11Dynamische Optimierung
Werbung

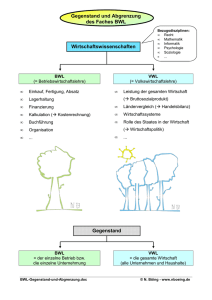
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
•
Übersicht
1. Einführung
2. Stufen-Zustand-Diagramm
3. Bellmann-Prinzip
4. Zeitplanung
Dynamische Optimierung
1
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Zustände
Stufen-Zustands-Diagramm
i
j
a
s
y
b
z
c
Stufen
n
Vorwärtsrechnung 1
k+1
k -1
k
k
k -1
k+1
Dynamische Optimierung
1 Rückwärtsrechnung
n
2
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Definition der Zielfunktion
f k ( y , xk )
ist der Zielfunktionswert im Zustand y ,
wenn dieser über den Übergang x k erreicht wird.
f k ( y ) = f k ( y, xk* )
*
ist der optimale Zielfunktionswert im Zustand y,
der vom günstigsten Übergang xk* aus erreicht wird.
f k ( y ) = opt
*
xi ∈ N ( y )
{d
y , xi
}
+ f k*−1 ( xi* )
Dynamische Optimierung
3
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Rückwärtsrechnung
Zustände
i
j
s
y
z
...
xk
l
Stufen
n
k +1
k
0
Rückwärtsrechnung
Dynamische Optimierung
4
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Vorwärtsrechnung
Zustände
i
y
s
xk
j
z
...
Stufen
0
k
k +1
n
Vorwärtsrechnung
Dynamische Optimierung
5
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Schritte der Dynamischen Optimierung (1)
1. Der Entscheidungsprozeß muss sich sequentiell in Stufen k und
Zustände i aufspalten lassen.
2. Auf den Übergängen, dargestellt durch Pfeile <i, j> sei eine
Übergangsfunktion di,j definiert.
3. Das Erreichen eines Zustandes wird durch eine Zustandsvariable y
beschrieben.
4. Sind mehrere Übergänge in einen Zustand möglich, so wird der dem
Zielkriterium nach beste gewählt, wobei der entsprechende
Übergang durch eine Entscheidungsvariable xi* beschrieben wird.
Dynamische Optimierung
6
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Schritte der Dynamischen Optimierung (2)
5. Eine Folge von Entscheidungen führt zu einer Politik, der ein
Zielfunktionswert fk (y, xk) zugeordnet werden kann.
6. Eine optimale Politik liegt vor, wenn über alle Übergänge der
Zielfunktionswert optimiert wird: f k* ( y ) = f k ( y , x k* )
7. Die optimale Politik wird rückwärts (vorwärts) rekursiv berechnet:
f k* ( y ) = opt {d y , xi + f k*−1 ( xi* )} → x k*
xi ∈N ( y )
8. Die Festlegung der Politik erfolgt vorwärts (rückwärts) ebenfalls
rekursiv durch Auflösen der Verkettung über die Nachfolger
(Vorgänger): x 0* → x1* → ... → x n*
Dynamische Optimierung
7
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Ein Beispiel: Wegnetz mit Entfernungen
Zustände
a
8
s
9
6
4
4 2
2
b 5
6
5 5
c
3
d
3
e
g
5
5
z
2
2
f
6
h
6
5
Stufen
4
3
2
Dynamische Optimierung
1
0
8
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 0:
Im Zielknoten ist der Restweg gleich Null; einen Nachfolger gibt es nicht.
Stufe
k
Zustand
y
Nachfolger
N(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈N ( y )
0
z
{d
-
y , xi
}
+ f k*−1 ( xi* )
→
xk*
0
Dynamische Optimierung
9
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 1:
Auf dieser Stufe gibt es zwei Zustände, beschrieben durch die Knoten g und h.
Von g aus gibt es einen Nachfolger (z) und einen Übergang in diesen Knoten
mit dem Zielfunktionswert 5.
Entsprechend gibt es in dem Zustand h einen Übergang nach z mit f = 6
Stufe
k
Zustand
y
Nachfolger
N(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈N ( y )
0
z
-
1
g
{z}
{d
y , xi
}
+ f k*−1 ( xi* )
→ xk*
0
f1 ( g ) = min {5 + 0} = 5 → x1* = z
*
z
h
{z}
f1 (h) = min {6 + 0} = 6 → x1* = z
*
z
Dynamische Optimierung
10
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 2:
Erst jetzt "beginnt" die dynamische Optimierung mit ihrer Wirkung:
Auf Stufe 2 gibt es die drei Zustände: d, e und f.
Der Zustand d besitzt zwei Nachfolger (g und h).
D.h. nach d kann man von g aus gelangen und den (bereits berechneten
optimalen Restweg berücksichtigen: 6 + 5 = 11
Oder von h aus und dessen optimalen Weg bis z: 3 + 6 = 9.
Damit hat der optimale Restweg von d aus bis z die Länge 9 und führt über h.
Analog sind für e zwei Nachfolger zu berücksichtigen: g und h
Und schließlich auch für f: g und h
Dynamische Optimierung
11
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 2:
Stufe
k
Zustand
y
Nachfolger
N(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈N ( y )
0
z
-
1
g
{z}
{d
y , xi
}
+ f k*−1 ( xi* )
→
xk*
0
f1 ( g ) = min {5 + 0} = 5 → x1* = z
*
z
h
{z}
f1 (h) = min {6 + 0} = 6 → x1* = z
*
z
2
d
{g,h}
f 2 (d ) = min {6 + 5;3 + 6} = 9 → x2* = h
*
g ,h
e
{g,h}
f 2 (e) = min {5 + 5; 2 + 6} = 8 → x2* = h
*
{ g , h}
f
{g,h}
f 2 ( f ) = min {2 + 5;5 + 6} = 7 → x2* = g
*
{ g , h}
Dynamische Optimierung
12
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 3:
Die Zustände der dritten Stufe (a, b und c) haben alle die drei Nachfolger d, e
und f, von denen aus die optimalen Politiken bis zum Endzustand (z) berechnet
sind: von d = 9, von e = 8 und von f = 7.
Zusammen mit den Übergangswerten ergeben sich jeweils die in der
nachfolgenden Tabelle den einzelnen Zuständen zugeordneten Minimierungen.
Das Ergebnis ist jeweils der Wert der optimalen Politik vom betrachteten
Zustand aus bis zum Ende (Zielfunktionswert) sowie der zugehörige
Nachfolgerknoten (Wert der zugehörigen Entscheidungsvariablen).
Dynamische Optimierung
13
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 3:
Stufe
k
Zustand
y
Nachfolger
N(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈N ( y )
3
{d
y , xi
}
+ f k*−1 ( xi* )
→ xk*
a
{d,e,f}
f3 (a) = min
{4 + 9; 2 + 8; 4 + 7} = 10 → x3* = e
b
{d,e,f}
f3 (b) = min
{2 + 9;5 + 8;6 + 7} = 11 → x3* = d
c
{d,e,f}
f3 (c) = min
{5 + 9;5 + 8;3 + 7} = 10 → x3* =
*
{d , e , f }
*
{d , e , f }
*
{d , e , f }
Dynamische Optimierung
f
14
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufe 4:
Die vierte (und letzte) Stufe hat nur noch einen – den Ausgangszustand s
mit drei Nachfolger: a, b und c.
Die Optimierung ergibt als Wert der optimalen Politik 16 und die Entscheidung,
den Nachfolger c zu wählen, will man die optimale Strategie verfolgen.
Stufe
k
Zustand
y
Nachfolger
N(y)
Rekursion
f k ( y ) = opt
Entscheidung
*
xi ∈N ( y )
4
s
{a,b,c}
f 4 ( s) = min
*
{ a ,b , c }
{d
y , xi
}
+ f k*−1 ( xi* )
→
xk*
{8 + 10;9 + 11;6 + 10} = 16 → x4* = c
Dynamische Optimierung
15
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Festlegen der optimalen Politik = Vorwärtrechnung
Nach Optimierung der Politik vom Startzustand aus, ist die Optimierung abgeschlossen.
Um den optimalen Weg durch das Stufen-Zustands-Diagramm festzulegen, werden nun
die getroffenen Entscheidungen in anderer Richtung gehend verfolgt. Dies ist in
diesem fall die Vorwärtrechnung.
Von s aus ist der optimale Nachfolger c.
Von dort aus hat man die optimale Politik bis zum Ende z einzuschlagen, die über den
Knoten f führt.
Der Zustand hat als optimalen Nachfolger den Konten g, von dem aus man den
Endzustand z erreicht.
Die optimale Politik ist also: s → c → f → g → z mit dem Wert 16.
Dynamische Optimierung
16
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Vorwärtsoptimierung
Es ist im Übrigen gleichgültig, ob man die Optimierung rückwärts oder vorwärts
durchführt. Die Festlegung der optimalen Strategie erfolgt dann stets in anderer
Richtung.
Bei umgekehrter Optimierung wird nicht der Restweg optimiert, sondern der
aus dem Ausgangszustand bis zum betrachteten Zustand zurückgelegte Weg.
Entsprechend werden die Zustände vom Vorgänger aus erreicht, für die die
optimale Strategie bereits bekannt ist.
Stufe
k
Zustand
y
Vorgänger
V(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈V ( y )
0
s
-
{f
*
(
x
i ) + d xi , y
k −1
*
}
→
xk*
0
Dynamische Optimierung
17
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufen 1:
Entsprechend werden die Zustände der nächsten beiden Stufen jeweils vom Vorgänger
aus optimiert:
Stufe
k
Zustand
y
Vorgänger
V(y)
Rekursion
Entscheidung
f k ( y ) = opt
*
xi ∈V ( y )
1
{f
*
(
x
i ) + d xi , y
k −1
*
}
→
xk*
a
{s}
f1 (a ) = min {0 + 8} = 8 →
x1* = s
b
{s}
f1 (b) = min {0 + 9} = 9 →
x1* = s
{s}
f1 (c) = min {0 + 6} = 6 →
x1* = s
c
*
{s}
*
{s}
*
{s}
Dynamische Optimierung
18
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufen 2
Stufe
k
2
Zustand
Y
Vorgänger Rekursion
*
V(y)
fk ( y) =
Entscheidung
opt
xi ∈V ( y )
{f
*
(
x
i ) + d xi , y
k −1
*
}
→
xk*
d
{a,b,c}
f 2 (d ) = min
{8 + 4;9 + 2;6 + 6} = 11 →
x2* = b, c
e
{a,b,c}
f 2 (e) = min
{8 + 2;9 + 5;6 + 5} = 10 →
x2* = a
f
{a,b,c}
f 2 ( f ) = min
{8 + 4;9 + 6;6 + 3} = 9
*
{a ,b ,c}
*
{a ,b ,c}
*
{a ,b ,c}
Dynamische Optimierung
→ x2* = c
19
Fachbereich Wirtschaftswissenschaften
BWL insb. Quant. Meth., Prof. Dr. D. Ohse
Stufen 3 und 4
Stufe
k
3
4
Zustand
Y
Vorgänger Rekursion
*
V(y)
f ( y) =
k
Entscheidung
opt
xi ∈V ( y )
{f
*
(
x
i ) + d xi , y
k −1
*
}
→
xk*
g
{d,e,f}
f3 ( g ) = min
{11 + 6;10 + 5;9 + 2} = 11 →
x3* = f
h
{d,e,f}
f3 (h) = min
{11 + 3;10 + 2;9 + 5} = 12 →
x3* = e
z
{g,h}
*
{d , e , f }
*
{d , e , f }
f 4 ( z ) = min {11 + 5;12 + 6} = 16 → x4* = g
*
{ g , h}
Optimale Politik: z ← g ← f ← c ← s mit dem minimalen Zielfunktionwert 16
Dynamische Optimierung
20