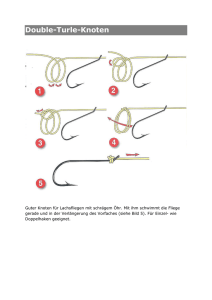
Algorithmische Grundlagen - Sommersemester 2016
Werbung

Algorithmische Grundlagen Sommersemester 2016 Martin Mundhenk Uni Jena, Institut für Informatik 5. Juli 2016 Vorlesung Algorithmische Grundlagen (Sommer 2016) Die Vorlesung/Übung orientiert sich am Buch Introduction to Programming in Python – An Interdisciplinary Approach von Robert Sedgewick, Kevin Wayne und Robert Dondero (Addison Wesley, 2015) Die Webseite zum Buch http://introcs.cs.princeton.edu/python/home/ ist auch für diese Vorlesung nützlich. Organisatorisches http://tinyurl.com/AlgorithmischeGrundlagen § § Vorlesung montags, 16-18 Uhr, Raum 3325 Ernst-Abbe-Platz 2 Übung donnerstags, 8-10 Uhr, Raum 3410 (Linux-Pool 2) EAP2 Zur Teilnahme brauchen Sie eine Nutzerkennung beim FRZ! § Es gibt ein wöchentliches Übungsblatt (ca. 12). Abgabe montags 16:15 Uhr (an [email protected]) § Zur Zulassung zur Modulprüfung müssen jeweils mindestens 50% der Punkte der Übungsblätter aus der ersten und der zweiten Hälfte erreicht sein. Die Abschlussprüfung ist mündlich und dauert ca. 30 Minuten. Prüfungstermine sind 8.8., 12.8. und 7.9. (oder nach Vereinbarung). Bitte tragen Sie sich für einen Termin auf die Prüfungsliste ein! Wer bei der Abschlussprüfung ein Programmierprojekt vorstellen will, muss alle Dateien bis spätestens 30 Stunden vor Beginn der Prüfung an mich schicken ([email protected]). § Inhaltsverzeichnis 1. Elemente des Programmierens 2. Funktionen und Module 4. Algorithmen 5. Abschlussprojekte (und Anmerkungen dazu) Die Nummerierung der Kapitel 1, 2 und 4 entspricht der Nummerierung im Buch von Sedgewick et al. 0.0.4 1 Elemente des Programmierens Ein Programm zu schreiben ist nicht schwieriger, als einen Aufsatz zu schreiben. Wir schauen uns die Grundbausteine von Python-Programmen an und starten mit dem Programmieren. 1. Elemente des Programmierens 1.1 Grundlegende Daten-Typen 1.2 Verzweigungen und Schleifen 1.3 Arrays 1.4 Ein- und Ausgabe 1.5 Page Rank 1.1 Grundlegende Datentypen Typ Werte Operatoren int ganze Zahlen ` ´ ˚ {{ % ˚˚ 2016 -12 11267456 float Dezimalbrüche ` ´ ˚ { ˚˚ 3.14 2.5 6.022e+23 bool Wahrheitswerte and str Zeichenfolgen or ` Beispiele für Literale not True 'AB' False 'Hello world' '2.5' int . . . integer float . . . floating-point number (Fließkommazahl) bool . . . boolean (George Boole, 1815-1864) str . . . string 1.1.1 Grundlegende Begriffe Ein (sehr) einfaches Python-Programm a = 123 b = 99 c = a + b * 2 Das Programm besteht aus drei Anweisungen. Es werden drei Objekte vom Typ int erzeugt. Die Variablen a, b und c werden an sie gebunden. Am Ende ist c an ein Objekt vom Typ int mit Wert 321 gebunden. 123 ist ein Literal, das einen Wert vom Typ int bezeichnet. a + b * 2 ist ein Ausdruck (expression). Der Ausdruck besteht aus Variablen, die an Objekte vom Typ int gebunden sind, einem int-Literal und den Operatoren + und *. Bei der Auswertung des Ausdrucks wird ein (neues) Objekt erzeugt, dessen Wert der Ausdruck beschreibt. 1.1.2 Ausdrücke vom Typ int bestehen aus § Literalen vom Typ int § Variablen, die an Objekte vom Typ int gebunden sind § den Operatoren + - * // % ** § ... + - * stehen für Addition, Subtraktion und Multiplikation. // ist die ganzzahlige Division. 17 // 6 ist 2 (da 17 “ 2 ¨ 6 ` 5), und -17 // 6 ist -3 (da ´17 “ ´3 ¨ 6 ` 1). Mathematische Schreibweise für die ganzzahlige Division: a // b entspricht t ba u txu ist die größte ganze Zahl ď x ( untere Gaußklammer“) ” 1.1.3 % ist der Rest bei der ganzzahligen Division (modulo-Operation). 17 % 6 ist 5 (da 17 “ 2 ¨ 6 ` 5), und -17 % 6 ist 1 (da ´17 “ ´3 ¨ 6 ` 1). Mathematische Schreibweise für a % b ist a mod b . ** ist die Potenz. 3**4 ist 81 (da 34 “ 3 ¨ 3 ¨ 3 ¨ 3 “ 81). Die Operatoren haben unterschiedliche Bindungsstärke (entsprechend Punktrechnung geht vor Strichrechnung“). ” Im Zweifel: Klammern setzen . . . Weitere Beispiele für int-Ausdrücke (mit int-Variablen): Stunden * 60 * 60 + Minuten * 60 + Sekunden (53 - 6) * 40 // LP pro Jahr Jahr - ( ((Monat-3)%12) // 10 ) (49*48*47*46*45*44*43)//(1*2*3*4*5*6) max( a, b ) 1.1.4 Anweisungen assignment statements Eine Anweisung besteht aus einer Variablen, = und einem Ausdruck. Jahrhundertzahl = (Jahr-(((Monat-3)%12)//10))//100 Arbeitsstunden pro LP = (53 - 6) * 40 // LP pro Jahr zaehler = zaehler + 1 Beim Abarbeiten einer Anweisung an eine Variable eines grundlegenden Daten-Typs wird § zuerst der Ausdruck ausgewertet und ein Objekt mit Typ und Wert des Ausdrucks erzeugt, § danach wird die Variable an das Objekt gebunden. 1.1.5 # Berechne das Volumen und die Oberfläche eines Quaders. # Zuerst werden die Maße des Quaders angegeben. Hoehe = 5 Breite = 12 Tiefe = 32 # Daraus können nach den bekannten Formeln # das Volumen und die Oberfläche berechnet werden. Volumen = Hoehe * Breite * Tiefe Oberflaeche = 2 * ( Hoehe*Breite + Hoehe*Tiefe + Breite*Tiefe ) Der Typ str . . . dient dem Verarbeiten von Texten. Literale sind Folgen von Zeichen, die durch ' ... ' eingeschlossen sind. 'Das folgende ist kein int-Literal.' '1234' Die Operation + schreibt Strings hintereinander (Konkatenation). 'Das ist ' + 'ein Satz.' ergibt 'Das ist ein Satz.' . Die Funktion str( ) macht aus einem Objekt einen String. Z.B. liefert str(123) den String '123'. Entsprechend macht die Funktion int( ) aus einem Objekt ein int-Objekt. Z.B. liefert int('123') ein int-Objekt mit Wert 123. 1.1.7 #----------------------------------------------------------------------# ruler.py #----------------------------------------------------------------------import stdio # # # # # Write to standard output the relative lengths of the subdivisions on a ruler. The nth line of output is the relative lengths of the marks on a ruler subdivided in intervals of 1/2^n of an inch. For example, the fourth line of output gives the relative lengths of the marks that indicate intervals of one-sixteenth of an inch on a ruler. ruler1 = '1' ruler2 = ruler1 + ' 2 ' + ruler1 ruler3 = ruler2 + ' 3 ' + ruler2 ruler4 = ruler3 + ' 4 ' + ruler3 stdio.writeln(ruler1) stdio.writeln(ruler2) stdio.writeln(ruler3) stdio.writeln(ruler4) #----------------------------------------------------------------------# python ruler.py # 1 # 1 2 1 # 1 2 1 3 1 2 1 # 1 2 1 3 1 2 1 4 1 2 1 3 1 2 1 1.1.8 #----------------------------------------------------------------------# einundausgabe.py #----------------------------------------------------------------------import stdio import sys # Lies drei Strings aus der Kommandozeile # und gib sie in umgekehrter Reihenfolge wieder aus. a = sys.argv[1] b = sys.argv[2] c = sys.argv[3] stdio.writeln( c + ' ' + b + ' ' + a ) #----------------------------------------------------------------------# python einundausgabe.py Hallo Martin . # . Martin Hallo # # python einundausgabe.py Hallo Martin. # Traceback (most recent call last): # File "einundausgabe.py", line 12, in <module> # c = sys.argv[3] # IndexError: list index out of range 1.1.9 int-Werte zu str-Werten umwandeln #------------------------------------------------------------------------# teilen_v1.py #------------------------------------------------------------------------import stdio a = 15 b = 213 stdio.write( str(b) + ' geteilt durch ' + str(a) + ' ergibt ' ) stdio.writeln( str( b//a ) + ' Rest ' + str( b%a ) + '.' ) #------------------------------------------------------------------------# # python teilen_v1.py # 213 geteilt durch 15 ergibt 14 Rest 3. # 1.1.10 str-Werte zu int-Werten umwandeln #------------------------------------------------------------------------# teilen_v2.py #------------------------------------------------------------------------import stdio import sys # Lies zwei Argumente a und b von der Kommandozeile. # Gib den (ganzzahligen) Quotienten und den Rest bei der Division von a durch b aus. a = int( sys.argv[1] ) b = int( sys.argv[2] ) stdio.write( str(a) + ' geteilt durch ' + str(b) + ' ergibt ' ) stdio.writeln( str( a//b ) + ' Rest ' + str( a%b ) + '.' ) #------------------------------------------------------------------------# python teilen_v2.py 1234 23 # 1234 geteilt durch 23 ergibt 53 Rest 15. # # python teilen_v2.py 1234 0 # File "teilen_v2.py", line 13, in <module> # stdio.writeln( str( a//b ) + ' Rest ' + str( a%b ) + '.' ) # ZeroDivisionError: integer division or modulo by zero 1.1.11 Der Typ float . . . dient dem Rechnen mit Dezimalbrüchen. Literale sind z.B. 4.0 123.45 3.141e+12 (steht für 3, 141 ¨ 1012 ) Die Operationen mit float sind + - * / ** . Kommt in einem Ausdruck ein float-Wert vor, dann hat das Ergebnis Typ float (und nicht Typ int). float-Werte haben nur beschränkte Genauigkeit. stdio.writeln(str(1.23456789012345e+12)) hat Ausgabe 1.23456789012e+14 1.1.12 Die quadratische Gleichung a ¨ x 2 ` b ¨ x ` c “ 0 hat die Lösungen ? ´b ˘ b 2 ´ 4 ¨ a ¨ c x1,2 “ . 2¨a # Das Programm mitternacht.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus. import stdio import sys import math a = float( sys.argv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) diskriminante = math.sqrt(b**2 - 4 * a * c) stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) 1.1.13 # Das Programm mitternacht.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus. import stdio import sys import math a = float( sys.argv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) diskriminante = math.sqrt(b**2 - 4 * a * c) stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) #-----------------------------------------------------------------------------------# python mitternacht.py 4 6 2 # -0.5 # -1.0 # python mitternacht.py 1 2 3 # Traceback (most recent call last): # File "mitternacht.py", line 17, in <module> # diskriminante = math.sqrt(b**2 - 4 * a * c) # ValueError: math domain error 1.1.14 float-Werte können ungenau sein #----------------------------------------------------------------------# fehler_mit_float.py #----------------------------------------------------------------------import stdio # 10^16 +1 wird als int-Literal dargestellt, # und 10^16 +1 wird als float-Wert dargestellt. int_zahl = 10000000000000001 float_zahl = 10.0**16 +1 # Beide Zahlen werden ausgegeben. stdio.writeln('int Zahl: ' + str(int_zahl)) stdio.writeln('float Zahl: ' + str(float_zahl)) stdio.writeln('float Zahl als int: ' + str(int(float_zahl))) #----------------------------------------------------------------------# python fehler_mit_float.py # int Zahl: 10000000000000001 # float Zahl: 1e+16 # float Zahl als int: 10000000000000000 1.1.15 Bemerkungen zu Funktionen Eingebaute“ Funktionen: ” str( ), int( ), float( ), bool( ), abs( ) (der Betrag einer Zahl), round( ) (nächster int-Wert), max( , ), min( , ) (Maximum bzw. Minimum zweier Zahlen) . . . Standard-Funktionen aus Standard-Modulen von Python: math.sqrt( ), math.log( , ), random.random() (eine zufällige float-Zahl x mit 0 ď x ă 1), random.randrange(x,y) (eine zufällige int-Zahl aus rx, y q), . . . Funktionen aus den Modulen für das Buch: stdio.write( ), stdio.writeln( ), . . . 1.1.16 Der Typ bool . . . dient dem Rechnen mit Wahrheitswerten True und False. Es gibt die Operation and, or und not auf bool-Objekten. a b False False False True True False True True a and b False False False True a or b False True True True a False True not a True False 1.1.17 Vergleichsoperationen liefern bool-Werte Operator == != < <= > >= Bedeutung Beispiel True False gleich 3==3 2==3 ungleich 2!=3 3!=3 kleiner als 2<3 3<3 kleiner oder gleich 3<=3 4<=3 größer als 4>3 3>4 größer oder gleich 4>=3 3>=4 1.1.18 #----------------------------------------------------------------------# leapyear.py #----------------------------------------------------------------------import stdio import sys # Accept an int year as a command-line argument. Write True to # standard output if year is a leap year. Otherwise write False. year = int(sys.argv[1]) isLeapYear = (year % 4 == 0) isLeapYear = isLeapYear and (year % 100 != 0) isLeapYear = isLeapYear or (year % 400 == 0) stdio.writeln(isLeapYear) #----------------------------------------------------------------------# python leapyear.py 2016 # True # python leapyear.py 1900 # False # python leapyear.py 2000 # True 1.1.19 #----------------------------------------------------------------------# tippspiel.py #----------------------------------------------------------------------import stdio import sys import random # # # # Spieler 1 gibt sein Zahl über die Kommandozeile ein. Anschließend würfelt Spieler 2 (das Programm) eine Zahl aus dem Bereich 1,2,3,4,5,6. Falls beide Spieler eine ungerade Zahl haben oder beide Spieler eine gerade Zahl haben, dann gewinnt Spieler 1. Sonst gewinnt Spieler 2. zahl_von_spieler_1 = int(sys.argv[1]) zahl_von_spieler_2 = random.randrange(1,7) stdio.write('Spieler 1 hat ' + str(zahl_von_spieler_1) + ' gewaehlt und ') stdio.writeln('Spieler 2 hat ' + str(zahl_von_spieler_2) + ' gewuerfelt.') ergebnis = ( (zahl_von_spieler_1 % 2 ) == (zahl_von_spieler_2 % 2) ) stdio.writeln('Spieler 1 gewinnt ist ' + str(ergebnis) + '.') #-------------------------------------------------------------------------# python tippspiel.py 3 # Spieler 1 hat 3 gewaehlt und Spieler 2 hat 3 gewuerfelt. # Spieler 1 gewinnt ist True. 1.1.20 Zusammenfassung § Wir haben die elementaren Daten-Typen int, float, str und bool von Python kennengelernt. § Wir können Ausdrücke aus Literalen, Variablen, Operatoren und Funktionen schreiben. § Wir können sehr einfache Programme mit Eingabe von Argumenten Abarbeitung einer festen Folge von Anweisungen Ausgabe eines Ergebnisses schreiben und deren Ausführung nachvollziehen. 1.1.21 1.2 Verzweigungen und Schleifen Die bisher betrachteten Programme bestanden aus Anweisungen, die der Reihe nach von der ersten bis zur letzten ausgeführt werden. Nun werden wir sehen, wie man diese Reihenfolge beeinflussen kann. Abhängig von Bedingungen können Anweisungs-Blöcke ausgeführt oder nicht ausgeführt werden (Verzweigungen), oder Anweisungs-Blöcke können mehrfach ausgeführt werden (Schleifen). Mittels Verzweigungen und Schleifen werden wir bereits viel mächtigere Programme schreiben können als bisher. 1.2.1 if-Anweisungen Viele Programme sollen bei verschiedenen Eingaben unterschiedlich arbeiten. Z.B. könnte das Programm teilen v2.py, das bei Eingabe zweier Werte a und b den Quotient und den Rest beim Teilen von a durch b berechnet, entweder 'Durch Null kann man nicht teilen!' ausgeben (falls b “ 0 ist) oder die gesuchten Werte ausgeben (falls b ‰ 0 ist). 1.2.2 Teilbarkeit überprüfen #------------------------------------------------------------------------# teilen_v3.py #------------------------------------------------------------------------import stdio, sys # Lies zwei Argumente a und b von der Kommandozeile. # Gib den (ganzzahligen) Quotienten und den Rest bei der Division von a durch b aus. a = int( sys.argv[1] ) b = int( sys.argv[2] ) if b == 0: stdio.writeln(’Durch Null darf man nicht teilen!’) else: stdio.write( str(a) + ’ geteilt durch ’ + str(b) + ’ ergibt ’ ) stdio.writeln( str( a//b ) + ’ Rest ’ + str( a%b ) + ’.’ ) #------------------------------------------------------------------------# python teilen_v3.py 1234 23 # 1234 geteilt durch 23 ergibt 53 Rest 15. # # python teilen_v3.py 1234 0 # Durch Null darf man nicht teilen! 1.2.3 Geschachtelte if-Anweisungen Bei der Lösung der quadratischen Gleichung a ¨ x 2 ` b ¨ x ` c “ 0 mittels der Formel ? ´b ˘ b 2 ´ 4 ¨ a ¨ c x1,2 “ 2¨a kann es 1. keine Lösung geben, da b 2 ´ 4 ¨ a ¨ c ă 0 oder a “ 0, 2. eine Lösung geben, da b 2 ´ 4 ¨ a ¨ c “ 0 und a ‰ 0, oder 3. zwei Lösungen geben, da b 2 ´ 4 ¨ a ¨ c ą 0 und a ‰ 0. 1.2.4 # Das Programm midnight.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus, falls sie import stdio, sys, math a = float( sys.agv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) z = b**2 - 4 * a * c if z<0 or a==0: stdio.writeln('Die Gleichung hat keine Loesung!') else: if z==0: stdio.writeln( -b / (2*a) ) else: diskriminante = math.sqrt(b**2 - 4 * a * c) stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) #-------------------------------------#-------------------------------------# python midnight.py 3 4 5 # python midnight.py 2 4 2 # Die Gleichung hat keine Loesung! # -1.0 # # # python midnight.py 3 8 5 # python midnight.py 0 8 5 # -1.0 # Die Gleichung hat keine Loesung! # -1.66666666667 # 1.2.5 # Das Programm midnight.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus, falls sie import stdio, sys, math a = float( sys.agv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) z = b**2 - 4 * a * c if z<0 or a==0: stdio.writeln('Die Gleichung hat keine Loesung!') elif z==0: stdio.writeln( -b / (2*a) ) else: diskriminante = math.sqrt(b**2 - 4 * a * c) stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) #-------------------------------------#-------------------------------------# python midnight.py 3 4 5 # python midnight.py 2 4 2 # Die Gleichung hat keine Loesung! # -1.0 # # # python midnight.py 3 8 5 # python midnight.py 0 8 5 # -1.0 # Die Gleichung hat keine Loesung! # -1.66666666667 # # Das Programm midnight.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus, # falls sie existieren. import stdio, sys, math a = float( sys.argv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) z = b**2 - 4 * a * c if z<0 or a==0: stdio.writeln('Die Gleichung hat keine Loesung!') else: diskriminante = math.sqrt(z) if diskrimante > 0: stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) #-------------------------------------#-------------------------------------# python midnight.py 3 4 5 # python midnight.py 2 4 2 # Die Gleichung hat keine Loesung! # -1.0 # # # python midnight.py 3 8 5 # python midnight.py 0 8 5 # -1.0 # Die Gleichung hat keine Loesung! # -1.66666666667 # # Das Programm midnight.py liest float-Werte a, b und c von der Kommandozeile ein # und gibt die beiden durch die Mitternachtsformel bestimmten Lösungen aus, # falls sie existieren. import stdio, sys, math a = float( sys.argv[1] ) b = float( sys.argv[2] ) c = float( sys.argv[3] ) z = b**2 - 4 * a * c if z<0 or a==0: stdio.writeln('Die Gleichung hat keine Loesung!') else: diskriminante = math.sqrt(z) if diskrimante > 0: stdio.writeln( (-b + diskriminante) / (2*a) ) stdio.writeln( (-b - diskriminante) / (2*a) ) #-------------------------------------#-------------------------------------# python midnight.py 3 4 5 # python midnight.py 2 4 2 # Die Gleichung hat keine Loesung! # -1.0 # # # python midnight.py 3 8 5 # python midnight.py 0 8 5 # -1.0 # Die Gleichung hat keine Loesung! # -1.66666666667 # while-Schleifen Üblicherweise bestehen Programme aus Anweisungen, die häufig wiederholt werden. Die while-Schleife erlaubt die Wiederholung eines Anweisungs-Blocks, solange eine vorgegebene Bedingung erfüllt ist. 1.2.9 # Das Programm while-zaehler.py liest int-Wert a von der Kommandozeile ein # und gibt die Zahlen von 0 bis a aus. import stdio, sys a = int( sys.argv[1] ) zaehler = 0 while zaehler <= a: stdio.writeln(str(zaehler)) zaehler = zaehler + 1 #----------------------------# python while-zaehler.py 4 # 0 # 1 # 2 # 3 # 4 # 5 #----------------------------# python while-zaehler.py 9 # 0 # 1 # 2 # 3 # 4 # 5 # 6 # 7 # 8 # 9 1.2.10 # Das Programm alleteiler.py liest int-Wert a von der Kommandozeile ein # und gibt alle Teiler von a aus. import stdio, sys a = int( sys.argv[1] ) zaehler = 1 while zaehler <= a: if a%zaehler == 0: stdio.writeln(str(zaehler)) zaehler = zaehler + 1 #-----------------------------------------------------------------------------------# python alleteiler.py 8 # 1 # 2 # 4 # 8 1.2.11 #-----------------------------------------------------------# while_hochzaehlen.py # Gibt * mit größer werdendem Abstand zum linken Rand aus. #-----------------------------------------------------------import stdio n =12 i=0 while i<n: stdio.writeln(' '*i + '*') i = i+1 #-----------------------------------------------------------# python while_hochzaehlen.py # * # * # * # * # * # * # * # * # * # * # * # * 1.2.12 #------------------------------------------------------# zufallspfad.py # Gibt wiederholt * aus, dessen Abstand zum linken # Rand von Zeile zu Zeile # zufällig um -1,0,+1 verändert wird. #------------------------------------------------------import stdio, random i=0 abstand = 5 while i<20: abstand = abstand + random.randrange(-1,2) stdio.writeln(' '*abstand + '*') i = i+1 #-------------------------------------------------------- # python zufallspfad.py # * # * # * # * # * # * # * # * # * # * # * # * # * # * # * # * # * # * # Das Programm ganzlog.py liest int-Wert n von der Kommandozeile ein # und gibt den ganzzahligen Logarithmus von n zur Basis 2 aus. import stdio, sys n = int( sys.argv[1] ) ergebnis = 0 while n > 1: ergebnis = ergebnis + 1 n = n//2 stdio.writeln(str(ergebnis)) #-----------------------------------------------------------------------------------# python ganzlog.py 2016 # 10 # # python ganzlog.py 2048 # 11 # # python ganzlog.py 2047 # 10 # 1.2.14 # Das Programm ganzlog-trace.py liest int-Wert n von der Kommandozeile ein # und gibt den ganzzahligen Logarithmus von n zur Basis 2 aus. import stdio, sys n = int( sys.argv[1] ) ergebnis = 0 while n > 1: stdio.writeln('n ist ' + str(n) + ', ergebnis ist ' + str(ergebnis)) ergebnis = ergebnis + 1 n = n//2 stdio.writeln(str(ergebnis)) #-----------------------------------------------------------------------------------# python ganzlog-trace.py 538 n ist 538, ergebnis ist 0 n ist 269, ergebnis ist 1 n ist 134, ergebnis ist 2 n ist 67, ergebnis ist 3 n ist 33, ergebnis ist 4 n ist 16, ergebnis ist 5 n ist 8, ergebnis ist 6 n ist 4, ergebnis ist 7 n ist 2, ergebnis ist 8 9 1.2.15 # Das Programm zweierpotenz-w.py liest int-Werte n von der Kommandozeile ein # und gibt die 2erPotenzen 1,2,...,2^n aus. # falls sie existieren. import stdio, sys n = int( sys.argv[1] ) i = 0 potenz = 1 # der Zaehler fuer die Potenzen # die erste 2erPotenz ist 2^0 while i <= n: stdio.writeln(' 2 hoch ' + str(i) + ' ist ' + str(potenz) + '.') i = i + 1 potenz = potenz * 2 #--------------------------------------------------------------------------------# python zweierpotenz-w.py 5 # 2 hoch 0 ist 1. # 2 hoch 1 ist 2. # 2 hoch 2 ist 4. # 2 hoch 3 ist 8. # 2 hoch 4 ist 16. # 2 hoch 5 ist 32. 1.2.16 for-Schleifen Häufig wird in einer Schleife u.a. eine Variable hochgezählt und die Schleifen-Wiederholung endet, wenn ein bestimmter Wert erreicht wurde. Die for-Schleife erleichtert das Aufschreiben solcher Schleifen. 1.2.17 # Das Programm zweierpotenz-f.py liest int-Werte a von der Kommandozeile ein # und gibt die 2erPotenzen von 2^0, 2^1,...,2^n aus. import stdio, sys n = int( sys.argv[1] ) potenz = 1 # die erste 2erPotenz ist 2^0 for i in range(0,n+1): stdio.writeln(' 2 hoch ' + str(i) + ' ist ' + str(potenz) + '.') potenz = potenz * 2 #--------------------------------------------------------------------------------# python zweierpotenz-f.py 6 # 2 hoch 0 ist 1. # 2 hoch 1 ist 2. # 2 hoch 2 ist 4. # 2 hoch 3 ist 8. # 2 hoch 4 ist 16. # 2 hoch 5 ist 32. # 2 hoch 5 ist 64. 1.2.18 Simulation von Zufallsereignissen Zwei Würfel werden 24mal geworfen. Wie wahrscheinlich ist es, dass mindestens einmal dabei zwei 6en geworfen werden? Statt die Wahrscheinlichkeit exakt auszurechnen, simulieren wir das Experiment mit einem Programm. 1.2.19 #----------------------------------------------------------# zweiwuerfel.py #----------------------------------------------------------import stdio, sys, random erfolgszaehler = 0 for i in range(0,100000): # Zwei Würfel werden 24mal geworfen. # Das Spiel ist erfolgreich, wenn dabei ein Wurf aus zwei 6en gelingt. for i in range(24): if random.randrange(1,7)==6 and random.randrange(1,7)==6: erfolgszaehler +=1 break # Auswertung stdio.writeln(float(erfolg)/versuchszahl) #-----------------------------------------------------------# python zweiwuerfel.py # python zweiwuerfel.py # 0.49203 # 0.49133 # # # python zweiwuerfel.py # python zweiwuerfel.py # 0.49068 # 0.49023 # 17 und 4 Wir spielen 17+4 mit Würfeln. Zwei Spieler spielen. Jeder würfelt, ohne dass es der andere sehen kann. Ziel des Spiels ist es, den Wert 21 zu erreichen. Dazu würfelt der Spieler mit seinem Würfel und summiert die gewürfelten Zahlen. Man kann jederzeit aufhören zu würfeln. Das Ergebnis des Spielers ist seine Summe der gewürfelten Zahlen. Ein Spieler mit einem Ergebnis ą 21 hat verloren. Haben beide Spieler ein Ergebnis ď 21, dann gewinnt der Spieler mit dem höheren Ergebnis. Wir wollen ein Programm entwickeln, mit dem man eine gute Strategie für das Spiel finden kann. Zuerst schreiben wir ein Programm, das einen Spieler simuliert, der solange würfelt, bis er mindestens 21 erreicht hat. #----------------------------------------------------------------------------------# siebzehnundvier_1.py #----------------------------------------------------------------------------------import stdio, sys, random Wuerfelsumme = 0 while Wuerfelsumme<21: Wuerfelsumme = Wuerfelsumme + random.randrange(1,7) stdio.writeln('Wuerfelsumme ist ' + str(Wuerfelsumme)) stdio.writeln('Ergebnis: ' + str(Wuerfelsumme)) #-----------------------------------------------------------------------------------# python siebzehnundvier_1.py # Wuerfelsumme ist 5 # Wuerfelsumme ist 8 # Wuerfelsumme ist 10 # Wuerfelsumme ist 11 # Wuerfelsumme ist 15 # Wuerfelsumme ist 20 # Wuerfelsumme ist 21 # Ergebnis: 21 Eine Strategie ist es, nicht weiterzuwürfeln, wenn man 16 oder mehr erreicht hat. Dann hat man garantiert ein Ergebnis ď 21. #----------------------------------------------------------------------------------# siebzehnundvier_2.py #----------------------------------------------------------------------------------import stdio, sys, random Wuerfelsumme = 0 while Wuerfelsumme<=15: Wuerfelsumme = Wuerfelsumme + random.randrange(1,7) stdio.writeln('Wuerfelsumme ist ' + str(Wuerfelsumme)) stdio.writeln('Ergebnis: ' + str(Wuerfelsumme)) #-----------------------------------------------------------------------------------# python siebzehnundvier_2.py # Wuerfelsumme ist 6 # Wuerfelsumme ist 8 # Wuerfelsumme ist 10 # Wuerfelsumme ist 12 # Wuerfelsumme ist 16 1.2.23 Eine andere Strategie ist es, nicht weiterzuwürfeln, wenn man 17 oder mehr erreicht. Wenn man 16 erreicht hat, geht man ein kleines Risiko ein . . . #----------------------------------------------------------------------------------# siebzehnundvier_3.py #----------------------------------------------------------------------------------import stdio, sys, random Wuerfelsumme = 0 while Wuerfelsumme<=16: Wuerfelsumme = Wuerfelsumme + random.randrange(1,7) stdio.writeln('Wuerfelsumme ist ' + str(Wuerfelsumme)) stdio.writeln('Ergebnis: ' + str(Wuerfelsumme)) #-----------------------------------------------------------------------------------# python siebzehnundvier_3.py # Wuerfelsumme ist 2 # Wuerfelsumme ist 4 # Wuerfelsumme ist 7 # Wuerfelsumme ist 10 # Wuerfelsumme ist 14 # Wuerfelsumme ist 16 # Wuerfelsumme ist 22 # Ergebnis: 22 1.2.24 Welche der beiden Strategien ist besser? Wir wollen das experimentell überprüfen. Dafür lassen wir zwei Spieler mit den beiden Strategien gegeneinander spielen und schauen nach, wer gewinnt. #----------------------------------------------------------------------------------# siebzehnundvier_4.py #----------------------------------------------------------------------------------import stdio, sys, random # Spieler 1 spielt mit seiner Strategie. Wuerfelsumme1 = 0 while Wuerfelsumme1<=15: Wuerfelsumme1 = Wuerfelsumme1 + random.randrange(1,7) # Spieler 2 spielt mit seiner Strategie. Wuerfelsumme2 = 0 while Wuerfelsumme2<=16: Wuerfelsumme2 = Wuerfelsumme2 + random.randrange(1,7) # Der Gewinner wird bestimmt. if Wuerfelsumme1<=21 and ( Wuerfelsumme2>21 or Wuerfelsumme1>Wuerfelsumme2): stdio.writeln('Spieler 1 gewinnt.') elif Wuerfelsumme2<=21 and ( Wuerfelsumme1>21 or Wuerfelsumme2>Wuerfelsumme1): stdio.writeln('Spieler 2 gewinnt.') 1.2.25 Schließlich lassen wir die Spieler 100000mal gegeneinander spielen, und zählen, wie oft jeder gewinnt. 1.2.26 # Wir benutzen zwei Zähler für die Gewinne jedes Spielers. gewinne1 = 0 gewinne2 = 0 # Wir lassen die beiden Spieler 1000000 Spiele spielen. for i in range(100000): # Spieler 1 spielt mit seiner Strategie. Wuerfelsumme1 = 0 while Wuerfelsumme1<=15: Wuerfelsumme1 = Wuerfelsumme1 + random.randrange(1,7) # Spieler 2 spielt mit seiner Strategie. Wuerfelsumme2 = 0 while Wuerfelsumme2<=16: Wuerfelsumme2 = Wuerfelsumme2 + random.randrange(1,7) # Der Gewinner wird bestimmt und sein Gewinn-Zähler wird um 1 erhöht. if Wuerfelsumme1<=21 and ( Wuerfelsumme2>21 or Wuerfelsumme1>Wuerfelsumme2): gewinne1 = gewinne1 + 1 elif Wuerfelsumme2<=21 and ( Wuerfelsumme1>21 or Wuerfelsumme2>Wuerfelsumme1): gewinne2 = gewinne2 + 1 # Gib aus, wer öfter gewonnen hat. if gewinne1>gewinne2: stdio.writeln('Spieler 1 hat ' + str(gewinne1-gewinne2) + 'mal oefter gewonnen als Spieler 2.') else: stdio.writeln('Spieler 2 hat ' + str(gewinne2-gewinne1) + 'mal oefter gewonnen als Spieler 1.') #----------------------------------------------------------------------------------------------# python siebzehnundvier_5.py # Spieler 2 hat 26584mal oefter gewonnen als Spieler 1. 1.2.27 Zusammenfassung § Wir haben if-Anweisungen, while-Schleifen und for-Schleifen kennengelernt. § Wir kennen die Strukturierung von Programmen in Anweisungs-Blöcke. § Wir können einfache Programme mit Eingabe von Argumenten Abarbeitung von Anweisungs-Blöcken, die in Schleifen wiederholt oder durch if-Anweisungen ausgeführt oder übersprungen werden Ausgabe von Ergebnissen schreiben und deren Ausführung nachvollziehen. 1.3 Arrays Die bisher benutzten Daten waren recht einfach – Zahlen, Texte oder Wahrheitswerte. Eine Datenstruktur dient der Organisation von Daten zur Verarbeitung mit einem Computer-Programm. Eine einfache Datenstruktur sind Arrays, mit denen man z.B. beliebig lange Folgen von Zahlen verarbeiten kann. Das erlaubt uns Programme zu schreiben, die viel größere Mengen von Daten verarbeiten als bisher. 1.3.1 Beispiel für ein eindimensionales Array Die einfachste Vorstellung eines Arrays ist eine Zuordnung von Werten zu Indizes. a = [’Gallia’, ’omnis’, ’div’, ’est’] erzeugt ein Array a[] mit Index zugeordneter Wert 0 1 2 3 ’Gallia’ ’omnis’ ’div’ ’est’ a[2] hat den String ’div’ als Wert. a[3] = a[2] + ’isa’ ändert den Wert von a[3] zu ’divisa’ Array a[] Index zugeordneter Wert 0 1 2 3 ’Gallia’ ’omnis’ ’div’ ’divisa’ Die Länge von a[] ist 4 und ist das Ergebnis von len(a). 1.3.2 Beispiel für ein zweidimensionales Array a = [ [’b’, ’b’, ’c’], [’d’, ’e’, ’f’, ’g’], [’h’, 1], [2]] erster Index zweiter Index Wert 0 1 2 3 0 1 2 0 1 2 3 0 1 0 ’b’ ’b’ ’c’ ’d’ ’e’ ’f’ ’g’ ’h’ 1 2 a[1][2] hat den str-Wert ’f’. Die Länge des zweidimensionalen Arrays a[][] ist 4, d.h. len(a) hat den Wert 4. a[0][] hat das Array [’b’, ’b’, ’c’] als Wert. Die Länge von a[0][] ist 3, d.h. len(a[0]) hat den Wert 3. 1.3.3 Berechnung des Durchschnitts der Werte eines Arrays #---------------------------------------------------------# durchschnitt.py #---------------------------------------------------------import stdio # Berechne den Durchschnitt der Werte, # die im Array werte[] gespeichert sind. werte = [17, 4, 23, 999, 46, 24, 1, 1, 13, 18] summe = 0 for i in range(len(werte)): stdio.writeln('i: ' + str(i) + ' summe = summe + werte[i] #-----------------------# python durchschnitt.py # i: 0 summe: 0 # i: 1 summe: 17 # i: 2 summe: 21 # i: 3 summe: 44 # i: 4 summe: 1043 # i: 5 summe: 1089 # i: 6 summe: 1113 # i: 7 summe: 1114 # i: 8 summe: 1115 # i: 9 summe: 1128 # 114.6 summe: ' + str(summe)) stdio.writeln(str(float(summe)/len(werte))) werte[] ist ein Array der Länge 10. Die Elemente von werte sind mit werte[0], werte[1],werte[2],. . . , werte[9] ansprechbar. len(werte) ist die Länge des Arrays werte. Man kann das auch kompakter aufschreiben #---------------------------------------------------------# durchschnitt.py #---------------------------------------------------------import stdio # Berechne den Durchschnitt der Werte, # die im Array werte[] gespeichert sind. werte = [17, 4, 23, 999, 46, 24, 1, 1, 13, 18] summe = 0 for i in werte: stdio.writeln('i: ' + str(i) + ' summe += i summe: ' + str(summe)) stdio.writeln(str(float(summe)/len(werte))) #-----------------------# python durchschnitt.py # i: 17 summe: 1146 # i: 4 summe: 1163 # i: 23 summe: 1167 # i: 999 summe: 1190 # i: 46 summe: 2189 # i: 24 summe: 2235 # i: 1 summe: 2259 # i: 1 summe: 2260 # i: 13 summe: 2261 # i: 18 summe: 2274 # 114.6 Das Gleiche für ein zweidimensionales Array . . . #-------------------------------------------------------# ddurchschnitt.py # Berechnet den Durchschnitt aller Werte # eines 2-dimensionalen Arrays. #-------------------------------------------------------import stdio werte = [ [17, 4], [23, 999, 46], [24, 1, 1, 13], [18] ] summe = 0 anzahl = 0 for z in range(len(werte)): for s in range(len(werte[z])): stdio.writeln('z: ' + str(z) + ' s: ' + str(s) + ' summe: ' + str(summe)) summe = summe + werte[z][s] anzahl = anzahl + 1 stdio.writeln(str(float(summe)/anzahl)) #------------------------# python ddurchschnitt.py # z: 0 s: 0 summe: 0 # z: 0 s: 1 summe: 17 # z: 1 s: 0 summe: 21 # z: 1 s: 1 summe: 44 # z: 1 s: 2 summe: 1043 # z: 2 s: 0 summe: 1089 # z: 2 s: 1 summe: 1113 # z: 2 s: 2 summe: 1114 # z: 2 s: 3 summe: 1115 # z: 3 s: 0 summe: 1128 # 114.6 . . . und nochmal kompakter aufgeschrieben #--------------------------------------------------------#--------------------------# ddurchschnitt-k.py # python ddurchschnitt-k.py # Berechnet den Durchschnitt der durchschnittlichen # [17, 4] 0 # Zeilensummen eines 2-dimensionalen Arrays. # s: 17 zeilens.: 0 #--------------------------------------------------------# s: 4 zeilens.: 17 import stdio # [23, 999, 46] 10.5 # s: 23 zeilens.: 0 werte = [ [17, 4], [23, 999, 46], [24, 1, 1, 13], [18] ] # s: 999 zeilens.: 23 # s: 46 zeilen.: 1022 durchschnittsumme = 0 # [24, 1, 1, 13] 366.5 # s: 24 zeilens.: 0 for z in werte: # s: 1 zeilens.: 24 stdio.writeln(str(z) + ' ' + str(durchschnittsumme)) # s: 1 zeilens.: 25 zeilensumme = 0 # s: 13 zeilens.: 26 for s in z: # [18] 376.25 stdio.writeln(' ' + ' s: ' + str(s) + # s: 18 zeilens.: 0 ' zeilens.: ' + str(zeilensumme)) # 98.5625 zeilensumme += s durchschnittsumme += float(zeilensumme)/len(z) stdio.writeln(str(durchschnittsumme/len(werte))) #-------------------------------------------------------# array-kopieren.py #-------------------------------------------------------import stdio, stdarray a = [1, 2, 3, 4, 5] # Kopiere Array a ins Array b. # Dazu wird zuerst ein Array der Länge 0 erzeugt. b = [] for i in range(len(a)): stdio.writeln('Laenge von b: ' + str(len(b))) b += [a[i]] # hänge Wert a[i] an das Array b an #-------------------------# python array-kopieren.py # Laenge von b: 0 # Laenge von b: 1 # Laenge von b: 2 # Laenge von b: 3 # Laenge von b: 4 # [1, 2, 3, 4, 5] # Laenge von c: 5 # Laenge von c: 5 # Laenge von c: 5 # Laenge von c: 5 # Laenge von c: 5 # [1, 2, 3, 4, 5] stdio.writeln(b) # Kopiere Array a ins Array c. # Dazu wird zuerst ein Array der Länge len(a) erzeugt. c = stdarray.create1D(len(a),0) for i in range(len(a)): stdio.writeln('Laenge von c: ' + str(len(c))) c[i] = a[i] stdio.writeln(c) 1.3.8 Lesen vieler Eingaben von der Konsole #-------------------------------------------------------------------------# durchschnitt-eingabe.py #-------------------------------------------------------------------------import stdio, sys # Berechne den Durchschnitt der Werte, die über die Konsole eingegeben werden. # Sie stehen im Array sys.argv[] unter den Indizes 1,2,...,len(sys.arg)-1 summe = 0 for i in range(1,len(sys.argv)): summe = summe + int(sys.argv[i]) # for i in sys.argv[1:] # summe = summe + int(i) stdio.writeln(str(float(summe)/(len(sys.argv)-1))) #-------------------------------------------------------------------------# python durchschnitt-eingabe.py 1 2 3 4 5 6 7 8 9 10 # 5.5 1.3.9 # Es wird ausprobiert, wielange man mit einem Würfel mit n Zahlen # würfeln muss, bis man alle n Zahlen gewürfelt hat. n = int(sys.argv[1]) # gewuerfelt ist ein Array mit n Einträgen. # Eintrag i gibt an, ob Zahl i bereits gewuerfelt wurde. gewuerfelt = stdarray.create1D(n,False) runden = 100000 wurfzaehler = 0 # Das Experiment wird runden mal ausgeführt. for i in range(runden): # Solange nicht jede Zahl einmal gewürfelt wurde, wird weitergewürfelt. while not min(gewuerfelt): wurf = random.randrange(0,n) wurfzaehler += 1 gewuerfelt[wurf] = True # Nachdem alle Zahlen gewürfelt wurden, wird alles wieder zurückgesetzt. for i in range(len(gewuerfelt)): gewuerfelt[i] = False stdio.writeln('Um ' + str(n) + ' Zahlen zu wuerfeln braucht man im Mittel ' + str(wurfzaehler/runden+1) + ' Wuerfe.') 1.3.10 # Es wird ausprobiert, wie oft man mit einem Würfel mit n Zahlen würfeln muss, # bis man eine Zahl zum zweiten Mal wirft. (Geburtstagsparadoxon) n = int(sys.argv[1]) gewuerfelt = stdarray.create1D(n,False) wurfzaehler = 0 # Der Versuch wird runden mal wiederholt. runden = 10000 for i in range(runden): # Es werden Zahlen aus 0..n-1 gewuerfelt. # Sobald eine Zahl zum zweiten Mal gewürfelt wird, ist das Experiment beendet. for j in range(n): gewuerfelt[j] = False runde_beenden = False while not runde_beenden: z = random.randrange(0,n) wurfzaehler += 1 if gewuerfelt[z]: runde_beenden = True else: gewuerfelt[z] = True stdio.writeln('Um mit einem ' + str(n) + '-Wuerfel eine Zahl doppelt zu wuerfeln, ' +'braucht man im Mittel ' + str(float(wurfzaehler)/runden) + ' Versuche.') #---------------------------------------------------------------------------------------------# python geburtstagsparadoxon.py 6 # Um mit einem 6-Wuerfel eine Zahl doppelt zu wuerfeln, braucht man im Mittel 3.759 Versuche. # # python geburtstagsparadoxon.py 365 # Um mit einem 365-Wuerfel eine Zahl doppelt zu wuerfeln, braucht man im Mittel 24.5187 Versuche. 1.3.11 #------------------------------------------------------------------------# minsort.py # Sortieren mittels Minimum-Suche. # Die zu sortierenden Strings werden von der Kommandozeile gelesen. #------------------------------------------------------------------------import stdio, sys m = sys.argv[1:] for i in range(len(m)-1): # Bestimme den Index des kleinsten Elements im Indexbereich i..len(m) min = i for j in range(i+1,len(m)): if m[min] > m[j]: min = j # Tausche das kleinste Element im Indexbereich i..len(m) # mit dem Element mit Index i. t = m[min] m[min] = m[i] m[i] = t stdio.writeln(m) #--------------------------------------------------------------------------# python minsort.py Gallia est omnis divisa in partes tres . # ['.', 'Gallia', 'divisa', 'est', 'in', 'omnis', 'partes', 'tres'] 1.3.12 #--------------------------------------------------------------# magicsquare.py # Überprüfe, ob das eigegebene Zahlenquadrat ein # magisches Quadrat ist. # Dazu müssen alle Zeilen, Spalten und Diagonalen # die gleiche Summe haben. #--------------------------------------------------------------import stdio, sys ms = [ [16, 3, 2, 13], [5, 10, 11, 9], [9, 6, 7, 12], [4, 15, 14, 1] ] # Prüfe, ob das Array ein Quadrat ist. laenge = len(ms) for s in range(laenge): if len(ms[s]) != laenge: stdio.writeln('Das ist kein Quadrat!') # Berechne die Mastersumme: das ist die Summe der ersten Zeile. mastersumme = 0 for s in range(laenge): mastersumme += ms[0][s] # Vergleiche sie mit den Summen der anderen Zeilen. for z in range(1,laenge): zeilensumme = 0 for s in range(len(ms[z])): zeilensumme += ms[z][s] if zeilensumme != mastersumme: stdio.writeln('Zeile ' + str(z) + ' stimmt nicht!') 1.3.13 # Vergleiche die Mastersumme mit den Summen der Spalten. for s in range(0,laenge): spaltensumme = 0 for z in range(laenge): spaltensumme += ms[z][s] if spaltensumme != mastersumme: stdio.writeln('Spalte ' + str(s) + ' stimmt nicht!') # Vergleiche die Mastersumme mit den Summen der Diagonalen. diagonalsumme1 = 0 diagonalsumme2 = 0 for d in range(0,laenge): diagonalsumme1 += ms[d][d] diagonalsumme2 += ms[d][laenge-1-d] if diagonalsumme1 != mastersumme or diagonalsumme2 != mastersumme: stdio.writeln('Eine Diagonale stimmt nicht!') #--------------------------------------------------------------------------------------# python magicsquare.py # Zeile 1 stimmt nicht! # Spalte 3 stimmt nicht! 1.3.14 Zusammenfassung Wir wissen grundlegend, wie man Arrays erzeugt und auf ihre Elemente zugreift. Erzeugen von Arrays: [1, 2, 3, [4, 5], 6] Angabe des gesamten Arrays b += [15] Anhängen eines Elements an ein Array stdarray.create1D(n, val) Array der Länge n, jedes Element hat Wert val stdarray.create2D(n, m, val) n-mal-m Array, jedes Element hat Wert val a[i:j] aus Array a[] wird ein neues Array [a[i], a[i+1], ..., a[j-1]] erzeugt, i hat Default 0 und j hat Default len(a) Zugriff auf Elemente von Arrays: a[i] das i-te Element von a[] (indizierter Zugriff) a[i] = x ersetze das i-te Element von a[] durch x (indizierte Zuweisung) for v in a: weise v jedes Element von a[] zu (Durchlaufen) a[i:j] ein neues Array [a[i], a[i+1], ..., a[j-1]], i hat Default 0 und j hat Default len(a) (Slicing) Funktionen zum Arbeiten mit Arrays: len(a) die Anzahl der Elemente von a[] sum(a) die Summe der Elemente von a[] min(a) ein kleinstes Element von a[] max(a) ein größtes Element von a[] (sie müssen summierbar sein) (sie müssen vergleichbar sein) (sie müssen vergleichbar sein) 1.4 Ein- und Ausgabe Die bisher benutzten Programme konnten Eingaben von der Kommandozeile lesen und Ausgaben auf dem Bildschirm ausgeben. Eingabe von der Kommandozeile § können über das Array sys.argv[] benutzt werden § sind stets vom Typ string und müssen mittels Funktionen wie int() oder float() zum passenden Typ konvertiert werden. Ausgaben auf dem Bildschirm § können mit den Funktionen stdio.write() und stdio.writeln() gemacht werden § sind stets vom Typ string § bilden den Datenstrom standard output. Standard output Ausgabe auf standard output: stdio.write(x) schreibe String x auf standard output stdio.writeln(x) schreibe String x und einen Zeilenumbruch auf standard output (wenn x weggelassen wird, wird nur ein Zeilenumbruch geschrieben) stdio.writef(fmt, arg1, arg2, ...) schreibe die Argumente arg1, arg2, ... auf standard output entsprechend der Formatierung durch fmt 1.4.2 # wuerfele.py # # Das Programm liest eine Zahl n von der Kommandozeile # und gibt n Würfe mit einem Würfel aus. import stdio, sys, random n = int(sys.argv[1]) for i in range(n): stdio.writeln(random.randrange(1,7)) #------------------------------------------------------------------# python wuerfele.py 7 # 4 # 4 # 1 # 2 # 4 # 6 # 1 # # python wuerfele.py 100000 > wuerfelergebnisse.txt # Man kann das Programm beliebig viele Werte ausgeben lassen (Datenstrom). Standard output kann auch in eine Datei umgeleitet werden. 1.4.3 # fmt-1.py import stdio, math n = 1000 r = math.sqrt(n) # gib int n und float r aus stdio.writef('Die Wurzel von %d ist %f .\n', n, r) # gib int n mit 5 Zeichen und float r mit 10 Zeichen aus stdio.writef('Die Wurzel von %5d ist %10f .\n', n, r) # gib int n mit 5 Zeichen unf float r mit 8 Zeichen und 3 Nachkommastellen aus stdio.writef('Die Wurzel von %5d ist %8.3f .\n', n, r) # wie zuvor, aber r wird linksbündig ausgegeben stdio.writef('Die Wurzel von %5d ist %-8.3f .\n', n, r) # wenn die angegebene Zahl der Zeichen zu klein ist, wird das ignoriert stdio.writef('Die Wurzel von %2d ist %2.3f .\n', n, r) #---------------------------------------------------# python fmt-1.py # Die Wurzel von 1000 ist 31.622777 . # Die Wurzel von 1000 ist 31.622777 . # Die Wurzel von 1000 ist 31.623 . # Die Wurzel von 1000 ist 31.623 . # Die Wurzel von 1000 ist 31.623 . 1.4.4 # fmt-2.py # Würfele 100000-mal mit zwei Würfeln; zähle, wie oft # welche Summe gewürfelt wurde und gib die relative Häufigkeit zur Summe 2 aus. import stdio, stdarray, random wurfsumme = stdarray.create1D(13,0) for i in range(100000): wurf1 = random.randrange(1,7) wurf2 = random.randrange(1,7) wurfsumme[wurf1+wurf2] += 1 fmt = 'Summe %2d wurde %5d-mal gewuerfelt (Faktor %4.2f).\n' for i in range(2,len(wurfsumme)): stdio.writef(fmt, i, wurfsumme[i], float(wurfsumme[i])/wurfsumme[2]) #-----------------------------------------------------------------------------------------# python fmt-2.py Summe 2 wurde 2855-mal gewuerfelt (Faktor 1.00). Summe 3 wurde 5588-mal gewuerfelt (Faktor 1.96). Summe 4 wurde 8283-mal gewuerfelt (Faktor 2.90). Summe 5 wurde 11166-mal gewuerfelt (Faktor 3.91). Summe 6 wurde 13870-mal gewuerfelt (Faktor 4.86). Summe 7 wurde 16608-mal gewuerfelt (Faktor 5.82). Summe 8 wurde 13708-mal gewuerfelt (Faktor 4.80). Summe 9 wurde 11126-mal gewuerfelt (Faktor 3.90). Summe 10 wurde 8424-mal gewuerfelt (Faktor 2.95). Summe 11 wurde 5514-mal gewuerfelt (Faktor 1.93). Summe 12 wurde 2858-mal gewuerfelt (Faktor 1.00). 1.4.5 Standard input Standard input ist ein Datenstrom für Daten, die von einem Programm als Eingabe gelesen werden. Der Datenstrom wird als Folge von Token aufgefasst, die durch Leerzeichen (Zeilenumbrüche, Tabs etc.) getrennt sind. Zum Lesen von Token gibt es die folgenden Funktionen. stdio.isEmpty() liefert True, falls der Eingabestrom beendet ist, sonst False stdio.readInt() liest ein Token, konvertiert es zu int und gibt es zurück stdio.readFloat() liest ein Token, konvertiert es zu float und gibt es zurück stdio.readBool() liest ein Token, konvertiert es zu bool und gibt es zurück stdio.readString() liest ein Token und gibt es zurück 1.4.6 # # # # ein-aus.py Von der Kommandozeile wird n eingelesen. Anschließend wird die Eingabe von n int-Werten erwartet. Der Durchschnitt der Werte wird ausgegeben. import stdio, sys # Die Anzahl der zu lesenden Werte wird von der Kommandozeile gelesen n = int(sys.argv[1]) summe = 0 for i in range(n): stdio.write('Bitte geben Sie Wert ' + str(i+1) + ' von ' + str(n) + ' ein: ') summe += stdio.readInt() stdio.writef('Der Durchschnitt ist %.2f.\n', float(summe)/n) #--------------------------------------------------------------------------------# # # # # # # python ein-aus.py 5 Bitte geben Sie Wert Bitte geben Sie Wert Bitte geben Sie Wert Bitte geben Sie Wert Bitte geben Sie Wert Der Durchschnitt ist 1 von 2 von 3 von 4 von 5 von 18.80 5 5 5 5 5 ein: ein: ein: ein: ein: 12 20 22 28 12 # python ein-aus.py 5 # Bitte geben Sie Wert 1 von 5 ein: # Bitte geben Sie Wert 2 von 5 ein: geben Sie Wert 3 von 5 ein: Bitte Wert 4 von 5 ein: 40 23 # Bitte geben Sie Wert 5 von 5 ein: Durchschnitt ist 24.60. 10 20 30 Bitte geben Sie Der 1.4.7 # # # # ein-aus-2.py Es werden float-Werte eingelesen, bis die Eingabe beendet wird (an der Konsole mit <Strg-d>, sonst mit Dateiende). Der Durchschnitt der Werte wird ausgegeben. import stdio, sys n = 0 summe = 0 while not stdio.isEmpty(): summe += stdio.readFloat() n += 1 stdio.writef('\nEs wurden %d Werte eingegeben.\n', n) stdio.writef('Der Durchschnitt ist %.2f.\n', summe/n) #-----------------------------------------------------------------------------# python ein-aus-2.py # 12 # 13 # 15 89 # 56 # # Es wurden 5 Werte eingegeben. # Der Durchschnitt ist 37.00. 1.4.8 Bisher haben wir den Datenstrom standard input an der Konsole erzeugt. Die Eingabeumleitung erlaubt auch das Lesen einer Datei. # # # # ein-aus-2.py Es werden float-Werte eingelesen, bis die Eingabe beendet wird. (an der Konsole mit <Strg-d>, sonst mit Dateiende). Der Durchschnitt der Werte wird ausgegeben. import stdio, sys n = 0 summe = 0 while not stdio.isEmpty(): summe += stdio.readFloat() n += 1 stdio.writef('\nEs wurden %d Werte eingegeben.\n', n) stdio.writef('Der Durchschnitt ist %.2f.\n', summe/n) #-----------------------------------------------------------------------------# python ein-aus-2.py < Jena-hoechsttemp.txt # # Es wurden 9497 Werte eingegeben. # Der Durchschnitt ist 15.11. Funktionen zum Lesen des ganzen (restlichen) Eingabestroms auf einen Schlag“: ” stdio.readAllInts() liest alle Token und gibt sie als Array von int zurück stdio.readAllFloats() liest alle Token und gibt sie als Array von float zurück stdio.readAllBools() liest alle Token und gibt sie als Array von bool zurück stdio.readAllStrings() liest alle Token und gibt sie als Array von string zurück stdio.readAllLines() liest alle Zeilen und gibt sie als Array von string zurück stdio.readAll() liest den Rest von standard input und gibt ihn als string zurück 1.4.10 # durchschnitt.py # Es werden float-Werte von standard input eingelesen. # Der Durchschnitt der Werte wird ausgegeben. import stdio, sys summe = 0.0 eingabe = stdio.readAllFloats() for v in eingabe: summe += v stdio.writeln(float(summe)/len(eingabe)) #----------------------------------------------------------# python durchschnitt.py < Jena-hoechsttemps.txt # 15.1101821628 # # python durchschnitt.py # 1 3 5 8 # 23 # 45 # # 14.1666666667 1.4.11 Funktionen zum Lesen ganzer Zeilen von standard input: stdio.hasNextLine() hat standard input noch eine weitere Zeile? stdio.readLine() liest die nächste Zeile und gibt sie (als string) zurück stdio.readAllLines() liest alle Zeilen und gibt sie als Array von string zurück 1.4.12 (Direktes) Verarbeiten einer csv-Datei Eine csv-Datei (comma separated values) enthält in Zeilen zusammengehörige Daten, die als Strings dargestellt und durch Kommas (o.ä.) getrennt sind. Bsp.: Datei airports.csv mit Namen, Breiten- und Längengrad etc. von Flughäfen. 1,"Goroka","Goroka","Papua New Guinea","GKA","AYGA",-6.081689,145.391881,5282,10,"U","Pacific/Port 2,"Madang","Madang","Papua New Guinea","MAG","AYMD",-5.207083,145.7887,20,10,"U","Pacific/Port_Mor 3,"Mount Hagen","Mount Hagen","Papua New Guinea","HGU","AYMH",-5.826789,144.295861,5388,10,"U","Pa 4,"Nadzab","Nadzab","Papua New Guinea","LAE","AYNZ",-6.569828,146.726242,239,10,"U","Pacific/Port_ 5,"Port Moresby Jacksons Intl","Port Moresby","Papua New Guinea","POM","AYPY",-9.443383,147.22005, 6,"Wewak Intl","Wewak","Papua New Guinea","WWK","AYWK",-3.583828,143.669186,19,10,"U","Pacific/Por Wir wollen nun die Koordinaten jedes Flughafens ausgeben. Dazu können wir jede Zeile in ein Array aufteilen, dessen Elemente die durch Kommas getrennten Stellen der Zeile sind. zeile = '1,"Goroka","Goroka","Papua New Guinea","GKA","AYGA",' + '-6.081689,145.391881,5282,10,"U","Pacific/Port_Moresby"' array = string.split( zeile, ',' ) stdio.writeln(array) liefert ['1', '"Goroka"', '"Goroka"', '"Papua New Guinea"', '"GKA"', '"AYGA"', '-6.081689', '145.391881', '5282', '10', '"U"', '"Pacific/Port_Moresby"'] 1.4.13 # coords-aus-csv.py # Es werden die Zeilen einer csv-Datei eingelesen. # Die Einträge an Stelle 6 und 7 werden ausgegeben. import stdio, string while stdio.hasNextLine(): line = stdio.readLine() breitengrad = string.split(line,',')[6] laengengrad = string.split(line,',')[7] stdio.writef('%8s %8s\n', breitengrad, laengengrad) #--------------------------------------------------------# python coords-aus-csv.py < airports.csv # -6.081689 145.391881 # -5.207083 145.7887 # -5.826789 144.295861 # -6.569828 146.726242 # -9.443383 147.22005 # -3.583828 143.669186 # ... 1.4.14 Eine csv-Datei vom DWD mit den in Jena gemessenen Tageshöchsttemperaturen. Element;Messstation;Datum;Wert;Einheit;Geo-Breite (Grad);Geo-Länge (Grad);Höhe (m);Sensorhöhe (m); Erstellungsdatum;Copyright; Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-01;1,5;Grad C;50,925;11,583;155;keine Daten vorhanden;2016-04-22;© Deutscher Wetterdienst 2016; Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-02;1,4;Grad C;50,925;11,583;155;keine Daten Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-03;0,4;Grad C;50,925;11,583;155;keine Daten Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-04;2,2;Grad C;50,925;11,583;155;keine Daten Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-05;1,2;Grad C;50,925;11,583;155;keine Daten Lufttemperatur Tagesmaximum;Jena (Sternwarte);1990-01-06;1,5;Grad C;50,925;11,583;155;keine Daten ... Lufttemperatur Lufttemperatur Lufttemperatur Lufttemperatur Lufttemperatur Tagesmaximum;Jena Tagesmaximum;Jena Tagesmaximum;Jena Tagesmaximum;Jena Tagesmaximum;Jena (Sternwarte);2015-12-28;9,5;Grad (Sternwarte);2015-12-29;8,7;Grad (Sternwarte);2015-12-30;6,3;Grad (Sternwarte);2015-12-31;3,8;Grad (Sternwarte);2016-01-01;2,7;Grad C;50,925;11,583;155;keine C;50,925;11,583;155;keine C;50,925;11,583;155;keine C;50,925;11,583;155;keine C;50,925;11,583;155;keine Daten Daten Daten Daten Daten 1.4.15 # temperaturen-aus-csv.py # Es werden die Zeilen einer csv-Datei vom DWD eingelesen. # Der Eintrag an Stelle 3 wird ausgegeben. import stdio, string # In der ersten Zeil der csv-Datei stehen andere Informationen. stdio.readLine() while stdio.hasNextLine(): line = stdio.readLine() temperatur = string.split(line,';')[3] # Da in der csv-Datei die Temperaturen mit Komma (2,3) statt Punkt (2.3) # stehen, muss das Komma durch einen Punkt ersetzt werden. temperatur = string.replace(temperatur, ',', '.') stdio.writef('%4s\n', temperatur) #--------------------------------------------------------------# python temperaturen-aus-csv.py < Jena_Temperaturen.csv # # 1.5 # 1.4 # 0.4 # 2.2 # 1.2 # ... # # python temperaturen-aus-csv.py < Jena_Temperaturen.csv > JT.txt # 1.4.16 # tage-ueber-30.py # Als Eingabe wird Jena-hoechsttemps.txt erwartet. # Dort steht der Reihe nach für jeden Tag vom 1.1.1990 bis 1.1.2016 # die Tageshoechsttemperatur, die an der Sternwarte Jena gemessen wurde. # Es wird für jedes Jahr ausgegeben, an wievielen Tagen es über 30 Grad warm war. import stdio, sys, stdarray temperaturen = stdio.readAllFloats() # Zähle die Anzahl der Tage pro Jahr mit Temperaturen über 30 Grad for jahr in range(26): if (jahr+2)%4 == 0: schalttag = 1 else: schalttag = 0 jahreslaenge = 365 + schalttag anz_warme_tage = 0 for d in range(jahr*365 + (jahr+2)/4, jahr*365 + (jahr+2)/4 + jahreslaenge) : if temperaturen[d] >= 30: anz_warme_tage += 1 stdio.writeln(anz_warme_tage) #------------------------------------------------------------------------------------------------# python tage-ueber-30.py < JT.txt > Tage-ueber-30-pro-Jahr.txt # 1.4.17 Piping Die Ausgabe eines Programms kann direkt als Eingabe für ein anderes Programm verwendet werden. # python wuerfele.py 10000 | durchschnitt.py 3.5197 # ( python temperaturen-aus-csv.py < Jena Temperaturen.csv ) | python tage-ueber-30.py > Tage-ueber-30-pro-Jahr.txt 1.4.18 Zusammenfassung standard input und standard output Wir haben gesehen, wie Daten § von der Konsole eingelesen und auf der Konsole ausgegeben werden können § aus Dateien eingelesen und in Dateien geschrieben werden können (Eingabeumleitung < und Ausgabeumleitung >) § als Ausgabe eines Programms weitergereicht und als Eingabe eines anderen Programms benutzt werden können (Piping |). Graphische Ausgabe mit standard drawing Das Modul stddraw erlaubt das Malen von Punkten, Strichen, Kreisen, Rechtecken etc. # Es wird ein Strich gemalt. import stddraw # die x- und y-Kooordinate des ersten Punktes x1 = 0.2 y1 = 0.3 # die x- und y-Kooordinate des zweiten Punktes x2 = 0.9 y2 = 0.9 # male eine Linie vom ersten zum zweiten Punkt stddraw.line(x1, y1, x2, y2) # zeige das gemalte Bild stddraw.show() 1.4.20 Graphische Ausgabe mit standard drawing Das Modul stddraw erlaubt das Malen von Punkten, Strichen, Kreisen, Rechtecken etc. # Es wird ein Strich gemalt. import stddraw # die x- und y-Kooordinate des ersten Punktes x1 = 0.2 y1 = 0.3 # die x- und y-Kooordinate des zweiten Punktes x2 = 0.9 y2 = 0.9 px2, y 2q px1, y 1q # male eine Linie vom ersten zum zweiten Punkt stddraw.line(x1, y1, x2, y2) # zeige das gemalte Bild stddraw.show() 1.4.20 stddraw.line(x0, y0, x1, y0) male eine Linie von px0, y 0q zu px1, y 1q stddraw.point(x, y) male einen Punkt an px, y q stddraw.show() zeige das Bild im standard-drawing-Fenster (und warte, bis es vom Nutzer geschlossen wird) stddraw.setPenRadius(r) setze die Stiftdicke auf r (Default-Wert von r ist 0.005) stddraw.Xscale(x0, x1) setze den Bereich der x-Werte auf x0 ď x ď x1 (Default ist x0 “ 0 und x1 “ 1) stddraw.Yscale(x0, x1) setze den Bereich der y -Werte auf y 0 ď y ď y 1 (Default ist y 0 “ 0 und y 1 “ 1) stddraw.setCanvasSize(w, h) setze die Bildgröße auf w -mal-h Pixel (Default für w und h ist 512) # Male das Haus vom Nikolaus. Es hat fünf Ecken: ul (unten links), ur, # ol, or, gi (Giebel), die jeweils mit x- und y-Koordinate # angegeben werden. import stddraw ul_x = 0 ul_y = 0 ur_x = 1 ur_y = 0 ol_x = 0 ol_y = 1 or_x = 1 or_y = 1 gi_x = float(ol_x + or_x)/2 gi_y = ol_y + 0.5 stddraw.setXscale(-0.5,1.5) stddraw.setYscale(-0.5,2) stddraw.line(ul_x,ul_y,ur_x,ur_y) stddraw.line(ul_x,ul_y,ol_x,ol_y) stddraw.line(or_x,or_y,ol_x,ol_y) stddraw.line(or_x,or_y,ur_x,ur_y) stddraw.line(or_x,or_y,gi_x,gi_y) stddraw.line(ol_x,ol_y,gi_x,gi_y) stddraw.show() 1.4.22 #----------------------------------------------------------------------# plotfilter.py (aus dem Buch) #----------------------------------------------------------------------import stdio import stddraw # Read x and y scales from standard input, and configure standard # draw accordingly. Then read points from standard input until # end-of-file, and plot them on standard draw. x0 y0 x1 y1 = = = = stdio.readFloat() stdio.readFloat() stdio.readFloat() stdio.readFloat() stddraw.setXscale(x0, x1) stddraw.setYscale(y0, y1) # Read and plot the points. stddraw.setPenRadius(0.002) while not stdio.isEmpty(): x = stdio.readFloat() y = stdio.readFloat() stddraw.point(x, y) stddraw.show() #---------------------------------------# python plotfilter.py < usa.txt Datei usa.txt: 669905.0 247205.0 1244962.0 700000.0 1097038.8890 245552.7780 1103961.1110 247133.3330 1104677.7780 247205.5560 1108586.1110 249238.8890 1109713.8890 250111.1110 ... 1.4.23 Wir wollen plotfilter.py benutzen, um eine Karte mit den Flughäfen zu malen. Deren Koordinaten haben wir ja bereits. Dazu müssen wir coords-aus-csv.py so modifizieren, dass es zu plotfiler.py passt: § In der ersten Zeile der Ausgabe müssen die Werte x0, y 0, x1, y 1 für die Bereiche der x-Werte (x0 ď x ď x1) und die Bereiche der y -Werte (y 0 ď y ď y 1) stehen. § In den darauffolgenden Zeilen folgen x-Koordinate (Längengrad) und y -Koordinate (Breitengrad) jedes Flughafens. #----------------------------------------------------------------------# airports-to-plotfilter.py #----------------------------------------------------------------------# Es werden die Zeilen einer csv-Datei eingelesen. # Die Ausgabe passt als Eingabe für plotfilter.py . # Zuerst werden die Bereiche für die x- und y-Koordinaten ausgegeben. # Die x-Koordinaten sind die Längengrade (-180 ... 180) und # die y-Koordinaten sind die Breitengrade (-90 .. 90). # Der Eintrag an Stelle 6 der csv-Datei ist der Breitengrad, # und der Eintrag an Stelle 7 ist der Längengrad. import stdio, string # Ausgabe der Bereiche für die x- und y-Koordinaten stdio.writeln('-180.0 -90.0 180.0 90.0') while stdio.hasNextLine(): zeile = stdio.readLine() xkoordinate = string.split(zeile,',')[7] ykoordinate = string.split(zeile,',')[6] stdio.writef('%8s %8s\n', xkoordinate, ykoordinate) #-------------------------------------------------------------------------# ( python airports-to-plotfilter.py < airports.csv ) | python plotfilter.py # 1.4.25 Zeichnen des Graphs einer Funktion Zum Zeichnen des Graphs einer Funktion f pxq im Bereich l ď x ď r § muss man festlegen, wieviele Funktionswerte man im Bereich l ď x ď r berechnen will (das Intervall l . . . r wird in gleichmäßige Abschnitte unterteilt), § die Argument-Wert-Paare px, f pxqq berechnen und § die Funktionswerte benachbarter Argumente durch eine Linie verbinden. Man beachte, dass stets nur eine Näherung berechnet wird, deren Qualität von der Anzahl der berechneten Funktionswerte abhängt. 1.4.26 # # # # # # # # functiongraph.py (aus dem Buch) Der Graph der Funktion f(x) = sin(4x)+sin(20x) wird im Intervall 0..pi gezeichnet. Zuerst wird von der Kommandozeile die Sampling-Dichte (die Anzahl der zu zeichnenden Punkte) eingelesen. Anschließend werden die Punkte berechnet - die x-Koordinate des i-ten Punkts wird in x[i] gespeichert und die y-Koordinate in y[i]. Anschließend werden Linien zwischen benachbarten Punkten gezeichnet. import math, sys, stdarray, stdio, stddraw n = int(sys.argv[1]) x = stdarray.create1D(n+1,0.0) y = stdarray.create1D(n+1,0.0) python functiongraph.py 20 for i in range(n+1): x[i] = math.pi * i/n y[i] = math.sin(4.0*x[i]) + math.sin(20.0*x[i]) stddraw.setXscale(0, math.pi) stddraw.setYscale(-2.0, +2.0) for i in range(n): stddraw.line(x[i], y[i], x[i+1], y[i+1]) python functiongraph.py 200 stddraw.show() Darstellung der Anzahl der warmen Tage in Jena Wir haben bereits das Programm tage-ueber-30.py, mit dem wir die Anzahl der warmen Tage pro Jahr in Jena von 1990 bis 2015 ausgeben. Wir wollen nun das Ergebnis graphisch darstellen: als Kurve und als Säulendiagramm. 1.4.28 # temperatur-kurve.py # Als Eingabe wird für jedes Jahr von 1990 bis 2015 eine Zahl gelesen. # Die Zahlen werden als Funktionsgraph dargestellt. import stdio, stddraw # lies die Werte für jedes Jahr werte = stdio.readAllInts() stddraw.setXscale(-2, 26) stddraw.setYscale(-2, max(werte)+2) stddraw.setPenRadius(0.002) # male ein Koordinatensystem stddraw.setPenColor(stddraw.BLUE) stddraw.line(0,0,26,0) stddraw.line(0,0,0,max(werte)+0.5) # beschrifte die Achsen des Koordinatensystems for i in range(max(werte)/10 + 1): stddraw.text(-0.5, i*10, str(i*10)) for i in range(6): stddraw.text(i*5, -0.7, str(1990 + 5*i)) # male die Kurve stddraw.setPenColor(stddraw.BLACK) for i in range(len(werte)-1): stddraw.line(i, werte[i], i+1, werte[i+1]) stddraw.show() #------------------------------------------------------------# ( python temperaturen-aus-csv.py < Jena_Temperaturen.csv ) | # python tage-ueber-30.py | python temperatur-kurve.py # temperatur-kurve.py # Als Eingabe wird für jedes Jahr von 1990 bis 2015 eine Zahl gelesen. # Die Zahlen werden als Funktionsgraph dargestellt. import stdio, stddraw # lies die Werte für jedes Jahr werte = stdio.readAllInts() stddraw.setXscale(-2, 26) stddraw.setYscale(-2, max(werte)+2) stddraw.setPenRadius(0.002) # male ein Koordinatensystem stddraw.setPenColor(stddraw.BLUE) stddraw.line(0,0,26,0) stddraw.line(0,0,0,max(werte)+0.5) # beschrifte die Achsen des Koordinatensystems for i in range(max(werte)/10 + 1): stddraw.text(-0.5, i*10, str(i*10)) for i in range(6): stddraw.text(i*5, -0.7, str(1990 + 5*i)) # male die Kurve stddraw.setPenColor(stddraw.BLACK) for i in range(len(werte)-1): stddraw.line(i, werte[i], i+1, werte[i+1]) stddraw.show() #------------------------------------------------------------# ( python temperaturen-aus-csv.py < Jena_Temperaturen.csv ) | # python tage-ueber-30.py | python temperatur-kurve.py # temperatur-kurve.py # Als Eingabe wird für jedes Jahr von 1990 bis 2015 eine Zahl gelesen. # Die Zahlen werden als Funktionsgraph dargestellt. import stdio, stddraw # lies die Werte für jedes Jahr werte = stdio.readAllInts() stddraw.setXscale(-2, 26) stddraw.setYscale(-2, max(werte)+2) stddraw.setPenRadius(0.002) # male ein Koordinatensystem stddraw.setPenColor(stddraw.BLUE) stddraw.line(0,0,26,0) stddraw.line(0,0,0,max(werte)+0.5) # beschrifte die Achsen des Koordinatensystems for i in range(max(werte)/10 + 1): stddraw.text(-0.5, i*10, str(i*10)) for i in range(6): stddraw.text(i*5, -0.7, str(1990 + 5*i)) # male die Kurve stddraw.setPenColor(stddraw.BLACK) for i in range(len(werte)-1): stddraw.line(i, werte[i], i+1, werte[i+1]) stddraw.show() #------------------------------------------------------------# ( python temperaturen-aus-csv.py < Jena_Temperaturen.csv ) | # python tage-ueber-30.py | python temperatur-kurve.py Weitere Funktionen zum Malen von Kreisen etc. stddraw.circle(x, y, r) male einen Kreis mit Mittelpunkt px, y q und Radius r import stddraw x = 2 y = 3 r = 4 stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.circle(x, y, r) stddraw.show() 1.4.30 Weitere Funktionen zum Malen von Kreisen etc. stddraw.circle(x, y, r) male einen Kreis mit Mittelpunkt px, y q und Radius r import stddraw x = 2 y = 3 r = 4 stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.circle(x, y, r) stddraw.show() 4 p2, 3q 1.4.30 stddraw.square(x, y, r) male ein Quadrat mit Mittelpunkt px, y q und Radius r import stddraw x = 2 y = 3 r = 4 stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.square(x, y, r) stddraw.show() 1.4.31 stddraw.square(x, y, r) male ein Quadrat mit Mittelpunkt px, y q und Radius r import stddraw x = 2 y = 3 r = 4 stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.square(x, y, r) stddraw.show() 4 4 p2, 3q 1.4.31 stddraw.polygon(x, y) male ein Vieleck mit den Ecken pxr0s, y r0sq, pxr1s, y r1sq, . . . (x und y sind Arrays) import stddraw x = [1,0,3,4,5] y = [2,3,4,6,1] stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.polygon(x,y) stddraw.show() stddraw.polygon(x, y) male ein Vieleck mit den Ecken pxr0s, y r0sq, pxr1s, y r1sq, . . . (x und y sind Arrays) p4, 6q import stddraw x = [1,0,3,4,5] y = [2,3,4,6,1] stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.polygon(x,y) stddraw.show() p3, 4q p0, 3q p5, 1q p1, 2q Alle Formen können auch gefüllt gemalt werden mittels stddraw.filledCircle(x,y,r), stddraw.filledSquare(x,y,r), stddraw.filledPolygon(x,y). stddraw.filledPolygon(x, y) male ein ausgefülltes Vieleck mit den Ecken pxr0s, y r0sq, pxr1s, y r1sq, . . . (x und y sind Arrays) import stddraw x = [1,0,3,4,5] y = [2,3,4,6,1] stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.setPenColor(stddraw.BLACK) stddraw.filledPolygon(x,y) stddraw.show() 1.4.33 Alle Formen können auch gefüllt gemalt werden mittels stddraw.filledCircle(x,y,r), stddraw.filledSquare(x,y,r), stddraw.filledPolygon(x,y). stddraw.filledPolygon(x, y) male ein ausgefülltes Vieleck mit den Ecken pxr0s, y r0sq, pxr1s, y r1sq, . . . (x und y sind Arrays) p4, 6q import stddraw p3, 4q x = [1,0,3,4,5] y = [2,3,4,6,1] stddraw.setXscale(0, 6) stddraw.setYscale(0, 6) stddraw.setPenColor(stddraw.BLACK) stddraw.filledPolygon(x,y) stddraw.show() p0, 3q p5, 1q p1, 2q 1.4.33 aus: Sedgewick, Wayne, Dondero: Introduction to Programming in Python – An Interdisciplinary Approach (Addison Wesley 2015) 1.4.34 Zusammenfassung standard draw Wir haben gesehen, wie Bilder aus einfachen Elementen (Punkte, Striche, Kreise, Rechtecke, Schrift) gestaltet werden können. Mit diesen Mitteln lassen sich auch Funktionen und Messwerte graphisch ansprechend darstellen. 1.4.35 1.5 PageRank Bei Anfragen an Suchmaschinen im Internet werden häufig Millionen von Webseiten zu einem Suchwort gefunden. Wie kommt es zu der Reihenfolge, in der die Seiten als Suchergebnis angezeigt werden? Für jede Seite wird ein PageRank bestimmt – das ist die Wahrscheinlichkeit, mit der ein Websurfer, der nach bestimmten Regeln (s.u.) zufällig von einer Webseite zur nächsten surft, die Seite erreicht. Bei der Anzeige eines Suchergebnisses werden die Seiten mit absteigendem PageRank angezeigt (neben möglichen anderen Kriterien). Das hat sich als nützlich erwiesen. Wir wollen an kleinen Beispielen den PageRank ausrechnen. 1.5.1 aaa.de bbb.com aaa.de ddd.org ccc.edu aaa.de bbb.com eee.eu ddd.org ccc.edu bbb.com ddd.org ccc.edu aaa.de eee.eu 1.5.2 1 0 2 3 4 1.5.2 1 0.2082 0.2083 0 0.2116 2 0.1612 3 0.2106 4 Ziel: berechne die Wahrscheinlichkeit, dass der Random Surfer einen Knoten besucht: er startet auf Seite 0 er läuft durch das Netz wie folgt: zu 90% wählt er einen Link zu 10% wählt er irgendeine Seite 1.5.2 1 0.2082 0.2083 0 0.2116 2 0.1612 3 0.2106 4 Ziel: berechne die Wahrscheinlichkeit, dass der Random Surfer einen Knoten besucht: er startet auf Seite 0 er läuft durch das Netz wie folgt: zu 90% wählt er einen Link zu 10% wählt er irgendeine Seite 5 0 graph.txt: 1 2 4 1 0 4 1 0 1 3 4 3 0 1 3 1 2 2 0 1.5.2 Simulation des Random Surfers: § lies den Graph ein § starte auf Seite 0 § mit Wahrsch. 0.9: wähle zufällig einen Link und folge ihm zu einer Nachbarseite mit Wahrsch. 0.1: wähle zufällig irgendeine Seite § wiederhole den letzten Schritt n mal § zähle dabei, wie häufig welche Seite besucht wurde Da es keine festgelegte Form der Darstellung von Graphen gibt, schreiben wir zuerst ein Programm, das einen Graph aus einer Form in die von uns benutzte Form bringt. Teil 1: Einlesen des Graphen Zuerst wird der Graph als 2-dimensionales Array graph[][] gespeichert, so dass graph[i][j] die Anzahl der Kanten von i nach j ist. Dieses Array wird dann ausgegeben. 5 0 1 2 4 1 0 4 1 0 1 3 4 3 0 1 3 1 2 2 0 wird zu [ [ [ [ [ [ 0, 2, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, graph[][] 0 0 1 0 0 ], ], ], ], ] ] #----------------------------------------------------------------------# graph-zu-am.py # # Liest eine Graph-Datei ein # und gibt die Knotenzahl gefolgt von der Adjazenzmatrix des Graphen aus. #-----------------------------------------------------------------------import stdio, stdarray # Die Graph-Datei beginnt mit der Anzahl Seiten (Knoten). n = stdio.readInt() stdio.writeln(str(n)) graph = stdarray.create2D(n, n, 0) # Der Rest der Graph-Datei besteht aus Zahlepaaren, die für Links (Kanten) stehen. # Zähle die Kanten in der Adjazenzmatrix in graph[][]. while not stdio.isEmpty(): i = stdio.readInt() j = stdio.readInt() # Wir vertrauen nicht darauf, dass der eingelesene Graph # nur aus zulässigen Kanten besteht und fragen das sicherheitshalber ab. if i<n and j<n: graph[i][j] += 1 # Gib die Adjazenzmatrix aus. for zeile in graph : for eintrag in zeile : stdio.writef('%d ', eintrag) stdio.writef('\n') 1.5.5 Teil 2: Simulation des Random Surfers Der Random Surfer geht wiederholt von einer Seite zur nächsten. Er wählt die nächste Seite nach der 90-10-Regel aus: zu 90% wird einem Link auf der aktuellen Seite gefolgt zu 10% wird irgendeine Seite ausgewählt Zufällige Auswahl eines Links auf der aktuellen Seite: Seite 1 hat folgende Links: graph[1]: [ 2, 0, 1, 1, 0 ] Das sind 4 Links – jeder muss mit gleicher Wahrscheinlichkeit gewählt werden. # Die Variable seite enthält die aktuelle Seite. anzahl_links = sum(graph[seite]) r = random.randrange(1, anzahl_links+1) Zufallszahl s = 0 Link zu Seite for j in range(n): s += graph[seite][j] if s >= r : seite = j break 1 0 2 0 3 2 4 3 # random_surfer.py # Lies runden von der Kommandozeile ein, n und graph[][] von standard input. ... # In seitenzaehler wird gespeichert, wie oft jede Seite besucht wurde. seitenzaehler = stdarray.create1D(n,0) # Starte auf Seite 0 und "surfe" runden mal zu einer (neuen) Seite. seite = 0 for i in range(runden): anzahl_links = sum(graph[seite]) if random.randrange(10)==0 or anzahl_links==0 : # mit Wahrscheinlichkeit 0.1: seite = random.randrange(n) # gehe zu einer zufällig gewählten Seite else : # mit Wahrscheinlichkeit 0.9: r = random.randrange(1, anzahl_links+1) # wähle zufällig einen der Links s = 0 # von der Seite und benutze ihn for j in range(n) : s += graph[seite][j] if s >= r : seite = j break seitenzaehler[seite] += 1 # Gib die Page Ranks aus. for v in seitenzaehler: stdio.writef('%f ', float(v)/runden) stdio.writeln() 1.5.7 Benutzung der Programme # python graph-zu-am.py < GraphVL05.txt | python random surfer.py 100000 0.2072 0.2106 0.2114 0.1607 0.2101 # python graph-zu-am.py < Graph500.txt | python random surfer.py 100000 0.0005 0.0054 0.0022 0.0006 0.0020 0.0027 0.0012 0.0007 0.0003 0.0002 0.0007 0.0011 ... Graphische Darstellung der berechneten Page Ranks zu verschiedenen Zeitpunkten. 1.5.8 Verbesserungsmöglichkeiten anzahl links wird immer wieder neu berechnet, um die Wahrscheinlichkeit des Wechsels von einer zu einer anderen Seite zu bestimmen. Stattdessen: schreibe diese Wahrscheinlichkeiten direkt in den Graph. Aus graph[][] wird ein Array prob[][] bestimmt, so dass p[i][j] die Wahrscheinlichkeit dafür ist, dass der Random Surfer in einem Schritt von i zu j geht: prob[i][j] = 0.9 * graph[i][j]/sum(graph[i]) + 0.1 * 1 / n [ [ [ [ Aus [ [ 0, 2, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, graph[][] 0 0 1 0 0 ], [ [ 0.02, 0.47, 0.02, ], [ 0.47, 0.02, 0.24, ], [ 0.02, 0.02, 0.02, ], wird [ 0.02, 0.02, 0.92, ] ] [ 0.47, 0.47, 0.02, prob[][] 0.47, 0.24, 0.02, 0.02, 0.02, 0.02 0.02 0.92 0.02 0.02 ], ], ], ], ] ] #---------------------------------------------------------------------------------# graph-zu-prob.py # # Liest eine Graph-Datei ein und gibt die Matrix aus, # die die Übergangswahrscheinlichkeiten des Random Surfers bei einem Schritt enthält. #----------------------------------------------------------------------------------import stdio, stdarray # Die Graph-Datei beginnt mit der Anzahl Seiten (Knoten). n = stdio.readInt() stdio.writeln(str(n)) graph = stdarray.create2D(n, n, 0) # Der Rest der Graph-Datei besteht aus Zahlepaaren, die für Links (Kanten) stehen. # Zähle die Kanten in der Adjazenzmatrix in graph[][]. while not stdio.isEmpty(): i = stdio.readInt() j = stdio.readInt() if i<n and j<n: graph[i][j] += 1 # Gib die Matrix mit den Übergangswahrscheinlichkeiten aus. for zeile in range(n) : zeilensumme = sum(graph[zeile]) for eintrag in graph[zeile] : if zeilensumme>0 : stdio.writef('%f ', 0.9 * float(eintrag)/zeilensumme + else : stdio.writef('%f ', 0.1/n ) stdio.writef('\n') 0.1/n ) 1.5.10 #----------------------------------------------------------------------# quicker_surfer.py #----------------------------------------------------------------------import stdio, sys, stdarray, random, stddraw # Liest runden von der Kommandozeile, n und prob[][] von standard input. # Simuliert den Random Surfer in dem Graph # entsprechend den Übergangswahrscheinlichkeiten in prob[][]. ... # Starte auf Seite 0. seite = 0 seitenzaehler = stdarray.create1D(n,0) for i in range(runden): # Lasse den Random Surfer zur nächsten Seite wechseln. r = random.random() s = 0.0 for j in range(n): s += prob[seite][j] if s >= r : seite = j break seitenzaehler[seite] += 1 for v in seitenzaehler: stdio.writef('%4.4f ', float(v)/runden) stdio.writeln() 1.5.11 Benutzung der Programme # python graph-zu-prob.py < Graph500.txt | python quicker surfer.py 100000 0.0007 0.0058 0.0025 0.0007 0.0021 0.0030 0.0011 0.0006 0.0004 ... Graphische Darstellung der berechneten Page Ranks zu verschiedenen Zeitpunkten. 1.5.12 Die Übergangswahrscheinlichkeiten von Knoten 1 sind prob[1]: [ 0.48, 0.02, 0.24, 0.24, 0.02 ] d.h. die die die die die Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, zu zu zu zu zu Knoten Knoten Knoten Knoten Knoten 0 1 2 3 4 zu zu zu zu zu gehen, gehen, gehen, gehen, gehen, ist ist ist ist ist 0.48 0.02 0.24 0.24 0.02 1.00 0.00 0.48 0.50 0.74 0.98 1.00 Wähle r zufällig mit 0 ď r ă 1. r = random.random() s = 0.0 for j in range(n): s += prob[seite][j] if s >= r : seite = j break Damit hat der Random Surfer den Schritt zu seite gemacht. Die Übergangswahrscheinlichkeiten von Knoten 1 sind prob[1]: [ 0.48, 0.02, 0.24, 0.24, 0.02 ] d.h. die die die die die Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, Wahrscheinlichkeit, zu zu zu zu zu Knoten Knoten Knoten Knoten Knoten 0 1 2 3 4 zu zu zu zu zu gehen, gehen, gehen, gehen, gehen, ist ist ist ist ist 0.48 0.02 0.24 0.24 0.02 1.00 0.00 0.48 0.50 0.74 0.98 1.00 Wähle r zufällig mit 0 ď r ă 1. r = random.random() s = 0.0 for j in range(n): s += prob[seite][j] if s >= r : seite = j break Damit hat der Random Surfer den Schritt zu seite gemacht. + + + + prob[1][0] prob[1][1] prob[1][2] prob[1][3] prob[1][4] Direkte Berechnung statt Simulation Anstatt mit dem Random Surfer die Wahrscheinlichkeit des Besuchs einer Seite zu simulieren, können wir die Wahrscheinlichkeit auch direkt ausrechnen. Grundlage ist die Matrix mit den Übergangswahrscheinlichkeiten. In Zeile i stehen die Wahrscheinlichkeiten dafür, in einem Schritt von Seite i zu den anderen Seiten zu kommen. » — — — – [ 1.0 0.0 0.0 0.0 0.0 ] Am Anfang ist RS mit Wahrscheinlichkeit 1 auf Seite 0. 0.02 0.48 0.02 0.02 0.47 prob[][] 0.47 0.02 0.47 0.02 0.24 0.24 0.02 0.02 0.02 0.02 0.92 0.02 0.47 0.02 0.02 fi 0.02 0.02 ffi ffi 0.92 ffi fl 0.02 0.02 [ 0.02 0.47 0.02 0.47 0.02 ] Nach einem Schritt ist RS mit diesen W.keiten auf einer der Seiten. 1.5.14 Multiplikation von Matrizen Eine Matrix A aus z Zeilen und s Spalten hat m ¨ n Einträge aij für 1 ď i ď z und 1 ď j ď s. Bsp.: Matrizen mit 5 Zeilen und 4 Spalten: ¨ ˛ ¨ a11 a12 a13 a14 4 12 ˚a ‹ ˚ ˚ 21 a22 a23 a24 ‹ ˚3 1 ˚ ‹ ˚ ˚a31 a32 a33 a34 ‹ ˚2 5 ˚ ‹ ˚ ˝a41 a42 a43 a44 ‚ ˝1 6 a51 a52 a53 a54 7 11 ˛ 3 4 5 5‹ ‹ ‹ 4 3‹ ‹ 2 9‚ 0 17 Eine Zeilenvektor entspricht einer Zeile einer Matrix. ` v1 v2 v3 v4 v5 ˘ ` ˘ 3 2 11 8 1 Man kann einen Zeilenvektor mit einer Matrix multiplizieren, wenn die Anzahl der Spalten des Zeilenvektors gleich der Anzahl der Zeilen der Matrix sind. Das Produkt eines Zeilenvektors v mit n Spalten und einer Matrix A mit n Zeilen und m Spalten ist ein Zeilenvektor w “ pw1 w2 ¨ ¨ ¨ wm q mit m Spalten und wk n ÿ “ vi ¨ aki . i“1 Bsp: Produkt eines Zeilenvektors mit 5 Spalten und einer Matrix mit 5 Zeilen und 4 Spalten ergibt einen Zeilenvektor mit 4 Spalten. ˛ ¨ 4 12 3 4 ˚3 1 5 5 ‹ ˚ ‹ ˚2 0 4 3 ‹ ˚ ‹ ˝1 6 2 0 ‚ ` ˘ ` 7 11 0 17˘ 3 2 11 8 1 55 97 79 72 1.5.16 » — — — – [ 0.02 0.47 0.02 0.47 0.02 ] Nach einem Schritt ist RS mit diesen W.keiten auf einer der Seiten. [ 0.24 0.04 0.55 0.13 0.04 ] 0.02 0.48 0.02 0.02 0.47 prob[][] 0.47 0.02 0.47 0.02 0.24 0.24 0.02 0.02 0.02 0.02 0.92 0.02 0.47 0.02 0.02 fi 0.02 0.02 ffi ffi 0.92 ffi fl 0.02 0.02 [ 0.24 0.04 0.55 0.13 0.04 ] Nach zwei Schritten ist RS mit diesen W.keiten auf einer der Seiten. [ 0.05 0.15 0.15 0.14 0.51 ] Nach zwei Schritten ist RS Nach drei Schritten ist RS mit diesen W.keiten auf einer der Seiten. mit diesen W.keiten auf einer der Seiten. [ 0.21 0.21 0.21 0.16 0.21 ] Nach 14 Schritten ist RS mit diesen W.keiten auf einer der Seiten. [ 0.21 0.21 0.21 0.16 0.21 ] Nach 15 Schritten ist RS mit diesen W.keiten auf einer der Seiten. 1.5.17 #----------------------------------------------------------------------# markov_surfer.py #----------------------------------------------------------------------import ... # Lies runden von der Kommandozeile ein, n und prob[][] von standard input. ... # ranks speichert die berechneten PageRanks der Seiten, newRanks ist ein Zwischenspeicher. ranks = stdarray.create1D(n,0.0) ranks[0] = 1.0 # Der Random Surfer startet auf Seite 0. newRanks = stdarray.create1D(n,0.0) for xxx in range(runden): # multipliziere ranks[] mit prob[][] for s in range(n): newRanks[s] = 0.0 for i in range(n): newRanks[s] += ranks[i] * prob[i][s] # kopiere das Ergebnis von newRanks[] nach ranks[] for s in range(n): ranks[s] = newRanks[s] # Ausgabe der Page Ranks for pagerank in ranks: stdio.writef('%f ', pagerank) stdio.writef('\n') 1.5.18 Benutzung der Programme # python graph-zu-prob.py < Graph500.txt | python markov surfer.py 100000 0.000651 0.005746 0.002346 0.000618 0.001825 0.002567 ... Ergebnis von quicker surfer.py nach einer Weile Ergebnis von markov surfer.py nach sehr kurzer Zeit markov surfer.py erreicht viel schneller ein stabiles Ergebnis als quicker surfer.py ! 1.5.19 Zusammenfassung § Wir haben gesehen, dass man mit den bisher erlernten Mitteln bereits Programme für interessante Probleme schreiben kann. § Das Programm ist ein Beispiel für ein datengetriebenes Programm. Solche Programme werden häufig verwendet. Wir können verschiedene Arten, Graphen zu speichern, in die von unseren Programmen benutzte Art überführen. § Es ist nicht immer leicht, ein fehlerfreies Programm zu schreiben. Die Überprüfung, dass ein Programm fehlerfrei ist, erfordert gründliche Arbeit. § Es ist nicht immer leicht, ein schnelles Programm zu schreiben. 2 Funktionen und Module Funktionen erlauben (mehr als Verzweigungen und Schleifen) den Programmfluss zwischen verschiedenen Stellen des Programmcodes hin und her springen zu lassen. Sie machen es auch möglich, den gleichen Programmcode an verschiedenen Stellen des Programms wiederzubenutzen. Schließlich kann man Funktionen in Module auslagern, so dass der gleiche Programmcode in verschiedenen Programmen benutzt werden kann. 2. Funktionen und Module 2.1 Definition von Funktionen 2.2 Module und Klienten 2.3 Module und Rekursion 2.4 Versickerung (ein Anwendungsbeispiel) 2.1 Wie man Funktionen definiert Wir haben bereits verschiedene Funktionen benutzt: math.sqrt( ) stdio.writeln( ) str( ) Aufgaben eines Programms, die klar abgegrenzt sind, sollte man auch abgrenzen und z.B. als Funktion aufschreiben. Dadurch bekommt der Programmcode eine bessere Struktur. Fehlersuche, Wartung und Wiederbenutzung werden vereinfacht. 2.1.1 Beispiel: Berechnung von harmonischen Zahlen Die n-te harmonische Zahl ist 1 ` 21 ` 13 ` 41 ` . . . ` n1 . Mathematisch als Funktion aufgeschrieben: n ÿ 1 hpnq “ i i“1 Wir wollen ein Programm harmonisch.py schreiben, das Argumente von der Kommandozeile einliest und deren harmonische Zahlen ausgibt: python harmonisch.py 1 2 4 6 liefert die Ausgaben 1.0 1.5 2.08333333333 2.45 2.1.2 #--------------------------------------------# harmonische_zahlen.py #--------------------------------------------import sys, stdio def harmonische_zahl(n): summe = 0.0 for i in range(1,n+1): summe += 1.0/i return summe for i in range (1,len(sys.argv)): argument = int(sys.argv[i]) wert = harmonische_zahl(argument) stdio.writeln(wert) Was bei der Ausführung von python harmonische zahlen 1 2 4 (informell) passiert: i = 1 argument = 1 harmonische_zahl(1) n = 1 summe = 0.0 i = 1 summe = 1.0 return 1.0 wert = 1.0 i = 2 argument = 2 harmonische_zahl(2) n = 2 summe = 0.0 i = 1 summe = 1.0 i = 2 summe = 1.5 return 1.5 wert = 1.5 i = 3 argument = 4 harmonische_zahl(4) n = 4 summe = 0.0 i = 1 summe = 1.0 i = 2 summe = 1.5 i = 3 summe = 1.83333333 i = 4 summe = 2.08333333 return 2.08333333 wert = 2.08333333 Definition von Funktionen Signatur Funktionsname Parameter-Variable def harmonische_zahl( n ): lokale Variable summe = 0.0 for i in range(1,n+1): Funktions-Rumpf summe += 1.0/i return-Anweisung return summe Rückgabewert 2.1.4 Aufruf von Funktionen for i in range(1, len(sys.argv)) argument = int(sys.argv[i]) Funktions-Aufruf wert = harmonische_zahl( argument ) stdio.writeln(wert) Argument 2.1.5 Gültigkeitsbereich (scope) von Variablen argument und wert sind hier unbekannt def harmonische_zahl(n): summe = 0.0 for i in range(1,n+1): summe += 1.0/i return summe Gültigkeitsbereich von n, summe und i zwei verschiedene Variablen for i in range (1,len(sys.argv)): argument = int(sys.argv[i]) wert = harmonische_zahl(argument) stdio.writeln(wert) Gültigkeitsbereich von i, argument und wert n und summe sind hier unbekannt 2.1.6 Funktionen mit mehreren Argumenten Berechnung des punktweisen Produkts zweier Vektoren: px0 , x1 , x2 , . . . , xn q ˆ py0 , y1 , y2 , . . . , yn q “ x0 ¨ y0 ` x1 ¨ y1 ` x2 ¨ y2 ` . . . ` xn ¨ yn ` n ÿ “ xi ¨ yi ˘ i“0 #----------------------------------# vektor_produkt.py #----------------------------------import stdio def vektor_mal_vektor(x, y): summe = 0 for i in range(len(x)): summe += x[i]*y[i] return summe a = [1, 2, 3] b = [4, 5, 6] e = vektor_mal_vektor(a,b) stdio.writeln(e) #------------------------------------# python vektor_produkt.py # 32 Informeller Programmablauf (nur grobe Vorstellung): a = [1,2,3] b = [4,5,6] vektor_mal_vektor([1,2,3],[4,5,6]) x = [1,2,3] y = [4,5,6] summe = 0 i = 0 summe = 4 i = 1 summe = 14 i = 2 summe = 32 e = 32 Benutzung mehrerer Funktionen Informeller Programmablauf (nur grobe Vorstellung): a = [1,2,3] m = [[4,5,6],[7,8,9]] vektor_mal_matrix([1,2,3],[[4,5,6],[7,8,9]]) ve = [1,2,3] ma = [[4,5,6],[7,8,9]] ergebnis = [0,0] def vektor_mal_vektor(x, y): i = 0 summe = 0 vektor_mal_vektor([1,2,3],[4,5,6]) for i in range(len(x)): x = [1,2,3] summe += x[i]*y[i] y = [4,5,6] return summe summe = 0 i = 0 summe = 4 def vektor_mal_matrix(ve,ma): i = 1 summe = 14 ergebnis = stdarray.create1D(len(ma),0) i = 2 summe = 32 for i in range(len(ma)): ergebnis = [32,0] ergebnis[i] = vektor_mal_vektor(ve, ma[i]) i = 2 return ergebnis vektor_mal_vektor([1,2,3],[7,8,9]) x = [1,2,3] a = [1, 2, 3] y = [7,8,9] m = [[4, 5, 6],[7, 8, 9]] summe = 0 i = 0 summe = 7 e = vektor_mal_matrix(a,m) i = 1 summe = 23 stdio.writeln(e) i = 2 summe = 50 #---------------------------------------ergebnis = [32,50] # python vektor_matrix_produkt.py e = [32,50] # [32, 50] #-----------------------------------# vektor_matrix_produkt.py #-----------------------------------import stdio, stdarray Funktionen mit mehreren return-Anweisungen def isPrime(n): if n < 2: return False i = 2 while i*i <= n: if n%i == 0: return False i += 1 return True 2.1.9 Funktionen ohne return-Anweisung (mit Seiteneffekt) #--------------------------------------------------# balkendiagramm.py #--------------------------------------------------import stdio,stddraw def balkendiagramm(vektor) : m = max(vektor) balkenbreite = 1.0/len(vektor) for k in range(len(vektor)): stddraw.filledRectangle(k*balkenbreite, 0, balkenbreite-0.01, float(vektor[k])/m) balkendiagramm([1,2,3,4,5,6,7,8,9,10]) # balkendiagramm([1,2,3,4,5,6,5,4,3,4,5,6,9,7,4,1]) stddraw.show() 2.1.10 Funktionen ohne return-Anweisung (mit Seiteneffekt) #--------------------------------------------------# balkendiagramm.py #--------------------------------------------------import stdio,stddraw def balkendiagramm(vektor) : m = max(vektor) balkenbreite = 1.0/len(vektor) for k in range(len(vektor)): stddraw.filledRectangle(k*balkenbreite, 0, balkenbreite-0.01, float(vektor[k])/m) balkendiagramm([1,2,3,4,5,6,7,8,9,10]) # balkendiagramm([1,2,3,4,5,6,5,4,3,4,5,6,9,7,4,1]) stddraw.show() 2.1.10 Funktionen ohne return-Anweisung (mit Seiteneffekt) #--------------------------------------------------# balkendiagramm.py #--------------------------------------------------import stdio,stddraw def balkendiagramm(vektor) : m = max(vektor) balkenbreite = 1.0/len(vektor) for k in range(len(vektor)): stddraw.filledRectangle(k*balkenbreite, 0, balkenbreite-0.01, float(vektor[k])/m) balkendiagramm([1,2,3,4,5,6,7,8,9,10]) # balkendiagramm([1,2,3,4,5,6,5,4,3,4,5,6,9,7,4,1]) stddraw.show() 2.1.10 Übergabe von Argumenten beim Funktionsaufruf Erstmal: Allgemeines über Objekte in Python Die “grobe Vorstellung” bei den informellen Programmabläufen über die Speicherung von Daten stimmt natürlich nicht – wir verfeinern die Vorstellung jetzt. Die Daten werden durch Objekte repräsentiert. Jedes Objekt hat eine Identität, einen Typ und einen Wert. Die Identität bestimmt das Objekt eindeutig. (Vorstellung: Adresse des Objektes im Speicher des Computers.) § Der Typ beschreibt das Verhalten des Objektes (d.h. die Werte, die es annehmen kann, und die Operationen, die auf ihm erlaubt sind). § Der Wert ist der Datentyp-Wert, den es repräsentiert/speichert. Bsp.: ein Objekt vom Typ int kann den Wert 99 speichern. § Eine Objekt-Referenz ist eine konkrete Darstellung der Identität des Objektes. Python-Programme benutzen Objekt-Referenzen um § auf den Wert des Objektes zuzugreifen oder ihn zu ändern, § auf die Objekt-Referenz zuzugreifen oder sie zu ändern. 2.1.11 § Ein Literal weist Python an, ein Objekt mit einem bestimmten Wert zu erzeugen. Bsp.: das Literal 99 weist Python an, ein int-Objekt mit Wert 99 zu erzeugen. § Eine Variable ist ein Name für eine Objekt-Referenz. § Ein Ausdruck weist Python an, ein Objekt mit dem Wert des Ausdrucks zu erzeugen. Bsp.: wenn das an die Variable a gebundene Objekt den Wert 3 hat, dann weist der Ausdruck 4*a+2 Python an, ein int-Objekt mit Wert 14 zu erzeugen. § Eine Zuweisung ăVariableą=ăAusdrucką weist Python an, ein Objekt mit dem Wert des Ausdrucks zu erzeugen und die Variable daran zu binden. Falls der Ausdruck nur eine Variable ist, dann wird kein neues Objekt erzeugt, sondern das an die Variable gebundene Objekt genommen. Bsp.: wenn das an die Variable a gebundene Objekt den Wert 3 hat, dann wird für die Zuweisung b = 4*a+2 ein Objekt mit dem Wert 14 erzeugt und dieses Objekt wird an die Variable b gebunden. a = 3 a 3 b = 4*a + 2 b 14 Variable Objekt-Referenz Objekt 2.1.12 Programmablauf auf dem Objekt-Level Ein 3-zeiliges Python-Programm und dessen Wirkung auf dem Objekt-Level: a = 1234 a 1234 b = 47 a 1234 b 47 a 1234 b 47 c 1281 c = a + b 2.1.13 Vertauschung der Werte zweier Variablen. t = a a 1234 b 47 a 1234 b 47 t a = b a 1234 b 47 t b = t a 1234 b 47 t 2.1.14 Auswirkung von Anweisungen. s = ’Abcd’ s ’Abcd’ s = s + ’ ef’ s ’Abcd’ ’ ef’ ’Abcd ef’ Objekte der Standard-Typen int, float, string und boolean sind nicht veränderbar. Wenn einer Variablen dieses Typs ein Wert eines Ausdrucks zugewiesen wird, dann wird ein neues Objekt mit diesem Wert erzeugt. i = 15 i 15 i = i + 1 i 15 1 16 2.1.15 Arrays 0 1 2 a a = [5, 9, 11] 3 5 9 11 0 1 2 b = a a 3 b 5 9 11 0 1 2 b[1] = 17 a 3 b 5 9 11 17 Objekte vom Typ array sind veränderbar (mutable) (anders als Objekte der Standard-Typen int, float, string und boolean)! Kopieren eines Arrays 0 1 2 a a = [5, 9, 11] 3 5 9 11 0 1 2 b = [] a 3 for v in a: 5 b += [v] 9 11 0 1 2 b 3 2.1.17 Kopieren eines Arrays 0 1 2 a a = [5, 9, 11] 3 5 9 11 0 1 2 b = [] a 3 for v in a: 5 b += [v] 9 b[1] = 17 11 0 1 2 b 3 17 2.1.17 Übergabe von Argumenten beim Funktionsaufruf Argumente werden stets als Objekt-Referenzen übergeben. Beispielprogramm: def inc(j): j += 1 Programmablauf auf dem Objekt-Level: i = 99 i 99 Aufruf inc(i) i j 99 j += 1 i j 99 i = 99 inc(i) Informeller Programmablauf: i = 99 j = 99 j = 100 1 100 Nach der Ausführung i 99 1 100 2.1.18 Übergabe des Ergebnisses nach Funktionsausführung Beispielprogramm: def inc(j): j += 1 return j i = 99 i = inc(i) Ergebnisse werden stets als Objekt-Referenzen übergeben. Programmablauf auf dem Objekt-Level: i = 99 i 99 Aufruf inc(i) i j 99 j += 1 i j 99 Informeller Programmablauf: i = j j i = 99 = 99 = 100 100 1 100 Nach der Ausführung i 99 1 100 Seiteneffekte mit Arrays a = [17, 4, 21] def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp a = [ 17, 4, 21 ] tausche(a, 0, 1) 0 1 2 a 3 17 4 21 Seiteneffekte mit Arrays a = [17, 4, 21] 0 1 2 a 3 def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp a = [ 17, 4, 21 ] tausche(a, 0, 1) 17 Aufruf von tausche(a,0,1) 4 21 0 1 2 a 3 b i 17 4 21 0 j 1 Seiteneffekte mit Arrays 0 1 2 a a = [17, 4, 21] 3 def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp a = [ 17, 4, 21 ] tausche(a, 0, 1) 17 4 21 0 1 2 a Aufruf von tausche(a,0,1) 3 b i temp = b[i] 17 4 21 0 j 1 0 1 2 a 3 b temp 17 4 21 i 0 j 1 2.1.20 Seiteneffekte mit Arrays 0 1 2 a Aufruf von tausche(a,0,1) def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp 3 b i 17 4 21 0 j 1 a = [ 17, 4, 21 ] tausche(a, 0, 1) temp = b[i] 0 1 2 a 3 b b[i] = b[j] temp 17 4 21 i 0 j 1 0 1 2 a 3 b temp 17 4 21 i 0 j 1 Seiteneffekte mit Arrays temp = b[i] def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp 0 1 2 a 3 b temp 17 4 21 i 0 j 1 a = [ 17, 4, 21 ] tausche(a, 0, 1) b[i] = b[j] 0 1 2 a 3 b b[j] = temp temp 17 4 21 i 0 j 1 0 1 2 a 3 b temp 17 4 21 i 0 j 1 Seiteneffekte mit Arrays b[i] = b[j] def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp 0 1 2 a 3 b temp 17 4 21 i 0 j 1 a = [ 17, 4, 21 ] tausche(a, 0, 1) b[j] = temp 0 1 2 a 3 b Nach der Ausführung temp 17 4 21 i 0 j 1 0 1 2 a 3 17 4 21 2.1.20 #-------------------------------------------# sort.py # Sortieren mittels Minimum-Suche. #-------------------------------------------import stdio, sys def tausche(b, i, j): temp = b[i] b[i] = b[j] b[j] = temp def minsuche(a, anfang): min = anfang for i in range(anfang+1,len(a)-1): if a[min] > a[i] : min = i return min Funktionen helfen beim Strukturieren von Programmen. #-------------------------------------------m = sys.argv[1:] for i in range(len(m)-1): min = minsuche(m,i) tausche(m, min, i) stdio.writeln(m) Zusammenfassung § Mittels Funktionen lässt sich die Programmiersprache erweitern. § Man muss sich den Ablauf eines Programms nicht mehr Schritt für Schritt in elementaren Anweisungen vorstellen, sondern kann abstrakter über Funktionsaufrufe und Rückgabewerte argumentieren. § Wir können nun Programmcode schreiben, der einfacher zu verstehen, zu verbessern und zu warten ist. 2.2 Module und 2.3 Rekursion Module erlauben es, Funktionen für Programme in verschiedenen Dateien zu definieren. Sie unterstützen die Idee des strukturierten Programmierens. Rekursive Funktionen rufen sich selbst auf. Die Möglichkeit zur Rekursion liefert eine mächtige allgemeine Programmiertechnik, die wir an verschiedenen Beispielen betrachten werden. Bsp. 1: Die Fakultätsfunktion n! (gesprochen n Fakultät“ oder Fakultät von n“) ” ” ist das Produkt der Zahlen von 1 bis n, also: 0! 1! 2! 3! 4! 5! .. . “ “ “ “ “ “ 1 1¨2 1¨2¨3 1¨2¨3¨4 1¨2¨3¨4¨5 .. . “ “ “ “ “ 1 1 2 6 24 120 Allgemein: 1. n! “ 1looooooooooomooooooooooon ¨ 2 ¨ 3 ¨ . . . ¨ pn ´ 1q ¨n (Anm.: 0! “ 1), oder pn´1q! 2. 0! “ 1 und n! “ pn ´ 1q! ¨ n für alle n ě 1. 2.3.1 Implementierung der direkten Variante n! “ 1 ¨ 2 ¨ 3 ¨ . . . ¨ pn ´ 1q ¨ n (Anm.: 0! “ 1) #----------------------------------------------# fakultaet_iterativ.py #----------------------------------------------import stdio, sys def fakultaet(n): ergebnis = 1 for i in range(1,n+1): ergebnis *= i return ergebnis m = int(sys.argv[1]) for i in range(m): stdio.writef("%2d! = %d \n", i, fakultaet(i)) #-------------------------------# python fakultaet_iterativ.py 12 # 0! = 1 # 1! = 1 # 2! = 2 # 3! = 6 # 4! = 24 # 5! = 120 # 6! = 720 # 7! = 5040 # 8! = 40320 # 9! = 362880 # 10! = 3628800 # 11! = 39916800 2.3.2 Implementierung der rekursiven Variante 0! “ 1 und n! “ pn ´ 1q! ¨ n für alle n ě 1. #------------------------------------------------# fakultaet_rekursiv.py #------------------------------------------------import stdio, sys def fakultaet(n): if n == 0: return 1 else: return fakultaet(n-1) * n m = int(sys.argv[1]) for i in range(m): stdio.writef("%2d! = %d \n", i, fakultaet(i)) #-------------------------------# python fakultaet_rekursiv.py 12 # 0! = 1 # 1! = 1 # 2! = 2 # 3! = 6 # 4! = 24 # 5! = 120 # 6! = 720 # 7! = 5040 # 8! = 40320 # 9! = 362880 # 10! = 3628800 # 11! = 39916800 2.3.3 fakultaet(5) n=5 120 fakultaet(5): return fakultaet(4)*5 n=4 24 fakultaet(4): return fakultaet(3)*4 n=3 6 def fakultaet(n): if n == 0: return 1 else: return fakultaet(n-1) * n fakultaet(3): return fakultaet(2)*3 n=2 2 fakultaet(2): return fakultaet(1)*2 n=1 1 fakultaet(1): return fakultaet(0)*1 n=0 def fakultaet(n): if n == 0: return 1 else: m = fakultaet(n-1) * n return m 1 fakultaet(0): return 1 2.3.4 Die Spur der Funktionsaufrufe Die Aufrufe und Rückgabewerte bei fakultaet(5): fakultaet(5) | fakultaet(4) | | fakultaet(3) | | | fakultaet(2) | | | | fakultaet(1) | | | | | fakultaet(0) | | | | | |_return 1 | | | | |_return 1 | | | |_return 2 | | |_return 6 | |_return 24 |_return 120 (Ergebnis (Ergebnis (Ergebnis (Ergebnis (Ergebnis (Ergebnis von von von von von von fakultaet(0)) fakultaet(1)) fakultaet(2)) fakultaet(3)) fakultaet(4)) fakultaet(5)) def fakultaet(n): if n == 0: return 1 else: return fakultaet(n-1) * n 2.3.5 Mathematische Schreibweise für die Fakultätsfunktion n! “ # 1, pn ´ 1q! ¨ n, falls n “ 0 sonst 2.3.6 Bsp. 2: Binärzahlen 2er-Potenzen sind 20 , 21 , 22 , 23 , 24 , . . ., also 1, 2, 4, 8, 16, . . .. Jede natürliche Zahl lässt sich als Summe von 2er-Potenzen darstellen. Bsp.: 46 “ 32 ` 8 ` 4 ` 2 “ 25 ` 23 ` 22 ` 21 5 4 “ 1 ¨ 2 ` 0 ¨ 2 ` 1 ¨ 23 ` 1 ¨ 22 ` 1 ¨ 21 ` 0 ¨ 20 “ ˆ 101110 139 “ 128 ` 8 ` 2 ` 1 “ 27 ` 23 ` 21 ` 20 7 6 5 “1¨2 `0¨2 `0¨2 `0¨24 `1¨23 `0¨22 `1¨21 `1¨20 “ ˆ 10001011 Die Darstellung einer Zahl n als Binärzahl ist eine Folge bm bm´1 . . . b1 b0 m ř (mit bi P t0, 1u) mit der Eigenschaft n “ 2i ¨ bi . i“0 Eigenschaften von Binärzahlen Bsp.: 1 hat 2 hat 4 hat 9 hat 18 hat 37 hat 74 hat 75 hat die die die die die die die die Binärdarstellung Binärdarstellung Binärdarstellung Binärdarstellung Binärdarstellung Binärdarstellung Binärdarstellung Binärdarstellung binp37q “ 1, binp37q “ 10, binp37q “ 100, binp37q “ 1001, binp37q “ 10010, binp37q “ 100101, binp74q “ 1001010 und binp75q “ 1001011. $ ’ 0, falls n “ 0 ’ ’ ’ &1, falls n “ 1 binpnq “ ’ binpt n2 uq0, falls n ě 2 und gerade ’ ’ ’ % binpt n2 uq1, falls n ě 2 und ungerade 2.3.8 Etwas kompaktere Darstellung der Funktion $ ’ 0, falls n “ 0 ’ ’ ’ &1, falls n “ 1 binpnq “ ’ binpt n2 uq0, falls n ě 2 und gerade ’ ’ ’ % binpt n2 uq1, falls n ě 2 und ungerade “ # n, falls n “ 0 oder n “ 1 binpt n2 uqn mod 2, falls n ě 2 2.3.9 Rekursive Implementierung #-----------------------------------------------# binaer.py #-----------------------------------------------import stdio, sys def bin(n): if n==0 or n==1: stdio.write(str(n)) else: bin(n/2) stdio.write(str(n%2)) n = int(sys.argv[1]) for i in range(n): stdio.writef('# %d hat Binaerdarstellung bin(i) stdio.writef('.\n') ',i) #---------------------------------# python binaer.py 21 # 0 hat Binaerdarstellung 0. # 1 hat Binaerdarstellung 1. # 2 hat Binaerdarstellung 10. # 3 hat Binaerdarstellung 11. # 4 hat Binaerdarstellung 100. # 5 hat Binaerdarstellung 101. # 6 hat Binaerdarstellung 110. # 7 hat Binaerdarstellung 111. # 8 hat Binaerdarstellung 1000. # 9 hat Binaerdarstellung 1001. # 10 hat Binaerdarstellung 1010. # 11 hat Binaerdarstellung 1011. # 12 hat Binaerdarstellung 1100. # 13 hat Binaerdarstellung 1101. # 14 hat Binaerdarstellung 1110. # 15 hat Binaerdarstellung 1111. # 16 hat Binaerdarstellung 10000. # 17 hat Binaerdarstellung 10001. # 18 hat Binaerdarstellung 10010. # 19 hat Binaerdarstellung 10011. # 20 hat Binaerdarstellung 10100. Die Spur der Funktionsaufrufe bin(37) | bin(18) | | bin(9) | | | bin(4) | | | | bin(2) | | | | | bin(1) | | | | | |_stdio.write(1) | | | | |_stdio.write(2%2) | | | |_stdio.write(4%2) | | |_stdio.write(9%2) | |_stdio.write(18%2) |_stdio.write(37%2) die bisher ausgegebene Binärzahl ist 1 = 1 10 = 2*1 + 0 = 2 100 = 2*2 + 0 = 4 1001 = 2*4 + 1 = 9 10010 = 2*9 + 0 = 18 100101 = 2*18 + 1 = 37 Bsp. 3: Schnelles Potenzieren 313 “ p36 q2 ¨ 3 Bsp.: “ pp33 q2 q2 ¨ 3 “ ppp31 q2 ¨ 3q2 q2 ¨ 3 “ ppp30 ¨ 3q2 ¨ 3q2 q2 ¨ 3 Allgemein gilt: n a “ $ ’ ’ &1, falls n “ 0 t n2 u 2 pa q , ’ ’ %pat n2 u q2 ¨ a, falls n ě 1 und gerade falls n ě 1 und ungerade Diese Methode nennt man auch Potenzieren durch wiederholtes Quadrieren“. ” 2.3.12 Rekursive Implementierung des schnellen Potenzierens #-----------------------------------------# pot_schnell.py #-----------------------------------------import stdio, sys def potenziere(a,n): if n==0: return 1 else: z = potenziere(a,n/2) z_quadrat = z*z if n%2==0: return z_quadrat else: return z_quadrat*a a = int(sys.argv[1]) n = int(sys.argv[2]) for i in range(n): stdio.writeln( potenziere(a,i) ) #------------------------------# python pot_schnell.py 123 10 # 1 # 123 # 15129 # 1860867 # 228886641 # 28153056843 # 3462825991689 # 425927596977747 # 52389094428262881 # 6443858614676334363 Die Spur der Funktionsaufrufe potenziere(4,19) | potenziere(4,9) | | potenziere(4,4) | | | potenziere(4,2) | | | | potenziere(4,1) | | | | | potenziere(4,0) | | | | | |_return 1 | | | | |_return 4 | | | |_return 16 | | |_return 256 | |_return 262144 |_return 274877906944 4**0 1*1 * 4 4*4 16*16 256*256 * 4 262144*262144 * 4 = = = = = = Anzahl Multiplikationen: 1 0 4 2 16 1 256 1 262144 2 274877906944 2 --8 Allgemein gilt: die Anzahl der rekursiven Aufrufe von potenziere() beim Ausführen von potenziere(a,n) ist ď 1 ` log2 n. Bei jedem Aufruf werden höchstens 2 Multiplikationen ausgeführt. Also werden z.B. beim Ausführen von potenziere(2,1000000) höchstens 40 Multiplikationen ausgeführt. 2.3.14 Vergleich der Rechenzeiten 6 210 7 210 8 210 einfache Multiplikation 21 s 2253 s ?? wiederholtes Quadrieren 0.0047 s 0.045 s 0.55 s direkt in Python 0.0046 s 0.044 s 0.54 s Man braucht große Potenzen“ z.B. beim Ver- und Entschlüsseln von Daten, ” die über das Internet übertragen werden (https). 2.3.15 Bsp. 4: Die Fibonacci-Zahlen $ ’ ’ &0, fibpnq “ n fibpnq 1, ’ ’ %fibpn ´ 1q ` fibpn ´ 2q, falls n “ 0 falls n “ 1 falls n ě 2 0 1 2 3 4 5 6 7 8 9 10 . . . 0 1 1 2 3 5 8 13 21 34 55 . . . 2.3.16 Die direkte Implementierung (ist nicht so gut) #----------------------------------------------# fibonacci_rekursiv.py #----------------------------------------------import stdio, sys def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) n = int(sys.argv[1]) for i in range(n): stdio.writef('# fib(%d) = %d \n',i,fib(i)) #--------------------------------# python fibonacci_rekursiv.py 99 # ... # fib(22) = 17711 # fib(23) = 28657 # fib(24) = 46368 # fib(25) = 75025 # fib(26) = 121393 # fib(27) = 196418 # fib(28) = 317811 # fib(29) = 514229 # fib(30) = 832040 # fib(31) = 1346269 # fib(32) = 2178309 # ... Ab fib(32) fängt es (auf meinem Rechner) an, dass die Rechenzeit länger dauert. Ab fib(38) wartet man schon über eine Minute auf das Ergebnis . . . 2.3.17 Die Spur der Funktionsaufrufe fib(5) | fib(4) | | fib(3) | | | fib(2) | | | | fib(1) | | | | |_return 1 | | | | fib(0) | | | | |_return 0 | | | |_return 1 | | | fib(1) | | | |_return 1 | | | |_return 2 | | fib(2) | | | fib(1) | | | |_return 1 | | | fib(0) | | | |_return 0 | | |_return 1 | |_return 3 | fib(3) | | fib(2) | | | fib(1) | | | |_return 1 Das ist der Anfang der Spur der Funktionsaufrufe bei der Berechnung von fib(5). Man sieht, dass sehr viele Funktionsaufrufe die gleichen Argumente haben – es werden also ständig Funktionswerte berechnet, die schon mal berechnet wurden. Das ist eigentlich unnötig. In diesem Fall ist es also nicht hilfreich, die rekursive Definition der Funktion zu implementieren. Wieviele Funktionsaufrufe werden ausgeführt? # anz aufrufepnq “ 1, falls n “ 0 oder n “ 1 1 ` anz aufrufepn ´ 1q ` anz aufrufepn ´ 2q, falls n ě 2 n 0 1 2 3 4 5 6 7 8 9 10 ... fibpnq 0 1 1 2 3 5 8 13 21 34 55 ... anz aufrufepnq 1 1 3 5 9 15 25 41 67 109 177 . . . def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) 2.3.19 Eine schnelle aber ungenaue Berechnung der Fibonacci-Zahlen 1 fibpnq “ ? ¨ 5 ˜ˆ ? ˙n ˆ ? ˙n ¸ 1` 5 1´ 5 ´ 2 2 #--------------------------------------------------------------------------------# fibo_gold.py #--------------------------------------------------------------------------------import stdio, sys, math def fib_gold(n): return (1/math.sqrt(5)) * ( ((1+math.sqrt(5))/2)**n - ((1-math.sqrt(5))/2)**n) n = int(sys.argv[1]) for i in range(n): stdio.writef('fib(%d) = %f\n',i,fib_gold(i)) 2.3.20 Wo sieht man Fehler im Ergebnis? #----------------------------------------# python fibo_gold.py 100 # fib(0) = 0.000000000 # fib(1) = 1.000000000 # fib(2) = 1.000000000 # fib(3) = 2.000000000 # fib(4) = 3.000000000 # fib(5) = 5.000000000 # fib(6) = 8.000000000 # fib(7) = 13.000000000 ... # fib(29) = 514229.000000000 # fib(30) = 832040.000000001 # fib(31) = 1346269.000000001 # fib(32) = 2178309.000000002 ... # fib(68) = 72723460248141.171875000 # fib(69) = 117669030460994.265625000 # fib(70) = 190392490709135.437500000 # fib(71) = 308061521170129.750000000 # fib(72) = 498454011879265.187500000 # fib(73) = 806515533049395.000000000 Beim Rechnen mit float-Werten treten Rundungsfehler auf, die schließlich ein falsches Ergebnis liefern. Wie entwickelt sich die Abweichung von den korrekten Werten? 2.3.21 Fibonacci-Zahlen mit Matrix-Potenzierung berechnen In Aufgabe 18 hatten wir (für n ě 1): ˆ 0 1 1 1 ˙n ˆ “ fibpn ´ 1q fibpnq fibpnq fibpn ` 1q ˙ Das Potenzieren von Matrizen kann genauso wie das Potenzieren von Zahlen beschleunigt“ werden. ” Da wir die Matrizen-Multiplikation bereits in Aufgabe 17 hatten, wollen wir sie wiederverwenden. Definition von Modulen zur Wiederverwendung von Funktionen #------------------------------------------# Aufgabe17.py: Matrizen ... # multiplizieren, eingeben und ausgeben #------------------------------------------import stdio, sys, stdarray # multMM(A,B) gibt das Produkt der Matrizen # A und B als Ergebnis zurück. def multMM(A,B): C = stdarray.create2D(len(A),len(B),0) for z in range(len(A)): for s in range(len(B)): for i in range(len(A)): C[z][s] += A[z][i]*B[i][s] return C # matrix2D_einlesen liest eine # 2-dimensionale Matrix von standard input. def matrix2D_einlesen(): ... return C # matrix2D_ausgeben(A) gibt Matrix A # im o.g. Format aus. def matrix2D_ausgeben(A): ... #----------------------------------# Lösung von Aufgabe 17: # zwei Matrizen einlesen # und ihr Produkt ausgeben. def main(): A = matrix2D_einlesen() B = matrix2D_einlesen() matrix2D_ausgeben(multMM(A,B)) #-----------------------------------if __name__ == '__main__': main() 2.3.23 Implementierung der Fibonacci-Funktion mit schneller Matrix-Potenzierung Die schnelle Matrix-Potenzierung geht genau wie die schnelle Zahlen-Potenzierung. A muss eine quadratische Matrix sein (also jeweils m Zeilen und Spalten). $ ’ falls n “ 0 ’ m, &E ` t n u ˘2 n A “ A2 , falls n ě 1 und gerade ’ ’` t n u ˘2 % A 2 ¨ A, falls n ě 1 und ungerade Em ist die Einheitsmatrix mit m Zeilen und Spalten. Ihre Einträge Ei,i “ 1 auf der Diagonalen sind 1, alle anderen Einträge sind 0. Es gilt Em ¨ A “ A und A ¨ Em “ A. Die Matrix-Multiplikation nehmen wir aus Aufgabe17.py . 2.3.24 #-----------------------------------------------------------------------# fibo_pot.py # Berechnung der Fibonacci-Funktion mit schneller Matrix-Potenzierung. #-----------------------------------------------------------------------import stdio, sys, stdarray, Aufgabe17 def einheitsM(A): E = stdarray.create2D(len(A),len(A),0) for i in range(len(E)): E[i][i]=1 return E # schnelles Potenzieren von Zahlen def potM(A,n): def potenziere(a,n): if n==0: return einheitsM(A) if n==0: return 1 else: else: Z = potM(A, n/2) z = potenziere(a,n/2) Zquadrat = Aufgabe17.multMM(Z,Z) z_quadrat = z*z if n%2==0: return Zquadrat if n%2==0: return z_quadrat else: return Aufgabe17.multMM( Zquadrat, A ) else: return z_quadrat*a def fib_pot(i): return potM([ [0, 1], [1, 1] ], i )[0][1] def main(): n = int(sys.argv[1]) for i in range(n): stdio.writef('fib(%d) = %d\n', i, int(fib_pot(i))) if __name__ == '__main__': main() Vergleich der Ergebnisse von fib gold und fib pot Das folgende Programm vergleicht die Ergebnisse der Funktionen fib gold() und fib pot(), und gibt die Unterschiede aus. #-------------------------------------------------------# fibo_diff.py #-------------------------------------------------------import stdio, sys, math import fibo_gold, fibo_pot n = int(sys.argv[1]) for i in range(1,n): diff = int(fibo_gold.fib_gold(i)) - fibo_pot.fib_pot(i) if diff != 0: stdio.writef('%d: %d\n', i, diff) #----------------------# python fibo_diff.py 100 # 72: 1 # 73: 2 # 74: 3 # 75: 5 # 76: 8 # 77: 14 # 78: 24 # 79: 39 # 80: 59 # 81: 102 # 82: 169 # 83: 279 ... # 94: 59713 # 95: 98879 # 96: 166784 # 97: 265663 # 98: 440639 # 99: 722686 2.3.26 Die Berechnung der Fibonacci-Zahlen mit Speicherung der benötigten Zwischenergebnisse #-------------------------------------------------------# fibo_direkt.py #-------------------------------------------------------import stdio, sys def fib_direkt(n): f = [ 0 , 1 ] for i in range(2,n+1): f[i%2] = f[0] + f[1] return f[n%2] def main(): n = int(sys.argv[1]) for i in range(n): stdio.writef('%d!= %d\n', i, fib_direkt(i)) if __name__ == '__main__': main() 2.3.27 Welche Implementierung läuft am schnellsten? #-----------------------------------------------------------------------------------------# fibo_vergleich.py #-----------------------------------------------------------------------------------------import stdio, sys, time, fibo_pot, fibo_direkt n = int(sys.argv[1]) # Berechne fib(n) mit fib_direkt() anfangszeit = time.time() fibo_direkt.fib_direkt(n) endzeit = time.time() stdio.writef('Rechenzeit fuer fib(%d) von fib_direkt(): %2f\n', n, endzeit-anfangszeit) # Berechne fib(n) mit fib_pot() anfangszeit = time.time() fibo_pot.fib_pot(n) endzeit = time.time() stdio.writef('Rechenzeit fuer fib(%d) von fib_pot(): %2f\n', n, endzeit-anfangszeit) #---------------------------------------------------------------------------------------- n Rechenzeit fib direkt(n): Rechenzeit fib pot(n): 1234 0.0002 s 0.0001 s 123456 0.227 s 0.007 s 1234567 18.14 s 0.28 s 4321234 223 s 2s 2.3.28 Zufällige Texte erzeugen Das Beispiel auf den folgenden Seiten führt zum Erzeugen eines zufälligen Satzes. Dazu wird § eine Textdatei eingelesen (z.B. Goethes Faust oder Joyces Ulysses) § alle Paare von aufeinanderfolgenden Wörtern gefunden § ein Satz erzeugt, in dem jedes Paar aufeinanderfolgender Wörter auch in der gelesenen Textdatei vorkommt. Direktes Einlesen von Dateien Man kann Dateien zeilenweise als Strings einlesen. def zeilenweise(dateiname): # Lies Datei dateiname zeilenweise in ein Array text_zeilenweise = open(dateiname).readlines() return text_zeilenweise def test(): tzw = zeilenweise("SchillerBriefe3.txt") for i in range(len(tzw)): print i, tzw[i] if __name__ == '__main__': test() 2.3.30 Die Funktion einstring(d) macht einen String aus der ganzen Datei. # einlesen.py import string def einstring(dateiname): # Lies Datei dateiname als einen (langen) String datei = open(dateiname,"r") text_als_ein_string = '' for zeile in datei: text_als_ein_string += string.rstrip(zeile) datei.close() return text_als_ein_string def test(): taes = einstring("SchillerBriefe3.txt") print taes if __name__ == '__main__': test() Die Funktion string.rstrip(z) entfernt Leerzeichen und Zeilenumbrüche am Ende des Strings z. 2.3.31 Zerlegen eines Textes in Wörter Die folgende Funktion zerlege.in woerter § erhält als Eingabe einen String, der z.B. durch Einlesen eines Textes aus einer Datei entstanden ist, § ersetzt alle Satzendezeichen durch . “ ” (dadurch wird der Punkt durch Leerzeichen vom Rest getrennt), § entfernt Zeichen aus dem String, die wir nicht brauchen, und § trennt den String an allen (Folgen von) Leerzeichen auf und erhält dadurch ein Array aus den Teilen des Strings (d.h. den Wörtern), die zwischen zwei Leerzeichen stehen. In dem Array stehen die Wörter in der gleichen Reihenfolge wie im Text. Als Ergebnis wird das Array der Wörter zurückgegeben. 2.3.32 #-------------------------------------------------------# zerlege.py #-------------------------------------------------------import string, einlesen def in_woerter(text): # Ersetze alle Satzendezeichen durch " ." for zeichen in "?!.": text = string.replace(text,zeichen," .") # Ersetze störende Zeichen durch " ". for zeichen in '''"',;:-)([]<>*#_\n\t\r''': text = string.replace(text,zeichen," ") # Zerlege den Text in Wörter. woerter = string.split(text,' ') # Entferne "leere Wörter". woerterliste = [] for i in range(len(woerter)): if len(woerter[i])>=1: woerterliste.append(woerter[i]) return woerterliste def test(): text = einlesen.einstring("SchillerBriefe.txt") woerter = in_woerter(text) print woerter if __name__ == '__main__': test() 2.3.33 Dictionaries Ein Dictionary ist eine Liste aus Paaren ’key’:’value’. Der value kann über den key angesprochen werden. # woerterbuch.py # Erzeuge ein leeres Dictionary. woerterbuch = {} # Trage Wortpaare ein. woerterbuch['Aal'] = 'eal' woerterbuch['Adler'] = 'eagle' woerterbuch['Buch'] = 'book' print woerterbuch for i in woerterbuch: print i, woerterbuch[i] #----------------------------------------------------------------------------------# python woerterbuch.py # {'Aal': 'eal', 'Buch': 'book', 'Adler': 'eagle'} # Aal eal # Buch book # Adler eagle 2.3.34 Erzeugen eines Dictionaries mit aufeinanderfolgenden Wörtern eines Textes Die Aufbereitung des Textes wird abgeschlossen mit der Erstellung eines Dictionaries, in dem zu jedem Wort x des Textes ein Array aller Wörter steht, die im Text auf x folgen. Der Dictionary-Eintrag ’heute’ : [’ist’, ’wird’, ’ist’, ’ein’, ’mal’, ’.’] steht dafür, dass im Text auf das Wort heute zweimal das Wort ist und jeweils einmal das Wort wird, ein bzw. mal und einmal das Satzendezeichen . folgt. #-------------------------------------------------------# wortpaare.py #-------------------------------------------------------import sys, string, zerlege, einlesen def konkordanz(woerterliste): wortfolgen = {} for i in range(len(woerterliste)-1): if not woerterliste[i] in wortfolgen: wortfolgen[woerterliste[i]] = [] wortfolgen[woerterliste[i]].append(woerterliste[i+1]) return wortfolgen def test(): text = einlesen.einstring(sys.argv[1]) woerter = zerlege.in_woerter(text) liste = konkordanz(woerter) print liste if __name__ == '__main__': test() Aus einem Text wird ein Dictionary erzeugt, das zu jedem Wort im Text einen String mit allen seinen direkten Folgewörtern enthält. 2.3.36 Erzeugen eines Satzes wie im Text“ ” Schließlich können wir einen Satz erzeugen. Wir beginnen mit einem Wort, das hinter einem .“ steht. ” Anschließend wählen wir aus dem Dictionary wiederholt ein Folgewort aus, bis wir wieder bei einem .“ ankommen. ” 2.3.37 # schreibe.py import sys, string, zerlege, einlesen, wortpaare, random def schreibe_einen_satz(k): satzende = False satz = '' wort = "." while not satzende: wuerfelwurf = random.randrange(len(k[wort])) wort = k[wort][wuerfelwurf] if wort==".": satzende = True else: satz = satz + ' ' + wort return satz def test(): text = einlesen.einstring(sys.argv[1]) woerter = zerlege.in_woerter(text) liste = wortpaare.konkordanz(woerter) print schreibe_einen_satz(liste) + "." if __name__ == '__main__': test() 2.3.38 Zusammenfassung § Rekursion ist ein nützliches Hilfsmittel zum Schreiben schneller Programme. Wir haben Beispiele gesehen, bei denen man mittels Rekursion recht einfach sehr viel schnellere Lösungen programmieren kann als ohne Rekursion. Wir haben aber auch ein Beispiel gesehen, bei dem Rekursion nicht direkt geholfen hat. § Es ist sehr hilfreich, Programme gut zu strukturieren, damit man ihre Teile als Module nutzen kann. 2.3.39 2.4 Anwendungsbeispiel: Durchlässigkeit Es soll ein Modell für Durchlässigkeit z.B. bei Versickerung von Wasser im Boden oder Leitfähigkeit von gemischten Materialien für Strom oder Wärme aufgestellt und untersucht werden. 2.4.1 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Das Modell und die Aufgabe Das Material besteht aus durchlässigen und undurchlässigen Teilen. Wir stellen uns vor, dass Wasser von oben nach unten durchgelassen werden soll. p“ 38 64 , durchlässig p“ 38 64 , undurchlässig Das Material stellen wir uns aus n ˆ n Zellen bestehend vor. Die Dichte des Materials ist der Anteil an durchlässigen Zellen. Wir wollen feststellen, wie die Dichte die Durchlässigkeit beeinflusst, d.h. wie wahrscheinlich die Durchlässigkeit abhängig von der Dichte ist. 2.4.2 Die Aufteilung der Aufgabe – grober Versuch § Prüfe, ob eine Materialprobe durchlässig ist. § Produziere Materialproben abhängig von der Dichte. § Stelle für eine gegebene Dichte fest, wie groß die Wahrscheinlichkeit der Durchlässigkeit seiner Materialproben sind. § Untersuche das allgemein für jede Dichte. Materialproben werden in jedem Teil verwendet. Wir benutzen 2-dimensionale Arrays (gleichviele Zeilen und Spalten) mit Einträgen vom Typ bool für die Materialproben. Eintrag False steht für eine undurchlässige Zelle, und Eintrag True steht für eine durchlässige Zelle. (1) Prüfe, ob eine Materialprobe durchlässig ist Zum Prüfen, ob eine Materialprobe durchlässig ist, § setzt man sie unter Wasser (d.h. man lässt Wasser von oben nach unten durchlaufen) und § schaut nach, ob ganz unten Wasser angekommen ist. Das unter-Wasser-setzen liefert als Ergebnis ein Array der gleichen Größe wir die Materialprobe, bei dem in jeder Zelle steht, ob sie vom Wasser erreicht wurde (False/True). Damit können wir ein Gerüst für das Modul entwerfen. Das Gerüst für das Modul pruefe.py #--------------------------------------------------# pruefe0.py # Das Gerüst für ein Modul zum Prüfen der # Durchlässigkeit einer Materialprobe. #--------------------------------------------------import stdio, sys, stdarray def waessere(durchlaessige_Zellen): n = len(durchlaessige_Zellen) gewaesserte_Zellen = stdarray.create2D(n,n,False) # # hier fehlt noch das Programm # return gewaesserte_Zellen def ist_durchlaessig(material_probe): n = len(material_probe) gewaesserte_Zellen = waessere(material_probe) for s in range(n): if gewaesserte_Zellen[n-1][s]: return True return False def modultest(): probe = stdarray.readBool2D() stdarray.write2D(waessere(probe)) stdio.writeln(ist_durchlaessig(probe)) # # # # # # # # # # # # # # # # # # # # # # more test8a.txt 8 8 0 0 1 1 1 0 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 0 0 1 1 1 1 0 0 1 0 1 0 1 0 1 1 0 0 1 0 1 0 1 1 0 python pruefe0.py < test8a.txt 8 8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 False 2.4.5 Entwicklung der Funktion waessere() Beim Wässern einer Materialprobe setzt man zuerst alle durchlässigen Zellen der obersten Schicht unter Wasser. #------------------------------------------------------------- # # pruefe1.py # # Arbeit im Gerüst des Moduls zum Prüfen der Durchlässigkeit # # einer Materialprobe an der Funktion waessere(). # #------------------------------------------------------------ # import stdio, sys, stdarray # # def waessere(durchlaessige_Zellen): # n = len(durchlaessige_Zellen) # gewaesserte_Zellen = stdarray.create2D(n,n,False) # # # in Zeile 0 laufen alle durchlaessigen Zellen voll # # for i in range(n): # gewaesserte_Zellen[0][i] = durchlaessige_Zellen[0][i] # # # # # hier fehlt noch der Rest des Programms # # # return gewaesserte_Zellen # # ... # ... more test8a.txt 8 8 0 0 1 1 1 0 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 0 0 0 0 1 1 1 1 1 1 1 0 0 0 1 1 1 0 0 1 1 1 1 0 0 1 0 1 0 1 0 1 1 0 0 1 0 1 0 1 1 0 python pruefe1.py < test8a.txt 8 8 0 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 False Dann lassen wir von oben nach unten in allen Schichten jetzt erstmal nur das Wasser in die direkt darunterliegenden Zellen versickern. # more test8a.txt # 8 8 # 0 0 1 1 1 0 1 0 # 1 0 0 1 1 1 1 1 #------------------------------------------------------------# 1 1 1 0 1 1 0 0 # pruefe2.py # 0 0 1 1 1 1 1 1 # Arbeit im Gerüst des Moduls zum Prüfen der Durchlässigkeit # 1 0 0 0 1 1 1 0 # einer Materialprobe an der Funktion waessere(). # 0 1 1 1 1 0 0 1 #-----------------------------------------------------------# 0 1 0 1 0 1 1 0 import stdio, sys, stdarray # 0 1 0 1 0 1 1 0 # def waessere(durchlaessige_Zellen): # python pruefe2.py < test8a.txt n = len(durchlaessige_Zellen) # 8 8 gewaesserte_Zellen = stdarray.create2D(n,n,False) # 0 0 1 1 1 0 1 0 # 0 0 0 1 1 0 1 0 # in Zeile 0 laufen alle durchlaessigen Zellen voll # 0 0 0 0 1 0 0 0 for i in range(n): # 0 0 0 0 1 0 0 0 gewaesserte_Zellen[0][i] = durchlaessige_Zellen[0][i] # 0 0 0 0 1 0 0 0 # 0 0 0 0 1 0 0 0 for z in range(1,n): # 0 0 0 0 0 0 0 0 # in Schichten 1..n-1 laufen zuerst alle offenen Zellen voll, # 0 0 0 0 0 0 0 0 # bei denen es eine darüberliegende gewässerte Zelle gibt # False for s in range(n): gewaesserte_Zellen[z][s] = durchlaessige_Zellen[z][s] and gewaesserte_Zellen[z-1][s] # # hier fehlt noch der Rest des Programms # return gewaesserte_Zellen 2.4.7 Nachdem Wasser von oben in eine Schicht gesickert ist, verteilt es sich von jeder Zelle in der Schicht nach rechts (und danach nach links). #----------------------------------------------------------------------------------# pruefe3.py # Arbeit im Gerüst des Moduls zum Prüfen der Durchlässigkeit einer Materialprobe. #----------------------------------------------------------------------------------import stdio, sys, stdarray def waessere(durchlaessige_Zellen): n = len(durchlaessige_Zellen) gewaesserte_Zellen = stdarray.create2D(n,n,False) # In Schicht 0 laufen alle durchlässigen Zellen voll. for z in range(n): gewaesserte_Zellen[0][z] = durchlaessige_Zellen[0][z] for s in range(1,n): # In Schichten 1..n-1 laufen zuerst alle offenen Zellen voll, # bei denen es eine darüberliegende gewässerte Zelle gibt. for z in range(n): gewaesserte_Zellen[s][z] = durchlaessige_Zellen[s][z] and gewaesserte_Zellen[s-1][z] # Danach laufen in der Schicht alle Zellen voll, # die durchlässig sind und einen gewässerten linken Nachbarn haben. # Dazu geht man die Schicht von links nach rechts durch. for z in range(1,n): gewaesserte_Zellen[s][z] = gewaesserte_Zellen[s][z] or (durchlaessige_Zellen[s][z] and gewaesserte_Zellen[s][z-1]) # der Rest fehlt noch 2.4.8 Nachdem Wasser von oben in eine Schicht gesickert ist, verteilt es sich von jeder Zelle in der Schicht abschließend danach nach links. Damit ist das Modul pruefe.py fertig. #----------------------------------------------------------------------------------# pruefe.py # Modul zum Testen der Durchlässigkeit einer Materialprobe. #----------------------------------------------------------------------------------import stdio, sys, stdarray def waessere(durchlaessige_Zellen): n = len(durchlaessige_Zellen) gewaesserte_Zellen = stdarray.create2D(n,n,False) # In Schicht 0 laufen alle durchlässigen Zellen voll. ... for s in range(1,n): # In Schicht s laufen die Zellen zuerst von oben und dann von links nach rechts voll. ... # Abschließend laufen in der Schicht alle Zellen voll, # die durchlässig sind und einen gewässerten rechten Nachbarn haben. # Dazu geht man die Schicht von rechts nach links durch. for z in range(n-2,-1,-1): gewaesserte_Zellen[s][z] = gewaesserte_Zellen[s][z] or (durchlaessige_Zellen[s][z] and gewaesserte_Zellen[s][z+1]) return gewaesserte_Zellen ... 2.4.9 Das API für das Modul pruefe.py API . . . application programming interface Es wird angegeben, welche Funktionen des Moduls benutzt werden können, mit welchen Parametern sie aufgerufen werden und was sie als Ergebnis liefern. API für pruefe.py: waessere(m) ist durchlaessig(m) setzt Materialprobe m unter Wasser und gibt ein Array bool[][] zurück, in dem alle Zellen, in denen Wasser steht, True sind liefert bool bestimmt, ob Materialprobe m durchlässig ist m ist ein n ˆ n Array bool[][] 2.4.10 (1a) Was beim Programmieren von pruefe.py passiert sein kann . . . Beim Programmieren sollte man stets mit verschiedenen Daten (hier: Materialproben) testen. Dabei ist die Darstellung von Arrays mit stdio nicht gut lesbar und es ist optisch nicht so leicht zu erkennen, ob das Programm alles richtig macht. Da schafft die schöne graphische Darstellung von gewässerten Materialproben Abhilfe. Das machen wir in einem weiteren Modul. #-------------------------------------------------------# zeige.py #-------------------------------------------------------import stdarray, stddraw, pruefe def wasserstand(Probe,gewaesserte_Zellen,zeit=0): n = len(Probe) stddraw.setXscale(-1,n) python zeige.py < test8a.txt stddraw.setYscale(-1,n) # Jede Zelle wird gemalt: schwarz (undurchlässig), # blau (gewässert) oder weiß (durchlässig und ungewässert). for schicht in range(n): for z in range(n): if not Probe[schicht][z]: stddraw.setPenColor(stddraw.BLACK) else: if gewaesserte_Zellen[schicht][z]: stddraw.setPenColor(stddraw.BLUE) else: stddraw.setPenColor(stddraw.WHITE) stddraw.filledSquare(z,n-schicht-1,0.5) if zeit>0: stddraw.show(zeit) else: stddraw.show() def test(): Probe = stdarray.readBool2D() n = len(Probe) wasserstand(Probe,pruefe.waessere(Probe)) if __name__ == '__main__': test() Das API für das Modul zeige.py wasserstand(m,g,z=0) stellt Materialprobe m mit gewässerten Zellen g für z Millisekunden im standard drawing window dar; falls z=0, wird die Darstellung nicht abgebrochen 2.4.13 (2) Erzeuge Materialproben Die Dichte p (0 ď p ď 1) gibt den Anteil der durchlässigen Zellen an. Eine Materialprobe mit Seitenlänge n hat n2 Zellen. Eine Materialprobe mit Seitenlänge n und Dichte p hat also p ¨ n2 Zellen mit Wert True und alle anderen Zellen haben Wert False. Zum Erzeugen einer Materialprobe mit Seitenlänge n und Dichte p gehen wir wie folgt vor: 1. Erzeuge ein banales“ 1-dimensionales Array mit Dichte p: ” die Einträge mit Indizes 0 bis p ¨ n2 sind True und die übrigen Einträge sind False. 2. Mische die Einträge mit stdrandom.shuffle(). 3. Speichere die gemischten Einträge der Reihe nach in eine 2-dimensionales Array um, das eine Materialprobe darstellt. #-------------------------------------------------------# materialprobe.py #-------------------------------------------------------import sys, stdrandom, stdarray, zeige python materialprobe.py 20 0.4 # Erzeuge eine zufällige Materialprobe # mit Seitenlänge n und Dichte p. def erzeugen(n, p): # VorProbe[] ist ein Array der Länge n*n mit Dichte p: # VorProbe[0:p*n*n] hat stets Wert True und # VorProbe[p*n*n:n*n] hat stets Wert False. VorProbe = stdarray.create1D(n*n,False) for s in range(int(round(p*n*n))): VorProbe[s] = True stdrandom.shuffle(VorProbe) python materialprobe.py 20 0.66 # Mache aus 1d-Array VorProbe nun das 2d-Array Probe. Probe = stdarray.create2D(n,n,False) for s in range(n): for z in range(n): if VorProbe[s*n+z]: Probe[s][z] = True return Probe def test(): n = int(sys.argv[1]) p = float(sys.argv[2]) zeige.wasserstand(erzeugen(n,p),stdarray.create2D(n,n,False)) if __name__ == '__main__': test() Das API für das Modul materialprobe.py erzeugen(n,p) liefert eine zufällige Materialprobe mit Seitenlänge n und Dichte p 2.4.16 Jetzt können wir mal eine Materialprobe wässern #-------------------------------------------------------------------# spiel1.py #-------------------------------------------------------------------import sys, materialprobe, pruefe, zeige # Erzeuge eine Materialprobe mit Seitenlänge n # und Dichte p, wässere sie und stelle sie dar. n = int(sys.argv[1]) p = float(sys.argv[2]) Probe = materialprobe.erzeugen(n,p) gewaesserte_Probe = pruefe.waessere(Probe) zeige.wasserstand(Probe,gewaesserte_Probe) #---------------------------------------------------------------------# python spiel1.py 200 0.65 2.4.17 (3) Stelle für eine Dichte fest, wie groß die Wahrscheinlichkeit der Durchlässigkeit seiner Materialproben sind. Erzeuge wiederholt Materialproben der gleichen Größe und mit der gleichen Dichte und zähle, wieviele davon durchlässig sind. 2.4.18 #------------------------------------------------------------------------------------------------# experiment.py #------------------------------------------------------------------------------------------------import sys, stdio, pruefe, materialprobe def w(n, p, wiederholungen): zaehler = 0 for i in range(wiederholungen): Probe = materialprobe.erzeugen(n, p) if pruefe.ist_durchlaessig(Probe): zaehler += 1 return zaehler/float(wiederholungen) def n p r test(): = int(sys.argv[1]) = float(sys.argv[2]) = int(sys.argv[3]) erg = w(n,p,r) stdio.writef('Versickerungswahrscheinlichkeitsabschaetzung bei n=%d und p=%f ist %f.\n', n, p, e if __name__ == '__main__': test() #------------------------------------------------------------------------------------------------# python experiment.py 50 0.3 10000 # Versickerungswahrscheinlichkeitsabschaetzung bei n=50 und p=0.300000 ist 0.000000. # # python experiment.py 50 0.4 10000 # Versickerungswahrscheinlichkeitsabschaetzung bei n=50 und p=0.400000 ist 0.000000. # # python experiment.py 50 0.7 10000 2.4.19 Ein erster Blick auf die Resultate Wahrscheinlichkeit w der Durchlässigkeit für 100000 Proben mit Seitenlänge n “ 50 in Abhängigkeit von der Dichte p. p w ppq 0.3 0.0 0.4 0.0 0.5 0.0002 0.6 0.47 0.7 0.99 0.8 1.0 Die Funktion w p q ist offensichtlich monoton wachsend (d.h. wenn Argument p größer wird, dann wird auch w ppq größer). Wie sieht der Graph der Funktion aus? Für welches p ist w ppq “ 0.5? 2.4.20 (4) Untersuche die Funktion w p q (für Materialproben mit Seitenlänge n “ 50) Zuerst wollen wir (möglichst genau) die Dichte p mit w ppq “ 0.5 finden. Wir wissen, dass w p q monoton wachsend ist, und dass das gesuchte p zwischen u “ 0 und o “ 1 liegt. Wir können nun wie folgt vorgehen: def p_suche(u,o,fehler): m = (u+o)/2 wenn w(m) höchstens Abstand fehler von 0.5 hat: dann return m sonst wenn w(m)>0.5: dann return p_suche(u,m,fehler) (d.h. suche in der unteren Hälfte) sonst return p_suche(m,o,fehler) (d.h. suche in der oberen Hälfte) def main(): p_suche(0,1,0.0001) 2.4.21 #------------------------------------------------------------------------------------------------# mitte.py #------------------------------------------------------------------------------------------------import sys, stdio, pruefe, experiment def p_suche(unten, oben, n, fehler, wiederholungen): # Finde die Dichte p mit w(p)=0.5 m = (unten+oben)/2 w_m = experiment.w(n,m,wiederholungen) if abs(w_m-0.5) < fehler: return m elif w_m > 0.5: return p_suche(unten, m, n, fehler, wiederholungen) else: return p_suche(m,oben, n, fehler, wiederholungen) def n f w test(): = int(sys.argv[1]) = float(sys.argv[2]) = int(sys.argv[3]) erg = p_suche(0.0,1.0,n,f,w) stdio.writef('Bei n=%d ist w(p)=0.5 (mit Fehler %f) bei p=%f.\n', n, f, erg) if __name__ == '__main__': test() #------------------------------------------------------------------------------------------------# python mitte.py 20 0.001 10000 # Bei n=20 ist w(p)=0.5 (mit Fehler 0.001000) bei p=0.593445. # # python mitte.py 50 0.001 10000 # Bei n=50 ist w(p)=0.5 (mit Fehler 0.001000) bei p=0.602295. # 2.4.22 Abschließend wollen wir den Graph der Funktion w p q zeichnen. Die einfachste Methode: für alle x “ 0.00 0.01 0.02 . . . 0.98 0.99 1.00: berechne w pxq zeichne den Strich von w px ´ 0.01q zu w pxq in die Grafik ein Nachteil: wenn die Berechnung eines Funktionswertes w pxq nur 1 Minute dauert, dann dauert diese Berechnung der Grafik 1000 Minuten (über 16 Stunden). Stattdessen: wir berechnen nur die für uns wichtigen Funktionswerte . . . Zuerst berechnen wir alle x-Werte, für die der Funktionswert w pxq gezeichnet werden soll, rekursiv. Dazu halbieren wir das Intervall, das gezeichnet werden soll, solange, bis der Abstand zwischen den x-Werten klein genug ist. 2.4.23 #--------------------------------------------------------------------------# graph1.py n r # Vorbereitung zum Zeichnen des Graphen. # Wir malen rekursiv von links nach rechts, bis die x-Werte # einen Minimalabstand erreichen. #--------------------------------------------------------------------------import experiment, sys, stddraw, stdio def kurve_zeichnen(x_li, y_li, x_re, y_re, n, wiedh=100, x_abstand): if ( x_re-x_li < x_abstand ): stddraw.line(x_li,y_li, x_re,y_re) stdio.writef('%f\n',y_re) stddraw.show(1) else: x_mi = (x_li+x_re) / 2.0 f_x_mi = experiment.w(n, x_mi, wiedh) kurve_zeichnen(x_li, y_li, x_mi, f_x_mi, n, wiedh, x_abstand) kurve_zeichnen(x_mi, f_x_mi, x_re, y_re, n, wiedh, x_abstand) def main(): n = int(sys.argv[1]) x_abstand = float(sys.argv[2]) python graph1.py 20 0.1 stddraw.setXscale(-0.05,1.05) stddraw.setYscale(-0.05,1.05) stddraw.setPenRadius(0.002) kurve_zeichnen(0.0, 0.0, 1.0, 1.0, n, 100, x_abstand) stddraw.show() 2.4.24 #--------------------------------------------------------------------------# graph1.py n r # Vorbereitung zum Zeichnen des Graphen. # Wir malen rekursiv von links nach rechts, bis die x-Werte # einen Minimalabstand erreichen. #--------------------------------------------------------------------------import experiment, sys, stddraw, stdio def kurve_zeichnen(x_li, y_li, x_re, y_re, n, wiedh=100, x_abstand): if ( x_re-x_li < x_abstand ): stddraw.line(x_li,y_li, x_re,y_re) stdio.writef('%f\n',y_re) stddraw.show(1) else: x_mi = (x_li+x_re) / 2.0 f_x_mi = experiment.w(n, x_mi, wiedh) kurve_zeichnen(x_li, y_li, x_mi, f_x_mi, n, wiedh, x_abstand) kurve_zeichnen(x_mi, f_x_mi, x_re, y_re, n, wiedh, x_abstand) def main(): n = int(sys.argv[1]) x_abstand = float(sys.argv[2]) python graph1.py 20 0.01 stddraw.setXscale(-0.05,1.05) stddraw.setYscale(-0.05,1.05) stddraw.setPenRadius(0.002) kurve_zeichnen(0.0, 0.0, 1.0, 1.0, n, 100, x_abstand) stddraw.show() 2.4.24 Nun bauen wir ein weiteres Kriterium für den Abbruch der Halbierung eines Intervalls ein: wenn der Funktionswert f x mi für den Mittelpunkt x mi des Intervalls nicht zu stark vom geschätzten Funktionswert y re ´ y li 2 abweicht, dann vermuten wir, dass die übrigen Fuktionswerte im Intervall auch mittels dieser Abschätzung gut genug bestimmt werden können. Die geduldete Abweichung steht in Variable fehler. 2.4.25 #--------------------------------------------------------------------------------# graph.py #--------------------------------------------------------------------------------import experiment, sys, stddraw def kurve_zeichnen(x_li, y_li, x_re, y_re, n, wiedh=100, x_abstand=0.01, fehler=0.0025): x_mi = (x_li+x_re) / 2.0 y_mi = (y_li+y_re) / 2.0 f_x_mi = experiment.w(n, x_mi, wiedh) if ( x_re-x_li < x_abstand ) or ( abs(y_mi-f_x_mi) < fehler ): stddraw.line(x_li,y_li, x_re,y_re) stddraw.show(1) else: kurve_zeichnen(x_li, y_li, x_mi, f_x_mi, n, wiedh, x_abstand, fehler) kurve_zeichnen(x_mi, f_x_mi, x_re, y_re, n, wiedh, x_abstand, fehler) def main(): n = int(sys.argv[1]) w = int(sys.argv[2]) stddraw.setXscale(-0.05,1.05) stddraw.setYscale(-0.05,1.05) stddraw.setPenRadius(0.002) kurve_zeichnen(0.0, 0.0, 1.0, 1.0, n, w) stddraw.show() if __name__ == '__main__': main() 2.4.26 Zusammenfassung § Modulares Programmieren (Systeme aus kleinen Programmen zusammensetzen) ist praktisch. § Fehlersuche in kleinen Modulen ist einfacher als in großen Programmen. § Entwickele das Programm inkrementell. § Rekursion kann sehr nützlich sein. § Programmiere ggf. Werkzeuge, die beim Programmieren helfen. Modulares Programmieren ist (nur) der Anfang. Moderne Programmiersprachen bieten noch viele weitere Möglichkeiten. Das kommt dann in der Vorlesung im nächsten Semester . . . 4 Algorithmen Wir haben bisher Programme zur Lösung verschiedener Probleme geschrieben. Jedes Programm basiert auf einer Idee (Algorithmus), die man in jeder Programmierprache aufschreiben kann. Beim Entwickeln von Algorithmen geht es u.a. darum, möglichst schnelle Algorithmen mit wenig Speicherplatzbedarf zu finden. In diesem Kapitel schauen wir uns zuerst an, wie man feststellt, wie schnell“ ” ein Algorithmus ist. Anschließend schauen wir uns Algorithmen zum Sortieren an, die (viel) schneller als das Sortieren durch wiederholte Suche des Minimums ist. Abschließend betrachten wir noch Algorithmen zur Wegesuche in Graphen. 4. Algorithmen 4.1 Rechenzeit 4.2 Schnelles Sortieren 4.3 Suche nach Wegen in Graphen 4.1 Rechenzeit von Programmen und Zeit-Komplexität von Problemen Wir haben z.B. bei der Berechnung von Fibonacci-Zahlen gesehen, dass verschiedene Programme sehr unterschiedlich lang brauchen. Wir wollen diese Zeit messen. #--------------------------------------------# miss-fib.py # Misst die Rechenzeit fuers rekursive Berechnen # der Fibonaccizahlen. # time.time() gibt die aktuelle Zeit an. #-------------------------------------------import stdio, sys, time, fibo_rekursiv oberschranke = int(sys.argv[1]) for n in range(1,50): anfangszeit = time.time() fibo_rekursiv.fib(n) endzeit = time.time() rechenzeit = endzeit - anfangszeit stdio.writef('%d %f\n', n, rechenzeit) if rechenzeit > oberschranke: break # python miss-fib.py 10 # 1 0.000002 # 2 0.000002 # 3 0.000002 ... # 15 0.000405 # 16 0.000654 # 17 0.001052 ... # 32 1.441119 # 33 2.333346 # 34 3.771449 # 35 6.112324 # 36 9.876957 # 37 16.031817 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” Er ist ähnlich der Kurve von f pnq “ 2n . 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” Er ist ähnlich der Kurve von f pnq “ 2n . Und ziemlich genau der der Kurve von f pnq “ 0.00000155 ¨ 1.61n 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” Er ist ähnlich der Kurve von f pnq “ 2n . Und ziemlich genau der der Kurve von f pnq “ 0.00000155 ¨ 1.61n bzw. f pnq “ 0.0000004 ¨ 1.61n . 4.1.2 Beobachtungen Die Rechenzeit von Programmen wächst mit der Größe der Eingabe. Beispiel 1: Berechnung der Fibonacci-Zahlen def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Es wird die Rechenzeit in Sekunden abhängig vom Eingabewert n dargestellt. Hängt die Kurve vom Rechner ab? Der grobe Verlauf“ der Kurven ist gleich. ” Er ist ähnlich der Kurve von f pnq “ 2n . Und ziemlich genau der der Kurve von f pnq “ 0.00000155 ¨ 1.61n bzw. f pnq “ 0.0000004 ¨ 1.61n . Alle Kurven sind anscheinend welche von Funktionen f pnq “ c ¨ 1.61n für verschiedene c. n Deshalb sagen wir: die Rechenzeit von fibpnq ist „ 1.61 . 4.1.2 Beispiel 2: Quadrieren einer Matrix def quadratM(A): C = stdarray.create2D(len(A),len(A),0) for z in range(len(A)): for s in range(len(A)): for i in range(len(A)): C[z][s] += A[z][i]*A[i][s] return C Zuerst messen wir die Zeit für das Quadrieren einer Matrix mit 200 Zeilen und Spalten, wobei wir größer werdende Werte in die Matrix eintragen. Die Rechenzeiten bleiben ziemlich gleich: sie hängen kaum“ von der Größe ” der zu multiplizierenden Zahlen ab. 4.1.3 Beispiel 2: Quadrieren einer Matrix def quadratM(A): C = stdarray.create2D(len(A),len(A),0) for z in range(len(A)): for s in range(len(A)): for i in range(len(A)): C[z][s] += A[z][i]*A[i][s] return C Zuerst messen wir die Zeit für das Quadrieren einer Matrix mit 200 Zeilen und Spalten, wobei wir größer werdende Werte in die Matrix eintragen. Die Rechenzeiten bleiben ziemlich gleich: sie hängen kaum“ von der Größe ” der zu multiplizierenden Zahlen ab. Messen wir dagegen die Zeit abhängig von der Seitenlänge der Matrix, steigt die Rechenzeit stark an. 4.1.3 Beispiel 2: Quadrieren einer Matrix def quadratM(A): C = stdarray.create2D(len(A),len(A),0) for z in range(len(A)): for s in range(len(A)): for i in range(len(A)): C[z][s] += A[z][i]*A[i][s] return C Zuerst messen wir die Zeit für das Quadrieren einer Matrix mit 200 Zeilen und Spalten, wobei wir größer werdende Werte in die Matrix eintragen. Die Rechenzeiten bleiben ziemlich gleich: sie hängen kaum“ von der Größe ” der zu multiplizierenden Zahlen ab. Messen wir dagegen die Zeit abhängig von der Seitenlänge der Matrix, steigt die Rechenzeit stark an. Wir vermuten, dass die Kurve der von f pnq “ n3 ähnelt. Die Rechenzeit von quadratMpAq ist „ n3 . Die Eingabegröße n ist dabei die Seitenlänge der Matrix A. 4.1.3 Beispiel 2: Quadrieren einer Matrix def quadratM(A): C = stdarray.create2D(len(A),len(A),0) for z in range(len(A)): for s in range(len(A)): for i in range(len(A)): C[z][s] += A[z][i]*A[i][s] return C Zuerst messen wir die Zeit für das Quadrieren einer Matrix mit 200 Zeilen und Spalten, wobei wir größer werdende Werte in die Matrix eintragen. Die Rechenzeiten bleiben ziemlich gleich: sie hängen kaum“ von der Größe ” der zu multiplizierenden Zahlen ab. Messen wir dagegen die Zeit abhängig von der Seitenlänge der Matrix, steigt die Rechenzeit stark an. Wir vermuten, dass die Kurve der von f pnq “ n3 ähnelt. Die Rechenzeit von quadratMpAq ist „ n3 . Die Eingabegröße n ist dabei die Seitenlänge der Matrix A. 4.1.3 Beispiel 3: Sortieren eines Arrays mit MinSort def minsort(liste): for i in range(len(liste)-1): min = i for j in range(i+1,len(liste)): if liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t return liste Wir nehmen als Eingabegröße n gleich die Länge des Arrays. 4.1.4 Beispiel 3: Sortieren eines Arrays mit MinSort def minsort(liste): for i in range(len(liste)-1): min = i for j in range(i+1,len(liste)): if liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t return liste Wir nehmen als Eingabegröße n gleich die Länge des Arrays. Der Vergleich mit f pnq “ n3 scheint nicht zu gehen. 4.1.4 Beispiel 3: Sortieren eines Arrays mit MinSort def minsort(liste): for i in range(len(liste)-1): min = i for j in range(i+1,len(liste)): if liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t return liste Wir nehmen als Eingabegröße n gleich die Länge des Arrays. Der Vergleich mit f pnq “ n3 scheint nicht zu gehen. Der Vergleich mit f pnq “ n2 sieht vielversprechend aus. 4.1.4 Beispiel 3: Sortieren eines Arrays mit MinSort def minsort(liste): for i in range(len(liste)-1): min = i for j in range(i+1,len(liste)): if liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t return liste Wir nehmen als Eingabegröße n gleich die Länge des Arrays. Der Vergleich mit f pnq “ n3 scheint nicht zu gehen. Der Vergleich mit f pnq “ n2 sieht vielversprechend aus. Die Rechenzeit von minsortpAq ist „ n2 . Die Eingabegröße n ist dabei die Länge des Arrays A. 4.1.4 Beispiel 4: Suche des Maximums def maxsuche(liste): max = liste[0] for i in range(1,len(liste)): if liste[i] > max: max = liste[i] return max Wir nehmen als Eingabegröße n die Anzahl der Einträge im Array. 4.1.5 Beispiel 4: Suche des Maximums def maxsuche(liste): max = liste[0] for i in range(1,len(liste)): if liste[i] > max: max = liste[i] return max Wir nehmen als Eingabegröße n die Anzahl der Einträge im Array. Der Vergleich mit f pnq “ n scheint nicht zu gehen. 4.1.5 Beispiel 4: Suche des Maximums def maxsuche(liste): max = liste[0] for i in range(1,len(liste)): if liste[i] > max: max = liste[i] return max Wir nehmen als Eingabegröße n die Anzahl der Einträge im Array. Der Vergleich mit f pnq “ n scheint nicht zu gehen. Die Rechenzeit von maxsuche(liste) ist „ n. Die Eingabegröße n ist dabei die Länge von liste. 4.1.5 Zusammenfassung der Beobachtungen Wir haben die Rechenzeiten verschiedener Programme durch einfache Funktionen charakterisieren können. Funktion fib(m) quadratM(A) minsort(A) maxsuche(A) Eingabegröße n Wert von m Seitenlänge von A Länge von A Länge von A Rechenzeit „ n 1, 61 Bezeichnung der Rechenzeit exponentiell n 3 kubisch n 2 quadratisch n ¨ log n quasi-linear n linear Diese Art der Analyse der Rechenzeit beruht auf Experimenten (Ermittlung der Rechenzeit für einige Eingaben) und Herumprobieren, bis ein hinreichend ähnlicher Funktionsgraph gefunden wurde. Wie kann man ohne Experimente die Rechenzeit abschätzen? 4.1.6 Mathematische Analyse Die Rechenzeit einer einfachen Wertzuweisung an eine Variable dauert Zeit c, ist also „ 1. Beispiel: a = b + 2*c if liste[min] > liste[j]: min = j Eine Schleife (while, for) besteht aus einer Bedingung und einem Anweisungsblock. a = 0 while n > 1: n = n/2 a = a+1 for i in min = for j if range(len(liste)-1): i in range(i+1,len(liste)): liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t Die Rechenzeit einer Schleife ist die Summe der Rechenzeiten jeder Wiederholung des Anweisungsblocks . 4.1.7 Programm Rechenzeit „ n = int(sys.argv[1]) 1 a = 0 1 Wiederholungen der Schleife log n while n > 1: n = n/2 1 a = a+1 1 Die Rechenzeit des Programms ist „ 1 ` 1 ` 2 ¨ log n. Faustregeln für Abschätzungen mit „: § Formeln so weit wie möglich zusammenfassen. § Bei Summen streicht man alles bis auf den größten Summanden. Eine Summe 1 ` 1 ` 1 ` 1 ist „ 1. § Bei Produkten streicht man alle Konstanten Faktoren. Damit bleibt übrig: die Rechenzeit des Programms ist „ log n. Das ist im Prinzip“ die Anzahl der Wiederholungen der Schleife. ” 4.1.8 Im folgenden Programm ist die Eingabegröße n die Länge von liste. Programm max = liste[0] for i in range(1,len(liste)): if liste[i] > max: max = liste[i] Rechenzeit „ 1 Wiedh. der Schleife n´1 1 Die Rechenzeit des Programms ist „ 1 ` pn ´ 1q „ n. Das ist im Prinzip“ wieder die Anzahl der Wiederholungen der Schleife. ” 4.1.9 Im folgenden Programm ist die Eingabegröße n die Länge von liste. Programm for i in range(len(liste)-1): min = i for j in range(i+1,len(liste)): if liste[min] > liste[j]: min = j t = liste[min] liste[min] = liste[i] liste[i] = t Rechenzeit „ Wiedh. n´2 1 n´i ´1 1 1 1 1 Die Rechenzeit des Programms ist „ pn ´ 2q ¨ 4 ` pn ´ 2q ` pn ´ 3q ` pn ´ 4q ` . . . ` 1 “ pn ´ 2q ¨ 4 ` n´2 ÿ i “ pn ´ 2q ¨ 4 ` i“1 1 “ 4n ´ 8 ` ¨ pn2 ´ 3n ` 2q 2 „ 1 ¨ pn ´ 1q ¨ pn ´ 2q 2 n ` n2 ´ n ` 1 „ n2 Damit bleibt übrig: die Rechenzeit des Programms ist „ n2 . Im Prinzip“: ” zwei ineinandergeschachtelte Schleifen mit „ n Wiederholungen haben Rechenzeit „ n2 . 4.1.10 Im folgenden Programm ist die Eingabegröße n die Seitenlänge von A. # quadratM(A) gibt das Quadrat A**2 der quadratischen Matrix A # als Ergebnis zurück. def quadratM(A): C = stdarray.create2D(len(A),len(A),0) for z in range(len(A)): for s in range(len(A)): for i in range(len(A)): C[z][s] += A[z][i]*A[i][s] return C Die Rechenzeit für einen Funktionsaufruf von quadratM(A) ist „ n ¨ n ¨ n “ n3 . Faustregel“: ” drei ineinandergeschachtelte Schleifen mit „ n Wiederholungen haben Rechenzeit „ n3 . Die Analyse der Rechenzeit rekursiver Funktionen kann komplizierter sein. def fib(n): if n==0 or n==1: return n else: return fib(n-1) + fib(n-2) Wir definieren eine Funktion T , so dass T pnq die Rechenzeit von fibpnq ist. § Für T p0q “ 1 und T p1q “ 1. § Für n ě 2 ist T pnq “ T pn ´ 1q ` T pn ´ 2q. Man sieht: T pnq “ fibpn ` 1q. Wir erinnern uns: ˜ˆ ? ˙n ˆ ? ˙n ¸ 1` 5 1´ 5 1 ´ fibpnq “ ? ¨ 2 2 5 Dann ist 1 T pnq „ ? ¨ 5 ˜ˆ ? ˙n`1 ˆ ? ˙n`1 ¸ 1` 5 1´ 5 ´ 2 2 „ 1, 61n`1 ´ 0, 6n`1 „ 1, 61n 4.1.12 Wir haben bei der mathematischen Analyse die gleichen Ergebnisse gefunden wie bei der Analyse mittels Herumprobieren. Ein weiterer Vorteil der mathematischen Analyse ist, dass man die Rechenzeit eines Algorithmus analysieren kann, ohne dass man ihn in einer Programmiersprache implementiert haben muss. Eine mathematische Bemerkung: Wir schreiben „ an Stelle der mathematischen O-Notation ( Oh-Notation“). ” Die O-Notation dient dem Abschätzen des asymptotischen Wachstums von Funktionen. Wir schreiben f „ g statt f P Opg q. Deshalb bedeutet f „ g : f wächst asymptotisch nicht stärker als g . Die Rechenzeit ist „ n3“ bedeutet dann: ” die Rechenzeit wächst nicht stärker als n3 . Die formale Definition von f P Opg q ist Dc Dn0 @n ě n0 : f pnq ď c ¨ g pnq ` c. 4.1.13 Zusammenfassung Wir haben gesehen, dass es zur Abschätzung von Rechenzeiten von Programmen ein realistisches und gut benutzbares mathematisches Modell gibt. Die folgende Tabelle enthält typische Rechenzeiten und den Zuwachs an Rechenzeit eines Programm, das bei Eingabegröße m wenige Sekunden braucht, bei einer Eingabe der Größe 100 ¨ m. Rechenzeit Verlängerung der Rechenzeit (s.o.) linear wenige Minuten quasi-linear wenige Minuten quadratisch einige Stunden kubisch ein paar Wochen exponentiell ewig 4.1.14 4.2 Schnelle Algorithmen zum Sortieren Zum Sortieren der Elemente eines Arrays hatten wir MinSort gesehen, das Rechenzeit „ n2 zum Sortieren von n Elementen benötigt. Die Rechenzeit der Größenordnung n2 stammt daher, dass MinSort jedes der n Elemente mit jedem anderen vergleicht. Zum Sortieren von 32000 Elementen benötigt MinSort 28 Sekunden. Wir werden ein anderes Verfahren vorstellen (HeapSort), das wesentlich schneller ist und 32000 Elemente in 0.2 Sekunden sortiert. Die Rechenzeit ist „ n ¨ log n. Der Grund dieser dramatischen“ Verbesserung liegt darin, ” dass man zum Sortieren jedes Element der n Elemente durchschnittlich nur mit log n Elementen vergleichen muss. Man kann zeigen, dass es nicht besser geht. 4.2.1 Warum überhaupt sortieren? Damit man schneller etwas finden kann. Binäre Suche findet einen gesuchten Eintrag in einem sortierten Array aus n Elementen mit Rechenzeit „ log n, während vollständiges Durchsuchen Rechenzeit „ n hat. 4.2.2 #-----------------------------------------------------------------------------# suche.py #-----------------------------------------------------------------------------import stdio, sys, stdarray, math, random def binaer(liste,x,von,bis): while von < bis: mitte = (von+bis)/2 if liste[mitte]==x: return mitte elif liste[mitte] < x : # suche in der oberen Haelfte weiter von = mitte + 1 else: bis = mitte - 1 # suche in der unteren Haelfte weiter if von==bis and liste[von]==x: return von else: return False def linear(liste,x,von,bis): gefunden = False i = von while i<=bis and liste[i]!=x: i += 1 if i>bis: return False else: return i def main(): liste = [ 1, 2, 3, 4, 5, 7, 8, 9, 10, 11 ] for i in range (0,13): print linear(liste,i,0,9) if __name__ == '__main__': main() 4.2.3 Experimenteller Vergleich der Rechenzeit zwischen linearer und binärer Suche Die Eingabegröße ist die Anzahl der Einträge im Array. 1 sec angegeben. Die Rechenzeiten sind in 1000 Eingabegröße 103 104 105 106 107 linear 0.1 0.8 9.2 90.0 968.4 binär 0.005 0.007 0.009 0.012 0.015 Die Eingabegröße verzehnfacht sich in jedem Schritt. Die Rechenzeit der linearen Suche verzehnfacht sich ebenso (das entspricht Rechenzeit „ n). Die Rechenzeit der binären Suche wächst etwa um Faktor 1 14 (das entspricht Rechenzeit „ log2 n). 4.2.4 K.O.-Sortieren 17 2 5 23 22 11 4 13 4.2.5 K.O.-Sortieren max? 17 2 5 23 22 11 4 13 4.2.5 K.O.-Sortieren 17 2 5 23 22 11 4 13 4.2.5 K.O.-Sortieren 17 max? 2 5 23 22 11 4 13 4.2.5 K.O.-Sortieren 17 23 2 5 22 11 4 13 4.2.5 K.O.-Sortieren 17 23 2 5 max? 22 11 4 13 4.2.5 K.O.-Sortieren 17 23 2 5 22 11 4 13 4.2.5 K.O.-Sortieren 17 23 2 5 22 max? 11 4 13 4.2.5 K.O.-Sortieren 17 23 2 5 22 13 11 4 4.2.5 K.O.-Sortieren max? 17 23 2 5 22 13 11 4 4.2.5 K.O.-Sortieren 23 17 22 2 5 13 11 4 4.2.5 K.O.-Sortieren 23 17 5 2 22 13 11 4 4.2.5 K.O.-Sortieren 23 17 max? 5 2 22 13 11 4 4.2.5 K.O.-Sortieren 23 17 22 5 2 13 11 4 4.2.5 K.O.-Sortieren 23 17 22 5 2 11 13 4 4.2.5 K.O.-Sortieren max? 23 17 22 5 2 11 13 4 4.2.5 K.O.-Sortieren 23 22 17 5 2 11 13 4 4.2.5 K.O.-Sortieren 23 22 max? 17 5 2 11 13 4 4.2.5 K.O.-Sortieren 23 17 22 5 2 11 13 4 4.2.5 K.O.-Sortieren 23 17 2 22 5 11 13 4 4.2.5 K.O.-Sortieren 23 17 2 22 5 11 13 4 4.2.5 K.O.-Sortieren 23 max? 17 2 22 5 11 13 4 4.2.5 K.O.-Sortieren 23 22 17 2 5 11 13 4 4.2.5 K.O.-Sortieren 23 22 17 2 max? 5 11 13 4 4.2.5 K.O.-Sortieren 23 22 17 2 13 5 11 4 4.2.5 K.O.-Sortieren 23 22 17 2 13 5 11 4 4.2.5 K.O.-Sortieren 22 17 2 23 13 5 11 4 4.2.5 K.O.-Sortieren 22 23 max? 17 2 13 5 11 4 4.2.5 K.O.-Sortieren 22 23 17 13 2 5 11 4 4.2.5 K.O.-Sortieren 22 23 17 13 max? 2 5 11 4 4.2.5 K.O.-Sortieren 22 23 17 5 2 13 11 4 4.2.5 K.O.-Sortieren 17 5 2 22 23 13 11 4 4.2.5 K.O.-Sortieren 17 22 23 max? 5 2 13 11 4 4.2.5 K.O.-Sortieren 17 22 23 13 5 2 11 4 4.2.5 K.O.-Sortieren 17 22 23 13 5 2 max? 11 4 4.2.5 K.O.-Sortieren 17 22 23 13 5 2 11 4 4.2.5 K.O.-Sortieren 13 5 2 17 22 23 11 4 4.2.5 K.O.-Sortieren 13 17 22 23 max? 5 2 11 4 4.2.5 K.O.-Sortieren 13 17 22 23 11 5 2 4 4.2.5 K.O.-Sortieren 13 17 22 23 11 5 4 2 4.2.5 K.O.-Sortieren 11 5 13 17 22 23 4 2 4.2.5 K.O.-Sortieren 11 13 17 22 23 max? 5 4 2 4.2.5 K.O.-Sortieren 11 13 17 22 23 5 4 2 4.2.5 K.O.-Sortieren 11 13 17 22 23 5 2 4 4.2.5 K.O.-Sortieren 5 2 11 13 17 22 23 4 4.2.5 K.O.-Sortieren 5 11 13 17 22 23 max? 2 4 4.2.5 K.O.-Sortieren 5 11 13 17 22 23 4 2 4.2.5 K.O.-Sortieren 4 5 11 13 17 22 23 2 4.2.5 K.O.-Sortieren 4 5 11 13 17 22 23 2 4.2.5 K.O.-Sortieren 2 4 5 11 13 17 22 23 4.2.5 K.O.-Sortieren 2 4 5 11 13 17 22 23 Wieviele Vergleiche werden gemacht? 4.2.5 Wieviele Vergleiche werden beim K.O.-Sortieren gemacht? § § Bei jedem Vergleich gibt es einen Sieger. Jede Zahl landet irgendwann mal ganz oben. Beim K.O.-Sortieren von n Zahlen macht man also höchstens n multipliziert mit der Anzahl benötigter Siege, um von ganz unten nach ganz oben zu kommen viele Vergleiche. Wieviele Siege braucht man, um von ganz unten nach ganz oben zu kommen? Man braucht höchstens soviele Siege, wie der Baum Schichten hat. In der untersten Schicht sind n Plätze, in der Schicht darüber n2 usw. Von Schicht zu Schicht halbiert sich die Anzahl der Plätze. Also ist die Anzahl der Schichten die Zahl, wie oft man n durch 2 teilen kann, bis 1 herauskommt, und das ist log2 n. Also werden beim K.O.-Sortieren von n Zahlen höchstens n ¨ log2 n Vergleiche gemacht. 4.2.6 K.O.-Sortieren ist nicht so einfach zu implementieren, da das Auffüllen der Lücken im Baum etwas wirr“ ist. ” Wenn der Baum keine Lücken hat, dann steht das Maximum aller Zahlen im Baum ganz oben, und jeder Teilbaum hat die gleiche Eigenschaft. 23 17 22 2 5 1 11 3 13 4 Problem: die unterste Schicht ist nicht richtig schön . . . 4.2.7 Ein schöner Baum (MaxHeap) habe folgende Eigenschaften: 1. Das Maximum steht ganz oben. 2. Die unterste Schicht ist von links nach rechts gefüllt, und alle anderen Schichten sind komplett gefüllt. 3. Jeder Teilbaum ist ebenfalls schön. 23 17 22 4 2 5 1 11 13 3 4.2.8 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 23 17 22 4 2 5 1 11 13 3 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 17 22 4 2 5 1 11 13 3 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 3 17 4 2 22 5 11 13 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 3 17 4 2 22 max? 5 11 13 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 22 17 4 2 3 5 11 13 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 22 17 4 2 3 5 11 max? 13 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 22 17 4 2 13 5 11 3 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Das Entfernen des Maximums und die darauffolgende Reorganisation des MaxHeaps ist einfach. 22 17 4 2 13 5 11 3 1 Es ist klar, wo ein Platz im MaxHeap entfernt werden muss. Das Element von dort lässt man von oben an die richtige Stelle absinken. Die Anzahl der Vergleiche dazu in einem MaxHeap mit n Elementen ist höchstens 2mal die Anzahl der Schichten des MaxHeaps, also „ log2 n. 4.2.9 Mit Arrays kann man MaxHeaps zum Sortieren implementieren. 23 17 22 4 2 5 1 11 13 3 Der MaxHeap als Array: Index: 0 10 1 23 2 17 3 22 4 4 5 5 6 11 7 13 8 2 9 1 10 3 Länge Die beiden Kinder vom Knoten mit Index i haben Indizes 2i und 2i ` 1. 4.2.10 Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 4 8 5 9 10 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 4 8 5 9 10 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 4 5 10 6 6 7 7 8 8 9 9 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 4 8 10 9 5 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 4 5 10 6 6 7 7 8 8 9 9 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 4 8 10 9 5 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 9 5 10 6 6 7 7 8 8 9 4 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 9 8 10 4 5 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 3 4 9 5 10 6 6 7 7 8 8 9 4 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 3 9 8 10 4 5 6 7 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 7 4 9 5 10 6 6 7 3 8 8 9 4 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 7 9 8 10 4 5 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 2 3 7 4 9 5 10 6 6 7 3 8 8 9 4 10 5 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 2 7 9 8 10 4 5 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 10 3 7 4 9 5 5 6 6 7 3 8 8 9 4 10 2 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 10 7 9 8 5 4 2 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 1 2 10 3 7 4 9 5 5 6 6 7 3 8 8 9 4 10 2 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 1 10 7 9 8 5 4 2 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 10 2 9 3 7 4 8 5 5 6 6 7 3 8 1 9 4 10 2 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 10 9 7 8 1 5 4 2 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Beim Sortieren beginnt man mit einem beliebigen Array. Es hat bereits die richtige äußere Form eines MaxHeaps Alle Schichten sind komplett gefüllt, und die unterste Schicht ist von links nach rechts gefüllt. 0 10 Index: 1 10 2 9 3 7 4 8 5 5 6 6 7 3 8 1 9 4 10 2 Länge Man muss noch die innere Form herstellen. § Das Maximum steht ganz oben. § Jeder Teil des MaxHeaps ist ebenfalls ein MaxHeap. Gehe den MaxHeap rückwärts durch. 10 9 7 8 1 5 4 2 6 3 Wird ein Knoten gefunden, der kleiner als eines seiner Kinder ist, dann lasse ihn absinken. Der Ablauf von HeapSort Gegeben: ein Array mache aus dem Array einen MaxHeap solange der MaxHeap noch ein Element enthält: entferne das größte Element aus dem Heap und reorganisiere ihn mit einem Element weniger Zusätzlicher Trick: man kann das Array, das man als MaxHeap benutzt, gleichzeitig als Array zm Speichern der sortierten Elemente benutzen. Index: unsortiertes Array: 0 8 1 13 2 7 3 22 4 11 5 4 6 3 7 17 8 24 Länge MaxHeap: 8 24 13 22 11 4 3 17 7 nach 1.Entfernen: 7 22 13 17 11 4 3 7 24 nach 2.Entfernen: 6 17 13 7 11 4 3 22 24 nach 3.Entfernen: 5 13 11 7 3 4 17 22 24 nach 4.Entfernen: 4 11 4 7 3 13 17 22 24 nach 5.Entfernen: 3 7 4 3 11 13 17 22 24 nach 6.Entfernen: 2 4 3 7 11 13 17 22 24 nach 7.Entfernen: 1 3 4 7 11 13 17 22 24 nach 8.Entfernen: 0 3 4 7 11 13 17 22 24 Die Rechenzeit von HeapSort ist „ n ¨ log n Die Eingabegröße ist die Anzahl der zu sortierenden Elemente n. Um die Rechenzeit abzuschätzen, reicht es zu zählen, wieviele Vergleiche gemacht werden. Der MaxHeap hat „ log n Schichten. Ein Element im MaxHeap von der Wurzel aus absinken zu lassen, benötigt „ log n Vergleiche. Die Konstruktion des MaxHeaps aus dem unsortierten Array benötigt dann „ n ¨ log n Vergleiche. Jedes Entfernen eines Elements aus der Wurzel und die Reorganisation des MaxHeaps benötig „ log n Vergleiche. Da n Elemente entfern werden, benötigt man „ n ¨ log n Vergleiche. Insgesamt werden also „ n ¨ log n ` n ¨ log n „ n ¨ log n Vergleiche benötigt. 4.2.14 Jedes Sortierverfahren, das auf Vergleichen der zu sortierenden Element basiert, benötigt mindestens n ¨ log n Vergleiche. Also ist HeapSort ein optimales Sortierverfahren (dieser Art). 4.2.15 #-----------------------------------------------------------------------------# maxheap.py #-----------------------------------------------------------------------------def maxnachfolger(mheap,i): # Gibt den Index des größten Nachfolgers des Elements mit Index i # im Heap mheap zurück (das kann auch i sein). if mheap[0]>=2*i+1: # der Eintrag mit Index i hat zwei Nachfolger if mheap[2*i+1]>=mheap[2*i]: m1 = 2*i+1 else: m1 = 2*i if mheap[i]>=mheap[m1]: m1 = i elif mheap[0]==2*i: # der Eintrag mit Index i hat einen Nachfolger if mheap[2*i]>mheap[i]: m1 = 2*i else: m1 = i else: m1 = i return m1 def tausche(liste,a,b): # Tausche im Array liste die Elemente mit Indizes a und b t = liste[a] liste[a] = liste[b] liste[b] = t def absinken(mheap,i): # Lasse im MaxHeap mheap das Element mit Index i absinken. mm = maxnachfolger(mheap,i) while mm > i: tausche(mheap,i,mm) i = mm mm = maxnachfolger(mheap,i) 4.2.16 #------------------------------------------------------------------------------------# heapsort.py #------------------------------------------------------------------------------------import maxheap, stdarray, random def heapsort(liste): # Sortiere die Einträge mit den Indizes 1..len(liste)-1 im Array liste. liste[0] = len(liste)-1 # Trage die Anzahl der zu sortierenden Elemente in liste[0] ein. for i in range(liste[0]/2, 0, -1): maxheap.absinken(liste,i) # Mache aus liste einen MaxHeap. for i in range(1, liste[0]+1): maxheap.tausche(liste,1,liste[0]) liste[0] -= 1 maxheap.absinken(liste,1) # Entferne das größte Element aus dem MaxHeap # und schreibe es ans Ende von liste, bis alle # Elemente entfernt wurden - dann ist liste sortiert. def main(): liste = stdarray.create1D(100,0) for i in range(1,len(liste)): liste[i] = random.randrange(100) liste[0] = 99 heapsort(liste) print liste if __name__ == '__main__': main() 4.2.17 Experimenteller Vergleich der Rechenzeit von MinSort und HeapSort Die Eingabegröße ist die Anzahl der Elemente im Array. Die Rechenzeiten sind in Sekunden angegeben. Eingabegröße 103 104 105 106 107 MinSort 0.04 s 4.86 s 491.98 s HeapSort 0.01 s 0.12 s 1.52 s 18.22 s 213.08 s Die Eingabegröße verzehnfacht sich in jedem Schritt. Bei MinSort verhundertfacht sich dabei die Rechenzeit, da MinSort Rechenzeit „ n2 hat. Bei HeapSort verzwölffacht sich die Rechenzeit etwa. 4.2.18 Zusammenfassung Manche Probleme kann man mit viel schnelleren Programmen lösen, als man denkt. Sortieren ist ein Beispiel dafür. Wir haben HeapSort als einen verblüffend schnellen Algorithmus gesehen. Andere schnelle Algorithmen zum Sortieren sind z.B. QuickSort, MergeSort oder BucketSort. Wir haben gesehen, dass die Verwendung einer guten Datenstruktur (MaxHeap) ein wesentlicher Grund für die Schnelligkeit des Programms ist. 4.3 Wege finden in Graphen Das Konzept des Graphen hatten wir bereits in VL05 benutzt. Dort hatten wir uns Webseiten und Links dazwischen als die Knoten und die Kanten eines Graphen vorgestellt. Genauso kann man sich § Kreuzungen und Straßen dazwischen in einem Straßennetz Menschen und likes“ dazwischen ” als Graphen vorstellen. § Wege zwischen zwei Knoten in einem Graphen sind dann z.B. § eine Anleitung, wie man von einer Webseite zu einer anderen surft § eine Beschreibung, wie man von einer Stadt zur anderen fährt § ein Hinweis darauf, ob die beiden Menschen Ähnliches mögen. 4.3.1 Unterschiedliche Arten von Graphen Ein gerichteter Graph ohne Gewichte: e c d a Der Graph besteht aus 5 Knoten und 7 Kanten. Er enthält 3 Wege von Knoten a zu Knoten d: sie haben Längen 2, 3 und 4. Er enthält keinen Weg von Knoten c zu Knoten a. b Ein gerichteter Graph mit Gewichten: 1 e 4 c 2 3 5 10 a 1 d Der Graph besteht aus 5 Knoten und 7 Kanten. Er enthält 3 Wege von Knoten a zu Knoten d: sie haben Längen 11, 9 und 7. Er enthält keinen Weg von Knoten c zu Knoten a. b Ungewichtete Graphen entsprechen gewichteten Graphen, bei denen alle Kantengewichte 1 sind.4.3.2 Man interessiert sich für folgende Fragen: § Gibt es einen Weg von Knoten x zu Knoten y ? § Gibt es einen Weg von Knoten x zu jedem anderen Knoten? § Welcher Weg von x zu y ist der kürzeste? § Finde alle kürzesten Wege von Knoten x zu allen anderen Knoten! Wir werden uns Algorithmen für diese Fragen für Graphen mit und ohne Gewichte anschauen: § Breitensuche (für ungewichtete Graphen) § Algorithmus von Dijkstra (für gewichtete Graphen) Hat dieser Graph einen Weg vom roten zum blauen Knoten? Welcher Weg ist der kürzeste? 4.3.4 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 1 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 2 1 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 3 3 2 1 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 4 4 3 3 2 4 1 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 5 4 5 4 3 4 3 2 5 1 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 6 5 4 5 4 3 4 3 2 5 1 6 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 7 6 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 8 7 8 6 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 9 8 9 7 8 6 9 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 9 10 8 9 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 11 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 12 12 11 12 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 13 12 12 11 12 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 13 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 13 12 12 11 12 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 13 14 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 13 14 15 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 13 14 9 10 11 15 8 9 11 16 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 16 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 9 10 11 8 9 11 7 8 10 6 9 10 5 4 5 4 3 4 3 2 5 1 6 13 17 14 17 15 16 16 17 17 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 13 14 17 9 10 11 18 15 16 8 9 11 17 16 17 7 8 10 18 17 18 6 9 10 5 4 5 4 3 4 3 2 5 1 6 18 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 13 14 17 9 10 11 18 15 16 19 8 9 11 17 16 17 18 7 8 10 18 17 18 19 6 9 10 19 5 4 5 4 3 4 3 2 5 1 6 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 12 11 12 13 14 17 20 9 10 11 18 15 16 19 8 9 11 17 16 17 18 7 8 10 18 17 18 19 6 9 10 19 20 5 4 5 4 3 4 3 2 5 1 6 20 20 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 13 12 21 12 11 12 13 14 17 20 21 9 10 11 18 15 16 19 20 8 9 11 17 16 17 18 21 7 8 10 18 17 18 19 6 9 10 19 20 21 20 5 4 5 4 3 4 3 2 5 1 6 21 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 13 12 12 11 12 13 14 17 20 21 9 10 11 18 15 16 19 20 8 9 11 17 16 17 18 21 7 8 10 18 17 18 19 22 6 9 10 19 20 21 20 21 5 4 5 4 3 4 3 2 5 1 6 22 22 22 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 9 10 11 18 15 16 19 20 23 8 9 11 17 16 17 18 21 22 7 8 10 18 17 18 19 22 23 6 9 10 19 20 21 20 21 22 5 4 5 4 3 4 3 2 5 1 6 22 23 23 23 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 24 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Breitensuche – die Idee starte mit dem roten Knoten färbe alle Nachbarn von roten Knoten oder grauen Knoten ebenfalls grau, bis der blaue Knoten erreicht ist und merke Dir dabei den Verursacher“ jeder Graufärbung ” 13 14 15 22 21 22 23 13 12 12 11 12 13 14 17 20 21 24 9 10 11 18 15 16 19 20 23 24 8 9 11 17 16 17 18 21 22 23 7 8 10 18 17 18 19 22 23 24 6 9 10 19 20 21 20 21 22 23 5 4 5 23 24 4 3 4 3 2 5 1 6 22 24 7 4.3.5 Programm zur Breitensuche in Graphen Der Graph liegt als Adjazenzmatrix AM[][] vor: AM[i][j] ist True, falls es eine Kante von Knoten i zu Knoten j gibt. Anderenfalls ist AM[i][j] False. Wir hatten bereits ein Programm geschrieben, das die Folge der Kanten eine Graphen einliest und daraus eine Adjazenzmatrix macht. 4.3.6 #---------------------------------------------------------------------------# einlesen.py # # Liest eine Graph-Datei ein # und gibt die Adjazenzmatrix des Graphen als Rückgabewert zurück. #---------------------------------------------------------------------------import sys, stdio, stdarray, string def graph(dateiname): datei = open(dateiname,"r") # Die Graph-Datei beginnt mit der Anzahl Knoten. n = int(string.strip(datei.readline())) # AM ist die Adjazenzmatrix, in die die Graph-Datei umgewandelt werden soll. AM = stdarray.create2D(n, n, False) # Der Rest der Graph-Datei besteht aus Zeilen mit Zahlenpaaren, # die für Kanten stehen. # In der Adjazenzmatrix AM[][] an die entsprechende Stelle True geschrieben. for zeile in datei: Z = string.split(zeile) if len(Z)==2 and int(Z[0])<n and int(Z[1])<n: AM[int(Z[0])][int(Z[1])] = True return AM #-----------------------------------def test(): print graph(sys.argv[1]) if __name__ == '__main__': test() #----------------------------------# python einlesen.py GraphVL13.txt # [[False, True, False, True, False], # [True, False, True, True, False], # [False, False, False, False, True], # [False, False, True, False, False], # [True, True, False, False, False]] #-----------------------------------GraphVL13.txt ist folgende Datei: 5 0 1 0 3 1 0 1 0 1 3 1 2 2 4 3 2 4 1 4 0 4.3.8 Wir stellen uns den eben durchgespielten Algorithmus rundenweise“ vor: ” § in der ersten Runde werden alle Nachbarn des roten Knoten grau gefärbt § in der zweiten Runde werden alle ungefärbten Nachbarn der Knoten, die in der ersten Runde grau gefärbt wurden, grau gefärbt § ... § in der pn ` 1qsten Runde werden alle ungefärbten Nachbarn der Knoten, die in der n ten Runde grau gefärbt wurden, grau gefärbt Man muss Kontrolle darüber haben, von welchen Knoten die Nachbarn grau gefärbt werden müssen. Es ist wichtig, die Knoten rundenweise abzuarbeiten, damit der kürzeste Weg (mit den wenigsten Kanten) gefunden wird. Dazu benutzen wir die Idee der Datenstruktur Warteschlange. Wenn ein Knoten grau gefärbt wird, wird er hinten an die Warteschlange drangestellt. Der Knoten, der vorne in der Warteschlange steht, wird bedient“, ” d.h. seine Nachbarn werden grau gefärbt. 4.3.10 #----------------------------------------------------------------------# warteschlange.py # Stellt die Funktionen einfuegen(W,int), kopf(W), entfernen(W) und ist_leer(W) # für Warteschlangen zur Verfügung. # Es ist unschön, dass bei einfuegen(W,x) mit Seiteneffekten gearbeitet wird. # Aber ohne Objektorientierung geht das nicht anders. #-----------------------------------------------------------------------def einfuegen(W,x): # Stelle x hinten an die Warteschlange W an. W += [x] def kopf(W): # Gib den Eintrag am Anfang der Warteschlange W zurück. return W[0] def entfernen(W): # Entferne das erste Element aus der Warteschlange W # und gib die veränderte Warteschlange als Ergebnis zurück. return W[1:] def ist_leer(W): # Gib zurück, ob die Warteschlange W leer ist. return len(W)==0 #------------------------------------------------------------------4.3.11 Nun muss die Breitensuche mit Benutzung der Warteschlange formuliert werden. am Anfang besteht die Warteschlange nur aus dem roten Knoten solange die Warteschlange nicht leer ist und der blaue Knoten nicht erreicht wurde: nimm den ersten Knoten aktueller knoten aus der Warteschlange färbe alle seine ungefärbten Nachbarn grau, hänge sie hinten an die Warteschlange an und merke dir, dass sie wg. aktueller knoten gefunden wurden 4.3.12 #------------------------------------------------------------------------------# breitensuche.py # # Liest einen Dateinamen von der Kommandozeile, liest den Graph aus der Datei ein # und führt Breitensuche auf dem Graphen durch. # Rückgabewert ist ein Array mit den Vorgängerknoten aller gefundener Knoten. #--------------------------------------------------------------------------------import sys, stdio, stdarray, einlesen, warteschlange def breitensuche(AM, von, nach): # AM: die Adjazenzmatrix des Graphen, # von: der Startknoten, nach: der Zielknoten # n: die Anzahl der Knoten n = len(AM) # grau: enthält für jeden Knoten die Markierung, # ob er bei der Breitensuche bereits gefunden wurde. grau = stdarray.create1D(n, False) # vorgaenger enthält für jeden Knoten, der gefunden wurde, # den Knoten (seinen Vorgänger), von dem aus er gefunden wurde. vorgaenger = stdarray.create1D(n,-1) 4.3.13 # Die Breitensuche wird vorbereitet. grau[von] = True WS = [von] # Die Breitensuche wird gestartet. while not warteschlange.ist_leer(WS) and not besucht[nach]: aktueller_knoten = warteschlange.kopf(WS) # Durchsuche alle Nachbarn des aktuellen Knotens. for nachbar in range(n): if AM[aktueller_knoten][nachbar] and not grau[nachbar]: warteschlange.einfuegen(WS,nachbar) grau[nachbar] = True vorgaenger[nachbar] = aktueller_knoten WS = warteschlange.entfernen(WS) return vorgaenger def ausgabe_weg(V,von,nach): # V ist das Array, das von breitensuche(AM,von,nach) zurückgegeben wird. # Da dort der gefundene Weg "rückwärts" drinsteht, # benutzen wir Rekursion, um ihn vorwärts auszugeben. if not nach==von: ausgabe_weg(V,von,V[nach]) print V[nach], nach 4.3.14 #----------------------------------------------------------------------------def test(): dateiname = sys.argv[1] von = int(sys.argv[2]) nach = int(sys.argv[3]) AM = einlesen.graph(dateiname) V = breitensuche(AM, von, nach) if not V[nach]==-1: ausgabe_weg(V, von, nach) else: stdio.writef('Es gibt keinen Weg von %d nach %d.\n', von, nach) if __name__ == '__main__': test() #------------------------------------------------------------------------------- 4.3.15 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra 1 Suche nach kürzestem Weg von a nach d: e c 3 f 4 a 2 1 4 5 10 3 d b 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 4 a 0 1 3 2 1 8 f 5 4 8 c 10 3 8 d b 8 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 1 3 8 f 5 8 c 3 8 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 8 0 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 1 3 8 f 5 8 c 3 8 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 8 0 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 1 3 8 f 5 8 c 3 8 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 1 3 8 f 5 8 c 3 8 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 8 e 1 3 8 f 5 8 c 3 8 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 6 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 6 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 6 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 11 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Suche nach kürzesten Wegen in gewichteten Graphen Der Algorithmus von Dijkstra Suche nach kürzestem Weg von a nach d: zu Beginn hat a Entfernung 0 und alle anderen Knoten haben Entfernung 8 3 e 1 3 5 f 4 c 5 3 7 wiederhole, bis alle . . . Knoten abgearbeitet sind: d 4 10 4 2 suche den nicht-abgearbeiteten Knoten x mit 1 kleinster Entfernung a b markiere alle Nachbarn von x wie folgt: 0 1 wenn ein Nachbar mit 8 markiert ist: markiere ihn mit Markierung von x + Gewicht der Kante von x zu ihm sonst: wenn der Nachbar nicht abgearbeitet ist: markiere ihn mit dem Minimum seiner bisherigen Markierung und Markierung von x + Gewicht der Kante jetzt ist der Knoten abgearbeitet 4.3.16 Um den Algorithmus zu programmieren, modifizieren wir das Programm für die Breitensuche. Zuerst ergänzen wir einlesen.py um eine Funktion graph gew zu Einlesen gewichteter Graphen. Die Funktion hat als Rückgabewert eine Adjazenzmatrix AM[][], so dass AM[i][j] das Gewicht der Kante von Knoten i zu Knoten j ist, falls der Graph diese Kante enthält, und anderenfalls ist AM[i][j] undendlich, d.h. float(’inf’). 4.3.17 #-----------------------------------------------------------------# einlesen.py # # Liest eine Graph-Datei ein # und gibt die Adjazenzmatrix des Graphen als Rückgabewert zurück. #-----------------------------------------------------------------import sys, stdio, stdarray, string def graph_gew(dateiname): # Der Graph ist gerichtet und gewichtet (mit positiven int Gewichten). # In der Eingabedatei steht in der ersten Zeile die Anzahl der Knoten, # in jeder darauffolgenden Zeile steht eine Kante und ihr Gewicht in Form von drei Zahlen. # Die zurückgegebene Adjazenzmatrix hat float Einträge. # Jeder Eintrag ist entweder das Gewicht oder float('inf) (falls keine Kante zwischen den Knoten datei = open(dateiname,"r") # Die Graph-Datei beginnt mit der Anzahl Seiten (Knoten). n = int(string.strip(datei.readline())) # AM ist die Adjazenzmatrix der einzulesenden Datei. AM = stdarray.create2D(n, n, float('inf')) # Der Rest der Graph-Datei besteht aus Zahlentripeln, die für Kanten und ihre Gewichte stehen. # In der Adjazenzmatrix AM[][] wird das Gewicht an die entsprechende Stelle gesetzt. for zeile in datei: Z = string.split(zeile) if len(Z)==3 and int(Z[0])<n and int(Z[1])<n and float(Z[2])>0: AM[int(Z[0])][int(Z[1])] = float(Z[2]) return AM 4.3.18 Bei der Breitensuche hatten wir graue“ Knoten. ” Das sind genau die Knoten, deren korrekte Entfernung zu Startknoten bereits bestimmt wurde. Im Programm für den Algorithmus von Dijkstra verwenden wir dafür den Begriff abgearbeitete Knoten“. ” Wir müssen uns stets merken, welche Entfernungs-Markierung für jeden Knoten bestimmt wurde. Ansonsten benutzen wir die gleichen Daten wie in der Breitensuche. 4.3.19 #----------------------------------------------------------------------# dijkstra-einfach.py # # Liest einen Dateinamen von der Kommandozeile, # liest aus der Datei einen gerichteten gewichteten Graphen ein # und führt den Algorithmus von Dijkstra auf dem Graphen durch. # Rückgabewert ist ein Array mit den Vorgängerknoten # auf dem gefundenen Weg. #-----------------------------------------------------------------------import sys, stdio, stdarray, einlesen def suche(AM, von, nach): # n ist die Anzahl der Knoten n = len(AM) # abgearbeitet enthält für jeden Knoten eine Markierung, # ob seine exakte Entfernung zum Startknoten von bereits berechnet ist. abgearbeitet = stdarray.create1D(n, False) # vorgaenger enthält für jeden Knoten, der besucht wurde, # den Knoten (seinen Vorgänger), von dem aus er gefunden wurde. vorgaenger = stdarray.create1D(n,-1) # weglaenge enthält für jeden besuchten Knoten die Länge # des bisher zu ihm gefundenen Weges. weglaenge = stdarray.create1D(n, float('inf')) 4.3.20 # Die Suche wird initialisiert. weglaenge[von] = 0.0 # Die Suche wird gestartet. while not min(abgearbeitet): # Suche den nicht-abgearbeiteten Knoten mit minimaler Entfernung vom Startknoten. for i in range(n): if not abgearbeitet[i]: kandidat = i break for z in range(i+1,n): if not abgearbeitet[z] and weglaenge[z]<weglaenge[kandidat]: kandidat=z aktueller_knoten = kandidat if weglaenge[aktueller_knoten] == float('inf'): break abgearbeitet[aktueller_knoten] = True # Durchsuche alle Nachbarn des aktuellen Knotens. for nachbar in range(n): if not abgearbeitet[nachbar]: if weglaenge[nachbar] > weglaenge[aktueller_knoten] + AM[aktueller_knoten][nachbar]: weglaenge[nachbar] = weglaenge[aktueller_knoten] + AM[aktueller_knoten][nachbar] vorgaenger[nachbar] = aktueller_knoten return vorgaenger 4.3.21 def ausgabe_weg(V,von,nach): if not nach==von: ausgabe_weg(V,von,V[nach]) print V[nach], nach #-----------------------------------------------------------------------def test(): dateiname = sys.argv[1] von = int(sys.argv[2]) nach = int(sys.argv[3]) AM = einlesen.graph_gew(dateiname) V = suche(AM, von, nach) if V[nach] < float('inf'): ausgabe_weg(V, von, nach) else: stdio.writef('Es gibt keinen Weg von %d nach %d.\n', von, nach) #----------------------------------------------------------------------if __name__ == '__main__': test() Datei GraphVL13gew.txt: #-------------------------------------------6 0 1 1.0 # python dijkstra-einfach.py GraphVL13gew.txt 0 3 1 2 5.0 # 0 1 1 3 10.0 # 1 4 1 4 2.0 # 4 2 1 5 4.0 # 2 3 4 5 3.0 4 2 1.0 2 3 3.0 5 6 3.0 Abschätzung der Rechenzeit Breitensuche Die Größe eines Graphen wird durch die Anzahl n seiner Knoten und die Anzahl m seiner Kanten beschrieben. Bei der Breitensuche wird jeder Knoten (höchstens) einmal in die Warteschlange eingefügt. Also wird die große while-Schleife n mal durchlaufen. In der while-Schleife wird für jeden Knoten überprüft, ob er Nachbar des gerade aktuellen Knotens ist. Also hat jeder Durchlauf der while-Schleife Rechenzeit „ n. Mit der Anzahl der Durchläufe der while-Schleife erhält man Rechenzeit „ n2 . Speichert man den Graph so, dass man direkt Zugriff auf die von den Knoten ausgehenden Kanten hat (und nicht alle Knoten auf potentielle Nachbarschaft untersuchen muss), dann erhält man Rechenzeit „ m. Da m ď n2 , kann das besser sein. 4.3.23 Abschätzung der Rechenzeit Algorithmus von Dijkstra Jeder Knoten wird (höchstens) einmal aktueller Knoten. Also wird die große while-Schleife n mal durchlaufen. In der while-Schleife wird der aktuelle Knoten bestimmt – das hat Rechenzeit „ n. Dann werden wieder alle Nachbarn des aktuellen Knotens betrachtet – das hat Rechenzeit „ n. Beides summiert sich zu 2 ¨ n – also hat jeder Durchlauf der while-Schleife Rechenzeit „ n. Mit der Anzahl der Durchläufe der while-Schleife erhält man Rechenzeit „ n2 . Verbesserungspotental: (1) Graph so speichern, dass man direkt Zugriff auf die von den Knoten ausgehenden Kanten hat. (2) Suche nach dem aktuellen Knoten mit Hilfe eines Heaps (Rechenzeit „ log n statt „ n). Damit erreicht man Rechenzeit „ m ` n ¨ log n. 4.3.24 Zusammenfassung Graphen eignen sich zum Modellieren vieler verschiedener Zusammenhänge. Breitensuche ist ein klassisches“ algorithmisches Verfahren. ” Die Datenstruktur Warteschlange (queue) ist eng damit verbunden. Der Algorithmus von Dijkstra (1959) ist ebenfalls ein Klassiker. Der Algorithmus löst ein Optimierungsproblem mit einer einfachen Idee (die trotzdem nicht so leicht zu finden ist). Mit geschickter Auswahl von Datenstrukturen hat der Algorithmus sehr kurze Rechenzeit. Alles in allem ist das typisch Informatik“. ” Anhang: Abschlussprojekte § Pycman § Zielschießen § n-body simulation § Gebirgspfade § Racko § Derivate § Sudoku § Autorschaft-Erkennung § Das Spiel PIG Ausführliche Beschreibungen finden Sie auf der Webseite mit den Übungsblättern. Pycman Eine Pacman-Variante in Python: Sie laufen durch ein Labyrinth, müssen Punkte sammeln und werden dabei von Monstern verfolgt . . . 5.0.2 Zielschießen Die Flugkurve einer Kanonenkugel lässt sich abhängig von ein paar Parametern mittels einer mathematischen Funktion berechnen. Schreiben Sie ein Programm mit schöner grafischer Ausgabe, mit dem man ein Ziel trotz Hindernissen treffen kann. 5.0.3 n-body simulation Sir Isaac Newton formulierte 1687 in seiner Principia die Gesetze, die die Bewegung zweier Körper unter dem gegenseitigen Einfluss ihrer Gravitation beschreiben. Newton war jedoch nicht in der Lage, das Problem für mehr als zwei Körper zu lösen. In der Tat ist dies für drei oder mehr Körper nur numerisch lösbar. Oft werden aber derartige Simulationen gebraucht, um komplexe physikalische Systeme zu studieren. Schreiben Sie ein Programm dafür. 5.0.4 Gebirgspfade Finden Sie Wege durch Gebirge mit möglichst geringen Höhenunterschieden. 5.0.5 Racko Racko ist ein Kartespiel für zwei (oder mehr) Spieler. Jeder Spieler spielt mit 10 Karten auf der Hand. Er darf die Reihenfolge seiner Handkarten nicht ändern. Das Ziel ist es, eine sortierte Folge von Karten auf der Hand zu haben. In jedem Zug kann er eine Karte aufnehmen (nach bestimmten Regeln) und gegen eine Handkarte tauschen . . . Schreiben Sie ein Programm, das bei Racko gewinnt. 5.0.6 Derivate 5.0.7 Sudoku Schreiben Sie ein Programm, das Sudokus löst und lösbare Sudokus produziert. Versuchen Sie, ein möglichst schnelles Programm zu schreiben. 5.0.8 Autorschafts-Test Jeder Text/Autor besitzt eine Signatur aus § durchschnittlicher Wortlänge, § die Anzahl verschiedener Wörter im Verhältnis zur Anzahl der Wörter des Textes, § die Anzahl aller Wörter, die nur einmal im Text vorkommen, im Verhältnis zur Anzahl aller Wörter des Textes, § die durchschnittliche Anzahl von Wörtern pro Satz, und § die durchschnittliche Anzahl von Satzteilen pro Satz. Signaturen lassen sich vergleichen. Aufgabe: bestimme Signaturen von ein paar Autoren und die Ähnlichkeit der Signatur eines Textes zu denen der (bekannten) Autoren. Das Spiel PIG PIG ist ein Würfelspiel für 2 Spieler mit einem Würfel. Die Spieler machen abwechselnd einen Zug. Ein Zug besteht aus einer Folge von Würfen des Würfels. Der ziehende Spieler bestimmt, wann er aufhört zu würfeln. Wenn er im Zug eine 1 würfelt, dann endet der Zug und ergibt 0 Punkte. Wenn der Spieler aufhört zu würfeln, bevor er eine 1 gewürfelt hat, dann erhält er die Summe aller Würfe im Zug als Punkte. Es gewinnt der Spieler, der zuerst aus der Summe seiner Züge mindestens 100 Punkte erreicht. Aufgabe: programmiere Wettkampf zwischen zwei Spielern. Finde eine gute Gewinnstrategie. Die Modulprüfung Die Modulprüfung ist eine mündliche Prüfung und dauert ca. 30 Minuten. Das Prüfungsthema ist entweder der Inhalt von Vorlesung und Übung oder die Vorführung und Diskussion Ihres Abschlussprojekts. Das Abschlussprojekt kann aus der Liste der Projekte gewählt werden oder ein eigenes Projekt sein (nach Rücksprache mit mir). Bei Vorführung und Diskussion des Abschlussprojekts müssen alle notwendigen Dateien (Module und Daten) mindestens 30 Stunden vor Beginn der Prüfung bei [email protected] eingetroffen sein. 5.0.11