B-Baum - oliver.huber[at]
Werbung

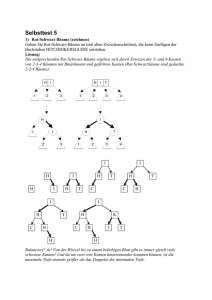
B-Baum 1. Einführung Ausgangspunkt der dynamischen Baumverfahren im Datenbankbereich ist ein ausgeglichener, balancierter Suchbaum. Suchbaum bedeutet dabei, dass die Daten im Baum sortiert nach einem Zugriffsattributwert gespeichert werden. Befindet sich an einem bestimmten Knoten im Baum der Wert w, so werden die Wert w‘ < w im linken Teilbaum bzw. die Werte w‘ > w im rechten Teilbaum von w gespeichert. Ausgeglichen oder balanciert bedeutet dabei, dass das Einfügen in einen Suchbaum immer einen Baum ergibt, in dem alle Pfade von der Wurzel zu den Blättern des Baumes gleich lang ist. Das Problem ist dabei, Algorithmen zum Einfügen und löschen von Elementen des Baumes zu finden, die diese Eigenschaften bewahren. Als Hauptspeicher-Implementierungsstruktur sind binäre Suchbäume beliebt, zB. die AVL-Bäume. Im Datenbankbereich werden die Knoten von Suchbäumen nun zugeschnitten auf die Seitenstruktur des Datenbanksystems. Ist eine Seite etwa 1024 Bytes groß, wollen wir auch entsprechend viele Informationen in dem Knoten unterbringen. Wie in den Indexseiten der indexsequentiellen Organisation, werden nun mehrere Zugriffsattributwerte auf einer Seit untergebracht. Der Suchbaum ist dadurch nicht mehr binär (zwei Nachfolger für einen Indexeintrag), sondern verzweigt breiter. Man nennt diese Suchbäume dann auch Mehrwegbäume. Prinzipieller Aufbau eines B-Baumes 2. Prinzip Im Prinzip ist der von Bayer eingeführte B-Baum ein dynamischer, balancierter Indexbaum, bei dem jeder Indexeintrag auf eine Seite der Hauptdatei zeigt. Ein Mehrwegbaum würde völlig ausgeglichen sein, wenn 1 alle Wege von der Wurzel bis zu den Blättern gleich lang sind, und jeder Knoten gleich viele Indexeinträge aufweist. Da ein solches, vollständiges Ausgleichen nach Änderungsoperationen zu teuer wird, wurde folgendes Kriterium als Balancierungskriteritum für den B-Baum eingeführt: Jede Seite außer der Wurzelseite enthält zwischen m und 2m Daten. Die Konstante m wird dann auch als Ordnung des B-Baumes bezeichnet. Falls dann n Datensätze in der Hauptdatei gespeichert werden, ist der Zugriff auf die richtige Seite in logm(n) Seitenzugriffen möglich. Vorteile des Bayer-Kriteritums sind folgende: Durch das Balancierungskriteritum wird eine Eigenschaft nahe an der vollständigen Ausgeglichenheit erreicht (das erste Kriterium wird vollständig erfüllt, das zweite zumindest näherungsweise). Das Kriterium garantiert mindestens 50% Speicherplatzausnutzung. Es gibt einfache, schnelle Algorithmen zum Suchen, Einfügen und Löschen von Datensätzen, die jeweils eine Komplexität von O(logm(n)) aufweisen. Ein B-Baum ist als Primär- und Sekundärindex geeignet. Nimmt man zB. die Datensätze direkt in die Indexseiten auf, hat man den B-Baum als Dateiorganisationsform eingesetzt. Verweist man aus den Indexseiten auf die Datensätze in den Hauptseiten, so ist der B-Baum ein Sekundärindex. Die Ordnung eines B-Baumes ist die minimale Anzahl der Einträge auf den Indexseiten außer der Wurzelseite, die der B-Baum garantiert. Ein B-Baum der Ordnung m=8 faßt damit auf jeder Indexseite zwischen 8 und 16 Einträgen. Die genaue Charakterisierung von B-Bäumen der Ordnung m findet sich nun in der folgenden Definition. Ein Indexbaum ist ein B-Baum der Ordnung m, wenn er die folgenden Eigenschaften erfüllt: Jede Jede Jede ihrer Seite enthält höchsten 2m Elemente Seite, außer der Wurzelseite, enthält mindestens m Elemente. Seite ist entweder eine Blattseite ohne Nachfolger oder hat i+1 Nachfolger, falls i die Anzahl Elemente ist. 3. B+-Baum Bild 1 (B-Baum) Bild 2 (B+-Baum) Die in der Praxis am häufigsten eingesetzte Variante des B-Baumes ist der B+-Baum, der effizientere Änderungsoperationen und eine Verringerung der Baumhöhe ermöglicht. Der B+-Baum integriert die Datensätze der Hauptdatei auf den Blattseiten des Baumes. Bild 1 und 2 zeigen zwei Beispielbäume im Vergleich. Während im B-Baum die inneren Knoten wie die Blattknoten sowohl Zugriffsattribute als auch Verweise auf die Datensätze oder sogar die Datensätze selbst beinhalten, werden im B+-Baum die Datensätze erst auf den Blattseiten gespeichert. In den inneren Seiten des B+-Baumes wird nur der Zugriffsattributwert und die Zeiger auf die nachfolgenden Seite der nächsten Stufe aufgenommen. 2 Ein B+-Baum wie in Bild 2 ist ein hohler Baum, da die inneren Knoten keine Information tragen und nur zum Verweis auf die Blattseiten dienen. Jeder Zugriff benötigt nun gleichmäßig O(log m(n)) Schritte, da immer bis zu den Blattseiten gesucht werden muß. Wenn wir zB. nach dem Datensatz mit dem Zugriffsattributwert 25 suchen, finden wir im B+-Baum zwar bereits in der Wurzel den Verweis, müssen nun jedoch auch bei Gleichheit zum rechten Nachfolger im Baum gehen (die Datensätze mit den Werten x < k befinden sich im linken Teilbaum des Wertes k, die Datensätze mit den Werten x >= k rechts davon). Der Begriff Ordnung muß für einen B+-Baum nun neu definiert werden: die Ordnung ist eine Wertepaar (x,y), bei dem x die Mindestbelegung der Indexseiten und y die Mindestbelegung der Datensatzseiten beschreibt. Üblicherweise ist x natürlich sehr viel größer als y. Während das insert-Verhalten sich kaum ändert, wird ein delete gegenüber dem B-Baum weitaus effizienter durchführbar sein. Im Normalfall hat ein delete nur Auswirkungen auf der Blattseite. Ein „Ausleihen“ eines Elementes von der Blattseite durch eine im Inneren des Baumes vorzunehmende Löschung findet nicht statt. Im Gegenteil: Zugriffattributwerte im Inneren des B +-Baumes können stehenbleiben, auch wenn der letzte Datensatz mit diesem Wert gelöscht wird. Nur bei UnterlaufSituationen muß der B+-Baum ausgeglichen werden, um die üblichen Eigenschaften zu erhalten. In der Praxis wird der B+-Baum häufig als Primärindex eingesetzt, da er die Hauptdatei in seine Struktur integriert. Die Höhe wird meist gegenüber dem B-Baum reduziert sein, da die Indexseiten weniger Daten beinhalten. Der B-Baum in seiner Ausprägung mit Verweisen auf die Datensätze wird häufiger als Sekundärindex eingesetzt. Sein Hauptvorteil liegt eher im didaktischen Bereich: Da die Ordnung nur von einem Parameter abhängt, sind Berechnungen für den Aufwand von Operationen für den B-Baum leichter durchzuführen als für den B+-Baum. Vergleicht man den B+-Baum mit einer mehrstufigen indexsequentiellen Datei, so stellt sich heraus, dass jeder B+-Baum eine indexsequentielle Datei darstellt. Die Dynamik der Überlaufbehandlungen, das automatische Wachsen und Schrumpfen des Baumes und die garantierte Speicherplatzausnutzung unterscheiden den B+-Baum bei Operationen aber positiv von der indexsequentiellen Datei. Analog zur indexsequentiellen Datei ist jedoch zB. die lineare Verkettung der Hauptdatei-Seiten untereinander. Diese realisiert die sequentielle Grundstruktur der Hauptdatei (siehe Bild 3). Bild 3 4. B*- und B#-Baum Das Problem beim B-Baum ist das häufige Aufspalten von Seiten und die geringe Speicherplatzausnutzung von nahe 50%. Zwei Varianten des B-Baumes, der B*-Baum und der B#-Baum, lösen dieses Problem. Bei diesen Varianten wird das Aufteilen von Seiten bei einem Überlauf zunächst durch ein Neuverteilen der Datensätze auf eventuell nicht voll ausgelastete Nachbarseiten ersetzt. Falls dies nicht möglich ist, wird nicht eine Seite in zwei Seiten aufgeteilt, sondern zwei Seiten in drei. Dies ermöglicht eine durchschnittliche Speicherplatzausnutzung von über 66% statt 50%. 5. Suchen Die lookup-Operation des B-Baumes greift die Idee der statischen Indexverfahren auf. Startend auf der Wurzelseite wird eine Eintrag im B-Baum ermittelt, der den gesuchten Zugriffsattributwert w überdeckt. w liegt also zwischen zwei Werten k1 und k2 in der B-Baum-Seite (oder ist kleiner als der erste bzw. größer als der letzte Wert). Der entsprechende Zeiger auf die nächste Stufe des B-Baumes wird verfolgt 3 und die entsprechende B-Baum-Seite der nächsten Stufe geladen. Hier wiederholt sich der Prozess. Ist eine Blattseite erreicht und der Wert w wurde nicht gefunden, so existiert kein entsprechender Datensatz in dieser Datei. Wurde der Wert gefunden, so wird der zugeordnete Datensatz gelesen. In Bild 5 wird ein B-Baum der Ordnung 2 mit 3 Stufen gezeigt. Vor und nach jedem Zugriffsattributwert k im B-Baum befindet sich ein Zeiger, der auf alle Werte kleiner bzw. größer als k verweist. Suchen wir etwa den Datensatz zum Attributwert 38, so verfolgen wir in der Wurzel den Zeiger nach der 25, in der darauffolgenden Seite den Zeiger zwischen 20 und 40 und finden schließlich den gesuchten Wert auf der Blattseite. Bild 5 Suchen wir den Wert 20, so verfolgen wir in der Wurzel den Zeiger links von der 25 und finden den Wert bereits auf der zweiten Stufe des Baumes. Suchen wir dagegen den Wert 6, so verfolgen wir auf der Wurzelseite den Zeiger links von der 25, auf der zweiten Stufe den Zeiger links von der 10. Auf der Blattseite ist der Wert jedoch nicht vorhanden, so dass ein Datensatz mit dem Zugriffsattributwert 6 nicht existiert. 6. Einfügen Wir werden nun zunächst die Einfügeoperation in eine B-Baum an einem einfachen Beispiel erläutern. Bild 4 zeigt, wie die Buchstaben des Worte „ALGORITHMUS“ der Reihe nach in einen B-Baum der Ordnung m=1 eingefügt werden. Ordnung 1 heißt dabei, dass mindestens ein und höchstens zwei Datensätze in den Seiten enthalten sein können. Während A und L noch problemlos auf der ersten Seite des B-Baumes Platz finde, wird bei Einfügen von G in die bisher einzige Seite eine Überlaufbehandlung erforderlich. Der Überlauf einer Seite wird im B-Baum nach einem einfachen Schema behandelt: Der in der Ordnung mittlere Datensatz (hier G) wird in eine höhere Ebene des B-Baumes geschoben. Da diese in unserem Beispiel noch nicht existiert, wird eine neue Wurzel angelegt. Der Datensatz von G auf der höheren Eben verweist nun auf zwei neue Seiten, die bezüglich der Ordnung kleinere Datensätze bzw. größere Datensätze beinhalten mit dem linken bzw. rechten Zeiger auf der Seite. Für n Datensätze eine Nicht-Blattseite sind jeweils n+1 Zeiger auf Nachfolgeseiten auf die Nicht-Blattseite Bild 4 aufgenommen. Das Einfügen von O in den resultierenden B-Baum geschieht noch unproblematisch. Zunächst muß im Baum die passende Blattseite gesucht werden. Steigt man bei der Wurzel ein, so erkennt man, dass O > G und somit O in das rechte Blatt des Baumes eingefügt werden muß. Dies gilt auch für das Einfügen von R im nächsten Schritt. Leider ist nun die rechte Blattseite mit drei Datensätzen übervoll. Nach dem üblichen Prinzip wird nun der mittlere Datensatz O auf die höhere Ebene verschoben und die restliche 4 Seite auf zwei Seiten aufgeteilt. Die Wurzelseite besteht nun aus den zwei Datensätzen G und O und drei Zeigern auf die Seiten mit Datensätzen x in der Ordnung x < G, G < x < O und O < x. Das Einfügen von I und T geschieht wiederum problemlos auf die entsprechenden Blattseiten. Das Einfügen von H bewirkt nun jedoch einen Überlauf auf der mittleren Blattseite. Auf dieser Seite ist I das mittlere Element, das auf eine höhere Eben geschoben wird. Die restliche Blattseite wird auf zwei neue Blattseiten aufgeteilt. Leider ist nun aber die Wurzelseite mit G, I und O ebenfalls übergelaufen. Auch auf Nicht-Blattseiten wird nun das gleiche Prinzip angewendet: Das mittlere Element I wird auf eine höhere Eben geschoben (die nicht existiert, deshalb bildet sich eine neue Wurzel), die restliche Seite auf zwei aufgetrennt. Man sieht bereits, dass wir mit B-Bäumen einen mehrstufigen Index realisieren können. Bei Bedarf wächst der B-Baum jeweils um eine Stufe an. Während M wiederum unproblematisch in die lexikographisch passende Blattseite einsortiert werden kann, verursacht U wieder einen Überlauf auf der letzten Blattseite. Das mittlere Element T dieser Seite kann aber ohne Probleme in die höhere Eben (auf die Seite mit O) aufgenommen werden. Der letzte einzuführende Buchstabe S wird ohne Überlauf auf eine der Blattseiten aufgenommen. Die insert-Operation muß das dynamische Teilen von Seiten im Bedarfsfall realisieren. Das Einfügen eines Wertes w wird folgendermaßen ausgeführt: Zunächst wird mit lookup die entsprechende Blattseite gesucht. Falls die passende Seite n < 2m Elemente besitzt, wird w einsortiert und das insert ist beendet. Falls die passende Seite n=2m Elemente besitzt, muß die Seitenstruktur möglichst lokal verändert werden, dies geschieht dadurch, dass eine neue Seite erzeugt wird, die ersten m Werte auf der Originalseite verbleiben, die letzten m Werte auf die neue Seite gespeichert werden und das mittlere Element auf die entsprechende Indexseite nach oben weitergereicht wird. Dieses Weiterreichen wird wieder mit derselben insert-Prozedur realisiert. Eventuell wird dieser Prozess rekursiv bis zur Wurzel des Baumes fortgesetzt. 7. Löschen Die delete-Operation muß einen „Unterlauf“ auf einer Seite (weniger als m Elemente auf der Seite) behandeln und den B-Baum im Bedarfsfall wieder schrumpfen lassen. Das Löschen eines Wertes w wird folgendermaßen ausgeführt: Zunächst wird mit lookup die entsprechende Seite gesucht. Falls w auf einer Blattseite gespeichert ist, wird der Wert gelöscht und eventuell ein Unterlauf behandelt. Falls w nicht auf einer Blattseite gespeichert ist, so muß der Wert im inneren Knoten gelöscht und durch das lexikographisch nächstkleinere Element von einer Blattseite ersetzt werden. Nun kann man wie im Fall des Löschens auf einer Blattseite verfahren. Eventuell muß auf dieser Blattseite ein Unterlauf behandelt werden. Die Unterlaufbehandlung in beiden Fällen kann nun durch ein Ausgleichen mit der benachbarten Seite oder durch Zusammenlegen zweier Seiten zu einer erfolgen. Das Ausgleichen erfolgt, falls die benachbarte Seite n Elemente mit n > m hat. Hat die Nachbarseite dagegen n=m Elemente, so werden die Unterlaufseite und die Nachbarseite zusammengelegt und das „mittlere“ Element von der Indexseite darüber heruntergeholt. Die neue Blattseite hat dann genau 2m Elemente, die Indexseite darüber verliert ein Element. Eventuell muß auf der Indexseite wiederum ein Unterlauf behandelt werden. 5 Bild 5 In Bild 5 soll zB. der Datensatz zum Attributwert 24 gelöscht werden. Sie Seite enthält damit nur noch einen Datensatz (bei Ordnung 2 bedeutet dies einen Unterlauf). Da die Nachbarseite zur linken genügend Elemente besitzt, können die vier Datensätze 13, 14, 15, 18, das mittlere Element 20 und die 22 der betroffenen Seite neu verteilt werden. In diesem Fall würden die 13, 14, 15 auf die linke Seite, die 20 und 22 auf die rechte Seite, und die 18 als mittleres Element nach oben verteilt. Löscht man dagegen 28, 38 und 35, so haben die zwei ersten Blattseiten im rechten Teilbaum insgesamt nur noch drei Einträge: 26, 27 und 32. Daher muß hier das mittlere Element der höheren Stufe auf die Blattseite geholt werden. Die Blattseite besteht dann aus den vier Einträgen 26, 27, 30 und 32 und hat ihre Kapazität genau ausgeschöpft. Allerdings ist nun auf der Seite darüber ein Unterlauf entstanden, der ausgeglichen werden muß. Da auch auf der nächsten Stufe die beiden benachbarten Indexseiten mit 10, 20 und 40 nur noch drei Elemente besitzen, wird er einzige Wert der Wurzel (25) heruntergeholt. Da die Wurzel leer geworden ist, wird sie gelöscht und die Seite mit den Werten 10, 20, 25 und 40 die neue Wurzel eines B-Baumes mit nur noch zwei Stufen. 8. Komplexität der Operationen Der Aufwand beim Einfügen, Suchen und Löschen im B-Baum beträgt gleichmäßig immer O(logm(n)) Operationen. Dabei ist m die Ordnung des Baumes und n die Anzahl der Elemente im Baum. Diese Komplexität entspricht genau der „Höhe“ des Baumes. Je breiter der Baum, desto höher der Wert m und desto niedriger der Wert logm(n). Während für die lookup-Operation einsichtig ist, dass bei der Suchprozedur im schlechtesten Fall genau eine Seite auf jeder Stufe des Baumes geladen werden muß, wollen wir uns die Komplexität der insert- und delete-Operation noch einmal kurz veranschaulichen. Auch bei diesen beiden Operationen pflanzt sich eine Änderung durch Über- oder Unterlaufbehandlungen maximal von der Blattseite bis zur Wurzel fort. Zwar ist der Faktor vor dem logm(n) bei der konkreten Berechnung des Aufwands höher (schließlich muß zunächst eine Suche und dann eine Über- oder Unterlaufbehandlung mit je drei Seiten auf jeder Stufe vorgenommen werden), die Komplexität jedoch bleibt gleich. 9. Beispiel für Einfügen und Löschen Bild 6 Ein abschliessendes Beispiel soll das Einfügen und Löschen im B-Baum in je einem Schritt noch einmal demonstrieren. In Bild 6 ist ein Baum vor dem Einfügen des Elementes 22 gezeigt. Bild 7 Wird das Element 22 eingefügt, so wird der Überlauf in der zweiten Seite durch Anlegen einer neuen Seite und Verschieben des mittleren Elements auf die Wurzelseite behoben. Bild 7 zeigt den Baum nach dem Einfügen des Elements 22. Bild 8 Löschen wir aus diesem Baum nun wieder das Element 22, so entsteht durch die Unterlaufbehandlung der Baum aus Bild 8. 6