23_8335_700-RDBM-Systemarchitektur - Offene
Werbung

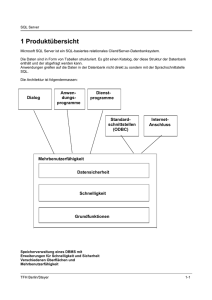
1 In diesem Abschnitt wollen wir uns mit der Architektur von Datenbank Managements Systemen beschäftigen. Zunächst stellt sich die Frage: Warum soll ich mich mit der Architektur eines DBMS beschäftigen? Ich will Datenbanken doch nur anwenden können. Danach schauen wir uns an, nach welchen Prinzipien fast alle relationalen Datenbanksystem arbeiten. Dies soll uns u.a. helfen effizientere Programme zu erstellen. 2 Zunächst nun die Frage: Warum soll ich mich mit der Architektur eines DBMS beschäftigen? Ich will Datenbanken doch nur anwenden können. Die Antwort ist in der Abbildung ersichtlich. Das Ziel ist es, effiziente Anwendungen zu erstellen und die DB Ressourcen entsprechend sinnvoll auch auszunutzen. Was wir von der Architektur wissen sollten, schauen wir uns jetzt näher an. 3 Beginnen wir mit dem, am Anfang bereits erwähnten, SPARC / ANSI Modell. In diesem Modell werden nur ganz grob drei Schichten beschrieben: • Externe Sicht – externe Sicht für den Anwender / Anwendung • Logische Sicht – logisches Datenmodell • Physikalische Sicht – nur diese hat Kenntnisse darüber, wie die Daten in einem Filesystem abgelegt sind. Das Hauptziel war die strikte Trennung zwischen Applikation und Dateisystem. 4 Das SPARC/ANSI Model ist sehr allgemein und die einzelnen Hersteller haben dies auch mehr oder weniger unterschiedlich umgesetzt. Bestimmte Prinzipien und Verfahren sind jedoch bei jedem Hersteller ähnlich gelöst. Und genau diese Themen wollen wir uns als nächstes näher ansehen. 5 Wie aus der Abbildung ersichtlich ist, sind genau zwei Themenbereiche von Bedeutung, deren Kenntnisse für die Anwendungsentwicklung wichtig sind. Zwar kann man auch ohne dieses Wissen gute Datenbank-Anwendungen erstellen. Unser Ziel ist es jedoch auch effiziente Anwendungen zu erstellen. Insbesondere dann, wenn auf die Datenbank sehr viele Benutzer gleichzeitig zugreifen. Thema 1 : Hauptspeicher und Festplatte Thema 2: Schnelle Zugriffe mit Index 6 Thema 1 : Hauptspeicher und Festplatte Bei diesem Thema steht die Frage im Vordergrund: Wie kommen die Daten von der Festplatte in die Anwendung? Hierzu betrachten wir folgende drei Ebenen. Festplatte Die Daten, welche mittels einer SQL INSERT Anweisung in eine Tabelle eingetragen werden, sind auf einer Festpatte persistent hinterlegt. Jeder Hersteller hat dabei seine eigene Implementation. Es gibt DBMS Implementationen, die legen die Daten der einzelnen Tabellen in Dateien ab, manche speichern diese in einem RAW-Device. Dies bedeutet, das DBMS verwaltet die Festplatten selbst. Wie dies genau geschieht, soll für eine Anwendung keine Rolle spielen. Genau dies will man ja mit dem SPARC/ANSI Model erreichen. An dieser Stelle soll uns die Verwaltung der Festplatte auch nicht weiter 7 beschäftigen. Wichtig ist nur, dass ein DBMS auf Festplatten zugreifen, muss um Tabelleninhalte zu lesen. Hauptspeicher Wenn nun eine Anwendung eine SELECT-Anweisung ausführt, so muss das DBMS die Select-Anweisung analysieren, die Ergebnismenge bestimmen und die Daten im Hauptspeicher ablegen. Die Daten in dem Hauptspeicher sind dort anders organisiert als auf der Festplatte. Im Hauptspeicher werden die Daten in sogenannten PAGES abgelegt. Ein PAGE ist dabei nichts weiter als eine Speicherbereich (Block) der einige Kilo-Byte groß ist. Meist sind diese Pages 4KB oder auch 8KB groß. Einige DBMS Hersteller haben hierfür auch einen Konfigurations-Parameter, um das System optimal anpassen zu können. Anwendung Anwendungen können nun auf die Ergebnissemenge im Hauptspeicher zugreifen. Die jeweiligen Datenbank-APIs übernehmen hierbei die Abbildung, welcher Datensatz in einer Ergebnismenge, in welcher PAGE im Hauptspeicher abgelegt ist. Nachdem wir uns das Prinzip verdeutlich haben, wie DBMS ihre Daten einer Anwendung zur Verfügung stellt, schauen wir uns im nächsten Schritt an, wie die Abbildung der Daten genau erfolgt. 7 In dieser Abbildung sehen Sie die wichtigsten Kernprinzipien eines DBM Systems. Die wichtigsten Fakten sind in den Boxen aufgelistet: 1. PAGES im Hauptspeicher werden in einem Cache-verwaltet werden. 2. Die meisten DBMS Hersteller bieten zu Tuning-Zwecken entsprechende Konfigurationsparameter an, wie zum Beispiel die Größe des Caches. 3. Die Cache Strategie ist LRU – Last recently used. Die Seiten (Pages), die am wenigsten gebraucht werden, werden ausgelagert. 4. Ein PAGE enthält dabei immer nur Daten aus derselben Tabelle. Hierbei können folgende Situationen auftreten: 5. Eine PAGE enthält mehrere Zeilen aus einer Tabelle 6. Eine Zeile aus einer Tabelle kann so groß (Datenmenge), dass sie in mehrere PAGES abgelegt werden muss. 7. Um die Konsistenz zwischen den Daten im Hauptspeicher und der Festplatte zu gewährleisten, verwenden DBM-Systeme ein sogenanntes CheckpointVerfahren. Dieses Verfahren erlaubt es nachzuhalten, welche Daten noch nicht auf die Platte geschrieben wurden. 8 Damit die einzelnen Zeilen innerhalb der Pages und auf der Festplatte effektiv verwaltet werden können, verwenden die DBM-Systeme innerhalb des Systems nicht den Primary-Key, sondern bilden diesen auf eine Datenbank-interne Row-Id ab. Dies dient dazu, um die einzelnen Zeilen ein-eindeutig identifizieren zu können. 9 Das zweite wichtige Thema ist die Index-Verwaltung. In Fachbüchern finden wir üblicherweise einen Index. Die ist meist alphabetisch organisiert und soll uns helfen, bestimmte Abschnitte/Kapitel in dem jeweiligen Buch zu finden. Den gleichen Verwendungszweck hat auch ein INDEX in einem DatenbankSystem. Dort kann man zu einer Tabelle angeben, ob ein Index erstellt werden soll und wie dieser aufgebaut sein soll. Der entsprechende SQL Befehl lautet CREATE INDEX. Ein genaue Beschreibung des Befehles für Oracle bzw. SQL Server finden sind unter den nachfolgend angegebenen URLs. Siehe auch: • http://www.datenbanken-verstehen.de/datenmodellierung/datenbank-index/ • ORACLE - – SQL CREATE INDEX Anweisung: http://docs.oracle.com/cd/B19306_01/server.102/b14200/statements_5010.htm • Microsoft SQL Server – SQL CREATE INDEX Anweisung: https://msdn.microsoft.com/de-de/library/ms188783.aspx 10 Wie in der Abbildung ersichtlich,, unterscheiden die meisten DBMS zwei Arten von INDEX. Clustered-Index Beim Clustered-Index werden die Daten zusammen mit dem Index gespeichert. Die Daten sind somit unmittelbar im Zugriff. Non-Clustered Index Beim Non-Clustered Index wird lediglich ein Verweis auf die Daten gespeichert. Somit ist ein weitere Zugriff notwendig, um die Daten lesen zu können. Siehe auch: • Microsoft SQL Server: https://www.mssqltips.com/sqlservertip/1206/understanding-sql-serverindexing/ 11 Ein weiteres Unterscheidungsmerkmal für Indices bezieht sich auf die Eindeutigkeit. Unique-Index Bei diesem Typ von Index wird garantiert, dass es zu einem Index Eintrag genau eine Zeile in der Tabelle gibt. Beispiel: In deiner Tabelle mit Produktbezeichnungen, muss der Produktname immer eindeutig sein. In diesem Fall würde man in der Praxis einen Unique-Index auf den Produktnamen definieren. Zum einen stellen wird damit sicher, dass • die Produktnamen eindeutig sind und • zum anderen erlaubt es uns einen schneller Zugriff auf Produkte, sofern in der WHERE Bedingung des entsprechenden Select-Statements der Produktname als Bedingung aufgeführt wird. Non-Unique-Index Bei diesem Typ von Index kann es zu einem Eintrag in dem Index ein oder auch 12 mehrere Zeilen in der Tabelle geben. 12 Die wichtigsten Datenstrukturen für den Aufbau eines INDEX sind in der Abbildung dargestellt. Hash-Map Eine Hash-Map ist ein Assoziativer-Speicher wie man ihn auch von der Programmiersprache Java her kennt. Bäume Bäume sind in der Praxis ebenfalls sehr häufig anzutreffen. Welche Datenstruktur am besten geeignet ist, ist abhängig von: • der Where-Bedingungen, die in einer Applikation verwendet werden • Und auch von den Hersteller-Empfehlung. Für Anwendungs-Programmierer, Datenbank-Schema Modellierer und Datenbank Administratoren bedeutet dies, dass man sich sehr genau mit der Anwendung selbst (also Art der Selects) und auch den Empfehlungen des Hersteller auseinandersetzen muss, um die geeignete Index Definition zu finden. Dies erfolgt in der Regel in einer speziellen Performance Tuning Phase der 13 Anwendungsentwicklung. Siehe auch: • ORACLE: https://docs.oracle.com/cd/E11882_01/server.112/e40540/indexiot.htm#CNCPT721 13 In dieser Abbildung sehen Sie ein Beispiel für die Organisation eines Index a BBaum wie es in ORACLE verwendet wird. (siehe Quellenangabe). Wie man hier sehr schön sehen kann, werden als Verweise die Row-Ids verwendet, um die entsprechenden Daten zu referenzieren. 14 15 16 17