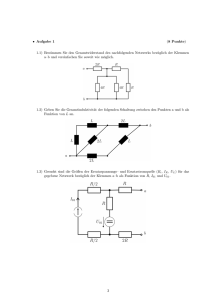
Zusammenfassung In der vorliegenden Arbeit - diko
Werbung

Zusammenfassung In der vorliegenden Arbeit: “Datenanalyse im Marketing“ wird in Anlehnung an Fayyad auf die Wissensentdeckung in Datenbanken eingegangen, wobei es um den Prozess der Identifikation von bisher nicht erkannten Mustern in großen Datenbeständen geht. Dieser Prozess wird im alggemeinen unter dem Begriff “Data Mining“ zusammengefasst, wobei über 80 Prozent der schon produktiven Data Mining-Lösungen im Marketing eingesetzt werden. Es lassen sich dabei 4 Hauptaufgabenbereiche unterscheiden, auf die in dieser Arbeit näher eingegangen wird. Der erste Bereich der Klassifikation wird häufig im Bereich der Kreditwürdigkeitsprüfung eingesetzt. Beim zweiten Anwendungsbereich handelt es sich um das so genannte Clustering, wobei die direkte Kundenansprache als Hauptziel zu nennen ist. Als drittes Hauptaufgabengebiet ist die Assoziierung zu nennen, wobei das Hauptanwendungsfeld in der Sortimentsanalyse des Einzelhandels zu sehen ist. Abschließend wird noch die Prognose angesprochen, bei der es beispielsweise um die optimierte Werbeträgerplanung geht. Diese Aufzählung macht dabei deutlich, wie vielfältig Data Mining heutzutage speziell im Marketing eingesetzt wird, weshalb diese Thematik im Mittelpunkt dieser Arbeit steht. Datenanalyse im Marketing Tim Brüggemann 20.01.2003 Inhaltsverzeichnis 1 Einleitung 3 2 Anwendungsgebiete und angewendete Methoden 5 3 Klassifikation - Bereich der Bonitätsprüfung 3.1 Anwendungsgebiete, Motivation und Verfahren der Bonitätsprüfung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2 Diskriminanzanalyse als Verfahren der Bonitätsprüfung in der Bankenbranche . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3 Entscheidungsbäume als Verfahren zur Bonitätsprüfung in der Bankenbranche . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.4 Verfahrensvergleich der Methoden zur Bonitätsprüfung im Versandhandel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.5 Fuzzy Logik zur Bonitätsprüfung im Factoring . . . . . . . . . 3.6 Fazit bezüglich der vorgestellten Verfahren der Bonitätsprüfung 6 . 6 . 7 . 9 . 10 . 12 . 13 4 Clustering - Praxisbeispiele aus dem Bereich der Kundensegmentierung 4.1 Allgemeine Vorgehensweise des Clustering . . . . . . . . . . . . . 4.2 Kundensegmentierung in der Bankenbranche . . . . . . . . . . . 4.3 Käuferidentifikation im Automobilhandel . . . . . . . . . . . . . 4.4 Werbekampagnenentwurf der Lauda-Air . . . . . . . . . . . . . . 15 15 16 18 19 5 Klassifikation + Clustering am Beispiel einer Kündigerprävention auf dem Mobilfunktmarkt 21 6 Sortimentsanalyse im Einzelhandel 23 6.1 Assoziationsanalyse zur Bildung von Assoziationsregeln im Einzelhandel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 6.2 Clustering zur Aufdeckung der Verbundwirkungen innerhalb eines Warensortiments . . . . . . . . . . . . . . . . . . . . . . . . . 24 6.3 Anwendung einer modernen Neurocomputing-Methode zur Quantisierung von Warenkorbdaten . . . . . . . . . . . . . . . . . 26 7 Prognose zur sandhäusern optimierten Werbeträgerplanung bei Ver28 8 Schlussfogerungen und Bezug zur Projektgruppe 30 9 Glossar 32 2 Kapitel 1 Einleitung In den letzten Jahren ist die Einsicht gewachsen, dass Informationen genauso den wirtschaftlichen Produktionsfaktoren zuzuordnen sind, wie Rohstoffe, Arbeit und Kapital. Mit dieser Erkenntniss sind gleichzeitig die Bedürfnisse gewachsen, große Datenbestände bezüglich wichtiger, bisher unbekannter Informationen hin zu analysieren. Zur Analyse werden dabei immer häufiger Verfahren des Data Mining eingesetzt, wobei unter diesem Begriff die Anwendung spezifischer Algorithmen zur Extraktion von Mustern aus Daten verstanden wird.(vgl. [FAY96]) Im Zentrum der vorliegenden Arbeit steht dabei die Frage, inwiefern Data Mining in der Praxis, insbesondere im Marketing eingesetzt wird? Der Marketingsektor wird dabei angesichts der Anwendungshäufigkeit als größtes Einsatzgebiet für Data Mining angesehen, wobei der Marketingbegriff, aufgrund verschiedener Definitionsebenen, häufig verschiedene Bereiche umfasst. Anhand der ausgewählten Praxisbeispiele wird dabei deutlich gemacht, wie vielfältig sich der Einsatz von Data Mining in der Praxis darstellt. Dementsprechend werden im ersten Teil der Arbeit einige Anwendungsbereiche und die dort angewendeten Data Mining Verfahren angesprochen, um im folgenden auf die Praxisbeispiele genauer einzugehen, bei denen der Einsatz von Data Mining zur Datenanalyse am häufigsten angewendet wird. Der erste Bereich ist dabei die Bonitätsprüfung, bei der beispielsweise Kunden der Bankenbranche oder des Versandhandels, mit Hilfe einer Klassifikation als kreditwürdig oder als nicht kreditwürdig eingeschätzt werden. Danach wird der Bereich der Kundensegmentierung behandelt, wobei Händler verschiedener Branchen durch Anwendung von Clustering versuchen, ihre Kunden in Untergruppen (Cluster) zu unterteilen. Ziel dieser Unterteilung ist ein anschließendes, gezieltes One-to-one Marketing, wobei das Marketingverhalten auf spezielle Kunden oder Kundengruppen ausgerichtet ist. Durch das folgende Beispiel aus der Mobilfunkbranche wird versucht, deutlich zu machen, dass die beiden Verfahren Klassifikation und Clustering häufig auch kombiniert zur Anwendung kommen. Das nächste große Anwendungsgebiet von Data-Mining sind Sortimentsanalysen, aus denen Rückschlüsse auf die Kundenpräferenzen und deren Kaufverhalten gezogen werden. Der folgende Abschnitt beschäftigt sich mit der Prognosewirkung des Data Mining, wobei es um eine zukünftige Planung von Werbeträgern eines Versandhauses geht. Bei allen vorgestellten Beispielen wird der Prozess des Knowledge Discovery in Databases (KDD) deutlich, wobei es um die Identifizierung valider, neuer, potentiell nützlicher und schließlich verständlicher Muster in Daten geht.(vgl. 3 [FAY96]) 4 Kapitel 2 Anwendungsgebiete und angewendete Methoden Die Einsatzmöglichkeiten von Data Mining sind als sehr vielfältig zu bezeichnen. Dieses bezieht sich sowohl auf die Anwendungsgebiete, als auch auf die einzelnen Data-Mining Verfahren, die sich in ihren Einsatzmöglichkeiten weitestgehend nicht auf spezielle Problembereiche beschränken. Anwendungsbereiche lassen sich beispielsweise wie folgt gliedern: (vgl. [SÄU 2001]) • die Astronomie (Satellitenmissionen) • die Biologie (Umweltstudien, Klimaforschung) • die Chemie (Ähnlichkeitsanalyse chemischer Verbindungen) • das Ingenieurwesen (Werkstoffanalysen) • der Finanzsektor (Bonitätsanalyse) • der Medizinsektor (Entdeckung von neuen Medikamenten) • die Textanalyse (Extrahieren von Informationen aus Texten) • der Telekommunikationssektor (Kundenpflege) Die speziellen Anwendungsgebiete im Marketing, welches im Mittelpunkt dieser Ausarbeitung steht, sind ebenso vielfältig. Data Mining Verfahren werden in diesem Bereich zur Preisfindung, zur Marktsegmentierung, bei der individualisierten Kundenansprache, der Sortimentsanalyse, der Kundenbindung, zur Bonitätsprüfung und zur Betrugsentdeckung eingesetzt.[vgl. MEY00] Als konkrete Data Mining Verfahren kommen dabei am häufigsten neuronale Netze, Entscheidungsbäume, Clusteranalysen sowie Assoziationsanalysen zur Anwendung. Die einzelnen angesprochenen Verfahren lassen sich dabei jeweils noch in weitere Unterverfahren unterteilen, welche bei den konkreten Praxisbeispielen noch näher erläutert werden. Die hohe Anzahl der Anwendungsgebiete und der angewendeten Verfahren macht dabei klar deutlich, wie vielfältig der Einsatz des Data Mining in der Praxis ist, was auch an den nun folgenden Praxisbeispielen gut zu erkennen ist. 5 Kapitel 3 Klassifikation - Bereich der Bonitätsprüfung Die klassischen Bonitätsprüfung, die häufig auch als Kreditwürdigkeitsprüfung bezeichnet wird, soll bei der Entscheidung helfen, ob ein Kunde als kreditwürdig (zahlungsfähig) oder als nicht-kreditwürdig (nicht zahlungsfähig) eingestuft wird. Bei den folgenden Praxisbeispielen aus der Bankenbranche, dem Versandhandel und des Factorings spielt diese Einstufungsmöglichkeit eine entscheidende Rolle. In der Bankenbranche wird anhand der Bonitätsprüfung entschieden, ob einem Kunden ein Kredit gewährt werden kann, oder nicht. Für Versandhäuser geht es um die Verhinderung von Zahlungsausfällen durch nicht bezahlte Rechnungen. Beim Factorringgeschäft hilft die Bonitätsprüfung dem Factor bei der Entscheidung, ob er Forderungen aus Warenlieferungen oder Dienstleistungen von Factoringkunden ankaufen soll, oder nicht.(vgl. Abschnitt 3.5) 3.1 Anwendungsgebiete, Motivation und Verfahren der Bonitätsprüfung Die Bonitätsprüfung hat in allen behandelten Praxisbeispielen generell das Ziel, Fehler 1. und 2. Art zu verhindern (vgl. Abb.3.1). Solche Fehler treten immer Fehler 1. und 2. Art Gute prognostizierte Bonität Schlechte prognostizierte Bonität gute tatsächliche Bonität schlechte tatsächliche Bonität OK Fehler 1. Art Fehler 2. Art OK Abbildung 3.1: Fehler 1. und 2. Art dann auf, wenn es einen Unterschied zwischen der prognostizierten und der tatsächlichen Bonität gibt. Ein Fehler 1. Art entsteht immer dann, wenn ein Kunde als kreditwürdig oder zahlungsfähig eingeschätzt wird, dieses im Nachhinein jedoch nicht der Fall ist. Das Auftreten eines Fehlers 2. Art bedeutet, dass ein Geschäft aufgrund fehlender Bonität abgelehnt wird, dieses sich jedoch später als Fehleinschätzung erweist. 6 Unternehmen verfolgen im betriebswirtschaftlichen Sinn die Ziele der Gewinnmaximierung sowie der Minimierung des eigenen Risikos und müssen daher in der Praxis beide Fehlerarten gegeneinander abwägen. Würde ein Unternehmen beispielsweise versuchen, den Fehler 1. Art komplett zu verhindern, so würde es gar keine Kredite mehr vergeben. Dieses entspricht zwar dem Ziel nach geringem Risiko, ist jedoch hinderlich bei der Gewinnmaximierung. Eine Verringerung des Fehlers 1. Art führt dabei also zwangsläufig zu einer Steigerung des Fehlers 2. Art.(vgl. [Ung01]) Ziel einer Bonitätsprüfung ist daher nicht nur die Verhinderung des Fehlers 1. Art, sondern ein ausgewogenes Verhältnis beider Fehlerarten. Bei der Bonitätsprüfung wird im Allgemeinen das Data Mining-Verfahren Klassifikation angewendet. In der Praxis werden häufig traditionelle Verfahren wie die Prüfung durch Kreditsachbearbeiter oder Scoringsystemen angewendet. In den letzten Jahrzehnten haben sich jedoch immer mehr formalisierte Klassifikationsverfahren wie Entscheidungsbäume, Diskriminanzanalysen, Neuronale Netze, Regressionsanalysen und Fuzzy Logik durchgesetzt.(vgl. [MET94]) Der Einsatz von Data Mining-Methoden ermöglicht dabei eine Optimierung beim Kreditentscheid und damit eine Verringerung der Kreditrisiken sowie eine Ertragssteigerung. 3.2 Diskriminanzanalyse als Verfahren der Bonitätsprüfung in der Bankenbranche Der Einsatz von Diskriminanzanalysen in der Bankenbranche dient dazu, mit Hilfe von ausgewählten Variablen wie monatliches Einkommen, beantragte Kredithöhe, einbehaltene Gewinne, Umsatz usw. einen Kreditbewerber (Privatperson, Unternehmen) in kreditwürdig oder nicht kreditwürdig zu klassifizieren.(vgl. [MEY00]) Diskriminanzanalytische Verfahren lassen sich dabei in univariate und multivariate Verfahren unterscheiden. Auf univariate Verfahren wird in dieser Arbeit jedoch nicht weiter eingegangen, da sie nur eine Variable zur Klassifikation der Daten heranziehen. Bei multivariaten Verfahren wird hingegen aus mehreren Variablen eine Kennzahl zur Klassifizierung gebildet, was die Performance, aufgrund der höheren Aussagekraft, gegenüber der univariaten Variante wesentlich steigert. (Vgl.[UNG01]) Um die prinzipielle Vorgehensweise von Diskriminanzanalysen deutlicher zu machen, wird die lineare Diskriminanzanalyse sowohl an einem grafischen, als auch an einem Zahlenbeispiel aus der Praxis dargestellt. Bei der grafischen Darstellung handelt es sich um eine Risikoanalyse aus der Bankenbranche, bei der es um die richtige Bonitätseinschätzung von Kreditkunden geht. Die Bank besitzt in ihrer Datenbank Informationen über die Kredithöhe und das Einkommen aller Kunden, die in der Vergangenheit einen Kredit bei der Bank aufgenommen haben. Diese Informationen werden nun in ein zweidimensionales Achsensystem eingetragen, wobei den Kunden, die den Kredit zurückgezahlt haben, die 1 zugeordnet wird, während Kunden, die den Kredit nicht zurückgezahlt haben, mit einer 0 gekennzeichnet werden. (vgl. Abb. 3.2) Dieses Regressionsverfahren hat dabei das Ziel, aus den gespeicherten Daten ein Vorhersagemodell zu erstellen, welches die neuen Kreditkunden in vordefinierte Klassen zuordnet.(vgl. [MET94]) Gesucht wir dabei immer die Diskriminanzfunktion, die die Kreditkunden aufgrund der gegebenen Variablen (Einkommen und Gehalt) am eindeutigsten klassifiziert. In diesem Fall ent7 Kredithöhe 0 1 0 0 1 0 1 1 0 0 1 1 0 0 1 1 1 0 t Einkommen Abbildung 3.2: Diskriminanzanalyse steht eine lineare Diskriminanzfunktion aus der die folgende Regel abgeleitet werden kann: “Wenn das Einkommen eines Kunden kleiner als t ist, dann zahlt der Kunde den Kredit nicht zurück, andernfalls ist eine Kreditvergabe relativ risikolos“. [RIE99] Auf die Höhe des Einkommens, welches die Diskriminanzfunktion bestimmt, wird in der Quelle nicht genauer eingegangen. Anhand der Grafik lässt sich zudem erkennen, dass zwei Kunden durch die gebildete Diskriminanzfunktion falsch klassifiziert worden sind. Bei der 0 auf der rechten Seite handelt es sich um einen Fehler 1. Art, da dem Kunden eine gute Bonität prognostiziert wurde, er den Kredit aber nicht zurückgezahlt hat. Die 1 auf der linken Seite stellt einen Fehler 2. Art dar, da der Kunde den Kredit zurückgezahlt hat, obwohl die Bonität als schlecht prognostiziert worden ist. Ein solcher Fehler kommt in der Praxis jedoch nicht vor, da bei schlechter Prognose generell kein Kredit gewhrt wird. Da eine 100-prozentige Klassifikation kaum realisierbar ist, muss der Anwender daher von Fall zu Fall entscheiden, ob die vorliegende Fehlerrate für ihn noch akzeptabel ist oder ob er eine erneute Klassifizierung, zum Beispiel auf der Basis anderer Variablen, durchführen will.(vgl. [RIE99]) Ein Zahlenbeispiel zur linearen Diskriminanzanalyse stellt der so genannte ZWert von Altmann dar.(vgl. [UNG01]) Er wird dabei von Banken zur Klassifikation in solvente bzw. insolvente Klassen von öffentlich gehandelten Produktionsunternehmen in den USA verwendet.(Vgl. Abb.3.3) Die angegebenen VaZ = 1,2 * x1 + 1,4 * x2 + 3,3 * x3 + 0,6 * x4 + 1,0 * x5 x1= Umlaufvermögen x2= Einbehaltene Gewinne x3= Gewinn vor Zinsen und Steuern x4= Marktwert des EK / Buchwert des FK x5= Umsatz Z < 2,675 Einordnung in insolvente Gruppe Z > 2,675 Einordnung in solvente Gruppe Abbildung 3.3: Z-Wert von Altmann riablen gehen dabei durch den jeweiligen Multiplikator verschieden stark in den letztlich entstehenden Z-Wert ein, wobei der Gewinn vor Zinsen und Steuern mit einem Wert von 3,3 hier mit Abstand die stärkste Bedeutung zugemessen wird.(vgl. [UNG01]) Der hohe Wert von 3,3 kommt daher zustande, da der Gewinn vor Zinsen und Steuern in der Vergangenheit häufig ein eindeutiges Indiz 8 für die Einstufung der Unternehmen dargestellt hat und daher einen starken Einfluß auf den entstehenden Z-Wert haben muß. Neben der in Abbildung 3.3 gezeigten Klassifikationsregel hat Altmann weiterhin herausgefunden, dass im Bereich von 1, 81 < Z < 2, 9 die Gefahr einer Fehlklassifikation am höchsten ist, weshalb er diesen Bereich als “zone of ignorance“ bezeichnet hat. [vgl. MET94] Unternehmen mit einem zugeordneten Z-Wert ausserhalb der gerade beschriebenen “zone of ignorance“ können daher relativ eindeutig in die Gruppe solvent bzw. insolvent klassifiziert werden, was den Banken wiederum hilft, eine verlustbringende Fehlklassifikation zu verhindern. 3.3 Entscheidungsbäume als Verfahren zur Bonitätsprüfung in der Bankenbranche Das Bilden von Entscheidungsbäumen ist das am weitesten verbreitete Verfahren bei der Klassifizierung. Sie werden dabei mit Hilfe von verschiedenen Verfahren wie CART, CHAID und C4.5., automatisch aus gegebenen Datensätzen extrahiert und dienen schließlich als Vorhersagemodell bezüglich neuer Daten. Ein Entscheidungsbaum besteht aus Knoten, die durch gerichtete Kanten miteinander verbunden sind. Ein Knoten, der keinen Nachfolger besitzt, wird als Endknoten oder Blatt bezeichnet.(vgl. [NIE00]) Ein Knoten ohne Vorgänger dient als Ausgangspunkt oder auch Wurzel des Baumes. Jeder Knoten in einem Entscheidungsbaum kann mit einem Test bezüglich des Knotenmerkmals beschrieben werden. In dem, in Abbildung 3 dargestellten Beispielbaum wird im Wurzelknoten beispielsweise ein Test bezüglich des Merkmals “Berufsfähig“ durchgeführt. Für jedes Testergebnis (hier ja oder nein) gibt es dabei eine KanBerufsfähig ? Ja Nein 30 < Alter <35 ? ... Jahresgehalt < 200.000 DM Schulden > 500.000 DM Kein Kredit Student ? ... Bürgschaft der Eltern ? ... Vermögen Kredit ... ... Kein Kredit Abbildung 3.4: Entscheidungsbaum te, die wiederum zum nächsten Knoten führt. Dieses Verfahren wird so lange fortgeführt, bis ein Endknoten erreicht wird und dadurch ein Klassifikationsergebnis für die zu testenden Daten vorliegt. Anhand des beschriebenen Beispielsbaumes lassen sich bestimmte Vorhersagen bezüglich der Kreditwürdigkeit neuer Kunden treffen. So wird ein Neukunde der berufstätig ist, zwischen 30 und 35 Jahre alt ist, ein Jahresgehalt unter 200.000 DM bezieht und Schulden über 500.000 DM angehäuft hat, beispielsweise als nicht kreditwürdig eingestuft. Einem Studenten, der eine Bürgschaft der Eltern vorlegen kann, wird anhand des Entscheidungsbaumes wiederum ein Kredit gewährt. 9 Im Normalfall sind Entscheidungsbäume allerdings viel komplexer, da sie wesentlich mehr Knoten und Kanten besitzen. Generell sind aber einfache Baumstrukturen den komplexeren vorzuziehen, da der Gesamtüberblick bei der Betrachtung von komplexen Entscheidungsbäumen sehr schwer fällt. Aufgrund dieser Problematik werden auf die komplexen Entscheidungsbäume häufig Beschneidungsverfahren, auch Pruning-Stragtegien genannt, angewendet, die Entscheidungsbäume auf die wesentliche Länge stutzen, indem sie beispielsweise nur eine bestimmte maximale Tiefe zulassen, ab der keine weitere Vezweigung mehr durchgeführt wird.(vgl. [KWZ98]) Ziel dieses Vorganges ist es, die mit dem “Overfitting“ verbundene hohe Fehlerrate bei der Anwendung des impliziten Prognosemodells auf neue Daten wieder zu reduzieren. (vgl. [KÜS00]) 3.4 Verfahrensvergleich der Methoden nitätsprüfung im Versandhandel zur Bo- Im Versandhandel ist es heutzutage aufgrund der zahlreichen Wettbewerber und dem daraus resultierenden Konkurrenzdruck üblich geworden, auch Neukunden bei ihren Bestellungen Kredite zu gewähren. Für Versandhändler stellt diese Ausgangslage ein erhebliches Problem dar, da dieses häufig zu Zahlungsausfällen führt.(vgl. [BA00]) Der Baur-Versand unternimmt daher große Anstrengungen im Bereich der Bonitätsprüfung, um künftige Zahlungsausfälle in der Häufigkeit des Auftretens stark einzuschränken. Zu diesem Zweck sind verschiedene Verfahren zur Klassifizierung miteinander verglichen worden, um ein Verbesserungspotential des vom Baur-Verlag benutzten Credit-Scorings aufzudecken.(vgl. [HR00]) Bei den Verfahren handelt es sich um ausgewählte Verfahren der Diskriminanzanalyse, um verschiedene Entscheidungsbaumverfahren, sowie um die in dieser Arbeit bisher noch nicht dargestellten Verfahren der logistischen Regression und der Neuronalen Netze.(vgl. [HR00]) Mit neuronalen Netzen versucht man dabei die Vorgänge im menschlichen Gehirn abzubilden. Neuronale Netze zeichnen sich durch eine hohe Adaptionsfähigkeit aus, durch die auch hochkomplexe nicht-lineare Zusammenhänge dargestellt werden können. Die angesprochene Adationsfähigkeit erreicht man durch die Verwendung künstlicher Variablen, den Neuronen, die durch nicht-lineare Funktionen der erklärenden oder klassifizierenden beobachteten Variablen gebildet werden.(Vgl.[BA00]) Bei der logistischen Regression geht es um den Einfluss erklärender Variablen X1,.....,Xm auf eine Zielvariable Y. Handelt es sich bei Y beispielsweise um die Zielvariable Krankheit, so zeigt die logistische Regression, welche erklärende Variable zur Krankheit beitragen, und welche nicht.(vgl. [BZL02]) Das bisher benutzte Scoringmodell des Baur-Verlages basiert auf Datenstichproben vorhandener Kunden, von denen schon bekannt ist, ob sie als kreditwürdig gelten oder nicht. Anhand der bekannten Kundendaten (Name, Adresse usw.) wird nun ein Schwellenwert berechnet, der im vorliegenden Beispiel ein Zahlungsausfallrisiko von 25 Prozent gerade noch akzeptiert. Für Neukunden wird nun auf Basis der gleichen Daten, die bei der Erstbestellung bekannt sind, ein Scoringwert berechnet, der anschließend mit dem errechneten Schwellenwert verglichen wird. Liegt der Wert oberhalb des Schwellenwertes wird der Kunde als kreditwürdig eingeschätzt. Bei einem Scoringwert unterhalb des Schwellenwertes wird er als nicht kreditwürdig eingestuft.(vgl. [BA00]) 10 Dieses Modell des Baur-Verlages hat sich in der Praxis bewährt, es wird jedoch trotzdem nach Verbesserungspotenzialen gesucht. Diese Suche hat sich dabei auf die oben angesprochenen Verfahren bezogen, denen als Grundlage die Kundendaten von ca. 160.000 Erstbestellern des Baur-Verlages zur Verfügung stehen. Bei den 66 erklärenden Variablen für die Klassifikationen, die dem BaurVerlag aufgrund der Bestelldaten bekannt sind, hat es sich hier beispielsweise um das Alter, den Wohnort des Kunden, die Preise der bestellten Artikel und die gewünschte Zahlungsweise des Kunden gehandelt. Das primäre Ziel dieses Projektes ist dabei nicht primär eine möglichst gute Klassifizierung der Neukunden gewesen, sondern eine Maximierung des wirtschaftlichen Nutzens der Neukunden. (vgl. [HR00]) Die Berechnung dieses Wertes geschieht dabei durch die Formel: W irtschaf tlichkeit(N utzenzuwachsproKunde) = U msatz ∗ x − Abgabe ∗ y Die Multiplikation des Umsatzes mit dem Faktor x entspricht dabei der Bildung eines Deckungsbeitrages, während die Abgaben noch mit y gewichtet werden, da ein Teil der noch ausstehenden Forderungen beispielsweise durch Inkassobüros eingetrieben wird.(vgl. [HR00]) Ausgehend von dieser Formel ist dann die Wirtschaftlichkeit der Neukunden ohne Bonitätsprüfung ermittelt worden. Auf Basis dieses Benchmark-Wertes konnten dann schließlich die angewendeten Verfahren bezüglich des Zuwachses an Wirtschaftlichkeit (Nutzenzuwachs pro Kunde) gegenübergestellt werden (Vgl. Abbildung 3.5), wobei die einzelnen Verfahren vorher bezüglich möglichst geringer Fehler 1. und 2. Art optimiert worden sind. Grundsätzlich ist anhand Verfahren Nutzenzuwachs pro Kunde Neuronale Netze 10,85 DM Logistische Regression 10,52 DM OC1 10,32 DM (multivariates Entscheidungsbaumverfahren) 9,79 DM Diskriminanzanalyse CHAID 9,33 DM (univariates Entscheidungsbaumverfahren) 9,09 DM BAUR-Modell CART 8,58 DM (univariates Entscheidungsbaumverfahren) 0,00 DM Keine Prüfung Abbildung 3.5: angewendete Verfahren und Ergebnisse der Abbildung zu erkennen, dass alle ausgewählten Verfahren eine wesentliche Steigerung der Wirtschaftlichkeit gegenüber dem Benchmarkwert erbracht haben. Das bisher angewendete Modell des Baur-Verlages schneidet im Vergleich zu den anderen Verfahren eher schlecht ab. Der Unterschied der Wirtschaftlichkeitsunterschiede scheint dabei zwar relativ gering zu sein, was sich allerdings relativiert, wenn man bedenkt, dass die Anzahl der Neukunden des Baur-Versands sehr hoch ist. Um das optimale Verfahren für den Baur-Verlag herauszufinden, muss man zwischen der Klassifikationsleistung und der Interpretierbarkeit der einzelnen Verfahren unterscheiden. Die beste Klassifikation hat dabei das ausgewählte Verfahren aus dem Bereich der Neuronalen Netzte erbracht. Betrachtet man 11 allerdings auch noch die Interpretierbarkeit der Ergebnisse, so ist eher die logistische Regression vorzuziehen, die ähnlich gute Klassifizierungsergebnisse geliefert hat, dabei jedoch wesentlich leichter zu interpretieren ist.(vgl. [HR00]) Der Grund dafür wird in der Literatur häufig mit dem Begriff Black-Box umschrieben, was bedeutet, dass besonders im Fall neuronaler Netze, die maschinell getroffenen Entscheidungen schwer nachzuvollziehen sind und daher eine Interpretation der Ergebnisse schwer durchzuführen ist.(vgl. [UNG01]) Die Aufgabe des Baur-Verlages hat nun schließlich darin bestanden, zwischen den Variablen der Klassifikationsleistung und der Interpretierbarkeit der einzelnen Verfahren abzuwägen, und sich auf dieser Grundlage für eines der aufgelisteten Verfahren zu entscheiden, um die dargelegten Verbesserungspotentiale zu realisieren. Im Vergleich zum angewendeten Scoring-Verfahren könnte der Verlag so seine Fehlklassifikationen minimieren, was sich schließlich positiv auf die Geschäftstätigkeit auswirken würde. Inwieweit der Baur-Verlag dieses umgesetzt hat geht aus den verwendeten Quellen leider nicht hervor. 3.5 Fuzzy Logik zur Bonitätsprüfung im Factoring Data Mining Technologien wie Fuzzy Logik sind in Zeiten komplexer werdender Aufgabenstellungen und knapper Ressourcen unverzichtbar geworden, um auf Dauer wettbewerbsfähig zu bleiben. Bei Fuzzy Logik handelt es sich um eine unscharfe Logik, mit der es gelingt, vage formulierte menschliche Erfahrungen (beispielsweise die eines Kreditsachbearbeiters) mathematisch zu beschreiben und zur Entscheidungsfindung einzusetzen.(vgl. [PN00]) Das Verfahren wird dabei seit einiger Zeit zur Lösung komplexer Aufgabenstellungen eingesetzt. Im Bereich der Bonitätsprüfung ist eine ähnliche Entwicklung zu erkennen. Traditionelle Verfahren, wie die Bonitätsbeurteilung durch einen Kreditsachbearbeiter, liefern in diesem Bereich zwar immer noch zufrieden stellende Ergebnisse, geraten bei komplexeren Sachverhalten aufgrund großer Datenmengen jedoch an ihre Grenzen. Daraus hat sich schließlich die Motivation des Einsatzes von Fuzzy-Logik im Bereich der Wirtschaftlichkeitsprüfung ergeben. Im konkreten Beispiel hat dieses Modell Anwendung bei der Kreditlimitvergabe im Factoring gefunden. Factoring kann dabei als Finanzdienstleistung beschrieben werden, die sich in Branchen mit hohem Liquiditätsbedarf immer größerer Beliebtheit erfreut. Der so genannte Factor kauft dabei beispielsweise die Geldforderungen eines Warenlieferanten gegenüber eines Kunden an. Der Factor übernimmt dabei innerhalb eines bestimmten Limits das volle Ausfallrisiko, wobei die Höhe dieses Limits von der Finanzsituation des Kunden abhängt, welche durch eine Bonitätsprüfung bestimmt wird. Um sicher zu gehen, dass die angekauften Forderungen auch zurückgezahlt werden können, überprüft der Factor dabei ständig die Bonität des Kunden.(vgl. [PN00]) Für den Warenlieferanten hat dieses System dabei den Vorteil, dass er das Risiko eines Zahlungsausfalles nicht mehr trägt und sofort die Rechnung bezahlt bekommt. Der Factor verlangt für die Risikoübernahme eine Factoringgebühr, die bei der Zahlung an den Warenlieferanten einbehalten wird, indem er nicht die volle Rechnung begleicht. Verdeutlicht wird dieses Vorgehen noch einmal an Abbildung 3.6. Es ist dabei offensichtlich, dass die Existenz des Factors von einer relativ exakten Bestimmung der Bonität des Kunden bzw. von der korrekten Bestimmung des Limits abhängig ist. Die Bestimmung der Werte geschieht dabei, wie oben schon angedeutet, mit Hilfe eines wissensbasierten Fuzzy-Systems. Ein Fuzzy-System besteht dabei aus drei Arbeitsschritten, der Fuzzyfizierung, 12 Factoring Kunde Lieferung der Ware Verkauf der Forderung „Factoring“ Zahlung des Kaufpreises abzüglich einer Factoringgebühr Bezahlung der Forderung Abnehmer Factor Bonitätsprüfung Abbildung 3.6: Das Factoringgeschäft der Inferenz und schließlich der Defuzzyfizierung.(vgl. [ZIM87]) Bei der Fuzzyfizierung wird das Wissen erfahrener Anwender, was häufig in Form von Regeln ausgedrückt werden kann, auf Terme der Linguistischen Variablen abgebildet und so dem Rechner zugänglich gemacht. Die Linguistische Variable beschreibt dabei eine Variable, deren Ausprägung nicht numerische Ausdrücke sind. Die linguistische Variable nimmt dabei keinen konkreten Wert an, sondern besitzt mehrere mögliche Ausprägungen. Zusammen mit den Daten des Kunden werden daraus dann bei dem Schritt der Inferenz neue Schlußfolgerungen gezogen. Es werden dabei neue Fakten hergeleitet, für die dann wieder entsprechende Regeln gesucht weden.(vgl. [PN00]) Bei dem Schritt der Defuzzyfizierung werden diese gewonnenen Ergebnisse dann wieder in konkrete Handlungsempfehlungen umgesetzt. Im Beispiel des beschriebenen Factorringgeschäftes ist so ein Kriterienbaum entstanden, dessen Regeln mit Hilfe von Fuzzy Logik aus der Wissensbasis (konkrete Kundendaten + vorhandenes Expertenwissen) generiert worden sind. Der Factor kann schließlich anhand dieses Kriterienbaumes die Bonitätsentscheidung des Systems analysieren, wobei ihm eine komfortable grafische Benutzeroberfläche zur Verfügung steht.(vgl. [PN00]) Der Einsatz von wissensbasierten Fuzzy-Systemen zur Entscheidungsunterstützung hat sich dabei in der Praxis als sehr zuverlässig erwiesen und erlaubt so ein profitables Arbeiten des Factors im Factoringgeschäft. 3.6 Fazit bezüglich der vorgestellten Verfahren der Bonitätsprüfung Der Wettbewerbsdruck in allen angesprochenen Branchen hat sich in den Zeiten einer schwachen Konjunktur erheblich erhöht. Es wird dabei immer wichtiger, bei Kreditwürdigkeitsprüfungen die angesprochenen Fehler 1. und 2. Art zu minimieren, welches durch eine Steigerung der Vorhersagegenauigkeit bezüglich der Bonität zu erreichen ist. Die auf subjektiven Entscheidungen beruhenden Beratungen eines Kreditsachbearbeiters oder traditionelle Scoringsy13 stem können dabei bezüglich der Genauigkeit einer Kreditwürdigkeitsvorhersage nicht mit den formalisierten Verfahren der Bonitätsprüfung mithalten. (vgl. [GER01]) Diese Erkenntnis setzt sich in der Praxis erst langsam durch, wobei aber eine Ablösung der traditionellen Verfahren immer weiter voranschreitet. Es muss dabei jedoch auch bedacht werden, dass eine Anwendung der formalisierten Verfahren nicht in allen Fällen als sinnvoll anzusehen ist. Vorteile gegenüber den traditionellen Verfahren sind vor allem in der Möglichkeit der größeren Datenverarbeitung zu sehen, weshalb nur Banken oder große Unternehmen mit jeweils großen Datenmengen diese Verfahren sinnvoll einsetzen können. Die optimale Wahl des anzuwendenden Verfahrens ist dabei immer von konkreten Anwendungsfall abhängig und stellt daher im Bezug auf die Ergebnisqualität den entscheidenden Schritt einer Bonitätsprüfung dar. Es ist dabei nicht möglich, das “optimale Ergebnis“ zu erreichen, da die Bandbreite der einsetzbaren Verfahren zu groß ist. Um dennoch ein möglichst gutes Ergebnis bezüglich der Vorhersagegenauigkeit zu erreichen, müssen daher mehrere Verfahren bezüglich ihrer Leistung verglichen werden. Bei dieser Wahl spielen neben der Vorhersagequalität außerdem noch Kostenaspekte eine entscheidende Rolle, welches die Verfahrenswahl weiter erschwert. 14 Kapitel 4 Clustering - Praxisbeispiele aus dem Bereich der Kundensegmentierung Unter dem Begriff Kundensegmentierung versteht man die Tätigkeit, homogene Kundengruppen zu ermitteln und dieses ihren Bedürfnissen und Qualitäten entsprechend zu betreuen. Für Unternehmen spielt die Kundensegmentierung eine immer grösere Rolle, da sie ermöglicht, vorhandene Erfolgspotentiale zu realisieren, indem Kunden durch Werbemaßnahmen direkt angesprochen werden können. Dieses führt schließlich zu zu einer Stärkung der Kundenzufriedenheit und deren Loyalität gegenüber den Unternehmen. Zur Durchführung der Kundensegmentierung wird dabei das Verfahren des Clustering angewendet, wobei es um das Auffinden von Clustern anhand von Proximitätskriterien ohne vordefinierte Klassen geht.(vgl. [LP00]) Nach der genaueren Erklärung der Ideen des Clustering folgen in diesem Kapitel schließlich Praxisbeispiele einer Bank, eines Autohändlers und der Fluggesellschaft Lauda Air, wobei unterschiedliche Clusterverfahren und abweichende Weiterverarbeitungsmöglichkeiten der Clusterergebnisse dargestellt werden. 4.1 Allgemeine Vorgehensweise des Clustering Bei dem Verfahren des Clustering werden Objekte (hier Kunden) anhand verschiedener Merkmale in möglichst unterschiedliche, aber in sich weitestgehend homogene Cluster unterteilt.(vgl. Abbildung 4.1) Der Unterschied zur Klassifikation besteht also darin, dass beim Clustering die Klassen zu denen die Objekte zugeordnet werden, noch nicht bestehen, sondern durch das Clustering erst gebildet werden. Methodisch besteht eine Clusteranalyse dabei jeweils aus zwei Schritten. Zunächst werden auf der Basis aller Variablen Abstände (Distanzen) zwischen den Objekten der zu untersuchenden Menge berechnet, woran sich die Zuteilung in die einzelnen Cluster anschließt.(vgl. [KWZ98]) Bei den folgenden Beispielen aus der Praxis werden den entdeckten Clustern immer gewisse Kundengruppen zugeordnet, wobei das Ziel immer ein gezieltes One-to-One Marketing ist, welches die Marketinganstrengungen effektiver machen und daher ein hohes Kosteneinsparungspotential mit sich bringen. 15 Merkmal 1 X X X X X X X X X X X X Merkmal 2 Abbildung 4.1: Clustering 4.2 Kundensegmentierung in der Bankenbranche In der Bankenbranche findet man heute eine verschärfte Wettbewerbssituation vor, welche sich durch eine zunehmende Globalisierung der Märkte und durch sinkende Eintrittsbarrieren begründen lässt. Bemerkbar macht sich dieses beispielsweise an der Fülle von Near- oder Nonbanks wie Versicherungen und Automobilunternehmen.(vgl. [MOO99]) Es ist bei den Bankkunden zusätzlich der Trend einer abnehmenden Kundenloyalität und die hohe Bereitschaft zum Bankenwechsel zu erkennen. (vgl. [SÜC98]) Banken sind daher gezwungen, die Kundenzufriedenheit durch ein gezieltes Beziehungsmanagement zu stärken und um so wieder eine erhöhte Kundenloyalität zu erreichen. Die Bedeutung der Kundenpflege wird dabei noch einmal besonders deutlich, wenn man sich vor Augen hält, dass für die Pflege schon bestehender Kunden nur 20 Prozent des Aufwandes einer Neukundengewinnung anfällt.(vgl. [HS00]) Der Ausgangspunkt des gezielten Beziehungsmanagement zur Stärkung der Kundenloyalität ist dabei in einer Clusteranalyse zu sehen, durch die Kunden in einzelne, möglichst homogene Kundengruppen aufgeteilt werden. Dieses erlaubt dabei schließlich ein gezieltes One-to-one Marketing und trägt wesentlich zur Stärkung der Kundenloyalität bei. Das hier vorgestellte Beispiel bezieht sich dabei auf eine Untersuchung einer Bank, die besonders im Privatkundengeschäft große Verbesserungspotentiale gesehen hat. Sie stellte als Grundlage der Clusteranalyse die Daten von ca. 66.000 Kunden zur Verfügung, die jeweils durch fast 700 Variablen beschrieben worden sind. Ziel der Bank ist es gewesen die Kundensegmentierung anhand des Produktnutzungsverhaltens und der soziodemographischen Merkmale der Kunden durchzuführen, weshalb es ausgereicht hat, sich bei der Untersuchung auf 66 Variablen zu beschränken, die für die beiden Untersuchungsschwerpunkte relevant sind. (vgl. [HS00]) Durch die hohe Anzahl unterschiedlicher Verfahren der Clusteranalyse zur Kundensegmentierung, ist es nicht garantiert, im Voraus das optimale Verfahren zu bestimmen. Im konkreten Fall sind daher ein partionierende (k-meansVerfahren) und zwei hierarchische Fusionsalgorithmen (Average Linkage und Ward Verfahren) bezüglich ihrer Ergebnisse verglichen worden. (vgl. [HS00]) Das partionierende Verfahren K-means ist ein globales Verfahren mit exakter Zuordnung, das Clusterzentren zur Clusterbildung verwendet.(vgl. [LP00]) Average Linkage bezeichnet die durchschnittliche Ähnlichkeit aller Paare von 16 Individuen x Element C und y Element D. (vgl. [GRA00]) Beim Ward Verfahren werden zuerst Mittelwerte für jede Variable innerhalb der einzelnen Cluster berechnet. Anschließend wird für jeden Fall die Distanz zu den Cluster-Mittelwerten berechnet und summiert. Bei jedem Schritt sind die beiden zusammengeführten Cluster diejenigen, die die geringste Zunahme in der Gesamtsumme der quadrierten Distanzen innerhalb der Gruppen ergeben. Das Ward Verfahren wird dabei allgemein als das am häufigsten eingesetzte und empirisch erfolgreichste Verfahren angesehen (vgl. [BLE89]). Dieses hat sich auch in diesem konkreten Fall bestätigt, wobei aufgrund der Vielzahl an möglichen Verfahren, keine Garantie besteht, die optimale Lösung gefunden zu haben. Bei der konkreten Anwendung hat sich schließlich herausgestellt, dass die schon einmal eingeschränkte Datenmenge für den benutzten Arbeitsspeicher weiterhin zu groß ist. Aus diesem Grund hat man sich auf eine Zufallsstichprobe von 2000 Kundendaten beschränkt und zusätzlich noch eine Faktorenanalyse durchgeführt. Ziel dabei ist es, redundante Informationen in den Variablen rauszufiltern, und so die Vielzahl an Variablen auf die Wesentlichen zu reduzieren. Im vorliegenden Fall hat sich dabei eine Reduktion auf 14 relevante Variablen ergeben. Das Ward Verfahren liefert bei der Kundensegmentierung Cluster, die etwa gleich viele Kunden aufweisen. Aufgabe des Anwenders ist es dabei aber noch, festzulegen, wie viele Cluster die Lösung endgültig enthalten soll. Als Hilfe dient dabei die jeweilige Veränderung der Fehlerquadratsummen.(vgl. [HS00]) Es hat sich dabei als sinnvoll erwiesen, 13 Cluster zu erstellen, da eine weitere Erhöhung der Clusteranzahl nur wenig Auswirkungen auf die Fehlerquadratsummenveränderung gehabt hätte. Den einzelnen Clustern sind daraufhin Clusternamen zugeordnet worden, welche versuchen, die speziellen Charakteristika der einzelnen Cluster zu beschreiben. (Vgl. Abbildung 4.2) Zur anschaulichen Darstellung der Clusterergebnisse Cluster 1 2 3 4 5 6 7 8 Cluster Name Vermögende Privatkunden Wirtschaftlich Selbständige (geringer Finanzierungsbedarf) Kreditkunden Gemeinschaftskunden Wirtschaftlich Selbständige (hoher Finanzierungsbedarf) Jugendmarkt Kunden mit geringer Nutzung von Bankleistungen Ausländische Bankkunden 9 Baufinanzierungskunden 10 Kunden in der Aufbauphase 11 Altkunden 12 Sparbuch-Kunden 13 Kunden mit hohem Gehalt Abbildung 4.2: Clusterzuordnung sind schließlich die soziodemographischen Merkmale und das Produktnutzungsverhalten der Kunden eines jeden Clusters mit den Werten der Grundgesamtheit verglichen worden. Auf diese Weise kann einer Abweichung bezüglich der Kundeneigenschaften der einzelnen Cluster im Vergleich zum ’durchschnittlichen Kunden’ dargestellt werden.(vgl. [HS00]) Für Cluster 10 hat sich dabei u.a. eine intensive Nutzung der Anlageleistungen 17 und des Zahlungsverkehrs, eine geringe Altersstruktur sowie ein mittleres Gehalt im Vergleich zum “durchschnittlichen Kunden“ herausgestellt. Aufgrund dieser Fakten ist bei den Kunden dieses Clusters in naher Zukunft beispielsweise mit einem Immobilienkauf zu rechen, der durch eine Bank finanziert werden muss. Es macht daher Sinn, gezielte Marketingaktionen speziell für Kunden dieses Clusters durchzuführen um ein Wechsel des Kreditinstitutes zu verhindern. Auf diese Weise kann für jedes Cluster untersucht werden, welche speziellen Eigenschaften die enthaltenen Kunden aufweisen um schließlich ein gezieltes One-to-one Marketing (Individual Marketing) durchzuführen. Während die vorgestellte Bank das Ziel gehabt hat, mit Hilfe vom Clustering ihre Angebote auf die jeweiligen Kunden zuzuschneiden, sieht die Motivation beim nun vorgestellten Autohändler etwas anders aus. Das Ziel ist hier nicht das Angebot den Kunden anzupassen, sondern zu erfahren, welche Kundengruppen sich für das schon bestehende Angebot interessieren. 4.3 Käuferidentifikation im Automobilhandel Das Autohaus “Somi“ hat bei diesem Praxisbeispiel das Ziel anhand eines Clustering, potentielle Käufer der Marke ’Somi’ zu identifizieren. Man hat sich dabei auf die Suche nach Kunden konzentriert, die der Marke positiv oder zumindest offen gegenüberstehen, da in dieser Kundengruppe die meisten potentiellen Käufer vermutet worden sind. Als Clusterkriterium ist dabei das Image der Marke “Somi“ herangezogen worden. Als Datengrundlage zur Bestimmung des Images ist eine Befragung durchgeführt worden, wobei die Befragten Antwortmöglichkeiten auf einer Skala von 1 (trifft zu) bis 7 (trifft berhaupt nicht zu) vorgegeben waren. Diese Daten haben dabei als Grundlage für die folgende Clusteranalyse gedient, bei der Gruppen gebildet worden sind, Unterschiede zwischen diesen Gruppen extrahiert wurden, sowie anhand von typischen Verhaltensweisen versucht worden ist, diese Gruppen bezüglich ihrer Mitglieder zu interpretieren. Ziel der Automobilherstellers “Somi“ ist es letztendlich gewesen innerhalb dieser Cluster potentielle Käufergruppen zu spezifizieren und daraufhin eine gezielte Kundenansprache bzw. Marketingaktion zu starten. Um Vergleichswerte zu erhalten ist die Clusteranalyse dabei sowohl als K-Means (partionierendes Verfahren) als auch als künstliches neuronales Netz (genau als Self Organizing Map-SOM ) durchgeführt worden. Das Ziel von SOM in der topologieerhaltenden Abbildung hochdimensionaler Merkmalsräume in einen Outputraum niedriger Dimension. SOM sind dabei in der Lage, unbekannte Strukturen in der zu analysierenden Datenbasis ohne a priori Informationen selbstständig zu extrahieren und zu visualisieren.(vgl. [PS00]) Die so entstandenen Clusterergebnisse beider Verfahren sind schließlich anhand von zwei verschiedenen Gütemaßen (Homogenitäts-/Heterogenitätswert und FWert) verglichen worden. Bei der Untersuchung des Homogenitäts- bzw. Hetreogenitätswertes wird die Bewertung bezüglich der Güte der Cluster durchgeführt. Die Güte der Cluster steigt dabei, wenn die Cluster in sich geschlossen, untereinander aber möglichst verschieden sind. .(vgl. [PET98]) Bei dem F-Wert werden zur Ergänzung schließlich noch mal signifikante Unterschiede zwischen den Clustern untersucht, wodurch die Güte der Clusterergebnisse weiter spezifiziert wird. Als Ergebnis hat sich schließlich bezüglich der Gütequalität ein Clustering mittels SOM angeboten, wobei sich eine Clustermenge von 5, bezüglich der klaren Clustertrennung, als am sinnvollsten 18 herausgestellt hat. Die Clusteranalyse hat dabei ergeben, dass die Segmente 1 und 4 der Marke positiv gegenüberstehen, während die Personen der anderen Cluster eher nicht als potentielle Kunden angesehen werden können.(vgl. Abb.4.3) Erkennen lässt sich dieses, wie oben schon angedeutet, anhand der Item n Gutes Preis-/Leistungsverhältnis Segment1 180 2,52 Segment2 367 3,81 Segment3 171 3,04 Segment4 151 2,04 Segment5 89 4,42 Hohe Sicherheit Geringer Kraftstoffverbrauch Hoher Austattungsgrad Lange Wartungsintervalle Geringe Reparaturkosten Hohe Werkstattdichte 2,73 2,88 2,73 3,27 3,46 3,61 3,94 3,93 3,96 3,99 4,02 3,99 3,26 3,32 3,16 4,2 4,52 2,88 1,98 2,15 2 2,53 2,6 1,9 4,56 4,36 4,56 4,65 5,2 4,64 Fortschrittlich Hohe Zuverlässigkeit Hohe Servicequalität Hoher Wiederverkaufswert 2,73 2,52 3,01 3,52 3,99 3,99 4,01 4,1 2,76 3,13 3,48 5,38 1,79 1,72 3,48 5,38 4,81 5,07 4,92 5,98 Abbildung 4.3: Fragebogenauswertung vergleichsweise kleinen Werte bezüglich der einzelnen Bewertungskriterien, die sich aus der Fragebogenaktion ergeben haben. Für die weitere Nutzung dieses Analyseergebnisses es ist nun das Ziel des Automobilherstellers gewesen, herauszufinden, welche Kunden sich in den Segmenten 1 und 4 befinden, was die Kunden der Cluster sich wünschen bzw. erwarten und wo sich diese Kunden bezüglich eines neuen Automobils informieren. Es hat sich dabei u.a. herausgestellt, dass sich viele Angestellte in den Clustern befinden, wobei ihnen ein niedriger Kaufpreis, eine hohe Werkstattdichte und eine hohe Sicherheit sehr wichtig sind. Die Informationsquellen der einzelnen Segmente wurden wiederum aus einer daraufhin ausgerichteten Frage des Ausgangsfragebogens herausgefiltert. Auf Grundlage dieser Ergebnisse hat der Automobilhersteller ’Somi’ einer Werbekampagne erarbeitet, bei der nur die potentiellen Käufer angesprochen worden sind, in der zusätzlich auf deren Bedürfnisse eingegangen worden ist und die nur in Informationsquellen publiziert wurde, die von den potentiellen Kunden auch gelesen wird. Das Beispiel zeigt dabei, wie die Ergebnisse einer Data Mining-Analyse als Grundlage für eine gezielte Marktbearbeitungsstrategie genutzt werden können. Die richtige Clusterbildung, die anschließende Kundenzuordnung und die daraus abgeleitete Marketingstrategie ist dabei durch das besser laufende Tagesgeschäft (höhere Verkaufszahlen) bestätigt worden.(vgl. [LP00]) 4.4 Werbekampagnenentwurf der Lauda-Air Ende März 1998 hat die Lauda Air die Werbekampagne ’Golden Standard’ gestartet, um bei den Kunden der Fluggesellschaft eine klare Trennung zwischen Charter- und Liniengeschäft zu erreichen. Das Ziel dabei ist es gewesen, die Charterkunden bezüglich ihrer Serviceansprüche zu spezifizieren, um so ein Einsparpotential an Serviceleistungen gegenüber den teureren Linienflügen zu erreichen. Zur Gestaltung der Werbekampagne ist die Untersuchung dabei in zwei Hauptschritte unterteilt, wobei zuerst die typischen Eigenschaften von Charterkunden herausgefiltert worden sind, welches letztendlich bei der Ausgestaltung der Kampagne ’Golden Standard’ im Mittelpunkt steht. Im zweiten Schritt war 19 es dann das Ziel, durch eine Clusteranalyse mittels des Ward Verfahrens, weiterführende differenzierte Werbemaßnahmen zu entwickeln.(vgl. [WRR00]) Die Datengewinnung der Lauda-Air ist mit Hilfe einer Fragebogenaktion auf einer Ferienmesse durchgeführt worden, wobei es sich bei den Besuchern weitestgehend um Charterkunden gehandelt hat. Die 3.000 zufällig ausgewählten Kunden sind dabei hauptsächlich bezüglich ihrer Einschätzung der Wichtigkeit von Serviceleistungen und bezüglich ihrer demographischen Daten befragt worden. Bei der letztlichen Charakterisierung der Charterkunden haben sich so geschlechtsspezifische, altersspezifische und Fluggewohnheiten betreffende Präferenzen, aber auch wesentliche Unterschiede zwischen den einzelnen Kundengruppen herausgestellt. Trotz der vorliegenden Unterschiede hat diese Charakterisierung aber weitestgehend für die Erstellung der Werbekampagne ’Golden Standard’ gedient.(Vgl. Abbildung 4.4) „Was verstehen wir unter dem Golden Standard ? - Bordunterhaltung auf allen Flügen ( Audio und Video Vergnügen pur! ) - Catering von Wien’s Top Restaurant Do&Co - Bier, Wein & Softdrinks kostenlos - Nikis Kids Club für die jüngsten Passagiere - Eine der jüngsten Flugzeugflotten der Welt - Laufend neue Serviceideen - Freundliche Flugbegleiter - und das kleine bißchen ‚mehr’ an Herzlichkeit“ Abbildung 4.4: Werbekampagne ’Golden Standard’ Die erwähnten Unterschiede bezüglich des Alters, des Geschlechtes und der Fluggewohnheiten der Charterkunden machen dabei aber deutlich, wie sinnvoll in diesem Fall die anschließende Clusteranalyse für die Lauda Air sein kann. Für das durchzuführende Clustering ist die Ausgangsmenge der Objekte mit Hilfe des Proxitätsmaßes in eine Distanzmatrix umzuwandeln. Das Proxitätsmaß ist dabei eine, auf einem paarvergleich basierende Maßzahl, wobei für jedes Paar die Ausprägung der Eigenschaften und der Grad an den Übereinstimmungen untersucht werden.(vgl. [MEW01] Als Proxitätsmaß ist in diesem Fall die quadrierte euklidische Distanz gewählt worden, wobei die Summe der quadrierten Differenzen zwischen den Werten der Einträge herangezogen werden. (Vgl.[WRR00]) Man hat dabei die Bildung von 4 Clustern gewählt, da sich dieses bezüglich der Homogenität innerhalb der Cluster und bezüglich der Unterschiede zwischen den Clustern als am sinnvollsten herausgestellt hat. Den vier Clustern sind dann anschließend entsprechende Beschreibungen zugeordnet worden, wobei den einzelnen Clustern die Kundengruppen gesicherte Erlebnisurlauber, junge, aktive Freizeitkonsumenten, Familienurlauber und schwer zu Begeisternde zugeordnet worden sind. Anhand der Clusteranalyse konnten von der Lauda Air so Kundengruppen identifiziert werden, wobei sich noch speziellere Serviceanforderungen herauskristallisierten. Aufgrund der Data Mining-Methode des Clustering hat die Lauda-Air daher die Möglichkeit gehabt, weitere Werbekampagnen zu entwerfen, welche speziell auf die Kundengruppen zugeschnitten sind, und welche aufgrund des stärkeren Individual Marketing Charakters bessere Ergebnisse der Werbekampagnen erwarten lassen. 20 Kapitel 5 Klassifikation + Clustering am Beispiel einer Kündigerprävention auf dem Mobilfunktmarkt Das folgende Beispiel soll deutlich machen, dass sich die beiden Verfahren der Klassifikation und des Clustering in der Realität häufig nicht eindeutig trennen lassen und kombiniert zur Anwendung kommen. Im konkreten Fall geht es um das Auffinden von potentiellen Kündigern eines Mobilfunkanbieters. Anhand dieses Beispiels lässt sich dabei gut zeigen, welchen Vorteil ein kombiniertes Anwenden der beiden Verfahren gegenüber einer Einzelanwendung besitzt. Die Kundenloyalität hat innerhalb vieler Branchen in den letzten Jahren stark abgenommen. Dieser Trend macht sich dabei besonders stark auf HightechMärkten wie dem Telekommunikationsmarkt bemerkbar, weil die vielen Anbieter auf dem Markt mit allen Mittel versuchen, die Kunden für sich zu gewinnen. Mobilfunkanbieter versuchen daher schon lange Zeit vor Auslaufen des Vertrages zu erfahren, ob die Kunden erneut einen Vertrag bei dem entsprechenden Unternehmen abschließen werden, oder ob dafür eventuell das Anbieten spezieller Angebote nötig ist. Es macht jedoch aus wirtschaftlichen Gründen keinen Sinn, den Kunden ein spezielles Angebot zu unterbreiten, die auch ohne dieses Angebot automatisch verlängert hätten. Ziel des Mobilfunkanbieters ist es daher die Kunden in die zwei Klassen Kündiger und Nichtkündiger aufzuteilen. Verbunden wird diese Klassifikation dabei mit einem Clustering, welches die Kunden in 11 Cluster (Segmente) unterteilt (vgl. Abbildung 5.1). Als Grundlage für diese Untersuchungen dienen dabei die soziodemographischen Merkmale sowie Merkmale zum Mobilfunkvertrag von alten Kunden, von denen schon bekannt ist, ob sie gekündigt haben, oder nicht.(vgl. [PRU01]) Abbildung 5.1 zeigt dabei, wie die durch das Clustering entstandenen Segmente in der Reihenfolge der Anzahl der potentiellen Kündiger des Mobilfunkvertrages sortiert werden. Anhand der Tabelle oder mit Hilfe eines Gain-Charts, der die Güte eines Klassifikators darstellt, kann man schließlich beurteilen, wie das Ergebnis der Klassifikation zu beurteilen ist.(vgl. [PRU01]) In diesem Fall beinhalten die ersten 5 Cluster der Tabelle ca. 93 Prozent aller potentiellen Kündiger. Der Mobilfunkanbieter kann sich, aufgrund dieser hohen Erreichbarkeitsquote, bei der Kündigerpräventation nun ausschließlich auf Kunden dieser Cluster beschränken. Er läuft dabei nicht Gefahr, eine hohe Anzahl an poten21 Segment Nr. Gesamt 3 Kundenanzahl 50.000 3.803 Kündiger 20.000 3.537 Nichtkündiger 30.000 266 Anteil 40,0 % 93,0 % 6 10 4 9 7 11 2.482 5.185 9.561 2.509 5.891 4.720 2.023 4.469 7.247 1.262 1.034 234 459 716 2.314 1.247 4.857 4.486 81,5 % 86,2 % 75,8 % 50,3 % 17,6 % 5,6 % 2 5 1 8 7.148 1.568 6.048 1.067 150 13 29 2 6.998 1.573 6.019 1.065 2,1 % 0,8 % 0,5 % 0,2 % Abbildung 5.1: Kundeneinteilung tiellen Kündigern kein Angebot zu machen. Die ersten fünf berechneten Segmente liefern dabei eine Beschreibung der potentiellen Kündiger, was für Segment 3 bedeutet: “Kunden im Privat-Tarif, die unter 30 Jahre sind und eine Handy über 300 Euro besitzen, kündigen mit einer Wahrscheinlichkeit von 93 Prozent“ (vgl. [PRU01]) Fällt ein Kunde, dessen Vertrag bald auslaufen wird, also aufgrund seiner Daten in eines der ersten fünf Segmente, wird er als potentieller Kündiger behandelt und erhält vom Mobilfunkprovider ein spezielles Angebot. Andernfalls vertraut man auf die Analyseergebnisse und geht davon aus, dass der Kunde von alleine den Vertrag verlängert. Die Kombination von Clustering und Klassifikation ermöglicht es in diesem Fall die beim Clustering erhaltenen Segmente zusätzlich noch in die Klassen Kündiger und Nicht-Kündiger einzuteilen, was die Identifikation der gesuchten potentiellen Kündiger erheblich erleichtert. Anhand dieser Kombination kann daher recht genau bestimmt werden, welchen Kunden ein spezielles, neues Angebot unterbreitet werden muss, wobei verhindert werden soll, dass potentielle Kündiger übersehen werden und dass Nichtkündigern trotzdem ein Angebot unterbreitet wird (Fehler 1. und 2. Art). Der Mobilfunkanbieter kann auf diese Weise aufgrund einer minimierten Angebotsbreite Einsparpotentiale realisieren, die sich wiederum positiv auf das Geschäftsergebnis auswirken. 22 Kapitel 6 Sortimentsanalyse im Einzelhandel Als Datengrundlage zur Sortimentsanalyse steht dem Einzelhandel eine sehr große Menge an Daten zur Verfügung, die anhand der schon länger eingeführten Scannerkassen gewonnen wird. Dadurch ist es den Einzelhändlern ermöglicht worden, anhand der Bondaten täglich alle anfallenden Einkaufsvorgänge artikelgenau festzuhalten. Mittels der Datenanalyse können dabei Rückschlüsse auf die Kundenpräferenzen und deren Kaufverhalten geschlossen werden. (vgl. [NIE01]) Daraus lassen sich schließlich Schlußfolgerungen bezüglich des Sortimentsverbundes, der Warenplatzierung und der einzusetzenden Werbung ziehen. 6.1 Assoziationsanalyse zur Bildung von Assoziationsregeln im Einzelhandel Im ersten Anwendungsfall ist hier eine Assoziationsanalyse eingesetzt worden, um Beziehungen (Regeln) in den Abverkaufsdaten aufzuspüren. Die aus der Assoziationsanalyse abgeleiteten Assoziationsregeln werden dabei mittels Werten für die Relevanz, die Konfidenz und der Abweichung genauer spezifiziert. Bei der Relevanz geht es dabei um den Anteil einzelner Artikel oder Artikelkombinationen an der Gesamtzahl der analysierten Bons. Die Konfidenz sucht dann Abverkaufsverknüpfungen von Artikelkombinationen. Dabei geht es um den verkauften Anteil von Artikel A, wenn ein anderer Artikel B ebenfalls verkauft wird. Die relative Abweichung stellt schließlich einen Vergleich zwischen Relevanz und Konfidenz dar.(vgl. [MIC01]) Vergleicht man zum Beispiel einen beliebigen Artikel B (Relevanz 0,5 Prozent) mit dem Anteil der Käufer eines Artikels A, die ebenfalls Artikel B kaufen (Konfidenzwert 30 Prozent), so lässt sich daraus die Schlußfolgerung ziehen, dass Käufer des Artikels A 60 mal (Konfidenzwert/Relevanz) häufiger Artikel B kaufen, als alle anderen Kunden. (vgl. [MIC01]) Bei der Analyse sind letztlich Assoziationsregeln entstanden, die sich zunächst aber nur auf eine Warengruppenebene bezogen haben. In Abbildung 6.1 ist jedoch auch eine von mehreren Regeln dargestellt, die Beziehungen zwischen unterschiedlichen Artikelebenen darstellen. Die Relevanz beträgt dabei 0,051, was bedeutet, dass die Kombination aus Fleischkauf + Maggi Würze Nr.1 in 0,5 Prozent aller Bons auftaucht. Die Konfidenz von 5,4 bedeutet dann, dass Kunden die Fleisch kaufen, in 5,4 Prozent aller Fälle auch Maggi Würze Nr.1 kaufen. Die relative Abweichung von 12,1 bedeutet schließlich, dass Kunden die Fleisch kaufen, 12,1 mal häufi23 [Fleischabteilung] [Maggi Wuerze Nr.1] Relevanz : 0,051 Konfidenz : 5,4 rel. Abweichung : 12,1 Abbildung 6.1: Assoziationsregel ger Maggi Würze Nr.1 kaufen, als alle anderen Kunden. Neben diesen artikelbezogenen Analysen können aber genauso Zusammenhänge von Preisen, Mengen, Größen und Farben abgeleitet werden. In der Praxis entstehen so häufig sehr große Mengen an Assoziationsregeln, weshalb es wichtig ist, diese zu filtern und zu sortieren. So ist zum Beispiel das Herausfinden von unbekannten, aber wichtigen Beziehungen für die Einzelhändler von größerer Bedeutung, als schon bekannte oder triviale Beziehungen. Eine Sortierung kann beispielsweise ab- oder aufsteigend nach den Werten der Relevanz, Konfidenz und relevanten Abweichung durchgeführt werden. Die so erhaltenen Regelmengen können von den Einzelhändlern nun bezüglich verschiedener Entscheidungsfindungen benutzt werden. Beim Sortimentsverbund geht es für die Einzelhändler beispielsweise darum, diese zu erkennen und die jeweiligen Waren dieses Verbundes zur Verfügung zu stellen, um die Verbundwirkung nicht eizuschränken. Aus den Regeln ergeben sich weiterhin wichtige Hinweise, wie die einzelnen Waren zueinander platziert werden können, um das Potential von Sortimentsverbünden optimal zu nutzen. Es gibt dabei sowohl die Strategie, die Verbundwaren nebeneinander zu platzieren um einen gemeinsamen Verkauf zu sichern, oder diese an verschiedenen Punkten des Einkaufsmarktes zu platzieren, um auch auf andere Produkte aufmerksam zu machen. Für die Werbungsaktivitäten bieten Assoziationsanalysen schließlich die Möglichkeit nicht nur ein Produkt zu bewerben, sondern auch die entdeckten Sortimentsverbünde mit in die Marketingstrategie einzubeziehen. Für einen erfolgsanstrebenden Händler gilt deshalb letztendlich die Regel: Nicht der einzelne Artikel bringt den Erfolg, sondern das durch eine Assoziationsanalyse aufgedeckte Zusammenspiel aller Artikel bezüglich der Platzierung, Werbung, Listung usw.(vgl. [MIC01]) Während in diesem Beispiel die Aufsttellung von Assoziationsregeln zur Untersuchung der Verbundwirkung einzelner Produkte im Vordergrund gestanden hat, sieht es im nun folgenden Fall etwas anders aus. Untersuchungsziel ist es dort, den Einflußs von Werbemanahmen auf die Verbundwirkung innerhalb von Warenkörben zu untersuchen. 6.2 Clustering zur Aufdeckung der Verbundwirkungen innerhalb eines Warensortiments In diesem Beispiel geht es um eine konventionelle Verbundanalyse eines Filialunternehmens der Lebensmittelbranche. Ziel dieser Filiale ist es zunächst gewesen, anhand eines Clustering existierende Verbundbeziehungen innerhalb des Nahrungs- und Genussmittelbereichs aufzudecken. Des Weiteren ist es dann um die Auswirkung absatzpolitischer Maßnahmen auf die entdeckten Verbund24 beziehungen untersucht worden. Als Datengrundlage haben 15.000 verschiedene Warenkörbe und 26 Warengruppen gedient. Die Clusteranalyse typologisiert dabei diese 26 Warengruppen nach ihrer Ähnlichkeit im Verbundprofil.(Vgl. [SRJ01]) Die Euklidische Distanz hier wiederum als Proximitätsmaß und als Fusionierungsalgorithmus wird das WardVerfahren herangezogen. Unter Berücksichtigung der Fehlerquadratsumme und der Anwendung des Elbow-Kriteriums erwies sich hier eine Segmentierung in 4 Cluster als am sinnvollsten. Bei Anwendung des Elbow-Kriteriums werden dabei in einem x-y-Diagramm die Fehlerquadratsumme und die entsprechende Clusterzahl dargestellt. An der Stelle innerhalb dieses Diagramms, an dem sich der stärkste Heterogenitätszuwachs herausbildet, entsteht im Idealfall ein Knick in der Funktion in Form eines Ellbogens.(vgl. Abb. 6.1) An dieser Stelle Fehlerquadratsumme ElbowKriterium 0,5 3 Anzahl der Cluster Abbildung 6.2: Elbow-Kriterium lässt sich schließlich die optimale Clusterzahl im Bezug auf die Heterogenität zwischen den Clustern ablesen.(vgl. [EGF00]) Die einzelnen Cluster weisen dabei sehr unterschiedliche Verbundintensitäten aus, wobei die Verbundwirkung der Frischwaren, wie es auch zu erwarten gewesen ist, am höchsten ausgefallen ist. (vgl. Abb. 6.2) Der nächste Schritt bei der Cluster 1 - Fleisch/Wurst ( Bedienung), Käse ( SB ), Tiefkühlkost, Nährmittel, Gewürze/Feinkost, Obst-/Gemüsekonserven Cluster 2 - Obst/Gemüse, Milch/Molkereiprodukte Cluster 3 - Fleisch/Wurst, Käse ( Bedienung ), Butter, Öle/Fette, Fleisch-/Fischkonserven, Schokolade, Süßwaren, Gebäck Cluster 4 - Frischgeflügel, Suppen/Fertiggerichte, Fisch/Feinkost, Weine, Sekt, Spirituosen, Bier, Tabakwaren, Kaffee Abbildung 6.3: Verbundwirkung vorliegenden Untersuchung von Kaufverbundeffekten hat schließlich die Werbeaktivitäten mit in die Untersuchung eingeschlossen. Es sollte dabei beantwortet werden, wie sich die Verbundintensität einer Warengruppe verändert, wenn sie 25 beworben wird, und bei welcher Warengruppe sich die Werbeaktivitäten am stärksten auf die Verbundwirkung auswirkt. Als Untersuchungsgrundlage hat dabei die Warengruppe “alkoholfreie Getränke“ gedient, die sich aufgrund relativ starker Ausstrahlungseffekte nicht speziell einem der 4 Cluster in Abbildung 6.2 zuordnen lässt. Die “alkoholfreien Getränke“ sind dabei über eine Woche in vier vergleichbaren Filialen des Lebensmittelunternehmens mit unterschiedlichen Methoden beworben worden. Es hat sich dabei beispielsweise gezeigt, dass eine Preisreduzierung um 20 Prozent die Verbundwirkung ebenfalls mit 20 Prozent verstärkt, während eine Preisreduzierung in Verbindung mit In- und Out of Store Werbung, die Verbundwirkung sogar um 170 Prozent erhöht. Diese Untersuchung kann nun vergleichsweise mit anderen Warengruppen durchgeführt werden, wodurch schließlich herausgefunden werden kann, bei welcher Warengruppe Werbemaßnahmen die größten Auswirkungen haben. 6.3 Anwendung einer modernen NeurocomputingMethode zur Quantisierung von Warenkorbdaten Die im Handel anfallende Datenmenge ist aufgrund der Einführung von Scannerkassen so groß geworden, dass die in Abschnitt 6.2 vorgestellte konventionelle Verbundanalyse an ihre Grenzen stößt. Aus diesem Grund hat man sich deshalb letztendlich auch nur auf verschiedene Warengruppen aus dem Bereich der Nahrungsmittel beschränkt. Um allerdings Verbundeffekte in ganzen Handelssortimenten aufzudecken werden in der heutigen Zeit immer häufiger moderne Neurocomputing-Verfahren angewendet. Verfahren des Neurocomputing (meistens neuronale Netze, Entscheidungsbäume oder Clustering) besitzen dabei den Vorteil, dass keine Algorithmen und Regeln ermittelt, getestet und codiert werden müssen. Dieses Prozesse werden dabei durch das Lernen von Sachverhalten aus Vergangenheitsdaten ersetzt.(Vgl.[NEU02]) Das Verfahren der Vektor-Quantisierung, welches eine nachträgliche, disaggregierte Analyse von Verbundbeziehungen innerhalb eines Sortiments ermöglicht, bewirkt dabei eine Zerlegung der binären Warenkorbdaten. Jedem Warenkorb wird dabei ein zusätzliches nominales Merkmal zugeordnet, welches schließlich die Zugehörigkeit zu einer bestimmten Warenkorb-Klasse indiziert.(Vgl. [SRJ01]) Aus Homogenitäts- bzw. Heterogenitätsgrnden sind hier letztendlich 8 warengruppenspezifische Klassen-Centroide (Mittelwerte) gebildet worden, die die Kauftätigkeiten der Kunden für einen Supermarkt der LEH-Gruppe darstellen. Abbildung 6.3 zeigt auszugsweise eine auf diese Weise entstandene Warenkorbklasse mit absteigend sortierten Warengruppen-Centroiden. Der Wert 4,33 steht dabei für die durchschnittlich enthaltenen Warengruppen in der gewählten Warenkorb-Klasse. Der Wert 1,00 für die Limonade deutet dann daraufhin, dass in ca. 10 Prozent der Warenkörbe von Klasse 1 mindestens eine Limonade vorhanden ist. Des Weiteren befindet sich in 1,5 Prozent der Warenkörbe mindestens eine Flasche Wasser. Die Angaben in den Klammern geben also an, wie hoch die Wahrscheinlichkei ist, dass die entsprechende Warengruppe mindestens einmal im Warenkorb vorhanden ist. Da in dieser Klasse durchschnittlich 4-5 Warengruppen in einem Warenkorb kombiniert werden, sind daher am häufigsten die Warengruppen Limo,Wasser, Milch, Tragetasche und Flaschenbier im Warenkorb vorhanden. 26 Klasse 1 - # 4,33 Limo(1,00), Wasser(.15), Milch(.14), Tragetasche(.13), Flaschenbier(.11) Backwaren(.09), Joghurt(.09), Säfte(.09), Dosenbier(.09), Wurstwaren(.08) Südfrüchte(.07) Abbildung 6.4: Beispiel einer Warenkorbklasse Das Verwendungspotential ist allerdings mit der einzelnen Bedeutung der Warengruppen in den unterschiedlichen Warenkörben noch lange nicht ausgereizt. Dieses ist damit zu begründen, dass sich die so gewonnene Kenntnisse über die durchschnittlich enthaltenen Warengruppen pro Warenkorb noch mit anderen Merkmalen kombinieren lassen. Dazu gehören beispielsweise Merkmale wie Kauftag, Kaufuhrzeit, Filialstandort usw.. Es können so diverse Werbestrategien entworfen werden, indem zum Beispiel an bestimmten Tagen oder zu bestimmten Uhrzeiten Rabatte auf Warengruppen erhoben werden, die sonst zu dieser Uhrzeit eher selten nachgefragt werden. Ein anderes Beispiel ist eine tagesabhängige Bewerbung von Warengruppen, so dass typische Warengruppen an Tagen beworben werden, an denen die Nachfrage sonst nicht so hoch ist. Eine Quantisierung von personalisierten Daten mittels Kundenkarten liefert schließlich noch die Möglichkeit die Käufe direkt auf spezielle Kunden zu beziehen und ermöglicht so eine gezieltes Individual-Marketing. Zusammenfassend ist zu sagen, dass durch immer größer werdende Datenmengen eine Neuorientierung in Richtung der moderneren NeurocomputingVerfahren unumgänglich geworden ist, da sie ein wesentlich größeres Potential bezüglich der folgenden Marketingmanahmen bieten als konventionelle Analysen von Warenkörben. 27 Kapitel 7 Prognose zur optimierten Werbeträgerplanung bei Versandhäusern Bei der Prognose werden bisher unbekannte Merkmalswerte mit Hilfe anderer Merkmale oder mit Werten des gleichen Merkmals aus früheren Perioden vorhergesagt. Für die Aufgabe der Prognose existieren dabei verschiedene Ansätze. Wie aus den obigen Beispielen zu Bonitätsprüfung schon bekannt, kann auch das Verfahren der Klassifikation zur Prognose verwendet werden. Voraussetzung ist dabei, dass diskrete Werte wie “kreditwürdig“ oder “nicht-kreditwürdig“ vorhergesagt werden sollen. Bei der Prognose konzentriert man sich jedoch weitestgehend auf kontinuierliche quantitative Werte, weshalb die Prognose von der klassischen Aufgabe der Klassifikation abweicht. Für Prognosezwecke werden daher häufig Methoden aus dem Gebiet der künstlichen Intelligenz wie Neuronale Netze eingesetzt.(vgl. [NIE00]) In der Praxis spielt die Prognose beispielsweise im Werbeträgerplanungsprozess bei Versandhäusern eine große Rolle. Ziel dabei ist es, den Einsatz der Werbeträger so zu planen, dass das Verhältnis von Werbekosten und Umsatz optimiert wird. Für die Berechnung werden dazu verschiedene Kennzahlen und Formeln herangezogen, in den in Abbildung 7.1 einige dargestellt werden. Die KUR = (Werbekosten / Umsatz) * 100 = = Nettoumsatz Wareneinstandskosten Anteilige Logistikkosten Überhangverluste Deckungsbeitrag I Werbekosten Deckungsbeitrag II Deckungsbeitrag I = (Deckungsbeitrag II / Nettoumsatz) * 100[%] Deckungsbeitrag II = (Deckungsbeitrag I - KUR) * Nettoumsatz Abbildung 7.1: KUR sowie Deckungsbeitrag I und II Kosten-Umsatz-Relation(KUR) drückt dabei den prozentuellen Werbekostenanteil am Nettoumsatz aus. In Abhängigkeit von Nettoumsatz und Werbekosten ergeben sich die Deckungsbeiträge I und II. Die beiden unteren Formeln dienen 28 schließlich dazu, die Deckungsbeiträge mit der in Prozent ausgedrückten KUR in Verbindung zu setzen.(vgl. [NIE00]) Die Werbekosten sind dabei um so höher, je größer die Ausstattungsdichte der Kunden mit Katalogen ist. Für das Versandhaus ist es nun entscheidend, welche Ausstattungsdichte der Kunden mit Katalogen möglichst optimale Werte im Bezug auf den Umsatz, den Bruttobestellwert und schließlich den Deckungsbeitrag II liefert. In diesem Fall sind für die Prognose Neuronale Netze als selbständig lernende Prognosesysteme eingesetzt worden, um aus dem bekannten Kundenverhalten Schlüsse bezüglich der optimalen Ausstattungsdichte der Kunden mit Katalogen zu erlangen. Die schon vorhandenen Daten bezüglich des Kundenverhaltens in der Vergangenheit werden dazu in eine Trainings- und eine Testmengen unterteilt. Das Training des neuronalen Netztes erfolgt anhand der Trainingsmenge. Die dabei gewonnenen Zusammenhänge werden nun auf die Testmenge angewendet, wobei kontrolliert wird, ob sich die Ergebnisse der Trainingsmenge anhand der Testmenge bestätigen lassen. Diese beiden Schritte werden so lange wiederholt, bis ein hinreiched gutes Netz gefunden wird. Das in diesem Fall entwickelte neuronale Netz hat also die Aufgabe gehabt, den unbekannten Ursachen-Wirkungszusammenhang zwischen Werbeträger und Auswirkung auf die Kauftätigkeit der Kunden zu ermitteln. Zur besseren Bestimmung der ökonomischen Auswirkungen der Werbeträgeranzahl auf die oben beschriebenen Kennzahlen sind die Kunden schließlich noch in 20 verschiedene Klassen eingeteilt worden. Jede Klasse enthält dabei 5 Prozent aller Kunden, wobei die Kundenqualität von Klasse 1 bis Klasse 20 abnimmt. Als Ergebnisse bezüglich der Auswirkungen der Werbeträgeranzahl auf die angesprochenen Kennzahlen hat sich herausgestellt, dass ein maximaler Umsatz mit einer 100-prozentigen Austattungsdichte erreicht wird. Diese hohe Ausstattungsdichte wirkt sich jedoch aufgrund der höheren Kosten für die Werbeträger negativ auf die KUR aus. Interessanter ist daher eher, mit welcher Ausstattungsdichte welcher Deckungsbeitrag erreicht wird. Der höchste Deckungsbeitrag von 160.000 DM hat sich dabei bei einer Werbeträgerausstattung von 40 Prozent der besten Kunden eingestellt.(vgl. [NIE00]) Das Versandhaus hat also schließlich herausgefunden bzw. prognostiziert, welche Ausstattungsdichte mit Katalogen das Verhältnis bezüglich des Umsatzes und der Werbekosten optimiert. Man kann diese gewonnenen Erkentnisse schließlich für die zukünftige Werbeträgerplanung gewinnbringend nutzen, wobei jedoch gesagt werden muss, dass andere Aspekte, wie zum Beispiel die Kundenbindung oder die Kundenneugewinnung bei den Überlegungen keine Rolle gespielt haben, was sich wiederum negativ auf den Geschäftserfolg auswirken kann. 29 Kapitel 8 Schlussfogerungen und Bezug zur Projektgruppe In der Ausarbeitung zum Thema ’Datenanalyse im Marketing’ hat die Hauptaufgabe darin bestanden, anhand von zahlreichen Praxisbeispielen die vielfältigen Einsatzmöglichkeiten von Data Mining im Marketing, aber auch in anderen Bereichen aufzuzeigen. Des Weiteren hat im Mittelpunkt gestanden, inwiefern der Einsatz von Data Mining gegenüber klassischen Methoden der Datenanalyse Vorteile mit sich bringt. Es hat sich dabei gezeigt, dass der Einsatz von Data Mining in allen vorgestellten Beispielen Verbesserungspotentiale aufgedeckt hat. Nachdem die Einsatzgebiete und die konkret eingesetzten Verfahren vorgestellt worden sind, hat anschließend die Darstellung der Praxisbeispiele im Mittelpunkt gestanden. Eines der am weitesten verbreiteten Anwendungsgebiete für Data Mining ist im Risikomanagement zu sehen. Die Bonitätsprüfung stellt dabei eine Entscheidungsmöglichkeit für verschiedene Branchen dar, ob ein potentieller Kunde als kreditwürdig oder als nicht kreditwürdig klassifiziert wird. Ziel dabei ist es immer die angesprochenen Fehler 1. und 2. Art zu vermeiden, um so einen drohenden wirtschaftlichen Verlust zu verhindern. Die Untersuchung der einzelnen Beispiele hat dabei gezeigt, das zahlreiche Data Mining-Verfahren in diesem Gebiet zum Einsatz kommen, wobei zwischen diesen zudem deutliche Unterschiede im Bezug der Performance zu erkennen sind.(Vgl. Abschnitt 3.3) Dabei sind “aufwändigere“ Data-Mining Verfahren wie z.B. die Anwendung neuronaler Netze sowohl den ’einfacheren’ Data Mining-Verfahren wie beispielsweise der Diskriminanzanylyse, aber vor allem den klassischen Verfahren wie der Scoringmethode oder der Bearbeitung durch Kreditsachbearbeiter in ihrer Bonitätsbeurteilung deutlich überlegen. Im zweiten Anwendungsfeld für Data Mining geht es dann um den Bereich der Kundensegmentierung. Zunächst ist, das in diesem Bereich angewendete Clustering, näher erläutert worden, wobei verschiedene Verfahren zur Anwendung gekommen sind, die sich im Wesentlichen bezüglich der Homogenität bzw. Heterogenität der Cluster und dem Automatisierungsgrad zur Bestimmung der Clusteranzahl unterscheiden. Das Anwendungsfeld hat sich hier wiederholt als sehr vielfältig herausgestellt, wobei das Ziel generell immer darin besteht, die Kunden der jeweiligen Branchen in Cluster aufzuteilen, um sie schließlich durch gezieltes One-to-one Marketing persönlich anzusprechen. Die Vorteile liegen dabei im Erreichen einer höherer Kundenbindung verbunden mit der Realisierung von Einsparpotentialen, die aufgrund der Abwendung vom Massenmarketing realisiert werden. Mit dem Beispiel aus dem Mobilfunkmarkt sollte deutlich gemacht werden, 30 dass die beiden Verfahren Klassifizierung und Clustering in der Realität häufig zusammen angewendet werden, da dieses noch spezifischere Analyseergebnisse verspricht als eine getrennte Anwendung dieser beiden Verfahren. Als nächstes Anwendungsfeld wurde schließlich die Sortimentsanalyse bearbeitet, wobei häufig Assoziationsanalysen, aber auch Clustering oder auch moderne Neurocomputing-Methoden zum Einsatz kommen. Bei den konkreten Beispielen, die sich auf den Einzelhandel beziehen, geht es vordergründig darum, aufgrund der gewonnenen Scannerdaten auffällige Verbundwirkungen innerhalb des Warensortiments aufzudecken, und diese gewonnenen Erkentnisse schließlich bei der Sortimentspolitik und beim Marketing gewinnbringend umzusetzen. Kapitel 7 beschreibt abschließend mit der Prognosewirkung noch ein weiteres Feld der Anwendungsmöglichkeiten von Data Mining zur Datenanalyse. Es werden dabei Prognosen für die Zukunft erstellt, die aufgrund von schon vorhandenen Daten für verschiedene Anwendungsbereiche generiert werden. Die im konkreten Beispiel angesprochene Ähnlichkeit zur Klassifizierung macht dabei noch einmal deutlich, dass es schwierig ist, die einzelnen Data Mining-Verfahren strikt zu trennen, da sie wie gesagt häufig auch kombiniert zur Anwendung kommen. Neben der Vielfalt der Einsatzgebiete und eingesetzten Verfahren ist bei der Betrachtung der Praxisbeispiele vor allem das Potential des Data Mining zur Datenanylyse deutlich geworden, was sich darin gezeigt hat, dass durch die Anwendung von Data-Mining in allen besprochenen Beispielen Verbesserungspotentiale aufgezeigt worden sind. Dieses Ergebnis bestätigt dabei eine Studie der Universität Eichstätt-Ingolstadt, die herausgefunden hat, dass 87 Prozent der Unternehmen, die Data Mining zur Analyse ihrer Datenmengen einsetzen, mit der Profitabilität dieser Projekte sehr zufrieden sind. Trotz dieser überzeugenden Performance nutzen zur Zeit lediglich 50 Prozent der 500 größten deutschen Unternehmen Data MiningVerfahren zur Analyse ihrer großen Datenmengen (vgl. [LEB02]).Diese Erkenntnisse und die Feststellung, dass sich alle 18 Monate die Informationsmenge in der Welt verdoppelt, machen deutlich, dass Data Mining auch in Zukunft eine große Bedeutung zugemessen wird. Innerhalb des Projektgruppenszenarios soll Data Mining sowohl vom Kartenanbieter, als auch von beiden Hndlern betrieben werden. Die Händler geben zu diesem Zweck Kunden- und Karteninformationen direkt an den Kartenanbieter weiter. Dieser konzentriert sich im Bereich des Data Mining hauptsächlich auf die Bereiche Klassifikation und Clustering. Die so erhaltenen Analyseergebnisse werden zur weiteren Verarbeitung wieder an die Händler zurückgegeben. Die Händler sind dabei jedoch nicht von der Benutzung der Analyseergebnisse des Kartenanbieters abhängig. Auch sie besitzen die Möglichkeit, aufbauend auf den schon vorhandenen Analyseergebnissen, weiterhin Data Mining zu betreiben. Als Einsatzgebiete sind dabei, wie von mir vorgestellt, beispielsweise die Kundensegmentierung und Käuferidentifikation zu Marketingzwecken oder die Bonitätsprüfung zu nennen. Ziel der Händler ist es letztendlich, den Kunden ein personalisiertes Angebot anzubieten, um auf diesem Wege Wettbewerbsvorteile gegenüber Konkurrenten zu erlangen. 31 Kapitel 9 Glossar [Average Linkage]Average Linkage bezeichnet die durchschnittliche Ähnlichkeit aller Paare von Individuen x Element C und y Element D [Bonität]Die Bonität beschreibt die relative Ertragskraft des Schuldners in der Zukunft. [C4.5]C4.5 zählt zu den bekanntesten Entscheidungsbaumverfahren aus dem Bereich des induktiven Lernens. Das Auswahlkriterium in C4.5 basiert auf informationstheoretischen Überlegungen, es wird ein error-based Pruning eingesetzt. [CART]Die CART-Methode (Classification and Regression Trees) wurde von Breiman et al. 1984 als Ergebnis mehrjähriger Forschungsarbeit entwickelt. Das CART Entscheidungsbaumverfahren zählt zu den bekanntesten Top-Down Ansätzen mit entsprechender Pruning-Strategie. [CHAID]Der CHAID-Algorithmus (Chi-Squared Automatic Interaction Detection) gehört zu den Segmentierungs-Verfahren aus der AID-Familie, die sich durch verschiedene Implementierungen und vor allem durch ihre Zielkriterien unterscheiden. Sein Auswahlkriterium beruht auf dem Chi-Quadrat-Test auf Unabhängigkeit. Er zählt zu den direkten Top-Down-Verfahren ohne die Verwendung einer nachfolgenden Pruning-Phase [Clustering]Beim Clustering werden Cluster gebildet, die bezüglich der zu analysierenden Daten, in sich möglichst homogen und untereinander möglichst heterogen sind. [Data Mining]Data Mining ist die Suche nach Beziehungen und Mustern, die in Datenbanken versteckt sind, wobei rohe Daten in nützliche Informationen transformiert werden. Data Mining wird dabei als einer von mehreren Schritten im KDD-Prozess verstanden. [Diskriminanzanalyse]Die Diskriminanzanalyse untersucht den jeweiligen Datenbestand auf solche Attribute, die einen hohen Erklärungsgrad für eine bereits vorgegebene Klassifikation besitzen. Als Paradebeispiel ist hier die Anwendung der Diskriminanzanalyse als Frühwarnsystem bei der Bonitätsprüfung zu nennen. [Entscheidungsbäume]Bei der Methode der Entscheidungsbäume werden Objekte, deren Klassenzuordnung bekannt ist, sukzessive mit Hilfe einzelner Merkmale in Gruppen aufgeteilt, die in sich homogen, aber voneinander möglichst unterschiedlich sind. Am Ende des Verfahrens entsteht ein Baum, aus dessen Verzweigungskriterien Regeln gebildet werden können, die dann auf nicht zugeordnete Objekte angewendet werden können. [Factoring]Finanzierungsgeschäft, bei dem ein spezialisiertes Finanzierungsinstitut (Factor) von einem Verkäufer dessen Forderungen aus Warenlieferungen und Dienstleistungen laufend oder einmalig ankauft und die Verwaltung der 32 Forderungen übernimmt. [Fehlerquadratsumme] Die Fehlerquadratsumme ist die Summe der quadrierten Abweichungen der einzelnen Meßwerte von ihrem Gruppenmittelwert und stellt darum die Variation innerhalb der zu behandelnden Gruppe dar. [Gain-Chart]Ein Gain-Chart ist eine Möglichkeit, die Qualität eines Klassifikators darzustellen. Ein Gain Chart wird dabei durch 2 Kurven charakterisiert, die den Informationsgewinn auf den Lerndaten und den Evaluierungsdaten darstellen. Je größer der Abstand zwischen den beiden Kurven ist, um so geeigneter ist der Klassifikator. [K-means]K-means ist ein partitionierendes, globales Verfahren mit exakter Zuordnung, das Clusterzentren zur Clusterbildung verwendet. [KDD-Prozess]Unter der Bezeichnung Knowledge Discovery in Databases(KDD) versteht man den gesamten Prozess der Wissensentdeckung in Datenbanken. Der Prozess beinhaltet dabei Schritte von der ursprünglichen Datenauswahl bis hin zur Interpretation der gefundenen Muster und der folgenden Umsetzung. [Klassifikation]Bei der Klassifikation besteht die Aufgabe darin, betrachtete Objekte einer vorher bestimmten Klasse zuzuordnen. Die Zuordnung findet dabei aufgrund der Objektmerkmale und der Klassifikationseigenschaften statt. [One-to-one Marketing] Unter one-to-one Marketing oder auch Individual Marketing versteht man das auf spezielle Kunden oder Kundengruppen ausgerichtete Marketingverhalten, dass sich vom Massenmarketing abwendet. [Pruning-Strategien]Im Fall von komplexen und tiefgeschachtelten Entscheidungsbäumen, bei der die Klassifikation ungesehener Objekte häufig ungeeignet ist, verwenden mehrere Entscheidungsbaumverfahren Pruning-Strategien. Ein in einem ersten Schritt konstruierter eventuell tiefverästelter Baum wird dabei durch das Herausschneiden von Unterbäumen reduziert, die nur einen geringen Beitrag zur Klassifikation leisten. [quadrierte euklidische Distanz] Die quadrierte euklidische Distanz beschreibt die Summe der quadrierten Differenzen zwischen den Werten der Einträge. [SOM]Das Ziel von Self Organizing Maps(SOM) besteht in der topologieerhaltenden Abbildung hochdimensionaler Merkmalsräume in einen Outputraum niedriger Dimension. SOM sind dabei in der Lage, unbekannte Strukturen in der zu analysierenden Datenbasis ohne a priori Informationen selbstständig zu extrahieren und zu visualisieren. [Ward-Verfahren]Mit dieser Methode werden zuerst Mittelwerte für jede Variable innerhalb der einzelnen Cluster berechnet. Anschließend wird für jeden Fall die Quadrierte Euklidische Distanz zu den Cluster-Mittelwerten berechnet. Diese Distanzen werden für alle Fälle summiert. Bei jedem Schritt sind die beiden zusammengeführten Cluster diejenigen, die die geringste Zunahme in der Gesamtsumme der quadrierten Distanzen innerhalb der Gruppen ergeben. 33 Literaturverzeichnis [BA00] Bonne, Thorsten; Arminger Gerhard: Diskriminanzanalyse in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [BLE89] Bleymüller, J.: Multivariate Analyse für Wirtschaftswissenschaftler, Münster 1989 [BZL02] Bender, R.; Ziegler, A.; Lange, St.: Logistische Regression in Artikel Nr 14 der Statistik-Serie in der DMW Stuttgart 2002 [EGF00] Eschler, Gabi; Gotsch, Nikolaus; Flury, Christian: Polyprojekt Primalp : www.primalp.ethz.ch/pdf-files/Schlussbericht Komponentenprojekt E.pdf 2000 [FAY96] Fayyad, U. et al.: From Data Mining to Knowledge Discovery in Databases. AI Magazine, Fall 1996a [GER01] Gerke, Wolfgang, Theorie und Praxis des Kreditgeschäfts, Erlangen; siehe : www.bankundboerse.wiso.uni-erlangen.de [GRA00] Grabmeier, Johannes: Segmentierende und clusterbildende Methoden,in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [HR00] Hippner, Hajo; Rupp, Andreas: Kreditwürdigkeitsprüfung im Versandhandel, in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [HS00] Hippner, Hajo; Schmitz, Berit: Data Mining in Kreditinstituten - Die Clusteranalyse zur zielgruppengerechten Kundenansprache, in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [KÜS00] Küsters, Ulrich: Data Mining Methoden: Einordnung und Überblick, in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [KWZ98] Krahl, Daniela; Windheuser, Ulrich; Zick, Friedrich-Karl: Data Mining - Einsatz in der Praxis [LEB02] Leber, Martina: Data Mining: Jeder zweite Großbetrieb wertet Kundendaten systematisch aus, Katholische Universität Eichstätt-Ingolstadt 2002 [LP00] Löbler, Helge; Petersohn, Helge: Kundensegmentierung im Automobilhandel zur Verbesserung der Marktbearbeitung, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [MET94] A., Mettler: Formalisierte Bonitätsprüfungsverfahren und Credit Scoring, Referat gehalten anlässlich der Konferenz ’Risiokomanagement im Privatkundengeschäft’, Bad Homburg 1994 [MEW01] Antje, Mews: Multivariate Analyseverfahren: Die Clusteranalyse. Internetquelle: www.snafu.de/7Eherbst/clust1.html 7.12.2002 [MEY00] Meyer, Matthias: Data Mining im Marketing: Einordnung und Überblick, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [MIC01] Michels, Edmund: Data Mining Analysen im Handel - konkrete Einsatzmöglichkeiten und Erfolgspotenziale, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [MOO99] Moormann, J.: Umbruch in der Bankinformatik - Status Quo und Perspektiven für eine Neugestaltung in: Fischer, Th.: Handbuch Informationstechnologie in Banken. Wiesbaden 1999 [NEU02] Neurocomputing, Data Mining and neuronal Networks auf: www.neurocomputing.de/body index.html [NIE00] Joachim, Niedereichholz (Hrsg.): Data Mining im praktischen Einsatz, Eschborn 2000 34 [PET 98]Petersohn, H.: Beurteilung von Clusteranalysen und selbstorganisierenden Karten, in: Hippner, H.; Meyer, M.; Wilde, K.D.: Computer-Based Marketing, Wiesbaden 1998 [PN00] Poloni, Marco; Nelke, Martin: Einsatz von Data Mining für Kundenmodellierung am Beispiel der Bonitätsbeurteilung, in :Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [PRU01] Prudential System Software GmbH: Data Mining zur Erzeugung von Kundenprofilen mit dem prudsys Discoverer 2000; siehe http://www.prudsys.de [PS00] Poddig, Thorsten ; Sidorovitch, Irina: Künstliche Neuronale Netze: Überblick, Einsatzmöglichkeiten und Anwendungsprobleme, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [RIE99] Rieger, Anke: Entscheidungsunterstützung durch Data Mining: Der Aufwand zahlt sich aus, Fachartikel aus : ExperPraxis 99/2000 [SÄU00] Säuberlich,Frank: KDD und Data Mining als Hilfsmittel zur Entscheidungsunterstützung. Frankfurt u.a. 2000 [SRJ01] Schnedlitz, Peter; Reutterer, Thomas; Joos Walter: Data-Mining und Sortimentsverbundanalyse im Einzelhandel, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [SÜC98]Süchting, J.: Die Theorie der Bankloyalität - (Immer noch) eine Basis zum Verständnis der Absatzbeziehungen von Kreditinstituten ? in: H. Heitmüller (Hrsg.): Handbuch des Bankmarketing , Wiesbaden 1998 [UNG01] Unger, Gregor: Verfahren zur Bonitätsprüfung, in der Seminarreihe IT-Unterstützung für das Asset Management. 2001 [WRR00] Wagner, Udo; Reisinger, Heribert; Russ, Reinhold: Der Einsatz von Methoden des Data Mining zur Unterstützung kommunikationspolitischer Aktivitäten der Lauda Air, in: Wilde, Matthias (Hrsg.): Handbuch Data Mining im Marketing. Ingolstadt und München 2000 [ZIM87]= Zimmermann, H.-J.:Fuzzy Sets, Decision Making, and Expert Systems. Kluwer Academic Publishers, Boston,Dordrecht,Lancaster 1987 35 Abbildungsverzeichnis 3.1 3.2 3.3 3.4 3.5 3.6 Fehler 1. und 2. Art . Diskriminanzanalyse . Z-Wert von Altmann . Entscheidungsbaum . angewendete Verfahren Das Factoringgeschäft . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . und Ergebnisse . . . . . . . . . 4.1 4.2 4.3 4.4 Clustering . . . . . . . . Clusterzuordnung . . . . Fragebogenauswertung . Werbekampagne ’Golden 5.1 Kundeneinteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 6.1 6.2 6.3 6.4 Assoziationsregel . . . . . . . . Elbow-Kriterium . . . . . . . . Verbundwirkung . . . . . . . . Beispiel einer Warenkorbklasse 7.1 KUR sowie Deckungsbeitrag I und II . . . . . . . . . . . . . . . . . . Standard’ 36 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 . 8 . 8 . 9 . 11 . 13 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 17 19 20 24 25 25 27 . . . . . . . . . . . . . . . 28