tabex/4 java table cache
Werbung

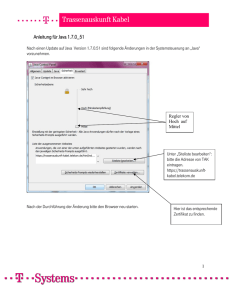
TABEX/4 Produktbeschreibung TABEX/4 JAVA TABLE CACHE TABEX/4 Ihre Anforderungen TABEX/4 ist die führende, plattformübergreifende Standardsoftware für Tabellenzugriff mit höchster Performance sowie sichere und komfortable Verwaltung und Pflege von Tabellen. Sie setzen TABEX/4 ein und schätzen seine hohe Zugriffsperformance, Zuverlässigkeit, Revisionssicherheit und die vielfältigen Möglichkeiten der Daten- und Zugriffsorganisation? TABEX/4 JAVA TABLE CACHE Sie wollen Ihre produktiven TABEX/4 Tabellendaten (Wertelisten) in einem Java Cache für den hoch performanten Zugriff aus dezentralen Java-Anwendungen bereitstellen? TABEX/4 JAVA TABLE CACHE, kurz JTC, ist ein Zusatzprodukt zu einer TABEX/4 Installation. JTC steht für die automatische Replikation von zentral verwalteten TABEX-Tabellen auf eine unbegrenzte Anzahl von dezentralen, in heterogenen IT-Umgebungen laufenden Server bzw. Clients (Windows, Linux, Unix, Mainframe) für den performanten Zugriff aus JavaAnwendungen. Die zentralen Daten können sowohl in TABEX/4 verwaltete, versionierte, temporale und nichttemporale TABEX-Tabellen sein (z.B. vom Mainframe und in LUW) als auch über TABEX angebundene Tabellendaten aus relationalen Datenbanken sein. Das Produkt JTC gibt es in zwei Versionen: Mit TABEX/4 JAVA TABLE CACHE SERVER EDITION, kurz JTC-SE, können Java Caches mit produkteigenen JTC-Methoden eingebunden und synchronisiert werden. Mit TABEX/4 JAVA TABLE CACHE ENTERPRISE EDITION, kurz JTC-EE, können Open Source Produkte und kommerzielle Enterprise Caching Lösungen - wie z.B. Caches von Hazelcast®, Terracotta® oder Infinispan® eingebunden werden und hierdurch die Synchronisation durchgeführt werden. Sie wollen hoch-performant auf Tabellendaten in relationalen Datenbanken (z.B. DB2® und Oracle® auf Mainframe / LUW) jederzeit aktuell in mehreren hundert Java Caches zugreifen? Sie wollen Ihre komplexe Datenorganisation (z.B. Test-, Integrations-, Produktions-Datenräume (ESA/SHS)) in einem Java Cache mit zentraler Konfiguration der Zugriffspfade für die Zugriffsprogramme umsetzen? Sie wollen - wie in TABEX/4 - eine revisionssichere Protokollierung aller im JTC angebotenen Datenstände? JTC erfüllt Ihre Anforderungen JTC nutzt das bekannte und über mehr als 30 Jahren bewährte TABEX-Zugriffskonzept und stellt die TABEX-Tabellenorganisation in dezentralen Java Table Caches zur Verfügung. Dabei werden ganze Tabellen für verschiedenste Arten des Zugriffs dezentral geladen. JTC stellt Ihre zentral gespeicherten Daten (Mainframe und Non-Mainframe) für Ihre Java Programme für den lesenden Zugriff zur Verfügung. © BOI Software Entwicklung und Vertrieb GmbH, Spazgasse 4, 4040 Linz,Austria. All rights reserved. Email: [email protected] , Web: www.boi.at, FN 81632y Landesgericht Linz¸ UID: ATU24421409 JTC ist für den performanten lesenden Java Zugriff optimiert und verfügt über Sicherheitsfeatures, wie z.B. die Zugriffssteuerung der Java-Programme auf die Java-Cache-Daten. JTC bietet die standardisierte Zugriffsschnittstelle für Ihr Gesamtunternehmen um aus Ihren Java Anwendungen auf Wertetabellen zuzugreifen. Neben TABEX können auch relationale Datenbanken auf Mainframe und Non-Mainframe an JTC angebunden werden. JTC bietet hierdurch die Möglichkeit, vorhandene Mainframe-Infrastruktur noch besser an Non-Mainframe-Infrastrukturen anzubinden und neue Java-Abläufe unter Ausnutzung der bestehenden Infrastruktur inklusive TABEX zu verwirklichen. Ihr Nutzen Freie Wahl der Größe und Komplexität der Tabellen: Einzigartig ist die Erweiterung des Zugriffs von Key/Value Paaren auf komplexe Tabellen. Freie Wahl bzgl. der Anzahl von dezentralen Servern. Freie Wahl ob die Datenreplikation mittels JTC-Methoden (Server Edition) oder mittels Enterprise Caching Produkte (Enterprise Edition) durchgeführt wird. Die Cache-Architektur ist optimiert für hohe Tabellen-Zugriffsperformance in den JavaAnwendungen – Tests ergaben, dass der Zugriff um bis zu 783x schneller ist als direkter Zugriff auf RDB via JDBC. Anbindung an relationale Datenbanken: Event- und zeitgesteuerte Aktualisierungen von Quell-Datenbanken wie z.B. DB2® oder Oracle® von Mainframe und LUW in dezentrale Java Caches. Revisionssicherheit: JTC protokolliert alle im Java Cache für den Zugriff angebotenen Daten. Einsatz von JTC Datenräumen: In diesen Datenräumen können Tabellen mit identen Namen und verschiedenen Inhalten angelegt werden. So ist die Umsetzung Ihrer komplexen Datenorganisation in einem Java Cache mit zentraler Konfiguration der Zugriffspfade auf Umgebungen wie z.B. Test, Integration und Produktions-Datenräume möglich. 24/7-Betrieb für Java-Anwendungen Kurze Replikationszyklen von der Datenquelle zum Java Cache Einfache Methodenzugriffe für die Anwendungsprogrammierung Autonomer Betrieb: Lauffähigkeit auch ohne bestehende Kommunikation zur Datenquelle durch offline-Daten in jedem Cache (z.B. bei Anwendung für Außendienst ohne Internetanbindung) Ausfallsicherheit: Bei Ausfall eines Replikationspfades stehen die replizierten Daten auf dem Client weiterhin zur Verfügung. Wenn der Replikationspfad wieder verfügbar ist, wird die Replikation fortgesetzt (kein Single Point Of Failure) Lastverteilung durch Aufteilung der Replikationspfade Einfache und zentrale Konfiguration der gesamten JTC Infrastruktur. „Installation“ (Deployment des boijtcReplikators) nur einmalig im replizierenden Application Server notwendig, da in verteilte Maps repliziert wird. Problemlose Erweiterbarkeit der Server während des laufenden Betriebs Geringer Wartungsaufwand: Nach erstellter Konfiguration ist Wartungsbedarf nur gegeben, wenn dezentrale Server hinzugefügt oder gelöscht werden, bzw. wenn sich Servername oder Port geändert haben. Funktionalität Der Inhalt des Java Table Cache wird automatisch von der Quelle (z.B. TABEX/4-Datenbanken, relationalen Datenbanken oder ESA/SHS Datenräume auf dem Mainframe/Non-Mainframe) repliziert, sodass der Zugriff auf die aktuellen Daten zu jedem Zeitpunkt gewährleistet ist. Die JTC-Replikation läuft unabhängig von der JavaAnwendung und beeinträchtigt daher nicht deren Laufzeit. Die JTC-Replikation läuft im Hintergrund. Die JavaAnwendung benötigt keine Informationen über die Quelle der Daten und den Replikationspfad. Die JTC-Replikation kann wahlweise in periodischen Abständen oder eventgesteuert durchgeführt werden. Die JTC-Replikation kann von der Quelle oder vom Ziel angestoßen werden (Push vs. Pull Verfahren). Die Replikationsinfrastruktur und die Replikationspfade sind zentral konfigurierbar. © BOI Software Entwicklung und Vertrieb GmbH, Spazgasse 4, 4040 Linz,Austria. All rights reserved. Email: [email protected] , Web: www.boi.at, FN 81632y Landesgericht Linz¸ UID: ATU24421409 Technische Details JTC besitzt eine mehrdimensionale Struktur, die weit über die Möglichkeiten bestehender eindimensionaler Schlüssel-Wert-Caches hinausgeht. JTC bietet die Möglichkeit, die Schlüssel-Wert-Paare in Tabellen zu organisieren. Dabei wird die bekannte Beschränkung auf zwei Spalten aufgehoben. Es können komplexe Tabellen eingesetzt werden, in denen die Schlüssel auch aus mehreren Spalten zusammengesetzt sind. Diese Tabellen können zusätzlich in ihrer zeitlichen Gültigkeit beschränkt werden. In diesem Fall existieren verschiedene Versionen ein und derselben Tabelle für verschiedene Gültigkeitszeiträume mit verschiedenen Daten im Java Cache, wobei über einfache Aufrufparameter automatisch auf die richtige Version der Tabelle hoch-performant zugegriffen werden kann. Neben der zeitlichen Dimension können die Daten auch noch in weiteren Ebenen organisiert werden. So können z.B. verschiedene Umgebungen, Instanzen oder frei wählbare Strukturen realisiert werden. JTC kann an ESA/SHS Datenräume angebunden werden. Mittels Konfiguration definieren Sie, welche TABEX-Tabellen und relationale Datenbanken in ESA/SHS Daten geladen werden und anschließend aus den ESA/SHS Datenräumen in welche JTC-Datenräume repliziert werden sollen. Vergleich von JTC-SE und JTC-EE Architektur von JTC-SE: Die Verteilung der Daten erfolgt in lokalen Caches. Abb. 1: Überblick JTC-SE © BOI Software Entwicklung und Vertrieb GmbH, Spazgasse 4, 4040 Linz,Austria. All rights reserved. Email: [email protected] , Web: www.boi.at, FN 81632y Landesgericht Linz¸ UID: ATU24421409 Architektur von JTC-EE: Der Zugriff auf der Daten erfolgt auf einen gemeinsamen verteilten Cache. Abb. 2: Überblick JTC-EE Die folgende Tabelle gibt einen Überblick über die funktionalen Unterschiede zwischen JTC-SE und JTC-EE. Nähere Informationen erhalten Sie unter [email protected] © BOI Software Entwicklung und Vertrieb GmbH, Spazgasse 4, 4040 Linz,Austria. All rights reserved. Email: [email protected] , Web: www.boi.at, FN 81632y Landesgericht Linz¸ UID: ATU24421409