11. Neuronale Netze
Werbung

11. Neuronale Netze
1
Einführung (1)
Ein künstliches neuronales Netz ist vom Konzept her eine Realisierung
von miteinander verschalteten Grundbausteinen, sogenannter Neuronen, welche in rudimentärer Form die Vorgänge im biologischen Vorbild, unserem Gehirn, nachahmen. Wichtige Eigenschaften sind:
• Lernfähigkeit,
• Parallelität,
• Verteilte Wissensrepräsentation,
• Hohe Fehlertoleranz,
• Assoziative Speicherung,
• Robustheit gegen Störungen oder verrauschten Daten,
2
Einführung (2)
Der Preis für diese Eigenschaften ist:
• Wissenserwerb ist nur durch Lernen möglich.
• Logisches (sequenzielles) Schließen ist schwer.
• Sie sind oft langsam und nicht immer erfolgreich beim Lernen.
Aus diesem Grunde werden Neuronale Netze nur dort angewandt, wo
genügend Zeit für ein Lernen zur Verfügung steht. Sie stehen in Konkurrenz z.B. zu Vektorraum-Modellen oder probabilistisches Modellen.
Es gibt viele fertige Softwarepakete für Neuronale Netze, siehe z.B.
Liste unter http://de.wikipedia.org/wiki/Künstliches_neuronales_Netz
3
Einführung (3)
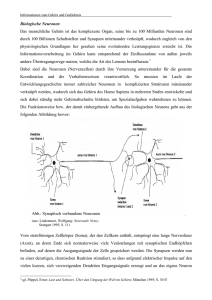
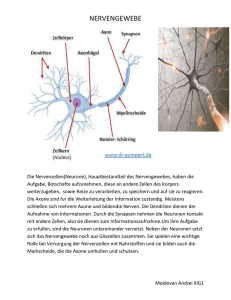
Der Grundaufbau einer Nervenzelle besteht aus
• einem Zellkörper,
• den Dentriten, welche die Eingabe des Netzes in die Zelle aufsummieren,
• und ein Axon, welches die Ausgabe der Zelle nach außen weiterleitet, sich verzweigt und mit den Dentriten nachfolgender Neuronen
über Synapsen in Kontakt tritt.
Dentriten
Zellkörper
Axon
ai
Axon
aj
Synapse
Dentriten
Dieses Modell dient als Grundlage “künstlicher neuronaler Netze”.
4
Einführung (4)
Ein Neuron i mit n Eingängen (Dentriten) bekommt einen Gesamtinput von neti und erhält damit einem Aktivitätswert ai.
Daraus folgt ein Ausgangswert oi (Axon), der über eine synaptische
Koppelung wi,j an das Neuron j koppelt.
net
j
neti
a
i
oi
w i,j
aj
oj
Neuronale Netze waren für längere Zeit auf Grund der “Lernprobleme” aus der Mode gekommen. Aber nach Wikipedia: In jüngster Zeit
erlebten neuronale Netzwerke eine Wiedergeburt, da sie bei herausfordernden Anwendungen oft bessere Ergebnisse als konkurrierende
Lernverfahren liefern.
5
Einführung (5)
Anwendungsgebiete nach Wikipedia (Stand 26. Dezember 2013):
• Regelung und Analyse von komplexen Prozessen
• Frühwarnsysteme
• Optimierung
• Zeitreihenanalyse (Wetter, Aktien etc.)
• Sprachgenerierung (Beispiel: NETtalk)
• Bildverarbeitung und Mustererkennung
* Schrifterkennung (OCR), Spracherkennung, Data-Mining
• Informatik: Bei Robotik, virtuellen Agenten und KI-Modulen in
Spielen und Simulationen.
• Medizinische Diagnostik, Epidemiologie und Biometrie
• Klangsynthese
• Strukturgleichungsmodell zum Modellieren von sozialen oder betriebswirtschaftlichen Zusammenhängen
6
Mathematisches Modell (1)
Mathematisches Modell von neuronalen Netzen
Ein künstliches neuronales Netz besteht aus folgenden Komponenten
1. Zellen mit einem Aktivierungszustand ai(t) zum Zeitpunkt t.
2. Eine Aktivierungsfunktion fact, die angibt, wie sich die Aktivierung
in Abhängigkeit der alten Aktivierung ai (t), des Inputs neti und
eines Schwellwerts Θi mit der Zeit ändert.
ai(t + 1) = fact (ai(t), neti(t), Θi).
3. Eine Ausgabefunktion fout, die aus der Aktivierung der Zelle den
Output berechnet
oi = fout(ai ).
7
Mathematisches Modell (2)
4. Ein Verbindungsnetzwerk mit den Koppelungen wi,j (Gewichtsmatrix).
5. Eine Propagierungsfunktion, die angibt, wie sich die Netzeingabe
aus den Ausgaben der anderen Neuronen berechnet, meist einfach
netj (t) =
X
oi(t)wi,j
i
6. Eine Lernregel, die angibt, wie aus einer vorgegebenen Eingabe
eine gewünschte Ausgabe produziert wird. Dies erfolgt meist über
eine Modifikation der Stärke der Verbindungen als Ergebnis wiederholter Präsentation von Trainingsmustern.
Auf diese Weise werden die “Zustände” geändert, bis ein stabiler (und
hoffentlich erwünschter) Endzustand eintritt, welcher in gewisser Weise das Ergebnis der Berechnungen eines neuronales Netzes darstellt.
8
Mathematisches Modell (3)
Beispiel: Ein nettes kleines bekanntes Netz mit wenigen Verbindungen
und welches im Kopf nachzurechnen ist, ist das XOR-Netzwerk mit 4
Zellen.
n4 0.5
-2
1 n3 1.5
1
n1
1
1
Die Neuronen beinhalten die
Schwellwerte,
die
Verbindungen sind mit den Gewichten
beschriftet.
n2
Als Aktivitätsfunktion wird eine Stufenfunktion gewählt
aj (t) = fact (netj (t), Θj ) ==
(
1
0
falls netj (t) ≥ Θj
.
sonst
9
Mathematisches Modell (4)
Die Ausgabefunktion ist einfach
oj = fout(aj ) = aj
Weiterhin wird die standardmäßige Propagierungsfunktion verwendet
netj (t) =
X
oi(t)wi,j
i
Aus der folgenden Tabelle ist
lich:
o1 o2 net3
0 0
0
0 1
1
1 0
1
1 1
2
die Funktionsweise des Netzes ersichtΘ3 o3 net4
1.5 0
0
1.5 0
1
1.5 0
1
1.5 1
0
Θ 4 o4
0.5 0
0.5 1
0.5 1
0.5 0
10
Mathematisches Modell (5)
Beschränkt man sich auf ebenenweise verbundene feedforward-Netze, so wird für
die XOR-Funktion ein weiterer verdeckter
Knoten benötigt.
n5 0.5
1
1
n3 0.5
1
n4 0.5
-1
n1
-1
1
n2
Eine kleine Übungsaufgabe: Wie sieht die zugehörige Tabelle von
Eingabe zur Ausgabe aus?
Andere häufig verwendete Aktivierungsfunktionen mit oi = ai als Ausgabefunktion sind die Sigmoide bzw. logistische Funktion
oi = ai = 1/(1 + exp(−c(neti + Θi)))
oder der Tangens Hyperbolicus
oi = ai = tanh(c(neti + Θi)).
Die Konstante c beeinflusst die Steigung der Funktion.
11
Darstellung von neuronalen Netzen (1)
Ein neuronales Netz ist ein Graph mit Kanten und Knoten. Neuronen
bzw. Zellen sind aktive Knoten oder Berechnungseinheiten, die lokal
auf Eingaben reagieren und Ausgaben produzieren, die über die Kanten
weiter gegeben werden.
Eine andere Darstellung besteht aus 3 Matrizen: Verbindungsmatrix,
Schwellwertmatrix und Anregungsmatrix. Rechnungen erfolgen durch
Neuberechnung der Anregungsmatrix.
Arten von Verbindungsnetzwerken
Je nach Netztopologie und der Art der Verarbeitung der Aktivitätswerte werden verschiedene neuronale Netze unterschieden.
12
Darstellung von neuronalen Netzen (2)
Eine Einteilung nach Rückkopplung:
1. Netze ohne Rückkopplung (feedforward-Netze),
• Ebenenweise verbundene feedforward-Netze,
• Allgemeine feedforward-Netze,
2. Netze mit Rückkopplung,
• Netze mit direkter Rückkopplung (direct feedback),
• Netze mit indirekter Rückkopplung (indirect feedback),
• Netze mit Rückkopplung innerhalb einer Schicht (lateral feedback),
• Vollständig verbundene Netze (lateral feedback).
13
Darstellung von neuronalen Netzen (3)
2 Beispiel-Topologien und ihre Verbindungsmatrizen:
6
3
7
4
1
6
5
2
3
feedforward,
ebenenweise
verbunden
7
4
1
5
2
vollständig verbunden,
ohne direkte
Rückkopplung
14
Lernen (1)
Mögliche Arten des Lernens
1. Entwicklung neuer Verbindungen
2. Löschen existierender Verbindungen
3. Modifikation der Stärke von Verbindungen
4. Modifikation der Schwellwerte der Neuronen
5. Modifikation der Aktivierungs-, Propagierungs- oder Ausgabefunktion
6. Entwicklung neuer Zellen
7. Löschen von Zellen
Meist wird die Modifikation der Stärke von Verbindungen wi,j verwendet, da diese Verfahren am einfachsten sind und die Entwicklung bzw.
das Löschen von Verbindungen mit eingeschlossen werden kann.
15
Lernen (2)
Lernverfahren
Prinzipiell werden 3 Arten von Lernverfahren unterschieden:
1. Überwachtes Lernen, bei dem einem Netzwerk zu einem Input ein
gewünschter Output gegeben wird, nach dem es sich einstellt.
2. Bestärkendes Lernen, bei dem zu einem Input die Information, ob
der Output richtig oder falsch ist, in das Netz zurückgegeben wird.
3. Unüberwachtes Lernen, bei dem sich das Netz selbst organisiert.
Am häufigsten ist das überwachte Lernen. Von den verschiedenen
Lernmethoden wird hier nur das klassische Backpropagation-Verfahren
vorgestellt.
16
Lernen (3)
Hebbsche Lernregel
Die einfachste Lernregel, die heute noch Grundlage der meisten Lernregeln ist, wurde 1949 von Donald O.Hebb entwickelt.
Wenn Zelle j eine Eingabe von Zelle i erhält und beide gleichzeitig
stark aktiviert sind, dann erhöhe das Gewicht wij , die Stärke der Verbindung von i nach j.
∆wij = ηoiaj
Die Konstante η wird als Lernrate bezeichnet. Verallgemeinert lautet
die Hebbsche Regel
∆wij = ηh(oi, wij )g(aj , tj )
tj ist die erwartete Aktivierung (teaching input), ein Parameter der
Funktion g. Fast alle Lernregeln sind Spezialisierungen der Funktionen
h und g.
17
Perzeptron (1)
Im folgenden werden wir uns aus Zeitgründen nur eine Art von Netz
mit einer Art von Lernregel genauer ansehen, ein Feed Forward Perzeptron mit der Backpropagation-Regel.
Ursprung hat das Perzeptron aus
der Analogie zum Auge, bei dem
die Retina die Input-Neuronen
beinhaltet, von der über eine Zwischenschicht eine Klassifikation der
einzelnen Bilder in der Ausgabeschicht erfolgt.
Dementsprechend werden solche
Netz z.B. in der Steuerung autonomer Fahrzeuge eingesetzt.
Ausgabeneuron
(Lenkung)
Eingabeneuronen (Straßenbild+entfernungen)
18
Perzeptron (2)
Aufbau:
• Es gibt eine Input-Schicht
• Es gibt keine, eine oder mehrere verborgene Schichten (hidden
layer)
• Es gibt eine Ausgabe-Schicht
• Die Kanten verbinden die Schichten eine nach der anderen in der
gleichen Richtung untereinander, d.h. die Informationen aller Knoten der Input-Schicht laufen in die selbe Richtung, nicht zurück
und nicht zwischen den Knoten einer Schicht.
In einigen Fällen wird der Begriff Perzeptron enger als feedforwardNetz mit keiner oder einer verborgenen Schicht verwendet.
19
Backpropagation-Regel (1)
Wiederholung lineare Ausgleichsrechnung, Kapitel 3
Definition 3.1 (Ausgleichsproblem)
Gegeben sind n Wertepaare (xi, yi), i = 1, . . . , n mit xi 6= xj für i 6=
j. Gesucht ist eine stetige Funktion f , die in einem gewissen Sinne
bestmöglich die Wertepaare annähert, d.h. dass möglichst genau gilt:
f (xi ) ≈ yi für i = 1, . . . , n.
Definition 3.1 (Fehlerfunktional)
Gegeben sei eine Menge F von stetigen Funktionen sowie n Wertepaare (xi, yi), i = 1, . . . , n. Ein Element von f ∈ F heißt Ausgleichsfunktion
von F zu den gegebenen Wertepaaren, falls das Fehlerfunktional
E(f ) =
n
X
(f (xi ) − yi)2
i=1
für f minimal wird, d.h. E(f ) = min{E(g)|g ∈ F }. Die Menge F nennt
man auch die Menge der Ansatzfunktionen.
20
Backpropagation-Regel (2)
Pp
Ist die Funktion f (xi ) linear in den Parametern, also f (x) = k=1 ak gk (x),
so lässt sich das Minimum des Fehlerfunktionals über die Nullstelle der
Ableitungen von E(f ) durch Lösen der Normalengleichung für die Parameter ak bestimmen.
Jetzt:
• Jedem x-Wert entspricht einem Satz von Eingabewerten bzw. ein
Eingabe-”Pattern” inp,i mit i ≤ 1 ≤ nin Werten.
• Jedem Ausgabewert y entspricht einem Satz von Ausgabewerten
bzw. Ausgabe-”Pattern” tp,j mit j ≤ 1 ≤ nout Werten
• Die Ausgleichsfunktion f (x) ist jetzt ein Satz von nicht-linearen
Funktionen in einer Anzahl von Parameter, z.B. in den Gewichten
des neuronalen Netzes: fi,j (inp,i) = op,j
21
Backpropagation-Regel (3)
• Dann lautet das Fehlerfunktional (die Summe der quadratischen
Abweichungen zwischen den berechneten und den “gewünschten”
Werten anstatt
P
Ei = (f (xi ) − yi)2
E= n
i=1 Ei
E=
X
p
Ep
out 2
1 nX
op,j − tp,j
Ep =
2 j
• Lösung des nicht-linearen Ausgleichsproblem: das Minimum von E
als Funktion der nicht-linearen Parameter.
Da die Funktionen jetzt nicht-linear in den Parametern sind, kann
das System nicht exakt gelöst werden, sondern das Minimum wird
gesucht, in dem z.B. die Parameter entlang der negativen Steigung
des Fehlerfunktionals als Funktion der Parameter geändert wird oder
Backpropagation ist ein Gradientenabstiegsverfahren, bei der eine Fehlerfunktion (oder Energiefunktion) minimiert wird.
22
Backpropagation-Regel (4)
Der Algorithmus ändert die Gewichte-Matrix entlang des negativen
Gradienten der Fehlerfunktion, bis diese (hoffentlich) minimal ist.
∆wij = −η
X ∂Ep
p ∂wij
.
Da die Funktion nicht-linear ist, hat sich sicher jede Menge lokaler
Minima, in denen das Verfahren “hängen” bleiben kann.
Im folgenden wird davon ausgegangen, dass sich der Output eines
Knotens als oj = fact (netj ) ohne weitere Abhängigkeiten schreiben
lässt. Es gilt die Kettenregel
∂Ep
∂Ep ∂netpj
=
.
∂wij
∂netpj ∂wij
23
Backpropagation-Regel (5)
Der erste Faktor wird als Fehlersignal bezeichnet
δpj = −
∂Ep
∂netpj
und der zweite Faktor ist
∂netpj
∂ X
=
opiwij = opi.
∂wij
∂wij i
Die Änderung der Gewichte berechnet sich dann durch
∆wij = η
X
p
opiδpj
Bei der Berechnung von δpj geht die konkrete Aktivierungsfunktion
ein, also wie die Zelle j den Input in einen Output verwandelt.
∂Ep
∂Ep ∂opj
∂Ep ∂fact(netpj )
δpj = −
=−
=−
.
∂netpj
∂opj ∂netpj
∂opj
∂netpj
24
Backpropagation-Regel (6)
Für den ersten Faktor muss zwischen den Ebenen, in denen sich die
Knoten befinden, unterschieden werden.
1. j ist Index einer Ausgabezelle. Dann gilt
∂Ep
= (tpj − ooj ).
−
∂opj
Der Gesamtfehler ist in diesem Fall
′
δpj = fact (netpj ) · (tpj − ooj )
2. j ist Index einer Zelle der verdeckten Ebenen. Die Fehlerfunktion
hängt von den Output oj indirekt über die Zwischenzellen k ab:
X ∂Ep ∂netpk
∂Ep
−
= −
∂opj
∂netpk ∂opj
k
X
X
∂ X
opiwik =
δpk wjk
=
δpk
∂opj i
k
k
25
Backpropagation-Regel (7)
Das bedeutet, dass man den Gesamtfehler der Zelle j für ein Muster
p aus den gewichteten Fehlern δpk aller Nachfolgezellen k und der
Gewichte der Verbindungen von j zu diesen k berechnen kann.
′
δpj = fact (netpj ) ·
X
δpk wjk
k
Meist wird als Aktivierungsfunktion die logistische Funktion verwendet
mit der Ableitung
d
d
1
flog (x) =
= flog (x) · (1 − flog (x))
−x
dx
dx 1 + e
Damit ergibt sich eine vereinfachte Formel für den Backpropagation
Algorithmus
∆pwij = ηopiδpj
26
Backpropagation-Regel (7)
mit dem Fehlersignal
δpj =
Beispiel:
(
opj (1 − opj )(tpj − opj )
P
opj (1 − opj ) k δpk wjk
n1
falls j Ausgangszelle ist
falls j verdeckte Zelle ist
n2
)
n3
W42
n4
W
74
n7
′
∆w42 = ηo4δ2 = ηo4(t2 − o2) ∗ f (net2)
∆w74 = ηo7δ4 = ηo7(−
3
X
′
δk w4k )f (net4)
k=1
27
Backpropagation-Regel (8)
Das Verfahren zusammengefasst
1. Zu einer gegebenen Menge von Input-Pattern mit ninput Neuronen
und gewünschten Output-Pattern mit noutput Neuronen entwerfe
ein neuronales Netz z.B. ein Perzeptron mit nhidden Neuronen in
einer verborgenen Schicht.
2. Wähle eine Aktivierungs-, Propagierungs- und eine Ausgabefunktion aus.
3. Würfele zufällige Anfangswerte für die Gewichtsmatrix.
4. Durchlaufe für alle Input-Pattern solange bis der Output nahe beim
gewünschten Output liegt:
(a) Berechne die Aktivierung der Neuronen Schicht für Schicht bis
zur Ausgabeschicht (vorwärts).
(b) Vergleiche die Ausgabe mit der gewünschten Ausgabe und berechne die Fehlerfunktion.
(c) Korrigiere die Gewichtsmatrix von der höchsten Ebene beginnend bis zur Eingabeschicht (rückwärts)
28