Java für Computerlinguisten - Institut für Maschinelle
Werbung

Java für Computerlinguisten
4. Computerlinguistische Anwendungen
Christian Scheible
Institut für Maschinelle Sprachverarbeitung
30. Juli 2009
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
1 / 40
Übersicht
1
Besprechung der Übungen vom Mittwoch
2
UIMA
3
OpenNLP
4
Lucene
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
2 / 40
UIMA
Unstructured Information Management Architecture [1]
• Unstrukturierte Information: Text
• Strukturierte Information: Annotierter Text
• Unstrukturierte Information → Strukturierte Information
UIMA-Homepage
http://incubator.apache.org/uima/
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
3 / 40
UIMA
Unstrukturierte Information → Strukturierte Information
Beispiel: Satzgrenzen
Es war spät abends, als K. ankam. Das Dorf lag in tiefem
Schnee. Vom Schloßberg war
nichts zu sehen.
→
<sentence>Es
war
spät
abends,
als
K.
ankam.</sentence>
</sentence>Das Dorf lag in
tiefem Schnee.</sentence>
<sentence>Vom
Schloßberg
war
nichts
zu
sehen.</sentence>
• Annotation von Beginn und Ende
• Annotation mit einem bestimmten Typ
• Mehrere Typen möglich
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
4 / 40
UIMA
Übersicht
• Pipeline-Architektur
→ Verkettung von Annotatoren
• Design patterns
→ Standardisierung
• Verschiedene Datenrepräsentationen
• Hauptspeicher
• Festplatte (XML)
• Abhängigkeit der Werkzeuge vom Kenntnisstand der Entwickler
Text
Christian Scheible
Tokenizer
Tagger
Java für Computerlinguisten
Parser
...
30. Juli 2009
5 / 40
UIMA
Demo
UIMA
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
6 / 40
UIMA + eclipse = ♥
Übersicht
• Am einfachsten: Programmieren mit eclipse-Plugins
Einstellungen
• Eclipse-Plugins installieren (an IMS-Rechnern schon erledigt)
• Classpath in Eclipse hinzufügen (einmal pro Workspace)
• jar-Dateien zum Build Path im Projekt hinzufügen (einmal pro
Projekt)
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
7 / 40
UIMA + eclipse = ♥
2
1
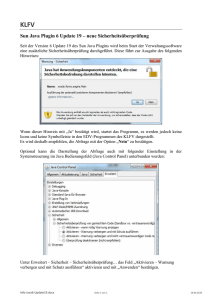
Window → Preferences → Java → Build Path →
Classpath Variables → New
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
8 / 40
UIMA + eclipse = ♥
Name:
Path:
UIMA_HOME
/usr/local/uima-home/lib
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
9 / 40
UIMA + eclipse = ♥
2
1
3
Project → Properties → Java Build Path → Libraries →
Add External JARs... → alle aus /usr/local/uima-home/lib
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
10 / 40
UIMA
Ablauf
1
Typen definieren
2
Java-Klassen der Typen generieren
3
Java-Code für den Annotator schreiben
4
Analysis Engine Descriptor generieren
5
Testen
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
11 / 40
UIMA
Types
• Klasse, die definiert, womit annotiert werden soll
• Beispiel: Token
• Beschreibung in xml-Format
→ Generierung in Eclipse
• Mehrere Typen möglich im Type System Descriptor
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
12 / 40
UIMA
Demo
Type System Descriptor
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
13 / 40
UIMA
Annotator
• Klasse, die definiert, wie annotiert werden soll
→ Muss von JCasAnnotator_ImplBase erben!
• Wichtige Methoden:
• initialize: Was muss am Anfang gemacht werden?
• process: Wie wird annotiert?
• Eingabe:
• Dokument/Annotation
• Annotation
• Daten sind in einem Objekt des Typs JCas (Common Analysis
Structure) verfügbar
Input
CAS
Christian Scheible
Annotator
Java für Computerlinguisten
Output
CAS
30. Juli 2009
14 / 40
UIMA
Tokens Annotieren
public class TokenAnnotator extends JCasAnnotator_ImplBase {
@Override
public void process(JCas cas) throws AnalysisEngineProcessException {
System.out.println(cas.getDocumentText());
String document = cas.getDocumentText();
String[] tokens = document.split(" ");
int start = 0;
int end = 0;
for (int i = 0; i < tokens.length; i++) {
Token t = new Token(cas); // neues Token
t.setBegin(start); // Anfang setzen
end = start + tokens[i].length();
t.setEnd(end); // Ende setzen
start = end + 1;
t.addToIndexes(); // Annotation speichern
}
}
}
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
15 / 40
UIMA
Dokument
Text
Tokens
Tokenizer
Tags
Tagger
...
Annotatoren müssen nicht unbedingt Text verarbeiten. Hier: Token
verarbeiten.
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
16 / 40
UIMA
Über Tokens iterieren
public class Tagger extends JCasAnnotator_ImplBase {
@Override
public void process(JCas cas) throws AnalysisEngineProcessException {
AnnotationIndex tokens = cas.getAnnotationIndex(Token.type);
FSIterator iter = tokens.iterator();
while (iter.hasNext()) {
Token token = (Token) iter.next();
String tokenText = token.getCoveredText();
// Mach was mit dem Token
}
}
}
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
17 / 40
UIMA
Demo
Annotatoren
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
18 / 40
UIMA
Analysis Engine
• Konstrukt, das die Annotatoren verwendet
• Primitive (ein Annotator)
• Aggregate (mehrere Analysis Engines)
Primitive Analysis Engine
Annotator
1
Christian Scheible
Aggregate Analysis Engine
AE 1
Java für Computerlinguisten
AE 2
AE 3
30. Juli 2009
19 / 40
UIMA
Demo
Analysis Engines
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
20 / 40
UIMA
Testen
• Document Analyzer
→ Eingabe-Dokumente (Verzeichnis)
→ Ausgabeverzeichnis
→ Analysis Engine
• Lässt sich in Eclipse auf Run legen
→ Eclipse fragt, Document Annotator aus der Liste auswählen
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
21 / 40
UIMA
Demo
Document Analyzer
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
22 / 40
Zusammenfassung: Ablauf in Eclipse
1
Projekt erstellen
2
Dem Projekt UIMA Nature hinzufügen
3
Im Projekt die jar-Dateien in den Eigenschaften setzen
4
Typsystem schreiben
5
Annotator implementieren
6
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
23 / 40
OpenNLP
Überblick
• Verschiedene Werkzeuge zur Sprachverarbeitung
• Oft statistisch, modellbasiert
• Mitgelieferte Modelle
• Modelle selbst trainieren
• Open Source [3]
• In UIMA integrierbar (Handarbeit!)
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
24 / 40
OpenNLP
Werkzeuge
• Wörterbücher
• n-Gramm-Verarbeitung
• PoS-Tagger
• Satzgrenzenerkenner
• Chunker
• Parser
• Klassifikator
• Koreferenz-Erkenner
• Named-Entity-Erkenner
opennlp.tools
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
25 / 40
OpenNLP
Sprachen
• Englisch
• Deutsch
• Spanisch
• Thai
opennlp.tools.lang
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
26 / 40
OpenNLP
Maximum-Entropy-Modelle
• opennlp.maxent
• Statistische Modelle für viele Anwendungen
→ Trainierte Modelle verfügbar
• Vorsicht: Modellversion muss zur OpenNLP-Version passen
Modelle:
• http://opennlp.sourceforge.net/models/
• /mount/studenten/java-kurs/models/
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
27 / 40
OpenNLP
Tokenizer
• WhitespaceTokenizer
• SimpleTokenizer: Benutzt Zeichenklassen
• TokenizerME: Maximum-Entropy-Modell
→ opennlp.tools.lang.german.Tokenizer
Tokenizer t = new Tokenizer("models/tokenModel.bin.gz");
String s = "Am 1.1.2009 hat K. ein Schloss gekauft. Er freut sich.";
String [] tokens = t.tokenize(s);
for (String token: tokens)
System.out.println(token);
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
28 / 40
OpenNLP
Satzgrenzenerkenner
• opennlp.tools.lang.german.SentenceDetector
SentenceDetector st =
new SentenceDetector("models/sentenceModel.bin.gz");
String s = "Am 1.1.2009 hat K. ein Schloss gekauft. Er freut sich.";
String [] sentences = st.sentDetect(s);
for (String sentence: sentences)
System.out.println(sentence + "\n");
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
29 / 40
OpenNLP
PoS-Tagger
• POSTaggerME
String s = "Am 1.1.2009 hat K. ein Schloss gekauft. Er freut sich.";
Tokenizer t = new Tokenizer("models/tokenModel.bin.gz");
String [] tokens = t.tokenize(s);
PosTagger p = new PosTagger("models/posModel.bin.gz", new Dictionary()
);
String[] tags = p.tag(tokens);
for (String tag: tags)
System.out.println(tag);
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
30 / 40
OpenNLP
Parser
• TreebankParser:
• Bottom-up-Parser
• Trainiert auf Baumbank
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
31 / 40
Lucene
Überblick
• Information-Retrieval-Bibliothek
→ Suchmaschine
• Verschiedene IR-Modelle
• Invertierter Index, Boolesche Suche
• Vektorraum-Modell
• Open Source von Apache [2]
Integration in UIMA
Lucas: Verarbeitet CAS
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
32 / 40
Lucene
Suche und Index
• In welchen Dokumenten steht ein bestimmtes Wort
• Wiederholtes durchsuchen von Dokumenten teuer
• Idee:
• Alle Dokumente vorher durchlaufen
• Für jedes Wort merken, in welchem Dokument sie vorkamen
→ Invertierter Index
• Index verarbeitet Queries
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
33 / 40
Lucene
Dokument
• Dokument besteht aus verschiedenen Feldern
→ Titel
→ Inhalt
→ ...
Query
• Suchanfrage
• Komplexe Anfragen mit AND, OR, NOT
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
34 / 40
Suchanfragen
Doc 1
Doc 2
Index
Doc 3
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
35 / 40
Lucene
Klassen
• Directory: Suchindex
• Document: Ein Textdokument
• IndexWriter: Schreibt in einen Index
• IndexSearcher: Durchsucht einen Index
• Query: Suchanfrage
• QueryParser: Erstellt Query aus String
• TopDocs: Gefundene Dokumente sortiert nach Score
• ScoreDoc: Gefundenes Dokument mit Score
Jar-Ressourcen
/mount/studenten/java-kurs/lib/lucene/
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
36 / 40
Lucene
StandardAnalyzer analyzer = new StandardAnalyzer(); // Tokenizer
Directory index = new RAMDirectory(); // Der Index
IndexWriter w = new IndexWriter(index, analyzer, true,
IndexWriter.MaxFieldLength.UNLIMITED);
Document doc1 = new Document(); // Erstes Dokument
String value1 = "Es war spaet abends, als K. ankam.";
// Feldname, Inhalt, soll gespeichert werden, soll tokenisiert werden
doc1.add(new Field("title", value1, Field.Store.YES, Field.Index.
ANALYZED));
w.addDocument(doc1);
Document doc2 = new Document(); // Zweites Dokument
String value2 = "Das Dorf lag abends in tiefem Schnee.";
doc2.add(new Field("title", value2, Field.Store.YES, Field.Index.
ANALYZED));
w.addDocument(doc2);
w.close();
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
37 / 40
Lucene
IndexSearcher searcher = new IndexSearcher(index);
TopDocCollector collector = new TopDocCollector(10); // 10 Ergebnisse
pro Seite
String querystr = "spt AND ankam";
Query q = new QueryParser("title", analyzer).parse(querystr);
searcher.search(q, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs;
for(int i=0;i<hits.length;++i)
{
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println((i + 1) + ". " + d.get("title"));
}
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
38 / 40
Mehr?
ClearTK
• Sehr umfangreiche Bibliothek für statistische NLP in UIMA
• Feature-Extraktion (z.B. Fenster, n-Gramme, ...)
• Machine Learning (Maxent, Mallet, SVMlight, ...)
• http://code.google.com/p/cleartk/
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
39 / 40
Literatur
Apache UIMA.
http://incubator.apache.org/uima/.
Lucene.
http://lucene.apache.org/java/docs/.
OpenNLP.
http://opennlp.sourceforge.net/.
Sun: JDK 6 Documentation.
http://java.sun.com/javase/6/docs/.
Sun: The Java Tutorials.
http://java.sun.com/docs/books/tutorial/.
C. Ullenboom.
Java ist auch eine Insel.
Galileo Press, 2003.
http://openbook.galileocomputing.de/javainsel8/.
Christian Scheible
Java für Computerlinguisten
30. Juli 2009
40 / 40