Musterlösung zur Klausur vom März 2009
Werbung

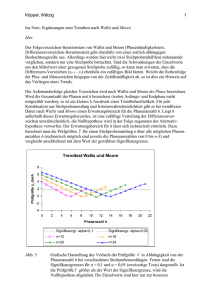
LOTSE Musterlösungen zur Klausur zum Modul 2 im B.Sc.-Studiengang „Psychologie“ Termin: 9. März 2009, 14.00 - 18.00 Uhr Prüfer bei Block 1 (Kurse 03607 und 33209): apl. Prof. Dr. H.-J. Mittag Prüfer bei Block 2 (Kurse 33254 und 33208): Prof. Dr. K.-H. Renner © 2009 FernUniversität in Hagen Fakultät für Kultur- und Sozialwissenschaften Alle Rechte vorbehalten. Multiple-Choice-Aufgaben zu Block 1 Aufgabe 1 (Messen / Verfahren der Datenerhebung ) Welche der folgenden Aussagen sind richtig ? (5 Punkte) (x aus 5) A) Die Validität eines Messinstruments charakterisiert, inwieweit ein Messinstrument bei wiederholter Messung die gleichen Messwerte liefert. B) Wenn man allgemeine Bevölkerungsumfragen als offene Online-Befragungen organisiert, ist mit erheblichen Verzerrungen zu rechnen. C) Die Randomized Response Technik ist ein Verfahren der Datenerhebung, bei dem in Interviews vollständige Anonymität der Befragten gewährleistet werden kann. D) Die „Total-Design-Methode“ ist ein Ansatz der Datenerhebung, der vor allem darauf abzielt, die Rücklaufquote bei schriftlichen Befragungen zu erhöhen. E) Das Quotenauswahlverfahren ist ein Verfahren der Zufallsauswahl, das Kostenvorteile gegenüber anderen Verfahren der Datenerhebung bietet. Lösung: B, C, D. Zu A: Schnell / Hill / Esser, Abschnitt 4.3. Wenn man in der Aussage „Validität (Gültigkeit)“ durch „Reliabilität (Zuverlässigkeit“ ersetzte, wäre sie richtig - vgl. auch Kromrey, Abschnitt 5.7. zu B: Diekmann, Kapitel X, Abschnitt 11; zu C: Diekmann, Kapitel X, Abschnitt 7; zu D: Diekmann, Kapitel X, Abschnitt 10; zu E: Kromrey, Abschnitte 6.3 - 6.4. Anmerkung: Aussage E besteht aus den Teilausaussagen „Das Quotenauswahlverfahren ist ein Verfahren der Zufallsauswahl“ und „Das Quotenauswahlverfahren bietet gegenüber anderen Datenerhebungsverfahren Kostenvorteile“. Die Gesamtaussage ist nur dann richtig, wenn beide Teilaussagen gleichzeitig zutreffen. Die erste Teilaussage ist aber unzutreffend (s. die Übersicht am Ende von Abschnitt 6.3 im Kurs von Kromrey), so dass der Wahrheitsgehalt der Gesamtaussage eindeutig beurteilbar ist. Dennoch wurde bei dieser Aussage generell ein Punkt vergeben, weil der Wahrheitsgehalt der zweiten Teilaussage aus der Pflichtlektüre nur schwer zu erschließen ist. 2 Aufgabe 2 (Befragungen) Welche der folgenden Aussagen sind richtig ? (5 Punkte) (x aus 5) A) Bei einem Telefoninterview ist der Einfluss von Einflüssen, die in der Person des Interviewers liegen, geringer als bei einem persönlichen Interview (Face-to-FaceInterview). B) Bei Befragungen wird manchmal die Methode der Klumpenauswahl herangezogen. Diese stellt ein zweistufiges Auswahlverfahren dar, bei dem auf der ersten Stufe eine Zufallsauswahl von Teilmengen einer Grundgesamtheit erfolgt und auf der zweiten Stufe eine Untersuchung aller Elemente der zufällig ausgewählten Teilmengen. C) Das narrative Interview ist ein Beispiel für eine strukturierte Befragung. D) Bei Interviews sind Antwortverzerrungen möglich, die z. B. in der Art der Frageformulierung begründet sein können. E) Non-Response, also Antwortausfälle durch Antwortverweigerung oder Nichterreichbarkeit bei Befragungen, kann die Repräsentativität einer Stichprobe stark beeinträchtigen, also zu verzerrten Stichproben führen. Lösung: A, B, D, E. Zu A: Diekmann, Kapitel X, Abschnitt 9; zu B: Kurs 33209, Abschnitt 3.2, und Kromrey, Abschnitt 6.3.2; zu C: Diekmann, Kapitel X, Abschnitt 12; zu D: Diekmann, Kapitel X, Abschnitt 4; zu E: Diekmann, Kapitel X, Abschnitt 11. 3 Aufgabe 3 (Merkmalsklassifikationen) (5 Punkte) Ein Konzern will im Rahmen von Neubauplanungen auch Informationen über den Bedarf an Parkplätzen und Kinderbetreuungsplätzen für seine Mitarbeiter gewinnen. Hierfür werden alle Beschäftigten gebeten, Angaben zu folgenden Merkmalen zu machen: 1 Anzahl der im Haushalt lebenden Kinder 2 Alter der im Haushalt lebenden Kinder 3 Verkehrsmittel, das für die Fahrt zur Arbeitsstätte überwiegend genutzt wird (z. B. eigener PKW, Fahrrad, Bus, ...) 4 Entfernung zwischen Wohnung und Arbeitsstätte 5 Einschätzung des vom Arbeitgeber aktuell vorgehaltenen Kinderbetreuungsangebots (1 = sehr gut, ... , 6 = völlig unzureichend). Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Die Merkmale 1, 2 und 4 sind metrisch skaliert. B) Das Merkmal 3 ist nominalskaliert, Merkmal 5 hingegen ordinalskaliert. C) Metrisch skalierte Merkmale lassen sich – unter Informationsverlust – auch auf einer Ordinalskala messen. D) Bei ordinalskalierten Merkmalen ist die Differenzenbildung zulässig, nicht aber bei nominalskalierten Merkmalen. E) Merkmal 1 ist ein Beispiel für ein diskretes Merkmal, Merkmal 4 für ein stetiges Merkmal. Hinweis: Der Begriff „metrische Skala“ wird als Oberbegriff für „Intervallskala“, „Verhältnisskala“ und „Absolutskala“ verwendet. Lösung: A, B, C, E. Zu D: Vgl. Kurs 33209, Tabelle 2.1. 4 Aufgabe 4 (Häufigkeitsverteilungen) (5 Punkte) Die nachstehende Abbildung zeigt im oberen Teil die relative Häufigkeitsverteilung anhand eines Stabdiagramms und im unteren Teil die relative kumulierte Häufigkeitsverteilung für einen 20 Werte umfassenden Datensatz, der durch ein Würfelexperiment zustande kam (20-maliges Würfeln mit einem Würfel). Die relativen Häufigkeiten sind im Stabdiagramm auch numerisch ausgewiesen. Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Bei den 20 Würfen trat 6-mal die Augenzahl 5 auf. B) Von den 20 Würfen führten 12 zu Augenzahlen, die unter 5 lagen. C) Von den 20 Würfen führten 14 zu Augenzahlen, die unter 5 lagen. D) Durch Angabe der relativen Häufigkeiten oder der kumulierten relativen Häufigkeiten ist die empirische Verteilung des Merkmals „Augenzahl X“ eindeutig bestimmt. E) Die relativen Häufigkeiten gehen aus den absoluten Häufigkeiten hervor, indem man letztere durch den Umfang n des Datensatzes dividiert. Lösung: A, B, D, E. Zu E: vgl. Kurs 33209, Formel (4.2). 5 Aufgabe 5 (Kenngrößen empirischer Verteilungen) (5 Punkte) Bei 20 Arbeitnehmern eines mittelständischen Betriebes mit 150 Beschäftigten wurde die Zeit gemessen, die sie täglich am Bildschirm verbringen (Angaben in vollen Stunden). Es ergab sich der nachstehende Datensatz: 3, 4, 1, 2, 2, 6, 5, 4, 3, 5, 2, 2, 5, 2, 5, 4, 1, 2, 5, 5. Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Der Datensatz besitzt zwei Modalwerte. B) Der Mittelwert des Datensatzes ist durch 3, 4 gegeben. C) Der Median des Datensatzes hat den Wert 3, 0. D) Streicht man bei obigem Datensatz den ersten Wert (also die erste 3), bleibt der Median unverändert. E) Die Spannweite des Datensatzes hat den Wert 6. Lösung: A, B. Zu A: Sowohl 2 als auch 5 treten je 6-mal auf (beides Modalwerte). Zu B: Der Mittelwert hat den Wert 3,4 (n = 20). Zu C und D: Der Median hat im Falle n = 20 den Wert 3,5, im Falle n = 19 den Wert 4,0. Zu E: Die Spannweite hat den Wert R = 6 − 1 = 5. 6 Aufgabe 6 (Visualisierung empirischer Verteilungen) (5 Punkte) Es sei erneut der 20 Werte umfassende Datensatz aus Aufgabe 5 betrachtet. Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Die durch obigen Datensatz definierte empirische Verteilung lässt sich z. B. anhand eines Stabdiagramms für absolute Häufigkeiten oder relative Häufigkeiten visualisieren. Beim Übergang von der einen zur anderen Darstellungsform ändert sich nur die Skalierung der Ordinatenachse. B) Die empirische Verteilung des Datensatzes lässt sich ohne Informationsverlust auch anhand eines Boxplots veranschaulichen. C) Ein Boxplot (einfachste Variante) veranschaulicht 5 Charakteristika des Datensatzes. Der Median ist genau in der Mitte der Box eingezeichnet. D) Anfang und Ende der Box sind durch das untere resp. das obere Quartil des Datensatzes bestimmt. E) Wenn man die Zeitangaben für alle 150 Beschäftigten hätte und zwar mit höherer Genauigkeit (Angaben in Minuten statt in vollen Stunden), könnte man die Daten zu Klassen zusammenfassen (z. B. Gruppierung der Daten zu 1-Stunden-Bereichen) und die Klassenbesetzungshäufigkeiten anhand eines Histogramms darstellen. Lösung: A, D, E Zu B: Die Aggregation von 20 Werten der Urliste auf nur 5 Kenngrößen ist natürlich mit Informationsverlust verbunden. Zu C: Der Median ist nur bei einer symmetrischen empirischen Verteilung in der Mitte der Box (vgl. auch Abbildung 5.4 in Kurs 33209). Anmerkung: Aussage C war als allgemeine Aussage konzipiert, deren Wahrheitsgehalt unabhängig von einem konkreten Datensatz beurteilt werden sollte. Die Aussage konnte aber auch so interpretiert werden, dass sie in Verbindung mit dem Datensatz aus Aufgabe 5 bewertet werden sollte – bei der Visualisierung dieses Datensatzes anhand eines Boxplots liegt der Median genau in der Mitte der Box. Aufgrund dieser Unschärfe wurde für Aufgabenteil C generell ein Punkt vergeben. 7 Aufgabe 7 (Zusammenhangsmessung) Welche der folgenden Aussagen sind richtig? (5 Punkte) (x aus 5) A) Der Korrelationskoeffizient r nach Bravais-Pearson misst die Stärke eines linearen Zusammenhangs zwischen zwei Merkmalen X und Y . B) Wenn r = 1 ist, bedeutet dies, dass die Datenpaare (x1 , y1 ), ..., (xn , yn ) alle auf einer steigenden oder fallenden Geraden liegen. C) Im Falle r = 0 ist noch nicht ausgeschlossen, dass zwischen den Merkmalen X und Y ein nicht-linearer Zusammenhang besteht. D) Der Rangkorrelationskoeffizient rSP nach Spearman ist ein für ordinalskalierte Merkmale anwendbares Zusammenhangsmaß, das – wie der Korrelationskoeffizient r nach Bravais-Pearson – stets Werte zwischen −1 und +1 annimmt. E) Der Rangkorrelationskoeffizient rSP lässt sich auch auf metrisch skalierte Merkmale anwenden. Die in den Daten enthaltene Information wird dann aber nicht ausgeschöpft, weil bei der Berechnung von rSP nur die Rangpositionen der Werte für X resp. für Y verarbeitet werden. Lösung: A, C, D, E. Zu B: Wenn alle Punkte auf einer fallenden Geraden liegen, gilt r = −1 (vgl. auch Abbildung 9.2 im Kurs 33209). 8 Aufgabe 8 (Kombinatorik) (5 Punkte) Eine „faire“ Münze, also eine Münze mit gleichen Eintrittswahrscheinlichkeiten für „Kopf“ und „Zahl“, wird n-mal geworfen und die Anzahl X der Ausgänge mit „Zahl“ festgestellt. Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Die Wahrscheinlichkeit dafür, im Falle n = 3 höchstens einmal „Zahl“ zu erhalten, ist 0, 5. B) Die Wahrscheinlichkeit dafür, im Falle n = 3 genau einmal „Zahl“ zu erhalten, ist 0, 375. C) Die Wahrscheinlichkeit dafür, im Falle n = 4 mindestens einmal „Zahl“ zu erhalten, ist kleiner als 0, 9. D) Die Wahrscheinlichkeit dafür, im Falle n = 4 mindestens einmal „Zahl“ zu erhalten, ist genau so groß wie die Wahrscheinlichkeit höchstens dreimal „Zahl“ zu erzielen. E) Die Anzahl X der Ausgänge mit „Zahl“ lässt sich durch eine Binomialverteilung mit den Parametern n und p = 0, 5 modellieren. Lösung: A, B, D, E. Zu A: Die Verteilungsfunktion F (x) der Binomialverteilung mit n = 3 und p = 0, 5 nimmt für x = 1 den Wert F (1) = 0, 500 an (s. Tabelle 19.1). Zu B: Die Differenz der Werte F (1) und F (0) der Verteilungsfunktion der Binomialverteilung mit n = 3 und p = 0, 5 ist gegeben durch F (1)−F (0) = 0, 500−0, 125 = 0, 375 (vgl. wieder Tabelle 19.1). Zu C: Die Wahrscheinlichkeit bei 4 Würfen 0-mal „Zahl“ zu erhalten, ist durch den Wert F (0) = 0, 0625 der Verteilungsfunktion der Binomialverteilung mit n = 4 und p = 0, 5 gegeben. Gesucht ist hier die Gegenwahrscheinlichkeit 1 − F (0) = 1 − 0, 0625 = 0, 9375. 9 Aufgabe 9 (Konfidenzintervalle) (5 Punkte) Welche der folgenden Aussagen, die sich auf Konfidenzintervalle für den Erwartungswert µ = E(X) eines normalverteilten Merkmals X mit bekannter Varianz σ 2 beziehen, sind richtig ? (x aus 5) A) Das Konfidenzintervall für µ zum Konfidenzniveau 1 − α wird schmaler, wenn der Stichprobenumfang n erhöht wird. B) Das Konfidenzintervall für µ zum Konfidenzniveau 1 − α wird schmaler, wenn 1 − α erhöht, also die Irrtumswahrscheinlichkeit α verkleinert wird. C) Der unbekannte Parameter µ kann auch außerhalb des Konfidenzintervalls liegen. D) Die Grenzen eines Konfidenzintervalls lassen sich als Ausprägungen von Stichprobenfunktionen interpretieren, also als Realisationen von Zufallsvariablen. E) Keine der vorstehenden Aussagen ist richtig. Lösung: A, C, D. Zu A: Vgl. hierzu in Kurs 33209 die Formel (14.15) sowie die Abbildungen 14.2 und 14.3. Zu B: Wenn in Formel (14.15) der Wert α verkleinert wird, bedeutet dies, dass p := 1 − α2 etwas größer wird und damit auch das Quantil zp (vgl. Tabelle 19.3 in Kurs 33209). Zu C und D: Die Abbildungen 14.2 und 14.3 des Kurses 33209 liefern Beispiele für die Korrektheit der Aussage. 10 Aufgabe 10 (Normalverteilung; Standardnormalverteilung) Welche der folgenden Aussagen sind richtig ? (5 Punkte) (x aus 5) A) Die Wahrscheinlichkeit dafür, dass eine normalverteilte Zufallsvariable eine Ausprägung x mit x ≤ 0 annimmt, beträgt 0, 5. B) Jede normalverteilte Zufallsvariable kann anhand einer Lineartransformation in eine standardnormalverteilte Zufallsvariable überführt werden. C) Der Wert der Verteilungsfunktion einer standardnormalverteilten Zufallsvariablen an der Stelle 1 stimmt mit dem Wert der Verteilungsfunktion an der Stelle −1 überein. D) Die Wahrscheinlichkeit P (X ≤ a) dafür, dass eine normalverteilte Variable X eine Ausprägung hat, die nicht größer als a ist, entspricht dem Wert der Verteilungsfunktion F (x) der betreffenden Normalverteilung an der Stelle x = a. E) Ist Z eine standardnormalverteilte Zufallsvariable, so ist für diese die Bedingung P (Z ≤ a) = 0, 975 erfüllt, wenn man für a den Wert a = 1, 96 wählt. Lösung: B, D, E. Zu A: Die Aussage gilt nur für die Standardnormalverteilung. Zu B: Vgl. in Kurs 33209 den Text vor der Tabelle 19.2. Zu C: Die Aussage wäre für die Dichtefunktion zutreffend, nicht aber für die Verteilungsfunktion Φ(z) (vgl. die obere Hälfte von Abbildung 12.2 in Kurs 33209). Für Φ(z) gilt gemäß (12.20) vielmehr Φ(1) = 1 − Φ(−1). Zu E: Der Wert a ist das 0, 975-Quantil der Standardnormalverteilung (s. Tabelle 19.2). 11 Aufgabe 11 (Testen, Fehler beim Testen) (5 Punkte) Es seien n Beobachtungen für ein Merkmal gegeben. Die Werte werden als Realisationen unabhängig identisch normalverteilter Stichprobenvariablen X1 , ..., Xn aufgefasst (Normalverteilung mit unbekanntem Erwartungswert µ und Varianz σ 2 ). Getestet werden soll H0 : µ = µ0 gegen H1 : µ 6= µ0 und zwar zum Signifikanzniveau α (zweiseitiger Test). Welche der folgenden Aussagen sind richtig ? (x aus 5) A) Wenn man die Varianz σ 2 als bekannt annimmt, kann man den standardisierten Stichprobenmittelwert Z = (X − µ0 )/σX als Prüfgröße für den Test heranziehen (Gauß-Test). Die Dichte dieser Prüfgröße ist symmetrisch bezüglich des Nullpunkts. B) Die Nullhypothese wird verworfen, wenn die Prüfgröße einen Wert annimmt, der innerhalb des Ablehnungsbereichs liegt. Die Grenzen des Ablehnungsbereichs hängen vom Signifikanzniveau α ab. C) Die fälschliche Verwerfung der Nullhypothese H0 wird als Fehler 1. Art bezeichnet. Die Wahrscheinlichkeit für den Eintritt eines Fehlers 1. Art hat beim hier betrachteten Test den Wert α. D) Wenn die Prüfgröße im Annahmebereich liegt, kann die Nullhypothese als statistisch „bewiesen“ angesehen werden, in dem Sinne, dass ihre Gültigkeit mit einer Irrtumswahrscheinlichkeit von α als gesichert angenommen werden kann. E) Wenn man bei obigem Test die Varianz σ 2 resp. die Standardabweichung σ nicht als bekannt voraussetzen kann und eine Schätzung σ b heranzieht (Schätzung von σ durch die korrigierte Stichprobenstandardabweichung), ist die resultierende Prüfgröße t-verteilt. Die Grenzen des Ablehnungsbereichs für die Nullhypothese liegen dann – bei unverändertem Signifikanzniveau α – enger zusammen. Beachten Sie auch Aufgabe 43, die an die vorstehende Aufgabe direkt anknüpft. Lösung: A, B, C. Zu C: Vgl. auch Tabelle 15.1 in Kurs 33209. Zu D: Wenn die Prüfgröße im Ablehnungsbereich liegt, kann die Alternativhypothese H1 (nicht aber die Nullhypothese) als statistisch „bewiesen“ angesehen werden, in dem Sinne, dass ihre Gültigkeit mit einer Irrtumswahrscheinlichkeit von α als gesichert angenommen werden kann. Zu E: Die Grenzen des Ablehnungsbereichs rücken etwas weiter auseinander (s. Abbildung 15.2 in Kurs 33209). 12 Numerische Aufgaben zu Block 1 Aufgabe 41 (Konzentrationsmessung) (4 Punkte) In einer Region konkurrieren fünf Energieversorgungsunternehmen. Es seien x1 = 10, x2 = 30, x3 = 40, x4 = 50 und x5 = 70 die Umsätze dieser Firmen im letzten Geschäftsjahr (Umsätze jeweils in Millionen Euro). Die nachstehende Abbildung zeigt die auf der Basis dieser Umsatzdaten errechnete Lorenzkurve (Polygonzug). Die Stützpunkte (ui , vi ) der Lorenzkurve sind auf der Lorenzkurve betont. In der Tabelle neben der Grafik sind die Abszissenwerte ui der Lorenzkurve schon eingetragen. i 0 1 2 3 4 5 ui 0 0,2 0,4 0,6 0,8 1 vi 0 v1 v2 v3 v4 1 Geben Sie den Flächeninhalt A an, der in der Abbildung dunkel markiert ist. Gemeint ist also der Inhalt der Fläche, die von der Lorenzkurve und der Strecke gebildet wird, die den Nullpunkt (0; 0) mit dem Punkt (1; 1) verbindet. Geben Sie Ihre Antwort mit drei Nachkommastellen rechtsbündig in das Antwortfeld ein. Verwenden Sie für das Dezimalkomma unbedingt ein eigenes Feld. Falls Sie also z. B. „0,36“ errechnen, tragen Sie in die letzten fünf Felder „0,360“ ein. Vergessen Sie nicht, Ihre Antwort rechtzeitig vor Ende der Klausur auf den Markierungsbogen zu übertragen. (numerisch) A= Lösung: Der unnormierte Gini-Koeffizient errechnet sich zu G = 0, 28 – vgl. auch Formel (6.5) in Kurs 33209. Die veranschaulichte Fläche entspricht G2 = 0, 14. Anmerkung: Wenn anstelle von 0, 14 der Wert 0, 28, also G statt G2 , eingetragen wurde, wurde nur ein Punkt abgezogen (Vergabe von 3 Punkten). Wenn der Wert 0, 56 angegeben wurde, der Wert G also versehentlich verdoppelt statt halbiert wurde, wurden 2 Punkte vergeben. 13 Aufgabe 42 (Kombinatorik) (4 Punkte) Bei der Deutschen Meisterschaft in der Disziplin 100-m-Lauf (Herren) treten im Endlauf sechs Kandidaten K1, K2, ...K6 gegeneinander an. Wieviele Möglichkeiten für die Verteilung der ersten drei Plätze gibt es? Tragen Sie Ihr Ergebnis rechtsbündig in das Antwortfeld ein. Übertragen Sie Ihr Ergebnis rechtzeitig vor Ende der Klausur auf den Markierungsbogen. (numerisch) Lösung: 6! 6 · 4 · ... · 1 = = 6 · 5 · 4 = 120. (6 − 3)! 3·2·1 Kommentar : In der Terminologie des Urnenmodells werden n = 3 Kugeln aus einer Urne mit N = 6 nummerierten Kugeln ohne Zurücklegen gezogen und mit Berücksichtigung der Anordnung. Es ist also die erste der in der ersten Zeile von Tabelle 10.1 des Kurs 33209 wiedergegebenen Formeln mit n = 3 und N = 6 anzuwenden. Anmerkung: Falls fälschlich die zweite Formel in der ersten Zeile von Tabelle 10.1 mit n = 3 und N = 6 angewendet wurde (das Ergebnis lautet dann 63 = 216), die sich auf den Fall des Ziehens mit Zurücklegen gezogen und mit Berücksichtigung der Anordnung bezieht, wurde ein Punkt vergeben, weil hier zumindest der Fall “Ziehen mit Zurücklegen“ erkannt wurde. Wenn versehentlich die erste Formel aus der zweiten Zeile von Tabelle 10.1 angewendet wurde, die beim Ziehen ohne Zurücklegen und ohne Berücksichtigung der Anordnung zutrifft, gab es nur deswegen die volle Punktzahl, weil hier – zufällig – ebenfalls der Wert 120 als Ergebnis resultiert. Aufgabe 43 (Gauß-Test) (4 Punkte) Berechnen Sie für den Gauß-Test aus Aufgabe 11 (s. dort die Aufgabenteile A-B) für den Fall α = 0, 05 zunächst die Grenzen des Annahmebereichs für die Nullhypothese und tragen Sie dann in das Antwortfeld ein, wie weit diese beiden Werte auseinander liegen. Es ist also die Länge des Annahmebereichs gesucht. Geben Sie ihre Antwort auf vier Dezimalstellen nach dem Komma genau an. Falls Sie für den Annahmebereich das Intervall [a; b] errechnen mit irgendwelchen Werten a und b und für die Länge b − a des Intervalls z. B. 4, 523, wäre 4, 5230 in die sechs Felder einzutragen. Das Dezimalkomma muss also auch hier unbedingt ein eigenes Feld belegen. 14 (numerisch) Lösung: Die Grenzen des Annahmebereichs sind durch die Quantile zα/2 = −z1−α/2 und z1−α/2 der Standardnormalverteilung gegeben (s. Abbildung 15.1), also durch −z0,975 und z0,975 . Nach Tabelle 19.2 ist z0,975 = 1, 96. Der Annahmebereich [−1, 96; 1, 96] ist also ein Intervall der Länge 3, 92. Anmerkung: Für die Standardisierung des Stichprobenmittelwerts und die mit ihr einhergehende Berechnung einer Realisation der Prüfstatistik Z (Formel 15.2 im Kurs) werden noch Informationen benötigt, die in der obigen Aufgabe fehlten – z. B. die Angabe des Stichprobenumfangs n. Erst mit Kenntnis des Werts der Prüfgröße kann eine Testentscheidung getroffen werden. Hier war allerdings nur die Berechnung der Länge des Annahmebereichs verlangt, für deren Berechnung bei diesem Test die Angabe eines Werts für die Irrtumswahrscheinlichkeit α genügt. Für diese Aufgabe wurde generell die volle Punktzahl gegeben (Ausnahmeregelung), weil es an einem Klausurort mit dieser Aufgabe ein Problem gab. Aufgabe 44 (Wahrscheinlichkeiten bei Normalverteilung) (4 Punkte) Bei der Serienfertigung eines bestimmten Schraubentyps ist aus der Auswertung eines Produktionsvorlaufs bekannt, dass der Durchmesser X des Schraubenkopfs normalverteilt ist mit Erwartungswert µ = 6, 0 (Zielwert) und einer Standardabweichung σ = 0, 01 (Angaben in mm), also X ∼ N (6; 0, 012 ). Weicht der Schraubenkopfdurchmesser bei einer Schraube um mehr als 0, 02 (mm) nach oben oder nach unten vom Zielwert ab, d. h. liegt eine beobachtete Realisation x von X nicht im Intervall [5, 98; 6, 02], so ist die Schraube für den vorgesehenen Einsatzzweck nicht brauchbar. Sie gilt dann als Ausschuss. Wie groß ist die Wahrscheinlichkeit P dafür, dass der Durchmesser einer Schraube im Intervall [5, 98; 6, 02] liegt, die Schraube also kein Ausschuss ist? Geben Sie das Ergebnis auf vier Stellen nach dem Dezimalkomma genau an. Verwenden Sie für das Dezimalkomma ein eigenes Feld. Falls Sie also z. B. „0,8934“ errechnen, tragen Sie in die letzten sechs Felder „0,8934“ ein. Vergessen Sie nicht, Ihre Antwort rechtzeitig vor dem Ende der Klausur auf den Markierungsbogen zu übertragen. (numerisch) P = Lösung: 0, 9544 15 Herleitung: P (5, 98 ≤ X ≤ 6, 02) = P (−0, 02 ≤ X − 6 ≤ 0, 02) = P (−2 ≤ Z ≤ 2) = Φ(2) − Φ(−2). Nach Tabelle 19.2 ist Φ(2) = 0, 9772. Ferner gilt Φ(−2) = 1 − 0, 9772 = 0, 0228. Damit ist Φ(2) − Φ(−2) = 0, 9544. Anmerkung: Bei der maschinellen Auswertung wurden Werte von 0, 95 bis 0, 96 als richtig anerkannt. Bei Eintragung des Wertes 0, 9772, also Φ(2) statt Φ(2) − Φ(−2), wurde ein Punkt vergeben, weil hier zumindest der Wert Φ(2) korrekt ermittelt wurde. Aufgabe 45 (Kleinst-Quadrat-Schätzung) (4 Punkte) Für zwei Merkmale X und Y stehen 6 Beobachtungswerte (x1 , y1 ), ..., (x6 , y6 ) zur Verfügung, nämlich die Werte (6, 0; 3, 0), (5, 0; 3, 2), (7, 0; 2, 5), (7, 0; 2, 3), (8, 0; 2, 0) und (9, 0; 2, 0). Für diesen Datensatz wurde nach der Methode der kleinsten Quadrate eine Regressionsgerade b yb = α b + βx. bestimmt, wobei sich für βb aus den Daten der Wert βb = −0, 34 ergab. Errechnen Sie auch den Wert α b, der sich nach der Kleinst-Quadrat-Methode ergibt. Tragen Sie Ihr Ergebnis rechtsbündig und auf zwei Stellen nach dem Dezimalstellen genau in das Antwortfeld ein. Sie würden also vier Felder benötigen, wenn etwa „5,43“ Ihre Lösung wäre, denn das Dezimalkomma muss auch hier wieder ein eigenes Feld belegen. Vergessen Sie nicht, Ihre Antwort rechtzeitig vor dem Ende der Klausur auf den Markierungsbogen zu übertragen. (numerisch) α b= Lösung: Es ist α b = y − βb · x. Aus den Daten erhält man x = 7 und y = 2, 5 und folglich α b = 2, 5 − (−0, 34) · 7 = 2, 5 + 2, 38 = 4, 88. Anmerkung: Bei der maschinellen Auswertung wurden Werte von 4, 87 bis 4, 89 als richtig anerkannt. Wenn allerdings anstelle von 4, 88 der Wert 0, 12 als Lösung eingetragen wurde, wurde nur ein Punkt abgezogen (Vergabe von 3 Punkten), weil hier offenbar nur ein Vorzeichen übersehen wurde und fälschlich α b = 2, 5−0, 34·7 = 2, 5 − 2, 38 gerechnet wurde. 16 Aufgaben zu Statistik 2 Aufgabe 12 (Moderator- und Mediatorvariablen) In der Psychologie werden häufig multivariate Zusammenhänge untersucht. Dabei werden u.a. sogenannte Moderator- und Mediatorvariablen berücksichtigt. Bei der statistischen Analyse solcher Zusammenhänge erhält man beispielsweise die nachfolgenden SPSSTabellen. Tabelle 1: Koeffizientena Standardisierte Nicht standardisierte Koeffizienten Koeffizienten Regressionskoeffizient Modell 1 B Standardfehler (Konstante) X1 -1,121 ,855 1,644 ,374 T Beta ,566 Sig. -1,311 ,197 4,401 ,000 a. Abhängige Variable: X2 Tabelle 2: Koeffizientena Standardisierte Nicht standardisierte Koeffizienten Koeffizienten Regressionskoeffizient Modell 1 B Standardfehler (Konstante) X1 2,932 ,399 ,446 ,175 T Beta ,371 Sig. 7,341 ,000 2,554 ,014 a. Abhängige Variable: Y Tabelle 3: Koeffizientena Standardisierte Nicht standardisierte Koeffizienten Koeffizienten Regressionskoeffizient Modell 1 B (Konstante) Standardfehler 3,012 ,408 X1 ,329 ,212 X2 ,071 ,073 T Beta Sig. 7,382 ,000 ,274 1,554 ,128 ,171 ,971 ,338 a. Abhängige Variable: Y 1 Welche der nachfolgenden Aussagen zu Moderatoren und Mediatoren sind richtig? A Grundsätzlich, d.h. unabhängig von den oben abgebildeten SPSS-Tabellen, liegt ein Moderatoreffekt vor, wenn die Enge des Zusammenhangs zwischen einer Prädiktorvariable (erklärende Variable, Regressor) und einem Response von der Ausprägung einer anderen erklärenden Variable abhängt. B Grundsätzlich, d.h. unabhängig von den oben abgebildeten SPSS-Tabellen, liegt ein Mediatoreffekt vor, wenn die Interaktion einer Prädiktorvariable mit einer anderen erklärenden Variable einen Response „beeinflusst“. C Aus den SPSS-Tabellen geht ein vollständiger Mediationseffekt von X2 hervor. D Aus den SPSS-Tabellen geht ein Moderatoreffekt von X2 hervor. E Aus der ersten SPSS-Tabelle geht hervor, dass der Prädiktor X1 mit dem potentiellen Mediator X2 korreliert ist. Lösung: A, E (vgl. Statistik 2, S. 81f sowie SPSS-Outputs mit Erläuterungen) Aufgabe 13: (Multiple Regression) Welche Aussagen zum Konzept der Multikollinearität sind richtig? A Multikollinearität liegt vor, wenn zwischen den Prädiktorvariablen in einem multiplen Regressionsmodell lineare Abhängigkeiten bestehen. B Multikollinearität liegt vor, wenn die Prädiktorvariablen in einem multiplen Regressionsmodell linear unabhängig sind. C Die Toleranz einer Prädiktorvariablen sei 0,852; dies weist auf starke Multikollinearität hin. D Konditionsindizes zwischen 10 und 30 indizieren mäßige Multikollinearität. E Multikollinearität beeinträchtigt die Interpretation der Regressionskoeffizienten. Lösung: A, D, E (Erläuterungen zu Kapitel 3 sowie SPSS-Outputs) 2 Aufgabe 14 (Varianzanalyse) Welche der nachfolgenden Aussagen sind richtig? A Einfaktorielle Varianzanalysen mit festen Effekten und einfaktorielle Varianzanalysen mit zufälligen Effekten basieren auf derselben Modellgleichung. B Der Scheffé-Test wird angewendet, um a priori festgelegte Unterschiede zwischen den Treatmentgruppen in einer Varianzanalyse zu prüfen. C In einer zweifaktoriellen Varianzanalyse können 3 voneinander unabhängige Nullhypothesen geprüft werden. D Bei der Zerlegung der totalen Quadratsumme SQTotal im Rahmen einer einfaktoriellen Varianzanalyse ist SQinnerhalb die Treatmentquadratsumme, die den Behandlungseffekt repräsentiert, und SQzwischen die Fehlerquadratsumme. E Die Kontrastkoeffizienten in der nachfolgenden SPSS-Tabelle zeigen, dass die zu den Behandlungen X1 – X4 konstruierten Kontraste 1 und 2 orthogonal sind. Kontrast-Koeffizienten Behandlung Kontrast X1 X2 X3 X4 1 1 -1 0 0 2 0 0 1 -1 Lösung: A, C, E (vgl. Statistik 2, S. 159 (Lösung A); S. 149f (falsche Antwort B), S. 206ff (Lösung C); S. 129 (falsche Antwort D), S. 138f (Lösung E) Aufgabe 15 (Rangvarianzanalyse) Welche Aussagen zur Rangvarianzanalyse sind richtig? A In der Rangvarianzanalyse müssen die Responsewerte normalverteilt sein. B Die Testgröße H des der Rangvarianzanalyse zugrunde liegenden Tests (KruskalWallis-Test) ist ein Maß für die Varianz der Stichprobenmittelwerte C Beim Kruskal-Wallis-Test aus Aufgabenteil B beinhaltet die Nullhypothese H0, dass alle Stichproben aus derselben Population stammen. D Beim Kruskal-Wallis-Test aus Aufgabenteil B beinhaltet die Alternativhypothese H1, dass alle Stichproben aus unterschiedlichen Population stammen. 3 E In der nachfolgenden Tabelle sind Fremdeinschätzungen der sozialen Kompetenz, die in Auswahlgesprächen mit Studierenden der Fächer A, B und C auf einer Skala von 1- 10 vorgenommen wurden, aufgelistet. Aus den Daten geht hervor, dass in der Rangvarianzanalyse Hkorr anstelle von H als Teststatistik bestimmt werden muss (Lösungshinweis: Hkorr bezeichnet eine bei Auftreten von Bindungen zu verwendende korrigierte Fassung von H). Einschätzungen der sozialen Kompetenz Studierende Fach A Studierende Fach B Studierende Fach C 2 4 1 5 10 9 4 8 3 6 6 3 8 9 2 4 4 6 3 5 2 Lösung: C, E: S. 162f (falsche Antwort A), S. 164 (falsche Antwort B, es geht um Rangmittelwerte! Und falsche Antwort D, mindestens 2, aber nicht unbedingt alle Stichproben stammen aus unterschiedlichen Populationen ), S. 164, 165 (richtige Antworten C und E), 4 Aufgabe 16 (Varianzanalyse mit Messwiederholungen) Es werden 2 Trainingsprogramme zur Verbesserung der sozialen Kompetenz über p = 3 Messzeitpunkte (A, B, C) mit jeweils n1 = n2 = 8 Probanden verglichen. Beim ersten Messzeitpunkt A wird die soziale Kompetenz vor dem jeweiligen Trainingsprogramm erfasst, beim zweiten Messzeitpunkt B nach der Durchführung der jeweiligen Trainingsprogramme und beim dritten Messzeitpunkt C einen Monat nach dem Trainingsende. Eine mit SPSS durchgeführte Varianzanalyse mit Messwiederholungen liefert die folgenden Tabellen. Deskriptive Statistiken Standardabweich Training A B C Mittelwert ung N 1 7,00 2,726 8 2 8,50 2,204 8 Gesamt 7,75 2,517 16 1 12,00 5,071 8 2 21,25 4,979 8 Gesamt 16,63 6,811 16 1 15,00 4,899 8 2 25,25 4,166 8 Gesamt 20,13 6,879 16 Mauchly-Test auf Sphärizitätb Maß:MASS_1 Epsilona Approximiertes Innersubjekteffekt Mauchly-W Messzeitpunkte ,809 Chi-Quadrat 2,750 Greenhousedf Sig. 2 ,253 Geisser ,840 Huynh-Feldt Untergrenze 1,000 ,500 5 Tests der Innersubjekteffekte Maß:MASS_1 Quadratsumme Quelle Messzeitpunkte vom Typ III Sphärizität Mittel der df Quadrate F Sig. 1302,167 2 651,083 62,220 ,000 Greenhouse-Geisser 1302,167 1,680 775,206 62,220 ,000 Huynh-Feldt 1302,167 2,000 651,083 62,220 ,000 Untergrenze 1302,167 1,000 1302,167 62,220 ,000 183,500 2 91,750 8,768 ,001 Greenhouse-Geisser 183,500 1,680 109,241 8,768 ,002 Huynh-Feldt 183,500 2,000 91,750 8,768 ,001 Untergrenze 183,500 1,000 183,500 8,768 ,010 293,000 28 10,464 Greenhouse-Geisser 293,000 23,517 12,459 Huynh-Feldt 293,000 28,000 10,464 Untergrenze 293,000 14,000 20,929 angenommen Messzeitpunkte * Sphärizität Training angenommen Fehler(Messzeitpunkte) Sphärizität angenommen Tests der Zwischensubjekteffekte Maß:MASS_1 Transformierte Variable:Mittel Quadratsumme Quelle Konstanter Term vom Typ III Mittel der df Quadrate F Sig. 10561,333 1 10561,333 339,125 ,000 Training 588,000 1 588,000 18,881 ,001 Fehler 436,000 14 31,143 6 Welche der nachfolgenden Aussagen zu der mit SPSS durchgeführten Varianzanalyse mit Messwiederholungen sind richtig? A Der Mauchly-Test lehnt Sphericity ab. B Die soziale Kompetenz nimmt über die 3 Messzeitpunkte signifikant zu. C Die beiden Trainingsprogramme unterscheiden sich nicht signifikant im Hinblick auf die Verbesserung der sozialen Kompetenz. D Die soziale Kompetenz verbessert sich über die 3 Messzeitpunkte und die beiden Trainingsprogramme signifikant unterschiedlich. E Bei der Prüfung der Innersubjekteffekte können die unkorrigierten F-Werte herangezogen werden. Lösung: B, D, E: S. 246ff (richtige Antwort E und falsche Antwort A), Beispiel 8.1, S. 251, restliche Alternativen (vgl. auch die eingestellte MC-Aufgabe zu Kapitel 8) 7