Indexstrukturen in SQL Indexstrukturen in SQL
Werbung

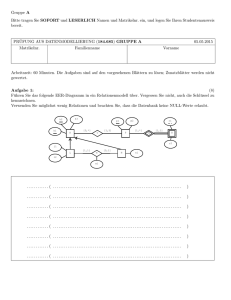
Indexstrukturen in SQL Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Anlegen eines Primärindex in SQL: create table Dozenten ( DNr integer primary key, Name varchar(50), Geburt date, ) um eindeutigkeit des Primärschlüssels zu verwalten wird automatisch ein Index angelegt Anlegen eines Sekundärindex in SQL: create [Unique] index indexname on tablename (columnName[ASC|DESC][,…]) Bsp: create index name_geb on Dozent (Name ASC, Geburt DESC) 1 Indexstrukturen in SQL Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Index Reihenfolge: 1.) create index name_geb on Dozent 2 (Name, Geburt) 2.) create index geb_name on Dozent (Geburt, Name ) Welcher Index unterstüzt folgende Anfrage besser: Select Name from Dozent where Name like ‘H%‘ Index „name_geb“ ist besser, da Name ein Praefix von Name, Geburt. Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Skript zur Vorlesung Datenbanksysteme I Wintersemester 2004/2005 Kapitel 10: Relationale Anfragebearbeitung Vorlesung: Christian Böhm Übungen: Elke Achtert, Karin Kailing Skript © 2004 Christian Böhm http://www.dbs.informatik.uni-muenchen.de/Lehre/DBS Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Relationale Anfragebearbeitung Zentrale Aufgabe der Anfragebearbeitung ist die Übersetzung der deklarativen Anfrage in einen effizienten, prozeduralen Auswertungsplan deklarative Anfrage Scanner/Parser View-Ersetzung algebraischer Ausdruck Anfrageoptimierung Auswertungsplan 4 Ausführung Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Kanonischer Auswertungsplan zu einer SQL-Anfrage (Ergebnis der ersten Übersetzungsphase) π [ A1 , A2 ] σ [ B2 ] select A1, A2, … from R1, R2, … σ [ B1 ] where B1and B2, … x R1 1. Bilde das kartesische Produkt der Relationen R1, R2, … 2. Führe Selektionen mit den einzelnen Bedingungen B1, B2, … durch. 3. Projiziere die Ergebnistupel auf die erforderlichen Attribute A1, A2, … R2 π A , A (σ B (σ B ( R1 × R2 ))) 5 1 2 2 1 Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Beispiel Autodatenbank Kunden(KNr, Name, Adresse, Region, Saldo) 6 KNr 201 337 444 108 Name Klein Horn Berger W eiss Adresse Lilienthal Dieburg München W ürzburg Region Bremen Rhein-Main München Unterfranken Saldo 200.000 100.000 300.000 500.000 View GuteKunden(KNr, Name, Adresse, Region, Saldo) = select * from Kunden where Saldo ≥ 300.000 Bestellt(BNr, Datum, KNr, Region, Saldo) Produkt(PNr, Bezeichnung, Anzahl, Preis) BNr 221 312 401 456 458 Datum 10.05.04 11.05.04 20.05.04 13.05.04 14.05.04 KNr 201 201 337 444 444 PNr 12 4 330 330 98 PNr 12 4 330 98 14 Bezeichnung BMW 318i Golf 5 Fiat Uno Ferrari 380 Opel Corsa Anzahl 10 40 5 1 14 Preis 40.000 25.000 18.000 180.000 17.000 Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Einfache SQL-Anfrage: Welche guten Kunden (Name) haben einen Fiat Uno bestellt (und Saldo ≥ 300.000) ? 7 select from where and and Name GuteKunden k, Bestellt b, Produkt p b.KNr = k.KNr b.PNr = p.PNr Bezeichnung = ‚Fiat Uno‘ Expansion der View: select from where and and and Name Kunden k, Bestellt b, Produkt p b.KNr = k.KNr b.PNr = p.PNr Bezeichnung = ‚Fiat Uno‘ Saldo ≥ 300.000 Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Übersetzung in relationale Algebra (kanonisch): π Name (σ Saldo≥30000 (σ Bezeichung = 'FiatUno ' (σ b. PNr = p. PNr (σ b. KNr = k . KNr (Pr odukt × ( Bestellt × Kunden))))) π [Name] σ [ Saldo ≥ 300.000] σ [ Bezeichnung ='...' ] σ [b.PNr = p.PNr ] σ [b.KNr = k .KNr ] x 8 Produkt Bestellt x Kunden Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Kunden: 9 KNr 201 337 444 108 Name Klein Horn Berger W eiss Adresse Lilienthal Dieburg München W ürzburg Region Bremen Rhein-Main München Unterfranken π [Name] 1 σ [ Saldo ≥ 300.000] 2 σ [ Bezeichnung ='...' ] Bestellt: Datum 10.05.04 11.05.04 20.05.04 13.05.04 14.05.04 BNr 221 312 401 456 458 Saldo 200.000 100.000 300.000 500.000 KNr 201 201 337 444 444 PNr 12 4 330 330 98 5 σ [b.PNr = p.PNr ] 25 σ [b.KNr = k .KNr ] 100 Produkt: PNr 12 4 330 98 14 Bezeichnung BMW 318i Golf 5 Fiat Uno Ferrari 380 Opel Corsa Anzahl 10 40 5 1 14 Preis 40.000 25.000 18.000 180.000 17.000 5 x Produkt 5 Bestellt 20 x 4 Kunden Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Beobachtungen: 10 • Der kanonische Auswertungsplan erzeugt das kartesische Produkt der 3 Relationen • Die Kardinalität des kartesischen Produkts ist |Kunden| * |Bestellt| * |Produkt| = 100 Tupel • Für jedes der 100 Tupel muss z.B. die Bedingung b.KNr=k.KNr ausgewertet werden • Günstiger wäre es z.B., wenn man sich gleich von Anfang an auf das Produkt ‚Fiat Uno‘ und die Kunden mit hohem Saldo beschränken würde: Relationale Anfragebearbeitung π [Name] π [Name] π [Name] Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung 1 σ [ Saldo ≥ 300.000] σ [b.PNr = p.PNr ] 2 σ [ Bezeichnung ='...' ] σ [ Bezeichnung ='...' ] 1 x 2 5 σ [b.PNr = p.PNr ] σ [b.PNr = p.PNr ] 25 σ [b.KNr = k .KNr ] 5 x Produkt 5 11 1 σ [ Saldo ≥ 300.000] σ [b.KNr = k .KNr ] 100 x 20 x 4 Bestellt Kunden Produkt σ [ Bezeichnung ='...' ] σ [b.KNr = k .KNr ] 5 Produkt 10 x 5 Bestellt 2 σ [ Saldo ≥ 300.000] x 4 Kunden Bestellt Kunden Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Relationale Anfragebearbeitung 12 • i.A. gibt es viele verschiedene, gleichwertige Auswertungspläne für dieselbe Anfrage • Die Performanz gleichwertiger Auswertungspläne variiert häufig zwischen wenigen Sekunden (schnellster Plan) und vielen Stunden (Standardplan) • Die Aufgabe der Anfrageoptimierung ist es, den günstigsten Auswertungsplan zu ermitteln (bzw. zumindest einen sehr günstigen Plan zu ermitteln) • Wegen des großen Unterschiedes zwischen günstigstem und ungünstigstem Plan ist die Optimierung bei der relationalen Anfragebearbeitung wesentlich wichtiger als z.B. bei der Übersetzung von (imperativen) Programmiersprachen Relationale Anfragebearbeitung Logische und physische Anfrageoptimierung: Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung • • Optimierungstechniken, die den Auswertungsplan betrachten und „umbauen“ werden als logische Anfrageoptimierung bezeichnet Physische Anfrageoptimierung: Auswahl einer geeigneten Auswertungsstrategie für Join-Operationen oder Entscheidung, ob für eine Selektionsoperation ein Index verwendet wird. Beispiel: Auswertungsstrategien für Joins • • • Erzeuge alle Tupel des kartesischen Produkts und prüfe JoinBedingung (Nested Loop) Sortiere beide Relationen nach dem Joinattribut und filtere passende Paare (Sort Merge) Betrachte alle Tupel der einen Relation und greife auf die Joinpartner über einen passenden Index der anderen Relation zu (Indexed Loop) 13 Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung Regel- und kostenbasierte Optimierung 14 • Es gibt zahlreiche Regeln (Heuristiken), um die Reihenfolge der Operatoren im Auswertungsplan zu modifizieren und so eine Performanz-Verbesserung zu erreichen, z.B. Push Selection: Führe Selektionen möglichst frühzeitig (vor Joins) aus Optimierer, die sich ausschließlich nach solchen starren Regeln richten, nennt man regelbasierte oder auch algebraische Optimierer Relationale Anfragebearbeitung Datenbanksysteme I Kapitel 10: Relationale Anfragebearbeitung • 15 Optimierer, die die voraussichtliche Performanz von Auswertungsplänen ermitteln werden als kostenbasierte Optimierer bezeichnet. Die Vorgehensweise ist meist folgende: – – – – – Generiere einen initialen Plan (z.B. Standardauswertungsplan) Schätze bei der Auswertung entstehende Kosten Modifizieren den aktuellen Plan gemäß vorgegebener Heuristiken Wiederhole die Schritte 2 und 3 bis ein Stop-Kriterium erreicht ist Gib den besten erhaltenen Plan aus Als Kostenmaß eignen sich der Erwartungswert der Antwortzeit (Einbenutzerbetrieb) oder die Belegung von Ressourcen wie z.B. Anzahl zugegriffener Blöcke oder CPU-Nutzung (Durchsatz-Optimierung va. im Mehrbenutzerbetrieb)