Fehlerdiagnose in Worthypothesengraphen - Friedrich
Werbung

Friedrich-Alexander-Universität Erlangen-Nürnberg
Lehrstuhl für Künstliche Intelligenz
Fehlerdiagnose in
Worthypothesengraphen
Diplomarbeit im Fach Informatik
vorgelegt von
Martin Hacker
Matrikelnummer: 1941575
am 7. Januar 2008
Betreuer: Dr.-Ing. Bernd Ludwig
Erklärung
Ich versichere, dass ich die vorliegende Arbeit ohne fremde Hilfe und ohne Benutzung anderer als der angegebenen Quellen angefertigt habe und dass die
Arbeit in gleicher oder ähnlicher Form noch keiner anderen Prüfungsbehörde
vorgelegen hat und von dieser als Teil einer Prüfungsleistung angenommen
wurde. Alle Ausführungen, die wörtlich oder sinngemäÿ übernommen wurden, sind als solche gekennzeichnet.
Ort, Datum:
Unterschrift:
i
Inhaltsverzeichnis
1 Einführung
1
1.1
Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
1.2
Problemstellung und Spezikation . . . . . . . . . . . . . . . .
2
1.3
Einschränkungen
4
1.4
Besondere Schwierigkeiten
. . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . .
2 Grundlagen
5
7
2.1
Wort- und Satzhypothesen . . . . . . . . . . . . . . . . . . . .
7
2.2
Merkmalstrukturen . . . . . . . . . . . . . . . . . . . . . . . .
8
2.3
Grammatikmodelle
9
. . . . . . . . . . . . . . . . . . . . . . . .
2.3.1
Variabilität der Wortstellung . . . . . . . . . . . . . . .
2.3.2
Phrasenstrukturgrammatiken
2.3.3
Dependenzgrammatiken
9
. . . . . . . . . . . . . .
10
. . . . . . . . . . . . . . . . .
13
2.4
Chart-Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . .
15
2.5
Kombinationen von Dependenz und Phrasenstrukturparsern
.
17
2.6
Grundlegende Topologie deutscher Sätze
. . . . . . . . . . . .
19
3 Ein Verfahren zur Fehleranalyse in Spracherkennerhypothesen
22
3.1
3.2
Das Verfahren im Detail
. . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . .
22
3.1.1
Architektur des Systems
22
3.1.2
Modellierung topologischer Strukturen
. . . . . . . . .
23
3.1.3
Präzedenzregeln . . . . . . . . . . . . . . . . . . . . . .
27
3.1.4
Konikte . . . . . . . . . . . . . . . . . . . . . . . . . .
30
3.1.5
Das Suchverfahren
3.1.6
Priorisierung
3.1.7
Weitere Optimierungsmaÿnahmen . . . . . . . . . . . .
40
3.1.8
Fehlerdiagnose
43
. . . . . . . . . . . . . . . . . . . .
33
. . . . . . . . . . . . . . . . . . . . . . .
38
. . . . . . . . . . . . . . . . . . . . . .
Ein Sprachmodell für das Deutsche
. . . . . . . . . . . . . . .
45
3.2.1
Satzmodi
. . . . . . . . . . . . . . . . . . . . . . . . .
45
3.2.2
Vollverben . . . . . . . . . . . . . . . . . . . . . . . . .
45
3.2.3
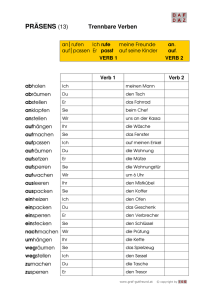
Trennbarer Verbzusatz bei trennbaren Verben
. . . . .
48
3.2.4
Kopulaverben . . . . . . . . . . . . . . . . . . . . . . .
49
3.2.5
Funktionsverbgefüge
. . . . . . . . . . . . . . . . . . .
49
3.2.6
Hilfsverben
. . . . . . . . . . . . . . . . . . . . . . . .
50
3.2.7
Modal- und Modalitätsverben
3.2.8
AcI-Verben
3.2.9
Doppel-Vollverb-Konstruktionen . . . . . . . . . . . . .
52
3.2.10 Aufbau komplexer Verbalstrukturen . . . . . . . . . . .
52
. . . . . . . . . . . . . .
51
. . . . . . . . . . . . . . . . . . . . . . . .
51
ii
3.2.11 Topologie der Verbformen
. . . . . . . . . . . . . . . .
3.2.12 Valenzalternation bei bestimmten Verbformen
53
. . . . .
54
3.2.13 Nominalphrasen . . . . . . . . . . . . . . . . . . . . . .
56
3.3
Behandlung von Koordinationen . . . . . . . . . . . . . . . . .
56
3.4
Die resultierende Sprache . . . . . . . . . . . . . . . . . . . . .
57
4 Implementierung
58
4.1
Implementierung des Suchalgorithmus . . . . . . . . . . . . . .
58
4.2
Implementierung des Sprachmodelles
. . . . . . . . . . . . . .
60
4.3
Implementierung des Topologiemodelles . . . . . . . . . . . . .
61
4.4
Implementierung des Präzedenzmodelles
. . . . . . . . . . . .
63
4.5
Implementierung des Koniktmodelles
. . . . . . . . . . . . .
63
5 Evaluation
64
5.1
Datengrundlage . . . . . . . . . . . . . . . . . . . . . . . . . .
64
5.2
Bewertung einzelner Hypothesen . . . . . . . . . . . . . . . . .
64
5.3
Nachkontrolle von Spracherkennerinterpretationen . . . . . . .
64
5.4
Lokalisierung des Fehlers . . . . . . . . . . . . . . . . . . . . .
65
6 Ausblick
66
6.1
Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . .
66
6.2
Perspektiven . . . . . . . . . . . . . . . . . . . . . . . . . . . .
67
iii
1
Einführung
1.1 Motivation
Die maschinelle Verarbeitung natürlicher Sprache gewinnt in der Praxis zunehmend an Bedeutung. Denn Fortschritte im Bereich der Künstlichen Intelligenz sind im Alltag in Kombination mit einem sprachlichen Eingabemodus
erst richtig wertvoll. Denn intelligente Systeme erfordern bei ihrer Bedienung
weit komplexere Angaben, für die einzelne Tasten auf dem Gerät oder der
Fernbedienung nicht mehr ausreichen. So könnte ein intelligenter Fernseher,
der Sendungen aus dem Fernsehprogramm nach den individuellen Wünschen
des Benutzers auswählt, auf eine Vielzahl teils vager zeitlicher und inhaltlicher Angaben reagieren, deren Formalisierung und Kodierung mittels Fernbedienung dem Benutzer kaum weniger Aufwand abverlangen würde als das
eigenhändige Stöbern in der Fernsehzeitschrift. Die Steuerung per Tastatur,
die sich bei Personalcomputern über Jahrzehnte bewährt hat, ist bei integrierten Systemen häug nicht möglich wie beim Autofahren oder für
den Benutzer nicht komfortabel wie bei der Bedienung des Fernsehers von
der Couch aus.
In der Automobilwelt oder bei Dialogsystemen zur telefonischen Auskunft
und Abwicklung sind Spracherkennungssysteme bereits heute gang und gäbe. Auch die Entwicklung intelligenter, sprachgesteuerter Haushaltsgeräte
wird von den Herstellern mit Nachdruck vorangetrieben. Die Szenarien reichen dabei vom modernen Allzweck-Haushaltsroboter, der den Bewohnern im
wahrsten Sinne des Wortes jeden Wunsch von den Lippen abliest, bis hin zu
Mobiltelefonen, die stets ein oenes Ohr für ihren Besitzer haben, um jegliche
Art der gewünschten Information per Internet zu aquirieren oder organisatorische Aufgaben zu übernehmen, indem es zum Beispiel Anweisungen an
die heimischen Haushaltsgeräte gibt.
Nun ist die natürliche Sprache aber ein schwer zu fassendes Konstrukt,
welches oft nicht den Gesetzen der Logik folgt und in Aussprache, Grammatik und Wortschatz groÿe individuelle, regionale, gesellschaftliche und situative Varietäten zeigt. Die Erkennungsrate heutiger Spracherkenner genügt
deshalb insbesondere wenn kein individuelles Training mit dem jeweiligen
Benutzer vorausgegangen ist selten den hohen Anforderungen künftiger
Anwendungen, die sich häug nicht mehr auf eine enggefasste sprachliche
Thematik beschränken. Damit intelligente Systeme in der Praxis überhaupt
Akzeptanz nden können, sind also Methoden gefragt, mit denen die Erkennungsrate gesteigert werden kann.
1
1.2 Problemstellung und Spezikation
Spracherkennungssysteme bilden Hypothesen für einzelne Wörter und Sätze
und bewerten diese in der Regel rein lokal, das heiÿt einerseits anhand eines
akustischen Abstandsmaÿes, andererseits mittels statistischer Erfahrungswerte für N-Gramm-Häugkeiten. Bedingt durch akustische Verwechslungen,
also falsche Wahl einzelner Wörter, entstehen semantisch oder syntaktisch
fehlerhafte Satzhypothesen. Vom Menschen können diese oft problemlos als
fehlerhaft eingeordnet werden, ohne die tatsächlich zugrundeliegende Äuÿerung zu kennen. Die semantischen Fehler können mit umfassendem Weltwissen, die syntaktischen durch eine globale Sicht auf die grammatikalische
Struktur des Satzes identiziert werden.
Die Idee dieser Arbeit besteht darin, im Anschluÿ an die Hypothesenbildung mit globalen maschinellen Parsing-Verfahren die grammatikalische
Korrektheit zu überprüfen. Auf diese Weise als ungrammatisch bewertete
Hypothesen können ausgeschlossen werden, was zu einer Verbesserung der
Erkennungsrate des Spracherkenners führen kann.
In einem weiteren Schritt kann der Versuch erfolgen, von den während
des Parsings aufgetretenen syntaktischen Konikten, die zur Einstufung der
Äuÿerung als ungrammatisch führten, auf die eigentliche Fehlerursache, das
verwechselte Wort beziehungsweise die verwechselten Wörter, zu schlieÿen.
Ist die Ursache einmal identiziert und somit der Fehler lokalisiert, kann über
das weitere Vorgehen entschieden werden. Dieses kann im Versuch bestehen,
das ursprüngliche Wort anhand von Alternativen im Worthypothesengraphen
oder anhand von lexikalischer und morphologischer Zusatzinformation zu erraten. Ist dies nicht aussichtsreich genug und wird keine andere Hypothese
als richtig bewertet, kann alternativ eine gezielte Nachfrage an den Benutzer
gestellt oder in schwierigen Fällen der Erkennungsversuch ganz abgebrochen werden, um den Benutzer um eine Wiederholung oder Umformulierung
zu bitten.
In den vergangenen Jahrzehnten wurde eine Menge verschiedenartiger
Parser entwickelt. Eine Neuentwicklung scheint jedoch angebracht, da sowohl die Anwendung als auch die Tatsache, dass es sich bei der Eingabe um
mündliches Deutsch handelt, spezielle Anforderungen an das System stellen:
•
Das Hauptaugenmerk liegt weniger auf bis ins Detail korrektem Parsing
grammatikalisch korrekter Sätze als vielmehr auf der Analyse fehlerhafter Äuÿerungen. Der Parser muss also in bestimmtem Maÿe fehlertole-
rant arbeiten. Lässt sich keine fehlerfreie Lösung nden, darf die Suche
nicht abgebrochen werden, sondern es muss die fehlerärmste Lösung
ermittelt werden, um Aussagen über die mutmaÿlichen Fehlerursachen
treen zu können.
2
•
Trotz gröÿeren Rechenaufwandes einer fehlertoleranten Suche soll das
Verfahren so ezient umsetzbar sein, dass ein Einsatz in einem EchtzeitDialogsystem im Bereich des Möglichen liegt.
•
Auf die speziellen, topologisch schwierigen Eigenheiten der deutschen
Sprache ist intensiv einzugehen.
•
In der gesprochenen Sprache entfällt die Interpunktion als nützliche
Hinweisquelle.
•
Das Verfahren muss oen für Umgangssprache und -grammatik sein.
•
Die akzeptierte Sprache soll möglichst weit gefasst sein, um False Negatives zu vermeiden. Denn wenn vom Spracherkenner korrekt gebildete
Hypothesen revidiert werden, besteht die Gefahr, dass sich die Erkennungsrate sogar verschlechtert.
•
Der Rechenaufwand wird in der Praxis durch den für gewöhnlich einfacheren Satzbau in der mündlichen Sprache vermindert, weil es sich
meist um sehr kurze Sätze handelt.
•
Da der primäre Gegenstandsbereich in der Sprache zur Bedienung technischer Geräte liegt, ist eine Spezialisierung auf einen kommandolastigen Sprachstil wünschenswert.
Aus obigen Postulaten wird bereits ersichtlich, dass sich die Arbeit in einem
Spannungsfeld zwischen Vollständigkeit und Ezienz sowie zwischen Fehlersensitivität und -toleranz bewegt. Tabelle 1 zeigt typische Methoden, die für
die jeweiligen Anforderungen in Frage kommen.
Fehlersensitivität
Fehlertoleranz
Vollständigkeit
Ezienz
Bottom-Up-Dependenzanalyse
PSG-Parsing
von Fachsprache
von Schriftsprache
Top-Down-Dependenzanalyse
Keyword Spotting
gesprochener Sprache
gesprochener Sprache
Tabelle 1: Geeignete Methoden für verschiedene Sprachstile, abhängig von
den Anforderungen
3
1.3 Einschränkungen
Da das Verfahren auf einzelnen Eingabeturns arbeitet, wird folgende Grundannahme getroen:
Annahme 1
Bei den Transkriptionen der Turns handelt es sich um vonein-
ander unabhängige, grammatikalisch korrekte satzförmige
1
Äuÿerungen. Es
existieren also insbesondere
•
keine syntaxrelevanten turnübergreifenden Beziehungen und Phänomene (wie zum Beispiel Ellipsen),
•
kein syntaxrelevanter Kontext.
Weiterhin wird angenommen:
Annahme 2
Die Erkennungsrate des Spracherkenners und die Satzlänge
der Eingabe sind so beschaen, dass die Wahrscheinlichkeit für
n+1
akus-
tische Verwechslungen in der Äuÿerung stets kleiner ist als die Wahrscheinlichkeit für
n
akustische Verwechslungen.
Aufgrund von Annahme 2 kann vom Parser eine Interpretation, die zum Beispiel auf einen einzigen Fehler schlieÿen lässt, einer anderen, die von mehreren
Fehlern ausgeht, vorgezogen werden.
Um die Komplexität des Verfahrens in Grenzen zu halten und den Rahmen dieser Arbeit nicht zu sprengen, werden vorerst folgende zusätzlichen
Einschränkungen getroen:
1. Auf eine semantische Analyse der Eingaben wird verzichtet, weshalb
2
eine Erkennung reiner Semantikfehler nicht möglich ist .
2. Die Eingabe enthält keine Ellipsen und Anakoluthe, keine Appositio-
3
nen
sowie keine Herausstellungsstrukturen und kein freies Topik.
3. Auf eine Auösung syntaktischer Ambiguitäten wird verzichtet, soweit
die resultierenden Alternativen hinsichtlich der Fehleranalyse gleichwertig sind. Denn es ist für die Bewertung eines Satzes ausreichend,
1 Satzförmige Äuÿerungen enthalten stets ein nites Verb, anders als satzwertige [7].
2 Zum Beispiel ist die Hypothese die sparte im orb aus drei_sat ist ausgewählt semantisch falsch, grammatikalisch jedoch nicht zu beanstanden. Die ursprüngliche Äuÿerung
lautete: die sparte talk auf drei_sat ist ausgewählt .
3 Jedoch werden für bestimmte Bezugswörter enge Appositionen zugelassen. Es han-
delt sich um Nomen, die im Subkategorisierungslexikon registriert sind und auf die üblicherweise ein Eigenname oder eine Buchstaben-Zahlen-Kombination folgt: Der Film
Der_Untergang ,
Die Sendung Monitor , Die Abkürzung ABS , im Januar 2008 .
4
zu beantworten, ob es eine zulässige syntaktische Interpretation der
fehlerfreien Passagen gibt. Es ist also zum Beispiel irrelevant, worauf
sich ein bestimmtes Satzglied bezieht, solange wenigstens eine zulässige
Interpretation möglich ist. So erlaubt der Satz
sie beehlt ihm zu folgen
zwei verschiedene Interpretationen, die in der Schriftsprache durch Interpunktion unterscheidbar sind:
Sie beehlt, ihm zu folgen
Sie beehlt ihm, zu folgen
Der Parser bricht die Suche ab, sobald eine der beiden Interpretationen
gefunden wurde. Genauso verhält es sich bei fehlerhaften Eingaben, solange der Fehler mit der Ambiguität nicht in Verbindung steht. So ist,
wenn man im Beispiel Sie durch Nie ersetzt, die Diagnose (fehlendes Subjekt) unabhängig von der Interpretation des restlichen Satzes.
Diese Einschränkung hat zur Folge, dass der entstehende Syntaxbaum
nur bedingt durch eventuelle nachgeschaltete Schritte für das Sprachverstehen genutzt werden kann. Dazu müsste der Parser durch ein Bewertungsmodell erweitert werden, welches die aus Ambiguitäten resultierenden Alternativen hinsichtlich ihrer Plausibilität bewertet.
1.4 Besondere Schwierigkeiten
Aus der Problemstellung und aus der gesprochenen Sprache als Gegenstandsbereich ergeben sich einige Probleme:
•
An einem syntaktischen Konikt sind meist zwei Elemente beteiligt,
zum Beispiel im Falle von Inkongruenz. Der eigentliche Fehler, die akustische Verwechslung, kann sich deswegen auf beiden Seiten der Koniktrelation benden. Im Beispiel
wer nden den fehler
tritt zwischen dem niten Verb nden und dem Subjekt wer eine
Inkongruenz bezüglich Numerus auf. Hinter der Hypothese können die
folgenden beiden Äuÿerungen vermutet werden:
Wer ndet den Fehler?
Wir nden den Fehler.
5
Manchmal ist nur eines der beiden Elemente, die am Konikt beteiligt
sind, bekannt:
nden ihn
Der Konikt besteht zwischen dem Verb und dem fehlenden Subjekt,
welches allerdings nicht lokalisiert werden kann.
Im manchen Fällen kann der Konikt gar an einer anderen Stelle im
Satz auftreten als der Fehler:
er wird den Kuchen essen
Versteht der Dekoder in diesem Fall besser statt essen, so tritt ein
Konikt auf, weil das Satzglied den Kuchen dem Verb wird nicht
zugeordnet werden kann. Der Fehler liegt indes weder beim Verb noch
beim Satzglied, sondern beim vermeintlichen Prädikatsadjektiv.
•
Auch die Anzahl gefundener Konikte korreliert nicht zwingend mit
der Anzahl der Fehler. Mehrere Konikte können infolge eines einzigen
Fehlers entstanden sein. Ebenso können sich die Konsequenzen mehrerer Fehler überlappen oder gegenseitig kompensieren, so dass weniger
Konikte als Fehler auftreten.
Dies ist insbesondere dann problematisch, wenn die Anzahl der Konikte beim Parsing als Bewertungsfunktion benutzt wird, da die koniktärmste Lösung nicht immer die mit den wenigsten Fehlern darstellt.
•
Aufgrund des spontanen Charakters der gesprochenen Sprache und ihrer fehlenden Möglichkeiten zur nachträglichen Korrektur ist ein gewisses Maÿ an Ungrammatizität bei den tatsächlichen Äuÿerungen zu
erwarten und somit nach Möglichkeit auch bei den Hypothesen zu tolerieren. Die Unterscheidung, ob ein syntaktischer Konikt auf eine
akustische Verwechslung zurückzuführen ist oder auf eine unsaubere
Formulierung der Äuÿerung, scheint jedoch schwer zu treen zu sein.
•
Vom Menschen als ungrammatisch empfundene Sätze können manchmal doch als grammatisch klassiziert werden, wenn es eine syntaktische (wenn auch semantisch falsche) Interpretion gibt, die so abwegig
ist, dass man sie gar nicht erahnen würde. So könnte die Hypothese solange die sendung oder die uhrzeit das nicht eindeutig festgelegt kann
die aufnahme nicht starten vom Parser ähnlich interpretiert werden
wie Solange sie das nicht eindeutig unvorbereitet kann, die Aufnahme
(bitte) nicht starten!.
6
2
Grundlagen
2.1 Wort- und Satzhypothesen
Ein Spracherkenner (Dekoder ) analysiert das Sprachsignal und bildet eine
Menge von Hypothesen für Wörter. Die Worthypothesen lassen sich als Tripel (from,
to, token)
beschreiben, wobei
from
und
to
sich auf Anfang
und Ende des betreenden Signalausschnittes auf der Zeitachse beziehen
und
token
die symbolische Repräsentation des Wortes darstellt [11]. Un-
ter den Worthypothesen benden sich auch Hypothesen für Pausen, also für
Zwischenräume zwischen nicht verbunden ausgesprochenen Wörtern. Pausen
werden üblicherweise durch das Symbol
ε
gekennzeichnet.
Eine Satzhypothese besteht aus einer Kette von Worthypothesen, deren
Entsprechungen im akustischen Signal sich auf der Zeitachse nicht überlagern
und diese vollständig abdecken.
Die Bewertung der einzelnen Worthypothesen erfolgt anhand eines akustischen Ähnlichkeitsmaÿes. Dazu werden statistische Modelle für Wörter oder
Wortuntereinheiten, üblicherweise Hidden-Markov-Modelle (HMM), verwendet. Die Wahrscheinlichkeit, dass ein HMM die akustische Beobachtung erzeugt, ist das Ähnlichkeitsmaÿ. Die Wahrscheinlichkeit, dass eine bestimmte Worthypothese zutrit, ist aber nicht unabhängig vom Rest des Satzes.
Deswegen wird statistisches Wissen über N-Gramm-Häugkeiten mit einbezogen, um unwahrscheinliche Wort- oder Wortartfolgen abzuwerten (für eine
detaillierte Darstellung siehe [12]).
Als Schnittstelle zwischen Dekoder und Parser kann eine der folgenden
Strukturen dienen [11]:
1.
m
m
beste Ketten : Aus dem Worthypothesengraphen werden diejenigen
Satzhypothesen extrahiert, für die die höchste A-posteriori-Wahr-
scheinlichkeit errechnet wurde.
2. Isolierte Worthypothesen : Die Menge aller isolierten Worthypothesen
wird übergeben, ohne auf Abhängigkeiten, also Übergangswahrscheinlichkeiten, Bezug zu nehmen.
3. Vollständige Worthypothesengraphen : Sie enthalten neben den Worthypothesen auch alle Übergangswahrscheinlichkeiten.
Das in dieser Arbeit beschriebene Satzanalyseverfahren ist auf Eingaben der
Typen 1 und 2 ausgelegt.
7
2.2 Merkmalstrukturen
Grammatikalische Merkmale werden in der Linguistik üblicherweise gebündelt in Form von Merkmalstrukturen repräsentiert (siehe [5] für eine ausführliche Darstellung). Diese bestehen aus einer Menge von Attribut-WertPaaren. Die Werte können entweder Zeichenketten sein (atomare Merkmale )
oder selbst wieder Merkmalmengen (komplexe Merkmale ), so dass hierarchische Strukturen aufgebaut werden können.
dom(M ) einer Merkmalstruktur M bezeichnet die
Menge aller direkten Attribute von M .
Der Wert eines Attributes A ∈ dom(M ) kann über den Term M (A) referenziert werden. In der vereinfachten Schreibweise M (A B) = (M (A))(B) (mit
A als Attributname eines komplexen Merkmales) können beliebig lange PfaDer Denitionsbereich
de beschrieben werden, um hierarchische Merkmalstrukturen zu durchlaufen.
Merkmalstrukturen können Koreferenzen enthalten. Eine Koreferenz bindet
den Wert eines Attributes an den Wert eines anderen. Sie wird über eine
fortlaufende Nummer identiziert, die bei der Darstellung vor die entsprechenden Attributwerte geschrieben wird.
Die Darstellung von Merkmalstrukturen kann in Form von verschachtelten
Matrizen (vgl. Abb. 1), als gerichteter azyklischer Graph oder als Gleichungssystem erfolgen. Auf das Verfahren der Unikation, das zwei kompatible
Merkmalstrukturen zusammenfasst, sei an dieser Stelle nur am Rande hingewiesen (s. dazu [5]).
Denition 1
formal
M ≤N
Eine Merkmalstruktur M subsumiert eine Merkmalstruktur N,
genau dann, wenn
M ≡N
a)
M, N
b)
M, N komplex und ∀A ∈ dom(M ) : M (A) ≤ N (A) und
∀A, B ∈ dom(M ) : M (A) = M (B) → N (A) ≡ N (B),
wobei
=
atomar und
oder
die Identität zweier Werte (das heiÿt, es existiert eine Koreferenz)
bezeichnet und
≡
4
ihre Gleichheit .
Der Begri Subsumption bezieht sich semantisch nicht auf die Merkmalstrukturen selbst, sondern auf die durch sie repräsentierten Klassen:
N
genau dann, wenn alle durch
N
subsumiert
beschriebenen Objekte auch mit
tibel sind. Mit anderen Worten: Bei
von
M
N
M
kompa-
handelt es sich um eine Spezialisierung
M.
4 Soll die Subsumptionsbeziehung erhalten bleiben, auch wenn Werte geändert werden,
sind auch die beiden Vorkommen von
≡
durch
=
zu ersetzen. Technisch würde dies be-
deuten, dass die Attributwerte Zeiger auf dieselbe Speicherstelle darstellen.
8
[VP]
[ich schreibe]
category
text
[PRON]
[personal]
[ich]
category
pos_0
pos_1
form
(3)
type
text
kasus
form
numerus
(1)
person
(2)
[NOM]
[SG]
[1 ]
[VP]
[schreibe]
category
text
modus
form
modus
numerus
(3)
person
numerus
(1)
person
(2)
[INDIKATIV]
[SG]
[1 ]
[INDIKATIV]
[SG]
[1 ]
Abbildung 1: Komplexe Merkmalstruktur mit Koreferenzen (Matrixdarst.)
2.3 Grammatikmodelle
2.3.1 Variabilität der Wortstellung
Natürliche Sprachen unterscheiden sich unter anderem in Bezug darauf, wie
variabel die Wortstellung in Sätzen ist, das heiÿt, wie viele Möglichkeiten
es gibt, ein und denselben Sachverhalt durch sich nur in der Reihenfolge
der einzelnen Wörter unterscheidende Sätze auszudrücken. Sprachen können
die grammatikalischen Funktionen der Wörter nämlich entweder syntaktisch
über die Wortstellung markieren oder morphologisch durch Flexion. Flexionsarme Sprachen wie das Englische benötigen daher eine feste Wortstellung,
während exionsreiche Sprachen wie Russisch oder Latein in der Lage sind,
breite Variationsmöglichkeiten zuzulassen. Das Deutsche bendet sich etwa
in der Mitte einer solchen Skala [2], da hier einerseits die Stellung der meisten Satzglieder sehr variabel, andererseits aber die Position des Prädikates
streng reglementiert ist. Zum Beispiel kann der Satz
This man has read the novel
im Englischen nur auf diese eine Weise formuliert werden. Das Deutsche
dagegen erlaubt die beiden Varianten
9
Dieser Mann hat den Roman gelesen
Den Roman hat dieser Mann gelesen
Aufgrund der im Deutschen ausgeprägten Flexion ist im zweiten Fall eine
Zuordnung der grammatikalischen Funktionen Subjekt und Objekt weiterhin
5
problemlos möglich , während im Englischen der transformierte Satz
The novel has read this man
jene alleine aufgrund der Positionen vertauscht. Weiterhin ist im Englischen
die Position des gesamten Prädikates streng festgelegt, während im Deutschen dessen zweiter Teil auch vorgezogen werden kann, was zu den weiteren
Varianten
Gelesen hat dieser Mann den Roman
Gelesen hat den Roman dieser Mann
Den Roman gelesen hat dieser Mann
führt. In Sprachen mit noch höherer Variabilität kann in der Regel darüber
hinaus zum Beispiel auch der erste Prädikatsteil (die Entsprechung von hat)
am Satzanfang oder -ende stehen.
2.3.2 Phrasenstrukturgrammatiken
Sprachen mit fester Wortstellung lassen sich mit denselben Mitteln verarbeiten wie formale Sprachen, was den Erfolg von PhrasenstrukturgrammatikModellen (PSG) beim Parsen englischer Sätze erklärt [2]. Jene werden in
der maschinellen Sprachverarbeitung in der Regel mit Hilfe kontextfreier
6
(Chomsky-Typ-2)-Grammatiken implementiert. PSG interpretieren die Eingabesätze (Wörter im Sinne der formalen Sprachen) als Hintereinanderreihung von Phrasen (nichtterminale Symbole), welche sich aus aneinandergereihten Konstituenten zusammensetzen, wobei die erlaubten Zusammensetzungen durch Produktionsregeln beschrieben sind. Die einzelnen Konstituenten lassen sich wiederum als Phrasen betrachten und in Konstituenten
zerlegen, bis man zu den einzelnen Wörtern (terminale Symbole) gelangt.
So entsteht ein Syntaxbaum, der den hierarchischen Aufbau des Satzes und
dessen grammatikalischer Bestandteile abbildet.
5 Bei Wortformen wie Neutrum oder Plural, wo die Flexion nicht zwischen Subjekt und
Objekt unterscheidet, führt die Flexibilität der Wortstellung zu Ambiguitäten: Bei Das
Buch hat das Kind gelesen
muss die Semantik hinzugezogen werden, um die Funktio-
nen identizieren zu können. Gibt auch die Semantik keinen Aufschluss, wird zu fester
Wortstellung übergegangen, bei der die Standardreihenfolge Subjekt-vor-Objekt vorgeschrieben ist: Romeo küsst Julia.
6 Zur Theorie formaler Sprachen siehe [6].
10
G = ({S , NP , VP , DP , N , V , DET },
{die, hunde, männer, lügen, bellen},
P, S)
P = {S →
S
→
VP
→
DP
→
NP
→
DET
→
N
→
V
→
,
VP ,
NP VP
DP
V
,
DET NP
N
,
,
die,
|
|
lügen
lügen
hunde
|
männer,
bellen,
Abbildung 2: Ein sehr einfaches Beispiel für eine PSG
Auf der untersten nichtterminalen Ebene entsprechen die Symbole den
Wortarten. Neben der Wortart werden für das Parsing aber auch Informationen über die grammatikalische Kategorisierung der Wortform benötigt,
welche zuvor mittels morphologischer Analyse ermittelt in den jeweiligen Knoten des Syntaxbaumes in Form von Merkmalstrukturen gespeichert
werden können. Die Anwendbarkeit der einzelnen Produktionsregeln unterliegt zum Teil bestimmten Kongruenzbedingungen, das heiÿt, für verschiedene Symbole auf ihrer rechten Seite müssen bestimmte Merkmale übereinstimmen. So müssen bei der Bildung von Nominalphrasen Artikel und
Adjektive mit dem Nomen in den Merkmalen Numerus, Kasus und Genus
übereinstimmen. Beim Parsing können die Kongruenz durch Unikation der
Merkmalstrukturen überprüft und die Merkmale auf die nächsthöhere Ebene
propagiert werden.
7
Parser lösen also das Wortproblem
für kontextfreie Sprachen unter Be-
rücksichtigung spezieller Kongruenzbedingungen und erstellen dabei einen
Syntaxbaum.
In vielen anderen Sprachen stoÿen PSG jedoch an ihre Grenzen. Probleme
entstehen zum einen durch variable Wortstellung, ein Phänomen, das vor al-
7 Der Begri bezieht sich auf Wörter im Sinne der formalen Sprachen, also den kompletten natürlichsprachlichen Satz.
11
lem in der maschinellen Sprachverarbeitung gewöhnlich auch als Scrambling
bezeichnet wird. Dieser Begri resultiert aus einem umstrittenen Syntaxmodell, nach dem es zu jedem semantischen Sachverhalt (mit vorgegebenen
Wörtern) genau eine fest vorgegebene Linearisierung gibt und alle anderen
Satzbauvarianten aus dieser Standardreihenfolge mittels Durcheinanderwürfeln der Satzglieder entstehen, wobei die zulässigen Modikationen durch
Transformationsregeln beschrieben werden [1]. Abgesehen von der erkenntnistheoretischen Inadäquatheit (es ist kaum vorstellbar, dass die Satzsynthese
im menschlichen Gehirn auf diese Weise abläuft) ergibt sich ein praktisches
Problem bei der Umsetzung dieses Modelles: Es mag zwar für die Satzsynthese einen akzeptablen Workaround bieten, doch für das Parsing müssten die
Transformationsregeln invers angewandt werden, denn es liegt ja nur das Ergebnis des Scramblings vor und nicht der Ausgangssatz [2]. Darüber hinaus
könnte man argumentieren, dass es keinen Sinn ergibt, eine Unterscheidung
zwischen ursprünglichen und transformierten Sätzen herbeizuführen [1].
Doch nicht nur die variable Reihenfolge der Konstituenten bereitet bei
der Verwendung von PSG Schwierigkeiten, sondern auch das Phänomen der
diskontinuierlichen Konstituenten [2]. Dabei handelt es sich um syntaktische
Einheiten, deren Bestandteile nicht aneinandergereiht sind, sondern an verschiedenen Stellen im Satz erscheinen:
8
Das Buch hat niemand diesem Mann versprochen zu lesen .
In diesem Beispiel bildet Das Buch zu lesen eine Verbalphrase. Der Versuch,
für diesen Satz einen PSG-Ableitungsbaum zu erstellen, scheitert daran, dass
sich Kanten überschneiden müssten, was bei PSG nicht möglich ist [1].
Der Grund dafür, dass die betroenen Zweige nicht neu ausgerichtet werden können, um die Überlappungen zu lösen, liegt darin, dass bei PSG die
Anordnung der Knoten des Ableitungsbaumes untrennbar mit der Oberächentopologie des Satzes verknüpft ist. Die Topologie beeinusst jedoch nicht
die grundlegende Semantik des Satzes, sondern spiegelt lediglich phonologische Aspekte [1] wie Akzentuierung und Ähnliches wider. Die Semantik
dagegen ist hauptsächlich in den grammatikalischen Beziehungen der Wörter zueinander zu nden [1]. Es liegt also nahe, Semantik und Topologie
zu trennen, indem man ein Grammatikmodell ndet, welches ausschlieÿlich
diese Beziehungen analysiert, und dieses durch ein Topologiemodell ergänzt,
welches sicherstellt, dass es sich bei der konkreten Implementation der semantischen Struktur um eine wohlgeformte Äuÿerung handelt.
8 Aus [1].
12
2.3.3 Dependenzgrammatiken
Dieser Gedanke leitet über zu einer völlig anderen Grammatikkonzeption,
deren Ansatz bereits seit Jahrhunderten bekannt ist und die von [3] (Tesnière 1959) begründet wurde: Die Dependenzgrammatik (DPG). Sie geht davon
aus, dass sich die semantische Struktur eines Satzes durch eine Menge von
Dependenzen darstellen lässt. Unter Dependenz versteht man eine Relation
zwischen zwei Wörtern, die die Abhängigkeit zwischen dem übergeordneten
Wort, dem Regens, und dem untergeordneten Wort, dem Dependens dokumentiert. Da es sich dabei um eine antisymmetrische, nichtreexive Relation
handelt, lässt sich die Menge aller Dependenzen, die in einem Satz bestehen, als gerichteter Graph darstellen. Jedes Regens ist allen seinen direkten
und indirekten Dependenten syntaktisch stets übergeordnet, deswegen ist der
Graph azyklisch. Zusammen mit folgender Annahme ergibt sich eine Baumstruktur, der Dependenzbaum :
Annahme 3
In einem Satz füllt jedes Wort genau eine grammatikalische
Funktion aus.
Als Konsequenz dieser Annahme besitzt also jedes Wort genau ein Regens,
bis auf eines, das die grammatikalische Funktion des absoluten Regens einnimmt, als solches von keinem anderen Wort regiert wird und deswegen die
Wurzel des Dependenzbaumes bildet. Dabei handelt es sich um das rang-
9
höchste Wort des Prädikates, üblicherweise das nite Verb .
Im Gegensatz zu PSG sind die Kanten nicht als Teil-Ganzes-Beziehung,
sondern als semantische Subkategorisierung zu interpretieren. Während in
PSG jede komplexe Phrase aus zwei oder mehr Konstituenten besteht, die
sich auf demselbem Niveau benden, besitzt in DPG jede Phrase ein einzelnes Wort als Repräsentanten, das alle anderen Wörter in der Phrase direkt
oder indirekt regiert. So werden zum Beispiel Nominalphrasen wie der sehr
groÿe Baum durch das Nomen ( Baum) repräsentiert, dem die zugehörigen
Adjektive ( groÿe) und Artikel ( der ) als Dependenten untergeordnet sind,
wobei das Adverb sehr wiederum dem Adjektiv als Dependens untersteht.
Dependenzgrammatiken stellen also ein weitaus mächtigeres Werkzeug
zur Modellierung natürlicher Sprachen dar als PSG. Insbesondere beim Parsen ergeben sich allerdings einige neue Schwierigkeiten:
9 Man könnte aber zum Beispiel in Hilfsverbkonstruktionen auch das Vollverb als dem
Hilfsverb übergeordnet betrachten, da es die eigentliche Grundaussage des Prädikates enthält, die durch das Hilfsverb lediglich in bestimmten grammatikalischen Kategorien (Tempus, Modus, Genus verbi) moduliert wird. Ebenso obliegt es der Denition der jeweiligen
Dependenzgrammatik, ob in Adverbialsätzen die einleitende Subjunktion dem niten Verb
über- oder untergeordnet ist.
13
1. Prinzipiell kann jedes Wort mit jedem in Beziehung stehen, im Gegensatz zu PSG, wo immer nur benachbarte Chunks in Betracht gezogen
werden. Deswegen expandiert die Suche bei DPG wesentlich mehr in
die Breite, weshalb eine deutlich höhere Komplexität des Algorithmus
zu erwarten ist als bei PSG-Parsern. Eine weitere Folge ist, dass tendenziell viel mehr Lösungen existieren als bei PSG. Dem Vorhandensein
eines adäquaten Bewertungssystemes, das die Auswahl der besten Alternative forciert, kommt daher eine groÿe Bedeutung zu.
2. Dependenzgrammatiken enthalten keine Aussagen zur Wortstellung,
lassen also von sich aus jede beliebige Reihenfolge zu. Um die daraus resultierende, viel zu weit gefasste Sprache einzugrenzen, ist die
Kombination mit einem Topologiemodell erforderlich, das unzulässige
Linearisierungen des Dependenzbaumes im Nachhinein oder besser bereits während dessen Aufbaus ausschlieÿt. Da für die Auösung von
Ambiguitäten auch die Topologie relevant ist, kann ein solches Modell
auch hierzu herangezogen werden, falls es in der Lage ist, gewichtete
Aussagen zu treen.
3. Dependenzgrammatiken lassen grundsätzlich keine Koordinationen zu,
da nur binäre Dependenzrelationen erlaubt sind:
Der Vogel fängt und frisst den Wurm.
4. Die Unterscheidung zwischen Komplementen und Supplementen (Erklärung siehe S.15) fällt nicht immer leicht, da teilweise ieÿende Übergänge vorhanden sind.
Die Anzahl und Art der Dependenten, die ein bestimmtes Wort benötigt,
hängt nur zum Teil von seiner Wortart ab. Vielmehr existieren in dieser Hinsicht insbesondere bei Verben gravierende Unterschiede von Wort zu Wort
und sogar von Lesart zu Lesart. Diese Informationen müssen dem Dependenzparser mittels eines Valenz- oder Subkategorisierungslexikons zur Verfügung
gestellt werden.
Denition 2
w
10
Die Valenz
v(r) ∈ IN einer Lesart r ∈ R(w) eines Wortes
w in der Lesart r regieren muss, damit der
gibt an, wieviele Dependenten
10 Der Begri Valenz stammt aus der Valenztheorie, nach der Verben eine bestimmte
Anzahl von Satzgliedern an sich binden, nach dem Vorbild der Atome in der Chemie.
Er bezieht sich ursprünglich ausschlieÿlich auf Verben, wird hier aber auf alle Wortarten
erweitert.
14
Satz grammatikalisch vollständig ist
Denition 3
Valenzstelle
11
. Man sagt auch,
Der zugehörige Valenzrahmen
si = (M, g), 0 ≤ i < v(r),
w
sei
v(r)-stellig.
V (r) = {si } speziziert für jede
die erforderliche Beschaenheit des
Dependens Einschränkungen bezüglich Wortart, Lemma und grammatikalischen Kategorien sowie Kongruenzbedingungen sind in der Merkmalstruktur
M
angegeben und seine grammatikalische Funktion
g.
Beispiele:
•
Das Verb geben in der üblichen, nicht übertragenen Lesart ist dreistellig, denn es benötigt neben dem Subjekt ein Objekt, das im Akkusativ
steht, und ein indirektes Objekt, das im Dativ steht: Er gibt ihr das
Buch. Keine der drei Valenzstellen kann unbesetzt bleiben.
•
Regnen ist ein nullstelliges Verb. Allerdings ist im Deutschen bei
fehlendem Subjekt stets ein Expletivum es zu ergänzen: Es regnet.
•
Das Verb erschrecken besitzt zwei Lesarten mit unterschiedlicher Valenz: In der intransitiven Variante ist es einstellig, weil nur ein Subjekt
erforderlich ist: Ich erschrecke. Dagegen fordert die transitive Lesart
zusätzlich ein Akkusativobjekt: Ich erschrecke ihn.
Neben den obligatorischen Komplementen, das heiÿt den Ergänzungen, die
durch den Valenzrahmen gefordert werden, können die meisten Wörter zusätzlich optionale Supplemente, das heiÿt freie Angaben wie zum Beispiel
Präpositionalobjekte, regieren. Diese sind häug wortartspezisch und können mehrfach besetzbar sein oder nicht.
Für die vorliegende Arbeit wurde ein Parser entwickelt, dem eine Dependenzgrammatik zugrunde liegt. Diese bietet gröÿere Chancen, den Anforderungen der gesprochenen Sprache und der Fehlertoleranz gerecht zu werden.
2.4 Chart-Parsing
Beim Parsing ist es aus Ezienzgründen erstrebenswert, bereits aufgebaute Teilanalysen wiederzuverwerten (nach [4], auch im Folgenden). Dies kann
beim PSG-Parsing dadurch erreicht werden, indem alle Teilanalysen in einer
sogenannten Chart abgelegt werden. Dabei handelt es sich um einen gerichteten Graphen. Seine Knoten entsprechen den Übergängen zwischen den einzelnen Wörtern, unterliegen also einer totalen Ordnung entsprechend deren
11 Die Valenz bezieht sich bei Verben auf deren kanonische Form Indikativ Aktiv. Liegt
das Verb in einer anderen Verbform vor, kann es zur Valenzalternation kommen (s. Abschnitt 3.2.12).
15
Position auf der Zeitachse. Die Kanten repräsentieren Teilanalysen, umspannen also einzelne Wörter oder ganze Phrasen. Hierbei muss unterschieden
werden zwischen inaktiven Kanten, welche abgeschlossenen Teilanalysen entsprechen, und aktiven Kanten, welche anzeigen, dass eine Regel nur teilweise
angewandt wurde.
Im Verlauf des Parsings werden neue Kanten erzeugt, indem bestehende
gemäÿ den Grammatikregeln verbunden werden. Entsteht eine inaktive Kante, die den gesamten Satz umspannt, so hat man eine Satzanalyse gefunden.
Um am Ende den Syntaxbaum aufbauen zu können, muss für jede Kante die
Information gespeichert werden, aus welchen Kanten sie zusammengesetzt
wurde.
12
Ein typischer Algorithmus für Bottom-Up-Chart-Parsing
lautet wie folgt:
1. Immer, wenn eine inaktive Kante entsteht, werden an ihrem Ausgangsknoten für jede Regel, bei der der Beginn der rechten Seite mit der
Kante übereinstimmt, aktive Kanten mit der Länge null eingefügt.
2. Die Chart wird initialisiert, indem in jedem Knoten für jede Wortform,
die das dort beginnende Wort ausbildet, eine inaktive Kante der Länge
eins erzeugt wird.
3. Danach durchläuft der Algorithmus iterativ von rechts nach links alle
aktiven Kanten und prüft, ob sie gemäÿ der jeweils zugewiesenen Regel
durch eine inaktive verlängert werden können. Gelingt dies, wird die
Verlängerung durchgeführt und in der Kante vermerkt, welcher Teil
der Regel bereits erfüllt ist. Ist die Regel vollständig erfüllt, wird die
Kante inaktiviert (und wie oben beschrieben entsprechende neue aktive
Kanten eingefügt).
Der beschriebene Algorithmus verfährt nach einem ähnlichen Prinzip wie
der CYK-Algorithmus
13
für kontextfreie Sprachen mit dem Unterschied,
dass die Produktionsregeln nicht in Chomsky Normalform
14
transformiert
werden müssen. Die initialen inaktiven Kanten entsprechen den terminalen
Symbolen kontextfreier Grammatiken, die später erzeugten inaktiven Kanten
den nichtterminalen. Aktive Kanten entsprechen der linken Seite von Regeln,
die (noch) nicht komplett abgearbeitet wurden.
Eine spezielle Art von Chart-Parser stellen sogenannte Chunk-Parser dar.
Sie berücksichtigen nur Regeln, die zum Aufbau von Chunks (also einfachen Nominalphrasen, Präpositionalphrasen etc.) führen und keine, die diese
12 Bottom-Up ist die verbreitetste Strategie für das Chart-Parsing, es sind aber auch
Top-Down-Strategien möglich.
13 Zum CYK-Algorithmus siehe [6] S. 64.
14 Zur Chomsky Normalform siehe [6] S. 52.
16
Chunks zu übergeordneten Phrasen (zum Beispiel komplexen Verbalphrasen)
oder ganzen Sätzen verbinden. Das Parsing wird also abgebrochen, sobald eine bestimmte Ebene im Syntaxbaum erreicht ist
15
.
Der Algorithmus lässt sich leicht modiziert auch dann anwenden, wenn
die Eingabe nicht in Form einer einzelnen Satzhypothese, sondern als Menge
von Worthypothesen vorliegt. In diesem Falle muss beim Initialisieren der
Chart (Schritt 2) berücksichtigt werden, dass die einzelnen Worthypothesen
unterschiedliche Längen besitzen können. Die initialen inaktiven Kanten können also bereits mehrere Knoten überspannen. Des weiteren muss durch den
Algorithmus oder durch die Grammatikregeln dem Fakt Rechnung getragen
werden, dass Phrasen auch Pausen enthalten können.
Denition 4
Ein
Chunk,
(li , ri , ti ), . . . , (lj , rj , tj )
der
sich
zusammensetzt,
aus
kann
Schreibweise (vgl. S. 7) als Chunkhypothese
den
in
Worthypothesen
Anlehnung
ck = (li , rj , ti . . . tj )
an
16
deren
geschrie-
ben werden. Der Chunkhypothese kann eine Merkmalstruktur zugeordnet
werden,
die
sich
gemäÿ
den
Grammatikregeln
aus
der
Unikation
der
Merkmalstrukturen der Bestandteile ergibt.
2.5 Kombinationen von Dependenz und Phrasenstrukturparsern
Das Phänomen diskontinuierlicher Konstituenten wurde auf S. 12 als eines
der Hauptargumente für die im Vergleich zum PSG-Parsing aufwändigere
Dependenzanalyse angeführt. Die meisten nichtverbalen Konstituenten in
Sätzen sind jedoch zusammenhängend und können somit von ezienteren
PSG-Parsern identiziert werden. Daher hat es sich bewährt, eine Kombination aus DPG und PSG zu verwenden. Dabei werden in einer ersten Phase
mit Hilfe eines Chunk-Parsers mögliche Konstituenten (Chunks ) vorgeschlagen, auf die in einer zweiten Phase bei der Dependenzanalyse zurückgegrien
werden kann. In [4] wird hierfür der Begri Two-Phase-Parsing verwendet.
Es gibt zwei Möglichkeiten, wie die beiden Teile ineinander greifen können:
1. Syntaxbaumtransformation: Alle Syntaxbäume nichtatomarer Chunks
werden während ihres Aufbaus oder nach Ablauf der ersten Phase durch
ein geeignetes Verfahren in Dependenzbäume übersetzt. Immer wenn
15 Beziehungsweise wird der Prozess erst auf einer Ebene unterhalb der Wurzel gestartet,
falls top down geparst werden soll.
16 Liegt eine einzelne Satzhypothese vor, können deren Wörter ebenfalls als Worthypo-
thesen geschrieben werden, wobei
to + 1
und
token
from
die Anzahl der voranstehenden Wörter,
das Wort ist.
17
from =
der Dependenzparser in der zweiten Phase eine Dependenz mit einem
Wort
w
als Dependens bildet, das in derselben Wortform als absolutes
Regens einer dieser Teilanalysen fungiert, können alle Dependenzen aus
der betreenden Teilanalyse übernommen werden, das heiÿt, die Teilanalyse kann im Dependenzbaum an den Knoten
w anmontiert werden.
Kommen mehrere Teilanalysen in Frage, so entsteht eine Verzweigung
des Suchbaumes, ähnlich wie wenn das Wort
w
Valenz 1 hätte und als
Dependens mehrere Alternativen möglich wären. Enthält eine Teilanalyse eine Dependenz, deren Dependens bereits anderweitig eingeordnet wurde, darf sie allerdings nicht verwendet werden, um Annahme 3
(S. 13) nicht zu verletzen.
2. Domänenerweiterung: Die Dependenzrelation wird dahingehend umdeniert, dass sie nicht auf der Menge der einzelnen Wörter angewandt
wird, sondern auf der Menge
17
formen enthält
C
der Chunks (die die Menge der Wort-
). Dependenzen bestehen also nicht zwischen Wör-
tern (denen dabei eine Wortform zugeordnet wird), sondern zwischen
Chunks, die aus (einer einzelnen oder mehreren) Wortformen gebildet
werden. Dafür müssen die Beschreibungen der Valenzstellen so umgeschrieben werden, dass für deren Besetzung auch bestimmte Phrasen
erlaubt sind. Die Menge der Wortarten wird also um die Menge der
komplexen Phrasentypen erweitert. So können zum Beispiel nicht nur
Nomen das Objekt zu einem Verb bilden, sondern auch Nominalphrasen.
Satz 1
Aus Annahme 3 folgt für die Domänenerweiterung:
(a) Da auch die einzelnen Wörter innerhalb der Chunks nur jeweils
eine grammatikalische Funktion ausfüllen können und parallel verlaufende Worthypothesen und Wortformen sich gegenseitig ausschlieÿen, darf jede Lösung nur Chunks enthalten, die sich gegenseitig zeitlich nicht überschneiden.
(b) Das Kriterium für eine abgeschlossene Satzanalyse, dass alle grammatikalischen Funktionen identiziert sind, ist genau dann erfüllt,
wenn die für den Dependenzbaum verwendeten Chunks die Äuÿerung auf der Zeitachse bis auf durch Hypothesen erlaubte Pausen
vollständig abdecken.
Die nichtatomaren Chunks dienen lediglich als Abkürzungen für bestimmte Suchpfade, substituieren also keineswegs ganze Zweige des Suchbaumes.
17 Der Chunk-Parser initialisiert seine Chart nämlich mit inaktiven Kanten über die
einzelnen Wortformen, siehe S. 16.
18
Führt die Verwendung eines solchen nicht zur gewünschten Lösung, müssen
demnach trotzdem Alternativpfade expandiert werden, die den Konstituenten mittels Dependenzanalyse aufbauen. Dies gilt erst recht, wenn eine vollständige Suche durchgeführt werden soll, die alle möglichen Lösungen ndet
in diesem Falle bringt die Kombination mit einem Chunk-Parser weniger
Ezienzgewinn. Bei einer unvollständigen Suche liefert das Vorhandensein
eines nichtatomaren Chunks allerdings eine wertvolle Heuristik: Da davon
ausgegangen werden kann, dass in deutschen Sätzen nichtverbale Konstituenten wesentlich häuger zusammenhängend als diskontinuierlich sind, leitet
ein nichtatomarer Chunk den Parser statistisch gesehen häuger zur gesuchten Lösung als eine atomare Alternative.
Satz 2
Werden nichtatomare Chunks gegenüber Einzelwörtern bevorzugt be-
handelt, kann deshalb die durchschnittliche Komplexität des Suchalgorithmus
deutlich verringert werden.
In dieser Arbeit wurde die Variante mit Domänenerweiterung implementiert. Deren Nachteil, dass der resultierende Dependenzbaum keine vollständige Analyse des Satzes wiedergibt einige zusammenhängende Knotenmengen sind ja durch Chunks substituiert , ist nur vorübergehender Natur,
da bei Bedarf im Nachhinein die Syntaxbäume aller verwendeten Chunks
in Dependenzbäume konvertiert und an die entsprechenden Stellen in den
Baum eingesetzt werden können. Die implementierte Dependenzgrammatik
verwendet für die nichtverbalen Konstituenten ausschlieÿlich die in Form von
Chunks bereitgestellten Teilanalysen. Dies hat zur Folge, dass der Parser in
der vorliegenden Form nur Nominal- und Präpositionalphrasen in Betracht
zieht, die vom verwendeten Chunk-Parser gefunden werden. Die Dependenzgrammatik ist allerdings erweiterbar, um zukünftig auch diese Konstituententypen mittels Dependenzanalyse aufbauen zu können.
2.6 Grundlegende Topologie deutscher Sätze
Die Topologie ist im Deutschen entscheidend durch die Stellung des Verbalkomplexes geprägt. Vorherrschend in der Linguistik ist die Theorie der
topologischen Felder. Hierbei formt im Allgemeinen das Prädikat des Satzes
eine Klammerstruktur, die den Satz in fünf Felder teilt:
Ich
habe
Sie leider nicht
verstanden
vorhin.
VORFELD
LINKE
MITTELFELD
RECHTE
NACHFELD
KLAMMER
(VF)
(LK)
KLAMMER
(MF)
19
(RK)
(NF)
Während die Reihenfolge der übrigen Satzglieder in den drei Stellungsfeldern
VF, MF und NF sehr frei ist und nur in speziellen Fällen Einschränkungen
unterliegt sonst existieren nur Präferenzen , ist die Besetzung der beiden
Klammerteile streng festgelegt und nur von der Verbstellung, das heiÿt von
der Position des niten Verbes im Satz, abhängig. Hierfür gibt drei Möglichkeiten:
•
Verb-Zweit-Stellung (VZ) : Sie ist die typische Verbstellung für Haupt-
sätze. Das nite Verb folgt nach dem ersten Satzglied und bildet alleine
die linke Klammer. Der Rest der Prädikates steht in der rechten Klammer und somit oft ganz am Ende des Satzes. Das Vorfeld muss durch ein
Satzglied besetzt sein, notfalls durch ein Expletivum: Es stimmt (, dass
es regnet)
•
18
.
Verb-Erst-Stellung (VE) : Hier bendet sich das nite Verb ebenfalls
alleine in der linken Klammer, allerdings vor dem ersten Satzglied und
somit häug wenn auch nicht zwingenderweise am Satzanfang. VE
ist typisch für Entscheidungsfragen. Der einzige topologisch relevante
Unterschied zu VZ besteht darin, dass das Vorfeld unbesetzt sein darf
•
19
.
Verb-Letzt-Stellung (VL) : Sie gilt in Sätzen (typischerweise Nebensät-
20
ze
), die entweder durch eine Subjunktion oder ein Relativpronomen
eingeleitet werden, und in abhängigen Fragesätzen. Während das einleitende Satzglied die linke Klammer bildet, steht das nite Verb am
Ende der rechten Klammer, also direkt nach dem Rest des Prädikates.
Das Vorfeld entfällt, sofern es nicht durch eine Satzkonjunktion gebildet
wird ( Und weil ...). Vertritt man die restriktive Position, dass nichtprädikative Satzglieder in den beiden Klammerteilen nicht erlaubt sind,
kann man die linke Klammer als eine Art Verschmelzung des Vorfeldes
mit der linken Klammer interpretieren.
In bestimmten Fällen ist die Verbstellung schwierig zu erkennen. Dann kann
eine gedankliche Ergänzung um weitere Satzglieder helfen. So herrscht zum
Beispiel im Fragesatz
18 Der Nebensatz übernimmt hier die Funktion des Subjekts. Als solches kann er auch
ins Vorfeld vorgezogen werden, wodurch das Expletivum entfällt: Dass es regnet, stimmt .
19 VE wird häug auch mit dem Begri Inversion umschrieben. Die zugrundeliegende
Sichtweise supponiert für Hauptsätze einen Standardsatzbauplan Subjekt-Verb-Objekt wie
im Englischen, und betrachtet VE daher als Vertauschung von Subjekt und nitem Verb.
20 Es gibt jedoch auch Fälle, in denen VL in Hauptsätzen möglich ist, z.B. in Exklama-
tivsätzen Wie lange das (heute doch wieder) dauert! oder deliberativen Fragesätzen:
Ob heute (wohl) ein guter Krimi läuft? .
20
Wer klingelt (an der Tür)?
VZ, während der gleichlautende Relativsatz
Wer (an der Tür) klingelt (, der will hinein).
VL aufweist. Verwechslungen kann es auch zwischen VE und VZ geben, wenn
einem VE-Satz Wörter im Vorfeld vorgeschaltet sind, die nicht satzgliedwertig und somit nicht vorfeldfüllend sind: Aber willst du das auch? . Dagegen
ist jedoch in Erstposition vorfeldfüllend, weshalb dem Satz Jedoch willst
du das auch VZ zuzuordnen ist
21
.
Auf der anderen Seite kann VZ leicht mit VE verwechselt werden, wenn
ein voranstehender Gliedsatz die Funktion des vorfeldfüllenden Satzgliedes
übernimmt:
(Dass Folgendes ein VZ-Satz ist,) ist schwierig zu erkennen
oder dieses in elliptischen Sätzen ganz weggelassen wird:
Er sieht das Meer. (Er) Zögert einen Moment. Und (er) beginnt dann zu
rennen.
21 Es sei denn, es handelt sich um zwei getrennte satzwertige Äuÿerungen, deren Grenze
durch ein geeignetes Satzzeichen zu markieren ist: Jedoch (frage ich dich): Willst du das
auch? 21
3
Ein Verfahren zur Fehleranalyse in Spracherkennerhypothesen
Im Folgenden wird das im Rahmen dieser Arbeit entwickelte Verfahren vorgestellt. Im ersten Teil dieses Kapitels werden die verwendeten Modelle, Algorithmen und Datenstrukturen theoretisch beschrieben, im zweiten Teil folgt
ein Auszug aus den konkreten Grammatik- und Topologieregeln, die für die
Implementierung verwendet werden.
3.1 Das Verfahren im Detail
3.1.1 Architektur des Systems
Das gesamte System besteht aus mehreren Modulen. Eine zentrale Kontrolleinheit steuert den Aufruf des Dekoders und der Parsermodule, analysiert
die Konikte und entscheidet über das weitere Vorgehen.
Zuerst lässt das Kontrollmodul die Äuÿerung von einem Dekoder analysieren und nimmt dessen Ausgabe entgegen, die in einer Liste der
n
besten
Satzhypothesen oder alternativ in einer Menge von Worthypothesen
vi
be-
steht. Im ersten Fall wird aus der besten Satzhypothese eine Worthypothesenmenge erzeugt, die keine Wortalternativen beinhaltet
einzelnen Wörter
w
22
. Dazu werden die
p im Satz durchnummevi = (p, p + 1, w) generiert.
aufsteigend nach ihrer Position
riert und für jedes von ihnen eine Worthypothese
Die Zeitangaben sind also relativ und verzerren die tatsächlichen Verhältnisse
auf der Zeitachse.
Jedes
vi
wird nun einer morphologischen Analyse unterzogen, mit deren
j
j
j
Hilfe alle jeweils möglichen Wortformen ui = (pi , pi +1, wi , si , Mi ) von vi ausj
j
ndig gemacht werden, wobei si die Wortart und Mi eine Merkmalstruktur
mit Informationen über grammatikalische Kategorien beschreibt. Die Menge
aller Wortformhypothesen wird nun an einen Chunk-Parser übergeben, der
aus ihnen mögliche Chunkhypothesen
ck = (pk , qk , tk )
bildet. Jedem
ck
ist
eine Chunkkategorie zugeordnet sowie eine Merkmalstruktur, die aus Unikation der Merkmalstrukturen der beteiligten Wortformen entsteht.
22 Die Analyse der
n
Hypothesen erfolgt sequentiell, da Wörter aus unterschiedlichen
Satzhypothesen zeitlich nicht verglichen werden können. Kann jedoch ein Verfahren dafür
gefunden werden zum Beispiel mit Hilfe der Methode der dynamischen Programmierung , könnte die Menge der Worthypothesen über alle Satzhypothesen erzeugt werden.
Diese hätte zwar quantitative Nachteile gegenüber der vollständigen Worthypothesenmenge des Dekoders. Jedoch ist anzunehmen, dass jede Hypothese in weiten Teilen die Äuÿerung korrekt wiedergibt. Somit wäre die Wahrscheinlichkeit hoch, dass eine so reduziert
rekonstruierte Worthypothesenmenge die richtige Lösung enthält, jedoch ezienter zu parsen ist als die ursprüngliche.
22
Im nächsten Schritt wird dem Dependenzparser die Menge der Chunkhypothesen übergeben. Er greift auf ein Topologiemodul und ein Dependenzmodul zurück, um sicherzustellen, dass alle Teilanalysen mit dem Topologiebeziehungsweise Dependenzmodell kompatibel sind. Diese Module stellen Regeln zur Verfügung sowie Mechanismen, die deren Einhaltung überprüfen.
Die Regeln und lexikalischen Daten werden einmalig aus Dateien eingelesen. Die Initialisierung der Module geschieht somit am besten vor der ersten
Spracheingabe. Die Daten können im Speicher behalten werden, damit sie für
nachfolgende Hypothesen oder Äuÿerungen nicht erneut eingelesen werden
müssen.
Der Parser liefert eine oder mehrere mögliche Analysen des Satzes, bewertet diese und liefert gegebenenfalls für jeden aufgetretenen Konikt Informationen über den Konikttyp und die Koniktmenge der beteiligten Wörter.
Sind die Interpretationen koniktfrei, wird die bestbewertete übernommen.
Andernfalls wird im Falle getrennter Satzhypothesen das gesamte Verfahren auf die nächste solche angewandt, bis auch die
n-te
Satzhypothese als
ungrammatisch bewertet wurde.
Wird keine fehlerfreie Lösung gefunden, kann eine Fehleranalyse
23
in Be-
tracht gezogen werden. Sie besteht darin, anhand der aufgetretenen Konikte
den mutmaÿlichen Fehler zu lokalisieren. Hierfür liefert diese Arbeit in Abschnitt 3.1.8 einige Anregungen, ein konkretes Fehlermodell konnte jedoch
im zeitlichen Rahmen dieser Arbeit nicht entwickelt werden.
Kann der Fehler lokalisiert werden, wird entschieden, ob eine gezielte
Nachfrage an den Benutzer gestellt wird oder ob sogar der Versuch erfolgen kann, den Fehler aufzulösen, indem zum Beispiel ein überschüssiges und
mutmaÿlich in der Äuÿerung nicht enthaltenes Wort gestrichen wird. Ist keine eindeutige Lokalisierung möglich, wird der Benutzer um eine Neueingabe
oder Umformulierung gebeten.
3.1.2 Modellierung topologischer Strukturen
Das im Rahmen dieser Arbeit erstellte Topologiemodell implementiert die
Theorie topologischer Felder sowie die in [1] vorgestellte Idee einer hierarchischen Untergliederung der Felder. Es ermöglicht die Modellierung komplizierter Strukturen und Matrixsätze mit verschachtelten Nebensätzen.
Übliche Topologiemodelle sind meist statisch, d. h. sie arbeiten mit vollständigen Dependenzanalysen. Sie arbeiten synthetisch, indem sie alle möglichen Linearisierungen eines Dependenzbaumes erzeugen, oder analytisch,
23 Die Implementierung des Analysemoduls ist im Rahmen dieser Arbeit jedoch nicht
vorgesehen.
23
indem sie prüfen, ob und inwiefern eine vorliegende Linearisierung bestimmten Anforderungen, in der Regel Constraints, genügt. Im Gegensatz dazu
handelt es sich bei dem in dieser Arbeit verwendeten Ansatz um ein interaktives Modell. Die topologische Struktur des Satzes wird während des Parsings
aufgebaut. Die Feldgrenzen bleiben anfangs unbestimmt oder vorläug und
werden erst nach und nach präzisiert. So kann immer, wenn eine neue Dependenz hinzugefügt werden soll, überprüft werden, ob das Dependens sich
nach den bisher gesammelten Informationen in einem der erlaubten Felder
benden kann oder nicht. Im ersten Fall werden die Feldgrenzen entsprechend
verschoben, wodurch im nächsten Schritt genauere Informationen zur Verfügung stehen. Das Modell wird durch ein Präzedenz-Modell ergänzt, das die
erlaubte und bevorzugte Reihenfolge der Konstituenten innerhalb der Felder
modelliert.
C von Chunk∈ IN und ti ∈ Σ∗ ∪ ε. Die
P = {(lj , rj , ε) ∈ C}.
Die zu analysierende Äuÿerung sei gegeben als eine Menge
hypothesen
ci = (li , ri , ti )
mit li
< ri ,
wobei li , ri
Menge aller Pausenhypothesen sei gegeben als
Denition 5
Die Relation
< auf der Menge C deniert eine Striktordnung24 :
∀ c1 = (l1 , r1 , t1 ), c2 = (l2 , r2 , t2 ) ∈ C : c1 < c2 ↔ r1 ≤ l2
c1 < c 2
gilt also genau dann, wenn
Denition 6
c1
Zwei Chunkhypothesen
zeitlich vollständig vor
c1 = (l1 , r1 , t1 )
und
c2
liegt.
c2 = (l2 , r2 , t2 )
aus
C heiÿen (miteinander) kompatibel, wenn sie sich auf der Zeitachse nicht
c1 < c2 oder c2 < c1 , also wenn r1 ≤ l2 oder
laute c1 6 k c2 .
sie inkompatibel, falls r1 > l2 und r2 > l1 . Analog
überschneiden, das heiÿt, wenn
r2 ≤ l1 .
25
Die Schreibweise
Im Umkehrschluÿ heiÿen
c1 k c2 .
Mengen A, B ⊆ C
schreibe man
Zwei
Denition 7
Eine Menge
ckung einer Menge
A 6 k B , wenn
∀(a, b) ∈ A × B : a 6 k b.
heiÿen kompatibel,
mit jedem in B kompatibel ist:
B⊆C
A ⊆ C
jedes Element in A
bildet eine vollständige einfache Abde-
genau dann, wenn beide folgenden Bedingungen
erfüllt sind:
A⊆B−P
∀ b ∈ B − P : (∃ a ∈ A
(1)
mit
a 6= b : a k b) ↔ b ∈
/A
(2)
24 Der Beweis der hinreichenden Eigenschaften Irreexivität und Transitivität ist trivial.
25 Das Symbol 6 k wurde gewählt, da es an eine negierte Parallelität erinnert. Inkompatible
Chunkhypothesen entsprechen nämlich parallel verlaufenden Kanten im Chartgraphen.
24
Eine vollständige einfache Abdeckung einer Menge
E
heiÿe minimal (maxi-
mal), wenn es keine vollständige einfache Abdeckung von
E
gibt, die eine
niedrigere (höhere) Kardinalität aufweist.
Denition 8
thesen:
Ein (topologisches) Feld ist eine Teilmenge aller Chunkhypo-
F ⊆C
Die Ausdehnung eines Feldes
F 6= ∅
ergibt sich wie folgt:
lef t(F ) =
min l
(l,r,t)∈F
right(F ) =
max r
(l,r,t)∈F
Denition 9
Ein Feld
S
(3)
(4)
heiÿe Satzfeld genau dann, wenn es genau aus den
fünf Feldern VFS , LKS , MFS , RKS und NFS besteht und diese in ebendieser
topologischen Reihenfolge angeordnet sind:
S = VFS ∪ LKS ∪ MFS ∪ RKS ∪ NFS
∀F ∈ {LKS , MFS , RKS , NFS } :
F 6= ∅ ∧ VFS 6= ∅ ↔ right(VFS ) ≤ lef t(F)
∀F ∈ {MFS , RKS , NFS } :
F 6= ∅ ∧ LKS 6= ∅ ↔ right(LKS ) ≤ lef t(F)
∀F ∈ {RKS , NFS } :
F 6= ∅ ∧ MFS 6= ∅ ↔ right(MFS ) ≤ lef t(F)
∀F ∈ {NFS } :
F 6= ∅ ∧ RKS 6= ∅ ↔ right(RKS ) ≤ lef t(F)
Denition 10
Ein Mengensystem von Feldern
bildet eine topologische Struktur
Denition 11
TC
über
Eine topologische Struktur
(5)
(6)
(7)
(8)
(9)
Fi ⊆ C, 0 ≤ i < n, n > 0
C.
TC
heiÿe wohlgeformt genau dann,
wenn alle folgenden Bedingungen erfüllt sind:
1. Umfasst ein nichtleeres Feld ein anderes topologisch, so umfasst es auch
26
alle darin enthaltenen Chunkhypothesen
:
∀F1 , F2 ∈ TC mit F1 6= ∅, F2 6= ∅ :
(lef t(F1 ) ≥ lef t(F2 ) ∧ right(F1 ) ≤ right(F2 )) ↔ F1 ⊆ F2
(10)
2. Es existieren keine teilweisen Überlappungen von Feldern:
∀F1 , F2 ∈ TC : F1 ∩ F2 6= ∅ → (F1 ⊆ F2 ∨ F1 ⊇ F2 )
26 Der Umkehrschluss (←) gilt aufgrund der Gleichungen 3 und 4 ohnehin
25
(11)
3. Es gibt ein Satzfeld
S ∈ TC ,
das alle anderen Felder in
TC
umschlieÿt:
∀G ∈ TC : G ⊆ S
4. Jedem Chunk
c∈S
ist ein Feld
Fc ∈ TC
(12)
zugeordnet, für das gilt:
∀H ∈ TC : (c ∈ H → Fc ⊆ H)
∀Satzfeld L ∈ TC : Fc ∈
/ {L, VFL , LKL , MFL , RKL , NFL })
∀d ∈ Fc mit d 6= c ∃K ∈ TC : d ∈ K ∧ K ⊂ Fc )
Fc
heiÿe das von
schreibe:
c
c
aufgespannte Feld oder kurz das Feld von
(15)
c.
Man
X ∈ TC , falls Fc diesem direkt
Fc ⊆ X ∧ (∀ Y ∈ TC : Fc ⊆ Y → X ⊆ Y ).
Eine wohlgeformte topologische Struktur
dig genau dann, wenn ihr mächtigstes Satzfeld
Abdeckung von
(14)
bendet sich in einem Feld
untergeordnet ist, das heiÿt
Denition 12
(13)
C
S
TC
heiÿe vollstän-
eine vollständige einfache
bildet.
Zu Beginn des Parsings wird eine minimale wohlgeformte topologische Struktur erstellt:
TC0 = {S, VF S , LK S , MF S , RK S , NF S }
mit S = ∅, VF S = ∅, LK S = ∅, MF S = ∅, RK S = ∅, NF S = ∅
Sei
TCi−1
(16)
die (wohlgeformte) topologische Struktur einer Teilanalyse. Die
Teilanalyse soll um eine Dependenz erweitert werden, so dass
cj ∈ C
die
g bezüglich seinem Regens r erhält.
Sr das kleinste Satzfeld27 , das r einschlieÿt, und Fr das von r aufgespannte
grammatikalische Funktion
Sei
Feld. Mit Hilfe des Topologiemodells soll entschieden werden, ob die Erweiterung topologisch zulässig ist. Dieses enthält eine Reihe von Topologieregeln
der Form:
Th (g, r, o) = (Z, p)
(17)
g die grammatikalische Funktion, in der cj zu r stehen
o ∈ {VE , VZ , VL } die in dieser Teilanalyse für Sr gewählte
Verbstellung. Die Regeln listen eine Menge Z von erlaubten Zielfeldern für
cj auf, wobei Z ⊆ {Fr , VFSr , LKSr , MFSr , RKSr , NFSr }. Bendet sich das
Feld des Regens Fr unter den Zielfeldern, gibt p ∈ {−1, 0, 1} an, ob cj darin
Dabei bezeichnet
soll, und
27 In einer topologischen Struktur können mehrere Satzfelder verschachtelt sein, wenn es
sich um einen Matrixsatz mit Nebensätzen handelt.
26
vor (p
= −1)
oder nach (p
möglich ist (p
= 0),
= 1)
seinem Regens
r
stehen muss oder ob beides
das heiÿt es gilt:
Z − Fr
Z
Zj =
Z − Fr
f alls p = −1 ∧ r < cj
f alls p = 0
f alls p = 1 ∧ cj < r
(18)
Zj,k ∈ Zj
um cj erweiterbar
i,j,k
ist, das heiÿt, ob folgende erweiterte topologische Struktur TC
wohlgeformt
ist:
Es wird nun geprüft, ob eines dieser Zielfelder
Fcj
i,j,k
TC
In
TCi,j,k
= {cj }
(19)
TCi−1
= {G ∈
| G 6⊇ Zj,k }
∪ {H ∪ cj | H ∈ TCi−1
∪ Fcj
und
H ⊇ Zj,k }
(20)
werden also das Zielfeld und um, wie in Gleichung 10 gefordert,
alle Inklusionen zu erhalten alle Felder, die es umschlieÿen, um
Zusätzlich wird das in Gleichung 13-15 geforderte von
cj
cj
erweitert.
aufgespannte neue
Feld hinzugefügt. Da Gleichung 12 unberührt bleibt, folgt für die maximal
mögliche Ausdehnung des Feldes
outmostlef t(Zj,k ) =
outmostright(Zj,k ) =
Satz 3 TCi,j,k ist
Zj,k ,
die die Wohlgeformtheit erhält:
max
right(G)
(21)
min
lef t(G)
(22)
{G∈T |right(G)≤lef t(Zj,k )}
{G∈T |right(Zj,k )≤lef t(G)}
topologisch zulässig, wenn es wohlgeformt ist und wenn zu-
sätzlich für alle darin enthaltenen Chunks die Positionierungsconstraints aus
Abschnitt 3.1.3 erfüllt sind. Dann gilt:
Ist
TCi,j,k
TCi = TCi,j,k .
zudem vollständig, ist die Analyse des vollständigen Satzes abge-
schlossen.
3.1.3 Präzedenzregeln
Die nichtprädikativen Satzglieder können fast beliebig auf die Stellungsfelder oder auf das Feld des jeweiligen Regens verteilt werden. So kann nahezu
jedes Satzglied das Vorfeld besetzen. Innerhalb eines Feldes ist ihre Reihenfolge zwar prinzipiell frei wählbar, unterliegt aber dennoch einigen Einschränkungen. Dies gilt insbesondere für das Mittelfeld, da dort üblicherweise die
gröÿten Ansammlungen von Gliedern vorzunden sind. Die Regeln lassen
sich jedoch auch auf andere Felder übertragen, zum Beispiel auf das von
27
Innitiv-Konstruktionen mit zu erzeugte Feld: Im Satz Ihm ein Buch zu
schenken, nde ich gut darf ihm nicht nach ein Buch stehen.
Manche Reihenfolgen lassen sich vollständig ausschlieÿen wie zum Beispiel Weil ihm er dankbar ist oder sind allenfalls in Lyrik vorstellbar wie
zum Beispiel Weil ein Buch ich ihm schenke. Andere sind zwar unüblich
und vermeintlich ungrammatisch, unter bestimmten Voraussetzungen (Betonung, bestimmte Verben) zumindest in gesprochener Sprache aber nicht
gänzlich unvorstellbar: Weil das Buch ICH ihm schenke.
Bei der Satzgliedreihenfolge gibt es also ieÿende Übergänge zwischen grammatisch und ungrammatisch. Bei der Beurteilung spielen viele Faktoren mit
(nach [7], S. 113-131):
•
Pronomialität: Pronomina stehen meist vor normalen Nominalphra-
sen.
•
Denitheit: Bestimmte Nominalphrasen stehen tendenziell weiter vor-
ne als unbestimmte. Ebenso sind Personalpronomina vor Demonstrativpronomina, und diese vor Indenitpronomina anzusiedeln.
•
Komplexität: Um das Verständnis des Satzes zu erleichtern, werden
28
komplexere Satzglieder möglichst weit hinten positioniert
•
.
Kasus bzw. syntaktische Funktion : Es gibt bestimmte Standardreihen-
folgen von Nominativ, Dativ und Akkusativ. Auch andere Satzglieder
wie Lokaladverbien, Temporaladverbien oder Präpositionalphrasen lassen sich hierin an bestimmten Stellen einordnen.
•
Kasussynkretismus: Ist der Kasus morphologisch nicht eindeutig mar-
kiert, kommt eine Standardreihenfolge
•
29
zur Anwendung.
Verschiedene lexikalische Faktoren: Verben können in verschiedene Klassen eingeteilt werden, die sich bezüglich der Reihenfolge ihrer Dependenten unterschiedlich verhalten.
•
Weitere morphosyntaktische, semantische und pragmatische Faktoren
können in Erwägung gezogen werden.
In der Computerlinguistik werden daher meist Gewichtungsmodelle verwendet, um die Grammatizität einer Äuÿerung zu bewerten (vgl. [7], S. 112
28 Auch der Faktor Pronomialität lieÿe sich in diesem Kontext sehen, da Pronomina nur
aus einem, andere Nominalphrasen dagegen meist aus zwei oder mehr Wörtern bestehen.
29 Die Verwendung des Begries Standardreihenfolge ist problematisch, da deren Exis-
tenz in der Linguistik umstritten ist ([7], S. 111).
28
und 133 . ). Hierzu wird eine gröÿere Menge anfechtbarer Constraints
verwendet, die sich statistisch aus Textkorpora ableiten lassen. Je mehr
dieser Regeln durch eine Äuÿerung eingehalten werden, desto besser wird
diese bewertet. Die Constraints sind sehr speziell und widersprechen sich
zum Teil, so dass in der Praxis keine Äuÿerung alle von ihnen erfüllt. Ab
einem bestimmten Schwellenwert wird die Äuÿerung akzeptiert.
Das für diese Arbeit entwickelte Modell geht von folgender vereinfachender
Annahme aus:
Annahme 4
Die Wirkung eines einzelnen Faktors auf die Stellung von Satz-
gliedern lässt sich durch binäre Präzedenzregeln vollständig beschreiben, das
heiÿt, die Frage, ob ein Satzglied
a
vor einem Satzglied
b
positioniert ist oder
nicht, ist unabhängig von der Existenz und der Position eines dritten Satzgliedes.
Die Präzedenzregeln haben die Form
M <N :w
wobei
M
und
N
Merkmalstrukturen sind und
(23)
w
eine (nicht negative) Zahl.
Die Präzedenzregel beschreibt den topologischen Zusammenhang zwischen
m und n in Satzgliedfunktion, deren Merkmalstrukturen von M
beziehungsweise N subsumiert werden und die sich im selben topologischen
Feld benden. Gilt m < n nicht, so ist die Interpretation der Äuÿerung
topologisch falsch, falls w = 0, beziehungsweise mit dem Gewicht w > 0
zu bestrafen. Die Bestrafung erfolgt durch zu w proportionale Senkung der
allen Chunks
Priorität (vgl. Abschnitt 3.1.6). Es gibt also zwei Typen von Präzedenzregeln:
a) Regeln mit
w=0
sind Positionierungsconstraints, die bei Nichteinhal-
tung absolut hemmend wirken.
b) Regeln mit
w>0
sind Präferenzregeln, die bei Nichteinhaltung relativ
hemmend wirken.
Im Gegensatz zu Positionierungsconstraints haben Präferenzregeln also keinen Einuÿ darauf, ob eine Interpretation der Äuÿerung als grammatisch
akzeptiert wird oder nicht. Sie können jedoch im Zweifelsfall die richtige
Auösung von Ambiguitäten fördern.
Aus Ezienzgründen wird nicht jedes Mal die Einhaltung aller Regeln
überprüft, wenn ein Dependenzkandidat auf seine topologische Zulässigkeit
hin überprüft wird. Stattdessen wird vor der Suche die Menge
C
analysiert
und eine Menge von Mutex-Verknüpfungen zwischen Chunks erstellt. Für
29
jedes Tupel von Chunks
M < N : w wird
und N die von n.
•
Falls
(m, n) ∈ C × C mit m > n und für jede Regel
M die Merkmalstruktur von m subsumiert
überprüft, ob
Ist beides der Fall, geschieht folgendes:
m = 0,
wird eine Mutex-Verknüpfung zwischen
m
und
n
aufge-
baut oder, falls vorhanden, eine bestehende verwendet. Sie erhält das
Gewicht
•
Falls
−1.
m > 0
und noch keine Mutex-Verknüpfung zwischen
m
vorhanden, wird eine derartige aufgebaut und mit dem Gewicht
und
w
n
ver-
sehen.
•
Falls
m > 0
und bereits eine Mutex-Verknüpfung zwischen
mit dem Gewicht
•
Falls
m > 0
−1
m
und
n
besteht, bleibt diese unverändert bestehen.
und bereits eine Mutex-Verknüpfung zwischen
mit einem positiven Gewicht besteht, wird dieses um
w
m
und
n
erhöht.
So entsteht eine Liste von absolut (−1) und relativ (>
1) hemmenden MutexVerknüpfungen. Diese gelten natürlich nur unter der Bedingung, dass m und
n im selben Feld untergebracht sind. Immer, wenn überprüft wird, ob ein
Zielfeld Z um einen Chunk c erweitert werden kann, ist das Vorgehen wie
folgt: Für alle Chunks d, die mit c mutex-verknüpft sind, wird geprüft, ob
sich d in Z bendet. Trit dies zu und ist die Verknüpfung
•
absolut hemmend, so ist die Zuweisung topologisch unzulässig.
•
relativ hemmend, werden die Gewichte der betreenden Mutex-Verknüpfungen
30
addiert. Das kumulierte Gewicht wird später
Auswahl von
c
zur Depriorisierung der
verwendet.
3.1.4 Konikte
Beim Parsing können Konikte der folgenden Typen auftreten:
•
Inkongruenz: Tritt auf, wenn die Subsumption scheitert, weil der Wert
eines oder mehrerer atomarer Merkmale nicht mit der Vorgabe übereinstimmt. Je nach Merkmal wird der Konikt höher oder niedriger
bewertet.
Beispiel: mein herz pochen.
30 Siehe Abschnitt 3.1.6.
30
Als nites Verb wurde pochen identiziert. Nun wird das Subjekt
gesucht anhand der Maske:
[NP]
category
kasus
form
numerus
person
[NOM]
[PL]
[3]
Ein Kandidat ist der Chunk mein herz mit der Merkmalstruktur:
text
[NP]
[mein
form
category
herz]
kasus
numerus
genus
person
[NOM]
[SG]
[NEUT]
[3]
In diesem Falle liefert der Subsumptionstest einen Inkongruenz-Konikt
numerus SG statt PL.
Stimmt die Chunkkategorie nicht überein, wird gar kein Konikt erzeugt, sondern der betreende Chunk gar nicht erst in Betracht gezogen: Im obigen Beispiel: auf mein herz pochen.
category
text
form
•
[PP]
[auf mein
kasrek
herz]
[AKK]
Falsche Topologie: Ein Dependens ist topologisch nicht zulässig
31
:
aufgenommen die sendung hat er nicht
aufgenommen hat die sendung er nicht
Dieser Konikt kann nicht durch Spracherkennerfehler verursacht werden und somit bei einer grammatikalisch korrekten Äuÿerung nur auftreten, wenn die Teilanalyse falsch ist. Deswegen wird auf diesen Konikttyp verzichtet und der Chunk bei der Suche nicht berücksichtigt.
•
Oene Valenzstelle: Eine Valenzstelle kann nicht besetzt werden, weil
kein topologisch zulässiger Chunk der geforderten Chunkkategorie mehr
zur Verfügung steht:
31 Vgl. Satz 3, S. 27.
31
ich möchte gerne anschauen
ich möchte gerne zu anschauen
•
Unbenutzter Chunk: Die Lösung deckt nicht die gesamte Äuÿerung ab,
sondern es bleiben Lücken übrig, in denen kein Komplement oder Supplement eines anderen Chunks gefunden wurde, und die auch nicht
durch Pausenhypothesen abgedeckt werden können:
ich möchte sie sendung anschauen
ich möchte gerne zu anschauen
Im zweiten Beispiel tritt sowohl ein Oene-Valenzstelle-Konikt auf
(kein Objekt zu anschauen` gefunden) als auch ein Unbenutzter-
32
Chunk-Konikt ( zu kann nicht zugeordnet werden)
.
Dieser Konikt kann nicht während des Parsings auftreten, sondern
erst, wenn alle Valenzstellen (erfolgreich oder erfolglos) abgearbeitet
wurden und am Ende noch Chunks übrigbleiben. Hier stellt sich die
Frage, wieviele Unbenutzter-Chunk-Konikte bestehen. Denn eine Interpretation, bei der mehrere Lücken übrigbleiben, ist schlechter als
eine mit einer Ein-Wort-Lücke. Pro Lücke sollte also mindestens ein
Unbenutzter-Chunk-Konikt diagnostiziert werden. Doch auch hier gibt
es Unterschiede: Eine Lücke kann aus einem einzigen falsch verstandenen Satzglied bestehen oder aus mehreren in diesem Fall bestehen
mehrere Konikte. Die Zahl und Ausdehnung der tatsächlichen Satzglieder ist jedoch unbekannt. Auch die Chunkhypothesen liefern nur bedingt Anhaltspunkte, da es sich ja oenbar um fehlerhafte Stellen handelt und deswegen möglicherweise kein Chunk gebildet werden konnte,
der das gesamte tatsächliche Satzglied abdeckt. Dennoch liegt es nahe,
dass angesichts der dürftigen Informationslage folgende Heuristik die
wohl bestmöglichste Annäherung liefert:
Annahme 5 U ⊆ C bezeichne die Menge aller für eine (Teil-)Analyse
verwendeten Chunks.
R
sei die Menge aller noch verfügbaren Chunks,
also die gröÿte Teilmenge aus
C − P,
die mit
U
kompatibel ist. Dann
entspricht die Anzahl der nicht zugeordneten Satzglieder und somit die
Anzahl der Unbenutzter-Chunk-Konikte der Kardinalität der minimalen vollständigen einfachen Abdeckung von
32 Im Gegensatz dazu liefert ich
R.
möchte gerne dem anschauen
Konikt, da hier die Chunkkategorie übereinstimmt.
32
einen Inkongruenz-
3.1.5 Das Suchverfahren
Bei der Suche wird der Raum aller Dependenzbäume für alle vollständigen
einfachen Abdeckungen von
C
durchsucht. Hierfür werden für jede Valenz-
stelle alle als Dependenten in Frage kommenden Chunks betrachtet. Für jeden dieser Chunks werden alle möglichen Lesarten untersucht, welche wiederum neue Valenzstellen schaen. Auf diese Weise entsteht ein Suchbaum, dessen Knoten Teilanalysen der Äuÿerung repräsentieren. Der Suchbaum wächst,
indem die jeweiligen Blätter expandiert werden, bis sie eine Interpretation der
vollständigen Äuÿerung beinhalten.
Am Anfang besteht der Suchbaum nur aus seiner Wurzel. Im ersten
Schritt, bei der Expansion der Wurzel, werden die Lesarten des Satzes, das
heiÿt alle möglichen Satzmodi getrennt nach Verbstellung (siehe 3.2.1), aufgelistet und für jede dieser Alternativen ein Nachfolgerknoten an die Wurzel
angehängt. Jeder Satzmodus besitzt einen Valenzrahmen, der im Normalfall
aus einer Valenzstelle für das nite Verb besteht. Die Valenzstellen werden
zur Valenzagenda des Knotens hinzugefügt.
In jedem weiteren Schritt wird eine Valenzstelle aus der Valenzagenda eines
Knotens genommen und die Menge aller mit der bisherigen Teillösung kompatibler Chunks nach in Frage kommenden Dependenten durchsucht. Dabei
wird für jedes mögliche (das heiÿt topologisch zulässige und mit der geforderten Chunkkategorie übereinstimmende) Dependens ein neuer Nachfolgerknoten erzeugt. Dieser muss zwischen den eventuell verschiedenen möglichen
Lesarten des gewählten Dependens unterscheiden, also eine weitere Verzweigung der Suche herbeiführen. Um diese aus Ezienzgründen so spät wie
möglich durchzuführen, wird die Information über die Lesartalternativen in
der Lesartagenda des Knotens zwischengespeichert. Erst wenn alle alten Valenzstellen in der Valenzagenda abgearbeitet sind, wird die Aufspaltung nach
Lesart vollzogen und die Valenzagenda neu aufgefüllt.
Knoten, die eine leere (Valenz- sowie Lesart-)Agenda besitzen und deren
Liste der verfügbaren Chunkkandidaten (siehe S. 35) leer ist, werden als terminal bezeichnet. Handelt es sich bei dem bestbewerteten Knoten um einen
terminalen Knoten, ist die Lösung gefunden und die Suche kann beendet
werden.
Ziel der Suche ist die Minimierung der Pfadkosten, also der Anzahl der
Spracherkennerfehler
33
, und der Suchkosten. Es soll also so schnell wie mög-
lich eine Lösung gefunden werden, die unter allen Lösungen im Sinne der
Fehlerminimierung optimal ist.
Jede Interpretation, die keinen Fehler aundet und somit koniktfrei
33 Vgl. Annahme 2, S. 4.
33
bleibt, ist optimal. So lässt sich für grammatikalisch korrekte Hypothesen
bzw. für Worthypothesengraphen, die eine grammatikalisch korrekte Hypothese als Pfad enthalten, problemlos eine optimale Lösung nden. Ist die
optimale Lösung allerdings nicht fehlerfrei, so ist eine erschöpfende Suche
erforderlich, da die Kosten für Teillösungen nicht ermittelbar sind. Denn aus
unvollständigen Satzanalysen lässt sich schwerlich auf Spracherkennerfehler
schlieÿen.
Stattdessen muss die Anzahl der Konikte als heuristische Schätzung der
Fehleranzahl dienen. Zwar ist eine Korrelation nicht garantiert (siehe S. 6).
Jedoch handelt es sich um eine inhärent pessimistische Schätzung, wenn man
von seltenen Fällen absieht, bei denen sich zwei Spracherkennerfehler gegenseitig neutralisieren. Da letztere in solchen Fällen aufgrund von Annahme 2
(S. 4) ohnehin nicht identizierbar sind, ist die Vernachlässigung dieser Fälle
gerechtfertigt.
Die Anzahl der Konikte steigt monoton. Verwendet man sie als Pfadkostenfunktion für eine Breitensuche mit uniformen Kosten, so liefert diese
deswegen stets eine optimale Lösung bezüglich der Koniktanzahl (jedoch
nicht in Bezug auf die Fehleranzahl) [9]. Bei diesem Suchverfahren werden
immer diejenigen Blattknoten expandiert, die unter allen Blättern die geringsten Pfadkosten aufweisen. Sobald sich unter diesen besten Blättern ein
terminales Blatt ndet, ist eine Lösung gefunden, die optimal bezüglich der
Pfadkosten ist.
Bei dieser Breitensuche handelt es sich um eine uninformierte Suche, da
nur die Kosten der bisher zurückgelegten Teilpfade betrachtet werden und
nicht die verbleibenden Restkosten. Findet sich eine geeignete Heuristik zur
Schätzung dieser, kann eine A*-Suche durchgeführt werden, die für Suchprobleme bezüglich Zeitkomplexität optimal ezient ist [9]. Dabei handelt es
sich um eine Breitensuche mit uniformen Kosten, die als Kostenfunktion die
Summe aus Pfadkosten und geschätzten Restkosten verwendet. Daher liefert
sie ebenfalls stets eine optimale Lösung, falls die Kostenfunktion monoton,
also die Restkostenheuristik inhärent optimistisch ist [9].
Dies erfordert, dass sichere Konikte vorausgesehen werden, bevor sie
auftreten. Möglich ist das immer dann, wenn die Mindestanzahl der oenen
obligatorischen Valenzstellen, die noch nicht abgearbeitet wurden, die Kar-
34
dinalität einer maximalen vollständigen einfachen Abdeckung
um
n
aller Lücken
übersteigt. Aufgrund Annahme 3 (S. 13) sind dann mindestens
tere Konikte unvermeidbar.
34 Denition 7, S. 24
34
n
wei-
Aus Ezienzgründen wird nicht der gesamte Suchbaum im Speicher gehalten, sondern nur die Liste der Blattknoten. Diese Liste ist aufsteigend
nach Pfadkosten und bei deren Gleichheit absteigend nach Priorität (siehe
3.1.6) sortiert. Nach der Expansion eines Blattes wird dieses aus der Liste
(und aus dem Speicher) gelöscht und seine Nachfolger einsortiert. Da die
Liste immer sortiert bleibt, kann das Einsortieren in
O(log n)
erfolgen. Dies
macht die Auswahl des jeweils besten Teilpfades (der ja immer durch den
ersten Knoten in der Liste repräsentiert ist) äuÿerst ezient. Ein Vorteil, der
nicht zu unterschätzen ist, da ja nach jedem Expansionsschritt die Auswahlfunktion aufgerufen werden muss.
Damit die inneren Knoten aus dem Speicher gelöscht werden können, muss in
jedem Suchknoten jedwede relevante Information über den bisherigen Suchpfad gespeichert werden:
Denition 13
Ein Suchknoten
n kann als Tupel (D, K, A, L, T , R) geschrie-
ben werden. Hierbei bezeichnet
• D
die Menge der bisher festgelegten Dependenzen: Es bietet sich an,
den Dependenzbaum während der Suche als Liste seiner Kanten zu
speichern. Aus dieser kann später problemlos eine äquivalente Baumstruktur erzeugt werden.
• K
die Menge der bisher aufgetretenen Konikte.
• A
die Agenda der oenen Valenzstellen: Diese Datenstruktur fungiert
als Zwischenspeicher, der notwendig ist, weil immer nur eine Valenzstelle auf einmal abgearbeitet werden kann, aber mitunter mehrere Valenzstellen in einem Schritt hinzugefügt werden.
• L die Lesartagenda: Sie enthält für jeden bereits verwendeten Chunk eine Menge von Lesarten, deren Valenzrahmen Valenzstellen enthält, die
noch nicht in die Valenzagenda überführt wurden. Dieser Zwischenspeicher ist aus Ezienzgründen notwendig, damit die lesartbedingte
Aufspaltung des Suchbaumes erst erfolgen muss, wenn alle alten oenen Valenzstellen abgearbeitet sind (sonst müssten diese für jede Lesart
erneut abgearbeitet werden, was erheblichen, unnötigen zusätzlichen
Rechen- und Speicheraufwand bedeutete).
• T die topologische Struktur: Ein Mengensystem
C , wie in Abschnitt 3.1.2 deniert.
• R
aus Teilmengen von
die Menge der noch verfügbaren Chunkkandidaten: Sie umfasst zu
Beginn der Suche alle Chunkhypothesen aus
C,
die keine Pausenhypo-
thesen sind. Zulässige Lösungen dürfen nach Satz 2a (S. 18) nur Chunks
35
enthalten, die miteinander kompatibel sind. Daher ist es angebracht,
jedes Mal, wenn ein Dependens bestimmt wurde, alle dazu inkompatiblen Chunkhypothesen für alle Nachfolgerknoten auszuschlieÿen.
n0 = (∅, ∅, ∅, ∅, TC0 , C − P ) festgelegt35 . Die
i
Expansion eines Knotens ni = (Di , Ki , Ai , Li , TC , Ri ) gestaltet sich wie folgt:
Als Wurzel des Suchbaumes wird
•
ni = n0 wird expandiert, indem für jede Verbstellung
o und für jeden dafür möglichen Satzmodus m ein Nachfolger no,m
1
o,m
= (∅, ∅, Am , ∅, TC0 , R0 ), wobei Am die Valenzstellen
erstellt wird mit n1
Der Wurzelknoten
des Satzmodus enthält.
•
Ist für
ni 6= n0
te aus
Ki .
die Menge der verfügbaren Chunkkandidaten Ri leer,
0
0
0
wird ein terminaler Knoten ni = (Di , Ki , ∅, ∅, TC,i , ∅) als einziger Nach0
0
folger erzeugt. Di enthält alle Dependenzen aus Di , Ki alle KonikFür alle noch oenen und somit nicht mehr besetzbaren
0
Ergänzungen sy ∈ Ai eines Chunks cy enthält Ki zusätzlich einen
0
entsprechenden Oene-Valenzstelle-Konikt und Di eine Dependenz
(cy , <undef>). Gleiches gilt für alle ltmin , wenn man für jede Menge
Lt ∈ Li von Lesarten eine bestimmte Lesart ltmin ∈ Lt betrachtet,
deren Valenzrahmen bezüglich der Anzahl oener, noch nicht in die
Valenzagenda überführten Ergänzungen minimal für
•
Lt
36
ist
.
ni 6= n0 eine nichtleere Valenzagenda Ai , wird die
nächste Valenzstelle sl = (M, g) aus Ai ausgewählt. Nun wird jeder
Chunkkandidat cj aus Ri betrachtet, dessen Chunkkategorie mit der
37
in M übereinstimmt. Ist cj topologisch zulässig , das heiÿt, ist eii
nes der topologischen Zielfelder Zj,k aus TC um cj erweiterbar, so dass
i,j,k
die erweiterte topologische Struktur TC
wohlgeformt ist, und werden
die Positionsregeln für Zj,k dadurch nicht verletzt, wird ein LesartBesitzt andernfalls
Nachfolgerknoten
nji = (Di ∪ {(ci , cj )}, Kij , Ai \sl , Li ∪ {Lj }, TCi,j,k , {r ∈ Ri | r k cj })
erstellt. Ist
sl
eine mehrfach besetzbare freie Angabe, wird Ai jedoch
Kij enthält alle Konikte aus Ki . Falls M
unverändert übernommen.
35 Zur Denition von T 0 siehe Gleichung 16, S. 26.
C
36 Auf gleiche Weise kann die Mindestanzahl der oenen obligatorischen Valenzstellen
bestimmt werden, die wie oben erwähnt als Heuristik für die A*-Suche verwendet
wird.
37 Vgl. Satz 3, S. 27.
36
die Merkmalstruktur von
cj
nicht subsumiert, wird
sprechenden Inkongruenz-Konikt erweitert. Bei
die Menge aller Lesarten von
cj
Lj
Kij
um einen ent-
handelt es sich um
in grammatikalischer Funktion
g.
j
Ist sl eine Ergänzung, und kann kein Nachfolgerknoten ni gefunden
werden, wird ein alleiniger Nachfolger
n∗i = (Di ∪ {(ci , <undef>)}, Ki ∪ {kO }, Ai \sl , Li , TCi , Ri )
erzeugt, das heiÿt, die Valenzstelle wird unbesetzt gelassen und stattdessen ein entsprechender Oene-Valenzstelle-Konikt
Handelt es sich bei
sl
kO
hinzugefügt.
dagegen um eine freie Angabe, wird stets ein zu-
sätzlicher Nachfolger erstellt, bei dem die Valenzstelle unbesetzt bleibt:
i
n+
i = (Di , Ki , Ai \sl , Li , TC , Ri )
•
Besitzt
ni 6= n0
dagegen eine leere Valenzagenda
Ai = ∅ ,
wird zuerst
geprüft, ob die Lesartagenda Li ebenfalls leer ist. In diesem Falle wird
0
0
ein terminaler Knoten ni = (Di , Ki , ∅, ∅, TC,i , ∅) als einziger Nachfol0
ger erzeugt. Ki enthält alle Konikte aus Ki sowie einen UnbenutzterChunk-Konikt für jedes Element der minimalen vollständigen einfachen Abdeckung von
Ist dagegen
Li
Ri
(vgl. Annahme 5, S. 32).
nicht leer, werden lesartabhängige Valenzalternativen
aus der Lesartagenda extrahiert. Dabei entstehen
x > 0
Nachfolger-
knoten
nxi = (Di , Ki , Ax , Lxi , TCi , Ri )
Die einfachste Möglichkeit für ein solches Extraktionsverfahren wäre,
eine Menge
lx ∈ L
L ∈ Li
von Lesarten auszuwählen und für jede Lesart
einen Nachfolgerknoten zu erzeugen. Dessen Valenzagenda
Ax
bestünde aus allen Valenzstellen des Valenzrahmens V (lx ), während die
x
neue Lesartagenda Li = Li \L wäre. Mit anderen Worten: Es würde ein
bereits verwendeter Chunk, dessen Dependenten noch nicht bestimmt
wurden, ausgewählt und der Suchprozess nach dessen Lesarten aufgespaltet. Jedoch enthalten die verschiedenen Lesarten von Verben oft
gleiche Valenzstellen wie zum Beispiel das Subjekt, deren Besetzung
somit für jede Lesart neu berechnet werden müsste. In Abschnitt 3.1.7
wird eine Variante für das Extraktionsverfahren vorgestellt, die diesbezüglich ezienter arbeitet.
37
3.1.6 Priorisierung
In der Praxis wird es meist eine ganze Reihe am besten bewerteter Blätter geben, die für den jeweils nächsten Expansionsschritt in Frage kommen. Um die
Reihenfolge festzulegen, in der die Alternativen bearbeitet werden, werden
den Suchknoten anhand der folgenden Heuristiken Prioritäten zugewiesen.
Diese Heuristiken sind jedoch nicht optimistisch, weshalb die Prioritäten nur
bei absoluter Gleichheit der A*-Pfadkostenfunktion einbezogen werden dürfen.
•
Fortschritts-Heuristik: Teillösungen, die mit ansonsten gleichen Kosten
38
bereits einen gröÿeren Teil der Äuÿerung
abdecken, werden bevorzugt,
da gröÿere Satzteile tendenziell fehleranfälliger sind.
P
h1 =
max
(l1 ,r1 ,t1 )∈C
•
r0 − l0
(l0 ,r0 ,t0 )∈U
r1 −
min
(l2 ,r2 ,t2 )∈C
l2
(24)
Eindeutigkeits-Heuristik: Chunks, deren inkompatible Alternativen al-
lesamt auf die gesuchte Valenzstelle passen, werden priorisiert, da ihre
Auswahl die späteren Suchschritte am wenigsten einschränkt. Diese
Heuristik erinnert an die Heuristik des am wenigsten beschränkenden
Wertes für Constraint-Satisfaction-Probleme (CSP), wie sie in [9] beschrieben wird.
Ihr Nutzen wird in folgendem Beispiel deutlich, in dem es zwei Kandidaten für das nite Verb gibt:
wähle die sparte unterhaltung aus
Während wähle eindeutig ein nites Verb darstellt, kann sparte
ein Nomen oder ein nites Verb sein. Die Eindeutigkeits-Heuristik bevorzugt das eindeutigere wähle. Würde die Wahl auf sparte fallen,
käme es mit hoher Wahrscheinlichkeit im späteren Verlauf zu einem
Konikt, da in der Regel
39
40
nur ein nites Verb
vorkommen darf und
wähle daher keinem anderen Regens zugeordnet werden kann.
38 Zu beachten ist, dass die Länge von Äuÿerungsteilen in Worteinheiten gemessen wird,
welche unterschiedlichen langen Intervallen auf der Zeitachse entsprechen. Nur im Falle
von Worthypothesen, deren
from-
und
to-Werte
absolute Zeitpunkte sind, ist dies nicht
der Fall.
39 Eine Ausnahme stellen Koordinationen dar sowie Matrixsätze, deren subordinierte
Sätze mit in der Äuÿerung enthalten sind.
40 Ähnlich verhält es sich mit trennbaren Verbpartikeln und Nominativ-Satzgliedern,
wobei von letzteren im Falle einer Kopula auch zwei möglich sind.
38
•
Positions-Heuristik: Bei der Auswahl des niten Verbes werden bei VL
zuerst die später beginnenden Kandidaten ausprobiert, während dies
bei VE oder VZ genau umgekehrt geschieht.
•
Wortstellungs-Heuristik: Satzgliedkandidaten, die Präferenzregeln für
ihre Stellung innerhalb von Feldern verletzen, erhalten eine niedrigere Priorität, entsprechend dem kumulierten Gewicht der betroenen
Regeln (siehe Abschnitt 3.1.3). Ebenso gibt es für einige Dependenten
bevorzugte Felder: zum Beispiel sind prädikative Elemente meist in der
rechten Klammer zu nden und nur selten im Vorfeld. Umgekehrt ist
das Vorfeld bei VZ die übliche Position für das Subjekt.
•
Simplizitäts-Heuristik: Einfache Lösungen werden priorisiert, da bei
diesen im Misserfolgsfall geringere Suchkosten anfallen. Durch die
Fortschritts-Heuristik ist bereits gewährleistet, dass bevorzugt auf
durch gröÿere Chunks bereitgestellte Abkürzungen zurückgegrien
wird, wie in Satz 2 (S. 19) postuliert. Da die groÿen Chunks nicht nur
Abkürzungen für Suchpfade darstellen, sondern mit relativ hoher Wahrscheinlichkeit auch die korrekte Teillösung enthalten, ist eine zusätzliche Förderung durch die Simplizitäts-Heuristik gerechtfertigt. Darüber
hinaus bevorzugt diese auch Lesarten mit kleinem Valenzrahmen.
•
Relative-Häugkeit-Heuristik: Häugere Lesarten und Satzmodi wer-
den zuerst expandiert, da sie mit höherer Wahrscheinlichkeit zutreen
und so die Average-Case-Komplexität verringert werden kann. Ohne
fundierte statistische Untersuchungen auf für die Anwendung repräsentativen linguistischen Korpora ist diese Heuristik jedoch nur bedingt einsetzbar.
Durch lineare Kombination der einzelnen Heuristiken erhält man eine Bewertung
b des Suchknotens. Zur Berechnung der Priorität müssen die Bewer-
tungen aller Vorgängerknoten dazu addiert werden, um Knoten, die keine
Geschwister sind, miteinander vergleichbar zu machen. Diese Summe muss
zudem normiert werden, damit die Prioritäten ebenenunabhängig sind. Die
Priorität einer Teillösung ergibt sich somit aus der durchschnittlichen Bewertung aller Knoten entlang des Suchpfades:
p(n0 , . . . , ni ) =
b(n0 ) + . . . + b(ni )
i+1
Da nur die Blattknoten im Speicher gehalten werden, ist nur noch die Bewertung des direkten Vorgängerknotens zugänglich. Dies ist jedoch ausreichend,
39
weil sich obige Gleichung auch in iterativer Form schreiben lässt:
p(n0 , . . . , ni ) =
Es muss also nur die Ebenenzahl
p(n0 , . . . , ni−1 ) i + b(ni )
i+1
i des Knotens bekannt sein, das heiÿt, diese
muss im Knoten gespeichert sein.
3.1.7 Weitere Optimierungsmaÿnahmen
Es fällt auf, dass das Parsing längerer, sehr ungrammatischer Sätze unverhältnismäÿig lange dauert. Dies ist nicht verwunderlich, müssen hier doch bis
zu einer bestimmten minimalen Koniktanzahl alle Zweige des Suchbaumes
expandiert werden. Da bei mehr als zwei Konikten eine genaue Fehlerdiagnose ohnehin utopisch zu sein scheint, liegt es nahe, eine Kostenobergrenze
(Maximalanzahl von Konikten) anzugeben, bei deren Überschreitung die
Suche abgebrochen wird. Suchknoten, deren Kosten diese Grenze überschreiten, werden nicht weiter expandiert und können zudem aus dem Speicher
gelöscht werden. Trit dies auf alle Knoten zu, wird die Satzanalyse als aussichtslos betrachtet und die Diagnose falsche Hypothese ohne zugehörigen
Syntaxbaum getroen.
Insbesondere, wenn das Verfahren in Echtzeitsystemen eingesetzt wird,
scheint es angebracht, zusätzlich eine Zeitobergrenze anzugeben, bei deren
Überschreiten die gleiche Konsequenz gezogen wird. Bei Sätzen, deren Analyse sehr lange dauert, ohne dass die Kostenobergrenze überschritten ist, expandiert die Suche oenbar unverhältnismäÿig in die Breite. Dies hat meist
zur Folge, dass für die Fehleranalyse eine ganze Reihe gleichwertiger Alternativen in Frage kommen, was eine vertrauenswürdige Fehlerdiagnose ebenfalls
unmöglich macht. Die Gefahr, dass durch den Abbruch nach Überschreitung
des Zeitlimits eine Fehldiagnose (False Negative) verursacht wird, ist gering,
wenn davon ausgegangen wird, dass das Parsing jedes grammatischen Satzes
in angemessener Zeit durchgeführt werden kann dank Priorisierungsheuristiken und Ausschluÿ aller Ein-Konikt-Alternativen. Beide Obergrenzen
sollen vom Benutzer anpassbar sein, um den Anforderungen der jeweiligen
Anwendung gerecht werden zu können.
Die Reihenfolge der Einträge in der Valenzagenda bestimmt, welche Valenzstellen zuerst besetzt werden. Hierfür ergeben sich folgende Heuristiken:
•
Die zwei ranghöchsten prädikativen Dependenten sollten stets am Anfang bestimmt werden, da sie die topologische Struktur des Satzes fest-
40
41
legen
und somit den Suchraum für die anderen Satzglieder einschrän-
ken.
•
Subjunktionen, die subordinierte Sätze einleiten, genieÿen höchste Priorität, da sie die Aufteilung des Matrixsatzes in getrennte Suchräume
vollziehen.
•
Die Heuristik der am stärksten beschränkten Variable (MRV minimum remaining value), wie [9] sie für Constraint-Satisfaction-Probleme
(CSP) vorschlägt: Je weniger in Frage kommende Chunks für die Besetzung eine Valenzstelle vermutet werden, desto früher wird diese besetzt.
Dies ist insbesondere der Fall, wenn lexikalische oder topologische Einschränkungen gegeben sind, wie zum Beispiel ein Reexivpronomen mit
gegebener Person und Kasus, ein bestimmter abgetrennter Verbzusatz
oder ein Chunk, der nur in der rechten Klammer erlaubt ist. Der Kandidatenkreis wird auch eingeengt, wenn passende Chunks nur an wenigen
Stellen des Satzes zu erwarten sind oder wenn die auf die Anforderung
passenden Wortformen eindeutig sind, so dass nicht mehrere parallele
Kandidaten auftreten.
•
Freie Angaben werden erst besetzt, wenn alle Ergänzungen abgearbeitet sind.
Daraus ergibt sich für die Reihenfolge, in der die Valenzstellen besetzt werden, folgende Einschätzung:
1. Abgetrennter Verbzusatz
2. Reexiv- oder Personalpronomen
3. Innitivpartikel
4. Präpositionalphrase mit gegebener Präposition
5. Innite Verbform
6. Konjunktion, Präposition
7. Pronomen oder Artikel
8. Adverb
9. Präpositionalphrase mit beliebiger Präposition
10. Adjektiv
11. Nominalphrase oder Nomen
12. freie Angaben in der gleichen Reihenfolge
41 Bei VL geschieht dies durch das nite Verb und die Subjunktion beziehungsweise das
Relativglied
41
Auf Seite 37 wurde ein einfaches, aber nicht optimal ezientes Verfahren
zur Extraktion von Valenzstellen aus der Lesartagenda beschrieben. Diese
enthält für verschiedene Chunks
Für jedes
c
c
eine Menge
L
von Lesarten.
bilden die Lesarten Disjunktionen: c besitzt Valenzrahmen 1
oder Valenzrahmen 2 oder . . . Die Valenzstellen innerhalb eines Valenzrah-
42
mens bilden dagegen Konjunktionen
: c fordert Subjekt und Objekt und
optional Präpositionalobjekt und . . . Konjunktionen sind billig, weil sie der Reihe nach auf einem Suchpfad abgearbeitet werden können. Disjunktionen hingegen sind teuer, weil sie eine zusätzliche Verzweigung des Suchbaumes erfordern. Diese Verzweigungen
sollten daher so spät wie möglich stattnden. Oftmals beinhalten mehrere
alternative Valenzrahmen eine oder mehrere gleiche Valenzstellen. So fordert
fast jeder Valenzrahmen eines niten Verbes ein Subjekt. Wird die Verzweigung der Suche sofort durchgeführt, muss für jede Lesart unter den selben
Bedingungen das Subjekt erneut gesucht werden. Viel ezienter wäre es, erst
nach den möglichen Subjekten aufzuspalten und danach die Trennung nach
Lesart zu vollziehen. Zwar bringt dies keine Reduzierung der Knotenanzahl
auf der untersten Ebene, also der Speicherkomplexität. Die Zeitkomplexität
ist jedoch entscheidend von der Zahl der teuren Durchsuchungen der Chunkmenge
R
abhängig, bei der jeder Chunk der gesuchten Chunkkategorie auf
Kompatibilität mit der Valenzstellenanforderung, der topologischen Struktur
und der Präferenzregeln überprüft werden muss. Durch eine sofortige Aufspaltung nach Lesarten multipliziert sich die Anzahl jener Operationen mit
der Anzahl der Lesarten.
Aus diesem Grunde wurde bereits in Abschnitt 3.1.5 die Lesart-Agenda
als Zwischenspeicher eingeführt, um die Verzweigung erst zu vollziehen, wenn
alle alten Valenzstellen abgearbeitet sind. Man muss jedoch nicht nach allen Alternativen gleichzeitig aufspalten, sondern kann durch Anwendung des
Distributivgesetzes die Lesarten in Gruppen einteilen, die eine gemeinsame
Valenzstelle besitzen und somit gemeinsam weitergeführt werden können.
Durch Anwendung des Distributivgesetzes lassen sich gemeinsame Valenzstellen ausklammern. Man könnte also im Beispiel aus Tabelle 2 eine Konjunktion
aus der Valenzstelle Subjekt und der Disjunktion der Valenzrahmenreste bilden und somit die Verzweigung um eine weitere Ebene verzögern. Alternativ
könnte man 3 Gruppen je nach abgetrenntem Verbzusatz (TVZ) bilden und
erst im nächsten Schritt das Subjekt ausklammern. Die Wahl der nächsten
auszuklammernden Valenzstelle könnte sich nach folgenden Kriterien richten:
42 Dies ist im übertragenen Sinne gemeint. Damit es sich im Sinne der Aussagenlogik um
korrekte Aussagen handelt, müssten für jede Lesart alle möglichen Valenzstellen, die nicht
besetzt werden dürfen, negiert ergänzt und alle freien Angaben die entweder besetzt
werden können oder nicht weggelassen werden.
42
1
subj(NOM)
p-obj(mit+DAT)
2
subj(NOM)
obj(AKK)
3
TVZ(auf )
subj(NOM)
p-obj(mit+DAT)
4
TVZ(auf )
subj(NOM)
obj(AKK)
5
TVZ(ab)
subj(NOM)
obj(DAT)
6
TVZ(ab)
subj(NOM)
obj(AKK)
p-obj(mit+DAT)
Tabelle 2: Lesarten für ein Verb
•
Es sollten möglichst wenige Gruppen entstehen.
•
Aus den einzelnen Gruppen sollte im nächsten Schritt wiederum eine
möglichst gute Ausklammerung möglich sein. Dies sicherzustellen, ist
allerdings ein komplexes Problem und seine Berechnung könnte den
Ezienzvorteil, der dadurch entsteht, wieder kompensieren.
•
Die Priorisierung der Valenzstellen von Seite 41 ist zu berücksichtigen.
Ergibt sich durch Ausklammerung der letzten Valenzstelle ein leerer Valenzrahmen, so kann dieser mit einem einelementigen Valenzrahmen zusammengefasst werden, indem dessen Valenzstelle zur freien Ergänzung wird.
VE und VZ unterscheiden sich topologisch nur in der Frage, ob das Vorfeld
ein vorfeldfüllendes Satzglied enthält. Deshalb kann VE bis zum Ende der
Suche als VZ geführt und gemeinsam mit dieser behandelt werden. Erst in
den terminalen Knoten erfolgt eine Entscheidung zwischen den beiden Verbstellungen, die pro VE ausfällt, falls sich kein vorfeldfüllendes Satzglied im
Vorfeld bendet. Auf diese Weise lässt sich ein ganzer Ast, der aus der Wurzel
des Suchbaumes wächst, einsparen, was zu einer Reduktion der Suchkosten
um 30 Prozent oder mehr führen kann.
3.1.8 Fehlerdiagnose
Die Fehler durch akustische Verwechslungen des Spracherkenners lassen sich
in fünf Klassen einteilen. Jede Fehlerklasse kann verschiedene Konikte auslösen:
•
Verwechslung: Ein Wort wird durch ein falsches Wort ersetzt. Handelt
es sich um die gleiche Wortart, tritt typischerweise ein InkongruenzKonikt auf: nachrichten angeschaltet statt nachrichten anschalten.
Sonst wird meist ein Unbenutzter-Chunk-Konikt verursacht: nimm
43
das bauch statt nimm das auf . Eine dritte Möglichkeit ist ein gemeinsames Auftreten eines Oene-Valenzstelle-Koniktes und eines Unbenutzter-Chunk-Koniktes: nimm dann auf statt nimm das auf .
•
Auslassung: Ein Wort wird ausgelassen: habe sie nicht verstanden
statt ich habe sie nicht verstanden. Typisch ist hier ein einzelner Oene-Valenzstelle-Konikt. Jedoch können als Folge zusätzlich Unbenutzter-Chunk-Konikte auftreten, wenn Dependenten des verschluckten
Wortes nicht eingeordnet werden können, gerade wenn das Wort Bestandteil einer Nominalphrase ist.
•
Einfügung: Ein Wort wird eingefügt, das nicht in der Äuÿerung enthal-
ten war: ich habe sie nicht verstanden um statt ich habe sie nicht
verstanden. Hier kommt es in den meisten Fällen zu einem Unbenutzter-Chunk-Konikt.
•
Zusammenziehung: Eine Wortfolge wird durch ein einzelnes Wort er-
setzt: auswählen statt tag wählen.
•
Trennung: Ein einzelnes Wort wird durch eine Wortfolge ersetzt: tag
wählen statt auswählen
Die Auswirkungen der letzten beiden Fehlerklassen sind schwer vorhersagbar. Eine korrekte Fehlerdiagnose gestaltet sich in diesen Fällen ohnehin
am schwierigsten, da mit diesen Fehlern immer auch eine akustische Verwechslung einhergeht.
Ist das Verb des Satzes in den Spracherkennerfehler verwickelt, ist eine Fehlerdiagnose nur möglich, wenn das Verb nicht in seiner Stammform,
sondern nur in seiner Flexion verändert ist. Sonst ist die Analyse nahezu
aussichtslos, da entweder kein nites Verb gefunden werden kann und somit
der Parsing-Prozess früh abgebrochen werden muss, oder ein anderes Verb
verwendet wird, das in der Regel andere Valenzstellen besitzt.
Betrit der Fehler einen ganzen Chunk dies ist insbesodere für EinwortChunks der Fall , ist eine Lokalisierung des Fehlers möglich, aber zweideutig,
wenn es sich um einen Inkongruenz-Konikt handelt. Dieser kann nämlich
sowohl durch das Regens, als auch durch das Dependens verursacht worden
sein.
Ist nur ein Teil eines Chunks betroen, sind die Auswirkungen schwer
vorhersagbar, da der Chunk-Parser den Chunk mit hoher Wahrscheinlichkeit
nicht mehr identizieren kann.
44
3.2 Ein Sprachmodell für das Deutsche
Im vorangegangenen Kapitel wurde beschrieben, wie sich grammatikalische
Informationen für das Parsing von Sätzen nutzen lassen. Es folgt nun eine
detaillierte Beschreibung der konkreten Valenzrahmen verschienender Satzglieder und der erlaubten Zielfelder ihrer Dependenten. Das Modell ist vorerst
auf Verben und vereinzelte freie Angaben für Nominalphrasen beschränkt.
3.2.1 Satzmodi
Generell betrachten Dependenzgrammatiken stets das nite Verb als absolutes Regens des Satzes. Es bietet sich jedoch an, als Wurzel des Dependenzbaumes und somit als absolutes Regens einen virtuellen Chunk S zu installieren,
welcher den gesamten Satz repräsentiert und die Merkmale Verbstellung und
Satzmodus beinhaltet.
Der Valenzrahmen von Sätzen besteht üblicherweise aus einem niten
Verb in der grammatikalischen Funktion des Prädikates. Gerade bei der Bedienung technischer Geräte sind aber häug kommandoartige Äuÿerungen zu
nden, die statt einem niten Verb einen Ersatzinnitiv in VL aufweisen:
Heute abend Monitor aufnehmen!
Einige VL-Satzmodi, die vor allem bei subordinierten Sätzen zu nden sind,
fordern zusätzlich eine Subjunktion oder ein Relativ-Satzglied in der linken
Klammer:
. . . , ob heute Tatort läuft.
. . . , was für Filme heute laufen.
Die unterschiedlichen Satzmodi
43
für VE und VZ sind für den Zweck die-
ser Arbeit äquivalent und ohne Zuhilfenahme von Prosodie oder Semantik
teilweise auch nicht unterscheidbar.
3.2.2 Vollverben
Die verschiedenen Lesarten der Vollverben und die zugehörigen Ergänzungen
sind im Subkategorisierungslexikon angegeben. Mögliche Ergänzungen sind:
•
Subjekt : Beim Subjekt handelt es sich um ein Satzglied im Nominativ,
das in Numerus und Person mit dem niten Verb kongruent sein muss.
Es wird üblicherweise durch eine Nominal- oder Determinalphrase oder
43 Eine detaillierte Beschreibung aller Satzmodi und ihrer Topologien ndet sich in [7],
Kapitel 2.
45
Lesart
VE/VZ-Satz
VL-Glied- oder
Attributsatz
VL-Relativsatz
Valenzstellen gramm. Funkt. Zielfeld
nites Verb
pred
LK
nites Verb
pred
RK
Subjunktion
subj
LK
nites Verb
pred_rel
RK
Relativglied
LK
Tabelle 3: Lesarten von Sätzen
durch ein Pronomen ausgedrückt. Die erlaubten Pronomenarten sind
personal, demonstrativ, in Fragesätzen auch interrogativ, in Relativsätzen auch relativ.
•
Akkusativ-, Dativ- oder Genitivobjekt : Für Objekte gilt das Gleiche wie
für Subjekte mit dem Unterschied, dass keine Kongruenzbedingungen
erfüllt werden müssen, das Satzglied jedoch den geforderten Kasus aufweisen muss.
•
Reexives Akkusativ- oder Dativ-Objekt : Hier handelt es sich zwingend
um ein Reexivpronomen, welches genauso wie das Subjekt in Numerus und Person mit dem niten Verb kongruent sein muss.
•
Präpositionalobjekt mit bestimmter Präposition und Kasus,
•
Konstituentensatz oder Innitivkonstruktion mit zu ,
•
Adverb.
Vollverben können zusätzlich folgende freie Angaben regieren:
•
freier Dativ : Falls der Valenzrahmen kein Dativ-Objekt enthält, kann
dennoch eines ergänzt werden:
Er hat ihm die Augen geönet.
Er hat seiner Frau den Koer getragen.
Du bist mir so einer!
Mir regnet es momentan zuviel.
•
Präpositionalphrase (mehrfachbesetzbar),
•
Adverbien und Partikel (mehrfachbesetzbar).
Die zulässigen Positionen für die Dependenten des Vollverbes sind
•
das Mittelfeld,
46
•
das Vorfeld, falls dieses noch nicht besetzt ist die Dependenten des
Vollverbes sind Satzglieder und somit vorfeldfüllend ,
•
vor dem Vollverb im von diesem aufgespannten Feld, es sei denn, jenes
bendet sich in der linken Klammer (das heiÿt, es handelt sich um ein
nites Verb in VE oder VZ),
•
in beschränktem Maÿe auch im Nachfeld
44
.
Alle Dependenten des Vollverbes können durch einen Gliedsatz, eine In-
45
nitivkonstruktion mit zu oder durch einen w-Relativsatz
substituiert
werden. Etwaige Kongruenzbedingungen übertragen sich dabei Gliedsätze
und Innitivkonstruktionen werden stets als 3. Person Singular Neutrum betrachtet, während ein Relativsatz die Merkmale seines Subjektes übernimmt.
Diese substituierenden Konstruktionen sind im Mittelfeld nicht zugelassen
und erfordern je nach Stellung zusätzlich ein korrespondierendes Demonstra-
46
tivpronomen, ein Expletivum (es) oder ein Adverb
. Sie können folgende
Positionen einnehmen:
•
Das Nachfeld. Hier muss das Vorfeld mit einem Expletivum es aufgefüllt werden, wenn es sonst unbesetzt bliebe. Ist das Vorfeld anderweitig besetzt (oder aufgrund von VE-/VL-Stellung nicht besetzbar),
47
so kann
das Expletivum optional im Mittelfeld ergänzt werden:
Es freut mich, dass heute zwei schöne Filme laufen.
Mich freut (es), dass heute zwei schöne Filme laufen.
Es gewinnt nicht, wer nicht wagt.
Jedoch gewinnt nicht, wer nicht wagt.
•
Das Vorfeld: Die substituierende Konstruktion ist vorfeldfüllend, es sei
48
denn, ihr wird ein korrespondierendes Satzglied direkt nachgestellt
:
44 Tendenziell wird es als ungrammatisch empfunden, wenn sich Satzglieder im Nachfeld benden. Gerade in der gesprochenen Sprache sind jedoch immer wieder Beispiele
für einzelne Satzglieder in Nachfeldposition zu nden. Unter bestimmten Umständen ist
diese auch in der Schriftsprache denkbar, zum Beispiel bei sehr langen Satzgliedern. Eine
Anhäufung von Satzgliedern im Nachfeld ist jedoch nahezu ausgeschlossen.
45 Ein Relativsatz, der nicht mit dem Relativpronomen der, die, das eingeleitet wird,
sondern mit dem Fragepronomen wer.
46 Wird ein Präpositionalobjekte substituiert, ist unabhängig von der Stellung immer ein
Präpositionaladverb zu ergänzen.
47 Jedoch nicht bei w-Relativsätzen.
48 In Wahrheit handelt es sich bei dieser Ausnahme jedoch um eine L-Herausstellung [7]
47
Dass heute zwei schöne Filme laufen, (das) freut mich.
Wer nicht wagt, (der) gewinnt nicht.
Dass heute zwei schöne Filme laufen, (das) freut mich.
•
Nach dem Vollverb (im Beispiel sehen) in dessen Feld, falls jenes sich
im Vorfeld bendet:
Zu sehen, dass heute zwei schöne Filme laufen, freut mich.
3.2.3 Trennbarer Verbzusatz bei trennbaren Verben
Trennbare Verben sind Verben, deren nite Formen in VE und VZ aus zwei
49
Teilen bestehen
. Die Klassikation der Verben geschieht wie folgt
50
:
1. Alle Verben mit den folgenden Präxen sind trennbar: ab-, an-, auf-,
aus-, bei-, ein-, empor-, her-, hin-, hoch-, los-, mit-, nach-, nahe-, näher-,
nieder-, vor-, weg-, zu-, zurück-, zusammen-.
2. Verben mit folgenden Präxen können trennbar oder nicht trennbar
sein: durch-, hinter-, oen-, um-, unter-, über-, voll-. Für viele dieser
Verben gibt es sowohl eine trennbare und eine nicht trennbare Lesart,
vgl. durchlaufen: ich laufe durch ich durchlaufe. Die trennbare Variante liegt genau dann vor, wenn der Wortakzent auf dem Präx liegt.
Jedoch besitzen nicht alle Verben eine trennbare Lesart, vgl. hinterfragen.
3. Alle Verben mit einem Präx, das sich aus Präxen der Kategorien 1
und 2 zusammensetzt, sind trennbar: einher-, heraus-, herum-, hervor-,
hinauf-, hindurch-, hinterher-, umher-, vorüber-, wieder-, . . .
Gleiches gilt für Kombinationen aus da- bzw. dar- und Präxen aus
Kategorie 1 sowie für ihre (umgangssprachlichen) Kurzformen: daher-,
dahin-, daran-, drauf-, drein-, drüber-, . . .
Ein solchen kombinierten Präxen vorangestelltes her- kann ebenfalls
verkürzt werden: ran-, raus-, rein-, runter-, . . .
In seltenen Fällen sind sogar Kombinationen aus mehr als zwei Präxen
möglich: hinterdrein-.
49 Übrigens werden auch das Partizip Perfekt ( auf|ge|gangen statt ge|aufgangen) und
der Innitiv mit zu ( auf|zu|gehen statt zu aufgehen) anders gebildet. Bei Partizip
Perfekt gibt es eine dritte Variante, bei der das Morphem ge- ganz weggelassen wird,
und zwar bei den Wörtern mit nicht abtrennbarem Verbzusatz. Vgl. auch Verben, die
beide Lesarten haben ( ich durchlaufe ich habe durchlaufen, ich laufe durch ich
bin durchgelaufen)
50 Die Liste erhebt keinen Anspruch auf Vollständigkeit.
48
4. Auch einige Adverbien dienen als trennbare Verbpräxe: daneben-,
entgegen-,
gegeneinander-,
gegenüber-,
nebeneinander-,
rückwärts-,
vorwärts-, weiter-.
5. Alle Verben mit anderem oder ohne Präx sind nicht trennbar: be-, er-,
ge-, miss-, ver- , zer-, . . .
Grammatikalisch gesehen ist der trennbare Verbzusatz (TVZ) ein Dependens
des Verbes. Gleichzeitig gibt es zu jedem trennbaren Verb auch ein eigenständiges Kernverb ohne TVZ. Diese beiden Tatsachen kann sich ein Parser
zunutze machen, indem Lesarten trennbarer Verben als zusätzliche Lesarten
des Kernverbes mit zusätzlichem Komplement TVZ interpretiert werden. Die
Lesart aufhören aus dem Subkategorisierungslexikon mit Valenzrahmen
Subjekt(Nominativ), Präpositionalobjekt(mit+Dativ)
wird also transformiert in eine Lesart hören mit Valenzrahmen
TVZ(auf ), Subjekt(Nominativ), Präpositionalobjekt(mit+Dativ).
3.2.4 Kopulaverben
Kopulaverben sind Verben, die neben einem Subjekt auch ein Prädikativum,
das heiÿt ein Prädikatsnomen oder ein prädikatives Adjektiv, regieren und
somit einen doppelten Nominativ fordern. Im Gegensatz zum Subjekt ist die
51
prädikative Ergänzung aber Teil des Prädikates
, was zur Folge hat, dass
sie sich topologisch nicht wie ein Satzglied verhält (das ja in jedem der drei
Stellungsfelder stehen darf ), sondern als Teil des Prädikates in der rechten
Klammer gebunden ist und ggf. lediglich ins Vorfeld vorgezogen werden darf.
3.2.5 Funktionsverbgefüge
Funktionsverben sind Verben, die zur Bildung des Prädikates einen festen No-
minalausdruck benötigen. Darunter fallen feste Wendungen wie zur Anzeige
bringen ebenso wie zusammengesetzte Verben wie Rad fahren
52
. Der No-
minalausdruck ist Bestandteil des Prädikates, mit denselben topologischen
Konsequenzen wie bei der Kopula (nach [7], S. 77, siehe auch für genauere
Abgrenzung).
51 In der Linguistik gibt es auch eine alternative Sichtweise, wonach das Prädikativum
alleine das Prädikat bildet. Aus Gründen der einfacheren Implementierung wird hier allerdings die Theorie eines mehrteiligen Prädikates vorgezogen.
52 Einige Verben aus letzterer Gruppe wurden nach alter Rechtschreibung zusammenge-
schrieben (vgl. radfahren vs. Auto fahren), verhielten sich also wie trennbare Verben.
49
Leider enthält das für die Implementierung verwendete Subkategorisierungslexikon keine Funktionsverbinformationen. Aus diesem Grund sind
Funktionsverbgefüge in der vorliegenden Implementation noch nicht berücksichtigt.
3.2.6 Hilfsverben
Die Markierung grammatikalischer Kategorien erfolgt im Deutschen normalerweise durch Flexion, wie z.B. beim Präteritum, auch im Folgenden). Einige Kategorien werden bei Verben jedoch anhand von Funktionswörtern
gekennzeichnet, sogenannten Hilfsverben, welche selbst keine Bedeutung tragen, sondern lediglich dazu dienen, die grammatikalischen Eigenschaften des
Verbes zu modizieren (nach [8]):
•
Das Perfekt wird im Deutschen durch die Hilfsverben haben oder
sein und dem Partizip Perfekt des Vollverbes gebildet. Verben der
Bewegung und der Zustandsänderung sowie sein als Vollverb bilden
ihr Perfekt mit sein, während alle anderen Verben, insbesondere reexive und reexiv verwendete (also auch sich bewegen als reexives
53
Bewegungsverb), mit werden ins Perfekt gesetzt werden
•
.
Das Plusquamperfekt wird analog zum Perfekt gebildet, wobei das
Hilfsverb ins Präteritum gesetzt wird.
•
Das Futur wird mit dem Hilfsverb werden und dem Innitiv des Vollverbes gebildet.
•
Für den Konjunktiv II wird in der gesprochenen Sprache und immer
häuger auch in der Schriftsprache die Umschreibung mittels Konjunktiv II Futur benutzt: Er würde zustimmen.
•
Das Passiv wird mit dem Hilfsverb werden und dem Partizip Perfekt des Vollverbes gebildet. Neben dieser auch Vorgangspassiv genannten Form existiert bei vielen Verben auch ein Zustandspassiv, bei dem
sein als Hilfsverb dient: Der Würfel ist gefallen.
•
In der Umgangssprache kann tun als Hilfsverb benutzt werden, um
dem Vollverb einen durativen Aspekt zu verleihen.
53 Im süddeutschen Sprachraum wird sein auch für Positionsverben (z.B. stehen)
verwendet, sofern diese nicht in einer übertragenen Bedeutung verwendet werden, wie bei
(im Gefängnis) sitzen
54 Ersatzinnitiv für Modal- und AcI-Verben, siehe später im Text.
50
Verb
Verbform
Markierung
Ergänzung
Beispiel
sein
Aktiv
Vergangenheit
PP
Er ist aufgewacht
haben
Aktiv
Vergangenheit
PP/INF
werden
Aktiv
Futur
INF
Er wird aufwachen
werden
Aktiv
Vorgangspassiv
PP
Es wird vollbracht
sein
Aktiv
Zustandspassiv
PP
Es ist vollbracht
tun
Präsens Aktiv
Durativ
INF
Er tut aufwachen
54
Er hat verstanden
Tabelle 4: Hilfsverben und ihre Eigenschaften
3.2.7 Modal- und Modalitätsverben
Modalverben verhalten sich ähnlich wie Hilfsverben. Sie modizieren den Mo-
dus des Vollverbes. Modalitätsverben
55
verhalten sich ähnlich wie Modalver-
ben, fordern aber einen Innitiv mit zu:
Er hat zu gehorchen.
Ich habe viel zu tun.
Es bleibt zu konstatieren, dass . . .
3.2.8 AcI-Verben
Beim Accusativus cum Innitivo (Akkusativ mit Innitiv, kurz AcI) handelt es sich um eine Konstruktion, die im Deutschen bei bestimmten Verben,
56
insbesondere bei Verben der Sinneswahrnehmung, auftreten kann
:
Er sah das Kind weinen.
Der AcI kann als Verschmelzung zweier Prädikate interpretiert werden, wes-
57
halb in vielen Fällen
eine äquivalente Gliedsatzkonstruktion gebildet wer-
den kann:
Er sah, dass das Kind weinte.
Diese AcI-Verben regieren neben einem Innitiv ein Akkusativobjekt, welches semantisch gleichzeitig als Subjekt des Innitivs dient. Eine derartige
Doppelfunktion eines Satzgliedes ist in Dependenzgrammatiken jedoch nicht
vorgesehen. Andernfalls wäre nämlich Annahme 3 (S. 13) verletzt, die besagt, dass jedes Wort im Satz nur einem Regens als Dependens dient, und
gewährleistet, dass es sich beim Dependenzgraphen um einen Baum handelt.
55 [7] S. 57. unterscheidet hier zwischen Modalitätsverben und modalem Innitiv.
56 Nach [7], S. 60 .
57 Ausnahmen s. ebd.
51
Im vorliegenden Grammatikmodell wird deswegen nur die Objektfunktion
berücksichtigt, das Akkusativnomen also als Dependens des AcI-Verbes betrachtet.
3.2.9 Doppel-Vollverb-Konstruktionen
Hinter dieser Bezeichnung nach [7], S. 55, verbirgt sich eine ähnliche Konstruktion. Zur Bildung des Prädikates wird ein zweites Vollverb verwendet,
welches dem niten Verb untergeordnet ist. Der Unterschied zum AcI besteht
darin, dass beide Verben dasselbe Subjekt teilen:
Er geht schwimmen.
Ich gehe Milch kaufen.
In den meisten Fällen gerät die eigentliche Bedeutung des übergeordneten
Verbes in den Hintergrund, weshalb sich eine gewisse Nähe zu Modalverbkonstruktionen attestieren lässt. So verleiht das Verb gehen der eigentlichen
Tätigkeit einen ingressiven Aspekt (das heiÿt, deren Beginn wird betont),
während es keine groÿe Rolle spielt, ob diese tatsächlich zu Fuÿ ausgeführt
wird.
3.2.10 Aufbau komplexer Verbalstrukturen
Wird ein Verb in einer seiner grammatikalischen oder modalen Kategorien
durch ein anderes Verb (zum Beispiel ein Hilfs- oder Modalverb) modiziert,
so übertragen sich alle anderen grammatikalischen Kategorien morphologisch
auf das modizierende Verb, indem dieses ektiert wird:
er geht
→
er will gehen
Wird dieses wiederum durch ein weiteres Verb modiziert, können Hintereinanderschaltungen mehrerer Hilfs- und Modalverben entstehen:
Ich würde von ihm ausgewählt worden sein wollen.
Grammatikalisch wird also das jeweils modizierende Verb modiziert, semantisch übertragen sich jedoch alle Modikationen auf das Vollverb. Auch
das Futur II kann auf diese Weise gebildet werden: Er wird gegangen sein.
Für die Reihenfolge, in der die grammatikalischen Kategorien markiert werden, und somit für die Rangordnung der Verben im Sinne der Dependenzgrammatik, gibt es klare Einschränkungen. Sie werden im Folgenden aus der
Sicht der Satzsynthese also im Dependenzbaum von unten nach oben angegeben (bei der Satzanalyse gilt entsprechend die umgekehrte Reihenfolge):
52
•
Die grammatikalischen Kategorien, die durch Flexion ausgedrückt werden, werden immer ganz am Ende markiert. Das bedeutet, das ranghöchste Verb wird zum niten Verb und somit zum absoluten Regens.
•
Für die Reihenfolge der übrigen Kategorien gilt: Das Passiv wird vor
58
dem Modus
und dem Perfekt gebildet, das Futur danach (vgl. obiges
Beispiel).
Zu beachten ist auÿerdem:
•
Das Hilfsverb tun wird in Kombination mit anderen modizierenden
Verben im Allgemeinen als ungrammatisch empfunden: Er will aufräumen tun.
•
Werden als Hilfsverb bildet sein Partizip Perfekt (worden) anders
als werden als Vollverb (geworden), was bei der Bildung des Perfekt
Passiv von Bedeutung ist:
Er ist aufgeweckt worden.
•
Bei der Perfektbildung von Modal- und AcI-Verben ist zu beachten,
dass statt dem Partizip Perfekt der Ersatzinnitiv verwendet wird:
Er hatte es nicht kaufen wollen.
Ich habe ihn weglaufen sehen.
3.2.11 Topologie der Verbformen
Das nite Verb steht bei VL in der rechten, sonst in der linken Klammer.
Innite Verbformen, die bei VE oder VZ von einem niten Verb regiert werden, benden sich in der rechten Klammer ganz auÿen rechts. Alle anderen
inniten Verbformen werden entweder unmittelbar vor dem Regens im von
ihm aufgespannten Feld oder im Vorfeld untergebracht. Letztere Variante ist
unter dem Begri Partial Verb Fronting bekannt. Hierbei verhält sich die
vorgezogene Verbalphrase wie ein Satzglied (also vorfeldfüllend) und erhält
den Satzakzent:
Aufnehmen habe ich das nicht wollen.
Gemeint hatte ich etwas anderes.
58 Im Unterschied zu gängigen Grammatiktafeln, in denen für den Modus nur die durch
Konjugation markierbaren Varianten Indikativ, Konjunktiv und Imperativ aufgelistet werden, sind hier auch die durch Modalverben markierten Modi wie Optativ einbezogen.
53
59
Der trennbare Verbzusatz ist allerdings in der Regel nicht vorfeldfähig [7]
.
Eine Besonderheit stellt die sogenannte Modalverbregel dar: Bei VL und
einer Kombination aus nitem Hilfsverb und innitem Modalverb
60
ben-
det sich das nite Hilfsverb am Anfang der rechten Klammer, also vor dem
restlichen Verbalkomplex [7]. So sagt man zum Beispiel nicht etwa
. . . , weil er ihn die Sendung aufnehmen lassen wollen hat,
sondern
. . . , weil er ihn die Sendung hat aufnehmen lassen wollen.
Dieses Phänomen ist jedoch durchaus kompatibel mit dem Topologiemodell
aus Kapitel 3.1.2. Der modale Innitiv als Dependens des niten Hilfsverbes
ist nach wie vor im durch das Regens aufgespannten Feld anzusiedeln, in
diesem Fall allerdings nicht links, sondern rechts vom Regens. Der modale
Innitiv fordert sein Dependens wie gewohnt auf seiner linken Seite, so dass
dieses zwischen das nite Hilfsverb und den modalen Innitiv rückt. Allerdings muss gewährleistet sein, dass ein vom Modalverb (direkt oder über
mehrere Schritte) abhängiges Vollverb seine Dependenten nicht in seinem eigenen Feld, sondern ausschlieÿlich in den Stellungsfeldern (also in der Regel
dem Mittelfeld) unterbringt, um falsche Konstruktionen wie die folgende zu
vermeiden:
. . . , weil er ihn hat die Sendung aufnehmen lassen wollen.
3.2.12 Valenzalternation bei bestimmten Verbformen
Der Valenzrahmen, der im Subkategorisierungslexikon angegeben ist, gilt nur
unter dem Vorbehalt, dass das betreende Verb im Indikativ Aktiv oder
Konjunktiv Aktiv steht. Bei anderen Formen gilt ein wie folgt abgewandelter
Valenzrahmen:
Imperativ
Es gibt drei Möglichkeiten zur Bildung des Imperativs (vgl. Tabelle 5):
•
Bei den echten Imperativformen für die zweite Person wird normalerweise das Subjekt weggelassen. Nur in sehr seltenen Ausnahmefällen,
wenn das Subjekt betont werden soll, kann es im Satz verbleiben.
59 s. [7], S. 91, für Ausnahmen
60 Aber nicht Modalitätsverb.
54
Verbstellung
Verbform
Subjekt
2. Pers. Sing.
(du)
Nimm (DU) das bitte auf !
VE
2. Pers. Plur.
(ihr)
Nehmt (IHR) das bitte auf !
VE
3. Pers. Plur.
Sie
VL
Innitiv
VE
61
Beispiel
Nehmen Sie das bitte auf !
Bitte die Sendung aufnehmen!
Tabelle 5: Möglichkeiten zur Bildung des Imperativs (Valenzalternation)
•
Die Höichkeitsform des Imperativs benutzt als Ersatzform die dritte Person Plural Indikativ Präsens. Die Nennung des Personalpronomens Sie als Subjekt ist hierbei obligatorisch. Da der Satzbau hierfür
dem eines VE-Entscheidungsfragesatzes gleicht, muss diese Variante im
Rahmen dieser Arbeit nicht berücksichtigt werden.
•
Für kommandoartige Anweisungen, wie sie bei Bedienungsanleitungen
oder der Kommunikation mit technischen Geräten üblich sind, wird
der Ersatzinnitiv in Verb-Letzt-Stellung verwendet, wobei das Subjekt
zwingend entfällt.
Partizip Perfekt
62
Bei Partizip Perfekt in Passivfunktion
entfällt das Agens das heiÿt das
Subjekt des Aktiv-Valenzrahmens , kann aber als freie Angabe mittels Präpositionalphrase ausgedrückt werden. Zulässige Präpositionen hierfür sind
von/vom und durch. Dafür wird das Patiens das heiÿt das Akkusativobjekt des Aktiv-Valenzrahmens als Subjekt im Nominativ wiedergegeben,
wobei die Kongruenzbedingung zwischen Verb und Subjekt folglich auf das
neue Subjekt übertragen werden. Sieht der Valenzrahmen kein Patiens vor
dies ist bei einstelligen Verben der Fall , wird das Passiv entweder ganz
ohne Subjekt gebildet oder mit es als Expletivum im Vorfeld. Bei substantivisch oder adjektivisch verwendetem Partizip Perfekt entfällt das Patiens
jedoch ganz, da seine Funktion durch das Substantiv übernommen wird (vgl.
Tabelle 6).
61 Imperativ in VZ ist unüblich, jedoch in bestimmten Fällen denkbar: Das
übernimm DU heute bitte! Abspülen
62 In Aktivfunktion wird das Partizip Perfekt bei der Bildung der aktiven Perfektform
mit Hilfsverb verwendet (ohne Valenzalternation).
55
Funktion
Agens
Patiens
Beispiel
Aktiv
NOM
AKK
Der Rekorder zeichnet die Sendung auf.
Passiv
(Präp.)
NOM
Die Sendung wird (v. R.) aufgezeichnet.
adj. PP
(Präp.)
die (vom Rek.) aufgezeichnete Sendung.
subst. PP
(Präp.)
das (vom Rekorder) Aufgezeichnete.
Aktiv
NOM
Sie vertraut ihm.
Passiv
(Präp.)
Ihm wird (von ihr) vertraut.
Passiv
(Präp.)
Expl.
Es wird ihm (von ihr) vertraut.
Tabelle 6: Valenzalternation bei Partizip Perfekt
Innitiv
Beim Innitiv mit oder ohne zu entfällt das Subjekt. Seine Funktion wird
von einem Dependens des regierenden Verbes übernommen
63
.
Verbform
Subjekt
Beispiel
Innitiv
Dies zu glauben, fällt ihm schwer.
Tabelle 7: Valenzalternation bei Innitiv
3.2.13 Nominalphrasen
Für Nominalphrasen sind folgende freie Angaben vorgesehen, die vom ChunkParser nicht in die Chunks einbezogen werden:
•
Genitivattribute: Das Haus des Mannes.
•
Präpositionalattribute: Der Film mit Mads Mikkelsen.
•
Negationspartikel: Nicht diesen Film habe ich gemeint.
Die Dependenten von Nominalphrasen benden sich im Feld des Regens
unmittelbar nach der Nominalphrase, im Falle der Negation jedoch unmittelbar davor.
3.3 Behandlung von Koordinationen
Koordinationen wurden in dieser Arbeit nicht berücksichtigt. Das Sprachmodell ist jedoch leicht auf Konjunktionen erweiterbar, die keine elliptischen
Strukturen hervorrufen:
63 Von welchem, hängt von der Semantik des regierenden Verbes ab, vgl.: Er
zu handeln
und Er hält sie davon ab, zu handeln
56
verspricht,
Sie lacht, aber er weint.
Frauen und Männer sind gleichberechtigt.
Die Modellierung kann erfolgen, indem den Valenzrahmen von Satzgliedern
und Sätzen als freie Angabe ein entsprechender Koordinationspartner hinzugefügt wird, der die grammatikalische Funktion Konjunktionsglied übernimmt und alle Chunks, die diese Funktion innehaben, per Valenzalternation eine Ergänzung Konjunktion erhalten. Kommt es jedoch zu elliptischen Phänomenen, das heiÿt sind Dependenten des einen Konjunktionsgliedes gleichzeitig Dependenten des anderen, so ist Annahme 3 (S. 13) verletzt
und der Satz mit dem vorliegenden Verfahren nicht behandelbar:
Er nimmt den Blumenstrauÿ und bringt ihn seiner Frau.
3.4 Die resultierende Sprache
Das Sprachmodell stellt lediglich eine sehr grobe Annäherung an die sehr
komplexen, von vielzähligen Ausnahmen geprägten Eigenschaften deutscher
Verbalstrukturen dar. Exemplarisch für Details, die in der vorliegenden Arbeit noch nicht berücksichtigt werden konnten, stehen folgende Einschränkungen, die die Menge der akzeptierten Sätze vergröÿern:
•
Bei trennbaren Verbzusätzen, die sowohl trennbare als auch nicht trennbare Verben bilden können (Kategorie 2 auf Seite 48), sind für alle
Lesarten beide Varianten erlaubt, da das verwendete Subkategorisierungslexikon keinerlei Trennbarkeitsinformation beinhaltet. Dies führt
zu Akzeptanz von Sätzen wie Er läuft ein Tal durch oder Ich durchführe eine Untersuchung.
•
Bei allen Verben wird die Perfektbildung sowohl mit haben als auch
mit sein erlaubt, weil eine Unterscheidung der zwei Verbgruppen nicht
möglich ist, denn dazu bräuchte man entweder für eine der beiden Gruppen eine möglichst vollständige Liste der zugehörigen Verben, oder der
Parser müsste um Semantik erweitert werden, um eine automatische
Zuordnung anhand von semantischen Kriterien zu ermöglichen.
•
Es gibt Verben, die kein Passiv ausbilden können: ich wurde gegangen. Neben den Hilfs-, Modal-, AcI- und bestimmten Modalitätsverben
(sofern sie in diesen Funktionen verwendet werden), die im verwendeten Sprachmodell von der Passivbildung ausgeschlossen sind, handelt
es sich hierbei um eine echte Teilmenge der intransitiven Verben.
57
4
Implementierung
Die Implementierung des Verfahrens erfolgte in der Programmiersprache
C++. Dabei wurde ein bestehendes System, das ein morphologisches Analysewerkzeug und einen Chunk-Parser enthält, um ein zusätzliches Modul
erweitert. Als Schnittstelle dienen die Datenstrukturen, die für die Ausgabe des Chunk-Parsers verwendet werden. Dabei handelt es sich um Objekte
der Klasse
ChartEdge,
die Kanten des Chartgraphen und somit Chunkhy-
pothesen darstellen. Sie werden über eine fortlaufende Nummer referenziert.
Merkmalstrukturen sind in der Klasse
Feature
implementiert.
Es folgt ein Überblick über die grundlegenden Klassen und ihre wichtigsten Attribute und Methoden sowie Erläuterungen, wie die in Kapitel 3.1
eingeführten Modelle und Algorithmen umgesetzt wurden.
4.1 Implementierung des Suchalgorithmus
Der Ablauf der Suche nach 3.1.5 wird von der Klasse
Analyser
gesteuert.
Diese stellt die Schnittstelle des Moduls nach auÿen hin dar. Für jeden zu
parsenden Chartgraphen wird ein
Analyser-Objekt erstellt, das mit einem
DependencyGrammar-Objekt aus-
Pointer auf diesen und auf ein bestehendes
gestattet wird. Das
•
•
Analyser-Objekt
übernimmt folgende Aufgaben:
Initialisierung und Speicherung der Liste der Mutex-Verknüpfungen,
Verwaltung und Sortierung der Liste der aktiven Suchknoten (also aller
Blätter des Suchbaumes),
•
•
Auswahl des jeweils nächsten zu expandierenden Suchknotens,
Beenden des Suchprozesses und Bereitstellung der Ergebnisse.
Der Suchprozess wird durch Aufruf der Methode
run()
gestartet, der einige
Parameter wie Kosten- und Zeitobergrenze übergeben werden können.
+
+
+
+
+ Analyser
chg: Chart*
grammar: DependencyGrammar*
mutexList: MutexSet*
activeNodes: list<SearchTreeNode*>
Analyser()
run(): void
getDependencyTree(): DependencyTree*
getConflicts(): list<Conflict*>
Abbildung 3: Implementierung der Schnittstelle des Moduls
58
+
+
+
+
+
+
+
-
+ SearchTreeNode
terminalNode: bool
conflicts: list<Conflict*>
numConflicts: int
priority: float
topology: SentenceTopology*
usedChunkEdges: list<int>
availableChunkEdges: list<int>
valencyAgenda: ValencyAgenda
readingAgenda: ReadingAgenda
mutexList: MutexSet*
chg: Chart*
grammar: DependencyGrammar*
SearchTreeNode()
expand(): list<SearchTreeNode*>
getEstimatedError(): int
excludeParallelChunks(): int
markChunkAsUsed(): int
Abbildung 4: Implementierung der Suchknoten
Die Suchknoten nach Denition 13 (S. 35) sind Objekte der Klasse
SearchTreeNode. Die Menge D der Dependenzen und die Valenzagenda A
sind in valencyAgenda, die Lesartagenda L in readingAgenda, die Koniktmenge K in conflicts, die topologische Struktur T in topology und die
Menge R der noch verfügbaren Chunkkandidaten in availableChunkEdges
gespeichert. Mit Hilfe von excludeParallelChunks() werden alle mit einem
bestimmten Chunk inkompatiblen Chunks aus availableChunkEdges ausgeschlossen. Zudem kann über usedChunkEdges leicht auf die Menge aller
bereits in die Dependenzstruktur eingebauten Chunks zugegrien werden,
um aus Ezienzgründen eine Einschränkung der jeweils möglichen MutexPartner zu ermöglichen.
getEstimatedError()
implementiert die Kostenfunktion für die A*-
Suche, die sich aus den Pfadkosten
kosten zusammensetzt.
priority
numConflicts und den geschätzten Restliefert die Priorität des Pfades von der
Wurzel bis zum entsprechenden Suchknoten, wie sie in Abschnitt 3.1.6 beschrieben wird.
Durch Aufruf der Methode
expand
wird der Suchknoten expandiert und
eine Liste seiner Nachfolger zurückgegeben. Die Methode implementiert
den auf Seite 36. dargestellten Algorithmus, wobei auf die Methoden von
grammar
zurückgegrien wird.
59
+
+
+
+
+
+ DependencyGrammar
subcatLex: SubcatLexReader*
topologyRules: list<TopologyRule*>
precedenceRules: list<precedenceRule*>
DependencyGrammar()
getMutexSet(): MutexSet*
getReadings(): list<Reading*>
subsumptionTest(): bool
extendTopology(): SentenceTopology*
Abbildung 5: Implementierung des Sprachmodelles
4.2 Implementierung des Sprachmodelles
Die Klasse
DependencyGrammar
stellt allgemeine Informationen grammati-
kalischer, topologischer und lexikalischer Art zur Verfügung, welche im Konstruktor aus Dateien eingelesen werden:
a) Subkategorisierungsinformationen für Vollverben (und einige wenige
Nomen und Adjektive) aus dem IMSLex [10],
b) Subkategorisierungsinformationen für Hilfsverben, Modalverben etc.,
c) Subkategorisierungsregeln für freie Angaben und für andere Chunkkategorien sowie Lesarten für Sätze,
d) lexikalische Informationen über mögliche trennbare Verbzusätze, Subjunktionen und Partikelarten,
e) Topologieregeln,
f ) Präzedenzregeln.
Es genügt, ein einziges
DependencyGrammar-Objekt zu erstellen, das für alle
Parsing-Vorgänge verwendet werden kann. Es stellt folgende Methoden bereit, um obige Informationen abzurufen und die Einhaltung der Regeln zu
überprüfen:
• getMutexSet()
liefert zu einem gegebenen Chartgraphen alle Chunk-
paare, die eine Regel aus f ) verletzen, falls sie sich in einem gemeinsamen Feld benden. Diese Methode wird von Objekten der Klasse
Analyser aufgerufen, in denen die konkreten Mutex-Paare gespeichert
werden. Da DependencyGrammar-Objekte unabhängig von der konkreten Eingabe sind, können sie nur die allgemeinen Präzedenzregeln enthalten.
60
• getReadings() gibt alle Lesarten zu einem bestimmten Chunk anhand
von a) bis c) zurück. Eventuelle Valenzalternation ist dabei bereits
berücksichtigt. Alternativ liefert die Methode die Lesarten für Sätze
mit der angegebenen Verbstellung.
• subsumptionTest()
prüft, ob ein Chunk auf eine Valenzstelle passt,
das heiÿt ob die Merkmalstruktur des Chunks von einer der möglichen
Merkmalstrukturen der Valenzstelle subsumierbar ist und gibt eine Liste der aufgetretenen Inkongruenz-Konikte zurück.
• subsumptionTest() versucht, eine gegebene topologische Struktur um
einen Chunk zu erweitern, indem versucht wird, den Chunk einem der
nach e) erlaubten Zielfelder zuzuordnen, wobei überprüft wird, ob dadurch Mutex-Verknüpfungen aktiv werden. Findet sich eine zulässige
Erweiterung, wird die erweiterte Topologie und das kumulierte Gewicht
aller verletzten hemmenden Mutex-Verknüpfungen zurückgegeben.
Valenzstellen sind Objekte der Klasse
Valency.
Sie übersetzen die im Sub-
kategorisierungslexikon angegebene Valenzstellenbeschreibung in eine Merkmalstruktur oder gegebenenfalls in eine Liste alternativer Merkmalstrukturen. In Objekten der Klasse
ValencySet
sind mehrere Valenzstellen zusam-
mengefasst, um die Menge aller oenen Valenzstellen aus einem Valenzrah-
Reading sind Lesarten konkreter WörValencySet-Objekt, das dem Valenzrahmen der Lesart
men darzustellen. Objekte der Klasse
ter. Sie enthalten ein
entspricht.
4.3 Implementierung des Topologiemodelles
In Abschnitt 3.1.2 wurde das Topologiemodell mengentheoretisch eingeführt.
Aus den Gleichungen 3 und 4 sowie 10 und 11 (S. 25f.) folgt für wohlgeformte
topologische Strukturen die Äquivalenz der Sichtweisen auf Felder als Mengen
und als Intervalle auf der Zeitachse. Bei der Implementierung sind die Fel-
Topology,
SentenceTopology repräsen-
der als Intervalle dargestellt. Felder sind Objekte der Basisklasse
Satzfelder werden durch die abgeleitete Klasse
tiert.
Die Felder einer topologischen Struktur sind hierarchisch verschachtelt:
Jedes
Topology-Objekt
besitzt eine Liste
fields
mit Pointern auf die Fel-
der der nächsten untergeordneten Ebene. Diese enthalten entsprechend einen
parent auf das übergeordnete Feld. Die (nur nach auÿen verschiebbaren) Grenzen des Feldes sind in den Variablen minPos und maxPos angegeben,
wobei diese den Wert −1 aufweisen, solange sie noch undeniert sind (das
Pointer
61
#
#
#
#
#
#
+
+
#
+
+
+
+ Topology
+ SentenceTopology
parent: Topology*
- verbOrder: int
fields: list<Topology*>
- vf_occupied: int
minPos: int
←− + SentenceTopology()
maxPos: int
+ getVerbOrder()
myChunkLeft: int
+ isVF_occupied()
myChunkRight: int
+ addChunk(): Topology*
Topology()
addChunk(): Topology*
expand(): bool
getFieldOfChunk(): Topology*
getUnderlyingSentence():
SentenceTopology*
print(): void
Abbildung 6: Implementierung topologischer Strukturen
heiÿt, solange das Feld leer ist). Die Grenzen des Chunks, der das Feld aufspannt, werden in
myChunkLeft
und
myChunkRight
gespeichert. Sie können
nach der Initialisierung durch den Konstruktor nicht mehr verändert werden.
Es gibt kein separates Objekt für topologische Strukturen. Eine solche
wird durch ein
SentenceTopology-Objekt repräsentiert, wodurch Gleichung
12 garantiert erfüllt ist.
Die Methode
getUnderlyingSentence()
liefert einen Pointer auf das
kleinste übergeordnete Satzfeld, also den Haupt- oder Nebensatz, dem das
Feld zuzuordnen ist. Umgekehrt liefert
getFieldOfChunk() das kleinste Feld,
in dem ein Chunk enthalten ist, also das von diesem aufgespannte Feld.
Die Topologieregeln nach Gleichung 17 (S. 26) werden aus einer Datei eingelesen. Dies geschieht jedoch in der Klasse
DependencyGrammar,
da
Topology-Objekte im Speicher nicht persistent sind.
Die Methode addChunk() implementiert den Versuch, sich selbst als Zielfeld einen neuen Chunk hinzuzufügen, und gibt im Erfolgsfall einen Pointer
auf ein neu erstelltes untergeordnetes Feld zurück. Dieses ist das vom neuen
Chunk aufgespannte Feld. Ein Misslingen der Erweiterung wird durch Rückgabe des Wertes
NULL signalisiert. In diesem Falle bleibt die alte topologische
Struktur bestehen. Dies ist der Fall, wenn
a) bereits ein untergeordnetes Feld existiert, das sich mit dem Chunk überschneidet oder
b) die relative Position des neuen Chunks zum Chunk des Feldes nicht den
in der Topologieregel spezizierten Angaben entspricht oder
62
c) der neue Chunk nicht innerhalb der Intervallgrenzen des Feldes liegt
und diese nicht entsprechend ausdehnbar sind. Der Versuch der Aus-
dehnung erfolgt über die Methode
expand() des übergeordneten Feldes.
10 auf den Parameter dir der gemäÿ der Topologie-
Durch einen Oset von
Regel die relative Position des neuen Chunk zu dem Chunk, der das Feld
aufspannt, angibt wird der Methode signalisiert, dass das neue Feld ein
64
Satzfeld sein soll
.
4.4 Implementierung des Präzedenzmodelles
Die Methode
addChunk
der Klasse
Topology
überprüft nicht die Einhal-
tung der Präzedenzregeln nach Gleichung 23 (S. 29). Diese werden von der
Klasse
DependencyGrammar
aus einer Datei eingelesen und verwaltet. An-
hand dieser kann dort zu einem konkreten Chartgraphen eine Reihe von
Mutex-Verknüpfungen zwischen Chunks erstellt werden. Dabei handelt es
sich um Objekte der Klasse
mit dem Gewicht
rightChunk
weight
Mutex,
die besagen, dass eine Präzedenzregel
verletzt ist, falls sich die Chunks
leftChunk und
MutexSet
im selben topologischen Feld benden. Die Klasse
speichert eine Menge von
Mutex-Objekten
und wird als Container für alle
Mutex-Verknüpfungen innerhalb des Chartgraphen verwendet. Die Methode
getMuticesOfChunk()
ermöglicht eine eziente Suche nach allen Mutex-
Verknüpfungen, an denen ein bestimmter Chunk beteiligt ist.
+
+
+
+ MutexSet
mutexList: list<list<Mutex*>*>
MutexSet()
addMutex(): void
getMuticesOfChunk(): list<Mutex*>*
+
+
+
+
+ Mutex
leftChunk: int
rightChunk: int
weight: int
Mutex()
Abbildung 7: Implementierung von Mutex-Verknüpfungen
4.5 Implementierung des Koniktmodelles
Conflict, zu der für
die einzelnen Konikttypen abgeleitete Klassen CongruencyConflict,
OpenValencyConflict und SpareChunkConflict existieren.
Die
Konikte
sind
Objekte
der
Basisklasse
64 Auf einen zusätzlichen Parameter wurde verzichtet, damit diese Option in den Topologieregeln mit angegeben werden kann.
63
5
Evaluation
5.1 Datengrundlage
Für die Evaluierung wurden insgesamt 248 Hypothesen zu 53 satzförmigen
Äuÿerungen verwendet. Zu jeder Äuÿerung sind neben der Transkription die
in der Regel fünf vom Spracherkenner bestbewerteten Satzhypothesen
enthalten. Die Daten stammen aus Aufnahmen gesprochener Spontansprache
bei der Kommunikation mit einem Fernseher, die im Rahmen des EMBASSIProjektes aufgezeichnet wurden.
5.2 Bewertung einzelner Hypothesen
46 der 53 Transkriptionen wurden vom Parser als fehlerfrei eingestuft, was
einer Treerrate von 87 Prozent entspricht. 169 der 212 falschen Hypothesen
wurden als falsch erkannt (80 Prozent). Letzteres relativiert sich, da bei 37
der 43 False Positives der Fehler rein semantisch und somit vom Parser nicht
zu erkennen war (vgl. S. 4, Einschränkung 1). Lässt man diese auÿer Acht,
ergibt sich eine Treerrate von 96,6 Prozent für ungrammatische Spracherkennerhypothesen.
5.3 Nachkontrolle von Spracherkennerinterpretationen
Der verwendete Spracherkenner erkannte 34 der Äuÿerungen korrekt, das
heiÿt, die am besten bewertete Hypothese entspricht in diesen Fällen der
Transkription. Dies entspricht einer Erkennungsrate von 64 Prozent. Lässt
man die jeweils bestbewertete Hypothese vom Parser überprüfen, gibt es nur
1 False Negative, das heiÿt, nur eine vom Spracherkenner korrekt getroene
Interpretation wurde fälschlicherweise revidiert. Von den 19 Fehlinterpretationen wurden 17 revidiert (2 False Positives). Die Korrektheit unter den
bestätigten Spracherkennervarianten liegt also bei 94 Prozent, ebenso hoch
ist der Prozentsatz der tatsächlich fehlerhaften unter den zurückgewiesenen
Varianten.
In fünf Fällen konnten Spracherkennerinterpretationen konstruktiv korrigiert werden, indem eine Alternativhypothese als fehlerfrei eingestuft wurde
(im Zweifelsfall die vom Spracherkenner zuvor besser bewertete). In nur zwei
Fällen erfolgte die Korrektur jedoch durch die Transkription, in den drei anderen wurde eine falsche Spracherkennervariante durch eine falsche Alternative ersetzt. Allerdings befand sich in 14 der 17 Fälle die tatsächliche Version
gar nicht unter den fünf besten Hypothesen. In 10 dieser Fälle hätte der Parser die Transkription akzeptiert. Wäre diese in der Spracherkennerausgabe
64
zu nden die Wahrscheinlichkeit dafür wäre höher, wenn 10 beste Hypothesen oder gar der ganze Worthypothesengraph übergeben würden , bestünde
also Potenzial für bis zu 10 weitere richtige, konstruktive Korrekturen.
5.4 Lokalisierung des Fehlers
Analysiert wurden 39 falsche Hypothesen (darunter 5 vom Dekoder bestbewertete), bei denen nur ein einziger Konikt aufgetreten war. In 33 Fällen (69
Prozent) ist die Koniktmenge eindeutig, das heiÿt, anhand des Koniktes
kommt nur eine mögliche Fehlerposition in Frage (eindirektionaler Konikt).
In gut der Hälfte dieser Fälle (19) stimmt diese mit der Position des tatsächlichen Fehlers überein; bei den 14 anderen Hypothesen bendet sich der
Fehler an einer anderen Stelle im Satz als der Konikt.
In den restlichen 6 Fällen ist das fehlerhafte Wort zwar in der Koniktmenge enthalten, die Fehlerposition ist jedoch nicht eindeutig ausndig zu
machen. Es handelt sich um bidirektionale Inkongruenz-Konikte, bei denen
unklar ist, ob sie auf das Regens, auf das Dependens oder auf beide zurückzuführen ist.
65
6
Ausblick
6.1 Zusammenfassung
Ausgehend vom Prinzip der Dependenzgrammatiken und von der Theorie
topologischer Felder wurde ein Sprach- und Topologiemodell entwickelt, das
die wesentlichen Grundzüge der deutschen Sprache wiedergibt. Komplexe
topologische Phänomene wie Scrambling, Partial Verb Fronting oder Modalverbregel wurden ebenso berücksichtigt wie Matrixsätze mit geschachtelten
Nebensätzen. Das Sprachmodell ist durch Modikation der Regeln leicht erweiterbar und anpassbar.
Es wurde ein Suchalgorithmus vorgestellt und implementiert, der ein fehlertolerantes Parsing ermöglicht. Durch den Rückgri auf Teilanalysen, die
von einem Chunk-Parser gefunden wurden, durch die Verwendung eines interaktiven Topologiemodelles, mit dessen Hilfe viele Alternativen bereits frühzeitig ausgeschlossen werden können, und durch die Anwendung von Heuristiken arbeitet der Parser trotz geforderter Fehlertoleranz sehr ezient.
Jedoch ist der resultierende Syntaxbaum für nachgeschaltete Zwecke des
Sprachverstehens unbrauchbar, da nur bedingt eine Auösung von Ambiguitäten stattndet, indem Präferenzregeln für die Satzgliedfolge in Feldern
herangezogen werden. Allerdings gibt es viele andere Arten von Ambiguitäten (siehe dazu [4]), deren Analyse in die Priorisierung der Suchknoten mit
einieÿen müssten.
Im Zuge der Evaluierung wurde deutlich, dass das Verfahren sehr gut
geeignet ist, fehlerhafte Spracherkenneranalysen zu identizieren. Eine konstruktive Korrektur ist bisher jedoch nur in wenigen Fällen möglich, insbesondere weil keine semantische Analyse möglich ist. Die Lokalisierung des
Fehlers ist in einigen Fällen möglich, kann aber noch nicht zuverlässig erfolgen. Ein Rückschluÿ auf die tatsächliche Äuÿerung scheint aus momentaner
Sicht utopisch, wenn nicht alle ihrer Wörter unter den Worthypothesen des
Spracherkenners zu nden sind.
Die Besonderheiten der gesprochenen Sprache konnten im Sprachmodell
bisher keine Berücksichtigung nden. Hierfür wäre eine ausführliche separate und systematisch auf verschiedenste Dialekte und Sprachstile eingehende
Untersuchung notwendig, um die Unterschiede zur Schriftsprache zu kategorisieren und zu formalisieren. Ein Teil dieser Phänomene kann durch lexikalische Zusatzinformation und dem Chart-Parser vorgeschaltete Transformationsregeln abgedeckt werden. Bei anderen stellt sich die grundsätzliche
Frage, ob es sich um Eigenschaften einer separaten Sprache handelt oder um
Ungrammatizitäten, die auf die Spontanität der gesprochenen Sprache und
ihre mangelnden Möglichkeiten zur Korrektur zurückzuführen ist.
66
Auf die Einbeziehung semantischer, kontextueller und prosodischer Information wurde im Rahmen dieser Arbeit bewusst verzichtet. Gleiches gilt
für Ellipsen, die mit der bisherigen Konzeption unvereinbar sind. Tiefes Parsing diskontinuierlicher Nominal- und Präpositionalphrasen, die vom ChunkParser nicht aufgefunden werden können, wurde vorerst ausgeschlossen, kann
jedoch leicht durch Hinzufügen neuer Regeln realisiert werden.
6.2 Perspektiven
In vielen Bereichen besteht enormes Potenzial für Erweiterungen, die die Leistungsfähigkeit des Systems steigern können. Insbesondere die Erkennungsrate und die Fähigkeit zur Lokalisierung von Spracherkennerfehlern scheinen
verbesserungsfähig zu sein.
Mit Hilfe von tiefem Parsing könnten Fehler innerhalb von Chunks lokalisiert werden. Akustische Verwechslungen betreen häug einzelne Wörter,
und der Chunk-Parser kann gröÿere Chunks nicht ausndig machen, wenn
diese durch das verwechselte Wort auseinandergerissen werden. Aus diesem
Grunde scheint eine künftige Erweiterung des Sprachmodells angebracht, weil
ein tiefes Parsing eine genauere Lokalisierung von Spracherkennerfehlern verspricht.
Durch die möglichen Erweiterungen des Sprachmodelles kann die Erkennungsrate insbesondere für grammatikalisch korrekte Sätze deutlich gesteigert werden. Gleichzeitig ist jedoch eine Einengung der Sprache erforderlich, um zu verhindern, dass eine Interpretation für oensichtlich unsinnige
Hypothesen gefunden wird. Die Einbeziehung einer semantischen Analyse,
die parallel zum Parsing erfolgen kann [4], ist für eine entscheidende Weiterentwicklung des Systems also unverzichtbar. Sie könnte die Anzahl der
jeweils möglichen Dependenten stark begrenzen, so dass der Suchraum deutlich verkleinert wird. Dies würde nicht nur zu einer besseren Identikation
ungrammatischer Sätze führen, sondern gleichzeitig auch die Ezienz des
Parsers erhöhen.
Der Nachteil semantischer Modelle liegt jedoch darin, dass sie stets nur
einen sehr begrenzten Ausschnitt der Welt abbilden können. Für einen stark
eingrenzbaren Anwendungsbereich wie der Bedienung eines Fernsehers stellt
diese Einschränkung kein groÿes Problem dar. Universell einsetzbare Geräte,
die die natürlichsprachlichen Eingaben auch wirklich zuverlässig verstehen,
bleiben jedoch nach wie vor ferne Zukunftsmusik.
67
Literatur
[1] Gerdes, K.; Kahane, S. (2001). Word Order in German: A Formal Dependency Grammar Using a Topological Hierarchy. Université Paris, Pa-
ris.
[2] Covington, M. A. (1990). A Dependency Parser for Variable-WordOrder Languages, University of Georgia.
[3] Tesnière, L. (1959). Eléments de syntaxe structurale. Klincksieck, Paris.
[4] Knorr, M. (2002). Repräsentation und Bewertung von Ambiguitäten in
und zwischen Chunks beim Parsen gesprochener Sprache. Diplomarbeit,
FAU Erlangen-Nürnberg.
[5] Johnson, M. (1988). Attribute-Value Logic and the Theory of Grammar.
CSLI Publications, Stanford.
[6] Schöning, U. (2001). Theoretische Informatik kurzgefasst. Spektrum
Verlag, Heidelberg/Berlin.
[7] Altmann, H.; Hofmann, U. (2004). Topologie fürs Examen. 1. Auage
März 2004. VS Verlag für Sozialwissenschaften, Wiesbaden.
[8] Donhauser, K.; Eichinger, L. M. (Hrsg.) (1998). Deutsche Grammatik
Thema in Variationen. Festschrift für Hans-Werner Eroms zum 60.
Geburtstag. C. Winter Universitätsverlag, Heidelberg.
[9] Russell, S. J.; Norvig, P. (1995). Articial intelligence. Prentice Hall,
Englewood Clis, NJ.
[10] Fitschen, A. (2004). Ein Computerlinguistisches Lexikon als komplexes
System. Universität Stuttgart.
[11] Staab,
S.
(1995).
GLR-Parsing
von
Worthypothesengraphen.
FAU
Erlangen-Nürnberg.
[12] Huang, X.; Acero, A.; Hon, H.-W. (2001). Spoken Language Processing A Guide to Theory, Algorithm, and System Development. Prentice Hall,
New Jersey.
68