Deklarative Datenreinigung mit AJAX - VSIS
Werbung

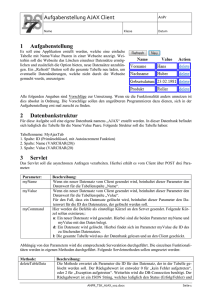
Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Verteilte Systeme und Informationssysteme Hausarbeit im Seminar: Informationsintegration Deklarative Datenreinigung mit AJAX Oliver Vietor [email protected] Studiengang Informatik Matr.-Nr. 6334524 Fachsemester 2 Betreuer: Dipl.-Inf. Fabian Panse Deklarative Datenreinigung mit AJAX III Inhaltsverzeichnis 1 Einleitung.................................................................................................................... 1 2 Datenreinigung ........................................................................................................... 2 3 4 5 2.1 Probleme ............................................................................................................. 2 2.2 Existierende Tools ............................................................................................... 3 2.3 Deklarative Datenreinigung ................................................................................ 4 AJAX ........................................................................................................................... 5 3.1 Benutzerinteraktion ............................................................................................. 5 3.2 Trennung von Logik und Implementation ........................................................... 5 Deklarative Sprache..................................................................................................... 7 4.1 Mapping.............................................................................................................. 7 4.2 View.................................................................................................................... 8 4.3 Matching ............................................................................................................. 9 4.4 Clustering...........................................................................................................10 4.5 Merging..............................................................................................................10 Fazit ...........................................................................................................................11 Literaturverzeichnis ..........................................................................................................12 Deklarative Datenreinigung mit AJAX 1 1 Einleitung Wenn versucht wird, unstrukturierte Daten aus mehreren verschiedenen Datenquellen zu einem einheitlichen Format zusammenzuführen, liegen diese einerseits meistens in vollkommen verschiedenen Formaten vor und andererseits stehen Teile dieser Daten miteinander im Widerspruch zueinander. Das Ziel von Datenreinigung ist es, Inkonsistenzen und Fehler in Datenbeständen zu finden und anschließend zu korrigieren bzw. zu beheben. Ein Tool, was die Reinigung von Daten ermöglicht, ist das von Galhardas et al. entwickelte AJAX. Es umfasst eine eigene Sprache, ein Ausführungsmodel sowie mehrere Algorithmen. Im Rahmen dieser Ausarbeitung wird AJAX allgemein vor gestellt und auf die dazugehörige Sprache eingegangen. Hauptquellen für diese Ausarbeitung sind das Paper „Declarative Data Cleaning: Language, Model, and Algorithms“ von Galhardas et al. [GFS+01] sowie die überarbeitete bzw. ergänzende Fassung aus dem Jahr 2006 von Galhardas [Gal06]. Leider ist die dazugehörige Projekthomepage [Gal+12] nur noch teilweise verfügbar. So zeigen die Verweise in der Kategorie ‚Tutorials‘ leider nicht mehr auf herunterladbare Beispiel-Daten sowie das Tool selber inklusive Konfigurations- und Gebrauchsanleitungen, sondern führen nur noch ins leere. 2 Oliver Vietor 2 Datenreinigung Der Kontext der Datenreinigung und im weiteren Verlauf das Konzept von AJAX wird anhand eines Beispiels vorgestellt. Das Ziel des Beispielszenarios ist es, aus verschiedenen Quellen einheitliche Literaturangaben zu generieren, die dann zum Beispiel für eine digitale Bücherei bzw. Suchmaschine wie CiteSeer [Cit15] verwendet werden können. Das Ziel ist es folgende zwei Quellenangaben, die aus zwei verschiedenen Werken stammen, zusammenzufügen. [QGMW96] Dallan Quass, Ashish Gupta, Inderphal Singh Mumick, and Jennifer Widom. Making Views Self-Maintainable for Data Warehousing. In Proceedings of the Conference on Parallel and Distributed Information Systems. Miami Beach, Florida, USA, 1996. Available via WWW at wwwdb.stanford.edu as pub/papers/selfmaint.ps. Quellenangabe aus Werk A [12] D. Quass, A. Gupta, I. Mumick, and J. Widom: Making views self -maintanable for data, PDIS'95 Quellenangabe aus Werk B Die beiden Quellenangaben verweisen beide auf dasselbe Paper, wobei sie sich jedoch in ihrem Umfang und ihrer Form grundlegend unterscheiden. 2.1 Probleme Während im Werk A als Verweis auf die Quelle innerhalb des Dokumentes die Bezeichnung QGMW96, also die Anfangsbuchstaben der j eweiligen Autoren zusammen mit der Jahreszahl verwendet wird, werden die Quellen im Werk B lediglich durchnummeriert. Eine eindeutige Bezeichnung – also eine allgemeingültige ID – gibt es also in beiden Fällen nicht. Wenn jedoch festgestellt wird, dass zwei Quellenangaben auf dasselbe Werk verweisen, ließe sich eine neue, global eindeutige ID automatisch generieren. Eine weitere Kategorie von Unterschieden sind Unterschiede formaler Art. Im Werk A werden die Autoren vollständig mit Vor- und Nachnamen genannt, wohingegen in Werk B jeweils nur der erste Buchstabe des Vornamen angegeben ist. Ebenso wird die Konferenz, auf der das Paper entstanden ist, verschieden referenziert. Während im Werk A der Name der Konferenz vollständig ausgeschrieben wird (Conference on Parallel and Distributed Information Systems), wird im Werk B lediglich das Akronym PDIS angegeben. Mögliche Datenreinigungsverfahren müssten also alle Darstellungsmöglichkeiten solcher Angaben nacheinander vergleichen, was sehr aufwendig ist. Deklarative Datenreinigung mit AJAX 3 Ein weiteres Problem ist die Inkonsistenz der Daten. So wird einerseits als Erscheinungsjahr 1996 und andererseits 1995 angegeben. Wenn nur ein Werk eine von allen anderen Werken verschiedene Angabe zu einer Quelle macht, könnte diese relativ leicht herausgefiltert werden. Wenn es aber nur die zwei Angaben gibt, muss das korrekte Ergebnis manuell ausgewählt werden. Ebenso können Daten fehlerhaft sein. Dies kommt zum Beispiel durch verdrehte oder fehlende Buchstaben, welche durch die automatische Texterkennung der PDF-Dateien zustande kommen können. So fehlt im Titel der Quellenangabe im Werk B […maintanable…] ein Buchstabe. Hierbei helfen Verfahren, die die Wörter aufgrund von Ähnlichkeiten vergleichen. Die letzte Problemquelle bei der Zusammenführung mehrere Quellenangaben sind der unterschiedliche Umfang der Informationen. So ist im Werk A eine Angabe zur Entstehungsort vorhanden, im Werk B allerdings nicht. Aufgrund der auf vielen verschieden Weisen darstellbaren Angaben, ist hier eine Zusammenführung aufwendig und schwierig. 2.2 Existierende Tools Bereits 2001, als das Paper von Galhardas et al. veröffentlicht wurde, gab es eine Vielzahl an Tools, die zur Datenreinigung eingesetzt wurden. Das Hauptziel solcher Tools ist es, Datenflussgraphen zu erstellen, die effektiv dirty data – also nicht-einheitliche Daten – bereinigen können und dabei ebenfalls effizient mit einer großen Anzahl von Eingabedaten umgehen können. Jedoch haben die existierenden Tools eine Reihe von problematischen Eigenschaften, die durch die Entwicklung von AJAX verbessert werden sollten. Zum einen soll in AJAX die sonst mangelhafte Trennung zwischen der logischen Spezifikationen der Daten Transformation und der dazugehörigen physikalischen Implementation verbessert werden. So würden zum Beispiel einige Tools für die Unifikation der Autorenangaben bereits feste Algorithmen und dadurch Implementationen einsetzten. Wenn diese Algorithmen jedoch aufwändig ausgetauscht werden, müssen meistens ebenfalls die logischen Spezifikationen mit geändert werden, welches durch die strikte Trennung der beiden Schichten verhindert werden soll. Zum anderen sollen die Interaktionsmöglichkeiten des Benutzers mit dem Tool verbessert werden. Die Interaktion mit bereits existierende Tools fand in der Regel nur über erstellte Logfiles statt. Bei den zwei verschiedenen Jahresangaben ist also nach der Ausführung des Tools eine manuelle Durchsicht der Logfiles nötig und daraufhin eine manuelle Anpassung der Daten. Ob nach dieser Änderung die Daten übereinstimmen und ob bei der manuellen Änderung keine weiteren Fehler hinzugekommen sind, ließe sich nur über eine erneute Ausführung des Tools herausfinden. Das zweite Hauptziel von AJAX ist diesen Interaktionsprozess zu verbessern. Im Kapitel 3 wird näher auf diese beiden Hauptaugenmerke eingegangen. 4 Oliver Vietor 2.3 Deklarative Datenreinigung Der Begriff der deklarativen Datenreinigung ist auf die in AJAX verwendete Sprache zurückzuführen. Einerseits gibt es imperative Programmiersprachen wie Java oder C++, bei denen die Programme aus Befehlen (lat. imperare = befehlen) bestehen. Im Gegen satz dazu gibt es deklarative Programmiersprachen wie z. B. SQL oder Prolog. Bei imperativen Sprachen liegt dabei das wie soll etwas durchgeführt werden im Vordergrund, während bei deklarativen Sprachen das was im Fokus ist bzw. welche Ergebnisse abgefragt werden sollen. [Mic15] Deklarative Datenreinigung mit AJAX 5 3 AJAX AJAX ist ein Tool zur Datenreinigung, welches im Jahr 2000 am Nationalen Forschungsinstitut für Informatik und Automatisierung in Frankreich entwickelt worden ist. Es ist in Java geschrieben und arbeitet auf Oracle Datenbanken. Verwenden lässt sich das Tool über die Entwicklungsumgebung Eclipse, wobei mittlerweile die entsprechenden Dateien nicht mehr auf der Projekthomepage verfügbar sind [Gal+12]. Die wesentlichen Neuerungen im Vergleich zu bereits bestehenden Tools werden in den folgenden Unterkapiteln erläutert. 3.1 Benutzerinteraktion Bei den bisherigen Datenreinigungstools wurde bei nicht automatisch behandelbaren Diskrepanzen zwischen den verschiedenen Eingabedaten lediglich ein Eintrag in einer Logdatei angelegt, die anschließend manuell durchgegangen werden musste und woraufhin die Daten schlussendlich noch manuell bearbeitet werden mussten. AJAX ergänzte die Logdateien durch interaktive Abfragen, bei denen der Benutzer auswählen kann, welche Daten korrekt welche fehlerhaft sind und somit korrigiert werden sollen. Außerdem ermöglichen Exceptions eine bessere Behandlung von Fehlerfällen. So würde ein leerer Autorenname oder ein Veröffentlichungsdatum, welches mehr als 200 Jahre zurückliegt, als fehlerhaft angegeben werden. Datenbereinigung mit AJAX lässt sich dadurch wesentlich bequemer betreiben und es werden eher manuelle Fehler behoben bzw. vermieden. 3.2 Trennung von Logik und Implementation Um die logischen Spezifikationen und die dazugehörigen physischen Implementierungen zu trennen, beinhaltet AJAX eine deklarative Sprache, auf die im Kapitel 4 genauer eingegangen wird. Der Beispielkontext ist weiterhin die Zusammenführung der verschiedenen Quellenangaben aus unterschiedlichen Werken. Ziel ist es, aus den ‚schmutzigen‘ Eingabedaten die Informationen zu den Autoren, der Events sowie die Publikationen herauszufiltern. Anhand der Nummerierungen (1-5) auf der logischen Schicht (Abbildung 1) werden im Folgenden die einzelnen Teilschritte des Datenreinigungsprozesses erläutert. Auf die physische Ebene, also auf die Implementierung der jeweiligen Funktionen, wird im Rahmen dieser Ausarbeitung nicht genauer eingegangen. 6 Oliver Vietor Abbildung 1 Übersicht AJAX Framework – [Gal06] Seite 334 Deklarative Datenreinigung mit AJAX 7 4 Deklarative Sprache Die in AJAX beschriebene Sprache baut auf der ebenfalls deklarativen Sprache SQL auf. Dabei werden SQL-Statements durch neue Schlüsselworte um weitere Funktionen ergänzt. Syntaktisch hat jeder Operator eine FROM Klausel, welche die Eingabedaten angibt, eine CREATE Klausel, welche neben der Bezeichnung des Operators den Namen für die Ausgabe angibt, eine SELECT Klausel, welche das Format der Ausgabedaten angibt sowie eine WHERE Klausel, mit der nicht relevante Tupel aus den Eingabedaten herau sgefiltert werden können. Durch die optionale LET Klausel kann die nötige Transformationslogik, die auf jedes Eingabetupel angewendet werden muss, um Ausgabetupel daraus zu erstellen, angegeben werden. Durch die LET Klausel können einerseits lokale Variablen deklariert werden und andererseits externe Funktionen aufgerufen werden. Zum Gruppieren der Ausgabetupel wird die BY METHOD Klausel verwendet. Abbildung 2 Eingabe- und Ausgabedaten des Datenreinigungsbeispiels – [Gal06] Seite 331 Der Ablauf von Eingabe- und Ausgabedaten des Datenreinigungsprozess ist in Abbildung 2 analog dargestellt. Die Code-Auszüge sind jeweils entweder aus [GFS+01] oder [Gal06], die Beschreibungen angelehnt an ebendiesen oder an [GFS+00]. 4.1 Mapping Der Mapping-Operator versucht, die Daten in ein standardisiertes Daten-Format zu bringen. So wird, wenn möglich, zum Beispiel das Datumsformat angeglichen [Gal+12] . Außerdem wird jedes Tupel der Relation DirtyData{paper} in ein Tupel der Relation KeyDirtyData{paperKey, paper} umgewandelt. Jedem Paper wird also ein generierter Schlüssel zugeordnet (Abbildung 1 Ziffer 1). Dies geschieht mit Hilfe der LET Klausel und dem Aufruf von generateKey. Durch das SELECT INTO Statement, wird der neu 8 Oliver Vietor generierte Schlüssel zusammen mit den Informationen des Papers in einer neuen Relation KeyDirtyData gespeichert. Durch die geschweiften Klammern um das SELECT INTO werden jeweils die einzelnen SELECT INTO Unterabfragen zur besseren Übersicht von einander getrennt. zu Abbildung 1 Ziffer 1: AJAX: CREATE MAP AddKeytoDirtyData FROM DirtyData LET Key = generateKey(DirtyData.paper) {SELECT Key.gernerateKey AS paperKey, DirtyData.paper AS paper INTO KeyDirtyData} Der aus dem AJAX Code erstellte, äquivalente SQL-Aufruf sieht wie folgt aus: SQL: CREATE TABLE KeyDirtyData(paperKey varchar2(100), paper varchar2(1024) NOT NULL); INSERT INTO KeyDirtyData SELECT dd.paper paper, generateKey(paper) paperKey FROM DirtyData dd Die AJAX und SQL Aufrufe sind sich hier relativ ähnlich. Neben der anderen Reihenfolge der Teilstatements unterscheidet sich der AJAX Code im Wesentlichen dadurch, dass Angaben zum Typ und zur Länge der Spalte weggelassen werden. Im nächsten Schritt (Abb. 1 Ziffer 2) wird die Relation KeyDirtyData durch weitere Mapping-Operationen weiter unterteilt: Aus jedem Eingabetupel werden die Namen der Autoren, die Titel der Publikationen, die Namen der Events sowie die Verbindung zwischen Titeln und Autoren hergestellt und in einzelne Tabellen gespeichert. Jedes der drei SELECT INTO Statements (DirtyTitles, DirtyEvents und DirtyAuthors), die hier im entsprechenden AJAX Code verwendet werden, wird hierbei durch die geschweiften Klammern voneinander getrennt. Im dritten Schritt (Abb. 1 Ziffer 3) werden alle Informationen wie Auflage, Nummer, Land, Stadt und Erscheinungsjahr extrahiert. Mithilfe von Wörterbüchern werden die Städtebzw. Ländernamen mit allen möglichen alternativen Sch reibweisen bzw. deren Synonyme aufgelistet, was eine Vereinheitlichung der Daten ermöglicht. 4.2 View Der View-Operator entspricht im Wesentlichen dem gleichnamigen SQL-Statement. In diesem Schritt (Abb. 1 Ziffer 4) werden die Ergebnisse aus den beiden Vorverarbeitungsschritten (Abb. 1 Ziffer 2 und 3) wieder zusammengeführt. Dabei werden mehrere Eingabetupel, die die Autornamen, die Titel und die Events beinhalten, zu einem Ausgabetupel zusammengefügt. Anders als bei dem aus SQL bekannten VIEW Statement Deklarative Datenreinigung mit AJAX 9 wird die Angabe, welche Spalten in die View übernommen werden sollen, nicht an zweiter Position des Statements gestellt (CREATE VIEW name SELECT culumn1, column2, …), sondern wird ähnlich bei dem Mapping Operator (Kapitel 4.1) an das Ende des Statements gestellt. Es ist dabei ebenso möglich, über die geschweiften Klamern mehrere SELECT INTO Statements zu verwernden. Ein weiterer Unterschied zum regulären SQL ViewOperators ist es, dass AJAX zusätzlich die Verwendung von Exceptions ermöglicht. zu Abb. 1 Ziffer 4: AJAX: CREATE VIEW viewPublications FROM DirtyPubs p, Titles t WHERE p.pubkey = t.pubKey {SELECT p.pubkey AS pubKey, t.title AS title, t.eventKey AS eventKey, p.volume AS volume, p.number AS number, p.country AS country, p.city AS city, p.pages AS pages, p.year AS year, p.url AS url INTO Publications } 4.3 Matching Der Matching-Operator erhält als Eingabe zweimal die Relation DirtyAuthors{authorKey, name}. Daraufhin wird versucht, paarweise doppelte Einträge, also Duplikate, in der Relation zu finden (Abb. 1 Ziffer 5). In der LET Klausel wird dafür die Edit-Distanz (auch Levenshtein-Distanz), also die minimalen Kosten, die zur Umformung von Autor1 in Autor2 entstehen, berechnet. Durch die WHERE Klausel werden diejenigen Tupel aussortiert, deren Edit-Distanz größer ist, als die Distanz der längsten 15% aller Autorennamen (vgl. [GFS+01] Abschnitt 3.3.). Durch das INTO Statement wird, ähnlich wie zuvor bei den SELECT INTO Statements, der Name der Ziel-Relation angegeben. zu Abb. 1 Ziffer 5: AJAX: CREATE MATCH MatchDirtyAuthors FROM DirtyAuthors a1, DirtyAuthors a2 LET distance = editDistanceAuthors(a1.name, a2.name) WHERE distance < maxDist(a1.name, a2.name, 15) INTO MatchAuthors 10 Oliver Vietor Der äquivaltente SQL-Aufruf sieht wie folgt aus: SQL: CREATE TABLE MatchAuthors(authorKey1 varchar2(100), authorKey2 varchar2(100), distance number); INSERT INTO MatchAuthors SELECT authorKey1, authorKey2, distance FROM (SELECT a1.authorKey authorKey1, a2.authorKey authorKey2, editDistanceAuthors(a1.name, a2.name) distance FROM DirtyAuthors a1, DirtyAuthors a2) WHERE distance < maxDist; 4.4 Clustering Der Cluster-Operator ist vergleichbar mit dem SQL GROUP BY, wobei der Unterschied dazu ist, dass der AJAX Cluster-Operator im Gegensatz zum GROUP BY auch beliebige Cluster-Algorithmen zulässt. Ziel dieses Schrittes ist es, durch das Bilden der transitiven Hülle, in den vorher nur paarweise verglichenen Autoren nun auch transitive Duplikate zu entfernen: Autor1 und Autor2 sowie Autor2 und Autor3 wurden im Matching-Schritt als Duplikate erkannt; im Clustering-Schritt werden nun auch Autor1 und Autor3 als zusammengehörige Duplikatenpaare erkannt. zu Abb. 1 Ziffer 5: AJAX: CREATE CLUSTER clusterAuthorsByTransitiveClosure FROM MatchAuthors BY METHOD transitive closure WITH PARAMETERS authorKey1, authorKey2 INTO clusterAuthors 4.5 Merging Der Merging-Operator hat kein direktes Pendant in SQL, ist allerdings mit AggregationsFunktionen vergleichen. Die gruppierten Datensätze, die durch den Cluster-Operator erstellt wurden, werden vom Merging-Operator jeweils zu einem Eintrag zusammengefasst. Als Autorenname wird dabei der längste der ggf. verschieden geschriebenen Autorennamen übernommen, da bei einigen Quellenangaben Teile der Autorennamen abgekürzt oder komplett weggelassen werden. Ebenso wird aus dem Autorennamen eine eindeutige ID generiert. zu Abb. 1 Ziffer 5: AJAX: CREATE MERGE MergeAuthors USING clusterAuthors(cluster_id) ca LET name = getLongestAuthorName(DirtyAuthors(ca).name) key = generateKey(name) {SELECT key AS authorKey, name AS name INTO Authors} Deklarative Datenreinigung mit AJAX 11 5 Fazit Es gibt zwar diverse Standards in diesem Beispiel zur Angabe von Quellen, allerdings werden diese nicht einheitlich angewendet. Fehlende oder fehlerhafte Felder führen dazu, dass Daten bereinigt werden müssen, wie in dem Beispiel der Zusammenführung von Quellenangaben. Effiziente und für den Benutzer bequem und zuverlässig zu benutzende Tools sind dabei unerlässlich. Die Neuerungen, die durch die Entwicklung von AJAX zu diesen Tools hinzugefügt wurden, zeigen aber auch, dass Datenreinigungs-Tools längst noch nicht vollständig und fehlerfrei sind. Auch, wenn AJAX selber mittlerweile nicht mehr weiter entwickelt wird – ist laut Projekthomepage [Gal+12] auch lediglich nur ein Prototyp —, beziehen sich heutzutage dennoch weiterhin viele Publikationen in diesem Bereich auf die Paper [GFS+01] und [Gal06]. Heutzutage gibt es neben der Zusammenführung von Quellenangaben sehr viele weitere Anwendungsgebiete für Datenreinigung. So müssen zum Beispiel Preisvergleichsportale – egal was dort nun verglichen werden soll – die Daten der einzelnen Bezugsquellen vor der Weiterverarbeitung bereinigen. 12 Oliver Vietor Literaturverzeichnis [Cit15] Pe nnsylvania State Unive rsity (2015): Cite SeerX. http://csxstatic.ist.psu.edu. [GFS+00] Galhardas, He le na; Florescu, Danie la; Shasha, De nnis; Simon, Eric: An e xte nsible Frame work for Data Cle aning. In: 16th Inte rnational Conference on Data Engine ering. San Die go, CA, USA, 29 Fe b.-3 March 2000, S. 312. [GFS+01] Galhardas, He le na; Florescu, Danie la; Shasha, De nnis; Simon, Eric; Saita, CristianAugustin (2001): De clarative Data Cle aning: Language, Mode l, and Algorithms. In: Proce edings of the 27th Inte rnational Confe rence on Ve ry Large Data Bases. [Gal06] Galhardas, He le na (2006): Data Cle aning and Transformation Using the AJAX Frame work. In: David Hutchison, Take o Kanade , Josef Kittle r, Jon M. Kle inbe rg, Frie de mann Mattern, John C. Mitche ll e t al. (Hg.): Ge ne rative and Transformational Te chnique s in Software Engine ering, Bd. 4143. Be rlin, He ide lbe rg: Springe r Be rlin He ide lbe rg (Le cture Note s in Compute r Science), S. 327–343. [Gal+12] Galhardas e t al. (2012*): AJAX. A Data Cle aning Prototype. Proje kthomepage. http://we b.ist.utl.pt/~he le na.galhardas/Ajax/index.html *le tzte Ände rung 2012 [Mic15] Microsoft (2015): Functional Programming vs. Imperative Programming. MSDN Library. https://msdn.microsoft.com/en-US/library/bb669144.aspx.