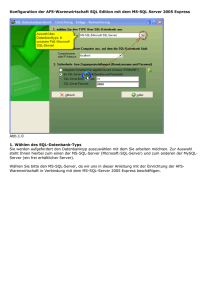
Entwurf und Realisierung eines datenbankgestützten Visualisierers
Werbung

Rheinische Friedrich-Wilhelms-Universität Bonn
Institut für Informatik III
Diplomarbeit
Entwurf und Realisierung eines
datenbankgestützten Visualisierers
für genealogische Daten
Ping Ni
Aus Shanghai
Oktober 2005
Erstgutachter:
Prof. Dr. Rainer Manthey
-1-
Danksagung
Zum Gelingen dieser Arbeit haben viele Menschen beigetragen, durch ihre direkte Mithilfe,
aber auch durch ihre indirekte. In erster Linie bedanke ich mich ganz herzlich bei Herrn
Professor Rainer Manthey für sein außergewöhnliches Engagement und für sein stets offenes Ohr für meine Fragen während der Entstehung dieser Arbeit.
Ganz besonders bedanke ich mich bei meinen Freunden, Johannes Kaiser und Mathias
Hauptmann, für die ausdauernde und tatkräftige Unterstützung meiner Diplomarbeit. Zusätzlich danke ich sie für die Erklärungen, die mir immer viel geholfen haben. Weiterhin
bedanke ich mich bei Thomas Pitz für die Mühe, die er sich beim Korrekturlesen dieser Arbeit gemacht hat.
Ein ganz lieber Dank geht auch an meinen Freund Thorsten Chmura für die Geduld, die er
mit mir während der Entstehungszeit dieser Arbeit hatte und für die Unterstützung, die er
mir auf vielfältige Art und Weise gegeben hat.
Zuletzt möchte ich meinen Eltern einen ganz besonderen Dank für die Ermöglichung meines
Studiums und für ihre Unterstützung in jeder Situation aussprechen.
-2-
INHALTSVERZEICHNIS
Danksagung ............................................................................................................................. 2
1. Einleitung ......................................................................................................................... 5
2. Genealogie........................................................................................................................ 8
2.1.
Geschichte ............................................................................................................... 8
2.2.
Begriffsbildungen .................................................................................................. 10
2.3.
Wissenschaftliche Arbeitstechnik.......................................................................... 12
2.3.1. Sammeln ............................................................................................................ 13
2.3.2. Auswerten.......................................................................................................... 15
2.3.3. Dokumentieren .................................................................................................. 16
2.3.4. Veröffentlichen .................................................................................................. 22
2.4.
Computergenealogie als Hilfsmittel ...................................................................... 22
2.4.1. Genealogie-Datenbanken .................................................................................. 22
2.4.2. Genealogie-Programme ..................................................................................... 25
3. Grundlagen von Datenbanken ........................................................................................ 30
3.1 Datenmodelle und Relationale Datenbanken .......................................................... 31
3.2.
SQL........................................................................................................................ 34
3.2.1. DDL in SQL ...................................................................................................... 34
3.2.2. DML in SQL...................................................................................................... 35
3.2.3. Anfragen mit SQL ............................................................................................. 36
3.3.
MySQL .................................................................................................................. 37
4. Grundlagen von Java ...................................................................................................... 44
4.1.
Java im Überblick.................................................................................................. 44
4.1.1 Klassen, Objekte und Methoden........................................................................ 44
4.1.2 Vererbung und Schnittstelle............................................................................... 46
4.1.3 Pakete ................................................................................................................ 47
4.1.4 Ausnahmen ........................................................................................................ 48
4.2.
Graphikprogrammierung mit Java......................................................................... 49
4.2.1. AWT .................................................................................................................. 49
4.2.2 Swing................................................................................................................. 51
4.3
JDBC ..................................................................................................................... 53
4.3.1 Überblick ........................................................................................................... 54
4.3.2 JDBC-Treiber für den Zugriff ........................................................................... 55
4.3.3 JDBC im Beispiele .......................................................................................................... 56
-3-
5. Graphentheoretische Grundlagen der Genealogie.......................................................... 60
5.1.
Grundlagen der Graphentheorie ............................................................................ 60
5.2.
Stammbäume ......................................................................................................... 65
5.2.1. Stammbäume in verschiedenen Anwendungsgebieten...................................... 65
5.2.2. Eigenschaften der Stammbäume ....................................................................... 68
5.3.
Verwandtschaftsgraphen der Genealogie und Biologie......................................... 70
6. Konzepte zur Visualisierung genealogischer Daten ....................................................... 72
6.1.
Diskussion von Alternativen und Problemen der statischen Darstellung.............. 72
6.1.1 Diskussion der möglichen Gestaltung eines Stammbaums ............................... 72
6.1.2. Gestaltung der Knoten eines Stammbaums ....................................................... 75
6.1.3 Gestaltung der Kanten eines Stammbaums ....................................................... 78
6.2.
Diskussion von Alternativen und Problemen der dynamischen Darstellung ........ 81
6.2.1. Navigieren in einem Stammbaum ..................................................................... 81
6.2.2. Gesamtes Layout für unbalancierte Stammbäume ............................................ 83
7. Das genealogische Visualisierungssystem FaTVis......................................................... 85
7.1.
Visualisierungskonzept.......................................................................................... 85
7.1.1. Layout................................................................................................................ 85
7.1.2. Navigation ....................................................................................................... 89
7.2.
Architektur und Komponenten .............................................................................. 91
7.3.
Entwurf genealogischer Datenbanken für FaTVis ................................................ 93
7.3.1. Entwurf des Datenbankschemas und die Basistabellen..................................... 93
7.3.2. Entwurf und Realisierung von Verwandtschaftsbeziehungen mittels Schichten
96
7.4.
Struktur und Funktionalität des Benutzerinterfaces .............................................. 99
7.4.1. DB-Fenster ........................................................................................................ 99
7.4.2. Personenfenster................................................................................................ 100
7.4.3. Suchfenster ...................................................................................................... 101
7.4.4. Duplikatfenster ................................................................................................ 102
7.5.
Ausgewählte Aspekte der Implementierung........................................................ 103
7.5.1. Datenbank-Kopplung ...................................................................................... 104
7.5.2 Generierung von Stammbäumen ..................................................................... 109
7.5.3. Layoutberechnung ........................................................................................... 113
8
Zusammenfassung und Ausblick ................................................................................ 119
8.1 Zusammenfassung und Bewertung........................................................................ 119
8.2.
Ausblick............................................................................................................... 120
Literaturverzeichnis ............................................................................................................. 122
-4-
KAPITEL 1
1.
Einleitung
Im weitesten Sinne ist Genealogie beinahe so alt wie die Menschheit selbst. Schon der Historiker Johann Christoph Gatterer (1727-1799), der 1788 einen „Abriss der Genealogie“ veröffentlichte, erkannte, dass es „Genealogie eher unter den Menschen gab als Historie“. Die Frage „Was war vor mir?“ spricht schon von Ahnenkulten der sogenannten „Naturvölker“, in denen das Wissen um die Vergangenheit des eigenen Stammes durch meist
mündliche Überlieferung präsent gehalten wird. Erst mit dem Auftreten schriftlicher Quellen
lässt sich genauer erfassen, wie und warum frühere Völker die Erinnerung an ihre Vorfahren
wachgehalten haben. Von der Abkunft erzählen (so die wörtliche Übersetzung des griechischen γενεαλογιν) „ist in einer urtümlichen, von Familienclans beherrschten Gesellschaft
ein notwendiges, mit Stolz geübtes Wissen“ [Bur95].
Als Wissenschaft im modernen Sinn gilt die Genealogie erst seit dem Ende des 18. Jahrhunderts. Sie erforscht anhand historischer Quellen verwandtschaftliche und familiäre Zusammenhänge, beschreibt und dokumentiert diese und stellt sie der wissenschaftlichen Interpretation durch andere Disziplinen (etwa Geschichtswissenschaft oder Soziologie) zur
Verfügung. Normalerweise wird die Genealogie als sogenannte „historische Hilfswissenschaft“ eingestuft. Der Verfasser des Lehrbuchs "Lehrbuch der gesamten wissenschaftlichen
Genealogie", der Geschichtsprofessor Ottokar Lorenz, verstand die Genealogie als Bindeglied zwischen Natur-, Sozial- und Geschichtswissenschaft: "Die Brücke, auf welcher sich
die geschichtliche und Naturforschung begegnen und begegnen müssen, ist die Genealogie."
Genealogie ist nicht nur eine historische Hilfswissenschaft, sie unterlag auch einer eigenen
Entwicklung in ihrer wissenschaftlichen Arbeitstechnik. Vereinfacht gesagt lässt sich die
Arbeitsweise auf vier grundlegende Schritte reduzieren, die im Folgenden erläutert werden
sollen. Die Arbeitsschritte sind:
•
•
•
•
Sammeln
Auswerten
Dokumentieren
Veröffentlichen
Besonders beim Dokumentieren der genealogischen Daten entwickelt sich die Darstellung
von Personenkarteien in Textform, der Ahnenliste und Stammliste, bis hin zur visualisierten
Form Ahnentafel, Stammtafel und Stammbaum. Bislang stellt es immer noch eine Schwierigkeit dar, eine geeignete übersichtliche und strukturierte Darstellung für genealogische
Daten aus einem größeren Datensatz zu erreichen.
Die neueste Generation der Computergenealogie, die methodische Unterstützung der Genealogen durch Computer, ermöglicht nicht nur effizientere, sichere Verwaltung und
schnellere Aufbereitung genealogischer Daten, sondern auch eine übersichtliche und mäch-5-
KAPITEL 1
tige Darstellungsform. Eine zur Online-Darstellung von genealogischen Datensätzen werden
häufig Stammlisten verwendet. Auf Grund ihrer relativ einfachen Erstellung und großer
Spielräume bei umfangreicheren Datenbeständen werden die Stammlisten von vielen Privatpersonen benutzt, die sich für Genealogie interessieren und ihre eigenen Daten im Internet darstellen möchten. Aber für Hobbygenealogen und genealogische Vereine wird eine
relativ große Datenmenge benötigt. Dadurch führt eine umfassende Stammliste zur Unüberschaubarkeit. Statt der Textform wird deswegen eine visualisierte Darstellungsform mit einer speziellen Art von Graph, nämlich der so genannte Stammbäumen, für den fachlichen
Gebrauch eingesetzt.
Es existiert im Internet zwar eine ganze Reihe frei zugänglicher genealogischer Programme
für die Erstellung von Stammbäumen, es fehlen aber vielen Entwicklern solcher Genealogie-Programme die fachlichen Grundkenntnisse der Genealogie. Entweder werden die Programme bei komplizierten Verwandtverhältnissen durch den Stammbaum falsch interpretiert, oder die Baumstruktur geht verloren. Die Schwierigkeit einer übersichtlichen Darstellung genealogischer Daten wird trotzdem dadurch nicht beseitigt. Es fehlt ein mächtiges und
wissenschaftlich orientiertes Visualisierungssystem mit übersichtlichen graphischen Darstellungen und interaktiver Manipulation von genealogischen Daten. Das Ziel dieser Arbeit
ist es, ein solches System zu entwerfen und zu realisieren.
Das in dieser Arbeit implementierte Visualisierungssystem wurde als „FaTVis“ benannt,
was aus dem Kontext Family Tree Visualizer kam. Auf der Basis einer genealogischen Datenbank mit dem relationalen Datenbankmanagementsystem MySQL im Hintergrund wird
eine spezielle graphische Darstellung der Stammbäume im Vordergrund erzeugt. Damit
kann die Datenverarbeitung wie Anfragen und Änderungen der existierenden Daten statt in
MySQL direkt in Stammbäume interaktiv durchgeführt werden. Stammbäume werden
heutzutage nicht nur in der Genealogie, sondern auch in verschiedenen anderen wissenschaftlichen Gebieten, wie der Genetik, der Medizin, der Mathematik und der Linguistik als
Hilfsmittel mehr und mehr eingesetzt. Die Implementierung eines Stammbaumvisualisierungssystems ist in diesem Zusammenhang sicher ein wichtiger Schritt und gewinnt an Bedeutung.
Daher wurden folgende Fragestellungen berücksichtigt:
•
•
•
•
•
Entwurf eines verlustlosen und abhängigkeitbewahrenden Relationenschemas für
genealogische Daten
Definition von Verwandtschaftsbeziehungen mit der iterativen Methode
Darstellung von Verwandtschaftsverhältnisse in einer Baumstruktur
Erzeugung eines intuitiven übersichtlichen Stammbaums
Manipulation von Stammbäume
In Kapitel 2 wird zunächst eine allgemeine Einführung in das Fachgebiet Genealogie gegeben. In den Kapiteln 3 und 4 werden die erforderlichen Grundlagen über Datenbanken und
Java zusammengestellt. Der Akzent wird auf die Datensprache SQL, RDBMS, My SQL und
-6-
KAPITEL 1
Java-Applikationen in Datenbanken, sowie JDBC gesetzt. In Kapitel 5 wird unter Berücksichtigung der speziellen visualisierten Form von Stammbäumen auf spezielle Grundlage
der Graphentheorie eingegangen.
In Kapitel 6 folgt eine Diskussion der Alternativen und Probleme bei der Darstellung und
Manipulation genealogischer Daten. Die praktische Ausarbeitung wird in Kapitel 7 dargestellt, beginnend mit dem eigenen Konzept, die im System FaTVis verwendet wird. Abschließend erfolgt eine Beschreibung von der Architektur vom FaTVis. Auf Basis der Architektur werden alle wichtigen Aspekte wie die Datenbankentwicklung, die Implementierung und das Benutzerinterface in allen Einzelheiten vorgestellt.
Abschließend erfolgt eine Auswertung von FaTVis unter Berücksichtigung, der im Kapitel 2
erwähnten, schon existierenden Programme. Zum Schluss werden in einem Ausblick mögliche Verbesserungen des Visualisierungssystems und die Zukunft der Computergenealogie
diskutiert.
-7-
KAPITEL 2
2. Genealogie
2.1.
Geschichte
Schon im Altertum war, die Weitergabe von Wissen um die Vorfahren und deren Lebensgewohnheiten durch Höhlenmalereien und Totenkulten verbreitet; auf derselben Stufe stehen
die Ahnenkulte der so genannten „Naturvölker“, in denen das Wissen um die Vergangenheit
des eigenen Stammes durch meist mündliche Überlieferung präsent gehalten wird.
Erst mit dem Auftreten schriftlicher Quellen lässt sich genauer erfassen, wie und warum frühere Völker die Erinnerung an ihre Vorfahren wach gehalten haben. Denn der Ahnenstolz war
gesellschaftliches Programm. Ob in Ägypten, Griechenland oder Rom, überall war man bemüht, die Abstammung der Sippe von mythischen, meist halbgöttlichen Helden und darüber
hinaus von einer Gottheit selbst nachzuweisen. Es ist daher eine wichtige Feststellung, dass
Genealogie in der Antike niemals zweckfrei im Sinne einer modernen empirischen Wissenschaft betrieben wurde. Wenn Ahnenreihen zusammengestellt wurden, dann immer mit einer
konkreten Absicht, der im Zweifelsfalle die historische Wahrheit untergeordnet wurde
[Web03].
Im Mittelalter in Griechenland wurde auf eugeneía (= gute, edle Herkunft) „größter Wert gelegt, doch nicht die Stammreihe selbst war wesentlich, sondern der Stammvater, der an ihrem
Anfang stand“ [HeRi72]. Daher versteht sich fast von selbst, dass nur der Adel „genealogiefähig“ ist, da er von göttlicher Herkunft, war und ebenso, dass der Nachweis einer biologischen Abstammung weder möglich noch beabsichtigt sein konnte. Im antiken Rom lagen die
Verhältnisse zunächst etwas anders. „In den griechischen Genealogien wurden die Vorfahren
unter Missachtung ihrer individuellen Züge und Taten heroisiert; der Römer schätzte dagegen die individuelle Leistung für die Gesellschaft. Verdienste im religiösen, im staatlichen
und militärischen Bereich eines Ahnen wurden auf das Geschlecht übertragen, das noch in
späteren Generationen daraus Nutzen zog“ [HeRi72]. Mit der griechischen Kultur übernahmen jedoch auch altadelige römische Familien die Leidenschaft der Suche nach Ahnen,
Stammvätern und -müttern aus mythischer Zeit nachzugehen. Ein wichtiger Aspekt der römischen Genealogie war es, dass als Ahnen nicht nur die biologischen Vorfahren galten, sondern dass man auch durch Adoption die ganze Ahnenreihe seines Ziehvaters erbte. Berühmtestes Beispiel hierfür ist der Kaiser Octavian Augustus, der Adoptivsohn des Gaius Julius
Caesar. Augustus war es schließlich, der durch rigorose Ehegesetze eine neue Ära im Verwandtschaftswesen des römischen Kaiserreiches einleitete, indem er z.B. für Blutsverwandte
ein Eheschließungsverbot erließ. Wie vieles aus dem antiken römischen Recht fanden auch
diese Bestimmungen Eingang zunächst in das kirchliche, das so genannte kanonische Recht,
und schließlich auch in das Recht des Deutschen Reiches.
Charakteristisch für das Mittelalter ist die Tatsache, dass genealogische Arbeiten meist im
Rahmen von Literaturgattungen wie Annalen und Chroniken auftauchen. Zunächst waren es
ganze Volksstämme, deren Abstammungslinien behandelt wurden, dann einzelne Herrscherhäuser und später einzelne Herrschergestalten; schließlich interessierten sich auch niedrigere
Adelsschichten für ihre Familiengeschichte. Freilich änderte sich dadurch an der Grundtendenz der Genealogie wenig: Man gebrauchte sie als Mittel zur Festigung des eigenen Machtanspruches, egal auf welcher Ebene dieser angesiedelt war. Fälschungen waren daher wohl an
der Tagesordnung, auch wenn sie nicht als Delikt im strafrechtlichen Sinn betrachtet wurden.
-8-
KAPITEL 2
Wenn bei der Bewerbung um Ämter eine Ahnenprobe zum Nachweis freier oder adeliger Abstammung verlangt war, mag dies aus heutiger Sicht noch einleuchten; daß selbst die Teilnahme an Turnieren von einer Ahnenprobe abhing, mutet hingegen eher merkwürdig an, doch
entspricht dies genau dem Ziel einer Abgrenzung der verschiedenen Gesellschaftsschichten
voneinander.
Die Neuzeit schließlich brachte den Beginn dessen, was man als genealogische Forschung
nach heutigem Wissenschaftsverständnis bezeichnen kann. Einer der ersten Vertreter dieser
Literatur war Ladislaus Suntheim (ca. 1440-1513) mit seinem Werk über die Häuser Habsburg und Babenberg. Waren zunächst nur adelige Geschlechter Gegenstand der Forschung, so
richtete sich das Interesse ab etwa 1600 auch mehr und mehr auf die Geschichte bürgerlicher
Familien. Die Genealogie wurde Lehrfach an den Universitäten, Historiker und Juristen waren ihre Hauptvertreter. Das 1788 erschienene Buch des Göttinger Historikers Johann Christoph Gatterer (1727-1799) „Abriß der Genealogie“ gilt als die erste systematische Darstellung der Genealogie, auch wenn seine Bedeutung erst Jahrzehnte später gewürdigt wurde.
Von ihm stammt auch die Definition der Genealogie als der „Darstellung aller von einem und
ebendemselben Vater abstammenden Personen, entweder der männlichen allein oder der
männlichen und weiblichen zusammen“ [Web03].
Die französische Revolution von 1789 und die mit ihr einhergehende Entmachtung des Adels
bescherte der bis dahin sehr auf Adelsgeschlechter fixierten Genealogie einen enormen Bedeutungsverlust, obwohl gerade die Einführung der staatlichen Registrierung von Personenstandsangelegenheiten durch die Napoleonische Regierung eine bedeutende Grundlage für
nachfolgende genealogische Tätigkeiten erst schuf. Erst in der zweiten Hälfte des 19. Jahrhunderts erlebte die Genealogie eine neue Blüte, die sich in der Gründung der heraldischen
Gesellschaften „Herold“ (Berlin 1869) und „Adler“ (Wien 1870) manifestierte.
Gleichzeitig wurde immer deutlicher, dass sich die Genealogie in zwei Lager spaltete. Der
Genealoge Stephan Kekulé von Stradonitz, dem das heute meist angewandte System zur
Nummerierung von Ahnenreihen zugeschrieben wird, gilt als Vertreter einer soziologisch
und historisch orientierten Genealogie, bei der eine umfassende Familienkunde und die praktischen Probleme der Forschung im Vordergrund standen; der Historiker Ottokar Lorenz vertrat eine naturwissenschaftlich ausgerichtete, auf der Evolutionstheorie und Vererbungslehre
basierende Genealogie, die zu einem bloßen Hilfsmittel der Humangenetik zu werden drohte.
Aus heutiger Sicht kann zudem festgestellt werden, dass gerade auf dieser Richtung auch das
genealogische Denken der nationalsozialistischen Rassen-Ideologie basierte. Das schon 1934
eingerichtete Amt für Sippenforschung der NSDAP, später umbenannt in Reichsstelle für
Sippenforschung und schließlich 1941 in Reichssippenamt, besorgte die Gleichschaltung und
ideologisch korrekte Ausrichtung aller familienkundlichen Aktivitäten, die es bis dahin in
Deutschland gab. Hier liegt der Grund für die große Abneigung, mit dem man der Familienforschung nach dem zweiten Weltkrieg in Deutschland begegnete [Wik_6].
Nach 1945 konnten die verschiedenen familienkundlichen Einrichtungen nur langsam wieder
Tritt fassen; die Nachkriegsgenealogie erhielt gerade durch die zahllosen Vertriebenen neue
Impulse. Zudem wurde der Schwerpunkt genealogischer Arbeit nun klar auf sozial- und regionalgeschichtliche Aspekte gelegt, während die naturwissenschaftliche Richtung weitgehend abgelehnt wurde.Seit den siebziger Jahren des 20. Jahrhunderts ist ein ständig wachsende Interesse an der privaten Familienforschung zu verzeichnen, das durch die immer besser zugänglichen Quellen und die neuen Bearbeitungsmöglichkeiten durch EDV noch verstärkt wird.
-9-
KAPITEL 2
Heutzutage existieren weltweit enorm viele genealogische Vereine, deren Mitglieder sich
beruflich mit der Abstammungskunde beschäftigen. Nicht mehr nur Adel und Bürgergeschlechter, auch die Lebensgeschichten so genannter „einfacher“ Leute wie Handwerker- und
Bauernfamilien werden nun für wert befunden, erforscht zu werden; und groß ist meist der
Stolz, wenn es möglich ist nachzuweisen, dass ein Bauernhof schon seit vielen Generationen
in Familienbesitz ist, oder dass in der Familien ein bestimmtes Handwerk schon eine lange
Tradition hat. Das Zauberwort Internet schließlich darf hier nicht unerwähnt bleiben. Seine
Fähigkeiten, was die Ahnenforschung betrifft, müssen allerdings realistisch eingeschätzt
werden. Wenn man z. B. über die Suchmaschinen Google oder Altavista das Stichwort Genealogie (in deutscher Schreibweise) abfragt, erhält man eine Trefferquote von über 300.000
Webpages, auf denen dieses Stichwort vorkommt; beim englischen „genealogy“ dagegen
sind es bereits fast 31 Millionen Webpages. In dieser Masse genau das zu finden, was für einen selbst brauchbar ist, scheint fast unmöglich.
In Zukunft wird es für den Familienforscher in mancher Hinsicht einfacher werden, seine
Familiengeschichte auf die Spur zu kommen. Die Erfassung wichtiger Quellen in Computer-Datenbanken ist bereits teilweise erfolgt und wird mit Sicherheit schnelle Fortschritte
machen. Die Dokumentation von Biografien ist durch die moderne staatliche und kirchliche
Verwaltung fast lückenlos. Und trotzdem: jede Familie ist so einzigartig wie jedes einzelne
ihrer Mitglieder; und weil der Mensch eben nicht über Jahrhunderte hin immer gleich ist,
wird es in jeder, aber auch wirklich jeder Familiengeschichte irgendwo Überraschendes, Besonderes, Unvermutetes geben. Und dieses Besondere zu entdecken, das meine Familie (und
dadurch auch mich) aus dem Durchschnitt heraushebt, macht den großen Reiz der Genealogieforschung aus [Web03].
2.2.
Begriffsbildungen
Der Begriff „Genealogie" leitet sich aus dem Lateinischen und dem Altgriechischen ab. Das
Wort „geneá" bedeutet soviel wie „Geschlecht", „Familie“ oder „Abstammung", während
sich „lógos" mit „Kunde" oder „Lehre" übersetzen lässt. ); „genealogía“ (vgl. Einleitung) als
zusammengesetztes Wort bedeutet im Griechischen und Lateinischen ursprünglich Geschlechterkunde oder Abstammungskunde und beschäftigt sich mit Ursprung und Schicksal
von Familien, ihren Vorfahren und Nachkommen [GHGRBc].
Genealogie bezeichnet heute in erster Linie die wissenschaftliche Auseinandersetzung mit
familienkundlichen Themen, während die deutschen Begriffe Ahnenforschung, Familienforschung, Sippenforschung eher für die hobbymäßige Beschäftigung mit der Geschichte der
eigenen Familie verwendet werden. Es handelt sich dabei um Übersetzungen für das Wort
Genealogie, die synonym gebraucht werden können. Familienforschung ist heute der gängigste
Ausdruck, Ahnenforschung gilt als etwas antiquiert, Sippenforschung ist seit der NS-Zeit so
ideologisch belastet, dass der Begriff praktisch nicht mehr verwendet wird. Im folgenden ist
normalerweise von Ahnenforschung die Rede, weil damit die Suche nach den Vorfahren
besser zum Ausdruck kommt, während Familienforschung einen weiteren Bogen in die Gegenwart schlägt. Viele deutschstämmige Amerikaner beispielsweise sind mehr an der Suche
nach heute noch in Deutschland lebenden Nachfahren ihrer ausgewanderten Ahnen interessiert
als an den Vorfahren selbst [Web03].
- 10 -
KAPITEL 2
Anschießend sollen für diese Arbeit wichtige Begriffe aus dem Bereich der Genealogie definiert werden. Sie helfen dabei Arbeitstechniken der Genealogieforschung zu verstehen.
Abstammung
Abstammung ist ein biologischer Begriff, der auf der Weitergabe von Genen über die Generationen hinweg beruht. Er wird im übertragenen Sinn auch für die Weitergabe und Fortentwicklung Ideen und anderer Abstrakta verwendet.
Bei Menschen wird der Begriff Abstammung verwendet, um einerseits die evolutionäre Entwicklung ("Der Mensch und der Affe stammen von gemeinsamen Vorfahren ab"), andererseits die familiäre Herkunft zu beschreiben. Abstammung ist somit die Herkunft eines Menschen (oder eines anderen Lebewesens) von seinen leiblichen Eltern, d. h. von der Mutter, die
ihn geboren hat (also nicht die Stiefmutter, Adoptivmutter und auch nicht die Leihmutter)
und vom Vater, der ihn erzeugt hat, und weiter in gleicher Weise von seinen Großeltern und
allen weiteren Ahnen [Wik_10].
Ahnen
Die Ahnen (als Einzelperson Ahn) ist ein Sammelbegriff für alle Personen männlichen und
weiblichen Geschlechts, von denen ein Mensch (Proband) abstammt. Ein anderes Wort für
Ahnen ist Vorfahren. Die Darstellung der namentlich bekannten Ahnen erfolgt in der Genealogie in einer Ahnenliste oder Ahnentafel [Wik_9].
Nachkommen
Beim Menschen heißen sie auch Nachfahren und bezeichnen geschlechtsunabhängig die
Gesamtheit der Personen, die von einem Probanden (Stammvater, Stammmutter) bzw. Probanden-Elternpaar (Stammeltern) abstammen. In dieser Arbeit werden Stammvater, Stammmutter und Stammeltern allgemein als Stammvater benannt. In wissenschaftlichen Terminologie findet man für die Nachkommenschaft den Begriff Deszendenz (von lateinisch „descendere“, herabsteigen) [Wik_7].
Proband
Ein Proband ist, nach dem lateinischen Wort „probare“-prüfen, eine Person, die sich einer
Prüfung unterzieht oder als Test-oder Vergleichsperson einer Prüfung im weitesten Sinne unterzogen wird. Dabei wird der aktive und passive Aspekt unterschieden, wobei es sich beim
aktiven Aspekt um eine konkrete Prüfungssituation handelt. Beim passiven Aspekt geht es
um Tests und Bewertungen allgemeinster Art, die meist im wissenschaftlichen Rahmen
durchgeführt werden. Der Proband bleibt hier aber anonym und dient in seiner Probandenrollte dem Wissenschaftler als „Versuchskaninchen“ oder „Prüfstein“ für eine zu belegende
Theorie [Wik_8].
Stammlinie
Die Stammlinie, auch Stammreihe oder Väterlinie genannt, ist die Abstammungslinie, die nur
über Männer bzw. Väter führt. In der Regel ist sie auch die Linie, in der Familienamen vererbt
worden ist: Stammvater -Sohn - Enkel - Urenkel - etc.
Die ältere Genealogie beschränkte sich oft auf die Erforschung der Stammreihe. Alle Linien
sind aber soziologisch und biologisch gleich wichtig. Die moderne Genealogie strebt deshalb
- 11 -
KAPITEL 2
nach umfangreichen, alle Linien berücksichtigenden Ahnenlisten, und die Väterlinie hat keine Sonderstellung [Bio_1].
Verwandtschaft
Die Verwandtschaft hat in verschiedenen Bereichen verschiedene Bedeutungen. Im Folgenden werden vier Arten von Verwandtschaft und drei Arten von Klassifikationen gegeben:
•
Blutsverwandtschaft im anthropologischen und soziologischen Sinnen, infolge Abstammung von gemeinsamen Voreltern(-teilen), Blutlinie von Abkömmlingen. Es darf
nicht mit einem Schwiegerverhältnis, Verschwägerung, verwechselt werden
[Wik_11].
•
Juristische Verwandtschaft, nach dem Recht der Bundesrepublik Deutschland nur
die Blutsverwandtschaft, auch durch Adoption, aber keine Schwägerschaft.
•
Natürliche Verwandtschaft, auf die Abstammung begründete, inklusive die Blutverwandtschaft und auch die Ehegatten, die so genannte „angeheiratete“ Verwandtschaft.
•
Künstliche Verwandtschaft, steht der natürlichen Verwandtschaft gegenüber, entsteht durch Zusammenschluss blutsfremder Familien zu einer dauernden Gemeinschaft, durch Milchverwandtschaft, Pflegevaterschaft, besonders häufig durch Adoption. [Thi]
•
Verwandtschaftssysteme, durch die Anthropologie werden Bluts- und/oder Heiratsbeziehungen zwischen Menschen gruppiert und klassifiziert. In patrilinearen
Verwandtschaftssystemen wird die Zugehörigkeit des Individuums zu einer Verwandtschaftsgruppe nach der männlichen Linie gerechnet. Dazu gehören die Kinder
des Sohnes, nicht aber die Kinder der Tochter. Es wird manchmal als Vaterstamm genannt. In matrilinearen Verwandtschaftssystemen werden Kinder der Tochter, aber
nicht die Kinder des Sohnes, zur Abstammungslinie der Mutter gerechnet. Deswegen
nennt man sie auch Mutterstamm. In bilinearen Abstammungsformen wird die Zugehörigkeit zu einer bestimmten Verwandtschaftsgruppe nach beiden Abstammungslinien gerechnet [Wik_12].
2.3.
Wissenschaftliche Arbeitstechnik
Genealogie unterlag einer eigenen Entwicklung in ihrer wissenschaftlichen Arbeitstechnik.
Die Wissenschaftlichkeit der Arbeitsmethoden bedeutet für die Genealogen die Objektivität
der Forschung, unabhängig von der Person, die sie betreibt. Das heißt, dass Abstammungen
nur dann als belegt gelten können, wenn andere Forscher, die von den vorhandenen Quellen
ausgehen, zu denselben Ergebnissen gelangen müssen. Bestehen Zweifel und Unsicherheiten,
so sind diese in den Ahnenlisten usw. als solche zu kennzeichnen. Errechnete Werte oder bloße Vermutungen müssen als solche erkennbar sein [Wik_03].
Vereinfacht gesagt lässt sich die Arbeitsweise auf vier grundlegende Schritte reduzieren, die
im Folgenden etwas erläutert werden sollen, nämlich sammeln – auswerten – dokumentieren – veröffentlichen [Web03].
- 12 -
KAPITEL 2
2.3.1. Sammeln
Als erstes stellt sich auch hier die Frage, was überhaupt sammlungswürdig und was als Quelle für Familienforschung brauchbar ist. Informationen finden sich erfahrungsgemäß hauptsächlich in den nachfolgend
genannten Bereichen:
Mündliche Überlieferungen: was alte Familienmitglieder aus ihrer Erinnerung noch an
Einzelheiten berichten können, geht oft weit über alles hinaus, was sich anhand von schriftlichen Unterlagen jemals ermitteln lässt. Vor allem alltägliche Vorkommnisse, die in keinem
Kirchenbuch oder Standesamtsregister aufgezeichnet werden, können durch solche Berichte
vor dem Vergessenwerden bewahrt werden.
Ein Beispiel hierfür liefert der bekannte bayerische Volksmusikant und Gstanzlsänger Roider
Jackl aus Weihmichl bei Landshut. Dass er am 17. Juni 1906 als sechzehntes und letztes
Kind des Kleinbauern und Webers Johann Baptist Roider und seiner Frau Franziska geboren
wurde, ließe sich anhand einer standesamtlichen Urkunde ermitteln, wahrscheinlich sogar
die Uhrzeit seiner Geburt; auch der Tauftag sowie sein Taufpate könnten durch einen Blick
in die Pfarrmatrikel festgestellt werden. Doch wie wenig verraten diese dürren Zahlen über
das damalige freudige Ereignis, verglichen mit den Schilderungen seiner Mutter über die
Umstände seiner Geburt [See01]:
„Am Pranga-Sunnta ... hab i in da Früah no gar net dro denkt, daß ma mia auf
d‘ Nacht scho um an Buam mehra hom kaanntn. I hab an Vatern der zwoa
kleanan, d‘ Lena und an Wastl, zammagricht, damit ers‘ in d‘ Prozession
mitnehma hat kinna. Wia alls ausn Haus gwen is, hob i des Gröba no schnell
a bissl zammagramt ... und nach hab i ‘s Kocha ogfangt. Und mittn unterm
Knödleilegn, grad wias beim zwoatn Evangelium ‘s drittemal gschossn ghabt
ham, is de Sach mit dir auf aramal gehat wordn. Bald waar i nimma in
d‘ Kamma num kemma und bis i ‘s Gwand obabracht hab, bist scho da gwen
aa.“
Privatarchive: Bei Privatpersonen findet man eher selten mehrere der bisher genannten
Quellenarten vereint in einem regelrechten (geordneten) Archiv. Wo ein solches vorhanden ist,
bildet es natürlich einen unvergleichlichen Schatz für eigene Forschungen. Häufiger tritt eine
derartige Sammlung von wichtigen Unterlagen bei alteingesessenen Firmen auf; schließlich
gehören auch die (fachmännisch betreuten) Firmenarchive der heutigen Großkonzerne zur
Kategorie der Privatarchive. Und nicht zuletzt sind es immer noch Adelsfamilien, die in der
Regel über gut organisierte und umfangreiche Sammlungen von großem historischem Wert
verfügen, seien es nun schriftliche Unterlagen, Bilder- und Fotosammlungen oder andere
Zeugnisse mehr oder weniger ruhmreicher Vergangenheit.
Öffentliche Quellen sind unverzichtbarer Bestandteil genealogischer Arbeit und stellen den
Hauptanteil an Informationen zur Verfügung, da sie meist in ältere Zeiten zurückreichen.
Zugleich haben sie den Vorteil, dass sie meistens „objektiv“, d. h. ohne direkte Einflussnahme der betroffenen Personen entstanden sind.
Standesämter: Für eine Familienforschung, die von unserer Zeit ausgeht, sind die erste und
wichtigste öffentliche Quelle der Forschung die Personenstandsunterlagen der Standesämter.
Wie schon erwähnt, wurde schon unter Napoleonischer Verwaltung die Zivilehe und die
standesamtliche Beurkundung des Personenstandes eingeführt, doch erst das "Reichsgesetz
- 13 -
KAPITEL 2
über die Beurkundung des Personenstandes und der Eheschließung" vom 6.2.1875 führte
zum 1. Januar 1876 das Standesamtswesen für das gesamte Deutsche Reich verbindlich ein.
In Österreich trat dieses Gesetz 1938 nach dem Anschluss Österreichs an das Deutsche Reich
in Kraft. Der Staat protokolliert in diesen Ämtern alle Geburten, Ziviltrauungen und Sterbefälle, aber auch Adoptionen, Namensänderungen, Scheidungen, Kirchenaustritte, und sogar
Geschlechtsumwandlungen, kurz alles, was irgendwie mit dem persönlichen Rechtsstatus eines Bürgers zusammenhängt.
Aus diesem Grund ist es in Deutschland auch nur unter strengen Auflagen möglich, Auskünfte aus dem Datenbestand eines Standesamtes zu erhalten. Die Bedingungen sind im § 61
des Personenstandsgesetzes genau geregelt. Für den privaten Forscher ist wichtig zu wissen,
dass nur Personen auskunftsberechtigt sind, die mit der gesuchten Person in direkter Linie
verwandt sind (also Kinder, Enkel, Eltern, Großeltern etc.) – keine Tanten und Onkel; ansonsten ist nur noch der rechtmäßige Ehegatte des Betroffenen berechtigt, Angaben über seinen Partner einzuholen, nicht aber über dessen Vorfahren.
Grundsätzlich wird jedes Ereignis in dem Standesamtsbezirk beurkundet, in dem es stattfand.
Seit 1935 werden dabei Randvermerke (etwa über die erfolgte Eheschließung oder den Tod)
aufgenommen, so dass eine Person auch bei wechselnden Wohnorten zurückverfolgt werden
kann. Heute gibt es daneben für jede Familie ein so genanntes Familienbuch, das mit der Eheschließung angelegt wird und im jeweiligen Wohnsitzstandesamt geführt und ergänzt wird.
Kirchenarchive: Nicht immer sind die Kirchenbücher einer Pfarrei im Pfarrbüro aufbewahrt.
In größeren Städten existieren zum Teil so genannte Matrikelämter, die alle Kirchenbücher
der diversen Stadtpfarreien zentral führen und verwalten.
Die Familie Langenberg im katholischen Kirchenbuch Uedem [Lan03]:
„In der zweiten Hälfte des 17. Jahrhunderts erscheinen im Taufregister der katholischen Pfarrkirche St. Laurentius in Uedem drei Langenbergs, die um die Jahrhundertmitte geboren wurden und
offensichtlich Geschwister waren, da sie, wie es in Uedem allgemein üblich war, wechselseitig
Patinnen und Paten der Kinder ihrer Geschwister waren:
JOHANNES LANGENBERG verh. mit MARIA VAN LOTT (VERLOT). Aus der Ehe des Johannes
Langenberg mit Maria van Lott (Verlot) wurden folgende Kinder getauft:
1.
2.
3.
4.
5.
6.
7.
8.
18.02.1669 Johanna verh. mit I. Josephus Lavat; II. Petrus Bruickers; III. Johannes Holl.
11.01.1671 Petrus verh. mit Catharina Janßen.
29.01.1673 Aleidis.
25.03.1675 Johann Arnold Pankratius.
13.08.1677 JOHANNES verh. mit JOHANNA KÖPPEN, getauft (getauft) am 17.12.1679.
23.10.1679 Luzia.
21.02.1682 Heinrich.
03.07.1684 Aleidis.
... „
Staatsarchive: Die Personenstandsunterlagen von kirchlichen und staatlichen Behörden bilden nur einen Teil des Aktenmaterials, das für familiengeschichtliche Forschung interessant
ist. In ihnen finden sich fast nur Lebensdaten, während z. B. Angaben über Besitz – v. a.
Grund- und Immobilienbesitz – dort nur eine marginale Rolle spielen. Dieser Aspekt der familiären Verhältnisse lässt sich in der Regel in den Staatsarchiven untersuchen. Dort findet
- 14 -
KAPITEL 2
man unter anderem Unterlagen wie Kataster, Grundbücher und vor allem die wichtigen
Briefprotokolle, in denen bis etwa 1800 die beim jeweiligen Landgericht beurkundeten Verträge (Hofübergaben, Erbschaften, Heiratsverträge und dergleichen) in Kopie aufbewahrt
wurden.
Abb.2.3.1.1: Alphabetisches Einwohner im Stadtbuch der Stadt Heidelberg in 1919
[Alp19]
2.3.2. Auswerten
Der nächste und eigentlich interessanteste Schritt in der Forschung ist die Auswertung des
gesammelten Materials. Hier sind drei Arbeitsschritte wichtig: die Quellenkritik, die Identifizierung des Inhalts und die Systematisierung.
Quellenkritik bedeutet, sich zu fragen, wie zuverlässig ist die vorhandene Quelle bezüglich
der Informationen, die sie mir bietet? Hatte der Verfasser womöglich bestimmte Absichten
mit seiner Aufzeichnung verbunden, die den Inhalt verfälschen können, oder handelt es sich
um eine weitgehend objektive Quelle? Da der private Ahnenforscher meistens nur mit amtlichen Urkunden zu tun hat, stellt sich die Frage nach der Zuverlässigkeit der Quelle meistens
erst dann, wenn Ungereimtheiten in den Aussagen mehrerer Quellen auftreten. Für die Beurteilung des Sachverhaltes sollte dann am besten Personal derjenigen Institution herangezogen
werden, welche die Quellen verwaltet, also z. B. das jeweilige Archivpersonal, oder aber externe Spezialisten.
- 15 -
KAPITEL 2
Die Identifizierung des Inhalts schließlich ist der umfangreichste Arbeitsschritt. Weniger
geschwollen ausgedrückt heißt dies, man muss herausbringen, was z. B. in den Schriftstücken
drinsteht. Dazu muss man das Schema kennen, nach dem die Aufzeichnungen angefertigt
sind, man muss die Schrift entziffern können, und man muss die Sprache verstehen (egal, ob
altes Deutsch oder Latein). Schließlich sollte man auch die grundlegenden Rechtsvorschriften
im Kopf haben, die für ein beurkundetes Ereignis zum damaligen Zeitpunkt galten. Dies alles
sind Kenntnisse, die man nicht von heute auf morgen besitzt, zumal es bislang keine eigentliche Ausbildung zum Genealogen gibt.
Als Beispiel sei genannt, dass sich zwar mit der Kenntnis einiger „Schlüsselbegriffe“ viele
lateinische Einträge wenigstens grob durchschauen lassen; aber spätestens, wenn ein längerer
lateinischer Text nicht mehr nur Namen aufzählt, sondern die näheren Umstände erläutert,
warum ein Brautpaar die Dispens von einem kirchlichen Ehehindernis benötigte, ist man ohne solide Lateinkenntnisse schnell und im wörtlichsten Sinne mit seinem Latein am Ende;
und selbst das einmal mühsam eingepaukte altklassische Schullatein hilft angesichts des in
Kirchenbüchern verwendeten Kirchenlateins mit seinen zahlreichen Fachbegriffen nur begrenzt weiter. Hier kann der Punkt kommen, wo es für den Laien sinnvoll ist, einen Teil der
Arbeit einem bezahlten Berufsgenealogen zu übertragen, der zwar eine Stange Geld kosten
mag, aber für die Richtigkeit der ermittelten Ergebnisse doch eine gewisse Gewähr bietet.
Jede Quelle und ihr Inhalt haben nur solange einen Wert für die Ahnenforschung, wie man
auch in der Lage ist, sie systematisch einzuordnen und wieder zu finden. Wie oben schon erwähnt, ist eine genaue Quellenangabe für jeden Fund unerlässlich. Doch auch der Inhalt bedarf der Ordnung. Sehr beliebt und seit langem bewährt sind Familienkarteien, die bei Fachverlagen in beliebiger Anzahl erhältlich sind und in denen für jede einzelne Person alle
denkbaren Angaben samt ihren Beziehungen zu anderen Personen festgehalten werden können. Dieselbe Funktion, allerdings mit weitaus größeren Bearbeitungsmöglichkeiten, erfüllen
Computerprogramme zur Erfassung der gefundenen Personen [Wim89], [Web03].
2.3.3. Dokumentieren
Die Personenkarteien eignen sich zwar für die Registrierung zahlreicher Einzelangaben zu
einer bestimmten Person, die Übersichtlichkeit bezüglich größeren Zusammenhängen lässt
dabei aber sehr zu wünschen übrig. Daher kommt der Dokumentation der gewonnenen Daten
in einer einheitlichen Form eine große Bedeutung zu.
Die Grundentscheidung, auf welche Art die Abstammungen einer Familie wiedergegeben
werden sollen, lautet zunächst: will ich vom jüngsten Spross ausgehen (= Aszendenz) oder
vom ältesten bekannten Glied (= Deszendenz)? Nach dieser Festlegung stehen verschiedene
Darstellungsmöglichkeiten zur Verfügung, nämlich für die Aszendenz die Ahnentafel oder
Ahnenliste, für die Deszendenz die Nachkommentafel oder Nachkommenliste bzw. Stammtafel oder Stammliste und letztendlich der Stammbaum. Im Folgenden werden diese Darstellungsformen beschrieben.
- 16 -
KAPITEL 2
Ahnenliste
In der Ahnenliste sind alle bekannten Vorfahren in der Reihenfolge ihrer Kennziffer aufgeführt. Die Bestimmung der Kennziffer wird in „Ahnen-Numerierungssystem“ vorgestellt. Da
auch die jeweilige Mutterlinie integriert ist, kann sie einen weitaus aussagekräftigeren Eindruck der Familiengeschichte vermitteln als die Stammlinie. Um gezielt nach einer namentlich bekannten Person zu suchen, empfiehlt sich die alphabetische Ahnenliste [GHGRBa],
[Glo05].
Ahnentafel
Eine Ahnentafel stellt die Vorfahren eines Probanden schematisch in graphischer oder tabellarischer Form dar. Sie bietet die beste Übersicht über alle Ahnen, wobei sie mit dem Probanden und seinen Eltern als der untersten genealogischen Einheit beginnt. Es folgen dann
die weiteren Generationen, die, wie bei einer Ahnenliste, beginnend mit den Eltern des Probanden durch römische Ziffern gekennzeichnet werden. So lässt die Ahnentafel auf einen
Blick die Vorfahren des Probanden über mehrere Generationen erkennen, wobei sie im Gegensatz zum Stammbaum von der Gegenwart bis in die Vergangenheit weist [Ber91a],
[Wik_2], [Reu01a]. Abb. 2.3.3.1 zeichnet die Ahnentafel von Friedrich Franz IV., dem letzten
herrschenden Großherzog von Mecklenburg-Schwerin (4 Generationen):
Ahnen-Numerierungssystem
Stephan Kekulé von Stradonitz (deutscher Mathematiker, 1863 - 1933) verwendete 1898 in
seinem "Ahnentafel-Atlas" ein Ahnen-Numerierungssystem, das später nach ihm benannt
wurde und noch heute in Gebrauch ist, die Kekulé-Zahlen.
Bei dieser Nummerierung der Vorfahren einer Ahnenliste oder Ahnentafel wird dem Probanden die Nummer 1, seinen Eltern die Nummern 2 und 3, den Großeltern die Nummern 4-7
zugeteilt etc. Gerade Zahlen werden dabei für männliche Vorfahren, ungerade Zahlen für
weibliche Vorfahren verwendet. Die Nummer des Vaters einer Person ist somit immer das
Doppelte der Nummer dieser Person; die Nummer jeder Mutter ist immer das Doppelte der
Nummer ihres Kindes plus eins [Rau].
- 17 -
KAPITEL 2
Abb. 2.3.3.1 Ahnentafel [Pie94]
Generation Bezeichnung
Kekulé-Nr.
I
Proband
1
II
Eltern
2-3
III
Großeltern
4-7
IV
Urgroßeltern
8-15
V
Alteltern
16-31
VI
Altgroßeltern
32-63
VII
Alturgroßeltern 64-127
VIII
Obereltern
128-255
IX
Obergroßeltern 256-511
X
Oberurgroßeltern 512-1023
XI
Stammeltern
1024-2047
XII
Abb. 2.3.3.2
Generation XII
2048-4097
Ahnen-Numerierungssystem [Glo05]
- 18 -
KAPITEL 2
Nachkommenliste
Eine Darstellungsform der Nachkommenschaft eines Probanden als fortlaufender Text, der
gegenüber der Darstellung als Nachkommentafel erhebliche Raum- und Kosteneinsparung
bedeutet [Bio_2].
Nachkommentafel
Die Darstellung der Nachkommenschaft eines Probanden in Tafelform. Die Nachkommen
werden dabei nach Generationen geordnet, die Geschwisterschaften, sofern bekannt, nach dem
Geburtsjahr. Nachkommentafel eignen sich in der Genealogie vorzüglich, um zu einem raschen Überblick über Nachkommelisten zu gelangen oder als Skizze in einer Familienchronik
[Ber91c].
Nachkommen-Nummierungssystem
Da die genaue Zahl der Nachkommen unbekannt bzw. unsicher ist, lässt sich für eine Nachkommenliste, ebenso für Stammliste, keine derart ideale Bezifferung finden. Die praktische
Zweckmäßigkeit der Bezifferung hängt davon ab, wie viele Generationen die Liste bzw. Tafel
umfasst und wie umfangreich das Gesamtmaterial ist bzw. wie oft dieselben Nachkommen
mehrfach und in verschiedenen Generationen vorkommen. Nachkommenlisten, vor allem die
das 19. Jahrhundert überspannenden, haben die Tendenz, mit einem Faktor weit größer als 2 in
einer jeden Generation geradezu zu explodieren. Modernen Methoden der Datenverarbeitung
wird ein einfaches Verfahren gerecht, das jedem bekannten Nachfahren eine fortlaufende Zahl
(z.B. 362) zuordnet und jede Person dann durch ihre eigene Zahl und die ihres Vaters oder ihrer
Mutter (z.B. 110) in aufsteigender Linie eindeutig kennzeichnet (im Beispiel also 362-110).
Neu aufgefundene Nachkommen erhalten dann einfach eine weitere Zahl, unabhängig von
ihrer Stellung in der Nachkommenfolge. Übersichtlicher wird dieses System, wenn für jede
Generation ein Zahlenbereich reserviert wird, der theoretisch nicht überschritten werden kann.
Üblich ist auch die Hinzufügung einer römischen Zahl für die jeweilige Nachkommengeneration [Bio_2].
Stammliste
Die Stammliste ist ein Ausschnitt aus einer Nachkommenliste, der meistens nur die Träger
desselben Familiennamens umfasst. Ihr entscheidender Vorteil ist, dass in ihr relativ problemlos Nachträge und Erweiterungen eingearbeitete werden können, dass sie also mit der
Entwicklung der Forschung (und der Entwicklung der Familie) Schritt halten kann, ohne
Probleme mit der Formatierung zu bekommen [GHGRBb].
- 19 -
KAPITEL 2
Abb.
2.3.3.3
Nachfahren-Liste von Josef Anton Haag [Hag]
Stammtafel
Eine Stammtafel ist ein Ausschnitt aus der Nachfahrentafel, der nur die Träger des gleichen
Familiennamens und deren Ehepartner umfasst, wobei ein stringentes. Das Durchhalten dieser Regel, zum Beispiel aufgrund von Namensänderungen, Adoption, ausländischen Namensrecht nicht immer möglich ist. Die Stammtafel hat gegenüber der Stammliste den Vorteil
der größeren Übersichtlichkeit, wird mit dem Anwachsen der betrachteten Familie ebenfalls
schnell unhandlich [GHGRBb].
Stammbaum
Ein Stammbaum zeigt die Nachkommen eines Stammvaters, d.h. des ältesten, direkten männlichen Vorfahrs, der nachgewiesen werden kann. Die Darstellung der Verwandtschaftsbeziehungen erfolgt dabei in Baumform, wobei der Stammvater die Wurzel und die folgenden
Generationen die Äste und Zweige bilden. Der Stammbaum eines Probanden besteht dabei im Gegensatz zur Ahnentafel - aus allen lebenden und verstorbenen Familienmitgliedern, die
seinen Familiennamen tragen. Somit zeigt also ein Stammbaum von der Vergangenheit in die
Gegenwart [Wik_4], [Wik_5], [Lex90b].
- 20 -
KAPITEL 2
Johann Sebastian Bach verfasst einen Stammbaum seiner Familie 1735 - mit fünfzig Jahren
(Abb. 2.3.3.4). Auf siebzehn handgeschriebenen Seiten dokumentiert er Lebensdaten und
Berufe seiner Vorfahren und Kinder [Bac05].
No. 1. Vitus Bach, ein Weißbecker in Ungern, hat im 16ten Seculo der lutherischen Religion halben
aus Ungern entweichen müßen....
No. 2. Johannes Bach, des vorigen Sohn, hat anfänglich die Becker profession ergriffen. Weilen er
aber eine sonderliche Zuneigung zur Music gehabt so hat ihn der StadtPfeiffer in Gotha zu sich in die
Lehre genommen. . .
No. 3. Deßen Bruder-Bach, ist ein Teppichmacher worden, und hat 3 Söhne gehabt so die Music
erlernet und welche der damahligst regierende Graf zu Schwartzburg Arnstadt auf seine Unkosten
nach Italien hat reisen laßen, um die Music beßer zu excoliren . . .
...
No. 24. Joh. Sebastian Bach, Joh. Ambrosii Bachens jüngster Sohn, ist gebohren in Eisenach An.
1685, den 21ten Martij. Ward (1) Hoffmusicus in Weimar bey Herzog Johann Ernsten, An. 1703. (2)
Organist in der neüen Kirche zu Arnstadt 1704. (3) Organist zu St. Blasii Kirche in Mühlhausen An.
1707. (4) Cammer und HoffOrganist in Weimar, An. 1708 . . .
...
Abb. 2.3.3.4 Stammbaum von der musicalisch-Bachischen Familie [Bac05]
- 21 -
KAPITEL 2
2.3.4. Veröffentlichen
Für den fortgeschrittenen Familienforscher gibt es schließlich die Möglichkeit, seine Forschungsergebnisse nicht nur im engen Familienkreis bekannt zu machen, sondern sie in geeigneter Form zu veröffentlichen. Dies lohnt sich vor allem dann, wenn die Arbeit für einen
größeren Kreis von Personen von Interesse ist (z. B. bei Heimatvertriebenen, die aus derselben Ortschaft stammen und wahrscheinlich eine größere Anzahl von Vorfahren gemeinsam
haben). Je nach inhaltlichem Schwerpunkt unterscheidet man üblicherweise:
Familienbücher, die die Geschichte einer einzelnen Familie umfassend beschreiben, die also
nicht nur die Lebensdaten der Personen enthalten, sondern auch eine Vielzahl sonstiger Angaben, oft Fotos und Anekdoten.
Häuserbücher beschreiben die Geschichte eines bestimmten Hauses, z. B. eines Bauernhofes, und dokumentieren deren (womöglich wechselnde) Besitzer im Laufe der Jahrhunderte,
wobei deren Lebensdaten natürlich nicht fehlen dürfen.
Ortsbücher schließlich erfassen die oben genannten Daten zu allen Häusern und ansässigen
Familien eines ganzen Ortes; dass wegen der Überfülle von Daten eine wirklich vollständige
Darstellung nur in den seltensten Fällen möglich sein wird, liegt auf der Hand [Web03].
2.4.
Computergenealogie als Hilfsmittel
Den Begriff Computergenealogie gibt es seit rund zwanzig Jahren. Man bezeichnet damit
die methodische Unterstützung der Genealogie durch Computer, aber auch durch Möglichkeiten des Datenaustausches im Internet. Zu den Pionieren der Computeranwendung in der
Genealogieforschung gehörten in den 1980er Jahren R. Gröber, G. Junkers und K. Thomas
(Leverkusen/ Köln), die von 1985 bis 1998 die nichtkommerzielle Zeitschrift herausgaben.
Seit 2001 erscheint eine Fortsetzung als Magazin im Zeitschriftenhandel, herausgegeben
durch ein Unternehmen von S. Ziegler (Bad Nauheim) [Bur03].
Wie im Abschnitt 2.3 „Arbeitstechnik“ schon erwähnt, wird ein Genealoge im Laufe seiner
Forschungstätigkeit eine Vielzahl von genealogischen Daten sammeln, speichern und interpretieren. Computer erleichtern diese Arbeit in vielfacher Hinsicht. Sie ermöglichen nicht nur
effizientere, sichere Verwaltung und schnellere Aufbreitung genealogischer Daten, sondern
auch eine übersichtliche und interaktive Interpretierung.
2.4.1. Genealogie-Datenbanken
Eine relativ neue Entwicklung stellen genealogische Datenbanken dar, die in den letzten Jahren zunehmend angelegt wurden. Genealogische Datenbanken gibt es heute auf ganz verschiedenen Medien: auf Papier als Karteien oder Bücher, auf Filmen als Mikrofiche und auf
elektronischen Datenträgern wie Festplatte, Diskette oder CD-ROM, insbesondere auch im
Internet. In ihnen sind Angaben zu bestimmten Personenkreisen (wechselnd je nach Quelle)
enthalten, die standardisiert über eine Suchmaske ausgewertet werden können [Web03].
- 22 -
KAPITEL 2
Ein anderes Unterscheidungsmerkmal ist der regionale Umfang; so gibt es regionale, nationale und internationale Datenbanken. Schließlich ist für Familienforscher auch der Zeitraum
wichtig, auf die sich die genealogischen Eintragungen beziehen.
In fast allen genealogischen Datenbanken bestehen die Eintragungen jeweils nur aus: Name,
Vorname, Ereignis (Geburt, Tod etc.) Zeitpunkt, Ort (Land/Region), Quelle, und dies teilweise in verkürzter oder verschlüsselter Form. Damit stellen die Datensätze keinen Ersatz für das
Lesen des Originals dar, sondern sind nur Suchhilfen. Genau darin besteht auch der Wert einer genealogischen Datenbank: Bei "toten Punkten" in der Forschung will man in der Masse
an Informationen Hinweise auf die Herkunft eines Vorfahren oder auf den Verbleib von
Nachkommen finden. Eine der größten Datenbanken ist diejenige der Mormonen in Salt Lake
City. Sie enthält über 650 Millionen verzeichnete Namen, die aus den Akten stammen, die die
Mormonen in jahrzehntelanger Tätigkeit auf der ganzen Welt gesammelt und konserviert und
schließlich in eine Datenbank eingespeist haben [Bur03].
Von zunehmender Bedeutung für die Familienforschung sind heute die Internet-Datenbanken,
unter ihnen besonders die der Mormonen.
Der IGI (International Genealogical Index) ist die Zusammenfassung von zahlreicher Kirchenbücher aus der ganzen Welt. Er umfasste knapp eine Milliarde Namen. Die „Jesus Christ
of Latter-day Saints“ (LDS) Kirche hat als erste den IGI im Internet bereitgestellt. Die IGI
verwendet eine siebenstellige „Batchnummer“. Der erste Buchstabe oder die ersten Zahlen
weisen auf den Quellentyp hin. Es gibt drei grundlegende Arten von Quellen [Sib03]:
1. Extrahierte Aufzeichnung von Kirchen- und Zivilgeburten, Taufen und Heiraten.
Buchstaben C, J, K und P zeigen Taufen- oder Geburten an. E und M (ausgenommen
M17, M18) zeigen Heiraten. Die Nummern 725, 745 und 754 beziehen sich auf zivile
Daten und 744 auf andere Extraktionen.
2. Von einem Mitglied eingereicht (eingereicht seit 1969). Der Buchstabe F und
Nur-Ziffern-Nummern (mit der 3. Ziffer kleiner als 4) zeigen Ihnen Familiengruppenaufzeichnungen, Einzelpersonen-Eintragungen und Heiratseintragungen an. Eine
Nur-Ziffern-Nummer zeigt häufig an, daß jemand den Namen erforscht hat. Die Zahlen 01-23 zeigen Familiengruppenaufzeichnungen an, die außerhalb der US eingereicht wurden.
3. Aufzeichnungen ausgewählter Tempel und verstorbener Mitglieder der LDS-Kirche.
Pedigree Resource File (PRF): Die Stammtafelquellendateil ist eine seit wenigen Jahren
aufgebaute Sammlung von Ahnen- und Stammtafeln, die in der Originalsprache abgespeichert werden. Dieser Bestand umfasst derzeit etwa 40 Millionen Namen. Anders als im AF
und PRF sind die Namen im IGI nicht genealogisch untereinander verknüpft.
Ancestral File (AF):Die Ahnen Datei entstand aus einer Sammlung US-amerikanischer Ahnentafeln, umfasste Ende 2000 etwa 35,6 Millionen Namen und wird – auch mit internationalen Ahnentafeln – weiter ergänzt.
GEnealogical Data COMmunications (GEDCOM): Die GEDCOM bietet keine Organisation für den Austausch, sondern ist ein sehr starker Standard zur Darstellung komplexer genealogischer Daten in einer sequentiellen Datei, die sehr gut für die Datenfernübertragung
- 23 -
KAPITEL 2
geeignet ist. GEDCOM ist eine "Zwischensprache" für zwei Partnerprogramme, die von
Haus aus beliebige Datenstrukturen ("Datensprachen") benutzen, die aber ihre Dateien in das
GEDCOM-Format hin- und zurückübersetzen können.
+-------------------------+
+-------------------------+
| Programm A am Ort A
|
+----------+--------------+
+--------------+----------+
|benutzt
|übersetzt Da- |
|Datei mit |tenformat A in|
|
Programm B am Ort B |
|übersetzt GED-|benutzt
|
|COM-Format in |Datei mit |
|Struktur A|GEDCOM-Format |
|Datenformat B |Struktur B|
+----------+--------------+ ===> +--------------+----------+
Abb.2.4.4.1 Übertragung der GEDCOM-Datei
GEDCOM organisiert Personen- und Familiendaten in hierarchischen Ebenen. Zur Bezeichnung der Datentypen verwendet es spezifische Feldbezeichner als Schlüsselwörter, und zwischen Personendaten und Familiendaten bestehen Verweise als Zeiger [Kei].
Jedem Datenelement ist seine Ebenen-Nummer (0, 1, ...) und sein Feldbezeichner vorangestellt. Beispiele für Feldbezeichner sind:
•
•
•
•
•
INDI = Individuum
FAMI = Familie
RFN = Referenznummer
BIRT = Geburt
...
Jedes Datenelement belegt eine eigene Zeile. Die höchste Ebene ist 0. Jedes Datenelement
der Ebene 1 gehört zum vorangegangenen Datenelement der Ebene 0, und jedes Datenelement der Ebene 2 gehört zum vorangegangenen Datenelement der Ebene 1. Auf der obersten
logischen Ebene (= Ebene 0) beginnt jeweils ein neuer Satz (HEAD = Kopfsatz, INDI = Personensatz, FAMI = Familiensatz), und dahinter folgen auf den Ebenen 1, und 2 die Datenelemente dieses Satzes, bis der nächste Satz wieder mit Ebene 0 beginnt.
Der Kopf beinhaltet Informationen wie das Ausgangsprogramm, das diese GEDCOM-Datei
erzeugt hat und viele andere Details [Reu04]:
0 HEAD
1 SOUR REUNION
2 VERS V5.0
1 DEST ANSTFILE
1 DATE 12 NOV 1997
1 FILE Paternal Family File 4.0
2 VERS 4.0
1 CHAR IBM DOS
// das Programm, das die Datei erzeugt hat: Reunion
// Versions-Nummer des Programmes
// das Programm, das die Datei importiert
// Tag der Erstelung der GEDCOM Datei)
// Name der Familien-Datei
// die Versions-Nummer des angewandten Gedcom
// das character set der importierenden Software
- 24 -
KAPITEL 2
2.4.2. Genealogie-Programme
Mit der weltweiten Verbreitung der Computer seit dem Beginn der 80er Jahre des letzten
Jahrhunderts entstanden schon frühzeitig die ersten Programme für Familienforschung. Mit
Hilfe dieser „Genealogieprogramme" können alle Forschungsergebnisse durch Computer
festgehalten und jederzeit ergänzt werden. Besondere Vorteile sind dabei die systematische
Verwaltung, die schnelle und leichte Weitergabe der Daten und die Möglichkeit, immer einen
Ausdruck auf dem neuesten Stand herstellen zu können.
Von den zahlreichen Programmen konnten sich nur wenige auf dem Markt behaupten. So
werden heute wegen mangelnder Zuverlässigkeit kostenlose Public-Domain-Programme und
billige Shareware kaum noch benutzt. Für welches Produkt sich ein Familienforscher, der
„den Papierkram loswerden möchte", entscheidet, hängt von seinen Vorstellungen über das,
was das Programm leisten soll, ab. Einige dieser Programme werden im Folgenden vorgestellt und an diesen Beispielen die schon existierenden Anwendungen erläutert.
FamilySearch™ Personal Ancestral File 5.2
Sehr empfehlenswert ist das kostenlos erhältliche, einfach zu bedienende und seit 20 Jahren
weltweit zuverlässig arbeitende Programm der Mormonen PAF (Personal Ancestral File).Es
kann in deutscher Sprache von der englischen Homepage der Mormonen heruntergeladen
werden. Updates und eine deutsche Bedienungsanleitung stehen dort ebenfalls kostenlos zur
Verfügung. Ausdrucke von Ahnen- und Stammtafeln sowie Familienblätter sind hier einfacher Form möglich. Mit diesem Programm können familienbezogene Angaben zu Tausenden
von Personen angelegt und gespeichert werden.
Die Angaben können auf drei verschiedene Arten betrachtet werden [Fam]:
•
Die Familien-Ansicht zeigt ein Fenster, das eine Person und ihren Ehepartner, ihre
Kinder und Eltern anzeigt.
2.4.2.1 Familien-Ansicht
- 25 -
KAPITEL 2
•
Die Stammbaum-Ansicht zeigt eine Person und ihre direkten Vorfahren (Eltern,
Großeltern, Urgroßeltern usw.).
2.4.2.2 Stammbaum-Ansicht
•
Die Personen-Ansicht führt alle Personen in der .paf-Datei auf. Diese Liste wird nach
Namen oder nach der Datensatznummer (RIN) sortiert.
2.4.2.3 Personen-Ansicht
- 26 -
KAPITEL 2
GES 2000
Seit über 15 Jahren bewährt und bei vielen Familienforschern immer noch beliebt. Benutzer
müssen für eine Vollversion zwar über 100 € bezahlen, können aber dann einen Onlineservice
wahrnehmen. Die Programme sind komfortabel und bieten u. a. gute graphische Ausgabemöglichkeiten.
Entsprechend können die Angaben auf die folgende verschiedene Arten betrachtet werden
[Kno05]:
•
In den meisten Fällen werden Personen innerhalb eines Familienverbundes erfassen,
also als Vater, Mutter oder Kind:
Abb. 2.4.2.4
•
Familien-Ansicht
Über die Schaltfläche <Ahnen> im Personenformular oder die Schaltfläche <Vat-Ahne>
bzw. <Mutt-Ahne> wird die Ahnentafel wie folgt angezeigt:
- 27 -
KAPITEL 2
Abb. 2.4.2.4 Ahnentafel-Ansicht
•
Über die Schaltfläche <Nachfahr> im Personen- oder Familienformular wird die Nachfahrentafel angezeigt. Mit den Schaltflächen <L>, <O>, <R> und <U> kann der Benutzer in den Nachfahren blättern. Die Anzeige in der Bildleiste zeigt die Generation
und die Position der gewählten Personen (Abb. 2.4.2.5).
•
In GES-2000 kann 22 verschiedene Attributen darunter nach Namen, Vornamen, Familien, Personen- und Familiennummern, Titel, Beruf, Geburtsort und Geburtsdatum
gesucht werden. Der Suchmodus stellt noch Suchen nach Teilworte des Namens, auch
mit Gatten und Datum bereit. Nach der Eingabe eines Suchbegriffs in die Suchfelder
wird mit <Enter> die Suche gestartet. Die Anzeige beginnt, mit der zum Suchbegriff
am Besten passenden Personen. Danach werden weitere Personen angezeigt (Abb.
2.4.2.6).
Daneben gibt es weitere Programme, die von Forschern gerne benutzt werden. Sie können über die Seite http://www.genealogie-software.de heruntergeladen werden [Bur03].
- 28 -
KAPITEL 2
Abb. 2.4.2.5
Nachfahrentafel-Ansicht
Abb. 2.4.2.6
Suchmodus-Ansicht
- 29 -
KAPITEL 3
3. Grundlagen von Datenbanken
In Kapitel 2 wurden einige Beispiele gegeben, wofür eine genealogische Datenbank gebraucht wird. Aber wie kann eine genealogische Datenbank bearbeitet werden und welche
DBMS stellt sie zur Verfügung? Um diese Frage zu beantworten, wird zunächst ein kurzer
Überblick zu Datenbanken gegeben. Die Darstellung in den Abschnitten 3.1 und 3.2 stützt
sich auf die Quellen: [Kem97], [Man03].
Eine Datenbank (DB) ist eine systematisch strukturierte, langfristig verfügbare Sammlung
von Daten. Mit einem DBMS (Daten Bank Management System) zusammen kann man die
Datenbanken als das DBS (Datenbanksystem) bezeichnen. Eine Datenbank muss äußerst
sorgfältig entworfen und in einer geeigneten Datendefinitionssprache beschrieben werden. In
der Regel werden mehrere Datenbanken von einem DBMS verwaltet. Die wichtigsten Aufgaben und Funktionen eines DBMS sind Schemaverwaltung, Anfragebearbeitung, Transaktionsverwaltung und Speicherverwaltung.
Ein wesentlicher Aspekt bei Datenbankanwendungen ist die Unterstützung der Datenunabhängigkeit durch das DBMS. Das Konzept der Datenunabhängigkeit hat das Ziel, eine (oft
langlebige) Datenbank von notwendigen Änderungen der Anwendung abzukoppeln (und
umgekehrt). Sie kann in zwei Aspekte, Implementierungsunabhängig (physische Datenunabhängigkeit) und Anwendungsunabhängigkeit (logische Datenunabhängigkeit) aufgeteilt werden.
Die beiden Aspekte der Datenunabhängigkeit werden durch eine Drei-Ebenen-Architektur
realisiert. Diese Architektur unterteilt ein Datenbankschema in drei aufeinander aufbauende
Ebenen. Von untern nach oben sind die folgenden Ebenen vorgeschlagen:
•
Das Interne Schema beschreibt die systemspezifische Realisierung der Datenbank.
Die Beschreibung des internen Schemas ist abhängig vom verwendeten Basissystem
und der von diesem angebotenen Sprachschnittstelle.
•
Das Konzeptuelle Schema beinhaltet eine implementierungsunabhängige Modellierung der gesamten Datenbank in einem systemunabhängigen Datenmodell.
•
Das Externes Schema ist die Benutzersicht. Dort werden die Daten in einem speziell
auf den Benutzer zugeschnittenen externen Schema dargestellt.
Eine Datenbanksprache umfasst die Datendefinitionssprache (DDL), die zur Darstellung
eines Schemas dient, und die Datenmanipulationssprache (DML) zur Formulierung von
Anfragen, Änderungen und Eingaben.
Eine Transaktion ist eine Folge von Operationen (Aktionen), die die Datenbank von einem
konsistenten Zustand in einen neuen Zustand überführen, wobei das so genannte ACID-Prinzip eingehalten werden muss. Der Begriff “ACID”ist von den ersten Buchstaben der
vier englischen Wörtern abgeleitet: Atomicity, Consistency, Isolation and Durability.
- 30 -
KAPITEL 3
3.1
Datenmodelle und Relationale Datenbanken
Ein Datenmodell besteht aus einer bestimmten Zusammenstellung von Konzepten zum Modellieren von Daten in der realen Welt und/oder im Rechner. DBS werden meist nach dem
unterstützten Datenmodell klassifiziert.
•
•
•
•
relationale Datenbanken
objekt-orientierte Datenbanken
hierarchische Datenbanken
Entity-Relationship Datenbanken
Relationale Datenbanken sind seit einiger Zeit die dominierende Speicherungsmethode für
strukturierte Datenbestände. Ältere Datenmodelle wie das hierarchische und das Netzwerkmodel werden insbesondere bei Neuentwicklungen durch relationale Datenbanken abgelöst.
Konzeptionell ist eine relationale Datenbank eine Ansammlung von Tabellen. Hinter Tabellen steht mathematisch die Idee einer Relation, Relationenalgebra, ein grundlegender Begriff, der dem gesamten Ansatz den Namen gegeben hat. Beide sind Bezeichnungen für die
Form von Datenbankobjekten in einer relationalen Datenbank. Eine Tabelle ist ein 2-dim.
Array aus Zeilen und Spalten, das geordnet ist und in dem doppelte Zeilen möglich sind. Relation ist Menge von Tupeln, ungeordnet und duplikatfrei. Relationen lassen sich in Tabellenform visualisieren, wenn man eine bestemmte Anordnung wählt. Tabellen lassen sich als
Relationen formalisieren, wenn man keine Duplikate zulässt und von der Anordnung absieht.
In der folgenden Tabelle ist ein Ausschnitt aus den Daten unserer Genealogischen Datenbank
dargestellt. Sie beinhaltet die Informationen zum Entity-Typ Person.
personID
15
16
17
Born
28.05.1660
05.09.1666
30.10.1683
BirthPlace
Osnabrück
Celle
Hanover
Died
11.06.1727
02.11.1726
25.10.1760
DeathPlace
bei Osnabrück
Ahlden
Kensington Pal
Abb.3.1.1 Tabelle “person”
Es wird für die Tabelle „person“ die folgenden begrifflichen Konventionen:
•
•
•
•
Die erste Zeile gibt jeweils die Struktur einer Tabelle an: Anzahl und Benennung der
Spalten. Diese Strukturinformation bezeichnet man als Relationenschema.
Die weiteren Einträge in der Tabelle nennen wir Relation zu diesem Schema. Eine
einzelne Zeile der Tabelle bildet ein Tupel.
Spaltenüberschriften werden als Attribut bezeichnet.
Eine Relation ist eine Menge von Tupeln. Prinzipiell ist in relationalen Datenbanken
die Reihenfolge der Tupel irrelevant.
- 31 -
KAPITEL 3
Um mit relationalen Datenbanken effektiv arbeiten zu können, sind die folgenden Konzepte
wichtig:
•
•
•
•
Jedem Attribut ist ein Wertbereich zugeordnet.
Ein Schlüssel ist ein Attribut oder eine Attributkombination, wodurch die Tupel in
einer Relation eindeutig identifiziert werden.
Ein Fremdschlüssel ist ein Attributwert, der einen Schlüsselwert in einer anderen
Tabelle darstellt und somit als eindeutiger Verweis auf einen Datensatz in der anderen
Tabelle zeigt.
Fremdschlüssel dürfen nie als dangling pointer ins Leere zeigen. Diese Eigenschaft
bezeichnet man als referenzielle Integrität.
Die elementaren Operationen zum Arbeiten mit Relationen bilden die so genannte Relationenalgebra. Wir listen diese Operatoren kurz auf:
•
•
•
•
Selektion (σ): Tupel/Zeile einer Tabelle auszuwählen
Projektion (П): Spalten auszublenden
Natürlicher Verbund ( ): Zwei Tabelle derart zu verschmelzen, dass Tupel, die in
den gleich lautenden Attributen der beiden Tabellen die gleichen Werte haben, zu einem Tupel zusammengefasst werden.
Mengenoperationen: Vereinigung (∪), Durchschnitt (∩), Differenz (─) und Produkt
(x) kombinieren zwei strukturell gleich aufgebaute Tabellen.
Eng verbunden mit dem relationalen Datenbankmodell ist die Relationale Entwurfstheorie.
Aufgabe des relationalen Entwurfs ist primär eine Verbesserung eines relationalen Schemas
mit dem Ziel der Redundanzvermeidung. Um die Güte des Entwurfs überprüfen zu können
und ein besseres Datenbankschema zu konstruieren, müssen wir ein Maß für die Qualität finden. Hierzu werden Abhängigkeiten zwischen Attributen eingeführt, die den Einsatz formaler
Entwurfsverfahren ermöglichen, die auch in üblichen Datenbank-Entwurfswerkzeugen eingesetzt werden:
•
Überflüssige Felder entfernen: Felder, die aus anderen Feldern berechnet werden,
sind überflüssig und benötigen zusätzlichen Speicherplatz. Diese Felder können jederzeit neu berechnet werden. Sie werden daher normalerweise nicht in die Tabelle
aufgenommen.
•
Zerlegung der Tabelle in mehrere Tabellen: Die Tabelle wird in mehrere Tabellen
zerlegt, so dass möglichst keine unerwünschten Nebeneffekte auftreten. Damit wird
die Datenbank flexibel. Die unerwünschte Nebeneffekte sind:
o Redundanz: Wiederholung von Information
o Änderungs/Update- Anomalien: Änderung von der Zuordnung A<->B kann
zum Verlust der Zuordnung B<->C führen
o Einfüge/Lösch -Anomalien: Zwang zum Einfügen/Löschen von Nullwerten
beim Einfügen/Löschen
Eine sinnvolle Zerlegung von Relation, die als eine verlustlose und abhängigkeitsbewahrende
Zerlegung bezeichnet, basiert vollständig auf funktionale Abhängigkeiten. Eine funktionale
Abhängigkeit ist ein Paar von Attributmenge, für die gilt, dass die Werte der ersten Attribut-
- 32 -
KAPITEL 3
menge X die Werte der zweiten Menge Y in jeder erlaubten Ausprägung eindeutig bestimmen.
Normiert wird die Abhängigkeit als X →Y. Die bereits eingeführten Schlüssel sind Spezialfall funktionaler Abhängigkeiten:
•
•
•
•
Ein Schlüssel ist eine Attributmenge, die alle restlichen Attribute einer Relation funktional bestimmt.
Ein Schlüsselkandidat ist ein Schlüssel mit minimaler Anzahl Attribute Eine Relation kann mehrere Schlüsselkandidaten haben.
Ein Primärschlüssel ist ein beliebig ausgewählter Schlüsselkandidat, der zur eindeutigen Identifizierung jeder Zeile benutzt wird.
Ein Schlüsselattribut ist ein Attribut, das Teil mindestens eines Schlüsselkandidaten
ist. Alle anderen Attribute sind Nicht-Schlüsselattribute.
•
Das Ziel der Normalisierung von Relationenschemata besteht darin, alle Abhängigkeiten
auf Schlüsselabhängigkeiten zurückzuführen. Hierzu müssen alle Relationenschemata, in denen dies nicht gilt, aufgeteilt werden. Hierfür werden die so genannten Normalformen für
Relationenschemata definiert:
Erste Normalform (1NF): Eine Relation ist in der Ersten Normalform, wenn jeder Attributwert atomar ist. Ein Attributwert ist atomar, wenn er nicht aus mehreren Werten zusammensetzt ist.
Zweite Normalform (2NF): Eine Relation ist in der Zweiten Normalform, wenn sie in der
Ersten Normalform ist und jedes Nicht-Schlüsselattribut von jedem Schlüsselkandidaten
vollständig funktional abhängig ist. Vollständig funktional abhängig bedeutet, dass das
Nicht-Schlüsselattribut nicht nur von einem Teil der Attribute eines zusammengesetzten
Schlüsselkandidaten funktional abhängig ist, sondern von allen Teilen.
Dritte Normalform (3NF): Eine Relation ist in der Dritten Normalform, wenn Sie in der
Zweiten Normalform ist und jedes Nicht-Schlüssel-Attribut von keinem Schlüsselkandidaten
transitiv abhängig ist (d.h. direkt funktional abhängig).
Die Transitive Abhängigkeit bedeutet: Seien X, Y und Z Attribute. Ist Y von X funktional
abhängig und Z von Y, so ist Z von X funktional abhängig.
Boyce-Codd Normalform (BCNF): Eine Relation ist in Boyce-Codd Normalform, wenn
jedes Attribut direkt von jedem Schlüsselkandidaten abhängt.
Alle 2NF- und 3NF- Zerlegungen sind verlustlos und abhängigkeitsbewahrend. Dagegen
kann aber BCNF-Zerlegung die Abhängigbewahrung nicht garantieren. Es wird in Kapitel 7
mit Beispiele ausführlich beschrieben, wie ein relationales Schema damit verbessert werden
kann.
- 33 -
KAPITEL 3
3.2.
SQL
Diese Kurzeinführung soll einen knappen Überblick über den Gesamtumfang von SQL
geben, die allerdings aus Zeit- und Platzgründen nicht vollständig sein kann.
SQL (ausgesprochen "sequel") steht für Structured Query Language und wird als Schnittstelle zu relationalen Datenbanken benutzt. SQL ist nach dem ANSI -American National
Standards Institute normiert und damit auf viele RDBMS (Relational Database Management
Systems) anwendbar, z.B. Oracle, Sybase, Microsoft SQL Server, Access, Ingres, mysql, etc.
Erst mit SQL2, auch als SQL92 bekannt, wurde eine Norm standardisiert, an die sich die
meisten Hersteller halten konnten. SQL3 schließlich wurde 1999 verabschiedet und ist deshalb auch unter SQL: 1999 bekannt. Dieser letzte Standard wurde mit Konzepten wie Rekursion und objektorientierten Ansätzen erweitert [NL_5].
SQL kann als „stand alone“ -Sprache benutzt werden oder auch eingebettet in eine allgemeine Programmiersprache. SQL ist eine vollständige DB-Sprache, die als DDL-Teilsprache oder auch als DML-Teilsprache mit Anfrage- und Änderungsmöglichkeiten verwendet werden
kann.
3.2.1. DDL in SQL
Beim Einrichten/Erzeugen einer neuen Tabelle wird es dem Datendefinitionsbefehl CREATE
TABLE verwendet:
CREATE TABLE table-name
(list-of-table-elememts)
Die “table-elements”-Tabellenelemente bestehen aus zwei Teile:
•
•
Festlegungen von Spaltennamen mit Datentypen
Festlegungen deren Integritätsbedingungen
Integritätsbedingungen sind Bedingungen, die für einzelne Spalten oder die ganze Tabelle
gelten müssen. Die Syntax von Spaltebeschränkungen („column-constraint“ in English) wird
so definiert:
[NOT NULL|Unique]
[PRIMARY KEY]
[DEFAULT {Literal|Null}]
[References table-name]
[CHECK condition]
- 34 -
KAPITEL 3
Die Syntax von Tabellenbeschränkungen („table-constraint“) wird entsprechend wie folgt
definiert:
[CHECK condition]
[UNIQUE ( list-of-column-names ) ]
[ PRIMARY KEY ( list-of-column-names ) ]
[FOREIGN KEY ( list-of-column-names )REFERENCES table-name]
Im Folgenden wird ein Beispiel angegeben, wie die Tabelle „person“ in SQL erzeugt wird.
Die letzte Zeile „PRIMARY KEY (personID) “ ist eine Tabellenbeschränkung.
personID
15
16
17
Born
28.05.1660
05.09.1666
30.10.1683
BirthPlace
Osnabrück
Celle
Hanover
Died
11.06.1727
02.11.1726
25.10.1760
DeathPlace
bei Osnabrück
Ahlden
Kensington Pal
CREATE TABLE person (
personID BIGINT NOT NULL AUTO_INCREMENT,
Born DATE,
Died DATE,
BirthPlace VARCHAR(40),
DeathPlace VARCHAR(40),
PRIMARY KEY (personID)
)
Beim Entfernen einer Tabelle aus dem Schema wird der Befehl DROP TABLE verwendet und
bei Änderungen von Spaltendefinitionen und Integritätsbedingungen wird die ALTER TABLE
-Anweisung benutzt.
3.2.2.
DML in SQL
Nach der Einrichtung von Basistabellen wird man zunächst Daten in diese Tabellen eintragen
wollen. Mit der INSERT-Anweisung werden einzelne Tupel oder eine Tupelmenge in eine
Tabelle eingefügt. Fehlende Attributwerte werden mit Nullwerten aufgefüllt. Da keine Attribute angegeben werden, fügt man sie in der gleichen Reihenfolge wie in der Schemadefinition
ein.
INSERT INTO person
VALUES (18, NULL, ‘Köln’, NULL, NULL )
Der DELETE-Operator löscht eine Tupelmenge oder einzelne Tupel, die im WHERE-Teil
spezifiziert werden; falls der WHERE-Teil nicht angegeben ist, werden sämtliche Inhalte der
Relation gelöscht.
DELETE FROM person
WHERE personID=16
- 35 -
KAPITEL 3
Die UPDATE-Anweisung ist nichts anderes als eine nacheinander ausgeführte DELETE- und
INSERT-Anweisung. Die UPDATE-Anweisung kann bedingungslos ausgeführt werden; in
diesem Fall werden alle Tupel der Tabelle geändert. Um nur bestimmte Tupel einer Tabelle zu
ändern, wird dieses im Bedingungssteil separat angegeben[Man98], [KeEi97].
UPDATE person
SET DeathPlace = ‘London’
WHERE personID = 18
3.2.3.
Anfragen mit SQL
Anfragen werden in SQL mit SELECT-FROM-WHERE-Blöcken gestellt. Der WHERE-Teil ist optional und kann daher entfallen.
In den SELECT-Teil kommen die auszugebenden Attribute mit expliziter Relationszugehörigkeit, falls es nicht eindeutig ersichtlich ist, zu welcher Relation sie gehören. Der
FROM-Teil beschreibt, welche Relationen an der Anfrage beteiligt sind und teilt ihnen für
die Anfrage einen Namen zu, falls eine Relation beispielsweise mehrfach auftritt:
SELECT Xi1.A1, . . . , Xim.Am
FROM R1 X1,. . . , Rn Xn
WHERE Bedingung
SELECT person.*
//Anfrage der Frau durch gegebene
FROM person, married
/IdNr. ihrer Mann
WHERE person.id = married.wifeId and married.husbandId = husbandId
Als wesentliche Möglichkeit, Daten aus zwei Relationen miteinander zu verknüpfen, nutzt
SQL das Kreuzprodukt und nicht den natürlichen Verbund. Wie im Beispiel gezeigt, dass
die Angabe* die Ausgabe aller Attribute erwirkt.
Es ist zu beachten, daß Ergebnisse von Anfragen in SQL keine Relationen sind, sondern Multi- Mengen. Sie können Duplikate enthalten. Um Duplikate zu vermeiden, muß dies explizit
mit dem Schlüsselwort DISTINCT gefordert werden.
SELECT-Blöcke können auf drei Arten mit Operatoren im WHERE-Teil geschachtelt werden:
1. Schachtelung mit dem IN-Operator in WHERE-Teil, um zu prüfen, ob Attribute in
dem geschachtelten SELECT-Block enthalten sind.
SELECT Name
FROM Person
WHERE ID IN ( SELECT ID
FROM Professoren
WHERE Name= Manthey )
- 36 -
KAPITEL 3
2. Schachtelung mit Vergleichsoperatoren mit Quantoren; die sechs Quantoren (>, =, <,
<>,≥, ≤) existieren, gefolgt von ALL oder SOME .
SELECT Name
FROM Professor
WHERE PersNr = ALL
(SELECT PersNr
FROM Professor)
// Namen der Professoren mit der kleinsten
Personalnummer
3. Schachtelung mit dem Existenzquantor EXISTS; analog dazu wird NOT EXISTS
angewendet. SQL kennt keinen Allquantor; deshalb müssen alle Anfragen mit Hilfe
des aus der Prädikatenlogik bekannten Zusammenhangs ?für allex(P) =﹁Exist x( ﹁)P)?
umgewandelt werden.
SELECT Name
FROM Professor
WHERE EXISTS ( SELECT *
FROM Professor
WHERE PersNr= 15466)
SQL bietet eine Reihe von weiteren Möglichkeiten zur Anfragebearbeitung an. Wie Aggregatfunktionen: COUNT,SUM,AVG,MAX und MIN, Gruppierung: GROUP BY und HAVING und Sortierung: ORDER BY, ASC und DESC. Weitere Beschreibungen kann in der
einschlägigen Literatur gefunden werden [HS95].
3.3.
MySQL
Ein relationales Datenbank-Managementsystem (RDBMS) ist in vielen Bereichen überaus
wichtig, angefangen bei den traditionelleren Anwendungen in Wirtschaft, Forschung und Bildung bis hin zu neueren Anwendungen wie z.B. bei Suchmaschinen im Internet. Wenn ein
kostenloses oder günstiges Datenbank-Managementsystem gesucht wird, stehen mehrere Optionen zur Auswahl: Access, MySQL, mSQL, ANSI SQL 92, Microsoft SQL 7.0, Postgres...
Wenn man eine Entscheidung zwischen verschiedener RDBMS treffen muss, sollten Leistung,
Support, Funktionsumfang wie SQL-Anpassung, Erweiterungen, Portabilität und Lizenzbedingungen berücksichtigt werden. In dieser Arbeit wird das relationale Datenbanksysteme
MySQL verwendet. Zunächst werden die allgemeinen Informationen über MySQL gegeben.
Anschließend werden einige sprachlichen Besonderheiten von MySQL vorgestellt.
Die Darstellung in diesem Abschnitt stützt sich auf die Quelle: „MySQL“ von Paul Dubois,
2000; „MySQL Datenbankhandbuch“ von Guido Stepken, 1999.
MySQL, ist ein aus Skandinavien (MySQL AB) stammendes, relationales Client / Server-DBMS mit SQL. Zu MySQL gehören ein SQL-Sever, Client-Programme für den Serverzugriff, Administrations-Tools sowie eine Programmierschnittstelle, damit der Benutzer
seine eigenen Programme
schreiben kann. MySQL ist nicht nur in der Opern-Source_gemeinde populär. Es ist auch portierbar und läuft ebenfalls auf kommerziellen
- 37 -
KAPITEL 3
Betriebssystemen (wie z.B. Solaris, Irix und Windows). Die folgenden Eigenschaften zeigen,
dass MySQL eine Hochleistungs-RDBMS ist:
• Geschwindigkeit: MySQL ist ein sehr schneller und robuster, Multi-Thread und Mul
ti-User SQL-Datenbank-Server.
•
Volle Unterstützung der Anfragesprache SQL. SQL-Funktionen sowie LEFT
OUTER JOIN und RIGHT OUTER JOIN sind durch eine hoch optimierte Klassenbibliothek implementiert
•
Große Datensätze mit fester oder variabler Länge: z.B. es kann große Datenbaken
mit Millionen von Datensätzen handhaben.
•
Potenzial: Viele Clients können sich gleichzeitig mit dem Server verbinden (Multi-User). Darüber hinaus sind mehrere APIs für Sprachen wie C, Perl, Java, PHP und
Python erhältlich.
•
Netzwerkanbindung und Sicherheit: Da MySQL voll netzwerktauglich ist, kann
die Daten ortsunabhängig genutzt werden. Doch MySQL bietet auch Zugriffskontrollen, so dass Datensicherheit besteht.
•
Portabilität: MySQL läuft auf vielen Unix-Varianten sowie auf anderen Betriebssystemen wie Windows und OS/2.
Abb. 3.4.2 Erzeugen einer Tabelle in MySQL [SQL_1]
- 38 -
KAPITEL 3
Wer sich bereits mit anderen SQL Datenbanken auskennt, der wird sicher bei MySQL einige
Funktionen vermissen, die in anderen Datenbanken selbstverständlich sind. Da bei MySQL
viele Pre- und Postprozessoren einfach nicht existieren, kann MySQL erheblich schneller sein,
als alle teuren, professionellen Datenbanken. Für Internet-Anwendungen mit vielen simultanen Clients können Pre - und Postprozessoren die Performance erheblich verlangsamen. Unter MySQL werden diese Performancekiller erst gar nicht unterstützt. MySQL ist als Internet-Datenbank mit vielen tausend simultanen Clients konzipiert. Zur Beschleunigung von
ACCESS 95/97/2000 ist MySQL ohne Probleme einsetzbar, da ACCESS als Frontend fast
alle der hier aufgeführten Features entweder nicht unterstützt wie „Subselects“ oder auf die
eine oder andere Art bereits implementiert hat wie „Joins“. Nun werden diese Funktionen in
MySQL vorgestellt:
SubSELECTs
Subselects kann man durch JOINS recht einfach umschreiben. Es erhöht zwar nicht gerade
die Lesbarkeit, ein (self) JOIN ist aber ein vollständiger Ersatz. In der nächsten Version ist
aber damit zu rechnen, dass Subselects untestützt werden. Übrigens gibt es in vielen Datenbanken Beschränkungen der Schachteltiefe auf nur wenige „SELECT * FROM WHERE
...SELECT * FROM ... WHERE“ Statements. Es sind auch oft nicht alle Kombinationen mit
anderen Parametern erlaubt. Daher sind Subselects nicht unbedingt das K.O. Kriterium für
die Auswahl von (nicht MySQL) Datenbanken, insbesondere nicht für User, die von ACCESS her sich MySQL widmen möchten, da hier einige Statements nicht zugelassen sind.
Ein Beispiel ist der Ausdruck von der Menge aller Kursteilnehmer, die nicht in dem zweiten
Kurs sind:
SQL> SELECT NAME FROM KURS_1 MINUS SELECT NAME FROM KURS_2
Diese Schreibweise ist zwar sehr elegant, aber auch einfach mit SELF-JOINS zu umschreiben. Hier die Schreibweise in anderen SQL Dialekten:
SELECT * FROM table1 WHERE id IN (SELECT id FROM table2);
SELECT * FROM table1 WHERE id NOT IN (SELECT id FROM table2);
Hier der Ersatz in MySQL
SELECT table1.* FROM table1,table2 WHERE table1.id=table2.id;
SELECT table1.* FROM table1 LEFT JOIN table2 ON table1.id=table2.id where table2.id IS NULL
JOINs
Es gibt bei vielen Datenbanken einige JOIN - Formen nicht. Auch Microsoft SQL 7.0 besitzt
hier z.B. erhebliche Abweichungen vom ANSI SQL 92 Standard. MySQL besitzt alle Möglichkeiten der Verknüpfung von Tabellen.
- 39 -
KAPITEL 3
MySQL unterstützt die folgenden JOIN Ausdrücke in SELECT Statements:
table_reference, table_reference
table_reference [CROSS] JOIN table_reference
table_reference STRAIGHT_JOIN table_reference
table_reference LEFT [OUTER] JOIN table_reference ON conditional_expr
table_reference LEFT [OUTER] JOIN table_reference USING (column_list)
table_reference NATURAL LEFT [OUTER] JOIN table_reference
{ oj table_reference LEFT OUTER JOIN table_reference ON conditional_expr }
JOIN und , (Komma) sind von der Syntax her völlig äquivalent. Beide führen einen vollen
JOIN Befehl zwischen zwei Tabellen aus. Normalerweise sollten Tabellen mit Hilfe der
WHERE Bedingung verbunden werden. Der Ausdruck ON beschreibt ein konditionales
"Wenn es übereinstimmt", und kann mit dem Ausdruck WHERE verbunden werden. Wenn es
keinen passenden Eintrag für die richtige Tabelle in einem LEFT JOIN gibt, wird eine Reihe,
wo alle Spalten auf NULL gesetzt sind, für die rechte Tabelle verwendet. Es können somit
Einträge gefunden werden, die kein entsprechendes Gegenstück in einer anderen Tabelle besitzen:
mysql> select table1.* from table1
LEFT JOIN table2 ON table1.id=table2.id
WHERE table2.id is NULL;
Der einfachste JOIN ist der sogenannte "EQUI-JOIN". Ein Beispiel :
SELECT A.EineSpalte, B.EineAndereSpalte
FROM Tabelle1 AS A, Tabelle2 AS B
WHERE A.EinWert = B.EinAndererWert;
Dieses Beispiel findet alle Reihen in Tabelle 1 mit einem ID Wert, der nicht in Tabelle 2 enthalten ist. Das setzt voraus, daß table2.id ist als NOT NULL definiert worden.
Die der Ausdruck USING column_list benennt eine Liste von Spalten, die in beiden Tabellen
existieren müssen. Ein Beispiel:
LEFT JOIN B USING (C1,C2,C3,...)
ist identisch mit dem Ausdruck:
A.C1=B.C1 AND A.C2=B.C2 AND A.C3=B.C3,...
Das NATURAL LEFT JOIN zweier Tabellen ist identisch zu dem Ausdruck LEFT JOIN mit
USING. Es werden dann alle Spalten genommen, die in beiden Tabellen exstieren. STRAIGHT
JOIN ist identisch mit JOIN, abgesehen davon, dass die linke Tabelle vor der rechten Tabelle
ausgelesen wird.
- 40 -
KAPITEL 3
Ein paar Beispiele:
mysql> select * from table1,table2 where table1.id=table2.id;
mysql> select * from table1 LEFT JOIN table2 ON table1.id=table2.id;
mysql> select * from table1 LEFT JOIN table2 USING (id);
mysql> select * from table1 LEFT JOIN table2 ON table1.id=table2.id
LEFT JOIN table3 ON table2.id=table3.id;
Gegeben sei folgende Aufgabe : Eine Preisliste soll gedruckt werden, und überall dort, wo es
einen Lieferanten aus England gibt, soll dessen Name angedruckt werden. Bei den anderen
Artikeln soll diese Ergebnis Spalte leer bleiben. Ein einfacher JOIN reicht hier nicht mehr.
Wir brauchen also etwas anderes : den OUTER JOIN. Der sieht so aus :
SELECT A.ArtikelNr, B.Lieferant
FROM Artikel AS A LEFT OUTER
JOIN Lieferanten AS B ON A.LieferantID = B.LieferantID
WHERE B.Land = 'GB';
Bei einem OUTER JOIN gibt es immer eine Tabelle, die als erhaltene Tabelle bezeichnet wird;
alle ihre Zeilen bleiben erhalten. Wenn es sich um einen LEFT OUTER JOIN handelt, ist die
linke Tabelle die erhaltene Tabelle; bei einem RIGHT OUTER JOIN ist es die rechte Tabelle.
Somit dürfte auch klar sein, wie man einen "RIGHT JOIN" mit MySQL realisieren kann:
nämlich einfach durch Vertauschung der linken und rechten Tabelle.
UNION
UNION ermöglicht bei Subselects die Verknüpfung von Mengen miteinander. Da MySQL
und ACCESS keine Subselects unterstützen, sind auch UNION´s nicht notwendig:
In ANSI SQL 92 werden Mengen so verknüpft:
SELECT db1.tabelle .....
UNION
SELECT db2.tabelle ....
ORDER BY name
Das funktioniert so bei MySQL nicht. Im Grunde wird bei dem Statement UNION in anderen
Datenbanken durch den Pre-Prozessor ebenfalls eine temporäre Tabelle angelegt. Bei
MySQL muss stattdessen eine schnelle, temporäre Tabelle angelegt werden, die bei den neuen MySQL Versionen im RAM angelegt, und evtl. auch automatisch auf den Swap-Speicher
ausgelagert wird. Darin ist eine Option HEAP erwähnt, die superschnelle Tabellen im RAM
anlegt. Das Statement SET ermöglicht Tuning während der Laufzeit.
CREATE TABLE tmp1 (tabelle ....);
INSERT INTO tmp1 SELECT db1.tabelle .....;
INSERT INTO tmp1 SELECT db2.tabelle .... ;
SELECT * FROM tmp1 WHERE ... ORDER BY name;
Danach kann man entweder die ganze Tabelle Löschen, oder nur deren Inhalte, damit man
diese noch mal verwenden kann.
- 41 -
KAPITEL 3
Foreign Keys
„Foreign Keys“ (Fremdschlüssel in Deutsch) werden in SQL im Allgemeinen nicht verwendet, um Tabellen zu verknüpfen, sondern um sicherzustellen, dass die Integrität der verschiedenen einiger Spalten von Tabellen sichergestellt ist. Beispielsweise kann man hiermit erzwingen, dass wenn ein Datensatz verändert wird, in einer anderen Tabelle entsprechende
Veränderungen automatisch vorgenommen werden. Es gibt aber auch viele Gründe, diese
möglichst wenig einzusetzen:
•
„Foreign Keys“ verkomplizieren das allgemeine Datenbankhandling. Die Einfachheit
von MySQL, z.B. im Intranet eine Datenbank zu pflegen, und täglich in das Internet
zu kopieren, wäre dahin.
•
Die Geschwindigkeit von INSERT und UPDATE Statements wäre ebenfalls gefährdet,
da die Datenbank nach einem INSERT oder UPDATE alle foreign keys einzeln durchlaufen muss. Im Allgemeinen werden ohnehin INSERTS stets in den richtigen Tabellen mehrere INSERT/UPDATES in mehreren Tabellen gleichzeitig durchgeführt. Abfragen und Verknüpfungen über mehrere Tabellen sind aber stets erlaubt, damit keine
Missverständnisse aufkommen.
•
„Backups“ und „Restores“ werden fast unmöglich gemacht. Der einfache Vorgang,
eine einzelne Tabelle bei Mangel an Datenintegrität (Festplattenfehler) einfach zu löschen, und dann von der Backup-Platte oder dem Tape zu restaurieren, funktioniert
bei Datenbanken mit foreign keys nicht mehr. Es muss in diesen Fällen dann immer
die gesamte Datenbank restauriert werden, und es muss eine bestimmte Reihenfolge
peinlich genau eingehalten werden. Bei großen Datenbanken, die über mehrere Millionen Einträge verfügen, ist dann mit längeren Ausfällen zu rechnen. Beim Einsatz im
Internet muss die Datenbank jedoch den "mission critical" Anforderungen entsprechen.
•
Bei „foreign keys“ passiert es recht häufig, dass rekursive Bezüge entstehen, die zwar
erlaubt sind, jedoch verhindern, dass man eine Tabelle so einfach mit einem CREATE
Befehl erzeugen kann. Hierfür sind oft sehr komplexe Statements notwendig.
•
Und nun eine gute Nachricht: MySQL wird in absehbarer Zeit um foreign keys erweitert, im SQL
Parser sind diese schon enthalten.
Transaktionen
Transaktionen fassen viele Lese und Schreibzugriffe zu einem Prozess zusammen, der dann
sehr schnell ausgeführt wird. Hierzu ist ein Transaktionspuffer notwendig, der verzögert alle
Änderungen in die Datenbank schreibt. Mit Transaktionen kann man das Schreiben von vielen Clients in eine Datenbank drastisch beschleunigen. Zumindest hat dann der User den Eindruck, die Datenbank würde schnell arbeiten. In Wirklichkeit werden diese INSERT und
UPDATE Befehle in eine Art QUEUE geschoben, die dann langsam abgearbeitet wird. Hierzu wird im Allgemeinen mit BeginTrans/CommitTrans und dem Verwerfen einer Transaktion
„RollbackTrans“ gearbeitet. CommitTrans sorgt dafür, dass die Änderungen auch tatsächlich
durchgeführt werden.
- 42 -
KAPITEL 3
MySQL kann jedoch die Befehle, wie INSERT mit einer niedrigen Priorität versehen
(LOW_PRIORITY), sodass der Befehl erst dann ausgeführt wird, wenn MySQL eine kurze
Pause hat. Dank der Multi-Thread Architektur ist das ohne Probleme möglich.
Ein guter Workaround ist der Einsatz von MySQL zusammen mit PERL oder besser PHP3.
Unter PHP3 kann man die Suchergebnisse in eine temporäre Datei schreiben, und in diesen
dann mit Hilfe des PHP3 Interpreters blättern. Schreibvorgänge kann man logischerweise
ebenso mit PHP3 3.0/4.0 speichern, und später unter Verwendung des Ausdrucks
low_priority verzögert in die Datenbank schreiben. Im Grunde funktioniert der Transaktionsmechanismus anderer Datenbanken ebenfalls mit Hilfe eines vorgeschalteten Programms,
welches diese Transaktionen bündelt und optimiert. Angesichts der wenigen Zeilen zusätzlich, die man in PHP3 3.0/4.0 benötigt, um diesen Mechanismus zu implementieren, ist dies
keine Hindernis, sondern eher ein Vorteil bei verteilten Datenbanksystemen, da man die
temporären Dateien via FTP oder sogar via E-Mail über das Internet verbreiten und somit die
Datenbanken synchronisieren kann. Auf diese Art und Weise werden sogar Standleitungen
entbehrlich.
- 43 -
KAPITEL 4
4.
4.1.
Grundlagen von Java
Java im Überblick
Java ist eine objektorientierte Programmiersprache, die von Sun Microsystems entwickelt
und erstmals 1995 für die Öffentlichkeit freigegeben wurde. Der Erfolg von Java ist neben
der Politik der prinzipiell kostenlosen Weitergabe der Java-Umgebung durch Sun vor allem
auf die folgenden Eigenschaften zurückzuführen: Objektorientierung, Einfachheit, Architektur-Neutralität und reichhaltiges API. Wir werden dabei keine vollständige Einführung zu
allen Aspekten der Programmierung mit Java geben, sondern nur einen kurzen Überblick zu
den wichtigen Teilen.
Der Abschnitt 4.1 stützt sich auf die Quelle: „Datenbanken & Java“ von Gunter Saake,
Kai-Uwe Sattler, und „Java ist auch eine Insel“ von Christian Ullenboom.
4.1.1 Klassen, Objekte und Methoden
Klassen sind Sammlungen von Daten und Methoden, die auf diesen Daten operieren. Sie beschreiben Eigenschaften und Verhalten von Objekten. Alle Objekte, die zu einer bestimmten
Klassen gehören, besitzen die gleiche Struktur und werden als Instanzen dieser Klasse bezeichnet. Eine Klasse bildet das wesentliche Abstraktionskonzept der objektorientierten Programmierung: Attribute und Methoden Können nur im Rahmen von Klassen definiert werden.
Das folgende Beispiel zeigt die Definition einer Klasse in Java:
public class Book
{
private String title;
private String isbn;
private float price;
public Book (String isbn)
{
this.isbn = isbn;
}
public void setTitle (String s)
{
title = s ;
}
public float getPrice ()
{
return price;
}
// Attribute
// Konstruktor
// Methoden
// Methoden
}
- 44 -
KAPITEL 4
Dieses Beispiel illustriert gleichzeitig verschiedene Konzepte:
•
Attribute zur Repräsentation von Eigenschaften werden als Variablen deklariert.
•
Methoden sind Funktionen oder Prozeduren, die auf den Attributen operieren. Sie
können Parameter besitzen und einen Wert zurückgeben.
•
Spezielle Methoden mit dem Namen der Klasse werden als Konstruktoren bezeichnet
und beim Erzeugen eines Objektes dieser Klasse aufgerufen. So lassen sich
beispielsweise Initialisierung der Attribute vornehmen.
•
Sowohl für die Klasse selbst als auch für die Attribute und Methoden kann die Sichtbarkeit definiert werden. Hierfür stehen die folgenden Schlüsselwörter zur Verfügung:
o public: außerhalb der Klasse sichtbar
o private: nur innerhalb der Klasse selbst, d.h. für Methoden dieser Klasse
sichtbar
o protected: für die Klasse und davon abgeleitete Subklassen sowie innerhalb
des gleichen Paketes sichtbar
Ohne Angabe eines Sichtbarkeitsmodifikators ist das Attribut bzw. die Methode nur
innerhalb der Klasse sowie im gleichen Paket sichtbar.
Ein Objekt als Instanz einer bestimmten Klasse wird mit Hilfe des new-Operators erzeuget,
gefolgt vom Klassennamen und einer optionalen Parameterliste für den Konstruktsraufruf.
Das erzeugte Objekt kann einer Variablen zugewiesen werden, die die Klasse als Datentyp
besitzt. Diese Variable ist jedoch nicht das Objekt selbst, sondern verweist nur auf dieses Objekt, d.h., die Variable ist eine Referenz auf das Objekt:
Book b = new Book ();
// Instanzierung
Book c = b;
So wird im obigen Beispiel der Variablen c keine Kopie des Objektes zugewiesen. Stattdessen verweisen beide Variablen auf das gleiche Objekt. Ein spezieller Wert ist null, der für
„kein Objekt“ oder „keine Referenz“ steht. Ein explizites Löschen eines Objektes ist nicht
notwendig. Der Garbage Collector erkennt, wenn ein Objekt nicht mehr in Benutzung ist,
d.h. wenn keine Variable oder kein anderes Objekt mehr darauf verweist, und löscht dieses
Objekt automatisch.
Über die Referenzvariable können nun die Objektmethoden aufgerufen werden:
b.setTitle („Genealogy“);
float p = b.getPrice();
// Methodenaufruf
Bei der Angabe von Parametern ist zu beachten, dass primitive Datentypen (byte, short, int,
long, float, double, char, boolean) immer als Wert „by value“ und Referenzdatentypen (Objekte, Strings und Arrays) als Referenz „by reference“ übergeben werden.
- 45 -
KAPITEL 4
Im Rahmen einer Objektmethode kann auf Attribute oder andere Methoden dieses Objektes
ohne Referenzvariable zugegriffen werden. Sollten dabei Konflikte zwischen den Attributen
des Objektes und Parametern der Methode auftreten, kann durch Voranstellen des Schlüsselwortes this als Referenz auf das eigene Objekt das Instanzattribut explizit gekennzeichnet
werden. So bezeichnet im folgenden Beispiel this.isbn das Attribut isbn, während isbn der
Parameter der Methode ist:
public Book (String isbn)
{
this.isbn = isbn;
}
// „this“ als Referenz auf das eigene Objekt
Das Schlüsselwort this kann in Verbindung mit einer Parameterliste auch im Rahmen eines
Konstruktors eingesetzt werden und bezeichnet in diesem Kontext den Aufruf eines anderen –
zur Parameterliste passenden - Konstruktors. Dieser Aufruf muss jedoch die erste Anweisung
sein. Das Schlüsselwort super wird in vergleichbarer Weise verwendet; nur referenziert es
die Superklasse und ermöglicht damit den Zugriff auf Attribute bzw. Konstruktoren der Superklasse.
Eine besondere Form von Attributen und Methoden sind Klassenattribute bzw. –methoden,
die global für alle Instanzen einer Klasse gelten und durch das Voranstellen des Schlüsselwortes static definiert werden.
public class MyClass
{
public static int CONSTANT = 1;
}
// Klassenmethoden
Da diese Attribute bzw. Methoden keinem Objekt zugeordnet sind, werden sie über den Klassennamen angesprochen:
int val = MyClass.CONSTANT;
// Klassenattribute
Auf diese Weise lassen sich z.B. Konstanten oder globale Methoden vereinbaren.
4.1.2 Vererbung und Schnittstelle
Vererbung als Spezialisierung- bzw. Generalisierungsbeziehung zwischen Ober- und davon
abgeleiteten Unterklassen wird in Java durch die folgende Notation ausgedrückt:
public class X extends Y { . . . }
// Die Klasse X vererbt die Klasse Y
Das bedeutet, dass alle in der Klasse Y definierten Attribute und Methoden unter Berücksichtigung der oben aufgeführten Sichtbarkeitsregeln an die Klasse X vererbt werden.
Mehrfachvererbung von Klassen ist in Java nicht zulässig. Einen Ausweg bietet aber das
Schnittstellenkonzept.
- 46 -
KAPITEL 4
Eine Schnittstelle interface ist eine Sammlung von Konstanten und/oder abstrakten Methoden ohne Implementierung und wird wie folgt definiert:
public interface FamilyRelation
// Eine Schnittstelle FamilyRelation
{
public ResultSet getSon(int parentId);
...
}
Schnittstellen können voneinander abgeleitet werden, wobei hier auch Mehrfachvererbung –
jedoch nur Schnittstellenebene – möglich ist:
interface X extends Y, Z
{
...
}
// Mehrfachvererbung durch Schnittstellen
Eine Klasse kann nun eine oder mehrere solcher Schnittstellen implementieren, wobei für jede abstrakte Methode eine entsprechende Implementierung bereitzustellen ist:
public class FamilyRelationImpl implements FamilyRelation
{
public ResultSet getSon(int parentId)
{
if (parentId == 0)
//Die Klasse FamilyRelationImpl
...
// implementiert
}
// die Schnittstelle FamilyRelation
}
Es sei hier noch einmal auf den Unterschied zwischen Vererbung auf Implementierungsebene und auf Schnittstellenebene hingewiesen. Auf Implementierungsebene kann eine
Klasse Attribute und Methodenimplementierungen von genau einer Basisklasse erben. Dagegen kann eine Klasse von mehreren Schnittstellen abgeleitet werden und erbt damit nur die
abstrakten Methoden ohne Implementierung bzw. die Konstantendefinitionen.
Vom Typ der Schnittstelle lassen sich Variablen deklarieren, denen ein Objekt einer Klasse,
die diese Schnittstelle implementiert, zugewiesen werden kann und über die die in der
Schnittstelle definierten Methoden aufgerufen werden können.
4.1.3
Pakete
Packages oder Pakete sind ein Mechanismus zur Organisation von Java-Klassen. Durch Pakete werden Namensräume gebildet, die Konflikte durch gleiche Bezeichnungen verhindern.
So kann eine Klasse „Object“ definiert werden, ohne dass es dadurch zu Konflikten mit der
Standardklasse java.lang.Object kommt. Ein Paket mapinterface wird beispielsweise durch
die Anweisung vereinbart, wobei diese Anweisung am Anfang der Quelldatei anzugeben ist :
package mapinterface;
Jede Klasse, in deren Quelldatei diese Anweisung steht, wird dem Paket „mapinterface“ zugeordnet. Über die Notation mapinterface.MyClass kann danach die Klasse eindeutig identi-
- 47 -
KAPITEL 4
fiziert werden. Diese Schreibweise lässt sich jedoch abkürzen, indem zu Beginn der Quelldatei eine import-Anweisung eingefügt wird:
import
family.database.mapinterface.FamilyRelation;
Danach kann die Klasse FamilyRelation ohne vorangestellten Paketnamen verwendet werden.
Alle Klassen eines Paketes lassen sich durch Angabe eines * importieren:
import family.database.mapinterface.*;
// Importieren alle Klassen des Paketes
Wobei können die Paketnamen hierarchisch aufgebaut werden, wobei die einzelnen Namensbestandteile durch „.“ getrennt werden. Allerdings wird durch Angabe des „*“ beim
Import kein rekursives Importieren durchgeführt, sondern es sind nur die Klassen des bezeichneten Paketes betroffen.
Packete liefern dem Java-Compiler auch Hinweise, wo die kompilierten Klassendateien (Dateien mit der Endung „.class“) abgelegt werden sollen. Danach werden Punkte im Paketnamen durch den Separator für Verzeichnisnamen ersetzt. Eine Klassendatei der Klasse family.beans.Children wird demzufolge im Verzeichnis family/beans unter dem Namen Chindren.class abgelegt.
4.1.4
Ausnahmen
Zur Behandlung von Situationen, die Abweichung vom normalen Programmablauf darstellen,
wird in Java der Exception-Mechanismus verwenet. Eine Exception oder Ausnahme ist ein
Signal, das das Eintreten einer besonderen Bedingung meldet, z.B. einen Fehler beim Öffnen
einer Datei oder beim Zugriff auf ein Feld außerhalb der definierten Grenzen. Eine Ausnahme
wird mit Hilfe der throw-Anweisung ausgelöst und zur Behandlung in einem catch-Block
abgefangen. Wird eine Ausnahme nicht direkt behandelt, so wird diese den Aufrufstack entlang „aufwärts“ propagiert, bis sie abgefangen wird.
Deklaration
Im Java-API sind für viele mögliche Situationen bereits eine ganze Reihe von Ausnahmen
vordefiniert. Alle Ausnahmen sind Objekte einer Subklasse von java.lang.Throwable und
werden nach folgendem Schema erzeugt, wobei MyException als entsprechende Klasse definiert ist:
void aMethod () throws MyException
{
...
throw new MyException ();
// Ausnahme als Objekt der Klasse MyException ()
}
Beim Erzeugen der Ausnahme wird gleichzeitig der Konstruktor aufgerufen, wodurch zusätzlich Parameter übergeben werden können, die den Fehler näher beschreiben. Weiterhin muss
jede Ausnahme, die im Rahmen einer Methode auftreten kann und nicht von Error oder RuntimeException abgleitet ist, in der Signatur der Methode nach dem Schlüsselwort throws
deklariert werden.
- 48 -
KAPITEL 4
Behandlung
Die Behandlung einer Ausnahme erfolgt durch einen try/catch/finally - Block:
try
{
...
// Aufruf einer Methode, die eine Ausnahme
//der Klasse MyException melden kann.
}
catch (MyException exc)
{
//Fehlerbehandlung
}
finally
{
...
//Aufräumen
}
Einige Beispiele sind später bei der Fehlerbehandlung der Datenbanken „SQLException“ und Graphik noch zu sehen.
4.2.
Graphikprogrammierung mit Java
4.2.1. AWT
Das AWT „Abstract Window Toolkit“ definiert einen Satz von plattformenabhängigen
Widgets (Window Elements) – etwa Schaltflächen („Buttons“ auf Englisch), Textfelder und
Menüs – sowie Containern, die die Gruppierung der Elemente erlauben und grafischen
Grundprimitiven wie Zeichenstifte. Leider ist das AWT teilweise so frugal, dass eine professionelle Oberfläche nur mit Mühe zu erstellen ist. Nun werden einige mit Komponenten vorgestellt, die auch im Rahmen dieser Diplomarbeit verwendet wurden.
Erstellen eines Fensters
Damit unter Java ein Fenster geöffnet werden kann, muss zunächst einmal das awt-Paket miteingebunden werden. Dann können wir eine Klasse Frame und deren Methoden nutzen. Das
Listing ist sehr kurz:
import java.awt.Frame;
public class HelloFrame
{
public static void main( String args[] )
{
Frame f = new Frame( "Das Fenster zur Welt" );
f.setSize( 300, 200 );
f.show();
}
}
- 49 -
KAPITEL 4
Abb. 4.2.1.1 Erstellen des Fensters
Punkte und Linien
Die grafischen Objekte werden in einem Koordinaten-System platziert, welches seine Ursprungskoordinaten als (0,0) links oben definiert. Die Angabe ist absolut zum Fensterrahmen.
Zu den wichtigsten grafischen Objekten gehören:
•
Punkte: Ein Punkt ist durch zwei oder mehrere Koordinaten gekennzeichnet. Da er, mathematisch
gesehen, keine Ausdehnung hat, dürfen wir ihn auf dem Bildschirm eigentlich gar nicht sehen. In
Java gibt es keine Funktion, mit der Punkte gezeichnet werden. Diese können nur durch einen Linienbefehl erzeugt werden.
•
Pixel: Ein Pixel beschreibt einen physikalischen Punkt auf dem Bildschirm und ist daher nicht zu
verwechseln mit einem Punkt. Pixel besitzen ebenfalls wie Punkte Koordinaten und wird ein grafisches Objekt gezeichnet, so werden die entsprechenden Punkte auf dem Bildschirm gesetzt. Die
Anzahl der Pixel auf dem Monitor ist beschränkt, unter einer Auflösung von 1024 x 768 ›Punkten‹
sind dies also 786.432 Pixel, die einzeln zu setzen sind. Einen Pixel zu setzen heisst ihm eine andere
Farbe zu geben.
•
Linien: Auch bei Linien müssen wir uns von der Vorstellung trennen, die uns die Analytische
Geometrie vermittelt. Da sie eindimensionale Objekte sind, besitzen sie eine Länge aber keine Dicke. In der Analytischen Geometrie ist eine Linie als kürzeste Verbindung zwischen zwei Punkten
definiert. Auf dem Bildschirm besteht eine Linie nur aus endlich vielen Punkten und wenn eine Linie gezeichnet wird, dann werden Pixel gesetzt, die nahe an der wirklichen Linie liegen.
import java.awt.Graphics
void drawLine( int x1, int y1, int x2, int y2 )
Zeichnet eine Linie zwischen den Koordinaten (x1, y1) und (x2, y2) in der Vordergrundfarbe.
void drawLine ( int x, int y, int x, int y )
Setzt einen Punkt an die Stelle (x, y).
- 50 -
KAPITEL 4
4.2.2
Swing
Die Java Foundation Classes (JFC) sind eine Erweiterung des ursprünglichen Abstract Window
Toolkit (AWT). Die neuen Klassen bestehen im Wesentlichen aus:
•
»Swing« GUI Komponenten
Unter den Swing-Set-Komponenten fallen ganz neue grafische Elemente. Diese
sind, anders als die plattformabhängigen Peer-Komponenten des herkömmlichen
AWTs, komplett in Java implementiert. Ohne diese Abhängigkeiten können beispielsweise das Aussehen geändert werden. Der Name Swing war ein Projektname
dieser Komponenten. Obwohl sie nun Teil der JFC sind, bleibt der Name bestehen.
•
Pluggable Look and Feel
Dies gibt uns die Fähigkeit, das Aussehen der Komponenten zur Laufzeit, also ohne das Programm neu zu starten, zu ändern. Alle Komponenten des Swing-Sets besitzen die Fähigkeit
automatisch.
Accessibility: Unterstützung für Leute mit Behinderungen
Mit dieser API lassen sich mit neuen Interaktionstechniken auf die JFC und AWT
Komponenten zugreifen. Zu diesen Techniken zählen unter anderem Lesegeräte für
Blinde, Lupe für den Bildschirm und auch Spracherkennung.
•
Drag and Drop
Daten können mittels Drag and Drop leicht von einer Applikation zur anderen übertragen
werden. Dabei profitieren Java Programme auch von der Möglichkeit, Daten von
nicht-Java Programmen zu nutzen.
•
Der Unterschied zwischen AWT und Swing
Es soll an dieser Stelle einmal auf Unterschiede zwischen einer AWT-Applikation und einem
Swing-Programm hingewiesen werden. Um ein Objekt zu einem Fenster hinzuzufügen, verwendet man beim AWT-Programm folgende Anweisung:
frame.add( component );
Da die Frame Klasse nichts anderes ist als ein spezielles Container Objekt, bekommt es von
dort die add() Methode, die ein Component Objekt übergibt. Bei Swing ist das anders. Es wird
vom Frame abgeleiteter JFrame verwendet.
Bei JFrame ist eine anderere Vorgehensweise nötig. Hier muss das Component Objekt erst zu
der Zeichenfläche, die „ContentPane“ genannt wird, zugefügt werden. Eine „ContentPane“ ist
kein spezielles Objekt, sondern nur ein Container Objekt.
Container con = frame.getContentPane();
con.add( component );
Dies lässt sich dann zu einer Zeile abkürzen:
frame.getContentPane().add( component );
- 51 -
KAPITEL 4
Jbutton
Die Swing Variante besitzt zum AWT-Button den Unterschied, dass sich Icon und Text auf der
Schaltfläche befinden können. Zudem ist die Hintergrundfarbe beim „Standard-Look&Feel“
eine etwas andere, denn sie besitzt die Hintergrundfarbe des Containers.
Das Beispielprogramm zeigt drei Schaltflächen nebeneinander. Zwei davon tragen Bilder,
wobei das erste Bild über den Konstruktor vergeben wird. Die zweite bebilderte Schaltfläche
zeigt jedoch, dass sich die Bilder auch nachträglich mit setIcon() setzen lassen. Beim dritten
JButton haben wir Bild und Text gemeinsam auf einer Schaltfläche.
class PanelDemo extends JPanel
{
public PanelDemo()
{
JButton b1 = new JButton( "Knopf1" );
add( b1 );
Icon icon = new ImageIcon( "tipp.gif" );
JButton b2 = new JButton( icon );
b2.setBackground( SystemColor.control );
add( b2 );
JButton b3 = new JButton( "Spartipp" );
b3.setIcon( icon );
add( b3 );
}
}
Abb. 4.2.2.1 JButton als Schaltfläche mit Text, Icon und Text/Icon
JcomboBox
Die JComboBox ist ein Auswahlmenü, welches ein Textfeld zur Eingabe anbietet und zudem
ein
Aufklappmenü enthält. In diesem können Texte in beliebigen Modellen dargestellt und ausgewählt werden;
ein Tastendruck lässt die Liste zu dem Eintrag springen, dessen Buchstabe eingegeben wurde.
Ob das Textfeld editiert werden kann, bestimmt setEditable(). Ist es nicht editierbar, verhält es sich ähnlich zur AWT-Komponenten Choice. Befinden sich zu viele Einträge in der Liste, stellt Swing automatisch
eine scrollende Liste dar. Ab welcher Anzahl Elemente die scrollende Liste dargestellt wird, bestimmt
setMaximumRowCount(). Mit addItem() lassen sich Elemente hinzufügen, mit removeItem() wieder
entfernen. Mit getItemAt(index) lassen sich die Elemente erfragen und das aktuell ausgewählte Elemente
erfahren wir mit getSelectedItem(); den Index mit getSelectedIndex().
- 52 -
KAPITEL 4
Abb. 4.2.2.2 JComboBox
class PanelDemo extends JPanel
{
public PanelDemo()
{
String lang[] = { "Java", "C++", "Perl", "Cobol", "Forth",
"Lisp", "Eiffel", "Smalltalk", "Apl" };
JComboBox combo1 = new JComboBox();
JComboBox combo2 = new JComboBox();
for ( int i=0; i<lang.length; i++ ) {
combo1.addItem( lang[i] );
combo2.addItem( lang[i] );
}
combo2.setEditable( true );
combo2.setSelectedItem( "Sather" );
combo2.setMaximumRowCount( 4 );
add( combo1 );
add( combo2 );
}
}
Die Methode addItem() funktioniert nur dann, wenn im Konstruktor kein spezielles Modell
angegeben wurde. Mit Modellen werden wir uns zu einem späteren Zeitpunkt näher beschäftigen.
4.3
JDBC
Für den Zugriff auf SQL-Datenbanken aus einer Programmiersprache heraus bietet nahezu
jeder DBMS-Hersteller eine Programmierschnittstelle an. Ursprünglich für Windows entwickelt steht inzwischen aber auch für andere Plattformen mit ODBC, Open Database Connectivity, von Microsoft eine Lösung zur Verfügung, die eine allgemeine Datenbank-Zugriffsschnittstelle für SQL bereitstellt.
Java lässt uns mit dem jetzigen Modell JDBC auf relationale Datenbanken zugreifen. Für die
objektorientierten Datenbanken ist noch kein fertiges Konzept geschaffen. Dies liegt unter
anderem auch daran, dass zurzeit die meisten Datenbanken noch relational sind und Standards fehlen. Mit JDBC-2 Treibern ist jedoch ein Übergang zum SQL3-Standard geschaffen,
in dem objektorientierte Konzepte eine größere Rolle spielen.
Der Abschnitt 4.3 stützt sich auf die Quelle: „Datenbanken & Java“ von Gunter Saake,
Kai-Uwe Sattler, und „Java ist auch eine Insel“ von Christian Ullenboom.
- 53 -
KAPITEL 4
4.3.1
Überblick
JDBC ist die Abkürzung für Java Database Connectivity und bezeichnet einen Satz von
Klassen und Methoden um von Java relationale Datenbanksysteme zu nutzen. Obwohl JDBC
die objektorientierten Eigenschaften von Java nutzt, ist es doch ein Low-Level-API,
d.h.,JDBC erfordert die direkte Nutzung von SQL-Anweisungen. Höherwertige Abstraktionskonzepte wie etwa die Abbildung zwischen Java-Klassen und Tabellen der Datenbank
werden dagegen nicht unterstützt. Durch die Bereitstellung einer abstrakten, datenbankneutralen Zugriffsschnittstelle kann JDBC aber die Basis für solche High-Level-Lösungen wie
z.B. Embedded SQL oder Mapping-Werkzeuge bilden.
Gegenüber ODBC zeichnet sich JDBC durch eine bessere Übersichtlichkeit und einfachere
Benutzung aus. Die Gründe liegen in der Nutzung objektorientierter Mechanismen: So sind
in JDBC die verschiedenen Konzepte wie Datenbakenverbindung, SQL-Anweisung oder Anfrageergebnis in Klassen gekapselt und streng typisiert.
JDBC besteht aus einer Menge von Klassen und Schnittstellen, die in den Java-Packages java.sql und javax.sql zusammengefasst sind. Das Package java.sql enthält dabei die Schnittstellen für die „normale“ Datenbankarbeit, während in javax.sql spezielle Techniken für die
serverseitige Verarbeitung. Hier werden wir „normale“ Datenbankarbeit vorstellen. Abbildung 4.2.1.1 gibt einen Überblick zur Struktur des API aus dem java.sql-Package. Die
wichtige Klassen und Schnittstellen haben hierbei folgende Aufgaben:
•
java.sql.DriverManager bildet den Einstiegspunkt, indem über diese Klasse Treiber
registriert und Verbindungen zur Datenbank aufgebaut werden können.
•
java.sql.Connection repräsentiert eine Datenbankverbindung.
•
java.sql.Statement ermöglicht die Ausführung von SQL-Anweisungen über eine
gegebene Verbindung.
•
java.sql.ResultSet verwaltet die Ergebnisse einer Anfrage in Form einer Relation
und
unterstützt den Zugriff auf einzelne Spalten.
- 54 -
KAPITEL 4
Abb. 4.3.1.1 Struktur der JDBC.
4.3.2
JDBC-Treiber für den Zugriff
JDBC stellt einen so genannten Treibermanager bereit und definiert abstrakte Klassen (genauer: Schnittstellen) für den Datenbankzugriff. Die eigentliche Kommunikation mit dem
jeweiligen DBMS erfolgt durch konkrete Treiber, die diese Schnittstellen implementieren.
Java Soft unterscheidet vier Treiber Kategorien:
•
JDBC-ODBC Bridge Treiber (Typ1)
Da es am Anfang der JDBC-Entwicklung keine Treiber gab, haben die Entwickler
folgendes Konzept gewählt: Eine JDBC-ODBC Brücke, die die Aufrufe von JDBC
in ODBC-Aufrufe der Client-Seite umwandelt. Der Vorteil dieser Lösung ist, dass
kein separater JDBC-Treiber entwickelt und bereitgestellt werden muss. Vielmehr
lassen sich vorhandene ODBC-Treiber nutzen. Die Methoden sind nativ. Im Folgenden werden wir dann die Brücke einsetzen, wenn wir Access über ODBC ansprechen.
•
Native-API-Treiber (Typ2)
Diese Treiber übersetzen die JDBC-Aufrufe direkt in Aufrufe der Datenbank API.
Die Treiberlösung basiert auf den DBMS-spezifischen Programmierschnittstellen.
Die Methoden sind ebenfalls nativ.
•
JDBC-Net-Treiber (Typ3)
Hier wird ein in Java programmierter Treiber genutzt, der beim Datenbankzugriff
auf den Client geladen wird. Er steuert dann über native Methoden die Datenbank.
•
Native-Protocol-Treiber (Typ4)
Diese Treiber sind vollständig in Java programmiert und kommunizieren mit dem
Datenbankserver.
- 55 -
KAPITEL 4
Insgesamt kann man davon ausgehen, dass die beiden letztgenannten Varianten die am besten
geeigneten Treiberlösungen sind, während die anderen Treiberformen eher als Überganslösungen bis zur Verfügbarkeit besserer Treiber anzusehen sind. Zum Zeitpunkt ist Version 3.0
des JDBC-API aktuell. JDBC 3.0 ist Bestandteil der Java-2-Plattform Version 1.4 und ersetzt
damit Core API und Optional Package API von JDBC 2.0, das als Teil der Java-2-Plattform
Version 1.2 ausgeliefert wurde.
4.3.3
JDBC im Beispiele
Hier werden einige kurze Beispiele angezeigt, um Architektur und Anwendung von JDBC
vorzustellen. Der prinzipielle Ablauf einer JDBC-Datenbankanwendung umfasst die folgenden Schritte:
1.
2.
3.
4.
5.
Laden des Treibers
Aufbau einer Verbindung zur Datenbank
Senden einer SQL-Anweisung
Verarbeiten der Anfrageergebnisse
Freigeben der Ressourcen
Laden des Treibers
Voraussetzung für den Aufbau einer Datenbankverbindung ist das Laden eines geeigneten
Treibers. Der Datenbanktreiber ist eine ganz normale Java Klasse, die sich bei einem Treibermanager automatisch anmeldet. Unsere Aufgabe ist es nur, ein Treiber-Objekt einmal zu
erzeugen. Um eine Klasse zur Laufzeit zu laden und so ein Laufzeit-Objekt zu erschaffen gibt
es mehrere Möglichkeiten. Eine davon geht über die native statische Methode forName() der
Klasse Class. Die Syntax für das Laden der JDBC-ODBC Bridge lautet somit.
Class.forName( "sun.jdbc.odbc.JdbcOdbcDriver" );
Die Klasse muss nicht zwingend zur Laufzeit geladen werden. Sie kann auch in der Kommandozeile über den -D Schalter eingebunden werden. Dazu setzen wir mit der Eigenschaft
jdbc.drivers einen Datenbanktreiber fest.
java
-Djdbc.drivers=sun.jdbc.odbc.JdbcOdbcDriver <Javaklasse>
Aufbau einer Verbindung zur Datenbank
Hierfür stellt der Treibermanager, d.h. die Klasse java.sql.DriverManager, eine eigene Methode getConnection bereit.
conn = DriverManager.getConnection( "jdbc:odbc:family",
"user", "password" );
Als Argument dieser Methode muss eine URL , Uniform Resource Locator, angegeben werden, die den Verbindungsmechanismus und damit den zu verwendenden Treiber bezeichnet.
Die URL beginnt immer mit dem Präfix „jdbc:“. Dahinter steht der Name des Treibers: url =
"jdbc:odbc:family". Der Anmeldename und das Passwort sind optional.
- 56 -
KAPITEL 4
Es wird im statischen Initialisierungsblock so dargestellt:
private static String user = "";
private static String password = "";
private static String url = "jdbc:odbc:family";
public static Connection getConnection()
{
Connection conn = null;
try {
conn = DriverManager.getConnection(url,user, password);
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
Wir sehen hier, dass der Treiber sich selbständig im DriverManager anmeldet. Dazu bildet er
ein Exemplar von sicht selbst über den Standardkonstruktor. Sollte hier etwas schief gehen,
dann fangen wir eine SQLException auf. Dies müssen wir auch, da uns die Methode getConnecton() diese Ausnahmebehandlung vorschreibt.
Ausführung von Anfragen
Mit dem Connection-Objekt kann nun eine SQL-Anweisung erzeugt werden. Wir wollen
zunächst eine Anfrage betrachten, die mit executeQuery ausgeführt wird: die Sönne mit
vorgegebene Informationen von Eltern werden gesucht.
Die executeQuery()-Methode liefert ein ResultSet-Objekt, das die Ergebnisse der Anfrage
verwaltet. Die Navigation über die Ergebnismenge erfolgt nach dem Cursorprinzip. D.h. die
Ergebnismenge kann als eine Tabelle angesehen werden, auf die zunächst zeilenweise und
dann spaltenweise zugegriffen werden kann.
public ResultSet getSon(int parentId)
{
...
Statement stat = conn.createStatement();
String sql = "select person.id, person.surname, person.firstname, "
+ "person.gender "
+ "from person, children "
+ "where person.id = children.childId and "
+ "(children.fatherId = " + parentId
+ " or children.motherId = " + parentId
+ ") and person.gender like 'ÄÐ' ";
System.out.println("getSon(): --" + sql);
ResultSet rs = stat.executeQuery(sql);
...
}
Verarbeiten der Anfrageergebnisse
In JDBC existiert jedoch kein expliziter Cursor, vielmehr wird die aktuelle Position in der
Ergebnismenge vom ResultSet intern verwaltet. Zum Weitersetzen des Cursors wird die Methode next() verwendet. Damit wir zunächst in die erste Zeile springen. Die Methode liefer so
- 57 -
KAPITEL 4
lange den Wert „true“, bis das Tabellenende erreicht ist. Danach sind mit getXXX() die
Spalten dieser Zeile auszuwerten. Um weitere Zeilen zu erhalten wird dann wieder next()
benutzt. Die Abfragen befinden sich somit oft in einer while-Schleife:
while ( rs.next() ) {
String s = rs.getString(1);
double d = rs.getDouble(2);
System.out.println (s + "\n" + d + "\n" );
}
Wichtig ist dabei, dass der Spaltenindex mit „1“ beginnt, d.h. die erste Spalte wird durch
„1“ bezeichnet, die zweite mit „2“ usw.
Verbindungsabbau/Recourcenfreigabe
Zum Abschluss werden die benutzten Ressourcen durch Aufruf der close() Methoden von
ResultSet und Statement freigegeben:
rs.close();
stmt.close();
Es ist jedoch ein guter Programmierstil, die close() Methoden aufzurufen, wenn die Objekte
nicht benötigt werden. Ohne das explizite Schließen bleiben diese Cursor unter Umständen
belegt und weitere Anfragen schlagen fehl.
Fehlerbehandlung
Fehler werden in JDBC grundsätzlich als Ausnahmen der Klasse SQLException signalisiert
und sind daher in geeigneter Weise mit einem try ... catch-Block abzufangen und zu behandeln. Der entsprechende Programmausschnitt zur Fehlerbehandlung ist danach wie folgt zu
formulieren:
try
{
...
}
catch(Exception e)
{
e.printStackTrace();
}
//Aufruf von JDBC-Anweisungen, die Exception generieren
Mit Hilfe der bisher vorgestellten Klassen und Methoden können wir nun die erste vollständige JDBC-Anwendung erstellen:
public ResultSet getSon(int parentId)
{
if ( parentId == 0)
{
return null;
- 58 -
KAPITEL 4
}
Connection conn = null;
Statement stat = null;
ResultSet rs = null;
try
{
conn = DefaultConnectionFactory.getConnection();
stat = conn.createStatement();
String sql = ". . .";
System.out.println("getSon(): --" + sql);
rs = stat.executeQuery(sql);
}
catch(Exception e)
{
e.printStackTrace();
}
return rs;
}
- 59 -
KAPITEL 5
5.
Graphentheoretische Grundlagen der Genealogie
Wie in Kapitel 2 beschrieben gehören die Ahnentafel und der Stammbaum zu den bekanntestem graphischen Visualisierungsmöglichkeiten für genealogische Daten. Am weitesten verbreitet ist der Stammbaum. Im diesem Kapitel wird aus Sicht der Graphentheorie gezeigt,
warum der Stammbaum eine beliebte Interpretation zur Visualisierung der genealogische Daten ist. Ferner diskutieren wir welche Beschränkungen der Stammbaum bei der Darstellung
der Verwandtschaftsbeziehungen hat und welche weitere Lösung es dafür gibt.
5.1.
Grundlagen der Graphentheorie
Dieser Abschnitt 5.1 stützt sich auf die Quelle: „Einführung/Algorithmen und Datenstrukturen“ von R. Dumke und „Graphen und Bäume“ in „Algorithmen und Datenstrukturen“, Kapitel 3.2 von Christel Baier. Ein Graph besteht aus Knoten und Kanten:
Abb. 5.1.1 Knoten und Kanten
Jede Kante verbindet genau zwei Knoten. Dabei kommt es nicht auf die Lage und Form der
Ecken und Kanten an. Wichtig ist lediglich, welche Knoten durch wie viele Kanten miteinander verbunden sind. So wollen wir beispielsweise zwischen dem Graph in Abb. 5.1.1 und
diesem linken Graph in Abb. 5.1.2 nicht unterscheiden. Demgegenüber stellt der rechte
Graph in Abb. 5.1.2 einen davon echt verschiedenen Graphen dar. Ein Graph drückt also in
gewisser Weise eine "Beziehungsstruktur" zwischen den Knoten aus.
Abb. 5.1.2 Gleichheit von Graphen
- 60 -
KAPITEL 5
Definition 5.1:
Ein Graph ist ein Tupel G=(V,E) bestehend aus einer Menge V von
Knoten und einer Menge E von Kanten. Die Kanten stehen für Verbindungen zwischen
den Knoten und können gerichtet oder ungerichtet sein.
• Für gerichtete Graphen (englisch “directed graph”), im folgenden auch kurz Digraph genannt, ist E⊆V×V. Ist e=<v,w>∈E, dann heißt v der Anfangsknoten von e und w der Endknoten von e. Kanten der Form <v,v> werden auch Schleifen genannt.
•
Für ungerichtete Graphen ist E eine Menge von ungeordneten Paaren (v,w) mit v, w ∈V
und v ≠ w.
Beispiel:
für eine formale Charakterisierung eines gerichteten / ungerichteten Graphen:
Knotenmenge V = {v,w,k,y}
•
Kantenmenge E
Für den gerichteten Graphen in Abbildung 5.1.3 ist die Kantenmenge Edirected = {(v,w,), (v,x),
(w,x), (x,y), (y,x)}. Im ungerichteten Fall ist Eundirected = {(v,w,), (v,x), (w,x), (x,y)}.
•
Abb. 5.1.3 Gerichteter Graph vs. ungerichteter Graph
Wir werden im Folgenden weitere Definitionen benötigen:
Definition 5.2: Sei G = (V,E) ein (gerichteter oder ungerichteter) Graph. Ein Pfad in G ist
eine Knotenfolge π = v0, v1, . . . , vr mit r ≥ 0 und (vi,vi+1) ∈ E, i =0,1, . . ., r-1. Wir sprechen von einem Pfad, der von v nach w führt, wenn der Anfangsknoten v0 = v und der
Endknoten vr = w ist. Der Pfad π heißt einfach, falls v0, . . . , vr paarweise verschieden oder
v0 = vr und v0, v1, . . ,vr-1 paarweise verschieden sind. Die Länge von π ist r, also die Anzahl an Kanten, die in π durchlaufen werden.
Definition 5.3:
Wir verwenden folgende Bezeichnungen:
Post(v) = {w Є V : (v,w) Є E} bezeichnet die Menge aller (direkten) Nachfolger
von v,
Pre(v) = {w Є V : (w,v) Є E} = {w Є V : v Є Post(w)} die Menge aller (direkten)
Vorgänger von v,
Post*(v) = {w Є V : w ist von v in G erreichbar} die Menge aller von v erreichbaren Knoten,
Pre*(v) = {w Є V : v Є Post*(w)} die Menge aller Knoten, die v erreichen können.
- 61 -
KAPITEL 5
In ungerichteten Graphen werden zwei Knoten v, w, die über eine Kante miteinander
verbunden sind (d.h. (v,w) Є E), auch benachbart genannt. Wir schreiben in diesem Fall
Post(v) = Pre(v) und Post*(v) = Pre*(v).
Definition 5.4: Sei G = (V,E) ein ungerichteter Graph und C ⊆ V. C heißt zusammenhängend, falls je zwei Knoten v, w Є C voneinander erreichbar sind (d.h. w Є Post*(v) und v
Є Post*(w)). C heißt Zusammenhangskomponente von G, falls C eine nicht leere maximale zusammenhängende Knotenmenge ist. (Maximalität bedeutet dabei, daß C in
keiner anderen zusammenhängenden Teilmenge C’ von V enthalten ist.) G heißt zusammenhängend, falls V zusammenhängend ist (Abb. 5.1.4).
Abb. 5.1.4 Unzusammenhängender Graph vs. zusammenhängender Graph
Definition 5.5: Ein einfacher Zyklus in einem Digraphen ist ein einfacher Pfad π = v0, v1, .
. . , vr der Länge r ≥1 mit v0 = vr . In einem ungerichteten Graphen ist ein einfacher Pfad π= v0,
v1, . . . , vr mit v0 = vr und r ≥3.
einfacher Zyklus, r ≥3
Mehrfacher Zyklen, r=2
Abb. 5.1.4 Mehrfacher Zyklen vs. einfacher Zyklus in einem ungerichteter Graph
- 62 -
KAPITEL 5
Definition 5.6: Ein gewichteter Graph ist ein gerichteter oder ungerichteter Graph, der an
seinen Kanten oder in den Knoten eine Kennzeichnung semantischer Inhalte in Form so
genannte Gewichte w besitzt. Formal zu definieren, sei ein Graph ein Tupel (V,E). Dann
ist ein gewichteter Graph ein Tripel (V, E, w) mit w: E/V Æ IR+ .
Abb. 5.1.5 Ein gewichteter Graph mit einer Kantenbewertung
Eine für diese Arbeit wichtige Klasse von Graphen sind Hypergraphen. Bei Hypergraphen
verbindet eine Kante nicht nur zwei, sondern mehrere Knoten gleichzeitig. Sie sind meist nur
schwer darstellbar, da die Darstellung von Hypergraphen mit vielen Kanten schnell unübersichtlich wird. In der Regel zeichnet man eine Menge die Knoten, welche durch geschlossene
Linien umkreist werden. Die geschlossenen Linien entsprechen dann den Hyperkanten. Formal wird der Hypergraph wie folgend definiert:
Definition 5.7: Ein Hypergraph H ist ein Tupel (V, E), wobei V eine Menge von Knoten ist
und E ⊆ P(V) eine Menge von Hyperkaten, wobei P(V)= {e | e ⊆ V} die Potenzmenge
von V [Ber73].
Abb. 5.1.6 Zusammenhängender ungerichteter Hypergraph.
- 63 -
KAPITEL 5
Wie in der Abb. 5.1.6 gezeigt:
•
•
•
Falls für eine Kante Ei: | Ei| > 2 gilt, wird dies als eine Kurve dargestellt, die alle zugehörigen Knoten einkreist.
Falls für eine Kante Ei: | Ei| = 2 gilt, wird dies als eine Linie dargestellt, die zwei
Knoten verbindet.
Falls für eine Kante Ei: | Ei| = 1 gilt, wird es als eine von dem Knoten sich selbst ausund eingehende Schlinge dargestellt.
Definition 5.8: Sei H= (V,E) ein Hypergraph, zwei Knoten v, w heißt zusammenhängend,
falls es eine Kante Ei gibt, die die beide Knoten enthaltet. Zwei Kanten Ei und Ej sind zusammenhängend, falls Ei ∩Ej ≠ Ø [Ber73].
Die Abb. 5.1.6 stellt ein Beispiel für einen zusammenhängenden Hypergraphen dar.
Ein Baum ist eine spezielle Art von Graphen mit folgenden Eigenschaften:
Definition 5.9: Ein ungerichteter Baum ist ein zusammenhängender azyklischer (ungerichteter) Graph (Abb. 5.1.7).
Ein gerichteter Baum ist ein Digraph T= (V,E), für den gilt:
•
•
Entweder ist V=Ø (in diesem Fall wird T der leere Baum genannt)
oder es existiert ein Knoten v0 ∈ V, von dem jeder Knoten v ∈ V
nau einen Pfad von v0 erreichbar ist.
ge-
Der Knoten v0 ist eindeutig bestimmt und wird Wurzel genannt.
Jeder Knoten v ∈ V mit Post(v) ≠ Ø heißt innerer Knoten von T .
Die Knoten w ∈ Post(v) werden Kindknoten von v genannt.
Alle Knoten v ∈ V mit Post(v) = Ø heißen Blätter von T .
Die Höhe eines nicht-leeren Baums T = (V,E) ist die Länge eines längsten Pfads in T
und wird mit H(T) bezeichnet.
o Die Tiefe von v (in T) ist die Länge des (eindeutig bestimmten) Pfads vom Wurzelknoten v0 zu v.
o
o
o
o
o
- 64 -
KAPITEL 5
Abb. 5.1.7
Die Gültigkeit bezüglich un-/gerichteter Bäume [Dum01b]
In einem Binärbaum hat jeder Knoten höchstens zwei Kindknoten, diese sind nach linkem
Kindknoten und rechtem Kindknoten unterschieden. Ein Baum heißt balanciert, wenn alle
Blätter dieses Baums die gleiche Höhe haben.
Auf Basis der Grundkenntnisse von Graphentheorie kann nun eine ausführliche „Analyse“ der Stammbäume durchgeführt werden. Hier werden zwei Aspekte betrachtet: die Anwendungsgebiete der Stammbäume und die Eigenschaften bzw. die Besonderheiten von
Stammbäumen.
5.2.
Stammbäume
Der Begriff von „Stammbaum“ wurde in Kapitel 2 schon erläutert: Ein Stammbaum zeigt die
Nachkommen eines Stammvaters. Die Darstellung der Verwandtschaftsbeziehungen erfolgt
dabei in Baumform, wobei der Stammvater die Wurzel und die folgenden Generationen die
Äste und Zweige bilden. Heutzutage werden Stammbäume nicht nur in der Genealogie, sondern auch in anderen wissenschaftlichen Gebieten, wie der Genetik, der Medizin, der Mathematik und der Linguistik als Hilfsmittel mehr und mehr eingesetzt. Von einem Stammbaum sollte man allerdings nur sprechen, wenn die grafische Darstellung in Baumform gemeint ist.
5.2.1. Stammbäume in verschiedenen Anwendungsgebieten
Ein Familienstammbaum (Abb.5.2.1.1) ist eine Darstellung aller Nachfahren einer Familie
in der Genealogie. Ein Familienstammbaum geht immer von einem Elternpaar, dem Stamm,
los und verzweigt sich dann in die Äste, je nachdem wie viele Kinder geboren wurden. Diese
wiederum spalten sich je nach der Anzahl der Enkel auf und werden immer feiner gegliedert.
Spätestens hier gibt es Kollisionen innerhalb der Generation und über Generationen hinweg.
Der gesamte "Baum" ist somit nur ein gerichteter Graph. Solche Probleme wie Kollisionen
werden später noch diskutiert.
Der evolutionäre Stammbaum (Abb. 5.2.1.2), er wird heute fallweise eher als Busch, denn
als Baum bezeichnet, beginnt mit einem hypothetischen gemeinsamen Vorfahren aller bekannten Arten von Lebewesen auf der Erde und fächert sich dann entsprechend der Abstammung nach der Evolutionstheorie immer weiter auf.
- 65 -
KAPITEL 5
Abb. 5.2.1.1 Stammbaum der norwegischen Königsfamilie [Ard]
- 66 -
KAPITEL 5
Abb. 5.2.1.2 Stammbaum der Bären und Hunde [Bio03]
Die Stammbaumtheorie in der Linguistik wurde von August Schleicher (1821-1868) Mitte
des 19. Jahrhunderts entwickelt. Er ging davon aus, dass sich Sprachen analog der Evolution
biologischer Arten aus Ursprachen entwickeln. Danach verhalten sich die Beziehungen und
Verwandtschaftsverhältnisse zwischen Sprachen genau so wie die Relationen der Arten in der
Biologie, die sich in Form von Stammbäumen darstellen lassen. Stammbaummodelle sind
hierarchische Modelle, in denen sich Tochtersprachen "genetisch" zusammenhängend aus Elternsprachen entwickeln. So sind die romanischen Sprachen Tochtersprachen von Latein, Latein ist eine Tochtersprache von Italienisch eine Tochtersprache des Indoeuropäischen.
Stammbaummodelle werden heute verwendet, um die Beziehungen zwischen Sprachen darzustellen und sie zu gruppieren [Wik_1].
In Abb. 5.2.1.3 ist ein Stammbaum der Sprachfamilie zu sehen. Es wird hier ein Maß, Genetische Distanz (GenD), für die zeitliche Dauer der Trennung zwischen Gruppen verwendet.
Z.B. sei GenD (Neuguineer/Australier) = 0,013 = 13 Promille. Angenommen, dass diese
Trennung vor 52.000 Jahren stattfand, dann entspricht jedes Promille 4.000 Jahren [Wun].
- 67 -
KAPITEL 5
Abb. 5.2.1.3 Stammbaum der Sprachfamilie nach GenD1 [Wun]
Gebräuchlich auch in anderen Bereichen, die mit Abstammung und Vererbung zu tun haben;
so gibt es beispielsweise den "Stammbaum der Programmiersprachen" in der Informatik
und den „Stammbaum der mathematischen Wissenschaft“ in der Mathematik.
5.2.2. Eigenschaften der Stammbäume
Aus den Beispielen können wir zu der Schlussfolgerung kommen, dass ein Stammbaum eine
spezialisierte Art von dem gerichteten Baum ist, um Abstammung von Lebewesen oder Erscheinungen darzustellen. Wir haben bisher zwei Typen von Stammbäumen gesehen: verschachtelte Stammbaum (der linke Stammbaum in Abb. 5.2.2.1) und verzweigender
Stammbaum (der rechte Stammbaum in der Abb. 5.2.2.1).
Wir nennen ihn verschachtelter Stammbaum, weil er formal als verschachtelte Zusammenfassung der Blätter dargestellt werden kann. Im obigen Beispiel „Stammbaum der Sprachfamilien“ können wir die Sprachfamilien durch das Maß GenD in der komprimierten Form
{{{A, B},C},D} umschreiben. Um den Stammbaum aufzubauen, brauchen wir nur die Verschachtelungen wieder aufzurollen. [Emb03c]
- 68 -
KAPITEL 5
Abb. 5.2.2.1 Zwei Typen von Stammbäumen
Häufiger verwendet wird der verzweigende Stammbaum, der üblicherweise nicht nur in den
Blättern, sondern auch in den inneren Knoten und der Wurzel Informationen enthält. Wie gerade gezeigt verwenden wir in der Genealogie und Biologie die Stammbäume, um die Verwandtschaftsverhältnisse von Menschen, Pflanzen oder Tieren zur Beschreibung der Herkunft durch Nachweis möglichst vieler Vorfahren aufzustellen. Wie in der Abb. 5.2.1.1 gezeigter „Stammbaum der Norwegischen Königsfamilie“. Entsprechend hat jede Elemente des
Stammbaums ihre eigene Bedeutung.
•
•
•
Wurzel steht für den Stammvater der Familie oder die Urahnen der Tierarten.
Gerichtete Kanten stehen für die Erbfolge oder Stammesentwickelung
Knoten stellen die weiblichen/männlichen Familiemitglieder oder Individuen dar
Wie bereits erwähnt, handelt es sich bei den verzweigenden Stammbaum um gerichtete Kanten, obwohl wir uns das Zeichnen von Pfeilen ersparen: Jede Kante weist von den Vorfahren
zu den Nachkommen, was wir als absteigend bezeichnen. Wollen wir eine Kante in umgekehrter Richtung durchlaufen, so nennen wir sie aufsteigend. Sei x ein Individuum. Ein
Nachkomme von x ist ein (von x verschiedenes) Individuum, das von x über einen absteigenden Kantenzug erreicht werden kann. Ein Vorfahr von x ist ein (von x verschiedenes)
Individuum, das von x über einen aufsteigenden Kantenzug erreicht werden kann
Zwei Individuen x und y sind miteinander verwandt, wenn sie (innerhalb des Baums) zumindest einen gemeinsamen Vorfahren besitzen. Ein Individuum wird als Wurzel genannt, wenn
von ihm keine aufsteigende Kante ausgeht, d.h. wenn seine Eltern nicht im Stammbaum erfasst sind [Emb03c].
In der Genealogie sind noch weitere Varianten durch die erweitete Bedeutung der gerichteten
Kanten für die Familiestammbäume zu sehen, nämlich der Vorfahrenstammbaum. Ein Vorfahrenstammbaum besteht, im Gegensatz zur Ahnentafel, aus allen lebenden und verstorbenen Familienmitgliedern, die seinen Familiennamen tragen. Somit zeigt also der Stammbaum
von der Vergangenheit in die Gegenwart. Eine ausführliche Diskussion findet im Kapital 6
statt, in dem die Alternativen vorgestellt werden.
- 69 -
KAPITEL 5
5.3.
Verwandtschaftsgraphen der Genealogie und Biologie
Die Darstellung der Verwandtschaftsverhältnisse von Menschen (auch Tieren) wird in der
Praxis oft als verzweigende "Stammbäume" bezeichnet, sind aber genau genommen nicht
immer "Bäume" im graphentheoretischen Sinn. Individuelle können sie auch durch Graphen
dargestellt werden. Wir nennen sie Verwandtschaftsgraphen. Formal handelt es sich um
knoten- und kanten- gerichtete Graphen. Im Fall von Organismen, die sich nur auf sexuelle
Weise fortpflanzen können. So gibt es hier beispielsweise Kinder, die denselben Vater, aber
verschiedene Mütter haben (Halbgeschwister). Weiters ist eine Verbindung von Cousin und
Cousine ("Vetternehe"), die zwei Kinder hervorgebracht hat, dargestellt. Mit Verwandtschaftsgraphen ist es dann möglich, alle möglichen Familienverhältnisse darzustellen .
Ein typischer Verwandtschaftsgraph besitzt drei Knotentypen und zwei Kantentypen. Zwei
Knotentypen stellen weibliche ( ) und männliche( ) Individuen dar. Graue ausgezogene
Kanten ( ) bezeichnen die Paarungen von je zwei verschiedengeschlechtlichen Individuen.
Sie enden in einem dritten Eckentyp ( ), der für die geschlechtliche Fortpflanzung steht. Von
ihm gehen rote ausgezogene Kanten ( ) zu den von dem betreffenden Elternpaar gezeugten
Kindern aus. Auch weisen die absteigende Kanten wie im Stammbaum von den Vorfahren zu
den Nachkommen. Die Zeit (genauer: die Generationenfolge) verläuft von oben nach unten.
Hier sind von insgesamt 11 Individuen die unmittelbar vorausgehenden Abstammungsverhältnisse dargestellt. Auch die 5 Elternteile stammen natürlich ihrerseits von Eltern ab, werden aber als nicht miteinander verwandt betrachtet: Als verwandt gilt nur, wer das auf der
Basis des Graphen ist.
Abb. 5.3.1
Ein typischer Verwandtschaftsgraph
Aufgrund der Eigenschaft „Zyklus“, kann ein Verwandtschaftsgraph, im Vergleich zum
Stammbaum, kompliziertere Verwandtschaftsverhältnisse sowie Inzucht darstellen. Von Inzucht (Inzest, inbreeding) sprechen wir ganz allgemein, wenn Verwandte Nachkommen
zeugen. In einem Verwandtschaftsgraphen erweist sie sich durch die Existenz zumindest eines nicht-trivialen Kreises, der aus einem aufsteigenden und einem Kantenzug besteht. Liegt
in einem Graphen keine Inzucht vor, so nennen wir ihn inzuchtfrei. Enthält ein Graph keinen
- 70 -
KAPITEL 5
Kreis, so nennen wir ihn baumartig. (Wir verlangen nicht, dass er zusammenhängend ist - er
stellt also nicht notwendigerweise einen "Baum" im graphentheoretischen Sinn dar). Jeder
baumartige Graph ist inzuchtfrei. Hier paar Beispiele, deren mittleres zeigt, dass nicht jeder
inzuchtfreie Graph baumartig ist:
baumartig
Abb. 5.3.2
nicht baumartig,
inzuchtfrei
nicht baumartig,
nicht inzuchtfrei
Verschiedene Varianten der Verwandtschaftsgraphen
Ein Graph ist genau dann inzuchtfrei, wenn jedes Individuum mit jedem Gründer durch
höchstens einen aufsteigenden Kantenzug verbunden werden kann. (Beweis: Gäbe es zwei
solcher Kantenzüge von x zu einem Gründer - die sich o.B.d.A. unmittelbar oberhalb von x
trennen -, so wäre dieser Gründer ein gemeinsamer Vorfahr der Eltern von x, letztere also
miteinander verwandt. Sind umgekehrt die Eltern von x miteinander verwandt, so kann man
von einem ihrer gemeinsamen Vorfahren bis zu einem Gründer aufsteigen und hätte damit
zwei verschiedene Wege von x zu diesem Gründer konstruiert).
Ein Verwandtschaftsgraph ist genau dann baumartig, wenn je zwei verwandte Individuen
durch genau einen Weg W (d.h. einen Kantenzug, dessen Kanten alle voneinander verschieden sind) verbunden werden können. W besitzt eine eindeutig bestimmte Umkehr-Ecke, die
(falls sie vom Typ oder ist) den jüngsten gemeinsamen Vorfahren oder (falls sie vom Typ
ist) das jüngste gemeinsame Vorfahrenpaar darstellt. Dank dieser Eigenschaft sind baumartige Verwandtschaftsgraphen besonders leicht zu behandeln.
Der Abschnitt 5.3 stützt sich auf die Quelle: „Verwandtschaft1“ in „Von Graphen, Gene und
dem WWW“, von Franz Embacher.
- 71 -
KAPITEL 6
6. Konzepte zur Visualisierung genealogischer Daten
Bei einer Visualisierung müssen zahlreiche Aspekte berücksichtigt werden. Besonders wichtig sind hierbei die Arten der Informationen, die statisch und dynamisch dargestellt werden.
Für eine statische Darstellung, werden drei Aspekte berücksichtigt: die gesamte Gestaltung,
die Knoten und die Kanten. Die durch Kanten interpretierten Beziehungen sowie eine mehrfache Adoption, die in der Datenbank leicht implementiert werden kann, jedoch stellt die visualisierte Darstellung in einem Stammbaumartigen Graphen eine Schwierigkeit dar. Mit dem
Begriff dynamischen Darstellung eines Stammbaums wird beschrieben, dass der Baum im
Hinblick auf genealogische Daten interaktiv manipuliert werden kann. Die Aktionen in einer
dynamischen Darstellung können mit den Handlungen: direkt Einfügen, Löschen, Änderung
und Anfrage in einem Stammbaum statt in eine Datenbank, beschrieben werden. Im Kapitel 6
wird auf diese Thematik näher eingegangen. Durch einen Verwandtschaftsgraphen kann eine
größere Zahl von Verwandtverhältnissen als in einem Stammbaum interpretiert werden, dennoch erscheint die Darstellung in einem Stammbaum viel übersichtlicher als die Darstellung
eines Verwandtschaftsgraphen. Es wird versucht, die Darstellungsform eines Verwandtschaftsgraphs mit einem Stammbaum zu verschmelzen.
6.1.
Diskussion von Alternativen und Problemen der statischen
Darstellung
6.1.1 Diskussion der möglichen Gestaltung eines Stammbaums
Zuerst stellt sich die Frage, wie ein Stammbaum „wachsen“ soll. Im Hinblick auf die Wachstumsrichtung kann ein Stammbaum von unten nach oben, von oben nach unten oder von
links nach rechts wachsen. Die Ausdehnungsrichtung von links nach rechts wird nicht mitberücksichtigt, weil Schriftzeichen zumeist von rechts nach links orientiert sind. Werden die
Personendaten in einem Quadrat dargestellt, ist es irrelevant, in welcher Richtung sich der
Baum ausdehnt. In diesem Fall kommt es dann lediglich auf den Geschmack des Nutzers oder des Entwicklers an. Häufig hat ein von links nach rechts wachsender Baum eine flachere
und breitere Ausdehnung als ein von oben nach unten expandierender Baum (Abb. 6.1.1.1).
Bei Abfrage einer Person aus einer Datenbank können drei „Verwandschaftsrichtungen“ angezeigt werden. Zum einen können nur die Vorfahren oder nur die Nachkommen angezeigt
werden. Die dritte Verwandtschaftsrichtung verbindet die beiden zuvor genannten zu einer
Vorfahren und Nachkommen-Darstellung. Auf diese Weise erzeugte Stammbäume enthalten nur aus Benutzersicht interessante Daten, sowie Vorfahren und Nachkommen der angefragten Person; andere Verwandtschaftsbeziehungen sind nicht direkt zu sehen. Dennoch erscheint es sehr nützlich, wenn in einer großen genealogischen Datenbank auf die Daten einer
bestimmten Person schnell zugegriffen werden soll. Mit anderen Worten, der in Kapitel 5
diskutierte Stammbaum ist nur eine Variante des vom Stammvater ausgehenden, von oben
nach unten wachsenden Nachkommenstammbaums, die am häufigsten verwendet wird. Eine
Ahnentafel ist in diesem Sinne ein von links nach rechts wachsender Vorfahrenstammbaum.
Entsprechend haben wir auch von unten nach oben und von oben nach unten wachsenden
Vorfahrenstammbäumen b. 6.1.1.2). Der Vorfahren- und der Nachkommen-Stammbaum ist
- 72 -
KAPITEL 6
einfach die Kombination eines Vorfahrenstammbaums und eines Nachkommenstammbaums
einer ausgewählten Person, was genau genommen im graphentheoretischen Sinn kein
„Baum“ mehr ist.
Abb. 6.1.1.1 Nach rechts wachsender Nachkommenstammbaum vs. nach unten wachsendem Nachkommenstammbaum
Auf das Zeichnen von Pfeilen wurde manchmal zugunsten der Übersichtlichkeit verzichtet,
dennoch ist die Interpretation der gerichteten Kanten wichtig, um einen von oben nach
unten wachsenden Nachkommensstammbaum von einem von oben nach unten wachsenden
Vorfahrensstammbaum zu unterscheiden. Im Nachkommensstammbaum verweist jede Kante
von den Vorfahren zu den Nachkommen, was als absteigend ↓ (oder zeitliche Abfolge) bezeichnet wird. Im Gegensatz dazu verweist in einem Vorfahrensstammbaum jede Kante von
den Nachkommen zu den Vorfahren, was als aufsteigend ↑ (oder rückläufig) bezeichnet wird.
Die Darstellung eines Vorfahrensstammbaums ist einfacher als die Darstellung eines Nachkommenstammbaums, weil die Anzahl der ausgehenden Kanten pro Knoten in der Regel
immer zwei ist (Abb. 6.1.1.3).
Abb. 6.1.1.2 Nach unten wachsender Nachkommenstammbaum vs. Vorfahrenstammbaum
- 73 -
KAPITEL 6
Abb. 6.1.1.3 Nachkommenstammbaum vs. Vorfahrenstammbaum
Eine weitere Problematik stellt die Festlegung der anzuzeigenden Personen in einem
Stammbaum dar. Die Frage besteht darin, welche Personen miteinander verwandt sind und im
Stammbaum einer Familie zugehörig gezeigt werden sollen. Gehört eine angeheiratete Person
zu der Familie ihres Partners? Wenn ja, was geschieht mit ihren Kindern in der Darstellung,
die sie mit in die Familie bringt. Werden sie mitgezählt? Soll ein adoptiertes Kind als ein Familienmitglied betrachtet werden? Diese Fragestellungen stellen ein wichtiges Problem für
Genealogen und Ahnenforscher dar.
Zunächst ist zu bestimmen, welche Art von Verwandtschaft im Stammbaum dargestellt werden soll. In Kapitel 2 wurden die Definitionen verschiedener Verwandtschaftsarten gegeben.
Unter Blutsverwandtschaft versteht man, dass die Verwandten durch Geburt, welche die Abstammung von gemeinsamen Vorfahren beanspruchen, im Unterschied zu Verwandtschaft
durch Heirat, der Schwägerschaft. D.h. die Verschwägerung und die adoptierten Kinder werden nicht eingeschlossen. Dieser Begriff der Blutsverwandtschaft wird in den Wissenschaftsbereichen der Soziologie und Anthropologie verwendet. Unter „natürlicher Verwandtschaft“ oder „Affinialverwandtschaft“ ist der Begriff der Blutverwandtschaft zusammen mit
dem Ehepartner zu verstehen. Die meisten Genealogen und Ahnenforscher setzen diese
Mischform in ihrem Forschungsgebiet ein. Im Bereich der Rechtswissenschaft wird häufig
der Begriff „juristische Verwandtschaft“ benutzt, indem sowohl die natürliche Verwandtschaft
und als auch die Adoption mitberücksichtigt werden.
Nachdem eine bestimmte Art von Verwandtschaft ausgewählt wird, sollte darauf noch das
Interpretationssystem des Verwandtschaftssystems festgelegt werden, d.h. ob es sich um in
patrilineares, matrilineares oder ein bilineares Verwandtschaftssystem handelt. In matrilinearen Verwandtschaftssystemen werden Kinder der Tochter, aber nicht die Kinder des Sohnes,
zur Abstammungslinie der Mutter gerechnet. In einem patrilinearen Verwandtschaftssystem
werden lediglich die männlichen Familienmitglieder mitgerechnet. Diese Form ist für die
wissenschaftliche Forschung in (Nach-)Namenkunde unabdingbar. In bilinearen Abstammungsformen wird die Zugehörigkeit zu einer bestimmten Verwandtschaftsgruppe nach beiden Abstammungslinien gerechnet, was am häufig verwendet wird.
Insgesamt lässt sich sagen, dass nicht alle miteinander verwandten Personen zwangsläufig
demselben Verwandtschaftssystem angehören und nicht alle Personen innerhalb einer Ver-
- 74 -
KAPITEL 6
wandtschaftsgruppe tatsächlich (biologisch) miteinander verwandt sind. Die verwendeten
Begriffe für Verwandtschaft und ihre Beziehungen können je nach der Ansicht und der Klassifikationsmethode untereinander sehr spezifisch und unterschiedlich sein. Daher ist es
schwer, ein eindeutiges Prinzip zu geben, um die Zugehörigkeit des Individuums zu einer
Verwandtschaftsgruppe zu bestimmen. Deswegen muss der Entwickler dieses schon vor der
Implementierung eines Visualisierungssystems festlegen.
Es führt dann aber zu weiterer Fragen: wie sollen alle oben gegebene Arten von Verwandtschaft in einem bestimmten Verwandtschaftssystem graphisch dargestellt werden? Sind die
alle graphischen Darstellungen wirklich Stammbäume? Diese Fragen sind nur für die Anfrage von Nachkommen einer ausgewählten Person gestellt. Für die Anfrage von Vorfahren einer ausgewählten Person wird immer die graphische Darstellung als Binärbaum gewählt, falls
die Eltern der Kinder bekannt sind. Hiermit werden die Darstellungen für alle Arten von
Verwandtschaft in einem bilinearen System diskutiert. Für die Darstellungen der anderen
beiden Verwandtschaftssysteme brauchen wir nur die weiblichen oder männlichen Knoten
mit ihren zugehörigen Kanten von den originalen Darstellungen im bilinearen System zu löschen. Weiterhin wird vorausgesetzt, dass wegen des möglichen negativen Effekts von Inzucht, der Fall von Verwandtenheiraten, nämlich die Inzucht nicht berücksichtigt wird.
Die „reinste“ Art von Verwandtschaft, Blutsverwandtschaft, kann gut in Stammbäumen interpretiert werden, da die Baumstruktur genau dieses Verwandtschaftsverhältnis abbildet:
Wurzel Æ Stammvater, Knoten Æ Individuen und gerichtete Kanten Æ Stammesentwicklung. Bezüglich der Darstellung von der natürlichen Verwandtschaft wurde im letzten Kapitel
diskutiert, dass die zusätzlichen partnerschaftlichen Beziehungen durch einen zweiten Katentyp interpretiert werden können. Die Eigenschaften des Stammbaums können dann schwer
erfüllt werden, da die Kanten nicht nur die Abstammung interpretiert und die Mehrfachheirat
mitberücksichtigt werden muss. Bei der Darstellung der juristischen Verwandtschaft sollte
theoretisch die Baumstruktur nicht zerstört werden, da die Darstellung von adoptierten Kindern keinen weiteren Katentyp benötigt. Nur die gerichteten Kanten, die im Blutsverwandtschaftstammbaum die Stammesentwicklung interpretiert, müssen im juristischen Verwandtschaftsstammbaum die Adoption noch interpretieren. Um sie von den leiblichen Kindern zu
unterscheiden, können beschriftete Katen verwendet werden. Daher muss das Problem der
Mehrfachadoption, das für leibliche Kinder nicht auftritt, betrachtet werden. In den folgenden
Abschnitten werden die möglichen Darstellungen für diese drei Arten von Verwandtschaft
und die möglichen Lösungen für die oben erwähnten Probleme vorgestellt.
6.1.2. Gestaltung der Knoten eines Stammbaums
In einem verzweigten Stammbaum stehen die Knoten für Individuen. Zunächst ist zu entscheiden, wie die Individuen optisch im Stammbaum dargestellt werden. Sollen die Daten
einer Person einfach als Text ohne Umrandung dargestellt werden oder mit einer Umrandung in Form eines Rechtecks oder einer anderen Form in den Stammbaum aufgenommen
werden? Wenn die Daten einzelner Personen ohne Umrandung in einem großen komplizierten Stammbaum dargestellt werden, sind diese schwer zu lesen. Aus diesem Grund bieten
Daten, die durch eine Umrandung abgegrenzt sind, eine bessere Übersicht. Darüber hinaus
können durch die verschiedenen Darstellungsmöglichkeiten einer Umrandung weibliche und
männliche Familiemitglieder unterschiedlich gekennzeichnet werden. Bei solcher Interpretation mit geschlechtsspezifischen Umrandungen müssen auch unbekannte Personen, deren
- 75 -
KAPITEL 6
Existenz zwar erwiesen ist, deren Informationen sowie Name und Geschlecht jedoch nicht
bekannt sind, durch eine dritte Art der Umrandung wiedergegeben werden. Bild 6.1.2.1 zeigt
einen Stammbaum mit geschlechtsspezifischer Umrandung.
Bild 6.1.2.1 Ein Stammbaum mit geschlechtsspezifischer Umrandung
Die Beschriftung von Daten einer zugehörigen Person muss innerhalb eines Platzhalters
vordefiniert werden. Mit verschiedenen Schriftarten oder mit verschiedenen Farben können
die Geschlechter mit derselben Umrandung unterschiedlich dargestellt werden. Beispielweise
können Männer durch grün, Frauen durch rot und Unbekannte durch grau interpretiert werden.
Ein zweiter Aspekt der Beschriftung ist es, die Entscheidung zu treffen, wieviele Informationen über eine Bezugsperson innerhalb eines Platzhalters angezeigt werden sollen. Im Idealfall
würden alle zugehörigen Daten einer Person angezeigt werden. Da jede Person in einer Datenbank sehr unterschiedliche Datenmengen enthalten kann, werden individuell angepasste
Platzhalter mit häufig wechselnden Darstellungen schnell unübersichtlich. Folglich werden
zwei Möglichkeiten gegeben:
1. Verwenden einer von Personen unabhängigen, einheitlichen Größe des Platzhalters.
Die Rest-Daten der Person mit mehreren Informationen werden durch „...“ ersetzt.
Durch Anklicken der Knoten sind alle Daten zu sehen.
2. Verwenden eines Platzhalters mit einheitlicher Größe und gleichförmigen Daten sowie „ID“, „Name“, „Vornamen“ und „Geburtsdatum“, mit der Personen identifizierbar sind.
Es kommt häufig vor, dass in einer Datenbank Daten über eine Person fehlen und dass sie
andererseits für manche Personen sehr ausführliche Informationen enthalten. In diesem Fall
hat ein Benutzer die Schwierigkeit, die wichtigen Informationen aller Familienmitglieder zu
finden. Die Darstellung der zweiten Möglichkeit bietet einen besseren Überblick, ist aber un-
- 76 -
KAPITEL 6
flexibel. Für eine ziemlich große Datenbank ist die standardisierte Größe zu detailliert, und
so kann nur ein kleiner Teil des Stammbaums dargestellt werden. Für eine kleine Datenbank
mit nur drei Generationen ist die Größe des Platzhalters zu grob und besitzt nur eine Ecke des
ganzen Fensters. Eine noch bessere Idee, um das Problem der Flexibilität zu lösen, besteht
aus einer dynamischen Darstellung, die im kommenden Abschnitt diskutiert wird.
Abb. 6.1.2.2 Dynamische Größe des Platzhalters vs. standardisierte Größe des Platzhalters
Da die natürliche Verwandtschaft keine Darstellung angeheirateter Verwandten erlaubt, soll
der Ehepartner einer Bezugsperson mit im Stammbaum angezeigt werden. Für die Darstellung der partnerschaftlichen Beziehungen bieten sich mehrere Möglichkeiten an:
1. Ein zweiter Kantentyp mit einer anderen Farbe im „Verwandtschaftsgraphen“ oder
mit einem Eheringsymbol „oo“ dargestellt wird.
2. Ein Hyperknoten, der den Ehepartner zusammen mit der Bezugsperson enthält.
Durch einen zweiten Kantentyp sind die partnerschaftlichen Beziehungen zwar direkt erkennbar, aber die Baumstruktur geht verloren. Für eine relativ große Datenbank mit sehr
komplizierten Verwandtverhältnissen sowie mehrfacher Heirat ist eine übersichtliche und
strukturierte Darstellungsform schwer zu erreichen. Mit dem Hyperknoten wird die partnerschaftliche Beziehung zu einer Person ohne weitere Kanten aufgezeigt. Die Ehe-Beziehung
ist zwar nur implizit dargestellt, dennoch bleibt die Baumstruktur erhalten. In einer großen
Datenbank ist solch eine strukturierte Form sehr vorteilhaft.
Der trivialste Fall der Aufstellung eines Hyperknotens ist eine Auflistung aller Daten eines
Partners unter der jeweiligen Bezugsperson, wobei deren Platzhalter größer gewählt werden
muß. Dabei tritt wiederum das Problem auf, wie die Größe der Platzhalter bestimmt werden
soll, durch eine festgelegte Größe oder individuell angepasste Größen. Es ist schwer, eine
standardisierte Größe festzulegen, wenn eine Person mehrere Partner hat oder eine Person gar
keinen Partner hat. Zudem gestaltet es sich als schwierig, eine dynamische angepasste Größe
zu verwenden, da die Symmetrie des Baums dadurch schnell zerstört wird. Für diesen Fall
werden die Partner mit eigenen Platzhaltern rechts oder unter den zugehörigen Personen angeordnet. Abbildung 6.1.2.3 zeigt zwei Varianten der Aufstellung eines Hyperknotens.
- 77 -
KAPITEL 6
Abb. 6.1.2.3 Zwei Varianten der Aufstellung eines Hyperknotens.
6.1.3 Gestaltung der Kanten eines Stammbaums
Die Beziehungen „child_of“ und „parents_of“ werden in Stammbäumen durch gerichtete
Kanten interpretiert. In einem Nachkommensstammbaum verweist jede Kante von den Vorfahren zu den Nachkommen, wobei in einem Vorfahrensstammbaum von den Nachkommen
zu den Vorfahren verwiesen wird. Die Pfeile an den Kanten werden normalerweise wegen
der Übersichtlichkeit nicht im Baum gezeigt. Abbildung 6.1.3.1 zeigt zwei mögliche Liniengestaltungen: gerade Linien in Winkel-Form oder in direkter Form.
Abb. 6.1.3.1 Kanten mit grader Linien in Winkel-Form vs. in direkter Form
Es bieten sich mehrere Möglichkeiten zur identifizierten Interpretation der Verwandtverhältnisse. Ob diese durchgehenden Linien, unterbrochenen Linien, doppelten Linien oder
doppelt-unterbrochenen Linien dargestellt werden, ist lediglich Geschmacksache der Entwickler. Aber wenn eine Kombination verschiedener Kantendarstellungen im Stammbaum
verwendet wird, können die leiblichen Kinder von den adoptierten oder angeheirateten Kindern und die leiblichen Eltern von den Pateneltern oder Stiefeltern unterschieden werden. Eine andere Variante zur identifizierten Interpretation ist durch beschriftete Kanten möglich.
- 78 -
KAPITEL 6
Eine mit „U“ beschriftete Kante beispielsweise bedeutet im Nachkommensbaum ein unleibliches Kind. Im Vorfahrensbaum werden mit „P“ die Pateneltern gekennzeichnet. Abbildung
6.1.3.2 zeigt diese beiden Varianten.
Abb. 6.1.3.2 identifizierten Interpretation der Kanten
Falls eine Person mit mehreren aufeinander folgenden Partnern jeweils mehrere Kinder hat,
kommt die Darstellung der Zuordnung der Kinder zum betreffenden Partner in Frage.
Falls die partnerschaftlichen Beziehungen durch einen zweiten Kantentyp dargestellt werden,
kann die Verbindung der Kinder zu den jeweiligen Partnerschaften mit getrennten Kanten
dargestellt werden. Der rechte Graph der Abbildung 6.1.3.1 zeigt eine mögliche Darstellung
aus diesem Fall. Es ist aber schwer, falls die Bezugsperson mit allen Partnern als einen Hyperknoten betrachtet wird, weil die Verbindung der Kinder zu dem ganzen Hyperknoten aufweist. Durch den Einsatz der identifizierten Interpretation mit Beschriftung wird das Problem
gelöst:
1. Beschriftete Knoten mit zusätzlicher Information wie „Child 1 Marriage 1“, „Child 2
Marriage 3“.
2. Beschriftete Kanten etwa mit der Notation „I“, „II“.
Beide Alternativen bieten die Möglichkeit, die Kinder von verschiedenen Partnern zu erkennen. Im zweiten Kantentyp wird die Beziehung „parents-of“ ohne zusätzliche Informationen
anschaulicher dargestellt, allerdings erscheint diese Darstellungsform bei einer Familie mit
vielen Mehrfachheiraten als unübersichtlich(Bild 6.1.3.1).
- 79 -
KAPITEL 6
Bild 6.1.3.1 Zwei Varianten für die Zuordnung der Kinder zum betreffenden Partner
Weiter werden beschrifteten Kanten in einem juristischen Verwandtschaftsstammbaum eingesetzt. Die Adoption gehört dann zur Nachkommenschaftsbeziehung. Um sie von den leiblichen Kindern zu unterscheiden, können die Beziehungen von Eltern und der adoptierten
Kinder beispielsweise durch mit „A“ beschriftete Kanten dargestellt werden. Ein weiteres
Problem bestünde darin, dass, falls ein Kind von mehreren Ehepaaren adoptiert wird, in einem Stammbaum Kreuzungen und Zyklen auftauchen können. So ginge die Baumstruktur
verloren. Um den Baumstruktur zu bewahren, wird eine mehrfach Präsenz einer Person erlaubt. Daher ist aber der Stammbaum nicht mehr duplikatfrei. In Abb. 6.1.3.3 wird ein Beispiel gezeigt: die Eltern A sind mit der Eltern B verwandt. A hat die Kinder 1,2,3 adoptiert. B
hat die Kinder 2,3,4 adoptiert.
Abb. 6.1.3.3 Naive Darstellung der mehrfachen Adoption vs. Verbesserte Darstellung
- 80 -
KAPITEL 6
6.2.
Diskussion von Alternativen und Problemen der dynamischen Darstellung
Mit einem statischen Stammbaum können die genealogischen Daten statisch interpretiert
werden. Wenn die Entwickler und die Benutzer in der Datenbank die Daten einfügen, löschen
oder anfragen, sollte entsprechend die Darstellung des Stammbaums synchronisiert geändert
werden. Mit einem dynamischen Stammbaum werden nicht nur die Änderungen aus der Datenbank simultan übergenommen, sondern es ist zudem eine direkte Bearbeitung der Daten
im Stammbaum statt in der Datenbank möglich. Andere Aspekte wie eine Traversierung eines
riesigen Stammbaums oder ein verbessertes Layout für unbalancierte Stammbäume gehören
ebenfalls zur Manipulation der Stammbaumdarstellung. In diesem Abschnitt werden diese
drei Varianten der dynamischen Darstellung im Detail diskutiert.
6.2.1. Navigieren in einem Stammbaum
In der statischen Darstellung wird empfohlen, einen Platzhalter mit einheitlicher Größe und
gleichförmige Daten wie „ID“, „Name“, „Vornamen“ und „Geburtsdatum“, die Personen identifizieren, zu verwenden. Für eine große Familie mit langer Geschichte ist es unmöglich,
alle Familiemitglieder mit einem standardisierten Platzhalter anzuzeigen. Was im Hauptfenster angezeigt wird, ist nur ein Teil des Stammbaums.
Die Situation ist ähnlich dem Online-Suchen einer Straße in einem Stadtplan. Der angezeigte
Plan ist nur ein kleiner Ausschnitt der Stadtkarte. Mit Hilfe dynamischer Funktionen „zoom
in“ und „zoom out“ wird der angezeigte Plan proportional vergrößert und verkleinert. Bei der
Vergrößerung ist der vom Benutzer gesuchte Ort deutlicher zu sehen. Dagegen wird bei Verkleinerung die erweiterte Umgebung des ausgewählten Orts angezeigt, damit der Benutzer
die beste Fahrtroute bestimmen kann. Mit vier Pfeiltasten kann der Benutzer in dem Plan
umherwandern.
- 81 -
KAPITEL 6
Bild 6.1.3.1 Speedmap Bonn Stadtplandarstellung
Ein wie oben beschriebenes „Navigationssystem“ kann auch für einen Stammbaum implementiert werden. Dafür können drei verschiedene standardisierte Größen (z.B. „ID“; „ID,
Vorname und Nachname“ und „ID, Vorname, Nachname, Geburtsdatum und Todesdatum“)
gegeben werden, um sich der „Zoom“-Funktion besser anzupassen. Wenn eine angefragte
Person und ein dazu gewünschten Nachkommens- oder Vorfahrens- Stammbaum ausgewählt
werden, ist im Hauptfenster ein Teilbaum mit standardisiertem Platzhalter „ID, Vorname und
Nachname“ zu sehen. Mit „Zoom in“ ist es möglich, sich über ID, Vorname, Nachname, Geburtsdatum und Todesdatum der Eltern, Großeltern oder Kinder, Enkelkinder und der angefragte Person informieren. Weiter entfernte Verwandte können durch mehrmaliges „zoom
out“ besucht werden. Je größer der Anteil des gewünschten Stammbaums ist, desto weniger
persönliche Daten der angezeigten Personen stehen im Platzhalter.
Um einen Stammbaum zu navigieren, kann durch die vier Pfeiltasten realisiert werden. Um
immer sicher zu stellen, zu welchem Teil der Benutzer gerade gelangt, sollte ein Übersichtsstammbaum zur Verfügung stehen. Der Übersichtsstammbaum ist eine Übersicht für den
Hauptstammbaum, der oben beschrieben wird. Der Übersichtsstammbaum gibt in einem
kleineren Maßstab zur Übersicht wieder und enthält normalerweise sehr simple Information
sowie die IDs der Personen. Die beiden Fenster sollten synchronisiert sein, so dass die
Hauptdarstellung des Stammbaums immer einen Teil einer bestimmten Stelle aus der Übersicht zeigt.
- 82 -
KAPITEL 6
6.2.2. Gesamtes Layout für unbalancierte Stammbäume
Ein wichtiges Thema in der Baumstruktur ist die Balancierung eines Baums. Ein AVL-Baum
beispielsweise ist ein balancierter Binärbaum. In einem Stammbaum besteht auch eine ähnliche Aufgabe, die Form eines möglichsten balancierten Stammbaum zu wählen, um wenige
Freiräume zu schaffen. Das Problem ist bei „Mehrfachheiraten“ schon bekannt. Hierbei stellt
sich wieder die Frage, wie der Abstand zwischen Geschwistern ausgewählt wird, wenn manche Geschwister viele Nachkommen haben und manche überhaupt keine.
Die naive Methode besteht darin, denselben Abstand für alle Geschwister zu haben. Die
Symmetrie wird in der Höhe des Stammbaums bewahrt, allerdings wird der ganze Stammbaum wegen der großen unterschiedlichen Nachkommensmenge nicht mehr im Gleichgewicht bleiben. Je größer die Datenbank ist, desto häufiger wird das Problem von unterschiedlichen Nachkommensmengen auftreten, und desto größere Freiräume werden auf diese Weise
innerhalb des Stammbaumes geschaffen. Daher reicht die statische Darstellung nicht mehr
aus. Mit einer dynamischen Methode kann die Lösung verbessert werden: anpassende größere Abstände werden an der benötigten Stelle eingefügt, wodurch die Freiräume verringert
werden, so bleibt aber der Stammbaum nicht immer im Gleichgewicht. Abbildung 6.2.2.1
zeigt den beiden Darstellungen. („Mehrere Freiräume vs. Wenige Freiräume aber Ungleichgewicht“Æder Satz steht im Bild)
Abb. 6.2.2.1 Derselbe Abstand für alle Geschwister vs. größere Abstände an der benötigten Stellen
- 83 -
KAPITEL 6
Eine noch bessere Möglichkeit, die Symmetrie des Stammbaums beizubehalten und größere
Freiräume zu schaffen, bietet eine Folder-Funktion. Das Prinzip der Folder-Funktion kann
so beschrieben werden:
•
•
Wähle gleiche Abstände für alle Geschwister in der gleiche Höhe des Baumes aus
Definiere eine maximale Anzahl der Nachbekommen, die im Stammbaum angezeigt
werden darf
• Zeichne die Geschwister mit dem Symbol „+“, deren Anzahl der Nachkommen die
vordefinierte maxmale Anzahl überschrittet. Falte die restlichen direkten Nachkommen.
• Anklicken dem Symbols „+“, der restliche Nachkommensstammbaum wird in einem
kleinen Nebenfenster angezeigt.
Weiterhin ist diese Funktionalität bei Mehrfachheiraten einsetzbar. Die standardisierte Anzeige ist jedes Individuum mit einem Partner, dem ersten Ehepartner. Durch Anklicken werden im Nebenfenster die späteren Partner dargestellt.
Durch die Folder-Funktion wird die Symmetrie des Stammbaums bewahrt und eine standardisierte Sicht des Baums gegeben. Die Struktur des Stammbaums ist nicht mehr von der
komplizierten Beziehungsstruktur abhängig und ist immer gleichförmig dargestellt. Der
Nachteil besteht darin, dass nicht alle Familiemitglieder auf den ersten Blick ersichtlich sind.
- 84 -
KAPITEL 7
7. Das genealogische Visualisierungssystem FaTVis
Das genealogische Visualisierungssystem wurde aus dem Kontext Family Tree Visualizer als
„FaTVis“ benannt. Beruhend auf den in Kapitel 6 diskutierten verschiedenen Visualisierungskonzepten wird in diesem Kapitel zunächst das eigene Visualisierungskonzept vorgestellt. Anschließend wird die 5-Schicht-Architektur des FaTVis Systems erläutert. Auf Basis
der 5-Schicht-Architektur werden alle wichtigen Aspekte Schicht für Schicht vorgestellt.
7.1.
Visualisierungskonzept
7.1.1. Layout
In Kapitel 6 wurde schon erläutert, dass die verschiedenen Arten von Verwandtschaft mit
verschiedenen Arten von Verwandtschaftsgraphen dargestellt werden können. Es wird im
FaTVis das Verwandtschaftsverhältnis „natürliche Verwandtschaft“ im bilinearen Verwandtschaftssystem aufgenommen. Die Entscheidung wird aus zwei Gründen getroffen:
•
•
das Anwendungsgebiet der zu implementierenden Verwandtschaft
die Möglichkeit, einen Verwandtschaftsgraph in Form eines Stammbaums darzustellen
Da heutzutage Frauen und Männer in den meisten Ländern als gleichberechtigt betrachtet
werden, findet ein bilineares System die häufigste Verwendung. Für die meisten Genealogen,
die das Interesse auf historische Geographie, allgemeiner Quellenkunde und Urkundenlehre
legen und die natürliche Verwandtschaft am häufigsten erforschen, wird somit die natürliche
Verwandtschaft in unserem System visualisiert. D.h. Blutsverwandte werden zusammen mit
ihren Ehegatten bei einer Visualisierung aufgenommen.
Aufgrund der möglichen negativen Effekte von Inzucht wird seit alters her das Heiraten von
Verwandten ersten Grades, nämlich die Inzucht, verboten. Da Zyklen dadurch vermieden
werden, kann ein Verwandtschaftsgraph annähernd in einem Stammbaum dargestellt werden.
Die Adoption ist wegen ihres schwachen Zusammenhangs mit der Ahnenforschung nicht in
unserem Visualisierungssystem eingeschlossen. Ohne Berücksichtigung der Mehrfachadoption kann die Darstellung der Verwandtschaftsverhältnisse leicht in Form eines Stammbaums
realisiert werden, da die Verwandtschafsbeziehungen der Blutsverwandten in der Struktur des
Stammbaums realisiert werden können.
Im System FaTVis werden für alle Verwandtschaftsbeziehungen drei Darstellungsformen
gegeben: „Nachkommenstammbaum“, „Vorfahrenstammbaum“ und ein aus diesen zwei
Stammbäumen kombinierter Verwandtschaftsgraph, der „Vorfahren- und Nachkommens-Stammbaum“. Die ersten zwei Arten sind Grundformen von Stammbäumen und die
letzte Form ist eine kombinierte Form der beiden. Um sie von einander unterscheiden zu
können, wird für einen Nachkommensbaum eine Wachstumsrichtung „von oben nach untern“ und für einen Vorfahrensbaum „von untern nach oben“ gewählt. Dadurch verweist die
zeitliche Abfolge eindeutig von unten nach oben. Die drei Darstellungen werden immer nur
für eine angefragte Person als Wurzel erzeugt, welche nur Teilbäume der ganzen Familie sind.
Für eine Auskunft einer ganzen Familie sollte in einem Nachkommenstammbaum die Wurzel
von Stammvater der Familie ausgehend dargestellt werden. Die Stammväter werden mit dem
- 85 -
KAPITEL 7
Zeichen „ψ“ notiert. Diese personenbezogenen Darstellungen sind besonders vorteilhaft,
wenn der Benutzer in einer großen Datenbank schnell auf die Daten einer bestimmten Person
zugreifen möchte.
Die Knoten stehen für die Personen in einer Familie. Für die Darstellung eines Knotens werden folgende Aspekte berücksichtigt: die Form des Knotens, die Farbe des Randes, die
Beschriftung und die anzuzeigenden Daten innerhalb des Knotens. Die Knoten werden in
rechteckiger Form dargestellt. Eine andere Form wie z.B. die Ellipse kann ebenfalls benutzt
werden. Aber um die Daten einer Bezugsperson in einem Knoten passend darzustellen, ist ein
Rechteck als ein Textfeld die geeignete Wahl. Um die Geschlechter spezifizieren zu können,
wird der Rand in verschiedenen Farben gezeichnet: dunkelblau für Männer, rot für Frauen
und schwarz für Unbekannte. Die blaue Farbe steht für Männer, da es in der psychologischen
Forschung Ergebnisse gibt, die dieser Farbe eine männliche Note zuweisen, somit kann der
Benutzer auf den ersten Blick intuitiv die Geschlechter erkennen. Innerhalb des Knotens
werden standardisierte Informationen angezeigt, wie „ID“, „Name“, „Vorname“, „Geburtsdatum“ und „Todesdatum“. Unbekannte Daten werden mit drei Fragezeichen „???“ dargestellt. Die Farbe der Beschriftung wird so definiert: damit die ID’s die Personen identifizieren
können, wird der Beschriftung „ID“ die auffällige Farbe rot zugewiesen und die restlichen
Elemente werden schwarz dargestellt. Die Namentexte werden größer als die ID’s und die
Daten dargestellt, da der Benutzer die Namen aller Personen in einem Stammbaum zunächst
wissen möchte.
In der Graphentheorie wurde diskutiert, ob die partnerschaftlichen Beziehungen durch einen
zweiten Kantentyp dargestellt werden, somit ist es eher ein Verwandtschaftsgraph als ein
Stammbaum, da die Anzahl der eingehenden Kanten eines Knoten gleich „2“ (Vater und
Mutter) ist. Um alle Verwandtschaftsbeziehungen, also auch die partnerschaftlichen Beziehungen in Form eines Stammbaums darstellen zu können, wird die Beziehung statt durch einen zweiten Kantentyp durch einen Hyperknoten der Bezugsperson implementiert: die
Partner sind mit eigenen Platzhaltern unter den zugehörigen Personen angeordnet und werden
zusammen als ein Hyperknoten betrachtet. D.h. die Knoten stehen nicht mehr nur für einzelnes Familienmitglied, sondern eine Gruppe von Personen, die verheiratet sind mit dem Familienmitglied oder verheiratet waren. Die Knoten, in denen angeheiratete Personen angezeigt
sind, werden als Nebenknoten von einem Hyperknoten bezeichnet. Die Knoten, die ein Familienmitglied darstellen, werden als Hauptknoten oder Hauptpersonen des Hyperknotens
bezeichnet. Nur die Hauptknoten stellen Blutverwandte einer Familie dar. Die Nebenknoten
sind im rechtlichen Sinne keine Verwandtschaft, geben aber die zusätzliche Information über
die Heirat der Bezugsperson an. Die Operation Löschen des Hauptknotens eines Hyperknotens führt zu einem Löschen des Hyperknotens mit allen zugehörigen Nebenknoten. Im Vergleich dazu wird der Hyperknoten beim Löschen eines Nebenknotens nicht ganz gelöscht,
sondern nur der Nebenknoten selbst.
Mit anderen Worten sind die im FaTVis dargestellten Vorfahrenstammbäume und Nachkommenstammbäume im eigentlichen Sinne drei-dimensionale Hyperbäume:
•
Betrachtet man die Hyperknoten als Einheiten (Hyperknoten, Hyperknoten), so
ist der Stammbaum ein normaler zwei-dimensionaler Stammbaum. Da die Kanten die
Stammesentwicklung abbilden, werden nur Blutverwandte einer Familie in dem
zwei-dimensionalen Baum angezeigt.
- 86 -
KAPITEL 7
•
•
Betrachtet man die inneren Knoten eines Hyperknotens (Hauptknoten, Nebenknoten), werden zusätzlich die partnerschaftlichen Beziehungen einer Bezugsperson
dargestellt.
Zusammen wird die Blutverwandtschaft mit der ehelichen Verwandtschaft in einem
Hyperstammbaum folgendermaßen implementiert: ((Hauptknoten, Nebenknoten),
(Hauptknoten, Nebenknoten)).
Um den drei-dimensionalen Hyperbaum in einer zwei-dimensionalen Ebene darstellen zu
können, werden verschiedene Farben innerhalb eines Hyperknoten vergeben. Die innere
Farbe des Hyperknotens wird wie folgt vergeben: gelb für Hauptknoten, bzw. die Familienmitglieder, hellblau für Nebenknoten, bzw. die angeheiratete Personen. Dadurch kann die
dritte Dimension wieder in einer zwei-dimensionalen Ebene integriert werden. Die Farben
werden so ausgewählt, da sie heller sind als die Farbe des Randes und damit besser unterscheidbar sind. In Abb. 7.1.1.1 wird gezeigt wie das Geschlecht und die Rolle einer Person
mit Innen- und Außenfarbe eines Knotens kombiniert, dargestellt wird.
Außenfarbe: dunkelblau ÆMann
rot Æ Frau
Innenfarbe: gelb Æ Hauptknoten (Familienmitglied)
hellblauÆNebenknoten (angeheiratete Person)
(Außenfarbe, Innenfarbe) => {(Mann, Hauptknoten), (Mann, Nebenknoten),
(Frau, Hauptknoten), (Frau, Nebenknoten)}
Abb. 7.1.1.1 Verschiedene Kombinationen von Innen- und Außenfarben
Für die Hauptknoten werden die Daten wie im normalen Knoten in zwei Farben beschriftet:
rot für ID und schwarz für den Rest. Für die Nebenknoten in einer Mehrfachheirat müssen
noch folgende Probleme berücksichtigt und zusätzliche Prinzipien gegeben werden:
•
•
•
Bezeichne die Reihenfolge der Ehegatten innerhalb eines Nebenknotens.
Unterscheide zwischen einem geschiedenen Partner und einem gestorbenen Partner
der Hauptperson.
Stelle eine Person im Nebenknoten dar, die in verschiedener Zeit mit verschiedenen
Hauptpersonen innerhalb eines Stammbaums verheiratet war.
Es wird vorausgesetzt, dass eine Person gleichzeitig maximal einen Ehepartner haben darf.
Die Mehrfachheirat bedeutet in diesem Sinne, dass eine Person mehrere Ehepartner zu verschiedenen Zeitpunkten hat. Da das Datum der Heirat nicht im Knoten angezeigt wird, sollte
zusätzlich eine Nummer innerhalb eines Nebenknotens für die Reihenfolge der Ehegatten
vergeben werden. Die Nummer wird hinter den Namen mit einer runden Klammer in rot dargestellt. Für geschiedene Partner werden die Namen in der Farbe grau dargestellt. Die dritte
Farbe grau wird in den Nebenknoten eingesetzt, um zwischen den beiden Fällen unterscheiden zu können ob der ehemalige Partner von der Hauptperson geschieden war oder früher
gestorben ist. Falls der ehemalige Partner früher gestorben ist, bleib der Name schwarz.
Ein extremer Fall der Mehrfachheirat wäre beispielsweise eine Frau A, die sich früher mit
dem älteren Bruder Christian Müller und später mit seinem jüngeren Bruder Emil Müller
verheiratet hat. Um das Kreuz zu vermeiden und die Baumstruktur zu bewahren, darf die
- 87 -
KAPITEL 7
Frau A zweimal im Stammbaum der „Müller“ Familie auftreten. Daher ist unser Stammbaum
in diesen Fall nicht mehr duplikatfrei. Es ist aber in semantischem Sinne duplikatfrei, da das
erste „A“ zum Hyperknoten von „Christian Müller“ gehört und das zweite „A“ zum Hyperknoten von „Emil Müller“ gehört.
Die gerichteten Kanten, die auf die Nachkommens- und Vorfahrens- Beziehungen abbilden,
werden durch die Pfeillinien dargestellt. Die Pfeillinien verweisen gemäß der zeitlichen Abfolge eindeutig von der Vergangenheit (Vorfahren) zur Zukunft (Nachkommen). D.h. in einem von oben nach untern wachsenden Nachkommensbaum, zeigen die Pfeilen von oben
nach unten. Entsprechend in einem von untern nach oben wachsenden Vorfahrensbaum, zeigen die Pfeile von unten nach oben.
Da die Eltern zusammen als ein Hyperknoten betrachtet werden, kommt die Zuordnung der
Kinder zum betreffenden Partner bei Mehrfachheiraten in Frage, was eigentlich nur in der
dritten Dimension dargestellt werden kann. Durch beschriftete Kanten mit Nummern “1“, “2“,
“3“ kann das Problem der Zuordnung in einer zwei-dimensionalen Darstellungsform integrieret werden. Die Nummern von Kanten verweisen auf die Nummern von Nebenknoten, um
zu erläutern, welche Kinder zu welchem Partner gehören. Aber die neben den Kanten stehende Nummer die wie ein dangling pointer ins Leere zeigt, somit sehen die dargestellten
Stammbäume nicht „sauber“ aus. In unserem System werden stattdessen beschriftet Knoten
verwendet: ähnlich den beschrifteten Kanten. Die als Hauptknoten dargestellten Kinder, da
sie Familienmitglieder sind, werden mit zusätzlichen Nummern beschriftet. Dies bedeutet,
dass die Kinder zu dem Nebenknoten mit der gleichen Nummer also zu dem anderen Elternteil gehören. Aber falls eines der Elternteile von einem Kind der Hauptknoten ist und das andere Elternteil unbekannt ist, wird dies in dem Kindknoten mit der Sondernummer „0“ bezeichnet.
Zusammenfassend ist zu sagen, dass mit der Sonderform von Stammbäumen, den Hyperstammbäumen, die Blutverwandtschaft mit der ehelichen Verwandtschaft zusammen dargestellt werden kann. Die Hauptknoten und die Nebenknoten der Hyperknoten werden mit verschiedenen Innenfarben dargestellt. Die durch diese Regelung auftretenden Probleme, wie die
Mehrfachheirat und die Zuordnung der Kinder zum betreffenden Partner, werden in FaTVis
mit zusätzlichen Nummern gelöst. Die Nummern, die in Nebenknoten der Hyperknoten stehen, bezeichnen die Reihenfolge der Ehegatten als Hauptpersonen. Die Nummern, die in den
Hauptknoten der Hyperknoten stehen, verweisen auf die Nummern der Nebenknoten, der direkten Vorgängerhyperknoten. Die Abb. 7.1.1.2 zeigt eine Beschriftung oberhalb des Textes
innerhalb eines Hyperknotens.
#ID
Vorname Name (Nr.)
* Geburtsdatum
+ Todesdatum
„Nr.“: Æ in Nebenknoten: der Zähler von Ehegatten der Bezugshauptknoten
Æ in Hauptknoten : die Zuordnung der Kinder zum betreffenden Partner
Abb. 7.1.1.2 Verschiedene Bedeutungen von „Nr.“ in Neben-/Hauptknoten
- 88 -
KAPITEL 7
Abbildung 7.1.1.3 zeigt ein Beispielsstammbaum „The Müllers“: Der „Anton Müller“ hat mit
seiner erste Frau „Bella Pitz“ ein Kind „Christian Müller“. Sie haben sich später getrennt.
Dann hat er mit seiner zweiter Frau „Dora Schulz“ auch ein Kind „Emil Müller“. Der alte
Christian hat die junge Schauspielerin „Lisa A“ geheiratet und hat eine Tochter „Fiona Müller“. Zwei Jahre später haben sie sich getrennt. „Lisa A“ hat den Bruder ihres ersten Mannes
„Emil Müller“ geheiratet und mit diesem noch ein Kind Namens „Frank Müller“. In diesem
Stammbaum sind die geeigneten Lösungen für die Mehrfachheirat und die Zuordnung der
Kinder bei einer Mehrfachheirat zu sehen.
Abb. 7.1.1.3 Ein Nachkommensbaum von „The Müllers
“
7.1.2.
Navigation
Für eine große Familie mit langer Geschichte ist es unmöglich, alle Familiemitglieder mit
einem standardisierten Platzhalter anzuzeigen. Was im Hauptfenster angezeigt wird, ist nur
ein Teil des Stammbaums. Dafür wird ein Navigationssystem benötigt. Das in Kapitel 6 erwähnte Navigationssystem wird in FaTVis teilweise realisiert:
1. Proportionale Vergrößerung und Verkleinerung eines Stammbaums durch die dynamische Funktionen „zoom in“ und „zoom out“
2. Umherwandern in dem Stammbaum durch das Bildschirmrollen
3. Ein Stammbaumnavigator Minimap
- 89 -
KAPITEL 7
Die Abbildung 7.1.2.1 zeigt, dass die Funktionen „zoom in“ und „zoom out“ durch die untern
in der Mitte stehenden zwei Buttons „+“, „–“ realisiert werden. Die Darstellung wird immer
proportional um zehn Prozent vergrößert oder verkleinert. Die maximale Vergrößerung und
Verkleinerung werden vorgegeben, um zu vermeiden, dass die Darstellung unendlich groß
oder unendlich klein ist. Eine in Kapitel 6 erwähnte bessere Implementierung wäre es, dass
verschiedene Texte für verschiedene Größen einer Darstellung geeignet sind. Beispielweise
kann „ID“ für sehr kleine Darstellung mit Zoom von Stufe 0,2 bis 1,0 gegeben werden. Der
Text über „ID, Vorname und Nachname“ kann für eine mittelgroße Darstellung mit dem
Zoom von Stufe 1,2 bis 2,0 gegeben werden und somit der detaillierte Text. „ID, Vorname,
Nachname, Geburtsdatum und Todesdatum“ für den Zoom von Stufe 2,2 bis 3,0. Die so angezeigten Darstellungen erhalten bei Vergrößerung und Verkleinerung einen lesbaren Text. Im
FaTVis wird das Konzept wegen der Technikschwierigkeiten noch nicht implementiert, wird
aber als ein Aspekt folgender Softwareentwicklung berücksichtigt.
Falls eine Familie zu groß ist oder der angezeigte Stammbaum mehrfach vergrößert wird,
ist im Hauptfenster nur ein Teil des Stammbaums zu sehen. Um den ganzen Stammbaum mit
einer bestimmten Größe trotzdem sehen zu können, muss der Benutzer in dem Stammbaum
umherwandern. Die Traversierung eines Stammbaums kann durch das Bildschirmrollen realisiert werden, dieses ist bekannt aus „Microsoft Word“ und dem „Adobe Reader“.
Der Stammbaumnavigator Minimap ist ein Übersichtsstammbaum für den Hauptstammbaum.
Sie gibt in einem kleineren Maßstab eine Übersicht wieder. Es wird in einem Navigationssystem verwendet, um immer sicher zu stellen, zu welchem Teil der Benutzer gerade gelangt.
Bezüglich einer Übersichtsdarstellung des gesamten Stammbaumes erfolgte die Entscheidung
für zwei verschiedene Zeichnungsbereiche: ein Hauptfenster für Hauptstammbaum und ein
kleineres Nebenfenster für den Übersichtsstammbaum. Unabhängig davon, ob der Benutzer
im Hauptfenster oder im Nebenfenster scrollt, bleiben die beiden Fenster synchronisiert. D.h.
dass die Hauptdarstellung des Stammbaums immer einen Teil einer bestimmten Stelle aus der
Übersicht zeigt (Abb. 7.1.2.1).
- 90 -
KAPITEL 7
Abb. 7.1.2.1 Das Traversierungssystem im FaTVis
7.2.
Architektur und Komponenten
Dem System FaTVis liegt die folgende Architektur zugrunde (Abb. 7.2.1). Wie gezeigt wird
die gesamte Architektur in fünf Schichten aufgeteilt:
1. Die Datenbanken speichern alle genealogischen Daten und liegen ganz unten am
Fundament der Architektur.
2. Unter dem RDBMS MySQL werden die Datenbanken abgelegt und verwaltet.
3. Über die JDBC-Brücke kommuniziert MySQL mit dem System FaTVis.
4. Das System FaTVis visualisiert die genealogischen Daten.
5. Die Benutzter kommunizieren mit dem System durch das Benutzerinterface.
Das auf diese Weise aufgebaute System lässt die fünf Schichten schichtweise mit einander
kommunizieren. Daher sind alle Schichten transitiv abhängig in beiden Richtungen. Falls die
Daten in der untersten Schicht „DB“ geändert werden, sollte die Änderung auf MySQL weitergeführt werden. Durch die JDBC-Brücke führt es zur Änderung im System FaTVis.
Schließlich werden im Vordergrund des Benutzerinterface geänderte Daten visualisiert angezeigt. Es kann genau umgekehrt so propagiert durchgeführt werden. Die transitiven Abhängigkeiten in beiden Richtungen können auch als interaktive Graphik-Daten-Verarbeitung
bezeichnet werden.
- 91 -
KAPITEL 7
Benutzer
Benutzerinterface(GUI)
fatvis.ui
↕
fativis.model
↨
DBFactory
FaTVis
JDBC
MySQL
DB
DB
DB
Hiermit wird eine Übersicht der wichtigen Aufgaben aller Schichten erläutert:
1. DB:
Bestimme den Datenbanktyp für die anzulegenden Daten und blende unnötige Daten aus: Da unser System sich mit den genealogischen Daten von Familien beschäftigt, werden andere Datenbanken sowie geographische oder genetische Datenbanken nicht berücksichtigt. Das Ziel der zweiten Phase ist die Auswahl der nötigen
Informationen. Die adoptierten Kinder oder die Kinder, die von den angeheirateten
Personen mit in der Familie gebracht wurden, sind nach dem Konzept unseres Systems keine relevanten Daten.
2. MySQL: Die Datenbankentwickelung wird in drei Schritten durchgeführt:
•
•
•
Entwurf des relationalen Datenbankschemas gemäß der vorhandene Daten und Umsetzung in Tabelleformen.
Entwurf der Verwandtschaftsbeziehungen.
Anlegung der Daten in Tabellen unter MySQL
3. JDBC: Java-Datenbank-Schnittstelle: Das FaTVis kann jede Zeit die Verbindung
mit einer bestimmen Datenbank aufbauen oder trennen.
- 92 -
KAPITEL 7
4. FaTVis: Implementierung des Visualisierungssystems für genealogische Daten. Die
Implementierung wieder in drei Aspekte aufgeteilt:
DBFactory:
o Lesen die Daten aus der Datenbank und Schreiben der Daten in die
Datenbank.
o Durchführung der Änderungen der Daten in der Datenbank.
ii.
fativis.model:
1.
Konstruktion der relevanten Daten einer angefragten Person als
Knoten oder Hyperknoten.
2.
Erzeugung der abstrakten Baumstruktur, Berechnung der Tiefe
und Bereite des Baums.
iii.
fatvis.ui:
o Berechnung der horizontalen und vertikalen Abstände zwischen allen
(Hyper-) Knoten.
o Positionierung der Knoten und Darstellung des Stammbaums im
Vordergrund.
i.
5. GUI:
Entwurf und Implementierung der Struktur und Funktionalität des Benutzerinterfaces. Es ist zu berücksichtigen wie Benutzer von Datenbanken und von Daten
einer bereits geöffneten Datenbank die Daten bearbeiten kann.
In den folgenden Abschnitten werden die Aspekte der Datenbankentwickelung, der Implementierung und dem Benutzerinterface in allen Einzelheiten vorgestellt. Um die Implementierung besser zu verstehen, wird sie nach der Vorstellung der Datenbankentwickelung und
des Benutzerinterfaces an letzter Stelle erklärt.
7.3.
Entwurf genealogischer Datenbanken für FaTVis
Da die genealogischen Daten in einer relationalen Datenbank gespeichert werden, sollte die
Datenbank in drei Phase entwickelt werden: Anforderungsanalyse, Entwurf und Realisierung. Die Anforderungsanalyse wurde schon im Visualisierungskonzept ausführlich erklärt.
Hier werden nun der Entwurf eines relationalen Datenbankschemas und die Erstellung der
SQL Views für die Verwandtschaftsbeziehungen diskutiert.
7.3.1. Entwurf des Datenbankschemas und die Basistabellen
In Kaptitel 3 wurde erläutert, dass auf Grund der Datenunabhängigkeit und der dadurch aufgebauten 3-Schicht-Architektur der Entwurf eines Datenbankschemas entsprechend in drei
Schritte aufgeteilt werden kann: Sie werden in den Konzeptioneller Entwurf Æ Logischer
Entwurf Æ Physischer Entwurf aufgeteilt. Daher wird der Entwurf unseres genealogischen
Datenbankschemas schritt für schritt durchgeführt.
Die konzeptionelle Modellierung, das Entity-Relationship(ER)-Modell wird erfolgreich als
Mittel zum "Vorentwurf" eines relationalen Datenbankmodells verwendet. Zuerst stellt sich
die Frage, wie viele Entity-Typen und wie viele Relationship-Typen einer genealogischen
- 93 -
KAPITEL 7
Datenbank vorgegeben werden sollen. Da eine Familie aus einer Menge von Personen, die in
verschiedene Relationen (oder Verwandtverhältnisse) verschiedene Rolle spielen besteht,
können die Personen als Entities und Verwandtverhältnisse als Relationships betrachtet werden. Anschließend kommt es zu der Überlegung ob alle Personen zu einem Eintity-Typ „person“ oder zu zwei mit Geschlechte spezifische Entity-Typen „Male“ und „Female“ angeordnet werden sollen.
Im Vergleich mit den beiden ER-Modellen ist zu sehen, dass mit der „person“ Modell häufig
vorkommende Verwandtverhältnisse sowie „sister_of“ und „child_of“mit geeigneter Relationship-Typen problemlos dargestellt werden können. Mit der „Male-Female“ Modell sind die
Rollen in manchen Relationen sowie „married_to“ direkt durch die Kanten erkennbar, allerdings sind manche Relationen sowie „sister_of“ oder „father_of“ wegen des vordefinierten
Geschlechts sehr problematisch darzustellen. Eine mögliche Lösung ist der Relationship-Typ
„father_of“, der durch zwei Untertypen „father_of_son“ und „father_of_daughter“ ersetzt
wird. Das ER-Modell „Male-Female“ ist zwar dann das richtige, aber in der Realität schwer
zu verwenden, da man immer vorher das Geschlecht der angefragten Person kennen muss.
Hier wird das ER-Modell mit dem einzigen Entity-Typ „person“ ausgewählt. Der Entity-Typ
„Person“ ist durch die folgenden Attribute vollständig charakterisiert:
{ID*: integer, Surname: string, Firstname: string, Titel: string, Gender: string, Occupation:
string, Birthplace: string, Birthdate: Date, Deathplace: string, Deathdate: Date}
Das Schlüsselattribut ist “ID”. Die Verwandtschaftsbeziehungen werden dann entsprechend
durch Relationshiptypen interpretiert. Zum Beispiel wird die partnerschaftliche Beziehung
durch den Relationship-Typ „married_to“ in ER-Modell bezeichnet. Bei dieser Beziehung
spielt „Person“ durch zwei Kanten „Husband“ und „Wife“ zwei verschiedene Rollen. Nachkommenschaftliche Beziehungen werden im ER-Modell „child_of“ genannt. Die drei Kanten
interpretieren drei Rollen von „Person“ nämlich „Mother“, „Father“, und „Child“.
Die „married_to“ Beziehung ist eine N:M Beziehung, da ein Mann gleichzeitig nur mit einer
Frau verheiratet sein darf, aber in seinem Leben mit mehrerer Frauen verheiratet sein kann;
dasselbe gilt auch für die Frau. Es wird angenommen, das die Polygamie, eine Person hat
gleichzeitig mehrere Ehepartner, nicht gestattet ist. Die „child_of“ Beziehung kann als 1:1:N
Beziehung bezeichnet werden, wenn sie sich nur auf die Blutverwandtschaft bezieht. Bei der
juristischen Verwandtschaft wird der Fall der „Adoption“ mitberücksichtigt. Da es gesetzlich
erlaubt ist, dass die Eltern mehrere Kinder adoptieren oder umgekehrt ein Kind mehrfach
adoptiert wird, ist es in dem Fall der L:N:M Beziehung dargestellt.
Die Relationship-Typen „child_of“, „married_to“ werden in unserem Modell als Basis-Relaitonship-Typen genannt. Die weiteren Beziehungen so wie „sibling_of“, „grandchild_of“ , oder weiter entfernte Verwandte werden als abgeleitete Reltionship-Typen bezeichnet, da sie durch den Basis Relationship-Typen ableitbar sind. Dadurch kann der Speicherplatzbedarf verringert werden.
Die Arbeit des logischen Entwurfs erfolgt in zwei Schritten:
1.
2.
Umsetzung eines konzeptuellen Schemas in ein relationales Schema in Tabellenform.
Verbesserung des relationalen Schemas.
- 94 -
KAPITEL 7
Für den Entity-Typ „person“ wird im relationalen Schema eine Tabelle „person“ eingerichtet. Die Attribute werden in den Spaltennamen der Tabelle umgesetzt. Das Schlüsselattribut „Id“ wird auf der Primärschlüssel-Spalte abgebildet. In Abb. 7.1.2.1 ist die Struktur der
Tabelle „person“ gezeigt.
person
Feld
Typ
Id
bigint(20)
enum('male',
Gender
'female')
Born
date
Died
date
Title
varchar(40)
Name
varchar(40)
FirstName varchar(40)
BirthPlace varchar(40)
Occupation varchar(40)
DeathPlace varchar(40)
Null
Standard
Verweise
Kommentare
MIME
Nein
Ja
NULL
Ja
Ja
Ja
Ja
Ja
Ja
Ja
Ja
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
Abb. 7.3.1.1 Die Struktur der Tabelle „person“
Eine weitere Überlegung nach der Verbesserung des Schemas ist, ob die Tabelle ”person” in
zwei Tabellen „person“ und „personDetail“ zerlegt werden soll. Beim Einfügen einer
neuen Person, für die nur „Gender“ und „Name“ bekannt ist, müssen in allen anderen Stellen Nullwerte eingefügt werden „Einfügeanomalie“. Denn noch sind alle
Nicht-Schlüssel-Attribute von dem Primärschlüssel “Id“ nicht transitiv abhängig (3NF), so ist
eine verlustlose und abhängigbewahrende Zerlegung möglich. Hier wird aber diese Zerlegung nicht durchgeführt, da beim Anfragen einer Person jedes Mal für die zwei Tabellen ein
„JOIN“ durchgeführt werden muss. Somit würde dann Zugriffseffizienz sehr gestört. Um auf
das häufig angefragte Attribut „Gender“ zugreifen zu können, kann eine „Index“ Eigenschaft gegeben werden.
ALTER TABLE `person` ADD INDEX ( `Gender` )
Da der Relationship-Typ “married_to” eine N:M Beziehung ist, muss eine eigenständige
Tabelle „marriage“ aufgebaut werden. Die Spaltennamen werden nach den verschiedenen
Rollen der beteiligten Personen als „HusbandId“ und „WifeId“ benannt. Es ist möglich, dass
zwei Personen von einander geschieden sind, jedoch zwei Jahre nach der Scheidung zusammenkommen möchten. Um diese Fälle zu identifizieren, wird das Datum für die Heirat „Married“ benötigt. Das Scheidungsdatum „Divorced“ wird in der Tabelle angegeben, um zu unterscheiden, ob das Ehepaar geschieden (mit Angabe des Scheidungsdatums) ist oder einer
der Ehepartner gestorben ist (mit Angabe „Null“). Es ist problematisch beim Mehrfachheiraten mit unbekannter Zeitangabe die Ehe zu identifizieren. Dann wird noch eine Spalte „marriageId“ als Primärschlüssel eingesetzt.
marriage
Feld
MarriageId
HusbandId
WifeId
Married
Divorced
Typ
bigint(20)
bigint(20)
bigint(20)
date
date
Null
Nein
Ja
Ja
Ja
Ja
Standard
Verweise
Kommentare
NULL
NULL
NULL
NULL
Abb. 7.3.1.2 Die Struktur der Tabelle „marriage“.
- 95 -
MIME
KAPITEL 7
Im konzeptionellen Entwurf wird festgelegt, dass die „child_of“ für Blutverwandtschaft eine
1:1:N Beziehung ist. Theoretisch soll der Relationship-Typ „child_of“ in den Entity-Typ
„person“ mit zusätzlichen zwei Spalten „father“ und „mother“ eingebettet werden. Aber wenn
ein Ehepaar mehrere Kinder hat, d.h. N sehr groß ist, wird in der Tabelle „person“ die redundanten Informationen gespeichert. Wenn eine Person eingefügt wird, deren Eltern noch unbekannt sind, müssen Nullwerte eingefügt werden. Um die Probleme „Redundanz“ und
„Einfügeanomalie“ zu beheben, wird im zweiten Schritt „Verbesserung des relationalen
Schemas“ eine Zerlegung benötigt. Daher erfordert dies die Zerlegung der Tabelle „child“ von
der Tabelle „person“. Die Tabelle besteht aus drei Spalten: „ChildId“ bildet die Rolle “child”
ab, „FatherId“ und „MotherId“ interpretieren die Rolle father und mother.
child
Feld
Typ
ChildId
bigint(20)
FatherId bigint(20)
MotherId bigint(20)
Null
Nein
Ja
Ja
Standard
Verweise
Kommentare
MIME
0
NULL
NULL
Abb. 7.3.1.3 Die Struktur der Tabelle „child“
7.3.2. Entwurf und Realisierung von Verwandtschaftsbeziehungen mittels
Schichten
Um den Speicherplatzbedarf zu verringern wird im letzten Abschnitt nur zwei Basisverwandtschaftsbeziehungen „marriage“ und „child“ in Tabellenform interpretiert. Anhand der
Basisrelationen können alle Verwandtschaftsverhältnisse durch Datalog abgeleitet und in
SQL Form umgesetzt werden. Der Implementierungsprozess erfolgt in zwei Schritten:
1. Realisierung der atomaren Verwandtschaftsbeziehungen in SQL.
2. Realisierung der komplexen Verwandtschaftsbeziehungen durch Iteration.
Die Verwandtschaftsbeziehung, die nicht weiter in Beschreibung ihrer Beziehung zerlegbar
ist, wird als atomar bezeichnet. Im Gegensatz dazu stehen die komplexen Verwandtschaftsbeziehungen, die aus mehreren Beziehungen aufgebaut sind. Beispielweise kann die Verwandtschaftsbeziehung „parents“ als eine Komplexe Verwandtschaftsbeziehung definiert
werden, da sie mit Berücksichtigung des Geschlechterunterschieds in „mother“ und
„father“ zerlegt werden. In unserem FaTVis System jedoch gehören Männer und Frauen zusammen zur Tabelle „person“ und werden als denselben Entity-Typen „person“ betrachtet.
Deswegen kann die „parents“-Beziehung ohne Berücksichtigung des Geschlechterunterschieds als eine atomare Beziehung definiert werden, da der Unterschied zwischen den Geschlechtern nicht betrachtet wird und diese Beziehung dann nicht mehr zerlegbar ist. Die
Frage, ob die angezeigte Person Mutter oder Vater ist, ist leicht durch die in Konzepten vorgestellte geschlechtspezifizierte Darstellung zu erkennen.
- 96 -
KAPITEL 7
Die folgenden Verwandtschaftsbeziehungen werden in unserem System als atomare Beziehungen definiert:
•
•
•
•
Anfrage der Ehegatten von Person „q“: listSpouses (Person q)
Anfrage der Eltern von Person „q“: listParents (Person q)
Anfrage der Kinder von Person „q“: listChildren (Person)
Anfrage der Geschwister von Person „q“: listSiblings (Person q)
Die Implementierung der Anfragen der atomaren Beziehungen wird mit SQL realisiert. Die
Anfrage der Ehegatten einer Bezugsperson listSpouses(Person q) beispielsweise kann mit
SQL so formuliert werden:
SELECT * FROM Marriage INNER JOIN Person
ON HusbandId=Id WHERE WifeId= q.Id
SELECT * FROM Marriage INNER JOIN Person
ON WifeId=Id WHERE HusbandId= q. Id;
Da die komplexen Verwandtschaftsbeziehungen aus mehreren Bebeziehungen zusammengesetzt sind, ist es dann einfacher statt mit SQL mit der iterativen Methode zu implementieren.
Die Großeltern sind Eltern von Eltern, die Neffe und Nichte sind Kinder von Geschwistern
usw. Mit iterativen Methoden kann zum Beispiel die Suche nach Neffen und Nichten aus
zwei Schleifen konstruiert werden:
1
2
Suche nach allen Geschwistern einer Person q
Suche aller Kinder für jedes Geschwister
Die Methode kann gekürzt in einer Klausel so dargestellt werden:
listNiecesNephews(Person q) Å listChildren(listSiblings(Person q))
Andere komplexe Verwandtschaftsbeziehungen können auch auf diese Weise dargestellt
werden. Aus dem Bild 7.3.2.1 sind viele Beziehungen direkt ablesbar und durch die beschrifteten Kanten darstellbar. Angenommen, dass „Ich“ die ausgewählt Person ist, dann wird die
Verwandte „Cousine“ anhand der Abbildung so dargestellt:
listCousins(Person q) Å listChildren(listUnclesAunts(Person q))
listUnclesAunts(Person q) Å listParents(listSiblings(Person q)
Mit Iteration implementierte komplexe Verwandtschaftsbeziehungen lassen sich einfacher
erweitern, falls später eine Anfrage nach sehr entfernten Verwandten eingeführt werden soll.
Im Gegensatz dazu ist der mit SQL dargestellte Text zu aufwendig.
- 97 -
KAPITEL 7
Abb. 7.3.2.1 Die Baumstruktur bildet die Verwandtschaftsbeziehungen ab
- 98 -
KAPITEL 7
7.4.
Struktur und Funktionalität des Benutzerinterfaces
In den letzten Abschnitten wurde das System FaTVis aus Sicht des Entwicklers vorgestellt.
Um die Funktionalität des Systems zu beschreiben und die Idee der Implementierung später
besser zu erklären, wird hier das FaTVis aus Sicht der Benutzter, nämlich das Benutzerinterface vorgestellt.
7.4.1. DB-Fenster
Die Software FaTVis kann durch den Klick „fatvis.jar“ geöffnet werden. Während des Starts
von FaTVis wird ein leeres Hauptfenster mit einem leeren Nebenfenster angezeigt. Das
Hauptfenster ist für die Darstellung eines Hauptstammbaums „Family Tree“ zuständig, und
das Nebenfenster für einen Übersichtsstammbaum „Minimap“. In der Menüleiste stehen zwei
Arten von Befehlen zur Verfügung:
•
•
„Database“ Bearbeiten von Datenbanken
„Person“:
Bearbeiten von Daten einzelner Personen in einer bereits geöffneten
Datenbank
Nach dem Programmstart erscheinen zuerst viele der Bedienelemente grau statt bunt unterlegt, dieses bedeutet, dass das FaTVis noch mit keiner Datenbank verbunden ist. Mit dem
Menübefehl „Database--->Connec.“ kann eine existierte Datenbank vom MySQL Server im
FaTVis geladen werden. Der Benutzer muss in einem „Enter connection datails“ Dialog den
Benutzername, das Passwort und die URL von dem Server mit dem Namen der zu ladenden
Datenbank eingeben. Wenn eine neue Datenbank in die bestehende Datenbank eingelesen
wird, sollte der Benutzer den Befehl „Database--->Creat a new database“ wählen. Dazu
muss noch in dem „Enter connection datails“ Dialog der Name für die neue Datenbank gegeben werden (Abb.8.3.1).
- 99 -
KAPITEL 7
Abb. 7.4.1.1
Anlage eine neue Datenbank im MySQL
Sobald die Verbindung mit dem Server aufgebaut wird, bleiben alle anderen Bedienelemente
aktiv. Mit dem Befehl „Database-->Import...“ kann eine andere Datenbank in die bereits geöffnete Datenbank eingefügt werden. Es ist besonders nützlich für das Verwandtschaftsverhältnis „Verschwägerung“. Der Benutzer darf auch direkt in FaTVis die Datenbank löschen
durch Wählen des Befehls „Database-->Clear“. Der Menübefehl „Database-->Disconnect“ steuert den Abbau der Verbindung zur Datenbank. Wie praktisch alle
Windowsprogramme kann das FaTVis über den Befehl „DatabaseÆExit“ beendet und werden.
7.4.2. Personenfenster
Falls eine Datenbank aus dem Server geladen wird, können die Daten statt in MySQL direkt
im System bearbeitet werden. Über den Menübefehl „PersonÆNew Person“ kann immer
eine neue Person in der Datenbank eingefügt werden. Im Vordergrund wird ein leeres Personenfenster angezeigt. Die Darstellungsform ähnelt der einer Karteikarte. Es enthält alle
Grundinformationen einer Person und teilt sich drei Bereiche: „Personal Data“, „Parents“ und
„Marriages „(Abb. 8.3.2). Um den Fall die unbekannten Daten mit der negierten zu unterscheiden, ist für jeden Eintrag noch ein Ankreuzfeld vorhanden. Falls eine Person gestorben
und das Todesdatum unbekannt ist, bleibt der Eintrag „Death Date“ leer wird aber angekreuzt.
Falls eine Person noch lebt, bleiben sowohl das Eintragsfeld „Death Date“ und das Ankreuzfeld leer.
- 100 -
KAPITEL 7
Abb. 7.4.2.1
Anlage einer neuen Person in einem Personenfenster.
7.4.3. Suchfenster
Mit dem Befehl „Person-ÆSearch person“ wird ein Dialog zum Suchen angezeigt (Abb.
8.3.3). Alle zu dieser Datenbank zugehörigen Personen werden in einer Listenform mit dem
Inhalt Name, Vorname, Geburtsdatum und Todesdatum angezeigt. Ganz unten stehen verschiedene Knöpfe „Buttons“ für verschiedene Operationen zur Verfügung. Mit „Edit“ kann
der Benutzer von einer ausgewählten Person in ihrem Personenfenster bearbeiten und mit
„Delete“ dieser Person aus der Datenbank löschen. Der Button "Ancestors" steurt ein Vorfahrensstammbaum einer ausgewählten Person zu erzeugen. Und die Schaltfläche „Descendents“ oder "Both A&D" entsprechend ein Nachkommensbaum oder ein Vorfahrens und
Nachkommensstammbaum. Die Anfragen von Verwandtschaftsbeziehungen können durch
die Befehltaste "Relatives..." realisiert werden.
Das dritte Element in der „drop down“ Liste von „Pserson“ ist „Relative Search...“. Die
Funktion ist ähnlich wie „Relatives...“ im „Search person“ Dialog: Anfrage der Verwandtschaftsbeziehungen von einer bestimmten Person. Daher werden zwei Auswahl-Felder in einem Relative Search Dialog benötigt. Es werden die Auswahl von einer bestimmten Person
und die Auswahl von einer Beziehung in Listform benötigt. Die Folgenden Beziehungen einer Bezugsperson sind ermöglicht zu ermitteln: die Ehegatten („spouses"), die Eltern („Parents"), die Kinder ("Children"), die Geschwister ("Siblings"), die Onkeln und Tanten ("Aunts
& Uncles"), die Nichten und Neffen ("Nieces & Nephews"), die Cousins und Cousinen
- 101 -
KAPITEL 7
("Cousins"), und die Cousins und Cousinen im zweiten Grades ("Cousins in 2nd degree"), die
Großeltern ("Grandparents"), die Enkelkinder ("Grandchildren"), die Schwiegereltern ("Parents in Law"),der Schwager und die Schwägerin („Siblings in Law"). Die Ergebnisse werden
in einem Fenster „Search results“ aufgelistet. Der Benutzer kann eine Person von der Liste
auswählen und die geeignete Daten ansehen, bearbeiten oder einen gewünschten Stammbaum
sehen so wie dies auch beim Personensuchen der Fall ist.
Abb. 7.4.3.1
Ein „Search Dialog“ mit verschiedener Funktionen
7.4.4. Duplikatfenster
Da auf eine Datenbank von mehreren Benutzern zugegriffen und bearbeitet werden darf,
kann eine Person doppelt erfasst werden. Mit Hilfe des Menübefehls „PersonÆMerge Persons…“ lassen sich die beiden so genannten Duplikate zu einer Person verschmelzen (Abb.
8.3.4). Hierbei hat die zweite Person höhere Priorität. Dies bedeutet, die „Personen 2“ nimmt
die Daten aus der „Person 1“ als Ergänzung. Falls verschiedene Einträge für dieselbe Art von
Daten vorhanden sind, werden die Daten von „Person 2“ aufgenommen. Mit den neuen gemischten Daten werden die „Person 2“ überschrieben. Die erste Person wird nach „Merge“ gelöscht.
- 102 -
KAPITEL 7
Abb. 7.4.4.1
Die „Person 1“ verschmelzt zur „Person 2“
Das Bearbeiten eines dargestellten Stammbaums wurde schon im Kapitel „Visualisierungskonzept“ in allen Einzelheiten vorgestellt. Zusätzlich kann der Benutzer in einem bereits erzeugten Stammbaum alle Knoten in einem Baum, die entsprechenden Personen in der Datenbank, bearbeiten. Der Benutzer kann für einen beliebigen Knoten innerhalb des Baums
einen geeigneten Stammbaum anzeigen lassen.
In FaTVis kann nur ein Stammbaum gleichzeitig dargestellt werden. Nach dem Suchen einer
bestimmten Person wird eine Art eines Stammbaums nach Wunsch der Benutzer dargestellt
werden. Die ausgewählte Person stellt immer der „Ausgangspunkt“ dar, also die Wurzel des
Baums. Ein häufig verwendeter Stammbaum ist ein vom Stammvater ausgehender kompletter
Nachkommensstammbaum. Um dieses darstellen zu können, werden alle Stammväter einer
Datenbank mit dem Sonderzeichen „Ж“ markiert. Mit den Befehl „Descendents“ ist ein normaler kompletter Stammbaum zu sehen.
7.5.
Ausgewählte Aspekte der Implementierung
Um eine Übersicht zu geben, wie alle Pakete mit einander zusammenarbeiten, wird hier eine
kleine Einleitung gegeben. Direkt unter FaTVis gibt es insgesamt zwei Pakete und drei Klassen. Die Aufgabe der zwei Pakete fatvis.model und favis.ui wurden bereits erklärt. Die drei
Klassen sind FatvisMain, DBFactory und LoopException. Die Main()-Methode steckt in der Klasse
FatvisMain. Beim Aufruf der Main()-Methode wird ein Startfenster mit dem Titel „FaTVis Family Tree Visualizer" angezeigt.
- 103 -
KAPITEL 7
7.5.1. Datenbank-Kopplung
Unter der „Datenbank-Kopplung“ versteht man die Kommunikation des Java-Programms mit
in MySQL abgelegten genealogischen Daten. Die zugehörenden Aufgaben werden wie folgt
gegeben:
•
•
Lesen der Daten aus der Datenbank und Schreiben der Daten in die Datenbank.
Interaktive Manipulation der Daten zwischen dem Java-Programm und der
Datenbank.
Um die Daten aus den Tabellen zu lesen und in einem Java-Programm zu speichern, werden
zunächst anhand der Tabelleformen „person“, „child“ und „marriage“ drei Projekte in Java-Programm konstruiert. Die Projekte werden entsprechend als „Person“, „Child“ und
„Marriage“ (unter fatvis.model) genannt. Für das „Person“-Objekt beispielsweise wird die
Tabelle „person“ so abgebildet:
1. Für jede Spalte werden eine Variable entsprechend der set()-/get()-Methode zugeordnet:
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
2. Für jede Tabelle gibt es eine parseResultSet-Methode, damit die Ergebnisse der Anfrage Spalte aus der Spalte der Datenbank gelesen und dann als ein Objekt rekonstruiert werden kann.
Nach der Konstruktion der drei Objekte lässt Java uns mit dem JDBC auf die Datenbanken
zugreifen. Der Lesen-Prozess erfolgt in drei Schritten:
1.
Aufbau einer Verbindung zur Datenbank: Daher wird zunächst der für MySQL
spezifizierte Treiber geladen. Der Treibmanager DriverManager wird so eingeladen.
public void init(String url, String user, String pw)
throws Exception
{
Class.forName(“com.mysql.jdbc.Driver”);
connection=DriverManager.getConnection(url,user,pw);
}
2. Lesen der Daten aus der Datenbank: Die Methode listAllPersons() (unter
DBFactory), wie alle Personen aus der Datenbank ausgeholt werden, ist wie folgendes
gezeigt: Die Personenanfragen werden erst durch eine SQL-Anweisung „k“ formuliert
und mit excuteQuery ausgeführt. Das Ergebnis wird zunächst durch ein Result- 104 -
KAPITEL 7
Set-Objekt verwaltet und dann auf ein Person-Objekt abgebildet. Die Ergebnismenge
wird in Vektoren gespeichert und verwaltet.
public Person [] listAllPersons() throws SQLException{
String k="SELECT * FROM Person ORDER BY Id";
ResultSet rs=connection.createStatement().executeQuery(k);
Vector v=new Vector();
while (rs.next()) {
Person p=Person.parseResultSet(rs);
v.add(p);
}
Person[]a=new Person[v.size()];
for (int i=0;i<v.size();i++)
a[i]=(Person)v.get(i);
return a;
}
3. Verbindungsabbau: Zum Abschluss werden die benutzten Ressourcen durch Aufruf
der close() Methoden von ResultSet und Statement freigegeben und die Verbindung
wird dadurch abgebrochen:
con.close();
Der Schreiben-Prozess, wie die Daten in Datenbanken eingelegt werden, ist ähnlich wie
dem Lesen Prozess. An Stelle der SQL Anfragensbefehle „SELECT-FROM-WHERE“, werden DDL Befehle verwendet. Die creatNewDatabase
wird so konstruiert:
public static void createNewDatabase (adminName,adminPass, daminDb)
throws Exception
{
Class.forName("com.mysql.jdbc.Driver");
// Verbindungsaufbau
Connection con=DriverManager.getConnection(adminDb,adminName,adminPass);
String k[]=new String[]{
"CREATE DATABASE "+dbName,
// DDL Befehle in SQL
"CREATE TABLE Person …",
// DB und DBsschema
"CREATE TABLE Child …”,
"CREATE TABLE Marriage …"
};
for (int i=0;i<k.length;i++)
con.createStatement().execute(k[i]);
// Ausführung der Befehle
con.close();
// Verbindungsabbau
}
Das „Manipulieren“ von Daten erfolgt hauptsächlich durch die Durchführung von Änderungen. Dazu gehörende Aufgaben sind Löschen, Einfügen einer Person, einer Beziehung
oder einer ganzen Datenbank. Das Einfügen und Löschen von Personen, partnerschaftlichen
Beziehungen und Kinderbeziehungen werden mit der Methode „performInsert“ und „performDelete“ in den drei Objekten „Person“, „Marriage“ und „Child“ eingebaut.
Die Operation Löschen einer Person wird zunächst in der Tabelle „person“ durchgeführt. Da
die Tabelle „marriage“ eine zweistellige Relation (Husband, Wife) bezeichnet, führt das Lö-
- 105 -
KAPITEL 7
schen von irgendeiner der beiden Personen zu einem kompletten Löschen dieser Relation. Es
bedeutet, dass die ganze Zeile gelöscht werden muss. Im Vergleich dazu ist die Tabelle
„child“ eine dreistellige Relation (Child, Father, Mother). Daher sollte die Lösch-Operation
getrennt bearbeitet werden:
•
•
•
Lösche die ganze Zeile falls die zulöschende Person in der Spalte „ChildId“ steht.
Ersetze die Spalte durch NULL falls die zulöschende Person in der Spalte „FatherId“ oder „MotherId“ steht.
Lösche die ganze Zeile falls die beiden Spalten „FatherId“ und „MotherId“ Null-Werte enthalten.
Abbildung 8.4.1.1 zeigt ein Beispiel. Mit grauer Farbe wie die Person mit Id „27“, die in den
drei Tabellen gelöscht wird, unterlegt. In der Tabelle „child“ wird für die Id „27“, die in verschiedenen Spalten steht, auf verschiedene Weise getrennt bearbeitet. Für ein weiteres Löschen von der Person mit Id „28“ betrifft in der „child“ Tabelle dann den dritten Fall. Dies
wird durch die Farbe Gelb dargestellt.
I person
Id*
25
27
28
Gender
Female
Male
Female
Born
1935-07-08
1943-11-12
1938-06-19
BirthPlace
Bonn
Köln
Siegburg
…
…
…
…
II marriage
MarriagId*
5
6
WifeId*
25
28
HusbandId*
19
27
Married
1959-10-01
1966-05-01
Divorced
NULL
NULL
III child
ChildId*
27
44
FatherId
14
NULL / 27
MotherId
16
28
Abb. 7.5.1.1 Grau fürs Löschen von 27, Gelb fürs Löschen von 27, 28
In Java wird eine zusätzliche Methode performUpdate definiert. Dadurch wird nach der Änderung der Datenbank der Speicher entleert und die aktualisierten Daten neu eingelesen.
- 106 -
KAPITEL 7
Die Methode mergePerson ist eine Sonderoperation für den Duplikatcheck. Falls eine Person zweimal in der Datenbank gespeichert wird, können die beiden gleichen Personen durch
„merge“ in eine Person verschmolzen werden. Die Idee besteht darin:
1. Suche die Eltern von P1, Schreibe in die Tabelle „child“ als Pnew
Suche die Eltern von P2, überschreibe die Daten in Pnew
2.
3. Löschen von P1, P2
4. Wiederhole die letzten drei Schritte für die Tabelle „marriage“
Schritt 1:
ChildId
P1
P2
Pnew
FatherId
NULL
18
NULL
MotherId
25
NULL
25
ChildId
P1
P2
Pnew
FatherId
NULL
18
18
MotherId
25
NULL
25
ChildId
P1
P2
Pnew
FatherId
NULL
18
18
MotherId
25
NULL
25
Schritt 2:
Schritt 3:
Schritt 4: Wiederhole dies für die Tabelle „marriage“
Das Einfügen von einer oder mehreren Datenbanken in eine bereits geöffnete Datenbank
ist besonders nützlich, wenn das Verwandtschaftsverhältnis „Verschwägerung“ betrachtet
wird. Wenn ein Mann sich mit einer Frau verheiratet hat und nach seinen Schwiegereltern
angefragt wird, oder der Bruder des Manns nach seiner Schwägerin angefragt wird. Dafür ist
die Methode addDatabase() (unter FatvisMain()) zuständig. Beim Einfügen einer Datenbank DB2 in eine bereits geöffnete Datenbank DB1 lassen sich die ID Nummern ändern, da
sie von DBMS automatisch vergeben werden. Daher wird eine Hashtable gebraucht, um die
Änderungen zu speichern. Der ganze Ablauf wird wie folgt definiert:
1.
2.
3.
4.
5.
6.
Lese die Daten aus der Tabelle „person“ der DB2.
Schreibe die ausgelesenen Daten in die Tabelle „person“ der DB1
Verwende eine Hashtable, um die alten IDs mit der neuen IDs als Tupel zu speichern.
Lese aus DB2 die Daten von der Tabelle „child“
Ersetze IDs aus den „child“ mit Werten der Hashtable
Wiederhole die Schritte von 4,5 für die Tabelle „marriage“
- 107 -
KAPITEL 7
Schritte 1-2:
person
Id
1
...
42
43
Name
Selten
...
Schröder
Müller
person
Id
1
...
14
...
...
...
...
...
Name
Müller
...
Meier
...
...
...
...
DB2
DB1
Schritt 3:
Hashtable
OldId
1
3
4
...
42
NewId
43
44
45
...
54
Schritte 4-5:
child
ChildId
6
...
42
45
FatherId
1
...
38
43
child
ChildId
4
...
12
MotherId
3
...
35
44
FatherId
1
...
4
MotherId
3
...
9
DB2
.... DB1..
Einfügen Anhand der Abbildung von Hashtable (1,43), (3,44), (4,45)... ...
Schritt 6: Einfüge in die „marriage“ Tabelle der DB1 analog zu den Schritten 4-5
- 108 -
KAPITEL 7
7.5.2
Generierung von Stammbäumen
Mit Hilfe der Suchealgorithmen DFS (Tiefensuche) und BFS (Bereitsuche) kann ein Stammbaum auf zwei verschiedene Weisen so generiert werden, dass ein Stammbaum entweder in
die Tiefe oder in die Bereite wächst. Außerdem werden die zwei Algorithmen auch zur Bestimmung der Tiefe des Baums und der Breite der Ebene verwendet.
Die Grundidee des Aufbaus eines Vorfahrensstammbaums wird in den folgenden Schritte
erläutert:
1. Konstruiere die angefragte Person als ein Objekt „AncestorNode“. Betrachte die
Person als die Wurzel „rootNode“, also als den Ausgangspunkt.
2. Rekursive Aufrufe der Methode iterateFill(), um die Eltern des Wurzelknotens und
Eltern von Eltern usw. zu finden.
3. Speicher alle gefundenen Personen als Objekte AncestorNode in Vektoren loopDetector.
4. Berechne die Tiefe des Baums getDepth()
5. Berechne die Breite für jede Ebene calculateWidth (int level)
Abb. 7.5.2.1 Vorstellung der Objekten und
Methoden eines Vorfahrenstammbaums
In Abb. 7.5.2.1 werden die Funktionalitäten aller Methoden durch einen Vorfahrensstammbaum deutlich gezeigt. In der Methode loopDetector werden nicht nur alle relevanten Personen als Vektoren gespeichert, sondern es wird auch geprüft, ob es einen Zyklus gibt. Angenommen, dass der Benutzer den Vater von „Anton Müller“ mit seinem Enkelkind „Gari
Müller“ falsch eingegeben hat, wird der Fehler direkt von loopDetector aufgefangen. Dadurch
sind Vorfahrensstammbäume immer zyklusfrei.
- 109 -
KAPITEL 7
Die Methoden iterateFill(), getDepth() und calculateWidth (int level) sind alle durch Rekursionen
realisiert. Die Methode getDepth() ist beispielweise ein DFS Algorithmus und wird wie folgt
konstruiert:
1. Initialisiere die Variabeln m, f mit der Wert -1.
2. Expandiere den Vorfahrensbaum vom Wurzelknoten aus und speichere alle Vorfahren
anhand der Geschlechter in zwei Stacks „Mother“ und „Father“.
3. Rufe rekursiv für jeden der Knoten in der beiden Stack „Mother“ und „Father“ auf.
i. Solange es im Stack „Mother“ noch Elemente gibt, wird der Wert m um 1 erhöht
und das Element vom Stack entfernt.
ii. Solange es im Stack „Father“ noch Elemente gibt, wird der Wert f um 1 erhöht
und das Element vom Stack entfernt.
iii. Falls die beide Stacks leer sein sollten, brich die Berechnung ab und gib den
Wert max(m,f) zurück.
public int getDepth(int i) {
int m=-1,f=-1;
if (mother!=null) {
m=mother.getDepth(i+1);
}
if (father!=null) {
f=father.getDepth(i+1);
}
if (father==null && mother==null)
return i+1;
return Math.max(m,f);
}
Für die Generierung eines Nachkommensstammbaums muss mehr berücksichtigt werden
als bei einem Vorfahrensstammbaum. Da die Anzahl der Kinder und die Anzahl der Partner
einer Bezugsperson sehr unterschiedlich sein können, müssen für jede Ebene die Höhe und
die Bereite berechnet werden. Die Bereite hängt von der gesamten Anzahl der Kinder aller
Bezugspersonen in derselben Ebene ab. Und die Höhe hängt von der größten Anzahl der
Partner aller Bezugspersonen in derselben Ebene ab. Daher müssen die Kinder und die Partner in Vektoren gespeichert werden. Der Ablauf der Generierung sieht wie folgt aus:
1. Konstruiere die angefragte Person als ein Objekt „DescendentNode“. Betrachte sie
als die Wurzel „rootNode“ und den Ausgangspunkt.
2. Aufruf der Methode getDescendentNodeForPersonRec() (unter DBFactory), um
alle Partner und alle Kinder mit ihrer zugeordneten Eltern und Nummern für jeden
DescendentNode zu finden und in Vektoren zu speichern.
3. Berechne für jede Ebene die Höhe nach der maximalen Anzahl der Partner aller Bezugspersonen setMaxChildrenHeight(). Speichere in dem Array MaxHeigt
[Level+1].
4. Berechne für jede Ebene die Breite nach der maximalen Anzahl der Kinder aller Bezugspersonen setMaxChildrenWidth().Speichere in dem Array MaxWidth [Level+1].
5. Gehe eine Ebene Tiefer setTreeRecursive(DescendentTree tree,int level). Wiederhole die Schritte 2 bis 4.
- 110 -
KAPITEL 7
Abb. 7.5.2.2 Vorstellung der Objekte und
Methoden eines Nachkommenstammbaums
Abbildung 7.5.2.2 zeigt dass die Partner eines DescendentNodes nicht als ein Projekt DescendentNode konstruiert werden, sondern als ein anderes Projekt PersonFormatter definiert
sind. Es liegt daran, dass für die Partner die Nebenkonten innerhalb eines Hyperknotens liegen mit ihrer Bezugsperson. Der so genannte Hauptknoten wird immer zusammenbetrachtet
werden können.
Die Suche nach den Kindern und Partnern wird durch die Methode getDescendentNodeForPersonRec((Person q, int parentId)) realisiert. Um die Zuordnung der Kinder zum betreffenden
Partner identifizieren zu können, werden die Eltern als einem Parameter „parentId“ berücksichtigt. Der Ablauf der Suche wird so konstruiert:
1. Suche alle Partner der Hauptperson.
2. Suche für jeden Partner die gemeinsamen Kinder und weise die Zuordnung ParentId
anhand der Reihe des Ehepaars zu.
3. Suche das Letzte die Kinder der Hauptperson mit dem unbekannten anderen Elternteil
und gib die ParentId dem Wert -1.
Diese Methode wird lediglich nur für die Hauptperson in allen Hyperknoten gestartet. Dadurch kann eine doppelte Suche der zu dem Ehepaar gehörenden Kinder vermieden werden.
Es ist auch vorteilhaft eine Verwechslung der Kinder zu vermeiden, falls die Kinder der angeheirateten Person mit in die Familie gebracht wurden. Angenommen: ein Mann A hat sich
mit einer Frau B verheiratet und hat Kinder A1 und A2. Die Kinder werden beim ersten Aufruf der Suchemethode getDescendentNodeForPersonRec(A) gefunden. Der Aufruf der Suchemethode von Frau B ist hier nicht nötig. Zusätzlich kann noch die Verwechslung vermieden werden, falls die Frau B früher mit einem anderen Mann C ein Kind C1 hat, was nicht
zur Familie des Mannes A gehört.
- 111 -
KAPITEL 7
Um die Höhe und die Breite aller Ebenen zu bestimmen, werden hier wie beim Vorfahrensbaum auch die Rekursionen verwendet. Die Bestimmung der Breite aller Ebenen wird wie
folgt definiert:
1. Gehe von der Wurzel aus und bestimme die maximale Suchtiefe.
2. Prüfe, ob die maximale Suchetiefe schon erreicht wurde.
• Falls ja: Abbruch ohne Ergebnis.
• Falls nein:
° Schreibe die gesamte Anzahl der Knoten von der aktuellen Ebene „level“ in dem Array getMaxWidth() [level+1].
° Rufe rekursiv für jeden Kinderknoten auf die aktuelle Ebene die Methode
setMaxChildrenWidth() auf. Erhöhe die Ebene um 1 und wiederhole den
Schritt 2 von vorne
public void setMaxChildrenWidth() {
int m=children.size();
if (level+1>=tree.getMaxWidth().length)
return;
if (tree.getMaxWidth()[level+1]<m)
tree.getMaxWidth()[level+1]=m;
for (int i=0;i<children.size();i++)
((DescendentNode)children.get(i)).setMaxChildrenWidth();
}
Mit Hilfe der vorhandenen Methoden für die Generierung von Vorfahrenstammbäumen und
Nachkommenstammbäumen ist es dann einfach, die dritte Variante: Vorfahren- und Nachkommenstammbaum zu erzeugen, da er eine Unionsform der ersten zwei Stammbäume ist.
Die Generierung wird so konstruiert:
1. Erzeuge den Vorfahrenstammbaum für die angefragte Person und Lösche die Wurzel.
1 Erzeuge den Nachkommenstammbaum für die angefragte Person.
2 Verbinde die ausgehenden Kanten von der gelöschten Wurzel im Vorfahrensstammbaum mit dem Wurzelknoten im Nachkommensbaum.
Statt Löschen des Wurzelknoten im Nachkommensbaum wird der Wurzelknoten im Vorfahrensbaum gelöscht, da die Anzahl der ausgehenden Kanten im Vorfahrensbaum einfacher zu
bestimmen ist und dadurch die Verbunden-Operation im Schritt 3 erleichtert wird.
Die vorhergehende Erläuterung der Generierung kann in zwei Sätze zusammengefasst werden: Alle relevanten Daten einer angefragten Person wurden aus der Datenbank gelesen und
als Knoten oder zusammen als Hyperknoten konstruiert. Der Baum wurde durch den rekursiven Aufruf aller Unterknoten von der angefragten Person erzeugt. Dies sind aber nur abstrakte Strukturen von Stammbäumen. Um die Bäume im Vordergrund graphisch darzustellen,
also das Layout, muss mehr berücksichtigt und berechnet werden, wie die Abstände der
Knoten oder die vertikale Anordnung aller Knoten. Dieser Vorgang wird in den nächsten
Abschnitt detailliert beschrieben.
- 112 -
KAPITEL 7
7.5.3. Layoutberechnung
7.5.3.1. Vorüberlegungen für die Layoutberechnung
Um einen Stammbaum graphisch im Vordergrund darzustellen, wird neben der abstrakten
Baumstruktur eine explizite Layoutberechnung benötigt. Die Klasse TreeInternalFrame unter
fatvis.ui sind dafür geeignet. Die Abbildung 7.5.3.1. zeigt wie die Methode DrawAncestorTree(Person) unter TreeInternalFrame zusammen mit der Klasse AncetorTree(Person)
gearbeitet wird:
1. Die Methode DrawAncestorTree(Person) ruft die Methode drawAncestorsRec (…) und
sendet die Daten von AncetorTree(Person) zu.
2. Mit Hilfe der Daten aus AncetorTree(Person), wird für einen bestimmten Knoten die
Methode drawAncestorsRec (…) rekursiv aufgerufen.
3. Mit Hilfe der bereits erzeugten abstrakten Baumstruktur in AncetorTree(Person), berechnet die Methode drawAncestorNode(…) die genaue Position der Knoten, die auf
dem Bildschirm dargestellt werden soll.
4. Die Schritten 2, 3 werden so lange wiederholt, bis es keine Eltern vom dargestellten
Knoten gibt.
Die Suche nach einem bestimmen Knoten wurde im letzten Anschnitt beschrieben: Gehe von
der Wurzel aus und suche rekursiv nach den Eltern. Mit der abstrakten Baumstruktur werden
alle zur Layoutberechnung benötigten Parameter sowie die Anzahl der Generationen vorgegeben.
Graphische Darstellung im Vordergrund
DrawAncestorTree(Person)
Aus Daten erzeugende abstrakte Baumstruktur
AncestorTree(Person)
AncestorNode()
drawAncestorsRec(AncestorNode n, x, y, base)
Explizite Layoutberechnung
drawAncestorNode(AncestorNode n, x,y)
Abb. 7.5.3.1 Graphische Darstellung = abstrakte Baumstruktur + Layoutberechnung
Der Prozess, um einen Nachkommstammbaum im Vordergrund darzustellen, funktioniert
ähnlich wie bei dem Vorfahrenstammbaum. Dafür sind bei Layoutberechnung die folgenden
drei Methoden geeignet: DrawDescendentTree(Person), drawDescendentRec() und drawAncestorNode(). Die Berechnung ist aber kompliziert, da die Anzahl der Patenteltern und Kinder
der gesamten Familie nicht eindeutig ist. Es wird im nächsten Abschnitt vorgestellt: wie das
Layout genau berechnet und die Knoten im Bildschirm dargestellt werden.
- 113 -
KAPITEL 7
7.5.3.2. Positionierung der Knoten in Pseudocode
Der ganze Ablauf des Layouts wird in die folgenden Schritte durchgeführt:
1. Bestimme die Breite und die Höhe eines Knotens
2. Bestimme den Abstand zwischen allen Ebenen und für Hyperknoten noch den Abstand
zwischen allen Nebenknoten innerhalb eines Hyperknoten
3. Ausgehend vom Wurzelknoten, rekursiv berechne die Startposition (xi, yi) für den gefolgten Knoten i
4. Zeichne das Rechteck für den Knoten i mit der Startposition (xi, yi), mit der bekannten
Breite und der Höhe
5. Verbinde die Knoten von zwei benachbarten Ebenen mit Pfeillinien
Da in den Schritten 1 und 2 die benötigten Parameter vorgegeben werden und die Breite und
die Höhe aller einzelnen Knoten gleich ist. Die Höhe eines Hyperknoten ist gleich der gesamten Höhe aller einzelnen Knoten mit der Summe der Abstände zwischen allen einzelnen
Knoten. Die Schritte 4 und 5 erzeugen graphische Darstellungen mit allen festgesetzten Parametern. Die eigentliche Methode steckt in Schritt 3: wie die Startposition (x, y) für jeden
Knoten berechnet wird und wie die Rekursion konstruiert werden soll. In dieser Arbeit wird es
als Positionierung der Knoten bezeichnet. Im Folgenden wird vorgestellt, wie die Knoten in
einem Vorfahrenstammbaum und einem Nachkommenstammbaum positioniert werden.
Vorfahrenstammbaum
Sei
∆x := minimaler X-Abstand zwischen zwei direkter benachbarter Knoten
∆y := Y-Abstand zwischen zwei direkter benachbarter Ebene
X := Breite eines Knotens
Y := Höhe eines Knotens
n := Anzahl der Generationen
Die Positionierung der Knoten wird ausgehend vom Wurzelknoten (also dem Knoten, der
die jüngste Generation repräsentiert) rekursiv vorgenommen. Dessen Position ist
x0 = (∆x +X)2n−2 + ∆x
y0 = (∆y + Y)(n − 1) + ∆y
(1)
(2)
Mit diesen Werten wird die unten angegebene Prozedur aufgerufen:
zeichneKnotenRekursiv(Wurzel, x0, y0, 0)
PROCEDURE zeichneKnotenRekursiv (Knoten k, int x, int y, int basis)
BEGIN
zeichneKnoten (k, x, y)
// zeichne Knoten k an Stelle (x,y)
IF (k.vater != NULL) THEN
ZeichneKnotenRekursiv (k.vater, x –(x−basis)/2 , y − ∆y − Y, 0)
IF (k.mutter != NULL) THEN
ZeichneKnotenRekursiv (k.mutter, x + (x−basis)/2 , y − ∆y − Y,
x)
END
- 114 -
KAPITEL 7
Der minimale X-Abstand ∆x ist eigentlich der Abstand zwischen den Blättern die die Knoten in
der letzten Ebene im Vorfahrenstammbaum bilden. Denn ausgehend von der Wurzel liegt in der
letzten Ebene die maximale Anzahl von Knoten. Daher sollte der Abstand in der letzten Ebene
kleiner sein als in allen anderen Ebenen, die ausgewählt werden. Abb. (xi, yi)zeigt, wie die
Startposition (x, y) eines Knotens berechnet wird. Für die Startposition (x0, y0) des Wurzelknotens ist die Variable n gleich die Höhe des Baums, die mit der Methode getDepth() in
AncestorTree() berechnet wurde. Ausgehend vom Wurzelknoten werden alle Startpositionen
für alle folgenden Knoten rekursiv berechnet. Die Variable n wird Ebene für Ebene immer um
1 verringert.
Die Grundidee der Prozedur wird wie folgt beschrieben:
•
•
•
Angenommen, dass die Position des Knotens i (xi, yi)
Bestimme die Position des Vaterknotens yvi = yi − ∆y − Y, xvi,= xi - A
Bestimme die Position des Mutterknotens ymi = yi − ∆y − Y, xmi,= xi + A
Die yvi und ymi sind aus der Abb. 7.5.3.2.1 einfach zu verstehen. Da der Vaterknoten und der
Mutterknoten symmetrisch von der Kindknoten sind, und die X-Position vom Vaterknoten xi A ist, sollte die X-Position des Mutterknotens einfach um xi + A .
Abbildung 7.5.3.2.1: Positionierung der Vorfahrenknoten (x0,y0).
Nachkommensstammbaum
Sei
∆x := minimaler X-Abstand zwischen zwei direkt benachbarten Hyperknoten
∆y := Y-Abstand zwischen zwei direkten benachbarten Ebene
∆h := Y-Abstand zwischen zwei Knoten in einem Hyperknoten
X := Breite eines Knotens
Y := Höhe eines Knotens
n := Anzahl der Generationen
- 115 -
KAPITEL 7
pi := maximale Anzahl der Partner aller Personen in Ebene i im Nachkommensbaum
c := maximale Anzahl der Kinder aller Personen in der ersten Ebene im Nachkommensbaum
Die Positionierung der Knoten wird wie beim Vorfahrenbaum ausgehend vom Wurzelknoten
(also dem Knoten, der die älteste Generation repräsentiert) rekursiv vorgenommen. Die rekursive Positionierungsprozedur wird wie folgt aufgerufen:
zeichneKnotenRekursiv(Wurzel, 0, 0,(X + ∆x)c)
PROCEDURE zeichneKnotenRekursiv (Hyperknoten k,int level, int minx, int
maxx)
BEGIN
x := minx + (maxx−minx)/2
level
y:=
∑
[(Y + ∆h)pi + ∆y]
i =1
zeichneHyperknoten (k,x,y)
// zeichne Hyperknoten k an (x,y)
FOR i :=1 TO (#k.kinder)
zeichneKnotenRekursiv(k.kinder[i],
level+
minx+[i*(maxx−minx)]/ #k.kinder,
maxx+[(i+1)*(maxx−minx)]/ #k.kinder)
NEXT
1,
END
Bei der Positionierung der Knoten im Nachkommenbaum werden die Parameter in der Prozedur minx, maxx verwendet. Die zwei Parameter geben zusammen ein Intervall für den bezogenen Knoten an. D.h. die X-Position von Knoten i sollte in der Mitte von minx und maxx
(x := minx + (maxx−minx)/2 ) und alle X-Positionen von seiner Kinderknoten dürfen das
Intervall nicht überschreiten. Die Berechnung der Startposition (xi, yi) wird in der Abb.
7.5.3.2.2 angezeigt.
- 116 -
KAPITEL 7
Abbildung 7.5.3.2.2: Positionierung der Nachkommenknoten (x0,y0).
Die Grundidee der Prozedur wird wie folgt dargestellt:
•
•
•
•
Angenommen, dass das Intervall I vom Knoten k ist, wobei Ik = maxxk−minxk.
Bestimme das Intervall für die Kinder i vom Knoten k mit Iki = Ik / #k.kinder, wobei
#k.kinder Anzahl der Kinder ist.
Gehe alle Kinder vom Knoten k durch.
Bestimme für den i-ten Kindknoten die Parameter minxki = minxk + i * Iki und
maxxki = maxxk + (i +1)* Iki.
- 117 -
KAPITEL 7
Die Parameter „minxk“ und „maxxk“ werden hier verwendet um das Intervall Ik zu bestimmen.
Das Intervall „Ik“ ist ein Teilintervall des gesamten Intervalls I. Es wird hier benötigt, um
genug Platz für die direkten Nachkommen der Bezugsperson k zu „reservieren“. D.h. wer
mehrere Kinder hat, bekommt in der nächsten Ebene einen größeren Anteil des gesamten Intervalls, um alle Kinder innerhalb ihres Teilintervalls einpassen zu können. Auf diese Weise
wird das Problem verschiedener Nachkommensmengen zwischen Geschwistern gelöst: an der
benötigten Stelle werden anpassende größere Abstände eingefügt, wodurch die Freiräume
verringert werden.
Sowohl im Vorfahrenstammbaum als auch im Nachkommenstammbaum wird die Positionierung der Konten mittels Rekursion realisiert. Es liegt daran, dass die Anzahl der Generationen
bzw. die Tiefe des Baums vorher schwer zu bestimmen ist. Die Methode wird so lange rekursiv aufgerufen bis die unterste Ebene erreicht wird, nämlich die Blätter. Die Traversierung
erfolgt in eine Reihenfolge „Preorder“, in der die rekursive Regel so definiert werden kann.
1. Besuche die Wurzel.
2. Besuche den linken Teilbaum.
3. Besuche den rechten Teilbaum
Abb. 7.5.3.2.2 „Preorder“: A B D E C F H I G
- 118 -
KAPITEL 8
8
Zusammenfassung und Ausblick
8.1
Zusammenfassung und Bewertung
In dieser Arbeit wurde ein (datenbankgestütztes) Visualisierungssystem für genealogische
Daten entwickelt. Die Entwicklung erfolgt in zwei Phasen: Entwurf und Implementierung.
•
Entwurf
o Entwurf des Datenbankschemas für genealogische Daten
o Entwurf der Verwandtschaftsbeziehungen mit der iterativen Methode
o Entwurf eigener Visualisierungskonzepte auf Grundlagen der Genealogie
und der Graphentheorie
•
Implementierung
o Erstellung einer Beispielsdatenbank „The Müllers“ unter MySQL
o Erzeugung Verwandtschaftsbeziehungen mittels Sichten
o Visualisierung der Blutsverwandtschaft mit den angeheirateten Personen in
drei Arten von Stammbäume in Java
o Einrichtung eines Navigationssystems
o Manipulation von Stammbäume
Im Vergleich zu den schon existierenden Anwendungen zur Visualisierung genealogischer
Daten ist das Visualisierungssystem FaTVis mehr wissenschaftlich orientiert, weil es ein
vollständiges Konzept zur Visualisierung der Grundlagen der Genealogie und der Graphentheorie darstellt. Im Folgenden wird ein Vergleich zu anderen bestehenden Anwendungen
gegeben:
•
MySQL statt Access: Im FaTVis wurde das RDBMS MySQL statt Access verwendet.
Da MySQL ein schneller und robuster, Multi-Thread und Multi-User
SQL-Datenbank-Server ist, ist es für eine relativ große genealogische Datenbank, mit
der viele Benutzer im Internet gleichzeitig arbeiten möchten das idealste DBMS. Ein
anderer Vorteil ist, dass MySQL die Anfragesprache SQL besser unterstützt und die
SQL Funktionen sowie OUTER JOIN und Subselects erlaubt.
•
Vollständiges Visualisierungskonzept: Das Visualisierungskonzept wurde auf
wissenschaftliche Grundlagen der Genealogie und der Graphentheorie erstellt.
•
Drei Arten von Stammbäumen: Statt eines „traditionalen“ Stammbaums, der die
Nachkommen eines Stammvaters zeigt, wurde im FaTVis drei verschiedene Varianten
angeboten. Der Benutzer kann je nach dem Bedarf auswählen, ob die Nachkommen
einer Bezugsperson oder Vorfahren einer Bezugsperson oder gleichzeitig Nachkommen und Vorfahren dargestellt werden sollen. Wobei die dritte Variante im graphischen Sinne ein aus zwei Bäumen mit einer gemeinsamen Wurzel kombinierter Graph
ist.
- 119 -
KAPITEL 8
•
Hyperstammbaum statt ein „normaler“ Stammbaum: Der Begriff „Hyperstammbaum“ ist an den graphentheoretischen Begriff „Hypergraph“ angelehnt. Er wurde im
FaTVis verwendet, um neben der Blutsverwandtschaft noch die angeheirateten Personen im Stammbaum darstellen zu können, was in einem traditionellen Stammbaum
nicht mitberücksichtigt wird.
•
Verringerte Freiräume: Mit der entwickelten Methode zur Layoutberechnung werden
an Personen, die mehr Nachkommen als andere haben, angepasste größere Räume
gegeben, wodurch die Freiflächeverringert werden.
•
Navigationssystem: Das Navigationssystem ermöglicht einen Überblick über sehr
große Stammbäume, dadurch dass immer nur ein Teilbaum im Hauptfenster angezeigt
wird.
•
Benutzerfreundlichkeit:
o Statt mit MySQL, können Benutzer direkt im Vordergrund mit den Daten arbeiten. Es können z. B. Operationen wie „Neu Einfügen“, „Löschen“ und „Editieren“ am Bildschirm durchgeführt werden.
o Mit Hilfe einer vollständigen Definition von Sichten können die Verwandtschaftsbeziehungen nicht nur von Eltern, Kinder sondern auch von Schwiegereltern und Schwager einer Bezugsperson angefragt werden.
o Ein erzeugter Stammbaum kann mit „save“ als „.png“ Datei gespeichert werden,
wodurch der Benutzer den dargestellten Stammbaum an andere Personen weiterleiten oder in eine Forschungsarbeit einfügen kann.
o Unter MySQL können die Daten gemeinsam genutzt werden. Um die Sicherheit
zu garantieren, bietet FaTVis auch Zugriffskontrolle sowie Passwort, so dass
keine Unbefugten auf die Daten zugreifen können.
•
Verringerte Laufzeit: Mit der entwickelten Methode zur Layoutberechnung und zum
Erzeugen des Stammbaums, kann ein ausgewählter Stammbaum relativ schnell im
Vordergrund angezeigt werden. MySQLs ermöglicht auch den schnellen Zugriff auf
Daten in externen Datenbanken.
8.2.
Ausblick
An dieser Stelle werden einige Erweiterungsmöglichkeiten besprochen. Ein technischer Erweiterungsvorschlag ist, dass nicht nur ein Stammbaum sondern gleichzeitig mehrere
Stammbäume, d. h. ein Wald, dargestellt werden könnten. Es erscheint dann sehr nützlich,
wenn zu verschiedener Familienstammbäume gehörende zwei Personen sich mit einander
verheiratet haben. Die Anfrage der Verschwägerung kann dann im „Wald“ durchgeführt werden. Mit einer „Drag and Drop“ Funktion könnte für zwei Familienstammbäume ein „UNION“ realisiert werden. Dies bedeutet, die zwei verheiratete Personen durch „Drag and
Drop“ in einen Hyperknoten verschmelzen. Somit können die zwei getrennten Stammbäume
als ein zusammenhängender Verwandtschaftsgraph dargestellt werden. Die relativ komplizierte Verwandtschaftsbeziehung-Verschwägerung wird durch den zusammenhängenden
Verwandtschaftsgraph implementiert.
- 120 -
KAPITEL 8
Weiterhin wäre die Möglichkeit einer gezielten Suche nach Personen eine sinnvolle Erweiterung. Um einen personbezogenen Stammbaum darzustellen, sollte immer vorher eine bestimmte Person ausgewählt werden. Aber für eine genealogische Datenbank mit über hundert
Personen ist es unmöglich, alle Personen aufzulisten. Daher ist es sehr schwierig in eine solchen Auflistung eine bestimmte Person zu finden. Eine gezielte Suche nach dem Nachnamen
und/oder Vornamen, nach dem Geburts- und/oder Todesdatum kann diesen Suchprozess beschleunigen. Der Benutzer braucht nur ein paar Informationen einzugeben und die gesuchte
Person wird mit einer Markierung dann aufgelistet.
Bei der Vorstellung des Konzepts vom FaTVis wurde schon erwähnt, dass im Navigationssystem durch „zoom in“ und „zoom out“ Texte ihre Größe veränderten können sollten. Diese
dynamischen Texte werden vom FaTVis noch nicht implementiert sondern sind als ein Aspekt fortfolgender Softwareentwicklung berücksichtigt. Beispiel: bei einer sehr kleinen Darstellung, mit Zoom von Stufe 0,2 bis 1,0 wird nur die „ID“ angezeigt. Bei einer mittelgroßen
Darstellung mit Zoom von Stufe 1,2 bis 2,0 wird „ID, Vorname und Nachname“ und bei
Zoom von Stufe 2,2 bis 3,0 „ID, Vorname, Nachname, Geburtsdatum und Todesdatum“ angezeigt. Dadurch können die angezeigten Darstellungen bei Vergrößerung und Verkleinerung
immer einen lesbaren Text erhalten.
Eine wünschenswerte Erweiterung des Systems wäre die Möglichkeit, einen GEDCOM Datensatz aus den Daten in der genealogischen Datenbank oder den in das Programm importierten Daten zu erstellen. Weiterhin sollte es möglich sein, eine GEDCOM-Datei mit Hilfe des
Systems zu importieren, so dass der Austausch von genealogischen Daten zwischen verschiedenen Programmen möglich wäre. Die dabei bestehende Schwierigkeit liegt in dem
nicht einheitlichen GEDCOM-Standard. Obwohl GEDCOM als einheitliches Format zum
Austausch von genealogischen Daten entwickelt wurde, haben viele Entwickler geringe Änderungen in die GEDCOM-Struktur eingebracht, so dass der Export einer GEDCOM-Datei
oft auf verschiede Arten verwirklicht wird. Dadurch sind diese häufig inkompatibel zu anderen Anwendungen, die selbst GEDCOM-Daten exportieren und/oder importieren können.
Noch eine wichtige Erweiterungsmöglichkeit wäre der Einsatz des Visualisierungssystems
auch in anderen wissenschaftlichen Gebieten. In Kapitel 6 wurde vorgestellt, dass heutzutage
Stammbäume nicht nur in der Genealogie, sondern auch in der Genetik, der Medizin, der
Mathematik und der Linguistik als ein wichtiges Hilfsmittel viel eingesetzt werden. Es wäre
sinnvoll, ein Visualisierungssystem so zu implementieren, dass es nicht nur Familienstammbaum, sondern auch evolutionärer Stammbaum, Genetischer Stammbaum und Stammbaum
der mathematischen Wissenschaft dargestellt werden können. Dafür benötigt man aber ein
sehr intelligentes Datenbankschema, um verschiedene Arten von genealogischen Daten zu
verwalten. Es gibt zwar Gemeinsamkeiten verschiedener Arten von genealogischen Daten. Es
ist aber sehr problematisch, die Daten bzw. die Datentypen mit demselben Format zu speichern. Falls die Schwierigkeit beseitigt wird und ein solches Visualisierungssystem implementiert werden kann, ist es sicher ein wichtiger Beitrag, nicht nur für die Genealogieforschung, sondern auch für die ganze Wissenschaft, zumindest nach meiner Auffassun
- 121 -
LITERATURVERZEICHNIS
Literaturverzeichnis
[Alp19]
„Alphabetisches Einwohner“ in Stadtbuch der Stadt Heidelberg nebst dem
angrenzen den Teile der Gemeinde Rohrbach für das Jahr 1919, S. 165-367
Heidelberg 1919
[Ard]
ARD:
http://www.ndrtv.de/tv/royalty/koenigs/norwegen/stammbaum.html
[Bai04]
Christel Baier: „Graphen und Bäume“ in Algorithmen und Datenstrukturen,
Kapitel 3.2, 2004,
http://web.informatik.uni-bonn.de/I/Lehre/Vorlesungen/InfoIV-SS04/Baier-Inf
oIV-SS04.pdf,
[Bac05]
Peter Bach: Leben | Chronik der musicalisch-Bachischen Familie, 2005,
http://www.bach.de/leben/chronik.html
[Ber73]
Claude Berge: Graphs and Hypergraphs, Noth-Holland Publishing Company,
Amsterdam und London 1973
[Ber91a]
Bertelsmann Universal Lexikon in 20 Bänden, Band 1 A-Aso, Verlagsgruppe
Bertelsmann GmbH/Bertelsmann Lexikon Verlag GmbH, Gütersloh 1991
[Ber91b]
Bertelsmann Universal Lexikon in 20 Bänden, Band 6 Feu-Gier, Verlagsgruppe Bertelsmann GmbH/Bertelsmann Lexikon Verlag GmbH, Gütersloh 1991
[Ber91c]
Bertelsmann Universal Lexikon in 20 Bänden, Band 12 Met-Nizo, Verlagsgruppe Bertelsmann GmbH/Bertelsmann Lexikon Verlag GmbH, Gütersloh
1991
[Bio_1]
Biologie Lexikon: Stammlinie,
http://www.bioboard.de/lexikon/Stammlinie,erklaerung.htm
[Bio_2]
Das Biologie Wiki: http://www.biologie.de/biowiki/Nachkommenliste
[Bio_03]
Biokurs 2003, Evolutionsfaktoren, Stammensentwicklung, http://www.merian.
fr.bw.schule.de/Beck/skripten/13/bs13-36.htm
[BrVo97]
Markus Brantl und Georg Vogeler: Die Geschichtlichen Hilfswissenschaften
stellen sich vor, 1997,
http://www.geschichte.uni-muenchen.de/ghw/allgemeines_geneal.shtml
[Bur03]
Franz Josef Burghardt: „Computergenealogie“ in Familienforschung, 5. Auflage, Meschede 2003, http://www.familiengeschichte.de/computer/
[Bur95]
W. Burkert: „Art. Genealogiai“ in Lexikon der Alten Welt, Bd. 1, Augsburg
1995
- 122 -
Royalty,
LITERATURVERZEICHNIS
[Dub00]
Paul Dubois: MySQL---Entwicklung, Implementierung und Referenz, Markt+
Technik Verlag, München 2002
[Dum01a]
R..Dumke: „gewichtete Graphen“ in Einführung/Algorithmen und Datenstrukturen 2001,
http://ivs.cs.uni-magdeburg.de/~dumke/EAD/Skript41.html
[Dum01b]
R. Dumke: „Bäume“ in Einführung/Algorithmen und Datenstrukturen 2001,
http://ivs.cs.uni-magdeburg.de/~dumke/EAD/Skript33.html
[Emb03a]
Franz Embacher: „Graph“ in Von Graphen, Gene und dem WWW, Kapitel 2,
2003, http://www.ap.univie.ac.at/users/fe/Lehre/aussermathAnw/Baeume.html
[Emb03b]
Franz Embacher: „Von Bäumen, Wurzel und Blättern, Tieren und Menschen“
in Von Graphen, Gene und dem WWW, Kapitel 4, 2003,
http://www.ap.univie.ac.at/users/fe/Lehre/aussermathAnw/Baeume.html,
[Emb03c]
Franz Embacher: „Verwandtschaft1“ in Von Graphen, Gene und dem WWW,
Kapitel 9, 2003, http://homepage.univie.ac.at/franz.embacher/Lehre/ausser
mathAnw/Verwandtschaft1.html
[Fam]
“PAF Download and Installation” in Familysearch,
http://www.ldscatalog.com/webapp/wcs/stores/servlet/StoreCatalogDisplay?st
oreId=10001&catalogId=10001&langId=-1
[Fis03a]
Stefan Fischer: „Graphen“ in Algorithmen und Datenstrukturen II, 2003,
http://www.ibr.cs.tu-bs.de/lehre/ss03/aud/AuD-SS03-Kap08-Graphen-1S.pdf
[Fis03b]
Stefan Fischer: „Bäume“ in Algorithmen und Datenstrukturen II, 2003,
http://www.ibr.cs.tu-bs.de/lehre/ss03/aud/AuD-SS03-Kap06-Baeume-1S.pdf
[GHGRBa]
Genealogisch-Heraldische Gesellschaft der Region Basel: Ahnenlist, 2004,
http://www.ghgrb.ch/genealogicalIntroduction/glossary.html#A
[GHGRBb]
Genealogisch-Heraldische Gesellschaft der Region Basel: Stammtafel, 2004,
http://www.ghgrb.ch/genealogicalIntroduction/glossary.html#S
[GHGRBc]
Genealogisch-Heraldische Gesellschaft der Region Basel: Verwandtschaft,
2004, http://www.ghgrb.ch/genealogicalIntroduction/verwandtschaft.html
[Gjo04]
Marijan Gjoreski: Visualisierung und interaktive Manipulation genealogischer Daten, 2004
[Glo05]
David Glowsky: Family Glowsky, 2005,
http://wwwstud.rz.uni-leipzig.de/~ges99emr/index.html
[Hag]
Judith & Paul Haag: „Nachfahren-Liste von Josef Anton Haag“ in der Familie
Haag aus Schweiz, http://haag-ch.net/
- 123 -
LITERATURVERZEICHNIS
[HeRi72]
Eckart Henning und Wolfgang Ribbe: Handbuch der Genealogie, Neustadt a.
d. Aisch 1972
[HS95]
A.Heuer und G.Saake.:Datenbanken:Konzepte und Sprachen. International
Thomson Publishing, Bonn, 1995.
[KeEi97]
Alfons Kemper und André Eickler: Datenbanksysteme , 2. aktualisierte und
erweiterte Auflage, R. Oldenbourg-Verlag, München, Wien 1997
[Kei]
Ewald Keil: GEDCOM, http://www.geocities.com/ekeilde/d-ged.htm
[Kel98]
Andreas Kelz:: Relationale Datenbanken, 1998, http://v.hdmstuttgart.de/~ riekert/lehre/db-kelz/
[Kno05]
Hans-W. Knol: GES-2000, Version 2005, http://www.ges-2000-knoll.de/
[Lan03]
Julius Langenberg: Die Familie Langenberg im katholischen Kirchenbuch
Uedem, 2003, http://home.arcor.de/stefan.langenberg/chronik/node8.html
[Lex]
Lexikon
und
Information:
Bäume
als
Datenstruktur,
http://www.hochschul-stellen.de/info/b/bi/bina_rbaum.html
[Lex90a]
Neues großes Lexikon in Farbe 1 A-L, o.A. des Verlags, 1990
[Lex90b]
Neues großes Lexikon in Farbe 1 M-Z, o.A. des Verlags, 1990
[Man03]
Rainer Manthey: Skript zur Vorlesung Informationssysteme WS 03/04,
Rheinische-Friedrich-Wilhelms-Universität Bonn Institut für Informatik III.
[Man04]
Rainer Manthey: Skript zur Vorlesung Deduktive Datenbanken I SS 2004,
Rheinische-Friedrich-Wilhelms-Universität Bonn Institut für Informatik III.
[Neu]
Ulf Neundorfer: Verwandtschaftsbeziehungen,
v-bez.html
[Pie94]
Eike Pies: Abenteuer Ahnenforschung, Solingen, 1994
[PVC]
PVCC Help Desk: Everything You Ever Wanted To Know About Microsoft Access 2000, http://www.pvcc.edu/helpdesk/tutorials/access/adataentry.htm.
[Rau]
Heribert Rau: Genealogische Methodik, http://www.heribert-rau.de/Ahnen-seite _von_Heribert_Rau/Genealogie/body_genealogie.html
[Reu01a]
Doris Reuter: Aufbau einer Ahnentafel ,
http://www.genealogie-forum.de/allgemein/ahnentafel.htm
[Reu01b]
Doris Reuter: Was ist GEDCOM?, 2001,
http://www.genealogie-forum.de/allgemein/gedcom/gedcom01.htm
- 124 -
http://www.ulfneundorfer.de/
LITERATURVERZEICHNIS
[Reu04]
Doris Reuter: „Was bedeutet Gedcom“ in Das Genealogie Forum, 2004,
http://www.genealogie-forum.de/allgemein/gedcom.htm
[SaSa03]
Gunter Saake, Kai-Uwe Sattler: Datenbanken & Java, 2.,überarbeitete und
aktualisierte Auflage, dpunkt.verlag GmbH, Heidelberg 2003.
[See01]
Maximilian Seefelder, Der Roider Jackl. Volkssänger, Gstanzlsänger, Kommenta tor (1906-1975), in: Booklet zur CD Roider Jackl. 1: Die frühen Jahre:
Lieder, Gstanzl, Erzählungen, Rottach-Egern 2001
[Sib03]
Christa Siebes: Batchnummern, 2003, http://www.siebes.de/html/batch.html
[Ste99]
Guido Stepken: MySQL Datenbankhandbuch, 1999
http://www.little-idiot.de/mysql/mysql.html#toc17
[SQL_1]
MySQL Tools: http://www.mysqltools.com/mysqlexp.htm
[Thi]
Georg Christian Thilenius, “Verwandtschaft” in Deutsches Kolonial-Lexikon,
Band III, S.618, http://www.ub.bildarchiv-dkg.uni-frankfurt.de/dfg-projekt/
Lexikon-Texte/V/Verwandtschaft.html
[Ull03]
Christian Ullenboom: Java ist auch eine Inse, aktualisierte und erweiterte
Auflage, Galileo Computing 2003
[Web03]
Tobias Weber: Einführung in die genealogie, 2003
http://www.vilstal.net/users/tobiasweber/einfuehrung.htm#einführung-3,
[Wik_1]
Wikipedia: Stammbaumtheorie, http://wikipedia.org/wiki/Stammbaumtheorie
[Wik_2]
Wikipedia: Ahnentafel, http://de.wikipedia.org/wiki/Ahnentafel
[Wik_3]
Wikipedia: API,
http://de.wikipedia.org/wiki/Application_Programming _Interface
[Wik_4]
Wikipedia:
stamm-baum
[Wik_5]
Wikipedia: Stammbaum, http://de.wikipedia.org/wiki/Stammbaum
[Wik_6]
Wikipedia: Genealogie, http://de.wikipedia.org/wiki/Genealogie
[Wik_7]
Wikipedia: Nachkommen, http://de.wikipedia.org/wiki/Nachkommen
[Wik_8]
Wikipedia: Proband, http://de.wikipedia.org/wiki/Proband
[Wik_9]
Wikipedia: Ahnen, http://de.wikipedia.org/wiki/Ahnen
[Wik_10]
Wikipedia: Abstammung, http://de.wikipedia.org/wiki/Abstammung
Familienstambaum,
- 125 -
http://de.wikipedia.org/wiki/Familien-
LITERATURVERZEICHNIS
[Wik_11]
Wikipedia: Blutsverwandtschaft,
http://de.wikipedia.org/wiki/Blutsverwandt-schaft
[Wik_12]
Wikipedia: Verwandtschaftssystem,
http://de.wikipedia.org/wiki/Verwandt-schaftssystem
[Wim89]
Erika Wimmer-Webhofer: Die Konservierung von Archivalien in Literaturarchiven. Empfehlungen zur Lagerung, Benützung und Sicherung von Nachlässen, München / New York / London / Paris 1989
[Wun]
Dieter Wunderlich: Biologischer und sprachlicher Stammbaum des Menschen
nach Cavalli-Sforza:
http://user.phil-fak.uni-duesseldorf.de/~wdl/ Gen-Stammbaum.pdf
- 126 -
ERLÄRUNG
Hiermit erkläre ich Eides statt, diese Arbeit selbstständig angefertigt und keine außer den angegebenen
Hilfsmitteln verwendet zu haben.
Bonn, den 19. Oktober 2005
________________________
Ping Ni
- 127 -