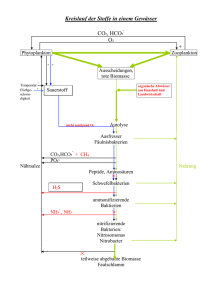
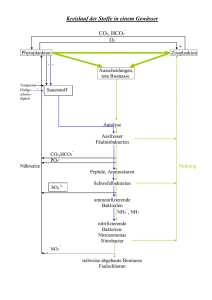
10. Übung (Korrelation und lineare Regressionsanalyse) Es wird
Werbung
 Es wird")
Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 10. Übung (Korrelation und lineare Regressionsanalyse) Es wird untersucht, ob ein linearer Zusammenhang zwischen zwei Variablen besteht. Mit anderen Worten: ob ein solcher Zusammenhang gibt, wenn der beobachteter Wert einer Variable grösser ist dann der entsprechende Wert der anderen Variable charakteristischerweise grösser (oder kleiner) ist. So entsteht ein positiver (oder negativer) Zusammenhang. Im Falle der Regressionsanalyse kann man dieser Zusammenhang formelmäßig auch angeben. Mit Hilfe der linearen Regression kann man nur lineare oder durch eine Transformation linear umgeformte Zusammenhänge untersuchen. z.B. wenn die Werten einer Variable zwischen -3 und 3 ändern und die andere Variable ist der Quadrat der ersten drei ganzen Zahlen, dann mit Hilfe der linearen Regression kann keinen Zusammenhang angeben, weil dieser Beziehung im Intervall (-3, 0) negativ und im Intervall (0,3) positiv ist. Mit einer linearen Formel lässt sich diesen Zusammenhang nicht anzugeben. Hier wird der theoretische Hintergrund wegen der knappen Erfassung nicht erläutert. Man muss hier der Gefahr betont werden, dass man ohne theoretische Kenntnisse oft zu einer falschen Folgerung kommen kann. Es werden die Blutparameter zu den Untersuchungen gebraucht. Eine Gedächtnisstütze für die Scatterplot-Matrix An der 3. Übung wurde die Anfertigung der Scatterplot-Matrix erläutert. Mit deren Hilfe kann man gleichzeitig mehrere Variable miteinander vergleichen, ob man dabei einen Zusammenhang erkennen kann. Zu dieser Abbildung kehrt man immer wieder zurück. Börzsönyi L. 1 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 Korrelation Die Korrelationen unter der Variablen kann man durch das folgende Menü: Statistics/Summaries/Correlation matrix angeben. Mit Hilfe der Ctrl-Taste kann man auch mehrere Variablen auswählen (markieren). Zu den stetigen Variablen braucht man lieber den Pearsonschen Korrelationskoeffizient, zu diskreten ist es besser den Spearmanschen Korrelationskoeffizient zu brauchen. Zum Schluss kann man eine Hypothesenprüfung zu bitten: Das erhaltene Ergebnis besteht aus die Tabellen: > rcorr.adjust(Blut[,c("HB","HCO3","K","pCO2","pH","PO2")], type="pearson") HB HCO3 K pCO2 pH PO2 HB 1.00 0.21 0.02 0.10 0.15 0.25 HCO3 0.21 1.00 -0.38 0.74 0.76 -0.22 K 0.02 -0.38 1.00 -0.35 -0.29 0.40 pCO2 0.10 0.74 -0.35 1.00 0.23 -0.39 pH 0.15 0.76 -0.29 0.23 1.00 -0.07 PO2 0.25 -0.22 0.40 -0.39 -0.07 1.00 n= 69 Diese Tabelle erscheint für alle Fälle, was die Korrelationskoeffizienten enthält. Eine positive (negative) Zahl weist auf eine positive (negativen) Beziehung hin. Wenn alle Punkten im Scatterplot an einer Gerade anpassen, dann entsteht perfekte (am stärksten) Korrelation. In diesem Falle kann man einen genauen funktionalen Zusammenhang, die Gleichung der entsprechenden Gerade y=ax+b angeben. Wenn a>0 (a<0) ist, dann hat man eine positive (negative) Korrelation und nun der Korrelationskoeffizient ist +1 (-1). In der vorigen Tabelle, in der Hauptdiagonale liegen lauter 1. Das ist selbstverständlich, nämlich das ist die Korrelation einer Variablen mit sich selbst. Manchmal spricht und schreibt man über eine „starke“, „mittlere“ und „schwache“ Korrelation. Es soll nicht bedeuten, dass der Korrelationskoeffizient nach der vorigen Terminologie unbedingt im Intervallen [0.75, 1], [0.5, 0.75] und [0.25, 0.5] liegen müsste. Diese Charakterisierung braucht man ziemlich frei und nicht offiziell. Aus der vorliegenden Tabelle kann man darauf schließen, dass zwischen den Variablen pH und HCO3 eine starke Korrelation bzw. zwischen pH und PO2 eine sehr schwache Korrelation besteht. Wenn der Korrelationskoeffizient Null ist, dann zwischen den zwei Variablen kein linearer Zusammenhang besteht. Es bedeutet keine Unabhängigkeit, andere Zusammenhänge (z.B. quadratische usw.) können vorliegen. Den Wert genau Null bekommt man kaum, der Börzsönyi L. 2 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 Korrelationskoeffizient liegt meist bei null. Es ist nicht einfach zu entscheiden, ob ein linearer Zusammenhang zwischen zwei Variablen besteht oder er ist sehr schwach. Man kann eine Hypothesenprüfung durchführen, wobei die Nullhypothese ist: der Korrelationskoeffizient ist Null. Man muss um den paarigen Variablenvergleich bitten und dann bekommt man die folgende Tabelle: P HB HB HCO3 K pCO2 pH PO2 0.0878 0.8673 0.3958 0.2228 0.0416 HCO3 K 0.0878 0.8673 0.0014 0.0014 0.0000 0.0029 0.0000 0.0172 0.0745 0.0008 Adjusted p-values HB HCO3 HB 0.4467 HCO3 0.4467 K 1.0000 0.0153 pCO2 1.0000 0.0000 pH 0.8912 0.0000 PO2 0.3327 0.4467 pCO2 0.3958 0.0000 0.0029 pH 0.2228 0.0000 0.0172 0.0601 0.0601 0.0010 0.5558 (Holm's method) K pCO2 pH 1.0000 1.0000 0.8912 0.0153 0.0000 0.0000 0.0286 0.1547 0.0286 0.4210 0.1547 0.4210 0.0099 0.0123 1.0000 PO2 0.0416 0.0745 0.0008 0.0010 0.5558 PO2 0.3327 0.4467 0.0099 0.0123 1.0000 Die Korrektion von Bonferroni oder Holm Von den vorigen zwei Tabellen die obere zeigt das Ergebnis des paarigen Vergleichs. Einfach zu sehen, dass es zwischen HCO3 und pH ein signifikanter Zusammenhang gibt (der Korrelationskoeffizient abweicht signifikant von Null, p<0.001). Bis z.B. zwischen pH und PO2 gibt es kein signifikanter Zusammenhang, weil p=0.558 ist. In Praxis braucht man diese Tabelle doch nicht, weil die Wahrscheinlichkeit für Fehler erster Art bei jedem Vergleich 5% ist. Mit anderen Worten, wenn man die H0 Hypothese ablehnt, dann irrt man durchschnittlich mit 5% Wahrscheinlichkeit, d.h. aus 100 Fällen irrt man 5-mal. Man könnte etwa auch sagen, dass man aus 20 Fällen durchschnittlich 1-mal irrt. Bei der vorliegenden Aufgabe hat man 15 verschiedenen Vergleichen gemacht. Es ist schon ziemlich nahe zu 20 ist! In solchen Fällen werden die p-Werten korrigiert, dass der Irrtum insgesamt 5% sei. Die Bonferronische Korrektion besteht darin, dass er im Falle von 15 Untersuchungen die erhaltenen p-Werte durch 15 multiplizierte. Wenn er einen von 1 größeren Wert bekommen hat, dann hat er den 1 betrachtet. Die H0 Hypothese hat er dann ablehnt, wenn der erhöhte p-Wert derart noch immer unter 5% war. Später wurde festgestellt, dass diese Methode zu streng ist. Neulich braucht man die Holmsche Korrektion, dessen Ergebnisse sind in der zweiten Tabelle zu finden. Auf Grund der Holmsche Korrektion kann man folgendes Festlegen. Zwischen den folgenden Paaren gibt es ein signifikanter Zusammenhang: HCO3-K, HCO3-PCO2, HCO3-pH, K-PCO2, PCO2PO2. Lineare Regression Mit Hilfe der linearen Regression kann man den Zusammenhang zwischen zwei Variablen zahlenmäßig auch ausdrücken. In gewissen Fällen ist es auch dafür zu brauchen, dass man in Kenntnisse einer Variablen durch die erhaltene Formel den Wert der anderen Variablen schätzen kann. Damit muss man vorsichtig sein, nämlich man ist daran gewöhnt, wenn man durch eine Formel etwas im Koordinatensystem darstellt, dann der an der x-Achse liegende Börzsönyi L. 3 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 Wert den zugehörigen y-Wert bestimmt, wenn zwischen den Variablen ein kausaler Zusammenhang besteht. Die von uns untersuchten Variablen gilt es nicht! Man muss darauf auch achten, dass die zwei Variablen im Falle der Korrelationsanalyse symmetrisch sind. Wenn die Rolle der Variablen umgetauscht wird, dann bekommt man das selbe Ergebnis. Im Falle einer Regressionsuntersuchung ist die Rolle der zwei Variablen völlig verschieden. Betrachte man den Zusammenhang zwischen HCO3 und pCO2: Es ist ganz klar zu sehen, wenn die Werte einer Variablen wachsen, dann die Werte der anderen Variablen auch wachsen. Man schaue nach, wie? Man wähle das Menü: Statistics /Fit models/Linear regression Man muss nur die Variablen zu der waagerechten und vertikalen Achse (unabhängiger und abhängiger Variablen) bestimmen und danach gibt man eine Name dem anfertigenden Modell. Das Ergebnis ist: > RegModel.1 <- lm(pCO2~HCO3, data=Ver) > summary(RegModel.1) Call: lm(formula = pCO2 ~ HCO3, data = Ver) Residuals: Min 1Q -15.4467 -3.2860 Median -0.3617 3Q 2.1483 Max 15.9569 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 18.9931 2.0713 9.170 1.67e-13 *** Börzsönyi L. 4 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 HCO3 0.9842 0.1069 9.208 1.42e-13 *** --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 5.41 on 68 degrees of freedom Multiple R-squared: 0.555, Adjusted R-squared: 0.5484 F-statistic: 84.79 on 1 and 68 DF, p-value: 1.422e-13 Die Koeffizienten ergeben die Parameter des Modells. In unserem Falle hat man den nächsten Zusammenhang: PCO2=0.9842 HCO3 + 18.9931 Die sind nur Schätzungen und ihre Genauigkeit kann man von den Ergebnissen auch ablesen. Der Koeffizient von HCO3 liegt z.B. im Intervall 0.9842 2 0.1069 ungefähr mit 95% Sicherheit. Am Ende der Zeilen sind die p-Werten. Der p-Wert ist im Falle der X-Ache-Schnitt nicht so vielsprechend, aber die anderen p-Werte sind sehr wichtig. Von diesen Werten kann man ablesen, ob die Wirkung des vorliegenden Parameters die unabhängige Variable signifikant beeinflusst. In unserem Falle ist die Wirkung von HCO3 signifikant. (Es werden später solche Ergebnisse ergeben, wobei die Ergebnisse mehrere Zeilen haben.) Der R2-Wert (R-sqared) ist auch wichtig. Das ist das Quadrat des Korrelationskoeffizienten und sie heißt Bestimmungsmaß. Der R2-Wert drückt aus, dass die Änderung der Werte von unabhängigen Variablen in welchem Verhältnis der Änderung der Werte der abhängigen Variable erklärt. Modelldiagnostik Die Anwendung der Regression hat noch Voraussetzungen. Wenn die nicht erfüllen, dann die erhaltenen Ergebnisse sind falsch. Diese Voraussetzungen werden durch einen Inaugenscheinnahme überprüft. Man kann merken, dass die vorher angegebene Modellname auf den Bildschirm erscheint. Wenn man auf die blaue Beschriftung klickt, dann kann man unter den Modelle genau so wählen, wie früher unter den eingefüllten Datenmengen. Es ist wichtig, dass man ganz am Anfang der Diagnostik das passende Modell ausgewählt wird! Man wähle das folgende Modell: Models/Graphs/Basic diagnostic plots Man bekommt vier Grafiken: Hier hat man die sogenannten Residuen. Vorher hat man die Formel PCO2=0.9842 HCO3 + 18.9931 bekommen, womit der Zusammenhang zwischen den zwei Variablen am besten abschreiben kann. Durch den Formel erhalten Wert sind nicht gleich mit den richtigen Börzsönyi L. 5 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 gemessenen PCO2 Werten! Die Differenz der berechneten und gemessenen Werte sind die Residuen. An dieser Abbildung sieht man das Wesen. Die Punktwolke ist nicht hufeisenförmig (d.h. an den rechten und linken Seiten sind die Werte niedriger als in der Mitte) und die Breite der Punktwolke wächst und vermindert sich nicht, wenn man nach rechts geht. An dieser Abbildung will man die normale Verteilung der Residuen kontrollieren. Der größte Teil der Punkte muss auf einer Gerade anpassen. Es ist hier in Ordnung. An dieser Abbildung sind einige Werte, die 2.0 annähern. Die über 2 liegenden Werte können Ausreiser (vorspringende Werte) sein. Wenn man einen vorspringender Wert vorkommt, dann sieht man ihre Ordinalzahlen an der Abbildung. Man überprüfe, ob der Wert zu glauben ist. Es gibt kein Schreibfehler oder Messfehler! Die letzte Abbildung zeigt die missgebildeten Punkte, wenn die existieren. Die Punkte, die außer der Linie 1 liegen, können die Ergebnisse völlig deformieren. Wenn solche Punkte Börzsönyi L. 6 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 vorkommen, dann fertige man die Untersuchung auch ohne diese Punkt immer an! (Die einfachste Methode ist diesen Punkt von der Tabelle löschen.) Hausaufgabe: Löschen sie die 20. Beobachtung und wiederholen sie die Untersuchung! Vergleichen sie die Ergebnisse! (Es gibt kein allgemeines Rezept zu entscheiden, welches Ergebnis ist gut. Man muss von fachlicher Seite her unterstützen, in dem hilft die Mathematik nicht mehr.) Auf linear zurückführbare Regression Es kommt oft vor, dass ein Zusammenhang zwischen zwei Variablen besteht, aber das ist nicht mehr linear. z.B. so einer ist der Zusammenhang zwischen HCO3 und pH. In solchen Fällen kann man den Logarithmus einer oder der anderen oder aber der beiden Variablen bilden, wenn es von fachlicher Seite her sinnvoll ist. Für die transformierten Variable(n) lässt sich die lineare Regression durchführen. Man gehe aus der Gleichung y=a xb aus. Die Gleichung ist nicht mehr linear, wegen der Potenzfunktion. Diese Gleichung ist durch Logarithmieren linearisierbar. Nämlich die Gleichung lny=lna+b lnx ist schon in x linear. d.h. man muss die abhängige und unabhängige Variable logarithmieren. (ln entspricht in R log (ln log)) Die transformationsbefehle in R sind folgende: Blut$logHCO3=log(Blut$HCO3) Blut$logpH=log(Blut$pH) Man vergesse nicht den Menüpunkt: Data/Active data set/Refresh active data set wenn man die neue Variablen brauchen will. Die lineare Regression: Das Ergebnis der linearen Regression: lm(formula = logpH ~ logHCO3, data = Blut) Residuals: Min 1Q -0.0193514 -0.0046217 Median 0.0007653 3Q 0.0057344 Max 0.0179833 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.897611 0.007938 239.05 <2e-16 *** logHCO3 0.032063 0.002760 11.62 <2e-16 *** --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Börzsönyi L. 7 Vet. Med. Uni. Budapest 10. Übung Biomathematik 2017 Residual standard error: 0.008243 on 68 degrees of freedom Multiple R-squared: 0.665, Adjusted R-squared: 0.6601 F-statistic: 135 on 1 and 68 DF, p-value: < 2.2e-16 Die Gleichung der Gerade: logpH = 0.032 logHCO3 + 1.8976 Man kann schreiben: ln pH = 0.032 ln HCO3 + 1.8976 Die Gleichung muss man entlogarithmieren: pH = e1.8976 HCO30.032 Man berechne die Zahl e1.8976 In R gilt: exp(1) = e, dann ist exp(1.8976) = 6.669868 gerundet 6.67 Unser nichtlinearer Zusammenhang ist: pH = 6.67 HCO30.032 Die Modelldiagnostik bei der linearen Regression ist folgendes: Vom „Component+residual plot…“ kann man ahnen, dass es eine bessere Regression, als die lineare auch gibt. Hier ist der Bestimmtheitsmaß: R2 = 0.665. Börzsönyi L. 8