Normalverteilung - mmm.ethz.ch
Werbung

Metrologie
Wissenschaft und Technik des Messens
Kontakt mit dem Autor
© Copyright
ETH Zürich, Schweiz
Institut für Werkzeugmaschinen und Fertigung
Mitarbeit
d0000358; rev01
Modul
Normalverteilung
Karl H. Ruhm
Inhalt
Einleitung
1
Normalverteilung in der Stochastik
2
Standardnormalverteilung
3
Normalverteilung in der Statistik
4
Test auf Normalverteilung
5
Nutzen der Normalverteilung
Zusammenfassung, Ausblick
1
2
4
4
5
5
5
Schlüsselwörter
Verteilung, Normalverteilung, Gauß-Verteilung, Wahrscheinlichkeitsdichtefunktion, Verteilungsdichtefunktion,
arithmetischer Mittelungswert, Varianz, Standardabweichung, Nominalverteilung, Hypothese, Stochastik,
Statistik
Kurzbeschreibung
Eine der wichtigsten Verteilungen ist die Normalverteilung, auch wenn deren Annahme häufig nicht gerechtfertigt ist. Sie ist Ausgangspunkt unzähliger Varianten. Die Eigenheiten der Verteilung werden dargestellt.
Einleitung
Die Normalverteilung (Gauß-Verteilung; normal distribution) ist in der grafischen Form der Glockenkurve eine
der bekanntesten und ältesten Verteilungen (de Moivre (1733), Gauß (1812), Laplace (1812)).
Carl Friedrich Gauß (1777 – 1855)
Sie kann aus verschiedenen Blickwinkeln betrachtet werden. Die wichtigsten Bereiche sind Physik, Stochastik und Statistik sowie Signal- und Systemtheorie.
Stochastik und Statistik
Die Normalverteilung nimmt eine Sonderstellung ein. Mit Hilfe des Grenzwertsatzes der Stochastik kann man
zeigen, dass die Überlagerung vieler, beliebig verteilter Zufallsvorgänge tendenziell zu einer Zufallsvariable
mit Normalverteilung führt. Es ist deshalb in der Stochastik oft gerechtfertigt, bei komplexeren Vorgängen
Normalverteilung anzunehmen.
Hinzu kommt, dass die mathematische Beschreibungsform der Normalverteilung viele angenehme Eigenschaften hat, was von anderen Verteilungen nicht behauptet werden kann.
Im Umgang mit Messdaten (Statistik) sollte man beurteilen können, welche Verteilungsform hinter einem Datensatz stecken könnte. Besonders für eine nichtlineare Parameteridentifikation (Regressionsanalyse) ist es
wichtig, die richtige Hypothese für die Verteilungsform gewählt zu haben.
Signal- und Systemtheorie
Die Normalverteilungsdichtefunktion der Stochastik ist vom Standpunkt der Mathematik und der Signaltheorie aus gesehen eine Impulsfunktion (Glockenkurve). Impulsfunktionen spielen in Wissenschaft und Technik
eine große Rolle. In der Signaltheorie gehören sie zur Klasse der Energiesignale, deren Signalenergie (Fläche unter der quadrierten Funktion) endlich ist (Zusatz → Modul " Leistung und Energie von Signalen").
Insofern ist die Behandlung der Normal-Verteilungsdichtefunktion in einem größeren Rahmen zu sehen. Viele dieser Impulsfunktionen sind durch irgendwelche Transformationen miteinander verwandt. Zum Teil sind
sie sehr ähnlich. Dies ist sowohl in der Theorie als auch in den Anwendungen interessant. Selbst die Impulsfunktion (uneigentliche Funktion, Distribution) kann aus den üblichen geraden Impulsfunktionen als
Grenzfall hervorgehen.
2
Wichtig ist die Frage nach der Wirkung von Zufallsvariablen auf dynamische Prozesse. Kann man hier rechnen, simulieren, prognostizieren? Die Signal- und Systemtheorie bietet eine umfangreiche Werkzeugpalette.
Zusammen mit der Verteilung des Gleichsignals und des harmonischen Signals ist die Normalverteilung die
einzige Funktion, deren Form sich bei der Übertragung durch lineare dynamische Systeme nicht ändert, eine
besonders angenehme Eigenschaft.
Didaktische Spielwiese
Dies alles erklärt, warum die Normal-Verteilung bevorzugt als Lehr- und Übungsobjekt eingesetzt wird. Sie
lässt auch eine genügende und nachvollziehbare Tiefe bei der Ergründung der Stochastik zu.
Andere Verteilungen haben andere, individuelle Eigenschaften, werden aber prinzipiell nach denselben Methoden wie bei der Normalverteilung behandelt.
Vorgehen
In den folgenden Abschnitten findet man wichtige Beziehungen über die normalverteilte Eingrößenverteilungsdichtefunktion. Die Behandlung des Themas erfolgt primär im Bereich der Stochastik, bei der keine Daten zur Auswertung vorliegen. Die Zufallsvariable x sei wertkontinuierlich. Es besteht keine Zeitabhängigkeit
(Zusatz → Modul "Ensemble und Muster von Signalen").
Dies sind erste idealisierende Annahmen. Sie sind einer Erweiterung jedoch nicht hinderlich. Insbesondere
ist der Übergang zur allgegenwärtigen, diskreten Zufallsvariable einfach möglich (Zusatz → Modul "Häufigkeiten, Wahrscheinlichkeiten klassierter Daten"). Er benötigt keinen weiteren methodischen Aufwand.
1
Normalverteilung in der Stochastik
Die Normalverteilung gehört als Verteilung einer wertkontinuierlichen Zufallsvariable zu den wertkontinuierlichen Verteilungen. Sie wird demnach durch eine Wahrscheinlichkeitsdichtefunktion pd(x) beschrieben, denn
die Wahrscheinlichkeit, dass man einen bestimmten Wert xn aus dem unendlich großen Wertevorrat antrifft,
ist gleich Null. Hingegen haben wir die endlich wahrscheinliche Chance, dass ein bestimmter Wert xn in einem bestimmten Intervall xa < xn < xb auftritt.
Im Bereich der Stochastik (Vorwärtsanalyse) ergeben sich die mathematischen Strukturen von Verteilungen
aus der Modellbildung von Zufallsvorgängen mit Hilfe der Wahrscheinlichkeitstheorie. Dies ist auch bei der
Normalverteilung der Fall. Aus grundsätzlichen Überlegungen ergibt sich häufig, dass gewisse Zufallsvorgänge die Struktur der Normalverteilungsdichtefunktion besitzen müssen.
Diese Struktur dient dann in der Statistik (Rückwärtsanalyse) bei der Auswertung von Datenmaterial als
Hypothese (Erwartungsfunktion). Ein Hypothesetest (Verifikation) muss nach der Datenanalyse zeigen, ob
die Wahl dieser speziellen Verteilung auch wirklich gerechtfertigt war.
Entwicklung der Funktion
Der Grenzwertsatz der Stochastik (central limit theorem) zeigt, dass die mathematische Grundstruktur der
normalverteilten Verteilungsdichtefunktion eine der bekannten Varianten der Exponentialfunktion ist.
2
y ex
Sie entspricht der vertrauten Glockenkurve und hat verschiedene angenehme mathematische Eigenschaften.
Das Integral dieser Funktion ist eines der wichtigen Integrale der Mathematik.
A tot
x 2
e
Eine Variante dieses Integrals ist die mathematisch neutrale Fehlerfunktion err(x) (error function) mit der typischen S-Form.
Definition: Fehlerfunktion
err(x)
e
x2
dx
Dieses Integral ist nicht elementar lösbar. Durch numerische Integration erhält man diskrete Funktionswerte
in beliebig fein tabellierter Form.
Anpassung der Funktion
Wir benötigen nun kennzeichnende Parameter. Die Gleichung muss einheitenkonform sein und zudem müssen die Bedingungen für eine Wahrscheinlichkeitsdichtefunktion erfüllt sein. Die Grundfunktion wird ergänzt.
Der Faktor 1/2 im Exponent kommt direkt aus dem Grenzwertsatz. x ist die Zufallsvariable und y wird die gesuchte Verteilungsdichtefunktion sein. Die beiden freien Parameter berücksichtigen die physikalische Einheit
der Zufallsvariablen und der gesuchten Verteilungsdichtefunktion. Sie sind so zu bestimmen, dass das Integral (Fläche Atot) unter der Funktion gerade gleich eins ist. Dies bedeutet, dass die Wahrscheinlichkeit, dass
3
ein Ereignis zwischen –∞ und +∞ auftritt, eins beziehungsweise hundert Prozent ist. Dies führt nun zur
bekannten Form der Normalverteilungsdichtefunktion (Gauß-Verteilungsdichtefunktion) (Zusatz → Modul
"Kennwerte der Normalverteilung").
Definition: Normalverteilungsdichtefunktion
pd (x)
–
1
2x
2
e
1 (x x )2
2 2x
[{x 1}]
gültig für
x
Bemerkung
Bei der Bezeichnung der Wahrscheinlichkeitsdichte pd [{x–1}] wurde bewusst das "d" für «Dichte» angefügt,
um sie deutlich von der Wahrscheinlichkeit p [–] zu unterscheiden.
Parameter
Die beiden Kennwerte Parameter legen die Funktion vollständig fest:
der arithmetische Mittelungswert x [{x}] als Lagemaß
(Positionsparameter; arithmetic mean, measure of position)
die Standardabweichung x [{x}] als Streuungsmaß
(Dispersionsparameter; standard deviation, measure of dispersion)
•
•
Daher schreibt man oft präzisierend pd(x, x, x) oder auch (x, x, x).
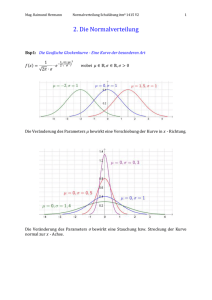
Je größer die Standardabweichung x ist, umso flacher verläuft die Funktion und umso tiefer liegt das Maximum pdmax, da die Fläche A unter der Kurve immer gleich eins sein muss. Das heißt, die genaue Form der
Funktion hängt nur von der Standardabweichung x ab (Zusatz → Animation "Normalverteilung").
p d/ x – 1
0.48
σx
Wendetangenten
0.40
σx
0.24
σx
Wendepunkt
A tot = 1
B0215
p d (x)
μx – 2σx
μ x– σ x
μx
μ x + σx
μ x +2σx
x [{x}]
Zufallsvariable
Rund 68% der Werte fallen in den Bereich (x ± x), je rund 16% auf die beiden Randzonen (siehe Tabelle).
Persönliche Bemerkung
Diese rein mathematischen Eigenschaften prägen viele Bereiche des Zufallsprozesses "Tägliches Leben".
Falls man sich nämlich auf Wertungen irgendwelcher Eigenheiten und Vorgänge einlässt, dann kann dies
zum Beispiel bedeuten, dass davon rund zwei Drittel als "mittelmäßig" zu bezeichnen sind, dass rund ein
Sechstel als "katastrophal" erscheint und dass nur rund ein Sechstel als "hervorragend" auftritt.
Skizze
Die Glockenfunktion lässt sich mit Hilfe weniger Hilfspunkte leicht skizzieren: Es existieren zwei Wendetangenten, die mit der asymptotischen Abszisse ein gleichschenkliges Dreieck bilden. Die Fußpunkte liegen bei
(x – 2x) und (x + 2x) sowie die Spitze bei rund 0.48/x. Das Maximum der Funktion finden wir bei etwa
0.4/x. Man erhält es, indem man für den Funktionswert x den arithmetischen Mittelungswert x einsetzt. Die
Exponentialfunktion wird dabei zu eins. Die Wendepunkte haben die Koordinaten (x – x, 0.24/x) und (x +
x, 0.24/x).
Man sieht, dass allein durch die Angabe der Standardabweichung x einer Zufallsvariablen x die Skalierung
der Ordinate eindeutig festgelegt ist!
Eigenschaften
Die Verteilung ist symmetrisch zur Geraden x = x und erstreckt sich im Wertebereich von x von minus bis
plus Unendlich, was bei realen Prozessen an sich nie auftritt. Trotzdem ist die Normalverteilung eine
zweckmäßige Idealisierung, besonders in der Nähe des arithmetischen Mittelungswertes x.
Die Fläche A unter der ganzen Verteilungsdichtefunktion ist wie immer definitionsgemäß eins, denn die
Wahrscheinlichkeit, dass ein Ereignis beziehungsweise ein Wert zwischen minus Unendlich und plus Unendlich liegt, ist 100% beziehungsweise 1.
4
Wert / Bereich
Dichte
Wahrscheinlichkeit
x [{x}]
pd(x) [{x–1}]
p A [–]
x ± 3 x
≈ 0.004 / x
0.9973
x ± 2.5 x
≈ 0.018 / x
0.9876
x ± 2 x
≈ 0.054 / x
0.9544
x ± 1.5 x
≈ 0.130 / x
0.8664
x ± 1 x
≈ 0.242 / x
0.6827
x ± 0.5 x
≈ 0.352 / x
0.3830
x ± 0 x
≈ 0.399 / x =
0.0000
1/ 2x
2
2
Wahrscheinlichkeit
Bereichsgrenzen
p A [–]
x [{x}]
0.500
x ± 0.68 x
0.900
x ± 1.65 x
0.950
x ± 1.96 x
0.990
x ± 2.58 x
0.999
x ± 3.29 x
1.000
x ± ∞ x
Standardnormalverteilung
Bei theoretischen Überlegungen arbeitet man häufig mit der standardisierten Normalverteilung, unter der
Annahme, dass die Zufallsvariable zentriert ist (arithmetischer Mittelungswert x = 0 [{x}]) und die Varianz x2
= 1 [{x2}] besitzt (Vorsicht bei der Einheitenkontrolle!): (x, 0, 1).
Definition: Standardnormalverteilung
pd (x)
3
1 2
1 – 2x
e
2
[{x 1}]
Normalverteilung in der Statistik
Verteilungen sind primär in der Stochastik (stochastics) definiert. Sie werden dort aus Zufallsvorgängen in
Prozessen theoretisch begründet. Und damit können auch Prognosen gestellt und Simulationen durchgeführt werden. Es handelt sich dabei um die Betrachtung im Sinne und in der Blickrichtung von Ursache und
Wirkung (Vorwärtsanalyse). Konkrete Daten sind dabei nicht im Spiel.
Falls man jedoch Daten aus Erhebungen oder Messungen erhalten hat, mutmaßt man im Rahmen der Statistik (statistics), welchen Verteilungsgesetzen diese Daten des Prozesses entstammen könnten. Es handelt
sich dabei um den Schluss von der entstandenen Wirkung auf die ursprüngliche Ursache (schließende Statistik), also in der entgegengesetzten Blickrichtung als bei der Stochastik (Rückwärtsanalyse).
Es wird also aus gewonnenen Daten auf die wirksame Verteilung geschlossen. Die primitivste, im allgemeinen aber sehr aussagekräftige Methode zeichnet die bezüglich der Zufallsvariablen x diskrete Verteilung erhobener oder gemessener Daten direkt auf beziehungsweise lässt sie durch geeignete Programme aufzeichnen (beschreibende Statistik) (Zusatz → Modul "Häufigkeiten, Wahrscheinlichkeiten unklassierter Daten" Zusatz → Modul "Häufigkeiten, Wahrscheinlichkeiten klassierter Daten"). Diese Verteilung ist eine mehr
oder weniger grobe Schätzung: p̂d (x) (Zusatz → Modul "Grundgesamtheit und Stichproben"). Auf Grund des
ersten Eindrucks stellt man die Hypothese der Verteilung auf, hier Normalverteilung. Die Lage der vermuteten Nominalverteilung pd (x) (hypothetische Verteilung, Erwartungsverteilung) ist durch den geschätzten
5
arithmetischen Mittelungswert ̂ x und durch die geschätzte Standardabweichung ̂ x gegeben (Zusatz →
Modul "Mittelung an einer Variablen").
3
BML0027
^d
p (x)
-1
d
Häufigkeitsdichte p (x) / [{x }]
2.5
2
pd(x)
1.5
1
0.5
0
1.8
2
2.2
2.4
2.6
Zufallsgröße x / [{x}]
2.8
3
3.2
Der aufwändigere Weg, die nichtlineare Parameteridentifikation (Regressionsanalyse) der hypothetischen
Verteilung aus den Daten, wird nur selten begangen, obwohl die Hilfsmittel in Form von Rechnerprogrammen vorhanden sind.
4
Test auf Normalverteilung
Die Statistik bietet Kontrollen (Test, Verifikation), ob man eine Verteilung, die man für einen Satz erhobener
oder gemessener Daten annimmt, als Schätzung (estimation) einer Normalverteilung betrachten darf oder
nicht. Den einfachsten Test der Hypothese "Normalverteilung" ermöglicht die grafische Darstellung der Verteilung im speziell skalierten Häufigkeitssummendiagramm, in dem die ideale Funktion als Gerade auf dem
Bildschirm oder Ausdruck erscheint. Exakter ist der 2-Test.
5
Nutzen der Normalverteilung
Obwohl jeder mindestens weiß, was eine Normalverteilung ist, wird kaum konkret mit Verteilungen gearbeitet. Die Hypothese, die erhaltenen Daten seien normalverteilt, wird gerne aufgestellt, weil sie einen von weiteren statistischen Arbeiten entbindet: Denn der arithmetische Mittelungswert x und die Standardabweichung x, die eine Normalverteilung vollständig bestimmen, kann man bereits direkt aus den Daten erhalten.
Eine sorgfältige Analyse der Daten bezüglich ihrer Verteilung wäre allerdings sinnvoll, zumal der Aufwand
durch Informatikhilfsmittel stark reduziert ist. Allerdings ist gewisse Erfahrung in der Interpretation der Verteilungen notwendig, gerade wenn keine Normalverteilung vorliegt.
Sobald man jedoch bei der Arbeit mit Zufallsvariablen und den damit verbundenen Schätzungen Angaben
zur Qualität der Schätzungen machen möchte, muss man die damit verbundenen Unsicherheiten spezifizieren. In der Messtechnik wird die Angabe der Messunsicherheit verlangt. Die Unsicherheiten können aber nur
mit der Kenntnis der wirksamen Verteilungen ermittelt werden.
Zusammenfassung, Ausblick
Die Normalverteilung ist eine der wichtigsten Verteilungen. Ihre Kennwerte sind aus der Sicht der Stochastik
(Vorwärtsbeschreibung) und aus der Sicht der Statistik (Rückwärtsanalyse) definiert. Beide sind bei unendlichem Aufwand im Bereich der Statistik identisch.
Zitieren
Beziehen Sie sich auf dieses Dokument durch folgenden Zitiermodus:
Ruhm, Karl H.; Normalverteilung
Internet-Portal "Wissenschaft und Technik des Messens"; Dokument: http://www.mmm.ethz.ch/dok01/d0000358.pdf
Versionen
Es existiert eine englische Version dieses Dokuments: d0000xxx
Änderungen
Rev. Datum
Änderung
00
16.11.2004
Erstausgabe
01
24.11.2005
Kleinere Änderungen
6