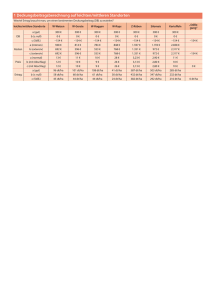
Beschreibung
Werbung

TLGen Beschreibung EJB3 Backend Code-Generator Version 2.5 (Deutsch) Autoren: Titus Livius Rosu ([email protected]) Titus Rosu ([email protected]) Liviu Rosu ([email protected]) Letzte Änderung: 27. April 2011 Table of Contents Inhaltsverzeichnis ABBILDUNGSVERZEICHNIS ............................................................................................................................... 3 TABELLENVERZEICHNIS .................................................................................................................................... 3 1. ALLGEMEINE INFORMATION .................................................................................................................... 4 1.1 ZIELE ............................................................................................................................................................... 6 1.2 TLGEN´S ARCHITEKTUR-KONZEPT ......................................................................................................................... 7 1.2.1 Input für die Code-Generierung ............................................................................................................. 8 1.3 BESCHREIBUNG DER MÖGLICHKEITEN DURCH TLGEN ................................................................................................ 8 1.3.1 Code Generierung mit einem Domain Model (UML) ............................................................................. 9 1.3.2 Code Generierung mit einer schon vorhandenen Datenbank .............................................................. 10 2. TLGEN CODE-GENERIERUNG UND DIE ANALYSE VON DATENBANKEN ................................................... 11 2.1 ANALYSE DES DOMAINMODELLS UND DER DATENBANK ........................................................................................... 12 2.2 DATEN KLASSEN - INTERFACES ............................................................................................................................ 16 2.3 SESSION BEAN ................................................................................................................................................. 17 2.3.1 Interfaces für eine Session Bean .......................................................................................................... 19 2.3.2 XML Persistente Datei ......................................................................................................................... 20 2.3.3 Interface Klassen zu Fachlogik Komponenten ..................................................................................... 21 2.3.4 Interceptors ......................................................................................................................................... 21 2.4 CLIENTS, BCI (BUSINESS COMMON INTERFACE)..................................................................................................... 22 2.4.1 Test Klassen ......................................................................................................................................... 23 2.4.1.1 Verwendung von Test Daten aus externen Dateien ...................................................................................... 24 2.5 MANAGER KLASSEN ......................................................................................................................................... 25 2.5.1 Manager Interfaces ............................................................................................................................. 27 2.6 ENTITY BEANS ................................................................................................................................................. 28 2.6.1 Relationen ........................................................................................................................................... 32 2.6.1.1 Relation „OneToMany“ .................................................................................................................................. 32 2.6.1.2 Relation „ManyToOne“ .................................................................................................................................. 33 2.6.1.3 Relation „OneToOne“ .................................................................................................................................... 34 2.6.1.4 Relation „ManyToMany“ ............................................................................................................................... 34 2.7 GENERIERUNG VON DATENBANK UND SQL SKRIPTE................................................................................................ 37 2.8 REGEL FÜR DIE GENERIERUNG VON NAMEN .......................................................................................................... 37 2.9 LOG DATEIEN BESCHREIBUNG............................................................................................................................. 38 2.10 MESSAGE DRIVEN BEAN.................................................................................................................................. 40 2.11 SERVICES ...................................................................................................................................................... 40 2.11.1 Timer Service ..................................................................................................................................... 40 2.11.2 Web Services...................................................................................................................................... 41 2.11.3 Callback Klasse .................................................................................................................................. 41 2.12 FREE KLASSE ................................................................................................................................................. 41 3. VERGLEICH ZWISCHEN TLGEN UND ANDEREN CODE GENERATOREN ..................................................... 43 TLGen 2 StarData GmbH Table of Contents Abbildungsverzeichnis ABBILDUNG 1: IT PROJEKT-ARCHITEKTUR............................................................................................................... 5 ABBILDUNG 2: TLGEN ARCHITEKTUR-KONZEPT ...................................................................................................... 8 ABBILDUNG 3: TLGEN-GENERIERUNGSPROZESS VOR EINER DATENBANK ........................................................... 11 ABBILDUNG 4: UML-KLASSENDIAGRAMM I .......................................................................................................... 13 ABBILDUNG 5: UML-KLASSENDIAGRAMM II ......................................................................................................... 13 ABBILDUNG 6: UML-KLASSENDIAGRAMM III ........................................................................................................ 14 ABBILDUNG 7: UML-KLASSENDIAGRAMM IV ........................................................................................................ 14 ABBILDUNG 8: „ONETOMANY“ ............................................................................................................................. 33 ABBILDUNG 9: „ONETOMANY“ DATENMODELL ................................................................................................... 33 ABBILDUNG 10: „MANYTOMANY“ DARSTELLUNG IM UML DOMAINMODELL ..................................................... 35 ABBILDUNG 11: „MANYTOMANY“ DB RELATION ................................................................................................. 35 Tabellenverzeichnis TABELLE 1: JAVA-TYPEN ........................................................................................................................................ 16 TABELLE 2: ANNOTATIONEN ................................................................................................................................. 18 TABELLE 3: AUTOMATISCH GENERIERBARE DEFAULT METHODEN ...................................................................... 25 TABELLE 4: ANNOTATIONEN FÜR MANAGER KLASSEN ........................................................................................ 27 TABELLE 5: ANNOTATIONEN FÜR ENTITY BEANS (EJB3) ....................................................................................... 29 TABELLE 6: NAMEN-REGEL .................................................................................................................................... 38 TABELLE 7: ANNOTATIONEN FÜR MESSAGE DRIVEN BEAN .................................................................................. 40 TLGen 3 StarData GmbH V 2.501 1. Allgemeine Information „Wissen ist Macht“ hat der englische Philosoph Francis Bacon im sechzehnten Jahrhundert gesagt. Um sich Wissen anzueignen, braucht man Daten. Daten sind darstellbare Elemente einer Information, mit deren Hilfe Eigenschaften einer Aktivität beschrieben und in Systemen verarbeitet werden. Heutzutage entsprechen diese Systeme den Computern, die in einer digitalen Form Daten verarbeiten. Durch die stetig ansteigende Computerleistung in Verbindung mit Datenbankensystemen und Vernetzung (z.B. durch Internet) sind wir begraben unter einer Flut an Daten, die Systeme regelrecht zusammenbrechen lassen. Wir benötigen für den täglichen Tagesablauf eine Fülle an Informationen (z.B. Banküberweisungen, Emailverkehr, CRM/ERP-Systeme), die wir immer öfter nicht mehr in einer effizienten Form erhalten (z.B. Systemabstürze, Unterbrechungen, fehlende Daten). Ein Hauptgrund dieser Problematik findet sich in den Verfahren mit dem die Daten gesucht sowie abgespeichert werden. Das heutige Standardverfahren für die Datenverwaltung der Informationen bevorzugt den Einsatz von relationalen Datenbanken (z. b. Oracle, DB2 von IBM, MySQL, SQL Server von Microsoft etc.) sowie von Applikation Servern bevorzugt (z. b. JBoss, WebLogic von Oracle, WebSphere von IBM etc.). Die zwei Komponenten - Datenbanken und Application Server -, werden in einer Persistenzschicht integriert, welche Teil eines Programms ist, das die Fachlogik darstellt, notwendig für eine bestimmte Aktivität (siehe Abbildung 1). Der Nutzer (User) verwendet ein Programm über die Bedienoberfläche (GUI oder Web), die sich meist auf einem getrennten Computer, dem Client, befindet. Der Client holt sich die Informationen, die er benötigt, von einem Server, wo sich die Fachlogik des Programms sowie die Datenbank befinden. Nach heutigem technischem Stand wird die Steuerung der Kommunikation zwischen Client und Server durch einen Application Server gesteuert, der gleichzeitig die Daten innerhalb der Datenbank mit Hilfe von so genannten CRUDs (Create, Read, Update, Delete) verwaltet. Die Persistenzschicht ist ein essentiell wichtiger Teil eines jeden IT Programms und verursacht den Hauptanteil der Programmentwicklungskosten zusammen mit Wartung und Erweiterungen durch neue Features. Der Kostenwand wird durch den Einsatz von relationalen Datenbanken weiter ausgebaut. Zurzeit sind die wichtigsten Gründe für erhöhte Kosten im IT Sektor: Falsche Modellierung von Daten-Modellen sowie die Anwendung von DatenModellen, die nicht genormt sind (wichtig ist die dritte Normalform) Daten-Modelle, die Historisch gewachsen sind Die Persistenzschicht ist nicht optimal gestaltet worden und benötigt einen zu großen Aufwand an Wartung und Weiterentwicklung Mischung von technischem mit fachlichem Code (siehe Anmerkung) Anmerkung: In der Softwareentwicklung sind drei Typen von Code zu unterscheiden: Technischer Code: Code, der zu 100 % unabhängig von der Fachlogik ist. Generierbarer Code: Ist gemischter Code, der aus technischem und fachlogischem Code besteht (nur Datenstruktur). Dieser Code Typ lässt sich zu 100 % generieren und somit die Entwicklung-, Wartung- sowie Weiterentwicklungs-Kosten von IT Projekten enorm reduzieren. TLGen 4 StarData GmbH V 2.501 o In Abb. 1 entspricht dieser Code Typ den Session Beans, der Persistence Data (Objects/Interfaces), den Managern, der Entity Beans, BCI, JUnit (Test) und den Interfaces der Business Tier. Das umfasst 40 – 80 % der Entwicklungskosten eines IT Projekt (siehe 1.2.1). Fachlogik-Code: Ist zu 100 % spezifisch für jedes einzelne IT Projekt. Zu diesem Typ gehören z.B. die Gestaltung der Oberfläche (Präsentation Tier) oder die Kommunikationsschnittstellen für Partnersysteme etc. Abbildung 1: IT Projekt-Architektur TLGen ist ein Generator für den gemischten Java Code auf Basis von EJB 3, eine Thematik, die detailliert in Kapitel 1 erläutert wird (siehe auch www.tlgen.com). In Kapitel 2 wird die Verwendung von TLGen mit der genauen Offenlegung seiner Features in Kombination mit der Ordnerstruktur der Konfigurationsdatei, woraus man die Projektarchitektur gestalten kann, beschrieben. In Kapitel 3 werden Beispiele zur Code-Generierung mit Hilfe der Konfigurationsdatei genannt. TLGen 5 StarData GmbH V 2.501 Kapitel 4 behandelt die Möglichkeiten, die TLGen ermöglicht, um z.B. die Datenmodelle zu optimieren oder Kreise in Datenmodelle zu vermeiden. Gleichzeitig werden die Logdateien beschrieben, die bei der Generierung entstehen. Im Kapitel 5 wird die Installation und Verwendung von TLGen in IT Projekte beschrieben. 1.1 Ziele TLGen ist ein Code-Generator auf Basis von EJB3 mit Java Annotationen. Ziel unserer Arbeit war, die Kosten für die Backend-Softwareentwicklung durch eine komplette Generierung von Code zu minimieren. Aktuelle Code-Generatoren auf Basis des MDA Ansatzes (Hibernate, TopLink etc.) benötigen nach der Generierung auch einen bedeutenden Arbeitsaufwand durch die Entwickler, nachträgliches Customizing, so dass der angesetzte Zeitgewinn durch weiteren Aufwand verfällt. Der Mix aus generiertem Code und den von Programmierern entwickelten Code (manuelle Entwicklung) führen in der Realität zu einer Anzahl von Problemen (unterschiedliche Logik, Layout, Auseinanderdriften von Modell und Code, Fehler etc.). Dies ist der Grund, warum der Ansatz von TLGen eine klare Trennung zwischen dem generierten und manuell entwickelten Code fordert. In der IT wurde des Öfteren bewiesen, dass sich ein sehr großer Teil von Code vollständig generieren lässt. TLGen ermöglicht diese Generierung mit Hilfe des Daten-Inputs in Form eines Domainmodells (neue Projekte) oder einer schon existieren Datenbank (Refactoring Projekte von Legacy Systemen) in Verbindung mit zwei Konfigurationsdateien (beinhalten die Steuerungsparameter für die Generierung). TLGen benötigt zwei Konfigurationsdateien: eine für allgemeine Definitionen, wie DatenTypen, Konvertierung, etc., die nur selten zu ändern ist (wird mit TLGen mitgeliefert) und eine Projekt-Konfigurationsdatei, die wichtige Informationen beinhaltet, wie Namen, Regeln, Umwandlungen, Projekt-Struktur (wichtig für Legacy-Projekte), Verknüpfung von Tabellen zu bestimmten Session Beans, usw. Zusätzlich bietet TLGen die Möglichkeit an eine Datenbank oder ein Domainmodell zu analysieren und unterbreitet Vorschläge für deren Optimierung. Ist die Entwicklungsphase eines IT-Projektes beendet, werden stetig weitere Features für neue Praxis-Anforderungen implementiert und somit die benötigte Datenbank durch Erweiterung angepasst (gemeint ist nur die Datenstruktur). Diese historisch wachsenden Datenbanken führen eher selten zu einer Fortführung optimaler Datenstrukturen und letztendlich zu hohen Wartungskosten in Verbindung mit dem Zwangsstart von Refactoring Projekten. Das Datenmodell sollte, mindestens in der dritten Normalform vorliegen (siehe z.B. http://de.wikipedia.org/wiki/Normalisierung_%28Datenbank%29 ). Die Normalisierung ist ein wichtiges Hilfsmittel, um die Konsistenz der Daten zu gewährleisten. Das erleichtert die Wartung sowie die Upgrade-Möglichkeiten für zukünftige Anforderungen der Applikation, ohne die Datensätze zu verändern. Da es für viele Datenbanken keine grafische Darstellung der Datenstruktur gibt, um so die Möglichkeit der Optimierung des Datenmodells zu gewährleisten, wird die Arbeit der Erstellung eines neuen Modells erheblich erschwert. TLGen bietet jetzt die Möglichkeit an aus einem existierenden Datenbankmodell die Grafik bzw. das Domainmodell zu generieren, zusammen mit Optimierungsvorschlägen. Durch die schnelle Code-Generierung können diese Änderungen sofort für die obligatorischen Projekt-Tests bereitstehen und somit einen schnellen Überblick über das Entwicklungsvorhaben ermöglichen. Diese grafische Darstellung als Domainmodell (UML) ist sehr wichtig für die Optimierung einer alten Datenbank. TLGen 6 StarData GmbH V 2.501 Des Weiteren wird erst durch das neu-erstellte Domainmodell eine Generierung des Backend‟s möglich, da jede Zeile aus einer Datenbanktabelle als Java Bean-Objekt im generierten Code abgebildet wird (dabei spielt es keine Rollte, ob als Join/Mapping aus mehreren Tabellen oder aus einer Zeile einer Tabelle). Der generierte Backend-Code entspricht dem Software-Architekturkonzept, welches in Abb. 2 anschaulich erklärt wird. 1.2 TLGen´s Architektur-Konzept In Abbildung 2 wird das Architektur-Konzept von TLGen dargestellt, zusammen mit den Komponenten, welche TLGen generiert: Test Klassen(JUnit), Data Klassen/Interfaces Sessions Beans Manager Beans Entity Beans Message Driven Beans Timer Services Web Services Callback Klassen Free Klassen Log Dateien (beschreiben im Detail die generierte Elemente) Datenbank-Skripte (notwendig, um eine Datenbank zu erstellen). Für das Ändern einer schon vorhandenen Datenbank werden nur die Differenz-Skripte generiert, um so die existierenden Daten nicht zu löschen. Für die Änderung einer existierenden Datenbank werden nur die Differenz Skripte generiert, um so die vorhandenen Daten nicht zu löschen. Diese Skripte können direkt in dem Generierungsprozess verwendet werden oder erst später, bei Bedarf (siehe 1.3 und 2). TLGen 7 StarData GmbH V 2.501 Abbildung 2: TLGen Architektur-Konzept 1.2.1 Input für die Code-Generierung Damit TLGen den Code generieren kann, wird folgender Input benötigt: Ein Datenstruktur-Modell, was entweder ein Domainmodell (siehe Abb. 2) sein kann, designed in UML für den Start neuer IT-Projekte (siehe Kapitel 1.3.1) oder ein Datenbankmodell (z. B. eine existierende Datenbank – Abb. 2) beim Einsatz in Legacy-Projekten (siehe Kapitel 1.3.2), die einen Refactoring Prozess benötigen. Ein Default Konfigurationsdatei (im XML-Format), welche die Werte für Definitionen beinhaltet, wie z.B. allgemeine Regeln für die Namen-Konventionen, UML Domainmodell Regel, Standard-Methoden für die Datenbankzugriffe, eine Tabelle mit Konvertierung zwischen den Variablen-Typen in Java Code und in der Datenbank. Ein Konfigurations-Datei (im XML-Format) mit unterschiedlichen Informationen, die vom Projekt abhängen (siehe Kap. 3). Oben genannte Input-Informationen werden in Projekten immer von den Designern oder Datenmodellieren erstellt. Lediglich die Konfigurationsdatei ist neu für den Code, denn das Daten- oder Datenbankmodell (DM oder DB) ist immer eine Notwendigkeit in der Entwicklung von IT-Projekten. 1.3 Beschreibung der Möglichkeiten durch TLGen Im fortlaufenden Kapitel werden alle detaillierten Möglichkeiten beschrieben, die TLGen für die Codegenerierung sowie die Analyse von Datenbanken bietet. Die detaillierte Struktur der Konfigurationsdateien wird in Kap. 4.4 erläutert. TLGen 8 StarData GmbH V 2.501 Wie schon im Kapitel 1.2 erwähnt, steuert TLGen den Generierungs-Prozess mit Hilfe von zwei Konfigurations-Dateien, eine für Default-Werte, die in der Regel keinen großen Änderungsbedarf besitzt sowie eine Konfigurations-Datei, die individuell für jedes Projekt ist. TLGen bietet für die Generierung von Code folgende Möglichkeiten an: Das Einbauen von Kommentaren innerhalb des generierten Codes (siehe Kap. 3.1) Regel für die Namen-Generierung der Datenbanken sowie für den generierten Code (siehe Kap. 3.3) Der Einsatz aller Annotationen im generierten Code, die EJB3 anbietet Informationen für die Generierung mit Hilfe von Apache Tool „ant“ und einer „ear“ Datei Der generierte Code entspricht dem EJB 3-Standard und ist verwendbar auf allen Applicationen Server, die momentan am Markt vertreten sind (WebLogic, WebSphere, JBoss, GlasFish, IoNas, etc.) Folgender Code wird generiert: o Session Beans mit allen Annotationen (siehe Kap. 2.3) o Manager Klassen für die Steuerung von Entity Beans mit allen möglichen Zugriffen für CRUD (Create, Read, Update, Delete). Beim Manager ist es auch möglich eigene SQLs einzubinden (werden aus den Konfigurationsdateien gelesen) (siehe Kap. 2.5). o Entity Beans, wo alle Relationen automatisch generiert werden (von Domainmodell oder aus der Datenbank) - OneToOne, OneToMany, ManyToOne, ManyToMany (siehe Kap. 2.6 und 2.7) o Clients Klassen für BCI (Business Common Interfaces); diese ermöglichen die Verbindung zwischen Client und Server (Session Beans). o Test Klassen auf Basis von JUnit. Die Daten für Test Klassen können durch TLGen generiert oder von einer XML Datei geladen werden. Auch die Struktur von den XML-Daten-Dateien kann von TLGen generiert werden. TestKlassen sind in zwei Modi zu verwenden, indem die Daten direkt geprintet oder über die Mechanismen von JUnit getestet werden. o Datenbank-Skripte o Klassen für die Interfaces für Fachlogik Code o Interceptoren o Daten Klassen/Interfaces o XML Datei für Persistenz (persistence.xml), eine für jede Session Bean TLGen kann mit den „ant“ Apache Tool genutzt werden, da TLGen einen eigenen Tag „generator“ besitzt. 1.3.1 Code Generierung mit einem Domain Model (UML) Die Generierung mit Hilfe eines Domainmodells als Informations-Input findet seine Anwendung bei neuen IT-Projekten. Ein IT-Architekt (oder ein Architektur-Team - die Wahl hängt vom Projekt ab) designend zusammen mit der Fachabteilung ein Domainmodell, das die Datenstruktur und dessen Verbindungen für das Programm darstellt. Auf dieser Basis kann man letztendlich mit TLGen den kompletten Code generieren und diesen sofort testen. TLGen 9 StarData GmbH V 2.501 Für solch ein Projekt bietet TLGen zu den Eigenschaften aus Kapitel 1.3 zusätzliche Möglichkeiten an: Eine Analyse des Domainmodells nach falschen Namen (z. B. zu lang für eine Datenbank), eventuelle Kreise in den Verbindungen zwischen Objekten (Tabellen) und mögliche Verbesserungenvorschläge (siehe Kap. 2.1). Innerhalb von einem Domainmodell können Klassen-Typen und Enume verwendet werden. Daten und Klassen-Typen können in jeder beliebigen Art und Weise verschachtelt werden, so wie die benötigte Logik der Applikation. 1.3.2 Code Generierung mit einer schon vorhandenen Datenbank Nachdem TLGen einen Zugang zur Datenbank erhalten hat, bezieht TLGen alle relevanten Information für die Code-Genierung, wie z.B. Tabellen, Spalten, Relationen, Sequenzen etc. TLGen ist kompatibel zu allen momentan Datenbanken. Für ein Projekt, dass mit einer Datenbank als Input startet (z.B. Refactoring von LegacySystemen) bietet TLGen zu den in Kap. 1.3 aufgehführten Eigenschaften weitere Möglichkeiten an, wie: Regel für die Verwendung von Tabellen, Spalten etc. für den generierten Code, konform den existierenden Namen-Konventionen im Code Generierung von Datenbank-Skripte für eine neue Datenbank oder nur Änderungsskripte, die dann nur die Differenzen beinhalten TLGen 10 StarData GmbH V 2.501 2. TLGen Code-Generierung und die Analyse von Datenbanken TLGen ist ein einfaches Tools mit höchstem Grad an technischen Hintergrund für die Generierung von Backend Code auf Basis von EJB3. Wie in den Kapiteln zuvor erklärt, generiert TLGen den Code mit einem Domain- oder Datenbankmodell (siehe Abb. 3) und bietet gleichzeitig Optimierungsmöglichkeiten nach eigener Analyse der Modelle an. Abbildung 3: TLGen-Generierungsprozess vor einer Datenbank In diesem Kapitel werden detailliert die generierten Objekte sowie zur Verfügung stehende Steuerungsmöglichkeiten beschrieben. Allgemeine Features, die zentral für die gesamte Generierung möglich sind (für Details siehe Kap. 4.5): Projekt-Name Application Server, z.b. „JBoss“, “Weblogic” etc. Der Application Server ist wichtig für die Verwendung des generierten Codes für „Clients“, weil jeder App.Server verwendet für die Variable „datasource“ eigene Darstellung und für die Connection zwischen Client und Server eigene Klassen, z.B. für JBoss folgende Klassen verwendet: initialcontextfactory="org.jnp.interfaces.NamingContextFactory" initialcontextpkgprefix="org.jboss.naming:org.jnp.interfaces" 1. Listing Datenbank-Namen mit Zugriff für die berechtigten User samt Passwörter zum Auslesen der Informationen (Tabellen, Spalten, Sequences, etc., für Legacy Projekte oder Ziele, wo die Tabellen generiert werden sollten) Projekt-Steuerungs-Attribut. Ein Refactoring-Projekt durch eine schon vorhandene Datenbank (wichtig bei vorhandener Legacy-IT) oder Entwicklung einer neuen Applikation durch ein Domainmodell. Für die Generierung einer neuen Datenbank kann diese vollständig neu erstellt oder nur die Änderungen übernommen werden ohne schon vorhandene Daten zu löschen. Notwendige Informationen für die Generierung von SQL Skripte wie Tablespace etc. „ear“ Datei-Name Die generierte Code-Formatierung kann frei gewählt werden (Standard JavaFormatierung z.B. mit geschweiften Klammern in derselben oder nächsten Zeile oder TLGen 11 StarData GmbH V 2.501 ob z.B. die Import-Deklarationen am Klassenanfang oder direkt im Code mit den vollständigen Import-Pfaden angezeigt wird.). import eu.stardata.core.hlp.dataif.CoLanguageDataIf; import javax.persistence.OneToMany; class { private CoLanguageDataIf … … } 2. Listing oder ohne Import in Code: class { @ javax.persistence.OneToMany(cascade = { javax.persistence.CascadeType.PERSIST}, targetEntity = eu.stardata.server.core.formular.entity.PageEntity.class) private eu.stardata.server.core.doclist.entity.DocumentlistEntity … … } 3. Listing 2.1 Analyse des Domainmodells und der Datenbank Die Relationen von Klassen eines Domainmodells oder von Datenbank-Tabellen können je nach Anforderungen unterschiedlich komplex sein. Betrachten wir als Beispiel Abbildung 4 eines UML-Klassendiagramms, wo beim Neuanlegen der Klasse C mindestens ein B über zwei verschiedene Pfade gleichzeitig benötigt wird. Doch, wenn noch kein B existiert, muss dieses erst neuangelegt werden. Dies ist in diesem Fall aber nur möglich, falls ein C über eine Relation von Pfad A schon existiert. Das Klassendiagramm ist logisch nicht inkorrekt (z.B. sei A ein Produkt, B ein Element des Produkts und C ein Bestellauftrag). Aber die Klassen des Beispiel Domainmodells, jeweils als Tabelle in einer Datenbank abgebildet, führen zum Problem, dass C B direkt benötigt (not null) genauso wie A (not null) doch A benötigt und auch ein B (not null), dass zu diesem Zeitpunkt schon existieren muss. TLGen 12 StarData GmbH V 2.501 Abbildung 4: UML-Klassendiagramm I Anmerkung: Ein UML-Klassendiagramm, wo beim Neuanlegen der Klasse C B über 2 verschiedene Pfade benötigt wird. Beim Neuanlegen von B kann dieses dagegen noch nicht existieren, da C noch nicht über die Relation von Pfad A existiert. Kreise, durch Pfade in der Erreichbarkeit der Klasse „C“, sind hier folgende: Die Klasse „C“ ist über die Klasse „B“ durch folgende Pfade erreichbar: [B (NOT NULL)->A (NOT NULL)] ---> [C] [B (NOT NULL)] ---> [C] Genau in diesem Schema werden alle Pfade in der Erreichbarkeit einer Klasse (hier „C“), über welche Klassen (hier „B“) diese Pfade verlaufen, in der Debug-Log Datei bei der Generierung des Codes durch TLGen dargestellt. Fälle wie in Abbildung 4 werden mit einem „Fatal Error“ in der Debug-LOG Datei und Error-LOG Datei ausgegeben. Dagegen werden Kreise von Relationspfaden, die nicht über unterschiedliche Klassen in der Zielklasse enden, mit einem „Warning“ angezeigt (vgl. Abbildung 5). Abbildung 5: UML-Klassendiagramm II Wie Abb. 1, aber in der Relation von [B(Null)] ---> [C] ist null erlaubt. Somit kann B und C über den Relationen von A gleichzeitig angelegt werden. Direkte Kreise, d.h. Zielklasse ist auch die Startklasse in einem Relationspfad, werden in den LOG-Dateien als „Fatal Error“ deklariert (vgl. Abbildung 6), falls alle Klassen im Relationspfad voneinander abhängig sind (hier: [A (NOT NULL)->C (NOT NULL) ->B (NOT NULL)] ---> [A]) und nur mit einem „Warning“, falls dies nicht zutrifft (vgl. Abbildung 7: [A (NOT NULL)->C (NULL) ->B (NOT NULL)] ---> [A]) TLGen 13 StarData GmbH V 2.501 Abbildung 6: UML-Klassendiagramm III Ein direkter Relationspad, wo jede Startklasse auch Zielklasse ist und alle voneinander abhängig sind. Abbildung 7: UML-Klassendiagramm IV Ein direkter Relationspad, wo jede Startklasse auch Zielklasse ist, aber nicht alle voneinander abhängig sind. Im Folgenden ist ein Knoten äquivalent mit einer Klasse des Domainmodells oder einer Datenbanktabelle. Die Debug-LOG Datei beinhaltet folgende Informationen, um Pfade zu analysieren: „CHECK RELATIONS METHODS - Adjacency list”: Die Liste zeigt alle Knoten (TARGET), die über verschiedene Relationspfade erreicht werden können: Node: 'TARGET': [ungeordneter Relationspfad] ---> [TARGET] [alle passierten Vorknoten der Pfade aufsummiert] Beispiel: [C,B] ---> [A] [C(1),B(2)] „CHECK RELATIONS METHODS - CIRCLE PATH (direct)”: Die Liste zeigt alle Kreise der Knoten (TARGET), die über verschiedene Relationspfade über den TARGET selber erreicht werden können: Node: 'TARGET': [geordneter Relationspfad beginnend mit TARGET] ---> [TARGET] Beispiel: [A(NULL)->C (NOT NULL)->B (NOT NULL)] ---> [A] TLGen 14 StarData GmbH V 2.501 „CHECK RELATIONS METHODS – ALL PATHS”: Die Liste zeigt alle Pfade der Knoten (TARGET), die über andere Knoten erreicht werden können: Node: 'TARGET': [geordneter Relationspfad] ---> [TARGET] Beispiel: [C (NOT NULL)->B (NOT NULL)] ---> [A] Wenn neben dem Pfad ein „FATAL” steht, dann ist TARGET von sich selber abhängig. „CHECK RELATIONS METHODS - CIRCLE PATHS (not direct)”: Die Liste zeigt alle Pfade der Knoten (TARGET), die von verschiedenen Knoten (SOURCE) über unterschiedliche Relationspfade erreicht werden können: 'TARGET': 'SOURCE': [geordneter Relationspfad mit SOURCE] ---> [TARGET] Beispiel: -'C': [C (NOT NULL)->B (NOT NULL)] ---> [A] Wenn neben dem Knoten SOURCE „FATAL” erscheint, dann sind mehrere Pfade, die in TARGET enden, von SOURCE abhängig (siehe oben, z.B. [C->D]--->[A] und [C->B]--->[A]). Wenn ein „Warning” erscheint, dann sind mehrere Pfade, die in TARGET enden, von SOURCE abhängig, wobei diese über denselben Knoten in TARGET (siehe oben, z.B. [C->D->B]--->[A] und [C->B]--->[A]) enden. Die Error-LOG Datei beinhaltet folgende Informationen, um Pfade zu analysieren: „Direct circles in relations” o „Warning“, wenn es einen Relationspfad gibt, wo Start- und Endknoten derselbe ist. Beispiel: [A (NULL)->B (NOT NULL)] ---> [A]) o „FATAL Error“, wenn es einen Relationspfad gibt, wo Start- und Endknoten derselbe ist und voneinander abhängig sind. Beispiel: [A (NOT NULL)->B (NOT NULL)] ---> [A] „Relation Problems?” o „Warning“, wenn man den Zielknoten über verschiedene Relationspfade desselben Startknotens erreichen kann und diese voneinander abhängig sind, aber in den Zielknoten immer über denselben Vorgängerknoten endet. Beispiel: [C (NOT NULL)->B (NOT NULL)] ---> [A] und [C (NOT NULL)->D (NOT NULL)->B (NOT NULL)] ---> [A]) o „FATAL Error“, wenn man den Zielknoten über verschiedene Relationspfade desselben Startknotens erreichen kann und diese voneinander abhängig sind. Beispiel: [C (NOT NULL)->B (NOT NULL)] ---> [A] und [C (NOT NULL)->D (NOT NULL)] ---> [A] TLGen 15 StarData GmbH V 2.501 2.2 Daten Klassen - Interfaces TLGen kann Daten, Klassen/Interfaces aus einem Domainmodell oder aus einer vorhandenen Datenbank generieren. Es wandelt die Datenbank-Tabellen mit seinen Spalten in Klassen/Interfaces mit ihren Variablen um. Die Daten-Typen von Spalten umwandelt es in Java Daten-Typen wie in Tabelle 1 dargestellt. Für Sonderwünsche der Typ-Verwendung kann in der Default Konfiguration Datei eigene Umwandlung definiert werden (siehe 4.4). Tabelle 1: Java-Typen Nr. Datenbank Type Java (Code) Type 1 CHAR char 2 NCHAR char 3 DATE java.util.Date 4 TIMESTAMP java.util.Date 5 DECIMAL double 6 BINARY_DOUBLE double 7 BINARY_FLOAT float 8 INTEGER int 9 NUMBER long 10 VARCHAR java.lang.String 11 VARCHAR2 java.lang.String 12 NVARCHAR2 java.lang.String 13 LONG java.lang.Long 14 RAW java.lang.String 15 LONG RAW byte[] 16 CLOB java.lang.String 17 NCLOB java.lang.String 18 BLOB byte[] 19 TEXT java.lang.String 20 LONGTEXT java.lang.String 21 INT int 22 BIGINT long 23 DATETIME java.util.Date 24 SMALLINT short In Konfigurationsdateien ist es möglich auch die Klassen/Interface Path mit „extends“ zu definieren. Diese „extends“ sind Basis Klassen/Interfaces, die eventuelle Variablen beinhalten, die die komplette Applikation beinhaltet und kann von TLGen Anwender geschrieben werden. TLGen liefert auch diesen Code für Standard Anwendungen mit. Diese Superklassen sind nicht unbedingt notwendig für das Programm. TLGen 16 StarData GmbH V 2.501 TLGen hat auch eigene Basis Klassen/Interfaces, die als Default verwendet werden, falls der TLGen Anwender nicht eigene schreibt (siehe 4.4.2.1). In Konfigurationsdateien werden auch das Path für Klassen „Typen“ und „Enums“ definiert, falls diese in der Applikation verwendet werden. TLGen generiert für die Relationen, die in der Datenbank- oder in dem Domainmodell vorhanden sind entsprechende Variablen als Liste oder einfache Variablen wie für Interfaces: public abstract List<CoPageDataIf> getPage(); public abstract void setPage(List<CoPageDataIf> arg); 4. Listing und für Klassen: private List<CoPageDataIf> m_page; public List<CoPageDataIf> getPage() { return m_page; } public void setPage(List<CoPageDataIf> arg) { m_page = arg; } 5. Listing Für die Klassen/Interfaces, die seitens Domainmodells generiert sind, werden alle Attribute übernommen, persistente und nicht persistente, aber in den SQL Skripten (die für die Datenbank Generierung notwendig sind) werden nur die persistenten Variablen verwendet. Für die Klassen/Interfaces, die von einer vorhandenen Datenbank generiert werden, können neue Variable eingefügt werden, die nicht persistent sind. 2.3 Session Bean Session Bean ist eine wichtige Klasse und die erste Klasse, welche von einem Client über RMI aufgerufen wird. Sie hat innerhalb von EJB3 eine vordefinierte Form und kann mit mehreren Annotationen verwendet werden (siehe Tabelle 2). Mit Hilfe der Steuerung über die Konfigurationsdateien können für die Session Beans folgende Features generiert werden: Annotationen mit Parameter Selbst geschriebene „extends“ Klassen oder die von TLGen Default Session Bean Basis Klassen Interceptoren (siehe 2.3.4) Clients (Siehe 2.4) Manager Klassen (siehe 2.5) Entity Beans (siehe 2.6) XML Persistente Datei (siehe 2.3.2) TLGen 17 StarData GmbH V 2.501 Definiert die Methoden, die von Client aufgerufen wird. Diese Methoden können von den Manager Klassen übernommen werden. Kann bestimmen, welcher Type von Transaktionen verwendet wird. Interface-Klassen die, die Verbindung zwischen generiertem Code und Fachcode ermöglichen. Tabelle 2: Annotationen Annotationen Verwendung Kommentar in TLGen 2.1 javax.ejb.Stateless ja Definiert eine Stateless Session Bean javax.ejb.Stateful ja Definiert eine Stateful Session Bean javax.ejb.EJB ja Definiert eine Lokale References z. B. Name eines Manger Interface (siehe 2.5) javax.ejb.Remote ja Bezeichnet eine Remote Verwendung von Session Bean javax.ejb.Local ja Ist für eine Lokale Verwendung javax.ejb.ApplicationException nein javax.ejb.EJBs ja javax.ejb.Init nein javax.ejb.LocalHome nein Entspricht nicht der Philosophie von EJB3 javax.ejb.PostActivate ja Methode wird nach dem Aktivierung von Session Bean aufgerufen javax.ejb.PrePassivate ja Nur für Stateful Session Bean javax.ejb.RemoteHome nein Entspricht nicht der Philosophie von EJB3 javax.ejb.Remove ja Call Methode mit den Annotation PreDestroy (nur für Stateful Session Bean) javax.ejb.Timeout ja Session Bean wird nach Ablauf von timeout verworfen javax.ejb.TransactionAttribute ja Transaction Type (REQUIRED, MANDATORY, etc.) javax.ejb.TransactionManagement ja Transaction management (CONTAINER or BEAN) Definiert eine von mehreren EJB Annotationen Für eine Session Bean kann man eine oder mehrere Manager Klassen mit seiner Entity Beans aufrufen. Von einem Domainmodell kann für jedes Package eine Session Bean generiert werden und innerhalb der Session Bean für jedes Element-Objekt ein Tandem vom Manager, Entity Bean und Datenbank-Tabelle. Für die Legacy Projekte (Refactoring), die auf Basis einer vorhandenen Datenbank durchgeführt werden, soll in der Konfigurationsdatei eine Liste von Tabellen, die zu einer Session Bean gehören, vorhanden sein. Session Bean Code Beispiel: TLGen 18 StarData GmbH V 2.501 package eu.stardata.server.core.formular; import eu.stardata.server.core.formular.bci.ExecBci; import eu.stardata.server.core.formular.bci.TablecolBci; …………………………………….. import javax.ejb.EJB; @Stateless(name = FormularBci.JNDI_NAME, mappedName = "efp/"+FormularBci.JNDI_NAME+"/remote") @Remote(FormularBci.class) public class FormularSessionBean extends BaseSessionBean implements FormularBci { private static final long serialVersionUID = 196502766; // Session annotations and fields for local manager @EJB private EntryBci m_EntryBci; ……………………………………. /** * Session method "createEntry()" * @param arg * @return * @throws PersistenceException */ public CoEntryDataIf createEntry(CoEntryDataIf arg) throws PersistenceException { try { return m_EntryBci.create(arg); } catch(Exception ex) { throw new PersistenceException(ex.getMessage(),ex,1); } } 6. Listing 2.3.1 Interfaces für eine Session Bean Session Bean benötigt ein Interface mit allen definierten Methoden, die von Client aufgerufen werden. Diese Interfaces für Session Bean verwenden zwei Annotationen: @Remote für eine Remote-Verbindung vom Client sowie @Local für eine lokale Verwendung. In diesem Interface sind auch drei vordefinierte Variablen, die für EJB3 sehr wichtig sind: String JNDI_NAME = Wert, ist der notwendige Name für den Client-Aufruf und eindeutig für die gesamte Applikation. TLGen verwendet für diese Variable den Inhalt des kompletten Session Bean Namens, z. B. "eu.stardata.server.core.formular.FormularSessionBean" String MANAGER_NAME = "managerFormular". Diese Variable ist wichtig für die Verwendung der Manager Klasse (siehe Kapitel 2.5). String EAR_NAME = "efp". Diese Variable bekommt den Wert aus der Konfigurations-Datei und wird in der XML Persistenz Datei verwendet (siehe Kapitel 2.3.1). Ein Beispiel für ein Session Bean Interface als „Remote“: package eu.stardata.client.core.formular.bci; import eu.stardata.core.form.dataif.CoRuletypeDataIf; …………………………………………………………………….. TLGen 19 StarData GmbH V 2.501 import eu.stardata.core.form.dataif.CoRulefieldDataIf; import javax.ejb.Remote; import java.lang.String; import eu.stardata.core.form.dataif.CoFormularDataIf; import eu.stardata.server.common.exception.PersistenceException; import eu.stardata.core.form.dataif.CoExecDataIf; @Remote public interface FormularBci { // Client interface Fields public final static String JNDI_NAME = "eu.stardata.server.core.formular.FormularSessionBean"; public final static String MANAGER_NAME = "managerFormular"; public final static String EAR_NAME = "efp"; // Session - Client interface methods public void clearExec() throws PersistenceException; public CoFieldDataIf createField(CoFieldDataIf arg) throws PersistenceException; public CoFieldDataIf[] findAllField() throws PersistenceException; ……………………………………………… public CoElementDataIf createElement(CoElementDataIf arg) throws PersistenceException; public void clearWebstyle() throws PersistenceException; } 7. Listing 2.3.2 XML Persistente Datei Ab EJB 3 ist nur eine XML Datei für das Deployment Description notwendig, alle anderen Dateien der Vor-Versionen sind entweder abgeschafft oder werden als Annotation verwendet. Zusätzlich gibt es noch eine XML Datei „orm.xml“ für das Mapping für Version 3 von EJB, doch diese wird aus Gründen der Performance mit TLGen nicht genutzt. TLGen erlaubt das Mapping direkt im generierten Java Code und zwar in den Entity Beans (siehe Kapitel 2.6 sowie 4.5.3.3) In der Datei „persistence.xml“, die für jede Session Bean generiert wird, sind automatisch folgende Informationen enthalten: In Tag „persistence-unit“ die Parameter name ManagerName Variable und Transaction-type In Tag „jta-data-source“ die Data Source im Format, das der jeweilige Applikation Server benötigt (jede hat ein eigenes Format) Eine vollständige Liste von allen in der Applikation vorhandenen Entity Beans mit vollständig definierten Namen In Tag „propertie“ allgemeine Informationen für den Application Server Ein Beispiel für eine generierte „persistence.xml“: <?xml version="1.0" encoding="UTF-8"?> <persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd" version="1.0"> <persistence-unit name = "managerFormular" transaction-type = "JTA"> <jta-data-source>java:/efpPool</jta-data-source> <class>eu.stardata.server.core.user.entity.UserEntity</class> <class>eu.stardata.server.core.hlp.entity.OperationEntity</class> <class>eu.stardata.server.core.hlp.entity.FormatEntity</class> <class>eu.stardata.server.core.hlp.entity.KeyEntity</class> <class>eu.stardata.server.core.formular.entity.FieldEntity</class> TLGen 20 StarData GmbH V 2.501 <class>eu.stardata.server.core.hlp.entity.FieldtypeEntity</class> ……………………………………………….. <properties> <property name="hibernate.dialect" value="org.hibernate.dialect.Oracle10gDialect"/> </properties> </persistence-unit> </persistence> 8. Listing In der Datei „persistence.xml“ können einige Informationen definiert werden, die vom Applikation Server benötigt werden (in einer „properties“ Tag). Hinweis: Für den Applikation Server „JBoss“ Version 5 sollte die Oracle Datenbank in Version 10 genutzt werden, da diese Oracle Version 11 noch nicht erkennt. 2.3.3 Interface Klassen zu Fachlogik Komponenten Innerhalb eines Session Bean kann bzw. können eine oder mehrere Klassen definiert werden, die zu oder von anderen Systemen gehören bzw. aufgerufen werden oder für die Kodierung reiner Fachlogik benötigt werden. Wurden diese einmal generiert, lässt der Generator es zu, diese dort abzuspeichern, um den dort manuell entwickelten Code nicht zu löschen. Nach unserer Erfahrung ist es weder produktiv noch notwendig generierten Code mit selbst entwickelte zu mischen (merging). Daher ermöglicht TLGen eine vollständige Trennung dieser Code-Arten. 2.3.4 Interceptors Ein Interceptor ist eine einfache Java Klasse deren Methoden immer dann aufgerufen werden, wenn die Methoden der Session Bean benützt werden. Die Interceptoren sind Klassen, die eigentlich zum Beispiel unter anderem zur Überwachung einer Session Bean, zur Übernahme der Informationen-Protokollierung oder Zeitmessen gedacht sind. Diese Java Klassen können über die Konfigurationsdateien in den generierten Code eingebettet werden. Es können entweder selbst geschriebene Klassen sein oder die von TLGen Default Interceptoren zur Verfügung gestellten. Ein einfaches Bespiel von einer Interceptor Klasse für die Zeitmessung: public class TimeFormular { // Session annotations and fields for interceptor /** * Default Constructor */ public TimeFormular() { super(); } // Session class methods /** * Interceptor method "timeTrace()" * @param invocation * @return * @throws PersistenceException */ TLGen 21 StarData GmbH V 2.501 @AroundInvoke public java.lang.Object timeTrace(InvocationContext invocation) throws PersistenceException { long start = 0; boolean toTime = true; try { if(toTime) { start = System.currentTimeMillis(); } return invocation.proceed(); } catch(Exception ex) { throw new PersistenceException(ex.getMessage(),ex,1); } finally { if(toTime) { // Example to time long ende = System.currentTimeMillis(); String klasse = invocation.getTarget().toString(); String methode = invocation.getMethod().getName(); System.out.println(klasse + ":" + methode + " -> " + (ende - start) + "ms"); } } } } 9. Listing 2.4 Clients, BCI (Business Common Interface) Auf der Client Seite befindet sich das User Interface, mit dem dieser die Applikation nutzen kann. Auf dem Server hingegen befindet sich die Logik der Applikation, mit dem benötigten Code. TLGen generiert vollständig die Klassen, die notwendig für die Kommunikation zwischen Client und Server sind. Für den Client generiert TLGen auch die Test Klassen (auf Basis von JUnit), die für die Tests der Applikation benötigt wird. Als Beispiel ein generierter Aufruf vom Server, um einen Satz in eine Datenbank abzuspeichern: CoFormularDataIf clFormular = getFormularObject(); // make a factory client for call the session bean FormularBci factory = FormularBciFactory.getFormularBci(); // call the session bean method over the client factory clFormular = factory.createFormular(clFormular); 10. Listing Dieser Serveraufruf ist in zwei Schritten durchzuführen: Zuerst wird die notwendige Factory aufgerufen (diese entspricht in der Regel einer bestimmten Session Bean auf der Server Seite) und letztendlich mit Hilfe der Factory die gewünschte Methode. Im oberen Beispiel ist die Speicherung in der Datenbank eines Formular Objekts dargestellt. TLGen generiert zwei Klassen/Interfaces, die diese Aufgabe erfüllen. In unserem Beispiel, die Klasse FormularBciFactory.java und die Interface FormularBci.java, Teil des generierten Code für die Factory: /** * getFormularBci() */ TLGen 22 StarData GmbH V 2.501 public static synchronized FormularBci getFormularBci() throws PersistenceException { return (FormularBci)getBciImplementation(FormularBci.class); } 11. Listing Als auch für die Interfaces: @Remote public interface FormularBci { // Client interface Fields public final static String JNDI_NAME = "eu.stardata.server.core.formular.FormularSessionBean"; public final static String MANAGER_NAME = "managerFormular"; public final static String EAR_NAME = "efp"; ……………………………………………. public CoFormularDataIf createFormular(CoFormularDataIf arg) throws PersistenceException; ………………………………….. } 12. Listing 2.4.1 Test Klassen TLGen generiert für die gewünschten Aufrufe die kompletten Test Klassen mit generierten Test-Werten oder aus einer Daten-Datei die geladenen Test-Daten. Für welche Aufrufe die Test Klassen (JUnit) zu generieren sind, soll in der Konfigurations-Datei eingetragen werden (für weitere Details siehe Kapitel 4.4.8 und 4.5.3.6). Test Klassen kann man testen und die Ergebnisse in einer Datei printen oder direkt auf den Bildschirm ausgeben (z. B. in Eclipse) oder aber im JUnit, wo sie mit Hilfe von Asset Methode zu Verfügung gestellt werden, ersehen. Listing 13 zeigt ein Beispiel für eine Test Klasse: public class FormularWriteReadTest extends TestCase { private static final long serialVersionUID = 435512065; // Test class data fields private static CoFormularDataIf m_clFormular = null; /** * Default Constructor */ public FormularWriteReadTest() { super(); // Insert your configuration data for application server de.stardata.base.config.InitProgramm.put(de.stardata.base.config.ConfigKeyNames.INITIAL_CONTEXT, "jnp://localhost:9099"); de.stardata.base.config.InitProgramm.put(de.stardata.base.config.ConfigKeyNames.INITIAL_CONTEXT _FACTORY,"org.jnp.interfaces.NamingContextFactory"); de.stardata.base.config.InitProgramm.put(de.stardata.base.config.ConfigKeyNames.INITIAL_PKG_PRE FIXES,"org.jboss.naming:org.jnp.interfaces"); } // Test class methods /** * Test method "testCreateFormular()" */ public void testCreateFormular() { try { m_clFormular = new CoFormularData(); // initialize data for test class m_clFormular.setCoreId(3); …………………………………………………………………….. m_clFormular.setLanguage(writeLanguage()); m_clFormular.setMandant(writeMandant()); // make a factory client for call the session bean TLGen 23 StarData GmbH V 2.501 FormularBci factory = FormularBciFactory.getFormularBci(); // call the session bean method over the client factory m_clFormular = factory.createFormular(m_clFormular); // print the new primary key System.out.println("New primary key is = " + m_clFormular.getFormularId()); } catch(PersistenceException ex) { ex.printStackTrace(); } } 13. Listing Test Klassen Beispiel 2.4.1.1 Verwendung von Test Daten aus externen Dateien Mit Hilfe der Konfigurations-Datei kann man eine XML Datei generieren, welche die DatenStruktur einer oder mehrerer Test-Objekte nachbildet. Diese XML kann mit den gewünschten Daten erweitert und für Tests genutzt werden. Solch eine Datei wird in Listing 14 dargestellt: <?xml version="1.0" encoding="UTF-8"?> <TestMethod xsi:noNamespaceSchemaLocation = "C:/Project-TLGen2.1/source/generated/TestDataSchema.xsd" name = "testCreateFormular" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" type = "void"> <Variable name = "FormularId" value = "2" type = "long"/> <Variable name = "CoreId" value = "2" type = "long"/> ……………………………………………………………………………………………….. <Variable name = "Document_id" value = "2" type = "long"/> ………………………………………………………………………………………………. <Method name = "writeMandant" type = "eu.stardata.core.cor.dataif.CoMandantDataIf"> <Variable name = "MandantId" value = "4" type = "long"/> ……………………………………………………………………………………………….. <Variable name = "Code" value = "-628" type = "java.lang.String"/> </Method> </TestMethod> 14. Listing Die verwendete Schema-Datei “TestDataSchema.xsd” hat folgende Struktur: <?xml version="1.0" encoding="UTF-8" standalone="no"?> <!--W3C Schema generated by XMLSpy v2009 (http://www.altova.com)--> <!--Please add namespace attributes, a targetNamespace attribute and import elements according to your requirements--> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <xs:import namespace="http://www.w3.org/XML/1998/namespace"/> <xs:element name="Variable"> <xs:complexType> <xs:attribute name="name" use="required" type="xs:anySimpleType"/> <xs:attribute name="type" type="xs:anySimpleType"/> <xs:attribute name="value" type="xs:anySimpleType"/> </xs:complexType> </xs:element> <xs:element name="Type"> <xs:complexType mixed="true"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="Variable"/> <xs:element ref="Type"/> <xs:element ref="Enum"/> </xs:choice> <xs:attribute name="name" use="required" type="xs:anySimpleType"/> <xs:attribute name="type" type="xs:anySimpleType"/> TLGen 24 StarData GmbH V 2.501 </xs:complexType> </xs:element> <xs:element name="TestMethod"> <xs:complexType mixed="true"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="Variable"/> <xs:element ref="Method"/> <xs:element ref="Type"/> <xs:element ref="Enum"/> </xs:choice> <xs:attribute name="name" use="required" type="xs:anySimpleType"/> <xs:attribute name="type" type="xs:anySimpleType"/> </xs:complexType> </xs:element> <xs:element name="Method"> <xs:complexType mixed="true"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element ref="Type"/> <xs:element ref="Enum"/> <xs:element ref="Variable"/> <xs:element ref="Method"/> </xs:choice> <xs:attribute name="name" use="required" type="xs:anySimpleType"/> <xs:attribute name="type" type="xs:anySimpleType"/> </xs:complexType> </xs:element> <xs:element name="Enum"> <xs:complexType> <xs:attribute name="name" use="required" type="xs:anySimpleType"/> <xs:attribute name="type" type="xs:anySimpleType"/> <xs:attribute name="value" type="xs:anySimpleType"/> </xs:complexType> </xs:element> </xs:schema> 15. Listing 2.5 Manager Klassen Eine Manager Klasse ist eine lokale Stateless Session Bean, die für die Steuerung der Persistenz (Entity Bean) genutzt wird. Manager Klassen können Default Methoden für Datenbank-Administration für CRUD sein oder aber auch Datenbank-Zugriffsmethoden, generiert auf Basis von selbst geschriebenen SQL‟s. In Tabelle 3 sind die Default Methoden, welche TLGen automatisch generieren kann: Tabelle 3: Automatisch generierbare Default Methoden Nr. Method Name Parameter Return Funktionalität 1 create“Name“ Objekt Objekt Speichern eins neuen Objekts in der Datenbank 2 update“Name“ Objekt - Aktualisieren eines Objekts in der Datenbank 3 remove“Name“ Object - Löschen eines Datenbank 4 flusch“Name“ Object - Beenden des Vorgang 5 close“Name“ - - Schließt eine Entity Object 6 clear“Name“ - - TLGen 25 Objekts in der StarData GmbH V 2.501 7 findByPrimaryKey“Name“ Object PK 8 findAll“Name“ 9 findBy“Name“ mit Object Lesen ein Objekt von DB mit den PK - Object[] Lesen aller gespeicherter Objekte Parameter List Object[] Lesen aller Objekte für die Parameter List Ein Beispiel für generierten Code aus Tabelle 3, Zeile 9 ist in Listing 16 dargestellt: public class ProductManager extends BaseManager implements ProductBciIf { private String m_getNameAndOffer = "select u from ProductEntity u where u.name = :name and u.productOfferingId = :productOfferingId"; ……………………………………………………………… /** * Manager method "findByNameAndOffer()" * @param name * @param productOfferingId * @return * @throws PersistenceException */ public ProductDataIf[] findByNameAndOffer(String name, String productOfferingId) throws PersistenceException { try { ProductDataIf[] listData = null; List<?> list = m_manager.createQuery(m_getNameAndOffer).setParameter("name", name).setParameter("productOfferingId",productOfferingId).getResultList(); if(list != null && list.size() > 0) { listData = new ProductDataIf[list.size()]; int idx = 0; for(Object entity : list) { if(entity != null) { listData[idx++] = ((ProductEntity)entity).callProduct(); } } } return listData; } catch(Exception ex) { throw new PersistenceException(ex.getMessage(),ex,1); } } ……………………………………………………………….. } 16. Listing Das Lesen, Speichern oder Löschen von Objekten kann direkt im Aufruf gesteuert werden, ob nur das „Vater“ Objekt gelesen, gespeichert oder gelöscht wird oder aber zusammen mit seinen „Kindern“ (solange die Beziehungen zwischen diesen „Null“ akzeptiert). Für das selbst geschriebene SQL bietet TLGen eine Fülle von Modellen an, die sehr einfach in der Konfigurations-Datei zu nutzen sind, mit der letztendlich TLGen den entsprechenden Code generiert. In der Regel ist es nur sehr selten notwendig ein solches SQL zu schreiben, weil durch automatisches Einbeziehen von Relationen werden alle benötigen Objekte gelesen und abgespeichert. Es folgt ein Ausschnitt einer generierten Manager Klasse: package eu.stardata.server.core.formular.manager; TLGen 26 StarData GmbH V 2.501 import javax.persistence.EntityManager; ……………………………………………….. import javax.ejb.Local; @Stateless(name = eu.stardata.server.core.formular.bci.FormularBci.JNDI_NAME) @Local(eu.stardata.server.core.formular.bci.FormularBci.class) public class FormularManager extends BaseManager implements eu.stardata.server.core.formular.bci.FormularBci { private static final long serialVersionUID = 644414680; // Manager class data fields @PersistenceContext(unitName = FormularBci.MANAGER_NAME) public EntityManager m_manager = null; private String m_getName = "select o from FormularEntity o where o.formular = :formular"; private String m_SQL_FIND_ALL = "select o from FormularEntity o"; ………………………………………………………………… /** * Manager method "findByPrimaryKey()" * @param arg * @return * @throws PersistenceException */ public CoFormularDataIf findByPrimaryKey(CoFormularDataIf arg) throws PersistenceException { try { CoFormularDataIf classData = null; FormularEntity entity = m_manager.find(FormularEntity.class, arg.getFormularId()); if(entity != null){ classData = entity.callFormular(); } return classData; } catch(Exception ex){ throw new PersistenceException(ex.getMessage(),ex,1); } } ………………………………………………. } 17. Listing Alle in den Manager Klassen verwendeten Methoden können von den dazugehörigen Session Bean übernommen werden oder auch nicht. Dies kann über die KonfigurationsDatei gesteuert werden (Default bedeutet, dass alle übernommen werden). In Tabelle 4 die Annotationen, die für eine Manager Klasse verwendet werden. Tabelle 4: Annotationen für Manager Klassen Annotationen Vervendung inTLGen Kommentar Stateless ja Bezeichnet eine Session Stateless Bean Local ja Ist nur lokal zu verwenden PersistenceContext ja Definiert den Namen des Managers 2.5.1 Manager Interfaces Weil Manager Klassen eigentlich lokale Session Beans sind, benötigen sie ein eigenes Interface. Diese werden auch automatisch von TLGen generiert. TLGen 27 StarData GmbH V 2.501 Ein Beispiel für ein Interface einer Manager Klasse: 18. Listing import eu.stardata.core.form.dataif.CoFormularDataIf; import java.lang.String; import eu.stardata.server.common.exception.PersistenceException; import eu.stardata.server.core.formular.bci.FormularBci; import eu.stardata.server.core.formular.entity.FormularEntity; public interface FormularBci { // Manager interface data fields public String JNDI_NAME = "eu.stardata.server.core.formular.bci.FormularBci"; public String EAR_NAME = "efp"; // Manager interface methods public CoFormularDataIf findByPrimaryKey(CoFormularDataIf arg) throws PersistenceException; ……………………………………………………………………… public void close() throws PersistenceException; } 2.6 Entity Beans Die Entity Beans sind das Tor zur Datenbank, besser gesagt, sie sind die Schnittstellen für eine relationale Datenbank. Eine Entity Bean sollte einer Tabelle in der Datenbank entsprechen und so eine saubere sowie strukturierte Architektur für die Persistenzschicht ermöglichen. Das ist sehr wichtig für die Wartung des Codes und für weitere Entwicklungen. Entity Beans sind POJO‟s (Old Java Objects), d. h. sie sind normale Java Klassen und anders als die Session Beans, brauchen sie keine Interfaces. Jede Entity Bean muss einen Standardkonstruktor besitzen, weil es unter anderem Aufgabe einer Manager Klasse ist, eine Instanz für die Entity Bean zu erzeugen. TLGen generiert in einer Entity Bean die notwendigen Annotationen, Variablen, Default Konstruktor, Mapping Methoden zwischen Daten Objekt Attributen, Tabellen-Spalten, einige Hilfs-Methoden, die diese Mapping unterstützen und die Methoden für die Relationen. Für eine Entity Bean werden auch mehrere Annotationen und Variablen generiert, wie in Listing 19 dargestellt: package eu.stardata.server.core.formular.entity; import javax.persistence.GeneratedValue; ………………………………………………………………….. import javax.persistence.Entity; @Entity @Table(name="CORE_FORMULAR") @SequenceGenerator(name="SEQ_STORE_FORMULAR", sequenceName="CORE_FORMULAR_SEQ", initialValue=1, allocationSize=20) public class FormularEntity { private static final long serialVersionUID = 802995295; // Entity data field private CoFormularDataIf m_formular = null; // Fields from relations tables private List<PageEntity> m_page = new ArrayList<PageEntity>(); private List<DocumentlistEntity> m_documentlist = new ArrayList<DocumentlistEntity>(); private LanguageEntity m_language = null; …………………………………………………………………………. // constructors /** * Default Constructor */ TLGen 28 StarData GmbH V 2.501 public FormularEntity() { } /** * Constructor * @param arg */ public FormularEntity(CoFormularDataIf arg) { m_formular = arg; fillFormular(); } // Helper methods /** * Helper Method "makeFormular" */ public CoFormularDataIf makeFormular() { if(m_formular == null) { m_formular = new eu.stardata.core.form.data.CoFormularData(); } return m_formular; } ………………………………………………………………………… } 19. Listing In Tabelle 5 sind die Annotationen dargestellt, die für Entity Beans von EJB3 vorgesehen sind: Tabelle 5: Annotationen für Entity Beans (EJB3) Annotationen Vervendung inTLGen Kommentar Entity ja Definiert eine Entity Bean Table ja Table, die zu eine Entity gehören Column ja Spalte einer Table (für Mapping) SequenceGenerator ja Definiert die Art von Sequence Generator GeneratedValue ja Generiert eine Sequence (für die automatische Generierung von ID„s) Id ja Definiert eine PK ManyToMany ja Relation Typ (siehe 2.6.1.4 und 4.5.3.8) ManyToOne ja Relation Typ (siehe 2.6.1.2 und 4.5.3.8) OneToMany ja Relation Typ (siehe 2.6.1.1 und 4.5.3.8) OneToOne ja Relation Typ (siehe 2.6.1.3 und 4.5.3.8) Version ja Verwendet für die Versionskennzeichnung, wird für Locking verwendet PostLoad ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden PostPersist ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden PostRemove ja Hilfsmethoden, welche vor oder nach Processing TLGen 29 StarData GmbH V 2.501 aufgerufen werden PostUpdate ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden PrePersist ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden PreRemove ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden PreUpdate ja Hilfsmethoden, welche vor oder nach Processing aufgerufen werden JoinColumn ja Verbindungsspalte für eine Relation JoinColumns ja Mehrzahl von Verbindungs-Columns JoinTable ja Verbindung DB Tabelle für eine ManyToMany Relation Embeddable ja Verwendet für komplexe Primary Key NamedQuery ja Definiert eine named SQL Query NamedNativeQuery ja Definiert eine named Native Query OrderBy ja Sortiert die Ergebnisse Enumerated nein Vorgesehen für die nächste Version EmbeddedId nein Vorgesehen für die nächste Version Transient nein Vorgesehen für die nächste Version TableGenerator nein Vorgesehen für die nächste Version Temporal nein Vorgesehen für die nächste Version Lob ja Verwendet für Blob und Clob (Große Daten) SecondaryTable nein Vorgesehen für die nächste Version Basic ja Wird zusammen mit Lob verwendet PersistenceProperty nein Vorgesehen für die nächste Version PersistenceUnit nein Vorgesehen für die nächste Version UniqueConstraint nein Vorgesehen für die nächste Version Inheritance nein Vorgesehen für die nächste Version Innerhalb einer Entity Bean generiert TLGen eine Reihe von Hilfsmethoden, die für das Mapping von Daten-Relationen notwendig sind. Diese Methoden sind: fill„Name“(), hat keine Parameter und wird in Constructor aufgerufen. Diese ist notwendig für das Speichern eines neuen Objektes in der Datenbank für eine “ManyToOne” Relation add„Name“(), hat keine Parameter und wird vom Manager aufgerufen. Diese ist notwendig für das Speichern eines neuen Objekts in der Datenbank für eine “OneToMany” Relation call„Name“(), wird für alle Relationen beim Lesen eines Objektes aus der Datenbank benutzt. Listing 20 zeigt ein Beispiel-Code: /** * Helper Method "callFormular" TLGen 30 StarData GmbH V 2.501 */ public CoFormularDataIf callFormular() { // Relation ManyToOne, read data for "Formular" child, "Language" if(getLanguage() != null) { makeFormular().setLanguage(getLanguage().callLanguage()); } // Relation ManyToOne, read data for "Formular" child, "Mandant" if(getMandant() != null) { makeFormular().setMandant(getMandant().callMandant()); } // return the data object return makeFormular(); } 20. Listing In Listing 21 ist das Beispiel einer Mapping-Methode mit einem Sequence Generator für Primary Key dargestellt: // Methods from columns @Id @Column(name = "FORMULAR_ID") @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "SEQ_STORE_FORMULAR") public long getFormularId() { return makeFormular().getFormularId(); } public void setFormularId(long arg) { makeFormular().setFormularId(arg); } 21. Listing TLGen generiert auch automatisch komplex verschachtelte Aufrufe für das Mapping. Beispiel: @Column(name = "authentificationFirstname", length = 255) public String getAuthentificationFirstname() { if(makeUser().getAuthentification() != null && makeUser().getAuthentification().getName() != null) { return makeUser().getAuthentification().getName().getFirstname(); } return null; } public void setAuthentificationFirstname(String arg) { if(makeUser().getAuthentification() == null) { makeUser().setAuthentification(new Authentification()); } if(makeUser().getAuthentification().getName() == null) { makeUser().getAuthentification().setName(new Name()); } makeUser().getAuthentification().getName().setFirstname(arg); } 22. Listing TLGen 31 StarData GmbH V 2.501 2.6.1 Relationen Ein wichtiger Bestandteil von Entity Beans sind die Relationen zwischen verschiedenen Objekten, die in einer Datenbank abgespeichert oder ausgelesen werden. In diesem Kapitel werden die Verwendung von Relationen sowie der von TLGen generiertem Code beschrieben. 2.6.1.1 Relation „OneToMany“ „OneToMany“ Relation wird verwendet, wenn ein Objekt mehrere Subobjekte (Kinder) besitzt. In einer Datenbank wird dieses durch eine Tabelle, die eine „OneToMany“ Relation zu einer anderen Tabelle hat, dargestellt. In Daten-Interface ist so eine Relation durch eine Liste wie in Listing 23 erkennbar: public interface CoFormularDataIf extends BaseDataIf { ……………………………………………………………… public abstract List<CoPageDataIf> getPage(); public abstract void setPage(List<CoPageDataIf> arg); ……………………………………………………………… } von “Formular” Objekt zu “Page” Object { ……………………………………………………………… public abstract CoFormularDataIf getFormular(); public abstract void setFormular(CoFormularDataIf arg); ……………………………………………………………….. } und von “Page” Objekt zu “Formular” Objekt. 23. Listing und in Entity Bean wie in Listing 24. // Methods from relations tables @OneToMany(cascade = {CascadeType.PERSIST,CascadeType.MERGE,CascadeType.REMOVE}, mappedBy = "formular",targetEntity = PageEntity.class) public List<PageEntity> getPage() { return m_page; } public void setPage(List<PageEntity> arg) { m_page = arg; } 24. Listing Ob solch ein Objekt gespeichert werden muss oder nicht hängt von der Art der Relation ab, „not null“ oder „null“. All seine Kinder werden automatisch gespeichert, wenn im Vater Objekt die Kinderdaten vorhanden sind. Der Speicherungsprozess von Daten erfolgt automatisch durch einen einzigen Aufruf von einer „create“ Methode (siehe Listing 13). Beim Lesen werden zusammen mit dem Vater auch alle seine Kinder geholt, wenn diese vorhanden sind. Die Tiefe von Relations-Ebenen kann gesteuert werden, d. h. es kann nur der Vater gelesen/gespeichert werden oder die Ebenen können immer weiter um die Kinder erweitert werden. Diese Ebenenerweiterungen werden dann möglich, wenn die Art der Relationen „null“ ist. (Beispiel: ein „Formular“ hat mehrere „Pages“ und jede Page hat mehrere „Fields“ und so weiter) TLGen 32 StarData GmbH V 2.501 Eine UML-Darstellung für so eine Relation befindet sich in Abbildung 8. Zwischen „Formular“ Objekt und „Page“ Objekt existiert eine „null OneToMany“ Relation und zwischen „Page“ Objekt und „Fields“ Objekt eine „not null OneToMany“ Relation. Als Datenmodell wird diese Relation in Abbildung 9 dargestellt. Abbildung 8: „OneToMany“ 2.6.1.2 Relation „ManyToOne“ Diese Relation ist eine symmetrische Relation zu „OneToMany“, d. h. ein Objekt kann in mehrere andere Objekte verwendet werden. Auch bei dieser Art von Relation kann eine „not null“ Verbindung existieren und dieser Link muss immer mit Daten versorgt werden, d. h. in der Datenbank muss der Fremdschlüssel in den Kinder-Tabellen „not null“ sein (z.B. ein FK =Fremdschlüssel) mit dem Typ „long“ soll immer größer als 0 sein und in der Tabelle, wo der FK zeigt, muss ein richtiger Satz vorhanden sein). Abbildung 9: „OneToMany“ Datenmodell Die UML Darstellung ist gleich mit der Abbildung 8 und das Datenmodell wie Abbildung 9, aber die Richtung ist umgekehrt als bei der Relation „OneToMany“, das gilt auch für die Code-Darstellung in Listing 22. Für den Entity Bean Code ist Listing 25 zu beachten: @ManyToOne(optional = true,targetEntity = WebstyleEntity.class) @JoinColumn(name = "WEBSTYLE_ID",insertable = true, updatable = true, nullable = true, unique = false,referencedColumnName = "WEBSTYLE_ID") public WebstyleEntity getWebstyle() { return m_webstyle; } public void setWebstyle(WebstyleEntity arg) { m_webstyle = arg; } TLGen 33 StarData GmbH V 2.501 25. Listing 2.6.1.3 Relation „OneToOne“ Die Relation „OneToOne“ verbindet zwei Objekte so, dass eines ein einziges Kind besitzt. Auch bei dieser Relation ist eine „null“-Verbindung möglich, d. h. der Fremdschlüssel kann null sein, oder „not null“. In diesem Fall muss der Fremdschlüssel immer vorhanden sein und zu einem vorhandenen Satz in der Datenbank die Verbindung anzeigen. Auch bei dieser Verbindung gibt es einen Vater und ein Kind. Code für diese Relation ist im Listing 26 für die Daten Interfaces und im Listing 27 für die Entity Bean zu sehen. public interface CoFieldDataIf extends BaseDataIf { ………………………………………………………… public abstract CoTableDataIf getTable(); public abstract void setTable(CoTableDataIf arg); …………………………………………………………. { 26. Listing public class FieldEntity { private TableEntity m_table = null; ………………………………………………………… @OneToOne(cascade = {CascadeType.PERSIST,CascadeType.MERGE,CascadeType.REMOVE}, targetEntity = TableEntity.class,optional = true) @JoinColumn(name = "TABLE_ID",insertable = false, updatable = false, nullable = true, unique = false,referencedColumnName = "TABLE_ID") public TableEntity getTable() { return m_table; } public void setTable(TableEntity arg) { m_table = arg; } ………………………………………………………….. } 27. Listing 2.6.1.4 Relation „ManyToMany“ Die Relation „ManyToMany“ ist die komplexe Form für das Verbinden mehrerer Objekte/Tabellen. Auf der Code-Ebene hat jedes Objekt eine Liste mit den anderen Objekten wie in der Listing 28: public interface UserDataIf extends BaseDataIf { …………………………………………………….. // Methods from relations tables public abstract List<UserRoleDataIf> getUserRole(); public abstract void setUserRole(List<UserRoleDataIf> arg); …………………………………………………….. } Von “User” Objekt, und von “UserRole” Objekt: TLGen 34 StarData GmbH V 2.501 public interface UserRoleDataIf extends BaseDataIf { …………………………………………………….. // Methods from relations tables public abstract List<UserDataIf> getUser(); public abstract void setUser(List<UserDataIf> arg); …………………………………………………….. } 28. Listing Auf der Datenbank-Ebene ist für diese Relation eine dritte Tabelle notwendig, eine so genannte Mapping Tabelle, wie in Abbildung 11. Die Darstellung in einem Domain Modell ist in Abbildung 10 zu ersehen. Abbildung 10: „ManyToMany“ Darstellung im UML Domainmodell Aus einem Domain Modell generiert TLGen für „ManyToMany“-Relationen automatisch die nötige Mapping Tabelle als SQL Skript. Abbildung 11: „ManyToMany“ DB Relation In den Entity Beans werden Annotationen mit den dazugehörigen Methoden, wie in unserem Beispiel, sowohl in der „UserEntity“ Bean als auch in „UserRoleEntity“ Bean generiert (siehe Listig 29): @Entity @Table(name="UserTable") @SequenceGenerator(name="SEQ_STORE_USER", sequenceName="USERTABLE_SEQ", initialValue=1, allocationSize=10) public class UserEntity extends BaseData implements Serializable { // Entity data field private UserDataIf m_user = null; …………………………………………………………………… TLGen 35 StarData GmbH V 2.501 // Methods from relations tables @ManyToMany(targetEntity = UserRoleEntity.class) @JoinTable(name = "UserRole_UserTable",inverseJoinColumns = {@JoinColumn(name = "UserRole_ID",insertable = true, updatable = true, nullable = false, unique = false)}, joinColumns = {@JoinColumn(name = "UserTable_ID",insertable = true, updatable = true, nullable = false, unique = false)}) public List<UserRoleEntity> getUserRole() { return m_userRole; } public void setUserRole(List<UserRoleEntity> arg) { m_userRole = arg; }…………………………………………………………………… } Für “User” und @Entity @Table(name="UserRole") @SequenceGenerator(name="SEQ_STORE_USERROLE", sequenceName="USERROLE_SEQ", initialValue=1, allocationSize=10) public class UserRoleEntity extends BaseData implements Serializable { private static final long serialVersionUID = 413271821; // Entity data field private UserRoleDataIf m_userRole = null; ……………………………………………………………………………….. // Methods from relations tables @ManyToMany(cascade = {CascadeType.PERSIST,CascadeType.MERGE,CascadeType.REMOVE}, mappedBy = "userRole",targetEntity = UserEntity.class) public List<UserEntity> getUser() { return m_user; } public void setUser(List<UserEntity> arg) { m_user = arg; } …………………………………………………………………………….. } Für “UserRole” 29. Listing In der Praxis haben wir 3 Möglichkeiten Tabellen zwischen denen eine „ManyToMany“ Relation existiert, abzuspeichern, wie folgt: Speichern beider Objekte gleichzeitig; das „User“ Objekt beinhaltet die Daten für dessen „UserRole“ und in der Datenbank werden drei Sätze gespeichert, einer in der „USERROLE“ Tabelle, der andere in die „USER“ Tabelle und der dritte Satz in die Tabelle „USER_USERROLE“ mit beiden ID‟s (USER_ID und USERROLE_ID). Speichern einer „UserRole“ von einem oder mehreren Objekten in der „USERROLE“ Tabelle Speichern eines „User“ Objektes, der mit einem „USERROLE_ID“ einer vorhandenen „USERROLE“ versorgt wird, in dem Datenbank Objekt einer „UserRole“. In diesem Fall werden zwei Sätze in der Datenbank gespeichert, einer in die „USER“ Tabelle und ein zweiter in der Tabelle „USER_USERROLE“ mit beiden ID‟s. Falls der „USERROLE_ID“ zeigt, dass ein „USERROLE“ in dieser Tabelle nicht vorhanden ist, wird eine Exception zurück zu den Client gesendet und eine Roll - Back Transaktion folgt. TLGen 36 StarData GmbH V 2.501 2.7 Generierung von Datenbank und SQL Skripte TLGen kann ein Datenbank SQL Skript aus einem Domainmodell, mit seinen Tabellen, Spalten, Relationen, Indexes und Sequenzen generieren. Wenn der Datenbankzugriff (User und Password) in der Konfiguration Datei vorhanden ist, verwendet TLGen das generierte Skript, um die Datenbank zu generieren. Dies ist auch möglich, wenn die Datenbank schon vorhanden ist. Dann werden nur die Änderungen (es wird auch ein Änderung-Skript generiert) generiert, und somit werden die schon vorhandenen Daten nicht gelöscht. Skript-Beispiele werden in Listing 30 gezeigt: ----------- Drop all Tables ----------DROP TABLE Contract CASCADE CONSTRAINTS; DROP TABLE Product CASCADE CONSTRAINTS; ………………………………………………………… ----------- Create Tables ----------CREATE TABLE Product ( Product_ID NUMBER(19,0) NOT NULL, DB_VERSION NUMBER(16) NULL, description VARCHAR2(255) NULL, ……………………………………………………… shortName VARCHAR2(255) NULL, CustomerService_ID NUMBER(19,0) NULL, PRIMARY KEY (Product_ID) USING INDEX TABLESPACE XINDEX ) Tablespace XDATA; ……………………………………………………… ----- Foreign key -----ALTER TABLE Product ADD CONSTRAINT FK201A7DE FOREIGN KEY (CustomerService_ID) REFERENCES CustomerService; ALTER TABLE Contract ADD CONSTRAINT FKF96859 FOREIGN KEY (Customer_ID) REFERENCES Customer; ALTER TABLE Contract ADD CONSTRAINT FK31C7538 FOREIGN KEY (AccessControlContext_ID) REFERENCES AccessControlContext; ALTER TABLE Contract ADD CONSTRAINT FK7FE790 FOREIGN KEY (Offer_ID) REFERENCES Offer; …………………………………………………. ----------- Create Sequences ----------CREATE SEQUENCE Contract_SEQ START WITH 1 INCREMENT BY 1 CACHE 10 MINVALUE 1; CREATE SEQUENCE Product_SEQ START WITH 1 INCREMENT BY 1 CACHE 10 MINVALUE 1; 30. Listing Die sofortige Generierung einer Datenbank ist wichtig für den Datenbank OptimierungsProzess (neue und alte Projekte) siehe Kap. 2.1 2.8 Regel für die Generierung von Namen TLGen verwendet im Code-Generierungs-Prozess zwei Arten von Regeln für die NamenGenerierung: Die Domainmodell-Namen sind eigentlich Namen nach den Java Konventionen für Datenbank-Namen. In diesem Fall verwendet die Generierung der Datenbank Namen, schon vorhandene Namen aus dem Domainmodell. Bei einer schon vorhandenen Datenbank (Legacy Projekte) sind in den meisten Fällen Namen, die anders sind als die Java Namenskonventionen. Für diesen Fall sind acht Namensumwandlungen möglich: TLGen 37 StarData GmbH V 2.501 o Aus den Groß geschriebenen Namen, aus mehreren Teilen mit ein „underscore“ verbunden, wird ein Name kleingeschrieben, ohne „underscore“, bedeutet das die Default Einstellung, siehe Tab 6, Zeile 1 o „underscore“ wird nicht mehr verwendet, d.h. der erste Buchstabe ist groß, Zeile 2 o „underscore“ wird nicht verwendet, der Rest ist gleich, Zeile 4 und 5 o „underscore“ wird verwendet, der restliche Name bleibt gleich, Zeile 6 o underscore“ wird verwendet, und der Rest verwendet die Java NamenKonvention, Zeile 7 o keine Namen-Änderung. Tabelle 6: Namen-Regel Nr. Datenbank Format Java Format 1 CORE_FORMULAR Formular 2 CORE_FORMULAR CoreFormular testCoreFormular TestCoreFormular CORE_FORMULAR CoreFormular testCoreFormular TestCoreFormular FORMULAR Formular CORE_FORMULAR COREFORMULAR testCoreFormular TestCoreFormular CORE_FORMULAR CoreFormular testCoreFormular Testcoreformular 6 CORE_FORMULAR COREFORMULAR 7 CORE_FORMULAR Core_formular 8 CORE_FORMULAR CORE_FORMULAR 3 4 5 Diese Regeln werden einmal für das gesamte Projekt gesetzt, aber wenn unterschiedliche Regeln für die Namen innerhalb einer Session Bean mit seinen Komponenten erwünscht sind, müssen diese gesetzt werden. Details siehe auch Kapitel 4.4. Diese Regeln können auch von dem Domain Modell in Bezug auf der Datenbank verwenden werden, aber die meisten Datenbanken machen keinen Unterschied zwischen Klein- und Gross- Schreibung. 2.9 Log Dateien Beschreibung TLGen erzeugt im Generierungs-Prozess mehrere Log-Dateien, in welchen alle Schritte eingetragen werden. Durch diese Log-Dateien kann kontrolliert werden, ob das ProjektDesign den gewünschten Ergebnissen entspricht. Die Verwendung von Log-Dateien ist einstellbar und der Name ist wählbar, d. h. es kann bzw. können nur eine oder mehrere verwendet werden. Sind es mehrere, weil die TLGen 38 StarData GmbH V 2.501 Information in diesen Dateien sehr groß ist, wird die Verwendung dieser Dateien somit erleichtert. TLGen kann folgende Log-Dateien verwenden: Eine Log-Datei für die Generierung allgemeiner Schritte (beschreibt nur wichtige Schritte) Eine Log-Datei für die Generierung von Session Beans Eine Log-Datei für die Generierung von Entity Beans Eine Log-Datei für die Generierung von Test Classen Eine Log-Datei für die Generierung von Daten Classen/Interfaces Eine Log-Datei für die Generierung von Manager Classen. Es gibt eine Error Log-Datei, in der die Generierung Error, wie zu lange Namen, Fehler im Domainmodell (z. B. Kreise in Relationen) eingetragen werden. Ein Beispiel für eine Error Log-Datei befindet sich in Listing 31 (siehe auch Kap. 2.1): Time Start : Sat Feb 05 13:29:11 CET 2011 0 Domain Error | Class-name is too lang[35] + 'AverageFlatDurationCalculationParam' ==== Direct circles in relations ============================================== Warning: TARGET [Order] in a path starting with himself as SOURCE [Order]: [Order(NOT NULL)>Customer(NULL)->Asset(NOT NULL)->AssetItem(NOT NULL)] ---> [Order] Warning: TARGET [Offer] in a path starting with himself as SOURCE [Offer]: [Offer(NOT NULL)>Customer(NULL)->Asset(NOT NULL)->AssetItem(NOT NULL)->Order(NOT NULL)->Contract(NOT NULL)] ---> [Offer] ……………………………………………….. ==== Relation Problems? ================================================== FATAL Error: [ServiceDescriptiontItem] needed by different mandatory relations starting from [AssetItemStatus] [AssetItemStatus->AssetItem->Order->Contract->ServiceDescription] ---> [ServiceDescriptiontItem] [AssetItemStatus->AssetItem->OrderItem] ---> [ServiceDescriptiontItem] FATAL Error: [ServiceDescription] needed by different mandatory relations starting from [AssetItem] [AssetItemStatus->AssetItem->Order->Contract] ---> [ServiceDescription] [AssetItemStatus->AssetItem->Order->Contract->Offer] ---> [ServiceDescription] Warning: [ProductRelation] can be reached over [AssetItem] in different relations: [AssetItemStatus->AssetItem->OrderItem->ServiceDescriptiontItem->Product] ---> [ProductRelation] [ServiceDescriptiontItem->AssetItem->OrderItem->Product] ---> [ProductRelation] [OrderItem->ServiceDescriptiontItem->AssetItem->Product] ---> [ProductRelation] 31. Listing TLGen 39 StarData GmbH V 2.501 2.10 Message Driven Bean In komplexen Anwendungen müssen die Aufgaben manchmal nicht sofort erledigt werden, sondern erst zu einem späteren Zeitpunkt, nachdem der Anwendung eine Nachricht zugekommen ist. Für die Message Driver Bean läuft die Kommunikation zwischen Client und Server über JMS (Java Message Service) ab. TLGen kann die Message Driver Bean mit sehr viel weniger Aufwand generieren. Die so generierte Message Driver Bean kann über die Callback Klasse (siehe 2.8.3) mit der Applikation kommunizieren und so eine klare Trennung zwischen der technischen und der fachlichen Schicht realisieren. Mit Hilfe der Steuerung über die Konfigurationsdateien können für die Message Driver Bean folgende Features generiert werden: Annotationen mit Parameter (Tabelle 7) Client Klassen Message Driver Bean Klassen selber Callback Klasse für die Verbindung mit der Fachlogik-Schicht Tabelle 7: Annotationen für Message Driven Bean Annotationen Verwendung Kommentar in TLGen 2.5 javax.annotation.Resource ja Definiert die Ressource Message Driven Bean javax.ejb.MessageDriven ja Definiert eine Message Driven Bean javax.ejb.ActivationConfigProperty ja Setzt die Properties für eine Message Driven Bean 2.11 Services Der Applikation Server für EJB 3 bietet zwei Services an, eine Time Service, mit deren Hilfe ein bestimmter Prozess zu einer bestimmten Zeit mehrmals aufgerufen werden kann und ein Web Service, die ein Aufruf einer Session Bean über das Inter/Intra-Net ermöglicht. TLGen kann beide Services generieren. 2.11.1 Timer Service Ein Timer Service kommt in einer Applikation zum Einsatz, wenn eine zeitgesteuerte Verarbeitung nötig ist. Der Methodenaufruf kann wahlweise erfolgen, einmalig oder aber in einem bestimmten Zeitintervall dauerhaft. TLGen 40 StarData GmbH V 2.501 TLGen generiert ein Timer Service mit seinen Komponenten wie Client für Timer Service Start, Timer Service selbst als auch eine Callback Klasse (siehe 2.8.3) für die Implementierung der Fachlogik, notwendig für dieses Service. Timer Service werden von TLGen in drei Varianten generiert: 1. Vollkommen automatisch; In diesem Fall sollten Start-, Stopp-Zeit und die periodische Wiederholung automatisch nach eine Timer Service Initialisierung, erfolgen. 2. Start- und Stopp-Zeit, gesteuert durch einen Client Aufruf 3. Automatische und manuelle Steuerungsmöglichkeiten Der Timer Service kann mit einer Session Bean oder mit einer Message Driven Bean verwendet werden. 2.11.2 Web Services Eine Web Service ist ein beliebiger Service (z. B. eine Session Bean), der von einem entfernt liegenden Client über ein World Wide Web verwendetes Protokoll aufgerufen werden kann. Es gibt zwei Webservice-Arten, RPC(Remote Procedure Call) und DOCUMENT. RPC ist eigentlich ein Aufruf von einer Methode (z. B. eine Methode einer Session Bean) über das Web. Der Unterschied zwischen einem Aufruf vom Client zu einer Session Bean (über Applikation Server Techniken) und einem Client Aufruf einer WebServices liegt in der Aufrufart. Diese basiert auf XML und ist standardisiert. Somit ist jeder Aufruf in der Lage sich mit einfachen Mitteln an der Kommunikation zu beteiligen. TLgen generiert für diesen Service den Client, den Webservice selber als auch eine Callback Klasse (siehe 2.8.3), falls nötig. 2.11.3 Callback Klasse Diese Art von Klasse befindet sich als Schnittstelle zwischen dem technischen Code, komplett von TLGen generiert, und dem Fach-Code, welcher die Fachlogik der Applikation beinhaltet. Diese Klasse kann in drei Modi generiert werden und hat, abhängig von einem Parameter „merge“, folgende Werte: merge = 0, TLGen generiert diese Klasse immer wieder neu merge = 1, diese Klasse wird generiert nur wenn sie nicht existiert merge = 2, wird sie neu generiert und der manuell erstellte Code mit dem neu generierten Code gemergt 2.12 Free Klasse Diese Klassen sind für den Programmteil, welcher die Fachlogik beinhaltet, gedacht. Der Inhalt dieser Klasse ist manuell zu implementieren. Findet der Generator diese Klassen, abhängig vom Parameter „merge“, dann ergeben sich folgende Werte: Folgende Attribute werden für diesen Tag verwendet: TLGen 41 StarData GmbH V 2.501 merge = 0, TLGen generiert diese Klasse immer wieder neu merge = 1, diese Klasse wird generiert nur wenn sie nicht existiert merge = 2, wird neu generiert und der manuell erstellte Code mit dem neu generierten Code gemergt TLGen 42 StarData GmbH V 2.501 3. Vergleich zwischen TLGen und anderen Code Generatoren EJB (Enterprise Java Beans) sind standardisierte Komponenten innerhalb eines Applikation Servers, mit dem Ziel, komplexe, mehrschichtige sowie verteilte Software Systeme mit der Programmiersprache Java zu vereinfachen. Die erste Spezifikation von EJB wurde von IBM im Jahr 1997 durchgeführt und von Sun Microsystems mit der Bezeichnung EJV 1.0 und 1.1 angenommen. Kurz danach erschienen die ersten Applikation Server „WebSphere“ von IBM und „WebLogic“ von BEA auf dem Markt. Das EJB-Konzept sollte die Softwareentwicklung von komplexen verteilten Applikationen stark vereinfachen. Das ist aber nur teilweise gelungen, da der persistente Teil (auf Basis von Entity Beans) erhebliche Performance-Verluste verbuchte. Aus diesem Grund sind eine Reihe von Applikationen als „Verbesserungs-Tools“ (z.B. „Hibernate“, „iBatis“, „TopLink“ etc) entwickelt worden, hauptsächlich um diesen Zustand, zu korrigieren. Version 2 von EJB verbessert diesen Zustand wesentlich, eine bessere Performance ist vorhanden. Aber geblieben ist eine gewisse Schwierigkeit durch sehr komplexe und aufwendig zu entwickelnde XML Dateien, notwendig für das Deployment von Applikation. Als Hilfe dafür ist das Tool „XDoclet“ gedacht, welches mit Hilfe von eigenen Tags relativ einfach diese komplexe XML Dateien generiert. Ab Version 3.0 und 3.1 von EJB sind alle Probleme von EJB sehr gut gelöst worden. Eine vernünftige Verwendung der Annotationen (neue Features von Java) lässt die komplette Generierung des notwendigen Java Codes, nur auf Basis von Domainmodell oder Datenmodell, zu. Die Generierungs-Steuerung (die nicht sehr umfangreich ist) übernimmt eine Konfigurations-Datei. Tools wie Hibernate sind für EJB 3 eigentlich nicht mehr notwendig, sie verkomplizieren sogar die gesamte Applikation. Diese Applikationen bergen folgende Nachteile: Die Applikation muss in der Running Zeit diese Tools in der Applikation einbeziehen: o das verkompliziert die Applikation o veranlasst eine Tool-Versions-Abhängigkeit sowie o Miteinbeziehung der Tool-Fehler Verwendet eine extra Code-Schicht als von EJB3 vorgesehen ist All diese Tools bringen nicht eine komplette neue Lösung in der Verwendung von Datenbanken mit sich, sondern sind nur eine Extraschicht für einen Applikation Server, um die Entwicklung mit allen diesen Nachteilen zu erleichtern. Eine reine Nutzung von EJB3 ohne zusätzliche Tools (wie z.B. Hibernate, Toplink, etc.) ist im direkten Vergleich zur Tool-Nutzung immer im Vorteil (siehe auch Anhang 1 - folgt in Kürze). Die Verwendung der Tools (wie z.B. Hibernate, TopLink, iBatis, etc.) mit einem EJB3 Applikation Server ist weder erforderlich noch empfehlenswert, es verkompliziert nur das ITProgramm ohne dabei Vorteile zu erbringen. So ein Tool ist nur für kleine Applikationen, die keinen Applikation Server benötigt, zu gebrauchen. In Gegensatz zu diesen Tools (Hibernate, TopLink, iBatis, etc.) bringt TLGen durch eine komplette Generierung des notwendigen Java Codes eine wesentliche Vereinfachung in der Verwendung von EJB3, so dass sich die Entwicklung nur auf die Fachlogik einer Applikation konzentrieren kann. Die Verwendung von TLGen bringt folgende Vorteile: TLGen 43 StarData GmbH V 2.501 Komplette Code-Generierung: Test Klassen, Client Technische Klassen, Session Beans, Manager Beans, Entity Beans, „persistence.xml“ Dateien, Daten Klassen/Interfaces und Interceptor Klassen TLGen beteiligt sich nicht bei der Applikation in Running Zeit, d. h. keine Abhängigkeit von der TLGen Version Der von TLGen generierte Code hat das gleiche Layout wie der Code, welcher ein Programmierer selber schreiben könnte Durch die sofortige Code-Generierung mit Test Klassen, können die Designer und Architekten die Ergebnisse von Konzepten sofort ersehen und eventuell optimieren (siehe Kap. 2.1) TLGen 44 StarData GmbH