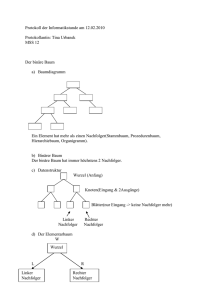
Bestcase: „vollständig balancierter Baum“
Werbung

Bestcase: „vollständig balancierter Baum“
Sei n = 2k − 1.
20 Daten
Suchzeit 1
21 Daten
Suchzeit 2
22 Daten
Suchzeit 3
2k−1 Daten
Suchzeit k
. – Seite 277/726
Erwartete Suchzeit =
1 k−1
· k·2
+ (k − 1) · 2k−2 + (k − 2) · 2k−3 + · · ·
n
1 k−1
=
2
+
n
k−2
2
+
k−3
2
+1 · 20
+ ···
+
+2k−1 +
2k−2 +
2k−3 + · · ·
+2k−1 +
2k−2 +
2k−3 + · · · +22
+21
1 k
2 =
2 −1
n
0
+2k − 2
+2k − 22
...
+2k−1 )
+2k − 2k−1
1
k
k
= · k · 2 − (2 − 1)
n
1
= · log(n + 1) · (n + 1) − n
n
1
· log(n + 1) − 1 ≈ log n.
= 1+
n
. – Seite 278/726
Zwischen log n und
n+1
2
liegen Welten! Was ist typischer?
Modell: n Daten werden in zufälliger Reihenfolge in einen
leeren Baum eingefügt, dann erwartete Suchzeit,
Daten o. B. d. A. 1, . . . , n.
Dies ist ein „doppelter“ Erwartungswert:
– Wahl einer von n! Datenreihenfolgen nach
Gleichverteilung,
– Wahl eines von n Daten für die Suche nach
Gleichverteilung.
Vereinfachung: C(T ) := Kosten eines Suchbaums T
:= Summe der Suchkosten für alle Daten.
(Ergebnis durch n teilen.)
C(n) := durchschnittliche Kosten aller Suchbäume zu allen
Datenreihenfolgen.
. – Seite 279/726
Wir wollen eine Rekursionsgleichung erstellen.
C(0) = 0, C(1) = 1.
1 X
C(n) = n +
(C(i − 1) + C(n − i)), n ≥ 2.
n
1≤i≤n
Begründung für den allgemeinen Fall, n ≥ 2:
– Jeder Suchpfad besucht die Wurzel, Summand n.
– Die Wurzel enthält das erste eingefügte Datum, mit
Wskt. 1/n ist es das Datum i.
– Dann Daten 1, . . . , i − 1 in den linken Teilbaum.
– Diese Daten kommen in zufälliger Reihenfolge, also
durchschnittliche Suchkosten C(i − 1).
– Analog Daten i + 1, . . . , n in den rechten Teilbaum,
durchschnittliche Suchkosten C(n − i).
. – Seite 280/726
Schwierige Rekursionsgleichung, aber
– typische Methoden und
– dieselbe Rekursionsgleichung bei Quicksort.
. – Seite 281/726
1 P
C(n) = n +
(C(i − 1) + C(n − i))
n 1≤i≤n
2 P
=n+
C(i).
n 1≤i≤n−1
Ziel: C(1), C(2), . . . , C(n − 1), C(n) → C(n − 1), C(n).
n · C(n)
= n2 + 2 · (C(1) + · · ·
+C(n − 2) + C(n − 1)).
I − II
2
(n − 1) · C(n − 1) = (n − 1) + 2 · (C(1) + · · ·
+C(n − 2)).
n · C(n) − (n − 1) · C(n − 1) = 2n − 1 + 2C(n − 1)
⇒ n · C(n) − (n + 1) · C(n − 1) = 2n − 1.
passt nicht gut zusammen → Division durch n · (n + 1).
. – Seite 282/726
C(n)
C(n − 1)
2n − 1
−
=
.
n+1
n
n(n + 1)
C(n)
−→
Z(n) :=
n+1
2n − 1
Z(n) = Z(n − 1) +
n(n + 1)
X 2i − 1
= Z(0) +
|{z}
i(i + 1)
1≤i≤n
=0
=
1
1
1
= −
i(i + 1)
i
i+1
X
1 −
(2i − 1) ·
i
i+1
X
X 1
X
X 1
i
2−
−2
+
.
i
i+1
i+1
1≤i≤n
=
1≤i≤n
1
1≤i≤n
1≤i≤n
1≤i≤n
2n
−1 +
1
n+1
. – Seite 283/726
−2
X
1≤i≤n
X
X 1 i
1−
= −2 ·
i+1
i+1
1≤i≤n
1≤i≤n
2
= −2n + 2 · H(n) − 2 +
n+1
Damit:
Z(n) = 2n − 1 +
2
1
− 2n + 2 · H(n) − 2 +
n+1
n+1
3
= 2 · H(n) − 3 +
n+1
Also erwartete Suchzeit:
n+1
n+1 3
n+1
C(n)/n =
Z(n) = 2 ·
· H(n) − 3 ·
+
n
n
n
n
= 2 · ln n − O(1) = (2 ln 2) log n − O(1).
| {z }
≈1,386
Nur 38, 6% schlechter als im Bestcase.
. – Seite 284/726
In vielen Anwendungen ist die Annahme einer zufälligen
Reihenfolge der Daten nicht gerechtfertigt.
Ziel: Suchbaumvarianten mit worst case Tiefe O(log n).
. – Seite 285/726
3.4 2–3–Bäume (Hopcroft, 1970)
Definition
– Pro Knoten ein Datum oder zwei Daten.
– Ein Datum x, dann zwei Zeiger, links nur kleinere und
rechts nur größere Daten als x.
– Zwei Daten x und y > x, dann drei Zeiger, links nur
Daten kleiner als x, in der Mitte nur Daten zwischen x
und y , rechts nur Daten größer als y .
– Die Zeiger, die einen Knoten verlassen, sind alle nil
oder alle nicht nil.
– Alle Blätter auf einer Ebene.
. – Seite 286/726
Existenz von 2-3-Bäumen mit n Daten?
– Beweis durch INSERT-Prozedur.
Speicherplatzausnutzung?
Knoten
Zeiger
Datum
Zeiger
Datum
Zeiger
Die letzten beiden Komponenten können leer sein.
Worstcase-Tiefe?
Einfach zu analysieren.
. – Seite 287/726
n Daten, Tiefe d ⇒ ⌈log3 (n + 1)⌉ − 1 ≤ d ≤ ⌊log2 (n + 1)⌋ − 1.
Größte Datenzahl auf d + 1 Ebenen:
2 · (1 + 3 + · · · + 3d ) = 3d+1 − 1.
Also n ≤ 3d+1 − 1 und d ≥ ⌈log3 (n + 1)⌉ − 1.
Kleinste Datenzahl auf d + 1 Ebenen:
1 + 2 + · · · + 2d = 2d+1 − 1.
Also n ≥ 2d+1 − 1 und d ≤ ⌊log2 (n + 1)⌋ − 1.
. – Seite 288/726
Suchbereiche
(v, y)
x
(v, x) (x, y)
(v, z)
x, y
(v, x) (x, y) (y, z)
SEARCH(x)
Verlauf sollte klar sein.
Hierbei wird Suchpfad auf Stack abgespeichert.
. – Seite 289/726
INSERT(x) nach erfolgreicher Suche
Angekommen an nil-Zeiger in Blatt.
1. Fall: Einfügeposition an Blatt mit 1 Datum y .
1.1: x < y , Einfügeposition links.
y
y
p1
nil
p
p
p
p2
nil
q
x
p2
nil
q1
q2
nil
nil
Rebalancierungsproblem
am Zeiger q
x
y
q1
q2 p 2
nil nil nil
Wieder 2-3-Baum!
1.2: y < x, Einfügeposition rechts. Analog zu Fall 1.1.
. – Seite 290/726
2. Fall: Einfügeposition an Blatt mit 2 Daten y < y ′ .
p
y
nil
y′
nil
nil
2.1: x < y , Einfügeposition links.
2.2: y < x < y ′ , Einfügeposition Mitte.
2.3: y ′ < x, Einfügeposition rechts.
Hier nur 2.1 ausführlich, Rest analog.
. – Seite 291/726
2.1: x < y , Einfügeposition links.
p
p
y
nil
y
y′
q p2 p3
nil nil
x
q1
q2
nil nil
p
y′
nil
nil
p
nil
y′
y
x
nil
nil
y
q
nil
(Kein legaler Knoten!)
q1
nil
x
q2
pneu
y′
p2 p3
nil nil nil
Ebene d
Ebene d + 1
. – Seite 292/726
Fortsetzung 2.1, Rebalancierung:
p
y
Ebene d
x
nil
y′
nil
nil
Ebene d + 1
nil
Neues Rebalancierungsproblem an Zeiger p auf
Ebene d − 1 lösen. Dazu Zeiger p vom Stack holen.
– Wenn dies nicht der Zeiger auf die Wurzel ist,
Rebalancierung dort fortsetzen.
– Wenn dies der Zeiger auf die Wurzel ist,
Rebalancierung abgeschlossen,
Gesamttiefe um 1 gewachsen.
. – Seite 293/726
Die Tiefe des 2-3-Baumes wächst, wenn die Wurzel
erreicht und „gesplittet“ wird.
→ „2-3-Bäume wachsen über die Wurzel.“
Beispiel: Einfügen der Buchstaben
A, L, G, O, R, I, T, H, M, U, S
in einen leeren 2-3-Baum.
. – Seite 296/726
A
A,L
G
A,L
G
G
A
G
A
A
L,O
L
G
O
A
L,O
L
R
G,O
A
L
G,O
R
A
I,L
R
G,O
R
A
I,L
R,T
. – Seite 297/726
G,O
A
A
R,T
I,L
H
I
O
H
L
A
I
G
L,M
R,T
A
H
L,M
L
H
R,T
I
O
G
O
G
R,T
H
I
A
I
G,O
G
R,T
A
O,T
H
L,M
R
U
U
I
G
A
O,T
H
L,M
R,S
U
. – Seite 298/726
DELETE(x) nach erfolgreicher Suche
(1) Falls x nicht in einem Blatt:
a) Suche das größte Datum y mit y < x.
– Starte an Knoten, der x enthält:
x
x
z
z
x
(v, x)(x, w) (v, x)(x, z)(z, w) (v, z)(z, x)(x, w)
– Folge danach stets dem rechtesten Zeiger.
Irgendwann nil-Zeiger (an Blatt angekommen).
b) Vertausche x und y und entferne dann x aus
einem Blatt. Korrektheit analog zu binären
Suchbäumen.
. – Seite 299/726
Noch zu behandeln: Entfernung aus einem Blatt.
(2) Zu löschendes Datum x in Blatt.
a) Blatt enthält 2 Daten:
Datum x einfach löschen. Fertig.
p
p
x
nil
y
nil
y
nil
b) Blatt enthält nur x:
p
nil
p
x
nil
nil
?
nil
nil
→ Knoten ohne Datum mit einem Zeiger → (3).
. – Seite 300/726
(3) Wir haben „2-3-Baum mit Fehler“.
Der Fehler ist ein Knoten ohne
Datum mit einem Zeiger.
Suchbaumeigenschaften gelten.
Abbruchkriterium: Fehler an der Wurzel, diese entfällt und
Kind ist neue Wurzel.
„2-3-Bäume schrumpfen über ihre Wurzel.“
. – Seite 301/726
Ansonsten zwei Fälle:
1. Fall: ∃ direkter Geschwisterknoten mit 2 Daten
→ Datenrotation.
v
...c
p
...d
p
q
u
w
d, e
p′
q1
u
q2 q3
(b, c) (c, d) (d, e) (e, f )
v
p′
c
e
q1 q2
w
q3
(b, c) (c, d) (d, e) (e, f )
Rebalancierung abgeschlossen.
. – Seite 302/726
2. Fall: Direkte Geschwisterknoten enthalten nur ein Datum,
o. B. d. A. existiert ein rechter Geschwisterknoten.
v
...c
p
p∗
q
u
d
p′
q1
v
...
w
q2
(b, c) (c, d) (d, e)
c, d
p′
w∗
q1
q2
(b, c) (c, d) (d, e)
– Hatte Elterknoten zwei Daten:
Rebalancierung abgeschlossen.
– Hatte Elterknoten ein Datum:
Problem eine Ebene nach oben verschoben.
. – Seite 303/726