Statistische Methodenlehre
Werbung

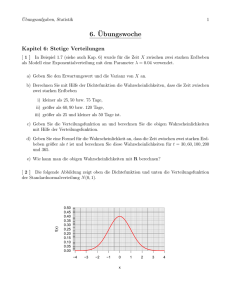
Vorschau Statistische Methodenlehre KE 1 1.3 Merkmale 1.3 Seite: 15 Merkmale Bei einer statistischen Analyse werden, wie oben gesagt wurde, statistische Einheiten erfasst. Man interessiert sich jedoch meistens nicht für die Einheit schlechthin (Ausnahme: wenn man die Anzahl von Einheiten, die zu einer Masse gehören, ermitteln will), sondern für irgendwelche Eigenschaften der Einheiten. Weiter oben wurde z.B. darauf hingewiesen, dass bei einer Volkszählung Angaben über Alter, Geschlecht, Religionszugehörigkeit, Beruf, Einkommen usw. der erfassten Personen erfragt wird. Eine Eigenschaft einer statistischen Einheit, für die man sich bei einer statistischen Untersuchung interessiert, heißt Merkmal. Für allgemeine Aussagen werden die Merkmale mit großen lateinischen Buchstaben bezeichnet: X, Y, Z, A, B, . . . . Da die Merkmale an den statistischen Einheiten erhoben werden, werden letztere auch als Merkmalsträger bezeichnet. Beispiel 9: a) statistische Einheit: Student Merkmale: Alter, Schulabschluss, Studienfach, Statistiknote b) statistische Einheit: landwirtschaftlicher Betrieb Merkmale: Ackernutzfläche, Rinderbestand, Milchproduktion in einem Monat Welche Merkmale bei den statistischen Einheiten erfasst werden, hängt von der jeweiligen Aufgabenstellung ab. Wegen des mitunter erheblichen Erhebungsaufwands ist es bei statistischen Untersuchungen manchmal empfehlenswert, möglichst viele Merkmale zu erfassen, auch wenn zunächst noch nicht sicher ist, ob alle erfassten Merkmale für die Analyse wirklich benötigt werden. Beispiel 10: Soll das Sparverhalten der Bundesbürger untersucht werden, so ist von vornherein nicht mit Sicherheit zu sagen, ob z.B. das Zinsniveau das Sparverhalten wesentlich beeinflusst. Man wird also das Merkmal Zinsniveau“ zunächst miterfassen und erst im Verlauf der statistischen ” Untersuchung entscheiden, ob es für die weitere Analyse berücksichtigt werden muss oder nicht. Merkmal Merkmalsträger KE 2 2.3 Zentralwert oder Median Seite: 35 In vielen Analysen reicht es aus, eine empirische Verteilung mittels mehrerer Charakteristika in Form des sogenannten Box-Plots grafisch darzustellen. In der einfachsten Variante werden die fünf Kennzahlen x̃0,25 , x̃0,5 , x̃0,75 , xmin und xmax herangezogen. Bei einem einfachen Box-Plot werden die Quartile x̃0,25 und x̃0,75 durch eine Box dargestellt, in deren Inneren der Median als Punkt oder als Linie dargestellt ist. Die Extremwerte xmin und xmax werden mit der Box durch Striche ( whisker“) ” verbunden. Folgende Grafik zeigt eine Variante des einfachen Box-Plots, bei der nicht die Extremwerte mit der Box verbunden sind sondern der größte und der kleinste normale“ Wert, der noch nicht als Ausreißer angesehen wird. ” Ausreißer werden hierbei mittels eines Kreises dargestellt. Als Ausreißer gelten Werte, die weiter als 1,5 Boxlängen unterhalb bzw. oberhalb der Box liegen. Zugrundegelegt wurden die Arbeitslosenzahlen aus 33 Agenturen für Arbeit in NRW im Februar 2008. Abbildung 11: Arbeitslosenzahlen nach Altersklassen sortiert, Box-Plot erstellt mit SPSS 15.0 Box-Plot Seite: 14 1 HÄUFIGKEITSVERTEILUNGEN ZWEIER MERKMALE KE 3 In den Wirtschaftswissenschaften und den anderen Anwendungsgebieten der Statistik (z.B. der Medizin oder Biologie) lassen sich Zusammenhänge nicht immer eindeutig durch eine Funktion beschreiben. Das wollen wir uns an dem folgenden Beispiel klarmachen. Beispiel 4: Bei 40 Personen wurden die Körpergrößen x(in cm) und Körpergewicht y(in kg) gemessen. Für jede Person erhält man dann ein Paar von Messergebnissen (xi , yi ). xi gibt die Körpergröße und yi das Körpergewicht der Person Nummer i an. Die Messergebnisse sind in der folgenden Tabelle enthalten. Größe xi in cm 150 150 150 150 152 153 155 155 157 160 Gewicht yi in kg 48 51 55 58 63 57 50 63 70 58 xi 160 160 160 165 165 165 166 167 170 170 yi 63 68 75 55 62 73 79 65 60 75 xi 170 170 172 175 175 175 176 176 178 180 yi 80 85 68 64 68 84 73 77 93 65 xi 180 180 181 185 186 186 186 189 189 189 yi 75 85 89 80 74 85 90 77 85 96 Diese Wertepaare kann man in einem (x, y)-Koordinatensystem grafisch 1 als Punkte darstellen, so wie im folgenden Bild. 3abb1.nb Gewicht in kg y 100 90 80 ≈ 70 ≈ 60 50 150 160 170 180 190 Größe in cm Abbildung 1: Grafische Darstellung x KE 3 1.1 Das gemeinsame Auftreten von Merkmalen Abbildung 1 macht deutlich, dass zwischen Körpergröße und Körpergewicht der untersuchten Personen kein eindeutiger Zusammenhang besteht. Man kann die beiden Merkmale nicht über eine einfache Funktion zueinander in Beziehung setzen. Andererseits ist aus der Zeichnung zu erkennen, dass größere Leute im Schnitt auch schwerer sind. Körpergröße und Körpergewicht hängen offensichtlich voneinander ab, wobei diese Beziehung aber nur tendenziell gilt. Bei großen Personen wird man im Durchschnitt ein höheres Gewicht registrieren als bei kleineren. Im Einzelfall muss diese Aussage nicht zutreffen, wie ein Vergleich der beiden in Abbildung 1 besonders kenntlich gemachten Punkte zeigt. Im einen Punkt hat man eine Person, die 180 cm groß und 65 kg schwer ist und im anderen Fall eine, die nur 160 cm groß, aber 75 kg schwer. Das Beispiel zeigt deutlich das wichtigste Problem bei der Betrachtung des gemeinsamen Auftretens mehrerer Merkmale. Zwischen den Ausprägungen der Merkmale besteht ein tendenzieller Zusammenhang. Dieser lässt sich aber für die Beobachtungswerte nicht auf eine eindeutige Form bringen. Deshalb untersucht man vor allem zwei Fragen: • Wie ausgeprägt ist ein Zusammenhang? Tritt er sehr deutlich hervor, ist er nur schwach oder ist gar kein Zusammenhang vorhanden? • Von welchem Typ ist ein Zusammenhang oder die durchschnittliche Tendenz eines Zusammenhangs? Ist er linear oder quadratisch oder von einer anderen Form? Seite: 15 KE 3 1.3 Grafische Darstellung zweidimensionaler Verteilungen 1.3 Seite: 21 Grafische Darstellung zweidimensionaler Verteilungen Ein wichtiger Gesichtspunkt, der bei der grafischen Darstellung zweidimensionaler Verteilungen zu beachten ist, ist die Übersichtlichkeit. Inwieweit die Übersichtlichkeit gewährleistet werden kann, hängt nicht nur von der Darstellungsform sondern auch von der Struktur des Datensatzes ab. Desweiteren wird die Wahl der Darstellungsform von der zugrundeliegenden Zielsetzung bestimmt. Im folgenden sind für das Beispiel 6 und die Aufgabe 2 zwei verschiedene Darstellungsformen gewählt. Eine dreidimensionale Grafik und ein zweidimensionales Säulendiagramm, bei dem die Säulen nach dem zweiten1 3abb3neu.nb Merkmal unterteilt sind. I Anlageart I A V A V 14 8 4 M 12 Geschlecht 6 14 10 8 8 6 6 F 4 2 12 10 4 2 2 0 F M Geschlecht I 1 Mathematiknote 1 2 3 4 5 10 8 6 4 A Anlageart 2 3 1 V 4 5 5 4 24 Mathematiknote 3abb3neu.nb 24 20 20 3 16 16 12 12 8 8 2 2 4 4 1 0 2 1 4 3 5 Englischnote 1 2 3 4 Englischnote 5 Abbildung 3: Häufigkeitsverteilungen der Daten aus Beispiel 6 und Aufgabe 2. KE 3 4.2 Lineare Kleinste-Quadrate-Regression 4.2 Lineare Kleinste-Quadrate-Regression Aufgabe der Regressionsrechnung ist es, die Tendenz des Zusammenhangs zwischen quantitativen Merkmalen durch eine einzige Funktionsgleichung ŷ = f (x) zu beschreiben. Da y in Abhängigkeit von x beschrieben wird, spricht man auch von y-x-Regressionsfunktion. Das ŷ wird bei Regressionsfunktionen aus folgendem Grund verwendet: Regressionsfunktionen beschreiben im allgemeinen nicht einen eindeutigen Zusammenhang, sondern nur die durchschnittliche Tendenz eines statistischen Zusammenhangs zwischen Merkmalen. Die einzelnen Paare von Beobachtungswerten (xj , yj ) werden im allgemeinen nicht auf der Regressionsfunktion liegen, sondern um die Funktion herum streuen. Es wird also nicht ein Zusammenhang zwischen den Ausprägungen x des Merkmals X und den genauen Werten des Merkmals beschrieben, sondern ein Zusammenhang zwischen den Ausprägungen des Merkmals X und den zugehörigen durchschnittlichen Werten des Merkmals Y . Zu einem gegebenen x-Wert lässt sich über die Regressionsfunktion nicht eindeutig ein y-Wert bestimmen, sondern nur der Durchschnittswert y des Merkmals Y zu diesem x-Wert. Bei der Bestimmung einer Regressionsfunktion geht man folgendermaßen vor: Der Typ der Regressionsfunktion wird vorgegeben. Man legt fest, ob der Zusammenhang zwischen den quantitativen Merkmalen durch eine Gerade: Parabel: Potenzfunktion: Exponentialfunktion: ŷ ŷ ŷ ŷ = a + bx = a + bx + cx2 = axb = abx oder einen anderen Funktionstyp beschrieben werden soll. Mit der Vorgabe eines Funktionstyps ist das Problem der Bestimmung einer Regressionsfunktion aber noch nicht gelöst. Aus den unendlich vielen Geraden (oder Parabeln oder Exponentialfunktionen oder Funktionen eines anderen Typs) ist diejenige herauszusuchen, die den Zusammenhang möglichst gut beschreibt. Seite: 45 Seite: 46 4 Kriterium der Kleinsten Quadrate REGRESSIONSRECHNUNG KE 3 Die Koeffizienten der Regressionsfunktion werden so bestimmt, dass die Summe der quadrierten Abweichungen der Beobachtungswerte y, von den Regressionsfunktionswerten f (xi ) ein Minimum wird (Kriterium der KleinstenQuadrate). Für den Fall einer linearen y-x-Regressionsfunktion besagt das Kriterium der Kleinsten-Quadrate, dass die Koeffizienten a und b der linearen y-xRegressionsfunktion ŷ = a + bx so zu bestimmen sind, dass die Summe der Quadrate der Abweichungen ui = yi − ŷi der y-Koordinaten yi der beobachteten Wertepaare (xi ; yi ) von den durch die Regressionsfunktion bestimmten Koordinaten ŷi = a + bxi , ein Minimum wird. Wenn insgesamt n Wertepaare vorliegen, bestimmt man also a und b so, dass die Funktion f (a, b) = n X i=1 3abb6.nb 2 (yi − ŷi ) = n X (yi − a − bxi )2 i=1 ein Minimum wird. Abbildung 6 verdeutlicht den Zusammenhang. y ` Hxi ,yi =a+bxi ) ` ` ui =yi-yi Hxi ,yi L a x Abbildung 6: Streuungsdiagramm mit Regressionsgerade 1 KE 3 5.2 Korrelationskoeffizient eines linearen Zusammenhangs 5.2 Seite: 61 Korrelationskoeffizient eines linearen Zusammenhangs Wir haben in Abschnitt 1.6 die Kovarianz als Parameter für die gemeinsame Streuung zweier Merkmale eingeführt. Dividiert man die Kovarianz Cov(XY ) durch das Produkt der Standardabweichungen (s̃x bzw. s̃y ) der Randverteilungen der beiden Merkmale, so erhält man den Korrelationskoeffizienten, der nach dem englischen Statistiker Pearson benannt wurde. Der Pearsonsche Korrelationskoeffizient Pn (xi − x)(yi − y) Cov(X, Y ) r = = pPn i=1 Pn 2 2 s̃x · s̃y i=1 (yi − y) i=1 (xi − x) Pn xi yi − nx y = p Pn 2 i=1 2 Pn 2 ( i=1 xi − nx )( i=1 yi − ny 2 ) ist ein Maß für den Grad des linearen Zusammenhangs zweier quantitativer Merkmale. Beispiel 20: Für die Häufigkeitsverteilung in Beispiel 10, wurde als Kovarianz COV(X, Y ) = −0, 08 errechnet. Bei Vorliegen einer zweidimensionalen Häufigkeitsverteilung erfolgt die Berechnung der einzelnen Standardabweichungen für X und Y über die entsprechende Randverteilung. r p 1 (4 · 15 + 0 · 20 + 4 · 15) = 2, 4 = 1, 55 s̃x = 50 und r s̃y = p 1 (1 · 15 + 0 · 25 + 1 · 5 + 4 · 5) = 0, 8 = 0, 89. 50 Für den Pearsonschen Korrelationskoeffizienten ergibt sich damit r= −0, 08 = −0, 05799. 1, 55 · 0, 89 Pearsonscher Korrelationskoeffizient Seite: 62 5 KORRELATIONSRECHNUNG KE 3 Der Pearsonsche Korrelationskoeffizient kann Werte im Bereich von −1 bis +1 annehmen, d.h. es gilt: −1 ≤ r ≤ 1. Liegt überhaupt kein linearer Zusammenhang vor, so gilt r = 0. Liegen alle Beobachtungswerte auf einer steigenden Geraden, so gilt r = 1. Liegen alle Wertepaare auf einer fallenden Geraden, so gilt: r = −1. 3abb12.nb Je enger sich die Beobachtungswerte um eine Gerade scharen, desto näher kommt der Wert des Korrelationkoeffizienten +1 oder -1. Abbildung 12 verdeutlicht das. 1 y r=1 y r = -1 x y x y rª1 x y rª0 r ª -1 x Abbildung 12: Streuungsdiagramm mit unterschiedlichen Korrelationskoeffizienten x Seite: 34 3 3.4 DIE WAHRSCHEINLICHKEIT KE 6 Statistische Definition der Wahrscheinlichkeit Die in diesem Abschnitt behandelte statistische Definition der Wahrscheinlichkeit beruht auf einem Zusammenhang zwischen relativen Häufigkeiten und Wahrscheinlichkeiten. Wir betrachten ein Zufallsexperiment, das wir unter völlig gleichen Bedingungen beliebig oft durchführen können. Wir führen dieses Zufallsexperiment nacheinander n-mal durch und registrieren nach jeder Durchführung die relative Häufigkeit für das Auftreten des Ereignisses A. Wenn wir diese relativen Häufigkeiten näher betrachten, werden wir folgendes feststellen: Bei den ersten Versuchen schwanken die berechneten relativen Häufigkeiten für das Auftreten des Ereignisses A sehr stark. Je größer die Anzahl der Versuche des Zufallsexperimentes ist, desto enger schwanken die relativen Häufigkeiten um einen festen Wert. Dazu betrachten wir folgendes Beispiel. Beispiel 20: Ein Würfel wurde 200-mal hintereinander geworfen Nach jedem Durchgang wurde die relative Häufigkeit für das Ereignis A= Auftreten ” der Augenzahl 6“ registriert. Für jeden Durchgang ist die Anzahl n der Würfe (x-Achse) und die zugehörige relative Häufigkeit fn (A) (y-Achse) in Bild 3 grafisch dargestellt. Dieser Vorgang wurde 9 mal wiederholt. Frequenz.nb 1 0.75 0.5 0.25 0 -0.25 -0.5 0 50 100 150 200 Abbildung 3: Relative Häufigkeit für das Auftreten von Augenzahl 6“ in Abhängigkeit der Anzahl ” der Würfelwürfe 1 KE 6 3.4 Statistische Definition der Wahrscheinlichkeit Seite: 35 In Beispiel 20 schwanken die relativen Häufigkeiten immer weniger um den Wert 16 . Je häufiger man das Zufallsexperiment durchführt, desto besser stabilisieren sich die relativen Häufigkeiten. Offensichtlich streben die relativen Häufigkeiten einem Grenzwert“ zu. Dieser Grenzwert ist ” die Wahrscheinlichkeit für das Ereignis A. Diese Eigenschaft der relativen Häufigkeit führt uns zu der statistischen Definition der Wahrscheinlichkeit. Nach der statistischen Definition ist die Wahrscheinlichkeit für das Auftreten des Ereignisses A gleich dem Grenzwert der relativen Häufigkeiten, den man erhält, wenn man das Zufallsexperiment unendlich oft durchführt: statistische Definition der Wahrscheinlichkeit P (A) = lim fn (A). n→∞ Da es uns in der Wirklichkeit nicht möglich ist, ein Zufallsexperiment unendlich oft durchzuführen, ist es natürlich ebenso unmöglich, auf die angegebene Art eine Wahrscheinlichkeit zu bestimmen. Die Bedeutung der statistischen Definition der Wahrscheinlichkeit ergibt sich für uns daraus, dass wir über die Berechnung von relativen Häufigkeiten zumindest eine Annäherung an die dem Zufallsexperiment zugrunde liegenden Wahrscheinlichkeiten bekommen. Bei zahlreichen Fragestellungen der angewandten Wahrscheinlichkeitsrechnung und Statistik, bei denen es unmöglich ist, auf andere Art Wahrscheinlichkeiten zu ermitteln, verwendet man die beobachteten relativen Häufigkeiten als Näherungen oder Schätzungen für die (unbekannten) Wahrscheinlichkeiten. Die statistische Definition der Wahrscheinlichkeit verschafft uns den leichtesten Zugang zum Wahrscheinlichkeitsbegriff und stellt außerdem für zahlreiche praktische Fragestellungen, wie bereits erwähnt, die einzige Möglichkeit zur Bestimmung von Wahrscheinlichkeiten dar. Man spricht dann manchmal auch von sogenannten empirischen Wahrscheinlichkeiten. empirische Wahrscheinlichkeit Seite: 32 6 6 6.1 NORMALVERTEILUNG KE 8 Normalverteilung Definition der Normalverteilung Die Normalverteilung ist die wichtigste stetige Verteilung. Sie spielt bei nahezu allen Anwendungen der Statistik eine große Rolle. Normalverteilung Dichtefunktion Die Dichtefunktion der Normalverteilung lautet: 1 (x − µ)2 fX (x) = √ exp − 2σ 2 σ 2π Die Verteilungsfunktion der Normalverteilung ist nicht mehr mit Hilfe elementarer Funktionen darstellbar. Die Parameter der Normalverteilung lauten: Erwartungswert und Varianz E(X) = µ und Var(X) = σ 2 . Eine normalverteilte Zufallsvariable X wird als N (µ, σ 2 )verteilt bezeichnet. Die Schreibweise lautet X ∼ N (µ, σ 2 ). Erwartungswert und Varianz bzw. Standardabweichung der Normalverteilung lassen sich also unmittelbar aus der Dichtefunktion ablesen. Aus der Dichtefunktion ergibt sich, dass die Normalverteilung in einem konkreten Fall durch die Angabe von µ und σ 2 jeweils spezifiziert werden muss. Es gibt also nicht nur eine Normalverteilung, sondern eine ganze Klasse von Normalverteilungen. Die Dichtefunktion der Normalverteilung hat folgende typische Gestalt: 8abb7.nb fHxL m-s m m+s Abbildung 6: Dichtefunktion der Normalverteilung x 1 KE 8 6.1 Definition der Normalverteilung Seite: 33 Die Dichtefunktion ist symmetrisch und hat ihren Gipfel bei x = µ. An den Stellen x = µ − σ und x = µ + σ befinden sich Wendepunkte. In der Abbildung 7 sind Normalverteilungen für verschiedene Werte von µ und 1 8abb813.nb σ 2 dargestellt. Dichtefunktion fHxL Dichtefunktion NH0,1L fHxL 0.4 0.4 0.3 0.3 0.2 0.2 0.1 0.1 -3 -2 -1 0 1 2 3 -3 -2 -1 0 4 x Dichtefunktion fHxL fHxL 0.4 0.4 0.3 0.3 0.2 0.2 0.1 0.1 1 2 3 fHxL 0.4 0.4 0.3 0.3 0.2 0.2 0.1 0.1 1 2 3 4 x 1 2 3 4 x 3 4 x Dichtefunktion NH0,3L -3 -2 -1 0 2 NH1,2L -3 -2 -1 0 4 x Dichtefunktion fHxL 1 Dichtefunktion NH0,2L -3 -2 -1 0 NH1,1L 3 4 x NH1,3L -3 -2 -1 0 1 2 Abbildung 7: Verschiedene Normalverteilungen Die Normalverteilung mit dem Erwartungswert 0 und der Varianz 1, also N (0, 1), heißt Standardnormalverteilung. Will man die Wahrscheinlichkeit dafür bestimmen, dass ein normalverteiltes Merkmal X zwischen x1 und x2 liegt, d.h., sucht man P (x1 ≤ X ≤ x2 ), so müsste man dazu das folgende Integral ausrechnen: Standardnormalverteilung Seite: 12 2 2 SCHÄTZFUNKTIONEN UND PUNKTSCHÄTZUNG KE 10 Schätzfunktionen und Punktschätzung 2.1 Schätzfunktionen Die Ausführungen dieses Abschnitts knüpfen unmittelbar an Kurseinheit 9, insbesondere die Abschnitte 4 und 5 an. Dabei beschäftigen wir uns hier zunächst mit Punktschätzungen, die auf den folgenden Grundgedanken aufbauen: Es soll ein unbekannter Parameter (z.B. µ, Θ oder σ 2 oder ein anderer) der Grundgesamtheit geschätzt werden. Diesen unbekannten Parameter bezeichnen wir allgemein mit q. Für die Schätzung wird der Grundgesamtheit eine Zufallsstichprobe entnommen. Ihre Elemente werden als Realisationen der Zufallsvariablen X1 , X2 , ..., Xn aufgefasst. Aus den Stichprobenwerten muss nun ein geeigneter Schätzwert q̂ für den unbekannten Parameter q berechnet werden. Zur Ermittlung eines Schätzwertes q̂ für den Parameter q dient die Stichprobenfunktion Q̂n = Q̂n (X1 , ..., Xn ), die vom Umfang und den Elementen der Stichprobe abhängt. Schätzfunktion Schätzwert Punktschätzung Eine für Schätzungen verwendete Stichprobenfunktion heißt auch Schätzfunktion. Der sich für bestimmte Stichprobenwerte x1 , x2 , ..., xn ergebende Wert q̂ der Schätzfunktion heißt Schätzwert oder Punktschätzung. Als Schätzfunktion verwendet man in vielen Fällen den Stichprobenparameter, der dem zu schätzenden Parameter der Grundgesamtheit entspricht, wie die folgenden Beispiele zeigen. Beispiel 1: a) Die Schätzfunktion n 1X X= Xi n i=1 liefert einen Schätzwert µ̂ für den Mittelwert (Parameter µ) der Grundgesamtheit bzw. für den Erwartungswert E(Xi ) der Zufallsvariablen Xi . KE 10 2.1 Schätzfunktionen Seite: 13 b) Die Schätzfunktion ( 0 mit Xi = 1 n 1X X = P = Xi n n i=1 für A tritt ein“ ” für A tritt ein“ ” liefert einen Schätzwert Θ̂ für den Anteilswert Θ der Grundgesamtheit bzw. für die unbekannte Wahrscheinlichkeit Θ für das Auftreten des interessierenden Ereignisses A. Der aus den Stichprobenwerten x1 , x2 , ..., xn berechnete Wert der Schätzfunktion ist der Schätzwert für den unbekannten, wahren Wert des Parameters der Grundgesamtheit. ··· Eine Schätzfunktion Q̂ für einen Parameter q ist eine Zufallsvariable, die bei einem Merkmal durch eine Dichtefunktion fQ̂ (q̂) beschrieben werden kann. In Abbildung 2 sind die Dichtefunktionen von drei Schätzfunktionen für denselben Parameter q eingezeichnet. 10abb1.nb 1 ` fQ` i HqiL fQ` 2 fQ` 3 fQ` 1 ` EHQiLi=1,2 ` EHQ3L Abbildung 1: Dichtefunktion drei verschiedener Schätzfunktionen für denselben Parameter q ` qi KE 12 4.2 Der Vorzeichentest 4.2 Seite: 53 Der Vorzeichentest Es wird von zwei beliebig verteilten Grundgesamtheiten ausgegangen, und es soll die Hypothese geprüft werden, ob beide Grundgesamtheiten die gleiche Verteilung haben. Aus beiden Grundgesamtheiten werden Stichproben vom Umfang n gezogen (X1 , ..., Xn und Y1 , ..., Yn ), wobei man die einzelnen Stichprobenwerte als Paare (Xi , Yi ) erhält. Die Zufallsvariable Zi definiert man als Zi = Xi − Yi und es sei Di = 1 falls Zi > 0 0 falls Zi < 0 i = 1, ..., n Ist Zi = Xi − Yi = 0, so lässt man das entsprechende Wertepaar unberücksichtigt und reduziert entsprechend n. Ist die Nullhypothese, dass beide Grundgesamtheiten die gleiche Verteilung besitzen, richtig, dann muss die Anzahl der positiven Differenzen genau so groß sein wie die der negativen Differenzen. Die Summe Dn = n X Di i=1 ist also B(n; 0, 5)-verteilt und wird als Prüfgröße des Vorzeichentests verwendet. Dn entspricht der Anzahl der positiven Differenzen. Die zu einem gegebenen Signifikanzniveau α gehörenden Annahmebereichsgrenzen cu und co können dann mittels der Binomialverteilung bestimmt werden, indem man die Werte x bestimmt, bei der die Verteilungsfunktion FX (x) den Wert α2 bzw. 1 − α2 annimmt. Da die Binomialverteilung eine diskrete Verteilung ist, wird man dabei meistens auf benachbarte Werte zurückgreifen müssen, die einem kleineren Signifikanzniveau entsprechen. Testgröße Dn Seite: 54 4 VERTEILUNGSFREIE TESTVERFAHREN KE 12 Beispiel 16: Die Untersuchung des Weizenertrages bei der Verwendung zweier unterschiedlicher Düngemittel A und B unter sonst gleichen Bedingungen hat folgendes Ergebnis geliefert (die Düngemittel wurden jeweils auf benachbarten Flächenstücken angewendet, die fortlaufend nummeriert worden sind): Fläche 1 2 3 4 5 6 7 8 9 10 Düngemittel A 46 58 50 50 52 46 46 58 55 45 Düngemittel B 48 49 49 48 45 47 42 56 56 50 Differenz -2 Fläche 11 12 13 14 15 16 17 18 19 20 Düngemittel A 48 60 52 40 44 50 50 56 44 60 Düngemittel B 40 55 49 38 47 45 49 54 42 50 Differenz 8 9 5 1 3 2 2 7 -3 -1 5 4 1 2 -1 2 -5 2 10 Es ist zu testen, ob die Düngemittel signifikant unterschiedliche Ergebnisse liefern. Die Nullhypothese lautet: Beide Düngemittel liefern den gleichen Durchschnittsertrag. Für die Anzahl Dn der positiven Vorzeichen, die Testgröße, erhalten wir die Ausprägung dn = 15. Dn ist B(20; 0, 5)-verteilt. Bei einem Signifikanzniveau von 0,05 erhalten wir als Annahmegrenzen cu = 6 und co = 14. Da dn = 15 > 14 = co ist, wird die Nullhypothese abgelehnt. Seite: 14 3 3 Phasen des Forschungsprozesses DER FORSCHUNGSPROZESS KE 13 Der Forschungsprozeß Im Rahmen des quantifizierenden Paradigmas lassen sich Phasen des Forschungsprozesses unterscheiden, die möglicherweise mehrmals durchlaufen werden. Ein grafisches Schema ist Abb. 1 zu entnehmen (vgl. Schnell et al. 1999, S. 8, Bortz, 1999, S. 3). Nach Bortz (1999, S. 3 ff) werden die Stadien 1. Erkundungsphase, 2. Theoretische Phase 3. Planungsphase 4. Untersuchungsphase 5. Auswertungsphase 6. Entscheidungsphase unterschieden. 3.1 Exploration In der Erkundungsphase muss das Problemfeld exploriert werden (Literaturrecherche, Kontakt zu einschlägigen Forschern und Praktikern bzw. den entsprechenden Institutionen oder Firmen). Dabei soll die eigene Studie in einen theoretischen Kontext eingeordnet werden. Je nach Gegenstand gibt es elaborierte Theorien oder man betritt wissenschaftliches Neuland. Aus Theorien können dann Folgerungen und Hypothesen abgeleitet werden. In der explorativen Phase ist ein besonders starkes Wechselspiel zwischen Theorie und Empirie zu beobachten, das die größte Nähe zu den qualitativen Methoden aufweist. Auch sind hier erste Voruntersuchungen (explorative Studien) einzuordnen. 3.2 theoretische Struktur Erkundungsphase Theoretische Phase Empirische Überprüfungen einer Theorie sind nur sinnvoll, wenn zumindest ihre theoretische Struktur bestimmte Gütekriterien erfüllt. Man muss prüfen, ob 1. die Theorie präzise formuliert ist, 2. ob sie einen Informationsgehalt besitzt, KE 13 3.2 Theoretische Phase Abbildung 1: Phasen der empirischen Forschung (Bortz, 1999) Seite: 15 Seite: 16 3 DER FORSCHUNGSPROZESS KE 13 3. logisch konsistent ist, 4. mit anderen Theorien vereinbar 5. und empirisch überhaupt überprüfbar ist. Erläuterungen zu den einzelnen Punkten: Indikatoren Operationalisierung Likert-Skala Falsifikatoren Konditionalsatz 1. Grundlegend ist die möglichst präzise Definition der Begriffe, die in einer Theorie vorkommen (Konzeptspezifikation, Operationalisierung). Beispielsweise ist der Begriff ethnische Identität zunächst unklar, da zuerst die Teilbegriffe Ethnisch und Identität definiert und abgegrenzt werden müssen. Damit in Zusammenhang steht die Frage, ob es beobachtbare Sachverhalte (Indikatoren) gibt, die mit den theoretischen Begriffen möglichst übereinstimmen. Die Frage, wie den Begriffen die Indikatoren zugeordet werden, wird unter dem Titel Operationalisierung geklärt. Dies beinhaltet Anweisungen, wie Messungen vorgenommen werden sollen. Etwa wird Intelligenz durch Ausfüllen eines Intelligenz-Tests und einer bestimmten Aggregationsmethode der Teilaufgaben (items) operationalisiert. Meistens ist dies die Summe (der Rohwerte; Likert-Skala) und darauf folgende Standardisierungen. 2. Der Informationsgehalt (empirische Gehalt) der Aussagen einer Theorie bezieht sich auf ihre Falsifikatoren. Betrachtet man sogenannte Konditionalsätze (wenn-dann-Satz oder je-desto-Satz), so steigt der Informationsgehalt mit der Zahl der Ereignisse, die mit dem dann (bzw. desto)-Teil in Widerspruch stehen. Beispielsweise ist für den Satz A: Wenn der Blutalkoholspiegel 0.5 Promille übersteigt, sinkt die Reaktionsfähigkeit der Nachweis einer verbesserten Reaktionsfähigkeit ein Falsifikator. Dagegen sind Sätze wie B: Wenn der Hahn kräht auf dem Mist, ändert sich das Wetter oder es bleibt wie es ist nicht falsifizierbar, da der Dann-Teil immer wahr ist. Auch verringern vage, unpräzise Begriffe den Informationsgehalt eines Satzes, etwa kann die Reaktionsfähigkeit durch präzise Reaktionszeitmessungen oder lediglich durch Beobachtung ermittelt werden. Im ersteren Fall gibt es mehr Ereignisse, die dem Satz widersprechen. KE 13 3.2 Theoretische Phase 3. Theoretische Aussagen sollten keine Tautologien oder Kontradiktionen sein, die immer wahr oder falsch sind. Etwa ist Satz B tautologisch, da er immer wahr ist (und daher auch nicht empirisch überprüft werden muss). Versteckte Tautologien stecken in Kann-Sätzen, etwa Seite: 17 Tautologien, Kontradiktionen C: Rauchen kann Krebs verursachen. In diesem Fall ist sowohl das Auftreten als auch das Nicht-Auftreten von Krebs mit der Aussage vereinbar. Überprüfbar wird der Satz erst durch eine Häufigkeits- oder Wahrscheinlichkeitsaussage, etwa D: Bei Rauchern ist die Wahrscheinlichkeit für Krebs höher als bei Nichtrauchern. Entsprechend müssen die bedingten Häufigkeiten für Krebs in den Gruppen der Raucher/Nichtraucher ermittelt und getestet werden, jedoch ist im Einzelfall keine empirische Überprüfung möglich. 4. Liegen mehrere Theorien vor, die sich auf den gleichen Gegenstandsbereich beziehen, so muss untersucht werden, ob logische Widersprüche zwischen den Theorien bestehen. Sind keine logischen Widersprüche auffindbar, so bedeutet dies nicht, dass die Theorien wahr sind. Dies kann, wie gesagt, nur durch empirische Überprüfung herausgefunden werden. 5. Schließlich muss die empirische Überprüfbarkeit (bzw. Falsifizierbarkeit) der Theorie analysiert werden. Es ist möglich, dass eine Theorie im Prinzip falsifizierbar ist, jedoch beim gegenwärtigen Stand der Forschung die Begriffe noch nicht genau oder weit genug meßbar sind. Dann müssen erst geeignete Meßinstrumente entwickelt werden. Beispiel 4: In der physikalischen Forschung sind bestimmte Theorien erst dann überprüfbar, wenn neue Beschleuniger gebaut werden, die Prozesse mit hoher Energie zum Nachweis bestimmter Elementarteilchen erlauben. Im Allgemeinen kann eine Theorie nicht vollständig überprüft werden, sondern nur bestimmte Folgerungen und deduzierte Teilaspekte. logische Widersprüche Verifikation, Falsifikation