suessenguth99
Werbung

0. Inhaltsverzeichnis
0.
Inhaltsverzeichnis
1.
Aufgabenstellung
Thema
Vorbemerkung
Arbeitsumfang
Erläuterung des Problems
Lösungsweg
Singulärwertzerlegung
Kovarianzanalyse
Zählverfahren
JAVA
Einleitung
Beschreibung von JAVA
Objektorientiert
Einfach
Verteilt
Dynamisch
Interpretiert
Robust
Sicher
Architekturneutral
Hochleistungsfähig
Multithreadfähig
Unterschiede der JAVA-Versionen
JDK 1.0 – JDK 1.1
JDK 1.1 – JDK 1.2
Wahl der Version
CORBA
Client & Server
2-Tier-Architektur
3-Tier-Architektur
n-Tier-Architektur
Entwicklung von CORBA
OMG
ORB
IDL
Services
Facilities
Mapping
Alternativen
Socket
RPC
DCOM
RMI
Leistungsfähigkeit
Simulation der FCG
Simulation der Credit Suisse
1.1
1.2
1.3
2.
2.1
2.2
2.3
2.4
3.
3.1
3.2
3.2.1
3.2.2
3.2.3
3.2.4
3.2.5
3.2.6
3.2.7
3.2.8
3.2.9
3.2.10
3.3
3.3.1
3.3.2
3.3.3
4.
4.1
4.1.1
4.1.2
4.1.3
4.2
4.2.1
4.2.2
4.2.3
4.2.4
4.2.5
4.2.6
4.3
4.3.1
4.3.2
4.3.3
4.3.4
4.4
4.4.1
4.4.2
Seite
1
1
1
1
2
2
3
3
5
6
6
6
7
8
8
9
9
9
11
13
13
14
14
14
17
18
20
20
21
21
22
22
22
23
24
24
25
26
27
27
27
27
27
28
28
29
I
0. Inhaltsverzeichnis
5.
5.1
5.1.1
5.1.2
5.1.3
5.2
5.2.1
5.2.2
5.2.3
6.
6.1
6.1.1
6.1.2
6.1.3
6.2
6.2.1
6.2.2
6.3
6.3.1
6.3.2
6.3.3
6.3.4
6.3.5
6.3.6
6.3.7
7.
7.1
7.1.1
7.1.2
7.2
7.2.1
7.2.2
8.
8.1
8.1.1
8.2
8.2.1
9.
9.1
9.2
9.3
9.4
9.5
9.6
9.7
C/C++ und Fortran
Allgemein
Main-Methode
Naming-Conventions
Subroutines
Datenübergabe
Strings
Arrays
Andere Datentypen
Client
Anforderung an den Client
Statisches System / Lasten
Benutzungsoberfläche
Verteiltes System
Entwurf
Einleitung
Gliederung des Programms
Klassen des Client
Start
Programm
Module_ClientChoice
Module_Construction
Module_SVD
Module_KVA
Module_RES
CORBA-Schnittstelle
SVD
Structs
Interface
KVA
Structs
Interface
Server
SVD-Server
CORBA-Objekt
KVA-Server
CORBA-Objekt
Probleme und Lösungswege
Lasten
Singulärwertzerlegung
Server-Adresse
Verbindungsabbruch
Datenmenge
Multithreading
Applet
Seite
30
30
30
30
30
31
31
31
32
33
33
33
33
34
36
36
36
37
37
38
39
39
42
43
43
44
45
45
45
45
45
46
47
47
47
48
48
50
50
51
51
52
52
52
53
II
0. Inhaltsverzeichnis
10.
10.1
10.1.1
10.1.2
10.2
10.2.1
10.2.2
10.3
10.3.1
10.3.2
10.3.3
10.3.4
10.3.5
10.3.6
10.3.7
10.3.8
10.3.9
10.3.10
10.3.11
10.3.12
10.3.13
10.3.14
10.3.15
10.4
10.5
10.6
11.
11.1
11.1.1
11.1.2
11.1.3
11.1.4
11.2
11.2.1
11.2.2
11.2.3
11.2.4
11.2.5
12.
Benutzerhandbuch
Systemvoraussetzungen
Client
Server
Installation und Starten des Client
Installation
Starten
Construction
Neues Projekt
Öffnen eines bestehenden Projekts
Speichern des aktuellen Projekts
Programm beenden
Tragwerk drucken
Knoteneingabe
Stabeingabe
Lasteingabe
Wöhlerlinie definieren
Materialeigenschaften definieren
Profil definieren
Verteilung anzeigen
Startmenü
Hilfe aufrufen
Pop-Up-Menü
SVD
KVA
RES
Beispiel
Rahmentragwerk
Knoten und Stäbe
Lasten
SVD
KVA
Stütze
Knoten und Stäbe
Lasten
SVD
KVA
Ergebnisse
Quellenangabe
Seite
54
54
54
54
55
55
55
57
57
58
58
58
59
60
61
62
63
65
66
67
67
67
68
69
69
70
71
71
71
73
74
74
75
75
76
76
76
77
79
III
1. Aufgabenstellung
1.
Aufgabenstellung
1.1
Thema
Erstellung eines verteilt arbeitenden Programmsystems mit dem Standard-Kommunikationsmedium CORBA am Beispiel der lebensdauerorientierten Bemessung von
Tragwerken.
1.2
Vorbemerkung
Die gegenwärtige Entwicklung in der Computertechnologie sind durch den Wunsch
gekennzeichnet, bestehende Anwendungsgrenzen, die durch verschiedene Plattformen
in heterogenen Computernetzwerken gegeben sind, zu überwinden. Das Internet und
seine Möglichkeiten, die noch gar nicht alle ausgenutzt sind, gewinnen dabei
zunehmend an Bedeutung. Es ist beispielsweise möglich, Programme auf entfernten
Rechnern auszuführen und lokal zu steuern. Voraussetzung hierfür sind geeignete
Schnittstellen und sinnvolle Vereinheitlichungen, so daß die Systemarchitekturgrenzen
aufgehoben werden. Hier bietet sich die Technologie CORBA (Common Object
Request Broker Architecture) an.
1.3
Arbeitsumfang
Mit Hilfe von CORBA sollen verschiedene für die lebensdauerorientierte Bemessung
von Tragwerken vorliegende Routinen in ein Programmsystem eingebunden werden.
Diese Programmroutinen dienen der Parametrisierung der Lastprozesse, der
Kovarianzanalyse zur Ermittlung von Parametern für die Beschreibung der
Spannungsdoppelamplituden, der Abschätzung der Schädigung und der
Zuverlässigkeitsberechnung mit einem MonteCarlo-Simulationsverfahren.
Es ist ein Steuerprogramm zu schreiben, welches die Kontrolle über den Arbeitsablauf
übernimmt. Für die vorliegenden Programmroutinen sind dabei Pre- und
Postprozessoren zu erstellen, so daß das Programmäußere dem aktuellen
Benutzungsoberflächen-Standard entspricht.
Im einzelnen sollen für die Dateneingabe und die Ergebnisse graphische Darstellungen
gewählt werden. Insbesondere ist dies für das FEM-Programmmodul erforderlich.
Desweiteren sind Schnittstellen für alle verwendeten Module nötig, um so eine
fehlerfreie Datenübertragung zu gewährleisten.
Die erstellten Programme sollen vorwiegend in der Programmiersprache JAVA
geschrieben werden. Anschließend ist die Anwendung des aufgebauten
Programmsystems für vorgegebene Konstruktionen aus der Ingenieurpraxis Rahmentragwerk, Durchlaufträgersystem- beispielhaft nachzuweisen und zu
dokumentieren.
4
2. Erläuterung
2.
Erläuterung
Thema des Teilprojektes C5 des Sonderforschungsbereiches 398 ist die Entwicklung
eines parallelen/verteilten Entwurfssystems für die lebensdauerorientierte Auslegung
von Tragwerken unter Berücksichtigung von Schädigungen.
„Ziel des Projektes C5 ist es, ein computerbasiertes Entwurfssystem für
Stahltragwerke zu entwickeln, das alle die Lebensdauer beeinflussenden Effekte
berücksichtigt und eine optimale Tragwerksauslegung erlaubt.“ (/18/)
Die Grundlagen bei dem Entwurf von Systemen werden nach dem Grad ihrer
Komplexität klassifiziert (/19/).
•
•
•
Level I:
Die Bemessungsvariablen werden durch einen einzigen Wert, i.d.R. der
Mittelwert, beschrieben. Dieses Vorgehen entspricht dem Niveau der heutigen
Normen, wobei die normengebenden Gremien dafür garantieren, daß die
Versagenswahrscheinlichkeit akzeptabel klein ist.
Level II:
Die Bemessungsvariablen werden durch zwei Kennwerte (Mittelwert und Standardabweichung) beschrieben.
Level III:
Die Bemessungsvariablen werden durch ihre Verteilungsfunktionen beschrieben.
Die Schwierigkeiten bei der Methode nach Level III im Bauwesen liegen darin, daß
häufig Werte auftreten, die stark von den Mittelwerten ihrer Verteilungen abweichen
(Jahrhundertereignisse). Außerdem liegen häufig nur relative wenig Meßwerte vor
oder die Meßverfahren sind unzureichend.
Die Bemessung auf Grundlage stochastischer Belastungen ist extrem kompliziert und
für die Praxis kaum geeignet.
2.1
Lösungsweg
Um die o.g. schwierige Aufgabe zu lösen ist der Einsatz von schnellen Computern und
moderner Software unerläßlich. Durch den Einsatz von Programmen ist eine Lösung
in zwei Schritten möglich.
•
•
Reduktion der Lastdatenmenge ohne die wesentlichen Informationen zu verlieren
Ermittlung der stochastischen Parameter zur Beschreibung der Verteilung der
Tragwerksantworten (spektrale Momente)
Im zweiten Schritt wird dabei die dynamische Berechnung durch eine
Kovarianzanalyse unter Kopplung der Lastseite mit der Strukturseite ersetzt.
Anschließend kann die Verteilungsfunktion der Tragwerksantworten durch die
spektralen Momente beschrieben werden. Die Beschreibung der Verteilung erfolgt
dabei analytisch, was eine Effizienzsteigerung gegenüber der numerischen Methode
bedeutet. Die Genauigkeit bewegt sich dabei in akzeptablen Grenzen. Nach der
Emittlung der Tragwerksantworten kann die Schädigung durch Schadensakkumulation
nach der Palmgren-Miner-Regel berechnet werden und die Zuverlässigkeit des
Bauwerks bestimmt werden. Eine Optimierung kann durch mehrere
Programmdurchläufe erreicht werden.
2
2. Erläuterung
2.2
Singulärwertzerlegung
Die Singulärwertzerlegung ist ein der Kovarianzanalyse vorgeschalteter Prozeß,
bestehend aus informationsreduzierenden Algorithmen.
Aus Versuchen im Windkanal, wurden zu einem Tragwerk diskretisierte
Druckbeiwerte cp an verschiedenen Meßpunkten ermittelt. Daraus kann später der
Winddruck je Flächeneinheit der Bauwerksfläche ermittelt werden: w = cp ⋅ q
Da aus solchen Versuchsreihen sehr große Datenmengen entstehen (mehrere
Gigabyte!), ist es erforderlich diese auf eine leicht und schnell zu verarbeitende Menge
zu reduzieren. Als Ergebnis aus diesen Operationen erhält man die normierten
Parametermatrizen A, B und C. Durch die man algebraisch die stochastischen
Erregerprozesse des Mikrozeitbereiches beschreiben kann. Unterschiedliche
Windgeschwindigkeiten können abgebildet werden, da die Erregerprozesse auf
normierten Werten beruhen.
Dadurch ist es möglich, eine einmalige algebraische Rechenoperation statt
aufwendiger, wiederholter Zeitbereichssimulationen zur Berechnung der streuenden
Tragwerks-antworten durchzuführen. Auf diese Weise können die Antwortzeiten der
Computersysteme extrem verkürzt werden.
2.3
Kovarianzanalyse
Gesucht ist die Verteilung der Spannungsschwankungen, da diese in die
Schadensakkumulation eingehen. Gegeben sind die o.g. Zeitreihen der
Belastungsschwankung. Ziel ist die Kopplung der beiden Prozesse Belastung und
Tragwerksantwort. Eine dynamische Berechnung entfällt, da sie viel zu aufwendig und
kompliziert ist. Eine Lösung des Problems liegt in der Kovarianzanalyse.
3
2. Erläuterung
Durch Hintereinanderschaltung eines Formfilters (s.o.), mit dem die Parametrisierung
der aerodynamischen Übertragung gelingt (die Lasteinwirkung wird auf ein ideelles
weißes Rauschen zurückgeführt) und eines Filters für das mechanische System (dies
stellt den Zusammenhang zwischen den Lasteinwirkungen und den
Tragwerksantworten her), lassen sich über die Kovarianzanalyse sämtliche Streuungen
und spektralen Momente aller interessierenden Strukturantworten berechnen.
Die spektralen Momente ergeben sich aus:
∞
λk = ∫ ω k Gxx (ω )dω
0
wobei Gxx (.) die sogenannte einseitige Spektraldichte ist, die für die meisten
physikalischen Probleme anstatt der zweiseitigen Spektraldichte Sxx (.) verwendet wird
(/18/).
Die spektralen Momente, durch welche die stochastischen Tragwerksantworten
beschrieben werden können, haben folgende physikalische Bedeutung:
λ0 =
Varianz des Prozesses X (t )
λ1 =
gewonnen aus dem Korrelationskoeffizienten zwischen X (t ) und
.
∨
der Hilberttransformierten X (t ) von X (t ) gewinnen
λ2 =
Varianz des Ableitungsprozesses
λ4 =
Varianz von X (t )
..
Diese erhält man unmittelbar als Ergebnis aus der Kovarianzanalyse.
4
2. Erläuterung
2.4
Zählverfahren
Früher wurden die Schwingweiten numerisch ausgezählt, was einen langwierigen
Prozeß darstellt, wogegen heutzutage die Ergebnisse analytisch gewonnen werden.
Aus den Spektralmomenten kann der funktionale Verlauf der Verteilungsdichte der
Schwingweite als Überlagerung einer Exponentialverteilung und zweier
Rayleighverteilungen gewonnen werden (/20/):
fs ( s ) =
2
1 s 2
1
2
s
D3
D2
2⋅s
−
+
⋅
⋅
+
⋅
⋅
−
⋅ exp −
exp
exp
s
s
2
2
2 2 ⋅ σ
2 2 ⋅ R ⋅ σ 4 ⋅ σ 2
σ
σ ⋅ D1 4 ⋅ σ ⋅ R
mit:
σ = λ0
R=
α − Xm − D12
1 − α − D1 + D12
Xm =
λ1 λ 2
⋅
λ0 λ4
D1 = 2 ⋅
D2 =
1 − α − D1 + D12
1− R
D 3 = 1 − D1 − D 2
Xm − α 2
1+α2
Die Schädigungsanteile aus den Spannungsverteilungen werden anschließend
integriert. Auf Grundlage der so gewonnen Daten kann die Zuverlässigkeit eines
Systems bestimmt werden und in weiteren Schritten optimiert werden.
5
3. JAVA
3.
Java
3.1
Einleitung
Ende des Jahres 1995 wurde von der Firma SUNTM ein vollständig neues
Softwarekonzept vorgestellt. Mit der Version 1.0 der Programmiersprache JAVA hatte
man nun erstmalig die Möglichkeit, Programme unabhängig von der zu Grunde
liegenden Plattform zu entwickeln. Dies bedeutet, daß es für den Programmierer
unerheblich ist, ob er die Software für Windows 95/98, Windows NT, Linux oder
Mac-OS entwirft. Das Programm ist - ohne auch nur eine Zeile Code zu ändern - auf
allen Systemen lauffähig. Diese Portabilität ist allerdings mit dem Nachteil verbunden,
daß die Programme im Vergleich zu C++-Programmen 20mal langsamer sind.
Mit Einführung der Release 1.1 verdoppelte sich die Ausführungsgeschwindigkeit.
Allerdings waren C++-Programme immer noch annähernd um den Faktor 10 schneller
als entsprechende JAVA-Programme.
Zu dem Geschwindigkeitssprung kamen noch weitere Entwicklungen, wie z.B.:
- Drucken aus Applikationen
- Remote Methode Invocation
- Zugriff auf Datenbanken
- digitale Signaturen
- Internationalisierung
- neues Eventmodell
- Verschlüsselung von Nachrichten
Auf diese Neuerungen wird in Kapitel 3.3.1 beim Vergleich der Versionen noch
genauer eingegangen.
3.2
Beschreibung von JAVA
Java wird von SUNTM als eine Sprache mit folgenden Eigenschaften beschrieben:
objektorientiert, einfach, verteilt, dynamisch, interpretiert, robust,
architekturneutral, portabel, hochleistungsfähig und multithread-fähig
(/1/ S. 69)
sicher,
Dabei ist interessant, daß JAVA-Programme auf zwei grundsätzlich verschiedenen
Konzepten beruhen können. Sie können als Applet und/oder als Applikation entworfen
werden.
Ein Applet ist ein Programm, welches innerhalb eines HTML-Dokumentes aufgerufen
wird, und nur durch einen JAVA-fähigen Browser in einer geschützten Umgebung
ausgeführt werden kann. Diese Umgebung wird auch als Sand-Box bezeichnet. In
dieser Umgebung sind die Rechte auf Systemressourcen extrem eingeschränkt,
wodurch Applets sehr sicher sind.
6
3. JAVA
Eine Applikation, auch als stand-alone bezeichnet, wird durch den Aufruf der JVM
über eine Kommandozeileneingabe aufgerufen. Das Programm läuft dann wie jedes
andere Programm auch und unterliegt keinen Einschränkungen (speichern, laden,
löschen, drucken ...). Als JAVA-Virtual-Machine (JVM) wird dabei der Interpreter
bezeichnet, der die compilierten class-Dateien ausführt.
Der Aufruf kann natürlich durch eine batch-Datei vereinfacht werden. Er hat
allerdings immer folgende Form: java Start.class. Mit Start.class wird hierbei die
Klasse bezeichnet, welche die main-Methode enthält und java ist der Interpreter, der
im Verzeichnis /bin des Installationspfades von JAVA liegt. Entsprechend sind
besonders die Hinweise bezüglich der CLASSPATH-Variable bei der Installation von
JAVA zu beachten.
3.2.1 Objektorientiert
Im Gegensatz zu anderen Hochsprachen wie zum Beispiel C, Fortran oder PASCAL
ist JAVA objektorientiert. Im Mittelpunkt des Entwurfes objektorientierter Programme
stehen Konstrukte, die Daten und Methoden (zur Manipulation dieser Daten) zu einer
Einheit zusammenfassen. Diese Konstrukte zur formalen Beschreibung von beliebigen
Objekten werden Klassen genannt.
Die besonders großen Vorteile dieses Konzeptes liegen in der Möglichkeit der
Wiederverwertbarkeit und Vererbung von Klassen. Vererbung heißt, daß eine Klasse
von einer anderen Klasse ihre Elementdaten und Elementfunktionen übernimmt (/2/ S.
462). Allerdings existiert in JAVA nur eine Einfachvererbung, wogegen C++ auch die
Mehrfachvererbung kennt.
Mit Vererbung wird eine OO-Technik bezeichnet, die es gestattet Eigenschaften
(Attribute und Methoden) an nachgeordnete Klassen weiterzugeben. Diese verfügen
dann ebenfalls über die Eigenschaften der Vaterklasse, ohne sie neu definieren zu
müssen.
Viereck
Parallelogramm
Rechteck
In diesem Fall erben die Klassen Rechteck und Parallelogramm die Eigenschaften der
Klasse Viereck (z.B. Breite, Höhe, Flächenberechnung usw.). Da sie nur von einer
Klasse erben, nennt man dies Einfachvererbung.
Bei der Technik der Mehrfachvererbung können Klassen von mehr als einer Klasse die
Eigenschaften erben.
7
3. JAVA
Auf diese Weise entstehen Klassenhierarchien, an deren Spitze die Stammklasse steht.
In JAVA ist diese Stammklasse die Klasse java.lang.Object. Alle weiteren Klassen
sind von ihr abgeleitet (erben ihre Eigenschaften).
Die von JAVA mitgelieferten Klassen sind in Pakete geordnet. Die wichtigsten sind:
- java.applet
- java.io
- java.util
- java.awt
- java.lang
- java.awt.event
- java.math
In diesen Paketen sind Klassen enthalten, die eine einfache Programmentwicklung
ermöglichen, ohne jedesmal elementare Klassen und Funktionalitäten neu schreiben zu
müssen.
Die einzigen Elemente in JAVA, die nicht zugleich Objekte sind, sind die elementaren
Datentypen:
- boolean
- short
- float
- char
- int
- double
- byte
- long
3.2.2 Einfach
Um die Sprache JAVA einfach zu gestalten, wurden relativ wenig Sprachkonstrukte
eingeführt, die gleichzeitig auch noch eng an die Bezeichnungen von C/C++ angelehnt
sind. Dadurch wurde die Fehleranfälligkeit von Programmen verringert, da vielen
Softwareentwicklern JAVA vertraut wirkte.
Allerdings existieren zwischen diesen Sprachen wesentliche Unterschiede, die
unbedingt beachtet werden müssen. Dazu gehört unter anderem die automatische
Speicherverwaltung (Garbage-Collector, vgl. 3.2.6), wodurch es nicht mehr
erforderlich ist, den delete-Operator zu verwenden. Außerdem wird unter JAVA nicht
zwischen Objekten und Referenzen auf Objekte unterschieden. Zudem sind selbst
Arrays und Strings Objekte, womit auf jede Zeigerarithmetik verzichtet werden kann
(vgl. 3.2.1).
3.2.3 Verteilt
Java unterstützt Netzwerke durch Klassen aus den Paketen java.net und java.rmi /
java.rmi.server die der Programmentwickler ohne Hintergrundwissen über die zu
Grunde liegenden Protokolle nutzen kann. Dadurch könne entfernte Daten und
Ressourcen auf sehr einfache Art und Weise wie lokale verwendet werden.
Aus dem Paket java.net kann die Klasse URL verwendet werden, um die durch eine
URL bezeichnete Netzwerk-Ressource herunterzuladen. Diese Klasse wird
hauptsächlich dazu verwendet, um URLs zu repräsentieren und zu parsen (/3/ S.213).
Dabei können Daten durch Datagramme (paketorientiert) als auch durch Sockets
(stream-orientiert) versendet werden.
8
3. JAVA
Mit Parsen wird der Vorgang bezeichnet, durch den eine Datenstruktur in ein
gewünschtes Format gewandelt wird (z.B. intàdouble, String àURL etc.)
In den Paketen java.rmi / java.rmi.server sind Klassen enthalten, die es ermöglichen
Client- und Server-Anwendungen zu schreiben.
RMI bedeutet Remote Methode Invocation (= entfernter Methodenaufruf). Der Client
kann Methoden eines Serverobjektes so aufrufen, als ob es sich um ein lokales Objekt
handelt. Diese Technik entspricht in vielen Details der von CORBA (vgl. Kap. 4.3.4).
3.2.4 Dynamisch
Jede Klasse muß erst zur Laufzeit des Programms geladen werden. Dadurch läßt sich
besonders bei der Verwendung von JAVA im Internet Leistung einsparen. Außerdem
können Informationen über Objekte ebenfalls zur Laufzeit ermittelt werden. Diese
Möglichkeit ist z.B. in C++ erst in der letzten Version in den Sprachstandard
aufgenommen worden (RTTI = Runtime Type Information).
Durch die Reflection-API aus dem java.lang-Paket kann ein JAVA-Programm sich
selbst inspizieren und manipulieren. Dabei handelt es sich um die Möglichkeit die
Eigenschaften, Events und Methoden zu ermitteln, welche z.B. von einem Bean zur
Verfügung gestellt werden. Diese Technik ist allerdings nicht nur auf Beans (Konzept
für wiederverwendbare Softwarekomponenten) sondern auf alle Klassen anwendbar.
Es ist dadurch möglich, während der Laufzeit des Programms, Informationen über die
Attribute, Methoden und Konstruktoren einer Klasse zu erhalten.
3.2.5 Interpretiert
Durch das Compilieren der Quellcode-Dateien (Extension *.java) werden vom JAVACompiler Byte-Code-Dateien erzeugt (Extension *.class). Dieser Byte-Code ist
allerdings kein Maschinencode, wie er beim Compilieren von C/C++-Quellcode
erzeugt wird. Er kann anschließend von jeder JVM ausgeführt werden, welche immer
einen Interpreter und Laufzeittypen enthält.
Das Ausführen des Byte-Codes stellt kein Linken wie unter C/C++ dar, da die Klassen
nacheinander zur Laufzeit des Programms geladen werden (vgl. 4.2.4), sondern ist ein
inkrementeller Prozeß, da eine Klasse erst dann geladen wird, wenn sie zur
Programmausführung benötigt wird.
Dadurch ist der Compilationsvorgang zur Erzeugung des Byte-Codes erheblich
schneller und einfacher als das umständliche Compilieren-Linken-Ausführen unter
C/C++.
3.2.6 Robust
Im Gegensatz zu C++, welches zu C abwärts kompatibel sein sollte, kann JAVA
wesentlich stärker seine Datentypen kontrollieren. Dadurch kann der Compiler Fehler
durch falsche Datentypennutzung erkennen und dem Programmierer mitteilen.
9
3. JAVA
Außerdem können unter JAVA Methoden lediglich explizit deklariert werden,
wodurch der Compiler fehlerhafte Methodenaufrufe ebenfalls meldet.
Um die Stabilität weiter zu unterstützen, sind Speichermanipulationen durch Zeiger
und Zeigerarithmetik nicht möglich. Wie oben bereits erwähnt, werden selbst Arrays
und Strings als Objekte betrachtet, welche über Methoden und nicht über Zeiger
verändert werden. Sie werden zur Laufzeit des Programmes ständig auf Gültigkeit hin
überprüft. Dadurch wird das Überschreiben von Speicherbereichen oder Daten
verhindert, was unter C++ fast zwangsläufig zum Programmabsturz führt. Im diesem
Zusammenhang ist auch der Garbage-Collector zu sehen. Er verhindert durch das
automatische Freigeben von Speicherbereichen, auf die keine Referenz vorhanden ist,
das Entstehen von Speicherlecks. Dadurch ist der Programmierer von der Aufgabe
entbunden mit delete den allokierten Speicher wieder dem System bereitzustellen.
Ein weiterer Aspekt, um die Lauffähigkeit eines Programmes sicherzustellen, ist das
Exception-Handling. Damit können Fehler, die während des Programmablaufes
auftreten, abgefangen werden. Für diesen Mechanismus gibt es in JAVA das
Konstrukt try-catch-finally. Fehlerbehandlung wird durch diese Gruppierung von
verschiedenen Ausweichmöglichkeiten für den Programmierer stark vereinfacht. Zum
Beispiel kann an den User eine Fehlermeldung ausgegeben werden, wenn eine zu
ladende Datei nicht gefunden wurde.
Ebenfalls eine wichtige Technik ist das Casting von Objekten zur Laufzeit. Damit ist
die Konvertierung eines Objektes von einem Klassentyp in einen anderen gemeint,
was grade bei Vererbungsstrukturen sehr häufig auftritt.
All diese Fähigkeiten von JAVA machen das Programmieren wesentlich einfacher und
sicherer als unter anderen Sprachen, entbinden den Programmierer aber keineswegs
von seiner Qualitätssicherungsaufgabe.
Um diese zu gewährleisten, gehört in erster Linie ein strukturiertes Programmieren zu
den Aufgaben des Entwicklers, so daß auch ein Dritter das Programm sofort verstehen
und erweitern kann. Folgendes kurzes Beispiel soll das verdeutlichen:
r+=r<<2;
Dies sieht harmlos aus, allerdings ist unklar von welchem Datentyp r ist. Ein
ordentlicher Entwickler weist im Namen auf den Typ hin:
r_ul +=r_ul<<2;
So weiß man auf den ersten Blick, daß die Variable vom Typ unsigned long ist.
Microsoft propagiert für diesen Zweck die „Ungarische Notation“ von Charles
Simonyi (/5/ S.170).
10
3. JAVA
3.2.7 Sicher
Da JAVA immer wieder als die „Internet-Sprache“ propagiert wird, ist es nicht
verwunderlich, daß dem Sicherheitsaspekt eine besonders große Bedeutung
zugewiesen wird. Niemand würde JAVA-Code aus dem Internet herunterladen und
auf seinem Rechner ausführen lassen, wenn damit ein Risiko für seine Daten
verbunden wäre. Da aber die Funktionsweise des Codes im allgemeinen unbekannt ist,
sind notwendigerweise Einschränkungen bei den Zugriffsrechten erforderlich, um die
Sicherheit zu gewährleisten.
Wie unter 3.2.6 bereits erwähnt, finden bei JAVA Zeiger keine Verwendung. Damit ist
grundsätzlich sichergestellt, daß kein direkter Speicherzugriff möglich ist.
Dies alleine würde aber noch nicht den heutigen Sicherheitsanforderungen genügen.
Während der Ausführung des Byte-Codes überprüft die JVM zur Laufzeit des
Programms den Code auf dessen Gültigkeit. So wird ausgeschlossen, daß -bewußt
oder unbewußt- ein fehlerhaft erstellter Code ausgeführt wird. Ein Über- oder
Unterlauf des Stacks ist dadurch ausgeschlossen. Außerdem können eventuelle
Implementierungslücken in der JVM nicht illegal genutzt werden.
Ein weiterer Mechanismus zur Sicherung der eigenen Datenbestände ist die Sandbox.
Dabei kann das Applet im „Sandkasten spielen“, d.h. in der Sandbox laufen, ohne in
der realen Umgebung Schaden anzurichten. Sicherheitsrelevante Methodenaufrufe des
Programmes werden durch den Security-Manager unterbunden, der eine SecurityException auswirft. Der Programmablauf wird an der Stelle sofort angehalten.
Selbstverständlich kann keine Sprache dem Anspruch auf 100%-ige Sicherheit gerecht
werden. Aber die junge Sprache JAVA erkennt und schützt vor den meisten bisher
bekannten Angriffsmethoden bei verteilten Anwendungen. Zudem können die
heutigen Browser, in denen Applets ablaufen, zusätzliche Sicherheitsstufen einrichten.
Auf der nächsten Seite wird gezeigt, wie diese Security-Level genutzt werden, um das
Verhalten von Applets dem persönlichen Sicherheitsbedürfnis des Benutzers anpassen
zu können.
11
3. JAVA
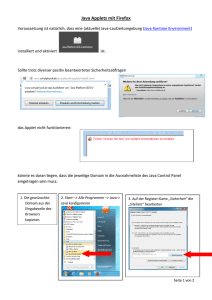
Oben abgebildet sind die Möglichkeiten zur Sicherheitseinstellung für JAVA-Applets
im Microsoft Internet-Explorer 4.0. Diese Einstellungen gelten für die „Sand-Box“.
12
3. JAVA
3.2.8 Architekturneutral
Der wohl größte Vorteil von JAVA ist die Architekturneutralität des Codes. Ein Programm kann auf jeder Plattform ausgeführt werden, für die eine JVM existiert. Derzeit
bietet SUNTM die Entwicklungsumgebung JDK (= JAVA Developers Kit) für SPARC/
Solaris, X86/Solaris, MS-Windows 95/98/NT und MacOS an. Außerdem gibt es
Portierungen von IBM für OS/2 und von Randy Chapman für Linux.
Die Auswirkungen zeigen sich z.B. bei dem primitiven Datentyp int. Dieser kann
unter C/C++ 16, 32 oder 64 Bit groß sein, unter JAVA dagegen einheitlich 32Bit auf
jeder Plattform. Die Anwendungsentwicklung wird dadurch erheblich vereinfacht.
SUNTM beschreibt diesen Vorteil mit dem Satz: Write Once, Run Everywhere.
Da aber die GUI-Elemente (Graphical User Interface) unter den verschiedenen Betriebssystemen unterschiedlich aussehen, ist eine Oberflächenprogrammierung immer
noch mit Schwierigkeiten verbunden. Unterschiedliche Font-Größen oder Farben
führen immer wieder zu Problemen (/15/).
Oben abgebildet ist die Darstellung des Startmenüs bei einem Applet unter
Verwendung des MS-Internetexplorers. Die Schrift, die bei Netscape keine Probleme
bereitet, kann nicht dargestellt werden
3.2.9 Hochleistungsfähig
Da JAVA keine Compilersprache wie C/C++ ist, ist die Ausführungsgeschwindigkeit
natürlich auch deutlich geringer. Die Version 1.0 des JDK war ungefähr 20mal
langsamer als C/C++. Mit dem JDK 1.1 ist es immerhin gelungen die Geschwindigkeit
zu verdoppeln, ist aber immer noch ca. 10mal langsamer als C/C++.
Allerdings muß dabei beachtet werden, daß bei verteilten Anwendungen, dem
typischen Anwendungsgebiet von JAVA, die Geschwindigkeit nur eine
untergeordnete Rolle spielt. Den größten Teil der Zeit wartet das Programm auf
entfernte Daten, die über das Netzwerk geladen werden sollen.
Zeitkritische Anweisungen, die nicht ausgelagert werden können, sind in
Maschinencode geschrieben, und daher ausreichend schnell. Dazu gehören
Zeichenverkettungen und –vergleiche bei Strings.
Wenn eine Leistungssteigerung unbedingt erforderlich ist, besteht die Möglichkeit den
Byte-code mit einem Just-In-Time-Interpreter auszuführen. Der Byte-Code wird
während der Programmausführung für das entsprechende System optimiert und ist
13
3. JAVA
dadurch extrem kurz, kompakt und schnell. Die dadurch erreichte Geschwindigkeit
liegt in der Größenordnung von C/C++. Natürlich ist der Vorteil der
Architekturneutralität damit verloren.
Eine weitere Möglichkeit zur Ausführungsbeschleunigung besteht darin, zeitkritische
Routinen in C/C++ zu schreiben und über die bereitgestellten Schnittstellenmethoden,
in das JAVA-Programm einzubinden. Aber auch dadurch wird der o.g. Vorteil
zunichte gemacht.
Insgesamt kann über die Geschwindigkeit von JAVA gesagt werden, daß sie zwischen
den reinen Interpretersprachen wir Tcl, Pearl oder Shell-Skripten und den echten
Compilersprachen wie C/C++ oder Fortran liegt.
3.2.10 Multithreadfähig
Unter einem Thread versteht man einen eigenständig ablaufenden Programmfaden.
Ohne diese Threads sind moderne, interaktive Programme kaum vorstellbar. Die
Möglichkeiten in JAVA-Programmen Threads einzusetzen sind gegenüber C/C++
erheblich vereinfacht. Durch den Einsatz von Klassen, die direkt Threads unterstützen,
ist ein Multithreading ohne großen Aufwand möglich. Diese Klassen sind in dem
Paket java.lang enthalten, welches standardmäßig importiert wird.
Auch ohne Zutun des Programmierers verwendet JAVA bei zeitlich nicht
berechenbaren Aktionen eigene System-Threads. Das Laden und Anzeigen eines
Bildes aus dem Internet ist eine Anwendung, deren Zeitbedarf nicht vorhersagbar ist.
Da es aber unsinnig wäre das gesamte Programm während des Ladevorganges
anzuhalten, startet der JAVA-Compiler dafür einen eigenen Thread. Diese Technik
wird bei verschiedenen anderen Situationen angewendet.
Ein laufendes Applet kann durch Threads z.B. simultan eine Grafikdatei laden, eine
Sounddatei abspielen und gleichzeitig auf Eingaben des Benutzers reagieren.
3.3
Unterschiede der JAVA-Versionen
Bei einer so jungen Sprache wie JAVA werden ständig neue Versionen veröffentlicht.
Dies hat besonders in den ersten Jahren der Entwicklung ständig zu weitreichenden
Veränderungen in der Architektur geführt. Die wesentlichsten wurden in den zwei
nachfolgend erläuterten Schritten durchgeführt.
3.3.1 JDK 1.0 – JDK 1.1
Mit der Vorstellung des JDK 1.0 im Jahre 1995 wurde eine Entwicklung gestartet, die
in z.T. sehr kurzen Entwicklungsschritten bis heute fortgeführt wurde und keineswegs
beendet ist. Die Version 1.1 brachte einige Änderungen, die für jeden Entwickler von
Interesse waren.
Die wichtigste Neuerung, die alle GUI-Programme betrifft, ist das vollständig neu
Konzept zur Ereignisbehandlung (Eventhandling). Es wurde für jedes Event eine
eigene Klasse geschaffen, was erstens dem objektorientierten Ansatz wesentlich besser
14
3. JAVA
Rechnung trägt und außerdem die Routinen bedeutend einfacher und übersichtlicher
werden läßt.
Die Behandlung von Events sah bis zur Version 1.02 im wesentlichen wie folgt aus:
public boolean handleEvent( Event evt ){
if( evt.target==okBUTTON && evt.id==Event.ACTION_PERFORMED ){
// do something }
else
if(
evt.target==yesRADIOBUTTON
&&
evt.id==
Event.ACTION_PERFORMED ){
// do something other }
else if( ....){ }
return super.handleEvent( evt );
}
Die Informationen über das auslösende Objekt und die Art des Events sind in den
Attributen target (Referenz auf das auslösende Objekt) und id (Art des Ereignisses)
gekapselt. Man kann sofort erkennen, daß diese Technik sehr umständlich und
langsam ist, da immer eine, unter Umständen sehr lange, Reihe von Alternativen
geprüft werden muß. Und das, obwohl keineswegs sicher ist, ob das Event überhaupt
verarbeitet werden soll. Diese Vorgehensweise wird auch als Event-Tourismus
bezeichnet, da ein Ereignis ungezielt von allen Klassen mit einer handleEventMethode bearbeitet werden kann.
Demgegenüber verwendet das JDK 1.1 ein Verfahren, welches von SUNTM als
Multicast-Technik beschrieben wird. Dabei wird zwischen verschiedene EventKlassen und den Listenern (Hörern) unterschieden, die auf diese Ereignisse reagieren
sollen. Das auslösende Objekt sendet das Event dabei lediglich an die bei ihm
registrierten Listener. Nachstehend eine Beispielklasse, die auf ActionEvents und
ItemEvents reagieren kann, da die Interfaces ActionListener und ItemListener
implementiert worden sind. Die entsprechenden Methoden actionPerformed sowie
itemStateChanged sind überschrieben, um eigene Aktionen zu realisieren.
public class Test implements ActionListener, ItemListener {
// Attribute, Konstruktoren, Methoden ...
public void actionPerformed( ActionEvent a_evt ){
// Reaktion auf Buttons o.ä.
}
public void itemStateChanged( ItemEvent i_evt ){
// Reaktion auf Choice o.ä.
}
}
15
3. JAVA
Die Objekte der Klasse Test können auf Button-Klicks oder eine Auswahl in einem
Choice-Element reagieren, wenn sie bei den entsprechenden Objekten als Listener
eingetragen sind.
// Code-Auszug
Test
t1= new Test();
Test
t2 = new Test();
Button
b = new Button(„ok“);
Choice
c = new Choice();
b.addActionListener( t1 );
c.addItemListener( t1 );
Das Objekt t1 kann jetzt auf Benutzereingaben reagieren, wohingegen das Objekt t2
unberührt bleibt.
In der Eventhierarchie herrscht folgende Vererbungsstruktur (/4/ S.353):
16
3. JAVA
Durch die oben beschriebene Vorgehensweise ist ein beträchtlicher
Geschwindigkeitsgewinn erzielt worden. Als Schwierigkeit erweist sich jedoch die
Tatsache, daß mehrere Objekte auf ein Event reagieren können, wobei nicht festgelegt
ist, in welcher Reihenfolge sie dies tun.
Eine weitere Änderung, die große Bedeutung für Anwendungen hat, ist die Fähigkeit
von JAVA zu drucken. Statt der grafischen Darstellung auf dem Bildschirm wird
einfach auf dem Drucker gezeichnet. Dafür muß lediglich mit folgender Anweisung
ein Objekt der Klasse PrintJob verwendet werden:
PrintJob pjob = getToolkit().getPrintJob( this, „titel“, printProperties );
Der Rest geschieht laut SUNTM „automagically“. In der Methode paint kann dann ein
Graphics-Objekt verwendet werden, um auf dem Drucker zu zeichnen.
Eine ebenfalls wichtige Neuerung, ist die Möglichkeit, Daten aus/in das Clipboard zu
lesen/schreiben und das Entwickeln von mehrsprachigen Anwendungen mit dem
Internationalization-Framework. Die beiden letztgenannten Techniken finden in dieser
Arbeit keine Anwendung, so daß darauf an dieser Stelle nicht weiter eingegangen
wird.
Als Nachteil der neuen Version muß genannt werden, daß einige Methoden des
JDK 1.0 als deprecated (veraltet) eingestuft wurden und in späteren Releases nicht
unbedingt unterstützt werden. Dazu gehört z.B. das gesamte handleEvent-Modell, was
die Weiterentwicklung bereits bestehender Projekte sehr schwierig gestaltet. Zudem ist
nicht bekannt, ab welcher Version diese Methoden nicht mehr zum Sprachstandard
gehören. Solange SUNTM die alleinige Herrschaft über die Entwicklung von JAVA
besitzt und nicht einem unabhängigen Standardisierungsremium unterworfen ist, wird
sich an dieser Tatsache auch nichts ändern. Den Programmierern bleibt also keine
andere Alternative, als sich an den Empfehlungen von SUNTM zu orientieren (/6/
S.371).
Leider sind die Neuerungen nicht abwärts kompatibel. Wenn JAVA-Programme als
Applet entworfen wurden, müssen Browser der neuesten Generation verwendet
werden. Die am meisten genutzten Browser Netscape 4 und InternetExplorer 4 bieten
eine Unterstützung für JAVA 1.1 an, doch kann nicht vorausgesetzt werden, daß jeder
Anwender diese benutzt. Ältere Versionen können lediglich über PlugIns entsprechend
programmierte Applets ausführen. PlugIns werden von SUNTM zur Verfügung gestellt.
3.3.2 JDK 1.1 – JDK 1.2
In der nächsten Runde der Entwicklung wurden weitere Neuerungen implementiert,
die dem Programmierer erweiterte Möglichkeiten erschließen.
Als wesentliche optische Neugestaltung gibt es nun die Möglichkeit, das grafische
Erscheinungsbild der Programme plattformunabhängig zu gestalten. Swing ist eine
komplett neue Menge von Oberflächenelementen, die es dem Programmierer und dem
Benutzer erlauben, daß Erscheinungsbild zur Laufzeit zu verändern. Bisher existieren
Bibliotheken, um das Look&Feel von MS-Windows, Motif und einer JAVA eigenen
Optik zu erstellen. Dabei ist Swing selbst 100%-pure JAVA-Code, also ebenfalls
absolut plattformunabhängig.
17
3. JAVA
SWING mit Java-Look&Feel
SWING mit Motif-Look&Feel
Für
verteilte
Anwendungen
von
besonderer
Bedeutung
sind
die
Sicherheitsverbesserungen im JDK 1.2. Das Sicherheitskonzept erweitert bzw. ersetzt
das alte Sand-Box-Modell. Bisher durften Applets fast gar nichts, wohingegen
Applikationen vollen Zugriff auf alle Funktionalitäten haben. Das Modell beinhaltet
verschiedene Ressourcen, wie den Schreib- oder Lesevorgang aus speziellen
Verzeichnissen oder Dateien, die explizit freigeschaltet werden können. Falls die
geforderte Ressource nicht freigeschaltet ist, wird der Zugriff unterbunden. Zusätzlich
ist es möglich JAVA-Archive (JAR-Dateien) mit Zertifikaten zu versehen, die eine
größere Funktionalität erlauben als das bisherige unzertifizierte Sand-Box-Modell.
Eine verbesserte Möglichkeit zur 2D-Grafik- und Bildverarbeitung ist durch die
JAVA2D-Klassenbibliothek erreicht worden. Sie ist eine Erweiterung der bisherigen
Bibliotheken java.awt und java.awt.image und verknüpft Text, Bilder und Line-Art zu
einem einheitlichen Modell. Das API bietet einen komfortablen Alpha-Channel, also
verschiedene Durchsichtigkeitsstufen.
Das von anderen Systemen her bekannte Drag&Drop erlaubt den Datenaustausch
zwischen „nativen“ Programmen und in JAVA erstellten Programmen bzw. unter
JAVA-Programmen. Unter Programmen sind hierbei sowohl Applets als auch
Applikationen zu verstehen. Der Datentransfer zwischen JAVA-Programmen und den
nativen Programmen kann, da Systemfunktionen verwendet werden müssen, nicht
plattformunabhängig sein. Die entsprechenden Klassen sollten daher nur eingesetzt
werden, wenn es sich nicht vermeiden läßt.
Zur Vereinfachung der Bedienung von GUI-basierten Programmen wurden
Application Services eingeführt. Sie erlauben dem Benutzer, innerhalb eines
Programmes auch mit der Tastatur statt nur mit der Maus zu navigieren. In diesem
Zusammenhang ist auch die Möglichkeit zu sehen, das Aussehen des Mauszeigers und
den aktiven Punkt der Maus (HotSpot) selbst zu definieren.
Da die letzte Version des JDK noch sehr neu ist, wird sie von keinem Browser
standardmäßig unterstützt. Lediglich über PlugIns kann das reibungslose
Funktionieren gewährleistet werden. Derzeit steht das JDK1.2, welches jetzt JDK2
18
3. JAVA
heißt, auf der Website von SUNTM für die Plattformen WIN95/98/NT und SOLARIS
zum Download bereit.
3.3.3. Wahl der Version
Das zu entwickelnde Programm soll sowohl als Applet als auch als Applikation
laufen. Es werden also zwei Forderungen gestellt. Das Programm soll möglichst von
allen Browsern dargestellt werden können und es sollte mit ausreichender
Geschwindigkeit ablaufen. Wie in 3.3.1 ausgeführt, können Applets, die mit dem JDK
1.0 erstellt wurden, in jedem JAVA-fähigen Browser ablaufen, jedoch ist die
Ausführungsgeschwindigkeit unzureichend.
Unter 1.2 programmierte Applets haben den Vorteil, eine plattformunabhängige Optik
bereitzustellen, werden aber derzeit von keinem Browser unterstützt. Einen guten
Kompromiß stellt das JDK 1.1 dar, welches auf breiter Ebene unterstützt wird und
außerdem relativ schnell ist. Dieser Geschwindigkeitsvorteil wirkt nicht nur bei
Applets, sondern auch bei Applikationen.
Aus den oben genannten Gründen kann die Wahl zur Entwicklung eines Programmes
derzeit nur auf das JDK 1.1 fallen. Das unter Kapitel /10/ beschriebene Programm
wurde mit der Version 1.1.7 entwickelt, in der einige kleine Fehler der vorherigen
Versionen 1.1 – 1.1.6 beseitigt wurden.
19
4. CORBA
4
CORBA
4.1
Client & Server
Die Zeiten, als ein Großrechner für die Applikation und den Datenbestand
verantwortlich war, ist seit Ende der 70er Jahre endgültig vorbei. Damals begann der
Siegeszug der kleinen PCs, die heutzutage in jedem Büro stehen. Das hatte allerdings
zur Konsequenz, daß ein Modell gefunden werden mußte, mit dem alle Benutzer z.B.
auf einen Datenstamm zugreifen können.
Das Aufteilen der Programme und/oder Daten auf verschiedene Systeme (verteilte
Anwendungen), hat sowohl für den Programmierer, als auch den Nutzer der Software
enorme Vorteile. Durch die Lastverteilung auf mehrere Rechner, kann auch relativ alte
Hardware mit geringer Leistung heutige Aufgaben bewältigen. Zudem ist durch die
Verteilung von Daten und Applikationen die Gefahr eines völligen Datenverlustes sehr
gering. Das System, welches die Daten bereitstellt, kann vor bewußten und
unbewußten Angriffen von außen besser geschützt werden, als bei Sicherung aller
benutzten PC’s.
Diese Technik unterscheidet sich demnach grundsätzlich von der bisherigen
Arbeitsweise. Unter Windows-Betriebssystemen wurden Programm und die
zugehörigen Daten auf den eigenen Rechner kopiert, um dort lokal auf dem eigenen
Rechner zu arbeiten. Dagegen wird z.B. unter Unix lediglich die Bildschirmausgabe
umgeleitet. Die Arbeit wird auf dem entfernten Rechner durchgeführt. Mit CORBA
können Programme und Daten auf verschiedenen, durch ein Netzwerk verbundenen
Rechnern liegen und über eine definierte Schnittstelle kommunizieren. Dadurch wird
z.B. auch ein paralleles Rechnen ermöglicht, was die vorhandene Hardware wesentlich
besser ausnutzt.
Für den Programmierer ergibt sich der Vorteil, daß eine Anwendung, die Dienste
bereitstellt (Server), nur einmal entwickelt werden muß, und nicht für jede Plattform
neu. Dadurch ist auch der Einsatz von spezieller Hardware rentabel.
Als Nachteile ergeben sich die erhöhte Komplexität der Software verbunden mit der
geringen Erfahrung der Entwickler mit dieser noch relativ jungen Technik.
Als Client wird in diesem Zusammenhang ein Programm bezeichnet, wenn es von
einem anderen, dem Server, einen Dienst in Anspruch nimmt.
20
4. CORBA
Der Vorteil von verteilten Anwendungen kommt allerdings erst bei mehreren Clients
voll zum Tragen. Hierfür kommen drei grundsätzliche Architekturen in Frage:
•
•
•
2-Tier-Architektur
3-Tier-Architektur
n-Tier-Architektur
4.1.1 2 –Tier-Architektur
Hierbei haben die Clients direkten Zugriff auf die Dienste des Servers. Dadurch wird
als negativer Nebeneffekt die Netzbelastung sehr hoch, da jede Anfrage über das Netz
geleitet werden muß. Außerdem liegt beim Client die gesamte Anwendungslogik, was
die Wartung der Applikationen wesentlich erschwert.
4.1.2 3 –Tier-Architektur
Bei dieser Technik existieren nur „Thin-Clients“, welche lediglich der Interaktion mit
dem User dienen. Außerdem ist die Netzbelastung wesentlich geringer als bei der
2-Tier-Technik. Als Vorteil für den Entwickler liegt die Anwendungslogik zentral vor,
wodurch die Wartung und Weiterentwicklung erheblich vereinfacht wird.
4.1.3 n –Tier-Architektur
21
4. CORBA
Diese Technik erweitert die 3-Tier-Architektur, indem die Anwendungslogik ebenfalls
auf mehrere Server aufgeteilt wird. Dadurch erhält man einen Vorteil hinsichtlich
Wiederverwendung, Flexibilität, Wartbarkeit und Entwicklung.
4.2
Entwicklung von CORBA
Aus den oben genannten Punkten wird schnell ersichtlich, daß eine Schnittstelle
existieren muß, durch welche die einzelnen Module miteinander kommunizieren
können. Optimal ist in diesem Zusammenhang ein Medium, das zum einen
sprachunabhängig und zum anderen systemunabhängig ist. Mit der Entwicklung von
CORBA (Common Object Request Broker Architecture) ist es gelungen diese Punkte
zu vereinen.
4.2.1
OMG
Die Unabhängigkeit von verwendeter Programmiersprache und dem System wird
durch die Organisation Object Managing Group (OMG) gewährleistet. Die OMG
wurde 1989 mit acht Mitgliedern gegründet und umfaßt mittlerweile 760 Firmen und
Einrichtungen. In dieser Organisation sind neben zu erwartenden Firmen wie
MicroSoftTM, IBM oder Netscape auch andere vertreten, die ihren Nutzen aus
verteilten Anwendungen ziehen. Dazu zählen z.B. Deutsche Flugsicherung, Deutsche
Telekom, Dresdner Bank, SAP und Daimler Chrysler /7/.
Im Jahr 1990 wurde die Version 1.0 von CORBA veröffentlicht. Kurz darauf im Jahr
1991 bereits der Nachfolger 1.1. Dieser enthielt bereits das Prinzip des ObjektNachfrage-Dienstes Object Request Broker (ORB) , welches allerdings keine
standardisierte Kommunikation gewährleistete.
Mit der Veröffentlichung der Version 2.0 enthielt CORBA auch das StandardProtokoll Internet-Inter-ORB-Protokoll (IIOP), welches von allen Herstellern
implementiert werden mußte, wollten sie ihr Produkt CORBA 2.0-Kompatibel nennen.
Dadurch konnte eine echte Interoperabilität zwischen Programmen verschiedener
Anbieter sichergestellt werden. Leider ist dieses Protokoll nur auf Netzwerken mit
TCP/IP anwendbar, was aber sowohl im Internet, als auch in den meisten Intranets
gewährleistet ist.
22
4. CORBA
Die konkrete Realisation der durch die OMG veröffentlichten Standards ist allerdings
Firmensache. Es müssen keineswegs alle Möglichkeiten, die CORBA bietet,
implementiert werden.
4.2.2
ORB
Der ORB ist eine Softwarekomponente, die die Kommunikation zwischen Objekten
erleichtern soll.
Er sorgt dafür, daß eine Anwendung ein entferntes Objekt (Remote Object) findet,
wenn eine entsprechende Objekt-Referenz vorhanden ist. Diese Referenz besteht aus
einem 96Byte großen Schlüssel, über den eine eindeutige Identifizierung des
entfernten Objektes sichergestellt ist. Diese Objektreferenz wird auch als IOR
bezeichnet. Alle Methodenaufrufe erfolgen über diese Referenz. Das bedeutet, daß das
Objekt entfernt bleibt ( Call-by-Reference ).
ETA
(Server)
Startadresse eines
Corba-Objekts auf
Server-Seite
Speicherauszug
0 0 0 A F 1 7 D 9
0 B 0 0 0 0 0 0 0
ORB.object_to_string
KAPH
(Client)
ORB.string_to_object
Aufruf von Methoden
des entfernten CORBAObjekts über Referenz
LAN, WAN
Internet
23
4. CORBA
Durch die Referenz des CORBA-Objekts ist gewährleistet, daß sowohl das Objekt
selbst, als auch der Rechner, auf dem sich das Objekt befindet, eindeutig identifiziert
werden können. Der Referenz-String kann z.B. in einer Datei gespeichert und
übertragen werden.
In der Referenz sind folgenden Angaben geschlüsselt:
IP-Adresse, Port, Objekt-Typ, Objekt-Schlüssel
Beispielreferenz ( Server läuft auf Einzelplatzrechner ohne Netzwerk )
IOR:000000000000001449444c3a4b56415f436f726a6563743a312e30000000000100
0000000000005800010000000000244d6173746572426c61737465722e727a2e727568
722d756e692d626f6368756d2e64650004040000000000080000000000000000000000
00000000000000000000000000000000000000000000000000
4.2.3
IDL
Die Interface-Definition-Language dient der Definition der Schnittstelle zwischen
Client und Server. Sie stellt die Grundlage der Sprachunabhängigkeit dar. Durch eine
Abbildung der IDL-Dateien auf die Zielplattform (mapping) wird eine Umsetzung in
die Sprache des Clients bzw. Servers erreicht. Dabei bleibt die IDL absolut
unabhängig von der gewählten Zielplattform. Dies hat selbstverständlich zur Folge,
daß lediglich eine Deklaration von Methoden möglich ist, die erst in der
entsprechenden Zielsprache definiert werden können.
4.2.4
Services
Die Services, die von CORBA bereitgestellt werden, sind allgemeine Dienste, die für
den Betrieb eines verteilt arbeitenden Systems hilfreich oder erforderlich sind. Sie
haben keine Beziehung zu einer speziellen Anwendung. Von der OMG sind die in der
folgenden Abbildung genannten Services offiziell spezifiziert.
24
4. CORBA
Wie oben bereits erwähnt, kann die konkrete Umsetzung von CORBA von Firma zu
Firma variieren. In keiner Implementierung von CORBA sind alle aufgeführten
Dienste realisiert. Es ist überhaupt so, daß Object-Services nur in geringem Umfang
umgesetzt werden. Die wichtigsten drei von ihnen sind (/8/ S.42ff) die folgenden:
• Naming Service
Durch diesen Dienst können Objekte mit einem frei wählbaren Namen angesprochen
werden, dessen Grundlage der „Context“ ist. Der Context selber ist wieder ein Objekt,
in dem anderen Objekten ein Name zugewiesen werden kann. Mit diesen Namen
können Objekte dann angesprochen werden. Zu diesem Namen gehört auch ein
jeweiliges Typ-Attribut, welches ebenfalls frei gewählt werden kann. Dieses ist
vergleichbar mit der Extension einer Datei.
• Persistant Object Service
Der Zweck dieses Dienstes liegt darin, ein gemeinsames Interface für das Managen
persistenter Objekte zu schaffen. Zu Speicherung der Objekte können verschiedene
Formate gewählt werden (normale Datei, relationale DB, objektorientierte DB), für die
jedoch jeweils ein spezieller Anpassungscode geschrieben werden muß. Wichtig ist
bei dem Interface nur, daß ein Objekt die Einheit für die Speicherung darstellt, nicht
wie sonst üblich die Tabelle.
• Transaction Service
Durch diesen Dienst werden die sogenannten ACID-Charakteristiken sichergestellt,
die als Anforderungen bei einer Transaktion erfüllt werden müssen.
- Falls eine Transaktion nicht vollständig und korrekt beendet werden kann, muß
- der ursprüngliche Zustand wieder hergestellt werden. Dies nennt man „atomic“;
- nach Beendigung einer Transaktion muß der erzeugte Zustand „consistent“ sein;
- der Ablauf der Transaktion ist nach außen nicht sichtbar („isoliert“);
- die Änderungen, die durch eine Transaktion erzeugt wurden, müssen dauerhaft
- sein.
Eine Transaktion kann dabei auf zwei Arten beendet werden. „Commit“ schreibt den
durch die Transaktion herbeigeführten Zustand fest, wogegen „Roll-back“ den
Zustand vor Beginn der Transaktion wieder herstellt.
4.2.5
Facilities
In der Abbildung unter 4.2.4 sind neben den Services auch die Facilities aufgeführt.
Facilities sind Services, welche selbst Anwendungen darstellen. Ein
Dokumentationssystem kann z.B. ein „Facility“ sein. CORBA-Facilities gehören
damit zur Anwendungsebene, während die CORBA-Services der Systemebene
zugeordnet sind.
(/8/ S. 44)
25
4. CORBA
4.2.6
Mapping
Die IDL beschreibt das Interface der Klassen in einer von der Programmiersprache
unabhängigen Weise. Das hier entwickelte System wird aber in C++ bzw. JAVA
realisiert. Daher müssen die Klassen, Strukturen, Methoden usw. der IDL
entsprechend umgesetzt werden. Grundsätzlich gilt, daß die Namen unverändert
übernommen werden. Bei dieser Umsetzung (mapping) werden einige Klassen
erzeugt, die im weiteren näher erläutert werden sollen.
• Klassen der Server-Seite
Die Klasse ImplBase enthält die Basisklasse der aus der IDL erzeugten Methoden
(Skeletons). Diese Klasse wird vererbt an die Impl-Klasse, welche die einzige Klasse
ist, die vom Programmierer manipuliert wird. Dort werden die Methoden
plattformspezifisch definiert. In der Klasse Impl können auch weitere Attribute
eingeführt werden, die in der IDL noch nicht genannt sind.
• Klassen der Client-Seite
Auf der Seite des Client enthält die Klasse StubFor<KlassenName>.java die ClientStubs. Sie repräsentieren die Klassen im Client-Adressraum. Bei der Ausführung
werden daraus sogenannte Proxy-Objekte erzeugt, welche die eigentlichen Objekte im
Server-Adreßraum darstellen. Diese werden vom Client angesprochen und die Proxies
geben dann den Methodenaufruf an die eigentlichen Objekte im Server-Adreßraum
weiter.
Die Klassen <KlassenName>Helper.java enthalten Utility-Funktionen für die
entsprechende Klasse. So muß z.B., bevor ein CORBA-Objekt angesprochen werden
kann, eine Bind-Methode ausgeführt werden, welche die Verbindung zum Objekt
aufbaut.
Die Klassen vom Typ <KlassenName>Holder.java werden in bestimmten Fällen der
Parameterübergabe benötigt. JAVA kennt nur eine Übergabe per Referenz. CORBA
dagegen erweitert die Übergabemöglichkeiten mit den Angaben „in“, „inout“ und
„out“. Bei „out“ und „inout“ wird ein Holder-Objekt übergeben, welches den
Parameterwert als Datenfeld enthält. Dieses Datenfeld kann vom aufgerufenen Objekt
modifiziert werden.
26
4. CORBA
4.3
Alternativen zu CORBA
CORBA ist nicht die einzige Möglichkeit Daten zwischen verteilten Anwendungen
auszutauschen. Allerdings bietet CORBA, im Vergleich zu den folgenden Alternativen
die besten Möglichkeiten, Daten über eine objektorientierte Schnittstelle und
plattformneutral zu übermitteln.
4.3.1
Socket
Unter einem Socket versteht man einen Kanal, der dem Schreiben und Lesen von
Daten dient. Da eine Übertragung über Sockets sehr hardwarenah geschieht, ist diese
Technik für komplexe Datentypen nicht geeignet.
4.3.2
RPC
Der Remote-Procedure-Call stellt eine funktionsorientierte Schnittstelle dar, die aber
auf der Verwendung von Sockets beruht. Sie ist relativ einfach zu verwenden, da sie
wie CORBA objektorientiert aufgebaut ist. Leider ist sie nicht standardisiert und kann
daher nicht allgemein verwendet werden.
4.3.3
DCOM
Das Distributed-Component-Object-Model der Firma MicroSoft entspricht ebenfalls
einer objektorientierten Schnittstelle und ist bereits in Win95/98 und NT integriert.
Allerdings ist es außerhalb der MS-Architektur kaum zu finden.
4.3.4
RMI
JAVA bietet ein Remote-Method-Invocation ab der Version 1.1 des JDK an. Dies ist
der CORBA-Technik sehr ähnlich, bietet aber jetzt schon ein call-by-value an, was
erst in den kommenden Versionen von CORBA implementiert werden soll. RMI ist
allerdings ein JAVA-spezifisches Verfahren und daher zur Datenübertragung
zwischen Programmen verschiedener Sprachen nicht geeignet.
27
4. CORBA
4.4
Leistungsfähigkeit
Der Aufruf einer entfernten Methode über ein CORBA-Objekt dauert ca. 10ms,
wogegen der Aufruf einer lokalen Methode nur ca.10ns benötigt. Daraus ergibt sich
eine um den Faktor 1000 größere Latenzzeit. Diese Verzögerung ist größtenteils durch
das Netzwerk bedingt und kann nur unwesentlich beeinflußt werden. Durch ein
günstiges Design kann die Anzahl der Methodenaufrufe minimiert werden, wodurch
der Ablauf des Programmes optimiert werden kann. Es ist i.d.R. günstig, wenig
Methodenaufrufe zu starten und gleichzeitig viele Daten als Parameter zu übergeben.
4.4.1
Simulation der FCG
Bei einer Simulation der Forschungsgruppe Computergeometrie und Grafik am Institut
für Informatik und angewandte Mathematik der Universität Bern wurde die Latenzzeit
bei einem einfachen Methodenaufruf gemessen. Dabei wurde ein reiner Echo-Server
implementiert:
Dabei wurden folgende, nicht repräsentativen, Zeiten gemessen:
C++ORB
JAVA
-ORB
JAVA
Socket
HTTP/
CGI
FCGLAN
1
Cam
pus
10
Interne
t
160
4
13
172
2
11
165
600
/
/
Man kann erkennen, daß sich die im Vergleich zu C++ wesentlich geringere
Ausführungsgeschwindigkeit von JAVA kaum auswirkt. Die Verzögerungen entstehen
im wesentlichen durch das Internet. Die Ursachen können Router oder Firewalls sein.
Ebenfalls ist ersichtlich, daß die Verwendung von CGI-Skripten nicht empfohlen
werden kann (/13/ S.42 ).
28
4. CORBA
4.4.2
Simulation der Credit Suisse
/14/
- 100 Clients (Zürich) greifen acht Tage lang fortwährend auf den Server (New York)
über das CS eigene WAN zu
- Die Zeit umfaßt das Senden von Parametern, die Operation und das Zurücksenden
des Resultates
- Ca. 100 Operationen/Sekunde
- Server: SUN Ultra1, 64MB RAM
- ORB: Orbix von IONA
29
5. C++ und Fortran
5
C++ und Fortran
5.1
Allgemein
Auf die Programmiersprachen C/C++ sowie Fortran soll an dieser Stelle nicht weiter
eingegangen werden. Lediglich der Aufruf von Routinen, die in den beiden Sprachen
geschrieben wurden, soll hier erläutert werden.
Damit der Quellcode von Routinen, die in Fortran oder C++ programmiert wurden, auf
Objektebene kompatibel ist, müssen sämtliche Funktionen als extern „C“ deklariert
werden. Dies gilt sowohl für den Aufruf von C++-Routinen von Fortran aus, als auch in
umgekehrter Richtung (/9/ S. 1ff).
5.1.1 Main-Methode
Da diese Arbeit aus verschiedenen Programmmodulen zusammengesetzt ist, ist ein
weiterer Punkt zu beachten.Die Main-Methode, die in jedem Programm nur einmal
vorhanden sein darf, sollte im C++-Teil enthalten sein. Falls es notwendig sein sollte,
kann in der C++-Main-Methode auch nur der Aufruf einer Fortran-Routine stehen, die
anschließend das weitere Programmverhalten bestimmt. Das hat zur Folge, daß in den
Fortran-Modulen nur Subroutinen stehen dürfen, aber keinesfalls ein vollständiges
Programm.
5.1.2 Naming-Conventions
Im Gegensatz zu den C++-Compilern behandeln Fortran-Compiler Variablen- und
Funktionsnamen ohne case-sensitivity. Das heißt, daß keine Unterscheidung zwischen
Groß- und Kleinschreibung vorgenommen wird. Daher sollten alle Methoden, auf die
von Fortran zugegriffen wird ausschließlich mit Kleinbuchstaben benannt werden.
Alle Funktions- und Variablennamen, die von C++ in Fortran verwendet werden,
werden automatisch „downgeshifted“.
5.1.3 Subroutines
Beim Aufruf von Subroutinen, ist zusätzlich zu den sonstigen Naming-Conventions zu
beachten, daß neben der Kleinschreibung noch ein Underscore angehängt wird. Dieser
ist zu berücksichtigen, da ansonsten die Routine nicht gefunden wird.
Außerdem existiert die Einschränkung, daß Subroutines innerhalb von Modulen von
C++ nicht aufgerufen werden können (/10/).
30
5. C++ und Fortran
5.2
Datenübergabe
Die Datenübergabe zwischen C++ und Fortran kann, wie bei der CORBA-Schnittstelle
im Übrigen auch, nur durch „call-by-reference“ realisiert werden. Unter C++ existieren
dafür zwei verschiedene Möglichkeiten.
-
Übergabe der Adresse des Parameters mittels des Derefenzierungsoperators
Übergabe mit Referenzvariablen (übliche Methode)
Dabei ist zu beachten, daß Felder jeder Art von C++ grundsätzlich per Referenz
übergeben werden. Um ein Maximum an Kompatibilität zu erreichen, sollte von der
Übergabe komplizierter Strukturen abgesehen werden und nur Basisdatentypen
verwendet werden.
5.2.1 Strings
Bei der Übergabe von Strings ist zu beachten, daß sie in C++ und Fortran
unterschiedlich terminiert werden. Fortran definiert einen String durch dessen
Startadresse und seine Buchstabenanzahl. C++ terminiert Strings durch ein angehängtes
NULL.
Um dennoch korrekt Strings an Methoden oder Subroutines übergeben zu können,
wird am einfachsten eine Klasse oder Struktur definiert, die wie folgt aussehen kann:
structure fstring
{
long i;
char* s;
}
Wichtig ist in diesem Zusammenhang auch die Verwendung von Strings in Fortran,
die, im Gegensatz zu C++ oder JAVA, keine variable Länge besitzen können.
Dieser Unterschied macht es unmöglich, Strings auf herkömmliche Art von C++ nach
Fortran zu übergeben. Durch ein struct ist es möglich, logisch zusammenhängende
Variablen zu verknüpfen, und über einen gemeinsamen Namen anzusprechen. Im
Gegensatz zu einer echten Klasse kennt ein struct allerdings keine Methoden.
In diesem Fall übergibt man die Adresse einer Zeichenkette und ihre Länge. Aus
diesen Informationen kann die Zeichenkette wiederhergestellt werden.
5.2.2 Arrays
Die Verwaltung von mehrdimensionalen Feldern erfolgt nach unterschiedlichen
Konzepten. C++ speichert Arrays gemäß der „row-major-order“ Fortran aber nach der
„column-major-order“. Um die jeweils richtigen Elemente zu erhalten, muß also ein
Konvertierungsalgorithmus entworfen werden, der die Felder transponiert.
Erschwerend kommt hinzu, daß bei C++ der Zählindex bei „0“ beginnt und nicht wie
bei Fortran mit „1“. Zusätzlich verlangt Fortran bei dynamischen Feldern die „leading
dimension“, damit das Feld korrekt belegt werden kann.
Um Schwierigkeiten so weit wie möglich aus dem Weg zu gehen, sind alle Felder eindimesional übergeben worden, und auf Fortran-Seite unter Benutzung der Zeilen- und
Spaltenzahl neu angelegt worden.
31
5. C++ und Fortran
5.2.3 Andere Datentypen
Unter Berücksichtigung der oben genannten Restriktionen ist eine Verwendung der
Basisdatentypen wie int, long, double, float etc. ohne weitere Einschränkungen
möglich.
32
6. Client
6
Client
6.1
Anforderungen an den Client
6.1.1 Statisches System / Lasten
Für das statische System soll eine grafikunterstützte Eingabemöglichkeit gegeben sein.
Hierbei müssen Daten wie Knotenkoordinaten, Querschnittsangaben und
Materialwerte interaktiv eingegeben werden können. Dabei ist der stochastische
Charakter der Parameter ( insbesondere der Materialdaten ) zu berücksichtigen. Aus
diesen Eingaben sollen auf Serverseite automatisch die FEM-Eingangsdaten zur
Kovarianzanalyse generiert werden.
Für Windlasten sind die signifikanten Angaben ebenfalls grafikunterstützt einzulesen.
Eine Übertragungsmatrix zum Server soll automatisch erstellt werden.
Querschnittseingaben sind in einer zu erstellenden Datenbank zu speichern. Dabei ist
die Möglichkeit zu berücksichtigen, daß sowohl selbstdefinierte Profile, als auch
genormte Profilreihen Verwendung finden können. Der stochastische Charakter der
Abmessungen ist, ebenso wie bei den Materialdaten, zu beachten.
6.1.2 Benutzungsoberfläche
Insgesamt soll sich die Optik der Benutzungsoberfläche an den Standardprogrammen
orientieren. Durch die Verwendung von Icons wird die Steuerung des
Programmablaufs wesentlich vereinfacht und beschleunigt.
Zu den Standard-Icons, wie sie in jedem Windows-Programm Verwendung finden,
gehören (v.l.n.r.):
Beenden, Neu, Öffnen, Speichern, Drucken, Netzwerk, Hilfe
Zur Eingabe der Tragwerksdaten wurden selbst entworfene Icons eingefügt. Sie sind
ebenfalls selbsterklärend gestaltet (v.l.n.r.):
Knoteneingabe, Stabeingabe, Lasteingabe, Profileingabe, Materialeingabe,
Verteilungsanzeige, Wöhler-Kurven
Auf die Verwendung von Pull-Down-Menüs wurde verzichtet. Da das Programm als
Applet und als Applikation lauffähig sein soll, ist diese Technik nicht anwendbar.
Menüs können nur einem Objekt der Klasse java.awt.Frame zugewiesen werden, und
keinem Objekt java.applet.Applet.
Zusätzlich zu den Icons kann in der Zeichenfläche mit einem Klick mit der rechten
Maustaste im Zeichenbereich ein kontext-sensitives Pop-Up-Menu aufgerufen
werdem. In Abhängigkeit von dem darunter liegenden Objekt stehen verschiedene
Aktionsmöglichkeiten zur Auswahl.
33
6. Client
Damit die Verwendung des Programms nicht unnötig unübersichtlich wird, ist die
gesamte Oberfläche lediglich in vier Bereiche geteilt (s. Kap. 10.3).
•
•
•
•
MenüIcon-Bereich:
In diesem Bereich sind ständig die Icons dargestellt, mit denen zwischen den
verschiedenen Eingabemodi gewechselt werden kann.
Zeichen-Bereich:
Hier werden wahlweise das Tragwerk, Querschnitte, Wöhlerlinien oder
Verteilungen dargestellt. Bei der Darstellung des Tragwerkes kann zusätzlich
angegeben werden, ob Knotennummern, Stabnummern, Lasten oder
Randbedingungen angezeigt werden sollen.
Informations-Bereich:
Es werden schriftliche Informationen zu den Objekten angegeben, die mit der
Maus überfahren werden.
Eingabe-Bereich:
Im Eingabe-Bereich können Daten zu Knoten, Stäben, Materialien, Lasten oder
Wöhlerlinien eingegeben werden. Die Datenfelder zur Eingabe wechseln mit
einem Klick auf das entsprechende Icon.
Im Abschnitt „Benutzerhandbuch“ wird auf die Verwendung der Oberflächenelemente
und anderer Optionen genauer eingegangen.
6.1.3 Verteiltes System
Da es sich um ein verteilt arbeitendes System handelt, soll als Schnittstelle zu den
Servern das Standard-Kommunikationsmedium CORBA verwendet werden. Auf diese
Weise sollen die bisher getrennt arbeitenden Module zu einer logischen Einheit
zusammengefügt.
Der Client übernimmt in diesem Zusammenhang die Aufgaben der Dateneingabe,
Aufbereitung für den jeweiligen Serverprozeß und Darstellung der zurückgegebenen
Ergebnisse.
Es wurde die denkbar einfachste Möglichkeit einer Client-Server-Anwendung
gewählt. Dabei handelt es sich um die unter 4.1.1 beschriebene 2-Tier-Architektur,
wenn das Programm als Applikation gestartet wird. Führt man es als Applet aus, kann
man die Architektur auch als 3-Tier interpretieren, da die Anwendungslogik vom
Arbeitsplatz des Clients gelöst ist und von einem weiteren Server zur Verfügung
gestellt wird. Allerdings müßte dann noch eine Anbindung an ein Datenbank realisiert
werden, da das Speichern aus einem Applet heraus unmöglich ist. Am besten hierfür
geeignet ist eine Objektorientierte Datenbank wie z.B. Oracle8i.
34
6. Client
Symbolische Darstellung bei Verwendung des Clients als Applet aus dem Internet
Datenbank-Server
KVA-Server
Arbeitsplatz
mit Internetanschluß
und Browser
Applikationsserver
SVD-Server
weitere Server
Verwendung des Clients als Applikation innerhalb eines beliebigen Netzwerkes
SVD-Server
KVA-Server
weitere Server
Arbeitsplatz
35
6. Client
6.2
Entwurf
6.2.1 Einleitung
Der Entwurf eines Programmes ist die eigentliche Schwierigkeit bei der
Programmierung. Dabei werden die zu verwendenden Klassen mit ihren Attributen
sowie Methoden entwickelt. Zur Darstellung der Beziehung der Klassen untereinander
hat sich die Unified-Modeling-Language (UML) weitgehend durchgesetzt.
Die Entwicklung eines Modells für Software vor ihrer Umsetzung ist ebenso wichtig
wie der Bauplan für ein großes Gebäude. Ein gutes Modell ist für die Kommunikation
innerhalb eines Projektteams genauso bedeutend wie für das spätere Funktionieren des
Programms. Es gibt verschiedene Faktoren, die auf den Erfolg eines Projektes Einfluß
haben, aber der Einsatz eines eindeutigen Standards für die „modeling language“ ist
ein besonders wichtiger Punkt. Eine „modeling language“ muß daher folgendes
beinhalten:
•
•
•
Modellelemente
Notation
Richtlinien
Da in der heutigen Zeit Softwaresysteme unglaublich komplex geworden sind, ist die
Visualisierung durch Modellelemente extrem wichtig geworden. UML ist eine
ausgereifte Antwort auf diese Anforderungen und hat sich mittlerweile zu einem
Industriestandard entwickelt (/11/ S.2).
Alle Objektdiagramme, Klassen- oder Instanzendiagramme, sind entsprechend der
Version 1.1 dieser Notation entworfen (vgl. /12/).
6.2.2 Gliederung des Programms
Das vorliegende Client-Programm JARL kann in einem ersten Schritt grob in folgende
Klassen gegliedert werden:
java.applet.
Applet
Start
1
erzeugt
0..*
Programm
1
1
Module_ClientChoice
1
Module_Construction
1
Module_SVD
1
Module_KVA
1
Module_RES
Dabei sind unter den Modulen nicht eigenständige Programme zu verstehen, als
vielmehr Codesequenzen, die jeweils eine spezielle Aufgabe erfüllen.
36
6. Client
6.3
Klassen des Client
Im folgenden werden ausgewählte Klassen des Clients näher beschrieben. Dabei wird
allerdings nicht näher auf verwendete Algorithmen eingegangen, deren Funktion im
Quellcode sehr ausführlich kommentiert ist.
Hier alle Klassen aufzuführen und zu beschreiben ist ohnehin überflüssig, da sie mit
allen Attributen und Methoden in der HTML-Online-Dokumentation
zusammengestellt wurden. Dort sind alle Attribute und Methoden, deren Bedeutung
bzw. Parameterliste und Ergebniswerte aufgeführt.
In diesem Dokument werden ebenfalls die vorhandenen Beziehungen zu geerbten
Klassen und Interfaces in einer Baumstruktur sofort ersichtlich. Dieses OnlineDokument kann mit jedem Browser betrachtet werden. Als Startseite dient entweder
die Datei tree.html oder AllNames.html aus dem Verzeichnis \Client auf dem
beiliegenden Datenträger.
6.3.1 Start
Da das Programm JARL sowohl als Applet als auch als Applikation lauffähig sein
soll, kommt der Klasse Start eine zentrale Bedeutung zu. In Abhängigkeit der
Ausführungsform werden dort verschiedene Methoden aufgerufen, die wiederum eine
Instanz der Klasse Programm sowie die Oberfläche erstellen.
Wenn die Anwendung als Applet gestartet wird, wird zuerst der Konstruktor der
Klasse Start aufgerufen, danach die Methode init(), die wiederum ein ProgrammObjekt erzeugt.
Als Applikation gestartet, wir zunächst die main()-Methode gestartet. Dort wird dann
das Programm-Objekt instanziiert.
class notation: implementation-level details
Start
{ public,
author = S.Sü.,
status = tested }
programm
<<constructor>>
+Start( )
<<query>>
+init( )
+main( s:String[] )
+paint( g:Graphics )
:
Programm
:
void
:
:
:
void
void
void
Auf der vorangegangenen Seite ist die oben erwähnte Online-Hilfe zu dieser Klasse
beispielhaft angegeben. Zu beachten ist, daß in dem HTML-Dokument Links zu
entsprechenden Klassen vorhanden sind.
37
6. Client
Der Konstruktor der Klasse Start muß nicht überladen werden, da er keine besondere
Aufgabe erfüllt. Im Sinne einer „ordentlichen“ Programmierung sollte er aber immer
neu geschrieben werden.
6.3.2 Program
Wie unter 6.2.2 bereits dargestellt, ist das Programm in fünf Abschnitte unterteilt.
Diese bilden eine logische Einheit und können nicht getrennt voneinander ablaufen.
Diese Module (Klassen) sind als Attribute in der Klasse Program gekapselt.
Bei der interaktiven Eingabe von Daten kommt der Oberflächengestaltung eine
erhebliche Bedeutung zu. Um die Bedienung unabhängig von der Ausführungsform
des Programms (Applet oder Applikation) einheitlich zu gestalten, muß die
Vererbungsstruktur von Java ausgenutzt werden. Da Applet, genauso wie Frame, die
Klasse Container erbt, kann auf diese Weise elegant ein Oberflächenattribut
geschaffen werden, welches das Frontend beinhaltet.
class notation: implementation-level details
Program
{public,
author = S.Sü.,
status = tested }
-isAnApplet
-module_clientChoice
-module_construction
-module_svd
-module_kva
-module_RES
-container
<<constructor>>
Programm( container:Container )
<<query>>
-createAttribs( container:Container )
-makeFunctionality( )
-makeOutfit( )
<<eventhandling>>
+windowClosing( w_evt:WindowEvent)
<<set & get>>
+getIsAnApplet( )
+getModule_clientChoice( )
+getModule_construction( )
+getModule_kva( )
+getModule_svd( )
:
:
:
:
:
:
:
boolean
Module_ClientChoice
Module_Construction
Module_SVD
Module_KVA
Module_RES
Container {size=1000*650, frozen }
:
:
:
void
void
void
:
void
:
:
:
:
:
boolean
Module_ClientChoice
Module_Construction
Module_KVA
Module_SVD
Aus der Klassennotation ist ersichtlich, daß der Container, der das Frontend enthält,
für die gesamte Laufzeit des Programms seine Größe nicht ändern darf. Das liegt
wiederum an der Tatsache, daß der Client als Applet und als Applikation laufen kann.
Bei einem Applet wird die Größe des sichtbaren Bereiches durch das HTMLDokument definiert, worauf der Nutzer keinen Einfluß hat. Damit ein einheitliches
Erscheinungsbild gewährleistet ist, wird die Größe des Frames für die Applikation auf
dieselben Abmessungen festgelegt.
38
6. Client
6.3.3 Module_ClientChoice
Das Objekt der Klasse Module_ClientChoice stellt lediglich eine Auswahlmöglichkeit
für den Benutzer dar. Die optische Repräsentation dieses Objektes kann zu jedem
beliebigen Zeitpunkt angezeigt werden, um einen anderen Programmabschnitt zu
starten. Es macht allerdings nur Sinn einen Server zu starten, wenn die Ergebnisse aus
den vorangegangenen erforderlichen Berechnungen vorliegen.
6.3.4 Module_Construction
Das Module_Construction enthält alle für ein Tragwerk wesentlichen Angaben zu
Knoten, Stäben und deren Eigenschaften. Die Attribute umfassen aber nicht nur die
Daten eines einzelnen, speziellen Systems, sondern auch Datenbanken mit allen
verwendeten, aber auch nicht verwendeten, Wöhlerlinien, Profilen und Materialien.
Aus diesen Datenbanken können die entsprechende Objekte für das aktuelle Tragwerk
benutzt werden. Es ist allerdings auch möglich, neu eingegebene Elemente zu
verwenden, die automatisch in der entsprechenden Datenbank gespeichert werden.
1
Construction
1
1
WoehlerData
Base
CrossSection
DataBase
besteht aus
Module_Construction
1
1
MaterialData
Base
1
Programm
1
1
FrontEnd_
Construction
java.awt.
Container
39
6. Client
Das Module besitzt, wie alle anderen Module auch, eine optische Darstellung. Dort
kann das Tragwerksprojekt über eine Menüleiste gesteuert werden. Näheres ist dem
Benutzerhandbuch zu entnehmen.
Die interaktive Oberfläche zur Eingabe und Visualisierung der Eingabedaten sind
hierbei, neben dem Tragsystem, das komplexeste Objekt des gesamten Projekts.
•
FrontEnd_Construction
In dem Objekt der Klasse FrontEnd_Construction sind alle Oberflächenelemente
zur vollständigen Eingabe eines Tragwerkes enthalten. Die oben bereits erwähnte
Aufteilung der Arbeitsoberfläche in vier logisch getrennte Module wird hier durch
die Attribute deutlich:
Class notation: implementation-level details
FrontEnd_Construction
{ public,
author: S.Sü.
status: tested }
- drawArea
- statusArea
- drawArea
- inputArea
- nodesInputArea
- beamsInputArea
- loadInputArea
- materialInputArea
- crossSectionInputArea
- verteilungInputArea
- woehlerInputArea
- drawAreaPropertyInputArea
- layout
- all
- module_construction
:
:
:
:
:
:
:
:
:
:
:
:
:
:
:
DrawArea
StatusArea
DrawArea
InputArea
NodesInputArea
BeamsInputArea
LoadInputArea
MaterialInputArea
CrossSectioninputArea
VerteilungInputArea
WoehlerInputArea
DrawAreaPropertyInputArea
BorderLayout
Container
Module_Construction
<<constructor>>
+ FrontEnd_Construction( module_construction: ModuleConstruction
all
: Container )
<<query>>
- createAttribs( )
- makeFunctionality( )
- makeOutfit( )
+ repaint( )
+ paint( g : Graphics )
+ mousePressed( m_evt : MouseEvent )
+ mouseClicked( m_evt : MouseEvent )
+ mouseReleased( m_evt : MouseEvent )
+ mouseEntered( m_evt : MouseEvent )
+ mouseExited( m_evt : MouseEvent )
:
:
:
:
:
:
:
:
:
:
void
void
void
void
void
void
void
void
void
void
<<set-methoden>>
+ setContainer( c : Container )
+ setMenuArea( ma : MenuArea )
+ setDrawArea( da : DrawArea )
+ setInputArea( ia : InputArea )
+ setStatusArea( sa : StatusArea )
+ setCrossSectionInputArea( csia : CrossSectionInputArea )
:
:
:
:
:
:
void
void
void
void
void
void
<<get-methoden>>
+ getAll( )
+ getMenuArea( )
+ getDrawArea( )
+ getInputArea( )
+ getNodesInputArea( )
+ getBeamsInputArea( )
+ getLoadInputArea( )
+ getWoehlerInputArea( )
+ getStatusArea( )
+ getDrawAreaPropertyInputArea( )
+ getCrossSectionInputArea( )
+ getMaterialinputArea( )
+ getVerteilungInputArea( )
+ getModule_construction( )
:
:
:
:
:
:
:
:
:
:
:
:
:
:
Container
MenuArea
DrawArea
InputArea
NodesInputArea
BeamsInputArea
LoadInputArea
WoehlerInputArea
StatusArea
DrawAreaPropertyInputArea
CrossSectionInputArea
MaterialInputArea
VerteilungInputArea
Module_Construction
40
6. Client
Innerhalb des FrontEnd_Construction-Objektes kommt der Klasse DrawArea eine
zentrale Bedeutung zu. Sie stellt den Zeichnungsbereich dar. Dort ist eine
besondere Interaktion mit dem Nutzer erforderlich, um das Arbeiten so einfach wie
möglich zu gestalten. Alle Events innerhalb der Zeichnungsfläche müssen dort
bearbeitet werden( verbinden von Knoten mit Stäben, markieren von Knoten oder
Stäben, PopUp-Menüs ). Daher sind die Routinen zum Eventhandling
entsprechend umfangreich. Durch das neue Event-Modell im JDK 1.1 ist eine
Aufteilung nach Ereignissen jedoch problemlos möglich und relativ übersichtlich.
Für jeden Ereignistyp existiert eine eigene Methode zum abfangen der
Benutzereingabe.
•
Construction
Statische Systeme bestehen aus einer unterschiedlichen Anzahl von Knoten und
Stäben. Knoten können Randbedingungen bezüglich der Freiheitsgrade aufweisen;
Stäbe können aus verschiedenen Materialien bestehen und verschiedene
Querschnitte aufweisen. Bauteile können einem Kerbfall zugeordnet werden,
Lasten können auf Bauteile wirken.
Aus dieser sehr kurze Beschreibung von Tragwerken, kann bereits ein einfaches
Klassenmodell entwickelt werden:
Construction
NodesDataBase
BeamsDataBase
Dabei enthalten die Datenbanken die zum System gehörenden Knoten und Stäbe
mit allen ihnen zugewiesenen Attributen.
•
Datenbanken
Da das Programm in erster Linie entworfen wurde, um als Applikation abzulaufen,
sind die Datenbanken integraler Bestandteil der Anwendung. Bei einer
Verwendung als Applet, welches wie bereits erwähnt durch zahlreiche
Einschränkungen begrenzt ist, muß ein Datenbankserver implementiert werden.
Als dynamische Daten liegen zum einen die Tragwerksdaten vor, zum anderen die
Daten für Profile, Materialien und Wöhlerlinien, womit der Benutzer Tragwerke
schnell und unkompliziert eingeben kann.
Um Daten dynamisch speichern zu können, d.h. die Datenbank wächst bei Bedarf,
kann eine einfach oder doppelt verkettete Liste benutzt werden. Die Einführung
besonderer Klassen hierfür ist unter JAVA allerdings unnötig, da das Paket
java.util verschiedene Versionen für solche Ketten zur Verfügung stellt. Die
Klasse Vektor ist eine verkettete Liste, die Methoden besitzt, mit der ein
Programmierer beliebige Objekte hinzufügen oder entfernen kann. Eine
Alternative zur Klasse Vektor ist Hashtable, in der Objekte über einen Schlüssel
eingefügt und ausgelesen werden.
41
6. Client
Die drei Datenbanken werden bei jeder Eingabe aktualisiert und bei Beendigung des
Programmes komplett als Objekt in dem File databases.wcm gespeichert. Die
Extension .wcm bedeutet dabei: woehler, cross-section, material
Hier repräsentativ die Datenbank der Materialien:
class notation: implementation-level details
MaterialDataBase
{ public,
author: S.Sü.
status: tested }
- module_construction
- dataBase
:
:
Module_Construction
Vector
<<constructor>>
+ MaterialDataBase( module_construction : Module_Construction )
<<query>>
+ addMaterial( material : Material )
+ delMaterial( material : Material )
+ getMaterial( name : String )
+ getMaterial( pos : int )
+ materialExist( material : Material )
:
:
:
:
:
void
void
Material
Material
boolean
<<set & get>>
+ setDateBase( dataBase : Vector )
+ getDataBase( )
:
:
void
Vector
Alle anderen Datenbanken sind analog aufgebaut.
6.3.5 Module_SVD
Im Rahmen dieser Diplomarbeit wurde das Programm zur Singulärwertzerlegung nich
vollständig auf den Serverbetrieb umgestellt. Provisorisch wurde das Modul zur
Herstellung einer Verbindung mit dem SVD-Server so implementiert, daß eine spätere
Erweiterung ohne Schwierigkeiten erfolgen kann.
Die Klasse Module_SVD stellt Methoden bereit, durch die mit dem Server zur
Singulärwertzerlegung kommuniziert werden kann. Im derzeitigen Stadium des
Programms werden nur Matrizen vom Server zum Client übertragen (vgl. Kap. 7.1).
Hierzu wird aus einem String, der in der Datei reference.svd gespeichert ist und
eine Referenz auf ein entferntes Objekt darstellt, mit der CORBA-Methode
string_to_object( <string> ) der Klasse ORB ein Objekt der Klasse KVA_Corject
erstellt. Über die Referenz auf dieses Objekt können Methoden verwendet werden, die
unter anderem der Datenübertragung dienen.
Aus oben genannten Gründen, liest der Server derzeit nur eine Ergebnisdatei aus, und
überträgt diese Daten an den Client, der sie wiederum für die weitere Verwendung
beim KVA-Server aufbereitet. Wenn die Aufrufe der entsprechenden FortranSubroutines angepaßt wurden, ist das Einbinden in die verteilte Architektur sehr
einfach, da die entsprechende Schnittstelle bereits vorhanden ist.
42
6. Client
6.3.6 Module_KVA
Wie die Klasse Module_SVD auch, dient Module_KVA der Verbindungsaufnahme
mit einem Server. Allerdings werden hier sämtliche Tragwerksdaten und einige
zusätzliche Informationen (Windlasten, Dämpfung etc.) benötigt. Durch geeignete
Methoden werden diese Daten an den Server übertragen, der dann die Berechnung
ausführt. Weitere Informationen zu den Servern werden in Kapitel 8 gegeben.
6.3.7 Module_RES
Die Klasse Module_RES stellt lediglich Funktionalitäten bereit, mit denen die
gewonnenen Ergebnisse grafisch aufbereitet und angezeigt werden können.
43
7. CORBA-Schnittstelle
7.
CORBA-Schnittstelle
Wie bereits im 4. Kapitel ausführlich beschrieben, dient die IDL der Definition der
Schnittstelle zwischen dem Client und dem Server. Dabei können mit interfaces und
structs klassenähnliche Strukturen gebildet werden.
Ein struct dient der Zusammenfassung verschiedener, logisch zusammenhängender
Variablen unterschiedlichen Datentyps zu einer Einheit. Diese Daten können
anschließend mit einem gemeinsamen Namen angesprochen werden.
Ein Interface definiert die Schnittstellenoperationen einschließlich der Parameter und
der Rückgabewerte. Unterschiedliche Interfaces können zu einem Modul
zusammengefaßt werden, was in diesem Projekt aber nicht benötigt wurde.
Methodenaufrufe können dabei auf die zwei Arten blocked und unblocked geschehen.
Bei der ersten Methode wartet der Client mit der Ausführung weiterer
Programmschritte, bis der Server die Methode abgearbeitet hat. Dies bedeutet, daß der
Client unter Umständen eine relativ lange Zeit keine Antwort auf Benutzereingaben
geben kann. Um dem Verdacht eines Programmabsturzes entgegenzutreten, ist es
sinnvoll, den Client, und entsprechend natürlich auch den Server, multi-thread-fähig
zu entwerfen. Über einen Fortschrittsbalken kann der zeitliche Ablauf der Aktion
visualisiert werden. Unter JAVA würde dies mit den Klassen aus dem Paket
java.lang.* keine Schwierigkeiten bereiten. Da aber die Fortran-Module nur unter
erheblichen Arbeitsaufwand auf diese Eigenschaft umgeschrieben werden können,
zumal Fortran kein multithreading unterstützt, wurde darauf verzichtet.
Bei der unblocked-Methode arbeitet der Client nach dem Aufruf der entfernten
Methode den Code weiter ab. Das hat zur Konsequenz, daß in regelmäßigen
Abständen überprüft werden muß, ob die Ergebnisse des Servers vorliegen. Eine
weitere Lösungsmöglichkeit ist, daß der Client ein CORBA-Objekt erzeugt, über
welches der Server dann Methoden auf Client-Seite aufrufen kann, wenn er die
Berechnung beendet hat. Bei dieser Technik ist keine eindeutige Trennung in Client
und Server möglich, da beide Programme Dienste bereitstellen bzw. anfordern.
Im vorliegenden Fall werden die Methoden des Servers blocked aufgerufen, wobei der
Client eine entsprechend lange Wartezeit hat, bis der Server antwortet.
Da entfernte Aufrufe besonders langwierig sind, stellt eine Verwendung von wenigen
Methoden mit vielen Parametern eine Optimierung dar. Dies wurde besonders bei der
Übertragung der Matrizen beachtet, die in einem einzigen Feld als Parameter
übergeben werden. Hinsichtlich der Sicherheit und Stabilität der Datenübertragung
wird in Kapitel 9 näher darauf eingegangen.
44
7. CORBA-Schnittstelle
7.1
SVD
7.1.1 Structs
Da im Falle des Servers zur Singulärwertzerlegung bereits bestehende Matrizen aus
einer Binär-Datei gelesen werden, und diese Daten sofort an den Client gesandt
werden, ist die Schnittstelle zwischen Client und Server sehr einfach gestaltet. Die
Fortran-Routinen werden dabei nicht aufgerufen.
Aus diesem Grund existiert nur ein struct zur Übertragung der vollständigen Matrix:
•
7.1.2
Matrix_SVD_Corject:
Rows, columns, 1-D-Feld mit reellwertigen Zahlen
Interface
Da, wie oben erwähnt, das Fortran-Programm zur Singulärwertzerlegung nicht
vollständig auf den Betrieb als Server umgestellt ist, sind hier nur drei Methoden
erforderlich um die Ergebnismatrizen A, B und C zu übertragen.
Gemäß Namenskonvention werden sie getMatrix_A() usw. genannt. Diese Methoden
haben als Rückgabewert ein CORBA-Objekt vom Typ SVD_Matrix_Corject, in dem
ebenfalls Angaben über Spalten und Zeilen gekapselt sind.
7.2
KVA
7.2.1 Structs
Alle logisch zusammenhängenden Datenstrukturen, die für die Kovarianzanalyse von
Bedeutung sind, werden in den klassenähnlichen structs zusammengefaßt. Für die
Kovarianzanalyse sind die Tragwerksdaten und einige Zusatzinformationen zur
Berechnung unverzichtbar. Um deutlich zu machen, daß es sich dabei um CORBAStrukturen handelt, wurde eine einheitliche Nomenklatur der Form
Name_KVA_Corject eingeführt. Dadurch wird eine Verwechslung mit Klassen des
Client verhindert.
Folgende Strukturen wurden daher zur Übertragung der Systemeigenschaften
eingeführt:
•
Material_KVA_Corject:
Nummer, E-Modul, G-Modul, Wichte
•
CrossSection_KVA_Corject:
Nummer, h, b, s, t, r, a, aq, iy
•
Beam_KVA_Corject:
Nummer, LKnotenNr, RKnotenNr, MaterialNr, ProfilNr
•
Node_KVA_Corject:
45
7. CORBA-Schnittstelle
•
•
Nummer, x-Koordinate, y-Koordinate, u, v, phi (Freiheitsgrade )
H_KVA_Corject:
iVon, iBis, incr, offset
Matrix_KVA_Corject:
Rows, columns, 1-D-Feld mit reellwertigen Zahlen (zum Übertragen der
Ergebnissmatrizen lambda und v)
Es wurde bewußt auf eine objektorientierte Modellierung des Gesamttragwerkes
verzichtet, da die Daten auf Client-Seite bereits strukturiert vorliegen. Nebenbei
können die relevanten Informationen direkt übergeben werden, wodurch unnötige
Methodenaufrufe entfallen und die Performance gesteigert wird(vgl. 4.4).
Eine Abbildung des gesamten Tragwerkes in CORBA-Objekten ist zwar möglich und
auch sinnvoll, wenn es um die Darstellung bzw. Speicherung in einer Datenbank geht.
Bei einer interaktiven Benutzungsoberfläche, wie sie hier vorliegt, ist diese Technik
allerdings erheblich zu langsam, da bei jeder Benutzereingabe (d.h. auch bei einer
Mausbewegung) Daten vom Tragwerk angefordert werden. Außerdem sollte das
Tragwerksmodell auf Client-Seite gebildet werden, da kein Datenbankserver existiert,
auf den alle anderen Server zugreifen können, um Informationen zu erlangen.
7.2.2 Interface
Als Interface zur Übertragung der Strukturen wurde ein Interface KVA_Corject
gebildet, das die notwendigen Methoden zur Datenübertragung zur Verfügung stellt.
Dabei wurde die bei objektorientierten Programmen übliche Namengebung set und get
verwendet, um Daten zu schicken und zu empfangen. Als Beispiele hierfür gelten:
•
•
•
•
setNode(Node_KVA_Corject)
setMatrix_A(Matrix_KVA_Corject)
getLambda()
getV()
Als Methode zum Starten der eigentlichen Berechnungsroutinen unter Fortran dient
serverStartCalculation(). In ihr wird die Fortran-Subroutine KVA aufgerufen, wobei
alle Parameter, die zur Kovarianzanalyse erforderlich sind, in einem einzigen Schritt
übergeben werden.
46
8. Server
8.
SERVER
Ein Server ist, wie in Kapitel 4.1 beschrieben, ein Programm, welches Dienste für
andere Programme bereitstellt. Es stehen in diesem Fall mehrere Server zur
Verfügung, wobei jeder Teilrechnungen für die Lebensdaueroptimierung durchführt.
Jeder Server besteht hierbei aus einem C++- und einem Fortran-Teil. Die C++-Sequenz
erzeugt das jeweilige CORBA-Objekt, wandelt es in einen Referenz-String und stellt
diesen dem Client zur Verfügung. Dies wird bei einer Applikation gewährleistet,
indem der String in einer Datei gespeichert wird, die vom Benutzer in das
Programmverzeichnis der Client-Anwendung kopiert werden muß. Soll der Client als
Applet gestartet werden, ist der String in ein entsprechendes HTML-Dokument zu
schreiben, aus dem der Client ihn als Parameter auslesen kann (vgl. Kap. 9.3).
Nachdem dieser String auf Client-Seite wieder in ein CORBA-Objekt überführt
wurde, kann der Client alle Schnittstellenmethoden des entfernten Objektes aufrufen
und die notwendigen Daten übertragen. Anschließend wird die Fortran-Subroutine
aufgerufen, welche die eigentliche Aktion ausführt. Ergebnisse aus diesen
Berechnungen werden in den Attributen der Serverobjekte gespeichert bis der Client
sie anfordert.
8.1
SVD-Server
Die Fortran-Routinen zur Singulärwertzerlegung sind bisher nicht vollständig an den
Betrieb als Server angepaßt worden. Da einige Schnittstellenmethoden bereits
implementiert sind, ist dies allerdings ohne großen Aufwand möglich. Es ist hierzu nur
erforderlich, daß Funktionen zur Übertragung erforderlicher Daten und entsprechende
Attribute zur Zwischenspeicherung im CORBA-Objekt ergänzt werden.
8.1.1 CORBA-Objekt
Das Schnittstellenobjekt, welches auf Client- und auf Server-Seite in Abhängigkeit der
verwendeten Sprache implementiert werden muß, hat einen sehr einfachen Aufbau. Da
nur Daten vom Server zum Client gesandt werden, reichen drei get-Methoden, um die
Matrizen A, B und C zu übergeben.
SVD_Corject_Impl
{ public,
author: S.Sü.
status: tested }
+ getMatrix_A( )
+ getMatrix_B( )
+ getMatrix_C( )
:
:
:
Matrix_SVD_Corject
Matrix_SVD_Corject
Matrix_SVD_Corject
47
8. Server
8.2
KVA-Server
Der Server zur Kovarianzanalyse ist vollständig auf Serverbetrieb umgestellt worden.
Er führt seine Berechnung auf Grundlage der übertragenen Tragwerksdaten und der
bereitgestellten Zusatzinformationen (Wind, Dämpfung etc.) aus.
Diese Daten werden jetzt nicht mehr aus einer umständlich zu editierenden ASCIIDatei gelesen, sondern vom Client in aufbereiteter Form zu Verfügung gestellt.
Dadurch ist eine erhebliche Fehlerquelle beseitigt.
8.2.1 CORBA-Objekt
Da beim Aufruf der Fortran-Subroutine alle erforderlichen Parameter in der
Parameterliste enthalten sein müssen, sind entsprechende Felder und Variablen zur
Speicherung der Daten bereitzustellen.
Das Objekt hat folgendes Aussehen:
class notation: implementation-level details
KVA_Corject_Impl
{ public,
author : S.Sü.
status : tested }
+ server
+v
+ lambda
+ matrix_A
+ matrix_B
+ matrix_C
+ matrix_Wind
+ nodeAmount
+ beamAmount
+ materialAmount
+ crossSectionAmount
+ alpha
+ beta
:
:
:
:
:
:
:
:
:
:
:
:
:
KVA_SERVER
Matrix_KVA_Corject
Matrix_KVA_Corject
Matrix_KVA_Corject
Matrix_KVA_Corject
Matrix_KVA_Corject
Matrix_KVA_Corject
int
int
int
int
double
double
<<constructor>>
+ KVA_Corject_Impl( server : KVA_SERVER )
<<query>>
+ setConstructionData( nodeAmount
beamAmount
materialAmount
crossSectionAmount
+ setNode(
node
+ setBeam(
beam
+ setMaterial(
material
+ setCrossSection(
crossSection
+ setDamp(
alpha
beta
+ setMatrix_A( matrix_A
+ setMatrix_B( matrix_B
+ setMatrix_C( matrix_C
+ setMatrix_Wind( matrix_Wind
+ serverStartCalculation( )
+ getLambda( )
+ getV( )
: short,
: short,
: short,
: short )
: Node_KVA_Corject )
: Beam_KVA_Corject )
: Material_KVA_Corject )
: CrossSection_KVA_Corject )
: double
: double )
: Matrix_KVA_Corject )
: Matrix_KVA_Corject )
: Matrix_KVA_Corject )
: Matrix_KVA_Corject )
: void
: void
: void
: void
: void
: void
: void
: void
: void
: void
: void
: Matrix_KVA_Corject
: Matrix_KVA_Corject
48
8. Server
Mit diesen hier definierten Schnittstellenfunktionen ist es möglich, alle Daten zu
übertragen, in den Attributen zu speichern und dem Fortran-Programm zu übergeben.
Der Aufruf der eigentlichen Berechnungsroutine erfolgt in der Methode
serverStartCalculation(). An dessen Anschluß erlangt der Client wieder die
Kontrolle über den Ablauf der Handlung und kann die Ergebnismatrizen anfordern.
Danach ist es möglich, die Ergebnisse visuell darzustellen.
Nachdem der Server die Berechnung abgeschlossen hat, kann der Client, unter
Benutzung der dafür vorgesehenen zwei Methoden, die Ergebnisfelder anfordern.
Diese Matrizen lambda und v enthalten stochastische Parameter. Die Matrizen v für
die Verschiebungen der Knoten und lambda für die Stabendschnittgrößen enthalten für
jeden Knoten bzw. jedes Stabende die Parameter µ, λ0, λ1, λ2 und λ4.
49
9. Probleme & Lösungen
9.
Probleme & Lösungswege
9.1
Lasten
Die Fortran-Routinen zur Singulärwertzerlegung sind bis zur Fertigstellung dieser
Arbeit noch nicht auf den Betrieb als Server angepaßt worden. Daher ist die Eingabe
von dynamischen Lastprozessen noch nicht erforderlich. Um eine spätere Erweiterung
zu erleichtern, sind entsprechende Schnittstellen bereits implementiert.
Derzeit ist nur die Eingabe von Streckenlasten auf Stäbe implementiert. Um beliebige
Lasten verarbeiten zu können, muß das derzeitige Klassenmodell entsprechend
erweitert werden. Eine Möglichkeit ist die folgende:
Last
EinzelLast
StabEinzelLast
StreckenLast
KnotenEinzelLast
Beim Entwurf der Klassen ist in jedem Fall zu berücksichtigen, daß Lasten
verschiedene Eigenschaften haben können:
•
•
statisch / dynamisch
stochastisch / deterministisch
Durch Kombinationen ergeben sich folgende Möglichkeiten
•
•
•
•
statisch – stochastisch
statisch – deterministisch
dynamisch – deterministisch
dynamisch – stochastisch
Die letzte Kombination ist die in diesem Projekt betrachtete.
50
9. Probleme & Lösungen
9.2
Singulärwertzerlegung
Wie bereits mehrfach erwähnt, sind die Fortran-Routinen zur Singulärwertzerlegung
nicht auf den Betrieb als Server umgeschrieben. Da bereits eine Schnittstelle
implementiert wurde, ist dies allerdings ohne großen Aufwand möglich. Es müssen
nur Methoden bereitgestellt werden, mit denen die Lastenprozeßdaten dem Server zur
Verfügung gestellt werden. Der Aufbau des CORBA-Objektes und Aufruf der
Subroutinen hat analog zur KVA zu erfolgen.
9.3
Server-Adresse
Ein Problem im Zusammenhang mit der Verwendung als Applet, ist die Bereitstellung
der Information über die Adresse des Serverobjekts. Was bei der Applikation sehr
einfach ist, nämlich das Auslesen einer Datei, die einem String enthält, ist bei einem
Applet durch das Sand-Box-Konzept nicht zu realisieren. Das HTML-Dokument,
durch welches das Applet gestartet wird, muß diese string-Information bereits als
Parameter enthalten, welche von dem Applet zur Laufzeit ausgelesen werden können.
Anschließend besteht zwischen der Applikation und dem Applet kein Unterschied,
was den Aufruf des entfernten Objekts betrifft.
Das HTML-Dokument muß von einem Applikationsserver bereitgestellt werden, der
Zugriff auf die Server zur Berechnung und gegebenenfalls auf den Server zur
Speicherung besitzt. Dieser Applikationsserver liest die reference.*-Dateien und
schreibt den Inhalt in eine von ihm zu erstellende HTML-Datei. Diese kann folgendes
Aussehen haben:
<HTML>
<HEAD>
<TITLE> JARL </TITLE>
</HEAD>
<BODY>
<APPLET code=Start width=1000 height=610></APPLET>
<PARAM name=KVA value="REFERENCE-STRING DES KVASERVERS">
<PARAM name=SVD value="REFERENCE-STRING DES SVDSERVERS">
<PARAM name=DB value="REFERENCE-STRING DES DATENBANKSERVERS">
</BODY>
</HTML>
Über die Namen können die Werte der Strings eindeutig aus der HTML-Datei gelesen
werden. Diese Technik steht nicht im Widerspruch zum Sicherheitsgedanken von
JAVA, da die Strings nicht lokal gelesen werden, sondern von der URL des HTMLDokuments stammen.
51
9. Probleme & Lösungen
9.4
Verbindungsabbruch
Das unkontrollierte Zusammenbrechen der Datenübertragung ist ein Problem, welches
im Internet heutzutage leider immer noch zu häufig auftritt und auf das der Anwender
keinen Einfluß hat. Dies liegt an der ungenügenden Bandbreite der Provider, der
Überlastung eines Routers an einem Knotenpunkt oder einer schlechten
Telefonleitung.
Um den vollständigen Verlust der Daten zu vermeiden, ist es sinnvoll, Daten
paketweise zu zerlegen. Bei Matrizen kann dies am leichtesten erreicht werden, wenn
sie zeilen- oder spaltenweise übertragen werden. Bricht die Leitung zusammen,
können nach einer erneuten Verbindungsaufnahme die fehlenden Daten angefordert
werden. Zu diesem Zweck ist es erforderlich weitere Schnittstellenmethoden
einzuführen, die eine Matrix zerlegen können, und eine geforderte Zeile/Spalte als
Rückgabewert haben.
9.5
Datenmenge
In engem Zusammenhang zur Datenmenge steht auch das Problem der Zeit, die für die
Übertragung der Daten notwendig ist. In einem Lokal Area Network (LAN) ist die
Größe der zu übermittelnden Matrizen weniger wichtig, da die Übertragungsrate
ausreichend ist, um Zeitprobleme zu vermeiden. Sollen die Daten aber über das
Internet verschickt werden, ist selbst bei ISDN mit Kanalbündelung und den dadurch
erreichbaren 128kB/s schnell der vertretbare Zeitaufwand überschritten. Eine verteilte
Anwendung ist unter solchen Bedingungen nur sinnvoll, wenn die Rechendauer der
Server die Zeit zur Datenübertragung wieder gewinnt.
Wenn die Datenmenge mehrere MegaByte oder sogar GigaByte beträgt, sind andere
Wege kostengünstiger und schneller. Eine Möglichkeit besteht darin, die Daten auf
einen Massenspeicher (Bandlaufwerk, ZIP, CD o.ä. ) zu speichern und an den
Betreiber der Server-Rechner zu schicken. Eine entsprechende Leistungsfähigkeit der
Server wird dabei natürlich vorausgesetzt, damit dieses Vorgehen noch wirtschaftlich
ist.
Mit neuen Techniken in der Datenübertragung ( ADSL ) und sinkenden Kosten für die
Leitungsnutzung, werden verteilte Anwendungen in Zukunft eine immer bedeutendere
Rolle spielen.
9.6
Multithreading
Da das Programm bislang so entworfen wurde, daß der Client während der
Berechnungen durch den Server keine eigene Aufgaben durchführen kann, kann bei
dem Nutzer schnell der Eindruck entstehen, das Programm sei abgestürzt.
Ein Lösungsweg besteht darin, den Server und den Client multithreading-fähig zu
entwerfen. Unter JAVA ist das kein Problem, da bereits Klassen und Methoden
bereitgestellt werden, die diese Technik unterstützen. Unter C++ ist das aber nur unter
relativ großem Aufwand zu bewerkstelligen und Fortran unterstützt Threads überhaupt
nicht. Es müßte der Fortschritt in der Berechnung protokolliert werden und in Relation
zur Gesamtzeit gesetzt werden, um den Verlauf der Berechnung prozentual
darzustellen.
52
9. Probleme & Lösungen
9.7
Applet
Um die Ladezeit bei einem Applet zu verringern, ist es möglich die erforderlichen
Ressourcen in einer gepackten Datei zu speichern. SUNTM hat dafür das JAR-Format
entwickelt. Dieses Format basiert auf der ZIP-Technik, enthält aber weitere
Informationen zu den enthaltenen Dateien in einer ASCII-Datei mit der Bezeichnung
„MANIFEST.MF“.
Durch diese Technik lassen sich die zu übertragenden Dateien um mehr als 50%
komprimieren, was eine erhebliche Geschwindigkeitssteigerung bedeutet. Bei diesem
Projekt konnte die ursprüngliche Datenmenge von 436kB auf 152kB reduziert werden,
was eine Reduktion auf 35% entspricht.
53
10. Benutzerhandbuch
10. Benutzerhandbuch
10.1 Systemvoraussetzungen
10.1.1 Client
Grundsätzlich läuft ein JAVA-Programm nur auf einem mindestens 32Bit-System.
Daher fallen DOS, Win3.11 oder ähnliche, veraltete Betriebssysteme als Grundlage
für diese Anwendung aus.
Ansonsten läuft der Client auf jeder Maschine, für die eine JVM oder ein JAVA 1.1fähiger Browser angeboten wird. SUNTM bietet im Augenblick das JDK, welches die
JVM beinhaltet, für Win95/98/NT und Solaris (SPARC und Intel x86) an. Es
existieren allerdings noch zahlreiche JVM von Drittanbietern z.B. für Linux, MacOS,
OS/2. Zur Installation der JVM sind unbedingt die entsprechenden Anweisungen der
Firma SUNTM zu beachten.
Eine generelle Mindestausstattung, um in vernünftiger Geschwindigkeit arbeiten zu
können, kann daher nicht gegeben werden. Dieses Programm wurde unter Windows
NT entwickelt. Dort hat sich eine Mindestausstattung mit folgenden Komponenten als
sinnvoll erwiesen:
Prozessor:
Speicher:
Grafikkarte:
Bei Applet
Browser:
Pentium MMX 200
64MB
beliebig
MS-IE 4.0, Netscape 4.0 oder andere JAVA 1.1 taugliche
Browser
Bei Applikation
JVM für JAVA 1.1
Die Software (Browser, JVM) ist kostenlos auf folgenden Internetseiten
erhältlich:
Browser:
JVM:
http://www.netscape.com
http://www.microsoft.com
http://www.javasoft.com
Da der Client stark grafikorientiert arbeitet, wird der Aufbau der Grafiken bei einem
langsamen Prozessor zu einer langwierigen Angelegenheit.
10.1.2 Server
Die verschiedenen Berechnungsserver werden i.d.R. nicht vom Anwender des Clients
gestartet oder beendet. Vielmehr sind es Programme, die autonom auf einem
entfernten Rechner ohne Unterbrechung laufen. So haben beliebige Clients ständigen
Zugriff auf deren Ressourcen. Daher wird an dieser Stelle nicht auf deren
Anforderungen eingegangen.
54
10. Benutzerhandbuch
10.2 Installation & Starten des Client
10.2.1 Installation
In Abhängigkeit von der Betriebsform sind unterschiedliche Programme zu
installieren.
• Applet
Um das Programm als Applet zu starten, ist es erforderlich einen JAVA 1.1
kompatiblen Browser installiert zu haben. Dafür können die beiden weitestverbreiteten
Browser Netscape 4.5 und MS-IE 5.0 verwendet werden. Beide sind unentgeltlich im
Internet erhältlich.
• Applikation
Die JVM von SUNTM muß installiert werden, damit der Client gestartet werden kann.
Danach ist eine besondere Installationsroutine für den Client nicht zu beachten. Das
Programm kann entweder auf die HD in ein beliebiges Verzeichnis kopiert werden,
oder direkt von der CD gestartet werden.
Achtung: Hinweise hinsichtlich der CLASSPATH-Variable bei der Installation der
JVM sind unbedingt zu beachten!
10.2.2 Starten
Der Client kann wahlweise auf zwei Arten gestartet werden. Zum einen als Applet aus
dem Internet (auch lokal möglich) oder als Applikation.
•
Applet
Nach dem Starten des Browser kann mit Datei->Seite öffnen die Datei
Diplomarbeit.htm geöffnet werden.
Öffnen des Applet mit Netscape 4.5 (eng.)
55
10. Benutzerhandbuch
Nach dem Öffnen des entsprechenden HTM-Dokuments und dem automatischen
Laden aller erforderlichen JAVA-Dateien, erscheint folgende Oberfläche:
Client als Applet im Netscape 4.5 ( Startansicht )
Um in ihr optimal arbeiten zu können, sollte eine Auflösung von min. 1024x768
mit 256 Farben eingestellt sein. Um bestmögliche Ergebnisse zu erzielen, sollte die
Grafikkarte 1152x864 Pixel darstellen.
•
Applikation
Zum Starten als Stand-alone, ist eine Kommandozeileneingabe über eine Shell
erforderlich. Unter Windows 95/98/NT kann dazu die MS-DOS
Eingabeaufforderung verwendet werden. Nach dem Wechsel in das Verzeichnis
Client auf der CD kann mit der Eingabe von
java Start <ENTER>
der JAVA-Interpreter gestartet werden, der das Client-Programm ausführt. Es
erscheint die in jeder Hinsicht gleiche Oberfläche wie bei dem als Applet
gestarteten Client. Auch bezüglich der Bedienung der einzelnen Module ergeben
sich keine Unterschiede.
Im weiteren wird davon ausgegangen, daß der Client lokal als Applikation gestartet
wurde. Bei Unterschieden zur Version als Applet wird explizit darauf hingewiesen.
Nachdem das Programm gestartet wurde, erscheint eine Auswahlmöglichkeit unter
verschiedenen Modulen.
56
10. Benutzerhandbuch
10.3 Construction
Nachdem man vom Startmenü ausgehend Construction gewählt hat, erscheint
folgende, in vier Teile gegliederte, Oberfläche:
Module_Construction Bedienoberfläche (Applikation)
Menüberei
Eingabe
bereich
Eingabeberei
Zeichenbereic
Statusbereic
Neben den Icons sind natürlich alle Windows-Elemente (Systemmenü, Titelleiste,
Schließen-Button) vorhanden.
In diesem Modul werden alle Aktionen zur Tragwerkseingabe interaktiv durchgeführt.
Die Steuerung erfolgt, mit Ausnahme der Dateneingabe, durch die Maus. Die Icons im
oberen Teil wurden selbsterklärend bzw. entsprechend denen der Standardsoftware
gestaltet.
Damit
ist
eine
einheitliche
Benutzerführung
unter
allen
Windowsprogrammen gewährleistet, was die Einarbeitung in JARL stark vereinfacht.
Von links nach rechts bedeuten die Icons:
10.3.1 Neues Projekt
Nachdem das Icon angeklickt wurde, wird ein bestehenden Projekt gelöscht und ein
neues angelegt. Gleichzeitig wird der Zeichenbereich gelöscht, damit ein neues
Tragwerk dargestellt werden kann.
Ein, unter Umständen bereits bestehendes Projekt, wird in jedem fall vorher gesichert.
57
10. Benutzerhandbuch
10.3.2 Öffnen eines bestehenden Projekts
Wenn dieses Icon angeklickt wird, erscheint eine plattformspezifische Maske, in der
die zu ladende Datei ausgewählt werden kann. Leider ist in diesem Feature ein von
SUNTM dokumentierter Bug enthalten. Es ist nicht möglich, nur Dateien mit einer
bestimmten Extension anzeigen zu lassen.
Das Öffnen einer Datei kann nur bei einer Applikation erfolgen, da das Sand-Box
Modell von SUNTM einen derartigen Eingriff in das System nicht gestattet.
10.3.3 Speichern des aktuellen Projekts
Genauso wie beim Öffnen eines Projekts, erscheint hierbei eine plattformspezifische
Maske, in der ein Pfad zum speichern und der Dateiname gewählt werden kann. Die
beim Laden geltenden Einschränkungen verbieten auch das Speichern eines Projekts
bei einem Applet.
10.3.4 Programm beenden
Das Programm wird ohne weitere Warnung sofort beendet. Die Datenbank und das
eventuell zuletzt bearbeitete Projekt werden allerdings noch gespeichert.
Da ein Applet nicht beendet werden kann, muß der Browser geschlossen werden,
wenn das Programm beendet werden soll.
58
10. Benutzerhandbuch
10.3.5 Tragwerk drucken
Das in der Zeichenfläche dargestellte Tragwerk kann auf jedem angeschlossenen
Drucker ausgegeben werden. Bei der Druckerauswahl hilft wieder eine Maske, die der
Druckerauswahl auf der jeweiligen Plattform entspricht.
Der Bildschirmabzug zeigt die Druckerauswahl unter Windows 95 mit den dort
üblichen Optionen.
Wenn das Programm als Applet abläuft ist diese Option nicht anwählbar, allerdings
läßt sich die gesamte, im Browser dargestellte Seite durch Datei->Drucken ausgeben.
59
10. Benutzerhandbuch
10.3.6 Knoteneingabe
Ein Tragwerk besteht aus Knoten und Stäben. Bevor allerdings Stäbe eingegeben
werden können, müssen entsprechende Knoten definiert werden. Dazu ist die Eingabe
einer Knotennummer, der Koordinaten und der Restriktionen erforderlich. Die
Koordinaten werden dabei, wie im Stahlbau üblich, in Millimetern angegeben. Die
Knotennummern werden automatisch bei eins beginnend durchgezählt. Eine Nummer
ist standardmäßig vorgegeben, kann aber auch selbst eingegeben werden. Durch einen
Klick auf den entsprechenden Button kann der definierte Knoten in der Datenbank
gespeichert, aktualisiert oder aus der Datenbank gelöscht werden.
Unter dem Button „save“ wird die Anzahl der bisher eingegebenen Knoten angezeigt.
Maske zur Knoteneingabe
Fehlermeldung bei falscher
Knoteneingabe
Bei der Eingabe von Knoten wird der Maßstab zur Darstellung des Tragwerks
automatisch so gewählt, daß immer das gesamte System im Zeichenbereich dargestellt
wird. Dadurch wird erreicht, daß der zu Verfügung stehende Platz optimal genutzt
wird und das Tragwerk immer proportional wiedergegeben wird.
Falls Angaben zu dem Knoten fehlerhaft sein sollten, erscheint eine entsprechende
Fehlermeldung.
Bei der Eingabe ist zu beachten, daß es nicht möglich ist negative Werte, Buchstaben
oder reellwertige Daten einzugeben. Dadurch ist eine große Fehlerquelle eliminiert.
60
10. Benutzerhandbuch
10.3.7 Stabeingabe
Nachdem Knoten eingegeben wurden, besteht die Möglichkeit, zwei Knoten mit
einem Stab zu verbinden. Dabei muß der linke und rechte Knoten vorgegeben werden.
Dies Information über die Knoten wird noch bei der Lasteingabe verwendet.
Desweiteren können Angaben über den verwendeten Querschnitt des Stabes, sein
Material und die ihm zugeordnete Wöhlerlinie gemacht werden. Aus den
entsprechenden Auswahlmenüs können die Eigenschaften ausgewählt werden. Falls
ein Attribut nicht vorhanden ist, muß es erst unter dem jeweiligen Punkt der
Datenbank hinzugefügt werden.
Maske zur Stabeingabe
Fehlermeldung bei falschen
Stabdaten
Wenn die Knotenangaben inkorrekt sind, erscheint eine Fehlermeldung, die auf den
entsprechenden Fehler hinweist. Die Angaben sind fehlerhaft, wenn z.B. kein Knoten
mit der eingegebenen Nummer existiert.
Bei der Eingabe ist, wie bei den Knoten, zu beachten, daß es nicht möglich ist negative
Werte, Buchstaben oder reellwertige Daten einzugeben. Dadurch ist auch bei der
Stabdateneingabe eine große Fehlerquelle eliminiert.
Zur Vereinfachung der Stabeingabe besteht die Möglichkeit zwei Knoten mit
gedrückter linker Maustaste zu verbinden. Dabei werden ebenfalls die eingestellten
Daten zu Profil, Wöhlerlinie und Material übernommen.
61
10. Benutzerhandbuch
10.3.8 Lasteingabe
Lasten können in dieser Version von JARL nur als Streckenlasten auf Stäbe
eingegeben werden. Dabei können aber beliebig viele Lasten, an beliebigen Orten, auf
einen Stab aufgebracht werden.
Der Stab, auf den die Last einwirkt, wird über den linken und rechten Knoten
definiert. Mit dist und length wird der Abstand der Last vom linken Knoten und die
Länge der Streckenlast beschrieben. Amount bezeichnet den Betrag der Last in kN/cm.
Lasteingabe auf einen Stab
Um den stochastischen Charakter der Last zu berücksichtigen, muß die Verteilungsart
und die Standardabweichung angegeben werden. Der Betrag der Last wird dabei als
Mittelwert der Verteilung angenommen.
Bei der Verteilung kann, wie bei allen anderen Eingaben auch, zwischen den vier
Typen gewählt werden (Umrechnung gem. /19/ S.160)
•
•
Normalverteilung mit dem Parameter σ und dem eingegebenen Betrag als
Mittelwert µ
Log-Normalverteilung mit den Parametern λ und ζ die aus µ und σ berechnet
werden:
•
•
1
2
σ
1
ζ = ln + 1
λ = ln µ − ⋅ ζ 2
µ
2
Exponentialverteilung mit dem Parameter λ, berechnet aus µ
1
λ=
µ
Gumbel, Extremwert I max. (T1L) mit den Parametern u und α
2
62
10. Benutzerhandbuch
π
σ⋅ 6
10.3.9 Wöhlerlinie definieren
α=
u=µ−
γ
α
γ ≅ 0.577216
Bei der Definition der Ermüdungsfestigkeitskurven kann zwischen verschiedenen
Arten gewählt werden. Dabei werden für die Wöhlerlinie in jedem Fall ∆σ bei 1*104
Lastspielen, Dauerfestigkeit mit ∆σD und Anzahl der Lastspiele sowie Cut-off-limit
mit ∆σL und der zugehörigen Lastspielzahl angezeigt.
•
Definition gemäß EC 3
Es werden nur die Kerbgruppen des EC 3 definiert
•
Definition analog EC 3
Dabei sind Dauerfestigkeit und Cut-off limit wie im EC 3 definiert, aber die
Kerbgruppe kann selbst bestimmt werden. Die Steigungen betragen in jedem Fall
wie im EC3 m1 = 3 und m2 = 5
Wöhlerlinie mit selbst definierter Kerbgruppe KF 150
•
Lineare Wöhlerlinie
Die Steigung der Wöhlerlinie kann selbst definiert werden, aber die Wöhlerlinie ist
nur linear.
63
10. Benutzerhandbuch
•
Bilineare Wöhlerlinie
Die Steigungen der Ermüdungsfestigkeitskurven können selbst definiert werden.
Eingabe einer Bilinearen Wöhlerlinie
Hierbei kann der stochastische Charakter der maßgebenden Parameter der
Wöhlerlinie durch Eingabe der Verteilungsart und der Standardabweichung
explizit berücksichtigt werden. Als Mittelwert wird wieder der eingegebene Wert
angenommen.
64
10. Benutzerhandbuch
10.3.10 Materialeigenschaften definieren
Bei den Materialien können neben dem Namen alle weiteren Parameter
eingegebenwerden, die für die Berechnung innerhalb eines FEM-Programms von
Bedeutung sind. Wie bei den Wöhlerlinien und den Lasten ist hier ebenfalls der
stochastische Charakter zu berücksichtigen. Als Mittelwert der Verteilung werden
wieder die eingegebenen Werte angenommen.
Das Tragwerk wird während dieser Option nicht angezeigt.
Eingabe eines Materials
65
10. Benutzerhandbuch
10.3.11 Profil definieren
Bei der Eingabe eines Profils kann zwischen DIN-Profilen und selbst hergestellten
Querschnitten unterschieden werden. Wenn ein Profil selbst definiert werden soll,
kann der Radius null Millimeter betragen.
Die Daten des Profils werden im Zeichenbereich nicht maßstäblich angezeigt.
Trotzdem kann eine Falscheingabe besser erkannt werden, als in den Textfeldern.
Eingabe eines Profils
Wie bei allen anderen Eingaben auch, ist hier der stochastische Charakter der
Parameter zu beachten. Zu jeder Abmessung ist die Verteilungsart und die
Standardabweichung einzugeben. Als Mittelwert wird die jeweilige Abmessung
angenommen.
66
10. Benutzerhandbuch
10.3.12 Verteilung anzeigen
Bei dieser Option kann die gewählte Verteilung nur angezeigt werden. Die
eingegebenen Parameter σ für die Standardabweichung und µ für den Mittelwert
werden in die entsprechenden Parameter der gewählten Verteilung umgerechnet (vgl.
Kap. 10.3.8).
Anzeige einer Normalverteilung
10.3.13 Startmenü
Nachdem ein Tragwerk geladen bzw. definiert wurde, können die Server aufgerufen
werden und die entsprechenden Berechnungen durchgeführt werden. Im Anschluß an
die Serverberechnungen können die Ergebnisse dargestellt werden.
10.3.14 Hilfe aufrufen
Die Hilfefunktion bezieht sich nur auf Informationen zum Quellcode und nicht auf die
Bedienung des Programms. Als Hilfe ist der Statusbereich gedacht, in dem angezeigt
wird, auf welchem Knoten / Stab sich die Maus befindet, bzw. welche Bedeutung das
Icon hat, auf dem sich der Mauszeiger befindet.
Die Hilfe kann nur aufgerufen werden, wenn das Programm als Windows-Applikation
ausgeführt wird, da hierfür der Netscape-Browser aufgerufen wird.
67
10. Benutzerhandbuch
10.3.15 Pop-Up-Menü
Unabhängig von der durch ein Icon gewählten Aktion, kann im Zeichenbereich auch
mit Pop-Up-Menüs gearbeitet werden. Dies ist allerdings nur möglich, solange das
Tragwerk angezeigt wird, was bei der Eingabe von Knoten, Stäben und Lasten
gewährleistet ist. Durch einen Klick mit der rechten Maustaste wird ein
kontextsensitives Menü geöffnet. In Abhängigkeit von der Mausposition und dem dort
liegenden Objekt, sind verschiedenen Optionen möglich.
Pop-Up im Zeichenbereich
Pop-Up auf Stab
Pop-Up auf Knoten
In dem Menü wird angezeigt welches Objekt man angeklickt hat, und welche
Aktionen möglich sind. Wählt man properties, wird im Eingabebereich für Knoten
und Stäbe die Eingabemaske für das entsprechende Objekt angezeigt. Bei properties
für den Zeichenbereich, erscheint im Eingabebereich eine Maske, in der angegeben
werden kann, was im Zeichenbereich angezeigt werden soll. Zur Auswahl stehen:
- Knotennummern
- Knotenrandbedingungen
- Stabnummern
- Lasten
68
10. Benutzerhandbuch
10.4 SVD
Nachdem das Programm gestartet wurde, kann die Verbindung zu dem SVD-Server
aufgebaut werden. Dies macht allerdings nur Sinn, wenn auch ein System mit
Belastung geladen bzw. eingegeben wurde.
Ist ein Tragwerk vorhanden und wird dieses Modul aufgerufen, dann übernimmt das
Programm die Verbindungsaufnahme zu dem entsprechenden Server und überträgt die
erforderlichen Daten über die CORBA-Schnittstellenfunktionen.
Nachdem die Datenübertragung erfolgreich abgeschlossen wurde und die Ergebnisse
vorliegen, gibt das Programm eine entsprechende Mitteilung aus:
Singulärwertzerlegung
abgeschlossen
10.5 KVA
Bevor das Modul zur Verbindungsaufnahme mit dem Kovarianzanalyse-Server
aufgerufen werden kann, muß SVD erfolgreich beendet worden sein, da die
Ergebnisse aus der Singulärwertzerlegung hierfür benötigt werden. Der Datentransfer
erfolgt wieder vollkommen automatisch.
Zusätzlich zu den Ergebnissen aus der Singulärwertzerlegung werden folgende
weiteren Angaben benötigt:
•
•
•
matrix with wind
values for h
damp
69
10. Benutzerhandbuch
Ist die Übertragung und Berechnung abgeschlossen, erhält der Client als Ergebnis die
spektralen Momente, die visualisiert werden können.
Sollte die Verbindung zu einem Servern nicht aufgebaut werden können, so erscheint
eine Fehlermeldung, die auf diesen Fehler hinweist. Wenn dieser Fehler gemeldet
wird, ist die Adresse, die in dem reference.*-File angegeben wahrscheinlich nicht
korrekt oder die Datei existiert nicht. Dann muß die entsprechende Datei vom Server
in das Verzeichnis kopiert werden, in dem sich auch das Programm JARL befindet.
Ist der geforderte Dienst nicht verfügbar, weil der Server außer Betrieb ist, hat der
Nutzer auf Client-Seite keine Möglichkeiten zur Fehlerbehebung.
Fehlermeldung: Server kann nicht
gefunden werden
10.6 RES
Wird im Hauptmenü die Option RES gewählt, können die Ergebnisse aus der
Kovarianzanalyse visuell dargestellt werden.
Dabei kann für jeden Knoten des Tragwerks eine Windlast gewählt werden und die
Verteilung der zugehörigen Verschiebungen grafisch angezeigt/ausgedruckt werden.
70
11. Beispiele
11. Beispiel
Hier soll anhand zweier Beispiele gezeigt werden, wie man die einzelnen Optionen
nutzen kann, um ein Tragwerk einzugeben. Dabei können sowohl bereits bestehende
Daten aus den Datenbanken verwendet, als auch neu eingegebene Daten benutzt
werden.
Die Datenbanken beinhalten in der Grundversion jeweils 20 Kerbgruppen (/16/ S.10)
und DIN-Profile (/17/ S.8.83ff) bzw. vier Materialien. Diese können durch Hinzufügen
ständig erweitert werden.
11.1 Rahmentragwerk
11.1.1 Knoten und Stäbe
Um ein Tragwerk einzugeben, ist im Startmenü die Option Construction anzuwählen.
Anschließend können Knotenkoordinaten und Stäbe in den Eingabemasken, die durch
die Icons aktiviert werden, eingegeben werden. Die Stäbe können auch zwischen zwei
Knoten erstellt werden, indem mit der Maus vom einen zum anderen Knoten, bei
gedrückter linker Maustaste, gezogen wird.
Stab von Knoten 3 nach 4 mit den ausgewählten Eigenschaften (mit Maus gezogen)
71
11. Beispiele
Dem Stab können über die Auswahlmenüs bestimmte Eigenschaften zugeordnet
werden:
Ist ein entsprechendes Attribut nicht in der Datenbank enthalten, kann es der
Datenbank hinzugefügt werden. Anschließend ist es in der Auswahl vorhanden und
kann verwendet werden.
In diesem Beispiel sind folgende Knoten und Stäbe eingegeben worden
Knoten
1
2
3
4
5
X-Koord
0
0
50000
10000
10000
Y-Koord
0
5000
6000
5000
0
u
1
0
0
0
1
v
1
1
0
1
1
phi
1
0
0
0
1
Links
Rechts
Material
Profil
Kerbfall
1
2
3
4
2
3
4
5
St 52-4
St 52-4
St 52-4
ST 52-4
HEA 300
IPE 200
IPE 200
HEA 300
KF 125
KF 71
KF 71
KF 125
Stab
1
2
3
4
72
11. Beispiele
11.1.2 Lasten
Wie bereits erwähnt, können Lasten in dieser Version des Programms nur als
Streckenlasten auf Stäbe wirken. Dabei können beliebig viele Lasten auf einen Stab
einwirken.
Eingabe von Lasten auf ein Tragwerk
In diesem Beispiel wurden folgende Lasten eingegeben:
Links
2
2
2
3
1
Rechts
3
3
3
4
2
Dist
0
1500
3500
0
0
Length
1000
500
1500
4000
-
Amount
200
100
250
150
50
Da das Programm zur Singulärwertzerlegung nicht an den Betrieb als Server angepaßt
wurde, ist die Eingabe der Lasten z.Z. noch überflüssig.
73
11. Beispiele
11.1.3 SVD
Durch anklicken des Symbols
gelangt man wieder in das Hauptmenü. Dort
erreicht man den SVD-Server durch den Button SVD. Von dort können anschließend
die Tragwerksdaten durch send an den Server gegeben werden. Der wiederum führt
die Berechnung aus. In der Zeit, in der die Server-Berechnung durchgeführt wird, ist
keine weitere Eingabe möglich. Wenn der Client anschließend wieder freigegeben
wurde, gelangt man durch den back-Button erneut in das Startmenü.
Meldung: SVD abgeschlossen
11.1.4 KVA
Nachdem die Singulärwertzerlegung durchgeführt wurde, kann die Kovarianzanalyse
gestartet werden. Dort sind einige ergänzende Angaben erforderlich, die vorläufig
standardmäßig gesetzt werden und nicht verändert zu werden brauchen. Da diese
Daten bei der Berechnung aber noch nicht verwendet werden, sind sie eigentlich
überflüssig. Dies kann später ergänzt werden.
Eingabe für den KVA-Server
•
•
•
matrix with wind
values for h
damp
74
11. Beispiele
11.2 Stütze
11.2.1 Knoten und Stäbe
Als zweites Beispiel soll eine Eingespannte Stütze dienen, die aus fünf Knoten und
vier Stäben besteht.
Wie im Beispiel des Rahmentragwerks, können den Knoten und Stäben Eigenschaften
zugewiesen werden.
Knoten
1
2
3
4
5
X-Koord
0
0
0
0
0
Y-Koord
0
5000
6000
5000
0
u
1
0
0
0
0
v
1
0
0
0
0
phi
1
0
0
0
0
Links
Rechts
Material
Profil
Kerbfall
1
2
3
4
2
3
4
5
St 52-4
St 52-4
St 52-4
ST 52-4
IPE 100
IPE 100
IPE 100
IPE 100
KF 160
KF 160
KF 160
KF 160
Stab
1
2
3
4
75
11. Beispiele
11.2.2 Lasten
Auf die Eingabe von Lasten, wurde bei diesem Beispiel verzichtet. Da der SVDServer, der die Lasten verarbeiten soll, nicht fertiggestellt werden konnte, wurden
bereits erzeugte Ergebnismatrizen benutzt.
11.2.3 SVD
Obwohl keine Lasten eingegeben wurden, muß der SVD-Server dennoch aufgerufen
werden. Die benötigten Matrizen liegen auf Server-Seite und müssen zum Client
übertragen werden.
11.2.4 KVA
Die Kovarianzanalyse wurde mit den folgenden Parametern aufgerufen.
76
11. Beispiele
11.2.5 Ergebnisse
Die Ergebnisse der Kovarianzanalyse lassen sich grafisch darstellen. Auf der X-Achse
wird dabei die Verformung dargestellt, auf der Y-Achse die Häufigkeiten. Abgedruckt
sind die horizontalen Verschiebungen der Knoten 2, 3, 4 und 5.
77
11. Beispiele
Die dargestellten Ergebnisse entsprechen den Erwartungen. Je näher ein Knoten an der
Einspannstelle liegt, desto geringer ist die horizontale Verschiebung.
An der Form der Kurven wird die Überlagerung der verschiedenen Verteilungsarten
gut deutlich.
78
12. Quellenangabe
12
/1/
/2/
/3/
/4/
/5/
/6/
/7/
/8/
/9/
/10/
/11/
/12/
/13/
Quellenangabe
Das große Buch JAVA
Data Becker
1. Auflage 1996
Borland C++ 4.5 Das Kompendium
Einführung, Arbeitsbuch, Nachschlagewerk
Markt & Technik, 1995
JAVA Examples in a Nutshell
O’Reilly
1. Auflage 1998
JAVA in a Nutshell
O’Reilly
2. erweiterte und aktualisierte Auflage 1998
C’t Magazin für Computertechnik, Ausgabe 19/1998
C’t Magazin für Computertechnik, Ausgabe Juni/1997
http://www.omg.org/cgi.bin/membersearch.pl
JAVA-Magazin 6/98
„Verteilte Objekte“
Programmierschnittstelle: C++ / Fortran (77)
Alexander Lichius
16. Januar 1997
MIPSpro7 Fortran 90 Commands and Directives Reference Manual
„Calling a Fortran90 Subroutine from C“
Online-Dokument
Unified Modeling Language
„Summary“ Version 1.1, September 1997
http://www.rational.com/uml
Unified Modeling Language
„UML Notation Guide“ Version 1.1, September 1997
http://www.rational.com/uml
Universität Bern
Forschungsgruppe Computergeometrie und Grafik
/14/
/15/
Institut für Informatik und angewandte Mathematik
Seminarvortrag
Thomas Wenger
November 1997
Informatik/Informatique
Zeitschrift der schweiz. Informatikorganisationen
Nr. 3 – Juni 1997 (JAVA)
Java-Magazin 5/98
„write once – debug everywhere“
79
12. Quellenangabe
/17/
/18/
/19/
/20/
/21/
Arbeitsunterlagen zur Lehrveranstaltung
Brücken- und Hochbauten in Stahl- und Verbundbauweise Teil 1
Bemessung ermüdungsgefährdeter Stahlkonstruktionen
Stand: September 1996
Schneider Bautabellen für Ingenieure
Mit europäischen und nationalen Vorschriften
11. Auflage, Werner-Verlag
Teilproject C5 des SFB 398
Paralleles/verteiltes Entwurfssystem für die lebensdauerorientierte Auslegung von
tragwerken unter Berücksichtigung von Schädigungen
Leiter: Prof. Dr.-Ing. Dietrich Hartmann
Prof. Dr.-Ing. Hans-Jürgen Niemann
Sicherheit und Zuverlässigkeit im Bauwesen
Grundwissen für Ingenieure
Jörg Schneider, Hans Peter Schlatter
1994, vdf
Dirlik T.: Application of Computers in Fatigue Analysis
Dissertation University of Warwick; 1985
80