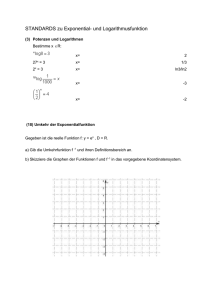
Robust Optimal On-Board Reentry Guidance of an European Space
Werbung

Robust Optimal On-Board
Reentry Guidance of an
European Space Shuttle
Seminar Differentialspiele
Stephan Schmidt
Gliederung
Der Wiedereintritt
–
–
–
–
Zielsetzung
Was macht einen Wiedereintritt aus?
Die Probleme an eine Steuerung
Das Differentialspiel als Lösung
Das robuste Differentialspiel
–
–
–
–
–
–
–
Der Kontrollprozess (Kinematik Equation)
Die Nebenbedingungen
Robust-Optimalität
Die Isaacs Gleichung (Main Equation II)
Neue Lösungsverfahren
„Open-Loop“-Verfahren
Bessere Verfahren
Gliederung
Neuronales Netz
–
–
–
–
–
–
–
–
–
–
–
Was ist ein künstliches neuronales Netz?
Das künstliche Neuron
Ideen für Funktionen eines Neurons
Approximierbarkeit
Praktische Realisierung
Gewichtselimination
Sigmoide Aktivierungsfunktionen
Praktische Approximation
Approximationsfehler
Gradient des Fehlers
Der Backpropagationsalgorithmus
Zusammenfassung
Teil 1: Der Wiedereintritt
Zielsetzung
Finde eine automatische Steuerung,
die einen Space Shuttle ähnlichen Gleiter
trotz Auftretens von unvorhergesehen Ereignissen
auf dem optimalen Weg sicher zurück zur Erde
bringt.
Die Steuerung muss mit den an Bord zur Verfügung
stehenden Mitteln in Echtzeit berechenbar sein.
Was macht einen Wiedereintritt aus?
Ziele:
–
–
–
Kontrollierter Abbau von hoher Bewegungs- und
Lageenergie
Beibehalten der Flugstabilität und Steuerbarkeit
Alleinige Umwandelbarkeit der überschüssigen Energie
durch Reibung, kein Antrieb
Randbedingungen:
–
–
–
–
Hitze außen und innen
Druck auf den Shuttlerahmen
Tragflächenbelastung
Fluglage bei hoher Geschwindigkeit
Die Probleme an eine Steuerung
„Robust-Optimalität“:
–
–
Berechenbarkeit
–
Ionisierung der Luft verhindert Funkkontakt zur
Bodenstation
Echtzeit
–
Ungenauigkeiten bei der Modellierung
Unvorhersehbare bzw. nicht-messbare Einflüsse
Die Daten werden sofort benötigt
Zufall
–
Alle Größen sind abhängig vom Luftdruck, welcher in sehr
großer Höhe unvorhersehbar schwankt und nicht messbar
ist
Das Differentialspiel als Lösung
Problem:
Finde Wiedereintrittsflugbahn trotz stark schwankender
Größe des Luftdrucks p(h)
Idee:
Betrachte „worst case“: Wenn selbst bei einem „planmäßig
bösartig“ handelnden Luftdruck eine Steuerung zum
Wiedereintritt gefunden werden kann, so sollte dies bei
einem zufällig handelnden Luftdruck erst recht möglich sein
Lösung:
Betrachte Luftdruck und Shuttle als zwei Spieler in einem
Differentialspiel
Teil 2: Das robuste Differentialspiel
Der Kontrollprozess
Dem Differentialspiel soll folgende Mechanik zugrunde liegen:
d
z (t ) f ( z (t ), u (t ), w(t ))
dt
z IR n , u IR m , w IR p
mit:
z: Spielzustand, State Variable
u:
Kontrollvariable Spieler I, Control Variable
w:
Unbekannt, nicht messbar, Schwankung, Modellfehler oder
Kontrollvariable Spieler II
Die Nebenbedingungen
Folgende Bedingungen sollen zusätzlich erfüllt werden:
1) u U ( z ) abgeschlos sen
z IR n
2) w W ( z ) abgeschlos sen z IR n
3) Der Prozess endet nach endlicher Zeit t f t0
Eine Steuerung u(z) heißt genau dann zulässig, wenn
z IR n , w W ( z ) : u(z) erfüllt 1) und 3)
Eine Steuerung w(z) heißt genau dann zulässig, wenn
z IR n , u U ( z ) : w(z) erfüllt 2) und 3)
Robust-Optimalität
Menge aller kontrollierbaren Zustände:
S c {z IR n | u ( z ) zulässige Steuerung}
Performance-Index zur Leistungsmessung des Spielers:
( z ) : IR n IR
Eine zulässige Steuerung u*(z) heißt robust-optimal genau dann,
wenn:
*
z Sc löst u : min max ( z (t f ))
uU ( z ) wW ( z )
Für z aus Sc sei unter Benutzung eines robust-optimalen u* die
Auszahlung (Value) definiert als:
V ( z ) ( z (t f ))
Die Isaacs Gleichung
Optimalitätskriterium:
An differenzierbaren Stellen des Values ergibt sich für u* die
Optimalitätsbedingung:
V f ( z, u * ( V , z ), w* ( V , z )) 0
z
z
z
z S c
Dies wird bei Isaacs als Main Equation II bezeichnet
Herkömmliches Differentialspiel dadurch nach Betrachten
der singulären Hyperebenen lösbar durch multiple Shooting
und Rückwärtsdifferentieren
Robustes Differentialspiel:
w: Schwankung, Unbekannt oder Modellfehler
Neue Lösungsverfahren
Problem:
w wird nicht optimal, sondern zufällig gewählt
Ansatz:
Diskretisiere die Zeit
Lösung: Rückkopplungssteuerung
1.
2.
3.
4.
Bestimme derzeitigen Spielzustand z
Löse Isaacs-Gleichung für z und benutze so gewonnenes
u als Steuerung
Verbleibe bei u als Steuerung für selbst gewähltes
Zeitintervall
Gehe zu 1.
„Open-Loop“-Verfahren
Bessere Verfahren
Problem:
–
In jedem Schritt muss das RWP der Isaacs-Gleichung neu
gelöst werden
–
Bei realistischer Mechanik nicht in Echtzeit zu
bewerkstelligen
Idee:
–
Berechne so viel wie möglich im Voraus
–
Interpolation der Pfadfunktion
Neuronales Netz
Teil 3: Das Neuronale Netz
Was ist ein künstliches neuronales Netz?
Abbildung eines Eingabevektors x unter
Berücksichtigung eines Gewichtsvektors (w,q) auf
Ausgabevektor y
f NN : ( x, w ,q ) y
Gerichteter, gewichteter Graph
Knoten: künstliche Neuronen, Funktionen
Funktionskomposition
Nicht-linear
Das künstliche Neuron
Gewichten und Aggregieren
aller Eingaben:
f con : IR 2 IR
Eingabewert netj (t):
f inp, j : IR k IR
Grad der Aktivierung aj (t):
f act , j : IR3 IR
Ausgabe oj (t):
f out, j : IR IR
Ideen für Funktionen eines Neurons
Eingabefunktion:
k
f inp, j f con wij oi
i 1
Aktivierungsfunktion:
f act , j
1,
0,
Ausgabefunktion
f out, j id
f inp, j q j
sonst
Approximierbarkeit, Behauptung
f C[a, b]d , f const , 0 w , q , neuronales Netz f
maxd
x[ a ,b ]
f ( x) f
NN
( x, w , q )
Jede stetige, nicht konstante Funktion f ist durch ein
(mehrschichtiges) neuronales Netz beliebig genau
approximierbar
NN
:
Approximierbarkeit, Beweisskizze
Stetige, nicht konstante Funktionen sind beliebig genau
durch Treppenfunktionen approximierbar (WT1)
Sei f : [a, b]d IR m , stetig , 0
f TR TR[a, b]d mit : maxd
x[ a ,b ]
Dann gilt : I : i IN
f ( x) f TR ( x)
f TR const auf [ai , bi ]d
Setze für i I : const i : f TR
[ ai ,bi ]d
, iI
Approximierbarkeit, Beweisskizze
Definiere Neuronen der ersten Schicht als:
ni1 ( x) (consti , x) , i I
Definiere Neuronen der zweiten Schicht als:
ni2 (consti , x) const i Ind[ a ,b ]d ( x) , i I
i
i
Mit w 1-Matrix und q 0-Vektor gilt dann:
f TR ( x) f NN ( x, w ,q ) x [a, b]d
Damit gilt die Behauptung
Praktische Realisierung
Beweis liefert nur begrenzten Bezug zur Anwendbarkeit:
–
–
–
I im Allgemeinen sehr groß
Bei Steigerung der Genauigkeit müssen Schichten neu gestaltet
werden
Gewichte werden kaum beachtet
Für Anwendung in Praxis:
–
–
Netzarchitektur vereinfachen
Netz differenzierbar gestalten
Gewichtselimination
Gilt für die Aktivierungsfunktion:
f act , j (net j ,q j ) f act , j (net j q j ,0)
So können die Schwellwerte q als Gewichte w
aufgefasst werden:
q
o1
o2
w2j
w3j
w1j
nj
o3
f NN ( x, w ,q ) f NN ( x, w )
o1
o2
o3
1
w1j
w2j
w3j
q
nj
Sigmoide Aktivierungsfunktionen
Problem:
Indikatorfunktion macht das Netz nichtdifferenzierbar
Substituiere Indikatorfunktion durch sigmoide
Funktion fsig:
1
0,8
0,6
–
–
fsig ist streng monoton steigend
Grenzwert ist +/- 1
Üblich:
tanh oder 2/p arctan
-5
–
-4
-3
0,4
0,2
0
-2
-1
0
-0,2
-0,4
-0,6
-0,8
-1
1
2
3
4
5
Praktische Approximation
Sei I Menge mit den zu approximierenden
Punktepaaren
I x1 , f ( x1 ) , x2 , f ( x2 ), ... , x2 k , f ( x2 k )
Zufälliges Aufteilen von I in Trainings- und
Validierungsmenge
IT x1 , f ( x1 ), x2 , f ( x2 ), ... , xk , f ( xk )
IV xk 1 , f ( xk 1 ) , xk 2 , f ( xk 2 ) , ... , x2k , f ( x2k )
Approximationsfehler
Für beliebige differenzierbare Metrik definiere:
T (w )
V (w )
f NN ( xk , w ) f ( xk )
f NN ( xk , w ) f ( xk )
kI T
kIV
Lernproblem mit Gradientenabstiegsverfahren:
min T (w )
w
unter V (w ) möglichst klein
Gradient des Fehlers
Bei Verwendung der 2-Norm ergibt sich:
T (w )
w
w
2 f
kI T
NN
f
kI T
NN
( xk , w ) f ( x k )
( xk , w ) f ( x k )
f
w
NN
2
( xk , w ) : w
Idee zur Berechnung der Ableitung des neuronalen
Netzes:
Der Backpropagationsalgorithmus
1.
2.
3.
4.
5.
Initialisierung: Wähle wij zufällig
Feedforward: wähle z aus IT zufällig, berechne
Ausgabewerte yi schichtweise und speichere die
Ableitung sj der Neuronen
Backpropagation: Traversiere das Netz rückwärts
mit der Eingabe zi-yi. Berechne rückwärtigen Fehler
d in Ausgabeschicht und verdeckten Schichten:
d i s i ( zi yi )
d j s j d i wij
i
Korrigiere Netzgewichte:
wij di y j , 0
Gehe zu 2.
Zusammenfassung
physikalische und technische Gegebenheiten
verlangen die Berücksichtigung zufälliger
Luftdruckschwankungen.
Dem Luftdruck wird planmäßiges Handeln zu
Grunde gelegt und als Gegenspieler eines
Differentialspieles aufgefasst
Lösung als Open-Loop ist nicht echtzeitfähig.
Das Neuronale Netz zur Approximation
Anlernen des Netzes mit Backpropagation