Document
Werbung

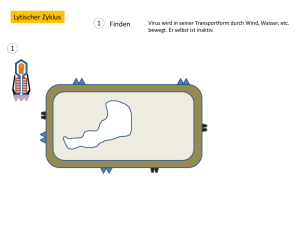
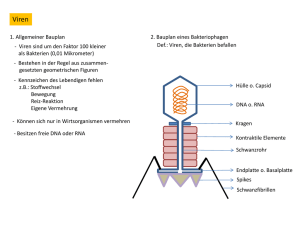
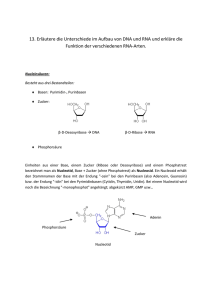
5. DNA, RNA und der Fluss der genetischen Information 5.1 Eine Nucleinsäure besteht aus vier verschiedenen Basen, die mit einem Rückgrat aus Zucker- und Phosphatgruppen verknüpft sind Die Nucleinsäuren DNA und RNA sind lineare Polymere. Jedes Monomer innerhalb des Polymers besteht aus 3 Komponenten: einem Zucker, einem Phosphat und einer Base. Die Abfolge der Basen ist für jede Nucleinsäure einzigartig. DNA (Desoxyribonucleinsäure) und RNA (Ribonucleinsäure) unterscheiden sich durch ihren Zucker:Der Desoxyribose fehlt im Gegensatz zur Ribose am 2'-Kohlenstoff das Sauerstoffatom. Dadurch ist der RNA eine zusätzliche Verknüpfung über 2'5' möglich. (Entfernung von Introns und Zusammenführung von Exons, kap. 28) Die Phosphodiesterbrücken (Rückgrat einer Nucleinsäure) sind über die ganze Länge einer DNA/RNA gleich. Die Basen hingegen unterscheiden sich von Monomer zu Monomer: Zwei der Basen sind Derivate des Purins: Adenin (A) und Guanin (G) Die anderen von Pyrimidin: Cytosin (C) und Thymin (T, nur in DNA), bzw. Uracil (U, nur in RNA) (3.Unterschied zwischen RNA und DNA) Bei allen prokaryotischen und eukaryotischen Organismen ist DNA das Molekül der Vererbung (Fehlen der 2'-Hydroxylgruppe erhöht Resistenz gegenüber einer Hydrolyse), bei Viren ist es entweder DNA oder RNA. Eine Einheit aus Base und Zucker heisst Nucleosid. Ein Nucleotid ist ein Nucleosid, das über eine Esterverbindung mit einer oder mehreren Phosphatgruppen verbunden ist. Also: Monomere Einheit der Nucleinsäure (DNA oder RNA) = Nucleotid. Eine DNA-Kette besitzt Polarität, genau wie ein Polypeptid. Das eine Ende der Kette besitzt eine freie 5'-OH Gruppe (oder eine mit einem Phosphat verknüpfte 5'-OHGruppe), das andere eine 3'-OH-Gruppe; beide sind nicht mit einem anderen Nucleotid verknüpft. Man hat sich darauf geeinigt, die Basensequenz in 5'3'-Richtung zu schreiben. (Abb. 5.7) Natürlich vorkommende DNA-Moleküle sind bemerkenswert lang, da bereits genetische Information für die einfachsten Organismen sehr viele Nucleotide erfordert. Das menschliche Genom besteht aus ungefähr 3 Milliarden Nucleotiden. 5.2 Zwei Nucleinsäureketten mit komplementären Sequenzen können eine Doppelhelix bilden Jede zelluläre DNA ist aus zwei sehr langen, in Helixform um eine gemeinsame Achse gewundenen Polynucleotidsträngen aufgebaut. Das Zucker-Phosphat-Gerüst befindet sich auf der Aussenseite und die Purin- und Pyrimidinbasen im Inneren der Helix. Spezifische Wasserstoffbrücken halten diese Basenpaare zusammen. Guanin lässt sich mit Cytosin und Adenin mit Thymin vereinigen. Beide Paare haben dann eine weitgehend gleiche Form. (Abb. 5.12) Der Abstand zwischen zwei Basen beträgt 0,34 nm. Die Basen ziehen einander mittels van-der-Waals-Kräfte an. Zusätzlich stabilisiert der hydrophobe Effekt die Doppelhelix. Die Stapelung der Basen oder vielmehr die zwischen ihnen stattfindenden hydrophoben Wechselwirkungen führen dazu, dass die mehr polaren Oberflächen dem umgebenden Wasser zugewandt werden. Die Abfolge der Basen auf einem Strang der Doppelhelix determiniert zwangsläufig die Abfolge auf dem anderen Strang, da immer ein Guanin auf dem einen Strang einem Cytosin gegenübersteht und so weiter. Bei der Replikation von DNA wird ein Strang des Tochter-DNA-Moleküls neu synthetisiert, während der andere unverändert von der Eltern-DNA übernommen wird. Diese Verteilung der elterlichen Atome wird durch die semikonservative Replikation erzielt. D.h. jedes Tochtermolekül erhält einen Strang der Eltern-DNA. Bei der DNA-Replikation und anderen Prozessen müssen die beiden Stränge der Doppelhelix zumindest stellenweise voneinander getrennt werden. Dieses Aufwinden wird im Labor oft Schmelzen genannt, weil es bei einer bestimmten Temperatur relativ plötzlich auftritt. Die Schmelztemperatur (Tm) ist definiert als diejenige Temperatur, bei der die Helixstruktur zur Hälfte verloren gegangen ist. Sobald die Temperatur unter Tm sinkt, finden sich die voneinander getrennten komplementären Nucleinsäurestränge spontan wieder zur Doppelhelix zusammen. Diesen Renaturierungsprozess bezeichnet man manchmal als annealing. Im Zellinnern werden Doppelhelices natürlich nicht durch Erwärmen geschmolzen. Hier sogen Proteine, Helikasen, unter Einsatz von chemischer Energie (aus ATP) dafür, dass die Struktur doppelsträngiger Nucleinsäuremoleküle stellenweise aufgebrochen wird. Die DNA Moleküle menschlicher Chromosomen sind linerar organisiert. In anderen Organismen jedoch sind sie ringförmig (bezieht sich auf die Kontinuität des DNAStranges, nicht auf seine geometrische Form). Bei der Umwandlung einer linearen DNADoppelhelix in ein geschlossenes ringförmiges Molekül kann sich die Achse der Doppelhelix noch einmal zu einer Superhelix verdrillen (Abb. 5.18A) Eine ringförmige DANN ohne Superhelixstruktur wird als entspanntes (relaxed) Molekül bezeichnet. Vorteile der Superhelix: 1.Kompaktere Gestalt als die entspannte Form, 2. beeinflusst die Superhelixbildung die Entspiralisierungsfähigkeit der Doppelhelix und damit ihre Wechselwirkungen mit anderen Molekülen. Einzelsträngige Nucleinsäuren (die meisten RNA) können komplexe Formen annehmen. Das einfachste und geläufigste Strukturmotiv ist die Stamm-Schleife-Struktur (Abb. 5.19). Sie entsteht dort, wo innerhalb eines Einzelstranges zwei komplementäre Sequenzen zusammenkommen und eine Doppelhelixstruktur ausbilden. 5.3 DNA wird durch Polymerasen repliziert, die ihre Instruktionen von Matrizen beziehen DNA-Polymerasen katalysieren die schrittweise Addition von Desoxyribonucleotideinheiten an eine DNA-Kette. Wichtig ist dabei, dass der neue DNAStrang direkt an der existierenden DNA-Matrize (=Vorlage) gebildet wird. Die Matrize kann ein einzelner DNA-Strang sein oder auch ein Doppelstrang, bei dem eine der Ketten an einer oder mehreren Stellen unterbrochen ist. Im Falle eines Einzelstranges muss die DNA-Matrize an einen Primer mit einer freien 3’Hydroxylgruppe gebunden sein. Die aktivierten Vorstufen bei der DNA-Synthese sind die vier Desoxyribonucleosid-5’triphosphate. Der neue Strang wird in 5’3’-Richtung durch nucleopilen Angriff des 3’- OH-Endes des Primerstranges auf das innerste PHosphratom des neuen Desoxyribonucleosidtriphosphats synthetisiert. Die DNA-Polymerase katalysiert die Bildung einer Phosphodiesterbrücke nur dann, wenn die Base des neuen Nucleotids komplementär ist zu der Base auf dem Matrizenstrang. Sie ist also ein matrizenabhängiges Enzym, das ein Produkt hervorbringt, dessen Basensequenz zu einer Vorlage komplementär ist. Viele DNAPolymerasen verfügen zusätzlich noch über eine eigene Nucleaseaktivität, die sie in die Lage versetzt, Fehler in der DNA zu korrigieren und falsch eingebaute Nucleotide durch eine zweite Reaktion wieder zu entfernen. Die Gene sämtlicher prokaryotischen und eukaryotischen Organismen bestehen aus DNA. Bei einigen Viren jedoch bestehen die Gene aus RNA. (Viren sind in Proteinhüllen verpackte genetische Elemente, die von einer Zelle zur andren gelangen können, aber nicht imstande sind, sich selbst zu vermehren.) Die Replikation seiner Virus-RNA katalysiert eine RNA-abhängige RNA-Polymerase. Eine weiter wichtige Klasse von RNA-Viren bilden die Retroviren, bei denen der Fluss der genetischen Information von der RNA zur DNA erfolgt, statt wie üblich von der DNA zur RNA. (HIV-Virus) Retroviruspartikel enthalten zwei Kopien eines einzelsträngigen RNA-Moleküls. Beim Eintritt in die Zelle wird diese RNA durch ein virales Enzym, die Reverse Transkriptase in DNA umgeschrieben (Abb. 5.23). 5.4 Genexpression bedeutet Umsetzung der in der DNA enthaltenen Information in funktionale Moleküle Die in der DNA gespeicherte Information wird erst dann nützlich, wenn sie in RNA und Proteine umgesetzt wird. Dies geschieht in zwei Stufen: Als erstes wir eine RNA-Kopie angefertigt („Fotokopie“ der ursprünglichen Information). Dann sind auf dem RNAMolekül Instruktionen für die Proteinsynthese codiert, die entschlüsselt werden müssen, damit sie von Nutzen sein können. Die Information auf einer Messenger-RNA wird in ein funktionstüchtiges Protein übersetzt. Die Synthese von RNA anhand einer DNA-Vorlage wird Transkription genannt, die Proteinsynthese, die folgt Translation. Eine Zelle enthält verschiedene Sorten von RNA. 1. Die Messenger-RNA (mRNA) ist die Matrize für die Translation. (5% der gesamten RNA) 2. Transfer-RNAs (tRNA) transportieren Aminosäuren in aktivierter Form zum Ribosom, wo in der durch die mRNA Matrize festgelegten Reihenfolge Peptidbidungen geknüpft werden. (15%) (tRNA verfügt über eine Aminosäureanheftungsstelle une eine Matrizenerkennungsstelle. Die tRNA transportiert eine bestimmte Aminosäure in aktivierter Form zum Ort der Proteinsynthese.) 3. Die ribosomale RNA (rRNA) ist der Hauptbestandteil der RIbosomen und spielt bei der Proteinsynthese sowohl eine strukturelle als auch eine katalytische Rolle. (80%) Die Transkription in diese RNA-Typen erfolgt durch das Enzym RNA-Polymerase. Die aktivierten Vorstufen sind Ribonucleosidtriphosphate und die Syntheserichtung ist wie auch bei der Herstellung von DNA 5’3’. Die RNA-Polymerase unterscheidet sich von der DNA-Polymerase darin, dass sie ohne Primer auskommt. Wie die DNA-Polymerasen bekommt auch die RNA-Polymerase ihre Anweisungen von einer DNA-Matrize. Die Transkription beginnt in der Nähe von Promotorstellen (Promotoren binden spezifisch die RNA-Polymerase und bestimmen, wo die Transkription beginnt) und endet an Terminationsstellen. Also: es gibt in der DNA-Matrize getrennte Start- und Stoppsignale für die Transkription. Für jede der 20 Aminosääuren gibt es mindestens eine spezifische Synthetase. Die Matrizenerkennungsstelle auf der tRNA ist eine Sequenz von drei Basen, die man als Anticodon. Das Anticodon erkennt auf der mRNA jeweils eine komplementäre Sequenz von drei Basen, das Codon. 5.5 Die Aminosäuren werden ab einem bestimmten Startpunkt von Gruppen aus jeweils drei Basen codiert Der genetische Code ist die Beziehung zwischen der Basensequenz der DNA (oder ihrer mRNA-Transkripte) und der Aminosäuresequenz der Proteine. 1. Drei Nucleotide codieren eine Aminosäure. Proteine bestehen aus einem Grundbausatz von 20 Aminosäuren, aber es gibt nur 4 Basen. Zur Codierung von mind. 20 Aminosäuren sind minimal drei Basen erforderlich. 2. Der Code ist nicht überlappend. Bsp: bei einem Code ABCDEF steht ABC für die erste Aminosäure, DEF für die zweite und nicht BCD. 3. Der Code verfügt über keine Zeichensetzung, also dient keine Base quasi als „Komma“. Die Basensequenz wird vielmehr fortlaufend von einem bestimmten Startpunkt an abgelesen. 4. Der genetische Code ist degeneriert. Es gibt 64 mögliche Tripletts und nur 20 Aminosäuren. Für die meisten Aminosäuren gibt es daher mehr als ein Codewort. Drei der 64 Tripletts stehen aber nicht für eine Aminosäure, sondern signalisieren das Ende der Translation und werden als Stoppcodons bezeichnet. Alle 64 Codons sind heute entschlüsselt (Tab. 5.4). Nur 2 Aminosäuren (Typtophan und Methionin) werden von einem einzigen Triplett codiert. Für alle anderen gibt es mindestens zwei Codons. Dabei korreliert die Zahl der Codons mit der Häufigkeit des Auftretens der Aminosäure in Proteinen. Codons, die die gleiche Aminosöäure codieren, heissen Synonyme. Die meisten Synonyme unterscheiden sich nur in der letzten Base des Tripletts. XYC und XYU stehen immer nur für eine Aminosäure während XYG und XYA meistens die gleiche Aminosäure codieren. Warum ist der genetische Code degeneriert? Wäre er es nicht, würden 20 Codons Aminosäuren codieren und 44 eine Kettentermination bewirken. So wäre die Wahrscheinlichkeit für Mutationen, die zum Kettenabbruch führen, weitaus grösser. Also minimiert die Degeneration die schädlichen Auswirkungen von Mutationen. An den Ribosomen, grossen Molekülkomplexen aus Proteinen und ribosomaler RNA, wird die Messenger RNA in Proteine translatiert. Das Signal für die erste Aminosäure einer Polypeptidkette muss komplexer sein als für alle folgenden. AUG (oder GUG) ist ein Teil des Initiationssignals (in Bakterien). Sobald das Initiations-AUG lokalisiert ist, steht das Leseraster (der reading frame) fest. Der genetische Code ist nahezu, aber nicht vollständig universell. Abweichungen treten eindeutig in Mitochondrien auf, sowie bei Arten, die in der Evolution der Eukaryoten frühzeitig einen eigenen Weg beschritten haben. Die meisten Abweichungen vom genetischen Standardcode gehen in Richtung einfacheren Codes. 5.6 Die meisten eukaryotischen Gene sind Mosaike aus Introns und Exons Die meisten Gene höherer Eukaryoten sind diskontinuierlich. Das heisst, codierte Sequenzen (Exons) sind durch nicht-codierte Zwischensequenzen (Introns) voneinander getrennt. Beim Spleissen erkennen Spleissosomen (enzymatische Apparate) Signale im RNAPrimärtranskript, welche die Spleissstellen markieren. An diesen Stellen werden die Zwischensequenzen herausgeschnitten und die codierenden Sequenzen verknüpft. Nahezu alle Introns beginnen mit GU und enden mit einem AG, dem ein pyrimidinreicher Abschnitt vorausgeht (Abb. 5.35). Diese Consensussequenz ist ein Teil des Spleisssignals. Introns waren bereits in den Urgenen vorhanden und gingen während der Evolution von Organsimen, die für sehr rasches Wachstum optimiert wurden – etwa Prokaryotenverloren. Viele Exons codieren bestimmte strukturelle und funktionelle Einheiten von Proteinen. Eine Hypothese besagt, dass während der Evolution neue Proteine durch Neuordnung von Exons entstanden, die bestimmte strukturelle Elemente, Bindungsstellen und katalytische Regionen codieren. Die Aufspaltung von Genen bietet einen weiteren Vorteil: Sie eröffnen die Möglichkeit, durch unterschiedliches Spleissen eines RNA-Primärtranskripts eine Reihe von verwandten Proteinen hervorzubringen.