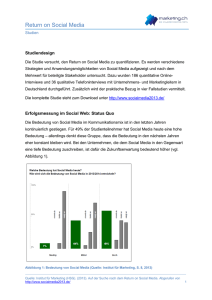
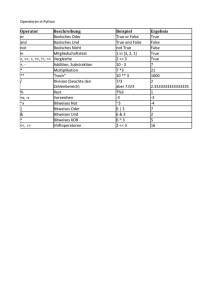
Grundlagen der Mathematik (Mathematik vom Standpunkt des
Werbung

Grundlagen der Mathematik (Mathematik vom Standpunkt des Informatikers) überarbeitete Version vom 17.07.2014 Prof. Dr. Hans-Jürgen Steens Fachhochschule Kaiserslautern Standort Zweibrücken [email protected] 17. Juli 2014 2 Zur Philosophie der Vorlesung Grundlagen der Mathematk Im Zuge der Umstellung auf die neuen gestuften Studiengänge am Standort Zweibrücken erhöhte sich der Umfang der mathematischen Grundausbildung. Dies bot die Möglichkeit, die Rolle der Mathematik in der Informatik neu zu überdenken und neue Schwerpunkte zu setzen. Mathematik in der Informatik vice versa Sie man vom grundsätzlich emanzipatorischen Aspekt der Mathematik ab1 , so spielt die Mathematik in der Informatik mindestens eine Doppelrolle: Sie ist einerseits Objekt für die Informatiker, die wichtige mathematische Algorithmen seien sie aus der Statistik, der linearen Optimierung, der Strömumgsmechanik oder anderen Gebieten in geeigneten Programmiersprachen implementieren. Sie wird andererseits, und zwar insbesondere in der theoretischen Informtik, als Vehikel der Modellbildung in und für die Informatik benutzt. Darüberhinaus durchziehen klassische mathematische Beweistechniken etwa bei der Verikation von Algorithmen oder deren Komplexitätsanalyse wie selbstverständlich die gesamte Informatik. Man könnte in diesem Sinne die Rollen der Mathematik mit denen einen Compilers in der Informatik vergleichen. Dieser kann dort einerseits die Rolle eines Objekts annehmen, wenn es um Fragen der ezienten Implementierung und Optimierung von Sprachübersetzern geht. Andererseits wird er als selbstverständliches Werkzeug für das Programmieren benutzt, über dessen Innenleben man bei der Codierung keinen Gedanken zu verlieren braucht. Diese Doppelrolle des Compilers ist natürlich kein Zufall. Sie ist, wenn man so will, in der Doppelgesichtlichkeit einer Turingmaschine begründet. Diese kann einerseits als reiner Algorithmus andererseits aber auch als Maschine aufgefasst werden, auf der Algorithmen zum Ablauf gebracht werden können (eben als Vehikel für sie). Insgesamt haben die bis zum Beginn des letzten Jahrhunderts zurückreichenden Versuche, die Mathematik in ihrer Gesamtheit durchzualgorithmisieren, zu einer sehr groÿen Überlappung der Gegenstandsbereiche der Mathematik und der Informatik geführt (auch wenn sie infolge der Gödelschen Unvollständigkeitssätze nicht zu einem endgültigen Erfolg geführt haben). Gehören also die metamathematischen Untersuchungen zur Berechenbarkeit zur Domäne der (theoretischen) Informatik? Oder sind umgekehrt die Probleme der für die Informatik relevanten formalen Sprachen nicht auch der Mathematik zuzurechnen? Deren Fragestellungen haben ihren Ursprung ja direkt in einigen der berühmten von Hilbert zu Beginn des 20. Jahrhunderts formulierten Problemen. Es stellt sich also nicht die Frage (und sie hat sich auch ernsthaft nie gestellt), ob eine mathematische Grundlagenausbildung zum Grundkanon der Informatik gehören sollte oder nicht. Man kann sich allerdings die Frage stellen, inwieweit die oensichtliche Verwobenheit von Mathematik und Informatik nicht stärker in der 1 Dieser Aspekt könnte treend mit der Kantschen Auorderung Habe Mut dich deines eigenen Verstandes zu bedienen ausgedrückt werden. 3 Methodologie der Mathematikausbildung zum Tragen kommen sollte.2 Dies führt zu einem Lehrbuch, dass zwar von der Warte der Informatik her geschrieben ist, aber eben nicht einfach nur ein Mathematiklehrbuch für Informatiker sein will. Auch und gerade ein Student der reinen Mathematik sollte hier Anregungen nden, die ihn wichtige Zusammenhänge so hoe ich leichter verstehen lassen. Methodologie der Informatik als Modell für die Mathematik Sprechen wir von methodologischen Gemeinsamkeiten, die die Informatik und Mathematik in ihren jeweiligen Vorgehensweisen verbinden, dann fallen uns zunächst die Abstrahierungen ein. So nden sich in der Mathematik von Beginn an dieselben Konzepte, wie sie in der Softwaretechnik auf natürliche Weise in Form der funktionalen oder auch der objektorientierten Kapselung Anwendung nden. Sie manifestieren sich einerseits in der Zerlegung mathematischer Beweise in Hilfssätze, Sätze und Folgerungen, andererseits in der Zerlegung von Algorithmen in Funktionen (Prozeduren") und Unterfunktionen (wobei diese Analogie nicht nur oberächlich besteht.) Bereits die Zahlen selbst sind auch wenn dies zu Beginn des Studiums durch die jahrzehntelange Beschäftigung mit ihnen in Vergessenheit geraten ist ein rein abstraktes Konstrukt und letztlich nur durch ihr äuÿeres Verhalten charakterisierbar. Softwaretechnisch können sie deshalb auf natürliche Weise als sog. abstrakte Datentypen modelliert werden. Spätestens hier wird dann klar, dass die Mathematik mehr ist, als ein add-on für die Informatik. Vor diesem Hintergrund wurde nun das Experiment gewagt, die in der Informatik letztlich ganz selbstverständlich genutzten Konzepte der systematischen Abstraktion in der einführenden MathematikVorlesung von Beginn an strategisch einzusetzen. Wie angedeutet kann man hier schon beim Zahlbegri selbst ansetzen. Nun werden Zahlen in der Informatik zwar generell durch die Zustände bistabiler Bausteine repräsentiert, wobei schon die Darstellung negativer Zahlen ganz unterschiedliche Implementierungen etwa in Form des 1er oder 2er Komplements erlaubt. Zahlen und insbesondere die hiermit zusammenhängenden arithmetischen Operationen werden also i.A. durch spezialisierte Hardware realisiert. Theoretisch könnte man sie aber auch mittels Software auf einer weniger spezialiserten Hardware implementieren. Letztlich stehen wir hier vor der Frage nach der Wahl eines speziellen Modells der Zahlen. In der Mathematik wird ein Zahlmodell bevorzugt auf das Modell einer Mengenlehre zurückgeführt. Hier bietet sich in der Informatik die Chance, Modelle der Zahlen von vornherein als abstrakte Datentypen zu konzipieren, die ihr äuÿeres, ihr systemisches Verhalten durch geeignete Sätze zugesicherter Eigenschaften erhalten. Die Mengenlehre als Vehikel für eine solche Modellierung kann dabei selbst als abstrakter Datentyp ausgedrückt werden. Die systemischen Eigenschaften dieses Datentyps werden dann in Form der Axiome von Zermelo und Fraenkel formuliert. Der Versuch einer (konzeptuellen) Implementierung des geschilderten Ansatz mit 2 Ich denke da insbesondere an die Behandlung der Mengenlehre, die ich übertreibe ein wenig wie Puderzucker auf einen Kuchen gestreut, dort auch wieder weggeblasen werden könnte, ohne dass es am Geschmack etwas änderte. Charakteristisch hierfür ist die auch in neuesten Lehrbüchern immer noch benutzte Cantorsche Mengendenition, als Grundlage der Mengenlehre. 4 Hilfe einer Programmiersprache kommt mit erstaunlich wenigen Sprachfeatures aus: Es genügten z.B. ein einziger vordenierter Datentyp Set sowie zwei in der Sprache vordenierten zweistelligen booleschen Operationen (in der Rolle von Prädikaten) namens isElement(x,y) und isEqual(x,y). Die Implementierung dieses Datentyps zusammen mit den beiden Operationen auf einer geeigneten Hardware könnte dem Benutzer/Programmierer verborgen bleiben. Sie müsste einzig und allein dafür Sorge tragen, dass die Operationen die geforderten von auÿen sichtbaren systemischen Eigenschaften aufwiesen. Für den Datentyp Set wären dies eben die im Axiomensystem von Zermelo und Fraenkel formulierten Eigenschaften. Damit stoÿen wir technisch natürlich auf ein nur allzubekanntes Problem. Die Eigenschaften von Zermelo und Fraenkel können nur dann gewährleistet werden, wenn die Implementierung von Set eine Datenbank mit (bei Inanspruchnahme eines sog. Herbrandschen Modells) mindestens abzählbar unendlich viele Objekte dieses Typs bereithält. Hypothetische NonplusultraProzessoren . . . Somit wäre vor einer Verbindung zwischen Informatik und Mathematik auf dieser Ebene zunächst einmal zu klären, inwieweit eine Hardware zur Implementierung von Set überhaupt vernünftig denkbar sein kann. Operationell manifestierte sich der Sachverhalt, dass wir es notwendig mit einem (abzählbar) unendlichen Modell zu tun haben, in der Existenz unendlich oft zu durchlaufenen Schleifen. Die programmiertechnische Umsetzung der Eigenschaften von Zermelo/Fraenkel führte in der Codierung nämlich auf Konstrukte der Art for Set x ..., wobei eine Schleifenvariable x alle Objekte des Typs Set und das sind abzählbar unendlich viele in für den Benutzer endlicher (Eigen)Zeit zu durchlaufen hätte. 3 Interessanterweise sind Prozessoren, die hierzu in der Lage wären, unter den Randbedingungen einer extremen Physik durchaus denkbar. Ein solcher Prozesor müsste (zeitlich) hyperbolisch beschleunigt werden, etwa derart dass ein Befehlszyklus jeweils nur die Hälfte der Zeit des zeitlich vorhergehenden Zyklus benötigte. Ein solcher Prozessor wäre demnach in der Lage, in einem endlichen Zeitintervall (abzählbar) unendlich viele Befehlszyklen zu durchlaufen. In erster Näherung kann man hier an die physikalischen Phänomene im Umfeld des Ereignishorizontes eines schwarzen Loches denken. Hierzu stellen wir uns vor, dass wir auÿerhalb des schwarze Lochs (auÿerhalb des Ereignishorizontes) in einer festen Entfernung hiervon einen klassischen Prozessor plazierten. Seine Befehlszyklen sind gemessen in seiner Eigenzeit, gemessen also mit einer am Prozessor selbst angebrachten Uhr jeweils von konstanter Dauer. Bezogen auf einen Beobachter, der sich in Richtung auf den Ereignishorizont bewegte, würde derselbe Prozessor jedoch genau das vorhin beschriebene quasi hyperbolische Beschleunigungsverhalten aufweisen. Der sich bewegende Beobachter würde in einem endlichen Intervall seiner Eigenzeit theoretisch in der Lage sein unendlich viele Zyklen des Prozessors zu erleben. Damit wäre der Beobachter theoretisch in der Lage, eektiv zwischen unendlich oft durchlaufenen Schleifen und nur endlich oft durchlaufenen Schleifen zu untescheiden: Die Beendigung einer nur endlich oft durchlaufenen Schleife könnte dem Beobachter mittels eines Signals zum Ereignishorizont hin mitgeteilt werden. Bei einer unendlich oft durchlaufenen Schleife bliebe ein solches Signal aus. Der in endlicher Eigenzeit den Ereignishorizont erreichende Beobachter würde in eben 3 Für die Programmierung haben wir hier das in der Programmiersprache Java 5 gebräuchliche Konstrukt einer foreachSchleife über Collections in einer vereinfachten Form hergenommen. 5 dieser endlichen Eigenzeit Gewissheit über das Vorliegen oder Nichtvorliegen einer unendlichen Programmschleife gewinnen können. In der geschilderten quickanddirty-Implementierung wäre ein solcher uendlicher Zyklus allerdings nur einmal für den Benutzer/Beobachter zu durchlaufen.4 Dennoch haben wir hier zumindest einen Denkansatz, der ausgehend von der realen Physik unseres Universums einen hyperbolisch beschleunigten Prozessor vorstellbar macht. Zusätzlich müsste unsere Implementierung nun dafür sorgen, dass bei jedem Schleifendurchlauf ein jeweils neues Objekt aus Set dem Prozessor zur Verfügung gestellt wird. Eine Speicherung dieser Objekte erforderte einen unendlich groÿen Speicherplatz, der bei einem angenommenen unendlichen Universum allerdings nicht notwendig allen verfügbaren Platz einnehmen müsste.5 Eine statische Speicherung dieser Objekte vorab käme nicht in Frage. Man könnte die für einen Zugri benötigten Objekte jedoch jeweils onthey erzeugen. Auf Grund der Endlichkeit der Lichtgeschwindigkeit dauerte der Zugri zwar immer länger, dennoch könnten theoretisch in der endlichen Eigenzeit des bewegten Benutzers alle Objekte in der unendlichen Schleife angesprochen werden.6 . . . und eine zugehörige Programmierumgebung Soweit zur Theorie. Eine Programmiersprache, die auf einer solchen Hardware aufsetzte, brauchte wir haben es oben schon erwähnt zur Interpretation der ZermeloFraenkelschen Regeln nur sehr wenige Konstrukte. Eine kleine Teilmenge der Programmiersprache Java genügte ja völlig. Programmiertechnisch könnte man auf eine vollständig implementierte Mengenlehre in Form eines vordenierten abstrakten Datentyps aufzusetzen, nämlich der (Software)Klasse Set. Alle relevanten mathematischen Objekte beginnend mit den natürlichen Zahlen lieÿen sich hierauf aufbauend nun im Rahmen selbstdenierter Datentypen zu realsieren und dies ist in der Softwaretechnik etwas ganz Alltägliches. Bezüglich der Didaktik erönen sich hier neue Horizonte: 1. Die natürlichen Zahlen werden explizit als das sichtbar, was sie schon immer gewesen sind, was aber in der langen Beschäftigung mit ihnen in Vergessenheit geraten ist: als das Ergebnis eines Abstraktionsprozesses. 2. Die Programmierung ist bei der Mathematik von Anfang an dabei und zwar voll integriert. Sie erweist sich als Vehikel für die Mathematik. 3. Die Mengenlehre ist nicht mehr nur eine aufgesetzte Sprechweise, die man nebenher benutzt. Sie ist vielmehr direkt implementiert in unserem (hypothetischen) Prozessors als Interpreter des abstrakten Datentyps Set. Die Beschreibung der Regeln geschieht in einer sehr einfachen prädikatenlogische Sprache. Ihre Einführung im Curriculum erfolgt damit schon früh und kann auf natürliche Weise motiviert werden. In unserer Programmiersprache erhält sie eine direkte Semantik. 4 Dieser müsste nebenbei bemerkt von einem extremen faustischen Erkenntniswillen getrieben sein. Abgesehen davon, dass es keine triviale Aufgabe sein dürfte, den Prozessor bezogen auf seine Eigenzeit (und die des restlichen Universums) unendlich lange am Laufen zu halten. 5 Die Hälfte oder 6 Jetzt fehlte nur ein Drittel oder ein Viertel etc. des Universums würden es auch tun. . . . noch der Geldgeber. 6 Didaktische Spinos Spätestens zu diesem Zeitpunkt werden i.d.R. reexhaft Bedenken gegen die formale Behandlung einer axiomatischen Mengenlehre laut. Sie gilt dann im Rahmen eines einführenden Textes in die Mathematik als zu schwierig und in Anfängervorlesungen auch zeitlich nicht zu bewältigen. Hierzu ist zu sagen, dass es uns gar nicht um eine ächendeckende Behandlung der Mengentheorie geht7 , sondern um einen Grabenstich, der uns nicht mehr (aber auch nicht weniger) als den benötigten abstrakten Datentypen liefert. Zu ersterem ist festzustellen, dass die Komplexität der prädikatenlogischen Beschreibung der axiomatischen Mengenlehre nicht über die hinaus geht, wie sie etwa auch für die formale Beschreibung eines Grenzwertes in der Analysis benötigt wird. Vier Quantoren werden für die Beschreibung der Konvergenz entsprechend dem Cauchyschen Konvergenzkriterium benötigt. Maximal drei Quantoren erfordert die formale Beschreibung der ZermeloAxiome für die Mengenlehre. Wenn es also üblich ist, dem mathematischen Anfänger bereits im ersten Semester regelmäÿig die Cauchyschen Konvergenzkriterien in Form der Epsilontik zuzumuten, dann sollte man auch die Axiomatik der Mengenlehre für von vorn herein zumutbar halten. Dies umsomehr, als dass zur Interpretation dieser prädikatenlogischen Ausdrücke die Semantik eines sehr kleines JavaSubsets genügt. Die Notwendigkeit, eine eigene prädikatenlogische Modelltheorie zu entwickeln, entfällt. Prädikatenlogik kann also eingeführt werden und direkt durch geeignete JavaFunktionen interpretiert werden. Dem Studienanfänger der Informatik kann damit die Bedeutung der Prädikatenlogik sehr viel direkter vermittelt werden, noch dazu mit Mitteln, die später zu seinem unmittelbaren Handwerkszeug gehören werden. Der Verweis auf mögliche Implementierungen der (mengentheoretischen) Prädikate in Tabellenform hier haben wir es i.W. nur mit einem einzigen Prädikat zu tun lässt bereits einen Ausblick auf das Konzept relationaler Datenbanken zu. Und zeigt an dieser Stelle noch einmal, dass das mengentheoretische Prädikat ∈ keiner intensionalen Semantik bedarf, sondern einzig vom äuÿeren Verhalten her seine Bedeutung erhält. Für den Informatiker ergibt sich in dem frühen Kontakt mit der axiomatischen Mengenlehre ein weiterer Vorteil: Sie bietet ihm einen ersten und intensiven Kontakt mit dem Konzept einer formalen Sprache, also mit etwas, was für den Informatiker z.B. in seiner Beschäftigung mit Programmiersprachen unverzichtbar ist. Haben sich diese gedachten Vorteile des didaktischen Konzeptes nun in der Praxis tatsächlich bewährt? In der Tat waren die Erfahrungen ermutigend. Insbesondere, wenn man berücksichtigt, dass die Fachhochschule nicht nur dem Abiturienten eine akademische Heimat geben will, sondern auch diejenigen erreichen will, die ohne die mathematischen Vorkenntnisse einer gymnasialen Oberstufe ihr Studium der Informatk beginnen. Die von den Anfängern mitgebrachten Vorkenntnisse sind demnach gerade auf mathematischem Gebiet höchst ungleich verteilt. Eine Anfängervorlesung ähnelt deshalb einer Fahrt zwischen Scylla und Charybdis. Man wird fast zwangsläug eine Gruppe unter und eine andere Gruppe überfordern. Vor diesem Hintergrund hat es sich bewährt, den Sto im geschilderten neuen Gewand zu präsentieren. Auf diese Weise ist er für alle Gruppen von Anfängern gleichermaÿen neu und anregend gewesen. 7 Den Experten wird auallen, dass gar nicht alle Axiome der Zermelo-Fraenkelschen Mengen- lehre eingesetzt werden, auÿer Acht gelassen wird u.a. das Auswahlaxiom. 7 So hat die Aussicht, sich wichtige Grundlagen der Mathematik souverän von den grundlegenden Axiomen der Mengenlehre her selbst erarbeiten zu können, mehr als einen unserer Studenten angetrieben, es wissen zu wollen. Selbstverständlich hat man auch eine Verantwortung gegenüber denjenigen Studenten, die, aus unterschiedlichen Gründen, einen solchen Steilkurs nicht vollständig mitgehen können. Hier erleichtern die in der Informatik üblichen Abstraktionen (im Sinne der Trennung zwischen dem Was und dem Wie) die Schaung geeigneter Aufsetzpunkte. Dies bedeutete in unserem Fall, dass man nach den Grundlagen der Mengentheorie, dessen vordergründiges Ziel letztlich die Implementierung eines speziellen Modells der natürlichen Zahlen (das Wie) gewesen ist, im Folgekapitel die natürlichen Zahlen nur noch als abstrakten Datentyp zu betrachten braucht. Er ist (bis auf sog. Isomorphie) eindeutig durch sein Verhalten (dem Was) bestimmt. So konnte dieses Folgekapitel ohne Probleme als EinsprungKapitel, als ein neuer Aufsetzpunkt benutzt werden, wenn man in der Mengenlehre selbst abgestürzt sein sollte. Auswirkungen auf das Selbstverständnis der Mathematik Die (mit unschuldiger Miene) postulierten Eigenschaften unseres hypothetischen Prozessors berühren letztendlich auch einige Grundlagenfragen der Mathematik. Oensichtlich benutzt unser Prozessor innite Methoden. Das geht natürlich wesentlich über das hinaus, was typischerweise akzeptiert wird. Hier mag es sich einmal lohnen, auf die Gründe einzugehen, die zu den klassischen Einschränkungen geführt haben. Reektieren diese doch in weiten Teilen die technischen Möglichkeiten, die einem (idealisiert) zur Verfügung standen. So haben wir Grund anzunehmen, dass die in der geometrischen Algebra typische Beschränkung der konstruktiven Mittel auf Zirkel und Lineal vor dem Hintergrund der Fähigkeiten zu sehen ist, diese Hilfsmittel mit einfachsten Mittel exakt zu konstruieren (oder zumindest die Illusion zu haben, dies tun zu können). Beim Zirkel ist dies oensichtlich. Für die Konstruktion eines Lineals kann man auf das wechselseitige Schleifen dreier Schleifsteine zurückgreifen.8 In ähnlicher Weise kann in der Theorie der formalen Sprachen die Beschränkung auf abzählbare Symbole durch das technische Unvermögen begründet werden, überabzählbar viele Symbole eektiv unterscheiden zu können. Dennoch lieÿe sich eine perfekte platonische Welt mit passenden Naturgesetzen vorstellen(Platon hat ja genau das getan), in der eben dies möglich ist. So lieÿen sich beliebige reelle Zahlen durch Streckenabschnitte repräsentieren, die sich beliebig wenig voneinander unterscheiden dürften und dennoch eektiv unterschieden werden könnten. Mit Hilfe der stereographischen Projektion lieÿen sich diese Zahldarstellungen sogar so kompaktizieren, dass man alle reellen Zahlen auf einen Blick erfassen könnte. Geht man in dieser platonischen Physik noch einen Schritt weiter und stellt sich also einen Prozessor vor, dessen Befehlszyklus hyperbolisch beschleunigt abläuft, dann haben wir es mit einer Technik zu tun, in der z.B. beliebige Fragen zu der Dezimalbruchentwicklung von π eektiv beantwortet werden könnten. Die insbesondere vom Konstruktivismus praktizierte Beschränkung auf nite Methoden erscheint unter diesem Aspekt philosophisch nicht zwingend. Vor allem dann, wenn man die 8 Wir vernachlässigen hierbei einmal die Eekte der Relativitätstheorie in Form einer Krüm- mung des Raumes selbst, die natürlich nicht weggeschlien werden kann, und sehen auch ab von den Eekten des Atomismus und seiner Unschärfen im Rahmen der quantenmechanischen Phänomene. 8 Mathematik als unabhängig von den herrschenden Naturgesetzen ansieht.9 Letztendlich bieten damit so hoe ich die Konzepte der Informatik (gekoppelt mit den hypothetischen technischen Erweiterung) eine neue und erfrischende Sicht auf die Mathematik.10 9 Stellvertretend möchte ich hierfür auf die Ausführungen von Roger Penrose Do natural num- bers need the physical world? in seinem Buch The Road to Reality verweisen. 10 Die hier geschilderte Sicht ist nicht die einzig mögliche Sicht auf die Mathematik. Immer noch sehr lesenswert in diesem Zusammenhang ist die Kontroverse zwischen René Thom und Jean Dieudonné über die moderne Mathematik aus den 70er Jahren des letzten Jahrhunderts. Einen Gedanken Dieudonnés aufgreifend, dass es viel einfacher sei, abstrakte Mathematik zu lehren als eine gute Intuition, möchte ich festhalten, dass es mir hier genau nicht darum geht, abstrakte Mathematik zu lehren, sondern ein Gefühl für den Prozess der Abstrahierung wachzurufen, wie er in Informatik und Mathematik gleichermaÿen wesentlich ist. Kapitel 1 Präliminarien: Zahlen 1.1 Welche Objekte dürfen es denn sein? Jede Wissenschaft hat ihren sog. Objektbereich, mit dem sie sich beschäftigt: Die Chemie z.B. betrachtet Atome und Moleküle, die Biologie die Panzen und Tiere und die Literaturwissenschaft die geschriebenen Bücher, Aufsätze und sonstigen Dokumente. Aufgabe dieser Wissenschaften ist es, die Eigenschaften der jeweiligen für sie relevanten Objekte zu beschreiben und ihre Beziehungen untereinander zu erforschen. So werden in der Chemie u.a. die Atomgewichte bestimmt, es wird erforscht aus welchen Atomen welche Moleküle gebildet werden können und welche anderen Moleküle (als Katalysatoren) dabei gegebenenfalls zugegen sein müssen (wodurch sich mannigfache Beziehungen zwischen den Objekten der Chemie, den Molekülen, ergeben). In der Literaturwissenschaft untersucht man z.B. Typologie, Aufbau, stilistische Mittel, Wortwahl der Dokumente und evtl. deren Verwandtschaft untereinander und gegenseitige Beeinussung. Die Objekte der Mathematik sind zunächst einmal die Zahlen (siehe aber auch den Beginn des nächsten Kapitels). Diese unterscheiden sich von den Objekten anderer Wissenschaften in zwei wesentlichen Gesichtspunkten: sie sind von vornherein abstrakt und es sind ihrer unendlich viele (und es gibt gute Gründe anzunehmen, nicht nur einfach unendlich viele sowie man sich in einem unendlichen Weltall unendlich viel Atome vorstellen könnte sondern im wahrsten Wortsinne potenziert unendlich viele). Hinzu kommt, dass die meisten Eigenschaften der Zahlen sich als verkappte Beziehungen zwischen den Zahlen herausstellen. Die Eigenschaft einer Zahl Primzahl zu sein outet sich demnach in Wirklichkeit als das Bestehen (oder besser Nichtbestehen) von Teilbarkeitsbeziehungen zu anderen Zahlen. Dies ist bereits ein erstes Indiz dafür, dass es bei den Zahlen tatsächlich nicht so sehr um ihre einzelnen Eigenschaften geht, ihr Wesen, sondern dass die Zahlen durch ihr Verhalten charakterisiert werden und durch ihre Beziehungen zueinander. Es sind also die sog. systemischen Eigenschaften, die die Zahlen letztlich charakterisieren. Die Frage was sind Zahlen sollte also verstanden werden im Sinne von wie verhalten sich Zahlen. Damit ist gleichzeitig klar, dass Zahlen eigentlich von vornherein nur als abstrakte Objekte aufzufassen sind. Interessanterweise ist uns dies seit frühester Kindheit mit dem Erfassen und Erlernen des Zahlbegries so in Fleisch und Blut übergegangen, dass wir hierüber keinen Gedanken mehr verschwenden und in der Zwischenzeit die Zahlen als etwas ganz Konkretes empnden. Dies mag damit zusammenhängen, 9 10 KAPITEL 1. PRÄLIMINARIEN: ZAHLEN dass jeder Mensch seine ganz persönlichen geistigen Repräsentationen, Vorstellungen, der Zahlen benutzt.(s. Zitat aus Feynman Biographie S.98 u. 167). Abstraktion steht also eigentlich schon am Beginn des Rechnens mit Zahlen und beginnt nicht erst, wenn man sich mit allgemeinen Formeln, mit algebraischen Gruppen, mit Vektorräumen etc. beschäftigt. Die Beschäftigung mit Zahlen gehört untrennbar zur menschlichen Geschichte. Zahlzeichen gehören zu den ältesten Spuren menschlicher Schrift. Letztlich ist es das mathematische Denken (und nicht besondere Gefühle), das den Menschen vom Tier unterscheidet. Es gibt nur Mathematiker und Idioten, so ist es einmal beschrieben worden (wobei diese Aussage so zu verstehen ist, dass jeder, der kein Idiot ist, die prinzipiellen Fähigkeiten eines Mathematikers besetzt, nicht etwa umgekehrt). Kommen Sie deshalb nie mit der Ausrede, Sie seien mathematisch unbegabt. 1.2 Darf es auch etwas mehr sein? Wir sollten uns kurz klarmachen, dass das, was als Zahl durchgeht, selbst immer liberaler gesehen wurde. Bei den Griechen z.B. ng die Zahl erst bei 2 an und nicht bei der 1. So heiÿt es bei Euklid: Zahl ist die aus Einheiten zusammengesetzte Menge. Und da die Einheit nicht aus Einheiten zusammengesetzt ist, fassen Euklid und Aristoteles sie nicht als Zahl auf, sondern als Grundlage des Zählens, der Ursprung der Zahl. Brüche wurden bei den alten Griechen ebenfalls nicht als Zahlen angesehen. Sie sprachen stattdessen von Proportionen. Die Null erhielt zunächst bei den indischen Mathematikern Bürgerrechte im Reich der Zahlen. Die negativen Zahlen setzten sich in der Renaissance durch. (Die alten Babylonier gaben negativen Zahlen die Bedeutung von Schulden). Brüche werden systematisch erst in der Neuzeit als rationale Zahlen eingeführt. Ein besonderes Problem stellen die Irrationalzahlen dar. Lassen sich die rationalen Zahlen als Brüche ganzer Zahlen noch (zumindest theoretisch) auf eine endliche Weise vollständig darstellen (s.u.), so ist diese Möglichkeit bei den Irrationalzahlen nicht mehr gegeben. Ihre Dezimalbruchentwicklungen sind nichtperiodisch. Deswegen schrieb man noch zu Beginn der Neuzeit: So wie eine unendliche Zahl keine Zahl ist, so ist eine irrationale Zahl keine wahre Zahl, weil sie sozusagen unter einem Nebel der Unendlichkeit verborgen ist. Bereits die Pythagoreer hatten ihre liebe Not mit den Irrationalzahlen: nach ihren Vorstellungen sollten alle Strecken kommensurabel sein, d.h. es sollte für zwei beliebige Strecken stets eine (kleinere) Strecke geben, die in beiden Strecken ganzzahlig enthalten ist. Dies hätte zur Folge, dass ihre Proportionen stets in einem rationalen Verhältnis stünden. Die Entdeckung irrationaler Proportionen löste eine regelrechte Weltanschauungskrise aus. Mit der Einbeziehung der Irrationalzahlen sind die rationalen Zahlen erweitert worden zu den sog. reellen Zahlen. Aber auch zu diesem Zahlenbereich sind weitere neue Zahlen hinzugekommen, nämlich die imaginären Zahlen. Auch sie tauchen das erste Mal in der Renaissance auf in dem Bemühen, kubische Gleichungen zu lösen (Cardano). Man rechnete mit Ihnen, gab aber zu, dass man sich von imaginären Gröÿen noch keine Vorstellungen machen könne (Descartes). Eine geometrische Deutung dieser Zahlen als Punkte der Zahlenebene wurde dann von Gauss entwickelt, womit auch die komplexen Zahlen als vollwertige Zahlen angesehen wurden. Aber auch der Bereich der komplexen Zahlen ist noch zweimal zu hyperkomplexen Systemen erweitert worden: den Quaternionen (Hamilton) und den Caley 1.3. ZAHLDARSTELLUNGEN 11 Zahlen. Damit sind die Möglichkeiten, den Zahlenbereich zu erweitern an ihr denitives Ende gekommen (wie sich mit mathematischer HighTech beweisen lässt). Mit den letzten Erweiterungen hat man einen gewissen Preis zahlen müssen, indem man sukzessiv auf gewisse Eigenschaften verzichten musste: bei den komplexen Zahlen verliert man die Möglichkeit, Zahlen der Gröÿe nach zu ordnen, bei den Quaternionen muss man auf das allgemeine Kommutativgesetz bei der Multiplikation verzichten und bei den CaleyZahlen sogar auf das Assoziativgesetz. Unter algebraischen Gesichtspunkten kann man die komplexen Zahlen als den vollkommensten Zahlenbereich ansehen. Sie sind mit einigen physikalischen Theorien so eng verzahnt, dass diese Theorien ohne sie gar nicht formuliert werden könnten (z.B. Quantenmechanik). So gesehen kommen die komplexen Zahlen durchaus in der Natur vor. 1.3 Zahldarstellungen Es hat im Laufe des Geschichte ganz unterschiedliche Darstellungen der Zahlen gegeben. Die Strichnotation (die wir z.B. auch noch beim Auszählen von Stimmen benutzen) ist eine der ersten und einfachsten für die natürlichen Zahlen. Man stellt selbstverständlich schnell fest, dass man zusätzliche Symbole zur Abkürzung groÿer Zahlen benötigt. Das Zahlensystem der Griechen war von dieser Art. bekannter ist das heute noch in Einzelfällen benutzte System der römischen Zahlen. Für eine efziente Arithmetik ist ein solches System denkbar ungeeignet. (Versuchen Sie nur einmal zwei römische Zahlen miteinander zu multiplizieren). Der Durchbruch zu einem fortschrittlichen Positionssystem erfolgte bereits vor ca. 2000 Jahren in Indien. Da ein solches System ein Zeichen für die Null erfordert, ist es kein Zufall, dass die Null bei den Indern schon früh als Zahl akzeptiert wurde (s.o.). Seit Adam Riese ist es in unserem Kulturkreis das System der Wahl. Unter Einbeziehung des Minuszeichens und der Bruchnotation (ggfs. als periodischer Dezimalbruch) kann man damit jede rationale Zahl darstellen (i.A. auf mehrere Weisen). Bemerkungen zur maschinellen Verarbeitung von Zahlen Das dezimale Stellenwertsystem ist in jüngerer Zeit in Zusammenhang mit der elektronischen Datenverarbeitung ergänzt worden zu einem dualen bzw. hexadezimalen Stellenwertsystem. Die Darstellung negativer Zahlen erfolgt dabei nicht durch ein separates Minuszeichen, sondern durch eine sog. Komplementdarstellung (häug Zweierkomplement). Man erhält hierdurch einen einfacheren maschinellen Prozessor. Interessanterweise benutzt man in der EDV unterschiedliche Repräsentationen für ganze und rationale Zahlen. Letztere werden in sog. Flieÿkommadarstellungen repräsentiert. Einerseits führt dies zu einer gröÿeren Performanz, andererseits hat man aber hierfür einen Preis in Form von Rundungsfehlern zu bezahlen. (Genaueres erfahren Sie in den Spezialvorlesungen des Grundstudiums.) 1.4 Analoge Darstellungen In der Proportionenlehre der Griechen nden wir einen Ansatz, Zahlen mit der Länge einer Strecke regelrecht zu identizieren. (Gedanklich sind die Griechen allerdings nicht bis zu diesem Punkt gegangen). Hierzu nimmt man eine beliebige Gerade, legt 12 KAPITEL 1. PRÄLIMINARIEN: ZAHLEN willkürlich einen Nullpunkt fest und trägt eine frei gewählte Strecke vom Nullpunkt auf der Geraden ab, deren Länge die Eins repräsentiert. Der Vorteil dieses Ansatzes besteht darin, dass man damit auf einen Schlag sämtliche reellen Zahlen erhält. Man hat natürlich das praktische Problem, die Zahlen genau abzulesen. Die arithmetischen Operationen in dieser Darstellung ergeben sich bzgl. der Addition und Subtraktion durch einfache Streckenaddition bzw. Subtraktion. Die Multiplikation und Division lassen sich einfach mit Hilfe der sog. Strahlensätze geometrisch realisieren. Streckenverhältnisse sind demnach genau dann kommensurabel, haben also ein gemeinsames kleineres Maÿ, das jeweils ganzzahlig in ihnen enthalten ist (s.o.), wenn die durch die Strecken repräsentierten Zahlen ein rationales Verhältnis bilden, wenn also die Division der beiden Zahlen ein rationale Zahl ergibt. und y die beiden betrachteten Strecken und sei ε ein gemeinsames x = n · ε und y = m · ε mit ganzen Zahlen n und m. Dann ist x : y = (n · ε) : (m · ε) = n : m wie sich durch Kürzen von ε sofort ergibt. Seien x te also Maÿ. Es geloensichtlich das Verhältnis x : y = n : m also rational, x und y den Wert ε = x/n = y/m wählen x : n = y : m). Damit ist nämlich n · ε = n · x/n = x Ist umgekehrt für beliebig vorgegebenes x und y dann können wir als ein gemeinsames Maÿ von x : y = n : m gilt m · ε = m · y/m = y . (wegen und nämlich Wenn man nun Grund zur Annahme hat, dass zwei Strecken x und y ein gemeinsames Maÿ ε haben (also x = n · ε und y = m · ε), dann kann dieses gemeinsame Maÿ konstruktiv auf folgende Weise gefunden werden: i) Wir ziehen die kleinere Strecke (dies sei y ) von der gröÿeren (also von x) so lange ab, bis ein Rest kleiner als y bleibt. Wenn man Glück hat, geht es schon beim ersten Mal ohne Rest auf und dann ist y selbst das gemeinsame Maÿ. ii) In den meisten Fällen bleibt aber ein Rest ungleich Null wir bezeichnen ihn mit r0 der aber ebenfalls ein Vielfaches von ε sein muss. Das heiÿt, auch y und r0 haben ε als gemeinsames Maÿ. r0 tatsächlich ein Vielfaches von ε ist, erkennt man sofort wenn man ihn als die Difx − p · y schreibt. p sei also die Häugkeit, mit der man y von x ganzzahlig enthalten ist. x − p · y ist aber nach Voraussetzung gleich n · ε − p · m · ε. Wir können jetzt ε einfach ausklammern und erhalten (n − p · m) · ε, was oensichtlich ein ganzzahliges Vielfaches von ε ist. Dass ferenz iii) Man wiederholt das Verfahren jetzt mit y und r0 als neuen Strecken und erhält wieder einen Rest, den wir mit r1 bezeichnen. Dieser ist (wenn er nicht schon Null sein sollte) aus denselben Gründen wie in ii) wieder ein Vielfaches von ε. Mit den auf analoge Weise immer wieder neu gewonnenen Resten r2 , r3 , · · · erhalten wir immer kleinere Vielfache von ε, so dass das Verfahren irgendwann mit einem Rest = 0 enden muss. Der zweitletzte Rest muss dann das gesuchte gemeinsame Maÿ von x und y sein. (Genaugenommen nden wir auf diese Weise das gröÿte gemeinsame Maÿ von x und y . Dies kann ein Vielfaches von ε sein, dann nämlich wenn n und m nicht teilerfremd sind.) Das geschilderte Verfahren wurde genau so von den griechischen Handwerkern angewendet, um ein gemeinsames Maÿ für zwei gegebene Strecken zu nden (Verfahren der Wechselwegnahme). Euklid hat es in seinen Elementen beschrieben und ist deshalb unter dem Namen Euklidscher Algorithmus bekannt. 1.5. IRRATIONALZAHLEN 13 Exkurs: Pech für die Pythagoreer Kommen wir noch einmal zu den Pythagoreern. Sie gründeten ihre Philosophie auf die ganzen Zahlen (Alles ist Zahl) und waren der Überzeugung, dass ausnahmslos alle Strecken kommensurabel seien. Ausgerechnet beim Pentagramm, dem regelmäÿigen Fünfeck, das als Ordenssymbol der Pythagoreer galt, fand einer der Pythagoreer (vermutlich Hippasus) zwei nicht kommensurable Strecken. Eigentlich brach damit das ganze philosophische Gebäude der Pythagoreer zusammen. Wie reagierte man darauf? Bemerkenswert modern: Man versuchte diese Erkenntnis einfach nach auÿen hin zu verschweigen und tat so, als sei nichts geschehen. Als es doch einer ausplauderte, wurde dieser so die Legende auf oenem Meer ins Wasser geworfen. Dass es im Pentagramm nicht kommensurable Strecken gibt, zeigt man wie folgt: man betrachtet eine Seite und eine Diagonale und führt den Euklidschen Algorithmus für die- se beiden Strecken durch. Dabei stellt man fest, dass in diesem Fall der Algorithmus nicht terminieren kann, was er aber müsste, wenn diese Strecken kommensurabel wären (s.o). Die Schlussfolgerung kann nur lauten, dass eine Diagonale und eine Seite des Pentagramms kein gemeinsames Maÿ haben. Modern gesprochen kann mn sagen, dass ihr Verhältnis eine irrationale Zahl ist (nämlich 1.5 1/2(1 + √ 5)). Irrationalzahlen Mit der Existenz einer irrationalen Zahl erhalten wir sofort unendlich viele irrationale Zahlen: mit ι ist notwendig auch ι + p/q (für jedes p/q mit ganzzahligen p und q ) irrational. Irritierend ist, dass es überabzählbar viele irrationale Zahlen gibt und das die Beschreibung einer irrationalen Zahl anders als die einer rationalen einen sehr komplexen mathematischen Apparat erfordert (wenn man nicht wie oben Zuucht bei der Anschauung der Streckenlängen sucht). In einem wichtigen Sinne kann man mit irrationalen Zahlen auch nicht rechnen: jede Darstellung im Dezimalsystem kann praktisch nur endlich viele Dezimalstellen berücksichtigen. Sind Irrationalzahlen deshalb völlig irrelevant? Nein, denn in vielen Rechnungen kann man sie zunächst symbolisch mitführen mit anderen Irrationalzahlen symbolisch verrechnen, so dass im Endeekt doch ein rationales Ergebnis die Folge ist, oder zumindest ein Ausdruck entstanden ist, der näherungsweise gut zu berechnen ist, den man aber ohne Umweg über die Irrationalzahlen so nie hätte gewinnen können. Auch wenn dem digitalen Computer die Irrationalzahlen also völlig unzugänglich sind, so sind sie in der Aufbereitung eines Problems für die maschinelle Verarbeitung durch den menschlichen Analytiker doch unverzichtbar. √ 2 ist irrational Das bekannteste √ Beispiel einer Irrationalzahl in der Schulmathematik ist ohne Zweifel die Zahl 2. Ein entsprechender Beweis (als Widerspruchsbeweis) lässt sich leicht führen und wir werden ihn deshalb hier kurz präsentieren: Zur Erinnerung: ein Widerspruchsbeweis verläuft so, dass man das Gegenteil des zu beweisenden Sachverhaltes annimmt und hieraus einen inneren Widerspruch folgert, was dann nur bedeuten kann, dass das angenommene Gegenteil (der zu beweisenden Aussage) notwendig falsch sein muss. Nehmen wir also in unserem Falle an, dass √ 2 rational ist, dass es also eine Dar- 14 KAPITEL 1. PRÄLIMINARIEN: ZAHLEN stellung der Form √ 2= p q für geeignete ganze Zahlen p und q gibt. Wir können dann ohne Probleme darüber hinaus annehmen, dass p und q schon teilerfremd sind. (Wären sie es nämlich nicht, dann könnte man den Bruch p/q solange kürzen, bis Zähler und Nenner teilerfremd sind, und mit dem neuen gekürzten Zähler und Nenner weiterrechnen). Wenn wir demnach annehmen können, dass p und q teilerfremd sind, dann dürfen jedenfalls nicht beide ein Vielfaches von 2 sein, denn ansonsten wären sie nicht teilerfremd. Beginnen wir nun unsere Überlegungen mit der Gleichung √ p 2= q die wir links und rechts jeweils quadrieren, so dass das Gleichheitszeichen erhalten bleibt: p2 2= 2 q Damit erhalten wir p2 = 2 · q 2 . p2 ist also durch 2 teilbar. Wenn wir nun noch berücksichtigen, dass das Quadrat einer ungeraden Zahl notwendig ungerade ist, bleibt für p nur die Möglichkeit, eine gerade Zahl zu sein, ansonsten könnte ja p2 nicht gerade sein. Sei also p = 2 · n. Dann ist p2 = 4 · n2 . Damit ist 4 · n2 = p 2 = 2 · q 2 , und wenn wir links und rechts durch 2 dividieren, ergibt sich: 2 · n2 = q 2 . Jetzt können wir aber mit genau derselben Argumentation für p folgern, dass auch q eine gerade Zahl sein muss, da ansonsten das Quadrat von q keine gerade Zahl nämlich 2 · n2 ergeben könnte. So sind wir nun bei der Schlussfolgerung gelandet, dass sowohl p als auch q gerade Zahlen sein müssten, ganz im Gegensatz zu unserem √ Ausgangspunkt. Dies kann nur bedeuten, dass unsere ursprüngliche Annahme, 2 sei rational, falsch gewesen sein muss. 1.6 Exkurs: Die Zahlenerweiterungen von N bis R Man könnte den Aufbau des Zahlenssystems ausgehend von den natürlichen Zahlen vergleichen mit einer zunehmenden Nutzbarmachung des Zahlenstrahls. So hat man es bei der Betrachtung der natürlichen Zahlen N nur mit einer nach rechts hin oenen Folge von Punkten zu tun. Diese werden bei Einführung der negativen Zahlen Z nach links hin gespiegelt. Die Erweiterung von Z zu den rationalen Zahlen bedeutet die Einführung gleichmäÿiger Raster der Länge 1/q für jede natürliche Zahl q auf dem Zahlenstrahl. Diese Raster können beliebig klein sein, so dass man den Zahlenstrahl damit beliebig fein ausfüllen kann. Dennoch zeigt sich, dass damit viele Zahlen (in einem präzisen Sinne kann man sogar sagen die allermeisten) noch nicht erfasst sind. Es handelt sich hierbei um die sog. irrationalen Zahlen, die sich demnach ebenfalls auf dem Zahlenstrahl wiedernden. 1.7. KOMPLEXE ZAHLEN 15 Man kann die so betrachteten Zahlerweiterungen synchron zur Lösbarkeit gewisser Gleichungen sehen: 1 · x + n = m ist lösbar mit einem x ∈ N für alle m, n ∈ N, m = n, 1 · x + n = m ist lösbar mit einem x ∈ Z für beliebige m, n ∈ N p · x + n = m ist lösbar mit einem x ∈ Q für beliebige m, n ∈ N und p ∈ Z x + p · x + n = m ist lösbar mit einem x ∈ R für beliebige m, n ∈ N und p ∈ Z ( p )2 mit = (n − m). 2 2 Nun stecken in der letzten Gleichung noch zwei oene Enden. Eine ist explizit in ( )2 der Form der dort stehenden einschränkenden Bedingung, dass p2 = (n − m). Ein zweites Ende ist etwas verkappt, da wir hier nur eine quadratische Gleichung (ein Spezialfall einer sog. algebraischen Gleichung) betrachten. Als Lösungen solcher algebraischen Gleichungen erhalten wir zwar wie gesehen in der Tat irrationale Zahlen als Lösung aber (bei weitem) nicht alle irrationalen Zahlen. Die irrationalen Zahlen lassen sich√also selbst noch einmal unterteilen in sog. algebraische irrationale Zahlen wie z.B. 2 und in transzendente Zahlen, deren bekannteste Vertreter die Zahlen e und π sind, jeweils gewonnen aus e=1+ 1 1 1 + + + ··· 1·2 1·2·3 1·2·3·4 und 1 1 1 1 + − + − ··· . 3 5 7 9 Die letzte Formel bietet nebenbei bemerkt eine näherungsweise Lösung für die Quadratur des Kreises aber eben nur eine näherungsweise. π/4 = 1 − Nun werden wir das oene Ende der algebraischen Zahlen hin zu den transzendenten Zahlen hier nicht behandeln können, das erste oene Ende, die bedingungslose Lösbarkeit algebraischer Gleichungen, werden wir in einer abschlieÿenden Komplettierung unseres Zahlenbereiches noch behandeln. 1.7 Komplexe Zahlen Historisch gesehen war es nun nicht die Lösbarkeit oder Unlösbarkeit gewisser quadratischer Gleichungen, die man problematisierte: waren quadratische Gleichungen unlösbar, dann konnte man das gleichsam direkt sehen und wurde deshalb nicht als Problem empfunden. Zum eigentlichen Problem wurden die kubischen Gleichungen, also Gleichungen der Form x3 + ax2 + bx + c = 0. Solche Gleichungen haben unter Garantie stets mindestens eine Lösung, wie man sich an Hand des Graphen der Funktion x3 + ax2 + bx + c = y sofort klar machen kann. Die in der Renaissance gefundenen Lösungsalgorithmen (verbunden mit den Namen Tartaglia, Cardano, Bombelli u.a.) hatten als Zwischen ergebnisse Terme, die Quadratwurzeln aus negativen Zahlen enthielten. Die Endergebnisse waren also 16 KAPITEL 1. PRÄLIMINARIEN: ZAHLEN korrekt (und waren auch aus dem Bereich der reellen Zahlen), doch der Weg dahin führte durch einen Zahlenbereich, der irgendwie imaginär empfunden wurde. So erhalten wir nach den Verfahren jener Mathematiker für die (einzige positive) Lösung der Gleichung x3 = 15x + 4 die Lösungsformel x= √ √ √ √ 3 3 2 + −121 + 2 − −121, die, wenn (in unseren heutigen Bezeichnungsweisen) x = (2 + i) + (2 − i) = 4 ergibt. Die Ausdrücke 2 + i oder 2 − i bilden erste Beispiele der sog. komplexen Zahlen. Man konnte also mit den komplexen zahlen schon rechnen, bevor sie als Zahlen überhaupt anerkannt wurden. Und tatsächlich ist das Rechnen mit diesen Zahlen denkbar einfach. Im Grunde genügt es, eine einzige Zahl nämlich i den schon vorhandenen reellen Zahlen explizit hinzuzufügen, wobei i die Eigenschaften haben soll, dass ihr Quadrat gleich -1 ist. Ansonsten rechnet mit mit dieser Zahl unter Benutzung aller von den reellen Zahlen her bekannten Rechenregeln. Man kann also die Zahl i mit anderen Zahlen addieren, multiplizieren, kann Summanden bzw. Faktoren vertauschen, kann unterschiedliche Summanden unterschiedlich klammern, kann gemeinsame Faktoren ausklammern u.v.a.m. Streng genommen braucht man also für das praktische Rechnen mit komplexen Zahlen auÿer der Regel, dass i2 = −1 ist, nichts Neues dazuzulernen. Es ist klar, dass man durch die Rechenoperationen neben der bewuÿt eingeführten neuen Zahl i nun automatisch viele neue Zahlen erhält, etwa i + i, 3 + i oder 2 + 3 · i + 4 · i · i. Die Gesamtheit aller Zahlen, die man hierdurch erhält, nennt man wie schon gesagt komplexe Zahlen. Unter Benutzung der bekannten Rechenregeln erhalten wir sofort als erstes Ergebnis, dass sich jede komplexe Zahl z in die Form z =a+b·i überführen lässt, wobei a und b geeignete reelle Gröÿen sind. Um dies zu zeigen, genügt es strenggenommen, wenn wir zeigen, dass die Summe bzw. das Produkt je zweier komplexer Zahlen, die jeweils schon diese Form haben, wieder in diese Form überführt werden können. Wir führen diese Berechnungen (Umformungen) für beide Fälle einmal ausführlich aus: Es sei also z1 = a1 + b1 i und z2 = a2 + b2 i. dann gilt einerseits für die Addition: z1 + z2 = commut. = distr. = assoc. = a1 + b1 i + a2 + b2 i a1 + a2 + b1 i + b2 i a1 + a2 + (b1 + b2 )i (a1 + a2 ) + (b1 + b2 )i. 1.7. KOMPLEXE ZAHLEN 17 und andererseits für die Multiplikation: z1 · z2 (a1 + b1 i) · (a2 + b2 i) = distr. a1 · a2 + b1 i · a2 + a1 · b2 i + b1 i · b2 i = commut. = (i·i = −1) a1 a2 + b1 a2 i + a1 b2 i + b1 b2 ii = a1 a2 + b1 a2 i + a1 b2 i − b1 b2 commut. a1 a2 − b1 b2 + b1 a2 i + a1 b2 i = distr. = a1 a2 − b1 b2 + (b1 a2 + a1 b2 )i. Letztlich ist es die Regel i2 = −1, die dazu führt, dass man keine höheren Potenzen von i bei der Darstellung der komplexen benötigt. Führt man die komplexen Zahlen in der beschriebenen Weise ein, dann ist man jetzt oensichtlich in der Lage alle Berechnungen mit komplexen Zahlen praktisch durchzuführen. Eine Anschauung von den komplexen Zahlen hat man hierdurch natürlich nicht gewonnen. In der Informatik macht man ein solches Vorgehen zu einer Philosophie, in dem man sog. abstrakten Datentypen einführt und betrachtet, bei denen es nur auf das äussere Verhalten ankommt und nicht so sehr auf einen inneren Mechanismus, der das beobachtete Verhalten letztlich realisiert. In diesem Sinne könnte man die in der obigen Weise eingeführten komplexen Zahlen als einen abstrakten Datentyp ansehen. Für ein mechanisches Rechnen mit den komplexen Zahlen ist dies auch völlig hinreichend. Schlieÿlich sind abstrakte Datentypen ja für den Computer geschaen worden. Für ein echtes inhaltliches Verständnis der komplexen Zahlen ist dies jedoch zu wenig. Hier können geeignete Modelle der komplexen Zahlen über das maschinelle Bearbeiten hinaus sehr hilfreich sein, die komplexen Zahlen zu verstehen und wichtige Aussagen über die komplexen Zahlen direkt zu sehen. Gleichzeitig wird den komplexen Zahlen damit etwas von dem Mystizismus genommen, der im Begri imaginäre Einheit für die Zahl i noch durchscheint. Die Gausssche Zahlenebene Besonders geeignet ist die seit Gauss gebräuchliche Darstellung der komplexen Zahlen in der sog. Zahlenebene. In diesem Modell sind die komplexen Zahlen nichts anderes als Vektoren in der Ebene (der man ein kartesisches Koordinatensystem mitgegeben hat). Die Zahl i ist dann der Vektor (0, 1) und eine allgemeine komplexe Zahl a + ib wird zum Vektor (a, b) in der Ebene. Die reellen Zahlen a sind in diesem Bild identisch mit den Vektoren (a, 0) d.h. identisch mit den Punkten auf der xAchse. Interessant ist nun natürlich, wie die Addition und Multiplikation in diesem Bild oder Modell aussehen. Am einfachsten ist die Addition zu beschreiben: sie entspricht einfach der Vektoraddition. Etwas komplizierter liegt der Sachverhalt bei der Multiplikation: zwei Vektoren in der Ebene werden multipliziert, indem man denjenigen Vektor bildet, dessen Länge gebildet wird aus dem Produkt der Längen beiden Ausgangsvektoren, und der in demjenigen Winkel zur xAchse ausgerichtet wird, der aus der Summe der Winkel der Ausgangsvektoren gebildet wird. Addition und Multiplikation der komplexen Zahlen erhalten somit eine leicht nachzuvollziehende geometrische Bedeutung. Im Rahmen dieses Modells lässt sich jetzt 18 KAPITEL 1. PRÄLIMINARIEN: ZAHLEN umgekehrt leicht nachweisen, dass der Vektor (0, 1) (als Repräsentant der Zahl i) zum Quadrat genommen den Vektor (−1, 0) (als Repräsentant der reellen Zahl -1) ergibt. Der Ergebnisvektor aus (0, 1) · (0, 1) hat nämlich die Länge 1, da (0, 1) die Länge 1 hat, deren Quadrat natürlich wieder 1 ergibt. Der Winkel von (0, 1) zur xAchse beträgt 90◦ , der in diesem Fall bei der Multiplikation mit sich selbst zu verdoppeln ist. Als Ergebnis der Multiplikation von (0, 1) mit sich selbst erhalten wir also einen Vektor der Länge 1 der zu xAchse einen Winkel von 180◦ einnimmt. Das ist oensichtlich der Vektor (−1, 0). Damit ist in diesem Modell automatisch i2 = −1. Kapitel 2 Mengenlehre: die Sprache der Mathematik Zu Beginn des ersten Kapitels sprachen wir über die unterschiedlichen Objektbereiche in den verschiedenen Wissenschaften. Solche unterschiedlichen Objektbereiche haben mehr oder weniger subtile Auswirkungen auf die Sprachen, die in den jeweiligen Wissenschaften gesprochen werden. Nun sind die Sprachen, die man in den Wissenschaften spricht in den seltensten Fällen selbst Gegenstand der Untersuchungen in diesen Wissenschaften. Die benutzte Sprache dient vielmehr als Werkzeug für die Zwecke der Wissenschaft. So spielt sie eine ähnliche Rolle wie das Geologenhämmerchen für den Geologen. Mit Hilfe des Geologenhämmerchens können die eigentlich interessierenden Objekte (i.d. Fall Mineralien) untersucht werden, das Geologenhämmerchen an sich ist für den Geologen kein interessantes Objekt. Auch hier zeigt sich eine gewisse Sonderstellung der Mathematik. Denn die in der Mathematik benutzte Sprache kann in der Mathematik sowohl Gegenstand der Untersuchung sein als auch Mittel zur Beschreibung anderer mathematischer Sachverhalte (in denen es typischerweise um Zahlen geht). Das hat sie interessanterweise mit der Informatik gemein, auch dort gibt es Objekte, wie z.B. Compiler, die dieselbe Doppelrolle einnehmen: direktes Objekt der Untersuchung einerseits und Hilfsmittel andererseits. Um nun den Einstieg in die Besonderheiten der Sprache der Mathematik etwas einfacher zu gestalten, beginnen wir mit einer kurzen Aurischung dessen, was wir im Deutschunterricht gelernt haben (sollten). Unser Vorgehen weicht in diesem Kapitel etwas vom üblichen Weg ab. Die Gründe hierfür liegen darin, dass 1. die Mengenlehre als das sichtbar werden soll, das sie tatsächlich ist: nicht das Sahnehäubchen, das nachträglich über die Mathematik drübergestülpt wird, sondern die Hefe, die die Mathematik von innen her aufgehen lässt, 2. das gewählte Vorgehen die wichtige Methodik der Trennung zwischen dem Was und dem Wie in der Informatik an einem Paradebeispiel verdeutlicht, 3. in einem einfachen überschaubaren Bereich einige zentrale Konzepte der theoretischen Informatik, formale Grammatiken, zwanglos eingeführt werden können, 19 20 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK 4. die Interpretation prädikatenlogischer Konzepte mit für Informatiker naheliegenden Mitteln des Funktionsaufrufes gestaltet wird. Wir gehen bei all diesen Vorteilen nur ein geringes Risiko für den Studenten ein, da die im vorliegenden Kapitel gewählte Implementierung des Zahlbegris mit den Mitteln der Mengenlehre als abstrakter Datentyp ein inhaltlich problemloses Neuaufsetzen im Folgekapitel ermöglicht. 2.1 Grammatikalische Vorbereitungen 2.1.1 Ein Exkurs in den Deutschunterricht: Satzgegenstand und Satzaussage Wenn wir soeben erwähnt haben, dass die Objektbereiche Auswirkungen auf die in den Wissenschaften gesprochenen Sprachen haben, so sind es zunächst einmal die besonderen Substantive als Namen für die Objekte oder Klassen von Objekten, die für eine Wissenschaft spezisch sind (man spricht dann auch vom Fachjargon). In der Chemie sind dies die Namen der chemischen Elemente, Begrie wie Atom, Isotop, Wertigkeit, Katalysator u.v.a.m. Es sind dies die Gegenstände, über die in einem Satz chemische Sachverhalte betreend referiert wird, und die deshalb wie Sie es in der Schule gelernt haben in die Rolle von Satzgegenständen (gramm. Subjekte) schlüpfen können. Satzgegenstände allein bilden natürlich noch keine Aussage. Hierzu benötigen wir Prädikate, die zusammen mit den Satzgegenständen erst eine echte Aussage bilden, und die (zumindest in den ersten Schuljahren) deshalb Satzaussagen heiÿen. Ein Blick in die Wortkunde zeigt uns, dass Satzgegenstände i.A. aus ven gebildet werden und Satzaussagen aus Verben. Satzaussagen beschreiben häug das Bestehen oder Nichtbestehen von ten der Satzgegenstände. Substanti- Eigenschaf- Betrachtete man in der Chemie z.B. als Satzgegenstand die chem.Verbindung Kochsalz, dann kann man mit Hilfe des Prädikats wasserlöslich sein (bestehend also aus einem Hilfsverb und einem Prädikatsnomen) die (wahre) Aussage Kochsalz ist wasserlöslich. bilden. In diesem Fall beschreibt das Prädikat eine Eigenschaft des betrachteten Objektes. Satzaussagen können aber auch das Bestehen oder Nichtbestehen von Beziehungen zwischen Objekten beschreiben. In diesem Fall benutzt man Prädikate, die nicht nur ein Subjekt sondern auch (ein oder mehrere) direkte und indirekte Objekte erfordern (z.B. sog. transitive Verben). So kann man in der Chemie mit Hilfe des transitiven Verbs oxidieren die (ebenfalls) wahre Aussage Sauersto oxidiert Silizium zu Siliziumoxid. 2.1. GRAMMATIKALISCHE VORBEREITUNGEN 21 bilden. Das Prädikat (in seiner transitiven Variante) beschreibt hier eine Be- ziehung zwischen den betrachteten Objekten. Nun werden Prädikate in einzelnen Wissenschaften nicht notwendig durch Wörter der Umgangssprache gebildet, sie können etwas verkappt auch durch besondere Symbole repräsentiert werden. So wird in der Chemie die Aussage Sauersto oxidiert Silizium durch eine Reaktionsgleichung dargestellt: Si + O2 → SiO2 Das umgangssprachliche Prädikat oxidiert ist dabei (in etwas verallgemeinerter Form) repräsentiert durch den Pfeil “ → ”. Das letzte Beispiel ist insofern für die Mathematik relevant, als dass die in der Mathematik gebräuchlichen Prädikate fast ausnahmslos durch spezielle Sonderzeichen dargestellt sind. Kommen wir damit zur formalen Beschreibung von Sprachen. 2.1.2 Exkurs in die theoretische Informatik: formale Grammatiken Der syntaktische Aufbau sowohl von natürlichen Sprachen als auch von künstlichen Sprachen wird durch Grammatiken beschrieben. Dabei sind die Grammatiken von natürlichen Sprachen sehr viel komplexer wie die Grammatiken von Kunstsprachen, etwa Programmiersprachen. Grammatiken lassen sich auf natürliche Weise (hierarchisch) unterteilen in unterschiedliche Typen (Typ0 bis Typ3). In der praktischen Informatik benutzt man (aus Ezienzgründen) Grammatiken vom Typ2 und Typ3. dabei handelt es sich im Wesentlichen um sogenannte kontextfreie Grammatiken, deren Regeln eine gewisse Komplexität nicht überschreiten. Kontextfreie Grammatiken enthalten Regeln für die Bildung sprachlicher Ausdrücke. Hierzu werden formale Grammatikvariablen benutzt, die in der Rolle als Platzhalter regelgesteuert durch andere Variablen oder durch sog. terminale Sprachsymbole ersetzt werden können. Dies soll an einem einfachen Beispiel, dem syntaktischen Aufbau arithmetischer Ausdrücke, illustriert werden. In Umgangssprache kann man den Aufbau so formulieren, dass ein (arithmetischer) Ausdruck entweder eine einzelne Zahlvariable oder ein einzelnes Zahlliteral sein kann oder ein (schon gebildeter) arithmetischer Ausdruck der mit einem arithmetischen Operationssymbol und einem zweiten (schon gebildeten) arithmetischen Ausdruck (evtl. geklammert) verbunden werden kann. Eine formale kontextfreie Grammatik zur Beschreibung dieser Ausdrücke wird also wie folgt aussehen: Wir benötigen grammatikalische Platzhalter für den Begri arithmetischer Ausdruck sowie einige Hilfsvariablen. Folgende Regeln liefern uns dann die gewünschten Ausdrücke: <arithm. Ausdruck> <arithm. Ausdruck> ::= <atomarer Ausdruck> ::= <zusammenges. Ausdruck> <atomarer Ausdruck> <atomarer Ausdruck> ::= <Zahlvariable> ::= <Zahlliteral> <zusammenges. Ausdruck> ::= (<arithm. Ausdruck> + <arithm. Ausdruck>) <zusammenges. Ausdruck> ::= <arithm. Ausdruck> · <arithm. Ausdruck> 22 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Weitere Regeln für die Platzhalter <Zahlvariable> und <Zahlliteral> schlieÿen die Grammatik ab. Nun beschreibt die für die arithmetischen Ausdrücke gebildete Grammatik noch keine Aussagen sondern nur algebraische Ausdrücke (gewissermaÿen den Aufbau von Objekten ). Der hier in einer sehr einfachen Situation benutzte Grammatikformalismus lässt sich aber ohne Probleme mit derselben Strategie auch zur Beschreibung von Aussage formen anwenden, die Sätzen der Umgangssprache nachempfunden sind. Dies geschieht einfach dadurch, dass wir geeignete neue grammatikalische Platzhalter ins Spiel bringen, ohne den strukturellen Aufbau der Regeln verändern zu müssen. Schauen wir uns dies an einem einfachen Beispiel an: <Satz> <Subjekt> <Artikel> <Artikel> <Artikel> <Artikel> <Attribut> <Attribut> <Adjektiv> <Adjektiv> <Adjektiv> <Substantiv> <Substantiv> <Prädikat> <Objekt> ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= ::= <Subjekt><Prädikat><Objekt> <Artikel><Attribut><Substantiv> der die das ε <Adjektiv> <Adjektiv><Attribut> kleine bissige groÿe Hund Katze jagt <Artikel><Attribut><Substantiv> mit diesem Regelwerk sind wir in der Lage ausgehend von dem Platzhalter <Satz> folgende Sätze zu bilden: der kleine bissige Hund jagt die groÿe Katze oder auch der groÿe groÿe Hund jagt die bissige Katze Es ndet aber keine Berücksichtigung speziell deklinierter Formen etc. statt. Die Form ist gefunden, doch was soll sie bedeuten? Die Bedeutung solcher Aussagen besteht in der Behauptung eines Sachverhaltes, dessen Wahrheit (oder Falschheit) durch Beobachtung etc. festgestellt wird. Die Bedeutung der weiter oben eingeführten arithmetischen Ausdrücke besteht demgegenüber zunächst nicht in der Behauptung eines Sachverhaltes, der wahr oder falsch sein kann, sondern letztlich in der Festlegung eines (Zahl)Objektes. Die Bedeutung besteht also in einem Zahlenwert, dessen konkrete Berechnung maschinell durch einen geeigneten Funktionsaufruf erfolgen kann. 2.1. GRAMMATIKALISCHE VORBEREITUNGEN 23 In den heute benutzten Programmiersprachen sind die entsprechenden Funktionsaufrufe recht passgenau zu den (syntaktischen) arithmetischen Ausdrücken gebildet: Sie sind schon von der äuÿeren Form her kaum mehr vom ursprünglichen Ausdruck zu unterscheiden. 2.1.3 Exkurs in die Programmiersprachen So wird der formale arithmetische Ausdruck (1 + 2) · 3 in Java oder C++ umgesetzt in den Aufruf der Funktion + und dem nachfolgenden Aufruf der Funktion *, denen als aktuelle Parameter die den Zeichen 1, 2 und 3 entsprechenden Zahlen eins, zwei und drei mitgegeben werden: (1 + 2) ∗ 3 Man kann also mit Fug und Recht sagen, dass die Interpretation der arithmetischen Ausdrücke vollständig an den Rechner delegiert werden kann. Die den arithmetischen Ausdrücken entsprechenden Objekte, die Zahlen, können nun ähnlich wie Objekte der gegenständlichen Welt (also Hunde oder Katzen) in der Rolle als Subjekt und Objekt wieder in Aussageformen eingebracht werden. Mit anderen Prädikaten natürlich, da das Verb jagen in Bezug auf Zahlen wahrlich nicht passen würde. Als sinnvolle Prädikate in Zusammenhang mit arithmetischen Ausdrücken bieten sich neben dem Gleichheitsprädikat = z.B. die Prädikate der Ordnungsrelationen 5, <, · · · an oder auch das Prädikat | im Sinne von ist Teiler von. Die für natürliche Sprachen übliche Unterscheidung zwischen Subjekt und Objekt lässt man fallen, so dass man für die Aussageformen mit arithmetischen Ausdrücken folgende einfache Grammatik wählen kann: <arithm. <arithm. <arithm. <arithm. <arithm. ··· Aussage> Prädikat> Prädikat> Prädikat> Prädikat> ::= ::= ::= ::= ::= <arithm. Ausdruck><arithm. Prädikat><arithm. Ausruck> = 5 < | (weitere Prädikate) <arithm. Ausdruck> ::= (s. obige Regeln) Die Bedeutung der hiermit gewonnenen Aussageformen soll auch hier in der Behauptung gewisser Sachverhalte bestehen, die zutreen oder auch nicht. So würden wir eine arithmetische Aussage der Art (1 + 2) · 3 = 9 als zutreend, also wahr, interpretieren. Eine arithmetische Aussage der Art (1 + 2) · 3 < 8 würden wir als falsch ansehen. Dass wir die eine Aussage als wahr, die andere Aussage als falsch erkennen würden, ergäbe sich aber nicht auf Grund einer Beobachtung (eines Experimentes), sondern auf Grund der Konventionen, die wir im Umgang mit arithmetischen Ausrücken festgelegt haben (im Regelwerk der Addition, Multiplikation und der Zahldarstellung). Diese Konventionen können einem Rechner per Programm (oder sogar per 24 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Hardware) mitgegeben werden, so dass auch das Verizieren oder Falsizieren einer arithmetischen Aussage an ihn delegiert werden kann. (Achtung: Beschränkung durch Gödelsche Theoreme). Damit der Rechner diese Aufgabe erfüllen kann, benötigt er eine Implementierung der betreenden Prädikate (also von 5, <, · · · ) in Form von Funktionen, die als Ergebnis einen der beiden Wahrheitswerte true oder false liefern (also den Ergebnistyp boolean) haben. Diese Funktionen interpretieren die (arithmetischen) Prädikate gewissermaÿen. Auch hier bieten die Programmiersprachen passgenaue Operatoren: So wird die arithmetische Aussage (1 + 2) · 3 = 6 interpretiert durch den Aufruf (1 + 2) ∗ 3 == 6 mit dem Operator == als Funktion (mit Ergebnistyp boolean), der das Gleichheitsprädikat interpretiert. Die arithmetische Aussage 3|6 wird durch den (zusammengesetzten) Funktionsaufruf 6%3 == 0 interpretiert. Es wird also zunächst der Rest der Division von 6 durch 3 mit Hilfe der Funktion % berechnet (also ein Ausdruck interpretiert, durch die man ein Zahlobjekt erhält). Die hieraus erhaltene Zahl wird abschlieÿend mit 0 verglichen und der entsprechende Wahrheitswert (in diesem speziellen Fall true) geliefert. Die Logik der Bedingungen In der Programmierung werden arithmetische Aussagen typischerweise für die Steuerung von weiteren Rechenschritten benutzt. Es wird also z.B. geprüft, ob ein arithmetischer Ausdruck gröÿer ist als 0, und in Abhängigkeit hiervon werden gewisse Operationen durchgeführt (und andere Operationen nicht). Dies geschieht z.B. im Rahmen von ifAbfragen oder whileSchleifen: if(a > 0) abs = a; else abs = -a; Die Programmvariable a steht hier für eine <Zahlvariable> in der formalen Grammatik der arithmetischen Ausdrücke. Ihr soll im vorangegangenen Programmablauf ein konkreter Zahlwert zugewiesen worden sein, der jetzt beim Aufruf des Operators > mit 0 verglichen wird. Liefert der Operator true, stellt er also fest, dass der momentane Wert von a gröÿer ist als 0, wird die Zuweisung abs = a ausgeführt, ansonsten die Zuweisung abs = -a. In vielen Programmen stellt man aber sofort fest, dass die Bedingungen zur Steuerung der Algorithmen häug eine komplexere Form annehmen, und einzelne atomare Bedingungen mit Hilfe logischer Operationen noch weiter verknüpft werden. Wir benutzen also komplexere arithmetische Aussagen als in unserer obigen einfachen Grammatik vorgesehen. Wir müssen deshalb unsere formale Grammatik entsprechend erweitern: <arithm. Aussage> ::= <atomare arithm. Aussage> | <zusammeng. arithm. Aussage> 2.1. GRAMMATIKALISCHE VORBEREITUNGEN 25 <atomare arithm. Aussage> ::= <arithm. Ausdruck><arithm. Prädikat><arithm. Ausruck> <arithm. Prädikat> <arithm. Prädikat> <arithm. Prädikat> <arithm. Prädikat> ··· <arithm. Ausdruck> ··· <zusammeng. arithm. <zusammeng. arithm. <zusammeng. arithm. <zusammeng. arithm. ::= ::= ::= ::= = 5 < ··· ::= s.o. Aussage> ::= Aussage> ::= Aussage> ::= Aussage> ::= ¬ <arithm. Aussage> <arithm. Aussage >∨ <arithm. Aussage> <arithm. Aussage >∧ <arithm. Aussage> (<arithm. Aussage>) Die Bedeutungen der drei neuen Symbole sind die der üblichen logischen Verknüpfungen. Auch sie haben in den Programmiersprachen eine direkte Interpretation als logische Operationen gemäÿ der bekannten Wahrheitstabellen. Dabei werden ¬, ∨, ∧ durch die Operatoren !, |, & interpretiert. Die Umsetzung der arithmetischen Aussage (a > 0) ∧ (b > 0) in einen (ihn interpretierenden) Funktionsaufruf (mit einem Endergebnis true oder false) geschieht dann durch (a > 0) & (b > 0). Wir haben es hierbei mit insgesamt 3 einzelnen Funktionsaufrufen zu tun: Zwei der Funktionsaufrufe vergleichen a bzw. b mit 0 und liefert jeweils einen Wahrheitswert. Der dritte Funktionsaufruf verknüpft die beiden als Zwischenergebnisse gelieferten Wahrheitswerte zu einem Wahrheitswert entsprechend dem logischen und zum Endergebnis. Bedingungen mit verkapptem Indenitpronomen Es gibt Fälle, in denen die Durchführung weiterer Operationen davon abhängig gemacht wird, ob irgendeine in Frage kommende Zahl eine spezielle Bedingung erfüllt. Bei der Überprüfung z.B., ob es sich bei einer Zahl p um eine Primzahl handelt, muss gezeigt werden, dass keine Zahl Teiler dieser Zahl p ist (genauer: dass keine Zahl die gleichzeitig gröÿer 1 und kleiner p ist, Teiler von p ist). In natürlicher Sprache formuliert würde die arithmetische Aussage p ist Primzahl lauten: Für alle Zahlen i (ungleich 1 und p selbst) ist i kein Teiler von p. In dieser Aussage ist die Rede von für alle. Unsere bisherige Grammatik für arithmetische Aussagen besitzt hierfür (und auch für das Reden über irgendein) noch kein Konstrukt. Deshalb erweitern wir unsere Grammatik ein letztes Mal, um auch noch diese Lücke zu füllen: 26 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK <arithm. Aussage> ::= <atomare arithm. Aussage> | <zusammenges. arithm. Aussage> | <quantif. arithm. Aussage > <atomare arithm. Aussage> ::= <arithm. Ausdruck><arithm. Prädikat><arithm. Ausruck> <arithm. Prädikat> <arithm. Prädikat> <arithm. Prädikat> <arithm. Prädikat> ··· <arithm. Ausdruck> ··· <zusammenges. arithm. <zusammenges. arithm. <zusammenges. arithm. <zusammenges. arithm. ::= ::= ::= ::= = 5 < ··· ::= s.o. Aussage> Aussage> Aussage> Aussage> <quantif. arithm. Aussage> <quantif. arithm. Aussage> ::= ::= ::= ::= ¬ <arithm. Aussage> <arithm. Aussage >∨ <arithm. Aussage> <arithm. Aussage >∧ <arithm. Aussage> (<arithm. Aussage>) ::= ∀ <Zahlvariable> <arithm. Aussage> ::= ∃ <Zahlvariable> <arithm. Aussage> Die oben angeführte Aussage p ist eine Primzahl. lässt sich nun mit den erweiterten Mitteln unserer Grammatik wie folgt ausdrücken: ∀x (x ̸= 1 ∧ x ̸= p) ⇒ ¬(x|p). Das logische Operatorsymbol ⇒ wird gelesen als hieraus folgt und kann ersetzt werden durch die Kombination ¬ · ∨·, d.h. A ⇒ B entspricht ¬A ∨ B . Für die spätere Umsetzung in ein (interpretierendes) Programm ist es hilfreich, die Aussage noch etwas schärfer fassen, indem man formuliert: ∀x (x > 1 ∧ x < p) ⇒ ¬(x|p). Die Interpretation der sog. Quantoren ∀ (für alle) und ∃ (es gibt ein) geschieht im Rahmen der Programmiersprachen nun nicht direkt sondern implizit durch geeignete SchleifenKonstrukte: boolean is_Prime(int p){ for(int x = 2; x < p; x++) { if((p%x) == 0 ) return false; } return true; } Das ∀x wird also umgesetzt in eine Schleife mit Schleifenvariable x. Das (x > 1 ∧ x < p) wird so umgesetzt, dass die Werte der Schleifenvariable den Bereich 2 bis p-1 durchlaufen. Die arithmetische Aussage ¬(x|p) wird dann in jedem Schleifendurchlauf überprüft, und es wird Sorge dafür getragen, dass nur dann true ausgegeben wird, wenn für alle x (entsprechend dem ∀x) die Bedingung (p%x) == 0 nicht eintritt (entsprechend dem ¬(x|p)). Insbesondere kann also erst dann true ausgegeben werden, wenn alle in Frage 2.1. GRAMMATIKALISCHE VORBEREITUNGEN 27 kommenden Werte für x auf ihre Teilereigenschaft hin getestet worden sind. Auch eine mit ∃ quantizierte Aussage wird mit einer vergleichbaren Schleifenkonstruktion interpretiert. Die arithmetische Aussage p hat einen Teiler zwischen 2 und p-1, kann mit den Mitteln unserer Grammatik beschrieben werden als ∃x (2 5 x) ∧ (x 5 p − 1) ∧ (x|p). Die Umsetzung geschieht ebenfalls mit Hilfe einer Schleife: boolean has_Divisor(int p){ for(int x = 2; x < p; x++) { if((p%x) == 0 ) return true; } return false; } Hier wird also erst dann false ausgegeben, wenn alle potenziellen Zahlen geprüft und sich als Nicht-Teiler herausgestellt haben. Es fällt auf, dass der einzige Unterschied in den Funktionsrümpfen von is_Prime(int p) und has_Divisor in der systematischen Vertauschung der Ausgaben von true und false besteht. Dies ist kein Zufall, denn die Bedeutung der zweiten Aussage p hat einen Teiler zwischen 2 und p − 1 ist gerade die Negation der ersten Aussage p ist Primzahl. 2.1.4 Was geschieht unter der Decke die Funktionen als white box In der Interpretation der Wie werden die betrachteten Prädikate implementiert? Wir verlassen uns darauf, dass in der Programmiersprache die Umsetzung des Prädikats > korrekt vonstatten geht. Welche Vorstellungen könnte man von einer internen Umsetzung dieses Prädikats als Funktion auf dem Rechner haben? Funktionale Umsetzungen können generell ganz unterschiedlich gestaltet werden. (Beispiel Uhr, Beispiel Strom aus der Steckdose). Manche Umsetzungen sind gedanklich leichter zu erfassen und von gröÿerem didaktischen Wert, obwohl die darauf beruhende technische Realisierung unezient sein mag (Beispiel Sanduhr zur Zeitmessung). Beispiel Funktionen zur Interpretation der logischen Operationen to be done Wir haben es mit binären Prädikaten zu tun. Die einfachste Umsetzung besteht demnach darin, das Prädikat durch eine zweispaltige Tabelle zu interpretieren. Die der Relation < entsprechende Tabelle könnte demnach folgendes Aussehen haben: 28 · · 0 0 · · 1 1 1 · · KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK · · 1 2 · · 2 3 4 · · Soll die Tabelle vollständig sein, müsste sie natürlich unendlich viele Einträge enthalten. Von diesem praktischen Problem abgesehen, kann man sich die Interpretation einer Aussage x < y damit so vorstellen, dass in der Tabelle systematisch nach einer Zeile mit den Einträgen der Werte für x und y gesucht wird. Wird ein solcher Eintrag gefunden, wird die Aussage als wahr angesehen ansonsten als falsch. Halten wir also fest: Jedes zweistellige Prädikat kann prinzipiell durch eine zweispaltige Tabelle realisiert werden. Zurück zur Teilbarkeitsrelation In unserer ersten Interpretation der Teilbarkeitsbeziehung hatten wir diese durch eine geeignete Kombination der ganzzahligen Restebildung und des Vergleichs mit der Zahl 0 gebildet. Wir könnten uns jetzt natürlich auch eine groÿe (im Prinzip wieder unendlich groÿe) zweispaltige Tabelle vorstellen, die die Teilbarkeitsbeziehung wiedergibt: · · 2 2 · · 3 3 3 · · · · 2 4 · · 3 6 9 · · Eine (im Vergleich zur obigen) alternative Implementierung der Funktion is_Prime könnte jetzt lauten: boolean is_Prime(int p){ for(int x = 2; x < p; x++) { if((x,p) in Teilbarkeits-Tabelle) return false; } return true; } 2.1. GRAMMATIKALISCHE VORBEREITUNGEN 29 Die Bedingung (x,p) in Teilbarkeits-Tabelle ersetzt hier also die Bedingung (p%x) == 0 . Analog erhalten wir boolean exists_Divisor_of(int p){ for(int x = 2; x < p; x++) { if((x,p) in Teilbarkeits-Tabelle) return true; } return false; } So wie die atomare arithmetisch Aussage x|y interpretiert werden kann durch (x,y) ist in TeilbarkeitsTabelle, so kann im Prinzip jede atomare arithmetische Aussage x < P rädikat > y interpretiert werden durch (x,y) ist in <Prädikat>Tabelle. In der Quintessenz kann also jedes zweistellige Prädikat mit dem Vehikel einer zweispaltigen Tabelle interpretiert werden. 2.1.5 Exkurs: Skolemisierung Wenn wir davon ausgehen können, dass eine quantizierte arithmetische Aussage ∃xA wahr ist, beispielsweise ∃x x|15, dann muss es damit eine konkrete Zahl geben, die Teiler ist von 15. Wie kann man eine solche passende Zahl nden? Nun, einfach, indem man im Funktionsrumpf an derjenigen Stelle, an der true zurückgegeben wird, stattdessen den gerade gültigen Wert der Schleifenvariable zurückgibt. Diesen Vorgang nennt man Skolemisierung: int get_Divisor_of_15(){ p = 15; for(int x = 2; x < p; x++) { if((x,p) in Teilbarkeits-Tabelle) return x; } return -1; } Verallgemeinert für ein beliebiges zweistelliges Prädikat erhalten wir aus ∃x (x < P rädikat > y) die zugehörige Skolemfunktion: int get_value_for(int y){ for(int x = 0; x <= MAXIMUM ; x++) { if((x,y) in <Prädikat>Tabelle) return x; } return -1; } 30 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Verallgemeinert für eine beliebige Aussage A erhalten wir aus ∃x A mit der Interpretation func_A(· · · ) für A die zugehörige Skolemfunktion: int get_value_for(int y){ for(int x = 0; x <= MAXIMUM ; x++) { if(func_A(· · · )) return x; } return -1; } 2.2 Mengen und sie betreende Aussagen 2.2.1 Was verstehen wir unter Mengen? Wenn wir zu Beginn festgestellt hatten, dass die Objekte der Mathematik die Zahlen sind, so ist das zunächst nur die halbe Wahrheit. Strenggenommen sind die Objekte der Mathematik Mengen (und zwar ausschlieÿlich Mengen). Wie verträgt sich dies damit, dass die Mathematik hauptsächlich Zahlen untersuchen soll? Nun, die Zahlen lassen sich letztlich durch Mengen realisieren (ein Informatiker würde sagen: mit dem Vehikel der Mengen implementieren). Und den Weg dahin werden wir im Folgenden beschreiten. Nun ist in der Sprache der Mengenlehre nicht nur der Objektbereich (zumindest theoretisch) extrem einfach es gibt nur einen einzigen ObjektTyp, eben Mengen auch die Prädikate lassen sich an höchstens zwei Fingern abzählen. Es sind (je nach gewähltem Ansatz) nur ein oder zwei Prädikate vonnöten. Sie beschreiben ausnahmslos Beziehungen zwischen Objekten. Eines ist das durch das Zeichen “in′′ notierte Prädikat ist Element von. Das zweite ist das Gleichheitsprädikat (das theoretisch sogar selbst noch einmal auf ∈ zurückgeführt werden kann.) Reizt man die Sprache der Mathematik also völlig aus, dann kann man mit einem einzigen Typ von Objekten, gewissermaÿen einem einzigen Gattungsnamen und einem einzigen Prädikat auskommen. Theoretisch könnten also alle Aussagen der Mathematik aus Teilaussagen der Form x∈y zusammengesetzt werden (die mit Konjunktionen und Quantoren verbunden wären). Auch hier können wir eine Analogie zur Informatik ziehen. Theoretisch könnte man nämlich alles, was man als Algorithmen untersucht und beschreibt, auf eine einfache TuringMachine zurückführen, deren Befehlssprache geradezu trivial ist. An dieser Stelle ist allerdings ein Wort der Warnung angebracht. Die geschilderte konzeptuelle Einfachheit verführt gerne dazu, denn damit erfassten Objektbereich auch als praktisch einfach aufzufassen. Sehr schnell stellt sich allerdings heraus, dass der interessierende Objektbereich dann alles andere als einfach ist und dass es eine faktische Komplexität gibt, die es nachträglich auf 2.3. SYNTAX MENGENTHEORETISCHER AUSSAGEN 31 einer höheren Ebene zu strukturieren gilt. Und hier ist die eigentliche Arbeit zu leisten. Spätestens jetzt wird man sich fragen, wie man sich die Mengen der Mathematik vorstellen kann und wie man die Wahrheit der mit Hilfe des “ ∈ ”Prädikats behaupteten Aussagen feststellt. Die sich hieran anschlieÿenden Überlegungen kulminieren in der berühmten Frage: Was ist eine Menge? Auch diese Frage wird heute nicht mehr wie auch schon bei den Zahlen ontologisch, also durch eine Wesensbeschreibung beantwortet, wie es der Begründer der Mengenlehre Georg Cantor noch versucht hatte. (Nach seiner Denition war eine Menge eine beliebige Zusammenfassung von bestimmten wohlunterschiedenen Objekten unserer Anschauung oder unseres Denkens zu einem Ganzen.) Man beschreibt Mengen analog zu den komplexen Zahlen einfach über ihr Verhalten in Zusammenhang mit dem Prädikat “ ∈ ”: Mengen sind die Objekte eines abstrakten Datentyps Set, zu dem es eine Funktion boolean isElementOf(Set x, Set y) gibt (als Implementierung von x ∈ y ), wobei die Funktion isElementOf nur einige wenige Regeln zu erfüllen hat. So wie ein Programmierer mit einem abstrakten Datentyp Turingmaschine jeden beliebigen Algorithmus programmieren könnte, ohne zu wissen, wie dieser Datentyp unter der Decke realisiert ist, so kann ein Mathematiker mit dem abstrakten Datentyp Set alle Aussagen formulieren, die eine mathematische Relevanz haben (insbesondere auch diejenigen, die die Zahlentheorie bereen), ohne eine Vorstellung davon haben zu müssen, was Mengen eigentlich sind. Hat man bei den komplexen Zahlen noch ein anschauliches Modell, mit dessen Hilfe man den abstrakten Datentypen implementieren kann, so verzichtet man bei den Mengen auf die Beschreibung eines konkreten Modells. Man kann allerdings zeigen, dass ein Modell innerhalb der (unendlichen) Menge aller natürlichen Zahlen beschrieben werden könnte. Im Gegensatz zu der Gaussschen Zahlenebene bei den komplexen Zahlen, bietet jenes Modell der Mengenlehre keinen Ansatz zu einem besseren Verständnis, sondern ist selbst nur ein formales Konstrukt. Halten wir fest: für den Mathematiker ist die Frage nach dem Wesen einer Menge völlig uninteressant geworden, da für ihn nur das systemische Verhalten von Mengen interessant ist, und dieses (im Sinne von abstrakten Datentypen) ausschlieÿlich über spezielle Regeln für das Prädikat “ ∈ ” festzulegen ist. Wir beginnen mit der Syntax mengentheoretischer Aussagen, die sich an den bisher betrachteten Grammatiken orientiert: 2.3 Syntax mengentheoretischer Aussagen Nach den Vorbereitungen des letzten Abschnittes können wir leicht eine Grammatik für den Aufbau mengentheoretischer Aussagen gewinnen: <atomarer mAusdruck> ::= <mVariable> | <mLiteral> 32 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK <mVariable> <mLiteral> ::= x | y | z | x1 | · · · ::= ∅ <mAussage> ::= <atomare mAussage>| <zusammenges. mAussage> <quantiz. mAussage> <atomare mAussage> <atomare mAussage> <atomare mAussage> ::= ⊤ | ⊥ ::= <atomarerAusdruck> ∈ <atomarer mAusdruck> ::= <atomarer mAusdruck> = <atomarer mAusdruck> <zusammenges. mAussage> ::= <mAussage> ∨ <mAussage> <zusammenges. mAussage> ::= <mAussage> ∧ <mAussage> <zusammenges. mAussage> ::= ¬ <mAussage> <quantiz. mAussage> <quantiz. mAussage> ::= ∀ <mVariable> <mAussage> ::= ∀ <mVariable> <mAussage> Der Aufbau der mAussagen geschieht mit anderen Worten induktiv wie folgt: ia) Für beliebige atomare mAusdrücke x und y ist x ∈ y eine mAussage. (Das Prädikat “ ∈ ” wird gelesen als ist Element von.) ib) Für beliebige atomare mAusdrücke x und y ist x = y eine mAussage. (Das Gleichheitszeichen “ =′′ steht für das Prädikat ist gleich.) ic) Es werden zwei (ebenfalls atomare) Aussagen ⊤ und ⊥ eingeführt. (⊤ steht für eine Aussage, die stets wahr ist, und ⊥ für eine Aussage, die stets falsch ist.) iia) Liegen zwei beliebige mAussagen A1 und A2 vor, dann ist auch A1 ∧ A2 eine mAussage. (Der Junktor “ ∧ ” steht für die Konjunktion und.) iib) Liegen zwei beliebige mAussagen A1 und A2 vor, dann ist auch A1 ∨ A2 eine mAusage. (Der Junktor “ ∨ ” steht für die Konjunktion oder.) iic) Liegt eine beliebige mAussage A vor, dann ist auch ¬A eine mAussage. (Der Junktor “¬” steht für das Adverb nicht). iiia) Liegt eine beliebige mAussage A vor, und ist x eine beliebige mVariable, dann ist auch ∀x A eine mAussage. (Der Quantor “∀” steht für den präpositionalen Ausdruck für alle.) iiib) Liegt eine beliebige mAussage A vor, und ist x eine beliebige mVariable, dann ist auch ∃x A eine Aussageform. (Der Quantor “∃” steht für den sprachl. Ausdruck es gibt mindestens ein.) Falls es aus Gründen der besseren Lesbarkeit angebracht scheint, werden wir in 2.4. SEMANTIK MENGENTHEORETISCHER AUSSAGEN 33 die mAussagen mit Klammern versehen, die dann die übliche pragmatische Bedeutung haben sollen (ähnlich den Klammern in arithmetischen Ausdrücken). Sehen wir uns zunächst einige Beispiele von mAussagen an, die wir sukzessiv mit den Regeln ia) bis iiib) bilden können. 1. Die einfachsten Beispiele (wenn wir von der Regel ic) absehen) sind oensichtlich die nach den ersten Regeln ia) und ib) gebildeten Aussageformen, wie z.B: x ∈ y , x ∈ z , y ∈ z , z ∈ x, x ∈ x, x = y , x = x, z = y , u.ä. 2. Komplexere Aussageformen kann man darauf aufbauend jetzt leicht mit den weiteren Regeln bilden: nach iia): x ∈ y ∧ y ∈ z , x = y ∧ z = y , x ∈ y ∧ x = x, x ∈ y ∧ ⊤ u.ä. Pragmatisch geklammert sollen diese Aussageformen auch in der folgenden Form geschrieben werden können: (x ∈ y) ∧ (y ∈ z), (x = y) ∧ (z = y), (x ∈ y) ∧ (x = x), (x ∈ y) ∧ ⊤ u.ä. analog nach Regel iib): x = y∨z = y , nach Regel iic): u.ä. ¬x = y , nach iiia) und iiib): ∀z x = x, u.ä. ¬x ∈ y , ∃x x ∈ z , (x = y)∨(y ∈ z), ¬¬x = x, ∀z∃x x ∈ z , (x = y)∨⊥ u.ä. ¬(z = y) ∨ ¬(z ∈ x), ∀x∃y x = y , ∀y∀x x ∈ y , 3. Letztlich lassen sich auf diese Weise sukzessiv kleine Monster erzeugen: (∀x∃y∀z (∀x(x = x) ∧ (y = z))) ∧ (∀z(x ∈ z) ∨ ∃z(x = z) ∨ ∀x∀y∀z(y ∈ z)) 2.4 Semantik mengentheoretischer Aussagen Mengentheoretische Aussagen wollen wir nun analog zu den arithmetischen Ausdrücken (s.o.) durch Funktionsaufrufe interpretieren, die true oder false liefern. Hierzu erweitern/modizieren wir die Programmiersprache Java zu einer hypothetischen Sprache JavaZ. 2.4.1 Exkurs: JavaZ Die im folgenden beschriebene Programmiersprache JavaZ wird (jedenfalls bis auf weiteres) nicht implementiert werden können. Dies würde die Ausnutzung besonderer physikalischer Phänomene etwa schwarze Löcher erfordern. Im Endeekt erforderte eine Implementierung einen (abzählbar) unendlich groÿen Speicher, auf dessen Elemente alle in einer nach oben global beschränkten endlichen Zeit zugegrien werden kann, und einen Prozessor, der in der Lage ist, seine Taktfrequenz hyperbolisch zu beschleunigen, so dass in einem endlich Zeitraum (abzählbar) unendlich viele Operationen durchgeführt werden könnten. So etwas ist zugegebenermaÿen noch nicht auf dem Markt. Aber theoretisch vorstellen könnte man sich so etwas vielleicht doch. (Zumindest haben Hollywood Regisseure damit keine Probleme). Damit hätten wir ein Vehikel in der Hand, mit dem wir unsere Aussageformen sehr bequem interpretieren könnten. 34 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK In unserer Programmiersprache JavaZ gebe es (im Gegensatz zur existierenden Programmiersprache Java) nur zwei vordenierte Datentypen: boolean und Set. boolean stimmt mit dem gleichlautenden primitiven Datentyp aus Java überein, Set ist ein geeigneter Referenzdatentyp, dessen Objekte unsere mAusdrücke interpretieren sollen. Der Datentyp Set ist für den Benutzer ein abstrakter Datentyp. Internas sind eingekapselt und für den Benutzer typischerweise nicht einsehbar. Der Zugri auf Objekte dieses Datentyps geschieht wie üblich nur über vordenierte Zugrisoperationen. Variable von Typ Set werden in der üblichen Weise wie folgt deklariert: Set x; Wie in Java haben wir auch in JavaZ die Möglichkeit, Funktionen selbst zu denieren. Diese Funktionen können beliebig viele formale Parameter beinhalten. Ihr Ergebnistyp ist (zunächst) auf boolean oder Set beschränkt. Funktionen können wie üblich ineinander eingesetzt werden. Ein Funktionskopf in JavaZ kann also z.B. folgende Form haben: boolean function( Set x ) Zur Programmierung des Funktionsrumpfes stehen das konventionelle returnStatement zur Verfügung sowie die Verzweigung. Letztere hat die Form: if( <B> ) { return <E>; } Dabei ist <B> ein Platzhalter für einen Wahrheitswert, der i.A. durch einen Funktionsaufruf mit Ergebnistyp boolean geliefert wird. <E> ist ein Platzhalter für einen Ausdruck, der je nach Ergebnistyp der betrachteten Funktion auf ein Objekt vom Typ Set verweist oder einen Wahrheitswert liefert. Bis hierher sind die betrachteten Bausteine auf einem konventionellen Rechner implementierbar. Bei dem nächsten Baustein, einem speziellen Schleifenkonstrukt, ist das nicht mehr der Fall: forall (Set x) { <P> } Der Platzhalter <P> steht für einen beliebigen Programmierbaustein. Die Bedeutung des letzten Bausteines besteht darin, dass die Variable x nacheinender alle Objekte des Datentyps Set referenziert, und in Abhängigkeit hiervon der Baustein <P> ausgeführt wird. (Dies klingt auch noch harmlos, doch wir müssen davon ausgehen, dass Set unendlich viele unterschiedliche Objekte enthält. An dieser Stelle benötigen wir also den hyperbolischen Turbo für unseren Prozessor). Es gibt drei vordenerte Funktionen, die uns für den abstrakten Datentyp Set zur Verfügung gestellt werden: • boolean isElement(Set x, Set y); • boolean isEqual(Set x, Set y); • Set getEmptySet() 2.4. SEMANTIK MENGENTHEORETISCHER AUSSAGEN 35 Die Bedeutung von isEqual ist die der logischen Identität und wird wie in Java kurz notiert in der Form x == y. Die Bedeutung von isElement hingegen ist intentional überhaupt nicht festgelegt. Ihre Bedeutung ergibt sich ausschlieÿlich aus der systemischen (besser axiomatischen) Festlegung der Eigenschaften, also des nach auÿen hin sichtbaren Verhaltens von isElement (s.u.). Die Funktion getEmptyset() liefert (die Referenz auf) ein konstantes Objekt, dessen Internas dem Benutzer verborgen bleiben. Hinzu kommen die vordenierten booleschen Funktionen/Operationen |, &, ! 2.4.2 Interpretation der Aussageformen Nach diesen Vorbereitungen wollen wir die (induktiv) gebildeten mAussagen in der Sprache JavaZ interpretieren. Dabei gehen wir synchron zum induktiven Aufbau der mAussagen vor. Analog den arihmetischen Aussagen werden sowohl die mAusdrücke als auch die Prädikate mit den Mitteln von JavaZ interpretiert. Interpretation der mAusdrücke: • Eine mVariable x wird durch eine gleichlautende JavaZVariable von Typ Set repräsentiert: Set x; • Dem mLiteral ∅ entspricht dasjenige konstante Objekt (vom Typ Set), auf das eine Referenz mittels der vordenierten Funktion getEmptySet() geliefert wird. Interpretation der atomaren mAussagen: • Die mAussage x ∈ y wird interpretiert durch die Funktion isElement( x, y) . • Die mAussage x = y wird interpretiert durch die Funktion x == y . • Die mAussage ⊤ wird interpretiert durch den konstanten Wahrheitswert true . • Die mAussage ⊥ wird interpretiert durch den konstanten Wahrheitswert false Interpretation der zusammengesetzten mAussagen Gibt es für die mAussagen A, A1 , A2 bereits eine Interpretation in JavaZ durch die Funktionen func_A(· · · ), func_A1(· · · ), func_A2(· · · ) dann erhalten wir für die zusammengesetzten mAussagen folgende Interpretationen: . 36 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK • A1 ∨ A2 wird interpretiert durch die Funktion boolean func_A1_or_A2(· · · ) { return func_A1(· · · ) | func_A2(· · · ) } Beispiel: Die mAussage (x ∈ y)∨(y = z) wird interpretiert ausgehend von den Interpretationen der einzelnen mAussagen in Form von isElement(x, y) und y == z durch die Funktion func(x,y,z) mit boolean func1(Set x, Set y, Set z) { return isElement(x,y) | (y == z); } Wir bemerken hierbei, dass gemeinsame mVariablen in der Parameterliste von func1 nur einmal aufgeführt werden. • A1 ∧ A2 wird interpretiert durch die Funktion boolean func_A1_and_A2(· · · ) { return func_A1(· · · ) & func_A2(· · · ) } Beispiel: Die mAussage ((x ∈ y) ∨ (y = z)) ∧ z ∈ u wird interpretiert ausgehend von der Interpretation der ersten Teilaussage in Form von func1(x, y, z) durch die Funktion func2(x,y,z,u) mit boolean func2(Set x, Set y, Set z, Set u) { return func1(x,y,z) & isElement(z,u); } Wir bemerken, dass wir aus Optimierunsgründen um einen Funktionsaufruf zu sparen den Funktionsaufruf func1(x,y,z) gewissermaÿen inline ersetzen durch isElement(x,y) | (y == z), so dass wir func2(x,y,z,u) auch schreiben können als boolean func2(Set x, Set y, Set z, Set u) { return (isElement(x,y) | (y == z)) & isElement(z,u); } Auch hier ist die mVariabel z in der Parameterliste von func2 natürlich nur einmal vertreten. • ¬A wird interpretiert durch die Funktion boolean func_neg_A(· · · ) { return ! func_A(· · · ); } Interpretation der quantizierten mAussagen Gibt es für die mAussagen A bereits eine Interpretation in JavaZ durch die Funktion func_A(· · · ) dann erhalten wir für die quantizierten mAussagen folgende Interpretationen: • ∀xA wird interpretiert durch die Funktion 2.4. SEMANTIK MENGENTHEORETISCHER AUSSAGEN 37 boolean func_forall_A(· · · ){ forall(Set x) { if( !func_A(· · · )) return false; } return true; } Beispiel: Die mAussage ∀x x ∈ y wir interpretiert durch func3(x,y) mit boolean func3(Set y){ forall(Set x) { if( !(isElement(x,y)) return false; } return true; } Wir bemerken, dass in der Parameterliste von func3 die Variable x nicht aufgeführt wird, da sie in der forSchleife eigens deklariert wird. Die Variable x in ∀x x ∈ y heiÿt (durch den Quantor ∀) gebunden. • ∃xA wird interpretiert durch die Funktion boolean func_exists_A(· · · ){ forall(Set x) { if(func_A(· · · )) return true; } return false; } Die mAussage ∃y∀x x ∈ y wir interpretiert durch func4(x,y) unter Benutzung der Funktion func3(y) als Interpretation für ∀x x ∈ y : Beispiel: boolean func4(){ forall(Set y) { if( func3(y)) return true; } return false; } Beide Variablen x und y sind in der mAussage ∃y∀x x ∈ y gebunden, so dass die Funktion func4 keinen Parameter erhält. Auch hier können wir den Funktionsaufruf func3(y) ersetzen durch eine geeignete inlineExpansion vermöge einer zweiten forSchleife: boolean func4(){ L: forall(Set y) { forall(Set x) { if(! isElement(x,y)) continue L; } return true; } return false; } 38 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Das Konstrukt if( func3(y)) return true; kann also ersetzt werden durch forall(Set x) { if(! isElement(x,y)) continue L; } return true; 2.4.3 Boolesche Algebra Seien A1 und A2 zwei mAussagen. Wir nennen diese Aussagen äquivalent A1 ∼ = A2 wenn die Aufrufe die interpretierenden Funktionen func_A1(· · · ) und func_A2(· · · ) stets denselben Wahrheitswert liefern. Zwei Aussagen A1 und A2 sind genau dann äquivalent, wenn A1 ⇔ A2 gilt. Für äquivalente mAussagen erhält man alle Eigenschaften einer booleschen Algebra.: to be done Darüberhinaus gelten für beliebige mAussagen A die verallgemeinerten deMorganschen Regeln: ¬∀x A ∼ = ∃x ¬A sowie ¬∃x A ∼ = ∀x ¬A Die mAussage A werde interpretiert durch die Funktion func_A(· · · ), dann wird die Ausage ∀x A interpretiert durch die Funktion func(· · · ) mit Beweis. boolean func(· · · ){ for all (Set x){ if (!func_A(· · · )) return false; } return true; } Die Aussage ¬∀x A kann dann interpretiert werden, indem systematisch die Ausgabe true und false vertauscht werden: boolean neg_func(· · · ){ for all (Set x){ if (!func_A(· · · )) return true; } return false; } Wir betrachten nun die mAussage ∃x¬A. Die Aussage ¬A wird interpretiert durch neg_A(· · · ) mit 2.5. MENGENOPERATIONEN UND NOTATIONEN 39 boolean neg_A(· · · ){ return !func_A(· · · ); } Damit wird ∃x¬A interpretiert durch func_neg(· · · ) mit boolean func_neg(· · · ){ forall(Set x){ if(neg_A(· · · )) return true; } return false; } Da !func_A(· · · ) stets denselben Wert liefert wie neg_A(· · · ) liefern neg_func und func_neg stets denselben Wert. Die zweite Äquivalenz zeigt sich analog. 2.5 2 Mengenoperationen und notationen Die systemischen Eigenschaften unserer MengenObjekte stehen und fallen natürlich mit dem Aufbau der das ∈Prädikat interpretierenden Tabelle: Eine spezielle Tabelle wird gewisse spezielle mAussagen wahr und andere spezielle mAussagen falsch machen. Umgekehrt wird die Forderung, dass spezielle mAussagen wahr sein sollen, die Tabelle ganz speziellen Einschränkungen unterwerfen. Tendentiell wird der Aufbau einer ∈Tabelle umso stärkeren Einschränkungen unterworfen sein, je mehr Wahrheiten von der Tabelle gefordert werden. (Es ist eine interessante Frage, inwieweit es möglich sein könnte, mit einer gewissen Anzahl von mAussagen, deren Wahrheit von der Tabelle gewährleistet werden soll, eine solche Tabelle eindeutig bis auf triviales Umsortieren der Zeilen festgelegt werden könnte.) Beispiel: Haben wir es mit Mengen a, b, c, d, · · · zu tun, die auf folgende Weise in der ∈ Tabelle vorkommen · · a a · · b b · · · · b c · · c d · · dann bedeutet dies, dass die mAussagen a ∈ b, a ∈ c, b ∈ c, b ∈ d wahr sind, denn 40 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK die interpretierende Funktion isElement liefert für die Aufrufe isElement(a,b), isElement(a,c), isElement(b,c), isElement(b,d) in diesem Fall jeweils true. Aber auch komplexere Aussagen (zusammengesetzte mAussagen und qualizierte mAussagen) erweisen sich vor dem Hintergrund dieser Tabelle als wahr, wie z.B. ∃x x ∈ b oder ∃x∃y (a ∈ x) ∧ (a ∈ y) ∧ ¬(x = y). Wir werden im Folgenden den Weg gehen, gewisse Wahrheiten von der Tabelle zu fordern. Letztlich kommt es uns dabei gar nicht darauf an, dass wir es mit einer Tabelle zu tun haben, sondern dass unsere die mAussagen interpretierenden JavaZ Funktionen bei Aufruf derselben konsistent für diejenigen mAussagen, die in unserem System oder unserer Welt als wahr gelten sollen, den Wahrheitswert true liefern. Die Vorstellung, dass diese Funktionen so implemetiert sind, dass sie auf eine Tabelle zugreifen, dient nur didaktischen Zwecken. Unter der Decke könnte die Funktion isElement(), auf die sich alles bezieht, auch ganz anders implementiert sein. Hierin besteht ja gerade die Idee eines abstrakten Datentyps. Wir stellen also (nur) die Forderung, dass das Prädikat ∈ so durch die Funktion isElement() implementiert wird, dass die unten beschriebenen mAussagen hierdurch wahr werden. Die Situation ist ähnlich der Beschreibung der reellen Zahlen durch eine Reihe von Axiomen, mit denen grundlegende Eigenschaften der reellen Zahlen in Form von Aussagen formuliert werden, die jede Implementierung der reellen Zahlen zu erfüllen haben. Diese Axiome umfassen arithmetische Aussagen man spricht in diesem Fall von Gruppenaxiomen und Ordnungsaxiomen sowie weitere Axiome. 2.5.1 Eigenschaften des abstrakten Datentyps Set Wir beginnen mit der ersten Eigenschaft: Die Eigenschaft ∃x ⊤ (Ex) Die mAussage ∃x ⊤ soll wahr sein. Hierbei handelt es sich um eine Aussage, die sich ausnahmsweise nicht auf eines der beiden Prädikate (∈ oder =) bezieht. Die Wahrheit dieser Aussage wird im Rahmen der Implementierung des Datentyps Set also nicht durch Nachschauen in der PrädikatTabelle gezeigt. Sie beruht also auf einem anderen Faktum. Schauen wir uns hierzu die Interpretation dieser mAussage an. Sie ergibt sich aus den vorangegangenen Betrachtungen zur Interpretation quantizierter mAussagen zu: boolean func\_exists(){ forall (Set x){ if(true) return true; } return false; } Wenn von einer Implementierung des Datentyps Set also gefordert wird, dass diese Funktion true liefert, dann folgt daraus, dass die forSchleife mindestens einmal durchlaufen werden kann. Denn wird sie kein einziges Mal durchlaufen, dann würde sofort false ausgegeben. Wird Sie (mindestens) einmal durchlaufen, dann wird sie bei dem ersten Durchlaufen mit dem Ausgeben von true auch schon verlassen. 2.5. MENGENOPERATIONEN UND NOTATIONEN 41 Die mAussage ∃x⊤ wird also genau dann als true interpretiert, wenn in die for Schleife eingetreten werden kann. Dies ist genau dann der Fall, wenn es mindestens ein Objekt vom Typ Set gibt, auf das die Variable x beim ersten Durchlauf verweisen kann. Damit können wir festhalten, dass die mAussage ∃x⊤ genau dann als true interpretiert wird, wenn die Implementierung von Set mindestens ein Objekt umfasst. Das erste Axiom der Mengenlehre bedeutet also, dass es mindestens eine Menge gibt. Damit haben wir aber auch die Garantie, dass die folgende Funktion, die wir aus der Skolemisierung gewinnen, ein Ergebnis ungleich null liefert: Set get_exists(){ forall (Set x){ if(true) return x; } return null; } Diese Funktion tritt wie die Funktion func_exists (s.o.) in die Schleife ein und liefert dasjenige Objekt als Wert zurück, auf das beim ersten Schleifendurchlauf durch x verwiesen wird. Welches Objekt zurückgeliefert wird, hängt von der (zufälligen) Reihenfolge ab, in der die Objekte des Typs Set in Schleifen durchlaufen werden, welches Objekt bei einem Durchlauf also zufällig als erstes genommen wird. Das durch die skolemisierte Funktion geliefert Objekt ist also nicht eindeutig bestimmt. Die Eigenschaft ∀x ∀y ∀z (z ∈ x ⇔ z ∈ y) ⇒ (x = y) (Ext) Die mAussage ∀x ∀y ∀z (z ∈ x ⇔ z ∈ y) ⇒ (x = y) soll wahr sein. Diese Eigenschaft legt fest, dass die Gleichheit von zwei beliebigen Objekten x und y des Typs Set an der gleichzeitigen Gültigkeit oder Nichtgültigkeit der Aussagen z ∈ x und z ∈ y festgemacht wird (wie immer diese auch implementiert sein sollten). Das zweite Axiom bedeutet also, dass zwei Objekte genau dann identisch sind, wenn sie dieselben (anderen) Objekte (im Sinne von ∈) beinhalten. Machen wir uns klar, dass wir damit auf die Gleichheitsoperation == theoretisch ganz verzichten könnten, denn der Aufruf der Operation x == y liefert stets denselben Wahrheitswert wir der Aufruf der folgenden Funktion isEqual() für ∀z z ∈ x ⇔ z ∈ y : boolean isEqual(Set x, Set y){ forall (Set z){ if((isElement(z,x)&!isElement(z,y))|isElement(z,y)&!isElement(z,x)) return false; } return true; } Vom operationellen Standpunkt her bedeutet dies, dass wir die Gleichheit zweier (Mengen)Objekte a und b so zeigen können, dass wir zunächst ein beliebiges Objekt x aus a hernehmen und zeigen, dass es aus zu b gehört und dann umgekehrt, dass ein beliebig aus b entnommenes x auch zu a gehört. 42 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Die Eigenschaft ∀x∃y∀z(z ∈ y) ⇔ (z ∈ x ∧ A(z)) (Aus) Die mAussage ∀x ∃y ∀z (z ∈ y) ⇔ (z ∈ x ∧ A(z)) soll wahr sein. Diese Aussage hat den Zweck zu garantieren, dass Objekte möglichst eindeutig umschrieben/charakterisiert werden können. Diese Umschreibung soll durch möglichst beliebige (andere) Aussagen durchgeführt werden können. Der einfachste Ansatz könnte darin bestehen, dass man die Aussage (Aus) ersetzte durch die Aussage ∃y∀z(z ∈ y) ⇔ A(z)) wobei A(z) für eine beliebige mAussage steht, in der die Variable z vorkommt. Strenggenommen haben wir es hier also mit einem Aussagenschema zu tun. Setzt man für A(z) die spezielle mAussage ¬(z ∈ z) ein, dann erhielte man ∃y∀z(z ∈ y) ⇔ ¬(z ∈ z)). Skolemisierte man diese Aussage mit einem speziellen Objekt c, so erhielte man ∀z(z ∈ c) ⇔ ¬(z ∈ z). Mit c eingesetzt für z erhielte man letztendlich (c ∈ c) ⇔ ¬(c ∈ c). Es ist klar, dass es hierfür keine Implementierung geben kann. Dies also ist der Grund, dass man sich in der Umschreibung, in dem Festlegen eines Objektes jeweils auf ein schon vorhandenes (anderes) Objekt bezieht. Eine auf der Basis von (Aus) skolemisierte Funktion schneidet gewissermaÿen aus einem schon vorhandenen Objekt x ein (eindeutiges) y aus. y bestehend A(z) vor dem Das dritte Axiom garantiert also die Existenz eines speziellen Objektes aus (anderen) Objekten z charakterisiert durch eine beliebige Aussage Hintergrund eines Objektes x. Wählt man ein festes Objekt m für x, dann erhält man aus dem Aussagenschema (Aus) die mAussage ∃y ∀z (z ∈ y) ⇔ (z ∈ m ∧ A(z)) oder mit der Abkürzung Hm (z) für (z ∈ m ∧ A(z)): ∃y ∀z (z ∈ y) ⇔ Hm (z). Auf Grund der Eigenschaft (Ext) gibt es genau ein y , dass die letzte Aussage erfüllt (die zugehörige Skolemfunktion liefert also unabhängig von der Reihenfolge der in den forallSchleifen ausgewählten Objekte stets dasselbe Objekt). Das durch Skolemisierung gewonnene eindeutig bestimmte Objekt kann deshalb durch ein Literal gekennzeichnet werden. Wir notieren dieses Objekt mit: {u|Hm (u)}. Die Sprechweise hierfür ist: Menge, die aus genau denjenigen Objekten z besteht, für die Hm (z) wahr ist. Mit {u|Hm (u)} für y erhalten wir ∀z z ∈ {u|Hm (u)} ⇔ Hm (z). Wir erweitern die Möglichkeit, eine Menge in der gerade beschriebenen Literalform zu beschreiben, indem wir festlegen: ( ) ( ) ∀y∀x x ∈ y ⇔ H(x) ⇔ y = {x|H(x)} . Wenn es also schon eine Menge y gibt, deren Elemente x sich durch H(x) charakterisieren lassen, dann notieren wir diese Menge ebenfalls als Literal mit jenem H(x): {x|H(x)}. 2.5. MENGENOPERATIONEN UND NOTATIONEN 43 Mit x ∈ y als H(x) ist x ∈ y ⇔ H(x) stets wahr, deshalb ist stets: y = {x|x ∈ y}. Sind m, m′ Mengen mit m = {x|H(x)} und m′ = {x|H ′ (x)}, dann gilt m = m′ g.d.w. ∀x H(x) ⇔ H ′ (x). Vom operationellen Standpunkt her bedeutet dies, dass wir zwei durch Literale {z|H(z)} und {z|H ′ (z)} festgelegte Mengen dadurch auf Gleichheit hin untersuchen können, indem wir die beiden Aussagen H(z) und H ′ (z) auf Äquivalenz hin untersuchen, dass wir also zeigen ∀z H(z) ⇔ H ′ (z). Damit erhalten wir letztendlich für die Gleichheit von Mengen: {z|H(z)} = {z|H ′ (z)} g.d.w. ∀z H(z) ⇔ H ′ (z). Die Eigenschaft ∀x ∀y ∃z ∀u (u ∈ z) ⇔ (u = x ∨ u = y) (Paar) Umgangssprachlich lässt sich diese Eigenschaft so ausdrücken, dass es zu je zwei Mengen (hier x und y ) eine Menge (hier z ) gibt, die genau x und y als Elemente besitzt. Für diese Menge z benutzen wir als weiteres Literal {x, y}. Es gilt somit u ∈ {x, y} ⇔ u = x ∨ u = y . Sind x und y gleich, dann schreiben wir {x} anstelle von {x, y}. Beachten wir bitte, dass wir damit zwei verschiedene Literale für dasselbe Objekt erhalten, denn es ist nach den obigen Bemerkungen automatisch: {x, y} = {u|(u = x) ∨ (u = y)} mit der mAussage (u = x) ∨ (u = y) in der Rolle von H(u). Die Eigenschaft ∀x ∃y ∀z (z ∈ y ⇔ (∃v z ∈ v ∧ v ∈ x)) (U) Die ausgehend von einer Menge x nach (U) exitierende Menge y notieren wir auch in der Form ∪ v. v∈x Damit gilt z ∈ ∪ v∈x v ⇔ ∃v v ∈ x ∧ z ∈ v . wir haben es hier mit einer Eigenschaft zu tun, die uns die Möglichkeit der mengentheoretischen Vereinigungsoperation gewährleistet und den Rahmen dafür liefert. In Literalschreibweise gilt: ∪ v∈x v = {z|∃v v ∈ x ∧ z ∈ v}. Es wird also gewährleistet, dass alle in einer Menge x bendlichen Mengen mengentheoretisch vereinigt werden können. 44 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Die Eigenschaft ∀x ∃y ∀z (z ∈ y ⇔ z ⊂ x) (Pot) Die mAussage z ⊂ x stet abkürzend für die mAussage ∀u u ∈ z ⇒ u ∈ x. Für Literale gilt demnach automatisch: {z|H(z)} ⊂ {z|H ′ (z)} g.d.w. ∀z H(z) ⇒ H ′ (z). Das für ein Objekt c in der Rolle von x (durch Skolemisierung von y ) gewonnene Objekt bezeichnen wir auch mit 2c (Potenzmenge von c). Beachten wir, dass wir auch damit zwei unterschiedliche Literale für dasselbe Objekt erhalten, denn es gilt automatisch 2c = {z|z ⊂ c}. Die Eigenschaft ∃x (∅ ∈ x ∧ ∀y (y ∈ x ⇒ x ∪ {x} ∈ x)) (Inf ) Eine Menge x mit der Eigenschaft (Inf ) wird induktiv genannt. Diese Eigenschaft der Induktivität wird uns den Schlüssel liefern für ein Modell der natürlichen Zahlen innerhalb von Set. Der Operator ∪ (bei x ∪ {x}) wird weiter unten mit Hilfe der Eigenschaft (U) deniert. Zwischenbetrachtung: Wo stehen wir jetzt und wo wollen wir hin? Wir haben jetzt gewissermaÿen einen universellen Computer zur Verfügung zusammen mit einer Programmiersprache mit einem einzigen Datentyp Set (neben boolean) und einer einzigen vordenierten Funktion isElement() auf diesem Datentyp (neben ==). Die Programmiersprache gibt uns gewisse Konstrukte an die Hand (Schleifen, Verzweigungen u.a.), um selbst eigene Funktionen des Ergebnistyps boolean zu denieren und sie wie Programmierbausteine zu benutzen und in weiteren Funktionen einzusetzen. Der Konstrukteur des Computers garantiert uns nun, dass (zumindest) diejenigen programmierbaren Funktionen, die den oben beschriebenen Eigenschaften des Datentyps Set entsprechen, bei ihrem Aufruf true liefern. der Konstrukteur diese Garantie bewerkstelligt, braucht uns zunächst nicht zu interessieren. Wir könnten uns aber vorstellen, dass die Implementierung (unter Benutzunmg von Science ction Technologie) auf einer (unendlichen) Objektliste zusammen mit einer zweispaltigen Tabelle beruht, auf die booleschen Funktionen und insebsondere die isElement Funktion zugreifen und die sie in endlicher Zeit durchsuchen können. Wie Unser weiteres Ziel ist es nun, die Möglichkeiten unseres Rechners so zu nutzen, d.h. ihn so zu programmieren, dass wir ihn für unsere Zwecke nutzen können. Erstes Ziel soll es sein, ihn zu einem Rechner zu machen, d.h. uns ausgehend von dem Datentyp Set diejenigen Objekte zu identizieren, die als Modell der natürlichen Zahlen fungieren könnten und auf ihnen Operationen zu denieren, die als die üblichen Additions und Multiplikationsoperationen angesehen werden können. Damit hätten wir auf unserem Computer zumindest schon einmal die elementaren Taschenrechnerfunktionen implemetiert. 2.5. MENGENOPERATIONEN UND NOTATIONEN 45 Um zu zeigen, dass dieser Weg gangbar ist, führen wir im folgenden zunächst vorbereitend gewisse Mengenoperationen ein. Exkurs: Methodische Betrachtungen Gemäÿ unserem methodischen Rahmen haben wir es in unseren Ausssagen immer mit den oben eingeführten mAussagen zu tun. In vielen Fällen handelt es sich dabei um quantizierte mAussagen der Form ∀xA(x) oder ∃xA(x). Die Wahrheit dieser Aussagen könnte man in unserem Szenario durch Aufruf der interpretierenden Funktionen überprüfen. Natürlich ist das nur eine theoretische Möglichkeit, so dass wir in der Regel es selbst sein werden, die die Funktionsabläufe in Gedanken durchführen und so zu einem Ergebnis zu kommen. (Wir gehen gewissermaÿen zurück zum Kopfrechnen.) Wir gehen also so vor, dass zum Nachweis einer quantizierten Aussage vom Typ ∀xA(x) für ein beliebig herausgegrienes Objekt x gezeigt wird, dass die Aussage A(x) zutrit. Bei einer Aussage vom Typ ∃xA(x) suchen wir demgegenüber ein spezielles geeignetes Objekt x für das die Aussage A(x) zutrit. Betrachten wir als Beispiel die Aussage ∀xx ∈ a ⇔ x ∈ b. Dann haben wir für ein beliebig herausgegrienes Objekt x zu zeigen, dass die Aussage x ∈ a ⇔ x ∈ b zutrit, dass also x ∈ a wahr ist genau dann, wenn x ∈ b wahr ist. Wir gehen in einbem solchen Fall also so vor, dass wir aus der Annahme, dass x ∈ a gelte, folgern dass dann auch x ∈ b gelten muss und umgekehrt. 2.5.2 Elementare Mengenoperationen Die leere Menge ∅ Das spezielle Literal ∅ steht für ein spezielles Objekt. Wir erhalten es, indem wir von (Aus) ausgehen und für H(z) folgende Aussage bilden: z ∈ m ∧ ⊥. Wir erhalten damit die spezielle Menge ∅ = {z|z ∈ m ∧ ⊥}. Es sieht auf den ersten Blick so aus, dass ∅ noch von (der Interpretation von) m abhhinge. Man kann aber leicht zeigen, dass dies nicht der Fall ist. ∅ heiÿt leere für das gilt Menge. Das Literal steht für dasjenige eindeutig bestimmte Objekt, ∀x ¬(x ∈ ∅). Denn da z ∈ ∅ ⇔ z ∈ m ∧ ⊥ ⇔ ⊥, ist z ∈ ∅ stets falsch und es folgt ∀x ¬(x ∈ ∅) bzw. ¬∃x x ∈ ∅. 46 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Der Durchschnitt von Mengen Die Eigenschaft (Aus) liefert uns die Möglichkeit eine Operation auf Mengen zu denieren: Hierzu betrachten wir die Aussage H(z) ≡ (z ∈ a) ∧ (z ∈ a′ ). Die hierzu gehörende eindeutig bestimmt Menge {z|(z ∈ a) ∧ (z ∈ b)} notieren wir mit a∩b: a ∩ b = {z|z ∈ a ∧ z ∈ b}. Es gilt also ∀z z ∈ a ∩ b ⇔ (z ∈ a) ∧ (z ∈ b). Aufgabe: Schreiben Sie eine Funktion in JavaZ, die ausgehend von zwei Mengen a und b, die Menge a ∩ b als Ergebnis liefert. Hinweis: Gehen Sie aus von der Aussage ∃y ∀z (z ∈ y) ⇔ (z ∈ om ∧ A(z)) mit A(z) gwählt als z ∈ b und setzen Sie a in die Rolle von om, so dass wir folgende Aussage betrachten: ∃y ∀z (z ∈ y) ⇔ (z ∈ a ∧ z ∈ b). Skolemisieren Sie diese Aussage. Die Vereinigung von Mengen Die Eigenschaft (U) liefert uns eine weitere Operation auf Mengen, indem wir ausgehend von zwei Mengen a und ∪ b zunächst nach (Paar) die Menge {a, b} bilden und dann nach (U) die Menge v∈{a,b} v . Diese Menge notieren wir durch: a ∪ b. Es gilt nun für beliebiges z : ∪ z ∈a∪b ⇔ z ∈ v∈{a,b} (U) ⇔ ∃v z ∈ v ∧ v ∈ {a, b} ⇔ ⇔ ∃v z ∈ v ∧ (v = a ∨ v = b) ∃v (z ∈ v ∧ v = a) ∨ (z ∈ v ∧ v = b) ⇔ ⇔ ∃v (z ∈ a) ∨ (z ∈ b) (z ∈ a) ∨ (z ∈ b) Fassen wir also zusammen: ∀z z ∈ a ∪ b ⇔ (z ∈ a) ∨ (z ∈ b). a ∪ b kann deshalb als Literal wie folgt geschrieben werden: a ∪ b = {z|z ∈ a ∨ z ∈ b}. Aufgabe: Schreiben Sie eine Funktion in JavaZ, die ausgehend von zwei Mengen 2.5. MENGENOPERATIONEN UND NOTATIONEN 47 a und b, die Menge a ∪ b als Ergebnis liefert. Hinweis: Ausgehend von (Paar) betrachten wir zunächst die Aussage ∃z ∀u (u ∈ z) ⇔ (u = a ∨ u = b). Skolemisierung dieser Aussage liefert zunächst eine Funktion, die ausgehend von a und b zunächst die Menge {a, b} zum Ergebnis hat. Nennen wir das Ergebnis c und setzen c für x in (U) ein. Wir erhalten: ∃y ∀u (u ∈ y ⇔ (∃v u ∈ v ∧ v ∈ c)). Skolemisierung Sie diese Aussage. Die Dierenz von Mengen Nehmen wir für Ha (z) die Aussage z ∈ a∧¬(z ∈ b), dann notieren wir die zugehörige Menge mit a \ b, so dass gilt: ∀z z ∈ a \ b ⇔ z ∈ a ∧ ¬(z ∈ b). a \ b kann damit geschrieben werden als a \ b = {z|z ∈ a ∧ ¬(z ∈ b)}. 2.5.3 Geordnete Paare und mengentheoretische Funktionen Kartesisches Produkt Ausgehend von zwei vorgegebenen Mengen u, v kann man durch sukzessive Paarbildung die Menge {{u}, {u, v}} bilden.Wir schreiben hierfür: {{u}, {u, v}} = (u, v) (u, v) fungiert also als Literal und zwar als Abkürzung für das Literal {{u}, {u, v}}. Man kann zeigen (Übung), dass stets (u, v) = (a, b) g.d.w. u = a und v = b. Das kartesische Produkt von zwei Mengen a und b wird nun deniert mittels der Aussage H(z) = ∃u ∃v (u ∈ a ∧ v ∈ b ∧ z = (u, v)). Wir suchen also m.a.W. all diejenigen Objekte z , die sich als geordnetes Paar z = (u, v) herausstellen, wobei u ∈ a und v ∈ b sein muss. Für das kartesische Produkt zweier Mengen a und b benutzen wir das Literal a × b. Damit ist a × b = {z|∃u ∃v (u ∈ a ∧ v ∈ b ∧ z = (u, v))}. Für die rechte Seite benutzen wir als Abkürzung: {(u, v)|u ∈ a ∧ v ∈ b}. a × b = {(u, v)|u ∈ a ∧ v ∈ b}. Mengentheoretische Funktionen f :a→b Das Konzept einer Funktion zwischen zwei Mengen a und b lässt sich nun leicht auf das Konzept einer geigneten Teilmenge eines kartesischen Produktes zurückführen. Hierzu deniert man eine Funktion mengentheoretisch über ihren Graphen, also durch eine geeignete Teilmenge des kartesischen Produktes a × b. Damit eine 48 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK solche Teilmenge f als Graph einer Funktion aufgefasst werden kann, müssen zwei Bedingungen erfüllt sein: i) ∀u∈a ∃v∈b (u, v) ∈ f ii) ∀u∀v∀v ′ (u, v) ∈ f ∧ (u, v ′ ) ∈ f ⇒ v = v ′ . Bemerkung: ∀x∈a A(x) ist eine abkürzende Schreibweise und soll ∀x (x ∈ a ⇒ A(x)) bedeuten. Analog steht ∃x∈b A(x) für ∃x (x ∈ b ∧ A(x)). Ist (u, v) ∈ f , dann schreiben wir für v auch f (v) und nennen ihn Funktionswert von v der Funktion f . Anstelle von v = f (u) oder (u, v) ∈ f schreiben wir auch f u 7→ v Nach i) gibt es also für jedes u ∈ a (mindestens) einen Funktionswert f (u). Nach ii) gibt es nur einen Funktionswert. Wir beachten, dass eine Funktion als Mengenobjekt ein Objekt ist wie jedes andere aus unserer Mengenlehre. Was also macht eine Funktion zu einer Funktion? Folgt man unseren Überlegungen, dann erkennt unser Computer ein FunktionsObjekt f daran, dass folgende Aussage für dieses f zutrit: ( ) ( ) ( ) ∃a∃b f ⊂ a×b ∧ ∀x∈a ∃y∈b (x, y) ∈ f ∧ ∀x∀y∀y ′ (x, y) ∈ f ∧(x, y ′ ) ∈ f ⇒ y = y ′ . Und wie erhält man den Funktionswert f (x) einer Funktion f für das Objekt x? Nun einfach durch folgende JavaZ Funktion: Set evaluate_Function(Set f, Set x){ forall(Set y){ if( isElement((x,y),f)) return proj1(x,y); } return null; } Hierbei bezeichnet proj1 eine JavaZ Funktion, die (auf naheliegende Weise) die erste Komponente von (x,y), nämlich x, liefert. Auch bei (a,b) handelt es sich um eine verkappte JavaZ Funktion, die aus zwei Set Objekten a,b das entsprechende Set Objekt (a,b) liefert. 2.5.4 Mengenalgebren und Verbände In Vorbereitung auf den operationellen Umgang mit Mengen werden wir grundlegende Eigenschaften der vorhin eingeführten Mengenoperationen herleiten: Satz 2.1. Folgende Aussagen gelten: i) ∀a ∀b ∀c a ∪ (b ∪ c) = (a ∪ b) ∪ c ∀a ∀b ∀c a ∩ (b ∩ c) = (a ∩ b) ∩ c (Assoziativgesetze) ii) ∀a ∀b a ∪ b = b ∪ a ∀a ∀b a ∩ b = b ∩ a (Kommutativgesetze) iii) ∀a ∀b (a ∩ b) ∪ a = a 2.5. MENGENOPERATIONEN UND NOTATIONEN 49 ∀a ∀b (a ∪ b) ∩ a = a (Absorptionsgesetze) ∀a ∀b ∀c (a ∪ b) ∩ c = (a ∩ c) ∪ (b ∩ c) ∀a ∀b ∀c (a ∩ b) ∪ c = (a ∪ c) ∩ (b ∪ c). iv) (Distributivgesetze) Beweis. zu i): Seien a, b, c beliebige Mengen. Es gilt jeweils: a ∪ (b ∪ c) = {x|x ∈ a ∨ (x ∈ b ∨ x ∈ c)} sowie (a ∪ b) ∪ c = {x|(x ∈ a ∨ x ∈ b) ∨ x ∈ c}. Damit a ∪ (b ∪ c) = (a ∪ b) ∪ c, ist also zu zeigen, dass für beliebiges x gilt x ∈ a ∨ (x ∈ b ∨ x ∈ c) ⇔ (x ∈ a ∨ x ∈ b) ∨ x ∈ c. Dies folgt aber sofort aus der Aussagenlogik auf Grund der Assoziativität der Operation ∨ und der erste Teil von i) ist bewiesen. Der zweite Teil von i) und der Teil ii) zeigen sich analog. zu iii): Es ist: (a ∩ b) ∪ a = {x|(x ∈ a ∧ ∨x ∈ b) ∨ x ∈ a} und a = {x|x ∈ a}. Nun gilt (x ∈ a∧x ∈ b)∨x ∈ a ∨ und ∧), also folgt ⇔ x ∈ a (Eigenschaft der logischen Operationen (a ∩ b) ∪ a = {x|(x ∈ a ∧ ∨x ∈ b) ∨ x ∈ a} = {x|x ∈ a} = a. Der zweite Teil von iii) zeigt sich analog. zu iv): Übung 2 Satz 2.2. Es gilt: sowie ∀a ∀b a ∩ b = a ⇔ a ⊂ b ∀a ∀b a ∪ b = b ⇔ a ⊂ b. Beweis. Seien a, b beliebige Mengen mit a ∩ b = a. Dann gilt (für alle x) x ∈ a ⇔ x ∈ a ∧ x ∈ b. Da x ∈ a ∧ x ∈ b ⇒ x ∈ b, folgt damit x ∈ a ⇒ x ∈ b und damit a ⊂ b. Seien nun umgekehrt a, b beliebige Mengen mit a ⊂ b. Dann gilt für alle x, dass x ∈ a ⇒ x ∈ b. Es gilt zusätzlich stets x ∈ a ⇒ x ∈ a, so dass auf Grund der Regeln der Ausagenlogik daraus (für alle x) folgt x ∈ a ⇒ x ∈ a ∧ x ∈ b. Da gleichzeitig stets x ∈ a ∧ x ∈ b ⇒ x ∈ a, gilt (für alle x) x ∈ a ⇔ x ∈ a ∧ x ∈ b und damit a ∩ b = a. Damit ist der erste Teil bewiesen. Seien nun a, b beliebige Mengen mit a ∪ b = b. Dann gilt (für alle x) x ∈ a ∨ x ∈ b ⇔ x ∈ b. Da stets x ∈ a ⇒ x ∈ a ∨ x ∈ b, folgt aus den Regeln der Aussagenlogik (für alle x) x ∈ a ⇒ x ∈ b mithin a ⊂ b. 50 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Seien umgekehrt a, b beliebig mit a ⊂ b. Dann erhalten wir wie oben zunächst (für alle x) x ∈ a ⇒ x ∈ b. Da stets x ∈ b ⇒ x ∈ b folgt mt den Regeln der Aussagenlogik auch x ∈ a∨x ∈ b ⇒ x ∈ b. Da gleichzeitig stets auch x ∈ b ⇔ x ∈ a∨x ∈ a folgt (für alle x) x ∈ a ∨ x ∈ a ⇔ x ∈ b und mithin a ∪ b = b. Damit ist auch der zweite Teil bewiesen. 2 Folgerung 2.3. Es gilt: ∀a ∀b ∀c a ⊂ c ∧ b ⊂ c ⇒ a ∪ b ⊂ c. Beweis. Seien a, b, c beliebige Mengen mit a ⊂ c und b ⊂ c dann folgt aus Satz 2.2, dass a ∪ c = c und b ∪ c = c. Damit ist (a ∪ b) ∪ c = a ∪ (b ∪ c) = a ∪ c = c. Also ist (a ∪ b) ∪ c = c und mit Satz 2.2 erhalten wir a ∪ b ⊂ c. 2 Folgerung 2.4. Es gilt: ∀a a ∩ a = a = a ∪ a. Beweis. Sei a eine beliebige Menge. Nach dem ersten Absorptionsgesetz (mit a ( ) in der Doppelrolle für a und b) folgt (a∩a)∪a = a und somit (a∩a)∪a ∩a = a∩a. ( ) Nun ist nach dem zweiten Absorptionsprozess gleichzeitig (a ∩ a) ∪ a ∩ a = a. Damit folgt a ∩ a = a. Die zweite Teilbehauptung zeigt sich analog ausgehend von dem zweiten Absorptionsgesetz in Form von (a ∪ a) ∩ a = a. 2 Folgerung 2.5. Es gilt: ∀a ∀b a ∩ b ⊂ a ⊂ a ∪ b. Beweis. Für beliebige Mengen a, b gilt (nach den Absorptionsgesetzen) (a ∩ b) ∪ a = a. Unter Benutzung von Satz 2.2 folgt damit (in der Rolle von a für b und b für a ∩ b), dass a ∩ b ⊂ a. Nach dem Absorptionsgesetz (in der zweiten Form) gilt für beliebige Mengen a, b (a ∪ b) ∩ a = a. Damit erhalten wir für a ∪ b in der Rolle von b aus Satz 2.2 sofort a ⊂ a ∪ b. Damit ist die Folgerung vollstängig bewiesen. 2 Wir betrachten nun die Eigenschaften der der mengentheoretischen Dierenz. Satz 2.6. Es gilt: ∀a ∀b (a \ b) \ a = ∅ ii) ∀a ∀b a \ (a \ b) = a ∩ b iii) ∀a ∀b a \ (b \ a) = a iv) ∀a ∀b a ∪ (b \ a) = a ∪ b i) Beweis. Übung 2 2.5. MENGENOPERATIONEN UND NOTATIONEN Folgerung 2.7. Für alle Mengen a, b ∀a ∀b (a \ b) \ b = a \ b ii) ∀a a \ ∅ = a iii) ∀a ∀b a \ b ⊂ a iv) ∀a ∀b a ⊂ b ⇒ a \ b = ∅ v) ∀a ∀b a ∩ (a \ b) = a \ b vi) ∀a ∀b a ∩ (b \ a) = ∅ vii) ∀a ∀b a \ (a ∩ b) = a \ b. 51 gilt: i) Beweis. zu i): Nach Satz 2.6 iii) gilt b = b \ (a \ b) und damit (a \ b) \ b = (a \ b) \ (b \ (a \ b)). Unter nochmaliger Benutzung dieses Satzes (mit a \ b in der Rolle von a) erhalten wir (a \ b) \ (b \ (a \ b)) = a \ b, insgesamt also (a \ b) \ b = a \ b. Damit ist Teil i) bewiesen. zu ii): Nach dem Satz 2.6 i) folgt (mit ∅ für b) dass ∅ = (a \ ∅) \ a und somit a \ ∅ = a \ ((a \ ∅) \ a). Mit Satz 2.6 iii) (und mit a \ ∅ in der Rolle von b) erhalten wir a \ ((a \ ∅) \ a) = a. Damit ist stets a \ ∅ = a und ii) ist bewiesen. zu iii): Nach Satz 2.2 genügt es zu zeigen, dass (a \ b) ∩ a = a \ b. Nun gilt nach Satz 2.6 ii) und i) (mit a\b für a und a für b), dass (a\b)∩a = ((a\b)\((a\b)\a)) = (a\b)\∅. Unter Benutzung des gerade bewiesenen Teils ii) dieser Folgerung erhalten wir schlieÿlich (a \ b) ∩ a = (a \ b) \ ∅ = a \ b. damit ist iii) bewiesen. zu iv): Seien a, b beliebig mit a ⊂ b. Dann ist nach Satz 2.2 a = a ∪ b. Hieraus folgt (unter zusätzlicher Benutzung von 2.2 ii) und i)): a \ b = (a ∩ b) \ b = (b ∩ a) \ b = (b \ (b \ a)) \ b = ∅. Damit ist auch iv) bewiesen. zu v): ist gleichbedeutend zum gerade bewiesenen Teil iii) dieser Folgerung. zu vi): Nach Satz 2.6 ii) ist a ∩ (b \ a) = a \ (a \ (b \ a)). Mit Satz 2.6 iii) erhalten wir a \ (b \ a) = a, so dass wir hiermit erhaltena ∩ (b \ a) = a \ a = ∅. (Letzteres aus Satz 2.6 i)). Damit ist vi) bewiesen. Wegen a∩b = a\(a\b) (Satz 2.6 ii)) erhalten wir a\(a∩b) = a\(a\(a\b)) = a ∩ (a \ b) (Letzteres wiederum mit Satz 2.6 ii)). Nach dem gerade bewiesenen Teil v) dieser Folgerung ist a ∩ (b \ a) = a \ b und damit folgt insgesamt a \ (a ∩ b) = a \ b und vii) ist bewiesen. 2 zu vii): Mengentheoretische Komplemente Wir betrachten im Folgenden die Potenzmenge 2c einer festen Menge c. Aus den vorausgegangenen Theoremen und Folgerungen folgt, dass alle mengentheoretischen Operationen (∪, ∩, \) mit Mengen aus 2c wieder Mengen aus 2c liefert. Es gilt: Satz 2.8. Es gilt: sowie ∀a a ∩ ∅ = ∅ und ∀a a ∪ ∅ = a ∀a a ∈ 2c ⇒ a ∩ c = a und ∀a a ∈ 2c ⇒ a ∪ c = c. 52 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Beweis. Folgt sofort aus ∅ ⊂ a ⊂ c. Satz 2.9. Es gilt: Beweis. 2 ∀a a ∈ 2c ⇒ a ∩ (c \ a) = ∅. Es ist a ∩ (c \ a) = a \ (a \ (c \ a)) = a \ a = ∅. Denition 2.10. Auf der Potenzmenge die Operation a deniert durch ∪, ∩, ¯ eine Beweis. einer Menge c sei für alle a ∈ 2c a = c \ a. Folgerung 2.11. Die Potenzmenge nen 2c 2 2c einer Menge c bildet mit den Operatio- boolesche Algebra. aus den vorangegangenen Sätzen. 2 Die Inklusionsbeziehung als Ordungsbeziehung Die Teilmengenbeziehung hat alle formalen Eigenschaften einer Ordnung. Wir können also eine Sprachregelung der Art einführen, dass wir sagen, eine Menge a sei kleiner oder gleich einer Menge b, wenn asubsetb. Obwohl es Mengen a, b gibt, die bzgl. dieser Ordnung unvergleichbar sind für die also weder a ⊂ b noch bsubseta gilt gibt es Situationen, in denen man sinnvoll von einer kleinsten Menge sprechen kann. Das ist dann der Fall, wenn ausgehend von einer Menge c eine Menge m existiert mit ∀x x ∈ c ⇒ m ⊂ x, wenn also mit anderen Worten m kleiner/gleich ist wie alle Mengen aus c. Solche kleinsten Mengen spielen häug eine besondere Rolle. 2.6 Natürliche Zahlen revisited Wir haben alle technischen Voraussetzungen getroen, eine besondere Menge zu identizieren, der wir auf natürliche Weise die Rolle der natürlichen Zahlen zuweisen können. Wir machen dabei Gebrauch von der Tatsache, dass sich die natürlichen Zahlen eindeutig(!) durch den Zählprozess charakterisieren lassen. (Wir werden diesen Sachverhalt später noch genauer begründen.) Der Zählprozess kann nun so beschrieben werden, dass man ausgehend von einer Zahl 0 sukzessive immer weiter zu einer nächsten übergeht, und dass dieser Übergang eindeutig sein muss, dass es also nur eine nächste Zahl gibt. Mit dem Zählprozess verbinden wir auch die Vorstellung, dass wir beim Zählen nicht zweimal auf dieselbe Zahl treen, dass also der Zählprozess sich nicht irgendwann im Kreise dreht und auch die Null nicht irgendwann noch einmal auftritt. Wir nehmen auch ganz selbstverständlich an, dass wir jede (jede ) natürliche Zahl beim Zählen irgendwann einmal erreichten wenn wir nur genügend Zeit investierten. Versuchten wir diese Vorstellungen zu formalisieren, dann könnten wir mit unseren formalen Ausdrucksmittel sagen, dass die natürlichen Zahlen einen Objektbereich darstellen (einen unendlichen, und was das bedeutet, werden wir noch präzisieren können), eine Menge mithin, die normalerweise mit N notiert wird, mit einem besonderen Element, das mit 0 bezeichnet wird. Auf dieser Menge ist eine Funktion 2.6. NATÜRLICHE ZAHLEN REVISITED 53 deniert, die die Rolle der vorhin beschriebenen Zähl funktion einnimmt und die als Nachfolgerfunktion s bezeichnet wird: s:N→N Gilt für zwei Objekte x, y s(x) = y , dann wird x wird Nachfolger von x genannt. Vorgänger von y genannt, und y Damit s die oben beschriebene Rolle einnehmen kann, muss s dann folgende Eigenschaften besitzen: 1. Die 0 hat keinen Vorgänger, d.h. formal gilt ¬∃y∈N 0 = s(y). 2. Jedes Element hat höchstens einen Vorgänger, d.h. formal gilt ∀x∈N ∀x′ ∈N s(x) = s(x′ ) ⇒ x = x′ . 3. Man erfasst ausgehend von der 0 mit der Nachfolgerfunktion jede Zahl aus N. Formal kann man dies so präzisieren (machen Sie sich dies in Ruhe klar): ( ) ∀a⊂N ∀x∈N 0 ∈ a ∧ (x ∈ a ⇒ s(x) ∈ a) ⇒ a = N. (Zur Erinnerung: die Schreibweise ∃x∈u A(x) steht abkürzend für ∃x (x ∈ u) ∧ A(x), und ∀x∈u A(x) steht abkürzend für ∀x (x ∈ u) ⇒ A(x).) Was tun? Wollen wir also unter unseren Objekten von Typ Set ein Objekt nden, das als Modell der natürlichen Zahlen fungieren soll, müssen wir für dieses Objekt gleichzeitig eine geeignete Nachfolgerfunktion nden, also eine Funktion mit den oben beschriebenen Eigenschaften. Debei hilft uns die Beobachtung, dass die Eigenschaft einer induktiven Menge (siehe Axiom (Inf )) äuÿerliche Ähnlichkeiten mit der Eigenschaft 3. der Nachfolgerfunktion hat. Unser Ansatz wird also der sein, eine geeignete induktive Menge zu nehmen zusammen mit einer geeigneten Nachfolgefunktion, die die Induktivität wiederspiegelt. 2.6.1 Ein erster Versuch Gehen wir also hin und nehmen eine induktive Menge i auf der wir als Nachfolgerfunktion eine Funktion σ ⊂ i × i, d.h. σ:i→i mit σ(z) = z ∪ {z}. Die Induktivität von i garantiert uns zunächst, dass die so denierte Funktion tatsächlich nicht aus i hinausführt (dass i formal also tatsächlich als Teilmenge von i × i aufgefasst werden kann). 54 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK In i wäre auch das eine Folge der Induktivität die leere Menge als Element enthalten und könnte die Rolle der 0 einnehmen. Dies hätte sofort zur Konsequenz, dass diese 0 keinen Vorgänger z haben könnte (denn ein solcher Vorgänger z wäre konstruktionsbedingt es wäre ja σ(z) = z ∪ {z} ̸= ∅ in ∅ enthalten, was im Widerspruch zu den Eigenschaften von ∅ stünde. Man käme vielleicht auch noch mit der 2. Eigenschaft der Nachfolgeoperation durch, dass es nämlich stets nur einen einzigen Vorgänger gibt. Bei der 3. Eigenschaft aber wären Probleme nicht auszuschlieÿen, die einfach darauf beruhten, dass das i evtl. unnötig groÿ ausgefallen sein könnte. Und dies hätten wir zunächst auch nicht unter Kontrolle, da der Vorgang der Gewinnung einer induktiven Menge i auf dem Prozess der Skolemisierung beruhen würde, der uns seinerseits (ja nach Reihenfolge des Scannens nach induktiven Mengen) einfach die erstbeste induktive Menge liefern würde. Die also könnte einfach zu groÿ sein, um der 3. Eigenschaft unserer Nachfolgerfunktion σ zu genügen. Können wir unser Vorgehen retten? Ja, wir können. Denn das Problem lag daran, dass unsere induktive Menge zu groÿ sein könnte. Verkleinern wie sie also. Wie? Indem wir gleichsam systematisch alle Teil mengen von i daraufhin abklopfen, ob diese bereits schon für sich alleine induktiv sind. Auf diese Weise kommen wir oensichtlich zu kleineren induktiven Mengen. Schneiden wir schlieÿlich alle diese so gefundenen induktiven Teilmengen, dann haben wir sicher die kleinste gefunden, wenn ja wenn dieser Durchschnitt selbst wieder induktiv sein sollte. Diese kleinste induktive Menge wird ω genannt. Dies wäre der erste Schritt im Aunden einer Menge, die die natürlichen Zahlen würdig repräsentieren könnte. σ würde dasselbe Bildungsgesetz behalten und wir dürfen die Honung haben, dass auf dieser eingeschränkten induktiven Menge σ dann alle geforderten Eigenschaften aufweist. Im Erfolgsfalle wäre das dann die Situation: • Unsere natürlichen Zahlen N werden dargestellt durch die kleinste induktive Menge ω . • ∅ repräsentierte die 0. • σ(∅) stünde für die 1. • Generell stünde σ(z) für “z + 1”. Der Rest des Kapitels beschäftigt sich jetzt im wesentlichen mit der Aufgabe, die notwendigen Eigenschaft von ω und σ nachzuweisen. Ein letztes Wort zum Sonntag Natürlich können Sie mir glauben, dass das alles seine Richtigkeit hat und den Rest des Kapitels überspringen. Und wer glaubt nicht gerne einem deutschen Professor. Funktional werden Sie dadurch in den Folgekapiteln keine Einschränkungen verspüren. (Die Situation ist genauso wie beim Programmieren in höheren Programmiersprachen, das Sie professionell beherrschen können, ohne dass Sie sich Gedanken 2.6. NATÜRLICHE ZAHLEN REVISITED 55 über die Compilation des Codes in den eigentlichen Maschinencode machen müssen.) Dennoch: es ist ein schönes Gefühl, sich vom Professor zu emanzipieren, indem man etwas selbst durchdenkt, selbst versteht und vielleicht sogar selbst verbessert. Sie können es. 2.6.2 Denition von ω Wir zeigen: Satz 2.12. Es gibt eine kleinste induktive Menge. D.h. es gibt eine induktive Menge, die Teilmenge ist einer jeder anderen inuktiven Menge. Beweis. Nach (Inf ) gibt es ein (durch Skolemisierung gewonnenes) Objekt i, für die die Aussage ∅ ∈ i ∧ (∀z z ∈ i ⇒ z ∪ {z} ∈ i) wahr ist (d.h. als true interpretiert wird). Mit Hilfe von (Aus) können wir die Menge {x | x ∈ 2i ∧ (∅ ∈ x ∧ (∀z z ∈ x ⇒ z ∪ {z} ∈ x))} = c bilden. Wir bilden also mit anderen Worten diejenige Menge, die aus all denjenigen Teilmengen von i besteht, die selbst alle induktiv sind. Wir bilden abschlieÿend den Durchschnitt aller in c enthaltenen Mengen, d.h. wir bilden die Menge ∩ ω = x = {z|∀x∈c z ∈ x}. x∈c Es werden also ausgehend von i alle diejenigen z zu der Menge ω zusammengefasst, die in allen induktiven Teilmengen von i gleichzeitig enthalten sind. (Die Notation ∀x∈c z ∈ x dient als Abkürzung für ∀x x ∈ c ⇒ z ∈ x.) Aufgabe: Wodurch ist garantiert, dass Man sieht leicht, dass ∩ x∈c x existiert? ∀x x ∈ c ⇒ ω ⊂ x. Dies liegt daran, dass generell ∀x′ x′ ∈ c ⇒ (∩ ) x ⊂ x′ . x∈c Aufgabe: Gibt es dabei noch eine kleine fast unmerkliche Voraussetzung zu berücksichtigen? Wenn wir jetzt noch zeigen können, dass ω selbst induktiv ist, dann ist automatisch auch ω ∈ c und wir haben mit ω eine kleinste induktive Menge aus c gefunden. Bemerkung: Theoretisch könnte man mit einem anderen i zu einem anderen ω gelangen. Warum ist das nicht so? Warum ist das ω die unabhängig von i absolut kleinste induktive Menge? (Übung) Für die Induktivität von ω ist im einzelnen nun zu zeigen: i) ∅ ∈ ω ii) ∀z z ∈ ω ⇒ z ∪ {z} ∈ ω 56 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK zu i): Sei x ∈ c beliebig, dann ist x induktiv und nach Denition einer induktiven Menge ist ∅ ∈ x. ∅ ist also in allen x von c enthalten und damit nach Denition von ω auch in ω . Damit ist i) nachgewiesen. zu ii): Sei z ∈ ω beliebig gewählt. Dann ist nach Denition von ω dieses z gleichzeitig Element aller x ∈ c. Da jede der x ∈ c als induktiv vorausgesetzt ist, ist damit auch z ∪ {z} wieder in jedem x, das zu c gehört, und damit denitionsgemäÿ auch in ω . Für beliebig ausgewähltes z ∈ ω ist also auch z ∪ {z} ∈ ω . Dies zeigt ii). Damit ist ω als induktiv nachgewiesen. 2 Intuitiv sieht man, dass ω aus den Elementen ∅, {∅}, {∅, {∅}}, · · · besteht. 2.6.3 Denition und Eigenschaften der Nachfolgerfunktion σ Auf der im letzten Unterabschnitt denierten Menge ω wollen wir nun eine kanonische Funktion σ ⊂ ω × ω , d.h. σ:ω→ω denieren. Wir wählen als (die σ charakterisierende) Teilmenge aus ω × ω die Menge aller Paare (z, z ∪ {z}. Damit wird σ gleich σ = {(u, v)|(u, v) ∈ ω × ω ∧ v = u ∪ {u}}. Satz 2.13. Die Teilmenge σ ⊂ω×ω ist eine Funktion. Beweis. Damit eine Menge f als Funktion gelten kann, muss für dieses f folgende Aussage gelten (s.o.): ( ) ( ) ( ) ∃a∃b f ⊂ a×b ∧ ∀x∈a ∃y∈b (x, y) ∈ f ∧ ∀x∀y∀y ′ (x, y) ∈ f ∧(x, y ′ ) ∈ f ⇒ y = y ′ . Mit ω sowohl für a und b und mit σ für f ist also zu zeigen: i) ∀x∈a ∃y∈b (x, y) ∈ f und ii) ∀x∀y∀y ′ (x, y) ∈ f ∧ (x, y ′ ) ∈ f ⇒ y = y ′ . zu i): Sei x beliebig aus ω , dann können wir für y einfach die Menge x ∪ {x} wählen, so dass i) oensichtlich erfüllt ist. zu ii): Seien x, y, y ′ beliebig aus ω und seien (x, y) und (x, y ′ ) jeweils aus σ , dann ist nach Denition von σ y = x ∪ {x} und y ′ = x ∪ {x} und damit y = y ′ , so das auch ii) erfüllt ist. 2 Es gilt: Satz 2.14. Für alle M.a.W. z∈ω ist σ(z) ̸= ∅. ∀z z ∈ ω ⇒ σ(z) ̸= ∅. Beweis. Dies folgt sofort daraus, dass z ∈ σ(z) für alle z ∈ ω , und dass deshalb σ(z) immer mindestens ein Element nämlich z enthält. Also kann σ(z) nicht gleich 2.6. NATÜRLICHE ZAHLEN REVISITED der leeren Menge sein. 57 2 Sei f : a → b eine Funktion, dann hat f (x) eine unterschiedliche Bdeutung, je nachdem ob x ein Element oder eine Teilmenge von a ist. Bemerkung: Im ersten (üblichen) Fall ist mit f (x) der Funktionswert von f für den Wert x gemeint. f (x) ist dann ein Element aus b. Im zweiten Fall ist mit f (x) die Menge aller Funktionswerte f (y) mit y ∈ x gemeint. In diesem Fall ist also f (x) = {z|z ∈ b ∧ (∃x x ∈ a ∧ f (x) = z} eine Teilmenge von b. Wir zeigen jetzt: Satz 2.15. Wenn M.a.W. a⊂ω und ∅∈a und σ(a) ⊂ a, dann ist a = ω. ∀a a ⊂ ω ∧ ∅ ∈ a ∧ σ(a) ⊂ a ⇒ a = ω. Eine Teilmenge von ω , die ω. bzgl. σ abgeschlossen ist und die leere Menge ∅ enthält, ist selbst schon gleich Beweis. Wegen der Bedingung ∅ ∈ a und σ(a) ⊂ a ist a induktiv. Wegen der Minimalität von ω ist deshalb ω ⊂ a. Zusammen mit der Voraussetzung a ⊂ ω ist damit a = ω . 2 Weiter gilt: Hilfssatz 2.16. i) Für alle M.a.W. z∈ω gilt: x∈z für alle M.a.W. x⊂z für alle x. ∀z z ∈ ω ⇒ (∀x x ∈ z ⇒ x ⊂ z). ii) Es gilt auch eine Umkehrung, d.h. für alle x=z impliziert x ∈ ω. z∈ω gilt: x⊂z impliziert x∈z oder ∀z z ∈ ω ⇒ (∀x x ∈ ω ∧ x ⊂ z ⇒ x ∈ z ∨ x = z). Der kleine Unterschied in der Formulierung von i) und ii) bzgl. der Bedingung x ∈ ω in ii) rührt daher, dass für z ∈ ω mit beliebigem x ∈ z sich das Element x automatisch auch als Element von ω herausstellt. Für eine beliebige Teilmenge x ⊂ z trit dies nicht notwendig zu. D.h. eine beliebige Teilmenge x ∈ z muss nicht aus ω sein braucht insofern auch nicht Element von z zu sein. Die direkte Umkehrung von i) wäre demnach falsch. Beweis. zu i): Wir haben für alle z ∈ ω zu zeigen, dass ∀x x ∈ z ⇒ x ⊂ z . Wir gehen so vor, dass wir im ersten Schritt diejenigen Elemente z ∈ ω zu einer Menge a ⊂ ω zusammen, für die ∀x x ∈ z ⇒ x ⊂ z zutrit. Theoretisch kann a jetzt alles sein, von der leeren Menge bis zur Menge ω selbst. Stellt sich heraus, dass a = ω , dann ist i) beweisen. Wir werden den Nachweis so führen, dass wir zeigen, dass a induktiv ist und deshalb mit ω identisch sein muss. Zeigen wir also zunächst, dass ∅ ∈ a: ∅ in der Rolle von z führt zur Aussage ∀x x ∈ ∅ ⇒ x ⊂ ∅. Diese Aussage ist stets wahr. Damit ist ∅ ∈ a. Sei nun z ∈ a. D.h. es gelte für alle x ∈ z , dass auch x ⊂ z . Wir wollen zeigen, dass damit auch σ(z) ∈ a. Nun ist σ(z) ∈ a genau dann, wenn für alle x ∈ σ(z) 58 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK auch x ⊂ σ(z) ist. Sei also x ∈ σ(z) = z ∪ {z}, dann gibt es zwei Fälle zu unterscheiden: 1. Fall: x ∈ z 2. Fall: x ∈ {z} also x = z . Wir betrachten zunächst den 1. Fall: Da nach Voraussetzung z selbst bereits aus a sein sollte, ist mit x ∈ z auch x ⊂ z und damit x ⊂ z ∪ {z} = σ(z). Kommen wir zum 2. Fall: Mit x = z folgt x ⊂ {z} ⊂ z ∪ {z} = σ(z). In beiden Fällen erhalten wir also für x ∈ σ(z) auch x ⊂ σ(z). Damit gehört mit z automatisch auch σ(z) zu a und a ist als induktiv nachgewiesen. Damit ist a = ω und i) ist bewiesen. zu ii): Wir gehen wieder vor, wie bei i), d.h. wir fassen im ersten Schritt alle diejenigen z zu einer Menge a zusammen, für die jeweils die Aussage ∀x x ∈ ω ∧ x ⊂ z ⇒ x ∈ z ∨ x = z gilt. Auch hier werden wir wieder zeigen, dass die so gewonnene Menge a eine induktive Menge ist und deshalb mit ω identisch sein muss. Wir zeigen also als erstes wieder, dass ∅ ∈ a. Setzen wir ∅ in die Rolle von z , dann erhalten wir die Aussage ∀x x ∈ ω ∧ x ⊂ ∅ ⇒ x ∈ ∅ ∨ x = ∅. Diese Aussage stellt sich aber sofort als wahr heraus, denn nur diejenigen x ∈ ω sind Teilmenge von ∅, die selbst gleich ∅ sind, womit die Teilaussage x ∈ ∅ ∨ x = ∅ ebenfalls hierfür wahr sind, so dass die Gesamtaussage für z = ∅ wahr ist und ∅ als zu a gehörig nachgewiesen ist. Sei nun wieder z beliebig in a. Es gelte also für alle Teilmengen x ⊂ z die gleichzeitig Elemente von ω sind, dass x ∈ z oder x = z ist. Wir wollen zeigen, dass dann auch σ(z) ∈ a ist. Nun ist σ(z) ∈ a wieder genau dann, wenn für alle Teilmengen x ⊂ σ(z), die gleichzeitig Elemente von ω sind, auch gilt x ∈ σ(z) oder x = σ(z). Sei also x ⊂ σ(z) (und x ∈ ω ). Dann können wir wieder zwei Fälle unterscheiden: 1. Fall: z ∈ x 2. Fall: ¬(z ∈ x). Betrachten wir den 1. Fall: Aus z ∈ x folgt sofort {z} ⊂ x und nach dem schon bewiesenen Teil i) (mit x in der Rolle von z und umgekehrt) folgt aus z ∈ x auch z ⊂ x, insgesamt erhalten wir damit σ(z) = z ∪ {z} ⊂ x, also σ(z) ⊂ x. Zusammen mit der Voraussetzung x ⊂ σ(z) erhalten wir x = σ(z). Kommen wir zum 2. Fall: Aus ¬(z ∈ x) folgt sofort ¬({z} ⊂ x). Die Menge x umfasst also nicht die Menge {z}. Aus x ⊂ σ(z) = z ∪ {z} folgt demnach notwendig x ⊂ z , da z schon als zu a gehörig vorausgesetzt wurde, folgt x ∈ z ∨ x = z also x ∈ z ∨ x ∈ {z} also x ∈ z ∪ {z} = σ(z) In beiden Fällen erhalten wir also aus x ⊂ σ(z) (und x ∈ ω ) dass x ∈ σ(z)∨x = σ(z). Damit gehört mit z automatisch auch σ(z) zu a und a ist als induktiv nachgewiesen. Damit ist a = ω und ii) ist bewiesen. 2 2.6. NATÜRLICHE ZAHLEN REVISITED Folgerung 2.17. Für alle Wegen x ⊂ σ(z) z∈ω 59 gilt: Wenn x ∈ σ(z), dann ist x ̸= σ(z). x & σ(z). σ(z) enthält gleichsam mehr σ(z) selbst enthalten sind. ist also insgesamt Ele- mente als jede der Mengen, die als Elemente in M.a.W. ∀z z ∈ ω ⇒ (∀x x ∈ σ(z) ⇒ x ̸= σ(z)). Beweis. Sei wiederum a ⊂ ω die Menge der Elemente z für die obige Bedingung zutrit, für die also gilt: ∀x x ∈ σ(z) ⇒ x ̸= σ(z). Auch ist wiederum oensichtlich ∅ ∈ a. Sei nun z ∈ a, also ∀x x ∈ σ(z) ⇒ x ̸= σ(z). Zu zeigen ist jetzt, dass unter diesen Voraussetzungen auch σ(z) ∈ a also ∀x x ∈ σ(σ(z)) ⇒ x ̸= σ(σ(z)). Betrachten nun σ(σ(z)) = σ(z) ∪ {σ(z)}. Nach Voraussetzung an das z ist σ(z) ̸= x für alle x ∈ σ(z), d.h. σ(z)not ∈ σ(z) also {σ(z)} ̸⊂ σ(z). Deshalb ist also σ(σ(z)) = σ(z) ∪ {σ(z)} % σ(z). (Würde nämlich Gleichheit gelten, dann umfasste σ(z) doch {σ(z)}.) Sei nun x ∈ σ(σ(z)) = σ(z) ∪ {σ(z)}. Dann ist entweder wieder x ∈ σ(z) oder x ∈ {σ(z)} also x = σ(z). Sei im ersten Fall also x ∈ σ(z). Dann folgt nach dem Hilfssatz 2.16, dass x ⊂ σ(z) $ σ(z) ∪ {σ(z)} = σ(σ(z)), dass also insbesondere x ̸= σσ(z)) ist. Sei im zweiten Fall x = σ(z). Auch hierfür gilt jetzt nach i.W. derselben Ungleichungskette x = σ(z) $ σ(z) ∪ {σ(z)} = σ(σ(z)) also auch hier x ̸= σ(σ(z)). Damit ist wiederum a = ω , so dass die Behauptung für alle z ∈ ω nachgewiesen ist. 2 Folgerung 2.18. Für alle M.a.W. z∈ω ist z ̸= σ(z). ∀z z ∈ ω ⇒ z ̸= σ(z). Beweis. Die Behauptung ergibt sich unmittelbar aus Folgerung 2.17, da z ∈ σ(z) und deshalb die Voraussetzungen jener Folgerung erfüllt sind. 2 Satz 2.19. Für jedes mit z∈ω mit z ̸= ∅ ist z ∈ σ(ω), d.h. es gibt dann ein x∈ω σ(x) = z . M.a.W. ∀z z ∈ ω ∧ z ̸= ∅ ⇒ ∃x x ∈ ω ∧ z = σ(x). Beweis. Beweis durch Widerspruch. Annahme, es gebe ein z0 ∈ ω mit z0 ̸= ∅ und z0 ̸∈ σ(ω). Wir könnten dann die Teilmenge ω ′ = ω \ {z0 } bilden. Oensichtlich enthält auch ω ′ die leere Menge ∅ und mit jedem z auch σ(z) ∈ ω ′ , da die Herausnahme von z0 hierauf ja keinen Einuss hat. Damit wäre ω ′ eine kleinere induktive Menge als ω , was nach Konstruktion von ω nicht sein kann. 2 60 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK σ:ω→ω u = v. Satz 2.20. Die Funktion für u, v ∈ ω , M.a.W. dann ist auch ist injektiv, d.h. immer wenn σ(u) = σ(v) ∀u ∀v (u ∈ ω ∧ v ∈ ω ∧ σ(u) = σ(v) ⇒ u = v). Beweis. Beweis durch Widerspruch. Annahme es existieren zwei Elemente u, v ∈ ω mit σ(u) = σ(v) aber u ̸= v . Wir können dann annehmen, dass es ein x0 ∈ u gibt, mit x0 ̸∈ v oder umgekehrt. Sei also x0 ∈ u und x0 ̸∈ v . Vor. Dann ist also x0 ∈ u ⊂ u ∪ {u} = σ(u) = σ(v) = v ∪ {v}. Also ist x0 ∈ v ∪ {v}, obwohl x0 ̸∈ v (s.o). Damit ist notwendig x0 ∈ {v} also x0 = v . Dann ist aber auch v = x0 ∈ u also v ∈ u. Damit ist nach dem Satz 2.16 v ⊂ u andererseits aber auch automatisch {v} ⊂ u insgesamt haben wir wir also v ∪ {v} ⊂ u. Dies bedeutet aber nichts anderes, als dass σ(v) ⊂ u und da σ(v) = σ(u) erhielten wir hieraus σ(u) ⊂ u und damit wegen u ⊂ σ(u) letztlich u = σ(u) im Widerspruch zur Folgerung 2.18. 2 2.6.4 Unser Modell der natürlichen Zahlen Zusammenfassend lassen sich für σ folgende Eigenschaften feststellen: i) σ ist injektiv (siehe Satz 2.20) ii) ∅ ̸∈ σ(ω) (siehe Satz 2.14) iii) Wenn a ⊂ ω und ∅ ∈ a und σ(a) ⊂ a, dann ist a = ω . (siehe Satz 2.15) Unser ω zusammen mit der auf ihm denierten Nachfolgerfunktion σ dient als kanonisches Modell für die natürlichen Zahlen. Die Rolle der 0 wird durch die leere Menge ∅ wahrgenommen und die Nachfolgerfunktion bedeutet die Addition mit 1. Die natürlichen Zahlen erhalten wir also einfach als Elemente einer besonderen Menge, deren Existenz nach den postulierten Eigenschaften gesichert ist. 2.7 Java-Z-Funktionen Logische Hilfsfunktionen: boolean impl(boolean a, boolean b){ return !a | b; } boolean equiv(boolean a, boolean b){ return impl(a,b) & impl(b,a); } 2.7.1 Die leere Menge Die folgende Funktion ist eine testfunktion, die genau dann true liefert, wenn die eingegebene Menge y die leere Menge ist: boolean testEmptySet(Set y){ forall(Set z){ if(isElement(z,y)) return false; } return true; 2.7. JAVA-Z-FUNKTIONEN 61 } Die nächste Funktion realisiert die Existenzaussage für die leere Menge: boolean existsEmptySet(){ forall(Set y){ if(testEmptySet(y)) return true; } return false; } Diese Funktion liefert true, da die Existenz der leeren Menge axiomatisch verbürgt ist. Die Skolemisierung der Funktion existsEmptySet() liefert letztlich die leere Menge selbst: Set getEmptySet(){ forall(Set y){ if(testEmptySet(y)) return y; } return null; } 2.7.2 Vereinigungsmengen Gesucht wird diejenige Funktion die ausgehend von einer Menge x die Vereinigung ∪ v liefert und darauf aufbauend die Funktion, die uns bei Vorgabe zweier Menv∈x ∪ gen a, b die Vereinigungsmenge a ∪ b liefert (nämlich mit x = {a, b} als v∈{a,b} v ). Im ersten Schritt bilden wir die Unterfunktion zur Umsetzung von ∃v(u ∈ v∧v ∈ x): boolean existsBetween(Set u, Set x){ forall(Set v){ if(isElement(u,v) & isElement(v,x)) return true; } return false; } ( ) Funktion zur Umsetzung von ∀u (u ∈ y) ⇔ ∃v(u ∈ v ∧ v ∈ x) : boolean subFuncU(Set x, Set y){ forall(Set u){ if(!equiv(isElement(u,y), existsBetween(u,x))) return false; } return true; } Die Funktion boolean subFuncU(Set x, Set y) liefert genau dann true, wenn der Eingabeparameter y gerade die Vereinigungsmenge aller im Eingabeparameter x selbst enthaltenen Mengen ist. ( ) Umsetzung von ∃y∀u (u ∈ y) ⇔ ∃v(u ∈ v ∧ v ∈ x) : boolean existsU(Set x){ forall(Set y){ if(subFuncU(x,y)) return true; 62 } KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK } return false; Skolemisierung der Funktion existsU: Set getU(Set x){ forall(Set y){ if(subFuncU(x,y)) return y; } return null; } Die Funktion Set getU(Set x) liefert also bei Eingabe von x als Ergebnis die ∪ Menge v∈x v . Die Vereinigungsmenge a ∪ b zweier vorgegebener Mengen a und b erhalten wir mit Hilfe der Funktion Set getU(Set x) durch Verknüpfung mit der Funktion Set getPaar (Set a, Set b): Set union(Set a, Set b){ return getU(getPaar(a,b)); } 2.7.3 Durchschnittsmengen Gesucht wird diejenige Funktion die ausgehend von einer Menge x den Durchschnitt ∩ Menv∈x v liefert und darauf aufbauend die Funktion, die uns bei Vorgabe zweier ∩ gen a, b die Durchschnittsmenge a ∩ b liefert (nämlich mit x = {a, b} als v∈{a,b} v ). Im ersten Schritt bilden wir die Unterfunktion zur Umsetzung von ∀v(v ∈ x ⇒ u ∈ v): boolean forallBetween(Set u, Set x){ forall(Set v){ if(! impl(isElement(v,x) & isElement(u,v)) return false; } return true; } ( Funktion zur Umsetzung von ∀u (u ∈ y) ⇔ ∀v(v ∈ x ⇒ u ∈ v): boolean subFuncIntersect(Set x, Set y){ forall(Set u){ if(!equiv(isElement(u,y), forallBetween(u,x))) return false; } return true; } Die Funktion boolean subFuncU(Set x, Set y) liefert genau dann true, wenn der Eingabeparameter y gerade die Durchschnittsmenge aller im Eingabeparameter x selbst enthaltenen Mengen ist. ( ) Umsetzung von ∃y∀u (u ∈ y) ⇔ ∃v(u ∈ v ∧ v ∈ x) : boolean existsIntersect(Set x){ forall(Set y){ if(subFuncIntersect(x,y)) return true; } return false; } 2.7. JAVA-Z-FUNKTIONEN 63 Skolemisierung der Funktion existsIntersect: Set getIntersect(Set x){ forall(Set y){ if(subFuncIntersect(x,y)) return y; } return null; } Die Funktion ∩ Set getIntersect(Set x) liefert also bei Eingabe von x als Ergebnis die Menge v∈x v . Die Vereinigungsmenge a∩b zweier vorgegebener Mengen a und b erhalten wir mit Hilfe der Funktion Set getIntersect(Set x) durch Verknüpfung mit der Funktion Set getPaar (Set a, Set b): Set intersection(Set a, Set b){ return getIntersect(getPaar(a,b)); } 2.7.4 Teilmenge und Potenzmenge Die folgende Funktion testet zwei Mengen a und b daraufhin, ob a Teilmenge von b ist: boolean isSubset(Set a, Set b){ forall(Set x){ if(!impl(isElement(x,a),isElement(x,b)) return false; } return true; } Die nächste Funktion testet die Menge y daraufhin, ob sie die Potenzmenge von der Menge c ist (y = 2c = {z|z ⊂ c}): boolean testForPowerset(Set y, Set c){ forall(Set z){ if(!equiv(isElement(z,y),isSubset(z,c)) return false; } return true; } Die nächste Funktion realisiert die Existenzaussage der Potenzmenge einer Mnege c: boolean existsPowerset(Set c){ forall(Set y){ if(testForPowerset(y,c)) return true; } return false; } Sie liefert true, da die Existenz der Potenzmenge axiomatisch verbürgt ist. Die nächste Funktion liefert via Skolemisierung für eine eingegebene Menge c, deren Potenzmenge: Set getPowerset(Set c){ forall(Set y){ if(testForPowerset(y,c)) return y; 64 } KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK } return null; 2.7.5 Zweiermengen Gesucht wird diejenige Funktion, die bei Eingabe von zwei Mengen a, b als Ergebnis die Menge {a, b}, also die Menge, bestehend aus a und b liefert. Im ersten Schritt bilden wir die Unterfunktion zur Umsetzung von ∀u(u ∈ z) ⇔ (u = a) ∨ (u = b): boolean subFuncPaar(Set z, Set a, Set b){ forall(Set u){ if(!equiv(isElement(u,z), u==a | u==b)) return false; } return true; } Funktion zur Umsetzung von ∃z∀u(u ∈ z) ⇔ (u = a) ∨ (u = b): boolean existsPaar(Set a, Set b){ forall(Set z){ if(subFuncPaar(z, a, b)) return true; } return false; } Skolemisierung der Funktion existsPaar: Set getPaar(Set a, Set b){ forall(Set z){ if(subFuncPaar(z, a, b)) return z; } return null; } Die Funktion Set getPaar(Set a, Set b) liefert also bei Eingabe von a und b als Ergebnis die Menge {a, b}. 2.7.6 Induktive Mengen Der Test auf Induktivität für eine Menge i verläuft anhand der Aussage ∅ ∈ i∧∀z(z ∈ i ⇒ z ∪ {z} ∈ i). Für die zweite Teilaussage ∀z(z ∈ i ⇒ z ∪ {z} ∈ i) schreiben wir eine Hilfsfunktion: boolean subFuncInductive(Set i){ forall(Set z){ if(!impl(isElement(z,i), isElement(union(getPaar(z,z),z),i))) return false; } return true; } Der Test auf Induktivität einer Menge i ergibt sich dann zu: boolean isInductiveset(Set i){ return isElement(getEmptySet(), i) & subFuncInductive(i); } 2.7. JAVA-Z-FUNKTIONEN 65 Die nächste Funktion realisiert die Existenzaussage einer induktiven Menge: boolean existsInductiveSet(){ forall(Set i){ is(isInductiveSet(i)) return true; } return false; } Skolemisierung liefert eine Funktion, die eine induktive Menge zum Ergebnis hat: Set getArbitraryInductiveSet(){ forall(Set i){ is(isInductiveSet(i)) return i; } return null; } 2.7.7 ω als Modell für die natürlichen Zahlen Wir benötigen zunächst eine Funktion, die eine Menge x daraufhin testet, ob sie eine induktive Teilmenge einer Menge i ist: boolean testForInductiveSubset(Set x, Set i){ return isSubset(x,i) & isInductiveSet(x); } Die nächste Funktion testet die Menge c daraufhin, ob sie alle induktiven Teilmengen von i enthält: boolean containsAllInductiveSubsets(Set c, Set i){ forall(Set x){ if(!equiv(isElement(x,c), testForInductiveSubset(x, i))) return false; } return true; } Die folgende Funktion realisiert die Existenzaussage einer Menge, die alle induktiven Teilmengen einer induktiven Menge i enthält: boolean existAllInductiveSubsets(Set i){ forall(Set c){ if(containsAllInductiveSubsets(c, i)) return true; } return false; } Sie liefert aus axiomatischen Gründen true. Skolemisierung liefert ausgehend von einer induktiven Menge i, die Menge aller induktiven Teilmengen: Set getAllInductiveSubsets(Set i){ forall(Set c){ if(containsAllInductiveSubsets(c, i)) return c; } return null; } 66 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Folgende Funktion liefert nun ω (ω = ∪ x∈c x): Set getOmega(){ return getIntersect(getallInductiveSubsets(getArbitraryInductiveSet())); } 2.7.8 Skolemisierung von (Aus) Ist H(z) eine Aussage ( ) (genauer: Aussageform) für die die quantizierte Aussage ∃y∀z z ∈ y ⇔ H(z) wahr ist, erhält man hieraus die Menge dargestellt duch das Literal {z|H(z)}. Gesucht wird diejenige Funktion, die ausgehend von einer vorgegebenen Aussage H(z) und der zugehörigen Interpretation boolean h(Set z) die Menge {z|H(z)} als Ergebnis liefert. ( Im ersten Schritt bilden wir die Unterfunktion zur Umsetzung von ∀z z ∈ y ⇔ ) H(z) : boolean subFuncAusH(Set y){ forall(Set z) if(!equiv(isElement(z,y), h(z))) return false; return true; } ( ) Funktion zur Umsetzung von ∃y∀z z ∈ y ⇔ H(z) : boolean existsAusH(){ forall(Set y){ if(subFuncAus(y)) return true; } return false; } Skolemisierung der Funktion existsAusH: Set getAusH(){ forall(Set y){ if(subFuncAus(y)) return y; } return null; } ( ) Was passierte, wenn die Aussage H(z) von der Art ist, dass ∃y∀z z ∈ y ⇔ H(z) nicht wahr ist, wie im Fall der Russellschen Antinomie mit H(z) ( ) ≡ ¬(z ∈ z). In diesem Fall würde für jedes y die Aussage ∀z z ∈ y ⇔ H(z) falsch sein, d.h. dass subFuncAusH(Set y) für beliebig eingegebenes y als Ergebnis false lieferte. Damit lieferte getAusH() für H(z) ≡ ¬(z ∈ z) als Ergebnis null (also keine Menge) gewissermaÿen als exception. 2.7.9 Bildung kartesischer Produkte Die entsprechenden Funktionen können mit den vorhandenen Funktionsbausteinen leicht realisiert werden: Set getOrderedPaar(Set u, Set v) { return getPaar(getPaar(u,u), getPaar(u,v)); } 2.7. JAVA-Z-FUNKTIONEN 67 Die Funktion getOrderedPaar(Set u, Set v) liefert also bei Eingabe zweier Objekte u und v als Ergebnis das geordnete Paar (u, v) in der Form {{u}, {u, v}}. Die Funktion, die das komplette kartesische Produkt zweier Mengen a und b liefert, erhält man nun mit Hilfe der Funktion getAusH für H(z) ≡ ∃u ∃v (u ∈ a ∧ v ∈ b ∧ z = (u, v)). Um also im ersten Schritt die zugehörige Funktion subFuncAusH(Set y) zu bilden benötigen wir die Funktion h(Set z) (genauer die Funktion hPaar(Set a, Set b, Set z) da hier zusätzliche Eingabeparameter für die Mengen a und b benötigt werden). Dies geschieht auf Grund der zweifach vorhandenen Existenzquantoren in zwei Schritten. Im ersten Schritt die Unterfunktion für ∃v (u ∈ a ∧ v ∈ b ∧ z = (u, v)): boolean subFunc1H(Set a, Set b, Set z, Set u){ forall(Set v){ if(isElement(u,a) & isElement(v,b) & z == getOrderedPaar(u,v)) return true; } return false; } Und im zweiten Schritt die Funktion für ∃u ∃v (u ∈ a ∧ v ∈ b ∧ z = (u, v)): boolean hPaar(Set a, Set b, Set z){ forall(Set u){ if(subFunc1H(a,b,z,u)) return true; } return false; } Hieraus erhalten wir als Spezialfall von subFuncAusH: boolean subFuncAusHPaar(Set a, Set b, Set y){ forall(Set z) if(!equiv(isElement(z,y), hPaar(a, b, z))) return false; return true; } und als Spezialfall von existsAusH: boolean existsAusHPaar(Set a, Set b){ forall(Set y){ if(subFuncAusPaar(a, b, y)) return true; } return false; } Skolemisierung der Funktion existsAusHPaar liefert uns schlieÿlich die gewünschte Menge a × b als kartesisches Produkt von a und b: Set getKartProd(Set a, Set b){ forall(Set y){ if(subFuncAusPaar(a, b, y)) return y; } return null; } Hilfsfunktonen zum nden der ersten bzw. zweiten Komponente eines geordneten Paars z gewinnen wir wie folgt: 68 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Set getFirstComp(Set z){ forall(Set u){ forall(Set v){ if(z == getOrderedPaar(u,v)) return u; } } return null; } Set getSecondComp(Set z){ forall(Set u){ forall(Set v){ if(z == getOrderedPaar(u,v)) return v; } } return null; } 2.7.10 Mengentheoretische Funktionen Eine mengentheoretische Funktion wird aufgefasst als geeignete Teilmenge eines kartesischen Produktes a × b. Damit eine Menge f als Funktion aufgefasst werden kann, muss sie gewisse Bedingungen erfüllen. Die erste Bedingung lautet: ∀u u ∈ a ⇒ ∃v v ∈ b ∧ (u, v) ∈ f Wir bilden zunächst die zu ∃v v ∈ b ∧ (u, v) ∈ f gehörige Funktion: boolean existsValueFor(Set u, Set b, Set f){ forall(Set v){ if( isElemen(v,b) & isElement(getOrderedPaar(u,v), f)) return true } return false; } und erhalten damit die Funktion für ∀u u ∈ a ⇒ ∃v v ∈ b ∧ (u, v) ∈ f : boolean forAllExistsValue(Set a, Set b, Set f){ forall(Set u){ if(!impl(isElement(u,a), existsValueFor(u, b, f) )) return false; } return true; } Die zweite Bedingung lautet: ∀u∀v∀v ′ (u, v) ∈ f ∧ (u, v ′ ) ∈ f ⇒ v = v ′ . Die jeweiligen (Unter-)Programme für ∀v ′ (u, v) ∈ f ∧ (u, v ′ ) ∈ f ⇒ v = v ′ und ∀v∀v ′ (u, v) ∈ f ∧ (u, v ′ ) ∈ f ⇒ v = v ′ erhalten wir in Form von boolean subFunc1(Set u, Set v, Set f){ forall(Set v'){ if(!impl(isElement(getOrderedPaar(u, v), f) & isElement(getOrderedPaar(u, v'), f), v == v' )) 2.7. JAVA-Z-FUNKTIONEN } 69 return false; } return true; sowie boolean subFunc2(Set u, Set f){ forall(Set v){ if(!subFunc2(u, v, f)) return false; } return true; } Als Funktion für die zweite Bedingung erhalten wir damit abschlieÿend: boolean eindeutigeWerte(Set f){ forall(Set u){ if(!subFunc2(u, f)) return false; } return true; } Die Bedingung, dass die Menge f eine mengentheoretische Funktion ist, ergibt sich mit Hilfe einer Unterfunktion für ( ) ( ) ∃b f ⊂ a × b ∧ ∀x∈a ∃y∈b (x, y) ∈ f ∧ ∀x∀y∀y ′ (x, y) ∈ f ∧ (x, y ′ ) ∈ f ⇒ y = y ′ . subFuncIsFunktion(Set a, Set f){ forall(Set b){ if(isSubset(f, getKartProd(a, b)) & forAllExistsValue(a, b, f) & eindeutigeWerte(f)) return true; } return false; } zu boolean isFunktion(f){ forall(Set a){ if(subFuncIsFunktion(a, f)) return true; } return false; } Die Auswertung einer Funktion f , also die Bestimmung des Funktionswertes f (x) für ein Argument x, ergibt sich zu Set evaluateFunktion(Set f, Set x){ forall(Set y){ if(isElement(getOrderedPaar(x, y), f)) return y; } return null; } Due Funktion evaluateFunktion(Set f, Set x) liefert automatisch dann null, wenn f keine mengentheoretische Funktion ist oder wenn x nicht zum Denitionsbereich von f gehört. 70 2.7.11 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Die Nachfolgerfunktion auf σ ω boolean testForSucc(Set z){ if(isElement(z, getKartProd(\getOmega(), \getOmega()){ return getSecondComp(z) == union(getPaar(getFirstComp(z), getFirstComp(z)), getFirstComp(z)); } return false; boolean testSuccessorFunction(Set sigma){ forall(Set z){ if(!equiv(isElement(z, sigma), testForSucc(z))) return false; } return true; } boolean existsSigma(){ forall(Set sigma){ if(testSuccessorFunction(sigma)) return true; } return false; } Set getSigma(){ forall(Set sigma){ if(testSuccessorFunction(sigma)) return sigma; } return null; } 2.7.12 die Vorgängerfunktion pi auf ω Die Vorgeängerfunktion i ist deniert als Umkehrfunktion von der Nachfolgerfunktion σ : pi = {z|z ∈ ω × ω ∧ (z = (x, y) ⇒ (y, x) ∈ σ)}. Damit ist H(z) = z ∈ ω × ω ∧ z = (x, y) ⇒ (y, x) ∈ σ , die wie folgt umgesetzt wird: boolean hPi(Set z){ if(! isElement(z, getKartProd(getOmega(),getOmega()))) return false; if(isElement(getOrderedPaar(getSecondComp(z), getFirstComp(z)), getSigma())) return true; return false; } boolean subFuncAusHPi(y){ forall(Set z){ if(!equiv(isElement(z,y), hPi(z))) return false; } return true; } boolean existsAusHPi(){ forall(Set y){ if(subFuncHPi(y)) return true; } return false; } 2.7. JAVA-Z-FUNKTIONEN Set getPi(){ forall(Set y){ if(subFuncHPi(y)) return y; } return null; } 71 72 KAPITEL 2. MENGENLEHRE: DIE SPRACHE DER MATHEMATIK Kapitel 3 Natürliche Zahlen, ihre Operationen und Relationen Wir haben im letzten Kapitel ein besonderes Modell der natürlichen Zahlen erhalten. Es zeigt sich, dass jedes andere Modell der natürlichen Zahlen, sofern es dieselben äuÿerlichen Eigenschaften aufweist, zu diesem ersten Modell ω kanonisch isomorph ist. Man kann also mit Fug und Recht von den natürlichen Zahlen sprechen, sofern das betrachtete Mengenobjekt die erwähnten Eigenshaften aufweist. Folgende Sprachregelung ist damit gerechtfertigt: Wir nennen (ausgehend von der Menge ω und ihren Eigenschaften) eine Menge N die Menge der natürlichen Zahlen, wenn es auf N eine Funktion s:N→N und ein Element 0 gibt mit folgenden Eigenschaften: i) s ist injektiv. ii) 0 ̸∈ s(N) iii) Wenn A ⊂ N und 0 ∈ A und s(A) ⊂ A, dann ist A = N. Wie üblich legen wir fest 1 = s(0), 2 = s(1) = s(s(0)), · · · . Wir führen nun die Sprachregelung ein, mAussagen, die die natürlichen Zahlen betreen, als arithmetische Aussagen zu bezeichnen. Formal denieren wir also: Denition 3.1. Ist zelnen mAussagen B(x) eine mAussage, dann nennen wir die aus den einB(x) und x ∈ N gewonnene mAussage B(x) ∧ x ∈ N (oder eine zu ihr äquivalente mAussage) eine arithmetische Aussage. Die Aussage ∀x x ∈ N ⇒ ¬(s(x) = 0) ist also eine arithmetische Aussage. 3.1 Das Induktionsprinzip Die Eigenschaft iii) der natürlichen Zahlen beinhaltet das sogenannte Induktionsprinzip. es erönet die Möglichkeit sog. Induktionsbeweise : Betrachten wir hierzu eine aritmetische Aussage, in der eine Variable n frei vorkommt. Hierfür schreiben wir A(n). Nehmen wir an, wir könnten zeigen, dass 73 74KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN A(0) gilt und dass sich für alle n die Aussage A(n) ⇒ A(s(n)) also die Aussage ¬(A(n) ∧ ¬A(s(n))) zeigen lässt. (Man beachte, dass hier zunächst nicht gezeigt wird, dass A(n) gilt, sondern dass aus dem Gelten von A(n) notwendig das Gelten von A(s(n)) folgt.) Wir denieren ausgehend von der betrachteten arithmetischen Aussage A(n) nun eine Menge A = {n|n ∈ {N } ∧ A(n)} Da nach Voraussetzung A(0) wahr sein soll, ist 0 ∈ A. Auÿerdem ist mit jedem n ∈ A auch s(n) ∈ N, da mit A(n) und A(n) ⇒ A(s(n)) auch A(s(n)) wahr sein muss. Also ist nach Eigenschaft iii) der natürlichen Zahlen A = N. Dies bedeutet aber nach Denition der Menge N nichts anderes, als dass die Aussage A(n) für alle n ∈ N gelten muss. Halten wir damit fest: Satz 3.2. Wenn eine arithmetische Aussage beliebiges n die Aussage ( A(n) ⇒ A(s(N )) A(n) n = 0 gilt und wenn für A(n) für alle n. M.a.W. für gilt, dann gilt ) A(0) ∧ ∀n∈N A(n) ⇒ A(s(n)) ⇒ ∀n∈N A(n). Als erstes Beispiel für einen Beweis durch vollständige Induktion zeigen wir: Hilfssatz 3.3. Keine natürliche Zahl ist gleich ihrem eigenen Nachfolger. M.a.W. ∀n∈N ¬(n = s(n)). Beweis. Sei A(n) die arithmetische Aussage n ̸= s(n). Dann gilt nach Eigenschaft ii) der natürlichen Zahlen oensichtlich A(0). Aus (A(m)) also aus m ̸= s(m) folgt nun s(m) ̸= s(s(m)). Würde nämlich s(m) = s(s(m)) gelten, dann folgte daraus auf Grund der Eigenschaft i) der natürlichen Zahlen, dass m = s(m), was im Widerspruch zu m ̸= s(m) stünde. Zusammen mit A(0) gilt demnach auch ∀n∈N A(n) ⇒ A(s(n)). Damit gilt die Aussage A(n) für alle natürliche Zahlen und der Hilfssatz ist bewiesen. 2 3.2 Elementare Operationen Denition der Addition und Multiplikation und ihre Eigenschaften 3.2.1 Addition Wir haben auf der Menge der natürlichen Zahlen als Operation bisher nur die Nachfolgeoperation s als Zähloperation. Aufbauend auf s führen wir nun die Additionsoperation ein. Als Hilfsoperation denieren wir zuvor die zu s inverse Vorgängeroperation p. Zur Vorbereitung zeigen wir: Hilfssatz 3.4. Jede natürliche Zahl n ̸= 0 besitzt einen Vorgänger, d.h. ∀n∈N n ̸= 0 ⇒ ∃m∈N s(m) = n. Beweis. Wir führen einen Widerspruchsbeweis: Annahme es gebe ein n ∈ N (n ̸= 0), das keinen Vorgänger hat, für das es also kein m ∈ N gibt mit s(m) = n. Setzen wir A = N \ {0} (also A ̸= N), dann gilt 0 ∈ A und s(A) ⊂ N, aber nicht 3.2. ELEMENTARE OPERATIONEN 75 A = N. Dies steht im Widerspruch zur Eigenschaft iii) der natürlichen Zahlen. Damit ist der Hilfssatz bewiesen. 2 Folgerung 3.5. Die Menge eine Funktion Beweis. p = {(n, m)|n = s(m)} ⊂ (N \ {0}) × N deniert p : N \ {0} → N. Übung. 2 Satz 3.6. Es gilt für alle natürlichen Zahlen natürlichen Zahlen ungleich 0, dass s(p(n)) = n, n, dass p(s(n)) = n und für alle d.h. es gilt: ∀n∈N p(s(n)) = n und ∀n∈N n ̸= 0 ⇒ s(p(n)) = n. Beweis. Übung. 2 Wir denieren nun die Addition + als Funktion +:N×N→N (n, m) 7→ n + m (InxNotation) induktiv vermöge der folgenden Regeln: { n, m = 0; n+m= s(n) + p(m), m ̸= 0. (Man kann wiederum induktiv beweisen, dass hierdurch eine eindeutige Operation deniert wird.) Man sieht sofort, dass s(n) = n+1 ist, dass also die Nachfolgerfunktion als Addition mit 1 aufgefasst werden kann. Die klassischen Eigenschaften nder Addition (Kommutativität und Assoziativität) zeigt man induktiv. Zuvor beweisen wir noch einen Hilfssatz: Hilfssatz 3.7. Es gilt ∀n∈N ∀m∈N s(m) + n = s(m + n). Beweis. Wir führen einen Induktionsbeweis mit A(n) ≡ ∀m∈N s(m) + n = s(m + n) . Für A(0) erhalten wir ∀m∈N s(m)+0 = s(m+0), was äquivalent ist zu ∀m∈N s(m) = s(m), was oensichtlich wahr ist. Betrachten wir nun A(n0 ) für eine beliebige natürliche Zahl n0 , d.h. ∀m∈N s(m) + n0 = s(m + n0 ) und die Addition s(m) + s(n0 ). Dann gilt s(m) + s(n0 ) Def.von+ = 3.6 = A(n0 ) = 3.6 = Def.von+ = s(s(m)) + p(s(n0 )) s(s(m)) + n0 s(s(m) + n0 ) s(s(m) + p(s(n0 )) s(m + s(n0 )). 76KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Wir erhalten also s(m) + s(n0 ) = s(m + s(n0 )) (für alle m ∈ mathbbN . Wir erhalten also ∀m∈N s(m) + s(n0 ) = s(m + s(n0 )) ≡ A(s(n0 )). In der Herleitung von A(s(n0 )) haben wir (s.o.) die Aussage A(n0 ) benutzt, so dass wir gezeigt haben, dass A(n0 ) ⇒ A(s(n0 )) gilt. Zusammen mit dem Gelten von A(0) haben wir damit induktiv bewiesen, dass ∀n∈N A(n) und unser Hilfssatz ist bewiesen. 2 Folgerung 3.8. Es gilt für die Addition das Assoziativgesetz, d.h. ∀n∈N ∀m∈N ∀p∈N (p + m) + n = p + (m + n). Beweis. Wir führen eine Induktionsbeweis für A(n) = ∀m∈N ∀p∈N (p + m) + n = p + (m + n). A(0) stellt sich wiederum sofort als wahr heraus. Gehen wir aus von der Aussage A(n0 ) und betrachten (p + m) + s(n0 ): (p + m) + s(n0 ) Def.von+ = 3.7 = s((p + m) + n0 ) A(n0 ) = s(p + (m + n0 )) 3.7 = s(p) + (m + n0 ) 3.6 = s(p) + p(s(m + n0 )) Def.von+ = 3.7 = p + s(m + n0 ) p + (s(m) + n0 ) 3.6 = p + (s(m) + p(s(n0 )) Def.von+ = s(p + m) + p(s(n0 )) p + (m + s(n0 )). Wir erhalten also für beliebige natürliche Zahlen p, m die Gleichung (p+m)+s(n0 ) = p + (m + s(n0 )) und damit die Aussage A(s(n0 )) wobei wir bei der Herleitung von A(s(n0 )) die Aussage A(n0 ) benutzt haben. Diese Herleitung gilt für beliebige n0 , so dass gilt ∀n∈N A(n) ⇒ A(s(n)). Zusammen mit A(0) erhalten wir letztlich ∀n∈N A(n) und das Assoziativgesetz ist bewiesen. 2 Zum Beweis des Kommutativgesetzes benötigen wir noch einen Hilfssatz Hilfssatz 3.9. Es gilt ∀m∈N m + 0 = 0 + m. Beweis. Induktion mit A(m) ≡ m + 0 = 0 + m. Das Gelten von A(0) ist wieder klar. 3.2. ELEMENTARE OPERATIONEN 77 Wir betrachten A(m0 ) und gehen aus von s(m0 ) + 0: s(m0 ) + 0 3.7 = A(m0 ) = 3.7 = 3.6 = Def.von+ = s(m0 + 0) s(0 + m0 ) s(0) + m0 s(0) + p(s(m0 )) 0 + s(m0 ). Auch hier erhalten wir wieder mit Hilfe von A(m0 ) die Aussage A(s(m0 )) und letztlich das Gelten von A(m) für alle m. 2 Satz 3.10. Es gilt für die Addition das Kommutativgesetz, d.h. es gilt ∀n∈N ∀m∈N m + n = n + m. Beweis. Induktionsbeweis mit A(n) ≡ ∀m∈N m + n = n + m. Die Aussage A(0) ergibt sich unmittelbar aus dem letzten Hilfssatz. Wir betrachten A(n0 ) und gehen aus von m + s(n0 ): m + s(n0 ) Def.von+ = 3.6 = 3.7 = A(n0 ) = 3.7 = s(m) + p(s(n0 )) s(m) + n0 s(m + n0 ) s(n0 + m) s(n0 ) + m. Wir erhalten also mit A(n0 ) wiederum A(s(n0 )) und mit A(0) und ∀n∈N A(n) ist ∀n∈N A(n) und damit das Kommutativgesetz bewiesen. 2 Wir verallgemeinern nun die Eigenschaft, dass unterschiedliche natürliche Zahlen unterschiedliche Nachfolger haben, indem wir zeigen: Satz 3.11. Es gilt: ∀k∈N ∀m∈N ∀n∈N n + k = m + k ⇒ n = m . Beweis. Beweis durch Induktion über k mit A(k) ≡ ∀m∈N ∀n∈N n + k = m + k ⇒ n = m. Die Aussage A(0) ist wieder trivial und Aussage A(1) folgt unmittelbar aus der Injektivität der Nachfolgerfunktion. Wir betrachten nun die Aussage A(k0 ) und und gehen aus von der Gleichung n + s(k0 ) = m + s(k0 ). Hieraus erhalten wir: n + s(k0 ) = m + s(k0 ) s.o. ⇒ Injektivitt von s ⇒ A(k0 ) ⇒ s(n + k0 ) = s(m + k0 ) n + k0 = m + k0 n = m. 78KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Dies bedeutet also insgesamt, dass n + s(k0 ) = m + s(k0 ) ⇒ n = m. Dies entspricht der Aussage A(s(k0 )) und gezeigt haben wir sie mit Hilfe von A(k0 ). Damit haben wir gezeigt, dass (für beliebiges k ) A(k) ⇒ A(s(k)), so dass induktiv A(k) für alle k gilt und der Satz bewiesen ist. 2 3.2.2 Multiplikation Analog zur Addition führen wir eine zweite Operation, die Multiplikation, ein, die wiederum induktiv deniert wird mit Hilfe der schon denierten Addition. Sie wird in gewohnter Weise notiert mit “ · ” in InxNotation: · : N → N (n, m) 7→ n · m. Wenn keine Missverständnisse zu befürchten sind, kann der Punkt auch weggelassen werden. Wir legen fest: { 0, m = 0; n·m= n · p(m) + n, m ̸= 0. Auch hier kann wieder induktiv gezeigt werden, dass damit die Multiplikation eindeutig festgelegt wird. Hilfssatz 3.12. Es gilt ∀n∈N n · 1 = 1 · n = n. Beweis. : Es gilt mit Hilfe der gerade eingeführten Regeln der Multiplikation (und den schon bekannten Regeln der Addition): n · 1 = n · p(1) + n = n · 0 + n = 0 + n = n. Dass 1 · n = n zeigt man induktiv. (Übung) 2 Hilfssatz 3.13. Es gilt: ∀n∈N n · 0 = 0 · n = 0. Beweis. Dass n · 0 = 0 folgt unmittelbar aus der Denition und dass 0 · n = 0 zeigt man induktiv (Übung) 2 Addition und Multiplikation erfüllen zusammen ein Distributivgesetz: Satz 3.14. Es gilt: ∀k∈N ∀m∈N ∀n∈N (m + n) · k = m · k + n · k. Beweis. Per Induktion über k für A(k) ≡ ∀m∈N ∀n∈N (m + n) · k = m · k + n · k. 3.2. ELEMENTARE OPERATIONEN 79 Die Aussage A(0) ist wiederum trivial. Betrachten die Aussage A(k0 ) und gehen aus von dem Ausdruck (m + n) · s(k0 ): Def. der Multipl. (m + n) · s(k0 ) = (m + n) · p(s(k0 )) + (m + n) 3.6 (m + n) · k0 + (m + n) = A(k0 ) = (m · k0 + n · k0 ) + (n + m) mehrmal.Ass.und Komm.der Add. (m · k0 + m) + (n · k0 + n) = Def.der Multipl. = m · s(k0 ) + n · s(k0 ). Wir haben also wieder aus A(k0 ) die Aussage A(s(k0 )) hergeleitet und zuusammen mit A(0) damit dem Satz induktiv bewiesen. 2 Satz 3.15. Für die Multiplikation gilt das Kommutativgesetz, d.h. ∀n∈N ∀m∈N m · n = n · m. Beweis. Induktiv über n mit A(n) ≡ ∀m∈N m · n = n · m. A(0) folgt sofort aus 3.13. Betrachten nun A(n0 ) und gehen aus von m · s(n0 ): m · s(n0 ) Def.der Mult. = m · n0 + m A(n0 ) = n0 · m + m Komm.der Add. m + n0 · m = 3.12 = 1 · m + n0 · m Distrib. = (1 + n0 ) · m Komm.der Add. (n0 + 1) · m s(n0 ) · m. = = Dies bedeutet m · s(n0 ) = s(n0 ) · m also A(s(n0 ) unter Benutzung von A(n0 ). damit ist die Kommutativität induktiv bewiesen. 2 Folgerung 3.16. Es gilt auch ein zweites Distributivgesetz: ∀k∈N ∀m∈N ∀n∈N k · (m + n) = k · m + k · m. Beweis. tativgesetz. Unmittelbar aus dem ersten Distributivgesetz 3.14 und dem Kommu2 Satz 3.17. Für die Multiplikation gilt das Assoziativgesetz, d.h. es gilt ∀n∈N ∀m∈N ∀p∈N (p · m) · n = p · (m · n). 80KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Beweis. Induktion über n mit A(n) ≡ ∀m∈N ∀p∈N (p · m) · n = p · (m · n). A(0) ergibt sich sofort aus 3.13. Betrachten nun A(n0 ) und gehen aus von (p · m) · s(n0 ): (3.1) (p · m) · s(n0 ) Def.der Mult. = (3.2) A(n0 ) (3.3) Distributiv. (3.4) Def.der Mult. = = = (p · m) · n0 + (p · m) p · (m · n0 ) + p · m p · (m · n0 + m) p · (m · s(n0 )) Damit ist (p · m) · s(n0 ) = p · (m · s(n0 )) (also A(s(n0 ))) unter der Voraussetzung von A(n0 ) gezeigt und zusammen mit A(0) folgt der Satz induktiv. 2 3.3 3.3.1 Ordnungsrelationen Die kleiner/gleichBeziehung Auf N wird eine binäre Relation “ 5 ” (kleinergleich) eingeführt: Denition 3.18. Es ist n5m Folgerung 3.19. Die Relation i) ii) iii) g.d.w. es ein 5 k∈N gibt, mit n + k = m. hat folgende Eigenschaften: n 5 n für alle n ∈ N. n 5 m und m 5 n impliziert n = m. n 5 m und m 5 p impliziert n 5 p. Beweis. Der Fall i) ist trivial. Zum Fall ii): Sei n 5 m und m 5 n. Aus n 5 m folgt n+k =m für ein geeignetes k ∈ N. Und aus m 5 n folgt m+l =n für ein geeignetes l ∈ N. Setzen wir nun n + k für m aus der ersten Gleichung in die zweite Gleichung ein, dann erhalten wir n + k + l = n + (k + l) = n. Damit ist notwendig k + l = 0 und deshalb müssen auch die natürlichen Zahlen k und l gleich 0 sein. Also ist m = n. Zum Fall iii): aus den Voraussetzungen folgt sofort (für geeignete k, l): n + k = m und m + l = p. Also folgt p = (n + k) + l = n + (k + l). Damit ist denitionsgemäÿ n 5 p. 2 3.3. ORDNUNGSRELATIONEN 81 Eine Beziehung, die die Eigenschaften i) bis iii) von 3.19 erfüllt, nennen wir auch Ordnungsrelation. In Zusammenhang mit einer Ordnungsrelation gibt es eine Reihe technischer Begrie, die wir an dieser Stelle bereits einführen wollen. Wir formulieren diese Begrie an Hand der uns vorliegenden Relation “ 5 ”, bemerken aber, dass die jeweiligen Begrie auch für jede beliebige andere Ordnungsrelation die entsprechende Bedeutung haben. Denition 3.20. Sei i) Eine Zahl o ∈ N M⊂N jeweils eine nichtleere Teilmenge von heiÿe obere Schranke von Analog heiÿt eine Zahl u ∈ N A N. a 5 o für alle a ∈ A. u 5 a für alle a ∈ A. A existieren, dann heiÿt A auch g.d.w. eine untere Schranke g.d.w. Wenn solche oberen bzw. unteren Schranken für nach oben bzw. unten beschränkt. Ist A gleichzeitig sowohl nach unten als auch nach oben beschränkt, so heiÿt sie beschränkt. g ∈ A heiÿe gröÿtes Element oder Maximum von A g.d.w. a 5 g a ∈ A. Analog heiÿt eine Zahl k ∈ N kleinstes Element oder Minimum von A g.d.w. k 5 a für alle a ∈ A. (Merke: im Gegensatz zu i) wird hier von g bzw. k verlangt, dass es selbst Element ist von A). ii) Eine Zahl für alle Eine Teilmenge der natürlichen Zahlen ist oensichtlich stets nach unten (und zwar durch die 0) beschränkt. Die Eigenschaft der Beschränkheit nach unten wird für Zahlen also erst dann zu einer interessanten Eigenschaft, wenn auch die negativen Zahlen (s.u.) miteinbezogen werden. Denition 3.21. Wir schreiben Folgerung 3.22. Es ist n<m n<m g.d.w. g.d.w. es ein n5m k ̸= 0 und n ̸= m. gibt mit n + k = m. Beweis. Da n < m die Relation n 5 m impliziert, gibt es auf alle Fälle ein k ∈ N mit n + k = m. Dieses k muss aber ungleich 0 sein, da ansonsten n = m die Folge wäre. Das aber ist nach Denition von n < m ausgeschlossen. 2 Hilfssatz 3.23. Es gibt keine gröÿte natürliche Zahl, d.h. es gibt keine natürliche Zahl a mit n5a für alle natürlichen Zahlen n. Beweis. Widerspruchsbeweis. Annahme a sei eine gröÿte natürliche Zahl. Da s(a) aber ebenfalls eine natürliche Zahl ist für die automatisch gilt a 5 s(a) (wegen a+1 = s(a)) und für die auch gilt s(a) 5 a (wegen der getroenen Annahme, dass a eine gröÿte ganze Zahl ist) erhielten wir aus Eigenschaft ii) unserer Ordnungsbeziehung, dass a = s(a). Das aber widerspricht der Injektivität der Nachfolgerfunktion. Damit ist die Behauptung bewiesen. 2 Satz 3.24. Die Ordnungsrelation n, m gilt entweder n5m oder m 5 n. 5 ist total, d.h. für je zwei natürliche Zahlen Beweis. Widerspruchsbeweis. Wir nehmen also an, dass es zwei natürliche Zahlen a und b gebe, für die weder a 5 b noch b 5 a gelte. Hierfür zeigen wir, dass dann a und b gröÿte Zahlen sein müssten, was nach dem letzten Hilfssatz aber nicht gehen könnte. Dass a und b gröÿte Zahlen sein müssten, dass also n 5 a bzw. n 5 b für alle 82KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN n ∈ N, zeigen wir induktiv: n = 0: trivial, da 0 5 a und 0 5 b (wegen 0 + a = a und 0 + b = b). Sei nun n0 5 a und n0 5 b. Dies bedeutet n0 + l = a und n0 + k = b für geeignete k und l. Die natürlichen Zahlen k und l müssen aber ungleich 0 sein. Wäre nämlich etwa l = 0, dann ergäbe sich n0 = a und hieraus durch ersetzen von n0 durch a, dass a+k = b also a 5 b, was aber nach Voraussetzung ausgeschlossen war. Also ist l ̸= 0 (dasselbe lässt sich für k feststellen) und hat deshalb einen Vorgänger in N nämlich l − 1. Damit ist a = n0 + l = n0 + (l − 1) + 1 = n0 + 1 + (l − 1) = (n0 + 1) + (l − 1). Dies bedeutet aber, dass auch für den Nachfolger n0 + 1 von n0 gilt: n0 + 1 5 a. Und dasselbe lässt sich analog für b zeigen. Damit wären a und b gröÿte natürliche Zahlen, dass aber ist ein Widerspruch zum Hilfssatz 3.23. 2 Satz 3.25. Jede nach unten bzw. nach oben beschränkte (nichtleere) Teilmenge A⊂N enthält ein kleinstes bzw. ein gröÿtes Element. Da für den Bereich der natürlichen Zahlen jede Teilmenge automatisch nach unten beschränkt ist, hat also jede nichtleere Teilmenge der natürlichen Zahlen ein kleinstes Element. Beweis. Sei A nach unten beschränkt mit einer unteren Schranke u. Für beliebige a ∈ A ist also u 5 a. Sei U die (nichtleere) Menge aller unteren Schranken von A. Da 0 ∈ U muss es ein l ∈ U geben mit s(l) ̸∈ U andernfalls wäre U nach der Eigenschaft iii) der natürlichen Zahlen gleich der gesamten Menge der natürlichen Zahlen, was zur Folge hätte, dass u 5 a für alle natürlichen Zahlen u, was aber nach 3.23 ausgeschlossen ist. Da s(l) somit keine untere Schranke mehr für A ist, muss es ein a0 ∈ A geben, mit a0 < s(l) also a0 5 l. Andererseits muss auch gelten l 5 a0 , da l untere Schranke für alle Elemente von A ist. Damit ist auf Grund der Ordnungseigenschaften notwendig l = a0 . Da l 5 a für alle a ∈ A folgt sofort a0 5 a für alle a ∈ A. Also ist a0 kleinstes Element von A. Sei nun A nach oben beschränkt. Dann ist die Menge aller oberen Schranken O nach unten beschränkt, hat also nach dem bereits bewiesenen ein kleinstes Element o ∈ O. Damit ist o − 1 keine obere Schranke mehr für A und es muss ein a0 ∈ A geben mit o − 1 < a0 . Damit ist o 5 a0 . Umgekehrt gilt aber auf Grund der Schrankeneigenschaft von o auch a0 5 o, so dass wir auch hier wieder o = a0 erhalten mit a 5 a0 für alle a ∈ A. Somit haben wir in a0 ein gröÿtes Element in A. 2 Folgerung 3.26. Es gibt keine unendliche Folge natürlicher Zahlen a0 , a1 , a2 , · · · mit a0 > a1 > a2 > · · · . Beweis. Durch Widerspruch. Angenommen es gäbe eine solche Folge, dann hätte die Menge A = {x|∃i∈N x = ai } kein kleinstes Element. Widerspruch zu 3.25. 2 Satz 3.27. Jede nach oben bzw. nach unten beschränkte Menge Zahlen besitzt eine kleinste obere bzw. gröÿte untere Schranke. A natürlicher 3.3. ORDNUNGSRELATIONEN 83 Beweis. Nach 3.25 hat A ein gröÿtes bzw. kleinstes Element, was jeweils automatisch die Rolle einer kleinsten oberen Schranke bzw. eine gröÿten unteren Schranke einnimmt. 2 Der Begri einer kleinsten oberen Schranke bzw. gröÿten unteren Schranke fällt damit im Bereich der natürlichen Zahlen mit dem Begri des Maximums bzw. Minimums zusammen. Dies ist bei anderen Ordnungsrelationen und auch in erweiterten Zahlbereichen nicht mehr notwendig der Fall. Dort erhält der Begri der kleinsten oberen bzw. der gröÿten unteren Schranke eine eigenständige Bedeutung. Die Relation 5 ist verträglich mit der Addition und Multiplikation auf den natürlichen Zahlen: Satz 3.28. Es gilt: ∀k ∀n ∀m n 5 m ⇒ n + k 5 m + k . ii) ∀k ∀n ∀m n 5 m ⇒ n · k 5 m · k . i) Beweis. Teil i): Sei für beliebiges n, m ∈ nat n 5 m, dann gibt es denitionsgemäÿ ein l ∈ N so dass n + l = m. Es gilt nun: ⇒ n+l =m (n + l) + k = m + k Ass. u. Komm. ⇒ (für beliebiges k ) (n + k) + l = (m + k) Def. von 5 ⇒ n + k 5 m + k. Damit ist i) bewiesen. zu ii): Es gilt unter denselben Voraussetzungen: n+l =m ⇒ (n + l) · k = m · k Distr. u. Ass. ⇒ Def. von 5 ⇒ damit ist auch ii) gezeigt. (für beliebiges k ) n · k + (l · k) = m · k) n · k 5 m · k. 2 Auf analoge Weise zeigt man: Satz 3.29. Es gilt: ∀k ∀n ∀m n < m ⇒ n + k < m + k . ii) ∀k ∀n ∀m n < m ⇒ n · k < m · k . i) Beweis. Für den Leser. 2 Folgerung 3.30. Es gilt: ∀k∈N+ ∀m ∀n n · k = m · k ⇒ m = n. Beweis. Wir führen einen Widerspruchsbeweis. Es gelte also n ̸= m und gleichzeitig (für ein k > 0) n · k = m · k . Sei o.B.d.A. n < m. Dann folgt aus dem letzten Satz sofort n · k < m · k , was im Widerspruch zur Voraussetzung steht. 2 84KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN 3.3.2 Die Teilbarkeitsbeziehung Die kleiner/gleichBeziehung ist nicht die einzige Ordnungsrelation auf N. Ersetzt man bei der Denition der Relation 5 die Addition durch die Multiplikation, dann erhalten wir eine etwas andere Ordnungsrelation, die auch Teilbarkeitsbeziehung genannt wird. Dabei betrachten wir der Einfachheit halber nur natürliche Zahlen ungleich Null. Die Menge der natürlichen Zahlen ungleich Null notieren wir mit N+ : Denition 3.31. Gibt es für zwei natürliche Zahlen n · k = m, teilt m). dann nennen wir n einen Teiler von m n, m ∈ N+ ein k∈N n|m und notieren dies mit mit ( n Aus 3.13 folgt sofort, dass das in der Denition von | benutzte k ebenfalls aus N+ sein muss. Folgerung 3.32. Die Relation impliziert n5m | ist verträglich mit der Relation 5, d.h. n|m m.a.W. ∀n∈N+ ∀m∈N+ n|m ⇒ n 5 m. Beweis. n·k Sei n|m, also n · k = m für ein geeignetes k ̸= 0. Es gilt nun: n · s(p(k)) = Def.von Multipl. = 3.12 n · p(k) + n n · p(k) + n · 1 = Distributiv. = n · p(k) + n. Damit ist m = n · k = n + n · p(k) also n 5 m. Folgerung 3.33. Die Teilbarkeitsrelation i) ii) iii) 2 | hat folgende Eigenschaften: ∀n∈N+ n|n. ∀n∈N+ ∀m∈N+ n|m ∧ m|n ⇒ n = m. ∀n∈N+ ∀m∈N+ ∀p∈N+ n|m ∧ m|p ⇒ n|p. Sie ist also ebenfalls eine Ordnungsrelation. Beweis. Die Eigenschaft i) ist trivial: wähle für den Faktor k gleich 1. Die Eigenschaft ii) ergibt sich auf Grund der Verträglichkeit von | mit 5 direkt aus der entsprechenden Eigenschaft von 5. Auch die dritte Eigenschaft zeigt man analog zur Eigenschaft iii) von 5. 2 Man macht sich sofort klar, dass es sich hierbei nur um eine sog. partielle Ordnung handelt, dass es hier also im Ggs. zu der Relation 5 natürliche Zahlen n, m gibt, für die weder n|m noch m|n gilt. Die Teilbarkeitsbeziehung ist verträglich mit der Multiplikation (allerdings nicht mehr verträglich mit der Addition): Satz 3.34. Für alle k ∈ N+ gilt: n|m impliziert k · n|k · m, ∀kinN+ ∀n∈N+ ∀m∈N+ n|m ⇒ k · n|k · m. d.h. 3.3. ORDNUNGSRELATIONEN 85 Beweis. Es gelte n|m. Dann gibt es ein l mit n · l = m und deshalb auch k·(n·l) = k·m. Da auf Grund der Assoziativität der Multiplikation k·(n·l) = (k·n)·l folgt (k · n) · l = k · m also k · n|k · m. 2 Man ndet sofort heraus, dass es natürliche Zahlen gibt, die sich nicht durch andere Zahlen teilen lassen, auÿer durch 1 und durch sich selbst. Es sind dies die Primzahlen: Denition 3.35. Eine natürliche Zahl aus n|p folgt n=1 oder p>1 heiÿt Primzahl, genau dann wenn n = p. Wenn es um die Zerlegung einer vorgegebenen Zahl in einzelne Faktoren geht, sind die Primzahlen in der Rolle von Atomen. Indem man natürliche Zahlen so lange in immer kleinere Faktoren zerlegt, bis es nicht mehr geht, erhält man eine Zerlegungen der Zahlen in Primzahlfaktoren: n ∈ N, n > 1 lässt sich als Produkt n = p1 ·p2 · · · pk einzelp1 , p2 , · · · pk schreiben. Dabei können ein oder mehrere Primzahlen Satz 3.36. Jede Zahl ner Primzahlen auch mehrfach vorkommen. Beweis. Durch vollständige Induktion über n ab n = 2: Für n = 2 gibt es (nur) die Zerlegung 2 = 2. Es gebe nun für alle n 5 n0 eine Zerlegung in Primzahlfaktoren. Betrachten nun s(n0 ). Es gibt zwei Möglichkeiten: 1. Fall: s(n0 ) ist selbst eine Primzahl. In diesem Fall ist s(n0 ) = s(n0 ) die gewünschte Primzahlzerlegung. 2. Fall: s(n0 ) ist keine Primzahl. In diesem Fall gibt es eine Zerlegung von s(n0 ) in ein Produkt zweier Zahlen r, s mit 1 < r, s < s(n0 ). Damit treen für r und s die Induktionsvoraussetzung zu, so dass r = p1 · · · pk und s = p′1 . . . p′l Primzahlzerlegungen von r bzw. s sind. Damit ist p1 · · · pk · p′1 · · · p′l = r · s = s(n0 ) eine Primzahlzerlegung von s(n0 ). 2 Interessant ist nun die Frage, inwieweit eine solche Zerlegung (bis auf die Reihenfolge der Faktoren natürlich) eindeutig ist. Schaut man sich die Zerlegungen einiger kleiner Zahlen einmal an, stellt man schnell fest, dass diese jedenfalls nur auf eine einzige Weise zerlegt werden können. Hierzu probiert man mit brute force einfach einmal alle Möglichkeiten einer Zerlegung, die ja nach oben hin durch die Zahl selbst begrenzt ist, aus. Dies gibt Anlass zur Vermutung, dass sich jede natürliche Zahl nur auf eine einzige Art und Weise zerlegen lässt: Satz 3.37. Jede natürliche Zahl gröÿer als 1 ist (bis auf die Reihenfolge) ein- n>1 pi und qj Primzahlen seien und der Gröÿe nach geordnet seien, dann ist erstens k = l und zweitens pi = qi für alle i = 1 bis m (oder l). deutig in Primzahlfaktoren zerlegbar. M.a.W. Wenn für eine natürliche Zahl sowohl k = p1 · p2 · · · pm als auch k = q1 · q2 · · · ql wobei die Zahlen Beweis. Wir führen einen Beweis durch Widerspruch, d.h. wir nehmen an, dass es ein natürliche Zahl gibt, für die es zwei wesentlich unterschiedliche Primzahlzerlegungen gibt. Die Menge der Zahlen für die dies zutrit ist dann nach unten beshränkt hat also ein kleinstes Element (das nebenbei bemerkt gröÿer als 2 sein muss). Diese kleinste Zahl, die unterschiedliche Primzahlzerlegungen besitzt, nennen wir k . Für k existiere nun unterschiedliche Zerlegungen (mit der Gröÿe nach geordneten Primzahlfaktoren): k = p1 · p2 · · · pm 86KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN und k = q1 · q2 · · · ql . Oensichtlich sind alle qi von allen pj verschieden, da man ansonsten sofort eine kleinere Zahl als k nden würde, die unterschiedliche Primzahlzerlegungen besitzen würde. Also ist insbesondere p1 ̸= q1 . Sei ohne Beschränkung der Allgemeinheit p1 < q1 (ansonsten würden wir die Zerlegungen vertauschen). Ersetzen wir in der zweiten Zerlegung von k den ersten Faktor q1 durch p1 , dann erhalten wir mit der Dierenz k − p1 · q2 · · · ql =: k ′ eine Zahl k ′ , die kleiner ist als k . Dieses k ′ kann nun auf zweierlei Weise faktorisiert werden (wobei diese Faktoren nicht notwendig ausnahmslos Primzahlfaktoren sind): k′ = 1.Zerleg. von k = k − p 1 · q2 · · · ql p1 · p2 · · · pm − p1 · q2 · · · ql Distr. = p1 · (p2 · · · pm − q2 · · · ql ), 2.Zerleg. von k q1 · q2 · · · ql − p 1 · q2 · · · ql sowie k′ = Distr. = (q1 − p1 ) · q2 · · · ql . Nun ist die Primzahlzerlegung von k ′ eindeutig, da k die kleinste Zahl gewesen ist, für die es zwei unterschiedliche Zerlegungen gibt. Dies bedeutet aber insbesondere, dass die Primzahl p1 die in der ersten Faktorisierung von k ′ vorkommt auch in der zweiten Faktorisierung von k ′ vorkommen muss. Da sie verschieden ist von allen q2 , · · · , ql muss si demnach in der Faktorisierung von (q1 − p1 ) vorkommen, muss deshalb also auch ein Teiler von (q1 − p1 ) sein. Als folgt q1 − p1 = p1 · t für ein geeignetes t > 0. Damit folgt aber q1 = p1 · t + p1 = p1 · (t + 1). Dies aber widerspricht der Primzahleigenschaft von q1 . 2 Folgerung 3.38. Sei folgt p|n oder p eine Primzahl und seien n, m ∈ N mit p|n · m. Dann q|m. Beweis. Würde weder p|n noch p|m gelten, dann hätten wir letztlich eine Zerlegung in Primzahlfaktoren von n · m, die die Primzahl p nicht enthielte. Da es andererseits aber eine Zerlegung unter Benutzung der Primzahl p geben muss (dies besagt ja p|n · m), wäre dies ein Widerspruch zum vorangehenden Satz. 2 3.3.3 Suprema und Inma Anders als bei der gröÿer/gleichRelation haben wir bei der Teilbarkeitsrelation in einer vorgegebenen Menge von Zahlen nicht notwendig ein gröÿtes oder kleinstes Element (Maximum oder Minimum). Dies kann man sich bereits bei einer 2elementigen Menge klarmachen: sei z.B. M{2, 3}, dann gibt es in dieser Menge bzgl. “|” weder ein Minimum noch ein Maximum, da zwar 2|2 und 3|3 aber weder 2|3 noch 3|2 gilt und somit nach Denition eines kleinsten bzw. gröÿten Elementes weder 2 noch 3 diese Rolle hier einnehmen kann. 3.3. ORDNUNGSRELATIONEN 87 Dennoch hat diese Teilmenge eine obere und untere Schranke bzgl. “|” und zwar in Gestalt der Zahlen 1 und 6. Und wir können darüber hinaus zeigen, dass jede endliche Teilmenge M (ohne die 0) obere und untere Schranken bzgl. der Teilbarkeitsrelation besitzt. Hierzu können wir als (eine) obere Schranke einfach das Produkt aller Zahlen der vorgegebenen Teilmenge wählen und als untere Schranke die 1. Wenn wir nun z.B. von einer kleinsten oberen Schranke sprechen, müssen wir darauf achten, auf welche der vorhandenen Ordnungsrelationen wir uns dabei beziehen. Es würde zu Komplikationen führen, wenn wir den Begri der oberen Schranke mittels | denieren und die Menge aller oberen Schranken danach mittels 5 ordnen würden. Damit der Begri der kleinsten oberen Schranke (analog gröÿte untere Schranke) aus einem Guss deniert wird, dürfen wir nur mit einer einzigen Ordnungsrelation arbeiten, in diesem Falle also mit |. Kleinste obere und gröÿte untere Schranken werden (wenn Sie denn existieren) mit einem besonderen Begri belegt: Denition 3.39. Die bzgl. einer (beliebigen) Ordnungrelation gröÿte untere Schranke einer Menge Menge M M heiÿt Inmum von heiÿt Supremum von M. M, die kleinste obere Schranke einer Eine bzgl. | kleinste obere Schranke zweier Zahlen a, b, jetzt mit sup(a, b) bezeichnet, hat also die Eigenschaft, dass i) a| sup(a, b) und b| sup(a, b) ii) a|o und b|o impliziert sup(a, b)|c Nach i) ist sup(a, b) also (bzgl. | ) obere Schranke und nach ii) ist jede andere (bzgl. |) obere Schranke gröÿer (bzgl. |) als sup(a, b). Ähnliches gilt für das Inmum inf(a, b) zweier Zahlen a, b. In dieser Formulierung ist es ganz und gar nicht selbstverständlich, dass es zu je zwei Zahlen a, b ein Supremum bzgl. | tatsächlich immer gibt (und dasselbe gilt für das Inmum). Man könnte die Menge der oberen Schranken zwar mittels leqq ordnen, hätte jedoch zunächst keine Gewähr, dass für die bzgl. 5 kleinste obere Schranke auch die Eigenschaft ii) aufweisen würde. Die Existenz eines Supremums und eines Inmums im Sinne von i) und ii) lässt sich auf zwei Weisen zeigen: Man kann, wie in der Schulmathematik, von der Primzahlzerlegung zweier Zshlen a und b ausgehen. Aufgrund der Eindeutigkeit der Primzahlzerlegung einer Zahl folgt, dass die Primzahlfaktoren einer unteren Schranke eine Teilmenge (und zwar inklusive der Vielfachheiten) der Primzahlfaktoren der beiden Zahlen a und b sein muss. Wählt man diese Teilmenge (inklusiver der Vielfachheiten) maximal hat man oensichtlich eine gröÿte untere Schranke bzgl. “|”. Analog erhält man durch eine geeignet minimal gewählte Obermenge (inklusive der Vielfachheiten) der jeweiligen Primzahlfaktoren der Zahlen a und b eine kleinste obere Schranke bzgl. “|”. Man sieht sofort, dass die bzgl. “|” kleinste obere Schranke in einer Art Doppelrolle auch bzgl. 5 kleinstes Element aller oberen Schranken fungiert. Eine analoge Bemerkung gilt für die gröÿte untere Schranke. 88KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Das Inmum und Supremum für die Teilbarkeitsrelation hat nochmals einen besonderen Namen: Denition 3.40. Das Inmum einer Menge gemeinsamen Teiler (ggT) der Zahlen in M. M bzgl. “|” nennen wir gröÿten Das entsprechende Supremum nennen wir kleinstes gemeinsames Vielfaches (kgV). Das oben angedeutete Verfahren zur Gewinnung des ggT und des kgV ist, wie schon gesagt, das normalerweise in der Schulmathematik betrachtete Verfahren. Für groÿe Zahlen ist diese Methode allerdings nicht sehr ezient, da die Zerlegung in Primzahlfaktoren einen groÿen Auwand erfordert. Ezienter ist der Euklidsche Algorithmus. (Ausführung des euklidischen Algorithmus.) Satz 3.41. Der euklidsche Algorithmus liefert nach endlich vielen Schritten, den ggT zweier Zahlen. Beweis. 3.3.4 to be done 2 Synopsis der Ordnungsrelationen: Verbände Denition 3.42. Eine (partielle) Ordnung auf einer Menge zeichnen sie abstrakt mit ⊑ V wir be- heiÿt eine Verbandsordnung (und die Menge V heiÿt dementsprechend eine verbandsgeordnete Menge), wenn es für je zwei Objekte a, b ∈ V ein Supremum und ein Inmum bzgl. Das Supremum bzw. Inmum zweier Objekte a, b ⊑ gibt. bezeichnen wir mit sup(a, b) bzw. inf(a, b). Satz 3.43. Wenn auf einer Menge V zwei Operationen ⊔ und ⊓ deniert sind, so dass die Assoziativ, Kommutativ und Absorptionsgesetze gelten, wenn wir es also mit einem Verband zu tun haben, dann erhalten wir mit einer Relation ⊑, die deniert wird vermöge a⊑b g.d.w a⊓b=a (⇔ a ⊔ b = b) eine Verbandsordnung. Beweis. Zu zeigen sind zunächst die Ordnungseigenschaften. Wir zeigen als erstes, dass für beliebige a a ⊑ a. Dies folgt aber sofort wegen a ⊓ a = a. Ist a ⊑ b und b ⊑ a, dann gilt denitionsgemäÿ a ⊓ b = a und b ⊓ a = b und damit a = b. Ist a ⊑ b und b ⊑ c, dann gilt denitionsgemäÿ a ⊓ b = a und b ⊓ c = b. Damit ist a = a ⊓ b = a ⊓ (b ⊓ c) = (a ⊓ b) ⊓ c = a ⊓ c. Und damit ist a ⊑ c. Wir zeigen nun, dass a ⊔ b das Supremum von a und b ist. Zu zeigen ist als erstes, dass sowohl a ⊑ a ⊔ b und b ⊑ a ⊔ b gelten muss. Dies folgt sofort aus den Absorptionsgesetzen. Als zweites muss gezeigt werden, dass mit a ⊑ c und b ⊑ c auch folgt a ⊔ b ⊑ c. Nun bedeutet ersteres denitionsgemäÿ a ⊔ c = c und b ⊔ c = c. 3.4. ÄQUIVALENZRELATIONEN UND DIE EINFÜHRUNG NEGATIVER ZAHLEN89 Damit ist a ⊔ b ⊔ c = a ⊔ c ⊔ b ⊔ c = c ⊔ c = c, also a ⊔ b ⊑ c. 2 Analog für das Inmum. Es gilt auch die Umkehrung: Satz 3.44. Haben wir auf einer Menge halten wir vermöge V eine Verbandsordnung ⊑, dann er- a ⊔ b = sup(a, b) und a ⊓ b = inf(a, b) zwei Operationen auf Beweis. V, die Für den Leser V zu einem Verband machen. 2 Beispiele Für eine Menge c bildet 2c zusammen mit der mengentheoretischen Inklusion eine verbandsgeordnete Menge, deren zugehörige Verbandsoperationen die mengentheoretische Vereinigung und der mengentheoretische Durchschnitt sind. Für die Menge der natürlichen Zahlen bildet die Relation 5 eine Verbandsordnung, deren zugehörige Verbandsoperationen die Maximums und die Minimumsbildung sind. Für die Menge der natürlichen Zahlen haben wir eine zweite (von der ersten verschiedene) Verbandsordnung |, deren zugehörige Verbandsoperationen die Bildung des ggT und des kgV sind. Für die Menge der Wahrheitswerte repräsentiert durch 0 und 1 haben wir eine Verbandsordnung entsprechend der Ordnung 5, deren Verbandsoperationen wieder als Maximums oder Minimumsbildung aufgefasst werden können. 3.4 Äquivalenzrelationen und die Einführung negativer Zahlen 3.4.1 Die Subtraktion als Umkehrung der Addition Wir haben in den vorangegangenen Abschnitten die Addition als Operation kennengelernt, die ohne Einschränkungen für alle natürlichen Zahlen deniert ist. Die Operation der Subtraktion wird auf natürliche Weise als Umkehrung der Addition eingeführt: a − b = c genau dann, wenn a = b + c. Nun bedeutet die letzte Gleichung a = b + c denitionsgemäÿ aber, dass notwendig b 5 a, dass also die Operation der Subtraktion a − b zweier (natürlicher) Zahlen a und b (als Umkehrung der Addition) nur im Falle von b 5 a einen Sinn hat und nur hierfür deniert ist. M.a.W. wenn man den Bereich, für den eine Subtraktion durchgeführt werden soll, sinnvoll erweitern will, dann führt dies notwendigerweise zu einer Erweiterung des Zahlenbereiches selbst. Dies geschieht durch die Einführung sog. negativer Zahlen. 90KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Stichworte: negative Zahlen durch die formale Dierenz 0 − n, die man mengentheoretisch mit dem Paar (0, n) notieren könnte. Eine solche Erweiterung wäre praktisch durchführbar, hätte aber (zumindest) einige ästhetische Nachteile: Die Durchführung einer Subtraktion a−b müsste laufend über Fallunterscheidungen der Art a 5 b oder b 5 a gesteuert werden: { c, mit a = b + c falls b 5 a a−b= (0, c), mit b = a + c falls a 5 b. Darüberhinaus müssten bei ächendeckender Einführung der Subtraktion auch von negativen Zahlen und unter Einbeziehung der negativen Zahlen bei der normalen Addition etc. auch Ausdrücke wie a−(0, c) oder (0, c)+a etc. berücksichtigt und deniert werden. Das wird in der Schulmathematik alles erfolgreich (manchmal auch nicht so erfolgreich) durchgeführt. Spätestens wenn die Herleitung der allgemeinen Rechenregeln für den erweiterten Zahlenbereich ansteht, wird die unterschiedliche Repräsentation der natürlichen und der negativen Zahlen als Medienbruch empfunden, durch die sich die gewünschten Rechenregeln nur recht widerspenstig beweisen lassen (und deswegen in der Schulmathematik auch nicht ernsthaft geleistet wird). Die bloÿe Angleichung der äuÿerlichen Darstellung natürlicher Zahlen an die der negativen Zahlen etwa in der Form der Dierenz n − 0 entsprechend dem Paar (n, 0) löst das Problem nicht wirklich. Die Addition von (a, 0) + (0, a), was der Addition von a + (−a) entsprechen würde, wäre ja nicht über die Paarbildung per se deniert, also in der Form (a, 0) + (0, a) = (a, a) das Paar (a, a) würde nämlich erst einmal gar keine Zahl repräsentieren , sondern bliebe nach wie vor auf der Ebene der schon beschriebenen Fallunterscheidungen. Dennoch steckt in dem Ansatz, (a, 0) + (0, a) gleich (a, a) zu setzen, eine Attraktivität, der man sich schlecht entziehen kann, insbesondere wenn man sich überlegt, dass wenn man überhaupt (formale) Dierenzen einführt , man die (formalen) Dierenzen nicht auf die Dierenzen von oder mit 0 zu beschränken braucht. Das Paar (a, a) könnte in diesem Sinne auf natürliche Weise als (formale) Dierenz a − a gelesen werden, was pefekt passen würde. Generell würde man also versucht sein nur noch mit formalen Dierenzen zu rechnen, also mit Ausdrücken der Form (a, b) in der Lesart von a − b, egal ob a 5 b oder b 5 a. Zu berücksichtigen ist dabei jedoch, dass ein und dieselbe Zahl jetzt auf viele (genau genommen unendlich viele) Weisen dargestellt werden kann. So wäre die 0 = (0, 0) = (1, 1) = (2, 2) = · · · und es stellt sich die Frage, was denn jetzt (und dies betrit zumindest die neuen negativen Zahlen) die eigentlichen Zahlobjekte sind. Die (0, 1) wäre ja damit nur eine Repräsentation unter vielen für die Zahl −1, die jetzt auch durch (1, 2) oder (2, 3) etc. dargestellt werden könnte. In der Tat besteht die Lösung darin, alle Darstellung, die intuitiv dieselbe Zahl darstellen, auch gleichberechtigt nebeneinander stehen zu lassen und die Menge der Darstellungen einer Zahl als die Zahl selbst anzusehen. Die Zahl −1 wäre also identisch mit der Menge aller formalen Dierenzen (a, a + 1) also identisch mit der Menge {(0, 1), (1, 2), (2, 3), · · · }. Es bliebe letztendlich dann noch zu klären, inwieweit sich die unterschiedlichen Repräsentanten bei den in Frage kommenden Operationen der Addition und Subtraktion gewissermaÿen transparent verhalten. Damit ist gemeint, dass es keine 3.4. ÄQUIVALENZRELATIONEN UND DIE EINFÜHRUNG NEGATIVER ZAHLEN91 Rolle spielen darf, welche der Repräsentanten bei der Durchführung einer Operation denn gerade zufällig genommen wird. So darf bei der Addition von 2 mit −1, wenn wir sie denn in der Form (2, 0) + (a, a + 1) durchführen, es für eine unterschiedliche Wahl von a kein unterschiedliches Endergebnis geben. Repräsentierten wir die −1 etwa durch (0, 1), dann erhielten wir bei der formalen Paaraddition von (2, 0) und (0, 1) als Ergebnis (2, 1), bei der Darstellung von −1 durch (1, 2) als Ergebnis (3, 2). Beide Ergenisse sowohl (2, 1) als auch (3, 2) würden zwanglos als Darstellung derselben (i.d.Falle positiven) Zahl 1 und zwar einmal in der Form 2 − 1 und ein anderesmal in der Form 3 − 2 angesehn werden können. Die Transparenz der (willkürlich) ausgewählten Repräsentanten wäre also zumindest in diesem Beispiel gewährleistet. 3.4.2 Äquivalenzrelationen Dass unterschiedliche Repräsentanten dasselbe Objekt repräsentieren sollen, ist Anlass, sie als äquivalent anzusehen. Hiermit ist letztlich eine Beziehung gemeint, die als Relation spezielle Eigenschaften haben sollte. Welche Eigenschaften das sein sollten, schauen wir uns am besten am Bespiel unserer formalen Dierenzen an. Hier sollen ja zwei Paare (a, b) bzw. (a′ , b′ ) bestehnd aus natürlichen Zahlen intuitiv dann als äquivalent gelten, wenn a − b gleich a′ − b′ ist, oder da die Dierenzbildung ja nicht für alle natürlichen Zahlen direkt durchführbar ist wenn (unter subtiler Vorwegnahme der Rechenregeln für Gleichungen) a + b′ = b + a′ . Notieren wir unsere Äquivalenzrelation mit dem Zeichen ∼ = (was später auch für andere Relationen benutzt werden wird), dann können wir also festhalten: Denition 3.45. Für alle natürlichen Zahlen (a, b) ∼ = (a , b ) ′ ′ g.d.w. a, a′ , b, b′ ′ sei ′ a + b = a + b. Hieraus ergibt sich durch einfaches Nachrechnen: ∼ hat folgende Eigenschaften: Folgerung 3.46. Die Relation = i) ii) iii) (a, b) ∼ = (a, b) für alle a, b ∈ N. (a, b) ∼ = (a′ , b′ ) impliziert (a′ , b′ ) ∼ = (a, b). (a, b) ∼ = (a′ , b′ ) und (a′ , b′ ) ∼ = (a′′ , b′′ ) impliziert (a, b) ∼ = (a′′ , b′′ ). Beweis. Übung 2 Bei den Eigenschaften i) bis iii) spricht man auch von Reexivität, Symmetrie und Transitivität. Dies sind gleichzeitig die Eigenschaften, die man generell von (auch anderen) Äquivalenzrelationen fordert. Wir denieren deshalb vorab schon an dieser Stelle: Denition 3.47. Sei Wir nennen R M eine beliebige Menge und eine Äquivalenzrelation, wenn R R ⊂ M×M eine Relation. reexiv, symmetrisch und transitiv ist. Kommen wir damit zurück zu unserer speziellen Äquivalenzrelation der formalen Dierenzen. Hier war ja die Intension, alle äquivalenten Dierenzen zu jeweils einer Menge zusammenzufassen, die dann als neue Zahlenobjekte fungieren sollen. Dieses Vorgehen ist in der Mathematik so typisch, dass man der so gebildeten Menge einen besonderen Namen mitgibt: R ⊂ M × M eine Äquivalenzrelation, dann bezeichnet m ∈ M äquivalenten Objekte mit [m] und nennt diese Menge die Äquivalenzklasse von m. Die Menge aller Äquivalenzklassen wird auch mit M × M/R bezeichnet. Denition 3.48. Sei man die zu einem Objekt 92KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Die Eigenschaften einer Äquivalenzrelation implizieren sofort: Folgerung 3.49. Für zwei Äquivalenzklassen dann, wenn (m, m′ ) ∈ R, wenn also m und m′ [m] und [m′ ] ist [m] = [m′ ] genau äquivalent sind. Dies bedeutet auch, dass zwei Äquivalenzklassen entweder gleich oder völlig disjunkt sind. Die Tatsache, dass unsere neuen Zahlobjekte nun durch Äquivalenzklasse modelliert werden, bedeutet natürlich, dass wir dmit automatisch auch für die natürlichen Zahlen zu einem neuen Modell übergegangen sind. Bestand unsrer Standardmodell der natürlichen Zahlen N aus der Menge ω (s.o) konnten unsere (natürlichen) Zahlen also als Elemente von ω angesehen werden, so haben wir es jetzt formal gesehen bei unseren Zahlen mit Elementen aus 2ω×ω zu tun. Denn ω × ω liefert uns den Rahmen für die formalen Dierenzen, die wir ja als Paare dargestellt haben, und eine Äquivalenzklasse formaler Dierenzen (in der Rolle als Zahl) ist eine Teilmenge von ω × ω mithin ein Element von 2ω×ω . Wäre man von einem anderen Modell, generisch mit N bezeichnet, ausgegangen, hätte man es mit Elementen aus 2N×N zu tun, genaugenommen mit Äquivalenzklassen aus der Menge (N×N)/ ∼ = ⊂ 2N×N . Wie wir gesehen haben ist das auf Grund des Einzigkeitsatzes so lange kein Problem, so lange die systemischen Eigenschaften des neuen Modells dieselben sind, wie die des alten. Das allerdings muss in der Tat nachgeprüft werden. Hier kann man sich das Laben aber insofern etwas leichter machen, als dass man das alte Modell auf kanonische Weise in das neue Modell einbetten kann und hierbei die Verträglichkeit mit den vorhandenen Operationen sichert (s.u.). So sind auf den jetzt eingeführten Äquivalenzklassen die Addition und die Subtraktion gewissermaÿen nahtlos von unserem alten Modell zu übertragen. Hierbei wird es sich zeigen, dass es genügt die Addition zu übertragen, da sich die Subtraktion automatisch aus der Addition mit den neu erhaltenen negativen Zahlen ergibt. Wir legen also fest: Denition 3.50. Seien N)/ ∼ =. [(a1 , b1 )] und [(a2 , b2 )] zwei Äquivalenzklassen aus (N× Dann wird eine Addition + auf der Menge der Äquivalenzklassen deniert durch: [(a1 , b1 )] + [(a2 , b2 )] = [(a1 + a2 , b1 + b2 )]. Die Addition auf den Äquivalenzklassen wird also auf natürliche Weise zurückgeführt auf die Addition der natürlichen Zahlen. Wie schon angedeutet ist jetzt zu zeigen, dass die einzelnen Repräsentanten (a1 , b1 ) bzw. (a2 , b2 ) innerhalb der Klassen [(a1 , b1 )] bzw. [(a2 , b2 )] sich bezüglich dieser Zurückführung transparent verhalten, dass sich also alle Repräsentanten innerhalb ein und derselben Klasse hier gleich verhalten. Man spricht in diesem Falle von Wohldeniertheit. Folgendes ist formal zu zeigen: Satz 3.51. Seien (a1 , b1 ) und (a′1 , b′1 ) äquivalent und seien (a2 , b2 ) und (a′2 , b′2 ) äquivalent (und mithin Repräsentanten jeweils derselben Äquivalenzklasse), dann ′ ′ ′ ′ sind auch (a1 + a2 , b1 + b2 ) und (a1 + a2 , b1 + b2 ) äquivalent. [(a1 , b1 )] = [(a′1 , b′1 )] und [(a2 , b2 )] = [(a′2 , b′2 )] impliziert also [(a1 + a2 , b1 + b2 )] = [(a′1 + a′2 , b′1 + b′2 )]. Die Addition ist also wohldeniert und nicht wirklich abhängig vom einzelnen Repräsentanten, da alle Repräsentanten dasselbe Additionsverhalten zeigen. Wir führen nun folgende Sprachregelung ein: 3.4. ÄQUIVALENZRELATIONEN UND DIE EINFÜHRUNG NEGATIVER ZAHLEN93 Denition 3.52. Wir nennen die Äquivalenzklassen der Form Zahlen und notieren die entsprechende Menge mit [(a, b)] Z. Im Falle a5b [(a, b)] ganze bezeichnen wir als eine negative Zahl. Oensichtlich entsprechen die nichtnegativen ganzen Zahlen, also die Äquivalenzklassen [(a, b)] mit b 5 a eineindeutig den natürlichen Zahlen. Wir zeigen hierzu: Satz 3.53. Es gibt eine kanonische injektive Funktion ι : N → (N × N)/ ∼ = mit a 7→ ι(a) = [(a, 0)]. Diese injektive Funktion ist mit der Addition verträglich, d.h. es ist ι(a) + ι(b), ι(a + b) = und erfasst alle nichtnegativen ganzen Zahlen. Beweis. Übung 2 Damit ist klar, dass die nichtnegativen ganzen Zahlen dieselben systemischen Eigenschaften haben wie die natürlichen Zahlen und auf Grund des Einzigkeitssatzes als vollwertige natürliche Zahlen angesehen werden können. Von diesen natürlichen Zahlen ausgehend haben wir jetzt aber in Gestalt der oben eingeführten ganzen Zahlen eine Zahlerweiterung aus einem Guss, für die sich die gewünschten Eigenschaften der Addition etc. auf ungekünstelte Weise zeigen lassen. Insbesondere haben wir jetzt die uneingeschränkte Umkehrung der Addition in Form des folgenden Satzes: x, y, z ∈ Z mit x + y = z . Dann z + (−y) schreiben wir auch z − y und Satz 3.54. Seien x = z + (−y). Für gibt es ein −y so dass nennen diese Operation eine Subtraktion. Beweis. Wir führen den Beweis einfach mit Hilfe von Repräsentanten: sei also x = (a1 , b1 ), y = (a2 , b2 ) und z = (a3 , b3 ). Dann bedeutet x + y = z , dass [(a1 , b1 )] + [(a2 , b2 )] = [(a1 + a2 , b1 + b2 )] = [(a3 , b3 )]. Wähle nun als −y die Klasse [(b2 , a2 )]. Hieraus erhalten wir für z + (−y) den Ausdruck [(a3 , b3 )] + [(b2 , a2 )] = [(a1 + a2 , b1 + b2 )] + [(b2 , a2 )] = [(a1 + a2 + b2 , b1 + b2 + a2 )]. Nun ist das Paar (a1 + a2 + b2 , b1 + b2 + a2 ) wie man sofort nachrechnet (und sich an Hand der formalen Dierenz (a1 + a2 + b2 ) − (b1 + b2 + a2 ) auch leicht plausibel macht) äquivalent zu (a1 , b1 ), so dass die Äquivalenzklasse [(a1 +a2 +b2 , b1 +b2 +a2 )] gleich der Äquivalenzklasse [a1 , b1 ] d.h. gleich x ist. Damit ist die Behauptung bewiesen. Gleichzeitig haben wir gesehen, dass der Prozess des Übergangs von y zu −y einfach im Vertauschen der beiden Komponenten des repräsentierenden Paares besteht. 2 Folgerung 3.55. Für alle x∈Z Ebenso leicht rechnet man nach: ist −(−x) = x. 94KAPITEL 3. NATÜRLICHE ZAHLEN, IHRE OPERATIONEN UND RELATIONEN Satz 3.56. Notieren wir die Klasse x + 0 = 0 + x = x für alle x ∈ Z. ii) x + (−x) = 0 für alle x ∈ Z. [(0, 0)] wieder mit 0. Dann gilt: i) Ohne Beweis (Übung) stellen wir fest, dass in Z die bekannten Rechengesetze der Arithmetik gelten, also das Kommutativ, das Assoziativ und das Distributivgesetz. Begri der Gruppe Kapitel 4 Algebraische Strukturen, Gruppen, Ringe, Körper Ausgehend von den ganzen Zahlen kommen wir zu den grundlegenden algebraischen Begrien, Gruppe, Ring, Körper. Wir beginnen mit dem Begri der Gruppe, der sich unmittelbar aus der Verallgemeinerung der Eigenschaften der ganzen Zahlen ergibt. 4.1 Gruppen Die ganzen Zahlen beinhaltete (neben der Multiplikation, die beim Konzept eines Ringes eine Rolle spielen wird) eine Addition mit den Eigenschaften der Assoziativität, der Kommutativität, der Existenz eines neutralen Elementes, der 0, und der jeweiligen Existenz inverser Zahlen (gewonnen durch Vorzeichenwechsel). Hiervon abstrahierend gelangen wir zum Begri einer Gruppe. Unsere Objekte sind dabei nicht mehr notwendig Zahlen sondern Elemente einer (prinzipiell) beliebigen Menge, auf der eine binäre Operation deniert ist, die im allgemeinen Fall mit “◦′′ notiert wird. Eine Verknüpfung g1 ◦ g2 für zwei Gruppenelemente g1 , g2 kann man also in Analogie zu der Addition a + b zweier (ganzer) Zahlen sehen. Die Eigenschaftenm des Operators “◦′′ sollen nun denen der Addition entsprechen. Hierbei werden wir gegebenfalls eine Ausnahme zulassen: Die Kommutativität der Verknüfung, die bei der Addition von Zahlen ja so ganz selbstverständlich zu sein scheint, wird im allgemeinen Fall einer Gruppenoperation “◦′′ nicht mehr gefordert werden. Wir werden also zwischen Gruppen und kommutativen Gruppen, also Gruppen, bei denen das Kommutativgesetz erfüllt ist, unterscheiden. Warum machen wir diese Unterscheidung? Weil es in der Natur Gruppen gibt, die nicht kommutativ sind, und für die Naturbeschreibung eine wichtige Rolle spielen. 4.1.1 Grundlegende Eigenschaften Kommen wir damit zu der formalen Denition einer Gruppe: (G, ◦) besteht aus einer Menge G, “◦′′ deniert ist mit folgenden Eigenschaften: ∀ g1 , g2 , g3 ∈ G (g1 ◦ g2 ) ◦ g3 = g1 ◦ (g2 ◦ g3 ) Denition 4.1. Eine Gruppe binäre Operation i) 95 auf der eine 96KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER ii) iii) ∃ e ∈ G ∀g ∈ G e ◦ g = g ◦ e = g ∀ g ∃ g′ g ◦ g′ = g′ ◦ g = e Gilt zusätzlich das Kommutativgesetz also ∀ g1 , g2 ∈ G g1 ◦ g2 = g2 ◦ g1 dann sprechen wir von einer kommutativen Gruppe. Bemerkungen: Das durch Skolemisierung zu gewinnende g ′ ∈ G der Eigenschaft iii) ist, wie sich zeigen wird, eindeutig bestimmt. Es wird deshalb in Abhängigkeit von dem Element g , auf das es sich bezieht, im allgemeinen Fall mit g −1 bezeichnet, bei kommutativen Gruppen schreibt man für das Inverse von g auch −g in Anlehnung an die Bezeichnungen der kommutativen Gruppe der ganzen Zahlen. Eine analoge Bemerkung gilt für das aus einer konstanten Skolemfunktion erhaltene neutrale Element e: Es ist, wie wir noch sehen werden, ebenfalls eindeutig bestimmt. Es mag auallen, dass die Eigenschaften ii) und iii) einer Gruppr gewisse Anleihen bei der Kommutativität nehmen. Tatsächlich ist dies nur der Bequemlichkeit geschuldet, denn man kann zeigen, dass es reichen würde zu fordern ii′ )∃ e ∈ G ∀g ∈ G e ◦ g = g (Linksneutralität) iii′ )∀ g ∃ g ′ ◦ g = e (Linksinverses) Denn aus der Linksneutralität folgt notwendig auch die Rechtsneutralität (sie bedeutet also keine zusätzliche Forderung oder Einschränkung) und auch umgekehrt. Und eine Linksinverses element ist automatisch auch rechtsinvers (und umgekehrt). Wir werden dies im folgenden zeigen: Satz 4.2. Es gelten die Eigenschaften i), ii') und iii'). Ein linksneutrales Element ist auch rechtsneutral. Ein linksinverses Element ist auch rechtsinvers. Beweis. Sei also e ∈ G ein linksneutrales Element, für das ii') und iii') gilt. Sei g ∈ G beliebig. Dann gibt es zu g ein Linksinverses g ′ mit g ′ ◦ g = e (nach iii')). Gleichzeitig gibt es ein zu g ′ Linksinverses g ′′ mit g ′′ ◦ g ′ = e. Zusammen mit e ◦ g = g resp. e ◦ g ′′ = g ′′ erhalten wir Schritt für Schritt: g = e◦g = (g ′′ ◦ g ′ ) ◦ g = g ′′ ◦ (g ′ ◦ g) = g ′′ ◦ e (damit erhalten wir als Zwischenergebnis g = g ′′ ◦ e) = g ′′ ◦ (e ◦ e) (e ist auch für sich selbst linksinvers) = (g ′′ ◦ e) ◦ e = g ◦ e (mit Hilfe des Zwischenergebnisses). Damit ist e auch als rechtsneutral nachgewiesen. Kommen wir zum Linksinversen. Es sei also g ′ ◦ g = e sowie g ′′ ◦ g ′ = e′ . Es gilt dann s.o. Zwischenergebnis) g = g ′′ ◦ e = g ′′ , da e bereits als rechtsneutral nachgewiesen wurde. Damit folgt aber aus g ′′ ◦ g ′ = e mit (g = g ′′ ) sofort g ◦ g ′ = e womit g ′ auch als Rechtsinverses nachgewiesen ist. 2 Die Eindeutigkeit der neutralen Element und Inversen zeigt man jetzt wie folgt: Seien e, e′ jeweils neutral, dann ergibt sich aus der wechselseitigen Neutralität: e = e ◦ e′ = e′ . 4.1. GRUPPEN 97 Damit ist die Eindeutigkeit des neutralen Elementes nachgewiesen. Seien nun g ′ und gˆ′ Inverse zu g , dann gilt: e = g ◦ g ′ = g ◦ gˆ′ Verknüpfung von links mit g ′ ergibt: g ′ = g ′ ◦ e = g ′ ◦ (g ◦ g ′′ ) = (g ′ ◦ g) ◦ g ′′ = e ◦ g ′′ = g ′′ . Wir erhalten also auch die Eindeutigkeit der jeweiligen Inversen. In den ganzen Zahlen haben wir ein Beispiel einer kommutativen Gruppe kennengelernt. Eine wichtige nichtkommutative Gruppe erhaltenm wir in Form der Gruppe der Permutationen einer n-elementigen Menge. Formal können wir eine Permutation π = πn auassen als eine bijektive Abbildung π : {1, 2, · · · n} → {1, 2, · · · n} 4.1.2 Untergruppen Gewisse Teilmengen (nicht alle) einer Gruppe erben von der Gruppe gewissermaÿen die Gruppeneigenschafte. Solche Teilmengen heiÿen auch Untergruppen. Formal denieren wir: Denition 4.3. Eine Teilmenge wenn H dass also für beliebige und H H a, ∈ H heiÿt Untergruppe von G, H beschränken lässt a ◦ b in G wieder in H liegt einer Gruppe nichtleer ist und die Verknüpfung auf G G sich auf auch die Verknüpfung diesbezüglich wieder eine Gruppe ist. Besonders einfache Beispiele von Untergruppen einer Gruppe G ist die Gruppe G selbst und die die aus dem neutralen Element e bestehende Teilmenge {e} ⊂ G. Weitere Beispiele nden wir in den (für fest gewähltes n) durch n teilbaren Zahlen. Sie werden mit nZ notiert. Es gilt der Satz: Satz 4.4. Der mengentheoretische Durchschnitt zweier oder beliebig vieler Untergruppen von Beweis. G ist wieder eine Untergruppr von einfaches Nachrechnen G. 2 Wir können diesen Satz zur Grundlage folgender Denition machen: Denition 4.5. Sei G eine Gruppe und sei ge. Dann verstehen wir unter der von A A ⊂ G eine beliebige Teilmen- erzeugten Untergruppe Durchschnitt aller Untergruppen, die jeweils A < A >⊂ G den umfassen. Von besonderem Interesse sind von einzelnen Elementen g ∈ G erzeugte Untergruppen < g >. Diese Gruppen heiÿen auch zyklische (Unter-)Gruppen. Man rechnet leicht nach, dass eine zyklische Untergruppe < g > aus allen Elementen der Form g n für n ∈ Z besteht. Dabei bezeichne g n für n > 0 die n-fache −1 Verknüpfung g ◦ · · · ◦ g und g −n sei (g n ) für negatives −n. Schlieÿlich sei g 0 = e. Satz 4.6. Jede zyklische Gruppe ist notwendig kommutativ. 2 Beweis. Folgt sofort aus den hier leicht zu verizierenden Potenzrechenregeln. 98KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER 4.1.3 Endliche Gruppen (Symmetriegruppen) Beispiele in der Vorlesung. 4.1.4 Gruppenhomomorphismen Wir betrachten im folgenden Funktionen zwischen zwei Gruppen und zwar solche Funktionen, die verträglich sind bzgl. der Gruppenoperationen. Solche Funktionen heiÿen (Gruppen)Homomorphismen: Denition 4.7. Eine Funktion f : G → G′ zwischen zwei Gruppen G und G′ heiÿt Homomorphismus g.d.w. f (g1 ◦ g2 ) = f (g1 ) ◦ f (g2 ). G1 und G2 werden der Einfachheit halber mit notiert, obwohl es sich dabei um unterschiedliche Opera- Die Verknüpfungsoperationen auf demselben Zeichnen “◦” tionen handeln kann. Ein bijektiver Homomorphismus heiÿt auch Isomorphismus. Beispiele: a) Die Funktion Z → Z mit a 7→ 2 · a ist ein Gruppenhommorphismus. b) Die Funktion Z → G2 mit a 7→ a mod 2 ist eine Gruppenhomomorphismus. Es gilt folgender Satz: e, e ′ Satz 4.8. Sei f : G → G′ ein Homomorphismus zwischen zwei Gruppen. Seien G bzw. G′ . Dann gilt: die jeweiligen neutralen Elemente in f (e) = e′ . und für alle Beweis. g ∈ G′ ist to be done f (g −1 ) = f (g)−1 . 2 Oensichtlich ist die Komposition zweier Homomorphismen wieder ein Homomorphismus. f : G → G′ bezeichnet mit Kern f verstehen wir all diejenigen Elemente g ∈ G für die f (g) = e′ . Denition 4.9. Unter dem Kern eines Homomorphismus M.a.W. Kernf = {g|f (g) = e′ }. Der Kern eines Homomorphismus ist insofern interessant, als dass er einerseits selbst eine Gruppe ist und andererseits einen Hinweis darauf gibt, ob der betrachtete Homomorphismus injektiv ist oder nicht: 4.1. GRUPPEN 99 Satz 4.10. Ein Homomorphismus ist genau dann injektiv, wenn sein Kern nur aus dem neutralen Element besteht. to be done Beweis. 2 Folgerung 4.11. Der Kern und das Bild eines Gruppenhomomorphismus bilden Untergruppen der jeweiligen Gruppen. Beispiele: a) Das neutrale Element einer Gruppe für sich allein genommen bildet jeweils eine Untergrupe. b) Alle durch n teilbaren ganzen Zahlen (n fest gewählt) bilden eine Untergruppe der ganzen Zahlen. Folgender Begri wird sich als nützlich herausstellen: Denition 4.12. i) Als Ordnung einer Gruppe verstehen wir die Anzahl der Elemente von dass die Ordnung von G G. Ist G G bezeichnet mit ord G nicht endlich, dann sagt man, unendlich ist. g ∈ G heiÿe von endlicher Ordnung, wenn es eine natürliche Zahl g m = e. Die kleinste natürliche Zahl mit dieser Eigenschaft heiÿt von g . ii) Ein Element m>0 gibt mit dann Ordnung Es gilt: Satz 4.13. Ist eine Gruppe auch jedes Gruppenelement Beweis. G von endlicher Ordnung, g ∈ G von endlicher Ordnung. dann ist oensichtlich Wählen ein beliebiges Gruppenelement g ∈ G und betrachte die Folge: g = g1 , g ◦ g = g2 , g3 , g4 , · · · Da es nach Vor. nur endlich viele verschiedene Elemente in G gibt, muss es in der Folge der g 1 , g 2 , · · · Elemente irgendwann einmal doppelt geben. Seien also g i = g j mit i < j . Dann ist e = g i ◦ (g i )−1 = g j ◦ (g i )−1 = g j−i ◦ g i ◦ (g i )−1 = g j−i ◦ e = g j−i . also g j−i = e. Damit gibt es also eine natürliche Zahl m > 1, nämlich j − i, so dass g m = e. 2 Beispiele: a) Die ganzen Zahlen sind bis auf die 0 alle von unendlicher Ordnung. b) Die Elemente der zyklischen Gruppe der ordnung 4 haben jeweils die Ordnung 1,2 und 4. Bei vorgegebenem G und Untergruppe H kann man nun folgende Relation “ ∼ ” einführen, die sich als Äquivalenzrelation herausstellt: a, b ∈ G äquivalent und notieren dies mit a ∼H b, keine Missverständnisse zu befürchten sind, schreiben, wir Denition 4.14. Wir nennen wenn auch a−1 ◦ b ∈ H . Wenn einfach a ∼ b. 100KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER Satz 4.15. Die Relation “ ∼H ” ist eine Äquivalenzrelation. i) Zur Reexivität: Für alle a ∈ G ist a−1 ◦ a = e. Da jede Untergruppe H auch das neutrale Element e enthält, ist also a−1 ◦ a ∈ H und damit denitionsgemäÿ a ∼ a für alle a ∈ G. ii) Zur Symmetrie: Seien a, b ∈ G mit a ∼ b, d.h. a−1 ◦ b ∈ H . Da H als Untergruppe mit a−1 ◦ b auch das Inverse (a−1 ◦ b)−1 = b−1 ◦ (a−1 )−1 = b−1 ◦ a. Damit ist denitionsgemäÿ auch b ∼ a. iii) Zur Transitivität: Seien a, b, c ∈ G mit a ∼ b und b ∼ c. Damit ist also denitionsgemäÿ a−1 ◦ b ∈ H sowie b−1 ◦ c ∈ H . Da H eine Untergruppe ist, ist also auch (a−1 ◦ b) ◦ (b−1 ◦ c) = a−1 ◦ (b ◦ b−1 ) ◦ c = a−1 ◦ e ◦ c = a−1 ◦ c in H . Damit ist denitionsgemäÿ a ∼ c. 2 Beweis. Die Äquivalenzklassen lassen sich auf eine einfache Art und Weise darstellen: Satz 4.16. Die Äquivalenzklasse durch: von a bzgl. der Relation “∼” ergibt sich [a] = aH := {a ◦ h|h ∈ H}. Beweis. x ∈ [a] [a] Es ist a∼x a−1 ◦ x ∈ H a−1 ◦ x = h x=a◦h x ∈ aH . g.d.w. g.d.w. g.d.w. g.d.w. g.d.w. 2 Nun ist die Linksverknüpfung mit einem festen a aufgefasst als Abbildung G → G mit x 7→ a ◦ x eine bijektive Abbildung (jedoch kein Homomorphismus). Insbesondere ist die auf H eingeschränkte Abbildung eine Bijektion von H auf aH . Somit hat aH für jedes a genau so viel Elemente wie H . Da dies für alle Äquivalenzklassen [a] = aH gilt, haben damit alle Äquivalenzklassen also dieselbe Anzahl von Elementen. Für die Anzahl der Äquivalenzklassen selbst führen wir folgenden Begri ein: Denition 4.17. Die Anzahl der Äquivalenzklassen für die Relation der Untergruppe auch ind H nennt man auch den Index von H in G. ∼ bzgl. Hierfür schreiben wir H. Da alle Äquivalenzklassen gleich viele Elemente besitzen und paarweise disjunkt sind ergibt sich: Satz 4.18 (Satz von Lagrange). gilt: Ist H eine Untergruppe der Gruppe G, dann ord G = ord H · ind H. Sei nun H die von einem Element a ∈ G erzeugte zyklische Gruppe. Die Ordnung von a ist dann gleich der Ordnung von H und es folgt ord G = ord a · ind H . Also gilt: Folgerung 4.19. Für Folgerung 4.20 a ∈ G (G endlich) gilt: ord (Kleiner Satz von Fermat). aord G = e. a ist ein Teiler von ord Für jedes a∈G gilt: G. 4.1. GRUPPEN Beweis. eind H = e. 4.1.5 101 Wegen ord G = ord a·ind H ist aord 2 G = aord a·ind H = (aord a )ind H = Faktorgruppen Es stellt sich die Frage inwieweit auf der Menge der Äquivalenzklassen aH einer Äquivalenzraleation ∼H für eine Gruppe G mit Untergruppe H eine natürliche Gruppenstruktur besteht. Eine solche Gruppenstruktur sollte von der ursprünglichen Gruppenstruktur von G induziertÿein d.h. in folgender Form darstellbar sein: [a] ◦ [b] = [a ◦ b] für beliebige a, b ∈ G, wobei die Operation “ ◦ ” auf der linken Seite die induzierte Operation bezeichnet und die Operation “ ◦ ” auf der rechten Seite die induzierende also die ursprüngliche Operation auf G bezeichnet. Für nichtkommutative Gruppen G macht man sich allerdings schnell klar, dass die notwendige Forderung nach Wohldeniertheit"der induzierten Operation besondere Eigenschaften von H erforderlich macht, die nicht automatisch erfüllt sind. Schauen wir uns hierzu an, was die Forderung nach Wohldeniertheit für Konsequenzen nach sicht zieht: Wie wir oben gesehen haben, lassen sich [a] bzw. [b] auch repräsentieren durch a ◦ h bzw. b ◦ h′ mit beliebigem h, h′ ∈ H . Wohldeniertheit bedeutet nun, dass (a ◦ h) ◦ (b ◦ h′ ) dieselbe Äquivalenzklasse repräsentiert wie a ◦ b. Dies heiÿt, dass (a ◦ h) ◦ (b ◦ h′ ) ∈ [a ◦ b] und damit (a ◦ h) ◦ (b ◦ h′ ) = (a ◦ b) ◦ h′′ für ein geeignetes h′′ ∈ H . Multiplikation mit a−1 von links und mit h′−1 von rechts ergibt die Gleichung h ◦ b = b ◦ h′′ ◦ h′−1 . dies bedeutet aber, dass für beliebiges h ∈ H und jedes b ∈ G sich h ◦ b darstellen lassen muss in der Form b ◦ h̃ mit einem geeigneten h̃ ∈ H . Für nichtkommutative Gruppen ist das aber nicht immer der Fall. Untergruppen H einer (nichtkommutativen) Gruppe G erhalten also einen besonderen Namen, wenn diese Eigenschaft erfüllt ist: Denition 4.21. Eine Untergruppe gruppe oder Normalteiler, wenn für jedes H einer Gruppe G a ∈ G gilt: heiÿt normale Unter- aH = Ha. Dabei ist Ha (in Analogie zu aH ) deniert durch Ha = {h ◦ a|h ∈ H}. Oensichtlich ist jede Untergruppe einer kommutativen Gruppe stets ein Normalteiler. Folgerung 4.22. Sei G eine beliebige Gruppe und H ein Normalteiler von G. ∼H eine wohldenierte in- Dann existiert auf der Menge der Äquivalenzklassen bzgl. duzierte Gruppenoperation. Die hierdurch erzeugte Gruppe heiÿt Quotientengruppe von G nach Beweis. H (manchmal auch Faktorgruppe genannt) und wird mit Übung unter Benutzung der Vorüberlegungen. 2 G/H notiert. 102KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER Satz 4.23. Sei G eine beliebige Gruppe und H ein Normalteiler von G. Dann wird vermöge a 7→ [a] a ∈ G und [a] ∈ G/H ein (kanonischer) G/H deniert mit Kern π = H . für Beweis. 4.2 Übung. GruppenHomomorphismus π:G→ 2 Ringe Auf der Menge Z haben wir mit der Multiplikation und der Addition zwei unterschiedliche Operationen mit gewissen Veträglichkeitseigenschaften. Dies führt zum (verallgemeinerten) Begri eines Ringes: Denition 4.24. Auf einer Menge die mit den Zeichen “+” bzw. nieren eine Ringstruktur auf i) R “·” R, R seien zwei binäre Operationen gegeben, notiert werden. Diese beiden Operationen de- wenn gilt: “ + ” die Eigenschaften einer abelschen Gruppe. “ · ” ist assoziativ aber nicht notwendig koomutativ. alle a, b, c ∈ R: hat zusammen mit ii) Die Operation iii) Es gilt für a · (b + c) = (a · b) + (a · c) sowie (a + b) · c = (a · c) + (b · c). Zur Vermeidung von Klammern wird vereinbart, dass die Multiplikationÿtärker bilden soll wie die Addition". Das neutrale Element bzgl. der Additionÿoll mit 0 bezeichnet werden. Das zu einem Element a (bzgl. der Addition) inverse Element mit −a. Der einfachste Ring besteht nur aus einem einzigen Element, das alle relevanten Rollen selbst wahrnimmt. Dieser Rinmg ist dann trivialerweise auch kommutativ. Auch die ganzen Zahlen Z bilden zusammen mit der gewöhnlichen Addition und Multiplikation einen kommutativen Ring. Beispiel eines nichtkommutativen Ringes ist der Ring der linearen Funktionen, mit der normalen Addition und mit der Hintereinanderausführung als Multiplikation. Weitere Beispiele nichtkommutativer Ringe bilden die quadratischen Matrizen und die sog. Quaternionen. Die Distributivgesetze bei Ringen erlauben die Herleitung einiger wichtiger Gesetze: Satz 4.25. Für alle Elemente i) ii) a · 0 = 0 · a = 0. a · (−b) = (−a) · b = −(a · b). Beweis. Übung 2 a, b eines Ringes R gilt: 4.2. RINGE 103 Es gibt Ringe, in denen es ein bzgl. der Multiplikation neutrales Element n gibt, für das also gilt: a·n=n·a=a für alle a ∈ R. Ein solches Element heiÿt EinsElement und wird auch mit 1 bezeichnet. Ein solcher Ring wird dementsprechend auch als Ring mit 1 bezeichnet. Beispiele. In Analogie zur Eindeutigkeit des neutralen Elementes bei Gruppen kann man zeigen, dass das EinsElement wenn ein solches existiert eindeutig bestimmt ist. Es gibt nun Elemente a in R mit der Eiigenschaft, dass a · b = 0 für ein b ̸= 0. Hierfür denieren wir: Denition 4.26. i) Sei heiÿt a a∈R ein Element mit a·b = 0 für ein b ̸= 0. Dann ein Linksnullteiler. ii) Gilt analog b·a = 0 für ein b ̸= 0, dann heiÿt a Rechtsnullteiler. Links oder Rechtsnullteiler werden auch einfach als Nullteiler bezeichnet. iii) Ein Nullteiler a, der selbst ungleich 0 ist, heiÿt eigentlicher Nullteiler. iv) Ein Ring der keine eigentlichen Nullteiler enthält, heiÿt nullteilerfrei. Beispiele. Endliche Ringe mit Nullteiler. Für Element die nicht (Recht/Links)Nullteiler sind gibt es eine Kürzungsgesetz: Satz 4.27. Sei i) Gilt a, b, c ∈ R. a kein a·b = a·c und ist b·a=c·a und ist Linksnullteiler, dann folgt hieraus die Gleichung b = c. ii) Gilt a kein Rechtsnullteiler, dann folgt hieraus analog b = c. Beweis. Zu i):Aus a · b = a · c folgt a · b + (−(a · c)) = 0. Wegen −(a · c) = a · (−c) (s.o.) folgt unter Benutzung des Distibutivgesetzes a · (b − c) = 0. Da a nach Voraussetzung kein Linksnullteiler ist, folgt notwendig b − c = 0 also b = c. ii) zeigt man analog. 2 Folgerung 4.28. Sei R nullteilerfrei, dann ist für jedes a ̸= 0 die Funktion x 7→ a · x von R→R injektiv. Eine analoge Behauptung gilt für die Funktion x 7→ x · a. Begri eines Schiefkörpers, eines kommutativen Ringes und eines Körpers. Begri einer Einheit Satz 4.29. Die Einheiten eines Ringes mit 1 bilden bzgl. der Multiplikation eine Gruppe. Beweis. Übung. beweisend Beispiel. Einheiten in Z4 . Begri eines Integritätsringes. (kommutativ, Nullteilerfrei, 1 ̸= 0) 104KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER 4.3 Kommutative Ringe Ab jetzt betrachten wir nur noch kommutative Ringe mit EinsElement. Ringhomomorphismus und Kern eines Ringhomomorphismus Ideale und Restklassenringe. Wie erhalten wir die Einheiten eines Restklassenringes Z/nZ? Eür eine Einheit [a] muss gelten, dass es ein [b] gibt, mit [1] = [a][b] = [ab]. ab und 1 gehören also zurselben Äquivalenzklasse, d.h. es gilt ab − 1 = nr oder ab − nr = 1. Bei vorgegebenem a und n liegt hier eine ganzzahlige Gleichung vor, für die eine ganzzahlige Lösung mit den Unbekannten b und r gesucht wird. Betrachten wir also die Lösbarkeit von Gleichungen der Form ax + by = c mit vorgegebenen ganzen Zahlen a, b, c und den Unbekannten x, y . Wir haben es hier mit einer speziellen sog. diophantischen Gleichung zu tun. Eine solche Gleichung ist genau dann ganzzahlig lösbar, wenn die Zahl c ein Vielfaches des ggT von a und b ist. (Dies zeigt man leicht mit Hilfe des Euklidschen Algorithmus. Er leifert gleichzeitig ein konstruktives Verfahren zur Bestimmung der Lösung.) Hieraus folgt: Satz 4.30. Ein Element modulo n, wenn Beweis. a und n [a] ist genau dann eine Einheit im Restklassenring teilerfremd sind. Sind a und b teilerfremd, dann ist die Gleichung ax + ny = 1 lösbar und [a][x] = [1]. Sind a und b nicht teilerfremd mit einem gemeinsamen Teiler t > 1, dann lässt sich dieser gemeinsame Teiler als gemeinsame Faktor ausklammern ax+ny = tr, so dass es keine Möglichkeit zur Lösung der diophantischen Gleichung mit c = 1 gibt. 2 Es gibt also genau soviele Einheiten in Z/nZ, wie es zu n teilerfremde Zahlen in der Menge {1, 2, · · · n − 1} gibt. Folgerung 4.31. Ist Anzahl der Einheiten zu Beweis. n das produkt (p − 1)(q − 1). zweier Primzahlen Abzählen der teilerfremden Zahlen. 15m5n−1 dann ergibt sich die 2 Denition 4.32. Die Anzahl der zu einer Zahl Bereich pq , n teilerfremden Zahlen bezeichnet man als die Eulersche m im φ-Funktion. Ohne Beweis erwähnen wir: Satz 4.33. Für αm 1 α2 n = pα 1 p2 · · · pm ergibt sich für die Eulersche 1 −1 m −1 φ(n) = pα (p1 − 1)p2α2 −1 (p2 − 1) · · · pα (pm − 1) = m 1 n ∏ i=1 φ-Funktion i −1 pα (pi − 1) i zu 4.4. RSAVERSCHLÜSSELUNG Satz 4.34. Für jede Einheit 105 [a] des Restklassenringes Z/nZ gilt [a]φ(n) = [1] Beweis. nung φ(n). 4.4 Die Menge der Einheiten bildet eine (multiplikative) Gruppe der Ord2 RSAVerschlüsselung Wir beginnen mit zwei (im allgemeinen sehr groÿen) Primzahlen p und q . Ausgehend vom Produkt n = pq̇ dieser Primzahlen, führen wir zwei modulo Rechnungen durch: mod n und mod φ(n). Wir suchen zunächst zwei Zahlen e, d mit ed = 1 mod φ(n) d.h. ed − kφ(n) = 1 für ein geeignetes k . Wie wir gesehen haben, ist eine solche Gleichung stets lösbar, wenn wir mit einem e beginnen, das teilerfremd zu φ(n) = (p − 1)(q − 1) ist. Das Zahlenpaar (e, n) wird im folgenden als sog. öentlicher Schlüssel zum Verschlüsseln einer Nachricht benutzt. Zum Entschlüsseln benutzt man das Paar (d, n). Dabei wird jetzt modulo n gerechnet. Hierbei ist zu beachten, dass für die Äquivalenzklassen [a] mod n stets gilt (s.o): [a]φ n = [1] Verschlüsselung (Klartext sei als Zahl m gegeben): m ; [m]e = [me ] = [c] für einen geeigneten Repräsentanten c (der so gewählt wird, dass 0 5 c 5 n). Entschlüsselung: c ; [c]d = [cd ] Es ist dann [cd ] = [m], d.h. aus der verschlüsselten Nachricht [c] lässt sich der Klartext [m] rekonsruieren. Es ist nämlich: [cd ] = [(me )d ] = [m1+k·φ(n) ] = [m · mk·φ(n) ] = [m · (mφ(n) )k ] = [m] · [mφ(n) ]k = [m] · [1]k = [m]. 106KAPITEL 4. ALGEBRAISCHE STRUKTUREN, GRUPPEN, RINGE, KÖRPER Bemerkung: Wir haben hier stillschweigend unterstellt, dass die zu verschlüsselnde Nachricht m ebenfalls teilerfremd ist zu n. Das ist strenggenommen nicht immer der Fall. Man könnte nun argumetieren, dass dies (nämlich gemeinsame Teiler) nur ganz selten auftreten könnte. Man könnte sich aich aus der Aäre ziehen, indem man das m nicht nur kleiner als n sondern auch kleiner als p oder q wählte. Tatsächlich aber kann man zeigen, dass die Verschlüsselung mit anschlieÿender Entschlüsselung auch für diejenigen m < n funktioniert, die nicht teilerfremd sind. (Aber: e resp. d und φ(n) müssen in jedem Fall teilerfremd sein.)