Modul C2: Relationenbildung und Normalisierung
Werbung

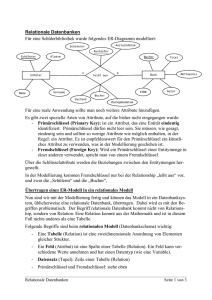
ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen C2: Relationenbildung und Normalisierung Lernziele: Nach der Bearbeitung dieser Lektion haben Sie folgende Kenntnisse erworben: Sie können • • • • • • den Anwendungsnutzen von Relationenmodellen wiedergeben. die ersten drei Normalformen wiedergeben und erläutern. Relationen in die 3. Normalform überführen. ERM-Modelle in Relationenmodelle transformieren. Inkonsistenzen (Anomalien) aufzählen und erläutern. Integritätsbedingungen nennen und erläutern. Keywords: Relation, Normalform, Anomalie, konzeptionelles Datenbankschema, Relationenmodell, ERM, Datensicht, DV-Konzept, Datenmodell. 2.1.1 Ziele und Vorgehensweisen Ein Hauptziel der Datenmodellierung ist die Implementierung einer Datenbank. Im Rahmen des DV-Konzepts werden semantische Datenmodelle des Fachkonzeptes in konzeptionelle bzw. logische Datenmodelle [53] umgesetzt. Das relationale Datenmodell stellt hierbei die Schnittstelle zu relationalen Datenbanken dar. Die Umsetzung eines ERM-Modells in ein Relationenmodell [10] erfolgt in drei Schritten: Im ersten Schritt werden die Informationsobjekte des Fachkonzepts zu Relationen, also Tabellen umgeformt. Im zweiten Schritt werden diese Relationen einem Optimierungsprozeß, der sogenannten Normalisierung, unterzogen. Hierdurch werden Anomalien bezüglich des Einfügens, Änderns oder Entfernens von Tupeln beseitigt, indem die übernommenen Rohrelationen des Fachkonzeptes weiter aufgespalten werden. Bei einer zu feinen Relationengliederung sind Performanceprobleme der zu entwickelnden Datenbank absehbar. In diesem Fall kann ein umgekehrter Prozeß, also eine Denormalisierung, durchgeführt werden [36]. Im dritten Schritt werden Integritätsbedingungen innerhalb und zwischen den Relationen definiert. Diese können einerseits aus den Kardinalitäten des Fachkonzepts übernommen und in die Schreibweise des Relationenmodells umgeformt oder aber aus der Sicht des DV-Konzepts neu hinzugefügt werden. Version vom 03.04.2002 Seite 1 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung 2.1.2 Begriffe und Definitionen Das Relationenmodell nach Codd beruht im Gegensatz zum ERM auf einer mathematisch mengentheoretischen Beschreibung oder einer tabellarischen Darstellungsform. Im folgenden wird jedoch von der rein mathematischen Beschreibung abgesehen. Die grundlegenden Definitionen des Relationenmodells sind [51]: • • • • • • • • • Relation, eine zweidimensionale Tabelle, die für einen Entitytyp steht. Tupel, das ein Entity, d.h. einen Datensatz bezeichnet (eine Zeile der Tabelle). Attribute, die die Spalten der Tabelle festlegen (und die Entities beschreiben). Grad der Relation, der durch die Anzahl der Attribute bestimmt wird. Domäne, die den Wertebereich eines Attributes vorgibt. Primärschlüssel (Primary-Key), der einen Datensatz (Tupel) eindeutig identifiziert. Ein Primärschlüssel kann sich aus mehreren Attributen zusammensetzen (Bsp.: Primärschlüssel der Beziehung "kaufen" (Artikel Kunde) : KNR und ANR). Fremdschlüssel, der in eine Relation als beschreibendes Attribut aufgenommen wird, jedoch Primärschlüssel einer anderen Relation ist. Datenbankschema, das sich aus der Gesamtmenge der Relationen und ihren Beziehungen zusammensetzt. Datenbank, in die die vollständig aus dem ERM transformierten Relationen als Tabellen implementiert werden. Als grundlegende Regel für Relationen gilt, dass die Zeilen der Tabelle, also die Datensätze, paarweise verschieden sein müssen. Die Reihenfolge der Spalten oder der Zeilen ist dagegen beliebig, kann ein Datensatz doch durch Primärschlüssel(kombination) eindeutig identifiziert werden. Version vom 03.04.2002 Seite 2 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung 2.2.1 Transformation von ER-Modellen Transformation ERM - 1. Schritt [18, 36] Das Relationenmodell nach Codd beruht im Gegensatz zum ERM auf einer mathematisch mengentheoretischen Beschreibung oder einer tabellarischen Darstellungsform. Im folgenden wird jedoch von der rein mathematischen Beschreibung abgesehen. Die grundlegenden Definitionen des Relationenmodells finden Sie in der Animation [51] Mit der Transformation werden konzeptionelle Datenmodelle des Fachkonzeptes in konzeptionelle Datenbankschemata überführt. Dies geschieht mit der Umsetzung eines ERM-Modells in ein Relationenmodell. Dazu werden die Entitytypen und Beziehungen nach einfachen Vorschriften in Relationen überführt: Animation: Das Relationenmodell Mit der Transformation werden konzeptionelle Datenmodelle des Fachkonzeptes in konzeptionelle Datenbankschemate überführt. Dies geschieht mit der Umsetzung eines ERM-Modells in ein Relationenmodell. Dazu werden die Entitytypen und Beziehungen nach einfachen Vorschriften in Relationen überführt: Die grundlegenden Definitionen des Relationenmodells sind: • Eine Relation ist eine zweidimensionale Tabelle, die für einen Entitytyp steht. Aus dem entitytyp Kunde wird die Relation Kunde. • Ein Tupel ist ein Datensatz, also eine Zeile der Tabelle durch den ein Entity beschreiben wird. • Attribute legen die Spalten der Tabelle fest und beschreiben die Entities . • Grad der Relation wird durch die Anzahl der Attribute bestimmt. • Die Domäne gibt den Wertebereich eines Attributes vor. • Der Primärschlüssel, auch (Primary-Key), identifiziert einen Datensatz (Tupel) eindeutig. Ein Primärschlüssel kann sich aus mehreren Attributen zusammensetzen. Z.B. Primärschlüssel der Beziehung „kaufen“ aus denen der Entities Artikel, Kunde : KNR und ANR. • Der Fremdschlüssel wird in eine Relation als beschreibendes Attribut aufgenommen, ist jedoch Primärschlüssel einer anderen Relation. • Als grundlegende Regel für Relationen gilt, daß die Zeilen der Tabelle, also die Datensätze, paarweise verschieden sein müssen. Die Reihenfolge der Spalten oder der Zeilen ist dagegen beliebig, kann ein Datensatz doch durch Primärschlüssel(kombination) eindeutig identifiziert werden. Alle Attribute der Objekte werden übernommen und bilden eine Spalte. In der Relation Kaufen ist der Primärschlüssel kombiniert aus den Schlüsselattributen Artikelnummer und Kundennummer. • ·Bei der Umsetzung von 1:n-Bezeihungstypen entsteht keine eigene Relation. Die Beziehung wird durch die Aufnahme eines Fremdschlüssels in die Relation mit der Kardinalitätsobergrenze 1 ausgedrückt. Das Fremschlüsselattribut ist immer in einer anderen Relation Promärschlüssel, hier in der Relation Eigentümer. • ·Im Falle einer 1:1-Beziehung entfällt der Beziehungstyp ganz. Die Attribute der beiden Entitytypen werden in einer Relation zusammengefasst. Aus den Version vom 03.04.2002 Seite 3 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung ursprünglichen Schlüsselattributen wird eines als Primärschlüssel für die Relation gewählt. • ·In mehrstelligen Beziehungen übernimmt die neue Relation alle Schlüssel der Entitytypen als Primärschlüssel. Voraussetzung ist allerdings, dass mindestens zwei Kardinalitäten mit der Obergrenze „n“ ausgestattet sind. • ·Für Generalisierungen/Spezialisierungen werden keine eigenen Relationen gebildet. In den bestehenden spezialisierten Relationen werden lediglich die Primärschlüssel der generalisierten Relationen vererbt und als Fremdschlüssel übernommen. • ·Bei rekursiven Beziehungen muß der Primärschlüssel aufgespalten werden. Durch die Umbenennung eines Schlüssels nach den Kantenrollenbezeichnungen kann die Trennung einfach vorgenommen werden. Mit diesen Transformationsschritten kann ein anfängliches Relationenschema erstellt werden, das jedoch weiter verfeinert werden muss. Mit diesen Transformationsschritten kann ein anfängliches Relationsschema erstellt werden, das jedoch weiter verfeinert werden muss. Version vom 03.04.2002 Seite 4 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung 2.2.2 Normalisierung von Relationen Ziel einer Datenbank ist die redundanzfreie Speicherung von Informationen innerhalb der Datenbanktabellen. Redundanzfrei bedeutet, daß gleiche Informationen (in Attributfeldern) nicht mehrfach gespeichert werden. Liegen in unterschiedlichen Tabellen die gleichen Informationen vor, so kann das Einfügen, Löschen oder Ändern von Daten zu Inkonsistenzen führen. Diese Effekte werden als Anomalien bezeichnet [36]. Die Normalisierung ist eine Vorgehensweise zur Verbesserung von Datenstrukturen. Ziel ist die optimale Zerlegung und Verteilung von Attributen auf Relationen, also die Entfernung von Redundanzen, ohne daß Informationsverluste entstehen [10]. So bildet die Normalisierung einerseits den zweiten Schritt der Umsetzung eines ERM in das Relationenmodell. Auf der anderen Seite können mit Normalisierungsprozessen unnormalisierte Tabellen, beispielsweise einer Datei oder Datenbank, gegliedert und optimiert werden. Insgesamt existieren 6 Normalformen (NF): 1.-3. NF, Boyce/ Codd NF, 4.-5. NF. Diese werden im Normalisierungsprozess sequentiell durchlaufen. Für viele Datenbankentwurfsverfahren stellt die dritte Normalform den optimalen Zerlegungszustand dar. Andere Verfahren werden wegen der Seltenheit ihres Auftretens nicht weiter betrachtet. Im folgenden wird die Vorgehensweise der Normalisierung anhand eines Beispiels durchlaufen. Ausgangspunkt der weiteren Betrachtung stellt die unnormalisierte Relation "Prüfungswesen" dar. Animation: Transformation ERM in ein Relationenmodell Der zweite Schritt der Transformation des ERM in ein Relationenmodell ist ein Optimierungsprozess, sie sog. Normalisierung. Damit wird einerseits eine Verbesserung der Datenstruktur innerhalb der Datenbanktabellen erreicht. Desweiteren werden Anomalien vermieden. Anomalien sind: Die Einfügeanomalie, die Anomalie beim Löschen und die Updateanomalie. • Die Einfüge-Anomalie entsteht, wenn z. B. ein neuer Student in die Datenbank aufgenommen werden soll, der noch keine Prüfung absolviert hat. Student Schulze kann nicht gespeichert werden. • Eine Anomalie beim Löschen tritt auf, wenn ein Prüfer, z. B. Prof. Müller, aus dem Prüfungsdienst ausscheidet und deshalb aus der Datentabelle gelöscht wird. Damit wird auch der Student Rosner gelöscht, obwohl dieser weiterhin studiert. • Eine Update-Anomalie besteht darin, daß z. B. bei der Änderung der Telefonnummer des Studenten Wagner alle Tupel der Relation Version vom 03.04.2002 Seite 5 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung R.PRÜFUNGSWESEN durchsucht werden, um zu gewährleisten, daß alle Daten auf den neuesten Stand gebracht werden. Eine Relation befindet sich in der ersten NF, wenn jeder Attributwert elementar ist, d. h. wenn alle zusammengehörenden Informationen in einzelne Tabellenfelder aufgeteilt wurden. Durch die logische Datenmodellierung, bspw. mit dem ERM, wird dieser Zustand einer Relation automatisch erreicht. Eine Relation befindet sich in der zweiten NF, wenn sie bereits in NF 1 ist und jedes Nichtschlüsselattribut von jedem Schlüsselattribut voll funktional abhängig ist. Die Datensätze einer Funktion müssen eindeutig unterschieden werden können. Daher müssen alle Schlüsselattribute, die in einer Relation vorhanden sind, identifiziert und mit den ihnen zugehörigen Daten in eine eigene Relation übertragen werden. Die Matrikelnummer jedes Studenten ist ein Schlüsselattribut, deswegen wird eine Relaltion Student gebildet. Die Relation Prüfer enthält die verbleibenden Dateninhalte der alten Relation Prüfungswesen. Gleichzeitig müssen die Beziehungen zwischen den getrennten Relationen und Attributen wiederhergestellt werden. Dies geschieht durch die Relation Prüfung. Auch die zweite Normalform wird von Relationen, die zuvor logische mit ERM modelliert wurden, häufig erreicht. Eine Relation befindet sich in der 3. Normalform, wenn sie in NF 2 ist und kein Nichtschlüsselattribut transitiv von einem Schlüsselattribut abhängig ist. Transitive Abhängigkeit bedeutet, daß aus einer Relation die Attribute ausgelagert werden müssen, die von einem Attribut abhängen, das vom Primärschlüssel bestimmt wird Zur Auflösung dieser Abhängigkeit eliminiert man die transitiv ab-hängigen Attribute (FAKNAME, DEKAN) in eine neue Relation und kopiert das zwischengeschaltete, bestimmte Attribut (FAKNR) in die-se Relation. In der Relation Student bleibt das Attribut FAKNR als Fremdschlüssel bestehen und verweist auf die Fakultät. Das Ziel, die redundanzfreie Zerlegung und Verteilung von Attributen auf Relationen, ohne daß Informationsverluste entstehen, ist hiermit also erreicht worden. Wenn sie die Gestaltungsoperatoren bei der Modellierung des ERMs betrachtet haben, sind die daraus abgeleiteten Relationen überwiegend in der dritten Normalenform. Die Relationen, die sich in der dritten Normalform befinden, bilden so den Ausgangspunkt für die Implementierung der Tabellen in ein Datenbanksystem. Version vom 03.04.2002 Seite 6 von 7 ARIS II - Modellierungsmethoden, Metamodelle und Anwendungen – Druckversion Lerneinheiten Modul C2: Relationenbildung und Normalisierung 2.2.3 Integritätsbedingungen Integritätsbedingungen [18] sorgen dafür, daß Datenbanken stets ein korrektes Abbild der Wirklichkeit darstellen. Die Integrität sichert also die Zulässigkeit bzw. Korrektheit der Datenbestände [6]. Da im Relationenmodell durch die Tabellendarstellung lediglich magere Möglichkeiten zur Definition semantischer Tatbestände bestehen, werden die Integritätsbedingungen in einer Datenmanipulationssprache definiert. Integritätsbedingungen können aber auch innerhalb eines Anwendungsprogrammes formuliert werden [36]. Animation: Transformation eines ERM in ein Relationenmodell Im dritten Schritt der Transformation des ERM in ein Relationenmodell werden Integritätsbedingungen innerhalb und zwischen den Relationen definiert. • Da im Relationenmodell durch die Tabellendarstellung lediglich magere Möglichkeiten zur Definition semantischer Tatbestände bestehen, werden die Integritätsbedingungen in einer Datenmanipulationssprache definiert. Integritätsbedingungen sorgen dafür, daß Datenbanken stets ein korrektes Abbild der Wirklichkeit darstellen. Die Integrität sichert also die Zulässigkeit bzw. Korrektheit der Datenbestände. Integritätsbedingungen werden nach ihrer Granularität klassifiziert, d. h. nach der Größe der betroffenen Dateneinheit (Attribut, Tupel, Relation, Datenbank). • Die Integrität eines individuellen Attributs kann durch die Angabe von Domänen (Wertebereichen) gewährleistet werden. Das Bankkonto eines Kunden kann nur bis zu seiner Kreditlinie belastet werden.Zwischen mehreren Attributen eines Tupels können Integritätsbedingungen definiert werden, so daß z. B. die Gehaltssumme einer Abteilung immer kleiner als ihr Jahresetat sein muß. • Für eine Relation kann z. B. gelten, daß ein bestimmtes Attribut immer im Format (TT.MM.JJ) angegeben werden muß. • Ein Beispiel für die relationsübergreifende Integritätsbedingungen ist die referentielle Integrität. Sie überwacht, daß in Relationen, die aus einem Beziehungstypen hervorgegangen sind, nur Tupel angelegt werden können, für die in allen beteiligten Relationen bereits ein Datensatz besteht. Bspw. wird so bereits auf fachlicher Ebene sichergestellt, daß nur diejenigen Kunden einen Artikel kaufen können, die bereits in der Datenbank verwaltet werden. Sobald ein ERM in Relationen der dritten Normalform überführt und die Integritätsbedingungen innerhalb und zwischen den Tabellen definiert wurden, können diese mit der Datenmanipulationssprache SQL in eine relationale Datenbank überführt werden. Version vom 03.04.2002 Seite 7 von 7