5.5.5 Die
Werbung

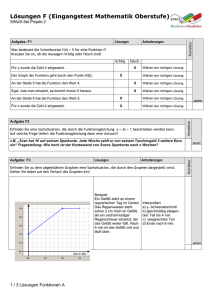
5.5.4 Quickprop Dem Quickprop-Verfahren liegt folgende Heuristik zugrunde: Man nimmt an, daß ein "Tal" innerhalb der Fehlerfunktion annäherungsweise durch eine nach oben offene Parabel beschrieben werden kann. Man verwendet nun Werte F/wi (t 1) , d.h. die Ableitung der Fehlerfunktion nach dem Gewicht wi zum vorhergehenden Zeitpunkt t 1, die Steigung F/w i (t) der Fehlerfunktion in Richtung wi zum aktuellen Zeitpunkt t und die letzte Änderung Δw i des Gewichts, um daraus den Scheitelpunkt der Parabel, d.h. das erwartete Minimum der Fehlerfunktion, zu bestimmen und in einem Schritt dorthin zu springen. Da der tatsächliche Verlauf der Fehlerfunktion meist nicht ganz mit der Parabel übereinstimmt, wird man nicht im tatsächlichen lokalen Minimum der Fehlerfunktion landen, sondern in der Nähe. Da es sich hier aber wie bei Backpropagation um ein iteratives Verfahren handelt, ist diese Abweichung nicht schlimm. F ( wij ) Fehlerfunktion Scheitel der Parabel dF / dwi (t 1) S (t 1) Minimum der Fehlerfunktion dF / dwi (t ) S (t ) Δw i (t) Δw i (t 1) S F / wi wi Steigung (Ableitung) der Parabel der lokalen Näherung der Fehlerfunktion S (t 1) S (t ) S(t 1) 0 Δw i (t) wi t 1 wi Abb. 5.5/6 Bestimmung des Scheitels der angelegten Parabel anhand der Steigung an zwei verschiedenen Punkten und ihrem Abstand. 1 Die angenäherte Bestimmung des lokalen Minimums wird dadurch sehr einfach und benötigt wie Backpropagation nur lokale Informationen eines Neuron Δ w i (t) S(t) Δ w i (t 1) S(t 1) S(t) Dabei ist S(t) F w i (t) die Steigerung der Fehlerfunktion in Richtung wi zum Zeitpunkt t . Die Herleitung dieser Formel ergibt sich direkt aus Abb. 5.5/6. Man sieht , wie der Scheitel der Parabel, für den die Steigung S(t 1) 0 ist, aus den beiden Steigungen S(t 1) und S (t ) und dem Abstand wi (t 1) berechnet werden kann. Zu bestimmen ist hier lediglich Δwi (t) , für das wegen der Ähnlichkeit der schraffierten Dreiecke in der Graphik der Ableitung der Parabel die Bedingung gilt Δw i (t) S(t) . Δw i (t 1) S(t 1) S(t) Man beachte, daß der Quotient dieser Gleichung im Prinzip einen veränderlichen MomentumTerm darstellt. Generell lassen sich vier Situationen unterscheiden: 1. Die aktuelle Steigung S( t ) ist kleiner als die vorhergehende Steigung S(t 1) , hat aber das gleiche Vorzeichen, d.h. S(t) S(t 1) und sgn (S(t)) sgn (S(t 1)) : Dann erfolgt die Gewichtsänderung in der gleichen Richtung wie vorher. 2. Die aktuelle Steigung verläuft in der umgekehrten Richtung wie die vorige Steigung S( t 1) , d.h. ( sgn S(t)) sgn (S(t 1)) : Dann haben wir ein Minimum übersprungen und sind jetzt auf der anderen Seite des Tales der Fehlerfunktion. In diesem Fall ergibt der nächste Schritt eine Position zwischen den beiden vorhergehenden Positionen. 3. Die aktuelle Steigung S( t ) ist gleich der vorhergehenden Steigung, d.h. S( t ) S( t 1) : Dann würde die Formel einen unendlich großen Schritt liefern bzw. das Simulationsprogramm würde wegen Division durch Null fehlerhaft abbrechen. 4. Die aktuelle Steigung S(t) ist größer als die vorhergehende Steigung mit gleichem Vorzeichen, d.h. S(t) S(t 1) und sgn (S(t)) sgn (S( t 1)) : In diesem Fall würde man rückwärts in Richtung eines lokalen Maximums gehen (weil der Algorithmus dann den Scheitel einer nach unten offenen Parabel sucht). Zur Lösung des Problems von Situation 3 kann man einen zusätzlichen Parameter einführen, den sog. Maximalen Wachtumsfaktor. Durch ihn wird über die zusätzliche Bedingung | Δwi (t) | μ | Δw i (t 1 ) | die Gewichtsänderung auf das max. μ -fache der letzten Änderung beschränkt. Hierbei sollte nicht zu groß gewählt werden. Als relativ guter Wert für μ hat sich eine Größenordnung 2 von 1,75 bis 2,25 bewährt. Bei Beginn des Verfahrens oder wenn der vorherige Schritt | Δw i (t) | 0 ist, muß der Lernprozeß (neu) gestartet werden. Üblicherweise geschieht dies durch das Standard-Backpropagation | Δw i (t) | - η F (t) wi Um die Gewichte nicht zu sehr anwachsen zu lassen, kann Quickprop zusätzlich mit Weight Decay kombiniert werden. Das Quickprop-Verfahren ist somit ein iteratives Verfahren zweiter Ordnung zur Bestimmung des Minimums der Fehlerfunktion eines Feedforward-Netzes, welches sich an das NewtonVerfahren anlehnt. Es wurde 1989 von Scott Fahlman entwickelt. In der Praxis hat es sich als ein relativ schnelles Verfahren bewährt, wobei wegen der zugrunde liegenden Heuristiken auch hier Gegenbeispiele existieren. Auch ist der Rechenaufwand für die einzelnen Schritte viel höher als bei dem Standard-Backpropagation-Verfahren. 3 5.5.5 Die δ - δ und die δ - δ -Regel Von Jacobs wurden 1988 in Zusammenarbeit mit Sutton folgende naheliegende Vorschläge zur Verbesserung der Backpropagation-Lernregel gemacht: Die Lernrate beeinflußt maßgeblich, wie stark die Gewichte modifiziert werden. Da aber eine einheitliche Lernrate nicht die, in jeder Dimension unterschiedliche, Krümmungseigenschaft der Fehleroberfläche berücksichtigt, sollte jedes Gewicht eine individuelle Lernrate besitzen. Jede Lernrate sollte mit der Zeit ihren Wert verändern können, da die Eigenschaften der Fehleroberfläche in einer Gewichts-Dimension nicht während des ganzen Verfahrens gleich bleiben. Dabei sollen die folgenden Heuristiken zur Steuerung der Lernraten benutzt werden: 1. Wenn die Ableitung für ein Gewicht über mehrere aufeinanderfolgende Schritte das gleiche Vorzeichen hat, wird seine Lernrate erhöht, da die Gewichts-Dimension dann meist schwach gekrümmt ist. 2. Wechselt die Ableitung für ein Gewicht dagegen in einigen aufeinanderfolgenden Schritten ihr Vorzeichen, so ist die Fehleroberfläche in der entsprechenden Koordinatenrichtung stark gekrümmt, weshalb die Lernrate verringert wird. Auch hier lassen sich Situationen konstruieren, bei denen diese Heuristiken nicht zutreffen und entsprechend dieses Verfahren versagt. Hierzu betrachtet man z.B. eine Oberfläche über einem zweidimensionalen Raum die ein Tal mit stark gekrümmten Wänden besitzt, das im 45-Winkel zu beiden Koordinatenrichtungen liegt. Von einem Punkt aus, der sich in diesem Tal (nicht auf dem Grund) befindet, ist dann die Krümmung der Oberfläche in beiden Koordinatenrichtungen stark, so daß nach Jacobs die zugehörigen Lernraten verringert würden. Besser wäre es dagegen, die Lernraten zu vergrößern, um schneller auf den "Boden" des Tals zu gelangen. Wir betrachten zunächst die erste Heuristik, d.h. die Einführung von individuellen Lernraten. Sei q die Anzahl der Gewichte eines Backpropagation-Netzes (also w IR q ), dann werden statt einer Lernrate η derer q (η1 ,, ηq 0) verwendet. Die neue Lernregel, nach der nun die Gewichte verändert werden, lautet allgemein: w ineu w ialt ηi F , wi oder - für den Gewichtsvektor des Netzes: neu alt alt q w w (η1E1,1 F(w) ηq E q, qF(w)) w ηi Ei,i F(w) . i 1 4 Dabei ist ηi 0 die zu wi gehörende Lernrate und E i,i ist eine q q Matrix, die nur in der i ten Zeile und Spalte eine 1 trägt und sonst in jeder Komponente Null ist (1 i q) . Durch die Verwendung individueller Lernraten wird ein Punkt auf der Fehleroberfläche von der Lernregel auch bei dieser Modifikation nicht mehr in die Richtung des negativen Gradienten verschoben, so daß kein Gradientabstiegsverfahren durchgeführt wird. Tatsächlich liegt nun eine Art Koordinatenabstiegsverfahren vor. Dabei wird nicht mehr F(w) direkt mini miert, sondern für jede Komponente wi von w wird nach dem min w i (F(w)) gesucht. Im Unterschied zu "normalen" Koordinatenabstiegsverfahren aus der Numerik, bei denen alle Gewichte nacheinander verändert werden, wurden hier alle Komponenten von w parallel modifiziert. Es läßt sich zeigen: Satz 5.5/1 Sei G : D IR q IR differenzierbar für w interior (D) . Für ein v IR q gelte G(w)v 0 . Dann gibt es ein β 0 , so daß . G(w α v) G(w), für alle α (0, β) () Beweis: Wegen der Differenzierbarkeit von G in w ist G(w α v) G(w) lim G(w)v 0 . α 0 α Da w interior (D) , gibt es 0 , so daß w α v D, für alle α (0, β) . Aufgrund von () kann dabei so klein gewählt werden, daß aus G ( w)v 0 G(w α v) G(w) G(w)v G(w) v α für alle α (0, β) folgt. G(w α v) G(w) 0 für alle α (0, β) α Behauptung . 5 Mit Hilfe dieses Satzes läßt sich zeigen: Korollar 5.5/1: Das oben beschriebene, parallele Koordinatenabstiegsverfahren besitzt die Eigenschaft der globalen Konvergenz, wenn die Lernraten eine gewisse Schranke nicht überschreiten. Beweis: F ist das MSE-Fehlermaß. Es ist bekannt, daß F : IR q IR differenzierbar in jedem beliebigen Vektor w IRq ist. Sei w IR q beliebig mit F(w) 0 . T F F ,, η'q IR q , Sei v η'1 w wq 1 Dann ist mit η'1 ,, η'q 0 . T q F F F F F 0 . F(w)v ,, η'1 ,, η'q η'i w w w w w i 1 1 q 1 q i 2 Damit sind die Voraussetzungen für Satz 5.5/1 erfüllt und es gilt: Es gibt 0 mit F(w α v) F(w) α (0,β) . Bemerkung: Ist F(w) 0, dann ist v 0 und es gilt : F(w α v) F(w) α IR . Insgesamt folgt die Behauptung, denn die η'i müssen nur so gewählt sein, daß für ein α0 (0,β) gilt : ηi η'i α0 für i 1,, q . α 0 v ist dann der Vektor, den das Koordinatenabstiegsverfahren von w subtrahiert. Die δ δ Regel Die Modifizierung der Gewichte erfolgt, wie oben beschrieben, nach der Regel: w ineu w ialt ηi F w i bzw. anders geschrieben durch w i (t 1) w i (t) ηi (t 1) F(t) w i (t) 6 Dabei ist wi (t) der Wert des Gewichtes wi im Schritt t und ηi (t 1) der Wert der zu wi gehörenden Lernrate im Schritt t 1 . Die Herleitung der Lernregel für die Lernratenmodifikation geschieht analog zur Herleitung der verallgemeinerten δ Regel: Die Regel sollen einen Gradientenabstieg auf einer Fehleroberfläche über dem "Lernratenraum" durchführen (die Fehlerfunktion, die durch Lernratenänderungen minimiert werden soll, ist also F) . Für eine Lernrate ηi ergibt sich trotzdem die folgende Modifizierungsregel, die wieder die Fehlerfunktion F benutzt: ηi (t 1) ηi (t) Δηi (t) Δη I (t) γ F(t) F(t 1) , w i (t) w i (t 1) wobei γ 0 die Schrittweite des Gradientenabstiegs im "Lernratenraum" ist. Stimmen nun die Vorzeichen zweier (zeitlich) aufeinanderfolgender Ableitungen eines Gewichtes überein, wird dessen zugehörige Lernrate vergrößert (ηi (t ) 0) , sonst verkleinert (ηi (t ) 0) . Die Lernraten-Modifizierungsregel der δ δ Lernregel implementiert also zunächst die anfangs beschiebenen Heuristiken Eine genauere Überlegung zeigt jedoch, daß diese Implementation der Vorschläge wieder neue Probleme aufwirft: 1. Auf flachen Gebieten der Fehleroberfläche von F sind beide Ableitungen gleichen Vorzeichens und betragsmäßig klein. Ist ihr Betrag sogar 1 , so ist ihr Produkt noch kleiner. Dadurch wird das Verfahren auf flachen Gebieten immer langsamer. Abhilfe schafft dann nur noch ein Vergrößern von γ , was zu Problemen führt, wenn das Krümmungsverhalten der Fehleroberfläche sich plötzlich ändert. 2. Ein weiteres Problem tritt bei starken Krümmungen auf: Die Ableitungen haben dort möglicherweise betragsmäßig große Werte und unterschiedliche Vorzeichen, so daß Δηi (t) 0 ist. Dann kann sogar ηi (t 1) 0 sein und wi (t 1) wird in eine falsche Richtung verschoben. Dies geschieht noch schneller, falls γ groß ist. Für eine zufriedenstellende Lernraten-Modifikationsregel ist es also nicht ausreichend, die heuristischen Ideen zur Steuerung der Lernraten zu implementieren. Dies darf nicht auf eine so kurzsichtige Art und Weise erfolgen, daß die Steuerung aus anderen Gründen versagt. Daher wird nun ein neuer Ansatz verfolgt, bei dem die Steuerung mit Hilfe einiger zusätzlicher Parameter "überwacht" wird. 7 Die δ δ Regel Auch bei dieser Lernregel sind Regeln zur Modifizierung von Gewichten und Lernraten erforderlich, wobei ebenfalls mit individuellen, variablen Lernraten gearbeitet wird. Die Gewichtsveränderung erfolgt nach derselben Regel wie bei der δ δ Regel. Die Lernraten werden folgendermaßen modifiziert: ηi (t 1) ηi (t) Δηi (t) , hierbei ist κ , falls Δη i (t) φ η i (t) , falls 0 sonst wobei δi (t) δ i (t 1) δ i (t) 0 δ i (t 1) δ i (t) 0 F(t) w i (t) und t δi (t) (1 θ)δi (t) θδi (t 1) (1 θ) θ jδi (t j) j 0 wi (t ) ist ein Gewicht des Netzes im Schritt t ,i (t ) die zugehörige Lernrate und κ, φ, θ sind Konstanten mit φ, θ 0, 1 und κ 0 . Die obige Formel zeigt, daß δ i ein exponentiell gewichteter Durchschnitt der momentanen und aller früheren Ableitungen für wi ist. Je "älter" eine frühere Ableitung ist, desto geringer ist ihr Einfluß auf δi (t ) ; da θ 0, 1 . Die δ δ Regel realisiert die Heuristiken wie folgt: Die δ δ Regel realisiert die Verbesserungsvorschläge wie folgt: Stimmt das Vorzeichen der momentanen (Schritt t ) Ableitung mit dem des exponentiellen Durchschnitts bis zum Schritt (t 1) überein ( die Fehleroberfläche ist flach), wird die Lernrate um eine Konstante κ vergrößert, da in diesem Fall δi (t 1)δi (t) 0 ist. Ist δi (t 1)δi (t) 0 , sind die Vorzeichen unterschiedlich ( die Fehleroberfläche ist stark gekrümmt) und die Lernrate wird um den -ten Anteil verringert. Die Modifikation der Lernraten erfolgt assymetrisch: Die δ δ Regel vergrößert Lernraten linear, womit verhindert wird, daß sie zu schnell zu groß werden können. 8 Die Lernregel verringert die ηi jedoch exponentiell; dadurch ist gewährleistet, daß immer ηi 0 gilt und daß die Lernraten schnell verringert werden können. Somit sind bei dieser Lernregel die Schwächen der δ δ Regel nicht vorhanden und tatsächlich liefert sie in der Praxis sehr zufriedenstellende Ergebnisse. Der Grad der Verbesserung der Leistungsfähigkeit des Netzes hängt nun wesentlich von der Setzung für κ ab: Wird es auf einen zu kleinen Wert gesetzt, können die Lernraten nur langsam wachsen. Damit liegt wieder das inzwischen bekannte Problem auf flachen Gebieten vor. Ist κ dagegen zu groß, wird das gesamte Verfahren zu ungenau, da die Lernraten zu schnell zu groß werden. Die δ δ Regel läßt sich durch zwei weitere Modifikationen noch verbessern: 1. Die δ δ Regel kann mit der Momentum-Variante kombiniert werden 2. Die Einführung eines variablen κ im Zusammenhang mit einer geeigneten Steue rung kann die Leistung der δ δ Regel steigern. Beide Modifikationen lassen sich mit Hilfe von Fuzzy-Controllern realisieren. 9