Relationale Datenbanktabellen, SAP-Tabellen, Dictionary
Werbung

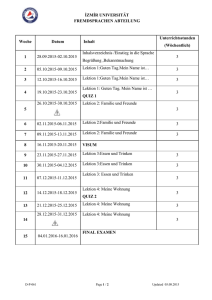
vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 In Lektion 12 lernen Sie die grundlegenden Kenntnisse über relationale Datenbanken kennen, die notwendig sind, um mit ABAP erfolgreich Datenbankauswertungen zu programmieren. Der Zusammenhang zwischen Daten, Datenbanktabellen, Datenbank und Dictionary wird erläutert. Sie lernen, wie Sie mit in ABAP eingebetteten SQL‐Befehlen auf Datenbankinhalte zugreifen können. Hinweis: zugehörige weitere Quellen sind Screencast‐Dateien (Videos), die inhaltlich relevant sind. Lektion L12: Relationale Datenbanktabellen, SAP‐Tabellen, Dictionary + Datenmodelle, Datenbank‐Zugriff über SQL‐Befehle Die Lektion L12 ist wie folgt gegliedert: 1. Relationale Datenbanktabellen 2. SAP‐Tabellen, Dictionary + Datenmodelle 3. Datenbank‐Zugriff über SQL‐Befehle Übersicht über die Screencasts der Lektion L12 Die folgenden Screencasts ergänzen die in diesem Skript ausformulierten Texte. Screencast Inhalt L12‐01 [21 Min.] Flugdatenmodell: ERM‐Modell im Dictionary, Fremdschlüssel, Wertetabellen L12‐02 [7 Min.] SELECT‐1: einfacher Select (Debugger) L12‐03 [9 Min.] SELECT‐2: Select single (Debugger) L12‐04 [8 Min.] SELECT‐3: mit WHERE (Debugger) Tabellen dienen im SAP‐System nicht nur zur Datenspeicherung, sondern auch zur Steuerung, d.h. zur Ausführung von Befehlen. Zentrale Steuerelemente des Systems sind über Tabellen realisiert. Selbst die Programmiersprache ABAP Objects wird intern in einen Zwischencode umgewandelt, der wiederum durch die Interpretation von Tabelleneinträgen entsteht. Wir gehen hier auf diese systeminternen Zusammenhänge nicht näher ein, sondern beschränken uns bei den Erläuterungen auf das Konzept der relationalen Datenbanken und Tabellen so, wie es für das Systemverständnis eines ABAP‐Programmierers notwendig ist. Hinweis Die folgenden Darstellungen ersetzen keine Vorlesung über Datenbanken und dienen nur zur Vorbereitung für das Reporting und die datenbankorientierte SAP‐Programmierung. L12.1: Relationale Datenbanktabellen In diesem Abschnitt wird das Konzept der relationalen Datenbanktabellen erläutert. Das Schlüsselprinzip sowie das Konzept der Fremdschlüsselprüfung wird beschrieben und Sie erfahren außerdem, wie Sie sich mit Hilfe von Systemfunktionen Tabelleninhalte anzeigen lassen bzw. diese verändern können. Relationale Datenbanken und Tabellen Beim relationalen Datenbankmodell (Relationenmodell) werden Objekttypen und Beziehungen sowie deren Attribute mittels Relationen abgebildet, die anschaulich durch Tabellen dargestellt werden können. Beim Relationenmodell werden Daten entsprechend ihrer Beziehungen untereinander gespeichert. Die Suche erfolgt über Schlüssel. Andere Datenmodelle sind z.B. das hierarchische Modell oder das Netzwerkmodell. Eine Datenbank ist eine Form der Datenspeicherung und enthält eine Menge von Informationen aus einem abgegrenzten Informationsbereich. Die Daten werden hier mit Verweisen auf ihre Abhängigkeit untereinander geprüft. Lektion 12: Seite 1 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Eine Tabelle ist eine Anordnung von Daten in Tabellenform. Eine Tabelle besteht aus Spalten (Menge von Datenwerten desselben Typs) und Zeilen (Datensätzen). Jede Tabellenzeile kann durch ein oder mehrere Felder eindeutig identifiziert werden. Beispiel: Bankkonto Als erstes Beispiel betrachten wir die Daten eines Bankkontos und überlegen uns, wie wir die Datensätze von allen Kontoinhabern abspeichern können. Abb. L12‐01 zeigt den ersten Entwurf. Es handelt sich hierbei um die so genannte 1. Normalform einer Tabelle. Abb. L12‐01: Bankkonten: Kundendaten in Tabellenform, erster Entwurf Diese Tabelle enthält neben sogenannten Stammdaten auch aktuelle Daten wie den Kontostand. Die Information, die man typischerweise bei einem Kontoauszug erhält, könnte wie in Abb. L12‐02 dargestellt werden. Diese Informationen werden oft als Bewegungsdaten bezeichnet: sie werden durch Transaktionen (Abbuchungen, Gutschriften aufgrund von durchgeführten Geschäftsprozessen) verursacht. Abb. L12‐02: Bankkonten: Bewegungsdaten in Tabellenform, erster Entwurf Schlüsselprinzip Datenelemente sind Datenfelder. Ein Datensatz besteht aus unterschiedlichen Datenelementen, die in einem Datensatz zusammengefasst sind und als Ganzes angesprochen werden können. Die Datenelemente in einem Datensatz können in Key‐Felder (Schlüsselfelder, Argumentteil) und in Nicht‐ Key‐Felder (Informationsfelder, Funktionsteil) eingeteilt werden: Key‐Felder Funktionsfelder Ein Schlüssel (Datenschlüssel, Key) ist eine Kombination von Datenelementen, mit der ein Datensatz eindeutig identifiziert werden kann. Für relationale Datenbanktabellen gilt das Schlüsselprinzip: Ein Datensatz ist eindeutig durch einen Schlüssel identifizierbar. Beispiel Das Autokennzeichen ist ein Schlüssel zur Identifizierung eines Datensatzes in der Datei “KFZ‐Halter”. Die Datenelemente Name und Vorname reichen in der Regel zur Identifizierung nicht aus, da es verschiedene Personen mit übereinstimmenden Namen geben kann bzw. eine Person mehrere Autos besitzen kann. 3. Normalform Zurück zum Beispiel „Bankkonto“: Wir überlegen uns jetzt, wie die erste Speicherversion (siehe Abb. L12‐ 01 und L12‐02) verbessert werden kann. Es ist hier nicht sinnvoll, die Kontostände als kurzlebige Daten zusammen mit allen langlebigen Daten (Adressdaten) in derselben Datei zu speichern. Hier wird man einen Primärschlüssel suchen (z.B. Kontonummer und Bankleitzahl) und die Daten wie in Abb. L12‐03 in getrennten Tabellen speichern. Lektion 12: Seite 2 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Um Daten so abzuspeichern, dass sie nicht unnötig mehrfach vorhanden sind, werden die Daten auf mehrere Tabellen verteilt so, dass eine Information nur einmal in einem eigenen Datensatz gespeichert wird und bei Verwendung in anderen Zusammenhängen darauf Bezug genommen wird. Dieses „Bezugnehmen“, quasi ein Link, wird dadurch erreicht, dass zwischen Tabellen Relationen (Beziehungen) definiert werden. Konkret sind dies Fremdschlüsselbeziehungen und Wertetabellen. Als Grundlage für diese Konstrukte ist ein Datenmodell erforderlich, dass der sogenannten 3. Normalform genügt, kurzgesagt: ein Modell mit redundanzfreier Datenhaltung. Für unser obiges Beispiel (Bankdaten) sehen Sie in Abb. L12‐03 einen ersten Entwurf. Die rot bzw. violett markierten Spalten sind Key‐Felder, wobei ein violettes Key‐Feld andeutet, dass es über Fremdschlüssel auf eine Prüftabelle verweist (durch Pfeil visualisiert). Blau markierte Spalten sind Informationsfelder, deren Inhalt aus einer Wertetabelle stammt, wobei der Bezug durch ein Key‐Feld hergestellt wird. In diesem Fall kommt der Kontoinhaber in der Belegtabelle aus der Kundentabelle, der Bezug zum Eintrag in der Kundentabelle wird über die Kunden‐ID in der Belegtabelle hergestellt. Abb. L12‐03: Redundanzfreie Datenspeicherung: Bankdaten in der 3. Normalform Aus fachlicher Sicht kann man Bankdaten (Name der Bank, Anschrift, ID), Kundendaten (Name, Anschrift, Kunden‐Nr.), Bankkunden (Konto‐Nr., Kunden‐ID, Bank‐ID) und Kontobelege (Datum, Text, Betrag, und als Belegkopf‐Info: Bank‐ID, Konto‐Nr., Kontoinhaber) unterscheiden. Diese Betrachtungen sind bewusst einfach gehalten, die Realität sieht noch etwas komplexer aus. Damit z.B. die Kundendaten nicht unnötig oft gespeichert werden müssen, arbeitet man mit einer eigenen Kundentabelle, in der jeder Kunde eindeutig über eine Kundennummer (Kunden‐ID) identifiziert werden kann. Jede Bank wird über einen eindeutigen Schlüssel (innerhalb eines Landes die Bankleitzahl BLZ, international: BIC) identifiziert und durch Bankbezeichnung und Anschrift ergänzt. Jedes Konto wird über eine Kontonummer (bzw. IBAN), zusammen mit Bank‐ID und Kunden‐ID, eindeutig festgelegt. Jeder Kunde kann jetzt mehrere Konten bei verschiedenen Banken sowie bei der derselben Bank haben und trotzdem sind sowohl Kundenanschrift als auch Bankanschrift nur jeweils einmal gespeichert. Lektion 12: Seite 3 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Greift man sich jetzt ein Konto eines Kunden bei einer Bank heraus, müssen dazu Kontobewegungen, verursacht durch Zahlungseingänge und ‐ausgänge, verbucht werden, d.h. diese Bewegungsdaten werden als Datensätze in einer Belegtabelle (Kontoauszugsbeleg) gespeichert. Würden jetzt für jede Kontobewegung alle zugehörigen Daten wie z.B. Adresse des Kunden, gespeichert, wäre dies nicht nur eine Speicherplatzverschwendung, sondern bei Änderungen der Adressdaten müsste dies bei jedem Belegsatz erfolgen. Bei redundanzfreier Datenhaltung muss eine Adressänderung nur an einer Stelle geschehen und ist trotzdem für alle relevanten Datensätze verfügbar. Damit kommen wir zu dem Datenmodell, dass in Abb. L12‐03 abgebildet ist: Bankdaten, Kundendaten, Konten (Bankkunden: welcher Kunde hat bei welcher Bank welche Konten?) und Bewegungsdaten (welche Aktion wird wann für welches Konto durchgeführt?) werden erfasst. Dafür verwendet man hier 4 verschiedene Tabellen. Die Beziehungen (Relationen) zwischen diesen Tabellen, die notwendig sind, damit man die fachlich geforderten Zusammenhänge gewährleisten kann, werden durch Fremdschlüsselbeziehungen und Wertetabellen‐Logik erreicht und sind hier durch einfache Pfeile visualisiert. Verbesserung des Datenmodells: Belegstruktur In der Belegtabelle wird Bank‐ID, Konto‐Nr. und Kontoinhaber mehrfach angezeigt, was dem oben erläuterten Prinzip der 3. Normalform widerspricht. Hierzu ist noch eine weitere Umformung notwendig, die wir aus Gründen der Übersichtlichkeit getrennt in Abb. L12‐04 darstellen: Ein typischer Belegaufbau besteht aus Kopfinformationen (1 Datensatz) und mehreren Positionen (n Datensätze). In unserem Beispiel bedeutet dies, dass ein Kontoauszug als betriebswirtschaftliches Objekt gemäß einer 1:n‐Relation (Beziehung) mit einer Belegkopf/Belegposition‐Logik so abgebildet wird, dass pro Beleg 1 Datensatz in einer Kopftabelle und n Datensätze in einer Positionstabelle gespeichert werden. Damit man die Positionen dem richtigen Kopf zuordnen kann, ist es notwendig, dass in der Kopf‐ und Positionstabelle je eine eindeutige Beleg‐ID verwendet wird. Dies ist in Abb. L12‐04 zu sehen. Abb. L12‐04: Belegkopf / ‐ Positionslogik Lektion 12: Seite 4 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Konsistenzprüfung Falls versucht wird, im Kopf bei Kunden‐ID 4720 und bei Konto‐Nr. 2000 einzugeben, wird geprüft, ob für diesen Kunden diese Konto‐Nr. bereits in der Prüftabelle Bankkunden eingetragen ist. Falls nicht, gibt es eine Fehlermeldung. Dadurch wird verhindert, dass auf Daten mit Schlüsselfunktion verwiesen wird, die es noch nicht gibt. L12.2: SAP‐Tabellen, Dictionary + Datenmodelle ( Screencast L12‐1) Die für diesen Kurs relevanten SAP‐Tabellen sind relationale Datenbanktabellen, bei denen man sich Gedanken über Fremdschlüssel, Prüf‐ und Wertetabellen machen muss. Im vorher erläuterten Beispiel (Bankkonto) haben Sie einen ersten Einstieg in die Überlegungen erhalten, die notwendig sind, um ein konsistentes Datenmodell erzeugen zu können. In diesem Kurs liegt der Fokus nicht auf dem Entwurf von Datenmodellen, sondern auf der korrekten Interpretation der Datenmodelle, die hinter den realen relationalen Datenbanktabellen liegen. Mit anderen Worten: Sie müssen nur lernen, diese Information aus dem System herauszulesen und müssen diese nicht schreiben. Anhand des folgenden durchgängigen Beispiels zeigen wir Ihnen, wo und wie Sie die notwendigen Informationen im System finden und wie Sie diese für das Reporting einsetzen können. SAP‐Flugdatenmodell Abb. L12‐05 zeigt Ihnen das in diesem Kurs verwendete Flugdatenmodell in verkürzter Version, d.h. mit der Beschränkung auf die wichtigsten 5 Tabellen des Modells. Die Datenbanktabellen des SAP‐ Flugdatenmodells sind Bestandteil jedes SAP‐Systems. In jedem SAP‐Standard‐System finden Sie dazu geeignete Datensätze bzw. können diese mit einem ebenfalls zum Standard gehörenden ABAP‐Programm generieren. Kurzgefasst kann man den Aufbau des Flugdatenmodells wie folgt erläutern: Flüge (SFLIGHT) werden von einer Fluggesellschaft (SCARR) auf einer Flugverbindung (SPFLI, Flug‐Nr., Flugroute) ausgeführt. Für jeden Flug gibt es Buchungen (SBOOK) von Kunden (SCUSTOM). Abb. L12‐05: vereinfachtes SAP‐Flugdatenmodell mit Kardinalitäten Die Realität ist natürlich etwas komplizierter, auch das SAP‐Datenmodell enthält noch mehr Informationen. So kann z.B. der Flugzeugtyp spezifiziert werden (Informationsfeld in der Tabelle SFLIGHT) und hat dafür Lektion 12: Seite 5 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 eine eigene Prüftabelle SAPLANE, in der Detaildaten zum Flugzeugtyp abgelegt sind. Ein Ticket muss entweder über ein Reisebüro (STRAVELAG) oder am Schalter der Fluggesellschaft (SCOUNTER) erworben werden, usw. Fremdschlüsselbeziehungen und ‐prüfungen bei der Datenpflege Damit alle Tabellen insgesamt eine konsistente Datenspeicherung ermöglichen, muss über so genannte Fremdschlüssel festgelegt werden, welche Felder in anderen Tabellen auf Existenz geprüft werden sollen. Wir gehen vom Beispiel in Abb. L12‐05 aus. Es sollen weitere Flüge in der Tabelle SFLIGHT eingetragen werden. Dazu muss geprüft werden, ob die dabei verwendeten Kürzel für CARRID und CONNID bereits in der Tabelle SPFLI vorhanden sind. Falls Sie z.B. einen Flug für eine Fluggesellschaft mit dem Kürzel XY und der Flugnummer 999 eingeben wollen, wird geprüft, ob für ‘XY 999‘ ein Datensatz in SPFLI vorhanden ist. Dort musste beim Eintrag geprüft werden, ob ‘XY‘ bereits in SCARR gepflegt war. Falls diese Prüfung nicht erfolgreich sein sollte, darf der Datensatz in SFLIGHT nicht eingefügt werden. Außerdem muss geprüft werden, ob die Start‐ und Zielorte in SPFLI in der Prüftabelle SGEOCITY eingetragen sind, usw. Bei Änderungen auf den Datenbanktabellen können folgende Probleme entstehen: Fall 1: Ein neuer (noch einzufügender) SCARR‐Eintrag enthält ein Währungskürzel für die Hauswährung der Fluggesellschaft, das in SCURX (Prüftabelle des Felds SCARR‐CURRCODE) nicht existiert. Dies würde in der weiteren Verarbeitung zu Widersprüchen führen, wenn z.B. die Währung benutzt werden soll und dazu weitere Informationen aus der Währungstabelle zu dieser Währung abgerufen werden. Dies passiert irgendwann später im System, wenn niemand mehr weiß, dass in SCARR ein Eintrag eingefügt wurde, ohne die Prüftabelle vorher mit dem fehlenden Eintrag zu füllen. Fall 2: Ein Eintrag aus SCARR soll gelöscht werden (z.B. Insolvenz einer Fluggesellschaft). In SPFLI, SFLIGHT und SBOOK wird aber auf diesen Eintrag Bezug genommen. Hier muss beim Löschen über einen „Verwendungsnachweis“ geprüft werden, ob das Löschen zu Komplikationen führen würde. Diese Prüfung ist aufwändiger als die Prüfung im Fall 1. Eine Veränderung von Datenbankinhalten findet meistens über eine Dialogtransaktion statt. Hierbei werden Werte in Eingabefelder auf einer Eingabemaske eingegeben. Das R/3‐System führt über diese Eingabefelder, falls für diese Felder im System eine Prüftabelle hinterlegt ist, eine Fremdschlüsselprüfung durch, d.h., das System prüft für Sie, ob das eingegebene Feld (bzw. die eingegebene Wertekombination) auf der Datenbank vorhanden ist. Im Fehlerfall sendet das System eine Nachricht, die Sie über diese Fehleingabe informiert, gibt Ihnen die Möglichkeit zur Korrektur der Eingabe und verhindert die weitere Verarbeitung. Beachten Sie aber, dass diese Systemreaktion nicht für alle Anwendungsprogramme automatisch aktiviert ist. Daraus ergeben sich für obige Problemfälle folgende Hinweise. Im 1. Fall besteht, sofern Sie die betroffenen Daten nicht über Dynpro‐Felder kontrollieren, die Notwendigkeit, die logischen Abhängigkeiten manuell zu programmieren. Im 2. Fall müssen Sie dies immer selbst programmieren. Im Dictionary können Sie die Fremdschlüsselprüfungen durch Prüftabellen erkennen, beispielsweise die Tabelle SPFLI in Abb. L12‐06. Dazu gehen Sie auf die Registerkarte Eingabeprüfungen: Sie können z.B. erkennen, dass das Key‐Feld CARRID (ID der Fluggesellschaft) gegen einen Eintrag in der Tabelle SCARR (Fluggesellschaft) geprüft wird. Das Feld CITYFROM (Abflugstadt) und CITYTO (Ankunftsstadt) wird mit einem Eintrag in der Tabelle SGEOCITY (Ortstabelle) verglichen. In Abb. L12‐07 sehen Sie die Möglichkeit, wie Sie sich die Details zur Fremdschlüsselprüfung anzeigen lassen können: Bei der Tabelle SBOOK auf der Registerkarte Felder markieren Sie die Zeile mit dem gewünschten Feld (hier: CUSTOMID) und drücken auf den Button mit dem Schlüssel‐Symbol. Es erscheint dann in einem Popup‐Fenster (rechter Screenshot) die Information, über welcher Feldern welcher Tabelle die Fremdschlüsselprüfung durchgeführt wird. Im unteren Bereich ist die Kardinalität angegeben, in diesem Fall 1:CN, d.h. jedem Satz aus der SCUSTOM können keiner, einer oder mehrere Sätze in der SBOOK zugeordnet sein. Über ein Icon auf diesem Popup erhalten Sie eine Anzeige der Bedeutung der Lektion 12: Seite 6 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Notationsform für die Kardinalität, die hier verwendet wird. Über die F4‐Taste bekommen Sie auch eine kurze Erläuterung angezeigt. Abb. L12‐06: Fremdschlüsselabhängigkeiten beim Flugdatenmodell (auszugsweise) Abb. L12‐07: Fremdschlüsselabhängigkeiten beim Flugdatenmodell: Details zu SBOOK‐CUSTOMID Das Flugdatenmodell ist in Abb. L12‐08 abgebildet, allerdings noch ohne Prüf‐ und Fremdschlüsseltabellen. Sie erhalten dies, indem Sie im Dictionary die Funktion Grafik (siehe Abb. L12‐07 das markierte Icon in der Symbolleiste) drücken, ausgehend von der Anzeige der Tabelle SBOOK. Es werden alle Tabellen in der Grafik angezeigt, die sich hierarchisch darüber befinden. Durch Drücken der Buttons Fremdschlüssel bzw. Prüftabelle können weitere abhängige Relationen angezeigt werden. Sie können im rechten Navigationsbereich durch das Verändern der Größe des Ausschnitts (grüner Rahmen) den gewünschten Modellteil im Hauptfensterbereich anzeigen. Sie schließen das Grafikfenster über die SAP‐ Navigationstasten, z.B. über „Zurück“ (F3). Lektion 12: Seite 7 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Abb. L12‐08: Data Dictionary: Anzeige Datenmodell (Abb. 2‐6) Tabellen zur System‐ und Anwendungssteuerung, Customizing Das R/3‐System wird in allen Bereichen von Tabellen gesteuert. So genannte Steuertabellen (z.B. Länder, Sprachen, Währungen) steuern indirekt die Abläufe, indem z.B. über das Länderkennzeichen länderspezifische Gesetzesregelungen und über die Sprache die jeweiligen Texte in der Landessprache prozessiert werden. Das Customizing erfolgt ebenfalls über Tabelleneinträge. In vielen Anwendungen wird Anwendungslogik statt in Programmen in Tabellen abgelegt. Durch geschicktes Manipulieren dieser Tabelleneinträge durch den Nutzer können Effekte erreicht werden, für die sonst das Erstellen von eigenen Programmen notwendig wäre, d.h., es sind dann keine Programmierkenntnisse und ‐berechtigungen notwendig. Datenbanktabellen und interne Tabellen Bei Datenbanktabellen handelt es sich um Speicherformen für eine dauerhafte Datenhaltung, die in allen SAP‐Programmen verfügbar ist. Die Veränderung des Aufbaus ist nur über das Dictionary möglich. Eine interne Tabelle ist nur innerhalb des ABAP‐Programms gültig und nur zur Laufzeit mit Werten gefüllt. Es handelt sich um eine temporäre und lokale Datenhaltung und ‐verarbeitung im Hauptspeicher. Diese internen Tabellen müssen im jeweiligen Programm deklariert werden. Typischer Einsatzbereich für die interne Datenverarbeitung mit internen Tabellen ist das Sortieren von Datenbeständen sowie die Gruppenstufenverarbeitung. Tabellen anzeigen und bearbeiten Es gibt anwendungsübergreifende Programme zur Anzeige bzw. Pflege von Tabelleneinträgen (Datensätzen). Weitere Informationen finden Sie auch in Block B unter Systemfunktionen. Erweiterte Tabellenanzeige / ‐pflege Über System Dienste Erweiterte Tabellenpflege kommen Sie zu einem Einstiegsbild zur Tabellenpflege (siehe Abb. L12‐09 oben). Durch das Drücken einer Taste (z.B. Anzeigen) gelangen Sie auf ein Bild mit der Anzeige der Datensätze (siehe Abb. L12‐09 unten). Hier können auch so genannte Views (Sichten auf Tabellen) bearbeitet werden. Lektion 12: Seite 8 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Tipp Mit etwas Übung können Sie diese Views über das Dictionary‐Infosystem durch geschicktes Maskieren des Tabellennamens herausbekommen. Dazu drücken Sie im Einstiegsbild des Dictionary im Fall View den Werthilfebutton. Hier wählen Sie Infosystem und dann alle Selektionen. Bei Primärtabelle geben Sie dann die Tabelle an, zu der Sie einen View suchen. In Abb. L12‐09 sehen Sie die Tabellenanzeige für die Mandanten‐Tabelle T000. Abb. L12‐09: Erweiterte Tabellenanzeige bzw. ‐pflege: Einstiegsbild und Pflegebild (Abb. 2‐7) Lektion 12: Seite 9 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Data Browser Mit dem Data Browser können Einträge von allen Tabellen angezeigt werden. Sie navigieren über Werkzeuge ABAP Workbench Übersicht Data Browser zu dieser Anwendung. Auf Abb. L12‐10 sehen Sie die Schritte zur Anzeige von Tabelleninhalten anhand des Beispiels der Tabelle SPFLI aus dem SAP‐Flugdatenmodell. Abb. L12‐10: Data Browser: Einstiegsbild, Selektionsbild und Anzeige der Tabelleneinträge (Abb. 2‐8) Dictionary‐Funktion Ausgehend von der Tabellenpflege (hier: nicht Pflege der Inhalte, sondern Pflege des Aufbaus) im Dictionary können Sie ebenfalls zum Data Browser verzweigen. Die Angabe der anzuzeigenden Tabelle ist hier nicht mehr nötig. Es erscheint gleich ein Selektionsbild, auf welchem Sie eingrenzen können, wie viel und welche Tabellensätze angezeigt werden sollen. Hier können nicht nur Datensätze angezeigt, sondern auch interaktiv verändert werden. Sie gelangen vom Dictionary aus zum Data Browser entweder über Hilfsmittel Tabelleninhalt Anzeigen oder über Umfeld Data Browser. In letzterem Fall muss die Tabelle angegeben werden. Anwendungsspezifische Funktionen Je nach betriebswirtschaftlicher Anwendung gibt es oft zusätzliche Möglichkeiten, sich aus den Menüs der jeweiligen Anwendung heraus Tabelleneinträge anzeigen zu lassen. Hier finden Sie i.Allg. kein einheitliches Layout. Dafür sind diese Funktionen angepasst an die spezifischen Bedürfnisse der jeweiligen Tabelle oder Transaktion. Oft werden dabei mehrere Tabellen „im Verbund“ verändert, um eine anwendungsspezifische Datenkonsistenz zu gewährleisten. Lektion 12: Seite 10 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 L12.3: Datenbankzugriff über SQL‐Befehle ( Screencast L12‐2 bis L12‐4) Der Zugriff auf Datenbanktabellen, um die gelesenen Daten aufbereitet auszugeben, ist eine Kernaufgabe der betriebswirtschaftlichen Anwendungen. ABAP verwendet dafür eine Untermenge der SQL‐Sprachbefehle und lehnt sich in der Syntax an die SQL‐ Syntax an (SQL = Structured Query Language, eine Datenbankabfragesprache). Der wichtigste Befehl hier ist der SELECT‐Befehl. Dazu gibt es zahlreiche Varianten und Zusätze, von denen wir für unsere jetzigen Ziele nur einen Teil benötigen. Abb. L12‐11 zeigt die Vorgänge beim Prozessieren eines ABAP‐Programms, das auf Daten einer Datenbank zugreift. Der erste Teil des Codes (Nr. 1 in Abb. L12‐11) sorgt dafür, dass auf einem Selektionsbild Eingabefelder erscheinen, in die der Benutzer seine individuellen Eingrenzungen schreiben kann. Der Datenbeschaffungsteil (Nr. 2 in Abb. L12‐11) besteht hier aus dem Lesen von Datenbanktabellen über eine SQL‐Schnittstelle. Nach dem Lesen und u.U. Zwischenspeichern in einer internen Tabelle werden die Daten weiterverarbeitet (Nr. 3 in Abb. L12‐11). Zum Schluss werden die aufbereiteten Daten auf einer Liste ausgegeben (Nr. 4 in Abb. L12‐11). Abb. L12‐11: Datenbankzugriff – SQL‐Befehle (Abb. 8‐9) Hinweis Als Beispiel für die Datenverarbeitung werden in Abb. L12‐11 interne Tabellen und bei der Ausgabe ein PERFORM‐Befehl verwendet. Diese beiden Features lernen Sie in Lektion 15 und 16 kennen. Hier benötigen wir sie noch nicht. Anforderung Sie wollen auf Datenbankinhalte zugreifen durch ABAP‐Code. Die Daten sollen aufbereitet ausgegeben werden und falls eine Datenhierarchie vorliegt, soll diese bei der Ausgabe berücksichtigt werden. Lösung Mit dem SQL‐Sprachbefehl SELECT sowie TABLES und SELECT‐OPTIONS. Selektionsbild: Dateneingrenzung zur Laufzeit Lektion 12: Seite 11 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Das Selektionsbild kann in der Grundform zwei Arten von Eingabefeldern, Parameters und Select‐Options, enthalten. Der PARAMETERS‐Befehl wird für die Deklaration von Eingabefeldern genutzt, bei denen genau ein Wert einzugeben ist. Bei SELECT‐OPTIONS (Selektionsoptionen) ist es möglich, Eingabe‐Intervalle, Bereiche, Muster oder komplexe Wertebereiche anzugeben, nach denen im Programm aus der Datenbank selektiert werden soll (s.u.). Die Angabe dieser komplexen Eingrenzungen muss nicht (!) kodiert werden. Sie können dies zur Laufzeit auf dem Selektionsbild durch das Drücken von leicht verständlichen Tasten erreichen (siehe unten in Abb. L12‐13). Sie können vom Selektionsbild aus die Programmausführung starten mit den von Ihnen eingegebenen Werten. Hiermit wird die Verarbeitung und Datenbeschaffung vorgenommen in Abhängigkeit von Ihren Eingabedaten aus dem Selektionsbild. Mit den Ausgabebefehlen wird dann entschieden, welche Daten in welcher Form als Ergebnis nach außen weitergegeben werden. Diese Daten werden als Liste präsentiert. Selektionsvarianten Es ist auch möglich, so genannte Selektionsvarianten anzulegen bzw. abzurufen. Diese Varianten stellen eine feste Zusammenstellung von Eingabewerten dar, die Sie z.B. beim letzten Aufruf des Programms unter einem Namen abgespeichert haben. Sie sparen sich damit das wiederholte Eingeben derselben Werte. Dies erleichtert die Bedienung, vor allem wenn die Anzahl der Eingabefelder groß und die Eingabewerte komplizierte Schlüssel sind. Eingrenzungsmöglichkeiten Bei einer Tabelle, die ein Zeilen‐/Spalten‐Konstrukt darstellt, bei dem jede Zeile denselben Aufbau hat und in Spalten aufgeteilt ist, können ohne jegliche Einschränkung alle Datensätze, alle Datensätze aber nur für bestimmte Spalten, nur wenige Datensätze aber mit allen Spalten oder wenige Datensätze und ein Teil der Spalten für eine Selektion gefordert werden. Oft wird auch explizit genau 1 Datensatz gesucht. Je nach Situation sieht dann der SELECT‐Befehl unterschiedlich aus. Sie finden hier die allgemeine Syntax, Bedeutung sowie ein Beispiel ausprogrammiert. Als Beispielszenario dient die Tabelle SPFLI, die die Flugverbindungen einer Fluggesellschaft enthält: die Key‐Felder sind CARRID (Fluggesellschaft) und CONNID (Fluglinie, Flug‐Nr.). Informationsfelder sind z.B. CITYFROM (Startort) und CITYTO (Zielort). Alle Spalten, alle Zeilen: uneingeschränkter Mengenzugriff ( Screencast L12‐2) Beim Select‐Statement muss im Prinzip nur die Tabelle angegeben werden (falls mit TABLES gearbeitet wird und dadurch die INTO‐Klausel wegfallen kann): TABLES: <dbtab>. SELECT * FROM <dbtab>. „Anweisungen“ ENDSELECT. Das Zeichen „*“ (Stern) steht für generische Selektion innerhalb einer Tabellenzeile, d.h., es werden alle Spalten der selektierten Zeile ausgewählt. „<dbtab>“ steht für den Namen einer Datenbanktabelle, die hier explizit angegeben werden muss. Dafür muss im Vorfeld eine so genannte Workarea vereinbart werden über den TABLES‐Befehl. Die Workarea ist eine Feldleiste für einen einzelnen Datensatz. In diese Feldleiste wird bei der Verarbeitung sukzessive ein Datenbanksatz nach dem anderen eingelesen, der dann über diese Workarea im ABAP‐Programm weiterverarbeitet werden kann. Wir nennen diese Workarea deshalb im Folgenden Arbeitszeile. Auf das Feld aus der Tabelle wird zugegriffen, indem Sie es mit Bindestrich an das Präfix <Datenbanktabellennname> hängen. Lektion 12: Seite 12 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Beispiel Es sollen alle Datensätze der Tabelle SPFLI gelesen und die Felder CARRID, CONNID, CITYFROM, CITYTO und DISTANCE ausgegeben werden. REPORT zdemo. TABLES: spfli. SELECT * FROM spfli. WRITE: / spfli-carrid, spfli-connid, spfli-cityfrom, spfli-cityto, spfli-distance. ENDSELECT. Alle Spalten, 1 Zeile: Einzelsatzzugriff mit SELECT SINGLE ( Screencast L12‐3) Hier wird ebenfalls mit „*“ für „alle Spalten“ gearbeitet. Da explizit nur 1 Datensatz gesucht wird, wird der Befehl SELECT SINGLE verwendet, gefolgt von einer WHERE‐Klausel, deren logischer Ausdruck so aufgebaut sein sollte, dass maximal genau ein Datensatz gefunden werden kann. Typischerweise spezifiziert man deshalb alle Key‐Felder mit „=“. SELECT SINGLE * FROM <dbtab> WHERE keyfeld1 = variable1 AND keyfeld2 = variable2 AND … . Unscharfe Eingrenzung beim SELECT SINGLE Man kann aber auch mit Sekundär‐Key‐Feldern arbeiten – bzw. nicht eindeutig (= teilgenerisch) eine WHERE‐Klausel formulieren. In diesem Fall gibt es weder einen Syntax‐ noch einen Laufzeitfehler. Es wird einfach der erste Datensatz von der Datenbank genommen, der die WHERE‐Klausel erfüllt, danach ist die Datenselektion beendet. Beispiel Es soll der Datensatz gesucht werden, der zur Fluglinie LH, 400 gehört. TABLES: spfli. REPORT zdemo. TABLES: spfli. DATA: feld1 TYPE spfli-carrid VALUE 'LH', feld2 TYPE spfli-connid VALUE '400'. SELECT SINGLE * FROM spfli WHERE carrid = feld1 AND connid = feld2. IF sy-subrc = 0. WRITE: / spfli-carrid, spfli-connid, spfli-cityfrom, spfli-cityto, spfli-distance. ELSE. WRITE: / 'kein Datensatz gefunden'. ENDIF. Mit einer Abfrage auf das Systemfeld SY‐SUBRC (liefert den Returncode 0, falls die Abfrage erfolgreich war) können wir feststellen, ob ein Satz gefunden wurde. Alle Spalten, n von m Zeilen: Mengenzugriff mit SELECT‐Schleife ( Screencast L12‐4) Der Mengenzugriff auf mehrere Datensätze ist mit dem Befehl SELECT ... ENDSELECT möglich und hat die Syntax SELECT * FROM <dbtab> WHERE <log. Ausdruck>. „Verarbeitung“ ENDSELECT. Da <log. Ausdruck> logisch wahr sein muss, wird je nach Wert des Ausdrucks zur Laufzeit eine Eingrenzung der Datenselektion durchgeführt. Als <log. Ausdruck> kann hier im Gegensatz zum SELECT Lektion 12: Seite 13 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 SINGLE auch eine Spezifizierung mit anderen Vergleichsoperatoren erfolgen, die als Ergebnis auch die Möglichkeit zulassen, dass u.U. viele Datensätze diesen logischen Ausdruck erfüllen. Das nennt man auch generische bzw. teilgenerische Qualifikation der Schlüsselfelder. Deshalb ist hier ein Schleifenkonstrukt notwendig. Die Schleife SELECT ... ENDSELECT wird so oft durchlaufen und die „Verarbeitung“ durchgeführt, wie auch Datensätze gefunden wurden. Als logische Ausdrücke sind fast alle Ausdrücke erlaubt, die auch beim IF‐Befehl zulässig sind. Details finden Sie unter SELECT in der F1‐ Hilfe im Editor. Beispiel Falls die Tabelle SPFLI zwei Schlüsselfelder hat und wir nur das erste spezifizieren, werden wir i.Allg. mehr als einen Datensatz dazu finden. Falls Sie Start‐ und Zielort spezifizieren, können auch mehrere Datensätze gefunden werden, da i. allg. mehrere Fluggesellschaften Flüge auf derselben Fluglinie anbieten. Diese werden mit dem folgenden ABAP‐Code gelesen und ausgegeben: REPORT zdemo. TABLES: spfli. DATA: feld1 TYPE spfli-cityfrom VALUE 'FRANKFURT', feld2 TYPE spfli-cityto VALUE 'NEW YORK'. SELECT * FROM spfli WHERE cityfrom = feld1 AND cityto = feld2. WRITE: / spfli-carrid, spfli-connid, spfli-cityfrom, spfli-cityto, spfli-distance. ENDSELECT. IF SY-SUBRC <> 0. WRITE: / 'kein Datensatz gefunden'. ENDIF. n von m Spalten: Teilzugriff auf Tabelle (nicht alle Attribute) Wir erläutern diese Anforderung für den Fall, dass mehrere Datensätze gesucht werden. Die Kombination mit der Suche nach allen Datensätzen bzw. nach nur einem Datensatz wird analog programmiert. Beachten Sie dabei, dass die Aufzählung der Tabellenfelder direkt nach SELECT ohne Klammern und ohne Kommata erfolgt, während beim INTO mit Klammern und Kommata gearbeitet werden muss. Vergessen Sie nicht, die Variablen zu deklarieren. SELECT f1 f2 f3 FROM <dbtab> INTO (v1, v2, v3) WHERE <log. Ausdruck>. „Verarbeitung“ ENDSELECT. Beispiel Es sollen alle Datensätze, aber nur die Spalten CITYFROM und CITYTO gelesen und ausgegeben werden. REPORT zdemo. TABLES: spfli. DATA: startort TYPE spfli-cityfrom, zielort TYPE spfli-cityto. SELECT cityfrom cityto FROM spfli INTO (startort, zielort) WRITE: / startort, zielort. ENDSELECT. Lektion 12: Seite 14 von 15 vhb‐Kurs «SAP‐Programmierung 1: ABAP Grundlagen» Block D Lektion 12 Verwendung der Spalteneingrenzung Bisher konnten Sie sich bei der Ausgabe immer auf wenige Spalten beschränken – auch dann, wenn Sie alle Spalten gelesen haben. Aus funktionaler Sicht gibt es also keinen Unterschied, nur die Performance wird sich verbessern, da nur eine Teilmenge der gesamten Daten gelesen werden muss. Jetzt können Sie maximal die Spalten ausgeben, die über die dem SELECT folgende Aufzählung in die passend vereinbarten Variablen hinter der INTO‐Klausel geschrieben werden. Sie müssen selbst dafür sorgen, dass die bei INTO aufgeführten Variablen gleich typisiert deklariert werden wie die zwischen SELECT und FROM aufgeführten Tabellen‐Spalten. Diese Variante der SELECT‐Programmierung wird meistens erst dann eingesetzt, wenn die Funktionalität selbst endgültig ist, d.h. wenn sich die Anforderung an die Menge der benötigten Tabellenspalten nicht mehr ändert. Ansonsten wäre der Änderungsaufwand deutlich höher. Verwendung von TABLES bzw. DATA Die als Beispiele im Folgenden aufgeführten ABAP‐Programme verwenden das TABLES‐Schlüsselwort. Sie können stattdessen auch mit DATA arbeiten und müssen dafür wie folgt vorgehen: Anstatt TABLES: spfli. schreiben Sie: DATA: wa TYPE spfli. Beim SELECT‐Statement schreiben Sie anstatt SELECT * FROM spfli jetzt mit der INTO‐Klausel: SELECT * FROM spfli INTO wa Sie lassen den Rest des SELECT‐Statements unverändert, und ersetzen beim WRITE‐Statement den Präfix „spfli‐“ durch „wa‐“. Wir haben hier mit der einfacheren TABLES‐Anweisung gearbeitet, werden im Folgenden beim Reporting mit DATA arbeiten, und kommen im vhb‐Kurs „ABAP‐Advanced“ in Block C bei der Dialogprogrammierung mit Tabellendarstellung wieder auf TABLES zurück. Hinweise Es gibt auch ein Konstrukt ohne Schleife, bei dem alle gefundenen Datensätze auf einmal in eine so genannte interne Tabelle (siehe Lektion 15 für die Erläuterung der internen Tabellen) geschrieben werden. Für den Vergleich von Mustern werden in der SQL‐Syntax andere Sonderzeichen verwendet als beim IF‐ Statement (statt * und + verwenden Sie hier % und _). Oft haben wir die Situation, dass wir nicht Daten aus einer Tabelle benötigen, sondern aus mehreren, die voneinander abhängen. Es liegen hierarchische Beziehungen vor, die sowohl bei der Lesereihenfolge als auch bei der Ausgabe berücksichtigt werden müssen (siehe Lektion 14). Zur Erleichterung gibt es logische Datenbanken (LDB), die Ihnen sowohl das Lesen der Daten von der Datenbank als auch die Ausgabe erleichtern (wird in Lektion 6 des vhb‐Kurses „ABAP‐Advanced“ erläutert). Lektion 12: Seite 15 von 15