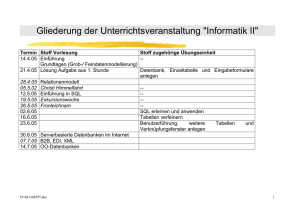
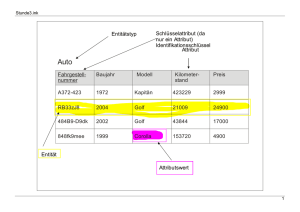
Datenbankdesign-Grundlagen
Werbung

Datenbankdesign-Grundlagen Relationale Datenbanken sind heutzutage die Basis von Unternehmensanwendungen, doch allzu oft wird ihrem Design nicht die nötige Aufmerksamkeit geschenkt. Diesem Umstand wird mit diesem Artikel abgeholfen, denn hier werden die Grundlagen für ein systematisches Vorgehen beim Entwurf und der Implementierung eines Datenmodells geschaffen und ein Überblick über die sich dahinter verbergenden theoretischen Ansätze gegeben. 1. Überblick: Thema Datenbankentwurf in Theorie und Praxis für relationale Datenbankmanagementsysteme (RDBMS). Anhand kleiner Beispiele werden die grundlegenden theoretischen Konzepte wie Relationen, Attribute, Beziehungen und referentielle Integrität in die Praxis und damit in eine Datenbank umgesetzt. Technik: Datennormalisierung; Entity-Relationship-Diagramme (ERD); ERD in ein physisches Datenmodell übersetzen. 2. Geschichtliches Zum Thema Datenbanken gehören aus heutiger Sicht vier Teilthemen, die hier kurz und nicht erschöpfend dargestellt werden sollen: • das relationale Modell, • das Entity-Relationship-Diagramm (ERD), • die relationalen Datenbankmanagementsysteme(RDBMS) und • SQL 2.1. Relationale Datenbanken E. F. Codd und andere entwickelten das Konzept der relationalen Datenbank (relationales Modell) um 1970 [1]. Davor wurden Daten meist hierarchisch oder netzwerkartig organisiert. Der erste konkrete Erfolg dieses Konzepts bestand in der Umsetzung durch die Forschungsarbeiten der IBM, die im Jahre 1977 mit dem System R im sog. Blue Book mündeten. Die Software-Pakete SQL/DS und DB2 bildeten zusammen mit ORACLE den Anfang einer langen Produktkette – bis in die heutigen Tage [2]. Damals waren in aller erster Linie Groß- und Minirechner Zielplattform. In den achtziger Jahren schuf Ashton Tate dann mit dBase den ersten Quasistandard auf PC-Basis. 2.2. Das Entity-Relationship-Modell Das für den Entwurf relationaler Datenbanken fast unumgängliche Entity-Relationship- Diagramm (ERD) wurde 1976 von Chen vorgestellt [3]. Das ERD beschreibt die Objekte (Entitätstypen), deren Eigenschaften (Attribute) sowie die zwischen den Objekten bestehenden Beziehungen (Relationships). Chen stellte eine mögliche Notation vor – bei einer Notation handelt es sich um eine Darstellung von Informationen durch definierte Symbole innerhalb eines vereinbarten Kontexts. Inzwischen existieren eine Reihe von Notationen für die Darstellung von ER-Diagrammen; dieser Punkt wird weiter unten nochmals genauer beleuchtet. Entität (Entity): wohlunterscheidbare konkrete oder abstrakte Objekte a thing which can be distinctly identified" (Chen) Beispiele: Buch, Schüler 2 unterschiedliche Aspekte: Entitätstyp (z.B. Schüler) - Instanz (z.B.Peter Meier) Beziehung (Relationship) eine Assoziation (bzw. Beziehung) zwischen zwei Entitäten z.B. die Beziehung „kauft“ zwischen der Entität Schüler und Buch Unterscheidung zwischen Beziehungstyp und Beziehungsexemplar Attribute (Attributes) Eigenschaften von Entitäten und Beziehungen Beispiele im Fall der Entität Schüler - Name, Schülernummer im Fall der Beziehung kauft - Kaufdatum, Menge VAHTLSTP - Stummer 75896599 - 10 / 2001 1 / 13 Unterscheidung zwischen Attributstyp (legt Wertevorrat fest) und Attributsexemplar (bzw. Attributswert oder –ausprägung Attribute Name Kaufdatum Nummer Titel Menge kauft Schüler Buch Beziehung Entität Abbildung 1 - Entity-Relationship-Modell 2.3. RDBMS Ein relationales Datenbankmanagementsystem ist eine Software, die in der Lage ist, Daten, die relational organisiert sind, zu verwalten. Daten sind relational organisiert, wenn sie in zweidimensionale Tabellen (Relationen) mit einer bekannten Anzahl an Spalten (Attributen) und einer unbekannten Anzahl von Zeilen/Datensätzen (Tupel) vorliegen. 2.4. SQL Bei SQL ( „Structured Query Language“ ) , der Definitions- und Abfragesprache für relationale Datenbanken, handelt es sich seit Oktober 1986 mit Erlangung der ISONorm 9075 um einen ANSI-Standard. Die Entwicklung von SQL setzte allerdings schon in den frühen siebziger Jahren ein und geht u.a. auf die Arbeiten von Champerlin / Broyce zurück. SQL teilt sich in folgende Bereiche auf: • DDL (Data Definition Language), • DML (Data Manipulation Language) und • DCL (Data Control Language) Die DDL ist der Sprachteil der SQL, welcher für die Definition von Tabellen, Feldern, Bedingungen – beispielsweise create, alter, drop – usw. zuständig ist, wohingegen der DML-Sprachteil für die Selektion (Zugriff), das Verändern, das Löschen usw. der gespeicherten Daten benötigt wird. Befehle der DML sind beispielsweise select, insert und update. DCL ist der Teil, der für die Sicherheit bei Zugriffen, Benutzervalidierung, Rechte- und Privilegienvergabe, Datenwiederherstellung usw. zuständig ist. Befehle der DCL sind beispielsweise grand, revoke und commit. 3. Datenbankdesign Nach dem ANSI / SPARC-Modell [4] können und sollen drei Ebenen bei der Sicht auf die in einer Datenbank gespeicherten Daten unterschieden werden. Hierbei handelt es sich um folgende Sichten: • die „Benutzersicht“ oder „externe Ebene“ • die „logische Gesamtsicht“ oder „konzeptionelle Ebene“ und • die „physische Sicht“ oder „interne Ebene“. Unter dem Design einer Datenbank soll der logische und physische Entwurf der Datenbank mit ihren Tabellen, Schlüsseln, Beziehungen, Feldern usw. verstanden werden. Die Frage lautet: Wie verteile ich die von meiner Anwendung benötigten Daten so auf die Datenbank, daß das ganze möglichst stabil, schnell und redundanzfrei ist (um nur einige Punkte zu nennen)? Für das logische Design wird vorausgesetzt, dass sich schon jemand darüber Gedanken gemacht hat, welche Daten überhaupt in der Datenbank gespeichert werden sollen. Wie die Daten später in der Datenbank abgelegt werden und vor allen Dingen, in welchem konkreten RDBMS dies geschehen soll – das sind Fragen, die beim physischen Entwurf eine Rolle spielen. Aber immer schön der Reihe nach: Das Design einer Datenbank lässt sich, dem vorgestellten ANSI/SPARCModell entsprechend, in folgende drei Phasen gliedern: • Erstellen des Entitätenmodells (externe Ebene) • Erstellen des konzeptionellen Datenbankmodells (logische Ebene) und • Erstellen des physischen Datenbankmodells (interne Ebene) VAHTLSTP - Stummer 75896599 - 10 / 2001 2 / 13 Abschließend wird das physische Datenbankmodell in ein konkretes RDBMS implementiert. Dies geschieht (normalerweise) über die DDL-Teilmenge der SQL. 3.1. Die externe Ebene Die externe Ebene hat die Frage zu klären, welche Anwendungen auf welche Daten in der Datenbank wie zugreifen dürfen; das heißt lesend (read), verändernd (update), löschend (delete) oder hinzufügend (insert). Dieser Frage liegt die Annahme zu Grunde, dass es in einem Unternehmen nur eine Datenbank gibt, auf die viele unterschiedliche Anwendungen zugreifen. Innerhalb der einzelnen Anwendungen muss dann beispielsweise geklärt werden, welcher KUNDE durch seine BESTELLUNGen wieviel Umsatz erzeugt hat oder welcher VERKÄUFER welchen KUNDEN betreut und welche ARTIKEL von diesem größtenteils erworben werden. 3.2. Die logische Ebene Auf der logischen Ebene, die manchmal auch als konzeptionelle bzw. konzeptuelle Ebene bezeichnet wird, muss der Entwickler die einzelnen Relationen (Informationsprojekte bzw. Entitätstypen – beispielsweise KUNDE, VERKÄUFER, BESTELLUNG usw.) und deren Attribute (Eigenschaften wie beispielsweise Name, Bestelldatum, PLZ usw. aus dem Problembereich, über den er Informationen speichern möchte, dergestalt zueinander in Beziehung setzen, dass diese den Regeln der Normalformen (siehe unten) entsprechen. Diese Aufgabe wird im weiteren detaillierter betrachtet. 3.3. Die interne Ebene Die interne Ebene wiederum hat die Implementierung in ein RDBMS vor Augen. Das Modell der logischen Ebene wird nun in ein konkretes RDBMS implementiert. Dies geht nicht 1:1 vonstatten – es sind einige Änderungen am vorhandenen konzeptionellen Modell vorzunehmen, damit es in die Strukturen eines RDBMS passt. Beispielsweise ist es auf der logischen Ebene ohne weiteres möglich, Beziehungen (relationships) mit der Kardinalität n:m (many to many) zu modellieren, aber kein RDBMS ist heutzutage in der Lage, eine solche Beziehung direkt umzusetzen. Wie eine solche Umsetzung funktioniert, wird etwas weiter unten dargestellt. Die Performance der Anwendung hängt zu einem großen Teil vom Datenbankdesign ab. Für ein performantes Datenbankdesign sind Implementierungsdetails von Bedeutung. Wurde die logische Ebene noch unter den Aspekten der Normalisierung betrachtet und entworfen, wird nun unter Gesichtspunkten der Performance eine gezielte Denormalisierung vorgenommen, da diese einiges an Geschwindigkeit herausholen kann. Für die beschriebenen Phasen existieren drei Hilfsmittel: • die Normalformen, • das Entity-Realtionship-Diagramm (ERD) und • Erfahrung. 4. Normalisierung Unter Normalisieren wird die Tätigkeit verstanden, die Daten, die gespeichert werden sollen, so auf Relationen (spätere Tabellen) zu verteilen, dass diese den Normalisierungsregeln entsprechen. Es gibt mehr als fünf, aber es sollen nur die ersten drei Regeln (Normalformen) besprochen werden, da diese die größte praktische Bedeutung haben. All diese Regeln bauen hierarchisch aufeinander auf 3. Normalform 2. Normalform 1. Normalform Abbildung 2 - Normalisierung VAHTLSTP - Stummer 75896599 - 10 / 2001 3 / 13 Das bedeutet, eine Relation kann nie in einer höheren – beispielsweise der dritten – Normalform (3NF) sein, ohne sich nicht gleichzeitig auch in allen niedrigeren Normalformen – hier erste (1NF) und zweite (2NF) – zu befinden. Für das Normalisieren gibt es verschiedene Gründe, beispielsweise ... • Vermeidung von Anomalien (unerwünschte Abhängigkeiten) bei der Ausführung von update-, delete- oder insert-Befehlen, • Vermeidung von Redundanzen (Datendoppelspeicherung), • Erleichterung der Wartung der Datenbankstruktur, beispielsweise bei der Realisierung von neuen Anforderungen. 4.1. Datenredundanz Mit Datenredundanz ist die Speicherung von doppelten Daten gemeint. Ein Datum, sprich ein Wert, sollte immer nur einmal vorkommen, um einer Vergeudung von Speicherplatz entgegenzuwirken und gleichzeitig die möglichst einfache Wartbarkeit der Daten zu gewährleisten. In Abbildung 3 wird der Fall der redundanten Datenspeicherung dargestellt: Wenn sich die Firmierung der „Hilbert OHG“ in „Hilbert AG“ ändert, wäre dieser Wert an zwei Stellen – Tabelle KUNDE und BESTELLUNG – zu ändern. Firma Mayer GmbH Hilbert OHG Bestellung Bestelldatum 28.10.2001 30.10.2001 Bestellnummer 150 186 Preis 153,44 188,00 doppelt vorhanden Kunde Firma Meier GmbH Hilbert OHG Strasse Hauptstr. 25 Berggasse 18 PLZ 5020 4810 Ort Salzburg Gmunden Abbildung 3 - redundanten Datenspeicherung Bei einem Datenbankdesign, welches die Redundanzfreiheit nicht fördert, kann nie mit Sicherheit gesagt werden, ob alle Daten immer auf dem selben Stand sind. 4.2. Daten, Relationen, Tupel, Entities und sonstige Dinge Ein Datum ist ein einzelner Wert, beispielsweise „Mayer“, „4711“ oder „Berggase 18“, welcher die kleinste der hier betrachteten Einheiten darstellt. Sicherlich lassen sich Werte in noch kleinere Einheiten – bis auf die Ebene der Bits – zerhacken, doch das ist hier, im Kontext der Datenmodellierung, eher von akademischem Wert. Ein Attribut (späteres Tabellenfeld) kann einen Wert annehmen und verkörpert eine Eigenschaft der Entität (spätere Tabelle), zu der es gehört. Ein Attribut darf keine Intervalle (1..7), Aufzählungen (A,B,C,D) oder sonst irgend etwas nicht atomares (griech. atomos = unteilbar) enthalten. Ein Attribut kann zu einer Domain gehören, wobei eine Domain auch für mehrere Attribute gelten kann. Eine Domain definiert den Wertebereich entweder als Intervall (1..8) oder als Aufzählung (Mo, Di, Mi, Do), den die Attributwerte annehmen können. Durch Domains werden Attributwerte in ihrer möglichen Ausprägung eingeschränkt. Beispielsweise kann eine Postleitzahl in Österreich nur aus 4 Ziffern bestehen. Das Attribut PLZ würde einen Wert „12345“ ablehnen, da dieser für dieses Attribut verboten ist. Die Sicherstellung der Domaingrenzen wird auch als DomainIntegrität bezeichnet. Ein Tupel (später Datensatz) ist eine definierte Menge von Attributwerten. Innerhalb einer Entität muss sichergestellt werden, dass jedes Tupel einmalig ist. Die Sicherstellung erfolgt über ein identifizierendes Attribut, über eine endliche Anzahl von Attributen, deren kombinierte Werte einmalig sein müssen. Die Einmaligkeit der Tupel macht es möglich, dass jedes Tupel (Datensatz) innerhalb einer Relation (Tabelle) eindeutig adressierbar ist. Diese eindeutige Adressierbarkeit wird auch Entity-Integrität genannt. Kann ein Attribut als identifizierendes Attribut verwendet werden, so handelt es sich gleichzeitig um einen Candidate Key – also sinngemäß um einen Kandidaten für einen Schlüssel. Das Attribut, welches nachher beim physischen Design wirklich zum Primary Key (Primärschlüssel, Hauptschlüssel) wird, war vorher ein Candidate Key. VAHTLSTP - Stummer 75896599 - 10 / 2001 4 / 13 5. Beziehungen Zwischen zwei Entitäten kann eine Beziehung (relationship type) bestehen. Diese stellt die Menge aller konkreten Beziehungen (relationship instance) zwischen den einzelnen Tupeln der beteiligten Entitäten dar. Beispielsweise gibt es eine Beziehung zwischen KUNDE und BESTELLUNG, da jeder KUNDE BESTELLUNGen aufgeben kann. Dass es zwischen diesen beiden Entitäten eine Beziehung (relationship type) gibt, sagt aber noch nichts darüber aus, welcher konkrete KUNDE denn nun welche konkrete BESTELLUNG aufgegeben hat. Die Aussage, dass beispielsweise Kunde 1234 die Bestellung 5678 aufgegeben hat, stellt eine Instanz der zwischen KUNDE und BESTELLUNG definierten Beziehung dar. 5.1. Kardinalität Beziehungen lassen sich in drei Kardinalitäten unterteilen, die sich auf die Relationship Instances beziehen: 1:1 Eine Eins-zu-eins-Beziehung sagt aus, dass ein Tupel einer Entität genau einem Tupel einer anderen Entität zugeordnet werden kann – ist Spezialfall einer 1:n Beziehung. (Abbildung 5). 1:m Die Eins-zu-viele-Beziehung (one-tomany) besagt, dass ein Tupel einer Entität mindestens einem Tupel der anderen Entität zugeordnet ist (Abbildung 6). m:n Bei einer Viele-zu-viele-Beziehung (many-to-many) können jedem Tupel einer Entität mehrere Tupel der anderen Entität zugeordnet werden und umgekehrt (Abbildung 7). 1:1 1:n n:m Abbildung 4 - Darstellung mittels Graphentheorie Beispiel 1 : 1 Ein Mitarbeiter kann (höchstens) eine Abteilung (1) leiten. Eine Abteilung wird von (genau) einem Mitarbeiter (1) geleitet leitet 1 1 Abteilung Mitarbeiter Abbildung 5 – Kardinalität 1:1 Beispiel 1 : n Ein Schüler kann mehrere Bücher (n) ausleihen. Aber ein Buch kann nur von einem Schüler entliehen werden ausleihen 1 n Schüler Buch Abbildung 6– Kardinalität 1:n Beispiel n:m Ein Schüler besucht mehrer Kurse und ein Kurs wird von mehrer Schülern besucht. Schüler m besucht n Kurs Abbildung 7– Kardinalität m:n VAHTLSTP - Stummer 75896599 - 10 / 2001 5 / 13 5.2. Beziehungsarten Des weiteren werden Beziehungsarten (Optionalitäten) unterschieden, die Aussagen über die „obligatorische Mitgliedschaft“ [5] der Tupel einer Relation in der Beziehung zu einer anderen Relation treffen. Diese werden für jede Beziehung und Relation festgelegt. Dabei wird, je nach Betrachtungsweise, zwischen zwei (Blickpunkt ist ein Beziehungsende) und vier Arten (Blickwinkel ist die Beziehung mit zwei Enden) unterschieden: • wahlfreie (kann, optional) und • zwingende (muss, mandatory) Beziehungen. Die Muss-Beziehung wird textuell beispielsweise durch Hinzufügen des Akronyms „C“ gekennzeichnet (1:1C, 1C:n usw.). Grafisch werden die Optionalitäten wie in Abbildung 8 dargestellt. Schüler m besucht n Kurs Abbildung 8 - Beziehungsarten Der Strich an dem Beziehungsende der Entität „Kurs“ sagt aus, dass für jedes Tupel in der Entität „Kurs“ immer mindestens ein Tupel in der Entität „Schüler“ existieren muss (Muss-Beziehung). Wo hingegen der Kreis am Beziehungsende der Entität „Schüler“ aussagt, dass für jedes Tupel der Entität „Schüler“ zwischen 0 und unendlich viele Tupel in der Entität „Kurs“ existieren können (Kann-Beziehung). In der Praxis sind nicht alle Kombinationsmöglichkeiten verwendbar. Eine 1C:1C-Beziehung ist z.B. nicht möglich, da in diesem Fall nicht entschieden werden kann, welcher Entität ein Tupel hinzugefügt werden kann, da in beiden Entitäten das Vorhandensein eines Tupels in der anderen Entität vorausgesetzt wird. Das impliziert, dass den in solch einer Beziehung stehenden Entitäten kein Tupel hinzugefügt werden kann. 6. 1. Normalform „Eine Tabelle (Entität) ist in der ersten Normalform (1NF), wenn alle ihre Attribute nur atomare Werte enthalten“ [5]. Das bedeutet nichts anderes, als dass ein Attribut einer Relation keine mehrdeutigen Attributwerte wie beispielsweise Kinder = „Mark, Sharon, Joe“, enthalten darf (Abbildung 9). Mitarbeiternummer 1001 1010 Vorname Franz Claudia Mitarbeiter Nachname Heller Müller Kinder Mark, Sharon, Joe Helmut Abbildung 9 – 1.NF Was aber ist zu tun, wenn festgestellt wird, dass – wie in unserem Beispiel – mehrere Kinder gespeichert werden müssen? Einer der Hauptfehler, die dann gemacht werden, besteht oft darin, einfach „noch ein paar mehr“ Kinder- Spalten an die Mitarbeiter zu hängen. Das geht vielleicht bei Kindern noch einigermaßen (hier kann man wahrscheinlich bei 10 Kinder- Spalten aufhören), aber wie viele zusätzliche Spalten braucht eine Bestellung, um alle Artikel aufzunehmen? So geht’s also nicht. Eine Relation, die sich nicht in der 1NF befindet, wird auf mehrere Relationen aufgeteilt – in diesem Beispiel auf die Relation MITARBEITER und die Relation KIND, die beide über die „MitarbeiterNr“ verknüpft werden, wobei zwischen diesen eine Beziehung mit der Kardinalität 1:n besteht. VAHTLSTP - Stummer 75896599 - 10 / 2001 6 / 13 Mitarbeiternummer 1001 1010 Mitarbeiter Vorname Franz Claudia Nachname Heller Müller Kind Kindnummer 1 2 3 4 Mitarbeiternummer 1001 1001 1001 1010 Vorname Mark Sharon Joe Helmut r Abbildung 10 – 1. NF Nun kann je Mitarbeiter eine beliebige Anzahl an Kindern gespeichert werden, ohne dass sich jemand darüber Gedanken zu machen braucht, wie viele Kinder denn nun eigentlich genau, höchstens usw. vorkommen könnten. Spätestens, wenn jemand auf die Idee gekommen wäre, zu den Kindern auch noch deren Geburtsdaten zu speichern, hätte die erste Lösung ziemlich viel Arbeit verursacht. Für jede KindSpalte hätte eine Geburtstag-Spalte hinzugefügt werden müssen. Bei der normalisierten zweiten Lösung könnte einfach durch das Anfügen einer zusätzlichen Spalte dem Wunsch nach Geburtsdaten entsprochen werden. 7. 2. Normalform Eine Tabelle (Entität) wird der zweiten Normalform (2NF) zugezählt, wenn sie sich in der ersten Normalform (1NF) befindet und keine funktionalen Abhängigkeiten der Nicht-Schlüssel-Attribute von Teilschlüsseln existieren. Ein Nicht-Schlüssel-Attribut ist ein Attribut, welches keinen Primärschlüssel darstellt. Ein Teilschlüssel ist „ein Teil des Schlüssels“ – wenn ein Primärschlüssel einer Tabelle beispielsweise aus den Attributen „Bestellnummer“ und „Artikelnummer“ besteht, ist jedes dieser Attribute für sich betrachtet ein Teil des Primärschlüssels. Eine funktionale Abhängigkeit ist gegeben, wenn zu jedem Wert des Attributs A genau ein Wert des Attributs B gehört – dies wird dann als funktionale Abhängigkeit des Attributs B von dem Attribut A bezeichnet. Wenn sich also der Wert von A ändert, ändert sich auch der Wert von B. Hierzu ein Beispiel: Das Attribut „Lagerbestand“ ist funktional abhängig vom Attribut „Artikelnummer“, da sich in der Realwelt der Lagerbestand immer auf eine Artikelnummer bezieht und sich folglich der Lagerbestand für jede Artikelnummer ändert. Da laut 2NF diese funktionalen Abhängigkeiten nicht zwischen Nicht-SchlüsselAttributen und Teilschlüsseln existieren dürfen, ist sie demnach nur für Relationen von Bedeutung, die mehr als ein Schlüssel-Attribut besitzen. In der dargestellten Tabelle BESTELLDETAILS (Abbildung 11) bilden die Attribute „Bestellnummer“ und „Artikelnummer“ den Primärschlüssel. Bestellnummer 4566 4567 Artikelnummer 4711 4712 Bestelldetails Einzelpreis 18,55 99,20 Anzahl 10 18 Abbildung 11 – 2.NF Jedes dieser Attribute stellt einen Teilschlüssel dar. Nach der 2NF dürfen nun keine Attribute in der Tabelle existieren, die funktional von einem Teilschlüssel, nicht aber von dem gesamten Schlüssel abhängen. Das Attribut „Einzelpreis“ erfüllt diese Forderung nicht – der Preis bezieht sich nur auf den Artikel, und jeder Artikel hat einen Einzelpreis. Das Attribut „Einzelpreis“ muss also aus der Relation BESTELLDETAILS entfernt und in die Tabelle ARTIKEL gebracht werden. Bestellnummer 4566 4567 VAHTLSTP - Stummer Bestelldetails Artikelnummer 4711 4712 Anzahl 10 18 Bestelldetails Artikelnummer Einzelpreis 4711 18,55 75896599 - 10 / 2001 7 / 13 8. 3. Normalform Eine Relation ist in der dritten Normalform, wenn sie sich in der 2NF – und damit auch in der 1NF – befindet und keine funktionalen Abhängigkeiten zwischen Nicht-Schlüssel-Attributen bestehen (ein Fremdschlüssel ist KEIN Nicht-Schlüsselfeld). Die funktionale Abhängigkeit eines Attributs von einem anderen Attribut, wobei beide nicht als Schlüssel definiert sind, wird auch als transitive Abhängigkeit (d. h. wenn Attribut A2 von Attribut P1 (dem Primärattribut) abhängt und Attribut A1 von A2, dann ist es transitiv abhängig von P1 (P1->A2 ^ A2->A1 => P1->A1)) bezeichnet. Die hier ausschnittsweise gezeigte Tabelle KUNDE befindet sich nicht in der 3NF. Zwischen den Attributen „Kontaktperson“ und „Durchwahl“ existiert eine transitive Abhängigkeit. Kundennummer 44885 40112 Name Myers GmbH ISP – AG Kunde Kontaktperson M. Böck H. Baum Telefon 475589 11245459 Durchwahl 13 450 Abbildung 12- 3. NF Dieses Problem läßt sich, wie in Abbildung 13 gezeigt, durch die Splittung der oben gezeigten Tabelle KUNDE beheben. Die beiden neuen Tabellen werden über die Kundennummer 1:N miteinander verknüpft Kundennummer 44885 40112 Kunde Name Myers GmbH ISP - AG Kundennummer 44885 44885 40112 Telefon 475589 11245459 Ansprechpartner Ansprechpartnernr Kontaktperson 1 M. Böck 2 E. Handel 10 H. Baum Durchwahl 13 15 450 Abbildung 13 - 3.NF Nach der Teilung können jetzt zusätzlich auch noch beliebig viele Ansprechpartner je Firma gespeichert werden. 9. Konzeptionelles Design Das Entity-Relationship-Diagramm zeigt das Modell der Daten. Um hier noch mal völlig für Begriffsverwirrung zu sorgen, haben sich die Gurus darauf geeinigt, die bisherigen Relationen in Entitytyp (Entitätstyp), die Tupel in Entities und die Beziehungen in Relationship umzubenennen. De facto bleibt alles beim alten, nur die Begriffe ändern sich. Nach [5] ist die Erstellung des konzeptionellen Modells in folgende zwei Phasen aufgeteilt: • Bestimmung der Entities und deren • Definition der Attribute und Relationen für die Entities und Relationships unter Anwendung der Normalisierungsregeln. Für die Erstellung des konzeptionellen Modells werden in der Literatur zwei diametral entgegengesetzte Vorgehensweisen genannt. Zum einen die Top-Down-Vorgehensweise, bei der, ausgehend von der Gesamtsicht „auf“ einen betrachteten Realitätsausschnitt, die Entitäten aus den Geschäftsvorfällen bestimmt werden. Zum anderen die Bottom-Up-Vorgehensweise, bei der die Entitäten und deren Attribute „von unten nach oben“ aus den „Anforderungen an die Verarbeitung“ extrahiert werden [6]. VAHTLSTP - Stummer 75896599 - 10 / 2001 8 / 13 9.1. ERD Für das Entity-Relationship-Diagramm werden verschiedene Notationen verwendet. Es gibt inzwischen so viele Varianten, daß in jedem aktuellen Projekt garantiert eine Notation verwendet werden wird, die einem noch nicht bekannt ist. Beispielhaft seinen hier zwei der bekannteren genannt: • Chen-Notation und • DSA-Notation. Die hier für das ERD verwendete Notation ist an die DSA-Notation angelehnt. Welche Notation bei einem Projekt verwendet wird, sollte entweder unternehmensweit geklärt werden oder jedes Projekt für sich entscheiden. Wichtig ist, daß alle Projektmitglieder diese Notation verstehen und anwenden können. Kunde KundeID Firma Strasse Land PLZ Ort Abbildung 14 – ERD Notation Das identifizierende Attribut (KundeID) vom Entitätstyp (Kunde) wurde fett ausgezeichnet, alle anderen Attribute wurden normal dargestellt. Die Beziehungen zwischen den Entitätstypen werden mit einer Linie symbolisiert. An den jeweiligen Linienenden werden die Optionalitäten und Kardinalitäten für diese Beziehungsseite angezeigt. viele kann viele muss eins kann eins muss Abbildung 15 - Optionalitäten und Kardinalitäten (ERD) Abbildung 15 zeigt die verschiedenen Enden einer Beziehung mit ihren Kardinalitäten und Optionalitäten. Eine Beziehung sollte beschriftet werden, damit erkennbar ist, welche fachliche Motivation hinter dieser Beziehung steckt. Beispielsweise kann die Beziehung zwischen KUNDE und BESTELLUNG mit dem Text „tätigt“ versehen werden, wodurch sich beim Lesen des Diagramms der (Relations-)Satz ergeben würde „Kunde tätigt Bestellung“. Der Sinn dieser Beziehung wird dadurch sofort deutlich Kunde tätigt KundeID Firma Strasse Land PLZ Ort Bestellung BestellungID Bestelldatum Versanddatum ... ... ... Abbildung 16 - ERD VAHTLSTP - Stummer 75896599 - 10 / 2001 9 / 13 9.2. Vorgehensweise Der erste Schritt bei der Erstellung des konzeptionellen Modells besteht in der Bestimmung der Entitätstypen und deren Beziehungen zueinander auf der Basis der funktionalen Anforderungen. Beispiel Bestellwesen: Liste der Entitätstypen Artikel Bestelldetails Bestellungen Kategorien Kunden Lieferanten Personal Versandfirmen Es wäre schön – ist sicherlich aber nur ein frommer Wunsch – wenn gleich zu Beginn immer alle Entitätstypen feststünden und auch alle gefunden würden. Wahrscheinlicher ist es jedoch, dass eine Liste erstellt wird und sich später herausstellt, dass diese Liste unvollständig ist. Das Erstellen eines ERD ist, wie so oft, ein iterativer Vorgang. Bei der Bestimmung der einzelnen Beziehungen muss entschieden werden, welcher Entitätstyp mit welchem anderen in einer Beziehung steht und wie diese Beziehung konkret im Hinblick auf Kardinalität und Optionalität aussieht. Im nächsten Schritt müssen dem Modell die Angaben hinzugefügt werden, um aus den Entitätstypen Entitäten bilden zu können. Zu diesem Zweck werden den einzelnen Typen (mit Ausnahme der schwachen Entitätstypen) identifizierende Attribute hinzugefügt. Das heißt, dass ein Attribut, welches sich als Schlüssel eignet (Candidate Key), als identifizierendes Attribut ausgewählt wird. Entitäten bei denen ein Exemplar nur dann existieren kann, wenn es ein bestimmtes Exemplar einer anderen Entität gibt werden als abhängige oder auch als schwache Entitäten bezeichnet. Diese verschwinden, wenn die "Existenz begründenden Entitäten" nicht mehr existieren. Ein schwacher Entitätstyp wäre beispielsweise BESTELLDETAILS, da sich sämtliche seiner Attribute sowohl auf ARTIKEL als auch auf BESTELLUNG beziehen. Abschließend sind die Entitäten des Modells um die Attribute zu vervollständigen. Nachdem dieser Schritt erfolgt ist, sollte sich der Modellierer zurücklehnen und das ganze unter den Gesichtspunkten der drei Normalformen noch mal durchdenken. Im Prinzip ist das Erstellen eines ERD genau so einfach wie hier beschrieben, nur daß der Teufel bekanntlich im Detail steckt. 10. Physisches Design Nachdem die konzeptionelle Ebene entworfen wurde, muss diese in ein physisches Modell überführt werden. Das physische Datenmodell stellt die Anpassung des konzeptionellen Modells an die Konstrukte eines konkreten DBMS dar. Im weiteren sollen die Modifizierungen besprochen werden, die notwendig sind, um das konzeptionelle Modell an das RDBMS MS Access anzupassen. Für jedes andere RDBMS sieht die Transformation ähnlich, aber eben nicht exakt gleich aus – spezifische Kenntnisse des RDBMS sind jeweils erforderlich. Entitätstypen werden in Tabellen umgewandelt.Die Entitäten werden zu Datensätzen. Attribute werden zu Tabellenspalten (Datenfelder). Die Attributnamen werden in Feldnamen umgesetzt. Die identifizierenden Eigenschaften der Entitätstypen werden zu Primärschlüsseln (primary key) der Tabellen. Schwache Entitätstypen werden zu Tabellen, die neben ihren eigenen Feldern (ehem.Attributen) zusätzliche Fremdschlüsselfelder (foreign key) erhalten. Diese Felder entsprechen den Primärschlüsseln der assoziierten Tabellen. Domänen werden von MS Access nicht direkt unterstützt. Mit den feldbezogenen „Gültigkeitsregeln“ kann aber eine Domain-Integrität erreicht werden. 10.1. Beziehungstransformation Beim konzeptionellen Design wurden Beziehungen verschiedener Kardinalität entworfen, die nun ebenfalls in das physische Design überführt werden müssen. Zur Umsetzung der Beziehungsart 1:1Beziehung erhält die abhängige Tabelle den Primärschlüssel der unabhängigen Tabelle als Primärschlüssel. Unter einer abhängigen Tabelle wird die Tabelle verstanden, die nur dann Datensätze (ehem. Entitäten) aufnehmen kann, wenn in der unabhängigen Tabelle ein entsprechender Datensatz vorhanden ist. Im Prinzip – oder besser aufgrund von technischen Aspekten – können Tabellen, die zueinander in einer 1:1-Beziehung stehen, auch zu einer einzigen Tabelle zusammengefasst werden. Bei der Umsetzung der 1:N-Beziehung zwischen zwei Tabellen wird der Detail-Tabelle der Primärschlüssel der Master-Tabelle als Fremdschlüssel (FK) hinzugefügt. Eine Viele-zu-viele-Beziehung (M:M) zwischen zwei Entitätstypen wird in drei Tabellen aufgeteilt, wobei die Relation (R3) die Primärschlüssel der Tabellen (R1,R2) als Fremdschlüssel enthält. Der Zwischen- oder Hilfstabelle steht, da sie erst beim physischen Design entstanden ist, kein schwacher Entitätstyp auf der konzeptionellen Ebene gegenüber. Später, wenn die Datenbank fertig ausgeliefert wurde VAHTLSTP - Stummer 75896599 - 10 / 2001 10 / 13 und die ersten Benutzer Daten eingeben, stellt sich die Frage, wie denn die festgelegten Optionalitäten durchgesetzt werden können. Es ist denkbar, dass ein Benutzer beispielsweise in einer Bestellung einen Kunden eingibt, der gar nicht existiert, oder dass ein Kunde einfach gelöscht wird und die ihm zugeordneten Bestellungen im luftleeren Raum hängen. Damit solche Aktionen verhindert werden, gibt es die Referentielle Integrität: Jedes Fremdschlüsselfeld einer Tabelle enthält entweder einen Wert, der ebenfalls Wert des Primärschlüsselfeldes der verbundenen Master- Tabelle ist, oder NULL. NULL ist ungleich der mathematischen Null (0) und ebenfalls ungleich einem Leerzeichen. NULL ist nicht definiert – es gilt NULL ungleich NULL. Damit wird sichergestellt, dass es keine Datensätze in Detailtabellen gibt, zu denen keine Datensätze in Master-Tabellen existieren. Bei delete-Operationen, die komplette Datensätze in der Master-Tabelle betreffen, kann MS Access auf zwei unterschiedliche Arten reagieren, um die Referentielle Integrität sicherzustellen: Kaskadierendes Löschen (cascade delete): Die mit dem zu löschenden Datensatz der MasterTabelle verbundenen Datensätze der Detailtabellen werden ebenfalls gelöscht. Befehl wird abgewiesen (restricted delete). Ebenso wie bei den vorgenannten delete-Operationen können Aktualisierungen der Primärschlüsselwerte die Referentielle Integrität gefährden. Auch hier kann zwischen Cascade Update (Änderungen werden an die Detaildatensätze weitergegeben) und Restricted Update unterschieden werden. Im letzteren Fall werden die Änderungen von der Datenbank nicht durchgeführt (abgewiesen). Bei Access-Datenbanken kann dieses Verhalten entweder über einen Dialog oder kaskadierende Aktualisierung kaskadierendes Löschen Abbildung 17 – Access Referentielle Integrität mit Hilfe von Quellcode über die Attributes-Eigenschaft der Relation-Objekte eingestellt werden. 10.2. Indizes Die Performance einer Datenbank hängt auch zu einem sehr guten Teil von einer guten Indizierungsstrategie ab. Alleine dieses Thema würde einen eigenen Artikel erfordern. Der Datenbankentwickler sollte sich aber darüber Gedanken machen, welche Daten seine Anwendung am häufigsten benötigt, welche Zugriffspfade auf diese Daten in Frage kommen und welche Zugriffspfade auch wirklich benutzt werden sollen. Beispielsweise wird auf die Datensätze in KUNDE in jeder Maske, in der diese benötigt werden, über die Kundennummer zugegriffen. Diese Kundennummer entspricht nicht dem Primärschlüssel (KundenID). Über diese KundenID wird auf den Kunden zugegriffen, wenn dieser Zugriff im Rahmen des Anwendungsquellcodes erfolgt. Es stehen also zwei Hauptfelder für den Zugriff zur Verfügung. Daraus folgt, dass die Kundennummer – neben dem Primärschlüssel – als Unique Key (eindeutiger Schlüssel) realisiert werden sollte. Dieser Unique Key wird über einen Index implementiert. Ein Index repräsentiert eine Art „Inhaltsverzeichnis“ einer Tabelle. Ein Indexeintrag ist ein Zeiger auf einen Datensatz in einer Tabelle. Die Indexeinträge werden häufig in einer separaten Datei, der sog. Indexdatei, gespeichert. Indizes werden zur Erreichung einer höheren Arbeitsgeschwindigkeit und zur Sicherung der Eindeutigkeit der Schlüsselfelder verwendet. Ein Index kann die Arbeitsgeschwindigkeit sowohl beschleunigen als auch verlangsamen. Bei Sortier- und Suchvorgängen sowie Datenzugriffen beschleunigt er den Arbeitsvorgang, bei Einfüge- und Löschvorgängen verringert sich die Arbeitsgeschwindigkeit, da neben der eigentlichen Datentabelle zusätzlich die Indextabelle gepflegt werden muss. Indizes werden nach ihrer Konsistenz und nach den Feldern, für die sie angelegt wurden, unterschieden. VAHTLSTP - Stummer 75896599 - 10 / 2001 11 / 13 Wird für jeden vorkommenden Wert eines Feldes ein Indexeintrag in der Indextabelle abgelegt, so spricht man von einem dichten Index. Wird nicht für jeden Wert ein Eintrag angelegt, so wird dagegen von einem dünnen Index gesprochen. Wurde ein Index für den Primärschlüssel einer Tabelle erzeugt, wird er Primärindex genannt. Ein Index für ein nicht-Schlüsselfeld wird als Sekundärindex bezeichnet [7]. 10.3. Toolunterstützung Je nach Projektgröße sollte man den Einsatz eines entsprechenden CASE-Tools berücksichtigen. Für kleinere Projekte bis zu 20 Tabellen kann ein entsprechendes Charting-Tool wie beispielsweise ABCFlowcharter oder Visio ausreichen. Bei größeren Projekten und gerade wenn absehbar ist, dass die Zielplattform (das RDBMS) einmal ausgetauscht werden soll, empfiehlt sich der Einsatz eines entsprechenden CASE-Tools wie beispielsweise StarDesigner, ErWin oder auch andere. Diese Tools unterstützen den Modellierer nicht nur beim visuellen Entwurf der Modelle durch entsprechende Zeichenwerkzeuge, Überprüfungen und dem Erstellen von Dokumentationen, sondern können gleichzeitig auch den entsprechenden SQL-Quellcode zur Generierung der Datenbank produzieren. Manche von ihnen sind sogar in der Lage, einen Basic-Quellcode zu erzeugen, der dann innerhalb von MS Access ohne SQL die entsprechenden Tabellen und Abfragen anlegt. Von den Möglichkeiten des Reverse Engineering (Rückwärtsentwicklung) mancher Tools, die gerade bei der Analyse von Uralt-Projekten sehr hilfreich ist, ganz zu schweigen. _ Literatur [1] E. F. Codd: A relational model of data for Large Shared Data Banks, CACM 13, Nr. 6, Juni 1970 [2] Finkenzeller et al: Systematischer Einsatz von SQL-Oracle, Addison-Wesley, 1989 [3] Chen: The EntityRelationship-Model: Towards a Unified View of Data, ACM Transactions on Database Systems, Vol. 1, No. 1 March 1976 [4] ANSI/X3/SPARC Study Group on Data Base Management Systems: Interim Report, FDT ACM SIGMOD 7,2 (1975) [5] Sauer, Hermann: Relationale Datenbanken, 4. Auflage, Addison- Wesley, 1998 [6] Brathwaite, Kenneth S.:Datenbankentwurf, eine Einführung, McGraw-Hill, 1990 [7] Vossen, Gottfried: Datenmodelle, Datenbanksprachen und Datenbankmanagementsysteme, 2. Auflage, Addison-Wesley, 1995 entnommen aus: basicpro 6/98 Autor: Dipl.-Kfm. Ilja Thieme VAHTLSTP - Stummer 75896599 - 10 / 2001 12 / 13 Inhaltsverzeichnis Datenbankdesign-Grundlagen .....................................................................................................................1 Überblick: ..................................................................................................................................................1 Geschichtliches .........................................................................................................................................1 2.1. Relationale Datenbanken ......................................................................................................................1 2.2. Das Entity-Relationship-Modell .............................................................................................................1 2.3. RDBMS .................................................................................................................................................2 2.4. SQL .......................................................................................................................................................2 3. Datenbankdesign ......................................................................................................................................2 3.1. Die externe Ebene ................................................................................................................................3 3.2. Die logische Ebene ...............................................................................................................................3 3.3. Die interne Ebene .................................................................................................................................3 4. Normalisierung ..........................................................................................................................................3 4.1. Datenredundanz....................................................................................................................................4 4.2. Daten, Relationen, Tupel, Entities und sonstige Dinge ........................................................................4 5. Beziehungen .............................................................................................................................................5 5.1. Kardinalität ............................................................................................................................................5 5.2. Beziehungsarten ...................................................................................................................................6 6. 1. Normalform ...........................................................................................................................................6 7. 2. Normalform ...........................................................................................................................................7 8. 3. Normalform ...........................................................................................................................................8 9. Konzeptionelles Design ............................................................................................................................8 9.1. ERD .......................................................................................................................................................9 9.2. Vorgehensweise................................................................................................................................. 10 10. Physisches Design ................................................................................................................................ 10 10.1. Beziehungstransformation .............................................................................................................. 10 10.2. Indizes ............................................................................................................................................ 11 10.3. Toolunterstützung ........................................................................................................................... 12 1. 2. Abbildungsverzeichnis Abbildung 1 - Entity-Relationship-Modell ............................................................................................................2 Abbildung 2 - Normalisierung ..............................................................................................................................3 Abbildung 3 - redundanten Datenspeicherung ....................................................................................................4 Abbildung 4 - Darstellung mittels Graphentheorie ..............................................................................................5 Abbildung 5 – Kardinalität 1:1 .............................................................................................................................5 Abbildung 6– Kardinalität 1:n...............................................................................................................................5 Abbildung 7– Kardinalität m:n .............................................................................................................................5 Abbildung 8 - Beziehungsarten ...........................................................................................................................6 Abbildung 9 – 1.NF ..............................................................................................................................................6 Abbildung 10 – 1. NF ...........................................................................................................................................7 Abbildung 11 – 2.NF ............................................................................................................................................7 Abbildung 12- 3. NF .............................................................................................................................................8 Abbildung 13 - 3.NF .............................................................................................................................................8 Abbildung 14 – ERD Notation .............................................................................................................................9 Abbildung 15 - Optionalitäten und Kardinalitäten (ERD) .....................................................................................9 Abbildung 16 - ERD .............................................................................................................................................9 Abbildung 17 – Access Referentielle Integrität ................................................................................................ 11 VAHTLSTP - Stummer 75896599 - 10 / 2001 13 / 13