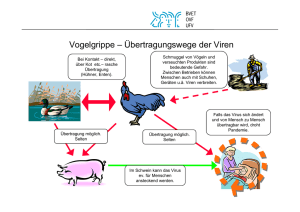
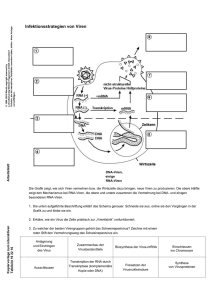
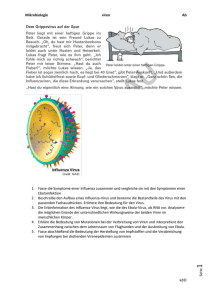
Eine exemplarische Untersuchung von Schülervorstellungen zu
Werbung

Eine exemplarische Untersuchung von Schülervorstellungen zu Phänomenen in der Schul-Informatik schriftliche Hausarbeit gemäß § 30 LPO I (2002) Robert Klaus LAG Inf/M Ludwig-Maximilians-Universität München Sommerhalbjahr 2012 Zusammenfassung Es wird ein Modell zur Erforschung von Schülervorstellungen zu informatischen Phänomenen vorgestellt. Dieses beinhaltet zwei Stufen: Erstens wird eine Möglichkeit aufgezeigt, geeignete Phänomene auszuwählen. Zweitens werden Personen zu diesem Phänomen befragt und die Antworten ausgewertet. Dies geschieht mittels Interviews, die einer Qualitativen Inhaltsanalyse unterzogen werden [MAYRING, 2008]. Deren Ergebnisse werden auf statistische Auffälligkeiten hin untersucht, sowie mittels Begriffsnetzen visualisiert. Als theoretische Basis dient dabei das Modell der Didaktischen Rekonstruktion nach [DIETHELM ET AL., 2011A]. Zusätzlich werden Elemente der Informatik im Kontext [ENGBRING & PASTERNAK, 2010] miteinbezogen. Einer theoretischen Einführung folgt eine Demonstration des Verfahrens anhand einer empirischen Untersuchung mit etwa 100 Teilnehmern zum Phänomen des Computer-Virus. Diese Arbeit entstand als schriftliche Hausarbeit im Rahmen der Zulassung zum ersten Staatsexamen für das Lehramt an bayerischen Gymnasien und wurde durch PROF. DR. PETER HUBWIESER (Leiter des Fachgebietes Didaktik der Informatik an der TUM School of Education) angeregt und betreut. Abstract A model for the investigation of students' conceptions towards computer science phenomena is presented. This includes two steps: First, a way to select suitable phenomena is shown. Second, people are asked about this phenomenon and the responses are evaluated. This is done through interviews, which are undergone qualitative content analysis [MAYRING, 2008]. The results are analyzed toward statistical anomalies and visualized using concept maps. The theoretical basis for this is the model of Educational Reconstruction by [DIETHELM ET AL., 2011A]. In addition, elements of Computer Science in Context by [ENGBRING & PASTERNAK, 2010] are incorporated. An theoretical introduction is followed by a practical demonstration of the method based on an empirical study with about 100 participants. In this study the phenomenon of computervirus is examined. This paper was written as part of admission to the erstes Staatsexamen for going-to-be teachers at Bavarian schools and was suggested and supported by PROF. DR. PETER HUBWIESER (Head of the department for Didactics of Computer Science at the TUM School of Education). 3 Inhaltsverzeichnis 1. Einleitung"............................................................................................................7 2. Theoretische Grundlage"....................................................................................8 2.1. Didaktische Rekonstruktion"..............................................................................8 Hintergrund Didaktische Rekonstruktion für die Informatik 2.2. Kontexte und Phänomene"................................................................................12 Kontexte Informatik im Kontext (IniK) Phänomene 2.3. Schad-Software"..................................................................................................14 Viren Würmer Trojanische Pferde Zusammenfassung 3. Verwandte Arbeiten"........................................................................................16 Didaktische Rekonstruktion Phänomene und Kontexte Schülervorstellungen Lehrerperspektiven 4. Allgemeine Forschungsmethoden"................................................................17 4.1. Qualitative Inhaltsanalyse"...............................................................................17 Begriffe Kodierung 4.2. Statistische Tests".................................................................................................18 U-Test nach Wilcoxon, Mann und Whitney Chi-Quadrat-Homogenitätstest Gauß-Test 5. Konkrete Durchführung".................................................................................22 5.1. Erste Befragung (Phänomene)".........................................................................22 Überblick Kodierung 5.2. Zweite Befragung (Schülerperspektiven)"......................................................22 Überblick / Stichprobe Kodierung 5.3. Begriffsnetze".......................................................................................................23 Dokument-Netze Kategorie-Netze Verwendete Software 6. Ergebnisse".........................................................................................................25 6.1. Erste Befragung (Phänomene)".........................................................................25 Zusammensetzung der Stichprobe Kodierung Auswertung 6.2. Zweite Befragung (Schülerperspektiven)"......................................................29 Zusammensetzung der Stichprobe Kodierung Auswertung 6.3. Begriffsnetze".......................................................................................................33 Dokumentnetze 4 Kategorienetze 6.4. Statistische Tests".................................................................................................40 U-Test nach Wilcoxon, Mann und Whitney Chi-Quadrat-Homogenitätstest Gauß-Test Bewertung der Tests 7. Diskussion"........................................................................................................44 Überblick Bewertung / Nutzen 8. Weitere Forschungsrichtungen"......................................................................46 9. Danksagungen".................................................................................................47 10. Quellenverzeichnis"..........................................................................................49 11. Anhang"..............................................................................................................54 11.1. 11.2. 11.3. 11.4. 11.5. Anhang 1. exemplarischer Bogen zur ersten Befragung".............................54 Anhang 2. exemplarischer Bogen zur zweiten Befragung"..........................55 Anhang 3. Datenmatrix des Dokumentnetz zu G1"......................................56 Anhang 4. Datenmatrix des Dokumentnetz zu G2"......................................58 Anhang 5. Datenmatrix des Dokumentnetz zu G3"......................................59 12. Erklärung gem. § 30 Abs. 6 LPO I (2002)".....................................................61 5 1. Einleitung "In der Informatik gibt es bisher außerhalb der Programmierung wenig Forschung zu Schülervorstellungen von bestimmten informatischen Sachverhalten", [DIETHELM ET AL., 2011A; S. 82] Diese Arbeit soll einen Beitrag dazu leisten, diesen Mangel zu lindern. Zu diesem Zweck wird eine Kombination von Forschungsmethoden vorgestellt und diese nach einer theoretischen Einführung anhand eines konkreten Beispiels aus der Unterrichtsforschung verdeutlicht. Der zugrundeliegende Gedanke dabei ist, dass Unterrichtsplanung nicht von den fachlichen Inhalten ausgehen soll, sondern die Inhalte erst ausgewählt werden können, wenn die Sichtweise der Schüler ausreichend gewürdigt wurde. Dieser Ansatz wird seit einiger Zeit im Zuge der Informatik im Kontext diskutiert (vgl. u.A. [ENGBRING & PASTERNAK, 2010], [DIETHELM & DÖRGE, 2011]). Dies möchte ich mit dem Modell der Didaktischen Rekonstruktion verknüpfen, da in der Fassung von DIETHELM ET AL. eben die Schülerperspektive eine wichtige Dimension darstellt. Konkret wird zuerst nach den Schülern bekannten bzw. sie interessierende Phänomenen der Informatik gesucht. Im zweiten Schritt wird dann eine Möglichkeit aufgezeigt, die Schülerperspektive bezüglich eines dieser Phänomene genauer zu untersuchen. Dabei wird hier das Phänomen des Computer-Virus betrachtet. Hierzu werden nacheinander zwei Befragungen durchgeführt und mittels Qualitativer Inhaltsanalyse untersucht. Um die Ergebnisse abzusichern folgt eine Reihe von statistischen Tests. Zusätzlich werden die Ergebnisse durch Graphen veranschaulicht, welche an concept maps angelehnt sind. Dabei sind weniger sofort nutzbare Ergebnisse das Ziel, als vielmehr eine Möglichkeit aufzuzeigen, Schüler-gerechte Phänomene auszuwählen um sie anschließend genauer untersuchen zu können. Um darüberhinaus direkt zur Planung und Gestaltung von Informatikunterricht beitragen zu können bedarf es weiterer Forschung. Diese Arbeit kann dazu hoffentlich als Grundlage dienen. Teile der hier vorgestellten Ergebnisse flossen bereits in [DIETHELM ET AL., 2012] ein. Dieser Artikel wurde soeben zur Koli Calling Conference zugelassen und wird an deren Anschluss veröffentlicht. 7 2. Theoretische Grundlage 2.1. Didaktische Rekonstruktion Um Unterricht im Allgemeinen – sowie Planung, Vorbereitung und Unterrichtsforschung im Speziellen – zu erforschen, braucht es einen theoretischen Unterbau, ein angemessenes Modell: Ich verwende hier das der Didaktischen Rekonstruktion in der erweiterten Form von DIETHELM ET AL.. Hintergrund Die Grundlage für die Rekonstruktion des Informatikunterrichts findet sich Mitte der 90er Jahre bei KATTMANN & GROPENGIEßER für die Biologie-Didaktik. Trotzdem war der Ansatz allgemein-didaktisch als Möglichkeit zur strukturierten Erfassung von naturwissenschaftlichen Unterricht gedacht. Dabei wird betont, dass "die Gegenstände des Schulunterrichts [..] als solche nicht vom Wissenschaftsbereich vorgegeben [sind]" und daher "in pädagogischer Zielsetzung erst hergestellt, d.h. didaktisch rekonstruiert werden [müssen]" [KATTMANN ET AL., 1997; S. 3]. Das Ziel ihres Ansatzes beschreiben sie an selber Stelle so: "Mit dem Modell der Didaktischen Rekonstruktion werden fachliche Vorstellungen […] mit Schülerperspektiven so in Beziehung gesetzt, dass daraus ein Unterrichtsgegenstand entwickelt werden kann." Bei der Didaktischen Rekonstruktion stehen drei "Module" in Beziehung: Fachliche Klärung, Erfassen von Schülerperspektiven und Didaktische Strukturierung. Dabei beeinflussen "die Ergebnisse der fachlichen Klärung [..] nicht nur den Umgang mit den Schülervorstellungen, vielmehr beeinflussen auch umgekehrt die erfassten Schülervorstellungen das Verständnis und die Darstellung der fachlichen Positionen". Mit dieser Grundlage können dann Unterrichtseinheiten strukturiert und angemessene "Lernwege" für die Schüler geplant werden. [KATTMANN ET AL., 1997; S. 5] Das Verfahren ist dabei iterativ und erfordert notwendigerweise "eine Vorgehensweise, die mit vorläufigen Untersuchungsergebnissen und wiederholten Perspektivenwechseln arbeitet" [KATTMANN ET AL., 1997; S. 13]. Die Beeinflussungen und Abhängigkeiten zwischen den Modulen werden im "Fachdidaktischen Triplett" dargestellt (Abbildung 1 nach [KATTMANN ET AL., 1997; S. 4]). Abbildung 1. Fachdidaktisches Triplett 8 Auf die einzelnen Bereiche soll hier noch nicht eingegangen werden. Ich wende mich direkt der Erweiterung dieses Modells zu – dort folgen ausführliche Erläuterungen, die auch auf dieses Modell zutreffen. Didaktische Rekonstruktion für die Informatik DIETHELM und ihre Arbeitsgruppe wollten dieses Modell auch für die Informatik – "sowohl in der Forschung als auch in der Unterrichtsplanung" [DIETHELM ET AL., 2011A; S. 77] – nutzbar machen. Dabei bemängeln sie allerdings die Nichtbeachtung der Lehrerperspektive, sowie der gesellschaftlichen Ansprüche. Und zurecht weisen sie auch darauf hin, dass "in der heutigen Welt [..] der Einfluss der Informationstechnologie im Alltag [..] immer größer [wird]", sich dabei aber "immer seltener sichtbar auf Informatiksysteme [bezieht]". Daher plädieren sie für eine stärker Beachtung des Phänomen-Begriffs um "den Schülern eine Sicht auf die Wirklichkeit der Welt aus dem Blickwinkel [der Informatik] zu erschließen um damit die Phänomene des Alltag erklären zu können". [DIETHELM ET AL., 2011A; S. 79] Durch Hinzunahme dieser zusätzlichen Dimensionen ergibt sich das Modell der Didaktischen Rekonstruktion für die Informatik (Abbildung 2 nach [DIETHELM ET AL., 2011A; S. 80]). Abbildung 2. Modell der Didaktischen Rekonstruktion Wie schon in KATTMANNs Modell beeinflussen sich die unteren Module gegenseitig, welche dann als Grundlage der didaktischen Struktur des Unterrichts dienen (vgl. die Pfeile in Abbildung 2). Dabei kommt es unter Anderem zwischen der didaktischen Struktur und den Phänome- 9 nen zu einer Wechselwirkung: Entscheidet man sich während der Strukturierungsphase für ein anderes, geeigneteres Phänomen, so ist eine Neubewertung auch der übrigen Aspekte notwendig [DIETHELM ET AL., 2011A; S. 80]. Im Folgenden will ich auf die einzelnen Aspekte genauer eingehen. Fachliche Klärung Als Ausgangspunkt der Rekonstruktion von Unterricht dient klassischerweise das Fach selbst. Die fachliche Klärung ist die Reflexion fachlicher Fragestellungen und Themen vor dem Hintergrund der Didaktik oder in der Formulierung von [KATTMANN ET AL., 1997; S. 11] die "kritische und methodisch kontrollierte systematische Untersuchung wissenschaftlicher Theorien, Methoden und Termini unter Vermittlungsabsicht". Dabei erfordern "[…] unterschiedliche Vermittlungsabsichten [..] unterschiedlich akzentuierte fachliche Klärungen" [KATTMANN ET AL., 1997; S. 14]. Die prinzipielle Notwendigkeit eine passende und korrekte Erklärung für das fragliche Thema zu finden steht dabei an erster Stelle. Da die Informatik aber in nahezu allen unterrichtsrelevanten Gebieten wenig Spielraum für Interpretationen oder persönliche Theorien lässt, "geht es in der fachlichen Klärung für die Informatik nicht so sehr darum, die »richtige« Erklärung auszuwählen", sondern "festzulegen, in welcher fachlichen Tiefe das Thema unterrichtet werden soll und welche für den Unterricht vereinfachten Modelle […] verwandt werden können" [DIETHELM ET AL., 2011A; S. 82]. Erfassung von Schülerperspektiven Allerdings besteht auch die Möglichkeit, den Rekonstruktions-Prozess von der Schüler-Seite zu beginnen. Da aber ohnehin kein Aspekt isoliert, sondern immer einschließlich der Wechselwirkungen mit dem gesamten Modell betrachtet werden soll, ist die Frage des Startpunkts von untergeordneter Bedeutung.1 Wurde während der fachlichen Klärung die Frage der angemessenen fachlichen Tiefe beantwortet, so ist einsichtig, dass dies ohnehin nur unter Berücksichtigung der Lernvoraussetzungen der von dieser Planung betroffenen Schüler sinnvoll möglich ist. Dabei sind insbesondere bereits bestehende Vorstellungen wichtig, da sie zwar nicht notwendigerweise falsch sein müssen, aber zumindest die Gefahr für darauf aufbauende Lern-Schwierigkeiten oder gar Missverständnisse in sich tragen könnten. [KATTMANN ET AL., 1997; S. 14] gehen dabei sogar noch weiter und sehen Schülervorstellungen als "notwendige Anknüpfungspunkte des Lernens". Zusätzlich wird hervorgehoben, dass keines der bisher beschriebenen Module gewichtiger ist ([KATTMANN ET AL., 1997; S. 15]): "Vorstellungen von Wissenschaftlern und Schülern werden gleichgewichtig für die didaktische Strukturierung nutzbar gemacht." Klärung gesellschaftlicher Ansprüche Schule und Unterricht sind ständig mit gesellschaftlichen Erwartungen konfrontiert und auch deren Erforschung kann also davon nicht frei sein. Nach [DIETHELM ET AL., 2011A; S. 80] geht es "in erster Linie um die Frage, welchen allgemeinbildenden Gehalt der zu Rede stehende Aspekt der Informatik hat". Darüber hinaus verweisen sie auf die Bildungsstandards und konkreten Empfehlungen der Gesellschaft für Informatik (vgl. [GI, 2008]). anzumerken ist, dass das Modell ohnehin keine Aussage über den Findungsprozess eines unterichtenswerten Themas macht 1 10 Erfassung von Lehrerperspektiven HILBERT MEYER bemängelt in [DIETHELEM ET AL., 2011A; S. 79], dass die Didaktik im allgemeinen von "idealisierten und hochkompetenten […] »Normallehrern«" ausgeht, was gerade in der Informatik oft nicht der Fall ist. Analog zur Betrachtung der Schülerperspektiven müssen auch die Voraussetzungen der Lehrkräfte berücksichtigt werden. Da in Bayern Informatik erst seit 2001 Unterrichtsfach ist2 , verwundert es auch nicht, dass die fachliche Qualifikation der Informatiklehrer noch sehr inhomogen ist. Das betrifft vermutlich weniger das fachliche Wissen, als mehr die Bereiche der Methodik und Didaktik. Trotzdem – oder vielmehr deshalb – ist die Berücksichtigung der Lehrerperspektive unbedingt notwendig. Auswahl informatischer Phänomene3 Gerade im kurzlebigen Bereich der Informatik werden Schüler wie Lehrer ständig mit neuen Phänomenen konfrontiert. Betrachtet man z.B. soziale Dienste (uA. Netzwerke, Medien, Kollaborationsplattformen), fällt auf, dass sich diese erst innerhalb der letzten zehn Jahren durchsetzten4 und vorher dem Massenpublikum unbekannt waren. Vermutlich werden in Zukunft wiederum andere Phänomene eine große Rolle im Alltag spielen. 5 Den überzeugendsten Grund, den Phänomenen in der Didaktischen Rekonstruktion den zentralen Platz einzuräumen, führen aber sicherlich [DIETHELM ET AL., 2011A; S. 81] an: "Im Informatikunterricht sind Schüler in der Lage [Phänomene] nicht nur zu erklären, sondern auch selbst die Erzeugung neuer informatischer Phänomene zu durchleben." Didaktischer Strukturierung des Unterrichts Alle diese Überlegungen sind aber nicht Selbstzweck, sondern münden schließlich in der Phase der didaktischen Strukturierung. [KATTMANN ET AL., 1997; S. 12] formulieren für ihr Modell typische Fragen, die in dieser Phase hilfreich sein können: • "Welche Korrespondenzen und unterrichtlichen Möglichkeiten eröffnen sich aus dem Vergleich der Vorstellungen von Wissenschaftlern und Schülern?" • "Welche Schülerperspektiven sind bei der Vermittlung von Begriffen und bei der Verwendung von Termini zu beachten?" • "Welche metafachlichen und metakognitiven Denkwerkzeuge können für ein angemesseneres und fruchtbares Lernen nützlich sein?" Dabei erinnere ich daran, dass gesellschaftlichen Ansprüche, Lehrerperspektiven und Phänomene erst im erweiterten Modell von DIETHELM ET AL. auftauchen und also in diesen Fragen nicht berücksichtigt wurden. Daher schlage ich folgende zusätzlichen Fragen vor: • 2 Welchen Einfluss haben gesellschaftliche Rahmenbedingungen (rechtlich, ethisch, …)? an Realschulen; an Gymnasien erst ab 2004 im Zuge der Einführung des G8 auf eine Definition des Phänomen-Begriffs und warum die Orientierung daran für Schüler nützlich sein kann, verzichte ich hier unter Verweis auf den folgenden Abschnitt 2.2 3 4 z.B. Wikipedia 2001, MySpace 2003, Facebook 2004, Twitter 2006 5 man denke nur an die Möglichkeiten, die sich Beispielsweise durch »augmented reality« bieten 11 • Haben die betroffenen Lehrkräfte die notwendigen fachlichen, methodischen und didaktische Voraussetzungen? • Ist das fragliche Phänomen aus Sicht der übrigen Perspektiven geeignet? Als Ergebnisse der didaktischen Strukturierung nennen [DIETHELM ET AL., 2011A; S. 83] (unter Verweis auf die Formulierungsebenen bei [GROPENGIEßER & KATTMANN, 1998; S. 12F.]): • "grundlegende Leitlinien oder Prinzipien" • "auf empirische Ergebnisse bezogene Unterrichtskonzepte oder entsprechende Curriculumeinheiten" • "eine Reihe aufeinander bezogener Unterrichtselemente" Diese Einteilung kann bei der Auswahl von für den Unterricht geeigneten Phänomenen hilfreich sein. 2.2. Kontexte und Phänomene Versuche Inhalte ohne jeglichen Zusammenhang mit bisherigem Wissen oder persönlichen Erfahrungen vermitteln zu wollen sind nicht leicht von Erfolg gekrönt. Bereits beim berühmten Milchdosenbeispiel von [COPEI, 1950; S. 105F.] wird deutlich, dass gerade die Konfrontation der Schüler mit Problemen aus ihrer eigenen Lebenswelt zu erfolgreichen Lernsituationen führt. Und sowohl in den nine events of instruction [GAGNÉ, 1988], als auch im ARCS-Modell von [KELLER, 1983] wird das Konzept der Attention sogar an erster Stelle der Voraussetzungen für Lernerfolg genannt. Auch [MERRILL, 2002; S. 44] expliziert dies als erstes seiner first principles of instruction: "Learning is promoted when learners are engaged in solving real-world problems." Kontexte Das lateinischen Substantiv contextus lässt sich zwar treffend mit Verbindung oder Verknüpfung übersetzen, allerdings weisen [DIETHELM & DÖRGE, 2011; S. 69]6 darauf hin, dass eine allgemein gültige und präzise Definition des Begriffs Kontext nicht möglich ist. Dennoch finden sie in [KOUBEK ET AL., 2009; S. 272] einen praktikable Erklärungsversuch: "Der Einfachheit halber sprechen wir im Weiteren [..] von Kontext als Menge von lebensweltlichen Themen bzw. Fragestellungen, die von den Schülerinnen und Schüler als zusammenhängend geordnet werden und die dadurch sinnstiftend auf deren Handlungen wirken." Im Unterschied zum problem-centered-Ansatz bei [MERRILL, 2002; S. 45FF.] ist in [KOUBEK ET AL., 2009; S. 268] von der "Orientierung an sinnstiftenden Kontexten" die Rede. Wichtig dabei ist, dass "die gewählten Kontexte mehr als nur motivierende Aufhänger [sind]" [FUCCIA ET AL., 2007; S. 274]. Informatik im Kontext (IniK) Beginnend zwischen 1997 und 2000 wurde mit Chemie im Kontext (CHiK) in Deutschland das erste der naturwissenschaftlichen Fächer mit einem Kontext-basiertem Unterrichtskonzept ausgestattet. Dabei wurden in [PARCHMANN ET AL., 2000] die Ziele "Sinnhaftigkeit der Beschäftigung mit Chemie" und die "Bedeutung der Chemie bei fächerübergreifenden Themen" ausgegeben. 6 die Autoren verweisen dabei wiederum auf [GILBERT, 2006] und [DURANTI & GOODWIN, 1992] 12 Ab etwa 2004 kam noch Physik im Kontext (piko) sowie Biologie im Kontext (bik) hinzu (vgl. [KOMOREK, 2004], [BAYRHUBER ET AL., 2007]). Zur gleichen Zeit folgten auch Fachdidaktiker der Informatik dem Vorbild der Chemie und entwickelten einen originären und zeitgemäßen Ansatz zur Informatik im Kontext. 7 Eine treffende Zusammenfassung des gesamten Konzepts findet sich bei [DIETHELM & DÖRGE, 2011; S. 69]: "[Der IniK-Ansatz] geht vom Kontext, von der Lebenswelt der Schüler aus und sucht aus deren Sicht nach für sie relevanten Inhalten. […] Das Interesse an den Inhalten ist somit bereits vorhanden, sodass die Lernenden mit ihrer Neugier die für sie relevanten Inhalte des Informatikunterrichts so weit als möglich selbst erarbeiten und entdecken." Dieses gründet auf den drei Prinzipien "Orientierung an Kontexten", "Orientierung an Standards für die Informatik in der Schule" und "Methodenvielfalt" [KOUBEK ET AL., 2009; S. 271]. Dabei ist das Begriffspaar Dekontextualisierung/Rekontextualisierung von zentraler Bedeutung ([KOUBEK ET AL., 2009; S. 273]): "Dekontextualisierung ist die Abstraktion vom flüchtigen Kontext zu den Grundprinzipien des Faches und den daraus abgeleiteten Kompetenzen" Die im Detail zu unterrichtenden Inhalte ergeben sich also aus den Kontexten. Dabei können sich diese Inhalte je nach fachlichem Blickwinkel8 erheblich unterscheiden. Erst auf dieser Grundlage kann dann die Rekontextualisierung als Anwendung dieser Basiskonzepte in anderen Kontexten erfolgen. Phänomene Als Phänomen (von altgriechisch "#$%ό'(%)% = Erscheinung) bezeichnet [PFEIFER, 2000]: "sich den Sinnen zeigende oder gedachte Erscheinung; seltenes, außergewöhnliches Vorkommnis; auffallende (Natur)erscheinung" Dieser sehr allgemeine Definition möchte ich eine Konkretisierung für die Informatik aus [DIETHELM & DÖRGE, 2011; S. 74] zur Seite stellen: "Bei einem informatischen Phänomen handelt es sich um ein Ereignis, das durch automatisierte Informationsverarbeitung verursacht wird und im realen oder mentalen Handlungsumfeld der Schüler stattfindet." Da Schüler zu lernende Inhalte auf bestehendem Wissen aufbauen (vgl. [MERRILL, 2002; S. 44]), ist es wichtig, dieses Vorwissen fassbar zu machen. Diese Notwendig wurde auch schon vor über 30 Jahren von [WAGENSCHEIN, 1976; S. 3] betont: Aus dem Blickwinkel der Wissenschaft auf die Realität entsteht "ein besonderes »Natur-Bild«, eine »Denkwelt«". Denn es "bildet [..] die uns umgebende sinnenhafte Wirklichkeit der Phänomene so ab, wie eine Landkarte die Landschaft, wie die Partitur eine Symphonie, wie der Schatten seinen Gegenstand" und kann somit nie vollkommen sein. Bei der Einordnung der Vorkenntnisse sind die three categories of phenomena von [HUMBERT & PUHLMANN, 2004; S. 4] hilfreich: • "Phenomena that are directly related to informatics systems" vgl. [SACK & WITTEN, 2009; S. 12] sowie [KOERBER & WITTEN, 2005; S. 18]: "Ein positives Beispiel für zeitgemäße Curriculumentwicklung liefert das Konzept »Chemie im Kontext«" 7 8 das betrifft natürlich insbesondere den fächerübergreifenden Unterricht 13 • "Phenomena that are indirectly linked with informatics systems" • "Phenomena that are not connected to informaticssystems but have an inherent informatical structure or suggest informatical reasoning" 2.3. Schad-Software Zwar wird es in dieser Arbeit im Detail um das Phänomen des Computer-Virus gehen – allerdings ist es vermutlich nicht nur für Schüler schwierig eine fundierte Unterscheidung zwischen Viren und anderen Arten von schädlichen Programmen zu treffen. Daher gebe ich auch Definitionen zu anderen weit verbreiteten Schadprogrammen an. Viren Das Computer-Virus ist sicherlich mit der bekannteste Begriff, wenn es um Schad-Software geht. Zum ersten Mal wurde es ausführlich in [COHEN, 1984; S. 2] beschrieben: "We define a computer »virus« as a program that can »infect« other programs by modifying them to include a possibly evolved copy of itself." Es handelt sich also um ein Programm, dass andere Programme infizieren kann. Diese Nähe zum biologischen Virus beschränkt sich dabei nicht auf die Ebene des Vokabulars, sondern ist auch konzeptionell. So beginnt auch das Kapitel zu Viren bei [ECKERT, 2012; S. 55] folgendermaßen: "Ein Virus […] bezeichnet in der Biologie einen Mikro-Organismus, der auf eine lebende Wirtszelle angewiesen ist, keinen eigenen Stoffwechsel besitzt und fähig ist, sich zu reproduzieren. Diese Eigenschaften sind direkt auf Computerviren übertragbar." Hier wird die Notwendigkeit eines bestehenden Wirts, sowie die Fähigkeit des Virus zu Vervielfältigung betont. Diese Eigenschaften fasst [ECKERT, 2012; S. 55] in folgender Definition zusammen: "Ein Computervirus ist eine Befehlsfolge, die ein Wirtsprogramm zur Ausführung benötigt. Viren sind zur Reproduktion fähig. Dazu wird bei der Ausführung des Virus eine Kopie (Reproduktion) oder eine modifizierte Version des Virus in einen Speicherbereich, der diese Befehlssequenz noch nicht enthält, geschrieben (Infektion). Zusätzlich zur Fähigkeit zur Reproduktion enthalten Viren in der Regel einen Schadenteil. Dieser kann unbedingt oder bedingt durch einen Auslöser aktiviert werden." Würmer Würmer sind autarke, sich vervielfältigende Programme. Genaue Definition nach [ECKERT, 2012; S. 67]: "Ein Wurm ist ein ablauffähiges Programm mit der Fähigkeit zur Reproduktion. Ein Wurm-Programm besteht in der Regel aus mehreren Programmteilen, den Wurm-Segmenten. Die Vervielfältigung erfolgt selbstständig meist unter Kommunikation mit anderen Wurm-Segmenten." 14 Trojanische Pferde Der Name dieses Schadprogramms ist für [ECKERT, 2012; S. 73] nicht zufällig gewählt, da das sagenhafte Trojanische Pferd die Charakteristika solcher Programme sehr genau beschreibt: "Es wird eine Funktionalität vorgetäuscht, die Vertrauen erweckt, die aber durch eine verborgene Schadens-Funktionalität ergänzt wird." Definition nach [ECKERT, 2012; S. 73]: "Das Trojanische Pferd (auch Trojaner gennant) ist ein Programm, dessen implementierte Ist-Funktionalität nicht mit der angegebenen Soll-Funktionalität übereinstimmt. Es erfüllt zwar diese Soll-Funktionalität, besitzt jedoch eine darüber hinausgehende, beabsichtigte zusätzliche, verborgene Funktionalität." Zusammenfassung In allen Definitionen taucht der Begriff des Programms auf – allerdings beinhaltet dies keine Einschränkung bezüglich des Betriebssystems oder der Hardware. So sind Schadprogramme nicht auf PCs beschränkt, sondern genauso auf anderen Plattformen wie Mobiltelephonen oder Navigationssystemen anzutreffen. Darüberhinaus ist es bemerkenswert, dass bereits [COHEN, 1984; S. 3] einen nützlichen Virus theoretisch beschrieben hat: "It should be pointed out that a virus need not be used for evil purposes or be a Trojan horse. As an example, a compression virus could be written to find uninfected executables, compress them upon the user's permission, and prepend itself to them. Upon execution, the infected program decompresses itself and executes normally. Since it always asks permission before performing services, it is not a Trojan horse, but since it has the infection property, it is still a virus. Studies indicate that such a virus could save over 50 % of the space taken up by executable files in an average system." Ich möchte den Abschnitt mit einer knappen Abgrenzung der beschriebenen Arten von SchadSoftware abschließen (Tabelle 1). Tabelle 1. Abgrenzung der Schadprogramme Virus Wurm Trojanisches Pferd Infektion von Wirtsprogrammen ja nein nein Reproduktionsfähigkeit ja ja nein selbständig lauffähiges Programm nein ja ja – – ja Unterschied von Ist- und Soll-Funktionalität 15 3. Verwandte Arbeiten Didaktische Rekonstruktion Die Didaktische Rekonstruktion in ihrer ursprünglichen Form wurde in [KATTMANN ET AL., 1997] eingeführt9 und in [GROPENGIEßER & KATTMANN, 1998] und [DUIT, 2007] ausführlich beschrieben. Die hier verwendeten erweiterte Form kann in [DIETHELM ET AL., 2011A] nachgelesen werden. Phänomene und Kontexte Wie wichtig Aufmerksamkeit und Interesse für erfolgreiches Lernen ist wird in [GAGNÉ, 1969], [KELLER, 1983] und [MERRILL, 2002] sehr eindringlich beschrieben. Darin werden Konzepte gefordert, die durchaus mit den Phänomenen übereinstimmen. Zur Phänomen- und Kontextorientierung gibt es in den naturwissenschaftlichen Schulfächern bereits einige Arbeiten, deren Ansätze zum Teil auch bezüglich der Informatik interessant sind: 10 • für die Chemie eine Einführung bei [PARCHMANN tungen in [GILBERT, 2006] und [FUCCIA ET AL., 2007] ET AL., 2000] sowie weitere Ausarbei- • für die Physik [KOMOREK, 2004] und [DUIT & MIKELSKIS-SEIFERT, 2010] • in der Biologie die lesenswerte Arbeit zu Schülervorstellungen von [RIEMEIER ET AL., 2010] Speziell zur Informatik im Kontext seien die wichtigen Artikel [KOUBEK ET AL., 2009], [DIETHELM ET AL., 2011B] und [DIETHELM & DÖRGE, 2011] genannt. Außerdem die Arbeiten von [KOERBER & WITTEN, 2005], [PASTERNAK & VAHRENHOLD, 2009] und [ENGBRING & PASTERNAK, 2010]. Schülervorstellungen Besonders möchte ich noch auf [DIETHELM & ZUMBRÄGEL, 2010] hinweisen. Dort wurden Schülervorstellungen zum Thema Internet untersucht. Dazu wurden mit 23 Schülern der 7. und 8. Jahrgangsstufe Leitfaden-gestützte Interviews bezüglich der Aspekte "E-Mail, Chat und Videostream" durchgeführt und daraufhin einer Qualitativen Inhaltsanalyse unterzogen. Im Unterschied zur vorliegenden Arbeit nutzen die Autoren allerdings dabei die Konzepte Kontext und Phänomen nicht. 11 Lehrerperspektiven Zur Erforschung der Lehrerperspektive im Informatikunterricht findet sich bisher wenig Literatur. 12 Im Zuge des ersten Abiturjahrgangs des Bayerischen G8 wurde durch [MÜHLING ET AL., 2010] eine Studie zur Einstellung der Lehrer bezüglich des neu eingeführten Fachs Informatik durchgeführt. 9 genau genommen wurde diese in [KATTMANN ET AL., 1995] zuerst veröffentlicht 10 diese Aufzählung ist natürlich nicht vollständig, sondern soll Einblick und Einstieg bieten wenigstens nicht explizit – implizit finden sich diese z.B. bei der Auswahl der im Fokus der Befragung stehenden Aspekte des Komplexes »Internet« 11 12 zumindest bezogen auf Deutschland 16 4. Allgemeine Forschungsmethoden Vor dem Hintergrund des Modells der Didaktischen Rekonstruktion werden im Verlauf dieser Arbeit die Aspekte Erfassung von Schülerperspektiven sowie die Auswahl informatischer Phänomene genauer betrachtet. Dazu werden verschiedene Untersuchungen angestellt, die hier zunächst vorgestellt werden. 4.1. Qualitative Inhaltsanalyse Begriffe Über die Bezeichnung der Konzepte in der Qualitativen Inhaltsanalyse herrscht kein Konsens, weshalb zuerst einige Begriffe definieren werden. Proband In den meisten Fällen ist nicht klar, ob die befragten Personen ihre Antworten selbst aufgeschrieben haben oder dies durch die die Befragungen durchführenden Studenten geschah. Daher werden einheitlich die befragten Personen als Probanden bezeichnet, unabhängig davon, wer die Dokumente letztlich verfasst hat. Dokument Nach [MAYRING, 2000; S. 2] kann Ausgangspunkt und damit "Gegenstand (qualitativer) Inhaltsanalyse [..] jede Art von fixierter Kommunikation sein". Hier sind dies die von den Probanden auf die verschieden Fragestellungen gegebenen Antworten. Diese liegen in Textform vor und werden Dokumente genannt. Code / Coding / Kategorie Ein Code bezeichnet einen Begriff bzw. ein Konzept, der einer bestimmten Stelle innerhalb des Dokuments zugeordnet wird. Die so kodierte Textstelle heißt Coding. Im iterativen Prozess der Inhaltsanalyse werden Codes immer weiter in abstrahierte Kategorien zusammengefasst. Dadurch entsteht eine hierarchische Struktur von Codes und Kategorien. Ein Beispiel aus [CORBIN & STRAUSS, 2008; S. 52] verdeutlicht dies: "For example […] flight is a higher-level concept than is bird, kite, or plane. Flight explains what these objects have in common." Eine Kategorie kann aber auch durchaus noch als Code auftreten, wenn sich die Ausführungen eines Proband auf einem entsprechend abstrakten Niveau befinden. 17 Kodierung Die Dokumente beider Befragungen werden einer Qualitativen Inhaltsanalyse unterzogen. Dabei orientiere ich mich an der verbreiteten Methode MAYRINGs. Da insgesamt etwa 200 Dokumente zu kodieren sind, wird dabei die Software MAXQDA13 verwendet. Generell unterscheidet man zwei Vorgehensarten, die hier kurz vorgestellt werden sollen. Induktive Kategorieentwicklung Ist a priori kein Kategoriesystem vorgegeben, so kann es direkt "aus dem Material heraus" entwickelt werden ([MAYRING, 2000; S. 3]). [MAYRING, 2008; S. 75] erklärt dies so: "Eine induktive Kategoriedefinition [..] leitet die Kategorien direkt aus dem Material in einem Verallgemeinerungsprozess ab, ohne sich auf vorab formulierte Theorienkonzepte zu beziehen." 14 Dabei werden, nach der Festlegung eines vorläufigen und ungefähren Abstraktionsniveaus, die Dokumente naiv, d.h. ohne vorige theoretische Überlegung der zu erwartenden Codes und Kategorien, durchgearbeitet. Dies geschieht üblicherweise Zeile für Zeile oder auch Satzweise. Wird eine relevante Aussage vorgefunden, wird möglichst nahe an der Original-Formulierung der erste Code als Begriff oder kurzer Satz festgehalten oder aber, die Aussage einem bereits bestehenden Code zugeordnet. Nach der so erfolgten Kodierung eines großen Teils des Materials (MAYRING nennt dabei, je nach Material-Umfang, 10-50 % der Dokumente) soll eine Revision des Kategoriesystems erfolgen. Spätestens dann erfolgt eine Zusammenfassung von Codes in Kategorien und daraus also die Entwicklung einer hierarchische Gliederung. Dabei muss überprüft werden, "ob die Kategorien dem Ziel der Analyse nahe kommen, ob das Selektionskriterium und das Abstraktionsniveau vernünftig gewählt worden sind" ([MAYRING, 2008; S. 76]). In mehreren Iterationen erfolgt dann die Zusammenfassung der so gefundenen Codes zu Kategorien, wodurch ein hierarchisches Kategoriesystem entsteht. Die einzelnen Stufen dieser Hierarchie entsprechen den unterschiedlichen Abstraktionsniveaus. Deduktive Kategorieentwicklung Im Gegensatz zum induktiven Verfahren wird beim deduktiven Verfahren das Kategoriesystem vorgegeben und "der qualitative Analyseschritt besteht [..] darin, deduktiv gewonnene Kategorien zu Textstellen methodisch abgesichert zuzuordnen" [MAYRING, 2000; S. 4]. Grundlage dieser Zuordnung sind transparente Regeln, auf deren Grundlage die Textstellen zu den verschiedenen Codes zu- und damit in das Kategoriesystem eingeordnet werden. Dazu dient üblicherweise ein Kodierleitfaden. 4.2. Statistische Tests Die Begriffsnetze zu den verschiedenen Vorbildungsgruppen legen die Vermutung nahe, dass sich diese Gruppen bezüglich der verwendeten Kategorien unterscheiden. Um dies fundiert zu überprüfen, werden statistische Berechnungen durchgeführt. 13 http://www.maxqda.de MAYRING unterscheidet hier nicht explizit zwischen »Codes« und »Kategorien« und verwendet für beide Konzepte den Begriff der »Kategorie« 14 18 U-Test nach Wilcoxon, Mann und Whitney Beim U-Test wird überprüft, ob den Stichproben X = (X1,…,Xm) und Y = (Y1,…,Yn) die gleiche Verteilung zugrunde liegt. Ich verwende das Verfahren nach [SACHS, 1968; S. 293FF.]. Voraussetzungen Das Verfahren kann nur auf mindestens ordinalen Skalen angewendet werden und zusätzlich müssen sowohl X und Y als auch alle Xi ∈ X bzw. Yj ∈ Y untereinander unabhängig sein. Hypothese Es wird die (zweiseitige) Nullhypothese getestet: H0: Die Stichproben X und Y sind identisch verteilt. Teststatistik Die Entscheidung, ob diese Hypothese aufrecht erhalten oder abgelehnt wird, wird mittels der Prüfgrößen U getroffen: U= m X n X S(Xi , Yj ) mit i=1 j=1 • S(Xi,Yj) = 1, falls Xi > Yj und S(Xi,Yj) = 0 sonst H0 wird verworfen, wenn U den kritischen Wert Ukrit nicht überschreitet. Dieser Wert ist in Abhängigkeit von m, n und dem Signifikanzniveau tabelliert. Chi-Quadrat-Homogenitätstest Beim #2-Homogenitätstest wird überprüft, ob zwei Stichprobe aus der selben Verteilung stammen. Ich verwende hier das Verfahren nach [RINNE, 1997; S. 549F.]. Voraussetzungen Die Stichproben müssen zufällig, unabhängig und annähernd #2-verteilt sein. Dabei hilft das Pearson-Theorem (zitiert nach [PESTMAN, 2009; S. 185]): "For large n the variable p X (Fi i=1 is approximately *2-distributed E(Fi ))2 E(Fi ) with p-1 degrees of freedom." Mit der Abschätzung n ≥ 5/min(,i) (wobei ,i = relative Häufigkeit des i-ten Merkmals) ist n für die Anwendung dieses Theorems hinreichend groß [GEORGII, 2009; S. 302]. [RINNE, 1997; S. 550] fordert zusätzlich: • nij ≥ 10 für alle i, j • Eij ≥ 1 für alle i, j • max. 20 % der Eij < 5 Hypothese Die Stichproben X = (X1,…,Xk) und Y = (Y1,…,Yk) werden paarweise verglichen. Die Nullhypothese lautet: H0: Die Stichproben X und Y entstammen der selben Verteilung. 19 Teststatistik Die Entscheidung, ob diese Hypothese aufrecht erhalten oder abgelehnt wird, wird mittels einer Prüfgröße *2 getroffen: 2 = k X m X (nij i=1 j=1 Eij )2 Eij mit • k = Anzahl der Merkmale je Stichprobe • m = Anzahl der Stichproben • nij = absolute Häufigkeit des i-ten Merkmals in der j-ten Stichprobe • Eij = n-jni-/n (geschätzte Häufigkeit des i-ten Merkmals in der j-ten Stichprobe) • n-j = Summe der absoluten Häufigkeiten in der j-ten Stichprobe • ni- = Summe der absoluten Häufigkeiten des i-ten Merkmals • n = Summe aller n-j (= Summe aller ni-) Zur Verdeutlichung ist das Schema in Tabelle 2 wiedergegeben. Tabelle 2. Kennzahlen der !2-Teststatistik Stichprobe 1 Stichprobe 2 n11 n12 n1! n21 n22 n2! … … … nk1 nk2 nk! n!1 n!2 n Dabei wird H0 verworfen, wenn #2 innerhalb eines Ablehnungsbereich A liegt. Dieser ist abhängig von der Anzahl der Freiheitsgrade und dem Signifikanzniveau tabelliert. Gauß-Test15 In diesem Fall ist der klassische t-Test nicht anwendbar, da die Normalverteilung der Stichproben nicht garantiert werden kann. Daher kommt der approximative Zweistichproben-GaußTest zum Einsatz. [BAMBERG & BAUR, 1991; S. 192F.] Dabei werden zwei Stichproben X und Y bezüglich ihrer Mittelwerte und Varianzen verglichen, um zu entscheiden, inwieweit sich die dazugehörigen Grundgesamtheiten unterscheiden. Voraussetzungen In diesem Fall dürfen die beiden Stichproben beliebig verteilt sein, müssen aber jeweils mehr als 30 Variablen beinhalten [BAMBERG & BAUR, 1991; S. 193]. Damit werden die Voraussetzungen des Zentralen Grenzwertsatz erfüllt und somit kann für die Stichproben die Normalverteilung angenommen werden. Teilergebnisse dieser Forschungsarbeit wurden bereits in [DIETHELM ET AL., 2012] zusammengefasst. Dabei wurde von HUBWIESER eine Variante des hier vorgestellten Gauß-Test eingesetzt. 15 20 Hypothese Es wird die (zweiseitige) Nullhypothese getestet: H0: Die Erwartungswerte der den Stichproben X und Y zugrunde liegenden Grundgesamtheiten sind gleich. Teststatistik Die Entscheidung, ob diese Hypothese aufrecht erhalten oder abgelehnt wird, wird mittels der Prüfgrößen V getroffen: X̄ Ȳ V =q 2 Sy2 Sx nx + ny mit • X̄ = arithmetisches Mittel von X • Ȳ = arithmetisches Mittel von Y S2 = • 1 n 1 n X i=1 (Xi X̄)2 Stichprobenvarianz Dabei wird H0 verworfen, wenn V ∈ B. Der Ablehnungsbereich B ist dabei für verschiedene Signifikanzniveaus tabelliert. 21 5. Konkrete Durchführung 5.1. Erste Befragung (Phänomene) Überblick In DIETHELMs Modell steht die Auswahl informatischer Phänomene im Mittelpunkt, weshalb dies auch hier Ausgangspunkt der Untersuchungen war. Dazu wurden Personen nach ihnen bekannten Phänomenen im Zusammenhang mit Informatik befragt. Die Befragung erfolgte durch 28 Studenten eines universitären Didaktik-Einführungskurses. Dabei sollten vor allem Schüler, möglichst ohne informatische Vorbildung, befragt werden. Die Fragestellung lautete: Bitte nennen Sie (insgesamt) drei Erscheinungen, Abläufe oder Vorgänge im Zusammenhang mit der alltäglichen Nutzung von Informations- und Kommunikationstechnik, die Ihnen besonders kompliziert, unverständlich oder schwer verständlich erscheinen. Zusätzlich zu den Antworten wurden Personendaten der (anonymen) Probanden erhoben: • Alter • Geschlecht • Beruf • Schulart, Jahrgangsstufe und besuchter Zweig (falls als Beruf Schüler angegeben wurde) • bisherige Informatikausbildung Ein ausgefüllter Fragebogen findet sich als Anhang 1. Die Meta-Daten dienten dazu, die Probanden in verschiedene Gruppen zu unterteilen. So konnten später fundierte Vergleiche mittels Teststatistiken durchgeführt werden. Dabei wurde insbesondere eine Einteilung bezüglich der informatischen Vorbildung vorgenommen. Damit könnten später eine Reihe von Hypothesen überprüft werden, z.B. in welchem Umfang die Schulinformatik dazu beiträgt, dass Probanden fachlich korrekte Antworten geben können. Allerdings ist das nicht erklärtes Ziel dieser Arbeit und soll hier nur als eine Möglichkeit für weitere Forschung genannt sein. Kodierung Da die Fragestellung offen formuliert worden war, konnten die Nennungen nicht einfach ausgezählt werden. Daher wurden die erhaltenen Antworten mit dem bereits beschriebenen Verfahren der Qualitativen Inhaltsanalyse nach MAYRING kodiert. Das Kategoriesystem wurde dabei induktiv entwickelt. 5.2. Zweite Befragung (Schülerperspektiven) Überblick / Stichprobe Aufgrund der Ergebnisse der ersten Befragung wurde entschieden, die Schülerperspektiven zum Phänomen des Computer-Virus zu untersuchen. Die Studenten des Kurses führten dazu kurze Interviews, wiederum bevorzugt mit Schülern ohne informatische Vorbildung. 22 Dabei wurde eine möglichst suggestionslose Frage gewählt: Was glauben Sie, wie Computer-Viren funktionieren? Auch hier wurden die Probanden gebeten, zusätzliche Angaben zur Person zu machen (vgl. Anhang 2). Kodierung Es wurde wieder das Verfahren der induktiven Kategorieentwicklung angewendet. Dabei stellte sich aber im Verlauf der Kodierung heraus, dass das resultierende Kategorieystem auch nach mehreren Kodierungs-Iterationen noch zu feingliedrig war. Dem wurde mit der Erstellung eines neuen Kategoriesystems auf Grundlage des deduktiven Ansatzes begegnet. Dazu wurde das alte Kategoriesystem auf die beiden abstraktesten Ebenen reduziert und für die weitere Betrachtung diejenigen Kategorien ausgewählt, die sich bezüglich der Häufigkeit im dritte Quartil Q0,75 befanden. 16 Diese neuen Kategorien stellten nun die Basis für eine erneute Qualitative Analyse nach dem bereits beschriebenem deduktiven Verfahren dar. Das resultierende Kategoriesystem wird als Tabelle 10 im Abschnitt 6.2 wiedergegeben. 5.3. Begriffsnetze Um erkennen zu können, inwieweit die Probanden in ihren Antworten übereinstimmen, wurde versucht die Dokumente der zweiten Befragung aufgrund der gegebenen Antworten in disjunkte Gruppen einzuteilen. Da die Befragung mit freien Kurzinterviews erfolgte war dies allerdings nicht sinnvoll möglich. Einen ähnlichen Ansatz nutzen [HUBWIESER & MÜHLING, 2011] bei der Betreuung von Studenten während einer Informatik-Einführungsveranstaltung. Dabei kommen sie zu dem Schluss, dass sich deren Lernfortschritt mittels concept maps sehr gut beobachten lässt. [MIERTSCHIN & WILLIS, 2007] verwenden concept maps zum Entwurf von interaktiven Lernumgebungen und sehen darin einen Nutzen bezüglich "organizing and simplifying learning environments". Auch wenn es in dieser Arbeit nicht um die Betrachtung eines dynamischen Lernvorgangs, sondern um eine Momentaufnahme der Vorstellung zu einem Phänomen geht, ist eine Visualisierung mittels Graphen trotzdem hilfreich. Diese erfolgte auf zwei verschiedene Arten, die hier nun näher beschrieben werden. Dokument-Netze Die Dokumente sind Knoten eines ungerichteten Graphen. Eine Kante zwischen zwei Knoten existiert dann, wenn beide Dokumente in mindestens einer Kategorie übereinstimmen. Das Kantengewicht ergibt sich aus der Anzahl der übereinstimmenden Kategorien. Da die Dokumente innerhalb dieses Modells als gleichberechtigt anzusehen sind, bekommen sie auch alle das gleiche Gewicht zugeordnet. Kategorie-Netze Die Kategorien sind Knoten, mit dazwischenliegenden Kanten, falls diese beiden Kategorien in mindestens zwei Dokumenten vorkommen. 16 drittes Quartil: das häufigste Viertel der Kategorien 23 Das Kantengewicht ist gleich der Anzahl der Dokumente, die in den Kategorien übereinstimmen. Das Knotengewicht ist gleich der Anzahl der Nennungen der entsprechenden Kategorie über alle Dokumente hinweg. Verwendete Software Die Datengrundlage für diese Graphen waren natürlich die kodierten Dokumente und das zugehörige Kategoriesystem. Die Berechnung der korrekten Knoten- und Kantengewichte ist allerdings mit MAXQDA nicht ohne weiteres möglich. Daher wurde zusätzlich ein entsprechendes Werkzeug in Java implementiert, dass die übereinstimmenden Kategorien für alle Dokument-Paare finden kann bzw. im zweiten Fall diejenigen Dokumente, die je zwei Kategorien gemeinsam haben. Die Erstellung der Graphen selbst (aufgrund der so gewonnen Daten) erfolgte mit der OpenSource-Umgebung Gephi17 (für die Dokument-Netze) sowie dem kostenlosen Editor yEd18 (für die Kategorie-Netze). 17 http://gephi.org/ 18 http://www.yworks.com/de/products_yed_about.html 24 6. Ergebnisse 6.1. Erste Befragung (Phänomene) Insgesamt wurden 86 Personen zu ihnen bekannten Phänomenen aus der Informatik befragt. Gemäß den persönlichen Angaben der Probanden wurden sie anschließend in verschiedene Gruppen eingeteilt, was auf Grundlage des angegebenen Berufs, des Geschlechts und der Vorbildung erfolgte. Zusammensetzung der Stichprobe Die Geschlechts-Verteilung innerhalb der Berufsgruppen lässt vermuten, dass die Stichprobe nicht sehr repräsentativ ist, weichen doch alle Gruppen (bis auf die Letzte) deutlich von einem realistischen Geschlechtsverhältnis von etwa 1:1 ab (Tabelle 3). Tabelle 3. Verteilung nach Berufsgruppe und Geschlecht19 Summe männlich weiblich ohne Angabe 100,00 % 39,53 % 59,30 % 1,16 % Schüler 22,09 % 9,30 % 11,63 % 1,16 % Studenten 34,88 % 12,79 % 22,09 % Arbeiter 4,65 % 4,65 % Angestellte 23,26 % 6,98 % 16,28 % Staatsbedienstete 5,81 % 1,16 % 4,65 % Andere 9,30 % 4,65 % 4,65 % Zum Grad der informatischen Vorbildung wurden drei Gruppen unterschieden: • keine oder informelle Vorbildung: Probanden, die nichts bzw. nur in informeller Form mit Informatik zu tun hatten, wie z.B. "Office-Kurs an der Volkshochschule" oder "autodidaktisch erworbene Programmierkenntnisse" • Schule: Probanden, die an Informatik-Unterricht im Rahmen des normalen Curriculums teilgenommen haben (also nicht ausschließlich als Wahlfach) • Studium / Ausbildung: nur einschlägige Studiengänge (z.B. "B.Sc. Informatik") bzw. praktische Berufsausbildungen (z.B. "Fachinformatiker") In dieser Stichprobe gehörten etwas mehr als % der Schüler zur zweiten Gruppe. Das deckt sich gut mit den etwa 70 % der Schüler eines jeden Jahrgangs, die in Bayern entweder die Realschule oder das Gymnasium besuchen – diejenigen weiterführenden Schulformen, die verpflichtenden Informatikunterricht (IT bzw. Informatik) anbieten. Da es diese Unterrichtsfächer in Bayern erst seit 2001 (Realschule) bzw. 2004 (Gymnasium) gibt, ist es durchaus plausibel, dass dieser Anteil unter den Nicht-Schülern hier deutlich niedriger war. die Prozent-Angaben beziehen sich in allen Tabellen auf die Menge aller Dokumente; z.B. waren in diesem Fall 9,30 % der Probanden männliche Schüler 19 25 Die genaue Verteilung bezüglich Berufsgruppen und Vorbildung liefert Tabelle 4. Tabelle 4. Verteilung nach Berufsgruppe und Vorbildung Summe G1 G2 G3 100,00 % 63,95 % 31,40 % 4,65 % Schüler 22,09 % 6,98 % 15,12 % Studenten 34,88 % 25,58 % 5,81 % Arbeiter 4,65 % 2,33 % 2,33 % Angestellte 23,26 % 16,28 % 6,98 % Staatsbedienstete 5,81 % 4,65 % Andere 9,30 % 8,14 % 3,49 % 1,16 % 1,16 % Kodierung Das Kategoriesystem umfasste am Ende 186 unterschiedliche Codes, welche fünf-stufig angeordnet waren (wie üblich mit den konkretesten Codes auf der ersten Ebene). Dabei wurden viele der höheren und damit abstrakteren Kategorien von Probanden auch explizit genannt, weshalb diesen auch direkt Codings zugeordnet wurden. Auswertung Um nun fundiert ein Phänomen zur weiteren Erforschung auszuwählen, wurde das höchste Abstraktionsniveau betrachtet. Diese sollte als Sammlung darunter subsumierter Codes dem zuvor beschriebenen Konzept der Kontexte entsprechen. Dabei wurden die Kategorien Software, Rechnersysteme, Internet und Datenübertragung jeweils von mindestens ¼ aller Probanden genannt. Alle Kategorien mit mehr als zehn Nennungen (einschließlich der Nennungen darunter liegender Codes) sind in Tabelle 5 aufgeführt. Tabelle 5. häufigste Kategorien Kategorien mit allen Unterkategorien/Codes Nennungen Software: Abhängigkeit von Betriebssystem, Benutzersteuerung, Funktionsvielfalt von Software, Office-Software, Parallele Programmabläufe, Softwareeinstallation, Spezielle Funktionen, Spezielle Softwaresysteme, Versionsunterschiede - Updates, Zeichensprache, Auto-Funktionen in Office, Dateiformate umwandeln, OpenOffice Base, Präsentationssoftware, Tabellenkalkulationsprogramme, Textverarbeitungsprogramme, Bearbeitung eines Dokuments, Drag&Drop, Papierkorb, Videos + Text etc. erstellen, Visual Effects, ArcGis, Auto-Vervollständigung durch Google, Bibliothekssoftware, Google, Google-Earth, GPS, iTunes, Navigationssysteme von Becker, Onlinebanking, Personen auf Fotos identifizieren, Robotik, Suchdienste im Web, TUMonline, Warenwirtschaftssystem SITE, Auto-Funktionen von Textverarbeitungen, MS Power Point, MS Excel, MS Word, PowerPoint, Excel-Hilfe, Pivottabellen, Bilder in MS-Word, Einstellungen in Word, Grafik und Sound in MS Word, Hilfesystem, MS Word Dateiformate, Seitennummerierung bei MS Word, Tabellen in MS Word 63 26 Rechnersysteme: Datenspeicherung ohne Stromanschluss, Fehlfunktionen, Funktionsweise, Konfiguration von PCs, Langsamkeit von PCs, Peripherie, Serverkonfiguration, Verkleinerung, Vernetzung, Abstürze, Überforderung, Arbeiten mit Wechseldatenträgern, Beamer, Computerbildschirm, Formatierung von Festplatten, Funktion von Touchscreens, Installation, Interaktion PC-Drucker, Problemlos Drucken, Scanner, Videoanschlüsse 34 Internet: Browser, Cookies, Datenaustausch im Internet, Datenübertragung im Internet, Funktionsweise, Herunterladen diverser Programme, ICQ, Internet-TV, Kosten von Internet-Angeboten, Legalität von Internet-Angeboten, Massenchat, Online Shopping, Soziale Netzwerke, Suchmaschinen, Verbindung Einrichten, Verbindungsunterbrechung beheben, Webseiten erstellen, Websites für Handy, "Wie groß kann das Internet noch werden?", Zugriff auf Websites, Facebook, Webseite Programmieren 33 Datenübertragung: Drahtlose Datenübertragung, FTP, Kommunikation über große Strecken, Router, Schnelligkeit der Datenübertragung, Bluetooth, Mobiles Internet, W-LAN, Datenverarbeitung eines Routers, Funktionsweise eines Routers, Speichern auf Karte/USB, Verwaltung eines Routers, W-LAN Anmeldung, W-LAN Datensicherung, W-LAN einrichten, W-LAN Funktionsweise, W-LAN Verbindung 24 Betriebssysteme: Accounts, Administratorrechte, Herunterfahren, Installation von Programmen, iOS, Kompatibilität, Öffnen einer Datei, Prozesse, Schnelligkeit von Programmstarts, Umstellung von Landessprachen, Ursachen für Abstürze, Windows, Hintergrundprozesse, Prozesse im Task-Manager, Fehlermeldungen von Windows, Komplexität von Windows 19 Mobilfunk: Abstürze von Handys, Funklöcher, Handy mit Computer updaten, Handy-Software, Handybedienung, iPhone, Komplizierte Betriebsanleitungen, SMS, Tarifsysteme Mobilfunk, Leere SMS, Schnelligkeit von SMS, SMS Datenverluste, Übertragungsdauer von SMS 18 Programmierung: GUI-Programmierung, Hacken, Klassen, Methoden, Programmiersprachen, Satzzeichen, Spiele programmieren, Testprogrammierung 17 Datenschutz und Datensicherheit: Datenschutzbestimmungen, Kryptographie, Sicherheit von Internetplattformen, Speicherung von Personendaten, Viren, Zugriff auf Daten, personalisierte Werbung, Verwendung von persönlichen Daten, Funktion von Antivirusprogrammen, Funktionsweise von Viren, Schutz vor Viren 16 spezielle Geräte: Bedienung von Autoradios, Fahrkartenautomaten, Headset verzerrt Sprache, MP3-Player, Telefon, TV, Uhren in Haushaltsgeräten, 3-D Fernsehen ohne Brille, Bedienung von TV, Bildformate, Digitales und analoges Fernsehen 14 Die meisten Nennungen bezogen sich dabei auf Phänomene, deren Verbindung zur Informatik offensichtlich ist und die somit nach [HUMBERT & PUHLMANN, 2004; S. 4] in die erste Kategorie von Phänomenen einzuordnen waren. Andererseits legte die Formulierung der Fragestellung auch nahe, eben solche Phänomene zu nennen. Dies stellt in meinen Augen allerdings keine Einschränkung dar, da ja explizit nach "komplizierten" und "schwer verständlichen" Phänomenen gefragt worden war. Die Nennung eines solchen Phänomens sollte also zumindest bedeuten, dass sich der Proband bereits Gedanken darüber gemacht hat und somit wohl auch Interesse an einer Erklärung dessen zeigen dürfte. 27 Die genannten Phänomene waren im Allgemeinen sehr abstrakt und für einen Phänomenzentrierten Ansatz eher ungeeignet. Daher wurden die am häufigsten direkt vergebenen Codes betrachtet und wider Erwartung fanden sich dabei keine klaren Häufungen. Es wurden überhaupt nur sieben Codes gefunden, die mindestens viermal genannt worden waren (Tabelle 6) – bei 86 Probanden, die noch dazu je drei Antworten geben konnten, ein geradezu ernüchterndes Ergebnis. Tabelle 6. Codes mit mindestens vier Nennungen Code Ebene Nennungen Programmierung 5 7 drahtlose Datenübertragung 3 6 MS Excel 1 5 Langsamkeit von PCs 1 5 Internet 5 4 Handybedienung 1 4 Versionsunterschiede und Updates 1 4 Die meisten dieser Codes stellten sich bei kritischer Betrachtung als ungeeignet heraus, da sie entweder zu abstrakt waren (Programmierung, Internet, Handybedienung) oder sich auf ein konkretes Softwareprodukt bezogen (MS Excel). Zusätzlich waren es in keinem Fall echte Phänomene. Die Themen Versionsunterschiede und Updates sowie drahtlosen Datenübertragung könnten zwar wohlwollend als Ausgangspunkt für einige Phänomene gelten, ich hielt sie aber aufgrund ihres Abstraktionsgrades und der sehr theoretischen bzw. technischen Grundlagen für ungeeignet. Womit als Letztes die Langsamkeit von PCs blieb. Dies stellte unter den Codes in Tabelle 6 mit Sicherheit das eindeutigste Phänomen im Sinne der Definition nach PFEIFER ("sich den Sinnen zeigende […] Erscheinung") dar. Aufgrund der komplizierten Ursachen-Komplexes (im Detail sehr technisch und nicht auf allen Computer-Plattformen in gleicher Weise erfahrbar), war allerdings zu befürchten, dass die anvisierte Zielgruppe der Schüler ohne informatische Vorbildung dafür kaum Erklärung finden könnte, die von Wert für die weitere Didaktische Rekonstruktion gewesen wären. Daher wurden nun die Kategorien der höheren Abstraktionsebenen betrachtet. Dabei fiel die Kategorie Computerviren auf, die (einschließlich der darunter subsumierten Codes Funktionsweise von Viren und Schutz vor Viren) von immerhin fünf Probanden erwähnt wurde und damit zu den häufigsten Kategorien zählte. Dieses klare Phänomen schien für die Forschungsarbeit geeignet, da es doch auch Schülern nicht zu schwer fallen sollte ihre persönliche Theorie dazu zu formulieren. Das auch Viren bei genauer Betrachtung eine sehr komplizierte Angelegenheit darstellen, stellte in meinen Augen kein Problem dar, da auch ohne zugehöriges Vor- oder Detailwissen interessante Erklärungsversuche zu erwarten waren. Wie bereits thematisiert, war es sicher nicht von Nachteil, dass auch Viren ein direkt mit der Informatik verbundenes Phänomen sind (erste Kategorie nach [HUMBERT & PUHLMANN, 2004]). 28 6.2. Zweite Befragung (Schülerperspektiven) Aufgrund der vorangegangen Befragung wurden anschließend insgesamt 130 Probanden zum Phänomen der Computerviren befragt. Das dabei 41 Probanden kein direktes Interview gaben, sondern die Beantwortung über eine, durch einen der beteiligten Studenten initiierte, Umfrage in einem sozialen Netzwerk erfolgte, wurde während der Auswertung berücksichtigt. Dabei stellte sich allerdings heraus, dass die Güte der Antworten nicht von denen der übrigen Probanden abwich, weshalb im weiteren Verlauf auf eine Unterscheidung verzichtet wurde. Zusammensetzung der Stichprobe Diesmal fanden sich unter allen Probanden exakt gleich viele Männer und Frauen und auch innerhalb der einzelnen Berufsgruppen war das Verhältnis nun ausgeglichener – gerade in der wichtigen Gruppe der Schüler war es sogar nur wegen der ungeraden Anzahl teilnehmende Schüler nicht genau 1:1 (Tabelle 7). Tabelle 7. Verteilung nach Berufsgruppe und Geschlecht Summe männlich weiblich 100,00 % 50,00 % 50,00 % Schüler 13,08 % 6,92 % 6,15 % Studenten 52,31 % 30,77 % 21,54 % Arbeiter 4,62 % 3,08 % 1,54 % Angestellte 21,54 % 7,69 % 13,85 % Staatsbedienstete 2,31 % Andere 5,38 % ohne Angabe 0,77 % 2,31 % 1,54 % 3,85 % 0,77 % Auch die Verteilung der Berufsgruppe Schüler auf die drei Vorbildungsgruppen war wieder realitätsnah. 20 In allen anderen Berufsgruppen fanden aber im Vergleich zur ersten Befragung deutliche Verschiebung zwischen den Vorbildungsgruppen statt. Diese zeigten nur in der Gruppe der Staatsbediensteten in Richtung niedrigere Vorbildung – in allen anderen Gruppen hingegen waren die Anteile in den Gruppen der höheren Vorbildung gestiegen. (Tabelle 8) Tabelle 8. Verteilung nach Berufsgruppe und informatischer Vorbildung 20 Summe G1 G2 G3 100,00 % 50,77 % 29,23 % 20,00 % Schüler 13,08 % 4,62 % 8,46 % Studenten 52,31 % 21,54 % 13,85 % 16,92 % Arbeiter 4,62 % 1,54 % 2,31 % 0,77 % Angestellte 21,54 % 15,38 % 3,85 % 2,31 % Staatsbedienstete 2,31 % 2,31 % Andere 5,38 % 4,62 % 0,77 % vgl. die Erklärung im Abschnitt 6.1 29 ohne Angabe Summe G1 G2 G3 100,00 % 50,77 % 29,23 % 20,00 % 0,77 % 0,77 % Auch wenn das Verhältnis von männlichen und weiblichen Teilnehmern insgesamt realitätsnah war, zeigt der Blick auf die Verteilung bezüglich der Vorbildungs-Gruppen, dass männliche Probanden in der obersten Gruppe über- und entsprechend in der untersten Gruppe unterrepräsentiert waren (Tabelle 9). Tabelle 9. Verteilung nach Geschlecht und informatischer Vorbildung Summe G1 G2 G3 100,00 % 50,77 % 29,23 % 20,00 % männlich 50,00 % 18,46 % 15,38 % 16,15 % weiblich 50,00 % 32,31 % 13,85 % 3,85 % Kodierung In den 130 Dokumenten wurden insgesamt 535 Textstellen kodiert. Das fünf-stufige Kategoriesystem umfasste am Ende 263 Codes. Die Beschränkung auf das dritte Quartil bedeutete im konkreten Fall, dass die Kategorien in mindesten elf Dokumenten zu finden sein mussten. Das neue Kategoriesystem umfasste 17 Kategorien; davon sechs auf höchster Abstraktionsebene und elf als Unterkategorien in einer zweiten Ebene. Der verwendete Kodierleitfaden folgt als Tabelle 10. Tabelle 10. Kodierleitfaden21 Kategorie K1 K1a K1b K1c Infektion Erklärung Virus gelangt von Außen auf den Computer (unspezifisch) Ankerbeispiel "Einschleusen auf den Rechner", Dokument: F__r-1 " Infektion per E-Mail Virus gelangt durch E-Mail auf "[Viren] werden v.a. durch mails den Computer übertragen", Dokument: W__r-01 " Infektion per Internet Virus gelangt durch das Internet auf den Computer "die [Viren] kommen übers Internet irgendwie auf meine Festplatte", Dokument: Z__u Infektion per Trägerdatei Virus gelangt Mittels einer "harmlosen" Datei auf den Computer "Computer-Viren verstecken sich in Anwendungen oder ausführbaren Dateien und befallen den Computer bei Ausführung der Datei/des Programms", Dokument: 2103831 " Ankerbeispiele sind so wiedergegeben, wie sie in den Dokumenten zu finden sind und werden dabei weder sprachlich geglättet, noch bezüglich der Rechtschreibung korrigiert; gleichwohl gibt es zum besseren Verständnis Ergänzungen/ Auslassungen 21 30 K1d K1e K1f Risikofaktoren Faktoren, die Infektion oder Schädigung durch das Virus erleichtern (explizit auch Unwissen des Nutzers etc.) "Viren nutzen eine Schwachstelle im Betriebsystem oder in einem Programm, oder die Naivität des Benutzers aus um sich zu installieren", Dokument: L__i-02 " Schutzfaktoren es existieren Möglichkeiten, sich gegen Infektion oder Schädigung durch das Virus zu schützen "man [kann] sie leicht durch ihre auffälligen Endungen ausfindig machen", Dokument: 2104939 " Weiterverbreitung das Virus gelangt von einem infizierten Gerät auf ein anderes (uU. selbstständig) "Schließlich versucht der Virus sich […] zu vermehren", Dokument: W__a-1 " K2 Krankheit Analogie zu biologischem Virus bzw. Krankheiten "Es entspricht so ca. dem biologischen Vorbild eines Virus", Dokument: 2103591 K3 Programm Virus ist ein normales Programm "Ein Virus ist ein Programm, das ausgeführt wird", Dokument: W__r-19 K3a " "Es ist eine Schadsoftware mit dem Virus wurde für eine bestimm- Ziel, den Schaden anzurichten, den te Aufgabe programmiert der Entwickler beabsichtigt hat", Dokument: K__s-4 K4 Schaden Virus schädigt den Computer auf abstrakte Weise K4a " Ausspähen Virus gibt Daten (z.B. Passwör- "[Viren] spähen Daten aus", ter) an Dritte weiter Dokument: E__n-1 K4b " Kontrolle Virus ermöglicht es Dritten, den Computer zu steuern K4c " Löschen Virus löscht Daten oder macht "greifen [..] Daten an (z.B. löschen sie auf andere Weise undiese)", Dokument: K__s-2 brauchbar K4d " Performanz "Programme, die andere ProgramVirus sorgt für eine Einschränme in ihrer Funktion hemmen.", kung der Rechenleistung Dokument: W__r-13 K5 K6 programmiert "sie zerstören den pc", Dokument: 2103400 "kann […] den Computer aus der ferne nutzen wie seinen eigenen", Dokument: L__g Tarnung das Virus ist nicht ohne weiteres zu erkennen (oder die Gefahr der Schädigung kann nicht erkannt werden) "Dazu werden die Viren, meist versteckt in anderen Programmen und Dateien, auf die fremden Rechner geladen", Dokument: W__r-06 verschiedene Arten von Viren es existieren verschiedene Arten von Schadprogrammen "Es gibt unterschiedliche Viren die (z.B. verschiedene Schadenunterschiedlich funktionieren", sszenarien; aber auch UnterDokument: M__i-3 scheidung von Virus, Trojaner, etc.) 31 Auswertung Nach der Kodierungs-Phase wurde ermittelt, wie Häufig die Kategorien erwähnt worden waren. Dabei wurden auch die drei Vorbildungs-Gruppen ausgezählt. Die Prozent-Angaben in Tabelle 11 beziehen sich dabei nur auf Dokumente der jeweiligen Gruppe: So waren beispielsweise 18,18 % der Dokumente aus Gruppe G1 der Kategorie Infektion zugeordnet. Tabelle 11. Nennung der Kategorien nach Vorbildung K1 Infektion Summe G1 G2 G3 23,08 % 18,18 % 26,32 % 30,77 % " Infektion per E-Mail 15,38 % 16,67 % 21,05 % 3,85 % " Infektion per Internet 16,92 % 16,67 % 23,68 % 7,69 % " Infektion per Trägerdatei 16,15 % 10,61 % 21,05 % 23,08 % K1d " Risikofaktoren 12,31 % 4,55 % 23,68 % 15,38 % K1e " Schutzfaktoren 9,23 % 7,58 % 10,53 % 11,54 % K1f " Weiterverbreitung 14,62 % 9,09 % 21,05 % 19,23 % K2 Krankheit 7,69 % 6,06 % 10,53 % 7,69 % K3 Programm 23,08 % 15,15 % 18,42 % 50,00 % K3a " 13,08 % 10,61 % 15,79 % 15,38 % K4 Schaden 45,38 % 48,48 % 42,11 % 42,31 % K4a " Ausspähen 25,38 % 24,24 % 31,58 % 19,23 % K4b " Kontrolle 12,31 % 13,64 % 7,89 % 15,38 % K4c " Löschen 14,62 % 16,67 % 15,79 % 7,69 % K4d " Performanz 16,15 % 18,18 % 18,42 % 7,69 % K5 Tarnung 8,46 % 7,58 % 7,89 % 11,54 % K6 verschiedene Arten von Viren 8,46 % 4,55 % 10,53 % 15,38 % K1a K1b K1c programmiert In nahezu allen Kategorien unterschieden sich die Häufigkeiten der drei Gruppen. Dem Anschein nach waren die Unterschiede in den Kategorien Infektion per E-Mail, Infektion per Internet, Risikofaktoren und Programm erheblich, wohingegen Schutzfaktoren, Tarnung, Krankheit und programmiert eine geringe Streuung aufwiesen. Der Vergleich dieser Antworten mit der Virus-Definition 22 förderte einen hohen Grad an Übereinstimmung zutage. Allerdings fiel auch auf, dass die Kategorie Programm sehr häufig (gerade in der Gruppe G3) kodiert worden war – im Gegensatz zur Definition nach ECKERT. Wobei 22 vgl. Abschnitt 2.3 32 noch mal betont werden muss, dass sich die Probanden selten konkret auf das Virus bezogen haben und oft Eigenschaften verschiedener Arten von Schadprogrammen vermischt wurden. Um dies richtig einschätzen zu können hilft ein Blick in die aktuellen Lehrpläne der bayerischen Realschulen und Gymnasien, da dies eben die beiden Schularten sein dürften, an denen die Gruppen G2 und G3 ihre informatische Vorbildung gewonnen haben.23 Für Realschulen sind dabei für den modularisierten Informatikunterricht die Lerninhalte Gefahren bei der Nutzung von Internetdiensten erkennen und berücksichtigen sowie Die Notwendigkeit von Datenschutz und Datensicherheit in lokalen und globalen Netzen kennen relevant. 24 Im Lehrplan des achtstufigen Gymnasiums findet sich das Thema Schadprogramme explizit nur in der Wirtschaftsinformatik der 10. Jahrgangsstufe [LEHRPLAN GYMNASIEN, 2009; ABSCHNITT WIN 10.3]. Ansonsten wären Anknüpfungspunkte in der 7. (E-Mail und Internet) und 9. Klasse (Datensicherheit und Datenschutz) denkbar, allerdings tauchen auch dort Risiken durch Schadprogramme höchstens implizit auf. Insgesamt bleibt also festzuhalten, dass die Schüler im Schulunterricht kaum Gelegenheit haben, direktes Wissen über Computer-Viren zu sammeln. Gleichwohl dürfte z.B. das Verständnis der Objekt-orientierten Analyse dazu beitragen, dass Schüler mögliche Erklärungsansätze zu Schadprogrammen entwickeln könnten. 6.3. Begriffsnetze Um die Fülle an so gewonnen Daten überblicken zu können bzw. sie auf einfach Weise zugänglich zu machen sollen Begriffsnetze dienen. Dabei werden aus den Kategorien und Dokumenten Graphen gebildet. Dokumentnetze Begonnen wurde mit den Beziehungen der Dokumente untereinander. Die Idee war, mehrere Graphen für verschiedene Teilmengen aller Dokumente zu zeichnen um sie nach auffälligen Mustern hin zu untersuchen. Konkret wurde erwartet, dass unter den Probanden mit höherer informatischer Vorbildung eher ein Konsens in der Erklärung der Viren zustanden gekommen sein sollte. Die Hoffnung dabei war, dass in diesem Graph die Knoten untereinander stark verknüpft sein sollten. Als Gegenbeispiel hätten die anderen Gruppen zu lose bis unzusammenhängenden Graphen führen können, was auf eine nicht einheitliche Ausbildung persönlicher Theorien hindeuten hätte können. Leider erfüllten sich diese Erwartungen nicht, da die Graphen nicht auffällig unterschiedlich ausfielen (Abbildungen 3 bis 5 auf den folgenden Seiten).25 wobei natürlich Probanden auch nicht-bayerische Schulen besucht haben könnten; das sollte bei einer neuerlichen Durchführung bereits bei Gestaltung der Fragebögen beachtet werden 23 Anfangsunterrichts-Modul »A4: Informationsbeschaffung, -bewertung und -austausch« bzw. Wahlplicht-Modul »F2: Entwicklung vernetzter Systeme und deren Absicherung« [Lehrplan Realschulen, 2008] 24 25 vgl. die Datenbasis als Anhang 3 bis 5 33 Abbildung 3. Dokument-Netz der Gruppe G1 Abbildung 4. Dokument-Netz der Gruppe G2 34 Abbildung 5. Dokument-Netz der Gruppe G3 35 Kategorienetze Anschließend wurde der umgekehrte Weg eingeschlagen: Kategorien als Knoten, mit Kanten bei gleichzeitigem Auftreten in mindestens einem Dokument – wieder getrennt für jede der Vorbildungsgruppen. Dabei wurde sehr genau darauf geachtet, dass die Knoten in allen drei Fällen an der gleichen Stelle auftauchten, um die Darstellungen vergleichbar zu machen. Dazu trägt auch die Verwendung eines einheitlichen Maßes bei: Kategorien derselben relativen Häufigkeit führten, auch innerhalb von verschiedenen Graphiken, zu Knoten der gleichen Fläche. Analog verhält es sich bei den Kanten.26 Die Abbildungen 6 bis 8 zeigen die Kategorien des finalen Kategoriesystems, sowie deren gemeinsames Auftreten in unterschiedlichen Dokumenten für jede der drei Gruppen. Um die Übersichtlichkeit zu waren, sind nur Kanten dargestellt, die sich bezüglich ihres Gewichts im Q0,9 der jeweiligen Gruppe befanden. 27 Das bedeutete hier je nach Gruppe, dass wenigstens fünf, vier bzw. drei Dokumente in zwei Kategorien übereinstimmen mussten, damit eine Kante eingezeichnet wurde. Abbildung 6. Kategorie-Netz der Gruppe G1 mit der Einschränkung, dass »yEd« nur sieben verschiedene Linienstärken anbietet; noch feinere Abstufungen sind aber hier sowieso kaum feststellbar 26 27 90 %-Quantil: die obersten 10 % der Kanten 36 Abbildung 7. Kategorie-Netz der Gruppe G2 Abbildung 8. Kategorie-Netz der Gruppe G3 37 Die bei der Präsentation des Zahlenmaterials erwähnten Unterschiede der Kategorien Infektion per E-Mail, Risikofaktoren und Programm waren in dieser Darstellungsform sehr gut zu sehen. Auffällig war dabei auch, dass in Abbildung 6 alle verbundenen Kategorien eine Kanten in Richtung Schaden aufwiesen. Bei genauem Hinsehen war zusätzlich zu erkennen, dass die Kanten in Abbildung 8 ein insgesamt höheres Gewicht, als die der anderen beiden Graphen hatten. Zwar waren nur die oberen 10 % der Kanten dargestellt, allerdings ließ dies die Vermutung zu, dass sich auch die übrigen Kanten auf höherem Niveau befanden. 0.05 0.10 0.15 0.20 Um dies zu überprüfen wurden die auftretenden relativen Häufigkeiten gegenübergestellt (Abbildung 9). G1 G2 G3 Abbildung 9. Box-Whisker-Plot28 der relativen Kategorie-Häufigkeiten Offenbar fanden sich bei den Gruppen höherer Vorbildung im Mittel tatsächlich höhere Kantengewichte: Die mittleren 50 % jeder Gruppe waren ebenso zueinander verschoben, wie auch die Mediane. Allerdings war der Median der dritten Gruppe niedriger als der der zweiten Gruppe – da in der dritten Gruppe deutlich weniger Probanden zusammengefasst waren, führt bereits eine einzige Verbindung zwischen zwei Kategorien zu einer hohen relativen Häufigkeit. Um diesen Umstand zu verdeutlichen, bot sich ein zusätzlicher Graph auf Grundlage der Varianzen an: Das Gewicht jedes Knotens war dabei die Varianz der Knotengewichte in allen drei Vorbildungsgruppen. Dabei ergaben sich hohe Knoten- und Kantengewichte, falls diese Elemente eine hohe Varianz aufwiesen und umgekehrt kleiner Knoten und dünnere Kanten bei geringerer Varianz. innerhalb der Box befinden sich die mittleren 50 % der Daten; der dunkle waagrechte Strich kennzeichnet den Median; bis zum oberen Ende der Whisker-Antenne sind 75 % der Daten abgedeckt; Ausreißer sind durch Kreise gekennzeichnet 28 38 In Abbildung 10 wurden aus Gründen der Übersichtlichkeit wieder nur Kanten des Quantil Q0,9 eingezeichnet. Abbildung 10. Varianz-Netz aller Vorbildungsgruppen Dabei zeigte sich, dass sich die Gruppen insbesondere bezüglich der Kategorien Programm, Risikofaktoren, Infektion per E-Mail und Infektion via Internet unterschieden. Zusätzlich waren die von der Kategorie Schaden ausgehenden Kanten besonders ausgeprägt. Dies wies darauf hin, dass die Gruppen Schaden mit unterschiedlichen Kategorien in Verbindung setzten. 39 6.4. Statistische Tests Um die, sich in den bisherigen Graphen abzeichnenden, Unterschiede weiter zu untersuchen, wurden die Eingangs vorgestellten statistischen Modelle angewendet. U-Test nach Wilcoxon, Mann und Whitney Die Nullhypothese (H0 : Die Stichproben sind paarweise gleichverteilt.) wurde zum Signifikanzniveau ' = 0,05 für drei Fälle überprüft: • Vergleich der Stichproben X = G1 und Y = G2 • Vergleich der Stichproben X = G1 und Y = G3 • Vergleich der Stichproben X = G2 und Y = G3 Die Stichproben ergaben sich aus den relativen Häufigkeiten der Nennung einer bestimmten Kategorie durch Mitglieder der drei Gruppen (Tabelle 12). Beispielsweise hatten sich 18,18 % der Mitglieder der ersten Gruppe zur Kategorie Infektion geäußert. Tabelle 12. relative Häufigkeit der Kategorie-Nennungen Anzahl der Dokumente K1 G2 G3 66 38 26 18,18 % 26,32 % 30,77 % " Infektion per E-Mail 16,67 % 21,05 % 3,85 % " Infektion per Internet 16,67 % 23,68 % 7,69 % " Infektion per Trägerdatei 10,61 % 21,05 % 23,08 % K1d " Risikofaktoren 4,55 % 23,68 % 15,39 % K1e " Schutzfaktoren 7,58 % 10,53 % 11,54 % " Weiterverbreitung 9,09 % 21,05 % 19,23 % K1a K1b K1c K1f 40 Infektion G1 K2 Krankheit 6,06 % 10,53 % 7,69 % K3 Programm 15,15 % 18,42 % 50,00 % K3a " 10,61 % 15,79 % 15,39 % K4 Schaden 48,49 % 42,11 % 42,31 % K4a " Ausspähen 24,24 % 31,58 % 19,23 % K4b " Kontrolle 13,64 % 7,90 % 15,39 % K4c " Löschen 16,67 % 15,79 % 7,69 % K4d " Performanz 18,18 % 18,42 % 7,69 % K5 Tarnung 7,58 % 7,90 % 11,54 % K6 verschiedene Arten von Viren 4,55 % 10,53 % 15,39 % programmiert Voraussetzung Die Stichproben setzten sich aus Prozentangaben zusammen und waren daher sogar Verhältnisskalierbar. Teststatistik Die Teststatistiken ergaben sich in den drei Fällen zu U12 = 88, U13 = 119 und U23 = 180. Für die zweiseitige (ungerichtete) Hypothese und die gewählten Irrtumswahrscheinlichkeit # = 0,05 fand sich in [SACHS, 1968; S. 296] der kritische Wert Ukrit = 87. Ergebnis Für U ≤ Ukrit hätte H0 verworfen werden können. Dies traf offensichtlich in keinem der Fälle zu. Zum Niveau # = 0,05 konnte also in keinem der drei Fälle ein signifikanter Unterschied nachgewiesen werden. Chi-Quadrat-Homogenitätstest Die Nullhypothese (H0: Die Stichproben X und Y entstammen der selben Verteilung.) wurde zum Signifikanzniveau ' = 0,05 für drei Fälle überprüft: • Vergleich der Stichproben X = G1 und Y = G2 • Vergleich der Stichproben X = G1 und Y = G3 • Vergleich der Stichproben X = G2 und Y = G3 Voraussetzung Der Stichprobenumfang zu #2-Approximation sollte nach [GEORGII, 2009; S. 302] zumindest n ≥ 5/min(,i) = 130 umfassen. Dies war zufälligerweise auch exakt die Anzahl der untersuchten Dokumente. Ansonsten waren die weiteren Voraussetzungen nur zu einem kleinen Teil erfüllt: nij ≥ 10 galt nicht immer und nur beim Vergleich der Gruppen G1 und G2 galt Eij ≥ 5 für annähernd 80 % aller Fälle. Teststatistik Die Teststatistiken ergaben sich zu #122 = 11,9340, #132 = 23,1024 und #232 = 15,5495. Da in den zwei Stichproben je 17 Merkmale betrachtet wurden, waren für den Homogenitätstest (17-1)(2-1) = 16 Freiheitsgrade zu berücksichtigen. Für den zweiseitigen Test und das Signifikanzniveau ' = 0,05 ergab sich nach [PESTMAN, 2009; S. 575] der Ablehnungsbereich zu A = ]26,3; +∞[. Ergebnis Da in allen drei Fällen jeweils *2 ∉ A galt, konnte H0 nicht verworfen werden. Also konnten zum Niveau ' = 0,05 keine paarweisen signifikanten Unterschiede nachgewiesen werden. Gauß-Test Die Nullhypothese (H0: Die Erwartungswerte der den Stichproben X und Y zugrunde liegenden Grundgesamtheiten sind gleich.) wurde bezüglich jeder der 17 Kategorien für die folgenden drei Fälle überprüft: • Vergleich der Stichproben X = G1 und Y = G2 41 • Vergleich der Stichproben X = G1 und Y = G3 • Vergleich der Stichproben X = G2 und Y = G3 Dabei wurde das übliche Signifikanzniveau von ' = 0,05 angelegt. Voraussetzung Die Stichprobenumfänge betrugen 66 (G1), 38 (G2) und 26 (G3). Daher waren die Voraussetzung (n > 30) in den Fällen, in denen G3 betrachtet wurde, nicht erfüllt. Teststatistik Tabelle 13 enthält die berechneten Prüfgrößen V für alle betrachteten Fälle. Tabelle 13. Prüfgrößen V des Gauß-Tests G1 vs. G2 K1 Infektion G1 vs. G3 G2 vs. G3 -0,9374 -1,2107 -0,3796 " Infektion per E-Mail -0,5387 2,1320* 2,2267* " Infektion per Internet -0,8375 1,2721 1,8195 " Infektion per Trägerdatei -1,3542 -1,3480 -0,1880 K1d " Risikofaktoren -2,5684* -1,4142 0,8262 K1e " Schutzfaktoren -0,4902 -0,5517 -0,1243 " Weiterverbreitung -1,5756 -1,1721 0,1761 K1a K1b K1c K1f K2 Krankheit -0,7635 -0,2677 0,3862 K3 Programm -0,4207 -3,1842* -2,6631* K3a " -0,7292 -0,5853 0,0432 K4 Schaden 0,6246 0,5296 -0,0158 K4a " Ausspähen -0,7881 0,5271 1,1248 K4b " Kontrolle 0,9342 -0,2087 -0,8844 K4c " Löschen 0,1159 1,2721 1,0095 K4d " Performanz -0,0300 1,4647 1,2914 K5 Tarnung -0,0578 -0,5517 -0,4685 K6 verschiedene Arten von Viren -1,0551 -1,4142 -0,5518 programmiert Zum Signifikanzniveau ' = 0,05 ergab sich nach [GEORGII, 2009; S. 383] der Ablehnungsbereich B = ]-∞; 1,96[ * ]1,96; +∞[. Ergebnis Damit konnte in fünf Fällen ein signifikanter Unterschied nachgewiesen werden: • 42 G1 äußerte sich seltener zur Kategorie Risikofaktoren als G2 (V = -2,5684) • G1 und G2 äußerten sich öfter zur Kategorie Infektion per E-Mail als G3 (V = 2,1320 bzw. V = 2,2267) • G1 und G2 äußerten sich seltener zur Kategorie Programm als G3 (V = -3,1842 bzw. V = -2,6631) Bewertung der Tests Mit den ersten beiden Verfahren ließen sich keine (zum Niveau # = 0,05) signifikanten Unterschiede der drei Vorbildungsgruppen bezüglich der Nennung der 17 Kategorien nachweisen. Aufgrund der Ergebnisse des Gauß-Tests ließ sich aber feststellen, dass in der Gruppe G1 Risikofaktoren und der Programm-Aspekt eine geringere Rolle spielen, wohingegen die Infektion per E-Mail öfter gennant wurde. Umgekehrt war in der Gruppe G3 die Kategorie Programm häufiger anzutreffen und die Infektion per E-Mail seltener. Dabei muss allerdings beachtet werden, dass nicht alle Voraussetzungen vollkommen erfüllt waren und so schon die weitere Anwendung der Tests einen formalen Verstoß darstellt. Wie bereits erwähnt, soll es aber hier mehr um das Aufzeigen von Methoden gehen, weshalb dieser Mangel hingenommen wurde. 43 7. Diskussion Überblick Intention war von Beginn an, eine Möglichkeit aufzuzeigen, wie Schülerperspektiven bezüglich eines informatischen Phänomens erforscht werden können. Dazu wurde ein mehrstufiges Verfahren vorgestellt. Mit diesem sollte im ersten Schritt herausgefunden werden, welchen Phänomene die Schüler Interesse entgegen bringen. Dies geschah hier durch eine offene Befragungen. Nach qualitativer Analyse der erhaltenen Antworten wurde ein Phänomen ausgewählt (Computer-Virus). Im zweiten Schritt wurde Kurzinterviews zu eben diesem Phänomen geführt. Auch diese wurden einer Qualitativen Inhaltsanalyse unterzogen, auf Grundlage deren Ergebnisse drei statistische Test durchgeführt wurden. Im Anschluss wurden die Ergebnisse zusätzlich durch Graphen visualisiert. Die nähere Untersuchung des Phänomens erfolgte dann mittels Kurzinterviews. Diese Interviews wurden anschließend einer Qualitativen Inhaltsanalyse unterzogen, die Ergebnisse auf statistische Auffälligkeiten hin untersucht und mit Begriffsnetzen veranschaulicht. Zusätzlich wurde das Modell der Didaktischen Rekonstruktion ausführlich beschrieben. Dazu wurden insbesondere die fachliche Hintergründe der Computer-Viren betrachtet. Darüber hinaus wurde ein Überblick über die Theorie der Kontexte und Phänomene geliefert – insbesondere zum Ansatz der Informatik im Kontext. Bewertung / Nutzen Bei der Auswahl des Phänomens ergab sich keine eindeutige Mehrheit für ein bestimmtes Phänomen. Das darüberhinaus einige Nennungen nicht der (Schul-) Informatik zuzuordnen waren oder aber überhaupt kein Phänomen darstellten war dagegen wohl unvermeidbar. Der Umfang der Untersuchung mit 130 Probanden in der zweiten Stufe ist sicher ein guter Anfang. Dazu muss aber die Frage gestellt werden, ob die Zusammensetzung dieser Stichprobe dazu geeignet war, auf deren Basis die entsprechenden Forschungsfragen zu beantworten. Auch wenn man dies beiseite lässt, waren trotzdem keine statistisch harten Ergebnisse nachzuweisen. Dies war auch aber nicht das Ziel. Mit dem hier vorgestellten Modellrahmen ist aber hoffentlich eine Beitrag zur weiteren Erforschung dieser und ähnlicher Themen geleistet. Bei einer erneuten (auch teilweisen) Durchführung sollten die folgenden Punkte beachtet werden: • Die Stichprobe sollte vorher sehr genau gewählt werden (z.B. sollte zur Untersuchung von Schülervorstellungen auch eine ausreichende Zahl von Schüler befragt werden). • Um die Voraussetzungen der statistischen Tests erfüllen zu können sollte auch über eine Vergrößerung der Stichprobe nachgedacht werden. Dabei spielt allerdings auch die Einteilung in Gruppen eine große Rolle: Hat eine der Gruppen nur einen kleinen Anteil an der gesamten Anzahl der Probanden, kann dies auch bei großem Stichprobenumfang zu Problemen führen. • Für die Befragung sollten einheitliche Standards herrschen. Da in dieser Arbeit die Befragung durch eine Vielzahl von Studenten erfolgte, führte dies unweigerlich zu qualitativ 44 sehr weit gefächerten Dokumenten. Abhilfe könnten Leitfaden-gestützte Interviews oder kleinschrittige Fragebögen schaffen. 29 • Ähnlich gelagert ist das Problem bei der Kodierung. Diese sollte am besten durch einen kleinen, eng zusammenarbeitenden Personenkreis erfolgen, der sich zusätzlich auf ein deduktiv entwickeltes Kategoriesystem stützen kann. Da aber durchaus eine induktive Kodierung nötig sein könnte (gerade bei freien Fragestellungen können natürlich nie alle Antwortmöglichkeiten vorausgesehen werden), ist auch ein induktives Vorgehen möglich. Dabei ist es besonders wichtig, dass sich ergebende Kategoriesystem rechtzeitig (und unter Umständen mehrmals) einer Revision zu unterziehen [MAYRING, 2008; S. 75F.].30 • Kodierung auf Grundlage eines deduktiv entwickelten Kategoriesystems (kann sich direkt aus den Thema ergeben31 oder aber muss durch induktive Kodierung eines Teils der Dokumente gewonnen werden). • Um zu einem deutlicheren Votum für ein Phänomen zu kommen, wäre unter Umständen ein zwei-schrittiger Ansatz zielführend: Nach einer freien Befragung mit anschließender Textanalyse werden die genannten Begriffe auf ein einheitliches Abstraktionsniveau gebracht und in einer Liste zusammengefasst. Dabei können evtl. unpassenden Nennungen auch begründet gestrichen werden 32 – wobei darauf geachtet werden sollte, nicht leichtfertig über Ideen der Schüler hinwegzugehen, um ein objektives Ergebnis zu erhalten. In einem zweiten Schritt wird diese Liste dann anderen Schülern vorgelegt, welche das interessanteste oder unerklärlichste Phänomen markieren (oder auch alle Phänomene auf einer Stufenskala anordnen) sollen. Die Auswertung erfolgt dann durch einfaches Auszählen (bzw. gewichtetes Auszählen) und ist so auch für sehr große Stichproben einfach durchführbar. vgl. dazu die detaillierten Fragebögen bei [HUMBERT & PUHLMANN, 2004; S. 3], die eine vielversprechende Möglichkeit zur genauen Erfassung von Vorstellungen zu Phänomenen darstellen 29 30 vgl. auch die Erklärungen im Abschnitt 4.1 31 vgl. das Modul »Fachliche Klärung« der »Didaktischen Rekonstruktion« 32 vgl. die Auswertung der ersten Befragung in Abschnitt 6.1 45 8. Weitere Forschungsrichtungen Bezüglich der Didaktischen Rekonstruktion wurden hier die Module Fachliche Klärung, Erfassung von Schülerperspektiven und Auswahl informatischer Phänomene eingehend behandelt. Zusätzlich wäre es wünschenswert, wenn die Ergebnisse einer erneuten Durchführung des hier beschriebenen Verfahrens dazu verwendet würden, eine konkrete Unterrichtseinheit vorzubereiten (im Sinne der Unterrichtsstrukturierung) und diese zu evaluieren. Auch zur Betrachtung der Lehrerperspektiven drängen sich einige Forschungsfragen auf. So stellt sich z.B. die Frage, inwiefern sich die von Lehrern erwarteten und die tatsächlich bei Schülern vorhandenen Vorstellungen zu einem bestimmten Thema unterscheiden. Oder ob Schüler die Einschätzung ihrer Lehrer bezüglich der Wichtigkeit und Interessantheit der Lerninhalte teilen. Das könnte mit einer klassischen Fragestellung zur Messung von Lernerfolg kombiniert werden: Inwieweit sich die Schüler im Unterricht Wissen über informatische Phänomene aneignen und ob sich dies mit den Erwartungen der jeweiligen Lehrkraft deckt. Zu den gesellschaftlichen Ansprüchen könnten Beispielsweise erforscht werden, inwiefern sich an Phänomenen angelehnte Unterrichtskonzepte dazu eignen, Eltern von der Notwendigkeit echten Informatikunterrichts abseits von Kursen zum Maschinenschreiben oder Anwenderschulungen zu überzeugen. 46 9. Danksagungen Anerkennung gebührt den Teilnehmern des Seminars "Didaktik der Informatik 1", das an der TU München während des Winter-Semesters 2011/2012 von Herrn HUBWIESER geleitet wurde. Sie haben die beiden Befragungen unter hohem persönlichen Einsatz durchgeführt und so maßgeblich dazu beigetragen, die Forschungsarbeit mit diesem Stichprobenumfang durchführen zu können. DINO CAPOVILLA möchte ich Dank aussprechen: Er hat hilfreiche Anmerkungen zur Interpretation der Graphen geliefert. Dank gebührt darüber hinaus IRA DIETHELM und PETER HUBWIESER, die es mir ermöglicht haben, Teilergebnisse dieser Arbeit in einen gemeinsamen Beitrag zur Koli Calling Conference einzubringen. PETER HUBWIESER hat insbesondere Hilfestellung bei der Kodierung der ersten Befragung, der Formulierung der Fragebögen sowie der statistischen Fassung der zweiten Umfrage geleistet. Darüber hinaus hat er mir zu jeder Zeit Hilfe geboten und mich im Lauf der letzten Monate in bemerkenswerter Weise betreut. Dafür möchte ich mich an dieser Stelle noch ausdrücklich und besonders bedanken. 47 10. Quellenverzeichnis [BAMBERG & BAUR, 1991] G. Bamberg & F. Baur (1991). Statistik. Oldenbourg Verlag, München/Wien. 7. Auflage. [BAYRHUBER ET AL., 2007] H. Bayrhuber, S. Bögeholz, S. Eggert, D. Elster, C. Grube, C. Hössle, M. Linsner, M. Lücken, J. Mayer, A. Möller, C. Nerdel, B. Neuhaus, H. Prechtl, A. Sandmann, N. M. Scheid, P. Schmiemann & G. Schoormans (2007). Biologie im Kontext: Erste Forschungsergebnisse. In: MNU, 60(5), S. 304–313. MNU, Hamburg. [COHEN, 1984] F. Cohen (1984). Computer Viruses: Theory and Experiments. PhD thesis, University of Southern California, Los Angeles. [COPEI, 1950] F. Copei (1950). Der fruchtbare Moment im Bildungsprozess. Quelle & Meyer, Heidelberg. Erstveröffentlichung 1930. [CORBIN & STRAUSS, 2008] J. Corbin & A. Strauss (2008). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory. Sage Publications, Thousand Oaks. 3. Auflage. [DIETHELM & DÖRGE, 2011] I. Diethelm & C. Dörge (2011). Zur Diskussion von Kontexten und Phänomenen in der Informatikdidaktik. In: M. Thomas (Hrsg.), INFOS, Ausgabe P-189 der LNI, S. 67–76. Gesellschaft für Informatik, Bonn. [DIETHELM & ZUMBRÄGEL, 2010] I. Diethelm & S. Zumbrägel (2010). Wie funktioniert eigentlich das Internet? Empirische Untersuchung von Schülervorstellungen. In: I. Diethelm, C. Dörge, C. Hildebrandt & C. Schulte (Hrsg.), DDI, Ausgabe 168 der LNI, S. 33–44. Gesellschaft für Informatik, Bonn. [DIETHELM ET AL., 2011A] I. Diethelm, C. Dörge, A.-M. Mesaroş & M. Dünnebier (2011). Die Didaktische Rekonstruktion für den Informatikunterricht. In: M. Thomas (Hrsg.), INFOS, Ausgabe P-189 der LNI, S. 77–86. Gesellschaft für Informatik, Bonn. [DIETHELM ET AL., 2011B] I. Diethelm, J. Koubek & H. Witten (2011). IniK - Informatik im Kontext: Entwicklungen, Merkmale und Perspektiven. In: LOG IN, Heft Nr. 169/170, S. 97-105. 49 [DIETHELM ET AL., 2012] I. Diethelm, P. Hubwieser & R. Klaus (TO APPEAR 2012). Students, Teachers and Phenomena: Educational Reconstruction for Computer Science Education. In: R. McCartney & M.-J. Laakso (Eds.), 12th Koli Calling International Conference on Computing Education Research. November 15th to 18th 2012. Tahko, Finland. ACM Digital Library. [DUIT & MIKELSKIS-SEIFERT, 2010] R. Duit & S. Mikelskis-Seifert (2010). Physik im Kontext: Konzepte, Ideen, Materialien für effizienten Physikunterricht. Friedrich Verlag, Seelze. [DURANTI & GOODWIN, 1992] A. Duranti & C. Goodwin (1992). Rethinking Context: Language as an interactive Phenomenon. Cambridge University Press, Cambridge. [ECKERT, 2012] C. Eckert (2012). IT-Sicherheit: Konzepte - Verfahren - Protokolle. Oldenbourg Verlag, München. 7. Auflage. [ENGBRING, 2003] D. Engbring (2003). Informatik im Herstellungs- und Nutzungskontext: Ein technikbezogener Zugang zur fachübergreifenden Lehre. Dissertation, Universität Paderborn, Paderborn. [ENGBRING & PASTERNAK, 2010] D. Engbring & A. Pasternak (2010). IniK: Versuch einer Begriffsbestimmung. In: G. Brandhofer, G. Futschek, P. Micheuz, A. Reiter & K. Schroder (Hrsg.): 25 Jahre Schulinformatik. Zukunft mit Herkunft, S. 100-115. Oesterreichische Computergesellschaft, Wien. [FUCCIA ET AL., 2007] D. di Fuccia, J. Schellenbach-Zell & B. Ralle (2007). Chemie im Kontext. In: MNU, 60(5), S. 274–282. MNU, Hamburg. [GAGNÉ, 1969] R. M. Gagné (1969). The Conditions of Learning. Holt, Rinehart & Winston, London/New York/Sydney/Toronto. [GAGNÉ, 1988] R. M. Gagné (1988). Principles of Instructional Design. Holt, Rinehart & Winston, London/New York/Sydney/Toronto. [GEORGII, 2009] H. O. Georgii (2009). Stochastik. de Gruyter, Berlin. 4. Auflage. [GILBERT, 2006] J. K. Gilbert (2006). On the Nature of "Context" in Chemical Education. In: International Journal of Science Education, 28(9), S. 957–976. 50 [HUBWIESER & MÜHLING, 2011] P. Hubwieser & A. Mühling (2011). What Students (should) know about Object oriented Programming. In: Proceedings of the seventh international Workshop on Computing Education Research, ICER '11, S. 77-84. ACM, New York. [HUMBERT & PUHLMANN, 2004] L. Humbert & H. Puhlmann (2004). Essential Ingredients of Literacy in Informatics. In: J. Magenheim & S. Schubert (Hrsg.), Informatics and Student Assessment. Nr. 1 in Lecture Notes in Informatics / S : Seminars, S. 65–76. Köllen Verlag, Bonn. [KATTMANN ET AL., 1995] U. Kattmann, R. Duit, H. Gropengießer & M. Komorek (1995). A model of educational reconstruction. Paper presented at the Annual Meeting of the National Association of Research in Science Teaching (NARST), San Francisco. [KATTMANN ET AL., 1997] U. Kattmann, R. Duit, H. Gropengießer & M. Komorek (1997). Das Modell der Didaktischen Rekonstruktion: Ein Rahmen für naturwissenschaftsdidaktische Forschung und Entwicklung. In: Zeitschrift für Didaktik der Naturwissenschaften, 3(3), S. 3–18. [KELLER, 1983] J. M. Keller (1983). Development and use of the ARCS Model of motivational Design. In: Toegepaste Onderwijskunde, Technische Hogeshool Twente. Enschede, Niederlande. [KOERBER & WITTEN, 2005] B. Koerber & H. Witten (2005). Grundsätze eines guten Informatikunterrichts. In: LOG IN, 25(135), S. 14–23. [KOMOREK, 2004] M. Komorek (2004). Physik im Kontext: Ein Programm zur Förderung der naturwissenschaftlichen Grundbildung durch Physikunterricht. In: A. Pitton (Hrsg.) Chemie- und physikdidaktische Forschung und naturwissenschaftliche Bildung, S. 215-217. LIT Verlag, Münster. [KOUBEK ET AL., 2009] J. Koubek, C. Schulte, P. Schulze & H. Witten (2009). Informatik im Kontext (IniK): Ein integratives Unterrichtskonzept für den Informatikunterricht. In: B. Koerber (Hrsg.), INFOS, Ausgabe 156 der LNI, S. 268-279. Gesellschaft für Informatik, Berlin. [LEHRPLAN GYMNASIEN, 2009] Bayerisches Staatsministerium für Unterricht und Kultus (Hrsg.) (2009). Lehrplan für das Gymnasium in Bayern G8. Kastner Verlag, Wolnzach. 2. Auflage. [LEHRPLAN REALSCHULEN, 2008] Bayerisches Staatsministerium für Unterricht und Kultus (Hrsg.) (2008). Lehrplan für die sechsstufige Realschule. J. Maiß Verlag, München. 2. Auflage. 51 [MAYRING, 2000] P. Mayring (2000). Qualitative Inhaltsanalyse. In: Forum Qualitative Sozialforschung, 1(2). [MAYRING, 2008] P. Mayring (2008). Qualitative Inhaltsanalyse: Grundlagen und Techniken. Beltz Verlag, Weinheim und Basel. 10. Auflage. [MERRILL, 2002] M. D. Merrill (2002). First Principles of Instruction. In: Educational Technology Research and Development, 50(3), S. 43–59. [MIERTSCHIN & WILLIS, 2007] S. L. Miertschin & C. L. Willis (2007). Using Concept Maps to navigate complex Learning Environments. In: Proceedings of the eigth ACM SIGITE Conference on Information Technology Education, SIGITE '07, S. 175–184. ACM, New York. [MÜHLING ET AL., 2010] A. Mühling, P. Hubwieser & T. Brinda (2010). Exploring Teachers' Attitudes towards Object oriented Modelling and Programming in secondary Schools. In: Proceedings of the sixth international Workshop on Computing Education Research, ICER '10, S. 59-68. ACM, New York. [PARCHMANN ET AL., 2000] I. Parchmann, B. Ralle & R. Demuth (2000). Chemie im Kontext: Eine Konzeption zum Aufbau und zur Aktivierung fachsystematischer Strukturen in lebensweltorientierten Fragestellungen. In: MNU, 53(2), S. 132–137. MNU, Hamburg. [PASTERNAK & VAHRENHOLD, 2009] A. Pasternak & J. Vahrenhold (2009). Rote Fäden und Kontextorientierung im Informatikunterricht. In: I.-R. Peters (Hrsg.), Informatische Bildung in Theorie und Praxis – 25 Jahre "INFOS – Informatik und Schule". LOG IN Verlag, Berlin. [PESTMAN, 2009] W. R. Pestman (2009). Mathematical Statistics. de Gruyter, Berlin. 2. Auflage. [PFEIFER, 2000] W. Pfeifer (2000). Etymologisches Wörterbuch des Deutschen. Deutscher Taschenbuchverlag, München. 5. Auflage. [RIEMEIER ET AL., 2010] T. Riemeier, M. Jankowski, B. Kersten, S. Pach, I. Rabe, S. Sundermeier & H. Gropengießer (2010). Wo das Blut fließt: Schülervorstellungen zu Blut, Herz und Kreislauf beim Menschen. In: Zeitschrift für Didaktik der Naturwissenschaften, 16, S. 77–93. [RINNE, 1997] H. Rinne (1997). Taschenbuch der Statistik. Verlag Harri Deutsch, Thun/Frankfurt am Main. 2. Auflage. 52 [SACHS, 1968] L. Sachs (1968). Statistische Auswertungsmethoden. Springer, Heidelberg. [SACK & WITTEN, 2009] L. Sack & H. Witten (2009). Zurück in die Zukunft? Zur Geschichte der Rahmen(lehr)pläne Informatik SekII in Berlin (West). In: INFOS 2009. [VOSS, 2000] W. Voß (2000). Taschenbuch der Statistik. Fachbuchverlag Leipzig, München/Wien. [WAGENSCHEIN, 1976] M. Wagenschein (1976). Rettet die Phänomene! In: Fragen der Freiheit, (121), S. 50–65. 53 11. Anhang 11.1. Anhang 1. exemplarischer Bogen zur ersten Befragung Technische Universität München TUM School of Education Fakultät für Informatik Prof. Dr. Peter Hubwieser Vorlesung „Didaktik der Informatik 1“ WS 2011/12 Garching, den 07.12.2011 Hausaufgabe: Umfrage nach kritischen Phänomenen Bitte führen Sie die folgende Umfrage bei 2-3 Personen möglichst ohne Informatikausbildung aus Ihrem Bekanntenkreis durch. Erheben Sie dabei bitte die folgenden Daten, tragen die diese jeweils in einen Fragebogen (pro Person) ein und laden Sie die Bögen in eDDI hoch. 1. Interviewer Name Christian Eickmann 2. Personendaten der/des Probanden 2.1. Alter 17 Allgemein Geschlecht O männl. X weibl. Beruf Schülerin 2.2. Nur, falls Beruf = Schüler(in) Art der gegenwärtig besuchte Schule X Gymnasium O FOS/BOS O Realschule O Berufsschule O Hauptschule Berufsbezeichnung: 2.3. Jahrgangsstufe 11 Zweig Naturwissenschaftlichtechnologisch Welche Informatikausbildung hatten Sie bisher? 2 Jahre Informatikunterricht (9+10) 3. Informatische Phänomene Bitte nennen Sie (insgesamt) drei Erscheinungen, Abläufe oder Vorgänge im Zusammenhang mit der alltäglichen Nutzung von Informations- und Kommunikationstechnik, die Ihnen besonders kompliziert, unverständlich oder schwer verständlich erscheinen? 54 1 Website erstellen 2 Programmieren allgemein 3 Binärsystem 11.2. Anhang 2. exemplarischer Bogen zur zweiten Befragung Technische Universität München TUM School of Education Fakultät für Informatik Prof. Dr. Peter Hubwieser Vorlesung „Didaktik der Informatik 1“ WS 2011/12 Garching, den 25.01.2012 Hausaufgabe: Interviews zu kritischen Phänomenen Bitte führen Sie die folgende Umfrage bei einer Person möglichst ohne Informatikausbildung aus Ihrem Bekanntenkreis durch. Erheben Sie dabei bitte die folgenden Daten, tragen die diese j eweils in einen Fragebogen (pro Person) ein und laden Sie die Bögen in eDDI hoch. Name des Interviewers: Florian Janus 1. Personendaten der/des Probanden Alter Geschlecht Beruf 32 O männl. X weibl. Lehrerin (Realschule) Nur, falls Beruf = Schüler(in) Art der gegenwärtig besuchte Schule O Gymnasium O Realschule O Hauptschule Jahrgangsstufe Zweig O FOS/BOS O Berufsschule Berufsbezeichnung: Welche Informatikausbildung hatten Sie bisher? Keine (nur Fortbildungen bzgl. MS Office Benutzung etc.) 2. Informatisches Phänomen: Computer-Viren Stellen Sie Ihrem Probanden die folgende Frage: „Was glauben Sie, wie Computer-Viren funktionieren?“ Protokollieren Sie die Antwort in diesem Formular und laden Sie dieses in eDDI hoch. „viren sind glaub ich wie kleine tierchen, die sich in irgendwelche computerprogramme einhäcken und da was verändern oder stören. sie sind böse, und manchmal schwer zu beseitigen weil man sie nicht so einfach identifizieren kann, um sie dann zu bekämpfen.“ 55 11.3. Anhang 3. Datenmatrix des Dokumentnetz zu G133 # 2 4 5 8 9 10 12 13 14 15 18 21 22 23 24 31 39 40 41 42 43 44 45 46 48 53 55 58 59 61 64 66 69 70 72 74 75 77 78 79 80 81 82 83 85 89 90 93 95 97 99 102 103 104 105 107 108 115 116 118 123 126 127 128 129 130 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 5 8 9 10 12 13 14 15 18 21 22 23 24 31 39 40 41 42 43 44 45 46 48 53 55 58 59 61 64 66 69 70 72 74 75 77 78 79 80 81 82 83 85 89 2 1 1 1 1 1 1 0 1 0 0 0 0 0 1 0 0 0 1 1 1 1 1 0 2 0 1 1 0 1 0 0 1 2 0 2 1 1 1 0 1 1 1 1 0 0 0 1 0 0 2 0 1 1 0 0 1 1 0 0 1 1 0 1 1 4 1 1 1 1 2 0 1 1 0 0 0 0 1 0 0 0 2 0 1 1 1 0 1 0 1 2 0 2 0 0 1 2 0 1 2 0 1 0 0 1 1 2 1 2 0 1 1 1 2 1 1 1 0 0 1 1 0 0 1 0 0 0 1 2 1 1 1 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 2 2 0 1 0 1 1 0 1 1 1 1 1 0 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 2 1 0 0 1 1 0 0 1 1 1 0 2 1 1 1 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 1 1 0 1 0 1 1 0 1 0 0 1 1 0 1 1 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 0 1 2 1 1 0 1 0 1 0 0 0 1 0 0 0 1 0 1 2 1 0 1 0 1 2 1 1 0 0 1 1 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 0 1 1 2 2 0 0 1 1 1 0 1 1 1 0 1 1 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 1 1 0 1 0 1 1 0 1 0 0 1 1 0 1 1 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 0 1 6 0 1 0 0 0 0 0 1 0 0 0 1 1 3 2 1 2 1 0 1 3 1 2 1 2 2 2 0 2 3 0 1 1 0 1 1 2 1 2 0 2 2 1 1 1 3 2 0 0 1 1 0 0 1 3 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 4 0 0 1 0 0 1 0 0 0 2 0 1 2 1 1 2 0 2 2 2 2 0 1 1 1 0 1 2 1 1 1 1 1 0 1 1 1 0 2 2 1 1 0 4 1 0 0 2 1 1 1 1 2 1 0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 1 0 0 1 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 1 0 1 0 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 1 0 1 0 1 1 0 1 0 0 1 1 0 1 1 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 1 1 1 1 2 0 2 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 0 2 1 0 0 1 1 0 0 1 0 0 0 1 2 1 0 0 0 1 0 0 0 0 0 0 1 0 1 0 1 0 1 0 0 1 0 1 0 1 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 0 1 0 3 2 1 1 1 0 1 2 1 1 0 2 2 2 0 2 2 0 1 1 0 1 0 1 1 0 0 2 0 1 1 0 2 2 0 0 1 1 0 0 1 1 0 1 1 6 2 1 1 0 1 4 2 2 2 3 2 2 0 2 3 0 1 1 0 2 1 1 3 1 0 2 0 0 1 1 5 2 0 0 2 2 1 0 1 5 3 1 2 2 0 1 0 1 1 0 1 1 1 1 1 0 1 1 0 1 0 0 1 1 1 1 0 0 1 0 0 1 0 2 1 0 0 1 1 0 0 1 1 1 0 2 3 1 0 1 1 2 0 0 1 1 1 0 1 1 1 0 2 1 0 0 0 0 1 0 1 2 0 0 0 2 0 0 0 0 0 0 0 0 2 0 1 0 3 0 2 1 1 1 0 0 1 2 0 2 1 2 1 1 2 1 1 1 0 0 0 1 1 0 2 0 2 1 0 0 1 1 0 0 1 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 0 1 0 0 0 1 1 0 1 0 2 1 0 0 1 1 0 0 1 0 0 0 1 5 2 3 0 2 2 2 0 2 3 0 1 1 0 1 1 2 2 1 0 2 1 0 1 2 4 2 0 0 2 1 1 0 1 3 2 1 1 4 0 0 1 1 1 0 1 2 1 0 2 1 0 0 0 1 0 0 2 2 1 0 1 4 1 0 0 0 0 2 1 0 3 1 1 0 3 0 1 1 1 0 1 2 0 1 0 0 1 1 2 1 1 0 1 1 0 1 1 2 1 0 0 2 1 0 0 1 1 1 0 1 3 1 0 0 0 0 1 0 0 0 0 1 1 0 1 1 0 0 0 0 0 0 2 0 0 0 0 1 0 0 0 3 1 0 1 4 1 1 0 1 1 0 0 1 0 0 1 0 3 1 0 1 0 1 0 0 3 1 0 0 1 0 0 0 0 3 2 1 1 3 2 0 2 2 0 1 1 0 1 1 1 0 0 0 2 0 0 1 0 3 1 0 0 1 1 0 0 1 1 0 1 1 4 0 3 2 1 1 1 1 1 1 1 0 1 0 2 0 0 3 0 2 1 0 0 1 1 0 0 1 2 0 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 2 1 1 1 1 1 1 1 0 0 0 2 0 0 2 0 2 1 0 0 1 1 0 0 1 2 0 2 1 5 0 1 1 0 2 1 2 0 0 0 3 2 1 1 1 3 1 0 0 1 2 1 1 1 3 0 1 1 2 0 1 2 0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 1 0 1 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 0 1 2 1 0 0 0 0 0 0 1 1 0 0 0 2 0 0 0 0 0 0 0 0 1 0 1 0 2 0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 1 0 1 0 2 0 1 0 0 0 1 0 0 1 0 1 1 0 0 1 2 0 0 1 1 0 0 1 4 1 1 0 0 0 1 0 1 1 2 0 0 0 0 0 0 0 0 2 1 1 1 2 0 0 0 1 1 0 1 1 1 1 0 0 1 1 0 0 1 0 0 0 1 5 2 0 0 0 2 0 1 3 2 0 0 1 0 1 0 0 3 3 0 1 In der Matrix werden die Dokumente (repräsentiert durch Nummern) paarweise verglichen. Die Zahl in der Zelle im Schnittpunkt gibt dabei die Anzahl übereinstimmender Codes an. Zur Kontrolle sind auf der Hauptdiagonalen (also dem Vergleich jedes Dokuments mit sich selbst) die Anzahl der Codes die diesem Dokument zugeordnet wurden eingetragen. Zu beachten ist, dass die Matrix natürlich symmetrisch wäre, aber aus Gründen der Übersichtlichkeit nur die untere Hälfte wiedergegeben wird. 33 56 # 2 4 5 8 9 10 12 13 14 15 18 21 22 23 24 31 39 40 41 42 43 44 45 46 48 53 55 58 59 61 64 66 69 70 72 74 75 77 78 79 80 81 82 83 85 89 90 93 95 97 99 102 103 104 105 107 108 115 116 118 123 126 127 128 129 130 90 93 95 97 99 102 103 104 105 107 108 115 116 118 123 126 127 128 5 0 0 1 1 1 0 2 0 0 0 1 0 0 0 0 3 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 1 1 1 0 3 1 0 0 1 1 1 1 1 2 0 1 1 4 1 0 1 2 0 0 0 0 0 1 1 0 2 0 0 0 4 0 0 1 1 0 0 1 0 1 1 0 1 0 0 0 3 0 1 1 0 0 1 1 0 0 1 1 0 1 1 2 1 1 0 0 0 0 1 0 0 1 1 0 0 9 2 0 0 2 1 2 1 1 6 3 1 2 3 0 0 1 1 1 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 1 0 0 1 1 1 0 1 2 0 0 1 1 0 0 1 2 1 0 2 1 0 0 1 0 1 0 0 0 1 0 0 0 1 9 3 2 1 3 0 1 57 11.4. Anhang 4. Datenmatrix des Dokumentnetz zu G234 34 # 6 7 17 28 29 30 33 34 38 47 49 50 51 52 56 57 60 63 65 67 68 84 86 88 91 94 100 106 110 112 113 114 117 119 120 121 122 124 6 3 7 0 4 17 0 2 4 28 0 1 1 3 29 0 0 0 0 0 30 0 1 2 2 0 3 33 0 0 1 2 0 2 3 34 1 1 1 0 0 1 0 3 38 0 0 1 2 0 2 2 0 2 47 0 0 0 0 0 0 0 0 0 1 49 0 0 0 0 0 0 1 0 0 0 3 50 1 1 2 1 0 1 1 0 1 0 0 4 51 0 1 1 0 0 1 1 1 0 0 2 0 4 52 0 1 1 1 0 1 2 0 1 0 2 0 2 4 56 0 1 1 2 0 2 2 1 2 0 0 1 0 2 5 57 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 60 0 1 2 2 0 2 2 1 2 0 1 2 1 2 3 0 5 63 1 2 2 1 0 2 1 2 1 0 0 3 1 0 3 0 3 6 65 0 0 0 1 0 1 2 0 1 1 2 1 2 1 1 0 1 1 5 67 0 2 2 1 0 1 1 0 1 0 0 1 1 2 2 0 2 1 1 4 68 0 2 2 2 0 3 2 1 2 1 0 1 1 2 3 0 2 2 2 2 5 84 0 0 1 1 0 1 2 0 1 0 1 0 2 2 1 0 1 0 2 2 1 3 86 0 0 0 0 0 0 1 0 0 1 1 0 2 1 0 0 0 0 3 1 1 2 3 88 0 1 1 0 0 1 0 1 0 0 1 0 1 0 1 0 0 2 1 0 1 0 0 3 91 0 0 0 0 0 0 1 0 0 0 2 0 3 2 1 0 1 1 2 1 0 2 2 1 4 94 0 1 2 2 0 1 1 0 1 0 0 1 0 1 1 0 1 0 0 1 1 1 0 0 0 3 100 0 0 0 1 0 1 1 0 1 1 0 1 0 0 1 0 1 1 2 0 2 0 1 0 0 0 2 106 1 0 1 1 0 1 1 1 1 0 0 0 0 1 1 0 1 0 0 1 1 1 0 0 0 1 0 2 110 1 0 1 1 0 1 1 1 1 1 0 0 0 1 2 0 1 1 1 1 2 1 1 1 1 1 1 2 4 112 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 1 2 0 1 1 0 1 0 0 0 0 2 113 1 2 0 1 0 0 0 2 0 0 0 0 0 1 2 0 1 1 0 1 1 0 0 0 0 1 0 1 1 0 4 114 0 1 1 0 0 0 1 0 0 0 1 1 1 2 2 0 0 1 1 1 1 1 1 1 2 1 0 0 1 0 1 4 117 2 1 1 2 0 2 2 2 2 0 0 1 0 2 4 0 3 2 1 2 3 1 0 0 0 1 1 2 2 0 3 1 6 119 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 120 0 1 1 0 0 1 0 1 0 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 1 121 0 1 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 2 122 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 2 0 0 0 2 124 1 2 3 1 0 2 1 3 1 1 1 1 3 2 2 0 4 3 2 3 3 2 2 1 2 1 1 2 3 2 2 0 3 0 1 0 1 vgl. die Erklärungen zu Anhang 3 58 8 11.5. Anhang 5. Datenmatrix des Dokumentnetz zu G335 35 # 1 3 11 16 19 20 25 26 27 32 35 36 37 54 62 71 73 76 87 92 96 98 101 109 111 125 1 2 3 0 3 11 0 0 1 16 0 0 0 0 19 1 1 0 0 3 20 1 0 0 0 0 3 25 0 0 0 0 0 0 3 26 1 1 0 0 0 1 0 2 27 1 0 0 0 0 1 0 1 2 32 0 0 0 0 0 1 1 0 1 5 35 1 0 0 0 1 0 1 0 0 2 3 36 1 1 0 0 0 1 0 2 1 1 1 3 37 2 1 0 0 2 1 1 1 1 0 1 1 5 54 0 0 0 0 1 0 0 0 1 1 0 0 0 2 62 1 0 0 0 2 0 0 0 0 0 1 0 1 1 2 71 0 0 0 0 0 0 1 0 1 1 0 0 0 1 0 2 73 0 1 0 0 1 0 1 0 0 1 1 1 3 0 0 0 4 76 2 1 0 0 1 3 1 2 1 1 1 2 4 0 1 0 2 8 87 2 0 0 0 1 2 0 1 2 3 1 1 2 1 1 1 0 3 5 92 1 0 0 0 1 0 0 0 1 1 1 0 1 1 1 1 0 1 2 2 96 2 0 0 0 2 1 1 1 1 1 2 1 2 1 2 0 0 2 2 1 4 98 1 0 1 0 1 1 0 0 0 2 1 0 1 0 1 0 0 2 3 1 1 4 101 2 1 0 0 1 1 0 1 1 0 1 1 2 0 1 0 0 2 2 1 2 1 3 109 1 0 0 0 0 1 2 1 2 2 1 1 2 1 0 1 1 2 2 1 2 0 1 4 111 1 0 0 0 1 0 1 0 1 1 1 0 2 1 1 1 1 2 2 2 1 1 1 2 3 125 1 0 0 0 1 0 0 0 0 0 1 0 1 0 1 0 0 1 1 1 1 1 1 0 1 1 vgl. die Erklärungen zu Anhang 3 59 12. Erklärung gem. § 30 Abs. 6 LPO I (2002) Hiermit erkläre ich, dass die vorliegende Hausarbeit von mir selbstständig verfasst wurde und dass keine anderen als die angegebenen Hilfsmittel benutzt wurden. Die Stellen der Arbeit, die anderen Werken dem Wortlaut oder Sinn nach entnommen sind, sind in jedem einzelnen Fall unter Angabe der Quelle als Entlehnung kenntlich gemacht. Diese Erklärung erstreckt sich auch auf etwa in der Arbeit enthaltene Graphiken, Zeichnungen, Kartenskizzen und bildliche Darstellungen. ______________________________ Ort, Datum _________________________ Unterschrift 61