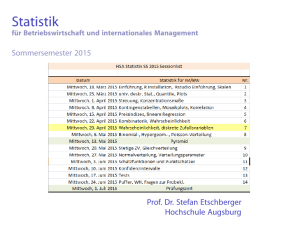
Häufigkeitsverteilungen
Werbung

Statistik I WS2004/05 Becker/Lautsch Häufigkeitsverteilungen Eine Häufigkeitsverteilung gibt die Verteilung eines erhobenen Merkmals an und ordnet jeder Ausprägung die jeweilige Häufigkeit zu. Bsp.: 100 Studenten werden gefragt, was sie studieren. Es ergibt sich folgende Verteilung: Anzahl Fach Psychologie 12 23 Erziehungswissenschaften Soziologie 45 Anglistik 3 Physik 17 % 12 23 45 3 17 kum. % 12 35 80 83 100 das zugehörige Balkendiagramm: 50 40 30 Absolute Werte 20 10 0 Psychologie Soziologie Erziehungswissenscha Physik Anglistik FACH Mit Häufigkeitsverteilungen werden statistische Daten dargestellt. Statistik I WS2004/05 Becker/Lautsch Theoretische Verteilungen Theoretische Verteilungen geben an, wie in ideellen Fall die Verteilung eines Merkmals in einer Stichprobe zu erwarten wäre. Bsp.: Typischerweise verteilen sich die Studenten in den Fächern Psychologie, Soziologie, Wirtschaftswissenschaften 2:1:2, also würde man beim Herausgreifen von 100 Studenten der zugehörigen Fachbereiche die folgende Verteilung erwarten: Anzahl Fach Psychologie 40 Soziologie 20 40 Wirtschaftswissenschaften % 40 20 40 kum. % 40 60 100 das zugehörige Balkendiagramm: 50 40 Absolute Werte 30 20 10 Psychologie Wirtschaftswissensch Soziologie TEST Mit theoretischen Verteilungen werden statistische Daten weiterverarbeitet und interpretiert. Statistik I WS2004/05 Becker/Lautsch Zufallsvariablen Definition: Eine Zufallsvariable ist eine Funktion, die jedem Ereigniss eines Zufallsexperiments eine reele Zahl zuordnet. Jenachdem, wie man die vorliegenden Daten interpretieren will, wählt man die zu betrachtenden Zufallsvariablen. Man kann zu jedem Experiment mehrere Zufallsvariablen betrachten. Man unterscheidet zwischen diskreten (ganzzahligen) und stetigen oder kontinuierlichen (fortlaufenden) Zufallsvariablen. Zwar scheinen diskrete Verteilungen auf den ersten Blick einfacher, sind aber rechentechnisch wesentlich schwerer zu handhaben als stetige Verteilungen. Verteilungsfunktion Definition: Eine Verteilungsfunktion ordnet jedem Wert einer Zufallsvariablen die Wahrscheinlichkeit zu, dass dieser Wert von der Zufallsvariablen angenommen wird. Bei stetigen Zufallsvariablen ist die Verteilungsfunktion i.A. eine stetige Funktion, d.h. sie kann ganz normal mit Mitteln wie Grenzwertbildung, Differenzieren, etc. behandelt werden. Statistik I WS2004/05 Becker/Lautsch Bsp.: Man betrachtet die Summe des Würfelns mit zwei Würfeln, diese reicht von 2 bis 12, wobei die mittleren Werte am wahrscheinlichsten sind: Summe Anzahl Ergebnisse 2 1 (1;1) 3 2 (1;2); (2;1) 4 3 (1;3); (2;2); (3;1) 5 4 (1;4); (2;3); (3;2); (4;1) 6 5 (1;5); (2;4); (3;3); (4;2); (1;5) 6 (1;6); (2;5); (3;4); (4;3); (5;2); (6;1) 7 8 5 (2;6); (3;5); (4;4); (5;3); (6;2) 4 (3;6); (4;5); (5;4); (6;3) 9 10 3 (4;6); (5;5); (6;4) 11 2 (5;6); (6;5) 12 1 (6;6) 7 6 5 4 Absolute Werte 3 2 1 0 2 3 SUMME 4 5 6 7 8 9 10 11 12 % kum. % 2,78 2,78 5,56 8,33 8,33 16,67 11,11 27,78 13,89 41,67 16,67 58,33 13,89 72,22 11,11 83,33 8,33 91,67 5,56 97,22 2,78 100 Statistik I WS2004/05 Becker/Lautsch Einige Verteilungen Binomialverteilung Die Binomialverteilung beschreibt ein mehrfach wiederholtes Experiment mit nur zwei Ereignissesn, bspw. Münzwürfe Multinomiale Verteilung Die Multinomiale Verteilung ist eine Verallgemeinerung der Binomialverteilung, sie beschreibt wiederholte Experimente mit mehreren Ausgängen. Hypergeometrische Verteilung Die Hypergeometrische Verteilung dient der Beschreibung eines Merkmals in einer Stichprobe aus einer verhältnismäßig kleinen Grundgesamtheit. Poisson-Verteilung Die Poisson-Verteilung benutzt man bei der Betrachtung seltener Ereignisse Für die Anwendung in den Gesellschafts- und Sozialwissenschaften besonders wichtig ist die: Normalverteilung Die Normalverteilung ist eine Modellvorstellung für die Verteilung eines Merkmals in der Gesamtheit - z.B. Intelligenz. Ihre besondere Bedeutung liegt darin, dass sie schon bei kleinen Stichproben eine sehr gute Annäherung an die reale Verteilung bietet und mathematisch gut verwendbar ist. Ebenso gehen die Poisson-Verteilung, die Hypergeometrische Verteilung und die Binomialverteilung (p = 0, 5) für n → ∞ in die Normalverteilung über. Statistik I WS2004/05 Becker/Lautsch Binomialverteilung Für die Binomialverteilung gilt folgende Formel: Die Wahrscheinlichkeit, bei n Wiederholungen genau k-mal das Ereignis mit der Wahrscheinlichkeit p zu erhalten beträgt: P (X = k) = nk · pk · (1 − p)n−k Bsp.: 3mal würfeln mit einem Würfel. Die Wahrscheinlichkeiten dafür, k Vieren zu würfeln: Formel % kum. % 1 0 5 3 3 57,9 57,9 · 6 0 · 6 3 1 1 5 2 · · 34,7 92,6 1 6 6 3 1 2 5 1 · · 6,9 99,5 2 6 6 3 1 3 5 0 · · 0,5 100 3 6 6 Anzahl Vieren 0 1 2 3 das zugehörige Balkendiagramm: 140 120 100 80 Absolute Werte 60 40 20 0 0 ANZAHL 1 2 3 Statistik I WS2004/05 Becker/Lautsch Multinomiale Verteilung Für die Multinomiale Verteilung gilt folgende Formel: Die Wahrscheinlichkeit, bei N Wiederholungen genau (n1, . . . , nK )-mal das Ereignis 1, . . . , K (jeweils mit den Einzelwahrscheinlichkeiten (p1, . . . , pK )) zu erhalten beträgt: N! n · pn1 1 · pn2 2 · . . . · pKK . P (X = (n1, . . . , nK )) = n1 ! · n2 ! · . . . · nK ! Bspw. denke man daran, Kugeln mehrerer Farben aus einer Urne zu ziehen. Hypergeometrische Verteilung Für die Hypergeometrische Verteilung gilt folgende Formel: Beim Ziehen einer Stichprobe der Größe n aus einer Grundgesamtheit N beträgt die Wahrscheinlichkeit, k von K Merkmalsträger zu ziehen: K N −K P (X = k) = k n−k N n Z.B.: Ziehen aus einer Urne ohne Zurücklegen Poisson-Verteilung Für die Poisson-Verteilung gilt folgende Formel: Bei bekanntem Mittelwert λ ein k-maliges Auftreten eines Ereignisses zu beobachten, hat die Wahrscheinlichkeit: λk −λ e P (X = k) = k! Statistik I WS2004/05 Becker/Lautsch Schätzung Die „Werte“ der Population werden mit µ für Mittelwert und σ für die Standardabweichung bezeichnet. In der Statistik werden entsprechend x und s verwendet. Oft möchte man aufgrund einer oder mehreren Stichproben eine Schätzung über die Verteilung in der Gesamtpopulation abgeben. Dabei wird man u.a. fordern, dass eine Schätzung erwartungstreu ist. Schließlich ergibt sich: • Der Mittelwert der Stichproben nähert sich bei steigender Stichprobenzahl dem Mittelwert der Gesamtpopulation an: E(x) = µ s • Für die Varianz der Stichproben gilt: √ liefert einen N −1 guten Schätzwert für die Varianz der Gesamtheit Statistik I WS2004/05 Becker/Lautsch Normalverteilung – N(µ, σ) Die Normalverteilung ist gegeben durch die Formel: (x − µ)2 − 1 2σ 2 f (x) = √ · e σ 2π 0.4 0.3 0.2 0.1 (Standard-) Normalverteilung (µ = 0; σ = 1)) -4 -2 4 2 0.8 0.6 0.4 0.2 gestauchte/gestreckte Normalverteilung (µ = 0; σ = 0.5 bzw. 2)) -2 -1 1 2 0.2 0.15 0.1 0.05 gestauchte/gestreckte Normalverteilung (µ = 0; σ = 0.5 bzw. 2)) -4 -2 2 4 Statistik I WS2004/05 Becker/Lautsch Standardnormalverteilung – N(0, 1) In den meisten Fällen benutzt man die sog. z-Transformation z = x−µ σ , um die betrachtete Normalverteilung N(µ, σ) in die Standardnormalverteilung N(0, 1) zu überführen. - Es ist schließlich einfacher, immer mit der gleichen Verteilung mathematisch arbeiten zu können und sie nur noch interpretieren zu müssen, als jedesmal alles neu zu berechnen (oder berechnen zu lassen). 0.4 0.3 0.2 0.1 (Standard-) Normalverteilung (µ = 0; σ = 1)) -4 -2 2 4 Der Graph der Standardnormalverteilung ist gegeben durch 2 1 − x2 √ f (x) = 2π · e Statistik I WS2004/05 Becker/Lautsch Normalverteilung – N(µ, σ) Typische Eigenschaften der Normalverteilung sind: • Die Verteilung hat einen glockenförmiger Verlauf. • Die Verteilung ist symmetrisch. • Modalwert, Median und Erwartungswert fallen zusammen. • Die Verteilung nähert sich asymptotisch (d.h. für x → ±∞) der x-Achse. • Zwischen den zu den Wendepunkten gehörenden x-Werten befindet sich ca. 23 der Gesamtfläche. Ihre Bedeutsamkeit zeigt sich in vier Aspekten: • die Normalverteilung als empirische Verteilung • die Normalverteilung als Verteilungsmodell für statistische Kennwerte • die Normalverteilung als mathematische Basisverteilung • die Normalverteilung in der statistischen Fehlertheorie Statistik I WS2004/05 Becker/Lautsch Stichprobenkennwerteverteilung Stichprobenmittelwertverteilung σ2 Standardabweichung σx = , auch genannt Standardfehler. n Der Standardfehler (σx) des Mittelwerts (x) ist als die Standardabweichung der Mittelwerte von gleichgroßen Zufallsstichproben einer Population definiert. Der Standardfehler kann durch die folgende Formel geschätzt werden: n X (xi − x)2 σ bx2 = i=1 n−1 Es ist bekannt, dass sich bspw. im Bereich µ ± 2 · σ ca. 95,5% aller Meßwerte befinden. Wir können also sagen, dass sich Mittelwerte aus Zufallsstichproben mit einer Wahrscheinlichkeit von ca. 95,5% im Bereich µ ± 2 · σx befinden. Das zentrale Grenzwerttheorem (Bernoulli-Theorem, siehe Übungen) besagt nun, dass der Mittelwert der Stichprobenmittelwertverteilung (xx) sich mit wachsender Anzahl der Stichproben dem Mittelwert der Grundgesamtheit µ immer weiter nähert. Es gilt: n→∞ xx −→ µ Statistik I WS2004/05 Becker/Lautsch Testung von Hypothesen Die Überprüfung von Vermutungen über die Grundgesamtheit mit Hilfe von Zufallsstichproben ist eine wichtige Aufgabe der schließenden Statistik. Man spricht in diesem Zusammenhang von Hypothesentests. Die Alternativhypothese • Unterschieds- und Zusammenhangshypothesen • Gerichtete und ungerichtete Hypothesen • Spezifische und unspezifische Hypothesen • Statistische Hypothesen Die Nullhypothse Die Nullhypothese ist eine Negativhypothese, mit der behauptet wird, dass die zur Alternativhypothese komplementäre Aussage richtig sei. Signifikanzniveau und Fehler: α- und β-Fehler Entscheidung auf Grund der Stichprobe zugunsten der H0 H1 In der Population gilt die: H0 H1 richtige β-Fehler Entscheidung richtige α-Fehler Entscheidung Statistik I WS2004/05 Becker/Lautsch Testung von Hypothesen II Mögliche Hypothesenpaare: (bezogen auf den Vergleich von Mittelwerten) H 1 : µ0 > µ 1 H 0 : µ0 ≤ µ1 H 1 : µ0 < µ 1 H 0 : µ 0 ≥ µ 1 H 1 : µ0 = 6 µ1 H 0 : µ0 = µ1 In ähnlicher Weise formuliert man statistische Hypothesen, die sich auf Zusammenhänge beziehen (z.B. H1 : ρ > 0; H0 : ρ ≤ 0) Statistik I WS2004/05 Becker/Lautsch Beispiel: t-Test für abhängige Stichproben Studenten sollen schätzen, wie viele von 8 Testaufgaben sie richtig beantwortet haben: Vp 1. Stichprobe 2. Stichprobe Schätzung Ergebnis 1 4 5 6 4 2 3 5 5 4 3 4 5 7 4 n P Es ergeben sich: n P d2i = 15, xd = i=1 σ bd = v n 2 u P u u n di uP 2 u di − i=1 t i=1 n n−1 q = di i=1 5 15− −0,6 5 4 di d2i +1 -2 0 +1 -3 1 4 0 1 9 3 = − sowie 5 = 1, 94 und σ bd σ bxd = √ ≈ 0, 87 5 Damit erhalten wir als Prüfgröße: temp = Aus der Tabelle ergibt sich: t(4; 2,5%) = −2, 776 und t(4; 97,5%) = 2, 776 U-Test und Wilcoxon-Test xd −0, 6 = = −0, 69 σ bxd 0, 87 Statistik I WS2004/05 Becker/Lautsch Gruppe 1 Gruppe 2 Schüler Rangplatz Schüler Rangplatz 1 8 1 12,5 2 3 2 21 3 9,5 3 6,5 4 5 4 9,5 5 14 5 12,5 6 3 6 18 7 6,5 7 17 8 11 8 20 9 1 9 3 10 15 10 3 11 19 T1 = 76 T2 = 155 (1) (2) (3) (4) vorher nachher di Rangplatz von |di| Betrieb 1 8 4 4 7,5 2 23 16 7 10 3 7 6 1 2 4 11 12 -1 2(-) 5 5 6 -1 2(-) 6 9 7 2 4,5 7 12 10 2 4,5 8 6 10 -4 7,5(-) 9 18 13 5 9 10 9 6 3 6 Summe der (-) Ränge: T = 11, 5 Summe der Ränge: T 0 = 43, 5 Statistik I WS2004/05 Becker/Lautsch Überprüfung von Korrelationshypothesen Ob eine empirisch ermittelte Korrelation mit der H0 : ρ = 0 zu vereinbaren ist, läßt sich mit dem folgenden Signifikanztest überprüfen: √ r· n−2 t= √ 1 − r2 t-verteilt, Freiheitsgrade df = n − 2 Ist man daran interessiert zu überprüfen, ob sich die Korrelationen, die für zwei unabhängige Stichproben (Umfänge n1, n2) ermittelt wurden signifikant unterscheiden, verwendet man den z-Wert (Standard-Normalverteilung): Z1 − Z 2 z= σ(Z1−Z2) q 1 + r i σ(Z1−Z2) = n11−3 + n21−3 ; Zi = 12 ln (tabelliert) 1 − ri Die punktbiseriale Korrelation erfaßt den Zusammenhang zwischen einem dichotomen Merkmal und einem intervallskalierten Merkmal . Die Signifikanzüberprüfung (H0 : ρ = 0) erfolgt durch folgenden Test: rpb t=s 2 1 − rpb n−2 t-verteilt, Freiheitsgrade df = n − 2 r y − y0 n0 · n1 mit rpb = 1 · sy n2 Statistik I WS2004/05 Becker/Lautsch Überprüfung von Korrelationshypothesen Die Korrelation zwischen zwei dichotomen Merkmalen mißt der Phi-Koeffizient Φ. Er läßt sich aus der zugehörigen Vierfeldertafel berechnen, die Signifikanzüberprüfung erfolgt über den 4-Felderχ2-Test: a·d−b·c Φ=p (a + c)(b + d)(a + b)(c + d) χ2 = n · Φ2, (df = 1) Der Zusammenhang zweier ordinalskalierter Merkmale wird durch die Rangkorrelation nach Spearman erfaßt. Mit di = Differenz der Rangplätze, die eine Untersuchungseinheit i bezüglich der Merkmale erhalten hat, ergibt sich: n P 6 · d2i i=1 rs = n · (n2 − 1) Die H0 : ρs = 0 kann für n ≥ 30 approximativ durch folgenden t-Test überprüft werden: rs t=r 1 − rs2 n−2 t-verteilt, Freiheitsgrade df = n − 2