Diskussion und Implementierung von Varianten des FP
Werbung

Leibniz Universität Hannover
Fakultät für Elektrotechnik und Informatik
Fachgebiet Datenbanken und Informationssysteme
Studienarbeit
im Studiengang Mathematik mit Studienrichtung Informatik
Diskussion und Implementierung von
Varianten des FP-Growth Algorithmus in
relationalen Datenbanksystemen
Maria Soldatova
Matr.-Nr. 2323220
Prüfer: Prof. Dr. Udo Lipeck
Betreuer: Dipl.-Math. Christian Stahlhut
28. September 2007
Erklärung
Hiermit versichere ich, dass ich die vorliegende Arbeit selbständig verfasst und dabei
nur die angegebenen Quellen und Hilfsmittel verwendet habe.
Hannover, den 28. September 2007
Maria Soldatova
Danksagung
Ich bedanke mich bei Herrn Dipl.-Math. Christian Stahlhut für die hervorragende
Betreuung meiner Studienarbeit.
INHALTSVERZEICHNIS
Inhaltsverzeichnis
1
2
3
4
Einleitung
2
1.1
Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
1.2
Gliederung dieser Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . .
2
Data Mining und Assoziationsanalyse
3
2.1
Aufgaben des Data Mining . . . . . . . . . . . . . . . . . . . . . . . . . .
3
2.2
Assoziationsanalyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3
2.3
Apriori-Algorithmus
4
Assoziationsanalyse ohne Kandidatengenerierung
8
3.1
Konstruktion des Frequent-Pattern Tree
8
3.2
Mining von frequenten Mustern mit Hilfe des FP-trees
. . . . . . . . . .
11
3.3
Top Down FP-Growth für Frequent Pattern Mining . . . . . . . . . . . .
17
. . . . . . . . . . . . . . . . . .
Implementierung
20
4.1
Verschiedene Möglichkeiten der SQL-basierten Implementierung
. . . . .
20
4.2
Überblick
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
28
4.3
Vorbereitung der Input-Daten . . . . . . . . . . . . . . . . . . . . . . . .
29
4.4
4.5
4.6
4.7
5
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Konstruktion des FP-tree . . . . . . . . . . . . . . . . . . . . . . . . . . .
31
4.4.1
Initialisieren der Header-Tabelle . . . . . . . . . . . . . . . . . . .
32
4.4.2
Bestimmung der ersten Items
33
4.4.3
Aufbau der Tabelle für die Darstellung des FP-tree
. . . . . . . . . . . . . . . . . . . .
. . . . . . . .
33
Mining des FP-tree . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
35
4.5.1
Erzeugung von Muster
. . . . . . . . . . . . . . . . . . . . . . . .
36
4.5.2
Bestimmung der Pfade . . . . . . . . . . . . . . . . . . . . . . . .
38
4.5.3
Aktualisieren der SIDELINKS-Attribute
4.5.4
Bestimmung der Sub-Header-Tabelle
Umwandlung der Ergebnisses
. . . . . . . . . . . . . .
39
. . . . . . . . . . . . . . . .
39
. . . . . . . . . . . . . . . . . . . . . . . .
40
. . . . . . . . . . .
41
4.7.1
Anwendung des Algorithmus am Beispiel (MovieDB)
Beispiel 1
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
41
4.7.2
Beispiel 2
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
43
Zusammenfassung
Literatur
45
46
1
Maria Soldatova
1
Studienarbeit
Einleitung
1.1
Motivation
Ansammlungen von Daten sind in der heutigen Zeit nicht mehr wegzudenken und sie
werden in Zukunft noch eine viel gröÿere Bedeutung einnehmen. Dabei kann es sich um
Kundendaten bei Banken und Versicherungen handeln, um die eingekauften Waren im
Supermarkt oder um den Datenverkehr im Internet. Überall dort sammeln sich riesige
Datenmengen an. Daraus ergibt sich jedoch das Problem der Verarbeitung der Daten.
Es müssen Lösungen gefunden werden, diese Masse an Daten beherrschbar zu machen,
um für den Benutzer sinnvolle Informationen aus ihnen gewinnen zu können. Genau mit
diesem Problem beschäftigt sich das Data Mining im Allgemeinen. Es soll sich in der
vorliegenden Arbeit jedoch auf ein Teilgebiet des Data Mining konzentriert werden, und
zwar auf die Suche nach häug vorkommenden Elementen in Datenmengen. Dies stellt
die wichtigste Grundlage für weitere Schritte der Verarbeitung im Data Mining dar, wie
zum Beispiel für die Bildung von Assoziationsregeln.
Die Datenanalyse mittels Assoziationsregeln ist eines der am häugsten eingesetzten Data Mining-Verfahren. Am Forschungszentrum der IBM in Almaden, Kalifornien,
USA, wurden Anfang der neunziger Jahre Assoziationsregeln als Methode der Abhängigkeitsanalyse eingeführt und erste Algorithmen zur Assoziationsregelgenerierung entwickelt. Der erste veröentlichte eziente Algorithmus zu dieser Thematik stammt von
Agrawal mit dem Namen Apriori (AS94). In dieser Arbeit soll zunächst eine kurze
Übersicht über diesen Algorithmus und seine Eigenschaften gegeben werden. Der zweite
grundlegende Ansatz, der gemacht wurde, stammt von Han et al. und trägt den Namen
FP-Growth (HPY00). Dieser Algorithmus und einige Varianten davon werden in dieser
Arbeit ausführlich vorgestellt und anhand von Beispielen analysiert. Weiterhin werden
einige Möglichkeiten der SQL-basierten Implementierung dieses Algorithmus besprochen
und eines der vorgestellten Verfahren auch getestet.
1.2
Gliederung dieser Arbeit
Die nachfolgenden Abschnitte sind folgendermaÿen gegliedert.
Kapitel 2 erläutert grundlegende Begrie des Data Mining und insbesondere der
Assoziationsanalyse. In diesem Kapitel wird der Apriori-Algorithmus als Ausgangspunkt
vorgestellt.
Kapitel 3 beschreibt eine neue Datenstruktur (den FP-tree), auf der sich der FPGrowth Algorithmus stützt, die Konstruktion dieses Baums und wichtige Eigenschaften
des FP-tree. Weiterhin wird der Prozess des Data Mining mit Hilfe von FP-trees beschrieben. Es werden der Algorithmus FP-Growth und die Eigenschaften, die für ihn
bedeutend sind, vorgestellt. Am Schluss dieses Kapitels wird eine weitere Variante des
Data Mining mit FP-trees vorgestellt, nämlich Top Down FP-Growth.
Im
Kapitel 4 werden verschiedene Ansätze zur Implementierung des FP-Growth
Algorithmus besprochen. Eine Implementierung wird anhand von Beispielen getestet.
2
Maria Soldatova
2
Studienarbeit
Data Mining und Assoziationsanalyse
2.1
Aufgaben des Data Mining
Data Mining bezeichnet den Prozess der Identizierung von versteckten und bisher unbekannten, aber interessanten und potentiell nutzbaren Zusammenhängen und Mustern
patterns )
(engl.:
in groÿen Datenmengen, also die Anwendung ezienter Algorithmen,
welche die in einer Datenbank enthaltenen gültigen Muster nden (ES00). Die wichtigsten Data Mining Aufgaben werden im Folgenden kurz erläutert:
•
Clustering/Entdecken von Ausreiÿern: Ziel des Clustering ist die Partitionierung
einer Datenbank in Gruppen (Cluster) von Objekten, so dass Objekte eines Clusters möglichst ähnlich, Objekte verschiedener Cluster möglichst unähnlich sind.
Ausreiÿer sind Objekte, die zu keinem der gefundenen Cluster gehören.
•
Klassikation: Gegeben sind hier Trainingsobjekte mit Attributwerten, die bereits
einer Klasse zugeordnet sind. Es soll eine Funktion gelernt werden, die zukünftige
Objekte aufgrund ihrer Attributwerte einer der Klassen zuweist.
•
Assoziationsanalyse: Gegeben ist eine Datenbank von Transaktionen. Assoziationsanalyse hilft die häug auftretenden und starken Zusammenhänge innerhalb
der Transaktionen zu nden.
2.2
Assoziationsanalyse
Das klassische Beispiel für die Anwendung der Assoziationsanalyse ist die sogenannte
Warenkorbanalyse. Ein einzelner Warenkorb ist eine Menge von zusammen eingekauften
Artikeln, Dienstleistungen oder Informationen eines Anbieters. Gegeben ist dabei eine
Datenbank von Warenkörben, die gewisse Kundentransaktionen repräsentieren. Als Beispiel für eine solche Transaktionsdatenbank kann die Sammlung der Daten, die durch die
Scannerkassen eines Supermarkts erhoben werden, dienen. Assoziationsregeln drücken
Zusammenhänge innerhalb der Transaktionen aus, die in der gesamten Datenmenge
häug vorkommen. Im Supermarkt-Beispiel können Zusammenhänge zwischen häug
gemeinsam gekauften Artikeln etwa durch Regeln der folgenden Art ausgedrückt wer-
⇒
den: (Mehl, Eier)
Butter. Diese Regel gilt, wenn in allen Warenkörben, die schon
Mehl und Eier enthalten, häug auch noch Butter enthalten ist. Diese Regel wäre natürlich nur dann interessant, wenn genügend viele Warenkörbe sowohl Mehl und Eier
als auch Butter enthalten. Das Wissen um solche Zusammenhänge kann auf vielfältige
Weise angewendet werden, beispielsweise Cross Marketing, für verbessertes KatalogDesign und Laden-Layout, oder etwa auch für eine automatische Kundensegmentierung
anhand von gemeinsamen, durch Assoziationsregeln ausgedrücktem Einkaufsverhalten.
Im Folgenden werden die wichtigsten Begrie erläutert:
Sei
X ⊆I
I = {i1 , ..., im }
wird auch
eine Menge von Literalen, genannt
Itemset
Items. Eine Menge von Items
genannt. Typischerweise sind die Items in
I
Bezeichnungen
oder Identikatoren von einzelnen Waren.
D
sei eine Menge von Transaktionen
eine Transaktion
T
T,
wobei
T ⊆ I.
Typischerweise repräsentiert
einen einzelnen Einkauf oder Warenkorb, und
D
repräsentiert eine
Datenbank, die alle Einkäufe eines Geschäfts in einem bestimmten Zeitraum abspeichert.
3
Maria Soldatova
Studienarbeit
X , das
X = (x1 , x2 , ..., xk ).
Ein Itemset
aus den Items
x1 , x2 , ..., xk
besteht, kann geschrieben werden als
Die Anzahl der Elemente in einem Itemset heiÿt Länge des Itemsets, und ein Itemset
der Länge
k
heiÿt auch
Für eine Menge
k-Itemset.
X⊆I
von Items ist der
prozentualle Anteil der Transaktionen in
X
D,
Support
Eine Itemset gilt als
X
in
D
deniert als der
X enthalten. Der Support einer Menge
in X vorkommenden Waren zusammen
die
ist also die relative Häugkeit, mit der die
gekauft wurden.
der Menge
frequent, wenn diese den denierten minimalen Support
für die
Assoziationsregel übersteigt.
Eine
Assoziationsregel
ist eine Implikation der Form
X ⇒ Y,
wobei
Itemsets sind, die kein gemeinsames Element haben, das heiÿt es gilt:
und
X ∩Y =∅
Der
X
∪
.
Support s
Y in
D,
X und Y zwei
X ⊆ I, Y ⊆ I
einer Assoziationsregel
X⇒Y
in D ist der Support der Vereinigung
das heiÿt die relative Häugkeit des gemeinsamen Auftretens aller Items
oder Waren, die in der Assoziationsregel vorkommen.
Die
Condence c
einer Assoziationsregel
X ⇒ Y in D ist deniert als der
Y enthalten, in der Teilmenge
zentualle Anteil der Transaktionen, die die Menge
proaller
D, welche die Menge X enthalten. Man kann auch sagen, eine Assoziationsregel X ⇒ Y gilt mit der Condence c in der Menge D von Transaktionen,
wenn c% aller Transaktionen in D , die X enthalten, auch Y enthalten. Die folgende TaTransaktionen aus
belle illustriert den Support und die Condence einer Assoziationsregel in einer kleinen
Beispieldatenbank
D.
Transaktion
gekaufte Items
1
Brot, Kaee, Milch, Kuchen
2
Kaee, Milch, Kuchen
3
Brot, Butter, Kaee, Milch
4
Milch, Kuchen
5
Brot, Kuchen
6
Brot
X = {Kaf f ee, M ilch}: 3 von 6 = 50%
Support von R = {Kaf f ee, Kuchen, M ilch}: 2 von 6 = 33%
Support von M ilch, Kaf f ee → Kuchen: = Support(R) = 33%
Condence von M ilch, Kaf f ee → Kuchen: 2 von 3 = 67% [= Support(R)/Support(X)]
Support von
Die Assoziationsanalyse wird normalerweise in zwei Phasen aufgeteilt: die erste Phase besteht aus der Bestimmung der frequenten Itemsets in der Datenbank und in der
zweiten Phase werden die Assoziationsregeln aus den frequenten Itemsets generiert. Für
die Bestimmung der frequenten Itemsets wurden verschiedene Methode entwickelt und
einige davon werden in den nächsten Abschnitten beschrieben.
2.3
Apriori-Algorithmus
Der Apriori-Algorithmus ist einer der bekanntesten Algorithmen für das Mining von den
frequenten Items für Assoziationsregeln und wurde 1994 von R.Agrawal und R.Srikant
4
Maria Soldatova
Studienarbeit
vorgeschlagen (AS94). Der Apriori-Algorithmus basiert auf der folgenden MonotonieEigenschaft für frequente Itemsets, die Apriori-Eigenschaft genannt wird:
menge eines frequenten Itemsets muss selbst auch frequent sein.
Jede Teil-
Um diese Eigenschaft
auszunutzen, müssen frequente Itemsets der Gröÿe nach bestimmt werden, das heiÿt
es müssen zuerst die einelementigen frequenten Itemsets bestimmt werden, dann die
zweielementigen usw.
Allgemein werden zum Finden von
(k + 1)-elementigen
(k+1)-elementigen frequenten Itemsets nur solche
k -elementigen
Teilmengen gezählt, die durch einen Join-Schritt aus
Itemsets gebildet werden können, von denen man schon weiÿ, dass sie häug in der Datenbank vorkommen. Der Algorithmus durchläuft mehrmals die Datenmenge, solange
bis bei einer bestimmten Länge keine frequenten Itemsets mehr gefunden werden können.
und
Lk bezeichnet dabei die Menge aller häug vorkommenden Itemsets der Länge k ,
Ck bezeichnet die zu zählenden Kandidaten-Itemsets der Länge k . Im ersten Schritt
werden die einelementigen Itemsets bestimmt, die minimalen Support haben. In allen
folgenden Durchläufen werden aus den im jeweils vorhergehenden Durchlauf bestimmten
k −1 Elementen) neue Kandidaten-Itemsets (mit k Elementen)
gebildet. Der Support dieser Kandidaten wird gezählt, indem für jede Transaktion T in
der Datenbank geprüft wird, welche der aktuellen Kandidaten in T enthalten sind. Anfrequenten Itemsets (mit
schlieÿend werden aus den Kandidaten diejenigen Itemsets für den nächsten Durchlauf
ausgewählt, die minimalen Support haben. Dies sind gleichzeitig die frequenten Itemsets
der Länge
k.
Die Kandidatengenerierung ist das Kernstück des Apriori-Algorithmus. Die Kandidaten der Länge
k + 1 werden in zwei Schritten gebildet, wobei vorausgesetzt wird, dass
die Items in den Itemsets lexikographisch sortiert sind. Im ersten Schritt (Join) wird
k -elementigen frequenten Itemsets mit sich selbst durchgeführt. Dabei wird
k -elementige frequente Itemset p jeweils um das letzte Item aller k -elementigen frequenten Itemsets q verlängert, welche mit p in den ersten k − 1 Items übereinstimmen.
ein Join der
jedes
Im zweiten Schritt (Pruning) werden aus der Menge der im Join-Schritt generierten
Kandidaten alle Itemsets entfernt, welche eine
nicht in der Menge der
(k − 1)-elementigen
k − 1-elementige Teilmenge enthalten, die
frequenten Itemsets vorkommt.
Die folgenden Tabellen illustrieren den Ablauf des Apriori-Algorithmus mit dem
minimalen Support 40% oder absoluten minimalen Support 1,6.
Datenbank D
Trans-ID
Items
100
A C D
200
B C E
300
A B C E
400
B E
C1
L1
Itemset
Sup.
Itemset
Sup.
(A)
2
(A)
2
DB-
(B)
3
(B)
3
Skan.
(C)
3
(C)
3
(D)
1
(E)
3
(E)
3
5
Maria Soldatova
Studienarbeit
C2
Itemset
C2
Sup.
L2
Itemset
Sup.
Itemset
Sup.
(A B)
1
(A C)
2
(A C)
(A B)
DB-
(A C)
2
(B C)
2
(A E)
Skan.
(A E)
1
(B E)
3
(C E)
2
(B C)
2
(B E)
(B C)
(B E)
3
(C E)
(C E)
2
C3
Itemset
(B C E)
C3
Sup.
L3
DB-
Itemset
Sup.
Itemset
Sup.
Skan.
(B C E)
2
(B C E)
2
Im Folgenden wird der Pseudo-Code des Algorithmus vorgestellt und erläutert (Han05).
Zeile 1 des Apriori-Algorithmus ndet
wird
Lk−1
für
k ≥ 2
L1
- frequente 1-Itemsets. In den Zeilen 2-12
benutzt um Kandidaten
Ck
zu generieren um
Lk
zu nden. Die
Kandidaten werden in der Zeile 3 generiert. Wenn alle Kandidaten generiert wurden,
wird die Datenbank durchlaufen (Zeile 4). Für jede Transaktion wird eine Funktion
benutzt, um alle Teilmengen der Transaktion zu nden, die in Frage kommen (Zeile 5),
6
Maria Soldatova
Studienarbeit
und der Zähler wird für jeden der Kandidaten erhöht (Zeile 6, 7 und 8). Anschlieÿend
bilden alle Kandidaten, die den minimalen Support haben (Zeile 11), die Menge
L
von
frequenten Itemsets (Zeile 13).
7
Maria Soldatova
3
Studienarbeit
Assoziationsanalyse ohne Kandidatengenerierung
In den meisten Fallen hat der Apriori-Algorithmus eine gute Performance, die durch
das Reduzieren der Gröÿe der Kandidatenmengen zustande kommt. Aber es gibt Situationen, z.B. bei groÿer Anzahl von Mustern, bei langen Mustern oder bei kleinem
minimalem Support, in denen der Apriori-Algorithmus enormen Aufwand hat (HPY00):
•
Es kann nötig sein eine enorme Anzahl von Kandidatenmengen zu generieren;
4
z.B. wenn es 10 frequente 1-Itemsets gibt, dann muss der Algorithmus mehr als
107 2-Kandidaten generieren. Auÿerdem braucht er mindestens 2100 − 1 ≈ 1030
Kandidaten, um ein frequentes Muster der Länge 100 zu nden.
•
Es kann nötig sein, die Datenbank mehrmals zu durchlaufen und groÿe Kandidatenmengen zu prüfen, aber es kostet sehr viel Aufwand, jede Transaktion in der
Datenbank zu prüfen, um den Support der Kandidaten-Itemsets zu bestimmen.
Um diese Probleme zu beheben, wurde ein Algorithmus entwickelt, der in diesem Kapitel
vorgestellt wird. Dieser Algorithmus heiÿt Frequent-Pattern Growth oder FP-Growth
und stützt sich auf einen divide and conquer Ansatz: Die Datenbank wird in mehrere
kleinere Datenbanken aufgeteilt und anschlieÿend wird für jede dieser Datenbanken das
Mining durchgeführt. Der Algorithmus vermeidet bei dem Mining der frequenten Itemsets die aufwändige Kandidatengenerierung und wandelt die Transaktions-DB in eine
komprimierte Form - einen Baum um, den sog. Frequent-Pattern Tree oder FP-tree, was
den Vorteil hat, dass die Datenbank nicht mehrmals durchsucht werden muss.
3.1
Konstruktion des Frequent-Pattern Tree
Für den FP-Growth Algorithmus muss zuerst eine neue Datenstruktur, nämlich der
FP-tree, ausgehend von folgenden Beobachtungen deniert werden:
•
Es ist notwendig, die Transaktions-DB einmal zu durchsuchen, um die Menge von
frequenten Items zu bestimmen.
•
Die Transaktions-DB muss nur einmal durchsucht werden, wenn die Menge von
frequenten Items für jede Transaktion in einer kompakten Datenstruktur gespeichert werden kann.
•
Wenn einige Transaktionen gleiche Teilmengen von frequenten Items besitzen, ist
es möglich diese Teilmengen gemeinsam zu speichern.
•
Es ist leichter zu prüfen ob zwei Mengen identisch sind, wenn die frequenten Items
in bestimmter Reihenfolge sortiert sind; zum Beispiel wenn die frequenten Items
in der absteigenden Häugkeit des Auftretens sortiert sind.
Basierend auf diesen Beobachtungen kann diese Datenstruktur folgendermaÿen deniert
werden:
8
Maria Soldatova
Studienarbeit
item-prex Teilfrequent-item-header
1. Sie enthält einen Baum, der eine leere Wurzel, eine Menge von
bäumen (von der Wurzel ausgehende Teilbäume) und eine
Tabelle hat. In der frequent-item-header Tabelle wird ein Zeiger auf das erste
Auftreten jedes Items in dem Baum gespeichert.
2. Jeder Knoten in einem item-prex Teilbaum besteht aus drei Feldern:
count
und
node-link,
item-name,
wobei item-name den Namen des Items enthält, count die
Anzahl der Transaktionen, die Items aus den zu diesem Knoten führenden Pfad
enthalten und node-link einen Zeiger auf den nächsten Knoten mit dem gleichen
item-name, wenn es solche gibt.
3. Jede Zeile in der frequent-item-header Tabelle hat folgende zwei Felder:
name
- Name des Items - und
head of node-link
item-
- Zeiger auf den ersten (in der
Reihenfolge des Einfügens der Transaktionen in den Baum) Knoten in dem FP-tree
mit demselben item-name.
Der FP-tree wird wie folgt konstruiert: im ersten Durchlauf der Transaktions-DB werden die frequenten 1-Itemsets bestimmt; die frequenten Items werden danach absteigend
nach der Häugkeit ihres Auftretens sortiert; die Transaktions-DB wird erneut durchlaufen und der FP-tree aufgebaut. Folgendes Beispiel illustriert die Konstruktion des
FP-tree. Sei folgende Transaktions-DB gegeben mit dem minimalen Support gleich 3:
TID
Gekaufte Items
(Sortierte) frequente Items
100
f, a, c, d, g, i, m, p
f, c, a, m, p
200
a, b, c, f, l, m, o
f, c, a, b, m
300
b, f, h, j, o
f, b
400
b, c, k, s, p
c, b, p
500
a, f, c, e, l, p, m, n
f, c, a, m ,p
Im ersten Durchlauf der Transaktions-DB werden die frequenten Items bestimmt,
die sich jetzt in der rechten Spalte der Tabelle benden. Die Häugkeit des Auftretens (Support) jedes Items wird gezählt, mit dem minimalen Support verglichen und
9
Maria Soldatova
Studienarbeit
die Liste der frequenten Items wird absteigend nach dem Support des Items sortiert:
h(f : 4), (c : 4), (a : 3), (b : 3), (m : 3), (p : 3)i. Die Reihenfolge dieser sortierten Liste legt
die Reihenfolge der Knoten beim Einfügen der Transaktionen in den zu konstruierenden Baum fest. Als Nächstes wird eine leere Wurzel des Baums erstellt. Beim zweiten
Durchlauf lässt sich aus der ersten Transaktion der erste Ast des Baums konstruieren:
h(f : 1), (c : 1), (a : 1), (m : 1), (p : 1)i.
Die Reihenfolge der Knoten entspricht der
Reihenfolge der sortierten Liste der frequenten Items. Die zweite Transaktion hat den
gemeinsamen Präx
hf, c, ai mit dem schon existierenden Pfad, deshalb wird der Zähler
(count) für jeden Knoten in diesem Präx um eins erhöht und es werden die neuen
Knoten
(b : 1)
als Kind-Knoten von
(a : 2)
und
(m : 1)
als Kind-Knoten von
stellt. Ähnlich in der dritten Transaktion wird der Zähler von Knoten
und ein neuer Knoten
(b : 1)
f
(b : 1)
er-
um eins erhöht
(f : 3) erstellt. Die vierte Transh(c : 1), (b : 1), (p : 1)i. Die letze Transaktion
als Kind-Knoten von
aktion liefert den zweiten Ast des Baums:
ist identisch mit der ersten, deshalb werden die Zähler für die entsprechenden Knoten
inkrementiert. Am Ende ergibt sich der oben angegebene FP-tree. Es kann jetzt der
Ablauf der Konstruktion des FP-tree vorgestellt werden:
DB. Sammle F, eine Menge von frequenten Items
und den Support von jedem frequenten Item auf. Sortiere F absteigend nach dem
Support. Sei FList eine Liste dieser sortierten Items.
1. Durchlaufe einmal die Datenbank
2. Erstelle die Wurzel
R
3. Für jede Transaktion
des Baums.
Trans
in
DB :
Trans und sortiere sie in der Reihenfolge der Liste
FList. Diese sortierte Elementen aus Trans sind von der Form [p|P], wobei p
der erste Element aus Trans und P die restliche Liste ist.
• Rufe insert_tree([p|P ], R) auf.
•
Wähle frequente Items aus
insert_tree([p|P ], R) geht folgendermaÿen vor: Wenn R ein Kind N mit
N.item-name = p.item-name hat, dann inkrementiere den Zähler von N. Sonst erstelle
einen neuen Knoten N - als Kind-Knoten von R - mit dem Zähler 1 und dem nodeLink zu den Knoten mit dem gleichen item-name. Wenn P nicht leer ist, dann rufe
insert_tree(P,N) rekursiv auf.
Die Funktion
10
Maria Soldatova
3.2
Studienarbeit
Mining von frequenten Mustern mit Hilfe des FP-trees
In diesem Abschnitt wird die oben beschriebene Datenstruktur FP-tree benutzt, um das
Mining von frequenten Muster durchzuführen; es wird ein rekursiver Mining Algorithmus
mit FP-trees vorgestellt. Anschlieÿend werden einige wichtige Eigenschaften des FP-tree
dargestellt und anhand von Beispielen erläutert.
Um die Vorgehensweise des Mining Algorithmus leichter zu verstehen, nehmen wir
an, dass der FP-tree nur einen Pfad enthält. Jetzt können alle frequenten Muster durch
die Aufzählung aller Kombinationen von Items bestimmt werden und der Support ist
dann der kleinste Support eines in einer Kombination enthalteten Items. Solche Typen
von FP-Bäumen heiÿen
Single prex path FP-tree. Ein Single prex path FP-tree
ist ein
FP-tree, der einen einzigen Pfad von der Wurzel bis zum ersten verzweigenden Knoten
branching node )
(
enthält, wobei ein verzweigender Knoten ein Knoten mit zwei oder
mehr Kindern ist; zum Beispiel:
Das ist ein
single prex path FP-tree, der einen Präxpfad h(a : 10) → (b : 8) → (c : 7)i
von der Wurzel bis zum verzweigenden Knoten
(c : 7)
hat. Um das Mining durchzufüh-
single prex path Teil P h(a : 10) → (b : 8) → (c : 7)i
und multipath Teil Q, wobei die Wurzel des multipath Teils Q durch eine Pseudowurzel
ren, wird dieser Baum in zwei Teile aufgeteilt:
R ersetzt wird. Für diese zwei Teile kann das Mining getrennt durchgeführt werden und
danach können die Ergebnisse des Mining zusammengeführt werden.
11
Maria Soldatova
Studienarbeit
Alle frequenten Muster, die mit dem
single prex path
Teil P in Frage kommen, können
durch die Aufzählung aller Kombinationen von Items in P gefunden werden. Also liefert
der Pfad P folgende Menge von frequenten Mustern:
freq_pattern_set(P) =
{(a : 10), (b : 8), (c : 7), (ab : 8), (ac : 7), (bc : 7), (abc : 7)}.
Das
Mining des zweiten multipath Teils Q führt zu folgendem Ergebnis: freq_pattern_set(Q)
=
{(d : 4), (e : 3), (f : 3), (df : 3)}.
Aber jedes frequente Itemset in Q bildet auch
(d : 4) ×
{(ad : 4), (bd : 4), (cd : 4), (abd : 4), (acd : 4), (bcd : 4), (abcd :
4)}, wobei das ×-Produkt wie folgt deniert sei: Seien zwei beliebige Mengen R = {a1 :
sa1 , a2 : sa2 , ..., an : san } und S = {b1 : sb1 , b2 : sb2 , ..., bm : sbm } gegeben, wobei sai der
Support des Itemsets ai und sbi der Support des Itemsets bi ist. Dann ist R × S = {a1 :
sa1 , a2 : sa2 , ..., an : san } × {b1 : sb1 , b2 : sb2 , ..., bm : sbm } = {a1 b1 : min(sa1 , sb1 ), a1 b2 :
min(sa1 , sb2 ), ..., a1 bm : min(sa1 , sbm ), ..., an b1 : min(san , sb1 ), an b2 : min(san , sb2 ), ...,
an bm : min(san , sbm )}. Der minimale Support des Ergebnisses wird immer dem mini-
noch mit jedem Muster aus P verschiedene frequente Muster, zum Beispiel:
freq_pattern_set(P) =
malen Support des Itemsets aus Q (in dem Beispiel Item d mit dem Support 4) entsprechen, weil die Liste der frequenten Items nach dem Support absteigend sortiert ist und
die Items in dieser Reihenfolge aus den Transaktionen in den Baum eingefügt werden,
d.h. dass die Items in Q immer den kleineren Support haben als die Items in P.
Ähnlich wird mit jedem frequenten Itemset aus Q solange weitergemacht, bis alle
Itemsets aus Q berücksichtigt worden sind. Die komplette Menge der frequenten Muster, die durch Zusammenfassen der Ergebnisse von P und Q gewonnen wird, ist also
freq_pattern_set(P)
×
freq_pattern_set(Q) mit dem Support von Itemsets aus Q.
Allgemein sei T ein FP-tree, der einen single prex path Teil P und multipath Teil Q
enthält. Dann besteht die komplette Menge der frequenten Muster von T aus folgenden
drei Teilen:
1. Die Menge der frequenten Muster aus P, die durch die Aufzählung aller Kombinationen der Items von P erhalten wird.
2. Die Menge der frequenten Muster aus Q.
3. Die Menge der frequenten Muster aus der Zusammenfassung von P und Q, die
12
Maria Soldatova
Studienarbeit
×-Produkt der frequenten Muster aus P und Q unter Einschränkung des
minimalen Supports erhalten ist (freq_pattern_set(P) × freq_pattern_set(Q)).
durch das
Wie die frequenten Muster aus Q bestimmt werden können, wird im Folgenden erläutert,
aber vorher müssen noch einige Eigenschaften des FP-tree erötert werden. Eine davon
ist die Node-link Eigenschaft.
Node-link Eigenschaft :
frequenten Itemsets, die
Für ein beliebiges frequentes Item
ai
werden. Es wird mit dem
enthalten, durch das Folgen der
node-link
von
ai
von
ai
erhalten
hf : 4, c : 3, a : 3, m : 2, p : 2i
und
Durch das Verfolgen der Knoten entlang die Pfade und Akkumulieren
deren Zähler ergibt sich, dass frequent somit ist:
Itemsets:
können alle möglichen
in der FP-tree Header Tabelle angefangen.
Zum Beispiel für das Item p ergeben sich zwei Pfade:
hc : 1, b : 1, p : 1i.
ai
node-links
hc : 3, p : 3i.
Alle möglichen frequenten
p, cp.
Eine weitere Eigenschaft des FP-tree, die für das Mining besonders wichtig ist, ist die
Präxpfad-Eigenschaft.
Präxpfad-Eigenschaft :
ai
Zur Bestimmung der frequenten Muster für einen Knoten
im Pfad P müssen nur die Präxpfade des Knoten
ai
in P gesammelt werden. Die
Häugkeit der Knoten in den Präxpfaden wird mit der Häugkeit des Knotens
abgeglichen. Die Knoten aus dem Pfad P, die tiefer als der Knoten
ai
ai
in dem Baum
stehen, müssen nicht berücksichtigt werden, weil die frequenten Muster für diese Knoten
zu diesem Zeitpunkt schon ermittelt worden sein sollen.
Eine Menge solcher Präxpfaden des Knotens
Mustern, die zusammen mit
men mit
|
ai ai
auftreten, heiÿt
ai
ai
bildet eine kleine Datenbank der
auftreten. Eine solche Datenbank der Muster, die zusam-
conditional pattern-base
von
ai
und wird als pattern_base
bezeichnet. Diese Präxpfade kann man wiederum als Menge von Transaktionen
conditional pattern-bases von ai
wird ein kleiner FP-tree gebildet, der conditional FP-tree von ai heiÿt und als FP-tree |
ai bezeichnet wird. Zum Beispiel wäre für das Item p der conditional FP-tree {(c : 3)}|p.
betrachten. Mit einem vorgegebenen Support aus diesen
Basierend auf den oben beschriebenen Eigenschaften kann das Mining wie folgt
durchgeführt werden:
13
Maria Soldatova
Studienarbeit
1. Bestimme die frequenten 1-Items in der Transaktions-DB und erstelle für jedes
Item seine
2. Aus den
conditional pattern-base.
conditional pattern-bases
3. Führe das Mining in den
bilde die entsprechenden
conditional FP-trees
conditional FP-trees.
rekursiv durch und füge die Ergeb-
nisse in die Menge der bisher gefundenen frequenten Items ein.
Dieser Mining Prozess wird jetzt an einem Beispiel ausführlicher erläutert.
1. Bestimmung der
•
conditional pattern-base
Für jedes Item
ai
für jedes Item:
folge dem node-link aus der frequent-item-header Tabelle
um den ersten Knoten mit diesem Item zu bestimmen.
•
Folge den Pfad von dem Knoten
ai
bis zur Wurzel über die Kanten und den
node-link von diesem Knoten bis zum anderen mit dem gleichen Namen.
•
Sammle transformierte Präxpfade und erstelle für jedes Item seine conditional pattern-base.
Item
Conditional pattern-base
p
{(fcam:2), (cb:1)}
m
{(fca:2), (fcab:1)}
b
{(fca:1), (f:1), (c:1)}
a
{(fc:3)}
c
{(f:3)}
f
∅
2. Erstellung der entsprechenden
conditional FP-trees : wie schon oben erläutert wur-
de, können die Präxpfade aus conditional pattern-bases wiederum als Transaktionen betrachtet werden. Zum Beispiel für das Item a:
hf : 3, c : 3i.
{(f, c), (f, c), (f, c)} ⇔
Der Prozess der Konstruktion der conditional FP-trees erfolgt dann
nach dem schon bekannten Algorithmus der Konstruktion des FP-tree.
•
Für jedes Item
ai
zähle die Summen der counts der Knoten mit diesem
Item auf und sortiere die Items nach dieser Häugkeit absteigend.
14
Maria Soldatova
•
Studienarbeit
Für die Items erstelle die conditional FP-trees, welche hier alle
path
FP-trees sind.
Item
Conditional pattern-base
Conditional FP-tree
{(fcam:2), (cb:1)}
{(c:3)}|p
m
{(fca:2), (fcab:1)}
{(f:3, c:3, a:3)}|m
b
{(fca:1), (f:1), (c:1)}
∅
a
{(fc:3)}
{(f:3, c:3)}|a
c
{(f:3)}
{(f:3)}|c
f
∅
∅
p
3. Rekursives Mining in den
•
Single prex
conditional FP-trees :
Erstelle für jedes Item die conditional pattern-base und die conditional FPtree und führe diesen Schritt für jeden conditional FP-tree rekursiv durch
(Ergebnis bezeichne als Menge Q). Dieses Vorgehen setzt sich rekursiv fort,
bis ein FP-tree entsteht, der nur einen Pfad enthält, aus dem man dann die
darin enthaltenen frequenten Itemsets (Menge P) direkt durch die Aufzählung
aller Kombinationen der Items ermitteln kann. Das passiert immer, weil sich
die Menge der Items in den conditional FP-trees mit jedem rekursiven Aufruf
verkleinert.
Wie oben schon erläutert wurde ist dann das endgültige Ergebnis:
Item
frequente Itemsets
p
cp
m
am, cm, fm, cam, fam, fcam, fcm
a
fa, ca, fca
c
fc
P ∪ Q ∪ (P × Q).
Jetzt kann der Pseudocode des FP-Growth Algorithmus vorgestellt werden.
15
Maria Soldatova
Studienarbeit
In diesem Abschnitt wurden die Konstruktion des FP-tree und die Arbeitsweise des FPGrowth Algorithmus vorgestellt. Es lassen sich folgende wichtige Vorteile des FP-tree
kurz zusammenfassen:
•
Kompaktheit wird durch die absteigende Sortierung des frequenten Items ermöglicht: die am häugsten auftretenen Items werden mit der gröÿeren Wahrscheinlichkeit gemeinsam benutzt und sie sind also näher an der Wurzel des Baums
platziert.
•
Vollständigkeit wird durch den Prozess der Konstruktion des FP-tree ermöglicht:
die frequenten Items aus jeder Transaktion aus der DB werden in einen Pfad in
dem Baum umgewandelt und somit enthält der FP-tree nach der Konstruktion die
vollständige Information für das Mining.
Laut der Studie die von J. Han et al. geleitet wurde ist der FP-Growth Algorithmus deutlich schneller als die Apriori-basierten Methoden. Besonders auällig sind die
Unterschiede wenn die Datenmengen lange Muster enthalten (HPY00).
Als Gründe dafür sind folgende Vorteile des FP-Growth Algorithmus zu nennen:
•
keine Kandidatengenerierung und Kandidatentests.
•
kein wiederholter Durchlauf der Datenbank.
•
Zerlegen der Mining-Aufgaben laut divide-and-conquer Ansatz.
•
kompakte und vollständige Datenstruktur.
16
Maria Soldatova
3.3
Studienarbeit
Top Down FP-Growth für Frequent Pattern Mining
In diesem Abschnitt wird der Top Down FP-Growth (TD-FP-Growth) Algorithmus
vorgestellt, der von Tang (WTHL02) vorgeschlagen wurde und für das Mining der frequenten Mustern benutzt wird. Dieser Algorithmus durchläuft den FP-tree top-down,
von oben nach unten , wobei das oben erläuterte Verfahren den FP-tree bottom-up,
von unten nach oben durchsucht. Der Vorteil dieses Algorithmus besteht darin, dass
die Konstruktion der conditional pattern-bases und der zugehörigen conditional FP-trees
dadurch vermieden wird und somit Zeit und Speicher gespart werden.
Zuerst wird wie auch bei dem originalen FP-Growth ein FP-tree konstruiert. Das
geschieht in zwei Durchläufe der Transaktionsdatenbank. Beim ersten Durchlauf werden
die Zähler für jedes Item bestimmt und beim zweiten wird der FP-tree erstellt. Der
Prozess der Konstruktion des FP-tree unterscheidet sich nicht von dem entsprechenden
Prozess im originalen FP-Growth Algorithmus. Es existiert auch eine frequent-itemheader-Tabelle, wo die Items mit den Zähler und node-links gespeichert werden.
Das folgende Beispiel erklärt die grundlegende Idee des TD-FP-Growth Algorithmus.
Sei folgende Transaktionsdatenbank gegeben mit dem minimalen Support gleich 2:
TID
Items
1
a, b, c, e
2
b, e
3
b, c, e
4
a, c, d
5
a
Mit dem Algorithmus für die Konstruktion des FP-tree lassen sich die folgenden FP-tree
und frequent-item-header-Tabelle erstellen.
Der Mining Prozess beginnt am Anfang der frequent-item-header-Tabelle, in dem Beispiel ist das Item
a.
node-links des Items
Das Item
a
a
ist frequent und es lässt sich durch das Verfolgen des
zeigen, dass Item
a
nur auf einer Ebene des Baums erscheint.
17
Maria Soldatova
Deshalb wird nur
Studienarbeit
{a} als ein frequentes Muster ausgegeben. Für das nächste Item b aus
der frequent-item-header-Tabelle werden zwei Knoten durch das Verfolgen des node-links
des Item
b
gefunden:
b : 2, b : 1.
Von diesen Knoten aus wird der Pfad bis zur Wurzel
entlang gegangen und werden die Zähler für die Knoten in diesen Pfad akkumuliert. Die
H_x für den aktuell
x. Für den Knoten b existieren zwei Pfade: root−b und root−a−b.
Knoten entlang dieser Pfade bilden eine sog. Sub-header-Tabelle
bearbeiteten Eintrag
Aus dem ersten Pfad werden keine weiteren Knoten bestimmt. Aus dem zweiten Pfad
ergibt sich der Knoten
a
mit dem akkumulierten Zähler 1, weil der Pfad
root − a − b
nur einmal in der Transaktionsdatenbank vorkommt. Deshalb wird in der Sub-headerTabelle H_b ein Eintrag mit dem Item
a
erstellt.
Der minimale Support ist 2, deshalb ist das Muster
{a, b}, das nur einmal in der Transak{a, b} frequent wäre, würde
tionsdatenbank vorkommt, nicht frequent. Wenn das Muster
das Verfahren mit der Konstruktion der Sub-header-Tabelle H_ab rekursiv fortgesetzt.
Allgemein, wenn der Eintrag
I
aus der Sub-header-Tabelle
H_x
gerade bearbeitet wird,
wird das Mining für alle frequenten Muster durchgeführt, die auf
Ix
enden. Auf diese
18
Maria Soldatova
Studienarbeit
c
existieren dann drei Pfade bis zur Wurzel: root − b − c, root − a − b − c und root − a − c.
Weise ndet der TD-FP-Growth Algorithmus alle frequenten Muster. Für den Eintrag
Die Knoten entlang dieser Pfade bilden die Sub-header-Tabelle H_c. Aus den Pfaden
ergeben sich zwei Knoten
a
und
b
mit den akkumulierten Zähler 2. Das Verfahren wird
c sind {c}, {b, c} und
{a, c}. Analog sind für den Eintrag e {e}, {b, e}, {c, e} und {b, c, e} die frequenten Mus-
rekursiv fortgesetzt und die frequenten Muster für den Eintrag
ter.
Im Unterschied zu dem FP-Growth Algorithmus bearbeitet der TD-FP-Growth Algorithmus zuerst die Knoten auf den oberen Ebenen des Baums. Das ist wichtig, weil so
sichergestellt wird, dass Aktualisieren der Zähler auf den oberen Ebenen keinen Einuÿ
auf die unteren Ebenen hat. Zu dem Zeitpunkt, als die unteren Ebenen bearbeitet werden, wurden die oberen schon bearbeitet. Um die conditional pattern-base für ein Muster
zu erstellen, wird einfach entlang der Pfade bis zur Wurzel gegangen und es werden die
Zähler für die Knoten in den Pfaden akkumuliert. Auf diese Weise werden die Zähler in
place aktualisiert und es werden keine conditional pattern-bases und conditional FPtrees während des gesamten Mining Prozess gebraucht. Dies ergibt einen groÿen Vorteil
im Vergleich zu dem bottom-up FP-Growth, was auch experimentell bestätigt wurde
(WTHL02).
19
Maria Soldatova
4
Studienarbeit
Implementierung
4.1
Verschiedene Möglichkeiten der SQL-basierten Implementierung
Es gibt einige Varianten wie man den FP-Growth Algorithmus in einem relationalen
Datenbanksystem mit SQL implementieren könnte. In allen Methoden, die in diesem
Abschnitt vorgestellt werden, wird der FP-tree als eine Tabelle dargestellt.
Zuerst ist es wichtig zu bestimmen, in welcher Form die Eingabe für den Algorithmus
erfolgt. Dafür gibt es zwei Schemata. Erstens kann als Input die Transaktionsdatenbank
tid )
vorgegeben sein, eine Tabelle T mit zwei Spalten: Transaktions-ID (
item ). Für eine bestimmte tid
(
und Item-ID
kann es mehrere Zeilen mit den unterschiedlichen Items
in der Transaktionsdatenbank geben. Die Anzahl der Items pro Transaktion ist variabel
und unbekannt zum Zeitpunkt der Konstruktion der Tabelle. Das Schema dieser Tabelle
ist folgendermaÿen deniert:
Spaltenname
Bedeutung
tid
ID der Transaktion
item
ID des Items
Als Alternative kann auch eine Input-Tabelle mit dem folgenden Schema benutzt werden:
(tid,
item1 , item2 ,
...,
itemk ),
wobei die Spalte
itemi
das
i-te
Item der Transaktion
enthält. Als eine weitere Alternative kann auch eine Input-Tabelle mit dem folgenen
Schema benutzt werden: (tid,
Attribut enthält, das zeigt,
item1 , item2 , ..., itemk ), wobei die Spalte itemi ein binäres
ob das i-te Item in dieser Transaktion vorkommt. Folgendes
Beispiel illustriert diese unterschiedlichen Input-Tabellen.
Tid
Item
Tid
Item1
Item2
Item3
Item4
1
a
1
a
b
c
d
1
b
2
c
d
1
c
3
a
d
e
1
d
2
c
Tid
a
b
c
d
e
2
d
1
ja
ja
ja
ja
nein
3
a
2
nein
nein
ja
ja
nein
3
d
3
ja
nein
nein
ja
ja
3
e
Aber die letzten beiden Tabellenschemata sind in manchen Situationen eher unpraktisch:
•
Die Anzahl der Items pro Transaktion kann gröÿer als die maximale von der Datenbank unterstützte Anzahl der Spalten sein.
•
Wenn die Anzahl der Items pro Transaktion ungleichmäÿig verteilt ist, führt das
möglicherweise zu Platzverschwendung.
Es wird deshalb die Tabelle mit zwei Spalten für Transaktions-ID und Item-ID als
Inputformat benutzt.
20
Maria Soldatova
Studienarbeit
Variante 1
Frequent Pattern
Als erstes wird der sog. FP-Ansatz (
Ansatz) (SSG04) erläutert. Ein
FP-tree wird wegen seiner Eigenschaften durch eine Tabelle FP repräsentiert, die drei
Spalten hat:
item );
•
Item-ID (
•
Präxpfad des Items (
•
Anzahl der Transaktionen, welche die Items in dem Pfad enthalten (
path );
count ).
Das Schema dieser Tabelle sieht folgendermaÿen aus:
Das Feld
path
Spaltenname
Bedeutung
item
ID des Items
count
Anzahl der Transaktionen
path
Präxpfad des Items
ist nicht nur für die Konstruktion der FP Tabelle, sondern auch für das
Suchen nach den frequenten Mustern in FP sehr vorteilhaft. In der Konstruktion der
FP Tabelle ist das Feld
path
das wichtigste Kriterium um zu entscheiden, ob das Item
in die Tabelle eingefügt werden muss. Wenn das Item in der FP Tabelle nicht existiert
oder es existieren die gleichen Items aber mit verschiedenen
paths, dann muss das Item
in die Tabelle eingefügt werden. Sonst wird einfach der Zähler des Items inkrementiert
count ). Während des Mining müssen conditional FP-trees und die ihn repräsentierende
Tabelle ConFP für jedes Item rekursiv erstellt werden. Mit Hilfe der Spalte path in der
(
FP Tabelle ist es leicht alle Items zu nden, die zusammen mit dem zu untersuchenden
Item auftreten. Die FP Tabelle kann folgendermaÿen konstruiert werden:
•
Sortiere die Items aus der Inputtabelle T absteigend nach der Häugkeit ihres
Auftretens.
•
Für die erste Transaktion füge alle frequenten Items in die FP Tabelle ein und
path des ersten Items a1
path des zweiten Items wird auf null:a1 gesetzt usw.
setze
•
count
jeweils auf 1. Der
wird auf
null
gesetzt, der
Für jedes frequente Item aus der zweiten Transaktion prüfe, ob das Item in die
Tabelle eingefügt werden muss oder der Zähler des Items inkrementiert werden
muss.
•
Für die restlichen Transaktionen wird es genauso weiter gemacht.
21
Maria Soldatova
Studienarbeit
Als Beispiel kann die folgende Transaktionstabelle (mit dem minimalen Support 3) benutzt werden:
TID
Items
Frequente Items
1
a, c, d, f, g, i, m, o
c, f, a, m, o
2
a, b, c, f, l, m, n
c, f, a, b, m
3
b, f, h, j, n
f, b
4
b, c, k, o
c, b, o
5
a, c, e, f, l, m, o
c, f, a, m, o
22
Maria Soldatova
Studienarbeit
Dann wird die folgende FP Tabelle erhalten:
Item
Count
Path
c
4
null
f
3
null : c
a
3
null: c : f
m
2
null : c : f : a
o
2
null : c : f : a : m
b
1
null : c : f : a
m
1
null : c : f : a : b
f
1
null
b
1
null : f
b
1
null : c
o
1
null : c : b
Nach der Konstruktion der FP Tabelle kann diese Tabelle jetzt für das eziente Mining
i wird die conditional
pattern base Tabelle P Bi konstruiert, die drei Spalten: tid, item, count hat. Das Schema
der frequenten Items benutzt werden. Für jedes frequente Item
dieser Tabelle wird folgendermaÿen dargestellt:
Daraus kann die
Spaltenname
Bedeutung
tid
ID der Transaktion
item
ID des Items
count
Anzahl der Transaktionen
conditional FP-tree
Tabelle
Schema hat wie die FP Tabelle, nämlich
ConF Pi
erstellt werden, die das gleiche
item, count, path. Die Konstruktion der ConF Pi
Tabelle erfolgt nach demselben Algorithmus wie die Tabelle FP. Das Mining wird gemäÿ
des FP-Growth Algorithmus rekursiv in der Tabelle
ConF Pi
durchgeführt.
Laut der Studie (SSG04) des FP-Ansatzes wurde festgestellt, dass die Prozedur der
Konstruktion der FP Tabelle am zeitaufwändigsten ist. Der wichtigste Grund dafür ist,
dass die frequenten Items aus jeder Transaktion nacheinander geprüft werden sollen um
zu entscheiden ob sie in die Tabelle eingefügt werden müssen.
23
Maria Soldatova
Studienarbeit
Variante 2
extended Frequent Pattern
Deshalb wird als nächstes der sog. EFP-Ansatz (
Ansatz)
(SSG04) vorgestellt, wo versucht wird die Performance des FP-Ansatzes zu verbessern.
Der Unterschied zwischen den zwei Ansätzen besteht in dem Prozess der Konstruktion der FP Tabelle. In dem EFP-Ansatz wird dazu die Tabelle EFP benutzt, die zwei
Spalten hat:
item
und
path.
Spaltenname
Bedeutung
item
ID des Items
path
Präxpfad des Items
Die EFP Tabelle kann direkt durch die Transformation der frequenten Items aus der
Input-Tabelle erhalten werden ohne die Items nacheinander zu prüfen. Zuerst wird der
path
des ersten frequenten Item
zweiten frequenten Item
mit
i2
i1
jeder Transaktion auf
wird weiter mit
null:i1
null
gesetzt. Der
initialisiert, der
path
path
des
des dritten -
null:i1 :i2 usw. Um die FP Tabelle daraus zu bekommen, werden die Items mit den
paths zusammengefasst. Das kann mit der folgenden SQL-Anweisung erfolgen:
gleichen
insert into FP
select item, count(*) as count, path
from EFP
group by item, path
Als Beispiel kann wiederum die folgende Transaktionstabelle (mit dem minimalen Support 3) benutzt werden:
TID
Items
Frequente Items
1
a, c, d, f, g, i, m, o
c, f, a, m, o
2
a, b, c, f, l, m, n
c, f, a, b, m
3
b, f, h, j, n
f, b
4
b, c, k, o
c, b, o
5
a, c, e, f, l, m, o
c, f, a, m, o
24
Maria Soldatova
Studienarbeit
Dann ergibt sich die folgende EFP Tabelle:
Item
Path
c
null
f
null : c
a
null: c : f
m
null : c : f : a
o
null : c : f : a : m
c
null
f
null : c
a
null : c : f
b
null : c : f : a
m
null : c : f : a : b
f
null
b
null : f
c
null
b
null : c
o
null : c : b
c
null
f
null : c
a
null : c : f
m
null : c : f : a
o
null : c : f : a : m
Mit der oben eingeführten SQL-Anweisung lässt sich die FP-Tabelle aus der EFP-Tabelle
bestimmen.
Item
Count
Path
c
4
null
f
3
null : c
a
3
null: c : f
m
2
null : c : f : a
o
2
null : c : f : a : m
b
1
null : c : f : a
m
1
null : c : f : a : b
f
1
null
b
1
null : f
b
1
null : c
o
1
null : c : b
Nachdem die FP Tabelle erstellt wird, kann jetzt der Mining Prozess durchgeführt werden, wobei sich die Vorgehensweise von dem ersten Ansatz (FP-Ansatz) nicht unterscheidet.
Fazit: Der SQL-basierte FP-Ansatz stellt den FP-tree als eine relationale Tabelle FP
dar und schlägt eine Methode zur Konstruktion dieser Tabelle vor. Um die Performance
dieses Ansatzes zu verbessern, wird eine weitere Tabelle (EFP Tabelle) eingeführt, die
alle Informationen über die frequenten Itemsets und deren Präxpfade für jede Transaktion enthält. Daraus kann die FP Tabelle einfach abgeleitet werden. Diese FP Tabelle
ist für den anschlieÿenden Mining Prozess zu benutzen.
25
Maria Soldatova
Studienarbeit
Variante 3
Im nächsten Ansatz (SL05) wird der FP-tree wieder als eine Tabelle dargestellt, aber
statt des Attributes
path
wird die
Eltern-Kind-(parent-child)-Beziehung
benutzt um die
Pfade von einem Knoten bis zur Wurzel zu bestimmen. Das Schema dieser Tabelle ist
das folgende:
Spaltenname
Bedeutung
node_id
ID des Knotens
parent_id
ID des Elternknotens
item
Item-ID
count
Anzahl der Transaktionen
sidelink
node-link
des Knotens
Wie im Kapitel 3 schon erläutert wurde, wird bei der Konstruktion des FP-tree der
neue Pfad in den Baum eingefügt oder wenn die Items schon im Baum vorhanden
sind, werden die Zähler der Items inkrementiert. Aber diese Vorgehensweise ist bei der
Implementierung in SQL nicht besonders ezient (SL05). In diesem Ansatz wird der FPtree schrittweise erstellt, in dem man alle Knoten, die sich in den Transaktionen auf einer
Ebene
benden (zum Beispiel, alle ersten Items aus den Transaktionen benden sich auf
der gleichen - ersten -
Ebene ),
in eine Ebene des Baums durch eine SQL-Anweisung
einfügt. Bei allen Knoten auf der ersten Ebene, welche die Wurzel als Elternknoten
haben, ist parent_id auf
null
gesetzt.
Für die Konstruktion des FP-tree werden folgende Tabellen benutzt: Input-Tabelle und
Präx-Tabelle. Das Schema der Input-Tabelle entspricht dem ersten vorgestellten Schema für die Input-Tabellen: (tid, item).
Die Präx-Tabelle repräsentiert Information über die gerade bearbeiteten Knoten. Wegen der bestimmten Reihenfolge des Einfügens der Knoten in den Baum werden aus
der Präx-Tabelle die IDs des Elternknotens für die nächsten zu bearbeitenden Knoten
erhalten. Das Schema dieser Tabelle ist folgendes:
Spaltenname
Bedeutung
tid
Transaktions-ID
node_id
ID des Knotens
Nach dem die Tabelle für die Darstellung des FP-tree erstellt wurde, wird der Mining
Prozess durchgeführt. In diesem Ansatz wird der Top-Down FP-Growth Algorithmus
dafür benutzt. Wie es im Kapitel 3 beschrieben wurde, lässt sich dadurch die Konstruktion der conditional pattern-bases und conditional FP-trees vermeiden.
26
Maria Soldatova
Studienarbeit
Für das Mining wird eine frequent-item-header-Tabelle mit folgendem Schema gebraucht:
Spaltenname
Bedeutung
header_id
eindeutige ID
item
ID des Items
count
Zähler des Items
Das Mining beginnt mit dem Item, das am Anfang der frequent-item-header-Tabelle
steht (chronologische Reihenfolge). Durch das Verfolgen der Eltern-Kind Beziehungen
für jeden Knoten lassen sich die Präxpfade von einem Knoten bis zur Wurzel des
Baums bestimmen und die Zähler der Knoten auf diesen Pfaden akkumulieren. Diese
Informationen werden in einer zusätzlichen Tabelle Sub-header-Tabelle, die das gleiche
Schema hat, gespeichert und weiterhin bearbeitet. Wenn der Eintrag I aus der Subheader-Tabelle H_x bearbeitet wird (d.h. der Knoten I aus den Präxpfaden des Items
x), wird das Mining rekursiv für alle frequenten Muster durchgeführt, die auf Ix enden.
Auf diese Weise lassen sich rekursiv alle frequenten Muster bestimmen. Die genauere
Vorgehensweise des Mining Prozesses in diesem Ansatz unterscheidet sich nicht von dem
in Kapitel 3 beschriebenen TD-FP-Growth Algorithmus.
Fazit: dieser SQL-basierte Ansatz schlägt die Methoden zur Konstruktion des FP-tree
und zum Top-Down Mining mit dem FP-tree vor und stellt den FP-tree als eine Tabelle dar. Im Vergleich zu den FP- und EFP-Ansätzen wird die Eltern-Kind-Beziehung
benutzt um auf den Pfad der Knoten zu zugreifen. Das ist von Vorteil, weil das in den
FP- und EFP-Ansätzen benutzte path-Attribut die spezielle Implementierung der Prozeduren für die Gewinnung der einzelnen Items aus den Pfaden erfordert. Das lässt sich
im diesem Ansatz vermeiden, in dem die Möglichkeiten des hierarchischen SQL benutzt
werden können. Im Vergleich zu dem originalen FP-Growth Algorithmus wird in diesem Ansatz das Mining von oben nach unten (top-down) durchgeführt. Dadurch lässt
sich die Konstruktion der conditional pattern-bases und conditional FP-trees während
des gesamten Mining Prozess vermeiden, was zur Verbesserung der Performance führt
27
Maria Soldatova
Studienarbeit
(WTHL02). Die Implementierung dieses Ansatzes wird weiterhin im nächsten Abschnitt
verfolgt und erläutert.
4.2
Überblick
In diesem Abschnitt wird ein Überblick über die gesamte Implementierung gegeben.
Weitere Abschnitte beschreiben die Aufgaben jeder benötigten Komponente.
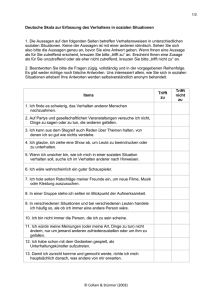
Die Implementierung wurde vollständig in Oracle 10g vorgenommen, wobei die storedprocedure language PL/SQL verwendet wurde. Eine Übersicht über wichtigen implementierten Funktionen ist anschaulich in der folgenden Abbildung dargestellt.
Die Implementierung des Algorithmus besteht aus drei Funktionen. In der ersten Funktion werden die Input-Daten vorbereitet, die zweite Funktion, die den FP-tree konstruiert,
und die dritte Funktion, die das Mining durchführt, aufgerufen und die Ergebnisse in
die endgültige Form gebracht.
Die Implementierung des Algorithmus lässt sich in vier Phasen unterteilen. In der
ersten Phase werden die Input-Daten für den Algorithmus vorbereitet. Aus diesen Daten lässt sich in der zweiten Phase der FP-tree konstruieren. Mit Hilfe dieses FP-tree
wird in der dritten Phase der Mining Prozess durchgeführt. Anschlieÿend werden die
gefundenen Muster endgültig in einer Tabelle dargestellt. In den Abschnitten 4.3 - 4.6
werden die einzelnen Phasen des Algorithmus erläutert und die für die Implementierung
notwendigen Tabellen vorgestellt. Im Abschnitt 4.7 wird die Arbeitsweise des Algorithmus auf einer realen Datenbank demonstriert. Der Algorithmus setzt sich aus folgenden
Teilen zusammen:
•
Vorbereitung der Input-Daten.
28
Maria Soldatova
•
Konstruktion des FP-tree.
•
Mining Prozess.
•
Darstellung der Ergebnisses.
Studienarbeit
Der Algorithmus wird mit dem Aufruf folgender Prozedur gestartet:
procedure mine(table_name in varchar2, tid_attr varchar2,
item_attr varchar2, minsup_perc number) is
sqls varchar2(2000);
data_count number;
minsupabs number;
begin
-- berechne den absoluten minimalen Support
count_minsupabs();
-- Vorbereitung der Input-Daten (Abschnitt 4.3)
prepare_input();
-- Konstruktion des FP-tree (Abschnitt 4.4)
build_fp_table(minsupabs) ;
-- Mining Prozess (Abschnit 4.5)
mine_tree(p_header_id => 1, p_minsupabs => minsupabs) ;
-- Umwandlung der Ergebnisses (Abschnitt 4.6)
get_result();
end;
Als Parameter werden der Name der Tabelle übergeben, für die das Mining durchgeführt
werden soll, der Spaltenname mit den Transaktions-IDs, der Spaltenname mit den Items
und der minimale Support in %. Um den absoluten minimalen Support zu bestimmen,
werden zunächst unterschiedliche Transaktions-IDs aufgezählt. Aus dieser Anzahl lässt
sich der absolute minimale Support wie folgt bestimmen:
data_count := select count(distinct tid_attr) from table_name;
minsupabs := data_count * ( minsup_perc /100 );
4.3
Vorbereitung der Input-Daten
Welche Spalten Transaktionen und Items enthalten, wird vom Benutzer deniert, und
evtl. sind die Daten nicht von der Form, in der sie sich für die Benutzung im Algorithmus
eignen, deshalb müssen diese Daten entsprechend vorbereitet und geändert werden um in
dem Algorithmus benutzt werden zu können. In der Implementierung wird angenommen,
dass Items mehrmals in einer Transaktion vorkommen können. Deshalb werden nur die
29
Maria Soldatova
Studienarbeit
unterschiedelichen Transaktions-IDs mit Hilfe von
distinct
bestimmt und betrachtet.
Der allgemeine Ablauf der 1. Phase setzt sich wie folgt zusammen:
•
Die Items aus den Transaktionen werden absteigend nach dem Support sortiert
und neue eindeutige IDs für die Items werden mit Hilfe einer Sequenz generiert,
was für die Reihenfolge der Konstruktion des Baums wichtig ist.
•
Um die ebeneweise Konstruktion des Baums zu ermöglichen, werden die Positionen
für jedes Item in einer Transaktion mit der analytischen Funktion
dense_rank()
bestimmt.
Um die Kompaktheit des FP-tree zu gewährleisten, werden zuerst die Items absteigend nach der Häugkeit des Auftretens in den Transaktionen sortiert. Jedem Item
wird eine eindeutige ID zugeordnet, so dass das am häugsten in den Transaktionen
auftretende Item die kleinste ID hat. Für die Generierung der eindeutigen IDs wird eine Sequenz benutzt, wobei sequence.NEXTVAL eine neue eindeutige Nummer erstellt.
Diese Daten werden in die Tabelle
fp_tdg_item_trans eingefügt, die folgendes Schema
hat:
table fp_tdg_item_trans
(
item_original number, -- die originalen Items aus der Transaktionen
item_new
number -- eindeutig generierte Item-IDs
)
insert into fp_tdg_item_trans
select ff.item_attr, fp_tdg_item_trans_seq.nextval
from (
select f.item_attr
from table_name f
group by f.item_attr
having count(distinct f.tid_attr) >= minsupabs
order by count(distinct f.tid_attr) desc ) ff;
Um die ebeneweise Konstruktion des FP-tree zu ermöglichen, müssen wir in der Lage
sein, die Position eines Items in der Transaktion zu bestimmen. Das ist mit Hilfe der
RANK-Funktionen möglich, die die Position einer Zeile in einer sortierten Gruppe der
Zeilen zurückgeben. In dieser Implementierung des Algorithmus ist es sinnvoll die analytische Funktion
dense_rank() dafür zu benutzen. Den gleichen Items innerhalb einer
Transaktion werden die gleichen Positionen zugeordnet, aber diese Funktion gibt die
Positionen als direkt aufeinanderfolgende Nummern zurück im Unterschied z.B. zu der
analytischen Funktion
rank(). Bei der Benutzung der Funktion rank() werden den glei-
chen Items innerhalb einer Transaktion auch die gleichen Positionen zugeordnet, aber
die weiteren Positionen können nicht direkt aufeinanderfolgend sein. Das ist wichtig für
den Fall, wenn Items mehrmals in einer Transaktion auftreten.
DENSE_RANK( ) OVER([ query_partition_clause ] order_by_clause)
30
Maria Soldatova
Studienarbeit
Query_partition_clause legt fest, wie die Gruppen der Zeilen gebildet werden, und
order_by_clause - wie die Zeilen innerhalb diesen Gruppen sortiert sind. Innerhalb
jeder Transaktions-ID werden die neuen generierten Items-IDs aufsteigend sortiert (d.h.
als erstes steht dann das am häugsten in dieser Transaktion auftretende Item, als
zweites das zweithäugste Item usw.) und innerhalb einer Transaktion wird den Items
eine Position zugeordnet, der die Stelle in der Transaktion zeigt, wo das Item auftritt.
Diese Daten werden in der Tabelle
fp_tdg_tdb
gespeichert, die das folgende Schema
hat:
table fp_tdg_tdb
(
tid
number, -- Transaktions-ID
item
number, -- Item-ID
item_rank number -- Position des Items in der Transaktion
)
insert into fp_tdg_tdb
select f.tid_attr, t.item_new,
dense_rank() over ( partition by f.tid_attr
order by t.item_new )
from table_name f, fp_tdg_item_trans t
where f.item_attr = t.item_original;
Aus der Tabelle
fp_tdg_tdb
lässt sich weiterhin, wie im Abschnitt 4.1 beschrieben
wurde, der FP-tree erstellen.
4.4
Konstruktion des FP-tree
Der FP-tree wird mit Hilfe der folgenden Prozedur konstruiert, die als Parameter den
absoluten minimalen Support hat:
procedure build_fp_table(p_minsupabs number) is
rowct number ;
level_ct number := 0 ;
main_header_id number ;
tname1 varchar2(50) ;
tname2 varchar2(50) ;
begin
-- fülle die Header-Tabelle aus (Abschnitt 4.4.1)
fill_header_table();
-- bestimme die ersten Items aus den Transaktionen (Abschnitt 4.4.2)
find_first_items();
-- baue die Tabelle für die Darstellung des FP-tree auf
loop (Abschnitt 4.4.3)
level_ct := level_ct + 1 ;
31
Maria Soldatova
Studienarbeit
-- Rotation der beiden Präfix-Tabellen in der Schleife
rotate_table();
-- die Items auf der aktuellen Ebene aus den Transaktionen werden
-- aus der aktuellen Präfix-Tabelle in die Tabelle für
-- die Darstellung des FP-tree eingefügt
fill_node_table();
-- die Items auf der nächsten Ebene aus den Transaktionen werden
-- bestimmt und in die andere Präfix-Tabelle eingefügt
fill_prefix_table();
end;
end loop;
Der allgemeine Ablauf der Konstruktion des FP-tree sieht wie folgt aus:
•
Die Header-Tabelle wird mit den Items aus der Input-Tabelle ausgefüllt.
•
Es werden die Items bestimmt, die sich in den Transaktionen auf der ersten Ebene
benden.
•
Für diese Items wird die ID des Elternknotens auf null gesetzt.
•
Diese Items werden in die Tabelle für die Darstellung des FP-tree eingefügt.
•
Die Items auf der nächsten Ebene werden bestimmt.
•
Für diese Items werden die IDs der Elternknoten aus den gerade eingefügten Items
bestimmt.
•
4.4.1
Der Ablauf wiederholt sich bis alle Transaktionen überarbeitet werden.
Initialisieren der Header-Tabelle
Als erstes in dieser Phase wird die Header-Tabelle
fp_tdg_header
erzeugt, die Infor-
mationen über die Items und deren Zähler enthält. In dieser Tabelle werden zuerst die
frequent-item-header Tabelle und später alle Sub-header-Tabellen gespeichert, die sich
durch
header_id
unterscheiden.
table fp_tdg_header
(
header_id number, -- eindeutige ID
item
number, -- ID des Items
item_count number -- Zähler des Items
)
Für die frequent-item-header Tabelle wird die aktuelle
generiert und in der Variable
main_header_id
header_id mit Hilfe der Sequenz
gespeichert.
32
Maria Soldatova
Studienarbeit
select fp_tdg_header_seq.nextval into main_header_id from dual;
Zunächst wird diese Tabelle mit den Items aus der Input-Tabelle ausgefüllt:
insert into fp_tdg_header
select main_header_id, r.item, count (distinct r.tid) support
from fp_tdg_tdb r
group by r.item
having count (distinct r.tid) >= p_minsupabs
4.4.2
Bestimmung der ersten Items
Es wird in dieser Phase die Präx-Tabelle
fp_tdg_tid_prefix
benötigt, die im All-
gemeinen die Informationen über die Knoten, die davor in die Tabelle
fp_tdg_node
eingefügt wurden und die als nächste zu bearbeiten sind (d.h. die als nächste in Tabelle
fp_tdg_node
einzufügen sind), enthält. Wegen der ebeneweisen Konstruktion des FP-
tree sind die Knoten, die davor in die Tabelle
fp_tdg_node
eingefügt wurden, für die
nächsten zu bearbeitenden Knoten die Elternknoten.
table fp_tdg_tid_prefix
(
tid
number, -- ID der Transaktion
node_id
number, -- ID des Elternknoten
next_item number -- ID des nächsten zu bearbeitenden Items
)
Zunächst werden die Items bestimmt, die sich in den Transaktionen auf der ersten Ebene
benden (d.h. die ersten Items aus allen Transaktionen) und die als erste zu bearbeiten
sind. Das geschieht mit Hilfe des Attributs
item_rank
aus der Tabelle
fp_tdg_tdb.
Die Items können innerhalb einer Transaktion mehrmals vorkommen, deshalb ist es
notwendig nur unterschiedliche Transaktions-IDs zu betrachten. Für diese Items wird
die ID des Elternknotens auf
Tabelle
fp_tdg_tid_prefix
null
gesetzt. Diese Informationen werden in die Präx-
eingefügt.
insert into fp_tdg_tid_prefix
select distinct db.tid, null, db.item
from fp_tdg_tdb db
where db.item_rank = 1 ;
4.4.3
Aufbau der Tabelle für die Darstellung des FP-tree
Weitere Aktionen werden in der Schleife ausgeführt, wobei
level_ct
eine Laufvariable
der Schleife ist und zeigt auf welcher Ebene die Bearbeitung gerade läuft. In der Schleife
fp_tdg_tid_prefix_tmp gebraucht, die das
fp_tdg_tid_prefix hat. Diese zwei Tabellen wer-
wird noch eine weitere zusätzliche Tabelle
identische Schema wie die Tabelle
den in der Schleife abwechselnd benutzt. Im Allgemein werden die folgenden Aktionen
durchgeführt:
33
Maria Soldatova
•
Studienarbeit
Die Items auf der aktuellen Ebene aus den Transaktionen werden aus der aktuellen
Präx-Tabelle in die Tabelle
•
fp_tdg_node
eingefügt.
Die Items auf der nächsten Ebene aus den Transaktionen werden bestimmt und
in die andere Präx-Tabelle eingefügt.
Wenn es keine weitere Items auf der nächsten Ebene aus den Transaktionen gibt, dann
wird die Schleife abgebrochen.
select count(*) into rowct from fp_tdg_tdb where item_rank = level_ct + 1;
if rowct = 0 then exit ; end if ;
Die Tabelle
fp_tdg_node
table fp_tdg_node
(
node_id
number,
parent_id number,
item
number,
count
number,
level
number,
sidelink char(1),
Teilbaum gehört
)
ist in der Phase für die Darstellung des FP-tree zu benutzen.
-------
eindeutige ID des Knotens
ID des Elternknotens
ID des Items in dem Knoten
Anzahl der Transaktionen
Nummer der aktuellen Ebene
zeigt, ob der Knoten zu dem zu bearbeitenden
Dieser Ablauf wird mit dem Code-Beispiel für die ersten Items aus den Transaktionen
illustriert. Nachdem die ersten Items in die Tabelle
fp_tdg_tid_prefix eingefügt wur-
den, kann jetzt diese Tabelle für Bestimmung der IDs der Elternknoten benutzt werden.
Die Knoten werden in die Tabelle
fp_tdg_node
eingefügt. Die IDs der Knoten wer-
den wiederum mit Hilfe einer Sequenz generiert. In dem Fall, wenn es innerhalb einer
Transaktion mehrere gleiche Items gibt, werden, wie oben schon erläutert wurde, nur
unterschiedliche Transaktions-IDs in die Präx-Tabelle eingefügt und deshalb ist die Information über die Anzahl mehreren gleichen Items innerhalb einer Transaktion nicht in
der Präx-Tabelle enthalten. Deshalb wird auch die Information aus der Input-Tabelle
fp_tdg_tdb
'Y' gesetzt.
gebraucht. Für alle Knoten in dieser Phase werden sidelink-Attributen auf
Später werden diese Attribute ausführlich erklärt und entsprechend geän-
dert.
insert into fp_tdg_node
select fp_tdg_node_seq.nextval node_id, parentt,
item, countt, level_ct, ''Y'' sidelink
from
(select db.item item, tp.node_id parentt,
count(db.tid) countt
from fp_tdg_tdb db, fp_tdg_tid_prefix tp
where db.tid = tp.tid and db.item_rank = level_ct
group by db.item, tp.node_id
);
34
Maria Soldatova
Studienarbeit
Weiterhin werden die Items aus der Input-Tabelle bestimmt, die sich auf der nächsten
Ebene benden (in diesem Beispiel auf der zweiten Ebene). Diese Items werden in die
zweite Präx-Tabelle als die nächsten zu bearbeitenden Items eingefügt. Als IDs der
Elternknoten für diese Items werden die IDs der Knoten, die gerade in die Tabelle
fp_tdg_node
eingefügt wurden, geschrieben.
insert into fp_tdg_tid_prefix_tmp
select pt.tid, n.node_id, db.item
from fp_tdg_node n, fp_tdg_tid_prefix pt, fp_tdg_tdb db
where decode(n.parent_id, null, 0, n.parent_id) =
decode(pt.node_id, null, 0, pt.node_id) and
n.item = pt.next_item and
db.item_rank = level_ct + 1 and
db.tid = pt.tid;
Es wird dieses Vorgehen so weiter in der Schleife wiederholt, bis es keine weitere Items
auf der nächsten Ebene aus den Transaktionen gibt. Am Ende ergibt sich die Tabelle
fp_tdg_node,
die den entsprechenden FP-tree darstellt und für das Mining dieses FP-
tree benutzt werden kann.
4.5
Mining des FP-tree
Der Mining Prozess wird mit dem Aufruf der folgenden Prozedur durchgeführt:
procedure mine_tree(p_header_id in number, p_minsupabs in number) is
h_rec fp_tdg_header%ROWTYPE ;
out_id number ;
new_header number ;
loop_ct number := 0 ;
begin
-- für jeden Eintrag h_rec.item aus der Header-Tabelle,
-- die mit der header_prefix_id gekennzeichnet ist
loop
if h_rec.item_count >= p_minsupabs then
(Abschnitt 4.5.1)
-- generiere von Muster
generate_patterns();
-- fülle der Header-Prefix Tabelle
fill_header_prefix_table();
-- fängt mit dem aktuellen Knoten an
loop (Abschnitt 4.5.2)
35
Maria Soldatova
Studienarbeit
-- gehe durch den Baum und
-- bestimme die Pfade bis zum Wurzel
upwalk_tree();
end loop;
-- aktualisiere die sidelinks-Attribute in der Node-Tabelle
(Abschnitt 4.5.3)
update_node_table();
-- bestimme die Knoten aus Sub-Header-Tabelle
(Abschnitt 4.5.4)
get_sub_header_table();
end;
mine_tree(new_header, p_minsupabs) ;
end if;
end loop;
Diese Prozedur wird zuerst mit dem
p_header_id = 1
aufgerufen, d.h. mit der origi-
nalen frequent-item-header Tabelle, die Items aus der Input-Tabelle enthält und die in
der zweiten Phase ausgefüllt wurde. Für jeden Eintrag aus der Header-Tabelle werden
weitere Aktionen in der Schleife durchgeführt. Die 3. Phase hat im Allgemein folgenden
Ablauf:
•
Für den aktuellen Knoten wird durch das Verfolgen der Eltern-Kind Beziehungen
der Präxpfad bestimmt.
•
Aus diesen Präxpfaden ergeben sich die gesuchten Muster.
•
Wenn diese Muster frequent sind, dann wird der Mining Prozess rekursiv fortgesetzt.
4.5.1
Erzeugung von Muster
Für diese Phase werden einige zusätzliche Tabellen benötigt, eine davon ist die Tabelle
fp_tdg_long_pattern,
die für die Speicherung der gefundenen Muster benutzt wird.
Das Schema dieser Tabelle ist folgendes:
table fp_tdg_long_pattern
(
pattern_id number, -- eindeutige ID des Musters
item
number, -- ID des Items
support
number -- Zähler des Items
)
Allgemein, wenn der Eintrag I aus der Header-Tabelle H_x gerade bearbeitet wird, wird
das Mining für alle frequenten Itemsets durchgeführt, die auf Ix enden. Das wird durch
36
Maria Soldatova
Studienarbeit
eine zusätzliche Tabelle
header_id
fp_tdg_header_prefix
gewährleistet, die für eine bestimmte
(d.h. für eine bestimmte Header-Tabelle) dieses Item x enthält.
table fp_tdg_header_prefix
(
header_id number, -- eindeutige ID der Rekursionsstufe
item
number, -- ID des Items
)
h_rec.item
und den Items aus den Präxpfaden die Muster, die in die Tabelle fp_tdg_long_pattern
Aus dieser Tabelle ergeben sich durch die Vereinigung des aktuellen Items
eingefügt werden. Die IDs des Muster werden mit Hilfe einer Sequenz generiert und in
der Variable
out_id
gespeichert.
select fp_tdg_long_pattern_seq.nextval into out_id from dual ;
insert into fp_tdg_long_pattern
(
select out_id, pt.item, h_rec.item_count
from
( ( select h_rec.item item from dual )
union
( select p.item item
from fp_tdg_header_prefix p
where p.header_id = p_header_id )
) pt
) ;
Als nächstes wird die Tabelle
fp_tdg_header_prefix ausgefüllt. Die eindeutige ID wird
new_header gespeichert.
mit Hilfe einer Sequenz generiert und in der Variable
select fp_tdg_header_seq.nextval into new_header from dual ;
insert into fp_tdg_header_prefix
( select new_header, p.item
from fp_tdg_header_prefix p
where p.header_id = p_header_id
) union
( select new_header, h_rec.item from dual ) ;
Für jeden Eintrag aus der Header-Tabelle werden durch das Verfolgen der Eltern-Kind
Beziehungen die Präxpfade für die aktuellen Knoten bestimmt. Um den Baum nach
oben zu durchlaufen wird eine Tabelle
fp_tdg_upwalk
benutzt, wo die Knoten entlang
dem Pfad mit der ID des Elternknotens und dem Zähler gespeichert werden.
table fp_tdg_upwalk
(
node_origin number, -- ID des Knotens
node_current number, -- ID des Elternknotens
count_origin number -- Zähler des Knotens
)
37
Maria Soldatova
Studienarbeit
Es wird mit dem aktuellen Knoten angefangen, der zuerst in die Tabelle
fp_tdg_upwalk
eingefügt wird.
insert into fp_tdg_upwalk
select n.node_id, n.parent_id, n.count
from fp_tdg_node n
where n.item = h_rec.item and n.sidelink = 'Y' ;
4.5.2
Bestimmung der Pfade
Weiterhin werden in der Schleife die Pfade von dem Knoten bis zum Wurzel bestimmt
und für die Knoten entlang den Pfaden werden die Zähler akkumuliert. Diese Information
wird in der Tabelle
fp_tdg_path
gespeichert.
table fp_tdg_path
(
node_id number, -- ID des Knotens
count
number -- Zähler des Knotens
)
Es wird ebeneweise durch den Baum nach oben gegangen.
update fp_tdg_upwalk uw
set uw.node_current = (select n.parent_id
from fp_tdg_node n
where n.node_id = uw.node_current ) ;
Wenn der Knoten in der Tabelle
fp_tdg_path
schon vorhanden ist, dann wird sein
Zähler inkrementiert, sonst wird dieser Knoten mit dem aktuellen Zähler in die Tabelle
MERGE() zu verwenden. Mit dieser Funktion
lässen sich mehrere Operationen wie z.B. INSERT, UPDATE und DELETE in einer Operation
eingefügt. Dafür ist es sinnvoll die Funktion
kombinieren. In einer Operation lässen sich mit dieser Funktion einige Zeile einfügen und
andere Zeilen aktualisieren. Die Entscheidung, ob die Zeilen eingefügt oder aktualisiert
werden sollen, wird basierend auf der Join-Bedingung getroen. Die Zeilen, die JoinBedingung erfüllen, werden aktualisiert, andere werden eingefügt.
merge into fp_tdg_path p
using (select uw.node_current, sum(uw.count_origin) csum
from fp_tdg_upwalk uw
where uw.node_current is not null
group by uw.node_current ) n
on ( n.node_current = p.node_id )
when matched then
update set p.count = p.count + n.csum
when not matched then
insert values (n.node_current, n.csum ) ;
Wenn es keinen weiteren Elternknoten gibt, dann wird die Schleife abgebrochen, d.h.
die Wurzel wurde erreicht.
38
Maria Soldatova
Studienarbeit
select count(node_current) into loop_ct from fp_tdg_upwalk ;
exit when ( loop_ct = 0 ) ;
4.5.3
Aktualisieren der SIDELINKS-Attribute
Die Informationen aus der Tabelle
fp_tdg_path
werden danach benutzt um die Zäh-
ler und sidelinks-Attribute der Knoten in der Tabelle
fp_tdg_node
zu aktualisieren.
Sidelinks-Attribute zeigen, ob der Knoten zu dem zu bearbeitenden Teilbaum gehört
oder nicht. Wenn die Tabelle
sidelinks-Attribute auf
Tabelle
fp_tdg_path
'Y'
fp_tdg_node
zum ersten Mal ausgefüllt wird, werden alle
gesetzt. In dieser Phase werden für die Knoten, die in der
vorhanden sind, die sidelinks-Attribute auf
'Y'
gesetzt. D.h. sie
benden sich auf den Pfaden von den aktuellen Knoten bis zur Wurzel und gehören
somit zu dem zu bearbeitenden Teilbaum. Für alle anderen Knoten, die sich im Vergleich zu den aktuellen Knoten auf höheren Ebenen des Baums benden, aber nicht in
der Tabelle
fp_tdg_path enthalten sind, werden die sidelinks-Attribute auf 'N' gesetzt,
d.h. diese Knoten gehören nicht zu dem zu bearbeitenden Teilbaum.
update fp_tdg_node n
set n.count =
(
select p.count
from fp_tdg_path p
where p.node_id = n.node_id ),
n.sidelink = 'Y'
where n.node_id in (select pp.node_id from fp_tdg_path pp);
update fp_tdg_node n
set n.sidelink = 'N'
where n.item < h_rec.item and
n.node_id not in (select pp.node_id from fp_tdg_path pp)
and n.sidelink = 'Y';
4.5.4
Bestimmung der Sub-Header-Tabelle
Weiterhin werden die Knoten aus der Sub-Header-Tabelle bestimmt und in die HeaderTabelle eingefügt mit der neuen ID.
insert into fp_tdg_header hd
( select new_header, n.item, sum(n.count)
from fp_tdg_node n
where n.item < h_rec.item and n.sidelink = 'Y'
group by n.item
) ;
Die Prozedur wird weiter rekursiv mit der neuen Header-ID aufgerufen.
mine_tree(new_header, p_minsupabs) ;
39
Maria Soldatova
4.6
Studienarbeit
Umwandlung der Ergebnisses
Nach dem der Mining Prozess abgeschlossen wird, sind die Ergebnisse des Mining in der
Tabelle
fp_tdg_long_pattern
zu nden. Aber diese Ergebnisse sollen noch entspre-
chend transformiert werden, in dem die Items in die originalen Items aus der Transaktionsdatenbank übersetzt werden. Die endgültigen Ergebnisse werden in der Tabelle
fp_tdg_result
gespeichert.
table fp_tdg_result
(
pattern_id number, -- eindeutige ID des Muster
item
number, -- Item aus der Transaktions-DB
support
number -- Zähler des Items
)
insert into fp_tdg_result
select p.pattern_id, t.item_original, p.support
from fp_tdg_long_pattern p, fp_tdg_item_trans t
where p.item = t.item_new ;
40
Maria Soldatova
4.7
Studienarbeit
Anwendung des Algorithmus am Beispiel (MovieDB)
In diesem Abschnitt soll der Algorithmus an einem realen Beispiel getestet werden.
Die Datenbank, die verwendet werden soll, ist eine Film-Datenbank, die im Folgenden
dargestellt ist.
Relationales Schema der Filmdatenbank MovieDB
PRODUCTION
(production, title
MOVIE
(production
GENRE
(production
WORKS
(person
null
, runtime
null
→PRODUCTION,
→PRODUCTION,
→PERSON,
, year
null
)
type)
genre)
production
→PRODUCTION,
job, credit_pos
null
Bei dieser Datenbank handelt es sich um eine Sammlung von Film-Informationen. Die
Tabelle
PRODUCTION
enthält Informationen zu Film- und Fernsehproduktionen. Jede
Produktion hat eine eindeutige Nummer (production). Zusätzlich sind jeweils (sofern
bekannt) der Titel (title), das Produktionsjahr (year) und die Laufzeit in Minuten (runtime) angegeben.
Die Tabelle
WORKS stellt eine Beziehung zwischen Produktionen und Personen her:
Für jede Mitwirkung einer Person an einer Produktion, wird deren Aufgabe (job) festgehalten: actor für Schauspieler, director für Regisseure, costumedesigner etc. Eine
Person kann mehrere Aufgaben in einer Produktion haben (etwa Schauspieler und Produzent). Zusätzlich kann bekannt sein, an welcher Position die Person im Abspann der
Produktion (bzgl. der Aufgabe) genannt wird (credit_pos).
In
GENRE
sind die Genres einer Produktion vermerkt, z.B. Action , Drama oder
SciFi .
4.7.1
Beispiel 1
Die Assoziationsanalyse sucht nach den Zusammenhängen innerhalb der vorhandenen
Daten. In der Film-Datenbank werden beispielsweise Zusammenhänge zwischen den Regisseure und Genres, in denen die Regisseure den Film gedreht haben, vermutet. Dabei
entsprechen die Filme den Transaktionen, Regisseure und Genres den Items. Um die
Zusammenhänge zwischen den Regisseure und Genres herauszunden, müssen die frequenten Muster gefunden werden. Das geschieht mit dem FP-Growth Algorithmus. Die
Daten für die Assoziationsanalyse müssen zunächst zusammengefasst und bereitgestellt
werden.
Insgesamt gibt es in der Film-Datenbank 26 verschiedenen Genres. Zuerst müssen
diese Daten transformiert werden, weil die Genres als eine Zeichenkette in der Datenbank
gespeichert sind.
insert into genre_transform
select genree, genre_sequence.NEXTVAL
from (select distinct genre genree
from moviedb.genre)
41
)
Maria Soldatova
Studienarbeit
Jetzt gibt es zu jedem Genre eine eindeutige ID, die in der Tabelle genre_transform
gespeichert sind. Als nächstes wird eine Tabelle mit Transaktionen erstellt. In diese
Tabelle werden die Daten aus der Datenbank eingefügt.
create table trans_tdb_first(tid_attr NUMBER(10), item_attr NUMBER(10));
Bzgl. Regisseure gibt es keine Einschränkungen in der Datenbank, aber es interessieren
hier nur die Regisseure aus einer Zeit, die der Autorin bekannt sein können, deshalb
werden folgende zusätzliche Bedingungen an die Auswahl der Regisseure gestellt:
•
Film wurde in den USA gedreht.
•
Film muss von Typ
•
Film stammt aus den Jahren zwischen 1970 und 2000.
•
Regisseur muss mindestens 10 Filme gedreht haben.
cinema
sein.
Mit den oben genannten Bedingungen werden weiterhin aus der Datenbank 11424 Einträge, 3514 Filmen und 1094 Regisseure und Genres ausgewählt. Im nächsten Schritt
wird der minimale Support festgelegt. Zum Beispiel wird mit dem minimalen Support
1% angefangen. Wenn es nötig ist, könnte der minimale Support noch korrigiert werden.
1% in diesem Beispiel bedeutet, dass Regisseure mindestens 35 Filmen in einem einzigen Genre gedreht haben müssen. Um die frequenten Muster zu nden, wurde durch
Herumprobieren der minimale Support bei mind. 0.1% festgelegt (also mind. in 3 von
3514 Filmen). Mit dem folgenden Aufruf des Algorithmus wurden die frequenten Muster
bestimmt.
begin
fp_tdg.mine(table_name =>'trans_tdb_first' , tid_attr =>'tid_attr' ,
item_attr =>'item_attr' , minsup_perc => 0.1) ;
end;
In dem folgenden Ausschnitt werden einige gefundenen frequenten Itemsets dargestellt.
PATTERN_ID
ITEM
SUPPORT
...
...
...
614
5
3
614
24
3
614
1
3
614
6
3
614
298361
3
...
...
...
1309
8
3
1309
24
3
1309
1
3
1309
6
3
1309
343439
3
...
...
...
42
Maria Soldatova
Studienarbeit
Mit dem Namen und Genren aus Datenbank ergibt sich zum Beispiel:
PATTERN_ID
ITEM
SUPPORT
...
...
...
614
comedy
3
614
thriller
3
614
action
3
614
crime
3
614
Hill, Walter
3
...
...
...
1309
drama
3
1309
thriller
3
1309
action
3
1309
crime
3
1309
Little, Dwight H.
3
...
...
...
Aus solchen frequenten Itemsets lassen sich mit einer bestimmten Condence weiter
verschiedene Assoziationsregeln generieren.
4.7.2
Beispiel 2
In der Masterarbeit von M. Spehling werden beispielsweise Zusammenhänge zwischen
den Schauspielern vermutet. Dabei entspricht der Film der Transaktion und die Schauspieler den Items. In diesem Beispiel wird nach solchen Zusammenhänge zwischen den
Schauspielern mit dem implementierten Algorithmus gesucht. Zuerst müssen die Daten für die Assoziationsanalyse bereitgestellt werden. Die bereitgestellten Daten bzgl.
Schauspieler besitzen folgende Einschränkungen:
•
Film wurde in den USA gedreht.
•
Film muss von Typ
•
Film stammt aus den Jahren zwischen 1950 und 2000.
•
Schauspieler muss mindestens 20 Filme mitgespielt haben.
•
Im Film müssen mind. zwei Schauspieler mitspielen.
cinema
sein.
Als nächstes wird eine Tabelle mit Transaktionen erstellt. In diese Tabelle werden die
Daten aus der Datenbank eingefügt.
create table trans_tdb_second(tid_attr NUMBER(10), item_attr NUMBER(10));
Mit den oben genannten Einschränkungen werden weiterhin aus der Datenbank 81485
Einträge, 7841 Filmen und 11265 Schauspielern ausgewählt. Im nächsten Schritt wird
der minimale Support festgelegt. Zum Beispiel wird es mit dem minimalen Support 1%
angefangen. Weiterhin wenn es nötig ist, könnte der minimale Support noch korrigiert
werden. 1% in diesem Beispiel bedeutet, dass einige Schauspieler in mindestens 78 Filmen
43
Maria Soldatova
Studienarbeit
zusammen mitgespielt haben müssen. Um die frequenten Muster zu nden, wurde durch
Herumprobieren der minimale Support bei mind. 0.1% festgelegt (also mind. in 7 von
7841 Filmen). Mit dem folgenden Aufruf des Algorithmus wurden die frequenten Muster
bestimmt.
begin
fp_tdg.mine(table_name =>'trans_tdb_second' , tid_attr =>'tid_attr' ,
item_attr =>'item_attr' , minsup_perc => 0.1) ;
end;
In dem folgenden Ausschnitt werden einige gefundenen frequenten Itemsets dargestellt.
PATTERN_ID
ITEM
SUPPORT
...
...
...
4114
438033
7
4114
320164
7
4114
245981
7
4114
326321
7
4114
383485
7
4114
458491
7
4114
110913
7
...
...
...
Mit den Namen der Schauspielern aus Datenbank ergibt sich zum Beispiel:
PATTERN_ID
ITEM
SUPPORT
...
...
...
4114
Shatner, William
7
4114
Kelley, DeForest
7
4114
Doohan, James
7
4114
Koenig, Walter
7
4114
Nimoy, Leonard
7
4114
Takei, George
7
4114
Nichols, Nichelle
7
...
...
...
Es lässt sich aus diesen Ergebnissen die Tatsache erkennen, dass zum Beispiel William
Shatner in sieben Filmen zusammen mit George Takei gespielt hat. Die weiteren Ergebnisse decken sich mit Ergebnissen von M. Spehling.
44
Maria Soldatova
5
Studienarbeit
Zusammenfassung
Mit dieser Arbeit wurde ein Überblick über die Grundlagen des Data Mining und einen
von seinen Bereichen, die Assoziationsanalyse, gegeben. Diesbezüglich wurde der klassische Algorithmus der Assoziationsanalyse - Apriori-Algorithmus - vorgestellt und analysiert.
In den meisten Fällen hat der Apriori-Algorithmus eine gute Performance, die durch
das Reduzieren der Gröÿe der Kandidatenmengen zustande kommt. Aber es gibt Situationen, z.B. bei groÿer Anzahl von Mustern, bei langen Mustern oder bei kleinem
minimalem Support, in denen der Apriori-Algorithmus enormen Aufwand hat.
Als eine eektive Alternative dazu wurde ein weiterer Algorithmus - FP-Growth vorgestellt und seine Funktionsweise anhand von Beispielen demonstriert. Es wurden
verschiedene Varianten des Algorithmus diskutiert und erläutert. Der Algorithmus FPGrowth hat einige Vorteile im Vergleich mit den anderen Methoden:
•
kompakte und vollständige Datenstruktur.
•
keine Kandidatengenerierung und Kandidatentests.
•
Zerlegen der Mining-Aufgaben laut divide-and-conquer Ansatz.
•
kein wiederholter Durchlauf der Datenbank.
Neben der ursprünglichen Variante des Algorithmus, der bottom-up arbeitet, wurde
auch der Top-Down FP-Growth diskutiert und erläutert. Diese Variante des Algorithmus
hat bestimmte Vorteile, die auch experimentell in der Studie von Tang bestätigt wurden.
Es wurden einige Möglichkeiten der SQL-basierten Implementierung dieses Algorithmus dargestellt und analysiert. Eine Möglichkeit der Implementierung wurde ausführlich
erläutert und anhand von Beispielen illustriert. Im ersten Beispiel wurde nach Zusammenhängen zwischen den Regisseuren und Genres, in denen die Regisseure ihre Filme
gedreht haben, gesucht. Das zweite Beispiel deckt sich mit der Masterarbeit von M.
Spehling: es wurde nach den Zusammenhängen zwischen den Schauspielern gesucht.
Es ergeben sich weitere Möglichkeiten in der Erweiterung und Anwendung des vorgestellten Algorithmus. Das Mining der frequenten Muster generiert oft die groÿe Anzahl
der frequenten Mengen des Items und das verhindert die Eektivität des Mining, weil
die Benutzer viele Miningregeln durchsuchen müssen um die nützliche davon zu nden.
Eine Alternative - das Mining für die geschlossenen Mengen des frequenten Items - wurde von Pasquier et al. 1999 vorgeschlagen. Eine weitere Anwendung ist das Mining der
sequentiellen Muster. Die meisten früheren Methoden für das Mining der sequentiellen
Muster basieren auf dem Apriori Algorithmus, aber der Apriori Algorithmus hat nach
wie vor die Probleme wenn die Sequenzdatenbank zu groÿ ist oder sequentielle Muster
lang sind. Die FP-growth Methode kann für das Mining der sequentiellen Muster erweitert werden. Eine eektive Methode für das Mining der sequentiellen Muster, genannt
PrexSpan, wurde von Pei et al. 2001 entwickelt.
45
Maria Soldatova
Studienarbeit
Literatur
[AS94] Rakesh Agrawal and Ramakrishnan Srikant.
association rules.
editors,
Fast algorithms for mining
In Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo,
Proc. 20th Int. Conf. Very Large Data Bases, VLDB,
499. Morgan Kaufmann, 1215
[ES00] Martin Ester and Jörg Sander.
niken und Anwendungen.
[Han05] Jiawei Han.
pages 487
1994.
Knowledge Discovery in Databases : Tech-
Springer, September 2000.
Data Mining: Concepts and Techniques.
Morgan Kaufmann
Publishers Inc., San Francisco, CA, USA, 2005.
[HPY00] Jiawei Han, Jian Pei, and Yiwen Yin.
Mining frequent patterns without
candidate generation. In Weidong Chen, Jerey Naughton, and Philip A.
Bernstein, editors,
2000 ACM SIGMOD Intl. Conference on Management
of Data, pages 112. ACM Press, 05 2000.
[SL05] Csaba Istvan Sidlo and Andras Lukacs. Shaping sql-based frequent pattern
mining algorithms. In
KDID, 2005.
[SSG04] Xuequn Shang, Kai Uwe Sattler, and Ingolf Geist. Sql based frequent pattern
mining without candidate generation. In
ACM symposium on Applied computing,
SAC '04: Proceedings of the 2004
pages 618619, New York, NY,
USA, 2004. ACM Press.
[WTHL02] Ke Wang, Liu Tang, Jiawei Han, and Junqiang Liu. Top down fp-growth for
PAKDD '02: Proceedings of the 6th Pacic-Asia
Conference on Advances in Knowledge Discovery and Data Mining, pages
association rule mining. In
334340, London, UK, 2002. Springer-Verlag.
46