Grundlagen der Genetik und der Gentechnik
Werbung

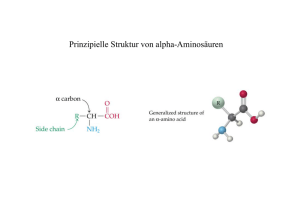
aktuell | ernährungslehre & -praxis Nr. 2 Februar 2008 „Gentechnik“. Der Begriff ist in aller Munde und auch die zugehörigen Produkte wähnt man ebendort und ist verunsichert. Im öffentlichen Diskurs werden statt Chancen meist nur Risiken gesehen, aber sachliche und fachlich korrekte Informationen über Hintergründe und Methodik der Gentechnik finden sich eher selten. Dem ein wenig abzuhelfen, ist Ziel einer kleinen Serie in Ernährungslehre & -praxis. ● Dr. Patricia Falkenburg Weidenweg 3 50259 Puhlheim Grundlagen der Genetik und der Gentechnik Teil 1: Nukleinsäuren und Proteine: Molekulare Bausteine des Lebens ● Im ersten Teil werden die molekularen Grundlagen der Genetik vorgestellt. Lesen Sie über die chemische Struktur von Nukleinsäuren und Proteinen und die biochemischen Zusammenhänge zwischen beiden sowie über ihre grundlegende Bedeutung in der Gentechnik. Die komplexe Biologie und Biochemie der Wissensbereiche Genetik, Gentechnik und Vererbungslehre können in dieser kleinen Einführung nur in stark verdichteter Form und mit einer Betonung der grundlegenden Zusammenhänge dargestellt werden. Für Detailinformationen sei hier auf entsprechende Lehrbücher der molekularen Genetik bzw. der Biochemie verwiesen. schreibung“ von auf der Nukleinsäure (meist DNA) hinterlegter Information in die jeweils benötigten Teilstücke (Boten- oder mRNA) – und die Translation – die „Übersetzung“ der Information auf der mRNA in die benötigten Proteine. Stellen wir uns die Erbinformation als umfassendes Handbuch zur Erstellung lebender Zellen vor, so ist die Transkription der zelluläre Prozess, der aus dem „Gesamtwerk“ die jeweils benötigten Seiten „herauskopiert“, die Translation, also die Proteinsynthese – wiederum bildlich betrachtet – ist die Herstellung eines Teils der Baustoffe und vor allem der Werkzeuge für alle weiteren biochemischen Schritte. Von der Erbinformation zum Produkt: ein Überblick Eine der bemerkenswertesten Eigenschaften der Nukleinsäuren ist es, dass sie aufgrund ihrer chemischen Struktur als Vorlage für die Erstellung genauer Kopien ihrer selbst dienen können. Dies ist ausschlaggebend nicht nur für die bereits genannte Transkription, sondern auch für die Replikation, („Verdoppelung“ von DNA-Molekülen – das „Gesamtwerk“ kann nach Bedarf im Ganzen vervielfältigt werden) bzw. die reverse Transkription (Umschreibung von RNA in DNA bei der Vermehrung von RNA-Viren – ein spezielles „Anleitungsheft“ wird in das „Gesamtwerk“ integriert). Nur so kann die genetische Betrachtet man die molekularen Grundbausteine alles Lebendigen, so findet man eine allgemein gültige Hierarchie von Biomolekülen: Nukleinsäuren (DNA oder RNA) stellen die genetische Information zur Verfügung, anhand derer Proteine synthetisiert werden, die ihrerseits in aller Vielgestaltigkeit den Aufbau sämtlicher weiterer Biomoleküle steuern. Wesentliche biochemische Prozesse sind dabei die Transkription – die „Um- Information, deren Träger die Nukleinsäure ist, vervielfacht und auf die Nachkommen weitergegeben werden. Das Detailwissen über diese grundlegenden Vorgänge ist im Verlauf der molekularbiologischen Forschung allmählich gewachsen: in allen Fällen sind die entscheidenden zellulären Werkzeuge Proteine, deren Einsatz durch Nukleinsäuren gesteuert wird. Neue Erkenntnisse wurden vielfach dadurch gewonnen, dass zelluläre Vorgänge mit den bereits identifizierten Komponenten in vitro (also „im Reagenzglas“) nachgestellt und weiter analysiert wurden. Diese Forschungsarbeiten sind eine der Grundlagen der Gentechnik, die reguläre zelluläre Prozesse zur planvollen, gezielten Veränderung des Erbguts nutzt, indem sie bestimmte Proteine – u. a. die Enzyme der Replikation, der Transkription, der Translation – einsetzt. Die veränderte („manipulierte“) Erbinformation wird sodann in Wirtszellen überführt, in denen sie den Vorgängen der Transkription und Translation zur Verfügung steht. Auch die „Einschleusung“ der gentechnisch veränderten DNA beruht auf der Nutzung normaler biologischer Vorgänge, die der Vererbung bzw. Weitergabe von genetischer Information zwischen verschiedenen Organismen dienen. Vo- Ernährungs Umschau | 2/08 B5 aktuell | ernährungslehre & -praxis raussetzung der Nutzung molekularbiologischer Kenntnisse im Rahmen der Gentechnik ist also genaues Wissen um die grundlegenden biochemischen und biologischen Vorgänge der Zellvermehrung, der Vererbung und der Expression der Erbinformation. Peptidbindungen NH3 -Ende COO H3N C H R Aminosäure (AS) allgemeine Struktur Molekülstrukturen COOH-Ende O H3 N N N R1 AS 1 O H R2 H O AS 2 H R4 N N R3 AS 3 H O AS 4 COO R5 AS 5 Peptid aus 5 Aminosäuren Polymere und Sequenzen Um diese Vorgänge im Einzelnen nachvollziehen zu können, müssen wir zunächst den chemischen Aufbau der beteiligten Moleküle verstehen. Sowohl Nukleinsäuren als auch Proteine sind komplexe, lineare Polymermoleküle, bestehen also aus sich wiederholenden Grundbausteinen (Monomeren), die auf immer die gleiche chemische Weise Abb. 2: Grundstruktur der Aminosäuren und allgemeiner Aufbau eines Peptids. miteinander verbunden sind (쏆 Abbildungen 1 und 2): ■ Nukleinsäuren sind aus Nukleotiden, ■ Proteine aus Aminosäuren aufgebaut. Dieses Prinzip – die unterschiedliche Kombination einer kleinen Anzahl verschiedener GrundbauHOCH HOCH O O steine zu Kolonnen großer OH OH Länge – ähnelt dem Zifferncode A OH OH OH H eines EDV-Programms (dort gibt Ribose (R) Desoxyribose (D) es nur die „Bausteine „0“ und O O NH „1“) und ermöglicht es, prakHC N NH NH tisch unbegrenzt viele InformaO O O tionen in DNA-Molekülen zu N N N H H H Thymin (T) Cytosin (C) Uracil (U) speichern bzw. in Proteine zu B O NH übersetzen. N N N NH Ein Nukleotid besteht aus einer N N NH Pentose (ein Zuckermolekül mit N N H H Adenin (A) Guanin (G) 5 Kohlenstoffatomen; Ribose bei der RNA – Ribonukleinsäure, Base engl. ribonucleic acid, DesoxyriN bose bei der DNA – DesoxyriboO N O C nukleinsäure, engl. deoxyriboO - P O CH2 Onucleic acid; 쏆 Abbildung 1A) Phosphatrest Pentose mit einer aromatischen Ring5´-Ende 3´-Ende struktur als Seitenkette (die „Basen“ Adenin, Thymin, Uracil, Guanin und Cytosin, abgekürzt A, T, U, G und C; 쏆 Abbildung H-BrückenA Bindungen G 1B) und einer Phosphatgruppe D C T (쏆 Abbildung 1C). CharakteriD D D D P P P P sierend für die einzelnen Nu3´-Ende 5´-Ende kleotide sind die basischen Seitenketten, wobei Adenin, Abb. 1: Aufbau der Nukleinsäuren. Ein Nukleotid Guanin und Cytosin bei DNA 쎻 C , der repetitive Grundbaustein der Nukleinsäuund RNA vorkommen, während A , einer ren, besteht aus einem Zuckermolekül 쎻 basischen Seitenkette 쎻 B und einem PhosphatThymin nur in der DNA und rest am C5-Atom des Zuckers. Über diese PhosUracil nur in der RNA gefunden phatgruppe werden die Nukleotide miteinander wird. Nukleotide werden über verbunden, wodurch ein lineares Zucker-Phosdie Phosphatgruppen zu langen, phat-Rückgrat entsteht. Im Falle der DNA lagern kettenförmigen Molekülen zusich zwei solcher Stränge in gegensinniger Richtung aneinander 쎻 D. sammengefügt. Pentosen 2 3 2 2 Nukleotid Purinbasen Pyrimidinbasen 2 2 P D C P D A P D T B6 Ernährungs Umschau | 2/08 Diese Moleküle können eine wirklich bemerkenswerte Länge erreichen: das einfache menschliche Genom (die Gesamtheit der menschlichen Erbinformation) besteht aus 3,2 Mrd. Basenpaaren, verteilt auf 23 Chromosomen. Die Gesamtlänge dieser DNA beträgt rund zwei Meter und das größte menschliche Chromosom (Chromosom 1) ist – vollständig entfaltet – ein durchgehendes Molekül von tatsächlich 8,4 cm Länge! Deutlich größere chemische Variabilität zeigen die Aminosäuren: 20 verschiedene Moleküle können je nach ihren chemischen Eigenschaften unterschiedlichen Klassen zugeordnet werden (basisch, sauer, neutral, bzw. aliphatische, aromatische oder heterozyklische Struktur). Diese unterschiedlichen Eigenschaften werden bestimmt von den Seitenketten des Aminosäuremoleküls („R“ in 쏆 Abbildung 2), das immer aus einem zentralen Kohlenstoffatom besteht, mit dem neben einem Wasserstoffatom und der genannten Seitenkette „R“ außerdem eine Aminogruppe (NH3-) sowie eine Carboxylgruppe (COOH-) verknüpft sind. Amino- und Säuregruppen gehen miteinander Peptidbindungen (-NH-CO-) ein und es ergibt sich der allgemeine Aufbau eines Polypeptidmoleküls (쏆 Abbildung 2). Jedes Polypeptid bzw. Protein trägt also an seinem einen Ende eine freie Aminogruppe, an seinem anderen Ende eine freie Carboxylgruppe. Bei der Aneinanderlagerung (Kondensation) von Aminosäuren reagiert die Carboxylgruppe der einen Aminosäure mit der Aminogruppe der anderen Aminosäure, es entsteht ein Peptid. Je nach Kettenlänge spricht man von Oligo- P D G peptiden (bis zu 10 Aminosäuren), Polypeptiden (etwa bis zu 100 Aminosäuren) bzw. Proteinen. Konfiguration im Raum Die Abfolge der jeweiligen Bausteine im Nukleinsäure- bzw. Proteinmolekül, die Sequenz, ist aber nur ein Teil seiner Struktur: chemisch spricht man von der Primärstruktur. Von ebenso großer Bedeutung ist die auf dieser Primärstruktur aufbauende räumliche Gestalt, die den Molekülen erst ihre Stabilität und Funktionsfähigkeit verleiht. Für die Sekundärstruktur der Nukleinsäuren ist die chemische Beschaffenheit der Basen wesentlich, die sich über Wasserstoffbrückenbindungen jeweils paarweise zusammenlagern können. So passen nach einem Schloss-und-SchlüsselPrinzip Adenin und Thymin (bzw. Adenin und Uracil) und Cytosin und Guanin zusammen. Diese Basenpaarungen ermöglichen das geregelte Aneinanderlagern von zwei Nukleinsäuresträngen. Hier zeigen sich nun auch weitere Unterschiede zwischen DNA und RNA. DNA kommt meistens als Doppelstrangmolekül vor, d. h. zwei DNAStränge mit komplementärer Basensequenz lagern sich aneinander (쏆 Abbildung 1 [D]), RNA hingegen ist meist ein Einzelstrang, der sich allerdings in sich selbst auffalten und zu doppelsträngigen Bereichen zusammenlagern kann. Dabei können sehr komplexe räumliche Strukturen entstehen – wie z. B. das typische „Kleeblatt“ bei der tranfer-RNA (tRNA), die für die Translation von entscheidender Bedeutung ist. Die Doppelstrangstruktur ist chemisch sehr stabil – und dies ist der Grund, warum in den meisten Organismen die Erbinformation als DNA vorliegt. Lediglich bestimmte Klassen von Viren haben ein RNA-Genom. Auch Proteine haben komplexe räumliche Strukturen. Bereits während der Translation bildet sich aus der Aminosäure-Sequenz (= Primärstruktur) der neu entstehenden Proteinkette die Sekundärstruktur, also die räumliche Zusammenlagerung der Aminosäuren. Wesentliche Strukturmerkmale sind dabei die α-Helix (also ein geschraub- ter Molekülfaden) und das β-Faltblatt mit Ziehharmonika-ähnlicher Struktur. Diese Sekundärstrukturen lagern sich zu übergeordneten räumlichen Gebilden zusammen und bilden damit die Tertiärstruktur. So werden Proteinabschnitte (= Domänen) und ganze Proteine komplex zusammengefaltet. Mehrere Proteine wiederum können sich zu Aggregaten zusammenfinden – eine komplexe Quartärstruktur entsteht. Dies ist z. B. der Fall bei vielen Enzymen oder dem Blutfarbstoff Hämoglobin, die aus mehreren Untereinheiten bestehen. Aber auch die Ribosomen, an denen die Translation abläuft oder die Histonkomplexe des Chromatins sind solche Proteinaggregate. Zerstört man – etwa durch Erhitzen beim Kochvorgang – die räumliche Struktur des Proteins (Eiweiß z. B. gerinnt), so geht damit auch die Funktion verloren. Chemisch nennt man dies Denaturierung. Wechselwirkungen untereinander Die komplexen Moleküle der Nukleinsäuren und der Proteine können nun auch in vielfältiger Weise miteinander in Wechselwirkung treten. Proteine binden an Nukleinsäuren ebenso wie sie untereinander in Kontakt treten können. So bilden Komplexe aus Proteinen und ribosomaler RNA (rRNA) die Ribosomen, die zellulären „Proteinfabri- ken“, an denen die Transkription abläuft. Hochkomplizierte Komplexe aus Proteinen und DNA bilden auch das Chromatin des Zellkerns in höheren Zellen. Erinnern wir uns an die Länge von DNA-Molekülen: nur weil die DNA der menschlichen Zellen im Chromatin verpackt ist, passt sie überhaupt in den Zellkern hinein. Diese Fähigkeit von Nukleinsäuren und Proteinen, miteinander zu interagieren, ermöglicht natürlich auch erst die Aktivität der in Replikation, Transkription und Translation wirksamen Enzyme. Moleküle und Nährstoffe Die meisten Organismen können die grundlegenden Syntheseleistungen zur Gewinnung der biochemischen Bausteine von Nukleinsäuren und Proteinen selbst erbringen. Auch im menschlichen Metabolismus können Zucker, Purin- und Pyrimidinbasen sowie viele Aminosäuren über natürliche Stoffwechselwege de novo, also aus anderen Ausgangsstoffen synthetisiert werden. Bestimmte Aminosäuren müssen allerdings mit der Nahrung aufgenommen werden, da wichtige Syntheseschritte aufgrund des evolutionären Verlustes der entsprechenden Enzyme nicht mehr durchgeführt werden können. Innerhalb der Zellen findet darüber hi- Kleiner Exkurs zur Natur chemischer Bindungen Chemisch sind die komplexen Strukturen der biologischen Makromoleküle nur möglich mittels so genannter „schwacher“ Bindungskräfte, die zwar stark genug sind, räumliche Strukturen zu stabilisieren, andererseits aber mit vergleichsweise geringem Energieaufwand wieder gelöst werden können. Zu nennen sind hier Wasserstoffbrückenbindungen, van-der Waals-Kräfte sowie Anziehung und Abstoßung von hydrophilen und hydrophoben Molekülgruppen, andererseits aber auch die ionische Anziehung zwischen unterschiedlich geladenen Molekülen. Entscheidend ist dabei die chemische Passgenauigkeit der Molekülgruppen, die miteinander in Wechselwirkung treten. Sie bildet die Grundlage der Wirkung von Enzymen. Nur weil solche Bindungen mit wenig Energieverbrauch geknüpft und gelöst werden können und weil andererseits das passgenaue Präsentieren von reaktiven Gruppen das Knüpfen fester chemischer Bindungen mit ebenfalls geringem Energieaufwand ermöglicht, ist die komplexe Chemie der DNA- und Proteinsynthese überhaupt unter zellulären Bedingungen möglich. Nur deshalb auch laufen die Methoden der Gentechnik unter den Bedingungen lebender Zellen ab: bei relativ niedriger Temperatur und niedrigem Druck im wässrigen Milieu. Ernährungs Umschau | 2/08 B7 쑺 aktuell | ernährungslehre & -praxis naus ein stetes „Recycling“ von Aminosäuren und auch Nukleotiden statt, die aus dem kontinuierlich stattfindenden Abbau von Proteinen und RNA stammen. Proteinverdauung Mit der Nahrung aufgenommene Proteine liegen – wie bereits erwähnt – in unterschiedlichem Ausmaß schon aufgrund des Kochvorgangs nicht mehr in ihrer ursprünglichen Konfiguration vor. Die weitere Denaturierung der Proteinmoleküle wird darüber hinaus im Magen durch die Magensäure bewirkt, in der die innermolekularen schwachen chemischen Bindungen aufgelöst werden. Bis zu welchem Grad die Proteine dabei denaturiert und somit verdaulich werden, hängt wesentlich von ihrer ursprünglichen Gestalt und biochemischen Konformation ab. Im Magen beginnt auch der eigentliche Abbau der Nahrungsproteine etwa durch das Enzym Pepsin. Es entstehen längere Peptidbruchstücke, die im Verlauf der weiteren Verdauung weiter zerlegt werden, bis nur noch einzelne Aminosäuren, Di- und Tripeptide übrig sind, die resorbiert werden können. Diund Tripeptide können durch spezielle Transportkanäle direkt in Zellen aufgenommen und dort in die einzelnen Aminosäuren aufgespalten werden. Die der Nahrung entstammenden Aminosäuren können nun ihrerseits direkt der Proteinbiosynthese zur Verfügung stehen, sie können aber auch in ganz andere Stoffwechselwege einfließen und z. B. als Rohstoffe für die Zuckersynthese genutzt werden (glucoplastische und ketoplastische Aminosäuren). Für die Proteinbiosynthese bedeutsam ist die Unterscheidung zwischen unentbehrlichen, konditionell unentbehrlichen und entbehrlichen Aminosäuren: während entbehrliche Aminosäuren im Organismus durch Biosynthesewege auch aus anderen Nahrungsbestandteilen „hergestellt“ werden können, müssen unentbehrliche Aminosäuren (Histidin, Valin, Leucin, Isoleucin, Lysin, Phenylalanin, Tryptophan, Methionin und Threonin) mit der Nahrung zugeführt werden. Konditionell unentbehr- liche Aminosäuren (Glycin, Prolin, Glutamin, Cystein, Arginin und Tyrosin) wiederum können bei besonderem Bedarf limitierend wirken, weil der natürliche Stoffwechselweg sie dann nicht mehr in ausreichender Menge zur Verfügung stellen kann [1]. Die Aminosäurekonzentration im Blut wird durch Regelmechanismen weitgehend konstant gehalten, um eine kontinuierliche Proteinbiosynthese unabhängig vom Nahrungsangebot zu gewährleisten. Maßgeblich ist hierbei der jeweilige Bedarf: bei körperlichem Training muss mehr Muskelmasse gebildet werden und der Bedarf steigt ebenso wie etwa bei der Abwehr von Krankheiten. Erinnern wir uns an die eingangs definierte Hierarchie der Moleküle, so wird klar, dass der Proteinsynthese entscheidende Bedeutung zukommt: ohne Proteine funktioniert im Körper nichts – es fehlen nicht nur strukturbildende Stoffe, Proteine fungieren auch als Hormone und sonstige Signalstoffe. Vor allem: Alle Enzyme sind Proteine, ohne sie kann praktisch keine biochemische Reaktion ablaufen. Verdauung von Nukleinsäuren Mit der Nahrung aufgenommene Nukleinsäuren werden im Dünndarm durch spezielle Enzyme, die Nukleasen, abgebaut. Sukzessive werden sie in Oligonukleotide, also kleinere Bruchstücke des Ausgangsmoleküls, und diese schließlich in Mononukleotide aufgespalten. Der Phosphatrest wird durch Phosphorylasen abgespalten und die entstehenden Nukleoside werden in ihren Zucker- und Basenanteil zerlegt. Absorbiert werden Nukleoside sowie in geringen Mengen die freien Basen. Die Konzentration an freien Basen wird aber niedrig gehalten, sie können weiter abgebaut werden, wobei die Pyrimidine vollständig zu CO2 und H2O zerlegt werden, wohingegen beim Abbau überschüssiger Purine bei Menschen Harnsäure entsteht, die letztendlich ausgeschieden wird. Immunonutrition Laut Hersteller bezeichnet die „Immunonutrition“ eine Form der klinischen Ernährung, die neben den üblichen notwendigen Nährstoffen zusätzlich Substanzen enthält, die das Immunsystem unterstützen und stärken sollen. Diese als „Immunonutrients“ bezeichneten Stoffe sind verschiedene Aminosäuren (Arginin, Glutamin, Glycin), RNS-Nukleotide sowie Omega-3Fettsäuren. Tatsächlich wird in einigen Studien beim Einsatz dieser Lösungen insbesondere etwa bei Krebspatienten bei Operationen im gastrointestinalen Bereich ein gewisser positiver Effekt im Sinne einer verringerten Komplikationsrate und schnelleren Wundheilung beobachtet [2]. Besondere Bedeutung scheint dabei dem Arginingehalt zuzukommen: Arginin ist eine semi-essenzielle Aminosäure und es wird vermutet, dass ihr erhöhter Bedarf in der gegebenen Krankheitssituation durch die vermehrte Gabe besser gedeckt wird. Während in diesem Fall die positive Wirkung biochemisch also gut nachvollziehbar ist und auch experimentell aufgezeigt werden kann, ist dies für den Zusatz der RNANukleotide nicht der Fall. Ihre immunmodulierende Wirkung ist nicht nachgewiesen, biochemisch können sie wie oben dargestellt aus den normalen Bestandteilen der Ernährung ohne Limitationen synthetisiert werden. Literatur ● 왎 1. Gaßmann, B (2006) Aminosäuren und Proteine. Teil 1: Aminosäuren. Ernährungs Umschau 53: 137–141 2. McCowen u. Bistrian (2003) Immunonutrition: problematic or problem solving. Am J Clin Nutr 77: 764–770. Weiterführende Literatur Lesen Sie in Teil 2: Vom Gen zum Organismus – Woher weiß die Zelle, wo ein Gen anfängt und wo es aufhört? ● 왎 Aubele M. Genetik für Ahnungslose. S. Hirzel, Stuttgart (2007) „Ernährungslehre und -praxis“, ein Bestandteil der „Ernährungs Umschau“. Verlag: UMSCHAU ZEITSCHRIFTENVERLAG Breidenstein GmbH, Sulzbach/Ts. Zusammenstellung und Bearbeitung: Dr. Eva Leschik-Bonnet, Deutsche Gesellschaft für Ernährung, Dr. Udo Maid-Kohnert, mpm Fachmedien (verantwortlich). B8 Ernährungs Umschau | 2/08