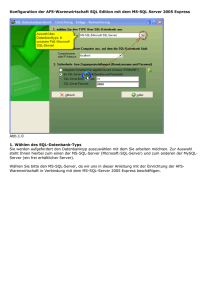
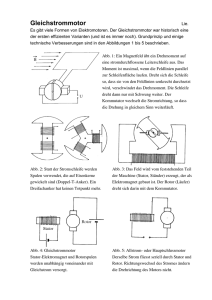
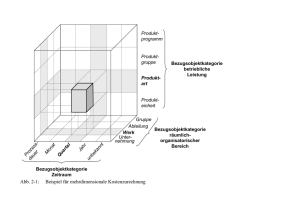
Analyse der Speicherung von Modelldaten eines elektrischen
Werbung

Analyse der Speicherung von Modelldaten eines elektrischen Stromsystems Bachelorarbeit des Studiengangs Elektrotechnik (Bachelor) an der Hochschule Mannheim Student: Denis Ilin Ludwig-Frank-Str. 11 68199 Mannheim Mat.-Nr.: 825280 [email protected] Tel.: +49 (621) 43771142 Mobil: +49 (177) 4656567 Zeitraum: 15. Dezember 2012 - 15. April 2013 Betreuer: Prof. Dr. Gerhard Dietrich Hochschule Mannheim - Mannheim University of Applied Sciences Fakultät für Elektrotechnik Institut für Automatisierungssysteme (IAS) Prof. Dr. Norbert Kniffler Hochschule Mannheim - Mannheim University of Applied Sciences Fakultät für Elektrotechnik Institut für Energiesysteme (IES) EHRENWÖRTLICHE ERKLÄRUNG Ich habe diese Bachelorarbeit selbständig verfasst, alle verwendeten Quellen und Hilfsmittel angegeben, keine unerlaubten Hilfen eingesetzt und die Arbeit bisher in keiner Form als Prüfungsarbeit vorgelegt. Ort, Datum Unterschrift (Denis Ilin) SPERRVERMERK Die vorliegende Bachelorarbeit mit dem Titel „Analyse der Speicherung von Modelldaten des Stromsystems“ enthält vertrauliche Daten des Karlsruher Instituts für Technologie, Institut für Angewandte Informatik (IAI). Die Bachelorarbeit darf nur dem Erst- und Zweitgutachter sowie befugten Mitgliedern des Prüfungsausschusses zugänglich gemacht werden. Eine Veröffentlichung und Vervielfältigung der Bachelorarbeit ist - auch in Auszügen nicht gestattet. Eine Einsichtnahme der Arbeit durch Unbefugte bedarf einer ausdrücklichen Genehmigung des Verfassers und des Karlsruher Instituts für Technologie, Abteilung Institut für angewandte Informatik. Hiermit wird bestätigt, dass Karlsruhe Institut für Technologie (KIT) mit der Herrn Denis Ilin verfassten Bachelorarbeit inhaltlich und formal einverstanden ist. Ort, Datum Unterschrift (Dr. Wolfgang Süß) II ABSTRACT ANALYSE DER SPEICHERUNG VON MODELLDATEN EINES ELEKTRISCHEN STROMSYSTEMS Hochschule Mannheim Energietechnik und erneuerbare Energien Bachelorarbeit April 2013 Denis Ilin In dieser wissenschaftlichen Arbeit, die durch das Karlsruher Institut für Technologie (KIT), Institut für angewandte Informatik (IAI) vorgegeben wurde, sollte eine Analyse der Datenbanksysteme für die Speicherung und das Abfragen von Modelldaten eines elektrischen Systems durchgeführt werden. Die Datenbankmanagementsysteme MySQL, Neo4j und MongoDB, sowie die Programmiersprache Java wurden für die Durchführung der Performanceanalyse vorgegeben. Um die Aufgabenstellung zu lösen, wurden die Datenbankmanagementsysteme untersucht und für die Durchführung der Performancemessungen mögliche Datenbankschemas erstellt. Es wurden mehrere Messreihen unterschiedlich großer Modelle auf Schreib-, Lese und Suchperformance für jeden Datenbanktyp mithilfe von Datenbankschnittstellen für die Programmiersprache Java durchgeführt. Für die Erfassung der benötigten Zeit für jeden Schreib- bzw. Lesevorgang wurde in Java ein Programm geschrieben. Die erfassten Messwerte mussten effizient ausgewertet werden. Dafür wurde ein Programm zum Durchsuchen einer Textdatei in AutoIt und einer Anpassung der gefundenen Werte mit VBA in Excel erstellt. Für die Analyse der Ergebnisse wurde eine graphische Auswertung der Messwerte durchgeführt. III OPTISCHES MEDIUM VERWENDUNGSHINWEISE Diese CD kann unter folgender Umgebung verwendet werden: Microsoft Windows XP, oder höher INHALT Bachelorarbeit als PDF Dokumente des Anlagenverzeichnisses Quellcode der Programme Evaluationsumgebung IV INHALT Ehrenwörtliche Erklärung ...................................................................................................... II Sperrvermerk .............................................................................................................................. II Abstract ......................................................................................................................................... III Analyse der Speicherung von Modelldaten eines elektrischen Stromsystems ... III Optisches Medium ..................................................................................................................... IV Inhalt ................................................................................................................................................V Abbildungsverzeichnis ......................................................................................................... VIII Tabellenverzeichnis ...................................................................................................................X Abkürzungsverzeichnis........................................................................................................... XI Danksagung ................................................................................................................................... 1 Vorstellung des Unternehmens und der Abteilung ......................................................... 2 1. Einleitung................................................................................................................................... 4 1.1. Stand der Technik.............................................................................................................................. 6 1.2. Aufgabenstellung ............................................................................................................................ 10 1.3. Lösungsvorschlag ........................................................................................................................... 11 2. Datenbanksysteme .............................................................................................................. 12 2.1. Relationale Datenbanksysteme................................................................................................. 13 2.2. Not only SQL Datenbanksysteme (NoSQL) ........................................................................... 14 3. Vergleich der verschiedenen Datenbankmanagementsysteme.......................... 15 3.1. Relationales Datenbankmanagementsystem MySQL ....................................................... 15 3.1.1. Interner Aufbau des MySQL - Dateisystems ............................................................ 15 3.1.2. Die Verwendung von MySQL mit Java ........................................................................ 18 3.2. Dokumentenorientiertes Datenbankmanagementsystem MongoDB ........................ 22 3.2.1. Interner Aufbau des MongoDB - Dateisystems ...................................................... 23 3.2.2. Die Verwendung von MongoDB mit Java .................................................................. 28 3.3. Graphdatenbankmanagementsystem Neo4J ....................................................................... 31 V 3.3.1. Interner Aufbau des Neo4j – Dateisystems .............................................................. 32 3.3.2. Die Verwendung von Neo4J mit Java .......................................................................... 35 3.4. Fazit...................................................................................................................................................... 37 4. Datenbankentwurf .............................................................................................................. 38 4.1. Zweck der Anwendung ................................................................................................................. 38 4.2. Aufbau eines Elektroenergiesystems ..................................................................................... 38 4.2.1. Erzeugung elektrischer Energie ................................................................................... 38 4.2.2. Übertragung elektrischer Energie ............................................................................... 41 4.2.3. Verbrauch elektrischer Energie.................................................................................... 50 4.3. Erstellung des Datenmodells ..................................................................................................... 51 4.4. Topologie des Datenmodells ...................................................................................................... 53 4.5. Datenbankstrukturen ................................................................................................................... 53 4.5.1. Datenbankschema MySQL .............................................................................................. 53 4.5.2. Datenbankmodell MongoDB .......................................................................................... 54 4.5.3. Datenbankgraph Neo4j .................................................................................................... 57 5. Implementierung ................................................................................................................. 58 5.1. Java als Hochsprache ..................................................................................................................... 58 5.2. NetBeans als Entwicklungsumgebung ................................................................................... 58 5.3. Erzeugung von Testdaten ............................................................................................................ 59 6. Datenbank APIs .................................................................................................................... 60 6.1. API ........................................................................................................................................................ 60 6.2. Datenbank APIs ............................................................................................................................... 60 6.2.1. Schnittstelle für MySQL.................................................................................................... 60 6.2.2. Neo4j und MongoDB API ................................................................................................. 61 7. Benchmarkentwurf ............................................................................................................. 62 VI 7.1. Voraussetzungen eines Benchmarks ...................................................................................... 62 7.2. Durchführung und Auswertung ................................................................................................ 63 8. Durchführung der Performancemessung ................................................................... 64 8.1. Inbetriebnahme............................................................................................................................... 64 8.2. Durchführung eines Benchmarks ............................................................................................ 64 8.3. Logging für Dokumentation der benötigten Zeit................................................................ 64 8.4. Versuchsaufbau ............................................................................................................................... 65 8.5. Besondere Hinweise ...................................................................................................................... 67 8.6. Testtabellen ...................................................................................................................................... 68 8.6.1. Speicherung .......................................................................................................................... 68 8.6.2. Extrema .................................................................................................................................. 70 8.6.3. Lesen aller Datensätze von bestimmten Komponenten ..................................... 74 8.6.4. Suchen nach bestimmten Datensätzen ...................................................................... 76 8.7. Fazit...................................................................................................................................................... 80 9. Evaluation ............................................................................................................................... 81 9.1. Bewertung ......................................................................................................................................... 81 9.2. Ausblick .............................................................................................................................................. 83 Anhang ............................................................................................................................................. i Quellen und Literaturverzeichnis .........................................................................................ii Anlagenverzeichnis ...................................................................................................................iv a. Quellcode Java Programm Verwaltung MongoDB ....................................................... v b. Quellcode Java Programm Verwaltung MySQL ............................................................ v c. Quellcode Java Programm Verwaltung Neo4j ............................................................... v d. Quellcode Java Programm Benchmarks MongoDB ..................................................... v e. Quellcode Java Programm Benchmarks Neo4j ............................................................. v f. Quellcode Java Programm Benchmarks MySQL ............................................................ v VII ABBILDUNGSVERZEICHNIS Abb. 1: Enterprise Service Bus für Kopplung IT-Systeme [26] ................................................... 9 Abb. 2: DBMS, DB, DBS .......................................................................................................................... 12 Abb. 3: Beispieltabelle einer relationalen Datenbank .............................................................. 15 Abb. 4: 1:1 - Beziehung ......................................................................................................................... 16 Abb. 5: 1:N - Beziehung ........................................................................................................................ 16 Abb. 6: N:M - Beziehung ....................................................................................................................... 17 Abb. 7: Schnittstelle JDBC in NetBeans ........................................................................................... 19 Abb. 8: Collections im Dateisystem von MongoDB .................................................................... 24 Abb. 9: Aufbau einer ObjectId ........................................................................................................... 25 Abb. 10: Schematischer Aufbau eines Dokuments .................................................................... 26 Abb. 11: Ausschnitt aus MongoVUE - Anwendung .................................................................... 27 Abb. 12: Erläuterung der Suchabfrage in Embedded Documents ....................................... 30 Abb. 13: Knoten und Kanten eines Graphs ................................................................................... 32 Abb. 14: Vergleich eines Graphen mit Tabellen eines RDBMS [20] ....................................... 32 Abb. 15: Property-Graph-Modell anhand Verbraucher eines Zimmers ............................ 34 Abb. 16: Erzeugung elektrischer Energie in Deutschland ...................................................... 39 Abb. 17: Spannungsebenen ................................................................................................................. 40 Abb. 18: Hierarchische Darstellung des Energieversorgungsnetzes [8, S.19]..................... 44 Abb. 19: Strahlennetz [22, S. 24] ............................................................................................................. 47 Abb. 20: Ringnetz [22, S. 24] ..................................................................................................................... 48 Abb. 21: Verzweigter Ring [22, S. 24] .................................................................................................... 48 Abb. 22: Maschennetz [22, S. 24]............................................................................................................. 49 Abb. 23: Verbrauch elektrischer Energie in Deutschland ....................................................... 50 Abb. 24: Modellnetz für die Performancemessung ................................................................... 52 Abb. 25: Datenbankschema MySQL ................................................................................................. 54 Abb. 26: DB - Schema mit Collections und Docs ......................................................................... 56 Abb. 27: Haus, Leitungen und Verbraucher als Graph ............................................................. 57 Abb. 28: Autokonvertier in AutoIt .................................................................................................... 63 Abb. 29: Ausschnitt aus der Logdatei .............................................................................................. 64 Abb. 30: Konfiguration des Testsystems ....................................................................................... 65 Abb. 31: Speicherung von Objekten – Gesamtkomposition ................................................... 69 Abb. 32: Schreibvorgang Neo4j - 1000 Messungen ................................................................... 70 Abb. 33: Schreibvorgang Neo4j - 1000 Messungen - Testsystem 2 .................................... 71 VIII Abb. 34: Auslastung des Arbeitsspeichers und des Prozessors mit Neo4j ....................... 72 Abb. 35: Schreibvorgang MongoDB - 1000 Messungen ........................................................... 73 Abb. 36: Schreibvorgang MySQL - 1000 Messungen................................................................. 73 Abb. 37: Lesevorgang aller Datensätze bestimmter Objekte ................................................. 75 Abb. 38: Standardabweichung der Ergebnisse des Lesevorgangs ...................................... 76 Abb. 39: Suchvorgang nach bestimmten Datensätzen ............................................................. 78 Abb. 40: Standartabweichung beim Suchvorgang bestimmter Datensätze ..................... 79 IX TABELLENVERZEICHNIS Tab. 1: Schreibperformance - Alle Datensätze ............................................................................ 68 Tab. 2: Leseperformance - Alle Datensätze .................................................................................. 74 Tab. 3: Legende Performancemessung-I ....................................................................................... 76 Tab. 4: Suchperformance – Bestimmte Datensätze ................................................................... 77 X ABKÜRZUNGSVERZEICHNIS Abkürzung AGPL API DB IEEE Java JSON MongoDB MySQL Neo4J NoSQL RGDC SQL Bedeutung GNU Affero General Public License Application Programming Interface Datenbank Institute of Electrical and Electronics Engineers Hochsprache JavaScript Object Notation, Dokumentenorientiertes Datenbanksystem Relationales Datenbanksystem Graphdatenbanksystem Not only SQL Research Group Distributed Computing Structed Query Language XI Kapitel 1: Einleitung DANKSAGUNG Ein wichtiger Teil des Studienverlaufs an der Hochschule Mannheim ist die Bachelorarbeit. Eine große Bedeutung kommt hierbei einem kompetenten und hilfsbereiten Ansprechpartner während dieser Zeit zu. Ich möchte mich herzlich bei der Research Group Distributed Computing (RGDC) für die Möglichkeit dieser abwechslungsreichen, herausfordernden und äußerst spannenden Bachelorarbeit bedanken. Insbesondere möchte ich mich bei Herrn Dr. Wolfgang Süß, Herrn Dr. Karl - Uwe Stucky und Herrn Dr. Wilfried Jakob für die gemeinsame Diskussionen der Problemstellungen, ihrer Ratschläge zur wissenschaftlichen Vorgehensweise und die vielen hilfreichen Anregungen bedanken. Diese haben sehr zum erfolgreichen Abschluss des Projekts und der Arbeit beigetragen. 1 Kapitel 1: Einleitung VORSTELLUNG DES UNTERNEHMENS UND DER ABTEILUNG Das Karlsruher Institut für Technologie (KIT) ist eine Universität des Landes Baden Württemberg und nationales Forschungszentrum in der Helmholtz - Gemeinschaft. Es „gliedert sich in eine Vielzahl wissenschaftlicher Einrichtungen sowie in Organisationseinheiten mit Dienstleistungsaufgaben in Infrastruktur und Verwaltung. Organisatorische Einheiten zur Bündelung von KIT - Forschungsprojekten stellen Zentren und Schwerpunkte dar. Diese bilden auch die Basis für die strategische Forschungsplanung. Die FuE - Arbeiten des Großforschungsbereichs sind eingebettet in die übergeordnete Programmstruktur der Hermann - von - Helmholtz Gemeinschaft und gliedern sich in vier Forschungsbereiche mit insgesamt zwölf Programmen. Die Forschung im Universitätsbereich ist den elf Fakultäten zugeordnet.“[1] „Das Institut für Angewandte Informatik (IAI) betreibt Forschung und Entwicklung auf dem Gebiet innovativer, anwendungsorientierter Informations-, Automatisierungs- und Systemtechnik.“ [2] „Im IAI werden Systemlösungen für Aufgabenstellungen aus den Programmen Erneuerbare Energien, Rationelle Energieumwandlung und Nutzung, Nano- und Mikrosysteme, Bio - Grenzflächen, Technologie, Innovation & Gesellschaft, Wissenschaftliches Rechnen sowie Atmosphäre und Klima erarbeitet. Die FuE Vorhaben umfassen alle Entwicklungsphasen vom Konzeptentwurf bis zur Prototyperstellung und praktischen Erprobung und beinhalten neben der Systemrealisierung auch die Entwicklung neuartiger Informatik- und Automatisierungsmethoden und -werkzeuge, die im Rahmen der Systemerstellung eingesetzt und weiterentwickelt werden. In den FuE - Vorhaben finden aktuelle Konzepte und Techniken aus den Gebieten Wissensverarbeitung (wie z. B. Fuzzy Konzepte, Künstliche Neuronale Netze, Maschinelles Lernen, Mustererkennung), Kommunikation, Hypermedia, Telepräsenz, Robotik, Bussysteme sowie Mess-, Regelungs- und Automatisierungstechnik Anwendung. Die Vorhaben werden in interdisziplinärer Kooperation mit Partnern aus Industrie, Verwaltung und anderen Forschungseinrichtungen im In- und Ausland bearbeitet. Das Institut ist an Projekten der EU und der deutschen Industrie beteiligt. Die 2 Kapitel 1: Einleitung Mitarbeiter des Instituts sind vielseitig in Normungsgremien, Fach- und Gutachtergremien und Programmkomitees aktiv.“ [3] 3 Kapitel 1: Einleitung 1. EINLEITUNG Die Bachelorarbeit wird am Karlsruher Institut für Technologie (KIT), Institut für Angewandte Informatik (IAI) durchgeführt. Es wurde ein Projekt aus dem Arbeitsgebiet Verteiltes Datenmanagement der Research Group Distributed Computing bearbeitet. Diese Dokumentation liefert Informationen über den grundsätzlichen Aufbau eines Datenbanksystems (DBS), über Funktionen und Bedienbarkeit dreier verschiedener Datenbankmanagementsysteme MySQL, MongoDB und Neo4j mit Java. Darauf aufbauend sind durchgeführte Performancemessungen des Speicher- und Abfrageverhaltens von in den Datenbanksystemen abgebildeten Systemkomponenten eines elektrischen Netzes. Ein semantisches Datenmodell beschreibt den topologischen Aufbau eines elektrischen Netzwerkes und liefert Informationen über das Netz und seine Komponenten. Alle Objekte dieses Datenmodells sollen künftig für wissenschaftliche Zwecke Informationen, wie: Datenblätter, Simulationsmodelle und ihre Ergebnisse, Informationen über die geplanten oder getätigten Änderungen, Informationen zur Verfolgung der Historie von Änderungen des Netzes und Standorte enthalten. Eine weitere wichtige Anwendung des semantischen Datenmodells ist die Speicherung von Messdaten der jeweiligen Komponente. Darüber hinaus soll das semantische Datenmodell als umfangreiche Bibliothek für Planungs- und Informationssysteme wie z.B. NEPLAN und für Modellierungssoftware wie z.B. „EASiMoV (Electric Grid Analysis Simulation Modelling and Visualization)“[33] dienen. Die vorhandenen Modelldaten sollen die Netzeingabe vereinfachen. Die Ergebnisse der Netzanalysen wie z.B. Lastfluss-, Spannungsabfalls-, Kurzschlussberechnung oder Oberschwingungsanalyse können nach einer weiterführenden Entwicklung des Datenmodells zu einem oder mehreren Objekten des Datenmodells verlinkt werden. In dieser Arbeit wird der Begriff „Energieerzeugung“ verwendet. Dieser hat sich umgangssprachlich etabliert, ist aber aus physikalischer Sicht falsch. Nach dem Energieerhaltungssatz kann Energie in einem abgeschlossenen System weder erzeugt noch vernichtet werden. Energie kann nur aus einer Form in eine andere umgewandelt werden, z.B. thermische Energie in mechanische oder in elektrische Energie. 4 Kapitel 1: Einleitung Historisch bedingt werden in der Informatik Größenangaben in Byte mit 2 als Basis in n - ter Potenz dargestellt. Die Größe wird in Byte, Megabyte (MB), Gigabyte (GB), usw. dargestellt. Dies entsprach nicht gängigen Normen. Daraufhin wurde normgerecht Byte, Mebibyte (MiB), Gibibyte (GiB), usw. eingeführt. Die normgerechte Darstellung von MB, GB, TB, usw. hat nun 10 als Basis. Bei der Darstellung der Einheiten wird in dieser Arbeit von der aktuellen Norm abgewichen und das historisch bedingte und in der Informatik immer noch weit verbreitete Verfahren mit 2 als Basis verwendet. Aufgrund der besseren Lesbarkeit ist das Kapitel Implementierung und Datenbank APIs den Vorstellungen der Datenbanksysteme angehängt. Bei den personenbezogenen Bezeichnungen (z.B. Mitarbeiter) gilt die gewählte Form aufgrund der besseren Lesbarkeit für beide Geschlechter gleichermaßen. Die verwendeten Screenshots unterliegen dem Urheberrecht der jeweiligen Firmen, insbesondere des KIT Karlsruher Institut für Technologie, IAI Institut für Angewandte Informatik. Alle Namen von Produkten und Dienstleistungen sind Marken der jeweiligen Firmen. Die Firmen sind jedoch nicht Herausgeber dieser Arbeit oder sonst dafür presserechtlich verantwortlich. Alle Bezeichnungen und Werte bei den Beispieldaten sind frei erfunden. Ähnlichkeiten zu real existierenden Unternehmen oder Personen sind rein zufällig und nicht beabsichtigt. Im Anlagenverzeichnis aufgelistete Dokumente, sowie Quellcodes sind in elektronischer Form auf dem beiliegenden optischen Medium gespeichert. 5 Kapitel 1: Einleitung 1.1. STAND DER TECHNIK Die Gewährleistung einer sicheren Verfügbarkeit von elektrischer Energie bildet die Grundlage für Wachstum und Wohlstand. Die Basis der Energieinfrastruktur ist das Elektroenergienetz. Im August 2011 wurden vom Bundestag und Bundesrat ein Ausstieg aus der Atomkraft und ein beschleunigter Ausbau, sowie ein Einstieg in die erneuerbaren Energien beschlossen. Nach dem Atomgesetz ist der komplette Ausstieg aus der Atomkraft bis 2022 vorgesehen. [9] Der dadurch fehlende Energiebedarf soll durch den Ausbau von erneuerbaren Energien abgedeckt werden. Nach §1, des Erneuerbare-Energien-Gesetzes (EEG) soll der Anteil erneuerbarer Energien an der Stromversorgung auf mindestens 80% des nationalen Energiebedarfs bis 2050 erhöht werden. [10] Aufgrund der neuen Anforderungen durch einen stark fluktuierenden elektrischen Energieflusses haben für die Energiewende die Elektroenergienetze die Aufgabe mithilfe von intelligenten Kommunikations- sowie Speichertechnologien die Balance zwischen dem Erzeuger und dem Verbraucher unter Berücksichtigung der Einhaltung der Spannungsqualität nach EN 50160 und einer konstanten Frequenz in allen Netzknoten auszugleichen. [11] Das Führen der Elektroenergienetze übernimmt das Netzleitsystem. Dabei handelt es sich um mehrere, hierarchisch den Spannungsebenen zugeordnete, miteinander kommunizierende Warten mit jeweils eigener Netzleitstelle. Jede Netzleitstelle kann die Schaltzustände von den Schaltanlagen und Schaltgeräten jeder Umspannstationen, die sich in ihrem Netzbereich befinden, ändern und überwachen. Dafür kommt die Fernwirktechnik zum Einsatz. Die Kommunikation findet über den Netzleitstellenrechner und in den Umspannwerken installierten Stationsleitrechner statt. Die Stationsleitrechner kommunizieren ihrerseits mit den Feldrechnern, die bestimmten Schaltfeldern zugeordnet sind. [8, S. 675 ff; 14] Der Informationsfluss von der Prozessebene in Richtung Hauptschaltleitung erfolgt über die auf dem Weg liegenden Netzleitstellen nach IEC 61850. Unter einer Hauptschaltleitung wird eine oberste Netzleitstelle in der hierarchischen Netzleitstellenstruktur verstanden. Sie führt das Transportnetz. [8, S. 678] 6 Kapitel 1: Einleitung Die Hauptaufgabe einer Netzleitstelle ist das Führen des ihr zugeordneten Netzes. Hierfür stehen in der Netzleitstelle Supervisory Control and Data Acquisition (SCADA) und Höherwertige Entscheidungs- und Optimierungsfunktionen (HEO) zu Verfügung. [8, S. 683 ff] SCADA sind Funktionen zum Überwachen und Melden der Prozesszustände sowie zum Steuern und Regeln der Prozesse. Die Antwortzeiten des Stationsleitsystems liegen im Millisekundenbereich. Unter einem Stationsleitsystem kann ein Industrie PC verstanden werden. Eine weitere wichtige Funktion von SCADA ist die Visualisierung der Netzwerktopologie und der Zustandsgrößen. Hier wird beispielweise ein aktueller Zustand des Netzes mit dazugehörigen Messwerten dargestellt. Dieses Prozessabbild wird in Form von sogenannten Fließbildern dargestellt. Somit werden Prozesswerte aktuell gehalten. Für die Dokumentation der Ereignisse werden vom System in Textform darstellbare Ereignis- sowie Störungslisten geführt. Neben den ereignisgesteuerten Listen werden die laufenden Mess- und Zählwerte in wählbaren Zeitrastern vom System erfasst. Die Daten dienen als Grundlage für die Energiebedarfsrechnung und der Kundenabrechnung. Alle gespeicherten Werte lassen sich auch graphisch darstellen. [8, S. 679 ff] Bei großen Netzleitstellen werden Informationen adäquat dargestellt. Hierbei kommt die Rückprojektionstechnik zum Einsatz. Der Unterschied dabei ist, dass die Visualisierung an einer großen Wand vor dem Bediener der Netzleitstelle erfolgt. Außerdem besteht mit SCADA auch die Möglichkeit die Schaltungstopologie mit geographischen Informationen zu verknüpfen. So kann die Fehlerortung und Störungsbeseitigung schneller erfolgen. [8, S. 682] Neben den SCADA - Funktionen für die Netzführung ermöglichen Netzleitsysteme noch die Funktionen für die wirtschaftliche Optimierung der Netzführung, der Verfügbarkeit und der Sicherheit des Personals. Dies sind sogenannte HEO Funktionen. Dies können Kurzschlussstromberechnung, z.B. Prognostizierung Lastbeeinflussung des durch Energiebedarfes, Fernwirktechnik, Fehlersuche im Falle einer Störung mit abschließender graphischer Darstellung usw. [8; 12, S. 684] 7 Kapitel 1: Einleitung Somit werden die Anforderungen an die Netze immer höher und die Netze werden immer komplexer. Daher sind innovative Lösungen der Netzprobleme und Optimierungen notwendig. Die oben genannten Funktionen sind bereits erprobt und befinden sich seit mehreren Jahren im Betrieb. Steigende Anzahl dezentraler Kraftwerke mit fluktuierendem Energiedargebot kann massive Auswirkungen auf Energieversorgungsunternehmen (EVU) haben, da die Netzstabilität und Versorgungssicherheit weiterhin auf gleichem Niveau gewährleistet werden müssen. Größere Anzahl an Kraftwerken bringt ein höheres Datenaufkommen mit sich. Die darin integrierten Anlagen müssen permanent überwacht und intelligent geregelt werden. Für die frühzeitige Erkennung von Engpässen, müssen Messdaten gespeichert und ausgewertet werden. Des Weiteren stehen IT-Systeme betreffend Interoperabilität zwischen den Unternehmen vor neuen Herausforderungen. Beispielweise der Austausch von Netzzuständen zwischen Übertragungsnetzbetreiber (ÜNB) oder modellierten neuen Komponenten. Aus technischer Sicht wird eine neue Kommunikationsinfrastruktur für alle Spannungsebenen, insbesondere Niederspannungsebene, benötigt. [23, S. 1 f] Die International Electrotechnical Commission (IEC) 61970 beschreibt eine Programmierschnittstelle für Energiemanagementsysteme (EMS). Sie legt ein abstraktes Modell fest, Common Information Model (CIM) genannt. Es umfasst alle wichtigen Objekte und Relationen zur Darstellung von Stromnetztopologien und Datenaustauschformate. Aktuell wird das CIM als United Modeling Language (UML) – Modell von Normungsgruppen zur freien Verfügung gestellt. [24, 25] Das CIM kann z.B. für die Kopplung verschiedener IT-Systeme mit einem „Enterprice Service Bus“ realisiert werden wie in Abb. 1: Enterprice Service Bus für Kopplung ITSysteme dargestellt. Für weitere Detailinformationen ist das Paper online verfügbar. [23] 8 Kapitel 1: Einleitung Abb. 1: Enterprice Service Bus für Kopplung IT-Systeme [26] 9 Kapitel 1: Einleitung 1.2. AUFGABENSTELLUNG In dieser Bachelorarbeit sollen Möglichkeiten zur Speicherung sowie das Abfragen von Modelldaten eines elektrischen Stromsystems untersucht werden. Das Stromsystem ist in den folgenden Datenbanken abzubilden und Performancemessungen durchzuführen: Relationale Datenbank MySQL Graphdatenbank Neo4j Dokumentenorientierte Datenbank MongoDB Als Nutzdaten sollen Stromsystemmodelle verschiedener Größen in den Datenbanken abgespeichert (bzw. in Graphen abgebildet) werden. Softwaremodule zur Bedienung der Datenbanken sollen in der Sprache Java realisiert werden. Aus dieser Aufgabenstellung ergeben sich folgende Teilaufgaben: Installation und Test der drei Datenbanksysteme Analyse der topologischen Eigenschaften des Stromsystemmodells Erstellung von Datenbankschemas für die Performancemessungen, aufbauend auf den Ergebnissen der Analyse Festlegung des Verfahrens der Performancemessungen in Java Durchführung der Performancemessungen in Java Dokumentation der Ergebnisse und Fazit 10 Kapitel 1: Einleitung 1.3. LÖSUNGSVORSCHLAG Zur Lösung der Aufgabenstellung werden zuerst die Datenbankmanagementsysteme MySQL, Neo4j und MongoDB untersucht. Danach wird ein vereinfachtes reales Beispielstromsystemmodell in den drei Datenbankmanagementsystemtypen abgebildet. Die Erzeugung von Testdaten, sowie Datenbankzugriffe werden in der Programmiersprache Java mithilfe herstellerspezifischer Datenbankschnittstellen realisiert. Die Voraussetzungen für die Durchführung der Performanceanalyse werden festgelegt. Es sollen Schreib-, Lese- und Suchzugriffe der drei Datenbanksysteme verglichen werden. Dafür soll in Java ein Programm zur Zeiterfassung entwickelt werden. Schließlich sollen Ergebnisse aus den Performancemessungen analysiert und ausgewertet werden. Daraus gewonnene Informationen sollen Hinweise auf weiterführende Messungen ergeben, die aufgrund des zeitlichen Umfanges im Rahmen einer Bachelorarbeit nicht durchzuführen sind. 11 Kapitel 2: Datenbanksysteme 2. DATENBANKSYSTEME Unter Datenbankmanagementsystem (DBMS) versteht man eine Software zur Verwaltung von Datenbanken. Die Datenbank selbst stellt einen zusammengehörigen Datenbestand dar. Das DBMS und Datenbanken bezeichnet man als Datenbanksystem (DBS). [4, S. 20] Abb. 2: DBMS, DB, DBS 12 Kapitel 2: Datenbanksysteme 2.1. RELATIONALE DATENBANKSYSTEME Das Konzept relationaler Datenbanken stammt aus den frühen Siebziegenjahren. Die Daten werden in Form von Tabellen, die miteinander verknüpft sein können, gespeichert. Für einen Zugriff auf die gespeicherten Daten wurde eine Sprache SQL entwickelt. [5, S. 23] SQL ist die Abkürzung für Structed Query Language (Strukturierte Abfragesprache) und sie definiert die Sprache, die verwendet wird, um Datenbankzugriffe zu realisieren. Die Hauptaufgabe von SQL ist das Lesen, Verändern und Hinzufügen von Daten in der(die) Datenbank. Der Begriff relational beschreibt wie die Datenbank technisch realisiert ist. Eine Relation stellt eine zweidimensionale Anordnung von Feldern dar, auch Array genannt. Typischerweise wird eine Relation durch eine Tabelle beschrieben. Jede Tabelle besteht aus Zeilen (auch Tupeln genannt) und Spalten (Attributen). Zelleninhalte bzw. in den Spalten vorhandene Einträge beschreiben die entsprechenden Attributwerte. Eine Relation kann sowohl ein Zusammenhang von Attributen bzw. Attributwerten innerhalb einer Tabelle, als auch eine Verknüpfung von mehreren Tabellen durch Fremdschlüssel sein. [34, S.34] 13 Kapitel 2: Datenbanksysteme 2.2. NOT ONLY SQL DATENBANKSYSTEME (NOSQL) Der Begriff „NoSQL“ steht für „Not only SQL“. Dabei sind neue Ansätze und Techniken gemeint, um Datenbanksysteme flexibler bezüglich Skalierbarkeit und Verfügbarkeit im Vergleich zu den relationalen Datenbanksystemen zu gestalten. Die aktuellen NoSQL - Datenbanksysteme haben einige Eigenschaften gemeinsam. Das zugrunde liegende Modell ist nicht starr, die Systeme sind auf eine skalierbare Verteilung ausgerichtet, für die Kommunikation mit den Clients werden andere Protokolle als SQL eingesetzt und es handelt sich um schemafreie Systeme. [6, S. 2] Neben den traditionellen Verfahren der klassischen relationalen Datenbanken gibt es in der NoSQL - Welt noch weitere Algorithmen und Protokolle, welche an dieser Stelle jedoch nicht von Bedeutung sind. [6, S. 11] 14 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3. VERGLEICH DER VERSCHIEDENEN DATENBANKMANAGEMENTSYSTEME Um den Unterschied zwischen drei verschiedenen Datenbankmanagementsystemen MySQL, MongoDB und Neo4j zu verdeutlichen, werden der interne Aufbau sowie ihre Verwendung mit Java genauer erläutert. 3.1. RELATIONALES DATENBANKMANAGEMENTSYSTEM MYSQL In diesem Kapitel wird ein RDBMS am Beispiel von DBMS MySQL erklärt. Als Grundlage für die Verwaltung des DBMS dient die Sprache SQL. 3.1.1. INTERNER AUFBAU DES MYSQL - DATEISYSTEMS In MySQL sind die grundlegenden Strukturelemente die Relationen und Assoziationen. Relationen manifestieren sich in der Praxis fast immer durch Tabellen, die zueinander in Beziehung stehen. Diese logischen Abhängigkeiten von Tabellen legen die Assoziationen fest. [13, S. 20 ff] Jede Tabelle besteht aus Spalten und Zeilen. Spalten stellen die Attribute der Werte dar und Zeilen beschreiben den Zusammenhang der Attribute. Die Spaltenwerte werden als Ausprägungen der Attribute bezeichnet. [13, S. 21] Abb. 3: Beispieltabelle einer relationalen Datenbank In einer relationalen Datenbank sollen keine redundanten Informationen vorhanden sein. Dies wird durch die Normalisierung realisiert. Darunter wird das Auslagern von redundanten Informationen in extra Tabellen verstanden. Die ausgelagerten Informationen werden mithilfe von primären und sekundären Schlüsseln 15 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme miteinander verknüpft und können so abgefragt werden. Darauf wird im Verlauf des Kapitels näher eingegangen. ASSOZIATIONEN Zwischen den Tabellen einer Datenbank können Beziehungen hergestellt werden. Es werden folgende Beziehungstypen unterschieden: [13, S. 22 f] 1:1 - Beziehung Einer Zeile einer Tabelle wird genau eine Zeile einer anderen Tabelle zugeordnet. Abb. 4: 1:1 - Beziehung 1:N - Beziehung Einer Zeile einer Tabelle werden mehrere Zeilen einer anderen Tabelle zugeordnet. Abb. 5: 1:N - Beziehung N:M - Beziehung Eine Zeile einer Tabelle kann Beziehungen zu mehreren Zeilen einer anderen Tabelle haben, während gleichzeitig die Zeilen einer anderen Tabelle ebenfalls jeweils mehrere Beziehungen zu der ersten Tabelle haben. 16 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Abb. 6: N:M - Beziehung JOINS Mithilfe von Joins können mehrere Tabellen anhand von gleicher Attributwerte zu einer Tabelle verknüpft werden. Joins können mit weiteren SQL - Anweisungen kombiniert werden, so dass der überflüssige Inhalt ausgeblendet wird. [13, S. 30] SCHLÜSSEL Ein Schlüssel ist ein Attribut, das eine Zeile in einer Tabelle eindeutig identifiziert Ein Schlüssel stellt einen Zugriffsmechanismus zur Verfügung, um eine Zeile von einer anderen zu unterscheiden, da er immer eindeutig sein muss. Es werden zwei Arten von Schlüsseln unterschieden Primärschlüssel Diese werden in einer Spalte oder in Spaltenkombinationen einer Tabelle eingetragen und identifizieren somit die vorhandenen Zeilen eindeutig. Sekundärschlüssel Das sind Spalten, mit deren Werten Spaltengruppen eindeutig gekennzeichnet werden. Fremdschlüssel Mit Hilfe eines Fremdschlüssels wird Bezug zu einer oder mehreren Primärschlüsseln einer anderen Tabelle realisiert. Dieser kann aus einer oder mehreren Spalten bestehen und muss nicht eindeutig sein. D.h. Fremdschlüssel 17 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme können sich wiederholen und bilden somit eine mehrfache Beziehung zu einer anderen Tabelle. [13, S. 38f] INDIZES Indizes sind ein wichtiger Bestandteil einer relationalen Datenbank und dienen dazu, die Abfragezeiten zu verkürzen. Ein Index ist eine Spalte der Datentabelle. Zu jeder Zeile in der Datentabelle wird eine entsprechende Zeile in der Indextabelle erstellt. Ein Index liefert Informationen, wo in der Tabelle die Zeile mit dem gesuchten Wert zu finden ist. Somit müssen weniger Speicherzugriffe gemacht werden, als bei der Suche ohne Index. Unersetzlich ist die Indizierung bei großen Tabellen. Beispielweise die Verarbeitung einer Tabelle mit 1.000.000 Einträgen würde mit Indizes ca. 17 Minuten dauern, ohne Indizes kann der Prozess bis zu fünf Stunden in Anspruch nehmen. [15, S. 133] Die Verwendung von Indizes muss abgewogen werden und einem langsameren Schreib- und Aktualisierungsverhalten des RDBMS gegenübergestellt werden. Ein Index muss nur einmal erzeugt werden und steht danach immer zur Verfügung, um den Datenzugriff zu beschleunigen. In SQL ist keine Methode definiert, um Indizes anzulegen. Anbieter von RDBMS haben diese Funktion selbst implementiert. In MySQL werden Indizes mit der Methode Create Index erstellt. [15, S. 134f; 27, S. 196ff] 3.1.2. DIE VERWENDUNG VON MYSQL MIT JAVA An dieser Stelle wird beschrieben, wie das DBS MySQL unter Verwendung der Programmiersprache Java funktioniert. Für den Zugriff auf die Datenbank über Java müssen noch die entsprechenden APIs hinzugefügt werden. Für MySQL wurde eine Schnittstelle JDBS verwendet. Sie ist als Bibliothek verfügbar. Um sie in der verwendeten Entwicklungsumgebung NetBeans (www.netbeans.org) zu implementieren, muss jedoch dem erstellten Projekt der JDBC Driver hinzugefügt werden (Abb. 7: Schnittstelle JDBC in NetBeans). 18 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Abb. 7: Schnittstelle JDBC in NetBeans VERBINDUNGSAUFBAU Beim Aufbau einer Verbindung mit Java muss zuerst die verwendete Bibliothek ausgewählt werden. Es wird ein Treiber verwendet, der im Package com.mysql.jbc liegt. Die Klasse heißt Driver. Mit folgendem Syntax wird der JDBC Treiber in die Laufzeitumgebung eingebunden und eine neue Verbindung zur Datenbank instanziiert. Es sind mehrere Verbindungen zur gleichen oder verschiedenen SQL gleichzeitig möglich. Class.forName("com.mysql.jdbc.Driver"); Connection conn = null; Conn = DriverManager.getConnection( "jdbc:mysql://host:port/dbname","user","password"); conn.close(); 19 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme EINFÜGEN VON DATEN Beim Einfügen von Daten wird mit if (conn != null) geprüft, ob eine Verbindung zur Datenbank besteht, ist dies der Fall, wird ein String erstellt und mit dem der Methode .query.executeUpdate (sql) in die SQL Datenbank geschrieben. Anschließend wird eine Statusmeldung über die Konsole ausgegeben. Sollte ein Fehler auftreten, oder keine Verbindung zur Datenbank bestehen, so wird der Fehler mit der Methode catch (Exception e) abgefangen und der Fehlerstack mit e.printStackTrace(); in der Konsole entsprechend ausgegeben. if (conn != null) { // Anfrage-Statement erzeugen. Statement query; try { query = conn.createStatement(); // Ergebnistabelle erzeugen und abholen. String sql = "CREATE TABLE "+ Tablename + " (id INTEGER not NULL, " + " Hausnummer INTEGER, " + " Strasse VARCHAR(255), " + " Stadt VARCHAR(255)," + " Verbrauch INTEGER," + " PRIMARY KEY ( Hausnummer ))"; query.executeUpdate(sql); System.out.println("Tabelle erfolgreich erstellt"); } catch (SQLException e) { e.printStackTrace(); } catch (Exception e) { //Handle errors for Class.forName e.printStackTrace(); } } 20 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme LESEN VON DATEN Beim Lesen der Daten wird in Java ein String erzeugt, welcher einem SQL Kommando entspricht, dieser wird mit der Methode statement.executeQuery ("Select * from stromsystemmodell.haus"); in die SQL Konsole über den JDBC Driver übertragen und anschließend ausgeführt. conn.setReadOnly(true); statement = conn.createStatement(); // Result set get the result of the SQL query resultSet = statement.executeQuery("Select * from stromsystemmodell.haus"); while (resultSet.next()){ System.out.println(resultSet.getInt(1)+" "+resultSet.getString(2)); } resultSet.close(); statement.close();} ÄNDERN VON DATEN Beim Ändern von Daten werden bestehende Datensätze aus der Datenbank geladen und mit der update Methode in die Datenbank geschrieben. 21 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.2. DOKUMENTENORIENTIERTES DATENBANKMANAGEMENTSYSTEM MONGODB Dokumentenorientierte Datenbanken sind strenggenommen keine echten Dokumentendatenbanken. Hier werden nicht die Word- und Textdateien, sondern z.B. JSON ähnliche - kodierte (JavaScript Object Notation) Datenstrukturen abgelegt. Unter einem JSON ähnlichem Objekt wird eine durch Komma getrennte Liste von Eigenschaften verstanden. Jede Eigenschaft besitzt einen Wert, wobei ein Wert wiederum eine Eigenschaft sein kann (Embedded Document). Somit können Dokumente beliebig verschachtelt werden. Sie ermöglichen komplexe Datenstrukturen und es sind keine Schemadefinitionen notwendig. JSON besitzt folgende Basistypen: Arrays, Zeichenketten, Zahlen, Objekte und Boolesche Werte. [6, S. 8; 16, S. 41] WAS BEDEUTET MONGODB Der Name leitet sich vom englischen humongous (gigantisch) ab. MongoDB ist eine in C++ geschriebene, skalierbare, hochperformante, schemafreie Open - Source - Datenbank der Firma 10gen (www.10gen.com) nach AGPL (GNU Affero General Public License) - Lizenz, die für die meisten gängigen Plattformen bereitgestellt wird. Firma 10get bietet kostenpflichtigen Support und Training rund um MongoDB an. [6, S. 132; 16, S. 11 ff] INSTALLATION Um MongoDB nutzen zu können, muss das Image von der Herstellerseite heruntergeladen und in ein passendes Verzeichnis entpackt werden. Danach wird ein Pfad angelegt, in dem später die Datenbank gespeichert wird. 22 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.2.1. INTERNER AUFBAU DES MONGODB - DATEISYSTEMS Jede MongoDB – Datenbank unterteilt sich in Collections, die den Tabellen einer relationalen Datenbank ähnlich sind und in Dokumente, die mit Zeilen einer Tabelle vergleichbar sind. Dokumente bestehen im Gegensatz zu Tabellenzeilen aus dynamischen assoziativen Arrays, d.h. Eigenschaften und ihre Datentypen müssen beim Erstellen einer Collection nicht definiert werden. [6, S. 133] EINE COLLECTION Intern besteht die Datenbank aus Collections, s. Abb. 8: Collections im Dateisystem von MongoDB. Sie entspricht einer Tabelle in einer relationalen Datenbank und enthält eine beliebige Anzahl an Feldern (Key) mit einem Wert (Value). Die Datenbank kann, wäre sie nicht systemseitig begrenzt, unendliche Anzahl von Collections enthalten. Diese werden nicht wie Tabellen in relationalen Datenbanken vorher erstellt, sondern erst bei Bedarf. Die Collections können je nach Inhalt (Dokumente) unterschiedlich groß sein. Collections können mithilfe von Punktnotation, wie in dem unterstehenden Beispiel gezeigt, gruppiert und hierarchisch dargestellt werden. Collection 1: Gebäude1.Stockwerk2.Raum001 Collection 2: Gebäude1.Stockwerk2.Raum002 Das Beispiel zeigt, dass mit solcher Benennung die Übersicht und Zuordnung von Räumen realisiert werden kann. Die maximale Zeichenlänge des Namens einer Collection liegt bei 128 Zeichen. Man unterscheidet in MongoDB zwischen normalen Collections mit Dokumenten des Users, System Collection und Capped Callection. Die System Collection beinhaltet alle Metainformationen der Datenbank. Sie kann nicht vom User zur Datenspeicherung genutzt werden. Die Capped Collection ist eine besondere Art einer normalen Collection. Sie darf nur eine bestimmte, vorher festgelegte Größe erreichen. Nach dem Überschreiten des Limits wird das älteste Dokument entfernt, um Platz für das Neue zu schaffen. Dabei ist zu beachten, dass die neuen Dokumente exakt so groß oder kleiner als die Alten sein müssen. [16, S. 44 ff] 23 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Abb. 8: Collections im Dateisystem von MongoDB EIN DOKUMENT Eine Collection enthält eine beliebige Anzahl von Dokumenten, s. Abb. 8: Collections im Dateisystem von MongoDB. Ein Dokument ist die kleinste Einheit von MongoDB und es entspricht einem Eintrag in einer relationalen Datenbank, also einer Tabellenzeile. Im Gegensatz zur relationalen Datenbank können die Einträge ein identisches Schema aufweisen, müssen aber nicht. Man spricht von einem schemafreien Design einer dokumentenorientierten Datenbank. Ein weiterer Unterschied zu einer relationalen Datenbank ist, dass ein Dokument eine hierarchische Struktur besitzen kann. Es ist ebenfalls zu erwähnen, dass ein Dokument auf 16 MB beschränkt ist. Dies verhindert lange Anfragezeiten, da große Dokumente den Arbeitsspeicher und das Netzwerk zu sehr auslasten. Für größere Dokumente oder Dateien bietet MongoDB das alternatives Dateisystem GridFS. Da in dieser Arbeit keine Dateien bzw. Dokumente größer als 16 MB gespeichert werden, wird auf GridFS nicht weiter eingegangen. [16, S. 46 f] 24 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme EINE OBJECTID Jedes Dokument bekommt unabhängig von seiner Größe eine _Id mit einem Wert vom Datentyp „ObjectId“. Die _Id ist sozusagen die genaue Identifizierung eines Datensatzes, wie Primäre Key in MySQL. MongoDB leitet Metadaten immer über sie ab. Die _Id wird vollautomatisch generiert und an den Eintrag angehängt. Sie kann aber auch auf Wunsch selbst erstellt werden. Die automatisch generierte _Id ist 12 Bytes lang. „51115c4b930f419a6b91b937“ ist ein Beispiel für eine automatisch generierte _Id. Die Bedeutung der einzelnen Bytes kann aus Abb. 9: Aufbau einer ObjectId entnommen werden. [16, S. 50 f] Abb. 9: Aufbau einer ObjectId REFERENZIERUNG MongoDB bietet im Gegensatz zu einer relationalen Datenbank keine Joins an. Die Zugehörigkeiten von Dokumenten werden mit Referenzen gesetzt. Es gibt drei Formen der Referenzierung. Als erstes wird erwähnt, wie man innerhalb einer Collection referenzieren kann. Dies ist mithilfe von ObjectIds möglich. Bei der Referenz auf ein Dokument einer anderen Collection wird der Datentyp DBRef verwendet. Die letzte Möglichkeit zu referenzieren ist das Erstellen von geschachtelten Dokumenten, den sogenannten Embedded Documents. Bei dieser Lösung werden die Abfragen performanter und der Speicherplatz, der für die Referenzen benötigt wäre, wird gespart. Jedoch sollte beachtet werden, dass ausschließlich nicht redundante Informationen eingebettet werden sollen. [16, S. 49f, 51f; 19, S- 161f] 25 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme DER AUFBAU EINES DOKUMENTES AN EINEM BEISPIEL Ein Dokument (Abb. 10: Schematischer Aufbau eines Dokuments) ist wie folgt aufgebaut: Das erste Key/Value - Paar im Dokument ist immer die ObjectID. Darauf können eine unbestimmte Anzahl Key/Value - Paare folgen. Aber nicht nur Verweise auf Werte sind möglich. Im Beispiel „Adresse“ wird nicht auf einen einfachen Wert verwiesen, sondern auf ein weiteres (internes) Dokument. Dies verdeutlicht, dass auch Dokumente innerhalb von Dokumenten angelegt werden können, die so genannten Embedded Documents. Der Vorteil von Embedded Documents besteht darin, dass die ansonsten entstehenden Referenzen auf externe Dokumente innerhalb der Collection wegfallen. Der Verweis auf eine vollkommen andere Collection der Datenbank (DBRef) wird mit dem Schlüssel „Fakultäten“ verdeutlicht. Auch muss nicht nur zwingend auf einen einzigen Wert verwiesen werden, sondern Verweise auf mehrere Elemente sind möglich. Abb. 10: Schematischer Aufbau eines Dokuments Mit Hilfe der Anwendung „MongoVUE“ oder „MongoExplorer“ lassen sich in den Dokumenten gespeicherte Einträge visualisieren. Das oben vorgestellte Dokument kann folgendermaßen dargestellt werden: 26 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Abb. 11: Ausschnitt aus MongoVUE - Anwendung 27 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.2.2. DIE VERWENDUNG VON MONGODB MIT JAVA Die folgenden Abschnitte und Codebeispiele beschreiben das Arbeiten mit MongoDB unter Verwendung der Programmiersprache Java. Um nun Zugriff auf MongoDB über Java zu erhalten, müssen noch die entsprechenden APIs geladen werden. Die aktuelle Version muss als Jar – File (Javabinärcode) heruntergeladen und als Bibliothek eingebunden werden. EINFÜGEN VON DATEN Im Code - Beispiel unten wird eine Instanz der Klasse Mongo, aus dem Paket com.mongodb, erstellt. Danach wird ein Objekt der Klasse DB unter Verwendung der Methode .getDB und dem Parameter als Datenbankname eingefügt. Mit der Methode .getCollection(“CollectionName“) wird eine Collection aufgerufen. Sollte diese nicht existieren wird sie erstellt, genau wie die eben erwähnte Datenbank. Die Methode .getCollection gibt ein Objekt zurück, welches den Zugriff auf die Collection der Datenbank gewährt (DBCollection). Dieses Objekt (im Beispiel col) hat eine Methode .insert, die neue Dokumente in die Datenbank einfügt. Diese Objekte, die der Methode .insert übergeben werden, müssen das Interface DBObject implementieren. [18; 6, S. 136] import java.net.UnknownHostException; import com.mongodb.*; public class MongoTest { public static void main(String[] args) { Mongo m = new Mongo("localhost",27017); DB db = m.getDB("TestDatenbank"); DBCollection col = db.getCollection("TestCollection"); BasicDBObject doc = new BasicDBObject(); doc.put("Name", "HS - Mannheim"); doc.put("Ranking in %", 100); BasicDBObject info = new BasicDBObject(); info.put("Straße", "Paul - Wittsack - Str. 10"); info.put("Stadt", "Mannheim"); info.put("PLZ", 68163); doc.put("Adresse", info); col.insert(doc); } } 28 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Eine Referenz in MongoDB zu realisieren funktioniert ähnlich, wie das Schreiben eines Key - Value - Paares. Ein Objekt der Klasse DBRef wird erstellt und in dieses der Key des Verweises geparst (verknüpft). Mit der Methode .fetch() wird die Referenz aus der Datenbank ausgelesen. [17] DBRef ref = (DBRef) cursor.next().get("Verweis"); System.out.println(ref.fetch()); LESEN VON DATEN Im folgenden Codebeispiel sind zwei Möglichkeiten des Lesevorgangs unter Java dargestellt. Die Methode .findOne() ruft das erste Dokument der Collection auf. Die Methode .find() greift ohne Parameter auf alle in der Datenbank vorhandenen Dokumente zu. Im folgenden Beispiel erfolgt der Zugriff auf die Ergebnismenge über ein DBCursor-Objekt, das ein Iterator für DBObject-Objecte ist. Die Ausgabe erfolgt hier mit der Methode System.out.println(). import java.net.UnknownHostException; import com.mongodb.*; public class MongoLesen { public static void main(String[] args) { Mongo m = new Mongo("localhost",27017); DB db = m.getDB("TestDB"); DBCollection col = db.getCollection("testCollection"); DBObject newDoc = col.findOne(); System.out.println(newDoc); DBCursor cursor = col.find(); while(cursor.hasNext()){ System.out.println(cursor.next()); } } } Man kann mit der find() Methode nicht nur Zugriffe realisieren, sondern auch Dokumente durchsuchen. Parallel, wie auch beim Zugriff, durchsucht die .find() Methode alle Dokumente in der Collection. [18; 6, S.137; 19, S. 153] BasicDBObject search = new BasicDBObject(“Schüssel”, "Wert",); newDoc = col.findOne(search); System.out.println(newDoc); DBCursor cursor = col.find(search); while (cursor.hasNext()){ System.out.println(cursor.next()); } 29 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Im folgenden Beispiel werden alle Dokumente gefiltert, deren Schlüssel auf den Wert „Adresse“ auf ein Unterdokument mit Schlüssel „Ort“ mit Wert „Karlsruhe“ verweisen, wie in Abb. 12: Erläuterung der Suchabfrage in Embedded Documents dargestellt ist. Abb. 12: Erläuterung der Suchabfrage in Embedded Documents BasiDBObject query = new BasicDBObject("Adresse", new BasicDBObject("Ort","Karlsruhe"); DBCursor cursor = col.find(query); Eine Wildcardabfrage (z.B. beliebige Bilddateien *.jpg unter Windows) wird über ein Pattern realisiert. Bei der Eingabe „Test*“ wird nach allen Dokumenten gesucht deren Wert im Schlüssel „filename“ mit „Test“ beginnt. Pattern p = Pattern.compile("Test*"); BasicDBObject query = new BasicDBObject ("filename", p); DBCursor cursor = col.find(query); Kompliziertere Vergleiche sind nur mit Hilfe von Operatoren umzusetzen. Die Operatoren beginnen mit einem $ - Zeichen. Im Beispiel werden alle Werte zwischen 18 und 24 vom Schlüssel „Alter“ gefiltert. [16, S.61 ff; 19, S. 153 f] BasiDBObject query = new BasicDBObject(); operator.put("$gte", 18); operator.put("$lte", 24); BasiDBObject query = new BasicDBObject("Alter",operator); Cursor cursor = col.find(query); 30 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.3. GRAPHDATENBANKMANAGEMENTSYSTEM NEO4J Neo4j ist ein in Java implementiertes Graphdatenbanksystem der Firma NeoTechnology. Graphdatenbanksysteme zeichnen sich durch die Möglichkeit, viele vernetzte Informationen abzuspeichern und schnell durch den Graphen navigieren zu können, aus. Neo4j ist bekannt als eine Graphdatenbank mit einer hohen Performance und vielen Schnittstellen für die unterschiedlichen Programmiersprachen. In dieser Arbeit wurde die Community - Edition des DBS verwendet. Diese ist unter GNU General Puplic License (GPL) lizensiert und somit frei erhältlich. Hier werden Daten schemafrei in Graphen gespeichert. 31 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.3.1. INTERNER AUFBAU DES NEO4J – DATEISYSTEMS Graphdatenbanken unterscheiden sich grundsätzlich von relationalen Datenbanken. WAS IST EIN GRAPH Graphen sind ein beliebtes Mittel zur Modellierung vernetzter Informationen und komplexer Fragestellungen. Diese bestehen aus Knoten (bzw. Ecken), welche mit Kanten verbunden sind. Man unterscheidet zwischen gerichteten und ungerichteten Kanten. Eine gerichtete Kante beschreibt eine einseitige Beziehung zwischen den Knoten und die ungerichtete Kante eine beidseitige Beziehung. Analog dazu spricht man von gerichteten oder ungerichteten Graphen. Bei der Verwendung von mehreren Beziehungen pro Knoten handelt es sich um einen Multigraphen. [6, S. 209] Abb. 13: Knoten und Kanten eines Graphs Ein Graph kann auch durch die in Beziehungen stehende Tabellen eines relationalen Datenbanksystems dargestellt werden. Ein graphischer Vergleich ist in der unterstehenden Abbildung dargestellt. Abb. 14: Vergleich eines Graphen mit Tabellen eines RDBMS [20] 32 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme DAS PROPERTY - GRAPH - MODELL In dieser Bachelorarbeit soll das native Graphdatenbanksystem Neo4j untersucht werden. Dieses modelliert Property - Graphen. Das bedeutet, dass sowohl Knoten als auch Kanten mit Eigenschaften (Properties) versehen werden können. Zum Beispiel kann der Ausdruck „Kraftwerk (Steinkohle) ist an einem Umspannwerk (800MVA) angeschlossen“ als Graph verstanden werden. Hier handelt es sich um eine Graphdatenbank mit drei Einträgen (Kraftwerk, Relation, Umspannwerk) mit jeweils entsprechenden Eigenschaften (Steinkohle, angeschlossen, 800MVA). Daraus wird ein Vorteil einer Graphdatenbank ersichtlich, die Relationen können viel schneller (als z.B. bei einer relationalen DB) nach Daten durchsucht werden. Die Eigenschaften von den Knoten und Kanten sind Key/Value - Beziehungen vom Typ <String,Object>, z. B. „Typ: Steinkohle“ oder „Bemessungsleistung: 800MVA“. Sie müssen nicht streng typisiert sein, jedoch kann der Typ bzw. das Schema einer Kante oder eines Knotens genau definiert werden. Es ist durchaus möglich, dass ein Knoten mehrere Typen besitzt. Kanten, Knoten sowie Kantentypen (auch Labels genannt), können ein Schema besitzen. Es ist möglich festzulegen, welche Knotentypen mit welchen Kantentypen verknüpft werden dürfen. Jeder Knoten und jede Kante werden durch einen Property - Schlüssel „Id“ eindeutig identifiziert. Der Wertebereich für Id kann sehr unterschiedlich sein. Dies können z.B. Integerwerte oder Zeichenketten sein. [6, S. 210 ff] 33 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme Abb. 15: Property-Graph-Modell anhand Verbraucher eines Zimmers TRAVERSIEREN VON GRAPHEN Das Traversieren von Graphen bedeutet nichts anderes als Durchsuchen von Graphen nach bestimmten Kriterien. Die Traversierung von Graphen ist eine der wichtigsten Operationen von Graphdatenbanksystemen. [6, S. 294 f] Dafür bedarf es fünf Angaben: Startknoten Expander (Art der Kanten, die berücksichtigt werden sollen, z.B. nur eingehende oder nur vom bestimmten Typ) Order (Reihenfolge des Durchsuchvorgangs, d.h. ob Breiten- oder Tiefensuche zuerst erfolgt) Uniqueness (Angabe ob Objekte, die mehrfach vorhanden sind ignoriert oder durchsucht werden sollen) Evaluator (Abbruchkriterium des Suchvorgangs, z.B. wenn ein Knoten mit bestimmter Eigenschaft oder ein Knoten einer bestimmten Tiefe gefunden wurde) 34 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.3.2. DIE VERWENDUNG VON NEO4J MIT JAVA Für die Zugriffe auf Neo4j über Java, müssen die mit DBS gelieferten APIs eigebunden werden. Diese befinden sich im Verzeichnis „lib“ der heruntergeladenen Datei. EINFÜGEN VON DATEN Für die Erstellung von Knoten muss zuerst eine Datenbank initialisiert werden. Hierbei muss noch das Verzeichnis der DB angegeben werden. Hiermit wird es spezifiziert, wo eine neue Datenbank angelegt werden soll oder aus welcher Datenbank Informationen geladen werden sollen. Dabei werden alle benötigten Services aus dem Packet org.neo4j.graphdb.* importiert. import org.neo4j.graphdb.* EmbeddedGraphDatabase dbgraph = new EmbeddedGraphDatabase("C:\\BSP.db"); Nachdem die Datenbank gestartet wurde, kann ein Graph in Form von Knoten und Kanten mit deren Eigenschaften implementiert werden. Im folgenden Beispiel werden Kanten mittels Java Enum vordefiniert, alternativ können sie auch dynamisch erstellt werden. public static enum Rel implements RelationshipType { unterrichtet, kennt } Transaction tr = graphdb.beginTx(); try { Node Professor = graphdb.createNode(); Node Student = graphdb.createNode(); Student.setProperty("Name", "Mustermann"); Relationship Prof_Stud = Professor.createRelationshipTo(Student, Rel.unterrichtet); tr.success(); } catch (Exception e) { tr.failure(); } finally { tr.finish(); } 35 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme GRAPH - TRAVERSALS Ähnlich des Suchbefehls in SQL, wird in Neo4j nach Verbindungen zwischen Objekten untereinander gesucht. So kann man nach bestimmten Verknüpfungen von Objekten miteinander suchen und Eigenschaften der verknüpften Objekte ausgeben lassen. Iterable<Relationship> Freundschaften = Student.getRelationships(Direction.OUTGOING, Rel.kennt); for (Relationship Freundschaft : Freundschaften) { System.out.println(Freundschaft.getEndNode().getProperty("Name")); } 36 Kapitel 3: Vergleich der verschiedenen Datenbankmanagementsysteme 3.4. FAZIT Alle drei Datenbanksysteme lassen sich mit Java verwalten und erfüllen somit die Anforderungen der Arbeit. Für das DBMS MySQL wird die JDBC API verwendet, um SQL - Anfragen an das DBS weiterzuleiten. Für die DBMS MongoDB und Neo4j werden Java APIs des jeweiligen Herstellers verwendet, um durch die objektspezifischenMethoden von Java die Datenbankabfragen realisieren zu können. Man erkennt Ähnlichkeiten der Datenbanksysteme wie z.B. eine eindeutige ID eines Datensatzes. Jeder Knoten, jedes Dokument sowie jede Zeile einer Tabelle werden dabei eindeutig definiert. Es besteht in allen Datenbanksystemen die Möglichkeit vorhandene Datensätze zu indizieren, um die Performance bei der Abfrage von den Feldern bzw. Knoteneigenschaften zu steigern. Alle Datensätze können miteinander verknüpft werden, um ihre Zugehörigkeit zu realisieren, jedoch bei jedem System auf unterschiedliche Weise. Es sind aber auch klare Unterschiede erkennbar. Die NoSQL-Datenbanken sind schemafrei. Das heißt, dass es nicht notwendig ist ein festes Schema der Inhalte von Collections, Dokumenten und Knoten festzulegen. Die Anzahl der Datensätze eines Dokumentes oder die Anzahl und der Datentyp von Eigenschaften eines Knotens müssen in NoSQL - DBs nicht vordefiniert werden. Diese Größen können von Dokument zu Dokument bzw. von Knoten zu Knoten unterschiedlich sein. Das Datenbankschema des DBMS MySQL muss dagegen vorher festgelegt werden. Es werden Tabellen definiert, die bestimmte Spalten haben, in denen ein Datensatz vom bestimmten Datentyp gespeichert werden kann. 37 Kapitel 4: Datenbankentwurf 4. DATENBANKENTWURF 4.1. ZWECK DER ANWENDUNG In den Datenbanken sollen miteinander verknüpfte Objekte eines elektrischen Netzes abgebildet werden. Unter Objekten sind physikalische Objekte wie z.B. Kraftwerk, Umspannwerk, Haus usw. zu verstehen. Für die Untersuchung von Möglichkeiten zum Speichern von Objekten in die Datenbanken soll das elektrische Energiesystem näher betrachtet werden. 4.2. AUFBAU EINES ELEKTROENERGIESYSTEMS Ein System, welches aus technischer Sicht alle Einrichtungen zur Erzeugung, Übertragung und Verteilung elektrischer Energie innerhalb bestimmter Systemgrenzen beinhaltet, nennt man Elektroenergiesystem. [7, S.16 f] 4.2.1. ERZEUGUNG ELEKTRISCHER ENERGIE Die Erzeugung elektrischer Energie erfolgt in Kraftwerken. Diese können unterschiedlich groß sein, einige kW bis über 1000MW. Bei der Erzeugung elektrischer Energie wird zwischen Primär- und Sekundärenergieträgern unterschieden. Unter Primärenergieträger versteht man unveränderte, natürlich vorkommende Energieträger, die zur Energieumwandlung verwendet werden kann. Man unterscheidet zwischen erschöpflichen (z.B. fossile Energieträger, wie Kohle, Erdöl und Erdgas) und unerschöpflichen (z.B. Sonnenstrahlung) Primärenergieträgern. Sekundärenergieträger sind dagegen durch Menschen beabsichtigt veränderte Energieträger (z.B. Benzin, Heizöl). Dabei ist die Sekundärenergie die umgewandelte Energieform (z.B. mechanische oder elektrische Energie). [35, S. 8] Alle vorhandenen Kraftwerke arbeiten parallel in einem Verbundnetz. So kann plötzlicher oder im Voraus geplanter Ausfall (z.B. aufgrund von Revisionsarbeiten) eines Kraftwerkes durch ein oder mehrere andere Kraftwerke abgedeckt werden. [7, S.18] Die Bruttoerzeugung elektrischer Energie pro Jahr liegt in Deutschland im Terrawattbereich. So wurde z.B. im Jahr 2007 etwa 680,8 TWh elektrischer Energie erzeugt. Folgende Kraftwerkstypen (Abb. 16: Erzeugung elektrischer Energie in Deutschland) wurden dabei beteiligt. [7, S. 30 f] 38 Kapitel 4: Datenbankentwurf Erzeugung el. Energie in Deutschland Erzeugung el. Energie in % 25,0% 20,0% 15,0% 10,0% 5,0% 0,0% Kernenergie Braunkohle Steinkohle Erdgas Kraftwerkstypen Abb. 16: Erzeugung elektrischer Energie in Deutschland Die Erzeugung elektrischer Energie in Deutschland wird überwiegend mit thermischen Großkraftwerken realisiert ist. Trotz der wachsenden Tendenz und dem Ausbau der Anlagen zur Erzeugung elektrischer Energie aus erneuerbaren Energieträgern, sowie einem erheblichen Rückgang der Energieerzeugung aus Kernenergie ist noch von der Dominanz fossiler Energieträger auszugehen. [7, S. 30] 39 Kapitel 4: Datenbankentwurf SPANNUNGSEBENEN Aufgrund des breiten Spektrums unterschiedlich hohen Kraftwerksleistungen, der Standortbindung von Kraftwerken, verschiedenen Verbrauchern (Klein- Großverbraucher) und aufgrund Reduktion der Verlustleistung bei der Übertragung elektrischer Energie besitzt das Energiesystem eine hierarchische Struktur. Nach IEC 60038 (DIN VDE 0175) werden in der Abb. 17: Spannungsebenen Netznominalspannungen für verschiedene Anwendungen empfohlen. [7 ,S. 59] Abb. 17: Spannungsebenen Daraus erkennt man, dass Netznominalspannungen zwischen 6 kV und 30 kV , sowie 220 kV und 380 kV in IEC 60038 unter Hochspannung ausgeführt sind, sie werden aber im Sprachgebrauch als Mittelspannungen und Höchstspannungen bezeichnet. [7, S. 59] 40 Kapitel 4: Datenbankentwurf 4.2.2. ÜBERTRAGUNG ELEKTRISCHER ENERGIE Für die Übertragung elektrischer Energie werden überwiegend folgende Systeme verwendet: Einphasige Systeme Aufgrund der Einspeisung in die Bahnfahrzeuge mit einer Leitung kommen einphasige Systeme überwiegend im Bereich des schienengebundenen Verkehrs vor. Dabei liegt an der Oberleitung eine einphasige Wechselspannung an. Dabei ist zu beachten, dass das Bahnnetz überwiegend mit einer Frequenz von 16,7 Hz betrieben wird. Es sind aber bereits einphasige 50 Hz Netze im Einsatz. [21, S. 77] Drehstromsysteme Transport elektrischer Energie in Netzen erfolgt heute überwiegend mit dreiphasigem Wechselstrom (Drehstrom). Darunter ist die Drehstrom Hochspannungs - Übertragung (DHÜ) zu verstehen. Für dieses Übertragungssystem werden in Deutschland üblicherweise die oben genannten Spannungsebenen verwendet. In anderen Ländern sind auch Spannungen von 500 kV und 735 kV üblich. Durch das Hochtransformieren der Spannungen kann die Verlustleistung minimiert werden und Material eingespart werden. Verschiedene Spannungsebenen werden über Transformatoren, die in den Umspannanlagen installiert sind, gekuppelt. Transformatortypen werden im Verlauf dieses Kapitels genauer erläutert. Im gesamten DHÜ - Verbundnetz muss in Europa eine einheitliche Übertragungsnetzfrequenz von 50 Hz gehalten werden. Auf weitere Kriterien wie Spannungsqualität und -stabilität, Netzsicherheit, zulässige Schwankungsbreite der Netzfrequenz, Oberschwingungsgehalt, Versorgungsunterbrechungen, Übertragungsnetzbetreiber usw. Regelzonen wird in dieser der Arbeit deutschen nicht näher eingegangen. [21, S. 78ff; 8, S. 397f] 41 Kapitel 4: Datenbankentwurf Gleichstromsysteme Gleichstromnetze finden ihre Anwendung hauptsächlich bei der Versorgung bestimmter Verbraucher wie z.B. Walzwerke oder bei der Hochspannungs Gleichstrom - Übertragung (HGÜ), für die Übertragung elektrischer Energie über große Entfernungen, zur Kupplung asynchroner Netze, zum Anschluss von großen Kraftwerken ohne Erhöhung der Kurzschlussleistungen etc. [21, S. 80; 8, S. 405] Beim Einsatz von HGÜ - Systemen kann elektrische Energie mit weniger Verlusten übertragen werden, da Spannungsabfall in der Leitung nur ohmschen Charakter hat. Die Reaktanzen haben somit keinen Einfluss, wie auch Blindleistungs- und Wirbelstromverluste. Allerdings ist bei diesem Übertragungssystem höherer technischer Aufwand erforderlich, da Wechselund Gleichrichterstationen an Anschlüssen der Leitung erforderlich sind. Der Break - Even - Point (Schwelle, ab der sich investierte Kosten durch Erlöse erwirtschaften) liegt z.B. im Falle der Übertagung elektrischer Energie über Freileitungen bei ca. 700 - 1000km. [22, S. 4] 42 Kapitel 4: Datenbankentwurf NETZE DER ENERGIEVERSORGUNG In der Energieversorgungstechnik werden folgende Netze unterschieden: Transportnetze Als Transportnetze werden Höchstspannungsnetze 380 kV und 220 kV bezeichnet. In diesen Netzen wechselt sich typischerweise die Energieflussrichtung abhängig vom Kraftwerkseinsätzen, sowie Liefer - bzw. Bezugsabsprachen mit anderen Energiesystemen ab. Beispiele sind der Transport elektrischer Energie von standortgebundenen Kohlekraftwerken zu Ballungsgebieten oder auch von Kernenergie über weite Strecken innerhalb des europäischen Verbundnetzes. Unter einem Verbundnetz wird ein elektrischer Zusammenschluss von Netzen unterschiedlicher Betreiber verstanden. Kernaufgabe dieses Netzes ist die korrelative Unterstützung benachbarter Kraftwerke bei einem Ausfall. Transportnetze weisen eine vermaschte Struktur auf, so dass jeder Netzknoten von mindestens zwei Seiten versorgt wird. Sollte eine Leitung ausfallen, wird die volle Last von einer anderen Leitung übernommen. Man spricht von einem N - 1 Prinzip. Typischerweise sind die Transportleitungen als Drehstrom - Höchstspannungsfreileitungen realisiert, es kommen aber auch Drehstrom - Höchstspannungskabel vor. [8, S. 19; S.398] Übertragungsnetze Zur Übertragung elektrische Energie von einem Entnahmeknoten der vorgelagerten Transportnetze zu den kleineren Verteilerunternehmen oder Sondervertragskunden innerhalb einer Region dienen die 110 kV Übertragungsnetze. Die Energieflussrichtung ist in der Regel monoton. Der Aufbau der Netze kann hier entweder vermascht oder strahlenförmig sein. Davon hängt die Funktion des Netzes ab, Transportfunktion bei vermaschtem Aufbau oder die Verteilfunktion beim strahlenförmigen. [8, S. 20; S. 401] Verteilungsnetze Die aus den vorgelagerten Übertragungsnetzen bezogene Energie wird über die Verteilungsnetze lokal über ein größeres Gebiet verteilt. Sie verbinden die Unterspannungsseite der 110 kV - Umspannstation mit der 43 Kapitel 4: Datenbankentwurf Oberspannungsseite der Ortsnetz-, Industrie- oder auch Schwerpunktstation von Ballungsgebieten und von der Industrie. Hierbei spricht man von einer Primärverteilung. [8, S. 20] Niederspannungsnetze Unter Niederspannungsnetzen sind 400 V - Netze, die aus den Ortsnetz- oder Schwerpunktstationen der Verteilnetze gespeist werden, zu verstehen. Diese Netze leiten die Energie an die Endabnehmer weiter. Im Gegensatz zu den Transport-, Übertragungs- und Verteilnetzen, die als Dreileiter realisiert sind, führen die Niederspannungsnetze noch einen vierten Leiter (den Neutralleiter) mit. Dabei spricht man von einer Sekundärverteilung. [8, S. 20; 21, S. 82] Die Abb. 18: Hierarchische Darstellung des Energieversorgungsnetzes [8, S.19] verdeutlicht nochmal die hierarchische Struktur und die Funktionen der Energieversorgungsnetze. [8, S.20; 8, S.399ff] Abb. 18: Hierarchische Darstellung des Energieversorgungsnetzes [8, S.19] An der Stelle muss erwähnt werden, dass in Deutschland oft die Transportnetze als Übertragungsnetze bezeichnet werden und die 110 kV - Netze abhängig von der Struktur als Übertragungsnetz (bei vermaschter Struktur) oder als Verteilungsnetz (bei sternförmiger Struktur). [8, S. 21] 44 Kapitel 4: Datenbankentwurf UMSPANNSTATIONEN Umspannstationen Technisch sind dienen zur Kuppelung Spannungsebenen über verschiedenen Transformatoren Spannungsebenen. gekuppelt. Eine Umspannstation besteht mindestens aus einer oberspannungsseitigen Schaltanlage, einem Transformator und einer unterspannungsseitigen Schaltanlage. TRANSFORMATOREN Zur Transformation von einer Spannungsebene zur einer anderen werden in der Elektroenergieversorgung Transformatoren eingesetzt. Wichtige Kenngrößen von Transformatoren sind Bemessungsscheinleistung, Bemessungsspannung und Kurzschlussspannung (Kurzschlussimpedanz). So kommen zur Speisung des Niederspannungsnetzes (0,4 kV) aus dem Mittelspannungsnetz (10 kV - 30 kV) Bemessungsscheinleistungen von 250 kVA bis 1600 kVA zum Einsatz (teilweise auch bis 2,5 MVA). Transformatoren mit der Bemessungsscheinleistung von 12 MVA bis 40 MVA) werden zwischen Hoch - (110 kV - 20 kV) und Mittespannungsnetzen verwendet. Die oben genannten Transformatoren werden als Drehstromtransformatoren ausgeführt. Zur Kupplung der 380 kV, 220 kV und 110 kV Netze werden Transformatoren mit der Bemessungsscheinleistung 100 MVA bis 1000 MVA eingesetzt. Diese sind im europäischen Verbundnetz als drei zusammengeschaltete Einphasentransformatoren realisiert, z.B. 3x333 MVA. Dabei spricht man von einer Transformatorbank. Hierbei handelt es sich um Verteiltransformatoren. Sie ermöglichen Leistungsübertragung zwischen Netzen unterschiedlicher Spannungsebenen. Zur Kopplung eines Kraftwerkes an das Stromnetz werden Blocktransformatoren (auch Maschinentransformatoren genannt) mit einer vom Generator des jeweiligen Kraftwerkes abhängigen Leistung, jedoch maximal bis 1200 MVA, gebaut. Typische Bemessungsleistung eines 45 Kapitel 4: Datenbankentwurf Blocktransformators liegt zwischen 300 MVA und 1000 MVA. Außerdem besitzen große Kraftwerke noch Dreiwicklertransformatoren für interne Zwecke. In der Industrie werden häufig noch Anfahrtransformatoren zum Anlauf von großen Maschinen, Lichtbogenofentransformatoren falls häufiges Schalten bei hohen Strömen erforderlich ist, Stromrichtertransformatoren für viele Endgeräte, die schaltend ausgelegt sind, usw. verwendet. Die Funktionsweise eines Transformators, sowie mögliche Dreieck-, Stern- oder Zickzackschaltungen von ober- oder unterseitigen Wicklungen sind für diese Arbeit nicht relevant. Diese werden in dieser Arbeit nicht weiter erläutert. [28, S. 219; 22, S. 40 f] 46 Kapitel 4: Datenbankentwurf TYPISCHE NETZSTRUKTUREN Die erste Netzstruktur, das Strahlennetz, wird hauptsächlich im Niederspannungsbereich verwendet. Wie in Abb. 19: Strahlennetz dargestellt, verlaufen die Leitungen von der Umspannstation aus strahlenförmig und können verzweigt werden. Typisch ist diese Anschlussart bei geringer Lastdichte oder bei großen Punktlasten. Vorteile dieses Anschlusses sind geringe Investitionskosten, sowie ein einfacher Betrieb. Nachteilig ist die Möglichkeit der Versorgungsunterbrechung beim Ausfall von Leitungen. Abb. 19: Strahlennetz [22, S. 24] Eine weitere Netzstruktur ist das Ringnetz, s. Abb. 20: Ringnetz. Hier werden die Enden von oben genannten strahlenförmigen Leitungen mit einer Trennstelle verbunden. Das Netz wird üblicherweise mit offenen Trennstellen betrieben, so dass wieder eine strahlenförmige Netzstruktur entsteht. Diese Netzstruktur weist im Vergleich zum Strahlennetz eine höhere Sicherheit auf (auch Eigensicherheit genannt). Tritt z.B. ein Kurzschluss innerhalb eines Ringnetzes auf, werden die angrenzenden Trennstellen die Kabelstrecke freischalten. Zugleich erfolgt eine Zuschaltung der Trennstelle, die beide Strahlennetze verbindet. So können alle Verbraucher, auch die sich am abgeschalteten Abschnitt eines Strahls befinden, weiter versorgt werden. Üblicherweise findet diese Form des Netzes eine Anwendung im Mittelspannungsbereich, selten aber auch im Niederspannungsbereich. 47 Kapitel 4: Datenbankentwurf Abb. 20: Ringnetz [22, S. 24] Eine besondere Form des Ringnetzes ist in der Abb. 21: Verzweigter Ring [22, S. 24] dargestellt. Sie ist bei erhöhter Lastdichte verbreitet. Eine steigernde Anzahl von Vermaschungen und Einspeisepunkte bringt höhere Eigensicherheit des Netzes. Abb. 21: Verzweigter Ring [22, S. 24] Ringnetze benötigen mehr Investitions- und Betriebsaufwand, sind aber durch eine bessere Versorgungszuverlässigkeit und geringere Ausfallzeit vorteilhaft. Vermaschte Netze, Abb. 22: Maschennetz [22, S. 24], trifft man vornehmlich im Hochspannungs-, sowie im Mittelspannungsbereich. Je nach Vorgaben der zu versorgenden Lasten, werden die Netze so gebaut und betrieben, dass die Versorgung bei einem normgerechten Spannungsprofil und ohne Überlastung für Ausfälle von einem oder mehreren Betriebsmitteln gewährleistet ist. Man spricht vom (n - 1) – Prinzip, wenn beim Ausfall eines Systems das zweite System 100% der Leistung des 48 Kapitel 4: Datenbankentwurf ausgefallen Systems übernimmt. Beim (n - k) – Prinzip kann die Versorgung trotz des Ausfalls mehrere Systeme gewährleitet werden. Abb. 22: Maschennetz [22, S. 24] Die Form des Maschennetzes kommt aber auch im Niederspannungsbereich vor. Mehrfache Versorgung von Knoten gewährleistet eine sehr hohe Versorgungssicherheit. [8, S. 6; 21, S.83 ff] NETZTOPOLOGIE In der Energieversorgung werden wie im Kap. Typische Netzstrukturen beschrieben, zwischen Strahlen-, Ring- und Maschennetz unterschieden. Ihr Aussehen kann von der Spannungsebene, Lageplan, landschaftlichen Gegebenheiten, gewünschten Versorgungssicherheit usw. anhängig sein. Darauf aufbauend können Netze Modifikationen aufweisen, wie z.B. Netze mit Gegenstation, Netze mit Stützpunkten, Netze mit durchlaufenden Verteilkabeln, offene und geschlossene Netz usw. Abgesehen davon besitzt jedes Netz eine Trennstelle für die Möglichkeit ein Teil des Netzes spannungsfrei zu schalten (z.B. aufgrund Wartungsarbeiten oder für die Beseitigung einer aufgetretenen Störung). Dies hat eine Topologieänderung zu Folge. [8, S. 474] Auf verschiedene mögliche Modifikationen eines Netzes wird aufgrund des zeitlichen Aufwandes nicht näher eingegangen. Für die Performancemessungen wird ein vereinfachtes Modell, wie in Kap. 4.3. Erstellung des Datenmodells beschrieben, verwendet. 49 Kapitel 4: Datenbankentwurf 4.2.3. VERBRAUCH ELEKTRISCHER ENERGIE Von dem Bruttoerzeugungswert sind Kraftwerkseigenverbrauch, Netzverluste sowie sonstige Verluste (z.B. nicht erfasste Werte) abzuziehen. Somit ergibt sich für das Jahr 2007 ein Wert in Höhe von 613,3 TWh der erzeugten elektrischen Leistung, die hauptsächlich in den folgenden Verbrauchssektoren abgegeben wurde Abb. 23: Verbrauch elektrischer Energie in Deutschland. Abb. 23: Verbrauch elektrischer Energie in Deutschland Es fällt sofort auf, dass knapp die Hälfte der erzeugten Energie im Verbrauchssektor „Industrie“ und etwa ein Viertel in den Sektoren „Haushalt“ und „Gewerbe“ umgesetzt wird. 50 Kapitel 4: Datenbankentwurf 4.3. ERSTELLUNG DES DATENMODELLS Für die ersten Performancemessungen der Datenbanksysteme wird aufgrund einer besseren Übersicht ein Teil eines elektrischen Netzes in einer vereinfachten Form betrachtet, wie in Abb. 24: Modellnetz für die Performancemessung dargestellt ist. Dabei werden drei Kraftwerke aus dem 380 kV – Netz, ein Kraftwerk, das in das 110 kV – Netz einspeist, und ein Kraftwerkpark in der Mittelspannungsebene modelliert. In weiterführenden Analysen sollte das Datenmodell ausgebaut werden und realitätsgetreu dargestellt werden. Umspannwerke werden aufgrund der besseren Übersicht als eine eigenständige Einheit dargestellt. Anzahl und Typen der Transformatoren werden als Eigenschaft eines Umspannwerkes implementiert. Weitere Komponenten wie Schaltanlagen, Feldrechner, Feldgeräte, Fernwirkgeräte usw. werden nicht betrachtet. Eigenschaften eines Objektes werden als Zeilen in einem Dokument bzw. in einem Knoten oder in separaten Spalten einer Tabelle des relationalen DBS eigetragen. Für die Darstellung der Niederspannungsnetze werden drei verschiedene Netzstrukturen verwendet, Strahlennetz, Maschennetz und Ringnetz. Es werden drei Arten von Verbrauchern unterschieden: Groß-, Kleinindustrie und Häuser in der Niederspannungsebene. Jedes Haus besitzt folgende Attribute: Stadt, Straße, Hausnummer, durchschnittlicher Verbrauchswert und jeweilige Referenzen zum Übergeordnetem Objekt (Leitung oder Umspannwerk). Alle Netzübertragungstypen werden in Graphdatenbanksystemen als Kanten realisiert. Sie haben jedoch unterschiedliche Attribute und verbinden unterschiedliche Knotenarten (z.B. Kraftwerkknoten und Umspannwerkknoten). In den zwei anderen Datenbanksystemen werden Netzübertragungssysteme in eine separate Tabelle ausgelagert. Zu dieser Tabelle werden Verbindungen durch Referenzen bzw. Joins realisiert, um eine Verbindung der zwei Objekte zu gewährleisten. Netzsammelschienen werden in diesem Modell als Knoten mit ankommenden und abgehenden Abzweige realisiert. Verknüpfungen von den Objekten sollen ebenso wie die Objekte selbst Eigenschaften besitzen. Zum Beispiel ein Kraftwerk vom Typ Kernkraftwerk ist an einem 51 Kapitel 4: Datenbankentwurf Umspannwerk in der Stadt Musterstadt angeschlossen. Die Verbindung stellt ein Kabel dar. Dieses hat bestimmte Eigenschaften, wie z.B. Querschnitt, Hersteller, Alter oder Spannungsebene. Abb. 24: Modellnetz für die Performancemessung 52 Kapitel 4: Datenbankentwurf 4.4. TOPOLOGIE DES DATENMODELLS Die Erzeugung elektrischer Energie erfolgt in dem erstellten Modell in fünf Kraftwerken (Braunkohle,- Steinkohle-, Kernkraftkraftwerke in der Höchstspannungsebene; ein mittelgroßes Kraftwerk in der Hochspannungsebene, sowie ein Kraftwerkpark aus Windrad und Solaranlagen in der Mittelspannungsebene). Die erzeugte elektrische Energie wird in den Umspannstationen zu einer passenden Spannungshöhe transformiert. Dies erfolgt mithilfe von Transformatoren. Für den Transport elektrischer Energie wurden 4 Leitungstypen vorgesehen: Höchstspannung- und Hochspannungsleitung realisiert als Freileitungen, sowie Mittelspannungs- und Niederspannungsleitung realisiert als Kabel. Verbraucher dieses Modells sind Großindustrie, Kleinindustrie und einzelne Häuser in der Niederspannungsebene. 4.5. DATENBANKSTRUKTUREN Jeder Datenbanktyp besitzt eigene Struktur zum Speichern und Setzen von Referenzen. Aus diesem Grund werden nachfolgend drei verschiedene Datenbankschemas zur Abbildung der Stromnetzkomponenten dargestellt. 4.5.1. DATENBANKSCHEMA MYSQL Für jeden Objekttyp wie z.B. ein Kraftwerk oder ein Umspannwerk wird eine eigene Tabelle erstellt. Wie im Abb. 25: Datenbankschema MySQL dargestellt, wird jede erstellte Tabelle mit einer erweiterten Tabelle mithilfe von Hilfstabellen verknüpft. Dafür werden Primär- und Sekundärschlüssel verwendet. Die Hilfstabellen beinhalten ausschließlich die Informationen über die Verbindungen der jeweiligen Zeilen. 53 Kapitel 4: Datenbankentwurf Abb. 25: Datenbankschema MySQL Für die Eindeutigkeit jeder Zeile einer Tabelle werden Primärschlüssel verwendet. Diese werden vom DBMS automatisch indiziert. Es besteht aber die Möglichkeit Indizies für weitere Spalten zu setzen, um auf bestimmte Informationen schnelleren Zugriff gewährleisten zu können. Das kann anwendungsspezifisch im Verlauf der weiteren Analysen festgelegt werden. 4.5.2. DATENBANKMODELL MONGODB Das DBMS MongoDB ist schemafrei. Aus diesem Grund wurde für einen besseren Vergleich mit MySQL ein ähnliches Schema festgelegt. Jeder Objekttyp wird in eine extra Collection gespeichert. Die Informationen über die Verknüpfungen werden im Gegensatz zu MySQL die Dokumente implementiert. In der Abb. 26: DB - Schema mit Collections und Docs wird in das Dokument „Kraftwerk_800MW_0“ aus der Collection „Kraftwerke“ mit einem Dokument „Umspannwerk_M/HH_800_0“ aus der Collection „Umspannwerke“ verknüpft. Für genauere Funktion von Referenzen s. Kap. Interner Aufbau des MongoDB - Dateisystems. In der oben genannten Abbildung ist dies in der Zeile „Ref-Umspannwerk“ veranschaulicht. Außerdem besteht die Möglichkeit mithilfe von Visualisierungssoftware durch Referenzen von einem Dokument zum referenzierten Dokument zu springen und so entlang den Referenzen zu navigieren. 54 Kapitel 4: Datenbankentwurf Es wäre aber auch möglich alle Stromsystemkomponen in einer Collection zu speichern und nur die besonders langen Informationen, wie z.B. Beschreibung eines Objektes in eine zusätzliche Collection auszulagern und mit Referenzen miteinander zu verknüpfen. Dies würde eine performante Such- und Leseabfragen von Stromsystemkomponenten gewährleisten und durch die Referenzen eine Abfrage von verlinkten Informationen ermöglichen. Es wäre auch denkbar, möglichst viele Informationen in ein Dokument als mehrere Embedded Documents (auch als Unterdokumente von Unterdokumenten) zu speichern, um Referenzen auf andere Collections zu ersparen, aber es darf nicht außer Acht gelassen werden, dass ein Dokument maximal 16 MB sein darf und dadurch Performance von Suchabfragen leiden würde. Somit entstehen (Abb. 26: DB - Schema mit Collections und Docs) vier Collections: Kraftwerke, Umspannwerke, Verbraucher und Leitungen. Für eine bessere Übersicht wurde bei jedem Dokument eine eigene _Id definiert. Dies bringt keine Nachteile mit sich, außer dass Bediener darauf achten müssen, dass es keine doppelte _Ids gibt. Für ausführliche Erläuterung s. Kap. 3.1.1. Interner Aufbau des MySQL - Dateisystems. Sollte vom Bediener ein Dokument mit einer bereits vorhanden _Id erstellt werden, wird das DBMS das bereits vorhandene Dokument ersetzen. Dies wird ausschließlich zur besseren Darstellung der Inhalte einer DB gemacht. Zukünftig soll die Aufgabe zur Generierung und Vergabe einer _Id das DBMS übernehmen. Allerdings können solche Dokumente nur mühsam mit Visualisierungssoftware benutzt werden, da anstatt „Kraftwer_800MW_0“ eine automatisch generierte Zahlenfolge stehen würde. Dies hat eine Auswirkung auf die Referenzierung von Dokumenten. Die _Ids wurden von DBMS automatisch generiert und sind dem Benutzer nicht bekannt. Daher müssen sie zuerst aus dem Dokument, auf das eine Referenz angelegt werden soll, ausgelesen werden. 55 Kapitel 4: Datenbankentwurf Abb. 26: DB - Schema mit Collections und Docs 56 Kapitel 4: Datenbankentwurf 4.5.3. DATENBANKGRAPH NEO4J Das DBMS Neo4j ist genauso wie das DBMN MongoDB schemafrei. Hier bietet sich an, jedes Objekt als einen Knoten darzustellen und die Verbindungen in Form von Freileitungen oder Kabel als Kanten. In Neo4j besteht keine Möglichkeit Hyperknoten (Zusammenfassung von Knoten zu einem imaginären Knoten) zu bilden, so dass keine Knotencluster entstehen. Alle Knoten, unabhängig vom Typ oder Art, befinden sich somit in einer Menge mit allen weiteren Knoten. Abb. 27: Haus, Leitungen und Verbraucher als Graph In der Abb. 27: Haus, Leitungen und Verbraucher als Graph ist ein Haus als großer Knoten in der Mitte und einzelnen einphasige Verbraucher (rote Knoten) des Hauses dargestellt. Drei weiterführende Knoten können z.B. drei kleine Kraftwerke mit jeweiligen Fernwirkgeräten (z.B. Funkrundsteuerempfänger) zur ferngesteuerten Reduzierung der Einspeiseleistung sein. Mehrere solche miteinander verbundene Graphen bilden das Niederspannungsnetz. Umspannstationen werden ebenfalls als Knoten dargestellt und mit Kanten zu jeweiligen Verbraucher bzw. Erzeuger verbunden. 57 Kapitel 5: Implementierung 5. IMPLEMENTIERUNG 5.1. JAVA ALS HOCHSPRACHE Java ist eine objektorientierte Hochsprache, welche aus den Sprachen C++ und Smalltalk hervorgegangen ist. Java wurde 1995 von dem Erfinder James Gosling das erste Mal der Öffentlichkeit vorgestellt. Aktuell ist Version 7, wobei zuletzt in der Version 5 größere Änderungen vorgenommen worden sind. [29] Ziel der Sprache ist es, so wenige Implementierungsabhängigkeiten wie möglich im Quellcode zu haben, d.h. möglichst viel Code weiterzuverwenden. Java ist im Gegensatz zur Sprache C++ vollständig plattformunabhängig, da der Compiler Bytecode erzeugt, welcher in der JVM (Java Virtual Machine) ausgeführt wird. Dieser Bytecode kann nach einmaliger Erzeugung auf jeglicher Plattform ausgeführt werden, für die eine JVM existiert. Es gibt neben der von Oracle bereitgestellten JVM auch noch freie JVM, die häufig in Linuxdistributionen aus Copyrightgründen als Defaultinstallation mitgeliefert werden. [30] 5.2. NETBEANS ALS ENTWICKLUNGSUMGEBUNG NetBeans (www.netbeans.org) IDE ist eine in Java programmierte Entwicklungsumgebung für die Sprachen Java SE, FX, EE, ME, HTML5, C/C++, Groovy und PHP. Sie unterliegt der GNU GPL und wird von vielen Entwicklern verwendet. NetBeans entstand aus einer Initiative von Sun Microsystems im Jahr 2000, die vor der Übernahme durch Oracle im Jahr 2008 nun von Oracle finanziert wird. Wie jede Entwicklungsumgebung stellt auch NetBeans die üblichen Funktionen, wie schreiben, compilieren, testen und debuggen zur Verfügung. NetBeans kann im Vergleich zu proprietären IDEs mit Plug-Ins erweitert werden. Aufgrund des Lizenzierungsmodells unterliegt NetBeans keinen Nutzungsbeschränkungen. 58 Kapitel 5: Implementierung 5.3. ERZEUGUNG VON TESTDATEN Daten von den erzeugten Objekten und seinen Eigenschaften wurden wie im Bild oben festgelegt. Die Zahl der Häuser als Endverbraucher wird variabel gehalten, um Performancemessungen mit unterschiedlicher Anzahl von Objekten durchführen zu können. 59 Kapitel 6: Datenbank APIs 6. DATENBANK APIS 6.1. API Eine API (application programming interface) ist ein Protokoll, welches zur Kommunikation verschiedener Softwarekomponenten untereinander eingesetzt wird. Unter einer API versteht man ein Paket, in der Regel bestehend aus Routinen, Datenstrukturen, Objekten, Klassen und Variablen. Das Aussehen einer API kann sehr vielfältig sein, es kann internationalen Standards wie beispielsweise POSIX (Portable Operating System Interface, IEEE Std 1003.11988) oder herstellerspezifischen Vorgaben wie z.B. der Microsoft Windows API entsprechen. Eine API wird in der Regel für jeweils eine Programmiersprache zur Verfügung gestellt. Im Gegensatz zur ABI (application binary interface) welche binärbasiert ist, ist eine API quellcodebasiert. 6.2. DATENBANK APIS Eine Datenbankschnittstelle, ist eine Programmierschnittstelle API genannt, die die Kommunikation zwischen einem Programm und einem Datenbanksystem ermöglicht. Damit können Datensätze erzeugt, verändert, gesucht oder auch angezeigt werden. 6.2.1. SCHNITTSTELLE FÜR MYSQL Für die Kommunikation mit dem MySQL Datenbankmanagementsystem wurde die Datenbankschnittstelle JDBC (Java DataBase Connectivity) [31] verwendet. Es handelt sich um eine einheitliche Schnittstelle für relationale Datenbanksysteme. Damit werden Zugriffe auf Datenbanken mit Java ermöglicht. Auf die Verwendung einer herstellerspezifischen Schnittstelle wurde verzichtet, da es für die Entwicklung eines Java - Programmes einen zeitlichen Mehraufwand bedeuten würde und bei den weiterführenden Arbeiten mit dem entwickelten Programm eine Einarbeitung vom Personal erforderlich wäre. 60 Kapitel 6: Datenbank APIs 6.2.2. NEO4J UND MONGODB API Für die Verwaltung der DBMS steht eine herstellerspezifische Schnittstelle für Java zur Verfügung. Version 2.2.0 stellt ein Framework vor. Es soll einfach und schnell zu benutzen sein, es übernimmt teilweise die Verwaltung von Variablen und Konstanten und verzichtet auf komplexe Map-Reduce Verfahren. Das Framework ist in C++ geschrieben worden. Folgendes Beispiel verdeutlicht die Verwendung von Konsolenbefehlen von MongoDB in Java. [32] { "_id" : ObjectId("503d5024ff9038cdbfcc9da4"), "employee" : 61, "department" : "Sales", "amount" : 77, "type" : "airfare" } Neo4j verwendet ähnlichen Syntax. Beispiele hierfür befinden sich im Anhang auf der CD. 61 Kapitel 7: Benchmarkentwurf 7. BENCHMARKENTWURF Für die Durchführung der Performancemessungen werden Festlegungen zur Abbildung der Objekte in jedem DBMS getroffen und ein Programm für die Auswertung der Messergebnisse entwickelt. 7.1. VORAUSSETZUNGEN EINES BENCHMARKS Jedes Objekt wie z.B. ein Kraftwerk oder ein Umspannwerk in jeder Datenbank besitzt gleiche Eigenschaften wie Spannungsebene, Orte, Kraftwerkstyp, Kraftwerksname und Bemessungsleistung. Auf die Erstellung von Unterdokumenten in MongoDB wird aufgrund eines anderen Aufbaus im Vergleich zu relationalen Datenbank verzichtet, um hier gleiche Bedingungen für die Benchmarks herzustellen. Grundsätzlich besteht die Möglichkeit in MongoDB, Adressen nicht in eine externe Tabelle bzw. externe Dokumente auszulagern und Referenzen zu setzen, sondern als Embedded Documents darzustellen. Es ist in zukünftigen Arbeiten zu diskutieren, ob dieses Verfahren hier sinnvolle Anwendung findet. Ein alternatives Verfahren zur Speicherung von Dokumenten ist unter Kap. 4.5.2 Datenbankmodell MongoDB ausgeführt. Alle Performancemessungen werden auf einem identischen Testsystem durchgeführt. Die Systemkonfiguration (8.4 Versuchsaufbau) ist identisch, die Datenbanken werden von einer zweiten magnetischen Festplatte geladen. Der größte Teil der elektrischen Verbraucher liegt in der Niederspannungsebene. Aus diesem Grund wird die Häuseranzahl mit ihren Eigenschaften variabel gestaltet, um elektrische Netze verschiedener Größen untersuchen zu können. 62 Kapitel 7: Benchmarkentwurf 7.2. DURCHFÜHRUNG UND AUSWERTUNG Abfragezeiten werden mit einem für diesen Zweck selbst entwickelten Java Programm (siehe Anhang a-f) erfasst und in einer Text - Datei gespeichert. Um möglichst reale Ergebnisse zu bekommen, wird jeder Test mehrfach (n=50) durchgeführt und schließlich ein arithmetischer Mittelwert aus den Ergebnissen gebildet. Eine manuelle Auswertung der Textdateien würde sehr viel Zeit in Anspruch nehmen. Dieser Prozess wird aus Effizienzgründen automatisiert. Dafür wird ein Programm in AutoIt (www.autoitscript.com/site/autoit), einer BASIC ähnlichen Scriptsprache erstellt. Dieses sucht alle Messwerte aus einer Textdatei heraus und stellt sie in tabellarischer Form dar. Abb. 28: Autokonvertier in AutoIt Danach können die Messwerte in eine Excel - Tabelle kopiert werden. Nach einer Anpassung der Messwerte mit VBA (Visual Basic for Applications) in Excel können diese ausgewertet und graphisch dargestellt werden. 63 Kapitel 8: Durchführung der Performancemessung 8. DURCHFÜHRUNG DER PERFORMANCEMESSUNG 8.1. INBETRIEBNAHME Alle Software wurden mit einem Windows - Betriebssystem verwendet. MongoDB erfordert einen besonderen Start über die Console mit der Angabe eines Pfades der Datenbank. Aus diesem Grund wurde eine Batch - Datei erstellt um nicht bei jedem Start den Pfad der Datenbank eingeben zu müssen. 8.2. DURCHFÜHRUNG EINES BENCHMARKS Es werden folgende Benchmarks durchgeführt: - Schreibvorgang verschiedener Anzahl von Objekten - Lesevorgang aller Objekte incl. Eigenschaften unterschiedlich großer Modelle - Suchvorgang nach bestimmten Objekten unterschiedlich großer Modelle. 8.3. LOGGING FÜR DOKUMENTATION DER BENÖTIGTEN ZEIT Für die Erfassung der Zeit für jeden Schreib- bzw. Abfragevorgang, wurde in Java eine Klasse zum Protokollieren des Programmablaufes erstellt. Damit lassen sich Zeiten vor und nach dem jeweiligen Schreib-, bzw. Lesevorgang erfassen. Die Differenz der erfassten Zeiten bildet die Dauer des Messvorganges. Die Zeitstempel, sowie die Messdauert werden, wie in Abb. 29: Ausschnitt aus der Logdatei dargestellt, in eine Textdatei geschrieben. Das Programm gibt die Zeit in Millisekunden zurück. Abb. 29: Ausschnitt aus der Logdatei 64 Kapitel 8: Durchführung der Performancemessung Die Textdatei wird im Unterverzeichnis log des Projektverzeichnisses gespeichert. Die erstellte Datei wird nach aktuellem Datum benannt. Existiert bereits die Textdatei, wird sie geöffnet und die neuen Messergebnisse werden den alten angehängt. Für die Wiederverwendbarkeit des Loggers in weiteren Projekten sind verschiedene Loglevels implementiert, unterschiedlichen Stellen so dass Meldungen verwendet nach werden Ihrer können. Wichtigkeit So an wurden Bedienerinformationen über den Startvorgang der Messung oder Informationen über das Ergebnis mit dem Level „INFO“ gespeichert und die unwichtigen Zeitstempel, die ausschließlich der Plausibilitätsprüfung dienen, mit dem Loglevel „FINE“. [40, S. 1315ff] 8.4. VERSUCHSAUFBAU Getestet wird das Geschwindigkeitsverhalten der drei DBMS, in Hinsicht auf Schreib und Lesegeschwindigkeit. Der Test wird durch ein eigens hierfür entwickeltes Java Programm ausgeführt. Das Programm führt die zu erledigenden Aufgaben (Schreib-, oder Abfragezyklen) durch und gibt die dafür benötigte Zeit in Millisekunden zurück. Die Tests werden auf einem System mit folgender Konfiguration durchgeführt (Abb. 30: Konfiguration des Testsystems): CPU: Intel Core AMD, RAM: 2048 MB, HDD: 2 x Western WDC10EARX 1000GB / 300MBps OS: Windows7 - 32bit Abb. 30: Konfiguration des Testsystems 65 Kapitel 8: Durchführung der Performancemessung Um einen Performanceverlust vorzubeugen, werden die zu bearbeitenden Dateien von einer Festplatte gelesen und auf eine andere geschrieben. Es wurden verschiedenste Tests bzgl. Schreib- und Lesegeschwindigkeit (Einzel- und Gesamtlesezyklus) durchgeführt. Aber auch das allgemeine Verhalten der Datenbank wurde getestet. Eine genaue Übersicht aller Test ist im Kap. 8. Durchführung der Performancemessung zu finden. 66 Kapitel 8: Durchführung der Performancemessung 8.5. BESONDERE HINWEISE MongoDB bringt keine Software zur Darstellung der vorhandenen Dokumente und ihrer Inhalte mit sich. Daher wurden zwei weitere Software zur Visualisierung der gespeicherten Daten verwendet. „MongoVUE“ liefert Datenbankinhalte incl. Datentypen in einer tabellarischen Form, wie man es von einer relationalen Datenbank gewohnt ist. Das Programm „MongoExplorer“ stellt die vorhandenen Dokumente und ihre Relationen zueinander graphisch dar. Der Anwender kann den Relationen folgen und somit durch die Dokumente und Collections einer Datenbank navigieren. Eine Besonderheit dieses Programmes ist, dass man keine Datentypen der einzelnen Werte auslesen kann. Die graphische Darstellung des graphenorientierten Datenbankmanagementsystems Neo4j war nicht ausreichend und bei größeren Datenbanken undurchschaubar. Aus diesem Grund wurde eine weitere Möglichkeit in Betracht gezogen Graphen und ihre Beziehungen darzustellen. „Gephi“ bietet die Möglichkeiten Graphencluster zu bilden und mit verschiedenen Algorithmen auf verschiedene Arten zu visualisieren. Es kann die Detailstufe der Graphendarstellung durch den Benutzer gewählt werden und Analyse des Graphes anhand Eigenschaften von Knoten (z.B. Analyse der vorhandenen Kantentypen oder Anzahl von Kanten bestimmter Knoten uvm.) durchgeführt werden. Die größte Herausforderung stellt die unterste 400 V Ebene dar, da die Verbraucherzahl deutlich die Zahl der Umspannwerke sowie der Kraftwerke übersteigt. Daher wird auf diese Ebene Schwerpunkt gelegt und noch zusätzlich zum erstellten Model eine Messung mit sehr vielen Zeilen (Dokumenten) einer Tabelle (Collection) zum Beispiel als Häuser in der Tabelle Verbraucher durchgeführt. 67 Kapitel 8: Durchführung der Performancemessung 8.6. TESTTABELLEN Ergebnisse der durchgeführten Messungen werden in folgenden Kapiteln tabellarisch dargestellt und diskutiert. 8.6.1. SPEICHERUNG Es wurden Messreihen mit einer steigenden Anzahl von Objekten durchgeführt (Tab. 1: Schreibperformance - Alle Datensätze). Ein Objekt besteht aus den Attributen: Haus, Lage, Besitzer, Verbrauch. Die für die Speicherung durchschnittlich benötigte Zeit wurde messtechnisch erfasst und statistisch ausgewertet. Tab. 1: Schreibperformance - Alle Datensätze Es ist offensichtlich, dass die NoSQL - Datenbanksysteme eine signifikant höhere Performance beim Speichern gleicher Objekte aufweisen (Abb. 31: Speicherung von Objekten – Gesamtkomposition). 68 Kapitel 8: Durchführung der Performancemessung Abb. 31: Speicherung von Objekten – Gesamtkomposition 69 Kapitel 8: Durchführung der Performancemessung 8.6.2. EXTREMA Bei der Durchführung dieser Performancemessung wurde festgestellt, dass das Datenbanksystem Neo4j am stärksten den PC ausgelastet hat. Ebenfalls weist Neo4j ein ungleichmäßiges Schreibverhalten im Vergleich zu den zwei weiteren Datenbanksystemen auf (Abb. 32: Schreibvorgang Neo4j - 1000 Messungen). Abb. 32: Schreibvorgang Neo4j - 1000 Messungen Es sind viele unterschiedlich große Messabweichungen vorhanden. Diese treten mit steigender Anzahl an Datensetzen häufiger auf und werden größer. In der oberen Abbildung ist das Schreibverhalten des DBS Neo4j abgebildet. Es wurden 2000 Knoten mit jeweils drei Attributen pro Datensatz erstellt. Nach jedem Datensatz wurde die Zeit gestoppt und aufgezeichnet. Der Datensatz wurde 1000mal hintereinander geschrieben. Insgesamt wurden 2 Mio. Knoten erzeugt. In der zweiten Hälfte der Abbildung, also ab ca. 600. Wiederholung des Schreibvorgangs ist eine Anhäufung großer Ausreißer zu beobachten. Diese liegen ungefähr mit Faktor 60 über dem Durchschnitt. Es ist zu erwähnen, dass bei der 600. Wiederholung in der Summe 600.000 Knoten in einem Durchlauf erzeugt wurden. 70 Kapitel 8: Durchführung der Performancemessung Daraufhin wurde das Verhalten der Auslastung des Arbeitsspeichers beobachtet. Es hat sich herausgestellt, dass bis ca. 600. Wiederholung des Schreibvorganges das Arbeitsspeicher rampenförmig bis zur Obergrenze befühlt wurde. Dies hat zur Folge, dass das DBS die Daten auf die Festplatte auslagern musste und dadurch die Anhäufung großer Ausreißer verursachte. Um die Hardwareabhängigkeit des Verhaltens des Datenbanksystems zu belegen, wurden gleiche Tests auf zwei weiteren Testsystemen durchgeführt (Abb. 33: Schreibvorgang Neo4j - 1000 Messungen - Testsystem 2). Es hat sich herausgestellt, dass bei Verwendung performanter Testsysteme, Messabweichungen seltener auftreten und diese deutlich kleiner sind. Die unterstehende Abbildung stellt das Ergebnis eines Benchmarks mit einem Testsystem, welches folgende Konfiguration besitzt, dar: Intel Core i5, 4 x 3,22GHz, 6 GB RAM, Hitachi 1000GB (3GB/s) Windows7 64 bit Abb. 33: Schreibvorgang Neo4j - 1000 Messungen - Testsystem 2 Es ist ein deutlicher Unterschied zum vorherigen Test zu erkennen. Die Ausreißer kommen seltener vor und sind wesentlich kleiner. Sie sind auf die treppenförmige Arbeitsspeicherauslastung des PCs durch das DBS zurückzuführen (Abb. 34: Auslastung des Arbeitsspeichers und des Prozessors mit Neo4j). Die Einzelheiten und 71 Kapitel 8: Durchführung der Performancemessung Hintergründe des Arbeitsspeicherverhaltens mit DBS Neo4j können in einer weiterführenden Arbeit genauer untersucht werden. Abb. 34: Auslastung des Arbeitsspeichers und des Prozessors mit Neo4j Aufgrund eines besseren Verhaltens von Datenbanksystemen mit der neuen Hardware werden alle weiteren Messungen auf diesem Testsystem durchgeführt. 72 Kapitel 8: Durchführung der Performancemessung Abb. 35: Schreibvorgang MongoDB - 1000 Messungen Die Datenbanksysteme MySQL (Abb. 36: Schreibvorgang MySQL - 1000 Messungen) und MongoDB (Abb. 35: Schreibvorgang MongoDB - 1000 Messungen) weisen ein ausgewogenes und gleichmäßiges Schreibverhalten, unabhängig von der benutzten Hardware auf. Abb. 36: Schreibvorgang MySQL - 1000 Messungen 73 Kapitel 8: Durchführung der Performancemessung 8.6.3. LESEN ALLER DATENSÄTZE VON BESTIMMTEN KOMPONENTEN Mit folgender Messung wurde die Zeit in ms erfasst, die jedes Datenbankmanagementsystem zum Lesen aller vorhandenen Inhalte eines Graphs und einer Tabelle bzw. einer Collection benötigt. Es wurde das oben beschriebene Stomsystemkomponentenmodell verwendet. Für die Variation der Messungen wurde die Anzahl der vorhandenen Häuser von 100 bis 500.000 erhöht. Die Eigenschaften aller Häuser sind dabei gleich geblieben bis auf die Hausnummer. Jede Messung wurde 50mal wiederholt. Aus den gewonnenen Ergebnissen wurde für jede Messreihe ein arithmetischer Mittelwert gebildet (Tab. 2: Leseperformance - Alle Datensätze). Tab. 2: Leseperformance - Alle Datensätze Es fällt sofort auf, dass das DBMS Neo4j an dieser Messung am schlechtesten abgeschnitten hat. Die Abfragezeiten liegen ca. fünffach über den Abfragezeiten des DBMS MySQL. Die Ergebnisse des zweiten NoSQL DBMS liegen nahe den Ergebnissen des DBMS MySQL. Die DBS sind ähnlich aufgebaut, eine Tabelle entspricht in etwa einer Collection und ein Eintrag in der Tabelle einem Dokument. Die Anzahl der Spalten der Tabelle entsprach in diesem Test der Anzahl der Zeilen in einem Dokument. Bei dem DBMS Neo4j wurden ebenfalls gleiche Inhalte ausgelesen, 74 Kapitel 8: Durchführung der Performancemessung allerdings wurden jedem Knoten die Inhalte als Eigenschaften hinzugefügt und schließlich abgefragt. Die graphische Auswertung der Ergebnisse (Abb. 37: Lesevorgang aller Datensätze bestimmter Objekte) unterstreicht nochmal das Ergebnis der Messung und verdeutlicht den Verlauf der Messkurve. Abb. 37: Lesevorgang aller Datensätze bestimmter Objekte Bei der Auswertung der Ergebnisse ist aufgefallen, dass die Standardabweichung der Messergebnisse bei NoSQL DBMS mit größerer Anzahl an Knoten im Verhältnis zu anderen DBMS unterschiedlich stark ausgeprägt ist (Abb. 38: Standardabweichung der Ergebnisse des Lesevorgangs). Das bedeutet, dass die Streuung der Messergebnisse um ihren Mittelwert bei den NoSQL DBS stark ausgeprägt ist, besonders bei dem graphenorientierten DBMS Neo4j. Dies ist im folgenden Bild dargestellt. Aus den Messwerten ist ein Zusammenhang ersichtlich, welcher sich auf den grundsätzlichen systematischen Aufbau der Datenbanksysteme zurückführen lässt. So sind MySQL und MongoDB in ihrer grundsätzlichen Struktur sehr ähnlich. (Kap. 3.2.1 Interner Aufbau des MongoDB - Dateisystems) 75 Kapitel 8: Durchführung der Performancemessung Abb. 38: Standardabweichung der Ergebnisse des Lesevorgangs 8.6.4. SUCHEN NACH BESTIMMTEN DATENSÄTZEN Für diesen Messverlauf wurden die bereits in der letzten Messung erstellten Tabellen, Collections bzw. Graphen verschiedener Größen genutzt, um die Datenbanken nach bestimmten Datensätzen zu durchsuchen. Es wurde nach der Hausnummer, die als fortlaufende Nummer in den DBs abgespeichert war, gesucht. Es wurden pro Messverlauf 100 Häuser gesucht. Das Schema der Abfragen wird wie folgt beschrieben: Zeilennummer in Tabelle Abfragenummer Anzahl der Einträge einer Tabelle Anzahl der Abfragen pro Messung Tab. 3: Legende Performancemessung-I Dabei ist die Abfragenummer der Durchlaufzeiger von 1 bis 100, die Anzahl der Einträge beschreibt die Anzahl der Zeilen einer Tabelle bzw. eines Dokumentes in einer Collection und die Anzahl der Abfragen wurde auf 100 pro Messung festgelegt. Da die Graphdatenbanken keine Tabellen oder Collections besitzen, bezieht sich die 76 Kapitel 8: Durchführung der Performancemessung Zeilennummer auf einen Knoten und die Anzahl der Einträge in einer Tabelle auf die Anzahl der Knoten in einem Graphen. So wurden DBs verschiedenen Größen untersucht. Das Ergebnis kann folgender Tabelle entnommen werden: Tab. 4: Suchperformance – Bestimmte Datensätze Die Hauptkomponenten eines Graphen in DBMS Neo4j werden Verbraucher aus dem Niederspannungsnetz sein, z.B. Häuser oder auch Einzelverbraucher eines Hauses, da ihre Anzahl am größten ist. Dieses würde eine Expansion des Graphen zur Folge haben und die Performance mit zunehmender Anzahl negativ beeinflussen (Tab. 4: Suchperformance – Bestimmte Datensätze). Die Ursache hierfür ist bei wachsenden Graphen dadurch begründet, dass auch einfache Abfragen längere Zeit in Anspruch nehmen, da alle Knoten sich in einem Cluster befinden. Vergleicht man in MySQL alle Objekte von Kraftwerk bis Einzelverbraucher durch suchen in einer Tabelle, sieht das Ergebnis genauso aus. In Abb. 39: Suchvorgang nach bestimmten Datensätzen ist der graphischer Verlauf der Messergebnisse dargestellt. Die DBMS MongoDB und MySQL haben annährend 77 Kapitel 8: Durchführung der Performancemessung sehr ähnlichen Verlauf, wobei MySQL bei jedem Suchvorgang etwas besser abgeschnitten hat. Abb. 39: Suchvorgang nach bestimmten Datensätzen Die Streuung der Messergebnisse ist in der nachfolgenden Abb. 40: Standartabweichung beim Suchvorgang bestimmter Datensätze graphisch dargestellt. Es ist ersichtlich, dass die Standabweichungen sehr stark variieren, was einen Vergleich schwierig macht. Betrachtet man letzte drei Ergebnisse (von den Größten Tabellen bzw. Graphen), so stellt sich heraus, dass MongoDB eine höhere Streuung der Ergebnisse als MySQL gezeigt hat. 78 Kapitel 8: Durchführung der Performancemessung Abb. 40: Standartabweichung beim Suchvorgang bestimmter Datensätze 79 Kapitel 8: Durchführung der Performancemessung 8.7. FAZIT Alle Messungen für die Schreib-, Lese- und Suchvorgänge mit drei vorgegeben DBMS unterschiedlich großer Datenbanken wurden erfolgreich durchgeführt. Die Ergebnisse wurden analysiert und miteinander verglichen. Die Kommunikation mit den DBMS erfolgte ausschließlich über die herstellerspezifischen Java-Schnittstellen. 80 Kapitel 9: Evaluation 9. EVALUATION Die erhobenen Messwerte werden miteinander verglichen und ausgewertet, hierbei wird auf eventuelle Probleme bei der Durchführung und zukünftigen Anwendungen eingegangen. 9.1. BEWERTUNG Die in der Bachelorarbeit durchgeführte Analyse erfüllt die gestellten Anforderungen in allen Punkten. Es können Stromsystemmodelle in den Datenbanksystemen gespeichert und von dort ausgelesen werden. Abfragezeiten von Datenbanken unterschiedlicher Größen wurden erfasst, analysiert und miteinander verglichen. Aus den Performancemessungen resultiert, dass DBMS MongoDB als performantester Kandidat der Schreibgeschwindigkeitsmessungen hervorging. Das DBMS MySQL hat ebenfalls ein sehr stabiles sequentielles Schreibverhalten, benötigt aber mehr als die fünffache Zeit für einen Datensatz gleicher Größe. Die Performancemessung des Leseverhaltens aller Informationen einer Tabelle bzw. eines Graphen zeigt, dass DBMS Neo4j am langsamsten abgeschnitten hat. Die Ergebnisse der beiden vorherigen DBMS liegen etwa gleich auf, jedoch weist das DBMS MySQL geringere Abweichungen vom Mittelwert auf. NoSQL Datenbankmanagementsysteme sind schemafrei, daher lassen sich Dokumente bzw. Knoten im Gegenteil zu den statischen Tabellen wie bei MySQL bei Bedarf dynamisch erweitern. In einer relationalen Datenbank müsste dafür eine neue Tabelle erstellt werden und durch das Setzen von Referenzen könnte dies ebenfalls realisiert werden, womit jedoch ein höherer, nachträglicher Programmieraufwand erforderlich ist. Die graphenorientierten Datenbanken lassen sich sehr gut mit verschiedenen Tools wie z.B. Gephi (www.gephi.org) visualisieren. Mit bestimmten Eigenschaften versehene Relationen eines Objektes zu einem anderen Objekt stellen im Stromsystemmodell gleichzeig die Stromleitungen dar. Dies bringt Transparenz und geringeren Programmieraufwand bei der Erstellung eines Datenmodells. 81 Kapitel 9: Evaluation Entsprechend der für das Graphdatenbanksystem Neo4j erhobenen Ergebnisse, eignet es sich sehr gut für Projekte die eine hohe Knoten- und Verknüpfungszahl fordern, da eine Modellierung in Graphenform möglich ist und eine Vielzahl an Beziehungen ohne großen Aufwand implementiert werden kann. MongoDB ist vorzugsweise auf horizontale Skalierbarkeit ausgelegt. Eine Methode der horizontalen Skalierung ist Sharding (Lastverteilung). Damit lässt sich eine Datenbank auf mehrere Server aufteilen und so kann die Auslastung verteilt werden. Die Kommunikation mit den DBMS erfolgte ausschließlich über die herstellerspezifischen Java-Schnittstellen. Ein weiterer Aspekt sind die unterschiedlichen Entwicklungsstände der DBMS. MySQL ist bereits seit vielen Jahren etabliert und ein Standard. Das DBMS ist somit ausgereift und bietet eine Vielzahl von Dokumentationen und Literatur. Die NoSQL Lösungen werden weiterentwickelt, sie bekommen neue Funktionen und etliche Verbesserungen. Zum Beispiel verspricht die neue Version (2.4) des MongoDB DBMS neben Verbesserungen, die Abfragen beschleunigen sollen, Volltextsuchfunktion, Felder mit fester Länge (capped Arrays) für bequemeres Arbeiter und bessere GeoFunktionen. Zählfunktion anhand der Indizes sind um das Zwanzigfache schneller als bisher. [41] Die Datenbanksysteme sind zu unterschiedlich, um einen kongruenten Vergleich zu ziehen. Es unterscheiden sich die Programmier-AIPs, der grundsätzliche Interne Aufbau, der Abfragesyntax, Funktionsumfang, Indizierungsfunktionen und Skalierungsmöglichkeiten hier zu stark. Ein Beispiel hierfür wäre, die softwareseitige Limitierung seitens der Java VM; Neo4j ist hier sehr stark systemabhängig. 82 Kapitel 9: Evaluation 9.2. AUSBLICK Für zukünftige Arbeiten wäre eine Einbindung realer Messdaten denkbar, derzeit liefert das Programm nur Beispieldaten, sowie: Durchführung der Messungen mit einer einheitlichen Schnittstelle JPA. Messung bei der Benutzung mehrerer Clients und gleichzeitiger Zugriffe auf eine DB Der Datenschutz der Datenbanken muss juristischen Anforderungen entsprechen. Hierzu sind jedoch Investitionen in Hardware und Kryptoanalytiker notwendig. Vergleich der bisherigen Performancemessungen im Rahmen des Projekts GDS SE (security environment) mit Performancemessungen über VPN Verbindungen. Diese werden nach derzeitigem Stand ab Juli 2013 von Alexander Kramer unter anderem im Rahmen seiner Bachelorthesis am IAI durchgeführt. 83 Anhang ANHANG Die folgenden Seiten beinhalten den Quellen Literaturverzeichnis Anlagenverzeichnis Raum Notizen i Quellen und Literaturverzeichnis QUELLEN UND LITERATURVERZEICHNIS Beschreibung Quelle [1] KIT [2] IAI [3] IAI http://www.kit.edu/kit/struktur.php [2013-02-20] http://www.iai.kit.edu/www-extern/fileadmin/PDF/IAI_Druckversion.pdf [2013-02-20] http://www.iai.kit.edu/www-extern/ [2013-02-20] [4] Datenbanksystem Datenbankkonzepte in der Praxis, Addison-Wesley, Sönke Cordts Einstieg in SQL, Marcus Throll, Oliver Bartosch, Galileo Computing, 4 DBRMS Auflage Einstieg in die Welt nichtrelationaler Web 2.0 Datenbanken, Hanser, Stefan NoSQL Edlich, 2.Auflage Elektrisches Netz Elektroenergieversorgung, Jürgen Schlabbach, 3. Auflage, VDE Verlag Elektroenergiesysteme- Erzegung, Transport Übertragung und Verteilung Elektrisches Netz elektrischer Enegrie, Adolf Schwab, 2.Auflage Atomgesetz http://www.gesetze-im-internet.de/bundesrecht/atg/gesamt.pdf http://www.eeg-aktuell.de/wp-content/uploads/2010/07/EEGEEG konsolidierte-unverbindliche-Fassung.pdf Energiewende http://www.netzentwicklungsplan.de/content/stromnetze Elektrische Energieversorgung 2: Energie- und Elektrizitätswirtschaft, HEO-Funktionen Kraftwerktechnik, alternative Stromerzeugung, Dynamik, Regelung und Stabilität, Betriebsplanung und -führung Java und Java und Datenbanken, Anwendungsprogrammierung mit JDBC, Servlets Datenbanken und JSP, Wolfgang Dehnhardt, Verlag Hanser EN50160 [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] SQL SQL für Dummies, Allen G. Taylor, 5.Auflage, Wiley-VCH Verlag [16] MongoDB MongoDB Sag ja zu NoSQL, Marc Boeker, entwickler.press, 2010 http://stackoverflow.com/questions/10756002/fetching-documents-frommongo-collection-using-karras# [2013-01-15] http://docs.mongodb.org/ecosystem/tutorial/getting-started-with-javadriver/#gsc.tab=0 Sieben Wochen, sieben Datenbanken, Moderne Datenbanken und die NoSQL-Bewegung, Eric Redmond & Jim R.Wilson, O'reilly, 2012 [17] MognoDB MongoDB mit [18] Java [19] DBS [20] Neo4j http://www.neo4j.org/learn/nosql [2013-02-10] Elektrische Energieversorgung, Klaus Heuck, Detlef, Schulz, 8. Auflage, [21] Elektrisches Netz Teubner Verlag [22] Elektrisches Netz Script aus der Vorlesung Elektrische Anlagen und Netze, G.Lipphardt, 2009 http://www-is.informatik.uni-oldenburg.de/publications/2440.pdf, [2013[23] CIM 04-01] [24] CIM http://de.wikipedia.org/wiki/IEC_61970 [25] CIM IEC 61970 http://smart-energy.blog.de/2010/10/08/ewe-setzt-cim-enterpriseservice-bus-9561225 [2013-04-01] Datenbanken Theorie, Entwurf und Programmierung relationaler Datenbanken, 2. Auflage, Matthias Schubert, Teubner Verlag [26] CIM [27] SQL [28] Elektrische Netze Java versions [29] history Java [30] Technetwork Java Technetwork [31] JDBC [32] MongoDB Elektrische Kraftwerke und Netz, D.Oeding, B.R.Oswald, 7.Auflage http://www.codejava.net/java-se/java-se-versions-history http://www.oracle.com/technetwork/java/javase/overview/javahistoryindex-198355.html http://www.oracle.com/technetwork/java/javase/jdbc/index.html http://docs.mongodb.org/ecosystem/tutorial/use-aggregation-frameworkwith-java-driver/ ii Quellen und Literaturverzeichnis [34] SQL International Workshop in Applied Measurements for Power Systems, Amps 2012 Proceedings, IEEE Catalog Number CFP12AMS-CDR, S. 143ff SQL für Dummies, Allen G. Taylor, 2.Auflage, Wiley-VCH Verlag [35] Energieträger Script aus der Vorlesung, Elektrische Anlagen und Kraftwerke, G.Lipphardt. [40] Java Java mehr als eine Insel, Christian Ullenboom, Galileo Computing, 1. Auflage http://www.heise.de/ix/meldung/MongoDB-bekommt-Volltextsuche-undbessere-Geo-Funktionen-1825419.html [2013-04-01] [33] EASiMoV [41] MongoDB iii Anlagenverzeichnis ANLAGENVERZEICHNIS a. Quellcode Java Programm Verwaltung MongoDB .................................................................... v b. Quellcode Java Programm Verwaltung MySQL ......................................................................... v c. Quellcode Java Programm Verwaltung Neo4j ............................................................................ v d. Quellcode Java Programm Benchmarks MongoDB .................................................................. v e. Quellcode Java Programm Benchmarks Neo4j .......................................................................... v f. Quellcode Java Programm Benchmarks MySQL ......................................................................... v iv Anlagenverzeichnis a. QUELLCODE JAVA PROGRAMM VERWALTUNG MONGODB sind auf beiliegendem Datenträger enthalten b. QUELLCODE JAVA PROGRAMM VERWALTUNG MYSQL sind auf beiliegendem Datenträger enthalten c. QUELLCODE JAVA PROGRAMM VERWALTUNG NEO4J sind auf beiliegendem Datenträger enthalten d. QUELLCODE JAVA PROGRAMM BENCHMARKS MONGODB sind auf beiliegendem Datenträger enthalten e. QUELLCODE JAVA PROGRAMM BENCHMARKS NEO4J sind auf beiliegendem Datenträger enthalten f. QUELLCODE JAVA PROGRAMM BENCHMARKS MYSQL sind auf beiliegendem Datenträger enthalten v