Folien 066 bis 078
Werbung

Nutzung von Seitenidentifikator/-typindikator
• Merke: „Nicht überall, wo Seite i draufsteht, ist auch Seite i drin …“ →
Seitenidentifikator hilft
z.B.
• Seitentypindikator:
≠ Tree
Tree
xyz
Tree
Tree
Tree
Tree
DATA
xyz
Hashtabelle
oder
DBTT
oder
...
• Verwendung:
Erweiterung des BEREITSTELLEN-Operators an der
Systempufferschnittstelle
BEREITSTELLEN Seite i, Modus, TYP, RC
Im Parameter TYP sagt die anfordernde Komponente (Record
Manager, Zugriffspfadverwaltung …), welchen Seitentyp sie erwartet
- Typangabe UNKNOWN muss erlaubt sein für "Segment Scan" →
keine Prüfmöglichkeit
- Seitentyp EMPTY hat einige Implikationen:
Fehlertoleranz
29.06.2006
66
arg
kostspielig
• leere Seiten müssen in die Datenbank auf Platte
zurückgeschrieben werden (nach FREIGEBEN …)
• leere Seiten müssen von der Datenbank (Platte) in den
Systempuffer übertragen werden (bei BEREITSTELLEN …)
Was ließe sich prinzipiell noch im Pufferverwalter prüfen?
Etwa seiteninterne Freiplatzverwaltung:
• Freiplatzbeginn, Freiplatzlänge zulässige Werte?
• Freiplatzbeginn + Freiplatzlänge …?
• ...
u.U. akzeptabel, aber noch weitergehende, seiteninhaltsbezogene
Prüfungen gehören nicht in den Pufferverwalter, sondern (mindestens)
„eine Etage höher“
Fehlertoleranz
29.06.2006
67
Freiplatzbeginn
Freiplatzbeginn
Seitenkopf
Freiplatzlänge
Satz 1
seiteninterne
Umsetztabelle
1. Seitenindex
2. Seitenindex
Freiplatz
Satz 2
Satz 1
Freiplatz
Satz 2
b) zwei Listen
a) eine Liste
Fehlertoleranz
29.06.2006
68
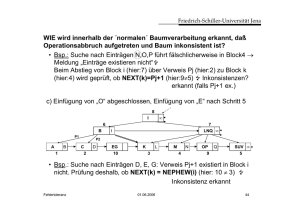
3. Lokale (seiteninterne) Konsistenzprüfungen durch Record Manager
und Zugriffspfadverwalter
3.1 Zur Lösung des Sortierordnungsproblems
Sortierte Schlüsselwerte häufig vorkommend in Datenbanksystemen
(und nicht nur dort):
• Sätze/Einträge innerhalb von Buckets in Hashtabellen
• … in Knoten von B-/B*-Bäumen
• etc.
Sortierte Eintragsfolgen können fehlerhaft sein etwa durch:
• Überschreiben/Verfälschen von Einträgen (Schlüsselwerten)
• Einfügungen unter Verstoß gegen die Sortierordnung (sollte nicht
vorkommen, aber …)
Mögliche Teillösung: Robust Contiguous List Storage (RCLS)
→ aber viel zu teuer
Fehlertoleranz
29.06.2006
69
Zumindest Verstöße gegen die Sortierordnung kann man im Prinzip
erkennen:
3
6
9
Konsistente Eintragsfolge
aufsteigend sortiert
3
5
9
nicht erkennbare Inkonsistenzen
6
9
prinzipiell erkennbare Inkonsistenz
"∞"
3
Verstoß gegen Sortierordnung
lahmgelegt
Aber: Normale Suchalgorithmen ohne Fehlererkennungsmaßnahmen
laufen auch bei prinzipiell erkennbaren Inkonsistenzen „in die Irre“:
erkennen keinen Fehler, melden gesuchten Schlüsselwert als nicht
vorhanden (→ etwa binäre Suche, sequentielle Suche …) und zwar nicht
nur für den einen verfälschten Schlüsselwert!
→ Offline-Fehlererkennung?
→ Geeignete Online-Fehlererkennung durch das DBVS?
Fehlertoleranz
29.06.2006
70
Frage: Wie kann man Suchalgorithmen so „ausstatten“ (erweitern), dass
sie Verstöße gegen die Sortierordnung in sortierten Eintragsfolgen quasi
nebenbei erkennen und melden? Nebenbedingung: EFFIZIENZ
Sortierte Eintragsfolgen / Suchalgorithmen / Anfragetypen existieren in
„beliebiger“ Vielfalt: feste/variable Schlüssellänge; fortlaufende, lückenlose
oder gekettete Speicherung; aufsteigend/absteigend sortiert; Suche auf "="
oder "≥"; …
Was wir im folgenden betrachten:
• b Schlüsselwerte Ki fortlaufend, ´lückenlos´ gespeichert
• Aufsteigende Sortierung, Duplikate zulässig
Konsistenzbedingung somit Ki≤Ki+1 (1≤i≤b-1)
• Gegeben Wert K; Suche min {1≤i≤b | K≤Ki} im folgenden auch als
FIND-LE ("less or equal") bezeichnet.
Anwendung u.a. in B*-Bäumen
• Falls K>Kb (also Suche erfolglos), soll Wert b+1 zurückgegeben
werden
Fehlertoleranz
29.06.2006
71
Knoten (Seite) in einem B*-Baum
b=3
P1
-∞ ..,3]
Fehlertoleranz
K1
K2
K3
3
6
9
P2
(3,6]
P3
(6,9]
29.06.2006
Schlüsselwerte
Ki
P4
(9,..) ..+∞
Schlüsselwertintervalle
Swi
72
Suchalgorithmen:
Sequentielle Suche
i:=1;
while (K>Ki) and (i<b) do i:=i+1;
if K>Kb then i:=b+1;
i liefert Suchergebnis
Binäre Suche
UG:=1; (∗Untergrenze∗) OG:=b+1; (∗Obergrenze∗)
repeat
i:=(UG+OG) div 2;
if K>Ki then UG:=i+1
else OG:=i
until (UG=OG);
Fehlermodell:
• Wir gehen zunächst von genau einem (pro Eintragsfolge) verfälschten
Schlüsselwert aus:
inkons. Wert
Kk (1≤k≤b) → Kk*
• Wir untersuchen Fehler, die prinzipiell – ohne zusätzl. red. Info –
erkennbar sind, also Verstöße gegen die Sortierordnung
- positive Verfälschung: Kk*>Kk+1≥Kk
- negative Verfälschung: Kk*<Kk-1≤Kk
Fehlertoleranz
29.06.2006
73
K1*
K2
K3
10
6
9
P1
..,10]
..,6]
-
(6,9]
K3
3
10
9
P2
P3
(3,10]
(3,10]
K3
3
0
9
P2
P3
-
(3,9]
(0,9]
K2
K3*
3
6
5
P3
(3,6]
(3,6]
-
2. Pos. Verfälschung von K2
Swi seq. Suche
Swi bin. Suche
3. Pos. Verfälschung von K2
P4
K1
P2
Swi seq. Suche
Swi bin. Suche
(10,..
(10,..
K2*
..,3]
-
(10,..
(9,..
P4
K1
P1
Fehlertoleranz
P4
K2*
..,3]
..,3]
..,3]
..,3]
P3
K1
P1
P1
P2
1. Pos. Verfälschung von K1
(9,..
(9,..
Swi seq. Suche
Swi bin. Suche
4. Pos. Verfälschung von K3
P4
(6,..
(6,..
29.06.2006
Swi seq. Suche
Swi bin. Suche
Swi = Schlüsselwertintervalle
74
Auswirkungen von Verfälschungen gemäß obigem Fehlermodell
Sequentielle Suche
• Positive Verfälschung des k-ten Schlüsselwerts (1≤k<b): Suche nach
Werten aus (Kk, Kk*] endet schon bei i=k anstatt bei i=k+1, i=k+2 …
• Negative Verfälschung des k-ten Schlüsselwerts (1<k≤b): Suche nach
Werten aus (Kk-1, Kk] endet erst bei i=k+1 anstatt i=k
Auswirkungen einer positiven Verfälschung somit abhängig von
Position (k) und Ausmaß der Verfälschung; bei einer negativen
Verfälschung bestehen diese beiden Abhängigkeiten dagegen nicht
Binäre Suche
Auswirkungen von Verfälschungen (positiv/negativ) abhängig von Position
k, an der Verfälschung auftritt; „worst case“ für k=(b+2) div 2, da dann
stets schon im ersten Suchschritt falsch verzweigt (d.h. Suche fortgeführt)
wird
Fehlertoleranz
29.06.2006
75
Fehlererkennungsmaßnahmen
Nahe liegend wäre:
Bei jedem Suchschritt (Schleifendurchlauf) prüfen: Ki-1≤Ki≤Ki+1
1 würde Vergleichsanzahl bei der Suche drastisch erhöhen (100%); bei seq. Suche
würde Prüfung Ki≤Ki+1 reichen: immer noch 50% mehr Vergleiche als bei
Basisalgorithmus
Wünschenswert wäre:
Suchschritte (Schleifendurchläufe) bleiben frei von zusätzlichen Prüfungen (Vergleichen)
Lösung
NACH Abschluss der Suche (mit Wert i) wird geprüft:
if i>2
then
if Ki-2>Ki-1 then INKONSISTENZ;
(∗ Neg. Verfälschung in Ki-1 möglich ∗)
if i<b
then
if Ki>Ki+1 then INKONSISTENZ;
(∗ Pos. Verfälschung in Ki möglich ∗)
Fehlertoleranz
29.06.2006
76
Bemerkungen dazu
• Funktioniert sowohl bei sequentieller als auch bei binärer Suche!
• Wenige Vergleiche (max. 4) NACH Abschluss der Suche → insgesamt
geringer Overhead
• Selbst bei Annahme, dass nur genau ein verfälschter Schlüsselwert
existiert, ist es im Fall einer erkannten Inkonsistenz oft nicht
entscheidbar, ob es sich um eine positive oder um eine negative
Verfälschung handelt
Bsp.:
…
12 19
18
21
…
wo liegt der Fehler?
aber:
…
12 22
18
21
…
Ki>Ki+1
Ki>Ki+2
und
hier ist der Fall klar, wenn nur genau ein…
• Mehrfachfehler: Falls jeder einzelne der n>1 falschen Schlüsselwerte
gleichzeitig auch einen Verstoß gegen die Sortierordnung
verursacht, wird die Inkonsistenz durch obige Prüfungen erkannt;
andernfalls nicht unbedingt
Fehlertoleranz
29.06.2006
77
Veranschaulichung
1. Sequentielle Suche
Suche 20
a) pos. Verfälschung
i
…
6
9
12
37
18
21
24
…
Ki>Ki+1
Fehler
Suche 20
b) neg. Verfälschung
i
…
6
9
12
15
18
7
24
…
Ki-2>Ki-1
Fehler
2. Binäre Suche
a) pos. Verfälschung
Suche 20
i
…
6
9
12
37
18
21
24
…
Ki>Ki+1
b) neg. Verfälschung
Fehler
Suche 20
i
…
6
9
12
15
18
7
24
…
Ki-2>Ki-1
Fehlertoleranz
29.06.2006
Fehler
78