datenbanken und anwendungen – eine einführung
Werbung

Department für Wissens- und Kommunikationsmanagement
Ziviltechniker Univ.Lektor
Dipl.-Ing. Dr. techn. Markus Schranz
D AT E N B A N K E N U N D A N W E N D U N G E N –
EINE EINFÜHRUNG
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
2
ABSTRACT / ZUR PERSON
A BS TR AC T
Die Veranstaltung Datenbanken und Anwendungen – Eine Einführung befasst sich mit
generellen Grundsätzen der Datenverwaltung mittels speziell dafür vorgesehener
Software: Den Datenbankmanagementsystemen (DBMS). Nach Motivation und
Einführung in den Themenbereich Datenbanken werden Spezialformen des
Datenmanagements diskutiert und die historische und qualitative Entwicklung von
DBMS diskutiert. Professionelle Lösungen und Erfahrungen mit insbesondere
relationalen DBMS stehen im Mittelpunkt und konkrete Anwendungen aus dem
Wirtschaftsbereich dienen zur Veranschaulichung des Einsatzbereiches.
Die Unterlagen dienen sowohl der Einführung in das Thema DBMS als auch dem
raschen und verständlichen Überblick über die Handhabung der standardisierten
Datenbankabfragesprache
SQL,
die
den
Kernbereich
der
praktischen
Übungskomponenten bildet. Die konkrete Anwendung der Datenbanklösung wird
anhand von Fallbeispielen der Österreichischen Content-Industrie und des
Kulturmanagements demonstriert.
Z UR P ER SO N
Entnehmen Sie der folgenden tabellarischen Aufstellung einige wesentliche Stationen
aus dem Berufsleben und der Ausbildung von ZT Universitätslektor Dipl.-Ing. Dr.
techn. Markus Schranz
1988: Matura im BG Oberschützen und Beginn des Diplomstudiums
Informatik an der Technischen Universität Wien
1994: Abschluss des Diplomstudiums Informatik mit Auszeichnung und
Eintritt in den Mittelbau des Lehrkörpers TU Wien als Universitätsassistent
1998: Promotion zum Doktor der technischen Wissenschaften an der TU Wien,
seither Univ.Lektor an der TU Wien
1999: Gastprofessur (winter term) University of California in Irvine, CA, USA
1999: IT-Berater bei Ernst&Young Österreich im Bereich Software
Einführungsmanagement und Web Service Management
2000-2004: Technischer Direktor pressetext.austria
Nachrichtenagentur,
Vorstand der pressetext AG
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
3
2002: Mitglied des Entwicklungsteams des Studienganges ICS, FH Eisenstadt
2003: Lektor Donau-Universität Krems
2003: Prüfung und Vereidigung zum staatlich befugten und beeideten
Ingenieurskonsulenten für Informatik (Ziviltechniker),
2004: Gründung der ZT Schranz Informationstechnologie KEG
geschäftsführender Gesellschafter mit Kunden aus dem IT News, Commerce
und Security Markt. Technische Direktion der Nachrichtenagentur pressetext
und Internet-Verantwortlicher des Kultur-Dienstleisters Culturall.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
Inhalt
Abstract...................................................................................................................2
Zur Person...............................................................................................................2
1 Einleitung
..................................................................................................................................6
1.1 Datenbanken......................................................................................................7
1.1.1 Was ist eine Datenbank............................................................................7
1.1.2 Wie speichert eine Datenbank Daten.......................................................9
1.1.3 Abfragen von Daten...............................................................................10
2 Erscheinungsformen von Datenbanken
................................................................................................................................13
2.1 Beispiele für Datenbanken – Grundlegendes...................................................13
2.2 Logische Datenbankmodelle............................................................................15
2.2.1 Das relationale Datenbankmodell..........................................................15
2.2.2 Das Objektorientierte Datenbankmodell................................................15
2.2.3 Das Hierarchische Datenbankmodell.....................................................16
2.2.4 Das Netzwerk-Datenbankmodell...........................................................17
2.2.5 Das logische Datenbankmodell..............................................................18
2.3 Literatur............................................................................................................19
3 Relationale Datenbanken
................................................................................................................................20
3.1 Tabellen und Relationen...................................................................................20
3.2 Das Entity-Relationship Diagramm.................................................................21
3.2.1 Entities, Domänen und Attribute............................................................22
3.2.2 Schlüssel.................................................................................................22
3.2.3 Definition und grafische Erstellung von Entities...................................24
3.2.4 Beziehungen bzw. Relationships............................................................26
3.2.5 Umfangreicheres Beispiel zum ER-Diagramm......................................28
3.3 Transformation von Entity-Typen in Relationsschemata.................................28
3.3.1 Transformation der m:n-Beziehung.......................................................31
3.3.2 Transformation der 1:n- bzw. n:1-Beziehung........................................33
3.3.3 Transformation der 1:1-Beziehung........................................................34
3.4 Normalformen..................................................................................................35
3.4.1 Abhängigkeiten zwischen Attributen.....................................................36
3.4.2 Anomalien..............................................................................................38
3.4.3 Normalformen........................................................................................40
Oktober 2007
4
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
3.4.4 Der Weg der Normalisierung - ausführliches Beispiel...........................45
3.4.5 Vorteile und Grenzen der Normalisierung.............................................49
4 Die relationale Algebra und die Abfragesprache SQL
................................................................................................................................51
4.1 Die relationale Algebra....................................................................................51
4.1.1 Die Selektion..........................................................................................52
4.1.2 Die Projektion........................................................................................52
4.1.3 Kombination von Selektion und Projektion...........................................53
4.1.4 Der Join..................................................................................................53
4.2 Die Datenabfragesprache SQL........................................................................57
4.2.1 Anlegen, Löschen und Auswählen einer Datenbank.............................59
4.2.2 Anlegen, Ändern und Definieren einer Tabelle.....................................60
4.2.3 Eine Tabelle mit Werten füllen, leeren und löschen...............................60
4.2.4 Daten auswählen und bearbeiten............................................................61
4.2.5 Aggregatfunktionen, Berechnungen, Sortierungen................................61
4.2.6 Bestehende Datensätze verändern oder gezielt löschen.........................61
4.3 Probleme mit SQL und dem relationalen Modell............................................62
4.4 Literatur............................................................................................................63
5 Datenbanken und Applikationen
Fallstudie pressetext.austria
Nachrichtenagentur........................................................................................65
5.1 Fallstudie pressetext.austria (pte, www.pressetext.at).....................................65
5.1.1 Dienstleistungen der pressetext.austria..................................................66
5.1.2 Technische Ausrüstung..........................................................................67
5.1.3 Service Detailbeschreibungen und DB-Auslastung...............................67
5.2 Aktuelle Entwicklungen...................................................................................69
Oktober 2007
5
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
6
1EINLEITUNG
Vor 100 Jahren bedeuteten große Fabriken, in denen mit großem Lärm und viel Schweiß
gewaltige Maschinen oder Maschinenteile produziert wurden, Wohlstand und Reichtum.
Man sprach vom Industriezeitalter.
Schaut man sich heute in Europa oder den USA um, so scheinen viele der großen
Fabriken verschwunden zu sein. Die riesigen Kamine, die von weitem den Fortschritt
ankündigten, sind weitgehend aus der Landschaft verbannt. An ihrer Stelle ragen heute
gewaltige Bürokomplexe in den Himmel. In den klimatisierten Räumen schwitzen die
Arbeiter auch nicht mehr, und die Geräuschquellen reduzieren sich auf
Kaffeemaschinen und Radios.
Was ist passiert?
Wir befinden uns im Informationszeitalter. Die Tätigkeit vieler Arbeitnehmer besteht
darin, Informationen zu erfassen, weiterzuverarbeiten und in gewünschter Form
wiederzugeben. Als Arbeitsgerät findet sich hauptsächlich der Computer - offensichtlich
eignet er sich zur Speicherung und Weiterverarbeitung von Daten in größeren Mengen
sehr gut.
Hier sind einige Beispiele solcher Unternehmen:
Die Post: Um effizient und preiswert transportieren zu können, werden die
Verteilzentren weitgehend automatisiert. Anhand der Ziel-Adresse eines Briefen wird er
automatisch in einen weltweit funktionierendes Verteilnetz integriert. Dieses Verteilnetz
kennt sozusagen die Adressen aller per Post erreichbaren Menschen dieser Welt.
Telekom: Informationen wie Dauer, Kosten und Telefonnummer der beiden Teilnehmer
eines jeden ausgehende Telefongespräch wird bei der Telekom gespeichert, um Ende
Monat jedem angemeldeten Haushalt eine detaillierte Rechnung zuzustellen. Bei einer
Million Apparaten mit jeweils 5 Gesprächen täglich sind dies immerhin 150 Millionen
einzelne Informationen, die auf einer Million Rechnungen korrekt erscheinen müssen!
Banken und Versicherungen müssen solche Probleme tagtäglich lösen. Solche
Unternehmen benötigen die Möglichkeit, riesige Mengen von Informationen zu
speichern und gezielt auf diese zugreifen zu können.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
7
Wir werden eine weit verbreitete Form zur Speicherung von Informationen betrachten:
Eine Datenbank. Als erstes werden ich erläutern, was eigentlich eine Datenbank ist und
wie sie im groben aufgebaut ist. Danach werden wir betrachten, in welcher Form eine
Datenbank diese Informationen speichert, und wie wir diese Informationen auch wieder
abfragen können.
1.1D ATEN BA NK EN
1.1.1W AS
IST EI NE
D ATEN BA NK
Wie es der Name bereits sagt, ist eine Datenbank eine Aufbewahrungsstelle für Daten,
auf die regelmäßig zugegriffen werden muss (im Gegensatz zu einem Archiv). Sie ist
speziell für große Mengen von Daten konzipiert - so können problemlos die
Kontoinformationen mehrerer Millionen Kunden gespeichert werden, und innerhalb
Sekunden auf die Informationen eines Kunden zugegriffen werden.
1.1.1.1Kennzeichen einer Datenbank
Von einer Datenbank, kann man dann sprechen, wenn sie zumindest die nachfolgenden
Eigenschaften auf sich vereint.
Sie enthält eine große Menge von Daten über Objekte unserer Umwelt.
Beispiel Telefonbuch: Im Telefonbuch sind die Telefonnummern und teilweise auch die
Adressdaten von einer Menschengruppe gespeichert.
Diese Daten sind nach bestimmten Merkmalen und Regeln erfasst, geordnet und
abgelegt.
Beispiel Telefonbuch: Erfassungsmerkmal einer jeden Person ist dabei der Name,
Vorname, Wohnort und Telefonnummer.
Der Zugriff auf die Daten und deren Änderung ist über vordefinierte Schnittstellen ohne
großen Aufwand für autorisierte Personen möglich.
Beispiel Telefonbuch: Sortiert sind diese dann nach Wohnort und alphabetischer
Reihenfolge, wodurch ein leichter Zugang möglich ist.
1.1.1.2Datenbankoperationen
Grundsätzlich stellt eine Datenbank folgende Operationen zur Verfügung:
Einfügen von Daten
Abfragen von Daten
Löschen von Daten
Ändern von Daten
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
8
Diese vier einfachen Operationen erlauben es einem Anwender, einfach und dennoch
effizient mit der Datenbank zu arbeiten. Wie und wo Daten gespeichert werden, muss
ich als Benutzer nicht wissen. Ich muss lediglich den 'Schalter' kennen, an dem ich
Daten abgeben oder abholen kann.
1.1.1.3Datenbankkomponenten
Schaut man ein wenig genauer hin, kann man die Datenbank in zwei wesentliche Teile
aufteilen:
Die gespeicherten Daten
Ein Verwaltungsprogramm, dass den Zugriff auf diese Daten ermöglicht
Dieses Verwaltungsprogramm stellt dem Anwender einfache Funktionen zur Verfügung,
mit denen er auf die gespeicherten Daten zugreifen kann, ohne über die technischen
Eigenschaften der Daten-Speicherung informiert zu sein. Ein direktes Zugreifen auf die
gespeicherten Daten ist im Normalfall nicht möglich. Das Verwaltungsprogramm
beschreibt die Spitze des Datenbankbetriebssystems. Dahinter verbirgt sich ein
Programm, mit dessen Hilfe man seinen Datenbestand erzeugen, verändern und
auswerten kann. Solche Systeme sind z.B. das ACCESS, das DBase (veraltet) aber auch
ein Adressbuch stellt ein solches System dar, wenn es auch in seiner Funktionalität stark
eingeschränkt ist.
Die Schnittstelle zum Benutzer stellt eine Abfragesprache dar, etwa die Sprache SQL
(Structured Query Language). Mittels dieser Sprache lassen sich Datenbanken abfragen
und auswerten. Je nach Qualität und Umfang des Programms werden dabei konkrete
Kenntnisse vom Benutzer verlangt oder nicht.
Der beschriebene Aufbau einer Datenbank lässt sich recht gut mit einem Lager
vergleichen. Möchte ein Kunde etwas aus dem Lager abholen, muss er zuerst den
Lagerverwalter angeben, was er denn genau möchte. Der Verwalter kann dann die
gewünschte Ware aus dem Lager holen und dem Kunden aushändigen. Ein Lieferant,
der etwas abzugeben hat, wendet sich auch an den Verwalter. Denn nur was der
Verwalter selber eingeräumt hat, wird er später auch wieder finden.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
1.1.2W IE
SPE ICH ER T EI NE
9
D ATEN BA NK D ATEN
Doch wie fügen wir Daten in eine Datenbank ein?
Um diese Frage beantworten zu können, betrachten wir den mechanischen 'Vorgänger'
der Datenbank: Den Karteikasten. Im Beispiel nehmen wir ein Fundbüro, das verlorene
Gegenstände in eine Kartei aufnimmt. Die enthaltenen Karten besitzen alle dieselbe Art
von Informationen, sie haben die gleiche Struktur. Eine Karte mit einer Zeichnung
würde in dieser Kartei keinen Sinn ergeben. Betrachten wir eine solche Karte genauer.
Sie enthält 2 Arten von Informationen
Die Art der Information
Die eigentlichen Informationen
Die Art der Information ist auf allen Karten identisch, nur die eigentlichen
Informationen sind jeweils verschieden. Würden wir die Informationen aller Karten
hintereinander auf ein Blatt Papier schreiben, wäre eine Tabelle die einfachste Art, da
wir die Art der Informationen (Nummer, Art, etc.) als Spaltenbezeichnung nur einmal
schreiben müssten.
Genauso speichern wir Daten in einer Datenbank. Wir definieren zuerst eine Tabelle
und fügen die Daten dann in diese Tabelle ein.
1.1.2.1Definition einer Tabelle
Natürlich möchte die Datenbank so viel wie möglich über die zu erwartenden Daten
wissen. Was wir implizit annehmen, wenn wir eine Karteikarte lesen, müssen wir bei
der Definition der Tabelle explizit angeben. Dies Angaben bestehen aus:
Name der Tabelle
Namen der Attribute (Nummer, Art, etc. bezeichnet man als Attribute)
Datentypen der Attribute
Sind die Attribute obligatorisch
Angabe eines Hauptschlüssels
Als Hauptschlüssel bezeichnet man ein Attribut, dessen Wert den Datensatz - die
Karteikarte - eindeutig identifiziert. Die Nummer 14556 identifiziert genau einen
Fundgegenstand, nämlich einen Schlüssel.
Bevor mit einer Datenbank gearbeitet werden kann, müssen also Tabellen definiert
werden, die dann Daten aufnehmen können. Versuchen wir doch gleich einamal eine
solche Definition zu erstellen:
1.1.2.2Sparsamkeit hat mit Faulheit nichts zu tun
Kommen wir wieder zurück zu unserem Fundbüro-Karteikasten. Ein etwas
schreibfauler Angestellter kam auf die Idee, im Feld 'Art' anstelle des Wortes 'Schlüssel'
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
10
nur noch eine '1' hinzuschreiben. '2' schrieb er für einen Regenschirm und so weiter. Um
sich die Zahlen merken zu können, schrieb er sie auf eine Liste.
Nun genau das ist in einer Datenbank auch möglich. Erzeugen wir doch einfach eine
neue Tabelle mit den jeweiligen Arten eines Fundgegenstandes. Die Tabelle mit den
Fundgegenständen müssen wir nun so anpassen, dass anstelle eines Textes in Feld 'Art'
nun eine Zahl hingeschrieben werden muss. Diese Zahl bezieht sich nun auf das Feld
'Nummer' der Tabelle 'Art'. Damit sparen wir zwar keine Zeit, aber beträchtlich
Speicherplatz, denn ein Text benötigt schnell einmal zehnmal mehr Platz als eine Zahl.
Ein anderer großer Vorteil besteht darin, dass das Wort 'Schlüssel' nur einmal
geschrieben werden muss. Wenn jedes Mal 'Schlüssel' eingegeben werden muss, kann
schnell einmal ein Fehler in der Eingabe passieren. Dann finden sich plötzlich
'Schluessel', 'Schlüsel' oder 'Schl.' in der Tabelle. Das Attribut 'Art' in der Tabelle der
Fundgegenstände bezeichnen wir als Fremdschlüssel, da sich der darin enthaltene Wert
auf den Hauptschlüssel einer anderen Tabelle bezieht.
Nun wird auch klar, wieso eine Tabelle einen Hauptschlüssel braucht: Bezieht sich ein
Wert in einer Tabelle auf eine andere Tabelle, so muss klar sein, welcher Datensatz
gemeint ist.
1.1.3A BF RA GE N
VO N
D ATEN
Wichtiger als das Speichern selbst ist das gezielte Abfragen der gespeicherten Daten.
Aus der Fülle der gespeicherten Daten möchte jeder Benutzer eine individuelle Auswahl
erhalten. Dazu stellt eine Datenbank die folgenden Operationen zur Verfügung:
Auswahl der angezeigten Felder
Einschränkung der anzuzeigenden Einträge
Sortieren der angezeigten Einträge
Kombinieren von Informationen aus mehreren Tabellen
1.1.3.1Auswahl:
Diese Auswahl hat zwei wesentliche Funktionen. Einerseits kann der Benutzer nur
diejenige Information eines Eintrages anzeigen, die ihn auch wirklich interessieren.
Andererseits kann so verhindert werden, dass ein Benutzer Informationen einsieht, zu
denen er keine Berechtigung hat. So darf ein Bankangestellter die Namen und
Telefonnummern aller Angestellten abfragen, jedoch nicht deren Privatadressen oder
Lohngruppen.
1.1.3.2Einschränkung:
Eine Person, die am Bahnhof einen Schirm verloren hat, kann die Liste aller Einträge
auf diejenigen reduzieren, bei denen es um einen Schirm geht.
1.1.3.3Sortieren:
Um gezielt nach Informationen zu suchen, ist es in vielen Fällen äußerst nützlich, wenn
die angezeigten Einträge nach beliebigen Feldern sortiert werden können.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
11
1.1.3.4Kombinieren:
Da das Attribut 'Art' bei den Fundgegenständen nur noch aus einer Nummer besteht,
möchten wir stattdessen das Feld 'Bedeutung' des entsprechenden Eintrages in der
Tabelle 'Art' anzeigen.
Diese vier Operationen lassen sich beliebig kombinieren. So lassen sich komplexe
Abfragen erstellen, die exakt die gewünschten Informationen zurückliefern.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
12
Z U S A M M E N FA S S U N G
Eine Datenbank ist ein Programm, das große Mengen von Daten speichern und
verwalten kann.
Daten werden in Tabellen gespeichert.
In diese Tabellen können Einträge eingefügt, geändert, gelöscht und abgefragt werden.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
13
2ERSCHEINUNGSFORMEN VON
D AT E N B A N K E N
Dieser Abschnitt zeigt in einem Überblick die verschiedenen Erscheinungsformen von
Datenbanken auf. Neben grundlegenden Erklärungen kommen verschiedenste Modelle
der Datenverwaltung zum Einsatz, die hier gegenübergestellt werden um ein
Gesamtbild der Datenverwaltung mittels DBMS zu erlangen.
2.1B EI SP IEL E
FÜ R
DATEN BA NK EN – G RU ND LE GE ND ES
Dem Grundgedanken, Daten für die weitere Verarbeitung persistent abspeichern zu
können, wird durch verschiedenste Datenarchivierungsmodelle Rechnung getragen. Je
nach der logischen Strukturierung und der Verwaltungsmethoden in Hardware und im
Datenbankbetriebssystem unterscheidet man folgende logische Modelle
Relational
Objektorientiert
Hierarchisch
Netzwerk
Logisch
Datenbanken treten uns im (techniknahen) Alltag häufig entgegen. Schon die Auflistung
einiger möglicher Informationssammlungen zeigt, wie häufig wir mit Datenbanken zu
tun haben:
Adressbuch im Handy
Kundendatenbank
Einwohnermelderegister
Kontobewegungsdatenbank
Genom-Datenbank
World Wide Web
Domain Name System
Datenbankmanagementsysteme
(DBMS)
unterstützen
uns
dabei,
im
Verarbeitungsprozess von komplexen Datenbeständen grundlegende Begriffe und
Aufgaben voneinander zu trennen. DBMS unterscheiden:
Physischem Datenbestand
die Daten an sich. Hier finden sich die Details der Daten, ausgedrückt in entsprechenden
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
Datentypen und identifizierenden Merkmalen
14
.
Logische Struktur der Daten
die Beziehung der einzelnen Detaildaten zueinander werden hier beschrieben. Hier
können zusammengehörige Datensätze gruppiert werden, Verweise auf andere Inhalte
definiert werden und/oder für die weitere Verarbeitung optimiert arrangiert werden.
Verarbeitungslogik
Für die Verarbeitung (auslesen, editieren, löschen) der Daten wird ein
Verarbeitungsmodell und Verarbeitungsoperationen benötigt. Kann die Verarbeitung
anhand eines mathematischen Modells beschrieben werden, spricht man von einer
Verarbeitungsalgebra. Dies werden wir für die relationale Algebra später genauer
behandeln.
Benutzeroberfläche
Die Art und Weise, wie der Benutzer auf die Daten zugreifen kann, wird in der
Benutzeroberfläche beschrieben. Diese kann entweder sehr systemnahe über die
Datenbankmanipulationssprache erfolgen oder über eigens dazu erstellte Software, die
die Datenbankzugriffe für den Endbenutzer in komfortable vorgefertigte
Abfragemasken abstrahiert.
Bei der Erstellung von Datenbanken (und hier ist in erster Linie der Inhalt, die Daten
selbst, gemeint, aber auch die Strukturierung der Daten für die weitere Verarbeitung)
werden oft Designhilfsmittel verwendet.
ER-Diagramme
Mithilfe der ER-Diagramme (Entity-Relationship-Diagramme) können komplexe
Zusammenhänge zwischen definierten Datenbanktabellen in einer grafischen Form
aufbereitet werden. Die Syntax (Schreibweise/Grammatik) der ER-Diagramme
behandeln
wir
detailliert
im
Abschnitt
Relationale
Datenbanken).
Softwaretools
Es existieren gemäß der fortgeschrittenen Standardisierung von bestimmten
Datenbanktypen (besonders relationalen Datenbanken) mehr und mehr SoftwareWerkzeuge, die den Erstellungs- und Strukturierungsprozess von Datenbanken
unterstützen. Solche Werkzeuge erlauben einen einfachere Manipulation der Daten
selbst, eine leichtere Verwaltung der Datenstrukturen bis hin zur Definition von
Relationen und Zusammenhänge zwischen verschiedenen Sturktureinheiten (meist
Tabellen). Einige dieser Werkzeuge werden im praktischen Teil demonstriert.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
15
2.2L OG ISCHE D ATEN BA NK MO DE LL E
2.2.1D AS
RE LATI ON AL E
D ATEN BA NK MO DE LL
Die wohl weitverbreitetste Form der Datenbanken sind heute Relationale Datenbanken.
Prinzipiell werden dabei Daten in Tabellen definiert und verwaltet. Die mathematische
Grundlage bilden dazu eine Menge an Tupeln, die in diesen Tabellen verwaltet werden
und eine mathematische Algebra zur Verbindung der Tupeln.
Identifiziert werden die Tupel aufgrund von Schlüssel, der Zugriff auf die Elemente ist
standardisiert über SQL.
Nähere Details zu dieser klar definierten und seit Jahrzehnten erfolgreich eingesetzten
Strukturierungsform im nächsten Kapitel.
2.2.2D AS O BJ EK TO RI EN TI ER TE D ATEN BA NK MO DE LL
Objektorientierte Datenbanken werden gerne im Bereich der objektorientierten
Programmierung (OOP, OO-Modelle) eingesetzt. OO-Programme beziehen sich in der
Programmverarbeitung auf Objekte, denen Attribute (Eigenschaften, Merkmale) und
Methoden (Verabreitungsanweisungen, operative Programmteile) zugeordnet werden.
Im statischen Bereich, also vor und nach dem Programmablauf eines OO-Programmes,
sind diese Objekte nicht existent, sie treten nur im dynamische Bereich, also bei der
Programmausführung in Erscheinung.
Um diese Kurzlebigkeit von Objekten auszuweiten, d.h. Daten in der OOP auch
dauerhaft verwalten zu können (abspeichern, ändern, löschen, erzeugen) und dennoch
die Vorteile der OO-Methodik zu wahren, wurde das objektorientierte Datenbankmodell
entwickelt. Objektattribute (und in manchen Ansätzen auch Methoden) werden in der
OO-DB gespeichert und verwaltet.
Manche akademische Entwicklung hat hierfür ein eigenes Datenbankkonzept
entworfen, andere halten es bei der Weisheit, das Rad nicht neu zu erfinden und
verwenden sogenannte Wrapper für relationale Datenbanken. Der Vorteil einer rein
objektorientierten Datenbank liegen bei OOP auf der Hand: Zur Datenmanipulation
wird keine 4GL-Sprache (wie SQL) für den Datenbankzugriff benötigt, hier wird
lediglich ein Datenbankobjekt verwendet und die darin enthaltenen Methoden
aufgerufen (vollkommen transparenter Zugriff auf die DB). Wenn die OO-DB nicht auf
einem relationalen Schema basiert, dann können zusätzlich Ressourcen eingespart
werden, weil keine Erstellung von dünn besetzten Tabellen erfolgt.
Als Beispiel sind die ZODB / ZEO Datenbank der ZOPE-Engine (basiert auf der WebProgrammiersprache Python) zu erwähnen oder die Datenhaltung in EJB-Servern. In
den meisten Fällen handelt es sich um persistente Storages, es werden keine
weitergehenden Funktionalitäten angeboten (Aggregatsfunktionen, stored procedures,
etc.)
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
16
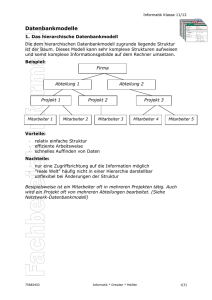
2.2.3D AS H IER AR CH ISC HE D ATEN BA NK MO DE LL
Hierarchische Datenbanken wurden Ende der 60er Jahre von IBM mit seiner
Entwicklung IMS/VS (1968) initiiert. Inzwischen ist IMS/VS ein stark optimiertes,
stabiles System mit einem komplexen Datenmodell und kryptischen Zugriff. Es
existieren mehrere tausend Seiten Systemliteratur dazu.
Die hierarchische Datenbankstruktur folgt einer Baumstruktur, die Navigation darin
geschieht explizit (Entlanghanteln nach der Verzweigungsform des Baumes). Pro
logischer Datenbank existiert eine Wurzel, alle Records hängen direkt oder indirekt von
den Wurzeln ab.
Ein Beispiel:
Die Zugriffssprache DL/1 (data language/one) findet sich eingebettet in COBOL, PL/1
und 370/Assembler. Die Datenein- und Ausgabe erfolgt über spezielle Variablen, die
Baumstruktur erlaubt ein Cascading Delete von abhängigen Datenblöcken.
Die Navigation erfolgt mittels expliziter Kommandos:
Gehe zu erstem Kind vom Typ Adresse
Gehe zu nächstem Kind
Suche Kind mit Strasse = "Meyerhofstr. 1"
2.2.4D AS N ET ZW ER K -D ATEN BA NK MO DE LL
Da Hierarchische Datenbanken nur Eins-zu-viele-Beziehungen (Details beim ERDiagram im nächsten Kapitel) darstellen können, wurde als Alternative das CODASYLModel (Conference on Data Systems Languages) entwickelt. Dieses Modell ist auch als
Netzwerkmodell bekannt. Die Modellierung der Realität erfolgt in Form eines
zusammenhängenden gerichteten Graphen mit Knoten und Kanten. Der einzelne EntityTyp aus dem ER-Diagramm wird als Record-Typ bezeichnet und durch einen Knoten
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
17
dargestellt. Die Beziehung zwischen zwei Entity-Typen wird über die Verbindung – die
Kante – zwischen den beiden zugehörigen Knoten modelliert. Hierbei sind jedoch nur
1:n-Beziehungen möglich. Die einzelne zweistellige Beziehung wird als Set-Typ
bezeichnet, die beiden an der Beziehung beteiligten Record-Typen als Owner-Typ und
Member-Typ. Der Owner-Typ liegt hierbei auf der 1-Seite und der Member-Typ auf der
n-Seite. Das heißt, die Records des Owner-Typs können jeweils mit mehreren Records
des Member-Typs in Beziehung stehen. Der wichtige Unterschied zum Hierarchischen
Datenbankmodell ist hierbei, dass die Anzahl und die Richtung der Beziehungen beim
Netzwerkmodell frei wählbar sind. Ebenso entfällt der Wurzeleintrag. Eine m:nBeziehung kann durch die Einführung eines sogenannten Kett-Record-Typ durch zwei
1:n-Beziehungen ersetzt werden.
Wir wollen dies anhand eines Beispiels näher betrachten und versuchen dazu die
Situation in einer Bibliothek über einen Graphen darzustellen.
Ein Buch wird grundsätzlich in nur einer Bibliothek eines Biblothek-Systems geführt
(beispielsweise können Studenten der TU Wien sowohl in der TU-Bibliothek als auch in
den Instituts-Bibliotheken Bücher ausleihen). Ein Kunde kann jedoch mehrere Bücher
ausleihen und ein Buch kann von mehreren Kunden ausgeliehen werden – unter der
Voraussetzung, dass dies nicht zum selben Zeitpunkt geschieht.
Um diese Beziehung im Netzwerkmodell zu modellieren, wird ein Kett-Record-Typ
Verleih eingeführt. Hiermit kann die m:n-Beziehung zwischen Buch und Kunde durch
eine 1:n-Beziehung zwischen Buch und Verleih und einer n:1-Beziehung zwischen
Verleih und Kunde ersetzt werden. Auf der n-Seite steht also jeweils der Kett-Record
Verleih, dieser stellt somit den Member-Typen zu den beiden Owner-Typen Buch und
Kunde dar. Eventuelle Attribute der zu ersetzenden m:n-Beziehung, können vom KettRecord-Typ aufgenommen werden. Bei 1:n-Beziehungen können Attribute der
Beziehung auf der n-Seite des Record-Typs aufgenommen werden.
Einer der Vorteile dieses Datenbankmodells ist, dass die Gegebenheiten der Realität oft
recht gut erfasst. Weiterhin sind durch die netzartige Struktur schnelle Zugriffe auf die
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
18
Informationen – Vermeidung langer Wege – möglich. Als Nachteil kann die aufwendige
Planung und Implementierung eines solchen Systems genannt werden. Ähnlich zum
hierarchischen Modell sind auch Netzwerkdatenbanken relativ inflexibel gegenüber
Anpassungen und Änderungen des Systems an neue Gegebenheiten.
Erste CODASYL-Normierungsbemühungen gab es gegen Ende der 60er Jahre. Die
aktuelle Implementierungen basieren auf 1978er Vorschlag. Produkte, die dieser
Netzwerkmodellierung folgen, sind DMS/100 (UNIVAC), IDMS (Cullinet Software),
DBMS (DEC) und UDS (Siemens, in Deutschland sehr erfolgreich).
2.2.5D AS
LO GI SC HE
D ATEN BA NK MO DE LL
Logische Datenbanken verwenden als Grundlage zur Datenverwaltung die direkte
Verarbeitung logischer Regeln. Die Regeln leiten Realitäten (Fakten) auf Basis von
bereits vordefinierten Fakten ab. Die Verarbeitung der Faktenbasis erfolgt etwa durch
die Datenbanksprache DATALOG (ähnlich PROLOG).
Die naschstehende Abfolge von Fakten und Regeln in DATALOG veranschaulicht die
Datenverarbeitung im logischen Datenbankmodell:
VaterVon(Hans, Otto).
VaterVon(Otto, Frank).
VaterVon(Otto, Peter).
GrossvaterVon(A, B) :- VaterVon(A,C), VaterVon(C, B).
2.3L ITERATU R
Gottfried Vossen, Kurt-Ulrich Witte (Hrsg): Entwicklungstendenzen bei
Datenbanksystemen, Oldenburg Verlag, München, 1991
PostgreSQL 7.1 User's Guide und PostgresQL 7.1 Programmer's Guide
http://www.postgresl.org/
Klaus Meyer-Wegener: Multimedia-Datenbanken: Einsatz von Datenbanktechnik in
Multimedia-Systemen, Teubner-Verlag, Stuttgart, 1991
Andrew M. Kuchling, ZODB & ZEO Introduction, http://www.amk.ca/zodb/zodbzeo.html
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
19
3 R E L AT I O N A L E D AT E N B A N K E N
Das Modell der relationalen Datenbanken wurde Mitte der 80er Jahr entwickelt und
bildet seit dieser Zeit den größten Anteil an Datenbanken in der Praxis. Bei einer
relationalen Datenbank besteht die konzeptionelle Ebene, also die logische Sicht auf die
Gesamtheit aller Daten, aus einer mehr oder weniger großen Anzahl von Tabellen. Den
Aufbau der einzelnen Tabellen mit Hilfe des relationalen Datenmodells werden wir im
Verlaufe dieses Kaptitel kennen lernen.
3.1T AB EL LE N
UN D
REL ATION EN
Die Tabellen eines relationalen Datenbanksystems bestehen aus vielen Zeilen, die
jeweils die Eigenschaften zu genau einem Datensatz enthalten. Zu jeder Zeile gehört
wiederum eine festgelegte Anzahl an Zellen. Diese stehen für die einzelnen Attribute
des Entities.
Beispiel für die Tabelle Person:
PerID
Name
Vorname
Strasse
Ort
007
Bond
James
Victoria Str.
London
206
Schranz
Markus
Ringofenstr. Leopoldsdorf
345
Meyer
Brigitte
Hahnenweg
Musterdorf
In der Kopfzeile der Tabelle werden die betrachteten Eigenschaften (Attribute)
aufgelistet. Sie ist die einzige Zeile der Tabelle die ohne Änderung der TabellenDefinition zeitinvariant bleibt. Jede Zeile der Tabelle enthält dann für eine spezielle
Person die Werte dieser Attribute (Datensatz einer bestimmten Person). Das kartesische
Produkt der Wertebereiche Di der Attribute ist die Menge aller Tupel, deren erster
Eintrag ein Element aus dem Wertebereich des ersten Attributs Name ist, deren zweiter
Eintrag ein Element aus dem Wertebereich des zweiten Attributs Vorname ist, usw. Jede
einzelne Zeile der Tabelle entspricht einem solchen Tupel. Somit ist die Menge aller in
der Tabelle aufgelisteten Tupel eine Teilmenge aus dem kartesischem Produkt der
Wertebereiche der Attribute. Mathematisch betrachtet ist eine solche Teilmenge aus
einem kartesischem Produkt eine Relation r.
r D1 × D2 × . . . × Dn
Im relationalen Modell wird das vereinfachte Abbild der realen Welt in Form von
Relationen dargestellt.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
20
Jede einzelne dieser Relationen kann als Tabelle veranschaulicht werden (Relation als
Tabelle). Jede Zeile der Tabelle entspricht einem Tupel der Relation. Als Menge darf die
Relation keine zwei gleichen Elemente enthalten, es müssen sich alle Zeilen der Tabelle
in ihrer Vollständigkeit voneinander unterscheiden – Werte einzelner Attribute dürfen
(je nach Definition) mehrfach vorkommen. Daher muss es in jeder Relation ein Attribut
oder eine Attributkombination geben, wodurch jedes Tupel der Relation eindeutig
identifiziert werden kann. Jede Tabelle einer relationalen Datenbank muss somit einen
Primärschlüssel enthalten. Im obigen Beispiel ist dies der künstlich eingeführte
Schlüssel PerID.
Die Beschreibung einer Relation geschieht über ein Relationenschema R(A1, . . . ,An).
Hierbei ist R der Name der Relation und die Ai sind die unterschiedlichen Attribute.
Gemäß der Theorie der relationalen Datenbanken müssen sie elementar sein, d. h. es
sind weder zusammengesetzte noch mehrwertige Attribute zulässig. Das
Relationenschema gibt somit die Bauanleitung (Kopfzeile) der Tabelle an.
Um nun aus dem gegebenen Realwelt-Ausschnitt die Relationenschemata für die
Tabellen zu erstellen, ist das ER-Diagramm äußerst hilfreich.
3.2D AS E NT ITY -R EL ATION SH IP D IAG RA MM
Mit der zu entwickelnden Datenbank sollen Fakten eines bestimmten Ausschnitts aus
der realen Welt gespeichert und verwaltet werden können. Hierzu ist es sinnvoll, diese
„Miniwelt“ anhand eines Datenmodells zu abstrahieren, sie also derart zu vereinfachen,
dass sie in einer Datenbank speicher- und verwaltbar wird.
In den 70er Jahren wurde das Entity-Relationship-Diagramm entwickelt, um eine
grafische Darstellung des vereinfachten Realwelt-Ausschnitts zu ermöglichen. Es
besitzt die beiden Grundbestandteile Entity und Relationship, die im Weiteren näher
erläutert werden. Das ER-Diagramm hat sich als eines der wichtigsten Instrumente im
Entwurf von Datenbanksystemen durchgesetzt, weil hier ein Konzept „lesbar“ gemacht
werden kann, ohne bereits von einem bestimmten DBS abhängig zu sein –
Beschränkungen, die mit der Systemimplementierung einhergehen, entfallen. So werden
Relationen in relationalen Datenbanken als Folgen von Tupeln, im ER-Diagramm als
Mengen betrachtet. Weiterhin sind die bereits erwähnten Grundelemente mit der
umgangssprachlichen Ausdrucksweise leicht zu verbinden, so das es leicht verständlich
ist.
3.2.1E NT ITI ES , D OM ÄN EN
UN D
A TT RI BU TE
Entities sind wohlunterscheidbare Dinge der realenWelt, wie z. B. Personen, Autos,
Firmen, Schulen, Städte, Bücher. Entities besitzen Eigenschaften, die Attribute genannt
werden. Eine Person besitzt zum Beispiel einen Namen, eine Adresse, ein
Geburtsdatum, eine Augenfarbe und eine Blutgruppe. Die konkrete Ausprägung eines
Attributs nennt man Wert. Man erhält also ein konkretes Entity, indem man den
Attributen Werte zuordnet.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
21
Für die Person Markus Schranz, mit dem Geburtsdatum 19.11.1969 liegen folgende
Werte vor:
Attribut
Wert
Vorname
Markus
Die Menge aller möglichen Nachname
Schranz
oder auch zugelassener Geburtsdatum
19.11.1969
Werte für ein Attribut bildet den Wertebereich bzw. die Domäne. Beschränkt man einen
Namen auf max. 20 Zeichen, können als Domäne für das Attribut Name die Menge aller
Zeichenketten der max. Länge 20 angegeben werden. Lässt der gegebene
Realitätsausschnitt z. B. nur die Namen „Max“ , „Moritz“ , „Fritz“ und „Hans“ zu,
besteht der Wertebereich dieser Menge aus genau diesen vier Namen. Bei einer
vierstelligen positiven Identifikationsnummer beispielsweise kann als Wertebereich die
Menge der positiven ganzen Zahlen bis 9999 genommen werden.
Attribute können einwertig oder mehrwertig sein. Im Allgemeinen hat eine Person nur
einen festen Vornamen, also ist das Attribut Vorname einwertig, es nimmt also genau
einen Wert aus der zugehörigen Domäne an. Ein Dozent kann aber durchaus in mehrere
Fachbereichen unterrichten – das entsprechende Attribut Fachbereich ist also
mehrwertig.
Ein zusammengesetztes Attribut besteht aus mehreren einzelnen Attributen.
Beispielsweise besteht ein Name aus den Komponenten Vorname und Nachname. Das
konkrete Entity hat für jedes dieser Komponenten einen Wert. Der Wertebereich eines
zusammengesetzten Attributs besteht dann aus dem kartesischen Produkt der
Wertebereiche der einzelnen Komponenten.
Ein Entity-Set ist die Zusammenfassung von einzelnen zusammengehörigen Entities
wie zum Beispiel alle Personen oder Autos einer Firma, alle Schüler einer Schule, alle
Einwohner einer Stadt. Alle Entities des Sets haben somit die gleichen Attribute.
3.2.2S CH LÜ SS EL
Ein spezielles Entity eines Entity-Sets muss natürlich auch als solches über die Angabe
ausgewählter Attribute identifiziert werden können. Eine Kombination von Attributen,
deren Werte zusammengefasst ein spezielles Entity eindeutig identifizieren, wird
identifizierende Attributskombination (Superkey) genannt.
Ein Superkey kann jedoch überflüssige Attribute enthalten. Entfernt man diese, erhält
man eine minimale identifizierende Attributskombination. Diese bezeichnet man als
Schlüssel (key) oder als Schlüsselkandidat (candidate key). Bei einem Schlüssel darf
also keines der Attribute herausgenommen werden, da sonst die Fähigkeit zur
Identifizierung und somit die Schlüsseleigenschaft verloren geht. Er ist also
redundanzfrei.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
22
Es kann durchaus mehrere Schlüssel bzw. Schlüsselkandidaten geben. Der hieraus zur
tatsächlichen Verwendung ausgewählte Schlüssel wird als Primärschlüssel, alle
restlichen Schlüssel werden als Sekundärschlüssel bezeichnet. Ein Primärschlüssel
sollte nach Möglichkeit aus nur einem Attribut bestehen. (Der Grund hierfür wird im
relationalen Datenmodell und dem Prozess der Normalisierung ersichtlich werden.)
Dies ist jedoch oft nicht möglich, da Namen, Geburtstage, Straßen etc. gerade bei
größeren Anzahlen von Entities sehr schnell mehrfach vorkommen können. In diesem
Fall fügt man dem Entity-Set ein weiteres künstliches Attribut hinzu, das dann für jedes
Entity des Sets einen eigenen Wert erhält. Bekannte Beispiele sind Personalnummern,
ISBN-Nummern bei Büchern, Inventar- und Gerätenummern. Dieses neue Attribut wird
dann gleichzeitig der Primärschlüssel.
Vorname Nachname Geburtsdatum Straße
Hausnr Plz
Ort
Telefon
Brigitte
Müller
06.05.1974
Burgstraße
45
8000
Graz
0240493975
Schmitz
Hans
12.07.1953
Neuhof
13
7000
Eisenstadt
02415083671
Schmitz
Hans
25.12.1982
Weststraße 3
5000
Salzburg
0240273064
Schranz
Markus
19.11.1969
Ringofenstr 2
2333
Leopoldsdorf 0223544444
Wie leicht zu erkennen ist, kann Hans Schmitz nicht durch alleinige Angabe seines
Namen identifiziert werden. So müsste nach diesem Konzept das Geburtsdatum als
weiteres Attribut dem Primärschlüssel hinzugefügt werden. Um eine leichtere
Auffindbarkeit der Daten zu einem bestimmten Hans Schmitz erreichen zu können, wird
als weiteres Attribut die Kundennummer eingeführt, die nur einmal vergeben werden
darf und somit sicher stellt, dass über die Kundennummer eine eindeutige Zuordnung
möglich ist.
KdNr. Vorname Nachname Geburtsdatum Straße
001
Brigitte
Müller
06.05.1974
Hausnr Plz
Burgstraße 45
8000
Ort
Telefon
Graz ...
Weiterhin sind die Einträge Straße, Hausnr und Plz, Ort als zusammengesetzte Attribute
zu erkennen. Als Strukturierung dieses Entities könnte folgende Definition getroffen
werden:
Attribut
Domain
KdNr.
dreistellige ganze positive Zahl
Vorname
Zeichenkette der Länge 20
Nachname
Zeichenkette der Länge 30
Geburtsdatum
Datumformat TT.MM.JJJJ
Straße Hausnr
Zeichenkette der Länge 50
Plz Ort
Zeichenkette der Länge 50
Telefon
Zeichenkette der Länge 40
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
3.2.3D EF INI TI ON
UN D GR AF ISCH E
E RS TE LL UN G
VO N
23
E NT ITI ES
Ein Entity-Set besteht aus einer Menge von Entities. Die formale Beschreibung dieser
gemeinsamen Eigenschaften kann durch den Begriff des Entity-Typs erfolgen:
Definition: Ein Entity-Typ (Entity-Deklaration) hat die Form E = ({X}, {K}). Er
besteht aus einem Namen E, einem Format X und einem Primärschlüssel K. Dieser ist
aus (einwertigen) Elementen von X zusammengesetzt. Die Elemente des Formats X
werden hierbei wie folgt notiert:
(i) Einwertige Attribute: A
(ii) Mehrwertige Attribute: {A}
(iii) Aus B1, . . . ,Bk zusammengesetzte Attribute: A(B1, . . . ,Bk)
Der Entity-Typ liefert somit eine formale Beschreibung der Eigenschaften des Sets.
Beispiel: Ein Mitarbeiter soll durch seinen Vornamen, Nachnamen, der Bereiche, in
denen er arbeitet und seiner Adresse beschrieben werden. Vor- und Nachname sind
einwertige, Bereiche ist ein mehrwertiges und die Adresse ist ein aus Straße und Ort
zusammengesetztes Attribut. Zur eindeutigen Identifikation gibt es einen künstlichen
Primärschlüssel in Form einer Personalnummer (PerNr). Wir haben folgende
Festlegung:
E des Entity-Typs ist „Mitarbeiter“
Format X = {PerNr, Vorname, Nachname, {Bereiche}, Adresse(Strasse,Ort)}
Primärschlüssel K = {PerNr}
Somit ergibt sich
Mitarbeiter = ({PerNr,Vorname,Nachname,{Bereiche},Adresse(Strasse,Ort)},{PerNr})
3.2.3.1Grafische Darstellung eines Entity-Typs:
Der Name des Typs steht in einem Rechteck. Für die einzelnen Attribute werden
Ellipsen verwendet, die durch nichtgerichtete Kanten mit dem Rechteck verbunden
sind. Der Primärschlüssel wird einfach unterstrichen. Bei mehrwertigen Attributen sind
diese Ellipsen doppelt umrandet. Bei zusammengesetzten Attributen werden die
einzelnen Komponenten durch eigene Unterellipsen dargestellt.
Mit der Entity-Deklaration kann nun auch das einzelne Entity e und das Entity-Set E t
zum Zeitpunkt t formal definiert werden:
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
24
Abbildung 3.1: Grafische Darstellung einer Entity
Definition: Gegeben sei eine Entity-Deklaration E = (X,K) mit X = (A1, . . . ,Am). Das
Attribut Ai habe den Wertebereich bzw. die Domäne dom(Ai) mit 1 i m.
i)
Ein Entity e ist ein Element aus dem Kartesischen Produkt aller
Wertebereiche, also e dom(A1) × . . . × dom(Am).
ii) Ein Entity-Set Et (zum Zeitpunkt t) ist eine Menge von Entities, welche K
erfüllt. D. h. derWert von K ist für jedes Entity verschieden. Also
Et dom(A1) × . . . × dom(Am).
Et ist also der Inhalt bzw. der aktuelle Wert des Typs E zur Zeit t. (Mathematisch
gesehen eine Teilmenge aus dem kartesischen Produkt der Domänen, also eine
Relation.)
Beispiel: Zu einer bestimmten Zeit t liegt folgendes Entity-Set Mitarbeiter aus 3
Mitarbeitern vor:
Mitarbeiter = {e1, e2, e3} mit
e1 = (123, „Andres“ , „Cvitkovich“ {„Entwicklung“ , „CRM“ }, („Bahnhofstr.
13“ , „5000 Salzburg“ ))
e2 = (124, „Sonja“ , „Knappitsch“ {„Redaktion“ },(„Rathausstr. 33“ , „8000
Graz“ ))
e3 = (125, „Markus“ , „Schranz“ {„Forschung“ , „Entwicklung“ }, („Am
Markt 2“ , „7000 Eisenstadt“ ))
e[A] heißt die Projektion von e auf A und liefert den Wert des Entities e für das Attribut
A.
Hier zum Beispiel:
e3[PerNr] = 125,
e3[Vorname] = „Markus“ ,
e3[Bereiche] = {„Forschung“ , „Entwicklung“ },
e3[Adresse] = („Am Markt 2“ , „7000 Eisenstadt“ ).
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
25
Während der Entity-Typ nach seinem Entwurf sich im Allgemeinen nicht mehr ändert
(also zeitinvariant ist), wird das Entity-Set durch die jeweils aktuellen Attributwerte der
einzelnen Entities festgelegt. Das Set hat also einen zeitabhängigen Inhalt.
3.2.4B EZ IEH UN GE N
BZ W .
R EL ATION SHI PS
Verschiedene Entity-Sets können miteinander in Beziehung stehen. Betrachten wir
beispielsweise die Mitarbeiter, die in einer Abteilung arbeiten. Hier werden die beiden
Entity-Sets Mitarbeiter und Abteilung über die Beziehung arbeiten miteinander
verknüpft. Eine Beziehung kann ebenfalls Attribute enthalten. Für arbeiten ist
Arbeitszeit ein naheliegendes Attribut.
Im ER-Diagramm werden Beziehungen durch eine Raute dargestellt. Ein
Beziehungstyp, der genau zwei Entity-Typen E1 und E2 miteinander verknüpft, heißt
binär. Zur Modellierung der Realität sind folgende binäre Beziehungstypen
gebräuchlich:
1:1 - Beziehung:
Jedem Entity e1 aus dem Set vom Typ E1 wird höchstens ein Entity e2 aus dem Set vom
Typ E2 zugeordnet und umgekehrt wird jedem Entity e2 aus E2 höchstens ein Entity e1
aus E1 zugeordnet. Sowohl in E1 als auch in E2 kann es Entities geben, die keinen
Partner haben.
Beispiel: Die klassisch-europäische Form der Eheschließung
Entity-Set E1 Frauen und Entity-Set E2 Männer werden über die Beziehung heiraten
miteinander verknüpft. Einer einzelnen speziellen Frau e1 aus E1 wird max. ein
bestimmter Mann e2 aus E2 zugeordnet. Sowohl in E1 also auch in E2 kann es ledige
Personen geben.
Abbildung 3.2: Grafische Darstellung einer 1:1 - Beziehung
1:n oder n:1 - Beziehung:
Jedem Entity e1 aus E1 können keines, eines oder mehrere Entities e2 aus E2 zugeordnet
werden. Jedoch kann jedes Entity e2 aus E2 nur maximal einen Partner e1 aus E1 haben.
Analog: Jedes Entity e1 aus E1 kann nur maximal einen Partner e2 aus E2 haben. Jedem
Entity e2 aus E2 können keines, eines oder mehrere Entities e1 aus E1 zugeordnet werden.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
26
Abbildung 3.3: Grafische Darstellung einer 1:n oder n:1 – Beziehung
Beispiel: E1: Abteilung, E2: Mitarbeiter, Beziehung: arbeiten
In jeder Abteilung können max. mehrere Mitarbeiter arbeiten, ein Mitarbeiter kann
jedoch nur für eine Abteilung arbeiten. Je nach Betriebsstruktur kann es evtl.
Mitarbeiter geben, die keiner Abteilung zugeordnet sind und vielleicht gibt es auch
Abteilungen, in denen nur noch Maschinen arbeiten.
m:n - Beziehung:
Jedes Entity e1 aus E1 kann mit keinem, einen oder mehreren (maximal M) Entities e 2
aus E2 in Beziehung stehen und umgekehrt gilt, dass jedes Entity e2 aus E2 mit keinem,
einen oder mehreren (maximal N) Entities von e1 aus E1 in Beziehung stehen kann.
Beispiel: E1: Arzt, E2: Patient, Beziehung: behandeln
Ein Arzt kann mehrere Patienten haben und ein Patient kann von mehr als einem Arzt
behandelt werden.
Abbildung 3.4: Grafische Darstellung einer m:n – Beziehung
3.2.5U MFAN GR EI CH ER ES B EI SPI EL
ZU M
ER-D IAG RA MM
Es sollen folgende Begebenheiten in einer Hochschule festgehalten werden:
eine Vorlesung hat die Attribute VorlNr (Primärschlüssel), SWS und Titel
Studenten haben die Eigenschaften MatrNr (Primärschlüssel), Name und Sem
ein Angestellter hat die Attribute PersNr (Primärschlüssel) und Name
ein Professor ist ein Angestellter mit den Eigenschaften Rang und Raum
ein Assistent ist ein Angestellter mit dem Attribut Fachgebiet
1 Professor hält keine bis mehrere Vorlesungen und prüft keine bis mehrere
Studenten bezüglich keiner bis mehrere Vorlesungen
je Prüfung wird eine Note als Eigenschaft zugewiesen
ein Student hört keine bis mehrere Vorlesungen und wird in keiner bis
mehreren Vorlesungen von keinem bis mehreren Professoren geprüft
ein Assitent arbeitet für einen Professor
einem Professor sind kein bis mehrere Assistenten zugeteilt
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
27
Daraus ergeben sich die nachstehenden Entity-Festlegungen:
Vorlesung = ({VorlNr, SWS, Titel}, {VorlNr})
Studenten = ({MatrNr,Name, Sem}, {MatrNr})
Angestellte = ({PersNr,Name}, {PersNr})
Assistenten = ({PersNr,Name, Fachgebiet}, {PersNr})
Professoren = ({PersNr,Name,Rang,Raum}, {PersNr})
3.3T RA NS FO RMATI ON
VON
ENT ITY -T YP EN
IN
REL ATION SS CH EMATA
Jeder Entity-Typ wird in (mindestens) ein eigenes Relationenschema transformiert.
Diesen Vorgang wollen wir uns am Beispiel einer Person näher anschauen.
Gegeben sei folgender Entity-Typ:
Person = ({PerID, Name, Vorname, Adresse(Strasse,Ort)}, {PerID})
Hier stellt die PerID den Primärschlüssel dar. Aufgrund der Forderung nach
elementaren Attributen sollte das zusammengesetzte Attribut Adresse durch seine
Einzelattribute Strasse und Ort ersetzt werden. Weiterhin ist es üblich, den Namen des
Relationenschemas und der Tabelle gleich oder ähnlich dem Namen des Entity-Typs zu
wählen. Der Primärschlüssel wird ganz links aufgelistet und unterstrichen. Dies ergibt
folgendes Relationenschema Person:
R(A1, . . . ,An) entspricht hier Person(PerID, Name, Vorname, Strasse, Ort)
oder
Person
PerID
Name
Vorname
Strasse
Ort
…
Dieses Beispiel wollen wir weiter verfeinern. Die obig beschriebene Person sei nun
ein(e) DozentIn.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
28
Dozent = ({DozID,Name, Vorname, Adresse(Strasse,Ort), {Bereich}}, {DozID})
Man kann versuchen, das Problem des mehrwertigen Attributs Bereich über die
Einführung eines zweiten Relationenschemas – also einer zweiten Tabelle Fachbereiche
für die konkreten Entities – zu lösen.
Dozent
DozID
Name
Vorname
Strasse
Ort
...
Fachbereiche
DozID
Bereich
...
Bereich wurde also aus dem ersten Schema hinausgenommen und in Form des zweiten
Schemas Fachbereich verarbeitet. So könnte es zu folgenden konkreten Tabellen
kommen:
Tabelle Dozent:
DozID
Name Vorname Straße Ort
001
Schahram Dustdar . . . . . .
002
Markus Schranz . . . . . .
003
............
Tabelle Fachbereich:
DozID
Bereich
001
Rechnernetzwerke
001
Einführung in die Datenverarbeitung
001
...
002
Algorithmen und Datenstrukturen
002
Web Service Engineering
002
PERL-Programmierung
002
Internet Services
003
...
Die Verbindung zwischen beiden Tabellen wird über den Primärschlüssel DozID aus der
Tabelle Dozent hergestellt. DozID ist in der Tabelle Fachbereich ein so genannter
Fremdschlüssel. Durch gemeinsame Schlüssel werden Tabellen miteinander verknüpft.
Da ein Dozent mehrere Fachbereiche haben kann, wird der Fremdschlüssel mehrmals
aufgelistet. Daher ist eine eindeutige Unterscheidung der einzelnen Tupel der Tabelle
Fachbereich nur über die Angabe der beiden Attribute DozID und Bereich möglich. Das
heißt der eigentliche Primärschlüssel für die Identifikation eines Datensatzes aus der
Tabelle Fachbereich besteht aus der Kombination dieser beiden Attribute.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
29
Jeder in Fachbereich aufgelistete Bereich soll einem Dozenten in der Tabelle Dozent
zugeordnet werden können. Daher kann der Fremdschlüssel DozID in Fachbereich nur
solche Werte annehmen, die auch als Wert für den Primärschlüssel DozID in der Tabelle
Dozent vorkommen. Somit bilden die Werte für DozID in der Tabelle Fachbereich eine
Teilmenge der Werte für DozID in der Tabelle Dozent.
Wir definieren:
Fachbereich[DozID] Dozent[DozID]
Die Werte des Fremdschlüssels DozID in Fachbereich sind also in gewisser Weise
abhängig von den Werten des Primärschlüssels DozID in Dozent. Die obige Definition
besagt, dass alle konkreten Ausprägungen des Attributs DozID der Relation (Tabelle)
Fachbereich in der Menge der konkreten Ausprägungen desselben Attributs der
Relation Dozent enthalten sein müssen. Es dürfen demnach keine Einträge in
Fachbereich für die DozID vorhanden sein, die nicht ebenfalls in der Relation Dozent
vorkommen. Würde dies trotzdem geschehen, so wären die Integritätsbedingungen
verletzt und es stehen „unsinnige/fehlerhafte“ Einträge in unserer Relation Fachbereich.
Allgemein formuliert: Der Wert eines Fremdschlüssels muss immer als Wert im
zugehörigen Primärschlüssel vorkommen. Wir haben es also hier mit einer
Abhängigkeit zwischen zwei Relationenschemata zu tun. Eine semantische Bedingung,
die zwischen mehreren Relationen gilt, wird auch als referentielle Integrität
bezeichnet. Es kann sich jedoch folgendes Problem ergeben: Bereiche, die mehrere
Dozenten gemeinsam unterrichten, würden in der Tabelle Fachbereiche wiederholt
aufgelistet werden. Das bedeutet unnötige Redundanz und die Gefahr von
Schreibfehlern – es könnten demnach Inkonsistenzen entstehen, die wir vermeiden
wollen. Um dieses Problem zu lösen, ist es ratsam, das ursprünglich mehrwertige
Attribut Bereich als eigenes Entity und den gegebenen Tatbestand mit der m:nBeziehung „Dozent lehrt Bereich“ oder „Dozent erteilt Kurs“ zu modellieren. Wie dies
genau umgesetzt werden kann, wird im nächsten Unterkapitel beschrieben.
3.3.1T RA NS FO RM ATION
DE R M : N -B EZ IEH UN G
Die m:n-Beziehung stellt den allgemeinen Fall dar. Dies soll an einem Beispiel
verdeutlicht werden. Ein Arzt kann mehrere Patienten behandeln und ein Patient kann
von mehreren Ärzten behandelt werden.
Arzt = ({ArztID,Name}, {ArztID})
Patient = ({PatientID,Name}, {PatientID})
Relation: behandeln mit Attribut Termin
Für die beiden Entity-Typen Arzt und Patient wird jeweils ein Relationenschema
benötigt:
Arzt
ArztID
Name
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
30
...
Patient
PatientID
Name
...
Die eigentliche Beziehung wird dann durch ein weiteres Relationenschema mit dem
Namen Behandeln beschrieben:
Behandeln
ArztID
PatientID
Termin
...
ArztID und PatientID sind Fremdschlüssel im Schema Behandeln. Die Kombination
dieser beiden Attribute ergibt den Primärschlüssel der neuen Tabelle Behandeln. Auch
hier zur Verdeutlichung drei konkrete Tabellen:
Tabelle Arzt:
ArztID
Name
A1
Meier
A2
Jansen
A3
Plum
...
....
Am
Pauly
Tabelle Patient:
PatientID
Name
P1
Jakobs
P2
Müller
P3
Bergstein
...
...
Pn
Hesel
Tabelle Behandeln:
ArztID
PatientID
Termin
A1
P1
...
A1
P2
...
A2
P2
...
A2
P3
...
A3
P1
...
A3
P2
...
A3
P3
...
...
...
...
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
31
Jedem konkreten Wert des Primärschlüssels ArztID in der Tabelle Arzt können mehrere
Einträge des gleich lautenden Fremdschlüssels in der Tabelle Behandeln zugeordnet
werden. Zwischen Arzt und Behandeln herrscht also sozusagen ein 1:n-Verhältnis.
Genauso können jedem konkreten Wert des Primärschlüssels PatientID in der Tabelle
Patient mehrere Einträge des gleich lautenden Fremdschlüssels in der Tabelle
Behandeln zugeordnet werden. Zwischen Patient und Behandeln herrscht also ebenfalls
ein 1:n-Verhältnis.
Hieran sieht man, dass mit Hilfe der dritten Tabelle Behandeln die ursprüngliche m:nBeziehung durch zwei 1:n-Beziehungen ersetzt wird. Die Abhängigkeiten bez. der
Primär- und Sekundärschlüssel lauten:
Behandeln[ArztID] Arzt[ArztID]
Behandeln[PatientID] Patient[PatientID]
Ganz analog kann das Beispiel „Dozent erteilt Kurse“ modelliert werden.
3.3.2T RA NS FO RM ATION
DE R
1: N -
BZ W . N :1- B EZ IEH UN G
Sie stellt eine Vereinfachung der m:n-Beziehung dar. Beispielsweise kann ein
Angestellter in nur einer Abteilung arbeiten, in einer Abteilung sind jedoch durchaus
mehrere Angestellte beschäftigt.
Angestellter = ({AngNr, AngName}, {AngNr})
Abteilung = ({AbtNr, AbtName}, {AbtNr})
Für die Relation arbeiten mit Attribut Dienstzeit existieren nun verschiedene
Möglichkeiten.
Möglichkeit 1:
Analog zur m:n-Beziehung ebenfalls 3 Schemata:
Angestellter
AngNr
AngName
Abteilung
AbtNr
AbtName
Arbeiten
AngNr
AbtNr
Dienstzeit
mit:
Arbeiten[AngNr] Angestellter[AngNr]
Arbeiten[AbtNr] Abteilung[AbtNr]
Der Vorteil ist die minimale Redundanz in den Tabellen. Jeder Angestellten- bzw.
Abteilungsname wird nur einmal aufgeführt. Angestellte, die keiner Abteilung
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
32
zugeordnet sind, oder neue Abteilungen, in denen noch niemand arbeitet, lassen sich
ebenfalls problemlos auflisten. Der Nachteil ist allerdings die hohe Tabellenanzahl, was
gerade bei komplexeren Abfragen eine erhöhte Rechenleistung erfordert. Schon bei
recht einfachen Abfragen wie „Zeige die Namen aller Angestellten, die in der
Verwaltung arbeiten“ müssen alle drei Tabellen miteinander verknüpft werden. Solche
Verknüpfungen von Tabellen werden als Join (siehe Kapitel Relationale Algebra)
bezeichnet und sind im Allgemeinen recht aufwändig.
Möglichkeit 2:
Aufgrund des eben erwähnten Nachteils wird die 1:n-Beziehung meistens in nur zwei
Tabellen dargestellt. Die entsprechenden Schemata:
Angestellter
AngNr
Abteilung
AngName
AbtNr
AbtNr
Dienstzeit
AbtName
Dem Schema für den Entity-Typ auf der n-Seite (hier Angestellter) werden der
Primärschlüssel AbtNr des Entity-Typen auf der 1-Seite (hier Abteilung) und das
Attribut Dienstzeit der Beziehung zugefügt. AbtNr wird dadurch zum Fremdschlüssel
im Schema für Angestellter.
Angestellter[AbtNr] Abteilung[AbtNr]
Nachteil:
Bei Angestellten, die keiner Abteilung angehören oder die keine feste Dienstzeit haben,
bleiben in der zugehörigen Tabelle die Werte der Attribute AbtNr und Dienstzeit
unbesetzt. Sie können dann sogenannte Nullwerte erhalten, was allerdings für das
DBMS einen erhöhten Verwaltungsaufwand erfordert und somit noch keine optimale
Lösung darstellt.
3.3.3T RA NS FO RM ATION
DE R
1:1- B EZ IEH UN G
Auch diese Beziehung wollen wir an dem bereist aus den vorangegangenen Kapiteln
verdeutlichen.
Ein Mann heiratet eine Frau:
Mann = ({MannID,MannName}, {MannID})
Frau = ({FrauID, FrauName}, {FrauID})
Relation: heiraten mit Attribut Termin
Es bestehen wieder mehrere Möglichkeiten diese Relation umzusetzen.
Möglichkeit 1:
3 Schemata:
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
33
Tabelle Mann
MannID
MannName
Tabelle Frau
FrauID
FrauName
Tabelle Heiraten
MannID
FrauID
Termin
mit:
Heiraten[MannID] Mann[MannID]
Heiraten[FrauID] Frau[FrauID]
Dieser Weg ist jedoch fast immer zu aufwändig, wenn auch er sehr gut für die
zusätzliche Aufnahme von unverheirateten Personen geeignet ist, da keine Nullwerte
entstehen.
Möglichkeit 2:
2 Schemata:
Tabelle Mann
MannID
MannName
Tabelle Frau
FrauID
MannID
FrauName
Termin
mit:
Frau[MannID] Mann[MannID]
Diese Möglichkeit ist vorzuziehen, wenn viele ledige Männer und nur sehr wenige
ledige Frauen aufzunehmen sind. Die ledigen Männer erzeugen dann hierbei keine
Nullwerte. Die entsprechende Umkehrung ist für den Fall von vielen ledigen Frauen
und wenigen bzw. gar keinen ledigen Männern geeignet.
Möglichkeit 3:
Oft wird nur eine Tabelle verwendet mit diesem zugehörigen Schema:
Tabelle Hochzeit
MannID
FrauID
MannName
FrauName
Termin
Hierbei entstehen jedoch bei jeder Aufnahme einer ledigen Person Nullwerte.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
34
3.4N OR MALF OR ME N
Wie zu Beginn des Kapitels 3 gesehen, besteht offenbar ein enger Zusammenhang
zwischen Entities und Relationen. Daher ist es auch relativ einfach – wie Kapitel 3.3
zeigt – die ER-Diagramme in die Tabellenschemata der relationalen Datenbanksysteme
umzuwandeln. In der Regel sollte es möglich sein, dass eine relationale Datenbank in
der dritten Normalform (wird im aktuellen Kapitel genauer definiert) vorliegt, nachdem
sie aus einem gut durchdachten ER-Diagramm in eine relationale Datenbank
transformiert wurde. Durch die vielen Möglichkeiten, die bei der Erstellung der ERDiagramme gegeben sind, kann dies jedoch nicht immer garantiert werden. Daher ist es
durchaus üblich zunächst anhand eines ER-Diagramms einen ersten Entwurf zu
erstellen, diesen dann über die Regeln der Normalisierung weiter zu verfeinern um
schließlich zu einem Relationenschema zu gelangen, dass alle geforderten Grundlagen
erfüllt. Welche Schritte dabei im Einzelnen durchzuführen sind, wollen wir in diesem
Kapitel näher betrachten.
Bei der Theorie der Normalformen gibt es über die dritte Normalform hinaus noch
weitere Normalformen – unter anderem die Boyce-Codd-Normalform, vierte und fünte
Normalform. Wir werden in dieser Vorlesung allerdings nur die erste bis dritte
Normalform behandeln. Interessierte, die sich weitergehend informieren möchten, seien
auf die aufgelisteten Werke der Fachliteratur verwiesen.
3.4.1A BH ÄN GI GK EI TE N
ZW ISCH EN
A TT RI BU TE N
Für die Erfüllung der Bedingungen zur Transformation eines Relationenschemas bis hin
zur dritten Normalform sind die Abhängigkeiten zwischen den einzelnen Attributen der
Entities von enormer Bedeutung.
Um ein besseres Verständnis für die Unterschiede zwischen funktionaler und voll
funktionaler Abhängigkeit beziehungsweise transitiver Abhängigkeit zu erlangen, soll
hier zunächst die eindeutige Definition dieser Begriffe vorgenommen werden und diese
anhand einiger Beispiele verständlich gemacht werden.
3.4.1.1Funktionale und volle funktionale Abhängigkeit
Definition der funktionalen Abhängigkeit:
In einem Relationenschema R ist das Attribut (bzw. die Attributkombination) Y
funktional abhängig vom Attribut (bzw. der Attributkombination) X, wenn zu jedem
Zeitpunkt jedem Wert von X genau ein Wert von Y zugeordnet ist.
Schreibweisen: R.X R.Y oder kürzer X Y
Zwei Tupel t1 und t2 der Relation haben nun die Werte x1 = t1[X], x2 = t2[X] und y1 =
t1[Y ], y2 = t2[Y ].
Die funktionale Abhängigkeit X Y bedeutet, dass aus gleichen Werten für X gleiche
Werte für Y folgen.
Also aus x1 = x2 folgt y1 = y2. (Bzw. aus t1[X] = t2[X] folgt t1[Y ] = t2[Y ].) D. h. mit
einem Wert von X wird eindeutig der Wert von Y festgelegt.
Anmerkung: Falls Y X gilt immer X Y .
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
35
Definition der voll funktionalen Abhängigkeit:
X sei nun ein aus mehreren Attributen zusammengesetzter Schlüssel, also eine
Attributkombination. Y sei ein einzelnes Attribut oder ebenfalls eine
Attributkombination. Y ist genau dann voll funktional abhängig von X, falls
X Y gilt und
es keine echte Teilmenge Z von X gibt mit Z Y .
Y ist also von der gesamten Attributkombination X funktional abhängig.
Schreibweisen:
R.X R.Y bzw. X Y
Anmerkung: Bei einer vollen funktionalen Abhängigkeit X
Y geht somit bereits beim
Entfernen eines einzelnen Attributs A aus der Attributmenge X die Abhängigkeit
verloren. Das heißt die um A verminderte Attributmenge Z = (X − {A}) bestimmt nicht
mehr funktional Y .
Veranschaulichung anhand eines Beispiels:
Relation r :
A
B
C
D
E
F
Tupel
1
2
3
4
5
6
(1)
1
3
0
0
1
7
(2)
2
1
0
0
2
3
(3)
3
2
5
6
7
8
(4)
1
0
3
0
6
6
(5)
Die Spalte Tupel ist hierbei eine Durchnummerierung der laufenden Tupel, also kein
Bestandteil der eigentlichen Relation.
A B gilt nicht, weil
(1) : x1 = t1[A] = 1, y1 = t1[B] = 2
(2) : x2 = t2[A] = 1, y2 = t2[B] = 3
Somit folgt aus x1 = x2 nicht y 1 = y2. ti[A] gibt hier also denWert des i-ten Tupels für das
Attribut A an. Zur Widerlegung einer Abhängigkeit reicht also die Angabe eines
Gegenbeispiels aus.
AC F, weil
(1) : x1 = t1[AC] = (1, 3), y1 = t1[F] = 6
(5) : x2 = t5[AC] = (1, 3), y2 = t5[F] = 6
Das „X“ in der allgemeinen Definition entspricht hier der Attributkombination AC. Da
dies die einzigen beiden Fälle sind, in denen AC die gleichen Werte hat, gilt hier:
aus x1 = x2 folgt y1 = y2.
E F, weil
je zwei Tupel aus r verschieden in ihrem Wert für das Attribut E sind. Es gibt keine
zwei gleichen Werte für E und somit kann die Behauptung E
F nicht widerlegt
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
36
werden. Jedem Wert von E wird genau ein Wert von F zugeordnet. In der vorliegenden
Relation könnte das Attribut E somit als Primärschlüssel dienen.
In unserem Beispiel Arzt behandelt Patient war der Name des Arztes/der Ärztin
eindeutig durch den Wert des Primärschlüssels ArztID festgelegt. Es galt also ArztID
Name. Zwei gleicheWerte für ArztID bestimmen somit ganz klar den selben Arzt/die
selbe Ärztin. Andererseits können zwei verschiedene Ärzte mit verschiedenen Werten
von ArztID den gleichen Namen haben. Zum Beispiel die Zahnärztin Müller und der
praktische Arzt Müller. Die Abhängigkeit gilt also nicht in umgekehrter Richtung.
3.4.1.2Transitive Abhängigkeit
Es gelten folgende Festlegungen:
Y ist abhängig von X, also X Y .
X ist jedoch nicht abhängig von Y , also Y X.
Z ist abhängig von Y , also Y Z.
Somit ist Z auch abhängig von X, also X Z. Z ist jedoch nicht direkt von X abhängig,
sondern über den „Umweg“ der Abhängigkeit zu Y . Z ist also transitiv (indirekt) von X
abhängig. Aufgrund der Forderung, dass nicht Y X ist, können die Werte von Z nicht
über Y die Werte von X bestimmen, also Z X gilt nicht.
3.4.2A NO MA LI EN
Sehr kleine Realwelt-Ausschnitte werden gerne „quick and dirty“ mit allen
notwendigen Attributen in einem einzigen Relationsschema und somit auch in nur einer
einzigen Tabelle zusammengefasst.
Beispiel: Ein Kunde kann mehrere Artikel bestellen und ein Artikel kann von mehreren
Kunden bestellt werden. Hierbei werden folgende Daten gespeichert:
Kunden-Daten: Name,Straße,Postleitzahl,Ort,Tel- und eine eindeutige Kundennummer
Artikel-Daten: Bezeichnung, Preis und eine eindeutige Artikelnummer
Weiterhin wird noch die Menge der bestellten Artikel festgehalten.
Für einen Tante-Emma Laden wird dieses gesamte Bestellwesen in einer einzigen
Tabelle Kunde-Artikel erfaßt:
KunNr ArtNr Name Strasse
PLZ
Ort
1
3941
Meier Rennweg_6
5455
0
1
1745
Meier Rennweg_6
1
7678
1
4598
Tel
Bezeichnung
Prei
s
Daun 12345
6
Öko-Toilettenpapier
2,30 1
5455
0
Daun 12345
6
Hundefutter„Wau-Wau” 2,50 4
Meier Rennweg_6
5455
0
Daun 12345
6
Waschmittel„Blitzblank” 3,50 1
Meier Rennweg_6
5455
0
Daun 12345
6
Gebäckmischung-Krone
Oktober 2007
Menge
2,00 2
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
2
2369
Jansen Gasse_56
4
7678
4
37
5459
5
Prüm 65763
5
Schoko-Osterhase
Pauly
Am_Berg_31 5455
0
Daun 86732
3
Waschmittel„Blitzblank” 3,50 2
5672
Pauly
Am_Berg_31 5455
0
Daun 86732
3
Öko-Toilettenpapier
1,80 2
5
?
Hinze Ringstr._5
5633
2
Loef 53512
0
?
?
?
6754
?
?
?
Taschentücher
1,50 ?
?
?
Jedes einzelne Tupel kann eindeutig durch die Kombination der beiden Attribute KunNr
und ArtNr identifiziert werden. Somit kann diese Kombination als Primärschlüssel
dienen. In obiger Tabelle sind die Attributwerte der beiden Entity-Typen Kunde und
Artikel sowie der Beziehung bestellen vermischt. Daher können bei diesem recht
„unsauberem“ Schema verschiedene Formen der Update-Anomalien auftreten, die im
Folgenden näher betrachtet werden sollen.
Einfüge-Anomalie:
Es wird ein neuer Artikel ins Sortiment aufgenommen (hier die Taschentücher). Für
diesen gibt es eine Artikelnummer, eine Artikelbezeichnung und einen Preis. Solange
der Artikel noch nicht von einem Kunden bestellt wird bleiben die Attribute KunNr,
Name, Strasse, PLZ, Ort, Tel. und Menge ohne konkreten Wert. Falls statthaft, können
sie mit Nullwerten aufgefüllt werden. Oder es wird eine neue Kundin aufgenommen
(hier die Frau Hinze), die jedoch noch keinen Artikel bestellt hat. Dabei können den
Attributen ArtNr, Bezeichnung, Preis und Menge ebenfalls nur Nullwerte zugeordnet
werden.
In beiden Fällen wird ein neuer Datensatz eingefügt, bei dem jedoch noch nicht für alle
Attribute konkrete Werte vorliegen. Beim Ersetzen der fehlenden Attributwerte mit
Nullwerten erhält in beiden Fällen ein Teil des Primärschlüssels einen Nullwert, diese
Situation sollte jedoch – wie anhand der Definition eines Primärschlüssels ersichtlich ist
– unbedingt vermieden werden.
Lösch-Anomalie:
Frau Jansen bestellt nur einen einzigen Artikel – den Schoko-Osterhasen.Wird dieser
Artikel beispielsweise nach Ostern aus dem Sortiment genommen und somit der
entsprechende Datensatz aus der Tabelle entfernt, gehen die Daten von Frau Jansen
ebenfalls verloren.Wird umgekehrt Frau Jansen als Kundin aus der Tabelle gestrichen,
gehen die Produktinformationen über den Schoko-Osterhasen verloren.
Änderungs-Anomalie:
Sobald ein Kunde mehrere Artikel bestellt, werden seine Daten mehrfach in der Tabelle
aufgelistet wie hier bei Herrn Meier ersichtlich ist. Analog geschieht ebenfalls eine
Mehrfachspeicherung der Artikel-Daten, falls ein Artikel von mehreren Kunden bestellt
wird – hier am Beispiel des Waschmittels „Blitzblank“ ersichtlich. Am Preis des „ÖkoOktober 2007
1,80 3
?
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
38
Toilettenpapiers“ lässt sich bereits erkennen, dass in Fehler bei der Preisaktualisierung
entstanden ist, das die Einträge in den Zeilen 1 und 7 unterschiedliche Werte aufweisen.
Falls dieser Fehler bereits länger zurückliegt und erst später entdeckt wird, kann
möglicherweise nicht mehr festgestellt werden, welcher Wert der momentan Richtige
ist.
Die Tabelle kann somit eine beträchtliche Redundanz an Dateneinträgen enthalten.
Ändert sich nun zum Beispiel der Preis eines Artikels oder der Wohnort eines Kunden,
muss diese Änderung unter Umständen in mehreren Tupeln der Tabelle durchgeführt
werden. Dieses Vorgehen ist sehr fehleranfällig und kann daher Inkonsistenzen
verursachen. Ursache für die Änderungs-Anomalie sind die durch den Tabellenaufbau
bedingten Redundanzen.
Diese drei Anomalien werden häufig unter dem Namen Update-Anomalien
zusammengefasst und können auftreten wenn:
Attribute (also Informationen) mehrerer Entity-Typen in einer Tabelle
vermischt werden.
Aber auch wenn Attributwerte eines Entity-Typen in mehreren Tabellen
und/oder mehrmals in einer Tabelle erscheinen (Redundanz).
Die Verwendung von Nullwerten ist lediglich ein notdürftiger Behelf und stellt keine
Lösung des Anomalien-Problems dar. Die Verwaltung zahlreicher Nullwerte belastet
das DBMS und bringt unter Umständen Effizienzprobleme mit sich.
3.4.3N OR MA LF OR ME N
Die Normalformenlehre vermittelt eine Theorie zur Verteilung der Attribute auf
Relationen. Die Bildung von Normalformen im Rahmen des sogenannten
Normalisierungsprozesses hat als Ziel die Minimalisierung von:
unbeabsichtigter Redundanz
Update-Anomalien (Einfügen, Löschen, Ändern)
Eine vollständige Vermeidung von Redundanz und Anomalien ist gerade bei größerem
Datenaufkommen und zahlreicher Tabellen so gut wie unmöglich. Die Erläuterung der
ersten drei Normalformen und ein erstes Beispiel zur Durchführung der Normalisierung
soll nun an der Relation Kunde-Artikel durchgeführt werden.
3.4.3.1Die erste Normalform
Eine Relation befindet sich in der ersten Normalform, wenn jedes ihrer Attribute nur
atomare Werte annehmen kann. Die Theorie der relationalen Datenbanken verlangt für
sämtliche Tabellen die Erfüllung der ersten Normalform. Somit sind in einem
Relationenschema und der zugehörigen Tabelle weder zusammengesetzte noch
mehrwertige Attribute statthaft. Daher wurde bei den diskutierten Beispielen ein
zusammengesetztes Attribut wie Adresse in seine Bestandteile Strasse, PLZ und Ort
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
39
zerlegt und ein mehrwertiges Attribut in ein eigenes Schema ausgelagert. Die Tabelle
Kunde-Artikel befindet sich somit bereits in der ersten Normalform.
3.4.3.2Die zweite Normalform
Eine Relation befindet sich in der zweiten Normalform, wenn sie die Bedingungen der
ersten Normalform erfüllt und jedes Nicht-Schlüsselattribut funktional vom gesamten
Schlüssel abhängt. Die zweite Normalform basiert also auf dem Konzept der vollen
funktionalen Abhängigkeit.
In der Tabelle Kunde-Artikel besteht der Primärschlüssel aus den beiden Attributen
KunNr und ArtNr. Der erste Bestandteil bezieht sich auf den Kunden, der zweite auf
den Artikel. Daher sind die kundenspezifischen Attribute Name, Strasse, PLZ, Ort und
Tel nur vom Schlüssel-Bestandteil KunNr abhängig. Die warenspezifischen Attribute
Bezeichnung und Preis sind dementsprechend nur vom Schlüssel-Bestandteil ArtNr
abhängig. Es gibt also Nicht-Schlüsselattribute, die nicht vom gesamten Schlüssel
abhängig sind. Das Relationsschema bzw. die zugehörige Tabelle liegt somit nicht in der
zweiten Normalform vor.
Der wesentliche Grund für die Verletzung der zweiten Normalform ist hier die
Zusammenfassung der Attribute der beiden Entities Kunde und Ware in eine Tabelle,
wodurch ein aus mehreren Attributen zusammengesetzter Primärschlüssel entsteht –
beziehungsweise notwendig wird. Die hier gegebene Situation kann durch die m:nBeziehung Kunde bestellt Artikel beschrieben werden.
Ein ER-Diagramm führt auf die folgenden 3 Relationenschemata:
Tabelle Kunde
KunNr
Name
Strasse
PLZ
Ort
Tel
Tabelle Artikel
ArtNr
Bezeichnung
Preis
Tabelle Bestellen
KunNr
ArtNr
Menge
Die Kombination der beiden Fremdschlüssel KunNr und ArtNr bildet also den
Primärschlüssel für die Identifizierung der einzelnen Tupel in dem Relationenschema
Bestellen. Zwischen den Attributen der einzelnen Tabellen gelten somit folgende
funktionale Abhängigkeiten:
KunNr {Name, Strasse, PLZ,Ort, Tel}
ArtNr {Bezeichnung, Preis}
{KunNr, ArtNr} Menge
Als Abhängigkeiten bezüglich der Fremd- und Primärschlüssel ergeben sich:
Bestellen[KunNr] Kunde[KunNr]
Bestellen[ArtNr] Artikel[ArtNr]
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
40
Die drei neuen Schemata Kunde, Artikel und Bestellen erfüllen nun alle die zweite
Normalform. Die konkreten Tabellen lauten wie folgt:
Tabelle Kunde:
KunNr
Name
Strasse
PLZ
Ort
Tel
1
Meier
Rennweg_6
54550
Daun
123456
2
Jansen
Gasse_56
54595
Prüm
657635
4
Pauly
Am_Berg_31 54550
Daun
867323
5
Hinze
Ringstr._5
Loef
535120
56332
Tabelle Artikel:
ArtNr
Bezeichnung
Preis
3941
Öko-Toilettenpapier
2,30
1745
Hundefutter_Wau-Wau
2,50
4598
Gebäckmischung_Krone
1,50
5672
Öko-Toilettenpapier
1,80
7678
Waschmittel_Blitzblank
3,50
2369
Schoko-Osterhase
1,80
6754
Taschentücher
1,50
Tabelle Bestellen:
KunNr ArtNr Menge
1
3941
1
1
1745
4
1
7678
1
1
4598
2
2
2369
3
4
7678
2
4
5672
2
Anhand der konkreten Tabellen sieht man auch sehr gut, dass in Bestellen das Attribut
Menge vom gesamten Primärschlüssel abhängt – also eine volle Abhängigkeit. Der
Kunde mit der Nummer 1 bestellt vom Artikel 3941 genau 1 Stück, vom Artikel 1745
genau 4 Stück, vom Artikel 7678 wiederum genau 1 Stück und vom Artikel 4598 genau
2 Stück. Bei Herausnahme des Schlüsselbestandteils ArtNr würden z. B. der
Kundennummer 1 die verschiedenen Mengen 4, 1 und 2 zugeordnet werden, was klar
der Definition der funktionalen Abhängigkeit widerspräche. Die Kundennummer allein
wäre also kein Schlüssel.
Analog würden bei Entfernung des Schlüsselbestandteils KunNr dem Artikel 7678 die
beiden Mengen 1 und 2 zugeordnet werden, was ebenfalls der funktionalen
Abhängigkeit widerspräche. Es gelten also weder KunNr Menge noch ArtNr Menge
sondern nur {KunNr, ArtNr} Menge.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
41
Anmerkung: Ein Relationenschema bzw. eine Tabelle, die bereits in der ersten
Normalform vorliegt und deren Primärschlüssel nur aus einem Attribut besteht (also
nicht zusammengesetzt ist), befindet sich automatisch in der zweiten Normalform. Als
Begründung dafür kann die Festlegung, die bei den funktionalen Abhängigkeiten
besagte, dass X Y immer gilt, falls je zwei Tupel für X unterschiedliche Werte
annehmen, genannt werden. Falls X nun den Primärschlüssel in Form eines einzelnen
Attributs bildet, kann X nur unterschiedliche Werte annehmen und es kann auch kein
Bestandteil von X weggenommen werden. Also ist jedes Nichtschlüsselattribut Y voll
von X abhängig.
Bei genauer Betrachtung der Tabelle Kunde fällt auf, dass beispielsweise der Ortsname
„Daun“ mitsamt seiner Postleitzahl 54550 mehrmals aufgelistet wird (Redundanz!).
Diese „Fehler“ wird im Rahmen der Diskussion um die dritte Normalform behoben
werden.
3.4.3.3Die dritte Normalform
Eine Relation befindet sich in der dritten Normalform, wenn sie
Normalform befindet und alle Nicht-Schlüsselattribute nur direkt
vom Schlüssel abhängen. Also kein Nichtschlüsselattribut
Primärschlüssel abhängig. Oder anders ausgedrückt: Es gibt
Abhängigkeiten zwischen den einzelnen Nichtschlüsselattributen.
sich in der zweiten
(also nichttransitiv)
ist transitiv vom
keine funktionalen
In den beiden Schemata Artikel und Bestellen ist diese Bedingung erfüllt. In Artikel
wird unter der gleichen Bezeichnung „Öko-Toilettenpaper“ ein Papier mit
unterschiedlichem Preis von 2.30 Euro und 1.80 Euro angeboten. Diese Papiere könnten
zum Beispiel aufgrund ihrer unterschiedlichen Artikelnummern von zwei verschiedenen
Lieferanten stammen – was die verschiedenen Preise erklären würde. Für den gleichen
Preis von 1.80 Euro werden die beiden völlig verschiedenen Artikel „ÖkoToilettenpapier“ und „Schoko-Osterhase“ verkauft. Also gelten für die beiden
Nichtschlüsselattribute Bezeichnung und Preis weder die funktionale Abhängigkeit
Bezeichnung Preis noch die Abhängigkeit Preis Bezeichnung.
Im Schema Bestellen gibt es nur das eine Nichtschlüsselattribut Menge und somit kann
es dort auch keinerlei Abhängigkeit zwischen (verschiedenen) Nichtschlüsselattributen
geben.
Zu den Nichtschlüsselattributen der Tabelle Kunde gehören unter Anderem die
Postleitzahl PLZ und der Ortsname Ort. Es soll nun vorausgesetzt werden, dass eine
Postleitzahl den Ortsnamen bestimmt. Gleiche Postleitzahlen bestimmen stets den
selben Ort. In obiger Beispieltabelle gehört zur mehrfach aufgeführten Postleitzahl
54550 stets der Ortsname „Daun“. Es gilt also die funktionale Abhängigkeit PLZ Ort.
Insgesamt gilt also:
KunNr PLZ
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
42
PLZ Ort und daher:
KunNr Ort.
Die geforderte Bedingung, dass nicht PLZ
KunNr gilt, ist hier ebenfalls erfüllt, da die
Postleitzahl nicht die Kundennummer bestimmt. Somit ist Ort also transitiv über PLZ
vom Primärschlüssel KunNr abhängig. Die Tabelle Kunde ist daher nicht in der dritten
Normalform. Um Kunde in die dritte Normalform zu überführen, muss die transitive
Abhängigkeit beseitigt werden. Dies geschieht über die Auslagerung der Abhängigkeit
PLZ Ort in ein separates Schema PLZ-Ort.
Das Attribut PLZ ist dann der Primärschlüssel von PLZ-Ort und ein Fremdschlüssel in
Kunde. Durch den Prozess der Normalisierung bis zur dritten Normalform ist das
ehemalige Schema Kunde-Artikel also in die folgenden vier Einzelschemata Kunde,
PLZ-Ort, Artikel und Bestellen aufgesplittet worden:
Tabelle Kunde
KunNr Name Strasse PLZ Tel
Tabelle PLZ-Ort
PLZ Ort
Tabelle Artikel
ArtNr Bezeichnung Preis
Tabelle Bestellen
KunNr ArtNr Menge
mit:
Kunde[PLZ] PLZ-Ort[PLZ]
Bestellen[KunNr] Kunde[KunNr]
Bestellen[ArtNr] Artikel[ArtNr]
als Abhängigkeiten bezüglich der Fremd- und Primärschlüssel.
3.4.4D ER W EG
DE R
N OR MA LI SIER UN G -
AU SFÜ HR LI CH ES
B EI SP IEL
Die Ziele der Normalisierung waren die Minimalisierung von Redundanz und Update
Anomalien (Einfüge, Lösch und Änderungsanomalie). Die Änderungsanomalie entsteht
hauptsächlich aufgrund von Redundanz.
Für die beiden anderen Anomalien ist die Vermischung der Attributwerte mehrerer
Entities und ggf. von Relationen in einem Schema verantwortlich.
Test auf 1. Normalform:
Die Relation darf keine zusammengesetzten oder mehrwertigen Attribute enthalten.
Außerdem sind keine Unterrelationen erlaubt.
Normalisierung: Zusammengesetzte Attribute in Einzelattribute, die alle atomar sind,
aufteilen. Für mehrwertige Attribute und Unterrelationen separate Schemata einführen.
Test auf 2. Normalform:
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
43
Falls eine Relation einen Primärschlüssel hat, der aus mehreren Attributen besteht, darf
kein Nichtschlüsselattribut von nur einem Teil des Primärschlüssels funktional abhängig
sein.
Normalisierung: Die Gesamtrelation wird dahingehend zerlegt, dass für jeden
Teilschlüssel P, von dem Attribute funktional abhängig sind, ein eigenes Schema
erstellt. Dieses Schema enthält dann den jeweiligen Teilschlüssel P als Primärschlüssel
und diejenigen Nichtschlüsselattribute, die von diesem Teilschlüssel funktional
abhängig sind. Außerdem wird ein Schema benötigt, welches den ursprünglichen
originalen (aus mehreren Attributen zusammengesetzten) Primärschlüssel und die von
ihm voll funktional abhängigen Nichtschlüsselattribute enthält.
Test auf 3. Normalform:
Eine Relation darf kein Nichtschlüsselattribut A enthalten, das funktional von einem
anderen (oder einer Menge von mehreren anderen) Nichtschlüsselattribute(n) abhängig
ist. Es darf also keine transitive Abhängigkeit eines Nichtschlüsselattributs A zum
Primärschlüssel bestehen.
Normalisierung: Das Nichtschlüsselattribut A und die anderen von ihm funktional
abhängigen Nichtschlüsselattribute in ein eigenes Schema auslagern. A wird dann im
neuen Schema der Primärschlüssel und bleibt im ehemaligen Schema ein
Fremdschlüssel.
Dies wollen wir mit Hilfe eines ausführliches Beispiels Schritt für Schritt durchführen.
Ausgangs-Tabelle Prüfungsdaten
PNr Fach
Pruefer MatNr
Name
Geb.
Adresse
FBNr FBName
123 LA
Meier
15345
6
Kaiser
23.09.8
0
Aachen,Bergstr.6
6
Mathematik Weber 2
15784
1
Berger
13.05.8
1
Eschweiler,Markt6 6
Mathematik Weber 3
14568
9
Michels 23.09.8
1
Alsdorf,Pfad56
8
Physik
Böhme 4
15345
6
Kaiser
23.09.8
0
Aachen,Bergstr.6
8
Physik
Böhme 3
15124
6
Müller
11.10.79 Jülich,Gasse78
8
Physik
Böhme 1
15137
8
Jansen
03.08.8
1
Stolberg,Parkallee1 8
Physik
Böhme 4
Plum
25.09.8
0
Aachen,AmHof4
8
Physik
Böhme 2
Scholz
12.07.8
1
Alsdorf,Hangstr.5
8
Physik
Böhme 5
562 Mechanik Bergs
981 Optik
Schulz 14991
7
15894
3
Test auf 1. Normalform:
Oktober 2007
Dekan Note
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
44
Auf die eigentliche Prüfung beziehen sich hier im Grunde nur die ersten drei Attribute
PNr (Prüfungsnummer), Fach und Pruefer. Die restlichen Attribute beschreiben
stattdessen den Prüfling, sein Ergebnis undden Fach bereich, in dem der Prüfling
geprüft wird.
Die Tabelle bzw. Relation Prüfungsdaten enthält sozusagen eine weitere Relation
Prüflings- und Fachbereichsdaten. Sie ist eine Unterrelation mit den Attributen MatNr,
Name, Geb., Adresse, FBNr (Fachbereichsnummer), FBName (Fachbereichsname),
Dekan und Note. Hierbei ist die Adresse auch noch ein aus den beiden Einzelattributen
Ort und Straße zusammengesetztes Attribut. Es liegt also ganz klar eine Verletzung der
1. Normalform vor.
Umwandlung in die 1. Normalform: Für die Unterrelation Prüflings- und
Fachbereichsdaten wird eine eigene Tabelle eingeführt und jede ihrer Zeilen wird noch
um den Primärschlüssel der übergeordneten Relation ergänzt. Außerdem wird das
mehrwertige Attribut Adresse durch die beiden Einzelattribute Ort und Strasse ersetzt.
Es ergeben sich also die beiden Relationen:
Tabelle Prüfung
PNr Fach
Pruefer
123 LA
Meier
562 Mechanik Bergs
981 Optik
Schulz
mit der funktionalen Abhängigkeit PNr {Fach, Pruefer}.
Prüflings- und Fachbereichsdaten1
PNr MatNr
Name
Geb.
Ort
Strasse
FBNr
FBName
123 153456
Kaiser
23.09.80
Aachen
Bergstr._6
6
Mathematik Weber 2
123 157841
Berger
13.05.81
Eschweiler Markt_6
6
Mathematik Weber 3
123 145689
Michels 23.09.81
Alsdorf
Pfad_56
8
Physik
Böhme 4
562 153456
Kaiser
23.09.80
Aachen
Bergstr._6
8
Physik
Böhme 3
562 151246
Müller
11.10.79
Jülich
Gasse_78
8
Physik
Böhme 1
562 151378
Jansen
03.08.81
Stolberg
Parkallee_1 8
Physik
Böhme 4
981 149917
Plum
25.09.80
Aachen
Am_Hof_4
8
Physik
Böhme 2
981 158943
Scholz
12.07.81
Alsdorf
Hangstr._5
8
Physik
Böhme 5
mit den funktionalen Abhängigkeiten
{PNr,MatNr} {FBNr, FBName,Dekan,Note}
MatNr {Name,Geb.,Ort, Strasse}
Oktober 2007
Dekan Note
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
45
Beide Relationen befinden sich nun in der 1. Normalform.
Test auf 2. Normalform:
Da in Prüfung der Primärschlüssel PNr nur aus einem Attribut besteht, befindet sich die
Relation automatisch auch in der 2. Normalform. Prüflings- und Fachbereichsdaten hat
hingegen einen Primärschlüssel, der aus den beiden Attributen PNr und MatNr besteht.
Die Attribute Name, Geb., Ort und Strasse hängen jedoch nicht vom gesamten
Schlüssel, sondern nur vom Teilschlüssel MatNr ab. Daher befindet sich diese Relation
nicht in der 2. Normalform.
Umwandlung in die 2. Normalform: Diejenigen Attribute, die nur vom Teilschlüssel
MatNr abhängen, werden in eine eigene Relation Prüfling ausgelagert.
Es ergeben sich somit die drei Tabellen:
Tabelle Prüfung (wie gehabt)
Tabelle Prüfling
MatNr
Name
Geb.
Ort
Strasse
153456
Kaiser
23.09.80 Aachen
Bergstr._6
157841
Berger
13.05.81 Eschweiler
Markt_6
145689
Michels
23.09.81 Alsdorf
Pfad_56
151246
Müller
11.10.79 Jülich
Gasse_78
151378
Jansen
03.08.81 Stolberg
Parkallee
149917
Plum
25.09.80 Aachen
Am_Hof_4
158943
Scholz
12.07.81 Alsdorf
Hangstr._5
mit der funktionalen Abhängigkeit MatNr {Name, Geb.,Ort, Strasse} und
Tabelle Prüfungsergebnis
PNr MatNr
FBNr
FBName
Dekan
Note
123 153456
6
Mathematik
Weber
2
123 157841
6
Mathematik
Weber
3
123 145689
8
Physik
Böhme
4
562 153456
8
Physik
Böhme
3
562 151246
8
Physik
Böhme
1
562 151378
8
Physik
Böhme
4
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
981 149917
8
Physik
Böhme
2
981 158943
8
Physik
Böhme
5
mit der funktionalen Abhängigkeit {PNr,MatNr}
46
{FBNr, FBName,Dekan,Note}. Alle
drei Relationen befinden sich nun in der 2. Normalform.
Test auf 3. Normalform:
Prüfung und Prüfling liegen bereits in der 3. Normalform vor, bei Prüfungsergebnis gilt
jedoch: FBNr
{FBName,Dekan} Es existiert also eine funktionale Abhängigkeit
zwischen den Nichtschlüsselattributen. Daher liegt Prüfungsergebnis nicht in der 3.
Normalform vor. Rein optisch erkennt man dies bereits an der enormen Redundanz bei
der Auflistung der Attributwerte von FBName und Dekan.
Umwandlung in die 3. Normalform: Hierzu wird Prüfungsergebnis in die beiden
Relationen Note und Fachbereich aufgeteilt.
Die Relationen in der dritten Normalform lauten somit:
Tabelle Prüfung (wie gehabt)
Tabelle Prüfling (wie gehabt)
Tabelle Note
PNr MatNr
Note FBNr
123 153456
2
6
123 157841
3
6
123 145689
4
8
562 153456
3
8
562 151246
1
8
562 151378
4
8
981 149917
2
8
981 158943
5
8
mit der funktionalen Abhängigkeit {PNr,MatNr} Note und
Tabelle Fachbereich
FBNr FBName
Dekan
6
Mathematik Weber
8
Physik
Böhme
mit der funktionalen Abhängigkeit FBNr {FBName,Dekan}.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
3.4.5V OR TE ILE
UN D
G RE NZ EN
DE R
47
N OR MA LI SIER UN G
Mit Hilfe der Normalisierung wollen wir sicherstellen, dass die Datenstrukturen über
die wird die relationale Datenbank bilden, möglichst effizient formuliert werden. Denn
dadurch erreichen wir folgende Eigenschaften bei unserem Datenbanksystem:
Verminderung der Redundanz,
Vermeidung von Inkosistenzen und Anomalien,
Übersichtlichkeit hinsichtlich der Attributanzahl durch Bildung vieler „kleiner“
Tabellen.
Wie bereits durch den letzten Punkt ersichtlich wird, hat die Normalisierung allerdings
auch einige Nachteile und Grenzen:
Der Realweltausschnitt wird oftmals durch die Transformation bis zur dritten
Normalform in zu viele und teilweise sehr kleine Tabellen „zerstückelt“, wodurch
möglicherweise der Überblick durch die Vielzahl an Tabellen und das Verständnis für
den Zusammenhang zwischen diesen Tabellen verloren gehen können.
Bei Abfragen, für deren Beantwortung auf Bestandteile mehrerer verschiedener
Tabellen zugegriffen werden muss, ist eine aufwändige Wiedervereinigung der
benötigten Tabellen erforderlich (Join-Bildung: siehe Kapitel „Relationale Algebra“ und
„Die Abfragesprache SQL“ ).
Gerade dieser zuletzt genannte Punkt setzt der Normalisierung in der Praxis Grenzen.
Die Theorie und Literatur empfiehlt zwar eine Normalisierung bis in die dritte
Normalform. Hierbei wird jedoch bereits bei recht einfachen Abfragen Information aus
mehreren Tabellen benötigt, deren Vereinigung allerdings gerade bei großem
Datenbestand meist eine enorm intensive Rechenleistung fordert. Aus diesem Grund
werden relationale Datenbanksysteme in der Praxis nur selten bis in die dritte
Normalform umgewandelt.
Die Normalisierung ist in gewisser Weise ein Balanceakt zwischen Nutzen und
Aufwand und wird im Zusammenhang mit der Designfrage eines Datenbanksystems
auch in Fachkreisen heiß diskutiert. In der Regeln muss immer aktuell anhand des
gegebenen Projektes beurteilt werden, welche Vorgehensweise sinnvoller ist und wie
weit normlisiert werden soll.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
48
4 D I E R E L AT I O N A L E A L G E B R A
UND DIE ABFRAGESPRACHE SQL
Im relationalen Datenmodell wird der interessierende Realitätsausschnitt durch eine
Menge von Relationen modelliert. In einer relationalen Datenbank werden diese
Relationen dann in Form von Tabellen angezeigt, die untereinander über Schlüssel
verknüpft sind.
Nur die wenigsten AnwenderInnen wollen den Informationsgehalt einer ganzen Tabelle
angezeigt bekommen. Stattdessen treten Fragestellungen wie zum Beispiel „Zeige
Name und Adressen aller Mitarbeiterinnen, die schon mehr als 5 Jahre angestellt sind
und in Abteilung 4 arbeiten“ auf. Als Ergebnis dieser Abfrage erwartet man eine
Auflistung der Namen und Adressen der betreffenden Mitarbeiterinnen.
4.1D IE
RE LATI ON AL E
ALG EB RA
Es soll also nur ein ganz bestimmter Ausschnitt aus einer Tabelle bzw. der Verknüpfung
mehrerer Tabellen angezeigt werden – dies wird auch die spezielle benutzerspezifische
Sicht auf das Datenmaterial genannt. Daher benötigt man ein Rechenmodell (eine
Algebra) und Operationen, die
bestimmte Zeilen und/oder Spalten einer Tabelle extrahieren können.
Tabellen miteinander verknüpfen können.
Die nachfolgenden Erläuterungen zu diesen Operationen sollen nun als Grundlage diese
Tabelle r verwenden, dabei ist die Durchnummerierung der laufenden Zeilen hierbei nur
eine Hilfestellung zur Berechnung der relationalen Datenmanipulationen und kein
Bestandteil der jeweiligen Relation.
Relation r :
A B C D Zeile
1 2 1 5 (1)
4 2 8 9 (2)
4 5 0 9 (3)
4 3 4 5 (4)
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
49
4.1.1D IE S EL EK TI ON
Eine Selektion ist dazu gedacht, aus einer Tabelle nur diejenigen Zeilen (Tupel)
herauszufiltern, in denen ein Attribut eine vorgegebene Bedingung erfüllt. Dabei
bleiben die selektierten Zeilen in ihrer Vollständigkeit – das heißt mit allen Attributen –
erhalten. Eine Selektion wird mit dem griechischen Buchstaben σ bezeichnet und
bekommt das Selektionsprädikat (die Bedingung) als Subskript angehängt.
Fragestellung: Zeige aus der Relation r alle Datensätze an, in denen das Attribut A den
Wert 4 hat.
Ergebnis:
Als Ergebnis erhalten wir demnach alle Zeilen der Ausgangstabelle r, die für die Spalte
A den Wert 4 eingetragen haben – hier Zeile (2) bis (4). Die Zeilen sind vollständig
erhalten, so dass alle Attribute erhalten bleiben.
4.1.2D IE P RO JEK TI ON
Wie wir oben gesehen haben, werden bei der Selektion einzelne Zeilen ausgewählt, die
ein bestimmtes Kriterium erfüllen. Die Projektion hingegen extrahiert eine oder mehrere
Spalten (Attribute) aus der gegebenen Relation. Eine Projektion wird mit dem Symbol
π gekennzeichnet und erhält als Subskript die auszuwählenden Attribute. Dabei ist zu
bemerken, dass Duplikatetupel, die durch eine Projektion auftreten, herausgefiltert und
im Ergebnis nicht mit angezeigt werden. Die Projektion blendet also bestimmte Spalten
der Relation aus und streicht danach eventuell mehrfach vorkommende Teiltupel. Diese
Duplikateliminierung kann verhindert werden, wenn unter den auszuwählenden
Attributen der vollständige Primärschlüssel der Relation enthalten ist.
Fragestellung:
Zeige von allen Datensätzen der Relation r die Werte der Attribute A und D an.
Ergebnis:
Die Projektion liefert somit drei Zeilen als Ergebnis, wobei nur die Attribute A und D
erhalten bleiben. Wie zu sehen ist, liefern die Zeilen (2) und (3) bei der gegebenen
Projektion ein identisches Ergebnis, so dass eines eliminiert wird. Es ist in der
Ergebnisrelation somit nicht mehr erkenntlich, auf welche Zeile der Ausgangsrelation
sich die neue zweite Zeile bezieht.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
4.1.3K OM BI NATI ON
VO N
S EL EK TI ON
UN D
50
P RO JEK TI ON
Da in der Praxis häufig äußerst umfangreiche Tabellen verwendet werden, ist oft die
Situation gegeben, dass nur bestimmte Werte eines Tupels angezeigt werden sollen, das
über eine gegebene Bedingung ausgewählt wird. Es wird also eine Kombination von
Selektion und Projektion notwendig.
Fragestellung:
Zeige aus der Relation r aus allen Datensätzen, die im Attribut A den Wert 1 haben und
zeige die Werte der Attribute C und D an.
Ergebnis:
Hierbei bearbeitet man zuerst die Selektion:
Auf dieses Tupel wird nun die Projektion angewendet. Syntax und Ergebnis der
gesamten Abfrage:
Es stellt sich vielleicht die Frage, warum man die Selektion vor der Projektion ausführt.
Das Ergebnis der Projektion sind nur bestimmte Spalten, also nur die Werte von
bestimmten Attributen – im gegebenen Beispiel sind dies die Spalten C und D. Die
Selektion gibt den Wert eines oder mehrerer Attribute (hier A) vor. A ist hier jedoch im
Ergebnis der Projektion nicht mehr enthalten, also könnte die Selektion gar nicht mehr
auf das Ergebnis der Projektion angewendet werden. Da das Ergebnis der Selektion alle
Attribute enthält, kann aber hierauf in jedem Fall die Projektion durchgeführt werden.
Aus diesem Grund bildet die Reihenfolge – Selektion vor Projektion – einer
notwendigen Kombination die Regel.
4.1.4D ER J OI N
Der Join verknüpft zwei oder mehr Tabellen miteinander, wobei diese Relationen oft ein
oder mehrere gemeinsame Attribute besitzen. Das kartesische Produkt (Kreuzprodukt)
von zwei oder mehr Mengen bildet oft eine enorm große Ergebnismenge (Aufblähung),
da die Mächtigkeit der Ergebnismenge n * m ist, falls die beiden betrachteten
Relationen n beziehungsweise m Tupel enthalten.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
Es seien drei Relationen r1, r2, r3 (bzw.ri mit 1 i
51
3) gegebenen, dann gelten für den
Verbund folgende Beziehungen:
Reflexivität:
ri ri = ri
Kommutativität:
r1 r2 = r2 r1
Assoziativität:
(r1 r2) r3 = r1 (r2
r3)
Falls die beiden Tabellen keine gemeinsamen Schlüsselattribute besitzen, ist der Join
gleich dem kartesischen Produkt der Relationen:
X1 X2 = 0 r1 r2 = r1 × r2
Falls in beiden Tabellen sämtliche Schlüsselattribute identisch sind, ist der Join gleich
dem Durchschnitt der Relationen:
X1 = X2 r1 r2 = r1 r2
Als Beispiel soll an drei Relationen das Assoziativgesetz durchgespielt werden.
r1 :
A B C Zeile
1 1 1 (1)
1 2 2 (2)
2 0 2 (3)
r2 :
A D Zeile
1 1 (1)
0 1 (2)
2 0 (3)
r3 :
C D E Zeile
1 1 0 (1)
0 1 1 (2)
2 1 0 (3)
2 2 1 (4)
Der Join zwischen r1 und r2 umfasst als Attributmenge die Vereinigungsmenge der
Attribute von r1 und r2, also A, B, C, D. Hierbei ist A gemeinsames Attribut. Nun
probiere man systematisch alle Kombinationen zwischen den Tupeln von r1 und r2. Von
diesen möglichen 3 · 3 = 9 Kombinationen werden für den Join dann nur diejenigen
verwendet, bei denen das gemeinsame Attribut A in r1 und r2 den gleichen Wert hat.
Tupel
Tupel
gem. Attribut A
Tupel des Joins r1
r2
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
aus r1
aus r2
(1)
(1)
1
1, 1, 1, 1
(1)
(2)
−
−
(1)
(3)
−
−
(2)
(1)
1
1, 2, 2, 1
(2)
(2)
−
−
(2)
(3)
−
−
(3)
(1)
−
−
(3)
(2)
−
−
(3)
(3)
2
2, 0, 2, 0
52
A,B,C,D
Aufgrund der Forderung nach gleichen Werten für das gemeinsame Attribut A bleiben
für den Join hier nur drei Kombinationen übrig:
r1 r2 :
A B C D Zeile
1111
(1)
1221
(2)
2020
(3)
Hätten r1 und r2 kein gemeinsames Attribut (beispielsweise hätte r2 durch eine
Projektion auf D nur noch dieses eine Attribut), so bestünde der Join aus allen 9
möglichen Kombinationen. Er wäre somit laut (iv) das kartesische Produkt der
Relationen r1 und r2 und würde folgendermaßen aussehen:
r1 πD(r2) :
A B C D Zeile
1111
(1)
1111
(2)
1110
(3)
1221
(4)
1221
(5)
1220
(6)
2021
(7)
2021
(8)
2020
(9)
Würde nun mit dem Join r1
r2 (drei Ergebniszeilen), der bereits oben gebildet wurde,
ein Join mit r3 gebildet, so gäbe es mehr Möglichkeiten – 3 · 4 = 12. Doch auch hier
können aufgrund der gemeinsamen Attribute C und D nur zwei gültige Tupel aufgelistet
werden:
(r1 r2)
r3 :
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
53
A B C D E Zeile
11110
(1)
12210
(2)
Ganz anolog zunächst die Join-Bildung zwischen r2 und r3, diese beiden Relationen
können 3 · 4 = 12 Möglichkeiten bilden
Tupel
aus r2
Tupel
aus r3
gem. Attribut D Tupel des Joins r2
A,C,D,E
(1)
(1)
1
1, 1, 1, 0
(1)
(2)
1
1, 0, 1, 1
(1)
(3)
1
1, 2, 1, 0
(2)
(4)
−
−
(2)
(1)
1
0, 1, 1, 0
(2)
(2)
1
0, 0, 1, 1
(2)
(3)
1
0, 2, 1, 0
(2)
(4)
−
−
(3)
(1)
−
−
(3)
(2)
−
−
(3)
(3)
−
−
(3)
(4)
−
−
r3
Wie zu sehen ist, hat dieser Join allerdings durch das gemeinsame Attribut D nur 6
gültige Tupel:
r2 r3 :
A C D E Zeile
1110
(1)
1011
(2)
1210
(3)
0110
(4)
0011
(5)
0210
(6)
Wird nun die Relation r1 wieder mit diesem bestehenden Join r2 ./ r3 gebildet ergibt
sich wieder eine Möglichkeit von 6 · 3 = 12, durch die gemeinsamen Attribute A und C
ergeben sich wieder nur zwei gültige Tupel:
r1 (r2
r3) :
A B C D E Zeile
11110
(1)
12210
(2)
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
54
Und wie erwartet können wir nun folgende Aussage bestätigen:
(r1 r2) r3 = r1 (r2 r3)
4.1.4.1Leistungsfähigkeit von Datenbankbetriebssystemen bei Joins
An diesem Beispiel sieht man, dass die Bildung eines Joins gerade bei großen
Relationen sehr aufwändig ist. Und je mehr Tabellen eine relationale Datenbank besitzt,
desto häufiger müssen bei Abfragen und Aktualisierungen Join-Bildungen durchgeführt
werden. Eine große Tabellenanzahl bedeutet somit neben der Zerstückelung der
Information auch oft eine Beeinträchtigung der Leistung (Performance). Durch die
Bildung von hohen Normalformen (z. T. höher als die Dritte) versucht man einerseits
jegliche Anomalien zu vermeiden, erhöht jedoch andererseits die Anzahl der Tabellen.
Daher ist es manchmal aus Performancegründen sinnvoller, nicht durch extreme
Normalisierung jede Anomalie beseitigen zu wollen.
Ansatz zur Optimierung
Bei einer Selektion wird durch die Auswahl von bestimmten Zeilen eine Tabelle
verkleinert. Bei vielen Abfragen sind sowohl Selektionen als auch Join-Bildungen
notwendig. In solchen Fällen versucht der Optimierer des DBMS, Selektionen vor JoinBildungen durchzuführen, damit die am Join beteiligten Tabellen möglichst klein sind.
4.2D IE D ATEN AB FR AG ES PR AC HE SQL
An einem vorhandenen Datenbestand können von Seiten des Benutzers zwei Arten von
Arbeiten vorgenommen werden:
Abfragen (Queries), wodurch die Daten keine Veränderung erfahren. Zum
Beispiel möchte die Chefin eine Auflistung der Personalnummern und Namen
aller Mitarbeiter, die in Abteilung 2 arbeiten. Das Ergebnis einer solchen
Abfrage ist eine spezielle Sicht (View) auf das Datenmaterial.
Aktualisierungen (Updates) in Form von Einfüge-, Lösch- und
Änderungsvorgängen. Beispielsweise wird das Gehalt der Mitarbeiterin Müller
um 10 Prozent erhöht.
Hierfür werden dem Benutzer sogenannte Datenmanipulationssprachen (DML) zur
Verfügung gestellt. SQL ist eine solche Sprache, die Abkürzung steht für Structured
Query Language – in der Literatur manchmal auch Standard Query Language genannt –
und bedeutet auf deutsch etwa “strukturierte Abfragesprache“. Das Absenden eines
SQL-Befehls
geschieht
auf
der
externen
Ebene
(ausserhalb
des
Datenbankbetriebssystems) über spezielle Eingabemasken, die Bestandteil der
grafischen
Oberfläche
des
Datenbanksystems
sind,
oder
über
eine
Kommandozeileneingabe. Nach der Entgegennahme des Befehls durch das DatenbankManagment-System wird dieser zunächst vom einem Parser auf seine syntaktische
Korrektheit geprüft, bevor er im Falle einer Fehlerfreiheit weiterverarbeitet wird.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
55
SQL-Anweisungen zum Erstellen, Konfigurieren und Löschen von Datenbanken und
Tabellen zählen sprachlich zu den Datendefinitionssprachen (DDL) der konzeptionellen
Ebene von DBMS.
Die SQL-Befehle zum Auswählen und Editieren vorhandener Datensätze werden
wiederum – wie oben erwähnt – den Datenmanipulationssprachen (DML) zugeordnet.
SQL stellt somit äußerst vielseitige Möglichkeiten zur Bearbeitung einer Datenbank.
Die folgende Tabelle zeigt einen Überblick über die Einsatzmöglichkeiten
(Kategorisierung der Befehlstypen in SQL):
Befehlskategorisierung in SQL
Gruppe
Abk.
Beschreibung
Datendefinition
DDL
Erstellen von Tabellen und CREATE, DROP, ALTER
wichtige Befehle
Indizes
Datenabfrage
DQL
Auswahl von Datensätzen aus SELECT
einer oder mehrerer Tabellen
Datenmanipulation
DML
Anfügen, ändern, löschen von INSERT, UPDATE,
Datensätzen
DELETE
Datenzugriffskontrolle DCL
Vergabe von Zugriffsrechten GRANT
für Tabellen
Die Anfänge dieser Sprache liegen in den frühen 70er Jahren. Bei IBM wurde schnell
die Bedeutung der relationalen Datenbanksysteme erkannt und die Sprache SEQUEL –
Structured English Query Language – entwickelt, die später in SQL umbenannt wurde.
Anfang der 80er Jahre erstellte das American National Standards Institut eine
Standardisierung der relationalen Datenbanken und somit auch der SQL-Sprache. 1986
wurde schließlich die erste Version mit Standard SQL1 (auch SQL86 genannt)
verabschiedet. Diese Version enthielt bereits alle Befehle zur Datenmanipulation sowie
die SELECT-Klauseln WHERE, GROUP BY und HAVING. Als Aggregatfunktionen
waren COUNT, SUM, MIN, MAX und AVG nutzbar und erste Formen von
Unterabfragen konnten durchgeführt werden. Die Befehle zur Definition der Datenbank
inklusive ihrer Tabellen waren allerdings noch recht unübersichtlich.
Die im Oktober 1989 veröffentlichte Version SQL89 umfasste bereits Möglichkeiten der
Integritätsprüfung wie beispielsweise die CHECK-Klausel und Gültigkeitsprüfungen für
neu einzufügende Werte. Die Elemente Primär, Sekundär und Fremdschlüssel wurden in
den Sprachumfang aufgenommen.
Standard SQL2 enthielt eine deutliche größere Funktionsvielfalt:
Einführung neuer Datentypen, Domäne als vordefinierte Typen, Änderung der
Tabellendefinition mit ALTER TABLE, Angleichung von OUTER und INNER JOIN,
Transaktionsmöglichkeiten
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
56
Die im Dezember 1999 verabschiedete Version SQL3 (auch SQL 99 genannt) wurde
nochmals um einige Funktionen erweitert, über die unter anderem nun auch
objektorientierte Programmierung der Datenbank möglich wird.
4.2.1A NL EG EN , L ÖS CH EN
UN D
A US WÄ HL EN
EI NE R
D ATEN BA NK
Bevor Daten in eine Datenbank eingegeben werden können, muss zunächst die
Datenbank angelegt und benannt werden. Anschließend sind die Tabellen zu erstellen
und konfigurieren, in die später Datensätze eingetragen werden sollen. Grundsätzlich
gilt, dass für die Namen von Datenbanken, Tabellen und Spalten nur solche Bezeichner
verwendet werden sollten, die keine SQL-Schlüsselwörter enthalten und deutsche
Umlaute sind zu vermeiden.
Der Befehl zum Anlegen einer Datenbank ist letztendlich eine sehr vereinfachte Form
des Tabellenerstellungsbefehls, den wir – wie auch die weiteren gennannten Vertreter –
im praktischen Teil der Veranstaltung detailliert betrachten wollen:
CREATE DATABASE <Datenbankname>
Der Befehl zum Löschen einer Datenbank ist ähnlich dem Erstellungsbefehl analog zum
Löschen einer Tabelle:
DROP DATABASE <Datenbankname>
Eine Übersicht über die vorliegenden Datenbanken des Servers ist erhältlich mit dem
Befehl
SHOW DATABASES
und eine konkrete Datenbank wird ausgewählt über:
USE <Datenbankname>
4.2.2A NL EG EN , Ä ND ER N
UN D
D EF INI ER EN
EI NE R
T AB EL LE
Tabellen stellen die Grundlage einer relationale Datenbank dar. In ihnen werden die
Informationen strukturiert nach den Vorgaben der Tabellendefinition abgespeichert.
Eine Übersicht der bestehenden Tabellen ist durch folgenden Befehl erhältlich:
SHOW TABLES
Ist die Definition einer bereits bestehenden Tabelle gewünscht gibt es einen
DESCRIBE-Befehl, der die Tabellendefinition aufführt:
DESCRIBE <Tabellenname>
Um eine Tabelle anlegen zu können, müssen im SQL-Befehl sowohl der Tabellename
genannt als auch die Spalten mit ihren Definitionen aufgeführt werden. Das
Relationenschema wird durch den folgenden SQL-Befehl als Tabelle in die Datenbank
eingefügt:
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
57
CREATE TABLE t_personal
(
key1 INTEGER NOT NULL PRIMARY KEY,
nachname VARCHAR(50),
...
)
Der SQL-Befehl zur Tabellenerzeugung beinhaltet auch Möglichkeiten zur Typgebung
der einzelnen Attribute, zur Setzung von (Primär)Schlüsseln oder auch Indizes.
Mittels dem Befehl:
ALTER TABLE ...
können Tabellen mit SQL verändert werden.
4.2.3E INE T AB EL LE
MI T
W ER TE N
FÜ LL EN , LE ER EN UN D LÖ SC HE N
Datensätze können in eine Tabelle mit dem Befehl:
INSERT INTO
eingefügt werden.
Mit dem Befehl:
DELETE FROM <tablename>
können ganze Tabellen gelöscht werden und mit dem Befehl
DROP TABLE <tablename>
wird die Tabelle vollständig aus der Datenbank entfernt.
4.2.4D ATEN
AU SWÄ HL EN UN D BE AR BE ITE N
Die wesentlichsten Operationen der relationalen Algebra werden im Befehl SELECT
abgebildet. Durch die Projektion auf bestimmte Teilattribute, durch die Selektion auf
bestimmte Werteausprägungen von benannten Attributen und durch die Bildung von
Joins können mit diesem Befehl die gewünschten Ergebnisse erreicht werden.
Beispiele:
SELECT * FROM <tablename>
SELECT A,C,E FROM <tablename>
SELECT B,D FROM <tablename> WHERE A >= 17
SELECT a.A, C,D,E FROM <tname1> a, <tname2> b WHERE a.A = b.A AND C=25
…
Für eine detaillierte Beschreibung der SELECT Statements sei hier auf die praktischen
Übungen und auf die Spezifikationen des Standards SQL verwiesen.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
58
4.2.5A GG RE GATF UN KT ION EN , B ER EC HN UN GE N , S OR TI ER UN GE N
SQL erlaubt auch Operationen, die über ganze Tabellenspalten Werte berechnen
können. Solche Aggregatfunktionen errechnen zum Beispiel das Minimum,
dasMaximum oder den Durchschnitt aller Werte in einer Spalte der untersuchten
Tabelle.
Weiters ist es möglich, Werte mit Standardfunktionen zu den untersuchte Datentypen zu
verknüpfen. So kann etwa eine gesamte Spalte mit einem Faktor multipliziert werden
(Umrechnung einer Schilling-Spalte in Euro, oder umgekehrt).
Darüber hinaus kann das Ergebnis einer Abfrage nach bestimmten Kriterien sortiert
oder im Falle von Aggregatfunktionen gruppiert werden. Auch dazu bringt die
Fachliteratur , aber auch der praktische Teil der Veranstaltung anschauliche Beispiele.
4.2.6B ES TE HE ND E D ATEN SÄ TZ E
VE RÄ ND ER N OD ER GE ZI ELT LÖ SC HE N
Nachdem nun Tabellen erstellt, Datensätze eingefügt und (selektiert) angezeigt wurden,
fehlen noch die Befehle, mit denen bestehende Datensätze verändert oder gezielt
gelöscht werden können.
4.2.6.1Ändern über UPDATE
Beim Ändern von Datensätzen ist zu unterscheiden, ob global die Werte einer
bestimmten Tabellenspalte verändert werden sollen oder nur diejenigen Zeilen von der
Änderung betroffen sein sollen, die eine bestimmte Bedingung erfüllen. Betrachten wir
zunächst den Fall der globalen Änderung. Wir beziehen uns dabei wieder auf die
Tabelle t_personal und möchten ein einheitliches Gehalt von 2000 Euro einführen.
Dazu senden wir folgenden Befehl an die Datenbank:
UPDATE t_personal SET gehalt=2000
Das SQL-Schlüsselwort UPDATE leitet hier die Aktualisierung ein und nach demWort
SET sind die betreffenden Spalten mit dem gewünschten neuenWert anzugeben. Als
nächstes wollen wir diese Aktualisierung nun auf einen bestimmten Datensatz
beschränken: Das Gehalt des Herrn Pauly soll auf 2500 Euro angehoben werden.
UPDATE t_personal SET gehalt=2500 WHERE nachname="Schranz"
Anstelle des Vergleiches des Nachnamens auf Gleichheit mit „Schranz“ , hätte auch die
Personalnummer angegeben werden können (WHERE pernr=3).
4.2.6.2Löschen mittels DELETE FROM ... WHERE
Wie die vollständig Leerung einer Tabelle über den Befehl DELETE FROM ...
funktioniert, haben wir bereits kennen gelernt. Nun wollen wir aber nur bestimmte
Zeilen aus einer Tabelle löschen und nicht alle. Dies geschieht wieder über die Angabe
einer Bedingung mit Hilfe des WHERE-Teils. Nehmen wir an, Herr Schranz hätte
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
59
gekündigt und wir wollten seinen Datensatz nun aus der Tabelle t_personal entfernen.
Dazu benötigten wir den nachstehenden Befehl:
DELETE FROM t_personal WHERE pernr=3
An dieser Stelle sollte der Benutzer möglichst immer mit der Angabe des
Primärschlüssels in der WHERE Bedingung arbeiten, damit keine Irrtümer auftreten
können.
4.3P RO BL EME
MI T
SQL
UN D DE M RE LATI ON AL EN
MOD EL L
Im folgenden sollen ohne Gewichtung und Wertung einige Problemfelder aufgezählt
werden, mit denen das relationale Datenbankmodell und wir als seine Anwender zu
kämpfen haben. Die sich daraus ergebenden konkreten Schwierigkeiten ergeben sich in
der Anwendung beim speziellen Einsatzfall und können von komplett irrelevant bis zu
enormen zusätzlichen Aufwänden in der Realisierung reichen. Trotz der aufgezählten
Problematiken ist der relationale Ansatz der meistverbreitete und erforschte in der
Datenbankwelt und kann auf vier Jahrzehnte Erfahrung und herausragender
Einsatzperformance und Leistungsfähigkeit verweisen.
Offene Probleme beim relationalen Ansatz
Tabellenfelder haben feste Maximalgröße
z. B. Foto von Studenten soll elektronisch in der Datenbank archiviert werden
Sehr aufwendige Modellierung bei komplexen, hierarchischen Objekten
z. B. Student hat mehrere Adressen oder Telefonnummern
z. B. Studiengang von mehreren Fakultäten gleichzeitig
Aufwendige Simulation von Polymorphie
z. B. Person, davon abgeleitet Student, Mitarbeiter, Professor
Dies führt zu:
Explosion der Tabellenanzahl
Komplexe Abfragen
Geschwindigkeitsprobleme
Sonderbehandlung von variablen, großen Objekten (BLOBs)
Insellösungen und Speziatricks der Datenbankimplementierer
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
60
4.4L ITERATU R
A. Kemper/A. Eickler: Datenbanksysteme 2001, Oldenbourg Wissenschaftsverlag
GmbH ISBN 3-486-25706-4
G. Vossen: Datenmodelle, Datenbanksprachen und Datenbankmanagmentsysteme,
2000, Oldenbourg Wissenschaftsverlag GmbH, ISBN 3-486-25339-5
Elmasri, Navathe: Fundatmentals of Database Systems, 2000, Addison-Wesley, ISBN 0201-54263-3
M. Ebner: SQL lernen, 2002, Addision-Wesley, ISBN 3-8273-2025-9
M. Schranz: Fragmentierung und Replikation in Verteilten Datenbanken, Diplomarbeit
1994, Technische Universität Wien
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
5 D AT E N B A N K E N
UND
61
A P P L I K AT I O N E N
FA L L S T U D I E P R E S S E T E X T. A U S T R I A
NACHRICHTENAGENTUR
In diesem Abschnitt soll ein kokretes Anwendungs-Fallbeispiel zeigen, wie
Datenbanken innerhalb von komplexen Wirtschaftsanwendungen zum Einsatz kommen.
Als Fallstudie wurde die in Österreich beheimatete und im gesamten deutschen
Sprachraum agierende Nachrichtenagentur pressetext.austria gewählt. Die Anwendung
scheint schon deshalb relevant, weil sowohl Informationsinhalte und Leserdaten einen
derart enormen Umfang erreichen, dass ohne klar strukturierte und leistungsfähige
Datenbanken ein wirtschaftlicher Betrieb der untersuchten Nachrichtenagentur nicht
möglich wäre.
Die Erfahrungen des Autoren gründen sich darauf, dass er selbst über vier Jahre im
technischen Management der Nachrichtenagentur tätig war und seither
pressetext.austria zu seinen bedeutendsten Kunden zählen kann.
5.1F AL LS TU DI E
PR ES SE TE XT . AUSTR IA
( PT E ,
WW W . PR ES SET EX T . AT )
pressetext.austria (pte) defniert sich selbst als eine rein online basierte
Nachrichtenagentur. Das Konzept der pte setzt sich einerseits aus der Qualitätsgarantie
durch selbst recherchierte hochqualitative Wirtschaftsnachrichten und andererseits
durch die Bereitstellung einer Nachrichten-Distributionsplattform für interessierte
Wirtschaftsunternehmen zusammen.
Gesellschaften, Vereine, Organisationen können die Nachrichtenplattform nutzen, um
selbst wirtschaftsrelevante Nachrichten an die – zum Stand Juni 2004 – mehr als 70.000
Abonnenten des Nachrichtendienstes zu versenden und die Meldung selbst in ein
ständig verfügbares und recherchierbares Nachrichtenarchiv (www.pressetext.at) online
zu stellen. Ergänzt werden diese Meldungen durch täglich recherchierte
Wirtschaftsnachrichten durch eine unabhängige Redaktion im Hause pressetext.austria,
die durch die Zahlungen der aussendenden Unternehmen finanziert wird, jedoch durch
ein Redaktionsstatut zur unabhängigen Berichterstattung befugt ist.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
5.1.1D IEN ST LE ISTU NG EN
62
DE R PR ES SET EX T . AU STR IA
Wie kann nun der interessierte Leser auf die Dienstleistungen der pressetext.Austria
zugreifen? Was wir hier beschreiben wollen, sollte technisch exakt eher
„Benutzerschnittstelle zum pte Service“ heißen, wir wollen aber den nüchternen Blick
etwas im Sinne des attraktiven Services von pte anreichern.
Jeder Leser von pressetext.austria kann als erste Anlaufstelle die Webseiten von pte
besuchen, um sich einerseits über aktuelle Wirtschaftsneuigkeiten zu informieren (pte
agiert passiv) und andererseits seine persönlichen Profile für individualisierte
Belieferungen an Wirtschaftsnachrichten festzulegen (pte agiert aktiv).
Beide Leistungen werden durch ein relationales Datenbankmanagementsystem
(RDBMS) unterstützt. Dem Leser/Besucher wird der Zugang zu den Datenbankinhalten
nicht direkt, sondern über die komfortable Schnittstelle WWW gewährt. So kann er jede
einzelne pte Nachricht über die Webseite recherchieren (Volltextsuche, Navigation),
thematisch verwandte Meldungen ansehen, die Meldungen ausdrucken oder an einen
interessierten Bekannten weiterleiten. Jede Meldung wird aktuell aus der Datenbank
ausgelesen und für die Anzeige im WWW-Browser in HTML generiert.
Jeder interessierte Leser kann sich für ein kostenfreies Abonnement über
benutzerfreundliche Web-Formulare registrieren. Dabei wird seinen thematischen
Vorlieben entsprechend in der Datenbank ein Profil angelegt. Je nach den gewünschten
Einstellungen kann der Leser dann jede einzelne Pressemitteilung sofort nach deren
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
63
Erstellung zugesandt erhalten (meist Journalisten, die die Meldungen sehr zeitkritisch
für ihren Beruf benötigen) oder aber eine Tageszusammenfassung der relevantesten
Meldungen zu seinem Themenprofil erhalten (hier wird abends für jeden Abonnenten
eine individuelle Zusammenstellung erarbeitet und versandt).
Neben diesen Basis-Dienstleistungen bedient pressetext.austria kommerzielle Kunden
(B2B) mit Nachrichtenstreams über ein Content Syndication Service (Content
Management System auf Basis XML Massennachrichtendistribution). Pte beliefert
damit u.a. yahoo, wallstreet-online, MSN und den Österreichischen Mobilfunkanbieter
ONE.
5.1.2T EC HN ISC HE A US RÜ ST UN G
Als österreichische KMU ist pressetext angehalten, Resourcen optimal auszuschöpfen,
weil im Gegensatz zu Großunternehmen der Zugang zu gigantischen Rechenzentren
und unerschöpflicher Manpower nicht möglich ist.
Die Strategie, die pressetext.austria seit seiner Gründung verfolgte, wurzelt im Einsatz
von Open Source Software auf Basis von qualitativ hochwertigen, aber handelsüblichen
Standard-Hardwaregeräten (COTS Komponenten).
Das eingesetzte relationale Datenbankmanagementsystem (RDBMS) ist das Open
Source System MySQL, mit dem pressetext.austria seit 1999 sehr positive Erfahrungen
sammeln konnte. Die gesamte Datenbank besteht aus 12 unanbhängigen Datenbanken,
die für das Basissystem pte bedeutendste Datenbank setzt sich aus 78 Relationen
(Tabellen) zusammen.
5.1.3S ER VI CE D ETAI LB ES CH RE IBU NG EN
UN D
DB-A US LA STU NG
Das eingesetzte Content Management System redN© ist mehrmandantenfähig und
betreut von der zentralen Datenbank aus die Nachrichtenportale pressetext.austria
(www.pressetext.at),
pressetext.deutschland
(www.pressetext.de)
und
pressetext.schweiz (www.pressetext.ch, www.pressetext.li).
Jedes der Portale erlaubt eine isolierte Recherche der länderspezifischen Nachrichten
und gliedert die Wirtschaftsbeiträge in die Bereiche (Channels) Hightech, Medien,
Business und Leben. Zusätzlich werden die Meldungen maximal 2 von 15 Ressorts
zugeordnet, was für die individuellen Profile zur Auslieferung verwendet wird.
Die Versendung von Wirtschaftsnachrichten erfolgt über eine Web-Schnittstelle, die nur
registrierten Aussendekunden zugänglich ist. Jeder Kunde erhält zur Bedienung der
Versendefunktionen ein Kundenkennwort und ein Passwort und kann dann einige
Funktionalitäten des CMS nutzen, um Wirtschaftsnachrichten über das pressetext
Netzwerk zu verteilen.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
64
Aktuell befinden sich in der Datenbank etwa 69.000 Wirtschaftsnachrichten, die alle
über die Web-Schnittstelle online und jederzeit recherchiert werden können. Mehr als
71.000 Abonnenten haben für sich selbst ein individuelles Profil angelegt und werden
dadurch (manche auch mehrmals) täglich mit pressetext Nachrichten beliefert (per
email). Neben den monatlich über 1,4 Millionen Seitenzugriffen (echte page
impressions) werden so auch zusätzlich mehr als 500.000 emails pro Werktag versendet.
Jede einzelne Webseite und jede einzelne Email werden aus zumindest einem
Datenbankzugriff erstellt, wodurch sich eine Datenbankbelastung von mehr als 5
Zugriffen pro Sekunde ergeben.
Das technische Service läuft großteils auf symmetrischen Servern, die mit einer
speziellen Variante der LAMP Architektur ausgerüstet sind (Linux, Apache, Mysql,
Perl/Mason).
Der Datenbankserver ist ein eigens für die Verwaltung des RDBMS abgestellter
Rechner, der durch eine Backup-Rechner gesichert wird.
Die Distribution der Wirtschaftsnachrichten erfolgt über zwei Mailserver, die B2BVariante wird von einem Syndikatsserver realisiert. Alle Komponenten bedienen sich
aber der unabhängig vom Service verwalteten Daten des Datenbankservers.
Oktober 2007
Department für Wissens- und Kommunikationsmanagement - Schranz / Datenbanken
65
5.2A KT UE LL E E NT WI CK LU NG EN
Obwohl die beschriebene Fallstudie ständig technischen Neuerungen unterworfen ist,
und etwa die CMS Komponenten, die Mail-Distributionskomponente oder die
Syndikatsservices zumindest einmal pro Jahr aktualisiert werden, sind die Daten und
das Datenbankbetriebssystem ein stabiles Kernstück des Gesamtservices.
Aktuell wird pressetext.austria als Partner im EU-Projekt OmniPaper und im EUProjekt Nedine seine Wirtschaftsnachrichten über den W3C-Standard SOAP an ein
europaweites Nachrichtenarchiv ausliefern (Projektende Mitte 2007). Die technischen
Realisierungen werden vom Projektkonsortium getragen, die Gesamtarchitektur wurde
von Dr. Schranz als Technischen Direktor des Projektes konzipiert.
Im
EU-Projekt
NEDINE
arbeiten
pressetext.austria,
die
Tschechiche
Nachrichtenagentur CIA und die slowakische Nachrichtenagentur SITA gemeinsam mit
Universitäten und PR-Agenturen aus ingesamt sechs Staaten Europas zusammen, um
ein Wirtschaftsnachrichten-Verteilnetzwerk in Mittel- und Zentraleuropa aufzubauen.
Auch hier werden moderne technische Konzepte zum Einsatz kommen, aber die Daten
stehen als Invariante fest im Mittelpunkt der zu entwickelnden Systeme.
Oktober 2007