VL 15 - Universität Trier
Werbung

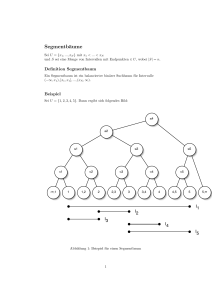
Algorithmen und Datenstrukturen SoSe 2008 in Trier Henning Fernau Universität Trier [email protected] 1 Algorithmen und Datenstrukturen Gesamtübersicht • Organisatorisches / Einführung • Grundlagen: RAM, O-Notation, Rekursion, Datenstrukturen • Sortieren • Wörterbücher und Mengen • Graphen und Graphalgorithmen 2 Binärbäume: Wozu? Datenstruktur zum schnellen (logarithmischen) Zugriff auf abgelegte Daten. . . . zumindest, wenn “Balance” gewahrt bleibt. . . Wie werden denn Daten abgespeichert ? 1. knotenorientiert Zu Jedem Knoten ist ein Datum assoziiert. 2. blattorientiert Die eigentliche Information findet sich lediglich an den Blättern. Die inneren Knoten sollen lediglich einen schnellen Weg zur Information anzeigen. Die in natürlicher Weise zu geordneten Mengen gehörige Speicherung ist die blattorientierte. 3 AVL-Bäume Adelson-Velskij/Landis 1962 Ein AVL-Baum ist ein 1-ausgeglichener Suchbaum, d.h., es handelt sich um einen binären Suchbaum, in dem sich für jeden inneren Knoten die Höhen der beiden anhängenden Teilbäume höchstens um Eins unterscheiden. Das Suchen nach einem Element funktioniert weiter wie bei “normalen” Suchbäumen (die Suchbaumeigenschaft ist ja erfüllt). Beim Einfügen und Löschen muss evtl. durch nachträgliches Rebalancieren die 1-Ausgeglichenheit wiederhergestellt werden. Das wollen wir zunächst beobachten in: http://webpages.ull.es/users/ jriera/Docencia/AVL/AVL%20tree%20applet.htm. 4 AVL-Bäume: Balance Jedem Knoten können wir als Balancewert die Differenz der Höhen des rechten und linken darunterhängenden Teilbaumes zuordnen: Satz: Alle (wichtigen) Operationen lassen sich auf AVL-Bäumen in Laufzeit O(log(n)) realisieren. 5 2. Fall: Doppelrotation AVL-Bäume: Aus der Balance: Zwei Grundfälle (bei Einfügen oder auch beim Löschen) 1. (einfache) Rotation 6 Ein günstiger Sonderfall Beim Löschen kann folgende Situation auftreten: Diese ist besonders günstig, da keine neuen Imbalance-Situationen höher im Baum erzeugt werden können. 7 Anwendung von balancierten Suchbäumen Schnitt von achsenparallelen Liniensegmenten (Segmentschnittproblem) Gegeben: Menge von insgesamt n vertikalen und horizontalen Liniensegmenten in der Ebene Gesucht: Alle Paare von sich schneidenden Elementen Trivialer Algorithmus: O(n2) Wie geht’s ? Paarweiser Vergleich der Segmente Anwendung z.B. bei VLSI-Schaltkreisen: VLSI-Designer will keine unerwarteten “Drahtüberschneidungen” Hinweis: Algorithmische Geometrie ist ein Gebiet, welches sich mit solchen Problemen befasst und in Trier von Herrn Näher vertreten wird. 8 Zur Anschauung des Problems 9 Vereinfachende Annahme nachfolgend: Alle Anfangs- und Endpunkte horizontaler Segmente und alle vertikalen Segmente haben paarweise verschiedene x-Koordinaten. (Allgemeine Lage) Idee: Vertikale Sweepline geht Ebene von links nach rechts durch; jedes aktuell von der Sweepline abgedeckte vertikale Segment kann höchstens Schnittpunkte mit gerade aktiven horizontalen Segmenten haben. Alternativ: Divide-and-Conquer-Ansatz, siehe auch: http://download.informatik. uni-freiburg.de/lectures/Algorithmentheorie/2006-2007WS/LectureRe Flash/01_3/Segmentschnittproblem.html 10 Algorithmus-Idee: Der Anfang Q ← {x | x ist x-Koordinate von Anfangs- oder Endpunkt eines horizontalen Segmentes oder x-Koordinate von einem vertikalen Segment }; Q merkt sich auch das Segment, zu dem es gehört. Q verwaltet also die Menge der Ereignisse, das sind die für die Sweepline interessanten x-Koordinaten. Zwischen zwei unmittelbar aufeinander folgenden Punkten aus x sind keine neuen Segmentschnitte zu verzeichnen. Sortiere Q (bzgl. x-Werten); Bei n Segmenten kostet dies (allein) bereits O(n log(n)) Zeit. Die Sweepline L enthält die jeweils aktiven horizontalen Segmente in aufsteigender y-Koordinaten-Reihenfolge. Eingangs gelte: L ← ∅. 11 Algorithmus-Idee: Der Durchführungsteil 12 Algorithmus-Idee: 13 Zur Implementierung der Sweepline Wir benötigen folgende Operationen auf L: —Einfügen & Entfernen —Bestimmen aller Elemente, die in gegebenem Bereich [yu, yo] fallen: Bereichsanfrage (Range Query) ; Implementation von L mit balanciertem Suchbaum mit blattorientierter Speicherung, wobei benachbarte Blätter verkettet sind. ; Mit AVL-Bäumen lassen sich die Sweepline-Operationen in O(log(n)) pro “Ereignis” realisieren. Die Sweepline ändert sich höchstens O(n) oft (; Ereignisse). Zusammen: Laufzeit O(n log(n) + k), wobei k die Gesamtzahl sich schneidender Segmente ist. Gilt also k = Θ(n2), ist der Algorithmus nicht besser als der naive, er ist aber ausgabesensitiv. Hinweis: D&C liefert asymptotisch dieselbe Laufzeit. 14 Höhenbalancierte Bäume Wir haben mit AVL-Bäumen ein Beispiel für sogenannte höhenbalancierte Bäume kennengelernt. Dies ist nicht das einzige Balance-Kriterium, wie wir gleich sehen werden. Es gibt viele weitere höhenbalancierte Baum-Modelle, z.B. Rot-Schwarz-Bäume. Diese werden (gemeinsam mit AVL) in der folgenden Semesterarbeit (an der Uni Leipzig) vorgestellt: http://leechuck.de/ginfin/baum1/index.html (auf den Seiten findet sich übrigens auch JAVA-Quellcode hierzu sowie ein nettes JAVA-Applet zu Mergesort) Wie im Buch von Sedgewick ausgeführt, gestatten Rot-Schwarz-Bäume einen Top-Down-Ansatz zur Rebalancierung, was insbesondere für ihre parallele Ausführung erhebliche Vorteile bringt. 15 Wurzelbalancierte Bäume V(T ) bezeichne die Blattmenge eines Baums T . Sei T ein binärer Baum mit linkem Teilbaum T` und rechtem Teilbaum Tr, also T = (T`, r, Tr). ρ(r) := ρ(T ) := |V(T`)| + 1 |V(Tr)| + 1 =1− |V(T )| + 1 |V(T )| + 1 ist die Wurzelbalance von r bzw. von T . Gilt für jeden Teilbaum T 0 von T α ≤ ρ(T 0) ≤ 1 − α, so heißt T von beschränkter Wurzelbalance α. B[α] sei die Menge aller Bäume von beschränkter Wurzelbalance α. 16 Wurzelbalancierte Bäume: Beispiel 17 Satz: Sei T ein BB[α]-Baum mit n Knoten und Höhe h(T ). Dann gilt log(n + 1) − 1 h(T ) ≤ log(1 − α) Ebenso ist die Pfadlänge von T im Mittel logarithmisch in n. Beweis: Wir beweisen nur die erste Satzaussage. Für die zweite verweisen wir auf das Buch von Mehlhorn mit der Warnung, dass M. eine abgewandelte Definition von Wurzelbalance benutzt. n = 1: Dann hat T Höhe null X Als Induktionsvoraussetzung nehmen wir die Gültigkeit der Aussage für Bäume mit höchstens n Knoten an. Betrachte einen Baum T 0 mit n + 1 Knoten. Sei T 00 derjenige echte Unterbaum von T 0 mit den meisten Knoten, nämlich n 00 . Da T 00 echter Unterbaum, hat T 00 höchstens n Knoten. log(n 00 + 1) − 1 IV ; h(T ) ≤ log(1 − α) 00 18 Der Baum T 0 ist genau um Eins höher als T 00 , und außerdem gilt die Balance-Bedingung für T 0 d.h. log((n + 1))(1 − α) − 1 h(T 0) ≤ +1 log(1 − α) Die Induktions-Behauptung folgt sofort durch leichtes Logarithmen-Rechnen. √ Zusatz: Eine besonders günstige Wahl ist α = 1 − 2/2 ≈ 0, 2929. Dann liegt die mittlere Suchzeit (mittlere Pfadlänge) um höchstens 15% über dem theoretischen Optimum, und die maximale Suchzeit liegt um höchstens einen Faktor von zwei über dem theoretischen Optimum. Problem: Zerstören der Wurzelbalance durch Einfügen und Löschen. Rebalancierung von BB[α]-Bäumen Problem: Durch Einfügen und Löschen in BB[α]-Bäumen kann deren Balance zerstört werden. Lösung: Die Balance kann nach solch einer Operation nur auf dem Suchpfad (Weg von der Wurzel zur Stelle der Änderung) zerstört werden. Längs dieses Suchpfades muss rebalanciert werden. Der Pfad hat logarithmische Länge. Unter der Voraussetzung 1√ 2 ≤α≤1− 2 ≈ 0.293 11 2 kann man zeigen, dass die lokalen Operationen Rotation und Doppelrotation auf dem Suchpfad zur Rebalancierung ausreichen. 19 20 21 22 23 24 25 26 27