08_8335_101-RDBM-Relationales Modell - Offene
Werbung

1
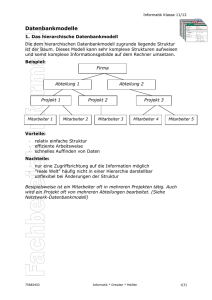
In diesem Abschnitt werden wir uns mit den theoretischen Grundlagen der
relationalen Datenbanken beschäftigen.
Hierzu werden wir uns die wichtigsten Konzepte, Ideen und Begriffe näher
ansehen, damit wir später ein tieferes Verständnis bekommen, wie relationale
Datenbanken arbeiten.
Im einzelnen werden wir klären:
• Was sind Mengen und Entitäten?
• Was ist das kartesische Produkt?
• Was ist eine Relation?
• Was ist eine Projektion?
• Was sind Schlüssel?
2
Da ist zunächst der Begriff der Menge.
Eine Menge besteht aus unterschiedlichen Elementen. Jedes Element ist dabei
eindeutig unterscheidbar, und es gibt keine doppelten Elemente in einer Menge.
Dabei unterliegen die Elemente keiner Ordnung.
Wichtig ist, dass wir hier nur endliche Mengen betrachten.
3
Schauen wir uns einmal ein Beispiel für eine Menge an.
Nehmen wir die Menge der Spielkartensymbole. In der Abbildung besteht die
Menge der Spielkartensymbolen aus 4 Elementen:
• Karo
• Herz
• Pik
• Kreuz
Eine weitere Menge könnte die Menge der Farben sein. In unserem Beispiel
besteht diese Menge aus den Elementen:
• Rot
• Gelb
• Grün
• Blau
4
Bei einem kartesischen Produkt bilden wir nun Paare aus je einem Element
zweier Mengen.
In der Abbildung sehen wir ein Beispiel.
Es gibt eine Menge A mit den Elementen { a,b,c }.
Die Menge B besteht aus den Elementen { 1, 2 }
Bei dem kartesischen Produkt bilden wir nun Paare, in dem wir ein Element der
Menge A mit einem Element der Menge B verknüpfen.
Für unser Beispiel bedeutet dies, dass wir folgende Paare bilden können:
•
(a, 1)
• (b, 1)
• (c, 1)
• (a, 2)
• (b, 2)
• (c, 2)
Die Menge A bestehet aus 3 Elementen
Die Menge B bestehet aus 2 Elementen.
5
Wie erhalten somit 2*3 = 6 Paare.
Die mathematische Schreibweise lautet A x B ( Sprich : „A kreuz B“ ) .Da die
Reihenfolge der beiden Elementen wichtig ist, ergibt sich , dass A x B nicht gleich B X A
ist.
Hinweis:
Bei dem kartesischen Produkt müssen die Mengen nicht unterschiedlich sein.
Wir können somit auch ein kartesisches Produkt A x A bilden.
Wenn wir nun zum Beispiel die Menge der reellen Zahlen R nehmen, erhalten wir bei R x
R ein Menge von Tupel der Form ( x, y) wobei x und y Elemente aus der Menge der
reellen Zahlen sind.
Die Tupel könnte dann als Punkt in einer Ebene aufgefasst werden.
5
Nun kommen wir zu dem wichtigsten Begriff Relation. Diesem Begriff
verdanken die relationalen Datenbanken ihren Namen.
Eine Relation ist dabei definiert als die Teilmenge eines kartesischen Produktes.
6
Wie wir gesehen haben, bestehen Relationen aus einer Menge von Tupel. Die
einzelnen Elemente eines Tupels werden auch als Komponenten bezeichnet.
Gibt man jeder Komponente einen Namen, welcher die Bedeutung der
Komponente wiedergibt, so nennt man dies Attributnamen oder oft auch nur
Attribut.
Der eigentliche Wert einer Komponente wird dann Attributwert genannt.
In der Abbildung sehen Sie ein Beispiel einer Relation, wobei die Elemente eines
Tupels die Attribute
• Kartensymbol
• Kartenfarbe
haben
7
Diese Abbildung zeigt anhand eines Kartenbeispiels, das z.B. beim Pokern ein
Full-House eine Relation ist.
Wie sie sehen, werden aus der Menge der Spielkarten-Symbole und der Menge
der Spielkarten-Werte Kombinationen gebildet. Sprich wir bilden eine Relation,
deren Elemente beim Pokern als Full-House bezeichnet werden.
8
Relationen lassen sich sehr gut als Tabellen darstellen.
Bei der Tabellendarstellung werden die Attributnamen als Spaltennamen
verwendet und die Attributwerte werden in die jeweiligen Zeilen unterhalb einer
Spalte eingetragen.
Ein Zeile entspricht dann einem Tupel aus der Relation.
Wie wir später sehen werden, implementieren relationale Datenbanksysteme
intern Tabellen, um die Daten (Relationen) abzulegen.
Hier sehen wir aber auch schon den Unterschied zwischen der Theorie und der
Praxis:
1. In einer Tabelle kann man auch doppelte Zeilen (Dubletten eintragen)
2. Tabellen implizieren eine Ordnung. Also was steht in der ersten Zeile und was
steht in der letzten Zeile.
Wie wir bereits gelernt haben, gibt es aber in der Theorie in Mengen keine
Dubletten und kein Ordnungskriterium.
9
Genau in diesen Punkt weichen Datenbanken und die damit verwendete
Programmiersprache SQL von der Theorie ab.
Es sind nämlich in Datenbanktabellen doppelte Tabelleneinträge erlaubt. Auch ermöglicht
SQL das sortierte Auslesen von Tabelleninhalten.
9
Ein weiterer wichtiger Begriff ist Projektion.
Wendet man ein Projekt auf eine Relation an, dann bedeutet dies, dass man
bestimmte Attribute aus dem Tupel einfach weglässt.
Schauen wir uns hierzu ein Beispiel an.
Gehen wir von einer Relation R aus mit den Attributen:
• PLZ – Postleitzahl
• Stadt – Name einer Stadt
• Straße – Name einer Straße
• Hausnummer – Nummer des Hauses in der Straße
Wenn wir nur an den Attributen :
• PLZ
• Stadt
interessiert sind, dann können wir ein Projekt anwenden und erhalten eine neue
Relation, bei denen die Tupel nur die gewünschten Attribute beinhalten.
10
Wie wir später sehen werden , ist dies bei SQL sehr einfach umgesetzt.
10
Auch Projektionen lassen sich somit in Form von Tabellen darstellen.
11
Wie wir ja wissen, enthalten Mengen keine Dubletten und jedes Element ist
eindeutig identifizierbar.
Somit stellt sich nun die Frage:
Wie kann ich die Elemente eindeutig identifizieren?
Die Antwort lautet:
Es muss ein oder mehrere Attribute geben, dessen Wert ein Element der Menge
(bzw. eine Zeile in einer Tabelle) eindeutig identifiziert.
Genau dies müssen wir uns als nächstes näher ansehen.
12
Attribute (genauer gesagt die Attributwerte), die ein Element/Zeile eindeutig
machen, werden als Schlüssel bezeichnet.
Gibt es mehr als ein Attribut, so nennt man dies zusammengesetzter Schlüssel.
In der Praxis kann es vorkommen, dass es mehrere unterschiedliche AttributKombinationen gibt, die man für die eindeutige Unterscheidung heranziehen
kann.
Somit ist jede Kombination ein Kandidat für einen Schlüssel. Daher bezeichnet
man diese als Schlüsselkandidat.
Beispiel für zusammengesetzte Schlüssel:
Gegeben ist die Relation mit den Attributen:
• Bestelldatum
• Kundennummer
• Rechnungsbetrag
• Zahlungsweise
13
Zur Eindeutigkeit dienen dann die Attribute :
• Bestelldatum
• Kundennummer
13
In der Praxis wählt man unter den Schlüsselkandidaten denjenigen aus, die die
wenigsten Attribute beinhalten.
Faßt man die Anzahl der Attribute als Länge auf, so sagt man auch, man wählt
den kürzesten Schlüsselkandidaten aus.
Den Schlüssel, den man ausgewählt hat, nennt man dann Primärschlüssel.
14
Nun kann es auch vorkommen, dass keine Kombination der Attribute ein
Element eindeutig macht.
Dies sieht man an dem Beispiel in der Abbildung.
Man kann nicht ausschließen, dass es Personen gibt, die
• Den gleichen Vornamen
• Den gleichen Nachnamen
• Das gleiche Alter und
• Das gleiche Gehalt haben
In solchen Fällen fügt man künstlich ein zusätzliches Attribut ein, dessen
Attributwerte immer eindeutig sind.
In unserem Beispiel ist dies das Attribut „PersNr“ (Personalnummer).
Dieses zusätzliche Attribut ist somit der Primärschlüssel.
In der Praxis spricht man auch von einem künstlichen Primärschlüssel.
15
In dem weiteren Beispiel verwenden wir nun immer eine Tabelle für die
Darstellung einer Relation. Da die wenigsten Aufgabenstellungen mit einer
Relation (sprich einer Tabelle) auskommen, treffen wir in der Praxis immer
gleich mehrere Tabellen an.
In der Abbildungen sehen Sie ein Beispiel für ein Unternehmen, in dem die Daten
für Bestellungen und Daten über die Kunden verwaltet werden müssen.
Hierzu werden zwei Relationen / Tabellen verwendet.
Die Frage, die sich nun stellt ist:
Gibt es Beziehungen zwischen den Daten in den einzelnen Tabellen und
wie gehe ich damit um?
Dieser Frage wollen wir als nächstes nachgehen.
16
Die Beziehungen zwischen den Tabellen werden im englischen als Relationships
bezeichnet.
Bei den Beziehungen handelt es sich im eine Verknüpfung bei der Zeilen aus
einer Tabelle mit Zeilen aus einer anderen Tabelle in Verbindung gebracht
werden.
17
Da Tabellen in der Regel immer über einen Primärschlüssel verfügen, liegt es
nahe, diese Schlüsselinformationen heranzuziehen, um eine Beziehung
herzustellen bzw. zu definieren.
In der Abbildung sehen Sie ein Beispiel mit zwei Tabellen A und B.
In der Tabelle A gibt es drei Zeilen. Der Primärschlüssel ist das Attribut A1,
welches die Werte 7,5,8 hat.
In der Tabelle B gibt es vier Zeilen. Der Primärschlüssel ist das Attribut 5,
welches die Werte 9, 10, 11, 12 hat.
Wenn wir nun eine Verbindung einer Zeile aus Tabelle A, mit dem
Primärschlüssel A = 5 und einer Zeile aus der Tabelle B , mit dem
Primärschlüssel B5=10, herstellen wollen, so können wir hierzu folgende
Relation verwenden:
AB-Relation= { A1, B5 }
mit den Elementen ( 5, 10)
18
Diese Relation können wir uns auch als Tabelle vorstellen, die wie folgt aussehen würde
A1
| B5
************
5
| 10
Wie wir später bei der Programmiersprache SQL sehen werden, können wir aber auch
Relationen bilden, die nicht notwendigerweise auf dem Primärschlüssel beruht.
18
Wie wir bisher gesehen haben, können wir zwischen Tabellen Relationen bilden
und dabei beliebige Attribute zur Verknüpfung heranziehen.
In der Praxis besteht aber sehr oft die Anforderung, dass Verknüpfungen zwischen
bestimmten Zeilen bestehen sollen.
Ein Beispiel soll dies verdeutlichen.
In der Abbildung sehen Sie zwei Tabellen. In der Tabelle „Kunde“ sind die
Kunden einer Firma hinterlegt. Bestellungen werden in der Tabelle
„Bestellungen“ abgelegt.
Für die Bearbeitung der Bestellungen ist es nun wichtig, dass eine Bestellung
genau einem Kunden zugeordnet werden kann.
Im Beispiel werden Kunden anhand der Kundennummer (Attribut „KundenID“)
eindeutig identifiziert. Das Attribut „KundenID“ ist also der Primärschlüssel.
Um eine eindeutige Zuordnung zwischen Bestellungen und Kunden herzustellen ,
fügt man in der Tabelle „Bestellungen“ ein zusätzliches Attribut (Spalte) ein, in
dem die Kundennummer hinterlegt ist, zu dem die Bestellung gehört. In der
Praxis verwendet man für den Namen der zusätzlichen Spalte den gleichen
Namen wie in der Tabelle aus der die Werte kommen. In dem Beispiel hat die
zusätzliche Spalte ebenfalls den Namen „KundenID“.
19
Wir fügen also als neue Spalten den Primärschlüssel einer anderen Tabelle ein. Diese
neue Spalte beinhaltet dann einen sogenannten Fremdschlüssel.
Der Name Fremdschlüssel deutet darauf hin, dass dies ein Schlüssel aus einer anderen
(fremden ) Tabelle ist.
Somit können wir sicherstellen , dass wir alle Bestellungen zu einem Kunden finden,
wenn wir die „KundenID“ kennen.
Wie wir später noch sehen werden, können wir damit aber auch sicherstellen , dass wir
keine Bestellung definieren können, zu denen es keine Kunden gibt.
Hinweis:
Hier sehen wir, ein Beispiel für die Definition von Integritätsregeln um sicherzustellen,
dass Daten konsistent sind.
19
20
21
22




![Aufgabe 1 [Relationale Abfragen: 30 Punkte] Aufgabe 2 [Query](http://s1.studylibde.com/store/data/006123063_1-f9bdc3ee9301ec6a3ba6f11be270bb03-300x300.png)

![Aufgabe 1 [Relationale Abfragen: 30 Punkte]](http://s1.studylibde.com/store/data/008623663_1-3d9d69ae0ddd6b0d6fe22baabc5e2faa-300x300.png)



