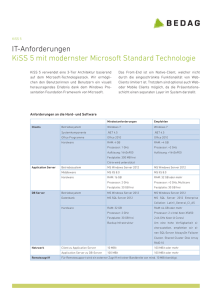
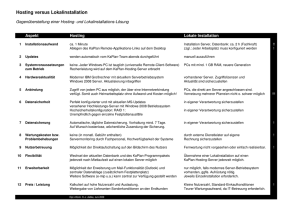
Netzwerkdokumentation von Felix:
Werbung

Netzwerkdokumentation von Felix: Ethernet "Ja, aber ich würde lieber den Bus nehmen. Es gibt nichts schöneres auf der Welt als einen Bus." Charles, Prince of Wales, als er gefragt wurde, ob er die Reise mit der königlichen Segelyacht nach Tobruk genossen habe. Der zur Zeit am weitesten verbreitete Standard für lokale Netze ist Ethernet. Er geht auf gemeinsame Spezifikationen von Intel, DEC und Xerox zurück. Der Name (Ether = Äther) weist noch auf die ersten Funknetze (ALOHA) hin. Die Datenübertragung erfolgt mit dem CSMA/CD-Verfahren. Auf dem Ethernet können verschiedene Protokolle laufen, z. B. TCP/IP, DECnet, IPX/SPX (Novell), etc. Das Ethernet besteht physikalisch aus verschiedenen Typen von 50-Ohm-Koaxkabeln oder paarweise verdrillten Leitungen (Twisted-Pair), Glasfasern, oder anderen Medien (siehe nächsten Abschnitt). Die Datenrate beträgt typisch 100 MBit/s (früher 10 MBit/s, 1000 MBit/s läuft an). Die wichtigsten Eigenschaften nach der ursprünglichen Spezifikation sind: Datenrate: 10 MBit/s Maximale Länge des gesamten Netzes: 2500 m Maximale Zahl der Knoten: 1024 Medium: Koaxkabel, Basisbandübertragung Zugriffsverfahren: CSMA/CD Datenprotokoll: Frames variabler Größe Die Daten werden in Paketen gesendet und mit Verwaltungsinfo zu Beginn und CRC-Prüfinfo am Ende versehen (Ethernet-Frame). Ethernet basiert, wie andere Netze auch, auf einer Sammlung von Medium- und Protokollspezifikationen. Zuunterst liegt die physische Ebene; sie umfaßt neben der Verkabelung auch die Signalerzeugung und -kodierung. Als Ethernet von DEC, Intel und Xerox aus der Taufe gehoben wurde, gab es nur eine Verkabelungsart, der heutige Ethernet-Standard kennt eine Vielfalt von Topologien. Ethernet-Anwender müssen bei der Vernetzung nicht nur zwischen den Protokollen auf den höheren Schichten wie TCP/lP und IPX/SPX unterscheiden, sondern auch noch den richtigen Ethernet-Frame wählen. 'Server not found' oder ähnliche Fehlermeldungen stellen sich manchmal selbst dann ein, wenn alle Ethernet-Treiber auf Workstation und Server korrekt geladen sind und keine Kabelprobleme bestehen. Der Grund liegt nicht selten darin, daß Ethernet nicht gleich Ethernet ist. Gleich vier verschiedene Dialekte sind heute in Gebrauch, die erschwerenderweise ziemlich inkonsistent benannt sind. Kein anderes lokales Netz weist diese Eigentümlichkeit auf. Groß sind die Unterschiede nicht; sie beschränken sich auf ein paar Bytes in den übertragenen Datenpaketen (Frames) und lassen sich in der Regel durch einfache Konfigurationsänderungen der Netztreiber regulieren. Die elektrischen Anschlußbedingungen im weitesten Sinne sind für die verschiedenen LAN-Typen standardisiert. Es handelt sich dabei um die Standards des IEEE (Institute of Electrical and Electronic Engineers, USA). Das IEEE ist eine internationale Vereinigung, die sich mit allen wesentlichen Aspekten der Elektrotechnik beschäftigt. Verbindlich für lokale Netze sind die Empfehlungen des Subkomitees mit der Kurzbezeichnung 802. Eine relativ neu gegründete Runde beschäftigt sich mit drahtlosen LANS (802.11). Physikalisch handelt es sich bei Ethernet immer um einen Bus, an den die Stationen elektrisch parallel angeschlossen sind. Das klassische Ethernet benutzt als Medium das yellow cable, ein dickes, vierfach abgeschirmtes Koaxkabel. Die beiden Enden des Kabels sind mit an den Wellenwiderstand des Kabels (50 Ohm) angepaßten Widerständen abgeschlossen, um Reflexionen zu vermeiden. Wenn eine Station nun Daten an eine andere senden will, schickt sie digitale Signale auf Reisen. Diese Signale breiten sich vom Anschlußpunkt der Station nach beiden Seiten hin gleichmäßig aus. Irgendwo auf dem Weg liegt dann der Empfänger, der die Signale am Kabel abgreifen kann und für die weitere Nutzung aufbereitet. Unabhängig davon wandern die Signale jedoch weiter, bis sie die Leitungsenden des Ethernet-Kabels erreicht hat. Dort wird ihre Energie vollständig von den Abschlußwiderständen aufgenommen, so daß es nicht zu Reflexionen kommt. Nach einer gewissen Zeit, die aus der Ausbreitungsgeschwindigkeit der Signale und der Entfernung der sendenden Station zu den beiden Kabelenden resultiert, sind die Signale 'verschwunden' und das Kabel wieder frei. Dieses Prinzip liegt allen Ethernet-Varianten zugrunde. Es gibt jedoch Unterschiede in der Topologie des Netzes und beim verwendeten Kabel. Die Daten werden in Paketen, sogenannten 'Frames' zusammengefaßt. Jedes Paket trägt zu Beginn Verwaltungsinformationen (z. B. Absender- und Empfängerstation, Länge, etc.) und nach den Nutzdaten schließt sich eine Prüfinformation an. Leider gibt es keinen einheitlichen Frame, sondern entwicklungsgeschichtlich bedingt Frames mit unterschiedlichem Aufbau. Es gab bereits Ethernet-Installationen, lange bevor dieses Netz unter der Nummer 802.3 vom IEEE (Institute of Electrical and Electronics Engineers) standardisiert wurde. Was Novell eigenmächtig als 'Ethernet 802.3' bezeichnet, ist jedoch etwas anderes. Ethernet II Eine der ältesten Framestrukturen ist Ethernet II. Charakteristisches Merkmal von Ethernet II ist das Typfeld, das aus zwei Bytes im Anschluß an die Start- und Zieladressen besteht und der Unterscheidung verschiedener höherer Protokolle dient. Alle anderen Formate enthalten hier eine Längeninformation. Die Unterscheidung der anderen Frames von einem Ethernet-IIFrame kommt dadurch zustande, daß dessen Typ-Nummer immer größer ist als die maximale Paketgröße von 1518 Bytes (Z.B. 0800h für IP, 8137h für IPX, 0600h für XNS oder 809Bh für AppleTalk). Ein Datenpaket besteht aus 576 bis 12208 Bits und hat folgenden Aufbau: Frame Ethernet Version 2.0 Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet-Frame, min. 64 Bytes, max. 1518 Bytes 6 Byte 6 Byte 2 Dest.- Source- Byte Addr. Addr. Type min. 46 Bytes, max. 1500 Bytes Daten Inter Frame 4 Gap Byte 9,6μs FCS Die Präambel dient zur Synchronisation, sie besteht aus einer Folge von '10101010'-Bytes. Der SFD hat an der letzten Stelle eine '1' (10101011). Die Längen der einzelnen Teile (in Byte) sind in der Grafik eingetragen. Sind weniger als 46 Datenbytes zu übertragen, muß mit Füllbits ergänzt werden, um die minimale Slot-Time zu erreichen. 802.3 raw (Novell) Als Novell Netware und das IPX/SPX-Protokoll auf den Markt brachte, war Ethernet noch nicht endgültig standardisiert. Die Netware-Entwickler warteten aber weder die Standardisierung ab, noch benutzten sie das gängige Ethernet-II-Format. Nein, Novell dachte sich für IPX einen eigenen Rahmentyp aus. Dieser Pakettyp enthält keine Protokollkennung wie Ethernet II, kann also allein IPX transportieren. Zu allem Überfluß benannte Novell diese proprietäre Lösung auch noch nach einer IEEE-Arbeitsgruppe '802.3'. Wie kann ein Rechner oder Router ein solches Novell-Paket aus anderen herausfiltern, die ebenfalls nach Start- und Zieladresse eine Längeninformation tragen? Gegenüber 'Ethernet II' werden die beiden Bytes der Protokoll-ID für die Rahmenlänge genutzt. Der einzige weitere Unterschied besteht darin, daß allein im 'Novell-802.3'-Paket zwei Bytes folgen, die nur aus Einsen bestehen (FF, FF). Prinzipiell ist das Gespann IPX-'802.3' also auch in heterogenen Umgebungen mit vielen Routern einsetzbar, erfordert aber immer einen gewissen ExtraAufwand. Novell geht die Sache inzwischen etwas vorsichtiger an und nennt sein IPXSpezial-Ethernet offiziell '802.3 raw'. Wir empfehlen, dem Rat von Novell neueren NetwareInstallationsprogrammen und -Handbüchern zu folgen und das standardisierte 'Ethernet 802.2'-Format zu verwenden. Hinter Novells Bezeichnung 'Ethernet 802.2' verbirgt sich das eigentlich waschechte 802.3-Format. Aber '802.3' hatte Novell bereits vergeben, und die Verwechslungsgefahr mit dem 'raw'-Format wäre zu groß geworden. Man übernahm daher einfach die Bezeichnung des IEEE-802.2-Protokollheaders, den die IEEE-802.3-Spezifikation vorschreibt und der den Unterschied zu Novells Alleingang ausmacht. Frame Ethernet 802.3 raw Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet-Frame, min. 64 Bytes, max. 1518 Bytes 6 Byte 6 Byte 2 Byte 2 Byte Dest.- SourceLength 0xFFFF Addr. Addr. min. 44 Bytes, max. 1498 Bytes Daten Inter Frame 4 Gap Byte 9,6μs FCS Frame IEEE 802.3 Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet-Frame, min. 64 Byte, max. 1518 Byte Inter Frame 6 Byte 6 Byte 1 1 min. 42 Bytes, max. 1497 4 Gap 2 Byte 1 Byte Dest.- SourceByte Byte Bytes Byte 9,6μs Length Control Addr. Addr. DSAP SSAP Daten FCS IEEE 802.2 und SNAP Bis zu Novells Entscheidung für die Verwendung von '802.2' als Default-Typ gab es kaum Anwendungen dieser Ethernet-Variante - abgesehen von der weiter unten beschriebenen SNAP-Erweiterung. Das IEEE-Gremium ersetzte das Typ-Feld von Ethernet II durch eine Längenangabe und ergänzte das Paket durch einen 802.2-Header von drei weiteren Bytes. Als Ersatz für das alte Typfeld mit der Protokoll-ID fungieren der 'Destination-' und der 'Source Service Access Point' (DSAP und SSAP); hinzu kommt ein 'Control Field', das manche Protokolle für Verwaltungszwecke benötigen. Ein offensichtlicher Nachteil der 802.2Definition gegenüber Ethernet II war die Limitierung der Typ-Codes auf ein Byte, zumal die Hälfte der möglichen 256 Werte von Anfang an reserviert war(z. B. 04 für IBM SNA oder 06 für IP). Frame IEEE 802.3 SNAP Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet-Frame, min. 64 Byte, max. 1518 Byte Inter Frame 6 Byte 6 Byte 1 1 5 min. 38 Bytes, 4 Gap 2 Byte 1 Byte Dest.- SourceByte Byte Byte max. 1492 Bytes Byte 9,6μs Length Control Addr. Addr. DSAP SSAP SNAP Daten FCS Daher folgte beinahe unweigerlich eine baldige Erweiterung: Das 'Sub Network Access Protocol' (SNAP) sorgte für Abhilfe. Diese 802.2-Erweiterung mit der eigenen Protokoll-ID AAh stellt weitere fünf Bytes für die Protokoll-Identifikation des darüberliegenden Protokolls bereit, davon drei für eine Herstellerkennung. Der bekannteste Nutznießer hiervon ist AppleTalk. Auch die Millionenschar der TCP/IP-Anwender könnte ihre Ethernet-II-Pakete mit der zwei Byte langen Protokoll-ID dank SNAP in ein IEEE-konformes Format bringen doch TCP/lP funktioniert auch ohne Standard und den zusätzlichen Protokoll-Overhead. Da TCP/lP eine von anderen Transportprotokollen unerreichte Bedeutung gewonnen hat (man denke allein an das Internet), empfiehlt es sich, wenn irgend möglich, durchgehend den Frame-Typ Ethernet II einzurichten. Häufig erzwingen die Gegebenheiten auch die weitere Berücksichtigung von Ethernet 802.3: Einige ältere, auf NetWare spezialisierte IPXPrintserver zum Beispiel mögen keinen anderen Rahmentyp. Der von Novell zur Zeit als Default-Typ verwendete 802.2 hat nur dann Berechtigung, wenn statt TCP/lP und IPX andere OSI-Protokolle zum Einsatz kommen sollen. Erweiterungen für VLANS Im Abschnitt über virtuelle LANS wird noch eine weitere Expansion des Datenrahmens zur Anwendung kommen, das sogenannte "tagged" Format. Der Vollständigkeit halber sollen auch dieser Frames hier aufgeführt werden, näheres dann im VLAN-Abschnitt. Frame Ethernet Version 2.0 tagged (VLAN) Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet-Frame, min. 68 Byte, max. 1522 Byte 6 Byte 6 Byte 4 2 Dest.- Source- Byte Byte Addr. Addr. Tag Type min. 46 Bytes, max. 1500 Bytes Daten Inter Frame 4 Gap Byte 9,6μs FCS Frame IEEE 802.3 tagged (VLAN) Bitfolge Bitfolge 1010101010... 10101011 Preamble SFD Ethernet Frame tagged min. 68 Byte, max. 1522 Byte Inter Frame 6 Byte 6 Byte 4 1 1 min. 42 Bytes, max. 4 Gap 2 Byte 1 Byte Dest.- Source- Byte Byte Byte 1497 Bytes Byte 9,6μs Length Control Addr. Addr. Tag DSAP SSAP Daten FCS MTU Die Abkürzung MTU steht für "Maximum Transmission Unit" und beschreibt die maximale Größe der Nutzdaten die in einem Datenpaket übertragen werden können. Ein StandardEthernetframe hat eine Maximalgröße von 1518 Bytes. Davon beanspruchen Header und Prüfsumme 18 Bytes. Somit verbleiben genau 1500 Byte für Nutzdaten (s. oben). Die MTU beträgt also 1500 Byte. Beim Internetzugang via DSL kommt auf der Verbindung zum DSL-Modem häufig das Protokoll PPPoE (Point-to-Point-Protocol over Ethernet) zum Einsatz. PPPoE beansprucht in jedem Frame zusätzlich 8 Bytes zur Übertragung von Verbindungsinformationen. Die MTU reduziert sich daher bei der Verwendung von PPPoE von 1500 auf 1492 Bytes. Durch den Einsatz weiterer Protokolle bei einigen Providern, kann sich die MTU noch weiter verringern. Je nach Provider schwankt die MTU zwischen 1400 und 1492. Normalerweise wird die richtige MTU bei der Verbindung zum Provider automatisch eingestellt. Eine manuelle Einstellung einer zu größen MTU führt zu Verbindungsproblemen. Unter Linux kann die MTU für ein Interface mit dem Kommando ifconfig eth0 mtu <wert> eingestellt werden. Identifizierung des Ethernet-Interfaces Jeder Ethernet-Adapter kann über seine in der Hardware verankerte Adresse eindeutig identifiziert werden. Diese Adresse besteht aus einem 3-Byte-Herstellercode und einer ebenfalls 3 Byte (24 Bit) langen laufenden Seriennummer. Auf diese Weise ist eine eindeutige Adressierung möglich - was aber auch bedeutet, daß die logische Adresse durch die Netzwerksoftware in eine Hardwareadresse umgesetzt werden muß. Die Angabe der Adresse erfolgt normalerweise sedezimal (hexadezimal), wobei zur besseren Lesbarkeit die einzelnen Bytes durch '.' oder ':' getrennt werden, z. B. 20:08:AA:10:00:CF. Diese Adresse wird auch gerne MAC-Adresse genannt. Bei einigen Interfaces, insbesondere bei vielen WLAN-Karten, kann die Adresse auch per Software konfiguriert werden (Speicherung im EEPROM). Signallaufzeiten, Slot Time Bei jedem Kabel gibt es eine Konstante, welche die Ausbreitungsgeschwindigkeit der elektrischen Signale in dem Kabel angibt. Die Maximalgeschwindigkeit, die Lichtgeschwindigkeit c, wird jedoch nie erreicht. Die Ausbreitungszeit für elektromagnetische Wellen ist abhängig vom Medium: AusbreitungsMedium faktor 1.00 Vakuum 0.77 Koax-Kabel 0.60 Twisted-pair-Kabel Aber wozu ist dieser Wert bei Netzen interessant? Nehmen wir als Beispiel für die folgenden Berechnungen das 10Base2-Ethernet-Kabel. Nehmen wir nun an, daß zwei Stationen A und B, die sich an gegenüberliegenden Enden des Kabelsegments befinden. Die Station A sendet zum Zeitpunkt t ein Datenpaket ab. Die Station B sendet ihrerseits zum Zeitpunkt t + (T - dt), also kurz bevor das Signal von A bei B ankommt. Damit A die Kollision erkennen kann, vergeht nochmals die Zeit (T - dt), also insgesamt t + 2*(T - dt). Für den Grenzfall können wir dt gegen 0 gehen lassen, woraus folgt, daß die Dauer der Übertragung eines Datenblocks mindestens 2*T betragen muß, damit eine Kollision bei CSMA/CD sicher erkannt wird. Ein Datenblock muß also mindestens diese Zeit 2*T zur Übertragung benötigen. Die kleinste erlaubte Packetgrösse von 64 Byte benötigt bei 10Base2 51.2 µs, um komplett gesendet zu werden. Ein Signal, das 51.2 µs dauert, legt im Coax-Medium folgende Strecke zurück: 0.77 * 3 * 108 = 231 * 106 m/s 231*106 * 51.2*10-6 = 11827.20 m = 11.82 km Das 64-Byte-Ethernetpacket benötigt also für die Strecke von 2 * 2,5 = 5 km im idealen Fall nur etwa die Hälfte der minimalen Übertragungsdauer von 51.2 µs. - die LAN-Sepzifikation beinhaltet somit eine Sicherheitsreserve um dem CSMA/CD-Protokoll des Ethernet auch im realen Fall zu genügen. Das ideale Beispiel ist sehr weit von der Realität entfernt. Es liefert jedoch ein Gefühl für die Zeiträume, mit denen beim Ethernetverkehr gerechnet wird. Für jeden Planer eines Netzes ist es wichtig, möglichst genau den "worst case" seines Netzes zu kennen, damit sicher gestellt ist, daß die Kollisionsbehandlung korrekt arbeitet. Dazu werden die jeweils am weitesten entfernten Netzwerkdevices einer Kollisionsdomäne betrachtet. Hierbei ist sowohl die Entfernung, als auch die zwischen Ihnen liegende Netzhardware zu beachten. Entsprechend jedem physikalischen Element auf der Strecke zwischen den Netzwerk-Devices (Hin- und Rückweg) werden bestimmte Werte addiert. Dies sind die sogenannten "Bitzeiten", die spezifisch für jede Hardware sind. Diese Bitzeiten sind entweder aus der Literatur oder der jeweiligen Herstellerbeschreibung zu entnehmen. Aber nicht immer findet man alle Werte; dann muß man allgemeingültige Werte benutzen, z. B. 8 Bitzeiten für einen Repeater. Diese Zahl soll das Zeitintervall repräsentieren, die ein Repeater benötigt um das Ethernetpaket weiterzuleiten. Ist jede auf der Strecke befindliche Hardware in die Rechnung eingeflossen, so erhält man den Round Trip Delay (RTD). Der RTD muß unter einem definierten Schwellwert liegen. Dieser Schwellwert von 51,2 µs entspricht 512 Bitzeiten. Zur Erinnerung: das kleineste Paket hat 64 Byte = 512 Bit Länge. Dieser Wert wird auch als "Slot-Time" bezeichnet. Das Kabel zwischen AUI (Attachment Unit Interface) und MAU (Media Attachment Unit) hat abweichende Spezifikationen (Twisted-Pair, jeweils für Senden und Empfangen getrennt, abgeschirmt), seine Maximallänge beträgt 50 m, die Mindestsignalausbreitungsgeschwindigkeit beträgt 0,65*c = 195000 km/s. Daraus folgt eine maximale Laufzeit von 0,05/195000 s = 0,256 Mikrosekunden. Da sich maximal drei 10Base2-Netzsegmente über Verstärker (Repeater) verbinden lassen, ergibt sich eine Maximallänge von 1500 m, und so eine Laufzeit von 13 Mikrosekunden. Dabei ist noch zu berücksichtigen, daß bis zu sechs Transceiverkabel beteiligt sein können (je eines an den Stationen und je zwei an den beiden Repeatern). Die maximale Verzögerung ist hier also 3,08 Mikrosekunden. Wenn man noch die Zeiten für die Collisionserkennung im Ethernet-Interface und weitere Hardwareparameter berücksichtigt, kommt man auf die im Ursprungsdokument von 1980 angegebene maximale Laufzeit von 45 Mikrosekunden. Zu lange Kabel, zuviele hintereinandergeschaltete Repeater, aber auch das Ausreizen der im Standard angegebenen Parameter kann durchaus im Zusammenspiel mit Komponenten, die am Rande der Toleranzgrenze liegen, zu Fehlfunktionen führen. Daher sollte man die angegebenen Längen immer unterschreiten. Auch bei der Planung von Netzen ist zu berücksichtigen, daß Kabel niemals in "Luftlinie" verlegt werden und die Kurven und Schleifen in den Kabelkanälen sich schnell addieren. Nicht verkleinern läßt sich jedoch der Overhead, der durch die Verwaltungsinformation im Ethernet-Frame (Adressen, Control-Info) entsteht. Der Overhead wird umso kleiner, je größer der Nutzdatenanteil ist. Die folgende Tabelle zeigt die Abhängigkeit von Overhead und Nutzdaten (berechnet): Im folgenden Diagramm ist der prozentuale Overhead gegen die Nutzdaten-Bytes aufgetragen. Einordnung Ethernet ins OSI-7-Schichten-Referenzmodell Layer Aufgabe 7 Application Später weitere Erläuterungen bis Presentation 4 Session Transport 3 Network Wegewahl, Vermittlung 2 Data Link Zusammenfassung der Bits in Blöcke (Bytes, Frames), Flußsteuerung, Reihenfolgesicherung Fehlererkennung in Blöcken und Korrektur 1 Physical mechanische Charakteristika (z.B. Pin-Belegung, etc.), elektrische, elektromagnetische, akustische, optische Charakteristika, Übertragungsart (z.B. analog/digital, synchron/asynchron, Modulation etc.) Ethernet und IEEE 802.3 sind im OSI-7-Schichten-Modell in der zweiten Schicht angesiedelt, wobei man diese Schicht beim IEEE802.3 zusätzlich einmal unterteilt in die Schichten 2a: Media Access Control (MAC) und 2b: Logical Link Control (LLC). Der Ethernet-Standard umfaßt Schicht 1 des OSI-Modells (Physikalische Schicht) und den unteren Teil von Schicht 2, der Verbindungsschicht. Dieser Teil wird MAC (Media Access Control) genannt. MAC und LLC (Logical Link Control) füllen zusammen Schicht 2 aus. Der Standard ist in drei Unterebenen eingeteilt. Von oben sind dies die eben genannte MAC und in Schicht 1 "PLS" (Physical Signaling) sowie "PMA" (Physical Medium Attachment). Die Schnittstelle zwischen ihnen ist auch im Standard definiert. Die Verbindung zwischen Medium und PMA wird "MDI" (Medium Dependent Interface) genannt. Die Einheit zwischen PMA und PLS wird mit "AUI" (Attachment Unit Interface) bezeichnet. "MDI" ist der Anschluß zum Netzkabel. MAC (Media Access Control) Die MAC-Ebene hat zwei Funktionen. Die eine ist die Datenhandhabung und umfaßt die Paketverwaltung (Datenaufbereitung, Adressierung und Fehlerkontrolle). Die andere ist die Zugangskontrolle, die dafür sorgt, daß die Pakete ohne Kollisionen ins Netz gelangen. Zudem handhabt die Zugangskontrolle die Kollisionen, die trotzdem entstehen. Die Datenhandhabung auf der MAC-Ebene arbeitet mit zwei Dienstprimitiven zur LLC: "Request" und "Indication". Request wird von der LLC generiert und ist die Anforderung nach Übertragung von Daten der eigenen LLC zur LLC in einer anderen Station. Parameter sind Zieladresse, Dateneinheit und Dienstklasse. Indication ist ein Hinweis an die LLC, daß MAC ein ankommendes Paket entgegengenommen hat. Hier sind die Parameter Zieladresse, Quelladresse, Dateneinheit und Empfangsstatus. Die Kollisionshandhabung benutzt mehrere Mechanismen. Beim Senden arbeitet ein Prozeß, der "Deference" (defer: nachgeben) genannt wird. Dieser kontrolliert, ob eine Aktivität im Kabel stattfindet (Carrier Sense). In diesem Fall beginnt ein Deferring-Zustand. Wenn das Kabel frei ist, wird eine Verzögerung von einem "inter frame spacing" initiiert und ein eventuell wartendes Paket losgeschickt. Wenn eine Kollision eintritt, wird ein Störungssignal gesandt, wonach die Sendung abgebrochen wird und der Backoff-Prozeß startet (siehe vorhergehendes Kapitel). Die Aufgaben der MACEbene können wie folgt zusammengefaßt werden: 1. Sendet Frames, indem sie: a. Daten von der LLC entgegennimmt, b. kontrolliert, ob ein PAD-Feld notwendig ist, und wenn ja, dieses erzeugt und es am Ende anfügt, c. kontrolliert, daß das Frame ganze Bytes enthält (daß die Anzahl der Bits ein ganzzahliges Vielfaches von 8 ist), die CRC berechnet (CRC = Cyclic Redundancy Check = Polynomprüfsumme) und am Ende als FCS (Frame Check Sum) ablegt, d. Preamble, Start Frame Delimiter und Adreßfeld am Anfang hinzufügt, e. das ganze Frame in serieller Bitform an die PLS schickt. 2. Empfängt Frames, indem sie: a. ein Frame nach dem anderen in serieller Bitform von der PLS akzeptiert, b. untersucht, ob die Zieladresse mit der lokalen Station übereinstimmt (individuelle Adresse, Gruppenadresse oder Broadcast), c. kontrolliert, daß das Frame ausreichend lang ist, daß er ganze Bytes enthält und daß die CRC stimmt, d. Preamble, SFD (Starting Frame Delimiter) und Adreßfeld abschneidet, das Längenfeld liest und eventuelle PAD-Bytes abschneidet, e. Daten an die LLC schickt. 3. Vermeidet Kollisionen und hält einen ausreichenden Abstand zwischen Frames im Medium aufrecht indem sie: a. vom Senden absieht, wenn das Medium belegt ist, b. wenn das Medium frei wird, einen festgesetzten Zeitraum (Inter Frame Gap) abwartet, ehe mit der Sendung begonnen wird. 4. Handhabt Kollisionen, indem sie, wenn die Station während des Sendens eine solche feststellt: a. ein Störsignal in Form eines zufälligen Bitmusters von einer bestimmten Länge (Jam Size) sendet, damit die Betroffenen Stationen die Kollision entdecken können, b. eine Zufallzahl generiert und in dem Zeitraum nicht sendet (Backoff), der von der Zufallszahl vorgegeben wird, c. wenn das Medium frei ist, nach dieser Zeit sendet, d. wenn eine neue Kollision stattfindet den Versuch mehrmals bis zu einer vorgegebenen Höchstgrenze wiederholt (Attempt Limit) und dann gegebenenfalls eine Fehlernachricht generiert. MAC-Adressen als physikalische Adressen Die Aufgabe der MAC-Adresse liegt darin, die miteinander kommunizierenden Stationen eindeutig zu identifizieren. MAC-Adressen haben eine feste Länge von 48 bit. Mit einer MAC-Adresse wird der physikalische Netzanschluß oder Netz-Zugriffspunkt einer Station adressiert. Sie heißt daher auch physikalische Adresse. Eine Station kann durchaus mehrere MAC-Adressen haben, wenn es über mehrere Netzanschlüsse verfügt. In manchen Dokumentationen ist zu lesen, dass es für Ethernet ganz spezielle, sogenannte Ethernet-Adressen gäbe. Dies ist absolut falsch. Alle bekannten Zugriffsverfahren der MACSchicht (wie z.B. CSMA/CD bzw. Ethernet, Token Bus, Token Ring, FDDI) verwenden einheitlich das im folgenden beschriebene MAC-Adressformat mit 48 bit langen MACAdressen. I/G U/L OUI OUA 1 bit 1 bit 22 bit 24 bit I/G = 0: Individual-Adresse (Unicast Address), die genau ein Interface identifiziert. I/G = 1: Gruppen-Adresse (Multicast Address), die eine Gruppe von Interfaces identifiziert (nur als Ziel-Adresse, nicht als Quell-Adresse möglich). U/L = 0: universelle Adresse (weltweit eindeutig und unveränderbar). U/L = 1: lokale Adresse (lokal veränderbar). Für die Festlegung von universellen Individual-Adressen werden von IEEE für die Bits 3 bis 24 weltweit eindeutige Werte vergeben und den Herstellern zugewiesen. Man bezeichnet eine solche Bitfolge daher als Organizationally Unique Identifier (OUI). Da bei universellen Individual-Adressen stets I/G = 0 und U/L = 0 gilt, werden diese beiden Bits häufig in den OUI mit einbezogen, so dass der OUI die ersten beiden Oktette der MAC-Adresse darstellt. Die Werte für die restlichen Bits 25 bis 48 werden von den Herstellern vergeben. Eine solche Bitfolge heißt daher Organizationally Unique Address (OUA). Die MAC-Schicht einer Station, das einen MAC-Rahmen empfängt, vergleicht die MAC-Zieladresse des Rahmens mit seiner eigenen MAC-Adresse und gibt den Inhalt des Rahmens nur dann an die höherliegenden Schichten weiter (LLC oder Schicht 3), wenn beide Adressen übereinstimmen. Ansonsten wird der Rahmen verworfen. Die MAC-Schicht beinhaltet also eine Filterfunktion für MAC-Adressen. Für die Darstellung von MAC-Adressen verwendet man am besten die kanonische Form: Die 48 Bits werden zu Bytes bzw. Oktetten derart zusammengefaßt, daß 6 Oktette entstehen, wobei die Bitreihenfolge nicht verändert wird und das I/G-Bit im 1. Oktett links steht und als Least-Significant-Bit (LSB) interpretiert wird. Unter der Festlegung, daß in jedem der 6 Oktette das LSB links steht, wird dann jedes Oktett durch zwei hexadezimale Ziffern dargestellt und die Ziffernpaare werden durch Bindestriche getrennt. Ein Beispiel mag dies veranschaulichen. Bitmuster: 00110101 01111011 00010010 00000000 00000000 00000001 Kanonische Form: AC-DE-48-00-00-80 Wenn ein MAC-Rahmen an mehrere bzw. an alle Stationen eines Netzes verschickt werden soll, spricht man von einem Multicast bzw. einem Broadcast. Entsprechende Multicast- bzw. Broadcast-Adressen gibt es verständlicherweise nur als Ziel-Adressen. Bei einem Broadcast lautet die MAC-(Ziel-)Adresse FF-FF-FF-FF-FF-FF. Einige standardisierte MulticastAdressen sind: 01-80-C2-00-00-00: 01-80-C2-00-00-10: 01-00-5E-00-00-00: CF-00-00-00-00-00: Spanning Tree Protocol Brücken-Management Internet Protocol (IP) Multicast Ethernet Configuration Test Protocol (Loopback) PLS (Physical Level Signaling) PLS kommuniziert teils mit der eigenen MAC, teils mit MACs in anderen Stationen. Die Service Primitive, die für die Datenübertragung benutzt wird, ist "DATA.request" von der MAC, die über "DATA.indication" auf Bitebene Daten an alle MACs im Netz sendet. Damit erhält auch die eigene MAC ihre ausgehenden Bits als Echo von PLS. Zur MAC gibt es auch die zwei Primitive, "CARRIER.indication" und "SIGNAL.indication". Diese werden benutzt, um der MAC die Zugangskontrolle zu ermöglichen. CARRIER hat zwei Stellungen ("on" und "off") und wird durch die PMA generiert, wenn diese feststellt, daß ein Bitstrom im Netzkabel eingeleitet oder beendet wird. Es wird benutzt, um anzuzeigen, ob das Medium frei ist oder nicht. SIGNAL zeigt die Qualität des Signals an und wird unter anderem dazu benutzt, Kollisionen anzuzeigen. MAU (Medium Attachment Unit) Von der PLS definiert der Standard eine Schnittstelle (Attachment Unit Interface oder AUI) zum Physical Medium Attachment (PMA) und von diesem eine weitere Schnittstelle (Medium Dependent Interface oder MDI) zum Medium. Zusammen bilden diese die MAU (Medium Attachment Unit), die auch als "Transceiver" bezeichnet wird. Bei 10Base5 hängt der MAU fest angekoppelt am Kabelstrang und versorgt den Rechner über Twisted-PairStichleitungen (AUI-Kabel). Der Hauptstrang ist damit von den Benutzern entkoppelt. Bei 10Base2 verzichtet man darauf. Historisches 1972 1976 1980 1981 1982 Entwicklung begann bei Xerox erste Vorstellung (3 Mbit/s Datenrate) Standard "Ethernet V1.0" (DEC, Intel, Xerox) Standard IEEE 802 Standard "Ethernet V2.0" Zitat aus The Ethernet Sourcebook, ed. Robyn E. Shotwell (New York: North-Holland, 1985): ``The diagram ... was drawn by Dr. Robert M. Metcalfe in 1976 to present Ethernet ... to the National Computer Conference in June of that year. On the drawing are the original terms for describing Ethernet. Since then other terms have come into usage among Ethernet enthusiasts.'' Die erste Skizze ist auch noch überliefert: For a report on the experimental Ethernet system by two of the inventors see: Ein Bericht der Erfinder über das Experimental-Ethernet findet man in dem Zeitschriftenartikel: Robert M. Metcalfe and David R. Boggs.``Ethernet: Distributed Packet Switching for Local Computer Networks,'' Association for Computing Machinery, Vol 19/No 7, July 1976. Entwicklung der Übertragungsmedien (IEEE 802.3) 10Base5 (Thick-Ethernet, Yellow-Cable) Ethernet mit einer Bandbreite von 10 Mbit/s Über Yellow-Cable. Die maximale Kabellänge eines Segments beträgt 500 Meter. Die beiden Kabelenden müssen mit Abschlußwiderständen abgeschlossen werden. Pro Segment dürfen 100 Endgeräte angeschlossen werden. Der Abstand zwischen zwei Stichleitungen muß ein Vielfaches von 2,5m betragen. Die Stichleitungen dürfen nicht länger als 50 Meter sein. 10Base-T Übertragung von 10 Mbit/s über Twisted-Pair-Kabel Hub notwendig Maximale Entfernung 100m Es werden zwei Adernpaare benötigt Kabel ab Kategorie drei Mit Switch Full-Duplex-Betrieb möglich Verbindung von 2 Stationen ohne Hub 10Base2 (Thin-Ethernet, Cheapernet) Ethernet über RG58 50-Ohm-KoaxKabel Nur für 10Mbit/s BNC-Stecker und T-Stücke zur Verbindung An beiden Enden ein 50-OhmAbschlußwiderstand Maximale Segmentlänge: 185m Mindest Stationsabstand: 0,5m Maximale Anzahl Stationen: 30 Keine Stichleitungen erlaubt 100Base-T Übertragung von 100 Mbit/s über Twisted Pair Kabel Hub notwendig Maximale Entfernung 100m Es werden zwei Adernpaare benötigt Kabel ab Kategorie fünf Mit Switch Full-Duplex-Betrieb möglich Verbindung von 2 Stationen ohne Hub mit Cross-Over-Kabel möglich 10BaseFB "B" für Backbone Übertragung von 10 Mbit/s Über LWL Maximal 15 Repeater Maximale Segmentlänge 2000m Signalisierung ist synchron mit Fehlererkennung 100BaseFX Übertragung von 100 Mbit/s über LWL Maximale Segmentlänge von 400m Max. Distanz zwischen zwei 100BaseFX Switches 2000m 1000BaseLX Übertragung von 1000 Mbit/s über LWL "L" für Long Wavelength von 1300nm Max. Distanz mit Multimodefasern 550m Max. Distanz mit Monomodefaser 3000m Full-Duplex 1000BaseCX "C" für Copper. Übertragung von 1000 Mbit/s über STP-Kabel 150 Ohm Wellenwiderstand Max. Distanz 25m Full-Duplex 10GBaseLX4 Übertragung von 10000 Mbit/s Über LWL "L" für Long Wavelength "X" für WWDW (Wide Wave Division Multiplexing) 8B/10BEncoding "4" für die vier Bereiche: mit Cross-Over-Kabel möglich 10BaseFL Übertragung von 10 Mbit/s über LWL Maximal 5 Repeater Maximale Segmentlänge 2000m. 100BaseT4 Übertragung von 100 Mbit/s über Cat5-Kabel Es werden alle 4 Adernpaare benutzt 1000BaseSX Übertragung von 1000 Mbit/s über LWL "S" für Short Wavelength 850nm Max. Distanz mit 62,5μm Multimodefasern 270m Max. Distanz mit 50μm Multimodefasern 550m Full-Duplex 1000BaseT Übertragung von 1000 Mbit/s über CAT-5-Kabel "T" für Twisted Pair Max. Distanz 100m. Alle vier Paare sind notwendig Full-Duplex 10GBaseSX4 Übertragung von 10000 Mbit/s über LWL "S" für Short Wavelength "X" für CWDW (Coarse Wave Division Multiplexing) "4" für die vier Bereiche: o 773,5nm - 786,5nm o o o o 1269,0nm - 1282,4nm 1293,5nm - 1306,9nm 1318,0nm - 1331,4nm 1342,5nm - 1355,9nm Max. Distanz mit 10μm Monomodefasern 10km Max. Distanz mit 50μm Multimodefasern 300m nur Full-Duplex 10GBaseSR Übertragung von 10000 Mbit/s über LWL "S" für Short Wavelength von 850nm "R" für Serial 64B/66B Encoding Max. Distanz mit 50μmMultimodefasern 65m nur Full-Duplex, nur Fiber o o o 10GBaseSW 10GBaseLW Übertragung von 10000 Mbit/s über LWL "L" für Long Wavelength von 1310nm "W" für Serial WIS (WAN Interface Sublayer) Encoding Ethernet in SONET STS192c Max. Distanz mit 10μmMonomodefasern 10km nur Full-Duplex, nur Fiber 10GBaseER Übertragung von 10000 Mbit/s über LWL "E" für Long Wavelength von 1550nm "R" für Serial 64B/66B Encoding Max. Distanz mit 10μmMonomodefasern 40km nur Full-Duplex, nur Fiber Übertragung von 10000 Mbit/s über LWL "S" für Short Wavelength von 850nm "W" für Serial WIS (WAN Interface Sublayer) Encoding Ethernet in SONET STS192c Max. Distanz mit 50μmMultimodefasern 65m nur Full-Duplex, nur Fiber 10GBaseLR Übertragung von 10000 Mbit/s über LWL "L" für Long Wavelength von 1310nm "R" für Serial 64B/66B Encoding Max. Distanz mit 10μmMonomodefasern 10km nur Full-Duplex, nur Fiber 10GBaseEW Promiscous Mode 789,5nm - 811,5nm 823,5nm - 836,5nm 848,5nm -861,5nm Max. Distanz mit 62μm Multimodefasern 100m Max. Distanz mit 50μm Multimodefasern 300m nur Full-Duplex, nur Multimodefasern kein Standard Übertragung von 10000 Mbit/s über LWL "E" für Long Wavelength von 1550nm "W" für Serial WIS (WAN Interface Sublayer) Encoding Ethernet in SONET STS192c Max. Distanz mit 10μmMonomodefasern 40km nur Full-Duplex, nur Fiber Normalerweise nimmt ein Netzwerkinterface nur Datenpakete an, die an seine Hardwareadresse gerichtet sind und leitet diese an die höheren Schichten weiter. Manche Interfaces lassen sich aber in den sogenannten "promiscous mode" schalten. In diesem Modus werden alle Frames an die höheren Schichten weitergeleitet. Dieser Modus wird beispielsweise von Netzwerk-Überwachungstools oder transparenten Bridges verwendet. Power over Ethernet Die Stromversorung von Endgeräten in der Netzwerktechnik wurde bisher den Herstellern der Endgeräte selber überlassen. Die lösten die Stromversorgung mit geringen Leistungen meist über Steckernetzteile. Dazu ist neben jeder Netzwerkdose auch eine Steckdose des 230VNetzes erforderlich. Mit dem IEEE-Standard Power-over-Ethernet (PoE) bzw. IEEE 802.3af wurde dieses Problem gelöst. Laut Spezifikation wird eine Leistung von 12,95 Watt zu Verfügung gestellt. Damit eignet sich diese Technik hervorragend um Webcams, Print-Server, IP-Telefone (Voice-over-IP), Wireless LAN Access Points, Handheld-Computer und sparsame Notebooks mit Strom zu versorgen. Die Stromversorgung über die Signalleitungen wirkt sich bei 10BaseT (10 Mbit/s) und 100BaseTX (100 Mbit/s) nicht allzu störend auf das Ethernet-Signal aus. Auf 1000BaseT Gigabit-Ethernet ist PoE zwar möglich, wird aber nicht empfohlen, da 1000BaseT alle 8 Adern im Kabel belegt und man deshalb in jedem Fall auf das ohnehin empfindliche GigabitEthernet-Signal einwirken würde. Bis alle eingesetzten Switches und Hubs über PoE verfügen muss man noch auf eine Bastellösung zurückgreifen. Bei einzelnen Komponenten, die über Power-over-Ethernet mit Strom versorgt werden können, tut es ein einfacher Power Injektor, der im Leitungsnetz zwischen Hub/Switch und Endgerät geschaltet wird. Gibt es in einem Netzwerk mehrere Power-over-Ethernet-Endgeräte, dann ist ein Power Hub nötig, der dann beim Hub/Switch installiert sein sollte. Die Technologie von Power over Ethernet erlaubt es kleinere Netzwerkgeräte, wie z.B. IPTelefone, Accesspoints, Netzwerkameras etc., ohne eine externe Stromquelle zu betreiben. Die Idee der Stromversorgung über die Netzwerkleitung ist jedoch schon älter, nur gab es bislang keinen gültigen Standard, so daß verschiedene Hersteller eigene Lösungen entwickelten. Dadurch war die Gefahr groß, daß man aus Versehen inkompatible Komponenten durch das Anschließen beschädigt. Im IEEE 802.3af wird zwischen 2 Kernkomponenten unterschieden. Power Sourcing Equipment (PSE). Diese Komponenten speisen das Netz mit Strom. Es sind meistens aktive Netzkomponenten oder Patchfelder mit PoE-Support. Powered Devices (PD). Dies sind die Energieverbraucher. Sie müssen PoE unterstützen. Bei den Stromeinspeisungen unterscheidet man zwischen Endspan und Midspan Insertion. Die Endspan-Systeme sind aktive Komponenten (hauptsächlich Switches), die die angeschlossenen Geräte direkt über die Ethernetports mit Strom versorgen. Der Nachteil dieser Geräte ist die hohe Leistungsaufnahme und eine hohe Abwärme. Die Midspan-Systeme nehmen die Daten der aktiven Komponente entgegen und leiten sie gemeinsam mit der Versorgungsspannung an die Endgeräte weiter. Die Übertragung der 48-V-Gleichspannung ist für maximal 100 Meter ausgelegt, was auf das Ethernet abgestimmt wurde. Die angeschlossenen Geräte dürfen 350 mA Strom abnehmen und die maximale Speiseleistung beträgt 15,4 W. Die Versorgung der Endgeräte erfolgt über Cat.5 Kabel mit RJ-45 Steckern. Das PoE-Verfahren macht sich die Tatsache zu nutze, dass von den 4 vorhandenen Adernpaaren lediglich 2 zur Datenübertragung benutzt werden. Schutzmechanismen Da man in einem LAN natürlich nicht nur PoE-Geräte betreiben will, hat das IEEE ein Verfahren erarbeitet, das Endgeräte vor möglichen Schäden schützt. Dieses Verfahren wird Resistive Power Discovery genannt. Hierbei prüft der PSE das PD auf Kompatibilität, indem es in zyklischen Abständen einen minimalen Strom einspeist und daran erkennt, ob das PD einen 25-Kiloohm-Abschlusswiderstand besitzt. Wenn nicht ist das Endgerät nicht PoE-fähig. Wenn ja kann der PSE das PD mit Energie versorgen. Jetzt wird das PD mit einer geringen Leistung versorgt. Das PD signalisiert nun dem PSE welcher der 5 Leistungsklassen es angehört. Die Erkennung erfolgt innerhalb einer Sekunde. Einen weiteren Schutz bietet der Disconnect-Schutzmechanismus. Wenn ein PD entfernt wird, deaktiviert der PSE automatisch die Stromversorgung des entsprechenden Ports. Dieser Mechanismus soll das Vertauschen von PoE-fähigen mit Standardgeräten verhindern. Es werden folgende Leistungsklassen unterschieden: Klasse Verwendung Max. Einspeiseleistung (PSE) Max. Entnahmeleistung (PD) 0 default 15,4 W 0,44 bis 12,95 W 1 optional 4,0 W 0,44 bis 3,84 W 2 optional 7,0 W 3,84 bis 6,49 W 3 optional 15,4 W 6,49 bis 12,95 W 1 reserviert 15,4 W Reserviert Belegung des RJ45-Steckers bei Power-over-Ethernet Für die Übertragung der Stromversorgung wird das Adernpaar 4/5 für den Pluspol und das Adernpaar 7/8 für den Minuspol verwendet. Pin Leitung Pin Leitung 1 TX+ 5 PoE/G 2 TX- 6 RX- 3 RX+ 7 PoE/-48V 4 PoE/G 8 PoE/-48V Wird die Netzwerkverkabelung auch für andere Anwendungen, z. B. für Telefonie, genutzt, dann ist Vorsicht beim Einsatz von Power-over-Ethernet-Netzwerk-Komponenten geboten. Mit einem Mechanismus sollten die Power-over-Ethernet-Netzwerkkomponenten vor dem Einschalten der PoE-Stromversorgung alle angeschlossenen Endgeräte auf PoE-Unterstützung überprüfen. Auf einen Anschluss sollte nur dann Spannung geschaltet werden, wenn dort auch ein Endgerät mit PoE-Unterstützung angeschlossen ist. Neues Kapitel Netzverkabelung und Netzplanung Grundlegendes Derzeit rüsten viele Unternehmen ihr Ethernet um. Der erste und meist teuerste Schritt auf diesem Weg ist die Neuverkabelung mit Twisted-Pair-Leitungen. Danach können weitere Maßnahmen ergriffen werden. Die klassische Maßnahme, das 'Bridging', wurde in KoaxNetzen häufig eingesetzt und lebt heute in den 'Switches' weiter. Das Aufteilen eines Netzes in mehrere Teilnetze, auch 'Collision Domains' genannt, läßt nicht mehr jedes Datenpaket zu jeder Station gelangen; es können so viele Transaktionen gleichzeitig stattfinden, wie Collision Domains im Netz vorhanden sind - im Extremfall (Switch) ist jeder Hub-Anschluß einer eigenen Collision Domain zugeordnet. An die Switch-Anschlüsse können in der Regel wieder gewöhnliche Repeating Hubs angeschlossen werden; Switching kann so nach und nach im Netz eingeführt werden, um die Collision Domains immer weiter zu verkleinern - bis im Idealfall jedem Rechner ein privates Segment zur Verfügung steht. Switches sind heute nicht teuerer als Hubs, daher spricht alles für eine Strukturierung des Netzes mit Switches. In einem Peer-to-Peer-Netz (z. B. Unix oder auch Windows ab 95) ohne zentrale Server genügt meistens ein reiner 10BaseT-Switch. Gibt es einige, wenige Server, so kann der Server über mehrere Ethernet-Segmente parallel mit dem Switch verbunden werden, so daß der Datenverkehr zwischen Server und Netz gebündelt wird. Es gibt auch Switches mit einem oder mehreren 100-MBit-Anschlüssen. Diese können an den oder die Server angeschlossen werden, um alle Anwender im Netz deutlich schneller mit Daten zu versorgen ohne daß deren LAN-Adapter auch nur berührt werden müßten. Die Server und zentralen Switches werden am besten in einem 19"-Schrank untergebracht, der zusätzlich noch Belüftung und eine USV (unterbrechungsfrei Stromversorgung) aufnehmen kann. Die Schränke besitzen Einschübe für die Server und sind so gestaltet, daß man von vorne und hinten guten Zugang zu den Rechnern hat. Das Bild rechts zeigt den Blick von hinten auf die Server im Schrank. Die Verschliessbarkeit des Schranks sorgt auch für einen Schutz der Server vor unberechtigtem Zugriff. Da Twisted-Pair-Kabel heutzutage den Standard darstellen, sollte man auf jeden Fall bei der Neuverkabelung gleich Cat-5-Kabel oder bessere verwenden, um für die Datenrate von 100 MHz gerüstet zu sein. Leider ist der verwendete RJ45-Stecker relativ filigran. Neben der Zerbrechlichkeit der Stecker kommt es bei Hochgeschwindigkeitsnetzen zu Problemen: Die Drähte und Kontakte werden über eine kleine Strecke parallel geführt, wodurch die Wirkung der Twisted-Pair-Kabel aufgehoben wird. Ein weiterer Kritikpunkt an der RJ45-Technik ist die Einheitlichkeit der Dosen. Der Anwender am Arbeitsplatz kann nicht erkennen, welchem Dienst die Dose zugeordnet ist (Netz, analogens Telefon, ISDN, etc.). Selbst Farbkennzeichnung oder Beschriftung hindert viele Leute nicht daran, 'es mal an der anderen Dose zu versuchen'. Und da kann die Rufspannung analoger Telefone schon einmal einen Netzwerkadapter 'killen'. 10 MBit/s (IEEE 802.3) und 100 MBit/s (IEEE 802.3u) verwenden eine HalbduplexÜbertragung über zwei Aderpaare. Bei einer Migration von 10 auf 100 MBit/s bleibt zumindest die Infrastruktur des Kabelnetzes bestehen. Demgegenüber setzt Gigabit-Ethernet (IEEE 802.3ab) auf eine Vollduplex-Übertragung über alle vier Paare. Zwar ermöglicht diese Technik die Verwendung der eigentlich nur bis 100 MHz spezifizierten CAT-5-Kabel, dazu müssen die Komponenten allerdings anders beschaltet werden. Strukturen der Gebäudeverkabelung Früher war eine "Bedarfsverkabelung" üblich. Die Netztechnik bestimmte die Art der Verkabelung (Ethernet: busförmige Koaxverkabelung, FDDI: ringförmig mit Lichtwellenleitern). Die Standorte der Rechner und Terminals bestimmte die Netzausdehnung. Heute gilt ganz klar die Prämisse: strukturierte Verkabelung. Die Netztechnik hat sich an eine genormte Verkabelung anzupassen. Jeder Arbeitsplatz bekommt automatisch eine Datennetzdose. Das bringt anfangs zwar höhere Investitionskosten, ist aber zukunftssicher. Fehler wirken sich nur lokal aus, denn jeder Anschluß hat sein eigenes Kabel. Basis der heutigen Gebäudeverkabelung von Netzen sind die in den letzten Jahren erarbeiteten Normen auf diesem Gebiet. Dabei gibt es im wesentlichen drei grundlegende Normen, die für bestimmte geographische Regionen von Bedeutung sind: EN 50173 (1995): Informationstechnik: Anwendungsneutrale Verkabelungssysteme ISO/IEC 11801 (1995): Generic cabling for customer premises EIA/TIA 568 A/B (1994): Commercial building telecommunications cabling standard Die EN 50173 und die ISO/IEC 11801 haben im wesentlichen den gleichen Inhalt und enthalten auch die gleichen Anforderungen an die Kabel und Komponenten. Die EN 50173 ist eine europäische Norm, während die ISO/IEC 11801 weltweit verwendet wird. Die EIA/TIA568 A/B wurde speziell für den nordamerikanischen Markt von der dortigen Telekommunikationsindustrie entwickelt. Sie ist eigentliche keine Norm, sondern lediglich eine Industrie-Spezifikation. Sie enthält auch geringere Anforderungen bezüglich der übertragungseigenschaften der Kabel als die anderen Bestimmungen. In der EN 50173 wird ebenso wie in der ISO/IEC 11801 die Gebäudeverkabelung in vier Bereiche eingeteilt. den Primär- oder Campusbereich für die Verbindung der Gebäude eines Standortes untereinander, den Sekundär- oder Steigbereich für die Verbindung der einzelnen Etagen eines Gebäudes, den Tertiär- oder Horizontalbereich für die Verbindung der Anschlußeinheiten wie die Wanddose mit dem Etagenverteiler und den Arbeitsplatzbereich für den Anschluß der Endgeräte an die Anschlußeinheiten. In allen drei Bereichen der Inhouse-Verkabelung (oft auch Ebenen genannt) können sowohl Verkabelungen mit symmetrischen Kupferkabel (Twisted Pair) und -komponenten als auch mit Lichtwellenleiterkabel und -komponenten verwendet werden. Im Campusbereich werden ausschließlich LWL-Kabel und -Komponenten verwendet. Campusverkabelung und Steigbereich Auf Grund der größeren übertragungsstrecken und dem steigenden Datenaufkommen hat sich sowohl für den Campus- als auch für den Steigbereich die Lichtwellenleiterverkabelung durchgesetzt. Im Außenbereich werden LWL-Außenkabel mit Multimodefasern verwendet. Sollten Kabellängen von größer 2000 m notwendig sein oder extrem hohe Datenraten anfallen, können ebenso Kabel mit Singlemodefasern verwendet werden. Die Faseranzahl sollte in jedem Fall so bemessen sein, daß zukünftiges Wachstum der Netzanforderungen erfüllt werden kann. Als Faustregel sollte man 50% Reserve zum derzeitigen Bedarf addieren. Werden also derzeit acht Fasern benötigt, sollte ein Kabel mit zwölf Fasern verwendet werden. Im Steigbereich werden meist LWL-Innenkabel, ebenfalls mit Multimodefasern, eingesetzt. Dabei empfiehlt die EN 50173 die Verwendung von 62,5-Mikrometer-Multimodefasern. Multimodefasern mit 50 Mikrometern sind aber ebenfalls zugelassen. Sind die Entfernungen klein (< 100 m) und die zu erwartenden Datenraten pro Teilnehmer gering (< 10 Mb/s), so kann im Steigbereich auch eine Verkabelung mit symmetrischen Kupferkabeln vorkommen. Dabei sollte aber ein qualitativ hochwertiges System eingesetzt werden, da ein Ausfall oder eine überlastung in diesem Bereich schwerwiegende Konsequenzen für das ganze Netz hat. Horizontalverkabelung und Arbeitsplatzbereich Im Horizontalbereich und für die Arbeitsplatzverkabelung werden zumeist hochwertige, geschirmte symmetrische Kupferkabel und -komponenten eingesetzt, da hier der Anschluß an viele einzelne Schnittstellen vorgenommen wird. Wird auch im Horizontal- und Arbeitsplatzbereich mit Lichtwellenleitern (LWL) verkabelt, stehen damit höhere Bandbreiten zur Verfügung und es lassen sich längere Strecken realisieren. LWL-Verkabelung kann auch dann sinnvoll sein, wenn man einfach die EMV-Immunität und die übertragungssicherheit ausnutzen will. Die Einführung von "Fiber-to-the-desk", der LWL-Verkabelung bis zum Arbeitsplatz, ist wohl bald Realität. Es ist auch möglich, beispielsweise den Steig- und den Horizontalbereich durchgehend mit LWL zu verkabeln, um damit Etagenverteiler einzusparen. Man spricht dann von einer zentralisierten Verkabelung. Netzstrukturen Die heutige Verkabelung wird im allgemeinen hierarchisch in einem physikalischen Stern aufgebaut. Der Standortverteiler (auch: Hauptverteiler) als zentrale Schaltstelle ist mit den Gebäudeverteilern in den einzelnen Gebäuden sternförmig verkabelt. In den Gebäuden werden die Etagen- verteiler ebenfalls sternförmig mit dem Gebäudeverteiler verkabelt. In der Horizontalebene schließlich findet eine ebenfalls sternförmige Verkabelung der Anschlußeinheiten wie der Wanddose mit dem Etagenverteiler statt. Als Verteiler zum Abschluß der Kabel werden Schränke und Gestelle in 19"-Technik eingesetzt. 19"-Einschübe übernehmen in diesen Schränken die Kabelbefestigung, die Speicherung einer Reservelänge, die Unterbringung von Spleißkassetten (falls verwendet) und das Montieren der Stecker und Kupplungen bzw. Buchsen auf den Verteilerfeldern. Werden nur kleinere Faserzahlen benötigt, so können statt der 19"-Schränke die kompakteren Wandverteiler eingesetzt werden. Im Tertiärbereich werden zum Kabelabschluß Wand- und Bodentankdosen verwendet. Diese Anschlußeinheiten übernehmen hier die Kabelbefestigung, die Speicherung der Reservelänge und das Montieren der Buchsen bzw. Stecker und Kupplungen. Sie bilden den Abschluß der diensteunabhängigen Verkabelung. Das Endgerät (der PC, die Workstation, der Drucker, das Telefon, etc.) wird mit konfektionierten Kabeln an die Wanddose oder den Bodentank angeschlossen. Die Verteilung der Switch- oder Routerports auf die Endgerätedosen erfolgt über ein Patchfeld. Es handelt sich dabei um ein Feld mit Netzwerk-Steckdosen (z. B. RJ-45Dosen), an welche die Kabel zu den Anschlußdosen in den einzelnen Rämen angeschlossen sind. Die Verbindung zu den aktiven Komponenten erfolgt dann über kurze Patchkabel. Die logische Netzstruktur der Verkabelung hängt davon ab, wie die einzelnen Netzwerkknoten miteinander kommunizieren. Darunter sind die Protokolle, Zugriffsverfahren und Konventionen auf der elektronischen Ebene zu verstehen. Die heute am weitest verbreiteten Standards für solche logischen Netzstrukturen sind: ISDN nach DIN EN 50098 für bis zu 2 Mbit/s in einer sternförmigen Verkabelung Ethernet nach IEEE 802.3 für 10 und 100 MHz übertragungsbandbreite als logischer Bus Token Ring nach IEEE 802.5 für 4 und 16 Mbit/s als logischer Ring FDDI bzw. TPDDI (PMD) nach ANSI X3T12 für bis zu 100 Mb/s als logischer (Doppel-)Ring ATM definiert im ATM-Forum für bis zu 622 Mbit/s Für die Umsetzung von der logischen in die physikalische Netzstruktur haben sich Netzwerkkonzentratoren etabliert. Hier werden alle wichtigen Netzwerkaktivitäten zusammengefaßt, was auch die Verkabelung und die Fehlersuche wesentlich erleichtert. Dadurch ist es möglich, beispielsweise das Ethernet 10/100BaseT-Verfahren als logisches Bussystem in einer sternförmigen Verkabelung zu realisieren. Netzplanung Aufgaben der Netzplanung Festlegen der Netzstruktur, die den gewünschten Funktionen des EDV-Systems gerecht wird. Umsetzen organisatorischer und topologischer Strukturen in die Netzstruktur Berücksichtigung von Datenschutz, Betriebs- und Einbruchssicherheit Koordination mit Provider, Registrierungs- und Ressourcenvergabestellen Netzwerkkomponenten, die zu berücksichtigen sind: o Hubs, Bridges, Router, Gateways o Paketfilter, Application Gateways o Accounting- und Diagnosetools Anforderungen an eine Netzwerkverkabelung o offen für verschiedene LAN-Techniken (heutige und zukünftige) o herstellerunabhängig o o o o o o genügend übertragungskapazität auch für die Zukunft zuverlässig, unempfindlich gegen Störeinflüsse wartungsarm wirtschaftlich gerechtfertigte Lösung Integration bestehender Installationen vorhandene Komponenten sollen einbindbar sein Ein grosses oder mehrere kleine Netze? Vorteile eines (grossen) zusammenhängenden Netzes: einheitliche Administration einfacher bei geringer Netzlast höchste Kommunikationsgeschwindigkeit zwischen allen Rechnern Manche Protokolle funktionieren nur auf einem (logischen) Netzwerkstrang, z. B. o bootp: Booten von Rechnern über ein Netzwerk o X-query: dynamisches Verbinden eines X-Terminals mit einer Workstation o Anschluß von Diskless Clients Nachteile eines zusammenhängenden Netzes: Bei Ethernet kommt jedes Paket an jedem Rechner vorbei. Die Netzlast addiert sich also und Datenpakete können an allen Stellen des Netzes gelesen werden. Eine einzelne fehlerhafte Komponente stört das ganze Netz. Vorteile kleinerer Teilnetze: Administrationsverantwortung leicht delegierbar Bessere Lastverteilung überwindung grösserer Entfernungen möglich Nachteile kleiner Teilnetze: Höherer Administrationsaufwand: Vergabe von Netznummern, Aufsetzen von Bridges/Routern und Routingtabellen Bei ungeschickter Vernetzung bilden Bridges/Router einen Flaschenhals. Man sollte Netze nicht aufteilen, solange sie überschaubar sind und keine Lastprobleme haben. Die Netze müssen aufgeteilt werden, wenn Last, Sicherheit oder Topologie es erfordern. Beim Aufteilen ist auf möglichst kurze Kommunikationswege zu achten. Die maximale Kabellänge und die Begrenzung der hintereinander schaltbarer Komponenten spielt eine Rolle (max. 4 Hubs hintereinander, max. 7 Bridges/Switches hintereinander). Auch bei kleinen Netzen sollte ein eigener Serverraum eingeplant werden. Der Serverraum sollte so plaziert sein, daß bei Netzerweiterungen die Verkabelung unproblematisch bleibt. Vom Serverraum zu den Verteilern (Switches) sollte aus Gründen der zukunftssicheren Verkabelung redundant ausgelegtes Cat-5-Kabel (optional Glasfaserkabel) verlegt werden. Das folgende Bild zeigt den Schnappschuß eines typischen Schaltschrank, der mit Switches bestückt ist. Ein KVM-Switch (Keyboard, Video, Mouse) erlaubt es, die Server über einen einzigen Monitor mit Tastatur und Maus zu bedienen. Viele KVM-Switches lassen sich per Netzwerkkabel expandieren, der Bedienmonitor kann dann sogar im Nebenzimmer stehen. Auswahl der Verbindungskomponenten Kabelarten: * Primärbereich: Glasfaserverbindungen * Sekundärbereich: Glasfaser- oder Twisted Pair-Verbindungen * Tertiärbereich: Twisted Pair-Verbindungen Repeater: + einfache Verbindung zweier Kabelsegmente gleicher Technologie - keine Lasttrennung, nur Durchreichen von Paketen Bridges: + Kopplung von Netzen verschiedener Technologie - keine Lasttrennung bei Diensten, die auf Broadcasts basieren Switches: + intelligente Kopplung, dadurch Lasttrennung - keine Lasttrennung bei Diensten, die auf Broadcasts basieren Router: + logische Trennung der Netze, getrennte Administration leichter möglich + Gesicherter übergang durch Paketfilterung - höherer Konfigurationsaufwand Vergabe von IP-Nummern Soll das Netz (evtl. später) an das Internet angeschlossen werden und die IP-Nummern nach aussen sichtbar sein? Dann müssen global eindeutige IP-Nummern beim Internet-Provider angefordert werden. Ansonsten verwendet man IP-Nummern für ausschließlich interne Verwendung (gem. RFC 1918): 10.0.0.0 - 10.255.255.255 172.16.0.0 - 172.31.255.255 192.168.0.0 - 192.168.255.255 (ein Class-A-Netz) (16 Class-B-Netze) (256 Class-C-Netze) Zum Anschluss dieser Netze an das Internet ist ein Router mit NAT und IP-Maskierung nötig. Die interne Adressenverteilung erfolgt in jedem Fall bevorzugt per DHCP-Protokoll (siehe unten), da in diesem Fall alle Clients gleich konfiguriert werden können und nur soviel Adressen gebraucht werden wie Rechner aktiv sind. Vergabe von Domainnamen Beantragt wird normalerweise eine Second-Level-Domain unterhalb von .de .com. net .org. Die Vergabe erfolgt in der Regel durch den Provider - sofern die Wunschdomain noch frei ist. Vergabe von Rechnernamen Sei netzmafia.de der benutzte Domainname. Dann sind gängige Aliase: gate.netzmafia.de mail.netzmafia.de news.netzmafia.de www.netzmafia.de ftp.netzmafia.de ns.netzmafia.de Die Zuordnung der Rechnernamen kann erfolgen als: Flacher Namensraum, z. B.: alpha.netzmafia.de beta.netzmafia.de gamma.netzmafia.de delta.netzmafia.de ... Hierarchischer Namensraum, z. B.: alpha.direktion.netzmafia.de beta.direktion.netzmafia.de ... alpha.vertrieb.netzmafia.de ... alpha.entwicklung.netzmafia.de ... Die Rechnernamen werden von mindestens zwei Nameservern verwaltet (Ausfallsicherheit). Beispiel einer Vorgabe zur Netzplanung Beispiel-Szenario: Die Firma Netzmafia, Hard- und Softwareentwicklungen, möchte Internet-Anschluß. Das Unternehmen sitzt in zwei Gebäuden: o Gebäude 1: Geschäftsführung, Vertrieb, Verwaltung, Personalbüro o Gebäude 2: Hardware-Entwicklung, Software-Entwicklung, Technik Alle Mitarbeiter sollen per E-Mail erreichbar sein und auf das WWW zugreifen können. Die Firma betreibt einen WWW-Server, auf dem die Entwicklungsabteilungen und der Vertrieb Informationen zur Verfügung stellen. Die Entwicklungsabteilungen stellen Patches und Treiber per FTP zur Verfügung. Die Hardware-Entwicklungsabteilung experimentiert gelegentlich mit instabilen Netzwerkkomponenten, während die übrigen Abteilungen auf ein zuverlässiges Netz angewiesen sind. Von sämtlichen Rechnern sollen regelmässig Backups angefertigt werden. Lösung (e pluribus unum): Reservierung des Domainnamens netzmafia.de Anforderung eines kleinen Netzes, z. B. eine Class-C-Netzes (254 Knoten) oder eines Class-C-Subnetzes (126, 62, 30 Knoten) Zuordnung der Namen: gate.netzmafia.de srv1.netzmafia.de srv2.netzmafia.de srv3.netzmafia.de 141.39.253.253 141.39.253.1 141.39.253.2 141.39.253.3 Dazu kommen noch Alias-Einträge: ns.netzmafia.de mail.netzmafia.de www.netzmafia.de ftp.netzmafia.de gate.netzmafia.de srv3.netzmafia.de srv3.netzmafia.de srv2.netzmafia.de Die übrigen Rechner erhalten interne IP-Nummer und können nur über Proxies auf gate.netzmafia.de auf das Internet zugreifen. Eingehende Mail gelangt über einen Mail-Proxy an den Mailserver. Von dort aus erfolgt die Verteilung per IMAP oder POP3. Ausgehende Mail wird direkt über den Mail-Proxy ins Internet verschickt. Der primäre Nameserver steht in Gebäude 2, der Secondary NS beim Provider. In Gebäude 2 ist zur Entlastung der Standleitung jeweils ein DNS- und WWWCache installiert. Das Testnetz der Hardwareabteilung ist abgetrennt, aber bei Bedarf manuell zuschaltbar. An diesem Beispiel lassen sich einige Aufgaben des Netzwerk-Managements feststellen: Planung der Protokoll-Konfiguration (Bezug der IP-Adresse über DHCP, Festlegung des Gateways und DNS-Servers) Bei Windows-basierten Systemen muß noch für jeden Client festgelegt werden, an welchem Fileserver er sich anmeldet und zu welcher Arbeitsgruppe er gehört. Der Anschluß von Druckern und anderen Peripheriegeräten wurde im Beispiel nicht berücksichtigt. Auch hier muß festgelegt werden, unter welchem Pfad die Drucker angesprochen werden können. ähnlich dem Internet Domain Name System (DNS) sind auch andere hierarchische Namensräume verfügbar, z. B. die Directory Services von Novell (NDS) oder die Directory Services und Domänen von Windows 2000/XP. Nach der Grundinstallation ist dann noch die Vergabe von Benutzer- und Zugriffsrechten nötig. Insbesondere die Zugriffsrechte auf bestimmte Geräte sind oft Restriktionen im Dienste des Benutzers. Man denke z. B. an einen freigegeben Drucker, der im Nachbargebäude steht. Die Benutzer würden in der Regel vergeblich am lokalen Drucker nach ihren Ausdrucken suchen und sich beschweren. Auf den Servern muß ggf. Backup-Software installiert und getestet werden. Administrative Clients werden mit Software zur Netzwerküberwachung eingerichtet. Zusammen mit der Planung wird das Netz dokumentiert. Neben Angaben über die Topologie sind auch alle Kabelwege, Standorte von Netzkomponenten (Hub, Switches, Router, usw.), Server und Peripheriegeräten zu dokumentieren. übersichtsgrafiken lassen sich recht schnell mit speziellen Tools wie Visio (Microsoft) oder Acrix (Autodesk) erstellen, für die Grafikbibliotheken mit speziellen Symbolen für die Netzkomponenten erhältlich sind. Unter UNIX gibt es ein Tool namens 'tkinetd', das die Rechner im Netz sucht und automatisch eine Grafik erzeugt. Die Standorte der Komponenten und Dosen trägt man am besten auf der Kopie des Bauplans ein. Netz-Dokumentation Bei vielen Administratoren gehört die Dokumentation des Netzwerkes zu den "unangenehmen" und vernachlässigten Aufgaben. Das Verkabelungspläne und Konfigurations-Beschreibungen sehr wichtig sind fällt den meisten erst dann auf, wenn die bestehende Leitungsführung verändert werden soll oder ein Fehler auftritt. Ohne ausreichende Dokumentation wird die Erweiterung und Fehlersuche zu einer sehr kostenintensiven und langwierigen Angelegenheit. Aber die Bedeutung einer kompletten und aktuellen Dokumentation für die schnelle Wiederherstellung des lokalen Netzes nach einem Unglück kann nicht hoch genug bewertet werden.Sie ermöglicht zudem den täglichen Überblick und bietet Hilfen bei der Fehlersuche. Zusammen mit der Planung wird das Netz dokumentiert. Neben Angaben über die Topologie sind auch alle Kabelwege, Standorte von Netzkomponenten (Hub, Switches, Router, usw.), Server und Peripheriegeräten zu dokumentieren. Die Praxis zeigt leider, daß die Dokumentation bei einer Neuistallation grade noch eben so klappt, nachträgliche Änderungen werden aber meist nicht mehr dokumentiert. Für kleine Netze genügt ein Gebäude- oder Raumplan, in den mit Bleistift und Lineal die Datenleitungen eingezeichnet werden. Dokumentiert werden Kabelführungen, Lage der Anschlußdosen, Standort der Stationen und Komponenten (Hubs, Switches, usw.). Für jedes eingezeichnete Element sollte eine sinnvolle Kurzbezeichnung vergeben werden, die die eindeutige Zuordnung erlaubt. Die Art der Bezeichnung sollte Raum für spätere Erweiterungen bieten. Soll ein bestehendes Netz in naher Zukunft in größerem Umfang erweitert werden, dann sollte der Lageplan mit Hilfe eines einfachen Zeichen-Programmes erstellt werden. Diese Lösung benötigt zunächst mehr Zeit als das einfache Einzeichnen in den Gebäudeplan, ist aber durch die vielfältigen Editiermöglichkeiten flexibler. Übersichtsgrafiken lassen sich recht schnell mit speziellen Tools wie Visio (Microsoft) oder Acrix (Autodesk) erstellen, für die Grafikbibliotheken mit speziellen Symbolen für die Netzkomponenten erhältlich sind. Unter UNIX gibt es ein Tool namen 'tkinetd', das die Rechner im Netz sucht und automatisch eine Grafik erzeugt. Die Kurzbezeichnungen der Elemente in den oben genannten Netzwerkplänen sind natürlich nur sinnvoll, wenn sie sich auf den entsprechenden Geräten und Anschlußpunkten wiederfinden. Dies wird über selbstklebene Etiketten erreicht. Alle Dosen, Hubs, Switches, Router und andere Geräte erhalten einen solchen Aufkleber. An den Stationen sollte das Etikett neben der Kurzbezeichnung auch den Netzwerk-Namen des Rechners, die Ethernet(MAC-Adresse) und gegebenenfalls die IP-Adresse aufführen. Für Kabel benötigt man mindestens zwei Beschriftungs-Fahnen: Eine am Anfang und eine am Ende der Leitung. Die Standorte der Komponenten und Dosen trägt man am besten auf der Kopie des Bauplans ein. Zeichnen Sie auch den Kabelzug ein. Erstellen sie eine schematische Zeichnung über alle Kabelsegmente, und zeichnen Sie alle Verbindungspunkte, Verbindungsausrüstungen und angeschlossenen Einheiten ein. Entwickeln Sie mit Hilfe dieser Zeichnung ein logisches System für die Benennung (Ziffern, Buchstaben) der Kabelsegmente und Ausrüstungen. Denken Sie daran, daß das Netz in Zukunft expandieren kann. Tragen Sie die Namen in die Zeichnungen ein. Erstellen Sie eine Liste über alle Kabelsegmente. Notieren Sie für jedes Segment dessen Name, Länge und Kabeltyp. Managebare Komponenten des Netzes (Switches, Router) werden oft wie Stecker und Kabel angesehen und vor dem Austausch einer Komponente nicht daran gedacht, die Konfiguration zu speichern oder zu dokumentieren. Bei Patch-Feldern kann abgelesen werden, welche logischen Zuordnungen durch Umstecken der Patch-Kabel möglich sind. Es ist daher sinnvoll, eine Kopie des Planes in der Nähe jeder "Patch-Einheit" aufzubewahren. Es versteht sich von selbst, daß jedes Kabel eindeutig identifizierbar sein muß. Es gibt im Handel genügend Systeme zur Kabelidentifizierung, z. B. kleine Plastikringe mit eingeprägten Nummern, die sich um das Kabel legen und verschließen lassen oder Kabelbinder mit Beschriftungsfahne. Damit ist eine Numerierung mit beliebig vielen Stellen möglich. Man kann aber auch Schlüsselanhänger aus Plastik nehmen, das Schildchen beschriften und den Anhänger mittels eines Kabelbinders am Kabel befestigen. Notfalls kann das Kabel auch mit einem wasserfesten Filzstift markiert werden. Die Kabelsegmente müssen an mindestens zwei Punkten (nämlich an jedem Ende) gekennzeichnet werden. Das Bild links zeigt einen Ausschnitt, bei dem man die weißen Markierungen gut erkennen kann. Genauso wie die Kabel müssen auch alle Ports von Patchfeldern beschriftet werden. Wenn sich Portzuordnungen häufig ändern, kann man die Ports auch durchnumerieren und in einer Liste die Zuordnung handschriftlich festhalten. Die Liste kommt in eine Prospekthülle, die im oder am Netzwerkschrank befestigt wird. Wenn man dann noch einen Stift an einer Schnur hängt, gibt es auch keine Ausreden mehr für fehlende Einträge. Zusätzlich zu Plänen und Beschriftungen sind, je nach Netzgröße, Aufstellungen in tabellarischer Form nützlich: Kabel-Tabelle: Hier wird jedes verlegte Kabel mit seiner Kurzbezeichnung und der aktuellen (gemessenen!) Länge aufgeführt. Es hat sich in der Praxis bewährt, die Längen bei Bus-Netzen von Zeit zu Zeit nachzumessen. So werden Leitungen entdeckt, deren Verlängerung nicht dokumentiert wurde, zum Beispiel weil sie nicht durch den Administrator, sondern durch die Anwender ausgeführt wurde. Patch-Tabelle: Diese Tabelle wird neben dem Patch-Feld ausgelegt und dokumentiert die aktuelle Zuordnung der einzelnen Leitungen. Stations-Konfiguration: In dieser Aufstellung wird die aktuelle NetzwerkKonfiguration jeder Station festgehalten. Je nach Anzahl der Rechner im Netz kann sie entweder per Hand (zum Beispiel auf Kartei-Karten) oder mit einem DatenbankProgramm erzeugt werden. Die Dokumentation des lokalen Netzes legt am besten in Form eines Betriebshandbuches an. Das Betriebshandbuch muß in mehreren Exemplaren vorhanden und dem Systemverwalter, Superusern und dem Benutzerservice sowie deren nächsten Vorgesetzten zugänglich sein. Das Betriebshandbuch sollte enthalten: Die LAN-Policy Ein kurzer Abriß der LAN-Politik des Unternehmens kann Informationen über Benutzergruppen, Paßwortpolitik und Möglichkeiten des externen Zugangs (remote login) enthalten. Das Kapitel kann außerdem Regelungen für die Ausleihe von PCAusrüstung nach Hause und Maßnahmen gegen PC-Viren, Hacker und das Kopieren von Software festlegen. Schlüsselpersonen Der Systemverwalter ist die absolute Schlüsselperson des lokalen Netzes. Außer diesem sind etwaige Benutzerservice-Mitarbeiter und Superuser wichtige Personen. Arbeitsgänge für Benutzerservice und -support Dieser Abschnitt beschreibt die Vorgehensweise beim Auftreten von Fehlern, die Aufgaben des Benutzerservices und Richtlinien für den Einkauf von Hardware und Software. Verwaltung von Hardware und Software Ein Hauptziel des Betriebshandbuches ist es, sicherzustellen, daß alle Standardkonfigurationsparameter dokumentiert sind, damit es möglich ist, Fehler und Unzweckmäßigkeiten zu berichtigen. Dieses Register ist auch für die Steuerung des Unternehmensbestandes an PCs und Zubehör sowie den Bestand an in Form von Originaldisketten oder -CDs von Bedeutung. Tägliche und wöchentliche Routinen des lokalen Netzes Das Betriebshandbuch kann Schulungs- und Anleitungsressourcen einsparen, indem es der Ort ist, wo alle administrativen Aufgaben beschrieben sind. Die wichtigsten Tätigkeiten sind das routinemäßige Backup und Restore, die Angaben der Verantwortlichen, Regeln für das Einrichten neuer Benutzer und die Erweiterung von Berechtigungen Sowie andere regelmäßige Tätigkeiten. Beschreibung der physischen Struktur des lokalen Netzes Die Dokumentation der Konfiguration von Servern und anderer zentraler Ausrüstung ist obligatorisch. Es ist besonders wichtig, daß Platten- und Volumenstrukturen des Fileservers sorgfältig dokumentiert werden, da diese Informationen entscheidend für ein problemloses Restore von Backups nach einem Systemausfall sind. Außer Fileservern umfaßt die zentrale Ausrüstung auch eventuell vorhandene Kommunikationsserver, E-Mail-Server, Testmaschinen und Netzdrucker.Die Kabelführung im lokalen Netz einschließlich der LAN-Struktur in Hauptzügen und eine etwaige Segmentierung muß ebenfalls gründlich dokumentiert sein. Beschreibung der logischen Struktur des lokalen Netzes Die Dokumentation der logischen Struktur des lokalen Netzes umfaßt die Zusammensetzung der Benutzergruppen, die Platten-, Verzeichnis- und Dateistruktur im Netz. Software des lokalen Netzes Für Programme auf dem Server kann es eine Hilfe sein, genau dokumentiert zu haben, was konfiguriert werden muß, wenn ein neuer Benutzer Zugang dazu haben soll. In vielen Fällen müssen außerdem Drucker, die Lage von Dateien und anderes konfiguriert werden. Es kann Zeit gespart werden, wenn diese Dinge in Form von Checklisten beschrieben sind. Gleichzeitig erhalten die verschiedenen Benutzer ein einheitliches Setup. Scheinbar unwichtig ist die Dokumentation von aufgetretenen Fehlern und die Maßnahmen, die zur Fehlerbehebung getroffen wurden. Gerade diese Informationen sich jedoch oft äußerst wertvoll. Einerseits kann man später beim Auftreten desselben Fehlers zu einem späteren Zeitpunkt die zu treffenden Maßnahmen nachlesen. Zum anderen kann durch Protokollierung der Fehler das sporadische Auftreten des gleichen Fehlers präventiv gearbeitet werden. Zeigt z. B. ein Fileserver alle paar Wochen defekte Sektoren, dann geht so etwas als Einzelereignis oft im Tagesgeschäft unter. Bei regelmäßiger Dokumentation kann gegebenenfalls rechtzeitig die Festplatte ausgetauscht werden. Kostenlose Software zur Netzplanung (für Windows) gibt es von Reichle & De-Massari: R&M Netplanner Fehlersuche/Belastungstest Fehlersuche Wenn man davon ausgeht, dass die reinen Harwaretest (Kabelanschlüsse, übersprechen, Dämpfung, usw.) erfolgreich verlaufen sind (siehe Fehlerquellen und Fehlersuche bei der Verkabelung), kann man u. a. folgende Massnahmen durchführen um die Funktionsfähigkeit des Netzes zu testen, wobei ich hauptsächlich Möglichkeiten anführe, die ohne besonderes Testequipment durchführbar sind. Entsprechende Test-Hardware leistet ähnliches: 1. Test aller aktiven Komponenten (Switches, Router, Glasfaser-Modems) auf Funktion (geht - geht nicht). Sind alle Ports eines Switches erreichbar usw. 2. Überprüfen der Konfiguration managebarer Komponenten (Übertragungsmodus, VLAN-Zuordnung, Aktivierung der Ports etc.). 3. Die Erreichbarkeit aller Endpunkte auf TCP/IP-Ebene lässt sich mit den Programmen "ping" und "traceroute" (bei Windows "tracert") testen. Hier lassen sich auch grobe Anhaltspunkte für Transferzeiten ermitteln. 4. Bei managebaren Komponenten lassen sich statistische Daten (Datendurchsatz, Kollisionen etc.) über die Managementfunktion (Webinterface, SNMP) abrufen. Verdächtig ist auf jeden Fall das Auftreten von Kollisionen. 5. Das Programm "iptraf" ist ein Linux-Programm, das umfassende Netzwerkstatistiken liefert, darunter transferierte Paket und Bytes, Interface-Statistik von IP, TCP, UDP, ICMP. IP checksum errors usw. Dazu gibt es einen Service-Monitor für TCP und UDP, der eine Port-Statistik liefert. Weitherhin liefert das Programm eine Statistik der Aktivitäten der verschiedenen Hosts. Filterfunktionen erlauben das Eingrenzen der Daten. Zu beziehen unter http://iptraf.seul.org/. 6. Das Programm "netio" ( http://freshmeat.net/projects/netio/) gibt es als Windows- und Linux-Version. Es misst den Netto-Durchsatz auf der Verbindung, also ohne den Overhead, der durch Applikationen wie FTP oder dem für das Filesharing erzeugt wird. Auch hat die Geschwindigkeit der Festplatte keinerlei Einfluss auf die übertragungsraten. Daher liegen die Werte von netio-Messungen immer über den Werten, die in der Praxis erreicht werden, dafür sind sie miteinander vergleichbar. Ein ähnliches Programm ist "iperf". Auch das Microsoft Tool "ttcp" kann verwendet werden (auf der Windows XP CD oder Service Pack CD unter \VALUEADD\MSFT\NET\TOOLS). Weitere Test sollten im Probebetrieb des Netzes erfolgen (Server sind online, zumindest einige Clients sind vorhanden). Dann können folgende Tools eingesetzt werden. 1. NTOP ist ein Tool zur Beobachtung und statistischen Auswertung des Netzwerkverkehrs. Interessant ist das Einlesen und Auswerten von gespeicherten Tracefiles mit der Option „-f“. Dann liest NTOP keine Daten von der Netzwerkkarte, sondern erzeugt lediglich Auswertungen für den vorhanden Trace. NTOP arbeitet auch mit NetFlow von Cisco zusammen. Der Zugriff auf NTOP erfolgt über einen Webbroser. NTOP ist auch in Kombination mit Hardware als nBox erhältlich. (http://www.ntop.org) 2. "Etherape" kann seine Daten sowohl direkt vom Netz als auch aus einem gespeicherten Trace beziehen. Aus diesen Daten erstellt es eine Reihe von grafischen Auswertungen zu Kommunikationsbeziehungen und Protokollverteilung. Etherape befindet sich noch in der Entwicklung und läuft momentan nur unter Linux mit Gnome-Desktop. 3. SmokePing ist spezialisiert auf die Messung der Round-Trip-Time. Es gibt Probes für eine Reihe von Protokollen (ICMP, TCP, HTTP, etc.). Die Zeiten werden in einer Datenbank festgehalten und können über ein Browserinterface visualisiert werden. SmokePing ist wie MRTG ein Tool zum Baselining eines Netzwerkes. In Problemfällen kann man mit diesen Tools sehr schnell Veränderungen und deren Auslöser erkennen. (http://oss.oetiker.ch/smokeping/) 4. Für WLAN eignet sich der "network stumbler" ( http://www.netstumbler.com). Mit diesem Windows-Programm kann die Reichweite und die Abdeckung der WLANs abgeschätzt werden. Belastungstest Schwieriger sind Sicherheitstests bei den Servern und eine Vorhersage über das Lastverhalten, wenn nicht nur ein paar Clients aktiv sind, sondern das Netz unter Vollast fährt. Ein Beispiel aus der Praxis ist die Notenbekanntgabe am Semesterende, wenn kurz nach Freigabe der Informationen das Netz bzw. die Webserver unter der Last der Anfragen zusammenbrechen. Das Belastungstest-Tool "Hammerhead" kann mehrere Verbindungen gleichzeitig öffnen und dabei auch Anfragen von verschiedenen IP-Aliasen und bis zu 256 verschiedenen Usern generieren. Nach der voreingestellten Testzeit liefert das Tool einen aussagekräftigen Report. Neben Anzahl der Threads, Timeout-Schwellen, Test-Zeit, Usern lassen sich noch viele weitere Parameter einstellen. Man kann sogar Erwartungswerte für Ergebnisse eingeben, die dann mit den realen Resultaten verglichen werden. Hammerhead wartet bei jedem Request auf Antwort vom Server. Ist der Server schlecht angebunden, kann es vorkommen, daß die voreingestellte Request-Rate unterschritten wird. Auch kann das Programm nur so schnell arbeiten, wie der Computer, auf dem es läuft. (http://hammerhead.sourceforge.net) Einfacher Hardware-Netzwerktester Bei größeren Netzen muss man oft prüfen, welche Dose oder welches Kabel mit einem Switch verbunden ist. Dazu genügt eine Netzwerkkarte für wenige Euro, die sich für die Wake-on-LANFunktion nicht nur aus dem PCI-Bus, sondern auch über einen dreipoligen Stecker mit Strom versorgen kann. Wenn an den richtigen Pins 5 Volt anliegen, genügt das der Karte, um eine Ethernet-Verbindung aufzubauen und dies mit ihren LEDs "Link-Status" und "10/100 MBit" anzuzeigen. Nur wenn am anderen Ende des Kabels keine aktive Komponente hängt, bleiben die LEDs dunkel. Man kann an den Wake-on-LAN-Stecker einfach Batterien anschließen. Vier Akkus zu je 1,2 Volt liefern 4,8 V, was dem meisten Karten genügt. Oder man nimmt einfach vier Zink-Kohle-Batterien (4 x 1,5 V = 6 V) und schaltet eine Diode zwischen Karte und Batteriebox, dann wird die Karte mit ca. 5,4 V versorgt, was den meisten Karten auch nichts ausmacht. Die ganz edle Variante ist ein 5-V-Low-Drop-Spannungsregler zwischen 6Volt-Batteriepack und Karte. Der so entstandene Ethernetport-Tester zeigt zuverlässig an, ob eine Dose oder ein Kabel mit einer Ethernet-Gegenstelle verbunden ist und wie schnell die Verbindung ist. Man darf ihn jedoch nicht mit einem Kabeltester verwechseln, denn ein Link kann durchaus zustande kommen, wenn nicht alle Adernpaare korrekt verbunden sind. Das Bild zeigt die Pins des Steckers auf der Netzwerkkarte: An Pin 1 müssen 5 Volt anliegen, an Pin 2 Masse. Pin 3 bleibt unverbunden, denn hier meldet die Karte, dass ein Wake-onLAN-Paket eingegangen ist. Universal-Netzkabel Neues Kapitel Protokolle In diesem Abschnitt werden beispielhaft einige höhere Protokolle für Internet-Dienste skizziert. Bemerkenswert ist, daß viele dieser Protokolle aus wenigen Anweisungen in lesbarem Klartext bestehen. Der Grund hierfür ist unter anderem, daß man diese Protokolle zum Testen einer Verbindung durch eine Telnet-Verbindung auf einem bestimmten Port (z. B. 80 für HTTP) von Hand nachvollziehen kann. Durch den Klartext ist auch die Fehlersuche bei einer Verbindung ohne großen Aufwand und ohne spezielle Tools möglich. Die vorgestellten Protokolle werden hier nicht bis ins Detail ausgebreitet, es soll Ihnen nur eine Vorstellung über die Arbeitsweise der Internet-Protokolle vermittelt werden. DHCP und RADIUS DHCP Um in einem IP-basierten Netzwerk Kontakt mit anderen Rechnern aufnehmen zu können, benötigt jeder Computer eine eigene, eindeutige IP-Nummer. Je größer das Netzwerk wird und je mehr verschiedene Rechnerplattformen darin vereint sind, desto höher ist der Aufwand für den Administrator: Wann immer ein neuer Rechner in das Netzwerk integriert wird, muß er zuerst konfiguriert werden. Ändert einer der zentralen Server seine Adresse oder wird er auf eine andere Maschine verlegt, müssen alle Netzwerk-Client umkonfiguriert werden. Einen zweiter Aspekt bringen sogenannte "nomadische" Systeme, z. B. Laptops, die irgendwo ins Netz eingebunden werden sollen. Dabei bieten sich verschiedene Zugangsmöglichkeiten für Rechner in das Intranet: Anschluß über einen Ethernet-Hub oder -Switch Zugang durch drahtlose Netze (und evtl. einen Router zum drahtlosen Subnetz) Zugang vom Internet über eine Firewall Modemzugang über einen Modemserver Günstig wäre es, wenn der Zugang eines Rechners zum Netz folgenden Anforderungen genügen würde: automatisiert, d. h. ohne manuellen Eingriff authentifiziert, d. h. nur zugelassene Systeme erhalten Zugriff vollständig (Netz-, System- und Anwendungskonfiguration) standardisiert, d. h. für alle Systeme in einheitlicher Form Eine Lösung für dieses Problem bietet DHCP (Dynamic Host Configuration Protocol). Dieser Dienst ermöglicht es, einem Client dynamisch eine IP-Nummer und andere Netzwerkparameter, wie den Netzwerknamen, die Gatewayadresse, etc., zuzuweisen, ohne daß der Administrator den Rechner überhaupt zu Gesicht bekommt. DHCP ist dabei völlig unabhängig von der eingesetzten Plattform. Das heißt, es kann sowohl Windows-Maschinen wie auch zum Beispiel Unix-Rechner mit den Netzwerkeinstellungen versorgen. Um ein Mindestmaß an Verfügbarkeitsanforderungen zu erfüllen, sollte natürlich mehr als nur ein DHCP-Server vorhanden sein, da sonst dessen Ausfall die Funktion sämtlicher Clienten beeinträchtigt. Das in RFC 2131 definierte Protokoll DHCP arbeitet nach dem Client-Server-Modell. Als Server wird ein Programm bezeichnet, das den Pool der zu vergebenden Nummern verwaltet und sich darum kümmert, daß eine Nummer nicht zweimal vergeben wird. Der Client ist ein Programm auf dem lokalen Rechner, das zunächst den Server selbsttätig im Netz suchen muß und ihn anschließend darum bittet, eine IP-Nummer zuzuteilen. Die Grundfunktion des Servers ist recht einfach aufgebaut: über eine Konfigurationsdatei teilt der Administrator ihm mit, welche Adreßbereiche er für die Weitergabe an Client zur Verfügung hat. Fragt ein Client nach einer IP-Adresse, dann muß der Server zunächst nachsehen, ob noch eine Adresse frei ist. Diese freie IP-Nummer liefert er an den Client aus. Gleichzeitig muß er eine Datei (Leases-File) führen, in der er protokolliert, welche Adresse bereits an wen vergeben ist. Bei der Adreßvergabe sind drei verschiedene Modi einstellbar: Automatic Allocation: Fordert ein Client eine IP-Nummer an, wird sie ihm auf unbegrenzte Zeit zugeteilt, solange noch Adressen zur Verfügung stehen. Sind alle Adressen verbraucht, kann kein neuer Client mehr konfiguriert werden, auch wenn ein Teil der zuvor bedienten Rechner im Moment gar nicht eingeschaltet ist. Manual Allocation: In dieser Betriebsart geht es nur darum, Verwaltungsaufwand zu minimieren. In der Konfigurationsdatei ist für jeden Client im Netzwerk eine IPNummer fest zugeordnet. Der Server ist lediglich für die Auslieferung der Adresse an den Client verantwortlich. Dynamic Allocation: Jeder Client bekommt auf Anfrage eine IP-Nummer, solange im definierten Pool noch Einträge frei sind. Der Unterschied gegenüber der Automatic Allocation besteht darin, daß die IP-Nummer nur für eine bestimmte, maximale Zeitspanne (Lease-Time) gültig ist und vom Client innerhalb dieser Zeit zurückgegeben werden kann, wenn sie nicht mehr benötigt wird. Als einzige der drei Betriebsarten erlaubt Dynamic Allocation, kleine IP-Nummern-Pools mit einer großen Anzahl von Rechnern zu teilen. Einzige Voraussetzung: nicht alle Maschinen dürfen gleichzeitg laufen. Damit lassen sich auch Computer, die eher selten ins Netzwerk integriert werden, wie Laptops, zuverlässig mit einer IP-Nummer versorgen. Wird der Rechner vom Netz getrennt, kann die Adresse für eine andere Station verwendet werden. In dieser Betriebsart werden die meisten DHCP-Server betrieben. DHCP ist eine Erweiterung des BOOTP-Protokolls und konkurriert in seiner Basisfunktionalität mit RARP. Gegenüber BOOTP zeichnet es sich vor allem durch die Flexibilität bezüglich der abfragbaren Konfigurationsparameter und durch das Konzept der Lease aus, d. h. die Möglichkeit eine Information dem Client gegenüber als nur begrenzt gültig zu markieren. Damit wird die Flexibilität bei Veränderungen der Netztopologie und weiterer Konfigurationsparameter gewahrt. Ferner ist die Unterstützung von großen Netzen, in denen nichts stets alle Systeme zugleich aktiv sind, mit limitierten Pools von Adressen möglich. Durch die Rückwärtskompatibilität zum PDU-Format von BOOTP ist die Verwendung existierender BOOTP-Relay-Agents in Subnetzen ohne DHCP-Server gewahrt. Beim Start des Systems schickt der Client ein DHCPDISCOVER-Paket in Form eines Broadcasts an 255.255.255.255 (Phase 1). Anhand der Identifikation des Client im Paket können sich einige (oder ein einzelner) DHCP-Server entscheiden, dem Client die gewünschte IP-Adresse sowie andere Konfigurationsinformation in Form eines DHCPOFFER-Pakets zuzuteilen. (Vor der Vergabe können und sollten die Server die Konfliktfreiheit bzgl. der Adresse mittels ICMP-Ping oder ARP prüfen.) Der Client kann sich in Phase 2 aus den Antworten eine für ihn geeignete aussuchen und bestätigt dies gegenüber dem Server durch ein DHCPREQUEST-Paket (Phase 3). Entscheidungsparameter können z.B. die Leasedauer (tl) oder die Menge der angebotenen Konfigurationsinformation. Bei korrekter Information im DHCPREQUEST bestätigt der Server die Lease durch ein DHCPACK-Paket, womit die Konfiguration abgeschlossen ist Bevor die IP-Adresse verwendet wird, sollte der Client ihre Einzigartigkeit durch ein Gratuitious ARP prüfen. Sollte der Client die angebotene Adresse ablehnen wollen, teilt er dies durch DHCPDECLINE-Paket dem Server und beginnt nach einer kurzen Wartefrist erneut mit Phase 1. Sobald der Client die Bestätigung durch DHCPACK erhalten hat, ist er für die Überwachung der Lease-Dauer selbst verantwortlich. Insbesondere kennt das Protokoll auch keine Methode, einem Client die Lease zu entziehen. Vor Ablauf der Lease-Dauer (meist nach der Hälfte der Zeit = 0,5 * tl) sollte der Client durch einen erneuten Durchgang durch Phase 3 versuchen, die Lease vom selben DHCP-Server verlängert zu bekommen. Gelingt ihm das nicht, kann er vor endgültigem Ablauf der LeaseDauer (meist nach ca. 0,8 * tl) die Phase 1 nochmals durchlaufen, um eine Verlängerung bzw. Neuausstellung der Lease (eventuell von einem anderen Server) zu erhalten. Die vorzeitige Aufgabe einer Lease sollte der Client dem Server durch ein DHCPRELEASE mitteilen, um den Pool freier Adressen möglichst groß und den Vergabestand im Server möglichst akkurat zu halten. Alle Zustandsübergänge im Client sind in folgender Abbildung zusammengefaßt. Die Komplexität hat in der Vergangenheit zu einigen Fehlimplementierungen mancher ClientSoftware geführt, die jedoch aufgrund der großen "Toleranz" im Protokoll meist keine kritischen Auswirkungen hatten. Der Vorgang "Lease erneuen" kann beliebig oft wiederholt werden, solange der Client die Adresse noch braucht und der Server nichts dagegen hat. Unter Umständen verweigert der DHCP-Server die Erneuerung. Falls die gewünschte Adresse für den DHCP-Server inakzeptabel ist, schickt er dem Client ein ablehnendes DHCPNAK. Der Client beginnt dann von Neuem. Was passiert, wenn der Client den DHCP-Server nicht mehr erreichen kann, der ihm seine IP-Adresse zugeteilt hat? Bevor sein Lease verfällt, soll der Client den DHCPREQUEST nicht mehr direkt an den DHCP-Server schicken, sondern es broadcasten. Somit hören alle DHCP-Server wieder mit. Wenn Failover richtig funktioniert, wird der Backup-Server jetzt das Lease erneuen. Kommt hingegen keine Antwort oder nur ein DHCPNAK, muß der Client wieder von vorne beginnen, und ein DHCPDISCOVER broadcasten usw. Das ist insofern schlecht, als er nun höchstwahrscheinlich eine ganz andere IP-Adresse bekommt. Bestehende Verbindungen, die noch die alte IP-Adresse verwenden, müssen abgebaut werden. Es darf natürlich nicht jeder beliebige Rechner Zugang zum LAN erhalten. Deshalb kann der DHCP-Server auch eingeschränkt werden - bis hin zu einer Liste von "erlaubten" MACAdressen. Man kann auch eine gemischte Versorgung der Rechner im Netz vorsehen, teils mit festen IP-Adresse (z. B. Server mit "Außenwirkung"), teils mit dynamisch zugewiesenen Adressen. Remote-Zugang mit RADIUS Der Zugang zum Netz über Wählleitungen (analoges Telefon, ISDN, xDSL) erfolgt normalerweise über einen oder mehrere Remote Access Server (RAS), in Einzelfällen auch über einen Rechner mit angeschlossenem Modem, ISDN-Karte oder xDSL-Anschluß. Deren Aufgabe ist es, ankommende digitale oder analoge Anrufe entgegenzunehmen, eine Benutzerauthorisierung durchzuführen und, falls diese erfolgreich war, die Verbindung des anrufenden Rechners mit dem internen Datennetz freizugeben. Der ferne Rechner verhält sich dann so, als ob er direkt am Datennetz angeschlossen wäre. Als Übertragungsprotokoll wird in der Regel PPP (Point to Point Protokoll, erlaubt IP- und IPX-Verbindungen), SLIP (Serial Line Internet Protokoll, veraltet, nur für IP-Verbindungen) und ggf. ARAv2 (Apple Remote Access Version 2) angeboten. Ein spezieller Terminalserver-Modus gestattet es, sich mit einem normalen Terminalprogramm (z.B. Hyperterminal, Kermit, usw.) auf dem Access-Server anzumelden und von dort aus Telnetverbindungen aufzubauen. IP-Adressen werden normalerweise aus einem IP-Adresspool vergeben. Oft werden auch "virtuelle Verbindungen" unterstützt. Diese erlauben den physikalischen Abbau von Verbindungen, wenn gerade keine Daten übertragen werden, ohne daß die logische Verbindung verloren geht. Die Verbindung wird automatisch mit den gleichen Parametern wie vorher wieder aufgebaut, wenn Daten wieder übertragen werden müssen. Für die standardisierte Authentifizierung am Modem- und Internetzugang setzt sich zunehmend das RADIUS-Protokoll (Remote Authentication and Dial-In User Service) durch. Seine Client-Proxy-Server-Architektur erlaubt die flexible Positionierung an Netzzugangspunkten und wird von fast allen Herstellern von Modemservern unterstützt. In Kombination mit DHCP und PPP ist die Aufgabe der Konfiguration der anwählenden Endsysteme in automatisierter Weise gelöst. Der Radius-Server ist ein zentraler Authentifizierungs-Server, an den sich alle RA-Server wenden. Auf diese Weise lassen sich unabhängig von der Netz-Infrastruktur alle Remote-User zentral verwalten und Benutzerprofile mit Zugangsrestriktionen definieren, aber auch zusätzliche Sicherheitsverfahren vorsehen. Beispielsweise kann festgelegt werden, dass der Nutzer nur nach einem Rückruf durch den Einwahlknoten an eine zuvor vereinbarte Rufnummer Zugriff auf das Unternehmensnetzwerk bekommen darf. Diese Informationen übergibt der RadiusServer an den RA-Server, der das weitere Login entsprechend koordiniert. Der Vorteil dieses Verfahrens liegt in den einmalig generierten Zugangsdaten der Nutzer, die auch in verteilten Netzwerken jederzeit aktuell verfügbar sind und mit einfachen administrativen Eingriffen an zentraler Stelle definiert und verändert werden können. Darüber hinaus ist die innerbetriebliche Abrechnung der Nutzung des Systems durch ein entsprechendes Accounting möglich. Das Radius-Protokoll setzt auf UDP auf. Die Struktur eines Radius-Pakets ist ausgesprochen einfach. Es besteht aus fünf grundlegenden Elementen: einem Radius-Code, einem Identifier, einer Angabe zur Paketlänge, einem Authenticator und gegebenenfalls aus einer Reihe von Attributen. Der Radius-Code beschreibt die Aufgabe des Datenpakets. Aufbau des Radius-Pakets Die Codes 1, 2 und 3 verwalten den reinen Access vom Request bis zur Bestätigung oder Abweisung. Die Codes 4 und 5 dienen dem Accounting. Der Identifier ist acht Bit lang und dient der Zuordnung von Anfragen und Antworten. Das sicherheitstechnisch wichtigste Feld eines Radius-Rahmens ist der Authenticator, der eine Länge von 16 Oktetts beziehungsweise vier 32-Bit-Worten hat. Dabei wird zwischen dem Request Authenticator und dem Response Authenticator unterschieden. Inhalt des Request Authenticators ist eine Zufallszahl, die das gesamte Feld ausfüllt. Die Länge dieser Zufallszahl gewährleistet mit einer sehr hohen Wahrscheinlichkeit die Einmaligkeit dieses Wertes. Damit bietet das System einen gewissen Schutz vor Hackerattacken. Mit dem Versand des Request Authenticators werden die Zugangsdaten des Nutzers, der sich im gesicherten Netzwerk anmelden möchte, als Attribute übergeben. Der Radius-Server wird diese Anfrage entweder mit einer Access-Accept-, Access-Reject- oder Access-Challenge-Nachricht beantworten, die ihrerseits mit einem 16 Oktett langen Response Authenticator versehen ist. Dieser ist ein MD5-Hash-Fingerprint setzt sich zusammen aus dem empfangenen Radius-Paket einschließlich der Attribute sowie den geheimen Zugangsdaten, die auf dem Server abgelegt sind, zusammensetzt. Die Attribute eines Radius-Pakets beinhalten alle wichtigen Informationen, die zwischen dem RAS und dem Radius-Server ausgetauscht werden müssen. Attribute sind sehr einfach aufgebaut Attribute werden in einer Liste mit variabler Länge im Anschluss an den Authenticator übertragen. In den Attributen können natürlich Nutzernamen und Passwörter, aber auch IPAdresse, Service-Typen, Status-Meldungen, Filter-IDs und - wichtig beim CHAP - ein entsprechender Challenge-Wert übergeben werden. Attribute werden in Datensätzen variabler Länge übertragen, die jeweils aus drei Feldern bestehen. Das erste aus acht Bit bestehende Feld benennt die Art des Attributes. Da nicht nur die Liste aller Attribute, sondern auch jeder einzelne Datensatz selbst in der Länge variabel ist, gibt das zweite Oktett die Länge des Attributes an. Erst ab dem dritten Oktett werden die eigentlichen Informationen übertragen. Im einfachsten Fall wird ein Radius-Request mit einer Legitimierung des Nutzers oder dessen Abweisung beantwortet. Dazu folgt auf dem Access-Request eine Access-Accept- oder eine Access-Reject-Nachricht vom Radius-Server. Die Art der Antwort wird mit dem Radius-Code angezeigt. Das Verfahren harmonisiert mit PAP und CHAP. SMTP - Simple Mail Transfer Protocol Der urspüngliche Standard für SMTP - niedergelegt im RFC 821 - stammt aus dem Jahr 1982 und gilt, abgesehen von einigen Erweiterungen, nach wie vor. Dieser RFC 821 legte ein Minimum an Schlüsselworten fest, die jede Implementation von SMTP (d. h. die Verkörperung von SMTP in einem Programm) beherrschen muß. Dies sind: Kommando Argument Beschreibung HELO Systemname Beginn, Name des sendenden Systems MAIL From: Absenderadresse Beginn der Übermittlung RCPT To: Empfängeradresse Adressat der E-Mail DATA Brieftext, Ende durch eine Zeile mit "." HELP Topic Hilfestellung VRFY Mailadresse Mailadresse verifizieren EXPN Mailadresse Mailadresse expandieren (z. B. Liste) RSET Senden abbrechen, Zurücksetzen NOOP nichts tun QUIT Verbindung beenden Die Verbindung eines MTA zu einem anderen läßt sich nachstellen: telnet lx-lbs.e-technik.fh-muenchen.de smtp Trying 129.187.106.196... Connected to lx-lbs.e-technik.fh-muenchen.de. Escape character is '^]'. 220 lx-lbs.e-technik.fh-muenchen.de Smail3.1.28.1 #1 ready at Sun, 25 Feb 96 23:15 MET helo www.netzmafia.de 250 lx-lbs.e-technik.fh-muenchen.de Hello www.netzmafia.de mail from: [email protected] 250 ... Sender Okay rcpt to: [email protected] 250 ... Recipient Okay data 354 Enter mail, end with "." on a line by itself Hallo Holm, zu Deiner Frage bezeglich der Reinigung von Morgensternen wollte ich Dir nur den Tip geben, dazu reine Kernseife zu verwenden. Damit ist die Drecksarbeit im Handumdrehen erledigt. Beste Gruesse, Paulsen . 250 Mail accepted quit 221 lx-lbs.e-technik.fh-muenchen.de closing connection Connection closed by foreign host. Beim Verbindungsaufbau meldet sich der lokale MTA mit einer "Begrüßungszeile". Der lokale empfangende MTA wird mit "HELO" angesprochen und als sendender MTA der des Systems www.netzmafia.de angegeben. Der lokale MTA antwortet mit einem Zahlencode, der dem Sender-MTA signalisiert, daß seine geforderte Aktion in Ordnung geht. Die Klarschrift nach dem Zahlencode dient nur der besseren Lesbarkeit für den Menschen (z. B. für den, der Fehler suchen muß). Auf "MAIL FROM:" folgt die Adresse des Absenders, und auf "RCPT TO:" die des Empfängers. Auf das Schlüsselwort "DATA" folgt schließlich der ganze Brief, also sowohl die Kopfzeilen, als auch der Text. Der Empfänger-MTA wird solange Text erwarten, bis ihm der Sender-MTA über eine Zeile, die nur einen Punkt enthält, signalisiert, daß der Brief zu Ende ist. Nach der letzten Bestätigung des Empfänger-MTAs könnte der Sender den nächsten Brief übermitteln, wiederum beginnend mit "MAIL FROM:". Nach dem Empfang des Briefes kopiert der lokale MTA den Brief in die Postfach-Datei des Empfängers. Der RFC 821 legte noch einige weitere Schlüsselworte fest, z. B. "EXPN" für expand, welches eine Unterstützung von Mailing-Listen erlaubt, oder "VRFY" für verify, mittels dessen eine Bestätigung der Empfänger-Adresse gefordert werden kann. Eine ganze Reihe von RFCs haben den Standard für SMTP erweitert. Die erweiterte Version heißt nun offiziell ESMTP (für Extended SMTP). Hinzugekommen sind beispielsweise Schlüsselworte für die Unterstützung von 8bit-Briefen (z. B. solche mit Umlauten), und die Möglichkeit eine maximale Größe für Briefe, die empfangen werden, festzulegen. Auf Arbeitsplatzrechnern, die normalerweise nicht ständig eingeschaltet sind, erfordert EMail spezielle Betriebsweisen. Falls der Rechner in ein lokales Netz integriert ist, bietet sich eine Lösung über den Netzwerkserver oder einen speziellen Mail-Server an. Es gibt auch die Möglichkeit, direkt vom PC-Kompatiblen oder Macintosh auf eine Unix-Mailbox zuzugreifen. Voraussetzung dafür ist, daß der Arbeitsplatzrechner direkt mit TCP/IP am Ethernet angeschlossen ist oder über eine Modem-Verbindung per PPP-Protokoll angebunden ist. Die Mailer sind lokale Programme am PC oder Mac. Der Vorteil ist, daß man in der PCUmgebung bleibt, und Dateien direkt aus dem PC-Directory-System versandt werden können. Die Mailbox des Benutzers liegt dabei selbst auf einem Mail-Server (Postfach). Der Zugriff vom PC auf das Mailsystem des Servers wird über den Client/Server-Mechanismus realisiert. Protokolle, die dieses erlaubt, sind POP ('Post Office Protocol') und IMAP ('Internet Message Access Protocol'). POP POP, genauer POP 3, ist die bisher noch gebräuchlichste Methode, um E-Mails von einem Provider zu empfangen, wenn der eigene Rechner nicht ständig mit dem Internet verbunden ist. Das Prinzip und der Funktionsumfang von POP sind einfach: Die für den Empfänger bestimmten E-Mails landen beim Provider im SpoolVerzeichnis und müssen dort vom Empfänger abgeholt werden. Der Provider stellt einen POP-Server zur Verfügung, welcher die Schnittstelle des POP-Clients auf dem Empfänger-Rechner darstellt. Der lokale POP-Client kommuniziert mit dem POP-Server beim Provider. Über ihn werden die vorhandenen E-Mails angeboten. Eine Kommunikation zwischen dem POP-Client und dem POP-Server beim Provider kann schematisch beispielsweise so aussehen : Client: Hast Du neue E-Mails für mich? Server: Ja, insgesamt fünf Stück! Client: Liste mir die Absender auf! Server: Meier, Mueller, Huber, Schulze Client: Zeige die E-Mails an! Server: ((Zeigt E-Mails an)) Client: ((Speichert E-Mails ab)) Client: Lösche alle angezeigten E-Mails Server: ((Löscht alle angezeigten E-Mails)) Wenn ein Client über POP3 Nachrichten abrufen möchte, baut er eine TCP-Verbindung über Port 110 auf. Ist die Verbindung zustande gekommen, sendet der Server eine Begrüßungsmeldung. Die weitere Kommunikation zwischen beiden Rechnern erfolgt über Kommandos, die aus drei oder vier Zeichen langen Wörtern (mit einem oder mehreren Argumenten mit bis zu je 40 Zeichen) bestehen. Antworten enthalten einen Status-Indikator und ein Statuswort sowie optionale Informationen. Es gibt zwei Status-Indikatoren: Positiv: +OK Negativ: -ERR Eine POP3-Verbindung durchläuft mehrere Stufen. Nach der Server-Begrüßung beginnt der "Authorization State". Der Client muß sich gegenüber dem Server identifizieren. Nach erfolgreicher Authorisierung beginnt der "Transaction State". Es werden alle Operationen zum Bearbeiten von Mails ausgeführt. Sendet der Client das Kommando QUIT, beginnt der "Update State". Der Server beendet die TCP-Verbindung und führt die vom Client im "Transaction State" angeforderten Änderungen durch. Viele POP3-Server haben zusätzlich einen Inaktivitäts-Timer. Laut Spezifikation muß dieser auf mindestens zehn Minuten eingestellt sein. Jedes Kommando des Clients setzt den Timer zurück. Ist der Timer abgelaufen, wird die TCP-Verbindung beendet, ohne in den "Update State" zu wechseln - eventuelle Änderungen werden auf dem Server nicht gespeichert. Nachdem der POP3-Client eine Verbindung zum Server aufgebaut hat, sendet dieser eine einzeilige Begrüßungsmeldung beliebigenInhalts, z. B.: Server: +OK POPEL-3 server ready Dabei handelt es sich bereits um eine Antwort des Servers, daher beginnt die Meldung immer mit einer positiven Bestätigung (+OK). Die Verbindung befindet sich nun im Zustand "Authorization". Der Client muß sich jetzt gegenüber dem Server identifizieren. Dies erfolgt über die beiden Kommandos USER und PASS. Kommandos im "Authorization State" Kommando Argument Beschreibung USER Name Das Argument identifiziert eine Mailbox. PASS String Der String enthält ein Mailbox-spezifisches Passwort. QUIT - Beendet die Verbindung. Die Kombination aus den Kommandos USER und PASS ist am gebräuchlichsten. Dabei werden die jeweiligen Parameter im Klartext an den Server gesendet. Ein Beispiel: Der Username für das Postfach soll "plate", das Passwort "XYZ1230" heißen. In diesem Fall wird folgender Authentifizierungsdialog ablaufen: Client: Server: Client: Server: USER plate +OK name is a valid mailbox PASS YXZ1230 +OK plates's maildrop has 9 messages (1600 octets) Bei falschen Angaben verweigert der Server den Zugang und gibt eine Fehlermeldung aus. Mögliche Dialoge bei falschem Usernamen: Client: USER plato Server: -ERR sorry, no mailbox for plato here Oder bei einem falschen Passwort: Client: Server: Client: Server: USER plate +OK name is a valid mailbox PASS tralala -ERR invalid password Die Tatsache, daß alle Dialoge im Klartext über das Netz abgewickelt werden, birgt ein hohes Sicherheitsrisiko. Mit dem Kommando APOP sieht die aktuelle POP3-Definition eine wesentlich sicherere Option zur Authentifizierung vor. Diese beschreibt in einem Kommando den User und identifiziert ihn mit einer Einweg-Hash-Funktion. Hat sich der Client beim Server identifiziert, wechselt die Verbindung in den "Transaction State". Dem Client stehen nun eine Reihe von Kommandos zur Behandlung der Mails zur Verfügung: Kommandos im "Transaction State" Kommando Argument Beschreibung STAT - Liefert die Anzahl der gespeicherten Mails und die Größe der Mailbox zurück (in Byte). LIST Nummer Liefert die Nummer und Größe (in Bytes) aller Mails zurück. Wird als Argument eine MailNummer angegeben, wird nur die Größe dieser Mail ausgegeben. RETR Nummer Gibt die Mail mit der als Argument übergebenen Nummer aus. DELE Nummer Löscht die Mail mit der übergebenen Nummer. NOOP - Bewirkt die Antwort "+OK". Dient zur Aufrechterhaltung der Verbindung, ohne daß ein Time-Out auftritt. RSET - Setzt die aktive Verbindung zurück. Noch nicht ausgeführte Änderungen werden verworfen. QUIT - Beendet die Verbindung und führt alle gespeicherten Änderungen aus. Der Server führt das Kommando DELE nicht unmittelbar aus. Die entsprechenden E-Mails werden als gelöscht markiert und erst bei Beenden der Verbindung endgültig vom Server gelöscht. Hat man eine Nachricht zum Löschen gekennzeichnet, möchte dies jedoch rückgängig machen, führt man das Kommando RSET aus. Der Server verwirft alle noch nicht ausgeführten Operationen. Sendet der Client das QUIT-Kommando, wechselt die Verbindung in den "Update State". Der Server trennt die TCP-Verbindung und führt alle gespeicherten Änderungen aus. Neben den hier vorgestellten, für eine minimale Implementation ausreichenden Kommandos gibt es noch weitere, die von den meisten Clients und Servern unterstützt werden. Details hierzu finden Sie in RFC1725. Im folgenden Beispiel sehen Sie den Ablauf einer POP3-Verbindung. Der Client identifiziert sich gegenüber dem Server und ruft eine Liste der gespeicherten E-Mails ab. Danach werden die Nachrichten einzeln heruntergeladen, auf dem Server zum Löschen gekennzeichnet, und die Verbindung wird beendet. Server: Client: Server: Client: Server: Client: Server: Server: Server: Server: Server: Client: Server: Server: Server: Client: Server: Client: Server: Server: Server: Client: Server: Client: Server: Client: Server: +OK POP3 server ready user plate +OK pass xyz1230 +OK LIST +OK 3 messages (520 octets) 1 120 2 190 3 210 . RETR 1 +OK 120 octets <... sendet Nachricht 1> . DELE 1 +OK message 1 deleted RETR 2 +OK 190 octets <... sendet Nachricht 2> . DELE 2 +OK message 2 deleted RETR 4 -ERR no such message QUIT +OK IMAP: Internet Message Access Protocol IMAP (genauer: IMAP, Version 4) löst das POP-Verfahren zunehmend ab und wird zum neuen Standard. Der Unterschied liegt unter anderem in der Funktionalität des IMAPVerfahrens. Das Prinzip ist dem POP-Verfahren jedoch sehr ähnlich. Die E-Mails werden wie beim POP-Verfahren beim Provider zwischengespeichert und können mit einem IMAP-Client auf den eigenen Rechner kopiert werden. IMAP bietet jedoch zusätzliche Funktionalitäten, die von POP noch nicht angeboten werden, z. B. kann der Mail-Body getrennt geladen werden, und auch die Attachments lassen sich getrennt abrufen. E-Mail-Client und Server tauschen bei IMAP ihre Daten über den TCP-Port 143 aus. Im Gegensatz zu den Protokollen SMTP und POP muß der Client bei IMAP nicht nach jedem gesendeten Kommando auf die unmittelbare Antwort des Servers warten. Es können mehrere Befehle hintereinander versendet werden, die jeweilige Rückmeldung vom Server kann später erfolgen. Dazu wird jedem Kommando seitens des Client eine Kennung vorangestellt, auch "Tag" genannt, zum Beispiel "X001" für den ersten Befehl und "X002" für den zweiten. Der Server kann dem Client auf mehrere Arten antworten: Mit einem Plus-Zeichen am Anfang der Zeile antwortet der Server, wenn er weitere Informationen zu dem vorangegangenen Kommando erwartet. Er signalisiert dem Client gleichzeitig seine Empfangsbereitschaft. Steht dagegen ein Sternchen am Anfang der Zeile, sendet der Server weitere Informationen an den Client zurück. Die Antwort eines Servers kennzeichnet den Erfolg oder Fehler eines Kommandos: OK (Kommando erfolgreich ausgeführt), NO (Fehler beim Ausführen) oder BAD (Protokoll-Fehler: Kommando unbekannt oder Syntax-Fehler). Die Antwort enthält denselben Tag wie das zugehörige Kommando, damit der Client erkennt, welcher Response welchem Befehl gilt. Wie bei POP durchläuft eine IMAP-Verbindung mehrere Sitzungsstufen: Non-Authenticated State: Unmittelbar nach dem Aufbau der Verbindung. Der User muß sich gegenüber dem Server identifizieren. Authenticated State: Der User hat sich erfolgreich identifiziert und muß nun eine Mailbox auswählen. Selected State: Eine Mailbox wurde ausgewählt. Mailbox und Mails lassen sich bearbeiten. Logout State: Die Verbindung wird beendet; der Server führt noch anstehende Tätigkeiten aus. Der "Non-Authenticated State" stellt mehrere Möglichkeiten zur Identifizierung des Anwenders zur Verfügung. Es gibt in diesem Zusatand folgende Kommandos: Kommandos im "Non-Authenticated State" Kommando Argument AUTHENTICATE AuthentifizierungsMechanismus Beschreibung Das Kommando bestimmt den AuthentifizierungsMechanismus, zum Beispiel "Kerberos" oder "S/Key". Details zu den Authentifizierungs- Mechanismen finden Sie in RFC1731. LOGIN Name/Passwort Identifiziert den Anwender über Benutzername und Passwort. Beispiel für eine Authentifizierung mit dem LOGIN-Kommando: Client: X001 LOGIN PLATE XYZ1230 Server: X001 OK LOGIN completed Im "Authenticated State" hat sich der User authentifiziert und muß nun eine Mailbox auswählen, welche in dieser Sitzung bearbeitet werden soll. Dazu stehen unter anderem folgende Kommandos zur Verfügung: Wichtige Kommandos im "Authenticated State" Kommando Argument Beschreibung SELECT Mailbox-Name Wählt eine Mailbox zur weiteren Bearbeitung aus. Als erfolgreiche Antwort sendet der Client Informationen zur gewählten Mailbox, wie beispielweise die Anzahl der gespeicherten Nachrichten. EXAMINE Mailbox-Name Identisch mit dem Kommando SELECT. Jedoch wird die Mailbox als "read-only" ausgewählt, es sind keine dauerhaften Änderungen möglich. CREATE Mailbox-Name Erstellt eine Mailbox mit dem als Argument übergebenen Namen. DELETE Mailbox-Name Löscht die als Argument übergebene Mailbox. RENAME Bestehender Mailbox-Name / Neuer MailboxName Ändert den Namen einer Mailbox. Beispiel: Löschen einer Mailbox: Client: X324 DELETE TRALALA Server: X234 OK DELETE completed Im "Selected State" gibt es viele Kommandos zum Bearbeiten einer Mailbox: Wichtige Kommandos im "Selected State" Kommando Argument Beschreibung CLOSE Entfernt alle zum Löschen - gekennzeichneten Mails und setzt die Verbindung in den Authenticated State zurück. EXPUNGE - Entfernt alle zum Löschen gekennzeichneten Mails, die Verbindung bleibt im Selected State. SEARCH ein oder mehrere Suchkriterien Erlaubt die Suche nach bestimmten Nachrichten in der aktuellen Mailbox. Das Kommando unterstützt logische Verknüpfungen. FETCH Gewünschte Daten einer Nachricht Bewirkt das Senden von Daten einer Nachricht vom Server zum Client. Beispiel: Suchen einer Nachricht. Ergebnis sind die Nummern der entsprechenden Mails: Client: X246 SEARCH SINCE 1-NOV-2001 FROM "ADAM" Server: * SEARCH 2 84 882 Server: X246 OK SEARCH completed Beendet der Client mit dem Kommando LOGOUT die Verbindung, wechselt der Server in den "Update State" und führt noch anstehende Arbeiten aus. Es gibt eine Reihe weiterer Befehle im "Authenticated State" und "Selected State", die in RFC2060 nachzulesen sind. Im abschließenden Beispiel sehen Sie den Ablauf einer IMAP4-Verbindung. Der Client identifiziert sich gegenüber dem Server, wählt eine Mailbox aus und lädt den Header einer Nachricht herunter. Server: Client: Server: Client: Server: Server: Server: Server: Server: Server: Client: Server: Server: Server: Server: Server: Server: Server: Server: Server: Server: Client: Server: Server: * OK IMAP4 Service Ready X001 login plate XYZ1230 X001 OK LOGIN completed X002 select inbox * 12 EXISTS * FLAGS (\Answered \Flagged \Deleted \Seen \Draft) * 2 RECENT * OK [UNSEEN 11] Message 11 is first new message * OK [UIDVALIDITY 2905753845] is first new message X002 OK [READ-WRITE] SELECT completed X003 fetch 9 rfc822.header * 9 FETCH (RFC822.HEADER {346} Date: mon, 11 Mar 2002 09:23:25 -0100 (MET) From: plate <[email protected]> Subject: Schulung Netzwerke am Donnerstag To: <[email protected]> Message-Id: <[email protected]> Mime-Version: 1.0 Content-Type: TEXT/PLAIN; CHARSET=iso-8859-1 ) X003 OK FETCH completed X004 LOGOUT * BYE IMAP4 server terminating connection X004 OK LOGOUT completed Nachdem der Mail-Client über TCP eine Verbindung zum SMTP-Server aufgebaut hat, wartet er auf einen Begrüßungstext des Servers. Im nächsten Schritt identifiziert sich der Client mit dem Kommando LOGIN, als Argument übergibt er den Benutzernamen und das Passwort. Nach dem Auswählen der Mailbox sendet der Server einige Informationen, z. B. die Anzahl der ungelesenen Nachrichten. Mit dem Kommando FETCH fordert der Client den Header der Nachricht 9 an. LOGOUT beendet die Verbindung. Bei Inbetriebnahme eines POP- bzw. IMAP-Clients (Outlook, Pegasus Mail, Netscape) muß dieser zunächst konfiguriert werden. Wichtige Angaben sind: Domainname des POP- bzw. IMAP-Servers, d.h. Systems, auf dem die eigentliche Mailbox liegt. Benutzernummer auf diesem System Paßwort für diese Benutzernummer für den Versand: Angabe des SMTP-Mail-Relayhosts POP/IMAP dient nur zum Abholen der Post vom Mail-Server. Der Versand von E-Mail vom PC oder Mac aus geschieht ganz normal mit SMTP (Simple Mail Transfer Protocol). FTP Ein weiterer zentraler Dienst in einem Intranet, der besonders dem Transport von Dateien auf andere Systeme dient, ist das File-Transfer-Protokoll. Die Besonderheit des Protokolls liegt in den getrennten Kanälen für die Daten und die Steuerung. Im RFC 959 ist für FTP TCP-Port 20 als Steuerungskanal und TCP-Port 21 als Datenkanal festgelegt. FTP verwendet als Transportprotokoll immer TCP, da dieses bereits einen sicheren Datentransfer garantiert und die FTP-Software sich nicht darum zu kümmern braucht. FTP besitzt eine eigene Kommandooberfläche, die interaktiv bedient wird. Der Aufruf dieses Filetransferprogrammes erfolgt durch das Kommando ftp. Die Vorteile von FTP liegen in den effizienten Verfahren zur Übertragung von Dateien beliebigen Formats und der Tatsache, daß der Zugriff seitens beliebiger Internet-Teilnehmern möglich ist. Andererseits kann bei größeren Archiven schnell die übersicht verlorengehen, wenn die Datenbestände nicht vernünftig sortiert sind. Bei umfangreichen Dateibäumen ist hingegen die Navigation durch die Verzeichnisse eine zeitraubende Angelegenheit. Es werden weiterhin zwei Betriebsmodi unterschieden: Benutzerspezifisches FTP Anonymous-FTP In beiden Fällen ist es möglich, Verzeichnisse einzusehen und zu wechseln, sowie Dateien zu empfangen und zu senden. Der Unterschied liegt in den Privilegien, die ein Benutzer besitzt. Während im ersten Fall der User eine Zugangsberechtigung zum System benötigt, so verfügt ein Gastzugang nur über eine eingeschränkte Sicht auf den Datenbereich des Servers, was als einfacher Sicherheitsmechanismus anzusehen ist. Der Kommandoaufruf des FTP-Kommandos lautet ftp [ -v ] [ -d ] [ -i ] [ -n ] [ -g ] [ host ] Wird beim Programmaufruf der gewünschte Kommunikationspartner (host) mit angegeben, so wird sofort versucht, eine Verbindung zu diesem Rechensystem aufzubauen. Ist der Versuch erfolglos, so wird in den Kommandomodus umgeschaltet. Der Prompt "ftp>" erscheint immer auf dem Bildschirm, wenn ftp-Kommandos eingegeben werden können. ftp verfügt über einen help-Mechanismus, über den sämtliche auf dem jeweiligen System verfügbare Kommandos mit Kurzerklärungen abfragbar sind. Nachfolgend werden wesentliche Kommandos nach Funktionalität gruppiert vorgestellt. Kommandos können soweit verkürzt eingegeben werden, als sie noch eindeutig erkennbar sind. Enthalten Kommandoargumente "Blanks", so sind die Argumente beidseitig mit Hochkommas eingeschlossen einzugeben. Nicht alle ftp-Implementierungen unterstützen alle ftp-Kommandos. help [ kommando ] zeigt kurze Informationen zu dem angegebenen Kommando. Wird das Kommando weggelassen, zeigt dieser Aufruf eine Liste der zulässigen Kommandos. open host Öffne einer Verbindung zu einem fernen Host. Je nach angewähltem System werden Benutzerkennung und Passwort abgefragt. user user-name [ password ] Eingabe von Benutzerkennung und Passwort. ! Aufruf einer (eingeschränkten) Shell auf dem lokalen System. Für Dateiübertragung relevante Kommandos wie mkdir, mv, cp, etc sind absetzbar. Verlassen wird diese Shell mit "exit". lcd pwd Anzeige des aktuellen Directories auf dem entfernten System. cd remote-directory Wahl des aktuellen Directories auf dem entfernten System. cdup [directory ] Wahl des lokalen Directories für die Dateiübertragung. Wechsel in das nächsthöhere Directory auf dem entfernten System. dir [ remote-directory [ local-file ] ] ls [ remote-directory [ local-file ] ] Ohne Optionen erfolgt eine Anzeige der Einträge des entfernten aktuellen Directories. Dabei liefert dir ausführliche und ls eine knappe Information bezüglich des Directory-Inhalts. Bei Angabe des remote-directory erfolgt die Anzeige der Einträge des entfernten Directories. Wird local-file angegeben, erfolgt eine Umlenkung der DirectoryAnzeige in die Datei local-file auf dem lokalen System. mdir remote-files [ local-file ] mls remote-files [ local-file ] Anzeige von Dateien aus dem entfernten aktuellen Directory und Abspeicherung in eine lokale Datei. mkdir directory-name Einrichten eines neuen Directories directory-name auf dem entfernten System. rmdir directory-name löscht das Directory directory-name auf dem entfernten System. rename [ from ] [ to ] Umbenennen einer Datei auf dem entfernten System von from nach to. delete remote-file Löschen der Datei remote-file auf dem entfernten System. mdelete remote-files Löschen mehrerer Dateien remote-files auf dem entfernten System. put local-file [ remote-file ] send local-file [ remote-file ] Dateiübertragung der Datei local-file vom lokalen zum entfernten System. Wird remote-file nicht angegeben, so wird auch auf dem Zielsystem der Dateiname local-file verwendet. append local-file [ remote-file ] überträgt die Datei local-file vom lokalen System an das entfernte System und hängt diese am Ende der Datei remote-file an. Wurde remote-file nicht angegeben, wird die Datei ans Ende der Datei local-file auf dem entfernten System angehängt. mput local-files Dateiübertragung einer Dateigruppe namensgleich vom lokalen zum entfernten System. get remote-file [ local-file ] recv remote-file [ local-file ] Dateiübertragung einer Datei remote-file vom entfernten System zum lokalen System. Wird local-file nicht mitangegeben, so erhält die Datei auch auf dem lokalen System den Dateiname remote-file. mget ascii type ascii remote-files Dateiübertragung einer Dateigruppe namensgleich vom entfernten zum lokalen System. Die Dateiübertragung findet im ASCII-Code statt. Gegebenfalls werden bei Binärdateien Zeichen verändert (z. B. die Zeilenendedarstellung ans Zielsystem angepaßt) oder Zeichen verfälscht. binary type image type binary Die Dateiübertragung findet transparent statt. case Mit diesem Schalter läßt sich einstellen, ob Dateinamen beim Empfangen (get, recv, mget) von Großbuchstaben nach Kleinbuchstaben übersetzt werden sollen. glob Mit diesem Schalter läßt sich einstellen, ob bei den Kommandos mdelete, mget und mput bei Dateinamen, die Metazeichen (*?[]~{}) enthalten, diese Metazeichen übertragen werden oder nicht. ("off" = keine Metazeichenbehandlung). ntrans [ inchars [ outchars ] ] Definition und Aktivierung einer Übersetzungstabelle für Dateinamen, wenn beim Dateiübertragungsauftrag (Senden und Empfangen) keine Zieldateinamen angegeben werden. Zeichen eines Dateinamens, die in inchars zu finden sind, werden durch das positionsgleiche Zeichen in outchars übersetzt. Ist inchars länger als outchars, so werden die korrespondenzlosen Zeichen von inchars aus dem Zieldateinamen entfernt. prompt Mit diesem Zeichen wird bei Mehrdateienübertragung gesteuert, ob jede zu übertragende Datei extra quittiert werden muß oder nicht. verbose Wenn der "verbose"-Modus eingeschaltet ist, erhält man für jede übertragene Datei den Dateinamen auf dem lokalen und entfernten Rechner, sowie die Datenmenge und die dafür benötigte Übertragungszeit angezeigt. bell Dieser Schalter bewirkt, daß je nach Stellung am Ende jedes Dateiübertragungsauftrages ein akustisches Signal ertönt oder nicht. status Anzeige der aktuellen logischen Schalterstellungen sowie des Verbindungszustandes. close disconnect Beendigung einer aktiven Verbindung. quit Beendigung des Programmes ftp. bye Beendigung einer aktiven Sitzung und des Programmes ftp. Die optionalen Parameter beim ftp-Kommando setzen logische Schalter für den ftpProgrammlauf. Im Kommandomodus sind die Einstellungen jederzeit wieder änderbar. -v -d -i verbose-Schalter einschalten. debug-Schalter einschalten. interactive-Modus für Mehrdateiübertragung einschalten. -n -g verhindert, daß FTP zum Beginn der Sitzung einen Login-Versuch unternimmt. glob-Schalter einschalten. Die Datei-Übertragung wird durch die Terminal "interrupt"-Taste (üblicherweise Ctrl-C) abgebrochen, was einen sofortigen Abbruch zur Folge haben soll. Nicht alle Kommunikationspartner verstehen die Abbruchaufforderung, wodurch dennoch die gesamte Datei übertragen wird. Dateinamen, die als Argumente von FTP-Kommandos Verwendung finden, werden wie folgt bearbeitet: Ist "file globbing" eingeschaltet, werden bei den Kommandos mget, mput und mdelete die Namen lokaler Dateien folgendermaß behandelt: Der * steht für eine beliebige Anzahl (auch Null) von Zeichen. Das ?steht für ein einziges beliebiges Zeichen. Wird im Dateinamen eine Zeichenfolge angetroffen, die zwischen eckigen Klammern oder zwischen geschweiften Klammern steht, so sind alle Dateinamen zutreffend, die an dieser Stelle ein einziges beliebiges Zeichen aus der Zeichenfolge innerhalb der Klammern enthalten. Steht die Zeichenfolge ~/ (Tilde, Schrägstrich) am Beginn des Dateinamens, so wird sie durch den Home-Directory-Pfad ersetzt. Das Zeichen ~, dem eine Benutzerkennung folgt, wird durch den Home-Directory-Pfad dieser Benutzerkennung ersetzt. Kommandos und Protokoll-Anweisungen: ftp-Client FTP-Protokoll Aufgabe login USER username anmelden PASS password help help command HELP Hilfe HELP command SYST Server-Identifikation STAT Transfer-Status STAT path wie LIST, über control-Verbindung dir path LIST path Kataloginhalt zeigen, ausführlich ls path NLST path Dateinamen zeigen delete path DELE path Datei löschen rename from to RNFR from-path Datei umbenennen RNTO to-path pwd PWD Arbeitskatalog zeigen cd path CWD path Katalog wechseln mkdir path MKD path Katalog erzeugen rmdir path RMD path Katalog löschen ascii TYPE A N Textübertragung (Voreinstellung) status binary TYPE I Datenübertragung PORT h,h,h,h,p,p Port des Klienten für dataVerbindung get remote-path RETR path Datei zum Klienten übertragen put local-path STOR path Datei zum Server übertragen append localpath APPE path an Datei auf Server anfügen interrupt ABOR _bertragung abbrechen quit QUIT Verbindung beenden Beispiel Benutzereingaben sind fett gedruckt. ftp multimedia.ee.fhm.edu Verbindung mit multimedia.ee.fhm.edu. 220 ProFTPD 1.2.2rc2 Server [multimedia.e-technik.fh-muenchen.de] Benutzer (multimedia.ee.fhm.edu:(none)): plate 331 Password required for plate. Kennwort: 230 User plate logged in. Ftp> ls 200 PORT command successful. 150 Opening ASCII mode data connection for file list. tmp Mail bin 226 Transfer complete. Ftp: 36 Bytes empfangen in 0.00Sekunden 36000.00KB/Sek. Ftp> cd tmp 250 CWD command successful. Ftp> lcd E:\www-netzmafia\skripten\perl Lokales Verzeichnis jetzt E:\www-netzmafia\skripten\perl. Ftp> cd /opt/www/skripten/perl 250 CWD command successful. Ftp> put perl3.html 200 PORT command successful. 150 Opening ASCII mode data connection for perl3.html. 226 Transfer complete. Ftp: 77604 Bytes gesendet in 9.17Sekunden 8.46KB/Sek. Ftp> put perl4.html 200 PORT command successful. 150 Opening ASCII mode data connection for perl4.html. 226 Transfer complete. Ftp: 30930 Bytes gesendet in 3.24Sekunden 9.55KB/Sek. Ftp> quit Active und Passive FTP Beim FTP-Zugriff werden zwei Modi unterschieden, active und passive FTP. Beim active mode FTP öffnet der Client eine Verbindung von einem unprivilegierten Port (Portnummer N > 1023) zum Kommandoport 21 des FTP-Servers. Dann spezifiziert der Client den Port N+1 als Datenport (PORT-Kommando). Der Server schickt seine Daten an den spezifizierten Port des Client von seinem Port 20 aus. Aus Sicht eines vorgeschalteten Firewall-Systems müssen demnach folgende Ports offen sein: FTP Serverport 21 von allen Ports ausserhalb (Client initiert die Verbindung) FTP Serverport 21 an Ports > 1023 (Server-Antwort auf Kommandos) FTP Serverport 20 an Ports > 1023 (Datenverbindung, Aufbau von Serverseite) FTP Serverport 20 von Ports > 1023 (Datenverbindung, Bestätigung vom Client) Sperrt ein Firewall im Netz des Client den Verbindungsaufbau von außen, ist keine Datenübertragung möglich (wohl aber die Kommandoverbindung). Zur Lösung dieses Problems kann der FTP-Client mit dem Befehl PASV in das passive mode FTP umgeschaltet werden. Der Client initiert nun Kommando- und Datenverbindung. Nach dem Umschalten in den passiven Modus, bietet der Server einen unprivilegierten Port > 1023 an, den der Client dann für den Datentransfer ansprechen kann. Aus Sicht eines vorgeschalteten Firewall-Systems müssen demnach folgende Ports offen sein: FTP Serverport 21 von allen Ports ausserhalb (Client initiert die Verbindung) FTP Serverport 21 an Ports > 1023 (Server-Antwort auf Kommandos) FTP Serverport > 1023 von überall (Datenverbindung, Aufbau von Clientseite) FTP Serverport > 1023 an Ports > 1023 (Datenverbindung, Bestätigung vom Server) Wenn auch nun die Probleme auf der Cleintseite gelöst sind, sind sie nun auf der Serverseite vorhanden. Der FTP-Server muß im Passivmodus alle Verbindungen von anderen Systemen auf Ports > 1023 zulassen. Um hier die Sicherheit zu verbessern, kann man bei etlichen Serverprogrammen den Portbereich per Konfiguration einschränken. Manche FTP-Clients können nicht in den Passivmodus schalten, es bleibt dann nur die Wahl eines anderen Programms. Dagegen können die Webbrowser im Passivmodus arbeiten (und tun dies meist per Default). HTTP - Hypertext Transfer Protocol HTTP ist ein Protokoll der Applikationsschicht, das alle Möglichkeiten der Übertragung von Hypermedia-Informationen bietet. HTTP ist nicht Hardware- oder Betriebssystemabhängig. Seit 1990 ist dieses Protokoll im Einsatz und wird derzeit meist in der Version 'HTTP/1.1' (seltener 1.0) verwendet. Heutige Informationssysteme benötigen weit mehr Funktionen als das einfache Senden und Empfangen von Nachrichten. Die Entwicklung von HTTP ist nicht abgeschlossen. Es bietet die Möglichkeit, weitere Funktionalität zu entwickeln. Die Adressierung von Ressourcen erfolgt dabei mittels URls, die zum einen Orte (URL) oder Bezeichner (URN) sein können. Diese zeigen gleichzeitig den gewünschten Übertragungsmechanismus an. Nachrichten werden in der gleichen Form übertragen, wie sie auch bei normalem Mail-Transport verwandt werden. Dabei kommt oft MIME zum Einsatz. HTTP/1.1 ist auch für den Zugriff auf Server mit anderen Protokollen geeignet. Hauptfunktionen des HTTP Die grundlegende Funktionsweise des HTTP folgt dem alten Frage-Antwort-Spiel. Ein fragendes Programm (WWW-Browser) öffnet eine Verbindung zu einem Programm, welches auf Fragen wartet (WWW-Server) und sendet ihm die Anfrage zu. Die Anfrage enthält, die Fragemethode, die URL, die Protokollversion, Informationen über den Dienst und möglicherweise etwas Inhalt in Form einer Nachricht. Der Server antwortet auf diese Frage mit einer Statusmeldung, auf die eine MIME-artige Nachricht folgt, die Informationen über den Server und eventuell schon das gefragte Dokument enthält. Direkt nach Beantwortung der Frage wird die Verbindung wieder abgebaut. So soll erreicht werden, daß die Leitungskapazitäten geschont werden. Derzeit finden HTTP-Verbindungen meist per TCP/IP statt. Das soll aber nicht heißen, daß HTTP nicht auch auf anderen Netzwerkprotokollen aufsetzen kann. Beide Seiten müssen auch dazu in der Lage sein, auf den vorzeitigen Abbruch der Kommunikation durch die andere Seite zu reagieren. Vorzeitiger Abbruch kann durch Aktionen von Benutzern, Programmfehler oder Überschreiten der Antwortzeiten ausgelöst werden. Durch den Abbruch der Verbindung durch eine der beiden Seiten wird der gesamte Vorgang abgebrochen. Struktur der HTTP-Botschaften Jede Kommunikation zwischen zwei WWW-Programmen besteht aus HTTP-Botschaften, die in Form von Anfragen und Antworten zwischen Client und Server ausgetauscht werden. Eine HTTP-Botschaft (HTTP-Message) kann entweder ein Simple-Request, eine Simple-Response, ein Full-Request oder eine Full-Response sein. Die beiden zuerst genannten Botschaftstypen gehören zum HTTP/0.9-Standard. Die beiden letzten Typen gehören schon zum HTTP/1.0. Allgemeinfelder des Botschaftskopfes Jedes der Felder eines HTTP-Botschaftenkopfes weist die gleiche Struktur auf. Im RFC 822 wurde definiert, daß jedes Feld mit einem Feldnamen und dem Feldinhalt erscheint. Auf den Feldnamen muß unbedingt ein Doppelpunkt folgen. Der Feldname kann alle Zeichen außer dem Doppelpunkt und der Escape-Sequenzen enthalten. Allgemeinfelder enthalten Informationen wie das Datum, die Message-ID, die verwendete MIME-Version und ein 'forwarded'-Feld, das angibt, ob das Dokument eigentlich von einer anderen Adresse stammt. Anfragen Bei Anfragen wird zwischen einfachen und komplexen Anfragen unterschieden. Eine einfache Anfrage besteht nur aus einer Zeile, die angibt, welche Information gewünscht wird. Ein Beispiel: GET http://www.netzmafia.de/index.html Dabei wird nur die Methode (GET) und die URL des Dokumentes angegeben. Es werden keine weiteren Felder erwartet und vom adressierten Server wird auch nur ein ganz einfacher Antwortkopf zurückgesendet. Es kann aber auch eine komplexere Anfrage erzeugt werden. Dabei muß die Zeile aus dem obigen Beispiel noch die Version des HTT-Protokolls angehängt werden. In einem Beispiel würde das folgendermaßen aussehen: GET http://www.netzmafia.de/index.html HTTP/1.0 Die Anfügung der HTTP-Version ist also der ganze Unterschied zwischen einer einfachen und einer komplexen HTTP-Anfrage. Der Unterschied zwischen einfacher und komplexer Anfrage wird aus Gründen der Kompatibilität gemacht. Ein Browser, der noch das alte HTTP/0.9 implementiert hat, wird nur eine einfache Anfrage losschicken können. Ein neuer Server muß dann eine Antwort, auch im Format des HTTP/0.9 zurücksenden. Felder einer komplexen Anfrage Um die Anfrage näher zu spezifizieren, wurden weitere Felder eingeführt. In den Anfragefeldern stellen z. B. Informationen über den Server und den benutzten Browser. Weiterhin kann man dort Informationen über den Gegenstand der Übertragung bekommen. In der folgenden kurzen Übersicht sind alle möglichen Felder einer Anfrage aufgeführt. Anfragezeile (Request-Line) Informationsanfrage wie oben geschildert. Die zugehörigen Methoden folgen im nächsten Abschnitt. Allgemeiner Kopf (General-Header) Im allgemeinen Kopf werden allgemeine Informationen über die Nachricht übermittelt. Anfragekopf (Request-Header) In diesen Feldern kann der Browser weitere Informationen über die Anfrage und über den Browser selbst absetzen. Diese Felder sind optional und müssen nicht erscheinen. Gegenstandskopf (Entity-Header) In diesem Feld werden Einträge übermittelt, welche den Inhalt der Nachricht näher beschreiben. Gegenstand der Nachricht (Entity-Body) Vor dem eigentlichen Inhalt muß definitionsgemäß eine Leerzeile stehen. Der Inhalt ist dann in dem Format codiert, das in den Gegenstandsfeldern definiert wurde (meist HTML). Fragemethoden Das an erster Stelle in einer Anfragezeile (Request-Line) stehende Wort beschreibt die Methode, die mit der nachfolgenden URL angewendet werden soll. Die Methodennamen müssen dabei immer groß geschrieben werden. Der Entwurf des HTTP-Standards erlaubt leicht eine Erweiterung. Kommen wir nun zur Bedeutung der einzelnen Methoden. GET Diese Methode gibt an, daß alle Informationen, die mit der nachfolgenden URL beschrieben werden, zum rufenden Client geholt werden sollen. Zeigt die URL auf ein Programm (CGI-Script), dann soll dieses Programm gestartet werden und die produzierten Daten liefern. Handelt es sich bei dem referenzierten Datum um eine Datei, dann soll diese übertragen werden. Beispiel: GET http://www.netzmafia.de/index.html HEAD Diese Methode ist identisch zur Methode GET. Die Antworten unterscheiden sich nur darin, daß bei der Methode GET ein komplettes Dokument übertragen wird und bei HEAD nur die Meta-Informationen gesendet werden. Dies ist nützlich, um Links auszuprobieren oder um die Erreichbarkeit von Dokumenten zu testen. Bei Anwendung der Methode HEAD wird der Kopf des referenzierten HTML-Dokuments nach 'link' und 'meta' Elementen durchsucht. POST Diese Methode wird hauptsächlich für größere Datenmengen verwandt. Man stelle sich vor, ein HTML-Dokument enthält ein komplexes Formular. Per POST wird dem Server angezeigt, daß er auch die Daten im Körper der Botschaft bearbeiten soll. Verwendet, wird es hauptsächlich bei Datenblöcken, die zu einem verarbeitenden Programm übertragen werden. Die wirkliche Funktion, die durch POST auf dem adressierten Rechner angestoßen wird, wird durch die URL bestimmt. Meist, sind es CGI-Scripte, die den Inhalt der Nachricht verarbeiten. PUT Die mit der Methode PUT übertragenen Daten sollen unter der angegeben URL gespeichert werden. Das soll ermöglichen, daß WWW-Seiten auch ohne direkten Zugriff auf den anbietenden Rechner erstellt und angeboten werden können. Wird ein Dokument mit der Methode PUT übertragen, dann wird unter dieser Adresse ein Dokument mit dem übertragenen Inhalt angelegt. War die Aktion erfolgreich, wird die Meldung '200 created' zurückgegeben. Existiert unter dieser Adresse schon ein Dokument, dann wird dieses überschrieben. War auch diese Aktion erfolgreich, dann wird nur '200 OK' zurückgemeldet. Der Hauptunterschied zwischen POST und PUT besteht darin, daß bei POST die URL eine Adresse eines Programmes referenziert, das mit den Daten umgehen kann. Bei PUT hingegen wird die URL als neue Adresse des Dokumentes gesehen, das gerade übertragen wurde. Meist jedoch ist die Methode PUT ausgeschaltet, weil ServerBetreiber befürchten, daß die Sicherheit, des Systems dadurch nicht mehr gewährleistet ist. DELETE Mit dieser Methode kann der Inhalt einer URI (Unified Resource Identifier) gelöscht werden. Diese Methode ist neben der Methode PUT eine der gefährlichsten. Wenn Server nicht richtig konfiguriert wurden, dann kann es mitunter vorkommen, daß alle Welt die Berechtigung zum Löschen von Ressourcen hat. LINK Mit dieser Methode können eine oder mehrere Verbindungen zwischen verschiedenen Dokumenten erzeugt werden. Es werden dabei keine Dokumente erstellt, sondern nur schon bestehende miteinander verbunden. UNLINK entfernt Verbindungen zwischen verschieden Ressourcen. Dabei wird nur die Verbindung gelöscht. Die Dokumente existieren trotzdem weiter. Mit diesen Methoden kann man alle möglichen Ressourcen erreichen, welche die verschiedenen Server zur Verfügung stellen. Die folgenden Felder beschreiben nun die Fragen etwas genauer. Es kann zum Beispiel verhindert werden, daß ungewollt umfangreiche Bilder übermittelt werden, wenn dies nicht gewünscht wird. Beispiel einer Konversation Benutzereingaben werden kursiv geschrieben. Das lokale System ist eine Windows-Kiste. plate@lx3-lbs:~ > telnet www.netzmafia.de 80 Trying 141.39.253.210... Connected to www.netzmafia.de. Escape character is '^]'. GET /index.html HTTP/1.0 HTTP/1.1 200 OK Date: Mon, 18 Sep 2000 13:59:58 GMT Server: Apache/1.3.6 (Unix) (SuSE/Linux) Last-Modified: Tue, 29 Aug 2000 08:08:58 GMT ETag: "134015-8e8-39ab6f9a" Accept-Ranges: bytes Content-Length: 2280 Connection: close Content-Type: text/html <HTML> <HEAD> <TITLE>Netzmafia</TITLE> </HEAD> <body bgcolor="#000000" text="#FFFFCC" link="#FFCC00" alink="#FF0000" vlink="#FF9900"> ... </BODY> </HTML> Connection closed by foreign host. Neues Kapitel Grundlagen Computernetze Einführung Der Zusammenschluß von diversen Computern und Peripheriegeräten zu Netzen gewinnt immer stärkere Bedeutung. Netze (Netzwerke) sind Verbindungssysteme, an die mehrere Teilnehmer zum Zweck der Datenkommunikation angeschlossen sind. Lokale Netze (LAN, Local Area Network) sind Netze in einem örtlich begrenzten Bereich (Raum, Gebäude, Gelände), der sich im Besitz einer einzigen Organisation (z. B. Firma) befindet. Die Verbindung mehrerer LAN-Segmente erfolgt über Koppelelemente (Hubs, Switches, Bridges, Router, etc.). Weitverkehrsnetze (WAN, Wide Area Network) sind Netze, die über weitere Entfernungen reichen (Stadt, Land, Welt). Die einzelnen Netze können über Router oder Gateways miteinander gekoppelt werden und dabei auch öffentliche Kommunikationsnetze nutzen. Jegliche Kommunikation zwischen zwei Partnern ist an bestimmte Voraussetzungen gebunden. Zum einen muß die Hardware der Partner und der Datenübertragungseinrichtungen über kompatible Schnittstellen verfügen und zum anderen müssen Vereinbarungen über die Art und Weise des Informationsaustausch getroffen werden (Protokolle). Zur Festlegung von Schnittstellen und Protokollen gibt es zahlreiche Standards (nationale und internationale Normen, Firmenstandards). Wie definiert die ISO (International Standardisation Organisation) ein LAN? "Ein lokales Netz (LAN) ist ein Netz für bitserielle Übertragung von Informationen zwischen untereinander verbundenenen unabhängigen Geräten. Das Netz unterliegt vollständig der Zuständigkeit des Anwenders und ist auf ein Grundstück begrenzt." Es werden also nicht nur Computer miteinander vernetzt, sondern auch andere Geräte wie Drucker, Monitore, Massenspeicher, Kontrollgeräte, Steuerungen, Fernkopierer und anderes. Der Unterschied eines LAN zu anderen Netzen wird von der ISO durch folgende Eigenschaften festgelegt: begrenzte Ausdehnung, hohe Datenübertragungsrate, geringe Fehlerrate, dezentrale Steuerung, wahlfreier Zugriff und die Übertragung von Datenblöcken. Kern der Datenkommunikation ist der Transport der Daten, also die Datenübertragung von einem Sender mittels eines Übertragungskanals zu einem Empfänger. Die zu übertragenden Daten werden im Rhythmus eines Sendetaktes auf das Übertragungsmedium gegeben. Damit die Information korrekt wiedergewonnen werden kann, muß am Empfangsort eine Abtastung der Signale zum richtigen Zeitpunkt erfolgen. Normalerweise verwendet man dazu eine Codierung, die eine Rückgewinnung des Taktes aus dem Signal erlaubt. Auf diese Weise kann sich der Empfänger jederzeit auf den Takt des Senders synchronisieren. ISO-Referenzmodell für die Datenkommunikation Eine wesentliche Forderung in der Datenfernverarbeitung ist das Zusammenschalten unterschiedlicher Stationen (verschiedener Hersteller). Dazu ist eine Schematisierung und Gliederung des Kommunikationsprozesses in wohldefinierte, hierarchische Ebenen (Schichten, Layers) notwendig. Es erfolgt eine Zuordnung der einzelnen Kommunikationsfunktionen zu bestimmten logischen Schichten. Wird in einer Schicht eine Anpassung (Änderung, Erweiterung) vorgenommen, bleiben die anderen Ebenen davon unberührt. ISO (International Standards Organisation) hat für offene Netze ein 7-Schicht-Modell, das OSI-Modell (OSI = Open Systems Interconnection), geschaffen. Dieses Modell liegt nahezu allen Kommunikationsgeräten und -Verfahren zugrunde (zur Not werden vorhandene Protokolle in das Schema von ISO/OSI gepreßt). Im OSI-Modell werden die grundsätzlichen Funktionen der einzelnen Ebenen und die Schnittstellen zwischen den Ebenen festgelegt. So ergibt sich eine universell anwendbare logische Struktur für alle Anforderungen der Datenkommunikation verschiedener Systeme. Das OSI-Model liefert Eine Basis für die Interpretation existierender Systeme und Protokolle in der Schichten-Perspektive (wichtig bei Änderungen). Eine Referenz für die Entwicklung neuer Kommunikationsverfahren und für die Definition neuer Protokolle, also eine Grundlage für kompatible Protokolle. Wesensmerkmale der hierarchischen Schichtenstruktur bei Rechnernetzen sind: Das Gesamtsystem wird in eine geordnete Menge von Teilsystemen gegliedert. Teilsysteme des gleichen Ranges bilden eine Schicht (engl. Layer). Die einzelnen Schichten liegen entsprechend ihrer hierarchischen Rangordnung übereinander. Eine hierarchisch tieferliegende Schicht dient der Erfüllung der Kommunikationsfunktion der jeweils übergeordneten Schicht. Jede Schicht stellt definierte Dienste bereit. Diese Dienste realisieren bestimmte Kommunikations- und Steuerungsaufgaben. Die einzelnen Schichten stellen somit definierte Schnittstellen zu ihren Nachbarn bereit (Schicht 4 hat z. B. Schnittstellen zu den Schichten 3 und 5). Die Kommunikation findet nur über diese Schnittstellen statt (in der Grafik senkrecht). Die rein logische Kommunikation zwischen den beteiligten Stationen A und B erfolgt jedoch auf der Basis gleicher Schichten (in der Grafik waagrecht, mit '.' gekennzeichnet). Lediglich bei Schicht 1 handelt es sich um eine physikalische Verbindung. Aufgabe der einzelnen Schichten: Die Schichten 1 - 4 werden der Transportfunktion zugeordnet Die Schichten 5 - 7 werden den Anwenderfunktionen zugeordnet Zunächst eine kurze Beschreibung der einzelnen Schichten. Dabei ist auch der zur Schicht gehörende Datenblock gezeigt. Jede Schicht kann (muß aber nicht) die Daten mit einem eigenen Header (bzw. Datenrahmen) versehen, der zur Kommunikationssteuerung auf dieser Schicht dient. Der Datenblock einer Schicht (mit Rahmen) wird von der Schicht als reine Nutzdaten betrachtet, sie kann so auch an dem Header der übergeorneten Schicht nichts ändern. 7. Anwendungs-Schicht (Application) Verbindung zum Anwenderprogramm und Dialog mit den Programmen. Eine Standardisierung ist hier noch in weiter Ferne. Es gibt aber eine Reihe von grundsätzlichen Diensten, die angeboten werden müssen: o Austausch von Dateien, d. h. Dateizugriffsdienste über das Netz. Für das eigentliche Anwenderprogramm ist nicht erkennbar, ob auf eine Datei lokal oder über das Netz zugegriffen wird. o Verwaltungsprotokolle für Benutzerzugang, Dateizugriffsrechte, elektronische Post, usw. o Remote Job Entry, d. h. absetzen von Rechenaufträgen an entfernte Systeme o o Virtuelle Terminals, d. h. Umleitung der Ein-/Ausgabe eines Programms auf dem fernen Rechner an den lokalen Bildschirm und die lokale Tastatur. Message-Handling-Systeme: Austausch und Verwaltung von Mitteilungen an Benutzer anderer Systeme. Die Schicht 7 besteht also trotz ihres Namens nicht aus den eigentlichen Anwenderprogrammen - diese setzen auf dieser Schicht auf. Das kann einerseits direkt geschehen, z. B. beim Zugriff auf Dateien eines anderen Rechners (Datei-Server) andererseits auch nur durch (lokale) Übergabe von Dateien an das Message-HandlingSystem. 6. Darstellungs-Schicht (Presentation) Hier werden für die Anwendung die Daten interpretiert. Überwachung des Informationsaustausches und Codierung/Decodierung (z. B. EBCDIC in ASCII) der Daten sowie Festlegung der Formate und Steuerzeichen. Diese Schicht bildet oft eine Einheit mit der Anwendungsschicht oder sie fehlt ganz, falls sie nicht benötigt wird. Hier können z. B. "virtuelle Terminals" eingebunden werden. Wie wir früher schon besprochen haben, besitzen Terminals ganz unterschiedliche Codes für die Tastatur und die Steuerung der Darstellung auf dem Bildschirm. In Schicht 6 können diese Codes in einen einheitlichen Code übersetzt werden. 5. Kommunikationssteuerung (Session) Diese Ebene steuert die Aufbau, Durchführung und Beendigung der Verbindung. Überwachung der Betriebsparameter, Datenfluß-Steuerung (bei Bedarf mit Zwischenspeicherung der Daten), Wiederaufbau der Verbindung im Fehlerfall und Synchronisation. Der Verbindungsaufbau ist ein bestätigter Dienst, d. h. beide Partner tauschen Parameterübergabe und Bestätigung im Wechselspiel aus. Danach befinden sich beide Partner in einem definierten Zustand. Das trifft nicht für die nächste Phase, den Datentransfer zu. Es ist aus Zeitgründen z. B. nicht sinnvoll nach dem Senden eines Datenblocks auf die Bestätigung zu warten. Es wird gleich der nächste Block geschickt und die Bestätigungen laufen zeitversetzt ein (immerhin muß alles die Schichten 4 - 1 durchlaufen). Durch sogenannte "Synchronisation Points" wird die Datentransferphase in Abschnitte unterteilt. Bei einer Störung oder Unterbrechung kann der Transfer an einen definierten Punkt wieder aufgenommen werden. Beide Partner können den Verbindungsaufbau beenden. Das kann ordnungsgemäß nach Beendigung aller Transfers geschehen (Ende mit Synchronisation) oder durch Unterbrechen der Verbindung (Ende ohne Synchronisation). In diese Ebene fallen auch das Ein- und Ausgliedern von Stationen beim Token-Ring und die Adressierung eines bestimmten Partners. 4. Transport (Transport) Reine Transportfunktion. Diese Schicht stellt sicher, daß alle Datenpakete den richtigen Empfänger erreichen. Aufbau der Datenverbindung zwischen zwei Partnern, Datentransport, Flußkontrolle, Fehlererkennung und korrektur. Diese Schicht verbirgt die Charakteristika des Netzes (LAN, WAN, ...) vor den darüberliegenden Schichten. Die Transportschicht kann z. B. auch bei einer Forderung nach höherem Datendurchsatz mehrere Verbindungen zum Parner aufbauen und die Daten in Teilströmen leiten (splitting/combining). Auch das Aufteilen der Daten in passende Blöcke und die Flußkontrolle obliegen dieser Schicht. Die Dienste der Transportschicht werden in fünf Klassen unterschieden: o Klasse 0 ist die einfachste. Es findet gegenüber der Schicht 3 keine Fehlerkontrolle statt und einer Transportverbindung enspricht genau eine Netzverbindung. o In der Klasse 1 kommt zwar keine Fehlerbehandlung hinzu, es wird jedoch versucht, von der Schicht 3 gemeldete Fehler zu beheben und nicht an die Schicht 5 weiterzuleiten. Z. B. kann bei Unterbrechung der Transportverbindung versucht werden, diese wieder aufzubauen, ohne daß dies oberhalb der Schicht 4 bemerkt wird. o Klasse 2 kann mehrere Transportverbindungen aufbauen (Multiplexverbindung). In diesem Fall darf die Netzverbindung erst dann getrennt werden, wenn die letzte Transportverbindung abgebaut ist. o Klasse 3 deckt die Leistungen der Klassen 1 und 2 ab, d. h. einfache Fehlerbehandlung und Multiplexen. o Klasse 4 enthält neben den Funktionen der Klasse 3 zusätzliche Mechanismen zur Fehlererkennung und -behandlung. Speziell bei Datagramm-orientieren Netzen (LAN) kann so ein verbindungsorientierter Dienst bereitgestellt werden (Sicherstellen von Vollständigkeit, Eindeutigkeit und Reihenfolge der Datenblöcke). 3. Vermittlung-/Paket-Schicht (Network) Diese Ebene dient hauptsächlich der Datenpaket-Übertragung. Sie ist zusändig für die Wahl der Datenwege (routing), für das Multiplexen mehrerer Verbindungen über einzelne Teilstrecken, für Fehlerbehandlung und Flußkontrolle zwischen den Endpunkten einer Verbindung (nicht zwischen den Anwenderprozessen). Die Flußkontrolle auf dieser Ebene schützt den Endpunkt einer virtuellen Verbindung für Überlastung. Die Fehlerbehandlung in dieser Schicht bezieht sich nicht auf Übertragungsfehler (dafür ist Schicht 2 ausreichend), sondern auf Fehler, die bei der virtuellen Verbindung auftreten: Erkennen und Beseitigen von Duplikaten, Beseitigen permanent kreisender Blöcke, wiederherstellen der richtigen Datenpaket-Reihenfolge, usw. Bei WANs behandelt diese Schicht die Umsetzung eines Protokolls in ein anderes (internetworking). Man kann daher die Schicht 3 in drei Teilschichten unterteilen: o 3a (Subnetwork Access): Abwickeln der Protokolle des jeweiligen Teilnetzes. o 3b (Subnet Enhancement): Funktionen der Teilnetze so ergänzen, daß die Anforderungen von 3c erfüllt werden. o 3c (Internetworking): Teilnetzunabhängige Protokolle abwickeln (Routing, globale Adressierung) 2. Sicherungs-Schicht (Data Link) Sicherstellen einer funktionierenden Verbindung zwischen zwei direkt benachbarten Stationen. Diese Schicht stellt einen definierten Rahmen für den Datentransport, die Fehlererkennung und die Synchronisierung der Daten zur Verfügung. Typische Protokolle: BSC, HDLC, usw. Die Information wird in Blöcke geeigneter Länge unterteilt, die als Datenrahmen (frames) bezeichnet werden und mit Prüfinfo für die Fehlererkennung und -korrektur versehen werden. Auf dieser Ebene erfolgt auch die Flußkontrolle für die Binärdaten. Es muß nicht jeder einzelne Rahmen bestätigt werden, sondern es kann auch eine vorgegebene Maximalzahl von Frames gesendet werden, bevor die Bestätigung abgewartet werden muß. Über die Bestätigung der Gegenstation wird der Datenfluß gesteuert. Datenrahmen und Bestätigungen müssen also nur innerhalb eines Bereichs ("Fenster") liegen. Bei lokalen Netzen wird diese Schicht nochmals unterteilt: o 2a (Media Access Control, MAC): Regelt den Zugriff auf das Übertragungsmedium o 2b (Logical Link Control, LLC): Vom übertragungsmedium abhängige Funktionen der Schicht 2 1. Bitübertragung (Physical) Hier erfolgt die physikalische Übertragung der Daten. Diese Ebene legt die elektrischen, mechanischen, funktionalen und prozeduralen Parameter für die physikalische Verbindung zweier Einheiten fest (z. B. Pegel, Modulation, Kabel, Stecker, Übertragungsrate, etc.) Veranschaulichung des Schichtenmodells mit einem Beispiel Das Beispiel arbeitet nur mit drei Schichten. Die Ausgangssituation besteht in zwei Wissenschaftlern in Arabien und China, die ein Problem diskutieren wollen. Nun sprechen beide nur Ihre Landessprache und auch Dolmetscher, die Arabisch und Chinesisch können, sind nicht aufzutreiben. Beide suchen sich nun Dolmetscher, die Englisch können. Der Weg der Nachrichten: Paketvermittlung vs. Leitungsvermittlung Hier soll kurz erklärt werden, wie die zu übertragenden Informationen in den meisten Netzen von einem auf den anderen Rechner kommen. Die Daten werden paketweise übertragen. Man spricht daher von einem paketvermittelten Netz. Zur Veranschaulichung ein Gegenbeispiel und ein Beispiel: Im Telefonnetz wird für jedes Gespräch eine Leitung zwischen zwei Gesprächspartnern benötigt. Diese Leitung bleibt auch belegt, wenn keine Information übertragen wird, also keiner spricht. Hier handelt es sich um ein leitungsvermitteltes Netz. Im Briefverkehr wird dagegen ganz anders vorgegangen. Wenn Informationsübertragung ansteht, wird ein Brief geschrieben und dieser mit einer Adresse versehen. Sodann wird dieses Informationspaket dem Netz überlassen, indem man es in einen Briefkasten wirft. Das örtliche Postamt entscheidet dann aufgrund der Empfängeradresse, ob der Brief direkt an den Empfänger (wenn dieser also im Versorgungsbereich dieses Postamtes wohnt) auszuliefern ist, oder durch Einschalten von mehr oder weniger Zwischenstationen. In der Regel findet der Brief dann ein Postamt, das die Auslieferung des Briefes an den Empfänger aufgrund der Adresse vornehmen kann. Schwierigkeiten bei der Auslieferung können dem Absender aufgrund der Absendeadresse mitgeteilt werden. Leistungsparameter Bandbreite (Übertragungsrate) o o o Übertragenes Datenvolumen pro Zeiteinheit Maßeinheit: Bits pro Sekunde (bps) Unterscheidung in Bandbreite der Leitung und Ende-zu-Ende Bandbreite (zwischen zwei Anwendungen) Durchsatz tatsächlich erreichte Bandbreite, also Datenmenge/Transferzeit Latenzzeit (Transferzeit) Zeit vom Beginn des Absendens einer Nachricht bis zu ihrem vollständigem Empfang. Die Transferzeit setzt sich zusammen aus: Signallaufzeit + Übertragungsdauer + Zeit für Pufferung in Zwischenknoten Signallaufzeit = Entfernung / Ausbreitungsgeschwindigkeit Übertragungsdauer = Nachrichtenmenge / Bandbreite Round-Trip-Time (RTT) Zeit, die benötigt wird, um eine Nachricht von A nach B und wieder zurück zu schicken Bandbreite und Signallaufzeit - Kurze Nachrichten: Signallaufzeit dominiert - Lange Nachrichten: Bandbreite dominiert Neues Kapitel Repeater, Bridge, Router Um die Längenbeschränkung eines EthernetSegmentes aufzuheben, verwendet man Repeater. Ein klassischer Repeater verbindet zwei EthernetSegmente (10Base5 oder 10Base2), er ist mit je einem Transceiver an jedes Segment angeschlossen. Ein Remote-Repeater ist ein Repeater-Paar, das durch einen max. 1000 m langen Lichtwellenleiter verbunden ist. In jedem Netz dürfen höchstens vier Repeater vorhanden sein, man erreicht so eine Gesamtlänge von 2500 m. Ein Remote RepeaterPaar zählt dabei wie ein lokaler Repeater. An den Lichtwellenleiter können keine Ethernet-Stationen angeschlossen werden. Der Repeater ist als reines Verstärkerelement in der untersten Schicht des OSI-Modells angesiedelt. Multiport-Repeater Der Multiport-Repeater bietet die Möglichkeit, mehrere (typischerweise bis zu acht) Cheapernet-Segmente zusammenzuführen und über einen Transceiveranschluß mit dem Standard-Ethernet zu verbinden. Bei zwei oder mehr anzuschließenden CheapernetSegmenten ist die Lösung kostengünstiger als der Einsatz von Standard-Repeatern. Hub Analog dem Multiport-Repeater besteht die Funktion eines Hub darin, mehrere Twisted-PairKabelsegmente über einen Transceiveranschluß mit dem Ethernet zu verbinden. Das englische Wort "Hub" bezeichnet die Nabe eines Speichenrades - wie die Speichen des Rades verteilen sich die Leitungen sternförmig vom Hub aus. Der Begriff "Hub" steht also für fast alle Verstärkerkomponenten, die eine sternförmige Vernetzung ermöglichen. Hubs haben immer mehrere Ports zum Anschluß von mehreren Rechnern. Bei Twisted-Pair-Verkabelung ist meist einer der Ports als "Uplink" schaltbar, d. h. es werden wie im 4. Kapitel beschrieben die Leitungen gekreuzt. Auf diese Weise lassen sich die Hubs kaskadieren. Typisch sind Hubs mit 4, 8, 12, 16, 24 und 32 Ports. Manche Repeater/Hubs lassen sich über spezielle Busports und in der Regel sehr kurze Buskabel verbinden. Vorteil dieser herstellerspezifischen Kaskadierung ist, daß alle so verbundenen Repeater/Hubs als ein Repeater bezüglich der Repeaterregel zählen. Repeaterregel (5-4-3-Regel) Die Anzahl der hintereinanderschaltbaren Repeater bei 10Base5 und 10Base2 ist jedoch limitiert (Addition von Laufzeiten, Phasenverschiebungen, usw.). Ein Remote-Repeater-Paar (10Base5, 10Base2) mit einer Punkt-zu-Punkt-Verbindung zwischen beiden Hälften wird als ein Repeater betrachtet. Weiterhin gilt: Es dürfen nicht mehr als fünf (5) Kabelsegmente verbunden werden. Zur Verbindung werden vier (4) Repeater benötigt und nur drei (3) der Segmente dürfen Rechner angeschlossen haben. Bei Ethernet (10Base5) können so 5 Segmente zu je 500 m verbunden werden, das gesamte Netz darf damit eine Ausdehnung von 2,5 km haben. Man kann diese Regel auch auf Twisted-Pair-Hubs anwenden - auch hier kann man nicht beliebig viele Hubs kaskadieren. Hier ist die Leitungslänge sogar auf ca. 100 m je Segment begrenzt. Eine Erweiterung ist durch aktive Elemente möglich (Switch, Router). Lichtwellenleiter (10BaseF, FOIRL) und Sternkoppler Zur Verbindung von Gebäuden werden oft Lichtwellenleiter (LWL) verwendet. Außerdem können mit ihnen in Gebäuden längere Entfernungen als mit Koaxkabeln überbrückt werden. Lichtleiter können wie TwistedPair auch im Ethernet-Verkehr nur für Punkt-zu-PunktVerbindungen eingesetzt werden. Lichtleiter werden zwischen Bridges, Switches und/oder Repeatern, einem Repeater und einer einzelnen Station mit Transceiver oder zwischen zwei Stationen mit Transceivern verwendet. Als Industriestandard für Lichtleiterprodukte hatte sich ursprünglich FOIRL (Fiber Optic InterrepeaterLink) durchgesetzt. Inzwischen wurde FOIRL vom offiziellen IEEE 802.3 10BASE-FL-Standard abgelöst, daher sollte man heute nur noch 10BASE-FL konforme Geräte einsetzen. An einem FOIRL-Segment kann ein FOIRL-kompatibles Gerät mit einem 10BASE-FL-Transceiver gemischt werden. In diesem Fall gelten jedoch die strengeren FOIRL-Regeln. Normalerweise ist das eingesetzte LWL-Kabel ein Multimode- (MMF-) Kabel mit ST- oder SC-Steckern. Die maximale Länge des Kabels ist 2000 m beim Einsatz von 10BASE-FL-Komponenten, 1000 m bei FOIRL. Sternkoppler können als Verstärker betrachtet werden, jedes Datenpaket, das von einem angeschlossenen Segment stammt, wird in alle anderen Segmente verbreitet, einschließlich Kollisionen und fehlerhafter Pakete. An einen Sternkoppler können Koax- oder Cheapernet-Segmente angeschlossen werden. Zudem gibt es direkte Transceiver-Anschlüsse und mittlerweile auch Anschlüsse für TwistedPair-Kabelsegmente. Bridge Eine Bridge trennt zwei Ethernet-LANs physikalisch, Störungen wie z. B. Kollisionen und fehlerhafte Pakete gelangen nicht über die Bridge hinaus. Die Bridge ist protokolltransparent, d. h. sie überträgt alle auf dem Ethernet laufenden Protokolle. Die beiden beteiligten Netze erscheinen also für eine Station wie ein einziges Netz. Durch den Einsatz einer Bridge können die Längenbeschränkungen des Ethernets überwunden werden, den sie verstärkt die Signale nicht nur, sondern generiert senderseitig einen neuen Bitstrom. Die Bridge arbeitet mit derselben Übertragungsrate, wie die beteiligten Netze. Die Anzahl der hintereinandergeschalteten Bridges ist auf sieben begrenzt (IEEE 802.1). Normalerweise wird man aber nicht mehr als vier Bridges hintereinanderschalten. Jede lokale Bridge ist über Transceiver an zwei Ethernet-LANs angeschlossen. Die Bridge empfängt von beiden Netzsegmenten, mit denen sie wie jede normale Station verbunden ist, alle Blöcke und analysiert die Absender- und Empfängeradressen. Steht die Absenderadresse nicht in der brückeninternen Adreßtabelle, so wird sie vermerkt. Die Bridge lernt und speichert so die Information, auf welcher Seite der Bridge der Rechner mit dieser Adresse angeschlossen ist. Ist die Empfängeradresse bekannt und der Empfänger auf derselben Seite wie der Absender, so vewirft die Bridge das Paket (filtert es). Ist der Empfänger auf der anderen Seite oder nicht in der Tabelle, wird das Paket weitergeschickt. Die intelligente Bridge lernt so selbständig, welche Pakete weitergeschickt werden müssen und welche nicht. Bei managebaren Bridges können zusätzliche Adreß-Filter gesetzt werden, die regeln an welche Adressen die Bridge Informationen immer weiterschicken muß oder nie weiterschicken darf. Eine Bridge arbeitet auf der Ebene 2 des OSI-Schichtenmodells. Bridges können Ethernet-Segmente auch über synchrone Standleitungen, Satellitenverbindungen, Funkverbindungen, öffentliche Paketvermittlungsnetze und schnelle Lichtleiternetze (z.B. FDDI) verbinden. In der Regel müssen solche Bridges immer paarweise eingesetzt werden. Bridges sind komplette, relativ leistungsfähige Rechner mit Speicher und mindestens zwei Netzwerkanschlüssen. Sie sind unabhängig von höheren Protokollen (funktionieren also z.B. mit TCP/IP, DECnet, IPX, LAT, MOP etc. gleichzeitig) und erfordern bei normalem Einsatz keine zusätzliche Software oder Programmierung. Nach Außen bildet ein mittels Bridge erweitertes LAN weiterhin eine Einheit, welches eine eindeutige Adressierung bedingt. Eine Bridge interpretiert die MAC-Adressen der Datenpakete. Weitere Features einer Bridge sind: Ausfallsicherheit Störungen gelangen von der einen Seite einer Bridge nicht auf die andere Seite. Sie werden auch in diesem Sinne zum Trennen von sog. Kollisions-Domänen (collision domain) eingesetzt. Datensicherheit Informationen, die zwischen Knoten auf einer Seite der Bridge ausgetauscht werden, können nicht auf der anderen Seite der Bridge abgehört werden. Durchsatzsteigerung In den durch Bridges getrennten Netzsegmenten können jeweils unterschiedliche Daten-Blöcke gleichzeitig transferiert werden. Hierdurch wird die Netzperformance erhöht. Allerdings erzeugen Brücken dadurch, daß sie die Blöcke zwischenspeichern eine zusätzliche Verzögerung und können deswegen bei kaum ausgelasteten Netzen die Performance sogar verschlechtern. Vermeidung von Netzwerkschleifen Eine Bridge unterstützt den sog. "Spanning-Tree-Algorithmus", wodurch es möglich ist, auch Schleifen- oder Ring-Konfigurationen (= redundante Verbindungen) im Netz zu erlauben. Die Bridges im Netz kommunizieren miteinander, im Gegensatz zu "dummen" Repeatern oder Hubs, und stellen über den Algorithmus sicher, daß bei mehreren redundanten Verbindungen immer nur eine gerade aktiv ist. Weitere Kenndaten einer Bridge sind die Größe der Adreßtabelle, die Filterrate, und die Transferrate. Die Größe der Adreßtabelle gibt an, wieviele Adressen (Knoten) insgesamt in der Bridge gespeichert werden können. Die Filterrate gibt an, wieviele Pakete pro Sekunde (packets per second, pps) eine Bridge maximal empfangen kann. Bei voller Last und minimaler Paketlänge können in einem Ethernet-Segment theoretisch bis zu 14.880 Pakete pro Sekunde auftreten. Auf beiden Ports hat eine 2-Port-Bridge also insgesamt maximal 29.760 Pakete pro Sekunde zu filtern. Alle modernen Bridges erreichen diese theoretisch möglichen Maximalwerte. Die Transferrate gibt an, wieviel Pakete pro Sekunde die Bridge auf die andere Seite weiterleiten kann. Der Maximalwert ist hier 14.880 pps, da bei dieser Transferrate beide Segmente voll ausgelastet sind. Switch Der Switch ist wie die Bridge ein Gerät des OSI-Layers 2, d. h. er kann LANs mit verschiedenen physikalischen Eigenschaften verbinden, z. B. Koax- und Twisted-PairNetzwerke. Allerdings müssen, ebenso wie bei der Bridge, alle Protokolle höherer Ebenen 3 bis 7 identisch sein! Ein Switch ist somit protokolltransparent. Er wird oft auch als MultiPort-Bridge bezeichnet, da dieser ähnliche Eigenschaften wie eine Bridge aufweist. Jeder Port eines Switch bildet ein eigenes Netzsegment. Jedem dieser Segmente steht die gesamte Netzwerk-Bandbreite zu Verfügung. Dadurch erhöht ein Switch nicht nur - wie die Bridge die Netzwerk-Performance im Gesamtnetz, sondern auch in jedem einzelnen Segment. Der Switch untersucht jedes durchlaufende Paket auf die MAC-Adresse des Zielsegmentes und kann es direkt dorthin weiterleiten. Der große Vorteil eines Switches liegt nun in der Fähigkeit seine Ports direkt miteinander verschalten zu können, d. h. dedizierte Verbindungen aufzubauen. Was ist nun der Unterschied zwischen einem Switch und einer Multiport-Bridge? Bei den Produkten der meisten Hersteller gibt es keinen. "Switch" klingt nach Tempo und Leistung, deswegen haben viele Hersteller ihre Multiport-Bridges Switches genannt. Der Begriff Switch für Multiport-Bridges wurde von der Firma Kalpana (inzwischen von Cisco aufgekauft) kreiert, da deren Produkte nicht der IEEE-Spezifikation einer Bridge entsprachen, konnte Kalpana die Produkte nicht Bridges nennen und hat den Namen Switch gewählt. Kalpana war nun sehr erfolgreich mit dem Marketing ihrer Switches. Deswegen haben andere Hersteller ihre Bridges auch Switch, Switch mit Bridge-Eigenschaften oder "Bridging Switch" genannt. Switches brechen die Ethernet-Busstruktur in eine Bus-/Sternstruktur auf. Teilsegmente mit Busstruktur werden sternförmig über je einen Port des Switch gekoppelt. Zwischen den einzelnen Ports können Pakete mit maximaler Ethernet-Geschwindigkeit übertragen werden. Wesentlich ist die Fähigkeit von Switches, mehrere Übertragungen zwischen unterschiedlichen Segmenten gleichzeitig durchzuführen. Dadurch erhöht sich die Bandbreite des gesamten Netzes entsprechend. Die volle Leistungsfähigkeit von Switches kann nur dann genutzt werden, wenn eine geeignete Netzwerktopologie vorhanden ist bzw. geschaffen werden kann. Die Datenlast sollte nach Möglichkeit gleichmäßig über die Ports verteilt werden. Systeme, die viele Daten übertragen, müssen unter Umständen an einen eigenen Switch-Port angeschlossen werden. Dies bezeichnet man dann als Private Ethernet. Außerdem sollte man versuchen, Systeme die viel miteinander kommunizieren, an einen gemeinsamen Port des Switches anzuschließen, um so die Datenmengen, die mehr als ein Segment durchlaufen müssen, zu reduzieren. Es haben sich drei grundlegende Realisierungsformen für Switches etabliert: Shared Memory: Alle Schnittstellen kommunizieren über einen zentralen Speicher. Bei dieser meist recht preisgünstigen Realisierung steht oft nur ein einfacher interner Rechnerbus zur Verfügung. Common Bus: Die Schnittstellen verfügen über einen lokalen Speicher und werden über einen gemeinsamen Bus mit den anderen Schnittstellen verbunden. Der interne Bus ist in der Regel schneller getaktet als die externen Schnittstellen (Zeitmultiplex) oder erlaubt als so genannte Backplane mehrere parallele Verbindungen (Raummultiplex). Crosspoint Matrix: Die Schnittstellen verfügen über einen lokalen Speicher und werden über eine flexible und leistungsfähige Schaltmatrix mit den anderen Schnittstellen verbunden. Diese Realisierungsform erlaubt in der Regel die höchste Leistungsfähigkeit, bedingt aber den größten Hardwareaufwand. Allgemein haben sich in der Switch-Technologie zwei Methoden der Weiterleitung herauskristallisiert: Cut-Through bzw. On The Fly Der Ethernet Switch wartet im Gegensatz zu normalen Bridges nicht, bis er das vollständige Paket gelesen hat, sondern er überträgt das ankommende Paket nach Empfang der 6-Byte-Destination-Adresse. Da nicht das gesamte Paket bearbeitet werden muß, tritt eine Zeitverzögerung von nur etwa 40 Mikrosekunden ein. Sollte das Zielsegment bei der Übertragung gerade belegt sein, speichert der Ethernet Switch das Paket entsprechend zwischen. Bei den Switches werden, im Gegensatz zu Bridges, mit Ausnahme von short frames (Pakete, die kleiner als die minimal zulässigen 64 Bytes sind), fehlerhafte Pakete auch auf das andere Segment übertragen. Grund hierfür ist, daß die CRC-Prüfung (Cyclic Redundancy Check) erst bei einem vollständig gelesenen Paket durchgeführt werden kann. Solange der Prozentsatz von fehlerhaften Paketen im Netz gering ist, entstehen keine Probleme. Sobald aber (z.B. aufgrund eines Konfigurationsfehlers, fehlerhafter Hardware oder extrem hoher Netzlast bei gleichzeitig langen Segmenten mit mehreren Repeatern) der Prozentsatz der Kollisionen steigt, können Switches auch dazu führen, daß die Leistung des Gesamtnetzes deutlich sinkt. Cut-Through-Switching bietet dann einen Vorteil, wenn man sehr geringe Verzögerungen bei der Übertragung zwischen einzelnen Knoten benötigt. Diese Technologie sollte also eingesetzt werden, wenn es darum geht, in relativ kleinen Netzen eine große Anzahl Daten zwischen wenigen Knoten zu übertragen. Store-and-Forward Die Switches dieser Kategorie untersuchen im Gegensatz zu den vorher erwähnten das gesamte Datenpaket. Dazu werden die Pakete kurz zwischengespeichert, auf ihre Korrektheit und Gültigkeit überprüft und anschließend verworfen oder weitergeleitet. Einerseits hat dies den Nachteil der größeren Verzögerung beim Weiterschicken des Paketes, andererseits werden keinerlei fehlerhafte Pakete auf das andere Segment übertragen. Diese Lösung ist bei größeren Netzen mit vielen Knoten und Kommunikationsbeziehungen besser, weil nicht einzelne fehlerhafte Segmente durch Kollisionen das ganze Netz belasten können. Bei diesen Anwendungen ist die Gesamttransferrate entscheidend, die Verzögerung wirkt sich hier kaum aus. Inzwischen sind Switching-Produkte (z.B. von 3Com, Cisco oder Allied Telesyn) am Markt, die beide Technologien unterstützen. Dies geschieht entweder per Konfiguration (Software) oder automatisch anhand der CRC-Fehler-Häufigkeit. Wird eine vorgegebene Anzahl von fehlerhaften Paketen überschritten, schaltet der Switch automatisch von "Cut Through" auf "Store and Forward" um. Die Performance eines Netzes kann man auf Basis vorhandener Standalone-Switches erhöhen, indem zusätzliche Switches über die Ethernetports kaskadiert werden. Alle Switches erlauben die Kaskadierung über einen einzelnen Ethernet-Port mit einer maximalen Transferrate von 10 Mbit/s (bzw. 100 Mbit/s bei Fast Ethernet Switches). Kann man das Netz in Teilnetze unterteilen, zwischen denen diese Transferrate ausreicht, ist dies eine sinnvolle Lösung. Doch meistens ist das nicht der Fall. Die nächste und wohl beste Möglichkeit der Kopplung von Switches ist der Einsatz von Produkten, die den Anschluß an einen High Speed Backbone erlauben. Im Gegensatz zu kaskadierten Standalone-Switches können weitere Geräte an den Backbone gehängt werden, ohne daß Ports für die Switch-zu-Switch-Verbindung verlorengehen. Eine Backbone-Lösung ist nicht nur schneller und flexibler sondern für große Netze auch kostengünstiger. Man muß unterscheiden zwischen Lösungen, die eine herstellereigene Verbindung benutzen (proprietär) und solchen, die auf einen Standard wie Fast Ethernet, Gigabit Ethernet, FDDI oder ATM setzen. Unterschiede Hub - Switch: Hub Switch Es kann immer nur ein Datenpaket nach dem anderen den Hub passieren Geschwindigkeit 10 oder 10/100 Mbps bei Dual Speed Hubs Hubs wissen nicht, an welchem Port welche Station angeschlossen ist, sie können es auch nicht lernen. Hubs müssen nicht konfiguriert werden. Mehrere Datenpakete können den Switch gleichzeitig passieren Die Gesamtbandbreite (der Datendurchsatz) ist wesentlich höher als bei einem Hub Switches lernen nach und nach, welche Stationen mit welchen Ports verbunden sind, somit werden bei weiteren Datenübertragungen keine anderen Ports unnötig belastet, sondern nur der Port, an dem die Zielstation angeschlossen ist Geschwindigkeiten sind heute 10, 10/100 oder 1000 MBit/s (Gigabit Ethernet) Switches müssen nicht konfiguriert werden inzwischen preisgünstiger als Hubs Latenzzeiten von Ethernet Switches Aufgrund der Arbeitsweise unterscheiden sich das Cut-Through-Verfahren und Store-andForeward-Verfahren in ihren Latenzzeiten. Der Cut-Through-Switch benutzt die Zieladresse als ein Entscheidungskriterium, um einen Zielport aus einer Adresstabelle zu erhalten. Nach der Bestimmung des Zielports wird eine Querverbindung durch den Switch geschaltet, und der Frame wird zum Zielport geleitet Da diese Switching-Methode nur die Speicherung eines kleinen Teils des Frames erfordert, bis der Switch fähig ist, die Zieladresse zu erkennen und den Switching-Vorgang einzuleiten, ist die Latenzzeit in diesem Fall nur minimal. Die Latenzzeit für einen 10-Mbps-Ethernet-Frame berechnet sich wie folgt: Der Switch muss zunächst 14 Bytes einlesen (8 Bytes für die Präambel und 6 Bytes für die Zieladresse). Für die Latenzzeit TL eines Cut-Through Ethernet-Switches ergibt sich TL = TIG + 14*8*TBK [µs] Mit einem Interframe-Gap von TIG = 9,6 µs und einer Bitdauer von TBK = 0,1 µs: TL = 9,6 + 14*8*0,1 = 9,6 + 11,2 = 20,8 µs Ein Store-and-Forward-Switch speichert erst den gesamten Frame, bevor die Verarbeitung der Datenfelder des Frames beginnt. Wenn der gesamte Frame im Zwischenspeicher angekommen ist, wird ein CRC-Check durchgeführt, optional auch weitere Filteraktionen. Ist der Frame fehlerfrei, wird er von Zwischenspeicher zum Zielport geleitet, anderenfalls verworfen. Für die Latenzzeit TL eines Ethernet Store-and-Foreward Switches gilt also theoretisch mit der Framegröße FG: TL = TIG + FG*8*TBK [µs] Da die minimale Größe eines 10-Mbps-Ethernet-Frames 72 Bytes beträgt, gilt für die minimale Latenzzeit TLmin eines Store-and-Foreward Ethernet-Switches: TL = TIG + 72*8*TBK [µs] Mit einem Interframe-Gap von TIG = 9,6 µs und einer Bitdauer von TBK = 0,1 µs ergibt sich: TL = 9,6 + 72*8*0,1 = 67,2 µs Aufgrund der Speicherung des gesamten Frames ist die Latenzzeit beim Store-and-Foreward Switching abhängig von der Framegröße, so daß für Frames maximaler Größe (1526 Bytes) gilt: TL = 9,6 + 1526*8*0,1 = 1,23 ms Router Große Netzwerke wie das Internet bestehen aus vielen kleineren Teilnetzwerken. Die Verbindung der verschiedenen Netze wird durch spezielle Rechner hergestellt. Das sind, neben Bridges, Switches und Gateways, im Internet vor allem Router. Diese haben die Aufgabe, Daten zwischen Rechnern in verschiedenen Netzen auf möglichst günstigen Wegen weiterzuleiten. Zum Beispiel wenn Rechner 1 im Netz B Daten an Rechner 2 im Netz C schicken möchte. Router verbinden, im Gegensatz zu Bridges, in OSI-Schicht 3 auch Netze unterschiedlicher Topologien. Sie sind Dreh- und Angelpunkt in strukturiert aufgebauten LAN- und WANNetzen. Mit der Fähigkeit, unterschiedliche Netztypen sowie unterschiedliche Protokolle zu routen, ist eine optimale Verkehrslenkung und Netzauslastung möglich. Routing wird erst dann erforderlich, wenn Kommunikation zwischen Stationen in unterschiedlichen Subnetzen erfolgen soll. Sie sind nicht protokolltransparent, sondern müssen in der Lage sein, alle verwendeten Protokolle zu erkennen, da sie Informationsblöcke protokollspezifisch umsetzen. Klassische Beispiele in Heim- und KMU-Netzen sind die ISDN- oder DSL-Router, welche die Verbindung zum Provider herstellen. Router operieren in der Ebene 3 des OSI-Referenzmodells. Sie verbinden Netzwerke über die entsprechenden Netzwerkprotokolle. Sie ermöglichen die Zerlegung großer Netzwerke in kleinere Verwaltungseinheiten. Sie leiten Datenpakete der Netzwerkschicht weiter (forwarding) und treffen Entscheidungen über Wegewahl und Erreichbarkeit zu anderen Netzwerken (routing). Der Router muß dafür die Adressierungsstruktur in der Netzwerkschicht kennen. Bevor ein Router ein Paket mit einer bestimmten IP-Adresse weiterleiten kann, muß er für diese Adresse zunächst den Weg durch das Netz zum Zielrechner bestimmen. Das geschieht mit Hilfe spezieller Protokolle wie ARP, RIP, OSPF, EGP/BGP. Er ist jedoch von der Schicht 2 unabhängig und kann deswegen verschiedene Schicht-2-Welten (zum Beispiel Ethernet und Token Ring) miteinander verbinden. Ein Router unterscheidet sich u.a. von einer Bridge darin, dass die Bridge für die Netzwerkteilnehmer völlig transparent ist, während die Adresse eines Routers jedem Host im Netzwerk explizit bekannt sein muß, wenn er dessen Dienste nutzen will. Ein Router kann einen von mehreren potentiellen Wegen zur Weiterleitung der Daten aussuchen, wobei er seine Entscheidung mit Hilfe von Parametern, wie zum Beispiel Übertragungszeiten, Knotenlast oder auch nur einfach Knotenanzahl, trifft. Wie Router die Wegeentscheidung treffen, hängt wesentlich vom konkreten Protokoll der Schicht 3 ab. In der Routingtabelle ist aber nicht der gesamte Weg zu einem Rechner mit einer bestimmten IP-Adresse gespeichert. Vielmehr kennt der einzelne Router nur die nächste Zwischenstation (engl. next hop) auf dem Weg zum Ziel. Das kann ein weiterer Router oder der Zielrechner sein. Grundlegende Komponenten von Routern Der Router besteht, wie ein Computer auch, aus CPU und Speicher. Dazu kommen mehrere Netzwerkadapter, die eine Verbindung zu jenen Netzen herstellen, die mit dem Router verbunden sind. Die Adapter sind meist über einen Systembus mit der CPU des Routers verbunden. Die CPU wiederum hält im Hauptspeicher des Rechners die Routingtabelle vor. LAN Interfaces: Die meisten Router haben ein oder mehrere LAN-Interfaces, je nach Topologie für TokenRing, Ethernet, 100BASE-T Fast Ethernet, FDDI oder auch ATM. Für den Anschluß entsprechender Medien sind entweder alternativ nutzbare Ports (z.B. Ethernet AUI, BNC, RJ45) vorhanden oder der Anschluß ist als Einschub realisiert und kann daher den Erfordernissen angepaßt werden. WAN Interfaces: WAN-Leitungen werden von unterschiedlichen Anbietern mit unterschiedlichen Geschwindigkeiten angeboten. Entsprechend variieren die Kosten und die Schnittstellen. Für kleinere Anbindungen (z.B. Workgroups) werden Verbindungen mit einer Übertragungsgeschwindigkeit von 64 Kbit/s empfohlen. Es gibt natürlich Applikationen, wo eine geringere Übertragungsrate ausreicht. Werden höhere Übertragungsraten benötigt, so bietet sich die in Europa übliche E1-Verbindung (im Prinzip ein ISDN Primärmultiplexanschluß) mit einer Übertragungsrate von 2048 kbit/s an. Router haben einen oder mehrere WAN-Ports, die entweder fest eingebaut sind oder bei modularen Modellen mit entsprechenden Schnittstellenmodulen aufgerüstet werden können. Übliche physikalische Schnittstellen für Synchronbetrieb sind RS449, V.35 und X.21, für asynchronen Betrieb das RS232-Interface. Für den Anschluß an ISDN wird die S0-Schnittstelle verwendet. Routing Da, wie gesagt, Routing auf Schicht 3 stattfindet, wird in diesem Abschnitt auf das InternetProtocol vorgegriffen (siehe Kapitel 10: 10 TCP/IP). Wenn einer der Netzwerkadapter ein Datenpaket erhält, so verarbeitet er zunächst die Schicht2-Protokolldaten, extrahiert dann das IP-Paket und reicht es zur weiteren Verarbeitung an die CPU weiter. Diese entnimmt dem Paketkopf die IP-Adresse des Zielrechners. Wenn nicht der Router selber adressiert ist, muß das Paket weitergeleitet werden. Dazu sucht die CPU in der Routingtabelle nach der passenden Next-Hop-Information. Die Next-Hop-Information beinhaltet zum einen die Nummer des Netzwerkadapters über den das Paket ausgegeben werden soll und zweitens die IP-Adresse des Next-Hop. Diese Adresse übergibt die CPU des Routers nun zusammen mit dem IP-Paket an den entsprechenden Netzwerkadapter. Dieser generiert daraus ein Schicht-2-Paket und sendet es ab. Werden auch Informationen im Kopf des Datagramms vor dem Weiterleiten geändert? Zunächst einmal wird bei Eintreffen eines IP-Datagrammes überprüft, ob die Prüfsumme mit den Daten des Paketes zusammenpasst. Wenn dies nicht der Fall ist, muß der Router eine Fehlermeldung an den Absender schicken. Anschließend wird der Zähler "time-to-live" im Kopf des Paketes dekrementiert. Erreicht er den Wert 0, wird das Paket verworfen. Auf diese Weise können Endlosschleifen vermieden werden. Da sich der Inhalt des Paketes deswegen verändert hat, muß eine neue Prüfsumme berechnet werden. Das neue Datagramm wird nun weitergeleitet. Ist eine lokale Auslieferung möglich, ist die physikalische Zieladresse die MAC-Adresse des IP-Zieles. Im Falle einer indirekten Auslieferung ist die physikalische Zieladresse die MAC-Adresse des Routers. Also ist die Information über den Router nicht im Kopf eines IP-Paketes vermerkt. Der Weg eines Datagrammes kann also nicht verfolgt werden. Bevor ein Router ein Paket mit einer bestimmten IP-Adresse weiterleiten kann, muß er ggf. für diese Adresse zunächst den Weg durch das Netz zum Zielrechner bestimmen. Das geschieht mit Hilfe spezieller Protokolle wie ARP, RIP, OSPF, EGP/BGP. Betrachten wir dazu ein stark vereinfachendes Beispiel. Dabei werden lokale Netze im folgenden nur noch als gelbe Ovale dargestellt. Innerhalb eines lokalen Netzes hat jeder Rechner eine eigene IPAdresse. Zwei Netze werden miteinander über Router (rotes Rechteck) gekoppelt. Bei der Verbindung von mehr als zwei Netzen existieren Knotenpunkte, an denen eine Richtungsentscheidung getroffen werden muß. Router mit mehreren Interfaces legen den Weg eines Paketes durch das Netz fest. Es ginge im Prinzip auch nur mit einem Interface - aber auf Kosten der Performance. Das Konzept wird rasch an vielen Stellen umgesetzt. Es entstehen miteinander gekoppelte Netze. Aber noch haben nicht alle Netze miteinander eine Verbindung. Durch weitere Verbindungen haben nun alle Netze Kontakt. Jeder Rechner kann mit jedem anderen Rechner kommunizieren, auch wenn sie nicht in zwei benachbarten Netzen liegen. Durch Querverbindungen entsteht ein vermaschtes System. Auch wenn eine der Verbindungen ausfällt, kann die Kommunikation weiterlaufen. Durch die für das Routen notwendige Untersuchung des Datenpakets, erhöht sich die Verweilzeit der Daten im Router selbst (Latenzzeit). Die eigentliche Stärke von Routern liegt in ihrer Fähigkeit mittels bestimmter Algorithmen den bestmöglichen Weg für ein Datenpaket zum Empfänger aus seiner Routing-Tabelle zu wählen. Um die Daten "routen" zu können, ist es notwendig, daß der Router alle angeschlossenen Netzwerkprotokolle versteht und diese auch die Fähigkeit des Routens unterstützen. Der Vorteil des Routers gegenüber der Bridge ist die logische Trennung und die Bildung von (Sub-)Netzen bei TCP/IP bzw. von Areas bei DECNET. Weitere Features von Routern sind ihre Netzwerk-Management- und die Filter-Funktionen. Durch geeignet gewählte Routing-Einstellungen ist es möglich, die Netwerk-Performance je nach Anforderungen ans Netz zu verbessern. Die Filterfunktionen auf NetzwerkProtokollebene sind ähnlich wie bei der Bridge. Router bieten aber eine generell höhere Isolation da sie z. B. Broadcasts in der Regel nicht weiterleiten. Außerdem können sie zusätzlich als "screening Router" verwendet werden, indem z. B. bestimmten IP-Adressen der Zugriff auf bestimmte Netzteile verwehrt wird. Aus den erwähnten Gründen sind Router in der Regel per Software konfigurierbar. Bei Hochgeschwindigkeitsnetzen im Gigabitbereich ist die oben beschriebene Struktur eines Routers nicht mehr ausreichend. Die CPU und der Systembus müßten dabei die Summe der Übertragungsraten aller angeschlossenen Netzwerke verarbeiten können. Bei 2 GBit/s Datenübertragungsgeschwindigkeit entspricht das bei einer angenommenen Paketgröße von 1000 Bits bis zu zwei Millionen IP-Paketen pro Sekunde und Netzwerkanschluß. Bei solchen Hochleistungsroutern geht man dazu über, die Aufgabe des Weiterleitens von IP-Paketen den einzelnen Netzwerkadaptern zu übertragen. Die Netzwerkadapter erhalten zu diesem Zweck eine eigene CPU und Speicher, in dem sich eine Kopie der zentralen Routingtabelle des Routers befindet. Trifft bei diesem Routermodell ein IP-Paket bei einem der Adapter ein, bestimmt dieser den Next-Hop und gibt das Paket direkt an den entsprechenden Ausgangsadapter weiter. Die CPU des Routers ist nur noch für die Ausführung der Routingprotokolle und die Verwaltung der zentralen Routingtabelle sowie anderer administrativer Aufgaben zuständig. Die zentrale Routingtabelle wird im Fall einer Änderung anschließend in die Speicher der einzelnen Netzwerkadapter kopiert. Die Routingtabelle Eine einfache Tabelle über alle 232 (bei IPv4) bzw. 2128 (bei IPv6) möglichen IP-Adressen wäre kaum machbar. Schließlich kann ein Router über die direkt mit ihm verbundenen Netze nur maximal einige tausend Rechner erreichen. In der Regel sind es sogar weniger als hundert. In der Routingtabelle ist auch nicht der gesamte Weg zu einem Rechner mit einer bestimmten IP-Adresse gespeichert. Vielmehr kennt der einzelne Router nur die nächste Zwischenstation (engl. next hop) auf dem Weg zum Ziel. Das kann ein weiterer Router oder der Zielrechner sein. Die IP-Adressen sind nicht einzeln wahllos auf Rechner in der ganzen Welt verstreut worden. Bei IPv4 ist der Adreßraum in fünf verschiedene Klassen A-E unterteilt worden, wobei hier nur die Klassen A - C interessieren. Jede IPv4-Adresse besteht aus einer Klassenkennung, einer Netzadresse, einer möglichen Subnetzadresse und einer Rechneradresse. Jede Organisation im Internet bekommt eine Netzadresse aus einer bestimmten Klasse zugewiesen. Mit den Netzadressen der verschiedenen Klassen sind unterschiedliche Kontingente von Rechneradressen verbunden, je nachdem wie viele Adressen von einer Organisation benötigt werden. So sind die Netzadressen der Klasse B 16 Bit lang, und für die Adreßverteilung innerhalb einer Organisation stehen 16 Bit zur Verfügung. Für die mögliche Aufteilung in Subnetze und die Verteilung der Adressen an einzelne Rechner innerhalb der Organisationen sind diese selber zuständig. Class A-Netz: 1 Byte Netzadresse, 3 Byte Rechneradresse. Class B-Netz: 2 Byte Netzadresse, 2 Byte Rechneradresse, Class C-Netz: 3 Byte Netzadresse, 1 Byte Rechneradresse, Class D-Netz: für Multicast-Anwendungen Class E-Netz: für Experimente Beispiel für drei IP-Netze mit Routern Das folgende Netz besteht aus drei IP-Netzen, die über Router verbunden sind. Jeder Router hat zwei Netzwerk-Interfaces, die jeweils in zwei der Netze hängen. Es ist nicht unbedingt erforderlich, für jedes Netz ein eigenes Interface zu verwenden; über sogenannte 'virtuelle Interfaces' kann man mehrere Netze auf ein Hardwareinterface legen. Die Routing-Tabellen dazu sehen so aus: Router 1 Router 2 Empfänger im Netzwerk Zustellung über Empfänger im Netzwerk Zustellung über 192.168.0.0 direkt 192.168.0.0 192.168.1.1 192.168.1.0 direkt 192.168.1.0 direkt 192.168.2.0 192.168.1.2 192.168.2.0 direkt Routingverfahren Das Routing (Wegewahl, Pfadsteuerung) hat die Aufgabe, Pfade für die Übertragung durch ein Netz festzulegen. Jeder Vermittlungsknoten fällt dabei eine Entscheidung auf welcher Übertragungsleitung ein eingelaufenes Paket weitergeleitet werden soll. Im Prinzip läuft die Entscheidung innerhalb des Routers folgendermaßen ab: Beim Routing werden diverse Ziele verfolgt: Geringe Paketverzögerung Hoher Durchsatz Geringe Kosten Fehlertoleranz Es gibt eine Reihe von Routingverfahren, die sich hinsichtlich Zentralisierung und Dynamik unterscheiden: Zentralisierung: Wo werden Wegewahlen getroffen? o Zentral, in einem Netzkontrollzentrum. o Dezentral, verteilt über die Vermittlungsknoten. Dynamik: Welche Größen beeinflussen die Wegewahlen? o Nicht-adaptive Verfahren. Wegewahl sind fest vorgegeben oder lange Zeit konstant. Der Zustand eines Netzes hat keinen Einfluß auf die Wegewahl. o Adaptive Verfahren. Wegewahlen hängen vom Zustand des Netzes ab (Topologie, Lastveränderungen usw.). Routing-Algorithmen benutzen zwei grundlegende Verfahrensweisen: Teile der Welt mit, wer deine Nachbarn sind: Link-State-Routing-Protokolle (z. B. OSPF) sorgen dafür, daß nach einiger Zeit jeder Router die vollständige Topologie des Netzwerkes kennt und sich die kürzesten Wege darin selbst ausrechnen kann. Teile deinen Nachbarn mit, wie für sie die Welt aussieht: Bei DistanzvektorProtokollen (z. B. RIP) teilen sich die Router untereinander nur mit, wie "gut" sie an verschiedene Zielknoten angebunden sind. Durch Auswahl des für ein bestimmtes Ziel optimalen Nachbarn wird die Suche nach dem kürzesten Weg auf mehrere Router verteilt. Eine etwas verallgemeinerte Form der Distanzvektorprotokolle mit einer verbesserten Form der Schleifenerkennung sind die Pfadvektor-Protokolle (z. B. das Border Gateway Protocol (BGP)). Weiterhin werden Routing-Algorithmen nach Ihrer Zentralisierung und Dynamik beurteilt: Zentralisierung: Wo ist der Algorithmus lokalisiert? Zentral in einem Netzkontrollzentrum oder dezentral verteilt auf die Vermittlungsknoten? Dynamik: Bei nicht adaptiven Verfahren bleibt die Routingtabelle im Vermittlungsknoten, verglichen mit der Verkehrsänderung, über längere Zeit konstant. Ist das Verfahren adaptiv, hängen die Routingentscheidungen vom Zustand des Netzes ab (Topologie, Lastverhältnisse). Aus diesen Punkten ergibt sich ein Zielkonflikt, da zentrale, nicht adaptive Verfahren das Netz weniger mit Routingnachrichten belasten, aber möglicherweise veraltete und unvollständige Informationen über den Zustand des Netzes benutzen. Je adaptiver und verteilter die Routingverfahren sind, desto besser sind die Informationen über das Netz verteilt. Durch den Austausch von häufigen Nachrichten mit Routinginformationen wird das Netz jedoch stärker belastet. Die Routingverfahren suchen hier einen möglichst idealen Mittelweg. Routingverfahren lassen sich auf dieser Basis in folgende Teile aufteilen: Paketweiterleitung: o Verbindungslose Vermittlung (Datagramme) Für jedes Datagramm wird die Wegewahl neu getroffen. o Verbindungsorientierte Vermittlung (Session-Routing) Die Wegewahl wird bei der Verbindungserstellung getroffen. Alle Pakete einer (virtuellen) Verbindung verwenden denselben Weg. Wegewahl (Routing): o Routing-Protokoll (Protokoll zum Austausch von Informationen, die für die Wegewahl benötigt werden). o Routing-Algorithmen (Verfahren zur Bestimmung von Wegen). o Routing-Tabellen (Datenstrukturen, die die Wegeinformationen speichern). Statisches Routing Statisches Routing (Static Routing, Directory Routing) ist nicht adaptiv und einfach aber sehr häufig benutzt. Die Eigenschaften sind: Jeder Knoten unterhält eine Routing-Tabelle, in der jeder mögliche Zielknoten durch eine Zeile gekennzeichnet ist. Jede Zeile enthält ein oder mehrere Einträge für die zu verwendende Übertragungsleitung in Richtung des Zieles. Jeder Eintrag enthält auch eine relative Gewichtung. Zum Weiterleiten eines Paketes wird sein Ziel bestimmt, die entsprechende Zeile aus der Tabelle gesucht und aus ihr die "beste" Übertragungsleitung ausgewählt. Auf dieser wird das Paket weitergesendet. Zentralisiertes Routing Zentralisiertes Routing arbeitet auf einem zentralen Knoten (Routing Control Center RCC). Es handelt sich um ein adaptives Verfahren: Jeder Knoten sendet periodisch Zustandsinformationen an das RCC (wie den Leitungszustand, Auslastung, Verkehr usw.). Das RCC sammelt diese Informationen und berechnet optimale Wege durch das gesamte Netz. Das RCC übermittelt Routingtabellen zu jedem Knoten. In großen Netzen dauert die Berechnung sehr lange. Durch Ausfall des RCC kann das gesamte Netz inoperabel werden. Isoliertes Routing Beim isolierten Routing wird die Wegewahl von jedem Knoten nur aufgrund von Informationen, die er selber sammelt, getroffen. Eine Anpassung an den globalen Zustand eines Netzes ist nur mit Hilfe beschränkter Informationen möglich. Verteiltes adaptives Routing Diese Verfahren sind gekennzeichnet durch: Jeder Knoten tauscht periodisch Informationen für die Routing-Entscheidungen mit seinen Nachbarn aus. Routingtabellen werden anhand der Informationen von den Nachbarn bestimmt. Routing-Informationen werden entweder in bestimmten Intervallen synchron ausgetauscht. Routing-Informationen werden asynchron bei lokalen Änderungen an die Nachbarn weitergegeben. Hierarchisches Routing Bei großen Netzen ist die Speicherung und Übermittlung von Routing-Tabellen kaum noch möglich (Speicherplatz, Netzbelastung). Desweiteren verlangsamt das Durchsuchen langer Tabellen die Weiterleitung der Pakete erheblich. Daher verfährt man wie folgt: Aufteilung des Netzes in Regionen. Die Knoten in den Regionen haben nur Routing-Informationen über die eigene Region. Mindestens ein Knoten dient als Schnittstelle zu anderen Regionen. Eine Hierarchisierung in Regionen, Zonen usw. ist möglich. Routing im Internet Prinzipiell unterscheidet man im Internet je nach Zweck zwei verschiedene Arten von Routing: Intradomain-Routing findet innerhalb eines autonomen Systems statt (Intranet). Es verwendet sogenannte Interior Gateway-Protokolle (IGP). Es geht in den meisten Fällen um eine technisch effizienten Nutzung des Netzwerkes. Typisch ist eine Wegewahl entlang kürzester Pfade. Der Administrator versucht, durch geschicktes Konfigurieren des Routings das durch das Netzwerk übertragene Datenvolumen zu maximieren (Traffic Engineering). Interdomain-Routing bezeichnet das Routing zwischen autonomen Systemen. Es verwendet sogenannte Exterior Gateway-Protokolle (EGP), meist das Border Gateway Protocol (BGP). Da Interdomain-Routing das Routing zwischen verschiedenen Providern regelt, liegt der Fokus beim Interdomain-Routing normalerweise auf einer finanziell effizienten Nutzung des Netzes. Dem zugrunde liegt die Idee, daß ein autonomes System nicht allen seinen Nachbarn die gleichen Informationen (Routen) zukommen lässt. Welche Informationen ausgetauscht werden, wird vertraglich geregelt und dementsprechend die Router konfiguriert. Man spricht in diesem Zusammenhang auch von "policy-basiertem Routing". (Der Namensbestandteil "domain" bezieht sich auf das autonome System, er hat nichts mit den "DNS-Domains" zu tun.) Zusammenwirken von Protokollen Abhängig davon, ob ein Router Teil eines autonomen Systems ist oder dessen Grenze bildet, verwendet er oftmals gleichzeitig Routing-Protokolle aus verschiedenen Klassen: Interior Gateway Protocols (IGPs) tauschen Routing-Informationen in einem einzelnen autonomen System aus. Häufig verwendet werden: o IGRP/EIGRP (Interior Gateway Routing Protocol/ Enhanced IGRP) o OSPF (Open Shortest Path First) o IS-IS (Intermediate System to Intermediate System) o RIP (Routing Information Protocol) o MPLS (Multi-Protocol Label Switching) Exterior Gateway Protocols (EGPs) regeln das Routing zwischen verschiedenen autonomen Systemen. Dazu gehören: o BGP (Border Gateway Protocol) ist heute weltweit der de-facto-Standard (BGP4). o EGP (Exterior Gateway Protocol) verband früher die Internet-Backbones. Es ist inzwischen veraltet. Ad hoc Routing-Protokolle werden in Netzen mit wenig oder keiner Infrastruktur verwendet. o OLSR (Optimized_Link_State_Routing) findet meist Verwendung im mobilen Bereich. o AODV (Ad-hoc On-demand Distance Vector-Routing) findet in kleineren Netzen mit hauptsächlich statischem Traffic Verwendung. Layer-3-Switching Layer-3-Switching ist eine neue Technologie. Sie kombiniert leistungsfähiges Switching (Layer 2) mit skalierbarem Routing (Layer 3). Herkömmliche Switches verwenden die MACAdresse der Ethernet-Frames zur Entscheidung, wohin die Frames transportiert werden sollen, während Router Datenpakete anhand von Routingtabellen und Accesslisten auf Layer-3weitervermitteln. Router sind in vielen Installationen als reine LAN-to-LAN-Router im Einsatz, um Subnetze zu verbinden und die Nebeneffekte von rein geswitchten Netzen, wie z. B. Broadcast-Stürme, fehlendes Subnetting etc. zu verhindern. Router, die auf der Transportebene arbeiten, müssen jedes IP-Paket aus den Ethernet-Frames zusammenbauen und vielfältige Operationen an IP-Paketen durchführen. Dies führt zu einer Verzögerungszeit und, im Vergleich zu Switches, geringerem Datendurchsatz. In reinen IP-Netzen kann das Layer-3-Switching, auch "Fast IP" genannt, diese LAN-to-LAN-Router ersetzen. Der Layer3-Switch liest beim ersten IP-Paket sämtliche Frames dieses Paketes, analysiert die Absenderund Empfänger-IP-Adressen und leitet das IP-Paket weiter. Alle nachfolgenden Frames dieses Stationspaars können daraufhin anhand der MAC-Adresse weitergeleitet werden. Der Layer3-Switch behandelt IP-Pakete beim ersten Mal wie ein Router, nachfolgende Daten können auf Frame-Ebene geswitcht werden. Nicht-IP-Daten, wie z. B. IPX-Pakete, werden vom Layer-3-Switch auf Layer 2 geswitcht. Das Konzept des Layer-3-Switching bedingt eine Erweiterung des Ethernet-Frameformats und ist bisher nur proprietär implementiert. Die Erweiterung des Layer-3-Switching auf andere Layer-3-Protokolle wie z.B. IPX ist geplant. Es ist anzunehmen, daß die herstellerspezifischen Implementationen in einen gemeinsamen Standard münden. Terminalserver Ein Terminal-Server dient dazu, einem beliebigen Endgerät, sofern es eine serielle, asynchrone V.24 (RS 232 C)-Schnittstelle besitzt, die Verbindung zu einem Rechner herzustellen. Der Terminal-Server ist über einen Transceiver an das Ethernet angeschlossen und stellt dem Terminal-Benutzer eine Kommandoschnittstelle zur Verfügung, so daß er Verbindungen aufbauen, abbauen und Parameter (z.B. Echo) setzen kann. Ein Terminal kann meist mehrere Verbindungen haben und zwischen ihnen wechseln. Es gibt Terminal-Server für verschiedene Protokolle, z. B. für TCP/IP (Telnet) und DECnet (LAT) oder auch beides zugleich. Die meisten Terminal-Server haben acht Ports zum Anschluß von Endgeräten, sie können auch kaskadiert werden. Der Einsatz eines Terminal-Servers ist immer nötig, wenn es für das Endgerät keine Möglichkeit gibt, eine Ethernet-Karte einzubauen. Gateway Gateways können völlig unterschiedliche (heterogene) Netze miteinander koppeln. Sie stellen einen gemeinsamen (virtuellen) Knoten dar, der zu beiden Netzen gehört und den netzübergreifenden Datenverkehr abwickelt. Gateways werden einerseits für die LAN-WANKopplung (oder die LAN-WAN-LAN-Kopplung) andererseits für den Übergang zwischen unterschiedlichen Diensten verwendet (z. B. das Absetzen von Fax-Nachrichten aus einem LAN). Ein Gateway ist ein aktiver Netzknoten, der von beiden Seiten aus adressiert werden kann. Er kann auch mehr als zwei Netze miteinander koppeln. Gateways behandeln auf beiden Seiten unterschiedliche Protokolle bis hinauf zur Schicht 7. Insbesondere ist das Routing über Netzgrenzen (korrekte Adressierung!) hinweg eine wichtige Aufgabe des Gateways. Man unterscheidet im wesentlichen zwei Typen: Medienkonvertierende Gateways (Translatoren), die bei gleichem Übertragungsverfahren die Verbindung zwischen unterschiedlichen Protokollen der unteren beiden Ebenen (bei unterschiedlichem Transportmedium) herstellen - also dort, wo ein Router nicht mehr ausreichen würde. Protokollkonvertierende Gateways, die unterschiedliche Protokolle der Ebenen 3 und 4 abwickeln und ineinander überführen. Der Gateway unterstützt hauptsächlich zwei wichtige Dienste: Die Übermittlung aufeinanderfolgender Nachrichten zwischen Quelle und Ziel als unabhängige Einheit und das Etablieren einer logischen Verbindung zwischen Quelle und Ziel. Um auf die unterschiedlichen Anforderungen der Flußkontrolle der zu verbindenen Netze eingehen zu können, muß der Gateway gegebenfalls Daten zwischenspeichern. Ist eines der beteiligten Netze leistungsfähiger als das andere, muß der Gateway dies erkennen und das "schnellere" Netz bremsen. Arbeiten beide Netze mit unterschiedlichen Paketgrößen, müssen Datenpakete "umgepackt" werden. Dies kann ganz einfach dadurch geschehen, daß zu große Pakete in kleinere Pakete aufgespalten und am Ziel gegebenenfalls wieder zusammengesetzt werden. Firewall-Rechner Als Schutz vor Einbruchsversuchen in lokale Netze, die über einen Anschluß an öffentliche Netze verfügen (z. B. Internet, aber auch ISDN), haben sich Firewall-Rechner, kurz 'Firewalls' bewährt. Ähnlich der Zugbrücke einer Burg erlauben sie den Zugang nur an einer definierten Stelle. Damit läßt sich der Datenverkehr von und nach außen kontrollieren. Normalerweise sind zahlreiche Rechner des Unternehmens, die unter diversen Betriebssystemen laufen, direkt aus dem öffentlichen Netz erreichbar. Eine Firewall kanalisiert die Kommunikation, indem alle Daten von und nach außen über dieses System laufen müssen. Die Kanalisierung erhöht zudem die Chancen, einen Einbruchversuch anhand ausführlicher Protokoll-Dateien zu erkennen, da der Eindringling erst die Firewall passieren muß. Eine Firewall kann aus einer einzelnen Maschine oder aus einer mehrstufigen Anordnung bestehen. Eine mehrstufige Anordnung ist vor allem dann sinnvoll, wenn man bestimmte Dienste der Öffentlichkeit zur Verfügung stellen will, etwa einen WWW- oder FTP-Server. Die entsprechenden Hosts können dann in einem Zwischennetz isoliert werden. Architektur mit Dualhomed-Host Eine Architektur mit Dualhomed-Host wird um einen Rechner herum aufgebaut, der über mindestens zwei Netzwerkschnittstellen verfügt. Ein solcher Host ist als Router zwischen den Netzen einsetzbar, die an die Schnittstellen angeschlossen sind. Er kann dann IP-Pakete von Netz zu Netz routen. Für diese Firewall-Architektur muß diese Routingfunktion jedoch deaktiviert werden. IP-Pakete werden somit nicht direkt von dem einen Netz (dem Internet) in das andere Netz (das interne, geschützte Netz) geroutet. Systeme innerhalb der Firewall und Systeme außerhalb (im Internet) können jeweils mit dem Dualhomed-Host, aber nicht direkt miteinander kommunizieren. Der IP-Verkehr zwischen ihnen wird vollständig blockiert. Die Netzarchitektur für eine Firewall mit Dualhomed-Host ist denkbar einfach: der DualhomedHost sitzt in der Mitte, wobei er mit dem Internet und dem internen Netz verbunden ist. Ein Dualhomed-Host kann Dienste nur anbieten, indem er entsprechende Proxies (Stellvertreter) oder Gateways einsetzt. Es ist jedoch auch möglich, direkte Nutzerzugriffe zu gestatten (Sicherheitsrisiko). Architektur mit überwachtem Host Die "screened host architecture" bietet Dienste von einem Rechner an, der nur an das interne Netz direkt angeschlossen ist, wobei ein getrennter Router verwendet wird. Der Bastion-Host befindet sich im inneren Netz. Auf diesem Router verhindern Paketfilter das Umgehen des Bastion-Host. Die Paketfilterung auf dem Sicherheitsrouter muß so konfiguriert werden, daß der Bastion-Host das einzige System im internen Netz darstellt, zu dem Rechner aus dem Internet Verbindungen aufbauen können (das einzige "nach außen sichtbare" System). Zusätzlich sind nur gewisse Dienste zugelassen. Alle externen Systeme, die auf interne Systeme zugreifen wollen, und auch alle internen Systeme, die externe Dienste wahrnehmen wollen, müssen sich mit diesem Rechner verbinden. Daraus ergibt sich ein besonderes Schutzbedürfnis für diesen Bastion-Host. Der Vorteil bei dieser Konstruktion ist die Tatsache, daß ein Router leichter zu verteidigen ist. Dies liegt u. a. daran, daß auf ihm keine Dienste angeboten werden. Nachteilig wirkt sich aus, daß bei einer eventuellen Erstürmung des Bastion-Host das interne Netz vollkommen schutzlos ist. Architektur mit überwachtem Teilnetz Die "screened subnet architecture" erweitert die Architektur mit überwachtem Host um eine Art Pufferzone, die als Grenznetz das interne Netz vom Internet isoliert. Diese Isolierzone wird auch "Demilitarisierte Zone" (DMZ) genannt. Bastion-Hosts sind von ihrer Art her die gefährdetsten Rechner in einer Firewallkonstruktion. Auch wenn sie in der Regel mit allen Mitteln geschützt sind, werden sie doch am häufigsten angegriffen. Die Ursache liegt darin, daß ein Bastion-Host als einziges System Kontakt zur Außenwelt unterhält. Zur Software-Konfiguration einer Firewall existieren zwei Grundstrategien: 'Es ist alles erlaubt, was nicht verboten ist' Dieser Ansatz schließt die Nutzung bestimmter Dienste (z. B. tftp, nfs) generell aus. Er ist benutzerfreundlich, da neue Dienste automatisch erlaubt sind, aber auch gefährlich, da der Administrator das Verhalten der Nutzer ständig beobachten und rechtzeitig Gegenmaßnahmen treffen muß. 'Es ist alles verboten, was nicht erlaubt ist' Diese Strategie könnte von den Nutzern als hinderlich angesehen werden, da diese neue Dienste erst umständlich beantragen müssen. Sie schützt aber auch vor Sicherheitslücken im Betriebssystem und in Anwendungsprogrammen, da sie den Zugriff auf unbekannte Ports unterbindet. Es gibt drei Arten von Firewall-Softwaresystemen: Paketfilter überprüfen die Quell- und Zieladresse (IP-Adresse und TCP/UDP-Port) eines Pakets und entscheiden, ob es passieren darf oder nicht. Der Vorteil besteht in der Transparenz für den Anwender. Diese Transparenz ist aber zugleich von Nachteil: Paketfilter können nicht zwischen Nutzern und deren Rechten unterscheiden. Paketfilter sind im allgemeinen auf Routern angesiedelt und werden heute von den meisten Herstellern mitgeliefert. Intelligente Paketfilter analysieren zusätzlich den Inhalt der Pakete und erkennen auch die Zulässigkeit von Verbindungen, die einfache Paketfilter nicht erlauben würden (z. B. Datenverbindung bei ftp). Circuit Level Gateways sind mit Paketfiltern vergleichbar, arbeiten jedoch auf einer anderen Ebene des Protokollstacks. Verbindungen durch solch ein Gateway erscheinen einer entfernten Maschine, als bestünden sie mit dem Firewall-Host. Somit lassen sich Infomationen über geschützte Netzwerke verbergen. Application Gateways, auch 'Proxy' (Stellvertreter) genannt, stellen ein anderes Firewall-Konzept dar. Hierbei wird auf dem Firewall-Host für jede zulässige Anwendung ein eigenes Gateway-Programm installiert. Der Client muß sich dabei oftmals gegenüber dem Proxy-Programm authentifizieren. Dieser Proxy führt dann alle Aktionen im LAN stellvertretend für den Client aus. Damit lassen sich zum einen benutzerspezifische Zugangsprofile (welche Zeiten, welche Dienste, welche Rechner) erstellen, zum anderen kann man die Festlegung der zulässigen Verbindungen anwendungsbezogen vornehmen. Die daraus resultierenden separaten kleinen Regelsätze bleiben besser überschaubar als der komplexe Regelsatz eines Paketfilters. Application Gateways sind typische Vertreter der 'Verboten-was-nicht-erlaubt'Strategie und als die sicherste, aber auch aufwendigste Lösung einzuschätzen. Da beim Proxy alle Zugriffe nach außen über eine Instanz laufen, kann man den Proxy gleichzeitig als Cache (Pufferspeicher) benutzen. Der Proxy speichert alle erhaltenen WWW-Seiten zwischen, so daß er bei einem erneuten Zugriff darauf - egal, ob vom selben oder einem anderen Anwender - keine Verbindung nach außen aufbauen muß. Der Einsatz von Firewalls bietet sich auch innerhalb einer Organisation an, um Bereiche unterschiedlicher Sensitivität von einander abzugrenzen. Firewalls bieten jedoch niemals hundertprozentige Sicherheit! Sie schützen nicht vor dem Fehlverhalten eines authorisierten Anwenders und können, etwa durch eine zusätzliche Modem-Verbindung, umgangen werden. Mehr zu diesem Thema finden Sie im Firewall-Kapitel des Sicherheits-Skripts. VLAN - virtuelle lokale Netzwerke Was ist ein VLAN? Die Abkürzung VLAN steht für "virtuelles LAN", also eine Netzstruktur mit allen Eigenschaften eines gewöhnlichen LAN, jedoch ohne räumliche Bindung. Während die Stationen eines LAN nicht beliebig weit auseinander liegen können, ermöglicht es ein VLAN hingegen, weiter entfernte Knoten zu einem virtuellen lokalen Netzwerk zu verbinden. VLANs sind geswitchte Netze, die logisch segmentiert werden können. Ohne Beschränkung durch die räumliche Position ist möglich, Server und Workstations nach ihrer Funktion zu dynamischen Arbeitsgruppen zusammenzufassen. VLANs können transparent und ohne physikalische Veränderungen des Netzes eingerichtet werden. Eine Umgliederung ist ohne Umpatchen oder Verlegen von Rechnern möglich, im Idealfall kann sie über Software erfolgen. Ein VLAN ist weiters eine Broadcast- und Kollisionsdomäne, die sich auch über mehrere Switches erstrecken kann. Der Broadcastverkehr ist nur in dem VLAN sichtbar. Diese Möglichkeit, VLANs komplett voneinander zu isolieren, erhöht die Sicherheit. Der Verkehr zwischen VLANs muß geroutet werden, hier gibt es Lösungen, die die Geschwindigkeit von Switches erreichen. Innerhalb des VLAN ist hingegen kein Routing nötig. Beliebige Netzteilnehmer aus verschiedenen Segmenten können nach unterschiedlichen Kriterien (Switch-Port, MAC-Adresse, Protokoll der Netzwerkschicht, logische Netzwerkadresse, Applikation) zu einem virtuellen Netz vereint werden, ohne daß das Netz physikalisch umstrukturiert werden muß. Warum virtuelle Netze? Broadcasts werden nicht über das gesamte Netzsegment verbreitet Einfache Abbildung der Organisationsstruktur auf die Netzwerkstruktur Unterstützung dynamischer Workgroups Räumliche Entfernung der Mitarbeiter spielt keine Rolle bei der Aufgabenverteilung Jeder Mitarbeiter zieht etwa alle paar Jahre innerhalb des Unternehmens um, verbleibt aber in seiner logischen Arbeitsgruppe Server in zentralen Technikräumen werden entfernten Arbeitsgruppen zugeordnet Teilweise kein Routing mehr nötig Bisher wurden Netze mit Hilfe von Routern segmentiert. Router sind teuer, es entstehen viele Subnetze, die Router beanspruchen viel Rechenzeit und der IP-Adressraum wird schnell zu klein. VLANs vereinigen die Vorteile von Bridges und Routern: Eine Station kann leicht hinzugefügt, entfernt oder geändert werden und das Netz kann strukturiert werden. Es können beispielsweise virtuelle Benutzergruppen gebildet werden und es ist nicht mehr erforderlich, Benutzer nur deshalb verschiedenen Subnetzen zuzuordnen, weil ihre räumliche Entfernung zu groß ist. Server, die in zentralen Räumen untergebracht sind, können räumlich entfernten Workgroups zugeordnet werden. VLANs können helfen, Geld zu sparen, denn Switches sind billiger als Router und leichter zu administrieren. Gerade das Ändern von Subnetzadressen, das mit VLANs vermieden wird, ist in großen Netzen sehr aufwändig und damit teuer. Der Broadcast-Traffic wird nicht auf alle Ports übertragen, sondern bleibt im entsprechenden VLAN. Broadcasts in fremden VLANs sind nicht sichtbar. Realisierung von VLANs VLANs werden mittels Switches gebildet. Diese unterstützen an jedem Port die volle Bandbreite und transportieren die Daten schneller als Router. Netzteilnehmer können nach verschiedenen Kriterien zu virtuellen Netzen vereinigt werden, und eine ManagementSoftware ermöglicht ggf. eine komfortable Verwaltung und Konfiguration der VLANs. Zur Inter-VLAN-Kommunikation muß Routing eingesetzt werden. Entweder ist ein Router über mehrere physische Ports als Teil mehrerer VLANs eingerichtet, oder es wird VLANTrunking eingesetzt. In diesem Fall muß der Router VLAN-Tags erkennen und verändern können. Abbilden von Ports auf VLANs Ausgangsbasis sind ein Switch oder mehrere miteinander verbundene Switches, bei denen die Ports unterschiedlichen VLANs zugeordnet werden. Die einfachste Form wäre ein Switch, bei dem die Hälfte der Ports dem VLAN A und die andere Hälfte dem VLAN B zugeordnet ist. Um den Geltungsbereich eines VLANs festzulegen, gibt es mehrere Strategien: 1. VLAN A belegt die Ports 1 bis k, VLAN B die Ports k+1 bis n. 2. Der Switch kann mit einer VLAN/Port-Zuordnung konfiguriert werden. 3. Der Switch kann mit einer VLAN/MAC-Adressen-Zuordnung konfiguriert werden. Er bestimmt dann dynamisch die VLAN/Port-Zuordnung aufgrund der MAC-Adresse. 4. Der Switch kann mit einer VLAN/IP-Präfix-Zuordnung konfiguriert werden. Er bestimmt dann dynamisch die VLAN/Port-Zuordnung aufgrund der Quell-IP-Adresse. 5. Der Switch kann mit einer VLAN/Protokoll-Zuordnung konfiguriert werden. Er bestimmt dann dynamisch die VLAN/Port-Zuordnung aufgrund des Protokolltyps. Bei den ersten beiden Punkten spricht man von "Port-basierenden VLANs", bei Punkt drei von "Level-2-VLANs" und den letzten Punkten von "Protokoll-basierenden VLANs". Port-basierende VLANs Die Ports eines Switches werden unterschiedlichen VLANs zugeordnet. An einem Port können immer nur Angehörige desselben VLANs angeschlossen sein. Die starre Zuordnung zwischen Port und VLAN vereinfacht die Fehlersuche. Soll eine Station zu mehreren VLANs gehören, so sind aber mehrere Netzwerk-Adapter nötig. Bei Broadcasts ist eine hohe Sicherheit gewährleistet. Die Flexibilität bei Umzügen ist nicht groß, denn ein Umzug einer Station muß durch den Administrator im VLAN-Manager nachgeführt werden. Im Gegensatz zu der Gruppierung nach MAC-Adressen oder IP-Adressen kann das Engerät nicht einfach den Umzug bekannt geben und das VLAN automatisch umgestaltet werden. Dieses Verfahren ist weit verbreitet, es ist durch IEEE 802.1Q standardisiert und wird von vielen Herstellern unterstützt. Level-2-VLANs Die Zugehörigkeit zu einem VLAN richtet sich nach der MAC-Adresse. Der Switch muß bei jedem empfangenen Datenpaket entscheiden, zu welchem VLAN es gehört. So können an einem Port auch Stationen verschiedener VLANs angeschlossen sein, aber es kann in diesem Fall auch zu Performance-Verlusten kommen. Der Umzug von Stationen ist leicht möglich, da die Zuordnung zum VLAN ja erhalten bleibt. Problematisch ist die Initialisierung, da die MAC-Adressen aller Endgeräte erfasst werden müssen. Gerade in großen Netzen, wo häufig VLANs eingerichtet werden müssen, ist dann aber die VLAN-Konfiguration der einzelnen Arbeitsplätze wieder sehr zeitaufwendig. Schema eines Netzwerkes aus zwei Layer-2 Switches und einem Router. Der Layer-2-Switch interpretiert wie eine Bridge nur die MAC-Adresse der Pakete. Es kann aber im Unterschied zu dieser parallel arbeiten und mehrere Pakete gleichzeitig weiterleiten, etwa von Port A nach C und von B nach D. Sobald jedoch mehrere Switches vernetzt sind, muß sichergestellt werden, daß die Adreßtabellen in allen Switches konsistent sind. Dazu müssen regelmäßig Informationen über das Netz übertragen werden. Genau dies ist aber das Hauptproblem der VLANs. Jeder Hersteller verwendet für diesen Informationsabgleich eigene Verfahren. Deshalb verstehen sich die Switches verschiedener Produzenten oft nicht. U. a. gibt es: den regelmäßigen Austausch der Adreßtabellen mit MAC-Adressen und VLANNummer. Die Tabellen werden etwa einmal pro Minute ausgetauscht. das Frame Tagging, bei dem die VLAN-Nummer als Tag vor das MAC-Paket gesetzt. Die zulässige Paketlänge kann dabei überschritten werden. das Zeitmultiplexverfahren, bei dem der Backbone zwischen den Switches in ZeitSlots aufgeteilt wird, die fest den einzelnen VLANs zugeordnet sind. Protokoll-basierende VLANs Layer-3-Switches bieten zusätzliche Möglichkeiten durch Basis-Routing-Funktionalität wie z.B. ARP. Der externe Router wird somit oft überflüssig. Diese Variante ist langsamer, da auch Layer-3-Informationen ausgewertet werden müssen. Die Zuordnung einzelner Datenpakete zu verschiedenen virtuellen LANs geschieht durch Auswertung der Subnetzadressen oder portbasiert. Innerhalb eines VLAN wird auf Layer 2 geswitcht. Bei der Verwendung nicht routingfähiger Protokolle treten Schwierigkeiten auf und dynamische Adresszuordnungsverfahren können nicht eingesetzt werden. Layer-3-Switches verwenden Routerfunktionen zur Definition virtueller Netze. Um effizient arbeiten zu können, wird innerhalb eines VLAN nur gebridged. Regelbasierende VLANs Hier werden logische Zuordnungen eingesetzt und die VLAN-Zugehörigkeit wird anhand des Ports, der MAC-Adresse, des Protokolls oder der Netzadresse bestimmt. Das System ist besonders flexibel, der Administrator kann selbst eine Balance zwischen Sicherheit, Verkehrsoptimierung und Kontrolle erreichen, aber dafür ist die Einrichtung aufwendig. Durch die Abarbeitung der einzelnen Regeln ergibt sich eine hohe Latenzzeit. Layer-2-Switches Layer-2-Switches arbeiten unabhängig von darüber liegenden Protokollen auf der Data-LinkLayer und garantieren eine transparente Verbindung der Endgeräte. Während des Betriebs lernt ein Switch alle MAC-Adressen und ordnet sie in einer MAC-Tabelle den Anschlussports zu. In dieser Tabelle sucht der Switch nach der Zieladresse und dem zugeordneten Zielport. Die Adresstabellen der Switches müssen um die Adressen der VLANs ergänzt und immer am aktuellen Stand gehalten werden. Dafür stehen hauptsächlich folgende Verfahren zur Verfügung: Austausch der MAC-Adresstabellen Wie beim Routing tauschen auch die Switches Informationen aus um ihre Adresstabellen abzugleichen. Wird eine neue Station an das Netz angeschlossen, so erkennt der lokale Switch am Port, zu welchem VLAN die Station gehört und ergänzt seine Adresstabelle. Dann sendet er die MAC-Adresse und die Adresse des VLANs an die anderen Switches. Wenn alle Switches die neue Endstation kennen, können deren Daten übertragen werden. Time Division Multiplexing (TDM) Beim Zeitmultiplexverfahren wird der Backbone, der die Switches verbindet, in Zeitslots aufgeteilt und jedes VLAN erhält exklusiv einen oder mehrere Slots zur Datenübertragung. Die Switches müssen nur wissen, welcher Zeitslot welchem VLAN zugeordnet ist. Es entfällt zwar der Overhead durch den Austausch von Adresstabellen oder aufgrund von Tags, aber Bandbreite, die von einem VLAN nicht genutzt wird, steht nicht für andere VLANs zur Verfügung. Für den sinnvollen Einsatz dieses Verfahrens ist eine an das tatsächliche Netzverhalten angepasste Zuordnung der Zeitslots nötig. Frame Tagging Das Frame Tagging wird am häufigsten eingesetzt. Beim impliziten Tagging werden keine zusätzlichen Informationen in das Datenpaket eingefügt, sondern die TaggingInformation wird aus der vorhandenen Header-Information hergeleitet und vom Switch in Tabellen gespeichert. Dadurch werden vorhandene Standards nicht verletzt. Beim expliziten Tagging wird in den Ethernet-Frame ein Marker (Tag) eingesetzt (VLAN-ID), der angibt, zu welchem VLAN das Datenpaket gehört. Dadurch ist kein Austausch von Adresstabellen nötig. Der erste Switch, der ein bestimmtes Datenpaket erhält, analysiert es auf seine VLAN-Zugehörigkeit und fügt die Kennung des VLANs als Tag an. Das Paket wird am Backbone von Switch zu Switch weitergeleitet, der letzte Switch entfernt das Tag und übergibt das Paket der Endstation. Die Switches müssen sehr leistungsfähig sein, um möglichst mit Wirespeed die Paketinformationen auswerten und mit den Tabellen vergleichen zu können. Das Einfügen von zusätzlicher Information in das Paket ist problematisch, wenn die Datenpakete schon die maximal zulässige Länge erreicht haben. Durch das Hinzufügen eines weiteren Tags würden dann die Vorgaben des MAC-Protokolls verletzt, das Paket als fehlerhaft erkannt und vernichtet. Daher setzen die Hersteller spezifische Techniken zur Vermeidung dieses Problems ein (Kapselung Encapsulation) - siehe unten. Layer-2-Systeme sind leichter zu konfigurieren als Ebene-3-VLANs, benötigen weniger Software und sind meist preisgünstiger und schneller. Außerdem sind sie protokollunabhängig und können auch nicht routbare Protokolle bedienen. Layer-3-Switches Layer-3-Switches arbeiten auf der Netzwerkebene (Layer 3 des ISO/OSI-Modells). Sie integrieren Routing-Funktionalität in die VLANs und machen externe Router zur Verbindung der VLANs überflüssig. Daher werden sie auch als "Switched Router" bezeichnet. Layer-3-Switches können Ebene-3-Informationen auswerten und deshalb VLANs auch abhängig vom verwendeten Protokolltyp definieren. So kann man z.B. alle IP-Stationen oder alle Netware-Stationen ortsunabhängig zu einem VLAN zusammenfassen. In Schicht-3-VLANs werden eigentlich nicht Endgeräte, sondern Datenpakete den VLANs zugeordnet. Diese Zuordnung geschieht durch Auswerten der Subnetzadressen und es ist kein Informationsaustausch zwischen den Switches wie bei den Layer-2-Systemen nötig. Obwohl auch die Ebene-3-Informationen ausgewertet werden, muß die RoutingFunktionalität nur zwischen den VLANs eingesetzt werden. Layer-3-Switches müssen auch Routing-Protokolle beherrschen. Unbekannte Datenpakete werden innerhalb des VLANs an alle Stationen geschickt (Broadcast). Der Broadcast-Traffic kann aber durch Bildung von Subnetzen eingedämmt werden. Im Vergleich zu klassischen Routern erlauben Layer-3-Switches einen sehr schnellen Durchsatz auf Ebene 3, da die Zuweisung der Daten über spezielle Hardware erfolgt. "Wirespeed Switched Router" sind in der Lage, Pakete ohne Verzögerung, also mit Leitungsgeschwindigkeit, weiterzuleiten. Für den Umzug von Mitarbeitern ist keine manuelle Rekonfiguration des Netzwerks nötig, sondern der Switch lernt automatisch die neuen Verbindungen und baut daraus Routing- bzw. Switching-Tabellen auf. Layer-3-Systeme sind für komplexe Netzwerke besser geeignet, der Overhead zur Synchronisation fällt weg. Broadcast kann gezielter übertragen werden und es stehen Filtermöglichkeiten zur Sicherung der VLANs zur Verfügung. Dynamische VLAN-Bindung, Switch-Switch Sehen wir uns nun den Fall an, wenn ein Switch an einen anderen Switch angeschlossen ist: Auf der Verbindung zwischen den beiden Switches können Pakete entweder zu VLAN 1 oder VLAN 2 gehören. Das Schema zum Hinzufügen von zusatzlichen Informationen zu einem Paket ist vom IEEE standardisiert. Es handelt sich um die "VLAN-Marke", damit Switches wissen, für welches VLAN ein Paket bestimmt ist. Ein Endgerät wäre jedoch verwirrt, wenn es ein Paket mit einer VLAN-Marke erhalten würde. Folglich müssen die Switches wissen, an welche Ports Switches und an welche Ports Endgeräte angeschlossen sind. Ein Switch entfernt die VLAN-Marke vom Paket, bevor er es zu einem Nicht-Nachbarswitch-Port weiterleitet. Die VLAN-Marke ist eine 2-Byte-Zahl, die drei Bits für die Prioriät, zwölf Bits für eine VLAN-ID und ein Bit enthält, das anzeigt, ob die Adressen im kanonischen Format vorliegen. Durch den Ethernet-Typ 81-00 wird angezeigt, daß eine VLANMarke vorhanden ist. Beispielsweise ist ein Ethernet-Paket folgendermaßen aufgebaut: Dasselbe Paket mit VLAN-Marke sieht dann folgendermaßen aus: Ein Paket im 802.3-Format wird in ein Format mit einer VLAN-Marke umgesetzt, indem dieselben vier Bytes (81-00 für Ethertype und die 2-Byte-VLAN-Marke) wie im EthernetPaket hinzugefügt wurden. Die Längenangabe und weitere Felder werden analog nach hinten verschoben. Auf anderen LANs als 802.3 ist es nicht möglich, das Ethernet-Format zu verwenden. In diesem Fall wird eine andere Kodierung verwendet, um die VLAN-Marke einzufügen. Ein Switch kann alle VLANs "lernen", die auf dem Port verügbar sind, der ihn mit einem anderen Switch verbindet. Er tut dies auf der Grundlage der VLAN-Marken in den Paketen, die auf diesem Port empfangen werden. Da die Endgeräte die VLAN-Marke nicht verstehen, muß der Switch so konfiguriert sein, daß er niemals ein Paket mit einer VLAN-Marke zu einem Port sendet, auf dem sich ein Endgerät befinden könnte. Einige Switch-Anbieter haben einen anbieterspezifischen Mechanismus zum Informationsaustausch darüber, welche VLANs auf dem Switch-zu-Switch-Port erreichbar sind. Auf diese Art lernt der Switch die VLANs über explizite Protokollnachrichten. Bisher existiert jedoch kein Standard dafür. Neues Kapitel Störquellen Auf die Verkabelung eines Netzes wirken die mannigfachsten elektromagnetischen Störquellen ein, z. B. elektrisch angetriebene Maschinen, Leuchtstofflampen, die Computer, Kopierer, und vieles andere. Aber auch die Kabel selbst verändern das Signal durch ihren ohmschen Widerstand und die Teifpaßcharakteristik. Alle Einflüsse ändern das eingespeiste digitale Signal - unter Umständen bis hin zu Fehlern auf Empfängerseite. Das Bild zeigt die wichtigsten Störeinflüsse und deren Auswirkungen. Dämpfung Wie schon erwähnt, wirkt die Leitung wie ein Tiefpaßfilter: sie läßt nur niedrige Frequenzen durch, hohe werden herausgefiltert. Diese Tiefpaßeigenschaft der Leitung zwingt dazu, nach einer gewissen Leitungslänge Verstärker (Repeater) einzubauen, um das Signal wieder zu regenerieren. Das Verhältnis von Aus- zu Eingangsspannung wird Dämpfung genannt und in Dezibel (dB) angegeben. Dabei gilt: 1 dB = 20 * log(Eingangsspannung/Ausgangsspannung) Ideal ist natürlich ein Verhältnis von 1:1 zwischen Ein- und Ausgangsspannung, also eine Dämpfung von 0 dB. Das bleibt aber ein Ideal, da jede Leitung einen gewissen Widerstand hat. Die naheliegendste Abhilfe liegt im Einsatz der Zwischenverstärker. Doch auch diesen sind prinzipielle Grenzen gesetzt. Auch mit Verstärkerelementen, sogenannten Repeatern, sind nicht beliebig lange Leitungen realisierbar. Auf jede Leitung wirken Störungen ein. Diese elektrischen Signale weisen meist ein zufällig verteiltes Frequenzspektrum auf. Alle möglichen Nutzfrequenzen werden also mehr oder weniger stark gestört. Wichtig ist dabei,daß das Nutzsignal noch eindeutig erkennbar bleibt. Das Amplitudenverhältnis von Nutz- und Rauschsignal (in dB) nennt man Störabstand oder auch Signal-Rausch-Abstand. Repeater können aber in der Regel nicht zwischen Nutz- und Störsignal unterscheiden, sondern verstärken das gesamte Eingangssignal. Damit hat zwar das Ausgangssignal einen hohen Pegel, aber der SignalRausch-Abstand hat sich dabei nicht verbessert. Auf der nächsten Leitungsstrecke kommt zwangsläufig wieder Rauschen dazu, so daß mit wachsender Leitungslänge das Nutzsignal von immer mehr Rauschen überlagert wird. Wenn der Rauschpegel genauso groß ist wie der Nutzpegel, kann kein Empfänger mehr Nutzund Störsignal voneinander unterscheiden. Einige Tricks gibt es doch, der einfachste ist natürlich eine möglichst undurchlässige Abschirmung der Leitung, um das Eindringen des Rauschens zu verringern. Sonst wäre das weltumspannende Telefonnetz überhaupt nicht funktionsfähig. Bei der Verlegung von Datenleitungen kommt es aber nicht allein auf eine gute Abschirmung an. Immer dann, wenn es um die elektrische Anpassung der Leitung an ein Gerät oder eine andere Leitung geht, kommt es auch auf die Beachtung des Eingangswiderstands oder der Impedanz der Leitung an. Anpassung ist immer dann gegeben, wenn der Ausgangswiderstand der einen Leitung genauso groß ist wie der Eingangswiderstand der anderen. Denn nur in diesem Fall kommt es nicht zu Reflexionen an den Übergangsstellen. Sonst geht eine ankommende Welle nicht vollständig in das neue Medium über, sondern wird teilweise an der Nahtstelle reflektiert und damit zum Störsignal. Begrenzung der Bandbreite Man kann sich ein typisches Digitalsignal auch zusammengesetzt aus einer größeren Anzahl von Sinussignalen unterschiedlicher Freqenzen vorstellen. Je höher die Frequenz ist, desto geringer ist die Amplitude des jeweiligen Signals. Von diesen Frequenzen gelangen nur die Anteile zum Empfänger, die innerhalb der Bandbreite der Übertragungsstrecke liegen. Je geringer die Bandbreite des Mediums ist, desto mehr wird das Rechtecksignal "verschliffen". Am Empfangsort muß dann die Rechteckform wieder regeneriert werden. Nyquist hat eine Formel abgeleitet, mit der sich die maximale Datenübertragungsrate bei gegebener Bandbreite ermitteln läßt. Bei einem Digitalsignal (also zwei unterschiedliche Signalpegel) können bei einer Bandbreite von B (in Hertz) 2*B Bit pro Sekunde Übertragen werden. Allgemein lautet die Formel für die Übertragungsrate C (in Bit/s) bei einer Bandbreite B und einer Anzahl der Signalpegel M: C = 2*B*ld(M) In der Praxis wird dieser Idealwert natürlich nicht erreicht, weil andere Störgrößen (z. B. Rauschen) dies verhindern. Eine Begrenzung der Bandbreite kann durch zu hohe Dämpfungswerte oder falsche Kabeltypen hervorgerufen werden. Insbesondere sollte man bei der Twisted-Pair-Verkabelung die geringe Mehrausgabe nicht scheuen und gleich Typ-5Kabel für 100 MBit/s verwenden, auch wenn man noch mit 10 MBit/s arbeitet. Bei einer späteren Aufrüstung ist das Neuverlegen wesentlich teuerer. Meist tritt jedoch die Bandbreitenbegrenzung bei WAN-Verbindungen über Modem in Erscheinung. Die derzeit erreichbaren Raten von 33600 bps und mehr sind bei normalen Telefonverbindungen schon am Rande des technisch möglichen. Verzerrungen durch Laufzeit Die Geschwindigkeit, mit der ein sinusförmiges Signal in einem Medium transportiert wird, variiert mit der Freqenz. Wenn also ein Rechtecksignal übertragen wird, das wir uns als Gemisch von Sinussignalen unterschiedlicher Frequenz vorstellen, dann kommen die einzelnen Frequenzanteile zu verschiedenen Zeiten beim Empfänger an (Laufzeitverzerrungen). Die Verzerrungen nehmen mit steigender Datenrate noch zu, weil das Signalgemisch nicht homogen wie bei einem stetigen 0-1-Wechsel ist. Die Signalanteile, die durch die Flanken des Digitalsignals hervorgerufen werden, kommen häufiger vor und interferieren zusätzlich mit anderen Signalanteilen. Man spricht deshalb auch von 'Intersymbol-Interferenzen'. Diese können dazu führen, daß bei der Abtastung des Signals beim Empfänger in der nominellen Bitmitte Fehler auftreten können. Bei manchen Empfängerschaltungen versucht man diesen Fehler zu umgehen, indem der Abtastzeitpunkt adaptiv geändert wird. Die Laufzeitverzerrungen sind auch der Grund dafür, daß nicht beliebig viele Repeater hintereinandergeschaltet werden können. Rauschen In einem idealen Übertragungskanal sind in Übertragungspausen außer dem Ruhepegel keinerlei elektrische Signale festzustellen. In der Praxis stahlen jedoch mannigfache elektromagnetische Wellen auf das Kabel ein. Quellen solcher Störsignale sind alle elektrischen Geräte und Maschinen in der Umgebung der Leitung und nicht zuletzt auch die natürliche Strahlung von Erde und Atmosphäre. Die Freqenzen und Feldstärken sind von zufälligen Faktoren abhängig. Alle diese auf das Übertragungsmedium einwirkenden zufälligen Signale nennt man 'Rauschen'. Dieses Rauschen läßt sich durch keinerlei Maßnahmen vollständig beseitigen, sondern nur mildern, z. B. durch abgeschirmte Kabel. Aber auch innerhalb der Übertragungsstrecke, etwa durch die Bewegung der Elektronen im Leiter wird ein, wenn auch sehr schwaches, zusätzliches Signal erzeugt. In den Übertragungsweg geschaltete Verstärker, z. B. Repeater, verstärken natürlich nicht nur das Nutzsignal, sondern auch den Rauschanteil. Wenn das Rauschen einen gewissen Pegel übersteigt, kann dies zu empfängerseitigen Fehlern führen. Von besonderem Interesse ist das Verhältnis von Nutzsignal zum Störsignal, da dieses 'Signal-Rauschverhältnis' wie schon die vorher erwähnte Bandbreite die maximale Übertragungsrate beeinflußt. Speziell bei der modulierten Übertragung spielt dieser Faktor eine wichtige Rolle. Das Signal-Rauschverhältnis wird meist in Dezibel angegeben: SR = 10 * log(Signalpegel/Rauschpegel) dB Ein hoher Wert für SR impliziert einen weiten Abstand zwischen Signalpegel und Rauschpegel. Ein niedriger Wert steht für 'schlechte' Leitungen. Ein schlechter Wert läßt sich immer auf zwei Wegen verbessern; entweder durch Anheben des Signalpegels oder durch reduzieren des Rauschpegels. Das theoretische Maximum der Datenübertragungsrate C abhängig von SR und der Bandbreite B wird durch das Gesetz von Shannon-Hartley definiert: C = B * ld(1 + SR) bps Maßnahmen zur Senkung des Rauschpegels sind einerseits Abschirmung (beim Koaxkabel), im Einstreuung von Störsignalen zu verhindern, und andererseits Differenzsignale (bei Twisted Pair), bei denen sich die eingestreuten Störungen auf den beiden Leitungen kompensieren. Reflexionen, Rückflußdämpfung, Nebensprechen Die meisten Netzverkabelungen setzen mittlerweile auf einer einheitlichen physischen Infrastruktur auf die bestimmten Anforderungen genügen muß. Die international wichtigsten Normen für Netzwerkverkabelungen sind: TIA 56813, ISO/IEC 11801 und DIN/EN 50173. Die Normen unterscheiden verschiedene Leistungsklassen der Netzwerkverkabelung: die TIA, die bekannten Kategorien Cat 3, Cat 5, Cat 5E, Cat 6 und Cat 7, und die ISO/IEC und EN die Klassen C, D, E und F. Category Type Spectral Length LAN Applications Notes B/W Cat3 UTP 16 MHz 100m 10Base-T, 4Mbps Now mainly for telephone cables Cat4 UTP 20 MHz 100m 16Mbps Rarely seen Cat5 UTP 100MHz 100m 100Base-Tx,ATM, Common for current LANs CDDI Cat5e UTP 100MHz 100m 1000Base-T Common for current LANs Cat6 UTP 250MHz 100m Emerging Cat7 ScTP 600MHz 100m Die Normen definieren verschiedene Verbindungsarten, englisch "Link". Die Basic Link Definition schließt die Messkabel mit ein. Inzwischen wird aber normkonform nur noch nach Permanent Link oder Channel gemessen. Bei der Permanent-Link-Messung (PL) darf der Einfluss der Messkabel nicht in die Messwerte eingehen. Damit belegt der Installateur seinem Auftraggeber die Funktion genau der Strecke, die er installiert hat, üblicherweise das fest verlegte Kabel inklusive der Dosen an beiden Enden. Die dritte Link-Definition, der Channel, schließt die Patchkabel mit ein, mit der die Endgeräte an die fest installierte Strecke angeschlossen werden. Bei dieser Messung wird der gesamte Übertragungsweg, über den die Netzkommunikation läuft, erfasst. Nicht in den Messwerten niederschlagen dürfen sich nach der normgemäßen Channel-Definition die Anteile der letzten Steckverbinder, mit denen die Patchkabel an die Messgeräte angeschlossen werden. Ein automatischer Test an einer Netzverkabelungs-Strecke schließt nach Norm die folgenden Messungen und Prüfungen ein: Verdrahtungsplan (Wiremap): Überprüft werden alle vier Aderpaare und Schirme auf Durchgang, Schluss und Vertauschung, wobei der Fehler "Split" besonders tückisch ist: Laufzeit, Laufzeitunterschied und Längen (Delay, Delay Skew und Length): Das Messgerät ermittelt die Signallaufzeiten auf allen Aderpaaren. Aus der Laufzeit errechnet der Kabelscanner unter Verwendung des NVP-Werts die Kabellänge. Auf Grund der unterschiedlichen Verdrillung sind die Laufzeiten auf den vier Aderpaaren leicht unterschiedlich. Damit Übertragungen, die Daten parallel über mehrere Aderpaare versenden, zuverlässig funktionieren, muß gewährleistet sein, daß die parallel gesendeten Daten auch gleichzeitig ankommen. Gleichstrom-Schleifenwiderstand (DC Loop Resistance): Den GleichstromSchleifenwiderstand sollte man nicht mit der Kabelimpedanz (komplexe Kabeleigenschaft) verwechseln, deren Ermittlung im Rahmen einer normalen Abnahmemessung einer installierten LAN-Verkabelung von keiner aktuellen Norm verlangt wird. Dämpfung bzw. Einfügedämpfung (Attenuation/Insertion Loss): Es wird die Dämpfung im Frequenzbereich der zu Grunde gelegten Norm für jedes Aderpaar erfasst und bewertet. Nahnebensprechen (Near End Crosstalk, NEXT): Da dieser Effekt frequenzabhängig ist, wobbelt der Tester alle Frequenzen durch (daher der Name Cable-Scanner, Wobbel-Messtechnik), die die Norm für die betreffende Kategorie bzw. Klasse fordert, für Cat 6/Klasse E also von 1,0 bis 250 MHz. Im NEXT-Test sendet das Messgerät jeweils auf einem Paar ein Signal und misst, wie viel davon in die verschiedenen benachbarten Paare eingekoppelt wird. Bei einem 4-Paar-Kabel ergeben sich so sechs Aderpaar-Kombinationen, nämlich 12-36, 12-45, 12-78, 36-45, 36-78 und 45-78, Entsprechend ergeben sich sechs Frequenzgangkurven. Da das NEXT von beiden Seiten der Leitung gemessen werden muß, erhält man insgesamt 12 Kurven. Starkes Übersprechen (niedriger Zahlenwert!) ist eine der häufigsten Ausfallursachen bei Abnahmemessungen. Gute Kabelscanner zeigen das NEXT im Abstand vom Messpunkt so, daß man Aufschluß darüber erhält, wie viel NEXT an den Steckverbindungen oder auf der eigentlichen Kabelstrecke auftritt. Attenuation to Crosstalk Ratio, ACR: Dies ist die Differenz von Dämpfung und NEXT und gibt Auskunft über den Störabstand zwischen dem (gedämpften) Nutzsignal und dem Störsignal NEXT. Der ACR wird nicht direkt gemessen, sondern auf Grundlage der gemessenen Dämpfungs- und NEXT-Werte vom Tester errechnet. Rückflussdämpfung (Return Loss, RL): Impedanzvariationen entlang der Verbindung führen zu Signalreflexionen, die einerseits das zum anderen Ende gelangende Signal schwächen (Anteile die reflektiert werden dringen nicht bis zur anderen Seite durch), andererseits aber auch vom anderen Ende ankommende, entsprechend gedämpfte Signale stören könnten. Speziell die Steckverbindungen sind, ähnlich wie beim NEXT, für RL kritisch. Allerdings können auch schlechte oder bei der Installation beschädigte Kabel RL-Probleme verursachen. Ein häufig unterschätztes Problem sind außerdem Impedanzsprünge zwischen Installations- und Patchkabel. Auch RL wird von beiden Seiten gemessen und in dB angegeben. Je größer der Zahlenwert, umso besser. Ausnahmeregel: Liegt die Dämpfung der gemessenen Strecke unter 3dB, wird das RL nicht bewertet, sondern nur informativ angegeben. Bei kurzen Strecken "sieht" der Kabelscanner nämlich nicht nur die Reflexion vom Anfang der Strecke, sondern teilweise auch vom anderen Ende (auf längeren Kabeln wird das vom fernen Ende reflektierte Signal auf dem Rückweg zum Scanner so stark gedämpft, daß es keine nennenswerte Rolle mehr spielt). Diese dann fast doppelt so starken Reflexionen können bei Messgeräten, die diese normgemäße Ausnahmeregel nicht berücksichtigen, zu Fehlbewertungen führen. FEXT/ELFEXT (Far End CrossTalk/Equal Level Far End CrossTalk): Hierbei wird, im Gegensatz zu NEXT, das Übersprechen von einem Aderpaar auf die anderen am fernen Ende gemessen. Da für den Signalempfang natürlich der Störabstand entscheidend ist und das Signal am anderen Ende gedämpft ankommt, bezieht man den gemessenen FEXT-Wert nicht auf das Sendesignal in seiner Originalstärke, sondern auf den Empfangspegel. ELFEXT ist also ein errechneter Wert, der aus der Subtraktion der Dämpfung vom gemessenen FEXT entsteht und in dB angegeben wird. Anders als NEXT kann FEXT richtungsabhängig sein, darum gibt es für jedes Ende der gemessenen Verbindung 12 Messwerte (Paarkombinationen), insgesamt also 24. Power Sum NEXT, ACR und ELFEXT (PSNEXT, PSACR, PSELFEXT): Bei Gigabit-Ethernet-Übertragungen über Klasse D Verkabelungen wird auf allen vier Aderpaaren gleichzeitig in beide Richtungen gesendet und empfangen. Das auf jedem einzelnen Paar empfangene Signal kann also von den Signalen gestört werden, die gleichzeitig auf drei anderen Paaren übertragen werden. Das heißt, die Störungen, die von den drei anderen Paaren im Kabel verursacht werden, addieren sich. Genauso werden auch die Power-Sum-Werte pro Paar durch Addition der auf jedes Paar einwirkenden Störgrößen ermittelt. Es handelt sich also nicht um Messungen, sondern um eine rechnerische Auswertung der zuvor mit den Messungen von Dämpfung, NEXT und ELFEXT ermittelten Werte. Ein genereller Problempunkt bei Messungen von Cat 6/Klasse E-Verkabelungen ist die elektrische Kompatibilität von Stecker und Buchse. Natürlich paßt jeder RJ-45-Stecker mechanisch in jede RJ-45 Dose, aber harmonieren Stecker und Dose auch elektrisch? Die Hersteller müssen spezielle Maßnahmen ergreifen, um die für Cat 6/Klasse E festgelegten Grenzwerte der Steckverbinder zu garantieren. Meist sind das kleine Leiterplatten mit Kondensatoren, die durch geeignete Verschaltung das in der gesteckten Verbindung (RJ-45 Stecker in Dose eingesteckt) entstandene Übersprechen kompensieren. Der Kompensationsschaltkreis kann dabei in Stecker oder Dose eingebaut sein. Wichtig für die Übertragungseigenschaften ist nur das hochfrequenztechnische Gesamtergebnis von Dose und Stecker. Die Erfüllung der Cat 6/Klasse E-Leistungsdaten von Steckern und Dosen verschiedener Hersteller miteinander ist nicht garantiert. Das betrifft leider auch die Stecker an den Permanent-Link-Adaptern der Kabeltester! Für den Installateur bringt eine Channel-Messung Vorteile. Bei Messungen nach Permanent Link werden ja die Permanent-Link-Adapter für jede Strecke einmal ein- und ausgesteckt. Die Stecker unterliegen also ständigem Verschleiß. Da sie Teil des Messaufbaus sind, kann man die Stecker an den Permanent-Link-Adaptern nicht einfach ersetzen, denn damit verändern sich die elektrischen Eigenschaften des Messaufbaus, was zu Verfälschungen der Messwerte führt. Der Permanent-Link-Adapter ist also ein Verschleißteil, das normalerweise nach einigen tausend Messungen ersetzt werden muß. Im Gegensatz dazu werden Messungen mit dem Channel-Adapter und einem Patchkabel durchgeführt. Das zum Zertifizieren verwendete Patchkabel kann dabei am Channel-Adapter eingesteckt bleiben, hier gibt es also kaum Verschleiß am Adapter. Nur der Stecker am anderen Ende des Patchkabels verschleißt, so daß nur dieses Kabel ersetzt werden muß. CAT5, CAT5e, and CAT6 UTP Solid Cable Specifications Comparison Category 5 Category 5e Category 6 Frequency 100 MHz 100 MHz 250 MHz Attenuation (Min. at 100 MHz) 22 dB 22 dB 19.8 dB Characteristic Impedance 100 ohms ± 15% 100 ohms ± 15% 100 ohms ± 15% NEXT (Min. at 100 MHz) 32.3 dB 35.3 dB 44.3 dB PS-NEXT (Min. at 100 MHz) no specification 32.3 dB 42.3 dB ELFEXT (Min. at 100 MHz) no specification 23.8 dB 27.8 dB PS-ELFEXT (Min. at 100 MHz) no specification 20.8 dB 24.8 dB Return Loss (Min. at 100 MHz) 16.0 dB 20.1 dB 20.1 dB Delay Skew (Max. per 100 m) 45 ns 45 ns no specification Erdschleifen (Ground Loops) entstehen durch einen Potentialunterschied zwischen Sender und Empfänger. Durch Erdschleifen werden u. U. sehr große Ströme auf der Abschirmung oder den Masseleitungen hervorgerufen, wodurch auch Störungen auf die Signalleitungen gelangen (Induktion). Durch das nur einseitige Erden der Abschirmung (meist im Verteiler oder am Patchfeld) lassen sich Erdschleifen vermeiden. Eine aufwendigere Methode ist der Einsatz von Optokopplern, die Sender und Empfänger galvanisch trennen. Eine Erdung von Datenkabeln erfolgt eigentlich nur im Bereich explosionsgefährdeter Industrieanlagen. Bei unsachgemäßer Verkabelung richtet die Erdung mehr Schaden als Nutzen an. Neues Kapitel Logische Struktur von Netzen In diesem Abschnitt wird ganz knapp die logische Struktur von Netzen behandelt, also die Art und Weise, wie die einzelnen Stationen miteinander verbunden werden. Bei der Verkabelung von LANs muß man aber zwischen logischer Stuktur und Verkabelungsstruktur unterscheiden, z. B. kann ein Netz mit logischer Busstruktur bei der Verkabelung mit 'Twisted Pair'-Kabeln wie ein Sternnetz aussehen. Sternstruktur Alle Teilnehmer werden an einen zentralen Knoten angeschlossen (früher z. B. häufig Anschluß von Sichtgeräten an einen Zentralrechner). Eine direkte Kommunikation der Teilnehmer untereinander ist nicht möglich, jegliche Kommunikation läuft über den zentralen Knoten (Punkt-zu-Punkt-Verbindung, Leitungsvermittlung). Die Steuerung der Kommunikation vom Knoten aus ist sehr einfach: Polling (regelmäßige Abfrage aller Stationen) oder Steuerung über Interrupt. Bei Ausfall der Zentrale sind sämtliche Kommunikationswege unterbrochen. Ringstruktur Es gibt keine Zentrale, alle Stationen sind gleichberechtigt. Jeder Teilnehmer verfügt über einen eigenen Netzanschluß (Knoten) und ist über diesen mit seinem linken und rechten Partner verbunden. Die Übertragung der Info erfolgt in einer Richtung von Knoten zu Knoten. Bei Ausfall eines Knotens sind sämtliche Kommunikationswege unterbrochen. Busstruktur Es gibt keine Zentrale und keine Knoten. Die Verbindung aller Teilnehmer erfolgt über einen gemeinsamen Übertragungsweg. Zu einem Zeitpunkt kann immer nur eine Nachricht über den Bus transportiert werden. Bei Ausfall einer Station bleibt die Kommunikation der anderen Stationen erhalten. Bei den Bussystemen kann man noch unterscheiden in BasisbandBussysteme und Breitband-Bussysteme. Bei Basisband-Bussystemen werden die elektrischen Pegel direkt übertragen; bei den für uns interessanten digitalen Informationen also 0- und 1Pegel. Bei Breitband-Bussystemen werden über das Kabel mehrere unabhängige Kanäle geleitet (modulierte Übertragung). Busnetze müssen auf beiden Seiten mit der Leitungsimpedanz abgeschlossen werden, damit keine Echos auftreten, die zu Empfangsfehlern führen. vermaschte Struktur Jeder Teilnehmer ist mit mehreren anderen verbunden. Es gibt keine Zentrale und es existieren mehrere, unabhängige Übertragungswege zwischen zwei Stationen. Manchmal gibt es keine direkte Verbindung zwischen zwei Stationen. Dann führt der Weg über eine oder mehrere andere Stationen. Je nach Bedarf können die o. g. Topologien auch miteinander kombiniert werden, z. B. Bus mit angeschlossenen Sternen oder Bus mit angeschlossenen Bussen, was zu einer Baumstruktur führt. Insbesondere bei Weitverkehrsnetzen (WAN) treten vermaschte Strukturen auf. Teilweise ergeben sich dabei redundante Leitungswege, die auch bei Unterbrechung eines Wegs den Datentransport sicherstellen. Neues Kapitel TCP/IP Die Protokolle der TCP/IP-Familie wurden in den 70-er Jahren für den Datenaustausch in heterogenen Rechnernetzen (d. h. Rechner verschiedener Hersteller mit unterschiedlichen Betriebssystemen) entwickelt. TCP steht für 'Transmission Control Protocol' (Schicht 4) und IP für 'Internet Protocol' (Schicht 3). Die Protokollspezifikationen sind in sogenannten RFCDokumenten (RFC - Request for Comment) festgeschrieben und veröffentlicht. Aufgrund ihrer Durchsetzung stellen sie Quasi-Standards dar. Die Schichten 5 - 7 des OSI-Standards werden hier in einer Anwendungsschicht zusammengefaßt, da die Anwendungsprogramme alle direkt mit der Transportschicht kommunizieren. In Schicht 4 befindet sich außer TCP, welches gesicherten Datentransport (verbindungsorientiert, mit Flußkontrolle (d. h. Empfangsbestätigung, etc.) durch Windowing ermöglicht, auch UDP (User Datagram Protocol), in welchem verbindungsloser und ungesicherter Transport festgelegt ist. Beide Protokolle erlauben durch die Einführung von sogenannten Ports den Zugriff mehrerer Anwendungsprogramme gleichzeitig auf einund dieselbe Maschine. In Schicht 3 ist das verbindungslose Internet-Protokoll (IP) angesiedelt. Datenpakete werden auf den Weg geschickt, ohne daß auf eine Empfangsbestätigung gewartet werden muß. IPPakete dürfen unter bestimmten Bedingungen (TTL=0, siehe unten) sogar vernichtet werden. In Schicht 3 werden damit auch die IP-Adressen festgelegt. Hier findet auch das Routing, das heißt die Wegsteuerung eines Paketes von einem Netz ins andere statt. Ebenfalls in diese Ebene integriert sind die ARP-Protokolle (ARP - Address Resolution Protocol), die zur Auflösung (= Umwandlung) einer logischen IP-Adresse in eine physikalische (z. B. Ethernet) Adresse dienen und dazu sogenannte Broadcasts (Datenpakete, durch die alle angeschloßenen Stationen angesprochen werden) verwenden. ICMP, ein Protokoll, welches den Austausch von Kontroll- und Fehlerpaketen im Netz ermöglicht, ist ebenfalls in dieser Schicht realisiert. Die Schichten 1 und 2 sind gegenüber Schicht 3 protokolltransparent. Sie können durch standardisierte Protokolle (z. B. Ethernet (CSMA/CD), FDDI, SLIP (Serial Line IP), PPP (Point-to-Point Protocol)) oder andere Übertragungsverfahren realisiert werden. Zur TCP/IP-Familie gehören mehrere Dienstprogramme der höheren OSI-Schichten (5 - 7), z. B.: Telnet (RFC 854) Ein virtuelles Terminal-Protokoll, um vom eigenen Rechensystem einen interaktiven Zugang zu einem anderen System zu realisieren. FTP (RFC 959) Dieses (File-Transfer-) Protokoll ermöglicht, die Dateidienste eines Fremdsystems interaktiv zu benutzen sowie die Dateien zwischen den Systemen hin und her zu kopieren. NFS (RFC 1094) Das Network File System ermöglicht den Zugriff auf Dateien an einem entfernten System so, als wären sie auf dem eigenen. Man nennt dies auch einen transparenten Dateizugriff. NFS basiert auf den zur TCP/IP-Familie gehörenden UDP- (UserDatagramm-) Protokollen (ebenfalls Schicht 4), RFC 768. Im Unterschied zu TCP baut UDP keine gesicherten virtuellen Verbindungen zwischen kommunizierenden Hosts auf. Aufgrund dieser Eigenschaft ist es für den Einsatz in lokalen Netzen vorgesehen. NNTP (RFC 977) Das Network News Transfer Protocol spezifiziert Verteilung, Abfrage, Wiederauffinden und das Absetzen von News-Artikeln innerhalb eines Teils oder der gesamten Internet-Gemeinschaft. Die Artikel werden in regional zentralen Datenbasen gehalten. Einem Benutzer ist es möglich, aus dem gesamten Angebot nur einzelne Themen zu abonnieren. SMTP (RFC 821/822) Das Simple-Mail-Transfer-Protokoll (RFC 821) ist ein auf der IP-Adressierung sowie auf der durch den RFC 822 festgelegten Namensstruktur basierendes Mail-Protokoll. DNS (RFC 920) Der Domain Name Service unterstützt die Zuordnung von Netz- und Host-Adressen zu Rechnernamen. Dieser Service ist z. B. erforderlich für die Anwendung von SMTP sowie in zunehmendem Maße auch für Telnet und FTP. Aus Sicherheitsgründen wendet sich der fremde Host an den DNS, um zu prüfen, ob der IP-Adresse des ihn rufenden Rechners auch ein (Domain-)Name zugeordnet werden kann. Falls nicht, wird der Verbindungsaufbau abgelehnt. Die TCP/IP-Protokolle Der große Vorteil der TCP/IP-Protokollfamilie ist die einfache Realisierung von Netzwerkverbunden. Einzelne Lokale Netze werden über Router oder Gateways verbunden. Einzelne Hosts können daher über mehrere Teilnetze hinweg miteinander kommunizieren. IP als Protokoll der Ebene 3 ist die unterste Ebene, die darunter liegenden Netzebenen können sehr unterschiedlich sein: LANs (Ethernet, Token-Ring, usw.) WANs (X.25, usw.) Punkt-zu-Punkt-Verbindungen (SLIP, PPP) Internet-Protokolle OSI-Schicht 7 Anwendung 6 Darstellung 5 4 Sitzung Internet Protokoll Suite File Transfer Electronic Mail File Transfer Protocol (FTP) RFC 959 Simple Mail Transfer Protocol (SMTP) RFC 821 Netzwerk 2 Sicherung Telnet Protocol (Telnet) RFC 854 Usenet News World Wide Web Usenet Hypertext News Transfer Transfer Protocol Protocol (HTTP) (NNTP) RFC RFC 2616 977 Address Resolution Protocol (ARP) RFC 826 Ethernet Internet Protocol (IP) RFC 791 Token Ring DQDB Domain Name Service Art der Kommunikation Domain Name Service (DNS) RFC 1034 Applikation User Datagram Host to Host Protocol Kommunikation (UDP) RFC 768 Transmission Control Protocol (TCP) RFC 793 Transport 3 Terminal Emulation DOD Schicht FDDI Internet Control Messsage Protocol RFC 792 Internet ATM lokales Netzwerk 1 Physikalische Übertragung Twisted Pair Lichtwellenleiter Coaxkabel Funk Laser Netzzugriff Es ist offensichtlich, daß die Gateways neben dem Routing weitere nichttriviale Funktionen haben, wenn sie zwischen den unterschiedlichsten Teilnetzen vermitteln (z. B. unterschiedliche Protokolle auf Ebene 2, unterschiedliche Datenpaketgröße, usw.). Aus diesem Grund existieren in einem Internet drei unabhängige Namens- bzw. Adressierungsebenen: Physikalische Adressen (z. B. Ethernet-Adresse) Internet-Adressen (Internet-Nummer, IP-Adresse) Domain-Namen Die Ethernet-Adresse wurde bereits behandelt, auf die anderen beiden Ebenen wird in den folgenden Abschnitten eingegangen. Die Umsetzung der höchsten Ebene (Domain-Namen) in IP-Adressen erfolgt durch das oben erwähnte DNS, worauf die Dienstprogramme der Schichten 5-7 zurückgreifen. ARP Die Umsetzung einer IP-Adresse in eine Hardware-Adresse erfolgt durch Tabellen und auf Hardware-Ebene (z. B. Ethernet) automatisch über ARP (Adress Resolution Protocol). Dazu ein Beispiel: Die Station A will Daten an eine Station B mit der Internetadresse I(B) senden, deren physikalische Adresse P(B) sie noch nicht kennt. Sie sendet einem ARP-Request an alle Stationen im Netz, der die eigene physikalische Adresse und die IP-Adresse von B enthält. Alle Stationen erhalten und überprüfen den ARP-Request und die angesprochene Station B antwortet, indem sie einen ARP-Reply mit ihrer eigenen physikalischen Adresse an die Station A sendet. Letztere speichert die Zuordnung in einer Tabelle (Address Resolution Cache). Auch für die Umkehrfunktion gibt es eine standardisierte Vorgehensweise, den RARP (Reverse ARP). Hier sendet die Station A unter Angabe ihrer physikalischen Adresse P(A) einen RARP-Request. Wenn im Netz nur eine Station als RARP-Server eingerichtet ist (eine Station, die alle Zuordnungen von P(x) <--> I(x) "kennt"), antwortet diese mit einem RARPReply an die anfragende Station, der I(A) enthält. Diese Funktion ist z. B. für sogenannte "Diskless Workstations" wichtig, die ihre gesamte Software von einem Server laden. IP - Internet Protocol Auf der Netzwerkschicht aufbauend liegt die Internet-Schicht, die die erste Abstraktionsschicht vom Transportmechanismus darstellt. Auf dieser Schicht 3 stellt das Internet-Protokoll (IP) den grundlegenden Netzdienst zur Verfügung, den Versand von Datenpaketen, sogenannten Datagrammen, über verschiedene Netze hinweg. Die Netzwerkschicht hat keine Information darüber, von welcher Art die Daten sind, die sie befördert. Nehmen wir als Beispiel das Ethernet: Von der Ethernet-Karte werden die vom Netz kommenden Daten an die Treibersoftware für die Karte weitergereicht. Diese interpretiert einen Teil dieser Daten als IP-Header und den Rest als Datenteil eines IPPaketes. Auf diese Weise ist der IP-Header innerhalb eines Ethernet-Paketes eingekapselt. Aber auch das IP-Paket selbst enthält wieder ein Datenpaket für eine höhere Protokollebene (TCP), dessen Header auf der IP-Ebene als Bestandteil der Daten erscheint. Man kann sich das so vorstellen, wie die russischen Puppen, die ineinandergeschachtelt sind. Die kleinste Puppe ganz innen repräsentiert die Nutzdaten, alle außen herum geschachtelten Puppen sind 'Protokoll-Verpackung'. IP ist ein verbindungsloses Protokoll. Es ist also nicht notwendig, eine IP-Verbindung zu einem Rechner zu 'öffnen', bevor man Daten zu diesem Rechner senden kann, sondern es genügt, das IP-Paket einfach abzusenden und darauf zu vertrauen, daß es schon ankommen wird. Bei einem verbindungsorientierten Protokoll wird beim Öffnen einer Verbindung getestet, ob der Zielrechner überhaupt erreichbar ist. Ein verbindungsloses Protokoll macht das nicht und kann demnach auch nicht garantieren, daß ein Datenpaket überhaupt beim Empfänger ankommt. IP garantiert auch nicht, daß von einem einmal abgeschickten Datenpaket nur eine Kopie beim Empfänger ankommt oder daß in einer bestimmten Reihenfolge abgeschickte Datenpakete auch wieder in dieser Reihenfolge empfangen werden. Normalerweise laufen die IP-Pakete über mehrere Zwischenstationen, bis sie am Zielrechner ankommen. Bricht irgendwann während der Übertragung ein Übertragungsweg zusammen, so wird ein neuer Weg zum Ziel gesucht und benutzt. Da der neue Weg zeitlich länger oder kürzer sein kann als der alte, kann man keine allgemeingültigen Aussagen darüber machen, in welcher Reihenfolge IP-Pakete beim Empfänger eintreffen. Es kann auch sein, daß bei dieser Umschalterei IP-Pakete verlorengehen oder sich verdoppeln. Das Beheben der so entstehenden Probleme überläßt das IP-Protokoll anderen, höherliegenden Schichten. Das Internet-Protokoll ist somit ein verbindungsloser Dienst mit einem 'Unreliable Datagram Service', d. h. es wird auf der IP-Ebene weder die Richtigkeit der der Daten noch die Einhaltung von Sequenz, Vollständigkeit und Eindeutigkeit der Datagramme überprüft. Ein zuverlässiger verbindungsorientierter Dienst wird in der darüberliegenden TCP-Ebene realisiert. Ein IP-Datagramm besteht aus einem Header und einem nachfolgenden Datenblock, der seinerseits dann z. B. in einem Ethernet-Frame "verpackt" wird. Die maximale Datenlänge wird auf die maximale Rahmenlänge des physikalischen Netzes abgestimmt. Da nicht ausgeschlossen werden kann, daß ein Datagramm auf seinem Weg ein Teilnetz passieren muß, dessen Rahmenlänge niedriger ist, müssen zum Weitertransport mehrere (Teil)Datagramme erzeugt werden. Dazu wird der Header im Wesentlichen repliziert und die Daten in kleinere Blöcke unterteilt. Jedes Teil-Datagramm hat also wieder einen Header. Diesen Vorgang nennt man Fragmentierung. Es handelt sich um eine rein netztechnische Maßnahme, von der Quell- und Zielknoten nichts wissen müssen. Es gibt natürlich auch eine umgekehrte Funktion, "Reassembly", die kleine Datagramme wieder zu einem größeren packt. Geht auf dem Übertragungsweg nur ein Fragment verloren, muß das gesamte Datagramm wiederholt werden. Es gilt die Empfehlung, daß Datagramme bis zu einer Länge von 576 Bytes unfragmentiert übertragen werden sollten. Format des IP-Headers Version Kennzeichnet die IP-Protokollversion IHL (Internet Header Length) Die Angabe der Länge des IP-Headers erfolgt in 32-Bit-Worten (normalerweise 5). Da die Optionen nicht unbedingt auf Wortlänge enden, wird der Header gegebenenfalls aufgefüllt. Type of Service Alle Bits haben nur "empfehlenden" Charakter. 'Precedence' bietet die Möglichkeit, Steuerinformationen vorrangig zu befördern. Total Length Gesamtlänge des Datagramms in Bytes (max. 64 KByte). Identification Dieses und die beiden folgenden Felder steuern die Reassembly. Eindeutige Kennung eines Datagramms. Anhand dieses Feldes und der 'Source Address' ist die Zusammengehörigkeit von Fragmenten zu detektieren. Flags Die beiden niederwertigen Bits haben folgende Bedeutung: Don't fragment: Für Hosts, die keine Fragmentierung unterstützen More fragments: Zum Erkennen, ob alle Fragmente eines Datagramms empfangen wurden Fragment Offset Die Daten-Bytes eines Datagramms werden numeriert und auf die Fragmente verteilt. Das erst Fragment hat Offset 0, für alle weiteren erhöht sich der Wert um die Länge des Datenfeldes eines Fragments. Anhand dieses Wertes kann der Empfänger feststellen, ob Fragmente fehlen. Beispiel siehe unten. Time-to-live (TTL) Jedes Datagramm hat eine vorgegebene maximale Lebensdauer, die hier angegeben wird. Auch bei Routing-Fehlern (z. B. Schleifen) wird das Datagramm irgendwann aus dem Netz entfernt. Da Zeitmessung im Netz problematisch ist, und keine Startzeit im Header vermerkt ist, decrementiert jeder Gateway dieses Feld --> de-facto ein 'Hop Count'. Protocol Da sich unterschiedliche Protokolle auf IP stützen, muß das übergeordnete Protokoll (ULP, Upper Layer Protocol) angegeben werden. Wichtige ULPs sind 1: ICMP Internet Control Message P. 3: GGP Gateway-to-Gateway P. 6: TCP Transmission Control P. 8: EGP Exterior Gateway P. 17: UDP User Datagram P. Header Checksum 16-Bit-Längsparität über den IP-Header (nicht die Daten) Source Address Internet-Adresse der Quellstation Destinantion Address Internet-Adresse der Zielstation Options Optionales Feld für weitere Informationen (deshalb gibt es auch die Header-Länge). Viele Codes sind für zukünftige Erweiterungen vorgesehen. Die Optionen dienen vor allem der Netzsteuerung, der Fehlersuche und für Messungen. Die wichtigsten sind: Record Route: Weg des Datagramms mitprotokollieren Loose Source Routing: Die sendende Station schreibt einige Zwischenstationen vor (aber nicht alle) Strict Source Routing: Die sendende Station schreibt alle Zwischenstationen vor. Timestamp Option: Statt seiner IP-Adresse (wie bei Record Route) trägt jeder Gateway den Bearbeitungszeitpunkt ein (Universal Time). Padding Füllbits Die Hauptaufgabe von IP ist es also, die Unterschiede zwischen den verschiedenen, darunterliegenden Netzwerkschichten zu verbergen und eine einheitliche Sicht auf die verschiedensten Netztechniken zu präsentieren. So gibt es IP nicht nur in Netzen, sondern auch als SLIP (Serial Line IP) oder PPP (Point to Point Protocol) für Modem- oder ISDNVerbindungen. Zur Vereinheitlichung gehören auch die Einführung eines einheitlichen Adressierungsschemas und eines Fragmentierungsmechanismus, der es ermöglicht, große Datenpakete durch Netze mit kleiner maximaler Paketgröße zu senden: Normalerweise existiert bei allen Netzwerken eine maximale Größe für ein Datenpaket. Im IP-Jargon nennt man diese Grenze die 'Maximum Transmisson Unit' (MTU). Natürlich ist diese Obergrenze je nach verwendeter Hardware bzw. Übertragungstechnik unterschiedlich. Die Internet-Schicht teilt IP-Pakete, die größer als die MTU des verwendeten Netzwerks sind, in kleinere Stücke, sogenannte Fragmente, auf. Der Zielrechner setzt diese Fragmente dann wieder zu vollständigen IP-Paketen zusammen, bevor er sie an die darüberliegenden Schichten weitergibt. Der Fragement Offset gibt an, an welcher Stelle in Bezug auf den IP-DatagrammAnfang das Paket in das Datagramm einzuordnen ist. Aufgrund des Offset werden die Pakete in die richtige Reihenfolge gebracht. Dazu ein Beispiel: Es soll ein TCP-Paket mit einer Länge von 250 Byte über IP versandt werden. Es wird angenommen, daß ein IP-Header eine Länge von 20 Byte hat und eine maximale Länge von 128 Byte pro Paket nicht überschritten werden darf Der Identifikator des Datagramms beträgt 43 und der Fragmentabstand wird in 8-Byte-Schritten gezählt. Das Datenfragment muß also durch 8 dividierbar sein. Da alle Fragmente demselben Datagramm angehören, wird der Identifikator für alle Fragmente beibehalten. Im ersten Fragment ist das Fragment Offset natürlich noch Null, das MF-Bit jedoch auf 1 gesetzt, um zu zeigen, daß noch Fragmente folgen. Im IP-Header des zweiten Fragments beträgt das Fragment Offset 13 (104/8 = 13) und zeigt die Position des Fragments im Datagramm an. Das MF-Bit ist noch immer 1, da noch ein Datenpaket folgt. Der Header des dritten Fragments enthält dann ein MF-Bit mit dem Wert 0, denn es handelt sich um das letzte Datenpaket zum Datagramm 43. Das Fragment Offset ist auf 26 gesetzt, da vorher schon 208 Daten-Bytes (8 * 26 = 208) übertragen wurden. Sobald das erste Fragment (gleich welches) im Empfänger ankommt, wird ein Timer gesetzt. Sind innerhalb der dort gesetzten Zeit nicht alle Pakete zu einem Datagramm eingetroffen, wird angenommen, daß Fragmente verlorengingen. Der Empfänger verwirft dann alle Datenpakete mit diesem Identifikator. Was geschieht aber, wenn der Kommunikationspartner nicht erreichbar ist? Wie schon erwähnt, durchläuft ein Datagramm mehrere Stationen. Diese Stationen sind in der Regel Router oder Rechner, die gleichzeitig als Router arbeiten. Ohne Gegenmaßnahme würde das Datenpaket für alle Zeiten durch das Netze der Netze irren. Dazu gibt es im IP-Header neben anderer Verwaltungsinfo auch ein Feld mit dem Namen TTL (Time To Live). Der Wert von TTL kann zwischen 0 und 255 liegen. Jeder Router, der das Datagramm transportiert, vermindert den Wert dieses Feldes um 1. Ist der Wert von TTL bei Null angelangt, wird das Datagramm vernichtet. Die Adressen, die im Internet verwendet werden, bestehen aus einer 32 Bit langen Zahl. Damit sich die Zahl leichter darstellen läßt, unterteilt man sie in 4 Bytes (zu je 8 Bit). Diese Bytes werden dezimal notiert und durch Punkte getrennt (a.b.c.d). Zum Beispiel: 141.84.101.2 129.187.10.25 Bei dieser Adresse werden zwei Teile unterscheiden, die Netzwerkadresse und die Rechneradresse, wobei unterschiedlich viele Bytes für beide Adressen verwendet werden: Die Bereiche für die Netzwerkadresse ergeben sich durch die Zuordnung der ersten Bits der ersten Zahl (a), die eine Erkennung der Netz-Klassen möglich machen. Netzklassen Klasse A - Netz Klasse B - Netz Klasse C - Netz Netz-ID 8 Bit = 1 Byte 16 Bit = 2 Byte 24 Bit = 3 Byte Host-ID 24 Bit = 3 Byte 16 Bit = 2 Byte 8 Bit = 1 Byte Netzmaske 255.0.0.0 255.255.0.0 255.255.255.0 Adressklassen- 0 ID (= Feste Bits im 1. Byte, 1. Quad) 10 110 Wertebereich (theoretisch) 0.0.0.0 bis 127.255.255.255 128.0.0.0 bis 191.255.255.255 192.0.0.0 bis 223.255.255.255 Anzahl der Netze 128 (= 27) 16384 (= 26*256 = 64*256) 2097152 (= 25*256*256 = 32*256*256) Anzahl der Rechner im Netz 16777216 (= 2563) 65536 (= 2562) 256 (= 2561) Besondere Adreßklassen Klasse D Klasse E Adressklassen-ID 4 Bit = "1110" 5 Bit = "11110" keine Netz-ID, sondern: 28 Bit-Identifikator 27 Bit-Identifikator Wertebereich 224.0.0.0 bis 240.0.0.0 bis Anwendungen 239.255.255.255 247.255.255.255 für Multicast-Gruppen reservierte Adressen für Zukünftiges Grundsätzlich gilt: Alle Rechner mit der gleichen Netzwerkadresse gehören zu einem Netz und sind untereinander erreichbar. Zur Koppelung von Netzen unterschiedlicher Adresse wird eine spezielle Hardwareoder Softwarekomponente, ein sogenannter Router, benötigt. Je nach Zahl der zu koppelnden Rechner wird die Netzwerkklasse gewählt. In einem Netz der Klasse C können z. B. 254 verschiedene Rechner gekoppelt werden (Rechneradresse 1 bis 254). Die Hostadresse 0 wird für die Identifikation des Netzes benötigt und die Adresse 255 für Broadcast-(Rundruf-)Meldungen. Die Netzwerkadresse 127.0.0.1 bezeichnet jeweils den lokalen Rechner (loopback address). Sie dient der Konsistenz der Netzwerksoftware (jeder Rechner ist über seine Adresse ansprechbar) und dem Test. Damit man nun lokale Netze ohne Internetanbindung mit TCP/IP betreiben kann, ohne IPNummern beantragen zu müssen und um auch einzelne Rechnerverbindungen testen zu können, gibt es einen ausgesuchten Nummernkreis, der von keinem Router nach außen gegeben wird. Diese "privaten" Adressen sind im RFC 1597 festgelegt. Es gibt ein Class-ANetz, 16 Class-B-Netze und 255 Class-C-Netze: Class-A-Netz: 10.0.0.0 - 10.255.255.255 Class-B-Netze: 172.16.0.0 - 172.31.255.255 Class-C-Netze: 192.168.0.0 - 192.168.255.255 Zusätzlich hat die IANA auch das folgende Class-B-Netz für private Netze reserviert, das schon von Apple- und Microsoft-Clients verwendet wird, sofern kein DHCP-Server zur Verfügung steht. Das Verfahren heißt APIPA (Automatic Private IP Addressing): 169.254.0.0 - 169.254.255.255 Der für IP reservierte Adressraum reicht nicht mehr aus, um alle Endgeräte anzusteuern. Mögliche Abhilfen: Dynamische Vergabe von IP-Adressen: Dieses Verfahren wird beim Dial-In beim Provider verwendet. Es eignet sich auch im lokalen Netz, wenn davon auszugehen ist, daß immer nur ein Teil der Rechner in Betrieb ist. Der Benutzer bekommt für die Dauer einer Verbindung eine IP-Adresse zugeteilt. Das bekannteste Verfahren heißt DHCP (dynamic host configuration protocol). Weiterentwicklung des IP-Protokolls: Mit IP Version 6 wird ein auf 128 Bit erweiterter Adressraum geschaffen. Damit stehen genügend Adressen zur Vefügung. Network Address Translation (NAT): Über ein Gateway wird im Internet eine andere IP-Adresse verwendet als im lokalen Netz (private Adressräume). Die Umsetzung erlaubt sogar, ein komplettes privates Netz (siehe oben) mit einer einzigen externen IP-Adresse zu betreiben. Network Address Translation (NAT) und IP-Masquerading Die begrenzte Verfügbarkeit von IP-Adressen hat dazu geführt, daß man sich Gedanken über verschiedene Möglichkeiten machen mußte, wie man mit den existierenden Adressen ein größeres Umfeld abdecken kann. Eine Möglichkeit, um private Netze (und dazu gehört letztendlich auch ein privater Anschluß mit mehr als einem PC) unter Verwendung möglichst weniger Adressen an das Internet anzukoppeln stellen NAT, PAT und IP Masquerading. Alle Verfahren bilden private Adressen gemäß RFC 1918 oder einen proprietären (nicht registrierten) Adreßraum eines Netzes auf öffentliche registrierte IP-Adressen ab. NAT (Network Address Translation) Beim NAT (Network Address Translation) werden die Adressen eines privaten Netzes über Tabellen öffentlich registrierten IP-Adressen zugeordnet. Der Vorteil besteht darin, daß Rechner, die in einem privaten Netz miteinander kommunizieren, keine öffentlichen IP-Adressen benötigen. IP-Adressen interner Rechner, die eine Kommunikation mit Zielen im Internet aufbauen, erhalten in dem Router, der zwischen dem Internet Service Provider (ISP) und dem privaten Netzwerk steht, einen Tabelleneintrag. Durch diese Eins-zu-Eins-Zuordnung sind diese Rechner nicht nur in der Lage, eine Verbindung zu Zielen im Internet aufzubauen, sondern sie sind auch aus dem Internet erreichbar. Die interne Struktur des Firmennetzwerkes bleibt jedoch nach außen verborgen. IP Masquerading IP Masquerading, das manchmal auch als PAT (Port and Address Translation) bezeichnet wird, bildet alle Adressen eines privaten Netzwerkes auf eine einzelne öffentliche IP-Adresse ab. Dies geschieht dadurch, daß bei einer existierenden Verbindung zusätzlich zu den Adressen auch die Portnummern ausgetauscht werden. Auf diese Weise benötigt ein gesamtes privates Netz nur eine einzige registrierte öffentliche IP-Adresse. Der Nachteil dieser Lösung besteht darin, daß die Rechner im privaten Netzwerk nicht aus dem Internet angewählt werden können. Diese Methode eignet sich daher hervorragend, um zwei und mehr Rechner eines privaten Anschlusses per DFÜ-Netzwerk oder ISDN-Router an das Internet zu koppeln. IP Masquerading rückt mit dieser Funktionalität sehr nahe an Proxy- und FirewallLösungen heran, wobei ein Proxy explizit für ein Protokoll (z. B. HTTP) existieren und aufgerufen werden muß. Subnetze Nachdem nun klar ist, was ein Netz der Klasse A oder B ist, soll auf die Bildung von Subnetzen hingewiesen werden. Diese dienen dazu, ein bestehendes Netz in weitere, kleinere Netze zu unterteilen. Subnetze sind Strukturierungsmöglichkeit für Netze, ohne daß man zusätzliche Klasse-A-, Klasse-B- oder Klasse-C-IP-Adressen braucht. Die Standardprozedur, um ein Netz in Unternetze (Subnetze) zu teilen, nennt man "Subnetting". Die Hostadresse des A-, B- oder C-Netzes teilt sich in die Bereiche Subnetzadresse (Subnet-ID, Teilnetz-ID) und Hostadresse (verbleibende, verkürzte Host-ID). Ein Teil des Hostadressbereiches wird also genutzt, um die Subnetze zu unterscheiden. Die Netzadresse und den Subnetzanteil des Hostadressraumes bezeichnet man als "erweiterte Netzadresse" (extended network prefix). Die interne Subnetz-Struktur von A-, B- oder C-Netzen ist nach außen hin unsichtbar. Damit Router in der Lage sind, Datagramme in das richtige Netz zuzustellen, müssen sie bei der IP-Adresse den Netz- und Hostanteil unterscheiden können. Dies geschieht traditionell durch die Netzmaske bzw. Subnetzmaske (subnet mask). Die Subnetzmaske dient dem Rechner dazu, die Zuordnung von Netzwerk-Teil und Host-Teil vorzunehmen. Sie hat denselben Aufbau wie eine IP-Adresse (32 Bit bzw. 4 Byte). Per Definition sind alle Bit des "Netzwerk-Teils" auf 1 zu setzen, alle Bit des "Host-Teils" auf 0. Für die o.a. Adreßklassen hat die Subnetzmaske demnach folgendes Aussehen: Adreß- Subnetzmaske (binär) Subnetzmaske Klasse (dezimal) Class A 11111111.00000000.00000000.00000000 255.0.0.0 Class B 11111111.11111111.00000000.00000000 255.255.0.0 Class C 11111111.11111111.11111111.00000000 255.255.255.0 Diese Subnetzmaske (auch "Default Subnetzmaske" genannt) kann manuell überschrieben werden. Eine Subnet-Maske für ein Netz der Klasse C lautet daher 255.255.255.0. Das bedeutet, daß die ersten drei Bytes die Netzadresse angeben und das vierte Byte die Rechner adressiert. Eine Subnetz-Maske mit dem Wert 255.255.0.0 würde folglich ein Netz der Klasse B angeben und für ein C-Netz steht die Maske 255.255.255.0. Aufteilung in Subnetze Netzwerkanteil in Bit Hostanteil Subnetz- Hostanzahl in Bit anzahl **) *) Subnetzmaske 8 24 1 16777216 255.0.0.0 9 23 2 128*65536 255.128.0.0 10 22 4 64*65536 255.192.0.0 11 21 8 32*65536 255.224.0.0 12 20 16 16*65536 255.240.0.0 13 19 32 8*65536 255.248.0.0 14 18 64 4*65536 255.252.0.0 15 17 128 2*65536 255.254.0.0 16 16 1 65536 255.255.0.0 B 17 15 2 128*256 255.255.128.0 18 14 4 64*256 255.255.192.0 19 13 8 32*256 255.255.224.0 20 12 16 16*256 255.255.240.0 21 11 32 8*256 255.255.248.0 22 10 64 4*256 255.255.252.0 23 9 128 2*256 255.255.254.0 Klasse A Klasse 24 8 1 256 255.255.255.0 Klasse C 25 7 2 128 255.255.255.128 26 6 4 64 255.255.255.192 27 5 8 32 255.255.255.224 28 4 16 16 255.255.255.240 29 3 32 8 255.255.255.248 30 2 64 4 255.255.255.252 Anmerkungen: *) Die erste und letzte bei der Unterteilung entstehenden Adressen dürfen nicht verwendet werden (Verwechslung mit Netz- und Broadcast-Adresse des übergeordneten Netzes). Die Anzahl der Subnetze verringert sich somit jeweils um zwei: Ist der Netzwerkanteil der IP-Adresse n Bits, dann erhält man (2n) - 2 Subnetze. **) Die Rechneranzahl verringert sich ebenfalls um zwei wegen Subnetz-Adresse (alle Rechnerbits auf 0) und Broadcast-Adresse (alle Rechnerbits auf 1): Ist der Hostanteil der IP-Adresse m Bits, dann erhält man (2m) - 2 Hosts pro Subnetz. Besitzt breispielsweise ein Unternehmen ein Netz der Klasse C, möchte man dieses vielleicht in zwei Segmente unterteilen, die voneinander getrennt sind. Der Broadcastverkehr des ersten Segments kann so das andere nicht beeinträchtigen. In diesem Fall kommt die Subnetz-Maske zum Einsatz, welche die Rechneradressen in zwei Bereiche gliedert. Sollen die Rechner in vier gleich große Subnetze mit je 64 Knoten eingeteilt werden, lautet die Subnetz-Maske 255.255.255.192. Es gilt die folgende Formel für das Maskier-Byte: Bytewert = 256 - (Anzahl der Knoten in einem Segment) Als das Subnetting erstmals standardisiert wurde, war es verboten die Subnetze zu nutzen, in denen alle Subnetzbits den Wert 0 oder 1 hatten (siehe Anmerkungen oben). Damit ergeben sich im Beispiel nur zwei Subnetze mit je 62 Hosts. Inzwischen beherrschen fast alle Systeme korrektes Subnetting ("classless" routing). Beispiel: Aufteilung in 4 Subnetze Ein Netz der Klasse C soll in vier gleich große Subnetze geteilt werden. Die Netzadresse beträgt 192.168.98.0. Der Administrator wählt daher zur Unterteilung die Subnetz-Maske 255.255.255.192. Die vier Rechner mit den IP-Adressen 192.168.98.3, 192.168.98.73. 192.168.98.156 und 192.168.98.197 befinden sich daher in vier Subnetzen zwischen denen geroutet werden muß. Broadcasts in Subnetz 1 werden somit nicht in die anderen Subnetze übertragen. Es ist nun zum Beispiel für das Unternehmen möglich, die Rechner des Vertriebs in Subnetz 1, die des Einkaufs in Subnetz 2, jene der Entwicklung in Subnetz 3 und ein Netz aus Demorechnern in Subnetz 4 zu organisieren. Damit ist gesichert, daß Störungen in einzelnen Subnetzen auch lokal auf diese beschränkt bleiben. Sie schlagen nicht auf die Datenstruktur des ganzen Unternehmens durch. Allgemein ergibt sich für ein C-Netz folgende Aufstellung: Subnetze eines C-Netzes In Klammern die reduzierte Anzahl der Subnetze (Anzahl - 2). Die rot unterlegten Möglichkeiten sind dann in der Praxis nicht einsetzbar. Subnetzbits Hostbits mögliche Subnetze Hostadressen Subnetzmaske 1 7 2 (0) 126 (0) 255.255.255.128 2 6 4 (2) 62 255.255.255.192 3 5 8 (6) 30 255.255.255.224 4 4 16 (14) 14 255.255.255.240 5 3 32 (30) 6 255.255.255.248 6 2 64 (62) 2 255.255.255.252 7 1 128 0 255.255.255.254 Beispiel: Aufteilung in 8 (6) Subnetze Von den acht variabel verwendbaren Bits nutzt er also die drei höchstwertigen Bits für das Subnetz und die fünf letzten Bits für die Hostadresse. Die erste Adresse jedes Subnetz ist die Adresse in der alle Hostbits den Wert 0 haben. Subnetzbits Hostbits Dezimale Wertigkeit des Bit 128 64 32 16 8 4 2 1 erstes Subnetz 0 0 0 0 dezimal 0 0 0 0 0 zweites Subnetz 0 0 1 0 0 0 0 0 32 drittes Subnetz 0 1 0 0 0 0 0 0 64 viertes Subnetz 0 1 1 0 0 0 0 0 96 fünftes Subnetz 1 0 0 0 0 0 0 0 128 sechstes Subnetz 1 0 1 0 0 0 0 0 160 siebtes Subnetz 1 1 0 0 0 0 0 0 192 achtes Subnetz 1 1 1 0 0 0 0 0 224 Damit sind die acht zur Verfügung stehenden Subnetze bekannt: 192.168.0.0/27 192.168.0.32/27 192.168.0.64/27 192.168.0.96/27 192.168.0.128/27 192.168.0.160/27 192.168.0.192/27 192.168.0.224/27 Anmerkung: Die Zahl hinter dem Schrägstrich (oben ist das die 27) gibt an, wieviele Bits der 32 Bit langen IP-Adresse als Netzanteil verwendet werden. Diese Subnetze können jetzt einzelnen Netzen zugeordnet werden. Die folgende Tabelle zeigt die Netz- und Broadcastadressen von jedem einzelnen Subnetz und die Rechneradressen. Subnetz IP-Adressen (letztes Oktett) Netz Hosts Broadcast erstes Subnetz 0 1-30 31 zweites Subnetz 32 33-62 63 drittes Subnetz 64 65-94 95 viertes Subnetz 96 97-126 127 fünftes Subnetz 128 129-158 159 sechstes Subnetz 160 161-190 191 siebtes Subnetz 192 193-222 223 achtes Subnetz 224 225-254 255 Als kleine Hilfe gibt es hier noch einen Subnetz-Rechner als Javascript-Programm. Eingegeben wird eine IP-Netzadresse in CIDR-Form (Classless Inter-Domain Routing, z.B. 10.1.2.0/24). Nach dem Klick auf "Berechnen" erscheinen im unteren Feld die Werte der Netzadresse, der Subnet-Maske und der Bereich der zugehörigen IP-Adressen, wobei die erste Adresse des angebenen Bereichs die Netzadresse darstellt und die letzte Adresse die Broadcast-Adresse. CIDR: 192.168.1.0/24 IP-Bereich: ICMP - Internet Control Message Protocol ICMP erlaubt den Austauch von Fehlermeldungen und Kontrollnachrichten auf IP-Ebene. ICMP benutzt das IP wie ein ULP, ist aber integraler Bestandteil der IP-Implementierung. Es macht IP nicht zu einem 'Reliable Service', ist aber die einzige Möglichkeit Hosts und Gateways über den Zustand des Netzes zu informieren (z. B. wenn ein Host temporär nicht erreichbar ist --> Timeout). Die ICMP-Nachricht ist im Datenteil des IP-Datagramms untergebracht, sie enthält ggf. den IP-Header und die ersten 64 Bytes des die Nachricht auslösenden Datagramms (z. B. bei Timeout). Die fünf Felder der ICMP-Message haben folgende Bedeutung: Type Identifiziert die ICMP-Nachricht 0 Echo reply 3 Destination unreachable 4 Source quench 5 Redirect (Change a Route) 8 Echo request 11 Time exceeded for a datagram 12 Parameter Problem on a datagram 13 Timestamp request 14 Timestamp reply 15 Information request 16 Information reply 17 Address mask request 18 Address mask reply Code Detailinformation zum Nachrichten-Typ Checksum Prüfsumme der ICMP-Nachricht (Datenteil des IP-Datagramms) Identifier und Sequence-Nummer dienen der Zuordnung eintreffender Antworten zu den jeweiligen Anfragen, da eine Station mehrere Anfragen aussenden kann oder auf eine Anfrage mehrere Antworten eintreffen können. Wenden wir uns nun den einzelnen Nachrichtentypen zu: Echo request/reply Überprüfen der Erreichbarkeit eines Zielknotens. Es können Testdaten mitgeschickt werden, die dann unverändert zurückgeschickt werden (--> Ping-Kommando unter UNIX). Destination unreachable Im Codefeld wird die Ursache näher beschrieben: 0 Network unreachable 1 Host unreachable 2 Protocol unreachable 3 Port unreachable 4 Fragmentation needed 5 Source route failed Source quench Wenn mehr Datagramme kommen als eine Station verarbeiten kann, sendet sie diese Nachricht an die sendende Station. Redirect wird vom ersten Gateway an Hosts im gleichen Teilnetz gesendet, wenn es eine bessere Route-Verbindung über einen anderen Gateway gibt. In der Nachricht wird die IP-Adresse des anderen Gateways angegeben. Time exceeded Für diese Nachricht an den Quellknoten gibt es zwei Ursachen: Time-to-live exceeded (Code 0): Wenn ein Gateway ein Datagramm eliminiert, dessen TTL-Zähler abgelaufen ist. Fragment reassembly time exceeded (Code 1): Wenn ein Timer abläuft, bevor alle Fragmente des Datagramms eingetroffen sind. Parameter problem on a Datagramm Probleme bei der Interpretation des IP-Headers. Es wird ein Verweis auf die Fehlerstelle und der fragliche IP-Header zurückgeschickt. Timestamp request/reply Erlaubt Zeitmessungen und -synchronisation im Netz. Drei Zeiten werden gesendet (in ms seit Mitternacht, Universal Time): Originate T.: Sendezeitpunkt des Requests (vom Absender) Receive T.: Ankunftszeit (beim Empfänger) Transmit T.: Sendezeitpunkt des Reply (vom Empfänger) Information request/reply Mit dieser Nachricht kann ein Host die Netid seines Netzes erfragen, indem er seine Netid auf Null setzt. Address mask request/reply Bei Subnetting (siehe unten) kann ein Host die Subnet-Mask erfragen. Für den User nutzbar ist ICMP vor allem für die Kommandos ping und traceroute (bei Windows "tracert"). Diese Kommandos senden ICMP-Echo-Requests aus und warten auf den ICMP-Echo-Reply. So kann man die Erreichbarkeit eines Knotens feststellen. Will man alle Knoten im lokalen Netz erkennen genügt ein ping auf die Broadcast-Adresse, z. B.: ping 192.168.33.255 Zum Anzeigen der Arp-Tabelle gibt es unter Windows wie unter Linux das arp-Kommando, mit arp -a erhält man eine Liste der aktuell gespeicherten MAC-Adressen und deren Zuordnung zu IP-Adressen. Führt man das obige ping-Kommando und das arp-Kommando nacheinander aus, erhält man eine liste der IP- umd MAC-Adressen der aktiven lokalen Knoten, z.B.: ping -b -c1 192.168.33.255 arp -a UDP - User Datagram Protocol UDP ist ein einfaches Schicht-4-Protokoll, das einen nicht zuverlässigen, verbindungslosen Transportdienst ohne Flußkontrolle zur Verfügung stellt. UDP ermöglicht zwischen zwei Stationen mehrere unabhängige Kommunikationsbeziehungen (Multiplex-Verbindung): Die Identifikation der beiden Prozesse einer Kommuninkationsbeziehung geschieht (wie auch bei TCP, siehe unten) durch Port-Nummern (kurz "Ports"), die allgemein bekannten Anwendungen fest zugeordnet sind. Es lassen sich aber auch Ports dynamisch vergeben oder bei einer Anwendung durch verschiedene Ports deren Verhalten steuern. Die Transporteinheiten werden 'UDP-Datagramme' oder 'User Datagramme' genannt. Sie haben folgenden Aufbau: Source Port Identifiziert den sendenden Prozeß (falls nicht benötigt, wird der Wert auf Null gesetzt). Destination Port Identifiziert den Prozeß des Zielknotens. Length Länge des UDP-Datagramms in Bytes (mindestens 8 = Headerlänge) UDP-Checksum Optionale Angabe (falls nicht verwendet auf Null gesetzt) einer Prüfsumme. Zu deren Ermittlung wird dem UDP-Datagramm ein Pseudoheader von 12 Byte vorangestellt (aber nicht mit übertragen), der u. a. IP-Source-Address, IP-Destination-Address und Protokoll-Nummer (UDP = 17) enthält. TCP - Transmission Control Protocol Welches übergeordnete Protokoll der Transportschicht das Datenpaket erhält, steht im 'Protokoll'-Feld eines jeden IP-Paketes. Jedes Protokoll der Transportschicht bekommt eine eindeutige Identifikationsnummer zugewiesen, anhand der die IP-Schicht entscheiden kann, wie weiter mit dem Paket zu verfahren ist. Eines der wichtigsten Protokolle der Transportschicht ist TCP. Die Aufgabe von TCP ist es, die oben geschilderten Defizite von IP zu verbergen. Für den TCP-Benutzer soll es nicht mehr sichtbar sein, daß die darunterliegenden Protokollschichten Datenpakete versenden, sondern es soll der Benutzer mit einem Byte-Strom wie bei einer normalen Datei (oder einem Terminal) arbeiten können. TCP garantiert vor allen Dingen den korrekten Transport der Daten - jedes Paket kommt nur einmal, fehlerfrei und in der richtigen Reihenfolge an. Zusätzlich können bei TCP mehrere Programme die Verbindung zwischen zwei Rechnern quasi-gleichzeitig nutzen. TCP teilt die Verbindung in viele virtuelle Kanäle ("Ports") auf, die zeitmultiplex mit Daten versorgt werden. Nur so ist es möglich, daß beispielsweise mehrere Benutzer eines Rechners zur selben Zeit das Netz in Anspruch nehmen können oder daß man mit einer einzigen Wählverbindung zum Provider gleichzeitig E-Mail empfangen und Dateien per FTP übertragen kann. Dieses Protokoll implementiert also einen verbindungsorientierten, sicheren Transportdienst als Schicht-4-Protokoll. Die Sicherheit wird durch positive Rückmeldungen (acknowledgements) und Wiederholung fehlerhafter Blöcke erreicht. Fast alle Standardanwendungen vieler Betriebssysteme nutzen TCP und das darunterliegende IP als Transportprotokoll, weshalb man die gesamte Protokollfamilie allgemein unter 'TCP/IP' zusammenfaßt. TCP läßt sich in lokalen und weltweiten Netzen einsetzen, da IP und die darunterliegenden Schichten mit den unterschiedlichsten Netzwerk- und Übertragungssystemen arbeiten können (Ethernet, Funk, serielle Leitungen, ...). Zur Realisierung der Flußkontrolle wird ein Fenstermechanismus (sliding windows) verwendet (variable Fenstergröße). TCP-Verbindungen sind vollduplex. Wie bei allen verbindungsorientierten Diensten muß zunächst eine virtuelle Verbindung aufgebaut und bei Beendigung der Kommunikation wieder abgebaut werden. "Verbindungsaufbau" bedeutet hier eine Vereinbarung beider Stationen über die Modalitäten der Übertragung (z. B. Fenstergröße, Akzeptieren eines bestimmten Dienstes, usw.). Ausgangs- und Endpunkte einer virtuellen Verbindung werden wie bei UDP durch Ports identifiziert. Allgemein verfügbare Dienste werden über 'well known' Ports (--> feste zugeordnete Portnummer) erreichbar. Andere Portnummern werden beim Verbindungsaufbau vereinbart. Damit die ständige Bestätigung jedes Datensegments den Transport nicht über Gebühr hemmt, werden zwei Tricks verwendet. Zum einen kann die Empfangsbetätigung einem Segment in Gegenrichtung mitgegeben werden - das spart ein separates Quittungssegment. Zweitens muß nicht jedes Byte sofort bestätigt werden, sondern es gibt ein sogenanntes 'Fenster'. Die Fenstergröße gibt an, wieviele Bytes gesendet werden dürfen, bis die Übertragung quittiert werden muß. Erfolgt keine Quittung, werden die Daten nochmals gesendet. Die empfangene Quittung enthält die Nummer des Bytess, das als nächstes vom Empfänger erwartet wird - womit auch alle vorhergehenden Bytes quittiert sind. Die Fenstergröße kann dynamisch mit der Quittung des Empfängers geändert werden. Werden die Ressourcen knapp, wird die Fenstergröße verringert. Beim Extremfall Null wird die Übertragung unterbrochen, bis der Empfänger erneut quittiert. Neben einem verläßlichen Datentransport ist so auch die Flußkontrolle gewährleistet. Das Prinzip des Fenstermechanismus ist eigentlich ganz einfach. Wenn man das Bild betrachtet, ergibt sich folgende Sachverhalt: Die Fenster größe im Beispiel beträgt drei Bytes. Byte 1 wurde von der Datenquelle gesendet und vom Empfänger quittiert. Die Quelle hat die Bytes 2, 3 und 4 gesendet, sie wurden aber vom Empfänger noch nicht quittiert (Quittung eventuell noch unterwegs). Byte 5 wurde von der Quelle noch nicht gesendet. Er geht erst dann auf die Reise, wenn die Quittung für Byte 2 (oder höher) eingetroffen ist. Das TCP-Paket wird oft auch als 'Segment' bezeichnet. Jedem TCP-Block ist ein Header vorangestellt, der aber wesentlich umfangreicher als die bisherigen ist: Source Port Identifiziert den sendenden Prozeß. Destination Port Identifiziert den Prozeß des Zielknotens. Sequence Number TCP betrachtet die zu übertragenden Daten als numerierten Bytestrom, wobei die Nummer des ersten Bytes beim Verbindungsaufbau festgelegt wird. Dieser Bytestrom wird bei der Übertragung in Blöcke (TCP-Segmente) aufgeteilt. Die 'Sequence Number' ist die Nummer des ersten Datenbytes im jeweiligen Segment (--> richtige Reihenfolge über verschiedene Verbindungen eintreffender Segmente wiederherstellbar). Acknowledgement Number Hiermit werden Daten von der Empfängerstation bestätigt, wobei gleichzeitig Daten in Gegenrichtung gesendet werden. Die Bestätigung wird also den Daten "aufgesattelt" (Piggyback). Die Nummer bezieht sich auf eine Sequence-Nummer der empfangenen Daten; alle Daten bis zu dieser Nummer (ausschließlich) sind damit bestätigt --> Nummer des nächsten erwarteten Bytes. Die Gültigkeit der Nummer wird durch das ACK-Feld (--> Code) bestätigt. Data Offset Da der Segment-Header ähnlich dem IP-Header Optionen enthalten kann, wird hier die Länge des Headers in 32-Bit-Worten angegeben. Res. Reserviert für spätere Nutzung Code Angabe der Funktion des Segments: URG Urgent-Pointer (siehe unten) ACK Quittungs-Segment (Acknowledgement-Nummer gültig) PSH Auf Senderseite sofortiges Senden der Daten (bevor Sendepuffer gefüllt ist) und auf Empfangsseite sofortige Weitergabe an die Applikation (bevor Empfangspuffer gefüllt ist) z. B. für interaktive Programme. RST Reset, Verbindung abbauen SYN Das 'Sequence Number'-Feld enthält die initiale Byte-Nummer (ISN) --> Numerierung beginnt mit ISN + 1. In der Bestätigung übergibt die Zielstation ihre ISN (Verbindungsaufbau). FIN Verbindung abbauen (Sender hat alle Daten gesendet), sobald der Empfänger alles korrekt empfangen hat und selbst keine Daten mehr loswerden will. Window Spezifiziert die Fenstergröße, die der Empfänger bereit ist anzunehmen - kann dynamisch geändert werden. Checksum 16-Bit Längsparität über Header und Daten. Urgent Pointer Markierung eines Teils des Datenteils als dringend. Dieser wird unabhängig von der Reihenfolge im Datenstrom sofort an das Anwenderprogramm weitergegeben (URGCode muß gesetzt sein). Der Wert des Urgent-Pointers markiert das letzte abzuliefernde Byte; es hat die Nummer <Sequence Number> + <Urgent Pointer>. Options Dieses Feld dient dem Informationsaustausch zwischen beiden Stationen auf der TCPEbene, z. B. die Segmentgröße (die Ihrerseits von der Größe des IP-Datagramms abhängen sollte, um den Durchsatz im Netz optimal zu gestalten). Ablauf einer TCP-Session Im Gegensatz zu IP ist TCP verbindungsorientiert. Das muß so sein, denn TCPVerbindungen sollen ja für den Benutzer prinzipiell wie Dateien zu handhaben sein. Das bedeutet, eine TCP-Verbindung wird wie eine Datei geöffnet und geschlossen, und man kann ihre Position innerhalb des Datenstroms bestimmen, genau wie man bei einer Datei die Position der Lese- oder Schreibposition angeben kann. TCP sendet die Daten auch in größeren Einheiten, um den Verwaltungsaufwand durch Header- und Kontrollinformationen klein zu halten. Im Gegensatz zu den IP-Paketen bezeichnet man die Einheiten der Transportschicht als "Segmente". Jedes gesendete TCP-Segment hat eine eindeutige Folgenummer, welche die Position seines ersten Bytes im Byte-Strom der Verbindung angibt. Anhand dieser Nummer kann die Reihenfolge der Segmente korrigiert und doppelt angekommene Segmente können aussortiert werden. Da die Länge des Segments aus dem IPHeader bekannt ist, können auch Lücken im Datenstrom entdeckt werden, und der Empfänger kann verlorengegangene Segmente neu anfordern. Beim Öffnen einer TCP-Verbindung tauschen beide Kommunikationspartner Kontrollinformationen aus, die sicherstellen, daß der jeweilige Partner existiert und Daten annehmen kann. Dazu schickt die Station A ein Segment mit der Aufforderung, die Folgenummern zu synchronisieren. Das einleitende Paket mit gesetztem SYN-Bit ("Synchronise-" oder "Open"-Request) gibt die Anfangs-"Sequence Number" des Client bekannt. Diese Anfangs-"Sequence Number wird zufällig bestimmt. Bei allen nachfolgenden Paketen ist das ACK-Bit ("Acknowledge", "Quittung") gesetzt. Der Server antwortet mit ACK, SYN und der Client bestätigt mit ACK. Das sieht dann so aus: Die Station B weiß jetzt, daß der Sender eine Verbindung öffnen möchte und an welcher Position im Datenstrom der Sender anfangen wird zu zählen. Sie bestätigt den Empfang der Nachricht und legt ihrerseits eine Folgenummer für Übertragungen in Gegenrichtung fest. Station A bestätigt nun den Empfang der Folgenummer von B und beginnt dann mit der Übertragung von Daten. Diese Art des Austausches von Kontrollinformationen, bei der jede Seite die Aktionen der Gegenseite bestätigen muß, ehe sie wirksam werden können, heißt "Dreiwege-Handshake". Auch beim Abbau einer Verbindung wird auf diese Weise sichergestellt, daß beide Seiten alle Daten korrekt und vollständig empfangen haben. Im zeitlichen Zusammenhang stellt sich eine TCP/IP-Verbindung folgendermaßen dar: Das folgende Beispiel zeigt die Arbeitsweise des TCP/IP - Protokolls. Es wird eine Nachricht von einem Rechner im grünen Netz zu einem Rechner im orangen Netz gesendet. Die Nachricht wird in mehrere Pakete aufgeteilt und auf der besten Route auf die Reise geschickt. Das verbindungslose IPProtokoll sorgt zusammen mit den Routern für den Weg. Da eine Strecke überlastet ist, werden die Pakete 3, 4 und 5 auf einer anderen Strecke weiter transportiert. Dieser Transport erfolgt zufälligerweise schneller als jener der Pakete 1 und 2. Die Pakete wandern ihrem Bestimmungsnetz entgegen. Das erste Paket ist bereits angekommen. Paket 3 kommt vor Paket 2 am Ziel an. Die Pakete 1, 2 und 3 sind - in falscher Reihenfolge - am Zielrechner angekommen. Auf der Strecke, auf der Pakete 4 und 5 transportiert werden, tritt eine Störung auf. Paket 4 ist bei der Störung verloren gegangen. Paket 5 wird auf einer anderen Route zum Zielnetz geschickt (wären die Routen statisch am Router eingetragen, ginge auch Paket 5 verloren). Alle überlebenden Pakete sind am Zielrechner angekommen. Das TCP-Protokoll setzt die Pakete wieder in der richtigen Reihenfolge zusammen und fordert das fehlende Paket 4 nochmals beim Sender an. Für den Empfänger ergibt sich ein kontinuierlicher Datenstrom. TCP-Zustandsübergangsdiagramm Den gesamte Lebenszyklus einer TCP-Verbindung beschreibt die folgende Grafik in einer relativ groben Darstellung. Erklärung der Zustände: LISTEN: Warten auf ein Connection Request. SYN-SENT: Warten auf ein passendes Connection Request, nachdem ein SYN gesendet wurde. SYN-RECEIVED: Warten auf Bestätigung des Connection Request Acknowledgement, nachdem beide Teilnehmer ein Connection Request empfangen und gesendet haben. ESTABLISHED: Offene Verbindung. FIN-WAIT-1: Warten auf ein Connection Termination Request des Kommunikationspartners oder auf eine Bestätigung des Connection Termination, das vorher gesendet wurde. FIN-WAIT-2: Warten auf ein Connection Termination Request des Kommunikationspartners. CLOSE-WAIT: Warten auf ein Connection Termination Request (CLOSE) der darüberliegenden Schicht. CLOSING: Warten auf ein Connection Termination Request des Kommunikationspartners. LAST-ACK: Warten auf die Bestätigung des Connection Termination Request, das zuvor an den Kommunikationspartner gesendet wurde. Zeitüberwachung In allen Protokollimplementierungen spielt die Zeit eine wichtige Rolle. So werden alle Abläufe zeitlich überwacht. Dazu werden in der Protokollimplementierung sogenannte "Timer" gestartet, deren Timeout zur Fehlerbehandlung führt. Paketwiederholungs-Wecker oder Retransmission Timeout In Weitverkehrsnetzen mit unterschiedlichsten Verbindungsarten, die noch dazu zeitlichen Schwankungen unterworfen sind, ist die Wahl der Wartezeit auf Bestätigungen schwierig. Der Retransmission Timeout (RTO) läuft ab, wenn der vorgegebene Zeitraum zwischen dem Aussenden eines TCP-Pakets bis zum Eintreffen der dazugehörigen Quittung überschritten wird. In diesem Fall muß das Paket noch einmal gesendet werden. Allerdings darf der Zeitraum nicht fest definiert sein, da man sonst TCP nicht über Netzwerke mit unterschiedlichen Laufzeiten betreiben könnte - wenn man z.B. Ethernet und eine serielle Verbindung über mehrere Gateways miteinander vergleicht, ergibt sich ein tausendfacher Unterschied in der Übertragungsrate. Daher wird in TCP bei jedem Paket die Zeit gemessen, die zwischen Senden und Empfangen einer Quittung vergeht, die sogenannte Round Trip Time (RTT). Die so gemessene Zeit wird über eine Formel umgerechnet, die Spitzen nach oben und unten herausfiltert, sich aber auch allmählich an eine verlängerte oder verkürzte Laufzeit anpaßt. Das Ergebnis ist die Smoothed Round Trip Time (SRTT), d.h. die mittlere Zeit, die für einen Paketaustausch verstreicht. Diese Zeit wird nochmals skaliert, um weiteren Spielraum für unvorhergesehene Verzögerungen zu schaffen. SRTT: RTO: S = aS + (1 - a)R T = min[U, max[L,ßS]] (L < T < U) S Smoothed Round Trip Time R Round Trip Time T Retransmission Timeout (z.B. 30 Sekunden) U Zeitobergrenze (z.B. 1 Sekunde) L Zeituntergrenze (z.B. 1 Minute) a Smoothing Factor (z.B. 0.9) ß Scaling Factor (z.B. 2.0) Die beiden Formeln werden durch den RFC 793 spezifiziert: zunächst den SRTT-Filter, danach die Ermittlung des RTO. Falls nach der Wiederholung des Pakets der Wiederholungstimer ein weiteres Mal abläuft, wird der RTO in der Regel bis zu zwölfmal exponentiell erhöht. Erst wenn auch diese Erhöhung keinen Effekt zeigt, gilt die Verbindung als unterbrochen. Persistance Timer Beim Austausch von Daten über TCP ist es im Prinzip möglich, daß das Empfangsfenster gerade auf 0 steht - und genau in diesem Moment ein Paket verlorengeht, das das Fenster wieder öffnen sollte. Als Ergebnis warten dann beide TCPs bis in alle Ewigkeit aufeinander. Ein Gegenmittel dazu ist der Persistenz-Timer, der in bestimmten Zeitabschnitten kleine TCPPakete (1 Byte) abschickt und damit überprüft, ob die Empfängerseite wieder bereit ist. Ist das Empfangsfenster nach wie vor 0, kommt eine negative Quittung zurück; ist es größer, können nach der positiven Quittung weitere Daten gesendet werden. Stillhaltezeit oder Quiet Time Jede Möglichkeit der Verwechslung von Verbindungen durch im Netz herumirrende überholte TCP-Pakete sollte verhindert werden. Daher werden nach dem Abbau von TCP- Verbindungen Portnummern erst wieder freigegeben, wenn eine bestimmte Zeitspanne, die zweimal die "Maximum Segment Lifetime" (MSL) beträgt, vergangen ist. Die MSL entspricht der Zeit, in UNIX die im TTL-Feld von IP eingetragen wird. Der UNIX-Anwender bemerkt diese Wartezeit, wenn er eine Verbindung zwischen gleichen Partnern (d.h. gleichen Portnummern) sofort nach dem Abbruch wieder eröffnen will. Das System teilt ihm dann mit, daß die verwendete Portnummer noch belegt ist. Erst nach Ablauf von ca. 30 Sekunden ist ein erneuter Verbindungsaufbau möglich. Keep Alive Timer und Idle Timer Dabei handelt es sich um zwei nicht in der TCP-Spezifikation vorgesehene Wecker, die aber in UNIX-Systemen implementiert sind. Beide stehen miteinander in Verbindung. Der Keep Alive Timer bewirkt, daß in regelmäßigen Zeitabständen ein leeres Paket abgeschickt wird, um das Bestehen der Verbindung zum Partner zu überprüfen. Antwortet der Partnerrechner nicht, wird die Verbindung nach Ablauf des Idle Timers abgebrochen. Eine Applikation aktiviert diese Timer mit der KEEP_ALIVE-Option über die Socket-Schnittstelle. In der folgenden Tabelle sind die Werte für die oben genannten Timer angegeben. Dazu ist zu bemerken, daß die Dauer der Timer implementationsabhängig ist und nicht immer auf die unten angegebenen Werte eingestellt sein muß. Einstellungen der TCP-Timer (implementationsabhängig) Timer Dauer [s] Retransmission Timeout dynamisch Persistance Timer 5 Quiet Timer 30 Keep Alive Timer 45 Idle Timer 360 Algorithmen zur Steigerung der Effizienz Zwischen einer TCP-Implementierung nach Spezifikation und einem optimierten TCPSubsystem, wie man es in UNIX-Systemen vorfindet, liegt ein weiter Weg. Zahllose Verbesserungen sind in den Jahren in die UNIX-TCP-Implementierungen eingeflossen und neue Algorithmen in Nachfolgeversionen integriert worden: Acknowledgement Delay Normalerweise sendet der Empfänger nach Erhalt eines Pakets ein Antwortpaket, in dem die Größe des Empfangsfensters verkleinert und die Daten quittiert werden. Nach Übergabe der Daten an den empfangenden Prozeß werden die Datenpuffer im System frei, was ein Absenden eines Pakets mit einer Vergrößerung des Empfangsfensters zur Folge hat. Hat das Programm die Daten verarbeitet, folgt in der Regel kurz danach eine Antwort, es sind also für eine Transaktion in der Regel drei Pakete notwendig. Man hat aber festgestellt, daß in manchen Fällen, z.B. beim Telnet- oder SSH-Betrieb, ein Verzögern des Quittungspakets um 0,2 Sekunden Vorteile bringt: nach dieser kurzen Wartezeit können alle drei Informationen Empfangsfenster, Quittung und Antwort - in einem einzigen Paket versendet werden. Damit Datentransfers, die hohen Durchsatz benötigen, nicht gebremst werden, unterbleibt die Verzögerung, wenn das Empfangsfenster um mindestens 35% oder zwei maximale Pakete verändert wurde. Silly Window Syndrome Avoidance In bestimmten Situationen werden Empfangsfensterangaben versendet, die derart klein sind, daß das Netzwerk und Rechner von den vielen Quittungspaketen über Gebühr belastet werden. Um das zu verhindern, wird das Empfangsfenster nur dann wieder vergrößert, wenn ausreichend Platz (mehr als 1/4 des Datenpuffers oder ein maximales Paket) zur Verfügung steht. Desgleichen verhält sich auch der Sender konservativ und sendet nur, wenn das angebotene Fenster ausreichend groß ist. Nagle Algorithm oder Small Packet Avoidance Benannt nach seinem Erfinder John Nagle, versucht dieser Algorithmus eben- falls, das Versenden von kleinen TCP-Paketen zu verhindern. do, In diesem Fall geht es aber darum, auf der Senderseite zu verhin- es dern, daß in kleinen Einheiten von der Applikation an TCP über- Ari gebene Daten auch in dieser Form weiterversendet werden. Ein Co erstes Paket wird sofort ausgesendet, weitere Daten auf der ge,~ Senderseite aber so lange gepuffert, bis ein volles maximales Seg- un ment geschickt werden kann oder eine Quittung für das erste gn Paket eingetroffen ist. Probleme ergeben sich mit diesem bis Algorithmus aber bei Anwendungen, die viele kleine Nachrich- un ten abschicken, ohne eine Antwort zurückzuerhalten, z.B. dem X In Window System. In diesem Fall kann der NagleAlgorithmus En verbindungsspezifisch abgeschaltet werden. pal Slow Start with Congestion Avoidance Diese miteinander verbundenen Algorithmen, manchmal auch als Jacobson-Algorithmen bezeichnet, sind erst in jüngster Zeit bekannt geworden und in erster Linie für langsame Netzwerke und den Betrieb von Netzen mit Gateways von Bedeutung. Man hatte in den letzten Jahren beobachtet, daß das Internet mit steigender Belastung immer weniger Datendurchsatz lieferte und zum Teil sogar nahezu zusammenbrach. Als man die Vorgänge näher betrachtete, wurde festgestellt, daß mehr als die Hälfte der Daten Wiederholungen verlorengegangener TCP-Pakete waren. Was war geschehen? Ein Netzwerkpfad Datenpuffer vom Sender über mögliche Gateways bis hin zum Empfänger - kann nur eine endliche Datenmenge aufnehmen. Wenn ein Gateway oder ein Host sehr durch Verkehr belastet sind, kann es vorkommen, daß nicht genügend Pufferplatz zur Aufnahme von Paketen vorhanden ist. In diesem Fall werden die Pakete vom Gateway verworfen, woraufhin der Absender des Pakets nach Ablauf des Retransmission Timeouts eine Wiederholung vornimmt und dadurch insgesamt die Belastung des Netzes weiter unnötig steigert. Der Slow StartAlgorithmus versucht nun zu ermitteln, wieviele Daten zu einem Zeitpunkt in Richtung Empfänger unterwegs sein können, ohne daß es dabei zu Verlusten kommt. Erreicht wird das über eine allmähliche Steigerung der ausgesendeten Datenmenge bis zu einem Punkt, an dem sich ein gleichmässiger Datenfluß ohne Wiederholungen ergibt. Wo früher die Menge der auszusendenden Daten durch die Größe bestimmt wurde, ist jetzt die Aufnahmekapazität des Netzwerkpfads, das sogenannte "Congestion Window", die bestimmende Größe, wobei das Congestion Window immer kleiner oder gleich dem Empfangsfenster (Receive Window) ist. Hat sich das Congestion Window eingependelt, wird es erst wieder verändert, wenn auftretende Wiederholungen ein Ansteigen der Netzwerklast signalisieren: in diesem Fall tritt die "Congestion Avoidance" in Kraft. Gleichzeitig wird durch ständiges vorsichtiges Vergrößern des Congestion Windows versucht, unter Umständen freiwerdende Ressourcen zu benutzen. Aufgrund des konservativen Verhaltens läßt sich der Durchsatz um bis zu 30% steigern und die Anzahl der wiederholten Pakete um über 50% senken. In Verbindung mit diesen beiden Algorithmen wurde auch die Ermittlung des Retransmission Timeouts verbessert. Dieser Wert paßt sich jetzt schneller an Veränderungen in der RTT an und verhindert zusätzliche Paketwiederholungen. Ports für jeden Dienst Server-Prozesse lauschen bei UDP und TCP auf bestimmten Portnummern. Per Übereinkunft werden dazu Ports niedriger Nummern verwendet. Für die Standarddienste sind diese Portnummern in den RFCs festgeschrieben. Ein Port im "listen"-Modus ist gewissermaßen eine halboffene Verbindung. Nur Quell-IP und Quellport sind bekannt. Der Serverprozeß kann vom Betriebssystem dupliziert werden, so daß weitere Anfragen auf diesem Port behandelt werden können. Die Portnummern werden auf dem Host-System konfiguriert und haben zwei Funktionen: o Allgemein verfügbare Dienste werden über 'well known' Ports (--> feste, per RFC zugeordnete Portnummer) erreichbar. Sie stehen also für ein Protokoll, das über die Nummer direkt angesprochen wird o oder sie werden beim Verbindungsaufbau vereinbart und einem ServerProgramm zugewiesen Die Portangabe ist nötig, wenn mehrere Serverprogramme auf dem adressierten Rechner laufen. Die Portnummer steht im TCP-Header und ist 16 Bit groß. Theoretisch können also bis zu 65535 TCP-Verbindungen auf einem Rechner mit einer einzigen IP-Adresse aufgebaut werden. Portnummern werden oft auch bei der Konfiguration von Internet-Clients als Parameter gefordert. Die Client-Prozesse verwenden normalerweise freie Portnummern, die vom lokalen Betriebssystem zugewiesen werden (Portnummer > 1024). Die "well known" Portnummern (0 bis 1023), die weltweit eindeutig adressiert werden müssen, werden durch die IANA (Internet Assigned Numbers Authority) vergeben. Einige Beispiele für TCP-Ports (UDP verwendet eine andere Zuordnung): Portnummer Protokoll 20 FTP (Daten) 21 FTP (Befehle) 22 Secure Shell 23 Telnet 25 SMTP 53 DNS-Server 80 HTTP (Proxy-Server) 110 POP3 143 IMAP Eine vollständige Portliste erhält man bei http://www.isi.edu/in-notes/iana/assignments/portnumbers. Well Known Ports 1 – 1023 Diese Ports sind fest einer Anwendung oder einem Protokoll zugeordnet. Die feste Zuordnung ermöglicht eine einfachere Konfiguration. Die Verwaltung dieser Ports übernimmt die Internet Assigned Numbers Authority (IANA). Registered Ports 1024 – 49151 Dynamically Allocated Ports 49152 – Diese Ports werden dynamisch zugewiesen. 65535 Jeder Client kann diese Ports nutzen. Wenn ein Prozess einen Port benötigt, fordert er diesen bei seinem Host an. Diese Ports sind für diverse Dienste vorgesehen. IP-Adresse und Portnummer definieren einen Kommunikationsendpunkt, der in der TCP/IPWelt "Socket" genannt wird. Die Grenze zwischen der Anwendungsschicht und der Transportschicht ist in den meisten Implementierungen zugleich die Grenze zwischen dem Betriebssystem und den Anwendungsprogrammen. Im OSI-Modell ist diese Grenze in etwa die Grenze zwischen den Schichten 4 und 5. Daher ordnet man IP meist ungefähr in die Ebene 3 und TCP ungefähr in Ebene 4 des OSI-Modells ein. Da TCP/IP jedoch älter und einfacher als das OSI-Modell ist, kann diese Einordnung nicht genau passen. Port-Scans Beim Scanning wird versucht, offene Ports eines Rechners zu ermitteln. Das ist meist auch der erste Schritt eines Angreifers, der in einem Rechner eindringen will. Deshalb dient ein Portscan auch dazu, die Sicherheit des eigenen Systems zu überprüfen. Bei den ScanningMethoden wurden Verfahren entwickelt, bei denen versucht wird, den Scanvorgang auf dem gescannten Rechern unentdeckt zu lassen. TCP-Connect-Scan Bei dieser Methode wird versucht, eine Verbindung zu einem Port auf dem Zielrechner aufzubauen. Der Scanner läßt einen vollständigen Dreiwege-Handshake zu, bevor er die Verbindung wieder unterbricht. Diese Art der Scans ist allerdings sehr leicht zu entdecken und kann auch leicht mit Hilfe von Firewalls abgeblockt werden. TCP-SYN-Scan Diese Methode wird oft als "Half-Open-Scan" bezeichnet. Der Scanner sendet ein SYN-Packet an den Zielrechner, wie bei einem ganz normalen Verbindungsaufbau. Wenn der Zielrechner mit einem RST antwortet, weiß der Scanner, daß dieser Port geschlossen ist. Antwortet der Zielrechner jedoch mit einem SYN/ACK, handelt es sich um einem offenen Port. In diesem Falle wird die Verbindung vom Scanner sofort mit einem RST beendet. Diese Art des Scannens ist nicht ganz so leicht auf dem Zielrechner zu entdecken wie der Connect Scan. Stealth FIN-Scan Stealth Scans sollen vom Zielrechner nicht entdeckt werden. Allerdings gibt es Programme, die genau solche Scans entdecken. Beim "Stealth FIN Scan" wird nur ein Packet mit einem FIN-Flag, ohne begleitendes ACK-Flag gesendet. Diese Art von Paket ist unzulässig. Wenn der Port offen ist, wird das Paket des Scanners vom Zielrechner ignoriert. Wenn der Port geschlossen ist, antwortet der Zielrechner mit einem RST-Paket. Stealth Xmastree-Scan Bei diesem Scan sind die FIN-, URG-, und PUSH-Flags alle gemeinsam gesetzt. Auch dieses Paket ist unzulässig. Wenn der Port offen ist, wird das Paket des Scanners vom Zielrechner ignoriert. Wenn der Port geschlossen ist, antwortet der Zielrechner mit einem RST-Paket. Stealth Null-Scan Bei diesem Scan sind alle Flags auf Null gesetzt. Alles Weitere wie oben. ACK-Scan Dieser Scan wird verwendet, um Firewalls zu testen ob sie mit "stateful inspection" arbeiten (z.B. Firewall 1) oder ob es sich nur um einfache Packetfilter handelt, die eingehende SYN Packete verwerfen. Der ACK-Scan sendet ein Packet mit gesetztem ACK-Flag und zufälliger Sequenznummer an die Ports. Wenn das Paket von der Firewall durchgelassen wird, sendet der Server ein RST, da das Paket nicht zuzuordnen ist. In diesem Fall wird der Port als "ungefiltert" klassifiziert. Wenn die Firewall den Status einer Verbindung überwacht, wird das Paket ohne eine Antwort vom Zielrechner abgewiesen oder es wird dem Scanner mit einer ICMP Destination unreachable Nachricht geantwortet. PPP Das Point to Point Protocol (PPP) findet gegenwärtig vielfachen Einsatz. Es arbeitet mit drei Teilprotokollen: Das Data Link Layer Protocol ermöglicht die Übertragung (Encapsulation) von Datagrammen über serielle Verbindungen mit Hilfe von HDLC. Das Link Control Protocol (LCP) steuert Aufbau, Konfiguration und Test der Verbindung. Das Network Control Protocol (NCP) ermöglicht die Übertragung von Konfigurationsdaten für verschiedene Protokolle der Vermittlungsschicht. PPP ist geeignet für den simultanen Einsatz verschiedener Protokolle der Vermittlungsschicht, es ist also ein so genanntes "Multi-Protokoll-Protokoll". Es ist ein zustandsorientiertes Protokoll: PPP ist ein verbindungsorientiertes Protokoll und unterscheidet drei Phasen Verbindungsaufbau, Datenübertragung und Verbindungsabbau. Die Realisierung dieser Phasen unter Berücksichtigung der Teilprotokolle von PPP zeigt das Bild unten. 1. Der anrufende PPP-Knoten sendet LCP-Rahmen zum Aufbau und zur Konfiguration der Verbindung (Data Link). Die LCP-Pakete verfügen über ein Feld mit Konfigurations-Optionen. Zu diesen Optionen zählen beispielsweise die Maximum Transmission Unit (MTU). Hierbei handelt es sich um die Angabe, ob bestimmte PPPFelder komprimiert werden, oder das Link Authentication Protocol (LAP). 2. In einer optionalen Phase wird überprüft, ob die Qualität der Verbindung für den Aufbau einer Übertragung der Pakete der Vermittlungsschicht ausreicht. 3. Es folgt eine Authentifizierungsphase. 4. Der anrufende PPP-Knoten sendet NCP-Rahmen zur Auswahl und Konfiguration des zu übertragenden Protokolls der Vermittlungsschicht. 5. Nun können die Daten übertragen werden. 6. Die Verbindung bleibt bis zur Beendigung durch LCP- oder NCP-Rahmen bestehen oder bis ein externes Ereignis auftritt. Zu diesen kann eine Unterbrechung durch den Anwender, der Abbruch der Übertragung oder der Ablauf eines "Inactivity Timers" zählen. PPP unterstützt verschiedene Protokolle zur Authentifizierung. Dabei realisieren alle Protokolle nur eine einseitige Authentifizierung. Dies bedeutet, dass sich der anrufende Knoten bzw. dessen Anwender authentifizieren und der angerufene Knoten diese Authentifizierung überprüfen muss. Der angerufene Knoten authentifiziert sich durch seine Verfügbarkeit unter dieser physischen Verbindung. Die wichtigsten Authentifizierungsprotokolle sind: das Password Authentication Protocol (PAP), das Shiva Password Authentication Protocol(SPAP), das Challenge Handshake Authentication Protocol (CHAP) sowie eine Variante des CHAP, das Microsoft-CHAP (MS-CHAP), das in zwei Versionen vorliegt. Die Authentifzierungsprotokolle mit der größten Verbreitung sind PAP und CHAP. Auch MS-CHAPv2 ist recht häufig anzutreffen. Die meisten ISPs fragen beim einwählenden Host zunächst CHAP an. PAP unterstützt ein so genanntes Zwei-Wege-Handshake. Die Kombination "Username/Password" wird vom anrufenden Knoten so lange übertragen, bis die Authentifizierung bestätigt oder abgelehnt wird. Im Falle der Ablehnung wird die Verbindung abgebrochen. Dieses Vorgehen bietet allerdings nur eine geringe Sicherheit: Das Passwort wird unverschlüsselt übertragen. Es ist eine beliebige Anzahl von Wiederholungen möglich. Und schließlich werden Häufigkeit und Geschwindigkeit der Versuche vom anrufenden Knoten bestimmt, so dass ein Brute-Force-Angriff möglich wird. CHAP bietet ein erhöhtes Sicherheitsniveau im Rahmen eines so genannten Drei-WegeHandshakes. Der anrufende Knoten darf erst die Authentifizierung beginnen, wenn er vom angerufenen Knoten dazu aufgefordert wurde. Auf diese Weise werden Häufigkeit und Geschwindigkeit der Versuche vom angerufenen Knoten bestimmt. Zusätzlich wird die Kombination "Username/Password" nur im Rahmen einer Ein-Wege-Hash-Funktion (Message Digest 5, MD5) übertragen. Die Überprüfung kann also nicht nur beim Verbindungsaufbau, sondern auch periodisch während der Verbindung stattfinden. IP Next Generation Das rasche (exponentielle Wachstum) des Internet zwingt dazu, das Internet Protokoll in der Version 4 (IPv4) durch ein Nachfolgeprotokoll (IPv6 Internet Protocol Version 6) zu ersetzen. Vinton Cerf (der 'Vater' des Internet) bezeichnet in einem Interview mit der Zeitschrift c't das Internet "(...) als die wichtigste Infrastruktur für alle Arten von Kommunikation.". Auf die Frage, wie man sich die neuen Kommunikationsdienste des Internet vorstellen könne, antwortete Cerf: "Am spannendsten finde ich es, die ganzen Haushaltsgeräte ans Netz anzuschließen. Ich denke dabei nicht nur daran, daß der Kühlschrank sich in Zukunft mit der Heizung austauscht, ob es in der Küche zu warm ist. Stromgesellschaften könnten beispielsweise Geräte wie Geschirrspülmaschinen kontrollieren und ihnen Strom genau dann zur Verfügung stellen, wenn gerade keine Spitzennachfrage herrscht. Derartige Anwendungen hängen allerdings davon ab, daß sie zu einem erschwinglichen Preis angeboten werden. Das ist nicht unbedingt ferne Zukunftsmusik; die Programmierer müßten eigentlich nur damit anfangen, endlich Software für intelligente Netzwerkanwendungen zu schreiben. Und natürlich muß die Sicherheit derartiger Systeme garantiert sein. Schließlich möchte ich nicht, daß die Nachbarkinder mein Haus programmieren!" Auf die Internet Protokolle kommen in der nächsten Zeit also völlig neue Anforderungen zu. Classless InterDomain Routing - CIDR Der Verknappung der Internet-Adressen durch die ständig steigende Benutzerzahl wird zunächst versucht, mit dem Classless Inter-Domain Routing (CIDR) entgegen zu wirken. Durch die Vergabe von Internet-Adressen in Klassen (A,B,C,...) wird eine große Anzahl von Adressen verschwendet. Hierbei stellt sich vor allem die Klasse B als Problem dar. Viele Firmen nehmen ein Netz der Klasse B für sich in Anspruch, da ein Klasse A Netz mit bis zu 16 Mio. Hosts selbst für eine sehr große Firma überdimensioniert scheint, ein Netz der Klasse C mit 254 Hosts aber zu klein. Ein größerer Host-Bereich für Netze der Klasse C (z. B. 10 Bit, 1022 Hosts pro Netz) hätte das Problem der knapper werdenden IP-Adressen vermutlich gemildert. Ein anderes Problem wäre dadurch allerdings entstanden: die Einträge der Routing-Tabellen hätten sich um ein Vielfaches vermehrt. Ein anderes Konzept ist das Classless Inter-Domain Routing (RFC 1519): die verbleibenden Netze der Klasse C werden in Blöcken variabler Größe zugewiesen. Werden beispielsweise 2000 Adressen benötigt, so können einfach acht aufeinanderfolgende Netze der Klasse C vergeben werden. Zusätzlich werden die verbliebenen Klasse-C-Adressen restriktiver und strukturierter vergeben (RFC 1519). Die Welt ist dabei in vier Zonen aufgeteilt, von denen jede einen Teil des verbliebenen Klasse C Adreßraums erhält: 194.0.0.0 - 195.255.255.255 Europa 198.0.0.0 - 199.255.255.255 Nordamerika 200.0.0.0 - 201.255.255.255 Mittel- und Südamerika 202.0.0.0 - 203.255.255.255 Asien und pazifischer Raum 204.0.0.0 - 223.255.255.255 Reserviert für zukünftige Nutzung Jede der Zonen erhält dadurch in etwa 32 Millionen Adressen zugewiesen. Vorteil bei diesem Vorgehen ist, daß die Adressen einer Region im Prinzip zu einem Eintrag in den RoutingTabellen komprimiert worden sind und jeder Router, der eine Adresse außerhalb seiner Region zugesandt bekommt diese getrost ignorieren darf. Internet Protokoll Version 6 - IPv6 (IP Next Generation, IPnG) Der vorrangige Grund für eine Änderung des IP-Protokolls ist auf den begrenzten Adreßraum und das Anwachsen der Routing-Tabellen zurückzuführen. CIDR schafft hier zwar wieder etwas Luft, dennoch ist klar absehbar, daß auch diese Maßnahme nicht ausreicht, um die Verknappung der Adressen für eine längere Zeit in den Griff zu bekommen. Weitere Gründe für eine Änderung des IP-Protokolls sind die neuen Anforderungen an das Internet, denen IPv4 nicht gewachsen ist. Streaming-Verfahren wie Real-Audio oder Video-on-Demand erfordern das Festlegen eines Mindestdurchsatzes, der nicht unterschritten werden darf. Bei IPv4 kann so ein "Quality of Service" jedoch nicht definiert - und damit auch nicht sichergestellt - werden. Die IETF (Internet Engineering Task Force) begann deshalb 1990 mit der Arbeit an einer neuen Version von IP. Die wesentlichen Ziele des Projekts sind: Unterstützung von Milliarden von Hosts, auch bei ineffizienter Nutzung des Adreßraums Reduzierung des Umfangs der Routing-Tabellen Vereinfachung des Protokolls, damit die Router Pakete schneller abwickeln können Höhere Sicherheit (Authentifikation und Datenschutz) als das heutige IP Mehr Gewicht auf Dienstarten, insbesondere für Echtzeitanwendungen Unterstützung von Multicasting durch die Möglichkeit, den Umfang zu definieren Möglichkeit für Hosts, ohne Adreßänderung auf Reise zu gehen (Laptop) Möglichkeit für das Protokoll, sich zukünftig weiterzuentwickeln Unterstützung der alten und neuen Protokolle in Koexistenz für Jahre Im Dezember 1993 forderte die IETF mit RFC 1550 die Internet-Gemeinde dazu auf, Vorschläge für ein neues Internet Protokoll zu machen. Auf die Anfrage wurde eine Vielzahl von Vorschlägen eingereicht. Diese reichten von nur geringfügigen Änderungen am bestehenden IPv4 bis zur vollständigen Ablösung durch ein neues Protokoll. Aus diesen Vorschlägen wurde von der IETF das Simple Internet Protocol Plus (SIPP) als Grundlage für die neue IP-Version ausgewählt. Als die Entwickler mit den Arbeiten an der neuen Version des Internet Protokolls begannen, wurde ein Name für das Projekt bzw. das neue Protokoll benötigt. Angeregt durch die Fernsehserie "Star Trek - Next Generation", wurde als Arbeitsname IP - Next Generation (IPnG) gewählt. Schließlich bekam das neue IP eine offizielle Versionsnummer zugewiesen: IP Version 6 oder kurz IPv6. Die Protokollnummer 5 (IPv5) wurde bereits für ein experimentelles Protokoll verwendet. Die Merkmale von IPv6 Viele der Merkmale von IPv4 bleiben in IPv6 erhalten. Trotzdem ist IPv6 im allgemeinen nicht mit IPv4 kompatibel, wohl aber zu den darüberliegenden Internet-Protokollen, insbesondere den Protokollen der Transportschicht (TCP, UDP). Die wesentlichen Merkmale von IPv6 sind: Adreßgröße: Statt bisher 32 Bit stehen nun 128 Bit für die Adressen bereit. Theoretisch lassen sich damit 2128 = 3.4*1038 Adressen vergeben. Header-Format: Der IPv6-Header wurde vollständig geändert. Der Header enthält nur sieben statt bisher 13 Felder. Diese Änderung ermöglicht die schneller Verarbeitung der Pakete im Router. Im Gegensatz zu IPv4 gibt es bei IPv6 nicht mehr nur einen Header, sondern mehrere Header. Ein Datengramm besteht aus einem BasisHeader, sowie einem oder mehreren Zusatz-Headern, gefolgt von den Nutzdaten. Erweiterte Unterstützung von Optionen und Erweiterungen: Die Erweiterung der Optionen ist notwendig geworden, da einige der bei IPv4 notwendige Felder nun optional sind. Darüber hinaus unterscheidet sich auch die Art, wie die Optionen dargestellt werden. Für Router wird es damit einfacher, Optionen, die nicht für sie bestimmt sind, zu überspringen. Dienstarten: IPv6 legt mehr Gewicht auf die Unterstützung von Dienstarten. Damit kommt IPv6 den Forderungen nach einer verbesserten Unterstützung der Übertragung von Video- und Audiodaten entgegen, z. B. durch eine Option zur Echtzeitübertragung. Sicherheit: IPv6 beinhaltet nun im Protokoll selbst Mechanismen zur sicheren Datenübertragung. Wichtige neue Merkmale von IPv6 sind hier Authentifikation, Datenintegrität und Datenverlässlichkeit. Erweiterbarkeit: IPv6 ist ein erweiterbares Protokoll. Bei der Spezifikation des Protokolls wurde nicht versucht, alle möglichen Einsatzfelder für das Protokoll in die Spezifikation zu integrieren. Über Erweiterungs-Header kann das Protokoll erweitert werden. Aufbau des IPv6-Basis-Headers Im IPv6 wird im Vergleich zum IPv4 auf eine Checksumme verzichtet, um den Routern die aufwendige Überprüfung - und damit Rechenzeit - zu ersparen. Ein Übertragungsfehler muss deshalb in den höheren Schichten erkannt werden. Der Paketkopf ist durch die Verschlankung nur doppelt so groß, wie ein IPv4-Header. Version: Mit dem Feld Version können Router überprüfen, um welche Version des Protokolls es sich handelt. Für ein IPv6-Datengramm ist dieses Feld immer 6 und für ein IPv4Datengramm dementsprechend immer 4. Mit diesem Feld ist es möglich für eine lange Zeit die unterschiedlichen Protokollversionen IPv4 und IPv6 nebeneinander zu verwenden. Über die Prüfung des Feldes Version können die Daten an das jeweils richtige "Verarbeitungsprogramm" weitergeleitet werden. Priority: Durch das Feld Priority (oder Traffic Class) kann angegeben werden, ob ein Paket bevorzugt behandelt werden muß. Dies ist für die Anpassung des Protokolls an die neuen Real Time Anwendungen nötig geworden. Damit können zum Beispiel Videodaten den E-Maildaten vorgezogen werden. Bei einem Router unter Last besteht damit die Möglichkeit der Flusskontrolle. Pakete mit kleinerer Priorität werden verworfen und müssen wiederholt werden.Mit den vier Bit lassen sich 16 Prioritäten angeben, wovon 1 bis 7 für "Non Real Time"- und 8 bis 15 für "Real Time"Anwendungen reserviert sind. Die Zahl Null gibt an, dass die Priorität des Verkehrs nicht charakterisiert ist. Flow Label Mit Hilfe des Feldes Flow Label können Eigenschaften des Datenflusses zwischen Sender und Empfänger definiert werden. Das Flow Label selbst ist nur eine Zufallszahl. Die Eigenschaften müssen durch spezielle Protokolle oder durch den Hop-by-Hop-Header in den Routern eingestellt werden. Eine Anwendung ist zum Beispiel, daß die Pakete eines Flusses immer den gleichen Weg im Netz nehmen. Durch Speichern der Informationen für das jeweilige Flow-Label, muß der Router bestimmte Berechnungen nur für das erste Paket ausführen, und kann danach für alle Folgepakete die Resultate verwenden. Erst die Einführung des Flow Labels ermöglicht die Einführung von Quality-of-Service-Parametern im IP-Verkehr. Payload Length Das Feld Payload Length (Nutzdatenlänge) gibt an, wie viele Bytes dem IPv6-BasisHeader folgen, der IPv6-Basis-Header ist ausgeschlossen. Die Erweiterungs-Header werden bei der Berechnung der Nutzdatenlänge mit einbezogen. Das entsprechende Feld wird in der Protokollversion 4 mit Total Length bezeichnet. Allerdings bezieht IPv4 den 20 Byte großen Header auch in die Berechnung ein, wodurch die Bezeichnung "total length" gerechtfertigt ist. Next Header Das Feld Next Header gibt an, welcher Erweiterungs-Header dem IPv6-Basis-Header folgt. Jeder folgende Erweiterungs-Header beinhaltet ebenfalls ein Feld Next Header, das auf den nachfolgenden Header verweist. Beim letzten IPv6-Header, gibt das Feld an, welches Transportprotokoll (z.B. TCP oder UDP) folgt. Hop Limit Im Feld Hop Limit wird festgelegt, wie lange ein Paket überleben darf. Der Wert des Feldes wird von jedem Router vermindert. Ein Datengramm wird verworfen, wenn das Feld den Wert Null hat. IPv4 verwendete hierzu das Feld Time to Live. Die Bezeichnung bringt mehr Klarheit, da schon in IPv4 die Anzahl Hops gezählt und nicht die Zeit gemessen wurde. Source Address, Destination Address Die beiden Felder für Quell- und Zieladresse dienen zur Identifizierung des Senders und Empfängers eines IP-Datengramms. Bei IPv6 sind die Adressen vier mal so groß wie IPv4: 128 Bit statt 32 Bit. Das Feld Length (Internet Header Length - IHL) von IPv4 ist nicht mehr vorhanden, da der IPv6-Basis-Header eine feste Länge von 40 Byte hat. Das Feld Protocol wird durch das Feld Next Header ersetzt. Alle Felder die bisher zur Fragmentierung eines IP-Datengramms benötigt wurden (Identification, Flags, Fragment Offset), sind im IPv6-Basis-Header nicht mehr vorhanden, da die Fragmentierung in IPv6 gegenüber IPv4 anders gehandhabt wird. Alle IPv6-kompatiblen Hosts und Router müssen Pakete mit einer Größe von 1280 Byte unterstützen. Empfängt ein Router ein zu großes Paket, so führt er keine Fragmentierung mehr durch, sondern sendet eine Nachricht an den Absender des Pakets zurück, in der er den sendenden Host anweist, alle weiteren Pakete zu diesem Ziel aufzuteilen. Es wird also vom Hosts erwartet, daß er von vornherein eine passende Paketgröße wählt. Die Steuerung der Fragmentierung erfolgt bei IPv6 über den Fragment Header. Das Feld Checksum ist nicht mehr vorhanden. Erweiterungs-Header im IPv6 Bei IPv6 muß nicht mehr der ganze optionale Teil des Headers von allen Routern verarbeitet werden, womit wiederum Rechenzeit eingespart werden kann. Diese optionalen Header werden miteinander verkettet. Jeder optionale Header beinhaltet die Identifikation des folgenden Header. Es besteht auch die Möglichkeit selber Optionen zu definieren. Derzeit sind sechs Erweiterungs-Header definiert. Alle Erweiterungs-Header sind optional. Werden mehrere Erweiterungs-Header verwendet, so ist es erforderlich, sie in einer festen Reihenfolge anzugeben. Header Beschreibung IPv6-Basis-Header Zwingend erforderlicher IPv6-Basis-Header Optionen für Teilstrecken (Hop-by-Hop Options Header) Dies ist der einzige optionale Header, der von jedem Router bearbeitet werden muß. Bis jetzt ist nur die "Jumbo Payload Option" definiert, in der die Länge eines Paketes angegeben werden kann, das länger als 64 KByte ist. Optionen für Ziele (Destination Options Header) Zusätzliche Informationen für das Ziel Routing (Routing Header) Definition einer vollständigen oder teilweisen Route. Er wird für das Source-Routing in IPv6 verwendet. Fragmentierung (Fragment Header) In IPv6 wird, wie oben beschrieben, die Fragmentierung nur noch End to End gemacht. Die Fragmentierinformationen werden in diesem optionalen Header abgelegt. Authentifikation (Authentication Header) Er dient der digitalen Signatur von Paketen, um die Quelle eindeutig feststellen zu können. Verschlüsselte Sicherheitsdaten (Encapsulating Security Payload Header) Informationen über den verschlüsselten Inhalt. Optionen für Ziele (Destination Options Header) Zusätzliche Informationen für das Ziel (für Optionen, die nur vom endgültigen Ziel des Paketes verarbeitet werden müssen). Header der höheren Header der höheren Protokollschichten (TCP, UDP, Schichten ...) (Upper Layer Header) IPv6-Adressen Die IPv6-Adressen sind zwar von 32 Bit auf 128 Bit angewachsen, trotzdem sind die grundsätzlichen Konzepte gleich geblieben. Die Adresse wird normalerweise Sedezimal (Hexadezimal, Basis 16) notiert und hat die allgemeine Form xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx:xxxx Sie ist damit recht länglich. Um die Schreibweise zu vereinfachen, wurden einige Regeln eingeführt: Führende Nullen Die führenden Nullen können mit Nullen oder Doppelpunkten zusammengefasst werden. 1234:0000:0000:0000:0000:0000:0000:1234 --> 1234:0:0:0:0:0:0:1234 --> 1234::1234 IPv4 kompatible Adressen haben die Form: 0:0:0:0:0:0:C206:AFFE oder ::C206:AFFE Um die Lesbarkeit zu erhöhen kann man auch eine gemischt Form verwenden: ::194.6.161.126 IPv4 gemappte IPv6 Adressen haben die Form: ::FFFF:C206:A17E Die Loopback Adresse ist neu (anstelle 127.0.0.1): ::1 In IPv4 wurden die Adressen anfänglich in die bekannten Klassen eingeteilt. Ein weiteres Problem bei den IPv4 Adressen ist, daß die Router keine Hierarchie in den Adressen erkennen können. Auch IPv6 ist in der allgemeinen Form unstrukturiert, es kann aber durch definierte Präfixe strukturiert werden. Die allgemein strukturiert Adresse sieht danach wie folgt aus: Die Strukturierung erlaubt die Einteilung der Adresse in Adresstypen. Jeder Präfix identifiziert somit einen Adresstyp. Die bereits definierten Adresstypen und die zugehörigen Präfixe sind: Adresstyp Reserviert für IPv4 und Loopback Präfix (binär) 0000 0000 NSAP-Adressen 0000 001 IPX-Adressen 0000 010 Anbieterbasierte Unicast-Adresse 010 Reserviert für geografische Unicast-Adresse 100 Zusammenfassbare globale Adressen 001 Standortlokale Adresse Multicast-Adresse 1111 1110 11 1111 1111 Wie man in der Tabelle erkennen kann, werden die Adressen grob in die Typen Unicast, Multicast und Anycast eingeteilt, deren Eigenschaften nachfolgend kurz erklärt werden sollen. Unicast Als Unicast-Adressen bezeichnet man die Adressen, die für Punkt-zu-PunktVerbindungen verwendet werden. Sie werden in verschiedene Gruppen eingeteilt: o Geographisch basierte Unicast-Adresse Für diese Adressen wurde erst der Adressbereich und der Präfix reserviert. Die Idee ist, dass ein hierarchisches Routing aufgrund der geographischen Lage ähnlich wie beim Telefon - möglich sein soll. o Anbieterbasierte Unicast-Adressen Dieser Adresstyp erlaubt ein hierarchisches Routing aufgrund der Adressräume der Anbieter. Diese Adressen werden von einem Register über ein großes Gebiet verwaltet. Diese Register geben die Adressen an die Anbieter weiter, welche ihrerseits Adressen weitergeben können. Somit ergibt sich eine AdressStruktur, die wie folgt aussieht: Die Einführung von nationalen Registern ergibt eine Aufteilung der Anbieterund Subscriber-ID in National-Register-, Anbieter- und Subscriber-ID. Linklokale und standortlokale Adressen Diese Adressen werden für die TCP/IP-Dienste innerhalb eines Unternehmens genutzt. Die Linklokalen Adressen werden nicht in das Internet geroutet und haben den folgenden Aufbau: Im Gegensatz dazu stehen die standortlokalen Adressen, die nur innerhalb eines Subnetzes gültig sind und deshalb von keinem Router behandelt werden. Multicast-Adressen In IPv4 wird das Rundsenden eines Paketes an mehrere Stationen durch das IGMP (Internet Group Management Protokoll) realisiert. In IPv6 ist das Prinzip übernommen, aber ein eigener Adresstyp definiert worden. IGMP entfällt somit gänzlich. Das Paket für Multicast-Meldungen sieht wie folgt aus: Das Flag gibt an, ob die Gruppen ID temporär, oder von der IANA zugewiesen ist. Der Scope gibt den Gültigkeitsbereich der Multicast Adresse an. Dieser reicht vom nodelokalen bis zum globalen Bereich. Anycast Adressen Diese Adressen sind neu definiert worden. es können mehrere Rechner zu einer Gruppe zusammengefasst werden und sie sind dann unter einer einzigen Adresse erreichbar. Damit ist beispielsweise eine Lastverteilung möglich: der Rechner, der am wenigsten belastet ist, behandelt das Paket. Die Adresse hat die folgende Struktur: Sicherheit Der Bedarf an digitalen Unterschriften oder elektronischen Zahlungsmöglichkeiten steigt ständig. Deshalb stand bei der Spezifikation von IPv6 die Sicherheit von Anfang an im Mittelpunkt. Für die Sicherheitsfunktionen von IPv6 ist eine spezielle Arbeitsgruppe "IPSec" zuständig. In IPv6 wurden Sicherheitsmechanismen für die Authentisierung und Verschlüsselung auf IP Ebene spezifiziert. Die Verschlüsselungsfunktionen definieren Verfahren, die das Mitlesen durch Unbefugte verhindern. Es gibt zwei unterschiedliche Ansätze. Bei der ersten Variante werden alle Nutzdaten (Payload) verschlüsselt. Der Header bleibt normal lesbar. Bei der anderen Variante ist es möglich, den Header ebenfalls zu verschlüsseln. Das codierte Paket wird in ein anderes IPv6-Packet verpackt und zu einem fixen Ziel befördert ("IP-Tunnel"). Am Ziel wird das Paket wieder entschlüsselt und über das sichere interne Netz übertragen. Authentisierungsmechanismen liefern den Beweis auf Unverfälschtheit der Nachricht und identifiziert den Absender (Digitale Unterschrift). Hier werden verschiedene kryptographische Verfahren eingesetzt. Die Verfahren für die Verschlüsselung und die Authentisierung können auch getrennt angewandt werden. Verwaltung und Verteilung der Schlüssel wird nicht von IPv6 gelöst. Das Standardverfahren für den IPv6-Authentisierungsmechanismus ist MD5 mit 128 Bit langen Schlüsseln. IPv6 schreibt keinen Verschlüsselungsmechanismus vor, jedes System im Internet muß jedoch den DES mit CBD (Cipher Block Chaining) unterstützen. Domain Name System (DNS) Es hat sich ziemlich früh herausgestellt, daß menschliche Benutzer die numerischen IPAdressen nicht benutzen wollen, sondern aussagekräftige und vor allem merkbare Namen bevorzugen. Außerdem ist es ein großer Nachteil der IP- Adressen, daß aus ihnen keinerlei geographische Information zu entnehmen ist. Man sieht einer Zieladresse nicht an, ob sie in Australien oder im Nebenzimmer lokalisiert ist, außer man kennt zufällig die gewählten Zahlen. Es wurde daher das Domain Name System entwickelt, das den Aufbau von Rechnernamen regelt. Es ordnet jedem (weltweit eindeutigen) Namen eine IP-Adresse zu. Dabei gibt es einige Varianten. Eine Maschine mit einer IP-Adresse kann mehrere Funktionen haben und daher auch mehrere Namen, die auf diese Funktionen hinweisen. Genauso kann eine Maschine (z. B. ein Router) viele IP-Adressen haben aber nur einen Namen. Beim "Domain-Name-System" (oder kurz: DNS) handelt es sich um einen Dienst, der zu einem Rechnernamen die zugehörige IP-Nummer liefert und umgekehrt. Das ist in etwa mit der Funktionsweise einer Telefonauskunft vergleichbar: Der Kunde ruft bei einer bestimmten Telefonnummer an und fragt nach der Rufnummer eines Teilnehmers. Nachdem er Name und Wohnort der gesuchten Person durchgegeben hat, erhält er als Antwort die gewünschte Nummer aus einem Verzeichnis. Genauso läuft eine DNS-Abfrage ab. Gibt ein Benutzer in seinem Webbrowser zum Beispiel die Adresse http://www.VereinGegenZuLangeDomainnamenEV.de ein, dann sorgt ein Teil der Netzwerk-Software auf seinem lokalen Rechner dafür, daß ein Name-Server nach der IP-Adresse des Rechners www.vereingegenzulangedomainnamenev.de gefragt wird. Dieser Softwareteil wird als Resolver bezeichnet und entspricht in obigem Beispiel dem Kunden, der die Auskunft anruft. Welche IP-Adresse dieser Server hat, muß dem Klientenrechner natürlich bekannt sein, genauso wie der Kunde eine einzige Telefonnummer wissen muß, nämlich die der Auskunft selbst. Auf der Serverseite arbeitet eine Software, die als "Domain-Name-Server" oder kurz "Name-Server" bezeichnet wird und anhand einer Datenbank ("Zone-File") die passende IPNummer zum Rechnernamen liefert, oder einen anderen Name-Server fragt, wenn die Adresse unbekannt ist. DNS ist ein typisches Beispiel für einen Verzeichnisdienst. Seine Aufgaben sind: Strukturierung der Namen. (Domänen-Konzept) Zuteilung und Verwaltung von Namen. Auflösen von Namen (="Nachschlagen") in beide Richtungen (Name zu Adresse und Adresse zu Name) Zwischenspeichern von Adressen (Caching) Einteilung der Daten in hierarchische Ebenen Verteilung der Daten auf verschiedene Knoten Bereitstellung von Redundanz (Secondary-DNS, Caching-Only-Server) Damit das DNS funktioniert muß es Instanzen geben, die Namen in IP-Adressen und IPAdressen in Namen umwandeln ('auflösen') können. Diese Instanzen sind durch Programme realisiert, die an größeren Maschinen ständig (meist im Hintergrund) im Betrieb sind und 'Nameserver' heißen. Jeder Rechner, der an das Internet angeschlossen wird, muß die Adresse eines oder mehrerer Nameserver wissen, damit die Anwendungen auf diesem Rechner mit Namen benutzt werden können. Die Nameserver sind für bestimmte Bereiche, sogenannte 'domains' oder 'Zonen', zuständig (Institute, Organisationen, Regionen) und haben Kontakt zu anderen Nameservern, so daß jeder Name aufgelöst werden kann. Domänen-Konzept In den Anfängen des ARPA-Nets, aus dem das Internet entstand, wurde die Namensauflösung über eine einzige Datei erledigt. Jeder Rechner kopierte sich Nachts per FTP diese Datei von einem Master-Server auf die lokale Platte. Dieses Konzept funktioniert natürlich nur, solange die Anzahl der Namen nicht groß ist. Die benötigte Bandbreite ist proportinal zum Quadrat der beteiligten Rechner. B ~ N2 Als Relikt aus dieser Zeit kennt fast jedes Betriebssystem auch heute noch eine Hosts-Datei, in der für kleine Netze Rechner/Nummern-Zuordnungen abgelegt werden könen. (Bei Windows im Verzeichnis \WINDOWS\HOSTS, bei Unix unter /etc/hosts, bei Novell unter SYS:SYSTEM/ETC/HOSTS, etc.) Die Syntax aller dieser Hosts-Dateien ist einfach. Für jeden Rechner gibt es eine eigene Zeile mit dem Inhalt: IP-Nummer Hostname Alias Alias .... Zum Beispiel: 192.168.112.1 192.168.112.2 192.168.112.3 192.168.112.4 192.168.112.5 192.168.112.6 192.168.112.7 192.168.112.7 192.168.112.8 chef dumpfbacke Snow-White Doc Happy Bashful Sneezy Sleepy Grumpy Dopey Der Begriff Alias läßt sich dabei am besten durch "Spitzname" (oder englisch Nickname) ersetzen; also ein weiterer Name für ein und den selben Rechner. Bei einer kleinen Menge von Rechnern ist die Namensverwaltung mit einer Datei noch möglich; für einen so großen und ständig wechselnden Verbund wie das Internet ist sie aber nicht geeignet. Hier ist eine dezentrale Verwaltung mit einem eigens darauf abgestimmten Namensraum nötig. Der Namensraum des DNS ist in sogenannte Domänen eingeteilt. Die Domänen sind hierarchisch als Baum angeordnet, Ausgehend von der Wurzel (=Root) des Baumes ist der Namensraum in sogenannte "Toplevel-Domains" eingeteilt. Man unterscheidet dabei zwischen zwei verschiedenen Klassen von Toplevel-Domänen: Den generischen und den länderspezifischen. Toplevel-Domänen generisch com Kommerzielle Organisationen edu (education) Schulen und Hochschulen gov (government) Regierungsinstitutionen mil militärische Einrichtungen net Netzwerk betreffende Organisationen org Nichtkommerzielle Organisationen int Internationale Organisationen arpa und das alte ARPA-Net bzw. RückwärtsAuflösung von Adressen Ende 2000 sind neue TLDs von der ICANN genehmigt worden: aero Luftfahrtindustrie coop Firmen-Kooperationen museum Museen pro Ärzte, Rechtsanwälte und andere Freiberufler biz Business (frei für alle) info Informationsanbieter (frei für alle) name Private Homepages (frei für alle, aber nur dreistufige Domains der Form <Vorname>.<Name>.name) länderspezifisch Jeweils ein Länderkürzel für jedes Land, z.B.: by Weissrussland de Deutschland at Östereich fr Frankreich to Tonga tv Tuvalu Unterhalb der Toplevel-Domänen folgen Subdomänen, die wiederum Domänen enthalten könen und schliesslich, als Blatt des Baumes, ein einzelner Rechner. Der Name www.netzmafia.de ist also so zu verstehen. In der Toplevel-Domäne ".de" ist die Subdomain "Netzmafia" bekannt. Innerhalb der Subdomain "netzmafia" gibt es einen Rechner namens "www". Analog zu unserem Beispiel mit der Telefonauskunft, ist mit "de" das Land, mit "netzmafia" der Ort und die Straße und mit "www" der Name eines Teilnehmers bestimmt. Die komplette Adresse eines Rechners in der beschriebenen Notation, z.B. bezeichnet man (www.netzmafia.de) als FQDN (Full-Qualified-Domain-Name). Für die Aufnahme einer Verbindung zwischen zwei Rechnern muß in jedem Fall der Rechnername in eine zugehörige IP- Adresse umgewandelt werden. Aus Sicherheitsaspekten ist es manchmal wünschenswert, auch den umgekehrten Weg zu gehen, nämlich zu einer sich meldenden Adresse den Namen und damit die organisatorische Zugehörigkeit offenzulegen. Komponenten des DNS Insgesamt sind es drei Hauptkomponenten, aus denen sich das DNS zusammensetzt: 1. Der Domain Name Space, ein baumartig, hierarchisch strukturierter Namensraum und die Resource Records. Das sind Datensätze, die den Knoten zugeordnet sind. 2. Name Server sind Programme bzw. Rechner, die die Informationen über die Struktur des Domain Name Space verwalten und aktualisieren. EinNameserver hat normalerweise nur eine Teilsicht des Domain Name Space zu verwalten. Oft wird auch der Rechner, auf dem das Nameserverprogramm läuft, als 'Nameserver' oder 'DNS-Server' bezeichnet. 3. Resolver sind die Programme, die für den Client Anfragen an den Nameserver stellen. Resolver sind einemNameserver zugeordnet; bei Anfragen, die er nicht beantworten kann (anderer Teilbereich des Domain Name Space). kann er aufgrund von Referenzen andere Nameserver kontakten, um die Information zu erhalten. Der Nameserver des DNS verwaltet also einzelne Zonen, die einen Knoten im DNS-Baum und alle darunterliegenden Zweige beinhalten. Auf jeder Ebene des DNS-Baums kann es Namesever geben, wobei jeder Nameserver seinen nächsthöheren und nächstniedrigeren Nachbarn kennt. Aus Sicherheitsgründen gibt es für jede Zone in der Regel mindestens zwei Nameserver (primary und secondary), wobei beide die gleiche Information halten. Nameservereinträge können nicht nur die Zuordnung Rechnername - IP-Adresse enthalten, sondern (neben anderem) auch weitere Namenseinträge für einen einzigen Rechner und Angaben für Postverwaltungsrechner einer Domain (MX, mail exchange). Basis des Nameservice bilden die "Root-Nameserver", die für die Top-Level-Domains zuständig sind. Federführende Organistation ist hier die ICANN (=Internet Corporation for Assigned Names and Numbers , Adresse: http://www.icann.org). Gründung 1998. ICANN beauftragt die Verwalter der Zone "." (Wurzel des DNS-Baumes) mit 13 Servern. Bis auf die Server I (Stockholm), K (London) und M (Tokio) stehen alle Server in den USA. Name Typ Betreiber URL a com InterNic http://www.internic.org b edu ISI http://www.isi.edu c com PSINet http://www.psi.net d edu UMD http://www.umd.edu e usg NASA http://www.nasa.gov f com ISC http://www.isc.org g usg DISA http://nic.mil h usg ARL http://www.arl.mil i int NordUnet http://www.nordu.net j ( ) (TBD) http://www.iana.org k int RIPE http://www.ripe.net l ( ) (TBD) http://www.iana.org m int WIDE http://www.wide.ad.jp Der Server A ist der primäre Server, alle anderen sind seine Secondaries. Eine Liste dieser Root-Server muss jeder DNS-Server haben (Ausnahme: Cache-Only-Server). Erzeugung der Liste mit dem Kommando: dig @rs.internic.net . ns > root.servers Die Namen, die im Internet verwendet werden müssen dabei einige Spezifikationen erfüllen: Die Länge eines Namensteiles (Domänen- oder Rechnername) darf maximal 63 Zeichen betragen. Die Gesamtlänge des Full-Qualified-Domain-Names darf 255 Zeichen nicht überschreiten. Nur Buchstaben, Ziffern und "-" sind in den Namen zugelassen. Dabei muss jeder Name mit einem Buchstaben oder einer Ziffer beginnen und enden. ("3bla-fasel" ist zulässig, "3bla-" aber nicht.) Zwischen Groß- und Kleinschreibung wird nicht unterschieden. Bei der Registrierung einer Domain unterhalb von ".de" gelten zusätzlich noch folgende Regeln: Der Domainname muß mindestens 3 Zeichen haben. Insgesamt gibt es in ".de" noch 4 Domains mit nur 2 Buchstaben, die aus Besitzstands-Gründen beibehalten werden. Wegen eines weit verbreiteten Fehlers in der Named-Server-Software sind Domains mit den gleichen Namen wie Toplevel-Einträge verboten. (Also z.B.: "at.de") Das ist in RFC 1535 näher beschrieben. KFZ-Kennzeichen können nicht registriert werden. Ein wichtiger Bestandteil des DNS-Konzeptes ist die Aufteilung der benötigten Datenbank auf viele verschiedene Rechner. Da das Gesamtsystem voll funktionsfähig bleiben muß, auch wenn ein Server ausgefallen ist, wird die Datenhaltung mit Hilfe von Zuständigkeiten gelöst: Zu jeder Domain gibt es mindestens einen zugehörigen Server, der verantwortlich die darin enthaltenen Subdomains oder Rechner verwaltet, oder die Verwaltung an einen weiteren Server weiterdelegiert. Am Stamm des DNS-Baumes sitzen dazu die "Root-Server", die alle Einträge ihrer jeweiligen Domain kennen. Das heißt, daß der Root-Nameserver der Domäne ".de" einen Eintrag für den Named-Server der Domain "netzmafia.de" besitzt. Dieser Server hat wieder eine Liste der in "netzmafia.de" enthaltenen Rechner und Subdomains. Die Frage eines Clients nach der IP-Nummern eines Rechners wird wie folgt abgewickelt: 1. Der Client-Rechner "grumpy.zwerge.org" stellt die DNS-Anfrage nach "www.netzmafia.de" an seinen zuständigen DNS-Server. Dessen IP-Nummer muss dem Client bekannt sein. 2. Kennt der Nameserver der Domain "zwerge.org" die Antwort nicht, so erkundigt er sich beim Root-Nameserver nach der Adresse des Nameservers von ".de" 3. Der Root-Nameserver antwortet dem zuständigen DNS-Server der Domain "zwerge.org" mit der Adresse des Nameservers von ".de" 4. Der Nameserver der Domain "zwerge.org" erkundigt sich beim Nameserver von ".de" nach der Adresse des Nameservers von "netzmafia.de". 5. Der Nameserver von ".de" antwortet dem zuständigen DNS-Server der Domain "zwerge.org" mit der Adresse des Nameservers von "netzmafia.de" 6. Der Nameserver der Domain "zwerge.org" erkundigt sich beim Nameserver von "netzmafia.de" nach der Adresse des Rechners "www.netzmafia.de". 7. Der Nameserver von "netzmafia.de" antwortet dem zuständigen DNS-Server der Domain "zwerge.org" mit der Adresse des Rechners von "www.netzmafia.de". 8. Der DNS-Server von "zwerge.org" liefert die IP-Nummer an den anfragenden Client. Damit ist die DNS-Abfrage abgehandelt. DNS-Typen Man unterscheidet folgende DNS-Typen Cache-Only o Besitzt keine eigenen Tabellen mit Rechnernamen (Zone-Files). o Alle Anfragen werden an einen übergeordneten Server weitergegeben. o Adressen werden zwischengespeichert. o Zweck: Z.B. Entlastung einer Providerleitung o Sehr einfach einzurichten. Secondary-DNS o Besitzt eigene Tabellen, die er vom Primary-DNS kopiert. o Die Tabellen können aber nicht verändert werden. o Zweck: Lastteilung, Backup o Einfach einzurichten. Primary-DNS o Besitzt eigene Tabellen für eine oder mehrere Zonen. o Tabellen können lokal verändert werden. o Server ist "authoritative" für seine Zone. o Relativ hoher Aufwand für Einrichtung und Pflege. DNS Resource Records Im Standardfall generiert ein DNS-Server seine interne Datenbank aus einer Textdatei, der sogenannten "Zonen-Datei". Damit er funktioniert, müssen bestimmte Einträge korrekt eingetragen worden sein. An dieser Stelle sollen nur ein paar grundlegende Eigenschaften der wichtigsten Typen von Resource Records betrachtet werden. Es gibt verschiedene RecordTypen: SOA-Records (Source of Authority) enthalten die technischen Angaben für die gesamte Zone sowie einige Steuerdaten für die Zusammenarbeit der Nameserver untereinander. SOA-Records sind weiter unten genauer erklärt. NS-Records (Name Server) verweisen auf die Nameserver, die für eine Zone authoritativ sind. Auf den eigenen Namen zeigende NS-Records dienen der Plausibilitätsprüfung; NS-Records für eine Subdomain weisen darauf hin, dass die Informationen für die Subdomain auf einem anderen Nameserver zu finden sind (Delegation). A-Records (Address) verknüpfen einen Domainnamen mit einer IP-Adresse. Um IPv4- und IPv6-Adressen zu unterscheiden, wird seit einiger Zeit für IPv4 der ARecord und für IPv6 der AAAA-Record verwendet. PTR-Records (Pointer) verknüpfen eine IP-Adresse "rückwärts" mit einem Domainnamen. CNAME-Records Canonical Name) definieren einen Domainnamen als Alias für einen anderen. Es gibt also für jedes System einen A-Record und ggf. noch beliebig viele CNAME-Records. MX-Records (Mail Exchanger) definieren, bei welchen Rechnern Mail für eine Domain eingeliefert werden soll. Auf diese Weise sind geneische Mailadressen wie z.B. "[email protected]" möglich. TXT-Records (Text) enthalten beliebige alphanumerische Informationen zu einem Domainnamen. Aufbau der Zonendatei Beispiel des Primary DNS "aella.serverzwerge.de": ; Zonendatei fuer die Domaene serverzwerge.de ; $TTL 1D @ in SOA aella.serverzwerge.de. dnsadmin.aella.serverzwerge.de. ( 2002051505 ; Seriennummer 10800 ; Refresh : 3 Stunden 3600 ; Retry : 1 Stunde 604800 ; Expire : 1 Woche 86400) ; Min. TTL: 1 Tag NS aella.serverzwerge.de. MX 10 aella.serverzwerge.de. MX 50 mail.irgendeinprovider.de. aella snowwhite doc happy bashful sneezy sleepy grumpy dopey A A A A A A A A A HINFO 10.23.200.100 10.23.200.17 10.23.200.18 10.23.200.19 10.23.200.20 10.23.200.21 10.23.200.22 10.23.200.23 10.23.200.24 "Hexium 7.5" "Linux" beispiel CNAME aella Der SOA-Record Jede Zone muss einen SOA-Record (Start of Authority) enthalten. Dort sind wichtige Informationen über die Zone abgelegt. Hier ein Beispiel: $TTL 1D @ in SOA aella.serverzwerge.de. dnsadmin.aella.serverzwerge.de. ( 2002051505 ; Seriennummer 10800 ; Refresh : 3 Stunden 3600 ; Retry : 1 Stunde 604800 ; Expire : 1 Woche 86400) ; Min. TTL: 1 Tag Das Semikolon leitet Kommentare ein, die natürlich nicht vorhanden sein müssen. Das erste Feld im SOA-Record benennt den primary master server. Dies ist der Server, der die endgültige Autorität über den Inhalt der Zone ist. Dort ist das Zonefile selbst abgelegt. Das zweite Feld des SOA-Records nennt die Mailbox der für die Zone verantwortlichen Person. Das @-Zeichen der E-Mail-Adresse wird hier durch einen Punkt ersetzt. Links vom @ stehende Punkte müssen als \. notiert werden, um eine eindeutige Zuordnung für den Punkt zu erreichen, der für den @ steht. Die Seriennummer spielt eine wichtige Rolle im Zusammenspiel zwischen MasterDNS und Slave-DNS: Slaves führen nur dann einen Zonentransfer durch, wenn die vom Master übermittelte Seriennummer größer ist als die der lokal gehaltenen Zone. Sie wird meist nach dem Schema yyyymmddnn gebildet: yyyy = Jahr (4-stellig), mm = Monat (2-stellig), dd = Tag (2-stellig) und nn die Viertelstunde (2-stellig) des aktuellen Tags. Der Refresh-Wert legt fest, wie häufig ein Slave beim Master nachfragt, ob sich die Zone verändert hat. Der Retry-Wert legt fest, wie häufig ein Slave einen fehlgeschlagenen Zonentransfer wiederholt, bis er aufgibt. Der Expire-Wert legt fest, wie lange ein Slave seine Kopie einer Zone noch als gültig ansieht, wenn er den Master nicht erreichen kann. Der Minimum-TTL-Wert legt fest, wie lange eine negative Antwort vom Client zwischengespeichert werden darf. Er ist einer der beiden wichtigsten Timer in einer Zonendatei (TTL = Time To Live). Der Eintrag in der $TTL-Zeile oberhalb des SOA-Records legt fest, welche Lebensdauer die Resource Records des Zonefiles in den Caches nicht authoritativer Nameserver haben sollen. Um die Last auf den für eine Zone authoritativen Nameservern zu verringern, speichern die von den Internetbenutzern verwendeten Forwarder die Auskünfte, die sie von den authoritativen Nameservern erhalten haben, für eine bestimmte Zeit zwischen. Der für die Zone zuständige Administrator kann das Caching der Forwarder in manchen Grenzen beeinflussen. Wird eine Nameserver-Anfrage positiv beantwortet, übermittelt der authoritative Nameserver zusammen mit dem angefragten Resource Record die gewünschte Lebenszeit des Eintrags in Form der TTL. Ist im Zonefile für den Resource Record keine TTL angegeben, so übermittelt der authoritative Nameserver den mit $TTL im Zonefile gesetzten Defaultwert. Der Forwarder übermittelt die Antwort weiter an die Quelle der Anfrage und speichert die Antwort für die übermittelte Zeitdauer zwischen, so dass weitere Anfragen nach dem gleichen Resource Record innerhalb dieser Zeitdauer ohne erneuten Zugriff auf den authoritativen Server beantwortet werden können. Bevor man zeitkritische Änderungen an einer Zone vornimmt (z.B. Umzug eines Web- oder Mailservers auf eine andere IP-Adresse), ist zu empfehlen, zuerst einen oder beide TTLWerte herunterzusetzen. Dies sollte mindestens einen TTL-Zeitraum vor der eigentlichen Änderung geschehen, damit die kürzere TTL sich herumgesprochen hat. Nachdem die Änderung erfolgreich durchgeführt wurde, kann die TTL wieder heraufgesetzt werden. Der MX-Record Nimmt eine Domain am E-Mailverkehr teil, so wird einer oder mehrere MX-Records in die Zone eingetragen. MX-Records haben zusätzlich zu ihrem Ziel eine Prioritätsangabe. soll eine E-Mail an die Domain zugestellt werden, versucht der absendende Mailserver zuerst den MXRecord niedrigster Priorität. Kann er die E-Mail dort nicht ausliefern, versucht er der Reihe nach die MX-Records höherer Priorität. Gibt es für einen Domainnamen keinen MX-Record, sondern nur einen A-Record, wird die Mail an diesen zugestellt. Dieses Verhalten ist historisch bedingt und nicht mehr sinnvoll. Trotzdem wird es immer noch so gehandhabt. Soll eine Domain nicht am E-Mailverkehr teilnehmen, so ist es sinnvoll, einen MX-Record auf ein System zu setzen, das für den Domainnamen eingehende E-Mail mit einem permanenten Fehler ablehnt. Netzwerkkonfiguration am Beispiel Linux Eigentlich ist es egal, welches Betriebssysem als Beispiel genommen wird - die Netzkonfiguration ist in etwa immer gleich. Auch viele der unten erwähnten Dateien finden sich z. B. bei Windows. Linux dient deshalb als Beispiel, weil man hier nicht nur irgendwelche Fenster anklickt, sondern sehen kann, wie mit ein paar Kommandos das Netzwerkinterface eingebunden wird und welche Effekte auf welche Art und Weise erzielt werden. Die wichtigsten Dateien, Bezeichnungen und Anwendungen: /etc/HOSTNAME oder /etc/hostname /etc/hosts /etc/networks /etc/host.conf /etc/resolv.conf /etc/nsswitch.conf ifconfig route netstat ping traceroute Netzwerkkonfiguration läuft im Normalbetrieb immer automatisch beim Systemstart ab. InitScripts übernehmen die Konfiguration der Schnittstellen, das Anlegen der Routen und vieles mehr. Trotzdem ist das Wissen um die manuelle Konfiguration wichtig, erstens für Problemlösungen und zweitens, weil damit auf die Schnelle auch eine Umkonfiguration von Netzwerkkarten oder ein experimenteller Aufbau möglich ist. Auf den (Hardware-)Treiber des Netzwerk-Interface wird aus diesem Grund nicht eingegangen. Um festzustellen, ob überhaupt ein Treiber geladen wurde, genügt das Kommando dmesg | more das alle Boot-Meldungen auflistet. Darin findet man auch die Meldungen zur Netzwerkkarte, z.B.: ... 8139cp 10/100 PCI Ethernet driver v0.0.6 (Nov 19, 2001) 8139cp: pci dev 00:0f.0 (id 10ec:8139 rev 10) is not an 8139C+ compatible chip 8139cp: Try the "8139too" driver instead. 8139too Fast Ethernet driver 0.9.24 PCI: Found IRQ 9 for device 00:0f.0 eth0: RealTek RTL8139 Fast Ethernet at 0xe081af00, 00:00:e8:76:2f:ea, IRQ 9 eth0: Identified 8139 chip type 'RTL-8139A' ... Aus dieser Meldung ist auch die MAC-Adresse des Netzwerk-Interface ablesbar (im Beispiel: 00:00:e8:76:2f:ea). Im Folgenden werden die wichtigsten Konfigurationsdateien für das Netz besprochen, wobei viele der Dateien - eventuell leicht modifiziert oder mit ähnlichem Nanen - auch bei Windows zu finden sind. Bei Linux findet man diese Daten traditionsgemäß im Verzeichnis /etc. Setzen des Hostnamens Die Netzwerksoftware verläßen sich darauf, daß der Name der Maschine einen sinnvollen Wert hat. Er wird im Normalfall während des Boot-Vorgangs mit dem Befehl hostname gesetzt. Um den Hostnamen auf name zu setzen, geben Sie folgendes ein: hostname name Es ist üblich, nur den Host-Namen ohne jede Domain-Angabe zu verwenden. /etc/hosts In dieser Datei werden die Systeme des Netzwerks mit ihrem Systemnamen und die dazu gehörenden Internet-Adressen aufgelistet. Auch, wenn man im normalen Betrieb DNS einsetzt, sollte man einen Teil der Rechnernamen in /etc/hosts eintragen. Oft möchte man nämlich auch während des Bootens, wenn noch keine Netzwerkschnittstellen aktiv sind, symbolische Namen verwenden. Um sicherzustellen, daß alle Programme ausschließlich /etc/hosts verwenden, um die Adresse eines Systems zu suchen, müssen Sie ggf. die Datei /etc/nsswitch.conf editieren. Interessant ist die Zeile, die mit "hosts:" beginnt. Dort sollte "files dns" stehen, was bedeutet, daß erst in der lokalen Datei /etc/hosts nachgesehen und dann erst ein Nameserver kontaktiert wird. Typischerweise sieht die Datei im Ausschnitt so aus: # /etc/nsswitch.conf # ... hosts: files dns networks: files ... Auf diese Datei wird weiter unten noch genauer eingegangen. Die Datei hosts enthält einen Eintrag pro Zeile, bestehend aus der IP-Adresse, dem Hostnamen und einer optionalen Liste von Aliasen für den Hostnamen. Die Felder sind durch Leerzeichen oder Tabulatoren voneinander getrennt, und das Adreßfeld muß in Spalte eins beginnen. Ein Doppelkreuz (#) leitet immer einen Kommentar ein. Namen können entweder mit voller Domainangabe (Full Qualified Domain Name, FQDN) oder relativ zur lokalen Domain sein. So ist das System sowohl unter seinem offiziellen als auch unter dem kürzeren lokalen Namen bekannt. Man kann in der Datei auch die Namen und IP-Adressen beliebiger anderer Rechner eintragen. Immer notwendig ist der Eintrag für den Rechner selbst, "127.0.0.1 localhost", denn sonst funktionieren gewisse Dienste (z.B. lpd) nicht. Für alle folgenden Beispiele werden für die Rechnernamen Schneewittchen und die sieben Zwerge (in der englischen Fassung von Walt Disney) verwendet. Damit keine Kollision mit real existierenden Internet-Domains auftreten, kann man als Domainnamen beispielsweise "zwerge.local" nehmen. Als Netz verwenden wir das private B-Netz 172.20.y.x - und davon sogar nur ein C-Subnetz, 172.20.20.x. Das folgende Beispiel zeigt, wie die Datei /etc/hosts im Zwergenwald aussehen könnte. # # Hostdatei fuer Snowwhite and Friends # # IP FQDN 127.0.0.1 localhost # die Zwerge 10.27.210.17 10.27.210.18 snowwhite.zwerge.local doc.zwerge.local Aliase snowwhite doc 10.27.210.19 10.27.210.20 10.27.210.21 10.27.210.22 10.27.210.23 10.27.210.24 ... happy.zwerge.local bashful.zwerge.local sneezy.zwerge.local sleepy.zwerge.local grumpy.zwerge.local dopey.zwerge.local happy bashful sneezy sleepy grumpy dopey Nach der Internet-Adresse wird der "offizielle" Name des Systems angegeben, gefolgt von Alias-Namen für dieses System. Wird als Argument für ein Netzwerk-Kommando ein Name angegeben, so wird in dieser Datei die zugehörige Internet-Adresse ermittelt. Erst über die Adresse wird eine Verbindung zum Zielsystem aufgebaut. Die Datei /etc/hosts wird jedoch auch für den umgekehrten Vorgang benutzt. Mit einem IP-Datagram wird nur die InternetAdresse des sendenden Systems mitgeschickt. Soll nun der zugehörige Name ermittelt werden, so geschieht dies ebenfalls mittels dieser Datei. Das Resultat ist jedoch immer der "offizielle" Name des Systems. Deshalb ist darauf zu achten, daß stets dieser Name verwendet werden muß, wenn ein Rechnername in weiteren Konfigurationsdateien eingetragen wird. Jetzt wissen Sie auch, daß der Eintrag "127.0.0.1 www.microsoft.com" in der /etc/hosts beispielsweise zu komischen Effekten führen würde (welchen?). /etc/networks Genau wie für IP-Adressen möchte man manchmal auch symbolische Namen für Netzwerknummern verwenden. Aus diesem Grunde gibt es parallel zu /etc/hosts die Datei /etc/networks, die Netzwerknamen auf Netzwerknummern abbildet. Diese Datei wird nicht unbedingt benötigt. Im Zwergenwald würden z.B. folgende networks-Datei installiert: # /etc/networks zwergenwald 172.20.20.0 Beachten Sie, daß die Namen in networks nicht mit den Hostnamen in der Datei hosts übereinstimmen und kollidieren, da manche Programme ansonsten seltsame Resultate produzieren. /etc/protocols In dieser Datei sind die Protokollnamen und Protokollnummern der Transportprotokolle eingetragen, die das System unterstützt. Dank dieser Datei kann man in vielen Programmen den symbolischen Namen eines Protokolls anstelle der Nummer angeben. Jede Zeile der Datei enthält den Namen des Transportprotokolls, die Protokollnummer und den Aliasnamen des Protokolls, zum Beispiel: ip icmp igmp ggp ipencap tcp egp udp ... 0 1 2 3 4 6 8 17 IP ICMP IGMP GGP IP-ENCAP TCP EGP UDP # # # # # # # # internet protocol, pseudo protocol number internet control message protocol Internet Group Management gateway-gateway protocol IP encapsulated in IP transmission control protocol exterior gateway protocol user datagram protocol /etc/services In dieser Datei werden die Namen von Netzwerkdiensten sowie die zugehörigen Portnummern und Protokollnamen gespeichert Dank dieser Datei kann man in vielen Programmen den symbolischen Namen eines Dienstes anstelle der Nummer angeben. Beispiel: ... ftp ssh telnet smtp whois domain gopher finger www www ... 21 22 23 25 43 53 70 79 80 80 tcp tcp tcp tcp tcp tcp tcp tcp tcp udp /etc/nsswitch.conf Diese Datei wird auch als "Resolver-Bibliothek" bezeichnet. Der Begriff Resolver bezieht sich nicht auf ein spezielles Programm, sondern auf eine Sammlung von Funktionen, die bei Linux zur Standard-C-Bibliothek gehören. Ihre wichtigsten Routinen sind gethostbyname(2) und gethostbyaddr(2), die alle zu einem Namen gehörenden IP-Adressen zurückliefern und umgekehrt. über die Datei /etc/nsswitch.conf können Sie einstellen, ob Sie die gewünschten Informationen in /etc/hosts nachschlagen, DNS-Server befragen oder die hosts-Datenbank des Network Information Service (NIS) benutzen wollen. In der Datei /etc/nsswitch.conf kann der Systemadministrator eine Vielzahl verschiedener Datenbanken konfigurieren. Wir besprechen hier nur diejenigen Optionen, die sich auf die Auflösung von Host- und Netzwerk-IP-Adressen beziehen. Optionen in /etc/nsswitch.conf müssen in getrennten Zeilen erscheinen, wobei die Argumente durch Leerzeichen oder Tabulatorzeichen voneinander getrennt sein müssen. Ein Doppelkreuz (#) leitet einen Kommentar ein, der sich bis zum Zeilenende erstreckt. Jede Zeile beschreibt einen bestimmten Dienst, z.B. die Auflösung von Hostnamen. Das erste Feld jeder Zeile gibt den Namen der Datenbank an und endet mit einem Doppelpunkt. Der Rest jeder Zeile enthält Optionen, die die Art des Zugriffs auf die betreffende Datenbank regeln. Die folgenden Optionen sind verfügbar: dns Verwendet das Domain Name System (DNS) zur Auflösung der Adresse. Das macht allerdings nur Sinn bei der Auflösung von Hostadressen, nicht von Netzadressen. Der Mechanismus benutzt die Datei /etc/resolv.conf. files Durchsucht eine lokale Datei nach den Host- oder Netznamen und ihren zugehörigen IP-Adressen. Diese Option verwendet die traditionellen Dateien /etc/hosts und /etc/networks. nis oder nisplus Verwendet das Network Information System (NIS) zur Auflösung einer Host- oder Netzadresse. In der Reihenfolge, in der die Dienste angegeben sind, werden sie auch abgefragt, wenn ein Name aufgelöst werden soll. Anspruch genommen, in der sie aufgelistet sind. Diese Liste befindet sich in der Datei /etc/nsswitch.conf in dem Abschnitt, in dem die Beschreibung der Dienste erfolgt. Die Dienste werden von links nach rechts abgefragt, und die Suche wird standardmäßig beendet, wenn ein Wert (oder Name) erfolgreich aufgelöst wurde. Zum Beispiel: # /etc/nsswitch.conf # hosts: dns files networks: files Dieses Beispiel veranlaßt das System, Hosts zuerst im DNS zu suchen und wenn dort nichts gefunden wird, die Suche in der Datei /etc/hosts fortzusetzen. Um Netzwerknamen aufzulösen, wird ausschließlich die Datei /etc/networks benutzt. Sie können das Suchverhalten noch genauer kontrollieren, indem Sie zusätzlich Aktionen (action items) angeben, die festlegen, welche Aktion nach dem jeweils letzten Namensauflösungsversuch durchgeführt werden soll. Auf diese Erweiterungen wird an dieser Stelle nicht weiter eingegangen. /etc/resolv.conf Wenn Sie die Resolver-Bibliothek für die Verwendung von DNS konfigurieren, müssen Sie ihr auch mitteilen, welche Server sie benutzen soll. Dafür gibt es eine separate Datei namens /etc/resolv.conf. Fehlt diese Datei oder ist sie leer, nimmt der Resolver an, daß sich der NameServer auf Ihrem lokalen Host befindet. Um einen Name-Server auf Ihrem lokalen Host laufen zu lassen, müssen Sie ihn separat einrichten. Normalerweise verwendet man einen bereits vorhandenen Name-Server. Bei einer Dialup-Verbindung ins Internet wird für gewöhnlich der Name-Server des Providers in der Datei /etc/resolv.conf eintragen. Die wichtigste Option in /etc/resolv.conf ist daher nameserver, welche die Adresse eines Name-Servers angibt. Wenn Sie die Option mehrmals angeben, werden die Server in der angegebenen Reihenfolge verwendet. Deshalb sollten Sie unbedingt den zuverlässigsten Server an erster Stelle eintragen. Wenn Sie keinen Name-Server eintragen, nimmt der Resolver an, daß einer auf der lokalen Maschine läuft. Gegenwärtig werden bis zu drei nameserver-Einträge in /etc/resolv.conf unterstützt. Zwei weitere Befehle, domain und search, geben Domainnamen an, die der Resolver an einen Namen anhängt, wenn die zugehörige Adresse beim ersten Versuch nicht gefunden wird. Mit domain können Sie eine Default-Domain angeben, die immer dann angehängt werden soll, wenn ein Name nicht aufgelöst werden konnte. Wird dem Resolver z.B. der Name "sleepy" übergeben, findet dieser den Namen "sleepy." nicht im DNS, da es eine solche Top-LevelDomain nicht gibt. Wird "zwerge.local" als Standarddomäne angegeben, wiederholt der Resolver seine Anfrage und hängt diese Standarddomäne an den Hostnamen an. Die Abfrage nach "sleepy.zwerge.local" ist nun erfolgreich (natürlich nur, wenn es einen Nameserver gibt). Mit der Option search kann eine Suchliste angegeben werden, gewissermaßen eine Verallgemeinerung der domain-Anweisung. Während bei domain nur eine einzelne Domain angeben werden darf, akzeptiert search eine ganze Liste davon, deren Einträge alle der Reihe nach durchprobiert werden, bis ein gültiger DNS-Eintrag gefunden wird. Die einzelnen Namen der Liste müssen durch Leerzeichen oder Tabulatoren voneinander getrennt werden. Die Befehle search und domain schließen einander aus und dürfen höchstens einmal auftauchen. Wenn keiner der beiden Befehle angegeben ist, versucht der Resolver, die Default-Domain mit Hilfe der Systemfunktion getdomainname(2) aus dem lokalen Hostnamen zu raten. Hat der Hostname keinen Domain-Teil, wird als Default-Domain die Root-Domain (.) angenommen. Werfen Sie einen Blick auf die Datei resolv.conf des Zwergenwaldes: # /etc/resolv.conf # Unsere Domain domain zwerge.local # # Wir benutzen "doc" als zentralen Name-Server: nameserver 172.20.20.1 Wenn Sie in dieser Konfiguration die Adresse von "dopey" suchen, wird der Resolver erst versuchen, "dopey." nachzuschlagen, und wenn das fehlschlägt, "dopey.zwerge.local". Netzwerk-Konfiguration für IP Zur Konfiguration der Ethernet-Schnittstellen und Initialisierung der Routing-Tabelle sind zwei Befehle von besonderer Bedeutung, nämlich ifconfig (Interface-Konfiguration) und route. Schnittstellenkonfiguration mit dem ifconfig-Kommando Das Starten von TCP/IP erfolgt (unter Unix) durch Shell-Skripte, die je nach Unix-Derivat anders heißen und sich an ganz unterschiedlichen Stellen des jeweiligen Dateisystems befinden können (Bei Linux beispielsweise im Verzeichnis /etc/init.d. So unterschiedlich die Shell-Skripte auch sein mögen, die Initialisierung der Netzwerksoftware erfolgt in jedem Falle durch das ifconfig-Kommando. Hier wird auch die Initialisierung der Netzwerkschnittstellen vorgenommen. Dabei gibt es folgende Arten von Schnittstellen: das Loopback-Interface, Broadcast-Interfaces und Point-to-Point-Interfaces. Das Loopback-Interface ist eine spezielle Schnittstelle, die zum lokalen System zurückgeführt. Dies bedeutet, daß alle Daten, die durch das Loopback-Interface geschickt werden, wieder im lokalen System empfangen werden, Dieser Mechanismus erlaubt eine Kommunikation von lokalen Prozessen über TCP/IP und wird insbesondere von TCP/IPVerwaltungsprozessen, aber auch von anderen Diensten genutzt (so z.B. bei Datenbanken). Die Standard-Internet-Adresse der Loopback-Schnittstelle ist 127.0.0.1 und sollte, obwohl es theoretisch möglich ist, nicht verändert werden. ifconfig dient dazu, eine Schnittstelle für die Netzwerkschicht des Kernels sichtbar zu machen. Das beinhaltet die Zuweisung einer IP-Adresse und verschiedener anderer Parameter sowie die Aktivierung des Interface, damit der Kernel die IP-Pakete über diese Schnittstelle senden und empfangen kann. Die einfachste Art, es aufzurufen, ist: ifconfig <interface> <ip-addresse> netmask <maske> Der Befehl weist "interface" die Adresse "ip-adresse" zu und aktiviert es. Alle anderen Parameter werden auf Standardwerte gesetzt. Fehlt die Netzmaske (netmask <maske>), wird sie aus der Netzwerkklasse der Adresse abgeleitet; für ein Klasse-B-Netz wäre das 255.255.0.0. Oftmals besteht das Kommando aber zumindest auf der Netzmaske als Parameter. Später dazu mehr. Initialisiert wird das Loopback-Interface durch das Kommando: ifconfig lo 127.0.0.1 Sogenannte "Broadcast-Interfaces" sind die üblichen Schnittstellen zu lokalen Netzwerken, über die mehrere Systeme erreichbar sind, und über die Broadcasts, also Nachrichten an alle, verschickt werden. Es handelt sich dabei um Schnittstellen zu Ethernet und TokenRing. Neben der Internet-Adresse werden bei der Initiatisierung des Broadcast-Interfaces auch die Netzmaske und die Broadcast-Adresse angegeben: ifconfig eth0 192.168.0.1 netmask 255.255.255.0 broadcast 192.168.0.255 Neben den Broadcast-Schnittstellen gibt es noch die sogenannten Point-to-PointSchnittstellen. Sie sind dadurch gekennzeichnet, daß man nur über sie ein anderes System erreichen kann. Beispiele sind SLIP (Serial Line IP) und das Point-to-Point-Protokoll PPP, die Verbindungen über die serielle Schnittstelle oder per Modem/ISDN-Adapter WANVerbindungen zulassen. Die Initialisierung einer Point-to-Point-Schnittstelle hat z.B. die folgende Form: ifconfig ppp0 192.168.1.1 192.168.1.2 netmask 255.255.255.240 So eine PPP-Verbindung bildet ein eigenständiges Netzwerk. Sollen mehrere Verbindungen kombiniert werden, so muß eine Unterteilung in Subnetze erfolgen. Das heißt, daß eine entsprechende Netzmaske gewählt werden muß. ifconfig kennt eine ganze Reihe von Optionen. Der allgemeine Programmaufruf lautet: ifconfig interface [address [parameters]] interface ist der Name der zu konfigurierenden Schnittstelle, und address ist die IP-Adresse, die ihr zugewiesen werden soll. Sie kann entweder als dotted quad angegeben werden oder als Name, den ifconfig in /etc/hosts nachschlägt. Ein Aufruf nur mit dem Interface-Namen gibt die Konfiguration des Interface aus. Wird es ganz ohne Parameter aufgerufen, zeigt es alle bisher konfigurierten Schnittstellen an; die Option -a erzwingt zusätzlich die Anzeige der inaktiven. Beispiel: # ifconfig eth0 eth0 Link encap 10Mbps Ethernet HWaddr 00:00:C0:90:B3:42 inet addr 172.20.20.2 Bcast 172.20.20.255 Mask 255.255.255.0 UP BROADCAST RUNNING MTU 1500 Metric 0 RX packets 3136 errors 217 dropped 7 overrun 26 TX packets 1752 errors 25 dropped 0 overrun 0 MTU gibt die maximale Blockgröße an. Die Metrik wird von einigen Betriebssystemen verwendet, um die Kosten einer Route zu berechnen. Linux benutzt diesen Wert bisher nicht, definiert ihn aber trotzdem aus Gründen der Kompatibilität. Die Zeilen RX und TX zeigen an, wie viele Pakete empfangen (RX - receive) bzw. gesendet wurden (TX - transmit), wie viele Fehler dabei auftraten, wie viele Pakete verworfen wurden (dropped) und wie viele wegen eines überlaufs (overrun) verlorengingen. Ein überlauf beim Empfänger tritt dann auf, wenn Pakete schneller hereinkommen, als der Kernel die Interrupts bedienen kann. Die folgende Liste zeigt die Parameter, die ifconfig versteht; die Namen der zugehörigen Flags stehen in Klammern. Optionen, die eine bestimmte Eigenschaft des Interface aktivieren, können mit vorangestelltem Minuszeichen (-) auch benutzt werden, um ihn wieder auszuschalten. up Aktiviert ein Interface für die IP-Schicht des Kernels. Sie wird impliziert, wenn auf der Kommandozeile eine Adresse angegeben ist. Sie kann auch dazu benutzt werden, ein Interface zu reaktivieren, wenn es mit der down-Option temporär deaktiviert wurde. Entspricht den Flags UP und RUNNING. down Markiert eine Schnittstelle als inaktiv, d.h. unzugänglich für die Netzwerkschicht. Dadurch wird jeglicher IP-Transport durch die Schnittstelle unterbunden. Beachten Sie, daß dadurch automatisch alle Routing-Einträge gelöscht werden, die diese Schnittstelle verwenden. netmask Weist des Interface eine Subnetzmaske zu. Sie kann entweder als eine 32-Bit-Hexadezimalzahl (mit führender 0x) oder als dotted quad (Beispiel: 255.255.255.0) angegeben werden. Maske Wird für Punkt-zu-Punkt-Verbindungen benutzt, die nur zwei Hosts miteinander verbinden. Sie wird beispielsweise für die Konfiguration von SLIP- und PLIP-Schnittstellen pointopoint Adresse benötigt und teilt dem Kernel die IP-Adresse des anderen Systems mit. Falls eine Punkt-zu-Punkt-Adresse gesetzt wurde, zeigt ifconfig das POINTOPOINT-Flag an ("pointopoint" wird wirklich so geschrieben). broadcast metric mtu arp Adresse Wert Bytes Die Broadcast-Adresse wird normalerweise aus der Netzwerknummer gebildet, indem alle Bits des Hostanteils auf eins gesetzt werden. Einige IP-Implementierungen verwenden dagegen eine Broadcast-Adresse, bei der die Bits des Hostteils auf null gesetzt sind. Die Option broadcast dient dazu, Ihre Konfiguration an eine derartige Umgebung anzupassen. Wenn dem Interface eine Broadcast-Adresse zugeordnet wurde, gibt ifconfig das Flag BROADCAST aus. Dem Routing-Tabellen-Eintrag des Interface einen Metrikwert zuordnen. Dieser Wert wird beispielsweise vom Routing Information Protocol (RIP) berücksichtigt, wenn es Routing-Tabellen für Ihr Netz erstellt. Die Default-Metrik, die ifconfig einem Interface zuweist, ist 0. Wenn Sie das Routing in Ihrem Netz nicht mit RIP regeln, benötigen Sie diese Option nicht; aber auch sonst wird die Option selten benutzt. Setzen der Maximum Transmission Unit (MTU), d.h. die maximale Anzahl von Bytes, die das Interface in einer Transaktion behandeln kann. Für Ethernets liegt der Defaultwert bei 1500; für SLIP beträgt er 296. Kann nur für Broadcast-fähige Netz wie Ethernet verwendet werden. Ermöglicht die Benutzung von ARP zur Zuordnung von IP-Adressen zu physikalischen Adressen. Für Broadcast-Netze wird sie per Voreinstellung eingeschaltet. Ist ARP abgeschaltet, zeigt ifconfig das NOARP-Flag an. - arp schaltet ARP explizit aus. promisc Versetzt die Schnittstelle in den promiscous mode. Auf Broadcast-Netzen hat das zur Folge, daß die Schnittstelle alle Pakete unabhängig davon empfängt, ob sie für einen anderen Host bestimmt sind oder nicht. Dadurch kann man den Netzwerkverkehr mit Paketfiltern wie tcpdump analysieren. -promisc schaltet den Modus ab. allmulti Multicast-Adressen sind wie Ethernet-Broadcast-Adressen, mit der Einschränkung, daß sie nicht automatisch jeden möglichen Adressaten berücksichtigen, sondern nur solche, die ausdrücklich zum Empfang vorgesehen (programmiert) sind. Sie eignen sich besonders für Anwendungen wie Ethernet-basierte Videokonferenzen oder Audioübertragungen übers Netz, die nur an Interessierte gerichtet sind. -allmulti schaltet Multicast-Adressen ab. Das route-Kommmando route erlaubt es Ihnen, Routen in die Routing-Tabelle des Kernels einzutragen oder aus ihr zu entfernen. Es kann aufgerufen werden als: route [add|del] [-net|-host] <target> [dev <if>] Dabei bestimmen die Argumente add bzw. del, ob die Route zu target eingetragen bzw. aus target entfernt wird. Die Optionen -net und -host teilen dem route-Kommando mit, ob target ein Netzwerk oder ein Hostrechner ist (letzteres wird angenommen, wenn Sie hier nichts angeben). Das Argument dev if ist optional und erlaubt Ihnen die Angabe einer Netzwerkschnittstelle, an die die Route gerichtet werden soll. Wenn Sie dem Kernel keine Informationen darüber geben, versucht er selbst, ein sinnvolles Argument herauszufinden. Den Rechner konfigurieren Das allererste Interface, die aktiviert werden muß, ist das Loopback-Interface: ifconfig lo 127.0.0.1 Manchmal wird anstelle der IP-Adresse auch der Name localhost verwendet. Der Befehl ifconfig sucht diesen Namen in der Datei /etc/hosts, wo er als Hostname für 127.0.0.1 definiert sein muß. Zur Anzeige der Konfiguration eines Interface rufen Sie ifconfig mit dem Namen des Interface auf. Ganz ohne Parameter wird die Konfiguration aller Interfaces gezeigt: ifconfig lo lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:3924 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 Collisions:0 Nun fehlt noch ein Eintrag in der Routing-Tabelle, der festlegt, daß dieses Interface als Route für das Zielsystem 127.0.0.1 dient. Dazu geben Sie folgendes ein: route add 127.0.0.1 Es kann auch hier wieder anstelle der IP-Adresse der Namen localhost verwendet werden (sofern er in /etc/hosts eingetragen ist). Es wäre auch möglich, das Netz von localhost einzutragen: route add -net 127.0.0.0 Als nächstes wird mit dem Programm ping getestet, ob alles einwandfrei funktioniert: ping localhost PING localhost (127.0.0.1): 56 data 64 bytes from 127.0.0.1: icmp_seq=0 64 bytes from 127.0.0.1: icmp_seq=1 64 bytes from 127.0.0.1: icmp_seq=2 ^C --- localhost ping statistics --- bytes ttl=255 time=0.4 ms ttl=255 time=0.4 ms ttl=255 time=0.4 ms 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.4/0.4/0.4 ms Pakete an 127.0.0.1 werden also korrekt ausgeliefert und es erfolgt sofort eine Antwort. Das beweist, daß die erste Netzwerkschnittstelle erfolgreich konfiguriert wurde. Die bisher beschriebenen Schritte reichen aus, um Netzwerk-Programme auf einem alleinstehenden Rechner zu benutzen. Die oben angegebenen Zeilen müssen in das NetzwerkInitialisierungsskript eingetragen werden, damit sie beim Systemstart ausgeführt werden. In der Regel wird zumindest die Konfiguration von "lo" beim Installieren des Systems bereits erledigt. Zur Einstimmung war das obige aber keine schlechte Übung. Nun sollte zum Beispiel telnet localhost eine telnet-Verbindung aufbauen und Ihnen den Login-Prompt Ihres Systems geben. Die Konfiguration von Ethernet-Schnittstellen geht fast genauso vonstatten wie eben. Man braucht nur ein paar Parameter mehr, um auch Subnetze verwenden zu können. Im Zwergenwald wird vom Klasse-B-Netz nur ein C-Subnetz verwendet. Um dies dem Interface mitzuteilen, sieht der ifconfig-Aufruf so aus: ifconfig eth0 172.20.20.2 netmask 255.255.255.0 oder unter Verwendung des Namens aus /etc/hosts: ifconfig eth0 doc netmask 255.255.255.0 Dies weist des Interface eth0 die IP-Adresse von doc (172.20.20.2) zu. Hätte man die Netzmaske weggelassen, wäre sie von ifconfig aus der Netzklasse der Adresse abgeleitet worden, was den inkorrekten Wert von 255.255.0.0 ergeben hätte. Ein schneller Test ergibt jetzt: ifconfig eth0 eth0 Link encap 10Mps Ethernet HWaddr 00:00:C0:90:B3:42 inet addr 172.20.20.2 Bcast 172.20.20.255 Mask 255.255.255.0 UP BROADCAST RUNNING MTU 1500 Metric 1 RX packets 0 errors 0 dropped 0 overrun 0 TX packets 0 errors 0 dropped 0 overrun 0 ifconfig hat die Broadcast-Adresse (im Bcast-Feld angezeigt) automatisch auf den passenden Wert gesetzt, nämlich die Netzwerknummer mit einem Hostteil, bei dem alle Bits auf eins gesetzt sind. Außerdem wurde die maximale übertragungseinheit (MTU = Maximum Transmission Unit, die maximale Größe der IP-Pakete) auf das Ethernet-spezifische Maximum von 1.500 Bytes eingestellt. Wie bereits bei der Loopback-Schnittstelle muß noch eine Route eingetragen werden. Für den Zwergenwald gilt: route add -net 172.20.20.0 Damit ist eine Route definiert, die alle Pakete, die ans Netz 172.20.20.0 gerichtet sind an die Ethernetkarte schickt. Das weiß das System, weil die Ethernetkarte ja die Adresse 172.20.20.2 hat, also die gleiche Netzadresse. Dieser Befehl ist bei modernen Versionen von ifconfig unnötig geworden, weil diese Route eben automatisch bei der Konfiguration angelegt wird. Vielleicht haben Sie bemerkt, daß die Angabe des Interface fehlt. Der Kernel prüft alle bisher konfigurierten Interfaces und vergleicht das Zielnetz (in unserem Fall 172.20.20.0) mit der Netznummer der Interface-Adresse, d.h. dem bitweisen UND der Interface-Adresse und der Netzmaske. Die einzige Schnittstelle, bei der diese beiden Werte übereinstimmen, ist eth0. Die Option -net ist nötig, da route sowohl Routen zu Netzwerken als auch zu einzelnen Hosts einrichten kann. Wenn man route eine IP-Adresse übergibt, versucht das Kommando festzustellen, ob es sich dabei um eine Host- oder Netzadresse handelt, indem es den Hostteil betrachtet. Ist der Hostteil null, wird angenommen, daß es sich um eine Netz-Adresse handelt, andernfalls ist es eine Hostadresse. Deshalb würde route in unserem Beispiel davon ausgehen, daß 172.20.20.0 eine Hostadresse ist (Netz: 172.20.0.0, Host: ...20.0). Da ein Subnetz verwendet wird, braucht das route-Kommando den Parameter "-net". Unter Verwendung des Eintrags in /etc/networks wird das Kommando einfacher: route add zwergenwald Nun sollte man überprüfen, ob das Ethernet tatsächlich arbeitet. Wählen Sie irgendeine bereits konfigurierte Maschine auf Ihrem lokalen Ethernet, z.B. grumpy, und geben Sie folgenden Befehl ein: # ping grumpy PING grumpy: 64 byte packets 64 bytes from 172.20.20.1: icmp_seq=0. time=10. ms 64 bytes from 172.20.20.1: icmp_seq=1. time=7. ms 64 bytes from 172.20.20.1: icmp_seq=2. time=8. ms ^C ----doc.zwerge.local PING Statistics---4 packets transmitted, 4 packets received, 0 packets lost Wenn ping keinerlei Antwort bekommt, sollten Sie die Schnittstellenkonfiguration mit netstat überprüfen. Die Paketstatistiken, die ifconfig ausgibt, geben an, ob überhaupt Pakete über das Interface übertragen wurden. Zusätzlich sollten Sie auf beiden Maschinen mit route die Routing-Informationen überprüfen. Wenn Sie route ohne weitere Parameter aufrufen, gibt es die Routing-Tabellen aus. Die Option -n sorgt dafür, daß es Adressen numerisch anstelle der symbolischen Hostnamen darstellt: route -n Kernel routing table Destination Gateway 127.0.0.1 * 172.20.20.0 * Genmask Flags Metric Ref Use 255.255.255.255 UH 1 0 112 255.255.255.0 U 1 0 10 Iface lo eth0 Die Spalte "Flags" enthält eine Liste von Flags für jedes Interface. U ist für aktive Schnittstellen immer gesetzt. Ein Flag H in dieser Spalte besagt, daß die Zieladresse einen einzelnen Host bezeichnet. Wenn eine eingetragene Route benutzt wird, ändert sich der Wert im Use-Feld ständig. Bisher wurde eine Maschine auf einem isolierten Ethernet eingerichtet (z.B. in einem Heimnetz). Der Regelfall ist allerdings, daß mehrere Netze durch Gateways miteinander verbunden sind (man will ja auch "nach draußen"). Diese Gateways verbinden zwei oder mehrere Ethernets miteinander, oder sie stellen das Tor zum Internet bereit. Um einen Gateway zu nutzen, muß der Netzwerkschicht zusätzliche Routing-Informationen zur Verfügung stehen. Zum Beispiel sind die Ethernets des Zwergenwaldes und des Feenreichs durch solch ein Gateway miteinander verbunden, nämlich doc, der bereits konfiguriert sei. Auf allen Maschinen des Zwergenwaldes muß nur noch eine weitere Route eingetragen werden, die angibt, daß alle Maschinen im Netzwerk der Feen über doc erreichbar sind. Der entsprechende Aufruf von route sieht so aus (sofern feenreich in /etc/networks eingetragen wurde): route add feenreich gw doc Dabei gibt gw an, daß das folgende Argument ein Gateway bezeichnet. Natürlich muß jedes System im Feen-Netz, zu dem Sie Verbindung aufnehmen wollen, einen analogen RoutingEintrag für das Zwergen-Netz haben. Sonst könnten Sie nur Daten vom Zwergen-Netz an das Feen-Netz senden, die Rechner im Feen-Netz wären aber zu keiner Antwort fähig. Das war nun ein Gateway, das Pakete zwischen zwei isolierten Netzen befördert. Nehmen Sie nun an, daß doc außerdem eine Verbindung ins Internet hat. Dann wäre es wünschenswert, daß Pakete für beliebige Zieladressen, die nicht im Zwergen-Netz liegen, an doc weitergereicht werden. Das erreicht man, indem doc zum Default-Gateway wird: route add default gw doc route add default gw 172.20.20.1 oder bei Angabe der IP-Adresse Die Netzwerkadresse default ist eine Abkürzung für 0.0.0.0, die Default-Route. Sie paßt zu jeder Zieladresse und wird immer dann benutzt, wenn keine andere eingetragene Route paßt. Es ist ziemlich einfach, eine Maschine als Gateway einzurichten. Nehmen wir an, wir befänden uns wieder auf doc, der mit zwei Ethernet-Karten ausgestattet ist, die jeweils mit einem der beiden Netze verbunden sind. Man muß nur beide Schnittstellen getrennt konfigurieren und ihnen eine Adresse auf dem jeweiligen Subnetz zuzuweisen. Dabei ist es recht nützlich, zusätzlich zum offiziellen Hostnamen doc zwei Namen für die beiden Schnittstellen in /etc/hosts zu definieren: 172.20.20.1 172.20.21.1 doc.zwerge.local doc-if2 doc doc-if1 Mit diesen Einträgen lautet die Befehlsreihenfolge für die Einrichtung der beiden Interfaces: ifconfig eth0 doc-if1 ... route add zwergenwald ifconfig eth1 doc-if2 ... route add feenreich Damit Pakete überhaupt zwischen den verschiedenen Netzwerkschnittstellen vermittelt werden, bedarf es in neueren Kerneln des Kommandos echo '1' > /proc/sys/net/ipv4/ip_forward Wenn es dann nicht funktioniert, überprüfen Sie, ob Ihr Kernel mit Unterstützung für IPForwarding übersetzt wurde. Sie brauchen nicht einmal eine zweite Netzwerkkarte, denn es gibt sogenannte "DeviceAliase". Dies sind virtuelle Geräte, die mit der gleichen physischen Hardware verbunden sind, jedoch gleichzeitig aktiviert werden können, um unterschiedliche IP-Adressen zu haben. Sie werden normalerweise mit dem Gerätennahmen gefolgt von einem Doppelpunkt und einer Zahl dargestellt (zum Beispiel eth0:1). Wenn Sie einen Alias verwenden, können weder das Interface noch der Alias zur Verwendung von DHCP konfiguriert werden. eth0:1 ist der erste Alias für eth0. Der zweite Alias hätte den Namen eth0:2, usw. Die Befehle um beide Netze über eine Netzwerkkarte zu routen, würden lauten: ifconfig eth0 doc-if1 ... route add zwergenwald ifconfig eth0:1 doc-if2 ... route add feenreich Die Fehlermeldungen des route-Kommandos sind relativ kryptisch. Bei Linux kann - im Gegensatz zu anderen Unixen - die Metrik-Angabe entfallen. Man kann mehrere Routen zu einem Ziel (mit identischer Netzmaske) eingeben, sofern jeweils ein anderer Gateway angegeben wird. Fehlermeldungen des route-Kommandos: SIODELRT ist eine Fehlermeldung beim Löschen einer Route (DELeting a RouTe) SIOADDRT ist eine Fehlermeldung beim Anlegen einer Route (ADDing a RouTe) SIOCADDRT: Network is unreachable route add default gw 1.2.3.4 Die angebene Adresse gehört nicht zum eigenen Netzwerk und so kann der Rechner keine Pakete dorthin weiterleiten. SIOCADDRT: File exists Die angegebene Route existiert bereits. SIOCADDRT: No such device Es wurde das Schlüsselwort gw vor der Default-Gateway-Adresse vergessen; also nicht: route add -net 10.2.2.76/24 10.1.1.22 sondern: route add -net 10.2.2.76/24 gw 10.1.1.22 SIOCDELRT No such process Versuch, eine Route zu löschen, die nicht existiert. SIOCADDRT: Operation not supported by device Es wurde das Schlüsselwort gw oder die Gateway-Adresse vergessen; also nicht: route add -net 10.0.0.0/8 10.1.1.254 oder route add -net 172.23.24.128/25 sondern: route add -net 10.0.0.0/8 gw 10.1.1.254 oder route add -net 172.23.24.128/25 gw 10.1.1.22 SIOCADDRT: Operation not permitted Sie arbeiten nicht mit root-Berechtigung. SIOCADDRT: Invalid argument Falsche Kommandosyntax (z.B. vergessene Netzmaske); also nicht: route add -net 10.2.2.0 gw 10.1.1.254 oder route del -net 172.23.0.0 sondern: route route route route add add del del -net -net -net -net 10.2.2.0 netmask 255.255.255.0 gw 10.1.1.254 10.2.2.0/24 gw 10.1.1.254 bzw. 172.23.0.0/16 oder 172.23.0.0 netmask 255.255.0.0 oder route: netmask doesn't match route address Die Netzmaske passt nicht zur Host- und Gateway-Adresse. route: netmask 00ffffff doesn't make sense with host route Meist wurde der Parameter -net vergessen. Das Kommando nimmt dann an, dass man eine Host-Route angeben will. Oder man hat bei einer Host-Route eine Netzmaske angegeben. addr: Unknown host Meist wurde eine falsche Netzmaske angegebn, die das Kommando falsch interpretiert. route: bogus netmask 255.255.255.25 Die Netzmaske ist falsch angegeben worden (z.B. '25' oder '2555' statt '255'). Anmerkung: Die Syntax des route-Kommandos variiert von System zu System. Offene Ports und Anwendungen finden mit netstat Ein offener Port im Status "Listen" ist ein potientielles Einfallstor für Eindringlinge. Auch Trojaner installieren gerne "Backdoors" und öffnen dazu einen freien Port. Daher ist es sehr zu empfehlen, sich von Zeit zu Zeit die offenen Ports seiner Systeme anzusehen. Für eine Kontrolle der offenen Ports ruft man "netstat -nlp" auf. netstat -npl Proto Recv-Q Send-Q PID/Program name tcp 0 0 25671/apache tcp 0 0 16417/ftpd tcp 0 0 1345/sshd tcp 0 0 26007/exim4 tcp 0 0 1022/apache-ssl Local Address Foreign Address State 72.139.238.24:80 0.0.0.0:* LISTEN 72.139.238.24:21 0.0.0.0:* LISTEN 72.139.238.24:22 0.0.0.0:* LISTEN 72.139.238.24:25 0.0.0.0:* LISTEN 72.139.238.24:443 0.0.0.0:* LISTEN Das System zeigt mit diesen Parameter nur Ports im Status "Listen" an. Zusätzlich wird in der letzten Spalte die Prozessnummer und der Name des zuständigen Dämons angezeigt. Alternativ kann unter Linux auch das Kommando "lsof" benutzt werden. Mit dem Aufruf lsof -i | grep -e LISTEN wird ebenfalls eine Liste der Ports im Status "Listen" angezeigt. Einsatz von nmap Zur Kontrolle der offenen Ports eines Host über das Netzwerk benötigt man einen Portscanner, z.B. nmap von Fyodor. Der Portscanner nmap kennt eine Unmenge von Optionen. Für einen ersten Scan nach offenen TCP-Ports wird lediglich der Parameter "-sT" und die IP-Adresse des Zielsystems benötigt. Damit scannt nmap alle well know TCP-Ports (1-1024) und alle Ports aus der Datei etc/services. nmap -sT 192.168.1.1 Starting nmap 3.20 ( www.insecure.org/nmap/ ) at 2004-10-16 23:17 CEST Interesting ports on Router (192.168.1.1): (The 1610 ports scanned but not shown below are in state: closed) Port State Service 80/tcp open http Nmap run completed -- 1 IP address (1 host up) scanned in 6.533 seconds Der hier untersuchte IP-Host bietet einen Dienst an: HTTP auf TCP-Port 80. Auf der Maschine läuft also höchstwarscheinlich ein Webserver. Um alle TCP-Ports von 1 bis 65535 zu untersuchen ruft man nmap mit den Optionen "-sT -p 1-65535" auf. Mit der Option "-sU" sucht nmap nach offenen UDP-Ports. UDP-Scanning ist allerdings oftmals sehr langsam. Ursache hierfür ist eine Begrenzung der Anzahl der ICMP-Meldungen die ein Host pro Zeiteinheit versendet. Viele Systeme begrenzen die ICMP-Meldungen nach RFC 1812. nmap erkennt dieses Verhalten und arbeitet entsprechen langsamer um keine Meldungen zu verlieren. tcpdump Wenn Probleme in einem Netz auftauchen, so kann mit Hilfe des Programms "tcpdump" jedes einzelne Paket des Netzes protokolliert und analysiert werden. Dazu wird die Netzwerkkarte in den promisquous-mode geschaltet. "tcpdump" zeigt jetzt die empfangenen Paket-Header an und ermöglicht so eine Diagnose der aufgetretenen Fehler. Die Anwendung ist ziemlich kompliziert und würde den Rahmen dieses Kapitels sprengen. Es genügt, zu wissen, daß es dieses Programm gibt und daß es folgendermaßen aufgerufen wird. tcpdump -i Interface Damit werden alle Pakete des genannten Interfaces abgehört. Das Interface wird mit seinem symbolischen Namen angegeben, also beispielsweise eth0. tcpdump hat eine eigene Art Abfragesprache, die Befehle ermöglicht wie tcpdump host blackhole Zeigt nur Pakete an den oder vom Rechner blackhole. tcpdump host doc and grumpy Zeigt nur Pakete, die zwischen den Rechnern doc und grumpy ausgetauscht werden. Die ARP-Tabelle Bei einigen Netzproblemen kann es aufschlußreich sein, einen Blick auf die ARP-Tabelle des Kernels zu werfen oder sie sogar zu verändern. Die Kommandozeilenoptionen von ARP lauten: arp [-v] [-t hwtype] -a [hostname] arp [-v] [-t hwtype] -s hostname hwaddr Alle hostname-Argumente können als symbolische Hostnamen oder als IP-Adressen angegeben werden. Der erste Aufruf gibt den ARP-Eintrag für die angegebene IP-Adresse bzw. Hostnamen aus. Fehlt hostname, werden Informationen über alle bekannten Hosts ausgegeben. Zum Beispiel ergibt die Ausgabe von arp auf www.netzmafia.de etwa folgendes: arp Address 129.187.206.254 ns.e-technik.fh-muenche proxy1.e-technik.fh-mue web1.e-technik.fh-muenc HWtype ether ether ether ether HWaddress 00:04:DE:FE:78:00 00:07:E9:24:EC:15 00:07:E9:24:EC:15 00:07:E9:24:EB:F5 Flags Mask C C C C Iface eth0 eth0 eth0 eth0 Die Ausgabe kann mit der -t-Option auch auf bestimmte Hardwaretypen beschränkt werden. Als Argument geben Sie ether, ax25 oder pronet an, was für 10 Mbps Ethernet, AMPR AX.25 und IEEE 802.5 Token Ring steht. Die Option -s dient dazu, die Hardwareadresse von hostname manuell in die ARP-Tabelle einzutragen. Das Argument hwaddr spezifiziert die Hardwareadresse, die normalerweise als Ethernet-Adresse aus sechs Byte in hexadezimaler Notation angegeben ist. Sie können solche Adressen auch bei anderen Hardwaretypen verwenden, wenn Sie zusätzlich die Option -t angeben. Die Festverdrahtung von Hardwareadressen im ARP-Cache ist eine drastische Maßnahme, um Maschinen aus Ihrem Ethernet daran zu hindern, sich als jemand anderes auszugeben. Wenn Sie arp mit der Option -d aufrufen, entfernt es alle Einträge für einen bestimmten Host. Es kann dazu benutzt werden, das Interface anzuweisen, eine bereits angeforderte Hardwareadresse einer IP-Adresse nochmals anzufordern, und ist besonders dann nützlich, wenn ein fehlerhaft konfiguriertes System falsche ARP-Informationen sendet (natürlich muß zuerst das fehlerhafte System erneut konfiguriert werden). Neues Kapitel Twisted-Pair-Verkabelung Stecker und Buchsen RJ45-Stecker zum Aufpressen der Kabeladern (Twisted-Pair-Stecker) RJ45Einbaudose (Aufputz) RJ45-Buchse zum Einlöten Steckerbelegung und Adernfarben Der Standard DIN EN 50173 regelt die Kabelbelegung zumindest bei Kupferkabeln in Netzen. Es gibt vier Kabelpaare: Blick in die Buchse Paar Paar Paar Paar 1 2 3 4 Pins Pins Pins Pins 4, 1, 3, 7, 5 2 6 8 Token Ring verwendet die Paare 1 und 3 10BaseT verwendet die Paare 2 und 3 (ebenso 100BaseTX) 100BaseT4 und VG-Anylan verwenden alle Paare ISDN verwendet die Paare 1 und 3 ATM verwendet die Paare 2 und 4 TP-PMD verwendet die Paare 2 und 4 AS 400 verwendet das Paar 1 IBM 3270 verwendet das Paar 2 Pin-Numerierung von Stecker und Kabel Für den IP65/67-Bereich in der Industrie kommen keine RJ-45-Stecker zum Einsatz, sondern es werden 4-polige M12-Steckverbinder mit D-Codierung verwendet. An diese Stecker kann die Profinet-AWG22-Leitung angeschlossen werden. Der Stecker ist abgeschirmt und für den rauhen Insustrieeinsatz ausgelegt. Adernfarben Hier gibt es zwei Belegungen (die aber bis auf die Farben zum gleichen Ergebnis führen). Man muß sich nur an einen der beiden Standards halten, damit man nicht durcheinander gerät. Normales 100BaseT- und 10BaseT-Kabel kommt mit den Adern an den Pins 1, 2, 3 und 6 aus. Die Pins 4, 5, 7 und 8 werden für 100BaseT4+ benötigt. Standard EIA/TIA-T568ABelegung: Pin 1 2 3 4 5 6 Farbe Weiß/Grün Grün Weiß/Orange Blau Weiß/Blau Orange Standard EIA/TIA-T568BBelegung: (Diese scheint die verbreitetste zu sein.) Pin Farbe 1 Weiß/Orange 2 Orange 3 Weiß/Grün 4 Blau 5 Weiß/Blau M12-Belegung: (ProfinetKabelfarben) Pin Farbe 1 (TD+) Gelb 2 (TD-) Orange 3 (RD+) Weiß 4 (RD-) Blau 7 8 Weiß/Braun Braun 6 7 8 Grün Weiß/Braun Braun Die Belegung ist grundsätzlich eins zu eins an beiden Steckern. Auf Dosen ist die Belegung aufgedruckt (bzw. die LSA-Klemmen sind einfach in der entsprechenden Farbe markiert). Die Kabelfarben kennzeichnen die verdrillten Adernpaare, die Paare müssen eingehalten werden. Crossoverkabel Crossoverkabel dienen zur Verbindung zweier Hubs. Auf diese Weise kann man die Zahl der verfügbaren Rechneranschlüsse erhöhen. Beachten Sie aber, daß sich nur eine begrenzte Zahl von Hubs kaskadieren lassen. Anschlußbelegung der Twisted-Pair-Unterputz-Kanaleinbaudose In der Regel wird das Fabrikat Telegärtner MJ45 LFS 8/8 verwendet. Die Darstellung zeigt die Draufsicht (anschlusseitig) der Dose. Die obere Klemmenreihe ist für die linke Dose, die untere Klemmenreihe für die rechte Dose. Beim Standardnetz sind nur vier Kabeladern pro Dose anzuschliessen (Pins 1,2, 3 und 6, siehe oben). Anschlußbelegung der Twisted-Pair-Stecker für Hub und Computer Cable-Sharing, Y-Kabel Y-Kabel sind spezielle Kabel, mit denen man ein voll ausgebautes RJ-45-Kabel, bei dem alle 4 Paare des Kabels angeschlossen sind, als Verbindungsleitung für zwei Endgeräte benutzen kann. Sinn des Ganzen ist, daß man nur ein Twisted-Pair-Kabel mit 8 Adern verlegen muß, um zwei Computer (oder andere Geräte) anschließen zu können (jedenfalls bei niedrigeren Übertagungsraten). An Ihrem Hub belegen Sie zwei Ports, die dann per Y-Kabel auf ein Kabel geleitet werden, das zu einem Verteilungspunkt (Dose im Büro) verlegt ist. Von dort wird mit einem weiteren Y-Kabel zu Ihren Endgeräten verteilen. Schema der Verbindung: Für die verschiedenen Sprach- und Datendienste sind in den internationalen Richtlinien unterschiedliche Buchsenkontaktbelegungen festgelegt worden. Damit die Signalleitungen an den richtigen Kontakten der Endgeräte angelegt sind, wurden für Y-Kabel (Cable Sharing Adapter) verschiedene Ausführungen entwickelt: mit Kontaktbelegung 1, 2, 3, 6 (Ethernet usw.) mit Kontaktbelegung 3, 6, 4, 5 (Token Ring, Telefonanschluss, ISDN) Es gibt auch fertige Adapter im Handel zu kaufen: Der Cable-Sharing-Adapter wird immer paarweise eingesetzt. Auf der einen Seite am Verteiler, um die beiden Dienste auf die Installationsleitung aufzuschalten und auf der anderen Seite (z. B. an der Dose), um die Dienste vom 8-adrigen Anschluss wieder abzugreifen. Durch die flexible Anschlußschnur wird eine gute Verteilung der Zugkräfte erreicht, die von der Anschlußschnur der Endgeräte bzw. von den Patchkabeln auf den Adapter einwirken. Verdrahtung des Kabels: Verteiler für 2 Ethernet-Anschlüsse Verteiler für Ethernet- und Telefon-Anschluß Verteiler für 2 Telefon-Anschlüsse 100Base-T4 und 1000BaseT 100Base-T4 und 1000BaseT nutzen im Gegensatz zu 10BaseT alle 4 Adernpaare. Die Steckerbelegung ist dann: und das Crossover-Kabel wird folgendermaßen verdrahtet: RJ-45-Stecker crimpen Zuerst sollten Sie alles Benötigte bereitlegen. Für eine TP-Verbindung braucht man das Kabel, zwei Knickschutzhüllen, zwei Crimpstecker, eine Crimpzange, ein scharfes Messer, einen Schraubenzieher und eine Kabelschere oder einen Seitenschneider. Schieben Sie die Knickschutzhülle auf das Kabel. Dann entfernen Sie ca. 2 cm der Isolierung. Oft ist an der Crimpzange ein entsprechendes Werkzeug vorhanden. Achten Sie darauf, die Abschirmung und die Adern nicht zu verletzen. Dazu noch ein Tipp von Thomas Schmieder: Die Knickschutzhülle wird ja gerne vergessen. Aber manchmal (oder eigentlich meistens) klappt das Aufschieben nicht, da das Material des Kabels und das der Hülle so aneinander kleben, dass man eher einen Kopfstand auf der Wasseroberfläche hinbekommt, als die Tülle aufzuschieben. Ein winziges Tröpfchen Speiseöl hat mir schon oft die Show gerettet. Natürlich tut's auch etwas Vaseline oder ein anderes Gleitmittel... Nun öffnen Sie vorsichtig die Abschirmfolie und klappen Sie diese nach hinten. Danach ordnet man die Kabelpaare parallel entsprechend der Adernbelegung nebeneinander an. Halten Sie die Kabel etwa 10 mm von der Isolierung entfernt parallel fest und schneiden Sie alle Adern ca. 4 mm vor den Fingern ab. Ab da sollten Sie die Adern weiter festhalten. Die Länge der freiliegenden isolierten Adern muß zwischen 10 mm und 14 mm liegen. Manche Steckertypen haben einen kleinen, rechteckigen Plastikschlitten als Montagehilfe beiliegen. In diesem Fall werden die Kabel zuerst in den Schlitten eingeschoben und danach abgeschnitten. Der Schlitten hat einen Nachteil: Manchmal kann man nicht erkennen, ob er tief genug im Stecker sitzt (dann gibt es keinen Kontakt beim abschließenden Crimpen). Wenn man den Plastikschlitten mit schwarzem Filzer am Rand einfärbt, kann man seine Lage leichter erkennen und sie gegebenenfalls korrigieren, indem man ihn mit Pinzette oder Schraubendreher tiefer in den Stecker schiebt. Schieben Sie die Kabel in den RJ45-Stecker (das Steckersichtfenster zeigt nach oben), und zwar solange, bis die Kabel bündig am Steckerabschluß sitzen. Sollte sich beim hineinschieben eine Ader verkanten, alles nochmal herausziehen und neu versuchen. Bei der Schlittenvariante führen Sie den Schlitten mit den Adern in den Stecker ein und stellen Sie sicher, daß alle Adern bis nach ganz vorne durchgeschoben werden. Beim nicht abgeschirmten Stecker: Während Sie Kabel und Stecker mit der einen Hand festhalten, schieben Sie mit dem Schraubenzieher die Abschirmung vorsichtig rechts und links neben die Adern in den Stecker (nicht zu tief). Damit wird ein stabilerer Sitz des Steckers und eine optimale Verbindung zwischen der Stecker- und Kabelmasse erreicht. Die einzelnen Adern müssen erkennbar sein, wenn man von vorne auf den Stecker schaut. Der Stecker wird vorsichtig in die Crimpzange eingeführt (er paßt nur in einer Richtung) und bis zum Anschlag hineingeschoben. Jetzt pressen Sie die Crimpzange einmal kräftig zusammen (soweit es geht), lösen sie wieder und ziehen den Stecker heraus. Beim nicht-abgeschirmten Stecker schieben Sie noch die Knickschutzhülle auf den Stecker. Nun sind die Litzen des Kabels fest mit dem Stecker verpreßt und gleichzeitig die Isolierung aufgetrennt worden - wie die folgende Schemazeichnung zeigt. Beim abgeschirmten Stecker werden die beiden Metallzungen der Abschirmung mit einer Flachzange vorsichtig um das Kabel herumgebogen und festgedrückt. Achten Sie auf guten Kontakt mit der Abschirmung des Kabels. Dann kann auch hier die Knickschutzhülle aufgeschoben werden. Das Kabel sollte jetzt fertig sein und man kann es testen. Das fertige Kabel wird mit einem Kabeltester überprüft, indem auf die eine Seite der entsprechende Adapter aufgesteckt und das andere Kabelende in den Tester gesteckt wird. Zur Not reicht auch ein Durchgangsprüfer. Auflegen der Kabel am Patchfeld/an der Dose In der Regel werden bei den Dosen zwei Varianten verwendet, entweder mit herkömmlichen Schraubklemmen oder mit LSA-Klemmen. Zur Schraubklemmen-Variante ist nicht viel zu sagen. Die Kabel werden abisoliert und die Abschirmung zurückgeschlagen. Anschließend wird auch die Isolierung der einzelnen Adern auf ca. 5 mm Länge entfernt und jede Ader einzeln in die Klemme eingeführt und verschraubt. "LSA" steht für "löt-, schraub- und abisolierfrei". Bei diesem Verbindungsverfahren wird zum Auflegen ein spezielles Werkzeug verwendet. Mit dem LSA-Auflegewerkzeug werden die einzelnen Adern an der Dose oder am Patchpanel aufgelegt. Damit wird jede Ader in einen Schlitz gequetscht und das überstehende Ende abgeschnitten. So kann eine Dose zuverlässig in wenigen Minuten angeschlossen werden. Zur Demonstation wird hier ein Stecker-Patchfeld verwendet, bei einer Dose ist die Vorgehensweise aber dieselbe. Meist sind die entsprechenden Leisten auch farbig markiert oder zumindest beschriftet, so daß man beim Auflegen der Kabel eigentlich nichts falsch machen kann. Das Kabel wird zuerst abisoliert. Hier sehen Sie eine Kabelvariante, bei der die Adernpaare nochmals einzeln abgeschirmt sind. Die Abschirmung des Kabels und die der Adern wird nur soweit wie nötig zurückgeschlagen. Dann werden die Adern entsprechend der Farbmarkierung in die Schlitze der Leiste eingelegt. Man kann entweder erst alle Kabel auflegen und dann die Verbindung herstellen oder man bearbeitet Paar für Paar. Liegt die Kabelader im Schlitz der Leiste wird das Auflegewerkzeug aufgesetzt und nach unten gedrückt. Mit diesem Vorgang wird die Kabelader abisoliert und die Kuferlitze in einen V-förmigen Schlitz aus Metall gepreßt, wo eine innige Verbindung zwischen Litzte und Metallkontakt hergestellt wird. Gleichzeitig schneidet das Werkzeug das überstehende Ende der Litze ab. Die rechte Abbildung zeigt die Situation bei einer EinzelSteckdose. Sind alle Adern korrekt aufgelegt, wird das Abschirmnetz zurückgezogen, zusammen mit dem Kabel unter die Zugentlastungs-Schelle gelegt und festgeklemmt. Die Schellen sind jeweils für ein Kabelpaar, so daß man normalerweise erst noch das zweite Kabel auflegt, bevor die Schraube der Schelle festgezogen wird. Zum Schluß wird als zweite Zugund Biegeentlastung das Kabel noch mit einem Kabelbinder etwas weiter hinten am Patchfeld befestigt. Bei einer Doseninstallation entfällt dieser Schritt. Dafür wird bei einer Dose noch der Abschirmdeckel zugeschraubt. Abschließend erfolgt auch hier der Test der Verbindung mit einem Kabeltester. Fehlerquellen und Fehlersuche Kabel beschädigt Beschädigungen an Netzwerkkabeln können viele Ursachen haben: Anwender rollen achtlos mit Bürostühlen über Leitungen, treten auf Kabel oder stellen Schränke darauf ab. Welche Folgen sich daraus ergeben hängt neben dem Grad der Beschädigung (Quetschung, Kurzschluß, Unterbrechung) von der verwendeten Netzwerkstruktur ab. Die schlimmsten Folgen ergaben sich bei den alten Bus-Netzen. Hier waren immer alle Rechner im Segment von der Störung betroffen. Bei den heutigen Sternstrukturen sieht die Situation günstiger aus. Nur die angeschlossene Station wird durch das beschädigte Kabel beeinflußt. Aber auch hier gibt es Ausnahmen: Handelt es sich bei der defekten Leitung um ein Link-Kabel zwischen zwei Hubs/Switches, können die Auswirkungen auch ganze Rechnerverbünde treffen. "Mechanische" Beschädigung einer Leitung führt immer zu einer Änderung der elektrischen Parameter. Der für Netzwerke wichtigste ist die Impedanz. Mit der Impedanz in direktem Zusammenhang steht der im Kabel auftretende Reflexionsfaktor (siehe Kapitel 7). An der Störstelle wird ein Teil (Quetschung) oder das komplette Signal reflektiert (Leerlauf und Kurzschluß). Die typischen Symptome von beschädigten Leitungen sind Verlangsamung oder Teilausfall des Datenverkehrs bei Quetschung des Kabels und Totalausfall des betroffenen Segmentes bei Leerlauf oder Kurzschluß. Schwieriger wird es mit Quetschungen. Weder ein einfaches Multimeter noch der Längenmesser helfen hier weiter. Bei sehr kleinen Netzen und ohne spezielle Meßgeräte hilft hier wieder nur die Sichtkontrolle. Wer über einen KabelScanner verfügt, kann die Impedanz oder den Reflexionsfaktor der Leitung nachmessen. Wichtig ist im Zusammenhang mit Quetschungen folgende Tatsache: Die Auswirkungen müssen sich nicht "sofort" zeigen. Hängen nur wenige Stationen im Netz oder herrscht nur geringer Datenverkehr, dann treten zwar mehr Kollisionen auf als in einem unbeschädigten Segment, sie sind aber nicht als Verlangsamung des Netzes spürbar. Erst wenn sich der Datenverkehr erhöht oder die Anzahl der Stationen vergrößert wird, macht sich die Störung bemerkbar. Solche "schleichenden" Fehler lassen sich mit künstlicher Erhöhung der Netzwerkauslastung durch Dumb-Loads finden. Fehlerhafte Stecker Egal ob selbst "gekrimpte" oder fertig konfektionierte Kabel verwendet werden: Fehler an den Steckern gehören in der "Netzwerkwelt" häufig zu den Störungsursachen. Im Gegensatz zur Beschädigung der Leitung sind sie allerdings meist nicht durch eine kurze Sichtkontrolle zu finden. Bei der Beschreibung der Fehlerquellen muß man zwischen der Herstellung und der Verwendung der Verbindungskabel unterscheiden. Zunächst zur Herstellung: Stecker/Leitungsverbindungen werden meist mit Hilfe vom Krimp-Werkzeugen hergestellt. Bei Twisted-Pair-Leitungen ist besonders auf den guten Sitz der einzelnen Kabel in den Kontaktklemmen zu achten. Immerhin gilt es, bis zu acht Leitungen im Stecker unterzubringen. Häufig werden beim Zusammenquetschen der Stecker falsch verlegte Adern gegeneinander kurzgeschlossen. Ein neu gekrimptes Kabel sollte auf jeden Fall einem Verdrahtungstest unterzogen werden. Die Verdrillung der einzelnen Adrenpaare sollte erst möglichst kurz vor dem Stecker aufgehoben werden, um die Auswirkung von Nahnebensprechen (NEXT) klein zu halten. Generell gilt für das Anfertigen von Steckverbindungen: Vorher üben! Um die Bedienung der Krimpzange zu erlernen, sollte man auf jeden Fall einige "Probeverbindungen" anfertigen. Die so gewonnene Routine zahlt sich in der Praxis aus. Bei Twisted-Pair-Leitungen fällt die Sichtprüfung leicht aus, da die meisten Stecker ein Klarsichgehäuse haben. In der Praxis werden oft einzelne Adern durch Zugbelastung abgetrennt. Auch die dünnen Rastnasen der Stecker werden häufig auf diese Weise abgebrochen. Ohne sie sitzen Steckverbindungen unter Umständen nur locker in der zugehörigen Buchse (Wanddose, Netzwerkadapter oder ähnliches). Wackelkontakte sind die Folge. Abgetrennte Adern findet man am leichtesten mit einem Verdrahtungsprüfer. Kabel mit abgebrochenen Rastnasen sollten grundsätzlich ausgetauscht werden. Maximallänge des Segmentes überschritten Zu den häufigsten Fehlern bei der Installation und Erweiterung von Netzen gehört die unzulässige Überschreitung der Segment-Maximallänge. Netze entstehen in aller Regel schrittweise. Gerade in kleineren Unternehmen werden zu Anfang oft nur einige wenige Rechner vernetzt. Hat sich die Netzwerktechnik mit ihren vielen Vorteilen erst einmal etabliert, beginnt der Ausbau der Verkabelungsstruktur. Nach und nach werden immer mehr Rechner an den Strang angeschlossen. Die wenigsten Administratoren machen sich in einem solchen Stadium des Netzausbaus Gedanken über die Kabellänge. Erst wenn das Netz beginnt, langsamer als gewöhlich zu werden, wird mit der Fehlersuche begonnen. Oftmals wird dann ein leistungsfähigerer Server gekauft, der aber keinerlei Verbesserung bringt. In anderen Fällen überschreiten Netzwerkverantwortliche wissentlich die zugelassene Länge, mit dem Argument: "Das Netz geht doch noch!" Tatsächlich mag das Netz noch ohne erkennbare Probleme funktionieren, allerdings nur bei der aktuelle Auslastung. Wird die Netzlast größer, bricht plötzlich die Kommunikation zusammen. Die Funktion von CSMA/CD-Netzen beruht auf der Einhaltung von Maximallaufzeiten. Wird ein Segment über seine zugelassene Länge hinaus erweitert, dann können Kollisionen nicht mehr zuverlässig erkannt werden. Das Auftreten einer Kollision ist abhängig von der aktuellen Netzlast. Will nur eine Station im ganzen Segment senden, kann kein Zusammenstoß von Paketen entstehen. Wollen aber viele Stationen im gleichen Zeitraum Daten verschicken, dann ist eine Kollision sehr wahrscheinlich. Die Aussage: "Das Netz geht zum Zeitpunkt X." sagt also nichts über den Zustand zur Zeit Y. Für die Bestimmung der Länge des Segmentes ist ein spezialisiertes Längenmeßgerät notwendig. Es ist ratsam, jedes verlegte Kabel-Segment zu vermessen und an wenigstens einer Seite mit einer Beschriftungsfahne zu versehen. Das Etikett sollte neben der Bestimmung des Stranges (zum Beispiel: "1. OG/West") auch die gemessene Kabellänge ausweisen. So kann bei einer anstehenden Erweiterung sofort entschieden werden, ob das Segment noch verlängert werden darf. Reicht die zur Verfügung stehende Länge nicht mehr aus, dann muß das Segment zum Bespiel über einen Switch in zwei Teilstücke getrennt werden. In der Praxis sollte man die geforderte Maximallänge um einen gewissen Prozentsatz unterschreiten. Dies gilt insbesondere, wenn Netzwerkkarten verschiedener Hersteller eingesetzt werden. Verschiedene Kabelkategorien gemischt Bei Twisted-Pair-Verkabelungen ist die Gefahr recht groß, verschiedene Kabelkategorien (zum Beispiel 3 und 5) versehentlich zu mischen. Solange das Netz nur mit 10 MBit/s lief, bereitete diese Situation keine Probleme. Erst wenn auf schnellere Technologien umgestiegen wurde, treten Fehler auf. Eines oder mehrere der verwendeten Kabel sind für die gewählte Geschwindigkeit nicht geeignet, obwohl die restlichen die Spezifikation einhalten. Liegen die Leitungen teilweise in Kabelkanälen, fällt die Ortung des falschen Kabels schwer. Mit einem "Cable-Scanner", der die TSB67 erfüllt, kann der komplette Link vor dem Umstieg auf eine schnellere Technologie geprüft werden. Routereinträge Ist ein IP-Netz in Subnetze unterteilt (zum Beispiel Class-C-Netze) dann kommmunizieren sie über Router miteinander. Jeder Rechner im Netz muß dazu einen Eintrag in einer Konfigurationsdatei besitzen, der ihm mitteilt, welche Adresse der Router-Rechner hat. Insbesondere bei PC-Software herrscht allerdings eine gewisse "Namensverwirrung". Hier werden Routereinträge oft als "Gateway" oder "Default-Gateway" angegeben. Fehlende oder falsche Routereinträge findet man relativ leicht mit folgender Methode: Zuerst wird ein einfacher Verbindungstest zu einem Rechner im eigenen Subnetz durchgeführt. Wenn dies erfolgreich war, wird der Test mit einem Rechner außerhalb des eigenen Netzes wiederholt. Funktioniert das nicht sollte man einen Blick auf die Router-KonfigurationsEinträge des aktuellen Rechners werfen. Falsche IP-Nummer Oft tritt nach der Verlegung von Rechnern in andere Gebäude folgender Fehler auf: Obwohl an der Konfigurations des Rechners nichts verändert wurde, kann über IP keine andere Maschine mehr angesprochen werden. Ähnlich verhält es sich mit Notebooks oder Laptops, die an verschiedenen Orten mit dem Netz verbunden werden. Die Lösung ist meist recht einfach: Beide Gebäude liegen innerhalb verschiedener IP-Subnetze. Dazu ein Beispiel: Das Notebook wichtel mit der IP-Nummer 129.177.206.99 ist für das Class-C-Netz 129.177.206.0 konfiguriert. Sein "Default-Router-Eintrag" lautet 129.177.206.254. Dieser Computer wird nun im Subnetz 129.177.106.0 (ebenfalls Class-C) an eine Netzwerkdose angeschlossen und nichts an der Konfiguration geändert. Sendet wichtel nun Pakete an Rechner mit der IP-Nummer 129.177.206.x dann werden sie von der Netzwerksoftware mit der Netzmaske (129.177.206.0) oder der Broadcastmaske (129.177.206.255) verglichen. Ergebnis des Vergleichs: es muß sich um einen lokalen Rechner handeln (gleiches Subnetz). Folglich schickt wichtel das Paket direkt, ohne den Standard-Router anzusprechen. Da sich der Rechner aber nicht mehr im Netz 129.177.206.0) befindet, kann der Empfänger nicht erreicht werden. Ähnlich verhält es sich, wenn wichtel versuchen würde mit einem Computer außerhalb von 129.177.206.0 zu kommunizieren. Dieses Paket würde zur Weiterleitung an den Standard-Router geschickt werden, den wichtel unter der Adresse 129.177.206.254 anspricht. Auch dieses Paket wird als "lokal" verschickt und kann damit den Empfänger nicht erreichen. Gegen das Problem "falsche IP-Nummer durch Standortwechsel" läßt sich bereits im Vorfeld einiges unternehmen: Sind alle Rechner mit einem Aufkleber ausgestattet, der den Namen, die IP-Nummer und eventuell auch die Ethernet-Adresse ausweist, dann läßt sich mit einem Blick klären, ob der Rechner nach einem Umzug neu konfiguriert werden muß. Anwender sollten auf alle Fälle darüber aufgeklärt werden, daß man nicht einen Rechner, der für Gebäude A konfiguriert ist, mit in Gebäude B nehmen kann, ohne etwas an der Konfiguration zu ändern. Insbesondere bei Laptops und Notebooks, deren Hauptzweck der Einsatz an verschiedenen Orten ist, ist die Einrichtung einer dynamischen IP-Konfiguration in jedem Subnetz sinnvoll (DHCP).Die Rechner erhalten dann keine feste IP-Nummer mehr, sondern holen sich die Nummer und die Konfiguration (Netzmaske, Broadcast und Router-Adresse) erst beim Start der Netzwerksoftware von einem DHCP-Server. Fehlersuchstrategien Neben den o. g. Fehlern können natürlich noch diverse andere Probleme auftreten angefangen beim Putzdienst, der den Netzstecker vom Server abzieht bis hin zum TelekomMitarbeiter, der bein Einziehen einer neuen Glasfaser die vorhandenen anderen Verbindungen schrottet. Es können eben auch in einem korrekt geplanten und installierten Netzwerk Fehler auftreten. Viele Administratoren neigen dazu, bei einer Störung relativ unkoordiniert einzelne Konfigurationen zu überprüfen. Oft werden dabei völlig ungeeignete Suchstrategien angewendet, wodurch die Zeit bis zur Lösung des Problems unnötig verlängert wird. Eine effiziente und schnelle Fehlersuche ist nur möglich, wenn geeignete Testverfahren verwendet werden. Nachdem die Anzahl der Fehler, die in Netzwerken auftreten können, unüberschaubar hoch ist, kann hier nicht auf Details bestimmter Konfigurationen eingegangen werden. Der nachfolgende Abschnitt beschreibt daher allgemein ein sinnvolles Vorgehen bei Netzwerkproblemen. Den Ausgangspunkt bilden Fehler, die sich direkt an den Stationen auswirken (Fehlermeldungen der Treiber, usw.). Im Netzwerkalltag ist das die sicherlich häufigste Ausgangs-Situation: Ein Anwender stellt fest, daß eine bestimmte Netzwerkfunktion nicht zur Verfügung steht und benachrichtigt den Netzwerkverwalter. Fehler an Koppelelementen wie Bridges und Routern werden ausgehend von den Fehlermeldungen der Stationen im Lauf der beschriebenen Tests ermittelt. Die wohl wichtigste Regel bei der Fehlersuche ist: "Ruhig bleiben!". Auch wenn der betroffene Rechner noch so wichtig ist, eine hektische Suchaktion führt nur selten zum Erfolg. Wird man als Netzverwalter von einem Anwender angerufen und muß am Telefon Hilfestellung leisten, dann sollte man sich die entsprechenden Fehler-Meldungen "Wort für Wort" vorlesen lassen. Durch die teilweise recht ungenauen Beschreibungen der Benutzer ("Das Internet geht nicht!", "Es druckt nicht!" oder "Ich komme nicht ans Netz!") gerät man sonst oft auf eine völlig falsche "Fährte". Der Administrator muß zunächst mit der Abgrenzung des Fehlerumfanges beginnen. Dazu gehört die Feststellung, ob nur eine Station oder mehrere Stationen betroffen sind. Client-Fehler Die Suche nach Client-Fehlern beginnt sinnvollerweise zunächst mit einer Befragung des Anwenders der Station. Oft verändern Benutzer unabsichtlich Konfigurationsdateien oder löschen für die Netzwerkfunktionen wichtige Dateien. Ein der Standardfragen sollte also lauten: "Ist an diesem Rechner irgend etwas geändert worden?". Auch wenn die Antwort ein "nein" ist, lohnt sich meist ein genaueres "Nachhaken" mit Fragen wie "Haben Sie ein neues Programm installiert?". Oft gelangt man mit dieser Methode schneller zum Ziel, als mit diversen Testprogrammen. Bei allen Antworten sollte allerdings ein wichtiger psychologischer Faktor nicht außer Acht gelassen werden: Viele Anwender verschweigen ihre Änderungen an der Rechnerkonfiguration aus Angst, für den Fehler verantwortlich gemacht zu werden. Die meisten erfahrenen Netzwerkverwalter haben schon einmal Situationen erlebt, in denen Benutzer beteuerten nichts am Rechner verändert zu haben, obwohl auf der Station zum Beispiel ein neues, völlig anderes Betriebssystem installiert wurde. Diesem Phänomen kann man nur begegnen, indem man alle "Netz-Nutzer" darüber aufklärt, daß das Interesse eines Administrators ausschließlich in der Funktionsfähigkeit des Netzwerkes und nicht in der Bestrafung von "Schuldigen" besteht. Vor dem Einsatz von Software für den Stationstest sollte man einen Blick auf das Netzwerkkabel des Rechners werfen. Werden bei Twisted-Pair-Verkabelungen Hubs mit je einer "Online-LED" pro Port verwendet, genügt für eine grobe Überprüfung zunächst das Betrachten dieser Anzeige. Leuchtet die Diode, dann ist das Kabel zumindest nicht kurzgeschlossen oder aufgetrennt. Leuchtet die LED nicht, dann kommt als Ursache das Kabel oder das Netzwerkinterface der Station in Frage. Ersteres läßt sich durch den Austausch der Leitung gegen eine andere ausschließen. Ist trotz aktiver LED kein Netzwerkzugriff möglich, dann muß die Überprüfung der Station mit dem Einsatz von Software fortgesetzt werden. Die einfachste Testmöglichkeit ergibt sich auf PCs. Man bootet den Rechner mit einer vorbereiteten Boot-CD/DVD (z. B. mit "Knoppix", einem Linux-Derivat).Hier kann das Netz schnell passend von Hand konfiguriert werden. Ist auch unter diesen "MinimalBedingungen" kein Netzwerkbetrieb möglich, ist ein Hardwarefehler zu vermuten. Server-Fehler Für die Suche nach einem Serverfehler ist zunächst einmal interessant, ob der entsprechende Rechner in einem lokalen, nahen (gleiches Gebäude wie die zugreifenden Stationen) oder in einem unzugänglichen, weit entfernten Segment steht (zum Beispiel in einem anderen Gebäude oder einer anderen Stadt). Lokale Server sollten vom Administrator direkt inspiziert werden. Meist erweist sich ein "ausgeschalteter" oder vom Netzkabel getrennter Server als Ursache. Kann bei dieser Überprüfung kein Fehler gefunden werden, dann sollte die einwandfreie Funktion des Netzwerkinterfaces im Server getestet werden. Dies ist bei fast allen Betriebssystemen durch die Ausgaben diverser Hilfs-Programme möglich. Um die zwischen der zugreifenden Station und dem Server-Rechner liegende Verkabelungsstruktur als Fehlerquelle auszuschließen, führt man sinnvollerweise einen erweiterten Verbindungstest zwischen beiden durch. Auf diese Weise erhält man detailierte Informationen über den Weg jedes Datenpaketes. Im Falle eines weit entfernten Rechners ist das oft die einzige Testmöglichkeit. Konfigurations-Fehler Konfigurations-Fehler treten in Netzen hauptsächlich nach der Neuinstallation an Stationen oder Servern auf. Hierbei handelt es sich um grundsätzliche Fehler in den Soft- oder Hardware-Einstellungen der Rechner. In einigen Fällen bleiben die Netzwerkprobleme vorerst unentdeckt, weil die betroffenen Netzwerkdienste zunächst nicht genutzt werden. Da die Bandbreite der möglichen Fehler sehr groß ist und natürlich vom jeweiligen Betriebs- und Netzwerksystem abhängt, kann hier keine allgemeingültige Fehler-Strategie angegeben werden. In der Praxis kommt der Administrator dabei nicht um eine genaue Überprüfung der einzelnen Konfigurations-Dateien der Rechner herum. Netzwerk-Fehler Wie bereits oben beschrieben, können in Netzwerken eine ganze Reihe von "HardwareFehlern" auftreten. Eine schnelle Bestimmung der Ursache ist nur mit dem Einsatz von Meßgeräten möglich. Vor dem Einsatz von Cable-Scannern oder ähnlichem sollte zunächst die Anzahl der betroffenen Segmente bestimmt werden. Über den Vergleich mit dem Netzwerkplan, den jeder Verwalter angelegt haben sollte, können sinnvolle Meßpunkte ausgewählt werden. In kleinen Netzen, bei denen der Administrator oft ohne entsprechende Meßgeräte auskommen muß, kann folgende Strategie angewendet werden, um den Fehler zumindest grob einzukreisen: Die Fehlersuche beginnt mit dem Betrachten der Status-, Activity und Collision-Anzeigen der eingesetzten Koppelelemente (Hubs, Repeater, Switches, usw.). In den meisten Fällen läßt sich damit das betroffene Netz-Teilstück ermitteln. Bei Bus-Netzen kann der Fehler über ein "Trial-and-Error-"Verfahren bestimmt werden. Dazu wird der Bus aufgetrennt und damit in Teilnetze zerlegt. Jeder Teil wird mit Hilfe eines zusätzlichen Widerstandes elektrisch abgeschlossen. In den beiden so entstandenen Einzel-Segmenten können Verbindungstests ausgeführt werden. Zum dem fehlerfreien Teilstück wird nun schrittweise ein Abschnitt des anderen Segmentes hinzugefügt und der Verbindungstest erneut ausgeführt, bis der Fehler auftritt. Auch wenn dieses Verfahren nicht bei allen möglichen Hardwarefehlern zum Erfolg führt, können damit zumindest die häufigsten Probleme ermittelt werden. Aktives Netzwerkmanagement Der hohe Hardware-Anteil an der Gesamtfehler-Häufigkeit von Netzwerken entsteht nicht etwa, weil die eingesetzten Komponenten unzuverlässig sind, sondern vielmehr durch prinzipielle Fehler bei Planung und Erweiterung der Kommunikationsstrukturen. Auch heute noch bestehen viele Netze bei der Erstinstallation aus nur wenigen Stationen. In dem Glauben, ein Netzwerk sei wirtschaftlich, wenn die Erstinvestition möglichst gering ausfällt, werden Komponenten nach dem Motto "Je billiger desto besser" eingekauft. Die Verdrahtung der Rechner untereinander wird "frei", das heißt ohne Kabelschächte und Verteilerelemente, vorgenommen. In aller Regel gibt es keinen Netzwerkadministrator, sondern die Verwaltungsarbeit wird von einem oder mehreren Mitarbeitern "nebenher" erledigt. Typischerweise werden allen Benutzern Rechte auf allen Dateisystemen vergeben. Fehler in der Verkabelung fallen zunächst nicht auf, da das Datenaufkommen und die verlegte Kabellänge gering sind. Mit zunehmendem Kommunikationsbedarf wachsen die Netze jedoch stetig. Aus relativ kleinen Strukturen entstehen damit schnell größere Installationen. Erst in diesem Stadium des Ausbaues werden die ersten Fehler sichtbar und die Teil- oder Totalausfälle häufen sich. Die Suche nach der Störung nimmt meist relativ viel Zeit in Anspruch, weil weder Pläne der Verkabelung noch Testgeräte zur Verfügung stehen. Neben den Kosten für die Unterbrechnung des Datenaustausches wächst auch der Unmut der Anwender. Mit den oben dargestellten Zusammenhängen dürfte klar werden, worauf die hohe Prozentzahl der Hardwarefehler zurückzuführen ist. Sie läßt sich auf einen sehr geringen Prozentsatz senken, wenn man bei Planung, Erweiterung und Betrieb von Netzen nach gewissen Regeln vorgeht. Die in diesem Abschnitt beschriebenen Maßnahmen werden als "aktives Netzwerkmanagement" bezeichnet. Um zu verstehen, was dazu nötig ist, muß man sich zunächst Gedanken über die heutigen Anforderungen an Netzstrukturen machen: Wirtschaftlichkeit: Die laufenden Betriebskosten sollten zum einen möglichst gering ausfallen, zum anderen kalkulierbar sein. Flexibilität: Die Kommunikationsstruktur soll leicht umkonfigurierbar sein. Zukunftssicherheit und Investitionsschutz: Die installierte Netzwerktechnik muß auch zukünftigen Anforderungen genügen. Vorhandene Komponenten sollten sich problemlos erweitern lassen. Auch mit der Auswahl der Komponenten (Interfaces, Hubs, Switches, etc.) können die laufenden Kosten für das Netzwerk erheblich beeinflußt werden. Werden im Netz PCs eingesetzt, dann beginnt ein Administrator normalerweise den Netzwerkaufbau mit dem Kauf der Steckkarten. Vielen ist allerdings unklar, daß damit über den später entstehenden Verwaltungs-Aufwand entschieden wird. Genauso wie bei der Anschaffung von Computern ist hier nicht der günstigste Kauf auch gleichzeitig der beste. Vielmehr sollte man bei der Anschaffung der Netzwerkkarten auf folgende Punkte achten: Kaufen Sie konservativ! Bei neu auf dem Markt erschienenen Karten sind die Treiberprogramme oft eher "Beta-Versionen". Die instabile Software kann eine ganze Reihe von Fehlern wie "Abstürze" der Stationen oder Übertragungsfehler auslösen. Oft findet der Administrator erst nach stundenlanger Suche heraus, daß der Treiber die Ursache ist. Support ist wichtig! Markenhersteller bieten in aller Regel einen Treibersupport per Mailbox oder FTP-Server an. Ist die Software für ein neues Betriebssystem nicht auf der zum Interface mitgelieferten Diskette enthalten oder ist das Programm fehlerhaft, dann kann der Kunde sich dort kostenlos ein Update besorgen. Die Hersteller von "No-Name-Hardware" bieten diesen Service nicht. Markentreue zahlt sich aus! Mit der Anzahl der verschiedenen Karten-Typen wachsen auch die Betriebskosten des Netzes. Der Administrator muß für alle vorhandenen Adapter Treiber für die unterschiedlichen eingesetzten Betriebssysteme auf Vorrat halten und aktualisieren. Besitzt man nur einige wenige oder nur einen Kartentyp, dann kennt der Systemverwalter dessen besondere Einrichtungsoptionen und findet einen Fehler in den Einstellungen schneller. Bei anderen Komponenten (Hubs, Switches, usw.) sollte nach folgenden Kriterien vorgegangen werden: Selbst bei kleinen Netzwerkstrukturen sind Anzeige-Elemente (LEDs, etc.) für Zustände wie zum Beispiel Aktivität (activity) und Kollision (collision) wichtig. Mit ihrer Hilfe läßt sich ein eventueller Fehler meist schon grob einkreisen. Diese Möglichkeit ist insbesondere dann wichtig, wenn keine oder nur wenige Meßgeräte zur Verfügung stehen. Ist etwa ein Stations-Kabel vom Hub getrennt, dann läßt sich das mit einem kurzen Blick auf die entsprechende "Online-Anzeige" feststellen. Je größer das Netz ist, desto wichtiger wird der Punkt "Remote-Monitoring". Mit dem Einsatz von Komponenten, die über SNMP-Funktionen verfügen, ist der Administrator in der Lage, von seinem Arbeitsplatz aus einzelne Geräte zu überprüfen. An der "Management-Konsole" kann ein Fehler oder eine drohende Überlastung einzelner Elemente meist frühzeitig erkannt werden. Mit Hilfe von Steuerfunktionen kann das unter Umständen sehr weit entfernte Gerät konfiguriert werden, ohne daß der Weg dorthin zurückgelegt werden muß. Vernünftiges und optimiertes Management kann daher die Betriebskosten des Netzwerkes erheblich senken. Wie bei den Netzwerkkarten ist der Support des Herstellers ein wichtiger Faktor beim Kauf anderer Komponenten. Die Router von Markenherstellern lassen zum Beispiel meist das Einspielen neuer Betriebssystem-Versionen zu. Die dazu benötigte Software und oft auch eine ganze Reihe nützlicher Tools können von den einzelnen Firmen über deren FTP-Server oder eine "Support-Mailbox" bezogen werden. Wie wichtig ein solcher Support ist, merken viele Systemverwalter erst, wenn sie den ersten Fehler in der Software ihres Routers finden der eine dringend benötigte Betriebsart nicht erlaubt. Neues Kapitel Übertragungsmedien Egal wie das Kabel letztendlich aussieht, gibt es bei allen Kabeln ein paar grundlegende Eigenschaften. Jeder Leiter hat einen gewissen Gleichstromwiderstand, der abhängt vom spezifischen Widerstand des Materials (r), vom Querschnitt des Leiters (A) und von seiner Länge (l): R = r * l/A Für die Anwendung im Netz wesentlich wichtiger ist der Wechselstromwiderstand des Kabels. Wenn wir ein kurzes Leitungsstück betrachten, bildet die Leitung eine Induktivität L, die in Serie zum ohmschen Widerstand liegt. Die nebeneinanderliegenden Leiter und der Rückleiter bilden eine Kapazität C. Schließlich gibt es zwischen beiden Leitern noch einen sehr hohen Isolationswiderstand G. Man kann das Leiterstück also durch eine Ersatzschaltung wie im Bild annähern. Das Kabel setzt sich dann aus vielen dieser kleinen Schaltungen zusammen, die hintereinandergeschaltet sind. Die Leitungs-Induktivität besitzt bei einer Frequenz f den induktiven Widerstand XL = 2 * Pi * f * L Daraus ergibt sich eine proportionale Steigerung des induktiven Widerstandes mit der Erhöhung der Frequenz auf der Leitung. Je länger die Leitung ist und umso höher damit die Leitungsinduktivität wird, desto höher ist die Dämpfung durch die Längsinduktivität. Die Leitungsinduktivität ist als eine eigene Materialkonstante zu verstehen, die in der Einheit mH/km angegeben wird. Neben der Längsinduktivität gibt es noch eine weitere und bedeutend einflußreichere frequenzabhängige Größe einer Leitung: die Parallelkapazität. Auch diese stellt für die hochfrequenten Signalströme ein Problem dar. Der Scheinwiderstand des Kondensators errechnet sich wie folgt: XC = 1/(2 * Pi * f * C) Auch dabei ist wieder der klare Zusammenhang mit der Frequenz zu erkennen, wobei jedoch der kapazitive Widerstand mit zunehmender Frequenz kleiner wird. Das Problem liegt jedoch darin, daß es sich um eine Parallelkapazität handelt, deren immer kleiner werdende Widerstand für die hochfrequente Signalspannung nahezu einem Kurzschluß gleichkommt. Durch Einsatz kapazitätsarmer Leitungen kann die Dämpfung infolge der Kabelkapazitäten erheblich reduziert werden. Anders ausgedrückt: Mit gutem kapazitätsarmem Kabel lassen sich bei ansonsten gleichen Qualitäts- und Leistungseigenschaften erheblich längere Reichweiten erzielen, als es mit Standardkabeln möglich ist. Jedes Kabel bildet also ein Tiefpaßfilter, d. h. bei höheren Frequenzen wird das Signal immer weiter abgeschwächt. Der Wellenwiderstand eines Kabels ist der Widerstand, den es der Ausbreitung einer elektromagnetischen Welle entgegenbringt. Er ist die Kenngröße eines Kabels, die angibt, mit welchem Ohmschen Widerstand eine Leitung abgeschlossen werden muss, damit Anpassung erfolgt (keine Reflexionen). Zur Berechnung des Wellenwiderstandes werden die physischen Eigenschaften einer Leitung benötigt, also konstante Größen, die von Leitungsmaterial und der Leitungsgeometrie abhängen. Der Wellenwiderstand wird in Ohm angegeben. Er ist ein Wechselstromwiderstand. In der Informations- und Kommunikationstechnik werden üblicherweise Kabel und Leitungen mit einem Widerstand abgeschlossen, um Reflexionen der Signale an den Kabelenden zu vermeiden. Mißt man den Wechselstromwiderstand eines Kabels indem man ein Wechselspannungssignal einspeist, erhält man den spezifischen Wellenwiderstand des Kabels. Dazu misst man den Strom bei offenen und kurzgeschlossenen Leitungsenden. Nach den Strommessungen berechnet man aus der Generatorspannung UG und gemessenem Strom den Kurzschluss- und Leerlaufwiderstand, RK und RL: RK = UG/IK (= ZK) RL = UG/IL (= ZL) Der Wellenwiderstand ZW der Leitung, ergibt sich aus Kurzschluss- und Leerlaufwiderstand: Beim Ethernet ist der Wellenwiderstand auf 50 Ohm festgelegt. Die Grenzfrequenz ist erreicht, wenn die Ausgangsspannung 70% der Eingangsspannung erreicht hat. Die digitalen Signale, die auf das Netzwerkkabel geleitet werden, bilden auch eine (sehr oberwellenreiche) Wechselspannung. Zu Beginn hat man sich beim Ethernet für Koaxialkabel entschieden. Sie bestehen aus einem äußeren Leiter, der einen innenliegenden Leiter vollständig umschließt und dadurch abschirmt. Die beiden Leiter sind durch einen Isolator elektrisch getrennt. Koaxkabel gibt es in verschiedenen Ausführungen, für das Ethernet werden Typen mit einem Wellenwiderstand von 50 Ohm verwendet. Die Konstruktion dieses Kabels ist aber nicht nur wegen der Abschirmung des inneren Leiters günstig, da sie noch einen anderes Phänomen der Hochfrequenztechnik ausnutzt: den Skineffekt. Bei sehr hohen Frequenzen fließt der Strom fast nur noch in einer dünnen Schicht an der Leiteroberfläche, während tiefer im Leiterinneren fast kein Strom mehr fließt. Durch dieses Verhalten wirkt allein der Außenleiter des Koaxkabels genauso wie ein massiver Leiter gleichen Durchmessers. Deshalb ist die 'Füllung' des Leiters verzichtbar und ein 'Rohr' zu verwenden. Im Inneren dieses Rohres ist Platz für den zweiten Leiter. Da der Skineffekt auf Innen- und Außenleiter wirkt, läßt sich die Leitfähigkeit des Kabels durch eine dünne Silberbeschichtung auf dem Innenleiter weiter erhöhen. Seit einigen Jahren werden auch verdrillte Zweidrahtleitungen (10BaseT) oder Glasfaserleitungen verwendet. Die Definition des physikalischen Kanals ist aber nur ein Teil der IEEE 802.3-Spezifikation. Der Standard beschreibt physikalische Übertragung, die auch unser Thema ist, und Zugriffsverfahren, die sogenannten Protokolle. Auf der physikalischen Ebene sind Bezeichnungen wie 10Base5, 10Base2 und 10BaseT von Belang. Entscheidend sind dabei drei Parameter: die Übertragungsrate, das Übertragungsverfahren (Basis- oder Breitband; 'Base' oder 'Broad') sowie Aussagen zur räumlichen Ausdehnung. Zur Unterscheidung und Charakterisierung der einzelnen Übertragungsmedien wurde folgende Systematik für die Kabelbezeichnung entwickelt: <Datenrate in MBit/s><Übertragungsverfahren><Max. Länge/100 m> Auch der Kabeltyp kann unterschiedlich sein. Vom Koaxkabel über Glasfasern bis zu verdrillten Zweidrahtleitungen ist alles vertreten. Standard-Ethernet, 10Base5 Im weiteren wollen wir aber nur auf die Ethernet-Verkabelung eingehen. Das StandardEthernet besteht aus dem, meistens gelb isoliertem, 50-Ohm-Koaxialkabel mit ca. 10 mm Durchmesser (10,3 mm bei PVC-Isolierung, 9,5 mm bei PEP). Ein Kabelsegment darf maximal 500 m lang sein. Im Mindestabstand von 2,50 m können Media Attachment Units (MAUs) gesetzt werden. Zu diesem Zweck sind auf dem Kabel Markierungen angebracht. Die Ursache für den vorgeschriebenen Mindestabstand liegt darin, daß man eine Beeinflussung der MAUs untereinander ausschließen wollte. Das Bild zeigt schematisch den Anschluß an das Kabel. An einen MAU kann über ein maximal 50 m langes Transceiverkabel eine Ethernet-Station angeschlossen werden. Maximal 100 Stationen können an einem Kabelsegment hängen. Der Biegeradius darf 20 cm nicht unterschreiten. Das Kabel muß zur Vermeidung von Reflexionen an beiden Enden mit einem 50-Ohm-Widerstand (1 Watt) terminiert werden. Der Transceiver im MAU wird über einen TAP angeschlossen, bei dem Mittelleiter und Schirm kontaktiert werden, ohne das Kabel - und damit den Datenfluß auf dem Netz - zu unterbrechen. Bei einem Defekt im Transceiverkabel wird das Netz nicht beeinflußt; lediglich die betroffene Station ist von der Kommunikation getrennt. Die paarweise verdrillten Leitungen im Transceiverkabel werden über Differenztreiber angesteuert, auf Empfangsseite sitzen Differenzverstärker. Störungen können sich so nur gering bemerkbar machen. Anbindung der Arbeitsplätze direkt an das Yellow-Cable Zum Anschluß der einzelnen Arbeitsplätze an das Netzwerk benötigt man pro Arbeitsplatz den oben erwähnten MAU. Er stellt die Verbindung von Rechner über den AUI-Port mit dem Netzwerk her. Diese Vorgehensweise birgt allerdings einige Probleme (z. B. Netzlast, usw.). Es existieren strenge Verlegevorschriften bezüglich Biegeradius, Anschlußmöglichkeiten der einzelnen Stationen usw. Das Yellow Cable ist heute veraltet und sollte für Neuinstallationen nicht mehr eingesetzt werden. Es ist aber noch relativ häufig anzutreffen. Bei Anschlußfehlern werden die benachbarten Teile des Netzes betroffen. Außerdem wird für den Anschluß des MAU ein Spezialwerkzeug benötigt. AUI-Kabel (Attachment Unit Interface, TransceiverKabel) An einen MAU kann über ein maximal 50 m langes AUI-Kabel (Impedanz 100 Ohm) eine Ethernet-Station angeschlossen werden, z. B. eine Workstation, ein Terminalserver oder ein PC mit Ethernet-Einschubkarte. Das Kabel bietet die nötige Bewegungsfreiheit bei dem doch recht sperrigen "yellow cable". Im Transceiver-Anschlußkabel existieren zwei Leitungspaare für die beiden Senderichtungen. Der eigentliche Sender ist im wesentlichen eine Stromschleife, die zirka 65 mA treibt. Der Empfänger realisiert einen hochohmigen Abgriff des Signals vom Kabel, damit das Signal auf der Leitung nicht zu stark gedämpft wird. Weitere Leitungen liefern Informationen über Kollisionen. Zusätzlich erfolgt über das Kabel auch noch die Stromversorgung des Transceivers. Die Verbindung zum Transceiver bzw. zum Ethernet-Contoller erfolgt über 15polige SUB-D-Stecker. Das Kabel trägt die Stecker an den Netzkomponenten sind die Buchsen angebracht. Die Belegung der Stecker ist so gehalten, daß übereinanderliegende Pins jeweils die zueinander inversen Signale leiten: Pin Signal Pin Signal 1 Schirm für Kollisionserkennung 2 Kollisionserkennung + 9 Kollisionserkennung - 3 Sendedaten + 10 Sendedaten - 4 Schirm für Empfangsdaten 11 Schirm für Sendedaten 5 Empfangsdaten + 12 Empfangsdaten - 6 Masse 13 + 12 bis 15 V DC 7 Control Out + 14 Schirm für Stromversorgung 8 Schirm für Control Out 15 Control Out - Thinwire-Ethernet (Cheapernet), 10Base2 Eine weitere Abweichung vom ursprünglichen Standard besteht im Einsatz dünnerer Koaxialkabel. Diese haben zwar eine höhere Dämpfung und geringere Störfestigkeit als das Yellow Cable, sind aber für kleinere Netze vollkommen ausreichend. Sie sind nicht nur billiger (daher auch der Spitzname 'Cheapernet'), sondern auch besser zu verlegen. Bei diesem Netz entfallen auch die externen Transceiver und die Anschlußkabel. Das Kabel wird unmittelbar an der Netzwerkkarte des Rechners vorbeigeschleift und mittels eines BNC-TStücks angeschlossen. Dazu muß das Koaxkabel durchtrennt und mit zwei BNC-Steckern versehen werden - das Netz wird also kurzzeitig unterbrochen. Der Transceiver ist mit auf dem Netzwerkinterface integriert. Es handelt sich um ein 50-Ohm-Kabel RG58A/U oder RG58C/U mit einem Durchmesser von 4,7 - 4,9 mm Durchmesser. Die maximale Länge eines Segmentes beträgt 185 m (nicht etwa 200 m, wie die "2" bei 10Base2 vermuten läßt) und es können bis zu 30 Stationen angeschlossen werden, deren Minimalabstand 0,5 m betragen muß. Beim Verlegen des Kabels darf der Biegeradius 5 cm nicht unterschreiten. Durch geeignete Repeater können Standard-Ethernet-Segmente mit dem Cheapernet verbunden werden. Die 50-Ohm-Abschlußwiderstände sind in BNC-Stecker integriert und werden bei den beiden äußeren Stationen direkt auf das T-Stück gesetzt. Ein Defekt im Kabel, das ja an allen Stationen über die T-Stücke angeschlossen ist, betrifft somit auch alle Stationen. Das direkte Vorbeischleifen des Kabels am Interface ist für das 10Base2-Interface zwingend notwendig, ein Verlängern des T-Stückes mit einer 'Stichleitung' ist aufgrund der Funktionsweise des Transceivers nicht möglich. Wenn man versuchen würde, einen 10Base2Anschluß durch eine Stichleitung zu verlängem, wäre die saubere Ausbreitung der Welle nicht mehr gewährleistet und Reflexionen am Anfang und Ende der Stichleitung die Folge. Den Nachteil des Vorbeischleifens macht das 10Base2-Kabel dadurch wett, daß es bei deutlich geringerem Preis einfacher zu verlegen ist als das herkömmliche Ethernet. Moderne Netzwerkkarten bieten übrigens Anschlußmöglichkeiten für Transceiver-Kabel (also konventionelles Ethernet), für BNC-T-Stücke (10Base2) und für 10BaseT-Kabel (siehe unten) und sind standardmäßig mit einem OnBoard-Transceiver ausgestattet. Damit ist eine große Flexibilität in der Installation gegeben, es muß lediglich auf der Netzwerkkarte die gewünschte Konfiguration eingestellt werden. Anschluß der Arbeitsplätze an einen BNC-Strang Die Ausführung eines Netzwerksegmentes mit BNC-Kabeln ist wesentlich kostengünstiger als mit Yellow-Cable. Das BNC-Kabel wird an einen BNC-Hub o. ä. angeschlossen welcher selbst beispielsweise am Yellow-Cable angeschlossen ist. Das oben erwähnte T-Stück wird direkt an der Netzwerkkarte angeschlossen, die im Rechner eingebaut ist. Sollte es sich um den ersten bzw. letzten Rechner im Segment handeln, so wird dieser auch mit einem T-Stück angeschlossen. Jedoch wird hier der freibleibende Anschluß durch einen 50 Ohm-Abschlußwiderstand bestückt. Der Kabelanfang und das Kabelende müssen jeweils mit einem 50 Ohm Abschlußwiderstand abgeschlossen werden. Die Verlängerung der einzelnen Segmente erfolgt mit Repeatern. Sie werden als Signalverstärker zwischen die einzelnen Segmente geschaltet. Mittels Multiportrepeatern kann man das Netzwerk an diesen Stellen auch aufsplitten und in verschiedene Einzelsegmente aufteilen. Allerdings sollte immer darauf geachtet werden, daß bei einer solchen Installation nicht zu viele Arbeitsplätze angeschlossen werden. Jede Arbeitsstation bedeutet zusätzliche Netzlast. Je geringer die Netzlast ist, desto höher ist die Arbeitsgeschwindigkeit des Netzwerkes. BNC-Netz mit eigenem Server Bei den beiden vorgenannten Versionen sind die Installationen abhängig von einem abgesetzten File-Server. Er liefert die notwendige Netzwerksoftware und evtl. die benötigten Programme. Soll nun aber ein bestimmter Bereich des Netzes unabhängig vom File-Server betrieben werden, so ist es unerläßlich, einen Server nur für diesen Bereich zu beschaffen. Allerdings ist die BNC-Verkabelung - wie das Yellow Cable - ein aussterbender Standard, da man mit dieser Technik bereits an die Grenzen des technisch Möglichen angelangt ist. Die Übertragungsgeschwindigkeit von 10 Mbit/s kann hier nicht überschritten werden kann. Für "Wohngemeinschaftsnetze" wird es wegen seiner Preisgünstigkeit aber immer noch verwendet. Twisted-Pair, 10BaseT Twisted-Pair ist ein vieradriges, paarweise verdrilltes Kupferkabel, bei dem zwischen Sender und Empfänger für jede Übertragungsrichtung zwei Kupferadern genutzt werden. Die typische Dicke der Adern beträgt 0,5 oder 0,6 mm. Die maximale Übertragungslänge variiert mit der Dämpfung und ist abhängig davon, ob die Drähte abgeschirmt sind oder nicht. Das Twisted-Pair-Kabel eignet sich für verschiedene Uebertragungsmethoden wie Token Ring und Ethernet. Bei einer Datenrate von 10 - 100 MBit/s kann ein Twisted-Pair-Kabel bis zu 100 m lang sein. Die Mindestlänge des Kabels beträgt 0,6 m. Das Kabel verbindet genau zwei Stationen miteinander. Zum Anschluß mehrerer Stationen müssen sogenannte Hubs (engl. "Hub" = Nabe eines Speichenrades) eingesetzt werden, es lassen sich dann bis zu 1024 Stationen miteinander koppeln. Als Verbinder kommen normalerweise RJ-45-Stecker (Western-Stecker) und -Dosen zum Einsatz. Auch hier werden wieder Differenztreiber und -empfangsverstärker eingesetzt. Der Pegel wechselt zwischen -2,5 V und +2,5 V. Mit der Twisted-Pair-Verkabelung hielt auch eine kaum überschaubare Anzahl unterschiedlicher Kabelvarianten Einzug in die Datentechnik. UTP, FTP, S/UTP, S/STP oder ITP beschreiben den Kabelaufbau, CAT 3, 5 oder 7 beschreiben die Kategorie hinsichtlich der Anforderung der Kabel und Steckverbinder. Die Kabelklasse (A - 100 kHz, B - 1 MHz, C - 16 MHz, D - 100 MHz, E - 300 MHz, F - 600 MHz) definiert die Anforderungen hinsichtlich der Übertragungsbandbreite. CAT-1 für Alarmsysteme und analoge Sprachübertragung CAT-2 für Sprache und RS232-Schnittstellen CAT-3 Datenübertragung bis 16 MHz CAT-4 Datenübertragung bis 20 MHz (IBM Token-Ring 16 MHz) CAT-5 Datenübertragung bis 100 MHz Kategorie 1 2 3 4 5 4 10 16 100 Dämpfun NEX g T (dB/100 (dB) m) Dämpfun NEX g T (dB/100 (dB) m) Dämpfun NEX g T (dB/100 (dB) m) Dämpfun NEX g T (dB/100 (dB) m) 2,6 2,6 41 2,1 56 2,1 62 4 5,6 32 4,3 47 4,3 53 8 8,5 28 6,2 42 5,9 48 10 9,9 26 7,2 41 6,6 47 16 13,1 23 8,9 38 8,2 44 10,2 36 9,2 42 25 10,5 41 31,25 11,8 40 Übertragungs geschwindigk eit (Mbit/s) Frequenz (MHz) 1 20 Dämpfun NEX g T (dB/100 (dB) m) 62,5 17,1 35 100 22 32 Bemerkung : Bei Kategorie 1 liegt die Impedanz im Bereich von 84 bis 113 Ohm Bei Kategorie 2 - 5 beträgt die Impedanz 100 Ohm ± 15% Die Bauart der Kabel hat einen ganz wesentlichen Einfluß auf die Störleistungsunterdrückung und damit die Störsicherheit der Kabel. Während UTP-Kabel eine typische Störteistungsunterdrückung von 40 dB haben, erreichen S/STP-Kabel Werte bis zu 90 dB. UTP-Kabel (Unshielded Twisted Pair, nicht abgeschirmte verdrillte Leitungen) gehörten früher typischerweise der Kategorie 3 an. Inzwischen gibt es sie auch als CAT-5-Kabel. UTP-Kabel haben im industriellen Bereich oder in der Datentechnik mit hohen Datenraten nichts verloren. S/UTP-Kabel (Screened/Unshielded Twisted Pair) haben einen Gesamtschirm aus einem Kupfergeflecht zur Reduktion der äußeren Störeinflüsse. FTP-Kabel (Foileshielded Twisted Pair) besitzen zur Abschirmung einen Gesamtschirm, zumeist aus einer alukaschierten Kunststoff-Folie. S/FTP-Kabel (Screened/Foileshielded Twisted Pair) sind heute Stand der Technik bei der Verkabelung sogenannter UTP-Dosen. Der Aufbau besteht aus einem Gesamtschirm aus alukaschierter Polyesterfolie und einem darüberliegenden Kupfergeflecht. Gute Kabel erreichen eine Störleistungsunterdrückung über 70 dB. STP (Shielded Twisted Pair) bezeichnt eine Kabelgattung mit Gesamtschirmung ohne weitere Spezifikation. S/STP-Kabel (Screened/Shielded Twisted Pair) besitzen eine Abschirmung für jedes Kabelpaar sowie eine Gesamtschirmung. Hierdurch kann eine optimale Störleistungsunterdrückung erreicht werden. Auch das Übersprechen zwischen den einzelnen Adernpaaren kann so wirksam unterdrückt werden. ITP (Industrial Twisted Pair) ist die industrielle Variante von S/STP. Während typische Netzwerkadern jedoch vier Adernpaare besitzen, beschränkt sich ITP auf zwei Paare. Die Preisunterschiede zwischen Cat-3-Kabeln und Cat-5-Kabeln ist so gering, daß es sich bei Neuinstallation auf jeden Fall empfiehlt, Cat-5-Kabel einzusetzen - schon, um mit 100 MBit/s arbeiten zu können. Elektrische Eigenschaften für installierte 100-Ohm-Kabel gemäß DIN EN 50173 bzw. ISO/IEC 11801, Kategorie 5 Größter Schleifenwiderstand 300 Ohm/km Größter Widerstandsunterschied 3% Isolationswiderstand 150 MOhm x km Impedanz Zo bei 0,064 MHz 125 Ohm +/- 25% Impedanz Zo bei 1 - 100 MHz 100 Ohm +/- 15% Kopplungswiderstand bei 10 MHz < 100 Ohm/km Rückflußdämpfung an 100 m Länge: 1..20 MHz >23 dB Rückflußdämpfung an 100 m Länge: >20 MHz 23 dB - 10 log (f/20) Erdunsymmetriedämpfung dB/BZL = 1000 m bei 64 kHz > 43 dB Größte Erdkopplung bei 0,001 MHz 1600 pF/km Kleinste Ausbreitungsgeschwindigkeit bei 1 MHz 0,60 c Kleinste Ausbreitungsgeschwindigkeit bei 10 MHz 0,65 c Kleinste Ausbreitungsgeschwindigkeit bei 100 MHz 0,65 c Die konventionelle Twisted-Pair-Ethernet-Verkabelung verwendet RJ-45-Steckverbinder. Auch hier gibt es die unterschiedlichsten geschirmten und ungeschirmten Ausführungen. Sie sind für den industriellen Einsatz nur teilweise geeignet. Von den acht Leitungen des RJ45Steckers werden nur vier verwendet: Pin Signal 1 Sendesignal + 2 Sendesignal 3 Empfangssignal + 6 Empfangssignal - Zwischen Rechner und Hub verbindet das Kabel die beiden Stecker 1:1. Bei speziellen Kabeln für die direkte Verbindung zweier Computer oder für das Kaskadieren von Hubs müssen die Leitungen gekreuzt werden. Die Verbindung ist dann: Pin (Signal) Pin (Signal) 1 (TX+) - 3 (RX+) 2 (TX-) - 6 (RX-) 3 (RX+) - 1 (TX+) 6 (RX-) - 2 (TX-) Die RJ-45-Buchsen sind inzwischen auch keine profanen Steckkontakte mehr, sondern in ihnen sind auch gleich Übertrager, Drosseln und Widerstände integriert. Damit wird nicht nur Leiterplattenplatz eingespart, sondern auch bessere EMV-Eigenschaften erzielt und Layoutfehler vermieden. Das folgende Bild zeigt die elektrische Beschaltung einer solchen Buchse: Die Übertrager sorgen gleichzeitig für eine Potentialtrennung zwischen der Buchse und der restlichen Schaltung und für die Ausblendung von Störungen. Im folgenden Bild ist eine typische Buchse für die Platinenmontage abgebildet und darunter sind die Abmessungen (Vorder- und Seitenansicht) gezeigt. Oft sind in die Buchsen noch ein oder zwei LEDs integriert. Twisted-Pair-Verkabelung Wie gesagt, verlegt man pro Rechner ein eigenes Kabel. Während BNC-Netze eine BusStruktur haben, zeichnen sich Twisted-Pair-Netze durch eine Baumstruktur aus. Die einzelne Kabellänge zu einem Rechner darf 100 m nicht überschreiten. Die Anzahl der im Netz verfügbaren Rechner ist abhängig von den eingesetzten Repeatern, die hier "Hub" heißen (4Port, 8-Port; usw.). Mehr dazu steht im Kapitel über Twisted-Pair-Verkabelung. Lichtwellenleiter Seit einiger Zeit werden Netzwerkleitungen teilweise als Lichtwellenleiter verlegt. Der zusätzliche Aufwand zum Konvertieren von Strom in Licht und zurück lohnt sich. Der Hauptvorteil liegt in der sehr hohen Übertragungskapazität der durchsichtigen Faser, die bis in den Bereich von GBit/s reicht. Die Datenübertragung via Lichtsignal läßt sich außerdem durch elektrische und elektromagnetische Störungen kaum beeinträchtigen. Dadurch ist das Glasfaserkabel besonders für die Datenübertragung in elektrisch verseuchten Räumen wie zum Beispiel einer Maschinenhalle geeignet. Auch spielt die schon beschriebene Problematik des sich unweigerlich immer weiter verschlechternden Rauschabstandes keine Rolle mehr. Lichtwellenleiter bieten gegenüber dem Kupferkabel entscheidende Vorteile: Lichtwellenleiter können beliebig mit anderen Versorgungsleitungen parallel verlegt werden. Es gibt keine elektromagnetische Störeinflüsse. Wegen der optischen Übertragung gibt es keine Störstrahlungen, Kontakt- oder Masseprobleme. Entfernungsbedingte Verluste des Signals aufgrund der Leitungs-Induktivitäten, Kapaziäten und -Widerständen treten nicht auf. Weitgehend frequenzunabhängige Leitungsdämpfung der zu übertragenen Signale. Übertragungsraten sind durch mehrere Trägerwellen mit unterschiedlichen Wellenlängen (Farbspektrum) erweiterbar. Allerdings sind Lichtwellenleiter teurer als Kupferleitungen. Dies betrifft nicht nur die Materialkosten sondern auch den Aufwand für die Verlegung. Und ganz so einfach ist die Datenübertrag via Lichtwellenleiter (LWL) auch nicht. Die Eigenschaften des Leiters hängen vom geometrischen Aufbau und den physikalischen Eigenschaften des verwendeten Materials ab. Physikalische Grundlage des LWL ist das Prinzip von Brechung und Reflexion. Allgemein bekannt ist das Brechungsgesetz: Licht wird, wie das Bild zeigt, beim Übergang von einem optisch dichteren in ein optisch dünneres Medium vom Einfallslot weg gebrochen. Die Ursache dafür liegt in der sich ändernden Ausbreitungsgeschwindigkeit. Diese hat in jedem Medium einen anderen Wert. In einem optisch dichteren Medium bewegt sich Licht langsamer fort als in einem optisch dünneren. Das Verhältnis der Lichtgeschwindigkeit c in Vakuum zur Lichtgeschwindigkeit v in einem anderen Medium ergibt die Brechzahl: n = c/v Typische Werte für die Brechzahl sind: für Glas etwa 1,5, für Wasser 1,33 und für das Vakuum 1. Bei jedem Medienübergang wird ein Teil des Lichts reflektiert je stumpfer der Einfallswinkel, desto stärker die Reflexion. Der Reflexionsgrad hängt vom Unterschied der beiden optischen Dichten und vom Einfallswinkel ab. Erreicht der Einfallswinkel einen kritischen Wert, gelangt überhaupt kein Licht aus dem Medium mit der höheren Brechzahl heraus. Auf dieser Totalreflexion beruht das Prinzip des Lichtwellenleiters. Die Aufgabe des Leiters besteht ja darin, das Licht verlustlos und ohne Impulsverformung über lange Strecken zu transportieren. Da sich Licht aber nach allen Seiten ausbreitet, muß man einen Käfig bauen, der das Licht im Leiter hält. Denn bei jeder Biegung des Kabels würde sonst nur ein Bruchteil des ursprünglichen Lichts im Kabel verbleiben und eine längere Übertragungsstrecke wäre völlig unmöglich. Deshalb konstruiert man den Lichtwellenleiter als optische Röhre. Im Innern der Röhre kann sich das Licht ungehindert fortpflanzen und an den Wänden wird es total reflektiert. So wird der Lichtstrahl gezwungen, sich innerhalb der Faser fortzubewegen. Der LWL mit dem einfachsten Aufbau besteht aus einem konzentrischen optischen Kern mit einer hohen Brechzahl n1, der mit einem optischen Mantel kleinerer Brechzahl n2 versehen ist. Licht, das in einem gewissen Winkelbereich in den LWL eintritt, wird durch fortlaufende Totalreflexion an der Grenze Kern/Mantel weiterbefördert. Neben dem reinen Transport ist die Verformung, die die Lichtimpulse während der Leitung erleiden, von Bedeutung. Sehen Sie sich dazu das Einspeisen des Lichts in den LWL etwas genauer an: Trifft das Licht in einem Winkel nahe dem maximalen Einfallswinkel für den Lichtleiter auf, wird es sehr oft im LWL reflektiert. Es heißt dann Licht hohen Modes. Entsprechend heißt Licht, welches in relativ guter Übereinstimmung mit der optischen Achse des LWL eintrifft, Licht niedrigen Modes. Licht hohen Modes legt insgesamt einen längeren Weg im Kabel zurück und benötigt dadurch mehr Zeit für den Durchlauf. Fällt nun Licht mit nicht genau definiertem Winkel in den LWL ein, kommt es bis zum Ausgang wegen der unterschiedlichen Laufzeiten für jeden Einfallswinkel zu einer Dehnung des Lichtimpulses. Dieser unschöne Effekt, die Dispersion, verbreitert die Signalimpulse und beschränkt damit die erreichbare Übertragungsrate. Unter Dispersion versteht man die Verbreitung eines Lichtimpulses durch Laufzeitunterschiede (Gruppenlaufzeit) der Moden (Eigenwellen), was eine Begrenzung der Übertragungsbandbreite von LWLs zur Folge hat. Man unterscheidet die Modendispersion und die chromatische Dispersion, die sich aus Materialdispersion und Wellenleiterdispersion zusammensetzt. Die Modendispersion ist ein Effekt der unterschiedlichen Signallaufzeiten der Moden, was zu einer Signalverzerrung führt. Die Materialdispersion, auch Manteldispersion bezeichnet, ist die Wellenlängenabhängigkeit der Brechzahl eines Materials. Die Wellenleiterdispersion (Waveguide Dispersion) ist gerade bei Singlemode-LWL von Bedeutung und bezieht sich auf die Wellenlängenabhängigkeit der Lichtverteilung zwischen Kern und Mantel. Die nutzbare Übertragungsbandbreite ist umgekehrt proportional zur Dispersion. Die Dispersion wird in einer Zeit- zu Längeneinheit (ns/km) angegeben und ist der reziproke Wert des Bandbreitenlängenproduktes. Beispiel: Dispersion 5ns/km <-> Bandbreite 200 MHz * km. Abhilfe schafft ein nach außen hin stetig abnehmender Brechungsindex. Dadurch gleichen sich die Geschwindigkeiten und Laufzeiten für die verschiedenen Einfallswinkel bei genügender Kabellänge wieder aus. Wegen des stetigen Übergangs von Kern zu Mantel werden diese Leiter Gradientenprofilfasern genannt. Es ergibt sich beim Einfall der unterschiedlichen Lichtwellen trotz unterschiedlich langer Wege in der Faser eine nahezu gleiche Laufzeit aller Wellen. Eine noch geringere Dispersion liefern die Monomode-Fasern. Im Gegensatz zu den Multimode-Fasern leiten sie nur Licht einer bestimmten Wellenlänge. Ihr Kerndurchmesser ist so klein, daß sich das Licht fast nur noch entlang der Längsachse ausbreiten kann. Mit diesen Monomode-Fasern sind also die steilsten Flanken und damit die größten Übertragungsraten zu erzielen. Wellenlängen Mit zunehmender Wellenlänge nimmt der Streuverlust eines LWL ab. Verunreinigung, z.B. Sauerstoffionen oder OH-Ionen, die bei der Herstellung in die Faser gelangen, absorbieren das Licht bei verschiedenen Wellenlängen. Bedingt durch die Absorptionsspitzen gibt es Dämpfungsspitzen bei ca. 950, 1.200 und 1.400 nm und günstige Wellenlängenbereiche, die auch "Fenster" oder "Arbeitswellenlängenbereiche" genannt werden. Heute werden bei LWLSystemen drei Fenster bei 850 nm, 1300 nm und 1550 nm genutzt. Typische LWL haben folgende Daten. MultimodeStufenindexFaser Multimodefase rn mit Stufenprofil haben einen Durchmesser von 200 µm. Durch sie werden mehrere Lichtwellen gleichzeitig geschickt. An den Wänden der Faser wird das Signal hart reflektiert. Das Ausgangssignal wird dadurch verbreitert (je nach Einfallswinkel dauert das Signal unterschiedlich lang, weil der Weg mal länger und mal kürzer ist) und bedämpft. Sie werden z.B. als Verbindungska bel beim Patchfeld verwendet. MultimodeGradientenFaser Multimodefase rn mit Gradientenprof il haben einen Durchmesser von 50 µm. Durch sie werden mehrere Lichtwellen gleichzeitig geschickt. An den Wänden der Faser wird das Signal weich reflektiert. Das Ausgangssignal wird zwar auch verbreitert, aber nicht so stark bedämpft. Sie werden für Verbindungen von Gebäuden oder Etagen eingesetzt. MonomodeStufenindexFaser MonomodeFasern (SinglemodeFasern) haben einen Durchmesser von 10 µm. Durch sie werden die Lichtwellen gerade hindurchgeleite t. Das Signal wird wenig bedämpft und auch nicht verbreitert. So ist eine hohe Bandbreite möglich. Sie werden für weite Strecken eingesetzt. Als Sender für die LWL-Übertragung stehen Leuchtdioden (LEDs) und Laserdioden (LD) zur Verfügung. dabei werden LEDs am besten im Bereich von 850/860 nm eingesetzt und LDs im Bereich von 1300 nm. LED LD Licht-Typ inkohärent kohärent Wellenlänge 850/860 nm und 1300 nm 1300 nm Spektralbreite 30 - 40 nm 1 - 3 nm Abstrahlwinkel mittel bis hoch gering einkoppelbare Leistung gering hoch Lebensdauer 106 Stunden 105 Stunden Die unten stehende Abbildung zeigt die Zusammenhänge von Faserart und Sendertyp im Hinblick auf das Einsatzgebiet bezüglich Übertragungsstrecke und Übertragungsrate. Die optischen Sender und Empfänger (meist Laserdioden) müssen genau auf die Faser abgestimmt sein, um verlustarm und reflexionsfrei übertragen zu können. Ein großes technisches Problem beim Verlegen von LWL ist immer noch der Übergang von einem Leiterstück auf ein anderes, das sogenannte 'Spleißen'. Im Gegensatz zum elektrischen Leiter, bei dem eine Klemm- oder Lötverbindung ohne große Sorgfalt genügt, müssen die Glasfasern genau in der optischen Achse plan miteinander verschweißt werden. Unter Laborbedingungen stellt das natürlich längst kein Problem mehr dar, aber im mobilen Einsatz sieht das schon etwas anders aus. Beim sogenannten 'Spleißen' von Glasfaserkabeln gibt es zahlreiche Fehlermöglichkeiten. Das beginnt nach dem Entfernen des Sekundärschutzes mit mangelhaftem Reinigen der Faser. Weitere Fehlermöglichkeiten sind zu sparsame Verwendung des Leims zum Verkleben der Faser im Kontaktkörper oder zu wenig Sorgfalt beim anschließenden Schleifen der Kontaktfläche. Das beste 'Meßinstrument' ist hier eine Lupe mit mindestens 10-facher Vergrößerung. Man leitet sichtbares Licht in die Faser und prüft die Fläche auf Verunreinigungen oder Kratzer. Zum Reinigen der Kontaktfläche verwendet man nichtdenaturierten reinen Alkohol. Dämpfung Bei Lichtwellenleitern ist die Dämpfung der Energieverlust des Lichtstrahls, der beim Durchlaufen der Faser in Form von Streuung und Absorption auftritt. Sie wird in dB angegeben und meistens auf eine Länge von einem Kilometer (dB/km) bezogen. Die Dämpfung ist abhängig von der verwendeten Wellenlänge. Günstige Wellenlängen für Quarzglas liegen bei 850 nm, 1.300 nm und 1.550 nm. Die Dämpfung sollte so niedrig wie möglich sein, um die Signalverluste bei der Übertragung so gering wie möglich zu halten. Typische Dämpfungswerte liegen bei ca. 3 dB/km für 850 nm Wellenlänge. Zum Vergleich haben Koaxialkabel eine Dämpfung von ca. 17 dB/km. 10Base-F Ethernet Schon früh wurden Glasfasern als Link-Segmente für die Verbindung zweier RepeaterKomponenten standardisiert (Fiber Optic Inter Repeater Link - FOIRL). Unter Beachtung der Repeaterregel und des Laufzeitverhaltens lassen sich so entfernte Segmente untereinander verbinden. Dieser Standard wurde mittlerweile so erweitert (10Base-F), daß sich auch Stationen über Glasfasern an Glasfaserrepeater anschließen lassen. Die Konfiguration entspricht etwa der von 10Base-T. Für die Verbindung werden sogenannte ST-Stecker vorgeschrieben. Link-Segmente mit FOIRL-Geräten können bis zu 1000 m lang sein und Segmente mit 10Base-F Geräten bis zu 2000 m. Maximale Länge von Glasfaserkabeln ohne Verstärkung: Typ Dämpfung Stufenindex Gradientenindex Monomode 20dB/km bei 900nm 3dB/km bei 850nm 0,1dB/km bei 1300nm Bitratenlängen5 MHz * km produkt 1,5 GHz * km 250 GHz * km max. Länge 1 km (ohne Repeater) 10 km 60 km/100 km Gigabit-Ethernet Während die Normierung der neuen Verkabelungsklassen bzw. Kategorien E/6 (250 MHz) und für die Bewertung von Verkabelungsanlagen F/7 (600 MHz) im Jahr 2001 zum Endspurt ansetzte, ist mit Gigabit-Ethernet eine Anwendung nachgerückt, die deutlich mehr Bandbreite als bisherige Übertragungsprotokolle beansprucht. Hierdurch sind Klasse C/Kategorie-3- und -4-Verkabelungen endgültig überholt. Aber auch Klasse D/Kategorie-5-Verkabelungen sind "Auslaufmodelle", insbesondere dann, wenn zukunftssichere Konzepte für Neuinstallationen gefragt sind. Gigabit Ethernet (IEEE 802.3z, 802.3ab) Gigabit Ethernet kann sowohl über Kupferkabel als auch über Glasfaser laufen: 1000Base-T Cat 5 UTP 1000Base-CX STP/Twinax 1000Base-SX Multimode Fiber (850nm) 1000Base-LX Monomode Fiber oder Multimode (1300nm) STP- und Fiber-Standards sind verabschiedet, zur Festlegung des UTP-Standards wurde ein eigenes IEEE-802.3ab-Subkommitee gebildet. Dieses hat das Ziel, einen Standard für eine Reichweite von 100m auf UTP Cat. 5 Kabeln zu erzielen. Gigabit Ethernet: 1000Base-T über Kupfer Auf Grund der schwachen+-+ Auslegung von Klasse D/Kategorie-5-Verkabelungen sind bei 2-paariger Übertragung und Schwerpunktfrequenzen bis etwa 60 MHz Übertragungsraten bis 155 MBit/s (ATM) möglich. Der Bandbreitenengpaß bei Kategorie-5-Verkabelungen (bis 100 MHz) erfordert deshalb die Verwendung von 4 Paaren, um die Übertragung von Gigabit Ethernet zu ermöglichen. 1000Base-T verwendet eine Symbolrate von 125 Mbaud und eine 5Level-Codierung (PAM 5). Da bei 1000Base-T auf allen 4 Paaren gleichzeitig in beiden Richtungen gesendet und empfangen wird, übernimmt jedes Paar 250 MBit/s und in Summe (alle Paare) 1 GBit/s. Bei der Voll-Duplex-Übertragung über 4 Paare wechseln die Sende- und Empfangszustände der GigaBit-Ethernet-Bausteine ständig einander ab. Die gleichzeitige Übertragung in zwei Richtungen und die wechselnden Sende- und Empfangszustände haben neue Übertragungsparameter für die Bewertung von Verkabelungen generiert: 1. Leistungssumme des Nahnebensprechens(PSNEXT) Power Sum NEXT (PSNEXT) beschreibt die Summe aller Störleistungen, die durch Nahnebensprechen in ein Paar eingekoppelt werden. Das kommt dem tatsächlichen Einsatzfall, d.h. wenn alle Paare in Betrieb sind, nahe. Maßgeblich ist immer der stärkste Störer. Nur bei hohen Paarzahlen gibt es deutliche Unterschiede zwischen NEXT und Power Sum NEXT. 2. Fernnebensprechen (FEXT) Mit FEXT (Far End Cross Talk) wird das Nebensprechen am fernen (empfängerseitigen) Ende bezeichnet, das im Allgemeinen geringere Störungen verursacht als das Nahnebensprechen.Man unterscheidet beim FEXT zwischen: o Input-Output-FEXT (l/O-FEXT) und o Equal-Level-FEXT (EL-FEXT). Beide Größen sind durch die Gleichung EL-FEXT = I/O - FEXT - Dämpfung verbunden, wobei das ELTEXT in etwa dem ACR beim NEXT entspricht. 3. Leistungssumme des Fernnebensprechens (PSFEXT) Power Sum FEXT (PSFEXT) beschreibt die Summe aller Störleistungen, die durch Fernnebensprechen in ein Paar eingekoppelt werden. Das kommt dem tatsächlichen Einsatzfall, alle Paare in Betrieb, nahe. 4. Delay und Skew Propagation Delay (Verzögerung der Ausbreitung) bezeichnet die Verzögerungszeit/Laufzeit der Signalübertragung über ein Paar. Sind die Signalverzögerungen frequenzabhängig, führt das zu Signalverzerrungen, auch "Dispersion" genannt. Der Wert "Delay Skew" gibt die Differenz der Verzögerungszeiten/Laufzeiten zwischen zwei Paaren an. 5. Rückflußdämpfung (RL) Die Rückflußdämpfung, auch "Return Loss" genannt, beschreibt die Inhomogenitäten/Fehlanpassungen entlang des Übertragungskanals anhand des Verhältnißes von rücklaufender zu hinlaufender elektromagnetischer Welle. 6. Störleistungsunterdrückung Die Störleistungsunterdrückung ist ein Maß für die Fähigkeit eines Kabels, elektrische externe Störungen zu bedämpfen. Je höher die Störleistungsunterdrückung ist, umso besser ist die elektromagnetische Verträglichkeit. Gigabit Ethernet: konkurrierende Eigenschaften Die untereinander konkurrierenden Parameter für die Übertragung von Gigabit Ethernet haben Einfluß auf die konstruktive Gestaltung der Kabel. Die Problematik läßt sich anhand der unterschiedlichen Übertragungsparameter in Abhängigkeit der bekannten Kabelbauarten mit verseilten Paaren aufzeigen. Je nach Anforderung werden dem Datenkabel möglichst kleine und unterschiedliche (für NEXT und FEXT) oder möglichst lange und gleiche Paarschlaglängen) (für Dämpfung, Return Loss, propagation delay und delay skew) abverlangt. Ein Kompromiß bei UTP und S/UTP-Kabeln ist äußerst diffizil und führt zu Einbußen bei dem einen oder anderen Parameter. Eine Ausnahme stellen die S/STP-Kabel dar. Hier werden die NEXT-, FEXT- und ACR-Anforderungen wesentlich durch Einzelschirmung der Paare (PiMF) sichergestellt. Dies erlaubt erhebliche Freiheitsgrade bei der Gestaltung der Paarschlaglängen. S/STP-Kabel stehen deshalb für sicheres Einhalten aller Eigenschaften bis 600 MHz und darüber hinaus (1200 MHz). Zudem verfügen sie auf Grund der doppelten Abschirmung über hervorragende EMV-Eigenschaften. Anmerkung: Die "Schlaglänge" ist die Länge (z. B. in Millimetern), bei der sich eine Ader vom Anfangspunkt A bis zum Endpunkt B einmal um 360 Grad gedreht hat. Zusammenfassung: 1000Base-T auf UTP Kabeln Verwendung einer 5 Level Codierung gleichzeitig Verwendung von 4 Adernpaaren Vollduplex Betrieb auf allen 4 Paaren Trellis Codierung (nicht 8B10B) Gegenüberstellung Ethernet - fast Ethergent - Gigabit-Ethernet Ethernet Standard Datenrate Fast Ethernet Gigabit Ethernet IEEE 802.3 IEEE 802.3u IEEE 802.3z 10 Mbit/s 100 Mbit/s 1000 Mbit/s Zeitdauer eines Bits 100 ns 10 ns 1 ns Kollisionsfenster 51,2 µs 5,12 µs 0,512 µs Größtes Datenpaket 1518 Byte 512 Byte Kleinstes Datenpaket 64 Byte (kleinere Datenpakete mit Carrier Extension) Zugriffsverfahren: CSMA/CD Bei Erhöhung der Übertragungsrate auf 1 Gbit/s möchte man auf die vorhandenen Verkabelungsstrukturen aufsetzen, d. h. die Leitungslängen sollen gleich sein wie bei 100Base-T (Da die Dauer des Kollisionsfensters nur noch 0,512 µs beträgt, dürften rein rechnerisch die Kabel nur noch maximal 10 m lang sein - nicht praktikapel). Daher muß bei gleicher Leitungslänge die minimale Paketgröße vergrößert werden. Es gilt daher beim Gigabit-Ethernet eine minimale Paketlänge von 512 Byte. Mit Hilfe eines "Kunstgriffs" wird diese Festsetzung ohne Änderung im Datenframe-Format gewährleistet: der Carrier Extension. Bei Gigabit Ethernet-Frames mit weniger als 493 Datenbytes (46 bis 492) werden die fehlenden Datenbytes durch das Aufrechthalten des Trägers nach dem Ende des eigentlichen Datenpakets überbrückt. Der Ethernet-Frame wird dabei nicht verändert, so dass es für die Kommunikationssoftware keinen Unterschied gibt. Muss Carrier Extension eingesetzt werden, steigt auch der Overhead des Ethernet-Protokolls. Um dieses Anwachsen möglichst zu kompensieren, führt Gigabit Ethernet das Frame Bursting ein, das ebenfalls auf dem Physical Layer integriert wird. Dabei wird im Physical Layer versucht, mehrere kurze Datenblöcke in einen Ethernet-Frame zu packen, um so die erforderliche Mindestlänge von 512 Byte ohne den Einsatz von Carrier Extension zu erreichen. Im Gegensatz zu Ethernet und Fast Ethernet werden bei Gigabit Ethernet alle vier Paare eines Twisted Pair-Kabels verwendet. Damit können im Vollduplex-Betrieb die Daten Ober jeweils zwei Paare gleichzeitig gesendet und empfangen werden. Für die Optik-Version bestehen folgende Randbedingungen: Bezeichnung Medium mm Max. Länge (m) 1000Base-SX Multimode Fiber (850nm) 62,5 260 1000Base-SX Multimode Fiber (850nm) 50 550 1000Base-LX Multimode Fiber (850nm) 62,5 440 1000Base-LX Multimode Fiber (850nm) 50 550 1000Base-LX Monomode Fiber 3000 8,3 Fibre Channel Ursprünglich entwickelt von HP, IBM und Sun als Möglichkeit einer Hochgeschwindigkeitsanbindung von Rechnern zu Peripheriegeräten. Fibre Channel (ANSIT11) ist allerdings auch als LAN-Technologie denkbar. Fibre Channel definiert die Schichten 1 und 2 des OSI-Modells. Übertragungsraten von 1 Gbit/s sind heute verfügbar (2 Gbit/s als Dual Channel), 4 Gbit/s ist in Entwicklung und 8 Gbit/s geplant. Vorteilhaft sind die Ausfallsicherheit bei Verwendung eines Dual Channel, der geringe Protokoll-Overhead und gesicherte Übertragung (keine Zellverluste wie bei ATM). Es ist eine Kabellänge bis 10 km möglich. Der Adreßraum umfaßt 16'000'000 Adressen im lokalen Fibre-Channel-Netz und ist so mit klassischen LAN-Technologien vergleichbar. Fibre Channel bildet die Grundlage für andere Technologien, z. B. ATM over Fibre Channel oder Gigabit Ethernet auf Fibre Channel. Die folgende Tabelle fasst nochmals knapp alle Medien zusammen: Datenrate [MBit/s] Bezeichnung Übertragungsmedium IEEENorm 10Base5 10 RG 8 Koaxialkabel 50 Ohm, 500 m Segmentlänge 802.3 10Base2 10 RG 58 Koaxialkabel 50 Ohm, 200 m Segmentlänge 802.3a 10Broad36 10 Koaxialkabel 75 Ohm, max.Ausdehnung 3600 Meter 802.3b 10BaseT 10 Twisted Pair Kabel, Kat.3, 100 m Segmentlänge 802.3i 10BaseFL 10 MMF-Lichtwellenleiter, 850 nm, 2000 m Segmentlänge 10BaseFB 10 MMF-Lichtwellenleiter, 850 nm, 2000 m Segmentlänge 100Base-TX 100 Twisted Pair Kabel, Kat.5, 100 m Segmentlänge 100Base-T2 100 Twisted Pair Kabel, Kat.3, 100 m Segmentlänge, 2x2 Adern 100Base-T4 100 Twisted Pair Kabel, Kat.3, 100 m Segmentlänge, 4x2 Adern 100Base-FX 100 MMF-Lichtwellenleiter, 1300 nm, 2000 m Segmentlänge 1000Base-T 1000 Twisted Pair Kabel, Kat.5, 100 m Segmentlänge 802.3ab 1000Base-SX 1000 MMF-Lichtwellenleiter, 830 nm, 550 m Segmentlänge 802.3z 1000Base-LX 1000 MMF-Lichtwellenleiter, 1270 nm, 5000 m Segmentlänge 802.3z 1000BaseCX Twinax-Kupferkabel, 150 Ohm, 25 m Segmentlänge 802.3z 1000 10GBase-SR 10 seriell, Lichtwellenleiter, 850 nm, 2-300 m, ohne WAN-Anpassung 10GBase-SW 10 seriell, Lichtwellenleiter, 850 nm, 2-300 m, mit WAN-Anpassung 10GBase-LR 10 seriell, Lichtwellenleiter, 1310 nm, 2-10.000 m, ohne WAN-Anpassung 10GBase-LW 10 seriell, Lichtwellenleiter, 1310 nm, 2-10.000 m, mit WAN-Anpassung 10GBase-ER 10 seriell, Lichtwellenleiter, 1550 nm, 2-40.000 m, ohne WAN-Anpassung 10GBase-EW 10 seriell, Lichtwellenleiter, 1550 nm, 2-40.000 m, mit WAN-Anpassung 10GBaseLX4 Lichtwellenleiter, 1310 nm, 2-10.000 m, WWDM-Technik m. 4 Kanälen 10 10 Gigabit Ethernet 10 Gigabit Ethernet ist die (zur Zeit) schnellste Übertragungsvariante für Ethernet. In der IEEE 802.3ae werden die Produktspezifikationen für die entsprechenden Geräte standardisiert. Anzeige-LEDs In den Slotblechen von Netzwerkkarten finden Sie in den meisten Fällen einige Leuchtdioden, welche die gleiche Aufgabe wie bei den Hubs haben. Typische Bezeichnungen und die damit verbundenen Funktionen sind in der Tabelle angegeben, wobei - je nach Typ - auch nur eine Teilmenge davon vorhanden sein kann. Bezeichnung Bedeutung 10 LNK Diese LED signalisiert, dass die Karte im 10 MBit/s-Mode (Standard-Ethernet) arbeitet. 100 LNK Diese LED signalisiert, dass die Karte im 100 MBit/s-Mode (Fast-Ethernet) arbeitet. ACT Action Es werden Daten gesendet oder empfangen, wenn diese LED aktiv ist. COL Collision Die LED blinkt bei auftretenden Datenkollisionen (CSMA/CD). FDX Full Duplex Diese LED signalisiert, dass eine Voll-Duplex-Verbindung besteht, also gleichzeitiges Senden und Empfangen möglich ist. Link (Beat) Link Die LED leuchtet, wenn eine Netzwerkverbindung besteht (Kabel angeschlossen, Datenverbindung möglich, usw.). LNK Link Die LED leuchtet, wenn eine Netzwerkverbindung besteht (Kabel angeschlossen, Datenverbindung möglich, usw.). NML Normal Der Hub arbeitet in der normalen Betriebsart und kann zum Test per Schalter in einen Testmodus geschaltet werden, woraufhin diese Diode dann nicht leuchtet. POL Polarity Diese LED ist eher selten zu finden und ist normalerweise aus. Sie leuchtet nur dann, wenn die Polarität der Datenempfangsleitungen vertauscht ist. In der Regel können Netzwerkkarten mit einer derartigen Anzeige automatisch die richtige Polarität herstellen, und dann leuchtet auch die LED. PWR Power Die Spannungsversorgung des Hubs ist vorhanden, wenn diese LED leuchtet. REC Receive Die LED blinkt, wenn gerade Daten von der Einheit empfangen werden. RX (DATA) Receive Data Die LED blinkt, wenn gerade Daten von der Einheit empfangen werden. T/R Die LED blinkt, wenn gerade Daten von der Einheit gesendet Transceive/Receive oder empfangen werden. TX (DATA) Transmit Data Die LED blinkt, wenn gerade Daten von der Einheit gesendet werden. Die Receive- und Transmit-Leuchtdioden sind nützlich, um den augenblicklichen Status einer Netzwerkkarte ablesen zu können. Falls keine LED leuchten will, ist der Treiber für die Karte wahrscheinlich (noch) nicht korrekt installiert worden oder die Karte wurde nicht korrekt mit dem Netz verbunden. Die Anzeige LNK (Link) oder ACT (Activity) sollte auf jeden Fall dann leuchten, wenn das Netzwerk aktiv ist. Außerdern sollte an einer Netzwerkkarte auch die Receive-Anzeige leuchten oder blinken, wenn Pakete im Netz übertragen werden. Ethernetkarten konfigurieren unter Linux Um die Parameter eines Netzwerk-Interfaces anzusehen oder um eine optimale Performance zu erzielen, braucht man ein Programm, das die Konfiguration des Interfaces gestattet. Unter Linux gibt es dafür "ethtool". Leider arbeiten nicht alle Treiber mit dem Programm zusammen. In der Regel funktioniert eine Verbindung im Ethernet auch ohne weitere Konfiguration. Um die verfügbare Bandbreite optimal auszunutzen, gilt es einige Grundregeln: Die Duplexeinstellung mussebei beiden Linkpartnern gleich sein. Also entweder beide Seiten eines Link auf Autonegotiation oder beide Seiten fest auf die selben Parameter einstellen. Viele preiswerte Switches bieten keine Einstellmöglichkeiten und arbeiten immer mit Autonegotiation. Die Netzwerkkarten der angeschlossenen Clients müssen also auch auf "Auto" stehen. Zur Anzeige der aktuellen Parameter wird "ethtool" mit dem entsprechenden Interface als Parameter aufgerufen. Hier die Ausgabe für das Interface eth0: netzmafia:~# ethtool eth0 Settings for eth0: Supported ports: [ TP MII ] Supported link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full Supports auto-negotiation: Yes Speed: 10Mb/s Duplex: Half Port: MII PHYAD: 0 Transceiver: internal Auto-negotiation: off Supports Wake-on: d Wake-on: d Mit ethtool ist es auch möglich, Einstellungen der Netzwerkkarte zu verändern. Das folgende Kommando stellt das Interface eth0 auf 100 MBit/s und Halbduplex ein. ethtool -s eth0 speed 100 duplex half Für "speed" sind die Parameter 10, 100 und 1000 erlaubt. Der Duplexmode kann auf "half" oder "full" eingestellt werden. Autonegotiation wird mit dem Paramter "autoneg on" eingeschaltet und mit "autoneg off" abgeschaltet. ethtool -s eth0 autoneg on Für Netzwerkinterfaces die WakeOnLAN (WOL) beherrschen (siehe oben), bietet ethtool auch einige Konfigurationsoptionen. Der Benutzer kann festlegen welche Art von Frame ein Aufwachen auslösen soll und ein Kennwort für Wake-on-LAN festlegen. Nicht alle Interfaces unterstützen diese Option. ethtool -s eth0 wol <argument> Das Argument von "wol" ist eine Kombination aus folgenden Buchstaben: p u m b a g s d Wake on phy activity Wake on unicast messages Wake on multicast messages Wake on broadcast messages Wake on ARP Wake on MagicPacket(tm) Enable SecureOn(tm) password for MagicPacket(tm) Disable (wake on nothing). Die Option "d" löscht auch alle anderen Optionen. ethtool -s eth0 sopass xx:yy:zz:aa:bb:cc Setzt das Wake-on-LAN-Passwort. Das Passwort wird als Folge von 6 Hexzahlen angegeben, die durch Doppelpunkte getrennt sind. Neuere Netzwerkkarten haben mitunter die Möglichkeit, eine LED manuell blinken zu lassen. Das ist zum Identifizieren einer Karte in komplexen Umgebungen sehr hilfreich. Dazu dient der Parameter "-p": ethtool -p eth1 Tabellen Normen Abkürzung, Begriff Erläuterung ISO International Standard Organization, internationale Normungsorganisation. www.iso.ch IEC International Electrotechnical Commission , Internationale Elektrotechnische Kommission, erstellt und veröffentlicht internationale Normen für Elektrotechnik, Elektronik und verwandtze Gebiete. www.iec.ch IEC 11801 Die internationale Entsprechung der TIA568B: Norm zur Definition strukturierter Gebäudeverkabelungen. Legt auch die bekannten ISO-Klassen D, E, und F fest. Klasse D Leistungsklasse für strukturierte Gebäudeverkabelung nach ISO/IEC 11801 bis 100MHz Klasse E Leistungsklasse für strukturierte Gebäudeverkabelung nach ISO/IEC 11801 bis 250MHz (Entwurf) Klasse F Leistungsklasse für strukturierte Gebäudeverkabelung nach ISO/IEC 11801 bis 600MHz (Entwurf) OSI Open Systems Interconnection, globaler Rahmen für die Standardisierung "Offener Kommunikation" zwischen kooperierenden Systemen. Die 7 Schichten des OSIReferenzmodells zerlegen, losgelöst von speziellen Implementierungen, den Funktionskomplex Kommunikation in sieben schichtdiskrete hierarchische Teilprozesse. TIA Telecommunications Industry Association, US-amerikanische Normungsorganisation für (u.a.) Netzwerkstandards. http://www.tiaonline.org TIA 568A Commercial Building Telecommunications Cabling Standard, US-Norm zur Definition strukturierter Gebäudeverkabelungen. Legt auch die bekannten Cat 5, Cat 5e, Cat 6 etc. fest. TIA 568B Heute (seit April 2001) gültige Version der US-Norm Cat 5 Engl. Abk. für Category 5 (Kategorie 5), Leistungsklasse für strukturierte Gebäudeverkabelung nach TIA568 bis 100MHz, legt (unter anderem) die bei der Endabnahme (Zertifizierung) anzuwendenden Grenzwerte für die zu messenden Parameter fest. Cat 5e "verbesserte" (engl. enhanced) Cat 5 mit etwas verschärften Grenzwerten bis 100MHz, die ausreichende Reserven zur Übertragung von Gigabit Ethernet (1000BaseT), für die Cat 5 ursprünglich nicht vorgesehen war, sicherstellen soll. Entspricht ISO 11801 Klasse D. Cat 6 Leistungsklasse für strukturierte Gebäudeverkabelung nach TIA568 bis 250MHz (Entwurf) Cat 7 Leistungsklasse für strukturierte Gebäudeverkabelung nach TIA568 bis 600MHz (Entwurf) EN European Norm, dt. Europäische Norm. Oberbegriff für die vom CEN (Comité Européenne de Normalisation) und CENELEC (Comité Européenne de Normalisation Electrotechnique) erarbeiteten Normen. EN 50173 "Europäisierte" Entsprechung der IEC 11801: Norm zur Definition strukturierter Gebäudeverkabelungen. Schnittstellendefinitionen/Steckernormen Abkürzung, Begriff Erläuterung RJ-45 Registered Jack, 8-Poliger Stecker BNC Bayonet Neill Concelman, für Koax-Verkabelungen üblicher Bayonet-Steckverbindertyp RS-232, RS232C Recommended Standard 232, serielle Schnittstelle, an PCs heutzutage meist mit DB-9 Steckergesicht DB-9, DB-9M, DB-9F In der Computer- und Telekommunikationstechnik verbreiteter 9-poliger Standard-Steckerverbinder. Einsatzbeispiele: TokenRing- und FDDI-Netze (STP), serielles Interface DB-9M (IBM AT Standard) eines Personalcomputers. 10 Base T Standard: IEEE 802.3, steht für Ethernet mit 10 Mbit/s Übertragungsgeschwindigkeit, Basisbandübertragung und TPVerkabelung (Twisted Pair) 100 Base TX "Fast Ethernet" mit 100 Mbit/s Twinax Twinaxialkabel, elektrisches Nachrichtenkabel, dessen Aufbau dem Koaxialkabel ähnelt, das jedoch zwei Innenleiter aufweist Siemon Tera "CAT 7" Steckverbinder, bei dem bis zu 4 Aderpaare einzeln geschirmt durch die Steckverbindung geführt werden. Weist gegenüber RJ-45 Steckverbinder weit bessere Leistungsdaten auf und kann daher bis zu weit höheren Frequenzen eingesetzt werden. www.siemon.com Kerpen E-Line 600 Weiterer "CAT 7" Steckverbinder, bei dem bis zu 4 Aderpaare einzeln geschirmt durch die Steckverbindung geführt werden. Weist gegenüber RJ-45 Steckverbinder weit bessere Leistungsdaten auf und kann daher bis zu weit höheren Frequenzen eingesetzt werden. www.kerpen.com Weitere Infos zur Verkabelungspraxis finden Sie im Kapitel Twisted-Pair-Verkabelung und Netzplanung. Neues Kapitel Übertragungsverfahren Bei der Übertragung von Daten in lokalen Netzen verwendet man generell Basisbandübertragung. Die Übertragungsleitung nimmt zwei (manchmal auch drei) Zustände (Pegel) abhängig von den zu übertragenden Binärwerten an. Bei Weitverkehrsnetzen wird teilweise auch modulierte Übertragung verwendet, wobei die Binärwerte einem höherfrequenten Signal (Sinusträger) aufmoduliert werden. Modulierte Übertragung findet man beispielsweise beim Datentransfer über die Telefonleitung, bei Satellitenverbindungen oder bei Breitband-Kabelnetzen. In diesem Text betrachten wir nur Netze mit Basisband-Übertragung. Die Leitungscodierung erfolgt grundsäzlich auch zwei Arten: Entweder werden die einzelnen Bits codiert (z. B. 0 V für "0" und 5 V für "1") oder es erfolgt die Codierung der Bit-Übergänge (z. B. bei NRZI, wo das Signal für eine "0" konstant bleibt und sich bei einer "1" ändert). Im Netzwerkbereich wird eine Codierung verwendet, die eine Rückgewinnung des Taktes aus dem Signal erlaubt. Bei lokalen Netzen kommen hauptsächlich drei Codes zur Abbildung der Binärwerte auf die Leitungszustände zum Einsatz: Ethernet: Manchester-Code "1": 0->1-Übergang in Bitmitte "0": 1->0-Übergang in Bitmitte Abhängig vom Wechsel der Zustände ist noch ein zusätzlicher Übergang am Anfang jedes Bits nötig. Über die Zeit gemittelt hat das Signal keinen Gleichstromanteil. Eine Rückgewinnung des Taktes aus dem Signal ist möglich. FDDI (Glasfaser, Fiber Distributed Data Interface): NRZI (non return to zero inverted)Code "0": Zu Beginn der Bitperiode Zustandswechsel (0->1 oder 1->0) "1": keine Änderung des Pegels. Der NRZI-Code erlaubt keine Taktrückgewinnung, da bei ungünstigen Bit-Folgen unter Umständen lange Zeit kein Zustandswechsel eintritt. Um trotzdem auch hier den Takt zu halten, erfolgt eine Codewandlung. Dies leistet zum Beispiel bei FDDI die 4B/5B-Umwandlung (4 binary 5 binary), bei der jeweils ein 4-BitBlock (Nibble) in einen 5-Bit-Block derart umgewandelt wird, daß in jedem 5-Bit-Block maximal zwei aufeinanderfolgende Nullen vorkommen. Das Bild zeigt Kodierung eines Signals mit verschiedenen Ethernet-Normen: Bei 10 Base T: Manchester-Code, bei Fast Ethernet: zuerst 4B5B-Code (siehe unten), dann Umwandlung auf dreiwertigen Code (–/0/+) mit fünf Schritten, was zur Reduzierung der oberen Grenzfrequenz führt. Ursprüngliche Umgewandelte Bitfolge Bitfolge (4-Bit-Block) (5-Bit-Block) 0000 11110 0001 01001 0010 10100 0011 10101 0100 01010 0101 01011 0110 01110 0111 01111 1000 10010 1001 10011 1010 10110 1011 10111 1100 11010 1101 11011 1110 11100 1111 11101 Die 8B/10B-Umwandlung (8 binary 10 binary) sieht ähnlich aus wie die 4B/5BUmwandlung. Hier werden jedoch 8-Bit-Blöcke in 10-Bit-Blöcke umgewandelt. Die 8B/10BUmwandlung wird bei Gigabit-Ethernet 1000Base-CX, -SX, -LX und beim Fibre-Channel eingesetzt. Alle für die Übertragung gültigen Kombinationen sind derart aufgebaut, dass 5 mal die "0" und 5 mal die "1" vorkommt, um Gleichstromfreiheit zu garantieren. Außerdem weisen diese Kombinationen mindestens 3 Zustandswechsel auf (von "0" nach "1" oder umgekehrt), um auf Empfängerseite die Taktrückgewinnung zu gewährleisten. Bei der 8B/6T-Kodierung (8 binary 6 ternary) wird ein 8-Bit-Block in einen 6T-Code umgewandelt. Jeder 6T-Code besteht aus 6 sogenannten"Tri-State-Symbolen", die als "-", "0" und "+" notiert werden. Übertragungstechnisch verbirgt sich hinter jedem der drei Symbole ein entsprechender elektrischer Pegel. Die Kodierung wird anhand einer Tabelle durchgeführt, die sämtliche 256 möglichen 8-Bit-Kombinationen enthält. Während 4B/5B nur eine BitUmwandlung darstellt, die noch eine anschließende Kodierung (NRZI oder MLT-3) erforderlich macht, beinhaltet 8B/6T bereits die komplette Kodierungsvorschrift. Die folgende Tabelle zeigt einen kleinen Ausschnitt der 8B/6T-Codes. Bitfolge 8B6T-Code 0 0 0 0 0 0 0 0 + - 0 0 + - 0 0 0 0 0 0 0 1 0 + - + - 0 . . . . . . . . . . . . . . 0 0 0 0 1 1 1 0 - + 0 - 0 + . . . . . . . . . . . . . . 1 1 1 1 1 1 1 0 - + 0 + 0 0 1 1 1 1 1 1 1 1 + 0 - + 0 0 Derzeit ist Fast-Ethernet 100BASE-T4 das einzige Verfahren, bei dem die 8B/6T-Kodierung eingesetzt wird. Beim Kodierungsverfahren 5-Level Pulse Amplitude Modulation (PAM5) wird pro Takt ein Symbol übermittelt, das einen von fünf verschiedenen Zuständen (-2, -1, 0, +1, +2) darstellt. Mit jedem Symbol werden zwei Bits übertragen. Da es vier verschiedene 2-BitGrupen ("00", "01", "10" und "11") gibt, bleibt noch ein Symbol übrig, das für Fehlerbehandlung eingesetzt werden kann. Die PAM5-Kodierung wird bei Fast-Ethernet 100Base-T2 und bei Gigabit-Ethernet 1000Base-T verwendet. Neues Kapitel Weitverkehrsnetze, Voice-over-IP, Poweline Communication, Funknetze Übertragungsmedien für Weitverkehrsnetze Datex-Netz (veraltet) DATEX-L DATEX ist eine Abkürzung für "Data Exchange" (Datenaustausch). Das L sagt aus, daß es sich um ein leitungsvermitteltes Netz handelt, d. h. es wird ein Leitungsweg zwischen zwei Kommunikationspartnern zur Verfügung gestellt. Beide Partnerstationen müssen in Datenrate, Code und Protokoll übereinstimmen. Der Vorteil gegenüber dem Telefonnetz liegt im schnellen Verbindungsaufbau (0.4 - 1 Sekunde). Da heute Datex-L keine Vorteile mehr gegenüber ISDN hat, ist Datex-L ein auslaufendes Modell. DATEX-P Das P steht für "Paket-Vermittlung". Die Daten werden in Form genormter und mit Adressinformation versehener Datenblöcke (Datenpakete) übertragen. Stationen, die nicht zur Paketübertragung in der Lage sind, werden über einen Umsetzer (PAD = Packet Assembly Disassembly) versorgt. Die angeschlossenen Stationen können mit unterschiedlichen Datenraten arbeiten. Die Paketübertragung selbst erfolgt im Netz mit 64 KBit/s, wobei derzeit das Netz auf 1,92 MBit/s ausgebaut wird. Jedes Datenpaket wird auf dem günstigsten Weg ohne Rücksicht auf die logische Reihenfolge übertragen. Zwischen zwei über DATEX-P verbundenen Partnern können u. U. mehrere Übertragungswege existieren. Beim Empfänger wird die korrekte Reihenfolge der Pakete wiederhergestellt. Inzwischen ist aber der Bedarf an schnellerer Datenübertragung erheblich gestiegen, so dass als Nachfolgetechnik nun vorzugsweise Frame Relay verwendet wird. Fernsprechnetze und ISDN/DSL Das Fernsprechnetz ist das mit Abstand am weitesten ausgebaute Weitverkehrsnetz. Es dient vor allem zur Übertragung von Telefongesprächen, aber auch für die Datenkommunikation. Das Telefonnetz ist ein Beispiel für ein Leitungsvermitteltes Netz. Jedem Verbindungskanal steht eine Bandbreite von 64 kBit/s zur Verfügung. Auf analogen Leitungen (Modem) wird diese Grenze allerdings nicht erreicht. Die Datenrate kann hier bei bester Leitungsqualität bis zu 56 kBit/s betragen. Bei einem Zugang über eine Mobilfunkstrecke ist die Bandbreite allerdings noch geringer. ISDN steht für "Integrated Services Digital Network" = diensteintegrierendes Netz (Siehe auch Näheres im Modem-Skript). Der ISDN-Basisanschluß bietet zwei Kanäle mit einer Bandbreite 64 kBit/s pro Kanal. Aufgrund der digitalen Übertragungsweise steht diese durchgehend zur Verfügung. Neben den beiden Basiskanälen steht noch der Signalisierungskanal (D-Kanal) mit 16 kBit/s zur Verfügung. Dieser wird nur für die Signalisierung genutzt, während die beiden B-Kanäle der eingentlichen Datenübertragung dienen. Neben dem Standardanschluß mit 64 kBit/s wird noch der ISDNPrimärmultiplexanschluß (PMxA) PMxA angeboten, der eine Bandbreite von 2 MBit/s bietet. Der PMxA hat 30 B-Kanäle mit einer Datenrate von jeweils 64 kBit/s. Dazu kommt noch ein D-Kanal, der hier im Unterschied zum ISDN-Ba auch eine Datenrate von 64 kBit/s hat, sowie ein weiterer Kanal für Rahmenbildung und Rahmenerkennung mit einer Rate von ebenfalls 64 kBit/s. Die Bandbreite für Modems ist selbst bei gutem Signal/Rausch-Abstand auf analogen Telefonleitungen ausgereitzt. Jedoch stellen die geringen Übertragungsraten kein Problem der Kupferadern des Telefonanschlusses bis zur Vermittlungsstelle dar. Das Problem liegt im Zusammenspiel aller beteiligten Komponenten des Netzes: Der Weg vom Anschluß zur Vermittlungsstelle, die Übertragungstechnik der Vermittlungsstellen untereinander und der Weg zu dem Anschluß der angewählt wurde. Ende der 80er Jahre hat man SDSL (Single Line Digital Subscriber Line) und HDSL (High Data Rate Digital Subscriber Line) entwickelt. So war es nun endlich möglich kostengünstige 2-MBit-Systeme anzubieten. HDSL hat einige Vorteile gegenüber SDSL: Drei- bis vierfache Leitungslänge ohne Regeneratoren durch Verwendugn eines andern Leitungsprotokolls und einer leistungsstarken Echokompensation. Außerdem verursacht HDSL relativ geringe Störungen der benachbarten Adern, diese können bei SDSL wegen der starken Einstrahlung kaum für andere Anwendungen (Telefonie) verwendet werden. ADSL (Asymetric Digital Subscriber Line) und VDSL (Very High Data Rate Digital Subscriber Line) wurden ebenfalls Anfang der 90er Jahre entwickelt, hierdurch wird noch mehr Bandbreite zur Verfügung gestellt. Mehr dazu im Modem-Skript. Frame Relay Aufgrund des immer breiteren Einsatzes von Glasfaserleitungen ist die Fehleranfälligkeit der Datenübertragung zurückgegangen. Die Rechenleistung der Endgeräte ist zudem mittlerweile genügend hoch, um auch Aufgaben der Flußsteuerung und Verbindungsüberwachung zu übernehmen. Aus diesem Grunde kann hier das Prinzip des "Fast Packet Switching" (schnelle Paketvermittlung) zum Einsatz kommen. Das Verfahren ist als "Frame Relay" standardisiert worden. Das Frame-Relay-Verfahren arbeitet mit Datenpaketen variabler Länge, die allerdings ohne Fehlerkorrektur vermittelt werden. Beim Frame-Relay-Verfahren findet die Datenübertragung über virtuelle Verbindungen statt. Die zugehörigkeit eines Datenpaketes zu einer virtuellen Verbindung wird im Paketheader codiert. Hierfür ist das DLCI (Data Link Connection Identifier) Feld vorgesehen, das insgesamt 10 Bit breit ist. Insgesamt sind maximal 1024 virtuelle Verbindungen gleichzeitig möglich. Die Zahl der virtuellen Verbindungen wird durch die Anzahl der Bits im Paketheader, die zur Codierung einer Verbindung dienen begrenzt. Mit 10 Bit können demnach 210 = 1024 virtuelle Verbindungen dargestellt werden. Effektiv nutzbar sind allerdings nur 976 virtuelle Verbindungen, da einige DLCI für Sonderaufgaben reserviert sind. Eine virtuelle Verbindung kann dauerhaft eingerichtete werden oder erst bei Bedarf aufgebaut und nachher abgebaut werden. Im Falle der dauerhaften Verbindung spricht man von einer "Permanent Virtual Circuit", abgekürzt PVC, anderenfalls von einer "Switched Virtual Circuit" (SVC). Die SVCs werden beispielsweise dann eingesetzt, wenn die Verbindung nur selten punktuell genutzt wird. Eine dauerhafte Verbindung würde in einem solchen Falle nur unnötige Kosten verursachen. Ein Beispiel hierfür ist z.B. die Anbindung von Telearbeitsplätzen an das Rechnernetz des Betriebes. Das Frame-Relay-Verfahren ermöglicht zwar einen schnellen Datenaustausch in paktetvermittelten Datennetzen, doch die Übertragung von Sprache und anderen echtzeitkritischen Datenströmen kann hiermit nicht erfolgen. Bei der Übertragung eines Datenpaktes ist die Leitung für die Zeit der Übertragung blockiert; eine begonnene Übertragung eines Paketes kann nicht mehr unterbrochen werden. Aufgrund der variablen Größe der Datenpaktete bei Frame Relay kann die Übertragung daher eine längere Zeit inanspruch nehmen. Ein Weg dieses Problem zu lösen wäre es, die Datenpaketgröße drastisch zu reduzieren, wie es z.B. beim ATM-Verfahren festgelegt wurde. Während das Datex-Netz bis zur Schicht 3 hinauf definiert ist, umfaßt der Standard von Frame-Relay nur noch die Schichten 1 und 2. Die Eigenschaften in Stichpunkten: Paketorientiertes Protokoll mit variabler Paketlänge Frames werden in derselben Reihenfolge Empfangen wie sie abgeschickt wurden, es ist also keine Zwischenspeicherung und Sortierung nötig. Keine Empfangsbestätigung, keine Flußkontrolle (bleibt höheren Protokollen vorbehalten). Fehlererkennung, aber keine Fehlerkorrektur. Nur fehlerfreie Frames werden weitergeleitet. Transparente Verbindung FPS FPS (fast packet switching) ist ein schneller Paketvermittlungsdienst, bei dem Rahmen fester Länge vermittelt werden. Die Rahmen werden auch als Zellen bezeichnet, man spricht von Zellenvermittlung (cell switching). ATM basiert auf FPS. FPS zeichnet sich durch eine variable Bandbreitenzuordnung aus. Nur die Informationen im Informationsteil (Header) der Zellen sind mit einer Fehlererkennung ausgestattet. Die Zellen werden wie bei ATM über virtuelle Verbindungen durch das Netz übertragen (zu virtuellen Verbindungen siehe 'ATM'). Zellen werden ununterbrochen generiert und übertragen, nicht belegte Zellen werden im Header als 'leer' gekennzeichnet. ATM ATM steht für asynchronous transfer mode = asynchrone Übertragungsart. Diese Hochgeschwindigkeits-Paketvermittlung wurde für Breitband-ISDN (B-ISDN) als Vermittlungstechnik entwickelt und ist für Daten, Sprache, Text und Bilder gleichermaßen geeignet. Es gilt als die Technologie der Zukunft. ATM basiert auf FPS (fast packet switching). Dabei werden die Daten zu Paketen zusammengefaßt und zum Ziel geroutet. Das zuständige Normungs- und Standardisierungsgremium ist nicht das IEEE, sondern das ATMForum. Im folgenden soll die Funktion von ATM vereinfacht dargestellt werden. ATM arbeitet verbindungsorientiert, d. h. vor der Übertragung muß eine Verbindung erst geschaltet werden. Wie bei der klassischen Telefontechnik wird die Verbindung "irgendwie" geschaltet; wenn der kürzeste Weg bereits ausgelastet ist, wird ein Ausweichweg verwendet (salopp gesagt: Wenn die Strecke Nürnberg-München ausgelastet ist, wird eben der Weg NürnbergFlensburg-München gewählt). Im Kontrollfeld (Header) werden auch keine expliziten Quell- und Zieladressen angegeben, sondern ein virtueller Pfad und ein virtueller Kanal. Ein virtueller Pfad (virtual path, VP) ist eine für kurze Zeit geschaltete Verbindung, die während ihrer Existenz so aussieht wie eine richtige Festverbindung (Standleitung). Dieser geschaltete Weg durch das Netz wird als virtuell bezeichnet, weil er nicht permanent fest geschaltet ist, sondern nur für die kurze Zeit der Datenübertragung. Zur Kennzeichnung wird ihr ein VPI (virtual path identifier) als Bezeichnung zugeordnet. Ein virtueller Kanal (virtual channel, VC) ist ein Übertragungskanal, der genau wie der virtuelle Pfad nur während der Datenübertragung existiert. Zur Kennzeichnung wird ihm ein VCI (virtual channel identifier) als Bezeichnung zugeordnet. Ein virtueller Pfad besteht aus mehreren virtuellen Kanälen, komplexe Anwendungen können mehrere virtuelle Kanäle gleichzeitig belegen. Die klassischen Standleitungen enthalten ebenfalls mehrere Übertragungskanäle, doch können die virtuellen Kanäle bei ATM die virtuellen Pfade (Leitungen) wechseln. Wenn beispielsweise zwei virtuelle Kanäle auf Pfad 1 ankommen, kann Kanal 1 durchaus auf Pfad 2 und Kanal 2 auf Pfad 1 zum selben Zielnetz geschaltet werden. Bei VP-Switches bleiben die Kanäle den virtuellen Pfaden fest zugeordnet, die Pfade werden durch das Netz geschaltet. Bei VC-Switches werden die Kanäle über verschiedene Pfade geschaltet. Bei den geschalteten Verbindungen gibt es zwei wichtige Arten: o Eine PVC (permanent virtual circuit = permanente virtuelle Verbindung) bleibt auch im unbenutzten Fall so lange geschaltet, bis sie wieder gewollt abgebaut wird. o Eine SVC (switched virtual circuit = geschaltete vinuelle Verbindung) bleibt nur für die Dauer der Übertragung geschaltet und wird nach Übertragungsende automatisch wieder abgebaut. Bei der Wegewahl wird eine einfache Art des Routings verwendet, um die Datenpakete durch das Netz zu senden. Der Weg, den das Datenpaket durch das ATM-Netz zurücklegt, besteht dabei aus drei Hauptabschnitten: 1. Vom Absender zum Switch, an dem der Absender angeschlossen ist. 2. Vermittlung innerhalb des ATM-Netzes von Switch zu Switch. 3. Vom Switch, an dem der Empfänger angeschlossen ist, zum Empfänger. Als Übertragungsverfahren wird bei ATM das Paketvermittlungsverfahren Cell Relay ("Zellenvermittlung") verwendet. Bei diesen Zellen handelt es sich um Rahmen fester Länge mit 5 Byte Header für Adressierung und Steueranweisungen sowie 48 Byte Nutzdaten, insgesamt also 53 Byte. Dabei wird zwischen zwei unterschiedlichen Zelltypen unterschieden. Die UNI-Zellen (user network interface) werden an der Schnittstelle zwischen Anwender und ATM-Netz verwendet und besitzen im Header 8 Bit für die Angabe des virtuellen Pfades und 4 Bit für die Flußkontrolle. Die NNI-Zellen (network node interface) werden zwischen den Netzwerkknoten (ATM-Switches) verwendet und besitzen 12 Bit für die Angabe des virtuellen Pfades, jedoch keine Flußkontrolle. Die Zellen werden von den Switches an den entsprechenden Trennstellen im ATM-Netz automatisch umgewandelt. Durch die sogenannte 'cell loss priority', die Verlustpriorität, wird festgelegt, welche Zellen auch bei sehr hoher Auslastung des Netzes noch unbedingt übertragen werden müssen (z. B. kritische Daten oder Synchronisationsanweisungen) und welche gegebenenfalls auch verloren gehen können (z. B. Bildinformation bei Bildtelefonie). Die Fehlerkontrolle bezieht sich nur auf den 5 Byte großen Header, nicht jedoch auf die Daten. Es ist ATM völlig egal, was übertragen wird, wichtig ist nur wohin und wie. Das ist auch ein Grund für die Schnelligkeit. Die wichtigsten Übertragungsraten sind 622 MBit/s (Lichtwellenleiter), 155 MBit/s (LWL und Kupferleitungen), 100 MBit/s (LWL und FDDI) und 26 MBit/s (Kupferleitungen). ATM kann Datenströme unterschiedlicher Bitraten flexibel übertragen und vermitteln. Die Übertragungsrate ist skalierbar, d. h. Übertragungsbandbreite wird flexibel bereitgestellt. Jedem Endgerät kann statisch (also vorab) oder dynamisch (also bei konkretem Bedarf) Bandbreite zugewiesen werden, die Netzleistung wächst also mit. Durch die transparente Übertragung in den Zellen werden bei den Netzübergängen keine Gateways benötigt, um von LAN- auf WAN-Protokolle umzusetzen. ATM ist gleichermaßen für LANs, schnelle Backbones und WANs geeignet. ATM ist verbindungsorientiert und baut immer eine Punkt-zu-Punkt-Verbindung auf. Für eine Übertragung muß also immer eine Verbindung zwischen zwei Stationen geschaltet werden (ATM basiert auf der Vermittlungstechnik). Klassische LANS sind verbindungslos, jede Station ist zu jeder Zeit mit allen anderen Stationen fest verbunden, alle teilen sich dasselbe Übertragungsmedium. ATM als LAN (lokales ATM, L-ATM) benötigt eine LAN-Emulation. So entsteht ein virtuelles Netz, bei dem das ATM-Netz mehreren Teilnehmern (Geräte/Software) ein nichtexistierendes LAN vorspiegeln muß. Dabei sind verschiedene Ansätze allerdings noch in Diskussion. Diese LAN-Emulationen arbeiten alle auf Schicht 2 des ISO-Schichtenmodells, dadurch eignen sie sich für routebare und nicht routebare Protokolle gleichermaßen. Für die Übertragung von IP-Paketen über ATM haben sich die nachfolgend beschriebenen 3 Verfahren heute etabliert. CLIP Dies ist die Abkürzung für "Classical IP". Hier werden die Datenpakete aus unterschiedlichen Netzen über ATM transportiert. Die Datenpakete aus verschiedenen Netzformen (wie Ethernet, Token-Ring) können in einem Fall nach der "Logical Link Control Encapsulation"-Methode alle über eine virtuelle Verbindung übertragen werden. Die ATM-Zellen werden mit Header-Informationen über den Protokolltyp des transportierten Datenpaketes versehen. Zur effizienten Gestaltung des Datentransportes kann auch je Protokolltyp eine virtuelle Verbindung aufgebaut werden. Das Feld mit der Typangabe für die transportierten Pakete kann enfallen, so das mehr Raum für Nutzinformationen zur Verfügung steht. Die mittels CLIP transportierten Datenpakete können allerdings hinsichtlich der IP-Adressen nur immer innerhalb eines IP-Subnetzes transportiert werden, da hier keine Möglichkeit des Routings über ATM besteht. LANE Das LAN-Emulationsverfahren (LANE) simuliert die Abläufe und Funktionen eines herkömmlichen LAN. Hierdurch kann eine existierendes LAN auf ATM abgebildet werden. Das emulierte LAN (ELAN) hat eine Client/Serverarchitektur, bei der jedes Endgerät einen softwareseitigen "LAN Emulation Client" (LEC) besitzt. Dieser unterhält Steuerverbindungen zu den einzelnen LANE-Servern. Eine Nutzdatenverbindung kann direkt zu den anderen LEC aufgebaut werden. Daneben kann auch eine Broadcastsendung verschickt werden, indem einen Nachricht an den "Broadcast and Unknown Server" (BUS) geschickt wird, der diese Nachricht dann an alle Clients verteilt. Das ELAN wird von einem "LAN Emulation Configuration Server" konfiguriert. Daneben ist noch ein LAN-Emulations-Server installiert, der zur Registrierung einzelner Clients und zur Ermittlung von Adressen dient. Die Teilnehmer des emulierten LAN gehören alle zu einem Subnetz. Es besteht mittels LANE keine Möglichkeit, Datenpakete zwischen einzelnen LANE-Netzen zu routen. Auch die Garantie einer Dienstgüte ist bei LANE nicht möglich. MPoA Das "Multiprotocol Encapsulation over ATM"-Verfahren beseitigt die Nachteile der anderen beiden Verfahren hinsichtlich des Routings zwischen den Subnetzen. Zudem kann hier die Dienstegüte für einzelne Dienste garantiert werden. Das Netz besteht aus MPoA-Servern und MPoA-Clients. Die MPoA-Server dienen als virtelle Router, welche die Aufgabe haben, die Route zum Zielnetz zu ermitteln. Im Gegensatz zu den herkömmlichen Routern, die auch den Transport der Daten übernehmen, sind die Router hier allerdings nur für die Wegewahl zuständig. Die MPoA-Clients bauen mit den Informationen der MPoA-Server die gewünschte Verbindung auf, und übernehmen den eigentlichen Datentransport. Gegenüberstellung der Technologien Telefonnetz Paketnetz (Datex, X.25) Frame-Relay ATM schnelle Vermittlungsprin Leitungsvermittlu Paketvermittlu Zellvermittlu Paketvermittlu zip ng ng ng ng Fehlerkorrektur im Netz nein ja nein nein Paketgröße keine Pakete variabel variabel fest (53 Byte) mehrere Verbindungen gleichzeitig nein ja ja ja Durchsatz der Netzknoten sehr hoch mittel hoch sehr hoch Punkt-zu-Punkt-Verbindungen Bei größeren Entfernungen zwischen zwei Punkten kommen fast ausschließlich Glasfaserleitungen zum Einsatz. Sie bieten theoretisch mögliche Kapazitäten im TBit/sBereich. In der Boom-Phase des Internet um die Jahrteusendwende vergruben die Telekommunikationsunternehmen zehntausende Kilometer teures Glasfaserkabel in ganz Europa. Einige Energieversorger sind ins Geschäft mit den Lichtwellenstrecken eingestiegen und machen sich dabei ihre bestehende Infrastruktur zunutze. Der Bedarf blieb jedoch hinter den Erwartungen zurück. Quelle: TeleGeography Research, PriMetrica Inc, www.telegeography.com Angemietet wurden die Lichtwellenleiter von den Providern meist "dunkel" (Dark Fiber), also unbeschaltet. Wenn ein IP-Carrier neue Punkt-zu-Punkt-Strecken benötigt, kann er bei den Dark-Fiber-Versorgern Faser(n) anmieten. Der Dark-Fiber-Anbieter verlegt Kabel verschiedener Hersteller. In einem LEAF-Kabel (Large Effective Area Fiber) beispielsweise stehen 144 Fasern zur Verfügung. Mit welcher Kapazität der Carrier die Fasern beschaltet, liegt in seinem Ermessen. Die technische Ausstattung dafür richtet er selbst ein. Um eine flächendeckende Versorgung mit seinem Backbone-Netz zu gewährleisten, muss ein IP-Carrier zumindest in mehreren Großstädten vertreten sein. Dazu betreibt er dann "Points of Presence" (PoPs), die über Punkt-zu-Punkt-Glasfasertrassen verbunden sind. Von dort aus führen sie außerdem IP-Leitungen zu ihren Kunden. Außerdem arbeiten die IP-Carrier oft auch als Internet Service Provider. In den PoPs finden überdies noch Router von kleineren lokalen Carriern Platz, die mit dem großen Nachbarn IP-Daten austauschen. Die PoPs dienen innerhalb des Carrier_netzes als Datendrehscheibe. Um mehr Bandbreite aus einer Faser herhauszuholen, hat sich das "Dense Wavelength Division Multiplexing" (DWDM) durchgesetzt. Dabei werden mehrere Signale multiplex in den Lichtwellenleiter eingespeist. Pro Wellenlänge und Faser lassen sich heutzutage Bitraten von 1 GBit/s bis 40 GBit/s erreichen. Auf dem Weg durch den Lichtwellenleiter wird das Signal gedäpft. Etwa alle hundert Kilometer müssen Repeaterstationen stehen, die mit optischen Faserverstärkern ausgestattet sind. Je nach Bedarf wird bei dieser Gelegenheit auch noch eine Abzweigung eingerichtet, um regionale Kunden zu versorgen. In nahezu jedem modernen Weitverkehrsnetz kommt als Transporttechnik in Europa die "Synchrone Digitale Hierarchie" (SDH) und in den USA der fast deckungsgleiche "Standard Synchronous Optical Network" (SONET) zum Einsatz. Mit einem Zeitmultiplexverfahren werden Nutzdaten in Transport-Container ("Synchrone Transport-Module", STM) verpackt und mit einem Header versehen. Jedes Paket hat je nach Streckenbandbreite eine bestimmte "Byte-Breite", dauert aber stets 125 Nanosekunden. SDH gestattet den Verkauf von Kapazitäten je nach Bandbreite. Im Angebot stehen beispielsweise STM-1 (155 MBit/s), STM-4 (622 MBit/s), STM-16 (2,5 GBit/s) und STM-64 (10 GBit/s). In den USA bietet der SONET-Standard die gleichen Geschwindigkeitsstufen unter anderen Bezeichnungen: Eine STM-4-Leitung entspricht in SONET einer OC-12Verbindung ("OC = Optical Carrier"), STM-16 entspricht OC-48, usw. Diese Klassifizierung ist für die Provider wichtig. Inoffiziell teilen sich die Unternehmen in "Tier"-Klassen ein (englisch "tier" = Stufe, Rang). "Tier 1" bedeutet über weite Strecken mindestens STM-16, ein autonomes System mit nationaler oder globaler Ausdehnung und rege Beziehungen zu anderen Carriern. "Tier-2"-Anbieter sind deutlich kleiner, und "Tier-3"-Provider verfügen über ein lokal beschränktes Glasfasernetz. Der Betrieb von Austauschknoten oder Transitpunkten benötigt Hardware und Wartung. Daher haben sich weltweit einige große öffentliche Knoten etabliert. Europas größter Knoten ist der "London Internet Exchange"(LINX). An den Knoten können die Provider ihre Daten kostenneutral von einem Netz ins andere leiten ("Commercial Internet Exchange", CIX). Sie sorgen dabei selbst für die Zuführung zum CIX und die Kosten. National existieren kleinere Knoten, in Deutschland beispielsweise der INXS in München, der BCIX in Berlin und der HHCIX in Hamburg sowie der internationam bedeutende DeCIX in Frankfurt (betrieben vom Provider-Verband eco). 141 Carrier und Provider sind dort derzeit angebunden. IP-Routen zwischen London, Paris und Frankfurt Statistiken über die Datenmenge, die durch den DeCIX rauscht erhalten Sie unter http://www.decix.com/info/traffic.html. Weiterführende Informationen zu diesem Thema: Roland Kiefer, Peter Winterling: Optische Netze, Technik, Trends und Perspektiven, c't 2/03, S. 152 Holger Bleich, Jürgen Kuri, Petra Vogt: Zwischen Boom und Baustopp, Schweinezyklus beim Ausbau der Internet-Backbones, c't 21/03, S. 184 Irene Heinen: Daten-Disponenten, Neue Internet-Knoten verkürzen Wegstrecken auf dem Daten-Highway, c't 25/03, S. 92 Holger Bleich: Bosse der Fasern, Die Infrastruktur des Internet, c't 07/05, S. 88 Voice over IP Der klassische Telefondienst wird heute im Fernbereich, Mobilkommunikation sogar generell über digitale Paketvermittlungsnetzwerke abgewickelt. Die Konvergenz von Internet und Telekommunikation ist ein Trend von erheblicher Bedeutung für die gesamte Informatik. Unternehmen mit eigenen Computernetzen und/oder festen Internet-Anschlüssen gehen deshalb dazu über, diese Netzwerke auch zur internen bzw. externen Sprachkommunikation zu nutzen. Das verwendete Protokoll in der Anwendungsschicht heißt "Voice-over-IP" (VoIP). Durch "Internet-Telefon-Gateways" läßt sich das klassische Telefonnetz mit dem IPNetz verbinden, so daß von Telefon zu Telefon über das Internet telefoniert werden kann. Bekanntester, aber wenig populärer Ableger ist die Internet-Telefonie. Zwar läßt sich damit billig mit Gesprächspartnern in der ganzen Welt telefonieren, dies müssen lediglich ebenfalls über ein Internet-Telefon oder die entsprechende Software verfügen. Aber da der Datenstrom im Internet unberechenbar ist und es keine Zustellgarantie für Datenpakete gibt, leidet die Sprachqualität. Im eigenen Firmennetz hingegen lassen sich Netzlast, Traffic, Laufzeiten und Verbindungswege kontrollieren. Das ändert zwar nichts daran, daß IP an sich ausschließlich zur Datenübertragung entwickelt wurde. Das IP-Protokoll ist aber wesentlich flexibler, als es ihm viele zutrauen. Firmen können Ihren gesamten internen Telefonverkehr über ihr Intranet kostenlos abwickeln. Privatanwendern und Firmen erschließen sich Kostenersparnisse bei Telefonaten ins Ausland oder zum Mobilfunknetz. Voice over IP stellt die erste Stufe der Konvergenz von Daten und Sprache dar. Die Sprachintegration auf der flexibleren EDV-Infrastruktur auf der Basis von IP bietet sich an. Die Schritte zur integrierten Telefonie bzw. der vollständigen Vereinigung der Kommunikationsplattformen sind: 1. Gemeinsame Infrastruktur In die Telefonapparate werden Netzwerk-Schnittstellen eingebaut. Das Telefon ist somit in die gleichen Services- bzw. Netzumgebung eingebunden wie der PC 2. Gemeinsames Management Die Funktionen der Telefonzentrale werden auf einem PC-Server integriert. Die Verbindung ins öffentliche Telefonnetz erfolgt via Router. Die Sprache wird auf dem Firmennetz gegenüber dem Datenverkehr privilegiert. 3. Gemeinsame Anwendungen Die Interaktion zwischen Daten und Sprache ist nun möglich: Eine Telefonnummer kann mit einer Produkt- oder Kunden-Nummer oder einer Homepage verknüpft werden etc. 4. Mehrwertdienste Die Internet-Telefonie bietet zusätzliche Leistungsmerkmale bei PC-Nutzung z. B. Videoübertragung, Whiteboard oder gemeinsames Bearbeiten von Dokumenten. Bei geringeren Kosten bietet die integrierte Telefonie bessere Leistung und ist bereits sehr stark auf die kommenden Geschäftsanwendungen ausgerichtet. Die Vorteile sind u. a.: Mit dem Zusammenlegen der Infrastruktur und dem Management verringern sich nicht nur die Investitionskosten (nur eine Verkabelung, nur ein Kommunikationsanschluss pro Arbeitsplatz), sondern insbesondere auch die Betriebskosten. Der Unterhalt und Betrieb eines einzigen Service für Sprache und Daten auf einer einzigen Kommunikationsinfrastruktur schlägt gegenüber zwei getrennten Systemen positiv zu Buche. Die lokale Telefonie innerhalb eines Netzwerkes ist gratis. Die Infrastruktur stellt einen lokalen Telefonanbieter dar; es fallen für lokale Gespräche keine Kosten bei einem externen Carrier an. Die Auslastung des bestehenden Netzwerkes wird optimiert. Die LAN-Architektur bietet grösstmögliche Flexibilität für Anpassungen an die Unternehmensstruktur. Zu einem kompletten Voice-over-IP-System gehört zunächst einmal eine TK-Anlage auf Softwarebasis. Als Kommunikationszentrale verwaltet sie die Berechtigungen und Profile der Nutzer. Sie stellt Verbindungen her und sorgt für die richtige Zuordnung, ohne daß die eigentliche Kommunikation über sie läuft. Der IP-Gateway ist der Mittler zwischen IPTelefonie und der bisher genutzten Telefontechnologie wie etwa ISDN. Am Ende der Leitung im VoIP-Netz steht entweder ein IP-Telefon oder ein Computer mit Sound-Karte und IPTelefonie-Software. Für die Sprachein- und -ausgabe wird ein Headset verwendet. Herkömmliche Telefone lassen sich aber mit einer Adapterkarte ebenso computertauglich anschließen. Bei Datenpaketen kommt es nicht so sehr darauf an, in welcher Reihenfolge und mit welcher Verzögerung sie übertragen werden. Der Empfänger speichert die eingehenden Pakete und setzt sie wieder in der richtigen Reihenfolge zusammen. Wird ein Paket beschädigt oder geht verloren, wird es erneut gesendet. Das funktioniert nicht bei zeitsynchronen Daten wie Sprache oder Video. Deshalb wurden im neuen IP-Standard, IPv6, zwei neue Sub-Standards implementiert: das Reservation Protocol (RSVP) und das Realtime Transport Protocol (RTP). RSVP erlaubt zwei Endpunkten einer Verbindung, bestimmte Parameter auszuhandeln, darunter eine maximale Verzögerung (Delay) und einen minimalen Durchsatz. Das IP-Netz garantiert mittels verschiedener Verfahren, daß diese als "Flowspec" bezeichneten Quality of Service (QoS) eingehalten werden. Am sichersten funktioniert das unter Verwendung des "Guaranteed-Service"-Verfahrens. Hierbei wird anderer Traffic im Netz unterbunden, sobald dieser die Flowspec gefährden könnte. Diesem starren, aber effizienten Verfahren steht "Controlled Load" gegenüber. Hierbei dürfen auch andere Stationen IP-Pakete solange senden, wie eine mittels Flowspec ausgehandelte Verbindung keine Beeinträchtigung in den vorgegebenen Parametern feststellt. "Controlled Load" bietet also mehr Dynamik und lastet das IP-Netz insgesamt besser aus. Ein Vorurteil ist, daß für Voice over IP Anwendungen bestimmte IP-Pakete mit Sprachdaten mittels RSVP priorisiert werden. Das stimmt nicht. RSVP dient nur zum Aushandeln und Überwachen der Verbindungsparameter. IP-Sprachpakete werden zwar in den meisten IPNetzen von Routern und Switches vorrangig behandelt, allerdings ist diese Priorisierung meist herstellerabhängig und somit proprietär. Das birgt Probleme, wenn Netzkomponenten unterschiedlicher Hersteller im IP-LAN Voice-Daten transportieren soll. Dem soll RTP entgegenwirken. Jedes IP-Paket erhält seit IP 6 zusätzlich einen Zeitstempel (Time Stamp) mit der Entstehungszeit sowie eine Folgenummer (Sequence Information). Dies erlaubt es dem Empfänger, Pakete nicht nur in richtiger Reihenfolge, sondern auch zeitsynchron zusammenzusetzen. Das Real Time Control Protocol (RTCP) koordiniert zudem Sender- und Empfängerprotokolle und sorgt für Monitoring und Management von Echtzeitverbindungen. Außerdem definiert RTP die Kodierung von Audiosignalen nach G.711 sowie G.723. Hierbei handelt es sich um Codecs (Coding/Decoding), die von der ITU zur analogen und digitalen Verschlüsselung von Sprache in Telefonnetzen definiert wurden. G.711 entspricht in etwa dem ISDN-Standard, Sprachdaten werden mit einem Datenstrom von 64 kbit pro Sekunde übertragen. Für Voice over IP kommt G.711 jedoch nicht zum Einsatz, da sich die Datenlast durch zusätzliche Komprimierung und bessere Abtastverfahren auf bis zu 9,6 kbps drücken läßt (dies entspricht dem GSM-Standard). Verbreitet ist vor allem das CELP-Verfahren (Codebook Excited Linear Predictive Coding), das mit einem komplizierten mathematischen Modell der menschlichen Sprache arbeitet. Als Ergebnis entsteht ein Datenstrom von 16 kbit pro Sekunde, der Telefonate in ISDN-Sprachqualität überträgt. Kombiniert mit Dualrate Speech Coding, definiert im G.723-Standard, genügt sogar ein Datenstrom von nur 5,3 kbps. Außer der geringeren Netzlast bringt dies den Vorteil, daß sich mehr Pakete puffern lassen, ohne die Echtzeitbedingung zu gefährden. Die Qualität der Sprachübertragung im IP-Netz gewinnt also, je kleiner die Datenrate für einen Sprachkanal ist. Ein weiterer wichtiger Standard für Voice over IP kommt vom Videoconferencing. H.323 umfaßt sowohl eine Codec-Technologie (wie G.723) wie auch die Signalisierung und Verbindungssteuerung für Videokonferenzsysteme. Für IP-Telefonie wurden Teile des H.323Standards übernommen. Über eine TCP-Verbindung wird zwischen Sender und Empfänger das Signalisierungsprotokoll H.245 ausgehandelt. Dies zeigt eingehende Rufe an und übermittelt Statusinformationen. Die Datenübertragung selbst erfolgt über UDP. TCP-Pakete werden dadurch bei jedem Hop auf Fehler kontrolliert und gegebenenfalls korrigiert beziehungsweise zurückgewiesen. UDP läßt diese Kontrolle aus, UDP-Pakete erreichen den Empfänger also schneller. Dafür muß der sich selbst um Fehlerkorrektur bemühen. Voice over IP kodiert hierzu entweder im selben Paket oder im Folgepaket Redundanz, aus der sich ein beschädigtes Paket beim Empfänger reparieren läßt, womit ein erneutes Senden defekter IP-Pakete vermieden wird. Zusätzlich erfolgt die Verbindungssteuerung einer Sprachübertragung im IP-Netz gemäß H.323 mit einem Q.931-konformen Signalisierungskanal. Dieser steuert die Sprachverbindung und ist für Funktionen wie etwa Makeln oder Rufnummernübermittlung zuständig. Um Voice over IP im LAN einzuführen, müssen sämtliche Switches und Router die entsprechenden Protokolle von IPv6 auf dem ISO/OSI-Level 3 unterstützen. Wichtig sind vor allem die Verarbeitung von RTP sowie die Unterstützung von RSVP. Für Konferenzen und Videodaten (die mittels der selben Verfahren wie Sprache übertragen werden), wird außerdem das relativ neue IP-Multicast genutzt. Dabei kopiert eine Netzkomponente einen eingehenden Datenstrom eigenständig und sendet ihn an alle Empfänger weiter. Dies vermeidet zusätzliche Datenkanäle zwischen dem Ursprung der Übertragung und jedem Empfänger. Statt dessen wird der Datenfluß an beliebiger Stelle im Netz dupliziert. Mittlerweile gibt es erste Ethernet-Telefone. Diese werden statt an eine Telefondose an eine RJ-45-Buchse eines Ethernet-Hubs angeschlossen. Alternative hierzu bieten sich CTI oder Wandlerkarten an. Auch etliche DSL-Router ermöglichen den Anschluß von herkömmlichen Analogtelefonen oder dienen sogar als Telefonanlage. Aber auch die Telefonie direkt am PC mit einem Headset und passender Software ist möglich (sogenanntes Softphone). VoIP läuft so zuverlässig wie die Internetverbindung selbst. Generell besteht damit kein Unterschied zur Festnetzanschluss. Auch können Gespräche in die Fest- und Mobilfunknetz geführt und entgegengenommen werden. Dazu erhalten Nutzer beim VoIP-Provider kostenlos ihre Ortsrufnummer, der auch die Notrufe 110 und 112 bereitstellt. Bei Voice-over-IP (VoIP) bestehen Sicherheitsmängel, die sich aus der Internetnutzung ergeben. Telefonate von VoIP-Nutzern lassen sich innerhalb lokaler Netze mit Hilfe von Software-Tools (Paket Sniffern) abhören und Rufnummern ausspionieren. VoIP-Adapter und -Telefone sind empfindlich gegenüber Hacker-Attacken, insbesindere Denial-of-ServiceAngriffen. Generell sollte auch die Konfigurationsoberfläche der VoIP-Hardware durch ein Passwort geschützt werden. Eindringlinge könnten sonst bestehende Guthaben abtelefonieren und eingehende Anrufe entgegennehmen. Im Gegensatz zur SPAM-Problematik bei E-Mail ist unerwünschte Werbung über VoIP, sogenannter SPIT, derzeit noch kein Problem. Gegenüber E-Mail ist der VoIP-Bereich nicht offen zugänglich, sondern abgeschottet. Realisiert wird dies durch die genaue Zuordnung der VoIP-Rufnummern. Jeder Nutzer ist damit dem VoIP-Provider bekannt. Anrufe, die außerhalb dieser vertrauenswürdigen Netze initiiert werden, sind nicht kostenlos und deshalb uninteressant für SPITTER. Ein Problem stellt die Signalisierung zwischen den einzelnen Telefonanbietern dar, die gewissermaßen "auf Vertrauensbasis" abläft. Überwindet ein Hacker die Signalisierungsprotokolle, kann er so ziemlich alles machen was er will. Powerline Communications die Stromleitung ist das Netzwerk Powerline Communications erlaubt die Obertragung von Daten mit Geschwindigkeiten von mehr als einem Mbit/s bis zum Endbenutzer über das Niederspannungs-Energieverteilnetz. Mit dieser Übertragungstechnik wird eine echte Alternative für die sogenannte "Letzte Meile" geschaffen. Mit der Powerline Communications Systemlösung von Siemens können Energieversorgungsunternehmen (EVU) und Stadtwerke vor allem den privaten Stromkunden neue Dienste wie beispielsweise "Internet aus der Steckdose" sowie Energie- und Mehrwertdienste auf eigener Infrastruktur anbieten. Das Stromverteilnetz ist die weltweit größte flächendeckende Kabelinfrastruktur bis in jeden Haushalt. Die bisher ausschließlich für die Energieversorgung genutzte Verkabelung ist im deregulierten Telekommunikationsmarkt der Schlüssel für den direkten Zugang zum privaten Kunden. Die EVUs können ihr existierendes Stromnetz für neue Dienstangebote nutzen und sich dadurch neue Einnahmequellen erschließen. Auf Basis der PLC Kommunikationsinfrastruktur werden EVUs weitere Anwendungen zur Effizienzsteigerung (z.B. Lastmanagement) und zusätzliche Dienste (z.B. Security, Fernüberwachung) entwickeln und so ihre Wettbewerbsposition in deregulierten Energiemärkten verbessern. Im Unterschied zu anderen Lösungsansätzen ermöglicht die Powerline Communications Lösung von Siemens die Nutzung des Niederspannungsnetzes bis zur Steckdose im Haushalt. Über das Stromnetz können zusätzlich zur Energie gleichzeitig Daten und Sprache übertragen werden. Bitraten von mehr als einem Mbit/s machen aus jeder Steckdose einen leistungsfähigen Kommunikationsanschluß. In die Lösung ist ein intelligentes Bandbreitenmanagement implementiert, das ermöglicht, den Benutzern je nach Bedarf Bandbreite zur Verfügung zu stellen. Siemens entwickelte für Powerline Communications ein neues, für das besondere Übertragungsverhalten des Stromnetzes optimiertes Übertragungsverfahren. Das Verfahren (Orthogonal Frequency Division Multiplexing, OFDM) ermöglicht hohe Datenraten selbst bei starken Störungen auf dem Energienetz. Die Siemens AG, Bereich Information and Communication Networks und der Schweizer Hersteller von Telekommunikationsausrüstung Ascom wollen die Entwicklung der breitbandigen Powerline Communications (PLC)-Technik für den Einsatz auf dem Niederspannungsnetz gemeinsam weiter vorantreiben. Beide Unternehmen führen Gespräche, um offene Fragen für die Regulierung zu klären und Spezifikationen für gemeinsame Schnittstellen zu erstellen. Heute gibt es bereits erste Feldversuche und Labormuster für die neue Technik. Aus Kundensicht sind die derzeit auf dem Markt angebotenen proprietären Lösungen jedoch nicht zufriedenstellend. Denn ein breiter Einsatz dieser PLC-Technik wird heute weniger durch den noch frühen Entwicklungsstand, als durch die nicht vorhandene Kompatibilität der Lösungen behindert. HomePlug: PC-Vernetzung über die Stromleitung "Power-Line-Communications" ist dezeit relativ tot, aber seit 2002 gibt es etwas Neues, die "Home-Plug-Technologie" wieder. Mit der Powerline-Technologie hat Home-Plug wenig zu tun. Jedoch haben die technischen Grundprinzipien eine neue und sinnvole Anwendung gefunden: Rechner über existierende 230-V-Leitungen im Haus miteinander zu vernetzen. Etliche Unternehmen bieten entsprechende Adapter an, die alle ähnlich arbeiten. Bei der Develo AG heißt das Teil "Micro-Link-DLAN" und sieht aus wie ein Steckernetzteil. Die Home-Plug-Technologie nutzt die bestehenden 230-V-Leitungen im Haus für die Datenübertragung. Mit einer maximalen Datenübertragungsrate von 14 Mbit/s und synchronem Up- und Download ist Home-Plug auch recht flott. In der Praxis lassen sich - je nach Leitungsqualität Bandbreiten zwischen 5 Mbit/s und 7 Mbit/s gewährleisten, was z. B.für die Verlängerung des DSL-Anschlusses in jedes Zimmer eines Hauses völlig ausreicht. Je nach Dämpfungsfaktor der Elektroinstallation lassen sich mit MicrolinkDLAN (Direct-LAN) Entfernungen bis 200 m überbrücken und beliebig viele Computer anschließen. Zusätzliche Geräte sind nicht notwendig, da die Phasenkopplung durch ein "Übersprechen" stattfindet. Die Installation der DLAN-Komponenten gestaltet sich einfach: Über den DLAN-Adapter verbindet man eine Netzkomponente an die nächstgelegene Steckdose, und sofort lässt sich jede andere beliebige Stromsteckdose im Haus als Netzwerkzugang verwenden. Ein Ethernet- oder ein USB-Kabel - je nach Modell - koppelt den PC an einen weiteren Micro-Link-DLAN-Adapter, dessen Stecker die Verbindung zum Heimnetz herstellt. Auf Grund automatischen Frequenzwechsels unterdrückt das System Einflüsse in der Datenübertragung durch aktive und Störungen ins Stromnetz sendende Haushaltsgeräte wie Waschmaschinen oder Kühlschränke. Im Unterschied zu drahtlosen Funknetzen wirkt bei HomePlug der Stromzähler im Haus als Sperre gegen unerwünschten Zugriff von außen (Signal wird stark gedäpft). Zusätzliche Sicherheit bietet eine leistungsfähige DES-Verschlüsselung (Datenverschlüsselung in Übertragungssystemen). Die Geräte sind kompatibel zum Home-Plug-Standard 1.0. Im vergangenen Jahr verabschiedete die Home-Plug-Powerline-Alliance diesen Standard, zu deren weltweit über 100 Mitgliedern unter anderem Compaq, Intel, Motorola, AMD, Cisco Systems, 3Com, Panasonic und Texas Instruments gehören. Die von der DLAN-Technik verwendeten Frequenzen liegen im Bereich von 4 MHz bis 21 MHz, somit werden die Rundfunkbänder nicht gestört (520 kHz bis 1605 kHz = Mittelwelle; 150 kHz bis 285 kHz = Langwelle; 87,20 MHz bis 108,00 MHz = UKW). Die Technik basiert auf dem Home-Plug-Standard, in dem die Sendepegel speziell in einigen Amateurfunkbändern abgesenkt sind. "Abgesenkt" heiß aber, daß das Signal ist in der Nähe durchaus noch feststellbar ist, teilweise sogar in störender Stärke. Übrigens betrifft die Absenkung nur die klassischen KW-Amateurfunk-Bänder 40m, 20m und 15m. Die seit einigen Jahren im Bereich 4 bis 21 MHz zusätzlich erlaubten Blöcke (30m und 17m) sehen keine Absenkung. Wenn sich DRM (www.drm.org) weiter ausbreitet, dürften sich auch die neuen Kurzwellendigitalrundfunkhörer über PLC ärgern - ebenso die Minderheit der Fernempfangsfreaks. Obwohl Home-Plug von der Leistungsfähigkeit herkömmlicher Ethernet-Verbindungen noch ein gutes Stück entfernt ist, stellt es für viele Gebiete eine interessante Alternative dar. Auch gegenüber Wireless-LAN bietet diese Technologie einige Vorteile. In der Praxis hängt die erreichbare Übertragungsgeschwindigkeit allerdings vom Zustand der Elektroinstallation im Haus und der Ausstattung der Steckdosen ab. Hier ist dann das Know-how des Elektroinstallateurs gefragt. Funk-LAN-Technologie Die Möglichkeit, Computer drahtlos zu vernetzen, ist auf den ersten Blick verlockend, konnte sich aber im Vergleich zu kabelgebundenen Lösungen bisher nur für einige Spezialaufgaben durchsetzen. Das hat vor allem folgende Gründe: Drahtlose Netzwerk-Adapter sind erheblich langsamer als herkömmliche Netzwerkkarten. Selten wird eine Geschwindigkeit von mehr als 22 MBit/s erreicht, meist erheblich weniger. Innerhalb der Reichweite (je nach Gebäudestruktur etwa 10...50 m) teilen sich die drahtlos vernetzten Computer die Übertragungsleistung. Die Netto-Geschwindigkeit sinkt dadurch weiter. Die Kosten für drahtlose Adapter liegen über jenen für konventionelle 10-MBit/sNetzwerkkarten. Bei den meisten Lösungen sind zusätzliche teure "Access Points" nötig, die die Schnittstelle zwischen einem Kabel-Netzwerk und drahtlosen Workstations darstellen. Die ersten "Radio LANs" arbeiteten überwiegend mit dem gegenüber Störungen relativ unempfindlichen Spread-Spectrum-Verfahren, bei dem die Daten auf viele Trägerfrequenzen verteilt werden, typisch auf einen Bereich von 20 MHz bei einer Datenrate von 2 MBit/s. Das Spreizen des Signals erfolgte entweder mit dem Zufallssystem Direct Sequence Spread Spectrum (DSSS) oder durch das zyklische Springen zwischen mehreren Frequenzbändern (FHSS, Frequency Hopping Spread Spectrum). Sicherheitshalber werden die Daten verschlüsselt. Technisch entsprechen diese Netze einem Bus-System ohne Kabel oder die SchnurlosStationen bilden zusammen eine Bridge. Seit 1997 werden Funk-LANs mit 1 oder 2 MBit/s im 2,4-GHz-Bereich mit der Norm IEEE 802.11 standardisiert. Als Sendeleistung ist maximal 1 Watt vorgesehen. Die Reichweite innerhalb von Gebäuden beträgt etwa 50 m, außerhalb davon einige hundert Meter. Neuere Entwicklungen erreichen bei 19 GHz bis zu 10 MBit/s, allerdings bei deutlich kleinerer Reichweite. Mit IEEE 802.11 (Teil der Standardisierungsbemühungen des IEEE-802-Komitees, zuständig für lokale Netzwerktechnologien) ist 1997 ein erster Standard für Funk-LAN-Produkte geschaffen worden. Mitte 1997 wurde der erste IEEE-802.11-Standard (2 Mbit/s Funk-LANTechnologie) veröffentlicht, welcher dann, im Oktober 1999, mit IEEE 802.11b (High Rate) um einen Standard für 11-Mbit/s-Technologie erweitert wurde. Der IEEE-802.11-Standard beschreibt die Übertragungsprotokolle bzw. Verfahren für zwei unterschiedliche Arten, FunkNetzwerke zu betreiben. Der 802.11-Standard basiert auf CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance). Der WLAN Standard ist ähnlich aufgebaut wie der Ethernet-Standard 802.3 (CSMA/CD), versucht aber, Kollisionen zu minimieren. Der Grund liegt darin, daß z.B. zwei mobile Einheiten zwar von einem Access Point erreicht werden, sich aber gegenseitig nicht "hören". Damit kann die wirkliche Verfügbarkeit des Access Points nicht in jedem Fall erkannt werden. Wie bei CSMA/CD hören alle teilnehmenden Stationen den Verkehr auf dem Funkkanal mit. Wenn eine Station übertragen will, wartet sie, bis das Medium frei ist. Danach wartet sie noch eine vorbestimmte Zeitperiode (DIFS) plus einer zufällig gewählten Zeitspanne, bevor sie ihren Frame übertragen will. Auch in dieser Zeitspanne (Wettbewerbsfenster) wird der Funkkanal weiter überwacht. Wenn keine andere Station innerhalb des Wettbewerbsfensters vor dem gewählten Zeitpunkt mit der Übertragung beginnt, sendet die Station ihren Frame. Hat aber eine andere Station innerhalb der Wartezeit mit der Übertragung begonnen, wird der Zeitzähler angehalten und nach der Übertragung der anderen Station weiter benutzt. Auf diese Weise gewinnen Stationen, die nicht übertragen durften, an Priorität und kommen mit einer erhöhten Wahrscheinlichkeit in den nächsten Wettbewerbsfenstern zum Zug. Eine Kollision kann nur entstehen, wenn zwei oder mehrere Stationen den gleichen Zeitslot auswählen. Diese Stationen müssen die Wettbewerbsprozedur erneut durchlaufen. Funknetz-Szenarien Das erste Funk-Netz-Szenario beschreibt die Kommunikation in einfachen "Ad-hoc"Netzwerken. Hierbei sind mehrere Arbeitsrechner in einem begrenzten Sendebereich miteinander verbunden. Zentrale Übermittlungs- bzw. Kontrollsysteme, sogenannte "AccessPoints" sind bei diesem Anwendungsfall nicht vorgesehen. Ein derartiges "Ad-hoc" Netzwerk könnte zum Beispiel zwischen den tragbaren Computersystemen während einer Besprechung in einem Konferenzraum aufgebaut werden. Im zweiten Anwendungsfall, dem sogenannten "Infratruktur-Modus", kommen "AccessPoints" zum Einsatz. Bei diesen Geräten handelt es sich um Netzwerkkomponenten, welche die Kommunikation innerhalb eines Funk-LANs, zwischen einzelnen Funk-LAN-Zellen und die Verbindung zwischen Funk-LANs und herkömmlichen LANs (Kabel basierend) ermöglichen und kontrollieren. Access-Points regeln die "gerechte" Verteilung der zur Verfügung stehenden Übertragungszeit im Funk-Netzwerk. Des Weiteren ermöglichen diese Komponenten mobilen Arbeitsstationen das unterbrechungsfreie Wechseln (Roaming) von einer Funk-LAN-Zelle in die Nächste. Verschiedene Systeme können mittels einer speziellen Frequenzwahl bis zu acht unterschiedliche Kanäle im Frequenzband alternativ oder teilweise auch gleichzeitig nutzen. Durch dieses Verfahren können in bestimmten Fällen z. B. auch durch Störungen belastete Frequenzen umgangen werden, um so die Übertragung zu sichern. Des weiteren können durch den Einsatz mehrere Accesspoints parallele Funkzellen auf unterschiedlichen Frequenzen aufgebaut werden und so die Gesamtübertragungskapazität eines WLANs erweitern. Die dadurch entstehende Möglichkeit unterschiedliche Frequenzen zur Datenübertragung mit getrennten Benutzergruppen zu nutzen, kann den Datendurchsatz in einem solchen Funknetz vervielfachen, da die einzelnen Frequenzsegmente jeweils die volle Bandbreite für den Datenstrom zur Verfügung stellen. Eine wichtige Frage, die sich im Hinblick auf den Einsatz von Funk-Technologie immer wieder stellt, ist die mögliche gegenseitige Störung von elektronischen Geräten (nicht nur von Funk-Sendern und Empfängern). Oftmals werden sogar Bedenken zu einem möglichen Gesundheitsrisiko durch die Nutzung von auf Funk basierenden Produkten geäußert. Auf Funk basierende Geräte müssen einer Vielzahl von Standards und strengen gesetzlichen Richtlinien entsprechen, die sicherstellen, daß die Beeinflussung zwischen verschiedenen auf Funk basierenden Geräten und auch anderen elektronischen Geräten entweder unmöglich ist, oder die festgelegten Grenzwerte nicht überschreiten, welche die internationalen und nationalen bzw. europäischen Standardisierungs-Gremien festlegen. Alle in Deutschland zugelassenen WLAN Systeme benutzen ein offiziell für industrielle und andere Zwecke reserviertes ISM-Frequenzband (Industrial Scientific Media) zwischen 2,400 und 2,483 GHz und übertragen durch Nutzung eines Teils der darin verfügbaren Frequenzen mit Datenraten von bis zu 11 Mbps (802.11b) oder 22 Mbps (802.11g). Der Standard 802.11a beschreibt Systeme, die im 5-GHz-Band betrieben werden und Brutto-Datenraten bis zu 54 Mbps ermöglichen. Im 5-GHz-Band steht ein größeres Frequenzband zur Verfügung - und damit mehr Kanäle. Wichtig ist auch, daß dieses Band ausschließlich für WLAN reserviert ist. Die Kanäle von 802.11b und ihre Frequenzen. Kanal o o o o o Mittenfrequenz (GHz) Kanal Mittenfrequenz (GHz) 1 2.412 8 2.447 2 2.417 9 2.452 3 2.422 10 2.457 4 2.427 11 2.462 5 2.432 12 2.467 6 2.437 13 2.472 7 2.442 14 2.484 Die Abstufung erfolgt in 5 MHz Schritten (ausgenommen Kanal 14). In den USA sind die Kanäle 1 - 11 verfügbar. In Europa sind die Kanäle 1 - 13 verfügbar. In Frankreich sind die Kanäle 10 - 13 verfügbar. In Japan ist Kanal 14 verfügbar. Da Funk-LAN-Produkte speziell für den Einsatz in Büros und anderen Arbeitsumgebungen entwickelt wurden, senden sie auch mit einer entsprechend niedrigen, gesundheitlich unbedenklichen Leistung. Diese Leistung liegt unter einem maximalen Wert von 100 mW und damit z. B. signifikant unter der Sendeleistung von gebräuchlichen GSM Telefonen (ca. 2 W bei Geräten GSM Klasse 4, d. h. Frequenzbereich 880-960 MHz). Erhöhte Gesundheitsrisiken konnten deshalb beim Umgang mit Funk-LANs im 2.4 GHz Frequenzband nicht festgestellt werden. Die größten Bedenken gelten üblicherweise der Technologie Funk selbst. Aber unberechtigtes "Mithören" erweist sich in der Praxis sogar als wesentlich schwieriger und aufwendiger als bei herkömmlichen auf Kupferkabeln basierenden Netzwerken. Sogenannte "Walls" sichern den Datenverkehr mittels eines Verfahrens zur Bandspreizung (Spread-Spectrum, SS) gegen Abhören und Störungen, dieses Verfahren entspricht einer komplexen Kodierung, die ein Abhören schon durch die eingesetzten technischen Prinzipien sehr schwer macht. Alle z. Zt. bekannten zugelassenen WLAN Systeme setzen zwei verschiedene Techniken ein, das sogenannte Direct Sequence SS (DSSS) und das Frequency Hopping SS (FHSS) Prinzip. Direct Sequence SS verschlüsselt jedes Bit in eine Bitfolge, den Chip, und sendet diesen auf das Frequenzband aufgespreizt. Für unbefugte Lauscher verschwindet das Signal dadurch im Hintergrundrauschen, erst der autorisierte Empfänger kann es wieder ausfiltern. Das DSSS System ist unempfindlicher gegen Störungen und hat sich als Lösung mit den meisten installierten Geräten in diesem Markt durchgesetzt. Beim Frequence Hopping vereinbaren Sender und Empfänger während des Verbindungsaufbaus eine Folge, nach der einige Male pro Sekunde die Sendefrequenz umgeschaltet wird. Ein nicht autorisierter Zuhörer kann diesen Sprüngen nicht folgen, die Synchronisation zwischen Sender und Empfänger bedeutet jedoch zusätzlichen Ballast (Overhead) in der Datenübertragung. Um das komplette Signal erfolgreich empfangen und interpretieren zu können, muß der Empfänger den korrekten Entschlüsselungsalgorithmus kennen. Daten während der Übertragung abzufangen und zu entschlüsseln wird dadurch recht schwierig. Die Sicherheit von Funk-LAN-Produkten beschränkt sich selbstverständlich nicht nur auf die Wahl von DSSS als Übertragungsverfahren. So sieht der IEEE-802.11-Standard optional auch verschiedene Methoden für Authentisierung und Verschlüsselung vor. Unter Authentisierung versteht man dabei all jene Mechanismen mit denen überprüft bzw. kontrolliert wird, welche Verbindungen im Funk-LAN zulässig sind. Mit der zusätzlichen Verschlüsselungstechnik WEP (Wired Equivalent Privacy), welche auf dem RC4-Verschlüsselungsalgorithmus basiert, wird ein Sicherheitsniveau erreicht, welches dem herkömmlicher LAN-Technologien mehr als entspricht. Als weitere sehr flexible Sicherheitsfunktion, erweisen sich auch Filter auf MAC-Adress-Ebene, die im Access-Point konfiguriert werden können. Über diese Filter kann die Kommunikation über den Access-Point sehr wirkungsvoll gesteuert werden. Funk-LAN-Technologie und -Produkte ergänzen in idealer Weise die "klassischen" LANLösungen. Die Bandbreite wird jedoch dann zu einem entscheidenden Faktor beim Einsatz von Funk-LAN-Installationen, wenn eine große Anzahl von Arbeitsstationen angebunden werden soll und der Einsatz sehr "bandbreitenintensiver" Multimedia-Anwendungen geplant ist. Man sollte nicht übersehen, daß Funk-LAN-Technologie sich wie jedes andere "SharedMedium" verhält und damit sehr ähnlich zu Ethernet-Lösungen ist. Ein weiterer wichtiger, zu beachtender Aspekt bei Planung und Einsatz von Funk-LANLösungen, liegt in den oftmals schwer einschätzbaren Umgebungseinflüssen, welche die Übertragungsqualität und Übertragungsreichweite vermindern können. So können Reichweite und Qualität der Übertragung nicht nur durch die Positionierung und Anordnung der Arbeitsstationen und Access-Points beeinflusst werden, sondern es entsteht auch eine, zum Teil gravierende, Beeinträchtigung durch die zu durchdringenden Hindernisse (Ziegelwände, Stahlbeton, etc.). Für die Realisierung eines Funk-Lan stehen zwei Betriebsarten zur Verfügung: Im Infrastructure Mode hingegen vermittelt eine spezielle Basisstation, Access Point genannt, zwischen den Clients. Er dient zum einen als Bridge zum drahtgebundenen Netz, vermittelt also Pakete zwischen den Netzen hin und her. Zum anderen arbeitet ein Access Point als Repeater, das heißt er empfängt die Pakete der Stationen und leitet sie an andere weiter - dabei sinkt natürlich der Durchsatz. Letztlich kann ein Access Point die Reichweite verdoppeln, wenn er zentral aufgestellt ist: Er lässt zwei Stationen miteinander kommunizieren, die so weit voneinander entfernt stehen, daß sie sich im Ad-hoc-Modus nicht "sehen" könnten. Bei der Raumabdeckung ist mit einem Radius von rund 50 Metern zu rechnen, innerhalb dessen sich die mobilen Stationen um einen Access-Point bewegen können. Im Ad-hoc-Modus kommunizieren die Stationen direkt miteinander. Im Grunde genommen handelt es sich um Punkt-zu-Punkt-Verbindungen, da aber jeder Rechner mehrere dieser Verbindungen unterhalten kann, spielt das praktisch keine Rolle. Mit einer Ausnahme: Es ist möglich, daß weit voneinander entfernte Stationen einander nicht "sehen" können, beide sehr wohl aber eine dritte Station dazwischen. Der Adhoc-Modus ist letztlich am besten geeignet, wenn man gar kein großes Funknetz aufbauen will, sondern nur zwei Netze oder Systeme verbinden will. Der Ad-hoc-Modus hat aber Haken: Viele Hersteller haben dieser Betriebsart anfangs wenig Aufmerksamkeit gewidmet und statt der verabschiedeten Standards proprietäre Verfahren implementiert. So kann es sein, daß die Karten zweier Hersteller im Adhoc-Modus nicht zueinander finden. Zur Inbetriebnahme eines Ad-hoc-Netzes muß man auf allen Clients einen einheitlichen Namen für das Funknetz einstellen. Bei einem Netz mit Access Point reicht es hingegen, dort den gewünschten Namen einzutragen; bei der Einstellung "any" auf den Clients erhalten diese automatisch den Namen übermittelt. Unter Umständen kann es im Ad-hoc-Netz Sinn machen, den Kanal vorzugeben, auf dem die Stationen funken sollen; im Normalfall finden sie aber selbstständig einen gemeinsamen Kanal. Eine gute Hilfestellung bietet die Software, die viele Hersteller ihren Funkkarten beilegen. WLAN-MIni-PCI-Karte und Adapter für den PCI-Bus im PC. Die Funk-LAN-Standards Ein gravierender Nachteil der ersten WLAN-Standards ist die geringe Datenrate von 11 MBit/s. Selbst bei guten Empfangsbedingungen ist nur etwa die Hälfte für Nutzdaten einsetzbar. Abhilfe versprach zunächst die Verdoppelung auf 22 MBit/s. Diese Erweiterung war aber proprietär. IEEE 802.11a ist mit nominell 54 MBit/s noch schneller, die Geräte arbeiten jedoch im 5-GHz-Bereich - bei einem Wechsel muß die gesamte Infrastruktur ausgetauscht werden. Zudem verschlechtert sich mit der doppelten Frequenz die Reichweite. Dagegen haben sich die Standards der Reihe IEEE 802.11 etabliert. Geräte nach dem Standard IEEE 802.11g sind abwärtskompatibel zu 802.11b und senden ebenfalls im 2,4GHz-Bereich, verwenden gegenüber der 11-MBit/s-Technik jedoch mehrere Kanäle und kommen so auf eine Bruttodatenrate von 54 MBit/s. So lassen sich auf den 13 WLANKanälen aber nur vier 802.11g-Netze am gleichen Ort nebeneinander betreiben. Fremde Netze nach 802.11b im Empfangsbereich können die 54-Bit/s-Technik jedoch ausbremsen: Im ungünstigsten Fall verteilen sich die langsamen Netze quer über die Kanäle, sodass keine Bündelung für die Breitbandtechnik mehr möglich ist. Weitere Störfaktoren sind BluetoothGeräte, auch sie arbeiten im 2,4-GHz-Bereich. An exponierten Standorten im Stadtgebiet können Access Points nach IEEE 802.11g wohl kaum ihre Leistung ausspielen, es gibt einfach zu viele langsame WLAN-Netze. Für den Betrieb in Gebäuden ist die Technik aber durchaus interessant: Störungen von außen gibt es hier kaum. Eigene Access Points nach 802.11b werden bei Kanalüberschneidungen umkonfiguriert oder kurzerhand ersetzt, die Workstations merken wegen der Abwärtskompatibilität von IEEE 802.11g zu 802.11b nichts davon. Die bisherigen Standards zeigt folgende Tabelle: Im einzelnen besitzen die Standards folgende Eigenschaften: IEEE 802.11 und IEEE 802.11 b Die erste Version des WLAN-Standards wurde 1997 unter der Nummer IEEE 802.11 verabschiedet und erlaubt Datentransferraten von 1 Mbit/s und 2 Mbit/s im lizenzfreien 2,4GHz-ISM-Band (Industrial, Scientific, Medical). Im Jahr 1999 folgte die Erweiterung IEEE 802.11 b, die Datenübertragungsraten bis 11 Mbit/s im 2,4-GHz-ISM-Band ermöglichte. IEEE 802.11 a Ebenfalls im Jahr 1999 wurde der im 5-GHzBand arbeitende Standard IEEE 802.11 a verabschiedet. Dieser Standard nutzt als Modulationsverfahren OFDM (Orthogonal Frequency Division Multiplex). Der genutzte Frequenzbereich ist grundsätzlich für den WLAN-Bereich reserviert, jedoch nutzen Militär und Flugsicherung ebenfalls diesen Bereich. Daher kann dieser Standard in Europa nur innerhalb von Gebäuden und mit verringerter Sendeleistung eingeschränkt eingesetzt werden. Auf Grund des Modulations verfahrens sind aber Übertragungsraten von bis zu 54 Mbit/s möglich. IEEE 802.11 e Dieser Standard beschreibt einen erweiterten Kanalzugriff, der eine Priorisierung verschiedener Verkehrsklassen und eine durch den Access-Point gesteuerte Kanalvergabe erlaubt. Mit dem Standard IEEE 802.11 e wird das Konzept des "Quality-of-Service", also die Dienstgüte, unterstützt. Besonders interessant ist dieser Standard für Echtzeitanwendungen wie beispielsweise Voice over IP. IEEE 802.11 g Beim Standard IEEE 802.11 g handelt es sich um die Nutzung des OFDMModulationsverfahrens im Frequenzbereich von 2,4 Ghlz. Da der IEEE 802.11 g-Standard abwärtskompatibel zum älteren IEEE-802,11 b-Standard ist, hat sich der neue Standard sehr schnell verbreitet und wird in den nächsten Jahren den Standard IEEE 802.11 b ablösen. Eine Datentransferrate von 54 Mbit/s wird erreicht, jedoch ist die Anzahl der benötigten Antennen relativ hoch, damit ein voller Datendurchsatz gewährleistet werden kann. IEEE 802.11 h Der Standard IEEE 802.11 h bietet 54 Mbit/s Datenübertragungsrate und arbeitet im 5-GHz Bereich. Dieser Standard ergänzt den Standard IEEE 802.11 a um die Funktionalitäten DFS (Dynamic Frequency Selection) und TPC (Transmit Power Control). Damit fallen die Einschränkungen des Standards IEEE 802.11 a fort, und das 5-GHz-Band kann so mit auch im Außenbereich genutzt werden. IEEE 802.11 i Die Arbeitsgruppe für WLAN-Sicherheit hat im Jahr 2004 den Standard IEEE 802.11 i verabschiedet. Bereits seit dem Jahr 2002 gab es mit WPA (WiFi Protected Access) übergangsweise einen Standard, der als sicher galt und die wichtigsten Sicherheitslücken von WEP (Wired Equivalent Privacy) schloss. Der WPA-Standard bietet gegenüber WEP besseren Schutz durch dynamische Schlüssel, die auf dem TKIP (Temporal Key Integrity Protocol) beruhen und abwärtskompatibel sind. Weiterhin wird durch die NutzerAuthentifizierung mittels PSK (Pre-Shared Key) oder EAP (Extensible Authentication Protocol) die Sicherheit erhöht. Der Standard IEEE 802.11 i ist bereits in allen neueren WLAN-Produkten integriert. Darüber hinaus ermöglicht der Standard IEEE 802.11 i die Verwendung von AES (Advanced Encryption Standard) zur Verschlüsselung der übertragenen Daten. IEEE 802.11 n Drahtlose Netzwerke auf Basis des neuen Standards IEEE 802.11 n versprechen erheblich höhere Datenübertragungsraten von bis zu 600 Mbit/s. Um diese Werte zu erreichen, wird zur Modulation das MCS (Modulation Coding Scheme) genutzt. Hierbei berücksichtigen die beteiligten Geräte möglichst viele Parameter, wie beispielsweise Interferenzen, Bewegung des Senders oder Abschwächung des Signals und optimieren so die Datenübertragung. In WLANs nach IEEE 802.11 n werden zwei bis vier Antennen genutzt. Dadurch kann ein Funkkanal im selben Frequenzbereich räumlich mehrfach eingesetzt werden und ermöglicht somit eine parallele Datenübertragung. Hierdurch wird nicht nur die Geschwindigkeit, sondern auch die Reichweite erhöht. Dieser Mechanismus wird als MIMO (Multiple Input, Multiple Output) bezeichnet. Auch für die Zukunft sind bereits neue Spezifikationen innerhalb des Standards IEEE 802.11 angekündigt, beispielsweise der Standard IEEE 802.11 p für den Einsatz in Fahrzeug-zuFahrzeug-Netzen. Modulationsverfahren Bei CCK wird nur eine Trägerfrequenz moduiert Die Komplementäre Code-Umtastung CCK dient als Basismodulation gegenwärtiger WiFiSysteme nach IEEE 802.11b und moduliert nur einen Träger. Bei der komplementären Code-Umtastung werden sowohl Präambel/Header als auch die Nutzinformation in CCK-Moduation ausgesendet. Parallele Datenübertragung im Frequenzmultiplex, kurz OFDM, ist eine Technologie, die gerade in den Markt drahtloser lANs eingeführt wird und sich in Geräten nach IEEE 802.11a für das 5-GHz-Band findet. Bis vor Kurzem verhinderten FCC-Vorschriften nämlich den Einsatz von OFDM im 2,4-GHz-Band. Dies änderte sich im Mai 2001: Seitdem ist OFDM auch für das 2,4-GHz-Band zugelassen, so daß jetzt beide Bänder (2,4 und 5 GHz) mit einem einzigen Modulationsformat abgedeckt werden können. OFDM ist ein MehrträgerModulationsverfahren, bei dem die Daten auf mehrere, eng beieinander liegende Unterträger aufgeteilt werden. Eine andere entscheidende Eigenschaft von OFDM ist die kürzere Präambel: Nur 16 ms gegenüber 72 ms bei CCK. Eine kürzere Präambel ist vorteilhaft, da sie weniger Grundaufwand für das Netzwerk bedeutet. Auch wenn die Präambel ein unverzichtbarer Teil des Datenpaketes ist, stört doch die von ihr beanspruchte Zeit, die für eine Nutzdatenübertragung nicht mehr verfügbar ist. Mit der kurzen Präambel bei OFDM steigt also die Nutzdatenrate - eine gute Sache! Reine OFDM-Systeme setzen OFDM sowohl für Präambel/Header als auch für die Nutzdaten ein. Wie der Name schon andeutet, handelt es sich bei CCK/OFDM um ein hybrides Verfahren, das als Option im Standardentwurf IEEE 802.11g enthalten ist. Wie in Bild 5 verdeutlicht, setzt CCK/OFDM die CCK-Modulation für Präambel/Header und OFDM für die Nutzdaten ein. Dabei bleiben die Modulationsarten mit dem Übergang zwischen Präambel/Header und Nutzdatenstrom separat und zeitlich getrennt. Dies wirft sofort eine naheliegende Frage auf: Wozu diese Trennung? Wie sich zeigen wird, gibt es gute Gründe dafür, die optionalen Hybridverfahren in den Standardentwurf aufzunehmen. Wenn nämlich ein Betrieb in Anwesenheit existierender WiFi-Geräte stattfindet, sorgt der ausgesendete CCK-Header dafür, daß alle WiFi-Geräte den Beginn einer Sendung mitbekommen, und vor allem, wie lange (in ms) diese Sendung dauern wird. Daraufhin folgt die Nutzinformation in OFDM. Auch wenn existierende WiFi-Geräte nicht in der lage sind, diese Nutzinformation aufzunehmen, wissen sie doch, wie lange die Sendung dauern wird, und starten in dieser Zeit keine Sendeversuche: Dies vermeidet Kollisionen und sorgt für friedliche Koexistenz mit neueren Geräten nach IEEE 802.11g mit CCK/OFDMModulation. Da hier die Präambel länger ist als bei reinem OFDM, steigt der Grundaufwand. Allerdings kann dies leicht in Kauf genommen werden, da CCK/OFDM höhere Datenraten zulässt (über 20 Mbit/s), was diesen Zeitverlust mehr als wettmacht, gleichzeitig aber Rückwärtskompatibilität mit existierenden CCK-Systemen sicherstellt. Es ist immer daran zu denken, daß CCK/OFDM lediglich als Option im angenommenen Standardentwurf IEEE 802.11g enthalten ist. Die verbindlich festgelegte OFDM-Modulation kann ebenfalls neben vorhandenen WiFi-Geräten existieren und mit ihnen zusammenarbeiten. Allerdings ist dafür eine andere Methode notwendig, die unter RTS/CTS bekannt ist. Diese wird im letzten Abschnitt des Artikels näher betrachtet. Das Modulationsverfahren PBCC (Packet Binary Convolutional Coding) basiert auf einem Träger, unterscheidet sich aber wesentlich von CCK. Es nutzt eine komplexere Signalkonstellation (8-PSK für PBCC statt BPSK/QPSK für CCK) und einen KonvolutionsCode statt des Block-Codes bei CCK. Damit unterscheidet sich der Decodier-Mechanismus sehr von den bisher besprochenen Verfahren. Wie bei CCK/ OFDM handelt es sich bei PBCC auch um ein hybrides Verfahren: CCK für Präambel/Header und PBCC für die Nutzdaten. Dies ermöglicht höhere Datenraten bei gewahrter Rückwärtskompatibilität mit existierenden WiFi-Systemen in gleicher Weise, wie oben für CCK/OFDM beschrieben wurde. Als maximale Datenrate für PBCC sind im Standardentwurf IEEE 802.11g 33 Mbit/s festgelegt. Dieser Wert liegt unter den Spitzenwerten für das vorgeschriebene OFDM und auch des optional möglichen CCK/OFDM. Hier ist festzustellen, daß PBCC als optionales Element auch im ursprünglichen Standard IEEE 802.11b enthalten ist, wobei aber noch keine Geräte auf den Markt gebracht wurden, die nach diesem Verfahren arbeiten. Verborgene Teilnehmer und RTS/CTS Unter üblichen Betriebsbedingungen können sich alle Teilnehmer in einem gemeinsamen Kanal auch gegenseitig hören. Es gibt aber Situationen, in denen die Partner Kontakt zur Basisstation haben, sich aber untereinander nicht hören können. Hier nützt der Grundsatz "Erst hören, dann sprechen" nichts: Wenn ein Teilnehmer einen vermeintlich freien Kanal feststellt und zur Basisstation zu senden beginnt, während diese gerade der Sendung eines anderen Teilnehmers lauscht, dann gibt es ein Problem, das auch als das Hidden-NodeProblem bekannt ist. Zur Lösung dieses Problems hält der Standard 802.11 einen bekannten Mechanismus bereit: RTS/ CTS (Request-To-Send/Clear-To-Send). Dazu muß jeder Teilnehmer eine Sendeanforderung RTS an die Basisstation senden und eine CTS-Antwort von der Basisstation abwarten, bevor er seine Sendung starten kann. Die Situation von CCK- und OFDM-Partnern, die im gleichen Kanal arbeiten, ähnelt sehr dem Hidden-Node-Problem, da die CCK-Partner keine OFDM-Sendungen hören können. Mit dem RTS/CTS-Mechanismus ist es also möglich, daß OFDM-Teilnehmer ohne Kollision im gleichen Kanal wie WiFiGeräte arbeiten können. Für den RTS/CTS-Ablauf ist eine zusätzliche Verkehrssteuerung im Netz notwendig. Sicherheit von Funknetzen Der größte Vorteil des Mediums Funk ist auch gleichzeitig sein größter Nachteil: Die Funkwellen gehen überall hin, auch dorthin, wo sie nicht hin sollen. Drahtlose Netze bestehen in der Regel aus einem Access-Point und einer Anzahl Clients mit drahtlosen Netzwerkkarten. Immer häufiger sind die notwendigen Zugangspunkte zum Internet, so genannte "Hotspots", an Flughäfen, in Cafes oder Hotels der Großstädte zu finden. Auch zuhause können sich Notebook-Nutzer recht einfach mit entsprechendem Zubehör einen Hotspot installieren und die Vorteile des kabellosen Surfens genießen. Bei vielen handelsüblichen Geräten ist der AP in einen DSL-Router integriert. Im Lieferzustand sind die Geräte nach dem Auspacken betriebsbereit, nach dem Einschalten können sich drahtlose Geräte bereits mit dem Accesspoint verbinden. In diesem Betriebsmodus besteht aber keinerlei Schutz des Netzwerks gegenüber der unerwünschten Mitbenutzung durch andere Teilnehmer, es ist auf jeden Fall eine Konfiguration seitens des Netzwerkbetreibers erforderlich. Ein großes Sicherheitsrisiko, das Nutzer von kabellosen Netzwerken haben, ist der Vertraulichkeitsverlust durch einen "Lauschangriff". Mittels Notebook und einer WLANKarte ist es für Dritte nicht allzu schwer, von außen in ein solches Netzwerk zu gelangen. Dabei "schmuggelt" sich der Eindringling in die Verbindung zwischen dem HotSpot und dem Notebook ein, quasi als "Man-in-the-Middle". Ohne Probleme gelangt er so an persönliche Daten oder kann sogar auf Kosten des Besitzers im Internet surfen, was viele noch mehr "schmerzen" dürfte. Inzwischen ist allein durch das Erlauschen des Datenverkehrs ein passiver Angriff auf WEP mit handelsübliche Hardware und frei erhältliche Software gelungen. Er beruht auf der Tatsache, daß WEP einen berechneten und nicht einen zufälligen Initialisierungsvektor im Klartext überträgt. So kann aus den erlauschten Daten der bei WEP verwendeten Schlüssel errechnet werden. Nach Schätzungen dauert das Berechnen eines 40-Bit-WEP-Schlüssels eine Viertelstunde, die bessere 128-Bit-Variante mit 104 Bit langem Schlüssel würde nur rund 40 Minuten dauern. Adresse für den Access-Point (SSID) setzen Der Service Set Identifier (SSID) stellt quasi den Namen des Funknetzes dar. Sie wird vom Hersteller des AP auf einen Standardnamen gesetzt. Mit dem SSID bestimmt der Administrator, auf welche Access-Points Notebooks oder PCs zugreifen können. Der SSID benennt einen oder eine Gruppe von Access Points (AP). Damit der Anwender drahtlos auf das Netz zugreifen kann, müssen auf den Notebooks die entsprechenden SSIDs hinterlegt sein. Der SSID funktioniert wie ein einfaches Passwort, wobei der Name des Access-Points vom Endgerät übermittelt wird. Jeder AP ist über seinen mit einem konkreten Wireless LAN verknüpft. Sendet das Notebook nicht die korrekte Adresse des Access Points, so erhält der Anwender keinen Zugriff auf die Daten. Eine Sicherheitslücke entsteht, wenn der Access-Point so konfiguriert ist, dass er seine SSIDs denjenigen Notebooks, die sich anmelden wollen, per Broadcastverfahren mitteilt.Ein weiteres Risiko besteht darin, dass die Anwender ihre Systeme selbst konfigurieren und anderen Personen die SSIDs möglicherweise mitteilen. Nach der Einrichtung von WEP/WPA und MAC-Filtern sollte das SSID-Broadcasting abgeschaltet werden, da die Clients fest eingerichtet sind und eine zyklische Bekanntgabe des Netzwerknamen (SSID-Broadcasting) nur noch ein Sicherheitsrisiko darstellt. Es versteht sich von selbst, daß alle voreingestellten Passwörter (z.B. beim AP) geändert werden. MAC-Adresse des Endgeräts speichern Anhand der MAC-Adresse kann der Administrator des AP festlegen, welche Endgeräte Daten über einen Access Point senden oder empfangen können. Die MAC-Adresse benennt das Laptop oder den Handheld-Computer. Um die Sicherheit in einem drahtlosen Netz zu erhöhen, lässt sich das System mit einer Liste von MAC-Adressen derjenigen Notebooks programmieren, denen Zugriff aufs LAN gestattet ist. Clienten,deren Adresse nicht in der Liste enthalten ist, erhalten keinen Zugang zum Access Point. Nachteile: Die Liste der Adressen muß vom Administrator in jeden Access Point manuell eingegeben und aktualisiert werden. Viele Netzwerkinterfaces erlauben die Konfiguration einer beliebigen MAC-Adresse, wodurch die Sperre unterlaufen werden kann. Erst in Kombination mit einer Verschlüsselung stellt diese Maßnahme eine weitere Steigerung der Sicherheit dar. Die MAC-Adresse eines Windows-Clients können Sie übrigens durch die kommandos ipconfig /all bzw. winipcfg ermitteln. Verschlüsselung der Datenpakete Die WEP-Verschlüsselung (Wired Equivalent Privacy) soll die Kommunikation innerhalb eines WLANs (Wireless Local Area Network) vor Lauschangriffen schützen. Damit Access Point und Notebook miteinander Daten ver- und entschlüsseln können, benutzen sie einen identischen Code. Das Verschlüsselungssystem codiert Datenpakete mit 128 Bit. Die Codierung dient als Zugangskontrolle: Einem Notebook wird der Zugriff auf einen AP verweigert, wenn die Schlüssel der beiden Komponenten nicht übereinstimmen. Der 802.11-WLAN-Standard sieht kein Protokoll für das Key-Management vor, so dass alle Schlüssel in einem Netz manuell administriert werden müssen. Die WEP-Sicherheit ist in Ad-hoc-Netzen, die keinen Access-Point benötigen, nicht verfügbar. Die WEP-Verschlüsselung ist mit relativ geringem Aufwand zu knacken. Im Ernstfall ist die Aufzeichnung und die Analyse von ca. 25 GB Datenverkehr ausreichend, um eine WEPbasierende Verschlüsselung zu knacken und erfolgreich über ein drahtloses Netzwerk in die Gesamtstruktur eines Unternehmensnetzweks einzudringen. Bei Verlust eines Notebooks muß der Administrator bei allen anderen Geräten und APs den Schlüssel ändern. Im Rahmen der Einrichtung ist es zweckmäßig, einen drahtgebundenen Zugang zum AP zu haben, um unbeabsichtigte Selbstaussperrungen zu vermeiden. Viele Geräte gestatten die Eingabe eines Schlüsseltextes (im Regelfall 13 Buchstaben oder Ziffern) zur Erzeugung eines Schlüsselcodes. Dieses Verfahren ist jedoch zwischen den verschiedenen Geräten nicht kompatibel, bei Problemen sollte hier ein 26-stelliger Hexadezimalcode verwendet werden (Schlüssellänge von 128 Bit). VPN im WLAN Ursprünglich bietet das VPN (Virtual Private Network) einen sicheren "Tunnel" durch das weltweite öffentliche Netz, seine Sicherheitsverfahren lassen sich aber auch auf ein lokales drahtloses Netzwerk anwenden. In Verbindung mit zentralisierten Authentifizierungslösungen wie RADIUS-Servern kommen dabei verschiedene Tunneling-Protokolle zum Einsatz. Die bereits vorhandene VPN-Infrastruktur im Unternehmen lässt sich leicht auf das Wireless LAN erweitern. Der Administrationsaufwand ist klein, da sich der VPN-Server zentral verwalten lässt.Es gibt noch Schwächen beim Roaming: Bewegen sich die Anwender von einem zum anderen drahtlosen Netz, werden sie zu einem erneuten Log-In aufgefordert. Für die Absicherung von Funknetzen bleiben damit nur Techniken, wie sie in Virtual Private Networks (VPNs) gebräuchlich sind - also Verfahren, die auf höheren Netzwerkebenen greifen. Das erfordert allerdings einige Umstellungen: Anstatt die Access Points schlicht in die bestehende LAN-Infrastruktur zu integrieren, muss man ein separates Netz für sie aufbauen. An einem Übergabepunkt zwischen WLAN und LAN muss dann die Zugriffsberechtigung überprüft werden. Man sollte dabei nicht nur von der normalen Benutzerverwaltung getrennte Passwörter verwenden, sondern diese möglichst lang machen. Deutlich sicherer geht es mit IPsec. Physische Sicherheit Man sollte gegebenenfalls die physischen Bedingungen in das Sicherheitskonzept mit einbeziehen. Bei der Abdeckung eines Geländes oder eines Gebäudes ist durch Auswahl der AP-Standorte, der Antennen und der Sendeleistung eine Einschränkung der Abdeckung auf den erwünschten Bereich möglich. So kann beispielsweise die Installation der APs in den Kellerräumen eine Abdeckung des Gebäudes und des naheliegenden Bereiches bieten, jedoch eine Absrahlung auf angrenzende Grundstücke wirkungsvoll vermieden werden. Die Verwendung von Antennen mit bestimmter Abstrahlungscharakteristik kann bei komplexen Umgebungen einen deutlichen Sicherheitsgewinn bringen. Warchalking Unter Warchalking versteht man die öffentliche Kennzeichnung offener drahtloser Netzwerke (Wireless LAN Hotspots) etwa durch Kreidezeichen an Hauswänden und auf Bürgersteigen. Genau wie die Reisenden früherer Zeiten sich durch Graffiti über die Qualität der lokalen Infrastruktur austauschten tun dies auch moderne Informationsnomaden. Um überall mit dem Internet verbunden zu sein nutzen sie oft auch die (unzureichend gesicherten oder absichtlich offen gelassenen) Wireless LANs von Institutionen und Privatpersonen, um über diese Netzwerke Verbindung mit dem Netz der Netze aufzunehmen. Welche WLAN-Hotspots in Deutschland frei zugäglich sind erfährt man unter www.hotspots-in-deutschland.de Technische Probleme WLANs benutzen sehr hohe Frequenzen 2,4 bis 2,5 GHz. In diesem Frequenzbereich ändern sich die Ausbreitungsbedingungen im Nahfeld schon mit kleinsten Veränderungen der Antennenposition und des Umfeldes der Antenne. So stören metallische Gegenstände in der Nähe der Antenne teilweise gewaltig. Um die starken Beeinflussungen der Ausbreitung zu verstehen, muß man die verwendete Wellenlänge berücksichtigen: 2,4 GHz entsprechen etwa 12,7 cm Wellenlänge. Jeder Gegenstand, der ungefähr so groß ist wie die Wellenlänge, kann die Abstrahlung der Antenne beeinflussen. Also nehmen Wasser, Pflanzen, Gebäude die Sendeenergie auf und setzen diese in Wärme um. Diese Energie steht dann nicht mehr für weitere Ausbreitung zur Verfügung. Ein weiterer Störfaktor sind Reflektionen. HF Energie wird von manchen Oberflächen hervorragend reflektiert oder abgelenkt. Dabei kann es zur Überlagerung des Originalsignals mit dem abgelenkten Signal kommen, was zu völliger Auslöschung aber auch zu einer Verstärkung führen kann. Durch Reflexionen verändert sich oft auch die Polarisation der Welle. Idealerweise sollten Sende- und Empfangsantenne die gleiche Polarisation haben, also beide vertikal oder beide horizontal. Ein konkrete, zuverlässige Vorhersage welche Antennen welche Reichweiten bringen ist ohne genaue Betrachtung der Umgebung nicht möglich. Wünschenswert sind dünne Kabel wegen ihrer größeren Flexibilität, Aber gerade die dünnen Kabel sogen für eine starke KabelDämpfung, die in in dB/100 m angegeben wird. Verringern lässt sich die Kabeldämpfung nur durch dickere Kabel, das liegt an der Physik. Das Problem ist, daß man zwar mit dicken Kabel im Aussenbereich und an einer festmontierten Antenne gut arbeiten kann, ein Notebook oder ein leichter Accesspoint aber vom dicken Kabel einfach weggehoben werden würde. Dadurch wird die Mobilität des WLANs wieder eingeschränkt. Um dieses Problem zu umgehen, wird mit sogenannten "Pigtails" gearbeitet. Dies sind kurze, hochflexible Kabelstücke mit den entsprechenden Steckern, die vom Notebook oder AP auf das dicke Kabel adaptieren. Dadurch kommt zwar wieder ein etwas stärker dämpfendes Kabel ins Spiel, aber das System bleibt flexibel. Dazu kommt noch das die üblichen Winzigstecker der Accesspoints oder PCMCIA-Karten gar nicht an ein dickes Kabel montiert werden können. Die folgende Tabelle zeigt typische Dämpfungswerte von HF-Kabeln: Kabeltyp Dämpfung bei 2.4 Ghz db/100m RG58 107 RG213 46 Aircom Plus 21,5 Aircell 7 39 WLAN-Stecker Lucent Sehr kleiner Stecker, der nur bei (Orinoco) PCMCIA-Karten verwendet wird. Passt nur an RG-316- oder RG174-Kabel. MMCX Sehr kleiner Stecker der nur bei PCMCIA Karte Verwendung findet. Passt nur an RG-316 und RG-174 Kabel.z.b. bei Cisco Aironet 350. SMA Kleiner Stecker für Access-Points, PCI-Karten o.ä. Kann an RG-316-, RG-58- und RG213-Kabel angeschlagen werden. SMA-Stecker: Innengewinde und innen Stift. SMA-Buchse: Aussengewinde und innen Kelch. ReverseSMA Wird sehr oft im WLAN-Bereich verwendet. z.B. D-Link ReverseSMA. Reverse-SMA-Stecker: Innengewinde und innen Kelch. Reverse-SMA-Buchse: Aussengewinde und innen einen Stift. TNC Etwas größerer Stecker, wird gelegentlich an WLANAccesspoints und -Clients gefunden. Passt an RG-316-, RG58- und RG213-Kabel. Achtung: Es gibt dieses System umgekehrt: Buchse (Kelch) anstelle des Stiftes für den Innenleiter, es nennt sich dann "Reverse-TNC". Wird häufiger im WLAN-Bereich verwendet. z.B. von Cisco. N Der Stecker für professionelle Montage und praktisch alle Kabeltypen. Dicke Kabel zur Antenne sollte man immer mit NStecker ausrüsten. Die Verbindung zum Notebook/AP wird dann mit einem Pigtail mit N-Buchse adaptiert. Weitere drahtlose Verfahren Das Nebeneinander verschiedener kabelloser Vernetzungstechniken ist nicht leicht zu durchschauen. Hier ein Überblick über Technik und Anwendung gängiger Systeme, die für den Heimbereich geeignet sind. WiMAX Die Wireless-Technologie Worldwide Interer operability for Microwave Access (WiMAX) hat nicht zuletzt aufgrund ihrer vielfältigen Anwendungsmöglichkeiten eine beachtliche Zukunft vor sich. Vor allem die breitbandige High-Speed-Übertragung zu mobilen Endgeräten nach dem Standard IEEE 802.16e verspricht eine weitergehende Verbreitung. Das Spektrum der WiMAX-Anwendungen reicht von der "Richtfunk-Anbindung" von Wohngebieten oder Industriekomplexen über die Versorgung mobiler Laptops bis hin zur Datenversorgung in Städten oder auch in größeren Gebieten, in denen sich wegen der dünnen Besiedelung das Verlegen von Kabeln nicht lohnt (Gebiete also, die niemals in den Genuss von DSL kommen werden). Die Funkzellendurchmesser betragen bis zu 20 km (typisch 10 km oder weniger). Auch die Installationskosten sind relativ niedrig, sie betragen etwa ein Drittel der Kosten für das Universal-Mobile-Telecommunications-System (UMTS). Die (Mobil-)Übertragungsraten liegen in der Praxis zwischen 5 Mbit/s und etwa 25 Mbit/s. Die heute bereits in vielen Ländern zur drahtlosen Breitband-Versorgung eingesetzte WiMAXTechnik beruht auf dem Standard IEEE 802.16. Bei der aktuellen Version ist der Wechsel der Funkzelle noch nicht möglich, die Anwendung ist also auf echte Festverbindungen ausgerichtet. Ende 2005 hat das IEEE-Gremium dann die Version 802.1 6e verabschiedet, womit auch der Wechsel der Funkzelle mit mobilen Endgeräten möglich sein wird. Die notwendigen Frequenzbereiche bei 2,5 GHz und 3,5 GHz sind verfügbar. Es wurde auch ein Quality of Service festgelegt, der auch Sprachübertragung erlaubt. IrDA Der IrDA (Infrared Data Association) - Standard für den Kurzstreckenbereich (wenige Meter) gehört schon fast zu den Veteranen der drahtlosen Technologien. Entsprechende Hardware ist sehr preisgünstig und heute Grundausstattung in Notebooks, Palm-, Handspring- und CEPlattformen sowie Handys. Mobile Telefone mit Infrarotschnittstelle gibt es beispielsweise von Siemens, Nokia, Qualcomm, Motorola und Ericsson. Seit einigen Monaten wird die Infrarot-Technologie mit 16 MBit/s-Transceiver ausgeliefert. Ein schwerwiegendes Handikap hat die IrDA-Technik, denn Sender und Empfänger benötigen eine direkte Sichtverbindung. Dieses Manko hat sich in der Praxis als so drastisch erwiesen, daß die Akzeptanz von IrDA sehr nachgelassen hat. Die Hersteller haben bereits reagiert - in vielen Fällen wird wohl IrDA demnächst von Bluetooth ersetzt, obwohl IrDA mit seinem Licht-Übertragungsmedium keine Rangeleien um Funkfrequenzen kennt und natürlich auch keinerlei möglicherweise gesundheitsschädliche Mikrowellen-Strahlung emittiert. Eine weitere Einschränkung der IrDA-Anwendung: Es sind nur Punkt-zu-Punkt-Verbindungen möglich. Bluetooth Über 200 Hersteller ziehen an einem Strang und entwickeln ein Verfahren zur drahtlosen Integration mobiler Geräte. Aus dem Projekt mit Codenamen "Bluetooth" ging bis zur CeBIT 1999 die erste Version einer Spezifikation hervor. Wer oder was ist "Bluetooth"? Der Held, um den es hier geht, regierte vor 1000 Jahren Dänemark und hieß Harald Blaatand, zu deutsch Blauzahn. Eines der wenigen Zeugnisse für die Existenz des Königs legt ein jütländischer Runenstein ab, auf dem steht: "... Harald, der ganz Dänemark und Norwegen gewann und die Dänen christianisierte." Was dieser Herrscher vergangener Tage mit drahtlosem Datenaustausch zu tun hat, versucht eine Powerpoint-Präsentation der "Bluetooth Special Interest Group" zu deuten: "Harald glaubt, daß mobile PCs und Handys kabellos miteinander kommunizieren sollten." Im Frühjahr 1998 beschlossen die Hersteller Ericsson, IBM, Intel, Nokia und Toshiba, gemeinsam eine Technik für die kurzreichweitige Funkverbindung von PCs, digitalen Kameras, Mobiltelefonen und anderen tragbaren Geräten zu entwickeln. Als Forum für den Austausch von Ideen gründeten sie die "Bluetooth Special Interest Group", eine Arbeitsgruppe, die zunächst Rahmenbedingungen formulierte und nach und nach einen Standard festlegen sollte. Die Initiatoren hatten ein Verfahren im Visier, das Anwendern von Notebooks das Leben erleichtert. Dementsprechend sollte die drahtlose Technik Stimme und Daten übertragen, überall funktionieren, automatisch Verbindungen aufbauen, Störeinflüssen von Mikrowellenherden widerstehen, mit kleinen Chips arbeiten, die auch in Handys passen, wenig Strom verbrauchen, auf offenen Standards beruhen und sehr billig sein. Am 20. Mai 1998 gab die Special Interest Group Einzelheiten zur Technik bekannt und begrüßte neue Mitglieder: 3Com, Axis, Cetecom, Compaq, Dell, Lucent, Motorola, Puma, Qualcomm, Symbionics TDK, VLSI und Xircom. Fünf Monate später wurde von bis dahin mehr als 200 Mitgliedern auf einer Entwicklerkonferenz in Atlanta die Version 0.7 der Bluetooth-Spezifikation aus der Taufe gehoben. Heute zählt die Teilnehmerliste rund 520 Einträge. Nun steht die Herausgabe der endgültigen Fassung 1.0 des Reglements kurz bevor. Nach dem Kalender der Bluetooth-Gruppe sollte das Dokument im 1. Quartal 1999 erscheinen, nach Möglichkeit bis zur CeBIT. Bis dahin blieben Detailinformationen in den Händen der Mitglieder. Kurz nach der Veröffentlichung, so lauten die Pläne, werden Entwicklungswerkzeuge für Bluetooth-Anwendungen erhältlich sein. Die ersten Produkte schließlich, welche die Technik umsetzen, könnten dann in der zweiten Jahreshälfte auf den Markt gehen. Auch wenn es bislang nocht keine Bluetooth-Chips zu kaufen gibt, können wir schon davon träumen; die Web-Site der Arbeitsgruppe (http://www.bluetooth.org) versorgt uns mit genügend Stoff: Handys schalten am Arbeitsplatz automatisch auf den kostenlosen Betrieb im firmeninternen Telefonnetz um und funktionieren zu Hause als Schnurlosapparate im Festnetz. Die Teilnehmer einer Konferenz brauchen ihre Notebooks nur einzuschalten, um sie miteinander zu verbinden. Auch der Referent braucht kein Kabel, wenn er den Projektor an einen PC anschließt. E-Mail, die der Anwender im Flugzeug auf seinem Notebook verfaßt, wird abgeschickt, sobald er nach der Landung sein Handy auf Stand-by schaltet. Der PDA des Außendienstmitarbeiters tauscht selbständig mit dem PC im Büro Informationen aus und aktualisiert seine Daten. Das Verfahren, nach dem Bluetooth-Geräte arbeiten, gründet zum Teil auf dem Standard 802.11 des Institute of Electrical and Electronics Engineers (IEEE). Eine 9 mal 9 Zentimeter große Chipkarte sendet im Mikrowellenbereich von 2,4 GHz bis 2,48 GHz. Dieser Abschnitt des gebührenfreien ISM-Bands (ISM = Industrial, Scientific and Medical) liegt sehr nahe an der Arbeitsfrequenz eines Mikrowellenherds, dessen Magnetron in der Regel mit 2,450 GHz schwingt. Daß der Funkverkehr trotzdem störungsfrei verläuft und auch neben anderen Wireless-Netzen funktioniert, soll eine Technik garantieren, die sich in dem sogenannten Baseband-Protokoll manifestiert. Hierin ist festgelegt, daß die Trägerfrequenz nicht konstant bleibt, sondern in einer zeitlichen Abfolge verschiedene Werte aus einer festen Menge von Frequenzen annimmt. Der Sender springt bis zu 1600 mal in der Sekunde zwischen 79 Stufen einer Frequenztreppe, die mit 1 MHz großen Abständen den Bereich von 2402 MHz bis 2480 MHz abdecken. Ein Gerät, das die Nachricht empfangen will, muß mit dem Sender synchronisiert sein und genau die gleiche Sprungfolge für die Trägerfrequenz verwenden. Nur Nachrichten, die diesen Fingerabdruck tragen, landen bei den Teilnehmern eines BluetoothNetzes, Signale anderer Quellen werden herausgefiltert. Die Daten schließlich werden der Sprungfolge durch eine binäre Frequenzmodulation angehängt. Bluetooth kann in einem asynchronen Modus Pakete übertragen, wobei in der Regel auf einen Slot, das heißt pro Element der Sprungfolge, ein Paket zu liegen kommt. Der Austausch erfolgt entweder symmetrisch mit einer Datenrate von 432 KBit/s oder asymmetrisch mit 721 KBit/s in einer Richtung und 57,6 KBit/s in der anderen. Reservierte Zeitfenster ermöglichen dabei einen Full-Duplex-Betrieb, bei dem Kommunikationspartner zur selben Zeit senden und empfangen dürfen. Alternativ zur Datenleitung kann eine Verbindung auch gleichzeitig drei Sprachkanäle mit jeweils 64 KBit/s Bandbreite unterbringen. Zum Umwandeln von Sprache in ein digitales Signal dient "Continuous Variable Slope Delta Modulation", ein Verfahren, das gegenüber Bitfehlern als vergleichsweise unempfindlich eingeschätzt wird. Ein Bluetooth-Netz ist aus einzelnen Blasen, sogenannten Piconets, aufgebaut, die jeweils maximal acht Geräte aufnehmen. Damit auch mehrere Teilnehmer drahtlos kommunizieren können, treten bis zu zehn Piconets eines Empfangsbereichs miteinander in Kontakt. Der Gründer eines Teilnetzes, nämlich das Gerät, welches die erste Verbindung herstellt, nimmt unter den übrigen Mitgliedern eine primäre Stellung ein und gibt die innerhalb des Piconet gebräuchliche Sprungfolge vor. Damit die anderen Geräte Schritt halten, schickt der Master Synchronisationssignale. Außerdem führt er Buch über die drei Bit langen Mac-Adressen der Piconet-Teilnehmer und versetzt diese nach Bedarf in eingeschränkte Betriebszustände. Den Aufbau einer Verbindung übernimmt das Software-Modul "Link-Manager". Dieses entdeckt andere Link-Manager in einem Empfangsbereich, mit denen es über ein eigenes Protokoll, das Link-Manager-Protokoll, Daten austauscht. Das Modul authentifiziert Geräte, behandelt Adreßanfragen, verfügt über eine einfache Namensauflösung und sendet und empfängt Anwendungsdaten. Darüber hinaus handelt es mit dem Kommunikationspartner den Verbindungstyp aus, der bestimmt, ob Sprache oder Daten über den Äther gehen. Auch an die Sicherheit haben die Entwickler gedacht. Bluetooth-Geräte weisen sich gegenseitig mit einem Challenge/Response-Mechanismus aus und kodieren Datenströme mit Schlüsseln von bis zu 64 Bit Länge. Abgesehen davon haben es Mithörer wegen der großen Zahl möglicher Sprungfolgen schwer, sich in ein Piconet einzuklinken. Eine Mitgliedschaft in der Special Interest Group ist für Unternehmen der EDV-Branche aus zweierlei Hinsicht interessant. Zum einen erhalten Entwickler die Gelegenheit, die Spezifikation nach ihren Vorstellungen mitzugestalten. So ist von den Gründern der Gruppe die Firma Ericsson für weite Teile des Baseband-Protokolls verantwortlich, während die Module für die PC-Integration von Toshiba und IBM stammen, Intel Wissen über integrierte Schaltungen einbringt und Nokia Software für Mobiltelefone liefert. Zum anderen bekommen Teilnehmer Zutritt zu den Vorabversionen des Standards und können frühzeitig mit der Entwicklung von Bluetooth-konformen Geräten und Programmen beginnen. Wer sich in die Gruppe aufnehmen lassen will, besucht die Bluetooth-Web-Site und schickt unter dem Link "Members" eine E-Mail mit verschiedenen Angaben an eines der fünf Gründungsmitglieder. Kurz darauf erhält der Bewerber in elektronischer Form zwei Vertragsformulare, die er unterschrieben per Post zurückschickt. Das eine, genannt "Adopters Agreement", sichert dem Teilnehmer die gebührenfreie Benutzung der Spezifikation für eigene Produkte, die ein Bluetooth-Label tragen dürfen. Wie das lauten wird, heißt es dort - denn Bluetooth ist lediglich ein vorläufiger Codename des Projekts -, entscheidet Ericsson. Die Vertragsanlage "Early Adopter Amendment" verpflichtet jene, die vor der Veröffentlichung des Standards beitreten, die Dokumente vertraulich zu behandeln. Damit Produkte das Bluetooth-Label erhalten, müssen sie nicht nur das Baseband-Protokoll unterstützen. Je nach ihrem Einsatzgebiet müssen sie auch mit Protokollen der Anwendungsebene arbeiten und verschiedene Datenobjekte integrieren. Mobiltelefone zum Beispiel sollten mit PCs oder PDAs elektronische Visitenkarten des V-Card-Standards austauschen, wohingegen ein Kopfhörer weniger Aufgaben zu erledigen hat. BluetoothGeräte bauen dabei nicht nur selbständig Verbindung zu ihren Kollegen auf, sie erkennen auch, mit welchen Fähigkeiten diese ausgestattet sind. Die Datenrate eignet sich eher für Anwendungen mit seltenem Datenaustausch in meist kleinem Umfang. So bildet Bluetooth keine Konkurrenz zu Wireless-LANs (WLANs), da dort inzwischen Bandbreiten von 11 MBit/s eingeführt wurden. Die wesentlichen BluetoothApplikationen, die in Betrieben von Mitarbeitern angenommen werden, bestehen aus unternehmenseigen Anwendungen wie Messaging, Knowledge Management (Unwired Portal), Datenbankabfragen usw. sowie dem Zugang zum Internet. Neues Kapitel Zugriffsverfahren Bei jedem Netz gibt es die physikalischen Verbindungswege (Kanäle), über welche die einzelnen Stationen miteinander kommunizieren. Die Art und Weise, wie die einzelnen Stationen diese Kanäle nutzen und belegen, hängt vom jeweiligen System des Zugriffs, dem Zugriffsverfahren, ab. In diesem Abschnitt werden die unterschiedlichen Zugriffsverfahren im Überblick besprochen, wobei nicht auf die Protokolle eingegangen wird. Das Zugriffsverfahren ist nicht von einer bestimmten logischen Netzwerkstruktur abhängig. Lassen Sie uns zu Beginn ein historisch interessantes Verfahren mit ein paar Sätzen würdigen, das Ausgangspunkt für die Entwicklung der heute üblichen Zugriffsverfahren war. ALOHA Dieses Verfahren ist eines der ältesten Zugriffsverfahren und wurde 1970 an der Universität von Hawaii entwickelt ("Aloha" = "Hallo"). Da man die Inseln nicht über Kabel verbinden konnte, hat man ein Funknetz aufgebaut. Die Grundidee ist recht einfach: Jede Station darf jederzeit senden. Danach wartet die sendende Station auf eine Bestätigung auf einem separaten Rückkanal. Senden zwei Stationen zur gleichen Zeit, treten Kollisionen auf - die Datenblöcke sind defekt und es erfolgt keine Bestätigung. Wurde eine Bestätigung empfangen, kann bei Bedarf weitergesendet werden. Im anderen Fall wartet jede Sendestation eine Zeitspanne, deren Länge zufällig bestimmt wird. Danach wird der Datenblock nochmals gesendet. Da die Wartezeit von einem Zufallsgenerator bestimmt wird, löst sich der Datenstau auf. Solange das Verhältnis von aktiver Sendezeit zu Leerlaufzeit hoch genug ist, arbeitet das System sehr gut. Sobald die "Netzlast" steigt, häufen sich Kollisionen, bis schließlich kein Datenblock mehr durchkommt. Der höchste Durchsatz ergibt sich, wenn die Sendeblöcke 18% der Gesamtzeit belegen. Zwei Jahre später wurde eine Verbesserung eingeführt: Slotted ALOHA. Jeder darf nun nur noch zu Beginn eines festgelegten Zeitintervalls mit dem Senden beginnen ("time slot"). Um nun alle Stationen zu synchronisieren, gibt es eine ausgezeichnete Station, die "Zeitmarken" senden darf. Die anderen Stationen synchronisieren sich mit diesem Markengeber. Der maximale Durchsatz wird hier bei einem Sendeanteil von knapp 36% erreicht. ALOHA wird immer noch bei manchen Formen der Kommunikation über Satelliten verwendet. CSMA/CD Die Abkürzung "CSMA/CD" steht für "Carrier Sense Multiple Access/Collision Detect". Dieses Verfahren findet häufig bei logischen Busnetzen Anwendung (z. B. Ethernet), kann aber prinzipiell bei allen Topologien eingesetzt werden. Bevor eine Station sendet, hört sie zunächst die Leitung ab, um festzustellen, ob nicht schon ein Datenverkehr zwischen anderen Stationen stattfindet. Erst bei freier Leitung wird gesendet und auch während der Sendung wird mitgehört, um festzustellen, ob eine Kollision mit einer Station auftritt, die zufällig zum gleichen Zeitpunkt mit dem Senden begonnen hat (Collision Detect). Bei allen Leitungen ist eine gewisse Laufzeit (siehe später) zu berücksichtigen, so daß auch dann eine Kollision auftritt, wenn zwei Stationen um eine geringe Zeitspanne versetzt mit dem Senden beginnen. In einem solchen Fall produzieren alle sendenden Stationen ein JAM-Singal auf der Leitung, damit auf jeden Fall alle beteiligten Sende- und Empfangsknoten die Bearbeitung des aktuellen Datenpakets abbrechen. Das JAM-Signal besteht aus einer 32 Bit langen Folge von 1010101010101010... Danach warten alle sendewilligen Stationen eine zufallsbestimmte Zeit und versuchen es dann nochmals. Alle Stationen im Netz überprüfen die empfangenen Datenpakete und übernehmen diejenigen, die an sie selbst adressiert sind. Wichtigster Vertreter für CSMA/CD ist das Ethernet, dem deshalb ein eigener Abschnitt gewidmet ist. Normalerweise tritt eine Kollision innerhalb der ersten 64 Bytes auf (Weiteres in Kapitel 4, "Slot Time"). Konfliktparameter k: k>1: Sender könnte eine ganze Nachricht an den Kanal übergeben, bevor ein Konflikt entsteht. Beim CSMA/CD-Verfahren inpraktikabel. k<1: CSMA/CD-Verfahren praktikabel Spezifikation: Bei größter zulässiger Netzlänge und kleinster zulässiger Paketlänge ergibt sich k~0,21. Wartezeit Die Wartezeit, die nach einer Kollision bis zum nächsten Sendeversuch vergeht, wird im Standard durch ein Backoff-Verfahren festgelegt (Truncated Binary Expotential Backoff). Es wird wie folgt definiert: Wartezeit = ZZ * T ZZ = Zufallszahl aus [0 < ZZ < 2n] n = Anzahl Wiederholungen des gleichen Blocks, jedoch maximal 10 T = Slot Time Die Slot Time entspricht der doppelten maximalen Signallaufzeit des Übertragungsmediums. Die Wartezeit steigt im statistischen Mittel nach 10 Versuchen nicht mehr an. Nach 16 Versuchen wird abgebrochen und eine Fehlermeldung erzeugt. Damit eine sendende Station eine Kollision sicher erkennen kann, muß die Dauer der Blockübertragung mindestens das Doppelte der Signallaufzeit zwischen den beiden beteiligten Stationen betragen. Somit ist die minimale Blocklänge abhängig von Signallaufzeit und Übertragungsrate. Das Rahmenformat von CSMA/CD ist nach IEEE 802.3 festgelegt. Neben Verkabelungsproblemen gibt es bei CSMA/CD-Netzen einige typische Fehlerquellen. Einige davon sollen hier kurz vorgestellt werden. 'Late Collisions' sind Kollisionen, die außerhalb des Kollisionsfensters von 512 Bit, also später, auftreten. Dafür gibt es generell drei Ursachen: Entweder eine Station mit Hardwaredefekt (Netzwerkinterface, Transceiver, etc.), ein Fehler in der Software (Treiber), wodurch sich die Station nicht an die CSMA/CD-Konventionen hält (Senden ohne Abhören), oder die Konfigurationsregeln für die Kabellänge sind nicht eingehalten worden (zu lange Signallaufzeit). Sendet eine Station ohne Unterbrechung längere Zeit, also Frames mit mehr als die maximal zugelassenen 1518 Bytes, dann bezeichnet man dies als 'Jabber' (zu deutsch 'Geplapper'). Hauptursache sind hier defekte Netzwerkkarten oder -Treiber. 'Short Frames' sind Frames, die kleiner als die minimal zugelassenen 64 Bytes sind. Grund hierfür sind auch Defekte beim Netzwerkinterface oder im Treiber. 'Ghost Frames' sind in Ihrer Erscheinung ähnlich einem Datenframe, haben jedoch Fehler schon im Start-Delimiter. Potentialausgleichsströme und Störungen, die auf das Kabel einwirken, können einem Repeater ein ankommendes Datenpaket vorspiegeln. Der Repeater sendet das Geisterpaket dann weiter ins Netz. Token-Ring Dieses Netz wurde von IBM entwickelt. Alle Rechner sind hintereinandergeschaltet und somit ringförmig verbunden. Im "Ruhezustand" (keine Station will senden) zirkuliert eine spezielle Nachricht im Netz, das sogenannte "Token" (genauer "Frei-Token", "free token"). Diese Nachricht wird von einem Rechner an den nächsten weitergegeben. Der Rechner, der im Besitz des Frei-Tokens ist, kann senden, indem er an dieses die Nachricht anhängt ("busy token"). Dieser Datenblock wird von Station zu Station weitergereicht, bis sie beim Empfänger angekommen ist. Der Empfänger bestätigt die Nachricht durch eine Acknowledge-Meldung, die mit dem Token weiter auf den Ring geschickt wird und schließlich wieder beim Absender eintrifft. Dieser schickt nun wieder ein Frei-Token auf die Reise. In der Regel berechtigt der Besitz des Tokens nur zur Sendung eines Blocks (non exhaustive), im anderen Extremfall könnte auch definiert werden, daß die Station soviele Datenblöcke senden kann, wie sie möchte (exhaustive). Damit könnte aber eine Station, die den Token besitzt, alle anderen dominieren. Normalerweise wird deshalb nur ein Block gesendet. Außerdem wird die Dauer der Sendeberechtigung befristet (Token Holding Time, z. B. 10 ms). Solange das Netz fehlerfrei funktioniert, stellt Token-Ring ein sehr einfach handzuhabendes Verfahren dar. Komplexer sind die Aufgaben beim Initieren des Netzes und beim Ein- oder Auskoppeln von Stationen. Token-Ring ist das einzige Netz mit aktiven Stationen, die aus Eingabe- und Ausgabeeinheit bestehen. Grundsätzlich sind alle Stationen gleichberechtigt, jedoch übernimmt eine von ihnen als "aktiver Monitor" besondere Überwachungsaufgaben im Netz. Eine andere Station überwacht als "passiver Monitor" den aktiven Monitor und kann gegebenenfalls dessen Aufgaben übernehmen. Die Aufgaben des aktiven Monitors sind: Erzeugen des Ringtaktes Überwachen des Tokens (Neuen Token erzeugen, falls er verloren geht, Verhindern mehrerer Tokens) Unterbinden permanent kreisender Blöcke oder Tokens erhöhter Priorität. (Generell: Ring säubern durch Senden eines "Purge Ring Frame" an alle Stationen und Erzeugen eines neuen Frei-Tokens). Verhindern, daß mehrere Monitore aktiv sind. Verzögerung des Token-Rahmens um 24 Bit-Zeiten (die Länge des Token-Rahmens beträgt 24 Bit). Auch bei extrem kleinem Ring wird so sichergestellt, daß eine Station den Token-Rahmen vollständig senden kann, bevor sie ihn wieder empfängt. In regelmäßigen Abständen sendet der aktive Monitor einen "Active Monitor Present Frame" an alle Stationen im Ring. Gleichzeitig wird dadurch eine Prozedur in Gang gesetzt, die allen Stationen die Adresse des jeweiligen Vorgängers im Ring liefert (NAUN = Nearest Active Upstream Neighbour) - eine Information, die nur im Fehlerfall wichtig ist. Ein Fehler auf Empfangsseite bedeutet, daß der eigene Empfänger oder der Sender des NAUN defekt ist. Die Auswahl des aktiven Monitors geschieht per "Claim-Token Process" durch: den derzeit aktiven Monitor, wenn dieser Probleme bei der Durchführung seiner Aufgaben hat, einen passiven Monitor, wenn der aktive Monitor nicht korrekt arbeitet (z. B. Timeout auftritt). eine neu eingegliederte Station, wenn diese das Fehlen des aktiven Monitors feststellt. Token-Ring-Netze werden normalerweise als Stern-Ring-Verbindungen mit passiven Ringleitungsverteilern aufgebaut. In den Ringleitungsverteilern befinden sich Relais (die von den Stationen gesteuert werden) zur Eingliederung von Stationen und zur Schaltung von Ersatzringen bei Defekten. Die Eingliederung einer Station erfolgt in fünf Schritten: 1. Ist ein Adapter vom Ring getrennt, sind gleichzeitig Eingangs- und Ausgangsleitung kurzgeschlossen. Es erfolgt zunächst ein Adaptertest. Nach dem Test versorgt der Adapter die Relais mit Strom und wird in den Ring eingegliedert. 2. Die Station hört nun den Ring ab. Wenn sie innerhalb einer festgelegten Zeit keine Aktivität des aktiven Monitors wahrnimmt, startet sie den Prozeß zur Auswahl des aktiven Monitors. 3. Durch Aussenden eines "Duplicate Address Test Frame" prüft die Station die Eindeutigkeit ihrer Adresse. Ist sie nicht eindeutig, koppelt sich die Station wieder ab. 4. Durch den NAUN-Prozeß erfährt die Station die Adresse ihres Vorgängers und ist nun ins Netz eingegliedert. 5. Von den Voreinstellungen abweichende Parameter können nun bei einer ServerStation abgefragt werden, sofern dies nötig ist. Die Funktionen von Monitor und der eingegliederten Stationen müssen nicht nur einmalig initiiert, sondern auch ständig überwacht werden. In vielen Fällen sind dies zahlreiche Aktionen, die auch viele Blöcke auf dem Netz zur Folge haben und in deren Verlauf auch Fehler- und Ausnahmebedingungen auftreten können. Der Nachteil von Token-Ring liegt darin, daß beim Ausfall einer Station oder bei Kabeldefekten das Netz unterbrochen wird. Wird die defekte Station hingegen abgeschaltet, schalten die Relais im Ringleitungsverteiler die Leitung durch. Token Ring ist genormt nach IEEE 802.5. Token-Bus Auch beim Token-Bus wird der Zugriff über Token-Passing geregelt, nur besitzt das Netz Bus- oder Baumstruktur. Hier haben wir also den Fall, daß eine logische Ringstruktur auf eine physikalische Busstruktur aufsetzt. Das Verfahren wird z. B. beim ARCNET und in der industriellen Automatisierung (MAP = Manufacturing Automation Protocol) verwendet. Anders als beim Token-Ring empfangen alle Stationen auf dem Bus die Daten. Daher wird die Reihenfolge der Stationen nicht durch die hardwaremäßige Verbindung, sondern rein logisch durch die Adreßzuordung erledigt. Die Tokens werden von der Station mit der höchsten Adresse an diejenige mit der nächstniedrigeren weitergereicht. Die Station mit der niedrigsten Adresse schließt den logischen Ring durch Adressierung auf die höchste Adresse Token Bus ist genormt nach IEEE 802.4. Neues Kapitel