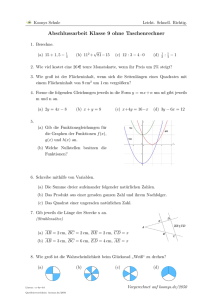
Einführung in die Theoretische Informatik
Werbung

Einführung in die Theoretische Informatik für Wirtschaftsinformatiker Michael Posegga Fakultät Informatik Institut für Theoretische Informatik TU Dresden, Mommsenstr. 13, D-01062 Dresden email: [email protected] Sommersemester 2009 Inhaltsverzeichnis 1 Mathematische Grundlagen 3 1.1 Algebraische Erzeugungssysteme. Vollständige Induktion . . . . . . . . . . 3 1.2 Wörter und Wortmengen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 1.3 Einige Begriffe der Graphentheorie . . . . . . . . . . . . . . . . . . . . . . 17 2 Elemente der Theorie formaler Sprachen und Automaten 22 2.1 Regelsprachen und Chomsky-Hierarchie . . . . . . . . . . . . . . . . . . . . 23 2.2 (Nicht-)Deterministische endliche Automaten und reguläre Sprachen . . . . 26 2.3 Mustervergleich (Pattern Matching), reguläre Ausdrücke und endliche Automaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 2.4 Zustandsäquivalenz und Zustandsminimierung von DFA . . . . . . . . . . . 43 2.5 Einige Aspekte kontextfreier Sprachen . . . . . . . . . . . . . . . . . . . . 47 3 Logik für Informatiker 53 3.1 Aussagenlogik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 3.2 Äquivalenzen der Aussagenlogik . . . . . . . . . . . . . . . . . . . . . . . 59 3.3 Zur Beweistheorie der Aussagenlogik . . . . . . . . . . . . . . . . . . . . . 65 4 Algorithmen und Datenstrukturen 69 4.1 Algorithmen und ihre Analyse . . . . . . . . . . . . . . . . . . . . . . . . . 69 4.1.1 Maschinen mit wahlfreiem Zugriff (RAM) und Zeitkomplexität . . . 71 4.1.2 Ein detailliertes abstraktes Rechnermodell . . . . . . . . . . . . . . 76 4.1.3 Ein vereinfachtes Rechnermodell . . . . . . . . . . . . . . . . . . . . 83 4.1.4 Asymptotische Notation . . . . . . . . . . . . . . . . . . . . . . . . 86 1 4.2 Datenstrukturen, Datentypen . . . . . . . . . . . . . . . . . . . . . . . . . 89 4.2.1 Fundamentale Datenstrukturen . . . . . . . . . . . . . . . . . . . . 89 4.2.2 Abstrakte Datentypen und Anwendungen . . . . . . . . . . . . . . 89 4.3 Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89 4.3.1 Sortieralgorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . 89 2 1 Mathematische Grundlagen 1.1 Algebraische Erzeugungssysteme. Vollständige Induktion In vielen Gebieten der Mathematik und insbesondere in der Theoretischen Informatik werden wichtige Mengen zu untersuchender Objekte konstruktiv eingeführt. Man nimmt dazu an, daß diese Objekte nach gewissen Regeln aus endlich vielen einfachen Objekten konstruiert werden können. Wir werden später sehen, daß das insbesondere die formalen Sprachen (auch Programmiersprachen) als Wortmengen (Menge aller syntaktisch korrekten Programme) und andere Mengen von Daten betrifft. Man gibt also eine Ausgangsmenge A von endlich vielen einfachen Objekten und eine Menge R von endlich vielen Regeln an, mit deren Hilfe man aus bereits erzeugten Elementen weitere ‘neue’ Elemente konstruieren (oder erzeugen) kann. Die so erzeugte Menge besteht dann aus allen Objekten, die sich durch endlich-malige Anwendung der Regeln aus Elementen der Ausgangsmenge A erzeugen lassen. Bezeichnung 1.1.1: (Algebraisches Erzeugungssystem) Ein algebraisches Erzeugungssystem besteht aus einer endlichen Menge A, der Ausgangsmenge, einfacher Objekte und aus einer endlichen Menge R von Regeln, wobei jede Regel op ∈ R festlegt, wie aus n Elementen x1 , . . . , xn , die bereits konstruiert worden sind, ein ‘neues’ Element op(x1 , . . . , xn ) auf einheitliche Weise (Operation) erzeugt wird. Die Festlegung der Elemente, die zur Konstruktion verwendet werden, kann durch Einführung von Sorten (Typen) für Elemente bzw. Regeln weiter präzisiert werden. Bezeichnung für ein Erzeugungssystem ist: E = (A, R). Die Menge der erzeugten Objekte, kurz die erzeugte Menge genannt, ist im allgemeinen unendlich und man stellt sich diese Menge als durch A und R repräsentiert vor. Beispiele: 1. Die Menge der natürlichen Zahlen Ein typisches Beispiel einer Menge, deren Intension uns völlig klar erscheint, und die auf vielfältige Weise konstruktiv dargestellt werden kann, ist die Menge der natürlichen Zahlen. Hier soll eine mögliche Darstellung dieser Menge auf relativ einfache Weise als algebraisches Erzeugungssystem diskutiert werden. Der italienische Mathematiker Guiseppe Peano (27.8.1858, Cuneo - 20.4.1932, Turin) stellte das nach ihm benannte ‘Peanosche Axiomensystem’ für die natürlichen Zahlen auf, das aus den folgenden fünf Axiomen besteht: 3 (P1) (P2) (P3) (P4) (P5) 0 ist eine natürliche Zahl. Jede natürliche Zahl n besitzt genau eine natürliche Zahl succ(n), ihren Nachfolger. Für alle natürlichen Zahlen m, n gilt: wenn succ(n) = succ(m), so auch n = m. 0 ist nicht Nachfolger irgendeiner natürlichen Zahl, d.h. für alle natürlichen Zahlen n gilt: succ(n) 6= 0. Jede Menge M natürlicher Zahlen, d.h. M ⊆ IN, die 0 als Element enthält (0 ∈ M) und die mit einer natürlichen Zahl n auch deren Nachfolger succ(n) als Element enthält (d.h. für jede natürliche Zahl n gilt: Wenn n ∈ M, so succ(n) ∈ M), umfaßt schon die Menge aller natürlichen Zahlen (d.h. M = IN). Mit anderen Worten: Die Menge der natürlichen Zahlen ist die ‘kleinste’ Menge, die die Axiome (P1) - (P5) erfüllt. Also kann man die Nachfolgerbildung als ein solches abstraktes Konstruktionsprinzip nehmen und hat so die Darstellung der Menge der natürlichen Zahlen als Erzeugungssystem Nat = ({0 : nat}, {succ : nat −→ nat}). Die Menge der erzeugten Elemente ist: nat = {0, succ(0), succ(succ(0)), . . . , succn (0), . . .} , die Menge der Terme. 2. Die Menge der binären Bäume Ohne den Begriff eines binären Baumes als ein Graph etwa exakt zu definieren, soll hier doch die Intension des Begriffes beschrieben werden. Ein binärer Baum ist ein Graph, der innere und Blattknoten besitzt. Jeder innere Knoten besitzt genau zwei Folgeknoten, die mit ihm durch Kanten verbunden sind. Blätter haben keine Folgeknoten. Ein Knoten, ohne Vorgängerknoten, wird als Wurzelknoten ausgezeichnet. Man kann sich einen binären Baum als Datenstruktur zur Aufnahme eines Stammbaumes vorstellen. Ein solcher binärer Baum ist z.B. 2 @ @ @ @ @ @ @ 2 @ @ @ 2 2 Gesucht ist eine abstrakte Darstellung der Menge der binären Bäume als Erzeugungssystem. Man überzeuge sich, daß das folgende Erzeugungssystem eine abstrakte Darstellung der binären Bäume liefert: BT = ({leaf : bt}, {mkT : bt, bt −→ bt}) 4 So kann der oben angegebene Baum durch den folgenden Term (Konstruktionsbeschreibung) beschrieben werden: mkT (leaf, mkT (mkT (leaf, leaf ), leaf )) Die Peano-Axiome des vorigen Beispiels können nun sinngemäß auf dieses Beispiel angewendet werden: (P1’) leaf ist ein binärer Baum. usw. Die Menge der erzeugten Elemente ist: bt = {leaf, mkT (leaf, leaf ), . . .} . Algebraische Erzeugungssysteme in ihrer abstrakten Bedeutung nennt man in der Informatik häufig abstrakte Datentypen. Deshalb soll hier die folgende Bezeichnung für die Spezifikation verwendet werden: Nat = BT = datatype leaf: bt mkT: bt, bt -> bt datatype 0: nat s: nat -> nat end Nat end BT Welche Schlußfolgerungen über das Vorhandensein von bestimmten Operationen und welche Vorteile kann man nun aus einer solchen Darstellung (Spezifikation) ziehen? 1. Konstruktoren Die Operationen in einer datatype-Definition, deren Ergebnis ein Objekt des zu definierenden Datentyps ist, nennt man Konstruktoren. Als Axiome kann man zusammenfassen: Axiom 1.1.1: Jedes Element des zu definierenden Datentyps muß das Ergebnis einer Konstruktor-Operation sein. Axiom 1.1.2: Zwei Elemente können nur gleich sein, wenn sie identisch konstruiert wurden. Axiom 1.1.3: Eine Datentyp-Spezifikation definiert die frei erzeugte universelle Algebra, die diese Spezifikation erfüllt. Weitere Beispiele: Bool = datatype true, false: bool end Bool Auf dieselbe Weise können alle endlichen Mengen durch Angabe ihrer Elemente spezifiziert werden. 5 Es besteht auch die Möglichkeit, Erzeugungssysteme nur fragmentarisch anzugeben. In der folgenden Spezifikation bezeichne elem eine beliebige noch festzulegende Menge. elem List = datatype null: list cons: elem, list -> list end elem List Mit dieser Spezifikation wird auf einheitliche Weise eine unendliche Menge von Listendatentypen definiert, für jede konkrete Menge elem einer. Im Zusammenhang mit dem Datentyp elem List sind verschiedene Bezeichnungsweisen üblich. Für die folgenden Beispiele sei angenommen a, b, c: elem : null, consNotation null cons(a, null) [ a | [ ] ] cons(a, cons(b, null)) head, tailNotation [ ] [ a ] [ a | [ b | [ ] ] ] abkürzende Notationen [ ] [ a | [ b ] ] [ a, b ] Alle diese verschiedenen Bezeichnungsweisen für die gleiche Liste werden in verschiedenen Programmsystemen erkannt und identifiziert. Binäre Bäume, deren Knoten mit Werten eines Typs elem markiert sind und den maximalen Verzweigungsgrad zwei haben, können wie folgt als algebraisches Erzeugungssystem definiert werden: elem BT = datatype empty: A -> bt mkT: bt, elem, bt -> bt end elem BT Diese Art binrer Bume werden wir im Verlauf der Vorlesung noch weiter untersuchen und sie werden in Anwendungen eine Rolle spielen. Für die beliebig verzweigten Bäume (die Anzahl der Nachfolger eines inneren Knotens kann beliebig sein) kann man sich folgende wechselseitige Konstruktion vorstellen: Tree = datatype nil: list cons: tree, treelist -> treelist leaf: tree mkT: treelist -> tree endTree 6 2. (Erkennende) Prädikate (engl. recognizers) Wegen der angegebenen Axiome kann man sagen, daß es für jedes Element der konstruierten Menge genau eine Weise gibt, es zu konstruieren. Daraus kann man für jeden Konstruktor das Vorhandensein Boolescher Operationen, sie werden Erkennende Prädikate genannt, annehmen, die genau dann zutreffen, falls das Datenobjekt mit diesem Konstruktor (im letzten Schritt) konstruiert wurde. Beispiele sind: Nat: BT: isZero: nat -> bool mit isSucc: nat -> bool mit isZero(0) = true isZero(succ(n)) = false isSucc(0) = false isSucc(succ(n)) = true isLeaf: bt -> bool isMkT: bt -> bool elem List: isEmpty: list -> bool is Nonempty: list -> bool usw. 3. Selektoren (engl. accessors, selectors) Wenn man weiß, welche Konstruktoroperation (im letzten Schritt) ein Datenobjekt konstruiert hat, ist es häufig notwendig, auch Zugriff auf die Komponenten dieses Konstruktionsschrittes zu haben. Für jeden nichttrivialen (nichteinfachen) Konstruktor und jedes Argument ist eine solche Zugriffsoperation vorhanden. Sie werden Selektoren genannt. Für die betrachteten Datentypen gibt es folgende Selektoren: Konstruktor succ:nat -> nat Selektoren pred:: nat -> nat mkT: bt, bt -> bt left:: bt -> bt right:: bt -> bt cons: elem, list -> list head:: list -> elem tail:: list -> elem usw. Natürlich sind Selektoren nur partielle Operationen, was durch :: gekennzeichnet wurde. Sie sind nur definiert für solche Datenobjekte, die mit dem entsprechenden Konstruktor (im letzten Schritt) konstruiert wurden. So hat man: dom(head) = dom(tail) = { l: list | isNonempty(l) } 7 Ferner gelten z.B. folgende Konstruktor-Selektor-Beziehungen: für alle x: elem, xs: list, ys: isNonempty: head(cons(x, xs)) = tail(cons(x, xs)) = cons(head(ys), tail(ys)) = x xs ys 4. Rekursive Funktionsdefinitionen Ein erheblicher Vorteil der Darstellung von Datenobjekten, als von Konstruktoren erzeugt, besteht darin, daß man Funktionen zwischen solchen Mengen durch Rekursion definieren kann. Rekursion heißt hier zunächst nur, daß die zu definierende Funktion im definierenden Ausdruck selbst vorkommt. Um auf einige Probleme im Zusammenhang mit rekursiven Funktionsgleichungen aufmerksam zu werden, betrachte man folgende beiden Gleichungen für eine Funktion f : nat −→ nat: f (0) = 0 f (x + 2) = f (x + 1) + 1 Lösung dieses Problems ist eine Funktion, die beide Gleichungen erfüllt. Davon gibt es aber unendlich viele, wie das folgende Tabellenfragment zeigt: x 0 1 2 3 4 . . . f0 0 0 1 2 3 . . . f1 0 1 2 3 4 . . . ... ... f27 0 27 28 29 30 . . . ... ... Bei all diesen Funktionen wird ein Funktionswert an der Stell x = 1 angenommen. Die weiteren Werte sind dann wieder eindeutig durch die Rekursionsgleichungen bestimmt. Man überzeuge sich, daß jede Funktion fi mit i = 0, 1, 2, . . . die beiden Gleichungen erfüllt. Es gibt also unendlich viele Lösungen. Meist meint man jedoch, mit solchen Funktionsgleichungen sei die ‘kleinste’ partielle Funktion f gemeint, die nur dort definiert ist, wo sie zu einer natürlichen Zahl reduziert (also ausgerechnet) werden kann. In unserem Fall also wäre das 0 falls x = 0 f (x) = undefiniert sonst Aber in vielen Fällen ist man überzeugt, daß die Rekursion erfolgreich genau eine totale Funktion bestimmt. Betrachten wir einige Fälle: 8 • Addition natürlicher Zahlen +: nat, nat -> nat mit (1) 0 + y = y und (2) s(x) + y = s(x + y). Hier steht s für succ! Im bisher diskutierten Sinne umfaßt die Menge der natürlichen Zahlen nur die Zahl 0 oder mit s konstruierte Elemente. Also hat eine Ausdruck s(s(0)) + s(s(s(0))) zunächst gar keinen Sinn, weil das Symbol + auftritt. Funktionsanwendung der Funktion + muß also bedeuten, das Symbol + aus diesem Ausdruck zu entfernen. Auf der Grundlage des Ersetzbarkeitstheorems der Gleichungslogik läßt sich das nach dem folgenden Berechnungsschema ausführen: – Finde einen Teilterm, auf den die linke Seite einer der beiden Gleichungen paßt (engl. matches). – Dabei ergeben sich für die Variablen (hier x, y) feste Werte. Diese Werte werden betrachtet. – Ersetze den gefundenen Teilterm durch die rechte Seite der entsprechenden Gleichung. Für die soeben angeführte Aufgabe wird dieses Berechnungsprinzip angewendet und ergibt nacheinander: Welche VariablenGleichung ersetzung s(s(0)) + s(s(s(0))) (2) x := s(0), y := s(s(s(0))) ⊢ s( s(0) + s(s(s(0))) ) (2) x := 0, y := s(s(s(0))) ⊢ s(s( 0 + s(s(s(0))) )) (1) y := s(s(s(0))) ⊢ s(s(s(s(s(0))))) Eine andere rekursive Definition der Addition natürlicher Zahlen ist die folgende: (3) 0 # y = y (4) s(x) # y = x # s(y). Bei der Ausführung dieser Funktion werden einfach die ‘führenden’ s von x, dem ersten Argument, nach y, dem zweiten Argument, ’umgeschaufelt’. Man benötigt bei einer Implementation dieser Definition keinen Arbeitsspeicher, die Umformung erfolgt ja in den vorhandenen Argumenten. • Multiplikation natürlicher Zahlen *: nat, nat -> nat 0 * y = 0 s(x) * y = x * y + y mit • Verkettung zweier Listen append: list, list -> list mit append(null, ys) = ys append(cons(x, xs), ys) = cons(x, append(xs, ys)) 9 • Gleichheit auf der Menge der natürlichen Zahlen =: nat, nat -> bool wie folgt: (0 = s(x)) = false (s(x) = 0) = false (0 = 0) = true (s(x) = s(y)) = (x = y) Man finde den unterliegenden Algorithmus heraus. • Als ein letztes Beispiel soll hier das Mischen zweier Listen nach dem Reißverschlußprinzip als rekursive Funktion definiert werden, wie es z.B. an Autobahnbaustellen bei Spurenverengung üblich ist. Hier ist z.B. klar, daß die eine Spur fortgeführt wird, wenn die jeweils andere leer ist. Es ergibt sich: merge: list, list -> list mit merge([ ], ys) = ys merge(xs, [ ]) = xs merge([x| xs], [y| ys]) = [x, y| merge(xs, ys)] bzw. in der ursprünglichen null-cons-Notation: merge(null, ys) = ys merge(xs, null) = xs merge(cons(x, xs), cons(y, ys)) = cons(x, cons(y, merge(xs, ys))) 5. Vollständige Induktion, auch strukturelle Induktion genannt Das letzte der Peanoschen Axiome (P5) wird auch als Induktionsaxiom bezeichnet. Für beliebige Erzeugungssysteme kann es so formuliert werden: “Wenn M eine Teilmenge der erzeugten Menge E ist, die alle einfachen Konstruktoren enthält und ‘abgeschlossen’ gegenüber den nicht-einfachen Konstruktoren ist, dann gilt M = E.” Mit der vertrauten Identifizierung zwischen den Teilmengen einer Menge und den auf ihr definierten einstelligen Prädikaten (Eigenschaften] ergibt sich aus diesem Axiom unmittelbar das folgende Induktionsprinzip, geschrieben als logische Schlußregel: Für Nat: M(0) ∀x : nat.(M(x) → M(succ(x))) ∀x : nat.M(x) Für BT: M(leaf ) ∀x, y : bt.((M(x) ∧ M(y)) → M(mkT (x, y))) ∀x.bt.M(x) Für elem List: M(nil) ∀x : elem.∀xs : list.(M(xs) → M(cons(x, xs))) ∀x : list.M(x) 10 usw. Das Induktionsprinzip wird sehr häufig dazu benutzt, um Eigenschaften rekursiv definierter Funktionen nachzuweisen. Das soll im folgenden an einigen Beispielen vorgeführt werden. Beispiele: (a) Mit unserer Intension der Menge der natürlichen Zahlen geht einher, daß wir den Nachfolger der Zahl x mit der Summe x + 1 identifizieren. In unserer Intension ist 1 das Element s(0) und die Addition wird durch die Gleichungen (1) und (2) definiert. Also müßte beweisbar sein, daß für alle natürlichen Zahlen x gilt: s(x) = x + s(x). (∀x : nat.s(x) = x + s(0)) (Anstelle von succ wird hier s geschrieben.) Mit M = {x : nat|s(x) = x + s(0)} muß hierfür gezeigt werden: M(0): Das gelingt aber sehr leicht, weil s(0) = 0 + s(0) wegen (1), in umgekehrter Richtung benutzt, gilt. Diesen Teil des Induktionsbeweises nennt man häufig Induktionsanfang. ∀x : nat.(M(x) → M(s(x))): Dieser Teil des Induktionsbeweises wird als Induktionsschritt bezeichnet. Wir argumentieren hier so: Es sei x eine natürliche Zahl, für die gilt: s(x) = x + s(0). Für ihren Nachfolger muß gezeigt werden, daß s(s(x)) = s(x) + s(0) gilt. Es gelten nacheinander: s(s(x)) = s(x + s(0)) nach Voraussetzung = s(x) + s(0) wegen (2) Wir haben also die Behauptung oben bewiesen. (b) Die Kommutativität der Addition natürlicher Zahlen wird beweisbar: Für alle natürlichen Zahlen x, y gilt: x + y = y + x. (∀x, y : nat.x + y = y + x) Hier ist eine geschachtelte Induktion notwendig. Prüfen Sie die folgende Argumentation! Es sei M = {x : nat|für alle y : nat.x + y = y + x}. Dann lautet der Induktionsanfang 11 M(0): Für alle y : nat.o + y = y + 0, was wiederum durch vollständige Induktion, nun über y, bewiesen wird. Sei dazu M0 = {y : nat|0 + y = y + 0}. M0 Das ist aber wirklich trivial, weil in 0 + 0 = 0 + 0 beide Seiten identische Terme sind. ∀y : nat. (M0 (y) → M0 (s(y))): Sei y eine natürliche Zahl, für die gilt 0 + y = y + 0. Dann gilt für ihren Nachfolger s(x) nacheinander: 0 + s(y) = = = = s(y) s(0 + y) s(y + 0) s(y) + 0 wegen (1) wegen (1) nach Voraussetzung wegen (2) und damit ist M(0) bewiesen. ∀x : nat. (M(x) → M(s(x))): Es sei x eine natürliche Zahl, für die füralle y : nat gilt: x + y = y + x. (a) Es muß gezeigt werden, daß für ihren Nachfolger s(x) für alle y : nat.s(x)+ y = y + s(x) gilt. Das wir wiederum durch Induktion über y gezeigt. Sei dazu M1 = {y : nat|s(x) + y = y + s(x)} M1 (0): Es folgt aber s(x)+0 = 0+s(x) unmittelbar aus dem Induktionsanfang M(0) mit y = s(x). ∀y : nat. (M1 (y) → M1 (s(y))) : Es sei also y eine natürliche Zahl, für die s(x) + y = y + s(x) (b) gilt. Dann gilt für ihren Nachfolger nacheinander s(x) + s(y) = = = = = = = s(x + s(y)) s(s(y) + x) s(s(y + x)) s(s(x + y)) s(s(x) + y) s(y + s(x)) s(y) + s(x) wegen (2) nach Voraussetzung (a) wegen (2) nach Voraussetzung (a) wegen (2) nach Voraussetzung (b) wegen (2). Damit sind alle Induktionsschritte bewiesen. 12 1.2 Wörter und Wortmengen Bestimmte Objekte, mit denen man algorithmisch arbeiten möchte, werden häufig als Zeichenfolgen dargestellt. Sinnvollerweise geht man dabei so vor, • daß man eine endliche Menge von Symbolen, das Alphabet, festlegt. • Dann betrachtet man alle möglichen Symbolfolgen, die daraus gebildet werden können, • und bildet durch geeignete Einschränkungen Mengen von sinnvollen Symbolfolgen. Diesen Weg werden wir im folgenden nachvollziehen. Bezeichnung 1.2.1: (Alphabet) Unter einem Alphabet versteht man eine beliebige endliche Menge, deren Elemente Symbole (Buchstaben, Zeichen, usw. ) genannt werden. Beispiele für Alphabete sind: • Lateinische Alphabet { A, B, C, . . . , Z, a, b, . . . , z }, • Binäres Alphabet {0, 1}, • Menge der ASCII-Zeichen, • Menge der Farbwerte von Rasterpunkten eines Bildes, • usw. usf. Aus den Buchstaben eines Alphabets entstehen durch Aneinanderreihung Wörter (auch Strings, Zeichenketten usw. genannt). Auf der Menge der Wörter über einem Alphabet Σ ist die Nebeneinanderschreibung (Verkettung) als Operation definiert und es gibt ein spezielles Wort ohne einen Buchstaben. Es wird das leere Wort genannt und mit ε bezeichnet. Definition 1.2.2: (Wortmenge über dem Alphabet Σ ) • Die Menge der Wörter über dem Alphabet Σ, mit Σ∗ bezeichnet, wird wie folgt als Erzeugungssystem definiert: W(Σ) = datatype ε: Σ∗ c: Σ, Σ∗ −→ Σ∗ end W(Σ ) (M.a.W. Wörter können als Listen von Buchstaben aufgefaßt werden.) 13 • Die Länge eines Wortes ist die Anzahl der Symbole, die aneinandergereiht wurden und wie folgt definiert: |ε| = 0 |c(a, w)| = |w| + 1 • Die Verkettung zweier Wörter über dem Alphabet Σ ist eine zweistellige Operation auf der Menge Σ∗ und ist wie folgt definiert: ⊗ : Σ∗ , Σ∗ −→ Σ∗ (1) ε⊗w = w (2) c(a, v) ⊗ w = c(a, v ⊗ w) Satz 1.2.3: Die Verkettungsoperation ⊗ : Σ∗ , Σ∗ −→ Σ∗ ist assoziativ und hat das leere Wort ε als neutrales Element. Beweis: Es ist zu zeigen, daß für alle Wörter u, v, w ∈ Σ∗ gilt: (u ⊗ v) ⊗ w = u ⊗ (v ⊗ w) Der Beweis wird durch vollständige Induktion über u geführt. u = ε Es gilt (ε ⊗ v) ⊗ w = v ⊗ w wegen (1) = ε ⊗ (v ⊗ w) ebenfalls wegen (1) u = c (a, u′ ) Es wird angenommen, daß für u′ gelten möge (u′ ⊗ v) ⊗ w = u′ ⊗ (v ⊗ w). Dann gilt nacheinander (c(a, u′ ) ⊗ v) ⊗ w = = = = c(a, u′ ⊗ v) ⊗ w c(a, (u′ ⊗ v) ⊗ w) c(a, u′ ⊗ (v ⊗ w)) c(a, u′ ) ⊗ (v ⊗ w) wegen (2) wegen (2) nach Voraussetzung wegen (2). Analog wird durch vollständige Induktion gezeigt, daß für jedes Wort u ∈ Σ∗ uε = u gilt. Wörter (Zeichenketten, Strings usw.) treten sehr häufig in der Informatik auf und haben sehr vielfältige Bezeichnungen in den unterschiedlichen Anwendungen, z.B. werden sie als 14 Listen [a1 , . . . , an ], Strings “a1 . . . an ” geschrieben oder häufig sogar unbezeichnet a1 . . . an gelassen. Auch die Verkettung wird meistens weggelassen. Natürliche Zahlen kann man auf sehr verschiedene Weise als Wörter über einem endlichen Alphabet darstellen. Eine Form, die der Darstellung als Erzeugungssystem mit 0 und Nachfolger-KonstruktorOperation succ folgt, ist die unäre Darstellung über einem einelementigen Alphabet {a}: ∧ 0 = a0 = ε ∧ s(n) s(n) = a = c(a, an ) ∧ Es ergibt sich also IN = {a∗ }. Der Nachteil dieser Darstellung der natürlichen Zahlen besteht darin, daß sie zu sehr langen Wörtern führt. Wesentlich kürzere Beschreibungen bekommt man durch die Dezimaldarstellung der natürlichen Zahlen, bzw, der Binärdarstellung usw. Alle diese Darstellungen beruhen auf dem folgenden Satz: Satz 1.2.4: Für jedes k > 1 läßt sich jede natürliche Zahl n auf genau eine Weise als n= m X ai · k i mit m ≥ 0, ai ∈ {0, 1, . . . , 9}, am ∈ {1, 2, . . . , 9} i=0 darstellen. Beweis: (Idee) Man suche die größte Potenz m von k, so daß k m ≤ n < k m+1 gilt und dividiere dann nacheinander durch die kleineren Potenzen von k. Diese Darstellung hat den Nachteil, daß nicht jedes Wort über dem Alphabet {0, 1, . . . , k} eine natürliche Zahl repräsentiert, wegen der sogenannten Vornullen. Verwendet man jedoch den folgenden Satz, so kommt man zur sogenannten k-adischen Darstellung der natürlichen Zahlen für ein gegebenes k ≥ 1. Satz 1.2.5: Für k ≥ 1 läßt sich jede natürliche Zahl n ≥ 1 auf genau eine Weise als n= m X ai · k i mit m ≥ 0 und ai ∈ {1, . . . , k} i=0 darstellen. Beweis: (Idee) Die Eindeutigkeit folgt wie im Satz 1.2.4 und die Existenz soll an einem einfachen Beispiel instruktiv gemacht werden. ∧ Dezimal 93002 = 9 · 104 + 3 · 103 + 0 · 102 + 0 · 101 + 2 · 100 ∧ = 9 · 104 + 2 · 103 + 10 · 102 + 0 · 101 + 2 · 100 ∧ = 9 · 104 + 2 · 103 + 9 · 102 + 10 · 101 + 2 · 100 15 Die noch nicht berücksichtigte Null wird durch das leere Wort ε repräsentiert und nun gibt es eine eineindeutige Zuordnung zwischen den natürlichen Zahlen und den Wörtern der Menge {1, . . . k}∗ . 2-adische Darstellung werden auch dyadische Darstellungen genannt. Damit gibt es für jedes beliebige Alphabet Σ eine einfache eineindeutige Beziehung zwischen der Menge der natürlichen Zahlen und der Wörter aus Σ∗ . So ist es z.B. für Berechenbarkeitsfragen häufig unwichtig zwischen Funktionen auf natürlichen Zahlen oder Zeichenketten zu unterscheiden. Definition 1.2.6: Eine beliebige Teilmenge L ⊆ Σ∗ wird als formale Sprache über dem Alphabet Σ bezeichnet. Neben den bekannten mengentheoretischen Operationen ∪ (Vereinigung), ∩ (Durchschnitt), \ (Komplement) und der leeren Menge ∅ werden bei Sprachen noch weitere Operationen benötigt, die wie folgt definiert sind. Definition 1.2.7: • Konkatenation von Sprachen def. L1 · L2 = {xy|x ∈ L1 und y ∈ L2 } Die Konkatenation wird häufig nicht bezeichnet. • Mengeniteration (Sternabschluß) L0 Ln+1 L∗ L+ def. = {ε} def. = L · Ln def. S n = n≥0 L def. S n = n≥1 L . Beispiele: {a, b}3 ∅∗ M ·∅ {a}∗ {a}∗ · {b}∗ usw. = = = = = {aaa, aab, aba, abb, baa, bab, bba, bbb} {ε} Beachte {ε} = 6 ∅! ∅·M =∅ {ai |i ≥ 0} {ai bj |i, j ≥ 0} = 6 {a, b}∗ Satz 1.2.8: Es seien Σ1 und Σ2 Alphabete. Jede Abbildung h : Σ1 −→ Σ∗2 kann erweitert werden zu einer Abbildung h∗ : Σ∗1 −→ Σ∗2 , 16 für die gilt h∗ (ε) = ε h∗ (a) = h(a) für a ∈ Σ1 ∗ h (v ⊗ w) = h∗ (v) ⊗ h∗ (w) für alle v, w ∈ Σ∗1 . 1.3 Einige Begriffe der Graphentheorie Im Rahmen der Graphentheorie unterscheidet man gerichtete und ungerichtete Graphen. Hier spielen die gerichteten Graphen eine Rolle. Definition 1.3.1: Ein gerichteter Graph G = (K, E, δ0 , δ1 ) besteht aus • einer endlichen Menge K, deren Elemente Knoten(punkte) heißen, • einer endlichen Menge E, deren Elemente Kanten heißen, • zwei Funktionen δ0 , δ1 : E −→ K; dabei heißt δ0 (e) bzw. δ1 (e) Anfangspunkt bzw. Endpunkt der Kante e ∈ E. Beispiel: Es seien K = {1, 2, 3, 4, } E = {a, b, c, d, e, f, g, h} und δ0 , δ1 : E −→ K durch die folgende Tabelle gegeben: E a b c d e f g h δ0 1 1 1 2 2 4 3 4 δ1 1 2 2 3 4 1 4 3 Der unterliegende Graph hat folgendes Bild * * '$ b c a &% 1n 17 2n HH HH HeH d H HH H j H f * h g ? 3n 4n Satz 1.3.2: Jeder zweistelligen Relation R über einer Menge M, d.h. R ⊆ M × M, kann man auf eindeutige Weise einen gerichteten Graphen G = (K, E, δ0, δ1 ) zuordnen. Dieser wird auch Relationsgraph von R genannt. Beweis: Es sei M und R ⊆ M × M gegeben. Der Relationsgraph wird wie folgt festgelegt: K := M; E := R; und δ0 (x, y) = x; δ1 (x, y) = y für (x, y) ∈ R. Der so entstandene Graph G hat die Eigenschaft, daß zwischen zwei Knoten höchstens ein Pfeil in ein und dieselbe Richtung verläuft. Jeder solche Graph definiert eine Menge M und eine zweistellige Relation R ⊆ M × M wie folgt: M := K; (x, y) ∈ R gdw. es gibt einen Pfeil von x nach y. Definition 1.3.3: (Weg der Länge n, Zyklus, Erreichbarkeit) • Eine Folge [e1 , . . . , en ] von Kanten eines Graphen nennt man Weg der Länge n, n ≥ 1, vom Knoten x zum Knoten y, wenn x = δ0 (e1 ); y = δ1 (en ) und δ1 (ei ) = δ0 (ei+1 ) für i = 1, . . . , n − 1 gilt. • Ein Zyklus in einem Graphen ist ein Weg [e1 , . . . , en ] mit δ0 (e1 ) = δ1 (en ). • Einen Knoten y nennt man erreichbar vom Knoten x aus, wenn es einen Weg [e1 , . . . , en ] von x nach y gibt. • Der Eingangsgrad eines Knoten y ist definiert als die Anzahl der Kanten e mit δ1 (e) = y. Analog ist der Ausgangsgrad des Knotens y definiert als die Anzahl der Kanten e mit δ0 (e) = y. Definition 1.3.4: (Baum) Ein Baum T ist ein gerichteter Graph T = (K, E, δ0, δ1 ) mit einem ausgezeichneten Knoten r ∈ K, der Wurzel genannt wird, und welcher folgende weitere Eigenschaften besitzt: (1) Der Eingangsgrad von r ist 0. (2) Der Eingangsgrad aller übrigen Knoten ist 1. (3) Jeder Knoten y ∈ K ist von r aus erreichbar. Satz 1.3.5: Jeder Baum T hat folgende Eigenschaften: 18 (a) In T gibt es keine Zyklen. (b) Für jeden Knoten y des Baumes T gibt es genau einen Weg von der Wurzel zu diesem Knoten y. Beweis: (a) Angenommen in T gäbe es einen Zyklus [e1 , . . . , en ]. Für die Knoten des Zyklus gilt, daß ihr Eingangsgrad gleich 1 ist. Deshalb kann r nicht Knoten im Zyklus sein. Andererseits gibt es einen Weg [g1 , . . . , gm ] von r zu einem beliebigen Knoten des Zyklus. Zu diesem Knoten führen die Kanten gm und ei , d.h. es gilt gm = ei wegen des Eingangsgrades 1. Geht man beide Wege rückwärts, ergibt sich, daß r doch ein Knoten im Zyklus sein muß, was im Widerspruch zur Voraussetzung steht. (b) Angenommen [g1 , . . . , gm ] und [e1 , . . . ; en ] seien zwei verschiedene Wege von r nach y. Wegen des Eingangsgrades 1 von y, gilt gm = en . Dieser Prozeß kann fortgesetzt werden, d.h. es folgt gm−1 = en−1 usw. Sei o.B.d.A. n > m. Dann folgt weiter g1 = en−m+1 und wegen δ0 (g1 ) = δ0 (en−m+1 ) = r und δ0 (e1 ) = r ist [e1 , . . . , en−m ] ein Zyklus, was wegen (a) ausgeschlossen ist. Definition 1.3.6: (Markierte Transitionssysteme) Ein markiertes Transitionssystem (engl. Labelled Transition System, LTS genannt) T = (S, L, next ⊆ S × L × S) besteht aus • einer nichtleeren Menge S von Zuständen (auch Konfigurationen usw. genannt), • einer nichtleeren Menge L von Marken (auch Aktionen, Transitionen usw. genannt) und • einer dreistelligen Relation next ⊆ S × L × S, mit der durch (s1 , a, s2 ) ∈ next zum Ausdruck gebracht wird, daß das Transitionssystem im Zustand s1 nach Ausführung der Transition a in den Zustand s2 übergehen kann. In manchen Lehrbüchern wird die dreistellige Relation next auch durch eine Familie von binären Relationen a {→⊆ S × S|a ∈ L} oder als Abbildung ν : L × S −→ P (S) 19 dargestellt. Dabei stehen die verschiedenen Bezeichnungsweisen in der Beziehung a (s1 , s2 ) ∈→ gdw. (s1 , a, s2 ) ∈ next gdw. s2 ∈ ν(s1 , a) zueinander. Man spricht von endlichen Transitionssystemen, wenn sowohl die Menge S der Zustände als auch die Menge L der Marken endlich sind. Endliche Transitionssysteme kann man sehr anschaulich als Transitionsdiagramme darstellen. Beispiel: Auf einem Gleisnetz der folgenden Gestalt (a, b, c, d bezeichnen die einzelnen Streckenabschnitte) ' $ c d a & b S S % fahren zwei Eisenbahnzüge in die gleiche Richtung (Uhrzeigersinn!). Es gibt zwei Aktionen: 1, d.h. Zug1 fährt in den folgenden Streckenabschnitt ein, 2, d.h. Zug2 fährt in den folgenden Streckenabschnitt ein. Es kann in einem Takt also immer nur höchstens ein Zug fahren. Eine Einfahrt in den folgenden Streckenabschnitt ist für einen Zug jedoch nur mglich, wenn dieser frei ist, d.h. beide Züge befinden sich niemals im gleichen Streckenabschnitt. Man gebe das Transitionssystem aller möglichen Zustände und Zustandsübergänge in graphischer Form an. Hinweis: Ein Zustand sollte als Paar (x, y) mit x, y ∈ {a, b, c, d} beschrieben werden, wobei das Paar (x, y) die Bedeutung hat: Zug1 befindet sich im Streckenanschnitt x und Zug2 im Abschnitt y. Man beginne im Zustand (a, b), d.h. Zug1 ist im Abschnitt a und Zug2 im Abschnitt b. Das Transitionssystem ist wie folgt beschrieben: T = ({(x, y)|x, y ∈ {a, b, c, d}, x 6= y}, {1, 2}, next) wobei die Relation next durch den folgenden Graphen gegeben ist: 20 - (a, b) 1 1 (c, b) 1 ? (d, b) 2 ? (d, c) 1 ? - (b, c) 2 ? 2 (b, d) @ @ @2 @ @ @ R @ @ I @ @ @ @ @ @ @ @ @ @ 1 @ 2 @ @ @ @ I @ @ @ @ @ @ @ @ @ @ 1 @ 2 @ @ @ @ @ @ @ 2 @@ R @ (a, c) 2 2 ? (a, d) 1 ? (c, d) 2 ? (c, a) 1 ? (d, a) 1 1 (b, a) 21 2 Elemente der Theorie formaler Sprachen und Automaten Um Algorithmen auf einem Rechner zu implementieren, bedient man sich einer geeigneten Programmiersprache und schreibt in dieser Sprache ein Programm. Programmiersprachen, mit ihrem Konzept und ihrer Implementation, sind syntaktisch und semantisch eindeutig festgelegt. Die Syntax beschreibt die Struktur und den Aufbau von Programmen und die Semantik ordnet jedem Programm eine inhaltliche Bedeutung zu. Gewöhnlich erlernt man eine Programmiersprache, indem man syntaktische und semantische Elemente gleichzeitig studiert, ausprobiert und seine Fähigkeiten festigt, sowohl syntaktisch korrekte Programme, die vom Übersetzer nicht zurückgewiesen werden, als auch semantisch richtige Programme zu schreiben, die den Rechner zwingen, die gewünschten Resultate zu liefern. In der Theoretischen Informatik stellt sich zunächst u.a. die Frage nach der Möglichkeit, sowohl Syntax als auch Semantik einer Programmiersprache exakt formal zu beschreiben. Eine formale Syntaxbeschreibung gibt nicht nur genaue und zuverlässige Hilfen bei der Formulierung von Programmen, sondern ist auch Voraussetzung dafür, Verfahren zur Syntaxanalyse und Übersetzung zu entwickeln. Die Notwendigkeit, auch die Semantik exakt formal zu beschreiben, ergibt sich aus der Forderung, Programme in eindeutiger Weise zu interpretieren und ihre Korrektheit zu prüfen und zu beweisen. In diesem Teil der Vorlesung soll deutlich gemacht werden, wie man die Syntaxbeschreibung und -erkennung algorithmisch lösen kann. Dabei ist es üblich, eine Sprache mit der Menge ihrer “Sätze” zu identifizieren, also eine Programmiersprache mit der Menge ihrer syntaktisch korrekten Programme, die ihrerseits eine Teilmenge der Menge aller Wörter über dem Alphabet der zu verwendenen Zeichen der Sprache sind. Definition 2.1: Gegeben sei ein endliches Alphabet Σ. • Eine Teilmenge L der Menge Σ∗ aller Wörter über dem Alphabet Σ nennt man eine formale Sprache über Σ. • Eine Programmiersprache besteht aus einer formalen Sprache L über Σ, einem Eingabealphabet E, einem Ausgabealphabet A und einer partiellen berechenbaren Funktion f :: L × E ∗ −→ A∗ , wobei L die Syntax und f die Semantik der Sprache darstellt. Anmerkung: Da im allgemeinen die Menge der Wörter einer Sprache L nicht endlich ist, besteht die entscheidende Frage darin, wie die Beschreibung der Sprache erfolgen kann, wobei nur solche Möglichkeiten interessant sind, die das Erkennen, ob ein beliebiges Wort w ∈ Σ∗ zur Sprache L gehört, algorithmisch lösen. 22 2.1 Regelsprachen und Chomsky-Hierarchie Eine Möglichkeit der Beschreibung einer Sprache L über Σ besteht in der Erzeugung der Wörter dieser Sprache durch die Anwendung von Regeln. Definition 2.1.1: ((Produktions-) Regelsystem) (1) Eine Produktionsregel ist ein geordnetes Paar r = (w1 , w2 ) ∈ Σ∗ × Σ∗ . in Bezug auf die spätere Anwendung wird eine Regel auch in der Form w1 −→ w2 geschrieben. (2) Ein Produktionssystem (Regelsystem) besteht aus einem Alphabet Σ und einer endlichen Menge R von Regeln. Die Bezeichnung ist: P = (Σ, R). Definition 2.1.2: (Ableitung, Ableitbarkeit) Es sei P = (Σ, R) ein Produktionssystem, v1 , v2 ∈ Σ∗ . Man sagt: (1) v2 ist in einem Schritt aus v1 ableitbar, wenn es Wörter x, y ∈ Σ∗ und eine Regel (w1 −→ w2 ) ∈ R gibt, so daß v1 = xw1 y und v2 = xw2 y gilt. Bezeichnung: v1 −→ v2 . (2) v2 ist ableitbar, wenn es Wörter w0 , . . . , wn ∈ Σ∗ , n ≥ 0 gibt, so daß v1 = w0 −→ w1 −→ . . . −→ wn = v2 ∗ gilt. Bezeichnung: v1 −→ v2 . (3) Die Folge [w0 , w1 , . . . , wn ] nennt man Ableitung der Länge n von w0 nach wn . (4) Eine Ableitung [w0 , w1 , . . . , wn ] heißt minimal, wenn wi 6= wj für alle 0 ≤ i, j ≤ n, i 6= j. Beispiel: Die Ableitbarkeit kann mann durch einen Graphen veranschaulichen, dessen Knoten Wörter aus Σ∗ sind und dessen Kanten die “Ein-Schritt-Ableitungen” sind. (1) (2) (3) Sei P = ({a, b, c}, {(ba, ac), (ac, ba), (b, aa)}). Ausgehend von bac erhält man z.B.: 23 bac acc bba aaac baaa aaba acaa aaaaa Jeder Weg in diesem Graphen entspricht einer Ableitung. Definition 2.1.3: ((Regel-) Grammatik) (1) Eine Regelgrammatik ist ein Quadrupel G = (N, Σ, R, S) mit N : ist eine endliche, nichtleere Menge, deren Elemente Nichtterminale heißen, Σ: ist eine endliche, nichtleere Menge, deren Elemente Terminalsymbole heißen, wobei gilt: N ∩ Σ = ∅, N ∪ Σ ist das Gesamtalphabet, R : ist eine endliche Menge von Regeln, von denen jede Regel r die Form r ∈ (N ∪ Σ)∗ N(N ∪ Σ)∗ × (N ∪ Σ)∗ hat, m.a.W. in den Regel (u −→ v) kommt in u mindestens ein Nichtterminal vor, S ∈ N ist ein ausgezeichnetes Nichtterminal und wird als Startzeichen bezeichnet. (2) Die Menge aller Wörter aus Σ∗ , die aus S ableitbar sind, heißt die von der Grammatik G erzeugte Regelsprache L(G), d.h. ∗ L(G) = {w ∈ Σ∗ |S −→ w}. (3) Zwei Regelgrammatiken G1 und G2 heißen äquivalent, wenn sie die gleiche Sprache definieren, d.h. L(G1 ) = L(G2 ) gilt. Aufgaben: 1. Gegeben sei die Grammatik G = (V, Σ, P, S) mit V = {S; A; B}, Σ = {a, b} und (1) (2) (3) (4) (5) P = {S −→ AB, A −→ ab, A −→ aAb, B −→ ba, B −→ bBa}. 24 a) Man gebe alle Ableitungsfolgen für den Satz abba an. b) Welche Sprache L(G) wird durch G beschrieben? 2. Man gebe eine Grammatik an, die die Sprache der vorzeichenbehafteten bzw. vorzeichenfreien Dezimalziffernfolgen ohne die sogenannten Vornullen erzeugt. (+0, −0 sollen ebenfalls nicht zu dieser Sprache gehören.) Chomsky-Hierarchie Von Noam Chomsky stammt folgende nach ihm benannte Einteilung von Grammatiken (bzw. Sprachen) in Typen nach der Form ihrer Regeln: Definition 2.1.4: (Chomsky-Hierarchie) • Jede Grammatik ist zunächst automatisch vom Typ 0, d.h. bei diesen Grammatiken sind den Regeln keinerlei weitere Einschränkungen hinsichtlich ihrer Form auferlegt. Man spricht auch von allgemeinen Phrasenstrukturgrammatiken. • Eine Grammatik ist vom Typ 1 oder kontextsensitiv, falls für alle Regeln w1 −→ w2 ∈ R gilt: |w1| ≤ |w2 |. • Eine Typ 1 - Grammatik ist vom Typ 2 oder kontextfrei, falls für alle Regeln w1 −→ w2 ∈ R gilt, daß w1 ein einzelnes Nichtterminal ist, d.h. w1 ∈ N. • Eine Typ 2 - Grammatik ist vom Typ 3 oder regulär, falls zusätzlich gilt: w2 ∈ Σ ∪ ΣN, d.h. die rechten Seiten von Regeln sind Terminalzeichen (abschließende Regeln) oder ein Terminalzeichen gefolgt von einem Nichtterminal. • Eine Sprache L ⊆ Σ heißt vom Typ 0 (bzw. Typ 1, Typ 2, Typ 3), wenn es eine entsprechende Grammatik G desselben Typs gibt mit L(G) = L. Aufgaben: 1. Gegeben sei die folgende Regelgrammatik G = (V, Σ, P, S) mit V = {S, A}, Σ = (1) (2) (3) {0, 1} und P = {S −→ 0A1, 0A −→ 00A1, A −→ ε}. a) Man bestimme die Sprache L(G), die durch diese Grammatik beschrieben wird. b) Ist die Sprache L(G) kontextfrei? Im positiven Fall gebe man eine kontextfreie Grammatik an, die die gleiche Sprache definiert. c) Ist die Sprache L(G) regulär? 25 2. a) Man gebe eine Grammatik für die Menge aller korrekt geschachtelten Klammerausdrücke bestehend aus den Klammern (, ), [, ], {, } an. (Beispiele: ( [ ( ) ] ) { [ ] } ist korrekt geschachtelt, ( [ ) und ( [ ] } [ ] jedoch nicht.) b) Man gebe eine Ableitung des korrekten Klammerausdrucks { ( ) ( [ ] ) } an. Satz 2.1.5: Die vier Chomsky-Klassen von Sprachen bilden eine Hierarchie, d.h. es gilt Typ 3 ⊂ Typ 2 ⊂ Typ 1 ⊂ Typ 0 Anstelle eines Beweises: L = {an bn |n ≥ 1} ∈ Typ 2 \ Typ 3 L = {an bn cn |n ≥ 1} ∈ Typ 1 \ Typ 2 unentscheidbare Sprache ∈ Typ 0 \ Typ 1 2.2 (Nicht-)Deterministische endliche Automaten und reguläre Sprachen Es sei G = (N, Σ, R, S) eine reguläre Grammatik, d.h. die Regeln in R haben sämtlich die Form A −→ a (abschließend) oder A −→ aB (nichtabschließend) mit A, B ∈ N und a ∈ Σ. Dieser Grammatik G kann man leicht ein markiertes Transitionssystem T = (Q, L, next) wie folgt zuordnen: • Die Menge Q der Zustände des Systems ist gleich der Menge der Nichtterminale, zu der ein weiterer Zustand X (d.h. X ∈ / N) hinzugefügt wurde: Q := N ∪ {X}, wobei X ∈ / N sein muß. • Für L gilt: L := Σ. • Für A, B ∈ N und a ∈ Σ wird festgelegt: < A, a, B >∈ next gdw. es gibt eine Regel A −→ aB ∈ R. 26 • Desweiteren wird festgelegt für A ∈ N und a ∈ Σ: es gibt eine abschließende Regel A −→ a ∈ R. < A, a, X >∈ next gdw. Beispiele: 1. Es sei G = ({S, B}, {a, b}, R, S) eine reguläre Grammatik mit den Regeln R = {S −→ a, S −→ b, S −→ aS, S −→ bB, B −→ b, B −→ bB}. Das zugehörige markierte Transitionssystem ist T = ({S, B, X}, {a, b}, next), wobei next durch den folgenden Transitionsgraphen beschrieben wird: a b - S @ @ @ a, b @ @ @ @ @ R @ b - B b X 2. Die Grammatik G = ({< integer >, < digits >, < non zero unsigned >}, {+, −, 0, 1, . . . 9}, R, < integer >) ist durch folgende Regel R gegeben: < integer >−→ 0|1| . . . |9 < integer >−→ 1 < digits > |2 < digits > | . . . |9 < digits > < digits >−→ 0|1| . . . |9 < digits >−→ 0 < digits > |1 < digits > | . . . |9 < digits > < integer >−→ + < non zero unsigned > | − < non zero unsigned > < non zero unsigned >−→ 1|2| . . . |9 < non zero unsigned >−→ 1 < digits > |2 < digits > | . . . |9 < digits > Das zugehörige markierte Transitionssystem ist T = ({< integer >, < digits >, < non zero unsigned >, X}, {+, −, 0, 1, 2, . . . , 9}, next), wobei next durch den folgenden Transitionsgraphen beschrieben wird: 27 1 +, − 1, ...,9 1, . . . , 9 - < digits > > H H A 0, 1, . . . , 9 HH A HH HH0, 1, . . . , 9 A 0, 1, . . . , 9 A HH A 1, . . . , 9 HH HH AAU j H < non zero unsigned > - < integer X Bemerkungen, Beobachtungen: 1. Im Begriff des markierten Transitionssystems sind Anfangs- und Endzustände, was dem Startsymbol und den abschließenden Regeln der Grammatik entspricht, noch nicht enthalten. In den Transitionsgraphen wurden sie bereits (offensichtlich durch den →-Eingangspfeil und -Doppelkreis) eingefügt. 2. Jeder Ableitung eines Wortes der Sprache, die durch die Grammatik erzeugt wird, entspricht ein Weg im Transitionsgraphen von S nach X, wobei die aneinandergereiten Markierungen dem abgeleiteten Wort entsprechen, d.h. die Menge aller Wege im Transitionsgraph von S nach X bestimmt also die von G erzeugte Sprache. 3. Für diese graphentheoretische Interpretation regulärer Grammatiken gibt es auch die Intension eines (abstrakten) Gerätes, eine nichtdeterministischen Akzeptors, der für ein gegebenes Wort beim zeichenweisen Lesen von links nach rechts nach einem mögli8chen Weg von S nach X sucht. 4. Im Zusammenhang mit dem Begriff eines nichtdeterministischen Automaten wird die Darstellung des markierten Transitionsgraphen als Abbildung ∆ : Q × L −→ P (Q) bevorzugt, P (Q) meint hier die Potenzmenge von Q. Definition 2.2.1: (Nichtdeterministischer endlicher Automat (NFA) (1) Ein nichtdeterministischer endlicher Automat (NFA) ist ein Quintupel M = (Q, Σ, ∆, S, F ), wobei 28 – Q eine endliche Menge ist, deren Elemente Zustände heißen, – Σ ist eine endliche Menge, das Eingabealphabet, – ∆ : Q × Σ −→ P (Q) ist die Transitionsfunktion, – S ⊆ Q ist die Menge der ausgezeichneten Startzustände, – F ⊆ Q ist die Menge der ausgezeichneten Endzustände. (2) Die Transitionsfunktion ∆ : Q × Σ −→ P (Q) wird auf natürliche Weise (rekursiv) erweitert zu einer Funktion ˆ : P (Q) × Σ∗ −→ P (Q) ∆ vermöge ˆ ∆(A, ε) = A (2.1) S ˆ ˆ (2.2) ∆(A, aw) = ∆( q∈A ∆(q, a), w) mit A ⊆ Q, a ∈ Σ, w ∈ Σ∗ . (3) Man sagt, der NFA M akzeptiert das Wort w ∈ Σ∗ , wenn ˆ ∆(S, w) ∩ F 6= ∅ gilt. (4) Die Sprache L(M), die vom NFA M erzeugte oder akzeptierte Sprache, wird nun definiert als die Menge der Wörter w ∈ Σ∗ , die von M akzeptiert werden, d.h. ˆ L(M) = {w ∈ Σ∗ | ∆(S, w) ∩ F 6= ∅} Intuitiv gesprochen, gibt ∆(q, a) die Menge der Zustände p des Automaten M an, die von q aus in einem Schritt beim Lesen des Buchstaben a erreicht werden können. Diese Menge kann natürlich auch leer sein. ˆ Dementsprechend gibt ∆(A, w) für A ⊆ Q und w ∈ Σ∗ die Menge der Zustände des Automaten M an, dienach Lesen des gesamten Eingabewortes w von einem beliebigen Zustand in A aus erreichbar sind. M akzeptiert das Wort w ∈ Σ∗ , wenn es einen akzeptierenden Endzustand q ∈ F gibt, der nach Lesen des Wortes w von einem beliebigen Startzustand p ∈ S aus erreicht werden kann, d.h. w ist die Liste der Markierungen eines Weges von einem beliebigen Startzustand p aus zu einem beliebigen Endzustand in F . Folgerung 2.2.2: Zu jeder regulären Grammatik G gibt es einen NFA M, der die von G erzeugte Sprache akzeptiert, d.h. es gilt L(G) = L(M). In Bezug auf das Akzeptieren von Wörtern durch nichtdeterministische endliche Automaten schließen sich zwei Fragen an: 29 1. Gilt auch die Umkehrung von Folgerung 2.2.2, d.h. ist die von einem beliebigen NFA akzeptierte Sprache stets regulär? 2. Kann der nichtdeterministische Prozeß des Akzeptierens, der ja ein nichtdeterministisches Suchen nach einem akzeptierenden Weg im Transitionsgraphen ist, auch algorithmisch, d.h. determiniert ablaufen? Beide Fragen können bejaht werden, die zweite führt auf den Begriff des deterministischen endlichen Automaten, der auf dem Weg zur Beantwortung der ersten Frage weiterhilft. Definition 2.2.3: (Deterministischer endlicher Automat (DFA)) (1) Ein deterministischer endlicher Automat (DFA) ist ein Quintupel M = (Q, Σ, δ, q0 , F ), wobei – Q eine endliche Menge ist, deren Elemente Zustände heißen, – Σ ist das endliche Eingabealphabet, – δ : Q × Σ −→ Q ist die Transitionsfunktion, – q0 ∈ Q ist der Startzustand, – F ⊆ Q ist die Menge der ausgezeichneten Endzustände. Anmerkung: Im Unterschied zum nichtdeterministischen endlichen Automaten hat ein deterministischer Automat genau einen Startzustand und die Transitionsfunktion ist anders getypt bzw. liefert stets genau einen Folgezustand. (2) Die Transitionsfunktion δ : Q × Σ −→ Q wird auf natürliche Weise (rekursiv) erweitert zu einer Funktion δ̂ : q × Σ∗ −→ Q vermöge δ̂(q, ε) = q δ̂(q, aw) = δ̂(δ(q, a), w) (3.1) (3.2) mit q ∈ Q, a ∈ Σ, w ∈ Σ∗ . (3) Man sagt, der DFA M akzeptiert das Wort w ∈ Σ∗ , wenn δ̂(q0 , w) ∈ F gilt. (4) Die Sprache L(M), die von M erzeugte (erkennbare, akzeptierte, ...) Sprache wird nun definiert als die Menge der Wörter w ∈ Σ∗ , die von M akzeptiert werden, d.h. L(M) = {w ∈ Σ∗ | δ̂(q0 , w) ∈ F }. 30 Beispiele und Aufgaben: 1. a) Man gebe eine reguläre Grammatik für die Sprache L = {ai bj | i + j ≥ 1} an. b) Man konstruiere einen (zugehörigen) endlichen Automaten M. Ist dieser deterministisch? 2. Man gebe einen deterministischen endlichen Automaten M an, der die folgende Sprache akzeptiert: die Anzahl der 1-en in w ist gerade } und w enthält mindestens zwei 1-en L = {w ∈ {0, 1}∗ | • Man zeige, daß 0110 ∈ L(M) gilt. • Zu M gebe man eine reguläre Grammatik GM an mit L(GM ) = L(M) = L entsprechend der in der Vorlesung angegebenen Methode. • Man zeige, daß 0110 ∈ L(GM ) gilt. 3. a) Man gebe einen deterministischen endlichen Automaten an, der die folgende Sprache akzeptiert: L = {(ab)n a| n = 2m + 1, m ≥ 0} b) Man gebe einen deterministischen endlichen Automaten an, der die folgende Sprache akzeptiert: L = {w ∈ {0, 1}∗ | w endet mit i und enthält dann } eine ungerade Anzahl von i’s, i ∈ {0, 1} Satz 2.2.4: Jede durch einen deterministischen endlichen Automaten erkennbare Sprache ist regulär. Beweis: Es sei M = (Q, Σ, δ, q0 , F ) ein DFA mit der akzeptierten Sprache L(M). Zunächst / F . Die reguläre Grammatik G, die dem wird angenommen, daß ε ∈ / L(M) ist, d.h. q0 ∈ Automaten M zugeordnet wird, entsteht folgendermaßen: G = (N, Σ, R, S) mit N := Q, S := q0 und R besteht aus den folgenden Regeln: 31 Jedem Transitionspfeil δ(q, a) = q ′ wird die Regel q −→ q ′ zugeordnet, a ∈ Σ, und zusätzlich, falls q ′ ∈ F , wird noch die abschließende Regel q −→ a der Grammatik zugeordnet. Es ist dann leicht zu sehen, daß L(M) = L(G) gilt. Falls q0 ∈ F und damit ε ∈ L(M) zugelassen sein soll, sind einige weitere Umstrukturierung notwendig: • Es wird die Regel q0 −→ ε hinzugenommen. Mit dieser Regel soll aber nur das leere Wort ε abgeleitet werden, d.h. es ist unzulässig, daß q0 auf der rechten Seite einer Regel vorkommt. • Kommt q0 auf der rechten Seite einer Regel vor, so ersetzen wir die alten Regeln durch folgende neue (wobei q0′ ein neues Nichtterminal ist): 1. q0 −→ die rechten Seiten der q0 -Regeln, mot q0 ersetzt durch q0′ , 2. alle Regeln mit q0 ersetzt durch q0′ , 3. S −→ ε. Satz 2.2.5: (Rabin, Scott) Jede von einem NFA akzeptierte Sprache ist auch durch einen DFA akzeptierbar. Beweis: Der Beweis benutzt die sogenannte Potenzmengenkonstruktion. Es sei M = (Q, Σ, ∆, S, F ) ein gegebener NFA, zu dem nun ein DFA M ′ = (Q′ , Σ, δ, q0 , F ′) konstruiert werden soll, der dieselbe Sprache akzeptiert: Q′ := P (Q), d.h. die Elemente von Q′ sind die Teilmengen von Zuständen aus Q. Die weiteren Bestimmungsstücke ergeben sich wie folgt: S ˆ δ(A, a) := q∈A ∆(q, a) = ∆(A, a) für X ⊆ Q, a ∈ Σ q0 := S F ′ := {A ⊆ Q| A ∩ F 6= ∅} Dann ist klar, daß folgender Zusammenhang besteht: Für alle w = a1 a2 . . . an ∈ Σ∗ gilt: w ∈ L(M) ˆ gdw. ∆(S, w) ∩ F 6= ∅ gdw. es gibt eine Folge von Teilmengen A1 , A2 , . . . , An ⊆ Q mit δ(Ai , ai+1 ) = Ai+1 für i = 0, . . . , n − 1 und An ∩ F 6= ∅ gdw. δ̂(S, w) ∈ F ′ gdw. w ∈ L(M). 32 Beispiele und Aufgaben: 1. Der folgende NFA akzeptiert genau die Wörter über {0, 1}, die mit ‘00’ enden, oder genau gleich ‘0’ sind: 0, 1 0 - q 0 ? - q 1 0 q2 Für diesen NFA konstruiere man einen DFA, der dieselbe Sprache akzeptiert. 2. Gegeben sei folgende reguläre Grammatik G = ({S, A}, {a, b}, P, S) mit (1) (2) (3) (4) (5) P = {S −→ bA, S −→ b, S −→ a, A −→ bS, A −→ b}. a) Man bestimme L(G). b) Man konstruiere einen nichtdeterministischen endlichen Automaten MN nach der in der Vorlesung angegebenen Methode, so daß L(MN ) = L(G) ist. c) Mit Hilfe der Potenzmengenkonstruktion (siehe Vorlesung!) bestimme man einen deterministischen endlichen Automaten MD mit L(MD ) = L(MN ) = L(G). Zusammenfassung: Der Begriff “Reguläre Sprache” ist definierbar durch einen der folgenden Begriffe. Der Zusammenhang wird durch die angegebenen Sätze hergestellt: Reguläre Grammatik ⇓ Folgerung 2.2.2 ⇐=⇐=⇐=⇐= ⇑ Satz 2.2.4 Nichtdeterministischer endlicher Automat ⇓ Satz 2.2.5 Deterministischer endlicher Automat ⇓ . =⇒=⇒=⇒=⇒=⇒=⇒=⇒ 33 2.3 Mustervergleich (Pattern Matching), reguläre Ausdrücke und endliche Automaten In der Informatik werden Muster häufig verwendet, um Wortmengen zu charakterisieren: • Im Betriebssystem UNIX ist das Symbol * ein Muster, auf das ein beliebiges Wort, einschließlich das leere Wort, paßt (engl. matches). Man sagt auch, ein beliebiges Wort entspricht dem Muster * . So sollte man nicht ohne Not das Kommando rm * (remove all files!) eingeben! • Die UNIX-Kommandos grep, fgrep, egrep sind grundlegende Mustererkennungswerkzeuge, die endliche Automaten zu ihrer Implementation nutzen. Es sei Σ ein endliches Alphabet. Ein Muster (engl. pattern) ist ein Wort, aufgebaut aus bestimmten Symbolen, die nicht notwendig aus dem Alphabet Σ stammen müssen, das eine bestimmte Menge von Wörtern über dem Alphabet Σ darstellt, die diesem Muster entsprechen. Die Menge der Muster wird formal durch Induktion definiert. Dabei gibt es atomare Muster und zusammengesetzte Muster, die unter Verwendung bestimmter Operatoren aus einfacheren Mustern aufgebaut werden (als Erzeugungssystem also!). Muster werden im folgenden durch griechische Kleinbuchstaben bezeichnet, α, β, γ, . . . Wenn man Muster (Syntax) definiert, muß man natürlich auch ihre Bedeutung als Wortmengen definieren (Semantik). Die Menge der Wörter in Σ∗ , die einem gegebenen Muster α entsprechen, wird mit L(α) bezeichnet, d.h. L(α) = {w ∈ Σ∗ | w paßt auf α}. Achtung: Im folgenden ist der UNIX- * zu vergessen. Das Symbol ‘*’ wird eine andere Bedeutung bekommen! Es gibt viele Möglichkeiten, Muster zu definieren. Hier soll repräsentativ die Menge der regulären Ausdrücke zusammen mit ihrer Bedeutung definiert werden: Definition 2.3.1: (Reguläre Ausdrücke, Syntax und Semantik) (1) Σ sei ein endliches Alphabet. Die Menge der regulären Ausdrücke über Σ wird wie folgt induktiv und ihre Bedeutung rekursiv definiert: Atomare reguläre Ausdrücke sind: a für jedes Symbol a ∈ Σ; auf den regulären Ausdruck a paßt nur das Symbol a selbst, d.h. L(a) = {a}. ε ; auf den nur das leere Wort paßt, d.h. L(ε) = {ε}. 34 φ ; auf den gar nichts paßt, d.h. L(φ) = ∅. Zusammengesetzte reguläre Ausdrücke werden induktiv unter Verwendung der Operatoren +, · (meistens wird es nicht explizit geschrieben) und ∗ definiert: Wenn α und β reguläre Ausdrücke sind, denen die Wortmengen L(α) bzw. L(β) entsprechen, dann gilt α + β ist ein regulärer Ausdruck, dem die Wortmenge L(α + β) := L(α) ∪ L(β) entspricht. αβ ist ein regulärer Ausdruck, dem die Wortmenge L(αβ) := L(α)L(β) entspricht. S α∗ ist ein regulärer Ausdruck, dem die Wortmenge L(α∗ ) = n≥0 L(α)n entspricht.. (2) Die Mengen von Wörtern, die durch einen regulären Ausdruck beschrieben werden können, nennt man reguläre Mengen. (3) Zwei reguläre Ausdrücke heißen äquivalent (gleich), wenn sie dieselbe Menge beschreiben, d.h. formal gilt α=β gdw. L(α) = L(β). Beispiele: 1. Es sei Σ = {a, b, c}. Dann haben die folgenden regulären Ausdrücke die angegebene Bedeutung: L(a + bb∗ (c + b)∗ ) = = = (2) L(φ∗ ) = L(φ)∗ = ∅∗ = (1) (3) L(a) ∪ L(bb∗ (c + b)∗ ) {a} ∪ {b} ⊗ {b}∗ ⊗ {c, b}∗ {a} ∪ {w|w = bn v, n ≥ 1, v ∈ {c, b}∗ } {ε} Deshalb bräuchte ε eigentlich nicht explizit als regulärer Ausdruck angegeben zu werden. L((a + b + c)∗ ) = Σ∗ 2. Nun sei Σ = {0, 1}. Es ergibt sich (4) L(01) (5) L(0∗ ) (6) L((0 + 1)∗ ) (7) L((0 + 1)∗ 011) = = = = {01} {0n |n ≥ 0} = {0}∗ {0, 1}∗ = Σ∗ 6= L(0∗ ) ∪ L(1∗ ) {w011|w ∈ {0, 1}} 35 Wenn ein regulärer Ausdruck kürzer uns überschaubar ist, so kann man leichter die zugehörige Wortmenge charakterisieren und damit z.B. auch entscheiden, ob zwei reguläre Ausdrücke äquivalent (gleich) im Sinne der vorigen Definition sind. Ist es überhaupt so, daß reguläre Mengen (Wortmengen, die sich durch reguläre Ausdrücke definieren lassen) und reguläre Sprachen (Wortmengen, die sich durch einen DFA charakterisieren lassen) den gleichen Begriff darstellen? Die folgenden beiden Sätze stellen wichtige Tatsachen über das Rechnen mit regulären Ausdrücken zusammen, die man bei der Vereinfachung solcher Ausdrücke benötigt. Satz 2.3.2: Für die Äquivalenz (Gleichheit) = von regulären Ausdrücken gilt: (1) = ist eine Äquivalenzrelation. (2) Es gilt das Ersetzbarkeitstheorem: Wenn α = β ist, kann man α durch β (und umgekehrt) in jedem regulären Ausdruck an beliebiger Stelle seines Vorkommens ersetzen und der resultierende reguläre Ausdruck ist zum ursprünglichen äquivalent (gleich). ohne Beweis Lemma 2.3.3: Für alle regulären Ausdrücke α, β, γ gelten: α + (β + γ) α+β α+φ α+α α(βγ) εα α(β + γ) (α + β)γ φα ε + αα∗ ε + α∗ β + αγ ≤ γ β + γα ≤ γ = = = = = = = = = = = ⇒ ⇒ (α + β) + γ β+α α α (αβ)γ αε = α αβ + αγ αγ + βγ αφ = φ α∗ α∗ α∗ ≤ γ βα∗ ≤ γ (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) Die Relation ≤ in (12) und (13) ist mit Hilfe der Teilmengenordnung definiert: α ≤ β gdw. L(α) ⊆ L(β) gdw. L(α + β) = L(β) gdw. α + β = β. Der Beweis wird in jedem Fall durch mengentheoretische Betrachtungen geführt. 36 Folgerung 2.3.4: Folgende Gleichungen folgen aus (1) - (13) und können somit ebenfalls bei Vereinfachungen benutzt werden: (αβ)∗ α (α∗ β)∗ α∗ α∗ (βα∗)∗ (ε + α)∗ αα∗ = = = = = α(βα)∗ (α + β)∗ (α + β)∗ α∗ α∗ α (14) (15) (16) (17) (18) ohne Beweis Anmerkung: Die Gleichungslogik von regulären Ausdrücken ist mit den Axiomen und Regeln (1) - (13) vollständig. Das bedeutet, daß alle wahren Gleichungen zwischen regulären Ausdrücken rein algebraisch mit Hilfe der Axiome und Regeln (1) - (13) und den Regeln der Gleichungslogik beweisbar sind. Ein Beweis dieser Tatsache liegt außerhalb des Rahmens dieser Vorlesung. Im folgenden soll zwischen regulären Ausdrücken und den durch sie beschriebenen Wortmengen nicht unterschieden werden, sofern keine Mißverständnisse auftreten. Gleichungen mit regulären Koeffizienten Bei der Arbeit mit Wortmengen verwendet man oft Gleichungen, bei denen Koeffizienten reguläre Ausdrücke sind und Unbekannte (Wort-)Mengen darstellen. Häufig sind dann rekursive Gleichungen der Form X = αX + β (*) mit regulären Ausdrücken α und β zu lösen. Offensichtlich ist die Menge X = α∗ β eine Lösung dieser Gleichung. Sie wird auch kleinster Fixpunkt (kleinste Lösung) der Gleichung (*) genannt. Ist α z.B. so beschaffen, daß ε ∈ L(α) gilt, dann ist natürlich auch X = α∗ (β + γ) mit beliebigem γ ebenfalls Lösung der Gleichung. Uns soll im folgenden jedoch nur die zuerst genannte kleinste Lösung interessieren. Definition 2.3.5: (1) Ein Gleichungssystem mit regulären Koeffizienten der folgenden Form X1 = α10 + α11 X1 + α12 X2 + . . . + α1n Xn X2 = α20 + α21 X1 + α22 X2 + . . . + α2n Xn ... Xn = αn0 + αn1 X1 + αn2 X2 + . . . + αnn Xn 37 wird (reguläres) Mengengleichungssystem in den Unbekannten ∆ = {X1 , X2 , . . . , Xn } genannt und mit EQ bezeichnet. (2) Σ sei ein Alphabet und EQ ein Mengengleichungssystem mit über Σ regulären Koeffizienten in den Unbekannten ∆ = {X1 , X2 , . . . , Xn }. Eine Abbildung f : ∆ −→ P (Σ∗ ) heißt Lösung des Systems EQ, wenn nach Ausführen der Substitution [X1 := f (X1 ), X2 := f (X2 ), . . . , Xn := f (Xn )] in EQ jede Zeile eine Mengenidentität ist. (3) Eine Abbildung f : ∆ −→ P (Σ∗ ) heißt kleinster Fixpunkt des Systems EQ, wenn f eine Lösung des Systems EQ ist und für jede andere Lösung g : ∆ −→ P (Σ∗ ) von EQ gilt: f (Xi ) ⊆ g(Xi) für i = 1, . . . , n. (engl. least fixed point) Satz 2.3.6: Jedes Mengengleichungssystem EQ in den Unbekannten ∆ = {X1 , X2 , . . . , Xn } besitzt genau einen kleinsten Fixpunkt. Anstelle eines Beweises wird hier nur der Lösungsalgorithmus angegeben: Eingabe: ein Mengengleichungssystem EQ in den Unbekannten ∆ = {X1 , X2 , . . . , Xn } Ausgabe: der kleinste Fixpunkt f : ∆ −→ P (Σ∗ ) FOR (i=1, n-1, i+1) { Man überführe die i-te Gleichung des Systems EQ in die Form Xi = αXi + β mit regulärem Ausdruch α und β = β0 + βi+1 Xi+1 + . . . + βn Xn , wobei β0 , βi+1 , . . . βn ebenfalls reguläre Ausdrücke sind. } Dann ersetze man in den Gleichungen i + 1, . . . , n Xi durch α∗ β. } Man überführe die n-te Gleichung in die Form Xn = αXn + β mit regulären α, β. FOR (i=n, 2, i-1) { Man setze Xi = α∗ β in die Ausdrücke für Xi−1 , . . . , X1 , die im ersten Schritt gebildet wurden, ein. } Die gefundenen regulären Ausdrücke X1 := α1 , . . . , Xn := αn bilden den kleinsten Fixpunkt. 38 Beispiel: Es sei ∆ = {X1 , X2 , X3 } und das System EQ laute: (1) (2) (3) (2’) (3’) (3”) X1 X2 X3 X1 X1 X2 X3 X2 X2 X3 X3 X3 X2 X1 = = = = = = = = = = = = = = = 0X2 + 1X1 + ε 0X3 + 1X2 0X1 + 1X3 1X1 + 0X2 + ε 1∗ (0X2 + ε) 0X3 + 1X2 01∗ (0X2 + ε) + 1X3 1X2 + 0X3 1∗ 0X3 01∗ (01∗0X3 + ε) + 1X3 (1 + 01∗ 01∗ 0)X3 + 01∗ (1 + 01∗ 01∗ 0)∗ 01∗ 1∗ 0(1 + 01∗ 01∗ 0)∗ 01∗ 1∗ (01∗ 0(1 + 01∗ 01∗ 0)∗ 01∗ + ε) 1∗ 01∗ 0(1 + 01∗ 01∗ 0)∗ 01∗ + 1∗ Sicherlich gibt es noch einfachere Darstellungen, man sieht aber X1 = {w ∈ {0, 1}∗| # 0 ist durch 3 teilbar} X2 = {w ∈ {0, 1}∗| # 0 ≡ 2 (3)} X3 = {w ∈ {0, 1}∗| # 0 ≡ 1 (3) } (1) (2) (3) Satz 2.3.7: (Kleene) Eine formale Sprache ist genau dann regulär, wenn sie durch einen regulären Ausdruck beschreibbar ist. Anstelle des Beweises soll hier nur angegeben werden, wie aus einer regulären Grammatik ein dieselbe Sprache definierender regulärer Ausdruck konstruiert werden kann: Gegeben sei die reguläre Grammatik G = (N; Σ, R, S) mit den Nichtterminalen N = {X1 , . . . , Xn } und S = X1 . Zu G wird folgendes Mengengleichungssystem EQ in den Unbekannten N = {X1 , . . . , Xn } konstruiert: Für 1 ≤ i ≤ n ist die i-te Gleichung des Systems Xi = αi0 + αi1 X1 + . . . + αXn , wobei die Koeffizienten wie folgt gebildet werden: • Wenn Xi −→ a1 | . . . |ak sämtliche abschließenden Regeln in R für das Nichtterminal Xi sind, dann ist αi0 = a1 + . . . + ak . • Wenn Xi −→ b1 Xj | . . . |bm Xj sämtliche Regeln in R von Xi nach Xj sind dann ist alphaij = b1 + . . . + bm , 39 1 ≤ j ≤ n. Dabei ist k = 0 oder m = 0 durchaus zugelassen, d.h. es gibt keine solchen Regeln, dann wird αi0 = φ bzw. αij = φ gesetzt bzw. als Bestandteil ganz weggelassen. Es gilt L(G) = f (X1 ), wobei f der kleinste Fixpunkt des Gleichungssystems EQ ist. Im zweiten Teil soll angegeben werden, wie aus einem regulären Ausdruck ρ ein NFA M konstruiert werden kann, der dieselbe Sprache definiert. Die Konstruktion von M erfolgt induktiv über den Aufbau von ρ, wobei folgende Fälle zu unterscheiden sind: ρ = φ: M = ({X1 }, Σ, ∆, S, F ) mit ∆(X1 , a) = ∅ für alle a ∈ Σ und S = {X1 } und F = ∅. ρ = ε: Hier ist M genauso wie eben mit der Ausnahme S = F = {X1 }. ρ = a ∈ Σ: Hier ist M = ({X1 , X}, Σ, ∆, S, F ) mit {X} falls x = a ∆(X1 , x) = ∅ sonst und ∆(X, x) = ∅ für alle x ∈ Σ, S = {X1 }, F = {X}. Im folgenden seien Mα = (Qα , Σ, ∆α , Sα , Fα ) und Mβ = (Qβ , Σ, ∆β , Sβ , Fβ ) zwei NFA mit L(α) = L(Mα ) und L(β) = L(Mβ ) für die regulären Ausdrücke α, β. Es wird ferner angenommen, daß Qα ∩ Qβ = ∅ ist, sonst ist das durch geeignetes Umbenennen zu erreichen. Dann wird konstruiert: ρ = α + β: Mα+β = (Qα ∪ Qβ , Σ, ∆α ∪ ∆β , Sα ∪ §β , Fα ∪ Fβ ) ρ = αβ: Es wird festgelegt: Qα ∪ Qβ Qαβ := falls ε ∈ / L(α) Sα Sαβ := Sα Sβ falls ε ∈ L(α) Fαβ := Fβ . Alle Zustände in Qα , die einen Pfeil zu einem Endzustand in Fα haben, erhalten zusätzlich einen genauso markierten Pfeil zu den Startzuständen in Sβ . ∆αβ ist die Vereinigung von ∆α und ∆β mit Hinzunahme der soeben definierten neuen Pfeile. ρ = α∗ : Falls ε ∈ / L(Mα ). so wir ein zusätzlicher Zustand S hinzugenommen, der zugleich Start- und Endzustand ist, aber keine weitere Verbindung mit dem Rest des Automaten hat. Dieser modifizierte Automat erkennt nun {ε} ∪ L(α). Mα∗ entsteht aus dem (evtl. modifizierten) Automaten Mα wie folgt: Er hat dieselben Start- und Endzustände. Ferner erhält jeder Zustand, der einen Pfeil zu einem der Endzustände besitzt, zusätzlich einen Pfeil, der genauso beschriftet ist und zu jedem Startzustand geht. So entsteht die notwendige Rückkopplung. 40 Aufgaben: 1. Man konstruiere einen nichtdeterministischen endlichen Automaten mit höchstens 4 Zuständen, der die durch den folgenden regulären Ausdruck beschriebene Sprache erkennt: ((( ab | aab ) | aba ))∗ 2. Es sei Σ = {a, b}. Gegeben ist der folgende Zustandsgraph eines deterministischen endlichen Automaten M: '$ a - '$ &% z1 &% b a '$ - z2 &% '$ a, b b - '$ &% z3 &% Man leite unter Verwendung des im Beweis des Satzes von Kleene angegebenen Verfahrens einen regulären Ausdruck α her, der die Sprache L(M) beschreibt. 3. Gegeben seien die beiden DFA Ai = (Z, Σ, δi, z0 , E), i = 1, 2 durch Σ = {0, 1}, Z = {z0 , z1 }, E = {z0 } und den beiden Überführungsfunktionen δ1 0 1 z0 z0 z1 z1 z1 z0 und δ2 0 1 z0 z1 z0 z1 z0 z1 a) Berechnen Sie für i = 1, 2 jeweils δ̂i (z0 , 00100), δ̂i (z0 , 01010), δ̂i (z0 , 0110). b) Geben Sie reguläre Ausdrücke für die durch diese DFA akzeptierten Sprachen an. Was können Sie hinsichtlich der Anzahl vorkommender Nullen und Einsen in beiden Fällen sagen? c) Geben Sie für den Durchschnitt beider Sprachen einen DFA und einen regulären Ausdruck an, die beide diese Sprache definieren. 4. a) Konstruieren Sie einen DFA, der die endlichen 0-1-Folgen, die das Teilwort ‘101’ nicht enthalten, als Sprache akzeptiert. b) Gesucht ist ferner ein regulärer Ausdruck ρ, der dieselbe Sprache beschreibt. 41 5. Gegeben sei das folgende Mengengleichungssystem mit regulären Koeffizienten: (1) (2) (3) (4) S A B C = = = = 0S + 1A + ε OS + 1B + ε 0C + 1B + ε (0 + 1)C a) Man gebe einen regulären Ausdruck als kleinsten Fixpunkt für die Menge der aus S ableitbaren Wörter an. Dabei beachte man, daß die Gleichung C = (0 + 1)C eigentlich C = (0 + 1)C + ∅ bedeutet. b) Man überprüfe insbesondere, ob das Wort ‘001011011’ aus S ableitbar ist. Begründung! c) Man gebe einen Akzeptorautomat A = (Z, T, F, {z0}, ZE ) an, der die Menge der nach dem obigen Gleichungssystem aus S ableitbaren Wörter über {0, 1} als Sprache akzeptiert. 6. Gegeben sei der endliche Akzeptorautomat EA = ({S, A, B, C}, {a, b}, F, {S}, {A}) mit dem Überführungsgraphen F : a/b - a S A I @ @ @ @ @ @ @ b b @ @ @ ? @ a C B a b a) Man leite aus dem Überführungsgraphen ein Mengengleichungssystem ab. Dabei beachte man, daß aus dem einem korrekten Endzustand (hier ist es der Zustand A) zugehörenden Nichtterminal das leere Wort ε ableitbar ist. b) Dieses Mengengleichungssystem löse man und bestimme damit einen regulären Ausdruck für die Sprache, die von dem Automaten akzeptiert wird. Man vergleiche das Ergebnis mit dem Überführungsgraphen und bestimme insbesondere, ob das Wort ‘abbbaba’ aus S ableitbar ist. 42 2.4 Zustandsäquivalenz und Zustandsminimierung von DFA Beim Lösen verschiedener Aufgaben haben wir bereits bemerkt: • Man kann Automaten durch Elimination unerreichbarer Zustände optimieren. Dabei ändert sich die zugehörige Sprache nicht. • Bezogen auf die zu definierende Sprache ist es oftmals nicht bedeutsam, bestimmte Zustände zu unterscheiden. Sie können identifiziert werden, ohne daß sich die zugehörige Sprache ändert. Die erste Möglichkeit kann, sobald sie auftritt, ausgeführt werden. Der zweite Gesichtspunkt soll in diesem Kapitel genauer untersucht werden. Dazu zunächst zwei Beispiele: Beispiele: 1. Bei dem folgenden DFA M = ({q0 , q1 , q2 , q3 }, {a, b}, δ lt. Graph , q0 , {q1 , q2 }) mit δ: q1 H * HH a, b a, b a H H HH j - q q3 0 HH * HH a, b b HH j H q2 der die Sprache L(M) = {a, b} beschreibt, müssen die beiden Endzustände q1 , q2 nicht unterschieden werden. Das führt auf den folgenden DFA M̄ : - q 0 a, b q1 , q2 a, b a, b q3 a q3 H * q1 H @ b a a, b HHa, b @ H HH @ j - q @ q5 0 HH * @ HH @ b HH b R @ a, b j q H - q 2 4 a 2. Bei dem nächsten DFA M mit 43 der die Sprache L(M) = {w ∈ {a, b}∗ | |w| ≤ 2} akzeptiert, bestehen verschiedene Identifizierungsmöglichkeiten für Zustände. Identifiziert man q3 , q4 führt das auf den folgenden DFA M̄1 : * q1 H H a, b a HH HH j H - q0 q3 , q4 * HH HH b HH a, b j H a, b - q5 a, b q2 Man sieht sofort noch die beiden weiteren Identifizierungsmöglichkeiten: M̄2 : - q0 a, b - q1 , q2 a, b und - q3 , q4 M̄3 - q0 a, b - q1 , q2 a, b - a, b a, b - q5 a, b q3 , q4 , q5 Weitere Identifizierungsmöglichkeiten sieht man nicht. Wann kann man zwei Zustände identifizieren? Unsere Intuition sagt uns: • Man kann sicherlich zwei Zustände identifizieren, wenn ihre Unterscheidung, bezogen auf die durch den DFA definierte Sprache, keine Bedeutung hat. • Andererseits kann man zwei Zustände dann identifizieren, wenn die ursprüngliche Transitionsfunktion δ : Q × Σ −→ Q zur Definition einer neuen Transitionsfunktion nach der Identifizierung herangezogen werden kann, indem man einen der beiden Zustände als Repräsentanten für beide Zustände wählt, d.h. Transitionsfunktion δ und Identifizierung müssen sich miteinander vertragen. Die erste Erkenntnis werden wir zur Definition einer Äquivalenzrelation auf der Zustandsmenge eines DFA verwenden und mit ihrer Hilfe einen Algorithmus zur Zustandsminimierung herleiten. Die zweite Überlegung führt auf den Begriff der Kongruenzrelation für DFA und der Faktorstruktur. Intuitiv gesprochen, werden wir festlegen, daß zwei Zustände eines DFA äquivalent sind, wenn die durch sie definierten Sprachen dieselben sind: 44 Definition 2.4.1: Gegeben sei ein DFA M = (Q, Σ, δ : Q × Σ −→ Q, q0 , F ). Für zwei Zustände q, q ′ ∈ Q legt man fest: q ∼ q′ gdw. für alle Wörter w ∈ Σ∗ gilt: δ̂(q, w) ∈ F gdw. δ̂(q ′ , w) ∈ F. Definition 2.4.2: (Kongruenzrelation für DFA) Gegeben sei ein DFA wie oben. Eine binäre Relation ≡ auf der Zustandsmenge Q heißt Kongruenzrelation, falls (1) ≡ ist eine Äquivalenzrelation, d.h. sie ist reflexiv, symmetrisch und transitiv, (2a) wenn q ∈ F und q ≡ q ′ , so q ′ ∈ F , (2b) wenn q ≡ q ′ , so gilt für jedes Symbol a ∈ Σ δ(q, a) ≡ δ(q ′ , a). Satz 2.4.3: Für einen DFA M = (Q, Σ, δ, q0 , F ) gilt: ∼ ist die größte Kongruenzrelation auf der Zustandsmenge Q. Beweis: Dazu werden wir zeigen: (a) ∼ ist eine Kongruenzrelation und (b) Für jede Kongruenzrelation ≡ gilt: wenn q ≡ q ′ , so q ∼ q ′ . Aus der Definition 2.4.1 läßt sich leicht ein Algorithmus zur Bestimmung äquivalenter Zustände, d.h zur Zustandsminimierung herleiten. Verneint man nämlich Definition 2.4.1, so erhält man q ≁ q′ gdw. es gibt ein Wort w ∈ Σ∗ , für das δ̂(q, w) ∈ F und δ̂(q ′ , w) ∈ / F (bzw. umgekehrt) gilt. Testet man nun alle Wörter aus Σ∗ der Länge nach durch, so erhält man Antwort, welche Zustände nicht identifiziert werden dürfen. Da wegen der Endlichkeit des DFA nur endlich viele Wörter zu testen sind, können dann alle anderen paarweise zu Klassen zusammengefaßt werden: 45 Algorithmus 2.4.4: (Minimalautomat) Eingabe: ein DFA M (ohne unerreichbare Zustände) Ausgabe: Angabe, welche Zustände von M identifiziert werden können. 1. Stelle eine Tabelle aller Zustandspaare < q, q ′ > mit q 6= q ′ auf. 2. Markiere alle Paare < q, q ′ > mit q ∈ F und q ′ ∈ / F (und umgekehrt!). 3. Für jedes noch unmarkierte Paar < q, q ′ > und jedes a ∈ Σ teste man, ob < δ(q, a), δ(q ′ , a) > bereits markiert ist. Wenn ja: markiere auch < q, q ′ >. 4. Wiederhole den letzten Schritt bis sich keine Änderung in der Tabelle mehr ergibt. 5. Alle jetzt noch unmarkierten Paare können jeweils identifiziert werden. So entstehen die entsprechenden Klassen von Zuständen. Aufgaben: 1. Gegeben sei der folgende DFA A = (Z, Σ, δ, z0 , F ) mit Z = {z0 , z1 , z2 , z3 , z4 , z5 } Σ = {a, b} E = {z2 , z3 } und δ laut δ z0 z1 a z1 z4 b z2 z5 Tabelle z2 z3 z4 z5 z0 z5 z1 z4 z3 z2 z0 z3 Geben Sie zu diesem DFA einen äquivalenten DFA an, dessen Zustandsmenge minimal ist. Geben Sie einen regulären Ausdruck an, der die akzeptierte Sprache beschreibt. 2. Gegeben seien die folgenden DFA M = (Z, Σ, δ, z0 , F ) mit den Bestimmungsstücken a) Z = {z0 , z1 , z2 , z3 , z4 , z5 } Σ = {a, b} F = {z1 , z4 } δ z0 z1 z2 z3 z4 z5 a z3 z4 z5 z0 z1 z2 b z1 z2 z0 z4 z5 z3 b) Z = {z0 , . . . , z6 } Σ = {a, b} F = {z0 , z1 } δ z0 z1 z2 z3 z4 z5 z6 a z3 z3 z2 z2 z5 z5 z5 b z2 z5 z6 z1 z4 z3 z0 Man gebe jeweils dazu äquivalente zustandsminimierte DFA an. 46 Das folgende sogenannte Pumping Lemma ist ein sehr wichtiger Satz, mit dessen Hilfe in vielen Fällen für eine Sprache L der Nachweis gelingt, daß sie nicht regulär ist. Lemma 2.4.5: (Pumping Lemma) Für jede reguläre Sprache L gibt es eine Zahl p (Pumping Zahl von L genannt), so daß sich alle Wörter x ∈ L mit einer Länge |x| ≥ p derart in Teilwörter x = uvw zerlegen lassen, so daß folgende Eigenschaften erfüllt sind: 1. |v| ≥ 1, 2. |uv| ≤ p, 3. für alle i ≥ 0 gilt: uv iw ∈ L. Als Anwendung für dieses Lemma seien folgende Aufgaben gestellt: Aufgaben: Welche der folgenden Sprachen sind regulär und welche nicht? 1. L = {an b2m |n ≥ 0, m ≥ 0} 2. L = {an bm |n = 2m} 3. L = {an bm |n 6= m} 4. L = {xcx|x ∈ {a, b}∗ } 5. L = {xcy|x, y ∈ {a, b}∗ } 6. L = {an bm |n ≥ m und m ≤ 5} 2.5 Einige Aspekte kontextfreier Sprachen In einem abschließenden Abschnitt soll auf einige Begriffe und Gesichtspunkte im Zusammenhang mit kontextfreien Sprachen eingegangen werden. Ich beginne mit zwei Aufgaben: Aufgaben: 1. Gegeben seien die folgenden Regeln einer kontextfreien Grammatik für eine einfache PASCAL-ähnliche Programmiersprache 47 <stmt> <if-stmt> <while-stmt> <begin-stmt> <stmt-list> <assg-stmt> <bool-expr> <compare-op> <arith-expr> <arith-op> <const> <var> −→ −→ −→ −→ −→ −→ −→ −→ −→ −→ −→ −→ <if-stmt> | <while-stmt> | <begin-stmt> | <assg-stmt> if <bool-expr> then <stmt> else <stmt> while <bool-expr> do <stmt> begin <stmt-list> end <stmt> | <stmt> ; <stmt-list> <var> := <arith-expr> <arith-expr><compare-op><arith-expr> < | > | ≤ | ≥ | = | 6= <var> | <const> | (<arith-expr><arith-op><arith-expr>) + | - | ∗ | / 0 | 1 | ... | 9 a | b | ... x | y | z Zeigen Sie durch Angabe einer Ableitungsfolge, daß die Anweisung while x < 5 do begin x := (x + 1) ; i := (i - 1) end syntaktisch korrekt ist. Schreiben Sie die einzelnen Ableitungsschritte untereinander. 2. Betrachten Sie folgende kontextfreie Grammatik G = (N, Σ, R, S) mit N = {S, A, B}, Σ = {a, b} und R = { S −→ ABS | AB, A −→ aA | a, B −→ bA } Welche der folgenden Wörter gehören zur Sprache L(G) und welche nicht? Geben Sie Ableitungen an bzw. argumentieren Sie, daß es keine geben kann. a) aabaaab b) aaaaba c) aabbaa d) abaaba. Die erste Aufgabe kann z.B. in folgender Strategie gelöst werden, indem das am weitesten links stehende Nichtterminal zuerst durch eine geeignete Regel eliminiert wird. Beispiele: Beispiele für Sprachen, die nicht regulär, aber kontextfrei sind: 1. L = {an bn |n ≥ 1} Eine Grammatik, die diese Sprache erzeugt, ist die folgende: G = ({S}, {a, b}, {S −→ ab|aSb}, S) 2. Die Sprache der Palindrome über dem Alphabet {a, b}: L = {w ∈ {a, b}+ |w = rev(w)} Eine Grammatik, die diese Sprache erzeugt, ist die folgende (Es werden nur noch die Regeln angegeben.): R = {S −→ a|b|aa|bb|aSa|bSb} 48 3. Balancierte Ketten von Klammern. Die Sprache wird wie folgt beschrieben: Σ = {(, )}. Für ein Wort w ∈ Σ∗ und einer Stelle x in diesem Wort bezeichnet L(w, x) die Anzahl der öffnenden Klammern in w bis zur Stelle x, R(w, x) die Anzahl der schließenden Klammern in w bis zur Stelle x. Ein Wort w ∈ Σ∗ ist ein balancierter Klammerausdruck, wenn L(w, x)−R(w, x) = 0 gilt, falls x die letzte Stelle in w ist und wenn für alle Stellen x in w L(w, x) − R(w, x) ≥ 0 gilt. Eine Grammatik für diese Sprache ist die folgende: R = {S −→ (), (S), SS} 4. Balancierte Bitfolgen L = {w ∈ {0, 1}+ |#0 (w) = #1 (w)} Hier bezeichnet #0 (w) (bzw. #1 (w)) die Anzahl der in w vorkommenden Symbole 0 (bzw. 1) für eine Bitfolge w ∈ {0, 1}+ . Eine Grammatik, die diese Sprache erzeugt, ist die folgende: R = { S −→ 0A|1B, A −→ 1|1S|0AA, B −→ 0|0S|1BB } Der nichtdeterministische Kellerautomat Ein nichtdeterministischer Kellerautomat (NPDA) arbeitet einem NFA vergleichbar, wobei er über einen Kellerspeicher als zusätzlichem Speicher verfügt, dessen Kapazität potentiell unbeschränkt ist. Der Kellerspeicher arbeitet nach dem Speicherprinzip LIFO (last-in-first-out). In jedem Schritt sind also aktueller Zustand, aktuell gelesenes Zeichen auf dem Eingabeband und oberstes Kellersymbol bekannt. Daraus berechnet das Programm des Automaten die möglichen Arbeitsgänge, die darin bestehen, daß der Lesekopf einen Schritt weiter nach rechts rückt, ein Folgezustand angenommen wird, und das oberste Kellersymbol (Top) mit einer Folge von Kellersymbolen überschrieben wird. Es gibt auch sogenannte ε-Übergänge, wo nur der Keller und der Zustand verändert werden, ohne daß das aktuelle Zeichen vom Eingabeband gelesen wird. 49 Eingabeband a1 a2 a3 a4 a5 a6 a7 a8 6 Q ... an Lesekopf, Bewegungsrichtung nach rechts % - A B endliche Kontrolleinheit C Kellerspeicher B ⊥ Definition: (Nichtdeterministischer Kellerautomat, NPDA) Ein NPDA M = (Q, Σ, Γ, δ, q0 , ⊥, F ) besteht aus • einer endlichen Menge Q von Zuständen, • einem endlichen Eingabealphabet Σ, • einem endlichen Kelleralphabet Γ, • einer Zustandsüberführungsfunktion δ : Q × (Σ ∪ {ε}) × Γ −→ P (Q × Γ∗ ) • einem Startzustand q0 , • einem initialen Kellersymbol ⊥, • einer Menge F ⊆ Q von akzeptierenden Endzuständen. Definition: (Konfiguration, Konfigurationsfolgerelation) (1) Eine Konfiguration oder Momentaufnahme eines Kellerautomaten M faßt eine aktuelle Gesamtsituation während der Arbeit des Kellerautomaten zusammen und ist daher eine Element der Menge (q, W, w) ∈ Q × Γ∗ × Σ∗ . 50 Hier stellt q den aktuellen Zustand, W den aktuellen Kellerinhalt und w das aktuell noch zu lesende Wort im Eingabeband dar. (2) Die Ein-Schritt-Konfigurationsfolgerelation ⊢M ist wie folgt definiert: wenn (q ′ , V ) ∈ δ(q, a, A), dann gilt für jedes w ∈ Σ∗ und W ∈ Γ∗ : (q ′ , AW, aw) ⊢M (q ′ , V W, w), und wenn (q ′ , V ) ∈ δ(q, ε, A), dann gilt für jedes w ∈ Σ∗ und W ∈ Γ∗ : (q ′ , AW, w) ⊢M (q ′ , V W, w). ∗ (3) ⊢M ist der reflexiv transitive Abschluß der Relation ⊢M und wird Konfigurationsfolgerelation genannt. Definition: (Das Akzeptieren eines Wortes) Es gibt zwei alternative Definitionen für das Akzeptieren eines Wortes durch einen Kellerautomaten, die beide in Gebrauch sind. Beide sind äquivalent, weil jede die jeweilige andere simulieren kann. • Akzeptieren mit Endzustand: ∗ L(M) = {w ∈ Σ∗ |(q0 , ⊥, w) ⊢M (q, W, ε) und q ∈ F }, • Akzeptieren mit leerem Keller: ∗ L(M) = {w ∈ Σ∗ |(q0 , ⊥, w) ⊢M (q, ε, ε)}. Normalformen: Chomsky Normalform Man sagt, daß die kontextfreie Grammatik G in Chomsky Normalform vorliegt, wenn jede Regel eine der folgenden Gestalten hat: A −→ BC oder A −→ a mit A, B, C ∈ N und a ∈ Σ. Eine kontextfreie Grammatik kann wie folgt in eine äquivalente kontextfreie Grammatik in Chomsky Normalform überführt werden: • Für jeden Terminalbuchstaben a ∈ Σ führe man ein neues Nichtterminal Aa und eine neue Regel Aa −→ a ein. • Eine Regel A −→ B1 . . . Bn mit n ≥ 3 ersetze man durch A −→ B1 C1 C1 −→ B2 C2 ... Cn−2 −→ Bn−1 Bn wobei C1 , . . . , Cn−2 neu eingeführte Nichtterminale sind. 51 Gegeben sei die kontextfreie Grammatik G = (N, Σ, R, S) in Chomsky Normalform. Ein Kellerautomat MG wird mit Hilfe von G wie folgt definiert: Q := {q0 }, Γ := N ∪ Σ, ⊥ := S und δ wie folgt: wenn A −→ w1 | . . . |wk die sämtlichen Regeln für das Nichtterminal A in G sind, dann wird festgelegt: δ(q0 , ε, A) = {(q0 , w1 ), . . . , (q0 , wk )} Außerdem nehme man für jeden Terminalbuchstaben a ∈ Σ hinzu δ(q0 , a, a) = {(q0 , ε)}. Satz: Es gilt L(G) = L(MG ). Aufgaben: 1. Man konstruiere einen Kellerautomaten zum Akzeptieren der balancierten Klammerausdrücke. 2. Man zeige mit Hilfe eines geeigneten NPDA und Breitensuche, daß das Wort abba ein Palindrom ist. Warum kann man keinen deterministischen Kellerautomaten zur Lösung finden? 52 3 Logik für Informatiker Die mathematische Logik, insbesondere die Prädikatenlogik der ersten Stufe, ist für die Informatik aus mehreren Gründen von Interesse. Zunächst sind in der mathematischen Logik zuerst Sprachen mit streng definierter Syntax und Semantik untersucht worden. Es war und ist Gegenstand intensiver Forschung, die Zusammenhänge zwischen semantischen Eigenschaften und deren syntaktischer Widerspiegelung zu untersuchen. Im Unterschied zu den künstlichen Sprachen der Informatik, etwa den Programmiersprachen, wurde die Semantik stets exakt definiert. Damit können die verschiedenen Sprachen der mathematischen Logik als Beispiele für die Untersuchung des Verhältnisses von Syntax und Semantik dienen. Ein weiterer Grund wurde von Robert KOWALSKI 1980 formuliert, man siehe SIGART Special Issue on Knowledge Representation: There is only one language suitable for representing information - whether declarative or procedural - and that is first–order predicate logic. There is only one intelligent way to process information and that is by applying deductive inference methods. In dieser Vorlesung wird in diesem Zusammenhang nur auf die Aussagenlogik eingegangen. 3.1 Aussagenlogik Grundlage der (klassischen, zweiwertigen) Aussagenlogik sind Aussagen, von denen vorausgesetzt wird, daß sie genau einen Wahrheitswert “wahr” oder “falsch” annehmen können. In Bezug auf die Anwendungen der Informatik kann man voraussetzen, daß für jede einzelne Anwendung stets eine Menge von einfachen Aussagen vorgegeben ist. Diese Aussagen beziehen sich inhaltlich auf den Anwendungsfall. Die Bestimmung des Wahrheitswertes, den eine solche Aussage in einem konkreten Zusammenhang bekommt, obliegt nicht der Logik, sondern ist allein durch den Anwender und den Anwendungsfall bestimmt. Stellen Sie sich vor, es gibt einen Katalog von Entscheidungsfragen, die im konkreten Zusammenhang mit ja/nein beantwortet werden können, z.B. ja nein - Über die Straße führt eine Brücke? ◦ ◦ - Die Straße ist naß? ◦ ◦ - Es hat geregnet? ... ◦ ◦ ... 53 Diesen Katalog auszufüllen, ist nicht Aufgabe eines Logikers, sondern erfolgt vom Anwender. Nur er verfügt über das Wissen und die Methoden, die Fragen richtig zu beantworten. Im allgemeinen wird es viele konkrete Situationen (Experimente z.B.) geben, so daß der Fragenkatalog onterschiedlich beantwortet werden kann. Man geht davon aus, daß im Anwendungsfall in jeder tatsächlich auftretenden Situation alle Fragen beantwortet werden können und daß für jede interessierende Information eine entsprechende Frage vorhanden ist. Die Fragen des Katalogs werden als elementare oder atomare Aussagen bezeichnet. Gegenstand der Aussagenlogik ist es festzustellen, wie sich die Wahrheitswerte, die den atomaren Bestandteilen einer Aussage zugeordnet werden, zu Wahrheitswerten komplizierterer Aussagen fortsetzen lassen. Außerdem müssen solche Begriffe wie Folgerung exakt bestimmt werden. Die Syntax der Aussagenlogik legt die Symbolik und Stelligkeit der zu untersuchenden Verknüpfungen (Konnektoren genannt) von Aussagen fest, die Semantik die Art der Fortsetzung der Wahrheitswerte. Welche Konnektoren untersucht werden sollen, ist durch die sprachliche Tradition bestimmt, wobei es durchaus in der umgangssprachlichen Praxis verschiedene Interpretationen geben kann. Hier ergibt sich für die Logik ihr normativer Charakter. Definition 3.1.1: (Syntax der Aussagenlogik ) Grundlage der Definition ist eine Menge A von Atomen. Die Menge AF (A) der aussagenlogischen Formeln über A wird induktiv wie folgt festgelegt (i) Für jedes Atom a ∈ A gilt, a ist eine aussagenlogische Formel, d.h. A ⊆ AF (A). (ii) Wenn F, G ∈ AF (A) , so auch (F ∧ G) ∈ AF (A) (F ∨ G) ∈ AF (A) ¬F , d.h. die Konjunktion von F, G, gelesen: “F und G” , d.h. die Disjunktion von F, G, gelesen: “F oder G” , d.h. die Negation von F, gelesen: “nicht F ” Also als Erzeugungssystem: Ausgangsmenge: Erzeugungsregeln: A ⊆ AF (A) Mit F, G ∈ AF (A) auch (F ∧ G), (F ∨ G), ¬F ∈ AF (A). bzw. in Backus-Naur-Form AF (A) ::= A | (AF (A) ∧ AF (A)) | (AF (A) ∨ AF (A)) | ¬AF (A) Als abkürzende Schreibweisen (Makros ) führen wir noch ein: F →G F ↔G statt statt (¬F ∨ G) gelesen: “F Pfeil G”, engl. “F implies G” (F ← G) ∧ (F → G) gelesen: F gdw. G Neben der Festlegung der korrekten Schreibweise bedarf jede Sprache noch einer Festlegung der Bedeutung, d.h. einer Semantik: Definition 3.1.2: (Formale Semantik der Aussagenlogik) 54 (i) Die Elemente der Menge {0, 1} werden Wahrheitswerte genannt, 0 bezeichnet den Wert falsch und 1 den Wert wahr. (ii) Unter einer Belegung (der Atome aus A mit Wahrheitswerten) versteht man eine Funktion ϕ : A −→ {0, 1}. (iii) Eine Belegung ϕ : A −→ {0, 1} wird wie folgt induktiv zu einer Abbildung wert( , ϕ) : AF (A) −→ {0, 1} erweitert: wert(a, ϕ) = ϕ(a) 1 wert((F ∧ G), ϕ) = 0 1 wert((F ∨ G), ϕ) = 0 1 wert(¬F, varphi) = 0 für a ∈ A falls wert(F, ϕ) = 1 und wert(G, ϕ) = 1 sonst falls wert(F, ϕ) = 1 oder wert(G, ϕ) = 1 sonst falls wert(F, ϕ) = 0 sonst Zur Illustration der Semantik der Aussagenlogik definieren wir für jeden logischen Konnektor ∧, ∨, ¬ eine Operation über den Wahrheitswerten {0, 1}, wobei 0 für den Wahrheitswert f alsch und 1 für den Wahrheitswert wahr steht: ¬∗ 0 1 1 0 ∧∗ 0 1 0 0 0 1 0 1 ∨∗ 0 1 →∗ 0 1 0 0 1 , woraus sich ergibt 0 1 1 1 1 1 1 0 1 Mit diesen Operationen über den Wahrheitswerten kann die Semantik–Definition auch durch folgende Gleichungen ausgedrückt werden, die eine rekursive Definition der Funktion wert( , ϕ) in Abhängigkeit von der Belegung ϕ darstellt: wert(a, ϕ) wert((F ∧ G), ϕ) wert((F ∨ G), ϕ) wert(¬F, ϕ) = = = = ϕ(a) für ein Atom a ∈ A wert(F, ϕ) ∧∗ wert(G, ϕ) wert(F, ϕ) ∨∗ wert(G, ϕ) ¬∗ (wert(F, ϕ) 55 Beispiel: Es gelte: ϕ(A) = 1, ϕ(B) = 1, ϕ(C) = 0, dann gilt wert(¬((A ∧ B) ∨ C), ϕ) = = = = ¬∗ (wert(((A ∧ B) ∨ C), ϕ)) ¬∗ (wert((A ∧ B), ϕ) ∨∗ wert(C, ϕ)) ¬∗ ((wert(A, ϕ) ∧∗ wert(B, ϕ)) ∨∗ wert(C, ϕ)) ¬∗ ((1 ∧∗ 1) ∨∗ 0) = 0. An diesem Beispiel wird deutlich, daß die Semantik jedes logischen Konnektors durch eine Operation über der Menge der Wahrheitswerte dargestellt wird. Damit ist auch sofort die Frage beantwortbar, wieviele Möglichkeiten zur Komposition von aussagenlogischen Formeln es geben kann, und welche Abhängigkeiten zwischen diesen Operationen bestehen. In Defintion 2.1.1 haben wir schon von den Abhängigkeiten der Wahrheitswertfunktionen gebrauch gemacht, indem wir die logischen Konnektoren der Implikation → und der Äquivalenz ↔ mit Hilfe der Konjunktion ∧, der Disjunktion ∨ und mit Hilfe der Negation ¬ konstruiert haben. Man kann alle Wahrheitswertfunktionen aus einer binären Funktion , der Sheffer’schen Strich–Operation ↑, mittels der Superpostion, d.h. mittels der Hintereinander-Ausführung, darstellen. Der Sheffer’schen Strich-Operation entspricht in der Schaltalgebra das NAND-Gate. Im folgenden werden wir semantisch motivierte Begriffsbildungen der Aussagenlogik einführen und diskutieren. Definition 3.1.3: Für eine aussagenlogische Formel F heißt eine Belegung ϕ : A −→ {0, 1} passend zu F , falls F ∈ AF (A). • ϕ |= F bedeutet: ϕ ist passend zu F und wert(F, ϕ) = 1; äquivalente Sprechweisen sind: ϕ ist ein Modell für F ; F gilt unter der Belegung ϕ. • ϕ 6|= F bedeutet: ϕ ist passend zu F und wert(F, ϕ) = 0; Sprechweise: ϕ ist kein Modell für F ; F gilt nicht unter der Belegung ϕ. • F heißt erfüllbar, falls mindestens ein Modell für F existiert, andernfalls heißt F unerfüllbar Eine Menge AX ⊆ AF (A) heißt erfüllbar, wenn es eine Belegung gibt, die für jedes F ∈ AX ein Modell ist. Schreibweise: ϕ |= AX . • |= F bedeutet: für jede zu F passende Belegung ϕ gilt wert(F, ϕ) = 1; In diesem Falle wird F eine Tautologie, oder (allgemein)gültig genannt. • Für eine Menge AX aussagenlogischer Formeln und eine Formel F bedeutet AX |= F , daß jede Belegung, die ein Modell für AX ist, auch ein Modell für F ist. In diesem Falle heißt F eine Folgerung aus AX. • F ≡ G bedeutet: für jede Belegung ϕ, die für F und für G passend ist, gilt wert(F, ϕ) = wert(G, ϕ). F und G heißen dann (semantisch) äquivalent. Aus diesen Begriffsbildungen ergeben sich nun sofort algorithmische Aufgabenstellungen: 56 • Erfüllbarkeitstest, • Tautologietest, • Äquivalenztest, • Folgerungstest. Sind dies vier wesentlich verschiedene Aufgabenstellungen, oder kann man die Lösung einer Aufgabenstellung auf eine Lösung einer anderen Aufgabenstellung zurückführen? Die oben definierte formale Semantik der Aussagenlogik erlaubt es , exakte Antworten auf diese Fragen zu geben. Eine Äquivalenz zwischen Tautologietest und Erfüllbarkeitstest stellt der folgende Satz der Aussagenlogik dar. Satz 3.1.4: Eine aussagenlogische Formel F ist genau dann eine Tautologie, wenn ¬F unerfüllbar ist. Beweis: F ist eine Tautologie gdw gdw gdw gdw für jede zu F passende Belegung ϕ gilt wert(F, ϕ) = 1, jede zu F und damit auch zu ¬F passende Belegung ϕ ist kein Modell von ¬F , denn wert(¬F, ϕ) = ¬∗ (wert(F, ϕ)) = ¬∗ (1) = 0, ¬F besitzt kein Modell, ¬F ist unerfüllbar. In analoger Weise kann man zeigen, daß der Äquivalenztest auf den Tautologietest zurückgeführt werden kann, da F ≡ G genau dann gilt, wenn F ↔ G eine Tautologie ist. Schließlich führt der folgende Satz den aus der Sicht der Anwendungen interessantesten Test, den Folgerungstest, auch auf den Tautologietest zurück. Satz 3.1.5: Die folgenden drei Aussagen sind äquivalent: (i) {A1 , . . . , An } |= G (ii) (A1 ∧ . . . ∧ An ) → G ist eine Tautologie (iii) (A1 ∧ . . . ∧ An ) ∧ (¬G) ist unerfüllbar Satz 3.1.6: Die folgenden beiden Aussagen sind äquivalent: (i) (F ≡ G) (ii) ((F → G) ∧ (G → F )) ist Tautologie. Bezeichnung: Für eine Menge von aussagenlogischen Formeln AX heißt die folgende Menge AX∗ = {F ∈ AF | AX |= F } die Folgerungshülle von AX. Die Folgerungshülle einer Menge von Formeln repräsentiert das implizite Wissen, das mit der gegebenen Menge von Formeln formalisiert ist. Im allgemeinen ist die Folgerungshülle eine abzählbar–unendliche Menge. In logischen Datenbanken repräsentieren Formeln einer geeigneten Logik Fakten– und Regel–Wissen über den jeweiligen Diskursbereich. Beim 57 Einschreiben neuen Wissens ist es von Interesse, ob die einzuspeichernde Formel zur Folgerungshülle der schon eingespeicherten Formeln gehört oder nicht. Im Falle der Zugehörigkeit zur Folgerungshülle wäre eine Einspeicherung sinnlos, da die eingespeicherte Formel kein neues Wissen über den Diskursbereich enthält. Tautologietest mittels Wahrheitswerttafel Durch systematische Berechnung des Wahrheitswertes einer Formel F für alle möglichen Belegungen der in F vorkommenden Aussagenvariablen wird geprüft, ob alle Belegungen den Wahrheitswert 1 liefern. Illustration am Beispiel F = (¬A → (A → B)): A 0 0 1 1 B ¬A (A → B) 0 1 1 1 1 1 0 0 0 1 0 1 F 1 1 1 1 Für eine Formel mit n atomaren Teilformeln (Aussagenvariablen) ist für den Tautologietest die Berechnung von 2n Zeilen erforderlich, da ja in der letzten Zeile auch noch der Wahrheitswert 0 als Resultat berechnet werden könnte. Gemessen in der Anzahl der enthaltenen Aussagenvariablen erfordert der Tautologietest mittels Wahrheitswerttafel exponentiellen zeitlichen Berechnungsaufwand. Aus der Komplexitätstheorie ist nun bekannt, daß der Tautologietest der Aussagenlogik ein NP-vollständiges Problem ist. Damit muß man mit fast absoluter Sicherheit annehmen, daß es keinen effektiveren Algorithmus für den Tautologietest gibt, d.h. daß man immer mit exponentiellen Aufwand rechnen muß. Effektivere Algorithmen kann man nur für eingeschränkte Klassen von aussagenlogischen Formeln erwarten. Aufgaben: 1. Sind die folgenden Formeln allgemeingültig (Tautologien), erfüllbar oder unerfüllbar? a) ((A → (B → C)) ↔ ((A ∧ B) → C)) b) ((A ∧ B) → C) c) (((A ∧ B) → C) ↔ (¬(A ∧ B) ∨ ¬C)) d) ((A → B) ∧ (B → C) ∧ ¬(A → C)) e) (¬(A → B) ↔ ¬(A ∧ B)) 2. Man beweise, daß die folgenden Aussagen äquivalent sind: (i) Es gilt: {F1 , . . . , Fn } |= G, V (ii) (( nk=1 Fk ) → G) ist Tautologie, V (iii) (( nk=1 Fk ) ∧ ¬G) ist unerfüllbar 58 für alle aussagenlogischen Formeln F1 , . . . , Fn , G. Was bedeutet n = 0, d.h. {F1 , . . . , Fn } = ∅? 3. Man gebe alle Modelle für die Menge aussagenlogischer Formeln AX = {((A ∨ B) → C), ¬(A ∨ B)} an und bestimme für die Formeln F = (A → (B ∧ C)) , G = ((A → C) ∨ (B → C)) und H = ¬((A ∧ B) → C), ob sie jeweils Folgerungen aus AX sind. 4. Gegeben sei die folgende Menge AX von aussagenlogischen Formeln AX = {(A → B), ((A → B) → (C → A)), ((C → A) → (B ∧ C))} Man überprüfe, ob die Formel (B ∨ C) aus AX folgt. 5. Man überprüfe, ob die folgende aussagenlogische Formel F = ((p → q) → (p → r)) aus der Menge AX von Formeln AX = {(p ∧ ¬r), (q → p)} folgt. Falls das nicht der Fall ist, gebe man eine Belegung als Gegenbeispiel an. 3.2 Äquivalenzen der Aussagenlogik Satz 3.1.7: Die semantische Äquivalenz ≡ ist eine Kongruenzrelation auf der Menge AF (A) der aussagenlogischen Formeln über A, d.h. (1) (2) (2a) (2b) (2c) ≡ ist eine Äquivalenzrelation. ≡ ist kompatibel bezüglich der ausagenlogischen Konnektoren, d.h. Wenn F ≡ G, so ¬F ≡ ¬G, wenn F1 ≡ F2 und G1 ≡ G2 so F1 ∧ G1 ≡ F2 ∧ G2 und F1 ∨ G1 ≡ F2 ∨ G2 . 59 Sei F eine aussagenlogische Formel, x ein Variablenname für atomare Formeln. Mit F (x) wird diejenige Formel bezeichnet, bei der einige der Atome in F durch die Aussagenvariable x ersetzt wurden. Für G ∈ AF (A) bezeichnet F (G) dann die Ersetzung aller auftretenden x in F durch die Formel G. Folgerung 3.1.8 (Ersetzbarkeitstheorem) Für jede Formel F (x) mit einer Variablen x für atomare Formeln und für alle Formeln G1 , G2 gilt: wenn G1 ≡ G2 , so F (G1 ) ≡ F (G2 ). Beweis: erfolgt durch vollständige Induktion über den Aufbau von F (x) unter Ausnutzung von 3.1.7. Im folgenden wird noch eine Liste wichtiger Äquivalenzen der Aussagenlogik zusammengestellt: Idempotenz F ∧ F ≡ F, Kommutativität F ∧ G ≡ G ∧ F, Assoziativität ((F ∧ G) ∧ H) ≡ (F ∧ (G ∧ H)), ((F ∨ G) ∨ H) ≡ (F ∨ (G ∨ H)), Absorption F ∧ (G ∨ F ) ≡ F, F ∨ (G ∧ F ) ≡ F, Distributivität (F ∧ (G ∨ H)) ≡ ((F ∧ G) ∨ (F ∧ H)), (F ∨ (G ∧ H)) ≡ ((F ∨ G) ∧ (F ∨ H)), Doppelnegation ¬(¬F ) ≡ F, deMorgansche Regeln ¬(F ∧ G) ≡ (¬F ∨ ¬G), ¬(F ∨ G) ≡ (¬F ∧ ¬G), Tautologie-Regeln F ∨ G ≡ F, falls F eine Tautologie ist, F ∧ G ≡ G, falls F eine Tautologie ist, Unerfüllbarkeits-Regeln F ∨ G ≡ G, falls F unerfllbar ist, F ∧ G ≡ F, falls F unerfllbar ist. 60 F ∨ F ≡ F, F ∨ G ≡ G ∨ F, Eine aussagenlogische Formel F ist in konjunktiver Normalform, wenn sie eine Konjunktion von Disjunktionen von Literalen ist, wobei ein Literal eine atomare Formel oder eine negierte atomare Formel ist, d.h. F = mi m _ ^ ( (Li,j )), Li,j ∈ {A1 , A2 , . . .} ∪ {¬A1 , ¬A2 , . . .}. i=1 j=1 Entsprechend ist eine Formel in disjunktiver Normalform, wenn sie eine Disjunktion von Konjunktionen von Literalen ist. Satz 3.2.1: Zu jeder Formel F gibt es eine äquivalente Formel in konjunktiver Normalform (KNF) und eine äquivalente Formel in disjunktiver Normalform (DNF). Beweis: Durch Angabe eines Algorithmus, der aus einer gegebenen aussagenlogischen Formel eine Formel in KNF konstruiert. 0. Ersetze jede Teilformel der Bauart (A → B) durch ihr Makro (¬A ∨ B). 1. Ersetze jedes Vorkommen einer Teilformel der Bauart (i) ¬(¬G) durch G, (ii) ¬(G ∧ H) durch (¬G ∨ ¬H)), (iii) ¬(G ∨ H) durch (¬G ∧ ¬H), bis keine derartige Teilformel mehr vorkommt. 2. Ersetze jedes Vorkommen einer Teilformel der Bauart (iv) (F ∨ (G ∧ H)) durch ((F ∨ G) ∧ (F ∨ H)), (v) ((F ∧ G) ∨ H) durch ((F ∨ H) ∧ (G ∨ H)), bis keine derartige Teilformel mehr vorkommt. Nach Abarbeitung der Schritte 1 und 2 entsteht eine Formel in konjunktiver Normalform. Es bleibt aber zu zeigen, daß jeder einzelne Umformungsschritt zu einer äquivalenten Formel führt, daß der obige Algorithmus für jede Formel nach endlich vielen Schritten abbricht und daß dieser Algorithmus genau dann abbricht, wenn er eine Formel in KNF erzeugt hat. Diese Einzelaufgaben werden nach dem folgenden Beispiel teilweise gezeigt. Beispiel F = (¬A → B) ∨ (A ∧ ¬C) F1 = (¬(¬A) ∨ B) ∨ (A ∧ ¬C) Beseitigung von → F2 = (A ∨ B) ∨ (A ∧ ¬C) (i) F3 = ((A ∨ B) ∨ A) ∧ ((A ∨ B) ∨ ¬C) (iv) F4 = (A ∨ B) ∧ (A ∨ B ∨ ¬C) Die Berücksichtigung der Assoziativität und der Idempotenz der logischen Konnektoren ’∧’ und ’∨’ ist im obigen KNF-Algorithmus nicht berücksichtigt. Der obige Algorithmus würde also bei der Formel F3 abbrechen. 61 Der KNF-Algorithmus ist ein Beispiel für die syntaktische Umformung von Termen entsprechend einem System von formalen Umformungsregeln rewrite rules. Der vollständige KNF-Algorithmus resultiert dabei aus dem folgenden System von Umformungsregeln: (R1) (R2) (R3) (R4) (R5) (R6) (R7) (R8) A→B ¬(¬A) ¬(A ∧ B) ¬(A ∨ B) A ∨ (B ∧ C) (A ∧ B) ∨ C A∧A A∨A =⇒ =⇒ =⇒ =⇒ =⇒ =⇒ =⇒ =⇒ ¬A ∨ B A ¬A ∨ ¬B ¬A ∧ ¬B (A ∨ B) ∧ (A ∨ C) (A ∨ C) ∧ (B ∨ C) A A Terminierung des KNF-Algorithmus: Man beweise, daß der angegebene Algorithmus, der aus einer beliebigen aussagenlogischen Formel eine Formel in KNF konstruiert, für jede Formel F als Eingabe nach endlich vielen Schritten abbricht, und zwar genau dann, wenn er eine Formel in KNF erzeugt hat. Das angegebene Verfahren zur Konstruktion der KNF (bzw. DNF) ist ein Beispiel für ein sogenanntes REWRITE-System. Durch die angegebenen Regeln (hier wird nur eine Teilmenge der Regeln (R1) − (R8) untersucht): (1) ¬¬G =⇒ G (2) ¬(G ∧ H) =⇒ (¬G ∨ ¬H) (3) ¬(G ∨ H) =⇒ (¬G ∧ ¬H) (4) (F ∨ (G ∧ H)) =⇒ ((F ∨ G) ∧ (F ∨ H)) (5) ((F ∧ G) ∨ H) =⇒ ((F ∨ H) ∧ (G ∨ H)) wird eine zweistellige Relation =⇒ auf der Menge aller aussagenlogischen Formeln wie folgt definiert: F =⇒ G, wenn es eine Regel L =⇒ R aus (1) - (5) derart gibt, daß in F eine Teilformel F ′ der Bauart der Formel L auf der linken Seite dieser Regel existiert und G dadurch aus F entsteht, daß diese Teilformel durch die entsprechende Formel der Bauart der Formel R auf der rechten Seite dieser Regel ersetzt wird. ∗ F =⇒ G ist dann der reflexive, transitive Abschluß von =⇒ . Die Frage nach der Existenz von Normalformen ist dann verbunden mit der Frage nach ∗ der eindeutigen Terminierung der Relation =⇒ . Terminierung meint hier: Es gibt für jede Formel F keine nichtabbrechende Kette F =⇒ F1 =⇒ F2 =⇒ . . . und für jedes i gilt Fi 6= Fi+1 . 62 Eine mögliche allgemeine Strategie zum Nachweis der Terminierung besteht darin, eine streng monoton wachsende Funktion f : AF (A) −→ IN anzugeben (D.h. es soll gelten f (¬F ) > f (F ) , f (F ∧ G) > f (F ), f (G) , f (F ∨ G) > f (F ), f (G) für alle Formeln F, G ∈ AF (A). ), für die aber für jede Regel L =⇒ R aus (1) - (5) gilt f (L) > f (R) ∗ Hieraus folgt dann sofort: Wenn F =⇒ G , so f (F ) > f (G) für alle Formeln F, G ∈ AF (A). Jede streng monoton fallende Folge von natürlichen Zahlen n1 > n2 > . . . muß aber nach endlich vielen Schritten abbrechen. Es ist der Beweis also folgendermaßen zu führen: Die Funktion f wird für alle aussagenlogische Formeln wie folgt definiert: f (a) f (¬F ) f (F ∧ G) f (F ∨ G) = = = = 2 , falls a Atom aus A ist, 2f (F ) , f (F ) + f (G) + 1, f (F ) ∗ F (G). Offensichtlich ist f nach Definition streng monoton wachsend. Andererseits gilt: f (G) (1) f (¬¬G) = 22 > f (G) für jeden Wert f (G), (2) f (¬(G ∧ H)) = 2f (G∧H) = 2f (G)+F (H)+1 = 2 ∗ 2f (G) ∗ 2f (H) und f (¬G ∨ ¬H) = f (¬G) ∗ f (¬H) = 2f (G) ∗ 2f (H) . Es gilt also f (¬(G ∧ H)) = 2 ∗ 2f (G) ∗ 2f (H) > 2f (G) ∗ 2f (H) = f (¬G ∨ ¬H). (3) Es gilt f (¬(G ∨ H)) = 2f (G)∗f (H) und f (¬G ∧ ¬H) = 2f (G) + 2F (H) + 1. Man kann allgemein durch vollständige Induktion über x zeigen, daß für alle natürlichen Zahlen x, y ≥ 2 gilt 2xy > 2x + 2y + 1. Im Induktionsanfang für x = 2 gilt nacheinander: 22y ≥ 2y+2 = 4 ∗ 2y = 2y + 3 ∗ 2y > 2y + 5 = 22 + 2y + 1 Im Induktionsschritt gilt nacheinander n.V. 2(x+1)y = 2xy+y = 2y ∗ 2xy > 2y ∗ (2x + 2y + 1) = 2x+y + 22y + 2y > 2x+1 + 2y + 1 63 (4) Es gilt nacheinander f (F ∨ (G ∧ H)) = f (F ) ∗ (f (G) + f (H) + 1) = f (F ) ∗ f (G) + f (F ) ∗ f (G) + f (F ) > f (F ) ∗ f (G) + f (F ) ∗ F (G) + 1 = f ((F ∨ G) ∧ (F ∨ H)) (5) Der Beweis ist analog zum Beweis von (4). Aufgaben: 1. Man überführe die folgenden Formeln jeweils in eine semantisch äquivalente konjunktive bzw. disjunktive Normalform: a) (¬(A → (B ∧ C)) ∧ ((¬A ∨ C) → B)) b) (((A → B) → (C → ¬A)) → (¬B → ¬C)) c) (((((A → B) → ¬A) → ¬B) → ¬C) → C) d) ((A → (B → C)) → ((A → ¬C) → (A → ¬B))) 64 3.3 Zur Beweistheorie der Aussagenlogik Typtheorie faßt Logik, funktionale Programmierung und konstruktive Mathematik zu einem einzigen System zusammen. Zunächst liegt die Aufmerksamkeit auf dem Beweisen von Aussagen, aber bald wird der Gegenstandsbereich auf konstruktive Mengen (wie sie in den mathematischen Grundlagen erwähnt wurden) und die Gewinnung berechenbarer Funktionen zwischen solchen Mengen ausgedehnt. Weitere interessierende Begriffe treten hinzu, deren Anwendungen z.B. in die Prinzipien der objektorientierten Programmierung Eingang gefunden haben: Modularität, Polymorphismus, Vererbung usw. Schließlich münden die Untersuchungen in die Theorie abhängiger Typen. Im Zentrum der Typtheorie steht die Dualität zwischen Aussagen und Typen (Mengen) bzw. zwischen Beweisen und Elementen. Ein Beweis p einer Aussage T kann man als ein Element p des Typs T ansehen und umgekehrt. Diese Dualität ist als Curry-HowardIsomorphismus oder als ’Formeln-sind-Typen’ Losung bekannt. Hier soll nur ein kleiner Teil betrachtet werden, der zur Beweistheorie der Aussagenlogik gehört und den wir modellieren wollen. Urteile, Regeln, Beweise und Herleitungen Wir beginnen mit der bekannten Syntax der Aussagenlogik. Als Konnektoren werden und (∧), oder (∨), impliziert (→) und die Absurdität (⊥) gewählt, um die Negation zu def definieren: (¬) wird durch ¬F = F → ⊥ definiert. Urteile sind Aussagen der beiden folgenden Formen “P ist eine Formel”, von der wir annehmen, daß sie wahr ist, wenn P eine syntaktisch korrekte aussagenlogische Formel ist, und “p : P ”, die besagt, daß p ein Beweis der Formel P ist. Syntaktisch gesehen, sind hier P eine Formel und p eine Variable oder ein Term eines Beweises. Eine Regel ist eine Kombination a1 . . . an < regelname > a0 65 mit den n Urteilen a1 . . . an über dem Ableitungsstrich und eine Urteil a0 unter dem Strich. Die angenommene Bedeutung besteht darin, daß man die Gültigkeit des Urteils unter dem Strich von der Gültigkeit der Urteile darüber herleiten kann. Somit bestimmen sie ebenfalls eine Logik auf der gegebenen Syntax. Für jeden Konnektor gibt es vier verschiedene Arten von Regeln: • Bildungs- oder Formationsregeln, die die Voraussetzungen beschreiben, unter denen eine spezielle Formel gebildet werden kann. Es handelt sich also um Regeln für die Syntax der Sprache der Aussagenlogik. In unserem Fall ist nur die syntaktisch korrekte Bildung der Teilformeln Voraussetzung; • Einführungsregeln, die dazu dienen, Formeln einzuführen, die den jeweiligen Konnektor betreffen; • Eliminationsregeln, die dazu dienen, Formeln mit derartigen Konnektoren zu eliminieren; • Berechnungs- oder Vereinfachungsregeln besagen, wie Beweise von Formeln, die den speziellen Konnektor enthalten, vereinfacht werden können, um z.B. eine Normalform herzustellen. 66 A ist Formel B ist Formel ∧F (A ∧ B) ist Formel A ist Formel B ist Formel ∨F (A ∨ B) ist Formel p:A q:B ∧I < p, q >: (A ∧ B) p:A ∨I1 inl(p) : (A ∨ B) p : (A ∧ B) ∧E1 f st(p) : A p:B ∨I2 inr(p) : (A ∨ B) p : (A ∧ B) ∧E2 snd(p) : B p : (A ∨ B) f : (A → C) case(p, f, g) : C g : (B → C) f st(< p, q >) 7−→ p case(inl(p), f, g) 7−→ (f p) snd(< p, q >) 7−→ q case(inr(p), f, g) 7−→ (gp) A ist Formel B ist Formel →F (A → B) ist Formel ⊥ ist Formel ⊥F [x : A] .. . e:B →I (λx : A.e) : (A → B) p : (A → B) (pa) : B a:A p:⊥ ⊥E !A (p) : A →E ((λx : A.e)a) 7−→ e[x := a] (!(A→B) (p)q) 7−→!B (p) f st(!(A∧B) (p)) 7−→!A (p) snd(!(A∧B) (p)) 7−→!B (p) Annahmeregel: case(!(A∨B) (p), f, g) 7−→!C (p) A is a formula ass x:A def ¬A = (A → ⊥) Abbildung: Regeln für die aussagenlogischen Konnektoren 67 ∨E Eine formale Herleitung des Urteils F ist eine endliche Liste [G1 , . . . , Gn ], n>0 von Urteilen, so daß (1) F = Gn gilt und (2) jedes Urteil in der Liste ist entweder - eine Annahmeregel (Assumption rule) oder - ist entstanden durch Anwendung einer Regelinstanz von Urteilen, die innerhalb der Liste diesem Urteil vorangehen. Formale Herleitungen werden oft in baumartiger Form geschrieben. Ein formaler Beweis ist eine Herleitung mit einem abgeschlossenen Beweisterm, d.h. er enthält keine freien Variablen bzw. alle Variablen sind durch einen λ-Ausdruck gebunden. Übungen 1. Man zeige, daß die Konjunktion assoziativ ist, indem man einen Beweis der Formel (A ∧ B) ∧ C → A ∧ (B ∧ C) herleitet. 2. Man zeige, daß die Formel (¬A ∨ B) → (A → B) gültig ist, indem man eine Beweisterm angibt. 3. Man zeige, daß man unter der Voraussetzung x : (A ∨ ¬A) einen Beweisterm für die Formel (¬¬A → A) herleiten kann. Man zeige, daß man einen Beweisterm für die konverse Formel (A → ¬¬A) ohne diese Annahme herleiten kann. 4. Zeigen Sie, daß Sie unter den Annahmen x : ((A ∧ B) → C) und y : A einen Beweis der Formel B → C finden können. Welche Formel ergibt sich aus der Abschließung der beiden Voraussetzungen und wie lautet der zugehörige Beweisterm. 5. Zeigen Sie, daß die folgenden Formeln gültig sind und diskutieren Sie die Bedeutung der Beweisterme in Bezug auf den Curry-Howard-Isomorphismus: a) (A → A) b) ((A → B) → ((B → C) → (A → C))) c) ((A → C) ∧ (B → C)) → ((A ∨ B) → C) 6. Betrachten Sie den folgenden λ-Term: λx : A.λy : (A → B).λz : (B → (C∧D)). case( inr(yx), λa : (C∨D).a, λb : B.inl(f st(zb))) Beantworten Sie folgende Fragen: a) Kodiert dieser Term einen Beweis einer aussagenlogischen Tautologie? Wenn das der Fall sein sollte, geben Sie die Formel an. b) Worin besteht die Gestalt des entsprechenden Beweisbaumes? Ist dieser Baum normalisiert? Wenn das nicht der Fall sein sollte, finden Sie einen reduzierten Beweisbaum mit zugehörigem λ-Term, der dieselbe Formel beweist. 68 4 4.1 Algorithmen und Datenstrukturen Algorithmen und ihre Analyse Ein Algorithmus ist ein wohldefinierter Berechnungsprozeß, der einen oder mehrere Werte als Eingabe entgegennimmt und daraus einen oder mehrere Werte als Ausgabe herstellt. So gesehen, besteht ein Algorithmus aus einer Folge von einfachen Berechnungsschritten, die das Eingabemuster in das Ausgabemuster transformieren. Ein Algorithmus muß jede Eingabe des Eingabemusters in endlich vielen Schritten in einen Wert des Ausgabemusters transformieren. Ausgedrückt (spezifiziert) wird ein Algorithmus in einer geeigneten Sprache. Die möglichen Sprachen zur Beschreibung von Algorithmen reichen von natürlichen Sprachen, über mehr oder weniger abstrakten Entwurfssprachen, wie z.B. Pseudocode-Sprachen es sind, bis hin zu mathematischen Formelsprachen und Programmiersprachen. Ein anderer Gesichtspunkt besteht darin, daß wir unter einem Algorithmus die Lösung eines wohlspezifizierten Berechnungsproblems verstehen. Als Beschreibung des Berechnungsproblems wird in allgemeinen Begriffen die gewünschte Eingabe/Ausgabe-Beziehung spezifiziert (extensionaler Aspekt). Beispiel: (Sortierproblem) Eingabe: Eine Folge von n Zahlenwerten < a0 , a1 , . . . , an−1 >. Ausgabe: Eine Permutation π der Menge {0, 1, . . . , n − 1}, so daß aπ(0) ≤ aπ(1) ≤ . . . ≤ aπ(n−1) gilt. Ein Algorithmus beschreibt einen speziellen Berechnungsprozeß als eine Folge einzelner Berechnungsschritte, die ein Berechnungsproblem löst (intensionaler Aspekt). Man kann also die Korrektheit eines Algorithmus konstatieren, indem man die Eingabewerte in Beziehung zu den zugehörigen transformierten Ausgabewerten setzt und mit der gewünschten Eingabe/Ausgabebeziehung vergleicht. Was kann man mit einem gegebenen Algorithmus tun? Nun, man kann ihn in eine Programmiersprache übersetzen, auf einem speziellen Rechner laufen lassen und das Verhalten für spezielle Eingabewerte beobachten. So wird man aber nicht zu allgemeinen Aussagen über den Algorithmus kommen. Einen Algorithmus zu analysieren, bedeutet die Spezifikation des Algorithmus zu studieren und allgemeine Schlußfolgerungen darüber ziehen, wie eine Implementation des Algorithmus (das Programm) sich im allgemeinen verhalten wird. Dabei kann man folgende Einzelheiten bestimmen: 69 • die Laufzeit eines Programms in Abhängigkeit seiner Eingaben, • den gesamten oder maximalen Speicherplatz, der für die Programmdaten benötigt wird, • die Gesamtgröße des Programmcodes, • ob das Programm die gewünschten Resultate korrekt berechnet (Korrektheit, Vollständigkeit - Terminierung), • die Verständlichkeit des Programms: Lesbarkeit, Verständlichkeit, Modifizierbarkeit usw., • die Robustheit des Programms, d.h. wie geht es mit unerwarteten und fehlerhaften Eingaben um, • usw. Hier soll in der Hauptsache die Laufzeit untersucht werden. Gelegentlich spielen auch Speicherplatzfragen eine Rolle. Faktoren, die die Laufzeit eines Programms beeinflussen, sind: • der Algorithmus selbst, • die Eingabedaten, • das Rechnersystem, auf dem das Programm läuft, • usw. Die Arbeitsweise eines Computers wird bestimmt durch: • die Hardware, d.h den Prozessor (Typ und Geschwindigkeit), den verfügbaren Speicherplatz (Cache und RAM), Plattensystem usw. • die Programmiersprache, in der das Programm spezifiziert wurde, • den Sprachkompiler/ -interpreter, der verwendet wurde, • die Betriebssystemsoftware • usw. Eine detaillierte Analyse eines Programms ist schwierig, zeitaufwendig und kaum von dauerhafter Bedeutung. Deshalb wird eine abstraktes Modell des Verhaltens eines Rechners zur Grundlage genommen. Häufig wird dazu eine abstrakte Maschine mit wahlfreiem Zugriff, eine Random-Access-Machine (RAM), verwendet, auf der die Algorithmen als implementiert angenommen werden. 70 4.1.1 Maschinen mit wahlfreiem Zugriff (RAM) und Zeitkomplexität Eine Maschine mit wahlfreiem Zugriff (englisch: random access machine, kurz RAM), auch Registermaschine genannt, ist ein abstraktes idealisiertes Maschinenmodell, das realen Computern ähnelt. Sie besteht aus einer unendlichen Anzahl von Registern, einem ausgezeichneten Register (dem Akkumulator) und dem Befehlszähler. Die Register können beliebige natürliche Zahlen speichern. Sie sind fortlaufend mit den natürlichen Zahlen addressierbar. Der Akkumulator ist das Register mit der Adresse 0. Der Inhalt des Registers i wird im folgenden mit c(i) bezeichnet. Die Register bilden zusammen den Arbeitsspeicher der RAM. Zusätzlich gibt es noch einen nur-lesbaren (read only) Speicher, in dem das auszuführende Programm abgespeichert ist. Im Programm sind die einzelnen Befehle ebenfalls mit den natürlichen Zahlen durchnummeriert. Zu Beginn der Arbeit wird der Befehlszähler mit 1 initialisiert. Im Laufe der Berechnung zeigt der Befehlszähler die Nummer des aktuell ausgeführten Befehls an. Programm Registermaschine (RAM) 01: LOAD #0 02: STORE 3 Befehlszähler 03: LOAD 1 Register Akkumulator c(0) 0003 c(1) c(2) c(3) 04: GOTO 9 c(4) ... c(5) ... Im folgenden sind die verfügbaren Befehle und deren Wirkungsweise (Bedeutung) in einer Tabelle zusammengestellt: Befehl LOAD STORE ADD #i i @i c(0) := i; b + + c(0) := c(i); b + + c(0) := c(c(i)); b + + − c(i) := c(0); b + + c(c(i)) := c(0); b + + c(0) := c(0) + i; b + + c(0) := c(0) + c(i); b + + c(0) := c(0) + c(c(i)); b + + • SUB c(0) := c(0) − i; b + + GOTO − IF ◦ 0 − GOTO END • • c(0) := c(0) − c(i); b + + c(0) := c(0) − c(c(i)); b + + b := i − b := i, wenn c(0) ◦ 0 − b + +, sonst Die Berechnung stoppt • Hierbei sind #i, i, @i die Operanden der Befehle und ◦ ∈ {=, 6=}. Die Funktion − 71 bezeichnet die modifizierte Differenz. Definition 2.2.1: Eine Funktion f : INk −→ IN heißt RAM-berechenbar, wenn es ein RAM-Programm R gibt, so daß für jedes k-Tupel (n1 , . . . , nk ) ∈ INk gilt: f (n1 , . . . , nk ) = y gdw. das RAM-Programm R, gestartet mit n1 , . . . , nk in den Registern 1, . . . , k jeweils, beendet seinen Lauf und liefert den Wert y im Register 1. Beispiele: 1. Gesucht ist ein RAM-Programm, das das Produkt zweier Zahlen x und y berechnet. Der Wert x steht zu Beginn im Register 1 und y steht im Register 2. 01: 02: 03: 04: 05: 06: 07: 08: 09: 10: 11: 12: 13: LOAD #0 STORE 3 LOAD 1 IF = 0 GOTO 11 SUB #1 STORE 1 LOAD 3 ADD 2 STORE 3 GOTO 3 LOAD 3 STORE 1 END 2. Um die indirekte Adressierung zu verdeutlichen, wird folgende Aufgabe gelöst: Es soll die Summe einer n-elementigen Folge (a1 , . . . , an ) berechnet werden. Es wird angenommen, daß im Register 1 die Anzahl der Summanden steht und daß der i-te Summand im Register i + 1 steht. Man überzeuge sich, daß das folgende Programm eine Lösung des Problems darstellt, insbesondere untersuche man wie hier die Summe gebildet wird. 01: 02: 03: 04: 05: 06: 07: LOAD 1 IF 6= 0 GOTO 6 LOAD #0 STORE 1 END LOAD 1 ADD #1 08: 09: 10: 11: 12: 13: 14: STORE 1 SUB #2 IF 6= 0 GOTO 14 LOAD 2 STORE 1 END LOAD 2 72 15: 16: 17: 18: 19: 20: ADD @1 STORE 2 LOAD 1 SUB#1 STORE 1 GOTO 9 Übungsaufgaben: 1. Man gebe ein RAM-Programm zur Berechnung der Funktion f : IN −→ IN mit f (x) = x! an. Berechnen Sie die Laufzeit Ihres Programms mit allgemeiner Eingabe x. 2. Gegeben sei folgendes RAM-Programm 01: 02: 03: 04: 05: 06: 07: 08: 09: 10: 11: 12: 13: LOAD #0 STORE 3 LOAD 2 ADD#1 STORE 2 LOAD 1 SUB 2 IF = 0 GOTO 14 STORE 1 LOAD 3 ADD#1 STORE 3 GOTO 6 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: LOAD 2 SUB 1 IF = 0 GOTO 20 LOAD 3 STORE 1 GOTO 23 LOAD 3 ADD#1 STORE 1 END a) Prüfen Sie dieses Programm mit der Eingabe (Register 1 := 4; Register 2 := 1) bzw. (Register 1 := 5; Register 2 := 2). b) Welche Funktion beschreibt dieses Programm? c) Berechnen Sie die Laufzeit des Programms. 3. Gegeben sei folgendes RAM-Programm 01: 02: 03: 04: 05: 06: 07: 08: 09: LOAD #1 STORE 3 LOAD 1 SUB 2 IF =0 GOTO 12: STORE 3 LOAD 2 STORE 1 LOAD 3 10: 11: 12: 13: 14: 15: 16: 17: 18: STORE 2 GOTO 03 LOAD 2 SUB 1 IF =0 GOTO 18: STORE 3 STORE 2 GOTO 03: END a) Prüfen Sie dieses Programm mit der Eingabe Register 1 := 25; Register 2 := 15 (bzw. Register 1 := 3 und Register 2 := 7). b) Welche Funktion beschreibt dieses Programm? Es soll dabei angenommen werden, daß es nur mit positiven Operanden angewendet wird. c) Berechnen Sie die Laufzeit des Programms. 73 Zeitkomplexität Im folgenden soll der Begriff der Komplexität eines Algorithmus definiert werden. Man unterscheidet dabei verschiedene Gesichtspunkte: Zeitkomplexität, Speicherplatzkomplexität, Beschreibungskomplexität. Hier wird die Zeitkomplexität eine Hauptrolle spielen. Man muß stets eine konkretes Rechnermodell angeben, auf dem man die Algorithmen implementiert. Das ist hier die gerade angegebene RAM. Am Anfang steht die Bestimmung der Größe einer Eingabe. Man unterscheidet hier die uniforme bzw. die logarithmische Eingabegröße: Die uniforme Eingabegröße nimmt nur die Anzahl der Register, die logarithmische Eingabegröße versucht auch die Größe der Zahlen in den Registern zu berücksichtigen. Deswegen ergeben sich folgende Definitionen: Definition: (Eingabegröße) Sei x = (x1 , . . . , xn ) eine Eingabe einer RAM, d.h. im Register i steht zu Beginn der Rechnung die Zahl xi . • Die uniforme Eingabegröße ist |x|u = n, also die Anzahl der durch die Eingabe belegten Register. • Die logarithmische Eingabegröße ist |x|log = Σni=1 l(xi ), d.h. die Summe der Längen der Binärdarstellungen der Zahlen in den Registern. Hier gilt l(z) = ⌊log(z)⌋ + 1 für eine natürliche Zahl z. Bei der nun folgenden Definition der Zeitkomplexität einer RAM wird wiederum zwischen dem uniformen Kostenmaß und dem logarithmischen Kostenmaß unterschieden. Dabei geht es darum, daß beim uniformen Kostenmaß angenommen wird, daß jede Operation der RAM gleich lang dauert. Da bei den Berechnungen beliebig große Zahlen auftreten können, ist das unrealistisch. Eine bessere Anpassung gibt daher das logarithmische Kostenmaß. Dabei werden die Operationen der RAM so gewichtet, daß die Kosten der Operation proportional zur Länge der Binärdarstellung der auftretenden Operanden sind. Im folgenden werden in einer Tabelle die logarithmischen Kosten der verfügbaren RAMOperationen und deren Wirkungsweise zusammengestellt: Befehl #i LOAD l(i) STORE − ADD l(c(0)) + l(i) SUB l(c(0)) + l(i) GOTO − IF ◦ 0 − GOTO END i l(i) + l(c(i)) l(i) + l(0) l(c(0)) + l(i) + l(c(i)) l(c(0)) + l(i) + l(c(i)) 1 l(c(0)) 1 74 @i l(i) + l(c(i)) + l(c(c(i))) l(i) + l(c(i)) + l(c(0)) l(c(0)) + l(i) + l(c(i)) + l(c(c(i))) l(c(0)) + l(i) + l(c(i)) + l(c(c(i))) − − Damit kann nun die Zeitkomplexität eines RAM Programms definiert werden: Definition: (Zeitkomplexität) Gegeben sei die Eingabe x = (x1 , . . . , xn ) einer RAM M. u • Die uniforme Zeitkomplexität TM (x) ist die Anzahl der Programmschritte, die M auf der Eingabe x ausführt. log • Die logarithmische Zeitkomplexität TM (x) ist die Summe der logarithmischen Kosten der einzelnen Schritte, die M auf der Eingabe x ausführt. Die Kosten entnimmt man der Tabelle. Für die Definition der Zeitkomplexität eines RAM-Programmes wird von den konkreten Eingaben abstrahiert und nur noch die Eingabegröße betrachtet. Dabei werden wiederum verschiedene Gesichtspunkte betrachtet: • die Zeitkomplexität eines RAM-Programmes in Abhängigkeit von der Eingabegröße im schlimmsten Fall (engl. worst case), • die Zeitkomlpexität eines RAM-Programmes in Abhängigkeit von der Eingabegröße im besten Fall (engl. best case), • die Zeitkomplexität eines RAM-Programmes in Abhängigkeit von der Eingabegröße im Durchschnitt (engl. average case). Für die uniforme Zeitkomplexität ergibt sich also: Definition: Es sei t : IN −→ IN eine Funktion. Eine RAM M nennt man uniform t(n)-zeitbeschränkt, wenn für alle Eingaben x der Größe n = |x|u • im schlimmsten Fall u u TM (n) := max{TM (x)| |x|u = n} ≤ t(n) • im besten Fall u u TM (n) := min{TM (x)| |x|u = n} ≤ t(n) • im Durchschnitt u u (n) := Σx:|x|u=n pn (x) ∗ TM (x) ≤ t(n) TM,P gilt. Hier ist P = {pn |n ∈ IN} eine gegebene Familie von Wahrscheinlichkeitsverteilungen für die Eingaben einer bestimmten Größe. Die logarithmische Zeitkomplexität eines RAM-Programmes wird analog definiert. In der Praxis ist es für qualitative Vergleiche ausreichend, wenn die Laufzeit proportional zu den gezählten Operationen ist. Deshalb werden oft nur charakteristische Operationen 75 gezählt. Außerdem wird oft das uniforme Kostenmaß angewendet, wenn z.B. bei dem meisten Operationen die Operanden annähernd gleich sind. 4.1.2 Ein detailliertes abstraktes Rechnermodell Da wir im folgenden Text Algorithmen häufig durch C++ Programme beschreiben werden, soll hier noch auf ein detailliertes abstraktes Rechnermodell des Laufzeitverhaltens von C++ Programmen eingegangen werden. Dieses Modell ist unabhängig von der unterliegenden Hardware und Systemsoftware. Man kann es als eine virtuelle C++ Maschine auffassen. Das angegebene Modell ist jedoch ausreichend komplex und detailliert für die Analyse der in den Programmen dargestellten Algorithmen: Axiom 1: Die Zeit, die erforderlich ist, um einen Operanden aus dem Speicher zu laden, ist eine Konstante, die mit τload bezeichnet wird. Die Zeit, die erforderlich ist, um einen Wert im Speicher abzulegen, ist eine Konstante, die mit τstore bezeichnet wird. Beispiele: y = x; hat die Laufzeit τload + τstore . y = 1; hat ebenfalls die Laufzeit τload + τstore . Axiom 2: Die Laufzeiten, die erforderlich sind, um die elementaren Operationen auf Operanden auszuführen, wie Addition, Subtraktion, Multiplikation, Division und Vergleich, sind Konstanten die jeweils mit τ+ , τ− , τtimes , τ: , τ< bezeichnet werden. Beispiel: y = y + 1; hat die Laufzeit 2τload + τ+ + τstore . C++ stellt für exakte die gleiche Berechnung noch alternative syntaktische Varianten zur Verfügung 76 y += 1; ++y; y++;. Alle diese Varianten haben exakt die gleiche Laufzeit. Axiom 3: Die Laufzeit, die erforderlich ist, um eine Funktion aufzurufen, ist eine Konstante, die mit τcall bezeichnet wird. Die Zeit, die erforderlich ist, um aus einer Funktion einen Rückgabewert zurückzugeben, ist eine Konstante, die mit τreturn bezeichnet wird. Axiom 4: Die Zeit, die erforderlich ist, um einer Funktion einen Argumentwert zu übergeben, ist gleich der Zeit, die zum Speichern benötigt wird, d.h τstore Beispiel: y = f(x); hat die Laufzeit τload + τcall + 2τstore + T f (x). Hier ist Tf (x) die Laufzeit der Funktion f für die Eingabe x. Aufgabe: Man berechne die Laufzeit der Summe der einfachen arithmetischen Reihe Σni=1 . Nun wird die Laufzeit für den Zugriff auf ein Element eines Feldes (Arrays) betrachtet: Axiom 5: Die Zeit, die erforderlich ist, um die Adresse für eine Zugriffsoperation auf ein Feldelement zu bestimmen, ist eine Konstante, die mit τ[.] bezeichnet wird. Sie enthält nicht die Zeit, die erforderlich ist, um den Indexwert zu bestimmen noch enthält sie die Zeit des eigentlichen Zugriffs, Laden oder Speichern des Feldelements. Beispiel: 77 y = a[i]; hat die Laufzeit 3τload + τ [.] + τstore . Es sind drei load Operationen erforderlich: • load a, lade die Adresse des Feldes a, • load i, lade den Index des Feldelementes, • load a[i], lade das Feldelement a[i] selbst. Aufgabe: Man gebe ein Programm an, das den Wert eines Polynoms nach dem Horner Schema berechnet und bestimme seine Laufzeit. Das Polynom p sei gegeben als Feld seiner n + 1 Koeffizienten a0 , . . . , an , x ist der Argumentwert. Es soll p(x) = Σni=0 ai xi berechnet werden. Analyse rekursiver Algorithmen Mit dem Beispiel der Fakultätsfunktion, die wie folgt rekursiv definiert ist: 1 falls n = 0 n! = n ∗ (n − 1)! falle n > 0 soll gezeigt werden, wie man die Analyse im Fall rekursiver Algorithmen durchführen kann. Diese Definition führt sofort auf das folgende Programm 1 2 3 4 5 6 7 unsigned int Factorial (unsigned int n) { if (n == 0) return 1; else return n * Factorial(n - 1); } Die Laufzeit hängt vom Ergebnis des Tests auf Zeile 3 ab. Die beiden verschiedenen Möglichkeiten sind zu betrachten. Wegen des rekursiven Aufrufs in Zeile 6 müssen wir die Laufzeitfunktion T für die Fakultätsfunktion selbst kennen. Die Analyse der Laufzeit kann also wie folgt erfolgen: 78 Zeit Anweisung n=0 n>0 3 2τload + τ< 2τload + τ< 4 τload + τreturn − 6 − 3τload + τ− + τstore + τ∗ + τcall + T (n − 1) Wenn wir die einzelnen Spalten jeweils addieren ergibt sich T (n) = t1 falls n = 0 T (n − 1) + t2 falls n > 0 mit t1 = 3τload + τ< + τreturn und t2 = 5τload + τ< + τstore + τ∗ + τcall + τreturn . Diese Art von Gleichung nennt man Rekurrenzbeziehung, weil die Funktion rekursiv durch sich selbst definiert wird. Das Lösen von Rekurrenzbeziehungen durch wiederholte Einsetzung Eine Methode zum Lösen von Rekurrenzbeziehungen nennt man wiederholte Einsetzung. Sie wird wie folgt angewandt: Gegeben sei T (n) = T (n − 1) + t2 , wofür wir auch schreiben können T (n − 1) = T (n − 2) + t2 , falls n > 1 gilt. Nun können wir T (n − 1) in der ersten Gleichung ersetzen und wenn wir diesen Vorgang wiederholen erhalten wir: T [n] = = = = = ... T (n − 1) + t2 (T (n − 2) + t2 ) + t2 T (n − 2) + 2t2 (T (n − 3) + t2 ) + 2t2 T (n − 3) + 3t2 Wie man leicht sieht, entsteht hier folgendes Ergebnis T (n) = T (n − k) + kt2 79 mit 1 ≤ k ≤ n Diese Idee kann man auch mit Hilfe vollständiger Induktion beweisen. Setzen wir k = n, ergibt sich T (n) = T (0) + n ∗ t2 = t1 + n ∗ t2 Vorhin haben wir die uniforme Eingangsgröße eines Feldes als die Anzahl der Feldelemente definiert. Das ist nicht immer realistisch, z.B. dann nicht, wenn der Algorithmus auch eine Abhängigkeit von den konkreten Feldelementen herstellt. Das folgende Problem gibt dafür ein Beispiel: Problem: Gegeben: ein Array von ganzen Zahlen a0 , . . . , an−1 Gesucht: das größte Element max0≤i<n ai Das folgende Programm löst dieses Problem durch lineare Suche: 1 2 3 4 5 6 7 8 int FindMax (int a[], unsigned int n) { int result = a[0]; for (unsigned int i = 1; i < n; n++) if (a[i] > result) result = a[i]; return result; } Die Berechnung der Laufzeit zeigt folgende Analyse Anweisung Laufzeit 3 3τload + τ[.] + τstore 4a τload + τstore 4b (2τload + τ< ) ∗ n 4c (2τload + τ+ + τstore ) ∗ (n − 1) 5 (4τload + τ[.] + τ< ) ∗ (n − 1) 6 (3τload + τ[.] + τstore ) ∗ ? 7 τload + τstore 80 Man sieht leicht, daß bei jedem Schleifendurchlauf die Variable result das bis zu diesem Zeitpunkt größte Element enthält. D.h. die Anweisung 6 wird im i-ten Schritt nur dann ausgeführt, wenn die folgende Bedingung ai > max0≤j<i aj gilt. Somit hängt die Laufzeit des gesamten Programms nicht nur von der Anzahl der Elemente des Feldes ab, sondern auch wie sich die Elemente zueinander verhalten: n−1 T (n, a0 , . . . , an−1 ) = t1 + n ∗ t2 + Σi=1 t3 {ai > max0≤j<i aj } mit t1 = 2τstore − τload − τ+ − τ< t2 = 8τload + 2τ< + τ[.] + τ+ + τstore t3 = 3τload + τ [.] + τstore Man sieht: Um das Laufzeitproblem exakt zu lösen, muß man das ursprüngliche Problem gelöst haben! Hier ist es also naheliegend, die Laufzeiten im schlechtesten, im besten Fall und im Durchschnitt zu diskutieren. Beginnen wir mit der Laufzeit im Durchschnitt: Angenommen, wir sind an der Funktion Taverage (n) interessiert, die die Laufzeit im Durchschnitt für ein n-elementiges Feld unabhängig von den konkreten Werten angibt. Es gilt n−1 Taverage = t1 + n ∗ t2 + Σi=1 pi t3 , wobei pi die Wahrscheinlichkeit ist, mit der Zeile 6 ausgeführt wird. Diese Wahrscheinlichkeit ist gegeben durch pi = P (ai > max0≤j<i aj ). Wenn wir Kenntnis von der konkreten Verteilung der Werte haben, würden wir in der Lage sein pi zu bestimmen, z.B. wenn das Feld aufsteigend sortiert ist, wäre pi = 1 und wenn es entgegengesetzt sortiert ist, dann wäre pi = 0. Im allgemeinen haben wir keine Kenntnis der Verteilung und sind daher auf Annahmen angewiesen, z.B. nehmen wir an, sie sind gleichverteilt, d.h. die Wahrscheinlichkeit, daß 1 . Wir haben also ai das größte unter den Elementen a0 , a1 , . . . an−1 ist, beträgt i+1 pi = 1 . i+1 81 Setzen wir das in die Gleichung oben ein, ergibt sich nacheinander n−1 1 Taverage (n) = t1 + n ∗ t2 + t3 Σi=1 i+1 = t1 + n ∗ t2 + t3 (Σni=1 1i − 1) = t1 + n ∗ t2 + t3 (Hn − 1) Hn = Σni=1 1i ist bekannt als die n-te harmonische Zahl. Der schlechteste Fall ergibt sich mit pi = 1 für alle 0 ≤ i < n: n−1 1 Tworstcase (n) = t1 + n ∗ t2 + t3 Σi=1 = t1 + n ∗ t2 + (n − 1) ∗ t3 = t1 − t3 + (T2 + t3 ) ∗ n. Der beste Fall wird angenommen, wenn pi = 0 ist. In diesem Fall gilt Tbestcase (n) = t1 + n ∗ t2 . Das letzte Axiom betrifft die Zeit, die zum Zuweisen und zur Freigabe von dynamischen Speicherplatz erforderlich ist. Axiom 6: Die Zeit, die zum Zuweisen eines festen Betrages an Speicherplatz aus dem Arbeitsspeicher mit Hilfe des Operators new erforderlich ist, ist eine Konstante, die mit τnew bezeichnet wird. Analog ist die Zeit, die zur Freigabe eines Speicherbereiches an den Arbeitsspeicher mit Hilfe des Operators delete erforderlich ist, ebenfalls eine Konstante und wird mit τdelete bezeichnet. Beispiele: int * ptr = new int; delete ptr; hat die Laufzeit τnew + τstore , erfordert eine Laufzeit von τload + τdelete . 82 4.1.3 Ein vereinfachtes Rechnermodell Das detaillierte Rechnermodell basiert auf einer Anzahl verschiedener Zeitparameter τload , . . . , τdelete . Für praktische Vorhersagen des Verhaltens ist es sehr schwerfällig. In einem realen Rechner sind alle diese Zeitparameter ganzzahlige Vielfache der Periodenlänge T eines Taktes der Maschine,z. B. gilt τload = kload ∗ T. Die Periodenlänge liegt bei modernen Rechnern zwischen 2 und 10 ns. Die Taktfrequenz liegt zwischen 100 und 500 MHz. Das vereinfachte Rechnermodell faßt alle diese verschiedenen Zeitparameter zusammen durch folgende Grundannahmen: • Alle Zeitparameter werden in Einheiten der Periodenlänge ausgedrückt, d.h. es gilt T = 1. • Die Proportionalitätskonstanten k jedes Zeitparameters sind gleich, d.h. wir nehmen ebenfalls an k = 1. Folgerung: Um die Laufzeit eines Programms zu bestimmen, muß man nur die Summe aller Zeitperioden bilden. Diese Vorgehensweise soll im folgenden am Beispiel der Berechnung der n-ten Teilsumme der geometrischen Reihe erläutert werden.. Dabei kommen zur Berechnung der n-ten Teilsumme der geometrischen Reihe verschiedene Algorithmen mit sehr unterschiedlicher Laufzeitkomplexität zum Einsatz. Aufgabenstellung: Man gebe Algorithmen zur Berechnung der n-ten Teilsumme der geometrischen Reihe als C++-Programme an und analysiere sie in Bezug auf ihre Laufzeitkomplexität, d.h. gegeben ist ein Wert x und eine nichtnegative Zahl n. Gesucht wird eine Berechnung der n-ten Teilsumme Σni=0 xi . 1. Ein naiver Algorithmus Eine erste Lösung gibt der folgende naive Algorithmus: 1 2 3 4 5 6 7 int GeometricSeriesSum (int x, unsigned int n) { int sum = 0; for (unsigned int i = 0; i <= n; i++) { int prod = 1; for (unsigned int j = 0; j < i; j++) 83 8 prod *= x; 9 sum += prod; 10 } 11 return sum; 12 } Die Berechnung der Laufzeit ergibt: Anweisung Laufzeit 3 2 4a 2 4b 3 ∗ (n + 2) 4c 4 ∗ (n + 1) 6 2 ∗ (n + 1) 7a 2 ∗ (n + 1) 7b 3 ∗ Σni=0 (i + 1) 7c 4 ∗ Σni=0 i 8 4 ∗ Σni=0 i 9 4 ∗ (n + 1) 11 2 Summe 11 2 n 2 + 47 n 2 + 27 Aufgabe: Man beweise Σni=1 i = n(n + 1) 2 2. Horner Schema Die Berechnung der n-ten Teilsumme ist gleich der Berechnung des Wertes eines Polynoms, dessen sämtliche Koeffizienten gleich 1 sind. Es kann also das Horner Schema angewendet werden: 1 2 int GeometricSeriesSum (int x, unsigned int n) { 84 3 4 5 6 7 int sum = 0; for (unsigned int i = 0; i <= n; i++) sum = sum * x + 1; return sum; } Die Bestimmung der Laufzeit ergibt Anweisung Laufzeit 3 2 4a 2 4b 3 ∗ (n + 2) 4c 4 ∗ (n + 1) 5 6 ∗ (n + 1) 6 2 Summe 13n + 22 3. Methode der iterierten Quadrate a) Aufgabe: Man beweise für die n-te Teilsumme der geometrischen Reihe die folgende geschlossene Formel für jede Zahl a: Σni=0 ai = an+1 − 1 a−1 b) Iteriertes Quadrieren zur Berechnung von Potenzen Anstatt eine Potenz xn mit Hilfe einer Schleife zu berechnen, kann man alternativ folgende Definition verwenden: falls n = 0, 1 n 2 ⌊n/2⌋ (x ) falls n > 0 und gerade, x = 2 ⌊n/2⌋ x(x ) falls n > 0 und ungerade was auf das folgende Programm führt: 1 2 3 4 5 int Power (int x, unsigned in n) { if (n ==0 ) return 1; else if (n % 2 == 0) 85 6 7 8 9 return Power (x * x, n / 2); else return x * Power (x * x, n / 2); } Eine Laufzeitberechnung ist die folgende Anweisung 3 n=0 3 Laufzeit n>0 n ist gerade 3 4 2 − − 5 − 5 5 6 − 10 + T (⌊n/2⌋) − 8 − − 12 + T (⌊n/2⌋) Summe 5 n>0 n ist ungerade 3 18 + T (⌊n/2⌋) 20 + T (⌊n/2⌋) Die Diskussion der Rekurrenzrelation ergibt im Durchschnitt T (n) = 19(⌊log2 n⌋ + 1) + 5. • Zusammenfassung Unter Verwendung der geschlossenen Formel zur Berechnung der n-ten Teilsumme der geometrischen Reihe ergibt sich folgendes Programm 1 2 3 4 5 6 int Power (int, unsigned int); int GeometricSeriesSum (int x, unsigned int n) { return (Power (x, n + 1) -1) / (x - 1); } Wenn man zur durchschnittlichen Laufzeit von Power noch die Schritte, die in Zeile 5 getan werden müssen, hinzuzählt, so ergibt sich eine durchschnittliche Laufzeit für diesen Algorithmus von T (n) = 19(⌊log2 (n + 1)⌋ + 1) + 18. 4.1.4 Asymptotische Notation Angenommen, wir haben zwei Algorithmen A und B, die beide dasselbe gegebene algorithmische Problem lösen. Außerdem sind aus der Analyse der beiden Algorithmen die Laufzeit TA (n) und TB (n) in Abhängigkeit von der Eingabegröße n bekannt. 86 Wie kann man das Laufzeitverhalten der beiden Algorithmen miteinander über den gesamten Bereich der Eingabegröße vergleichen? Dazu wird das asymptotische Verhalten der beiden Laufzeitfunktionen miteinander verglichen. Der Begriff der Wachstumsklasse einer Funktion wird eingeführt. Außerdem ist es meist sehr schwierig, exakte Angaben zu der maximalen Anzahl von Rechenschritten zu machen. Deshalb ist es üblich, die Laufzeitfunktion eines Algorithmus als Größenordnung anzugeben. Das hat auch den Vorteil, daß die Größenordnung weitgehend unabhängig von der konkreten Implementierung ist. Definition: (Asymptotische Notationen) Sei f : IN −→ IR≥0 eine Funktion. es wird definiert: • O(f) = Menge aller Funktionen g : IN −→ IR≥0 , für die es eine Konstante c > 0 und eine Zahl n0 ∈ IN derart gibt, daß g(n) ≤ c ∗ f (n) für alle n ≥ n0 • Ω(f ) = Menge aller Funktionen g : IN −→ IR≥0 , für die es eine Konstante c > 0 und eine Zahl n0 ∈ IN derart gibt, daß f (n) ≤ c ∗ g(n) für alle n ≥ n0 • Θ(f ) = Menge aller Funktionen g : IN −→ IR≥0 , für die es Konstanten c1 , c2 > 0 und eine Zahl n0 ∈ IN derart gibt, daß c1 ∗ f (n) ≤ g(n) ≤ c2 ∗ f (n) für alle n ≥ n0 Namen von Wachstumsklassen: Man sagt, eine Funktion f : IN −→ IN • ist konstant, wenn f (n) = O(1); • wächst logarithmisch, wenn f (n) = O(log(n)); • wächst linear, wenn f (n) = O(n); • wächst linear-logarithmisch, wenn f (n) = O(nlog(n)); • wächst quadratisch, wenn f (n) = O(n2 ); • wächst polynomiell, wenn f (n) = O(nk ) für ein gewisses k ∈ IN; • wächst exponentiell, wenn f (n) = O(2n ) gilt. 87 Aufgaben: 1. Zeigen Sie, daß für die beiden folgenden Funktionen f (n) = n(n + 1) 2 und g(n) = 3n2 + 2n − 100 g(n) ∈ O(f (n)) gilt. Welche Größenordnung ist das? 2. a) Geben Sie zu jeder der nachstehenden Funktionen gi : IN −→ IN eine möglichst einfache Funktion fi : IN −→ IN an, so daß gi (n) ∈ Θ(fi (n)) gilt: (a) g1 (n) = 2(n + 1)2 + 3n − 4 (b) g2 (n) = 2n + 3n (c) g3 (n) = log3 (n) + log2 (n) b) Beweisen oder widerlegen Sie: (a) 2n+1 ∈ Θ(2n ) (b) logn! ∈ Θ(lognn ). 3. Welche der folgenden Aussagen sind richtig? (a) 3n ∈ Θ(3n/2 ) (b) log7 (n2 ) ∈ Θ(logn) (c) log7 (nn ) ∈ Θ(logn). 88 4.2 Datenstrukturen, Datentypen 4.2.1 Fundamentale Datenstrukturen 4.2.2 Abstrakte Datentypen und Anwendungen 4.3 4.3.1 Algorithmen Sortieralgorithmen Vorbemerkungen, Problem des Sortierens Gegeben sei eine Folge von n Datensätzen D1 , . . . , Dn , wobei jeder Datensatz Di den Schlüssel ki besitzt. Auf der Menge aller möglichen Schlüssel ist eine totale Ordnung ≤ definiert: Definition: Eine solche Folge von Datensätzen heißt sortiert, wenn die Datensätze gemäß einer Permutation π ∈ Sn wie folgt vorliegen Dπ−1 (1) , . . . , Dπ−1 (n) , wobei die Schlüssel bzgl der totalen Ordnung ≤ eine aufsteigende bzw. eine absteigende Folge bilden, d.h. für π gilt: kπ−1 (1) ≤ kπ−1 (2) ≤ . . . ≤ kπ−1 (n) bzw. kπ−1 (1) ≥ kπ−1 (2) ≥ . . . ≥ kπ−1 (n) Ein Sortierverfahren heißt stabil, wenn Datensätze mit gleichem Schlüssel ihre ursprüngliche Reiehenfolge behalten. Die Analyse der Komplexität von Sortieralgorithmen erfolgt in der Anzahl der Vergleiche, weil die übrigen Operationen linear dadurch beschränkt sind. Sortieren durch Auswahl Beschreibung: Während des Sortierens stellt man sich die Datensätze in zwei Teile aufgeteilt vor: • einen bereits aufsteigend sortierten Teil, • einen unsortierten Bereich. 89 Zusätzlich wird angenommen, daß kein Schlüssel im sortierten Bereich größer als ein Schlüssel im unsortierten Bereich ist. Zu Beginn befindet sich kein Datum im sortierten Bereich. In jedem Schritt wird das kleinste Element im unsortierten Bereich bestimmt und an das Ende des sortierten Bereichs angehängt. Das kleinste Element einer Menge wird wie folgt bestimmt: Ein beliebiges wird als kleinstes Element gewählt. Nacheinander wird das aktuelle mit einem beliebigen Element verglichen, das noch an keinem Vergleich beteiligt war. Das kleinere der beiden wird als neues aktuelles kleinstes Element genommen. Als Programm in einer Funktionalen Programmiersprache: selectionSort: [Int] -> [Sort] selectionSort([]) = [] selectionSort([hd| tl]) = let (m, ys) = select([hd| tl]) in [m| selectionSort(ys)] select: [Int] -> (Int, [Int]) select([e]) = (e, []) select([u, v| tl]) = let (m, ys) = select([v| tl]) in if (n <= m) then (u, [m| ys]) else (m, [u| ys]) Als C++ Programm: 1 2 3 4 5 6 7 void SelectionSort(int a[], int len) { for (int i = 0; i < len; i++) for (int j = len -1; j > i; j--) if (a[j-1] > a[j]) swap(a[j-1], a[j]); } 8 void swap(int& a, int& b) 9 { 10 int tmp = a; a = b; b = tmp; 11 } 90 Analyse von SelectionSort: Vsel (n) bezeichne die Anzahl der benötigten Vergleiche, wenn die Eingabe aus n Datensätzen besteht (uniformes Kostenmaß). Es sind (k−1) Vergleiche ausreichend, um das Minimum aus einer Menge von k Elementen zu bestimmen. Es sind aber auch (k − 1) Vergleiche nötig, da jedes Element überprüft werden muß. Nun also zum Algorithmus: In der Phase, wo das Minimum bestimmt werden soll, um einen Schlüssel an Position i ∈ [0|n − 1] einzufügen, werden n − i − 1 viele Vergleiche ausgeführt. Damit gilt: n−1 n−1 (n − i − 1) = Σni=0 (n − i) = Σi=0 i= Vsel (n) = Σi=0 n n(n − 1) = (2) ∈ O(n2 ) 2 Aufgaben: 1. Man berechne nach diesem Verfahren selectionSort([3, 1, 4, 2]) und gebe dabei alle Zwischenschritte an. 2. Man programmiere einen geeigneten Testtreiber und teste den gegebenen Algorithmus. Sortieren durch Einfügen Beschreibung: Man stellt sich während des Sortierens die Datensätze wiederum in zwei Bereiche eingeteilt vor: • einen bereits sortierten Bereich, und • einen unsortierten Bereich. Zu Beginn befinden sich alle Elemente im unsortierten Bereich. Ein beliebiges Element (ggf. das erste) wird aus dem unsortierten Bereich gewählt und in den bereits sortierten Bereich einsortiert. Dabei wandert es von links nach rechts, bis es die Stelle gefunden hat, wo es eingefügt werden kann. In der Listendarstellung (Funktionales Programm) kann das Element einfach eingefügt werden, bei der Felddarstellung (Array) muß der hintere Teil des bereits sortierten Bereichs als Ganzes im Feld nach hinten geschoben werden. 91 Als Programm in einer funktionalen Sprache insertionSort: [Int] -> [Int] insertionSort([]) = [] insertionSort([hd| tl]) = insert(hd, insertionSort(tl)) insert: Int x [Int] -> [Int] insert(u, []) = [u] insert(u, [v | tl]) | (u > v) = [v| insert(u, tl)] (u <= v) = [u, v| tl] Als C++ Programm 1 2 3 4 5 void insertionSort(int a[], int len) { for (int i = 1; i<len; i++) right_shift(a, linearSearch(a, i, a[i]), i); } 6 int linearSearch(int a [], int len, int elt) 7 { 8 int j = 0; 9 while (j < len && a[j] <= elt) j++; 10 return j; 11 } 12 void right_shift(int a [], int l, int r) 13 { 14 int k = a[r]; 15 for (int j = r; j>l; j--) 16 a[j] = a[j-1]; 17 a[l] = k; 18 } Analyse von InsertionSort: Vins (n) bezeichne die maximale Anzahl (worst case) der für den InsertionSort-Algorithmus benötigten Vergleiche, wenn die Eingabe aus n vielen Datensätzen besteht. Es reichen m Vergleiche aus, um ein Element in eine Liste aus m sortierten Elementen einzufügen. 92 In der Phase, wo das Element an Position i ∈ [0|n − 1] in den bereits sortierten Bereich einsortiert wird, enthält dieser i Elemente. Es reichen also auch i Vergleiche maximal aus. Damit gilt unter Berücksichtigung aller Phasen n−1 i= Vins (n) = Σi=0 n n(n − 1) = (2) ∈ O(n2 ) 2 Rekursiver MergeSort Eine der ältesten Sortiermethoden ist das Sortieren durch Mischen. Die Idee hierfür beruht darauf, daß es recht einfach ist, zwei sortierte Folgen in eine sortierte Folge zu mischen. Beim Mischen zweier sortierter Folgen in eine geht man so vor: Man vergleicht jeweils die beiden kleinsten Elemente und hängt das kleinere von beiden an die bereits gemischte Folge an (reißverschlußartig). Hat man nun eine unsortierte Folge, teilt man diese in zwei Hälften und sortiert diese rekursiv mit demselben Verfahren und mischt die so erhaltenen Folgen nach dem gerade angeführten Reißverschlußprinzip in eine neue Folge. Beschreibung: Das gegebene Feld a wird unter Zuhilfenahme des Feldes b sortiert. Beim Mischen (Funktion merge) steht die linke Folge auf den Positionen [l|m−1] und die rechte auf den Positionen [m|r − 1] des Feldes a. Nach dem Mischen steht die sortierte Folge im Feld b und muß mit Hilfe der Funktion copy in das Feld a zurückkopiert werden. Für diesen Algorithmus wird ein zusätzliches Feld derselben Größe wie das zu sortierende benötigt. Als C++ Programm 1 void mergeSort(int a [], int b [], int l, int r) 2 { 3 if (l < r - 1) 4 { 5 int m = (l + r)/2; 6 mergeSort(a, b, l, m); 7 mergeSort(a, b, m, r); 8 merge(a, b, l, m, r); 9 copy(b, a, l, r); 10 } 11 } 12 void merge(int a [], int b [], int l, int m, int r) 13 { 14 for (int i = l; int j = m; int k = l; k<r; k++) 15 if ((j>=r)||((i<m) && (a[i] <= a[j]))) 16 b[k] = a[i++]; 17 else 93 18 19 } b[k] = a[j++]; 20 void copy(int b [], int a[], int l, int r) 21 { 22 for (int i = l; i<R; i++) 23 a[i] = b[i]; 24 } Analyse des rekursiven MergeSort: Quicksort Beschreibung: Das Grundprinzip von Quicksort ähnelt dem von Mergesort. Wie dort werden die Dat6en rekursiv in zwei Teile geteilt und jeder Teil für sich nach dem gleichen Muster sortiert. Dabei wird aus der Folge ein beliebiges Element gewählt. Man nennt dieses Element Pivotelement, kurz Pivot. Die Datensätze werden nun in zwei Teile geteilt: • einen Teil mit Schlüsseln, die kleiner als das Pivot sind, und • einen Teil mit Schlüsseln, die größer als das Pivot sind. Die beiden Teile werden rekursiv sortiert und später hintereinander zusammengefaßt. Der Einfachheit halber wiederum wird stets das rechteste Element (Schlüssel) als Pivot gewählt. Im folgenden wird angenommen, daß ein Teilbereich des Feldes a [] von der Position l bis zur Position r (einschließlich) sortiert werden soll. Beim Aufteilungsschritt wird dabei so vorgegangen: Das rechteste Element wird mit dem Pivot vertauscht, damit bleibt das Pivot immer am rechten Rand stehen. Mit einem Zeiger i wird von links ein Element gesucht, das größer als das Pivotelement ist, und mit einem zweiten Zeiger j wird von rechts ein Element gesucht, das kleiner als das Pivot ist. Hat man ein solches Paar gefunden, vertauscht man die beiden Elemente und setzt die Arbeit fort. Wird i ≥ j, dann wird die Arbeit abgebrochen, weil dann klar ist, daß links von i nur kleinere und rechts nur größere Elemente als das Pivot stehen. Wird i = j, wenn i heraufgezählt wurde, so zeigt i nun auf das Element, das im letzten Austauschschritt nach j kopiert wurde, bzw. falls es ein solches nicht gegeben hatte, auf das Pivot. Damit ist klar, daß i auf ein Element zeigt, das nicht kleiner als das Pivot ist. Wird anderenfalls i = j beim Heranzählen von j, dann zeigt i offensichtlich auf ein Element, daß größer als das Pivot ist. Also ist letzte Vertauschung des Pivot mit dem 94 Element an Position i zulässig. Nun ist i die Pivotposition und links davon stehen nur Elemente, die kleiner sind. Damit kann nun rekursiv quicksort(l, i-1) und quicksort(i+1, r) aufgerufen werden. Als C++ Programm 1 void quicksort(int a [], int l, int r) 2 { 3 if (l < r) 4 { 5 int pivot = partition(a, l, r, r); 6 if (pivot - l < r - pivot) 7 { 8 quicksort(a, l, pivot -1); 9 quicksort(a, pivot + 1, r); 10 } 11 else 12 { 13 quicksort(a, pivot + 1, r); 14 quicksort(a, l, pivot - 1); 15 } 16 } 17 } 18 int partition(int a [], int l, int r, int pivot) 19 { 20 int i = l - 1, j = r; /* linker und rechter Zeiger 21 swap(a[pivot], a[r]); /* bringe pivot nach rechts 22 pivot = r; 23 while (i < j) 24 { 25 do i++; while ((i < j) && (a[i] < a[pivot])); 26 do j--; while ((i < j) && (a[j] > a[pivot])); 27 if (i >= j) 28 swap(a[i], a[pivot]); 29 else 30 swap(a[i], a[j]); 31 } 32 return i; 33 } Analyse von Quicksort: 95