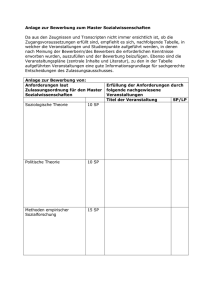
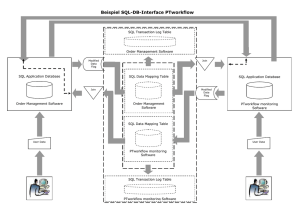
Datenbank-Synchronisation Bericht zur Master Thesis
Werbung

Datenbank-Synchronisation Bericht zur Master Thesis Abstract Die Konfigurationsdaten von Geschäftssystemen müssen zwischen den Datenbanken der Systemumgebungen für Entwicklung, Integration und Produktion abgeglichen werden. Ziel dieser Arbeit ist es, ein Tool zu entwickeln, mit dem die Synchronisation der Konfigurationsdaten einfach, fehlerfrei und nachvollziehbar durchgeführt werden kann. Schlüsselwörter: Datenbank, Synchronisation, Java, Rich-Client Master Thesis: MT-10-02.09 Klasse: MAS-IT-10-02 Datum: 23.03.2011 Student: Thomas Schenker XpertCenter AG, Seftigenstrasse 7, 3007 Bern 031 389 89 53 [email protected] Betreuer: Joachim Brandt XpertCenter AG, Seftigenstrasse 7, 3007 Bern 031 389 89 55 [email protected] Experte: Pierre Fierz [email protected] Bericht zur Master Thesis Inhaltsverzeichnis 1 2 3 4 Einleitung ....................................................................................................................... 5 1.1 Zweck dieses Dokuments ....................................................................................... 5 1.2 Zielpublikum ............................................................................................................ 5 1.3 Referenzierte Dokumente ....................................................................................... 5 Analyse .......................................................................................................................... 6 2.1 Vorgehen ................................................................................................................ 6 2.2 Anwendungsfälle ..................................................................................................... 6 2.3 Funktionale Anforderungen ..................................................................................... 6 2.4 Nicht-Funktionale Anforderungen ............................................................................ 7 2.5 System-Kontext ....................................................................................................... 7 2.6 Fachklassenmodell ................................................................................................. 8 2.7 Fachklassenmodell mit Änderungsverwaltung ......................................................... 9 2.8 Ablaufmodell der Synchronisation ..........................................................................10 Architektur und Grob-Design .........................................................................................13 3.1 Vorgehen ...............................................................................................................13 3.2 Applikations-Framework .........................................................................................13 3.3 Schichtenmodell .....................................................................................................14 3.3.1 Einführung.......................................................................................................14 3.3.2 Beschreibung des Schichtenmodells ...............................................................14 3.4 Verteilungsmodell ...................................................................................................16 3.5 Komponentenmodell ..............................................................................................17 3.5.1 Einführung.......................................................................................................17 3.5.2 Beschreibung des Komponentenmodells ........................................................18 Detail-Design und Implementation .................................................................................22 4.1 Die Hauptseite der Applikation ...............................................................................22 4.1.1 GUI-Design .....................................................................................................22 4.1.2 Implementation................................................................................................23 4.2 Benutzeridentifikation .............................................................................................23 4.2.1 Detail-Analyse .................................................................................................23 4.2.2 Detail-Design ..................................................................................................23 4.2.3 Klassenmodell .................................................................................................24 4.2.4 GUI .................................................................................................................24 4.2.5 GUI-Steuerung ................................................................................................25 4.2.6 Applikations-Steuerung ...................................................................................26 4.2.7 Geschäftsobjekt ..............................................................................................26 4.2.8 Datenbank-Zugriff mit O/R-Mapper .................................................................26 4.2.9 Datenbank.......................................................................................................26 4.3 Synchronisation......................................................................................................27 Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 2/54 Bericht zur Master Thesis 4.3.1 Detail-Analyse des Modells der Konfigurationsdaten .......................................27 4.3.2 Detail-Design ..................................................................................................27 4.3.3 Klassenmodell .................................................................................................28 4.3.4 GUI .................................................................................................................29 4.3.5 GUI-Steuerung ................................................................................................32 4.3.6 Applikations-Steuerung ...................................................................................32 4.3.7 Geschäfts-Komponente zur Differenz-Berechnung .........................................33 4.3.8 Modell der Differenz ........................................................................................35 4.3.9 Geschäfts-Komponente zur Differenz-Ausführung ..........................................36 4.3.10 Geschäftsobjekte ............................................................................................38 4.3.11 Datenbank-Zugriff mit JDBC............................................................................38 4.3.12 Datenbank-Zugriff mit O/R-Mapper .................................................................38 4.3.13 Datenbank.......................................................................................................39 4.4 5 4.4.1 Datenmodell ....................................................................................................40 4.4.2 GUI .................................................................................................................41 4.4.3 GUI-Steuerung ................................................................................................43 4.4.4 Applikations-Steuerung ...................................................................................44 4.4.5 Geschäftsobjekte ............................................................................................45 4.4.6 Datenbank-Zugriff mit O/R-Mapper .................................................................45 4.4.7 Datenbank.......................................................................................................45 Test ...............................................................................................................................46 5.1 Konzept ..................................................................................................................46 5.2 Testumgebung .......................................................................................................46 5.3 Testdaten ...............................................................................................................47 5.3.1 Testdaten für die Synchronisation ...................................................................47 5.3.2 Testdaten für das Datenmodell von DB-Sync ..................................................48 5.4 6 Synchronisationsprotokoll ......................................................................................40 Durchführung der Tests..........................................................................................49 5.4.1 Unit-Tests........................................................................................................49 5.4.2 Integrations-Tests ...........................................................................................49 Entwicklungs-Umgebung ...............................................................................................50 6.1 Entwicklungs-Rechner............................................................................................50 6.2 Rich-Client-Framework „CaptainCasa Enterprise Client“ ........................................50 6.2.1 Installation .......................................................................................................50 6.2.2 Lizenz .............................................................................................................50 6.3 Software-Entwicklungsumgebung ..........................................................................50 6.3.1 MyEclipse........................................................................................................50 6.3.2 Tomcat ............................................................................................................50 6.3.3 Entwicklungswerkzeuge von CaptainCasa Enterprise Client ...........................50 6.4 Datenbank ..............................................................................................................50 Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 3/54 Bericht zur Master Thesis 6.5 7 Tools ......................................................................................................................51 6.5.1 AQT ................................................................................................................51 6.5.2 Dia ..................................................................................................................51 6.5.3 JUDE ..............................................................................................................51 Zusammenfassung ........................................................................................................52 7.1 Resultat ..................................................................................................................52 7.2 Ablauf und Aufwand ...............................................................................................52 7.3 Schlusswort ............................................................................................................52 Anhang .................................................................................................................................53 A – Glossar .......................................................................................................................53 B – Quellenverzeichnis .....................................................................................................54 Abbildungsverzeichnis Abbildung 1: Systemkontext-Diagramm................................................................................. 7 Abbildung 2: Fachklassen-Diagramm .................................................................................... 8 Abbildung 3: Fachklassen-Diagramm mit Änderungsverwaltung ........................................... 9 Abbildung 4: Aktivitätsdiagramm zum Anwendungsfall "Daten synchronisieren" ..................11 Abbildung 5: Schichtenmodell ..............................................................................................15 Abbildung 6: Verteilungsmodell ............................................................................................17 Abbildung 7: Komponentenmodell Synchronisation ..............................................................20 Abbildung 8: Komponentenmodell Sync-Protokoll und Benutzeridentifikation (Login) ...........21 Abbildung 9: Hauptseite .......................................................................................................22 Abbildung 10: Statuszeile mit Erfolgs-, Warn- und Fehlermeldung, Popup mit Details ..........23 Abbildung 11: Klassendiagramm Benutzeridentifikation .......................................................24 Abbildung 12: Titelzeile mit dem angemeldeten Benutzer ....................................................24 Abbildung 13: Login-Seite ....................................................................................................25 Abbildung 14: Tabelle der Benutzeridentifikation ..................................................................26 Abbildung 15: Fachklassendiagramm Konfigurationsdaten-Modell .......................................27 Abbildung 16: Klassendiagramm Synchronisation ................................................................28 Abbildung 17: GUI Synchronisation ......................................................................................29 Abbildung 18: GUI Synchronisation: Auswahl der Konfigurations-Daten ..............................29 Abbildung 19: GUI Synchronisation: Anzeige der berechneten Differenzen..........................30 Abbildung 20: GUI Synchronisation: Auswahl der Differenzen..............................................31 Abbildung 21: GUI Synchronisation: Differenzen kopieren ...................................................31 Abbildung 22: GUI Synchronisation: Differenzen löschen .....................................................32 Abbildung 23: Klassendiagramm Synchronisations-Steuerungs-Komponente ......................32 Abbildung 24: Klassendiagramm Differenz-Berechnungs-Komponente ................................33 Abbildung 25: Klassendiagramm der Differenz .....................................................................35 Abbildung 26: Klassendiagramm Differenz-Ausführungs-Komponente .................................36 Abbildung 27: Klassendiagramm der Geschäftsobjekte ........................................................38 Abbildung 28: Klassendiagramm der Entitäts-Klassen für die Konfig-Daten .........................39 Abbildung 29: Tabellen des Konfigurationsdaten-Modells ....................................................39 Abbildung 30: GUI Synchronisations-Protokoll .....................................................................41 Abbildung 31: GUI Synchronisations-Protokoll: Auswahl der Konfigurations-Daten ..............42 Abbildung 32: GUI Synchronisations-Protokoll: Weitere Suchkriterien ..................................42 Abbildung 33: GUI Synchronisations-Protokoll: Anzeige der Einträge ..................................43 Abbildung 34: GUI Synchronisations-Protokoll: Kompletter Eintrag ......................................43 Abbildung 35: Klassendiagramm Steuerungs-Komponente Synchronisations-Protokoll .......44 Abbildung 36: Tabelle des Synchronisations-Protokolls........................................................45 Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 4/54 Bericht zur Master Thesis 1 Einleitung 1.1 Zweck dieses Dokuments Dieses Dokument ist dient als Abschlussbericht zur Master Thesis. Es beschreibt das im Rahmen der Master Thesis erstellte Tool mit dem Namen „DB-Sync“. Abgrenzung: Die Aufgabenstellung und die Anforderungen an DB-Sync sind im Pflichtenheft [Ref1] dokumentiert. 1.2 Zielpublikum Dieses Dokument richtet sich an: Pierre Fierz, Experte der SWS Joachim Brandt, Auftraggeber und Betreuer der XpertCenter AG alle Personen, die an dieser Master Thesis interessiert sind 1.3 Referenzierte Dokumente Die hier aufgeführten Dokumente sind in der ZIP-Datei mit den Anhängen zu dieser Master Thesis enthalten. Referenz Dokument [Ref1] Pflichtenheft, 14.11.10 [Ref2] Entwicklungsjournal [Ref3] Testprotokoll Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 5/54 Bericht zur Master Thesis 2 Analyse 2.1 Vorgehen Für die Analyse wurde im Pflichtenheft [Ref1] eine detaillierte Beschreibung der Ist-Situation erstellt (Pflichtenheft Kapitel 2.3). Daraus wurden die Anwendungsfälle (Pflichtenheft Kapitel 3.2) abgeleitet und die Anforderungen definiert (Pflichtenheft Kapitel 3.3 und 3.4). In diesem Dokument werden die Anwendungsfälle (Kapitel 2.2) und die Anforderungen (Kapitel 2.3) nochmals als Kurzreferenz aufgeführt. Angelehnt an das Buch „Analyse und Design mit UML“ [Lit1], werden in den weiteren Kapiteln der System-Kontext, das Fachklassenmodell und das Ablaufmodell einzelner Anwendungsfälle beschrieben. 2.2 Anwendungsfälle Der Haupt-Anwendungsfall „Synchronisieren“ besteht aus den Anwendungsfällen: UC-S1: Änderungen an den Daten im Änderungs-Protokoll eintragen UC-S2: Daten synchronisieren UC-S3: Synchronisation rückgängig machen UC-S4: Synchronisation der Daten im Änderungs-Protokoll eintragen Der Haupt-Anwendungsfall „Administrieren“ besteht aus den Anwendungsfällen: UC-A1: Umgebung konfigurieren UC-A2: Tabelle konfigurieren UC-A3: Synchronisations-Set konfigurieren 2.3 Funktionale Anforderungen FA-1 Benutzer-Identifikation Alle 1 – MUSS FA-2 Benutzer-Verwaltung Alle 3 – ERW. FA-3 Benutzeroberfläche Synchronisation S2+3 1 – MUSS FA-4 Synchronisations-Protokoll S3 1 – MUSS FA-5 Synchronisations-Protokoll erweitert S3 2 – KANN FA-6 Synchronisation mit SynchronisationsProtokoll rückgängig machen im Tool S3 3 – ERW. FA-7 Änderungsverwaltung S1, S4 3 – ERW. FA-8 Konfiguration A1-3 1 – MUSS FA-9 Konfigurations-Daten A1-3 1 – MUSS FA-10 Benutzeroberfläche Administration A1-3 2 – KANN FA-11 Sprache der Benutzeroberfläche Alle 1 – MUSS Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 6/54 Bericht zur Master Thesis 2.4 Nicht-Funktionale Anforderungen NFA-1 Applikations-Framework 1 - MUSS NFA-2 Datenbank-Unterstützung DB2 1 - MUSS NFA-3 Datenbank-Unterstützung andere 2 - KANN NFA-4 Betriebsystem-Unterstützung 1 - MUSS NFA-5 Kein Release für Tabellen- Änderungen 2 - KANN 2.5 System-Kontext Mit folgenden Akteuren und Systemen interagiert das System „DB-Sync“: Der Akteur „Entwickler“ ist der einzige Benutzer. Er bedient die grafische Oberfläche des Systems. Das System kommuniziert mit den Datenbank-Systemen die auf den Datenbankservern installiert sind. Die Kommunikation besteht aus SQL-Befehlen für die CRUD-Operationen. Das System liest die User-Id des Benutzers aus dem Betriebssystem des ClientRechners aus, auf dem es ausgeführt wird. Abbildung 1: Systemkontext-Diagramm Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 7/54 Bericht zur Master Thesis 2.6 Fachklassenmodell Eine Fachklasse beschreibt „etwas, über das die Fachleute im Zusammenhang mit dem System reden“ – also z.B. eine Person die das System benutzt, Dokumente die das System produziert sowie Abläufe, Tätigkeiten und Konzepte. Ein Fachklassenmodell zeigt die grundsätzlichen fachlichen Zusammenhänge auf – ohne Details. Das nachstehende Fachklassenmodell beschreibt das System „DB-Sync“. Es berücksichtigt sämtliche Anwendungsfälle – auch diejenigen die im System nicht umgesetzt werden, da für sie keine Muss-Anforderung definiert ist. Abbildung 2: Fachklassen-Diagramm Beschreibung der Fachklassen: Fachklasse Beschreibung Entwickler Der Entwickler benutzt das System und führt auch die Aktivitäten ausserhalb des Systems durch. Änderung an Daten in der Datenbank Eine Änderung an Daten in einer Datenbank besteht aus dem Einfügen, dem Verändern oder dem Löschen eines oder mehrerer Datensätze in einer Tabelle in einer bestimmten Umgebung. Synchronisations- Ein Synchronisations-Set dient zur Gruppierung von Tabellen, die z.B. Set zu einer Geschäftsanwendung gehören. Es kann aber auch eine Querschnittsgruppierung von bestimmten Tabellen über alle Geschäftsanwendungen abbilden. Dadurch kann eine Tabelle zu mehr als einem Synchronisations-Set zugeordnet sein. Tabelle Die Tabelle enthält die Daten, welche verändert wurden und synchronisiert werden sollen. Umgebung Eine Umgebung dient zur Auswahl der Quelle und des Ziels für die Synchronisation einer Tabelle. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 8/54 Bericht zur Master Thesis ÄnderungsProtokoll Im Änderungs-Protokoll werden sowohl die an den Daten vorgenommenen Änderungen als auch die Synchronisation dieser Änderungen zwischen den verschiedenen Umgebungen festgehalten. Siehe auch Anwendungsfälle UC-S1 und UC-S4. Synchronisation Die Synchronisation ist der Vorgang, bei dem die Daten in einer Tabelle A einer Umgebung X mit den Daten in der gleichen Tabelle A in einer anderen Umgebung Y verglichen und die Differenzen so bereinigt werden, dass die Daten in beiden Tabellen genau gleich sind. Dabei müssen nicht alle Daten in der Tabelle synchronisiert werden – welche das sind, bestimmt der Benutzer. Synchronisations- Jede Synchronisation wird vom System im Synchronisations-Protokoll Protokoll eingetragen. Falls der Entwickler eine Synchronisation rückgängig machen muss, kann er im Synchronisations-Protokoll nachschauen und findet dort die ausgeführten SQL-Statements. 2.7 Fachklassenmodell mit Änderungsverwaltung Das nachstehende Fachklassenmodell berücksichtigt zusätzlich die Anforderung FA-7 „Änderungsverwaltung“. Die Änderungsverwaltung ist eine Erweiterung, die grossen Einfluss auf das System haben wird. Deshalb wird hier ihr Einfluss auf das Fachklassenmodell genauer betrachtet, obwohl sie im System nicht umgesetzt wird. Abbildung 3: Fachklassen-Diagramm mit Änderungsverwaltung Beschreibung des Einflusses der Änderungsverwaltung: Die Änderungsverwaltung ist Teil des Systems und ersetzt das vom System lösgelöste Änderungs-Protokoll. Das hat grossen Einfluss auf die Arbeitsweise des Entwicklers. Die Unterschiede in der Arbeitsweise sind in folgender Tabelle aufgeführt: Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 9/54 Bericht zur Master Thesis Arbeitsweise mit Änderungs-Protokoll Arbeitsweise mit Änderungsverwaltung Der Entwickler trägt jede Änderung an den Daten im Protokoll ein. Welche Daten sich wie geändert haben, hält er (wenn überhaupt) nur mit einer groben Beschreibung in Textform fest. Der Entwickler zeichnet jede Änderung an den Daten mit der Änderungsverwaltung auf. Die Aufzeichnung geschieht mit einer simulierten Synchronisation, bei der die erzeugten SQL-Statements aber nicht ausgeführt sondern gespeichert werden. So werden die Änderungen an den Daten vollständig festgehalten. Der Entwickler schaut im Protokoll nach, welche Synchronisationen er durchführen muss. Dazu wird im Protokoll mit Einfärbung und Anweisungen in Textform (z.B. „Produktion erst mit Release XY“) gearbeitet. Der Entwickler schaut in der Änderungsverwaltung nach, welche Synchronisationen anstehen. Der Aufzeichner einer Änderung kann die Synchronisation dieser Änderung z.B. für die Produktions-Umgebung sperren. Der Entwickler trägt jede Synchronisation einer Änderung im Protokoll ein. Bei der Synchronisation wählt der Entwickler die betroffenen Differenzen aufgrund der Beschreibung im Protokoll aus. Der Entwickler lässt die Synchronisation einer Änderung von der Änderungsverwaltung durchführen. Dabei werden die vorher aufgezeichneten SQL-Statements ausgeführt. Wenn der Entwickler eine FehlSynchronisation rückgängig machen will, schaut er im vom System erzeugten Synchronisations-Protokoll nach, was genau geändert wurde. Er kann dann den Fehler durch eine Gegensynchronisation oder eine manuelle Änderung korrigieren. Eine Fehl-Synchronisation ist weitestgehend ausgeschlossen. Es kann aber vorkommen, dass ein Fehler beim Aufzeichnen einer Änderung gemacht wurde und die Änderung bereits synchronisiert wurde. Der Aufzeichner der fehlerhaften Änderung kann sich vom System eine „Gegen-Änderung“ erzeugen lassen und diese dann in die betroffenen Umgebungen synchronisieren. Fazit: Mit Hilfe der Änderungsverwaltung könnte die Synchronisation der Daten komplett unter der Kontrolle des Systems erfolgen. Dadurch könnte die Synchronisation noch sicherer und noch einfacher durchgeführt werden. Der Aufwand für die Implementierung der Änderungsverwaltung ist allerdings beträchtlich. Vor dem Entscheid, diese Erweiterung umzusetzen, müssen Aufwand und Nutzen also genau abgewogen werden. 2.8 Ablaufmodell der Synchronisation Der zentrale Anwendungsfall, den das System unterstützen muss, ist die Synchronisation der Daten. Der Ablauf der Synchronisation ist bereits in der Dokumentation zum Anwendungsfall UC-S2 „Daten synchronisieren“ beschrieben, wird hier aber zum besseren Verständnis zusätzlich mit Hilfe eines Aktivitätsdiagramms visualisiert. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 10/54 Bericht zur Master Thesis Abbildung 4: Aktivitätsdiagramm zum Anwendungsfall "Daten synchronisieren" Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 11/54 Bericht zur Master Thesis Bemerkungen zum Aktivitätsdiagramm: Im Diagramm ist der Standard-Ablauf beschreiben. Es gibt allerdings keine fachlich begründeten Alternativ-Abläufe. Das einzige was den Ablauf „stören“ könnte (von Systemfehlern natürlich abgesehen) ist der Abbruch durch den Benutzer. Der Benutzer hat nach beinahe jeder Aktivität die Möglichkeit den Ablauf abzubrechen. Dies ist im Diagramm mit dem gestrichelten Rahmen dargestellt. Ein Abbruch kann dazu führen, dass Daten nicht oder nur teilweise synchronisiert sind. Zusammenfassung: Die Synchronisation einer Tabelle beinhaltet die folgenden Kern-Aktivitäten: 1. Erkennen und Anzeigen der Differenzen zwischen den Daten in der Quell- und ZielUmgebung durch das System. 2. Auswahl der zur synchronisierenden Differenzen durch den Benutzer. 3. Auslösen der Synchronisation der ausgewählten Differenzen durch den Benutzer. 4. Erstellen und Ausführen der Datenbank-Befehle zum Einfügen, Kopieren und Löschen der ausgewählten Daten durch das System. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 12/54 Bericht zur Master Thesis 3 Architektur und Grob-Design 3.1 Vorgehen Wie schon im Pflichtenheft definiert, wird zuerst die Architektur und das Grob-Design der Applikation erstellt und in diesem Kapitel dokumentiert. Als erstes wird die Architektur des verwendeten Applikations-Frameworks beschrieben. Angelehnt an das Buch „Analyse und Design mit UML“ [Lit1] und die Skripte [Lit2] und [Lit3] zum Thema „Architektur und Design“, werden in den folgenden Unterkapiteln die Architektur und das Grob-Design in Form des Schichtenmodells, des Verteilungsmodells und des Komponentenmodells beschrieben. Aus den Komponenten werden Arbeitspakete gebildet und diese dann „agil“ implementiert – d.h. jede Komponente wird (wenn möglich) jeweils komplett fertiggestellt, mit Detaildesign, Implementierung, Test und Dokumentation. Das Detaildesign der Applikations-Komponenten wird also nicht schon hier festgelegt, sondern erst unmittelbar vor deren Implementierung. Dokumentiert wird das Detaildesign jeweils beim Beschrieb der Komponente im Kapitel 4 „Detail-Design und Implementation“. 3.2 Applikations-Framework Für die Applikation DB-Sync wird das Rich-Client-Framework „Captain Casa Enterprise Client“ eingesetzt. Siehe [Web1]. Wie in der Anforderung NFA-1 im Pflichtenheft definiert, soll das gleiche Framework eingesetzt werden, das für alle Geschäftssysteme der XpertCenter AG eingesetzt wird. So kann das im Entwicklungsteam vorhandene Know-How genutzt und die spätere Wartung sichergestellt werden. Das Framework dient zur Entwicklung von Java-Webapplikationen auf der Basis der JavaEnterprise-Technologie „Java Server Faces“ (JSF). Siehe [Web2]. Die Besonderheit des Frameworks ist seine Rich-Client-Architektur für das Erzeugen und Anzeigen der grafischen Benutzeroberfläche (GUI): Statt HTML wie bei JSF, verwendet das Framework eine eigene GUIBeschreibungssprache im XML-Format. Statt dem Browser zu Anzeige des HTML-GUI’s, verwendet das Framework einen eigenen Client, der die serverseitig erzeugte XML-GUI-Definition in Form von JavaSwing GUI-Komponenten anzeigt. Durch diese Technologie wird eine performante und an GUI-Elementen reiche grafische Benutzeroberfläche möglich. Einen technischen Überblick gibt [Web3] - eine Beschreibung des Einsatzes von JSF im Framework findet man in [Web4]. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 13/54 Bericht zur Master Thesis 3.3 Schichtenmodell 3.3.1 Einführung Der Hauptnutzen der Unterteilung einer Applikation in Schichten (die Schichten-Architektur) ist das Erreichen einer losen Kopplung. Lose Kopplung bedeutet, dass nur wenige Abhängigkeiten zwischen den Schichten, resp. den Komponenten der Schichten existieren. Eine Abhängigkeit entsteht durch den Zugriff aus einer Schicht in eine andere Schicht. Die Richtung der Zugriffe wird durch die Schichten-Architektur klar definiert: Obere Schichten greifen auf die unteren zu, nie umgekehrt. Nach Möglichkeit sollte die Schichten-Architektur strikt sein, d.h. es sollte kein Zugriff aus einer oberen Schicht auf eine weiter unten liegende erfolgen, bei dem dazwischen liegende Schichten übersprungen werden. Innerhalb einer Schicht sind Zugriffe beliebig möglich – es sollten aber so wenige wie möglich sein. Dadurch können z.B. die Komponenten welche die Geschäftslogik implementieren wieder verwendet werden, d.h. von verschiedenen Clients (Web-Applikation, Desktop-Applikation, Web-Service) oder anderen Geschäftslogik-Komponenten aufgerufen werden. Für verteilte Systeme ist die Schichtenbildung Voraussetzung dafür, dass sie überhaupt verteilt, d.h. ihre Komponenten auf verschiedenen Software- und Hardware-Knoten installiert werden können. Zwischen den verteilten Schichten gibt es dann wenige, über Schnittstellen klar definierte, stabile Zugriffswege. 3.3.2 Beschreibung des Schichtenmodells Im folgenden Schichtenmodell sind die in der Applikation vorhandenen Schichten und die generelle Zugriffs- resp. Abhängigkeits-Richtung aufgeführt. Die in den einzelnen Schichten enthaltenen Komponenten sind nur grob in Form von Paketen (Java-Packages) aufgeführt. Das detaillierte Design der Komponenten und deren Abhängigkeiten untereinander ist im Kapitel 3.5 beschrieben. Es gibt die drei Hauptschichten Präsentation, Geschäftslogik und Persistenz. Diese sind jeweils in zwei Unterschichten aufgeteilt. Innerhalb der Präsentations-Schicht und zwischen der Präsentations- und GeschäftslogikSchicht, sind die Zugriffe „strikt“, d.h. es wird keine der Schichten übersprungen. Die Zugriffe aus der Geschäftslogik-Schicht in die Persistenz-Schicht sind hingegen nicht strikt: Die Steuerungs-Komponenten der Geschäftslogik holen die im GUI benötigten Konfigurationsdaten (Sets, Tabellen und Umgebungen) direkt über den O/R-Mapper aus der Datenbank. Ausserdem greift die Differenz-Ausführungs-Komponente auch direkt auf die Datenbank zu, ohne die JDBC-Datenbankzugriffs-Komponente zu nutzen. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 14/54 Bericht zur Master Thesis Abbildung 5: Schichtenmodell Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 15/54 Bericht zur Master Thesis 3.4 Verteilungsmodell Das Verteilungsmodell zeigt, wo die Applikation installiert wird. Durch die Verwendung des CaptainCasa-Frameworks ist die Applikation grundsätzlich eine auf Client und Applikationsserver verteilbare Webapplikation. Sie wird aber wie eine reine Client-Applikation eingesetzt – d.h. auf jedem Client-PC wird die komplette Server-Applikation installiert und nicht nur der Client-Teil. Beide Teile der Applikation, Server und Client, laufen auf demselben Client-PC. Die Applikation wird also auf dem Client-PC des Entwicklers installiert und kommuniziert per JDBC mit der lokalen Entwicklungs-Datenbank und den Datenbanken auf den DatenbankServern der anderen Umgebungen. Die Applikation kann im normalen Modus verwendet werden, bei dem Client und Server über das HTTP-Protokoll kommunizieren. Dieser Modus wird für die Entwicklung der Applikation verwendet. Zum Starten der Applikation sind dabei folgende Schritte notwendig und folgende Varianten des Aufrufs möglich: 1. Start des Tomcat-Applikationsservers (Servlet Container) 2. Aufruf der Applikation per: a. URL im Browser für den Start als im Browser eingebettetes Applet b. URL im Browser für den Start als Java-Webstart-Applikation in einem eigenen Fenster ausserhalb des Browsers c. Batch-Datei für den Start als eigenständige Java-Applikation (Kommunikation mit dem Server trotzdem über HTTP) Die Applikation kann im sogenannten „Embedded-Modus“ verwendet werden, bei dem Client und Server direkt über Java-API-Aufrufe kommunizieren. Dazu wird der „Embedded-Modus“ des Tomcats genutzt. Dieser Modus wird für den produktiven Betrieb der Applikation verwendet. Beim Build der Applikation ist dazu ein spezielles Vorgehen notwendig. Siehe [Web5]. Zum Starten der Applikation wird eine Batch-Datei verwendet. Dabei wird sie als eigenständige Java-Applikation gestartet. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 16/54 Bericht zur Master Thesis Abbildung 6: Verteilungsmodell 3.5 Komponentenmodell 3.5.1 Einführung Eine Komponente ist eine abgeschlossene Einheit, die ein bestimmtes fachliches oder technisches Teilproblem innerhalb der gesamten Applikation löst. Durch die Bildung von Komponenten kann ein komplexes System in überschaubare, verständliche Teile gegliedert werden, die untereinander lose gekoppelt sind, d.h. über klar definierte, stabile Schnittstellen miteinander kommunizieren. Die in den Komponenten gekapselte Programmlogik ist besser wartbar, da: die Logik redundanzfrei, d.h. nur an einer einzigen Stelle, gepflegt wird. der Zugriff auf die Logik nur über die definierte Schnittstelle erfolgt und so die Details der Implementation verborgen werden. Änderungen an der Implementation haben dadurch keine Auswirkungen auf die nutzenden Komponenten. In Java besteht eine Komponente aus Klassen die in einem Package (evtl. mit UnterPackages) abgelegt sind. Die Schnittstelle der Komponente wird in Form eines Interfaces definiert. Einfache, stabile Komponenten können auch ohne Interface auskommen. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 17/54 Bericht zur Master Thesis 3.5.2 Beschreibung des Komponentenmodells Für das Design des Komponentenmodells wird die Applikation DB-Sync in die folgenden Teile (Subsysteme) unterteilt: 3.5.2.1 Synchronisation Für die Synchronisation braucht es Komponenten für das GUI, die GUI-Steuerung die Applikations-Steuerung, die Geschäftslogik und den Zugriff auf die Datenbank. Die Synchronisation besteht aus den beiden Teilschritten Differenz-Berechnung und Differenz-Ausführung. Diese Teilschritte sind als voneinander unabhängige GeschäftslogikKomponenten konzipiert. Damit wird eine optimale Flexibilität für zukünftige Erweiterungen erreicht (siehe unten bei „Änderungsverwaltung“.) Die Komponenten zur Differenz-Berechnung und Differenz-Ausführung greifen sowohl direkt als auch mit Hilfe der JDBC-Datenbankzugriffs-Komponente auf die Datenbanken der verschiedenen Umgebungen zu. Der direkte Zugriff erfolgt, weil es nicht für alle ZugriffsFunktionen sinnvoll ist, sie in die JDBC-Datenbankzugriffs-Komponente auszulagern (siehe Detaildesign der Differenz-Ausführungs-Komponente). Für den Zugriff auf das Datenmodell der Konfiguration und des Synchronisationsprotokolls gibt es die entsprechenden Geschäftsobjekte (Business-Objects, BO‘s). Diese stellen den Geschäftslogik-Komponenten die notwendigen Lese- und Schreib-Funktionen zur Verfügung und nutzen dazu die generierten Entitäts-Klassen (POJO‘s) des Objekt/RelationalenMapping-Frameworks für den Zugriff auf die Konfigurations-Datenbank. Für den (nur lesenden) Zugriff auf die Daten der Konfiguration zur Anzeige/Auswahl der Sets, Tabellen und Umgebungen im GUI, werden hingegen direkt die generierten Klassen (POJO‘s) des Objekt/Relationalen-Mapping-Frameworks verwendet. Dieses Design wurde gewählt, da auf die Synchronisations-Steuerungs-Komponente ausschliesslich durch das eigene GUI zugegriffen wird und nicht auch noch von anderen, externen Applikationen. Dadurch kann auf den Einsatz von Transfer-Objekten für die Konfigurationsdaten verzichtet werden – auch die entsprechenden BO’s werden nicht genutzt. Stattdessen werden durchgängig die O/R-Mapper-POJO’s verwendet. 3.5.2.2 Synchronisationsprotokoll Für die Anzeige des Synchronisationsprotokolls braucht es Komponenten für das GUI, die GUI-Steuerung, die Applikations-Steuerung und den Zugriff auf die Datenbank. Die Logik für die Suche/Filterung der Protokoll-Einträge ist direkt in der SynchronisationsSteuerungs-Komponente implementiert – es gibt keine separate GeschäftslogikKomponente. Für den (nur lesenden) Zugriff auf die Daten des Synchronisationsprotokolls zur Anzeige der Einträge im GUI, werden auch hier durchgängig die O/R-Mapper-POJO’s verwendet. 3.5.2.3 Hauptseite/Benutzeridentifikation Die Hauptseite bildet den Rahmen für die Applikation, in welchem das GUI, d.h. die Seiten für die Synchronisation und das Synchronisationsprotokoll angezeigt werden. Beim Start der Applikation wird die in der Muss-Anforderung FA-1 verlangte Identifikation des Benutzers durchgeführt. Zusätzlich wird noch ein Teil der Erweiterung FA-2 „Benutzer-Verwaltung“ implementiert: Für die berechtigten Benutzer wird in der Datenbank das Merkmal abgelegt, mit dem sie identifiziert werden (die User-Id des Betriebssystems) – nicht eingetragene Benutzer können die Applikation nicht benutzen. Für die Benutzeridentifikation und die damit verbundene Steuerung der Hauptseite der Applikation, braucht es Komponenten für das GUI, die GUI-Steuerung, die ApplikationsSteuerung und den Zugriff auf die Datenbank. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 18/54 Bericht zur Master Thesis Die Applikations-Steuerungs-Komponente ist als Singleton ausgelegt und stellt den anderen Komponenten die Informationen über den identifizierten Benutzer zur Verfügung. Für den Zugriff auf das Datenmodell der Benutzeridentifikation gibt es ein entsprechendes BO, welches die generierte Entitäts-Klasse (POJO) des Objekt/Relationalen-MappingFrameworks für den Zugriff auf die Konfigurations-Datenbank nutzt. 3.5.2.4 Administration/Konfiguration Das GUI für die Administration, d.h. für die Konfiguration der Synchronisations-Sets, Tabellen und Umgebungen, wird nicht realisiert – die entsprechende Anforderung FA10 hat die Priorität 2 (Kann). Für das Design wird es trotzdem berücksichtigt, damit es später problemlos eingebaut werden kann. Wie für die vorhergehenden Subsysteme, braucht es Komponenten für das GUI, die GUISteuerung, die Applikations-Steuerung und den Zugriff auf die Datenbank. Das GUI ist unabhängig vom Rest der Applikation. Die Applikations-Steuerung wird aber auf die BO’s des Konfigurationsdaten-Modells zugreifen. Die dafür notwendigen zusätzlichen Schreib-Funktionen, können in den BO’s aber problemlos eingebaut werden. Somit müssen im jetzigen Design keine besonderen Vorkehrungen getroffen werden. 3.5.2.5 Änderungsverwaltung Die Änderungsverwaltung ist eine Erweiterung (Anforderung FA-7) und wird nicht realisiert. Schon bei der Analyse (Kapitel 2.7 Fachklassenmodell mit Änderungsverwaltung) wurde die Änderungsverwaltung speziell berücksichtigt, da sie weitreichenden Einfluss auf das System hat. Für das Design muss sie deshalb ebenfalls berücksichtigt werden, damit es später überhaupt möglich ist, die Änderungsverwaltung einzubauen. Für die Änderungsverwaltung braucht es Komponenten für das GUI, die GUI-Steuerung die Applikations-Steuerung, die Geschäftslogik und den Zugriff auf die Datenbank. Das GUI ist unabhängig vom Rest der Applikation. Die Applikations-Steuerung wird auf die BO’s des Konfigurationsdaten-Modells zugreifen und die Applikations-Steuerung der Synchronisation benutzen – dies ist mit dem jetzigen Design bereits möglich. Neu hinzukommen wird das Datenmodell für die aufgezeichneten Änderungen und deren Synchronisation – ebenso die entsprechenden BO’s und O/R-Mapper-POJO’s. Die Aufzeichnung der Änderungen und deren davon getrennte Synchronisation ist der grosse Unterschied zur Synchronisation ohne Änderungsverwaltung. Die beiden Teilschritte Differenz-Berechnung und Differenz-Ausführung werden zeitlich getrennt ausgeführt: Die Differenz-Berechnung einmalig bei der Aufzeichnung der Änderungen, die DifferenzAusführung mehrmals bei der Synchronisation der Änderungen durch die verschiedenen Benutzer in den verschiedenen Umgebungen. Als Folge davon müssen diese Teilschritte bereits im jetzigen Design auf voneinander unabhängige Komponenten aufgeteilt werden. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 19/54 Bericht zur Master Thesis Abbildung 7: Komponentenmodell Synchronisation Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 20/54 Bericht zur Master Thesis Abbildung 8: Komponentenmodell Sync-Protokoll und Benutzeridentifikation (Login) Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 21/54 Bericht zur Master Thesis 4 Detail-Design und Implementation In diesem Kapitel werden das Detail-Design und die Implementation der einzelnen Teile und Komponenten der Applikation DB-Sync beschrieben. Alle in diesem Kapitel beschriebenen Klassen und die DDL-Skripts der beschriebenen Datenbank-Tabellen sind in der ZIP-Datei mit den Anhängen zu dieser Master Thesis enthalten. 4.1 Die Hauptseite der Applikation 4.1.1 GUI-Design Die Hauptseite der Applikation bildet den Rahmen, in welchem die Seiten für die Synchronisation und das Synchronisationsprotokoll angezeigt werden. Sie bietet verschiedene Grundfunktionen zur Bedienung der Applikation an. 1 2 3 4 5 Abbildung 9: Hauptseite Beschreibung der Hauptseite: 1. Fenster der Applikation mit den Standard-Funktionen zum Minimieren, Maximieren und Schliessen des Fensters. 2. Titelzeile mit dem Namen der Applikation. Rechts wird der Name des angemeldeten Benutzers angezeigt. 3. Navigation: Die vorhandenen Seiten werden in Form eines Registers aufgeführt. Mit einem Klick auf den Registertitel wird die entsprechende Seite angezeigt. 4. Die aktuelle Seite. Nach dem Start der Applikation ist immer die Seite für die Synchronisation sichtbar. 5. Statuszeile: In der Statuszeile werden Erfolgs-, Warnungs- und Fehlermeldungen anzeigt. Wird eine Meldung angezeigt, so kann mit einem Klick auf die Statuszeile ein Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 22/54 Bericht zur Master Thesis Popup-Fenster geöffnet werden, in dem zusätzliche Details zur Meldung angezeigt werden. Mit den Symbolen am rechten Rand kann die Applikation neu gestartet und der Dialog mit den Einstellungen für Skalierung und Sprache geöffnet werden. Abbildung 10: Statuszeile mit Erfolgs-, Warn- und Fehlermeldung, Popup mit Details 4.1.2 Implementation Das eingesetzte Rich-Client-Framework „Captain Casa Enterprise Client“ kennt das Konzept des „Arbeitsplatzes“ (Workplace). Die Hauptseite besteht aus den vorhandenen ArbeitsplatzKomponenten. So kann mit minimalem Aufwand eine ausgereifte Hülle für die Applikation erstellt werden. Die mit dem Layout-Editor der CaptainCasa-Entwicklungstools erstellte Hauptseite, ist in der Datei workplace.jsp abgelegt. 4.2 Benutzeridentifikation 4.2.1 Detail-Analyse Die Muss-Anforderung FA-1 gibt vor, dass der Benutzer der die Applikation startet, identifiziert werden muss. Eine weitergehende Benutzerverwaltung wird nicht verlangt – sie ist als Erweiterung in der Anforderung FA-2 definiert. Benutzt wird der identifizierte Benutzer für das Synchronisations-Protokoll. 4.2.2 Detail-Design Der Benutzer wird automatisch über das Betriebssystem identifiziert – es gibt keinen LoginDialog. Zugelassen werden aber nur „registrierte“ Benutzer. Diese Benutzer werden in der Tabelle „SYNCUSER“ in der Datenbank eingetragen. Dadurch wird auf einfache Weise der Benutzer-Kreis strenger kontrolliert als vorgegeben. Damit wird bereits ein Teil der Anforderung FA-2 umgesetzt. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 23/54 Bericht zur Master Thesis In der Datenbank eingetragene Benutzer können deaktiviert werden. Grund: Für das Synchronisations-Protokoll wird nur die Id des Benutzers gespeichert – damit im Protokoll der Name angezeigt werden kann, dürfen Benutzer nie gelöscht werden. 4.2.3 Klassenmodell Die Implementation erfolgt wie im Komponentenmodell definiert (siehe Abbildung 8). Das folgende Klassendiagramm gibt einen Überblick über die Klassen, welche die Benutzeridentifikation implementieren. Die einzelnen Klassen/Komponenten werden in den nachfolgenden Kapiteln beschrieben. Abbildung 11: Klassendiagramm Benutzeridentifikation 4.2.4 GUI In der Titelzeile der Hauptseite wird angezeigt, welcher Benutzer die Applikation gestartet hat. Abbildung 12: Titelzeile mit dem angemeldeten Benutzer Falls ein nicht registrierter Benutzer die Applikation startet, wird ihm nur die Login-Seite angezeigt – die Seiten für die Synchronisation und das Synchronisations-Protokoll sind ausgeblendet. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 24/54 Bericht zur Master Thesis Auf der Login-Seite wird angezeigt, mit welcher System-User-Id der Benutzer identifiziert wurde und dass er keine Berechtigung hat, die Applikation zu benutzen. Die mit dem Layout-Editor der CaptainCasa-Entwicklungstools erstellte Login-Seite, ist in der Datei login.jsp abgelegt. Abbildung 13: Login-Seite 4.2.5 GUI-Steuerung Grundsätzliches Das eingesetzte Rich-Client-Framework „Captain Casa Enterprise Client“ basiert auf dem „Java Server Faces“-Framework (JSF) der Java Enterprise Edition (JEE) [Web2]. In JSF wird das GUI durch „Managed Beans“ gesteuert [Web4], d.h. in der JSP-Seite mit der GUI-Definition wird die „Expression Language“ (EL) verwendet um auf Daten und Methoden in einem oder mehreren Beans zuzugreifen. Sämtliche Beans zur GUI-Steuerung sind im Package ch.xpertcenter.dbsync.ui abgelegt. Dispatcher-Bean CaptainCasa kennt das Konzept eines zentralen Managed Beans der „Dispatcher“ genannt wird [Web7]. Über den Dispatcher-Bean können die selbst erstellten Beans zur Steuerung der verschiedenen GUI-Seiten miteinander kommunizieren. Dieser Dispatcher-Bean wird beim Start der Applikation vom Framework instanziiert und ist der ideale Ort um die Identifizierung des Benutzers anzustossen und zu steuern, welche Seite(n) angezeigt werden. Der Dispatcher-Bean (Klasse Dispatcher) steuert die Hauptseite wie folgt: Im Konstruktor des Dispatcher-Beans wird über den LoginController ermittelt, ob der Benutzer berechtigt ist oder nicht. Falls er berechtigt ist, werden die Seiten für die Synchronisation und das SyncProtokoll angezeigt Falls er nicht berechtigt ist, wird nur die Login-Seite angezeigt. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 25/54 Bericht zur Master Thesis LoginUI-Bean Die Login-Seite wird durch den LoginUI-Bean (Klasse LoginUI) gesteuert, d.h. die LoginSeite holt aus dem LoginUI-Bean die angezeigte System-User-Id. 4.2.6 Applikations-Steuerung Die Login-Controller-Komponente im Package ch.xpertcenter.dbsync.business. login stellt der GUI-Steuerung die Schnittstelle zur Verfügung, über die sie die Daten des identifizierten Benutzers abrufen kann. Die Klasse LoginControllerImpl implementiert das Interface LoginController und ist als Singleton realisiert, damit immer dieselbe Instanz benutzt wird. So muss die Identifikation des Benutzers nur einmal durchgeführt werden und alle Anfragen liefern immer das gleiche Ergebnis. 4.2.7 Geschäftsobjekt Die Klasse UserBO im Package ch.xpertcenter.dbsync.business.login.bo stellt der Applikations-Steuerung die Daten zum Benutzer zur Verfügung. Sie prüft, ob zur übergebenen Betriebssystem-User-Id ein autorisierter Benutzer existiert und greift dazu mit dem O/R-Mapper auf die in der Datenbank abgelegten Benutzer zu. 4.2.8 Datenbank-Zugriff mit O/R-Mapper Der Zugriff auf das Datenmodell der Benutzeridentifikation erfolgt mit dem O/R-MappingFramework „Hibernate“ [Web8]. Die Objekte der generierten Klasse Syncuser im Package ch.xpertcenter.dbsync.database.hibernate repräsentieren dabei jeweils einen Datensatz aus der Tabelle SYNCUSER. 4.2.9 Datenbank Das Datenmodell der Benutzeridentifikation besteht aus der Tabelle SYNCUSER, welche wie folgt definiert ist: Abbildung 14: Tabelle der Benutzeridentifikation Beschreibung der Tabelle: SYNCUSER: Tabelle für die registrierten Benutzer der Applikation SYNCUSER.USER_ID: Generierter Primär-Schlüssel (automatische Inkrementierung durch die Datenbank) SYSTEM_USER_ID: User-Id, die aus dem Betriebssystem ausgelesen wird, um den Benutzer automatisch zu identifizieren (mit Unique-Constraint) USER_NAME: Name des Benutzer (zur Anzeige) SYNCUSER.IS_ACTIVE: Gibt an, ob der Benutzer aktiv ist. Nur aktive Benutzer können die Applikation benutzen. Werte: der Benutzer ist aktiv: ''1'' = true, der Benutzer ist nicht aktiv: ''0'' = false Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 26/54 Bericht zur Master Thesis 4.3 Synchronisation 4.3.1 Detail-Analyse des Modells der Konfigurationsdaten Konfiguriert werden Synchronisations-Sets, Tabellen und Umgebungen. Diese drei Fachklassen wurden aus den Anwendungsfällen UC-A1-3 des Haupt-Anwendungsfalls „Administrieren“ abgeleitet und sind dort (Pflichtenheft Kapitel 3.2.4) und im Fachklassenmodell (Kapitel 2.6) beschrieben. Für das Datenmodell sind die Beziehungen wichtig – deshalb werden sie hier noch detaillierter analysiert. Abbildung 15: Fachklassendiagramm Konfigurationsdaten-Modell Beschreibung der Beziehungen: Nr. Klasse Beziehung Multiplizität Klasse 1 Synchronisations-Set enthält 1..* Tabelle 2 Tabelle ist zugeordnet 1..* Synchronisations-Set 3 Umgebung wird verwendet von 1..* Tabelle 4 Tabelle ist definiert in 2..* Umgebung 1. Ein Synchronisations-Set kann eine oder mehrere Tabellen enthalten. Eine bestimmte Tabelle darf aber nur einmal darin vorkommen. 2. Eine Tabelle ist in der Regel einem, kann aber auch mehreren Synchronisations-Sets zugeordnet sein. 3. Eine Umgebung wird von einer oder mehreren Tabellen verwendet. 4. Eine Tabelle ist in zwei oder mehreren Umgebungen definiert. 4.3.2 Detail-Design Die wesentlichen Merkmale des Designs werden bereits beim Komponentenmodell beschrieben (Kapitel 3.5.2.1) – bis auf eines: die Differenz. Die Differenz wird in der Komponente zur Differenz-Berechnung erzeugt und ist eine Datenklasse, die folgendes enthält: Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 27/54 Bericht zur Master Thesis die Informationen, die zur Anzeige einer Differenz im GUI benötigt werden sämtliche Daten, die von der Komponente zur Differenz-Ausführung benötigt werden Über die Differenz-Objekte können die drei an der Synchronisation beteiligten Komponenten einfach und effizient Daten austauschen. Durch die Persistierung der Daten der Differenz-Objekte könnte die Berechnung, die Anzeige und die Ausführung einer Differenz auch zeitlich komplett entkoppelt werden – damit sind mit dem aktuellen Design bereits die Voraussetzungen für die Einführung der Änderungsverwaltung (siehe Kapitel 3.5.2.5) gegeben. 4.3.3 Klassenmodell Die Implementation erfolgt wie im Komponentenmodell definiert (siehe Abbildung 7). Das folgende Klassendiagramm gibt einen Überblick über die Klassen, welche die Synchronisation implementieren. Die einzelnen Klassen/Komponenten/Packages werden in den nachfolgenden Kapiteln beschrieben. Abbildung 16: Klassendiagramm Synchronisation Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 28/54 Bericht zur Master Thesis 4.3.4 GUI 4.3.4.1 Übersicht 1 2 3 4 5 Abbildung 17: GUI Synchronisation Beschreibung der Bereiche der Synchronisations-Seite: 1. Bereich für die Auswahl der Konfigurations-Daten 2. Buttons für die Berechnung der Differenzen und die Anzeige des SynchronisationsProtokolls aufgrund der ausgewählten Konfigurations-Daten 3. Bereich für die Anzeige der berechneten Differenzen 4. Buttons für die Auswahl/Markierung der berechneten Differenzen 5. Buttons für das Ausführen der ausgewählten Differenzen Durch den Einsatz von Icons [Web11], werden die Buttons besser erkenn- und unterscheidbar. Die Synchronisations-Seite ist in der Datei synchronisation.jsp abgelegt. 4.3.4.2 Auswahl der Konfigurations-Daten Das Set, die Tabelle, die Quell- und Ziel-Umgebung für die Differenz-Berechnung werden mit Hilfe der Auswahllisten (ComboBox) ausgewählt. Die Auswahllisten sind abhängig voneinander: Erst wenn ein Set ausgewählt ist, können die zugehörigen Tabellen angezeigt werden und erst wenn eine Tabelle ausgewählt ist, können die zugehörigen Umgebungen angezeigt werden. Sobald der Benutzer in einer übergeordneten Liste einen anderen Eintrag auswählt, wird die Auswahl in den untergeordneten Listen gelöscht. Abbildung 18: GUI Synchronisation: Auswahl der Konfigurations-Daten Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 29/54 Bericht zur Master Thesis 4.3.4.3 Berechnung der Differenzen Die Berechnung der Differenzen wird mit dem entsprechenden Button ausgelöst. Die Berechnung kann nur durchgeführt werden, wenn ein Set, eine Tabelle, die Quell- und die Ziel-Umgebung ausgewählt sind – andernfalls wird eine Warnmeldung angezeigt. Die Berechnung der Differenzen wird immer von der Quell-Tabelle ausgehend durchgeführt. Um alle Differenzen zwischen zwei Umgebungen zu finden, muss die Berechnung jeweils in beide Richtungen durchgeführt werden. Mit dem Button „Quelle und Ziel vertauschen“ kann die Richtung bequem geändert werden. 4.3.4.4 Synchronisations-Protokoll anzeigen Mit dem Button „Protokoll anzeigen“ wird zur Synchronisations-Protokoll-Seite gewechselt und mit den in der Synchronisations-Seite ausgewählten Konfigurations-Daten als Suchkriterien eine Suche ausgelöst. Zusätzlich wird noch auf den aktuell angemeldeten Benutzer eingeschränkt. So kann vor oder nach dem Berechnen/Kopieren/Löschen von Differenzen nachgeschaut werden, welche Differenzen man selber mit den aktuellen Einstellungen zuletzt synchronisiert hat. 4.3.4.5 Anzeige der berechneten Differenzen Nach der Berechnung werden die gefundenen Differenzen in einer zweiteiligen Tabelle angezeigt. In der Statusleiste wird zudem die Anzahl der gefundenen Differenzen angezeigt. Abbildung 19: GUI Synchronisation: Anzeige der berechneten Differenzen Der linke Teil der Tabelle enthält die Spalte in der der Typ der Differenz angezeigt wird. In der Spalte gibt es eine Checkbox die angezeigt, ob die entsprechende Differenz ausgewählt ist oder nicht. Diese Spalte ist statisch und bleibt immer sichtbar – sie kann nicht „weggescrollt“ werden. Der rechte Teil der Tabelle enthält die Spalten der Tabelle mit ihren Werten und wird jeweils, entsprechend der Struktur der Tabelle, dynamisch erzeugt. Für binäre Daten (z.B. PDFDateien) wird der Text „<BLOB>“ angezeigt, da es keinen Sinn macht, die Bytes anzuzeigen. NULL-Werte werden mit dem Text „<null>“ angezeigt. 4.3.4.6 Auswahl der Differenzen Die angezeigten Differenzen können auf zwei Arten ausgewählt (und auch wieder abgewählt) werden: 1. Mit einem (einfachen) Maus-Klick in irgendeiner Spalte der Differenz oder auch direkt auf die Checkbox. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 30/54 Bericht zur Master Thesis 2. Mit den Buttons „Alle auswählen“, „Neue auswählen“, „Geänderte auswählen“ und „Alle abwählen“. Die ausgewählten Differenzen sind am Haken in der Checkbox erkennbar. Abbildung 20: GUI Synchronisation: Auswahl der Differenzen 4.3.4.7 Synchronisation der Differenzen Das Synchronisieren von Differenzen kann auf zwei Arten erfolgen: Eine Differenz wird von der Tabelle der Quell-Umgebung in die Tabelle der ZielUmgebung kopiert. Eine Differenz wird in der Tabelle der Quell-Umgebung gelöscht. Der Typ der Differenz spielt dabei keine Rolle, d.h. DB-Sync schränkt z.B. das Löschen nicht auf Differenzen vom Typ „Neu“ ein – der Benutzer muss wissen was er macht. Das Änderungs-Protokoll in dem steht, welche Datensätze geändert, neu eingefügt oder gelöscht wurden, wird ausserhalb von DB-Sync geführt. Für das Kopieren und Löschen gibt es die Buttons „Ausgewählte kopieren“ und „Ausgewählte löschen“ – wie die Beschriftung schon sagt, betrifft das jeweils nur die ausgewählten Differenzen. Bevor kopiert/gelöscht wird, muss der Benutzer noch eine Sicherheits-Abfrage mit „Ja„ bestätigen. Nach dem Kopieren/Löschen wird in der Statuszeile eine entsprechende Erfolgsmeldung angezeigt. Abbildung 21: GUI Synchronisation: Differenzen kopieren Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 31/54 Bericht zur Master Thesis Abbildung 22: GUI Synchronisation: Differenzen löschen 4.3.5 GUI-Steuerung Die Synchronisations-Seite wird durch den SynchronisationUI-Bean (Klasse SynchronisationUI) gesteuert. Der Bean stellt dem GUI die Daten für die Auswahllisten und die Differenz-Tabelle zur Verfügung und enthält die Methoden die durch die Buttons aufgerufen werden. 4.3.6 Applikations-Steuerung Die Synchronisations-Steuerungs-Komponente im Package ch.xpertcenter.dbsync. business.sync stellt der GUI-Steuerung die Schnittstelle zur Verfügung, über die sie die Methoden für die Synchronisation aufrufen kann. Die Klasse SynchronisationControllerImpl implementiert das Interface SynchronisationController welches die folgenden Methoden anbietet: Abbildung 23: Klassendiagramm Synchronisations-Steuerungs-Komponente Neben den Methoden für das Berechnen/Kopieren/Löschen von Differenzen, gibt es noch die Methode getAllSynchronisationSets() welche eine Liste mit SyncSet-Objekten zurückgibt. Aus diesen O/R-Mapper-Objekten kann die GUI-Steuerung sämtliche Daten extrahieren, die sie für das Füllen der Konfigurationsdaten-Auswahllisten benötigt. Siehe Kapitel 4.3.12 „Datenbank-Zugriff mit O/R-Mapper“. Exception-Handling: Alle Fehler die in der Komponente selbst oder in den daraus aufgerufenen Komponenten auftreten, werden in eine SynchronisationException verpackt. Sie ist die einzige Exception die ans GUI weitergegeben wird. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 32/54 Bericht zur Master Thesis 4.3.7 Geschäfts-Komponente zur Differenz-Berechnung Die Differenz-Berechnungs-Komponente im Package ch.xpertcenter.dbsync. business.sync.diffcalculator stellt der Applikations-Steuerung die Funktion für die Berechnung der Differenzen zur Verfügung. Die Klasse DifferenceCalculatorImpl implementiert dabei das Interface DifferenceCalculator welches die Methode zur Berechnung von Differenzen anbietet: Abbildung 24: Klassendiagramm Differenz-Berechnungs-Komponente Implementation der Differenz-Berechnung: 1. Alle Datensätze der Quell-Tabelle werden aus der Datenbank geladen. 2. Zu jedem Quell-Datensatz wird mit Hilfe des Primär-Schlüssels der entsprechende Datensatz aus der Ziel-Tabelle geladen. Wenn kein entsprechender Ziel-Datensatz existiert, wird das als Differenz vom Typ „Neu“ erkannt. 3. Wenn ein entsprechender Ziel-Datensatz existiert, werden die Werte der Datensätze Spalte für Spalte verglichen. Sobald ein Unterschied festgestellt wird, wird das als Differenz vom Typ „Geändert“ erkannt. 4. Für jede erkannte Differenz wird ein Objekt der Klasse Difference erzeugt (siehe Kapitel 4.3.8 Modell der Differenz). Als Resultat der Berechnung wird eine Liste von Differenz-Objekten zurückgegeben. Die Berechnung geht immer von den in der Quell-Tabelle vorhandenen Datensätzen aus. Ein in der Quell-Tabelle gelöschter Datensatz wird auf diese Weise nicht als Differenz erkannt. Ein solcher Datensatz wird bei der Berechnung in der umgekehrten Richtung (Quell- und Ziel-Umgebung vertauscht) als Differenz vom Typ „Neu“ erkannt und kann dann gelöscht werden. Dieses Vorgehen (siehe auch Kapitel 2.8 Ablaufmodell der Synchronisation) ist nötig, da nicht genug Informationen vorhanden sind, um die Differenzen gleichzeitig in beide Richtungen zu berechnen und deren Typ richtig zu erkennen: Würde man die nur in der Ziel-Umgebung vorhandenen Datensätze auch noch berücksichtigen und z.B. als Typ „Gelöscht“ anzeigen, wäre das nicht in jedem Fall korrekt, da nicht erkannt werden kann, ob der Datensatz in der Quell-Tabelle gelöscht oder in der Ziel-Tabelle neu eingefügt wurde. Diese Information muss vom Urheber der Änderung im Änderungsprotokoll festgehalten werden. Ebenso kann nicht festgestellt werden, in welcher Umgebung ein geänderter Datensatz geändert wurde – ob ein Datensatz also von der Quelle ins Ziel oder in der umgekehrten Richtung kopiert werden muss, kann nur dem Änderungsprotokoll entnommen werden. Vergleich der Datensätze: Der Vergleich zweier Datensätze wird abgebrochen, sobald die Werte in einer Spalte verschieden sind. Falls weitere Spalten unterschiedliche Werte enthalten, ist das für die Erkennung einer Differenz ohne Bedeutung. Durch dieses (effiziente) Vorgehen kann nicht festgehalten werden, welche Spalten Änderungen enthalten – dadurch kann diese Information auch nicht im GUI angezeigt werden. Das wird in Kauf genommen, da diese Information vom Benutzer in der Regel nicht benötigt wird, resp. im Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 33/54 Bericht zur Master Thesis Änderungsprotokoll festgehalten wird. Eine entsprechende Erweiterung der Funktionalität wäre aber ohne weiteres möglich. Ein anderer Aspekt ist das sichere Erkennen von Unterschieden in den Daten. Die meisten Datentypen können mit der equals()-Methode ihrer Java-Repräsentation einfach verglichen werden. Bei binären Daten (BLOB, Binary Large OBject) geht das aber nicht – dort muss der Inhalt byte-weise verglichen werden. Konsequenz: Jeder Datentyp muss auf seine Vergleichbarkeit geprüft werden. Deshalb unterstützt die Differenz-BerechnungsKomponente nur geprüfte Datentypen und wirft eine Exception, wenn eine Tabelle einen nicht geprüften Datentyp verwendet. Die unterstützten Datentypen sind in der Klasse DifferenceCalculatorImpl im Set<Integer> SUPPORTED_SQL_DATATYPES abgelegt. Die Integer-Werte repräsentieren dabei den entsprechenden Datentyp der in der Klasse java.sql.Types definiert ist. Entkopplung von der Datenbankzugriffs-Schicht: Die Datensätze werden nicht direkt in der Differenz-Berechnungs-Komponente aus der Datenbank geladen. Dies geschieht in der Hilfsklasse JDBCDatabaseAccessor. So wird die Komponente vom umfangreichen Code für den Auf- und Abbau der Datenbank-Verbindungs-Objekte entlastet. Der JDBCDatabaseAccessor gibt die Datensätze als javax.sql.rowset.CachedRowSet zurück. Ein CachedRowSet ist ein ResultSet, das keine geöffnete Datenbank-Verbindung mehr unterhält und so komplett unabhängig von der Datenbank-Infrastruktur verwendet werden kann [Web10]. Durch die Verwendung des CachedRowSets kann die Entkoppelung noch verstärkt werden. Schutz vor Fehlmanipulationen in der Datenbank: Besonderes Augenmerk wurde auf das fehlerfreie Zusammenstellen der notwendigen SQL-Statements gerichtet. In den Konfigurationsdaten werden nur das Schema und der Name der Tabelle abgelegt. Die Primärschlüssel-Spalten werden direkt aus der Datenbank ausgelesen. Die Methode JDBCDatabaseAccessor.getPrimaryKeysOfTable() gibt ein CachedRowSet zurück, welches von der Methode generateSQLToSelectWithPrimaryKey() benutzt wird, um das Prepared-SQL-Statement für das Laden eines Datensatzes aus der Ziel-Tabelle zu erzeugen. Die für dieses SQL-Statement benötigten Werte der Primärschlüssel-Spalten, werden aus dem Quell-Datensatz gelesen, der sich wiederum im CachedRowSet mit allen Datensätzen der Quell-Tabelle befindet. Die Werte werden zusammen mit ihren Datentypen im Object[][] primaryKeyValuesAndTypes gespeichert. Das fehleranfällige Konfigurieren der Primärschlüssel-Spalten von Hand und das noch fehleranfälligere Zusammenstellen des SQL-Statements mit Primärschlüssel-Spalten-Werten als Strings wird so komplett vermieden. Unterstützung von Views: Für die Synchronisation von Tabellen werden Views eingesetzt um irrelevante oder störende Spalten auszublenden. Hier zwei typische Beispiele: Eine Tabelle mit Texten z.B. für Erfolgs-, Warn- und Fehlermeldungen, enthält eine Spalte in der das Datum des letzten Zugriffs abgelegt ist. Dieses Datum dient zur Pflege der Tabelle – es können damit nicht oder nicht mehr benutzte Texte erkannt und bereinigt werden. Bei der Synchronisation stört es, da ein unterschiedliches Datum keine inhaltliche Änderung darstellt. Die Synchronisation dieser Tabelle erfolgt deshalb über eine View, die diese Datums-Spalte nicht enthält, sonst aber mit der Tabelle identisch ist. Eine Tabelle enthält binäre Daten (als BLOB), z.B. PDF-Dokumente. Damit bei der Synchronisation einer Änderung in einer der anderen Spalten nicht jedesmal auch die BLOB-Spalte verglichen werden muss, wird zusätzlich zur Tabelle auch noch eine View benutzt, die diese BLOB-Spalte nicht enthält, sonst aber mit der Tabelle identisch ist. So kann beim Synchronisieren viel Zeit gespart werden, da das Vergleichen der umfangreichen BLOB-Daten lange dauert. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 34/54 Bericht zur Master Thesis Im Unterschied zu den Tabellen, können aus den JDBC-Metadaten einer View die Primärschlüssel-Spalten nicht ermittelt werden. Views können nämlich auch Spalten aus mehreren verschiedenen Tabellen enthalten und selbst wenn sich eine View nur auf eine Tabelle bezieht, muss sie nicht zwingend alle zum Primärschlüssel gehörenden Spalten umfassen. Damit auch für Views die Primärschlüssel-Spalten aus der Datenbank ausgelesen werden können und nicht von Hand konfiguriert werden müssen, unterstützt DB-Sync nur Views die folgende Bedingungen erfüllen: 1. eine View darf sich nur auf eine Tabelle beziehen 2. die View muss alle Primärschlüssel-Spalten der Tabelle enthalten 3. in der View dürfen die Primärschlüssel-Spalten der Tabelle nicht umbenannt werden Durch diese Bedingungen ist es möglich, die Primärschlüssel-Spalten über die Basis-Tabelle der View auszulesen und dadurch die genau gleichen Mechanismen wie bei den Tabellen zu nutzen. Ausserdem sind Views, welche sich auf mehr als eine Tabelle beziehen, so wie so schreibgeschützt und können deshalb für die Synchronisation gar nicht benutzt werden. Die Views, die als Hilfsmittel für die Synchronisation von Tabellen verwendet werden, sind aber so einfach, dass sie diese Bedingungen problemlos erfüllen. Die Funktionalität von DBSync wird durch das gewählte Design also nicht eingeschränkt. Exception-Handling: Auch hier werden alle Fehler die in der Komponente selbst oder in den daraus aufgerufenen Komponenten auftreten, in eine DifferenceCalculatorException verpackt. Sie ist die einzige Exception die an die Applikations-Steuerung weitergegeben wird. 4.3.8 Modell der Differenz Die Klasse Difference im Package ch.xpertcenter.dbsync.business.sync. difference repräsentiert eine Differenz. Sie wird in der Komponente zur Differenz-Berechnung erzeugt, im GUI zur Anzeige der Differenz benutzt und in der Komponente zur Differenz-Ausführung verwendet, um den Datensatz zur Differenz in der Datenbank zu aktualisieren, einzufügen oder zu löschen (siehe auch Kapitel 4.3.2 Detail-Design). Abbildung 25: Klassendiagramm der Differenz Die zentralen Datenelemente in der Klasse Difference sind das Prepared-SQL-Statement und die zugehörigen Werte und Typen der Primärschlüssel-Spalten. Mit diesen Angaben kann der zur Differenz gehörende Datensatz aus der Datenbank geladen werden. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 35/54 Bericht zur Master Thesis Der Typ der Differenz („Neu" DifferenceType definiert. oder "Geändert“) ist in der Enumeration-Klasse Die Enumeration-Klasse DifferenceExecutionType wird von der Differenz-AusführungsKomponente für den Eintrag im Synchronisations-Protokoll verwendet, ist aber wegen ihrer Verwandtschaft im selben Package wie die Differenz abgelegt. Die Daten für die Anzeige der Differenz im GUI, sind in einer eigenen Daten-Klasse definiert - der Klasse DifferenceDisplayInfo. 4.3.9 Geschäfts-Komponente zur Differenz-Ausführung Die Differenz-Ausführungs-Komponente im Package ch.xpertcenter.dbsync. business.sync.diffexecutor stellt der Applikations-Steuerung die Funktionen für das Kopieren und Löschen der Differenzen zur Verfügung. Die Klasse DifferenceExecutorImpl implementiert dabei das Interface DifferenceExecutor welches die beiden Methoden anbietet: Abbildung 26: Klassendiagramm Differenz-Ausführungs-Komponente Implementation der Differenz-Ausführung: Die Differenzen die kopiert oder gelöscht werden sollen, werden als Liste von Difference-Objekten übergeben. Diese Objekte enthalten alle Daten, die für das Ausführen notwendig sind. Nach dem erfolgreichen Ausführen einer Differenz, wird ein Eintrag im SynchronisationsProtokoll angelegt. Für diesen Eintrag werden zusätzlich die Id des Synchronisations-Sets und des Benutzers benötigt. Das Kopieren von Differenzen: 1. Der Datensatz zur Differenz wird aus der Quell-Tabelle geladen. 2. Der Datensatz zur Differenz wird aus der Ziel-Tabelle geladen. 3. Alle Daten aus dem Quell-Datensatz werden in den Ziel-Datensatz kopiert. 4. Bei einer Differenz vom Typ „Neu“: Der neue Ziel-Datensatz wird in der ZielTabelle eingefügt. 5. Bei einer Differenz vom Typ „Geändert“: Der geänderte Ziel-Datensatz wird in der Ziel-Tabelle aktualisiert. Es mag seltsam erscheinen, dass auch für eine Differenz vom Typ „Neu“ ein Datensatz aus der Ziel-Tabelle geladen wird – dort existiert ja noch gar kein solcher Datensatz! Das liegt aber an der Verwendung von JDBC-ResultSets: Um einen Datensatz in eine Tabelle einzufügen, muss ein ResultSet vorhanden sein, welches eine Datenbankverbindung zur Tabelle aufgebaut hat. In unserem Fall wird dazu das Select-Statement für den QuellDatensatz auf die Ziel-Tabelle angewendet. Das Resultat ist ein leeres ResultSet mit einer Verbindung zur Ziel-Tabelle. In diesem ResultSet wird mit der Methode moveToInsertRow() zu einer speziellen, leeren Einfüge-Zeile gewechselt. In diese Zeile Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 36/54 Bericht zur Master Thesis können dann die Daten des Quell-Datensatzes hineinkopiert werden. Mit der Methode insertRow() wird dann der neue Datensatz in die Ziel-Tabelle eingefügt. Bei einer Differenz vom Typ „Geändert“ werden alle Daten des Quell-Datensatzes in den bestehenden Ziel-Datensatz kopiert - der Ziel-Datensatz wird also komplett überschrieben. Es wird nicht selektiv kopiert, da in der Differenz nicht festgehalten wird, in welchen Spalten Daten geändert wurden. Mit der Methode updateRow() wird dann der bestehende Datensatz in der Ziel-Tabelle aktualisiert. Das Löschen von Differenzen: 1. Der Datensatz zur Differenz wird aus der Quell-Tabelle geladen. 2. Der Datensatz wird aus der Quell-Tabelle gelöscht. Hier ist das Prinzip das gleiche wie beim Kopieren: Mit der ResultSet-Methode deleteRow() wird der bestehende Datensatz in der Quell-Tabelle gelöscht. Eintrag im Synchronisations-Protokoll: Für einen Eintrag werden einerseits die übergebenen Daten benutzt, andererseits liefert die Differenz-Ausführungs-Komponente noch den Zeitstempel der Ausführung und den Ausführungs-Typ. Die möglichen Ausführungs-Typen sind: Eingefügt in der Ziel-Umgebung (Differenz vom Typ „Neu“ kopiert) Aktualisiert in der Ziel-Umgebung (Differenz vom Typ „Geändert“ kopiert) Gelöscht in der Quell-Umgebung (Differenz gelöscht) Sie sind in der Enumeration-Klasse DifferenceExecutionType im Package ch.xpertcenter.dbsync.business.sync.difference definiert. Entkopplung von der Datenbankzugriffs-Schicht: Wie in der Differenz-BerechnungsKomponente, wird für die Entkoppelung der JDBCDatabaseAccessor und das CachedRowSet benutzt. Die Entkoppelung kann allerdings nicht konsequent umgesetzt werden: Die eingesetzte Datenbank DB2 hat die Eigenheit, dass sie für das Einfügen, Aktualisieren und Löschen von Datensätzen, die Spalten vom Typ VARCHAR oder BLOB enthalten, nur ResultSets zulässt, die nicht navigierbar (scrollable) sind. Ein CachedRowSet ist per Definition aber immer navigierbar und kann daher nicht verwendet werden (siehe auch Klasse test.sync.TestInsertUpdateDelete). Darum muss für die Differenz-Ausführung das normale ResultSet benutzt werden. Da es nicht sinnvoll ist, die zentrale Funktionalität der Differenz-Ausführungs-Komponente in eine Hilfsklasse wir den JDBCDatabaseAccessor auszulagern, greift die Differenz-AusführungsKomponente also auch selbst direkt auf die Datenbank zu. Schutz vor Fehlmanipulationen in der Datenbank: In der Differenz-Ausführungs-Komponente werden keine SQL-Statements erzeugt – es wird ausschliesslich das Select-Statement und die zugehörigen Werte und Typen der Primärschlüssel-Spalten aus dem übergebenen Differenz-Objekt verwendet. Für das Laden des Quell-Datensatzes, das Aktualisieren/Einfügen der Daten in der ZielTabelle und das Löschen des Datensatzes in der Quell-Tabelle werden die Funktionen des CachedRowSets, resp. des normalen ResultSets verwendet – die Daten werden also nie „von Hand“ angefasst. Zusätzlich wird vor der Ausführung geprüft, ob das SQL-Statement in der Quell- und in der Ziel-Umgebung tatsächlich die richtige Anzahl Datensätze selektiert (einen oder keinen). Andernfalls wäre das ein Fehler im Select-Statement oder der Datensatz wurde seit der Berechung der Differenz verändert oder gelöscht. In einem solchen Fall wird eine Exception geworfen. Exception-Handling: Analog den anderen Komponenten, werden auch hier alle Fehler die in der Komponente selbst oder in den daraus aufgerufenen Komponenten auftreten, in eine Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 37/54 Bericht zur Master Thesis eigene Exception-Klasse, die DifferenceExecutorException, verpackt. Sie ist die einzige Exception die an die Applikations-Steuerung weitergegeben wird. 4.3.10 Geschäftsobjekte Die Geschäftsobjekte (BO's) kapseln die darunterliegende Datenzugriffs-Schicht. Für den Datenzugriff nutzen sie die vom O/R-Mapper generierten Entitäts-Klassen (POJO‘s). Die Geschäftsobjekte für das Modell der Konfigurationsdaten im Package ch.xpertcenter.dbsync.business.sync.bo bieten nur lesenden Zugriff auf die Konfigurationsdaten an. Ein Schreib-Zugriff ist im Moment nicht nötig, da die Konfigurationsdaten direkt in der Datenbank bearbeitet werden und (noch) nicht in der Applikation. Beim Geschäftsobjekt für das Modell des Synchronisations-Protokolls im Package ch.xpertcenter.dbsync.business.syncprotocol.bo ist es genau umgekehrt: Es bietet nur die Funktion zum Speichern eines neuen Eintrags in der Datenbank an. Es wird ausschliesslich von der Differenz-Ausführungs-Komponente zum Anlegen neuer Einträge verwendet. Abbildung 27: Klassendiagramm der Geschäftsobjekte 4.3.11 Datenbank-Zugriff mit JDBC Die Hilfsklasse JDBCDatabaseAccessor im Package ch.xpertcenter.dbsync. database.jdbc bietet statische Hilfsmethoden rund um den Datenbank-Zugriff mit JDBC an. So können die Geschäftskomponenten vom umfangreichen Code für den Auf- und Abbau der JDBC-Datenbank-Verbindungen entlastet werden. Ausserdem wird CodeDuplizierung in den einzelnen Komponenten vermieden. 4.3.12 Datenbank-Zugriff mit O/R-Mapper Die Objekte der durch Hibernate generierten Entitäts-Klassen (POJO‘s) im Package ch.xpertcenter.dbsync.database.hibernate repräsentieren jeweils einen Datensatz aus der entsprechenden Datenbank-Tabelle. Die Beziehungen zwischen den drei Klassen Syncset, Synctable und Synclevel werden durch beidseitig navigierbare java.util.Sets abgebildet. Dadurch muss dem GUI, für die Anzeige der Konfigurationsdaten in den Auswahllisten, nur die Liste mit den Synchronisations-Sets übergeben werden – die zugeordneten Tabellen und Umgebungen können dann über die java.util.Sets erreicht werden. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 38/54 Bericht zur Master Thesis Abbildung 28: Klassendiagramm der Entitäts-Klassen für die Konfig-Daten 4.3.13 Datenbank Das Datenmodell der Konfiguration besteht in der Datenbank aus den drei Tabellen SYNCSET, SYNCTABLE und SYNCLEVEL. Deren n-zu-n-Beziehungen werden durch die zwei Zwischentabellen SYNC_SET_TABLE und SYNC_TABLE_LEVEL abgebildet: Abbildung 29: Tabellen des Konfigurationsdaten-Modells Die Beschreibung der Tabellen und ihrer Spalten kann dem DDL-Skript „Tabellen für die Konfigurationsdaten.sql“ entnommen werden. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 39/54 Bericht zur Master Thesis 4.4 Synchronisationsprotokoll 4.4.1 Datenmodell 4.4.1.1 Detail-Analyse des Datenmodells Gemäss der Anforderung FA-4 „Synchronisations-Protokoll“ ergeben sich für einen Eintrag im Synchronisations-Protokoll mindestens folgende Attribute: Zeitstempel: Datum und Zeit des Eintrags. Benutzer: User-Id oder Benutzername des Benutzers, der die Synchronisation durchgeführt hat. SQL-Statement: Ausgeführtes Insert-, Update- oder Delete-Statement. Die Kann-Anforderung FA-5 „Synchronisations-Protokoll erweitert“ sieht vor, dass das Synchronisations-Protokoll neben dem ausgeführten SQL-Statement auch noch das „Umkehr“-Statement enthalten soll, damit eine Synchronisation einfach rückgängig gemacht werden kann. Diese Anforderung wird im Moment nicht umgesetzt, soll aber im Design berücksichtigt werden. 4.4.1.2 Detail-Design des Datenmodells Attribut „Benutzer“: Durch die Benutzeridentifikation kann die Datenbank-Id des Benutzers verwendet werden (siehe Kapitel 4.2.9). Attribut „SQL-Statement“: Das Design der Differenz-Berechnung und Differenz-Ausführung ist so ausgelegt, dass keine Insert-, Update- oder Delete-Statements generiert werden um einen möglichst hohen Schutz vor Fehlmanipulationen in der Datenbank zu erreichen. Als SQL-Statement wird im Protokoll daher das in der Differenz vorhandene SelectStatement und die zugehörigen Werte und Typen der Primärschlüssel-Spalten eingetragen (siehe Kapitel 4.3.8). Ein „Umkehr“-Statement kann aufgrund des Designs nicht erzeugt werden – die KannAnforderung FA-5 wird deshalb fallen gelassen. Weitere Attribute: Eingetragen werden auch die zugehörigen Konfigurationsdaten, sowie der Typ und der Ausführungs-Typ der Differenz. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 40/54 Bericht zur Master Thesis 4.4.2 GUI 4.4.2.1 Übersicht 2 1 3 4 Abbildung 30: GUI Synchronisations-Protokoll Beschreibung der Bereiche der Synchronisations-Protokoll-Seite: 1. Bereich für die Auswahl der Konfigurations-Daten, die als Suchkriterien dienen 2. Bereich für die Auswahl von weiteren Suchkriterien 3. Buttons für die Anzeige des Synchronisations-Protokolls aufgrund der ausgewählten Suchkriterien und zum Zurücksetzen der Suchkriterien 4. Bereich für die Anzeige der Protokoll-Einträge Die Synchronisations-Protokoll-Seite ist in der Datei synchronisation_protocol.jsp abgelegt. 4.4.2.2 Auswahl der Konfigurations-Daten Die Auswahl der Konfigurationsdaten ist genau gleich aufgebaut wie in der SynchronisationsSeite. Es gibt aber zwei Unterschiede: 1. Es gibt jeweils auch einen leeren Eintrag. So kann z.B. ein Synchronisations-Set als alleiniges Suchkriterium ausgewählt werden - eine Tabelle und die Umgebungen müssen nicht ausgewählt werden. 2. Es werden alle Sets, Tabellen und Umgebungen angezeigt – auch diejenigen die nicht (mehr) aktiv sind. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 41/54 Bericht zur Master Thesis Abbildung 31: GUI Synchronisations-Protokoll: Auswahl der Konfigurations-Daten 4.4.2.3 Die weiteren Suchkriterien Abbildung 32: GUI Synchronisations-Protokoll: Weitere Suchkriterien Beschreibung der weiteren Suchkriterien: „Auf den angemeldeten Benutzer einschränken“: Wenn markiert, werden nur Protokoll-Einträge angezeigt, die vom aktuellen Benutzer stammen. So sieht man nur die eigenen Synchronisationen. Benutzer: In der Auswahlliste werden alle in der Datenbank vorhandenen Benutzer angeboten – auch die nicht (mehr) aktiven. So kann auf die Protokoll-Einträge eingeschränkt werden, die vom ausgewählten Benutzer stammen. Wenn die obige Checkbox markiert ist, dann ist die Auswahlliste deaktiviert. Das Feld kann leer gelassen werden. Datum von: Wenn ein Datum eingetragen ist, werden nur Protokoll-Einträge angezeigt, die am oder nach diesem Datum angelegt wurden. Das Feld kann leer gelassen werden. Ein Kalender hilft bei der Auswahl des Datums. Er wird beim Klicken auf das Auswahl-Symbol (Dreieck) des Felds geöffnet. Datum bis und mit: Wenn ein Datum eingetragen ist, werden nur Protokoll-Einträge angezeigt, die am oder vor diesem Datum angelegt wurden. Das Feld kann leer gelassen werden. Ein Kalender hilft bei der Auswahl des Datums. Er wird beim Klicken auf das Auswahl-Symbol (Dreieck) des Felds geöffnet. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 42/54 Bericht zur Master Thesis 4.4.2.4 Suchkriterien zurücksetzen Mit dem Button „Suchkriterien zurücksetzen“ werden alle Suchkriterien gelöscht resp. auf ihre Standard-Werte zurückgesetzt. Standard-Werte gibt es für folgende Suchkriterien: Datum von: Heute vor einem Monat „Auf den angemeldeten Benutzer einschränken“: Ja (Checkbox ist markiert) 4.4.2.5 Anzeige der Protokoll-Einträge Mit dem Button „Protokoll anzeigen“ werden die Protokoll-Einträge, die den angegebenen Suchkriterien entsprechen, gesucht und im Bereich „Protokoll-Einträge“ in einer Tabelle angezeigt. In der Statuszeile wird die Anzahl der gefundenen Einträge angezeigt. Abbildung 33: GUI Synchronisations-Protokoll: Anzeige der Einträge Hier als Beispiel ein kompletter Eintrag: Abbildung 34: GUI Synchronisations-Protokoll: Kompletter Eintrag 4.4.3 GUI-Steuerung Die Synchronisations-Protokoll-Seite wird durch den SynchronisationProtocolUI-Bean (Klasse SynchronisationProtocolUI) gesteuert. Der Bean stellt dem GUI die Daten für die Auswahllisten der Suchkriterien und die Tabelle mit den Einträgen zur Verfügung und enthält die Methoden die durch die Buttons aufgerufen werden. Im Bean enthält ein Objekt der Klasse SyncProtocolSearchParams die Werte der Suchkriterien. Hier zeigt sich, wie komfortabel das Programmieren mit dem GUI-Framework ist: Die Felder der Suchkriterien im GUI sind direkt mit den Feldern in diesem Objekt Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 43/54 Bericht zur Master Thesis verknüpft – jede Wert-Änderung im GUI wird direkt ins Objekt geschrieben. Dasselbe Objekt wird dann beim Aufruf der Such-Methode der Applikations-Steuerungs-Komponente als Parameter mitgegeben. Im Bean selbst muss auf diese Weise nur ein einziges Feld angelegt werden, um die Werte aller Eingabefelder im GUI zu sammeln und weiterzugeben. 4.4.4 Applikations-Steuerung Die Steuerungs-Komponente für das Synchronisations-Protokoll im Package ch.xpertcenter.dbsync.business.syncprotocol stellt der GUI-Steuerung die Schnittstelle zur Verfügung, über die sie die Methoden für die Anzeige des SynchronisationsProtokolls aufrufen kann. Die Klasse SynchronisationProtocolControllerImpl implementiert das Interface SynchronisationProtocolController welches die folgenden Methoden anbietet: Abbildung 35: Klassendiagramm Steuerungs-Komponente Synchronisations-Protokoll Suche: Die Kriterien für die Suche werden der Methode search() in Form eines Objekts der Klasse SyncProtocolSearchParams übergeben. Durch diese Hilfsklasse bleibt die Signatur der Such-Methode übersichtlich und neue Suchkriterien können in Zukunft sehr einfach hinzugefügt werden. Die Suche ist direkt im Controller implementiert. Die Logik für die Suche ist einfach und übersichtlich, deshalb ist es nicht nötig sie in eine eigene Geschäftskomponente auszulagern. Auch hier wird das Select-Statement nicht „von Hand“ zusammengestellt. Die passenden Protokoll-Einträge können mit Hilfe des Hibernate Criteria API elegant und typsicher aus der Datenbank gelesen werden. Das Resultat wird als Liste von Syncprotocol-O/R-Mapper-Objekten zurückgegeben. Der GUI-Steuerung werden mit den Methoden getAllSynchronisationSets() und getAllUsers() die Daten zur Verfügung gestellt, die sie für das Füllen der SuchkriterienAuswahllisten benötigt. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 44/54 Bericht zur Master Thesis Für einen Protokoll-Eintrag wird in der Datenbank nur die Id des Sets, der Tabelle, der Umgebung, usw. abgelegt – nur das SQL-Statement wird in Textform gespeichert. Die GUISteuerung braucht für die Anzeige der Einträge aber den zugehörigen Namen oder Text. Um die Anzahl der dafür notwendigen Datenbankzugriffe zu minimieren, implementiert die Klasse SyncProtocolDisplayCache einen Cache für die Namen der Konfigurationsdaten und der Benutzer. Für den Differenz- und den Ausführungs-Typ ist der Text in der entsprechenden Enumeration-Klasse definiert. Exception-Handling: Auch hier werden alle Fehler, die in der Komponente selbst oder in einer daraus aufgerufenen Komponente auftreten, in eine eigene Exception, die SynchronisationProtocolException verpackt. Sie ist die einzige Exception die ans GUI weitergegeben wird. 4.4.5 Geschäftsobjekte Das Geschäftsobjekt für das Modell des Synchronisations-Protokolls, die Klasse SynchronisationProtocolEntryBO im Package ch.xpertcenter.dbsync. business.syncprotocol.bo, wird von der Differenz-Ausführungs-Komponente zum Speichern eines neuen Eintrags in der Datenbank verwendet (siehe Kapitel 4.3.10). Von der Applikations-Steuerung des Synchronisations-Protokolls wird es nicht benutzt, da die Protokoll-Einträge direkt über den O/R-Mapper aus der Datenbank gelesen werden. 4.4.6 Datenbank-Zugriff mit O/R-Mapper Der Zugriff auf das Datenmodell des Synchronisations-Protokolls erfolgt mit dem O/RMapping-Framework „Hibernate“ [Web8]. Die Objekte der generierten Klasse Syncprotocol im Package ch.xpertcenter.dbsync.database.hibernate repräsentieren dabei jeweils einen Datensatz aus der Tabelle SYNCPROTOCOL. 4.4.7 Datenbank Das Datenmodell wird in der Datenbank mit der Tabelle SYNCPROTOCOL abgebildet. Abbildung 36: Tabelle des Synchronisations-Protokolls Die Beschreibung der Tabelle und ihrer Spalten kann dem DDL-Skript „Tabellen für das Synchronisations-Protokoll.sql“ entnommen werden. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 45/54 Bericht zur Master Thesis 5 Test 5.1 Konzept Um die verschiedenen Komponenten des GUI’s, der Geschäftslogik und der DatenzugriffsSchicht zu testen, werden sowohl Unit-Tests also auch Integrations-Tests durchgeführt. Mit Unit-Tests werden einzelne Komponenten isoliert gestestet. Sie werden während der Implementation der Komponente mit Hilfe der Software-Entwicklungsumgebung durchgeführt. Unit-Tests beinhalten neben funktionalen Tests (siehe unten) vor allem strukturelle Tests, mit denen der innere Aufbau (Whitebox), also die Verzweigungen und Schleifen im Code, getestet wird. Mit Integrations-Tests wird das Zusammenspiel der Komponenten innerhalb der Applikation getestet. Sie werden nach Abschluss der Implementation mit der fertig zusammengebauten Applikation durchgeführt. Integrations-Tests sind funktionale Tests mit denen die Funktion einer Komponente „von aussen“ (Blackbox) durch den Aufruf ihrer öffentlichen Methoden getestet wird. Vor allem wird auch das Zusammenspiel der verschiedenen Komponenten getestet. 5.2 Testumgebung Die Tests werden auf dem Entwicklungs-Rechner durchgeführt – es wird keine davon getrennte Testumgebung aufgebaut, da der Entwicklungs-Rechner die Zielplattform ist, auf dem DB-Sync eingesetzt werden soll. Die Unit-Tests werden mit JUnit direkt in der Software-Entwicklungsumgebung ausgeführt. Für die manuellen Unit-Tests im GUI wird DB-Sync aus der Entwicklungsumgebung heraus gestartet. Für die Integrations-Tests wird ein Release erstellt, d.h. die Applikation wird komplett zusammengebaut und kann unabhängig von der Entwicklungsumgebung gestartet werden. In dieser Form wird DB-Sync dann auch den Benutzern ausgeliefert. Zentral für das Testen der Applikation sind die Datenbanken und die darin enthaltenen Testdaten. Die Test-Datenbanken sollen möglichst nahe an den realen Gegebenheiten der Systemumgebung sein, in der DB-Sync später betrieben wird - zugleich soll komplett unabhängig von der bestehenden Datenbank-Infrastruktur der XpertCenter AG getestet werden können. Zu diesem Zweck werden auf dem Entwicklungs-Rechner die folgenden Datenbanken angelegt, welche die drei realen Umgebungen repräsentieren: Lokale Test-Datenbank Repräsentierte Umgebung DBSYNCPR Produktion DBSYNCIN Integration DBSYNCDV Entwicklung Die Dateien mit den SQL-Befehlen zur Erzeugung der hier aufgeführten Test-Datenbanken sind im Verzeichnis „Datenbank“ in der ZIP-Datei mit den Anhängen zu dieser Master Thesis enthalten. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 46/54 Bericht zur Master Thesis 5.3 Testdaten Die Testdaten lassen sich in zwei Kategorien unterteilen: Testdaten für die Synchronisation: Das sind diejenigen Daten, die synchronisiert werden sollen. Jede Geschäftsapplikation hat mehrere Tabellen, in denen Daten abgelegt sind, die z.B. zur Steuerung des GUI’s dienen oder die Berechnungsfaktoren, Texte oder Dokumente enthalten. Testdaten für das Datenmodell von DB-Sync: Das sind die Daten für die Konfiguration von DB-Sync, d.h. die vom Benutzer angelegten SynchronisationsSets, die zu synchronisierenden Tabellen und die vorhandenen Umgebungen. Dazu kommen noch Daten für das Synchronisations-Protokoll und die Benutzer. Die Dateien mit den SQL-Befehlen zur Erzeugung der in den nachfolgenden Kapiteln aufgeführten Test-Tabellen und Test-Daten sind im Verzeichnis „Datenbank“ in der ZIP-Datei mit den Anhängen zu dieser Master Thesis enthalten. 5.3.1 Testdaten für die Synchronisation Es werden vier Geschäftsapplikationen simuliert. Jede hat in der Datenbank ein eigenes Schema. Ein Schema dient zur Gruppierung von Tabellen - es ist eine Art Namensraum in der Datenbank. So können für jede der Geschäftsapplikationen die gleichen Tabellennamen verwendet werden – durch den Schema-Namen als Präfix sind die Tabellen eindeutig definiert. Folgende Schemas werden für die die Simulation der Geschäftsapplikationen angelegt: (Die Schemas sind nach den vier Geschäftsbereichen der XpertCenter AG benannt) Test-Schemas TESTAPP_MOTORBUSINESS TESTAPP_INTERCLAIMS TESTAPP_RECOURSE TESTAPP_CIF Es werden die folgenden Test-Tabellen verwendet. Die Tabellen-Struktur ist den bei der XpertCenter AG existierenden Tabellen nachempfunden. Es wurde darauf geachtet, dass alle Daten-Typen, die synchronisiert werden müssen in mindestens einer Tabelle vorhanden sind. Auch die Primär-Schlüssel wurden entsprechend unterschiedlich gewählt. Test-Tabellen DATATYPES DECIMAL_CONSTANT DOCUMENT DOCUMENTINFO (View) ROLETASK TEXT Der Zugriff auf diese Tabellen erfolgt mit einem technischen Test-User. Dieser ist im Betriebssystem des Entwicklungsrechners als lokaler Benutzer definiert. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 47/54 Bericht zur Master Thesis Technischer Test-User SDBSYNCTEST (Passwort: sdbsynctest) Die Tabellen werden mit einem repräsentativen Satz an Test-Daten gefüllt. Diese Daten bilden den Ausgangspunkt für die Tests und sind auf allen Umgebungen gleich. Für die einzelnen Tests werden dann Daten hinzugefügt, gelöscht und verändert. 5.3.2 Testdaten für das Datenmodell von DB-Sync Die Tabellen des Datenmodells werden alle in demselben Schema angelegt. Für die Tests werden diese Tabellen in der Test-Datenbank DBSYNCPR angelegt, welche die Produktions-Umgebung repräsentiert. Schema für DB-Sync DBSYNC Der Zugriff auf alle Tabellen des Datenmodells von DB-Sync erfolgt mit einem technischen User. Dieser ist im Betriebssystem des Entwicklungsrechners als lokaler Benutzer definiert. Technischer User für DB-Sync SDBSYNC (Passwort: sdbsync) 5.3.2.1 Testdaten für die Konfiguration Die Tabellen für die Konfiguration sind im Kapitel 4.3.13 beschrieben. Konfigurations-Tabellen SYNCSET SYNC_SET_TABLE SYNCTABLE SYNC_TABLE_LEVEL SYNCLEVEL Die Konfigurations-Tabellen werden mit Test-Daten gefüllt, welche die vorhandenen TestGeschäftsapplikationen und deren Test-Tabellen abbilden. Diese Daten bilden die Basis für das Testen der Synchronisation. Diese Test-Daten werden auch für das Testen des Konfigurations-Modells verwendet - für bestimmte Tests werden noch Daten hinzugefügt, gelöscht und verändert. 5.3.2.2 Testdaten für das Synchronisations-Protokoll Die Tabelle für das Synchronisations-Protokoll ist im Kapitel 4.4.7 beschrieben. Tabelle Synchronisations-Protokoll SYNCPROTOCOL Die Synchronisations-Protokoll-Tabelle wird mit Test-Daten gefüllt, welche die durchgeführten Synchronisationen abbilden. Obwohl man bei der Durchführung der Tests für die Synchronisation automatisch Einträge in dieser Tabelle erhält, wird ein Satz von Testdaten von Hand erstellt, damit stabil und nachvollziehbar getestet werden kann. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 48/54 Bericht zur Master Thesis 5.3.2.3 Testdaten für die Benutzeridentifikation Die Tabelle für die Benutzeridentifikation ist im Kapitel 4.2.9 beschrieben. Tabelle Benutzeridentifikation SYNCUSER Die Benutzeridentifikations-Tabelle wird mit Test-Daten gefüllt, welche einerseits nicht existierende Test-Benutzer für Unit-Tests und andererseits reale Benutzer, welche die Applikation entwickeln und testen, repräsentieren. 5.4 Durchführung der Tests 5.4.1 Unit-Tests Während der Implementation der Komponenten wurden konsequent Unit-Tests durchgeführt. Mit diesen Unit-Tests wurde sowohl die Funktion als auch der innere Aufbau aller Methoden überprüft. Mit ihrer Hilfe sollten möglichst alle vorhandenen Fehler gefunden werden. Nur für einige, wenige Unit-Tests wurden Juni-Testklassen und -Methoden erstellt, die komplett eigenständig lauffähig sind. Das liegt vor allem an der aufwändigen Bereitstellung der notwendigen Testdaten in der Datenbank – dazu hätte ein Testframework wie z.B. DBUnit verwendet werden müssen. Darauf wurde aber wegen dem Aufwand für die Einarbeitung ins Framework und dem hohen Aufwand für die Erstellung solcher Tests verzichtet. Damit für jeden Test die genau gleichen Testdaten zur Verfügung stehen, wurden die komplett erstellten Testdaten mit dem DB2-Tool „db2move“ aus der Datenbank exportiert. So konnten sie vor jedem Test gelöscht und neu importiert werden. Für den überwiegenden Teil der Unit-Tests wurde eine JUnit-Klasse oder das GUI dazu benutzt, die zu testende Methode aufzurufen. Die Testdaten wurden vor dem Test in der Datenbank von Hand angepasst und nach dem Test in der Datenbank überprüft. Bedingungen, Verzweigungen und Schleifen innerhalb der Methoden wurden mit Hilfe des Debuggers der Entwicklungsumgebung getestet. 5.4.2 Integrations-Tests Die Integrations-Tests wurden nach der Implementation mit der fertigen, zusammengebauten Applikation durchgeführt. Sie sollen beweisen, dass die Applikation fehlerfrei und den Anforderungen entsprechend funktioniert. Bei den Testfällen für die Differenz-Berechnung und -Ausführung wurde besonders die Robustheit der Applikation gegenüber Fehler-Situationen geprüft, die auftreten können, wenn die Applikation läuft und gleichzeitig jemand anderes die Daten in der Datenbank verändert. Insgesamt wurden 22 (mehrteilige) Testfälle erstellt. Der Zweck, die Vorbedingungen und der genaue Ablauf dieser Testfälle sowie das Datum und das Resultat der Durchführung sind im Test-Protokoll dokumentiert. Dieses ist in der ZIP-Datei mit den Anhängen zu dieser Master Thesis enthalten. Wenn bei einem Testfall ein Fehler aufgetreten ist, wurde dieser korrigiert, die Applikation neu gebaut und der Testfall nochmals wiederholt. Nachdem alle Integrations-Tests fehlerfrei durchgeführt werden konnten, wurde die Applikation für den produktiven Einsatz im Entwicklungs-Team der XpertCenter AG freigegeben. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 49/54 Bericht zur Master Thesis 6 Entwicklungs-Umgebung 6.1 Entwicklungs-Rechner Für die Entwicklung wird der normale Laptop eingesetzt, den alle Entwickler der XpertCenter AG als Arbeitsgerät benutzen. Dieser Laptop ist zugleich die Zielplattform, auf der dann DBSync installiert und produktiv genutzt wird. Betriebssystem ist Windows XP mit SP3. 6.2 Rich-Client-Framework „CaptainCasa Enterprise Client“ 6.2.1 Installation Für Windows-Betriebssysteme existiert ein Installationsprogramm. Dieses kann von der Webseite des Herstellers heruntergeladen werden: http://captaincasa.com, auf der Seite „Forum/Download“. Für den Download muss man sich registrieren. Anleitung siehe [Web6]. 6.2.2 Lizenz Für den produktiven Einsatz des CaptainCasa Enterprise Clients, muss man beim Hersteller eine Lizenz beziehen. Neben den kostenpflichtigen Lizenzen (mit Support und bei Bedarf mit Source-Code) gibt es die sogenannte „binäre Lizenz“, mit der das Framework kostenlos eingesetzt werden kann. Siehe http://captaincasa.com/pdf/eclnt_Copyright.pdf 6.3 Software-Entwicklungsumgebung 6.3.1 MyEclipse Als Java-Entwicklungsumgebung wird MyEclipse Version 8.6.1 eingesetzt. MyEclipse ist eine kommerzielle Entwicklungsumgebung auf der Basis von Eclipse. MyEclipse kann runtergeladen und dann 30 Tage lang kostenlos getestet werden. Webseite: http://www.myeclipseide.com 6.3.2 Tomcat Als Applikationsserver (Servlet-Container) für das auf JSF [Web2] basierende Rich-ClientFramework wird der Tomcat in Version 6.0.29 eingesetzt. Der Tomcat ist OpenSource und kostenlos. Webseite: http://tomcat.apache.org 6.3.3 Entwicklungswerkzeuge von CaptainCasa Enterprise Client CaptainCasa bietet eine eigene Entwicklungsumgebung an, die so konfiguriert werden kann, dass sie problemlos mit MyEclipse und dem Tomcat zusammen arbeitet. In dieser Entwicklungsumgebung kann mit dem Layout-Editor das GUI erstellt und mit den Managed Beans verknüpft werden. Anleitung siehe [Web7]. 6.4 Datenbank Als Datenbank wird DB2 Version 9.7 von IBM eingesetzt. Auf dem Entwicklungs-Rechner ist eine Instanz des Datenbank-Managementsystems installiert. Pro Instanz können mehrere unabhängige Datenbanken betrieben werden. Neben verschiedenen kostenpflichtigen Versionen, stellt IBM auch eine kostenlose Version zu Verfügung: DB2 Express-C. Webseite: http://www-01.ibm.com/software/data/db2/express/. Für die Entwicklung werden drei Datenbanken angelegt, welche die drei realen Umgebungen repräsentieren. So kann komplett unabhängig von der bestehenden Datenbank-Infrastruktur der XpertCenter AG entwickelt und getestet werden. Diese Datenbanken sind im Kapitel 5.2 beschrieben. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 50/54 Bericht zur Master Thesis Für den manuellen Zugriff auf die Datenbanken wird das Datenbank-Tool „AQT“ eingesetzt. Der Zugriff erfolgt über CLI/ODBC (Open Database Connectivity). Dazu werden die Datenbanken per CATALOG-Befehl als „System Data Source“ registriert. Der Zugriff auf die Datenbanken aus der Applikation „DB-Sync“ heraus, erfolgt über JDCB (Java Database Connectivity) mit dem IBM-Treiber „com.ibm.db2.jcc.DB2Driver“. Dieser Treiber ist einer vom „Typ 4“, d.h. komplett in Java geschrieben, und greift über das Netzwerk-Protokoll TCP/IP auf die Datenbank zu. Es wird die neuste Version verwendet, die den JDBC-Standard 4.0 unterstützt. Die einzelnen Datenbanken werden in der Tomcat-Konfiguration als Ressourcen vom Typ „javax.sql.DataSource“ definiert. Diese DataSources können dann im Java-Code für den DBZugriff benutzt werden. 6.5 Tools 6.5.1 AQT AQT steht für „Advanced Query Tool“ und wird in der XpertCenter AG zur Administration und Abfrage von DB2-Datenbanken verwendet. AQT ist ein kommerzielles Produkt, also kostenpflichtig. Webseite: http://www.querytool.com/index.html 6.5.2 Dia Dia ist ein Diagramm-Zeichnungsprogramm ähnlich wie Visio von Microsoft. Mit Dia können u.a. auch UML-Diagramme gezeichnet werden. Dabei können bei Bedarf beliebige UMLElemente kombiniert werden, was hilfreich ist bei Diagrammen, die nicht zum Standard von UML gehören (z.B. das Systemkontext-Diagramm). Dia ist OpenSource und kostenlos. Webseite: http://live.gnome.org/Dia 6.5.3 JUDE JUDE Community 5.5 ist ein Tool zur Erstellung von UML-Diagrammen aller Art. Mit JUDE können aus bestehendem Java-Sourcecode Klassendiagramme erzeugt werden. JUDE Community ist kostenlos, mittlerweile wurde die Entwicklung aber eingestellt. Es gibt zwar den ebenfalls kostenlosen Nachfolger „astah* community“ – dieser enthält die ImportFunktion für Java-Sourcecode aber leider nicht mehr. Webseite: http://jude.change-vision.com/jude-web/index.html Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 51/54 Bericht zur Master Thesis 7 Zusammenfassung 7.1 Resultat Mit dem Resultat der Master Thesis bin ich sehr zufrieden. Die Applikation DB-Sync erfüllt alle im Pflichtenheft definierten Muss-Anforderungen. Auch das im Abstract formulierte Ziel wird voll und ganz erfüllt: mit DB-Sync kann die Synchronisation der Konfigurationsdaten einfach, fehlerfrei und nachvollziehbar durchgeführt werden. DB-Sync wird in der Entwicklungs-Abteilung der XpertCenter AG bereits produktiv eingesetzt. 7.2 Ablauf und Aufwand Die Arbeit konnte ich wie geplant durchführen. Besondere Probleme sind nicht aufgetreten. Der Ablauf lässt sich in die Phasen Pflichtenheft, Architektur und Grob-Design, Implementierung (mit Detaildesign, Codierung, Unit-Tests und Dokumentation im Code), Integrations-Tests und Abschlussarbeiten (Dokumentation im Diplom-Bericht, Poster, Vortrag) aufteilen. Für die Arbeit habe ich rund 400 Stunden aufgewendet – das sind 10% mehr als veranschlagt. Der Mehraufwand liegt im Rahmen meiner Erwartungen und verteilt sich gleichmässig auf alle Phasen. 7.3 Schlusswort Die Master Thesis war eine spannende, lehrreiche und anstrengende Zeit – genau so wie das gesamte MAS-IT. Bei der Master Thesis wollte ich möglichst viel von dem umsetzen, was ich in den vorangegangenen Semestern dazugelernt hatte. Das konnte ich besonders im Bereich Architektur und Design. Im Ganzen betrachtet hat sich diese Weiterbildung für mich sehr gelohnt – sie hat meine Kenntnisse in der Software-Entwicklung noch vertieft und abgerundet. Ich möchte mich bei allen bedanken, die mich während der Master Thesis und der gesamten Weiterbildung unterstützt haben. Besonders möchte ich auch meiner Arbeitgeberin, der XpertCenter AG danken, die mir diese Weiterbildung durch ihre grosszügige Unterstützung möglich gemacht hat. Ganz besonders danke ich meiner Familie. Sie hat mich immer inspiriert, motiviert und die Belastung dieser Weiterbildung mitgetragen. März 2011, Thomas Schenker Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 52/54 Bericht zur Master Thesis Anhang A – Glossar Begriff CRUD-Operationen POJO Schema SQL-Statement Synchronisation SynchronisationsSet Tabelle Tool Umgebung View Erklärung Die auf einer Datenbank für einen Datensatz ausführbaren Befehle: C = Create (Erstellen) R = Read (Lesen) U = Update (Ändern) D = Delete (Löschen) Plain Old Java Object. Wird als Bezeichnung für die Entitäts-Klassen verwendet, die vom O/R-Mapping-Framework generiert werden. Das sind normale, leichtgewichtige Klassen – im Gegensatz zu den früher verwendeten, schwergewichtigen Entity-EJB’s (Enterprise Java Beans). Ein Schema dient zur Gruppierung von Tabellen in der Datenbank es ist eine Art Namensraum in der Datenbank. So können z.B. für verschiedene Geschäftsapplikationen die gleichen Tabellennamen verwendet werden – durch den Schema-Namen als Präfix sind die Tabellen eindeutig definiert. Ein Befehl der Datenbank-Änderungs- und Abfragesprache SQL. Dient zum Ausführen der CRUD-Operationen auf der Datenbank. Synchronisation (auch Synchronisierung) ist der Vorgang, bei dem die Daten in einer Tabelle A einer Umgebung X mit den Daten in der gleichen Tabelle A in einer anderen Umgebung Y verglichen und die Differenzen so bereinigt werden, dass die Daten in beiden Tabellen genau gleich sind. Dabei müssen nicht alle Daten in der Tabelle synchronisiert werden – welche das sind, bestimmt der Benutzer. Ein Synchronisations-Set dient zur Gruppierung von Tabellen. Es ist ein Satz von Tabellen, die zusammengehören. Typischerweise besteht ein solcher Satz aus den Tabellen einer einzelnen Geschäftsanwendung. So trägt ein Synchronisations-Set normalerweise den Namen einer Geschäftsanwendung. In einer Datenbank sind die Daten in Form einer Tabelle, also in Zeilen und Spalten, abgelegt. englisch: „Werkzeug“, „Hilfsmittel für die Arbeit“. Software (Programm, Anwendung, Applikation) mit deren Hilfe eine Aufgabe erledigt werden kann. Eine Umgebung ist eine logische Gruppierung von Applikations- und Datenbank-Servern, die eine bestimmte Aufgabe erfüllen. Zum Beispiel eine Umgebung für die Entwicklung, eine für die Integration und eine für die Produktion. Bei der Synchronisation entspricht eine Umgebung einer bestimmten Datenbank auf einem der Datenbank-Server. Eine Umgebung dient zur Auswahl der Quell- und der Ziel-Tabelle für eine Synchronisation. Eine View ist, wie der Name schon sagt, eine „Sicht“ auf eine oder mehrere Tabellen in einer Datenbank. Eine View ist eine virtuelle Tabelle mit der z.B. nur bestimmte Spalten und/oder Datensätze einer Tabelle angezeigt werden können. Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 53/54 Bericht zur Master Thesis B – Quellenverzeichnis Literatur: [Lit1] Analyse und Design mit UML 2.3 - Objektorientierte Softwareentwicklung, Bernd Oesterreich, Oldenbourg Wissenschaftsverlag GmbH, München, 2009. [Lit2] Skript „Architektur und Design“, Stefan Meichtry, 2009 CAS Enterprise Application Development Java EE (EADJ), http://www.sws.bfh.ch/studium/cas/eadj.xhtml [Lit3] Skript „Architektur und Design“, Simon Martinelli, 2009 CAS Distributed Systems (DS), http://www.sws.bfh.ch/studium/cas/ds.xhtml Im Internet: [Web1] CaptainCasa Enterprise Client-Framework, http://captaincasa.com [Web2] JavaServer Faces (kurz: JSF), http://de.wikipedia.org/wiki/JavaServer_Faces [Web3] Einführung in die Technik des CaptainCasa Enterprise Client-Frameworks, http://captaincasa.com/pdf/eclnt_TechnicalOverview.pdf [Web4] Beschreibung des Einsatzes von JSF im CaptainCasa Enterprise ClientFramework, http://captaincasa.com/pdf/eclnt_JSFUtilization.pdf [Web5] Beschreibung des „Embedded-Modus“ des CaptainCasa Enterprise ClientFrameworks, http://captaincasa.com/pdf/eclnt_embeddedusagemode.pdf [Web6] Installation und Konfiguration des CaptainCasa Enterprise Client-Frameworks, http://captaincasa.com/pdf/eclnt_Installation.pdf [Web7] Entwickler-Handbuch für das CaptainCasa Enterprise Client-Framework, http://captaincasa.com/pdf/eclnt_DevelopersGuide.pdf [Web8] Hibernate, Objekt/Relationales-Mapping-Framework für Java, http://www.hibernate.org/ [Web9] Dokumentation der Datenbank DB2 von IBM, Version 9.7 für Windows http://publib.boulder.ibm.com/infocenter/db2luw/v9r7/index.jsp [Web10] Beschreibung des RowSets von JDBC, Java SE Dokumentation, http://download.oracle.com/javase/6/docs/technotes/guides/jdbc/getstart/rows etImpl.html#997347 [Web11] In der Applikation werden die kostenlosen „Silk“-Icons von famfamfam.com verwendet. http://www.famfamfam.com/lab/icons/silk/ Thomas Schenker, Master Thesis Datenbank-Synchronisation, MT-10-02.09 54/54