Algorithmische Skelette
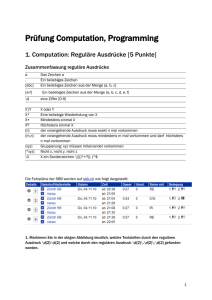
Werbung

Algorithmische Skelette
Michael Bruland
Michael Hüllbrock
Münster, den 12.06.03
Gliederung
(1)
(2)
(3)
(4)
Motivation
Grundlegende Technologien
Algorithmische Skelette
Alternativen zur Implementierung mittels
Bibliothek
(5) Fazit
2
1 Motivation (1)
„Low-Level-Programmierung“ auf Parallelrechnern
häufig erforderlich
Kommunikationsprobleme wie Deadlocks oder
Starvation schnell möglich
Einsatz von Programmiersprachen speziell für
Parallelrechner erfordert neue Einarbeitung
häufig Scheu vor Nutzung neuer
Programmiersprachen
Lernkurveneffekte
3
1 Motivation (2)
Portierbarkeit von Programmen erwünscht
Einsatz von Bibliotheken zur Erweiterung
bestehender Programmiersprachen
Programmiermuster für Parallelrechner
4
Gliederung
(1)
(2)
(3)
(4)
Motivation
Grundlegende Technologien
Algorithmische Skelette
Alternativen zur Implementierung mittels
Bibliothek
(5) Fazit
5
2 Grundlegende Technologien
Funktionen höherer Ordnung (Higher-OrderFunctions)
Parametrisierte Datentypen
Partielle Applikationen
Verteilte Datenstrukturen
6
2.1 Funktionen höherer Ordnung
Gleichstellung von Funktionen und Werten in
funktionalen Sprachen
Funktion mit Funktionen und/oder Ergebnissen als
Argumenten
Neustrukturierung von Problemen aufgrund
allgemeingültiger Berechnungsschemata möglich,
durch Funktionsparameter an Kontext anpassbar
Bsp.:
map : (a b) a b
wendet eine Funktion auf alle Werte
einer Kollektion an
7
2.2 Parametrisierte Datentypen
Schablonen von Berechnungsvorschriften
Typen erst durch Übergabe von Parametern in
Klassendefinition festgelegt
Überprüfung zur Laufzeit auf Typsicherheit
Implementierung in C++ durch Templates
8
2.3 Partielle Applikationen
Funktionen, die mit weniger Argumenten
angewendet werden können als eigentlich benötigt
Anwendung auf restliche Argumente führt zum
selben Ergebnis wie Auflösen der
Ursprungsfunktion
Ermittlung der letzten einstelligen Funktion und
Rückgabe an weitere Funktionen
Currying als Identifikation mehrstelliger Funktionen
mit einstelligen Funktionen höherer Ordnung
Ausgangsfunktion: (t1 , t2 ,..., tn ) t
t1 (t 2 ...(t n t )...)
Mit Currying:
9
2.4 Verteilte Datenstrukturen (1)
Kollektionen wie Listen, Arrays oder Matrizen
Verteilung auf die partizipierenden Prozessoren
Aufteilung durch verschiedene Verfahren möglich
Blockpartitionierung
Zyklische Partitionierung
…
10
2.4 Verteilte Datenstrukturen (2)
Bsp.: Aufteilung einer Matrix auf 4 Prozessoren
x11
x
21
x31
x41
x12
x13
x22
x32
x23
x33
x42
x43
x14
x24
x34
x44
Prozessor1
x11
x
21
x12
x22
Prozessor2
x13
x
23
x14
x24
Prozessor3
x31
x
41
x32
x42
Prozessor4
x33
x
43
x34
x44
11
2.5 Eigenschaften von C++ für die
Nutzung von Skeletten
Polymorphismus
Partielle Applikationen durch Currying ermöglicht
Parametrisierte Datentypen durch Templates
template <class E> class DistributedArray{…}
12
Gliederung
(1)
(2)
(3)
(4)
Motivation
Grundlegende Technologien
Algorithmische Skelette
Alternativen zur Implementierung mittels
Bibliothek
(5) Fazit
13
3 Algorithmische Skelette (1)
Programmiermuster für Interaktion und
Rechenoperationen zwischen Prozessen
Vorimplementierte, parametrisierte Komponenten
Globale Sichtweise bei Implementierung
Entweder Sprachkonstrukte oder Inhalte in
Bibliotheken
Realisierung basiert auf MPI
Abstraktion von „Low-Level-Programmierung“
Hardwareabhängige Implementierung
Portierbarkeit der Programme
14
3 Algorithmische Skelette (2)
Aufbau der Bibliothek in C++
Verteilte Datenstruktur ist Klasse
Nutzung der algorithmischen Skelette durch
Methodenaufrufe der Klassen
15
3.1 Klassifikation algorithmischer
Skelette
Datenparallele Skelette
Rechenskelette
Kommunikationsskelette
Taskparallele Skelette
16
3.2 Datenparallele Skelette (1)
Ermöglichen Ortstransparenz
Beherrschung von Datenparallelität
Aufteilung der Daten auf die Prozessoren
Steuerung der Prozessoren, wo welche Daten
bearbeitet werden sollen
Bsp.: map oder fold
17
3.2 Datenparallele Skelette (2)
Bsp.: Geometrisch
Daten werden partitioniert und auf die Prozessoren
verteilt
Kommunikation zwischen benachbarten Prozessoren
möglich
Ergebnisse werden von einem Prozess geordnet
Anwendung: Vektorberechnung
18
3.2 Datenparallele Skelette (3)
Nach Campbell 1996
19
3.2.1 Rechenskelette (1)
Arbeiten Elemente einer verteilten Datenstruktur
parallel ab
Map: wendet eine Funktion auf Teile einer verteilten
Datenstruktur an
Fold: kombiniert alle Elemente einer verteilten
Datenstruktur sukzessive mit einer
Verknüpfungsfunktion h
20
3.2.1 Rechenskelette (2)
Bsp.: Fold
Verknüpfungsfunktion h ist E plus(E,E)
A ist eine verteilte (4x4)-Matrix
A.fold(plus)
x11
x
21
x12
x22
x13
x
23
x14
x24
x31
x
41
x32
x42
x33
x
43
x34
x44
bildet die Summe über alle Elemente ( x11,..., x44 )
21
3.2.2 Kommunikationsskelette (1)
Tauschen Partitionen einer verteilten Datenstruktur
aus
Realisierung basiert auf MPI
Kein Austausch individueller Nachrichten erlaubt
→ Probleme wie Deadlock, Starvation etc. werden
verhindert
22
3.2.2 Kommunikationsskelette (2)
Bsp.: A.permutePartition(f)
x11
x
21
x12
x22
Partition Ai (an Prozessor i) wird an Prozessor f(i)
gesendet
Weiteres Kommunikationsskelett: rotate
23
3.3 Taskparallele Skelette (1)
Verarbeiten Strom von Eingabewerten in Menge von
Ausgabewerten
Teilen den Prozessoren Tätigkeiten zu
Tätigkeit kann Funktion oder wiederum Skelett sein
Verschachtelung von Skeletten möglich
Kann mit Funktion oder partieller Applikation
aufgerufen werden
24
3.3 Taskparallele Skelette (2)
Bsp.: Farm
Anzahl der Prozessoren ist gleich Anzahl der Worker
Auswahl vom Farmer nicht-deterministisch
Atomic
Worker
Initial
Atomic
Worker
Farmer
Final
Quelle: Kuchen 2002
25
3.3 Taskparallele Skelette (3)
Initial-Prozess
template <class O>
class Initial: public Process{
public:
Initial(O* (*f)(Empty))
void start()
}
26
3.3 Taskparallele Skelette (4)
Farm-Prozess
template<class I, class O>
class Farm: public Process{
public:
Farm(Process& worker, int n)
void start()
}
27
3.3 Taskparallele Skelette (5)
Final-Prozess
template <class I>
class Final: public Process{
public:
Final(void(*f)(I))
void start()
}
28
3.3 Taskparallele Skelette (6)
Bsp.: Divide and Conquer
Probleme werden rekursiv in Subprobleme unterteilt
Lösung der Subprobleme erfolgt unabhängig von
einander und parallel
Je nach Implementierung
unterschiedliche Anforderungen an Struktur
Unterstützung von konservativer und spekulativer
Parallelität
Anwendung: Quicksort, Branch and Bound
29
3.3 Taskparallele Skelette (7)
Nach Campbell 1996
30
3.3 Taskparallele Skelette (8)
Bsp.: Branch and Bound
Anwendung: Optimierungsprobleme
Vorgehensweise:
n Worker-Kopien durch Konstruktoraufruf
Verknüpfung mit internem Controller
Teillösungen werden vom Controller im Heap
gesammelt, falls besser als bestehende
Suboptimale Lösungen werden verworfen
31
3.3 Taskparallele Skelette (9)
Bsp.: Branch and Bound
template <class I>
class BranchAndBound:public Process{
public:
BranchAndBound(Process& worker, int n, bool
(* lth)(I,I), bool (* isSolution)(I))
void start()
}
32
3.4 Das 2-Ebenen-Modell (1)
Modell zur Kombination von task- und
datenparallelen Skeletten
äußere Ebene: miteinander verzahnte
taskparallele Skelette
innere Ebene: sequentielle Programme und
datenparallele Skelette
33
3.4 Das 2-Ebenen-Modell (2)
Aufgabe: Ein Musikstück soll
von Hintergrundrauschen befreit werden,
Hall hinzugefügt werden,
in ein best. Dateiformat (z.B. wav) konvertiert
werden
Lösung mit 2-Ebenen-Modell:
Äußere Ebene : Pipeline
Innere Ebene : sequentielle Bearbeitung oder
datenparalleles Skelett
34
3.5 Zusätzliche Funktionen
Keine Skelette
Flexible Optimierung des Quellcodes
Lokale und globale Sichtweise möglich
Beispiele:
getLocalRows() gibt die Anzahl der lokal
verfügbaren Zeilen zurück
getRows() gibt die Anzahl der Zeilen der
gesamten verteilten Matrix zurück
isLocal (int i, int j) ist wahr, wenn das Element mit
dem Index i,j lokal verfügbar ist
…
35
3.6 Laufzeitverhalten (1)
Skelette sind ein abstraktes Konstrukt
Wie hoch sind die Performanzeinbußen von Skeletten
gegenüber einer „reinen“ MPI Implementierung?
Vergleich von 5 Beispielprogrammen auf einer
Siemens hpcLine mit 4 bzw. 16 Prozessoren
36
3.6 Laufzeitverhalten (2)
Beispiel
n
Skelette
35.203
MPI
Quotient
Matrix Multiplikation
1024
29.772
1.18
Kürzester Pfad
1024
393.769 197.979
1.99
Gauss’sches
Eliminationsverfahren
1024
13.816
9.574
1.44
FFT
218
2.127
1.295
1.64
Samplesort
218
1.599
†
-
Quelle: Kuchen 2002
37
3.6 Laufzeitverhalten (3)
Beispiel
n
Skelette
MPI
Quotient
Matrix Multiplikation
1024
8.624
6.962
1.24
Kürzester Pfad
1024
93.825
44.761
2.10
Gauss’sches
Eliminationsverfahren
1024
7.401
4.045
1.83
FFT
218
0.636
0.403
1.58
Samplesort
218
0.774
†
-
Quelle: Kuchen 2002
38
3.6 Laufzeitverhalten (4)
Fazit Laufzeitverhalten:
Skelette sind um den Faktor 1,2 bis 2,1 langsamer
als „reines“ MPI
Grund:
Overhead bei der Parameterübergabe
Fehlende Optimierungsroutinen
39
3.7 Beispiele mit algorithmischen
Skeletten
3.7.1 Gauß‘sches Eliminationsverfahren
3.7.2 Matrixmultiplikation
40
3.7.1 Gauß (1)
Eliminationsverfahren nach Gauß
Lösungsmenge und Rang einer n x (n+1) Matrix
Hier: zusätzliche Voraussetzung a1,1 ≠ 0
Idee: Reduzierung der Variabeln durch
Addition/Subtraktion der einzelnen Zeilen mit der
Pivotzeile
41
3.7.1 Gauß (2)
#include „Skeleton.h“
inline double init(const int a, const int b){
return (a==b) ? 1.0 : 2.0;}
inline double copyPivot(const DistributedMatrix<double>&A,
int k, int i, int j, double Pij){
return A.isLocal(k,k) ? A.get(k,k) : 0;}
42
3.7.1 Gauß (3)
inline void pivotOp(const DistributedMatrix<double>& Pivot, int
rows,int firstrow, int k, double** A){
double Alk;
for (int l=0; l<rows; l++){
Alk = A[l][k];
for (int j=k; j<=Problemsize; j++)
if (firstrow+1 == k)
A[l][j] = Pivot.getLocalGlobal(0,j);
else A[l][j] -= Alk * Pivot.getLocalGlobal(0,j);}}
43
3.7.1 Gauß (4)
void gauss(DistributedMartix<double>& A){
DistributedMatrix<double>
Pivot(sk_numprocs,Problemsize+1,0.0,sk_numprocs,1);
for (int K=0; k<Problemsize; k++){
Pivot.mapIndexInPlace(curry(copyPivot)(A)(k));
Pivot.broadcastPartition(k/A.getLocalRows(),0);
A.mapPartitionInPlace(curry(pivotOp)(Pivot,A.getLocalRows();
A.getFirstRow(),k));}}
44
3.7.1 Gauß (5)
int main(int argc, char **argv){
try{
InitSkeletons(argc, argv);
DistributedMatrix<double>
A(Problemsize,Problemsize+1,&init,sk_numprocs, 1);
gauss(A);
A.show();
TerminateSkeletons();}
catch(Exception&){cout << “Exception” << endl <<flush;}
}
45
3.7.1 Gauß (6)
Ausführung auf 3-Prozessor-Maschine
Pivot.mapIndexInPlace(curry(copyPivot)(A)(k))
kopiert die Pivotzeile (I) in eine p x (n+1), also
eine 3x4 Matrix
broadcastPartition übermittelt diese Zeile weiter
Mit mapPartitionInPlace wird auf jeder Partition der
Matrix parallel pivotOP ausgeführt
46
3.7.1 Gauß (7)
die Zeile II wird mit -(9/6 * I) addiert und die Zeile
III mit –(3/6 * I)
Weitere Schritte analog
47
3.7.2 Matrixmultiplikation (1)
Matrixmultiplikation
Idee:
Multiplikation zweier verteilter Matrizen
A und B durch Blockpartitionierung und
Aufteilung auf n Prozessoren
48
3.7.2 Matrixmultiplikation (2)
#include „Skeleton.h“
#include „math.h“
inline int negate(const int a) {return –a;}
inline int add(const int a, const int b) {return a+b;}
template <class C>
C sprod (const DistributedMatrix<C>& A,
const DistributedMatrix<C>& B, int i, int j, C Cij){
C sum=Cij;
for(int k=0;k<A.getLocalRows();k++)
sum+=A.getGlobalLocal(i,k))*B.getLocalGlobal(k,j);
return sum;}
49
3.7.2 Matrixmultiplikation (3)
template <class C>
DistributedMatrix<C> matmult(DistributedMatrix<C>
A,DistributedMatrix<C> B){
//assumption: A, B have same square shape
A.rotateRows(& negate);
B.rotateCols(& negate);
DistributedMatrix<C> R(A.getRows(),A.getCols(),0,
A.getBlocksInCol(),A.getBlocksInRow());
for(int i=0;i<A.getBlocksInRow();i++){
R.mapIndexInPlace(curry(sprod<C>)(A)(B));
A.rotateRows(-1);
B.rotateCols(-1);}
return R;}
50
3.7.2 Matrixmultiplikation (4)
int main(int argc, char **argv){
try{
InitSkeletons(argc,argv));
int sqrtp=(int) (sqrt(sk_numprocs)+0.1);
DistributedMatrix<int> A(Problemsize,Problemsize,
& add, sqrtp, sqrtp);
DistributedMatrix<int> B(Problemsize,Problemsize,
& add, sqrtp,sqrtp);
DistributedMatrix<int> C=matmult(A,B);
C.show();
TerminateSkeletons();}
catch(Exception&){cout << “Exception” << endl << flush;};
}
51
Gliederung
(1)
(2)
(3)
(4)
Motivation
Grundlegende Technologien
Algorithmische Skelette
Alternativen zur Implementierung mittels
Bibliothek
(5) Fazit
52
4 Alternativen zur Bibliothek
P3L
SkIE
53
4.1 P3L (1)
Pisa Parallel Programming Language
Basiert auf C++
Skelette farm, map, pipe und loop sind vordefiniert
<skelettname> <bezeichner> in(<par>) out(<par>)
<prozedur> in(<p>) out(<p>)
end <skelettname>
54
4.1 P3L (2)
farm myfarm in(int inputA, int inputB) out(int
output)
p in(inputA,inputB) out(output)
end farm
Anzahl der Worker wird vom Compiler selbstständig
ermittelt
Compiler versucht den Speedup zu maximieren
„Mapping Problem“ wird durch implementation
templates gelöst
55
4.1 P3L (3)
Ausführung in 3 Stufen:
1.
Emitter empfängt Datenstrom und verteilt ihn an die
Worker
2.
Worker führen Prozesse aus und geben das Ergebnis
an den Collector
3.
Collector empfängt Ergebnisse und schreibt sie in
den Ausgabekanal
56
4.2 SkIE (1)
Skeleton-based Integrated Enviroment
Vorteile gegenüber P3L
Breitere Sprachunterstützung (C, C++, F90, Java,
…)
Einbindung von MPI und HPF
Grafische Benutzeroberfläche (VisualSkIE)
Analysetools
57
4.2 SkIE (2)
58
4.2 SkIE (3)
Anwendungsentwicklung mit SkIE in 3 Phasen:
Phase 1: Generieren des Codes und globale
Optimierungen
Phase 2: Debugging
Phase 3: Performanzanalyse
59
Gliederung
(1)
(2)
(3)
(4)
Motivation
Grundlegende Technologien
Algorithmische Skelette
Alternativen zur Implementierung mittels
Bibliothek
(5) Fazit
60
5 Fazit (1)
Skelette befreien den Programmierer von
Problemen der parallelen Hardware
Portierbarkeit von Programmen
Globale Sichtweise bei Konzeption und
Programmierung
Kommunikationsprobleme wie Deadlock oder
Starvation können nicht vorkommen
Integration einer Bibliothek in eine bekannte
Sprache überbrückt „Berührungsängste“
61
5 Fazit (2)
Vermeidung von Lernkurveneffekten durch Nutzung
bekannter Programmiersprachen
Kostenabschätzungen möglich
Performanzeinbußen sind im akzeptablem Rahmen
62
Fragen / Diskussion
63