauchen O(n*log n) Zeit • Gibt es einen schnelleren Sortieralgorithmus? • Wir zeigen: Jedes Sortierverfahren, das mittels Vergleichen arbeitet, braucht mindestens c⋅n⋅log n Vergleiche im worst case • Darstellung des Kontrollflusses als Entscheidungsbaum (alle möglichen Programmverzweigungen): 19.11.2009 19.11.2009 [email protected] 2 3 Beispiel: drei Zahlen a1, a2, a3: Innere Knoten: Vergleiche zwischen Elementen Blätter: Sortierte Reihenfolge des Inputs ⇒ Es gibt n! Blätter [email protected] 4 Untere Schranke für Sortieren Untere Schranke für Sortieren • Das worst-case Verhalten des Algorithmus entspricht dem längsten Ast im Entscheidungsbaum (# Knoten = # Vergleiche) • Der längste Ast wird kürzestmöglich, wenn alle Äste ungefähr gleich lang sind • Idealer Algorithmus entspricht einem vollständigen Binärbaum mit n! Blättern • Die Höhe eines Binärbaums mit n! Blättern ist Ω(n*log n) • ⇒ Ω(n*log n) ist eine untere Schranke für die Anzahl der zum Sortieren notwendigen Vergleiche • ⇒ Die Laufzeit vergleichsorientierter Sortierverfahren ist Ω(n*log n) • MergeSort und HeapSort sind worst-case optimal 19.11.2009 19.11.2009 [email protected] 5 RadixSort • Ein Sortierverfahren ist… – stabil: Elemente mit identischen Sortierschlüsseln erscheinen in Input und Output in gleicher Reihenfolge – adaptiv: (teilweise) vorsortierte Folgen werden effizienter sortiert (besseres Laufzeitverhalten für „fast“ sortierte Folgen) – worst-case optimal: Jede Eingabefolge wird in O(n*log n) Zeit sortiert (der unteren Schranke für vergleichsbasierte Sortierverfahren) – in-place: außer für einzelne Variablen (i, j, …) wird kein Zusatzspeicher (Hilfsfelder, …) benötigt Sortieren von n Dezimalzahlen der Länge d: RADIXSORT (A, d) 1: FOR i = 1 TO d 2: Ordne A nach i-ter Ziffer v.h. in Fächer ein (Streuphase) 3: Fasse die Fächer in aufsteigender Reihenfolge wieder in A zusammen (Sammelphase) T(n) = O(d*n) … linear, wenn d als konstant betrachtet wird! • Nach den ersten k Durchläufen sind die Zahlen, eingeschränkt auf die letzten k Ziffern, sortiert • Wichtig: Die vorige Reihenfolge innerhalb der Fächer muss aufrechterhalten werden [email protected] 6 Eigenschaften von Sortierverfahren • Beispiel für einen nicht vergleichsorientierten Sortieralgorithmus 19.11.2009 [email protected] 7 19.11.2009 [email protected] 8 Vergleich von Sortierverfahren Gestreute Speicherung (Hashing) • Wir suchen eine Datenstruktur, die das Wörterbuchproblem effizient löst • Wörterbuchoperationen: – Einfügen – Suchen – Entfernen • Anwendungen: Telefonbuch, Wörterbuch, Symboltabelle beim Kompilieren, … • Lineares Feld: Einfügen O(1) Zeit, Suchen und Entfernen O(n) Zeit 19.11.2009 [email protected] 9 Gestreute Speicherung (Hashing) j=0 h(w) = j Hashtabelle T j=1 10 • Die Hashfunktion sollte möglichst wenig Kollisionen liefern • Ideale Hashfunktion: Pr[h( w) = j ] = 1 m ∀w ∈ U , j ∈ {0,..., m − 1} • Behandlung von Kollisionen: – Überläuferlisten (Chaining) – Offene Adressierung Kollision Aktuelle Schlüssel w [email protected] Gestreute Speicherung (Hashing) • Idee: Anstatt zu suchen, berechne die Adresse eines Datums aus seinem Wert in O(1) Zeit • Hashtabelle: lineares Feld T[0..m-1]; Datum mit Wert w wird in T[h(w)] gespeichert • Hashfunktion: h: U → {0, 1, …, m-1} U = Universum aller möglichen Schlüssel 19.11.2009 h (w) = h (w´) j = m-2 j = m-1 19.11.2009 [email protected] 11 19.11.2009 [email protected] 12 Überläuferlisten (Chaining) Überläuferlisten (Chaining) • Bei einer Kollision werden die Daten in einer verketteten Liste angelegt: • Bei einer Kollision werden die Daten in einer verketteten Liste angelegt: Erwartete Laufzeit Einfügen: O(1) Suchen: O(1+α) Löschen: O(1+α) Einfügen: Am Beginn der Liste T[h(w)] Suchen: Durchsuchen der Liste T[h(w)] Löschen: Suchen von w, Ausklinken aus Liste T[h(w)] α= n m O(1+α) = O(1), wenn n=O(m) Worst-case: Θ(n) für Suchen, Löschen wenn zufällig alle Werte in dieselbe Liste gestreut 19.11.2009 [email protected] 13 19.11.2009 Hash-Funktionen n −1 [email protected] 14 • Divisionsmethode: – Jeder Index j=0,…,m-1 sollte gleichwahrscheinlich sein, um möglichst wenig Kollisionen zu liefern – h(w) soll möglichst effizient berechnet werden – Ähnliche Werte sollten möglichst gut getrennt werden – h(w) soll unabhängig von Mustern in den Daten sein • Wir kennen selten die genaue Verteilung der Werte • ⇒ Heuristische Wahl der Hashfunktion • Wir betrachten h: ℕ → {0, 1, …, m-1} [email protected] 1 prob = m Hash-Funktionen • Was ist eine gute Hashfunktion? 19.11.2009 Belegungsfaktor der Hashtabelle – Dividiere den Wert durch m und nimm den Rest: h( w) = w mod m – z.B.: w=100, m=12, h(100) = 100 mod 12 = 4 – Vorteil: schnell berechenbar – Nachteil: nicht für alle m gut • m=2k, m=10k: hängt nur von den letzten k Bits/Ziffern ab • Gut für m Primzahl und nicht zu nahe an 2k, 10k 15 19.11.2009 [email protected] 16 Hash-Funktionen Offene Adressierung • Alternative Methode zur Behandlung von Kollisionen • Alle Werte werden in T[0..m-1] selbst gespeichert ⇒ α=n/m≤1 • Bei einer Kollision wird solange eine neue Adresse berechnet, bis ein freier Platz gefunden wird • Multiplikationsmethode: – Multipliziere den Wert mit einer fixen Konstante A, 0<A<1, und multipliziere den gebrochenen Teil des Resultates mit m: h( w) = m ⋅ frac( w ⋅ A) i…0,1,2,…m-1 Versuchzahl (Probing) – Vorteil: m ist unkritisch (m=2k: durch ShiftOperationen effizient berechenbar) Guter Wert für A: 19.11.2009 A= i=1 noch frei i=2 5 −1 ≈ 0,6180... 2 [email protected] 17 19.11.2009 Offene Adressierung 19.11.2009 [email protected] [email protected] 18 • Einfügen und Suchen: Problem: benachbarte Felder wahrscheinlicher belegt (primary clustering) – Quadratic Probing: h( w, i ) = h′( w) + f (i ) mod m f(i)…quadratische Funktion; bei einer Kollision immer noch dieselbe Indexfolge (secondary clustering) – Double Hashing: h( w, i ) = h1 ( w) + ih2 ( w) mod m [ besetzt Offene Adressierung • Ideale Hashfunktion: Für jeden Wert w ist h(w,0), h(w,1), …, h(w,m-1) mit Wahrscheinlichkeit 1/m! eine der m! Permutationen von 0, 1, …, m-1. • In der Praxis verwendete Näherungen: – Linear Probing: h( w, i ) = [h′( w) + i ]mod m [ h : U × {0,1, K, m − 1} → {0,1,K, m − 1} h(w,i) = j Erwartete Laufzeit O 1 ] 1 −α • Problem beim Entfernen: ] w1, w2 eingefügt, w1 entfernt w2 wird nicht mehr gefunden ⇒ entfernte Werte markieren 19 19.11.2009 [email protected] 20 Danke für Ihre Aufmerksamkeit! Bis zum nächsten Mal. (Donnerstag, 26. Nov. 2009, 11:15, i13) 19.11.2009 [email protected] 21