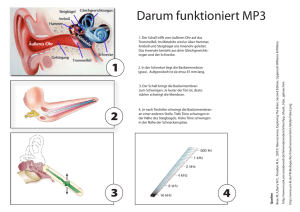
Audiokompression
Werbung

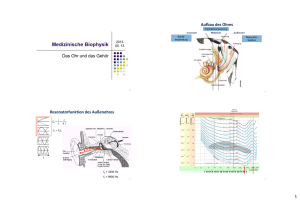
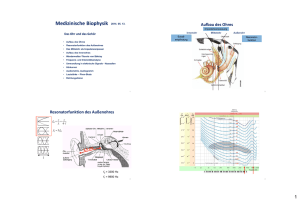
Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 1 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7. Audiodatenkompression Audiokompression verlustfrei maximal 1:4 da wenig Redundanz in Tönen verlustbehaftet Sprache gute Verständlichkeit geringstmögliche Datenrate Musik guter Klang Originalgetreue Vocoder ("ferngesteuerter Sprachsynthesizer") MP3 (weitestmögliche Überlistung des Gehörs) Auch Audiodaten können zunächst unter Eliminierung vorhandener informationstheoretischer Redundanz (verlustfrei) oder durch bloße Einschränkung der Tonqualität (verlustbehaftet) komprimiert werden. Die damit erzielbaren Kompressionsfaktoren sind jedoch relativ begrenzt. Höhere Kompressionsfaktoren lassen sich erzielen, wenn man im Hinblick auf die erwünschte Tonqualität auf Eigenschaften der menschlichen Tonsignalverarbeitungsfähigkeiten eingeht und daraufhin irrelevante Information eliminiert. Unterscheidung Sprache / Musik Bei Sprachübertragung ist das vorrangige Ziel die Verständlichkeit der zu übermittelnden Sprachlichen Information. Dies kann mit der geringsten Datenrate dann geschehen, wenn, die Sprache ganz ihrer physischen Erscheinungsform entkleidet wird und letztlich etwa nur eine Lautschrift übertragen wird, aus der auf der Empfangsseite eine synthetisch erzeugte Sprachausgabe erfolgt. Dies ist jedoch bei der telefonischen Kommunikation zwischen Menschen i.a. nicht ausreichend oder nicht befriedigend, da nichtverbale Zusatzinfomationen wie Geschlecht und Alter des Sprechers, Stimmungseindrücke im Tonfall, Bedeutungsunterschiede durch Betonung, etc. dabei wegfallen. Ziel der digitalen Sprachübertragung ist daher im Bereich der Telefonie bestmöglicher "Sprachklang" bei geringsmöglicher Datenrate. Bei Musik können die Anforderungen stark variieren, je nach Typ der Musik (U-Musik oder E-Musik) im allgemeinen wird das Ziel höchste Naturgetreue sein. Im Bereich Tonrundfunk können damit die Qualitätsanforderungen wechseln je nachdem ob es sich um Wortsendungen oder Musiksendungen handelt. Moderne Digitale Rundfunkverfah- Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 2 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 ren, die vor der Einführung stehen können z.T. mit variabler Datenrate und variabler Tonqualtät arbeiten. Bei Digitalen Audiodaten ist immer, um Verwirrungen zu vermeiden, zu unterscheiden zwischen Abtastrate, mit der das analoge Tonsignal abgetastet bzw. schließlich das digitale Signal dem DA-Wandler wieder zugeführt wird (das kann bei verlustbehafteter Kompression u.U. auch eine niedrigere Rate sein als beim Abtasten), und der Bitrate, die man benötigt, um das (komprimierte) Digitalsignal seriell zu übertragen. Beide Größen werden häufig (aber unkorrekterweise) mit der Maßeinheit Hz angegeben. Bei komplexeren Verfahren entspricht nicht mehr jeder analoge Abtastwert einem bestimmten Datenquantum, sondern es entsteht ein verschlüsselter Datenstrom, aus dem erst bei der Dekodierung wieder Abtastwerte zu bestimmten Zeitpunkten entstehen. Bei der Übertragung der digitalen Daten (z.B.) über das Internet ist noch zu berücksichtigen, daß die Daten nicht mit einer gleichmäßigen Datenrate, sondern Paketweise, und mit z.T. unterschiedlichen Laufzeiten ankommen können. verschiedene Audio-Codecs Unter Windows (95/98) werden die verschiedenen Codierungs- und Decodierungsverfahren (“Codecs”) vom Betriebssystem verwaltet, so dass sie den verschiedensten Applikationen zur Verfügung stehen. Unter [Einstellungen > Systemsteuerung > Multimedia > Geräte] ist eine Liste der installierten Audio-Codecs zu finden Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 3 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.1 Kompressionsmethoden ohne Ausnutzung von psychoakustischen Effekten G.711 PCM mit nichtlinearer Quantisierung ( µ-Law , A-Law) Eine Quantisierung von Tondaten im PCM-Code mit 8 Bit Auflösung wird i.a. als unbefriedigend empfunden, da diese Quantisierung bei nicht ausgeschöpfter Aussteuerung (d.h. wenn die Amplitude des Signals den zu Verfügung stehenden Dynamikbereich nicht ausfüllt, also zu leise ist) zu grob ist und im Vergleich zu leisen Signalen ein hörbares Quantisierungsrauschen mit sich bringt. Um z.B. ein Tonsignal mit der Frequenzbandbreite eines Telephonkanals zu digitalisieren, ist eine Abtastrate von 8kHz angebracht. Dies führt bei einer einer Quantisierung mit 14 Bit bereits zu einer Datenrate von 112 kBit/s. Ein digitaler Basiskanal (z.B. ISDN-Kanal) hat aber nur eine Kapazität von 64 kBit/s. Eine für diese Anwendung geeignete und übliche Form der Datenkompression benützt eine logarithmische Quantisierung, (in USA und Japan "µ-Law", in Europa eine leicht unterschiedliche Definition "A-Law"). Den kombinierten Vorgang von Kompression und Expansion bewerkstelligt eine Einrichtung die man "Compander" nennt. Die "µ-law compression" verzerrt das Signal nach folgender Formel: yx log1! x log1! Bei der Wiedergabe wird natürlich diese Verzerrung rückgängig gemacht. Die Größe des Quantisierungsrauschens ist jetzt proportional zur Laustärke und damit bei leisen Stellen gering, während es bei lauten Stellen groß ist. Nichtlineare Quantisierung nach -Law Die Datenkompression mittels nichtlinearer Quantisierungskennlinie bedeutet, daß noch jeder Abtastwert für sich behandelt wird. Jeder Wert wird also für sich hin und zurück umgerechnet. Dies kostet im Prinzip Rechenzeit, die jedoch bei heutigen Rechnern sehr gering ist im Vergleich zur Zeit zwischen zwei Abtastwerten. Bei allen weitergehenden Audiokompressionsverfahren werden dagegen Beziehungen zwischen mehreren aufeinanderfolgenden Abtastwerten ausgenutzt. Dies bedingt automatisch eine zusätzlich zur Rechenzeit auftretende Verzögerungszeit bei der Codierung und bei der Dekodierung zwischen jeweils dem Eingangsdatenstrom und dem Ausgangsdatenstrom. Diese Verzögerungszeiten können so lang werden, daß sie eine Begrenzung für die Verwendbarkeit eines Verfahrens werden können (z.B. bei 2-Weg Übertragungen, Gegensprechen) Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 4 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 DPCM Als effizienteres Codierungsverfahren mit sehr geringem Rechenaufwand bei der Codierung und Decodierung kann DPCM (Differential Pulse Code Modulation) verwendet werden. Dies beruht auf der Tatsache, daß die Änderung der Amplitude von Abtastwert zu Abtastwert i.a. viel kleiner ist als die Amplitude selbst, so daß der Wertebereich zur Quantifizierung der Änderung geringer sein kann als der zur Quantisierung der absoluten Größe und daher mit weniger Bits quantisiert werden kann. Wenn allerdings beliebig große Stufen im Signal vorkommen können und verfälschungsfrei wiedergegeben werden müssen, so kann die Differenzinformation von Abtastwert zu Abtastwert den gleichen Werteumfang annehmen wie das Signal selbst, und zumindest kann bei fester Codelänge dann keine Datenkompression erreicht werden. Allerdings ist die Wahrscheinlichkeit für hohe Werte bei der Differenzcodie-rung wesentlich geringer als bei PCM die Wahrscheinlichkeit gleich hoher Absolutwerte. Mit variabler Codelänge kann eine verlustlose Codierung bei gleichzeitig merklicher Kompression erreicht werden. Bei einer festen Abtastrate kann man jedoch variable Codelängen nur mit einen "elastischen" Zwischenspeicher mit Vorteil verarbeiten, da ja die Aufnahme und Wiedergabe von einer konstanten Datenrate ausgehen. Die andere Möglichkeit ist, bei der DPCM große Sprünge der Werte nur fehlerhaft, also verlustbehaftet zu codieren, da diese Fälle seltener vorkommen und der Verlust nicht sehr ins Gewicht fällt. Insofern ist die DPCM schon nicht mehr unter die verlustlosen Kompressionsverfahren zu rechnen, wenn man es genau nimmt. Ein weiteres Problem bei einer differentiellen Codierung ist, daß sich Fehler fortpflanzen können. ADPCM Eine verbesserung der DPCM erreicht man, indem ein variabler, laufend angepaßter Skalierungsfaktor verwendet wird, der die mit wenigen Bits codierten Differenzwerte jeweils skaliert. Dies nennt man eine Adaptive DPCM (ADPCM). . Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 5 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.2 Audiokompression unter Berücksichtigung von Psychoakustik Audiokompressionsverfahren, die nur versuchen, die Redundanz der Schalldaten an sich zu eliminieren können nicht sehr effizient sein, denn es ist schwer, nach rein informationstheoretischen Gesichtspunkten die Redundanz von Schalldaten zu ermitteln, da keine Statistik von Schalldaten vorgegeben ist, die als Maßstab dafür verwendet werden kann, wie groß der Informationsgehalt eines Bytes oder Wortes aus einem Schall-Datensatz ist. Der mehr versprechendere Weg besteht hier darin, Informationsdetails, die das menschliche Gehör gar nicht wahrnehemen kann, vorzugsweise zu eliminieren. Die Datenrate, die über den Hörnerv an das Gehirn läuft ist schließlich auch sehr viel geringer, als die Datenrate, die man aus der Bandbreite des Hörspektrums gemäß dem Abtasttheorem und einem realistischen Dynamikbereich des Gehörs zwischen leisesten und lautesten Tönen errechnen kann. 7.2.1 Einige physiologische und psychoakustische Gegebenheiten als Voraussetzungen für effiziente Audiokompression Aufbau des Ohrs: Außenohr Mittelohr Innenohr Gehörknöchelchen Gehörschnecke (ausgerollt gezeichnet) Trommelfell Basilarmembran Verbindung zum Rachenraum Aus dem Aufbau und der Funktionsweise des Ohres werden einige psychoakustische Fakten verständlich: Das Ohr besteht aus dem Außenohr mit der Ohrmuschel und dem Gehörgang, der den Luftschall bis zum Trommelfell leitet, einer Membran, die den Außenraum abschließt. Im ebenfalls luftgefüllten Mittelohr wird der Schall jedoch nicht durch die Luft, sondern als Körperschall mechanisch durch die Gehörknöchelchen vom Trommelfell auf das Innenohr übertragen. Das Innenohr ist eine flüssigkeitsgefüllte schneckenförmig aufgerollte Röhre, die der Länge nach durch die Basilarmembran in zwei Kammern geteilt ist. Durch die Gehörknöchelchen wird durch eine feine Membran der Schall in die Flüssigkeit in einen Kammer der Gehörschnecke eingekoppelt und damit wird die Basilarmembran zu Schwingungen angeregt. Die Basilarmembran enthält das eigentliche Sinnesorgan, das die Signale über den Hörnerv an das Gehirn sendet. Auf der Basilarmembran sitzen feine "Haarzellen", die bei Schwingun- Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 6 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 gen der Basilarmembran in Bewegung gesetzt werden, wodurch elektrische Impulse in entsprechenden Nervenzellen, die mit dem Hörnerv verbunden sind, entstehen. Die Basilar-membran wird durch den Schall in der Flüssigkeit in solcher Weise zu Schwingungen angeregt, daß die maximale Anregungsamplitude je nach Frequenz an verschiedenen Orten der Basilarmembran auftritt. Beschränkte Unterscheidungsfähigkeit verschiedener gleichzeitig erklingender Töne Der Bereich, der bei Erklingen eines Tones angeregt wird, ist bei verschiedenen Tonhöhen verschieden ausgedehnt. Wenn zwei benachbarte Töne gleichzeitig erklingen so können diese nur dann als zwei Töne wahrgenommen werden wenn sie einen gewissen Abstand in der Frequenz haben. Wenn sie näher beieinander liegen, dann werden Sie wie ein einziger Ton mit gewisser Rauhigkeit, oder auch periodisch moduliert wahrgenommen. Kritisches Band Frequenz der Tonempfindung glatt Schwebung glatt 10 Hz rauh rauh 0 Frequenzdifferenz Kritische Bänder Aufgrund der begrenzten Frequenzauflösungsfähigkeit (für gleichzeitig erklingende Töne) läßt der hörbare Frequenzbereich in so genannte “kritische Bänder” einteilen. Dies ist auf das begrenzte räumliche Auflösungsvermögen der Basilarmembran zurückzuführen. Die kritischen Bänder haben etwa eine Breite von 100 Hz im Frequenzbereich unter 500 Hz und nehmen mit der Frequenz in der Breite zu. Der gesamte Bereich hörbarer Frequenzen kann so in etwa 26 kritische Bänder eingeteilt werden. Der Frequenzbereich des Telefons, (300 bis 3400 Hz) in etwa 15 kritische Bänder (daraus ist schon ersichtlich, daß die höheren Frequenzen der gesamten Hörfrequenzbereichs psychoakustisch relativ unbedeutend sind). f kritische Bänder Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 7 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 Frequenzmäßige und zeitliche Maskierungseffekte Frequenzmäßige Verdeckung Ein Effekt, der mit der räumlichen Anregung der Basilarmembran zusammenhängt, ist der Frequenz-Maskierungseffekt. Laute Töne machen die gleichzeitige Wahrnehmung leiser Töne in einer gewissen Frequenzumgebung unmöglich. Im nachfolgenden Diagramm ist angedeutet wie durch einen Ton die Hörschwelle in seiner Umgebung für weitere, leisere Töne (= Mithörschwelle) angehoben wird, d.h. die Empfindlichkeit verringert wird. 80 dB 40 maskierender Ton maskierter Ton durch M askierung angehobene H örschw elle 0 0,02 0,1 0,2 0,5 1 2 5 10 20 kH z Nutzanwendung der frequenzmäßigen Verdeckung: Da der Abstand zwischen der Hörschwelle und der oberen Lautstärkegrenze (Dynamikbereich) dafür maßgeblich ist, wie fein ein Ton quantisiert werden muß, d.h. wieviele Bits pro Abtastwert verwendet werden müssen um alle möglichen Lautstärken zwischen der leisesten hörbaren und der lautesten darzustellen folgt: Bei einer anhebung der Hörschwelle (in einem gewissen Frequenzbereich) brauchen für Töne in diesem Bereich weniger Bits pro Abtastwert verwendet werden, damit der aktuelle (verringerte Dynamikbereich) richtig übertragen werden kann. Zeitliche Maskierung Dabei gibt es zusätzlich zu dieser Frequenzmaskierung eine zeitliche Maskierung: D.h. kurze Zeit sowohl vor als auch nach einem lauten Schallereignis ist der betreffende Eingangskanal unempfindlicher als nach einer Periode der Stille. Die Tatsache, daß vor einem lauten Ton ein leiserer weniger wahrgenommen wird spricht dafür, daß die Speicherung von zeitlich aufeinanderfolgenden Reizen beeinflußt wird. Auch die zeitliche Maskierung kann ausgenutzt werden indem kurz vor oder nach lauten Stellen der Klang, dort wo die Hörschwelle durch die Maskierung angehoben ist, mit gröberer Quantisierung und damit Bit-sparend codiert wird. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 8 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.2.2 Prinzip der Nutzung der begrenzten Frequenzauflösung des Ohres und des Maskierungseffektes zur Audiodatenreduktion Grundsätzlich kann man versuchen, die ans Ohr anzuliefernde Informationsmenge auf das zu reduzieren, was vom Gehör auch psychoakustisch nur tatsächlich aufgenommen werden kann. Das Audiosignal kann dann nach der Decodierung des Signals beträchtlich vom Originalsignal abweichen, und trotzdem u.U. selbst für einen äußerst kritischen Höhrer in der Qualität nicht vom unreduzierten Originalsignal unterscheidbar sein, also nach wie vor z.B. "CD-Qualität" Subbandcodierung Die begrenzte Frequenzauflösung des Gehörs kann man sich durch eine sogennante Subbandcodierung zunutze machen. Weil der Gehörvorgang im Ohr physisch tatsächlich über eine Frequenzanalyse führt, nämlich die räumlich je nach Frequenz verschieden angeregte Basilarmembran, ist es ein erfolgreich zu nutzender Weg, wenn man das zu codierende zeitliche Tonsignal in den Frequenzbereich transformiert und dort Information eliminiert, die bei der Signalverarbeitung durch das Gehör (Ohr + Hörnerv + Gehirn) ohnehin vorloren geht. Durch eine diskrete Fouriertransformation (z.B. FFT), kann man ein endliches zeitliches Intervall T eines zeitlichen Signalverlaufs, der durch m Abtastwerte repäsentiert ist, in sein Spektrum umrechnen, das durch eine gleich große Anzahl von m Frequenzamplituden dargestellt wird. m Abtastwerte Zeit Filterbank D CT wenige Subbandsignale m Spektralkomponenten Frequenz Die zeitliche Abfolge der einzelnen Spektralwerte ist so, dass nur alle m Abtastintervalle im ursprünlgichen Signal ein neuer Spektralwert anfällt. Wenn nun aber das Ohr gar nicht in der Lage ist, soviele diskrete Frequenzen gleichzeitig wahrzunehmen, wie eine Fouriertransformation ergibt, sondern nur 26 Frequenz-Subband-Signalamplituden, dann ist es naheliegend, die vielen, eigentlich aufgelösten Frequenzkanäle in nur wenigen, (z.B. 2 5 =32) Subbandsignalen durch Mittelwertbildungen nur summarisch zu repräsentieren. Dies geschieht mit Hilfe einer Filterbank, die aus den 32 Teilspektren nur je eine mittlere Amplitude bilden, die z.B. der Energie in dem jeweiligen Subband entspricht. Bei diesem Vorgang der Mittelwertbildung geht also eine Menge Information verloren, welche aber vom Ohr ohnehin nicht wahrgenommen werden kann. Die "Filterbank" besteht natürlich nicht aus physischen Frequenzfiltern, sondern wird durch digitale Rechenalgorithmen realisiert; ebenso die Mittelwertbildung über die Subbänder. Durch die Reduzierung der Frequenzauflösung ist also die Menge der Daten, die pro Zeiteinheit übertragen oder abgespeichert werden müssen schon wesentlich reduziert. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 9 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 Adaptive Quantisierung unter Berücksichtigung des Maskierungseffektes Nach Reduzierung des Spektrums mit hoher Auflösung in eine Repräsentation mit wenigen Subbändern kann noch die Quantisierungstiefe in jedem der Spektralen Subbänder minimiert werden indem berücksichtigt wird, wo gerade im jeweiligen Subband aufgrund der Lautstärke in den benachbarten Bändern die Mithörschwelle liegt. Durch den Frequenz-Maskierungseffekt wird ja die spektrale Empfindlichkeit des Ohres jeweils in der Nachbarschaft von lauten Bereichen verringert. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 10 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.3 Verfahren mit Nutzung von psychoakustischem Modell (wahrnehmungsbasierte Audiokompression) Die folgenden Tonkompressionsverfahren benützen die Möglichkeiten der Psychakustik in verschiedenem Maße. Sie unterscheiden sich je nach gewünschtem Kompressionsgrad und benötigter Tonqualität, sowie je nach möglichen Fehlerquellen, z.B. beim Abspeichern oder der Übertragung über einen gestörten Kanal. Bei Übertragung über Funkkanäle ist beispielweise eine höhere Fehlertoleranz erforderlich bzw. darf der auftretende Qualitätsverlust bei zunehmenden Übertragungsfehlern nicht katastophal sein sondern graduell zunehmen ("graceful degradation" = würdevolle Verschlechterung"), da das Störempfinden beim Hören schlechter Tonqualität sehr empfindlich reagiert. MPEG Audio-Codierung: Layer -1, -2, -3 MPEG ist der Name für eine Expertenorganisation, die sich um die Standardisierung von Videodaten kümmert (Motion Pictures Expert Group) Der MPEG-Standard ist international genormt und besteht aus drei Teilspezifikationen für Bild-, Ton- und Systemdaten, welche zusammen die koordinierte Übertragung von Bild und Ton von digitalem Video oder von digitalem Fernsehen ermöglichen sollen. Die verschiedenen Audio-Kategorien (Qualitätstufen) Layer -1, -2 und -3 sind nicht zu verwechseln mit den "Phasen" (Generationen, Entwicklungsstufen) MPEG-1, -2 und -4 für Video-Kompression (siehe nächstes Kapitel) Da es sich bei den MPEG-Audio-Standards um zunächst Tonstandards zur Begleitung von Videos handelt, die ohnehin sehr hohe Datenraten erfordern, ist das Hauptziel dieser Audio-Kompressionsverfahren nicht die Datenkompression für Sprache allein mit dem Ziel extrem niedriger Datenraten, sondern für die kompakte Codierung aller möglichen Klänge mit dem Ziel guten passablen Klangqualität für die jeweilige Anwendung. Es wurde daher zunächst von Ton mit hohen Abtastraten ausgegangen, um eine Beschneidung der Frequenzbandbreite zu vermeiden. MPEG-Schichten und MPEG-Phasen (Generationen) Der MPEG-Audio- Standard für sich eignet sich auch für Tonrundfunkübertragungen allein (ohne Video). Die Substandards Layer-1 und -2 wurden von Philips und dem Institut für Rundfunktechnik (IRT) in München entwickelt (MUSICAM Audiocodierung für DAB (Digital Audio Broadcasting)) und von MPEG adaptiert. Die Eckdaten der drei MPEG Audio-Schichten sind in folgendem Schema dargestellt. Orientierungspunkt des MPEG-Standards ist hauptsächlich die hochqualitative Tonübertragung, für die die sogenannte "CD-Qualität" der Maßstab ist, der sozusagen nicht zu überbieten ist. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 11 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 MP3 Das Format, das heute als MP3 für Sounddatenkompression sehr populär und bekannt geworden ist, ist eigentlich die so genannte Layer 3 des MPEG-Audio-Standards Das Verfahren arbeitet mit einer zweistufigen Umsetzung der Wellenformdaten in Spektrale Information, so dass schließlich ein Spektrum mit 576 diskreten Frequenzbändern vorliegt. Parallel zur Berechnung der Spektralen Information wird die Berechnung der jeweiligen Hörschwellen bei den verschiedenen Frequenzen berechnet. Die zeitliche Aktualisierung der Hörschwelleninformation ist wesentlich langsmer als die Abtastfrequenz der Kanalinformationen in den einzelnen Frequenzkanälen. Die so ermittelten Informationen [ a) der zeitliche Verlauf der Amplituden in den Frequenzkanälen und b) die Informationen über den zeitlichen Verlauf der Hörschwellen in den Kanälen und die resultierende minimal nötige Quantisierungsskalen ] werden dann noch nach redundanzminimierenden verlustreien Verfahren (Huffman-Codierung) kodiert und die verschiedenen Informationsströme in einen einzigen gemeinsamen seriellen Datenstrom gefädelt. Auf diese Weise kann man mit dem MP3 Verfahren Musik in “CD-Qualität”, d.h. den ganzen hörbaren Frequenzbereich mit einer Grunddynamik von 96 dB in zwei Stereokanälen, was unkomprimiert (PCM-kodiert) eine Datenrate von (44,1hHZ x 16bit x 2 Kanäle) = 1,41 Mbit/sec erfordert, auf eine Datenrate von 128 kbit/sec reduzieren. Dies entspricht einem Kompressionsfaktor von 11. Es gibt noch viele weitere Tonkompressionsverfahren: z.B. das bei Minidisk verwendete Verfahren ATRAC. Eine Minidisk kann nur ca. ¼ der Datenmenge speichern, die eine Audio-CD fasst, kann jedoch die gleiche Abspieldauer auf einem Medium unterbringen. Dies macht ein Audio-Kompressionsverfahren notwendig, das im Verhältnis 4:1 komprimiert, ohne dass ein Qualitätsverlust wahrnehmbar ist. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 12 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.4 Tonkompressionsverfahren für extrem niedrige Datenraten Für die Übertragung von Sprache ist, wie seit langem bekannt ist, nur eine Bandbreite von ca 3kHz nötig um eine verständliche Sparachqualität zu erreichen. Bei einer dem angepaßten Abtastrate von 8kHz und einer Quantisierungstiefe von 8 bit erhält man damit bereits eine Bitrate von 64 kB/s. Dies ist für viele Anwendungen bereits eine zu hohe Datenrate. Im digitalen Mobiltelefonsy-stem nach dem GSM-Standard steht für einen Gesprächskanal nicht einmal diese Datenrate zur Verfügung. Es wurden deshalb speziell zur Übertragung von Sprachsignalen Kompressionsverfahren entwickelt, die noch wesentlich geringere Datenraten erreichen. In Windows 95/98 ist bereits ein standardmäßig ein Kompressionsverfahren (G.723) eingebaut, das unter dem Namen TrueSpeech 8.5 geführt wird. Damit kann beispielsweise eine Kompression von Klängen mit einer Abtastrate von 5,5kHz (was noch für eine verständliche Sprachwiedergabe ausreicht) auf eine Datenrate von 7,7 kbps erreicht werden) Vocoder Toncodierungssysteme speziell für Sprache nennt man auch Vocoder (Voice Encoder) Die extremsten Vocoder benutzen ein Modell des menschlichen Stimmapparats und extrahieren aus dem Tonsignal einer Sprachnachricht Parameter, die anhand des Modells des Sprachtrakts Töne erzeugen, die so klingen, wie die zu übertragende gesprochene Sprache. Was dabei jedoch nur übertragen wird ist der zeitliche Fluß der sich gemäß dem Sprachfluss ändernden Parameter, die zur Erzeugung des Sprachklanges mit einem entsprechenden Organ notwendig sind. Dies kann man sich etwa so vorstellen, als ob man statt Tönen nur Steuerinformationen für Stimmbandspannung, Mund und Lippenbewegungen, Luftströmung in der Luftröhre und dgl. übertragen würde und damit eine Sprechmaschine steuerte. Die nächste Stufe der Abstraktion wäre dann, dass man statt Toninformationen nur Textdaten (also Schriftzeichen) überträgt, und daraus eine Sprechstimme synthetisch steuert (Text-to-Speech). Solche Sprachsyntheseprogramme gibt es bereits in guter Qualität. Die Schwierigkeit bei der Sprachübertragung nach dieser Methode liegt vielmehr in der Umwandlung von gesprochener Sprache in geschriebenen Text (Spracherkennung). Auch solche Programme gibt es bereits mit erstaunlicher Leistung. Allerdings ist die Zuverlässigkeit der Spracherkennung, obwohl schon bei weit über 90%, doch für den Alltagsgebrauch noch sehr unbefriedigend. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 13 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.5 Tonkodierungsverfahren für Synthetische Klänge Bei der wahrnehmungsbasierten (perzeptiven) Audiokompression wird die Datenkompression dadurch erreicht, dass Daten weggelassen werden, deren Inhalt vom Ohr nicht wahrgenommen werden können. Dazu muß zuerst eine Transformation der Information vorgenommen werden, die die Trennung dieses Anteils der Information von dem für das Gehör wahrnehmbaren Anteil überhaupt zulässt. Die Verfahren für Sprachkodierung (Vokoder) beruhen dagegen eher auf einer Modellierung der menschlichen Stimme. Man spricht daher auch in diesem Bereich von modellbasierter Audiokompression. Dabei wird ein Modell für die Tonerzeugung konstruiert, das es erlaubt, nur Parameter zu übertragen, die bei bekanntem Modell für die laufende Tonerzeugung benötigt werden. Wenn das Modell selbst nicht vordefiniert ist, dann müssen bei Beginn der Übertragung oder im Laufe der Übertragung immer wieder auch Parameter übertragen werden, die die Definition des Modells selbst ermöglichen, d.h. es müssen Daten übermittelt werden, die z.B. aus einem allgemeinderen Modell der menschlichen Stimme die spezifische Stimme eines bestimmten Sprechers definieren, wobei sich dieses Modell im Laufe der Zeit auch ändern kann, wenn z.B. der Sprecher heiser wird, oder sein Gemütszustand sich ändert (z.B. zuerst freundlich, dann wütend) Die modellbasierte Audiokompression lässt sich auch im Prinzip auf Musik anwenden. Dies läßt sich z.B. so verstehen, dass man die Tonaufnahme eines Klavierstückes nur eine Datei übermittelt, die die Information enthält wann welche Taste des Klaviers mit welcher Stärke gedrückt wurde. Damit ist es im Prinzip möglich, an einem anderen Ort mit einem Computergesteuerten Klavier dasselbe Stück mit allen Feinheiten wiederzugeben, wie sie ein großer Pianist gespielt hat. Verloren geht dabei allerdings die Information, wie die Akustik des Konzertsaals den Klang des Klavierstücks beeinflußt. Außerdem gehen die Feinheiten des Klangs des Originalklaviers verloren, wenn das computergesteurte Wiedergabeklavier nicht identisch aufgebaut ist im Vergleich zum Originalklavier, so dass z.B. interne Resonanzen des Intstruments anders sind. 7.5.1 MIDI-Standard Ein Versuch eines Datenstandards zur Steuerung von elektrischen/elektronischen Musikinstrumenten ist der MIDI-Standard (Music Instrument Digital Interface). In einer MIDI-Datei sind also folgende Informationen enthalten: angesprochenes Instrument Beginn und Ende einer Note Grundfrequenz und Lautstärke der Note Mit diesen Daten können entweder echte Musikinstrumente mit elektrischer Steuerung, oder Synthesizer, d.h. Hardware (oder in Software emulierte Hardware) zur synthetischen Klangerzeugung, gesteuert werden. Allerdings enthalten die MIDI-Daten quasi nur Namen der verwendeten Instrumente. Jeder Synthesizer kann daraus andere Klänge machen. Durch eine MIDI-Datei, die dem MIDI-Standard entspricht ist also der Klang beim Abspielen der Datei nicht wirklich festgelegt, so wie etwa eine Partitur auch nicht festlegt, wie ein Musikstück wirklich klingt. (Es kann z.B. der Part einer Geige auch von einer Flöte gespielt werden und dann klingt es entsprechend anders). Aber abgesehen von der Unbestimmtheit der klanglichen Wiedergabe bedeutet die Kodierung eines Musikstückes eine sehr gewaltige Datenreduktion gegenüber einer Tonaufnahme des entsprechenden Musikstückes. Man kann also auch hier von Audiokompression sprechen. Als Beispiel: Ein Bach-Stück von 8 Minuten Dauer kann in einer MIDI-Datei von 50 kB kodiert sein, während eine CD-Aufnahme von 8 Minuten in PCM-Codierung einen Umfang von 84 MB hat, also 1700 mal so umfangreich ist. Bach_bwv10521_mid.wav Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 14 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 7.5.1 MPEG-4 Structured Audio Im MPEG-4 Standard, der sich mit der Codierung von umfassenderen multimedialen Darstellungen unter Einbeziehungen hauptsächlich von synthetischen Video- und Audio-Elementen befasst wurde das in MIDI noch ungelöste Problem angegangen, dass beim Abspielen der MIDI-Daten der Klang nicht eindeutig spezifiziert ist. Unter dem Stichwort “Structured Audio” (SA) wird dort ein Schema beschrieben, mit dem zur Darstellung von Musik zuerst Tonquellen (also etwa Musikinstrumente) in einer Weise durch Signalverarbeitungsalgorithmen definiert werden können, dass ihr Klang eindeutig wird. Das kann z.B. eine rechnerisches Modell sein, das das physikalische Verhalten einer gezupften und dann schwingenden Saite wiedergibt. So ein Modell enthält dann jeweils einige wenige Parameter, die dann zum Aufbau von komplexeren Instrumenten und schließlich ganzen Orchestern herangezogen, und letzten Endes zur Darstellung eines Musikstückes herangezogen werden können. Es wird also in einer solchen Audio-Datei zuerst das Orchester mit all seinen relevanten Parametern, welche die möglichen Klänge genau definieren, spezifiziert, und dann werden die Daten angefügt, die notwendig sind, um dieses Orchester ein bestimmtes Musikstück spielen zu lassen. In diesem Schema könnte auch die menschliche Stimme oder die verschiedener Tiere, sowie die Geräusche, die Gegenstände verursachen, (Blätterrauschen, Schritte auf Asphalt, ... u.s.w.) als Instrumente spezifiziert werden, und so schließlich Klänge synthetisiert werden, wie man sie etwa in einem Zoo mit dem Mikrophon aufnehmen könnte. Vorlesung Multimediatechnik Prof. Dr. Hans P. Graßl 7. Audiodatenkompression S. 15 D:\_DOCS\METE_WI\07_Audiokompression.lwp 18.05.01 2:58 Fragen: Welche verschiedenen Anforderungen stellen Musik einerseits und Sprache andererseits an ein entsprechendes effizientes Audiokompressionsverfahren? Welche psychoakustischen Effekte werden bei Audiokomressionsverfahren, (etwa nach MP3) ausgenutzt um irrelavante Information von rlevanter zu trennen? Beschreiben Sie diese Effekte in eigenen Worten! Wie verhalten sich die Begriffe MPEG-1, MPEG-2, MPEG-4 zueinander? Was bedeutet die Unterscheidung “Layer 1”, “Layer 2”, Layer 3” bei MPEG-Audiokodierung? In wieviele Kanäle (Subbänder) wird bei MP3 das Klangspektrum aufgeteilt? Worin besteht der Datenkompressionseffekt bei der Aufspaltung in Subbänder? Wozu dient die bei MP3 zusätzlich zur Aufspaltung in Subbänder stattfindende Fouriertransformation? Was für Informationen werden schlißlich im MP3 Datenstrom übertragen? Wie groß ist etwa der Kompressionsfaktor bei MP3 für Musik in CD-Qualität ohne wahrnehmbaren Qualitätsverlust? Welches Audiokompressionsverfahren wird bei der (magnetooptischen, wiederbeschreibbaren) Minidisk verwendet? Welches Prinzip wird bei der Tonkomprimierung für Sprache mit dem Ziel möglichst niedriger Datenrate angewandt? Was für eine Art von Information wird im MIDI-Dateiformat gespeichert? Was ist beim MIDI-Format unbefriedigend und wie wird das m it “Structured Audio” unter MPEG-4 besser gelöst?