Generieren von Assoziationsregeln - www2.inf.h
Werbung

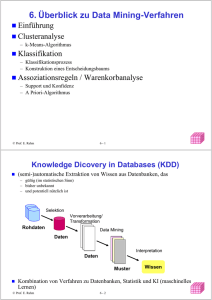
5. Generieren von Assoziationsregeln
Grundbegriffe
5. Assoziationsregeln
• Assoziationsregeln beschreiben gewisse Zusammenhänge und Regelmäßigkeiten zwischen verschiedenen Dingen, z.B. den Artikeln
eines Warenhauses.
• Die Zusammenhänge sind allgemeiner Art und nicht notwendigerweise kausal bedingt.
• Man unterstellt aber, daß implizite strukturelle Abhängigkeiten vorliegen. Diese möchte man erkennen.
• Typischer Anwendungsbereich: Verkaufsdatenanalyse
221
5. Generieren von Assoziationsregeln
Grundbegriffe
Itemmenge, Transaktion und Datenbasis
Definition 5.1. Die Dinge, deren Beziehungen zueinander analysiert
werden sollen, werden als Items bezeichnet. Es sei I = {i1, . . . , in} eine
endliche Menge von Items.
Eine Teilmenge X ⊆ I heißt Itemmenge. Eine k-Itemmenge ist eine
Itemmenge mit k Elementen.
Eine Transaktion t ⊆ I ist eine Itemmenge.
Die Datenbasis D = {d1, . . . , dm} ist eine Menge von Transaktionen.
222
5. Generieren von Assoziationsregeln
Grundbegriffe
Support
Definition 5.2. Es sei X ⊆ I eine Itemmenge. Der Support von X ist
der Anteil aller Transaktionen aus D, die X enthalten:
support(X) :=
|{t ∈ D | X ⊆ t}|
|D|
Beispiel 5.1. Bei der Verkaufsdatenanalyse eines Supermarktes sind
Items die Artikel aus dem Sortiment.
Die Transaktionen entsprechen den Einkäufen von Kunden.
Die Datenbasis besteht aus den Einkäufen der Kunden eines bestimmten Zeitraums.
Der Support der Itemmenge {Milch} ist dann der Anteil der Einkäufe,
bei denen u.a. Milch gekauft wurde.
223
5. Generieren von Assoziationsregeln
Grundbegriffe
Assoziationsregel
Definition 5.3. Gegeben seien zwei disjunkte Itemmengen X, Y, also
X, Y ⊆ I und X ∩ Y = ∅.
Eine Assoziationsregel hat die Form X → Y.
Eine Transaktion erfüllt die Regel X → Y gdw. X∪Y ⊆ t gilt, d.h. t enth ält
alle Items der Assoziationsregel.
Der Support von X → Y ist der Support der Itemmenge X ∪ Y
support(X → Y) := support(X ∪ Y)
224
5. Generieren von Assoziationsregeln
Grundbegriffe
Konfidenz
Definition 5.4. Gegeben sei die Assoziationsregel X → Y. Die Konfidenz von X → Y confidence(X → Y) ist definiert durch
confidence(X → Y) :=
=
|{t ∈ D|X ∪ Y ⊆ t}|
|{t ∈ D|X ⊆ t}
support(X → Y)
support(X)
Bemerkung 5.1. Die Konfidenz ist eine bedingte relative Häufigkeit
bzw. bedingte Wahrscheinlichkeit.
225
5. Generieren von Assoziationsregeln
Grundbegriffe
Beispiel 5.2.
Transaktion
1
2
3
4
5
6
Items
Brot, Kaffee, Milch, Kuchen
Kaffee, Milch, Kuchen
Brot, Butter, Kaffee, Milch
Milch, Kuchen
Brot, Kuchen
Brot
support({Kaffee, Milch}) = 0.5 = 50%
support({Kaffee, Kuchen, Milch}) = 0.33 = 33%
support({Milch, Kaffee} → {Kuchen}) = 0.33 = 33%
confidence({Milch, Kaffee} → {Kuchen}) = 0.67 = 67%
226
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Suche nach Assoziationsregeln
• Support und Konfidenz sind Parameter mit denen die Relevanz einer
Regel beurteilt wird.
• Beide Maßzahlen sollten möglichst groß sein.
• Finde alle Assoziationsregeln, die in der betrachteten Datenbasis
– einen Support ≥ minsupp und
– eine Konfidenz ≥ minconf haben.
Die Werte minsupp und minconf sind dabei benutzerdefiniert.
227
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Das Problem wird in zwei Teilprobleme zerlegt:
1. Finde alle Itemmengen, deren Support ≥ minsupp ist. Diese Itemmengen heißen häufige Itemmengen (frequent itemsets).
2. Finde in jeder häufigen Itemmenge I alle Assoziationsregeln
I0 → I \ I0
mit I 0 ⊂ I und mit Konfidenz ≥ minconf.
☞ Die wesentliche Schwierigkeit besteht in der Lösung des ersten Teilproblems.
☞ Enthält die Menge I insgesamt n Items, so sind prinzipiell 2n Itemmengen auf ihren Support hin zu untersuchen.
228
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Apriori-Algorithmus
Der sogenannte Apriori-Algorithmus nutzt folgendes bei der Suche nach
häufigen Itemmengen aus:
Für zwei Itemmengen I1, I2 mit I1 ⊆ I2 gilt
support(I2) ≤ support(I1)
Somit folgt:
• Alle Teilmengen einer häufigen Itemmenge sind ebenfalls häufige
Itemmengen.
• Alle Obermengen einer nicht häufigen Itemmenge sind ebenfalls
nicht häufig.
229
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Grober Ablauf des Apriori-Algorithmus:
• Der Apriori-Algorithmus bestimmt zunächst die einelementigen häufigen Itemmengen.
• In jedem weiteren Durchlauf werden die Obermengen mit k + 1 Elementen von häufigen k-Itemmengen darauf untersucht, ob sie ebenfalls häufig sind.
• Die Obermengen der häufigen k-Itemmengen werden mit dem Algorithmus AprioriGen ermittelt.
• Werden keine häufigen k + 1-Itemmengen mehr gefunden, bricht der
Algorithmus ab.
☞ Voraussetzung: Itemmengen sind lexikographisch geordnet.
230
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Algorithmus 5.1. [Apriori-Algorithmus]
L1 := { häufige 1-Itemmengen }
k := 2
while Lk−1 6= ∅ do
Ck := AprioriGen(Lk−1 )
for all Transaktionen t ∈ D do
Ct := {c ∈ Ck|c ⊆ t}
for all Kandidaten c ∈ Ct do
c.count := c.count + 1
end
end
Lk := {c ∈ Ck|c.count ≥ |D| · minsupp}
k := k + 1
end
return ∪kLk
231
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Algorithmus 5.2. [AprioriGen]
Ck := ∅
for all p, q ∈ Lk−1 mit p 6= q do
if |p ∩ q| = k − 2 and p = {e1, . . . , ek−2, ep} and q = {e1, . . . , ek−2 , eq} then
Ck := Ck ∪ {e1, . . . , ek−2, ep, eq}
end
for all c ∈ Ck do
for all (k − 1)-Teilmengen s von c do
if s ∈
/ Lk−1 then
Ck := Ck \ {c}
end
end
return Ck
232
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
Beispiel 5.3. minsupp = 40%
Transaktion
1
2
3
4
C1
Items
Itemm. Support
ACD
{A}
50%
−→ {B}
BCE
75%
ABCE
75%
{C}
BE
25%
{D}
75%
{E}
L1
Itemm. Support
{A}
50%
75%
{B}
75%
{C}
{E}
75%
233
5. Generieren von Assoziationsregeln
Apriori-Algorithmus
C2
C2
Itemm. Support
Itemm. Support
{A,B}
{A,B} 25%
{A,C}
{A,C} 50%
−→
{A,E} 25%
{A,E}
{B,C}
{B,C} 50%
{B,E}
{B,E} 75%
{C,E} 50%
{C,E}
L3
C3
C3
Itemm.
{B,C,E}
Itemm.
{A,C}
{B,C}
{B,E}
{C,E}
L2
Support
50%
50%
75%
50%
Support −→
Itemm.
{B,C,E}
Support
50%
Itemm.
{B,C,E}
Support
50%
234
5. Generieren von Assoziationsregeln
Datenstrukturen f ¨ur die Teilmengenoperation
Unterstützung der Teilmengenoperation
• Im Apriori- und im AprioriGen-Algorithmus werden sehr häufig Teilmengen überprüft.
• Um diese Tests effizient durchführen zu können, werden die Kandidatenmengen in einem Hash-Baum verwaltet.
• Struktur eines Hash-Baums:
– Innerer Knoten: Hashtabelle bezüglich Hashfunktion h; Buckets
der Hashtabelle verweisen auf die Sohnknoten.
– Blattknoten: enthält Liste von Itemmengen
235
5. Generieren von Assoziationsregeln
Datenstrukturen f ¨ur die Teilmengenoperation
• Suchen einer Itemmenge X = {i1, . . . , ik}:
– Innerer Knoten auf Ebene d: Anwendung der Hashfunktion h auf
id
– Das Ergebnis von h legt den Zweig fest, der weiter verfolgt wird.
– Blatt: Suche in der Liste der Itemmengen
• Einfügen einer Itemmenge X = {i1, . . . , ik}:
– Zunächst erfolgt eine Suche für X bis zu einem Blatt, in das die
Itemmenge eingefügt werden soll.
– Ist in dem Blatt Platz für eine weitere Itemmenge vorhanden, dann
wird X dort eingefügt.
– Kann das Blatt keine Itemmenge mehr aufnehmen, dann wird es
zu einem inneren Knoten und die Einträge werden gemäß h auf
neue Blätter verteilt.
236
5. Generieren von Assoziationsregeln
Datenstrukturen f ¨ur die Teilmengenoperation
Kapazität der Blätter = 3
0 1 2
{3,6,7}
{3,4,15}
0 1 2
h(K) = K mod 3
0 1 2
0 1 2
0 1 2
{3,5,7}
{7,9,12}
{1,4,11}
{7,8,9}
{2,3,8}
{3,5,11}
{1,6,11}
{1,7,9}
{1,8,11}
{5,6,7}
0 1 2
{2,5,6}
{2,5,7}
{5,8,11}
{3,7,11}
{2,4,6}
{2,4,7}
{3,4,11}
{3,4,8}
{2,7,9}
{5,7,10}
237
5. Generieren von Assoziationsregeln
Datenstrukturen f ¨ur die Teilmengenoperation
Suchen aller Itemmengen X, die von einer Transaktion t = {t1, . . . , tm}
erfüllt werden:
• Wurzel: Für jedes ti ∈ t wird h(ti) bestimmt und in den resultierenden Söhnen wird weitergesucht.
• Innerer Knoten: Hat man den Knoten durch h(ti) erreicht, dann wird
h(tj) für jedes tj mit j > i bestimmt.
Auf die so resultierenden Söhne wird das Verfahren in gleicher Weise
fortgesetzt, bis ein Blatt erreicht wird.
• Blatt: Prüfung, welche der in dem Blatt enthaltenen Itemmengen die
Transaktion t erfüllen.
238
5. Generieren von Assoziationsregeln
Datenstrukturen f ¨ur die Teilmengenoperation
t = {1, 3, 7, 9, 12}
0 1 2
{3,6,7}
{3,4,15}
0 1 2
h(K) = K mod 3
0 1 2
0 1 2
0 1 2
{3,5,7}
{7,9,12}
{1,4,11}
{7,8,9}
{2,3,8}
{3,5,11}
{1,6,11}
{1,7,9}
{1,8,11}
{5,6,7}
{3,7,11}
{3,4,11}
{3,4,8}
0 1 2
{2,5,6}
{2,5,7}
{5,8,11}
{2,4,6}
{2,4,7}
{2,7,9}
{5,7,10}
239
5. Generieren von Assoziationsregeln
Ermittlung der Assoziationsregeln
Bestimmung der Assoziationsregeln
Nach der Bestimmung der häufigen Itemmengen müssen noch die Assoziationsregeln mit einer Konfidenz ≥ minconf bestimmt werden. Diese werden aus den häufigen Itemmengen generiert.
Gegeben seien Itemmengen X, Y mit Y ⊂ X. Dann gilt:
confidence((X \ Y) → Y) ≥ minconf
=⇒ confidence((X \ Y 0) → Y 0) ≥ minconf für alle Y 0 ⊆ Y
Bei der Regelgenerierung nutzt man wiederum die Umkehrung aus.
Man beginnt mit einer möglichst kleinen Menge Y 0 und schließt alle
Obermengen von Y 0 aus, falls gilt:
confidence((X \ Y 0) → Y 0) < minconf
240
5. Generieren von Assoziationsregeln
Ermittlung der Assoziationsregeln
• Man erzeugt aus einer häufigen Itemmenge X zunächst alle Assoziationsregeln mit einelementiger Konklusion (rechter Seite).
• Alle Regeln mit Konfidenz ≥ minconf werden ausgegeben.
• Sei Hm die Menge der Konklusionen häufiger Itemmengen mit m Elementen. Wir setzen Hm+1 := AprioriGen(Hm).
• Für alle Konklusionen hm+1 ∈ Hm+1 überprüft man nun, ob
confidence((X \ hm+1 ) → hm+1 ) ≥ minconf
gilt. Falls ja, dann wird die Regel ausgegeben, ansonsten wird hm+1
aus Hm+1 entfernt.
241
5. Generieren von Assoziationsregeln
Ermittlung der Assoziationsregeln
Warenkorbanalyse
Beispiel 5.4. [Warenkorbanalyse]
ID
A
B
C
D
E
F
G
H
J
K
L
Artikel
Seife
Shampoo
Haarspülung
Duschgel
Zahnpasta
Zahnbürste
Haarfärbung
Haargel
Deodorant
Parfüm
Kosmetikartikel
t1
x
x
t2
t3
t4
x
x
x
x
x
x
x
x
x
x
x
x
x
t6
x
x
x
x
x
t7
x
x
x
t8
x
x
x
x
x
x
x
t5
x
t9
x
x
x
x
t10
x
x
x
x
x
x
x
x
x
x
x
x
support
0.4
0.8
0.6
0.6
0.4
0.2
0.3
0.1
0.6
0.2
0.5
242
5. Generieren von Assoziationsregeln
Ermittlung der Assoziationsregeln
Wir setzen: minsupp = 0.4, minconf = 0.7
L1 = {{A}, {B}, {C}, {D}, {E}, {J}, {L}}
C2 Tafel ✎.
L2 = {{B, C}, {B, D}, {B, J}, {B, L}, {C, J}, {C, L}}
C3 vor Teilmengencheck:
{{B, C, D}, {B, C, J}, {B, C, L}, {B, D, J}, {B, D, L}, {B, J, L}, {C, J, L}}
C3 nach Teilmengencheck: {{B, C, J}, {B, C, L}}
L3 = {{B, C, J}, {B, C, L}}
C4 = L 4 = ∅
243
5. Generieren von Assoziationsregeln
Ermittlung der Assoziationsregeln
Für die Generierung der Assoziationsregeln beginnen wir mit L2. Wir
erhalten: B → C, C → B, D → B, L → B, L → C
Aus {B, C, J} aus L3 ergeben sich die Regeln (Konfidenz in Klammern):
BC → J[0.67], BJ → C[1.00], CJ → B[1.00] und H1 = {{B}, {C}}
H2 = AprioriGen(H1) = {{B, C}}, aber J → BC[0.67] erfüllt nicht das
Konfidenzkriterium.
Aus {B, C, L} ergeben sich die Regeln:
BC → L[0.67], BL → C[0.8], CL → B[1.00]
Mit H2 = {{B, C}} ergibt sich L → BC[0.8]
244
5. Generieren von Assoziationsregeln
Regel
Shampoo
→
Haarspülung
→
Duschgel
→
Kosmetik
→
Kosmetik
→
Shampoo, Deodorant
→
Haarspülung, Deodorant →
Shampoo, Kosmetik
→
Haarspülung, Kosmetik
→
Kosmetik
→
Ermittlung der Assoziationsregeln
Haarspülung
Shampoo
Shampoo
Shampoo
Haarspülung
Haarspülung
Shampoo
Haarspülung
Shampoo
Shampoo, Haarspülung
Support
0.6
0.6
0.5
0.5
0.4
0.4
0.4
0.4
0.4
0.4
Konfidenz
0.75
1.00
0.83
1.00
0.80
1.00
1.00
0.80
1.00
0.80
245
5. Generieren von Assoziationsregeln
Zusammenfassung
Zusammenfassung
• Entscheidungsbäume
–
–
–
–
Aufbau einer Klassifikationshierarchie für eine Trainingsmenge
top-down, rekursives Verfahren
Wesentlich ist die Attributauswahl
ID3-Algorithmus: Attributauswahl auf Basis der Entropie
• Assoziationsregeln
–
–
–
–
Wesentlich: Berechnung häufiger Itemmengen
Apriori-Algorithmus zur Berechnung häufiger Itemmengen
Unterstützung des Apriori-Algorithmus durch Hash-Trees
Aus den häufigen Itemmengen werden unter Einsatz von AprioriGen die Assoziationsregeln generiert.
246