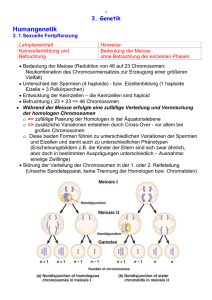
Genetischer Code - Ihre Homepage bei Arcor
Werbung

Genetischer Code Der genetische Code ist eine Regel, nach der Dreiergruppen aufeinanderfolgender Nukleotide (oder Nukleobasen) - Tripletts oder Codons genannt - in Aminosäuren übersetzt werden. Diese Übersetzung, Translation, findet bei der Bindung von Aminosäuren an verschiedene TransferRibonukleinsäuren (tRNA) statt, durch die sie für ihren Zusammenbau zu Proteinen vorbereitet bzw. aktiviert werden. Die Transfer-Ribonukleinsäuren unterscheiden sich durch ihr an einer prominenten Molekülstelle befindliches Nukleotid-Triplett, das aus jeweils drei Nukleotiden besteht, die zu den Nukleotiden eines bestimmten Codons komplementär sind, also ein dreigliedriges Anticodon bilden. Codon und Anticodon passen spezifisch zueinander und ihnen ist nach dem genetischen Code eine bestimmte Aminosäure zugeordnet. An jede Transfer-Ribonukleinsäure wird diejenige Aminosäure gebunden, für die das zum Anticodon der tRNA passende Codon steht. Auf diese Weise, durch die spezifische Bindung einer Aminosäure an eine tRNA mit einem dafür vom genetischen Code vorgesehenen Anticodon, wird also das Zeichen für eine bestimmte Aminosäure, das Codon, in die nach dem genetischen Code vorgeschriebene Aminosäure übersetzt. Streng genommen ist also die Translation schon in der Struktur der verschiedenen tRNA-Arten enthalten: Jedes tRNAMolekül enthält eine so strukturierte Aminosäure-Bindungsstelle, dass nur die nach dem genetischen Code zu dem Anticodon dieser tRNA passende Aminosäure daran gebunden werden kann. Nach Bindung der Aminosäuren an tRNA kann die Synthese des durch die Folge der Codons in einer Desoxyribonukleinsäure (DNA) festgelegten Proteins beginnen. Als Voraussetzung für diese Synthese wird der DNA-Abschnitt eines Gens zunächst in ein Messenger-Ribonukleinsäure (mRNA)-Molekül umgeschrieben (Transkription); danach werden meistens bestimmte Teile dieser mRNA gezielt entfernt (Spleißen). Schließlich werden die Aminosäuren der zu den Codons passenden tRNAs miteinander zu einer Polypeptidkette verknüpft. Alle nach der Synthese und dem Spleißen der mRNA folgenden Schritte bis einschließlich der Synthese der Proteine werden als Translation bezeichnet, da bei der Proteinsynthese die Umsetzung der Triplett-Folge der DNA in eine Aminosäure-Folge deutlich wird. Die eigentliche Anwendung des genetischen Codes, die Übersetzung eines Codons, eines Basen-Tripletts, in eine Aminosäure findet jedoch nur bei der Bindung der Aminosäuren an tRNA statt, also bei der Vorbereitung der Aminosäuren zum Zusammenbau der Proteine. Einige Codons stehen nicht für eine Aminosäure, sondern werden als STOPP-Zeichen behandelt, welches die Proteinsynthese beendet (Stopp-Codons). Das Rennen um das Verständnis des genetischen Codes fesselte die Biochemiker die erste Hälfte der sechziger Jahre des vorigen Jahrhunderts. Am 27. Mai 1961 um 3.00 Uhr gelang dem deutschen Biochemiker Heinrich Matthaei mit seinem Mitarbeiter Marshall Nirenberg mit dem Poly-U-Experiment der entscheidende Durchbruch: die Entschlüsselung des genetischen Codes. Dieses Experiment wird von einigen Genetikern als das bedeutendste des 20. Jahrhunderts bezeichnet. Alle Lebewesen benutzen in Grundzügen denselben genetischen Code. Die gebräuchlichste Version ist in den folgenden Tabellen angegeben. Sie zeigen, welche Aminosäuren von den 4³ =64 möglichen Codons kodiert werden (Tabelle 1), und welche Codons jede der 20 in der Translation verwendeten Aminosäuren kodieren (Tabelle 2). So steht zum Beispiel GAU für die Aminosäure Asp (Asparagin), und Cys (Cystein) wird von den Codons UGU und UGC kodiert. Die in der Tabelle verwendeten Basen sind Adenin, Guanin, Cytosin und Uracil der mRNA; in der DNA wird statt Uracil Thymin verwendet. Codon Als Codon bezeichnet man eine in mRNA-Molekülen vorkommende Sequenz von drei Nukleotiden, die im genetischen Code eine Aminosäure codiert. Insgesamt existieren 43 = 64 mögliche Codons, davon werden drei als Stopp-Sequenz benutzt, die restlichen 61 codieren insgesamt 20 proteinogene Aminosäuren. Für viele Aminosäuren gibt es daher mehrere verschiedene Codierungen. Die Codierung als Triplett ist trotzdem notwendig, da bei einer 2er-Codierung nur 42 = 16 mögliche Codons nicht genügend Möglichkeiten entstehen, um alle Aminosäuren abzudecken. Tabelle 1 : Standard-Codon-Tabelle. Diese Tabelle zeigt die 64 möglichen CodonTripletts. 2. Base U C A G UUU Phenylalanin UCU Serin UAU Tyrosin UGU Cystein UUC Phenylalanin UCC Serin UAC Tyrosin UGC Cystein U UUA Leucin UAA Stop UGA Stop UCA Serin UUG Leucin UAG Stop UGG Tryptophan UCG Serin 1. Base CUU Leucin C CUC Leucin CUA Leucin CCU Prolin CCC Prolin CCA Prolin CAU Histidin CAC Histidin CAA Glutamin CGU Arginin CGC Arginin CGA Arginin CUG Leucin AUU Isoleucin AUC Isoleucin A AUA Isoleucin 1AUG Methionin GUU Valin GUC Valin G GUA Valin GUG Valin Farbgebung für die Aminosäuren: hydrophob (unpolar) CCG Prolin CAG Glutamin CGG Arginin ACU Threonin ACC Threonin ACA Threonin ACG Threonin AAU Asparagin AAC Asparagin AAA Lysin AAG Lysin AGU Serin AGC Serin AGA Arginin AGG Arginin GCU Alanin GCC Alanin GCA Alanin GCG Alanin GAU Asparaginsäure GAC Asparaginsäure GAA Glutaminsäure GAG Glutaminsäure GGU Glycin GGC Glycin GGA Glycin GGG Glycin hydrophil neutral (polar) hydrophil und positiv aufladbar = basisch hydrophil und negativ aufladbar = sauer 1Das Triplett AUG dient sowohl als Codon für Methionin als auch als Startsignal der Translation, es wird daher auch als Startcodon bezeichnet. Eines der ersten AUG-Tripletts auf der mRNA wird das erste Codon, das zu Protein translatiert wird. Welches AUG genau verwendet werden soll, erkennen die Proteine an Signalen in der umliegenden Sequenz. Tabelle 2 : Umgekehrte Codon-Tabelle. Diese Tabelle zeigt die 20 Aminosäuren, die in Proteinen verwendet werden, und die Codons, die für sie kodieren. Ala GCU, GCC, GCA, Leu UUA, UUG, CUU, CUC, CUA, GCG CUG Arg CGU, CGC, CGA, Lys AAA, AAG CGG, AGA, AGG Asn AAU, AAC Met AUG Asp GAU, GAC Phe UUU, UUC Cys UGU, UGC Pro CCU, CCC, CCA, CCG Gln CAA, CAG Ser UCU, UCC, UCA, UCG, AGU, AGC Glu GAA, GAG Thr ACU, ACC, ACA, ACG Gly GGU, GGC, GGA, Trp UGG GGG His CAU, CAC Tyr UAU, UAC Ile AUU, AUC, AUA Val GUU, GUC, GUA, GUG START AUG, GUG STOP UAG, UGA, UAA Den drei STOPP-Codons wurden ursprünglich Namen gegeben - UAG war amber (bernsteinfarben), UGA war opal, und UAA war ochre (ocker), ein Wortspiel auf den Namen ihres Entdeckers (Bernstein). Während das mRNA-Codon UGA zumeist als STOPP gelesen wird, kann es selten und nur unter bestimmten Bedingungen für eine 21. Aminosäure stehen: Das Selenocystein (Sec). Die Biosynthese und der Einbaumechanismus von Selenocystein in Proteine unterscheidet sich stark von dem aller anderen Aminosäuren: seine Insertion erfordert einen neuartigen Translationsschritt, bei dem ein UGA im Rahmen einer bestimmten Sequenzumgebung und zusammen mit bestimmten Cofaktoren anders interpretiert wird. Hierzu ist eine strukturell einzigartige, Selenocystein spezifische tRNA (tRNASec) erforderlich, die bei Vertebraten mit drei verschiedenen, allerdings verwandten Aminosäuren beladen werden kann: Serin, Selenocystein und Phosphoserin. Die Translation beginnt mit einem Kettenstarter- oder START-Codon, aber dies alleine ist nicht ausreichend, um den Prozess zu beginnen. Bestimmte Initiationssequenzen nahe dem START-Codon sind ebenfalls notwendig, um die Transkription in mRNA und deren Bindung am Ribosom herbeizuführen. Das wichtigste Startcodon ist AUG, das auch für Methionin codiert. CUG und UUG, sowie GUG und AUU in Prokaryoten, funktionieren ebenfalls. In den allermeisten Proteinen ist die erste Aminosäure jedoch ein Methionin. Fehlertoleranz Wird während der Translation ein Codon falsch dekodiert (eine falsche Aminosäure verwendet), so stimmt die Struktur des hergestellten Eiweißes nicht mehr, und es funktioniert nicht mehr wie vorgesehen. Offenbar war es daher sehr früh in der Evolutionsgeschichte notwendig, den genetischen Code mit einer gewissen Fehlertoleranz auszustatten: Er ist ein so genannter degenerierter Code, das heißt, dass eine semantische Einheit durch mehrere unterschiedliche syntaktische Symbole codiert wird: Abzüglich der Stopp-Codons stehen ja 61 unterschiedliche Codons zu Verfügung, es müssen aber nur 20 Aminosäuren codiert werden. Wie in der Tabelle oben ersichtlich, werden also für manche Aminosäuren mehrere Codes verwendet. Diese unterscheiden sich dann in der Regel in nur einer der drei Basen. (Sie haben dadurch einen minimalen Abstand im Coderaum (siehe: Hammingdistanz). Wird also eine der Basen falsch gelesen, liegt die Wahrscheinlichkeit, dass trotzdem die richtige Aminosäure ausgewählt wird, noch immer bei 60%. Meist unterscheiden sich die betroffenen Codons zudem in der letzten (dritten) Base eines Codons, die bei der Translation am häufigsten falsch gelesen wird. Darüber hinaus haben Aminosäuren, die häufiger in Proteinen vorkommen als andere, mehr Codons, die für sie kodieren. Bemerkenswert ist die Tatsache, dass der Charakter einer Aminosäure weitgehend durch die mittlere Position eines Tripletts bestimmt wird: U - hydrophob C - polar bis neutral A - geladen G - geladen, neutral bis polar Daraus folgt, dass Radikalsubstitutionen (Tausch gegen Aminosäuren eines anderen Charakters) in erster Linie Folge von Mutationen in dieser zweiten Position sind. Mutationen in der ersten, besonders aber in der dritten Position ("wobble") erhalten dagegen häufig die Aminosäure oder zumindest ihren Charakter "konservative Substitution". Berücksichtigt man ferner, dass Transitionen (Umwandlung von Purinen bzw. Pyrimidinen ineinander) aus mechanistischen Gründen häufiger auftreten als Transversionen (Umwandlung eines Purins in ein Pyrimidin und umgekehrt; dieser Prozess setzt zumeist eine Depurinierung voraus), so ergibt sich eine weitere Erklärung für den konservativen Charakter des Codes. Ursprung des genetischen Codes Früher glaubte man, der genetische Code sei zufällig entstanden. Noch 1968 bezeichnete Francis Crick ihn als "eingefrorenen Zufall". Untersuchungen aus dem Jahr 2004 deuten jedoch darauf hin, dass er das Resultat einer strengen Optimierung hinsichtlich der Fehlertoleranz darstellt. Fehler sind besonders gravierend für die räumliche Struktur eines Proteins, wenn sich die Hydrophobie einer fälschlich eingebauten Aminosäure deutlich vom Original unterscheidet. Im Rahmen einer statistischen Analyse erweisen sich in dieser Hinsicht unter 1 Million Zufallscodes nur 100 besser als der tatsächliche. Berücksichtigt man bei der Berechnung der Fehlertoleranz zusätzliche Faktoren, die typischen Mustern von Mutationen und Lesefehlern entsprechen, so reduziert sich diese Zahl sogar auf 1 von 1 Million (Lit.: Freeland, 2004). Grundprinzip Bemerkenswert ist, dass der genetische Code im Prinzip für alle Lebewesen gleich ist, alle Lebewesen sich also der gleichen "genetischen Sprache" bedienen. Da also ein bestimmtes Codon immer für die gleiche Aminosäure steht ist es möglich, in der Gentechnik z.B. das Gen für menschliches Insulin in Bakterien einzuschleusen, damit diese Insulin produzieren. Dieses Prinzip wird als "Universalität des Codes" bezeichnet. Dies erklärt sich aus der Evolution so, dass der genetische Code schon sehr früh in der Entwicklungsgeschichte des Lebens ausgestaltet und an alle sich entwickelnden Arten weitergegeben wurde. Eine solche Generalisierung schließt nicht aus, dass die Häufigkeit verschiedener Codewörter (das so genannte Codon Usage) sich zwischen den Organismen unterscheiden kann. Ausnahmen Es gibt auch offensichtliche Ausnahmen von der Universalität des genetischen Codes: So wird in den Mitochondrien, energieumsetzenden Organellen, die vermutlich von symbiotischen Bakterien abstammen (Endosymbionten-Theorie), und die eine eigene Erbsubstanz (neben der DNA des Zellkerns) tragen, eine leicht abgewandelte Form des Codes benutzt. Auch die Ciliaten zeigen Abweichungen vom Standard-Code: UAG, und häufig auch UAA, kodieren für Glutamin; diese Abweichung findet sich auch in einigen Grünalgen. UGA steht auch manchmal für Cystein. Eine weitere Variante findet sich in der Hefe Candida, wo CUG Serin kodiert. Des weiteren gibt es einige Varianten von Aminosäuren, die von Bakterien (Bacteria) und Archaeen (Archaea) verwendet werden; das STOPP-codon UGA kann, wie oben beschrieben, Selenocystein und UAG Pyrrolysin kodieren. Es ist nicht auszuschließen, dass weitere Codierungs-Varianten existieren, die bislang noch nicht entdeckt wurden. Zur Zeit sind 16 Abweichungen der Zuordnung einer Aminosäure zu einem Codon (Basentriplett der mRNA) vom Standard-code bekannt: Codon Standard Abweichung Einige Arten der Pilzgattung Candida CUG Leucin Serin Mitochondrien z. B. bei Saccharomyces cerevisiae CU(U, C, A, G) Leucin Threonin Mitochondrien Höherer Pflanzen CGG Arginin Tryptophan Mitochondrien (bei allen bis jetzt untersuchten Organismen) UGA Stopp Trp Mitochondrien von Säugern, Drosophila und S. cerevisiae und AUA Ile Methionin = Protozoen Start Bakterien GUG Valin Start Eukarya (selten) CUG Leucin Start Eukarya (selten) GUG Valin Start Bacteria GUG Valin Start Bacteria (selten) UUG Leucin Start Eukarya (selten) ACG Threonin Start Mitochondrien von Säugern AGC, AGU Serin Mitochondrien von Drosophila AGA Arginin Stopp Mitochondrien von Säugern AG(A, G) Arginin Stopp Stopp Codogener Strang Als codogenen Strang bezeichnet man den Strangteil der Doppelhelix, der die genetische Information enthält. In der deutschen Fachliteratur beschreibt man damit denjenigen DNA-Einzelstrang einer DNA-Doppelhelix, dessen genetische Information während der Transkription der DNA dazu genutzt wird, mit Hilfe komplementärer Basenpaarungen einen mRNA-Einzelstrang zu bilden. Er unterscheidet sich von dem komplementären Strang durch die Existenz eines Promotors in Form einer bestimmten Basenfolge am Beginn eines Abschnittes, der der RNA-Polymerase als Startpunkt dient. Bei der Transkription werden also nur codierende Informationen in m-RNA umgeschrieben. Die genetische Information auf dem codogenen Strang liegt in Form von Basentripletts vor, die man Codogene nennt. Die genetische Information der Codogene liegt nach der Synthese der kompletten mRNA als Abfolge von Codons vor, die zu den Codogenen komplementär sind. In dieser Form wird die Information im Cytoplasma mit Hilfe der Ribosomen zum Aufbau von Polypeptidketten genutzt (siehe Translation). In der anglo-amerikanischen und der davon abgeleiteten neueren deutschen Fachliteratur verwendet man dagegen die Begriffe Sense-Strang (Sinn-Strang) und Antisense-Strang (Anti-Sinn-Strang, Matrizenstrang). Der Sense-Strang entspricht dabei dem DNA-Einzelstrang, der zum codogenen Strang komplementär ist und näherungsweise der chemischen Struktur der mRNA ähnelt. Der Antisense-Strang entspricht dem codogenen Strang. Daß der Antisense-Strang - also der codogene Strang - die Erbinformationen enthält, kann man sich leicht durch das Sprichwort "Antisense makes Sense" merken. mRNA Die mRNA (Boten-RNA, vom englischen messenger-RNA) ist eine direkte RNA-Kopie eines zu einem Gen gehörigen Teilabschnitts der DNA. Sie wird während des Vorgangs der Transkription durch das Enzym RNAPolymerase hergestellt. Transkription Die Transkription geschieht bei Prokaryoten im Cytoplasma, bei Eukaryoten im Zellkern (Karyoplasma). Der Prozess ist bei Prokaryoten (Lebewesen ohne Zellkern) und Eukaryoten (Lebewesen mit Zellkern) ähnlich, allerdings kann in Prokaryoten sofort die Translation (der eigentliche Vorgang der Synthese von Proteinen) beginnen. Ribosomen setzen sich an die mRNA, noch bevor die Transkription abgeschlossen ist. Die mRNA von Eukaryoten wird dagegen meist noch vor Ende der Transkription prozessiert und dann aus dem Zellkern ausgeschleust. Prokaryoten besitzen im Gegensatz zu den Eukaryoten nur eine Art des Enzyms RNA-Polymerase, welches die Synthese von RNA übernimmt. Dagegen besitzen Eukaryoten RNA-Polymerase I für rRNA, RNA-Polymerase II für mRNA und RNA-Polymerase III für tRNA. Ein weiterer wesentlicher Unterschied zwischen prokaryotischer und eukaryotischer mRNA besteht darin, dass prokaryotische mRNA polycistronisch sein kann, eukaryotische mRNA dagegen immer monocistronisch ist. Das ermöglicht es Prokaryoten auf nur einem einzigen mRNA-Transkript die Informationen von mehreren (auf der DNA hintereinanderliegenden) Genen zu haben. Ein solcher gemeinsam transkribierter Bereich heißt Operon. Auf diese Weise ist es möglich, dass bei Prokaryoten noch während der mRNA-Synthese bereits die ersten Proteine fertig translatiert werden. Eukaryotische prä-mRNA-Prozessierung In Eukaryoten muss die mRNA, die zunächst in einer Vorstufe ("prä-mRNA" or "hnRNA" (englisch: heteronucleic RNA oder pre-mRNA)) vorliegt, erst durch Splicing (Spleißen) (siehe unten) bearbeitet werden und dann durch die Poren des Zellkerns ins Cytoplasma gelangen, um dort von den Ribosomen erkannt zu werden, die mit der Proteinsynthese beginnen. Bevor die mRNA aus dem Zellkern ins Cytoplasma gelangt, werden an ihr noch einige Modifikationen vorgenommen: Ein 'Kopf' (5'-Cap-Sequenz) wird an den Anfang gehängt, der die Anlagerung an die Ribosomen erleichtert und ein Poly-A-Schwanz angehängt, welcher den vorzeitigen Abbau der mRNA verhindern soll. Etliche Introns, die nicht für das Protein kodierende Informationen enthalten, werden entfernt und die verbleibenden Exons miteinander verbunden (Splicing). Durch alternatives Splicing können aus derselben prä-mRNA unterschiedliche reife RNA-Versionen entstehen, die in der Translation zu unterschiedlichen Proteinen führen. An dieser Stelle greifen auch diverse Regulationsprozesse der Zelle ein. Über Antisense-RNA und RNAInterferenz kann mRNA wieder abgebaut werden und so die Translation verhindert. Weiterhin erfolgt in einigen Fällen die so genannte RNA-Edition, d.h. die Nukleotide in einer mRNA werden verändert. Ein Beispiel dafür ist die mRNA des Apolipoprotein B, welche in manchen Geweben editiert wird, in anderen nicht. Durch die Edition entsteht ein früheres Stop-Codon, welches bei der Translation zu einem kürzeren Protein führt. Translation und Degradation Der Prozess der Translation findet an den Ribosomen statt, welche frei im Cytoplasma oder am endoplasmatischem Retikulum zu finden sind. Die mRNA wird hier anhand des genetischen Codes abgelesen und Proteine werden dem entsprechend synthetisiert. Anschließend wird die mRNA durch das Enzym RNAse in ihre Einzelteile zerlegt. Die Bruchstücke werden dann von der Zelle wieder zum Aufbau neuer RNA-Moleküle genutzt. Der Abbau-Prozess findet dabei in den so genannten "P-Bodies" statt, spezifischen Zellstrukturen im Cytoplasma. Diese erst kürzlich entdeckten Strukturen bieten eine weitere Form der Expressionsregulation, bei der die mRNA auch, statt abgebaut, für eine erneute Translation zwischen-gelagert werden kann. Aminosäuresequenz Die Aminosäuresequenz bezeichnet die Reihenfolge der Aminosäuren in einer Polypeptidkette oder einem Protein. Übereinkunftsgemäß schreibt man die Aminosäuresequenz mit der N-terminalen Aminosäure beginnend. Die Schreibrichtung N-Terminus-zu-C-Terminus entspricht der Syntheserichtung an den Ribosomen. Proteinbiosynthese Die Proteinbiosynthese, früher auch Eiweißsynthese genannt, ist die Herstellung eines Proteins oder Polypeptids in Lebewesen. Sowohl Proteine als auch Polypeptide sind Ketten aus Aminosäuren, die sich in ihrer Länge und ihrer Abfolge unterscheiden. Sie werden auf Grund der in der Desoxyribonukleinsäure (DNA) gegebenen Erbinformation an den Ribosomen lebender Zellen gebildet. Schritte der Proteinsynthese Transkription unter dem EM. Markiert ist der Abschnitt eines Gens, das gerade (von rechts nach links) abgelesen wird. Die Proteinbiosynthese (griech. proteos = von äusserster Wichtigkeit) gliedert sich in folgende Schritte: Transkription: Transkription ist das Umschreiben von DNA in RNA. Durch Bindung einer RNA-Polymerase an einen Promotor wird der DNA-Strang entspiralisiert. Die Information der DNA wird durch die RNA-Polymerase in mRNA (vom englischen messenger-RNA, zu deutsch BotenRNA genannt) umgeschrieben, indem ein zum codogenen DNA-Strang komplementärer prä-mRNA- Strang synthetisiert wird. Bei Eukaryoten tritt eine zusätzliche Prozessierung der prä-mRNA auf (Capping, in den meisten Fällen (Splicing), Polyadenylierung, in manchen Fällen Editing). Die reife mRNA wird durch regulierten, aktiven Transport durch den "nuclear pore complex NPC" aus dem Zellkern ins Cytoplasma transportiert. Die einzelnen Schritte der mRNASynthese werden in Abhängigkeit voneinander reguliert. Translation: (wörtlich: Übertragung). Übersetzt wird die DNA-Information eines bestimmten DNA-Abschnittes (Gen) in eine Aminosäurekette (auch bezeichnet als Polypeptid). Dazu wird die Information auf der Boten-RNA (mRNA) zunächst "zwischengespeichert". Bei Eukaryoten verlässt diese mRNA den Zellkern (bei Bakterien bzw. Prokaryoten setzt sie sofort nach der Transkription ein) und wird im Cytoplasma, also außerhalb des Zellkerns, von Ribosomen (sog. Polysomen) schrittweise abgelesen und in eine Folge von Aminosäuren umgesetzt. Dies geschieht durch die tRNA, da für jede Aminosäure ein kompatibles tRNA-Molekül existiert, das über eine spezifische Bindungstelle für ebendiese Aminosäure verfügt. An dem tRNA-Molekül ist noch eine sog. "Anticodonschleife" vorhanden, deren Sequenz an Basen komplementär zu dem auf der mRNA vorhandenen Codon ist. Von daher wird diese Basensequenz als "Anticodon" bezeichnet. Ein Ribosom besitzt drei Bindungsstellen für tRNA -die A-Stelle (Aminoacyl-tRNA-Bindungsstelle), die PStelle (Peptidyl-tRNA-Bindungsstelle) und die E-Stelle (Exit, Abgangsstelle). Die A-Stelle steht für das die Aminosäure anliefernde tRNA-Molekül zur Verfügung. An der P-Stelle wird die Aminosäure an die wachsende Proteinkette gebunden. Die dann entladene tRNA wandert weiter an die E-Stelle, verlässt hier das Ribosom und wird enzymatisch mit einer neuen Aminosäure beladen. Das Ribosom wandert so lange auf der mRNA entlang, bis das gesamte Protein entsprechend den Anweisungen der mRNA hergestellt (synthetisiert) wurde – bis es an ein Stoppcodon gelangt, für das es keine passende tRNA gibt. Der verwendete genetische Code ist folgender: 4 "Buchstaben" der DNA (A,G,C,T) bilden die "Schrift" der Gene. Dieses "Morsealphabet" wurde 1961 von Heinrich Matthaei und Marshall Nirenberg gefunden. Die "Worte" sind je 3 Buchstaben lang (ein so genanntes Triplett oder Codon), also zum Beispiel GAC. Jedes dieser Tripletts wird später auf die mRNA kopiert und schließlich von Ribosomen in eine bestimmte Aminosäure (insgesamt wurden bisher 22 Aminosäuren entdeckt, die bei der Synthese von Proteinen verwendet werden) übersetzt. Hierbei muss beachtet werden, dass bei der RNA die Base Uracil komplementär zu Adenin ist und nicht wie bei der DNA, Adenin komplementär zu Thymin. Übertragen werden die Aminosäuren mit sog. Transfer-RNAs (tRNAs), die das entsprechende Anticodon tragen, somit an die mRNA gebunden sind und die korrekte Aminosäure, die sie an einer anderen spezifischen Bindestelle tragen, mit der vorhergehenden verknüpft. So wächst die Kette der Aminosäuren bis zum Stoppcodon des Transkripts, das ein Signal für das Ribosom ist, an dieser Stelle aufzuhören. Die Aminosäurekette des Proteins ist damit fertig. Das Protein selber kann nun aber noch weiter modifiziert werden. Proteintargeting Nicht alle Proteine sollen im Cytosol verbleiben, viele zählen zu den sekretorischen Proteinen oder zu den Membranproteinen. Alle diese Proteine, hierzu zählen auch solche, die in membranumhüllten Zellorganellen wie den Mitochondrien, dem endoplasmatischen Retikulum (ER) oder dem Golgi-Apparat vorhanden sind, enthalten eine typische N-terminale Signalsequenz, die von einem speziellen Protein, dem signal recognition particle (SRP), erkannt wird. Diese Sequenz ist 16-30 Aminosäuren lang und enthält typischerweise eine oder mehrere positiv geladene Aminosäuren, gefolgt von mehreren hydrophoben Aminosäuren. Ragt diese Sequenz weit genug aus dem Ribosom, was nach der Kopplung der ersten ca. 70 Aminosäuren der Fall ist, lagert sich das SRP an die naszierende Polypeptidkette und das Ribosom an und stoppt so die Translation. An der Oberfläche des (rauen) ER befindet sich ein SRP-Rezeptor, der das Ribosom bindet und in Position an das Translocon bringt. Das SRP wird wiederum abgespalten und kann erneut zur Markierung dienen. Die Polypeptidkette wird nun durch das Translocon in das Lumen des ER weitersynthetisiert, wobei das Enzym Signalpeptidase die Signalsequenz entfernt. Im Translocon bildet sich während dieser Phase eine Schleife, wodurch der N-Terminus der Polypeptidkette zum Cytosol weist. Dies ist wichtig für die korrekte Positionierung von membranständigigen Proteinen. Ist die Translation abgeschlossen, wird im ER-Lumen das Protein korrekt gefaltet, Disulfidbrücken bauen sich auf und weitere Modifikationen werden durchgeführt. Entscheidend für die Sekretion ist die Glykosylierung vieler membranständiger und sekretorischer Proteine. Sie findet sowohl im rauen ER als auch im Golgi-Apparat statt und dient als Zielmarkierung für die Proteine. Eine Mutation (lat. mutare verändern) ist eine Veränderung des Erbgutes eines Organismus durch Veränderung der Abfolge der Nucleotidbausteine oder durch Veränderung der Chromosomenzahl, die nicht auf Rekombination oder Segregation beruht. Dieser Begriff wird daher nur für einen Teilbereich aller möglichen Chromosomenaberrationen verwendet. Durch eine Mutation wird die in der DNA gespeicherte Information verändert und dadurch können einzelne Merkmale (der Phänotyp) verändert werden. Arten der Mutation Unterscheidung nach Erblichkeit Keimbahnmutationen sind Mutationen, die an die Nachkommen über die Keimbahn weitergegeben werden; sie betreffen Eizellen oder Spermien und werden durch Zellteilung an alle anderen Zellen weitergegeben. Diese Mutationen sind im Rahmen der Evolutionstheorie sehr wichtig, da sie von einer Generation zur nächsten übertragbar sind. somatische Mutationen sind Mutationen, die alle anderen Körperzellen aber nicht die Keimzellen betreffen können. Sie haben daher auch nur Auswirkungen auf die Zellen des Organismus, in denen sie stattfinden, d.h. somatische Mutationen werden nicht vererbt. Wenn diese somatischen Mutationen nur vereinzelt auftreten, haben sie keine oder nur geringe Folgen. Wird ihr Auftreten jedoch durch Mutagene wie z.B. energiereiche Strahlung oder Umweltgifte verstärkt, haben sie ein großes Gefahrenpotential. So können sich dadurch u.a. normale Körperzellen in ungebremst wuchernde Krebszellen umwandeln. Auch bei dem Alterungsprozess eines jeden Organismus spielen somatische Mutationen eine entscheidende Rolle. Sie haben daher in der praktischen Medizin eine zunehmende Bedeutung. Unterscheidung nach Ursache Spontanmutationen sind Mutationen ohne erkennbare Ursache, wie der chemische Zerfall eines Nukleotids (Cytosin desaminiert oxidativ z.B. spontan zu Uracil). induzierte Mutationen sind durch Mutagene (mutationsauslösende Stoffe oder Strahlungen) erzeugte Mutationen. Replikationsfehler DNA-Polymerasen haben unterschiedlich hohe Fehlerraten. Bevorzugt wird ein ATP eingebaut, da das Molekül am häufigsten in der Zelle vorkommt. Unzureichende Proof-reading-Aktivität Manche DNA-Polymerasen haben die Möglichkeit Fehleinbaue selbständig zu erkennen und zu korrigieren. Die DNA-Polymerase α der Eukaryoten besitzt jedoch z.B. keine proof-reading-Aktivität. Fehler bei prä- und postreplikativen Reparaturmechanismen Beim Einbau/Finden eines ungewöhnlichen Nukleotids, etwa von Uracil in der DNA, wird dieses entfernt, bei einer Fehlpaarung zwischen 2 DNA-typischen Nukleotiden muss sich das Repraturenzym entscheiden mit 50%iger Fehlerwahrscheinlichkeit. inäquales Crossing-over sind Fehlpaarungen bei der Meiose durch auf einem Strang naheliegende ähnliche oder identische Sequenzen, wie etwa Satelliten-DNA oder Transposons. Integration oder Herausspringen von Transposons Springende Elemente können in Gene oder genregulatorische Bereiche integrieren. Beim Herausspringen hinterlassen sie Spuren, sogenannte footprints. Unterscheidung nach erfolgter Veränderung 1. die Genmutation eine erbliche Änderung, die nur das einzelne Gen betrifft. Man unterscheidet zwischen Raster- und Punktmutation. Bei der Punktmutation wird lediglich eine organische Base im genetischen Code verändert (mutiert). Die Rastermutation jedoch führt zum Einschub oder Entfernen einer Base und verändert somit die gesamte Struktur des Gens. Deshalb hat die Rastermutation weit höhere Auswirkungen. 2. die Chromosomenmutation oder Segmentmutation ebenfalls eine erbliche Änderung, die einzelne Chromosomen in ihrer Struktur betrifft. 3. die Genommutation oder numerische Chromosomenaberration eine nicht-erbliche Änderung, bei der ganze Chromosomen oder gar Chromosomensätze vermehrt werden (Aneuploidie, Polyploidie) oder ganze Chromosomen verloren gehen. Mit der Entdeckung des alternativen Splicings kommt ein weiterer Mutationstyp hinzu: die veränderte Regulation des Splicings, die letztlich auch im Erbgut, aber meist an anderer Stelle, verankert ist. Gleiches gilt für Mutationen der die Expression regulierenden Regionen in Gennähe. Unterscheidung nach Folgen für den Organismus letale Mutationen sind Mutationen, die nach ihrem Auftreten einen Organismus unabhängig von seiner jeweiligen Lebensphase in jedem Falle töten. konditional-letale Mutationen sind Mutationen, deren Veränderung des Genprodukts einen Organismus nur bei bestimmten Wachstumsbedingungen tötet. loss of function Mutationen Hierbei wird ein Gen durch eine Mutation funktionslos. Ist der Funktionsverlust vollständig, spricht man auch von Nullallel oder einem amorphen Allel. Bleibt ein Teil der Wildtypfunktion erhalten, dann bezeichnet man es auch auch als hypomorphes Allel. loss of function Mutationen sind immer rezessiv, da ein anderes Allel den Funktionsverlust eines Gens auffangen kann. gain of function Mutationen Hierbei gewinnt ein Gen an Aktivität und wird dann auch als hypermorph bezeichnet. Entsteht durch die Mutation ein komplett neuer Phänotyp, dann bezeichnet man das Allel auch als neomorph. Eine gain of function Mutation erzeugt immer einen dominanten Phänotyp. neutrale Mutationen können den Phänotyp verändern, haben aber keine Fitnesskonsequenzen. stille Mutationen sind Mutationen, die keinerlei Folgen für den Organismus haben. Folgen keine Folgen - bei stillen, neutralen Mutationen Die meisten Mutationen führen dazu, dass eine Veränderung in einem DNA-Abschnitt keine Konsequenzen nach sich zieht, wenn die Stelle, die verändert wurde, nicht für eine genetisch relevante Information benutzt wird. Aber auch wenn die veränderte Stelle benutzt wird, kann es sein, dass der Informationsgehalt des Gens sich nicht verändert hat, da eine Reihe von Aminosäuren identisch kodiert sind (siehe: genetischer Code). Daher werden diese Mutationen stille Mutationen oder neutrale Mutationen genannt. Solche Arten von Mutationen führen dazu, dass innerhalb einer Gruppe von Organismen funktional gleiche Gene unterschiedliche genetische „Buchstaben“ innerhalb ihrer Nukleotid-Sequenz besitzen. Diese Unterschiede, die Polymorphismen heißen, lassen sich ausnutzen, um Verwandtschaftsbeziehungen zwischen Individuen abzuleiten, oder auch, um eine durchschnittliche Mutationsrate abzuschätzen. Zusätzlich kommt noch zum Tragen, dass nicht nur beim diploiden Chromosomensatz oft mehrere Gene die gleichen genetischen Eigenschaften codieren, sodass sich eine Mutation aus diesem Grunde nicht sofort nachteilhaft bemerkbar machen muss. negative Folgen Besonders größere Veränderungen im Erbgut führen oft zu nachteilhaften Veränderungen im Stoffwechsel oder auch zu Fehlbildungen und anderen Besonderheiten. Es gibt verschiedene Erbkrankheiten, die entweder vererbt sind oder durch Mutation neu auftreten können. Beispiele dafür sind: die Sichelzellenanämie, eine Blutkrankheit, bei der sich die äußere Form der roten Blutkörperchen ändert, was u. a. verringerte Sauerstoffaufnahme zur Folge hat, die Phenylketonurie, wobei der Abbau der Aminosäure Phenylalanin gestört ist, wodurch Schädigungen des kindlichen Gehirns hervorgerufen werden können, der Albinismus und die Mukoviszidose oder zystische Fibrose, die häufigste genetisch bedingte Krankheit Nordeuropas. Bei ihr ist das CFTR-Gen, das die Konsistenz der Drüsensekrete steuert, defekt. Wenn das Sekret zu zäh ist, kann es (je nach Drüse) die Atemwege oder die Ausführungsgänge der Drüsen verstopfen. Außerdem Formen von Minderwuchs, bei denen die Arme und Beine ungewöhnlich kurz sind, während der Körper ansonsten wie üblich gebaut ist, die Rot-Grün-Blindheit und die Bluterkrankheit, bei der die Blutgerinnung praktisch nicht einsetzt. positive Folgen Der Entwicklungslehre Darwins zufolge ist die Mutation mit für die Artenvielfalt auf der Erde verantwortlich. Mutationen sind so (aber nicht nur) ein natürliches Phänomen und ermöglichen erst die Entwicklung der Arten (siehe: Evolutionslehre). Obwohl die Mutation die Dynamik der Evolution ausmacht, ist nur in den selteneren Fällen mit einer Veränderung im Genom ein Vorteil für das Individuum zu erwarten (genauer sind 0,001% aller Mutationen positiv). Durch Austausch der Basenpaare werden Proteine verändert oder einfach nur anders reguliert, was eine Änderung im Körperbau, oder in Körperfunktionen und oder im Verhalten des Organismus bewirken kann, die ihm Vorteile gegenüber seinen unveränderten Artgenossen bietet. Wenn diese Mutation an die Nachkommen vererbt wird, hat sie eine erste Voraussetzung erfüllt, dass sie sich einst „durchsetzen“ kann. Der Mensch macht sich zudem den genomverändernden Effekt ionisierende Strahlen zunutze, um Mutationen künstlich auszulösen. Eine Anwendung besteht in der Bestrahlung von Blumen- und Pflanzensamen, um bisher unbekannte Formen zu erzeugen und wirtschaftlich zu nutzen. Das Verfahren hat meist aufgrund der breitgesteuten, zu umfangreichen und ungezielten Veränderung des Erbmaterials eine sehr geringe Erfolgsquote. Mutationen Genmutationen Mutation: Veränderung der Erbinformation Genmutationen werden in Basenaustauschmutationen und Rastermutationen unterschieden. Bei Basenaustauschmutationen handelt es sich um den Austausch einer Base in der DNA (s. a. Sichelzellanämie) Dies kann unterschiedliche Folgen haben: neutrale Mutation: Die Aminosäure bleiben gleich, d.h., der Austausch der Basen bewirkt nicht den Einbau einer anderen Aminosäure in das entsprechende Protein. Das Protein ist normal funktionsfähig. Fehlsinnmutationen: Es entsteht ein fehlerhafter Sinn, da durch den Austausch der Basen eine andere Aminosäure in das Protein eingebaut wird . Das Protein kann funktionsunfähig sein. Unsinnmutationen: Durch den Austausch einer Base entsteht z.B. ein Stopp-Codon, welches die Proteinbiosynthese vorzeitig beendet und somit das Protein stark verkürzt. Damit ist das Protein unvollständig und somit funktionsunfähig. Bei Rastermutationen werden Basen eingeschoben oder weggelassen. Baseneinschubmutationen: durch den Einschub einer zusätzlichen Base wird das Leseraster (vgl. genetischer Code) verschoben; es entsteht eine völlig neue Aminosäurenkette; das Protein ist funktionsunfähig. Basenverlustmutationen: Durch das Weglassen einer Base entsteht ebenfalls eine völlig neue Aminosäurenkette, da auch hierdurch das Leseraster verschoben wird, das Protein ist funktionsunfähig. Sonderfall: Baseneinschub- und Basenverlustmutation treten kurz nacheinander in der DNA auf: Durch den Einschub und das Weglassen einer Base in der DNA kann die Aminosäurenkette ein funktionsfähiges Protein bilden, da sie nur zu einem geringen Teil verändert wurde, denn das Leseraster ist nach der zweiten Änderung wieder korrekt. Chromosomenmutationen u. Genommutationen Außer Genmutationen gibt es noch weitere Mutationstypen, die Genommutationen (zahlenmäßige Veränderungen des Chromosomenbestandes einer Zelle) und Chromosomenmutationen (strukturelle Veränderungen der Chromosomen). Die verschiedenen Ursachen des Down-Syndroms stellen ein Beispiel für diese Mutationstypen dar. Chromosomenmutation Chromosomenmutation ist eine erbliche, strukturelle Chromosomenaberration oder Mutation, bei der die Abfolge der Gene verändert wird, die hintereinander auf einem DNA-Strang eines Chromosoms angeordnet sind. Arten der Chromosomenmutation Beispiele für Arten der Chromosomenmutation Man unterscheidet dabei zwischen verschiedenen Arten von Chromosomenmutationen: Deletion Ein Stück des Chromosoms (Endstück oder mittlerer Abschnitt) geht verloren Translokation Chromosomen können auseinanderbrechen und dabei Teilstücke verlieren, welche in die Chromatide eines nicht homologen Chromosoms angeheftet werden. Duplikation Ein Abschnitt des Chromosoms ist doppelt vorhanden, da ein auseinandergebrochenes Teilstück in die Schwesterchromatide eingegliedert wurde. Inversion Innerhalb eines Chromosoms kann sich nach einem doppelten Bruch ein Stück wieder umgekehrt einfügen. Dies führt zum Verlust oder zur Änderung der Reihenfolge des entsprechenden Gens. Insertion , Addition Hier besitzt ein Chromosom anschließend intern ein zusätzliches Teilstück. Substitution Austausch einer Base auf dem Gen, was eine Basentriplett Veränderung und somit eine mögliche Sinnänderung hervorruft. Für Eigenschaften eines Organismus ist nicht nur der Genbestand, sondern auch die Anordnung der Gene auf dem Chromosom maßgebend (Positions-Effekt). Auswirkungen Zum Teil führen diese Veränderungen der Struktur des Chromosoms zu schwer wiegenden Krankheiten, Behinderungen und Fehlbildungen. Der Grund dafür ist meistens der Gen-Dosis-Effekt: Üblicherweise liegt ein Gen nur in einer bestimmten Anzahl vor (beim Menschen zweimal = disom), mit Ausnahme der Gene des XChromosoms. Bei einer Deletion und Duplikation ist das aber nicht mehr der Fall, die Gene kommen dann mehr oder weniger als zwei mal vor. Dabei kann es bereits bei kleinen Veränderungen dieser Art zum Absterben der Zelle kommen. Translokationen und Inversionen müssen nicht zwangsläufig eine Auswirkung haben, da sich die Anzahl der Gene nicht verändert (= balancierte Translokation / balancierte Inversion), sondern nur ihre Position. Wenn sie eine Auswirkung haben, dann wegen des Positions-Effekts: Ein Gen kann nämlich in seiner Wirkungsweise von der Position auf dem Chromosom abhängig sein, insbesondere ist die Genregulation auch von der Lokalisation des Gens auf dem Chromosom abhängig. Genmutation Eine Genmutation ist eine erbliche Veränderung (Chromosomenaberration oder Mutation) eines Gens, die nur das jeweilige Gen selbst betrifft. Sind von der Veränderung mehrere Gene betroffen, handelt es sich um eine strukturelle Chromosomenaberration. Beschreibung Eine Genmutation liegt vor, wenn in der DNA nur eine Base verändert (Punktmutation), entfernt oder hinzugefügt (mögliche Rastermutation) wird. Sie ist die häufigste, wichtigste Art der Mutationen und tritt zufällig auf. Sie wird entweder durch eine fehlerhafte Replikation der DNA ausgelöst, oder ein Mutagen verursacht einen Basenaustausch im Erbgut. Meist entstehen Mutationen mit rezessiver Wirkung. Die Genmutation kann ohne Auswirkungen für den Träger, nachteilig, manchmal tödlich (letal) oder auch vorteilhaft sein. Genmutationsarten Nach Auftreten unterscheidet man zwei Genmutationsarten: gametische Genmutationen somatische Genmutationen Außerdem unterscheidet man folgende Genmutationstypen: Punktmutation durch Substitution Deletionsmutation durch Deletion Insertionsmutation durch Insertion bzw. Addition Duplikationsmutation durch Duplikation Rastermutation durch Addition Substitution Bei der Substitution findet ein Austausch einer einzelnen Base statt. Die Substitution bezeichnet also den Veränderungsvorgang der Punktmutation als einer Variante der Genmutation. Man unterscheidet hier zwei Typen der Substitution: Transition: Substitution einer Purin- gegen eine Purinbase bzw. einer Pyrimidin- gegen eine Pyrimidinbase. Transversion: Substitution einer Purin- gegen eine Pyrimidinbase oder umgekehrt. Es kann sich dabei entweder um eine „missense“-Mutation (sinnverändernde Mutation), also den Austausch einer Aminosäure bei der Translation handeln, oder um eine „nonsense“-Mutation (sinnentstellende Mutation), bei der ein Stop-Codon entsteht. Außerdem können „nonsense“-Mutationen in Introns Fehler beim Spleißen bewirken. Als dritte Möglichkeit kann es sich auch um eine stille Mutationen oder neutrale Mutationen handeln, bei der eine DNS-Base verändert wurde, aber weiterhin die gleiche Aminosäure kodiert wird. Das ist durchaus möglich, da es für manche Aminosäuren mehrere Kodierungsmöglichkeiten gibt. Siehe auch unter Mutation. Deletion Unter Deletion versteht man bei der Genmutation den Verlust eines oder mehrerer Basenpaare. Eine Deletion führt zur Verschiebung des Leserasters (frameshift). Man kann zwei Typen der Deletion unterscheiden: „out of frame“-Deletion: Es entsteht kein funktionsfähiges Protein. „in frame“-Deletion: Hierbei entsteht ein Protein mit Restfunktion, da das Leseraster erhalten bleibt. Das Leseraster kann beibehalten werden, wenn die Deletion von Basenpaaren eine Anzahl enthält, die durch drei teilbar ist. Werden zum Beispiel sechs Basenpaare in Folge deletiert, so fehlen dann auch zwei Aminosäuren im Protein (was ein defektes Protein zur Folge haben kann, nicht muss), jedoch ist das Leseraster erhalten geblieben. Insertion bzw. Addition Hierunter versteht man bei der Genmutation den Einbau von Sequenzen in die DNA. Auch dies führt zu einer Leserasterverschiebung (Frameshift), soweit nicht Triplett-Codons eingebaut werden. Duplikation Duplikationen entstehen bei der Genmutation zum Beispiel durch ungleiches crossing over entweder zwischen homologen Chromosomen oder zwischen Schwesterchromatiden. Sie werden auch Genduplikationen genannt. Man unterscheidet zwei Genduplikationsarten: partielle Genduplikationen vollständige Genduplikationen Rastermutation Bei der Rastermutation als eine Variante der Genmutation findet eine Verschiebung der Nukleotidsequenz der Nukleotidkette statt, indem zusätzliche Moleküle in sie eingebaut werden. Diese addierten Moleküle haben eine den Nukleinsäurebasen ähnliche Größe und Struktur. Dadurch kommt es zur Synthese eines veränderten Genprodukts (Protein). Beispiele Ein bekanntes Beispiel für eine Genmutation ist die Sichelzellanämie. Die Betroffenen bilden ein abnormes Hämoglobin und die veränderten roten Blutkörperchen werden von Leukozyten aufgelöst, was zu Blutarmut führt. Es gibt zwei Varianten: Homozygot (reinerbig): Schwere Blutarmut Heterozygot (mischerbig): Malariaresistent, nur in großer Höhe werden rote Blutkörperchen angegriffen Andere Beispiele sind: Rot-Grün-Blindheit Bluterkrankheit Genommutation Eine Genommutation, auch numerische Chromosomenaberration genannt, ist eine nicht-erbliche Veränderung der Gesamtanzahl der Chromosomen . Ursachen der Genommutation Der Grund für diese Veränderung liegt in einem fehlerhaften Zellteilungsprozess während der Meiose oder Mitose: Die Chromosomen (bzw. Chromatiden bei der zweiten meiotischen Teilung) werden nicht wie üblich getrennt (Non-disjunction). Diese Besonderheit kann sowohl bei den Gonosomen, als auch bei den Autosomen auftreten, wobei die Folgen bei den Autosomen häufig gravierender sind. Aberrationen bei den Autosomen findet man deswegen selten, meistens stirbt die Geschlechtszelle (Gamet) ab. Arten der Genommutation Es gibt zwei verschiedene Arten der Genommutationen: Polyploidien Bei einer Polyploidie liegen alle Chromosomen nicht doppelt, sondern mehrfach (also mindestens verdreifacht / trisom) vor. Aneuploidien Bei einer Aneuploidie ist die Zahl der Chromosomen vermehrt oder vermindert, was auf Unregelmäßigkeiten während der Zellteilung zurückgeführt wird. Beispiel Ein bekanntes Beispiel für eine Aneuploidie ist aufgrund seiner Auftretenshäufigkeit das Down-Syndrom (Trisomie 21): Bei dieser aneuploiden Chromosomenbesonderheit liegt das Chromosom 21 vollständig oder teilweise verdreifacht in allen Körperzellen oder in einem Teil der Körperzellen vor. Die homologen Chromosomen 21 trennen sich bei der Meiose (Entstehung der Freien Trisomie 21) oder Mitose (Entstehung der Mosaik-Trisomie 21) nicht oder eines der beiden Chromosomen 21 heftet sich an ein anderes Chromosom (Entstehung der Translokations-Trisomie 21). Karyogramm Ein Karyogramm ist die geordnete Darstellung der einzelnen durch ein Mikroskop fotografierten Chromosomen einer Zelle. Sortiert werden alle Chromosomen einer Zelle nach morphologischen Gesichtspunkten (Größe, Centromerlage, Bandenmuster). Die entsprechende Zelle muss sich hierfür in der Metaphase der Mitose befinden. Begriffsunterscheidung Der Ausdruck Karyogramm ist kein Synonym für den Begriff Karyotyp, sondern das Karyogramm gibt Auskunft über den Karyotyp der untersuchten Zelle eines Individuums oder einer genetischen Population. Herstellung Zu Beginn der Zellteilung verkürzen sich die Chromosomen und rollen sich spiralig auf. Sie können dann durch einfärben für ein Mikroskop sichtbar gemacht werden. Der Zellteilungsprozess wird nun mit Hilfe des Spindelgifts Colchizin - dem Gift der Herbstzeitlosen - gestoppt. Die Zelle bzw. deren Chromosomen werden fotografiert, die einzelnen Chromosomen aus der Fotografie ausgeschnitten und nach den unten genannten Kriterien angeordnet. Durch Farbstoffe lassen sich charakteristische Banden anfärben, die jedes Chromosom eindeutig charakterisieren, z.B. mittels Multicolour-FISH (Vielfarben Fluoreszenz in situ Hybridisierung). Die Farbunterschiede werden jedoch nur bei Einsatz einer hochempfindlichen CCD-Kamera und unter Anwendung von Computersoftware sichtbar. Oft wird es erst durch diese Technik möglich kleine Translokationen (Ortsveränderung von Chromosomen oder von Chromosomenabschnitten) zu erkennen, die bei normaler Fotografie nicht auffallen würden. Zudem kann mit der Technik der Einfärbung die Zusammensetzung von Markerchromosomen bestimmt werden. Die Chromosomen werden zu homologen Paaren angeordnet und dann nach Länge, Lage des Zentromers, der Satelliten, sekundärer Einschnürungen und des Nucleolusorganisators, sowie nach dem Muster der Chromosomenbänder sortiert. Die Autosomen werden dabei für gewöhnlich von den Gonosomen (Geschlechtschromosomen) abgesondert, in sieben Gruppen eingeteilt und nummeriert. Schematische Darstellung eines Karyogramms Meiose Bei der Meiose entstehen aus einer Mutterzelle vier/4 Tochterzellen. Eine meiotische Teilung besteht aus 2 Teilungsschritten. Im ersten Schritt wird die Zahl/Anzahl der Chromosomen auf die Hälfte reduziert. Dieser Teil heißt deshalb Reduktionsteilung . Der zweite Teil der Meiose läuft dann wie eine Mitose ab. Sichtbar werden die Chromosomen in der Prophase In der Metaphase I lagern sich die homologen Chromosomen paarweise in der Äquatorialebene an. In der Anaphase I werden diese Chromosomenpaare dann in einzelne Chromosomen getrennt, wobei zu jedem Pol ein Chromosom, bestehend aus zwei Chromatiden, gezogen wird. Die Phase, in der diese Chromosomen an den Polen ankommen, heißt Telophase I . In der Metaphase II lagern sich die Chromosomen einzeln in der Äquatorialebene an. Jedes Chromosom besteht aus zwei Chromatiden . Bei der anschließenden Anaphase II werden die Chromatiden voneinander getrennt und von jedem Chromosom geht ein Chromatid zu einem Pol, das andere zum anderen Pol. Am Ende haben wir vier/4 Zellen. Diese Chromosomenverteilung läuft bei Oogenese und Spermatogenese gleich ab. Lediglich beim Zellplasma/Zytoplasma/Cytoplasma findet eine Ungleichverteilung statt. Während bei den Spermien 4 gleichgroße und gleichberechtigte Zellen entstehen, sind bei der Oogenese die Teilungen inäqual . Dadurch entsteht eine große Eizelle mit viel Zellplasma, die nach der Befruchtung besonders besonders lebensfähig ist und 3 kleine Richtungskörperchen , die nicht überlebensfähig sind. Die Animation zeigt die Spermatogenese und nicht die Oogenese Meiose Unter Meiose (von griech.: meioo = vermindern, verkleinern), die auch als Reifeteilung oder Reduktionsteilung bezeichnet wird, versteht man eine besondere Form der Kernteilung, wobei, im Gegensatz zur echten mitotischen Zellkernteilung, der Mitose, der Chromosomensatz vom diploiden auf den haploiden Zustand reduziert wird. Die Meiose vollzieht sich immer in zwei Teilungsschritten (1. und 2. meiotische Teilung oder auch Meiose I und II genannt). In der Regel findet nach jedem dieser Teilungsschritte eine Cytokinese statt, was zu einer Bildung von 4 Einzelzellen führt, die als Keimzellen oder Gameten bezeichnet werden. Da die Cytokinese in der Regel mit der Meiose zusammenhängt, werden umgangssprachlich beide Phasen zusammen als Meiose bezeichnet. Allgemeinen kann man sagen, dass die Mitose nur der Zellvermehrung dient, die Meiose den Ploidiegrad der Diplonten reduziert. Bedeutung Die Körperzellen der meisten höheren vielzelligen Lebewesen (Metazoa) wie auch einigen einzelligen Eukaryoten (z.B. Paramecium der Wimpertierchen) sind diploid, das heißt, sie besitzen von jedem Chromosomtyp zwei gleiche (homologe) Exemplare, eines geerbt von der Mutter und eines vom Vater. Das setzt aber voraus, dass die Keimzellen (Gameten) der beiden Eltern einen haploiden Chromosomensatz aufweisen, also von jeden Chromosomtypen nur ein Exemplar besitzen. Wäre dies nicht der Fall, würde sich der Chromosomensatz mit jeder weiteren Generation verdoppeln. Bei den zweigeschlechtlichen, sich sexuell fortpflanzenden Organismen vollzieht sich die Reduzierung von den Urkeimzellen zu den Gameten während der Gametogenese: In der Oogenese werden die Eizellen und in der Spermatogenese die Samenzellen gebildet, welche mit einem haploiden Chromosomensatz ausgestattet sind. Die Phase, in der sich die Zellen in diesem haploiden Zustand befinden wird auch Haplophase genannt und geht über in die Diplophase, sobald sich beide Gameten durch die Befruchtung zur Zygote verschmelzen. Es gibt auch eine Reihe von haplontischen Organismen, das heißt ihre Körperzellen besitzen nur einen haploiden Chromosomensatz. Bei diesen Arten, zu denen zum Beispiel die Alge Chlamydomonas zählt, beschränkt sich die Diplophase auf das Zygotenstadium. Organismen, bei denen sich die Haplophase nur auf die Gameten beschränkt, wie bei den meisten mehrzelligen Lebewesen (auch wir Menschen), zählen zu den Diplonten. Die Meiose kann bis zu Jahren dauern. Phasen der Meiose Prinzip der zwei Teilungsschritte der Meiose: die Reduktionsteilung und die Äquationsteilung Die Meiose läuft in zwei Teilschritten ab: Die Reduktionsteilung, auch 1. meiotische Teilung, 1. Reifeteilung oder einfach Meiose I. Hier wird der verdoppelte Chromosomensatz der diploiden Zelle reduziert, wobei die Chromosomen auf verschiedene Arten miteinander rekombiniert werden können. Schon nach der Reduktionsteilung weisen die Zellen nur noch einen einzigen Chromosomensatz auf, müssen aber noch eine Teilung durchlaufen. Dies liegt daran, dass die Chromosomen immer noch als Zwei-Chromatiden-Chromosom vorliegen, da sich ja nur der Chromosomensatz, nicht die Chromosomen selbst getrennt haben. So wird nach der Reduktionsteilung auch keine Replikation angestoßen und nach einer sehr kurzen Interphase folgt Die Äquationsteilung, auch als 2. meiotische Teilung, 2. Reifeteilung oder Meiose II. Diese Phase ähnelt nun einer normalen Mitose, nur dass hier ein haploider Chromosomensatz vorliegt. Ansonsten werden die Chromosomen in den normalen Zellkernteilungsphasen voneinander getrennt. Da die Meiose zwei Teilungsschritte durchläuft und jeder einzelne Schritt meist mit einer abschließenden Cytokinese zwei Tochterzellen entstehen lässt, liegen nach der abgeschlossenen Meiose vier haploide Tochterzellen vor. Reduktionsteilung - Meiose I Die 1. meiotische Teilung beginnt mit der Prophase I, die im Vergleich zur Prophase der Mitose stark verlängert ist: Sie kann Tage bis zu Jahre, wie bei Primaten, andauern. Diese Phase wird in fünf Stadien unterteilt: Im Leptotän (von gr. leptos, dünn und lat. taenia, das Band) beginnen die Chromosomen sehr langsam zu kondensieren. Sie sind bis zum Ende der Prophase I an den Ärmchen-Enden, den sogenannten Telomeren, an der inneren Zellkernmembran befestigt. Das Zygotän (von gr. zygon, das Joch) ist durch die Paarung der homologen Chromosomen gekennzeichnet. Hier liegt nun ein klar sichtbares Chromatin vor. Die Chromosomenpaarung, auch Synapsis, verläuft reissverschlussartig, wobei sich zwischen beiden Chromosomensträngen ein sogenannter synaptonemaler Komplex bildet, der beide Stränge zusammenhält. Mit dem Pachytän (von gr. pachys, derb) ist die Chromosomenpaarung abgeschlossen und über Aufbrechungen innerhalb des Synaptonemalkomplexes können sich Chromatidenteile über Kreuz neu verknüpfen. Diese Art von Rekombination nennt man auch crossing over. In Diplotän (von gr. diploos, doppelt) werden die homologen Chromosomen voneinander getrennt, wobei die rekombinierten Stellen über sogenannte Chiasmata noch miteinander verbunden bleiben. Bei einigen Organismen findet währenddessen noch Transkription statt. Jene Bereiche werden als Schleifen symmetrisch ausgelagert, weswegen man diese Chromosomen nach ihrem Aussehen als Lampenbürstenchromosomen bezeichnet. Mit der Diakinese (von gr. diakinein, auseinander bewegen) endet die RNA-Synthese und die volle Kondensation beginnt. Zudem löst sich nun die Zellkernhülle auf und die Chromosomenverteilung verläuft vergleichbar wie in der Prophase und Prometaphase der Mitose. Nach Abschluss der Prophase I lagern sich die homologen Zwei-Chromatiden-Chromosomen in der Metaphase I in der Äquatorialebene nebeneinander an. Diese Anlagerung wird auch Chromosomenpaarung oder bivalente Paarung bezeichnet. Jedes homologe Chromosomenpaar bildet hierbei eine Chromatidentetrade. Dabei können im Lichtmikroskop Überkreuzungen benachbarter Nichtschwesterchromatiden sichtbar werden, die Chiasmata. Die für den Trennungsvorgang notwendigen Kinetochore werden dabei nur auf einer Seite der Schwesterchromatiden gebildet. So werden die Chromosomenpaare, nicht die Chromatiden, auseinandergezogen. Nach der Ausrichtung können mit Hilfe des Spindelapparats die homologen Zwei-Chromatiden-Chromosomen während der Anaphase I voneinander getrennt und zu verschiedenen Zellpolen gezogen werden. Während der Telophase I liegt dann an jedem Zellpol jeweils nur noch ein Zwei-Chromatiden-Chromosom jedes Typs. Es ist also zu einer Reduktion des Chromosomensatzes gekommen. Äquatorialteilung - Meiose II Die 2. meiotische Teilung läuft ähnlich wie die Mitose ab. Während der Teilungsphasen (Prophase II, Metaphase II, Anaphase II, Telophase II) werden die beiden Chromatiden jedes Zwei-ChromatidenChromosoms voneinander getrennt, so dass die entstandenen 4 Keimzellen nur jeweils ein Ein-ChromatidChromosom jedes Typs besitzen. Nach Abschluss der Meiose besitzen also alle Gameten den benötigten haploiden Chromosomensatz. Sie sind damit für den Befruchtungsvorgang vorbereitet. Biologische Bedeutung Die Bedeutung der Meiose kommt dadurch zum Tragen, daß ein Diplont, also ein Organismus mit einem somatisch diploiden Chromosomensatz, gegen Mutationen besser geschützt ist. Da hier die Erbinformationen in zwei Allelen auftritt, kann das gesunde Allel die Mutation abschwächen oder im besten Fall unwirksam machen. Der haploide Zustand, der bei den wenigen haplonten Formen auch im Soma vorkommt, ist dagegen sehr anfällig, da hier kein anderes Allel Änderungen im Gen abfangen kann. Darum hat es sich in der Evolution als Vorteil erwiesen, die haploide Phase drastisch zu reduzieren, wie es bei der Entwicklung von den Moospflanzen über den Farnpflanzen zu den Gefäßpflanzen am besten zu beobachten ist. Ist die Sporen entwickelnde haploide Generation der Moose noch deutlich zu erkennen und im Vergleich zur diploiden Generation deutlich länger, kann von einer echten haploiden Generation bei Gefäßpflanzen nicht mehr die Rede sein, da diese drastisch, zeitlich und lokal, in den Samen reduziert wurde. Den Vorteil, die diese Entwicklung hatte, kann man in der grossen Artenvielfalt der Bedecktsamer finden. In der Natur hat sich der sogenannte Kernphasenwechsel, also der Wechsel zwischen haploiden und diploiden Chromosomensatz, wohl unabhängig einmal bei den Pflanzen und einmal bei den Tieren entwickelt. Bei den Pflanzen wird der Kernphasenwechsel in der Regel von einem Generationswechsel begleitet. Herstellung Karyogramm Chromosomen aus menschlichen Zellen kann man einfach aus Blutzellen gewinnen, allerdings nur aus den weißen Blutkörperchen, da die roten Blutkörperchen keinen Zellkern mehr besitzen. Weiße Blutkörperchen sind im Blut seltener als rote Blutkörperchen. Um den Anteil der weißen Blutkörperchen zu erhöhen, die sich im Gegensatz zu den roten Blutkörperchen noch selbst vermehren können, gibt man das Blut in eine Kulturflüssigkeit , die alle für die Vermehrung der Blutkörperchen notwendigen Stoffe enthält und bebrütet die Kultur für 3 Tage bei Körpertemperatur. In dieser Zeit vermehren sich die weißen Blutkörperchen durch Mitosen/Mitose . Da man Chromosomen nur in kompakter Form im Lichtmikroskop gut erkennen kann, stoppt man die Mitosen in der Metaphase . Das gelingt mit Colchicin , dem Gift der Herbstzeitlosen, das die Ausbildung des Spindelfaserapparates hemmt und damit die Mitose in der Metaphase unterbricht. Nach der Colchicin-Zugabe sammeln/häufen sich immer mehr Zellen im Metaphase-Stadium an. Trotz der Vermehrung der weißen Blutkörperchen ist es immer noch schwierig/schwer , sie zwischen den roten Blutkörperchen zu finden. Deshalb versucht man, sie von diesen zu trennen/separieren/isolieren . Dazu wird zunächst die Kultur zentrifugiert , die Blutkörperchen konzentrieren sich dadurch unten im Zentrifugenglas und die Flüssigkeit oben kann abgesaugt werden. Die Zugabe einer bestimmten Menge von destilliertem Wasser führt zum Quellen der Blutzellen, wobei die weißen nur größer werden, die roten jedoch platzen. Zur Reinigung der Flüssigkeit von den Zellresten der roten Blutkörperchen wird nochmals zentrifugiert und der ungewünschte Überstand abgesaugt. Den weißen Blutkörperchen fügt man soviel eines Methanol-Eisessig-Gemischs hinzu, dass sich in einem Tropfen der Flüssigkeit ein weißes Blutkörperchen befindet. Aus einer Pipette lässt man einzelne Tropfen auf einen Objektträger fallen. Beim Aufprall platzen die gequollenen Zellen und die einzelnen Chromosomen verteilen sich. Jetzt kann das Präparat gefärbt und anschließend mikroskopiert werden. Die Chromosomen haben eine unterschiedliche Größe , je nach Lage der Spindelfaseransatzstelle durch die entstehenden Äste eine unterschiedliche Form und können sich bei entsprechender Färbung in der Musterung unterscheiden. Die auf ein Foto/Papierfoto übertragenen Chromsomen kann man ausschneiden und nach Größe, Form und Musterung sortieren. Beim Menschen findet man in den Körperzellen 23 Chromosomenpaare. 22 Paare sind die Autosomen und 1 Paar sind die Gonosomen , die Geschlechtschromosomen. Wenn keine Störung vorliegt, haben wir bei Frauen 2/zwei X-Chromosomen und bei Männern ein X-Chromosom und ein viel kleineres yChromosom.