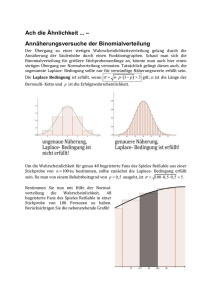
Skript - Hochschule Esslingen
Werbung

Statistik Dr. I. Fahrner basierend auf den Skripten von Prof. Dr. K. Melzer und Prof. Dr. P. Plappert [email protected] Contents 1 Einleitung und Übersicht 3 2 Datengewinnung (kurzer Überblick) 2.1 Planungsphase einer statistischen Untersuchung . . . . . . . . . . . . . . 2.1.1 Festlegung des Untersuchungsziels . . . . . . . . . . . . . . . . . 2.1.2 Festlegung der Grundgesamtheit und der statistischen Einheiten 2.1.3 Festlegung der zu erhebenden Merkmale . . . . . . . . . . . . . . 2.1.4 Festlegung von Art und Methode der Erhebung . . . . . . . . . . 2.2 Durchführung der Erhebung . . . . . . . . . . . . . . . . . . . . . . . . . 2.3 Datenbereinigung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.1 Behandlung von Ausreißern . . . . . . . . . . . . . . . . . . . . . 2.3.2 Behandlung fehlender Werte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 3 3 4 4 4 5 5 5 5 3 Beschreibende Statistik 3.1 Tabellarische und grafische Darstellung eines Merkmals . . . . . . . . . . . . . 3.1.1 Darstellung eines qualitativen Merkmals . . . . . . . . . . . . . . . . . . 3.1.2 Darstellung eines quantitativen Merkmals . . . . . . . . . . . . . . . . . 3.2 Statistische Kennzahlen für ein quantitatives Merkmal . . . . . . . . . . . . . . 3.2.1 Berechnung von Kennzahlen bei Vorliegen einer Messreihe . . . . . . . . 3.2.2 Berechnung von Kennzahlen bei Vorliegen einer Häufigkeitstabelle . . . 3.2.3 Kennzahlen bei Vorliegen einer Häufigkeitstabelle mit Klasseneinteilung 3.2.4 Verschiebung und Streckung . . . . . . . . . . . . . . . . . . . . . . . . . 3.3 Zusammenhang zwischen zwei quantitativen Merkmalen . . . . . . . . . . . . . 3.3.1 Grafische Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.2 Empirische Kovarianz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.3 Empirischer Korrelationskoeffizient . . . . . . . . . . . . . . . . . . . . . 3.3.4 Lineare Regression/Ausgleichsgerade . . . . . . . . . . . . . . . . . . . . 3.3.5 Bestimmtheitsmaß . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 6 6 7 7 7 8 9 9 9 9 10 10 11 11 4 Wahrscheinlichkeitsrechnung und Kombinatorik 4.1 Kombinatorik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Permutationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Die vier Grundaufgaben der Kombinatorik . . . . . . . . . . . . . . . . 4.2 Grundbegriffe der Wahrscheinlichkeitsrechnung . . . . . . . . . . . . . . . . . . 4.3 Berechnung von Wahrscheinlichkeiten . . . . . . . . . . . . . . . . . . . . . . . 4.3.1 Grundformel für Wahrscheinlichkeiten bei Laplace-Zufallsexperimenten 4.3.2 Gegenereignis und zusammengesetzte Ereignisse . . . . . . . . . . . . . 4.3.3 Wahrscheinlichkeiten zusammengesetzter Ereignisse . . . . . . . . . . . 4.3.4 Mehrstufige Zufallsexperimente . . . . . . . . . . . . . . . . . . . . . . . 4.4 Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4.1 Diskrete Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4.2 Kennzahlen von Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . 4.4.3 Verteilung, Verteilungsfunktion und Unabhängigkeit . . . . . . . . . . . 4.4.4 Stetige Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.4.5 Standardnomalverteilung Z ∼ N (0, 1) . . . . . . . . . . . . . . . . . . . 4.4.6 Summen von unabhängigen Zufallsvariablen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 11 12 13 13 14 14 14 15 15 16 16 17 18 19 19 20 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . CONTENTS 4.4.7 4.4.8 4.4.9 2 Approximation diskreter Verteilungen durch die Normalverteilung . . . . . . Quantile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Zufallsstreubereiche (ZSB) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Schließende Statistik 5.1 Punktschätzer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2 Vertrauensbereiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2.1 Konstruktion von Vertrauensbereichen . . . . . . . . . . . . . . . . . . . . 5.2.2 Tabellen für Vertrauensbereiche zur Vertrauenswahrscheinlichkeit 1 − α . Vertrauensbereich für µ bei bekannter Standardabweichung σ . . . . . . Vertrauensbereich für µ bei unbekannter Standardabweichung σ . . . . . Vertrauensbereich für die Differenz zweier Erwartungswerte µ1 − µ2 . . Vertrauensbereich für eine unbekannte Wahrscheinlichkeit p . . . . . . . 5.3 Hypothesentests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.1 Konstruktion von Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3.2 Generelles Vorgehen beim Testen von Hypothesen . . . . . . . . . . . . . 5.3.3 Tabellen für statistische Tests . . . . . . . . . . . . . . . . . . . . . . . . . Gauß-Test: Test für µ bei bekannter Standardabweichung σ . . . . . . . t-Test: Test für µ bei unbekannter Standardabweichung σ . . . . . . . . Zweistichproben-t-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . Test für eine unbekannte Wahrscheinlichkeit/einen unbekannten Anteil p 6 Statistische Methoden in der Qualitätssicherung 6.1 Qualitätsregelkarten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.1.1 Führen der Qualitätsregelkarte . . . . . . . . . . . . . . . . . . . . . . . 6.1.2 Berechnung der Eingriffsgrenzen . . . . . . . . . . . . . . . . . . . . . . 6.1.3 Grunderhebung (Vorlauf) zur Schätzung von µ und σ . . . . . . . . . . 6.2 Prozessfähigkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.3 Annahme-Stichprobenprüfung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.3.1 Allgemeines zur Annahme-Stichprobenprüfung . . . . . . . . . . . . . . 6.3.2 Ein AQL-Stichprobensystem . . . . . . . . . . . . . . . . . . . . . . . . 6.3.3 Ergänzungen zum Thema ”Annahme-Stichprobenprüfung” . . . . . . . 6.3.4 Übersichten und Tabellen zu den Normen MIL-STD-105E und DIN ISO Tabellen 21 21 22 . . . . . . . . . . . . . . . . 22 22 23 24 24 24 24 25 25 25 26 26 27 27 27 28 28 . . . . . . . . . . . . . . . . . . . . . . . . . . . 2859 28 29 29 30 30 31 32 32 33 34 35 . . . . . . . . . . . . . . . . 38 1 EINLEITUNG UND ÜBERSICHT 1 3 Einleitung und Übersicht Wichtiger Hinweis: Diese Dateien werden für Studierende ausschließlich zur Nutzung im Rahmen ihres Studiums an der Hochschule Esslingen bereitgestellt. Jede weitergehende Nutzung, insbesondere Vervielfältigung jeder Art oder Weitergabe an Dritte, ist untersagt. Die Statistik ist die Lehre von Methoden zum Umgang mit quantitativen Informationen. Sie befasst sich mit der Gewinnung, Darstellung und Auswertung von Daten. Ziel ist die Vorbereitung von Entscheidungen. In der Ökonometrie werden theoretische Modelle durch statistische Verfahren überprüft. Phasen einer statistischen Untersuchung und Kapitel der Vorlesung Planung ↓ Erhebung Datengewinnung (Kurzer Überblick in Kapitel 2) ↓ Bereinigung ↓ Darstellung (Kapitel 3: Beschreibende Statistik) ↓ Auswertung Analyse, Interpretation (Kapitel 5: Schließende Statistik) ↓ Entscheidung + Konsequenz Hilfsmittel für Kapitel 5: Kapitel 4 (Wahrscheinlichkeitsrechnung) Spezialfall der vorherigen Kapitel: Kapitel 6 (Statistische Methoden in der Qualitätssicherung) Beispiel: Von A nach B fahren zwei Züge mit je 200 Sitzplätzen. Eine Fahrgastzählung im Bahnhof A ergibt, dass 300 Personen die Züge benützen. Ergebnis der Umfrage: Es gibt mehr als ausreichend Sitzplätze, es kann sogar noch optimiert werden. Jedoch fahren 240 Personen in Zug 1 und 60 Personen in Zug 2. Eine Umfrage im Bahnhof B mit Frage ”War Ihr Zug überfüllt?” kommt zu dem Schluss, dass 240/300=80% aller Passagiere in überfüllten Zügen fahren müssen. Die Lokalzeitung formt dies in die sinnlose Schlagzeile ”4 von 5 Zügen überfüllt!” um (es gibt nur zwei Züge). Eine Kontrollumfrage durch ein zweites Institut (von einer anderen Stadt, stand im Stau und verpasst deswegen die Passagiere von Zug 1) ergibt, dass 0/60=0% der Passagiere in überfüllten Zügen sitzt. 2 2.1 Datengewinnung (kurzer Überblick) Planungsphase einer statistischen Untersuchung Überblick: 2.1.1 Festlegung 2.1.2 Festlegung 2.1.3 Festlegung 2.1.4 Festlegung 2.1.1 des Untersuchungsziels der Grundgesamtheit und der statistischen Einheiten der zu erhebenden Merkmale von Art und Methode der Erhebung Festlegung des Untersuchungsziels Fragen formulieren! 2 DATENGEWINNUNG (KURZER ÜBERBLICK) 2.1.2 4 Festlegung der Grundgesamtheit und der statistischen Einheiten Die zu untersuchende Grundgesamtheit muss präzise abgegrenzt werden in räumlicher, zeitlicher und sachlicher Hinsicht, d. h. es muss definiert werden, welche statistischen Einheiten (man sagt auch: ”Merkmalsträger” oder ”Objekte”) dazugehören und welche nicht. 2.1.3 Festlegung der zu erhebenden Merkmale Arten von Merkmalen und ihre möglichen Ausprägungen: 1. Quantitative Merkmale: • Die Ausprägungen sind Zahlen aus Messungen oder Zählungen. • Differenzen zwischen zwei Ausprägungen haben eine Bedeutung (z. B. ein Werkstück ist um 0, 3 mm länger als ein anderes). (a) Quantitativ-stetige Merkmale: • • • • Mögliche Ausprägungen sind alle Werte in einem Intervall. Stetige Merkmale treten vorzugsweise bei Messungen auf. Diese Merkmale besitzen meist einen Rundungsfehler. Beispiele: Länge, Gewicht, Temperatur, Geldbeträge in Euro (!). (b) Quantitativ-diskrete Merkmale: • • • • • Mögliche Werte sind nur einzelne Punkte auf dem Zahlenstrahl. Diskrete Merkmale treten vorzugsweise bei Zählungen auf. Es gibt keine Rundungsfehler. Als Ausprägungen sind dann nur 0, 1, 2, . . . möglich. Beispiel: Anzahl der Defektstücke in einer Lieferung. 2. Qualitative Merkmale: • Beschreiben Eigenschaften, die sich nicht durch Messen oder Zählen ermitteln lassen. • Können gelegentlich mit Hilfe von Zahlen codiert sein; dann haben aber die Differenzen der Codes keine Bedeutung. Z. B. bei Verschlüsselung 3 = ”gelb”, 6 = ”grün” ergibt es keinen Sinn zu sagen, Farbe ”grün” sei doppelt so groß wie Farbe ”gelb”. (a) Ordinale Merkmale: • Die Ausprägungen stehen in einer natürlichen Rangfolge. • Beispiel: Merkmal ”Interesse an Statistik-Vorlesung” mit Ausprägungen ”sehr groß” / ”groß” / ”mittel” / ”gering” / ”sehr gering”. (b) Nominale Merkmale: • Die Ausprägungen lassen sich nicht in eine Rangfolge bringen. • Beispiel: Merkmal ”Farbe”. 2.1.4 Festlegung von Art und Methode der Erhebung Arten von Erhebungen: • Totalerhebung (auch: ”Vollerhebung”) • Teilerhebung (Stichprobe) Einige wichtige Methoden zur Durchführung von Stichprobenuntersuchungen sind: • Reine Zufallsstichprobe • Systematische Auswahl, z. B. jeder hundertste produzierte Gegenstand • Schichtenstichprobe: Einteilung der Grundgesamtheit in Schichten, die bezüglich des Untersuchungsmerkmals möglichst homogen sind. Anschließend wird aus jeder Schicht eine bestimmte Anzahl von Stichprobenstücken gezogen. Der Anteil der in die Stichprobe aufgenommenen Objekte kann von Schicht zu Schicht unterschiedlich sein. 3 BESCHREIBENDE STATISTIK 5 • Klumpenstichprobe : Wenn sich die Grundgesamtheit in ”Klumpen” zerlegen lässt, die möglichst ähnlich wie Grundgesamtheit zusammengesetzt sind. Oft sind Klumpen geographisch definiert, z. B. Kreise, Stadtbezirke, Planquadrate, . . . Es werden gewisse Klumpen ausgewählt, für diese wird eine Vollerhebung erfasst. • Quotenverfahren: Durch Vorgabe von Quoten wird sichergestellt, dass die Stichprobe bei bestimmten Merkmalen wie z. B. Frau/Mann, Alter, Berufsgruppe, . . . die gleichen Anteile enthält wie die Grundgesamtheit → repräsentative Stichprobe 2.2 Durchführung der Erhebung Eine Erhebung wird technisch durchgeführt z. B. durch Befragung (Fragebogen, Internet, . . . ), Beobachtung oder Experiment. Die Nutzung von bereits vorhandenem (evtl. früher für andere Zwecke erhobenem) Datenmaterial bezeichnet man als ”Sekundärerhebung”. 2.3 2.3.1 Datenbereinigung Behandlung von Ausreißern Als ”Ausreißer” bezeichnet man Daten, die offenbar viel zu groß oder viel zu klein sind. Vorgehen: 1. Ausreißer identifizieren; 2. überprüfen, ggf. berichtigen; 3. wenn die Ausreißer nicht berichtigt werden können, (a) Datensatz streichen oder (b) fehlerhafte Daten abändern (z. B. Ersetzen durch den Mittelwert der nicht fraglichen Daten) oder (c) Datensatz unverändert beibehalten. Die Möglichkeiten 3(b) und 3(c) sollten nur mit größter Zurückhaltung angewendet werden. Im Zweifelsfall wende man Möglichkeit 3(a) an. Ähnlich wie bei Ausreißern geht man bei Werten vor, die zwar keine Ausreißer sind, die aber aus sonstigen Gründen unmöglich oder unplausibel sind. 2.3.2 Behandlung fehlender Werte Das Vorgehen bei fehlenden Werten entspricht sinngemäß dem bei Ausreißern: 1. Fehlende Werte identifizieren; 2. überprüfen, ggf. ergänzen; 3. wenn die fehlenden Werte nicht ergänzt werden können, (a) Datensatz streichen oder (b) einen Ersatzwert für die fehlende Daten berechnen (z. B. Mittelwert der nicht fehlenden Daten). Es ist wichtig, dass alle Phasen der Datengewinnung mit größter Sorgfalt durchgeführt werden. Im schlimmsten Fall können sonst die gewonnenen Daten nutzlos sein. 3 Beschreibende Statistik Ziel der beschreibenden Statistik Sachverhalte aufzeigen, die sonst nicht oder nicht so leicht ersichtlich wären. 3 BESCHREIBENDE STATISTIK 3.1 6 Tabellarische und grafische Darstellung eines Merkmals Vorbemerkung zur Objektivität bei Grafiken: Auch ein Diagramm muss die darzustellenden Größen objektiv wiedergeben. Hierzu gehören u. a. auch folgende Regeln, die hier aufgeführt werden, weil gegen sie besonders oft verstoßen wird: 1. Proportionalität von Fläche und darzustellendem Wert. Bei den meisten Diagrammtypen (z. B. den unten genannten: Kreisdiagramm, Säulendiagramm, Histogramm) müssen die Flächen im Diagramm proportional zu den darzustellenden Werten sein. Z. B. wäre es nicht korrekt, zwei Werte, von denen der zweite doppelt so groß ist wie der erste, grafisch durch zwei Quadrate wiederzugeben, von denen das zweite eine doppelt so große Seitenlänge wie das erste hat (denn die Fläche wäre dann viermal so groß wie die erste statt richtig doppelt so groß). 2. Skalierung der Achsen. Bei einem Säulendiagramm wird auf der y-Achse ein quantitatives Merkmal aufgetragen. Nach der Regel 1) oben müssen (bei konstanter Säulenbreite) die Höhen der Säulen proportional zu den darzustellenden Werten sein. Insbesondere darf daher die y-Achse nicht verzerrt sein und muss bei 0 beginnen. Sollte es ausnahmsweise erforderlich sein, die Achse nicht bei 0 beginnen zu lassen, muss dies deutlich kenntlich gemacht werden. Sinngemäß das gleiche gilt natürlich auch für die x-Achse (sofern hier ein quantitatives Merkmal aufgetragen wird) und für andere Diagrammtypen. Beispiel: Linke Grafik irreführend, rechte Grafik korrekt 3.1.1 Darstellung eines qualitativen Merkmals Es wird die Häufigkeit des Auftretens der verschiedenen Ausprägungen dargestellt. Hier gibt es u. a. folgende Möglichkeiten: • Häufigkeitstabelle. Wichtig: korrekte Beschriftung der Kopfzeile und der ersten Spalte; ggf. ist eine Summenzeile sinnvoll. Autofarbe Silber Weiß Rot Schwarz Summe • Säulendiagramm (auch: ”Stabdiagramm”). • Kreisdiagramm (auch: ”Tortendiagramm”). Anzahl 1800 900 200 1200 4100 3 BESCHREIBENDE STATISTIK 7 Achtung: Stellt man mehrere Datenreihen in je einem Kreisdiagramm dar, sollte die Fläche eines Kreises proportional zur Anzahl der dargestellten Datenwerte sein (d. h. der Radius eines Kreises proportional zur Wurzel aus der Anzahl der Datenwerte). Vgl. dazu oben Regel 1). 3.1.2 Darstellung eines quantitativen Merkmals • Bei einem diskreten Merkmal stehen grundsätzlich die gleichen Darstellungsmöglichkeiten wie bei einem qualitativen Merkmale zur Verfügung. • Bei einem stetigen Merkmal (oder bei einem diskreten Merkmal mit vielen Ausprägungen) müssen die Messwerte zunächst zu Klassen zusammengefasst werden. • Anschließend können die in Klassen eingeteilten Messwerte in einem Histogramm dargestellt werden. Histogramm = Säulendiagramm, bei dem die Säulen über den entsprechenden Klassenintervallen gezeichnet werden und daher an den Klassengrenzen aneinanderstoßen. • Folgende Regeln sind bei Histogrammen sinnvoll: – Klassen so wählen, dass keine Messwerte auf den Klassengrenzen liegen. – Gleiche Klassenbreite wählen, damit die Höhen der Säulen proportional zu den Häufigkeiten der Klassen sind. √ – Anzahl der Klassen k ≈ n , wobei n = Anzahl der Messwerte. Neben den in 3.1.1 und 3.1.2 genannten Diagrammtypen gibt es viele weitere Darstellungsmöglichkeiten, die je nach Ziel der statistischen Untersuchung ebenfalls sinnvoll oder sogar besser geeignet sein können. 3.2 Statistische Kennzahlen für ein quantitatives Merkmal Lagemaße: Geben an, wo die Messwerte im Mittel liegen, z. B. arithmetischer Mittelwert oder empirischer Median (Wo liegen die Daten? → Punkte) Streuungsmaße: Geben an, wie breit die Messwerte um den Mittelwert herum streuen, z. B. empirische Varianz, empirische Standardabweichung, Spannweite (Wie breit streuen die Daten? → Abstände) Ist die empirische Standardabweichung (bzw. empirische Varianz) klein, liegen also viele Messwerte in der Nähe des Mittelwertes. Ist sie groß, sind die Messwerte weiter vom Mittelwert entfernt. 3.2.1 Berechnung von Kennzahlen bei Vorliegen einer Messreihe Es ist eine Messreihe mit n Werten x1 , . . . , xn gegeben. Arithmetischer Mittelwert n 1 1X x = (x1 + x2 + · · · + xn ) = xi n n i=1 Empirische Varianz n 1 X 2 (xi − x) n − 1 i=1 " n ! # X 1 2 2 = xi − n · x n−1 i=1 s2 = 3 BESCHREIBENDE STATISTIK 8 Empirische Standardabweichung v u n √ u 1 X 2 2 s= s =t (xi − x) n − 1 i=1 v " n ! # u X u 1 2 2 t = xi − n · x . n−1 i=1 Die empirische Varianz gibt also die mittlere quadratische Abweichung von x an. Die zweite Formel für s2 ist einfacher anzuwenden; hier muss man aber x mit großer Genauigkeit berechnen! Die empirische Standardabweichung hat dieselbe Dimension wie die gegebenen Messwerte. Sind beispielsweise die Messwerte in der Einheit ”Gramm” angegeben, so gilt die empirische Standardabweichung auch die Einheit ”Gramm”. Nur in Ausnahmefällen wird man die Berechnung von x, s2 oder s tatsächlich mit den oben genannten Formeln durchführen. Viel kürzer ist es, die Datenreihe x1 , x2 , . . . , xn nur ein einziges Mal in den Taschenrechner (TR) einzugeben und anschließend sowohl x als auch s über die eingebauten TR-Funktionen abzurufen. Dabei ist die empirische Standardabweichung s auf dem TR oft mit dem Symbol σn−1 oder gelegentlich mit σx,n−1 o. ä. bezeichnet. (Die empirische Varianz erhält man dann, indem man den mit σn−1 abgerufenen Wert quadriert.) Beachten Sie hierzu ggf. auch die auf der Internetseite von Prof. Plappert bereitgestellten Taschenrechner-Bedienungsanleitungen. Für diese Bedienungsanleitungen wird keine Gewähr übernommen! Daher bitte anhand von Beispielen überprüfen. Empirischer Median Spannweite 3.2.2 x̃ = Messwert, der bei Sortierung der Messreihe nach der Größe in der Mitte steht (bei gerader Anzahl von Messwerten: arithmetisches Mittel der beiden Messwerte in der Mitte). R = größter Messwert − kleinster Messwert = xmax − xmin Berechnung von Kennzahlen bei Vorliegen einer Häufigkeitstabelle Es liegen Messwerte x1 , x2 , . . . , xk mit zugehörigen Häufigkeiten f1 , f2 , . . . , fk vor (Der Messwert Pk x1 wurde f1 -mal beobachtet, der Messwert x2 wurde f2 -mal beobachtet usw.). Es sei n = i=1 fi die Summe aller Häufigkeiten = Gesamtzahl aller Messungen. Merkmal x1 x2 .. . xk Summe Anzahl f1 f2 .. . fk n In den Formeln für x bzw. s müssen hier alle Summanden mit der jeweiligen Häufigkeit gewichtet (= multipliziert) werden. k 1X Arithmetischer Mittelwert x= fi · xi n i=1 k 1 X 2 2 Empirische Varianz s = fi · (xi − x) oder n − 1 i=1 " k ! # X 1 s2 = fi · x2i − n · x2 n−1 i=1 √ Empirische Standardabweichung s = s2 Die zweite Formel für s2 ist einfacher anzuwenden; hier muss man aber x mit großer Genauigkeit berechnen! Auch die Kennzahlen zu 3.2.2 kann man am kürzesten mit Hilfe der eingebauten TRFunktionen erledigen. Leider ist die Art der Dateneingabe der Häufigkeiten f1 , f2 , . . . bei verschiedenen TR-Typen unterschiedlich. 3 BESCHREIBENDE STATISTIK 3.2.3 9 Kennzahlen bei Vorliegen einer Häufigkeitstabelle mit Klasseneinteilung Es ist eine Häufigkeitstabelle (z. B. entstanden durch Klasseneinteilung eines stetigen Merkmals) gegeben. Es seien P k = Anzahl der Klassen, fi = Häufigkeit der i-ten Klasse, mi = Mittelpunkt der k i-ten Klasse, n = i=1 fi die Summe aller Häufigkeiten. Hier rechnet man so, als ob alle Messwerte in der Mitte der jeweiligen Klasse liegen, und verwendet dann die 3.2.2 entsprechenden Formeln, wobei nur xi durch mi ersetzt werden muss. k 1X x= Arithmetischer Mittelwert fi · mi n i=1 k 1 X 2 fi · (mi − x) oder Empirische Varianz s2 = n − 1 i=1 " k ! # X 1 2 2 2 s = fi · mi − n · x n−1 i=1 √ Empirische Standardabweichung s = s2 Die zweite Formel für s2 ist einfacher anzuwenden; hier muss man aber x mit großer Genauigkeit berechnen! 3.2.4 Verschiebung und Streckung Wie verhalten sich die Lagemaße x̃, x und die Streuungsmaße R, s, wenn man alle Messwerte um einen Wert b verschiebt oder mit einem Faktor a streckt? Maß/ Datensatz Median Mittelwert Spannweite Standardabweichung xi x̃ x R s xi + b x̃ + b x+b R s a · xi a · x̃ a·x a·R a·s Streuungsmaße reagieren also nicht auf Verschiebung. 3.3 Zusammenhang zwischen zwei quantitativen Merkmalen Werden an jedem Untersuchungsobjekt gleichzeitig zwei Merkmale gemessen, so erhält man eine Messreihe aus n Wertepaaren (x1 ; y1 ), (x2 ; y2 ), . . . , (xn ; yn ). 3.3.1 Grafische Darstellung Streudiagramm (Scatterplot) → ”Punktewolke” (hier mit Korrelation −0, 2, +0, 66, −0, 8 und +0, 99) Zwei Fragen sind von Interesse: 3 BESCHREIBENDE STATISTIK 10 • Kann man den Grad der Abhängigkeit zwischen den Zufallsgrößen durch eine geeignete Kennzahl ”quantifizieren” ; Korrelationsrechnung • Kann man einen (näherungsweisen) funktionalen Zusammenhang zwischen X und Y mathematisch formulieren ; Regressionsrechnung (Empirische) Regression bedeutet: eine Gerade oder eine Kurve ”möglichst gut” durch eine gegebene ”Punktewolke” legen. Im Falle einer Geraden spricht man von ”linearer Regression”, sonst von ”nichtlinearer Regression” (z. B. von ”quadratischer Regression”, wenn die Regressionskurve eine quadratische Parabel ist). 3.3.2 Empirische Kovarianz Wir definieren " Empirische Varianz der x-Werte 1 s2x = n−1 " Empirische Varianz der y-Werte 1 s2y = n−1 sx = Empirische Kovarianz sxy = ! x2i # − n · x2 i=1 p s2x Empirische Standardabweichungen n X 1 n−1 n X ! yi2 # −n·y 2 i=1 q , sy = s2y # " n ! X xi · yi − n · x · y oder i=1 n X (xi − x) · (yi − y) 1 n − 1 i=1 Beschreibt die Stärke und Richtung des linearen Zusammenhangs. sxy = 3.3.3 Empirischer Korrelationskoeffizient Zusätzliche Skalierung liefert den Empirischer Korrelationskoeffizient n X rxy ! xi · yi − n · x · y sxy i=1 v =v = ! ! u n u n sx · sy u X u X t x2 − n · x2 · t y2 − n · y2 i i=1 i i=1 • Werte von r: −1 ≤ rxy ≤ 1 • Linearer Zusammenhang spiegelt sich in der Aussage ”Je größer x, desto [größer/kleiner] ist tendenziell y”. • Falls |r| ≈ 1 , gibt es einen starken linearen Zusammenhang. (Aber nicht unbedingt einen ursächlichen Zusammenhang zwischen den x- und y-Werten!) • Falls r ≈ 0, gibt es keinen linearen Zusammenhang. (Aber in manchen Fällen einen Zusammenhang anderer Art, z. B. quadratisch!) • Falls r > 0, steigt die ”beste Gerade”, falls r < 0 fällt sie. • rxy = 1: alle Punkte (xi ; yi ) liegen auf einer Geraden mit positiver Steigung • rxy = −1: alle Punkte (xi ; yi ) liegen auf einer Geraden mit negativer Steigung rxy > 0: positive (gleichsinnige) Korrelation; großen Werten entsprechen überwiegend große Werte rxy < 0: negative (gegensinnige) Korrelation; großen Werten entsprechen überwiegend kleine Werte rxy ≈ 0: unkorreliert 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 3.3.4 11 Lineare Regression/Ausgleichsgerade • Gegeben: Stichprobe mit n Datenpunkten (x1 ; y1 ), (x2 ; y2 ), . . . , (xn ; yn ). Dabei wird angenommen, dass nur die y-Werte größeren (z. B. zufälligen) Schwankungen unterliegen können und die x-Werte fest (oder sehr genau bestimmbar) sind. • Gesucht: ”Beste Gerade” durch die zugehörige (xi | yi )-Punktwolke • Der y-Wert der Regressionsgeraden bei xi wird mit ŷi bezeichnet, ri = yi −ŷi heißt ”Residuum”. • Methode der kleinsten Quadrate (MKQ): n X ri2 soll minimal werden. i=1 • Die MKQ führt zu folgender Gleichung der empirischen Regressionsgeraden: ! n X xi · yi − n · x · y sxy i=1 ! und k =y−m·x y = mx + k mit m= 2 = n X sx 2 2 xi − n · x i=1 3.3.5 Bestimmtheitsmaß Für alle Regressionstypen (auch quadratische usw.) wird als Gütemaß das Bestimmtheitsmaß R2 verwendet, d. h. wie gut die Gerade/Kurve die Punktwolke beschreibt (nicht verwechseln mit der Spannweite R einer Messreihe!) Für das Bestimmtheitsmaß R2 gilt a) 0 ≤ R2 ≤ 1 b) Falls R2 ≈ 1 verläuft die Regressionsgerade (oder -kurve) gut durch die ”Punktewolke”. Falls R2 ≈ 0 gibt die Regressionsgerade (oder -kurve) die ”Punktewolke” nicht gut wieder. c) R2 beschreibt den Anteil an der Varianz der y-Werte, der durch die Regression erklärt werden kann. 2 Während a), b), c) auch für nichtlineare Regressionen gelten, ist die Gleichung R2 = rxy nur im Falle der linearen Regression richtig. (Der empirische Korrelationskoeffizient r bezieht sich nämlich ausschließlich auf die lineare Regression.) Bemerkung zur Berechnung von m und rxy bei linearer Regression Viele TR haben eine eingebaute Berechnungsmöglichkeit für die Parameter m und k der empirischen Regressionsgeraden und für den empirischen Korrelationskoeffizienten rxy nach Eingabe aller x- und y-Werte. Wer einen Taschenrechner besitzt, bei dem das so nicht möglich ist, benutzt am besten das gezeigte Berechnungsschema. Die angegebenen Formeln sind für die Berechnung ”von Hand” – also wenn im TR Regression und Korrelation nicht implementiert sind – am einfachsten anzuwenden. Bei der Berechnung von m und r müssen x und y aber mit großer Genauigkeit bestimmt werden! 4 Wahrscheinlichkeitsrechnung und Kombinatorik 4.1 Kombinatorik Die ”Lehre vom Abzählen” heißt Kombinatorik. Sie hat die Grundoperationen: • Anordnen der Elemente einer Menge (; Permutationen) • Auswählen einer Teilmenge aus einer Grundmenge (”Ziehen”) 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 12 Permutationen 1. Permutation ohne Wiederholung: Gegeben: n verschiedene Elemente. Wie viele Möglichkeiten gibt es, n Objekte anzuordnen? Für den ersten Platz gibt es n Objekte, für den zweiten n − 1 usw., also: Anzahl an Möglichkeiten (alle) n Elemente in eine Reihenfolge zu bringen: n! := n · (n − 1) · · · 2 · 1 (lies: ”n Fakultät”) Per Definition ist 0! = 1 (Definition) und die Berechnung mit dem Taschenrechner ist bis mindestens 69! möglich. 2. Permutation mit Wiederholung: Gegeben: n Elemente, davon k rot und n − k schwarz. Führt man eine künstliche Nummerierung durch, so gibt es n! ”nummerierte” Permutationen. Permutiert man innerhalb der roten oder der schwarzen Elemente, so ändert sich die ”unnumerierte” Permutation nicht. Für die roten Elemente gibt es k! Permutationen, für die schwarzen (n−k)!, also insgesamt gibt es zu jeder Permutation ohne Wiederholung k!·(n−k)! ”numerierte” Permutationen. Folglich gilt für die Anzahl der Permutuation mit Wiederholung n n! := k!(n − k)! k (lies: ”n über k”, Binomialkoeffizient) Wenn k klein ist, kürzt man (n−k)!. Im Zähler bleiben dann die k Zahlen n, n−1, . . . , n−k+1 und im Nenner die Zahlen k, k − 1, . . . , 1. 17 17 · 16 · 15 · (14)! 17 · 16 · 15 Beispiel: = = = 680; 3 3 · 2 · 1 · (14)! 3·2·1 hier stehen jeweils k = 3 Faktoren in Zähler (17 · 16 · 15) und im Nenner (3 · 2 · 1). n n n Es gilt: nk = n−k , 0 = nn = 1 und nk + k+1 = n+1 k+1 und somit das Pascaldreieck 1 1 1 1 1 1 2 3 4 1 3 6 1 4 1 Allgemein: Unter den n Elementen gibt es aber nur k verschiedene Elemente mit Anzahlen n1 , . . . , nk . D. h. von Objekt 1 gibt es n1 (gleiche) Exemplare, von Objekt 2 gibt es n2 (gleiche) Exemplare, . . . von Objekt k gibt es nk (gleiche) Exemplare. Auf wie viele Arten kann man die n = n1 + n2 + · · · + nk Objekte anordnen? Anzahl Möglichkeiten, diese n Elemente in eine Reihenfolge zu bringen: n! n1 ! · n2 ! · · · nk ! Bemerkung: • Für große Werte von n näherungsweise mit der Formel von Stirling: n 1 lg(n!) ≈ lg(2πn) + n lg 2 e hier bezeichnet lg den Logarithmus zur Basis 10 (Taschenrechner: Taste <LOG >). Berechnung von nk : • Wenn n und k groß sind, kann man die Formel n lg = lg(n!) − lg(k!) − lg ((n − k)!) k verwenden und anschließend die Stirling-Formel benutzen. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 13 Die vier Grundaufgaben der Kombinatorik Aus n verschiedenen Objekten werden k ausgewählt. Wie viele Möglichkeiten gibt es? Die Antwort auf diese Frage hängt davon ab, • ob die Reihenfolge des Auswählens eine Rolle spielt (”geordnet”, ”mit Beachtung der Reihenfolge”) oder nicht (”ungeordnet”, ”ohne Beachtung der Reihenfolge”); • ob ein Objekt mehrfach ausgewählt werden darf (”mit Wiederholung”, ”Ziehen mit Zurücklegen”) oder nicht. Stichprobenauswahl/Ziehe k aus n geordnet/mit Beachtung der Reihenfolge ungeordnet/ohne Beachtung der Reihenfolge n+k−1 k mit Mehrfachbesetzung n! (n − k)! n k ohne Mehrfachbesetzung mit unterscheidbaren Kugeln nicht unterscheidbare Kugeln Verteilen von k Kugeln auf n Zellen mit Zurücklegen n ohne Zurücklegen k Links oben: Für jedes Objekt/Kugel gibt es n Möglichkeiten/Zellen, also n · n · n · · · n = nk . Links unten: Für 1. Objekt/Kugel gibt es n Möglichkeiten/Zellen, für 2. Objekt/Kugel gibt es n − 1 Möglichkeiten/Zellen also n · (n − 1) · (n − 2) · · · (n − k + 1) = n!/(n − k)!. (Taschenrechner: nPr) Rechts unten: Jede ungeordnete Reihenfolge/Belegung kann mit einer künstlichen Nummerierung n n! /k! = k!-mal permutiert werden, also . (Taschenrechner: nCr) (n − k)! k Rechts oben (schwierig): Jede Verteilung kann grafisch durch eine Folge von ∗ für die Kugeln und | für die Zellen dargestellt werden (z. B. steht | ∗ ∗|| ∗ | für 2 Kugeln in der ersten Zelle, 0 in der zweiten und 1 in der dritten). Links und rechts steht ein |, dazwischen gibt es n − 1 + k Plätze für n − 1 Zellwände und k Kugeln. Aus diesen ziehen wir ohne Zurücklegen und ohne Reihenfolge k Plätze für die Kugeln, also gibt es n+k−1 Möglichkeiten. k Für die Stichprobe steht ∗ für ein Objekt und jedes | vor einem Objekt für einen Zug (also | ∗ ∗||∗ bedeutet, dass das 1. Objekt einmal gezogen wurde, das 2. Objekt gar nicht und das dritte zweimal). Die Sequenz endet mit ∗, davor gibt es n − 1 Plätze für die restlichen Objekte und k Plätze für die Züge, die man ungeordnet ohne Zurücklegen zieht, also gibt es n+k−1 Möglichkeiten. k 4.2 Grundbegriffe der Wahrscheinlichkeitsrechnung Zufallsexperiment: ein (prinzipiell) beliebig oft wiederholbares Experiment, dessen Ergebnis aufgrund von Zufallseinflüssen nicht vorhersehbar ist. Realisierung eines Zufallsexperiments: das Ergebnis der tatsächlichen Durchführung eines Zufallsexperiments. Ergebnisraum Ω: umfasst alle möglichen Ergebnisse eines Zufallsexperiments. Bsp: Münzwurf: Ω = {Kopf, Zahl} oder Ω = {Kopf, Zahl, Rand, Münze zerbricht}; Würfel: Ω = {1, 2, 3, 4, 5, 6} Ereignis: Teilmenge von Ω, enthält ein Ergebnis oder mehrere Ergebnisse, oder auch alle Ergebnisse oder gar kein Ergebnis. Bsp: Augenzahl gerade beim Würfel: A = {2, 4, 6} Wahrscheinlichkeit P(A) eines Ereignisses A: beschreibt, wie groß die Chance des Eintretens von A ist. Relative Häufigkeit eines Ereignisses A: Wird ein Zufallsexperiment n-mal realisiert, und tritt dabei das Ereignis A genau k-mal ein, so heißt hn (A) = k/n die relative Häufigkeit von A. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 14 Zusammenhang und Unterschied zwischen relativer Häufigkeit und Wahrscheinlichkeit: • Die Wahrscheinlichkeit P(A) ist eine (mathematische) Konstante. Die relative Häufigkeit hn (A) hingegen hängt von Zufall (von der konkreten Realisierung) ab. • Im Allgemeinen ist daher P(A) 6= hn (A). Es gilt aber das Gesetz der großen Zahlen: limn→∞ hn (A) = P(A). • Wenn man P(A) nicht ausrechnen kann, aber eine Realisierung des Zufallsexperiments vom Umfang n vorliegen hat, kann man P(A) unter Benutzung von hn (A) schätzen; siehe Kapitel 5. Nach dem Gesetz der großen Zahlen wird diese Schätzung um so besser sein, je größer n ist. • Eine Definition von Wahrscheinlichkeit: Wahrscheinlichkeiten sind Voraussagen für relative Häufigkeiten des Eintretens von Ereignissen auf lange Sicht (für den Grenzfall einer gegen Unendlich strebenden Anzahl von Versuchsdurchführungen). Schranken für Wahrscheinlichkeiten: • Es gilt 0 ≤ P(A) ≤ 1. • P(A) = 0 gilt für ein unmögliches Ereignis. Beispiel Würfelwurf: A = ”Augenzahl größer als 7”; hier ist P(A) = 0. • P(A) = 1 gilt für ein mit Sicherheit eintretendes Ereignis. Beispiel Würfelwurf: A = ”Augenzahl kleiner als 7”; hier ist P(A) = 1. • A ⊆ B impliziert P(A) ≤ P(B). 4.3 4.3.1 Berechnung von Wahrscheinlichkeiten Grundformel für Wahrscheinlichkeiten bei Laplace-Zufallsexperimenten Ein Laplace-Zufallsexperimenten liegt vor, falls die beiden folgenden Bedingungen erfüllt sind: 1. Bei dem Zufallsexperiment sind nur endlich viele Ergebnisse möglich. 2. Alle Ergebnisse in Ω sind gleich wahrscheinlich. Es gilt dann P(A) = Anzahl der Ergebnisse in A |A| = |Ω| Anzahl aller möglichen Ergebnisse Falls eine dieser beiden Bedingungen nicht erfüllt ist, also wenn Ω unendlich viele Elemente enthält oder wenn es in Ω Ergebnisse mit unterschiedlichen Wahrscheinlichkeiten gibt, muss man die Methoden aus Kapitel 5 anwenden, um P(A) zu schätzen. Beispiel: Faire Münze mit Ω = {Kopf, Zahl} und P(Kopf) = P(Zahl) = 1/2 ist Laplace-Zufallsexperiment, aber die Modellierung Ω = {Kopf, Zahl, Rand, Münze zerbricht} mit P(Kopf) = P(Zahl) = 1/2 und P(Rand) = P(Münze zerbricht) = 0 nicht. Unfaire Münze mit Ω = {Kopf, Zahl} und P(Kopf) = 0, 4; P(Zahl) = 0, 6 ist kein LaplaceZufallsexperiment Für die Berechnung von P(A) unter der Laplace-Annahme muss man in der Lage sein, |A| auszurechnen, also die in einem Ereignis enthaltenen Ergebnisse abzuzählen ; Kombinatorik. 4.3.2 Gegenereignis und zusammengesetzte Ereignisse Man kann Ereignisse miteinander verknüpfen, um andere/komplexere Ereignisse zu erhalten. A und B seien Ereignisse. A = ”nicht A” = Ω\A = A tritt nicht ein = Gegenereignis von A A ∪ B = ”A oder B” = A tritt eine oder B tritt ein oder beide treten ein = ”oder-Ereignis” A ∩ B = ”A und B” = A und B treten beide ein = sowohl A als auch B tritt ein = ”und-Ereignis” 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 15 Beispiel: Ein Würfel wird zweimal geworfen, A sei das Ereignis ”im ersten Wurf eine 6”, B sei das Ereignis ”im zweiten Wurf eine 6”. A = ”im ersten Wurf keine 6”, d. h. im ersten Wurf eine 1, 2, 3, 4 oder 5. A ∪ B = ”im ersten oder im zweiten Wurf (oder in beiden) eine 6” = mindestens eine 6. A ∩ B = ”im ersten und im zweiten Wurf eine 6” = zwei Sechsen. Hier gilt: P(A) = P(B) = 1/6, P(A) = 5/6, P(A ∪ B) = 11/36, P(A ∩ B) = 1/36. Formeln von de Morgan: A ∪ B = A ∩ B und A ∩ B = A ∪ B. Auch nützlich: A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C) und A ∪ (B ∩ C) = (A ∪ B) ∩ (A ∪ C) 4.3.3 Wahrscheinlichkeiten zusammengesetzter Ereignisse • Wahrscheinlichkeit des Gegenereignisses A von A: P(A) = 1 − P(A) • P(A ∪ B) - Berechnung mit dem Additionssatz: P(A ∪ B) = P(A) + P(B) − P(A ∩ B) – Additionssatz allgemein: P(A ∪ B) = P(A) + P(B) – Additionssatz für unvereinbare Ereignisse: Falls A und B nicht beide eintreten können, so heißen A und B unvereinbar (A und B schließen sich gegenseitig aus), dann ist A∩B = ∅. Nur in diesem Spezialfall (A und B können nicht beide eintreten) gilt dann also der Additionssatz in der Form P(A ∪ B) = P(A) + P(B) . • P(A ∩ B) - Berechnung mit dem Multiplikationssatz: – Multiplikationssatz allgemein: P(A ∩ B) = P(A) · P(B|A)[= P(B) · P(A|B)] – Multiplikationssatz für unabhängige Ereignisse: P(A ∩ B) = P(A) · P(B) Dabei ist P(A|B) = P(A ∩ B) P(B) (lies: ”Wahrscheinlichkeit von A unter der Bedingung B”) die (bedingte) Wahrscheinlichkeit, dass A eintritt, wenn sicher ist, dass B eintritt bzw. eingetreten ist. Wenn sich zwei Ereignisse (definitiv) nicht beeinflussen, spricht man von unabhängigen Ereignissen, dann gilt P(A|B) = P(A). Die Kenntnis von B verändert dann nicht die Wahrscheinlichkeit für A. Beispiel: Ein Würfel wird zweimal so geworfen (Ω = {(1, 1), . . . , (6, 6)}), dass zunächst nur der Werfer die Ergebnisse sieht. Für A = { im zweiten Wurf eine 6 } gilt P(A) = 6/36 = 1/6. Der Werfer verrät, dass G = { der zweite Wurf war höher wie der erste } eingetreten ist. Somit können die Elemente von A ∩ G nicht mehr eintreten, die neue Grundgesamtheit ist G: P(A|G) = P(A ∩ G) 5 1 = = . P(G) 15 3 Verrät der Werfer hingegen nur, dass B = { im ersten Wurf eine 3 }, so gilt P(A|B) = 1/6 = P(A). Wir erhalten keine zusätzliche Information, da die Würfe unabhängig sind. 4.3.4 Mehrstufige Zufallsexperimente Wir betrachten Zufallsexperimente, die sich aus 2 Einzelversuchen aufbauen lassen, die nacheinander oder gleichzeitig durchgeführt werden. Zur Beschreibung solcher zusammengesetzter Zufallsexperimente eignen sich Baumdiagramme oder Wahrscheinlichkeitsbäume. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK P(B|A) A∩B A P(A) P(B|A) A∩B P(B|A) A∩B Ω P(A) A P(B|A) Knoten Pfade ... ... A∩B 16 Berechnung von Wahrscheinlichkeiten im Baumdiagramm: • Wahrscheinlichkeit eines Pfades = Produkt der Wahrscheinlichkeiten längs des Pfades (Multiplikationsregel oder Pfadregel). ”Entlang der Pfade wird multipliziert” • Wahrscheinlichkeit für ein Ereignis = Summe der Wahrscheinlichkeiten aller zu diesem Ereignis führenden Pfade (Additionsregel oder Summenregel). ”Entlang der Äste wird addiert” (zufällige) Ereignisse (bedingte) Wahrscheinlichkeiten auftragen, Die Summe der Wahrscheinlichkeiten aller Verzweigungen ist gleich Eins. Oft sind bedingte Wahrscheinlichkeiten P(B|A) und P(B|A) gegeben und man möchte P(B) wissen. Es gilt: B = B ∩ Ω = B ∩ (A ∪ A) = (B ∩ A) ∪ (B ∩ A) unvereinbare Zerlegung, und somit P(B) = P(B ∩ A) + P(B ∩ A) = P(A) · P(B|A) + P(A) · P(B|A) 4.4 (Satz der totalen Wahrscheinlichkeit) Zufallsvariablen Eine Zufallsvariable X beschreibt, welche Ausprägungen eines quantitativen Merkmals in einem Zufallsexperiment auftreten können. Beispiel: X = Augenzahl beim Würfeln (kann Werte 1, 2, 3, 4, 5, 6 annehmen) D = Anzahl Defektstücke unter 100 Stück (kann Werte 0, 1, . . . , 100 annehmen) Xi = Bilanzgewinn im Jahr i Mit Zufallsvariablen kann man rechnen: X2016 + X2017 = Bilanzgewinn über zwei Jahre. Bei einer Reduktion des Geschäfts um 10% in 2017 erhält man X2016 + 0.9 · X2017 u. s. w. 4.4.1 Diskrete Zufallsvariablen Bei einem diskreten Merkmal spricht man von einer diskreten Zufallsvariable. Da mit X auch aX + b eine Zufallsvariable ist (oder auch eine andere Transformation), reicht es als Wertebereich N0 = {0, 1, 2, 3, . . . } zu betrachten. Kennt man pk = P(X = k) für alle k ∈ N0 , so lässt sich die Wahrscheinlichkeit für jedes Ereignis P∞ durch Aufsummieren bilden. {pk } heißt Zähldichte. Es gilt pk ≥ 0 und k=0 pk = 1. Beispiele: 1. X heißt Bernoulliverteilt mit Parameter p ∈ [0, 1], wenn P(X = 1) = p und P(X = 0) = 1 − p. Z. B. Qualitätskontrolle bei einer Kontrolle, defekt/nicht defekt 2. X die Augenzahl beim Würfel, Gleichverteilung mit P(X = k) = 1/6 für k = 1, . . . , 6. 3. Binomialverteilung, X ∼ B(n; p). Ein Bernoulliexperiment wird n-mal durchgeführt und X = X1 + · · · + Xn , d. h. die Anzahl der Einsen in den n Experimenten Bsp.: Anzahl Defektstücke unter n / Ziehen mit Zurücklegen bei N Kugeln mit M roten und N − M schwarzen und X = Anzahl der roten Kugeln bei n Zügen. Hier ist dann p = M/N n k P(X = k) = p (1 − p)n−k , k = 0, 1, . . . , n. k 4. Hypergeometrische Verteilung, X ∼ H(n; N ; M ) Ziehen ohne Zurücklegen bei N Kugeln mit M roten und N − M schwarzen und X = Anzahl der roten Kugeln bei n Zügen. M N −M k n−k , k = 0, 1, . . . , min{n, M } P(X = k) = N n 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 17 Bem: Ist N groß und n/N ≤ 0.1, so gilt H(n; N ; M ) ≈ B(n; M/N ). Beispiel: Die Anzahl der Fische in einem See soll geschätzt werden. Dazu werden 1000 Fische gefangen, mit einem roten Punkt markiert und wieder frei gelassen. Am nächsten Tag werden wieder 1000 Fische gefangen. 100 haben einen roten Punkt. Es gibt also mindestens 1900 Fische, allerdings ist es sehr unwahrscheinlich dann unter 1000 gefangenen 100 mit rotem Punkt zu sehen. Ist N die Anzahl der Fische im See, so gilt für die Anzahl X der Fische mit rotem Punkt unter 1000 gefangenen X ∼ H(1000; N ; 1000) und 1000 N −1000 100 P(X = 100) = 900 N 1000 =: P (N ). P (1900) ist eine sehr kleine Zahl mit ca. 430 Nullen nach dem Komma. Als Schätzer für N nimmt man denjenigen Wert von N , der P (N ) maximiert. Betrachtet man ( (N − 1000)2 > 1 N < 10000 P (N ) , = ··· = P (N − 1) N (N − 1900) < 1 N > 10000 so sieht man, dass N = 10000 Fische der ”Maximum Likelihood Schätzer” ist. Es gilt dann P (10000) ≈ 4.2%. 5. Die Poissonverteilung, X ∼ Po(λ) ist die Verteilung seltener Ereignisse mit P(X = k) = λk −λ e , k! k = 0, 1, . . . Dabei ist λ die mittlere Anzahl von Vorkommnissen in einer Zeit/Flächeneinheit und X die tatsächliche Anzahl der Vorkommnisse in einer Zeit/Flächeneinheit. Bem: Für n ≥ 30 und p ≤ 0, 1 gilt B(n; p) ≈ Po(n · p). Bsp: Warteschlange λ = 1 Kunde pro Minute Bem: λ skaliert mit der Zeit/Flächenenheit, z. B. λ = 60 Kunden pro Stunde. 6. Geometrische Verteilung X ∼ Geo(p). Ein Experiment gelingt mit Wahrscheinlichkeit p. X = Anzahl der Durchführungen bis zum ersten Erfolg P(X = k) = p(1 − p)k−1 , k = 1, 2, . . . Übung: Gedächtnislosigkeit der geometrischen Verteilung: Ein Student zählt die benötigten Würfe eines Würfels bis zum ersten Erscheinen einer 6. Für die Anzahl X gilt X ∼ Geo(1/6). Nach 10 Würfen ist noch immer keine 6 erschienen. Gilt jetzt immer noch X ∼ Geo(1/6)? Anwort: Ja, denn es gilt mit k0 = 10 P(X = k + k0 | X > k0 ) = P(X = k) für alle k, d. h. die zusätzliche Information ändert nicht die Zähldichte. Rechnung: P(X = k+k0 | X > k0 ) = P({X = k + k0 } ∩ {X > k0 }) P(X = k + k0 ) p(1 − p)k+k0 −1 = = = p(1−p)k−1 , P(X > k0 ) P(X > k0 ) (1 − p)k0 da ∞ X P(X > k0 ) = k−1 p(1 − p) = p(1 − p) k0 k=k0 +1 4.4.2 ∞ X (1 − p)k = p(1 − p)k0 k=0 Kennzahlen von Zufallsvariablen Für eine diskrete Zufallsvariable definieren wir Erwartungswert µ = E[X] = ∞ X k · P(X = k) k=0 ∞ X m-tes Moment E[X m ] = Varianz Var[X] = E[X 2 ] − µ2 p σ = Var[X] k=0 Standardabweichung k m · P(X = k) 1 . 1 − (1 − p) 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 18 µ ist ein Lagemaß und σ ein Streuungsmaß. Bei Verschiebung und Streckung der Zufallsvariablen gilt für Zahlen a, b E[aX + b] = aE[X] + b Var[aX + b] = a2 Var[X]. Sind X1 , . . . , Xn unabhängige Realisationen mit gleicher Verteilung wie X, so gilt nach dem Gesetz der großen Zahlen n x= 1X Xk → E[X] n s→σ und für n → ∞. k=1 x und s sind also Schätzer für µ und σ. Das Gesetz der großen Zahlen kann auch so geschrieben werden: Pn k=1 Xk ≈ nE[X] für große n. Beispiel: Beim Würfel gilt E[X] = (1 + 2 + · · · + 6)/6 = 7/2 und Var[X] = 35/12 und damit s ≈ 1, 71. Nach 10 Würfen wird die Augensumme ”in der Nähe von” 35 sein. Übersicht diskreter Verteilungen Name Bernoulli Kurz Dichte p1 = p, p0 = 1 − p Binomial B(n; p) pk = n k p (1 − p)n−k k k = 0, 1, . . . , n Hypergeometrisch H(n; N ; M ) Poisson Po(λ) Geometrisch 4.4.3 Geo(p) µ p N −M n−k pk = N n k = 0, 1, . . . , min{n, M } pk = M k n·p s2 p(1 − p) n · p · (1 − p) M n· N M n· N λk −λ e , k = 0, 1, . . . k! λ λ k−1 1 p 1 p pk = p(1 − p) , k = 1, 2, . . . M N −n 1− N N −1 1 −1 p Verteilung, Verteilungsfunktion und Unabhängigkeit Unter der Verteilung verstehen wir die Zuordnung von Wahrscheinlichkeiten zu (allen) Ereignissen. Die speziellen Ereignisse {X ≤ x} ergeben die Verteilungsfunktion F (x) = P(X ≤ x) für x ∈ IR. Dies ist eine rechtsseitig stetige, monoton wachsende Funktion mit F (−∞) = 0 und F (∞) = 1. Wegen der unvereinbaren Zerlegung {X ≤ k} = {X ≤ k − 1} ∪ {X = k} gilt P(X = k) = P(X ≤ k) − P(X ≤ k − 1) = F (k) − F (k − 1). Die Zähldichte lässt sich also aus der Verteilungfunktion gewinnen. F ist eine Treppenfunktion, d. h. zwischen k − 1 und k ist sie konstant, bei k springt sie um P(X = k). Allgemein gilt: P(X ≤ a) = F (a) P(a < X ≤ b) = P(X ≤ b) − P(X ≤ a) = F (b) − F (a) P(X > a) = 1 − P(X ≤ a) = 1 − F (a). Zwei Zufallszahlen sind unabhängig, wenn P({X ≤ k} ∩ {Y ≤ j}) = P(X ≤ k)P(Y ≤ j) für alle k, j gilt. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 4.4.4 19 Stetige Zufallsvariablen Stetige quantitative Merkmale nehmen jeden konkreten Wert mit Wahrscheinlichkeit 0 an: P(X = x) = 0 für jedes x. Anstelle der Zähldichte tritt hier eine Dichtefunktion Z ∞ f (x) ≥ 0 mit f (x)dx = 1, −∞ Rb Summen werden durch Integrale a f (x)dx ersetzt, die für die durch die Geraden x = a, x = b der x-Achse und der Kurve f (x) gegebenen Fläche stehen. Die Verteilungsfunktion ist gegeben durch Z b f (x)dx F (b) = P(X ≤ b) = −∞ Wie für diskrete Zufallsvariablen gilt F (−∞) = 0, F (∞) = 1 und F ist monoton wachsend, hat aber für stetige Zufallsvariablen keine Sprünge sondern ist stetig und sogar differenzierbar. Es gilt ∂ F (x). f (x) = F 0 (x) = ∂x Wie bei diskreten Zufallsvariablen definieren wir Z ∞ µ = E[X] = x · f (x)dx Z ∞−∞ E[X m ] = xm · f (x)dx Erwartungswert m-tes Moment −∞ Var[X] = E[X 2 ] − µ2 p σ = Var[X] Varianz Standardabweichung µ ist wieder ein Lagemaß und σ ein Streuungsmaß mit E[aX + b] = aE[X] + b und Var[aX + b] = a2 Var[X]. Beispiele: 1. Gleichverteilung auf [0, 1], X ∼ U [0, 1]. Hier ist f (x) = 1 für x ∈ [0, 1], ansonsten f (x) = 0. Es gilt F (x) = x für x ∈ [0, 1] und µ = 1/2 und σ 2 = 1/12. 2. Die Exponentialverteilung X ∼ Exp(λ) ist die stetige Version der geometrischen Verteilung mit F (x) = 1 − e−λx für x ≥ 0, f (x) = λe−λx für x ≥ 0, µ = 1/λ und Var[X] = 1/λ2 . Die Exponentialverteilung ist auch gedächtnislos, denn P(X > x) = 1 − F (x) = e−λx und somit P(X > x + x0 | X > x0 ) = P (X > x + x0 ) e−λ(x+x0 ) = = e−λx . P (X > x0 ) e−λx0 Sie dient zur Modellierung von Lebensdauern von Glühbirnen, Bauteilen etc. 3. Normalverteilung X ∼ N (µ, σ 2 ). Diese Verteilung hat zwei Parameter, die identisch zum Erwartungswert und zur Varianz sind: E[X] = µ, Var[X] = σ 2 . (Vorsicht: Manchmal wird als zweiter Parameter die Standardabweichung anstelle der Varianz benutzt.) Für die Dichte gilt (Gaußsche Glockenkurve) 1 x − µ 2 − 1 σ f (x) = √ e 2 , x ∈ IR. 2πσ 2 Eigenschaften: Achsensymmetrie zu x = µ, Wendepunkte bei µ ± σ. 4.4.5 Standardnomalverteilung Z ∼ N (0, 1) Für die speziellen Parameter µ = 0 und σ 2 = 1 wird die Verteilungsfunktion mit Φ(z) = P(Z ≤ z), z ∈ IR bezeichnet und ist für z ≥ 0 tabelliert, siehe Anhang im Skript. Aufgrund Symmetrie in der Dichte gilt Φ(−z) = 1 − Φ(z), z ∈ IR, so dass für alle z ∈ IR die Verteilungsfunktion tabelliert vorliegt. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 20 Standardisierung Ist X ∼ N (µ, σ 2 ), so ist (Verschiebung/Streckung von EW und Varianz) Z= X −µ ∼ N (0, 1) σ und umgekehrt, wenn Z ∼ N (0, 1), so ist X = σZ + µ ∼ N (µ, σ 2 ). Damit ergibt sich x − µ X − µ x − µ x − µ =P Z≤ =Φ ≤ P(X ≤ x) = P σ σ σ σ und analog b − µ a − µ P(a ≤ X ≤ b) = Φ −Φ σ σ a − µ P(X > a) = 1 − Φ σ wobei ≤ durch < und > durch ≥ ersetzt werden darf (wegen P(X = a) = 0). n − σ Regeln Für Z ∼ N (0, 1) gilt aufgrund Symmetrie für z > 0 P(−z < Z ≤ z) = P(Z ≤ z) − P(Z ≤ −z) = Φ(z) − Φ(−z) = 2Φ(z) − 1. Damit z 1 2 3 4.4.6 Φ(z) 0.8413 0.9772 0.9987 2Φ(z) − 1 68.26% 95.44% 99.74% Regel 2/3 Wkt.masse in [µ − σ, µ + σ] 95% Wkt.masse in [µ − 2σ, µ + 2σ] 99% Wkt.masse in [µ − 3σ, µ + 3σ] Summen von unabhängigen Zufallsvariablen Für zwei Zufallsvariablen X1 und X2 gilt allgemein E[X1 + X2 ] = E[X1 ] + E[X2 ]. Sind X1 ∼ N (µ1 , σ12 ) und X2 ∼ N (µ2 , σ22 ) unabhängig (!!!), so sind X1 + X2 und X1 − X2 auch normalverteilt: X1 + X2 ∼ N µ1 + µ2 , σ12 + σ22 X1 − X2 ∼ N µ1 − µ2 , σ12 + σ22 Allgemein: Sind X1 , X2 , . . . , Xn unabhängig mit der gleichen Normalverteilung N (µ, σ 2 ), so gilt für die Summe Sn = X1 + X2 + · · · + Xn ∼ N nµ; nσ 2 X1 + X2 + · · · + Xn σ2 ∼ N µ; für den arithmetischen Mittelwert X = n n Sn − nµ √ für die skalierte Summe ∼ N (0, 1) σ n Zentraler Grenzwertsatz – Summen von nicht normalverteilten Zufallsvariablen Sind X1 , X2 , . . . unabhängige Zufallsvariablen mit derselben Verteilung mit Erwartungswert µ und Varianz σ 2 , so gilt mit Sn = X1 + · · · + Xn Sn − nµ √ ≈ N (0, 1) σ n für große n. Insbesondere bedeutet das, dass eine Summe vieler unabhängiger Größen näherungsweise normalverteilt ist, selbst wenn die einzelnen Summanden nicht normalverteilt sind. Typische Anwendung: Messfehler/Produktionsabweichungen bestehen aus einer Summe von unbestimmbaren Fehlern, sind also normalverteilt. 4 WAHRSCHEINLICHKEITSRECHNUNG UND KOMBINATORIK 4.4.7 21 Approximation diskreter Verteilungen durch die Normalverteilung Die Binomialverteilung ergibt sich als Summe von Bernoulliexperimenten, lässt sich also durch die Normalverteilung approximieren. Dies ist auch der Fall für die Hypergeometrische Verteilung und die Poissonverteilung. Eine Faustregel lautet, dass dies in Ordnung ist, falls σ 2 ≥ 9. Als Parameter wählt man Verteilung µ σ2 X ∼ B(n, p) np np(1 − p) X ∼ H(n, N, M ) n X ∼ Po(λ) λ M N n M N − n M 1− N N N −1 Voraussetzung neben σ 2 ≥ 9 n/N ≤ 0.1 λ Hier sind zwei Dinge zu beachten: 1. Die Normalverteilung besitzt auf ganz IR Wahrscheinlichkeitsmasse. Somit darf auf den Bereichen {X < 0} oder {X > n} nicht approximiert werden. (Man würde sonst eine positive Wahrscheinlichkeit bekommen!) 2. Stetigkeitskorrektur: Wird eine diskrete Zufallsvariable X, die nur ganzzahlige Werte annehmen kann, durch eine Normalverteilung N (µ; σ 2 ) approximiert, sollten Wahrscheinlichkeiten mit den Formeln b − µ +0, 5 a − µ −0, 5 P(a ≤ X ≤ b) ≈ Φ −Φ σ σ b − µ +0, 5 P(X ≤ b) ≈ Φ σ a − µ −0, 5 P(a ≤ X) = P(X ≥ a) ≈ 1 − Φ σ berechnet werden. Achtung: Bei diesen Formeln darf ”≤” nicht durch ”<” ersetzt werden. a und b sind ganze Zahlen ≥ 0 und ≤ min{n, M }. Beispiel: Berechnen Sie P(9 ≤ X ≤ 11) für X ∼ B(1000, 1%). Genaue Rechnung ergibt: P(9 ≤ X ≤ 11) = P(X = 9) + P(X = 10) + P(X = 11) ≈ 0.125613 + 0.125740 + 0.114309 ≈ 36.56% Approximation ergibt µ = 10 und σ 2 = 9.9 > 9, somit 11 − 10 + 0.5 9 − 10 − 0.5 √ √ −Φ . P(9 ≤ X ≤ 11) ≈ Φ 9.9 9.9 Das Argument ist ca. ±0.48 (Symmetrie!) und aus der Tabelle liest man Φ(0.48) = 0, 6844, somit erhält man als Approximation 36.88%. Eine genauere Rechnung (mit Excel, genauere Tabelle) ergibt als Approximation 36.64%. Ohne Stetigkeitskorrektur würde man den ungenauen Wert 24.93% bekommen. 4.4.8 Quantile Die Verteilungfunktion F (x) gibt die Wahrscheinlichkeitsmasse links von x an. Quantile sind hierzu die Umkehrung: Für α ∈ (0, 1) heißt die (größte) Zahl q mit F (q) = P(X ≤ q) = α das α-Quantil. Sie gibt den Ort an, so dass links davon die Wahrscheinlichkeitsmasse α liegt. Für die Standardnormalverteilung schreiben wir zα für diese Zahl q. Die wichtigsten Quantile sind in einer Tabelle im Anhang des Skriptes angegeben. In EXCEL steht der Befehl NORMINV zur Verfügung. 5 SCHLIEßENDE STATISTIK 22 Beispiel: z0.99 = 2.326, d. h. P(Z ≤ 2.326) = 0.99 Für eine allgemeine Normalverteilung werden die Quantile mit qα bezeichnet. Mit den Formeln für die Standardisierung gilt qα = σ · zα + µ. Die Symmetrie der Standardnormalverteilung ergibt: zα = −z1−α . 4.4.9 Zufallsstreubereiche (ZSB) Zufallsstreubereich oder Prognoseintervall einer normalverteilten Zufallsvariable X: ein Intervall um den Erwartungswert µ, in dem sich die Ausprägungen von X mit einer Wahrscheinlichkeit p (z. B. p = 90%, 98%, 99%) befinden. Die Ausprägungen von X befinden sich außerhalb des Zufallsstreubereiches mit einer Wahrscheinlichkeit von α = 1 − p. Zufallsstreubereiche für eine normalverteilte Zufallsvariable X ∼ N (µ; σ 2 ): Zweiseitig q α2 ; q1− α2 = µ − z1− α2 · σ ; µ + z1− α2 · σ Einseitig nach oben beschränkt (−∞ ; q1−α ] = (−∞ ; µ + z1−α · σ] Einseitig nach unten beschränkt [qα ; ∞) = [µ − z1−α · σ ; ∞) Für einen zweiseitigen Zufallsstreubereich benötigt man das z1− α2 -Quantil der Normalverteilung, z. B. also für einen zweiseitigen 99%-Zufallsstreubereich z0,995 = 2, 576. Wegen zα = −z1−α genügt es, eine Tabelle mit Quantilen der Standardnormalverteilung für ”hohe” Wahrscheinlichkeiten (> 0, 5) zu haben. Pn Besonders wichtig sind ZSB für das arithmetische Mittel X = n1 k=1 Xk . Sind Xk ∼ N (µ, σ 2 ) unabhängig, so gilt X ∼ N (µ, σ 2 /n) und es ergeben sich folgende ZSB: σ σ Zweiseitig = µ − z1− α2 · √ ; µ + z1− α2 · √ n n σ Einseitig nach oben beschränkt = −∞ ; µ + z1−α · √ n σ Einseitig nach unten beschränkt = µ − z1−α · √ ; ∞ n Bsp: Gegeben eine Stichprobe vom Umfang 16 eine Standardnormalverteilung. Wo wird mit 99% Wahrscheinlichkeit X liegen? Wir wissen X ∼ N (0, 1/16) und somit liegt X mit 99% Wahrscheinlichkeit im Intervall [−2.576/4, 2.576/4] = [−0.644, 0.644]. 5 5.1 Schließende Statistik Punktschätzer Für eine Zufallsvariable X ist oft ist der Verteilungstyp bekannt, aber die entsprechenden Parameter nicht. Beispiele: Anwendung Eigenschaft Verteilung zu schätzende Parameter Lebensdauer Gedächtnislosigkeit Exponentialverteilung λ Messfehler, Produktionsfehler, ... ZGWS Normalverteilung µ, σ Bernoulli-Schema Erfolg – Misserfolg Bernoulli-/ Binomialverteilung p (bzw. µ = np) seltene Ereignisse Skalierung Poissonverteilung λ Aus einer Stichprobe X1 , X2 , . . . , Xn vom Umfang n sollen diese Parameter geschätzt werden 1 Pn (Punktschätzung), z. B. µ̂ = Xi . n i=1 5 SCHLIEßENDE STATISTIK 23 Wünschenswerte Eigenschaften eines Schätzers Tn für einen Parameter θ: 1. Tn soll im Wertebereich von θ liegen (z. B. keine negativen Zahlen für Wahrscheinlichkeiten oder Varianz) 2. Für wachsende Stichprobe soll der Schätzer sich dem Parameter annähern, Tn → θ (n → ∞) (Konsistenz) 3. Erwartungstreue: E[Tn ] = θ. Bsp.: E[s2 ] = σ 2 (daher auch die n − 1 im Zähler) 4. Suffizienz: Die gesamte Information der Stichprobe über den Parameter sollte verwendet werden. P Bsp.: n2 2i≤n X2i (nur jeder zweite Wert) ist auch ein Schätzer für µ, aber schlechter als µ̂. 5. Optimalität: Varianz sollte möglichst gering sein 6. (Approximative) Normalverteilung von Tn : erlaubt die Angabe von (approximativen) Zufallsstreubereichen. Wichtige Methoden zur Gewinnung von Schätzern: 1. Momentenmethode: Das Gesetz der großen Zahlen besagt, dass das m-te Stichprobenmoment Pn 1 m gegen das m-te Moment E[X m ] für n → ∞ konvergiert. Lassen sich die Parameter X i=1 i n aus den Momenten berechnen, so kann man diese mit den Stichprobenmomenten schätzen und bekommt P daraus Schätzer für die Parameter. 2 n 2 Bsp.: n1 ist der Momentenschätzer für σ 2 . Er ist nicht erwartungstreu, i=1 Xi − nX P 2 n 1 2 . deswegen verwenden wir s2 = n−1 i=1 Xi − nX 2. Maximum Likelihood: Man berechnet in Abhängigkeit der Parameter die Wahrscheinlichkeit für das Auftreten der beobachteten Stichprobe und wählt die Parameter so, dass diese Wahrscheinlichkeit maximiert wird, vgl. Fischbeispiel. Wichtige Beispiele: Unbekannter Parameter Punktschätzer Wahrscheinlichkeit p eines Ereignisses p̂ = nk (relative Häufigkeit, d. h. bei der Stichprobe vom Umfang n trat das gesuchte Ereignis k-mal auf) Erwartungswert µ µ̂ = x (arithmetischer Mittelwert der Stichprobe) Varianz σ 2 σˆ2 = s2 (empirische Varianz der Stichprobe) Standardabweichung σ σ̂ = s (empirische Standardabweichung der Stichprobe) Man wird versuchen, die möglichen Abweichungen zwischen dem geschätzten Wert und dem unbekannten wahren Wert zu quantifizieren. Dazu wird man z. B. für den Fall einer unbekannten Wahrscheinlichkeit p Fragen wie die folgenden stellen: 1. Kann man einen Bereich angeben, in dem p liegen kann, etwa in der Form ”p liegt im Intervall [0, 63; 0, 67]”? ; Vertrauensbereiche, Abschnitt 5.2 2. Kann man bestimmte Werte von p ausschließen, z. B. kann man ausschließen, dass gilt p ≤ 0, 5? ; Tests, Abschnitt 5.3 5.2 Vertrauensbereiche Bei Zufallsstreubereichen waren die Parameter (z. B. µ) bekannt und man hat einen Bereich angegeben, in dem X mit hoher Wahrscheinlichkeit liegt. Vertrauensbereiche sind Intervallschätzer für die unbekannten Parameter, d. h. hier ist X gegeben und gesucht ist ein Zufalls-Intervall (in Abhängigkeit von X), das µ mit hoher Wahrscheinlichkeit überdeckt. Der Zufallsstreubereich und der Vertrauensbereich haben unterschiedliche Mittelpunkte, nämlich µ und X, aber die gleiche Länge. 5 SCHLIEßENDE STATISTIK 5.2.1 24 Konstruktion von Vertrauensbereichen Bei vorliegender Stichprobe X1 , . . . Xn , sucht man eine Pivotgröße, 1. deren Verteilung (Quantile) bekannt ist und 2. die man nach dem gesuchten Parameter auflösen kann. Beispiele: 1. Normalverteilung mit bekannter Varianz σ 2 und unbekanntem Mittelwert µ. 2 Wir wissen X ∼ N (µ, σn ), d. h. (Standardisierung) X − µ√ Pivotgröße: Z = n ∼ N (0, 1). Aus σ P (−z1−α/2 ≤ Z ≤ z1−α/2 ) = 1 − α (symmetrisches Intervall ist das kürzeste!) ergibt sich durch Auflösen σ σ P (X − z1−α/2 √ ≤ µ ≤ X + z1−α/2 √ ) = 1 − α n n und ”µ liegt mit Wahrscheinlichkeit 1 − α im Intervall [X − z1−α/2 √σn ; X + z1−α/2 √σn ]”. 2. Normalverteilung mit unbekannter Varianz σ 2 und unbekanntem Mittelwert µ. Wir verwenden s2 als Schätzer für die unbekannte Varianz σ 2 . X − µ√ Pivotgröße: T = n s T besitzt eine t-Verteilung mit n − 1 Freiheitsgraden, T ∼ tn−1 . Die Quantile der t-Verteilung sind tabelliert, siehe Ende des Skripts. Sie sind breiter, als bei der Normalverteilung (weniger Information) und konvergieren gegen diese für große n (wenn man ”mehr” Information hat). X − Y − µ1 + µ2 eine sd t-Verteilung mit m + n − 2 Freiheitsgraden. (Definition sd siehe unten) 3. Für den Fall der Differenz zweier Normalverteilungen besitzt W = 4. Zählt X das Eintreten eines konkreten Eregnisses, so ist X ∼ B(n; p). Durch Approximation X −p √ X − np = pn n ≈ N (0, 1). mit der Normalverteilung entsteht eine Pivotgröße p np(1 − p) p(1 − p) 5.2.2 Tabellen für Vertrauensbereiche zur Vertrauenswahrscheinlichkeit 1 − α 1. Vertrauensbereich für µ bei bekannter Standardabweichung σ zum Vertrauensniveau 1 − α Der Vertrauensbereich wird auf Basis einer Stichprobe x1 , x2 , . . . , xn berechnet, deren arithmetischer Mittelwert x ist. Art des Vertrauensbereichs zweiseitig einseitig nach unten begrenzt einseitig nach oben begrenzt Vertrauensbereich für µ h x − z1− α2 · h √σ n ; x + z1− α2 · x − z1−α · √σ n ; ∞ −∞ ; x + z1−α · √σ n i √σ n i 2. Vertrauensbereich für µ bei unbekannter Standardabweichung σ zum Vertrauensniveau 1 − α Der Vertrauensbereich wird auf Basis einer Stichprobe x1 , x2 , . . . , xn berechnet, deren arithmetischer Mittelwert x und deren empirische Standardabweichung s ist. 5 SCHLIEßENDE STATISTIK Art des Vertrauensbereichs zweiseitig einseitig nach unten begrenzt einseitig nach oben begrenzt 25 Vertrauensbereich für µ h x − tn−1;1− α2 · √s n ; x + tn−1;1− α2 · h x − tn−1;1−α · √s n ; ∞ −∞ ; x + tn−1;1−α · √s n i √s n i tn−1;1−α : (1 − α)-Quantil der t-Verteilung mit n − 1 Freiheitsgraden 3. Vertrauensbereich für die Differenz zweier Erwartungswerte µ1 − µ2 zum Vertrauensniveau 1−α Es werden zwei Stichproben vom Umfang m und n mit den arithmetischen Mitteln x und y und mit den empirischen Standardabweichungen s1 und s2 gezogen. r q m+n 2 2 Berechne zunächst die Hilfsgröße sd = (m − 1) · s1 + (n − 1) · s2 · m · n · (m + n − 2) Art des Vertrauensbereichs zweiseitig Vertrauensbereich für µ1 − µ2 x − y − tm+n−2;1− α2 · sd ; x − y + tm+n−2;1− α2 · sd einseitig nach unten begrenzt [x − y − tm+n−2;1−α · sd ; ∞) einseitig nach oben begrenzt (−∞ ; x − y + tm+n−2;1−α · sd ] 4. Vertrauensbereich für eine unbekannte Wahrscheinlichkeit/einen unbekannten Anteil p einer Grundgesamtheit zum Vertrauensniveau 1 − α Tritt bei einer Stichprobe vom Umfang n das gesuchte Ereignis k-mal auf, verwendet man als Punktschätzer für die unbekannte Wahrscheinlichkeit die relative Häufigkeit p̂ = k n Der Vertrauensbereich zum Vertrauensniveau 1 − α berechnet sich dann als Vertrauensbereich für p Art des Vertrauensbereichs zweiseitig einseitig nach unten begrenzt q p̂) p̂ − z1− α2 · p̂·(1− − n 0,5 n q p̂) p̂ − z1−α · p̂·(1− − n einseitig nach oben begrenzt 5.3 ; p̂ + z 1− α 2 0 ; p̂ + z1−α · q · 0,5 n p̂·(1−p̂) n + q p̂·(1−p̂) n + 0,5 n ; 1 0,5 n Hypothesentests Beispiel: Eine Maschine stellt Glasscheiben her. Im Mittel entstehen 10 Bläschen pro m2 . Beschreibt die Zufallsvariable X die Anzahl der Bläschen auf 1m2 , so gilt X ∼ Po(λ) mit λ = 10. Der Produktiosleiter ändert die Arbeitsweise der Maschine und behauptet, dass es jetzt weniger Bläschen gibt, dass nun also λ < 10. Wie lässt sich dies überprüfen? Statistische Hypothese: Annahme über die Verteilung einer Zufallsvariablen. Ist die Verteilung vollständig bestimmt, so heißt die Hypothese einfach, ansonsten zusammengesetzt. 5 SCHLIEßENDE STATISTIK 26 Beispiel: Bei der Poissonverteilung: λ = 10 einfache Hypothese, λ < 10 oder λ 6= 10 sind zusammengesetzte Hypothesen. Die Hypothese, die man bestätigen will, bezeichnet man mit H1 , das ”Gegenteil” mit H0 , im Beispiel also: H0 : λ ≥ 10 vs. H1 : λ < 10. (Statistischer) Test: Regel, ob aufgrund einer Stichprobe H0 verworfen/abgelehnt wird oder nicht. H0 wird verworfen, wenn die Stichprobe in einem kritischen Bereich liegt. Bemerkung: Wird H0 abgelehnt, so gilt H1 als statistisch nachgewiesen (was man gerne möchte). Wird H0 nicht abgelehnt, so muss H0 nicht gelten, kann aber auch nicht ausgeschlossen werden. Mögliche Fehler bei statistischen Tests H0 wird nicht verworfen H0 wird verworfen H0 trifft zu Richtige Entscheidung Fehler 1. Art (α-Fehler) Wahrscheinlichkeit: höchstens α H1 trifft zu Fehler 2. Art (β-Fehler) Wahrscheinlichkeit: β Richtige Entscheidung α ist die Wahrscheinlichkeit, dass man H0 verwirft, obwohl es zutrifft (Irrtumswahrscheinlichkeit). Es wird als kleiner Wert vorgegeben. Falls H0 verworfen wird, sagt man auch, H1 sei ”signifikant” bei Signifikanzniveau α. Lautet die Regel ”H0 nie verwerfen” (leerer kritischer Bereich), so ist α = 0, aber dies ist nicht sinnvoll, da dann der Fehler 2. Art groß ist. Ziel ist es, Tests so zu konstruieren, dass bei gegebenem Signifikanzniveau der Fehler 2. Art möglichst klein wird (; optimale Tests) 5.3.1 Konstruktion von Tests Gauß-Test: Testet man ausgehend von einer Normalverteilung mit bekannter Varianz σ 2 die Hypothese H0 : µ = µ0 vs. H1 : µ 6= µ0 , so wissen wir, dass für eine Stichprobe unter H0 X ∼ N (µ0 ; σ 2 /n) gilt und (vgl. Abschnitt 4.4.9) σ σ P X 6∈ [µ0 − z1−α/2 · √ , µ0 + z1−α/2 · √ ] ≤ α. n n Liegt also X weiter als z1−α/2 · √σn von µ0 entfernt, so sollte H0 verworfen werden. Die Irrtumswahrscheinlichkeit ist kleiner als α. Man kann zeigen, dass dieser Test optimal ist. Für die anderen Fällen verwendet man analoge Teststatistiken wie bei den Vertrauensbereichen (Abschnitt 5.2.1). 5.3.2 Generelles Vorgehen beim Testen von Hypothesen 1. Hypothesen aufstellen (s.u.) 2. Signifikanzniveau α festlegen, z. B. α = 0, 05, α = 0, 01 oder α = 0, 001. 3. Berechnung des Zufallsstreubereichs (nach Tabelle) Falls H0 zutrifft, sollte die Teststatistik mit großer Wahrscheinlichkeit 1 − α in diesem Zufallsstreubereich liegen. 4. Berechnung der Teststatistik aus der Stichprobe Teststatistiken: x bzw. x − y bzw. nk 5. Testentscheidung: Teststatistik ∈ ZSB (=Annahmebereich) =⇒ H0 kann nicht verworfen werden/wird beibehalten Teststatistik ∈ / ZSB =⇒ H0 wird (zu Gunsten von H1 ) verworfen/abgelehnt 6. Antwortsatz d. h. ”Übersetzen” der Testentscheidung in das konkrete Anwendungsproblem 5 SCHLIEßENDE STATISTIK 27 Falls die Stichprobendaten der Nullhypothese nicht widersprechen, braucht man den ZSB nicht zu berechnen; z. B. wenn die Nullhypothese H0 : λ ≥ 10 lautet und x = 10, 7 ist. In einem solchen Fall wird die Nullhypothese nie verworfen; λ ≥ 10 kann natürlich nicht ausgeschlossen werden. Ergänzung: Aufstellen der Hypothesen für Parametertests H0 beinhaltet den für den unbekannten Parameter auszuschließenden Wert (bzw. die auszuschließenden Werte), H1 das ”Gegenteil” von H0 , also die zu bestätigenden Werte. Beispiele für Signalwörter im Text: . . . gleich . . . = . . . ungleich, weicht ab, . . . 6= . . . höchstens, nicht mehr als . . . ≤ . . . größer, mehr als, . . . > . . . mindestens, nicht weniger als . . . ≥ . . . kleiner, weniger als, . . . < H0 H1 H0 immer = , ≤ oder ≥ (”. . . gleich” steht vorne) H1 immer = 6 , < oder >. 5.3.3 Tabellen für statistische Tests Allgemeiner Hinweis zu den Tabellen auf den folgenden Seiten: Bei den zweiseitigen Tests ist das 1 − α2 -Quantil der Normalverteilung (bzw. t-Verteilung) zu benutzen. Ist zum Beispiel α = 5%, so muss bei der Normalverteilung das Quantil z1− α2 = z0,975 = 1, 96 benutzt werden. 1. Gauß-Test: Test für µ bei bekannter Standardabweichung σ zum Signifikanzniveau α Test (zum Signifikanzniveau α) einer Nullhypothese über den unbekannten Erwartungswert µ, z. B. (erster Eintrag in der Tabelle) die Hypothese, dass µ gleich einer vorgegebenen festen Zahl µ0 (etwa einem Sollwert oder dem bisherigen Wert) ist. Gegeben: Stichprobe x1 , x2 , . . . , xn . Die Messwerte sind Realisierungen von n unabhängigen N (µ, σ 2 )- verteilten Zufallsvariablen mit unbekanntem Erwartungswert µ, aber bekannter Varianz σ 2 . H0 H1 µ = µ0 µ 6= µ0 µ ≥ µ0 µ < µ0 µ ≤ µ0 µ > µ0 Zufallsstreubereich für X, falls H0 zutrifft σ σ α α √ √ µ0 − z1− 2 · ; µ0 + z1− 2 · n n σ µ0 − z1−α · √ ; ∞ n σ −∞ ; µ0 + z1−α · √ n H0 verwerfen falls x∈ / ZSB x∈ / ZSB x∈ / ZSB 2. t-Test: Test für µ bei unbekannter Standardabweichung σ zum Signifikanzniveau α Gegeben: Stichprobe x1 , x2 , . . . , xn . Die Messwerte sind Realisierungen von n unabhängigen N (µ, σ 2 )-verteilten Zufallsvariablen mit unbekanntem Erwartungswert µ, und unbekannter Varianz σ 2 . −→ Schätze σ durch s aus der Stichprobe. Deshalb müssen die Quantile der t-Verteilung (mit n − 1 Freiheitsgraden) statt der Normalverteilung benutzt werden. 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG H0 28 Zufallsstreubereich für X, falls H0 zutrifft H1 µ = µ0 µ 6= µ0 µ ≥ µ0 µ < µ0 µ ≤ µ0 µ > µ0 H0 verwerfen falls s s α α µ0 − tn−1;1− 2 · √ ; µ0 + tn−1;1− 2 · √ n n s µ0 − tn−1;1−α · √ ; ∞ n s −∞ ; µ0 + tn−1;1−α · √ n x∈ / ZSB x∈ / ZSB x∈ / ZSB s: Standardabweichung der Stichprobe, tn−1;1−α : (1 − α)-Quantil der t-Verteilung mit n − 1 Freiheitsgraden 3. Zweistichproben-t-Test Test (zum Signifikanzniveau α) Über die Differenz zweier Erwartungswerte µ1 − µ2 zweier Grundgesamtheiten bei unbekannter aber gleicher Standardabweichung σ. Zum Test werden zwei Stichproben vom Umfang m und n mit den arithmetischen Mitteln x und y und mit den empirischen Standardabweichungen s1 und s2 gezogen. r q m+n 2 2 Berechne zunächst die Hilfsgröße sd = (m − 1) · s1 + (n − 1) · s2 · m · n · (m + n − 2) Zufallsstreubereich für X − Y , falls H0 zutrifft H0 verwerfen falls µ1 − µ2 6= 0 −tm+n−2;1− α2 · sd ; tm+n−2;1− α2 · sd x−y ∈ / ZSB µ1 − µ2 ≥ 0 µ1 − µ2 < 0 [−tm+n−2;1−α · sd ; ∞) x−y ∈ / ZSB µ1 − µ2 ≤ 0 µ1 − µ2 > 0 (−∞ ; tm+n−2;1−α · sd ] x−y ∈ / ZSB H0 H1 µ1 − µ2 = 0 4. Test für eine unbekannte Wahrscheinlichkeit/einen unbekannten Anteil p einer Grundgesamtheit zum Signifikanzniveau α Bei einer Stichprobe vom Umfang n sei das gesuchte Ereignis k-mal eingetreten. H0 H1 p = p0 p 6= p0 p ≥ p0 p < p0 p ≤ p0 p > p0 k Zufallsstreubereich für , n falls H0 zutrifft √ p0 ·(1−p0 ) √ p0 − z1− α2 · − n H0 verwerfen falls √ 0,5 n ; p0 + z1− α2 · √ p0 ·(1−p0 ) √ p0 − z1−α · − n p0 ·(1−p0 ) √ n + 0,5 n 0,5 n ;1 √ p0 ·(1−p0 ) √ 0 ; p0 + z1−α · + n 0,5 n k ∈ / ZSB n k ∈ / ZSB n k ∈ / ZSB n wobei p̂ = nk : Anteil/relative Häufigkeit in einer Stichprobe vom Umfang n, wenn das gesuchte Ereignis k-mal aufgetreten ist. 6 Statistische Methoden in der Qualitätssicherung Ziel der statistischen Prozesskontrolle (SPC = statistical process control) ist 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 29 • ein zeitlich stabiler Produktionsprozess (der Prozess wird beherrscht ; 6.1) • das Einhalten gewisser Toleranzgrenzen (der Prozess ist prozessfähig ; 6.2) Dazu wird in regelmäßigen Zeitabständen eine Stichprobe genommen. Wir gehen von einem normalverteilten Merkmal aus. Beherrschbarkeit heißt dann, dass µ und σ zeiltlich konstant sind. Zur Überwachung trägt man daher jeweils den Stichprobenmittelwert x und die empirische Standardabweichung s in eine eigene Qualitätsregelkarten ein. Ergeben sich hier gewisse Muster oder Abweichungen, so muss in den Produktionsprozess eingegriffen werden. Bei Anwendung von SPC ergibt sich somit ein Regelkreis, bei dem Störungen des Prozesses möglichst rasch entdeckt und behoben werden, damit bei der produzierten Ware erst gar kein Ausschuss entsteht. 6.1 Qualitätsregelkarten Qualitätsregelkarten (QRK) können in einen Qualitätsregelkreis eingebunden werden, um die Qualität des produzierenden Prozesses zu überwachen: 6.1.1 Führen der Qualitätsregelkarte Zur Überwachung von µ trägt man x in eine Qualitätsregelkarte (x-Karte) ein. Ebenso trägt man s zur Überwachung von σ in eine weitere Qualitätsregelkarte (s-Karte) ein, z. B. Man definiert sich eine obere und untere Eingriffsgrenze (OEG, UEG). Werden diese überschritten, so muss der Prozess korrigiert werden. Eingriffe sind aber auch bei ungewöhnliche Messwertfolgen notwendig, so z. B.: • Mehr als 7 aufeinander folgende Werte liegen kontinuierlich ansteigend oder abfallend innerhalb der Eingriffsgrenzen (”Trend”). • Mehr als 7 aufeinander folgende Werte liegen auf derselben Seite der Mittellinie (”Run”). • Es treten regelmäßige Muster von Punkten innerhalb der Eingriffsgrenzen auf, die ggf. einen Zusammenhang mit äußeren Einflüssen (z. B. Schichtwechsel, Temperatur, . . . ) ausweisen. Bermerkung: Für andere Verteilungen müssen andere Parameter betrachtet werden. Auch bei der Normalverteilung kann man den Median (x̃-Karte) und die Spannweite (R-Karte) verwenden. 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 6.1.2 30 Berechnung der Eingriffsgrenzen UEG = untere Eingriffsgrenze; OEG = obere Eingriffsgrenze. Diese Werte ergeben sich aus dem 99%-Zufallsstreubereich: x-Karte: σ UEGx = µ − 2, 576 · √ ; n σ OEGx = µ + 2, 576 · √ n (F1) s-Karte: UEGs = a · σ; OEGs = b · σ (F2) Für µ und σ kommen zwei Möglichkeiten in Betracht: • Man verwendet Soll- oder Erfahrungswerte µ0 , σ0 : • Man schätzt µ und σ aus einem ungestörten Vorlauf: µ = µ0 , σ = σ0 . µ = µ̂, σ = σ̂ ; 6.1.3. Im ersten Fall sind µ0 und σ0 konstante Vorgaben (z. B. aus Gesetz, Norm oder Herstellungsvorschrift) oder Erfahrungswerte aus früheren, umfangreichen Untersuchungen des Prozesses; ein Vorlauf zur Schätzung von µ und σ ist bei dieser Alternative nicht erforderlich. Tabelle für die Berechnung der Eingriffsgrenzen bei der s-Karte n 2 3 4 5 6 7 8 9 10 6.1.3 s − Karte a b 0, 006 2, 807 0, 071 2, 302 0, 155 2, 069 0, 227 1, 927 0, 287 1, 830 0, 336 1, 758 0, 376 1, 702 0, 410 1, 657 0, 439 1, 619 n = Umfang der Stichproben, die bei Anwendung der QRK regelmäßig zu entnehmen sind Grunderhebung (Vorlauf) zur Schätzung von µ und σ Sind die Parameter µ und σ unbekannt und sind auch keine Sollwerte einzuhalten, kann man µ und σ in einer Grunderhebung (auch Vorlauf genannt) schätzen. Das Vorgehen bei einer Grunderhebung ist nun wie folgt: 1. Es werden k Messreihen mit je m Messwerten aufgenommen. Faustregel: k ≥ 20 und m (= Umfang der Vorlauf-Messreihen) mindestens so groß wie n (= Umfang der später bei Einsatz der QRK regelmäßig zu ziehenden Stichproben). (Eine andere Empfehlung lautet k · m = 200, also dass im Vorlauf insgesamt mindestens 200 Messwerte zu ermitteln sind.) Anmerkung: Liegt entgegen der Empfehlung k ≥ 20 in der Grunderhebung nur eine einzige Messreihe vor, die aber umfangreich ist (d. h. k = 1 und m groß), sollte man µ durch den arithmetischen Mittelwert dieser Messreihe und σ durch die empirische Standardabweichung dieser Messreihe schätzen. Man hat also in diesem Ausnahmefall µ̂ = x und σ̂ = s. 2. Aus jeder Messreihe werden der arithmetische Mittelwert sowie die empirische Standardabweichung ermittelt. Bezeichnungen: (1 ≤ j ≤ k) Arithmetischer Mittelwert der j-ten Messreihe = xj Empirische Standardabweichung der j-ten Messreihe = sj 3. Bildung des Mittelwerts über die Kennzahlen aller Messreihen x= k 1X xj k j=1 ; s= k 1X sj k j=1 (Diese Größen werden außerdem zur Orientierung als Mittellinien in die QRK eingezeichnet.) 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 31 4. Schätzer für µ und σ: Schätze µ durch µ̂ = x. Schätze σ durch σ̂ = 1 cm s. Tabelle mit Werten für cm m 2 3 4 5 6 7 8 9 10 6.2 cm 0, 798 0, 886 0, 921 0, 940 0, 952 0, 959 0, 965 0, 969 0, 973 m = Umfang der Messreihen bei der Grunderhebung Für m > 10 kann man σ durch σ̂ = s schätzen. Prozessfähigkeit Prozessfähigkeit (engl.: process capability): Die Möglichkeit/Fähigkeit eines Prozesses, Produkte innerhalb geforderter Toleranzgrenzen zu fertigen Die Toleranzgrenzen werden in der Regel durch den Kunden vorgegeben (wirtschaftliche, keine statistische Grundlage). Die Prozessfähigkeitswerte cp und cpk dienen der Überprüfung, ob ein Prozess vorgegebene Toleranzgrenzen (UGW = Unterer Grenzwert und OGW = Oberer Grenzwert) einhält. Annahmen: • Das beobachtete Merkmal im Prozess ist normalverteilt und • der Prozess ist beherrschbar. Mögliche Probleme: Toleranzgrenzen werden überschritten (= zu viel Ausschuss) weil • Prozessstreuung zu groß und/oder • Prozess zu nahe an den Toleranzgrenzen Man betrachtet immer zwei Prozessfähigkeitswerte: cp -Wert (Pozessfähigkeitswert – beurteilt den Prozess (nur) in Bezug auf die Streuung) cp = OGW − U GW T = 6σ 6σ cpk -Wert (kritischer Prozessfähigkeitswert – beurteilt den Prozess in Bezug auf die Lage, wenn der Prozess nicht zentriert ist. Ist die Prozessmitte zu nahe an den Grenzen?) cpk = min{OGW − µ; µ − U GW } Abstand von µ zur näheren Toleranzgrenze = 3σ 3σ wobei OGW = Oberer Grenzwert für das betrachtete Merkmal; UGW = Unterer Grenzwert; T = OGW − UGW (Toleranz) µ, σ = Erwartungswert, Standardabweichung des Merkmals Wie bei Qualitätsregelkarten gilt auch hier: wenn µ und σ nicht bekannt oder vorgegeben sind, müssen sie aus den vorliegenden Daten geschätzt werden: • Liegen die Stichprobendaten in Form einer einzigen Messreihe vor, so verwendet man die Schätzungen µ̂ = x und σ̂ = s, wobei x den arithmetischen Mittelwert der Messreihe und s deren empirische Standardabweichung bezeichnet. 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 32 • Wurden mehrere Messreihen durchgeführt (wie bei einer Grunderhebung), geht man zum Schätzen von µ und σ so wie im Abschnitt 6.1.3 beschrieben vor. Ein Prozess ist fähig (”der Prozess ist o.k.”), wenn gilt: cp ≥ 4/3 ≈ 1, 33 und cpk ≥ 4/3 ≈ 1, 33 Die Prozessfähigkeitswerte geben Aufschluss über die Qualität des Prozesses: Gilt cp < 1, 33 =⇒ Prozessstreuung σ zu groß. Gilt cp ≥ 1, 33 aber cpk < 1, 33 =⇒ Prozessmitte µ liegt zu nahe an einer der beiden Toleranzgrenzen (Streuung akzeptabel). Bemerkungen zu den Prozessfähigkeitswerten: Der cpk -Wert ist immer gleich oder kleiner als der cp -Wert: cpk ≤ cp (d.h. falls cp < 4/3 kann man aufhören). Die Forderung cp , cpk ≥ 4/3 ist wirtschaftlich und nicht statistisch motiviert! Es werden in der Praxis auch andere (zum Teil höhere) Werte gefordert. Maschinenfähigkeit Für die Beurteilung der Maschinenfähigkeit werden im Prinzip die gleichen Kennzahlen wie bei der Prozessfähigkeit betrachtet (Bezeichnung: cm , cmk ). Es liegt hier jedoch eine andere Art der Datengewinnung vor und evtl. werden andere Grenzwerte für die Kennzahlen verlangt. Datengewinnung: alle Parameter (Mensch, Material, Messmethode, Maschinentemperatur und FertigungsMethode) werden konstant gehalten, so dass nur der Einfluss der Maschine auf das Ergebnis gemessen werden kann. Mindestens 50 Teile hintereinander werden gefertigt und ausgewertet Anmerkungen zu den Begriffen”beherrschter Prozess” und ”fähiger Prozess” In mancher Literatur werden diese beiden Begriffe ein wenig anders definiert als in diesem Kapitel. Nach DIN 55350 Teil 33 ist ein ”beherrschter Prozess” ein Prozess, bei dem sich die Parameter der Verteilung der Merkmalswerte ”praktisch nicht oder nur in bekannter Weise oder in bekannten Grenzen ändern”. Es kommt aber wohl nur selten vor, dass sich die Parameter verändern und man sogar formelmäßig angeben kann, wie oder in welchen Grenzen sie sich verändern. Aus diesem Grund wurde in diesem Kapitel das ”in bekannter Weise oder in bekannten Grenzen ändern” nicht berücksichtigt. Da in den Abschnitten 6.1 und 6.2 zudem nur normalverteilte Qualitätsmerkmale besprochen werden, bedeutet ”die Parameter verändern sich nicht” hier, dass sich bei dem Prozess µ und σ der Normalverteilung des Qualitätsmerkmals im Verlauf der Zeit nicht ändern. Ebenfalls in DIN 55350 Teil 33 wird ”Prozessfähigkeit vorhanden” allein über die Ungleichung cp > 1, 33 definiert. Sollte diese erfüllt sein, aber der cpk -Wert unter 1, 33 liegen, gäbe es einen gewissen Anteil der im Prozess gefertigten Teile, bei dem die vorgegebenen Toleranzgrenzen nicht eingehalten werden. Das wäre — wie oben beschrieben — dann der Fall, wenn die Prozessmitte zu nahe an einer der Toleranzgrenzen liegt. Daher müsste in einem solchen Fall die Prozessmitte noch nachjustiert werden; die Möglichkeit des Nachjustierens ist also in der DIN-Definition vorausgesetzt. In diesem Kapitel wurde vorgezogen, Prozessfähigkeit erst zu bescheinigen, wenn das Nachjustieren der Prozessmitte nicht (oder nicht mehr) erforderlich ist, und deshalb wurde die Bedingung cpk ≥ 1, 33 in die Definition der Prozessfähigkeit eingeschlossen. 6.3 6.3.1 Annahme-Stichprobenprüfung Allgemeines zur Annahme-Stichprobenprüfung Zur Kontrolle z. B. von ein- und ausgehenden Lieferungen kann eine Stichprobenprüfung eingesetzt werden. Ein Prüfplan (auch ”Stichprobenanweisung” genannt) wird normalerweise in der Form (n|c) angegeben. Dabei ist n der Stichprobenumfang und c die Annahmezahl , d. h. die maximal erlaubte Anzahl von Defektstücken in der Stichprobe. 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 33 Normalerweise ist die Rückweisezahl d = c + 1 . (Ausnahme: Reduzierte Prüfung, wie in 6.3.2 erläutert.) Ist die gefundene Anzahl der Defektstücke in der Stichprobe mindestens so hoch wie die Rückweisezahl, wird die Lieferung zurückgewiesen. (Anmerkung: Der Vertrag zwischen Lieferant und Abnehmer muss regeln, wie im Einzelnen bei Annahme bzw. Zurückweisen der Lieferung zu verfahren ist.) Die Zufallsvariable X bezeichne nun die Anzahl der Defektstücke in der Lieferung. X ist hypergeometrisch verteilt. P(X ≤ c) nennt man die Annahmewahrscheinlichkeit. Oft wird man statt mit der hypergeometrischen Verteilung näherungsweise mit der Binomial- oder Poissonverteilung rechnen (vgl. Kapitel 4). Die Annahmewahrscheinlichkeit P(X ≤ c) hängt bei diesen Näherungsrechnungen außer von n nur noch davon ab, wie groß der Ausschussanteil p der Lieferung ist, denn falls die Näherungsrechnung zulässig ist, gilt X ≈ B(n, p) oder X ≈ Po(n · p) . Legt man eine Näherung mit BV oder PV zugrunde und zeichnet man dann die Annahmewahrscheinlichkeit in Abhängigkeit von p , erhält man die sog. Annahmekennlinie oder OC-Kurve. Die Annahmewahrscheinlichkeit bezeichnet man auch als Abnehmerrisiko (insbesondere für große Werte von p). Umgekehrt bezeichnet man die Wahrscheinlichkeit, dass die Lieferung nicht angenommen wird, das Produzentenrisiko oder Lieferantenrisiko (insbesondere für kleine Werte von p). Ein Produzent wünscht geringes Produzentenrisiko, wenn er gute Ware liefert (d. h. p klein ist), ein Abnehmer wünscht geringes Abnehmerrisiko, wenn er schlechte Ware erhält (d. h. p groß ist). Beide Risikoarten lassen sich (in Abhängigkeit von p) aus der OC-Kurve ablesen: das Abnehmerrisiko ist der Funktionswert der Kurve an der Stelle p, das Produzentenrisiko die Differenz zwischen dem Funktionswert und 1. (Für beide optimal wäre also eine möglichst ”steile” OC-Kurve, d. h. eine, die für kleine Werte von p fast 1 ist und für große Werte von p fast 0. Das lässt sich aber normalerweise nur durch sehr große Stichprobenumfänge n erreichen.) Der Aussschussanteil p der Lieferung, bei dem das Produzentenrisiko einen festgelegten kleinen Wert α annimmt, heißt AQL-Wert (AQL = ”Acceptable Quality Level”). Wir wählen α = 0, 1. Wichtig: Dabei ist p in Prozent anzugeben. AQL 0, 4 bedeutet für uns also: Beträgt der Ausschussanteil der Lieferung 0, 4%, so ist die Annahmewahrscheinlichkeit 90 %. (*) (*) bei den Normprüfplänen in 6.3.4.3A, B, C gilt diese Formel nur näherungsweise. AQL ist nur eine Kennzahl des Prüfplan; die englische Bezeichnung ist nicht so zu verstehen, dass diese Ausschussquote p ”akzeptabel” wäre. Zur genaueren Beurteilung eines Prüfplans benötigt man ohnehin die Annahmekennlinie (= OC-Funktion), AQL alleine genügt nicht. AQL als Kennzahl ist insbesondere nicht ausreichend, wenn nur ein einzelnes Los zu prüfen ist (d. h. keine regelmäßige Geschäftsbeziehung zwischen Lieferant und Abnehmer besteht). 6.3.2 Ein AQL-Stichprobensystem Dargestellte Normen In diesem Abschnitt wird das AQL-Stichprobensystem des früheren US-amerikanischen Military Standard MIL-STD-105E dargestellt. Dessen Vorversion D, die auch unter dem Namen ABC-STD105D bekannt war, war die Grundlage für die Norm DIN ISO 2859. Die beiden Normen stimmen weitgehend überein. Die hier (auszugsweise) dargestellten Tabellen- werte sind mit denen der DINNorm identisch. Einen Unterschied gibt es bei den Vorschriften zum Übergang von normaler zu reduzierter Prüfung. Allgemeine Begriffe; Anwendung der Tabellen Welcher Prüfplan gemäß den beiden Normen anzuwenden ist, hängt ab von: 1. Der Losumfang N und das Prüfniveau ergeben einen Kennbuchstaben 2. Beurteilungsstufe (normale, reduzierte oder verschärfte Prüfung) 3. AQL-Wert (siehe oben) und Kennbuchstabe ergibt Prüfplan (n|c) bzw. (n|c|d). 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 34 Als Prüfniveau wird normalerweise das Allgemeine Prüfniveau II gewählt. Kurze Anmerkungen zu den übrigen Prüfniveaus folgen in Abschnitt 6.3.3 c) und d) auf der nächsten Seite. Welche Beurteilungsstufe anzuwenden ist, hängt von den Ergebnissen eventuell vorangegangener Prüfungen ab. Grundidee: Wurden vorher viele Lose in Folge angenommen, kann man reduziert prüfen; musste öfter zurückgewiesen werden, wird verschärft geprüft. Der Übergang zwischen normaler und verschärfter/reduzierter Prüfung (und zurück) ist aus den folgenden Übersichten ersichtlich. Bei der reduzierten Prüfung ist zu beachten, dass für die Rückweisezahl d oft nicht d = c + 1 gilt. Der Prüfplan einer reduzierten Prüfung wird daher in der Form (n|c|d) angegeben, wobei n der Stichprobenumfang ist, c die Annahmezahl und d die Rückweisezahl. Hat man x Defektstücke in der Stichprobe gefunden, entscheidet man wie folgt: • Falls x ≤ c , so wird die Lieferung angenommen; die nächste Prüfung erfolgt ebenfalls reduziert; • Falls c < x < d, so wird die Lieferung zwar angenommen, aber die nächste Prüfung erfolgt als normale und nicht als reduzierte Prüfung; • Falls x ≥ d, so wird die Lieferung zurückgewiesen. (Nächste Prüfung erfolgt normal.) Mit Hilfe von Prüfniveau und Losumfang N findet man aus der Kennbuchstabentabelle den Kennbuchstaben der Prüfung, der die Zeile der folgenden Tabellen festlegt. Der AQL-Wert bestimmt dann die Spalte in der Tabelle, in der Annahmezahl c und Rückweisezahl d stehen. (Bei normaler oder verschärfter Prüfung ist natürlich d = c + 1.) Ausnahme: Trifft man auf einen Pfeil ↑ oder ↓, muss man die erste eingetragene Stichprobenanweisung über bzw. unter dem Pfeil nehmen (also die Zeile wechseln). Falls dadurch der Stichprobenumfang n größer wird als der Losumfang N , ist das Los vollständig zu prüfen. Hat man auf diese Weise die Zeile festgelegt, findet man in der letzten Spalte der Tabellen den Stichprobenumfang n . Wie bereits oben gesagt, stehen Annahme- und Rückweisezahl in der Spalte, die zum gewählten AQL-Wert gehört. 6.3.3 Ergänzungen zum Thema ”Annahme-Stichprobenprüfung” 1. Wir haben hier nur die sog. Attributprüfung = zählende Prüfung behandelt, d. h. es wird geprüft, wie viele der Stichprobeneinheiten fehlerhaft bzw. nicht fehlerhaft sind. Es gibt darüber hinaus auch Variablenprüfungen (= messende Stichprobenprüfungen). 2. Begriff Los: Ein Los ist ”eine Menge eines Produktes, die unter Bedingungen entstanden ist, die als einheitlich angesehen werden” (DIN 55350, Teil 31). Wenn wir in der Vorlesung oder im Skript von ”Lieferung” gesprochen haben, sind wir stets davon ausgegangen, dass die Lieferung ein Los in diesem Sinne ist. 3. Die Prüfniveaus S1 bis S4 sind Sonderniveaus für kleine Stichprobenumfänge, z. B. bei kostspieliger oder zerstörender Prüfung 4. Prüfniveau III ist schärfer als Prüfniveau II (= steilere OC-Funktion); Prüfniveau I ist weniger scharf als II. Eine höhere Prüfschärfe bedeutet eine Reduzierung sowohl des Abnehmerrisikos also auch des Produzentenrisikos. Dies zeigt das folgende Beispiel. Losumfang N = 2000; AQL 1,0; normale Prüfung. Prüfniveau I: Prüfniveau II: Prüfniveau III: Kennbuchstabe H Kennbuchstabe K Kennbuchstabe L Stichprobenvorschrift (50|1) Stichprobenvorschrift (125|3) Stichprobenvorschrift (200|5) Aus den OC-Funktionen ist ersichtlich, dass das Abnehmerrisiko bei großem Ausschussanteil p bei Niveau III am geringsten, bei Niveau I am höchsten ist. Ebenso ist aber auch bei kleinem p das Produzentenrisiko bei Niveau III geringer als bei Niveau II und dort wiederum geringer als bei Niveau I. 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 6.3.4 35 Übersichten und Tabellen zu den Normen MIL-STD-105E und DIN ISO 2859 Übergang zwischen normaler und verschärfter Prüfung Start Von 5 aufeinanderfolgenden Losen 2 zurückgewiesen Normale Prüfung 5 Lose in verschärfter Prüfung zurückgewiesen Verschärfte Prüfung 5 aufeinanderfolgenden Lose angenommen Prüfung ausgesetzt Der Lieferer verbessert die Qualität 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 36 Übergang zwischen normaler und reduzierter Prüfung [MIL-STD-105E] Start • 10 vorangegangene Lose normal geprüft und angenommen, und • Gesamtzahl fehlerhafter Einheiten in diesen 10 Losen überschreitet nicht vorgegebenen Maximalwert∗ , und • Produktion läuft gleichmäßig, und • reduzierte Prüfung wird vereinbart Reduzierte Prüfung Normale Prüfung • Los zurückgewiesen, oder • Anzahl fehlerhafter Einheiten zwischen Annahmezahl c und Rückweisezahl d, oder • Produktion läuft ungleichmäßig (oder ähnliche Gründe) ∗ Die Tabelle der Maximalwerte ist hier nicht abgedruckt. Tabelle: Kennbuchstaben Losumfang N 26 bis 50 51 bis 90 91 bis 150 Besondere S-1 S-2 A B B B B B Prüfniveaus S-3 S-4 B C C C C D Allgemeine Prüfniveaus I II III C D E C E F D F G 151 bis 280 281 bis 500 501 bis 1200 B B C C C C D D E E E F E F G G H J H J K 1201 bis 3200 3201 bis 10000 10001 bis 35000 C C C D D D E E F G G H H J K K L M L M N 35001 bis 150000 D E G J L N P Stichprobenanweisungen In den folgenden Tabellen gelten folgende Abkürzungen: KB Kennbuchstabe c Annahmezahl n Stichprobenumfang d Rückweisezahl KB D E F G H J K L M 0,040 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 0,065 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↑ 0,10 c d ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↑ ↓ AQL (normale Prüfung) 0,15 0,25 0,40 0,65 c d c d c d c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↓ ↓ 0 1 ↑ ↓ 0 1 ↑ ↓ 0 1 ↑ ↓ 1 2 ↑ ↓ 1 2 2 3 ↓ 1 2 2 3 3 4 1 2 2 3 3 4 5 6 n 1,0 c d ↓ 0 1 ↑ ↓ 1 2 2 3 3 4 5 6 7 8 1,5 c 0 2,5 d 1 ↑ ↓ 1 2 3 5 7 10 2 3 4 6 8 11 c d ↑ ↓ 1 2 3 5 7 10 14 2 3 4 6 8 11 15 8 13 20 32 50 80 125 200 315 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG KB D E F G H J K L M 0,065 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 0,10 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↓ 0,15 c d ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↓ ↓ AQL (verschärfte Prüfung) 0,25 0,40 0,65 1,0 c d c d c d c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↓ ↓ 0 1 ↓ ↓ 0 1 ↓ ↓ 0 1 ↓ ↓ 1 2 ↓ ↓ 1 2 2 3 ↓ 1 2 2 3 3 4 1 2 2 3 3 4 5 6 1,5 c d ↓ 0 1 ↓ ↓ 1 2 2 3 3 4 5 6 8 9 1 2 3 5 8 12 0,040 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 0,065 c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↑ 0,10 c d ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↑ ↓ AQL 0,15 c d ↓ ↓ ↓ ↓ ↓ 0 1 ↑ ↓ 0 2 1,0 c d ↓ 0 1 ↑ ↓ 0 2 1 3 1 4 2 5 3 6 1,5 c d 0 1 ↑ ↓ 0 2 1 3 1 4 2 5 3 6 5 8 KB D E F G H J K L M 37 (reduzierte Prüfung) 0,25 0,40 0,65 c d c d c d ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ 0 1 ↓ 0 1 ↑ 0 1 ↑ ↓ ↑ ↓ 0 2 ↓ 0 2 1 3 0 2 1 3 1 4 1 3 1 4 2 5 n 2,5 c 0 4,0 d 1 ↓ ↓ 2 3 4 6 9 13 c d ↓ ↓ 1 2 3 5 8 12 18 8 13 20 32 50 80 125 200 315 2 3 4 6 9 13 19 n 2,5 c d ↑ ↓ 0 2 1 3 1 4 2 5 3 6 5 8 7 10 3 5 8 13 20 32 50 80 125 6 Verteilungsfunktion Φ(z) der Standard-Normalverteilung N (0; 1) 0 0,5000 0,5398 0,5793 0,6179 0,6554 0,6915 0,7257 0,7580 0,7881 0,8159 0,8413 0,8643 0,8849 0,9032 0,9192 0,9332 0,9452 0,9554 0,9641 0,9713 0,9772 0,9821 0,9861 0,9893 0,9918 0,9938 0,9953 0,9965 0,9974 0,9981 0,9987 1 0,5040 0,5438 0,5832 0,6217 0,6591 0,6950 0,7291 0,7611 0,7910 0,8186 0,8438 0,8665 0,8869 0,9049 0,9207 0,9345 0,9463 0,9564 0,9649 0,9719 0,9778 0,9826 0,9864 0,9896 0,9920 0,9940 0,9955 0,9966 0,9975 0,9982 0,9987 2 0,5080 0,5478 0,5871 0,6255 0,6628 0,6985 0,7324 0,7642 0,7939 0,8212 0,8461 0,8686 0,8888 0,9066 0,9222 0,9357 0,9474 0,9573 0,9656 0,9726 0,9783 0,9830 0,9868 0,9898 0,9922 0,9941 0,9956 0,9967 0,9976 0,9982 0,9987 3 0,5120 0,5517 0,5910 0,6293 0,6664 0,7019 0,7357 0,7673 0,7967 0,8238 0,8485 0,8708 0,8907 0,9082 0,9236 0,9370 0,9484 0,9582 0,9664 0,9732 0,9788 0,9834 0,9871 0,9901 0,9925 0,9943 0,9957 0,9968 0,9977 0,9983 0,9988 4 0,5160 0,5557 0,5948 0,6331 0,6700 0,7054 0,7389 0,7704 0,7995 0,8264 0,8508 0,8729 0,8925 0,9099 0,9251 0,9382 0,9495 0,9591 0,9671 0,9738 0,9793 0,9838 0,9875 0,9904 0,9927 0,9945 0,9959 0,9969 0,9977 0,9984 0,9988 5 0,5199 0,5596 0,5987 0,6368 0,6736 0,7088 0,7422 0,7734 0,8023 0,8289 0,8531 0,8749 0,8944 0,9115 0,9265 0,9394 0,9505 0,9599 0,9678 0,9744 0,9798 0,9842 0,9878 0,9906 0,9929 0,9946 0,9960 0,9970 0,9978 0,9984 0,9989 6 0,5239 0,5636 0,6026 0,6406 0,6772 0,7123 0,7454 0,7764 0,8051 0,8315 0,8554 0,8770 0,8962 0,9131 0,9279 0,9406 0,9515 0,9608 0,9686 0,9750 0,9803 0,9846 0,9881 0,9909 0,9931 0,9948 0,9961 0,9971 0,9979 0,9985 0,9989 7 0,5279 0,5675 0,6064 0,6443 0,6808 0,7157 0,7486 0,7794 0,8078 0,8340 0,8577 0,8790 0,8980 0,9147 0,9292 0,9418 0,9525 0,9616 0,9693 0,9756 0,9808 0,9850 0,9884 0,9911 0,9932 0,9949 0,9962 0,9972 0,9979 0,9985 0,9989 8 0,5319 0,5714 0,6103 0,6480 0,6844 0,7190 0,7517 0,7823 0,8106 0,8365 0,8599 0,8810 0,8997 0,9162 0,9306 0,9429 0,9535 0,9625 0,9699 0,9761 0,9812 0,9854 0,9887 0,9913 0,9934 0,9951 0,9963 0,9973 0,9980 0,9986 0,9990 9 0,5359 0,5753 0,6141 0,6517 0,6879 0,7224 0,7549 0,7852 0,8133 0,8389 0,8621 0,8830 0,9015 0,9177 0,9319 0,9441 0,9545 0,9633 0,9706 0,9767 0,9817 0,9857 0,9890 0,9916 0,9936 0,9952 0,9964 0,9974 0,9981 0,9986 0,9990 Ablesebeispiel: Φ(0, 92) = 0, 8212 Werte für negatives z mit der Formel Φ(−z) = 1 − Φ(z), z. B. Φ(−1, 55) = 1 − 0, 9394 = 0, 0606 Lineare Interpolation für höhere Genauigkeit bei Zwischenwerten: Für x ist u die Zahl mit zwei Nachkommastellen und u < x < u + 0, 01. Dann ist Φ(x) ≈ Φ0 + 100 · (x − u) · (Φ1 − Φ0 ), wobei Φ0 = Φ(u) und Φ1 = Φ(u + 0, 01) aus der Tabelle gelesen werden, z. B. Φ(0, 924) ≈ 0, 8212 + 0, 4 · (0, 8238 − 0, 8212) = 0, 8222 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG z 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3,0 38 6 STATISTISCHE METHODEN IN DER QUALITÄTSSICHERUNG 39 Quantile tm;q der t-Verteilung mit m Freiheitsgraden und Quantile zq der Standard-Normalverteilung (NV) tm;q m 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 35 40 45 50 60 70 80 90 100 200 500 q 0,8 1,376 1,061 0,978 0,941 0,920 0,906 0,896 0,889 0,883 0,879 0,876 0,873 0,870 0,868 0,866 0,865 0,863 0,862 0,861 0,860 0,859 0,858 0,858 0,857 0,856 0,856 0,855 0,855 0,854 0,854 0,852 0,851 0,850 0,849 0,848 0,847 0,846 0,846 0,845 0,843 0,842 0,9 3,078 1,886 1,638 1,533 1,476 1,440 1,415 1,397 1,383 1,372 1,363 1,356 1,350 1,345 1,341 1,337 1,333 1,330 1,328 1,325 1,323 1,321 1,319 1,318 1,316 1,315 1,314 1,313 1,311 1,310 1,306 1,303 1,301 1,299 1,296 1,294 1,292 1,291 1,290 1,286 1,283 0,95 6,314 2,920 2,353 2,132 2,015 1,943 1,895 1,860 1,833 1,812 1,796 1,782 1,771 1,761 1,753 1,746 1,740 1,734 1,729 1,725 1,721 1,717 1,714 1,711 1,708 1,706 1,703 1,701 1,699 1,697 1,690 1,684 1,679 1,676 1,671 1,667 1,664 1,662 1,660 1,653 1,648 0,975 12,706 4,303 3,182 2,776 2,571 2,447 2,365 2,306 2,262 2,228 2,201 2,179 2,160 2,145 2,131 2,120 2,110 2,101 2,093 2,086 2,080 2,074 2,069 2,064 2,060 2,056 2,052 2,048 2,045 2,042 2,030 2,021 2,014 2,009 2,000 1,994 1,990 1,987 1,984 1,972 1,965 0,99 31,821 6,965 4,541 3,747 3,365 3,143 2,998 2,896 2,821 2,764 2,718 2,681 2,650 2,624 2,602 2,583 2,567 2,552 2,539 2,528 2,518 2,508 2,500 2,492 2,485 2,479 2,473 2,467 2,462 2,457 2,438 2,423 2,412 2,403 2,390 2,381 2,374 2,368 2,364 2,345 2,334 0,995 63,656 9,925 5,841 4,604 4,032 3,707 3,499 3,355 3,250 3,169 3,106 3,055 3,012 2,977 2,947 2,921 2,898 2,878 2,861 2,845 2,831 2,819 2,807 2,797 2,787 2,779 2,771 2,763 2,756 2,750 2,724 2,704 2,690 2,678 2,660 2,648 2,639 2,632 2,626 2,601 2,586 0,999 318,289 22,328 10,214 7,173 5,894 5,208 4,785 4,501 4,297 4,144 4,025 3,930 3,852 3,787 3,733 3,686 3,646 3,610 3,579 3,552 3,527 3,505 3,485 3,467 3,450 3,435 3,421 3,408 3,396 3,385 3,340 3,307 3,281 3,261 3,232 3,211 3,195 3,183 3,174 3,131 3,107 zq 0,842 1,282 1,645 1,960 2,326 2,576 3,090 Ablesebeispiele: t20;0,975 = 2, 086; z0,995 = 2, 576 Werte für q < 0, 5 mit den Formeln tm;1−q = −tm;q und z1−q = −zq . Beispiele: t30;0,1 = −t30;0,9 = −1, 310; z0,01 = −z0,99 = −2, 326.