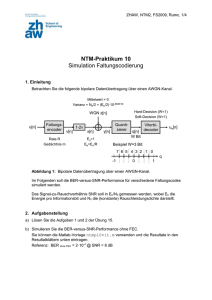
diplomarbeit - CAIA, Swinburne University
Werbung

Technische Universität Berlin Fachbereich Elektrotechnik Institut für Kommunikationsnetze DIPLOMARBEIT Thema: Tarifbasierte Dienstgüteauswahl für IP-Multimedia-Dienste mit Vorwärtsfehlerkorrektur Betreuer: Prof. Dr. Adam Wolisz Institut für Kommunikationsnetze Technische Universität Berlin Dr. Georg Carle GMD FOKUS / GloNe Tanja Zseby GMD FOKUS / GloNe angefertigt von: Sebastian Zander Tirschenreuther Ring 4 12279 Berlin Berlin, den 11.07.2001 Danksagung Ich danke allen, die mich bei dieser Diplomarbeit unterstützt haben insbesondere: • • • • • • Herrn Prof. Dr. Adam Wolisz dafür, daß ich meine Diplomarbeit bei ihm anfertigen durfte und für seine konstruktive Kritik, meinen Betreuern Dr. Georg Carle und Tanja Zseby für die umfangreiche Unterstützung und die vielen interessanten Diskussionen, Long Le für die moralische Unterstützung und die ständige Versorgung mit Keksen, Torsten Ackemann für die schöne Visualisierung der Preisentwicklung (Abbildung 7), Dorgham Sisalem für die Installation des RTP Reflektors, und meinen Eltern die mir das alles ermöglicht haben. Inhaltsverzeichnis 1 MOTIVATION UND ZIEL DER DIPLOMARBEIT 1 2 EINFÜHRUNG 3 2.1 TARIFIERUNG 2.1.1 MECHANISMEN ZUR SICHERSTELLUNG DER DIENSTQUALITÄT 2.1.2 GRUNDLAGEN DER TARIFIERUNG 2.1.2.1 Kriterien für ein Tarifmodell 2.1.2.2 Grundlegende Modelle 2.1.2.3 Beschreibung der Modelle 2.1.3 BEISPIELE FÜR TARIFMODELLE 2.1.4 KOSTENAUFTEILUNG BEI MULTICAST-KOMMUNIKATION 2.1.5 TARIFIERUNG FÜR INTEGRATED SERVICES 2.1.6 ONLINE TARIFIERUNG 2.2 DIENSTGÜTE 2.2.1 VERLUSTVERMEIDUNG 2.2.2 VERLUSTVERSCHLEIERUNG 2.2.3 VERLUSTKORREKTUR 2.2.3.1 Prinzip der Vorwärtsfehlerkorrektur 2.2.3.2 Reed-Solomon-Codes 2.2.3.3 Übertragungsprotokolle mit FEC Mechanismen 3 3 5 5 5 6 7 8 8 9 10 11 11 12 12 13 15 3 ÜBERTRAGUNG UND NUTZUNG VON DIENSTINFORMATIONEN 17 3.1 SYSTEMÜBERBLICK 3.1.1 SYSTEMKOMPONENTEN 3.1.1.1 CIP Client 3.1.1.2 C&A/CIP Server 3.1.1.3 C&A Management 3.1.1.4 FEC Gateway 3.1.1.5 Meßsystem 3.2 DAS CIP PROTOKOLL 3.2.1 ÜBERBLICK 3.2.1.1 Funktionalität 3.2.1.2 Dienste 3.2.1.3 Eigenschaften des Protokolls 3.2.1.4 CIP Adressen 3.2.2 PROTOKOLLABLAUF 3.2.3 TRANSAKTIONEN 3.2.4 CIP NACHRICHTEN 3.2.4.1 CIP Requests 3.2.4.2 CIP Responses 3.2.5 HEADER FELDER 3.2.5.1 Transaction-ID 3.2.5.2 Iseq 3.2.5.3 Encryption 3.2.5.4 From 3.2.5.5 Service 3.2.5.6 Vendor 17 17 18 18 19 19 20 21 21 21 22 22 22 23 23 24 24 26 27 28 28 28 28 28 29 3.2.5.7 Valid-Until 3.2.5.8 Valid-From 3.2.5.9 Currency 3.2.5.10 Guarantees 3.2.5.11 Parameter 3.2.5.12 Formula 3.2.5.13 Response-Key 3.2.5.14 Require 3.2.5.15 Filter 3.2.5.16 Authorisation 3.2.5.17 Endpoint 3.2.5.18 Mode 3.2.5.19 Reservation 3.2.5.20 Reservation-Parameter 3.2.5.21 Update-Frequency 3.2.5.22 Unsupported 3.2.5.23 Warning 3.2.5.24 Authenticate 3.2.5.25 Header Felder Kurzform 3.2.6 CIP TRANSPORT 3.2.6.1 REGISTER, CANCEL, SELECT 3.2.6.2 GET_INFO, INFO 3.2.6.3 CIP and Multicast 3.2.7 SICHERHEIT 3.2.7.1 Authentifizierung 3.2.7.2 Verschlüsselung 3.2.8 KOSTENAUFTEILUNG ZWISCHEN SENDER UND EMPFÄNGER 3.2.9 WEITERE ÜBERLEGUNGEN 3.2.9.1 CIP Directory-Server 3.2.9.2 Kostenkompensation zwischen Providern 3.2.9.3 Integration des CIP Protokolls in die existierende Protokollhierarchie 3.2.9.4 CIP als Erweiterung des DIAMETER Protokolls 3.2.10 IMPLEMENTIERUNG 3.3 SPEZIFIKATION VON TARIFFORMELN 3.3.1 ANFORDERUNGEN AN DIE SPRACHE 3.3.2 AUFBAU UND EIGENSCHAFTEN DER SPRACHE 3.3.2.1 Aufbau der Sprache 3.3.2.2 Operatoren, Funktionen, bedingte Ausdrücke und Konstanten 3.3.2.3 Global definierte Variablen 3.3.3 BEISPIELE 3.3.4 IMPLEMENTIERUNG 3.4 AUSWAHL DER OPTIMALEN SERVICEKLASSE 3.4.1 OPTIMALE SERVICEKLASSE 3.4.2 UTILITY-KURVEN 3.4.3 HERLEITUNG UND UNTERSUCHUNG DES ALGORITHMUS 3.4.4 VERSCHIEDENE SZENARIEN FÜR DIE OPTIMIERUNG 3.4.5 IMPLEMENTIERUNG 29 29 29 29 30 30 30 30 30 30 30 31 31 31 31 31 32 32 32 32 33 33 34 35 35 36 37 37 37 38 39 39 40 40 40 41 41 42 43 44 46 46 46 47 48 52 53 4 VERBESSERUNG DER DIENSTQUALITÄT DURCH FEC 57 4.1 RTP GATEWAY 4.1.1 GRUNDSÄTZLICHE FUNKTION 4.1.2 PAKETFORMAT 4.1.3 ERZEUGUNG DER REDUNDANZ 4.1.4 WIEDERHERSTELLUNG VERLORENER PAKETE 57 57 58 59 61 4.1.5 GATEWAY KONTROLLE 4.1.6 STATISTIKBERECHNUNG 4.1.7 VERLUSTSIMULATION 4.1.8 EINSATZMÖGLICHKEITEN 4.1.9 IMPLEMENTIERUNG 4.2 PERFORMANCE 4.2.1 REED-SOLOMON KODIERER 4.2.2 RTP GATEWAY 4.3 UNTERSUCHUNG DER ÜBERTRAGUNGSQUALITÄT 4.3.1 BURSTVERLUSTE 4.3.2 VERLUSTRATE 62 64 65 66 68 69 69 71 71 72 72 5 UNTERSUCHUNG EINES REALEN SZENARIOS 77 6 ZUSAMMENFASSUNG UND AUSBLICK 81 7 ANHANG 83 7.1 7.2 7.3 7.4 7.5 7.5.1 7.5.2 7.5.3 7.5.4 7.5.5 83 83 84 85 86 86 87 87 87 88 VERWENDETE NOTATION CIP PROTOKOLLABLAUF TFL TARIFFORMELN MEßWERTE MAN PAGES CIP CLIENT CIP SERVER RS PERFORMANCE MESSUNG OPTIMIERUNGSALGORITHMUS RTP GATEWAY 8 LITERATURVERZEICHNIS 91 Kapitel 1: Motivation und Ziel der Diplomarbeit 1 Motivation und Ziel der Diplomarbeit Die Benutzung von Multimedia-Anwendungen über IP-basierte Netze erfordert eine gewisse Ende-zu-Ende Dienstqualität (QoS). Das gilt insbesondere dann, wenn es sich um Anwendungen mit Echtzeitanforderungen wie zum Beispiel Videokonferenzen oder Telefonie handelt. Dienstqualitätsanforderungen lassen sich in IP-basierten Netzen gegenwärtig mit dem Integrated Service Modell oder dem Differentiated Service Modell unterstützen. Beide Modelle sorgen dafür, daß die von der Anwendung benötigte Dienstgüte durch einen IP-Dienst mit entsprechender Qualität gewährleistet wird. Da die einzelnen Nutzer grundsätzlich nicht kooperieren und Dienstqualität (in Form von Bandbreite) nicht unbegrenzt vorhanden ist, muß bei Diensten mit einer garantierten QoS eine Regulierung in Form einer Tarifierung erfolgen. Zur Realisierung einer verursachergerechten Tarifierung ist neben einer Auswertung der reservierten Ressourcen die vom Nutzer tatsächlich erzeugte Last (das Datenvolumen) von Bedeutung. Diese muß mit geeigneten Meßinstrumenten im Netz gemessen und dem einzelnen Verbraucher zugeordnet werden. Werden zusätzliche Maßnahmen zur Fehlerkontrolle eingesetzt, so kann auch unter Verwendung eines relativ preiswerten Dienstes eine verhältnismäßig hohe Qualität erbracht werden. Bei Echtzeitanwendungen sind insbesondere Vorwärtsfehlerkorrekturmechanismen (FEC) von Interesse, die die Verlustwahrscheinlichkeit von Datenpaketen auf Kosten der benötigten Bandbreite verringern. Im Rahmen dieser Diplomarbeit soll eine Diensterbringung von Multimedia-Diensten mit Fehlerkontrolle in Form von Vorwärtsfehlerkorrektur in Verbindung mit IP-Diensten unterschiedlicher Qualität untersucht werden. Hierbei sollen der Einsatz von RTP/RTCP zur Übertragung von Audio und Video sowie RTP-spezifische FEC-Mechanismen untersucht werden. Die unterschiedliche Qualität der IP-Dienste spiegelt sich in den unterschiedlichen Tarifen bzw. Kosten der einzelnen angebotenen Dienstklassen wieder. Damit sich Endsysteme und letztlich die Nutzer vor der Dienstauswahl und Dienstnutzung über die einzelnen Serviceklassen und die zugehörigen Tarife informieren können, soll im Rahmen dieser Arbeit ein Protokoll zur Übertragung von Tarifierungsinformationen für unterschiedliche Dienstklassen entwickelt werden. Weiterhin soll ein Modul entworfen werden, das anhand der Anforderungen der Anwendung und den angebotenen Serviceklassen den optimalen Tarif auswählt. Darüber hinaus soll das Modul zusätzlich bei Bedarf Vorwärtsfehlerkorrekturmechanismen einsetzen, wobei die FEC-Parameter automatisch dimensioniert werden. Im zweiten Kapitel wird zunächst eine kurze Einführung in die beiden Bereiche Tarifierung und Vorwärtsfehlerkorrektur gegeben. Es werden nur die wesentlichen Tarifierungsmechanismen sowie die grundlegenden Formeln zur Tarifierung vorgestellt. Bei der Betrachtung der Vorwärtsfehlerkorrektur steht die konkrete Realisierung als Teil eines Protokolls im Vordergrund, im wesentlichen werden hier nur Reed-Solomon-Codes (RS-Codes) behandelt. Auf die mathematischen Verfahren der Kodierung wird nicht näher eingegangen, es wird nur das grundlegende Prinzip erläutert. In Kapitel drei wird ein Protokoll zur Übertragung von Informationen über Dienstklassen anhand der verschiedenen Anforderungen definiert. Dabei werden verschiedene Szenarien zur Tarifierung untersucht und miteinander verglichen. Weiterhin wird untersucht, inwieweit sich das Preis-Leistungs-Verhältnis des gekauften Dienstes durch den gezielten Einsatz von Vorwärtsfehlerkorrektur optimieren läßt. Dazu wird das entsprechende Verfahren mathematisch hergeleitet und mit Hilfe von Beispielen die Auswirkungen gezeigt. Die bei der Tarifierung Seite 1 Kapitel 1: Motivation und Ziel der Diplomarbeit eingesetzten Tarifformeln müssen bei der Bestimmung des optimalen Tarifs durch einen Computer ausgewertet werden. Es werden die Anforderungen an eine Sprache zur Beschreibung der Formeln formuliert und eine entsprechende Grammatik entwickelt, die Ausdrücke dieser Sprache korrekt und zuverlässig erkennt und auswertet. Weiterhin wird ein implementierter Prototyp des Systems vorgestellt. Im vierten Kapitel wird ein Modul zur Vorwärtsfehlerkorrektur bei RTP-Datenströmen entwickelt. Zur Erzeugung der Redundanzinformationen wird ein bereits für die Paketübertragung optimierter RS-Kodierer eingesetzt. Der Einsatz der Vorwärtsfehlerkorrektur ist dabei völlig transparent, so daß bereits vorhandene Multimedia-Anwendungen eingesetzt werden können. Ein implementierter Prototyp wird in der Realität mittels verschiedener Szenarien untersucht. Dies ermöglicht es, zum einen Aussagen über die tatsächlichen Auswirkungen auf reale Anwendungen in einem existierenden Netz zu machen. Zum anderen können sowohl objektive als auch subjektive Qualitätsaussagen gemacht werden, da richtige Audio- bzw. Videodaten übertragen werden. In Kapitel fünf wird das gesamte System zur Dienstgüteauswahl anhand eines Beispielszenarios untersucht. Es soll der Eindruck vermittelt werden, wie der Einsatz eines solchen Systems in der Realität aussehen könnte. Das sechste Kapitel faßt die erzielten Ergebnisse zusammen und gibt einen Ausblick auf die zukünftige Entwicklung. Seite 2 Kapitel 2: Einführung 2 Einführung Das zweite Kapitel soll einen kurzen Einblick in die beiden Themenkomplexe Tarifierung und Dienstgüte geben, ohne dabei zu tief in die Materie vorzudringen. Hier soll lediglich eine Basis zum besseren Verständnis der nächsten Kapitel geschaffen werden. 2.1 Tarifierung In den letzten Jahren hat sich das Internet immer mehr von einem Forschungsnetz zu einem kommerziellen Netz entwickelt. Der wichtigste Katalysator für diese Entwicklung war sicherlich die Entwicklung des World Wide Web (WWW). Neben dem WWW und den klassischen Internet-Diensten wie FTP, Telnet oder Email entwickelten verschiedene Organisationen eine ganze Reihe von weiteren Anwendungen, die zum Beispiel Videokonferenzen, Radio und Telefonie oder E-Commerce im Internet ermöglichen, um sie dem potentiellen Kunden anzubieten. Viele dieser neuen Anwendungen haben allerdings im Gegensatz zu den klassischen Diensten bestimmte Anforderungen an das Netzwerk. Besonders Multimedia-Anwendungen mit Echtzeitanforderungen benötigen eine große Bandbreite, eine kleine Verzögerung und minimalen Jitter. Allerdings hatte niemand in den Anfängen des Internet an solche Anwendungen gedacht. Deshalb hatte das Internet in seiner ursprünglichen Form auch keine Mechanismen, um einen Dienst mit einer bestimmten geforderten Qualität bereitzustellen. Das Internet bietet nur einen sogenannten „Best Effort“ Service, d.h., es werden keinerlei Garantien gegeben. Das Netz versucht lediglich das Beste beim Transport von Paketen. Um die speziellen Anforderungen einer Anwendung zu erfüllen, wurden verschiedene Modelle zur Auswahl und Sicherstellung einer gewissen Dienstqualität während der Übertragung entwickelt. Diese Mechanismen werden kurz in Abschnitt 2.1.1 beschrieben. Da Netzwerkressourcen nicht unbegrenzt vorhanden sind, es sich also um sogenannte knappe Güter handelt, muß es Marktmechanismen zur Regelung des Angebots und der Nachfrage geben. Abschnitt 2.1.2 beschreibt die grundlegenden Überlegungen zur Tarifierung, während in Abschnitt 2.1.3 aus der Literatur bekannte Tarifmodelle vorgestellt werden. Die Abschnitte 2.1.4 und 2.1.5 stellen Lösungsansätze für die Kostenaufteilung bei MulticastÜbertragung und die Tarifierung bei IntServ vor. Abschnitt 2.1.6 gibt eine kurze Einführung in die Problematik der Online-Tarifierung. 2.1.1 Mechanismen zur Sicherstellung der Dienstqualität Um eine geforderte Dienstqualität in einem IP-basierten Netz bereitzustellen, gibt es momentan zwei Ansätze: • • RSVP/Integrated Services (Intserv) Differentiated Services (Diffserv) Die Integrated Services Architektur wird in [RFC1633] beschrieben. Intserv definiert Dienstklassen, die eine bestimmte Dienstgüte in IP-basierten Netzwerken bereitstellen. Die Sicherstellung der Dienstgüte erfolgt durch die Reservierung der benötigten Ressourcen im Netzwerk. Momentan gibt es zwei standardisierte Dienstklassen: Controlled Load und Guaranteed. In [GGPR96] wird eine weitere Dienstklasse vorgeschlagen: Guaranteed Rate. Der Controlled Load Dienst bietet dem Benutzer einen Dienst, der einem Best-EffortDienst in einem unbelasteten Netzwerk entspricht. Die Definition ist relativ unpräzise, was für Seite 3 Kapitel 2: Einführung den kommerziellen Einsatz – also den Verkauf eines solchen Dienstes – problematisch ist. Der Guaranteed Dienst ist für Anwendungen, die sehr harte Bedingungen an die zulässige Verzögerung stellen zum Beispiel Audio/Video-Konferenzen. Der Verkehrsstrom wird bei beiden Diensten durch einen Token Bucket charakterisiert und erhält seine geforderte Servicerate an jedem Router. Beim Guaranteed Dienst wird eine obere Grenze für die Verzögerungszeit garantiert. Die Garantie der maximalen Verzögerungszeit wird momentan durch eine Überreservierung der Servicerate erreicht. Der überreservierte Anteil bleibt jedoch die meiste Zeit ungenutzt. Deshalb wird in [GGPR96] der Guaranteed Rate Dienst vorgeschlagen, um diese ungenutzten Ressourcen besser zu nutzen als durch reinen Best-Effort Verkehr. Garantiert wird eine mittlere Senderate, aber keine maximale Ende-zu-Ende Verzögerung. Im Rahmen von Intserv wird RSVP (siehe [RFC2205]) als Signalisierungsprotokoll eingesetzt, um die Reservierungsanforderungen zu übertragen. Der Sender sendet RSVP PATHNachrichten an die Empfänger, welche die sogenannte Tspec enthalten. Die Tspec beschreibt den zu übertragenen Datenstrom. Die Empfänger antworten mit RESV Nachrichten, welche die sogenannte Rspec enthalten. Die Rspec definiert die vom Empfänger gewünschte Dienstgüte. Intserv-fähige Router auf der Strecke vom Empfänger zum Sender reservieren Ressourcen entsprechen der Rspec in den RESV Nachrichten. Die Reservierung der Ressourcen erfolgt bei Intserv also durch die Empfänger. Verschiedene Reservierungen können an Knotenpunkten im Netz (Router) unter Umständen zu einer zusammengefaßt werden. Einen anderen Ansatz zur Sicherstellung der Dienstqualität stellt das relativ neue Differentiated Services Modell (Diffserv) dar. Das Modell wird in [NiBl98] beschrieben. Diffserv versucht skalierbare Dienste anzubieten, ohne daß Zustandsinformationen über die einzelnen Ströme vorliegen. Außerdem gibt es keine Signalisierung wie bei Intserv. Bei Diffserv werden Pakete durch ein Type of Service (TOS) Feld klassifiziert, das sogenannte DS Byte. Jeder Router hat Informationen, wie ein Paket mit einem bestimmten DS Wert behandelt wird. Dabei bestimmt der Dienstanbieter, auf welche Weise Pakete mit einem bestimmten DS Byte behandelt werden. Um eine Änderung des DS Bytes am Übergang zwischen zwei Dienstanbietern zu vermeiden, sollte eine gleiche Dienstgüte allerdings auch durch den gleichen DS Wert gekennzeichnet werden (siehe [NiBl98]). Das RSVP Protokoll bietet einen per-flow Service für Applikationen, die eine bestimmte Dienstqualität benötigen. Im Rahmen der Entwicklung von RSVP/Intserv wurden die Grenzen der Lösung deutlich. Da bei RSVP/Intserv für jeden flow der momentane Zustand gespeichert werden muß und die Bearbeitung pro flow erfolgt, ergeben sich Probleme bei der Verbreitung in großen Netzwerken insbesondere natürlich im Internet. Außerdem geht bei RSVP die Signalisierung vom Endsystem aus, von denen allerdings viele noch nicht über RSVP verfügen. Der Diffserv Ansatz gewinnt in letzter Zeit immer mehr an Bedeutung, da er eine einfache Alternative zu Intserv darstellt. Es treten keine Skalierbarkeitsprobleme wie bei Intserv auf. Diffserv kann auch in großen Netzwerken eingesetzt und gewartet werden, eine Bereitstellung in jedem Endsystem ist nicht nötig. In [BeYF98] wird deshalb ein Framework für Ende-zu-Ende Dienstqualität vorgestellt, daß auf dem Zusammenwirken von Intserv und Diffserv basiert. Das Framework soll sowohl Dienstanbieter mit großen Netzwerken als auch die Benutzer, die letztlich die Dienstqualität benötigen, zufriedenstellen. Der Ansatz geht davon aus, daß es in Zukunft Diffserv Kernnetzwerke (Transit Netzwerke) geben wird, an deren Peripherie sich Intserv Netzwerke (Stub Netzwerke) anschließen. Auf diese Weise wird versucht, die Vorteile beider Technologien auszunutzen. Abbildung 1 zeigt eine schematische Darstellung des Netzwerkes. Aufgrund der Übersichtlichkeit ist nur ein Sender und ein Empfänger dargestellt. Seite 4 Kapitel 2: Einführung Stub Netzwerk Edge Router Transit Boundry Netzwerk Boundry Router Router Edge Router Sender Stub Netzwerk Empfänger Abbildung 1: QoS Ende-zu-Ende Framework Am Rande der Stub Netzwerke befinden sich Edge Router, die die Grenzen zwischen dem Intserv und dem Diffserv Netzwerk bilden. Edge Router enthalten quasi eine RSVP Hälfte und eine Diffserv Hälfte. Am Rande des Transit Netzwerkes befinden sich Boundry Router. Hierbei handelt es sich um normale Router, die Diffserv Policing unterstützen. Das Transit Netzwerk besteht aus Routern, von denen wenigstens einige Diffserv unterstützen. Ebenso besteht das Stub Netzwerk aus Routern, von denen wenigstens einige Intserv unterstützen. 2.1.2 Grundlagen der Tarifierung 2.1.2.1 Kriterien für ein Tarifmodell Da Netzwerkressourcen nicht unbegrenzt vorhanden sind, muß dem einzelnen Benutzer ein Anreiz zum verantwortlichen Umgang mit den vorhandenen Ressourcen gegeben werden. Daher sollte der Benutzer einen Preis zahlen, der der Höhe des Ressourcenverbrauchs entspricht. Der Ressourcenverbrauch umfaßt auch die vom Benutzer möglicherweise reservierten Ressourcen, unabhängig davon ob er diese ausnutzt oder nicht. Auch wenn der Benutzer die reservierten Ressourcen nicht nutzt, bleiben sie doch reserviert und stehen anderen Benutzern nicht automatisch zur Verfügung. Allerdings gibt es bereits Ansätze wie SoftQoS oder Measurement based Admission Control, bei denen reservierte aber unbenutzte Ressourcen auch für andere Anwender verfügbar gemacht werden können. Um die Akzeptanz eines Tarifmodells zu erhöhen, sollte es auch für den Laien verständlich sein. Auch die Möglichkeit, den Preis vorhersagen zu können, stellt einen wichtigen Faktor dar. Der Tarif sollte außerdem fair sein, d.h., der Preis sollte der reservierten und der tatsächlich erhaltenen Qualität angepaßt sein. Das Modell sollte die kooperative Netzaufteilung fördern und schnell auf Änderungen der Verkehrscharakteristik reagieren. Weitere Kriterien sind für die technische Realisierung relevant. Die Implementierung eines Modells sollte preiswert sein und es sollte ausreichend Sicherheitsmechanismen geben, um Manipulationen Dritter zu verhindern. Weiterhin sollte die Anpassung oder Erweiterbarkeit an neue Tarifmodelle leicht möglich sein. Hat der Benutzer jederzeit die Möglichkeit, die momentan anfallenden Kosten zu überprüfen, erhöht sich die Akzeptanz des Modells (siehe Abschnitt 2.1.6). Um weitere Anreize für den Benutzer zu schaffen, kann man kundenabhängige Tarifmodelle anbieten. Hier sind sowohl Rabatte entsprechend des Umsatzvolumens denkbar, als auch maßgeschneiderte Angebote für das jeweilige Dienstportfolio des Kunden. 2.1.2.2 Grundlegende Modelle Die einfachste Form der Tarifierung ist die sogenannte Flat Rate. Bei diesem Modell wird ausschließlich eine Zugangsgebühr erhoben, die normalerweise von der Bitrate des AnschlusSeite 5 Kapitel 2: Einführung ses abhängt. Es fallen keine Kosten für das übertragene Volumen oder die Dauer der Verbindung an. Das Modell hat den Vorteil, daß die Preise exakt vorhersagbar sind. Es bietet jedoch für den Nutzer keinen Anreiz sein Datenvolumen oder die Verbindungsdauer einzuschränken. Dies führt meist zu einem verschwenderischen Umgang mit den Netzressourcen. Wird der Preis nur auf Basis der Verbindungsdauer berechnet, handelt es sich um rein zeitbasierte Modelle. Der Benutzer wird nach Möglichkeit versuchen, seine Verbindungsdauer einzuschränken. Ein solches Modell bietet allerdings keine Anreize zur Verringerung des Datenvolumens. Dies kann zu einer Überlastung des Netzes führen. Handelt es sich um ein verbindungsorientiertes Netzwerk (zum Beispiel ATM) ist es sinnvoll, rein zeit-basierte Tarife mit einer Verbindungsaufbaugebühr zu kombinieren. Ansonsten wird der Benutzer mehrere Verbindungen aufbauen, um die Daten schneller übertragen zu können. Auch für das rein zeitbasierte Modell ergibt sich für den Benutzer ein vorhersagbarer Preis. Der Dienstanbieter hat den Vorteil, daß keine Volumenmessung im Netzwerk durchgeführt werden muß. Hängt der Preis bei einem Tarifmodell nur vom übertragenen Volumen ab, spricht man von einem rein volumen-basierten Modell. Hier muß der Dienstanbieter das übertragen Datenvolumen der einzelnen Kunden messen. Ein Nachteil des Modells ist, daß kein Anreiz zum Abbau bestehender Verbindungen besteht. Das bedeutet, der Benutzer erhält Verbindungen aufrecht, auch wenn längere Zeit keine Daten übertragen werden. Dieser Effekt verstärkt sich, wenn es eine Verbindungsaufbaugebühr gibt. Ist der Preis sowohl vom übertragenen Volumen als auch von der Verbindungsdauer abhängig, bietet das Modell einen Anreiz für den Benutzer, sowohl das Datenvolumen als auch die Verbindungsdauer entsprechend einzuschränken. Die Preise für Volumen- und Zeiteinheit sollten hier natürlich geringer als bei einem jeweiligen zeit- oder volumen-basierten Modell sein. Das extreme Nutzerverhalten, das bei einem rein zeit- oder volumen-basierten Modell entsteht, kann mit einem kombinierten Modell verhindert werden. Ein Nachteil des kombinierten Modells ist seine Komplexität. Für den Kunden wird es schwieriger, den entstehenden Preis abzuschätzen. Werden für eine aufgebaute Verbindung Ressourcen reserviert, muß dies in dem Tarifmodell berücksichtigt werden, da durch eine Reservierung Ressourcen gebunden werden und somit anderen Nutzern nicht automatisch zur Verfügung stehen. Dies stellt für den Benutzer außerdem einen Anreiz dar, seinen Ressourcenverbrauch möglichst genau im Voraus abzuschätzen. Um die Kosten für die Reservierung mit in den Preis eingehen zu lassen, können die Tarifmodellparameter als Funktion von den für die Verbindung reservierten Ressourcen formuliert werden. So könnte zum Beispiel der Preis pro Volumeneinheit in Abhängigkeit von der Dienstklasse berechnet werden. 2.1.2.3 Beschreibung der Modelle Die gängigsten Tarifmodelle können durch die folgende Formel beschrieben werden: Preis = CVER + P PT ⋅ T + V ⋅V UT UV Die Parameter CVER, PT, UT, PV und UV werden als Tarifmodellparameter bezeichnet und können ihrerseits von verschiedenen Faktoren abhängen. Sie können zum Beispiel von der Spitzenrate oder der Distanz abhängen: CVER = f(Spitzenrate, Distanz) Seite 6 Kapitel 2: Einführung CVER beschreibt die Gebühr, die für den Verbindungsaufbau erhoben wird. PT beschreibt die Kosten pro Zeiteinheit, UT die Länge der Zeiteinheit und T die Verbindungsdauer. Dementsprechend beschreibt PV die Kosten pro Volumeneinheit, UV die Menge einer Volumeneinheit und V das gemessene Datenvolumen. Für Tarifmodelle, die sich nicht befriedigend durch die obige Funktion beschreiben lassen, muß die Formel um einen zusätzlichen Term erweitert werden, der die speziellen Abhängigkeiten erfaßt. 2.1.3 Beispiele für Tarifmodelle In [WaKS97] wird ein Tarifmodell zur verbrauchsorientierten Tarifierung in ATM Netzen vorgestellt. Die Preise sind hier abhängig von der ATM Dienstklasse (CBR, VBR, ABR oder UBR). In der folgenden Tabelle sind die Preise pro Mbit nach Walker angegeben: Dienstklasse CBR VBR ABR UBR Preis pro Mbit [DM] 0,17 0,34 0,0085 0,0003 Tabelle 1: Preis pro Mbit nach Walker Der Preis berechnet sich dabei nach folgenden Formeln: Preis = CVER + Z ⋅T ⋅ PV UV für CBR, VBR Preis = CVER + V ⋅ PV UV für ABR, UBR Z ist entweder die Peak Cell Rate (PCR) bei CBR oder die Mean Cell Rate (MCR) bei VBR Verbindungen. In [McEn97] wird das Modell von Walker als zu teuer für CBR Verkehr kritisiert. Als Preis pro Mbit für CBR werden 0,0068 DM vorgeschlagen. Die nachfolgende Abbildung 2 zeigt die Preisentwicklung einer gemessenen CBR Verbindung nach Walker und McEntee. Die PCR beträgt 71000 Zellen/s, die Dauer der Messung beträgt ca. 6,5 Stunden. Seite 7 Kapitel 2: Einführung Abbildung 2: Vergleich von Tarifmodellen - Walker und McEntee 2.1.4 Kostenaufteilung bei Multicast-Kommunikation In [HSE97] wird die Zuordnung von entstehenden Kosten auf die einzelnen Benutzer im Multicast-Baum ausführlich diskutiert. Die Kostenzuteilung geschieht durch das Aufteilen der Kosten eines Links zwischen einer definierten Teilmenge der Benutzer. Die Definition der Teilmenge entscheidet über die Zuteilungsstrategie. Natürlich muß die Summe der einzelnen Kostenanteile den Gesamtkosten des Links entsprechen. Um einen solchen Ansatz zu realisieren, müssen die Kosten durch eine Funktion ausgedrückt werden, die linear von den Reservierungsparametern abhängig ist (siehe [KSWS99]). Im nächsten Abschnitt wird eine solche Kostenfunktion vorgestellt. In [CaHS98] und [LoLe98] wird ein Charging and Acounting Protocol (CAP) vorgestellt, durch das die einzelnen Teilnehmern einer Multicast-Gruppe Informationen über die anfallenden Kosten erhalten. Die Kosten werden dabei entsprechend den QoS-Anforderungen aufgeteilt. Das CAP Protokoll benutzt für die Übertragung der Kosteninformationen das RSVP Protokoll. 2.1.5 Tarifierung für Integrated Services In [KSWS99] wird ein Modell zur Kostenberechnung von Intserv Diensten vorgestellt. Es wird angenommen, daß der Ressourcenverbrauch bei Intserv Diensten nur von der Rate und dem Pufferbedarf abhängt. Es wird gezeigt, daß die Kosten für den Puffer (Speicher) nur bei ungefähr 1% der Gesamtkosten liegen und deshalb als einziger Parameter die Rate verwendet werden kann. Das Kostenmodell hat drei virtuelle Ressourcenparameter, denen die entsprechenden Intserv Parameter (je nach Dienstklasse) zugeordnet werden. Da die Kostenfunktionen linear sind, läßt sich eine Kostenaufteilung in Multicast-Bäumen problemlos durchführen. Die Kosten für die einzelnen Dienstklassen berechnen sich folgendermaßen: cost G (r , R) = a ⋅ r + b ⋅ ( R − r ) cost CL (r ) = a ⋅ r + c ⋅ e cost GR (r ) = c ⋅ r G: Guaranteed Service, CL: Controlled Load, GR: Guaranteed Rate R, r, e: Intserv Flow Spezifikation Seite 8 Kapitel 2: Einführung a, b, c: Kosten pro Ressourceneinheit 2.1.6 Online Tarifierung Das grundlegende Konzept der Online Tarifierung ist, daß der Benutzer eines Dienstes bereits während der Dienstnutzung Informationen über die anfallenden Kosten bekommt. Eine Online Tarifierung ermöglicht es dem Anwender, seine Dienstnutzung entsprechend der anfallenden Kosten zu steuern. Voraussetzung ist natürlich, daß der Benutzer oder eine entsprechende Anwendung die Möglichkeit hat, den Dienst bzw. dessen Parameter zu manipulieren. In diesem Fall gibt es quasi eine Rückkopplung zwischen der Preisberechnung und der Wahl der Dienstklasse. Eine solche Rückkopplung ist natürlich nur dann vorhanden, wenn der Preis in irgendeiner Weise auch von den Parametern abhängig ist. Online Tarifierung bietet sich daher besonders bei Tarifmodellen an, bei denen der Preis von den reservierten oder den tatsächlich verbrauchten Ressourcen im Netzwerk abhängt. Abbildung 3 zeigt eine schematische Darstellung der Online Tarifierung. Anzeige: - Dienstqualität - Kosten Entscheidung über Dienstwechsel Nutzer - Anwendung Dienstwechsel Kostenanzeige Datentransfer Accounting Tarifierung Tarifierungsinformationen Accounting Tarifierung Datentransfer Abbildung 3: Online Tarifierung Der Vorteil einer Online Tarifierung liegt für den Benutzer darin, daß er jederzeit den Bezug zwischen der Netznutzung und dem zu zahlenden Preis kennt. Er hat also immer die Kontrolle darüber, wieviel er tatsächlich bezahlt. Das Ziel des Benutzers ist es, eine seinen Zwecken entsprechende Qualität zu einem möglichst günstigen Preis zu bekommen. Basiert der Preis auf reservierten Netzressourcen, stellt dies einen Anreiz dar, den entstehenden Verkehr möglichst genau vorherzusagen bzw. zu schätzen. Dies hat für den Netzbetreiber den Vorteil, daß eine optimale Netzauslastung eher erreicht werden kann, da eine größere Anzahl von Reservierungen akzeptiert werden kann. Eines der wichtigsten Kriterien für die Akzeptanz eines Tarifmodells stellt die Vorhersagbarkeit des Preises für den Kunden dar [CAN_D5]. Wird der Nutzer laufend über die anfallenden Kosten informiert, steigert dies die Akzeptanz besonders bei komplexen Tarifmodellen. Dies führt letztlich zu einer erhöhten Dienstnutzung. Seite 9 Kapitel 2: Einführung 2.2 Dienstgüte Die Dienstgüte in einem paketorientierten Netz wird im wesentlichen durch drei Faktoren bestimmt: • • • Verlustwahrscheinlichkeit, Verzögerung und Jitter. Die Verlustwahrscheinlichkeit gibt an, mit welcher Wahrscheinlichkeit ein gesendetes Paket im Netz verloren geht. In drahtgebundenen Netzen – wie dem Internet – treten Verluste normalerweise durch Pufferüberläufe an Routern (Überlastsituationen) auf. In drahtlosen Netzen entstehen viele Verluste durch die schlechte Übertragungsqualität des Mediums. Die Verzögerung ist die Zeit, die ein Paket braucht, um vom Sender zum Empfänger zu gelangen. Die Verzögerung setzt sich aus der reinen Laufzeit des Pakets auf dem Medium und den Wartezeiten in Routern zusammen. Jitter ist die Varianz der Zwischenankunftszeiten der Pakete am Empfänger. Jitter entsteht durch unterschiedliche Laufzeiten der Pakete, d.h., die Verzögerung in den Routern ist unterschiedlich je nach Netzsituation. Außerdem können verschiedene Pakete auch unterschiedliche Wege zum Ziel nehmen. Jitter ist also eine Größe, die nur in paketvermittelten Netzen auftritt, nicht aber in leitungsvermittelten. Neben diesen drei Größen ist natürlich auch die maximal mögliche Bandbreite wichtig. Sie gibt an, mit welcher Qualität man Multimedia-Daten überhaupt übertragen kann. Da die Bandbreite stets begrenzt ist, wurden eine Vielzahl von Verfahren zur Komprimierung der Daten während der Übertragung entwickelt. Dabei muß zwischen verlustfreien und verlustbehafteten Komprimierungen unterschieden werden. Bei verlustfreier Komprimierung läßt sich das ursprüngliche Signal nach der Dekomprimierung exakt wiederherstellen. Bei der verlustbehafteten Komprimierung entstehen Verluste, die aber für den Menschen nicht unbedingt wahrnehmbar sein müssen. Als aktuelles Beispiel soll hier das MPEG Verfahren genannt werden, insbesondere MPEG Layer 3 (MP3). Bei der Komprimierung werden hörphysiologische Gegebenheiten des menschlichen Ohrs ausgenutzt. So klingt das dekomprimierte Signal trotz Verlusten genauso gut wie das Original. Die Verluste können vom menschlichen Ohr nicht wahrgenommen werden. Anzumerken in diesem Zusammenhang ist, daß im Internet burstartige Verluste auftreten, d.h., es geht meistens nicht nur ein einzelnes isoliertes Paket verloren, sondern mehrere aufeinanderfolgende. Lange Verlustbursts wirken sich bei Kodierverfahren, wo Kodierer und Dekodierer quasi kontinuierlich Statusinformationen austauschen, drastisch aus. Der Zustand auf Kodierer- und Dekodiererseite unterscheidet sich nach einem Verlustburst, so daß auch nachfolgende Pakete noch in Mitleidenschaft gezogen werden können. Die Verzögerung im Netz läßt sich grundsätzlich nicht beseitigen, weil die Geschwindigkeit des Informationsaustauschs begrenzt ist. Informationen können maximal mit Lichtgeschwindigkeit übertragen werden, bei leitungsgebundenen Systemen beträgt die Übertragungsgeschwindigkeit ungefähr zwei Drittel der Lichtgeschwindigkeit. Durch Priorisierung oder durch virtuelle Kanäle kann der Jitter gemindert aber nicht beseitigt werden. Jitter läßt sich aber am Empfänger durch einen Playoutbuffer ausgleichen. Dabei entsteht natürlich eine zusätzliche Verzögerung (Playoutverzögerung). Verluste im Netz lassen sich durch mehrere Verfahren ausgleichen. Kleine Verlustraten können vollständig kompensiert werden, hohe Seite 10 Kapitel 2: Einführung Verlustraten – insbesondere durch Überlast – können nur teilweise oder überhaupt nicht mehr ausgeglichen werden. Im einzelnen lassen sich die Verfahren folgenden Klassen zuordnen: • • • Verlustvermeidung, Verlustverschleierung und Verlustkorrektur. Bei der letzten Klasse gehen die korrigierten Verluste allerdings zu Lasten einer größeren benötigten Bandbreite und/oder einer größeren Verzögerung und höherem Jitter. 2.2.1 Verlustvermeidung Eine Möglichkeit der Verlustkontrolle ist die Verlustvermeidung durch Rate Control, d.h. Anpassen der Senderate. Da das Internet über keine Zugangskontrolle verfügt, ist es möglich, daß zu viele Benutzer auf einmal gleichzeitig Daten über eine Verbindung senden. Durch die Überlast treten dann Verluste auf. Das TCP Protokoll verfügt über eingebaute Mechanismen, die im Überlastfall die Senderate verringern. Um die Verluste im Netz zu reduzieren, müßten Echtzeitanwendungen die Senderate entsprechend senken. Für die meisten Echtzeitdienste (insbesondere für Audioübertragung) benötigt man allerdings eine konstante Bitrate. Verfahren zur Ratenanpassung für Videoströme sind wohlbekannt. Die große Reichweite der Bitraten mit guter Qualität macht den Einsatz von adaptiven Rate Control Algorithmen möglich. Verfahren zur Ratenanpassung bei Audioströmen existieren allerdings so gut wie keine. Ein weiteres Problem ist die Ratenanpassung beim Einsatz von Multicast, da hier die Verluste für jeden Empfänger anders sind. Eine Lösung des Problems ist eine hierarchische Kodierung kombiniert mit Layered-Multicast, d.h., die einzelnen „Schichten“ des Videos werden auf unterschiedlichen Multicast-Gruppen gesendet. Die Empfänger empfangen die unterschiedlichen „Schichten“ je nach auftretendem Verlust. Ratenkontrolle ist also ein Ansatz, um die Verluste durch Überlast im Netzwerk von vornherein zu vermeiden. Eine wirksame Verringerung der Verluste ist nur möglich, wenn alle oder zumindest fast alle Anwendungen eine Ratenkontrolle einsetzen. Problematisch ist außerdem, daß es momentan für Audio keine Verfahren zu Ratenanpassung gibt. 2.2.2 Verlustverschleierung Bei der Verlustverschleierung wird versucht, die aufgetretenen Verluste möglichst gut vor der Wahrnehmung des Menschen zu verbergen. Eine einfache Möglichkeit ist, mit Hilfe vorangegangener und/oder nachfolgender Daten die verlorenen Daten beim Empfänger näherungsweise zu erzeugen. Bei Audioströmen kann man zum Beispiel einfach das vorangegangene Paket duplizieren oder über das vorangegangene und das nachfolgende Paket interpolieren um die Lücke zu schließen. Ist die Lücke genügend klein, wird das Ergebnis als deutlich besser vom Menschen empfunden als ein Verlust, der eine kurze Unterbrechung des Signals bedeutet. Eine interessante Methode zur Verlustverschleierung ist das Adaptive Packetization and Loss Concealment (AP/C) Verfahren. Hier werden unterschiedlich lange Pakete erzeugt, je nachdem ob gerade stimmhafte oder nicht stimmhafte Laute vorliegen. Bei stimmhaften Lauten wird eine kleine Paketgröße gewählt, bei nicht stimmhaften Lauten eine große Paketgröße. Verlorene Pakete werden am Empfänger durch Kopieren und Resampling wiederhergestellt (siehe [San98]). Vorteile der Verlustverschleierung sind, daß keine oder kaum (AP/C) zusätzliche Bandbreite verbraucht wird und die zusätzliche Verzögerung klein ist. Ein Problem ist, daß die Verschleierung nur bei kleinen Lücken im Signal gut funktioniert. Bei großen Lücken – mehSeite 11 Kapitel 2: Einführung rere aufeinanderfolgende Pakete gehen verloren (Fehlerbursts) – ist die Qualität kaum besser als ohne Fehlerverschleierung. Da im Internet meist burstartige Verluste auftreten, funktioniert eine Verschleierung nur bedingt. Eine Idee ist, durch geeignetes Queue Management in den Netzknoten (Routern) dafür zu sorgen, daß möglichst keine Burstverluste auftreten (siehe [SaCa98]). 2.2.3 Verlustkorrektur Um die Übertragungsqualität in einem paketorientierten und verlustbehafteten Netz durch Verlustkorrektur zu verbessern, gibt es im wesentlichen drei Alternativen: • • • Erneute Übertragung fehlerhafter Pakete (ARQ-Verfahren), Vorwärtsfehlerkorrektur durch Redundanz (FEC-Verfahren) und Hybride Verfahren (Mischung aus ARQ und FEC). Für Multimedia-Anwendungen mit Echtzeitbedingungen bieten sich insbesondere FECVerfahren an, da diese die Verluste im Netz durch zugesetzte Redundanz ausgleichen und die Verzögerungszeit nicht weiter erhöhen. Die Übertragungszeit erhöht sich nur geringfügig durch den entstehenden Kodierungs- und Dekodierungsaufwand im Sender bzw. Empfänger. Bei ARQ Verfahren werden verlorengegangene Pakete komplett neu übertragen. Bei langen Übertragungszeiten zum Beispiel auf Satellitenverbindungen steigt die Verzögerungszeit bereits bei einer Wiederholung von ca. 260 ms auf ca. 780 ms. Diese langen Laufzeiten beeinträchtigen Dialoge stark, der Sprechwirkungsgrad liegt nur noch bei 0,1 (siehe [Noll96], Seite 131). Ein weiterer Nachteil bei der Fehlerkorrektur durch ARQ-Verfahren ist das Auftreten von Jitter. Jitter bedeutet, die Zwischenankunfszeiten der einzelnen Datenpakete sind nicht konstant, d.h., die Pakete kommen in sehr unterschiedlichen Abständen beim Empfänger an. Vorhandener Jitter läßt sich natürlich durch Mechanismen wie zum Beispiel einen Playoutbuffer kompensieren. Dadurch steigt allerdings wieder die Verzögerungszeit, was den Sprechwirkungsgrad gerade bei Dialogen negativ beeinflußt. Bei Multicast-Übertragung und vom Sender gesteuerten ARQ-Verfahren treten Skalierbarkeitsprobleme auf. Bei einer großen Anzahl von Empfängern in der Multicast-Gruppe kann es zu einer sogenannten (N)ACK-Implosion kommen. Die große Menge von (N)ACKs erzeugt nicht nur weitere Last im Netz – was zu zusätzlichen Verlusten führen kann – sondern kann auch den Sender überlasten. In [NoBT97] wird gezeigt, daß der Einsatz von FEC als transparente Schicht unterhalb von ARQ die Effizienz und Skalierbarkeit wesentlich verbessert. Weitere Vorteile ergeben sich, wenn FEC und ARQ integriert werden. 2.2.3.1 Prinzip der Vorwärtsfehlerkorrektur Bei der Vorwärtsfehlerkorrektur werden aus den ursprünglichen Daten mit Hilfe geeigneter Kodierungsverfahren Redundanzinformationen erzeugt, die zusätzlich über das Netz übertragen werden. Eine Gruppe von k Datenpaketen und h Redundanzpaketen bezeichnet man auch als FEC Block. Die Datenpakete innerhalb des Blocks werden Transmission Group (TG) genannt. Jeder FEC Block hat also die Größe n = k + h. Durch die Redundanzpakete ist der Empfänger in der Lage, verlorengegangene oder beschädigte Pakete wiederherzustellen, ohne das eine erneute Übertragung erforderlich ist. Der Empfänger kann den empfangenen FEC Block wiederherstellen, wenn er mindestens k der n gesendeten Pakete korrekt empfangen hat. Dabei ist es unerheblich, ob es sich bei einem der k Pakete um ein Datenpaket oder ein Redundanzpaket handelt. Für die höheren Protokollschichten ist dann kein Verlust sichtbar. Seite 12 Kapitel 2: Einführung Die nachfolgende Abbildung 4 zeigt eine schematische Darstellung der Übertragungsstrecke, auf der ein Datenpaket verlorengeht (D2). Das Paket D2 kann jedoch am Empfänger durch das noch übriggebliebene Redundanzpaket R2 rekonstruiert werden, so daß für höhere Protokollschichten kein Verlust sichtbar ist. D3 D2 D1 D3 R2 R2 R1 R1 D3 D2 D1 D1 R2 FEC Codierer D3 D2 D1 FEC Decodierer Abbildung 4: Übertragung mit FEC (k=3, h=2) Zur Erzeugung der Redundanz können verschiedene Kodierungsverfahren benutzt werden (siehe [Noll96], Seite 312-326). Besonders geeignet und häufig verwendet im Bereich der Übertragung und Speicherung digitaler Daten sind die zyklischen Blockcodes, insbesondere die BCH- und Reed-Solomon-Codes (RS-Codes). Reed-Solomon-Codes arbeiten mit Symbolen, die aus m Bit bestehen, anstatt mit einzelnen Bits. Im folgenden Abschnitt 2.2.3.2 soll das Reed-Solomon Verfahren zur Kodierung näher erläutert werden. 2.2.3.2 Reed-Solomon-Codes Reed-Solomon-Codes gehören zu den zyklischen Blockcodes, sie sind eine Teilmenge der BCH-Codes. Sie werden inzwischen in vielen Bereichen der digitalen Datenverarbeitung eingesetzt [RiRi98]: • • • • Speichermedien (Tape, Compact Disc, DVD, Barcodes) Drahtlose Kommunikation (Handys, Satelliten) Digitales Fernsehen (Digital Video Broadcasting - DVB) xDSL Modems Im Gegensatz zu BCH-Codes arbeiten Reed-Solomon-Codes auf Symbolen, die jeweils aus m Bit bestehen. Bei m = 8 werden also Bytes als Symbole verwendet, es können jedoch auch ganze Pakete als Symbole verwendet werden Es werden Kodierblöcke mit N = 2m – 1 Symbolen gebildet, von denen K = 1,2,...N-1 Informationssymbole sind. Ein von einem ReedSolomon-Kodierer erzeugtes Symbol soll im folgenden auch als Codewort bezeichnet werden. Es können alle Kombinationen aus T oder weniger Codewörtern korrigiert werden. Es gilt laut [Noll96]: T= d min − 1 mit dmin = N – K + 1 2 Dabei ist dmin der Mindestabstand zweier beliebiger Codewörter (minimaler Hammingabstand). Reed-Solomon-Codes können verkürzt werden, wenn im Kodierer eine Anzahl von Informationssymbolen zu Null gesetzt wird. Diese zu Null gesetzten Symbole werden nicht übertragen, sondern vor dem Dekodieren wieder eingefügt. Seite 13 Kapitel 2: Einführung Reed-Solomon Codewörter (Symbole) werden mit einem speziellen Generator-Polynom erzeugt. Alle gültigen Codewörter sind durch dieses Polynom teilbar. Die allgemeine Form des Generator-Polynoms ist: g ( x) = ( x − a i ) ⋅ ( x − a i +1 ) ⋅ ... ⋅ ( x − a i + 2T ) Das Codewort wird folgendermaßen konstruiert: c( x ) = g ( x ) ⋅ i ( x) Dabei ist g(x) das Generatorpolynom und i(x) der Informationsblock. Der Dekodierer am Empfänger kann das angekommene Codewort rekonstruieren, wenn 2 ⋅ s + r ≤ 2 ⋅ T (s = Fehler, r = bekannter Fehler) ist. Ein bekannter Fehler ist ein Fehler, dessen Position im Codewort bekannt ist. Kennt man die Positionen aller Fehler im Codewort, kann ein Reed-Solomon-Code doppelt so viele Fehler korrigieren. Normalerweise weiß man bei der Übertragung von Paketen aufgrund der Sequenznummern bereits vor dem Dekodieren, welche Pakete verloren wurden. Deshalb kann der Dekodierer genau so viele Pakete wiederherstellen, wie es Redundanzpakete gibt. Ein verlorenes Paket kann also nicht rekonstruiert werden, wenn weniger als k der übrigen n-1 Pakete beim Empfänger angekommen sind. Wenn p die ursprüngliche Verlustwahrscheinlichkeit ist, beträgt die Restverlustwahrscheinlichkeit bei Einsatz eines Reed-Solomon-Codes laut [NoBT97]: n −k −1 n − 1 j ⋅ p ⋅ (1 − p) n − j −1 mit 1 ≤ k ≤ n q(k , n, p) = p ⋅ 1 − ∑ j j Diese Formel gilt allerdings nur unter der Annahme, daß die auftretenden Fehler statistisch unabhängig sind. Abbildung 5 zeigt die Auswirkungen von FEC auf die Ankunftswahrscheinlichkeit eines Paketes in Abhängigkeit von der ursprünglichen Verlustrate. Die Wahrscheinlichkeiten wurden mit der obigen Formel berechnet. Da jeweils Symbole korrigiert werden, sind RS-Codes insbesondere zur Korrektur von Burstfehlern geeignet, soweit die Burstfehler innerhalb eines Symbols auftreten. Die m-bitorientierte Dekodierung ist sehr effizient und ermöglicht die Verwendung von langen Blöcken. Bei der Dekodierung können mit hoher Wahrscheinlichkeit empfangene nicht korrigierbare Codewörter erkannt werden. Das genaue mathematische Verfahren soll hier nicht näher erläutert werden, eine gute Einführung findet man in [Rett97]. Seite 14 Kapitel 2: Einführung 1 Ankunftswahrscheinlichkeit 0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1 FEC 6/3 FEC 6/4 ohne FEC 0 1,E-02 1,E-01 1,E+00 Paketverlustrate Abbildung 5: Auswirkung der Paketverlustrate auf die Ankunftswahrscheinlichkeit Eine Abschätzung der Geschwindigkeit eines Reed-Solomon-Dekodierers liefert die folgende Tabelle aus [RiRi98]: Code RS (255,251) RS (255, 239) RS (255, 223) Datenrate [Mbps] 12 2,7 1,1 Tabelle 2 : Geschwindigkeit eines Reed-Solomon-Dekodierers Die Geschwindigkeit wurde auf einem Pentium mit 166MHz ermittelt. Die Kodierung ist um einiges schneller, weil weniger Berechnungen erforderlich sind. Eine interessante neue Entwicklung auf dem Gebiet der Kanalkodierung sind die sogenannten Turbo Codes. Turbo Code Kodierer erzeugen mit Hilfe zweier schwacher Faltungskodierer und eines Interleavers einen sehr mächtigen Code. Trotz des mächtigen Codes ist die Struktur des Kodierers wesentlich einfacher als die vergleichbarer Reed-Solomon-Kodierer. Eine Einführung in die Theorie der Turbo Codes findet man in [Ryan98]. 2.2.3.3 Übertragungsprotokolle mit FEC Mechanismen In [PaWa98] wird ein adaptives FEC Verfahren zur Übertragung von Paketen für Echtzeitdienste vorgestellt. Es wird von der Annahme ausgegangen, daß die Menge an eingesetzter Redundanz entsprechend dem Zustand des Netzwerkes variiert werden muß. Sind die Verluste im Netzwerk gering, benötigt man nur wenig Redundanz. Sind die Verluste dagegen hoch, benötigt man entsprechend mehr Redundanz. Allerdings gibt es einen gewissen Punkt, ab dem man keine zusätzliche Redundanz mehr einsetzen sollte, da sich dann der Zustand des Netzwerkes durch die zusätzliche Redundanz stark verschlechtert. Die selbst erzeugten Verluste steigen dann rapide an, so daß die effektive Verlustrate am Empfänger schließlich größer wird, als mit einer kleineren eingesetzten Menge an Redundanz. Seite 15 Kapitel 2: Einführung Die Autoren definieren ein Protokoll, das die Redundanz am Sender entsprechend der erreichten Recovery-Rate am Empfänger wählt. Die vorgegebene Mindest-Recovery-Rate muß dabei natürlich kleiner oder gleich der optimalen Recovery-Rate sein. Die Analyse des Kontrollalgorithmus zeigt, daß es Instabilitäten gibt. Das Algorithmus wird instabil, wenn die eingesetzte Redundanz die Menge überschreitet, die zur Erreichung der optimalen RecoveryRate notwendig ist. Dieses Verhalten kann durch einen exponentiellen Backoff (wie bei TCP) beseitigt werden, wenn das System den stabilen Bereich verläßt. Instabilitäten durch die Verzögerung im Netzwerk werden durch einen der Verzögerungszeit angepaßten Faktor vermieden. [RFC2198] beschreibt ein Format für die Übertragung von redundanten Audiodaten mit dem RTP Protokoll. Die Übertragung von Redundanz erlaubt eine Verbesserung der Qualität, falls Verluste im Netzwerk auftreten. Wenn ein Paket im Netz verlorengeht, kann es am Empfänger aus den redundanten Daten, die mit einem späteren Paket eintreffen, rekonstruiert werden. An den RTP Header angrenzende zusätzliche Header spezifizieren die redundanten Daten. In [BoFT98] wird ein Algorithmus entwickelt, der eine kombinierte Raten- und Fehlerkontrolle ermöglicht. Dabei wird mit Hilfe von Utility-Kurven versucht, eine optimale subjektive Qualität zu erreichen. Zur Übertragung wird eine redundante Audioübertragung entsprechend [RFC2198] benutzt. In [RoSc98] wird ein Format spezifiziert, um Redundanzinformation zur Vorwärtsfehlerkorrektur in RTP zu übertragen. Das Format wurde speziell für Algorithmen entwickelt, die mit Paritätsinformationen (XOR) arbeiten. Sowohl die Mediendaten als auch alle wichtigen Felder des RTP Headers können am Empfänger wiederhergestellt werden. Die Redundanzinformationen werden hier als separater Strom gesendet, so daß eine Abwärtskompatibilität sichergestellt ist. Empfänger, die keine Vorwärtsfehlerkorrektur beherrschen, können die Redundanzpakete einfach ignorieren. Alle Informationen, die der Empfänger zu Wiederherstellung von verlorenen Paketen benötigt, werden in einem sogenannten FEC Header übertragen, der sich direkt an den RTP Header anschließt. Ein leicht modifiziertes Format zur Übertragung von Redundanzinformationen mittels Reed-Solomon Codes wird in [RoSc98-2] vorgestellt. Das Format ermöglicht beliebige Blocklängen. Die Parameter h und k können Werte zwischen 1 und 256 annehmen. Auch hier wird die Redundanz als separater Strom gesendet, so daß eine Abwärtskompatibilität sichergestellt ist. Empfänger, die keine Vorwärtsfehlerkorrektur beherrschen, können die Redundanzpakete einfach ignorieren. In [GuCW98] wird ein universelles, flexibel einsetzbares Format zur Übertragung von verschiedenen Medien innerhalb eines RTP Pakets vorgestellt. Das Format läßt sich sowohl für Video und Audio als auch für Szenenbeschreibungen nutzen. Außerdem bietet es die Möglichkeit, beliebig kodierte und an die Mediendaten angepaßte Redundanzinformationen zu übertragen. Medienspezifische Informationen befinden sich in sogenannten Extension Data Feldern, deren Bedeutung mit einem out-of-band Mechanismus zum Beispiel dem Service Description Protocol (SDP) signalisiert wird. Seite 16 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3 Übertragung und Nutzung von Dienstinformationen Um den Anwender über angebotene Dienstklassen und deren Tarife zu informieren, muß ein Datenaustausch zwischen Dienstanbieter und potentiellem Dienstnutzer stattfinden. Abschnitt 3.1 gibt einen Überblick über ein solches System und beschreibt die einzelnen Komponenten. Die Syntax und die Semantik des Datenaustausches wird durch ein Protokoll definiert. In Abschnitt 3.2 wird ein entsprechendes Protokoll, das Charging Information Protokoll (CIP), vorgestellt. Um Tarife mathematisch angeben zu können, wurde eine entsprechende Sprache entwickelt. Die Tariff Formula Language (TFL) wird in Abschnitt 3.3 definiert und anhand von Beispielen dargestellt. Da der Benutzer daran interessiert ist, eine angemessene Qualität für einen möglichst günstigen Preis zu bekommen, wird in Abschnitt 3.4 ein Verfahren zur automatischen optimalen Wahl der Dienstklasse vorgestellt. Dabei wird auch der Einsatz von Vorwärtsfehlerkorrektur (Reed-Solomon-Codes) berücksichtigt. 3.1 Systemüberblick 3.1.1 Systemkomponenten Die Abbildung 6 gibt einen Überblick über die einzelnen Komponenten eines Systems zur Dienstgüteauswahl mit Vorwärtsfehlerkorektur. Abgebildet sind hier sowohl die Komponenten auf der Seite des Benutzers, als auch die auf der Seite des Dienstanbieters. Die Schnittstelle zwischen beiden Seiten bildet der Zugangsrouter. Benutzer Dienstanbieter SNMP Anwendung unbekannt RTP/RTCP C&A/CIP Server CIP Client CIP FGCP C&A Management CIP Router SNMP Meßpunkt SNMP FEC Gateway RTP/RTCP – FEC Tunnel Meßpunkt Kontrollverbindung Datenverbindung Abbildung 6: System zur Dienstgüteauswahl Der Benutzer hat eine oder mehrere Multimedia-Anwendungen zum Beispiel ein Programm für Videokonferenzen oder ähnliches. Die Anwendung benutzt zur Übertragung der Seite 17 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Mediendaten das RTP Protokoll. Der CIP Client fragt die verfügbaren Dienstklassen beim CIP Server des Dienstanbieters ab und präsentiert sie dem Benutzer. Wenn der Benutzer eine bestimmte Dienstklasse wählt, wird dies dem CIP Server durch den CIP Client mitgeteilt. Hat der eingekaufte Dienst eine nicht vernachlässigbare Verlustrate, verbessert ein FEC Gateway durch Vorwärtsfehlerkorrektur die Ende-zu-Ende Dienstqualität. Zusätzlich zu den Medienpaketen werden Redundanzpakete gesendet, die am Empfänger zur Wiederherstellung verlorener Pakete eingesetzt werden. Auf der Seite des Dienstanbieters werden die reservierten und verbrauchten Ressourcen gemessen und der zu zahlende Preis berechnet. Ein Management System erlaubt die Konfiguration des C&A/CIP Servers. 3.1.1.1 CIP Client Der CIP Client fragt die Dienstklasseninformationen beim CIP Server des Dienstanbieters ab und präsentiert sie dem Benutzer. Bei der Anfrage kann ein entsprechender Filter angegeben werden, so daß der Benutzer nur über Dienstklassen informiert wird, die ihn auch interessieren. Der Client kann auf Basis der vom Anwender eingegebenen Informationen (zum Beispiel Bandbreite, Dauer) und der Tarife die entstehenden Kosten im Voraus berechnen. Der Benutzer weiß so bereits vorher, was ihn ein bestimmter Dienst kosten würde. Sind alle Parameter des gewählten Tarifs (mit Ausnahme der Zeit) konstant, kann der Client auch während der Nutzung die momentanen Kosten anzeigen. Es handelt sich also um eine sehr einfache Form der Online Tarifierung. Für eine allgemeine Online Tarifierung muß der Client außerdem Informationen über die verbrauchten und reservierten Ressourcen vom Server bekommen (siehe 3.1.1.5). Die Kommunikation zwischen Client und Server findet über das CIP Protokoll statt. Vor der Nutzung des Dienstes teilt der Client dem Server des Dienstanbieters die gewählte Dienstklasse mit. Dann kann die Reservierung der Ressourcen erfolgen (Intserv) bzw. der Zugangsrouter markiert den Medienstrom mit dem entsprechenden TOS (Diffserv). Hat der gewählte Dienst eine bekannte Verlustrate, kann der Client eine Verbesserung der Qualität durch Vorwärtsfehlerkorrektur veranlassen. Der Client bestimmt die optimalen Kodierparameter für den Datenstrom (siehe Abschnitt 3.4) und sendet sie an das FEC Gateway. Im Normalfall ist die Verlustrate bei Einkauf des Dienstes nicht bekannt. Der Client kann die tatsächlich auftretende Verlustrate für den Strom beim FEC Gateway abfragen. Die Kommunikation zwischen Client und FEC Gateway wird über ein sogenanntes FEC Gateway Control Protocol (FGCP) durchgeführt. Eine minimale Variante eines solchen Protokolls wird in Abschnitt 4.1.5 definiert. Weiterhin wäre eine direkte Kommunikation zwischen Anwendung und Client denkbar. Die Anwendung könnte dann zum Beispiel dem Client direkt die gewünschte Dienstqualität und die den Datenstrom beschreibende Parameter mitteilen. Eine solche Kommunikation erfordert die Definition eines neuen Protokolls sowie Änderungen an bereits existierenden Anwendungen. Für die Übertragung der Characteristik des Datenstroms wäre es denkbar, das Session Description Protocol (SDP) einzusetzen. 3.1.1.2 C&A/CIP Server Der in Abbildung 6 dargestellte C&A/CIP Server besteht in der Realität mit hoher Wahrscheinlichkeit aus mehreren unterschiedlichen Servern, die hier aber konzeptionell als ein Server betrachtet werden sollen. Seite 18 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Der allgemeine Carging&Accounting Teil des Servers hat die folgenden Aufgaben: • • • Sammeln von Meßdaten über die verbrauchten und reservierten Ressourcen (Accounting), Berechnung des Preises anhand des Tarifs und der Meßdaten (Charging) und Anfertigung der Rechnung (Billing). Im weiteren soll nur der CIP Teil näher betrachtet werden. Der CIP Server hat die Informationen über alle angebotenen Dienstklassen gespeichert. Auf Anforderung des Clients übermittelt der Server entweder die kompletten oder einen Teil der Informationen (bei Verwendung eines Filters). Es ist denkbar, daß bestimmte Dienste nur für ausgewählte Kunden angeboten werden. Der Server muß über einen Authentifizierungsmechanismus verfügen, der sicherstellt, daß diese Dienste nur den ausgewählten Kunden angeboten werden. Ein Beispiel für solche Dienste wären zum Beispiel kundenspezifische Sonderangebote. Der Server nimmt Dienstklassenanforderungen des Clients entgegen und veranlaßt dann die nötigen Maßnahmen, um den Dienst zur Verfügung zu stellen. Der Server sorgt außerdem dafür, daß die benötigten Ressourcen gemessen und am Ende der Dienstnutzung dem Kunden in Rechnung gestellt werden. Der Server kommuniziert mit den Servern anderer Dienstanbieter, um einen Ende-zu-Ende Dienst über mehrere Dienstanbieter zu ermöglichen (siehe 3.2.9.2). Weiterhin wäre ein Roaming von Diensten vorstellbar. Das bedeutet, man kann seinen üblichen benutzten Dienst auch über einen anderen Dienstanbieter beziehen, zum Beispiel wenn man verreist ist. 3.1.1.3 C&A Management Das C&A Management ist für die Konfiguration des C&A/CIP Servers zuständig. Das Management ermöglicht die Konfiguration des Meßsystems. Es kann zum Beispiel festgelegt werden, mit welcher Genauigkeit welche Parameter gemessen werden. Ebenso kann man sich die Konfiguration des Abrechnungssystems vorstellen. Das Management ermöglicht außerdem die Erzeugung und Einführung von neuen Diensten mit den entsprechenden Tarifen. Vorstellbar ist zum Beispiel die Erzeugung eines neuen Dienstes aus vorhandenen Dienstkomponenten. Diese Dienstkomponenten könnten dann grafisch einfach zusammengesetzt werden, so wie heutzutage bei den Intelligenten Netzen (IN) in der Telefonie. Werden bestimmte Dienste nur für ausgewählte Benutzer angeboten, müssen diese entsprechend authorisiert werden. 3.1.1.4 FEC Gateway Das FEC Gateway verbessert die Dienstqualität durch eine Vorwärtsfehlerkorrektur. Am Sender wird für den Medienstrom Redundanz erzeugt (Sender Gateway). Die Parameter des Kodierers können für jeden Strom beliebig eingestellt werden. Die hinzugefügte Redundanz erlaubt es, verlorengegangene Pakete am Empfänger wiederherzustellen (Empfänger Gateway). Denkbare Verfahren, um die Redundanz zu erzeugen, sind zum Beispiel Parity Codes oder Reed-Solomon Codes (auch in Kombination mit Interleaving). Die Kodierparameter werden dem Gateway durch das FEC Gateway Control Protocol (FGCP) mitgeteilt. Außerdem läßt sich die Dienstqualität (Verluste, Jitter), die die Empfänger erfahren, mit dem Protokoll auslesen. Seite 19 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.1.1.5 Meßsystem Das Meßsystem mißt die durch einen Datenstrom verbrauchten und reservierten Ressourcen. Die gemessenen Daten werden dann für die Preisberechnung benutzt. In [RFC2063] wird die Architektur für ein solches Meßsystem vorgestellt. Das System besteht aus Meßinstanzen (Metern), die das Volumen (Bytes und Pakete) der im Netzwerk auftretenden Ströme messen und aufzeichnen. Es werden also nur die verbrauchten Ressourcen gemessen. Der Meter arbeitet auf der Ebene von IP-Paketen, Meßskripte ermöglichen eine beliebige Filterung von Strömen beim Meßvorgang. Mit Hilfe der Sender- und Empfängeradresse kann die Messung zum Beispiel auf einen einzelnen Strom eingeschränkt werden. Die gemessenen Daten werden in einer MIB (siehe [Brow98]) gespeichert und können von einem Meter Reader per Simple Network Management Protocol (SNMP) abgefragt werden. In [CaMM98] wird eine Erweiterung für das oben beschriebene Meßsystem entwickelt, mit der auch durch RSVP reservierte Ressourcen gemessen werden können. Dazu werden die Felder der RSVP RESV Nachrichten ausgewertet. Abbildung 7 zeigt die Tarifierung eines gemessenen Stromes mit drei unterschiedlichen Tarifen. Die Tarife wurden in der TFL (siehe Abschnitt 3.3) spezifiziert und sind im Anhang 7.3 angegeben. Abbildung 7: Tarifierung einer gemessenen Verbindung Seite 20 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2 Das CIP Protokoll In den nächsten Abschnitten wird ein Protokoll definiert, das die oben gestellten Anforderungen erfüllt. Das Protokoll wurde, in Anlehnung an die Funktion, Charging Information Protokoll (CIP) genannt. 3.2.1 Überblick 3.2.1.1 Funktionalität Das CIP Protokoll hat zwei wesentliche Aufgaben. Erstens soll es dem Kunden Informationen über die vom Dienstanbieter angebotenen Dienstklassen und deren Tarife liefern. Die Informationen über eine Dienstklasse bestehen dabei aus: • • • • • Identifikation (Dienst, Anbieter), Gültigkeit, Tarif, QoS Garantien und Informationen über die Reservierung. Als zweites soll das Protokoll die Auswahl einer Dienstklasse durch den Kunden ermöglichen. Dabei kann der Kunde die Auswahl manuell treffen oder einem intelligenten Programm überlassen, das anhand der gewünschten Dienstspezifikation die günstigste Dienstklasse wählt. Eine gewählte Dienstklasse kann natürlich auch wieder abbestellt werden. Das CIP Protokoll funktioniert ausschließlich zwischen dem Client eines Kunden und dem Server des Dienstanbieters. Die Signalisierung zwischen mehreren Servern eines Dienstanbieters oder zwischen verschiedenen Dienstanbietern liegt außerhalb des Protokolls. Das CIP Protokoll ist ein Application-Layer-Protokoll, das existierenden Transportprotokolle zur Übertragung benutzt. Das Protokoll hat die folgenden Eigenschaften: • • • Sicher, zuverlässig und robust, einfach aber flexibel und skalierbar. Da das Protokoll sowohl die Angebote des Dienstanbieters als auch den Einkauf einer Dienstklasse durch den Benutzer ermöglicht, können sich Fehler oder Sicherheitslücken fatal auswirken. Es kann ein großer finanzieller Schaden auf der Seite des Anbieters oder des Benutzers entstehen. Das Protokoll muß also in erster Linie sicher und zuverlässig sein. Es muß einen Authentifizierungsmechanismus geben, der eine eindeutige Identifikation des Kunden oder des Dienstanbieters ermöglicht. Manipulationen durch Dritte müssen ausgeschlossen werden. Das Protokoll soll außerdem auch bei der Benutzung eines unzuverlässigen Transportdienstes zuverlässig arbeiten. Ist bei einer Transaktion ein Fehler aufgetreten, müssen die Ergebnisse der Transaktion verworfen und die Transaktion wiederholt werden. Der Protokollablauf ist einfach, um das Protokoll robust zu machen und eine einfache Implementierung zu ermöglichen. Gleichzeitig ist das Protokoll aber flexibel, so daß Änderungen einfach und schnell vorgenommen werden können. Das Protokoll soll außerdem skalierbar sein, d.h., auch bei einer größeren Anzahl von Benutzern muß das Protokoll zuverlässig und möglichst effizient arbeiten. Seite 21 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.1.2 Dienste Die durch das CIP Protokoll angebotenen oder eingekauften Dienste sind IP-Dienste. Der Dienst wird durch einen Strom von IP-Paketen realisiert, der eine bestimmte Dienstqualität bietet. Die Dienstqualität wird mit den üblichen QoS Parametern gemessen (Verlust, Verzögerung, Jitter) und durch Reservierung im Netzwerk sichergestellt. Als Mechanismen für die Sicherstellung der Dienstqualität kann sowohl das Intserv- als auch das Diffserv-Modell, sowie eine Kombination eingesetzt werden (siehe Abschnitt 2.1.1). 3.2.1.3 Eigenschaften des Protokolls Das CIP Protokoll macht nur minimale Annahmen über das darunterliegende Transportprotokoll. Das Transportprotokoll kann entweder einen zuverlässigen oder unzuverlässigen Dienst bereitstellen. Auf das Internet bezogen, kann CIP sowohl über das UDP- als auch über das TCP-Protokoll eingesetzt werden. UDP ermöglicht ein genaueres Timing der Nachrichten und der Retransmissions. Die Unterstützung von UDP erlaubt außerdem den Einsatz von Multicast und damit eine bessere Skalierbarkeit. TCP erlaubt einen einfacheren Einsatz bei Verbindungen über Firewalls und ermöglicht aufgrund des ähnlichen Protokolldesigns gemeinsame Server für CIP, SIP und HTTP (siehe [HaSS98]). Das Protokoll ist text-basiert, es wird die ISO 10646 UTF-8 Kodierung benutzt. Das vereinfacht das Debuggen und erleichtert die Implementierung in Sprachen wie Java, Tcl oder Perl. Ein text-basiertes Protokoll ist außerdem sehr flexibel, Erweiterungen oder Änderungen lassen sich leicht durchführen. Außerdem entstehen keine Konvertierungsprobleme bei der Übertragung von Fließkommazahlen. Aufgrund der vielen denkbaren Dienste und unterschiedlichen Tarife ist die Flexibilität wichtiger, als der durch ein text-basiertes Protokoll entstehende Overhead. Weiterhin wird hier angenommen, daß eine Änderung der Tarife in genügend großen Intervallen erfolgt, so daß der entstehende Overhead nicht signifikant ist. Das CIP Protokoll orientiert sich von der Form an dem in [HaSS98] definierten SIP Protokoll. Eine mögliche Integration der beiden Protokolle wird in Abschnitt 3.2.9.3 diskutiert. Für alle nun folgenden Definitionen wird die im Anhang 7.1 erläuterte Notation benutzt. 3.2.1.4 CIP Adressen CIP Server und CIP Client werden durch CIP Adressen identifiziert. Eine CIP Adresse besteht aus einem Benutzer und einem Host Teil. Die Adresse des CIP Servers eines Anbieters kann out-of-band abgefragt werden, etwa auf den WWW Seiten des Anbieters oder bei einem CIP-Directory-Server (siehe 3.2.9.1). CIP Adressen werden als CIP URLs angegeben. CIP URLs identifizieren Sender und Empfänger einer Nachricht. Eine CIP URL ist folgendermaßen definiert: CIP-URL benutzer passwort host nhost port digits = "cip:" [benutzer] [":" passwort] "@" (host | nhost) [":" port] = siehe [RFC1738] = (ZEICHEN)+ = siehe [RFC1738] = digits "." digits "." digits "." digits = digits = (ZIFFER)+ Eine CIP URL besteht aus dem Präfix "cip:", dem Benutzernamen, dem Paßwort, der Hostadresse und dem Port. Die Benutzeridentifizierung kann wegelassen werden, wenn es nur einen Benutzer auf dem Rechner geben kann (zum Beispiel der CIP Server). Das Paßwort kann als einfache Authentifizierung eines Benutzers für einen CIP Server benutzt werden. Im Seite 22 Kapitel 3: Übertragung und Nutzung von Dienstinformationen einfachsten Fall handelt es sich um das normale Paßwort des Benutzers. Diese Form der Authentifizierung darf nur über eine absolut sichere Netzwerk-Verbindung benutzt werden. Besteht die Möglichkeit, daß die Nachricht durch unbefugte Dritte abgehört werden kann, muß eine Authentifizierung entsprechend Abschnitt 3.2.7.1 durchgeführt werden. Wenn eine CIP Adresse keine Portnummer enthält, muß die CIP Standard-Portnummer benutzt werden. Die Standard-Portnummer für das CIP Protokoll wird vorläufig auf den Wert 4444 festgelegt. In beiden Fällen muß der Client zunächst versuchen, eine Verbindung per UDP herzustellen. Falls dies fehlschlägt, weil der Server kein UDP unterstützt, kann der Client eine TCP Verbindung aufbauen. 3.2.2 Protokollablauf Bei der Betrachtung des Protokollablaufs muß zwischen Unicast- und MulticastÜbertragung unterschieden werden. Bei einer Unicast-Übertragung registriert sich der Client beim Server. Der Server kann die Informationen dann entweder automatisch in bestimmten Abständen an den Client senden (push), oder der Client fordert die Informationen regelmäßig an (pull). Der Client kann bestimmte Dienstklassen auswählen und die Registrierung beim Server jederzeit beenden. Bei einer Multicast-Übertragung werden die Informationen in regelmäßigen Abständen an die Clients übertragen (push). Es gibt keine Bestätigungen oder Retransmissions. Die Zuverlässigkeit der Übertragung hängt damit von der Fehler- bzw. Verlustrate im Netz ab (siehe 3.2.6.3). Eine Multicast-Verbindung ermöglicht eine bessere Skalierbarkeit, außerdem müssen beim Server keine Zustandsinformationen gespeichert werden (minimal state). Exklusive Tarife für ausgewählte Benutzer müssen natürlich verschlüsselt werden, wenn es nur eine Multicast-Gruppe ohne Zugangsbeschränkungen gibt. CIP Nachrichten bestehen aus Requests und Responses. Ein Request wird an einen Empfänger gesendet und löst eine Response aus, die an den Sender geschickt wird. 3.2.3 Transaktionen Eine CIP Transaktion besteht aus einem Request und der dazugehörigen Response. Um festzustellen, ob eine Response zu einem bestimmten Request gehört, gibt es das TransactionID Feld. Der Sender eines Requests erzeugt eine Transaktions-ID und schickt die mit dieser ID versehene Nachricht an den Empfänger. Der Empfänger antwortet mit einer Response, die eine Kopie der Transaktions-ID enthält. Eine Transaktions-ID hat den folgenden Aufbau: Transaktions-ID = nummer ":" benutzer "@" (host | nhost) [":" port] nummer = ZAHL benutzer = siehe [RFC1738] host = siehe [RFC1738] nhost = digits "." digits "." digits "." digits port = digits digits = (ZIFFER)+ Beispiel: 453463747:[email protected] Seite 23 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.4 CIP Nachrichten CIP Nachrichten sind entweder ein Request oder eine Response. Eine CIP Nachricht ist folgendermaßen aufgebaut: cip_message start-line message-fields = start-line message-fields = request-line | status-line = (general-fields | request-fields | response-fields)* Alle Zeilen werden mit einem CRLF beendet. Leere Zeilen vor der ersten Zeile (start-line) werden ignoriert. Die verschiedenen Requests und Responses werden in den folgenden Abschnitten erläutert. Ein Beispiel für einen CIP Protokollablauf findet man in Anhang 7.2. 3.2.4.1 CIP Requests Ein CIP Request ist folgendermaßen aufgebaut: CIP_Request request-line method cip-version = request-line (general-fields | request-fields)* = method request-uri cip-version CRLF = "REGISTER" | "CANCEL" | "GET_INFO" | "INFO" | "SELECT" = "CIP/" digits "." digits Der Request beginnt mit dem Methodenbezeichner (method), gefolgt von der Empfängeradresse und der Version des Protokolls. Mit einem REGISTER Request registriert sich ein CIP Client bei einem CIP Server. Bei einer Registrierung im push Modus (Unicast) (siehe 3.2.5.18) schickt der Server den registrierten Clients in regelmäßigen Abständen Informationen über die angebotenen Dienstklassen mit INFO Requests. Es werden nur für den Client neue oder geänderte Dienstklassen übermittelt. Wenn keine neuen Dienstklassen existieren, wird ein INFO Request ohne Dienstklasse verschickt. Der Client muß am Ende jeder INFO Paketübermittlung mit einer Response quittieren. So können Server und Client feststellen, ob überhaupt noch eine Verbindung existiert und der Server weiß, welche Pakete er gegebenenfalls neu übertragen muß. Bekommt der Server für eine bestimmte Zeit keine Nachrichten vom Client, hebt der Server die Registrierung auf. Registriert sich der Client im pull Modus, muß er die Informationen mit GET_INFO Requests anfordern. Mit einem CANCEL Request beendet der Client die Registrierung beim Server. Weitere Requests werden erst nach einer erneuten Registrierung vom Server bearbeitet. Mit einem GET_INFO Request kann der Client jederzeit alle Dienstklassen abfragen. Der Server schickt alle Dienstklassen als INFO Response. Der Client sendet also keine Bestätigung an den Server. Falls der Client den Verlust eines Paketes erkannt hat, muß er einen erneuten GET_INFO Request an den Server schicken oder auf einen INFO Request des Servers warten. Der Server schickt in regelmäßigen Abständen einen INFO Request an den Client. Ein INFO Request besteht aus mehreren Paketen. Jede Dienstklasse wird in einem eigenen Paket verschickt. Der Client antwortet dann mit einem OK oder einer Fehler-Response. Aufgrund der Sequenznummern kann der Server die verlorenen INFO Pakete sofort neu übertragen. Seite 24 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Mit dem SELECT Request wählt der Client eine Dienstklasse beim Server aus. Der Client teilt dem Server den ausgewählten Dienst und den Endpunkt (das Ziel) der Verbindung mit. CIP Client CIP Server REGISTER 200 (OK) ........ INFO1 ........ INFOn 200 (OK) SELECT 200 (OK) ........ CANCEL 200 (OK) Abbildung 8: Protokollablauf Die Abbildung 8 zeigt den normalen Protokollablauf bei einer Unicast-Verbindung. Abbildung 9 zeigt ein verlorenes Paket bei einer vom Server ausgelösten Übertragung von INFO Paketen und die erneute Übertragung durch den Server. In Abbildung 10 fordert der Client die Information mit einem GET_INFO an. Das verlorene Paket wird nicht direkt neu übertragen, der Client muß einen erneuten GET_INFO Request senden. CIP Client CIP Server ........ INFO1 INFO2 ........ INFOn 403 (REQ TIMEOUT) INFO2 200 (OK) Abbildung 9: Protokollablauf - Verlorenes INFO Paket Seite 25 Kapitel 3: Übertragung und Nutzung von Dienstinformationen CIP Client CIP Server ........ GET_INFO (201) INFO1 (201) INFO2 ........ (201) INFOn GET_INFO ........ Abbildung 10: GET_INFO - Verlorenes INFO Paket Bei einer Multicast-Übertragung registriert sich der Client nicht beim Server. Der Client empfängt die regelmäßig vom Server gesendeten INFO Pakete. Der Client bestätigt keine empfangenen Pakete. Tritt bei der Übertragung ein Fehler auf (Paketverlust), muß der Client warten, bis der Server die Informationen erneut überträgt. SELECT Requests werden vom Client auf einem zusätzlichen Unicast Kanal an den Server gesendet (wie oben beschrieben). 3.2.4.2 CIP Responses Eine CIP Response ist folgendermaßen aufgebaut: CIP-Response status-line cip-version status-code reason-phrase = status-line (general-fields | response-fields)* = cip-version status-code reason-phrase CRLF = "CIP/" digits "." digits = success | client-error | server-error | global-failure = string Ein Request beginnt mit der Versionsnummer, es folgt der numerische Statuscode und eine Textbeschreibung des numerischen Codes (reason-phrase). Der Statuscode ist für eine maschinelle Auswertung gedacht, während die Beschreibung für einen menschlichen Benutzer lesbar ist. Die Statuscodes sind in folgende Gruppen unterteilt (siehe auch [HaSS98]): 2xx: Erfolg 4xx: Client Error - Der Request wurde erfolgreich empfangen und bearbeitet. - Der Request ist fehlerhaft oder kann nicht an diesem Server ausgeführt werden. 5xx: Server Error - Der Server kann den anscheinend korrekten Request nicht ausführen. 6xx: Global Failure - Der Request kann an keinem Server ausgeführt werden. Folgende Statuscodes und ihre Beschreibungen sind definiert: success = "200" ; OK = "201" ; INFO client-error = "400" ; Bad Request | "401" ; Unauthorized | "402" ; Forbidden Seite 26 Kapitel 3: Übertragung und Nutzung von Dienstinformationen | | | | "403" ; Request Timeout "420" ; Bad Extension (Require) "430" ; Bad Numeric Expression "440" ; Invalid Transaction-ID server-error = "500" ; Server Internal Error | "501" ; Not Implemented | "502" ; Service Unavailable | "503" ; Version Not Supported global-failure = "600" ; Global Failure 3.2.5 Header Felder Die Header Felder orientieren sich von der Syntax und der Semantik an HTTP. Die Reihenfolge der Felder in einer Nachricht ist beliebig. Tabelle 3 zeigt, welche Header Felder bei welchen Methoden benutzt werden müssen, welche optional sind und welche nicht angewendet werden dürfen. Header Felder haben die folgende Syntax: header-field field-name field-value = field-name ":" field-value = (ZEICHEN)+ = (WS | (ZEICHEN)+)* Folgende Nachrichtenfelder sind definiert: general-fields request-fields response-fields = Transaction-ID | Iseq | Encryption | From = Service | Vendor | Valid-Until | Valid-From | Currency | Guarantees | Parameter | Formula | Require | Filter | Authorisation | Endpoint | Mode | Response-Key | Reservation | Reservation-Parameter = Update-Frequency | Unsupported | Warning | Authenticate General-Fields können sowohl in Requests als auch Responses eingesetzt werden. Request- und Response-Fields dürfen entsprechend nur in Requests oder Responses vorkommen. Transaction-ID Iseq Encryption From Service Vendor Valid-Until Valid-From Currency Guarantees Parameter Formula Response-Key Require Type g g g g R R R R R R R R R R GET_INFO x o x o o INFO x x o x x x o o x o x x o - REGISTER x o x o o CANCEL x o x o - SELECT x o x x o o o Seite 27 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Filter Authorization Endpoint Mode Reservation ReservationParameter Update-Freqency Unsupported Warning Authenticate R R R R R R o o - o - o o o x x o - o x - r r(420) r r(401) o o o o o o - o o o o o o o o Tabelle 3 : CIP Header Felder Type: g = general, R = Request, r = response Anwendung: x = erforderlich, o = optional, - = nicht anwendbar 3.2.5.1 Transaction-ID Die Transaction-ID kennzeichnet eine Request-Response Transaktion (siehe 3.2.3). Beispiel: 453463747:[email protected] 3.2.5.2 Iseq Alle zusammengehörigen INFO Pakete werden mit fortlaufenden Sequenznummer versehen. Der Client schickt bei der Bestätigung die Sequenznummern aller angekommenen Pakete an den Server. Dieser kann dann die verlorenen Pakete neu übertragen. Iseq = "Iseq:" ZAHL Beispiel: Iseq: 25456 3.2.5.3 Encryption Das Encryption Feld wird in verschlüsselte Nachrichten eingefügt (siehe 3.2.7.2). 3.2.5.4 From Das From Feld ist eine CIP URL und kennzeichnet den Absender eines Requests. Es muß bei allen Requests verwendet werden. Beispiel: From: cip:[email protected] 3.2.5.5 Service Das Feld Service identifiziert eine Dienstklasse durch eine Nummer und eine Beschreibung. Service = "Service:" "id=\"" ZAHL "\"" "," "name=" string Beispiel: Service: id="1234", name="audio over IP" Seite 28 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.5.6 Vendor Das Vendor Feld identifiziert den Dienstanbieter einer Serviceklasse. Vendor = "Vendor:" "id=\"" ZAHL "\"" "," "name=" string Beispiel: Vendor: id="25", name="NEW-TEL INC." 3.2.5.7 Valid-Until Das Feld Valid-Until gibt an, bis zu welchem Zeitpunkt der Tarif gültig ist. Bei der Angabe eines Tarifs gibt es zwei Möglichkeiten. Entweder deckt der Tarif den vollständigen Zeitraum ab, d.h., in der Formel gibt es eine Fallunterscheidung nach der Zeit, oder die zeitliche Gültigkeit wird durch die Felder Valid-Until und Valid-From ausgedrückt. Es wird empfohlen, die Zeitabhängigkeit direkt in der Tarifformel auszudrücken. Valid-Until tag monat = "Valid-Until:" tag "," TAG monat JAHR HH ":" MM ":" SS ZEITZONE = "Mon" | "Tue" | "Wed" | "Thu" | "Fri" | "Sat" | "Sun" = "Jan" | "Feb" | "Mar" | "Apr" | "May" | "Jun" | "Jul" | "Aug" | "Sep" | "Oct" | "Dec" Beispiel: Valid-Until: Wed, 9 Dec 1998 18:00:00 MET 3.2.5.8 Valid-From Das Valid-From Feld gibt an, ab welchem Zeitpunkt der Tarif gültig ist. Es hat die gleiche Syntax wie das Valid-Until Feld (siehe 3.2.5.7). Beispiel: Valid-From: Wed, 9 Dec 1998 12:00:00 MET 3.2.5.9 Currency Das Currency Feld drückt die Währung aus, in der der Tarif abgerechnet wird. Im Rahmen dieser Arbeit wurden keine Bezeichner für die verschiedenen Währungen ausgearbeitet, deshalb soll hier nur ein Beispiel gezeigt werden. Beispiel: Currency: US-Dollar 3.2.5.10 Guarantees Das Feld Guarantees beschreibt die QoS Garantien, die die Dienstklasse bietet. Momentan können die maximalen Werte für die Verlustrate, die Verzögerung und den Jitter angegeben werden. Guarantees verluste verzögerung jitter = "Guarantees:" "loss=\"" verluste "\"" "," "delay=\"" verzögerung "\"" "," "jitter=\"" jitter "\"" = Verlustrate = Verzögerung in ms = Jitter in ms Beispiel: Guarantees: loss="0.2", delay="150", jitter="10" Seite 29 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.5.11 Parameter Mit dem Feld Parameter werden alle nicht global definierten Parameter beschrieben (siehe 3.3.2.3), die in der Tarifformel vorkommen. Parameter name wert = "Parameter:" name "=\"" wert "\"" (","name "=\"" wert "\"")* = (ZEICHEN)+ = ZAHL | TFL Ausdruck Beispiel: Parameter: c="0.1", ct="0.2", ut="60", cv="0.25", uv="1024" 3.2.5.12 Formula Das Feld Formula beschreibt die in der TFL (siehe 3.3) angegebene Tarifformel. Beispiel: c + (t/ut)*ct + (v/uv)*cv 3.2.5.13 Response-Key Das Feld Response-Key gibt an, mit welchem Schlüssel die Response verschlüsselt werden muß (siehe 3.2.7.2). 3.2.5.14 Require Das Require Feld teilt dem Server mit, daß der Client eine bestimmte Funktionalität voraussetzt (siehe [HaSS98]). Mit diesem Mechanismus lassen sich Erweiterungen in das Protokoll einfügen. Wenn der Server die Option nicht unterstützt, antwortet er mit einer Bad Extension Response, die das Unsupported Feld enthält. Beispiel: C->S: REGISTER cip:[email protected] CIP/1.0 Require: com.example.zone-billing Payment: zone="regional" S->C: SIP/1.0 420 Bad Extension Unsupported: com.example.zone-billing 3.2.5.15 Filter Das Filter Feld ermöglicht dem Client, eine Vorauswahl an Dienstklassen zu treffen. Das Filter Feld wird also nur bei Unicast eingesetzt. Filter filter = "Filter:" filter = TFL Ausdruck Beispiel: Filter: jitter<10 3.2.5.16 Authorisation Das Authorisation Feld ermöglicht eine eindeutige Identifizierung des Absenders (siehe 3.2.7.1). 3.2.5.17 Endpoint Mit dem Endpoint Feld legt der Client den Endpunkt (das Ziel) für eine eingekaufte Dienstklasse fest. Endpoint host Seite 30 = "Endpoint:" (host | nhost) [":" port] = siehe [RFC1738] Kapitel 3: Übertragung und Nutzung von Dienstinformationen nhost port digits = digits "." digits "." digits "." digits = digits = (ZIFFER)+ Beispiel: Endpoint: mycomputer.some-provider.de:10000 3.2.5.18 Mode Dieses Feld legt fest, ob der Server regelmäßig automatisch INFO Nachrichten an den Client sendet (push), oder ob der Client die INFO Pakete selber mit GET_INFO Requests anfordern muß (pull). Standardmäßig wird der push-Mode benutzt. Das Mode Feld kann nur bei Unicast Übertragung benutzt werden. Mode = "Mode:" "push" | "pull" Beispiel: Mode: pull 3.2.5.19 Reservation Das Reservation Feld kennzeichnet die Art der Ressourcenreservierung im Netzwerk. Momentan gibt es nur das Intserv und das Diffserv Verfahren. Reservation = "Reservation:" "Intserv" | "Diffserv" Beispiel: Reservation: Intserv 3.2.5.20 Reservation-Parameter Das Reservation-Parameter Feld legt notwendige Reservierungsparameter und ihre Werte fest. Reservation-Parameter name wert = "Reservation-Parameter:" name "=\"" wert "\"" (","name "=\"" wert "\"")* = (ZEICHEN)+ = ZAHL Beispiel: Reservation-Parameter: rate="5000" 3.2.5.21 Update-Frequency Mit dem Feld Update Frequency teilt der Server dem Client mit, in welchen Zeitabständen die Dienstklasseninformationen im push Modus übertragen werden. Im pull Modus bestimmt der Client das Intervall, in dem die Informationen gesendet werden (GET_INFO Request). Update-Frequency freq = "Update-Frequency:" freq = Update-Intervall in s Beispiel: Update-Frequency: 30 3.2.5.22 Unsupported Mit dem Feld Unsupported teilt der Server dem Client mit, welche per Require verlangten Optionen er nicht unterstützt (siehe 3.2.5.14). Seite 31 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.5.23 Warning Das Warning Feld dient zur Übertragung von zusätzlichen Informationen in einer Response. Warning = "Warning:" warn-code warn-text warn-code = 3*ZIFFER "." 2*ZIFFER warn-text = (ZEICHEN)+ Beispiel: Warning: 600.2 Multicast not available 3.2.5.24 Authenticate Mit diesem Feld teilt der Server dem Client mit, daß eine Authentifizierung nötig ist (siehe 3.2.7.1). 3.2.5.25 Header Felder Kurzform Um Bandbreite bei der Übertragung von CIP Nachrichten zu sparen, kann eine Kurzform der Headerfelder benutzt werden. Statt dem Feldbezeichner wird nur ein einziger Buchstabe angegeben. Gerade bei häufig benutzten Feldern lohnt sich eine solche Einsparung. In Tabelle 4 werden ein paar Kurzformen gezeigt, weitere können definiert werden. Feldname From Transaction-ID Service Vendor Guarantees Kurzform f i s v g Tabelle 4: Header Felder Kurzformen 3.2.6 CIP Transport CIP wurde so definiert, daß entweder UDP oder TCP als Transportprotokoll eingesetzt werden kann. Es verfügt über eigene Zuverlässigkeitsmechanismen, so daß es auch über unzuverlässige Transportprotokolle wie UDP eingesetzt werden kann. Das CIP Protokoll verwendet dazu Timeouts und Retransmissions. Das Protokoll kann bei UDP sowohl über Unicast als auch Multicast benutzt werden. Aufgrund des Overheads, der durch die Nachrichten der Clients an den Server entsteht, sollte bei Multicast allerdings eine einfachere Variante des Protokolls (nur INFO Requests, siehe 3.2.6.3) eingesetzt werden. Über eine TCP Verbindung können beliebig viele CIP Transaktionen abgewickelt werden, es muß nicht für jede CIP Transaktion eine neue TCP Verbindung hergestellt werden. CIP Nachrichten, die als UDP Datagramme verschickt werden, sollten normalerweise kleiner als die MTU sein. Wenn die MTU nicht bekannt ist, sollten die CIP Nachrichten kleiner als 1400 Byte sein. Kürzliche Studien haben gezeigt, daß die typische MTU bei ungefähr 1500 Byte liegt (siehe [HaSS98]). Zieht man davon die Länge der Paket-Header ab, so ergibt sich der Wert von 1400 Byte als maximale Länge einer CIP Nachricht. Seite 32 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.6.1 REGISTER, CANCEL, SELECT Der CIP Client sendet einen REGISTER, CANCEL oder SELECT Request solange im Abstand t1, bis er entweder eine Antwort vom CIP Server bekommt, oder die maximale Anzahl der Retransmissions erreicht ist. Der Standardwert für t1 ist 5s, die maximale Anzahl der Sendeversuche beträgt 5. Abbildung 11 zeigt den Ablauf der Transaktionen. CLIENT SERVER Request senden Request Fehler Timer t1 Request 200 (OK) Fehler? J N N Max Retrans? 200 (OK) Fehler J Abbildung 11: REGISTER, CANCEL, SELECT 3.2.6.2 GET_INFO, INFO Fordert der CIP Client die Tarife beim CIP Server an, sendet er den GET_INFO Request im Abstand t1 bis er eine Antwort bekommt oder die maximale Anzahl an Retransmissions erreicht ist (siehe 3.2.6.1). Mit Eintreffen des ersten INFO Paketes wartet der Client, bis entweder alle INFO Pakete eingetroffen sind oder der Timer t2 abgelaufen ist. Der Client kann feststellen, ob er alle INFO Pakete bekommen hat, da alle zusammengehörigen INFO Pakete die gleiche Transaktionsnummer haben und in jedem INFO Paket die Gesamtanzahl der Pakete steht. Außerdem sind alle INFO Pakete mit einer Sequenznummer (Iseq) durchnumeriert. Wenn der Client festgestellt hat, daß er nicht alle Pakete bekommen hat, sendet er einen erneuten GET_INFO Request. Der Timer t2 hat standardmäßig einen Wert von 5s. Komplizierter wird es bei der automatischen periodischen INFO Übertragung (Push Mode) durch den Server. Wenn der Client festgestellt hat, daß er nicht alle Pakete bekommen hat, sendet er eine TIMEOUT Response an den Server, welche die Sequenznummer aller empfangenden Pakete enthält. Der Server kann dann die nicht angekommenen Pakete erneut schicken (Selective Repeat). Hat der Client alle Pakete empfangen, quittiert er mit einer OK Response in der ebenfalls alle Sequenznummer enthalten sind. Ein Problem ergibt sich, wenn der Client überhaupt kein Paket bekommt. Er kann nicht wissen, ob der Server überhaupt kein Paket geschickt hat oder alle Pakete bei der Übertragung verloren wurden. Nach Absenden aller INFO Pakete setzt der Server den Timer t3. Wird innerhalb der Zeit t3 keine Rückmeldung vom Client empfangen, überträgt der Server alle INFO Pakete erneut. Auch hier gibt es eine maximale Anzahl der Retransmissions. Der Timer t3 hat einen standardmäßigen Wert von Seite 33 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 10s. Das Update Intervall des Server muß natürlich größer als t3 sein, standardmäßig ist es auf 30s gesetzt. Abbildung 12 zeigt den Ablauf beim Versenden der INFO Pakete. CLIENT SERVER Warten auf INFO INFO senden INFO INFO 1. Paket: Timer t2 starten komplett? N J 200 (OK) Timer t2 abgelaufen Timer t3 TIMEOUT 200 (OK) N J TIMEOUT N Max Retrans? J Warten auf INFO Abbildung 12: Empfang der INFO Pakete 3.2.6.3 CIP and Multicast Zur Übertragung des CIP Protokolls über eine Multicast-Verbindung wird ein wesentlich einfacheres Schema vorgeschlagen. Die vom Client zum Server gesendeten Requests führen bei Multicast zu einem relativ großen Overhead, da sie auch an alle anderen Clients gesendet werden. Bei Multicast versendet deshalb nur der Server die INFO Nachrichten an die Clients, alle anderen Requests werden nicht benutzt. Die INFO Pakete werden auch nicht durch die Clients bestätigt und es gibt keine unmittelbare Retransmission durch den Server. Die Übertragung der INFO Pakete erfolgt ansonsten genau wie bei Unicast Verbindungen. Der Client kann verlorene Pakete anhand der Transaktionsnummer und des Count Feldes erkennen. Erkennt der Client, daß Pakete verloren wurden, muß er warten, bis der Server diese neu überträgt. Die Auswahl einer Dienstklasse muß über einen zusätzlichen Unicast Kanal erfolgen, oder wird einer anderen Instanz überlassen (zum Beispiel einem sogenannten Bandwidth Broker). Wird der SELECT Request auf einem zusätzlichen Unicast Kanal benutzt, ist der Ablauf wie in 3.2.6.1 beschrieben. Die Zuverlässigkeit ist bei diesem Protokollablauf von der Übertragungsqualität im Netz abhängig und damit in der Regel geringer als bei der komplizierteren Unicast-Übertragung. Bei moderaten Verlustraten und relativ großen Update-Intervallen des Servers kann es schon etwas dauern, bis der Client alle INFO Pakete erhalten hat. Unter Umständen kann der Client natürlich auch schon einen Dienst wählen, wenn er nicht die Information über alle Dienste hat. Die Vorteile bei einer Multicast Übertragung sind der wesentlich einfachere Protokollablauf und die bessere Skalierbarkeit bei großen Zahlen von Benutzern. Ein Vorteil bei dem Unicast-Modell ist, daß jeweils nur für den Client neue Dienstklassen übertragen werden müssen. Bei kleinen Benutzerzahlen ist eine Unicast-Übertragung also sogar effizienter als eine Multicast-Übertragung zum Beispiel, wenn es nur einen kleinen Anteil an dynamischen Tarifen gibt. Seite 34 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.7 Sicherheit Gerade bei einem Protokoll wie dem CIP Protokoll ist die Sicherheit ein wichtiger Punkt, weil CIP Nachrichten sensible Daten enthalten und die mit Hilfe des Protokolls getroffenen Entscheidungen des Anwenders unmittelbar seinen Kontostand beeinflussen. Es ist möglich, daß ein GET_INFO Request durch einen Dritten belauscht wird. Der Lauscher kann dann dem Benutzer eine falsche Dienstklasse vorspielen. Das ist ein Problem, wenn ein Dienst mit dieser Identifikation tatsächlich existiert. Ein sehr teuerer Dienst könnte zum Beispiel so in einen sehr billigen Dienst verwandelt werden und der Benutzer zahlt unnötig viel Geld. Der Lauscher könnte auch einen SELECT Request des Benutzers fälschen. Der Benutzer muß dann für einen Dienst bezahlen, den er nie eingekauft hat. Um solche Manipulationen zu vermeiden, benötigt man eine Authentifizierung der Kunden und des Dienstanbieters. Außerdem muß sichergestellt sein, daß keines der Felder der Nachricht geändert wurde. Eine weitere Möglichkeit ist, daß der Lauscher ausspäht, welche Dienste ein Anwender zu welcher Zeit einkauft und so Profile über den Benutzer erstellen kann. Gibt es spezielle Tarife für bestimmte Benutzer, können auch diese ausgespäht werden. Ein Ausspähen der Daten kann mit einer Verschlüsselung verhindert werden. Die im folgenden gezeigten Sicherheitsmechanismen wurden aus [HaSS98] abgeleitet und basieren auf PGP (Pretty Good Privacy). Andere Mechanismen sind aber ebenso denkbar. 3.2.7.1 Authentifizierung Bei dem PGP Authentifizierungsschema identifiziert sich der Client durch die Signierung des Requests mit seinen privaten Schlüssel. Der Server kann den Sender eindeutig zuordnen, wenn er den öffentlichen Schlüssel des Clients kennt. Die Echtheit des öffentlichen Schlüssels muß durch eine Zertifizierungsinstanz bestätigt werden, die garantiert, daß der öffentliche Schlüssel auch der Person gehört, die vorgibt der Eigentümer zu sein. Die Zertifierungsinstanz kennt also die Person (Personalausweis), welcher der Schlüssel gehört. Ein Anbieter kann natürlich auch gleichzeitig als Zertifizierungsinstanz fungieren, wenn Kunden sich zum Beispiel mit einer Kopie des Personalausweises anmelden müssen. Wenn eine Authentifizierung erforderlich ist, kann dies der Server mit dem Authenticate Feld in einer Response anzeigen: Authenticate realm pgp-version pgp-algorithm = "Authenticate: " "pgp" realm "," pgp-version "," pgp-algorithm = "realm=" string = "version=\"" ZIFFER ("." ZIFFER)* (ZEICHEN)* "\"" = "algorithm=" ( "md5" | "sha1" ) Der Wert realm ist ein Text, der dem Benutzer die Art der geforderten Identität anzeigt. Der Wert pgp-algorithm zeigt den erwarteten Algorithmus an, mit dem die Signatur erzeugt wird (Message Integrity Check (MIS)). Der Wert pgp-version gibt die PGP Version an, die der Client benutzen muß. Beispiel: Authenticate: pgp realm="Your NEW-TEL identity please", version="5.0", algorithm="md5" Seite 35 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Der Client muß dann in seinem Request das Authorisation Feld verwenden: Authorisation realm pgp-version pgp-signature = "Authorisation: " "pgp" realm "," pgp-version "," pgp-signature "," = "realm=" string = "version=\"" ZIFFER ("." ZIFFER)* (ZEICHEN)* "\"" = "signature=" string Die Werte realm und pgp-version entsprechen den Werten des Authenticate Feldes und haben dieselben Werte wie in einer vorher empfangenen Response mit Authenticate Feld. Der Wert pgp-signature ist die von PGP erzeugte ASCII-armored Signatur zwischen dem "BEGIN PGP MESSAGE" und dem "END PGP MESSAGE" ohne die Versionsnummer. Die Signatur wird über die komplette Request Nachricht (mit Ausnahme des Authorisation Feldes) berechnet und ohne Zeilensprünge eingefügt. Beispiel: Authorisation: pgp realm="Your NEW-TEL identity please", version="5.0", signature="ZfguU78uzjht67567ufgvuzR/uzfvludouor6778d" 3.2.7.2 Verschlüsselung Das CIP Protokoll ermöglicht eine Ende-zu-Ende Verschlüsselung der Nachrichten. Die Nachricht wird mit dem öffentlichen Schlüssel des Empfängers verschlüsselt und kann nur von diesem mit dem privaten Schlüssel entschlüsselt werden. Der Request-Header, der Response-Header, Authorisation oder Authenticate Felder dürfen nicht verschlüsselt werden. Alle anderen Felder können verschlüsselt werden, müssen es aber nicht. Normalerweise sollte zum Beispiel das From Feld nicht verschlüsselt werden. Unverschlüsselte Felder müssen sich alle am Anfang der Nachricht vor dem verschlüsselten Teil befinden. Nach der Verschlüsselung wird das Encryption Feld in den unverschlüsselten Teil der Nachricht eingefügt: Encryption pgp-version pgp-encoding = "Encryption: " "pgp" pgp-version "," pgp-encoding = "version=\"" ZIFFER ("." ZIFFER)* (ZEICHEN)* "\"" = "encoding=" "ascii" Der Wert version hat dieselbe Bedeutung wie bei Authenticate oder Authorisation Feldern. Der Wert encoding beschreibt die benutzte Kodierung. Unterstützt wird momentan nur die ASCII-armored Kodierung von PGP ohne die Zeilen "BEGIN PGP MESSAGE" und "END PGP MESSAGE" und ohne Versionsnummer. Beispiel: Encryption: pgp version="5.0", encoding="ascii" In einem Request kann angegeben werden, mit welchem Schlüssel und welcher Kodierung eine Response verschlüsselt werden soll. Dazu wird das Response-Key Feld in den Request eingefügt: Response-Key pgp-version pgp-encoding pgp-key = "Response-Key:" "pgp" pgp-version "," pgp-encoding "," pgp-key = "version=\"" ZIFFER ("." ZIFFER)* (ZEICHEN)* "\"" = "encoding=" "ascii" = "key=" string Beispiel: Response-Key: pgp version="5.0", encoding="ascii", key="Gbuzlvulczk/(4580ztcdzdnmjl" Seite 36 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.8 Kostenaufteilung zwischen Sender und Empfänger Momentan bezahlt jeder an das Internet angeschlossene Benutzer seinen lokalen Service Provider, der ihm den Zugang ermöglicht. Der Service Provider wiederum bezahlt seinen regionalen oder Wide Area Provider. Das System hat den Effekt, daß jeder Benutzer quasi einen Teil der Kosten des in seiner Nähe befindlichen regionalen Netzwerkes bezahlt. In der Mitte des Netzes gibt es neutrale Punkte, an denen keine Bezahlung in die eine oder andere Richtung fließt. An diesen Punkten wird ein Gleichgewicht angenommen, d.h., die Provider auf beiden Seiten werden angemessen durch die an ihnen angeschlossenen Nutzer bezahlt (siehe [Clark96]). Eine virtuelle Verbindung im Internet wird also von beiden Benutzern bezahlt. Dies steht im Gegensatz zum klassischen Telefonsystem, wo eine Verbindung entweder vom Anrufer oder vom Angerufenden bezahlt wird. In [Clark96] wird gezeigt, daß eine Flexibilität der Kostenaufteilung zwischen Sender und Empfänger vorteilhaft ist. Als Lösung wird ein Zonen-basiertes Bezahlungsschema vorgeschlagen, bei dem jeder Teilnehmer für eine gewisse Region zahlt. Decken die Zone des Senders und die Zone des Empfängers nicht die gesamte Strecke ab, bekommt der Datenstrom für den unbezahlten Teil keine garantierte Dienstqualität (Best Effort). Der Autor zeigt außerdem, daß eine Implementierung des Schemas möglich ist. Es sind sowohl Informationen in den gesendeten Paketen als auch Zustandsinformationen pro Strom in den Routern nötig. Um ein solches System durch das CIP Protokoll zu unterstützen, muß der Provider zunächst Tarife anbieten, die auch von der Zone abhängig sind. Zonenabhängige Tarife werden in der traditionellen Telefonie weltweit benutzt und könnten entsprechend angepaßt verwendet werden. Mit der TFL (siehe Abschnitt 3.3) läßt sich eine solche Formel zum Beispiel folgendermaßen ausdrücken: preis = if(ZO==1,preis1, if(ZO==2,preis2)) ZO ist dabei die global bekannte Variable für die Zone, preis1 und preis2 repräsentieren beliebige Tariffunktionen. Da die TFL keine Vergleiche von Strings erlaubt, muß die Zone als numerischer Wert repräsentiert werden, beispielsweise 1=Ortszone, 2=Fernzone. Ein neues CIP Schlüsselwort in der SELECT Nachricht erlaubt dem Kunden dann, die Reichweite seiner Bezahlung festzulegen. Dabei reicht die Bandbreite von vollständiger Bezahlung, über die Bezahlung einer gewissen Zone bis hin zu überhaupt keiner Bezahlung. Die Umsetzung im Netz übernimmt dann das in [Clark96] vorgestellte Verfahren. Das neue Schlüsselwort wird folgendermaßen definiert: Payment = "Payment: " "full" | "none" | "zone=" ZONE ZONE spezifiziert dabei eine bestimmte Zone oder Region. Jeder Provider kann bestimmte Regionen und deren Reichweite festlegen. 3.2.9 Weitere Überlegungen 3.2.9.1 CIP Directory-Server Damit ein Kunde zwischen verschiedenen Dienstanbietern vergleichen kann, gibt es einen sogenannten CIP Directory-Server. Dieser Server liefert dem Kunden die CIP URLs der einzelnen Dienstanbieter. Der Kunde kann dann die Dienste der verschiedenen Anbieter abfragen, vergleichen und sich für den günstigsten entscheiden. In der einfachsten Form könnten die CIP URLs einfach in einer WWW Seite angegeben sein und der Kunde muß sie manuell Seite 37 Kapitel 3: Übertragung und Nutzung von Dienstinformationen in die Konfiguration seines Client übertragen. Besser wäre natürlich, wenn die URLs automatisch zum CIP Client übermittelt werden. Der CIP Client sucht dann den für den Benutzer günstigsten Tarif aus (siehe 3.4). Abbildung 13 zeigt eine Darstellung des CIP DirectoryServers. CIP Server CIP Server CIP Client Adreßanfrage Abfrage der Dienste CIP DirectoryServer CIP Server Abbildung 13: CIP Directory-Server 3.2.9.2 Kostenkompensation zwischen Providern Wenn IP-Ströme die Grenze zwischen verschiedenen Providern überschreiten, muß es eine Kostenkompensation zwischen den beiden Dienstanbietern geben. In [CaHS98] wird als Ansatz die Rekursive Accounting Methode vorgestellt. Jeder Provider stellt den angrenzenden Providern die verbrauchten Ressourcen in Rechnung, d.h., die Provider müssen für Ströme zahlen, die von ihrer Domäne in die betrachtete fließen. Ein Provider, der Dienste für Anwender anbietet, stellt diesen die verbrauchten Ressourcen in Rechnung. Für die verschiedenen Dienstanbieter ist es also ausreichend, untereinander Rechnungen auszutauschen. Ein Dienst, der bei einem Provider eingekauft wird, muß bei einem Übergang zu einem anderen Anbieter natürlich auf einen Dienst mit ähnlicher Dienstqualität abgebildet werden. Dieses Schema funktioniert, wenn der jeweilige Sender den Tarif seiner Heimatdomäne bezahlt. Für erweiterte Dienste wie zum Beispiel Roaming müssen zusätzliche Informationen zwischen den Providern ausgetauscht werden. Beim Roaming bezahlt der Benutzer für die verbrauchten Ressourcen beim entfernten Provider mit dem Tarif seines Heimat-Providers (zuzüglich Roaming-Gebühr). Dazu muß der momentane Provider dem Heimat-Provider die verbrauchten Ressourcen mitteilen. Eine Datenstruktur, die zur Übermittlung von Accounting Daten genutzt werden kann, ist der PIP-NAR (siehe [ETSI98]). Das dazu notwendige Protokoll und Datenformat liegen außerhalb der Anwendung des CIP Protokolls und sollen hier deshalb nicht näher betrachtet werden. [Clark96] zeigt, wie eine Kostenkompensation bei Anwendung des Zonen-basierten Kostenmodells erfolgen kann. Seite 38 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.2.9.3 Integration des CIP Protokolls in die existierende Protokollhierarchie Da Dienstauswahl und Dienstnutzung unmittelbar miteinander verbunden sind, ist eine Integration des CIP Protokolls in die Internet Multimedia Konferenz Architektur aus [HaCB98] denkbar. Zur Integration des CIP Protokolls gibt es zwei Ansätze: • • Integration als eigenständiges Protokoll und Integration durch Verschmelzung von CIP und SIP Protokoll. Bei der Integration als eigenständiges Protokoll bleibt das CIP Protokoll unabhängig von den anderen existierenden Protokollen. Dies entspricht mehr dem allgemeinen Internet Ansatz der kleinen überschaubaren, auf einen bestimmten Zweck ausgelegten Protokolle. Eine Verschmelzung des CIP und SIP Protokolls profitiert von den Gemeinsamkeiten der Protokolle. Nicht nur die Form beider Protokolle ist sehr ähnlich, auch bestimmte Mechanismen wie Authentifizierung, Verschlüsselung lassen sich gemeinsam nutzen. Ein Problem ist dann jedoch die deutlich zunehmende Komplexität gegenüber den beiden einzelnen Protokollen. In beiden Fällen ist der grundsätzliche Ablauf gleich. Der Einladende wählt eine Dienstklasse und legt fest, welchen Anteil an den Kosten er übernehmen will bzw. welche Zone er bezahlt (siehe 3.2.8). Die gewählte Dienstklasse erstreckt sich dabei über die gewählte Zone. Bei einer Integration von CIP und SIP kann die Kostenübernahme zum Beispiel durch die INVITE Nachricht (siehe [HaSS98]) übermittelt werden. Der Eingeladene kann dann entscheiden, ob er die restlichen Kosten übernehmen will und welche Dienstqualität er innerhalb seiner Zone haben will. Wenn er mit den Kosten nicht einverstanden ist, kann er die Einladung ablehnen. Anschließend wird dem jeweiligen Dienstanbieter die gewünschte Dienstklasse mitgeteilt und die Ressourcen im Netz werden reserviert. Während der Verbindung erhalten die Teilnehmer die eingekaufte Dienstqualität. Beendet ein Teilnehmer die Verbindung (BYE), wird die Dienstnutzung beendet und die reservierten Ressourcen werden freigegeben. Anhand der verbrauchten und reservierten Ressourcen, der Kostenübernahme und anderen relevanten Parametern wird der zu zahlenden Preis berechnet. Ohne das Zonenmodell von [Clark96] vereinfacht sich der obige Ablauf. Es gibt dann für den Sender nur die Möglichkeit zu bezahlen oder das Bezahlen dem Empfänger zu überlassen (Reverse Charging). Bei Multicast-Verbindungen können die Kosten auf die einzelnen Empfänger aufgeteilt werden (siehe 2.1.4). 3.2.9.4 CIP als Erweiterung des DIAMETER Protokolls Das in [CaRu98] beschriebene DIAMETER Protokoll stellt ein Rahmenwerk für beliebige Dienste im Authentification-, Authorization- und Accounting-Bereich (AAA) dar. Das Protokoll ist sehr flexibel und ermöglicht die Definition von Erweiterungen, um die Anforderungen eines bestimmten Dienstes zu erfüllen. Das DIAMETER Protokoll ist der Nachfolger des RADIUS Protokolls. Das DIAMETER Protokoll ist besser erweiterbar und ein DIAMETER Server kann unaufgeforderte Nachrichten an den Client schicken. Ein Server kann also eine Nachricht an einen Client senden, ohne daß er zuvor einen Request von dem Client empfangen hat. Außerdem wurde die Zuverlässigkeit bei der Übertragung gegenüber RADIUS verbessert. DIAMETER besteht aus einem Basis-Protokoll und mehreren Erweiterungen. Die Erweiterungen umfassen zum Beispiel Mobile-IP, QoS, Authentification und Ressourcen Management. DIAMETER Nachrichten bestehen aus einem Header und mehreren Attribut-WertPaaren (AVPs). Das erste Attribut-Wert-Paar einer Nachricht ist das Command AVP. Das Command AVP enthält das Kommando der Nachricht. Es folgen weitere AVPs mit Kommando-spezifischen Feldern. Seite 39 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Weil das RADIUS Protokoll mittlerweile weit verbreitet ist, wird sich wohl auch sein Nachfolger DIAMETER entsprechend durchsetzen. Deshalb erscheint es sinnvoll, das CIP Protokoll als DIAMETER Erweiterung zu realisieren. CIP Requests und Responses werden als DIAMETER Command AVPs definiert. Alle weiteren CIP Felder werden als DIAMETER AVPs definiert. Wenn es bereits Felder im DIAMETER Header oder AVPs mit der gleichen Semantik wie ein CIP Feld gibt, werden diese benutzt und es wird kein eigener AVP definiert. Der gesamte Protokollablauf von CIP wird in der DIAMETER Erweiterung übernommen. Der Protokollablauf bleibt also gleich, es kommt lediglich das Basis-Protokoll von DIAMETER hinzu. 3.2.10 Implementierung Im Rahmen dieser Diplomarbeit wurden der CIP Client und der CIP Server als Prototyp in der Sprache C++ implementiert. Es wurde nur die UDP Unicast-Übertragung realisiert, TCP und UDP Multicast lassen sich aber relativ einfach hinzufügen. Sicherheitsmechanismen wie Authentifizierung und Verschlüsselung und der Extension Mechanismus (Require) wurden nicht implementiert. Die Auswertung des Filter Headerfeldes wurde ebenfalls nicht implementiert. Um den Protokollablauf verfolgen zu können, werden alle gesendeten und empfangenen CIP Nachrichten ausgegeben. Beispiele für den Protokollablauf findet man in Anhang 7.2. 3.3 Spezifikation von Tarifformeln Um Tarifformeln beschreiben und auswerten zu können, benötigt man die Definition einer geeigneten Sprache und einen Parser, der Ausdrücke auf ihre Korrektheit überprüft und gegebenenfalls auswertet. 3.3.1 Anforderungen an die Sprache Die zu entwickelnde Sprache soll sowohl zur Beschreibung von Tarifen als auch zur Beschreibung von Utility-Kurven (siehe 3.4.2) verwendet werden. Die Sprache muß über die grundlegenden Operatoren wie zum Beispiel Addition oder Subtraktion und über die grundlegenden Funktionen wie zum Beispiel Wurzel- und Exponentialfunktion verfügen. Beliebige Klammerebenen sollen möglich sein. Ein weiterer grundsätzlicher Bestandteil sind Variablen, die sowohl durch Konstanten als auch durch komplexe Ausdrücke definiert werden können. Da beim CIP Protokoll keine Informationen über die Semantik bestimmter Variablen übertragen werden, müssen sogenannte wohlbekannte d.h. global geltende Variablennamen definiert werden. Unvollständige oder falsche Ausdrücke dürfen keinesfalls ausgewertet werden, der Fehler muß einer höheren Instanz mitgeteilt werden (CIP Client). Diese entscheidet dann, ob der fehlerhafte Tarif verworfen und/oder möglicherweise neu angefordert wird. Da Tarife oft von der Uhrzeit abhängig sind, muß es eine Funktion geben, die Zeitangaben in numerische Werte umrechnet. Um den Preis entsprechend der Uhrzeit zu bestimmen, muß die Sprache außerdem über bedingte Ausdrücke, Vergleichsoperatoren und die grundlegenden logischen Funktionen verfügen. Im Rahmen dieser Diplomarbeit wurde eine Sprache entwickelt, mit der sich auch komplexe Tarifformeln ausdrücken lassen. Diese Sprache soll im folgenden Tariff Formula Language (TFL) genannt werden. Seite 40 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.3.2 Aufbau und Eigenschaften der Sprache 3.3.2.1 Aufbau der Sprache Bei der TFL handelt es sich im Sinne der theoretischen Informatik um eine kontextfreie Sprache, die durch eine kontextfreie Grammatik beschrieben wird. Die Sprache orientiert sich von der Syntax her an der Formelbeschreibung gängiger Tabellenkalkulationen (EXCEL), allerdings ist der Funktionsumfang verringert. Die Operatoren entsprechen von der Syntax den bei der Sprache C gebräuchlichen. Die Funktionsnamen entsprechen ebenfalls zum großen Teil C Funktionsnamen. Die Sprache unterscheidet bei Schlüsselwörtern und Variablen nicht zwischen Groß- und Kleinschreibung. Komplexere Datentypen wie Variablen und Strings lassen sich aus den Terminalsymbolen (siehe Anhang 7.1) bilden: • • • • • • • • • • • var const string stunde minute sekunde tag monat jahr monat_name zeit_string = (ZEICHEN)+ = "E" | "PI" = "\"" (ZEICHEN)* "\"" = 2*ZIFFER = 2*ZIFFER = 2*ZIFFER = 2*ZIFFER = 2*ZIFFER = 4*ZIFFER = (ZEICHEN) + = "\"" stunde ":" minute ":" sekunde "\"" | "\"" tag (monat | monat_name) jahr stunde ":" minute ":" sekunde "\"" Im folgenden werden die komplexeren Produktionsregeln beschrieben: • eingabe = zeile | LEER | (zeile "\n" | "\n")* • zeile = ausdruck | string_ausdruck | prädikat • • vergleich prädikat = "==" | "!=" | ">=" | "<=" | ">" | "<" = ausdruck vergleich ausdruck | "OR" "(" prädikat "," prädikat ")" | "AND" "(" prädikat "," prädikat ")" | "NOT" "(" prädikat ")" | "(" prädikat ")" • string_ausdruck = string | "IF" "(" prädikat "," string_ausdruck ")" | "IF" "(" prädikat "," string_ausdruck "," string_ausdruck ")" • • operator funktion • • funktion2 zeit_funktion = "+" | "-" | "*" | "/" | "^" = "SIN" | "COS" | "ASIN" | "ACOS" | "TAN" | "ATAN" | "LN" | "EXP" | "SQRT" | "CEIL" | "FLOOR" | "RND" | "ABS" | "FAK" = "MAX" | "MIN" = "TIME" Seite 41 Kapitel 3: Übertragung und Nutzung von Dienstinformationen • ausdruck = NUM | var | const | var "=" ausdruck | "-" ausdruck | "(" ausdruck ")" | ausdruck operator ausdruck | funktion "(" ausdruck ")" | funktion2 "(" ausdruck "," ausdruck ")" | zeit_funktion "(" zeit_string ")" | "IF" "(" prädikat "," ausdruck ")" | "IF" "(" prädikat "," ausdruck "," ausdruck ")" Ein TFL-Ausdruck besteht also aus einer oder mehreren Zeilen, die durch einen Zeilenumbruch getrennt sind. Jede Zeile kann entweder aus einem Ausdruck, einem String-Ausdruck oder einem Prädikat bestehen. Prädikate sind Funktionen oder Operatoren, die einen boolschen Wert liefern. Ein String-Ausdruck liefert als Ergebnis einen String, während ein Ausdruck eine reelle Zahl als Ergebnis liefert. Variablen können nur mit Zahlen belegt werden, eine Zuweisung von Strings ist nicht möglich. Die Sprache verfügt über insgesamt elf Operatoren und 17 Funktionen, die im nächsten Abschnitt näher beschrieben werden. Außerdem werden die bedingten Ausdrücke und Variablenzuweisungen näher erläutert. 3.3.2.2 Operatoren, Funktionen, bedingte Ausdrücke und Konstanten In der Tabelle 5 werden die vorhandenen numerischen Operatoren beschrieben. Die Priorität nimmt von oben nach unten zu. Operator + * / ^ Bedeutung Addition Subtraktion Multiplikation Division Potenzfunktion Tabelle 5: TFL Operatoren Die Tabelle 6 beschreibt die vorhandenen Vergleichsoperatoren. Die Syntax der Operatoren entspricht der in der Sprache C üblichen. Wie bei C bedeutet ein „=“ eine Zuweisung, während ein „==“ den Test auf Gleichheit symbolisiert. Operator == != <= < >= > Bedeutung gleich ungleich kleiner gleich kleiner größer gleich größer Tabelle 6: TFL Vergleichsoperatoren Die Tabelle 7 beschreibt die in TFL vorhandenen Funktionen und gibt jeweils ein Beispiel. Seite 42 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Funktion SIN COS ASIN ACOS TAN ATAN LN EXP SQRT CEIL FLOOR RND ABS FAK MAX MIN TIME Bedeutung Beispiel Sinus sin(pi/2) = 1 Cosinus cos(pi) = -1 Asinus asin(1) = 1.57 Acosinus acos(1) = 3.14 Tangens tan(1) = 1.55 Atangens atan(pi/2) = 1.00 Natürlicher Logarithmus ln(e) = 1 Exponentialfunktion exp(1) = 2.71 Wurzelfunktion sqrt(81) = 9 Aufrunden ceil(4.5) = 5 Abrunden floor(4.5) = 4 Runden zur nächsten Ganzzahl rnd(4.5) = 5 Betrag abs(-2) = 2 Fakultätsfunktion fak(5) = 120 Maximum max(3,4) = 4 Minimum min(3,4) = 3 Zeitwert-Funktion, Zeit seit 1. time("1 jan 1970 01:00:01") Januar 1970 in Sekunden =1 Tabelle 7: TFL Funktionen Bedingte Ausdrücke lassen sich mit der IF-Anweisung formulieren. Dabei gibt es die zwei Formen: 1. IF(Bedingung, Wert1) 2. IF(Bedingung, Wert1, Wert2) Im ersten Fall ist der Rückgabewert Wert1, wenn die Bedingung wahr ist und Null, wenn die Bedingung falsch ist (if-then). Im zweiten Fall ist der Rückgabewert Wert2, wenn die Bedingung falsch ist (if-then-else). Eine Variablenzuweisung erfolgt mit dem "=" Operator. Dabei muß auf der linken Seite ein Variablenbezeichner stehen und auf der rechten Seite ein Ausdruck, der ausgewertet werden kann. Im Ausdruck auf der rechten Seite dürfen also keine undefinierten Variablen stehen. Schlüsselwörter der Sprache, sowie Funktionsnamen und Konstanten dürfen natürlich nicht als Variablenbezeichner angegeben werden. Die nachfolgende Tabelle 8 zeigt die vordefinierten Konstanten (hier nur mit den ersten fünf Nachkommastellen). Konstante PI E Wert 3,14159 2,71828 Tabelle 8: TFL Konstanten 3.3.2.3 Global definierte Variablen Das CIP Protokoll hat keine Möglichkeit, dem Empfänger die Semantik bestimmter Variablen mitzuteilen. Deshalb muß die Bedeutung von Variablen, deren Werte der Empfänger in Seite 43 Kapitel 3: Übertragung und Nutzung von Dienstinformationen die Funktion einsetzen muß, jedem Empfänger bekannt sein. Die Tabelle 9 zeigt diese global definierten Variablen. Diese Bezeichner dürfen keinesfalls in Zusammenhang mit einer anderen Bedeutung benutzt werden, es sei denn, alle potentiellen Empfänger wurden darüber informiert und die verwendete Software entsprechend angepaßt. Die Variablen TD und D können mit der TFL TIME-Funktion oder der UNIX time-Funktion (C) gesetzt werden. Bezeichner T TD V VP PL PLR BN R oder V K N D EBW ZO Einheit [s] [s] [byte] [packets] [bit/s] [packets] [packets] [s] [bit/s] Bedeutung Die Dauer einer Verbindung oder eines Flows Die momentane Uhrzeit (time of day, UNIX time_t) Das übertragene Volumen Das übertragene Volumen in Paketen Verlustrate Restverlustrate nach Fehlerkorrektur Normierte Bandbreite Rate oder Volumen pro Sekunde Anzahl der Medienpakete pro Gruppe Anzahl der Pakete pro Gruppe Das momentane Datum (UNIX time_t) Effektive Bandbreite Tarifzone Tabelle 9 : Global definierte Variablen Als weitere globale Variablen können Parameter der RSVP Flowspec wie zum Beispiel die Rate definiert werden (siehe Abschnitt 2.1.5). 3.3.3 Beispiele Im folgenden Abschnitt sollen zwei Beispiele für die Anwendung der TFL gegeben werden. Bei dem ersten Beispiel handelt es sich um den normalen City Tarif der Deutschen Telekom an Samstagen. Berechnet wird der Preis pro Zeiteinheit (10s). Variablen: • td = Uhrzeit Funktion: • einh_preis = IF(AND(td>=TIME("00:00:00"), td<TIME("05:00:00")), 0.5, IF(AND(td>=TIME("05:00:00"), td<TIME("21:00:00"), 0.8, 0.5)) Das zweite Beispiel zeigt eine Utility Funktion für MPEG Video nach [ReIz97]. Die Funktion setzt sich abschnittsweise aus drei Geraden zusammen. Variablen: • a = 0.5 • b = 0.45 • c = 0.1 • bn = Normierte Bandbreite Seite 44 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Funktion: • utility = IF(AND(bn>=C, bn<B), 1/(B-C)*bn+2-C/(B-C), IF(AND(bn>=B, bn<A), 1/(A-B)*bn+3-B/(A-B), IF(AND(bn>=A, bn<=1), 1/(1-A)*bn+4-A/(1-A),-1))) 1 0,9 Preis pro 10s [Pfennig] 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1 0 00:00:00 06:00:00 12:00:00 18:00:00 00:00:00 Uhrzeit Abbildung 14: TFL Beispiel - Telekom City Tarif 6 Utility [MOS] 5 4 3 2 1 0 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 Bandbreite/Bandbreite max Abbildung 15: TFL Beispiel - Utility Funktion Seite 45 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.3.4 Implementierung Die TFL wurde mit Hilfe des GNU Bison Parser Generators implementiert. Bison erzeugt anhand der gegebenen Grammatik, der lexikographischen Analyse und den Symboltabellen einen Parser, der nur korrekte Ausdrücke der Sprache auswertet. Um eine bessere Schnittstelle zu haben, wurde der Parser in einer C++ Klasse verpackt. Die TFL kann sehr einfach um neue Funktionen erweitert werden. Wenn eine Funktion als C-Funktion vorliegt, muß einfach nur ein entsprechender Eintrag in den Symboltabellen vorgenommen werden. Eine mögliche Erweiterung wären bedingte Ausdrücke, die sowohl Zahlen als auch Strings zurückliefern können, obwohl eine solche Funktionalität zur Tarifierung nicht unbedingt notwendig ist. Eine weitere Verbesserung wären intelligentere Fehlermeldungen bei falschen Ausdrücken. Das erfordert aber Änderungen an dem von Bison erzeugten Code. Im Extremfall läßt sich die TFL bis hin zu einer kleinen Skriptsprache mit beispielsweise Schleifen und Unterprozeduren erweitern. Es stellt sich allerdings die Frage, ob eine solche Sprache nicht etwas überdimensioniert für ihren Anwendungszweck ist. Derart komplizierte Tarifformeln wären vom Anwender nicht zu durchschauen und würden nicht akzeptiert werden. Die Tabelle 10 zeigt die Performance des Parsers. Gemessen wurde die Berechnungszeit anhand der beiden Formeln aus den Beispielen auf einem Pentium mit 133 MHz unter Linux. Formel Beispiel 1 Beispiel 2 Berechnungszeit 3,3 ms 1,4 ms Tabelle 10: TFL Parser Performance 3.4 Auswahl der optimalen Serviceklasse 3.4.1 Optimale Serviceklasse Das Ziel eines Benutzers ist es, die für seine Anforderungen optimale Dienstklasse einzukaufen. Optimal bedeutet in diesem Zusammenhang, die ausgewählte Dienstklasse erfüllt die Anforderungen des Benutzers hinsichtlich der Qualität und es gibt keine andere Dienstklasse, die ebenfalls die Anforderungen erfüllt und gleichzeitig billiger ist. Da eine solche Auswahl bei einer genügend hohen Anzahl von Dienstklassen mit einer Vielzahl von Parametern nicht mehr per Hand durchgeführt werden kann, muß das ein Programm mit einem entsprechenden Algorithmus übernehmen. Der Algorithmus muß versuchen, das Preis-Leistungs-Verhältnis für den Anwender zu maximieren. Das Preis-Leistungs-Verhältnis soll im folgenden als der Quotient von Qualität und Preis verstanden werden (Utility Price Ratio (UPR)). Die Frage ist nun, wie sich die Qualität eines Dienstes für den Benutzer bestimmen läßt. Eine Möglichkeit wären objektive Maße wie zum Beispiel die Verlustrate oder der Signal Noise Ratio (SNR). Diese Maße sagen jedoch nichts über die wirklich empfundene (subjektive) Qualität aus. Als subjektives Qualitätsmaß sollen im folgenden Utility-Kurven beschrieben werden. Seite 46 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.4.2 Utility-Kurven Das Konzept der Utility Kurven wird in [ReIz97] und [BoFT98] vorgestellt. Abbildung 15 zeigt die Utility für Video in Abhängigkeit von der normierten Bandbreite, wie sie in [ReIz97] beschrieben wird. Die Utility kann man auch als Mean Opinion Score (MOS) bezeichnen, d.h., es handelt sich um einen Qualitätsindex auf einer Skala. Je höher die Utility, desto besser wurde die Qualität von den Benutzern empfunden. Den Verlauf einer UtilityKurve kann man zwar theoretisch vorhersagen oder propagieren, letztendlich ergibt sich eine solche Kurve aber nur durch die Befragung einer ausreichenden Menge von Testpersonen. Die folgende Abbildung 16 aus [BoFT98] zeigt eine Utility-Funktion für Audio Kodierer (LPC, GSM, ADM4, ADM6 und PCM) bei Sprachübertragung. Die Bandbreite wurde auf die Bandbreite von PCM (64 kB/s) normiert. 1,2 ADM6 1 GSM PCM ADM4 Utility 0,8 0,6 0,4 0,2 LPC 0 0 0,2 0,4 0,6 normierte Bandbreite 0,8 1 Abbildung 16: Utility-Funktion für Audio Kodierer Die Qualität ändert sich nicht nur mit der benötigten Bandbreite, sondern auch mit der Verlustrate, die der Datenstrom erfährt. In [GrSt85] wurde die subjektive Qualität von Audio bei verschiedenen Verlustmustern untersucht. Abbildung 17 zeigt eine Utility-Funktion in Abhängigkeit von der Verlustrate. Die durch die Verluste entstehenden Lücken im Audiosignal waren dabei 16 ms und 64 ms lang. Seite 47 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 4 3,5 1 2 Utility [MOS] 3 2,5 2 1,5 1 16 ms Lücken 2 64 ms Lücken 1 0,00 0,01 0,10 1,00 Paketverlustrate Abbildung 17: Audio Qualität in Abhängigkeit von der Verlustrate 3.4.3 Herleitung und Untersuchung des Algorithmus Bei den folgenden Betrachtungen soll zunächst davon ausgegangen werden, daß keine Verluste auf der Übertragungsstrecke auftreten. Nach der Herleitung einer Lösung unter dieser vereinfachten Annahme, wird das Ergebnis um die Berücksichtigung von Verlusten erweitert. Das Ziel des Anwenders ist es, das maximale Utility-Preis-Verhältnis (UPR) zu erzielen. Das Utility-Preis-Verhältnis ist definiert als: UPR = Utility ( MOS ) Preis (1) Dabei müssen die folgenden beiden Randbedingungen beachtet werden: • • umin = Minimale Utility (Qualität) pmax = Maximaler Preis Die Frage ist nun, mit welcher Rate man das maximale Utility-Preis-Verhältnis erzielen kann. Das Optimum ergibt sich bei: ′ u ( B) = 0 und upr ′′( B ) < 0 upr ′( B) = p( B) unter den Randbedingungen: u ( B) ≥ u min und p ( B) ≤ p max Seite 48 (2) Kapitel 3: Übertragung und Nutzung von Dienstinformationen Betrachtet wird nur die Abhängigkeit des Preises von der Bandbreite bzw. Rate, d.h. der Preis pro Sekunde. Ist der Preis zusätzlich von der Zeit abhängig, setzt man die Anzahl der Zeiteinheiten auf 1 und betrachtet den Preis einfach als Preis pro Zeiteinheit. Dies ist möglich, da sich bei interaktiver Audio- oder Videoübertragung nur die Qualität mit der Übertragungsrate ändert, die Übertragungszeit aber nicht. Die Abbildung 18 zeigt die Funktionen g(B), u(B) und p(B) sowie die optimale zu wählende Bandbreite. Bereiche die außerhalb der Randbedingungen (umin = 2,75 und pmax = 4) liegen, sind grau dargestellt. u(B) ist hier die in [ReIz97] Utility Funktion für Video. Die Qualität ist oberhalb von u(B) = 3 als gut, unterhalb davon als schlecht definiert. Die Tariffunktion p(B) ist linear von der Bandbreite (Rate) abhängig. Man sieht, daß die optimale zu wählende Rate genau bei der Hälfte der maximalen Rate liegt. Die hier verwendete Tariffunktion lautet: p(V ) = PV P ⋅ V d.h. pro Zeiteinheit p ZE ( B ) = V ⋅ BZE UV UV (3) Nun soll die Bandbreite als variabel betrachtet werden, d.h. die Rate des Senders läßt sich beliebig zwischen einer minimalen (Null) und einer maximalen (Bmax) Rate regeln: p ZE ( B) = PV ⋅ BZE max ⋅ b mit 0 ≤ b ≤ 1 UV (4) Für die Abbildung 18 wurden die Parameter folgendermaßen gewählt: Parameter PV UV Bmax Wert 1 3000 15000 Tabelle 11: Parameter der Tariffunktion Diese Optimierung wird dann über alle möglichen Dienstklassen durchgeführt und die Dienstklasse mit dem größten Utility-Preis-Verhältnis ausgewählt: uprmax = max{upri ( B )} ∀i (5) Seite 49 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 6 Utility/Preis Utility 5 Preis 4 3 2 1 0 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 Bandbreite/Bandbreitem ax Abbildung 18: Optimale Wahl der Bandbreite In einem realen paketorientierten Netzwerk wie dem Internet treten allerdings ab einer gewissen Distanz Paketverluste auf, die die Qualität der Audio- oder Videoübertragung verschlechtern. Um die Qualität am Empfänger zu verbessern, wird eine Vorwärtsfehlerkorrektur eingesetzt. Der obige Algorithmus soll nun so erweitert werden, daß er das UtilityPreis-Verhältnis sowohl für die Bandbreite als auch für die Menge an eingesetzter Redundanz optimiert. Die Utility-Funktion ist jetzt sowohl von der Bandbreite als auch von der Verlustrate abhängig. Sie setzt sich im einfachsten Fall aus einem bandbreiten- und einem verlustabhängigen Faktor zusammen: u ( B, p L ) = u B ( B ) ⋅ u L ( p L ) (6) Abbildung 19 zeigt eine solche 3-dimensionale Utility Funktion. Dabei ist u ( B, pL ) die Utility-Funktion für Video aus [ReIz97] und uL wurde zu u L ( pL ) = exp(−3 ⋅ pL ) gesetzt. In der Realität läßt sich eine solche Funktion wahrscheinlich nicht mit zwei unabhängigen Faktoren darstellen, sondern die gesamte Funktion muß mit Hilfe von Testpersonen ermittelt werden. Seite 50 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 5 4 Utility 3 2 1 1 0 0.5 0.8 0.4 0.6 0.3 0.4 0.2 0.2 0.1 Verlustrate 0 0 normierte Bandbreite Abbildung 19: 3-dimensionale Utility Funktion Um die Qualität einer Dienstklasse (im Hinblick auf die Verluste) zu verbessern, kann Vorwärtsfehlerkorrektur eingesetzt werden. Zur Redundanzerzeugung sollen im weiteren ausschließlich Reed-Solomon-Codes eingesetzt werden. Der Einsatz von Redundanz erhöht natürlich den Preis, wenn dieser von der Rate abhängig ist. Andererseits steigt auch die Utility aufgrund der geringeren Restverlustrate nach der Dekodierung am Empfänger. Die Restverlustrate berechnet sich zu (siehe Abschnitt 2.2.3.2): n −k −1 n − 1 ⋅ p L j ⋅ (1 − p L ) n − j −1 mit 1 ≤ k ≤ n p L* = q(k , n, p L ) = p ⋅ 1 − ∑ j j (7) Die zu optimierenden Funktion ist nun also: upr ( B, p L , n, k ) = u ( B, p L* ) , die Redundanz ist h = n − k n p( ⋅ B) k (8) Zur Optimierung werden dann wieder die Gleichungen (2) und (5) verwendet. Als weitere Randbedingungen kommen jetzt k und nmax hinzu. Der Parameter k bestimmt die minimale, der Parameter nmax die maximale Verzögerung der Pakete. Außerdem legt die Differenz h = nmax − k die Menge an eingesetzter Redundanz fest. Um den Einsatz von zuviel Redundanz zu vermeiden, sollte ein adaptives Verfahren entsprechend [PaWa98] eingesetzt werden. Seite 51 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 3.4.4 Verschiedene Szenarien für die Optimierung Der entwickelte Optimierungsalgorithmus läßt sich ohne Problem bei UnicastVerbindungen (zum Beispiel Internet Telefonie) einsetzten. Zunächst soll hier eine Senderbezahlte Unicast-Verbindung betrachtet werden. Der Sender kennt die Tarife, die UtilityFunktion und die Verlustrate auf der Übertragungsstrecke und kann anhand dieser Parameter die Optimierung durchführen. Der Sender kennt die Verluste entweder durch Rückmeldung vom Empfänger (RTCP) oder durch die Garantien des Dienstanbieters. Optimiert wird dann das Verhältnis der Qualität am Empfänger und des Preises für den Sender. Die Optimierung läßt sich allerdings auch genauso bei einer Empfänger-bezahlten Unicast-Verbindung durchführen. Der Empfänger kennt ja ebenfalls die Tarife, die Utility-Funktion und die Verlustrate. Um die optimale Menge an Redundanz zu erzeugen, müssen die ermittelten Kodier-Parameter dem Sender signalisiert werden. Für den Einsatz des Optimierungsalgorithmus bei Multicast-Übertragungen müssen einige zusätzliche Überlegungen angestellt werden. Hier soll als erstes eine Sender-bezahlte Multicast-Verbindung betrachtet werden. Ein Beispiel für eine solche Verbindung wäre zum Beispiel Internet-Radio oder Internet-Fernsehen. Der Sender bezahlt zwar die Kosten der Verbindung, holt sich diese Kosten jedoch durch Abonnement-Beiträge der Empfänger zurück. Der Sender kennt wieder die Tarife und die Utility-Funktion. Er kennt außerdem die Verlustraten, welche die einzelnen Empfänger erleiden. Die Frage ist nun, wieviel Redundanz der Sender erzeugen soll, bzw. wie die einzelnen Verlustraten in die Optimierung eingehen. Ein intuitiver Ansatz um alle Empfänger optimal zufriedenzustellen, wäre die maximale Verlustrate für die Optimierung zu benutzen. Wenn die maximale Verlustrate allerdings wesentlich größer als die durchschnittliche Verlustrate im Multicast-Baum ist, führt dieser Ansatz zu einer Verschwendung von Ressourcen im Netz. Ist die maximale Verlustrate bereits sehr groß, erhöht die zusätzliche im Netz erzeugte Last die Verlustwahrscheinlichkeit nur überproportional. Ab einem bestimmten Punkt steigt dann auch die effektive Verlustwahrscheinlichkeit, trotz der zusätzlichen Redundanz, an (siehe 2.2.3.3). Möglicherweise werden auch weitere Empfänger in Mitleidenschaft gezogen. Eine weitere Alternative wäre, den Mittelwert der Verlustwahrscheinlichkeiten für die Optimierung zu benutzen. Dann ist die Qualität nicht mehr bei allen Empfängern optimal, aber es werden auch nicht so viele Ressourcen unnötig verbraucht. Eine bessere Lösung des Problems ist der Einsatz eines adaptiven Verfahren zur Bestimmung der optimalen Redundanzmenge wie in [PaWa98] vorgestellt. Die optimale Redundanzmenge wird für alle Empfänger bestimmt und das Maximum davon wird am Kodierer erzeugt. Zusätzlich wird durch eine Konstante festgelegt, welcher Anteil der Empfänger optimal versorgt wird. Setzt man die Konstante zum Beispiel auf 95%, erhalten 5% der Empfänger nicht die optimale Menge an Redundanz, der Preis für die Übertragung wird jedoch verringert. Eine weitere Idee ist, sogenannte Layered-FEC einzusetzen. Der Sender stellt dabei mehrere Ebenen an Redundanz zur Verfügung (verschiedene Multicast-Gruppen) und die Empfänger lauschen je nach Verlustrate auf mehr oder weniger Ebenen (Multicast-Gruppen). Dies entspricht dem Ansatz für Ratenadaption bei Videoübertragung. Auch hier ergeben sich einige Fragen. Wieviel Redundanz soll maximal zur Verfügung gestellt werden und wieviel Redundanz steht auf einer Ebene zur Verfügung? Abbildung 20 zeigt eine schematische Darstellung des Verfahrens. Empfänger 1 empfängt nur die erste, Empfänger 2 und Empfänger 3 empfangen die erste und zweite und Empfänger 4 empfängt alle drei FEC Ebenen. Seite 52 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Empfänger 1 Empfänger 2 Empfänger 3 Sender Empfänger 4 Ebene 1 Ebene 2 Ebene 3 Abbildung 20: Layered FEC Problematisch bei Sender-bezahltem Multicast ist, daß die Kosten für alle Teilnehmer steigen, wenn einige wenige Teilnehmer durch hohe Verlustraten die Menge an übertragenen Daten erhöhen. Durch die größere Menge an verbrauchten Ressourcen steigen die Kosten des Senders und da diese auf alle Empfänger gleichmäßig verteilt werden, steigen die Kosten für jeden Empfänger. Deshalb soll jetzt eine Empfänger-bezahlte Multicast-Verbindung betrachtet werden. Wie bei Unicast kann jeder Empfänger die Optimierung durchführen, die ermittelten Kodier-Parameter werden dem Sender signalisiert. Das führt im Prinzip zu dem selben Problem wie bei Sender-bezahltem Multicast: Wieviel Redundanz muß am Sender erzeugt werden? Bei Sender-bezahltem Multicast tritt das oben beschriebene Problem allerdings nur bei einem Best Effort Dienst auf. Gibt der Dienst gewisse Garantien hinsichtlich der Verlustrate und nimmt man weiterhin an, daß die Garantien auch über die Grenzen von Dienstanbietern hinweg erhalten bleiben (siehe 2.1.1), so hat man eine nahezu einheitliche Verlustrate im Baum und kann mit dieser optimieren. 3.4.5 Implementierung Der Algorithmus wurde entsprechend der Definition implementiert. Er akzeptiert beliebige Utility- und Tariffunktionen, die nötigen Randbedingungen müssen entsprechend vorgegeben werden. Für die Optimierung bzw. für die Maximierung der Utility-Preis-Funktion wurden zwei Algorithmen entwickelt: • • Brute Force Methode und Downhill Simplex Methode für mehrere Dimensionen. Bei der Brute Force Methode werden alle Punkte der Utility-Preis-Funktion ausgerechnet. Dabei beschränkt sich die Auflösung des Algorithmus bezüglich der Bandbreite auf 1%Schritte. Dies sollte im Normalfall allerdings auch völlig ausreichend sein. Da n und k ohnehin nur diskrete Werte annehmen können, braucht man hier keine weitere Einschränkung. Der Vorteil der Methode ist, daß innerhalb der Genauigkeit immer das globale Maximum der Funktion upr(B,pL,n,k) gefunden wird. Allerdings kostet die Berechnung relativ viel Zeit, weil alle Punkte (im Rahmen der Genauigkeit) der Funktion ausgerechnet werden müssen. Die genaue Berechnungsdauer hängt von der maximal möglichen Redundanz hmax = nmax − k und der Anzahl der Dienstklassen ab, über die die Optimierung durchgeführt wird. Werden viele Seite 53 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Dienstklassen angeboten, ist es sinnvoll anhand bestimmter Kriterien eine Vorauswahl zu treffen (siehe 3.2.5.15). Um eine schnellere Auswahl treffen zu können, wurde als zweiter Algorithmus die Downhill Simplex Methode implementiert (siehe [PFTV88]). Bei dieser Methode wird ein geometrisches Gebilde (der Simplex) über die gegebene Funktion bewegt. Der Simplex kann sich außerdem vergrößern und verkleinern. Auf diese Weise bewegt sich der Simplex durch die im allgemeinen n-dimensionale Funktion auf der Suche nach einem Maximum, d.h., er bewegt sich in Richtung größerer Funktionswerte. Liegt die Differenz des neuen nach der Bewegung berechneten und des vorherigen Funktionswerts unterhalb einer gewissen Schwelle, entscheidet der Algorithmus auf ein Maximum. Der Simplex besteht immer aus n+1 Punkten, d.h., im hier vorliegenden Fall der 2-dimensionalen Optimierung ist der Simplex ein Dreieck. Grundsätzlich ist es nicht möglich, mit dieser Methode das globale Maximum einer Funktion zu finden. Dafür benötigt der Algorithmus wesentlich weniger Funktionsberechnungen als die Brute-Force Methode. Da der Algorithmus normalerweise nur auf reellen Zahlen arbeitet, muß die Redundanzmenge h vor der Funktionsauswertung diskretisiert werden. Ein weiteres Problem ergibt sich, weil die Funktion upr(B,pL,n,k) in allen Dimensionen endlich ist. Da ein Punkt des Simplexes nicht den Wert undefiniert annehmen kann, muß dem Algorithmus hier ein sehr kleiner Funktionswert vorgetäuscht werden, so daß er sich wieder in die Funktion hinein bewegt. Entscheidend für den Erfolg des Algorithmus ist die Wahl eines geeigneten Start-Simplex. Da a priori keine Annahmen über die Funktion getroffen werden können und auch nicht sollen, werden die Punkte des anfänglichen Simplex per Zufall bestimmt. Es wird darauf geachtet, daß die Punkte nur im definierten Bereich der Funktion liegen. Außerdem muß vorausgesetzt werden, daß mindestens einer der Punkte sich von den anderen beiden im Wert unterscheidet. Haben alle n+1 Punkte den gleichen Wert, weiß der Algorithmus nicht, in welche Richtung er den Simplex bewegen muß. Um die Trefferquote auf das globale Maximum der Utility-Preis-Funktion zu erhöhen, wird der Algorithmus mehrmals mit jeweils zufällig gewählten Start-Simplexes durchlaufen. Das beste Ergebnis wird dann als Maximum zurückgeliefert. Es zeigt sich, daß bereits bei vier Durchläufen die Trefferquote recht hoch ist, obwohl die Berechnungsdauer um einiges kürzer als bei der Brute Force Methode ist. Der Zeitgewinn steigt natürlich mit der Größe der Differenz zwischen nmax und k. Als Beispiel sollen hier die optimalen Parameter für die in Abbildung 18 gezeigten Funktionen berechnet werden. Dabei soll die im Netz auftretende Verlustrate gleich 0,3 sein. Um die Verzögerung klein zu halten ist k=5 und nmax=10. Die folgenden Tabellen zeigen die Randbedingungen und das Ergebnis. Randbedingung umin pmax pL k nmax Wert 3 10 0,3 5 15 Tabelle 12: Randbedingungen für die Optimierung Seite 54 Kapitel 3: Übertragung und Nutzung von Dienstinformationen Ergebnis b n Nutzen Utility Preis Wert 0,5 9 0,746 3,358 4,5 Tabelle 13: Ergebnisse der Optimierung Die folgende Tabelle 14 zeigt den Performancegewinn der Downhill Simplex Methode für das eben berechnete Beispiel. Die Berechnung wurde auf einer SUN Sparc 20 durchgeführt: Algorithmus Brute Force Downhill Simplex Rechenzeit [s] 5,52 0,95 Tabelle 14: Performance des Optimierungsalgorithmus Die nachfolgende Abbildung 21 zeigt die gesamte Utility/Preis-Funktion. Die optimale Redundanzmenge (h=4) ist bei genauem Hinsehen zu erkennen. Die Abbildung 22 zeigt die Schnitte durch die Funktion bei h=0, h=4 und h=10. 2 Nutzen 1.5 1 0.5 1 0 10 0.8 8 0.6 6 0.4 4 0.2 2 Redundanz h 0 0 normierte Bandbreite Abbildung 21 : Die gesamte Nutzen Funktion Seite 55 Kapitel 3: Übertragung und Nutzung von Dienstinformationen 2 h=4 h=0 h = 10 1.8 1.6 Nutzen 1.4 1.2 1 0.8 0.6 0.4 0.2 0.1 0.2 0.3 0.4 0.5 0.6 normierte Bandbreite 0.7 0.8 0.9 Abbildung 22: Nutzen Funktion bei h=0, h=4 und h=10 Seite 56 1 Kapitel 4: Verbesserung der Dienstqualität durch FEC 4 Verbesserung der Dienstqualität durch FEC Dieses Kapitel beschreibt die Entwicklung eines Systems zur Vorwärtsfehlerkorrektur für RTP Medienströme, mit dem die Dienstqualität in bezug auf die Verlustrate verbessert wird. Die Redundanz wird durch ein RTP Gateway beim Sender erzeugt und die verlorenen Pakete werden durch ein RTP Gateway beim Empfänger wiederhergestellt. Aufbau und Funktion des RTP Gateways werden in Abschnitt 4.1 beschrieben. In Abschnitt 4.2 wird die Performance des Reed-Solomon Kodierers und des Gateways untersucht. Abschnitt 4.3 zeigt die gemessenen Verlustraten auf unterschiedlichen Strecken mit unterschiedlichen Mengen an Redundanz. Es werden sowohl künstlich erzeugte Verluste als auch eine reale Übertragungsstrecke untersucht. 4.1 RTP Gateway Zur Erzeugung der Redundanz soll ein Reed-Solomon Kodierer verwendet werden. ReedSolomon Kodierer sind bereits weit verbreitet und von der Theorie her bestens bekannt (siehe 2.2.3.2). Reed-Solomon Kodierer sind sehr flexibel. Sie arbeiten mit unterschiedlichen Paketgrößen und die Menge der erzeugten Redundanz läßt sich nahezu beliebig einstellen. Ein Nachteil von Reed-Solomon Codes ist die Komplexität und damit die Performance (insbesondere des Decoders). Heutzutage sind allerdings selbst die sogenannten Einsteiger-PCs schnell genug, um Audio- und Videoströme quasi nebenbei zu kodieren (siehe 4.2). Im Rahmen dieser Diplomarbeit wird der in [Rizzo97] vorgestellt RS-Kodierer benutzt. Dieser Kodierer wurde bereits für die Vorwärtsfehlerkorrektur bei einer Paketübertragung optimiert. Da der in Abschnitt 3.4 vorgestellte Optimierungsalgorithmus ein genereller Algorithmus für beliebige übertragene Medien ist, muß auch die Vowärtsfehlerkorrektur für beliebige Medien funktionieren. Weil es im Rahmen dieser Diplomarbeit nicht möglich ist, mehrere der existierenden Multimedia-Anwendungen zu modifizieren, wurde der Gateway-Ansatz gewählt. Zwischen Sender und Empfänger befinden sich zwei RTP Gateways. Das Gateway am Sender fügt Redundanz in den Medienstrom ein, die das Gateway am Empfänger zur Wiederherstellung von verlorenen Paketen benutzt. 4.1.1 Grundsätzliche Funktion Die grundsätzliche Funktion des Gateways soll anhand von Abbildung 23 erläutert werden. Der Benutzer sendet seine Mediendaten an das lokale Gateway. Das Gateway wartet, bis es einen Block von k RTP Paketen empfangen hat und generiert dann mit dem Reed-Solomon Kodierer die h = n-k Redundanzpakete zum Schutz der k Datenpakete. Die Größen k und h können sich von Block zu Block ändern. Die FEC Pakete werden als neuer Strom (getrennt von den Datenpaketen) versendet. FEC Pakete haben also eigene Sequenznummern. Das bedeutet, daß die FEC Pakete zum Beispiel auch an eine andere Multicast-Gruppe verschickt werden können als die Datenpakete. Das Gateway am Empfänger regeneriert den ursprünglich Block der k RTP Pakete, wenn mindestens k der n Pakete (RTP und Redundanz) eingetroffen sind. Die k Pakete werden dann an den Empfänger geschickt. Wenn innerhalb einer bestimmten Zeit nur i Pakete (i<k) von den n Paketen eingetroffen sind, werden diese i Pakete an den Empfänger weitergeleitet. Wenn mehr als n-k Pakete verloren wurden, kann keine Wiederherstellung der Pakete am Empfänger durchgeführt werden (siehe 2.2.3.1). Die Zuordnung der Redundanz- und Datenpakete erfolgt über den RTP Synchronization Source Identifier (SSRC), FEC Pakete haben die gleiche SSRC wie die Datenpakete (siehe [RoSc98]). Seite 57 Kapitel 4: Verbesserung der Dienstqualität durch FEC RTCP RTCP Benutzer RTP FEC Gateway RTP FEC LAN MAN/WAN Abbildung 23: Übertragung mit FEC Gateway RTCP Pakete werden von den Gateways ohne Veränderung weitergeleitet. Sie werden aber zur Auswertung der QoS benutzt (siehe 4.1.5). Für Sender und Empfänger ist das Gateway also absolut transparent. Nach [RFC1889] handelt es sich um einen RTP Translator. Aufgrund dieser Transparenz kann die ursprüngliche Forderung erfüllt werden. Existierende Anwendungen erhalten damit eine Vorwärtsfehlerkorrektur, ohne daß Änderungen an ihnen vorgenommen werden müssen. 4.1.2 Paketformat Das Paketformat der FEC Pakete wurde aus [RoSc98-2] übernommen. Die FEC Pakete haben einen RTP Header und einen FEC Header. Zunächst wird hier der Inhalt des RTP Header beschrieben. Die Versionsnummer wird auf 2 gesetzt. Das Padding-, Marker- und Extension-Bit sowie das CSRC Count (CC) Feld werden bei der Redundanzerzeugung berechnet. Unabhängig von den Werten des CC Feldes oder des Extension-Bits gibt es keine Contributing Source Identfiers (CSRC) Liste und keine Header Extensions. Die SSRC Nummer entspricht der SSRC Nummer des ursprünglichen Datenstroms. Die Seqenznummer entspricht der normalen Definition. Für jedes übertragenen FEC Paket wird die aktuelle Sequenznummer um 1 erhöht. Der Startwert der Sequenznummern wird wie bei den RTP Paketen mit einem Zufahlszahlengenerator bestimmt (MD5-Algorithmus). Der Timestamp aller h FEC Pakete wird auf den Wert des Timestamps des ersten der k Datenpakete gesetzt. Der Timestamp steigt also, unabhängig vom FEC Schema, monoton an. Der Wert des Payload Type Feldes muß entweder festgelegt werden (durch die IANA) oder sich im Bereich der dynamisch zu vergebenen Typen befinden (siehe [RFC1890]). Die Bedeutung des Payload Types kann dem Empfänger durch eine out-of-band Signalisierung übermittelt werden. Es bietet sich allerdings an, eine feste Nummer für Reed-Solomon kodierte FEC Pakete zu verwenden, da alle Parameter des RS-Codes, mit Ausnahme der Symbollänge, im FEC Header stehen. Eine kleinere Symbollänge als 8 ist allerdings nicht möglich und eine größere (zum Beispiel 16) verringert die Performance des Kodierers. Außerdem ist der maximale Wert für n bei einer Symbollänge von 8 bereits 255, was mehr als ausreichend ist. Bei Audioübertragungen müssen zum Beispiel wesentlich kleinere Werte für n und k benutzt werden, da sonst die Verzögerung zu groß wird. Die Symbollänge ist also im Prinzip auf den Wert 8 festgelegt. Die Abbildung 24 zeigt das Format des Reed-Solomon FEC Headers. SN Base ist die Sequenznummer des ersten Medienpaketes des von diesem FEC Paket geschützten Blockes von k Medienpaketen. Das Length Recovery Feld dient dazu, die Länge eines wiederhergestellten Paketes zu bestimmen. Es wird bei der Redundanzerzeugung über die Längen der Inhalte der Seite 58 Kapitel 4: Verbesserung der Dienstqualität durch FEC Medienpakete berechnet. Als Inhalt werden hier die Nutzdaten, die CSRC Liste, die Extension und das Padding betrachtet. Das Length Recovery Feld wird benötigt, weil die Medienpakete prinzipiell unterschiedlich lang sein können. Bei der Redundanzerzeugung müssen die Pakete für den RS-Kodierer aber alle gleich lang sein, d.h., sie werden mit Nullen auf die Länge des längsten Paketes aufgerundet. Das Length Recovery Feld wird bei der Wiederherstellung eines verlorenen Paketes benutzt, um die ursprüngliche Länge wieder herzustellen. Das E Bit zeigt eine Extension an, wenn es auf 1 gesetzt ist. Nach der momentanen Spezifikation muß es auf 0 gesetzt werden. Das PT Recovery Feld wird bei der Redundanzerzeugung über die Payload Types der Medienpakete berechnet. Das K Feld wird auf die Anzahl der Medienpakete eines Blockes (minus 1) gesetzt. Das N Feld ist die Anzahl aller Pakete eines Blockes minus 1. Das i Feld gibt an, daß das Paket das i+1-te FEC Paket (i<h) des Blockes ist. Das Timestamp Recovery Feld wird bei der Redundanzerzeugung über die TS Felder der Medienpakete berechnet. SN Base E PT Recovery Length Recovery N K i TS Recovery Abbildung 24: Reed-Solomon FEC Header Der Inhalt eines FEC Paketes wird bei der Redundanzerzeugung über die Nutzdaten, die CSRC Liste, die Extension und das Padding der Datenpakete berechnet. 4.1.3 Erzeugung der Redundanz Alle RTP Pakete von lokalen Sendern werden kopiert, bevor sie an das Gateway am Empfänger weitergeleitet werden. Wenn k Pakete eines Datenstromes beim Sender-Gateway eingetroffen sind, kann das Gateway die h Redundanzpakete erzeugen und übertragen. Die Kopien der k Pakete werden anschließend gelöscht. Wenn der Timer t1 abgelaufen ist und weniger als k Pakete eingetroffen sind, werden diese kopierten i Pakete verworfen und es wird keine Redundanz erzeugt. Die Pakete werden also ungeschützt übertragen, was die effektive Verlustrate am Empfänger möglicherweise erhöht. Eine Alternative ist, die i Pakete mit h* Redundanzpaketen zu schützen. h* wird so gewählt, daß das Verhältnis von Redundanz und Daten möglichst erhalten bleibt: i h * = ⋅ h k Die Klammern bedeuten dabei das Aufrunden auf den nächsten ganzzahligen Wert. Problematisch bei dieser Lösung ist, daß kürzere RS-Codes – auch wenn der Anteil an Redundanz gleich bleibt – weniger efektiv sind. Außerdem führt die zusätzliche Verzögerung zu einem höheren Jitter, der sich am empfangenden Gateway nachteilig auswirken kann. Für den Timer t1 gilt folgende Abschätzung: t1 = ti ⋅ k + to Die Zeit ti ist dabei die gemessene Zwischenankunftszeit (Interarrival-Time) der vom lokalen Sender ankommenden Pakete. Die zusätzliche Zeit to (Overhead-Time) dient dazu, den Seite 59 Kapitel 4: Verbesserung der Dienstqualität durch FEC Jitter des Paketstromes auszugleichen. Man beachte, daß Jitter nicht nur im Netzwerk entsteht, sondern auch an der Socket-Schnittstelle, wenn der Rechner unter hoher Last steht. Im Extremfall (kein Jitter) kann to auf 0 gesetzt werden. Bei der Redundanzerzeugung wird für jedes Paket die Länge des variablen Teils berechnet. Dazu werden die Längen von CSRC Liste, Extension, Nutzdaten und Padding addiert. Anschließend werden der Header, die berechnete Länge und der variable Teil hintereinander in einen Speicherbereich kopiert. Der Speicherbereich hat die Länge des größten der k Pakete plus 2 Byte für die berechnete Länge. Alle Bytes zwischen dem Ende der Paketdaten und dem Ende des Speicherbereichs werden mit Nullen initialisiert. Das Versionsfeld, die Sequenznummer und die SSRC Nummer des Headers werden ebenfalls auf 0 gesetzt. Dies ist einfacher und effektiver als das Weglassen dieser Felder und das umständliche Kopieren der restlichen Felder in [RoSc98-2]. Der Reed-Solomon Kodierer erzeugt mit den k Speicherbereichen h FEC Speicherbereiche mit den Redundanzinformationen. Jeder dieser h Speicherbereiche wird benutzt, um ein FEC Paket zu erzeugen. Die ersten 12 Byte des FEC Speicherbereichs entsprechen dabei genau einem durch den Kodierer erzeugten redundanten RTP Header. Das Padding Bit, das Extension Bit, das Marker Bit und das CC Feld werden aus dem FEC Speicherbereich (2te bis 9te Bit) in den RTP Header kopiert. Die anderen Felder des RTP Header werden wie in Abschnitt 4.1.2 beschrieben gesetzt. Das PT Feld (10te bis 16te Bit) wird in das PT Recovery Feld und das TS Feld (8te bis 12te Byte) wird in das TS Recovery Feld des FEC Headers kopiert. Die nächsten zwei Bytes des FEC Speicherbereiches (nach dem Header) werden in das Length Recovery Feld des FEC Headers kopiert. Die anderen Felder des FEC Headers werden auf die entsprechenden Werte des verwendeten Reed-Solomon Codes gesetzt. Die restlichen Bytes des FEC Speicherbereiches sind dann die Nutzdaten des FEC Paketes. Die erzeugten Redundanzpakete werden dann an das empfangene Gateway gesendet. Die Frage ist nun, mit welchem Abstand die Pakete gesendet werden sollen. Im Rahmen dieser Diplomarbeit durchgeführte Messungen haben gezeigt, daß ein burstartiges Senden (sehr kleiner Abstand) die Verlustrate erhöht. Die Abbildung 25 zeigt die kurz hintereinander mit verschiedenen Sendeabständen gemessenen Verlustraten auf einer realen Verbindung (siehe 4.3). Die Verlustrate ist hier die am Empfänger gemessene Verlustrate, es wurde keine FEC eingesetzt. Übertragen wurde ein PCM Audiostrom mit 160 Byte Nutzdaten pro RTP Paket. Man sieht, daß die Verlustraten bei kleinen Abständen der Pakete deutlich höher liegen. Um Fehler durch wechselnde Netzwerkeigenschaften auszuschließen, wurde die Messung mehrmals durchgeführt. Das qualitative Ergebnis war bei allen Messungen gleich. Da es keine Signalisierungsverbindung zwischen dem Sender- und dem EmpfängerGateway gibt, muß der Sendeabstand im Voraus bekannt sein. Das Gateway soll jedoch für beliebige Medienströme mit beliebigen Abständen der Datenpakete funktionieren. Es kann deshalb kein fester Abstand eingestellt werden, sondern der Abstand der FEC Pakete muß dynamisch festgelegt werden. Wenn der Sendeabstand der FEC Pakete sich vom Abstand der Datenpakete unterscheidet, müssen beide Abstände am Empfänger gemessen werden. Bei wenig Redundanz und genügend großer Verlustrate ist eine solche Schätzung für FEC Pakete allerdings nicht mehr möglich bzw. sehr ungenau, da nicht mehr genügend Pakete am Empfänger ankommen. Die FEC Pakete müssen also den gleichen Abstand wie die Datenpakete haben. Dann ist eine hinreichend gute Schätzung am Empfänger möglich. Diese Lösung hat zusätzlich den Vorteil, daß sie sich gut mit dem Piggy-backing Ansatz vereinbaren läßt (siehe 4.1.9). Seite 60 Kapitel 4: Verbesserung der Dienstqualität durch FEC Verlusrate am Empfänger 0,5 0,4 0,5 ms 2 ms 0,3 10 ms 20 ms 0,2 0,1 0 10 20 30 40 RTCP Intervall 50 60 Abbildung 25: Verlustrate bei unterschiedlichen Paketabständen 4.1.4 Wiederherstellung verlorener Pakete Die Wiederherstellung am Empfänger kann in zwei verschiedene Schritte unterteilt werden. Im ersten Schritt stellt das empfangene Gateway fest, wann eine Wiederherstellung durchgeführt werden muß. Der zweite Schritt ist die tatsächliche Wiederherstellung der Pakete. Der Ansatz für den ersten Schritt ist sehr einfach. Wenn k der n Pakete einer Transmission Group (TG) eingetroffen sind, kann die Wiederherstellung durchgeführt werden. Wenn die ersten k eingetroffenen Pakete die Datenpakete sind, können diese direkt an den Empfänger gesendet werden. Später eintreffende FEC Pakete der Gruppe können verworfen werden. Falls die k Pakete aus Daten- und FEC-Paketen bestehen, müssen verlorene Pakete vom ReedSolomon Decoder wiederhergestellt werden. Da es keine Signalisierung zwischen den Gateways gibt, muß für die Entscheidung im ersten Schritt zumindest das erste FEC Paket eingetroffen sein. Die Parameter n und k lassen sich dann aus dem FEC Header dieses Paketes ablesen. Wenn innerhalb einer Zeit t2 keine k Pakete eingetroffen sind, werden alle angekommenen Pakete der Gruppe an den Empfänger weitergeleitet. In diesem Fall bleibt die Vorwärtsfehlerkorrektur wirkungslos. Falls überhaupt keine FEC eingesetzt wird, müssen die eingetroffenen Pakete sofort ohne Verzögerung an den Empfänger gesendet werden. Die Zeit t2 ist also von den Parametern n und k abhängig. Falls FEC eingesetzt wird (n>k) ist die minimale Verzögerung: t 2 min = t i ⋅ k + t o Dies entspricht genau der Verzögerung t1. Die maximale Verzögerung ist: t 2 max = t i ⋅ n + t o Bei der maximalen Verzögerung können also alle h Redundanzpakete zur Reparatur eingesetzt werden. Die tatsächliche Verzögerung der TGs im Gateway wird gemessen und soll hier Seite 61 Kapitel 4: Verbesserung der Dienstqualität durch FEC als d bezeichnet werden. Die Zeit t2 muß also zwischen d und t2max liegen. Der genaue Punkt und die Konvergenzgeschwindigkeit lassen sich mit den Faktoren a und b einstellen. t 2’ = t 2 − (a ⋅ (t 2 − (t i ⋅ n + t o )) + b ⋅ (t 2 − d )) Ein Problem ist, daß die Pakete diese Verzögerung auch erleiden, wenn überhaupt keine FEC eingesetzt wird. Das empfangene Gateway weiß aufgrund der fehlenden Signalisierung nicht, wann keine FEC Pakete gesendet werden. Das Problem läßt sich jedoch sehr einfach lösen. Bei jedem Datenpaket, das durch einen Timeout (t2) an den Empfänger gesendet wird, wird die Zeit t2 verringert: t 2’ = t 2 − c ⋅ t 2 Die Geschwindigkeit mit der t2 auf Null fällt, läßt sich durch die Konstante c steuern. Dabei muß c ein bis zwei Größenordnungen kleiner als a sein, um die optimale Reparaturfähigkeit nicht durch gelegentliche Timeouts zu vermindern. Die momentanen in der Praxis benutzten Standardwerte für die Konstanten a, b und c findet man in Abschnitt 4.1.9. Wenn k Pakete einer TG eingetroffen sind, aber eines oder mehrere der k Datenpakete verloren wurden, müssen die verlorenen Pakete mit dem Reed-Solomon Decoder wiederhergestellt werden. Alle Datenpakete werden in Speicherbereiche (wie in 4.1.3 beschrieben) kopiert. Die FEC Pakete werden ebenfalls in Speicherbereiche kopiert. Es werden der RTP Header, das Length Recovery Feld aus dem FEC Header und der variable Teil (Nutzdaten) des FEC Pakets hintereinander kopiert. Das PT Feld und das TS Feld im kopierten RTP Header werden auf die Werte des PT Recovery Feldes und des TS Recovery Feldes des FEC Headers gesetzt. Versionsnummer, Sequenznummer und SSRC werden wie bei Datenpaketen auf 0 gesetzt. Die so erzeugten k Speicherbereiche werden dann an den RS-Decoder übergeben, der alle verlorenen Datenpakete wiederherstellt. Damit der Decoder weiß, welche Pakete verloren wurden, wird ihm noch ein Feld mit den Indizes der angekommenen Pakete übergeben. Die Indizes lassen sich mit den RTP Sequenznummern und den i-Feldern der FEC Pakete berechnen. Für jedes wiederhergestellte Paket wird ein neuer RTP Header erzeugt. Die Versionsnummer wird auf 2 und die Sequenznummer auf die Summe von SN_Base und dem Index des verlorenen Paketes (innerhalb der TG, beginnend bei 0) gesetzt. Die SSRC wird auf den Wert der SSRC des Datenstromes gesetzt. Alle anderen Felder werden aus dem wiederhergestellten RTP Header kopiert. Die Länge des variablen Teils des Datenpaketes steht in den zwei Byte hinter dem Header. Abschließend werden so viele Bytes wie das Längenfeld angibt (beginnend mit dem ersten Byte hinter dem Längenfeld) an den gerade erzeugten RTP Header angehängt. Diese Bytes sind die CSRC Liste, die Extension, die Nutzdaten und das Padding des RTP Paketes. Für die Wiederherstellung nicht benötigte FEC Pakete werden nach dem Timeout t2 gelöscht. 4.1.5 Gateway Kontrolle Das RTP Gateway verfügt über eine einfache Schnittstelle, um die Redundanzmenge für einzelne Datenquellen während des Betriebes zu verändern. Gleichzeitig kann über diese Schnittstelle die empfangene Qualität für jeden Sender ermittelt werden. Die Schnittstelle ist als UDP Port realisiert. Seite 62 Kapitel 4: Verbesserung der Dienstqualität durch FEC Um die RS-Parameter für einen Sender zu ändern, wird ein Paket mit der SSRC und den Parametern n und k an das Gateway gesendet. Abbildung 26 zeigt das Format des Paketes. SSRC N K Abbildung 26: Kontrollpaket - RS-Parameter Das RTP Gateway empfängt alle RTCP Nachrichten und wertet Sender- und Receiver Reports aus, um Informationen über die Qualität an den Empfängern zu bekommen. Für jede Sender-Empfänger-Kombination werden die Verlustrate und der Jitter gespeichert. Zusätzlich wird die Umlauf-Verzögerung (round trip delay) zwischen dem Empfänger und dem SenderGateway gemessen. Wenn man davon ausgeht, daß die Verzögerung zwischen SenderGateway und Sender klein ist, entspricht der gemessene Wert nahezu der UmlaufVerzögerung zwischen Sender und Empfänger: rtd = t RR − t SR − d LSR Die folgende Abbildung 27 zeigt den Ablauf der Messung. tSR Sender Report Gateway tRR Gateway Gateway dLSR Receiver Report Gateway Abbildung 27: Messung der Umlauf-Verzögerung Bekommt das Gateway ein Paket auf der Kontrollschnittstelle, antwortet es mit einem Paket, das die gemessenen Quality of Service (QoS) Informationen enthält. Die QoS Nachricht enthält für jeden Sender die Parameter Verlustrate, Jitter und Umlaufverzögerung. Die Parameter werden über alle berichtenden Empfänger gemittelt. Wenn noch kein bekannter Sender existiert, schickt das Gateway auch kein QoS Paket. In diesem Fall muß darauf geachtet werden, daß das abfragende Programm nicht blockiert. Abbildung 28 zeigt das Format des Pakets. Die Felder Fraction und Jitter entsprechend genau der Definition im RTCP Protokoll (siehe [RFC1889]). Das Delay Feld enthält die auf die nächste ganze Zahl gerundete UmlaufVerzögerung in ms. Seite 63 Kapitel 4: Verbesserung der Dienstqualität durch FEC SSRC_1 Fraction Delay Jitter SSRC_2 .... Abbildung 28: Kontrollpaket - QoS Informationen 4.1.6 Statistikberechnung Um die Funktion des Gateways beobachten zu können, wird in regelmäßigen Intervallen (alle 10 s) eine Statistik für jede SSRC angezeigt. Diese Statistik wird im Gateway berechnet, es werden keine Werte aus den RTCP Nachrichten benutzt. Das Problem ist, daß die Intervalle in denen die RTCP Nachrichten verschickt werden unterschiedlich lang sind und mit steigenden Teilnehmerzahlen immer größer werden (Skalierbarkeit). Dies führt zu großen Problemen, wenn Statistiken in regelmäßigen Intervallen ausgegeben werden sollen. Abbildung 29 zeigt eine Ausgabe der Statistiken am Sender- und Empfänger-Gateway über einen Zeitraum von 20 s. Die Bedeutung der einzelnen Felder wird in Tabelle Tabelle 15 erläutert. Sender SSRC Recv Med Trans Med Recv FEC Trans FEC Recover Timed Med Timed FEC Mean Delay Loss Eff Loss LMInt RMInt 1573926991 499 499 0 490 0 6 0 - 0.02 2361045661 0 0 0 0 0 0 0 SSRC Recv Med Trans Med Recv FEC Trans FEC Recover Timed Med Timed FEC Mean Delay Loss Eff Loss LMInt RMInt 1573926991 501 501 0 505 0 0 0 0.02 2361045661 0 0 0 0 0 0 0 - Empfänger SSRC Recv Med Trans Med Recv FEC Trans FEC Recover Timed Med Timed FEC Mean Delay Loss Eff Loss LMInt RMInt 1573926991 386 481 382 0 97 6 279 0.1041 0.2 0.0041 - 0.02 2361045661 0 0 0 0 0 0 0 SSRC Recv Med Trans Med Recv FEC Trans FEC Recover Timed Med Timed FEC Mean Delay Loss Eff Loss LMInt RMInt 1573926991 402 493 392 0 94 3 298 0.1071 0.2 0.014 - 0.02 2361045661 0 0 0 0 0 0 0 - Abbildung 29: Statistikberechnung Feld Received Media Transmitted Media Received FEC Transmitted FEC Recovered Timed Out Media Timed Out FEC Mean Delay Loss Effective Loss Local Media Interval Seite 64 Bedeutung Anzahl der empfangenen Medien Pakete (RTP Pakete) Anzahl der gesendeten Medien Pakete Anzahl der empfangenen FEC Pakete Anzahl der gesendeten FEC Pakete Anzahl der wiederhergestellten Medien Pakete Media Paket Timeouts (t1 oder t2) FEC Paket Timeouts (t2) Mittlere Verzögerung der Pakete in s Verlustrate zwischen den Gateway (Media und FEC) Verlustrate zwischen Gateway und Empfänger Paketintervall des lokalen Senders in s Kapitel 4: Verbesserung der Dienstqualität durch FEC Remote Media Interval Paketintervall zwischen den Gateways in s Tabelle 15 : Statistikberechnung Bei den Recovered Paketen ist zu beachten, daß nicht alle der wiederhergestellten Pakete auch gesendet werden (Duplikate). Timed out Media Pakete entstehen am Sender durch den Timer t1 und am Empfänger durch den Timer t2. Am Sender werden diese Pakete gelöscht, da es sich nur um Kopien handelt. Am Empfänger werden diese Pakete gesendet, allerdings werden auch hier keine Duplikate übertragen. Timed Out FEC Pakete entstehen am Empfänger. Nicht benutzte FEC Pakete werden nach Ablauf des Timers t2 verworfen. Loss ist die Verlustrate im Netzwerk (ohne FEC). Effective Loss gibt die tatsächliche Verlustrate (mit FEC) an, d.h. die Verlustrate, die ein Empfänger erleidet. Durch Jitter können allerdings zusätzliche Verluste am Empfänger entstehen, wenn der Jitter nicht durch den Playoutbuffer kompensiert werden kann. Der Effective Loss Wert kann auch negative Werte annehmen, weil die Meßintervalle nicht mit den Transmission Groups (TGs) synchronisiert sind. Das bedeutet, es können in einem Meßintervall mehr Pakete an den Empfänger gesendet werden, als in diesem Intervall angekommen sind. Pakete einer TG werden erst gesendet, wenn alle Pakete der TG eingetroffen bzw. wiederhergestellt wurden oder der Timer abläuft. Die korrekte effektive Verlustrate ergibt sich durch Addition der Werte der beiden aufeinanderfolgenden Intervalle. 4.1.7 Verlustsimulation Um das Gateway mit reproduzierbaren Verlustraten testen zu können, wurde eine Verlustsimulation eingebaut. Pakete von entfernten Sendern gehen am empfangenen Gateway verloren (siehe Abbildung 30). RTP Gateway RTP Gateway Abbildung 30: Paketverluste Zur Verlustsimulation gibt es zwei Möglichkeiten. Unabhängige Verluste werden einfach mit einer Funktion erzeugt, die gleichförmig verteilte Zufallszahlen zwischen 0 und 1 generiert. Ist die Zufallszahl kleiner als die Verlustwahrscheinlichkeit pL, dann ist das Paket verloren. Burstartige Verluste werden mit einem 2-state Markov Modell erzeugt (siehe [Noll96], Seite 285). Abbildung 31 zeigt die beiden Zustände und die Übergangswahrscheinlichkeiten. p 1-p 1-q lost arrived q Seite 65 Kapitel 4: Verbesserung der Dienstqualität durch FEC Abbildung 31: 2-state Markov Modell Das Markov Modell läßt sich durch eine Verlustrate pL und eine mittlere Burstlänge b beschreiben: pL p= b ⋅ (1 − p L ) q= 1 b Es muß beachtet werden, daß keine beliebigen Kombinationen von pL und b möglich sind. Es kann zum Beispiel keine Verlustrate größer als 50% mit einer mittleren Burstlänge von 1 erzeugt werden. Die Parameter können in einer Konfigurationsdatei angegeben werden. 4.1.8 Einsatzmöglichkeiten Das RTP FEC Gateway läßt sich in verschiedenen Szenarien einsetzen, da das Gateway in beide Richtungen sowohl Unicast als auch Multicast senden kann. Das Gateway läßt sich deshalb auch als Unicast-Multicast-Translator benutzen. Im einfachsten Fall läßt sich das Gateway für eine einzelne Unicast-Verbindung (zum Beispiel Internet-Telefonie) einsetzen (siehe Abbildung 32). Jedes Gateway empfängt einen Datenstrom vom lokalen Sender, erzeugt FEC Pakete und sendet die Daten- und FEC Pakete an das entfernte Gateway. Das Empfänger-Gateway repariert mit den FEC-Paketen verlorene Medien-Pakete. Benutzer A Gateway Gateway Benutzer B Abbildung 32: Szenario - Internet Telefonie Das Gateway läßt sich auch für Audio/Video-Konferenzen über Multicast-Verbindungen einsetzen. Abbildung 33 zeigt sechs Teilnehmer (A-F) an drei unterschiedlichen Orten. Paketverluste zwischen den Gateways (zum Beispiel im WAN) werden mit den FEC Paketen repariert. Die Multicastgruppen müssen natürlich mittels TTL- oder Administrative Scoping entsprechend dimensioniert werden. Seite 66 Kapitel 4: Verbesserung der Dienstqualität durch FEC C RTP D GW A RTP GW RTP/FEC B E RTP GW F Abbildung 33: Szenario - Audio/Video-Konferenz Da Audio- und Videoströme normalerweise auf unterschiedlichen Multicast-Gruppen gesendet werden, benötigt jeder Teilnehmer für Audio und Video jeweils ein Gateway. Im WAN kann für die Übertragung eine Multicast-Gruppe benutzt werden, im LAN müssen die Audio- und Videoinformationen wieder in zwei getrennten Multicast-Gruppen versendet werden. Ein weiterer interessanter Fall ergibt sich, wenn es sogenannte Legacy und FEC-enhanced Anwendungen gibt. Legacy-Anwendungen verfügen über keine FEC Mechanismen und sind auf ein Gateway angewiesen. FEC-enhanced Anwendungen verfügen über FEC Mechanismen und können sowohl FEC Pakete erzeugen als auch FEC Pakete empfangen und zur Reparatur benutzen. FEC-enhanced Anwendungen sind also nicht auf ein Gateway angewiesen. In Abbildung 34 haben die Benutzer A, B, C und D Legacy-Anwendungen und sind auf Gateways angewiesen. Benutzer E und F setzen FEC-enhanced Anwendungen ein und benötigen kein Gateway. C RTP D GW A RTP GW RTP/FEC E B F Abbildung 34: Szenario - Unterschiedliche Anwendungen Ein weitere Idee ist, nur eine Multicast-Gruppe für die Übertragung zu benutzen. Das bedeutet, die Gateways senden auf der selben Adresse von der sie auch empfangen. Das Gateway am Sender fügt also FEC Pakete in die Multicast-Gruppe ein und Gateways an den Empfängern können diese zur Wiederherstellung verlorener Pakete benutzen. Die wiederhergestellten Pakete werden dann ebenfalls in die Multicast-Gruppe eingefügt. Da bei diesem Szenario auch FEC Pakete bei Legacy-Anwendungen eintreffen, muß sichergestellt werden, daß diese am Empfänger als unbekannt klassifiziert und verworfen werden. Seite 67 Kapitel 4: Verbesserung der Dienstqualität durch FEC Die FEC Pakete können jetzt natürlich nicht mehr mit der gleichen SSRC Nummer gesendet werden, da sonst der Sender durch die auch bei ihm eintreffenden FEC Pakete ständig Kollisionen erkennt und seine SSRC Nummer wechselt. Aus dem selben Grund dürfen keine reparierten Pakete zurück zum Sender gelangen. Letzteres läßt sich zum Beispiel mit geeignetem TTL-Scoping verhindern. Der erste Punkt erfordert aber, daß FEC Ströme jetzt eine andere SSRC Nummer haben als der dazugehörige Datenstrom. Um eine Zuordnung zwischen FEC- und Medien-Paketen zu haben, werden FEC-Pakete mit einer SSRC markiert, die der SSRC der Medienpakete plus 1 entspricht. Der Raum der SSRC Nummern ist groß genug, um selbst bei einer hohen Anzahl von Empfängern die Kollisionswahrscheinlichkeit klein zu halten, wenn ein guter Zufallszahlenalgorithmus (zum Beispiel MD5) verwendet wird. Da das Gateway dann eigene SSRCs vergeben muß, muß es auch eigene RTCP Nachrichten versenden und eine SSRC-Kollisionsbehandlung durchführen. Es handelt sich dann nicht mehr um einen RTP Translator (siehe [RFC1889]) sondern um eine Mischung aus RTP Translator und RTP Mixer. 4.1.9 Implementierung Das RTP Gateway wurde als Prototyp in der Sprache C++ implementiert. Zur Speicherung von angekommenen oder ausgehenden Paketen wurde keine eigene Datenstruktur entwickelt, sondern es wurde auf die bewährte map-Klasse der Standard Template Library (STL) zurückgegriffen. Die map-Klasse ermöglicht außerdem eine automatische Vermeidung von Duplikaten und ein Reseqencing, weil die Pakete jeweils mit der Sequenznummer indiziert werden. Da das Gateway über keinen Playoutbuffer verfügt, ist die Duplikatvermeidung und das Resequencing auf jeweils eine TG beschränkt. Das Gateway wurde im wesentlichen so implementiert wie in den vorigen Abschnitten beschrieben. Die einzige Aussnahme ist, daß bei Ablaufen des Timers t1 am Sender-Gateway keine Redundanz erzeugt wird. Beim Abfragen der verschiedenen Sockets wird ein relativ großer Timeout von 1 ms benutzt. Das hat den Vorteil, daß das RTP Gateway keine unnötige Rechenzeit verbraucht. Ein Problem entsteht, wenn der Rechner durch andere Anwendungen stark ausgelastet wird. Es kommt zu Timing-Problemen, da das Gateway nicht mehr genug Rechenzeit erhält. Pakete können nicht mehr schnell genug von den Sockets abgeholt werden, so daß die Timer t1 und t2 quasi zu früh ablaufen. Die Effektivität der Vorwärtsfehlerkorrektur verringert sich deshalb entsprechend. Bei der Berechnung der Timeouts hat es sich gezeigt, daß es für eine optimale Audioübertragung günstig ist, die Konstante b auf 0 zu setzen. Die weiteren Konstanten werden zu a = 0,5 und c = 0,05 gesetzt. Die eigentliche Kodierung und Dekodierung wird in Child-Prozessen durchgeführt, die vom Gateway erzeugt werden (fork-Funktion). Dadurch ist der Parent-Prozess in der Lage, schneller wieder neue Pakete entgegenzunehmen, ohne die doch relativ lange dauernde Dekodierung abwarten zu müssen (siehe Abschnitt 4.2.2). Die Effektivität der Vorwärtsfehlerkorrektur könnte weiter gesteigert werden, wenn am Sender ein Interleaving der Pakete durchgeführt wird. Der Sender sendet die Pakete nicht mehr in der natürlichen Reihenfolge, sondern verwürfelt sie entsprechend dem IntervleavingFaktor. Ein Interleaving der Pakete am Sender verringert die Länge der Fehlerbursts und erhöht damit die Wahrscheinlichkeit, daß die Pakete am Empfänger wiederhergestellt werden können. Allerdings erhöht sich die entstehende Verzögerung ebenfalls, so daß der Einsatz von Interleaving nur bei nicht interaktiven Anwendungen sinnvoll erscheint. In der momentanen Implementierung werden die FEC Pakete als einzelne Pakete verschickt. Weil der Paket-Header im Verhältnis zu den Nutzdaten (zumindest bei Audiodaten) recht groß ist, entsteht ein unnötiger Overhead. Um Bandbreite im Netz zu sparen, kann man die FEC Informationen an später gesendete Datenpakete anfügen (piggy-backing). Als weitere Seite 68 Kapitel 4: Verbesserung der Dienstqualität durch FEC Verbesserungen sind eine direkte Integration in die Anwendung (FEC enhanced application) und eine automatische Adaption der Kodier-Parameter (siehe [PaWa98]) denkbar. Weiterhin könnte der Layered-FEC Ansatz für Multicast-Übertragung implementiert werden. Bei Versuchen mit Videoübertragung hat sich gezeigt, daß das Gateway weitaus weniger effektiv ist als bei Audioübertragung. Das Problem ist, daß die benutzte Anwendung über keinen Playoutbuffer verfügt. Weil das Gateway nur ein begrenztes Resequencing durchführt (innerhalb einer TG), kommen unter Umständen ganze TGs außerhalb der ursprünglichen Reihenfolge an. Zu spät angekommene Pakete haben dann natürlich die gleiche negative Wirkung wie verlorene Pakete. Deshalb wurde eine zweite Version des Gateways mit integriertem Playoutbuffer implementiert. Die Playout-Verzögerung ist bei gleichem RS-Code und gleichem Paketabstand konstant: d p = n ⋅ ti Verfügt die eingesetzte Anwendung über einen eigenen Playoutbuffer, kann diese Verzögerung dann natürlich auf den minimalen Wert 0 gesetzt werden. 4.2 Performance Um eine Abschätzung der Leistungsfähigkeit zu bekommen, wird in diesem Abschnitt die Performance des RS-Kodieres aus [Rizzo98] und des RTP Gateways untersucht. Kodiergeschwindigkeit [Mbps] 4.2.1 Reed-Solomon Kodierer Die Performance des Reed-Solomon Kodierers wurde auf einer Sparc Ultra 10 gemessen. Kodier- und Dekodiergeschwindigkeit sind hier als die Nutzdatenmenge, die pro Zeit kodiert bzw. dekodiert werden kann, definiert. Abbildung 35 zeigt, daß die Kodiergeschwindigkeit nahezu unabhängig von der Paketgröße ist. Nur bei sehr kleinen Paketgrößen fällt die Geschwindigkeit etwas geringer aus. Für die Messung wurde ein 255/223 Code benutzt (Vergleiche mit Tabelle 2). 12 10 8 6 4 2 0 0 512 1024 1536 2048 2560 Paketgröße [bytes] 3072 3584 4096 Abbildung 35: Kodiergeschwindigkeit in Abhängigkeit von der Paketgröße Die Abbildung 36 zeigt, daß die Kodiergeschwindigkeit abhängig von der erzeugten Redundanzmenge h ist. Die Kodiergeschwindigkeit ist umgekehrt proportional zu h, weil h verSeite 69 Kapitel 4: Verbesserung der Dienstqualität durch FEC schiedene Redundanzblöcke erzeugt werden müssen. Diese Beobachtung entspricht der Aussage in [Rizzo98]. Für die Messung wurde eine Paketgröße von 1024 Byte benutzt. Kodiergeschwindigkeit [Mbps] 350 300 250 200 150 100 50 0 0 20 40 60 h [Pakete] 80 100 Abbildung 36: Kodiergeschwindigkeit in Abhängigkeit von der Redundanzmenge Die Dekodiergeschwindigkeit ist abhängig von der Zahl der verlorenen Pakete und der Anzahl der Datenpakete k. Abbildung 37 zeigt die Abhängigkeit der Dekodiergeschwindigkeit von der Anzahl der verlorenen Pakete. Es wurde wieder ein 255/223 Code und eine Paketgröße von 1024 Byte benutzt. Man sieht, daß die Dekodiergeschwindigkeit umgekehrt proportional zur Anzahl der verlorenen Pakete ist (siehe auch [Rizzo98]). Auf eine Darstellung der Dekodiergeschwindigkeit in Abhängigkeit von k wurde hier verzichtet. Die Dekodiergeschwindigkeit ist auch zu k umgekehrt proportional. Dekodiergeschwindigkeit [Mbps] 250 200 150 100 50 0 0 5 10 15 20 Verlorene Pakete 25 30 Abbildung 37: Dekodiergeschwindigkeit in Abhängigkeit von den Verlusten Wie man anhand der Grafiken sieht, reicht die Performance des Kodierers bei weitem aus, um eine entsprechende Redundanz für Audioströme zu erzeugen. Ein PCM Audiostrom hat eine Rate von 64 kb/s, d.h., ein FEC Gateway kann mehrere Ströme gleichzeitig kodieren und Seite 70 Kapitel 4: Verbesserung der Dienstqualität durch FEC dekodieren. Auch für komprimierte Videoströme (H.261) reicht die Performance des Kodierers aus. 4.2.2 RTP Gateway Das RTP Gateway wurde so implementiert, daß möglichst wenig Rechenzeit unnötig verbraucht wird. Bei einem PCM Audiostrom mit 20 ms Paketisierung und einer simulierten Verlustrate von 0,2 liegt die Rechnerauslastung durch Empfänger- und Sender-Gateway bei 510% auf einer SUN Ultra-20. Die Kodierzeit für einen 10/5 Block beträgt ungefähr 3 ms, die Dekodierzeit liegt bei einer Verlustrate von 0,2 zwischen 1,5 und 3 ms. 4.3 Untersuchung der Übertragungsqualität In diesem Abschnitt wird untersucht, wie sich die Übertragungsqualität durch den Einsatz des FEC Gateways verbessert. Die Untersuchung beschränkt sich dabei auf die Übertragung von Audiodaten. Versuche mit H.261 Videoströmen lieferten allerdings vergleichbare Ergebnisse. Es werden sowohl Messungen mit künstlich erzeugten Verlusten als auch mit Verlusten auf einer realen Übertragungsstrecke durchgeführt. Die reale Übertragungsstrecke wurde mit Hilfe eines in den USA installierten RTP Reflektors realisiert (siehe Abbildung 38). Tabelle 16 zeigt die mit traceroute ermittelten Hops auf der Strecke zwischen winnie.fokus.gmd.de und systems.seas.upenn.edu. Diese Strecke wird natürlich zweimal von den RTP Paketen durchlaufen. Hop 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Name rockmaster (193.175.132.225) ferry (193.174.154.1) GMD-Berlin1 (188.1.1.101) ZR-Berlin1.WiN-IP.DFN.DE (188.1.162.73) ZR-Frankfurt1.WiN-IP.DFN.DE (188.1.144.106) IR-Perryman2.WiN-IP.DFN.DE (188.1.144.86) 166.48.39.253 (166.48.39.253) core3.WestOrange.cw.net (204.70.4.1) wor-verio-nap.WestOrange.cw.net (204.70.1.10) ucsc1-gw-h0-0-0.phl.pa.verio.net (205.238.52.106) upenn-gw.pa.verio.net (130.94.193.20) UPENN-VERIO.MAGPI.NET (198.32.242.2) DEFAULT1-GW-FE.UPENN.EDU (165.123.237.2) SYSTEMS.SEAS.UPENN.EDU (130.91.4.52) Tabelle 16: Reale Strecke - Traceroute rockmaster.fokus. gmd.de SYSTEMS.SEAS. UPENN.EDU winnie.fokus.gmd. de Abbildung 38: Reale Übertragungsstrecke Seite 71 Kapitel 4: Verbesserung der Dienstqualität durch FEC 4.3.1 Burstverluste Die Messungen über die reale Übertragungsstrecke zeigen, daß Verluste in der Realität nicht einzeln sondern immer burstartig auftreten. Die Verlustwahrscheinlichkeit eines Paketes ist also abhängig von der Tatsache, ob das vorherige Paket verloren wurde oder nicht. Diese Verlustbursts lassen sich dadurch erklären, daß Verluste im Internet in der Regel immer durch Überlast entstehen. Es kommt zu Pufferüberläufen in den Routern der Übertragungsstrecke. Weitere Ursachen für Verluste sind Fehlkonfigurationen oder Übertragungsfehler. Letztere treten aber nur bei drahtlosen Systemen nennenswert in Erscheinung. Abbildung 39 zeigt die relative Häufigkeit der Länge der Verlustbursts auf der realen Übertragungsstrecke. Die Messung wurde mit PCM Audiopaketen im Abstand von 20 ms durchgeführt. Die Wahrscheinlichkeit für einen Burstfehler (clp=p(l>1)) beträgt ungefähr 0,49. Dieses Ergebnis stimmt mit den Messungen in [Bolot93] überein. Für einen Paketabstand von 20 ms wurde dort eine Burstfehlerwahrscheinlichkeit von 0,42 gemessen. Die Burstfehlerrate verringert sich mit dem Paketabstand. Bei einem Paketabstand von 50 ms ist die Burstfehlerrate bereits auf 0,27 gesunken (siehe [Bolot93]). Weil die Effizienz von ReedSolomon Codes abnimmt, je größer die Wahrscheinlichkeit für Burstfehler ist, sollte bei der Übertragung ein größerer Paketabstand benutzt werden. Da größere Paketabstände zu höheren Verzögerungszeiten führen, kann der Abstand allerdings auch nicht beliebig groß gewählt werden. Bei den Tests auf der realen Strecke hat sich ein Paketabstand von 40 ms als geeignet erwiesen (Burstfehlerwahrscheinlichkeit 0,32). 0,6 Relative Häufigkeit 0,5 0,4 0,3 0,2 0,1 0 1 2 3 4 5 6 7 8 9 10 Länge des Verlustbursts [Pakete] Abbildung 39: Messung der Burstverluste 4.3.2 Verlustrate Abbildung 40 zeigt die gemessene effektive Verlustrate am Empfänger. Die simulierte Verlustrate beträgt im Mittel 30%, die Verluste sind statistisch unabhängig (keine Burstverluste). Weil keine Burstverluste auftreten, entspricht die effektive Verlustrate mit FEC den theoretisch erreichbaren Werten (siehe RS 10/5 – Theorie in Anhang 7.4). Seite 72 Kapitel 4: Verbesserung der Dienstqualität durch FEC 0,4 0,35 Effektive Verlustrate 0,3 0,25 keine FEC RS 8/5 RS 10/5 RS 15/5 0,2 0,15 0,1 0,05 0 0 50 100 150 200 Zeit [s] Abbildung 40 : Effektive Verlustrate - Simulierte Verluste Werden die Daten auf einer realen Strecke im Internet übertragen, verringert sich die Effektivität des Reed-Solomon Codes, weil ein großer Anteil der Verluste Burstfehler sind (siehe 4.3.1). Abbildung 41 zeigt die gemessenen effektiven Verlustraten mit den selben FEC Parametern wie in der vorangegangenen Abbildung. Die mittlere Verlustrate im Netzwerk beträgt ungefähr 23%. 0,35 0,3 Effektive Verlustrate 0,25 keine FEC 0,2 RS 8/5 RS 10/5 0,15 RS 15/5 0,1 0,05 0 0 50 100 150 200 Zeit [s] Abbildung 41: Effektive Verlustrate - Reale Strecke Seite 73 Kapitel 4: Verbesserung der Dienstqualität durch FEC Die beiden Messungen wurden mit einem PCM Audiostrom und einem Paketabstand von 20 ms durchgeführt. Die gemessene Verlustrate stimmt mit der für den Anwender tatsächlich hörbaren überein, Verluste durch Jitter traten nicht auf. Nun soll untersucht werden, wie die effektive Verlustrate von der Verlustrate abhängt. Die Abbildung 42 zeigt die effektiven Verluste ohne FEC, die theoretisch ermittelte effektive Verlustrate (siehe 2.2.3.2), die gemessene effektive Verlustrate bei simulierten unabhängigen Verlusten, die gemessene effektive Verlustrate auf der realen Übertragungsstrecke und die gemessene effektive Verlustrate bei simulierten burstartigen Verlusten. Übertragen wurde ein PCM Audiostrom mit 20 ms Paketlänge, zur Vorwärtsfehlerkorrektur wurde ein ReedSolomon 10/5 Code benutzt. Das Diagramm zeigt, daß die effektive Verlustrate bei unabhängigen Paketverlusten der theoretisch berechneten entspricht. Die Implementierung ist also offensichtlich korrekt. Die effektive Verlustrate auf der realen Strecke ist deutlich schlechter, weil hier burstartige Verluste die Effektivität des Reed-Solomon Codes verringern. Die Kurve mit den simulierten Burst-Verlusten zeigt einen ähnlichen Verlauf. Allerdings ist selbst auf der realen Übertragungsstrecke die für den Empfänger spürbare Verlustrate wesentlich geringer als die tatsächlich vorhandene, wenn die Verluste im Netz nicht über 30% liegen. Der Einsatz von FEC steigert die Übertragungsqualität also ganz erheblich. Die Funktionswerte der abgebildeten Kurven findet man in Anhang 7.4. 1 0,9 0,8 Effektive Verlustrate 0,7 keine FEC 0,6 RS 10/5 Theorie RS 10/5 Unabh. Verluste 0,5 RS 10/5 Reale Strecke 0,4 RS 10/5 Burst-Verluste 0,3 0,2 0,1 0 0 0,1 0,2 0,3 0,4 0,5 0,6 Verlustrate 0,7 0,8 0,9 1 Abbildung 42: Die Effektivität von FEC Die Abbildung 43 zeigt die gleichen Kurven wie die Abbildung 42 bis zu einer effektiven Verlustrate von 0,2. Zusätzlich wurde eine Messung mit einem Audiosignal mit Sprachpausen durchgeführt. Die effektive Verlustrate liegt etwas höher als die ideal berechnete, da bei der momentanen Implementierung unvollständige Blöcke vor einer Pause nicht durch FEC geschützt werden. Seite 74 Kapitel 4: Verbesserung der Dienstqualität durch FEC Effektive Verlustrate 0,2 keine FEC RS 10/5 Theorie RS 10/5 Unabh. Verluste 0,1 RS 10/5 Reale Strecke RS 10/5 Burst-Verluste RS 10/5 Silence Det. 0 0 0,1 0,2 0,3 Verlustrate 0,4 0,5 Abbildung 43: Effektive Verlustrate unterhalb 0,2 Um die Effizienz des RS Codes bei Burst-Fehlern zu steigern, gibt es zwei Möglichkeiten. Ein größeres Paketisierungsintervall verringert die Wahrscheinlichkeit für das Auftreten von abhängigen Verlusten (siehe 4.3.1). Als Alternative kann die Anzahl der Redundanzpakete h (bei gleichem Verhältnis von n und k) erhöht werden. Beide Maßnahmen verringern die effektive Verlustrate, verursachen aber eine zusätzliche Verzögerung. Diese Verzögerung ist dann akzeptabel, wenn es sich um eine nicht interaktive Übertragung handelt (zum Beispiel Radio). Bei interaktiver Kommunikation führt die zusätzliche Verzögerung allerdings zu Problemen (siehe 2.2.3). Seite 75 Kapitel 4: Verbesserung der Dienstqualität durch FEC Seite 76 Kapitel 5: Untersuchung eines realen Szenarios 5 Untersuchung eines realen Szenarios In diesem Abschnitt soll die Funktionsweise des in den vorangegangenen Kapiteln beschriebenen Systems zur Dienstgüteauswahl an einem realen Szenario vorgestellt werden. Das Szenario besteht aus zwei Anwendern, die per IP-Telefonie miteinander kommunizieren. Beide Anwender sind Kunden des selben Dienstanbieters, eine Kostenkompensation zwischen Dienstanbietern muß also nicht betrachtet werden. Abbildung 44 zeigt eine schematische Darstellung des Szenarios. Benutzer Dienstanbieter RTP Benutzer RTP FEC Tunnel FEC Gateway CIP CIP Server FEC Gateway CIP CIP Client CIP Client Abbildung 44: Szenario IP-Telefonie Der Dienstanbieter stellt die folgenden IP-Dienste mit den entsprechenden Tarifen zur Verfügung: Dienst Best Effort Controlled Load Guaranteed Rate Tarif CBE(r,t)=d.r.t CCL(r,e,t)=(a + c.e).r.t CGR(r,t)=c.r.t Parameter d=0,0002 a=0,001; c=0,0004; e=0,05 c=0,0004 Verlustrate ~25% <<1% ~5% Tabelle 17 : Angebotene Dienste Bei den hier angebotenen Diensten handelt es sich um zwei Intserv-Dienste und einen Best-Effort-Dienst. Die Tariffunktionen für die Intserv-Dienste wurden aus [KSWS99] entnommen. Der ratenabhängige Tarif wird zusätzlich mit der Verbindungsdauer multipliziert, d.h., die ratenabhängigen Kosten fallen pro Zeiteinheit an. Die Rate wird in kBit und die Zeit in Minuten angegeben. Die Verlustraten der einzelnen Dienste sind als bekannt vorausgesetzt, in der Realität müßte eine Messung durchgeführt werden. Es wird außerdem angenommen, daß die Verlustraten über eine gewisse Zeit relativ konstant sind. Dies scheint sogar bei einem Best-Effort Dienst der Fall zu sein (siehe Abbildung 41). Keiner der angebotenen Dienste gibt Garantien für die Verzögerung und den Jitter. Beide Benutzer starten ihren CIP-Client mit der Adresse des CIP-Servers des Dienstanbieters als Parameter. Die Informationen über die angebotenen Dienstklassen werden dann an die Clients übertragen. In Anhang 7.2 wird der Protokollablauf gezeigt. Die Utility-Funktion für Audio setzt sich aus der Funktion in Abbildung 16 und der als realistisch angenommenen in Abbildung 45 gezeigten Funktion zusammen und ist beiden Clients bekannt. Die Funktion in Abbildung 45 wurde in einem Selbstversuch ermittelt; der Verlauf entspricht aber im wesentlichen der Funktion in Abschnitt 3.4.2. Die Konstanten der abschnittsweisen Exponentialfunktionen lassen sich mit Hilfe des Start- und Endpunktes jedes Abschnitts berechnen. Seite 77 Kapitel 5: Untersuchung eines realen Szenarios 5 Utility [MOS] 4,5 4 3,5 3 2,5 2 1,5 1 0,5 0 0,01 0,1 1 Verlustrate Abbildung 45: Utility in Abhängigkeit von der Verlustrate Die gesamte Utility-Funktion ist in TFL ausgedrückt: u(bn, pl) = (if(bn==0.08,0.2,if(bn==0.19,0.85,if(bn==0.5,0.9,if(bn==0.75,0.95,if(bn==1,1,0)))))*5)* (if(pl==0,5,if(and(pl>0,pl<=0.02),10^(-3.1847*pl)*5.32663,if(and(pl>0.02,pl<=0.1),10^(6.4579*pl)*6.1932,if(and(pl>0.1,pl<=0.15),10^(-2.9226*pl)*2.7446,0))))/5) Dabei ist bn die normierte Bandbreite und pl die Paketverlustwahrscheinlichkeit. Anhand der in Tabelle 18 angegebenen Randbedingungen der beiden Benutzer kann dann der günstigste Tarif ausgewählt werden. Im einfachsten Fall bestimmt der Sender die Qualität, die der Empfänger bekommt und bezahlt für die übertragenen Daten. Im Normalfall will allerdings der jeweilige Empfänger die Qualität der erhaltenen Daten bestimmen, d.h., der Empfänger muß dem Sender die gewünschte Qualität übermitteln (Signalisierung). Jeder Empfänger zahlt dann die Kosten des anderen Senders und bekommt die gewünschte Qualität. Die Signalisierung der Qualität könnte bei Intserv zum Beispiel mit RSVP durchgeführt werden, bei Diffserv müßte ein entsprechendes Protokoll spezifiziert werden. Parameter umin pmax k nmax Anwender 1 3 (gerade noch gut) 0,04 DM/min 5 10 Anwender 2 4,75 (sehr gut) 0,25 DM/min 5 10 Tabelle 18: Randbedingungen der Anwender Die Parameter k und nmax werden durch die maximale zusätzliche Verzögerung und den maximalen Overhead durch die Redundanz bestimmt. Diese beiden Werte werden vom Benutzer eingestellt. Bei 20 ms Audio-Paketen entsprechen die obigen Parameter einer maximalen zusätzlichen Verzögerung von 200 ms, der Overhead durch die Redundanz kann maximal 50% betragen. Um den Gesamtpreis einfach berechnen zu können, soll angenommen werden, daß das Gespräch 30 Minuten dauert und während des Gespräches keine Parameter (Dienstklasse, Redundanz) geändert werden. Seite 78 Kapitel 5: Untersuchung eines realen Szenarios Die nachfolgenden Tabellen zeigen die Ergebnisse des Optimierungsalgorithmus für die beiden Anwender. Neben der Utility und dem Preis werden die optimalen Werte für die normierte Bandbreite und die Redundanz (h = n-k) angegeben. Dienstklasse Best Effort Controlled Load Guaranteed Rate Utility/Preis 6971,29 2990,17 5848,77 Utility 4,1392 4,5273 4,16725 Preis 3,6 Pf/min 9 Pf/min 4,2 Pf/min Bn 0,19 0,19 0,19 n 10 5 6 Tabelle 19 : Optimierung für Anwender 1 Für Anwender 1 ist also der Best Effort Dienst am besten, hier ergibt sich das beste UtilityPreis-Verhältnis. Der Best Effort Dienst hat zwar die geringste Utility, doch auch dieser Wert liegt noch weit über dem vom Anwender geforderten (umin = 3). Der Preis pro Minute ist bei Best Effort am günstigsten, daher resultiert auch das beste Utility-Preis-Verhältnis. Außerdem liegt der Preis gerade unterhalb des vom Anwender festgelegten maximalen Preises (pmax = 4 Pf/min). Die geforderte Qualität läßt sich bei Best Effort nur durch den maximalen Einsatz von FEC erreichen (n = 10). Deshalb ist die entstehende Verzögerung beim Best Effort Dienst am größten. Der Optimierungsalgorithmus berücksichtigt die durch FEC auftretende Verzögerung allerdings nicht. Der Einsatz von FEC wirkt sich also nicht negativ auf das Optimierungsergebnis aus. Hätte der Anwender sich zum Beispiel für den Controlled Load Dienst entschieden, müßte er für eine nur geringfügig bessere Qualität ca. 5 Pfenning mehr pro Minute zahlen. In diesem Fall wären alleine die Mehrkosten teuerer als der maximale Preis, den der Benutzer zahlen will. Allerdings entsteht beim Controlled Load Dienst keine zusätzliche Verzögerung, da auf den Einsatz von FEC verzichtet werden kann. Dienstklasse Best Effort Controlled Load Guaranteed Rate Utility/Preis 1558,29 1203,1 1914,95 Utility 4,86965 4,79362 4,78737 Preis 18,6 Pf/min 23,8 Pf/min 15 Pf/min Bn 1 0,5 0,5 n 10 5 8 Tabelle 20 : Optimierung für Anwender 2 Der Anwender 2 will eine wesentlich bessere Qualität haben und ist auch bereit, dafür einen entsprechend höheren Preis zu bezahlen. Das beste Utility-Preis-Verhältnis ergibt sich hier bei dem Guaranteed Rate Dienst. Der Preis pro Minute ist deutlich günstiger als beim Best Effort und beim Controlled Load Dienst. Der Best Effort Dienst ist hier relativ teuer, da neben der maximalen FEC auch mit höherer Bandbreite übertragen werden muß, um die geforderte Mindestqualität (umin = 4,75) zu erreichen. Der maximal vom Anwender bezahlte Preis pro Minute liegt hier oberhalb des Preises aller Dienste. Beim Controlled Load Dienst entsteht wieder keine zusätzliche Verzögerung, weil keine FEC eingesetzt werden muß. Legt der Benutzer großen Wert auf eine geringe Verzögerung, wird er sich vermutlich für den Controlled Load Dienst entscheiden, obwohl dieser 60% teurer als der Guaranteed Rate Dienst ist. Seite 79 Kapitel 5: Untersuchung eines realen Szenarios Seite 80 Kapitel 6: Zusammenfassung und Ausblick 6 Zusammenfassung und Ausblick Es ist abzusehen, daß in den nächsten Jahren immer mehr (interaktive) Multimedia-Dienste in paketvermittelten Netzten (insbesondere dem Internet) eingesetzt werden. Anwendungen wie beispielsweise die Internet-Telefonie oder Audio/Video-Konferenzen gewinnen immer mehr an Bedeutung. Um die nötige Dienstqualität im Netz bereitzustellen, gibt es bereits entsprechende Mechanismen (Intserv/Diffserv). Da Netzressourcen nicht unbegrenzt vorhanden sind, muß der Anwender für eine garantierte Dienstqualität einen angemessenen Preis bezahlen. Es muß also ein Marktmechanismus installiert werden. Die denkbare Bandbreite reicht dabei von Dienstklassen, die zu festen Preisen angeboten werden, bis hin zu einem dynamischen Angebot-Nachfrage-Modell. Je komplexer das Preismodell wird, desto geringer wird allerdings die Akzeptanz durch den Kunden. Kein Kunde wird einen Dienst kaufen, bei dem er nicht von vornherein die anfallenden Kosten abschätzen kann. Die Tatsache, daß der Kunde selbst auf die Dienstqualität einwirken kann (zum Beispiel durch Vorwärtsfehlerkorrektur) erhöht die Komplexität zusätzlich. Die Akzeptanz des Kunden wird deutlich erhöht, wenn er bereits vor der Dienstnutzung die entstehenden Kosten berechnen kann. Der Kunde kann dann den für ihn günstigsten Dienst auswählen. Wenn die Zahl der angebotenen Dienste groß ist, muß diese Auswahl automatisiert werden. Der Anwender legt bestimmte Kriterien fest, anhand derer der für ihn beste Dienst ausgewählt wird. Im Rahmen dieser Arbeit wird ein Protokoll definiert, daß die Übertragung aller relevanter Informationen über einen angebotenen Dienst ermöglicht. Das Protokoll wurde Charging Information Protokoll (CIP) genannt. Das Protokoll läuft zwischen einem Server des Dienstanbieters und einem Client auf dem Rechner des Anwenders. Insbesondere wurde die Darstellung und Übertragung von Tarifformeln untersucht. Hierfür wurde eine geeignete Sprache, die Tariff Formula Language (TFL), entworfen. Es wurde ein Prototyp in C++ implementiert, der die wesentlichen Funktionen des Protokolls enthält. Um die automatische Dienstauswahl zu ermöglichen, wurde ein Algorithmus entwickelt, der den für den Benutzer preiswertesten Dienst auswählt. Der Benutzer gibt bestimmte Parameter wie zum Beispiel die gewünschte Qualität vor und der Algorithmus bestimmt unter Beachtung dieser Randbedingungen die für den Benutzer günstigste Dienstklasse. Der Algorithmus berücksichtigt in der ersten Stufe den Tarif und die subjektiv erreichbare Qualität (Utility). In der zweiten Stufe berücksichtigt der Algorithmus zusätzlich den Einsatz von Vorwärtsfehlerkorrektur durch den Benutzer. Der Algorithmus wurde in C++ implementiert und in den CIP Client integriert. Um den Einfluß von Vorwärtsfehlerkorrektur bei verschiedenen MultimediaAnwendungen zu untersuchen, wurde ein System entwickelt, das bereits generierte Medienströme mit Vorwärtsfehlerkorrektur schützt. Das System basiert auf einem RTP Gateway, das für einen Strom von RTP Paketen zusätzliche Redundanzpakete erzeugt. Bei der Redundanzerzeugung wurde auf die bewährten Reed-Solomon-Codes zurückgegriffen. Das RTP Gateway läßt sich in verschiedenen Szenarien mit bereits vorhandenen Multimedia-Anwendungen flexibel einsetzen. Das RTP Gateway wurde als Prototyp in C++ implementiert. Bei den Untersuchungen zur Übertragungsqualität wurden sowohl simulierte Verluste als auch eine reale Übertragungsstrecke eingesetzt. Dabei hat sich gezeigt, daß die in der Realität erreichbare Verbesserung zwar unterhalb der theoretisch berechneten liegt, aber dennoch einen deutlichen Gewinn für die Übertragungsqualität bedeutet. Seite 81 Kapitel 6: Zusammenfassung und Ausblick Es ist abzusehen, daß in den nächsten Jahren Systeme zur Dienstauswahl entwickelt und bei Dienstanbietern (Internet Service Providern) installiert werden. Diese Systeme werden ab einer gewissen Ausbaustufe auch über große Teile der im Rahmen dieser Arbeit entwickelten Funktionalität verfügen. Das hier implementierte System basiert auf grundsätzlichen Überlegungen und Ideen, die sich auf andere Produkte übertragen lassen. Die realisierten Komponenten stellen den Prototyp einer vollständigen Lösung dar. Die bei der Entwicklung des Prototypen gewonnenen Erfahrungen sind außerdem sehr hilfreich für den Aufbau eines vollständigen Systems. Seite 82 Kapitel 7: Anhang 7 Anhang 7.1 Verwendete Notation Alle Definitionen in dieser Diplomarbeit werden mit Hilfe der (Backus Nauer Form) BNF definiert. Terminalsymbole, also Symbole die nicht weiter aufgelöst werden können, sind in Anführungszeichen oder in Großbuchstaben dargestellt. Nichtterminalsymbole werden mit Kleinbuchstaben dargestellt. Es werden die unter C üblichen \-Escape Codes verwendet. Die grundlegenden Terminalsymbole sind: Symbol LEER ZIFFER ZAHL ZEICHEN WS Bedeutung Das leere Wort Eine einzelne Ziffer Reelle Zahl ASCII 8-bit Zeichen White Space Tabelle 21 : Grundlegende Terminalsymbole 7.2 CIP Protokollablauf C->S: REGISTER cip:@farpoint.cs.tu-berlin.de:4000 CIP/0.1 From: cip:[email protected]:4000 Transaction-ID: 2350908038:[email protected] Mode: push S->C: CIP/0.1 200 OK From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 2350908038:[email protected] Update-Frequency: 20 S->C: INFO cip:[email protected]:4000 CIP/0.1 From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 745851385:@farpoint.cs.tu-berlin.de Count: 3 Iseq: 46456 Service: id="10", name="best effort" Vendor: id="23", name="NEW-TEL INC." Currency: DM Parameter: D="0.0002" Formula: D*r*t Guarantees: loss="0.25", delay="-1", jitter="-1" S->C: INFO cip:[email protected]:4000 CIP/0.1 From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 745851385:@farpoint.cs.tu-berlin.de Count: 3 Iseq: 46457 Service: id="11", name="controlled load" Seite 83 Kapitel 7: Anhang Vendor: id="23", name="NEW-TEL INC." Currency: DM Parameter: A="0.001", C="0.0004", EE="0.05" Formula: (A+C*EE)*r*t Guarantees: loss="1e-05", delay="-1", jitter="-1" Reservation: RSVP/IntServ S->C: INFO cip:[email protected]:4000 CIP/0.1 From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 745851385:@farpoint.cs.tu-berlin.de Count: 3 Iseq: 46458 Service: id="12", name="guaranteed rate" Vendor: id="23", name="NEW-TEL INC." Currency: DM Parameter: C="0.0004" Formula: C*r*t Guarantees: loss="0.05", delay="-1", jitter="-1" Reservation: RSVP/IntServ C->S: CIP/0.1 200 OK From: cip:[email protected]:4000 Transaction-ID: 745851385:@farpoint.cs.tu-berlin.de Iseq: 46456 46457 46458 C->S: SELECT cip:@farpoint.cs.tu-berlin.de:4000 CIP/0.1 From: cip:[email protected]:4000 Transaction-ID: 2432299901:[email protected] Service: id="10", name="best effort" Endpoint: darkstar.cs.tu-berlin.de:5000 S->C: CIP/0.1 200 OK From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 2432299901:[email protected] C->S: CANCEL cip:@farpoint.cs.tu-berlin.de:4000 CIP/0.1 From: cip:[email protected]:4000 Transaction-ID: 3273410552:[email protected] S->C: CIP/0.1 200 OK From: cip:@farpoint.cs.tu-berlin.de:4000 Transaction-ID: 3273410552:[email protected] 7.3 TFL Tarifformeln Hier werden die Tarifformeln, die in Abbildung 7 benutzt werden, beschrieben: Der erste Tarif ist ein zeit- und volumenabhängiger Tarif (Basisformel). p = sc + Seite 84 v t ⋅ p v + ⋅ pt uv ut Kapitel 7: Anhang TFL: p = sc + (v/vu)*pv + (t/tu)*pt Der zweite Tarif ist ein volumenabhängiger Tarif. Die Wurzel über das gemessene Volumen bewirkt eine Art Rabatt, je größer das Volumen wird. p = sc + v uv ⋅ pv TFL: p = sc + (sqrt(v)/vu)*pv Der dritte Tarif ist zeit- und volumenabhängig, nach 20 s und nach 40 s wird ein Rabatt gewährt. Diese Zeitkonstanten wurden hier so klein gewählt, um den Rabatt schnell sichtbar werden zu lassen. In der Realität könnte man zum Beispiel einen Rabatt nach zehn Minuten gewähren und einen zusätzlichen Rabatt nach 20 Minuten. p = sc + (min{t ,20} + max{min{t − 20,20},0} ⋅ 0,4 + max{t − 40,0} ⋅ 0,1) v ⋅ pt ⋅ pv + uv ut TFL: p = sc + (v/vu)*pv + ((min(t,20)+max(min(t-20,20),0)*0.4+max(t-40,0)*0.1)/tu)*pt 7.4 Meßwerte Verlustrate 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 Ohne FEC 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 RS 10/5 - Theorie 0 8,9092E-05 0,00391629 0,0296426 0,10662707 0,25 0,44005939 0,63083394 0,78433485 0,89994219 1,0 Tabelle 22 : RS 10/5 – Theorie RS 10/5 – Unabhängige Verluste Verlustrate Effektive Verlustrate 0 0 0,10052 0,00004 0,19778 0,00304 0,29908 0,02932 0,3968 0,10526 0,50344 0,26286 0,59806 0,43518 RS 10/5 – Burstverluste Verlustrate Mittlere Burstlänge 0 0 0,09826667 2 0,19610417 2 0,29385417 2,5 0,40102083 3 0,49266667 3,5 0,59679167 4,5 Effektive Verlustrate 0 0,00122222 0,0134375 0,051375 0,1545 0,271875 0,44322917 Seite 85 Kapitel 7: Anhang 0,6975 0,8 0,9 1,0 0,62382 0,78433 0,89994 1,0 0,7 0,8 0,9 1,0 ohne Messung 0,63083 ohne Messung 0,78433 ohne Messung 0,89994 1,0 Tabelle 23: RS 10/5 - Simulierte Verluste RS 10/5 – Silence Detection Verlustrate Effektive Verlustrate 0 0 0,09757143 0,001 0,20040816 0,00769388 0,2982449 0,03538776 0,39836735 0,11295918 0,49767347 0,26146939 0,59361224 0,44140816 0,7 0,63083 0,8 0,7843 0,9 0,8999 1,0 1,0 RS 10/5 – Reale Strecke Verlustrate Effektive Verlustrate 0 0 0,14526471 0,00935294 0,23275172 0,03098621 Tabelle 24: RS 10/5 - Silence Detection & Reale Strecke 7.5 Man Pages 7.5.1 CIP Client Der CIP Client wird mit den folgenden Parametern gestartet: cip_client -s <server addr>:<port> -u <pull interval> -U <util def> -C <constraint def> server addr port pull interval util def Adresse des CIP Servers (Name oder IP-Nummer) Portnummer des CIP Servers Der Client fordert die Dienstklasseninformationen in regelmäßigen Abständen beim Server an (pull mode). Wird diese Option nicht angegeben, sendet der CIP Server die Informationen mit seinem Update Intervall (push mode). Definition der angewendeten Utility-Funktion. Die ASCII Datei hat das folgende Format: <param1>=<ausdruck1> # <kommentar> .... <paramN>=<ausdruckN> u=<utility funktion> Alle Ausdrücke müssen in TFL Syntax angegeben werden. constraint def Definition der Randbedingungen des Benutzers. Die ASCII Datei hat das folgende Format: <umin> <pmax> Seite 86 Kapitel 7: Anhang <k> <nmax> <bmax> Kommentare werden mit einem # am Anfang der Zeile eingeleitet. Bmax ist die maximale Banbreite in bytes/s, also die Bandbreite bei bn=1. Beispiel: cip_client -s farpoint:4000 -U ../opt/functions/c5_util.txt -C usr_con/c5_usr1.txt 7.5.2 CIP Server Der CIP Server wird mit den folgenden Parametern gestartet: cip_server -s <service descr> -u <update freq> -p <port> service descr Diese ASCII Datei enthält die angebotenen Dienstklassen. Das Format entspricht dem bei den CIP INFO Nachrichten verwendeten. Kommentare werden mit einem # am Anfang der Zeile eingeleitet. update freq Das Intervall, in dem der CIP Server INFO Nachrichten an die Clients schickt (push mode). port Portnummmer des CIP Servers. Beispiel: cip_server -s serv_descr/c5_demo.txt -u 20 -p 4000 7.5.3 RS Performance Messung Mit dem Programm rs_test kann die Performance des RS Kodierers ermittelt werden: rs_test [-p error-prob] [-s packet-size] [-k k-value] [-n n-value] error-prob packet-size k-value n-value Die Paket-Verlustrate im Netz. Die Paketgröße in bytes. K N Beispiel: rs_test -p 0.1 -s 1024 -k 5 -n 10 Reed-Solomon Code is (10,5) using 8 bit symbols Enng time: 1.464ms Symbol Errors: 1024 Packet errors: 1 Lost Packets Network Packet Index: 1 Decoding time: 0.403ms Error Correction successfull Das Programm zeigt die Kodier- und Dekodierzeit sowie die Anzahl der verlorengegangenen Pakete und deren Index an. 7.5.4 Optimierungsalgorithmus Der Optimierungsalgorithmus kann mit dem Programm opt_test getestet werden: opt_test -T <tariff file> -U <utility file> -p <max price> -u <min utility> -l <loss prob> -k <K> -n <max N> -b <max bandw> -f tariff file Diese ASCII Datei enthält den zu verwendenden Tarif und Seite 87 Kapitel 7: Anhang hat das folgende Format: <param1>=<ausdruck1> # <kommentar> .... <paramN>=<ausdruckN> p=<preis funktion> Alle Ausdrücke müssen in TFL Syntax angegeben werden. utility file Diese ASCII Datei enthält die Definition der UtilityFunktion. Sie hat das gleiche Format wie in 7.5.1 beschrieben. max price Der maximal zu zahlende Preis. min utility Die minimale Qualität. loss prob Die Paket-Verlustrate im Netz. K K max N Der maximale Wert für N. max bandw Die maximale Bandbreite in bytes/s, d.h. die Bandbreite bei bn=1. -f Wenn dieser Schalter gesetzt ist, wird die Optimierung mit der Downhill Simplex Methode durchgeführt. Anderenfalls wird der Brute Force Algorithmus verwendet. Die Downhill Simplex Methode ist wesentlich schneller, liefert aber nicht immer das korrekte Ergebnis (globales Maximum). Beispiel: opt_test -T functions/c5_be.txt -U functions/c5_util.txt -p 1 -u 4 -l 0.1 -k 5 -n 10 -b 8000 time: 1.95365 eval: 606 bn=0.19, n=7 : upr=10018, util=4.16372, price=0.000415625 Das Programm liefert außerdem die Rechenzeit (time) und die Anzahl der Funktionsaufrufe (eval). 7.5.5 RTP Gateway Das RTP Gateway wird mit den folgenden Parametern gestartet: rtp_gw -l <address>:<port>/<ttl> -r <address>:<port>/<ttl> -c <ctrl port> -n <number> -k <number> -l <adress>:<port> <ttl> -r <address>:<port> <ttl> Seite 88 Die Adresse und Portnummer des lokalen Rechners. Die Adresse ist entweder der Name oder die IPNummer. Die TTL bei einer Multicastadresse. Die Adresse und Portnummer des Gateways auf der anderen Seite (remote). Die Adresse ist entweder der Name oder die IP-Nummer. Die TTL bei einer Multicastadresse. Kapitel 7: Anhang ctrl port Der Port auf dem das Gateway Kontroll Nachrichten sendet oder empfängt. n Der Startwert für N (bei allen SSRC) k Der Startwert für K (bei allen SSRC) Beispiel: rtp_gw -l rockmaster:4000/1 -r winnie:5000/4 -c 6000 -n 10 -k 5 In diesem Beispiel ist rockmaster der lokale Rechner auf dem die Audio/Video Anwendung läuft. Die mit FEC geschützten Medienpakete werden an das entfernte Gateway auf winnie gesendet. Das Gateway wird mit dem Programm rtp_gw_ctrl kontrolliert: rtp_gw_ctrl -c <adress>:<port> -s <ssrc> -n <number> -k <number> -c <address>:<port> Adresse und Portnummer des zu kontrollierenden Gateways. Die Adresse ist entweder der Name oder die IP-Nummer. Die Portnummer muß beim Gateway mit der -c Option angegeben werden. ssrc Die SSRC Nummer deren RS Parameter geändert werden sollen. Das Gateway liefert die entsprechenden QoS Informationen für alle bekannten SSRC. n N k K Beispiel: rtp_gw_ctrl –c winnie:6000 –s 435896984 –n 10 –k 5 Wenn nur die QoS Informationen ausgelesen und die RS Parameter nicht geändert werden sollen, kann für n und der k der gleiche (beliebige) Wert angegeben werden. Seite 89 Kapitel 7: Anhang Seite 90 Kapitel 8: Literaturverzeichnis 8 Literaturverzeichnis [BeYF98] Y. Bernet, R. Yavatkar, P. Ford, F. Baker, L. Zhang: „A Framework for Endto-End QoS Combining RSVP/Intserv and Differentiated Services“, IETF Internet Draft, <draft-bernet-intdiff-00.txt> (March, 1998) [Bier92] Ernst W. Biersack: „A Simulation Study of Forward Error Correction in ATM Networks“, In Proceedings of SIGCOMM 92 (1992) [Bolo93] Jean-Chrysostome Bolot: „Characterizing End-to-End Packet Delay and Loss in the Internet“, Journal of High-Speed Networks, vol. 2, no. 3, pp. 305-323 (December 1993) [BoFT98] Jean Bolot, Sacha Fosse-Parisis, Don Towsley: „Adaptive FEC-Based Error Control for Interactive Audio in the Internet“, to appear in IEEE Infocom ’99 (June 1998) [BrMR98] Brownlee, Mills, Ruth: „Traffic Flow Measurement: Architecture“, IETF Internet Draft, <draft-ietf-rtfm-architecture-04.txt> (September 1998) [Brow98] N. Brownlee: „Traffic Flow Measurement: Meter MIB“, IETF Internet Draft, <draft-ietf-rtfm-meter-mib-06.txt>, work in progress (September 1998) [CAN_D5] CANCAN AC014 Consortium: ATM Charging Schemes, ACTS Project AC014 – CANCAN: „Contract Negotiation and Charging in ATM Networks“, Deliverable D5 (Oktober 1996) [CaHS98] G. Carle, F. Hartanto, M. Smirnov, T. Zseby: „Charging and Acounting Architecture for QoS-enhanced IP services“, GMD FOKUS (1998) [CaMM98] Massimiliano Canosa, Martino De Marco, Alessandro Maiocchi: „Traffic accounting mechanism for Internet Integrated Services“, CEFRIEL, Politecnico di Milano (1998) [CaRu98] Pat R. Calhoun, Allan C. Rubens: „DIAMETER Base Protocol“, IETF Internet Draft, <draft-calhoun-diameter-07.txt> (November 1998) [CaSZ98] Georg Carle, Michael Smirnov, Tanja Zseby: „Charging and Acounting Architecture for IP Multicast Integrated Services over ATM“, 4th International Symposium on Interworking (Interworking ’98), Ottawa, Canada (Juli 1998) [CaZW98] Georg Carle, Tanja Zseby, Adam Wolisz: „Lastabhängige Tarifierung von IP Multicast-Diensten mit Dienstgüteunterstützung“, GMD FOKUS (1998) [Clark96] David D. Clark: "Combining Sender and Receiver Payments in the Internet", Telecommunications Research Policy Conference, M.I.T. (Oktober 1996) [ETSI98] H. Orlamünder (Editor): "Parameters and Mechanisms for Charging in IP based Networks [Network Aspects], TR/NA-080301 V1.0.4 (1998-06), ETSI Working Group NA8 Technical Document (Juni 1998) Seite 91 Kapitel 8: Literaturverzeichnis [GGPR96] Leonadis Georgiadis, Roch Guerin, V. Peris, R. Rajan: „Efficient Support of Delay and Rate Guarantees in an Internet“, Proceedings of ACM SIGCOMM ’96, Seiten 106-116 (August 1996) [GrSt85] John G. Gruber, Leo Strawczynski: „Subjective Effects of Variable Delay and Speech Clipping in Dynamically Managed Voice Systems“, IEEE Transactions on Communications, Vol. COM-33, No. 8 (August 1985) [GuCW98] C. Guilemot, P. Christ, S. Wesner: „RTP Generic Payload with Scaleable & Flexible Error Resiliency“, IETF Internet Draft, draft-guillemot-genrtp-00.txt (November 1998) [HaCB98] M. Handley, J. Crowcroft, C. Bormann, J. Ott: „The Internet Multimedia Conferencing Architecture“, IETF Internet Draft, <draft-ietf-mmusic-confarch00.txt> (January 1998) [HaSS98] Handley, Schulzrinne, Schooler, Rosenberg: „SIP: Session Initiation Protocol“, IETF Internet Draft, draft-ietf-mmusic-sip-07.txt (July 1998) [HSE97] Shai Herzog, Scott Shenker and Deborah Estrin: „Sharing the Cost of Multicast Trees: An Axiomatic Analysis“, IEEE/ACM Transactions on Networking, 5(6):847-860 (Dezember 1997) [KSWS99] Martin Karsten, Jens Schmitt, Lars Wolf and Ralf Steinmetz: „Cost and Price Calculation for Internet Integrated Services“, KiVS ’99 (Februar 1999) [LoLe98] Nguyen Tuong Long Le: „Charging and Acounting Protocol for IP Multicast over ATM with QoS Support“, Department of Telecommunications Engineering, Technical University of Berlin (August, 1998) [McEn97] A Techno-Economic Analysis of Selected ATM Charging Schemes of Aggregate LAN Interconnect, IEEE Colloquium on "Charging for ATM", London, U.K. (November 1997) [NiBl98] K. Nichols, S. Blake: „Differentiated Services Operational Model and Definitions“, IETF Internet Draft, draft-nichols-dsopdef-00.txt (Februar 1998) [NoBT97] Jörg Nonnenmacher, Ernst Biersack, Don Towsley: „Parity-Based Loss Recovery for Reliable Multicast Transmission“, Institut Eurecom/University of Massachusetts (October 1997) [Noll96] Peter Noll: „Nachrichtenübertragung I“, Institut für Fernmeldetechnik, Technische Universität Berlin (1996) [PaWa98] Kihong Park, Wei Wang: „AFEC: An Adaptive Forward Error Correction Protocol for End-to-End Transport of Real-Time Traffic“, Proc. International Conference on Computer Communications and Networks (1998) Seite 92 Kapitel 8: Literaturverzeichnis [PFTV88] William H. Press, Brian P. Flannery, Saul A. Teukolsky, William T. Vetterling: „Numerical Recipes in C – The Art of Scientific Computing“, Cambridge University Press, Cambridge (1988) [ReIz97] D. Reininger, R. Izmailov: „Soft Quality of Service with VBR+ Video“, International Workshop on Audio-Visual Services over Packet Networks, AVSPN ’97, Aberdeen, Scotland (September 1997) [ReRO98] D. Reininger, D. Raychaudhuri, M. Ott: „Market Based Bandwidth Allocation Policies for QoS Control in Broadband Networks“, C&C Research Laboratories, NEC USA (1998) [Rett97] Charles T. Retter: „An Intuitive Introduction to Reed-Solomon Codes“, http://homepage.arl.mil/~retter/coding.html (1997) [RFC1272] C.Mills, D.Hirsh, G. Ruth: „Internet Accounting: Background“, RFC 1272, IETF (November 1991) [RFC1633] R. Braden, D. Clark, S. Shenker: „Integrated Services in the Internet Architecture: An Overview“, RFC 1633, IETF (Juni 1994) [RFC1738] T. Berners-Lee, L. Masinter, M. McCahill: „Uniform resource locators (URL)“, RFC 1738, IETF (Dezember 1994) [RFC1889] H. Schulzrinne, S. Casner, R. Frederick, V. Jacobson: „RTP: A Transport Protocol for Real-Time Applications“, RFC 1889, IETF (Januar 1996) [RFC1890] H. Schulzrinne: „RTP Profile for Audio and Video Conference with Minimal Control“, RFC 1890, IETF (Januar 1996) [RFC2063] N. Brownlee, C. Mills,, G. Ruth: „Traffic Flow Measurement: Architecture“, RFC 2063, IETF (Januar 1997) [RFC2198] C. Perlins, I. Kouvelas et al.: „RTP Payload for Redundant Audio Data“, RFC 2198, IETF (September 1997) [RFC2205] R. Braden, L. Zhang, S. Berson, S. Herzog and S. Jamin: „Resource Reservation Protocol (RSVP), RFC 2205, IETF (September 1997) [RiRi98] Martyn Riley, Iain Richardson: „An Introduction to Reed-Solomon codes: Principles, architecture and implementation“, 4i2i Communications Ltd., http://www.4i2i.com (September 1998) [Rizzo97] Luigi Rizzo: "Effective Erasure Codes for Reliable Computer Communication Protocols", ACM Computer Communication Review, Volume 27, pp. 24-36 (April 1997) [RöCa97] Stephan Röösli, Georg Carle: „Multicast Error Control for Audio-Visual Services (MECAVS), Parameters & Module Configuration“, Institut Eurecom (September 1997) Seite 93 Kapitel 8: Literaturverzeichnis [RoSc98] J. Rosenberg, H. Schulzrinne: „An RTP Payload Format for Generic Forward Error Correction“, IETF Internet Draft, draft-ietf-avt-fec-04.txt (November 1998) [RoSc98-2] J. Rosenberg, H. Schulzrinne: „An RTP Payload Format for Reed Solomon Codes“, IETF Internet Draft, draft-ietf-avt-reedsolomon.txt (November 1998) [RuKT98] Dan Rubenstein, Jim Kurose, Don Towsley: „Real-Time Reliable Multicast Using Proactive Forward Error Correction“, Technical Report 98-19, Department of Computer Sciences, University of Massachusetts (March 1998) [Ryan98] William E. Ryan: „A Turbo Code Tutorial“, New Mexico State University, LasCruces, http://www.ee.virginia.edu/CSL/turbo_codes/overview.html (Juni 1998) [San98] H. Sannek: „Adaptive Loss Concealment for Internet Telephony Applications“, Proceedings INET ’98, Geneva/Switzerland (Juli 1998) [SaCa98] H. Sannek: „Predictive Loss Pattern Queue Managment for Internet Routers“, Proceedings SPIE Vol. 3529A, Boston, MA (November 1998) [WaKS97] D. Walker, F. P. Kelly, J. Solomon: „Tariffing in the New IP/ATM Environment“, Telecommunications Policy, Volume 21 pp. 283-295 (Mai 1997) Seite 94