Die Kontingenztabelle Randhäufigkeiten
Werbung

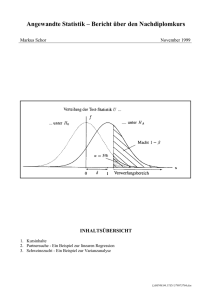
Wiederholung: zweidimensionales Datenmaterial Statistik 2 4. Vorlesung Die Kontingenztabelle a1 … am b1 h1,1 b2 h1,2 hm,1 hm,2 … bk h1,k hm,k Randhäufigkeiten wobei hi,j gibt die Häufigkeit diejenige Beobachtungen, die mit (ai,bj) identisch sind (gemeinsame Häufigkeiten). Unabhängigkeitshypothese pil=pi•p•l (i=1,…,k; l=1,…,m) wobei pil=P(X=ai,Y=bl) und pi•, p•l sind die Randverteilungen: pi•= P(X=ai), p•l=P(Y=bl). Alternativhypothese: Unabhängigkeit gilt nicht, also für wenigstens ein i und l pil≠pi•p•l n Beobachtungen, jeder hat Werte für m=2 Merkmaler, also jeder besteht aus 2 Merkmalausprägungen. z.B. wir notieren die Grösse und das Umsatz verschiedene Filialen (m=2). Beobachtungswerte von Merkmal X: x1, x2, x3,…, xn Beobachtungswerte von Merkmal Y: y1, y2, y3,…, yn h·,k= h1,k + h2,k+…+hm,k die Anzahl alle Beobachtungen, die bezüglich des zweiten Merkmals die Ausprägung bk aufweisen (auf der Kontengenztabelle kann man diese in die letzte Zeile auftragen), sowie hm,·= hm,1 + hm,2+…+hm,k die Anzahl alle Beobachtungen, die bezüglich des ersten Merkmals die Ausprägung am aufweisen (diese sind in die letzte Spalte aufgetragen). Teststatistik (Chi-Quadrat Statistik) T =∑ (hij − Eij ) 2 wo Eij ist die erwartete Eij i, j Häufigkeit der Ereignis X=ai,Y=bj unter der Nullhypothese: Eij = npˆ i. pˆ . j = hi. h. j / n Die Teststatistik folgt die Chi-Quadrat Verteilung mit Freiheitsgrad (k-1)(m-1). Die kritische Werte kann man von der Tabelle der Chi-Quadrat Verteilung bestimmen. 1 Beispiel E Werte Stetige Merkmale Niederschlag Temperatur Kühl Durchschnittlich Warm Summe wenig durchschn. viel Summe 15 10 5 30 10 10 20 40 5 20 5 30 30 40 30 100 Niederschlag Temperatur Kühl Durchschnittlich Warm Summe wenig durchschn. viel Summe 9 12 9 30 12 16 12 40 9 12 9 30 30 40 30 100 Falls wir stetige Merkmale haben, man soll die Daten klassifizieren. Achtung: möglichst wenig Klassen zu benutzen, weil um die Chi-Quadrat Verteilung anwenden zu können, man braucht wenigstens 3-5 Beobachtungen in alle Zellen. das Teststatistik ist approx. 21, FG=4, also wir können die Unabhängigkeit verwerfen, es gibt Zusammenhang zwischen die Variablen. Beispiel Andere Anwendung Fläche KaufFläche Tageshaus (Tausend umsatz No. QM) (Mio Ft) 1 51 125 2 25 54 3 13 39 4 10 24 5 120 184 6 43 58 7 59 85 8 20 75 9 36 50 10 80 85 Also für A1: F<40, A2: F≥40, B1:U<60, B2: U≥60 gross klein F<40 Umsatz wenig (U<60) 4 1 5 viel 1 5 4 5 5 T=3.6, FG=1, also wir können die Unabhängigkeit nur beim α=0.1 verwerfen, die Nullhypothese soll man bei α<0.1 beibehalten. χ 2 Anpassung-Test Diese Anwendung ist ein Anpassungstest. Mit ihm lässt sich prüfen, ob die beobachtete Verteilung der vorgegebenen Verteilung entspricht. Für jedes Intervall wird die quadrierte Differenz der Häufigkeiten der empirischen und der theoretischen Verteilung berechnet und durch die zu erwartenden Häufigkeiten dividiert. Die Summe dieser relativen 2 quadrierten Differenzen ist die χ -Testgröße. T =∑ i (hi − Ei ) 2 Ei Ei = npˆ i Als Nullhypothese wird angenommen, dass die zwei Verteilungen gleich und die Differenzen auf zufällige Fehler zurückzuführen sind. Viele statistische Tests setzen voraus, dass die Daten normalverteilt sind. Wir brauchen eine Methode, um festzustellen, ob diese Annahme über die Verteilung der Daten korrekt ist. Methoden: Visuell: das Histogramm der Daten mit der theoretischen Verteilungskurve optisch zu vergleichen. χ 2 -Test: Eine solide Methode, um empirische und bekannte (parametrische) Verteilungen zu vergleichen. Entscheidung über die Hypothese Die ungefähre Verteilung von ergibt sich aus dem folgenden theoretischen Hilfsmittel: Wenn die Hypothese über die Wahrscheinlichkeitsverteilung 2 zutrifft, strebt die Verteilung von T gegen eine χ k −s−1 Verteilung, wobei k ist der Anzahl der Intervalle s ist der Anzahl der geschätzten Parameter Da die Hypothese verworfen wird, wenn die Abweichungen und damit der Wert von T zu groß ausfällt, wird der kritische Bereich für eine gegebene Signifikanzzahl α gegeben mit T > χ 2 k −s−1,1−α 2 Beispiel: stetige Verteilung 4 24 5 24 6 15 Die Frage: kann man die Nullhypothese (Gleichverteilung) verwerfen? Wert der Statistik: 6,1 k=6, s=0 (keine Parameter war geschätzt), also FG=5. Kritische Wert: 11,07 Die Nullhypothese wird beibehalten (aber wie wir es schon früher gesehen haben, es ist kein Beweis für die Gleichverteilung). 0.020 3 18 0.015 2 25 Tagesumsatz 0.010 1 14 Wir haben Beobachtungen von Tagesumsatzwerte von 10 Filialen: 125,54,39,24,184,58,85,75, 50,85 (in M.Ft). Die Frage: passt es an eine Normalverteilung mit Erwartungswert 100 und Standardabweichung 20? Visuelle Vergleichung: Dichte Augenzahl Haufigkeit 0.005 Die Ergebnisse 120 Würfeln gaben die folgenden Häufigkeiten: 0.000 Beispiel: diskrete Verteilung 0 50 100 150 200 M.Ft Numerische Berechnung Fortsetzung 10 Beobachtungen also höchstens 4 Klassen (es ist das Minimum bei der Fall der geschätzten Parameter) Klassenwahl aus der Theoretischen Werte, mit gleichen erwartete Wahrscheinlichkeit: Klassengrenzen: 100-0.67*20,100, 100+0.67*20. Erwartete Häufigkeiten: 2.5 für alle Klassen. Beobachtete Häufigkeiten: 8,0,0,2 T=17.2, FG=3, Kritische Wert: 7.81 (α=0.05), oder 13.28 (α=0.01), also die Nullhypothese (Normalverteilung mit der gegebenen Parametern) wird verworfen. Regression (Wiederholung) Die Koeffizienten X: Einflussfaktor Y: abhängiges Merkmal Beispiel:Wir haben Daten vom 5 Hotels während der Formel 1 Rennen in Ungarn gesammelt. Distanz und % Besetzt sind in die Tabelle dargestellt. Entf (km) 25 17 5 2 1 Xbar=10 % Besetzt 50 83 98 99 100 Ybar=86 (xi-xbar)^2 225 49 25 64 81 88,8 (yi-ybar)^2 1296 9 144 169 196 362,8 (xi-xbar)(yi-ybar) -540 -21 -60 -104 -126 -170,2 Passen die daten an eine Normalverteilung? Hier soll man die beste Normalverteilung finden. Schätzungen: für den Erwartungswert: 77.9 MFt, Für die Standardabweichung: 46.84 MFt Klassengrenzen (wieder mit 4 Klassen, gleiche erwartete Häufigkeiten): 77.9-2*46.84/3, 77.9, 77.9+2*46.84/3, ausgerechnet:46.7 77.9 109.1 Daraus die empirische Häufigkeiten: 2,4,2,2 T=1.2, FG=1, Kritische Wert: 3.84 (α=0.05), oder 2.71 (α=0.1), also die Hypothese wird beibehalten. Das Modell: y~ax+b. Die Schätzung für die Koeffizienten: n ∑ ( x − x)( y i aˆ = i − y) i =1 n ∑ ( x − x) 2 , bˆ = y − aˆ x i yi 57.25 72.58 95.58 101.3 103.3 i =1 In unserem Beispiel: a=-170.2/88.8=-1.92, b=86-(-1.92)*10=105.2 Das Verfahren ist sehr empfindlich an ausreißer! 3 44 165 ∑ (x − x) ∑ ( y 2 i i =1 i 190 165 170 180 Höhe R2=0.83 R2=0.92 185 190 − y)2 185 190 46 44 42 Schuhgrösse Schuhgrösse 38 2 165 170 i =1 175 180 185 190 165 170 Höhe Beispiel (Fortsetzung) 175 40 − x) i =1 n Von hier das Anteil ∑ ( xi − x )( yi − y ) 2 der erklärte Variabilität: R = n i=1 n 185 44 i 180 Höhe 46 ∑ ( xi − x )( yi − y ) n Quadratsumme n ( yi − aˆxi − bˆ) 2 =∑ ( yi − y ) 2 − i =1 n der Residuen: ∑ 2 i =1 i =1 ∑ (x 175 42 n 170 2 40 42 2 i i =1 Schuhgrösse 42 Schuhgrösse n ∑ ( y − y) 38 Wie gut ist das Modell? Vollständige Variabilität: 38 38 40 Bestimmtheitsmass 40 44 46 R2=0.73 46 R2=0.56 175 180 Höhe Verbesserung Hotel-Daten vor Formel-1 Rennen, mit lin.Regr. 100 yi^ (yi-ybar)^2 (yi^-ybar)^2 57.25 1296 826.56 72.58 9 180.01 95.58 144 91.84 101.3 169 235.11 103.3 196 297.56 88.8 362.8 326.22 90 80 625 289 25 4 1 188,8 50 83 98 99 100 86 190270 10040 26830 34151 35269 296561 1296 9 144 169 196 1814 -22140 -837 180 -78 -126 -23001 50 60 Daraus R2=0.9, es ist ziemlich gut. (Nahe zur 1) Für den modifizierten Hotel-Modell Entf % (xi-x)^2 (yi-y)^2 (xi-x)(yi-y) (km)^2 Besetzt 70 Anteil der besetzten Zimmer (%) Entf (km) yi 25 50 17 83 5 98 2 99 1 100 Xbar=10 Ybar=86 5 (Obwohl es kann man mit einen Quadratische Faktor verbessern.) 10 15 20 Entfernungen (in km) Eigenschaften unserer Schätzer Modell: Y=aX+b+ε, wo ε ist Normal-verteilt mit Erwartungswert 0 und St.abweichung σ Standardabweichung der Koeffizienten der Regressionsgerade: D (aˆ ) = σ ∑ ( xi − x ) 2 ; D(bˆ) = σ 1 x2 + n ∑ ( xi − x ) 2 25 R2 =(-23001)*(-23001)/(296561*1814)=0.983 also es ist noch besser. a=-23001/296561=-0,0078; b=86-188,8*(-0,0078)=100.64 Hypothesen-Test Die Schätzung für σ: σˆ = ∑( y i − yˆ i ) 2 n−2 = ∑(y i − (aˆxi + bˆ)) 2 die Hypothese: a=0 (es ist kein Zusammenhang mit der Distanz). HA: a≠0. 2 Teststatistik: (t-Test) t = aˆ ∑ ( xi − x ) σ̂ das Freiheitsgrad ist n-2 (wir haben 2 Parameter geschätzt: a und σ). Ablehnungsbereich (wie beim allgemeines tTest, vom Alternativ-Hypothese abhängend). Jetzt zweiseitig. Aber für HA: a<0, t<- t1-α,n-2 n−2 4 Fortsetzung die Hypothese: b=0 Andere Hypothesen bˆ t= σˆ 1 x2 + n ∑ ( xi − x ) 2 Beispiel (Hotel-Daten mit Dist2 als X) a=-4600,2/59312,16=-0,078; b=86-188,8*(-0,078) = t= =100,64 axi+b Resid^2 52.169 4.7033 78.229 22.767 98.704 0.4959 100.33 1.7767 100.57 0.3199 Summe: 30.062 Also die Schätzung für σ: 3,17, t=-0,078*544,6/3,17=-13,4. Es ist sicher, dass der Unterschied zwischen die verschiedene Buchungsanteile ist kein Zufall. Mehrdimensionale statistische Verfahren multiple Regressionsmodelle Klassifizierung usw (Faktorstrukturen,...) Daraus der Bestimmtheitsmass: R2 = ∑ 0,643 3,165 0,2 + 35645 / 296561 = 0,359 Y: abhängiges Merkmal X1,...,Xm: Einflussfaktoren Regression: y~a1x1+ a2x2+...+ amxm+ b Die Koeffizienten kann man wieder mit der methode der kleinsten Quadrate schätzen. Beispiel:Wir haben die Monatsumsatz, Fläche und Anzahl der Angestellter bei ein Paar Filialen unserer Handelsfirma in die folgenden Tabelle dargestellt 250 40 6 265 40 8 300 54 9 230 20 10 330 40 12 Ergebnisse für den Beispiel Lösung mit der Methode der kleinsten Quadrate: Y~2,56X1+12,81X2+60,48. Bedeutung der (partiellen) Regressionskoeffizienten aj: Änderung der Zielgrösse (Monatsumsatz), wenn Xj um eine Einheit steigt, und die andere Einflüsse bleiben Konstant. n Residuen (Schätzfehler): yi − yˆ ( yˆ − y ) 2 = also diese Hypothese können wir annehmen. Monatsumsatz in T.Euro (Y) Fläche in TQM (X1 ) Anzahl Angestellter (X2 ) Lösung, Bedeutung, Residuen bˆ − b0 1 x2 + σˆ n ∑ ( xi − x ) 2 Multiple lineare Regression Simultane Zusammenwirken von Zufallsvariablen wird untersucht. Beispiele: H0: b=100 (kann der Konstant 100 sein?) Es ist die logische Wert. Statistik der t-Test: Monatsumsatz in T.Euro (Y) 250 265 300 230 330 Fläche in TQM (X1 ) 40 40 54 20 40 Anzahl Angestellter (X2 ) 6 8 9 10 12 Schätzungen Residuen (yi-ybar)^2 (yidach-ybar)^2 275 239.7 265.4 314 239.78 316.6 10.26 -0.36 -14.01 -9.78 13.4 625 100 625 2025 3025 6400 1243 92.93 1522 1240.4 1731 5829 R2 0.9108 i i =1 2 n ∑ (y i − y) i =1 5