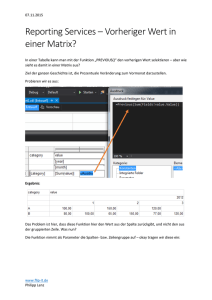
Validierung von Konzepten zur Messung des Marktrisikos
Werbung

econstor A Service of zbw Make Your Publications Visible. Leibniz-Informationszentrum Wirtschaft Leibniz Information Centre for Economics Mehmke, Fabian; Cremers, Heinz; Packham, Natalie Working Paper Validierung von Konzepten zur Messung des Marktrisikos: Insbesondere des Value at Risk und des Expected Shortfall Working Paper series, Frankfurt School of Finance & Management, No. 192 Provided in Cooperation with: Frankfurt School of Finance and Management Suggested Citation: Mehmke, Fabian; Cremers, Heinz; Packham, Natalie (2012) : Validierung von Konzepten zur Messung des Marktrisikos: Insbesondere des Value at Risk und des Expected Shortfall, Working Paper series, Frankfurt School of Finance & Management, No. 192 This Version is available at: http://hdl.handle.net/10419/60503 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Zwecken und zum Privatgebrauch gespeichert und kopiert werden. Documents in EconStor may be saved and copied for your personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich machen, vertreiben oder anderweitig nutzen. You are not to copy documents for public or commercial purposes, to exhibit the documents publicly, to make them publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, gelten abweichend von diesen Nutzungsbedingungen die in der dort genannten Lizenz gewährten Nutzungsrechte. www.econstor.eu If the documents have been made available under an Open Content Licence (especially Creative Commons Licences), you may exercise further usage rights as specified in the indicated licence. Frankfurt School - Working Paper Series No. 192 Validierung von Konzepten zur Messung des Marktrisikos - insbesondere des Value at Risk und des Expected Shortfall by Fabian Mehmke, Heinz Cremers, Natalie Packham June 2012 Sonnemannstr. 9-11 60314 Frankfurt am Main, Germany Phone: +49 (0)69 154 008 0 Fax: +49 (0)69 154 008 728 Internet: www.frankfurt-school.de Abstract Market risk management is one of the key factors to success in managing financial institutions. Underestimated risk can have desastrous consequences for individual companies and even whole economies, not least as could be seen during the recent crises. Overestimated risk, on the other side, may have negative effects on a company’s capital requirements. Companies as well as national authorities thus have a strong interest in developing market risk models that correctly quantify certain key figures such as Value at Risk or Expected Shortfall. This paper presents several state of the art methods to evaluate the adequacy of almost any given market risk model. Existing models are enhanced by in-depth analysis and simulations of statistical properties revealing some previously unknown effects, most notably inconsistent behaviour of alpha and beta errors. Furthermore, some new market risk validation models are introduced. In the end, a simulation with various market patterns demonstrates strenghts and weaknesses of each of the models presented under realistic conditions. Key words: Backtesting, Market Risk, Value at Risk, Expected Shortfall, Validation, Alpha Error, Beta Error, Time Until First Failure, Proportion of Failure, Traffic Light Approach, Magnitude of Loss Function, Markow-Test, Gauss-Test, Rosenblatt, Kuiper, Kolmogorov-Smirnov, Jarque-Bera, Regression, Likelihood Ratio, Truncated Distribution, Censored Distribution, Simulation JEL classification: C01, C02, C12, C13, C14, C15, C32, G32, G38 ISSN: 14369753 Contact: Fabian Mehmke Bergweg 1 61440 Oberursel [email protected] Prof. Dr. Heinz Cremers Centre for Practical Quantitative Finance Frankfurt School of Finance & Management Sonnemannstraße 9-11 60314 Frankfurt am Main [email protected] Prof. Dr. Natalie Packham Centre for Practical Quantitative Finance Frankfurt School of Finance & Management Sonnemannstraße 9-11 60314 Frankfurt am Main [email protected] 1 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Inhaltsverzeichnis 1. Einleitung 4 2. Validierung von Marktrisikomodellen 2.1. Statistische Verfahren und Testtheorie . . . . . . . . . . . . . . . . 2.1.1. Maximum Likelihood-Parameterschätzung . . . . . . . . . . 2.1.2. Hypothesentests . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.3. Likelihood-Quotienten-Tests . . . . . . . . . . . . . . . . . . 2.1.4. α- und β-Fehler sowie statistische Macht . . . . . . . . . . . 2.2. Prognose von Risiken . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.1. Risikomanagement & Marktrisikomodelle . . . . . . . . . . . 2.2.2. Vorhersage von Wahrscheinlichkeitsverteilungen . . . . . . . 2.2.3. Value at Risk . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.4. Überschreitungsfunktion . . . . . . . . . . . . . . . . . . . . 2.2.5. Expected Shortfall . . . . . . . . . . . . . . . . . . . . . . . 2.2.6. Regulatorische Auswirkungen der Risikoprognose . . . . . . 2.2.7. Überprüfung der Modelle . . . . . . . . . . . . . . . . . . . . 2.3. Validierung basierend auf Überschreitungen . . . . . . . . . . . . . 2.3.1. Time Until First Failure . . . . . . . . . . . . . . . . . . . . 2.3.2. Proportion of Failure . . . . . . . . . . . . . . . . . . . . . . 2.3.3. Baseler Ampelansatz / Traffic Light Approach . . . . . . . . 2.3.4. Magnitude of Loss Function . . . . . . . . . . . . . . . . . . 2.3.5. Markow-Test auf Unabhängigkeit . . . . . . . . . . . . . . . 2.4. Validierung basierend auf der gesamten Verteilung . . . . . . . . . . 2.4.1. Rosenblatt-Transformation zur Gleichverteilung . . . . . . . 2.4.2. CD-Verfahren: Kuiper-Statistik mit Worry Function . . . . . 2.4.3. Kolmogorov-Smirnov-Test mit Worry Function . . . . . . . . 2.4.4. Wahrscheinlichkeitsintegral zur Transformation in eine Normalverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.5. Jarque-Bera-Test auf Normalverteilung . . . . . . . . . . . . 2.4.6. Regression auf Mittelwert, Varianz und Autokorrelation . . . 2.4.7. Fazit zu ganzheitlichen Validierungsmodellen . . . . . . . . . 2.5. Validierung basierend auf einem Teilbereich der Verteilung . . . . . 2.5.1. Gestutzter Likelihood-Quotienten-Test . . . . . . . . . . . . Frankfurt School of Finance & Management Working Paper No. 192 6 6 6 8 11 13 18 18 18 21 22 23 23 24 26 26 37 43 47 49 56 56 58 62 65 68 70 74 76 76 2 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.5.2. Gauss-Test des Expected Shortfall bei gestutzter Verteilung 79 2.5.3. Sattelpunktapproximation mittels Lugannani Rice-Formel zum Überprüfen des Expected Shortfall . . . . . . . . . . . . . . 82 3. Simulation 3.1. Korrekt spezifiziertes Risikomodell . . . . . . . . . . . . . 3.2. Risikomodell mit rollierenden Varianzen . . . . . . . . . . 3.3. Risikomodell mit exponentiell geglätteten Varianzen . . . . 3.4. GARCH-Risikomodell . . . . . . . . . . . . . . . . . . . . 3.5. Konstante Risikounterschätzung . . . . . . . . . . . . . . . 3.6. Korrekter Value at Risk, unterschätzter Expected Shortfall 3.7. Zusammenfassung der Simulationsergebnisse . . . . . . . . 4. Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85 86 90 91 92 93 94 96 98 Literaturverzeichnis 100 Nomenklatur 102 A. Anhang 107 A.1. Tabellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107 3 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 1. Einleitung Zahlreiche Finanzinstitute sind einem beträchtlichen finanziellen Risiko durch Veränderung von Marktpreisen ausgesetzt. Aus diesem Grund wurde es immer bedeutender, daraus resultierende potentielle Folgen möglichst präzise vorhersagen zu können. Zur konkreten Quantifizierung derartiger Risiken setzten sich in der Praxis vorrangig zwei Kennzahlen durch: Der Value at Risk sowie der Expected Shortfall. Ersterer soll dabei eine Aussage über eine Verlustgrenze treffen, die höchstens mit einer bestimmten, geringen Wahrscheinlichkeit - meist 1% oder 5% - überschritten wird. Der Expected Shortfall hingegen soll den erwarteten Verlust unter der Bedingung, dass der Value at Risk überschritten wird, angeben. Beide Kennzahlen sind allerdings nur Kondensationen eines ganzheitlichen Risikomodells, welches nach unterschiedlichsten Annahmen und Kriterien strukturiert werden kann. Je nach Art und konkreter Anwendung verschiedener Modelle können dabei stark unterschiedliche Werte für Risikokenngrößen ermittelt werden. Eine bedeutende Aufgabe ist es deshalb, Marktrisikomodelle auf ihre Güte zu überprüfen. Es muss festgestellt werden können, ob ein Modell verlässliche Aussagen über das reale Marktrisiko trifft. Dieser Aspekt wird im Folgenden den Schwerpunkt unserer Arbeit darstellen: Wir werden Verfahren beschreiben und entwickeln, die Marktrisikomodelle anhand ihrer Prognosequalität beurteilen können. Im ersten Abschnitt des folgenden Kapitels werden wir dabei zuerst auf einige Grundlagen aus der Statistik eingehen, welche eine zentrale Rolle im Rest dieser Arbeit einnehmen werden. Anschließend werden wir detaillierter auf die Fragen eingehen, in welchem Zusammenhang Marktrisikomodelle zum allgemeinen Risikomanagement stehen, wie Marktrisikomanagement in der Praxis durchgeführt wird und welche Resultate es liefert. In Abschnitt 2.3 werden wir schließlich erste Verfahren zur Validierung von Marktrisikomodellen betrachten. Dabei wird vor allem die Frage, ob der Value at Risk korrekt modelliert wird, im Vordergrund stehen. Mit der Magnitude of Loss Function kommen wir dabei im Abschnitt auch auf ein Verfahren zu sprechen, das in der Literatur bislang wenig Beachtung fand. Anschließend werden wir Verfahren betrachten, die sich von dem reinen Fokus auf bestimmte Kennzahlen lösen und Marktrisikomodelle in ganzheitlichen Ansätzen Frankfurt School of Finance & Management Working Paper No. 192 4 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall validieren. Vorweggenommen sei an dieser Stelle, dass damit jedoch automatisch auch die Prüfung auf Korrektheit des Value at Risk und des Expected Shortfall mit inbegriffen ist, wenngleich auch nicht mehr als einziges Kriterium. Im Rahmen des Kolmogorov-Smirnov-Tests mit Worry Function kommen wir dabei auf ein bislang noch nicht näher erforschtes Verfahren zu sprechen. Danach werden wir auf Konzepte eingehen, welche ganz bestimmte Teilbereiche eines Risikomodells überprüfen. Damit wird es vor allem möglich sein, Spektralmaße wie den Expected Shortfall zu testen. Mit dem gestutzten Likelihood-QuotientenTest modifizieren wir dabei ein bekanntes Verfahren. Mit dem Gauss-Test des Expected Shortfall bei gestutzter Verteilung führen wir ein gänzlich neues Testverfahren ein. Zuletzt werden wir die bis dahin entwickelten theoretischen Verfahren in einer umfangreichen Simulation auf statistische Eigenschaften überprüfen, um die Qualität der einzelnen Testverfahren beurteilen zu können. Ein anschließendes Fazit wird die im Laufe dieser Arbeit gewonnenen Erkenntnisse abschließend zusammenfassen. 5 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2. Validierung von Marktrisikomodellen 2.1. Statistische Verfahren und Testtheorie Im Folgenden werden wir auf einige statistische Verfahren eingehen, die eine wichtige Basis für den weiteren Verlauf dieser Arbeit darstellen und unverzichtbar für jedes der später dargelegten Validierungskonzepte sein werden: 1. Die Schätzung unbekannter Verteilungsparameter 2. Hypothesentests zum Überprüfen bestimmter Aussagen, etwa Aussagen über die geschätzten Parameter 3. Likelihood-Quotienten-Tests als spezielle Form eines Hypothesentests 4. Fehler, die im Rahmen von Hypothesentests begangen werden können 2.1.1. Maximum Likelihood-Parameterschätzung Die Maximum Likelihood-Parameterschätzung dient, wie auch schon von Ruppert (2010) erläutert, zur Schätzung unbekannter Verteilungsparameter. Die Frage im Rahmen des Maximum Likelihood-Verfahrens ist: Wie sollten unbekannte Parameter gewählt werden um die Wahrscheinlichkeit zu maximieren, eine konkrete Stichprobe aus der spezifizierten Verteilungsform zu realisieren. Ausgangspunkt ist eine Zufallsvariable mit Dichtefunktion, welche von einem Parametervektor θ mit in der Regel einem oder mehreren unbekannten Komponenten abhängt. Beispielsweise könnte eine Zufallsvariable X vorliegen, von welcher wir wissen, dass sie normalverteilt mit bekannter Varianz 1, jedoch unbekanntem Parameter ϑ für den Erwartungswert ist. Dann ist θ = (ϑ, 1) , X ∼ N (ϑ, 1). Wir wollen nun basierend auf einer Stichprobe ermitteln, was der wahrscheinlichste Wert für ϑ ist. Frankfurt School of Finance & Management Working Paper No. 192 6 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Technisch gesehen liefert die Dichtefunktion einer kontinuierlich verteilten Zufallsvariable an einer einzigen Stelle keine sinnvoll interpretierbare Aussage über Wahrscheinlichkeiten, da im Kontinuierlichen die Wahrscheinlichkeit für den Erhalt irgendeines bestimmten Wertes stets exakt 0 ist. Eine konkrete Wahrscheinlichkeit erhält man lediglich durch Integration der Dichtefunktion auf einem bestimmten Intervall. Die hier betrachteten stetigen Dichtefunktionen stehen dennoch in enger Verbindung zu den Wahrscheinlichkeiten. Nicht ganz präzise könnte man interpretieren: Je höher das Ergebnis der Dichtefunktion an einer bestimmten Stelle x ist, desto höher ist die Wahrscheinlichkeit, eine Realisation der Zufallsvariable zu erhalten, die ungefähr x entspricht. Wir werden zur Lesbarkeit im Folgenden auf diese präzise Unterscheidung verzichten, sprechen implizit jedoch stets vom hier erwähnten Zusammenhang. Um auf unser Beispiel zurückzukommen: Wir wissen, dass die Dichtefunktion einer Normalverteilung ihr globales Maximum an der Stelle ihres Erwartungswerts hat. Eine Standardnormalverteilung hat also ihr Maximum an der Stelle 0, eine N (1, 1)Verteilung an der Stelle 1 usw. Nehmen wir an, wir beobachten nur eine Realisation x1 = 2 unserer Zufallsvariablen X. Unser Ziel ist es nach wie vor, den Parameter ϑ zu finden, für den der Erhalt unserer Stichprobe - hier also nur des Werts x1 = 2 - am wahrscheinlichsten ist. Dies können wir ganz intuitiv lösen: Wir wissen, dass die Dichtefunktion einer N (2, 1)-Verteilung ihr globales Maximum an der Stelle 2 hat. Bei dieser speziellen Verteilung wäre es also am wahrscheinlichsten, den Wert 2 zu erhalten. Wir wissen auch, dass jede andere Dichtefunktion N (ϑ, 1) , ϑ ∈ R\{2} ihr Maximum an einer anderen Stelle hat und somit die Wahrscheinlichkeit, aus irgendeiner anderen der angegebenen Normalverteilungen den Wert 2 zu erhalten, kleiner als bei der N (2, 1)-Verteilung ist. Dann haben wir unsere Fragestellung bereits gelöst: Die Verteilung, die mit höchster Wahrscheinlichkeit für die Generierung unserer Stichprobe verantwortlich ist, ist die N (2, 1)-Verteilung. Die Maximum Likelihood-Parameterschätzung erfolgt immer nach dem hier vorgestellten Prinzip. Wir suchen stets die Verteilung, die die größte Wahrscheinlichkeit für die Generierung einer konkreten Stichprobe liefert. Natürlich muss dieses Verfahren für realitätsnähere Einsatszwecke formalisiert werden. Wir definieren die allgemeine Dichtefunktion mit f (x1 , . . . , xN ; θ), wobei x1 , . . . , xN die Realisationen einer Folge unabhängiger Wiederholungen der Zufallsvariable darstellen und θ wie gehabt der Parametervektor ist. 7 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Wir definieren des Weiteren die Likelihoodfunktion L, welche die Wahrscheinlichkeit für den Erhalt der gesamten Stichprobe in Abhängigkeit vom Parametervektor θ angibt: L (θ) = f (x1 , . . . , xN ; θ) = N Y fXn (xn ; θ) n=1 Wir wollen also das θ finden, für das die Likelihood-Funktion am größten wird. Dies erreichen wir, indem wir die Funktion ableiten, gleich Null setzen und entsprechend nach den unbekannten Parametern auflösen. Das Ableiten stellt sich für große Produkte jedoch als relativ umständlich heraus. Aus diesem Grund ist es meist sinnvoll, die Likelihood-Funktion vorher zu logarithmieren. Da der ln eine monotone Funktion ist, verändert er nicht die Lage der Maximalstellen. Die so erhaltenen Maximum Likelihood-Schätzer haben hervorragende Eigenschaften. Sie sind konsistent, d.h. konvergieren gegen den unbekannten Parameter und sind so asymptotisch erwartungstreu. Zudem sind sie effizient, d.h. es gibt keinen anderen Schätzer mit vergleichbaren Eigenschaften, der eine asymptotisch kleinere Varianz aufweist. Auch ist es möglich, Hypothesentests mit ML-Schätzern zu konstruieren, da ihre Verteilung gegen eine Normalverteilung konvergiert. 2.1.2. Hypothesentests Die Grundlage eines jeden Hypothesentests sind zwei konkurrierende Hypothesen. Man unterscheidet bei Hypothesentests zwischen parametrischen und nichtparametrischen Testverfahren. Parametrische Tests sind solche, bei denen Aussagen über einen unbekannten Parameter einer gegebenen Verteilung getestet werden können. Wir führten im vorherigen Abschnitt eine normalverteilten Zufallsvariable mit unbekanntem Erwartungswert ein, X ∼ N (ϑ, 1). Nehmen wir an, wir treffen die Vermutung, dass der Erwartungswert eigentlich Null entsprechen müsste - wir können uns aber nicht sicher sein, ob dies auch wirklich stimmt. Also wollen wir zwei konkurrierende Hypothesen testen: H0 : θ = (0, 1) gegen H1 : θ = (ϑ, 1) , ϑ 6= 0 Wir testen also ganz konkrete numerische Werte für die Parameter. Auch wenn in diesem Beispiel nur ein Parameter, der Erwartungswert, variabel ist wurden im Beispiel die Hypothesen explizit in Abhängigkeit des gesamten Parametervektors Frankfurt School of Finance & Management Working Paper No. 192 8 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall inklusive der hier konstanten Varianz gewählt. Dies soll unterstreichen, dass parametrische Tests keineswegs auf nur einen einzigen Parameter beschränkt sind. Man kann simultan beliebige Parameterkombinationen testen. Die Hypothesen können dabei weitestgehend beliebig aufgebaut sein. Wir könnten in der Nullhypothese auch über verschiedene Parameterintervalle testen. Zudem muss die Alternative nicht auf Ungleichheit testen, sondern kann auch prüfen, ob die Parameter alternativ einen ganz konkreten Wert haben, kleiner als ein bestimmter Wert oder größer als ein bestimmter Wert sind. Wichtig ist jedoch, dass darauf geachtet werden sollte, dass stets eine der beiden Hypothesen wahr ist. Allgemeiner können wir also eine Hypothese wie folgt formulieren: H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ1 Θ0 ∪ Θ1 = Θ Nicht-parametrische Tests sind solche, bei denen wir nicht direkt numerische Parameter testen können. Wir haben im vorherigen Beispiel das Wissen vorausgesetzt, dass die Zufallsvariable X normalverteilt ist und nur den Mittelwert der Normalverteilung als unbekannt angenommen. Doch in der Realität können wir uns in den seltensten Fällen wirklich sicher sein, dass die Daten auch wirklich einer bekannten Verteilung entstammen. Könnte es im obigen Beispiel nicht etwa genauso gut sein, dass X t-Verteilt ist? In dem Fall würde der oben präsentierte Hypothesentest trügerisch sein, da unter Umständen die Daten einer t-Verteilung den gleichen Mittelwert und die gleiche Varianz wie normalverteilte Daten aufweisen könnten. Speziell die Verteilungsform ist aber kein einfach quantifizierbarer Zusammenhang. Wir können strikt gesehen niemals wirklich testen, ob X tatsächlich normalverteilt ist oder nicht. Wir können uns allerdings sehr wohl quantifizierbare Zusammenhänge zu Nutze machen. Wie wir später sehen werden, könnten wir beispielsweise testen, ob unsere Schätzung für Schiefe und Wölbung mit einer Normalverteilung vereinbar sind - dieser quantifizierte Zusammenhang wäre nun wieder überprüfbar. Doch genau betrachtet testen wir nun nicht mehr unsere wirkliche Hypothesen, sondern völlig neue Hypothesen, von denen wir vermuten, dass sie uns zumindest Indizien für die Beantwortung unserer ursprünglichen Problemstellung liefern. Der eigentliche Ablauf eines Hypothesentests lässt sich wie folgt darstellen: 9 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 1. Testproblem Im Verlauf dieser Arbeit werden wir stets Hypothesentests der folgenden Form verwenden: H0 : θ ∈ Θ0 gegen H1 : θ ∈ Θ1 dabei gilt für unsere Zwecke stets Θ0 ⊂ Rn , Θ1 = Rn \Θ0 , wobei n hier die Dimension des Parametervektors θ bezeichnet. Θ sei im Folgenden der gesamte Parameterraum, Θ = Θ0 ∪ Θ1 = Rn . Wir testen in dieser Arbeit stets zweiseitig, wobei die Nullhypothese eine einfache und die Alternativhypothese eine zusammengesetzte Hypothese ist. 2. Testfunktion Zum Überprüfen der im ersten Schritt aufgestellten Hypothesen benötigen wir nun eine Testfunktion, die uns anhand der für das Testproblem relevanten Daten einen überprüfbaren Wert liefert. In der Praxis bedeutet dies meist, dass man anhand aller Realisationen der relevanten Zufallsvariable(n) einen einzigen Wert berechnet, welcher einen Bezug zu unserem Testproblem hat. Bei einer suffizienten Testfunktion sollte die Komprimierung der komplexen Stichprobe auf eine Zahl dabei möglichst keinen Informationsverlust haben. Für unsere Zwecke genügt folgende Definition der Testfunktion T : T : Rn → R 3. Ablehnungsbereich Der Wert der Testfunktion alleine hilft uns bislang noch nicht weiter, denn wir wissen noch nicht, für welche Werte die Nullhypothese abgelehnt werden muss und für welche Werte sie nicht verworfen werden kann. Dazu definieren wir nun mit X = (X1 , . . . , XN )T einen Ablehnungsbereich A, A⊂R sup P (T (X) ∈ A|θ) = α θ∈Θ0 Frankfurt School of Finance & Management Working Paper No. 192 10 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die Wahrscheinlichkeit, dass die Testfunktion für eine richtige Hypothese in den Ablehnungsbereich fällt darf also nur α betragen. In der Regel kann α frei gewählt werden. 4. Entscheidungsregel Basierend auf den ersten drei Schritten kann man nun eine Regel aufstellen, wann die Nullhypothese verworfen werden muss, und wann sie nicht abgelehnt werden kann. Wir werden stets ablehnen, wenn die Testfunktion in den Ablehnungsbereich fällt, ansonsten werden wir die Nullhypothese nicht ablehnen: Ablehnung für T (x) ∈ A Nicht-Ablehnung für T (x) ∈ 6 A Anzumerken ist, dass eine Nicht-Ablehnung der Nullhypothese keiner expliziten Annahme derselbigen darstellt. Der Grund hierfür liegt in der Asymmetrie der Signifikanztests, auf welche wir im Abschnitt 2.1.4 genauer eingehen werden. 2.1.3. Likelihood-Quotienten-Tests Ein Verfahren, welches oft zur Bestimmung der Testfunktion zum Einsatz kommt, ist das sogenannte allgemeine Likelihood-Quotienten Testverfahren. Die Testfunktion ist hierbei ein Quotient aus dem Maximum der Likelihood-Funktion unter Einschränkung der Parameter auf die Bereiche der Nullhypothese zu dem maximalen Wert der uneingeschränkten Likelihood-Funktion, λ (x) = supθ∈Θ0 L (x; θ) supθ∈Θ L (x; θ) λ (x) kann hierbei offensichtlich einen Wert zwischen 0 und 1 inklusive annehmen. Je näher der Wert bei 1 liegt, desto eher kann man davon ausgehen, dass die Daten in x von einer Verteilung erzeugt wurden, deren Parameter mit der Nullhypothese in Einklang gebracht werden können. Aus diesem allgemeinen Quotienten lassen sich nahezu alle gängigen Testverfahren herleiten. So kann beispielsweise auch der sicherlich bekannteste und verbreitetste Test, der Gauss-Test, über einen allgemeinen Likelihood-Quotienten bestimmt werden. 11 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall In vielen Fällen kann jedoch nicht ohne weiteres eine einfache Verteilung für den Likelihood-Quotienten gefunden werden. Wir werden daher insbesondere an einer Transformation der Testfunktion interessiert sein, deren Verteilung unter bestimmten Annahmen zumindest asymptotisch bekannt ist: supθ∈Θ0 L (x; θ) Λ (x) = −2 ln supθ∈Θ L (x; θ) Um die Verteilung für Λ (x) zu bestimmen werden wir uns eines Theorems bedienen, welches von Suhov & Kelbert (2005) beschrieben wird: Wilks Theorem Seien die Realisationen der Stichprobe x = (x1 , . . . , xN )T i.i.d mit Dichtefunktion f (·; θ) , θ ∈ Θ. Sei Θ eine offene Menge im euklidischen Raum der Dimension |Θ| und der Maximum-Likelihood-Schätzer θ̂ des Parametervektors eine asymptotisch normalverteilte Zufallsvariable für N → ∞. Sei Θ0 ⊂ Θ, sodass Θ0 ebenfalls eine offene Menge im euklidischen Raum der Dimension |Θ0 | < |Θ| ist. Dann gilt unter H0 , dass Z ∞ ∀θ ∈ Θ0 , h > 0 : lim Pθ (Λ (x) > h) = fχ2d (x) dx N →∞ h mit d = |Θ| − |Θ0 | Die Teststatistik Λ ist dann also χ2 -verteilt mit Freiheitsgrad d. Gemäß Suhov & Kelbert (2005) existiert eine weitere Variante des Theorems, welche für unabhängige, aber nicht notwendigerweise identisch verteilte Zufallsvariablen gilt. Für den recht technischen Beweis des Theorems verweisen wir auf van der Vaart (2000), welcher auch die wesentlichen Restriktionen nochmals zusammenfasst: 1. Die Dichtefunktion muss differenzierbar in θ sein, da der Maximum Likelihood-Schätzer ermittelt werden muss. 2. Θ0 und Θ müssen lineare Räume sein - dies entspricht einer anderen Form der Bedingung der Offenheit. Für unsere Zwecke stellen diese beiden Bedingungen keine Einschränkungen dar, da Θ und Θ0 in unseren Hypothesentests stets lineare Mengen sein werden und, wie sich herausstellen wird, jede Dichtefunktion, welche wir betrachten werden, differenzierbar in θ sein wird. Als größerer Kritikpunkt ist jedoch vorab zu nennen, dass Wilks Theorem nur asymptotisch gilt. Wir testen oft jedoch nur in vergleichsweise kleinen Stichproben. Frankfurt School of Finance & Management Working Paper No. 192 12 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Dies ist leider ein übliches Problem in der Statistik, da die meisten Verfahren nur asymptotisch Gültigkeit aufweisen. Wir sollten uns jedoch durch diese Kritik umso mehr bewusst sein, dass Stichproben in der Regel möglichst groß gewählt werden sollten. Zudem müssen wir explizit auf Unabhängigkeit in den Daten achten - dafür werden wir jedoch separate Testverfahren vorstellen. 2.1.4. α- und β-Fehler sowie statistische Macht Ein Hypothesentest führt immer zu einer von zwei möglichen Entscheidungen: Entweder, wir verwerfen die Nullhypothese, oder wir verwerfen sie nicht. Auch wenn wir es meist nicht explizit wissen können, aber je nachdem, ob die Hypothese in der Realität zutrifft oder nicht, entscheiden wir uns dabei entweder richtig, oder wir begehen einen Fehler. Dieses Entscheidungsmuster lässt sich gut anhand einer Tabelle zeigen: Nicht-Ablehnung von H0 Ablehnung von H0 H0 korrekt Korrekte Entscheidung mit Wahrscheinlichkeit 1−α Fehler 1. Art mit Wahrscheinlichkeit α H1 korrekt Fehler 2. Art mit Wahrscheinlichkeit β Korrekte Entscheidung mit Wahrscheinlichkeit 1 − β (“statistische Macht”) Die Spalten sind dabei getrennt voneinander zu betrachten - es ist zwar immer wahr, dass H0 oder H1 korrekt ist, wir werden in der Praxis aber niemals wissen, welche der beiden Möglichkeiten tatsächlich zutrifft. Die Felder geben entsprechende Resultate und Wahrscheinlichkeiten an unter der unbekannten Tatsache des Zutreffens einer dieser beiden Möglichkeiten. Fehler 1. Art Wenn die Nullhypothese in Realität korrekt ist und wir sie basierend auf unserem Hypothesentest tatsächlich nicht ablehnen, dann haben wir die korrekte Entscheidung getroffen. Unter der Bedingung, dass H0 korrekt ist, passiert dies mit einer Wahrscheinlichkeit von 1−α. Sollten wir die Hypothese basierend auf unserem Test verwerfen, so treffen wir die falsche Entscheidung mit einer Wahrscheinlichkeit von α unter der Bedingung dass H0 korrekt ist. 13 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Bei einem guten Hypothesentest können wir α präzise selbst festlegen. Dies geht schon aus der Definition des Ablehnungsbereichs in Abschnitt 2.1.2 hervor. In der Praxis dieser Arbeit werden wir teils das Problem haben, dass bestimmte Testverfahren nur asymptotisch gelten. Insbesondere gilt diese Einschränkung bei Likelihood-Quotienten-Tests. In vergleichsweise kleinen Stichproben treten hier Ungenauigkeiten auf. Eine dieser möglichen Ungenauigkeiten ist, dass ein Hypothesentest ein vorgegebenes α-Niveau über- oder unterschreitet. Wenn also in der Theorie korrekte Hypothesen nur in α Prozent aller Fälle abgelehnt werden sollten, so kann es in der Praxis durchaus passieren, dass korrekte Hypothesen wesentlich häufiger oder wesentlich seltener abgelehnt werden. Dies ist tatsächlich ein erhebliches Problem. Eines der Grundprinzipien von Hypothesentests ist, dass man Nullhypothesen gegebenenfalls signifikant ablehnen kann. Dies ist genau deshalb der Fall, weil man sich in der Regel präzise seiner Fehlerwahrscheinlichkeit bei dieser spezifischen Entscheidung bewusst ist. Ist die Nullhypothese nämlich wahr, obwohl man sie ablehnt, befindet man sich in der Tabelle im Bereich “H0 korrekt, Ablehnung von H0 ”. Die Wahrscheinlichkeit dafür ist aber genau α. Wenn nun aber das Testverfahren nur asymptotisch gilt und der tatsächliche α-Wert von seinem theoretisch festgelegten Wert abweicht, so sind wir uns letztlich nicht mehr unserer Fehlerwahrscheinlichkeit bewusst. Leider lässt sich dieses Problem nicht ohne Weiteres beheben, denn auch in kleinen Stichproben ideale Testverfahren lassen sich meist nicht finden. Wir werden bei diversen Simulationen genauer die Auswirkungen des Phänomens betrachten. In der Praxis sollte dieser Aspekt eine Rolle bei der Wahl eines geeigneten Validierungskonzeptes spielen. Fehler 2. Art und statistische Macht Angenommen wir befinden uns nun in der Situation, dass H1 in der Realität korrekt ist. Da wir dies nicht wissen, kann unser Hypothesentest nach wie vor zu einer Nicht-Ablehnung von H0 oder zu einer Ablehnung von H0 , also einer Annahme von H1 , führen. Auch hierbei können zwei Situationen entstehen: Lehnen wir H0 nicht ab, so entscheiden wir uns falsch. Dies passiert mit der bedingten Wahrscheinlichkeit β. Lehnen wir H0 hingegen ab, so entscheiden wir uns mit einer bedingten Wahrscheinlichkeit in Höhe von 1 − β richtig. Frankfurt School of Finance & Management Working Paper No. 192 14 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Ein zentraler Begriff in der Statistik ist dabei die “statistische Macht”. Dies ist nichts anderes als die Wahrscheinlichkeit 1 − β. Die Macht sagt also letztlich aus, wie oft wir uns - gegeben die unbekannte reale Tatsache H1 ist korrekt - auch tatsächlich für eine Ablehnung von H0 entscheiden. Bei Parametertests lässt sich dies wie folgt ausdrücken: P (T ∈ A|θ ∈ Θ1 ) = 1 − β Perfekt sind dementsprechend natürlich Testverfahren, die eine hohe Macht aufweisen, denn sie minimieren den Fehler 2. Art. Oft wird zur Analyse der Macht die sogenannte “Gütefunktion”, im Folgenden mit G (·) bezeichnet, herangezogen. Sie gibt in Abhängigkeit des wahren, aber unbekannten Parametervektors θ die Wahrscheinlichkeit an, dass eine Stichprobe X1 , . . . , XN in den Ablehnungsbereich des Hypothesentests fällt: G (θ) = Pθ ((X1 , . . . , XN ) ∈ A) | θ ∈ Θ Wenn θ ∈ Θ0 , so gibt die Gütefunktion für G (θ) die Wahrscheinlichkeit für eine Fehlentscheidung an, denn in diesem Fall ist die Nullhypothese korrekt und G (θ) ist die Wahrscheinlichkeit, dass die Stichprobe dennoch in den Ablehnungsbereich fällt. Für θ ∈ Θ1 gibt die Gütefunktion Wahrscheinlichkeiten für korrekte Entscheidungen an. In diesem Fall ist nämlich die Nullhypothese falsch und G (θ) entspricht der Wahrscheinlichkeit, die Nullhypothese korrekterweise abzulehnen. Da θ in Realität unbekannt ist sind die Aussagen der Gütefunktion eher theoretischer Natur. Sie liefert Erkenntnisse darüber, wie hoch die Ablehnungsraten der Nullhypothese unter Eintreffen einer bestimmten Parameterkombination θ wären. Führen wir das Beispiel der vorherigen Kapitel weiter: Sei X ∼ N (ϑ, 1) und die zu überprüfende Hypothese H0 : θ = (0, 1) gegen H1 : θ = (ϑ, 1) , ϑ 6= 0 Wenn wir zur Überprüfung der Hypothese einen Gauss-Test mit α = 5% basierend auf einem Stichprobenumfang N = 9 durchführen, so stellt sich die Gütefunktion wie folgt dar: 15 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall ( 1 | 0 , 8 5 ) ( 0 | 0 , 0 5 ) ◄ ◄ ◄ ϴ0 ϴ Abbildung 2.1.: Exemplarische Gütefunktion eines Gauss-Tests Ersichtlich aus dem Schaubild ist beispielsweise, dass eine Stichprobe aus 9 Werten in rund 85% aller Fälle in den Ablehnungsbereich fallen wird, wenn der wahre Parameter ϑ = 1 und somit θ = (1, 1) ist. Da die Nullhypothese in diesem Fall falsch ist, entspricht die Ablehnung derselbigen einer korrekten Entscheidung. Wir werden im Sprachgebrauch dieser Arbeit sagen, dass die statistische Macht dieser Konstellation 85% beträgt. Für ϑ = 0 trifft die Nullhypothese zu. Der Wert der Gütefunktion an dieser Stelle ist genau 5% und entspricht der Wahrscheinlichkeit, die Nullhypothese fälschlicherweise abzulehnen. Der Wert von 5% ist genau der für den Hypothesentest spezifizierte α-Fehler. Für diesen zweiseitigen Gauss-Test können wir die Gütefunktion analytisch mit der Vorschrift √ √ α α − ϑ N + Φ −Φ−1 1 − +ϑ N G (ϑ) = Φ −Φ−1 1 − 2 2 angeben, wobei Φ (·) die Verteilungsfunktion der Standardnormalverteilung und Φ−1 (·) die inverse Verteilungsfunktion der Standardnormalverteilung ist. Bei nahezu allen Testverfahren, welche im Verlauf dieser Arbeit vorgestellt werden, wird es jedoch nicht möglich sein, eine konkrete Formel für die Gütefunktion zu finden. Um einen konkreten Wert zu berechnen müssten wir nämlich exakt wissen, was passiert, wenn H0 nicht eintritt. Im obigen Beispiel war dies relativ einfach: H1 besagt, dass die Werte normalverteilt mit bekannter Varianz und lediglich unbekanntem Erwartungswert sind. Frankfurt School of Finance & Management Working Paper No. 192 16 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall In den meisten Fällen dieser Arbeit umfasst H1 aber stets eine ganze Bandbreite sehr unterschiedlicher Alternativen. Wenn wir den obigen Hypothesentest etwa umformulieren zu H0 : X ∼ N (0, 1) gegen X 6∼ N (0, 1) dann umfasst die Alternativhypothese jegliche vorstellbare Verteilungsform angefangen von Gleichverteilungen, t-Verteilungen, Binomialverteilungen bis hin zu gänzlich parameterlosen Verteilungsformen. Wenn wir uns gegen H0 entscheiden wissen wir also nicht, was stattdessen zutrifft, sondern wir wissen bloß, dass H0 vermutlich nicht zutrifft. Dennoch werden wir an einigen Stellen dieser Arbeit die statistische Macht der Testverfahren unter bestimmten Bedingungen simulieren. Dies werden stets hypothetische “was wäre wenn”-Szenarien sein. Wir können beispielsweise simulieren, wie hoch die statistische Macht wäre, wenn die Daten alternativ einer U (0, 1)Verteilung oder einer B (250, 5%)-Verteilung entstammen würden. Wir führen also gewisse Annahmen und Restriktionen für die Alternativhypothese ein und können mit diesen Annahmen Werte einer Gütefunktion simulieren. Wenn man sich in der Praxis letztlich für ein konkretes Validierungskonzept entscheiden will, so kann man demzufolge nicht angeben, welches davon die höchste statistische Macht hat, denn einen konkreten Wert dafür gibt es nicht. Man kann allerdings sehr wohl betrachten, welche Testverfahren unter diversen hypothetischen Alternativbedingungen jeweils die größte Macht besitzen würden, und kann dies in die Entscheidung mit einfließen lassen. 17 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.2. Prognose von Risiken 2.2.1. Risikomanagement & Marktrisikomodelle Der Begriff “Risikomanagement” ist recht allgemein gehalten und umfasst besonders im Finanzsektor eine Vielzahl verschiedener Bereiche. Die eigentlichen Tätigkeiten, die im Rahmen eines modernen Risikomanagements durchzuführen sind, untergliedern sich im Wesentlichen in Identifikation, Analyse (Quantifizierung), Überwachung und Steuerung von Risiken. Die Risiken als solche lassen sich wiederum in zahlreiche Unterkategorien aufteilen. Die von Basel II vorgeschriebenen Mindestkapitalanforderungen etwa legen einen Fokus auf Marktpreis-, Kreditausfall- und operationelle Risiken. In der Praxis sind für Unternehmen jedoch noch deutlich mehr Aspekte von Bedeutung; exemplarisch zu nennen sind hier etwa Liquiditätsrisiken, wie nicht zuletzt die jüngste Bankenkrise zeigte, und die momentan stark an unternehmerischem Interesse gewinnenden Reputationsrisiken. Relevant für die in dieser Arbeit vorgestellten Themen sind in erster Linie Modelle, die der Überwachung von Marktpreisrisiken dienen. Eine für unsere Zwecke angemessene Definition dafür wird von Crnkovic & Drachman (1996) eingeführt. Hier wird das Marktrisikomanagement als Prozess, die Wahrscheinlichkeitsverteilungen der relevanten Risikofaktoren korrekt abzubilden, betrachtet. Die Grundannahme hierfür ist letztlich, dass wir den Wert unserer Produkte perfekt durch eine Kombination diverser quantifizierbarer Faktoren berechnen können - etwa durch Zinssätze, lineare oder auch nicht lineare Zusammenhänge zu anderen Produkten, Haltekosten usw. Sofern dies zutrifft können wir eine präzise Wertbestimmung zu jedem zukünftigen Zeitpunkt genau dann durchführen, wenn wir die Wahrscheinlichkeiten kennen, mit denen die relevanten Risikofaktoren ihre jeweiligen Wertzustände annehmen können. Der Schlüssel für ein gutes Management von Marktrisiken ist also eine realitätsnahe Modellierung zukünftiger Risikofaktoren durch Schätzung von geeigneten Wahrscheinlichkeitsverteilungen. 2.2.2. Vorhersage von Wahrscheinlichkeitsverteilungen Die Auswahl von Wahrscheinlichkeitsverteilungen von Risikofaktoren kann auf vielfältige Weise erfolgen. Frankfurt School of Finance & Management Working Paper No. 192 18 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall In der Praxis werden meist relative oder absolute zukünftige Wertänderungen modelliert. Eine detailliertere Aufteilung in elementarere Risikofaktoren1 ist zwar möglich, wird jedoch auf Portfolioebene in der Regel nicht vollzogen. Grundsätzlich kann man die statistischen Probleme in zwei Kategorien eingliedern: Parametrische und nicht-parametrische Verfahren. Parametrische Verfahren sind solche, bei denen anfangs eine konkrete Klasse von Dichtefunktionen angenommen wird und anschließend die dazugehörigen Parameter geschätzt werden. Die weitverbreitetste Annahme im Finanzbereich ist dabei sicherlich, dass logarithmierte Renditen r approximativ normalverteilt sind. Die Parameter der Verteilung werden dabei oft nach einer der folgenden Methoden bestimmt (Sanddorf-Köhle 2011): Gleitende Varianz p 1X rt−k für t ∈ N, T > p µ̂t = p k=1 p σ̂t2 1X (rt−k − µ̂t )2 = p k=1 Exponentiell geglättete Varianz T 1X µ̂ = rt T t=1 2 σ̂t2 = λσ̂t−1 + (1 − λ) (rt−1 − µ̂)2 und ein sinnvoll gewählter Startwert σ̂12 , z.B. σ̂12 = (r1 − µ̂)2 . 1 beispielsweise Zinssätze, Nutzenfunktionen, Halteprämien usw. 19 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Ein GARCH-Modell µ̂ = σt2 T 1X rt T t=1 =ω+ p X αi 2t−1 + q X 2 βj σt−i j=1 i=1 i.i.d. t = vt σt , vt ∼ mit E (vt ) = 0, V ar (vt ) = 1 und ω > 0, ∀i ∈ {1, . . . , p} : αi ≥ 0, ∀j ∈ {1, . . . , q} : βj ≥ 0 Ein GJR-GARCH-Modell T 1X µ̂ = rt T t=1 σt2 =ω+ p X 2 αi (|t−1 | − γi t−1 ) + i=1 q X 2 βj σt−i j=1 i.i.d. t = vt σt , vt ∼ mit E (vt ) = 0, V ar (vt ) = 1 und ω > 0, ∀i ∈ {1, . . . , p} : αi ≥ 0, ∀j ∈ {1, . . . , q} : βj ≥ 0, γ1 ∈ (−1, 1) , ∀i ∈ {2, . . . , p} : γi = 0 Nicht-parametrische Verfahren hingegen sind Methoden, die ohne a priori Festlegung auf eine bestimmte Verteilung auskommen. Dann wird meist die Stichprobe als solche als empirische Verteilungsfunktion gedeutet. Der Vorteil eines solchen Verfahrens ist eine recht hohe Flexibilität - in der Tat kennen wir in der Regel nie die unterliegenden Verteilungen, sodass parametrische Verfahren immer auf teils nicht sonderlich realitätsnahe Annahmen gestützt werden müssen. Nicht-parametrische Verfahren kommen hingegen ohne konkrete Annahmen über die Form der tatsächlichen Verteilung und auch ohne eine explizite Modellierung von Abhängigkeiten wie beispielsweise Korrelationswerten aus. Wie bereits von Kupiec (1998) sowie Dowd (2004) angesprochen, gibt es jedoch auch zahlreiche Nachteile nicht-parametrischer Verfahren, die ihren Einsatz in der Frankfurt School of Finance & Management Working Paper No. 192 20 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Praxis oft fragwürdig erscheinen lassen. Um die empirische Verteilung möglichst realitätsnah spezifizieren zu können werden enorme Datenmengen gebraucht, insbesondere bei überdurchschnittlicher Leptokurtosis der tatsächlichen Verteilung2 , denn hierbei ist es wichtig, auch in der Stichprobe schon viele Extremwerte vorliegen zu haben, die selbst unter Leptokurtosis nur mit vergleichsweise geringer Wahrscheinlichkeit und dementsprechend selten auftreten. Genau dieses Phänomen ist jedoch gerade bei Finanzwerten oft anzutreffen. Zudem können nichtparametrische Verfahren nur verlässliche Ergebnisse liefern, wenn die tatsächliche Verteilung stationär ist, sich also nicht im Zeitablauf verändert, denn es wird implizit davon ausgegangen, dass die Daten der Stichprobe allesamt der selben Verteilung entstammen. Auch dies ist im Finanzbereich in aller Regel höchst unrealistisch. Bei parametrischen Verfahren können sowohl Leptokurtosis als auch Nicht-Stationarität bewusst mit einbezogen werden, wenngleich es teils die entsprechende Modellschätzung erschwert. Ein typisches Beispiel eines nicht-parametrischen Verfahrens zur Bestimmung möglicher Portfoliowertänderungen ist die sogenannte “historische Simulation”, bei der eine empirische Verteilungsfunktion auf Basis der Stichprobe ∆vt , t ∈ {1, . . . , T } berechnet wird: 0 wenn x < ∆v[1] 1 F̂∆V (x) = max{t | ∆v[t] ≤ x} wenn ∆v[1] ≤ x < ∆v[T ] T 1 wenn x ≥ ∆v[T ] 2.2.3. Value at Risk Nachdem, wie im vorherigen Abschnitt erläutert, die möglichen Wertänderungen eines Portfolios modelliert wurden, stellt sich nun die Frage, wie sich daraus eine Kennzahl für das Risiko quantifizieren lässt. Im Bankbereich wird hierfür gerne der sogenannte “Value at Risk” herangezogen (Kupiec 1998). Mit der formalen Definition folgen wir Cremers (2011): V aRt (p) = − sup{x ∈ R|P (∆V (t|Ωt ) ≤ x) ≤ p} Er ist also der bezüglich der Verknüpfung + inverse Wert der größten Portfoliowertänderung ∆V , die mit einer Wahrscheinlichkeit von höchstens p unterschritten wird. ∆V ist dabei abhängig von einem Betrachtungszeitpunkt t sowie der Portfoliozusammensetzung zu diesem Zeitpunkt, Ωt . 2 auch bekannt als “Fat Tails” 21 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Diese recht formale Definition lässt sich jedoch für kontinuierliche Verteilungen anschaulicher interpretieren als negativer Wert der Inversen der Verteilungsfunktion der Wertänderungen: −1 V aRt (p) = −F∆V (t|Ωt ) (p) Der Verlust im Portfolio sollte also nur mit einer Wahrscheinlichkeit von höchstens p niedriger als −V aR sein. Typische Werte für p sind dabei 1% oder 5%. Bei diskreten Verteilungen müssen Alternativdefinitionen des Value at Risk genutzt werden. Dabei kann es vorkommen, dass die Überschreitungswahrscheinlichkeit eines völlig korrekt berechneten Value at Risk tatsächlich höher als p ist. Sollte mit diskreten Verteilungen gearbeitet werden muss diese Tatsache speziell bei Testverfahren, welche Überschreitungswahrscheinlichkeiten konkret beinhalten, beachtet werden. Diese Konstellation ist jedoch weder im Verlauf dieser Arbeit noch bei gängigen Praxisverfahren von Bedeutung. Wir werden deshalb nicht weiter darauf eingehen. 2.2.4. Überschreitungsfunktion Im Weiteren wird für uns eine Indikatorvariable relevant sein, die für jeden Zeitpunkt t ∈ τ, τ = {1, . . . , T } zwei Zustände annehmen kann: ( 1 wenn ∆Vt < −V aRt (p∗ ) It = 0 sonst. ∆Vt ist dabei die Wertänderung eines Portfolios vom Zeitpunkt t − 1 auf t. Mit der mathematischen Definition orientieren wir uns an Campbell (2006/2007).3 Die Funktion It nimmt also für den Zeitpunkt t den Wert 1 an, wenn die Value at Risk-Prognose für diesen Zeitpunkt tatsächlich überschritten wird, ansonsten 0. Bei einem korrekt spezifizierten V aR-Modell sollte gelten: ∀It , t ∈ τ : P (It = 1) = E (It ) ≤ p Die Wahrscheinlichkeit, dass die Indikatorfunktion zu einem beliebigen Zeitpunkt t den Wert 1 angibt, sollte genau der Risikowahrscheinlichkeit des zugehörigen 3 Wir weichen jedoch bewusst im Bezug auf die zeitabhängige Indizierung von Campbell (2006/2007) ab. Frankfurt School of Finance & Management Working Paper No. 192 22 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Value at Risk-Modells entsprechen - genau dann gilt im Fall einer kontinuierlichen Werteverteilung E (It ) = p. It ist dann bernoulliverteilt: ∀t ∈ τ : It ∼ BE (p) fIt (x) = (1 − p)p−x px für x ∈ {0, 1} Wir definieren zur künftigen Vereinfachung I als die Summe aller Überschreitungen. In einem korrekten Modell sollte sie als Summe unabhängig und identisch bernoulliverteilter Zufallsvariablen binomialverteilt sein: X I= It t∈τ I ∼ B (T, p) 2.2.5. Expected Shortfall Der Expected Shortfall ist eine weitere Risikokennzahl für das Portfolio. Er gibt an, wie hoch der durchschnittliche Portfolioverlust ist unter der Bedingung, dass der Value at Risk überschritten wird. Formal definiert wird er als 1 E ∆V (t|Ωt ) · 1{∆V (t|Ωt )≤−V aRt (p)} p + V aRt (p) · (P (∆V (t|Ωt ) ≤ −V aRt (p)) − p) ESt (p) = − oder für kontinuierlich verteilte ∆V auch vereinfacht durch Z 1 −V aRt (p) ESt (p) = − xf∆V (t|Ωt ) (x) dx p −∞ 2.2.6. Regulatorische Auswirkungen der Risikoprognose Value at Risk und Expected Shortfall sind im heutigen Bankalltag wichtige Kenngrößen zur Risikosteuerung. Doch nicht nur intern, sondern auch extern sind sie von großer Bedeutung. Campbell (2006/2007) legt dar, dass der Value at Risk auch von den Aufsichtsbehörden mittlerweile als hauptsächliches Mittel zur Beurteilung von Marktrisiken anerkannt wird. Banken müssen der Aufsichtsbehörde sowohl den V aR mit einem Konfidenzniveau von 99% auf Tagesbasis als auch auf 10-Tages-Basis mitteilen. Das Risikokapital, das es dafür zu hinterlegen gilt, ist schlussendlich entweder der 23 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 1% V aR auf 10-Tages-Basis oder der durchschnittliche 1% V aR auf 10-Tages-Basis der vergangenen 60 Tage. Tatsächlich können die Banken so das zu hinterlegende Risikokapital durch ihre internen Modelle bestimmen. Natürlich erscheint es hier im ersten Moment ökonomisch, einen möglichst geringen V aR auszuweisen, um so wenig Kapital wie möglich hinterlegen zu müssen. Allerdings werden Modelle, die den Value at Risk systematisch unterschätzen, streng von den Aufsichtsbehörden bestraft und die Kapitalanforderungen erhöht. Dies wird im Verlauf dieser Arbeit im Rahmen des Ampelkonzepts noch detaillierter erläutert. Zusammenfassend lässt sich festhalten, dass der Value at Risk sowohl für die interne Risikosteuerung als auch für externe Mindestkapitalhinterlegungen relevant ist. 2.2.7. Überprüfung der Modelle Angesichts der enormen Bedeutung des Value at Risk ist es offensichtlich, dass eine Qualitätsprüfung der Modelle notwendig ist. Für die Aufsichtsbehörden ist es unerlässlich beurteilen zu können, ob Modelle das Risiko systematisch unterschätzen. Für Banken, auf der anderen Seite, kann es durchaus auch von Interesse sein in Erfahrung zu bringen, wenn Modelle das Risiko überschätzen - dadurch würde an die jeweilige Bank nämlich eine höhere Mindestkapitalanforderung als eigentlich nötig gestellt. In den folgenden Abschnitten werden wir uns also dem Thema widmen, wie man die Prognosegüte von Marktrisikomodellen quantitativ einschätzen kann. Ein grundsätzliches Problem, das sich dabei stellt, ist jedoch, dass die Investments eines Portfolios selten konstant bleiben. Selbst wenn ein Modell Risikokennzahlen wie den Value at Risk absolut korrekt prognostiziert kann es durchaus sein, dass der zukünftige Value at Risk gänzlich anders ist, da sich bis dahin möglicherweise andere Werte im Portfolio befinden. Beispielsweise dürfte der wahre Value at Risk eines Portfolios, das ausschließlich Kassenhaltung betreibt, für den Zeitpunkt heute in einem Jahr nahezu bei Null liegen. Sollten wir jedoch das Vermögen nach einem Monat von der Kassenhaltung komplett in gehebelte Optionsscheine umschichten, so wird der wahre Value at Risk in 11 Monaten nun weitaus höher sein; die ursprüngliche Prognose wird statistisch gesehen also wesentlich zu häufig überschritten werden. Dies liegt aber nicht an einem ursprünglich falsch spezifizierten Modell, sondern lediglich an einem veränderten Portfolio. Um diese Problematik zu umgehen gibt es zwei Möglichkeiten: Frankfurt School of Finance & Management Working Paper No. 192 24 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 1. Wir berechnen die Risikokennzahlen stets nur auf sehr kurze Frist, z.B. für 1-Tages-Perioden. Dowd (2004) weist zwar darauf hin, dass es auch innerhalb von nur einem Tag zu deutlichen Änderungen der Bestände kommen kann, die Problematik wird dadurch aber zumindest stark vermindert. 2. Sollten die Bestandsänderungen dennoch zu erheblich sein, so kann man zum Vergleich der Prognosen auch das ursprüngliche Portfolio in Zukunft schlicht neu bewerten und vergleichen, ob diese theoretische Wertänderung mit der ursprünglichen Prognose vereinbar ist. Im Beispiel könnte man also in einem Jahr überprüfen, was der Wert eines ausschließlich aus Kassenhaltung bestehenden Portfolios wäre, und ob dieser Wert mit der Prognose zu t0 in Einklang zu bringen ist. Wir werden uns im Weiteren auf die erste Möglichkeit beschränken. Diese Vorgehensweise ist im akademischen und praktischen Bereich üblich und verhindert zudem Probleme, die durch überlappende Perioden bei der Berechnung der Risikokennzahlen entstehen. 25 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.3. Validierung basierend auf Überschreitungen Im Folgenden werden wir uns mit Validierungsmodellen beschäftigen, die hauptsächlich auf ein korrektes Verhältnis zwischen Über- und Unterschreitung einer bestimmten Risikogröße testen. Konkreter wird hier meist überprüft, ob der berechnete Value at Risk statistisch signifikant häufiger oder seltener überschritten wird, als die von uns selbst definierte Risikowahrscheinlichkeit p∗ dies annehmen lassen würde. Desweiteren werden wir mit dem Markow-Test ein Verfahren beschreiben, welches darauf prüft, ob Überschreitungen zeitlich unabhängig voneinander auftreten. 2.3.1. Time Until First Failure Dieser Test wurde ursprünglich von Kupiec (1998) eingeführt. Von Interesse ist hier die verstrichene Zeit, bis zum ersten Mal der Value at Risk überschritten wird. Das Grundprinzip hinter dieser Methode ist intuitiv nachvollziehbar: Je geringer die Wahrscheinlichkeit einer Überschreitung, desto länger sollte es statistisch gesehen dauern, bis die erste Überschreitung eintritt. Zufallsvariable Wir sind an einer Zufallsvariable X interessiert, die den Zeitpunkt angibt, zu welchem die Überschreitungsfunktion It zum ersten mal den Wert 1 annimmt. X ∈ N ist daher geometrisch verteilt,4 X = min (t | It = 1) t∈τ X ∼ G (p) 1 E (X) = p Die Wahrscheinlichkeit, dass diese Überschreitung an einem bestimmten Tag x eintritt, lässt sich wie folgt berechnen: P (X = x) = p (1 − p)x−1 4 Mit X ∈ N stellen wir heraus, dass wir von einer geometrischen Verteilung ausgehen, deren Realisationen mindestens den Wert 1 annehmen. X kann nie den Wert 0 annehmen. Frankfurt School of Finance & Management Working Paper No. 192 26 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Ein Value at Risk mit Konfidenzniveau 95%, d.h. Fehlerwahrscheinlichkeit p = 5%, 1 ) überschritten sollte im Durchschnitt das erste mal in der zwanzigsten Periode ( 5% werden. Sollte die tatsächliche Überschreitung im Durchschnitt wesentlich später auftreten, so überschätzt das Modell das Risiko und vice versa. Hypothesentest Wir haben ein statistisches parametrisches Problem der Form (X, P) mit P = {G (p) |p ∈ (0, 1)}. Wir konstruieren nun einen Test zur Überprüfung, ob unsere angenommene Risikowahrscheinlichkeit p∗ der tatsächlichen Risikowahrscheinlichkeit p entsprechen könnte: H0 : p = p∗ gegen H1 : p 6= p∗ Testfunktion Für die Überprüfung der Hypothese bietet sich ein Likelihood-Quotienten-Test der folgenden Form an: ∗ x−1 ! p 1 − p∗ Λ (x) = −2 ln p̂ 1 − p̂ 1 x Λ (x) ∼ χ21 pb = Der Freiheitsgrad der χ2 -Verteilung ergibt sich aus dim Θ0 = 0 und dim Θ = 1. Eine Herleitung für pb wird im Verlauf dieses Abschnitts aufgezeigt. Ablehnungsbereich Der Ablehnungsbereich ergibt sich durch das entsprechende Quantil einer χ21 Verteilung: −1 A = χ21 (1 − α) , +∞ 27 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Herleitung des Schätzers pb Als Schätzer für p verwenden wir den Maximum Likelihood-Schätzer pb, welcher aus Optimierung der Likelihood-Funktion5 resultiert: L (p) = p (1 − p)x−1 ln (L (p)) = ln (p) + (x − 1) ln (1 − p) δ ln (L (p)) 1 x−1 = − =0 p p 1−p 1 x−1 = p 1−p 1 (1 − p) = x − 1 p 1 − p = p (x − 1) 1−p =x−1 p 1−p +1=x p 1−p+p =x p 1 =x p 1 p= x Berechnung kritischer Werte für x Anhand dieses vorgestellten Tests lassen sich für ein Konfidenzniveau der Hypothese α und gegebene Wahrscheinlichkeiten p∗ kritische Werte für X errechnen, bei deren Überschreitung die Nullhypothese abgelehnt werden muss. Hierfür wird die LR-Funktion mit dem entsprechenden Quantil der χ21 -Verteilung gleichgesetzt: ∗ x−1 ! p 1 − p∗ 2 −1 (1 − α) = χ −2 ln 1 1 1 − x1 x 5 Die Likelihood-Funktion entspricht hier der Dichtefunktion einer geometrischen Verteilung. Frankfurt School of Finance & Management Working Paper No. 192 28 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Für gegebene Werte für p∗ und α lässt sich diese Gleichung numerisch nach x auflösen. Wir führten dies für verschiedene p∗ und α durch. Eine Tabelle mit den Resultaten für kritische Werte befindet sich in Anhang A.1 und A.2. Grafisch lässt sich die obige Gleichung visualisieren, indem man die Schnittpunkte der LR-Funktion mit einer horizontalen Geraden auf Höhe des (1 − α)-Quantils der χ21 -Verteilung darstellt. Wir stellen dies für p∗ = 0, 5% und α = 5% im Folgenden grafisch dar. Der Term links des Gleichheitszeichens resultiert dabei in der konvexen Kurve des Schaubilds. Der Teil rechts des Gleichheitszeichens resultiert in der horizontalen Gerade auf Höhe des 95%-Quantils der χ21 -Verteilung von ungefähr 3,84. Die xWerte der Schnittpunkte der beiden Funktionen stellen die Lösungen der Gleichung dar: y ( 1 1 , 8 9 | 3 , 8 4 ) ( 8 7 8 , 9 | 3 , 8 4 ) x Abbildung 2.2.: TUFF LR-Test, kritische Werte von X als Schnittpunkt zwischen LR-Funktion und 95%-Quantil der χ21 -Verteilung Dies kann nun wie folgt interpretiert werden: Der Hypothesentest H0 : p = 0, 5% gegen H1 : p 6= 0, 5% sollte dann abgelehnt werden, wenn der erste Fehler vor der Periode 11,89 (in der Praxis also in der 11. Periode oder früher) oder nach der Periode 878,9 (in der Praxis also in der 879. Periode oder später) auftritt, denn genau für diese Werte nimmt die Testfunktion einen Wert an, der oberhalb des 95%-Quantils der χ21 -Verteilung liegt. Die eben beschriebene Methode dient zum Berechnen kritischer Werte für feste α und p∗ . Wir führen diese Berechnung nun mehrmals für weiterhin feste α, aber variierende p∗ durch. Im Folgenden eine Darstellung der kritischen Werte für X auf der y-Achse für ein festes α = 5% in Abhängigkeit von verschiedenen p∗ -Werten von 1% bis 10% auf der x-Achse: 29 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall y * p Abbildung 2.3.: Kritische x-Werte für α = 5% und variable p∗ Die hellblau markierten Regionen stellen den Ablehnungsbereich, die weiß markierten Bereiche den Annahmebereich der Nullhypothese dar für das jeweils zugehörige p∗ mit einer Konfidenz von 95%. Erwartungsgemäß sinken die kritischen Werte mit wachsendem p∗ , der Annahmebereich wird dabei stets schmaler. Kritik - Mangelnde Ablehnungsmöglichkeiten für große p∗ Kupiec (1998) weist darauf hin, dass für eine Konfidenz in Höhe von 1 − α = 95% keine Modelle mit einem Fehler von 5% oder mehr erkannt werden können. Tatsächlich weist das Modell ein Problem bei der Ablehnung von Hypothesen mit großem p∗ auf. Hierbei ist nämlich der erste Fehler bereits zu einem sehr frühen Zeitpunkt zu erwarten. Wenn nun die tatsächliche Fehlerwahrscheinlichkeit nochmals größer als die angenommene Wahrscheinlichkeit ist, p > p∗ , dann kann die Nullhypothese zugunsten einer höheren Risikowahrscheinlichkeit nur dann verworfen werden, wenn der erste Fehler extrem früh eintritt. Konkret heißt dies, dass der erste Fehler teils bei X < 1 eintreten müsste, um die Nullhypothese ablehnen zu können. Da jedoch X ∈ N ist kann dies in der Praxis nicht passieren: Der erste Fehler kann schlicht nicht vor der ersten Periode auftreten. Dadurch wird es für große p∗ unmöglich, eine Risikounterschätzung zu identifizieren. Unsere Ergebnisse zeigen aber, dass dieses Problem erst später als von Kupiec berechnet auftritt; für eine Konfidenz in Höhe von 95% ist damit erst ab p∗ > 14% zu rechnen. Dies kann mittels der Tabelle in Anhang A.2 nachvollzogen werden: Für α = 5% unterschreitet der untere kritische Wert für X die Zahl 1 zum ersten mal bei einem p∗ zwischen 14% und 15%. Frankfurt School of Finance & Management Working Paper No. 192 30 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Gütefunktion und statistische Macht Wir simulieren nun Gütefunktionen des TUFF-Verfahrens, indem wir die Ablehnungsraten für diverse Kombinationen von p und p∗ berechnen. Wir gehen dazu wie folgt vor: 1. Wähle p∗ , p ∈ {0, 01, 0, 01005, 0, 01001, . . . , 0, 2}, sodass p∗ 6= p. Setze α = 5%. 2. Erzeuge eine Realisation x der Zufallsvariable X ∼ G (p) 3. Berechne Λ (x) mit dem im ersten Schritt gewählten p∗ 6= p 4. Lehne die Nullhypothese des TUFF-Tests ab, wenn Λ (x) > (χ21 ) −1 (1 − α) Diese Prozedur wird für jede einzelne Kombination von p und p∗ 1.000.000 mal durchgeführt, sodass insgesamt ca. 145 Milliarden Tests berechnet werden. Für jede Kombination von p und p∗ wird nun die gesamte Anzahl an Ablehnungen der Nullhypothese durch 1.000.000 geteilt, um die relative Ablehnungshäufigkeit zu berechnen. Für ein festes p∗ entsprechen die Simulationsergebnisse einer Gütefunktion des Testverfahrens, hier am Beispiel für p∗ = 5%: Abbildung 2.4.: Gütefunktion, α = 5%, p∗ = 5% Erwartungsgemäß hat die Funktion ihr Minimum ungefähr6 im Bereich von p = p∗ = 5% und umso höhere Werte, je weiter sich p von p∗ = 5% entfernt. Eigentlich 6 Eigentlich sollte die Funktion ihr Minimum exakt bei p = p∗ haben. Wie später noch herausgestellt wird ist der TUFF-Test hier in der Tat unpräzise. 31 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall sollte Gp∗ =5% (p∗ ) = α = 5% gelten, denn für p = p∗ ist die Nullhypothese wahr und die Gütefunktion sollte demzufolge Wert des α-Fehlers annehmen. Tatsächlich ist aber Gp∗ =5% (p∗ ) ≈ 6, 2% 6= α. Diesem Phänomen werden wir uns später genauer widmen. Wir Erweitern nun die Darstellung der Gütefunktion, indem wir auch p∗ variieren lassen. Jeder Querschnitt des folgenden Schaubilds entspricht einer Gütefunktion7 für das jeweilige p∗ : Abbildung 2.5.: Gütefunktionen für verschiedene p∗ mit α = 5% 7 Zur besseren Darstellung wurde die Höhenachse des Schaubilds 2.5 auf 0,5 begrenzt Frankfurt School of Finance & Management Working Paper No. 192 32 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Abbildung 2.6.: Konturplot der Gütefunktionen für verschiedene p∗ , α = 5% Gut zu sehen ist der sprunghafte Verlauf der Funktion im Bezug auf die angenommene Wahrscheinlichkeit p∗ . Dies liegt daran, dass der LR-Test Ablehnungsund Annahmebereich zwar auf eine Teilmenge aus R abbildet, geometrische Zufallsvariablen aber stets aus N stammen. An bestimmten Punkten unter- oder überschreitet der Ablehnungsbereich eine Ganzzahl - und genau an diesen Stellen verändert sich die Funktion sprunghaft. Deutlich erkennbar ist auch eine auffällige Verringerung der Funktionswerte ab einer angenommenen Wahrscheinlichkeit von ca. 14,7% oder höher - hier tritt genau das oben genannte Phänomen auf, dass es effektiv keinen unteren Ablehnungsbereich mehr gibt und somit keine Risikounterschätzung mehr erkannt werden kann. Der Eintritt dieses Phänomens kann durch eine Erhöhung des Fehlers 1. Art hinausgezögert werden. Eine genaue Tabellierung kritischer Werte befindet sich in Anhang A.1. Insgesamt nehmen die Gütefunktionen nur in sehr wenigen Konstellationen Werte größer als 0,4 an. Dies bedeutet, dass selbst falsche Modelle recht selten selbst bei großen Unterschieden zwischen p und p∗ abgelehnt werden, die statistische Macht ist also meist sehr niedrig. Selbst in der extremen Kombination p = 1%, p∗ = 20% wird die Nullhypothese nur in knapp 82% aller Fälle abgelehnt. 33 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Kritik an der Verteilung der Testfunktion Durch die Simulation der Gütefunktionen zeigte sich ein weiteres kritisches Phänomen: Der spezifizierte α-Fehler des Hypothesentests wurde nicht eingehalten. Dies wird deutlich, wenn wir die Simulationsdaten im Falle eines korrekt geschätzten Modells betrachten - also in den Fällen, in denen die geschätzte Wahrscheinlichkeit genau der tatsächlichen Wahrscheinlichkeit des datengenerierenden Prozesses entspricht, p = p∗ . Die konkreten Schritte einer solchen Simulation sind dabei: 1. Wähle einen bestimmten Wert für p ∈ {0, 01, 0, 02, . . . , 0, 20}. Setzte α = 5%. 2. Erzeuge eine Realisation x der Zufallsvariable X ∼ G (p) 3. Berechne Λ (x) für p∗ = p 4. Lehne die Nullhypothese des TUFF-Tests ab, wenn Λ (x) > (χ21 ) −1 (1 − α) Die Schritte 2-4 werden 1.000.000 mal wiederholt. Die relative Ablehnungshäufigkeit ergibt sich dann aus der Anzahl aller Ablehnungen der Nullhypothese geteilt durch 1.000.000. Anschließend wird ein anderer Wert für p gewählt die Prozedur erneut durchgeführt. Die Variable X simuliert also den Zeitpunkt der ersten Value at RiskÜberschreitung in einem Portfolio, das in jeder einzelnen Periode eine unabhängige Value at Risk-Überschreitungswahrscheinlichkeit von p hat. Der entscheidende Schritt in der Simulation ist der Dritte, denn dieser besagt, dass p∗ = p gesetzt wird. Das heißt, dass das Modell von einer Überschreitungswahrscheinlichkeit ausgeht, die gleich der tatsächlichen Überschreitungswahrscheinlichkeit ist. Das Modell ist also korrekt spezifiziert und sollte eigentlich nicht abgelehnt werden. Dies zeigt sich auch, wenn wir die Hypothese des TUFF-Tests betrachten: H0 : p = p∗ gegen H1 : p 6= p∗ . Mit p∗ = p gilt H0 : p = p gegen H1 : p 6= p. Die Nullhypothese ist eine Tautologie und somit immer wahr. Wenn der TUFF-Test die Nullhypothese dennoch ablehnt, so begeht er einen Fehler 1. Art. Dies sollte in genau α Prozent aller Fälle passieren. Völlig unabhängig von p sollte der TUFF-Test dann im Durchschnitt eigentlich stets in 5% aller Fälle der simulierten Konstellationen zur Ablehnung der Nullhypothese führen. Die Ergebnisse der Simulation sind im folgenden Schaubild dargestellt: Frankfurt School of Finance & Management Working Paper No. 192 34 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Pr oz e nt ua l eAbl e hnunge n de rNul l hypot he s e p Abbildung 2.7.: Ablehnungsraten eines korrekten Modells, α = 5% Es ist sehr deutlich zu erkennen, dass die Ablehnungsrate der Nullhypothese deutlich in Abhängigkeit von p variiert und fast nie genau bei ihrem eigentlich zu erwartenden Wert in Höhe von 5% liegt. Die gleiche Simulation erweitern wir nun, indem wir nicht mehr von einem festen α = 5% ausgehen, sondern auch α zwischen 1% und 20% variieren lassen. Zur besseren Interpretierbarkeit des Schaubildes stellen wir nun auf der Höhenachse nicht mehr die relative Ablehnungshäufigkeit der Nullhypothese dar, sondern die Differenz zwischen α und der relativen Ablehnungshäufigkeit. Diese sollte im Durchschnitt eigentlich konstant 0 sein. Abbildung 2.8.: Ablehnungsraten eines korrekten Modells für verschiedene Signifikanzniveaus 35 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Auch hier bestätigt sich, dass der TUFF-Test nicht in der Lage ist, einen vorgegebenen α-Fehler einzuhalten. Es zeigt sich, dass die Abweichungen charakteristisch für unterschiedlichste Parameterkombinationen sind. Das Problem ist am geringsten, wenn das Signifikanzniveau der Hypothese ungefähr der Fehlerwahrscheinlichkeit des Modells entspricht. Im Zweifelsfall sollte das Signifikanzniveau höher angesetzt werden als die Fehlerwahrscheinlichkeit des Modells, denn speziell im umgekehrten Fall weicht der Fehler erster Art stark von seinem zu erwartenden Wert ab. Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : p = p∗ gegen H1 : p 6= p∗ 2. Testfunktion Λ (x) = −2 ln p∗ p̂ 1 − p∗ 1 − p̂ x−1 ! Λ (x) ∼ χ21 Der Stichprobenwert x ist dabei die Realisation der Zufallsvariablen X = mint∈τ (t|It = 1). 3. Ablehnungsbereich A= χ21 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. Insgesamt ist der Time Until First Failure-Test wenig praxistauglich, da er kaum zwischen verschiedenen Alternativhypothesen zu unterscheiden vermag. Unter bestimmten Konstellationen ist der Likelihood-Ratio-Test sehr unzuverlässig. Seine statistische Macht ist selbst unter Idealbedingungen8 niedrig. Dies ist nicht verwunderlich - die einzige Information, die bei diesem Verfahren beachtet wird, ist 8 Idealbedingungen bezieht sich vor allem darauf, dass Value at Risk-Überschreitungen unabhängig sind und mit gleicher Wahrscheinlichkeit zu jedem Zeitpunkt auftreten Frankfurt School of Finance & Management Working Paper No. 192 36 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall die Zeit bis zur ersten Überschreitung des Value at Risk. Zwar liegen in aller Regel noch wesentlich mehr Informationen vor, beispielsweise die Höhe der Überschreitung sowie möglicherweise noch weitere Überschreitungen, diese werden jedoch vollständig im Test vernachlässigt. Wir werden im Folgenden daher Verfahren untersuchen, die weitere Informationen einbeziehen. 2.3.2. Proportion of Failure Der Proportion of Failure-Test ist, wie von Kupiec (1998) und Campbell (2006/2007) beschrieben, eine logische Weiterentwicklung des Time Until First Failure-Verfahrens. Statt reiner Fokussierung auf den erste Fehler werden nun zusätzliche Informationen einbezogen, indem eine Teststatisik konstruiert wird, die alle in der Stichprobe vorkommenden Value at Risk-Überschreitungen einbezieht. Zufallsvariable Wir betrachten nun nicht mehr nur die erste Überschreitung, sondern die Summe aller Überschreitungen, I:9 I ∼ B (T, p) T fI (k) = pk (1 − p)T −k für k = 0, 1, . . . , T k mit den ersten beiden Momenten E (I) = T p V ar (I) = T p (1 − p) Hypothesentest Für unser statistisches parametrisches Problem (I, P) mit P = {B (T, p) |p ∈ (0, 1)} können wir einen Test konstruieren und basierend auf allen vorliegenden Überschreitungen testen, ob unsere angenommene Fehlerwahrscheinlichkeit der empirischen Schätzung der realen Fehlerwahrscheinlichkeit entsprechen könnte: H0 : p = p∗ gegen H1 : p 6= p∗ 9 siehe dazu auch Abschnitt 2.2.4 37 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Testfunktion Ähnlich dem Time Until First Failure-Verfahren bietet sich ein Likelihood-QuotientenTest zum Test der Hypothese an. Mit i als Realisation der Zufallsvariable I nutzen wir folgende Testfunktion: T −i ∗ i ! p (1 − p∗ ) Λ (T, i) = −2 ln (1 − p̂) p̂ i T Λ (T, i) ∼ χ21 p̂ = Mit d = 1 da dim Θ0 = 0 und dim Θ = 1. Ablehnungsbereich Erneut ergibt sich der Ablehnungsbereich aus dem jeweiligen Quantil der χ21 Verteilung: −1 A = χ21 (1 − α) , +∞ Frankfurt School of Finance & Management Working Paper No. 192 38 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Herleitung des Schätzers pb Als Schätzer für p kommt erneut ein Maximum Likelihood Schätzer pb zum Einsatz, den wir durch Ableiten, Nullsetzen und Auflösen nach p der Likelihood-Funktion erhalten. i ist dabei die Realisation der Zufallsvariablen I. T L (T, i, p) = pi (1 − p)T −i i T ln (L (T, i, p)) = ln + i ln (p) + (T − i) ln (1 − p) i δ ln (L (T, i, p)) i T −i = − =0 δp p 1−p i T −i = p 1−p i (1 − p) = (T − i) p T −i 1−p = p i T i = − i i T = −1 i T 1−p +1= p i 1−p+p T = p i T 1 = p i i p= T 39 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Gütefunktion und statistische Macht Wir simulieren nun die Ablehnungsraten verschieden spezifizierter Modelle gemäß folgender Vorschrift:10 1. Setze α = 5%, T = 250 2. Wähle p∗ , p ∈ {0, 01, 0, 01005, 0, 01001, . . . , 0, 2}, sodass p∗ 6= p 3. Erzeuge eine Realisation i der Zufallsvariable I ∼ B (T, p) 4. Berechne Λ (i) mit dem im ersten Schritt gewählten p∗ 6= p −1 5. Lehne die Nullhypothese des POF-Tests ab, wenn Λ (i) > (χ21 ) (1 − α) Erneut wird die Ablehnungsquote der Nullhypothese durch 1.000.000 Simulationen für jede Kombination von p und p∗ berechnet. Analog zum vorherigen Abschnitt lässt sich auch hier eine Gütefunktion aus den Daten für ein festes p∗ , im beispiel mit p∗ = 5%, konstruieren: Abbildung 2.9.: Gütefunktion für T = 250, α = 5%, p∗ = 5% Wir sehen, dass Gp∗ (p∗ ) = 5, 8% 6= α gilt, auch hier wird also der α-Fehler des Hypothesentests nicht eingehalten. Wir werden im kommenden Abschnitt genauer darauf eingehen. 10 Die tatsächlich durchgeführte Simulation wurde wesentlich stärker hinsichtlich ihrer Berechnungseffizienz optimiert und weicht deshalb teilweise von den aufgeführten Schritten ab, funktioniert aber nach dem gleichen Prinzip und liefert die selben Resultate. Frankfurt School of Finance & Management Working Paper No. 192 40 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Wir werden nun wieder die Darstellung der Gütefunktion erweitern, indem wir p∗ variieren und somit verschiedene Gütefunktionen in einem Schaubild darstellen: Abbildung 2.10.: Gütefunktionen für variable p∗ mit T = 250, α = 5% Abbildung 2.11.: Konturplot der Gütefunktionen für variable p∗ mit T = 250, α = 5%. Auffällig ist hier zum einen, dass der Verlauf der Funktion relativ konstant ist. Es gibt keine erkennbaren Sprünge mehr, wie dies noch beim TUFF-Test der Fall war. Zudem erreicht die Funktion recht schnell hohe Werte bis hin zu Niveaus von 41 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 100%. Im Bezug auf die statistische Macht ist der POF-Test also erwartungsgemäß wesentlich besser als der TUFF-Test. Abweichungen vom erwarteten Fehler 1. Art Wir betrachten abschließend noch die Ablehnungsraten eines korrekt geschätzten Modells. Diese sollte bei den Simulationsdaten eigentlich konstant auf dem αNiveau von 5% liegen. Wir gehen dabei nach diesem Prinzip vor: 1. Setze α = 5%, T = 250 2. Wähle p ∈ {0, 01, 0, 01005, 0, 01001, . . . , 0, 2} und setzte p∗ = p 3. Erzeuge eine Realisation i der Zufallsvariable I ∼ B (T, p) 4. Berechne Λ (i) mit dem im ersten Schritt gewählten p∗ = p 5. Lehne die Nullhypothese des POF-Tests ab, wenn Λ (i) > (χ21 ) −1 (1 − α) p Abbildung 2.12.: Ablehnungsraten eines korrekten Modells, T = 250 Es zeigt sich, dass es auch hier Abweichungen vom theoretisch zu erwartenden Niveau der Ablehnungsraten gibt. Erneut lieben selbige nicht auf dem eigentlich zu erwartenden, konstanten 5%-Niveau. Die Abweichungen werden jedoch umso kleiner, je größer die reale und korrekt geschätzte Wahrscheinlichkeit für eine Value at Risk-Überschreitung wird. Die Fehler erweisen sich zudem immerhin als kleiner im Vergleich zum TUFF-Test. Frankfurt School of Finance & Management Working Paper No. 192 42 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : p = p∗ gegen H1 : p 6= p∗ 2. Testfunktion Λ (T, i) = −2 ln (1 − p∗ ) (1 − p̂) T −i p∗ p̂ i ! i T Λ (T, i) ∼ χ21 p̂ = 3. Ablehnungsbereich A= χ21 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. Das POF-Verfahren ist insgesamt unbedingt dem TUFF-Verfahren vorzuziehen, denn seine statistischen Eigenschaften erweisen sich wie erwartet als erheblich besser. Dies ist kaum verwunderlich, da es auf eine größere Anzahl an Informationen als das TUFF-Verfahren zurückgreift. Nichtsdestotrotz wird jedoch auch beim POF-Test eine hohe Menge an Daten benötigt, um verlässliche Ergebnisse berechnen zu können. 2.3.3. Baseler Ampelansatz / Traffic Light Approach Wir kommen mit dem sogenannten “Traffic Light Approach” nun zu einem von der Bundesanstalt für Finanzdienstleistungsaufsicht verwendeten Verfahren, welches auf Überschreitungen basiert. Es ist als maßgebliches Verfahren zur Beurteilung von Marktrisikomodellen aus Sicht der Aufsichtsbehörde von besonderer Bedeutung. 43 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Schröder & Schulte-Mattler (1997) liefern eine sehr gute Einführung in dieses Konzept. Auf Vorschlag des Baseler Ausschusses für Bankenaufsicht dient dieses Verfahren zur Beurteilung der Qualität eines Risikomodells aus Sicht der Aufsichtsbehörden. Konkret heißt dies, dass die Ergebnisse des Baseler Ampelansatzes Auswirkungen auf die Kapitalanforderungen an das jeweilige Institut haben. Ähnlich dem Proportion of Failure-Test wird auch hier versucht, ein Risikomodell basierend auf den beobachteten Value at Risk-Überschreitungen zu beurteilen. Von Interesse ist also auch hier die Zufallsvariable der Summe aller Überschreitungen I, wie sie bereits im vorherigen Kapitel definiert wurde. Vorgeschrieben wird nun eine Datenbasis von 250 Handelstagen. Von Interesse ist der Value at Risk auf einem Konfidenzniveau in Höhe von 99%. Dieser sollte in einem korrekten Modell, wie im vorherigen Kapitel beschrieben, im Durchschnitt 250 · 1% = 2, 5 mal überschritten werden. Jedoch ist es selbst bei einwandfreien Modellen sehr wahrscheinlich, eine höhere Anzahl an Überschreitungen zu erhalten. Die einzelnen Wahrscheinlichkeiten, in einem richtig spezifizierten Modell eine bestimmte Anzahl an Überschreitungen zu erhalten, lassen sich an der Dichtefunktion der entsprechenden Binomialverteilung ablesen: æ 0.25 æ 0.20 æ 0.15 æ 0.10 æ æ 0.05 æ æ 0 2 4 6 æ 8 æ æ 10 Abbildung 2.13.: Diskrete Dichtefunktion einer Binomialverteilung, T = 250, p = 0, 01. Selbst korrekte Modelle können also mit durchaus realistischer Wahrscheinlichkeit eine größere Anzahl an Überschreitungen generieren. Dies führt zu der Frage, ab wie vielen Überschreitungen man ein Modell ablehnen sollte. Wenn beispielsweise alle Modelle abgelehnt werden würden, die 4 oder mehr Überschreitungen generieren, dann würde man damit auch zahlreiche korrekte Modelle ablehnen. Die Wahrscheinlichkeit, dass ein richtiges Modell 4 oder mehr Fehler in den 250 Tagen generiert liegt dabei bei 1 − FI (3) ≈ 24, 19%. Frankfurt School of Finance & Management Working Paper No. 192 44 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Diese Fehlerwahrscheinlichkeit lässt sich in Abhängigkeit der Ablehnungsgrenze visualisieren: Fehlerwahrscheinlichkeit æ 0.8 æ 0.6 æ 0.4 æ 0.2 æ æ 2 4 æ 6 æ 8 æ Überschreitungen, ab denen 10 das Modell abgelehnt wird æ Abbildung 2.14.: Hypothetische Fehlerwahrscheinlichkeiten beim TLA-Verfahren Setzt man nun also den Ablehnungsbereich zu niedrig an, so wird man auch sehr viele Modelle ablehnen, die eigentlich richtig wären. Setzt man ihn auf der anderen Seite zu hoch an, so akzeptiert man zu viele Modelle, die in Wirklichkeit eigentlich falsch sind. Bedingt durch diese Problematik entschied sich die Kommission dazu, nicht eine einzelne statische Grenze im Bezug auf die maximale Anzahl an Überschreitungen zu setzen, sondern verschiedene Zonen in Abhängigkeit von den realisierten Überschreitungen zu definieren. Je nachdem, in welche Zone ein Modell fällt, entstehen dabei unterschiedliche Konsequenzen. Diese können von höheren Eigenkapitalanforderungen bis hin zu einem Verbot, das bestehende Modell weiterhin zu nutzen, reichen. Zone Überschrei- Erhöhung des Kumulierte Wahrscheinlichkeit tungen Multiplikators 0 0,00 8,11% 1 0,00 28,58% Grüne Zone 2 0,00 54,32% 3 0,00 75,81% 4 0,00 89,22% 5 0,40 95,88% 6 0,50 98,63% Gelbe Zone 7 0,65 99,60% 8 0,75 99,89% 9 0,85 99,97% Rote Zone ≥10 1,00 99,99% - 100% Tabelle 2.1.: Quelle: Supervisory framework for the use of “Backtesting“ in conjunction with the internal models approach to market risk capital requirements (1998) 45 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die grüne, gelbe und rote Zone wurden dabei in Abhängigkeit von den kumulativen Wahrscheinlichkeiten eingeteilt. Ein korrektes Modell wird mit 89,2% in die grüne Zone gelangen und mit einer Wahrscheinlichkeit von 99,97% in die grüne oder in die gelbe Zone. Die Wahrscheinlichkeit, dass ein korrektes Modell in die rote Zone gelangt, beträgt also nur 0,03%. In solchen Fällen besteht jedoch die Möglichkeit, den Aufsichtsbehörden glaubhaft darzulegen, dass das betroffene Modell eigentlich dennoch korrekt ist, um etwaige Konsequenzen zu vermeiden. Die kumulativen Wahrscheinlichkeiten, in einem korrekten Modell höchstens eine bestimmte Anzahl an Überschreitungen zu erhalten, lassen sich auch an folgendem Schaubild ablesen: 1.0 æ æ æ æ æ æ æ æ æ æ æ æ 0.8 æ 0.6 æ 0.4 æ 0.2 æ 0 5 10 15 Abbildung 2.15.: Verteilungsfunktion der Binomialverteilung mit T = 250, p = 0, 01 Das Baseler Ampelkonzept ist letztlich eine Art Weiterentwicklung des Proportion of Failure-Verfahrens. Mathematisch basiert es auf den selben Techniken und Gegebenheiten und führt lediglich eine Interpretation der Ergebnisse aus Risikogesichtspunkten mitsamt Auswirkung auf Eigenkapitalanforderungen ein. Die Güte der Ergebnisse sind somit aber eng Verbunden mit den Ergebnissen des POFVerfahrens. Es leidet deshalb unter den bereits im vorherigen Abschnitten präsentierten Kritikpunkten. Wie wir im Verlauf dieser Arbeit herausstellen werden gibt es zahlreiche Verfahren, deren Eigenschaften sich besser für die Validierung von Risikomodellen eignen. Es ist durchaus vorstellbar, dass die Aufsichtsbehörden in künftigen Novellierungen vermehrt andere Modelle fokussieren werden. Frankfurt School of Finance & Management Working Paper No. 192 46 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.3.4. Magnitude of Loss Function Das nun folgende Verfahren orientiert sich an Goethe Universität (2004). Wir erweitern es jedoch um eine Korrektur der Standardabweichung. Das in der Literatur eher selten diskutierte MLF-Verfahren erweitert die Überschreitungsfunktion It und lässt auch das Ausmaß einer Überschreitung mit einfließen. In welcher Art man das Ausmaß in die Funktion einfließen lässt ist vielfältig wählbar; wir entscheiden uns für folgende Funktion: 2 V aRt (p∗ ) + ∆Vt wenn ∆Vt ≤ −V aRt (p∗ ) 1+ ιt (∆Vt ) = σt 0 sonst. X ι (∆Vt ) = ιt (∆Vt ) t∈τ Wie Lopez (1998) beschreibt ist die genaue Verteilung von ι unbekannt. Indem wir im Gegensatz zur gängigen Praxis den Abweichungsterm durch die Standardabweichung des Portfolios zum jeweiligen Zeitpunkt dividieren erreichen wir aber zumindest eine gewisse parametrische Unabhängigkeit bei der Simulation kritischer Werte. σt ist dabei die Standardabweichung der Verteilung von ∆Vt . Wir müssen uns nunmehr lediglich auf eine Verteilungsform festlegen und können so kritische Werte für ι bestimmen. Im Folgenden berechnen wir kritische Werte für ι mit der Annahme, dass ∆V normalverteilt ist. In diesem Fall ist σt die Standardabweichung der Normalverteilung von ∆V zum Zeitpunkt t. Wir gehen bei der Simulation wie folgt vor: 1. Setze p ∈ {0, 001, 0, 01, 0, 05, 0, 1} , T = 250 2. Setze ι = 0 3. Erzeuge T standardnormalverteilte Werte ∆vt , t ∈ {1, . . . , T }. 4. Für jedes ∆vt < −V aRt (p), addiere 1 + (V aRt (p) + ∆vt )2 zu ι hinzu.11 Schritte 2-4 werden 1.000.000 mal wiederholt. Der kritische Wert ergibt sich dann aus dem (1 − α)-Quantil der berechneten ι-Werte. Anschließend kann die gesamte Prozedur für ein anderes p wiederholt werden. 11 Man beachte, dass die Daten hier aus einer Standardnormalverteilung stammen und die Verteilung somit eine Standardabweichung von 1 hat. In der Simulation muss der Abweichungsterm somit nicht mehr durch die Standardabweichung dividiert werden. 47 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Es ergeben sich folgende kritische Werte für ι in Abhängigkeit von p und α: p = 0, 1% p = 1% p = 5% p = 10% α = 0, 1% 3,7697 11,4310 34,5357 60,6839 α = 1% 2,3815 8,7251 29,1690 53,5564 α = 5% 1,3313 6,6593 24,9571 47,5656 α = 10% 1,0747 5,6623 22,8517 44,5336 Eine grafische Darstellung der kritischen Werte in Abhängigkeit von p und α liefert interessante Erkenntnisse: Abbildung 2.16.: Kritische Werte für T = 250 Der Zusammenhang scheint hier annähernd linear zu sein. Es bietet sich daher an, kritische Werte Kι für ι mit T = 250 in Abhängigkeit von p und α per Regression zu approximieren. Wir nutzen dazu folgendes Regressionsmodell: Kι = a + b · p + c · α + Kι , p und α sind dabei aus der Simulation bekannt, stellt das Regressionsresiduum dar und die Parameter a, b, c sollen durch die Regression gefunden werden und Aufschluss über den Zusammenhang der Werte geben. Die Methode kleinster Quadrate liefert für das Regressionsmodell: Kι = 6.098 + 463, 213 · p − 75, 415 · α + Selbstverständlich ist eine Approximation der kritischen Werte mittels dieser Regression weniger präzise als die eigentlichen simulierten Werte. Die Berechnung kritischer Werte mit der angegebenen Gleichung sollte daher nur genutzt werden, wenn Kombinationen von p und α benötigt werden, die nicht an der von uns angegebenen Tabelle ablesbar sind. Frankfurt School of Finance & Management Working Paper No. 192 48 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : Der Value at Risk unterschätzt das Risiko nicht signifikant gegen H1 : Der VaR unterschätzt das Risiko signifikant 2. Testfunktion ι (∆vt ) = X ιt (∆vt ) t∈τ 3. Ablehnungsbereich −1 A = FbMLF (1 − α) , +∞ −1 FbMLF ist inverse Verteilungsfunktion von ι (∆vt ) unter H0 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 2.3.5. Markow-Test auf Unabhängigkeit Eine Value at Risk-Überschreitung wird oft als ein Worst Case-Szenario bei Finanzinstituten angesehen. Damit keine Gefahr für die Solvenz eines Instituts besteht sollten eventuelle Überschreitungen daher nicht nur in ihrer durchschnittlichen Häufigkeit den Prognosen entsprechen, sondern sie sollten zudem nur zeitlich unabhängig voneinander auftreten. Finanzielle Aufwendungen für zeitlich stark konzentrierte Überschreitungen könnten ansonsten das Kapital eines Instituts schnell übersteigen. Die Auswirkungen von serieller Abhängigkeit lassen sich gut veranschaulichen. Betrachten wir zuerst eine Folge von Realisierungen unabhängig bernoulliverteilter Zufallsvariablen mit einer Erfolgswahrscheinlichkeit in Höhe von 50%: 49 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 1.0 0.8 0.6 0.4 0.2 10 20 30 40 50 Abbildung 2.17.: Unabhängiger Bernoulli-Prozess Die Wahrscheinlichkeit, zu einem bestimmten Zeitpunkt eine 1 (respektive 0) zu erhalten erscheint hier weitestgehend unabhängig von dem jeweils vorherigen Wert. Es ist keine wirkliche Struktur im Schaubild zu erkennen. Schauen wir uns nun einen stochastischen Prozess mit abhängig bernoulliverteilten Zufallsvariablen an:12 1.0 0.8 0.6 0.4 0.2 10 20 30 40 50 Abbildung 2.18.: Abhängiger Bernoulli-Prozess Der Unterschied ist hier sehr klar ersichtlich. Ein einmal angenommener Wert 0 oder 1 bleibt für eine lange Zeit erhalten. Die Wahrscheinlichkeit, zum Zeitpunkt t also einen bestimmten Wert zu realisieren, hängt hier stark von der vorherigen Realisation in t − 1 ab. 12 Zu jedem Zeitpunkt wird eine Realisation einer bernoulliverteilten Zufallsvariable mit Erfolgswahrscheinlichkeit p erzeugt. War der vorherige realisierte Wert 1, so wurde dafür p = 0, 9 gesetzt, andernfalls p = 0, 1. Frankfurt School of Finance & Management Working Paper No. 192 50 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die den beiden Schaubildern unterliegenden Bernoulliprozesse haben jedoch beide die selbe durchschnittliche Erfolgswahrscheinlichkeit in Höhe von 0,5, obwohl die konkreten Prozesse anschließend grundlegend unterschiedlich aussehen. Übertragen auf unsere Risikomodelle würde dies bedeuten, dass es so zu sehr langen Zeiten kommen könnte, in denen der Value at Risk jeden Tag überschritten wird, obwohl wir die durchschnittliche Wahrscheinlichkeit einer Überschreitung möglicherweise durchaus korrekt abgebildet haben. Wir sehen also sehr deutlich, dass es nicht ausreicht, nur auf die durchschnittliche Überschreitungswahrscheinlichkeit zu prüfen - es ist unerlässlich, auch die Unabhängigkeitseigenschaft zu testen. Im Folgenden werden wir zu diesem Zweck den Markow-Test auf Unabhängigkeit, zu welchem bereits Campbell (2006/2007) eine sehr gute Einführung liefert, präsentieren. Wir werden uns im Folgenden darauf fokussieren, auf Autokorrelation erster Ordnung zu prüfen - das heißt, nur auf mögliche Dependenzen von dem direkt vorhergegangenen Wert t − 1. Nicht prüfen werden wir auf Abhängigkeit von den Werten zu den Zeitpunkten t − 2, t − 3 etc. Zufallsvariable Von Interesse ist hier eine Folge an Realisationen i1 , . . . , iT der Zufallsvariablen I1 , . . . , IT . Hypothesentest Wir testen auf Autokorrelation erster Ordnung: H0 : It und It+1 sind unabhängig gegen H1 : It und It+1 sind nicht unabhängig Die Nullhypothese ist also, dass die Folge serielle Unabhängigkeit erster Ordnung aufweist. Die Alternativhypothese besagt, dass diese Annahme nicht zutrifft. Testfunktion Wir testen dies mittels Likelihood-Quotienten-Test, bU L Π b b Λ ΠML , ΠU = −2 ln b L ΠML b ML , Π b U ∼ χ2 Λ Π 1 51 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Eine Herleitung der Transitionsmatrizen erfolgt im Verlauf dieses Abschnitts. Dieser Test erlaubt uns, recht elegant auf Unabhängigkeit zu testen. Bei Bedarf kann er problemlos auch abgeändert werden, um Tests auf serielle Autokorrelation größer der ersten Ordnung zu erlauben. Ablehnungsbereich Durch die Verteilung der Teststatistik können wir den Ablehnungsbereich wieder als Quantil der χ21 -Verteilung ausdrücken: 2 −1 A = χ1 (1 − α) , +∞ Transitionsmatrizen Transitionsmatrizen geben systematisch Wahrscheinlichkeiten an, dass ein bestimmter heutiger Zustand (Überschreitung des Value at Risk / Keine Überschreitung) in einen bestimmten Zustand zum nächsten Zeitpunkt (Überschreitung / keine Überschreitung) übergeht. Transitionsmatrizen haben dabei die Form 1 − π01 π01 π00 π01 = Π= 1 − π11 π11 π10 π11 Die Bedeutungen der Symbole πab sind dabei: Symbol π00 π10 π01 π11 VaR heute Keine Überschreitung Überschreitung Keine Überschreitung Überschreitung VaR morgen Keine Überschreitung Keine Überschreitung Überschreitung Überschreitung Likelihood-Funktion eines Markow-Prozesses Wir betrachten nun unsere gesamte Stichprobe vom Umfang T und definieren Tab , a, b ∈ {0, 1} als Anzahl aller Beobachtungen, bei denen die Überschreitungsfunktion zu einem Zeitpunkt den Wert a annimmt und im nächsten Zeitpunkt den Wert b. Das heißt also, dass T01 beispielsweise die Anzahl aller Beobachtungen ist, bei denen auf eine Nicht-Überschreitung des Value at Risk eine Überschreitung folgt. Formal definieren wir dies wie folgt: Tab = |{(It , It+1 )|It = a, It+1 = b, t = 1, . . . , T − 1}| für a, b ∈ {0, 1} Frankfurt School of Finance & Management Working Paper No. 192 52 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die zugehörige Likelihood-Funktion des Markow-Prozesses ist T11 T10 T01 T00 · π11 · π10 · π01 L (Π) = π00 T11 T01 · (1 − π11 )T10 · π11 = (1 − π01 )T00 · π01 ML-Schätzung der Transitionsmatrix Wir können die Maximum Likelihood-Schätzer für π b01 und π b11 ermitteln, indem wir die Likelihood-Funktion ableiten, gleich 0 setzen und entsprechend auflösen. Dazu bestimmen wir zur Vereinfachung zuerst die logarithmierte Likelihood-Funktion: ln L (Π) = T00 · ln (1 − π01 ) + T01 · ln (π01 ) + T10 · ln (1 − π11 ) + T11 · ln (π11 ) Ableiten und Auflösen nach π01 liefert δ ln L (Π) T00 T01 ! =0 =− + δπ01 1 − π01 π01 T01 T00 = π01 1 − π01 1 − π01 1 π01 π01 = = − T01 T00 T00 T00 π01 1 − π01 1 π01 + = = T01 T00 T00 T00 1 1 T00 + T01 1 π01 · + = π01 · = T01 T00 T00 · T01 T00 T00 · T01 π01 = T00 · (T00 + T01 ) T01 π b01 = T00 + T01 Analog können wir π11 bestimmen: π b11 = 53 T11 T10 + T11 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die Schätzer π b00 und π b10 können wir nun sehr einfach bestimmen. Da zum morgigen Zeitpunkt zwangsläufig irgendein Zustand - d.h. eine Überschreitung oder keine Überschreitung - eintreten muss, müssen folgende Gleichungen gelten: π b01 + π b00 = 1 π b10 + π b11 = 1 Entsprechendes Umstellen liefert die ML-Schätzer π b00 = 1 − π b01 π b10 = 1 − π b11 Eine ML-Schätzung der Transitionsmatrix ergibt sich damit durch T00 T01 T00 + T01 b ML = Π T00T+ T01 T11 10 T10 + T11 T10 + T11 Schätzung einer Transitionsmatrix unter Unabhängigkeit Unter Unabhängigkeit hingegen müsste das Eintreten des morgigen Zustands vom heutigen unabhängig sein, das heißt es müsste gelten π01 = π11 = πU . Da, wie bereits ausgeführt, zum zukünftigen Zeitpunkt einer der beiden möglichen Zustände eintreten muss ergeben sich zudem direkt die Werte für π00 = π10 = 1 − πU . Unter Unabhängigkeit ist also die folgende Transitionsmatrix anzunehmen: 1−π bU π bU b ΠU = 1−π bU π bU Der ML-Schätzer für π bU kann dabei durch entsprechendes Ableiten, Nullsetzen und Auflösen der Likelihood-Funktion L (ΠU ) = (1 − πU )T00 +T10 · πUT01 +T11 ermittelt werden: ln L (ΠU ) = (T00 + T10 ) · ln (1 − πU ) + (T01 + T11 ) · ln (πU ) δL (ΠU ) T00 + T10 T01 + T11 ! =− + =0 δπU 1 − πU πU T01 + T11 π bU = T00 + T10 + T01 + T11 Frankfurt School of Finance & Management Working Paper No. 192 54 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : P (It (p) = 1|It−1 (p) = 1) = P (It (p) = 1|It−1 (p) = 0) gegen H1 : P (It (p) = 1|It−1 (p) = 1) 6= P (It (p) = 1|It−1 (p) = 0) 2. Testfunktion bU L Π = −2 ln b ML L Π b ML , Π bU Λ Π T11 T01 · (1 − π11 )T10 · π11 L (ΠML ) = (1 − π01 )T00 · π01 T01 π b01 = T00 + T01 T11 π b11 = T10 + T11 π b00 = 1 − π b01 π b10 = 1 − π b11 L (ΠU ) = (1 − πU )T00 +T10 · πUT01 +T11 T01 + T11 π bU = T00 + T10 + T01 + T11 b b Λ ΠML , ΠU ∼ χ21 3. Ablehnungsbereich A= χ21 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 55 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.4. Validierung basierend auf der gesamten Verteilung Wie bereits zu Anfang dieser Arbeit erläutert ist eine der wichtigsten Aufgaben des Marktrisikomanagements die korrekte Prognose zukünftiger Wahrscheinlichkeitsverteilungen. Wir werden nun Tests fokussieren, welche die korrekte Spezifikation der gesamten Risikoverteilung sicherstellen sollen. Im Folgenden ist also nicht nur von Interesse, ob ein ganz bestimmtes Quantil der Verteilung richtig geschätzt wird, sondern, ob die Verteilung in ihrer Gesamtheit richtig geschätzt wird. Sollte dies der Fall sein, so impliziert dies immer auch eine korrekte Schätzung von Value at Risk sowie Expected Shortfall. Als Kritikpunkt solcher Tests wird oft angeführt, dass es nicht nur wesentlich schwerer ist, eine komplette Verteilung korrekt zu bestimmen, sondern auch, dass dies zu einer Verwässerung des Risikobegriffs führt, da ein Risikomanagement in aller Regel eigentlich nur an den Randbereichen einer Verteilung interessiert ist. Campbell (2006/2007) und Berkowitz (2001) diskutieren diese Kritikpunkte exemplarisch. Dennoch erfreuen sich diese Tests in der Praxis großer Beliebtheit. Durch die Einbeziehung aller verfügbaren Informationen kann die statistische Macht teils deutlich erhöht werden. Da gerade dies bei überschreitungsbasierten Tests ein erhebliches Problem darstellt, sind die Tests der gesamten Verteilung eine praktikable Alternative. 2.4.1. Rosenblatt-Transformation zur Gleichverteilung Wir wollen im Folgenden überprüfen, ob unsere prognostizierten Verteilungen mit den real eingetretenen Werten vereinbar sind. Problematisch dabei ist, dass die prognostizierten Verteilungen abhängig von den jeweiligen Anforderungen und Annahmen unterschiedlichste Formen und Parameter annehmen können. Idealerweise sollten die Testverfahren dabei auf jede beliebige Verteilungsform anwendbar sein. Bei diesem Problem hilft uns die sogenannte“Rosenblatt-Transformation”, welche in diesem Kontext auch von Campbell (2006/2007) angewandt wird. Nehmen wir an, die Portfoliowertänderung ∆V (t|Ωt ) hat eine bestimmte, uns bekannte Verteilung mit Verteilungsfunktion F∆V (t|Ωt ) (·). Frankfurt School of Finance & Management Working Paper No. 192 56 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Wir definieren nun eine Zufallsvariable Zt als Verknüpfung der Zufallsvariablen ∆Vt und ihrer angenommenen Verteilungsfunktion. Die Rosenblatt-Transformation besagt nun, dass die Zufallsvariable Zt gleichverteilt auf dem Intervall (0, 1) ist: Zt = F∆V (t|Ωt ) (∆Vt ) für t = 1, . . . , T i.i.d. Zt ∼ U (0, 1) Crnkovic & Drachman (1996) liefern eine noch intuitiver verständliche Zusammenfassung dieser Transformation: Die Quantile dieser Dichtefunktionen sind gleichverteilt. Dies ist natürlich nur wahr, wenn die beobachteten Werte ∆vt auch tatsächlich den angenommenen Verteilungsfunktionen F∆V (t|Ωt ) entstammen. Mit anderen Worten: Wenn wir die Wahrscheinlichkeitsverteilungen korrekt prognostizieren, dann werden die Rosenblatt-Transformationen der realisierten Werte gleichverteilt sein. Wenn wir hingegen falsch prognostizieren, dann werden unsere transformierten Werte nicht gleichverteilt sein. Je schlechter unsere Prognose die Realität abbildet, desto stärker entfernt sich die Verteilung der Z-Werte von einer Gleichverteilung. Wie Berkowitz (2001) herausstellt gilt dies auch, wenn sich die Verteilungen im Laufe der Zeit verändern. Wir können die Transformation also auch problemlos für Portfolios mit sich ändernden Beständen und unterschiedlichen Verteilungsparametern, d.h. beispielsweise selbst bei Heteroskedastizität, verwenden. Damit haben wir die Aufgabe, die Korrektheit unserer prognostizierten Verteilungen zu bestimmen, wesentlich vereinfacht. Statt für jede erdenkliche Verteilungsform separate Testverfahren zu verwenden können wir nun eine einfache Transformation durchführen und überprüfen, ob die resultierenden Werte gleichverteilt sind. Können wir dies bejahen, so sind unsere Prognosen korrekt, andernfalls ist unser Modell fehlerhaft. Es müssen zwei wesentliche Eigenschaften geprüft werden: 1. Gilt Z ∼ U (0, 1), d.h. sind die Rosenblatt-Transformationen der realisierten Werte tatsächlich gleichverteilt auf dem Intervall (0, 1)? 2. Sind die Elemente der Folge Z1 , . . . , ZT unabhängig voneinander? Wir werden versuchen, die erste Frage über das CD-Verfahren sowie über einen Kolmogorov-Smirnov-Test zu überprüfen. Auf die Unabhängigkeitseigenschaft werden wir erst im nächsten Abschnitt im Rahmen einer Normalverteilung weiter eingehen. Sollte explizit die Unabhängigkeitsprüfung der Rosenblatt-transformierten Daten gewünscht sein, so könnte dies, 57 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall wie von Crnkovic & Drachman (1996) vorgeschlagen, beispielsweise durch einen hier nicht näher erläuterten Brock-Dechert-Scheinkman-Test durchgeführt werden. 2.4.2. CD-Verfahren: Kuiper-Statistik mit Worry Function Wir wollen die Hypothese H0 : Z ∼ U (0, 1) gegen H1 : Z 6∼ U (0, 1) überprüfen. Wohlgemerkt fordern wir hier nicht explizit die i.i.d.-Eigenschaft, Z muss also nicht unabhängig verteilt sein. Crnkovic & Drachman (1996) schlagen für die Überprüfung dieser Hypothese ein Verfahren vor, welches auf der Kuiper-Statistik zur Überprüfung auf eine bestimmte Verteilungsform basiert. Grundsätzlich wird hier die empirische Verteilungsfunktion von Z ermittelt und mit der Verteilungsfunktion einer perfekten U (0, 1)-Verteilung verglichen. Als Kennzahl für den Unterschied zwischen diesen beiden Funktionen dient dann die Summe aus größter Abweichung nach unten und größer Abweichung nach oben: 1.0 0.8 0.6 0.4 Größte Abweichung nach unten Größte Abweichung nach oben 0.2 0.2 0.4 0.6 0.8 1.0 Abbildung 2.19.: Zusammensetzung der Kuiper-Statistik Für dieses Verfahren müssen wir zuerst aus unseren Rosenblatt-transformierten Werten Z eine empirische Verteilungsfunktion berechnen: n (x) Fb (x) = , x ∈ (0, 1) T n (x) = max{t|z[t] ≤ x} t∈τ Frankfurt School of Finance & Management Working Paper No. 192 58 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall n (x) berechnet also die Anzahl aller Werte zt , die kleiner als x sind. F (x) ist demzufolge die Funktion, welche den Anteil an Werten zt ≤ x relativ zur gesamten Stichprobe angibt, also die Verteilungsfunktion von Z. Wir definieren nun die Kuiper-Statistik für eine Gleichverteilung: Q = max {Fb (x) − x} + max {x − Fb (x)} 0≤x≤1 0≤x≤1 Die Statistik Q ist die Summe der größten Differenzen nach unten und nach oben zwischen tatsächlicher Verteilungsfunktion und empirischer Verteilungsfunktion. Der Wert sollte möglichst klein sein. In Abhängigkeit der Stichprobengröße T lassen sich nun kritische Werte für Q per Monte Carlo Simulation approximieren, für die die Nullhypothese abgelehnt werden muss. Dazu wird ein Vektor x mit T Realisationen gleichverteilter Zufallsvariablen erzeugt und eine Teststatistik Q (x) berechnet, Q (x) = max Fb (xt ) − F (xt ) , Fb (xt+1 ) − F (xt ) t=1,...,T + max F (xt ) − Fb (xt ) , F (xt ) − Fb (xt+1 ) t=1,...,T Dies wird möglichst oft wiederholt. Alle dadurch berechneten Werte der Teststatistik werden schließlich im Vektor s zusammengefasst. Der Ablehnungsbereich dieses Testverfahrens zum Konfidenzniveau 1 − α ergibt sich nun aus den entsprechenden Quantilen der Verteilung der Teststatistik, A = s[gT (T (1−α))+1] , +∞ Für gängige Stichprobengrößen sind kritische Werte bereits berechnet und verfügbar. Doch erscheint es sinnvoll, die Abweichungen von der Gleichverteilung zu gewichten. Zwar haben wir in diesem Abschnitt durchaus Interesse daran, die korrekte Spezifikation der gesamten Verteilung zu beurteilen, dennoch interessieren uns im Bereich des Risikomanagements natürlich meist besonders die Randbereiche. Eine Abweichung an den Randbereichen sollte also mit größerem Gewicht in die Statistik eingehen als eine Abweichung in den Zentralbereichen. Genau dies lässt sich durch eine Gewichtung der tatsächlichen Verteilungsfunktion sowie der empirischen Verteilungsfunktion mit einer sogenannten “Worry Function” 59 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall bewerkstelligen. In Anlehnung an Crnkovic & Drachman (1996) entscheiden wir uns für die Funktion W (x) = − ln (x · (1 − x)) 2 Diese Gewichtungsfunktion verläuft wie folgt auf dem Intervall (0, 1): 4 3 2 1 0.0 0.2 0.4 0.6 0.8 1.0 Abbildung 2.20.: Worry Function Wir wenden die Worry Function nun auf die theoretische sowie auf die empirische Verteilungsfunktion an und erhalten dadurch eine gewichtete Statistik Qw , mittels welcher den Randbereichen eine größere Bedeutung zugemessen wird: Qw = max {W (x) Fb (x) − W (x) x} + max {W (x) x − W (x) Fb (x)} 0≤x≤1 0≤x≤1 Frankfurt School of Finance & Management Working Paper No. 192 60 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Auch hier müssen in Abhängigkeit von Stichprobengröße und Ausgestaltung der Worry Function kritische Werte wieder per Monte Carlo Simulation gefunden werden, indem bestimmte Quantile des Vektors sw , welcher die Teststatistiken Qw der simulierten Stichproben beinhaltet, betrachtet werden. Die folgende Tabelle stellt kritische Werte in Abhängigkeit von Stichprobengröße T und α-Wert basierend auf 10.000.000 unabhängigen Simulationen pro Zeitraum T dar: HH T HH α HH 0.1% 1% 5% 10% 15% 1 3.808 2.652 1.857 1.523 1.334 10 0.849 0.681 0.549 0.488 0.451 21 0.541 0.443 0.367 0.332 0.311 125 0.2 0.17 0.147 0.136 0.129 250 0.139 0.119 0.104 0.096 0.092 500 0.097 0.084 0.073 0.068 0.065 Tabelle 2.4.: Kritische Werte der Teststatistik Qw Das Problem des CD-Verfahrens ist die relativ große Datenmenge, die es benötigt. In der Regel wird von zwischen 500 bis 1000 Datenwerten ausgegangen, die für signifikante Ergebnisse mit in die Berechnung einfließen sollten. Dies entspricht in der Praxis einem Zeitraum von zwei bis vier Jahren, um genügend Daten akkumulieren zu können. Kupiec (1998) geht zudem davon aus, dass weitere Modifikationen des Tests bei einer asymmetrischen Verteilung nötig wären. Das CD-Verfahren ist also eine interessante Möglichkeit, die Verteilung mit einem Fokus auf bestimmte Teilbereiche zu überprüfen, scheitert in der Praxis oft aber an der großen Datenmenge, die es - wie die meisten nicht-parametrischen Testverfahren bedingen - benötigt. Zudem sind die Ergebnisse nur aussagekräftig, wenn keine Autokorrelation in den Daten vorliegt - dies muss gegebenenfalls separat überprüft werden. 61 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : Z ∼ U (0, 1) gegen H1 : H1 : Z 6∼ U (0, 1) 2. Testfunktion Qw (x) = max W (xt ) Fb (xt ) − W (xt ) F (xt ) , W (xt ) Fb (xt+1 ) − W (xt ) F (xt ) + t=1,...,T max W (xt ) F (xt ) − W (xt ) Fb (xt ) , W (xt ) F (xt ) − W (xt ) Fb (xt+1 ) t=1,...,T 3. Ablehnungsbereich A = sw[gT (T (1−α))+1] , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 2.4.3. Kolmogorov-Smirnov-Test mit Worry Function Wir kommen nun zu einer weiteren, in der Literatur bislang wenig diskutierten Methode, welche dem CD-Verfahren ähnelt. Ziel wird es erneut sein, zu überprüfen, ob unsere empirisch ermittelte Verteilungsfunktion mit der Verteilungsfunktion einer U (0, 1)-Verteilungsfunktion übereinstimmen könnte. Wir werden dazu allerdings eine andere Teststatistik als beim CD-Verfahren verwenden. Wir definieren also erneut die Hypothesen sowie die empirische Verteilungsfunktion durch H0 : Z ∼ U (0, 1) vs. H1 : Z 6∼ U (0, 1) n (x) , x ∈ (0, 1) Fb (x) = T n (x) = max{t|z[t] ≤ x} t∈τ Frankfurt School of Finance & Management Working Paper No. 192 62 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Der Unterschied zum CD-Verfahren liegt nun in der Art und Weise, auf die wir die Nullhypothese prüfen. Dazu führen wir hier die Kolmogorov-Smirnov-Teststatistik des Anpassungstests ein: D = sup {|Fb (x) − x|} 0≤x≤1 Im Gegensatz zur Kuiper-Teststatistik, die eine Summe der größten Abweichung nach unten und nach oben hin war, ist die Kolmogorov-Smirnov-Statistik also lediglich die insgesamt größte absolut gesehene Abweichung: 1.0 0.8 0.6 0.4 Größte absolute Abweichung 0.2 0.2 0.4 0.6 0.8 1.0 Abbildung 2.21.: Veranschaulichung einer Simulation einer exemplarischen Teststatistik für T = 10 Nun gibt es wohlbekannte Testverfahren zum Überprüfen der Nullhypothese anhand der Teststatistik D. Doch analog zum vorherigen Abschnitt wollen wir auch hier explizit Abweichungen an den Rändern der Verteilung stärker gewichten. Wir nutzen dafür erneut die bereits erläuterte Worry Function: W (x) = − ln (x · (1 − x)) 2 Durch Anwendung auf empirische und theoretische Verteilungsfunktion erhalten wir eine neue Teststatistik, Dw = sup {|W (x) Fb (x) − W (x) x|} 0≤x≤1 Durch Anwendung der Worry Function können wir nicht mehr etwa auf die Kolmogorovverteilung zur Ermittlung kritischer Werte der Teststatistik zurückgreifen, sondern müssen selbige per Monte Carlo Simulation finden. Wie im vorherigen Abschnitt ausführlicher dargestellt ergeben sich diese aus den Quantilen der 63 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall simulierten Verteilung der Teststatistik sdw . In einer Simulation mit 10.000.000 Wiederholungen pro Zeitraum ergeben sich folgende kritische Werte: HH T HH α HH 0.1% 1% 5% 10% 15% 1 3.798 2.637 1.81 1.447 1.233 10 0.656 0.514 0.406 0.357 0.326 21 0.406 0.325 0.263 0.234 0.216 125 0.145 0.12 0.101 0.092 0.087 250 0.1 0.084 0.071 0.065 0.061 500 0.07 0.059 0.05 0.046 0.043 Tabelle 2.5.: Kritische Werte der Teststatistik Dw Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : Z ∼ U (0, 1) gegen H1 : H1 : Z 6∼ U (0, 1) 2. Testfunktion Dw (x) = max |W (xt ) Fb (xt ) − W (xt ) F (xt ) |, |W (xt ) Fb (xt+1 ) − W (xt ) F (xt ) | t=1,...,T 3. Ablehnungsbereich A = sdw[gT (T (1−α))+1] , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. Frankfurt School of Finance & Management Working Paper No. 192 64 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.4.4. Wahrscheinlichkeitsintegral zur Transformation in eine Normalverteilung In den vorherigen Abschnitten haben wir die Rosenblatt-Transformation auf unsere Daten angewandt und schließlich versucht zu berechnen, ob die daraus resultierende empirische Verteilungsfunktion der einer Gleichverteilung entsprechen könnte. Wir haben dabei aber festgestellt, dass diese Tests Schwächen in kleinen Stichproben haben. Wir werden nun einen Schritt weiter gehen und nach der Rosenblatt-Transformation noch eine weitere Transformation per Wahrscheinlichkeitsintegral anwenden, um unsere Daten in eine idealerweise standardnormalverteilte Form zu bringen. Dies bietet für uns den Vorteil, dass wir parametrische Tests zum Prüfen der Verteilungsannahme anwenden können, welche mitunter bessere Eigenschaften in kleineren Stichproben haben. Wir wenden auf eine Serie von Zufallsvariablen, welche unabhängig gleichverteilt auf (0, 1) sind, die inverse Verteilungsfunktion der Standardnormalverteilung, Φ−1 (·), an. Das daraus resultierende Ergebnis ist eine Serie unabhängig standardnormalverteilter Zufallsvariablen (Christoffersen 2003): Qt = Φ−1 (Zt ) i.i.d. Qt ∼ N (0, 1) Wenden wir auf unsere Wertänderungen ∆Vt nun also erst die Rosenblatt-Transformation und anschließend die hier erläuterte Transformation an, so sollten wir eine Serie unabhängig standardnormalverteilter Werte bekommen: Qt = Φ−1 F∆V (t|Ωt ) (∆Vt ) i.i.d. Q ∼ N (0, 1) Dies gilt natürlich nur, wenn die Rosenblatt-transformierten Daten tatsächlich unabhängig gleichverteilt auf (0, 1) sind. Es gilt also nur, wenn sich unsere prognostizierten Wahrscheinlichkeitsverteilungen als korrekt herausstellen. Je weniger korrekt unsere Prognosen waren, desto stärker entfernt sich die Serie Qt von unabhängig standardnormalverteilten Werten. Dies lässt sich visualisieren, indem man zuerst ein korrekt spezifiziertes Modell betrachtet. In diesem Fall lassen wir tatsächliche Daten nach einer Standardnor- 65 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall malverteilung generieren und nutzen zur Prognose ebenfalls eine Standardnormalverteilung:13 Rosenblatt-Transformation, Dichtefunktion Rosenblatt-Transformation, Verteilungsfunktion 1.0 1.0 0.8 0.8 0.6 0.6 0.4 0.4 0.2 0.2 0.2 0.4 0.6 0.8 -0.5 1.0 Wahrscheinlichkeitsintegral, Dichtefunktion 0.5 1.0 1.5 Wahrscheinlichkeitsintegral, Verteilungsfunktion 0.4 1.0 0.8 0.3 0.6 0.2 0.4 0.1 -4 -2 0.2 2 -2 4 -1 0 1 2 Abbildung 2.22.: Transformation von korrekt geschätzten Daten In den Schaubildern stellen die schwarz gepunkteten Linien die Idealwerte dar, also z.B. Dichte- und Verteilungsfunktion einer U (0, 1)-Verteilung im Fall der Rosenblatt-Transformation und eine N (0, 1)-Verteilung für die Transformation per Wahrscheinlichkeitsintegral. Die blau gezeichneten Werte stellen die empirischen Dichte- und Verteilungsfunktionen dar. Man sieht, dass die empirischen Funktionen praktisch identisch mit den theoretischen Idealfunktionen sind. Doch wie sehen die transformierten Daten bei einem falsch spezifizierten Modell aus? Wir illustrieren dies anhand eines aus Risikosicht sehr relevanten Beispiels: Wir unterschätzen das Risiko nun bewusst, indem wir von standardnormalverteilten Daten ausgehen, die tatsächlichen Daten aber von einer Verteilung mit höherer Varianz, N (0, 2), generieren lassen: 13 Basiert auf jeweils 1,000,000 Simulationen Frankfurt School of Finance & Management Working Paper No. 192 66 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Rosenblatt-Transformation, Dichtefunktion Rosenblatt-Transformation, Verteilungsfunktion 1.4 1.0 1.2 0.8 1.0 0.8 0.6 0.6 0.4 0.4 0.2 0.2 0.2 0.4 0.6 0.8 -0.5 1.0 Wahrscheinlichkeitsintegral, Dichtefunktion 0.5 1.0 1.5 Wahrscheinlichkeitsintegral, Verteilungsfunktion 1.0 0.25 0.8 0.20 0.6 0.15 0.4 0.10 0.2 0.05 -4 -2 2 4 -2 -1 0 1 2 Abbildung 2.23.: Transformation von Daten, welche das Risiko unterschätzen Bei einer Risikounterschätzung weist sowohl die Transformation zur Gleichverteilung als auch die nachfolgende Transformation zur Standardnormalverteilung zu große Wahrscheinlichkeit in den Randbereichen auf. Dies ist intuitiv nachvollziehbar: Der datengenerierende Prozess hat eine höhere Varianz als im Modell angenommen. In unserem Modell, N (0, 1) würden wir beispielsweise erwarten, in rund 2,28% aller Fälle einen Wert ≤ −2 zu erhalten. Der datengenerierende Prozess, N (0, 2), wird jedoch in ca. 7,86% aller Fälle einen Wert ≤ −2 erzeugen. Wir erhalten also mit einer unerwartet hohen Wahrscheinlichkeit Werte, die in den Randbereichen unserer Modellverteilung liegen. Eine Risikoüberschätzung würde sich ebenfalls in empirischer Dichte- und Verteilungsfunktion widerspiegeln. Hierbei würden die empirischen Funktionen eine zu große Fläche im Zentralbereich aufweisen. Es wird also deutlich, dass die empirische Verteilung der per Wahrscheinlichkeitsintegral transformierten Daten eine Standardnormalverteilung approximiert, sofern das Modell korrekt ist. Ungenauigkeiten im Modell spiegeln sich sowohl nach der Rosenblatt-Transformation als auch in gleicher Weise nach der Wahrscheinlichkeitsintegral-Transformation in Abweichungen von der jeweils erwarteten Dichte- und Verteilungsfunktion wider. 67 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Diese Erkenntnisse helfen uns nun dabei, die Angemessenheit unseres Modells zu überprüfen. Nach Transformation per Wahrscheinlichkeitsintegral sollten unsere Daten unabhängig und identisch standardnormalverteilt sein. Dies werden wir anhand von drei Kriterien überprüfen: 1. Ist Qt normalverteilt? 2. Hat die Verteilung von Qt einen Mittelwert von 0 und eine Varianz von 1? 3. Sind die einzelnen Werte aus Qt unabhängig voneinander? Wenn all diese Fragen mit Ja beantwortet werden können, dann ist das Prognosemodell richtig spezifiziert. In den kommenden Abschnitten werden daher Tests erläutert, um genau diese drei Punkte zu beantworten. 2.4.5. Jarque-Bera-Test auf Normalverteilung Der Jarque-Bera-Test prüft, wie von Jost, Spree, Hapke, Mehmke & Huck (2011) beschrieben, ob vorliegende Daten einer Normalverteilung entstammen. Dazu vergleicht er Schiefe und Kurtosis, d.h. Wölbung, der empirischen Verteilung mit den entsprechenden Werten einer Normalverteilung. Selbige hat eine Schiefe von 0, ist also symmetrisch, und weist eine Kurtosis von 3 auf. Wenn die empirische Verteilung zu stark von diesen Werten abweicht, so ist davon auszugehen, dass der datengenerierende Prozess keiner Normalverteilung folgt. Schiefe S und Kurtosis K entsprechen einer Funktion µn (X) /σ n (X), also das n-te zentrale Moment normiert auf die n-te Potenz der Standardabweichung, für n = 3 (Schiefe) bzw. n = 4 (Kurtosis): S= mit b q= T 3 1 X qt − b q T t=1 ! 23 , K = T X 2 1 qt − b q T t=1 T 4 1 X qt − b q T t=1 ! T 2 2 1 X qt − b q T t=1 T 1X qt T t=1 Frankfurt School of Finance & Management Working Paper No. 192 68 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Wir testen nun die Hypothese H0 : Q ∼ N (·, ·) gegen H1 : Q 6∼ N (·, ·) mittels der Jarque-Bera-Teststatistik, welche unter der Nullhypothese χ22 -verteilt ist: ! 2 (K − 3) T S2 + JB = 6 4 JB ∼ χ22 Ein Problem ist freilich, dass wir die Nullhypothese durch diesen Test zwar gegebenenfalls signifikant ablehnen können, wir können sie aber nicht gesichert akzeptieren. Wir können uns also niemals statistisch wirklich gesichert dafür entscheiden, dass die Daten tatsächlich normalverteilt sind. Eine Analyse der statistischen Macht zeigt sich zudem als kompliziert, da die Verteilung unter der Alternativhypothese gänzlich unbekannt ist. Es ist jedoch anzunehmen, dass der Jarque-Bera-Test für eine ausreichend große Stichprobe in Verbindung mit den anderen beiden Tests zur Überprüfung auf Vorliegen einer Standardnormalverteilung genügend Aussagekraft besitzt, um eine Nicht-Zurückweisung der Nullhypothese als Annahme interpretieren zu können. 69 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : Q ∼ N (·, ·) gegen H1 : Q 6∼ N (·, ·) 2. Testfunktion T JB = 6 (K − 3)2 S2 + 4 ! JB ∼ χ22 3. Ablehnungsbereich A= χ22 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 2.4.6. Regression auf Mittelwert, Varianz und Autokorrelation Berkowitz (2001) schlägt vor, Mittelwert, Varianz und eine mögliche Autokorrelation erster Ordnung in den Daten durch eine Regression zu überprüfen. Wir orientieren uns hier an seinem Konzept und führen einen AR(1)-Prozess ein: Qt = µ + ρQt−1 + t t ∼ N 0, σ 2 Dieses Modell geht also davon aus, dass unsere Daten normalverteilt mit einer bestimmten Varianz sind und einem Erwartungswert, der sich aus einem konstanten Ausdruck und einem Anteil des vorherigen realisierten Wertes zusammensetzt. Wir wollen am Ende auf Vorliegen einer Standardnormalverteilung testen. Dafür sollte die Varianz σ 2 genau 1 sein, der konstante Erwartungswert µ sollte 0 sein. Zudem sollten die Daten unabhängig voneinander sein, das heißt ein Wert sollte Frankfurt School of Finance & Management Working Paper No. 192 70 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall unbeeinflusst von der jeweils vorherigen Realisation sein. Dies wäre für ρ = 0 der Fall. Die empirischen Werte dieser Parameter können wir durch einfache Regression erhalten. Doch müssen wir schließlich testen, ob sie gegebenenfalls auch signifikant von den unter Standardnormalverteilung zu erwartenden Werten sind - wir müssen also einen Hypothesentest durchführen. Dazu werden wir nun die der obigen Modellgleichung zugehörigen Likelihood-Funktion herleiten, über die wir letztlich einen Likelihood-Quotienten-Test der Hypothese durchführen können. Mit Parametervektor θ = µ, σ 2 , ρ gilt für Q1 : µ 1−ρ σ2 V ar (Q1 ) = 1 − ρ2 E (Q1 ) = Annahmegemäß ist t normalverteilt. Da dies die einzige Zufallsgröße ist, die in Y1 eingeht, ist auch Y1 normalverteilt mit Dichtefunktion 2 µ q1 − 1 1−ρ fQ1 (q1 ; θ) = s exp − 2 2σ 2πσ 2 2 1−ρ 1 − ρ2 Auch die bedingte Wahrscheinlichkeit aller nachfolgenden Werte (Q2 , Q3 , . . . ,QT ) sind, gegeben einer Realisation des jeweiligen vorherigen Wertes, normalverteilt mit E (Qt |Qt−1 ) = µ + ρqt−1 V ar (Qt |Qt−1 ) = σ 2 (Qt |Qt−1 ) ∼ N µ + ρqt−1 , σ 2 für 2 ≤ t ≤ T . Die bedingte Dichtefunktion für Qt ist also (qt − µ − ρqt−1 )2 fQt (qt |qt−1 ; θ) = √ exp − 2σ 2 2πσ 2 1 71 Frankfurt School of Finance & Management Working Paper No. 192 ! Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die Dichtefunktion eines beliebigen Qt ergibt sich nun also durch: fQt (qt , qt−1 , qt−2 , . . . , q1 ; θ) = fQ1 (q1 ; θ) · t Y fQi |Qi−1 (qi |qi−1 ; θ) i=2 Die Likelihood der gesamten Daten ergibt sich für t = T : L (q1 , . . . , qT ; θ) = fQ1 (q1 ; θ) · T Y fQi |Qi−1 (qi |qi−1 ; θ) i=2 2 µ ! q1 − T 1 (qi − µ − ρqi−1 )2 1−ρ Y 1 √ exp − exp − =s · 2σ 2 i=2 2πσ 2 2σ 2 2πσ 2 1 − ρ2 1 − ρ2 Durch logarithmieren ergibt sich die Log-Likelihood-Funktion: ln L (q1 , . . . , qT ; θ) 2 µ !! q1 − T 2 X 1 1 (q − µ − ρq ) 1 − ρ i i−1 = ln exp − + ln √ exp − 2 2 s 2 2σ 2σ 2πσ 2πσ 2 i=2 2 1 − ρ 1 − ρ2 2 µ !! q1 − T 2 X 1 1 (qi − µ − ρqi−1 ) 1−ρ + = ln ln √ exp − − + 2 s 2 2σ i=2 2σ 2 2πσ 2πσ 2 1 − ρ2 1 − ρ2 2 µ 21 ! q1 − 2 1 σ 1−ρ = ln (1) − ln (2π) 2 + − 2σ 2 1 − ρ2 2 1−ρ T X 1 (qi − µ − ρqi−1 )2 2 −2 − + ln 2πσ 2σ 2 i=2 Frankfurt School of Finance & Management Working Paper No. 192 72 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall also µ q1 − 2 1 σ 1 1−ρ + − ln L (q1 , . . . , qT ; θ) = − ln (2π) − ln 2 2σ 2 2 2 1−ρ 1 − ρ2 2 T X (qi − µ − ρqi−1 )2 T −1 T −1 2 − ln (2π) − ln σ − 2 2 2σ 2 i=2 Uns bietet sich nun die Möglichkeit, verschiedene Hypothesen mittels LikelihoodQuotienten-Test zu überprüfen. Wir können dabei bestimmte Aussagen über den Erwartungswert, die Varianz und die Autokorrelation erster Ordnung und jede beliebige Kombination dieser drei Charakteristika treffen. Da wir mit diesem Test Aussagen über eine mögliche unabhängige Standardnormalverteilung unserer Daten treffen wollen bietet sich ein gemeinsamer Test an, welcher auf einen Mittelwert von 0, eine Varianz von 1 und eine Autokorrelation erster Ordnung von 0 prüft: H0 : θ = µ, σ 2 , ρ = (0, 1, 0) vs. H1 : θ 6= (0, 1, 0) Als Teststatistik nutzen wir einen Likelihood-Quotienten-Test, Λ q, µ b, σ b2 , ρb = −2 ln L (q; (0, 1, 0)) − ln L q; µ b, σ b2 , ρb Λ q, µ b, σ b2 , ρb ∼ χ23 Zum bestimmen der empirischen Parameter θb = (b µ, σ b2 , ρb) könnte nun die LogLikelihood-Funktion optimiert werden - in unserem Fall bietet es sich aber an, eine einfache Regression nach der Methode kleinster Quadrate durchzuführen, welche hier auf die selben Ergebnisse wie die exakte Maximum Likelihood-Parameterschätzung kommt. 73 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : µ, σ 2 , ρ = (0, 1, 0) gegen H1 : µ, σ 2 , ρ 6= (0, 1, 0) 2. Testfunktion Λ q, µ b, σ b2 , ρb = −2 ln L (q; (0, 1, 0)) − ln L q; µ b, σ b2 , ρb µ q1 − 2 1 1 σ 1−ρ ln L (q; θ) = − ln (2π) − ln + − 2 2σ 2 2 2 1−ρ 1 − ρ2 2 T X (qi − µ − ρqi−1 )2 T −1 T −1 2 ln (2π) − ln σ − − 2 2 2σ 2 i=2 Λ q, µ b, σ b2 , ρb ∼ χ23 µ b, σ b2 , pb können per linearer Regression gefunden werden. 3. Ablehnungsbereich A= χ23 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 2.4.7. Fazit zu ganzheitlichen Validierungsmodellen In diesem Abschnitt sind wir zuerst auf die Rosenblatt-Transformation eingegangen, welche, bei korrekter Spezifikation des Risikomodells, die Realisationen unserer Risikoverteilung in eine Gleichverteilung transformieren kann. Wir testeten anschließend auf die Form der Gleichverteilung. Frankfurt School of Finance & Management Working Paper No. 192 74 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Um die Gleichverteilungsannahme zu überprüfen mussten wir auf nicht-parametrische Testverfahren zurückgreifen. Ein Nachteil dieser Testverfahren ist jedoch ihr schlechtes Abschneiden in Stichproben kleinen Umfangs. Um auf parametrische Tests zurückgreifen zu können haben wir die Daten anschließend nochmals transformiert, um - zumindest ebenfalls bei korrekt spezifiziertem Modell - standardnormalverteilte Daten zu erhalten. Wir testeten erneut auf die Form der eigentlichen Verteilung sowie auf Unabhängigkeit. Sowohl bei nicht-parametrischen als auch bei parametrischen Tests auf eine Verteilung stellte sich uns jedoch das Problem, dass das Zutreffen der Verteilungsannahme in der Nullhypothese angegeben werden musste. Damit kann die Verteilungsannahme, also die Annahme auf Gleich- oder Standardnormalverteilung, zwar signifikant abgelehnt werden, jedoch nicht statistisch gesichert angenommen werden. Eine genauere Analyse des β-Fehlers bzw. der statistischen Macht zeigt der Verfahren sich problematisch, da dazu konkrete Verteilungen für die Alternativhypothese angenommen werden müssten - dies wäre jedoch reine Spekulation und damit nicht aussagekräftig. Technisch gesehen können wir also auch durch die vorgestellten Tests keine absolut gesicherte Aussage über die Verteilungsform treffen. Vor allem in Zusammenhang mit ergänzenden Tests erscheint es jedoch gleichermaßen legitim wie unumgänglich, ein nicht-Ablehnen der Nullhypothese hier mit einer Annahme derselbigen gleichzusetzen. Mögliche praktische Auswirkungen werden sich gegebenenfalls in der Simulation in Abschnitt 3 zeigen. 75 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.5. Validierung basierend auf einem Teilbereich der Verteilung Im vorherigen Abschnitt versuchten wir abzuschätzen, ob die Prognose der kompletten Risikoverteilung mit der Realität vereinbar ist. Dies hatten den Vorteil, dass wir alle uns zur Verfügung stehenden Informationen über unsere Risikovariable nutzen konnten. Problematisch ist jedoch, dass für das Risikomanagement in aller Regel nicht die korrekte Spezifikation der gesamten Verteilung, sondern lediglich die korrekte Spezifikation der Randbereiche von Interesse ist. Wir werden uns daher nun der Frage widmen, wie man überprüfen kann, ob der Randbereich beginnend ab −∞ bis −V aR korrekt spezifiziert ist. Bei Zutreffen impliziert dies direkt eine korrekte Spezifikation des Expected Shortfall. Die nun vorgestellten Verfahren eignen sich also hervorragend zur Validierung desselben, da Abweichungen im relevanten Randbereich erkannt werden können, ohne dabei von Abweichungen in den für das Risikomanagement weniger interessanten Verteilungsbereichen beeinflusst zu werden. 2.5.1. Gestutzter Likelihood-Quotienten-Test Berkowitz (2001) schlägt vor, eine neue Zufallsvariable Q∗ einzuführen, welche den Wert unserer Risikovariable ∆V unter der Bedingung annimmt, dass das p-Quantil unterschritten wurde. Man kann sich dies in etwa so vorstellen, dass nur noch der Randbereich einer Verteilung von Bedeutung ist, exemplarisch durch den blau unterlegten Bereich folgender Abbildung dargestellt: 0.4 0.3 0.2 -4 F-1H5%L -2 0.1 2 4 Abbildung 2.24.: Stutzung einer Standardnormalverteilung bei Φ−1 (5%) Frankfurt School of Finance & Management Working Paper No. 192 76 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Die Abbildung ist insofern nicht ganz korrekt, als dass die Dichtefunktion der gestutzten Verteilung bezogen auf ihre Fläche noch auf 1 normiert werden muss. Dies ändert jedoch nur die Größenverhältnisse, nicht die eigentliche Form. Mathematisch definieren wir eine neue Zufallsvariable Q∗ wie folgt: P (Q∗ ≤ q ∗ ) = P Q ≤ q ∗ |Q ≤ FQ−1 (p∗ ) Wir weichen von Berkowitz (2001) ab, indem wir die neue Zufallsvariable nur für tatsächliche Quantilsüberschreitungen definieren.14 Wir gehen also von einer gestutzten statt von einer zensierten Verteilung aus. Die Dichtefunktion von Q∗ entspricht unter der Nullhypothese von der Form her einer Standardnormalverteilung, durch die Einschränkung jedoch nur noch von −∞ bis FQ−1 . Die Wertemenge von Q∗ ist also −∞, FQ−1 (p) . Die Dichtefunktion von Q∗ ist (x − µ)2 √ exp − 2σ 2 2πσ 2 ! fQ∗ (x) = FQ−1 (p) − µ Φ σ 1 ! 1 φ σ = Φ x−µ σ FQ−1 (p) − µ σ ! Zur Parameterschätzung und für Hypothesentests können wir nun erneut eine Likelihood-Funktion konstruieren. Sei T ∗ die die Anzahl der Q, die kleiner oder gleich dem p∗ -Quantil der Standardnormalverteilung sind. Dies entspricht im Übrigen genau unserer Zufallsvariable der summierten Anzahl aller Value at RiskÜberschreitungen I, also T ∗ = I. Mit θ = (µ, σ) gilt: ∗ L (q1∗ , . . . , qT∗ ; θ) = T Y fQ∗i (qi∗ ; θ) i=1 !! ∗ X T∗ T∗ −1 X F (p) − µ 1 q − µ Q φ i ln Φ − ln L (q1∗ , . . . , qT∗ ; θ) = σ σ σ t=1 i=1 " !# !! T∗ T∗ −1 2 ∗ X X 1 F (p) − µ (q − µ) − Q = ln 2πσ 2 2 exp − i 2 − ln Φ 2σ σ t=1 i=1 " # !! ∗ T X (qi∗ − µ)2 FQ−1 (p) − µ 1 2 ∗ − T ln Φ = − ln 2πσ − 2 2σ 2 σ i=1 14 Berkowitz definiert Q∗t für jedes Qt und berechnet dies als Q∗t = min Qt , Φ−1 (p) 77 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Wir testen nun die Hypothesen H0 : Q ∼ NT 0, 1, FQ−1 (p) gegen H1 : Q 6∼ NT 0, 1, FQ−1 (p) N (µ, σ 2 , T ) ist dabei die Normalverteilung N (µ, σ 2 ) mit Stutzung ab der Stelle T , d.h. Wertebereich ihrer Dichtefunktion von [−∞, T ]. Wir testen hier also letztlich, ob der linke Rand Q dem einer Standardnormalverteilung entspricht. Werte, die im Zentrum oder am rechten Rand der Verteilung liegen werden bewusst ignoriert. Den eigentlichen Test führen wir erneut durch einen Likelihood-Quotienten-Test durch: b, σ b2 Λ µ b, σ b2 = −2 ln L (0, 1) − ln L µ Λ µ b, σ b2 ∼ χ22 Die Schätzer µ b und σ b2 müssen numerisch durch Optimierung der logarithmierten Likelihood-Funktion gefunden werden. Zusammenfassend prüfen wir hier also darauf, ob der linke Randbereich der Verteilung korrekt abgebildet wird. Wir haben dabei jedoch nicht auf eine mögliche Autokorrelation der Daten getestet. Dies muss bei Bedarf separat, beispielsweise anhand des ebenfalls im Rahmen dieser Arbeit vorgestellten Markow-Tests, durchgeführt werden. Frankfurt School of Finance & Management Working Paper No. 192 78 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : Q ∼ NT 0, 1, FQ−1 (p) gegen H1 : Q 6∼ NT 0, 1, FQ−1 (p) 2. Testfunktion b, σ b2 Λ µ b, σ b2 = −2 ln L (0, 1) − ln L µ " # T∗ 2 ∗ X 1 (q − µ) L (q∗ ; θ) = − ln 2πσ 2 − i 2 − T ∗ ln Φ 2 2σ i=1 2 Λ µ b, σ b ∼ χ22 FQ−1 (p) − µ σ !! 3. Ablehnungsbereich A= χ22 −1 (1 − α) , +∞ 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 2.5.2. Gauss-Test des Expected Shortfall bei gestutzter Verteilung Unter der Nullhypothese einer korrekten Modellspezifikation sind die per Wahrscheinlichkeitsintegral transformierten Daten approximativ standardnormalverteilt. Im vorherigen Abschnitt definierten wir eine Zufallsvariable Q∗ , welche lediglich die transformierten Werte kleiner gleich des p∗ -Quantils der Standardnormalverteilt erfasst. Die Dichtefunktion dieser Variable wurde bereits angegeben. 79 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Unter Zutreffen der Nullhypothese können wir diese jedoch noch weiter vereinfachen, da die sich in diesem Fall auf die Standardnormalverteilung bezieht: φ (x) p∗ φ (Φ−1 (p∗ )) E (Q∗ |H0 ) = − p∗ 2 Φ−1 (p∗ ) φ (Φ−1 (p∗ )) −φ (Φ−1 (p∗ )) ∗ V ar (Q |H0 ) = 1 − − p∗ p∗ fQH∗0 (x) = Da Q∗ unter der Nullhypothese i.i.d. ist konvergiert der Erwartungswert der Folge Q∗1 , . . . , Q∗T ∗ gegen eine Normalverteilung mit Erwartungswert und Varianz wie oben angegeben. Aufgrund des zentralen Grenzwertsatzes gilt nun: ΥT ∗ (Q∗ ) = √ Q∗ − E (Q∗ |H0 ) T∗ p V ar (Q∗ |H0 ) ∗ mit Q∗ T 1 X ∗ = ∗ Q T i=1 i lim P (ΥT ∗ ≤ z) = Φ (z) T ∗ →∞ Das standardisierte arithmetische Mittel der Folge Q∗1 , . . . , Q∗T ∗ konvergiert also unter der Nullhypothese gegen eine Standardnormalverteilung. c∗ , in Wir prüfen nun, ob das arithmetische Mittel unserer realisierten Daten, Q Einklang zu bringen ist mit dem eigentlich anzunehmenden Erwartungswert der gestutzten Standardnormalverteilung, E (Q∗ |H0 ): c∗ gegen H : E (Q∗ |H ) 6= Q c∗ H0 : E (Q∗ |H0 ) = Q 1 0 Der Ablehnungsbereich A mit Signifikanzniveau α wird berechnet durch: α α A = −∞, Φ−1 ∪ Φ−1 1 − , +∞ 2 2 Wir lehnen die Nullhypothese ab, wenn die Teststatistik in den Ablehnungsbereich fällt, also bei ΥT ∗ (Q∗ ) ∈ A. Dieses eigentlich sehr elegante Verfahren wird in der Praxis leider oft von der geringen Mengen an verfügbaren Daten negativ beeinflusst. Die hier aus dem zentralen Grenzwertsatz gezogenen Schlussfolgerungen gelten nur für eine große Anzahl Frankfurt School of Finance & Management Working Paper No. 192 80 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall verschiedener Realisation von Q∗ . Bei etwa 250 Handelstagen würden, in einem korrekt spezifizierten Modell, jedoch im Durchschnitt weniger als 3 Realisationen von Q∗ vorliegen. Im nächsten Abschnitt werden wir versuchen, dieses Problem zu verbessern. Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem c∗ gegen H : E (Q∗ |H ) 6= Q c∗ H0 : E (Q∗ |H0 ) = Q 1 0 2. Testfunktion Υ (Q∗ ) = √ Q∗ − E (Q∗ |H0 ) T∗ p V ar (Q∗ |H0 ) ∗ Q∗ T 1 X ∗ = ∗ Q T i=1 i φ (Φ−1 (p)) p 2 Φ−1 (p) φ (Φ−1 (p)) −φ (Φ−1 (p)) ∗ V ar (Q |H0 ) = 1 − − p p ∗ Υ (Q ) ∼ N (0, 1) E (Q∗ |H0 ) = − 3. Ablehnungsbereich α α ∪ Φ−1 1 − , +∞ A = −∞, Φ−1 2 2 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. 81 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2.5.3. Sattelpunktapproximation mittels Lugannani Rice-Formel zum Überprüfen des Expected Shortfall Die bislang vorgestellten Verfahren zur Überprüfung einer Expected ShortfallPrognose litten vor allem an schlechten Eigenschaften in kleinen Stichproben ein großes Problem, da die Anzahl an Überschreitungen in der Praxis tatsächlich sehr klein ist. Die von Wong (2008) präsentierte, in diesem Abschnitt diskutierte Methode zielt darauf ab, auch in kleinen Stichproben bessere Aussagen erzielen zu können. Detailliertere Ausführungen zur Sattelpunktapproximation werden von DasGupta (2008) vorgestellt. Prinzipiell gesehen wird über die Inversion einer Fouriertransformation versucht, die Dichtefunktion zu rekonstruieren und diese zu integrieren, um die Verteilungsfunktion zu erhalten. Die Lugannani Rice-Formel, die auf diesem Prinzip basiert, gilt dabei als besonders präzise allgemein, aber auch im Speziellen in den Randbereichen. Ausgangspunkt ist unsere bereits definierte Zufallsvariable Q∗ , welche alle Werte, die unterhalb des FQ−1 (p∗ )-Quantils liegen, beinhaltet. Als Expected Shortfall der Verteilung von Q definieren wir daher ∗ ES = −Q∗ T 1 X ∗ =− ∗ Q T i=1 i Sei q = Φ−1 (p∗ ). Die momenterzeugende Funktion und ihre ersten drei Ableitungen bezogen auf die Zufallsvariable Q∗ sind definiert durch 2 1 t M (t) = ∗ exp · Φ (q − t) p 2 φ (q) M 0 (t) = t · M (t) − exp (t · q) ∗ p q · φ (q) M 00 (t) = t · M 0 (t) + M (t) − exp (q · t) · p∗ q 2 φ (q) M 000 (t) = t · M 00 (t) + 2M 0 (t) − exp (q · t) · p∗ Frankfurt School of Finance & Management Working Paper No. 192 82 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall und kumulantengenerierender Funktion K (t) = ln (M (t)) M 0 (t) K 0 (t) = M (t) 0 2 M (t) M 00 (t) 00 K (t) = − + M (t) M (t) 2M 0 (t)3 3M 0 (t) M 00 (t) M 000 (t) − + K (t) = M (t) M (t)3 M (t)2 000 Wir bestimmen nun den Sattelpunkt $ so, dass er dem arithmetischen Mittel der realisierten Werte unserer Zufallsvariable q ∗ entspricht, indem wir die folgende Gleichung numerisch nach $ lösen: K 0 ($) = q ∗ Anschließend berechnen wir zwei Werte η und ζ wie folgt: p η = $ T ∗ K 00 ($) q ζ = sgn ($) 2T ∗ ($q ∗ − K ($)) sgn (x) ist dabei die Signumfunktion. Mit diesen berechneten Werten können wir nun die Lugannani-Rice-Formel anwenden, welche die Wahrscheinlichkeit angibt, dass Q∗ unter der Nullhypothese kleiner gleich unserem empirischen Wert q ∗ ist: 1 1 −3/2 ∗ Φ (ζ) − φ (ζ) · − +O T für Q∗ < q η ζ 1 K 000 (0) ∗ −3/2 P Q∗ ≤ q ∗ = − + q +O T für Q∗ = µQ∗ 2 3 ∗ 00 6 2πT (K (0)) 1 für Q∗ ≥ q O ist hierbei ein Landau-Symbol, welches das Konvergenzverhalten des Ausdrucks beschreibt. Wir testen die Hypothese, ob der theoretisch zu erwartende Wert unserer Zufallsvariable mit ihrem realisierten arithmetischen Mittel vereinbar ist: H0 : E (Q∗ ) ≥ q ∗ gegen H1 : E (Q∗ ) < q ∗ 83 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Bei Zutreffen der Nullhypothese liegt der Expected Shortfall der Stichprobe in der Nähe des theoretisch zu erwartenden Expected Shortfall eines korrekt spezifizierten Modells. Zusammenfassung des Testverfahrens Hypothesentest 1. Testproblem H0 : E (Q∗ ) ≥ q ∗ gegen H1 : E (Q∗ ) < q ∗ 2. Testfunktion 1 1 ∗ −3/2 Φ (ζ) − φ (ζ) · − +O T η ζ 1 K 000 (0) ∗ −3/2 ∗ ∗ P Q ≤q = − + q +O T 2 ∗ (K 00 (0))3 6 2πT 1 P Q∗ ≤ q ∗ ∼ U (0, 1) für Q∗ < q für Q∗ = µQ∗ für Q∗ ≥ q 3. Ablehnungsbereich A = (0, α) 4. Entscheidungsregel H0 ablehnen, wenn die Testfunktion im Ablehnungsbereich liegt. Ansonsten H0 nicht ablehnen. Frankfurt School of Finance & Management Working Paper No. 192 84 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 3. Simulation Im Folgenden werden wir die vorgestellte Validierungsmodelle in einer Simulation überprüfen. Von Interesse wird dabei zum einen die Ablehnungsrate korrekter Risikomodelle (α-Fehler) als auch die Ablehnungsrate falscher Risikomodelle (statistische Macht) sein. Die Hypothese H0 wird dabei stets für die Angemessenheit eines Risikomodells stehen. Die Hypothese H1 steht für einen Fehler im Risikomodell, der beispielsweise in einer Über- oder Unterschätzung des Risikos resultieren könnte. Es werden für jede Iteration der Simulation von einem datengenerierenden Prozess 350 normalverteilte Werte erzeugt. Erwartungswert und Varianz folgen dabei bestimmten, später im Abschnitt genauer aufgeführten Vorschriften. Diese jeweils 350 Daten werden als “reale Renditen” betrachtet, die von einem Risikomodell abgebildet und eingeschätzt werden sollen. Ein Risikomodell trifft schließlich Prognosen für diese realen Werte. Die ersten 100 Realisationen werden nur zur Parameteradjustierung genutzt, die darauf folgenden 250 Werte werden vom Risikomodell schließlich auf täglicher Basis prognostiziert. Für jeden Zeitpunkt t = 1, . . . , 250 existiert also eine Schätzung bezüglich Erwartungswert und Varianz der Portfoliorenditen, die vom Risikomodell am Vortag t−1 berechnet wurde, und ein realer Wert, der im ersten Schritt vom datengenerierenden Prozess erzeugt wurde. Basierend auf diesen Daten können nun alle Werte berechnet werden, die von den Validierungsverfahren benötigt werden - etwa realisierte Value at Risk-Überschreitungen, die Rosenblatt-Transformation der realen Werte etc. Das Konfidenzniveau des Value at Risk wird in der Simulation stets 95% sein. Die Algorithmen sind dabei so konzipiert, dass zu jeder Teststatistik ein konkreter Signifikanzwert, auch bekannt als p-Wert, berechnet wird. Die Hypothese H0 wird verworfen, wenn der Signifikanzwert geringer als das gewünschte α-Niveau des Hypothesentests ist. Wir werden im Folgenden sechs verschiedene Ausgangssituationen betrachten: 1. Das Risikomodell ist korrekt spezifiziert. Wie hoch ist der α-Fehler der Validierungsmodelle? 85 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 2. Das Risikomodell ist falsch spezifiziert. Die Daten werden von einem GJRGARCH-Prozess erzeugt, das Risikomodell berechnet Parameter auf einfacher, rollierender Basis. 3. Das Risikomodell ist falsch spezifiziert. Die Daten werden von einem GJRGARCH-Prozess erzeugt, das Risikomodell berechnet Parameter mit exponentieller Glättung. 4. Das Risikomodell ist falsch spezifiziert. Die Daten werden von einem GJRGARCH-Prozess erzeugt, das Risikomodell berechnet Parameter mittels GARCHPrognose. 5. Das Risikomodell ist falsch spezifiziert und unterschätzt das reale Risiko konstant. 6. Das Risikomodell ist falsch spezifiziert. Zwar wird der Value at Risk korrekt abgebildet, jedoch wird der Expected Shortfall unterschätzt. Bei den letzten drei der genannten Punkte steht dabei die Analyse der statistischen Macht im Vordergrund. Die genutzten Verfahren zur Erzeugung der Daten und Prognose der Parameter entsprechen den in Abschnitt 2.2.2 erläuterten Methoden. Für jede Ausgangssituation werden wir 100.000 Simulationsdurchgänge durchführen. 3.1. Korrekt spezifiziertes Risikomodell Mit einem korrekt spezifizierten Risikomodell sollten die Signifikanzwerte einer Gleichverteilung folgen. Dies ergibt sich daraus, dass die Ablehnungsrate eines korrekten Modells genau dem α-Fehler des Hypothesentests entsprechen sollte der Signifikanzwert sollte also beispielsweise genau in 5% aller Fälle kleiner gleich 5% sein. Diese Eigenschaft werden wir nun für alle Testverfahren prüfen. Der datengenerierende Prozess der “realen Renditen” folgt zu jedem Zeitpunkt einer Normalverteilung mit Erwartungswert 0 und Varianz 1. Das Risikoprognosemodell geht ebenfalls in jedem Zeitpunkt von einem Erwartungswert in Höhe von 0 und einer Varianz in Höhe von 1 aus und ist somit korrekt spezifiziert. Wir betrachten nun die Histogramme der Signifikanzwerte der verschiedenen Testverfahren. Auf der x-Achse ist jeweils der Wert der Signifikanzwerte in Abständen von 5% pro Balken abgetragen, auf der y-Achse werden deren relative Häufigkeiten dargestellt. Idealerweise sollten alle relativen Häufigkeiten genau 5% betragen, d.h. genau auf Höhe der jeweils eingezeichneten schwarzen Linie sein. Frankfurt School of Finance & Management Working Paper No. 192 86 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall TUFF POF MLF Markow Kuiper Kolmogorov Jarque Bera Regression Gestutzt Gauss gestutzt Lugannani Rice Die meisten Testverfahren erzeugen in der Tat weitestgehend gleichverteilte Signifikanzwerte. Lediglich POF- und Markow-Verfahren weichen deutlich von einer Gleichverteilung ab. Dies wird nochmals verdeutlicht, wenn man die empirischen Verteilungsfunktionen der Signifikanzwerte betrachtet: 87 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall TUFF POF MLF Markow Kuiper Kolmogorov Jarque Bera Regression Gestutzt Gauss gestutzt Lugannani Rice Sowohl beim Proportion of Failure-Verfahren als auch beim Markow-Test auf Unabhängigkeit zeigen sich bereits hier deutliche Schwächen, da die tatsächlichen α-Fehler deutlich von ihren spezifizierten Werten abweichen. Beim POF-Verfahren ist dies ein kleineres Problem, da die Verteilung zumindest für kleine Signifikan- Frankfurt School of Finance & Management Working Paper No. 192 88 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall zwerte bis 5% noch recht präzise ist und somit die üblichen α-Niveaus von Hypothesentests weitestgehend realitätsnah sind. Die Verteilung des Markow-Tests weicht jedoch auch für kleine Werte bereits deutlich von einer Gleichverteilung ab. Der tatsächliche α-Fehler ist hier deutlich geringer als der erwartete α-Fehler. Dies bedeutet, dass der Markow-Test wesentlich seltener korrekte Modelle ablehnt als eigentlich zu erwarten wäre. Was zunächst sogar nach einem Vorteil klingt ist jedoch in der Praxis höchst problematisch, da in der Regel mit niedrigerem α-Fehler auch die statistische Macht eines Testverfahrens sinkt. 89 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 3.2. Risikomodell mit rollierenden Varianzen Wir gehen nun von einem Risikomodell aus, das die Parameter für die zukünftige Periode prognostiziert, indem es den jeweiligen Durchschnitt der vergangenen 90 Tage berechnet. Im Vergleich zum realen Prozess passen sich die Parameter hier deutlich zu langsam an, was schnell zu Über- und Unterschätzung von Risiken führen kann. Das Risikomodell ist eindeutig falsch und sollte daher von den Validierungsverfahren möglichst oft abgelehnt werden. Statistische Macht bei α = 5% Statistische Macht bei α = 1% Frankfurt School of Finance & Management Working Paper No. 192 90 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 3.3. Risikomodell mit exponentiell geglätteten Varianzen Im nun präsentierten Risikomodell erfolgen Parameterschätzungen über exponentielle Glättung mit Glättungsparameter 0,94. Das Modell sollte sich wesentlich schneller an Änderungen anpassen als das vorherige Risikomodell. Dennoch ist auch dieses Modell falsch und sollte von den Validierungsmethoden abgelehnt werden. Die relative Häufigkeit der Ablehnungen der Nullhypothese entspricht der statistischen Macht. Statistische Macht bei α = 5% Statistische Macht bei α = 1% 91 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 3.4. GARCH-Risikomodell Ein GARCH-Modell entspricht bereits relativ gut dem tatsächlichen datengenerierenden Prozess. Technisch gesehen ist auch dieses Risikomodell falsch, da es im Gegensatz zum realen GJR-GARCH-Modell keine Asymmetrie von stochastischen Einflüssen einbeziehen kann. In der Praxis würde sich allerdings die Frage stellen, ob wir mit diesem Modell nicht bereits nahe genug an der Realität liegen, um es als korrektes Modell anzuerkennen. Tatsächlich wird man es niemals schaffen, den realen Prozess exakt abzubilden. Mit der GARCH-Prognose liegen wir allerdings schon relativ nahe an der Realität und es könnte deshalb wünschenswert sein, das Modell im Einsatz zu belassen. Die nachfolgende der statistischen Macht sollte also mit Vorsicht interpretiert werden. Prinzipiell ist es zwar korrekt, das GARCH-Modell abzulehnen - in der Praxis könnte es aber dennoch sinnvoll sein, dieses Modell bewusst nicht abzulehnen. Statistische Macht bei α = 5% Statistische Macht bei α = 1% Frankfurt School of Finance & Management Working Paper No. 192 92 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 3.5. Konstante Risikounterschätzung Wir gehen nun dazu über, das Risiko bewusst konstant zu unterschätzen. Wir lassen Daten aus einer Normalverteilung mit Erwartungswert 0 und Varianz 1,5 generieren, gehen im Risikomodell aber von einer Normalverteilung mit Erwartungswert 0 und Varianz 1 aus. Statistische Macht bei α = 5% Statistische Macht bei α = 1% Die niedrige Macht des Markow-Verfahrens ergibt sich aus der Testkonstellation es liegt schlicht keine Autokorrelation in den Daten vor. Das Markow-Modell hat hier also keinen Anlass, das Modell zu verwerfen. Im ersten Moment überraschender erscheint hier das schlechte Abschneiden des Jarque Bera-Verfahrens. Im Rahmen dieser konkreten Simulationskonstellation entspricht die Serie, die durch Transformation per Wahrscheinlichkeitsintegral der 93 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Rosenblatt-transformierten Daten hervorgeht, genau der ursprünglich generierten Serie - hier also Realisationen einer Normalverteilung mit Erwartungswert 0 und Varianz 1,5. Der Jarque Bera-Test prüft jedoch lediglich auf Schiefe und Kurtosis. Diese beiden Werte sind natürlich unabhängig von Erwartungswert und Varianz der unterliegenden Normalverteilung. Wir hätten hier also Daten mit beliebigem Erwartungswert und beliebiger Varianz generieren können - der Jarque Bera-Test hätte das Modell trotzdem in ca. 1 − α Prozent aller Fälle nicht verworfen. Wir sehen hier sehr deutlich, dass der Jarque Bera-Test nicht ohne ergänzende Tests genutzt werden sollte, da er zwar gewisse Aspekte der Form einer Verteilung überprüft, nicht jedoch die Varianz der Daten. 3.6. Korrekter Value at Risk, unterschätzter Expected Shortfall Wir lassen nun Daten generieren aus einer T-Verteilung mit zwei Freiheitsgraden (blau gezeichneter Graph im Bild), gehen im Risikomodell jedoch von einer Normalverteilung mit Erwartungswert 0 und Standardabweichung 1,78 aus (gepunktete schwarze Linie im Bild): 0.35 0.30 0.25 0.20 0.15 0.10 0.05 -6 -4 -2 2 4 6 T- und Normalverteilung Bei beiden Verteilungen liegt das 5%-Quantil bei -2,92, sodass der Value at Risk auf 5%-Niveau identisch ist. Der Expected Shortfall der T-Verteilung beträgt 6,16, der Expected Shortfall der Normalverteilung hingegen ist 3,66. Das Risikomodell schätzt also einen korrekten Value at Risk, unterschätzt den Expected Shortfall jedoch deutlich. Frankfurt School of Finance & Management Working Paper No. 192 94 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Statistische Macht bei α = 5% Statistische Macht bei α = 1% TUFF und POF schneiden hier erwartungsgemäß schlecht ab, immerhin ist der Value at Risk ja in der Tat korrekt geschätzt. Auch der Markow-Test verwirft H0 praktisch nie, da es keine Autokorrelation in den Daten gibt. Jarque Bera-Test sowie Regressionsverfahren können ebenfalls nicht überzeugen, da hier die Form der Daten vermutlich nicht ausreichend unterschiedlich zu einer Normalverteilung ist. Am besten schneidet in der Tat der Kuiper-Test ab, der präzise erkennt, dass die reale Verteilung unterschiedlich zur im Risikomodell angenommenen Verteilung sein muss. Das Ergebnis wäre vermutlich jedoch weniger eindeutig, wenn nur der Randbereich unterschiedlich und der Rest der Verteilung identisch mit der im Risikomodell angenommenen Verteilung wäre. Hier zeigen vor allem der gestutzte Gauss-Test sowie das Lugannani Rice-Verfahren ihre Stärken, denn sie beinhalten nur die Value at Risk-Überschreitungen. Die 95 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall statistische Macht dieser beiden Verfahren ist im Test hervorragend, was ihre gute Eigenschaft zur Expected Shortfall-Validierung bestätigt. 3.7. Zusammenfassung der Simulationsergebnisse Die Simulation gibt interessante Einblicke in Art und Häufigkeit von Ablehnungen der verschiedenen Validierungskonzepte. Die folgenden Aussagen können selbstverständlich nur basierend auf den in der Simulation beinhalteten Konstellationen getroffen werden. Bei der Überprüfung, ob ein gegebener α-Fehler in einem korrekten Prognosemodell eingehalten wird zeigten manche Modelle bereits eklatante Schwächen. Speziell TUFF-, POF- und Markow-Verfahren zeigten in der Verteilung der Signifikanzniveaus deutliche Abweichungen von einer Gleichverteilung. Auch der Jarque Bera-Test sowie der gestutzte Gauss-Test wiesen, wenngleich auch geringfügigere, Abweichungen von den erwarteten α-Fehlern auf. Diese Abweichungen resultieren jedoch nicht aus Fehlern in den mathematischen Modellen, sondern schlichtweg aus der geringen Stichprobengröße. Im Versuch wurde jeweils mit einem realen Zeitraum von 250 Perioden gearbeitet, was an die Erfordernisse der Praxis angelehnt ist. Simuliert man jeweils einen weitaus längeren Zeitraum, beispielsweise 100.000 Perioden, so zeigt sich bei ausnahmslos allen Verfahren eine nahezu perfekte Gleichverteilung der Signifikanzniveaus. Derartig lange Zeiträume können in der Praxis selbstverständlich nicht umgesetzt werden. Diese erste Simulation liefert also bereits interessante Ergebnisse im Bezug auf die Praxistauglichkeit der Verfahren unter realitätsnahen Anforderungen an die verfügbare Datenmenge. In den drei folgenden Abschnitten (rollierende Varianz, exponentiell geglättete Varianz sowie GARCH-Modell) wurden die Ablehnungsraten falsch spezifizierter Risikomodelle überprüft. Erwartungsgemäß wies das TUFF-Verfahren durchschnittlich die geringste statistische Macht auf. Auch Markow- sowie Jarque-Bera-Test können durchschnittlich nicht überzeugen. Die besten Resultate liefert der Kuiper-Test. Seine Ergebnisse sind zudem stets besser als die des Kolmogorov-Smirnov-Tests. Da beide Verfahren auf eine bestimmte Verteilungsform testen sprechen die Ergebnisse dafür, dass der Kuiper-Test das geeignetere Verfahren hierfür ist. Ebenfalls sehr gute Ergebnisse zeigt das Regressionsverfahren. Eine Simulation konstanter Risikounterschätzung bestätigt im Wesentlichen die Einschätzung der Testverfahren und zeigt speziell nochmals die Anfälligkeit des Frankfurt School of Finance & Management Working Paper No. 192 96 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Jarque-Bera-Tests unter bestimmten Testkonstellationen. Als Schlussfolgerung daraus ist zu beachten, dass der Jarque-Bera-Test ausschließlich ergänzend mit anderen Verfahren genutzt werden sollte - etwa in Verbindung mit dem Regressionsverfahren. Eine abschließende Simulation, in welcher das Risikomodell zwar eine korrekte Einschätzung des Value at Risk, jedoch eine falsche Einschätzung des Expected Shortfall trifft, liefert interessante Resultate über diejenigen Testverfahren, die speziell einen Teilbereich der Verteilung testen. Alle drei Validierungskonzepte (Gestutzt, Gauss gestutzt, Lugannani Rice) weisen hierbei eine hervorragende statistische Macht auf. Interessanterweise zeigt sich dabei der von uns im Rahmen dieser Arbeit eingeführte gestutzte Gauss-Test als bestes Verfahren mit geringfügig höheren Ablehnungsraten als der reine gestutzte Test oder das Lugannani Rice-Verfahren. Auch der Kuiper- sowie der Kolmogorov-Smirnov-Test zeigen eine sehr hohe statistische Macht in dieser Simulationskonstellation. Dies liegt jedoch vermutlich daran, dass die zugrunde liegende T-Verteilung in ihrer Gesamtheit merklich von der genutzten Normalverteilung abweicht. Würde sie rechtsseitig des p-Quantils mit der Normalverteilung stärker übereinstimmen, so würde die Macht des Kuiper- sowie des Kolmogorov-Smirnov-Verfahrens deutlich geringer ausfallen, wohingegen die statistische Macht der drei anderen Verfahren (gestutzt, Gauss gestutzt, Lugannani Rice) nicht beeinflusst würde. Die letztgenannten Testverfahren sind also tatsächlich sehr effektiv, um Abweichungen im linken Randbereich der Verteilung festzustellen und dienen somit hervorragend zur Validierung des Expected Shortfall. 97 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall 4. Fazit Nach einer kurzen Einführung in relevante statistische Verfahren sowie eine einleitende Erklärung zum Marktrisikomanagement im Allgemeinen betrachteten alle gängigen Verfahren zur Validierung von Marktrisikomodellen. Wir erläuterten zuerst Verfahren, welche die Güte eines Risikomodells anhand Überschreitungen des Value at Risk beurteilen. TUFF, POF, das Ampelkonzept, die MLF sowie der Markow-Test auf Unabhängigkeit zählen zu diesen Verfahren. Weiterführend zur bisherigen Literatur zeigten wir dabei einige zusätzliche Aspekte einiger Testverfahren auf. Beim TUFF-Verfahren fanden wir erhebliche Inkonsistenzen bei der statistischen Macht sowie bei der Einhaltung des α-Fehlers. Wir zeigten ebenfalls, dass eine mangelnde Ablehnungsfähigkeit risikounterschätzender Modelle erst später auftritt als bisher von Kupiec (1998) angenommen. Vergleichend zu diesem Verfahren simulierten wir auch beim TUFF-Test α- und β-Fehler und fanden heraus, dass es auch bei ersterem kleinere Abweichungen gibt, letzterer sich jedoch wesentlich konstanter als beim POF-Verfahren entwickelt. Die MLF modifizierten wir im Unterschied zur bisherigen Praxis um eine Korrektur der Standardabweichung und berechneten kritische Werte für eine Normalverteilung. Anschließend betrachteten wir Verfahren, die die gesamte Verteilung validieren. Dazu zählt die Rosenblatt-Transformation und darauf basierend die Kuiper-Statistik mit Worry Function und der Kolmogorov-Smirnov-Test mit Worry Function sowie, basierend auf dem Wahrscheinlichkeitsintegral zur Normalverteilung, der JarqueBera-Test und eine Regression auf Mittelwert, Varianz und Autokorrelation. Mit dem Kolmogorov-Smirnov-Test führten wir ein neues Verfahren ein, welches sich jedoch im Bezug auf seine statistische Macht im Rahmen der getesteten Konstellationen später im Vergleich zur Kuiper-Statistik als geringfügig unterlegen herausstellte. Zu beiden Verfahren simulierten wir mit einer großen Datenmenge kritische Werte unter Einbeziehung der Worry Function. Zuletzt erläuterten wir Verfahren, welche speziell für die Validierung des Expected Shortfall von Interesse sind. Dazu zählt der gestutzte Likelihood-Quotienten-Test, der Gauss-Test des Expected Shortfall bei gestutzter Verteilung sowie die Sattelpunktapproximation mittels Lugannani Rice-Formel. Beim Erstgenannten wichen Frankfurt School of Finance & Management Working Paper No. 192 98 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall wir von der bisherigen Literatur zum Thema ab, indem wir statt einer zensierten Verteilung eine gestutzte Verteilung betrachteten und die entsprechenden Formeln herleiteten. Mit dem Gauss-Test bei gestutzter Verteilung führten wir ein gänzlich neues Verfahren ein. Abschließend simulierten wir für alle angeführten Testverfahren die Signifikanzniveaus sowie die statistische Macht unter verschiedenen Konstellationen. Wir zeigten Probleme einiger Modelle bei der Einhaltung des α-Fehlers, die Aufschluss über die Praxistauglichkeit der jeweiligen Verfahren bei realitätsnahen Datenmengen geben. Des Weiteren belegten wir, dass Verfahren, die nur auf Überschreitungen des Value at Risk basieren, in der Tat eine recht geringe statistische Macht aufweisen. Wir sahen, dass eine Validierung der gesamten Verteilung wesentlich erfolgreicher war und führten ebenfalls aus, dass die Verfahren, die auf einem Teilbereich der Verteilung basieren, extrem effizient bei der Ablehnung von Modellen mit falsch spezifiziertem Expected Shortfall arbeiten. Die Validierung von Marktrisikomodellen wird sicherlich weiterhin ein relevantes Thema in der Forschung und in der Finanzindustrie bleiben. Welche der vorgestellten Modelle tatsächlich in der Praxis genutzt werden sollten obliegt der Entscheidung des Risikomanagements. Es empfiehlt sich in den meisten Fällen, mehrere Verfahren zu kombinieren. Die Eigenschaften der Validierungsmodelle sollten dabei abgewogen und individuell auf die Prioritäten sowie die Charakteristika des Portfolios abgestimmt werden. Die Resultate dieser Arbeit dürften eine Hilfe dabei sein, konkrete Stärken und Schwächen der Modelle unter verschiedenen Konstellationen einzuschätzen. 99 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Literaturverzeichnis Berkowitz, Jeremy. 2001. “Testing Density Forecasts, With Applications to Risk Management.” Journal of Business and Economic Statistics p. 465. Campbell, Sean D. 2006/2007. “A review of backtesting and backtesting procedures.” The Journal of Risk p. 1. Christoffersen, Peter. 2003. Elements of Financial Risk Management. Academic Press. Cremers, Heinz. 2011. “Risikomanagement.” Vorlesungsskript. SS 2011. Crnkovic, Cedomir & Jordan Drachman. 1996. “Quality Control.” Risk 9:138–142. DasGupta, Anirban. 2008. Asymptotic Theory of Statistics and Probability. Springer. Dowd, Kevin. 2004. “A modified Berkowitz back-test.” Risk Magazine . Goethe Universität. 2004. “Mathematisch-Statistische Verfahren des Risikomanagements.” Präsentation. SS 2004. Jost, Julian, Thorsten Spree, Katarina Hapke, Fabian Mehmke & Niclas Huck. 2011. “Hypothesentests.”. Seminarbeit Quantitative Methoden der Ökonometrie. Kupiec, Paul H. 1998. “Techniques for Verifying the Accuracy of Risk Measurement Models.” Journal of Derivatives pp. 73–84. Lopez, Jose A. 1998. Methods for Evaluating Value-at-Risk Estimates. Technical report Federal Reserve Bank of New York. Ruppert, David. 2010. Statistics and Data Analysis for Financial Engineering (Springer Texts in Statistics). Springer. Sanddorf-Köhle, Walter. 2011. “Zeitreihenanalyse Sommersemester 2011.” Vorlesungsskript. Foliensatz Nr. 6. Schröder, Frank & Hermann Schulte-Mattler. 1997. “CD-Verfahren als Alternative zum Baseler Backtesting.” Die Bank 7. Frankfurt School of Finance & Management Working Paper No. 192 100 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Suhov, Yuri & Mark Kelbert. 2005. Probability and Statistics by Example: Volume 1, Basic Probability and Statistics (v. 1). Cambridge University Press. Supervisory framework for the use of “Backtesting“ in conjunction with the internal models approach to market risk capital requirements. 1998. Technical report Bank for International Settlements. van der Vaart, A. W. 2000. Asymptotic Statistics (Cambridge Series in Statistical and Probabilistic Mathematics). Cambridge University Press. Wong, Woon K. 2008. “Backtesting trading risk of commercial banks using expected shortfall.” Journal of Banking and Finance 32:1404–1415. 101 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Nomenklatur α Risikowahrscheinlichkeit eines Hypothesentests. Je nach Zusammenhang auch Parameter in einem APGARCH-Modell. β Fehler zweiter Art eines Hypothesentests. Je nach Zusammenhang auch Parameter in einem APGARCH-Modell. χ2d Chi-Quadrat-Verteilung mit Freiheitsgrad d δ Parameter in einem APGARCH-Modell t Residuum einer Regression λ Glättungsparameter bei exponentiell geglätteter Varianz Λ (·) Teststatistik eines allgemeinen Likelihood-Quotienten-Tests ln Natürlicher Logarithmus B (p) Bernoulliverteilung mit Parameter p. B (T, p) Binomialverteilung mit Parametern T und p. G (p) Geometrische Verteilung mit Parameter p. N Natürliche Zahlen N (µ, σ) Eine Normalverteilung mit Erwartungswert µ und Varianz σ 2 N (µ, σ 2 , T ) Normalverteilung mit Parametern µ, σ 2 , die an der Stelle T gestutzt ist. R Die reellen Zahlen S Menge aller Parameterkombinationen einer Simulation U Gleichverteilung auf dem Intervall (0, 1). Frankfurt School of Finance & Management Working Paper No. 192 102 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall O Landau-Symbol q Spaltenvektor aller q-Werte, (q1 , . . . , qT )T . T Stutzungsstelle einer Verteilung. Tij Absolute Häufigkeit, in der auf eine Value at Risk-Überschreitung (i = 1) bzw. einer Nicht-Überschreitung (i = 0) in einer Stichprobe eine Überschreitung (j = 1) oder eine Nicht-Überschreitung (j = 0) folgt. µ Erwartungswert ω Parameter in einem APGARCH-Modell Ωt Zustandsraum zum Zeitpunkt t · Mittelwert, z.B. wäre q der Mittelwert aller q1 , . . . , qT Φ (·) Verteilungsfunktion einer Standardnormalverteilung φ (·) Dichtefunktion einer Standardnormalverteilung Φ−1 (·) Inverse Verteilungsfunktion einer Standardnormalverteilung Π Transitionsmatrix eines Markow-Tests π Kreiszahl πij Elemente der Transitionsmatrix Π ΠM L Maximum Likelihood-Schätzung einer Transitionsmatrix ΠU Transitionsmatrix unter Unabhängigkeit P (·) Wahrscheinlichkeitsoperator ρ Korrelationskoeffizient / Autokorrelationsparameter bei einer linearen Regression σ Standardabweichung σ2 Varianz τ Die Menge aller Möglichen Zeitindizes {1, . . . , T }. 103 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Θ Θ0 ∪ Θ1 θ Parametervektor Θ0 Parameterraum einer parametrischen Nullhypothese Θ1 Parameterraum einer parametrischen Alternativhypothese Υ (·) Teststatistik des Gauss-Tests bei gestutzter Verteilung. ϑ Ein unbekannter Verteilungsparameter b· Empirische Schätzungen bestimmter Werte. Zum Beispiel µ b, σ b etc. A Ablehnungsbereich eines Hypothesentests D Kolmogorov-Smirnov-Teststatistik Dw Mit Worry Function gewichtete Kolmogorov-Smirnov-Statistik E (·) Erwartungswert-Operator ESt (p) Expected Shortfall zum Zeitpunkt t für Value at Risk-Vertrauenswahrscheinlichkeit 1 − p. fX (x; Θ) Dichtefunktion der Variable X an der Stelle x mit Parametervektor θ. Auch ohne X und θ geschrieben, sofern deren Bedeutungen aus dem Zusammenhang deutlich werden. FX (x; θ) Verteilungsfunktion der Zufallsvariable X an der Stelle x. Auch ohne X und θ geschrieben, sofern deren Bedeutungen aus dem Zusammenhang deutlich werden. H0 Nullhypothese H1 Alternativhypothese I Summe der Überschreitungsfunktionen zu jedem Zeitpunkt in τ . It Value at Risk-Überschreitungsfunktion zum Zeitpunkt t. JB Jarque-Bera-Teststatistik K Kurtosis einer Verteilung beim Jarque-Bera-Test Frankfurt School of Finance & Management Working Paper No. 192 104 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall K (·) Kumulantenerzeugende Funktion L (·) Likelihood-Funktion M (·) Momentenerzeugende Funktion N Umfang einer Stichprobe n (x) Anzahl aller Werte in einer Stichprobe z1 , . . . , zT , die kleiner als x sind. p Tatsächliche, unbekannte Wahrscheinlichkeit, dass der Value at Risk überschritten wird. p∗ Modellwahrscheinlichkeit, mit der der Value at Risk annahmegemäß überschritten werden sollte. Q Kuiper-Statistik Q∗ Zufallsvariable wie Q, jedoch nur definiert für Werte kleinergleich FQ−1 (p), d.h. also Stutzung von Q. Qt Per Wahrscheinlichkeitsintegral transformierte Zufallsvariable Zt Qw Mit Worry Fuction gewichtete Kuiper-Statistik rt Diskrete Rendite zum Zeitpunkt t S Schiefe einer Verteilung beim Jarque-Bera-Test T Die Anzahl der beobachteten Zeitpunkte. Je nach Kontext auch Teststatistik eines Hypothesentests. T (x) Testfunktion eines Hypothesentests, wobei x ∈ Rn T∗ Anzahl aller Realisationen von Q1 , . . . , QT , die kleinergleich FQ−1 (p) sind. V ar (·) Varianz-Operator V aRt (p) Value at Risk für den Zeitpunkt t mit Vertrauenswahrscheinlichkeit 1−p W (x) Worry Function X 105 Eine Zufallsvariable Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall Zt Eine Zufallsvariable, die der Rosenblatt-Transformation der Zufallsvariable t entspricht. s Vektor, der Werte einer Teststatistik zu verschiedenen Stichproben beinhaltet. d Unterschied der Dimensionen zwischen Θ und Θ0 . G (·) Gütefunktion gT (·) Ganzzahliger Teil einer Zahl. ML Maximum Likelihood MLF Magnitude of Loss-Function POF Proportion of Failure TLA Traffic Light Approach, entspricht dem Ampelkonzept. TUFF Time Until First Failure Frankfurt School of Finance & Management Working Paper No. 192 106 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall A. Anhang A.1. Tabellen α=0,1% 1% 2% 3% 4% p =1% <1|852.31 1.88|610.51 3.02|536.86 4.11|493.52 5.16|462.64 2% <1|424.26 1.23|303.96 1.78|267.33 2.32|245.77 2.83|230.4 3% <1|281.57 1.05|201.78 1.38|177.48 1.73|163.18 2.06|152.99 4% <1|210.22 <1|150.68 1.19|132.55 1.44|121.88 1.68|114.28 5% <1|167.41 <1|120.03 1.08|105.6 1.27|97.1 1.46|91.05 6% <1|138.86 <1|99.59 1.02|87.62 1.16|80.58 1.31|75.57 7% <1|118.47 <1|84.98 <1|74.78 1.09|68.78 1.21|64.51 8% <1|103.18 <1|74.03 <1|65.15 1.04|59.93 1.14|56.21 9% <1|91.28 <1|65.51 <1|57.66 1.01|53.04 1.09|49.75 10% <1|81.76 <1|58.69 <1|51.67 <1|47.53 1.05|44.59 11% <1|73.97 <1|53.12 <1|46.76 <1|43.03 1.02|40.36 12% <1|67.48 <1|48.47 <1|42.68 <1|39.27 1|36.84 13% <1|61.98 <1|44.53 <1|39.22 <1|36.09 <1|33.86 14% <1|57.27 <1|41.16 <1|36.25 <1|33.36 <1|31.3 15% <1|53.18 <1|38.23 <1|33.68 <1|31 <1|29.09 16% <1|49.61 <1|35.67 <1|31.43 <1|28.93 <1|27.15 17% <1|46.45 <1|33.41 <1|29.44 <1|27.1 <1|25.44 18% <1|43.65 <1|31.4 <1|27.67 <1|25.48 <1|23.91 19% <1|41.14 <1|29.6 <1|26.09 <1|24.03 <1|22.55 20% <1|38.88 <1|27.99 <1|24.67 <1|22.72 <1|21.33 Tabelle A.1.: TUFF-Test, kritische Werte für unterschiedliche p∗ ∗ 107 Frankfurt School of Finance & Management Working Paper No. 192 Validierung von Konzepten zur Messung des Marktrisikos insbesondere des Value at Risk und des Expected Shortfall α=5% 6% 7% 8% 9% 10% p =1% 6.2|438.6 7.2|418.9 8.2|402.2 9.1|387.7 10.1|374.8 11|363.3 2% 3.3|218.4 3.8|208.6 4.3|200.3 4.8|193.1 5.3|186.7 5.7|181 3% 2.4|145.1 2.7|138.6 3|133 3.4|128.3 3.7|124 4|120.2 4% 1.9|108.4 2.2|103.5 2.4|99.4 2.6|95.8 2.9|92.7 3.1|89.8 5% 1.7|86.3 1.8|82.5 2|79.2 2.2|76.4 2.4|73.8 2.6|71.6 6% 1.5|71.7 1.6|68.5 1.8|65.7 1.9|63.4 2.1|61.3 2.2|59.4 7% 1.3|61.2 1.5|58.4 1.6|56.1 1.7|54.1 1.9|52.3 2|50.8 8% 1.3|53.3 1.4|50.9 1.5|48.9 1.6|47.2 1.7|45.6 1.8|44.2 9% 1.2|47.2 1.3|45.1 1.4|43.3 1.5|41.8 1.6|40.4 1.7|39.2 10% 1.1|42.3 1.2|40.4 1.3|38.8 1.4|37.4 1.5|36.2 1.5|35.1 11% 1.1|38.3 1.2|36.6 1.2|35.1 1.3|33.9 1.4|32.8 1.5|31.8 12% 1.1|34.9 1.1|33.4 1.2|32.1 1.2|30.9 1.3|29.9 1.4|29 13% 1|32.1 1.1|30.7 1.1|29.5 1.2|28.4 1.3|27.5 1.3|26.7 14% 1|29.7 1.1|28.4 1.1|27.3 1.2|26.3 1.2|25.5 1.3|24.7 15% <1|27.6 1|26.4 1.1|25.3 1.1|24.5 1.2|23.7 1.2|22.9 16% <1|25.8 1|24.6 1|23.7 1.1|22.8 1.1|22.1 1.2|21.4 17% <1|24.1 1|23.1 1|22.2 1.1|21.4 1.1|20.7 1.2|20.1 18% <1|22.7 <1|21.7 1|20.9 1|20.1 1.1|19.5 1.1|18.9 19% <1|21.4 <1|20.5 1|19.7 1|19 1.1|18.4 1.1|17.8 20% <1|20.2 <1|19.4 <1|18.6 1|17.9 1|17.4 1.1|16.9 Tabelle A.2.: Fortsetzung TUFF-Test, kritische Werte für unterschiedliche p∗ ∗ Frankfurt School of Finance & Management Working Paper No. 192 108 FRANKFURT SCHOOL / HFB – WORKING PAPER SERIES No. Author/Title 191. Tinschert, Jonas / Cremers, Heinz Fixed Income Strategies for Trading and for Asset Management 2012 190. Schultz, André / Kozlov, Vladimir / Libman, Alexander Roving Bandits in Action: Outside Option and Governmental Predation in Autocracies 2012 189. Börner, René / Goeken, Matthias / Rabhi, Fethi SOA Development and Service Identification – A Case Study on Method Use, Context and Success Factors 2012 188. Mas, Ignacio / Klein, Michael A Note on Macro-financial implications of mobile money schemes 2012 187. Dietmar Harhoff, Elisabeth Müller, John Van Reenen What are the Channels for Technology Sourcing? Panel Data Evidence from German Companies n Decarolis, Francesco/ Klein, Michael Auctions that are too good to be true 2012 185. Klein, Michael Infrastructure Policy: Basic Design Options 2012 184. Eaton, Sarah / Kostka, Genia Does Cadre Turnover Help or Hinder China’s Green Rise? Evidence from Shanxi Province 2012 183. Behley, Dustin / Leyer, Michael Evaluating Concepts for Short-term Control in Financial Service Processes 2011 182. Herrmann-Pillath, Carsten Naturalizing Institutions: Evolutionary Principles and Application on the Case of Money 2011 181. Herrmann-Pillath, Carsten Making Sense of Institutional Change in China: The Cultural Dimension of Economic Growth and Modernization 2011 180. Herrmann-Pillath, Carsten Hayek 2.0: Grundlinien einer naturalistischen Theorie wirtschaftlicher Ordnungen 2011 179. Braun, Daniel / Allgeier, Burkhard / Cremres, Heinz Ratingverfahren: Diskriminanzanalyse versus Logistische Regression 2011 178. Kostka, Genia / Moslener, Ulf / Andreas, Jan G. Barriers to Energy Efficency Improvement: Empirical Evidence from Small- and-Medium-Sized Enterprises in China 2011 177. Löchel, Horst / Xiang Li, Helena Understanding the High Profitability of Chinese Banks 2011 176. Herrmann-Pillath, Carsten Neuroökonomik, Institutionen und verteilte Kognition: Empirische Grundlagen eines nicht-reduktionistischen naturalistischen Forschungsprogramms in den Wirtschaftswissenschaften 2011 175. Libman, Alexander/ Mendelski, Martin History Matters, but How? An Example of Ottoman and Habsburg Legacies and Judicial Performance in Romania 2011 174. Kostka, Genia Environmental Protection Bureau Leadership at the Provincial Level in China: Examining Diverging Career Backgrounds and Appointment Patterns 2011 173. Durst, Susanne / Leyer, Michael Bedürfnisse von Existenzgründern in der Gründungsphase 2011 172. Klein, Michael Enrichment with Growth 2011 171. Yu, Xiaofan A Spatial Interpretation of the Persistency of China’s Provincial Inequality 2011 170. Leyer, Michael Stand der Literatur zur operativen Steuerung von Dienstleistungsprozessen 2011 169. Libman, Alexander / Schultz, André Tax Return as a Political Statement 2011 168. Kostka, Genia / Shin, Kyoung Energy Service Companies in China: The Role of Social Networks and Trust 2011 167. Andriani, Pierpaolo / Herrmann-Pillath, Carsten Performing Comparative Advantage: The Case of the Global Coffee Business 2011 166. Klein, Michael / Mayer, Colin Mobile Banking and Financial Inclusion: The Regulatory Lessons 2011 186. Year Frankfurt School of Finance & Management Working Paper No. 192 2012 165. Cremers, Heinz / Hewicker, Harald Modellierung von Zinsstrukturkurven 2011 164. Roßbach, Peter / Karlow, Denis The Stability of Traditional Measures of Index Tracking Quality 2011 163. Libman, Alexander / Herrmann-Pillath, Carsten / Yarav, Gaudav Are Human Rights and Economic Well-Being Substitutes? Evidence from Migration Patterns across the Indian States 2011 162. Herrmann-Pillath, Carsten / Andriani, Pierpaolo Transactional Innovation and the De-commoditization of the Brazilian Coffee Trade 2011 161. Christian Büchler, Marius Buxkaemper, Christoph Schalast, Gregor Wedell Incentivierung des Managements bei Unternehmenskäufen/Buy-Outs mit Private Equity Investoren – eine empirische Untersuchung – 2011 160. Herrmann-Pillath, Carsten Revisiting the Gaia Hypothesis: Maximum Entropy, Kauffman´s “Fourth Law” and Physiosemeiosis 2011 159. Herrmann-Pillath, Carsten A ‘Third Culture’ in Economics? An Essay on Smith, Confucius and the Rise of China 2011 158. Boeing. Philipp / Sandner, Philipp The Innovative Performance of China’s National Innovation System 2011 157. Herrmann-Pillath, Carsten Institutions, Distributed Cognition and Agency: Rule-following as Performative Action 2011 156. Wagner, Charlotte From Boom to Bust: How different has microfinance been from traditional banking? 2010 155. Libman Alexander / Vinokurov, Evgeny Is it really different? Patterns of Regionalisation in the Post-Soviet Central Asia 2010 154. Libman, Alexander Subnational Resource Curse: Do Economic or Political Institutions Matter? 2010 153. Herrmann-Pillath, Carsten Meaning and Function in the Theory of Consumer Choice: Dual Selves in Evolving Networks 2010 152. Kostka, Genia / Hobbs, William Embedded Interests and the Managerial Local State: Methanol Fuel-Switching in China 2010 151. Kostka, Genia / Hobbs, William Energy Efficiency in China: The Local Bundling of Interests and Policies 2010 150. Umber, Marc P. / Grote, Michael H. / Frey, Rainer Europe Integrates Less Than You Think. Evidence from the Market for Corporate Control in Europe and the US 2010 149. Vogel, Ursula / Winkler, Adalbert Foreign banks and financial stability in emerging markets: evidence from the global financial crisis 2010 148. Libman, Alexander Words or Deeds – What Matters? Experience of Decentralization in Russian Security Agencies 2010 147. Kostka, Genia / Zhou, Jianghua Chinese firms entering China's low-income market: Gaining competitive advantage by partnering governments 2010 146. Herrmann-Pillath, Carsten Rethinking Evolution, Entropy and Economics: A triadic conceptual framework for the Maximum Entropy Principle as applied to the growth of knowledge 2010 145. Heidorn, Thomas / Kahlert, Dennis Implied Correlations of iTraxx Tranches during the Financial Crisis 2010 Fritz-Morgenthal, Sebastian G. / Hach, Sebastian T. / Schalast, Christoph M&A im Bereich Erneuerbarer Energien 2010 Birkmeyer, Jörg / Heidorn, Thomas / Rogalski, André Determinanten von Banken-Spreads während der Finanzmarktkrise 2010 142. Bannier, Christina E. / Metz, Sabrina Are SMEs large firms en miniature? Evidence from a growth analysis 2010 141. Heidorn, Thomas / Kaiser, Dieter G. / Voinea, André The Value-Added of Investable Hedge Fund Indices 2010 140. Herrmann-Pillath, Carsten The Evolutionary Approach to Entropy: Reconciling Georgescu-Roegen’s Natural Philosophy with the Maximum Entropy Framework 144 143. 2010 139. Heidorn, Thomas / Löw, Christian / Winker, Michael Funktionsweise und Replikationstil europäischer Exchange Traded Funds auf Aktienindices 2010 138. Libman, Alexander Constitutions, Regulations, and Taxes: Contradictions of Different Aspects of Decentralization 2010 Frankfurt School of Finance & Management Working Paper No. 192 137. Herrmann-Pillath, Carsten / Libman, Alexander / Yu, Xiaofan State and market integration in China: A spatial econometrics approach to ‘local protectionism’ 2010 136. Lang, Michael / Cremers, Heinz / Hentze, Rainald Ratingmodell zur Quantifizierung des Ausfallrisikos von LBO-Finanzierungen 2010 135. Bannier, Christina / Feess, Eberhard When high-powered incentive contracts reduce performance: Choking under pressure as a screening device 2010 Herrmann-Pillath, Carsten Entropy, Function and Evolution: Naturalizing Peircian Semiosis 2010 Bannier, Christina E. / Behr, Patrick / Güttler, Andre Rating opaque borrowers: why are unsolicited ratings lower? 2009 134. 133. 132. 131. 130. 129. Herrmann-Pillath, Carsten Social Capital, Chinese Style: Individualism, Relational Collectivism and the Cultural Embeddedness of the Institutions-Performance Link Schäffler, Christian / Schmaltz, Christian Market Liquidity: An Introduction for Practitioners 2009 2009 Herrmann-Pillath, Carsten Dimensionen des Wissens: Ein kognitiv-evolutionärer Ansatz auf der Grundlage von F.A. von Hayeks Theorie der „Sensory Order“ 2009 Hankir, Yassin / Rauch, Christian / Umber, Marc It’s the Market Power, Stupid! – Stock Return Patterns in International Bank M&A 2009 Herrmann-Pillath, Carsten Outline of a Darwinian Theory of Money 2009 127. Cremers, Heinz / Walzner, Jens Modellierung des Kreditrisikos im Portfoliofall 2009 126. Cremers, Heinz / Walzner, Jens Modellierung des Kreditrisikos im Einwertpapierfall 2009 125. Heidorn, Thomas / Schmaltz, Christian Interne Transferpreise für Liquidität 2009 124. Bannier, Christina E. / Hirsch, Christian The economic function of credit rating agencies - What does the watchlist tell us? 2009 Herrmann-Pillath, Carsten A Neurolinguistic Approach to Performativity in Economics 2009 128. 123. 122. 121. 120. 119. 118. Winkler, Adalbert / Vogel, Ursula Finanzierungsstrukturen und makroökonomische Stabilität in den Ländern Südosteuropas, der Türkei und in den GUSStaaten 2009 Heidorn, Thomas / Rupprecht, Stephan Einführung in das Kapitalstrukturmanagement bei Banken 2009 Rossbach, Peter Die Rolle des Internets als Informationsbeschaffungsmedium in Banken 2009 Herrmann-Pillath, Carsten Diversity Management und diversi-tätsbasiertes Controlling: Von der „Diversity Scorecard“ zur „Open Balanced Scorecard 2009 Hölscher, Luise / Clasen, Sven Erfolgsfaktoren von Private Equity Fonds 2009 Bannier, Christina E. Is there a hold-up benefit in heterogeneous multiple bank financing? 2009 116. Roßbach, Peter / Gießamer, Dirk Ein eLearning-System zur Unterstützung der Wissensvermittlung von Web-Entwicklern in Sicherheitsthemen 2009 115. Herrmann-Pillath, Carsten Kulturelle Hybridisierung und Wirtschaftstransformation in China 2009 114. Schalast, Christoph: Staatsfonds – „neue“ Akteure an den Finanzmärkten? 2009 113. Schalast, Christoph / Alram, Johannes Konstruktion einer Anleihe mit hypothekarischer Besicherung 2009 Schalast, Christoph / Bolder, Markus / Radünz, Claus / Siepmann, Stephanie / Weber, Thorsten Transaktionen und Servicing in der Finanzkrise: Berichte und Referate des Frankfurt School NPL Forums 2008 2009 Werner, Karl / Moormann, Jürgen Efficiency and Profitability of European Banks – How Important Is Operational Efficiency? 2009 117. 112. 111. Frankfurt School of Finance & Management Working Paper No. 192 110. Herrmann-Pillath, Carsten Moralische Gefühle als Grundlage einer wohlstandschaffenden Wettbewerbsordnung: Ein neuer Ansatz zur erforschung von Sozialkapital und seine Anwendung auf China 2009 109. Heidorn, Thomas / Kaiser, Dieter G. / Roder, Christoph Empirische Analyse der Drawdowns von Dach-Hedgefonds 2009 108. Herrmann-Pillath, Carsten Neuroeconomics, Naturalism and Language 2008 107. Schalast, Christoph / Benita, Barten Private Equity und Familienunternehmen – eine Untersuchung unter besonderer Berücksichtigung deutscher Maschinen- und Anlagenbauunternehmen 2008 106. Bannier, Christina E. / Grote, Michael H. Equity Gap? – Which Equity Gap? On the Financing Structure of Germany’s Mittelstand 2008 105. Herrmann-Pillath, Carsten The Naturalistic Turn in Economics: Implications for the Theory of Finance 2008 104. Schalast, Christoph (Hrgs.) / Schanz, Kay-Michael / Scholl, Wolfgang Aktionärsschutz in der AG falsch verstanden? Die Leica-Entscheidung des LG Frankfurt am Main 2008 Bannier, Christina E./ Müsch, Stefan Die Auswirkungen der Subprime-Krise auf den deutschen LBO-Markt für Small- und MidCaps 2008 Cremers, Heinz / Vetter, Michael Das IRB-Modell des Kreditrisikos im Vergleich zum Modell einer logarithmisch normalverteilten Verlustfunktion 2008 Heidorn, Thomas / Pleißner, Mathias Determinanten Europäischer CMBS Spreads. Ein empirisches Modell zur Bestimmung der Risikoaufschläge von Commercial Mortgage-Backed Securities (CMBS) 2008 Schalast, Christoph (Hrsg.) / Schanz, Kay-Michael Schaeffler KG/Continental AG im Lichte der CSX Corp.-Entscheidung des US District Court for the Southern District of New York 2008 Hölscher, Luise / Haug, Michael / Schweinberger, Andreas Analyse von Steueramnestiedaten 2008 Heimer, Thomas / Arend, Sebastian The Genesis of the Black-Scholes Option Pricing Formula 2008 Heimer, Thomas / Hölscher, Luise / Werner, Matthias Ralf Access to Finance and Venture Capital for Industrial SMEs 2008 96. Böttger, Marc / Guthoff, Anja / Heidorn, Thomas Loss Given Default Modelle zur Schätzung von Recovery Rates 2008 95. Almer, Thomas / Heidorn, Thomas / Schmaltz, Christian The Dynamics of Short- and Long-Term CDS-spreads of Banks 2008 94. Barthel, Erich / Wollersheim, Jutta Kulturunterschiede bei Mergers & Acquisitions: Entwicklung eines Konzeptes zur Durchführung einer Cultural Due Diligence 2008 93. Heidorn, Thomas / Kunze, Wolfgang / Schmaltz, Christian Liquiditätsmodellierung von Kreditzusagen (Term Facilities and Revolver) 2008 92. Burger, Andreas Produktivität und Effizienz in Banken – Terminologie, Methoden und Status quo 2008 91. Löchel, Horst / Pecher, Florian The Strategic Value of Investments in Chinese Banks by Foreign Financial Insitutions 2008 90. Schalast, Christoph / Morgenschweis, Bernd / Sprengetter, Hans Otto / Ockens, Klaas / Stachuletz, Rainer / Safran, Robert Der deutsche NPL Markt 2007: Aktuelle Entwicklungen, Verkauf und Bewertung – Berichte und Referate des NPL Forums 2007 2008 89. Schalast, Christoph / Stralkowski, Ingo 10 Jahre deutsche Buyouts 2008 88. Bannier, Christina E./ Hirsch, Christian The Economics of Rating Watchlists: Evidence from Rating Changes 2007 87. Demidova-Menzel, Nadeshda / Heidorn, Thomas Gold in the Investment Portfolio 2007 Hölscher, Luise / Rosenthal, Johannes Leistungsmessung der Internen Revision 2007 Bannier, Christina / Hänsel, Dennis Determinants of banks' engagement in loan securitization 2007 103. 102. 101. 100. 99. 98. 97. 86. 85. Frankfurt School of Finance & Management Working Paper No. 192 84. Bannier, Christina “Smoothing“ versus “Timeliness“ - Wann sind stabile Ratings optimal und welche Anforderungen sind an optimale Berichtsregeln zu stellen? 2007 83. Bannier, Christina E. Heterogeneous Multiple Bank Financing: Does it Reduce Inefficient Credit-Renegotiation Incidences? 2007 82. Cremers, Heinz / Löhr, Andreas Deskription und Bewertung strukturierter Produkte unter besonderer Berücksichtigung verschiedener Marktszenarien 2007 81. Demidova-Menzel, Nadeshda / Heidorn, Thomas Commodities in Asset Management 2007 80. Cremers, Heinz / Walzner, Jens Risikosteuerung mit Kreditderivaten unter besonderer Berücksichtigung von Credit Default Swaps 2007 79. Cremers, Heinz / Traughber, Patrick Handlungsalternativen einer Genossenschaftsbank im Investmentprozess unter Berücksichtigung der Risikotragfähigkeit 2007 78. Gerdesmeier, Dieter / Roffia, Barbara Monetary Analysis: A VAR Perspective 2007 Heidorn, Thomas / Kaiser, Dieter G. / Muschiol, Andrea Portfoliooptimierung mit Hedgefonds unter Berücksichtigung höherer Momente der Verteilung 2007 Jobe, Clemens J. / Ockens, Klaas / Safran, Robert / Schalast, Christoph Work-Out und Servicing von notleidenden Krediten – Berichte und Referate des HfB-NPL Servicing Forums 2006 2006 Abrar, Kamyar / Schalast, Christoph Fusionskontrolle in dynamischen Netzsektoren am Beispiel des Breitbandkabelsektors 2006 74. Schalast, Christoph / Schanz, Kay-Michael Wertpapierprospekte: Markteinführungspublizität nach EU-Prospektverordnung und Wertpapierprospektgesetz 2005 2006 73. Dickler, Robert A. / Schalast, Christoph Distressed Debt in Germany: What´s Next? Possible Innovative Exit Strategies 2006 72. Belke, Ansgar / Polleit, Thorsten How the ECB and the US Fed set interest rates 2006 71. Heidorn, Thomas / Hoppe, Christian / Kaiser, Dieter G. Heterogenität von Hedgefondsindizes 2006 Baumann, Stefan / Löchel, Horst The Endogeneity Approach of the Theory of Optimum Currency Areas - What does it mean for ASEAN + 3? 2006 Heidorn, Thomas / Trautmann, Alexandra Niederschlagsderivate 2005 Heidorn, Thomas / Hoppe, Christian / Kaiser, Dieter G. Möglichkeiten der Strukturierung von Hedgefondsportfolios 2005 67. Belke, Ansgar / Polleit, Thorsten (How) Do Stock Market Returns React to Monetary Policy ? An ARDL Cointegration Analysis for Germany 2005 66. Daynes, Christian / Schalast, Christoph Aktuelle Rechtsfragen des Bank- und Kapitalmarktsrechts II: Distressed Debt - Investing in Deutschland 2005 65. Gerdesmeier, Dieter / Polleit, Thorsten Measures of excess liquidity 2005 64. Becker, Gernot M. / Harding, Perham / Hölscher, Luise Financing the Embedded Value of Life Insurance Portfolios 2005 77. 76. 75. 70. 69. 68. 63. 62. 61. 60. 59. 58. 57. Schalast, Christoph Modernisierung der Wasserwirtschaft im Spannungsfeld von Umweltschutz und Wettbewerb – Braucht Deutschland eine Rechtsgrundlage für die Vergabe von Wasserversorgungskonzessionen? – 2005 Bayer, Marcus / Cremers, Heinz / Kluß, Norbert Wertsicherungsstrategien für das Asset Management 2005 Löchel, Horst / Polleit, Thorsten A case for money in the ECB monetary policy strategy 2005 Richard, Jörg / Schalast, Christoph / Schanz, Kay-Michael Unternehmen im Prime Standard - „Staying Public“ oder „Going Private“? - Nutzenanalyse der Börsennotiz - 2004 Heun, Michael / Schlink, Torsten Early Warning Systems of Financial Crises - Implementation of a currency crisis model for Uganda 2004 Heimer, Thomas / Köhler, Thomas Auswirkungen des Basel II Akkords auf österreichische KMU 2004 Heidorn, Thomas / Meyer, Bernd / Pietrowiak, Alexander Performanceeffekte nach Directors´Dealings in Deutschland, Italien und den Niederlanden 2004 Frankfurt School of Finance & Management Working Paper No. 192 56. Gerdesmeier, Dieter / Roffia, Barbara The Relevance of real-time data in estimating reaction functions for the euro area 2004 55. Barthel, Erich / Gierig, Rauno / Kühn, Ilmhart-Wolfram Unterschiedliche Ansätze zur Messung des Humankapitals 2004 54. Anders, Dietmar / Binder, Andreas / Hesdahl, Ralf / Schalast, Christoph / Thöne, Thomas Aktuelle Rechtsfragen des Bank- und Kapitalmarktrechts I : Non-Performing-Loans / Faule Kredite - Handel, Work-Out, Outsourcing und Securitisation 2004 53. Polleit, Thorsten The Slowdown in German Bank Lending – Revisited 2004 52. Heidorn, Thomas / Siragusano, Tindaro Die Anwendbarkeit der Behavioral Finance im Devisenmarkt 2004 Schütze, Daniel / Schalast, Christoph (Hrsg.) Wider die Verschleuderung von Unternehmen durch Pfandversteigerung 2004 Gerhold, Mirko / Heidorn, Thomas Investitionen und Emissionen von Convertible Bonds (Wandelanleihen) 2004 Chevalier, Pierre / Heidorn, Thomas / Krieger, Christian Temperaturderivate zur strategischen Absicherung von Beschaffungs- und Absatzrisiken 2003 48. Becker, Gernot M. / Seeger, Norbert Internationale Cash Flow-Rechnungen aus Eigner- und Gläubigersicht 2003 47. Boenkost, Wolfram / Schmidt, Wolfgang M. Notes on convexity and quanto adjustments for interest rates and related options 2003 46. Hess, Dieter Determinants of the relative price impact of unanticipated Information in U.S. macroeconomic releases 51. 50. 49. 2003 45. Cremers, Heinz / Kluß, Norbert / König, Markus Incentive Fees. Erfolgsabhängige Vergütungsmodelle deutscher Publikumsfonds 2003 44. Heidorn, Thomas / König, Lars Investitionen in Collateralized Debt Obligations 2003 43. Kahlert, Holger / Seeger, Norbert Bilanzierung von Unternehmenszusammenschlüssen nach US-GAAP 2003 42. 41. Beiträge von Studierenden des Studiengangs BBA 012 unter Begleitung von Prof. Dr. Norbert Seeger Rechnungslegung im Umbruch - HGB-Bilanzierung im Wettbewerb mit den internationalen Standards nach IAS und US-GAAP 2003 Overbeck, Ludger / Schmidt, Wolfgang Modeling Default Dependence with Threshold Models 2003 Balthasar, Daniel / Cremers, Heinz / Schmidt, Michael Portfoliooptimierung mit Hedge Fonds unter besonderer Berücksichtigung der Risikokomponente 2002 Heidorn, Thomas / Kantwill, Jens Eine empirische Analyse der Spreadunterschiede von Festsatzanleihen zu Floatern im Euroraum und deren Zusammenhang zum Preis eines Credit Default Swaps 2002 Böttcher, Henner / Seeger, Norbert Bilanzierung von Finanzderivaten nach HGB, EstG, IAS und US-GAAP 2003 Moormann, Jürgen Terminologie und Glossar der Bankinformatik 2002 Heidorn, Thomas Bewertung von Kreditprodukten und Credit Default Swaps 2001 35. Heidorn, Thomas / Weier, Sven Einführung in die fundamentale Aktienanalyse 2001 34. Seeger, Norbert International Accounting Standards (IAS) 2001 33. Moormann, Jürgen / Stehling, Frank Strategic Positioning of E-Commerce Business Models in the Portfolio of Corporate Banking 2001 32. Sokolovsky, Zbynek / Strohhecker, Jürgen Fit für den Euro, Simulationsbasierte Euro-Maßnahmenplanung für Dresdner-Bank-Geschäftsstellen 2001 Roßbach, Peter Behavioral Finance - Eine Alternative zur vorherrschenden Kapitalmarkttheorie? 2001 Heidorn, Thomas / Jaster, Oliver / Willeitner, Ulrich Event Risk Covenants 2001 40. 39. 38. 37. 36. 31. 30. Frankfurt School of Finance & Management Working Paper No. 192 29. Biswas, Rita / Löchel, Horst Recent Trends in U.S. and German Banking: Convergence or Divergence? 2001 28. Eberle, Günter Georg / Löchel, Horst Die Auswirkungen des Übergangs zum Kapitaldeckungsverfahren in der Rentenversicherung auf die Kapitalmärkte 2001 27. Heidorn, Thomas / Klein, Hans-Dieter / Siebrecht, Frank Economic Value Added zur Prognose der Performance europäischer Aktien 2000 Cremers, Heinz Konvergenz der binomialen Optionspreismodelle gegen das Modell von Black/Scholes/Merton 2000 Löchel, Horst Die ökonomischen Dimensionen der ‚New Economy‘ 2000 Frank, Axel / Moormann, Jürgen Grenzen des Outsourcing: Eine Exploration am Beispiel von Direktbanken 2000 23. Heidorn, Thomas / Schmidt, Peter / Seiler, Stefan Neue Möglichkeiten durch die Namensaktie 2000 22. Böger, Andreas / Heidorn, Thomas / Graf Waldstein, Philipp Hybrides Kernkapital für Kreditinstitute 2000 21. Heidorn, Thomas Entscheidungsorientierte Mindestmargenkalkulation 2000 20. Wolf, Birgit Die Eigenmittelkonzeption des § 10 KWG 2000 Cremers, Heinz / Robé, Sophie / Thiele, Dirk Beta als Risikomaß - Eine Untersuchung am europäischen Aktienmarkt 2000 Cremers, Heinz Optionspreisbestimmung 1999 Cremers, Heinz Value at Risk-Konzepte für Marktrisiken 1999 16. Chevalier, Pierre / Heidorn, Thomas / Rütze, Merle Gründung einer deutschen Strombörse für Elektrizitätsderivate 1999 15. Deister, Daniel / Ehrlicher, Sven / Heidorn, Thomas CatBonds 1999 14. Jochum, Eduard Hoshin Kanri / Management by Policy (MbP) 1999 13. Heidorn, Thomas Kreditderivate 1999 Heidorn, Thomas Kreditrisiko (CreditMetrics) 1999 Moormann, Jürgen Terminologie und Glossar der Bankinformatik 1999 10. Löchel, Horst The EMU and the Theory of Optimum Currency Areas 1998 09. Löchel, Horst Die Geldpolitik im Währungsraum des Euro 1998 08. Heidorn, Thomas / Hund, Jürgen Die Umstellung auf die Stückaktie für deutsche Aktiengesellschaften 1998 07. Moormann, Jürgen Stand und Perspektiven der Informationsverarbeitung in Banken 1998 Heidorn, Thomas / Schmidt, Wolfgang LIBOR in Arrears 1998 05. Jahresbericht 1997 1998 04. Ecker, Thomas / Moormann, Jürgen Die Bank als Betreiberin einer elektronischen Shopping-Mall 1997 03. Jahresbericht 1996 1997 02. Cremers, Heinz / Schwarz, Willi Interpolation of Discount Factors 1996 Moormann, Jürgen Lean Reporting und Führungsinformationssysteme bei deutschen Finanzdienstleistern 1995 26. 25. 24. 19. 18. 17. 12. 11. 06. 01. Frankfurt School of Finance & Management Working Paper No. 192 FRANKFURT SCHOOL / HFB – WORKING PAPER SERIES CENTRE FOR PRACTICAL QUANTITATIVE FINANCE No. Author/Title Year 33. Schmidt, Wolfgang Das Geschäft mit Derivaten und strukturierten Produkten: Welche Rolle spielt die Bank? 2012 32. Hübsch, Arnd / Walther, Ursula The impact of network inhomogeneities on contagion and system stability 2012 31. Scholz, Peter Size Matters! How Position Sizing Determines Risk and Return of Technical Timing Strategies 2012 30. Detering, Nils / Zhou, Qixiang / Wystup, Uwe Volatilität als Investment. Diversifikationseigenschaften von Volatilitätsstrategien 2012 29. Scholz, Peter / Walther, Ursula The Trend is not Your Friend! Why Empirical Timing Success is Determined by the Underlying’s Price Characteristics and Market Efficiency is Irrelevant 2011 28. Beyna, Ingo / Wystup, Uwe Characteristic Functions in the Cheyette Interest Rate Model 2011 27. Detering, Nils / Weber, Andreas / Wystup, Uwe Return distributions of equity-linked retirement plans 2010 26. Veiga, Carlos / Wystup, Uwe Ratings of Structured Products and Issuers’ Commitments 2010 25. Beyna, Ingo / Wystup, Uwe On the Calibration of the Cheyette. Interest Rate Model 2010 24. Scholz, Peter / Walther, Ursula Investment Certificates under German Taxation. Benefit or Burden for Structured Products’ Performance 2010 23. Esquível, Manuel L. / Veiga, Carlos / Wystup, Uwe Unifying Exotic Option Closed Formulas 2010 22. Packham, Natalie / Schlögl, Lutz / Schmidt, Wolfgang M. Credit gap risk in a first passage time model with jumps 2009 Packham, Natalie / Schlögl, Lutz / Schmidt, Wolfgang M. Credit dynamics in a first passage time model with jumps 2009 Reiswich, Dimitri / Wystup, Uwe FX Volatility Smile Construction 2009 Reiswich, Dimitri / Tompkins, Robert Potential PCA Interpretation Problems for Volatility Smile Dynamics 2009 18. Keller-Ressel, Martin / Kilin, Fiodar Forward-Start Options in the Barndorff-Nielsen-Shephard Model 2008 17. Griebsch, Susanne / Wystup, Uwe On the Valuation of Fader and Discrete Barrier Options in Heston’s Stochastic Volatility Model 2008 16. Veiga, Carlos / Wystup, Uwe Closed Formula for Options with Discrete Dividends and its Derivatives 2008 15. Packham, Natalie / Schmidt, Wolfgang Latin hypercube sampling with dependence and applications in finance 2008 Hakala, Jürgen / Wystup, Uwe FX Basket Options 2008 21. 20. 19. 14. 13. 12. 11. 10. Weber, Andreas / Wystup, Uwe Vergleich von Anlagestrategien bei Riesterrenten ohne Berücksichtigung von Gebühren. Eine Simulationsstudie zur Verteilung der Renditen 2008 Weber, Andreas / Wystup, Uwe Riesterrente im Vergleich. Eine Simulationsstudie zur Verteilung der Renditen 2008 Wystup, Uwe Vanna-Volga Pricing 2008 Wystup, Uwe Foreign Exchange Quanto Options 2008 Frankfurt School of Finance & Management Working Paper No. 192 09. Wystup, Uwe Foreign Exchange Symmetries 2008 08. Becker, Christoph / Wystup, Uwe Was kostet eine Garantie? Ein statistischer Vergleich der Rendite von langfristigen Anlagen 2008 07. Schmidt, Wolfgang Default Swaps and Hedging Credit Baskets 2007 Kilin, Fiodar Accelerating the Calibration of Stochastic Volatility Models 2007 Griebsch, Susanne/ Kühn, Christoph / Wystup, Uwe Instalment Options: A Closed-Form Solution and the Limiting Case 2007 Boenkost, Wolfram / Schmidt, Wolfgang M. Interest Rate Convexity and the Volatility Smile 2006 03. Becker, Christoph/ Wystup, Uwe On the Cost of Delayed Currency Fixing Announcements 2005 02. Boenkost, Wolfram / Schmidt, Wolfgang M. Cross currency swap valuation 2004 01. Wallner, Christian / Wystup, Uwe Efficient Computation of Option Price Sensitivities for Options of American Style 2004 06. 05. 04. HFB – SONDERARBEITSBERICHTE DER HFB - BUSINESS SCHOOL OF FINANCE & MANAGEMENT No. Author/Title Year 01. Nicole Kahmer / Jürgen Moormann Studie zur Ausrichtung von Banken an Kundenprozessen am Beispiel des Internet (Preis: € 120,--) 2003 Printed edition: € 25.00 + € 2.50 shipping Download: Working Paper: http://www.frankfurtschool.de/content/de/research/publications/list_of_publication/list_of_publication CPQF: http://www.frankfurt-school.de/content/de/cpqf/research_publications.html Order address / contact Frankfurt School of Finance & Management Sonnemannstr. 9 – 11 D – 60314 Frankfurt/M. Germany Phone: +49 (0) 69 154 008 – 734 Fax: +49 (0) 69 154 008 – 728 eMail: [email protected] Further information about Frankfurt School of Finance & Management may be obtained at: http://www.fs.de Frankfurt School of Finance & Management Working Paper No. 192