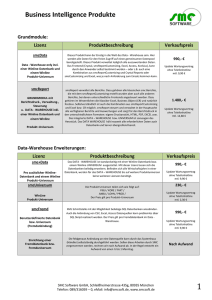
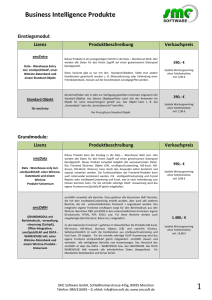
Data Warehouse Referenz Architektur_Juni_2006
Werbung

Data Warehouse Referenzarchitektur Copyright © 2005 by Oracle Corporation. All rights reserved 1/166 Data Warehouse Referenzarchitektur Autor: Historie: Alfred Schlaucher Version 4 Oktober 2006 Version 3 Mai 2005 (Draft) Version 2 Januar 2005 Version 1 Mai 2004 Korrekturen, Empfehlungen, Kommentare bitte direkt an [email protected] Copyright © 2005 by Oracle Corporation. All rights reserved 2/166 Data Warehouse Referenzarchitektur 3/166 Die Themen 1 “Viele Wege führen nach Rom”... ................................................................................ 7 1.1 Zu dieser Referenzarchitektur ..................................................................................... 7 1.2 Oracle Data Warehouse Referenz Architektur .......................................................... 10 1.2.1 Architektur ist Garant für eine effiziente Warehouse Plattform .............................. 10 1.2.1.1 Herausforderungen ............................................................................................. 10 1.2.1.2 Plattformbetrachtung statt Point Solution ............................................................ 10 1.2.2 Bestandteile und Gegenstand der Referenzarchitektur ......................................... 13 1.2.3 Ziel und Zweck der Referenzarchitektur................................................................. 13 2 Aktuelle Anforderungen an Data Warehouse Systeme ............................................. 14 2.1 Operationalisierung des Data Warehouse................................................................. 15 2.2 Serverbasiertes, zentrales Data Warehouse ............................................................ 16 2.3 Abdecken auseinanderdriftender Benutzeranforderungen ........................................ 17 2.4 Prozess - Unabhängigkeit des Data Warehouses ..................................................... 18 2.5 Auf Dauer gebaut - auf Langlebigkeit des Warehouses achten ................................ 19 2.6 Technologische Anforderungen ................................................................................. 20 2.7 Bereitstellen von Informationen für Benutzer ............................................................ 20 2.7.1 Flexible Auswertemodelle ...................................................................................... 20 2.7.2 Feste Kennzahlen................................................................................................... 22 3 Projekt und Projektmanagement ............................................................................... 23 3.1 Inkrementelle Entwicklung Software Entwicklung ..................................................... 23 3.2 Modelle sichern das Projekt ab ................................................................................. 24 3.3 Parallele Schichtenentwicklung ................................................................................. 25 3.3.1 Dokumentation ....................................................................................................... 26 3.3.2 Namenskonventionen ............................................................................................. 26 3.3.3 Templates ............................................................................................................... 27 4 Grundsätzliches Vorgehen zum Aufbau des Warehouse Systems .......................... 28 4.1 „Chaos in allen Gassen“ ............................................................................................ 28 4.2 Informationsplan ........................................................................................................ 28 4.2.1 In welcher Form können Informationen dokumentiert werden ............................... 28 4.3 Schichtenmodell ........................................................................................................ 29 4.3.1 Aufwand nur einmal leisten .................................................................................... 31 4.3.2 Begriffsabgrenzung „Schichtenmodell“ und „Hub and Spoke“ ............................... 32 4.3.3 Den Wechsel relationales / multidimensionales Speichern durchbrechen ............ 33 4.3.4 Wahlfrei den Ort einer Analyse bestimmen ............................................................ 34 4.4 Transformationen ....................................................................................................... 35 4.4.1 Wahlfrei den Ort der Transformation bestimmen ................................................... 35 4.4.2 Durchgängige Verwendung der Datenbanksprache (SQL) ................................... 36 4.4.3 Ladeprozess einfach und kompakt halten .............................................................. 37 4.4.4 Durch Datenbank basierten Ladeprozess Ressourcen schonen ........................... 37 4.4.4.1 Zur Historie: ......................................................................................................... 38 4.4.4.2 Nachteile Engine – basierter ETL - Tools ........................................................... 39 4.4.4.3 Gründe für die Verlagerung des Ladeprozesses in die Datenbank .................... 40 4.4.4.4 Performance schaffen durch Mengen – basierte Transformationen................... 41 4.4.4.5 Explizite Techniken zum Laden großer Datenmengen innerhalb von Oracle Datenbanken 42 4.4.4.6 Partition Exchange And Load (PEL) ................................................................... 43 4.4.5 Skalierungsanforderungen durch intelligentes Datenmanagement lösen.............. 44 4.4.6 Mit verteilten Architekturen den Ladeprozess flexibel halten und Netzlast minimieren 46 4.4.7 Keine versteckten oder geschachtelte Transformationen verwenden ................... 47 4.4.8 Ladeläufe sollten umkehrbar und wiederholbar sein.............................................. 47 4.4.8.1 Einsatz von Partitioning. ...................................................................................... 47 4.4.8.2 Kennzeichnung von geladenen Daten ................................................................ 48 4.4.8.3 Commit – Setzung ............................................................................................... 48 4.4.8.4 Umkehrung von Updates und Deletes ................................................................ 48 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 4/166 4.4.8.5 Wiederholung von Ladeläufen ............................................................................ 48 5 Aufbau der Schichten des Data Warehouses ........................................................... 49 5.1 Aufbau Sammelschicht / Staging Area ...................................................................... 49 5.1.1 Orphan Management ............................................................................................. 49 5.2 Aufbau Warehouse Schicht ....................................................................................... 50 5.2.1 Referenzdaten ........................................................................................................ 50 5.2.2 Stammdaten ........................................................................................................... 50 5.2.3 Bewegungsdaten .................................................................................................... 50 5.2.4 Historisierung in der Warehouse – Schicht ............................................................ 50 5.2.5 Abgrenzung zum Operational Data Store .............................................................. 51 5.2.6 Auswertungen direkt in der Warehouse - Schicht .................................................. 51 5.2.7 Funktionale Bestandteile der Warehouse – Schicht .............................................. 52 5.2.8 Security – Aspekte in der Warehouse - Schicht ..................................................... 52 5.3 Aufbau Auswerteschicht ............................................................................................ 53 5.3.1 Allgemeine Empfehlungen ..................................................................................... 53 5.3.2 Durch Granularisierung mehr Informationsvorrat und damit mehr Flexibilität........ 54 5.3.3 Data Mart ................................................................................................................ 55 5.3.4 Starschema ............................................................................................................ 55 5.3.4.1 Empfehlungen für den Aufbau der Dimensionen ................................................ 56 5.3.4.2 Indizierung und Schlüssel beim Aufbau der Dimensionen ................................. 58 5.3.4.3 Künstliche und originäre Schlüssel ..................................................................... 59 5.3.4.4 Verwendung von Btree und Bitmap – Indizes ..................................................... 60 5.3.4.5 Empfehlungen für den Aufbau der Faktentabelle ............................................... 60 5.3.4.6 Satzübergreifende Konsistenz in der Faktentabelle ........................................... 61 5.3.5 Einsatz von Materialized Views anstelle von Summentabellen ............................. 62 5.3.5.1 Vorteile von Materialized Views im Warehouse – Kontext ................................. 62 5.3.6 Bedienen unterschiedlicher Zielgruppen im Unternehmen .................................... 64 5.3.7 Umgang mit großen Faktentabellen ....................................................................... 65 5.3.8 Die Verwendung multidimensionaler Speichermodelle im Data Mart .................... 65 5.3.8.1 Sparsity ............................................................................................................... 66 5.3.8.2 Multidimensionale Speicherzellen und Materialized Views ................................ 67 5.3.8.3 Komplexität von Strukturen und Abfragen .......................................................... 67 5.3.8.3.1 Umgang mit unbalancierten Hierarchien ......................................................... 67 5.3.8.3.2 Komplexe Abfragen mit Zwischenergebnissen................................................ 70 5.3.8.4 Gegenüberstellung multidimensionaler und relationaler Datenhaltung .............. 70 5.3.8.5 Regeln im Umgang mit multidimensionaler und relationaler Datenhaltung ........ 71 5.3.8.6 Entscheidung leicht gemacht – Schneller Wechsel zwischen den Systemen .... 72 5.4 Umgang mit Partitions ............................................................................................... 73 5.4.1 Empfehlungen im Umgang mit Partitionen ............................................................. 74 6 Organisation und Aufbau von Ladeläufen und Transformationen ............................. 75 6.1 Spezielle Ladeverfahren für einzelne Warehouse – Bereiche .................................. 75 6.1.1 Informationsbeschaffungsprozess in der Übersicht ............................................... 75 6.1.2 Entgegennehmen der Daten .................................................................................. 75 6.1.2.1 Prüfen und Konsolidieren: ................................................................................... 76 6.1.2.2 Prüfen und Protokollieren .................................................................................... 76 6.1.2.3 Kennzeichnung von Daten .................................................................................. 78 6.1.2.4 Deltadatenerkennung .......................................................................................... 79 6.1.3 Normalisieren – der Weg in die Warehouse Schicht .............................................. 80 6.1.4 Denormalisieren – Aufbereiten für die Endbenutzer .............................................. 80 6.1.5 Laden von Faktentabellen ...................................................................................... 80 6.1.6 Laden von Dimensionstabellen .............................................................................. 81 6.1.7 Das Laden von künstliche Schlüsseln – Das Umschlüsseln .................................. 83 6.1.8 Optimistisches und Pessimistisches Laden von Dimensionsdaten in Abhängigkeit von Faktdaten 84 6.2 Management des Ladeprozesses (Workflow) ........................................................... 86 6.2.1 Aufgaben des Ladeprozesses ................................................................................ 86 6.2.2 Struktur des Ladeprozesses ................................................................................... 86 6.2.3 Interaktion mit anderen Systemen und Automatisierung ....................................... 87 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 5/166 7 Mehrfachverwendung von Bereichen und Objekten ................................................. 89 7.1 Verteilte (Mehrfach-) Verwendung von Data Mart Strukturen ................................... 91 7.2 Verwaltung gemeinsam genutzter Tabellen .............................................................. 92 7.2.1 Nutzerübergreifende, organisatorische Abstimmungen ......................................... 93 8 Metadaten 95 8.1 Metadaten im Warehouse - Umfeld ........................................................................... 95 8.1.1 Beispiele für Einsatzfelder der Metadaten ............................................................. 96 8.1.1.1 Warehouse Handbuch ........................................................................................ 96 8.1.1.2 Glossare und Definitionen ................................................................................... 97 8.1.1.3 Betriebshandbuch ............................................................................................... 97 8.1.1.4 Berichtsverifizierung / Legenden ......................................................................... 97 8.1.1.5 Aktualitätsscheck ................................................................................................ 97 8.1.2 Einmaliges, zusammenhängendes Speichern von Metadaten .............................. 98 8.1.3 Design – Time Metadaten ...................................................................................... 99 8.1.4 Runtime – Metadaten ............................................................................................. 99 8.1.5 Neutralität der Modelle gegenüber der physischen Implementierung .................... 99 8.2 Erweiterbarkeit des Metadaten - Repositories......................................................... 100 8.3 Automatisiertes Pflegen der Metadaten .................................................................. 100 8.3.1 Zusätzliche Verwaltungsinformationen................................................................. 101 9 Operativ genutzte Warehouse – Daten ................................................................... 102 9.1 Szenarien und Problembereiche bei operativ genutzten Warehouses ................... 102 9.1.1 Einsatzszenarien operativ genutzter Warehouses ............................................... 103 9.2 Operational Data Store Konzept .............................................................................. 104 9.3 Verfahren für aktivere Rollen des Warehouses (Realtime / Loop Back) ................. 106 9.3.1 Der Datenfluss im Real Time / Loopback Warehouse ......................................... 107 9.3.2 Organisatorisch – technische Anforderungen ...................................................... 108 9.3.3 Hochverfügbarkeit von Near Realtime - Systemen .............................................. 109 9.3.4 Event gesteuertes Warehouse ............................................................................. 109 9.3.4.1 Simulation von Event – gesteuerten Arbeitsphasen ......................................... 110 9.3.4.2 Testdaten .......................................................................................................... 110 9.3.5 Durch einheitliche Metadaten die Kontrolle bewahren ......................................... 110 9.3.6 Datenschutz und nicht Zugriffsschutz .................................................................. 110 9.3.7 Messagebasiertes Laden versus Batchbetrieb in der Datenbank ........................ 111 9.3.8 Entkopplung von ETL und Berichtserstellung ..................................................... 112 9.3.9 Vergleichbarkeit der Berichte (Aktualität) ............................................................. 113 9.3.10 Zusammenfassende allgemeine Empfehlungen .................................................. 114 10 Wo wird historisiert .................................................................................................. 115 10.1.1 Historisierungsverfahren ...................................................................................... 116 10.1.2 Historisierung in der Warehouse - Schicht ........................................................... 117 10.1.3 Abschließendes Konzept zur Historisierung ........................................................ 118 11 Minimieren von Hardware – Aufwenden.................................................................. 119 11.1 RAC sinnvolle Voraussetzung für neue Architekturen im Data Warehouse .......... 119 11.2 Kostenvorteile durch Verbund kleinerer Systeme ................................................... 119 11.3 Integration von Daten und Funktionsbereichen ....................................................... 120 11.4 Integration von Datenhaltungs- und Datenbewegungsaufgaben (Funktionale Integration) 121 11.5 Kostenminimierung durch zentralisiertes Analysieren ............................................. 122 11.6 Einsparen von Hardware für separate Auswertelösungen ...................................... 124 11.7 Gemeinsame Ressourcennutzung .......................................................................... 124 12 Verfahren für das Backup und Recovery (B+R) im Data Warehouse ..................... 127 12.1 Backup und Recovery im Data Warehouse............................................................. 127 12.2 Was wird alles gesichert? ........................................................................................ 128 12.3 Logging / Nologging ................................................................................................. 128 12.3.1 Nach dem Laden sichern – Kein Rollback nach Nolog - Aktionen ....................... 128 12.3.2 RMAN spart viel Arbeit ......................................................................................... 129 12.3.3 Read Only Tablespaces ....................................................................................... 130 12.3.4 Read Only Tablespaces und Partitioning ............................................................. 130 12.4 Beispiele für B+R Szenarien mit ETL Mitteln oder RMAN (NOLOGGING) ............. 131 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 6/166 12.4.1 Recovery – Strategie mit ETL – Mitteln: ............................................................... 131 12.4.2 Recovery – Strategie mit RMAN: ......................................................................... 131 13 Zusammenfassung .................................................................................................. 132 14 Anhang 134 14.1 Elf vermeidbare Fehler und Tipps für erfolgreiche Data Warehäuser .................. 134 14.2 Gründe für die Einführung eines Data Warehouses ................................................ 135 14.2.1 Nutzenpotentiale im Data Warehouse.................................................................. 135 14.3 Checkliste zur Optimierung der Warehouse Systeme ............................................. 136 14.3.1.1 Platten 136 14.3.1.2 Partitions ........................................................................................................... 136 14.3.1.3 Materialized Views ............................................................................................ 137 14.3.1.3.1 Allgemeine Hinweise...................................................................................... 137 14.3.1.3.2 Prüfungen auf Zustände ................................................................................ 137 14.3.1.3.3 Systemparameter ........................................................................................... 137 14.3.1.3.4 Rewrite Methoden .......................................................................................... 138 14.3.2 Hilfsmittel Datenbankoptimierung ......................................................................... 139 14.4 Glossar 142 14.5 Abbildungsverzeichnis ............................................................................................. 158 14.6 Index 162 14.7 Kommentare und Ergänzungen: .............................................................................. 166 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 7/166 1 “Viele Wege führen nach Rom”... Aber es gibt meistens einen kürzeren und bequemeren Weg. 1.1 Zu dieser Referenzarchitektur Diese Referenzarchitektur ist aus zwei Gründen erstellt worden: Der erste Grund: Ideen weiter geben: Oft investieren Projektteams sehr viel Zeit in das technische und methodische Konzept eines neuen Systems, obwohl die Methoden und Wege längst in bereits durchgeführten Projekten erkundet sind. Dabei gibt es kaum eine Technologie, die so einfach durch Regeln zu standardisieren ist, wie die Data Warehouse Technologie. Das macht sich diese Referenz – Architektur zu Nutzen. Sie setzt auf die Übertragbarkeit von Verfahren bei ähnlichen Anforderungen. Dies gelingt vor allem deswegen, weil der technische Rahmen durch die Oracle Datenbank vorgegeben ist. Der zweite Grund: endlich nutzen was man schon hat, die Datenbank! : Mittlerweile existiert bereits das Release 10g von der Oracle Datenbank. Das ist das 3. Release in Folge, in dem massiv Features in die Datenbank integriert wurden, die hauptsächlich für das Data Warehouse interessant sind. Die Oracle Datenbank ist damit längst die Datenbank mit dem höchsten Komfort bei der Lösung von Warehouse – spezifischen Anforderungen. Aber viele Oracle – basierte Warehouse – Systeme arbeiten heute noch so, wie zu Zeiten einer Oracle 7 oder 8 Datenbank. Die Referenzarchitektur soll dazu anregen, die Oracle Datenbank als echte Warehouse Plattform einzusetzen. Zum Umdenken anregen Es ist allerdings nicht nur der Einsatz von Materialized Views oder der Einsatz des Partitioning, um das volle Potential des jüngsten Datenbank – Releases auszunutzen. Es ist das Ausnutzen dieser Features um aktuelle Anforderungen in den heutigen Warehouse Prozessen zu lösen. Mit den neuen technischen Möglichkeiten im Hintergrund sollten alte Warehouse – Architektur – Konzepte hinterfragt werden. Oft ist das, was als feststehende „Wahrheit“ angenommen wird, nichts anderes als ein Relikt einer Zeit, in der es eben keine besseren Möglichkeiten gab. So finden sich heute noch massenweise Summentabellen die eigens gepflegt und mit Programmen gefüllt werden, anstatt sie endlich durch Materialized Views zu ersetzen. Mit effizienterem SQL können separate Ladeprogramme ersetzt werden. Das spart Tausende Euro und ist zudem noch effizienter. Anstatt Aufgaben intelligent durch bereits bezahlte Datenbankfeatures zu lösen, wird zusätzlich in Hardware investiert was dann auch noch zusätzliche Folgekosten verursacht. Das sind nur wenige Beispiele. Aber diese Beispiele haben es bereits in sich, denn bei genauerem Hinsehen hat der konsequente Einsatz dieser Architekturempfehlungen Auswirkungen auf das gesamte Warehouse – Design. Die Empfehlungen provozieren Fragestellungen und Entscheidungen wie: Wie viele redundante Tabellen erlaubt man? Wie viele Ladeschritte sind wirklich nötig? Wie schnell ist ein Warehouse mit neuen Daten befüllt? An welchen Stellen wird der Aufbau von Berichten vorbereitet? Wie viel Hardware Maschinerie braucht man wenn man das Datenbank – basierte oder das externe ETL anwendet? Oft wird das Thema Architektur auf die Kombination von Warehouse – Tools reduziert. Dabei sind Data Warehouse Architekturen längst mehr als das klassische Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 8/166 Dreigestirn “Datenbank / ETL / Reporting“ zu betrachten. Die Sichtweise auf Tools und isolierte Warehouse - Segmente versperrt den Blick auf die eigentliche Aufgabenstellung der Informationsaufbereitung. Wer heute noch in separaten Kategorien wie ETL, Reporting und Datenhaltung denkt, versperrt sich den Weg für neue Ansätze. Will man die Aufgabe ganzheitlich effizient lösen, so muss man über alle drei Bereiche „quer hinweg“ denken. „Aber bitte keine Features...“ Hier sollte allerdings nicht noch eine Auflistung aller Warehouse – Features von Oracle 7 bis Oracle 10g erfolgen. Dazu gibt es genügend Material, insbesondere den sehr empfehlenswerten Warehouse Guide als Bestandteil der Datenbank Dokumentation. Was allerdings immer wieder nachgefragt wird, ist eine Auflistung von sog. „Best Practices“ für den Aufbau eines Warehouse Systems. Es fehlt an konkreten Empfehlungen, an Wegbeschreibungen, an einer Auflistung von Verfahren und Methoden. Hier geht es um das „Wie wird was gemacht im Warehousing“. An wen wendet sich die Referenzarchitektur: Das Data Warehouse wird hier als fachneutrale Technologie zur Bereitstellung von Informationen verstanden. Diese Technologie ist notwendige Basis für die darauf aufbauende Business Intelligence Anwendungen, die ihrerseits eine fachspezifische Zielrichtung verfolgen. Business Intelligence Anwendungen werden jedoch nur am Rand erwähnt, z. B. wenn es um die Forderung nach einer flexiblen und effizienten Datenbasis geht. So richtet sich diese Referenzarchitektur an denjenigen Mitarbeiter, der unternehmensweit einzusetzende Oracle basierte Data Warehouse Systeme entwerfen und aufbauen. Wie kann man das Dokument nutzen: Wir wollen alle nicht so Text lesen. Am liebsten wollen wir schnell überfliegen und dennoch genau wissen, was gemeint ist. Um das leichter zu machen, sind viele Zwischenüberschriften gewählt und viele Graphiken genutzt worden. D. h. es eignet sich auch zum Nachschlagen. Einzelne Kapitel kann man losgelöst von anderen lesen, auch wenn sich generell der rote Faden des Integrationsgedankens durch die meisten Kapitel zieht und es einige Querverweise gibt. Die Themen: [Abschnitt 2] Zunächst werden aktuelle Anforderungen an Data Warehouse Systeme von heute vorgestellt. Diese haben sich in den Jahren seit der Einführung solcher Systeme vor ca. 15 Jahren gewandelt. [Abschnitt 3] Warehouse – spezifische Besonderheiten in der Projektarbeit folgen. [Abschnitt 4] Die eigentliche Architekturbeschreibung von Warehouse Systemen folgt erst ab Abschnitt 4. Hier werden zunächst grundsätzliche Verfahren vorgestellt. [Abschnitt 5] Der detaillierte Aufbau des Warehouses mit seinen verschiedenen Schichten folgt separat in der Reihenfolge in der Daten durch das Warehouse wandern. [Abschnitt 6] Ist die statische Struktur vorgestellt, wird auf spezielle Ladeverfahren eingegangen. Die Beschreibung der statischen Struktur und die Darstellung von Ladevorgängen kann allerdings nicht immer klar voneinander getrennt werden. [Abschnitt 7ff] Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 9/166 Weitere Spezialthemen wie verteilte Datenhaltung, Umgang mit operativen Daten, Realtime Warehouse, Verfahren zu Backup und Recovery, Einsatz von Hardware runden die Thematik ab. [Abschnitt 13] Ein kleines abschließendes Kapitel fasst die Referenzarchitektur noch einmal zusammen. Am Ende des Dokuments werden Sie aufgefordert ein Resümee zu ziehen und Dinge, die Sie anders sehen mitzuteilen. Vielleicht entsteht ein Dialog, der Sie und uns einen Schritt weiter bringt. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 1.2 10/166 Oracle Data Warehouse Referenz Architektur 1.2.1 Architektur ist Garant für eine effiziente Warehouse Plattform 1.2.1.1 Herausforderungen Data Warehouse Systeme gehören mittlerweile zur Standardausstattung moderner IT – Landschaften. Längst sind die Systeme aus den Nischen einzelner Abteilungen und dedizierter Aufgabenstellungen herausgetreten. Sie stellen heute zentrale Drehscheiben der Daten- und Informationsversorgung für eine Vielzahl anderer Systeme dar. Die Bedeutung des Data Warehouse – Konzeptes ist in den Jahren stark gewachsen. Im Zuge der Optimierung der IT – Systeme muss sich das Data Warehouse aber gleichzeitig einer peniblen Effizienzbetrachtung unterwerfen. Aus diesem Grund ist auch die Betrachtung einer besonders effizienten Architektur wichtig geworden. Mehr noch: Ein besonderes Architektur – Design kann nicht nur Auswirkungen auf die Effizienz des Warehouse – Systems selbst, sondern in jüngster Zeit auch auf die umliegenden Systeme haben. Dieser Aspekt ist umso wichtiger, je mehr das Data Warehouse mit klassischen, operativen Anwendungen zusammen wächst und die Grenzen verwischen. Drei Faktoren treiben die Effizienzbetrachtung moderner Warehouse – Architekturen: 1. Zunehmend heterogene Benutzerstrukturen (Endabnehmer der Informationen) lassen die Anforderungen auseinanderdriften. 2. Zunehmend komplexere Anwendungslandschaften und damit vielfältigere Quellenstrukturen. 3. Zunehmende Verflechtung von Unternehmensprozessen (Partnerunternehmen inbegriffen) führen zu einer Vervielfachung von relevanten Informationen und stärkere Absicherung der Qualität von Informationen über Prozessgrenzen hinweg. 1.2.1.2 Plattformbetrachtung statt Point Solution Data Warehouse Systeme sind mehr als nur einzelne Werkzeuge oder Programme. Ein Warehouse System besteht aus einer Reihe von auf einander abgestimmten Komponenten, die durch ihr Zusammenspiel eine Warehouse Plattform ergeben. Die isolierte Betrachtung einzelner Komponente ignoriert Wechselwirkungen zu anderen Komponenten und ist mit Flexibilitätsverlust zu bezahlen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 11/166 Warehouse – Plattform – mehr als nur eine Sammlung von Komponenten Eine wirkungsvolle Warehouse Plattform hat vor allem die Aufgabe die zunehmend vielschichtigeren Benutzergruppen mit Informationen aus mehr und mehr komplexer werdenden Datenbergen in den Unternehmen zu versorgen. Zur Data Warehouse Plattform gehören: Was gehört alles zu einer Warehouse – Plattform: Analysewerkzeuge zur Unterstützung unterschiedlicher Zielgruppen (Management, Fachmitarbeiter z. B. Controller / Planer, Mitarbeiter aus operativen Frontline – Prozessen). Extraktionsmittel zum Sammeln von Daten aus immer komplexer werdenden Systemlandschaften (Räume, Systeme, Anwendungen..). Warehouse – Architektur – Konzept (Schichtenmodell). Warehouse – Management (Steuerung, Verwaltung, Workflow - Prozesse). Infrastruktur zum Integrieren von Warehouse – Funktionen in die allgemeine Systemlandschaft. Auswertemodelle mit Branchenfokus zur Unterstützung von Auswertethemengebieten. Business Intelligence Anwendungen (z. B. Balanced Scorecard, Lösung für Finance Controlling...). Technische und fachliche Metadaten. An zentraler Stelle liefert die Warehouse Architektur entscheidende Voraussetzungen für alle anderen Komponenten. Ohne eine sinnvolle Warehouse Architektur kann z. B. eine Business Intelligence Anwendung ihre volle Leistungsfähigkeit nicht ausreichend entfalten, weil nicht schnell genug die richtigen Daten bereit stehen. Die hier vorliegende Referenz - Data Warehouse Architektur erfüllt diesen Anspruch. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 12/166 Data Warehouse – Architektur – Rückgrat einer effizienten Data Warehouse Lösung Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 13/166 1.2.2 Bestandteile und Gegenstand der Referenzarchitektur In der Referenzarchitektur zu dem Oracle Data Warehouse sind enthalten: Verfahrensempfehlungen und Regeln zu dem Aufbau eines Data Warehouse Systems auf der Basis der Oracle Warehouse – Technologie. Eine Auflistung und Beschreibungen der wesentlichen Komponenten mit ihren Funktionen. Erklärungen über das Zusammenspiel der Komponenten der Oracle Warehouse Plattform. Diese Referenzarchitektur ist kein Ersatz für die Oracle Warehouse – Dokumentation, sondern eine Sammlung von Empfehlungen auf der Basis von Praxiserfahrungen durchgeführter Projekte bzw. aufgrund von Reviews zu bestehenden Warehouse - Systemen. (Hier noch einmal der Hinweis auf die Oracle Dokumentation 10g („Warehouse Guide“.) 1.2.3 Ziel und Zweck der Referenzarchitektur 1. Viele auf einer Oracle Datenbank basierende Warehouse – Systeme, nutzen nur einen Teil der in der Oracle Warehouse Plattform zur Verfügung stehenden Funktionalität. Funktionalität wird oft zu gekauft, obwohl sie bereits in der Oracle Plattform vorhanden ist. In manchen Fällen erzwingt diese zusätzliche Funktionalität sogar eine Architektur, die das optimale Ausnutzen der Oracle Warehouse – Plattform verhindert. Obwohl zusätzliche finanzielle Mittel aufgewendet wurden, um diese Funktionalität zu erwerben, ergeben sich in der Summe durch den Mix der Funktionalitäten Nachteile. Diese Referenzarchitektur soll helfen, solche Architektur – Anomalien aufzudecken. Ziel ist das o möglichst effiziente Nutzen aktueller Oracle Warehouse – Funktionen und o damit verbunden das Minimieren von Ressourcen – und Kostenaufwand und o das Erreichen einer auf echte Anforderungen abgestimmten und durchdachten Architektur. 2. Ein weiteres wichtiges Ziel ist die Verringerung von Projektaufwand. Die Architekturbestandteile von Data Warehouse – Projekten muss das Projektteam nicht immer wieder neu erfinden. Architekturen sind immer wiederkehrend gleich und sollten als Standards abrufbar sein. Das Projektteam kann sich auf fachspezifische Anforderungen konzentrieren. 3. Die hier vorgestellte Architektur zielt auf einen unternehmensweiten Einsatz der Warehouse – Technologie ab. Ziel ist daher auch die Harmonisierung von unternehmens – und fachgruppenspezifischen Interessen. In vielen Unternehmen entstand in den vergangenen Jahren ein Wildwuchs sog. Data Marts. Die Folge sind wuchernde Kosten und nicht stimmige Auswerteergebnisse. Die hier vorliegende Architektur entwickelt einen Vorschlag zur Lösung dieses Konfliktes. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 14/166 2 Aktuelle Anforderungen an Data Warehouse Systeme Auch wenn sich das Data Warehouse in vielen Unternehmen als Standardverfahren etabliert hat, unterliegt es einem ständigen, technologischen Wandel. Verständlich, denn die Anforderungen in den Unternehmen ändern sich unter dem regelmäßigen Einfluss der wirtschaftlichen Rahmenbedingungen und Strategien. 1. CRM – Systeme und neue Kunden-Services oder genau ausbalancierte Beschaffungsprozesse benötigen vermehrt Daten, wie sie nur in Warehouse Systemen zu finden sind. Es sind z. B. strategisch verstandene Referenzdaten, die sich nicht mehr einem konkreten Kunden oder Lieferanten zuordnen lassen, aber taktisches Handeln und Tun dennoch bestimmen. Waren Data Warehouse Systeme in der Vergangenheit nur Konsumenten von Daten aus operativen Unternehmensanwendungen, so übernehmen sie heute oft eine neue Rolle als Informationslieferant für die operativen Systeme. Sie sind selbst Glieder von Prozessketten geworden (Operationalisierung des Warehouses). 2. Ein zweiter Trend ist die „Entprivatisierung“ der Data Marts. Entstanden in der Vergangenheit kleine, isolierte Business Intelligence Systeme mit einem fest umrissenen Aufgabenbereich, so versuchen Unternehmen heute diese „BI – Inseln“ aufgrund von Kostenkonsolidierung und Standardisierungsbemühungen in den Rahmen einer einheitlichen Warehouse – Strategie einzubetten. Abteilungsübergreifende Synergieeffekte sind erwünscht. Das Wissen einer Abteilung ist nicht länger Privatbesitz, es soll auch anderen Abteilungen zur Verfügung stehen. Warehouse Systeme werden in ein breit angelegtes Knowledge Management Konzept eingebettet. Damit ist das Data Warehouse als Teil eines umfangreicheren Informationshaushalts zu planen. Es wird wichtig zu überlegen, an welchen Stellen im Unternehmen Informationen entstehen und wie sie bereit zu stellen sind. Informationsflüsse sind vielfältiger. Es reicht nicht mehr, einem Controller am Monatsende eine Tabelle mit aktuellen Wertepositionen zu geben. Der Controller ist nicht mehr allein im Warehouse und seine Daten nicht mehr allein seine Daten. Die Folgen sind: Breitere Nutzergruppen, vermehrt Fachanwender der operativen Geschäftsprozesse (taktische Ebene) und damit vermehrt Einzelabfragen auf Warehouse – Daten. Vermehrt Detaildaten in dem Warehouse (Detaillierung auf dem Level der operativen Transaktionen). Steigende Bedeutung von Data Warehouse Systemen und damit Wachsen der Ansprüche und an die Sichtbarkeit, Verfügbarkeit und Qualitätssicherung. Stärkere Vernetzung der Warehouse Systeme mit anderen Anwendungen und damit wachsende Bedeutung von Integrations – und Infrastrukturtechnik. Stärkere Automatisierung des Vorgangs der Informationsbeschaffung und – aufbereitung (Integration in operative Prozesse). Kürzere Berichtszeiten („Latency“). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 2.1 15/166 Operationalisierung des Data Warehouse Ein Trend sollte besonders betont werden: Die Operationalisierung des Warehouses. Damit ist die wachsende Bedeutung der Warehouse Systeme für die operativen Systeme selbst gemeint. Die Warehouse Systeme sind in der Vergangenheit bewusst als Gegenpunkt zu den operativen Systemen erstellt worden. Die Datenhaltung wurde separat gewählt, weil die operativen Anwendungen bereits unter voller Auslastung litten. Die Daten wurde aggregiert, weil man in den Detaildaten keine Proportionen erkennen konnte. Die flüchtigen operativen Transaktionen wurden fast photographisch durch die dauerhafte Speicherung im Warehouse dokumentiert, um Trends zu erkennen. Daten wurden einheitlich gesammelt, um ein vollständiges Bild der Unternehmensentwicklung zu behalten usw. Die gegenwärtig erkennbare Operationalisierung des Warehouses ist nicht die Umkehrung dieser Entwicklung, sondern sie ist eine Anerkennung der besonderen Verfahren und Möglichkeiten, die die Warehouse – Technologie erfolgreich entwickelt hat. Man hat erkannt, dass zentrale, einmalige, konsolidierte und historisierte Datenbestände auch für operativ – taktische Zwecke hilfreich sein können. Waren in der Vergangenheit Business Intelligence und Warehouse – Systeme oft nur ein besonders aufwendiger Ersatz für Standard – Unternehmensreporting, mit periodisch gelieferten aggregierten Berichten für das Management und einem in sich geschlossenen stimmigen Zahlenwerk für das Controlling, so sind die Aufgabenstellungen heute wesentlich vielfältiger. Die ist letztlich eine Folge der Umstrukturierung der Unternehmen selbst. Die seit den 90er Jahren immer noch andauernden Process Reengineering - Maßnahmen haben einerseits zu einer Verschlankung der Unternehmenshierarchien geführt. Andererseits aber sorgten sie für mehr Komplexität und führten zu mehr Abhängigkeiten bei den Basisprozessen auf der taktischen Unternehmensebene. Ziel war und ist die einzelnen Prozessschritte stromlinienförmig möglichst ohne Reibungsverluste aneinander zu koppeln. Hinzu kommt eine stärkere Vernetzung der eigenen Geschäftsprozesse mit denen von Partnern. Plötzlich sind Schnittstellenabstimmungen zwischen den Teilprozessen wichtig. Der Informationsaustausch von Teilprozess zu Teilprozess muss stimmen. Die Leistungen innerhalb der Teilprozesse müssen genauer bewertet werden können. Die Planung von Prozess zu Prozess muss ermöglicht werden. Das mag abstrakt klingen, ist aber längst Realität und Beispiele gibt es genügend: Ein Produktionsunternehmen misst die Fehlerquote von Maschinen und leitet den rechtzeitigen Austausch von Bauteilen ein, wenn Schwellwerte überschritten sind. Die Schwellwerte liefert das Warehouse aufgrund historisierter Informationen. Produktionsausfall wird verhindert. Ein Speditionsunternehmen misst die Leistung von Subunternehmern, die Teiltransporte ausführen und erhält gleichzeitig Informationen darüber wann, welche Güter an welchem Ort sind. Eine Information, die den Service für Kunden erhöht. Eine Direktbank misst die Profitabilität von Kunden und entwickelt gezielte Angebote für profitable Kundensegmente. Ein Großhändler hat eine Vertriebskette von Lieferanten über Subhändler bis zu Kunden aufgebaut und braucht Informationen über Durchlaufzeiten von Waren und Leistungsdaten der Subunternehmer. U. a. Hier kommt das Warehouse in Spiel in dem es die neuen Informationsbedürfnisse besser bedienen kann als die operativen Systeme. Warehouse Systeme haben bewiesen, dass sie besondere Fähigkeiten für das Informationsmanagement besitzen, sie können Informationen prüfen, konsolidieren, verdichten. Sie machen Informationen vergleichbar. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 16/166 Sie messen, kontrollieren die einzelnen Schritte. Wichtig ist zeitnahes Messen, denn nur zeitnahes Messen führt zu schneller Einflussnahme und Steuerung. Dies sind Kernanforderungen von Methoden wie BAM (Business Activity Monitoring) oder CPM (Corporate Performance Management). Unternehmensprozesse werden nicht mehr nur Top Down sondern auch horizontal auf der unteren ebene gemessen Die Operationalisierung des Warehouses hat natürlich zwangsläufig Auswirkungen auf die Warehouse Architektur: Wird prozessübergreifendes Monitoring gebraucht, ist die Entscheidung für ein abteilungsübergreifendes, unternehmensweites Warehouse vorgegeben. Wird ein zeitnahes Monitoring gebraucht, entfallen zeitraubende Batchläufe. Sollen lediglich aktuelle Entwicklungen bzw. Zustände gemessen werden, so braucht man nur überschaubare Datenmengen in der Auswertedatenbank und keine riesigen Auswertedatenbestände usw. Auch Abfragezeiten müssen kürzer sein, als bei klassischen Warehouse – Systemen. Daten müssen schneller in das Warehouse fließen. Aufwendige Engine – Komponenten zum Laden von Daten sind hinderlich. Das klassische ETL (Extraction, Transition, Load) wächst mit der jüngeren Disziplin des EAI (Enterprise, Application, Integration) zusammen. Multidimensionale und relationale Analysen müssen Hand in Hand gehen. 2.2 Serverbasiertes, zentrales Data Warehouse Oracle begegnet diesen neuen Anforderungen durch einen serverbasierte, zentralisierten Lösungsweg. Serverbasiert bedeutet hier nicht die Bereitstellung eines zentralen Servers mit einer Datenbank. Die Warehouse – typischen Funktionen wie Integrieren, Konsolidieren, Zusammenfassen, Analysieren usw. werden zentral an einer Stelle konzentriert und als „Warehouse Services“ angeboten. Dieser Aspekt der Integration von Funktionen kommt den oben beschriebenen Trends entgegen. Mit zentrierten Services kann schneller kontrolliert werden. Diesem Konzept folgen die Einbettung von ETL -, Data Mining und MOLAP – Funktionen in dem Datenbank – Kern. Es entsteht die notwendige Nähe von Warehouse – Funktionen und Daten in der Datenbank. Datenbank - basierte Warehouse Services sind: Datentransportdienste (SQL/ETL) Datenmanagement (Datenhaltungsfunktion der Datenbank) Transformationen (Funktionen) Prüfungen ( Checks, Rules) Analysen (SQL – basierte analytische Funktionen) Multidimensionale Analysen (MOLAP) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 2.3 17/166 Data Mining Funktionen Abdecken auseinanderdriftender Benutzeranforderungen Die Informationen des Data Warehouses beliefern unterschiedliche Auswerteszenarien, beginnend bei mehr operativ angelegten Einzelabfragen mit granularen Daten, bis hin zu hochverdichteten Kennzahlen, die strategische Unternehmensentscheidungen steuern. Die Data Warehouse – Architektur, darf jedoch nicht von einzelnen Zielgruppen abhängen. Die Architektur ist so zu wählen, dass alle Arten der Informationsverwendung Unterstützung finden. Auf der einen Seite nur verdichtete Daten zu liefern, verhindert auf der anderen Seite die immer wichtiger werdende operative Verwendung. Nur fertig präparierte Tabellen für Standardberichte bereit zu halten, würde die freie Navigation derjenigen Benutzer behindern, für das ein neutrales, flexibles Datenmodell praktischer wäre, usw. . Das System muss strategische Entscheidungen des Managements durch aggregierte Kennzahlen ebenso unterstützen, wie taktische Entscheidungen der operativen Unternehmensebene durch mehr granulare Daten. Hauptziel ist zwar das Liefern von Informationen für konkrete Endbenutzer, es muss allerdings ein Datenmodell gefunden werden, das den konkreten Endbenutzer optimal bedient und gleichzeitig die Informationsbelieferung anderer Benutzer gewährleistet. Bandbreite der Verwendung der Warehouse – Informationen Folgende Datenstrukturen werden bzgl. der unterschiedlichen Auswertemethoden gebraucht: Data Mining: auf wenige Tabellen integrierte und schematisierte Daten, die maschinelles Auswerten ermöglichen. Simulation / Planung: hoch aggregierte Daten (Operationen mit Summen). Interaktive / individuelle Auswertungen: granulare Daten mit der Möglichkeit schnell und einfach zu verdichten, komplexe Datenzusammenhänge sind durch wenige, für Endbenutzer überschaubare Tabellen zusammenzufassen. Feststehende, vordefinierte Berichte: vorermittelte Ergebnisse. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 18/166 Zwischen diesen Welten gibt es fließende Übergänge, entweder / oder ist nicht möglich sondern sowohl als auch. Die weiter unten vorgestellten multidimensionalen Strukturen mit granularen Daten helfen bei diesen Anforderungen. 2.4 Prozess - Unabhängigkeit des Data Warehouses Eine wichtige Forderung an Warehouse – Systeme ist deren Unabhängigkeit von den operativen Prozessen selbst. Einige operative Systeme (u. a. ERP) liefern ihre eigene Auswerte- und Analysetechnologie mit. Das mag auf den ersten Blick wegen der zu erwartenden engen Integration praktisch sein. Doch es kann eine Art „Prozessblindheit“ eintreten, wobei der Betrachter wichtige Trends aufgrund von Voreingenommenheit nicht mehr erkennt. Dies ist nur eine Erkenntnis aus der „wilden Data Mart Euphorie“ aus den ersten Jahren der Data Warehouse – Entwicklung. In den Unternehmen entstanden an mehreren Orten (in mehreren Abteilungen) unabhängig von einander Data Mart Inseln, die dann genau so schnell wieder verschwanden als entweder der Geschäftsbereich, den die Abteilung betreute, aufgelöst oder ein neues Auswertetool angeschafft wurde. Das in dem Data Mart gespeicherte Wissen ging verloren. Ein Data Warehouse unterstützt Unternehmensprozesse, indem es Informationen zur Steuerung der Prozesse auf mehreren Ebenen bereitstellt. Da Unternehmensprozesse ständigen Änderungen unterliegen, muss in dem Data Warehouse auf solche Änderungen reagiert werden. Sind Warehouse – Strukturen vollständig von operativen Prozessen abhängig, fehlt in dem Data Warehouse die nötige Kontinuität, um längere Unternehmensentwicklungen dokumentieren zu können. Über das Data Warehouse können verschiedene Unternehmensprozesse synchronisiert werden (z. B. Abstimmung von Absatzentwicklung, Warenbeschaffung und Kampagnenplanung). Treten Änderungen einzelner operativer Prozesse auf, darf dies die Data Warehouse - Unterstützung anderer Prozesse nicht beeinträchtigen. Prozessunabhängigkeit von Warehouse Strukturen Auch die Anzahl der operativen Prozesse darf die Strukturen des Data Warehouse nicht beeinflussen. Eine Warehouse – Architektur muss eine Telefongesellschaft mit wenigen Prozessen genauso unterstützen können, wie ein Luftfahrtunternehmen mit sehr heterogenen und vielen Prozessen. Letztlich ist die Anzahl der Informationseinheiten (Entities) in dem Data Warehouse entscheidend. Viele Prozesse brauchen mehr Informationen, wenige eben weniger Entities usw. Die Struktur selbst muss stabil bleiben, allenfalls erweitert werden. Auswertungen, auf die sich bestimmte Benutzergruppen verlassen, dürfen durch das Einbinden neuer Prozesse nicht beeinflusst werden. Katastrophal wäre es eine Abteilung ihre gewohnten Informationen nicht mehr in der gleichen Qualität erhält, nur weil eine andere Abteilung zusätzliche Informationen aus dem System beziehen will. Ärgerlich wäre es, wenn neue Datenmodelle erstellt werden müssten, nur weil neue Sharts durch ein neue Endanwendertool gebraucht werden. Das noch zu beschreibende Mehrschichtenmodell erfüllt diese Anforderung. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 2.5 19/166 Auf Dauer gebaut auf Langlebigkeit des Warehouses achten Das Management von Informationen in einem Data Warehouse muss berücksichtigen, dass Informationen für einen noch nicht bekannten Zweck vorzuhalten sind. Warehouse Systeme sollten für einen langlebigen Betrieb aufgebaut sein und deren Die Informationen über lange Zeiträume hinweg Nutzen bringen. Hierfür sprechen 2 Gründe: 1. Einzelne Anwendungen haben oft eine kürzere Lebensdauer, z. T. unter 5 Jahre. Die Prozesse über die ein Unternehmen seinen Gewinn generiert, sind langlebiger. Die den Prozessen zugeordneten Geschäftsobjekte haben z. T. eine noch längere Lebensdauer, einige reichen bis an die Lebensdauer des Unternehmens selbst heran (z. B. die Geschäftsobjekte in der Kundenbeziehung eines Handelsunternehmens). In Warehouse Systemen ist das Wissen rund um die Geschäftsobjekte gespeichert. Die Datenmodelle des Data Warehouses sind also mindestens so stabil zu entwerfen, dass sie die Lebensdauer der Geschäftsobjekte erreichen. Das kann 10 Jahre und länger sein. Die Architektur eines Warehouse – Systems nur an konkreten Software – Systemen auszurichten wäre kurzsichtig). 2. In Warehouse – Systemen sind historische Sichten gespeichert. Trends über Jahresgrenzen hinweg müssen analysiert werden. Schon deswegen sollte das System für mehrere Jahre ausgelegt sein. Ein Verfahren das dieses Ziel unterstützt ist das Granularisieren von Informationen. D. h. das Isolieren von einzelnen Informationsbausteinen. Werden Informationen zusammenhängend oder von einander abhängig gespeichert, so sind in den Daten bereits Prozessabhängigkeiten versteckt. Werden Prozesse geändert, so steht die Information nicht mehr vollständig für neue Prozesse zur Verfügung. Beispiel: Die Information „GESCHÄFTSKUNDE“ ist bereits zusammengesetzt. Diese Information lässt sich granularisieren in „KUNDE“ und „GESCHÄFTSART“ (mit der Ausprägung „Geschäft“ und „Privat“). Wird man sich irgendwann entscheiden, neben den Geschäftskunden auch noch Privatkunden zu bedienen, so passt das Warehouse – Datenmodell auch dafür. Dies sind mit die Hauptgründe für die Erstellung einer eigenen Warehouse – Schicht, die in der Regel aus normalisierten Datenmodellen besteht. [Warehouse – Schichten werden separat behandelt.] Hier erkannt man, wie schwerwiegend die vorschnelle Auswahl von Data Warehouse – Werkzeugen ist. Es werden Fragen wichtig wie: Wie proprietär ist meine Datenhaltung? Wie viel Wissen wird in proprietären Transformationsprogrammen gekapselt? Wie viel verborgenes Wissen steckt in dem Aufbau des Warehouse Systems? Reicht es bei der Wahl von Frontend – Werkzeugen aus, nur auf die Optik zu schauen und dabei zu vernachlässigen, dass man sich eine gekapselte Datenhaltung anschafft, in der dann das strategische Wissen des Unternehmens über 10 oder 15 Jahre hinweg vorgehalten werden muss? Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 2.6 20/166 Technologische Anforderungen Daraus ergeben sich eine Reihe von technologischen Rahmenanforderungen. Heutige Warehouse Systeme brauchen eine stärkere Nähe zu operativen Vorsystemen. Sie sind Schnittstellen – Systeme. Sie sammeln Informationen, bereiten sie auf und verteilen diese wieder, z. T. an dieselben Vorsysteme zurück. Daten müssen schneller und leichter über ein Warehouse System bereitstehen und auch wieder an die operativen System zurückfließen (Rückkopplung, Loop back). Bezüglich der verschiedenen Benutzerschichten ist eine noch stärkere Flexibilität gefordert. Flexibilität meint hier den Grad der Wandlung von Daten zu Informationen für sehr stark auseinanderdriftenden Informationsbedürfnisse. Architektonische Leitlinien sind daher: Kurze Wege zwischen operativer und dispositiver Datenhaltung. Kompakte und integrierte Architekturen. Möglichst einheitliche Technologie mit wenig Brüchen. Modellflexibilität in den Endbenutzerschichten des Warehouses (relationale, multidimensionale, flache Modellstrukturen) Anwendungsneutralität (Warehouse als selbständige Komponente, die das Austauschen von Anwendungen übersteht). Technik – Neutralität /Zeit - Stabilität (Verwenden von zeitüberdauernden Standards). Das Konzept des datenbankbasierten Ladens von Daten mit Hilfe von Standard SQL realisiert diese Anforderung. 2.7 Bereitstellen von Informationen für Benutzer Effektive Data Warehouse – Architekturen tragen eine Hauptverantwortung für die sinnvolle Bereitstellung von Informationen für Entbenutzer. Je mehr diese Anforderung bei dem Design der Endbenutzerschichten berücksichtigt wird, um so weniger müssen sich Analysewerkzeuge um die Konfiguration von Daten bemühen. Es sind 2 Strukturarten bei der Informationsbereitstellung zu berücksichtigen: 1. Flexible Auswertemodell 2. Feste Kennzahlen 2.7.1 Flexible Auswertemodelle Das System stellt dem Benutzer wesentlich mehr Informationen zur Verfügung, als er zu dem Zeitpunkt einer konkreten Analyse benötigt. Allerdings darf das System den Benutzer nicht mit einer Vielzahl von einzelnen Informationsobjekten überschütten, so dass dieser die Orientierung verliert. Benötigt wird eine kompakte und damit übersichtliche Struktur, die durch eine geschickte Kombinationsmöglichkeit einzelner Bestandteile neue Informationen entstehen lässt. Multidimensionale Datenmodelle sind für diese Anforderungen konzipiert. Hier werden strukturierte Sichten auf Geschäftsobjekte angeboten (Dimensionen). Die Struktur einer solchen Dimension erlaubt z. B. Gliederungshierarchien. Jede Gliederungshierarchie einer Dimension ist mit Gliederungshierarchien anderer Dimensionen verknüpfbar. Die Kombinationsmöglichkeiten potenzieren sich, je mehr Dimensionen hinzukommen. Mehrere Tausend Abfrageoptionen sind für Endbenutzer möglich, obwohl es sich um ein überschaubares Datenmodell handelt. Das Starschema ist z. B. ein solches Datenmodell. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 21/166 Multidimensionales Modell Eine Vielzahl von Fragen lässt sich durch das in der Graphik dargestellte Datenmodell beantworten: Umsatz nach Monat/Land/Sparte Umsatz nach Jahr/Werk In welchem Land laufen welche Artikel am besten Usw. Die Flexibilität des Modells entsteht durch zwei Eigenschaften: 1. Die Konzentration der Merkmale von Geschäftsobjekten (Region, Produktionsstandort, Produkte) in kompakter Form an einer Stelle (Dimensionen). 2. Die wahlfreie geschäftsobjektübergreifende Kombinationsmöglichkeit dieser Merkmale untereinander. Kombinationsmöglichkeiten im multidimensionalen Modell Ein Modell mit 4 Dimensionen und jeweils 3 Merkmalen, lässt bei einem Faktwert bereits über 80 unterschiedliche Abfragen zu. Bei 4 Merkmalen pro Dimension sind es schon 256 Merkmale usw. Anzahl Dimensionen 4 4 4 Merkmale Dimension 3 4 5 pro Copyright © 2005 by Oracle Corporation. All rights reserved Anzahl Abfrageoptionen 81 256 625 Data Warehouse Referenzarchitektur 4 --- 22/166 6 --- 1296 --- Wie viele Abfrageoptionen wird ein Modell liefern mit 10 Dimensionen und jeweils 20 Merkmalen liefern? (Rechnen Sie es nicht aus, die Anzeige im Taschenrechner reicht nicht.) Natürlich sind viele potentiell möglichen Abfragen nicht sinnvoll. Aber sie könnten unter geänderten Voraussetzungen in der Zukunft sinnvoll werden. 2.7.2 Feste Kennzahlen Die zweite Abfragestruktur sind fertig vorbereitete Kennzahlen deren Inhalte der Benutzer lediglich abrufen muss. Eine Liste von fixen Werten (Kennzahlen) steht bereit. Die Kennzahlen sind zu dokumentieren. Semantik und Herkunft (Ableitung) sind als Metadaten bereitzuhalten (Endbenutzerorientierung). Liste von festen Kennzahlen Metadaten gesteuert über Browser dargestellt In der Praxis werden diese Kennzahlenlisten die Kernzellen der Standard – Berichte sein. Eine Sache ist es, dass Benutzer über die Existenz der Kennzahlen Bescheid wissen (z. B. durch einen Metadaten – Browser), die andere ist es, wie Benutzer auf diese Kennzahlen zugreifen können. Die wenigsten Benutzer werden mit SQL vorgegebene Zahlenwerke abfragen können. Feste Kennzahlen leiten sich im idealen Fall von den flexiblen Auswertemodellen ab. [Weiter unten wird das Konzept der Materialized Views vorgestellt, das dieses Verfahren ermöglicht.] Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 23/166 3 Projekt und Projektmanagement Warehouse – Architekturen werden mit Hilfe von Projekten realisiert. Daher muss die besondere Machart von Data Warehouse Projekten in die Betrachtung mit einfließen. (Es gibt genügend Projektmanagement- und Softwareentwicklungsmethoden. Dies muss hier nicht wiederholt werden. Hier sollen nur Warehouse – spezifische Aspekte angesprochen werden). 3.1 Inkrementelle Entwicklung Software Entwicklung Es liegt in der Natur des Data Warehouse Systems, dass es nur mit Hilfe eines Software - Entwicklungs- und Bereitstellungsprojektes zur Verfügung gestellt werden kann. Ein Data Warehouse kristallisiert Informationen aus unterschiedlichen Unternehmensbereichen und Prozessen und diese sind unternehmensspezifisch. Jeder Versuch eine sog. Standard – Lösung zu implementieren, mündet in den meisten Fällen zumindest in einem Anpassungsprojekt um den firmenindividuellen Gegebenheiten gerecht zu werden. Warehouse – Systeme sind firmen - individuelle Lösungen. Sie haben die Aufgabe zusammenzufassen, was in den Unternehmen an unterschiedlichsten Stellen über Jahre gewachsen und auseinander gedriftet ist. Und wie sich Unternehmen unterschiedlich entwickeln, so unterschiedlich sieht auch die Systemlandschaft aus. Außer für Teilaufgaben wie Controlling oder Finanzplanung, kann es daher kaum Standard - Pakete geben. Am Markt angebotene Standard – Lösungen tendieren zu einem Inseldasein, wenn sie nicht in eine definierte Architektur eingebettet sind (hier ist nicht nur das Bereitstellen einer Datenschnittstelle gemeint). Hinzu tritt die Forderung nach Flexibilität und Skalierbarkeit die durch Standardlösungen nicht erfüllbar ist. Data Warehouse Projekte unterscheiden sich von klassischen Software Projekten durch ihren sog. inkrementellen Ansatz. Das fertige System muss Informationsbedürfnisse befriedigen, die sich oft schon im Verlauf von Monaten wandeln. Während klassische Softwareprojekte auf eine über lange Zeit stabile Softwarespezifikation bauen können, müssen Warehouse Projekte die Zielanforderung ständig neu bestimmen und aktualisieren. Daher werden die Realisierungsphasen sehr kurz gewählt und ein Anforderungsblock (Inkrement) mit überschaubaren Teillösungen abgearbeitet. Die Teilaufgaben werden gewichtet. Die dringlichsten Aufgaben mit dem höchsten Ergebniswert (ROI), werden zu erst durchgeführt. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 24/166 Innerhalb der Teilprojekte gelten Phasenabschnitte, die mit einem Ergebnis abzuschließen sind: Nr. 1 Phase Informationsbedarfsanalyse 2 Prozessanalyse und Teilprozessauswahl Konzept 3 4 Datenanalyse Datenqualität 5 Realisierung 6 Einführung Wartung Ergebnistypen Mission Statement Dokumentation Informationsbedarf Analysemodell Objektmodell Auswertedatenmodelle (Starschema) Berichtsschema Informationsversorgungsplan Dokumentation Quellenmodelle Mappingmodell Datenflussmodell Warehouse – Tabellen Ladesystem, Berichte Steuerungssystem Benutzerstatement Mittel Fragebogen div. Mittel Fragebogen div. Mittel Warehouse Life Cycle Werkzeug (DM – Tool) Datenmodelle Warehouse Life Cycle Werkzeug Warehouse Life Cycle Werkzeug Ein Warehouse – Projektinkrement realisiert Komponenten vor dem Hintergrund der unten definierten 3 – Schichten Architektur. Da das Gesamtsystem nicht in einem Inkrement entsteht, ist zu Beginn aller Warehouse – Teilprojekte eine kurze Konzeptphase für die Gesamtarchitektur einzuplanen. Zur Realisierung der Projekte ist ein Warehouse Life Cycle Werkzeug einzusetzen, das nach Möglichkeit phasenübergreifend genutzt werden kann. Ein Schwerpunkt des Werkzeuges muss auf der Dokumentation des Systems liegen. Ideal ist es, wenn Spezifikationen und z. B. Datenmodellbeschreibungen nicht separat unabhängig von den Entwicklungswerkzeugen erstellt werden. Werden Datenmodelle beschrieben, so sollte das in einer Notation geschehen aus der heraus auch physische Definitionen ableitbar sind. Textliche Beschreibungen der Entitäten sollten in Beschreibungen der Zieltabellen überführbar sein usw. 3.2 Modelle sichern das Projekt ab Warehouse – Projekte müssen „nachvollziehbar“ durchgeführt werden. Jederzeit muss Sinn und Erfolg von Projektschritten transparent sein. Dies gelingt nur mittels Modellen, die Projekte steuern und kontrollieren. Mindestens die folgenden Modelle sollten vorhanden sein: Analysemodell o Erfassung und Beschreibung der zu unterstützenden Geschäftsprozesse. Objektmodell o Auflistung der in den Prozessen verknüpften Geschäftsobjekte. o Auflistung der Beziehungen zwischen den Geschäftsobjekten. Mappingmodell o Auflistung von relevanten Quellenstrukturen (Quellmodelle). o Zielmodelle. o Zuordnung zwischen Quell- und Auswertestrukturen. Nutzergruppenplan (Informationsbedarfsplan) o Auflistung aller potentieller Nutzergruppen und den benötigen Informationen. Kennzahlenzugriffskonzept o Auflistung der Art und Weise des Zugriffs zu den einzelnen Informationen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 25/166 [Die Machart der Modelle und ihre Herleitung sind hier nicht ausgeführt. Weitere Informationen bei dem Autor.] 3.3 Parallele Schichtenentwicklung In dem noch zu besprechenden Schichtenmodell des Warehouses (Stage/ Warehouse / Data Mart) liegen Abhängigkeiten vor auf die im Verlauf des Projektes Rücksicht genommen werden muss. Das kann bedeuten, dass man an unterschiedlichen Teilen des Gesamtmodells gleichzeitig entwickeln muss. Die Projekte beginnen in der Regel mit der Erhebung der Informationsbedürfnisse der Endanwender des Warehouse – Systems. Danach leitet sich dann auch die Entwicklung des Datenmodells für die Endanwender ab. Das ist dann meist das Model für die Data Marts. Weiter unten wird jedoch ausgeführt, dass Data Marts nicht isoliert von einander entwickelt werden sollten. Sie sollten im Verbunden mit anderen Data Marts gesehen werden und sie erhalten vorbereitete Informationen aus der Data Warehouse Schicht. Das bedeutet, das z. B. die Entwicklung einer denormalisierten Dimension in einem Data Mart, die Entwicklung einer normalisierten Struktur mit analogem Informationsinhalt in der Data Warehouse Schicht einhergehen sollte. Außerdem wird bei der Entwicklung einer integrierten Architektur immer zu prüfen sein, wie weit neu zu entwickelnde Objekte von existierenden Objekten ableitbar sind. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 26/166 Standardisierte Vorgehensweise Die Oracle Warehouse Architektur stellt eine Sammlung von Verfahren und Regeln dar. Diese ändern sich nicht und sind von Projekt zu Projekt übertragbar. Das reduziert den Projektaufwand enorm. Die technologische Konzeption muss nicht neu erfunden werden, Projektmitarbeiter wenden ein bestehendes Regelwerk an. Architekturen bestehend aus Technologien, Verfahren und Regeln sind standardisierbar und können von Projekt zu Projekt unabhängig von der fachlichen Anforderung wiederverwendet werden. Projekte, die die Oracle Warehouse Architektur anwenden, sind daher besonders kostenschonend. Hauptaugemerk liegt auf der Unterstützung der Unternehmensprozesse, nicht auf der Entwicklung neuer Techniken oder Verfahren, diese sind bereits vorhanden. 3.3.1 Dokumentation Dokumentation ist selbstredend. Aber die beste Dokumentation, ist diejenige, die man nicht mehr erstellen muss. Hier helfen Werkzeuge, die den Entwicklern zum einen eine Modellierungsplattform bieten, zum anderen aber das Modellierte (die Modelle) in ihrem Repository speichern. Eines nehmen sie allerdings oft nicht ab: Strukturierte Vorgehensweisen oder etwa sinnvolle Namensvergaben. Hier sind Entwicklerteams gefordert, sich im Zuge ihrer Projektorganisation z. B. auf Namenskonventionen zu einigen. 3.3.2 Namenskonventionen Aus der klassischen Datenadministration kennen wir die Verwendung von Namenskonventionen für die unterschiedlichen Objekttypen innerhalb der Warehouse – Modelle. Im Gegensatz zu der klassischen Handprogrammierung, bei der die Verwendung von Namenskonventionen zur Orientierung unverzichtbar war, leisten moderne Modellierungstools auch ohne Namenskonventionen gute Navigationshilfen durch die Metadaten und Modelle. Sie verleiten sogar dazu keine Namenskonvention zu verwenden und zwingen die Benutzer auch nicht dazu. Namenskonventionen sind dennoch auch bei der Verwendung von Tools hilfreich: Sie ordnen Objekte einen eindeutigen Platz innerhalb des Warehouse – Schichtenmodells. zu Z. B. STG_Kunde, DWH_Kunde, DM_Kunde: Wie sonst soll man erkennen, dass es sich hier um drei verschiedene Kundentabellen handelt. Man gewinnt mehr Flexibilität bei der Zuordnung von Tabellen in die Datenbankschemen. Alle drei Kundentabellen des vorher genannten Beispiels können mit Namenskonvention auch in einem zusammenhängenden Schema liegen. Damit wird die Verwaltung leichter. In den Metadatenlisten (Auswirkungsanalysen, Herkunftsanalysen) sind die Objekte leichter unterscheidbar. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 27/166 Verwendung von Namenskonventionen zur Orientierung bei Auswirkungs- und Herkunftsanalyse über Metadaten Es gibt drei Arten der Namenskonvention: Objekttypbezogene Namenkonvention z. B. TB_xxx für Tabelle, MP_xxx für Mapping usw. Schichtenspezifische Namenskonventionen z. B. STG_xxxx für Stage, DWH_xxx für Data Warehouse, ODS_xxxx für Operational Data Store, DM_xxxx für Data Mart usw. Verfahrensbezogene Namenskonventionen CTRL_xxxx für Controlling usw. Bei der Verwendung von Modellierungstools für das Warehouse macht es meist wenig Sinn, die Objekttypen selbst noch einmal mit Namenskonventionen zu kennzeichnen, denn diese sind meist schon durch die graphischen Symbole voneinander unterscheidbar gemacht. Verfahrensbezogene Namenskonventionen enden meist in dem Ergebnis, dass alle Objekte mit den gleichen Namensbestandteilen markiert werden. Hier gibt es dann kaum eine Unterscheidung. Also bleibt die Namenskonvention auf der Basis der Warehouse – Schichten. Aus der Datenadministration kennen wir besondere Namensvergaberegeln. Objekte werden von ihrer globalen Bedeutung her zuerst benannt und dann über angehängte Attribute näher qualifiziert: KONTO_VERECHNUNG KONTO_DEPOT KUNDE_PRIVAT KUNDE_PARTNER Das mag zwar umgangssprachlich nicht ansprechend sein, ist aber praktisch, wenn es darum geht eine Übersicht über alle Datenobjekte im Warehouse zu erhalten. Soll eine neue Datenausprägung von Kunde im Warehouse modelliert werden, so braucht man in den Metadaten nur nach den bestehenden KUNDEN_XXXX – Einträgen zu suchen, um Doppeldefinitionen zu vermeiden. Natürlich kann hierfür ein Repository - System verwendet werden, in dem Datenobjekte nach verschiedenen Kriterien, Schlagwörtern usw. gesucht werden können. Aber Namenskonventionen sind die einfachste Variante. 3.3.3 Templates Zur Standardisierung tragen auch Templates für Dokumente und Modelle bei. Neben der Arbeitsersparnis beim Erstellen, helfen sie auch bei der leichteren Orientierung innerhalb der Systemdokumentation. Templates sollten eine Hilfestellung sein, sie sollten nicht zur zusätzlichen Arbeitsbelastung führen nur weil sie aufgrund ihrer Existenz und vorgeschriebener Vorgehensweisen auszufüllen sind. Viele Projekte haben bereits große Teile ihres Zeitbudgets verbraucht, während sie nur Papier erstellten. Templates sollten vordefinierte Textbausteine und Listen zum Ankreuzen beinhalten. Das Ausfüllen der Templates darf nicht viel Zeit beanspruchen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 28/166 4 Grundsätzliches Vorgehen zum Aufbau des Warehouse Systems 4.1 „Chaos in allen Gassen“ Bevor ein sinnvolles Architekturkonzept erklärt wird, sollte ein Blick in die bestehende Realität existierender Warehouse Systeme geworfen werden um die Dringlichkeit einer sinnvollen Vorgehensweise zu unterstreichen. Gemeint sind gerade Warehouse – Systeme von großen Unternehmen, bei denen sich Heerscharen von Projektmitarbeitern verwirklicht haben. Ursprünglich sind solche Systeme oft von externen Mitarbeitern konzipiert und in einem ersten Wurf gebaut worden. Dann haben wechselnde internen Mitarbeitern die Systeme gewartet und punktuell weiterentwickelt. Es entstand ein Mix aus nicht oder falsch angewendeter Datenbanktechnologie und vermeintlich gültigen, nicht hinterfragten Methoden. Wie ist es sonst zu erklären, dass solche Systeme aus mehreren 1000 Tabellen über mehrere 1000 Laderoutinen verfügen. Die Ursachen sind vermutlich: Zu viele 1:1 Kopiervorgänge (aufgrund von Sicherheitsbedürfnissen oder zu vielen Systemwechseln) Die Verwendung von Summentabellen für jede gewünschte Abfrage. Jede Summentabelle muss über Transformationen separat gepflegt werden. Der fehlende Informationsplan. Die Warehouse – Verantwortlichen haben die Übersicht darüber verloren, welche Information an welcher Stelle bereits existiert. Schnell wird eine neue Tabelle und damit ein neues Ladeprogramm angelegt. Damit erklärt sich auch, warum diese Systeme in den Ruf von Kostenfressern und in jüngster Zeit verstärkt auf die Prüfstände der IT – Controller geraten sind. Diese Aussagen gelten gerade für große Systeme, die Ende der 90er Jahre entstanden. Die jüngeren Systeme sind wesentlich kleiner konzipiert und laufen naturgemäß weniger Gefahr der Verzettelung. Aber auch hier gilt: falscher Technikeinsatz führt zu unnötigen Kosten. 4.2 Informationsplan Eines der wichtigsten Hilfsmittel für die Entwicklung einer Warehouse – Architektur ist der sog. Informationsplan. Für die Effizienz eines Warehouses ist es entscheidend, an welchen Stellen welche Informationen liegen bzw. entstehen. Informationen können redundant bearbeitet werden, mit all den negativen Konsequenzen wie nicht stimmige Inhalte und mehrfachen Verwaltungsaufwand oder sie können konzentriert und einmalig an definierten Stellen vorliegen. Voraussetzung ist immer die Kenntnis darüber, welche Informationen gebraucht werden und welche bereits vorliegen. Das klassische Mittel hierfür ist das Metadaten Repository. Hier sollten alle Objekte in einer metasprachlichen Manier vorliegen und abfragbar sein. 4.2.1 In welcher Form können Informationen dokumentiert werden Eine wichtige, erste Quelle ist die Informationsbedarfsanalyse, die mit den jeweiligen Zielgruppen des Data Warehouse - Systems durchzuführen ist. Die Fachanwender benennen eine Reihe von Fragenstellungen in einer Textform. Diese Form ist allerdings ungeeignet, um sie in einer Liste katalogartig aufzuführen. Das Projektteam wird aus dieser Befragung heraus Kennzahlen identifizieren. Die Kennzahlen sind zunächst nur eine grobe Orientierung. Denn Kennzahlen können wieder von anderen Kennzahlen abgeleitet sein, und Kennzahlen lassen nicht auf den ersten Blick erkennen, welche beschreibenden Merkmale (Dimensionen) die Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 29/166 Kennzahl bestimmen. Aber auf die Grundbestandteile heruntergebrochene Kennzahlen sind sicher erste Vertreter im Informationsplan. Die zweite Gruppe der Einträge ist die Liste der Geschäftsobjekte. Eine solche Liste entsteht im Rahmen der Geschäftsprozess – Analyse und kann unabhängig von der Informationsbedarfsanalyse erstellt werden. Allerdings sollten nicht alle Geschäftsobjekte des gesamten Unternehmens in das Warehouse – Repository übernommen werden, sondern nur die relevanten. Das Pendant zu den Geschäftsobjekten sind die Entitäten der betroffenen Datenmodelle aus der Datenmodellierung und hierzu passen sehr schnell auch die Tabellen des Warehouses selbst. Gebraucht wird also ein Metadaten – Modell mit folgender Struktur: Metadatenmodell (- Ausschnitt) zum Informationsplan im Data Warehouse Die Darstellung einer notwendigen Metadaten – Struktur zur vollständigen Dokumentation ist sehr viel aufwendiger, als dies an dieser Stelle möglich ist. Daher sollten die hier genannten Metadaten - Objekte mit den zugehörenden Beziehungen untereinander zunächst ausreichen. Sind diese Informationen in einem Metadaten Repository gespeichert, dann kann dieses Repository dazu verwendet werden, um Listen zu ziehen. Üblicherweise sind die Repository – Eintragungen durch zusätzliche Schlagwortattribute gekennzeichnet, so dass die Objekte auch unter anderen Begrifflichkeiten abfragbar sind. 4.3 Schichtenmodell Eine Möglichkeit den Anforderungen nach Flexibilität und Skalierung im Warehouse gerecht zu werden, ist die Art, in der das Warehouse konzipiert ist: die Architektur. Data Mart – übergreifende Neutralität und zugleich Flexibilität wird mit dem sog. 3 – Schichtenmodell erreicht. Das Schichtenmodell ist eine Einteilung des Data Warehouse - Komplexes in mehrere logische oder funktionale Segmente. Es gibt Segmente für 3 Hauptaufgabenbereiche: Stage - Schicht, Data Warehouse – Schicht (oder Kern Data Warehouse), Endbenutzer – Schicht (Data Mart) (Operational Datastore) Die wesentlich umfassendere Data Warehouse – Schicht ist sachthemenorientiert und integriert bereichsübergreifende Fragestellungen (in der Regel nahezu 3. Normalform). Sie ist besonders gut für Konsolidierungszwecke geeignet, da sich Daten in der 3. Normalform leicht sortieren und vergleichen lassen. Die Data Marts Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 30/166 dagegen sind auf die einzelnen Zielgruppen mit ihren speziellen Fragestellungen zugeschnitten (z. B. Fachabteilungen). Sie sind meist denormalisiert als sog. Dimensionale Modelle (Starschema) oder Würfel (Cube) aufgebaut. Das gesamte System kann durch eine Staging Area von den Vorsystemen (OLTP Systeme) getrennt sein (Pufferschicht), damit sich die beiden Bereiche z. B. durch Performanceverluste, nicht gegenseitig behindern. Außerdem können die aus unterschiedlichen Vorsystemen stammenden Daten in der Staging Area validiert und zurecht geschnitten bzw. bereits konsolidiert werden. Das Schichtenmodell garantiert: Bereichs-/abteilungsübergreifende Neutralität und damit Vergleichbarkeit von Informationen. Entkoppelung von operativen und dispositiven Datenbeständen durch die trennende Warehouse - Schicht. Ausreichende Wandlungsflexibilität von Daten zu Informationen durch bewusste Normalisierungs- / Denormalisierungsschritte. Die Trennung in Schichten ist eine logische Einteilung nach Funktionsbereichen und nicht physikalisch zu verstehen. In einigen bestehenden Warehouse – Systemen hat diese Einteilung jedoch zu organisatorischen und technischen Strukturen geführt, z. B. wurden die Verantwortlichkeit für Data Marts in die Fachabteilungen gelegt oder Data Marts wurden technologisch völlig losgelöst von der Data Warehouse Schicht realisiert. Beides widerspricht der Anforderungen nach kurzen Wegen zwischen operativen und dispositiven Systemen und lässt zusätzliche Barrieren und Brüche in dem Wandlungsprozess entstehen. Zur Unterstützung von leichten und einfachen Zugriffen auf das Data Warehouse durch Mitarbeiter der operativen Prozessebene wird gelegentlich eine vierte Schicht, die sog. operational Data Store – Schicht, verwendet. Diese Schicht hat jedoch einige Überschneidungen mit dem Konzept der Warehouse Schicht. Darauf wird weiter unten eingegangen. 3 – Schichtenmodell für unternehmensweit eingesetzte Data Warehouse Systeme Das Ziel der 3 – Schichtenarchitektur ist der Entwurf einer möglichst umfassenden, mehrere Unternehmens- und Themenbereiche abdeckenden Informationsablage, die in kurzer Zeit konsolidierte Berichte und Analysen für alle (!) Zielgruppen des Unternehmens bereitstellt. Die Mehrschichtenarchitektur muss folgende Anforderungen erfüllen: Schichtenübergreifende Zugriffe: Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 31/166 o Das Erstellen von Berichten und Analysen muss auch über die Warehouse Schicht und nicht nur ausschließlich über die Endbenutzerschicht möglich sein. o Informationen (Tabellen) müssen auch gemeinsam nutzbar sein, z. B. sollte der Datenbestand von großen Faktentabellen, nicht aufgrund des Schichtenmodells oder organisatorischer Begebenheiten mehrfach vorgehalten werden müssen (siehe unten). Effiziente Schichtenwahl bei Transformationen: Ladeprozesse sollten vor dem Hintergrund aller Schichten entworfen werden. U. U. ist eine bestimmte Herleitung innerhalb der Staging – Schicht einfacher als zu einem späteren Zeitpunkt innerhalb der Data Marts. Das Verteilen der Transformationen über alle Schichten hinweg muss wahlfrei sein. Der Warehouse Architekt sollte die Freiheit besitzen, Transformationen an den Stellen platzieren zu können, an denen die effizienteste Verarbeitung möglich ist. Durchgängig gleiche Transformationsmittel: Dies ergibt sich bereits aus dem vorgenannten Punkt, denn die Wahlfreiheit bzgl. der Standorte von Transformationen ist auch abhängig von den Mitteln mit denen die Transformationen gemacht sind. Nur gleiche und standardisierte Komponenten sind durchgängig flexibel platzierbar (z. B. SQL). Gemeinsam genutzte Ladeprozesse: Abteilungsübergreifende Ladeprozesse (Datenversorgungsvorgänge) sollten innerhalb der ersten beiden Schichten erfolgen. Gemeinsam genutzte Analyseprozesse und Kennzahlen: Es gibt eine Reihe von Analysen und Kennzahlen, die nicht abteilungsspezifisch sind. Diese sollten innerhalb der Warehouse –Schicht durchgeführt und gepflegt werden. Schichtenübergreifende Dokumentation: Abhängigkeiten, Auswirkungen und Herkünfte von Informationen müssen schichtenübergreifend analysiert werden können. Zusätzlich sind auch die benachbarten Bereiche, die operativen Vorsysteme und die Berichtswerkzeuge in die Dokumentation mit einzubeziehen. 4.3.1 Aufwand nur einmal leisten Die Vorteile, die sich ergeben, wenn eine zentrale Warehouse – Schicht zwischen die konsolidierende Stage Schicht und die fachspezifischen Data Marts gesetzt wird, können nicht deutlich genug betont werden. Denn damit ist es möglich viele Aktivitäten, (ETL – Schritte, Erstellen von Kennzahlen und Standardberichten, Erstellen von einheitlichen Datenkatalogen usw.) an zentraler Stelle einmalig durchzuführen und durch den Wegfall redundanter und unkontrollierter Tätigkeiten Aufwand zu sparen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 32/166 Die Warehouse – Schicht steht für einmaligen Aufwand und verhindert unkontrolliertes „Werkeln“ in den Data Marts Gerade in Verbindung mit dem Datenbank – basierten Warehouse (und den Oracle – Techniken) macht diese Vorgehensweise besonders viel Sinn, denn durch das Schichtenmodell wird logisch / methodisch untermauert, was in der Datenbank technisch möglich ist. Hier sind Techniken angesprochen, Informationen im Hintergrund durch Datenbank – Mechanismen aufzubereiten. Das sind automatische Prozesse, die unabhängig von Benutzeranforderungen (Data Mart – Aktionen) laufen können. Es entstehen zentral in der Warehouse – Schicht Warehouse – Services, die von den nachgelagerten Data Mart genutzt werden können. Damit wird in den Data Marts Aufwand gespart. Metadaten kontrollierten die Zusammenhänge in dem 3 Schichtenmodell (Herkünfte und Auswirkungen sind offengelegt) 4.3.2 Begriffsabgrenzung „Schichtenmodell“ und „Hub and Spoke“ In ähnlichen Warehouse – Konzepten wird anstatt von 3 – Schichten Architektur auch von Hub and Spoke – Architektur geredet. Der Begriff ist der graphischen Darstellung nachempfunden, wobei mehrere Quellsysteme und mehrere Data Marts wie Speichen eines Rads mit dem zentralen Warehouse verbunden sind. Dieser Begriff ist schon alt (seit 1995). Bei der aktuellen Warehouse Architektur – Betrachtung muss sich jedoch die Funktion jeder einzelnen Warehouse – Schicht immer wieder hinterfragen lassen. Das kann dazu führen, dass Schichten ihre Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 33/166 Bedeutung verlieren oder neue Verwendungen hinzu kommen. Bei der hier vorliegenden Architektur – Betrachtung wird z. B. das alte Konzept der verteilten Data Mart hinterfragt und auf eine zusammenhängende einheitliche Data Mart – Schicht hingearbeitet. Hier passt der Name Hub and Spoke nicht mehr. 4.3.3 Den Wechsel relationales / multidimensionales Speichern durchbrechen Viele historisch gewachsene Architekturen sind durch technische Einschränkungen geprägt, wie sind in der Vergangenheit vorherrschten. Herkömmliche Datenbanksysteme hatten Mitte der 90er Jahre noch nicht den Datendurchsatz und die Flexibilität, die für die Bearbeitung multidimensionaler Datenmodelle und komplexere Analysen notwendig war. Eine Folge dieser Einschränkungen war das Herauslösen von Datenbereichen aus der Datenbank und das zusätzliche Aufbereiten in dedizierten Auswertewerkzeugen mit eigener Datenhaltung. Darauf aufbauende Architekturen haben zwar auch das mehrschichtige Modell verwendet, allerdings wurde die letzte Schicht lediglich als Datengrundlage für die nachgelagerten Auswertesysteme benutzt. Diese letzte Schicht stand den Benutzern wie die Warehouse – und Stage – Schicht nicht zur Verfügung. Letztlich entstand eine vierte Schicht, die Datenschicht des Auswertewerkzeugs selbst. Dies gilt vor allem für die besonderen Auswerteanforderungen in den Bereichen komplex multidimensionale Analysen und Data Mining. Dass mit einer solchen Vorgehensweise besonders hohe Aufwende verbunden sind, ist leicht nach zu weisen. Diese Architekturen halten heutigen ROI – Betrachtungen nicht mehr stand. Aufendige historisch gewachsene 4 – Schichten – Lösung Die Entscheidung darüber, ob Daten zu Auswertezwecken physisch relational oder physisch multidimensional vorgehalten werden, sollte eine dynamische Entscheidung sein, die innerhalb des Datenbeschaffungsprozesses in der Datenbank zu treffen ist. Nur so ist gewährleistet, dass man je nach Anforderungen zwischen beiden Arten der Datenspeicherung umschalten kann, und zwar dann, wenn eine der beiden Technologien Vorteile aufweist und nicht wenn eine Werkzeug – Grenze überschritten wird. Wenn frei gewählt werden kann, an welcher Stelle relational oder multidimensional gespeichert wird, dann bleiben diese Techniken nicht mehr nur der Data Mart – Schicht vorbehalten. Auf der Metadatenebene sollte es grundsätzlich keine Unterschiede geben. Separate Auswerteschichten aufgrund eines Tool - Wechsels fallen weg. ETL – Schritte werden weniger. Frühzeitig kann im Verlauf des Datenbeschaffungsprozesses bereits Vorsorge für eine spätere multidimensionale oder relationale Speicherung getroffen werden, ohne dass Wege für eine alternative Speicherung blockiert sind. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 34/166 Freie Wahl von multidimensionaler oder relationaler Datenspeicherung sowohl bei der Definition als auch bei der Datenbefüllung 4.3.4 Wahlfrei den Ort einer Analyse bestimmen Eine weitere wichtige Anforderung für effizientes Data Warehouseing ist die freie Wahl des Ortes, an dem eine Analyse stattfindet. Ein großer Teil der Zugriffe auf das Data Warehouse durch Benutzer (wenn nicht sogar die Mehrheit) sind Abfragen auf Standardinformationen. Das sind Abfragebedürfnisse, die man bereits im Vorfeld bei der Planung berücksichtigen kann. Es sind die bereits beschriebenen Kennzahlenlisten oder einfach nur die Sammlung aller Standardberichte. Solche Informationen sollten nur einmal aufbereitet werden. Wird eine Technologie verwendet, die eine solche Analyse nur mit besonderen Mitteln (Auswertetools) an besonderen Orten erlaubt, dann ist die Wahlfreiheit eingeschränkt. Die Aufbereitung dieser Informationen sollte innerhalb der Oracle – Datenbank an zentraler Stelle geschehen. Es gibt so gut wie keine Standardabfrage, die nicht mit relationalen Bordmitteln der Datenbank vorbereitet werden könnte. Hierzu ist in der Regel keine multidimensionale Speicherung nötig. Es z. B. die analytischen SQL Erweiterungen wie Ranking und Windowing Funktionen (MIN/MAX OVER PARTITION, LEAD LAG, RANK usw.). Diese Analysen sollten in der Regel in der Warehouse – Schicht angesiedelt sein und dann für die Data Marts zentral zum Abrufen zur Verfügung stehen. So müssen nicht unnötig viele Daten in die Data Marts kopiert werden. Wahlfrei den Ort einer Analyse für Standardberichte festlegen Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 4.4 35/166 Transformationen Transformationen haben die Aufgabe in den Quellsystemen einmal erfasste Daten in die jeweiligen Schichten des Warehouses zu überführen und sie in eine schichtenadäquate Form zu bringen. In der Regel handelt es sich dabei um datenmanipulierende Vorgänge, wie sie in der klassischen SQL DML (Data Manipulation Language) beschrieben sind. Darüber hinaus lassen sich Transformationen in einem Data Warehouse kategorisieren: Standardfunktionen Insert, Update, Delete, Merge (Insert/Update) 1:1 Transformationen (reines Kopieren, auch mit minimalen Änderungen) Selektionen (z. B. Where – Klauseln, Bedingungen) Gruppierende Transformationen (Aggregationen, Sortieren, Segmentieren) Pivotierende Transformationen (Verändern der Kardinalität von Zeilen und Spalten) Berechnungen (einfache oder komplexe, Funktionen oder Programme) Formatieren von Daten Zusammenführende und spaltende Transformationen (Join / Split) Anreichernde Transformationen (Referenzen auslesen, Lookups, Konstanten, Fallunterscheidungen) Aussortieren / Trennen von Datenbereichen Prüflogik (logisch / fachliche und physisch / technische) 4.4.1 Wahlfrei den Ort der Transformation bestimmen Das Schichtenmodell gibt bereits eine wichtige Orientierung darüber, an welchen Stellen entsprechende Transformationen stattfinden müssen bzw. auch wahlfrei stattfinden können. Dies ist eine erste Voraussetzung für effektiv platzierte Transformationen. Ziel ist es, gleichartige Informationen auch nur an einer Stelle einmalig zu erstellen, um so ETL – Aufwende zu sparen. Hierzu ist es empfehlenswert, zunächst den gesamten Ladeprozess global zu betrachten. So erkennt man gleichartige Aufgabenbereiche und findet die idealen Stellen der Transformationen in der Gesamtarchitektur. Wahlfreiheit bedeutet auch, dass es nicht passieren darf, dass nur aufgrund einer besonderen Analyseanforderung am Ausgang des Warehouses noch zusätzlich Ladeschritte erforderlich werden. Die Mittel um unnötige Transformationen zu sparen sind: Das Trennen einer Warehouse – Schicht mit einem Komplettvorrat aller wesentlichen Informationen und einer Data Mart – Schicht mit den tatsächlich durch Benutzer abgerufenen Daten. Das ist das hier beschriebene Schichtenmodell. Fehlt die Warehouse – Schicht, so erhöht sich der gesamte ETL – Aufwand aufgrund doppelter Transformationen für die separaten Data Marts. Das logische und physische Zusammenfassen der Data Marts an einer Stelle. Dieses Verfahren sieht zwar für die verschiedenen Zielgruppen und Abteilungen separate Auswertebereiche vor, die Auswertemodelle sind aber dennoch so weit integriert, dass sie gemeinsam verwaltet werden können [siehe separates Kapitel]. Geschicktes Definieren von generalisierten Auswertmodellen. Das sind z. B. granular gehaltene Starschemen. Spezielle Benutzerwünsche werden durch Materialized Views abgedeckt. [siehe separates Kapitel]. Ein Metadaten Repository, das alle Datenobjekte im gesamten Warehouse – System dokumentiert und zwar Data Warehouse - und Data Mart – übergreifend. Hier muss es möglich sein synonyme und homonyme Verwendungen von Datenobjekten durch gezielte Abfragen zu vermeiden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 36/166 Transformationsschritte sollten wahlfrei positioniert werden können, um sie möglichst konzentriert einmalig anzuwenden 4.4.2 Durchgängige Verwendung der Datenbanksprache (SQL) Da Warehouse – Systeme in der Regel auf der Basis von relationalen Datenbanken aufgebaut sind, empfiehlt sich SQL als das naheliegende Sprachmittel, um die in den Datenbanken gespeicherten Daten zu bearbeiten. SQL bietet alle Mittel um die oben beschriebenen Transformationen durchzuführen. SQL hat sich über Jahrzehnte als Datenbanksprache bewährt und wird ständig weiterentwickelt. SQL DML bietet das sprachbezogene Pendant zu den Tabellenstrukturierungsmitteln von SQL DDL. Das Sprachmittel SQL sollte über alle Warehouse Schichten hinweg Anwendung finden. Sowohl im Verlauf des Extrahierens, bei dem Wandern der Daten durch die einzelnen Schichten, als auch bei dem Aufbereiten der Daten für Endanwenderberichte. Damit gelten im Einzelnen die Regeln: Lesen mit SQL in Textdateien (anstelle von Datenbank – Loaderprogrammen). Lesen auf Remote – Quellen (relational wie hierarchisch). Zugriff erfolgt auf eine Remote – Instanz, als wäre diese Bestandteil des eigenen Hoheitsbereichs. Lesen mit SQL auch auf multidimensionale Datenmodelle bzw. Würfelstrukturen, auch wenn die Speicherungsstruktur nicht relational ist. SQL generierende Abfragewerkzeuge. Die Durchgängigkeit des Abfragemediums schafft einheitliche Sprachstile, standardisiert Datenlese- und Schreiboperationen (macht diese unabhängig von den Aufgabenstellungen, macht sie vergleichbar und nachvollziehbar), vermindert zusätzlichen Lernaufwand für alle Beteiligten, erleichtert die Kommunikation über Datenflüsse im Projekt, verhindert das Aufkommen zusätzlicher proprietären Toolsprachen. Hier nicht näher erläuterte Vorteile von SQL sind: Die Möglichkeit der mengenbasierten Transformation von Daten. Die Realisierung komplexer Logik durch neue SQL - Sprachmittel wie CASE. SQL Erweiterungen wie Multiple Inserts, Merge und das Lesen mittels SQL in Textdateien. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 37/166 Einheitliche Sprachmittel standardisieren alle Datenflüsse und Schnittstellen des 3 Schichtenmodells sowohl innerhalb des Systems als auch nach außen 4.4.3 Ladeprozess einfach und kompakt halten Aufgrund der genannten Anforderungen sollten auch Ladeprozesse frei planbar sein. In der Vergangenheit war freie Planung des Ladeund Transformationsprozesses bereits schon durch die Wahl eines bestimmten ETL – Tools behindert, denn das Tool setzte die Rahmenbedingungen. Daten wurden über weite Wegstrecken hinweg aus der Datenbank ‚ausgecheckt’ und mussten solange separat verwaltet werden, bis ein Transformationsschritt komplett beendet war. Das Lesen aus der Warehouse – Datenbank und das Schreiben in die Datenbank hinein stellten zusätzliche technologische Hürden dar. Kann man über den gesamten Transformationsweg frei verfügen, so lassen sich folgende Regeln für die Gestaltung festlegen: 1:1 Transformationen vermeiden (gemeint ist auch das 1:1 Laden in die Stage Area hinein). o 1:1 Transformationen sind nur unnötige Ladeschritte, die faktisch keinen Transformationsgewinn darstellen. o In der Regel entstehen dadurch zusätzliche redundante Speicherstellen mit dem entsprechenden Platzverbrauch. o Die unnötigen Ladeaktivitäten verursachen zusätzlichen Entwurfs-, Entwickelungs- und Verwaltungsaufwand. Zusätzliche Jobs sind zu starten. o Der so aufgeblähte Ladevorgang wirkt nach außen monströs und unhandlich. Das Erstellen von wenigen, kompakten Ladeschritten sorgt für eine unübersichtliche Gesamtstruktur. Objektbezogene Modifikationen bündeln. Das bedeutet z. B. Inserts, Updates und Deletes für eine Tabelle sind in einem sog. Mapping zusammenzufassen. Strukturänderungen an den Objekten lassen sich somit gefahrloser an einer Stelle bündeln. Vor-, Nach- und Hauptverarbeitung von Objekten sind in einer Routine übersichtlich zusammenfassen. 4.4.4 Durch Datenbank basierten Ladeprozess Ressourcen schonen Transformationen sollten innerhalb der Datenbank stattfinden. Hierdurch können erhebliche Kosten- , Performance- und Flexibilitätsvorteile erzielt werden. Die Datenbank selbst hat in der aktuellen Warehouse – Diskussion als optimale Ladeinstanz zunehmend Bedeutung gewonnen und löst ältere Modelle (ETL Tools der 1. und 2. Generation) ab. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 38/166 4.4.4.1 Zur Historie: An dieser Stelle ist es angebracht, die Entwicklung von Ladewerkzeugen näher zu betrachten. An ihr kann aufgezeigt werden, wie „landläufige Meinungen“ zu Fehlentwicklungen bei der Architekturplanung führen, anstatt rational die Fakten sprechen zu lassen. Als Mitte der 90er Jahre das Thema Data Warehouse zum ersten Mal in der jetzigen Form in aller Munde geriet, gab es einen besonderen Bedarf an Werkzeugen, die Daten automatisiert in ein Data Warehouse laden konnten. Die Datenbanken selbst, mit ihrem zu dieser Zeit noch rudimentären SQL, waren kaum geeignet, Datenbewegungen oder Datentransformationen zu erledigen. Bis zu diesem Zeitpunkt wurden dafür gerade in Mainframe – Umgebungen oftmals Programme in Cobol oder PL1 geschrieben, was einen ständigen Programmieraufwand verursachte. Es entstanden eine Vielzahl von individuellen Ladeprogrammen, die das Operating zu verwalten hatte. 1993/94 starteten Newcomer mit der Idee Cobolprogramm – Code zu generieren um zumindest den Programmieraufwand zu minimieren. Die generierten Programme liefen schnell (weil compiliert), aber die Handhabung gestaltete sich dennoch umständlich, weil bei jeder Änderungsanforderung, neu generiert, der Code zum Host transformiert und dort compiliert/gelinkt werden musste. Das war die Chance der ETL – Tools der sog. „2. Generation“, wie sich Tools von Informatica, Ascential, systemfabrik, Acta, Platinum u. ä. dann nannten. Sie glänzten mit graphischen Oberflächen und einer bereits vorkompilierten Engine, die sich im Workstation / PC – Umfeld bewegte und letztlich nur noch parametrisiert zu starten war. Plattformunabhängigkeit wurde propagiert, lesen von n – Sourcen und schreiben in n - Targets. Die Idee war neu und wurde schnell vom Markt aufgenommen. Es gründete sich das Segment der ETL – Tools (Extraktion, Transition, Load). Von nun an war ein neuer („Marketing-“) Standard gesetzt: Das Laden von Warehouse – Systemen war mittels graphischen Oberflächen zu entwerfen und ist durch eine sog. „Engine“ auf einem speziellen Server durchzuführen. Wie sich viele Techniken und Trends in der IT verselbständigen, so geschah dies auch mit den „Tools der 2. Generation“. War ein Warehouse neu aufzubauen, so gliederte sich diese Aktivität regelmäßig in drei Teilbereiche: Datenbank (Datenhaltung) ETL - Tools (Extraktion, Transition, Load) Auswerteprogramme (Front End). Die Beschäftigung mit der Historie ist wichtig, um zu verstehen, weshalb sich ETL – Tools entwickelten. Verstanden werden muss, dass ihre Entwicklung aus der Not der Stunde heraus sinnvoll war. Aber auch nur in dieser Not. Bereits ab Ende der 90er Jahre setzte eine schleichende Entwicklung auf dem Datenbankmarkt ein. Neben der reinen Datenhaltungsfunktion entwickelten sich die Datenbanken mehr und mehr zu einer umfassenden Datenmanagementumgebung. SQL entwickelte sich zu einer mächtigen Programmiersprache. Nur einige Beispiele: Die CASE WHEN – Anweisung erlaubt bedingte Verarbeitungen entsprechen der „if then else“ – Logik. Einer der fundamentalsten Bausteine von Programmiersprachen. JOIN / OUTER JOIN, MINUS, UNION usw. erlaubt gezielte Mengenoperationen. Dies entspricht Schleifenoperationen. Ranking und Windowing Funktionen (MIN/MAX OVER PARTITION, LEAD LAG, RANK usw.) machen analytische Operationen Out - of - the – Box möglich, wofür zuvor Programme benötigt wurden. Noch gravierender sind Funktionalitäten, die unmittelbar durch die Datenhaltung selbst bestimmt sind: Bedingtes Inserten gleichzeitig in mehrere Tabellen oder das wahlweise Absetzen von Inserts oder Updates (Merge). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 39/166 Einen weiteren Schritte machte gerade die Oracle – Datenbank, als unterschiedliche externe Datenstrukturen direkt in die Daten integriert bzw. eingelesen werden konnten. Das sind z. B. Flat File oder XML Strukturen. XML –Daten müssen erst gar nicht im Sinne von ETL interpretiert werden. Man legt sie einfach innerhalb der Datenbank als XMLTYPE ab. Das Datenbanksystem strukturiert sie innerhalb der Ablage, so dass jede Information der XML – Struktur gezielt gelesen werden kann. Analog verhält es sich mit Textdateien. Sie werden einfach als Tabelle innerhalb der Datenbank deklariert und stehen damit jedem SQL – Zugriff offen. So hat die Datenbankentwicklung die oben beschriebene Historie überholt. Aber es bedarf einiger Energie, um gegen überkommene Vorstellungen anzukommen. Es sind nicht nur die Hersteller der ETL – Tools, die die Notwendigkeit separater ETL – Tools aus verständlichem Interesse heraus proklamieren, sondern (und hier schon mal Entschuldigung für die deutlichen Worte) auch viele Berater, die es sicher gut meinen, aber die Entwicklung bislang nicht erkannt haben. 4.4.4.2 Nachteile Engine – basierter ETL - Tools Der Einsatz separater ETL – Tools hat im Vergleich zur Datenbanktechnologie folgende Nachteile: Nachteile Engine – basierter ETL – Werkzeuge 1. Verstärktes 1:1 Lesen. ETL – Engines können zwar Daten aus Flat – Files und anderen Quellen direkt einlesen und verarbeiten, damit sind sie aber noch nicht in der Datenbank gespeichert, sondern erst in dem ETL – Tool. Um den Extraktionsschritt des ETL – Prozesses abzusichern, entscheiden sich viele Entwickler für sog. 1:1 – Staging – Tabellen. D. h. die externen Daten, werden zunächst einmal als Kopie ohne Modifikation in eine Stage – Tabelle gelegt. Bei dem Datenbank – basierten Laden liegt das Ergebnis der Extraktion schon sofort in einer Staging – Tabelle. Der Transportweg ist damit kürzer. Man kann sich also eher dafür entscheiden, bereits bei der Extraktion einen Verarbeitungsschritt einzubauen. Datenbankbasierte ETL – Prozesse sind generell kürzer. 2. Die Verarbeitung der einzelnen Datensätze des Ladestroms erfolgt satzweise. Selbst wenn es gelingt die Menge der zu verarbeitenden Sätze in mehrere Portionen zu teilen, die dann über parallel gestartete Engines abgearbeitet werden können, bleibt die Verarbeitung innerhalb der Pakete eine satzorientierte. Der Datenbank - basierte ETL - Lauf, verläuft grundsätzlich parallelisiert. D. h. das Datenbanksystem sorgt automatisch für die gleichmäßige Ausnutzung mehrerer Rechnerknoten. Zudem findet die Verarbeitung mengenorientiert innerhalb des Datenbankkernes statt. Das Laden innerhalb der Datenbank ist bis 10 mal schneller, als das Laden mit Engines. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 40/166 3. Insert / Update – Steuerung. Engine – basierte Werkzeuge, haben ein großes Problem, wenn Sätze in die Datenbank geschrieben werden sollen und nicht bekannt ist, ob ein Satz bereits da ist oder nicht. Es müssen immer eine Insert - und im Fehlerfall des Inserts eine Update - Variante durch den Entwickler vorgesehen werden. Der Datenbank – basierte Lauf nutzt hier die Merge – Operation, bei der das Datenbanksystem selbständig von Insert auf Update umspringt, wenn ein Satz bereits vorhanden ist. Dies sind keine Nachteile eines bestimmten Tools, sondern generelle Nachteile, wie sie entstehen, wenn man Daten außerhalb der Datenbank transformiert anstatt innerhalb. 4.4.4.3 Gründe für die Verlagerung des Ladeprozesses in die Datenbank Wiederverwendung der Ressource Datenbank. Der Datenbankkern sorgt nicht nur für die Datenhaltung, sondern auch für den Datentransport und die Transformation. Es braucht dafür keine weitere Komponente gekauft zu werden. Bis zu 10 mal höhere Lade - Performance. Einfacher Zugriff auf alle Datenbankobjekte und damit höhere Flexibilität des Ladelaufs. Ausnutzen des Datenbank – Security – Systems und damit besserer Schutz der Daten im Verlauf des Ladeprozesses. Absicherung der Ladeläufe durch klassische Datenbanksicherungsmittel (Commit, Rollback). Backup – System der Datenbank kann auch für die Objekte des Ladeprozesses wieder verwendet werden (Ladeprozeduren, Design time – Runtime –Metadaten). Der Ladeprozess benötigt keinen zusätzlichen Hardwarebedarf. Datenhaltungsserver und Ladeserver sind identisch. Automatische Parallelisierung. Ausnuten der Cluster- und Gridfähigkeit der Datenbank zu besseren Skalierung. Neue Funktionen in der Datenbank sind automatisch auch für den Ladeprozess nutzbar. Datenbankverwaltungsaufgaben können schnell und einfach im laufenden ETL – Prozess erledigt werden. Z. B. das Ein – und Ausschalten von Constraints, das Aktualisieren von Indizes, das temporäre Absetzen von Grants, das Verwenden von Hints. Verwenden aller Datenbank – Optionen z. B. Ausführen von Java – Objekten, XML – DB – Strukturen, Zugriff auf Objekt – Relationale Strukturen. Zugriff auf Log – Informationen der Datenbank und damit eine Vielzahl zusätzlicher Zugriffe auf operative Daten. Ausnutzen der Realtime – Optionen der Oracle – Datenbank wie Streams, Change Data Capture, Advanced Queueing. Besondere Nähe zu multidimensionalen Objekten wie Dimensionale Tables oder Analytical Workspaces. Besondere Nähe zu den Data Mining Algorithmen in der Datenbank. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 41/166 4.4.4.4 Performance schaffen durch Mengen – basierte Transformationen Transformationsprozesse in der Datenbank sind in der Regel Mengenoperationen. Ein geschickt aufgebauter Ladeprozess nutzt mengenbasierte Operationen in der Datenbank (Set Based) und vermeidet das Verarbeiten einzelner Sätze. Datenbank – Checkoptionen (Constraints) helfen Prüfund Fehlerverwaltungsaufwand vermeiden. Dies gilt hauptsächlich für mengenbasierte Funktionen der Datenbank, z. B. für Ergebnis - Sets von SELECT – Befehlen, die kombiniert werden können. Es gilt nicht für Einzelprüfungen, wie etwa der Primary Key / Foreign Key - Prüfung. Diese sind auszuschalten. Das Prüfen auf Vorhandensein von Daten in Zielstrukturen sollte durch die Datenbank übernommen werden (Insert/Update – Management – Merge) (Set based Operation). Constraints sind im Verlauf des Ladens zu deaktivieren. Parallelisiertes Wiederherstellen von Indizes, wenn diese nicht mehr aktuell sind. Aufrufe von Stored Procedures sind zu vermeiden und wenn möglich durch Funktionsaufrufe zu ersetzen. Wenn dennoch mehrere Rückgabewerte benötigt werden, so ist die Prozedur in einer Table Function zu kapseln. Referenzprüfungen (Lookups) sind über Joins zu lösen (Set based Operation). Dynamisches SQL ist zu vermeiden. Dies führt meist zu einer satzweisen Verarbeitung. Cursor sind zu vermeiden, wenn das Abarbeiten der Sätze des Cursors nur über prozedurale Logik, z. B. Variablen – Wertezuweisungen, erfolgt. Cursor sind dann nutzbar, wenn ihre Abarbeitung mengenbasiert erfolgt, d. h. z. B. in Verbindung mit Table Functions. CTAS: Werden temporäre Tabellen genutzt so ist die Variante „Create Table Temp -Table as Select ....“ (CTAS) dem Schreiben mit reinen Insert – Kommandos vorzuziehen. Match-Verhalten: Merge – Kommandos sind bei Insert/Update – Vorgängen dem individuellen Prüfen auf Vorhandensein von Sätzen mit anschließendem Exception – Handling vorzuziehen. Für Inserts und Updates werden keine separaten Ladebausteine erstellt. Die gesamte auf eine Tabelle bezogene Verarbeitung sollte in einem einzigen Baustein stattfinden. FK / PK Prüfungen sollten mittels Joins erfolgen und nicht über die Constraint Prüfung der Datenbank. Die Constraints hierfür sollten ausgeschaltet werden. Fehlerprotokollierung: Oft können Regelverletzungen von Quelldaten nur durch eine Prüfung auf Satzebene protokolliert werden. Diese Vorgehensweise führt dann wieder zu einer satzbezogenen also langsamen Verarbeitung. Hier kann versucht werden die Prüfung auf Regelverletzungen durch eine mengenbasierte Operation zu ersetzen. Z. B. ist das Prüfen der Artikelnummern in den Bewegungsdaten (späteren Faktdaten) auf Vorhandensein in den Stammdaten (Dimensionsdaten) über einen Anti – Join bzw. eine MINUS – Operation möglich. Sind dennoch Einzelsatzprüfungen nötig, so sind diese an wenigen Stellen in dem Gesamtladelauf zu konzentrieren. Materialized Views sollten in einem Ladeszenario ON DEMAND gesteuert sein, sich also nicht ständig im Verlauf des Schreibens in die Basistabellen selbst aktualisieren. Indizes sollten deaktiviert sein und nach Ende des Ladelaufs aktualisiert werden. Bei partitionierten Tabellen muss lediglich der Index der aktualisierten Partition erneuert werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 42/166 Negativbeispiel: Schlechtes Beispiel: Hier wird satzweise geladen. Innerhalb einer PL/SQL – Schleife werden zusätzlich SELECT – Aufrufe für Lookups durchgeführt. Positivbeispiel: Zu bevorzugende Lösung: Alle Lookups werden mengenbasiert durchgeführt und das Ergebnis in eine temporäre Tabelle geschrieben, die anschließend zum Schreiben der korrekten Sätze in die Zieltabelle oder zum Schreiben von falschen Sätzen in eine Fehlertabelle genutzt werden kann. Hierfür nutzt man einen „Multiple Insert“. 4.4.4.5 Explizite Techniken zum Laden großer Datenmengen innerhalb von Oracle Datenbanken Das Laden großer Datenmengen und dann auch noch über Datenbankgrenzen hinweg, kann zur Herausforderung werden. Dies war und ist eine immer wiederkehrende Fragestellung. Einige grundsätzliche Vorgehensweisen sind in dem Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 43/166 vorhergehenden Punkt bereits genannt worden, z. B. Techniken, mit denen mengenbasiert geladen werden kann. Hier weitere spezielle Punkte: Schnelle Platten: Einer der wichtigsten Einflussfaktoren sind die Plattenzugriffe. Wenn das Plattensystem nicht schnell genug Daten liefert, nutzen viele CPU’s und viel Hauptspeicher wenig. Gerade im Warehouse – Umfeld sind Investitionen in schnelle Platten wichtig [siehe separate Punkte weiter unten]. Database Links: Database Links können Bremsen sein. Alternative Konzepte hierfür sind: o Verlagern von remote – liegenden Datenbanken in eine einzige zusammenhängende Datenbank. Hier unterstützt die Cluster – Technologie [siehe separates Kapitel]. o Verwenden von Transportablen Tablespaces. Diese können von einem System zum anderen über Betriebssystemgrenzen hinweg kopiert werden. o Partition Exchange And Load [siehe unten]. o Verwenden von Data Pump. Hier werden Daten schnell aus einer Quelldatenbank exportiert und in der Zieldatenbank wieder importiert. Der Vorgang ist parallelisierbar [sieh hierzu die Datenbankdokumentation]. 4.4.4.6 Partition Exchange And Load (PEL) Ein Verfahren sollte besonders hervorgehoben werden. Das Partition Exchange and Load Verfahren (PEL). Dieses Verfahren ist bei partitionierten Tabellen einsetzbar. Große Faktentabellen sind in der Regel partitioniert. Der besondere Vorteil besteht darin, dass alle Daten – addierenden Aktivitäten zunächst in einer separaten, meist temporären Tabelle vollzogen werden, was wesentlich schneller ist, als würde man in einer großen Zieltabelle satzweise addieren. Durch entsprechende Befehle wird diese kleine Tabelle als neue Partition an die Zieltabelle angefügt, das ist eine sehr schnelle Operation. Bei Löschvorgängen können Partitionen schließlich leicht mit DROP komplett entfernt werden. Notwendige Indexe werden auf der kleineren Tabelle erzeugt. Der gesamte Index der Zieltabelle, bleibt damit unberührt. So läuft auch das Erstellen der Indexe schneller. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 44/166 Verfahren Partition Exchange And Load (PEL) 4.4.5 Skalierungsanforderungen Datenmanagement lösen durch intelligentes In der Vergangenheit wurden gewünschte Leistungssteigerungen oft durch die zusätzliche Bereitstellung von Hardware erkauft. Das Verlagern des Ladeprozesses in die Datenbank ermöglicht intelligente datenbankbasierte Leistungssteigerungen ohne zusätzliche Hardware. Ressourcen - intensive Ladeschritte sind zeitversetzt zu starten. Weniger intensive können parallel gestartet werden. Hierzu ist die Datenbank – interne Prozesssteuerung (Workflow) zu nutzen. In Abhängigkeit von der bereitstehenden Anzahl an Prozessoren kann ein passender Parallelisierungsgrad eingestellt werden (DOP, Degree of Parallelism). Die Steuerung erfolgt sinnvoll ebenfalls durch die Datenbank (PARALLEL_AUTOMATIC_TUNING). Partitionierung von großen Tabellen unterstützt die Parallelisierung zusätzlich. Das geschickte Erstellen von temporären Tabellen ermöglicht Transformationen auf der Basis ganzer Tabellen. Das Laden ganzer Tabellen ist dem Laden über einzelne Sätze vorzuziehen (Mengenbasierte Operationen vs. Satzbasierte Operationen / Set Based versus Row based - siehe unten). Ersetzen von Ladeläufen und künstlichen Objekten durch datenbankeigene Funktionen. o Z. B. Aggregattabellen durch Materialized Views ersetzen spart den separaten ETL - Schritt für das Aufbauen der Aggregattabellen. (Aggregattabellen stellen in vielen älteren Warehouse Systeme eine Option zur Performanceoptimierung dar, indem man Abfrageergebnisse im Vorweg berechnet und speichert. Dies machte Ladeläufe zusätzlich aufwendig. ) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur o 45/166 Das Verwenden von External Tables erspart das 1:1 Befüllen von Stage Tabellen. (Dies ist auch eine Ersetzung des SQL Loaders durch External Tables). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 46/166 4.4.6 Mit verteilten Architekturen den Ladeprozess flexibel halten und Netzlast minimieren Klassische Datenbewirtschaftungslösungen sehen separate Ladeund Transformationsserver vor. Im Sinne einer Hub and Spoke – Hardware - Architektur bündeln sich an einer Stelle alle Quelldaten und verteilen sich von dieser Stelle aus wieder, um die Zieldatenbanken zu versorgen. Diese Architektur hat Nachteile: Zusätzliche Netzlast durch das Ansteuern des Transformationsservers. Dem wird häufig durch hohe Netzkapazität begegnet (zusätzlicher Kostenaufwand durch besondere Hardware). Bottleneck – Situation durch dedizierten Transformationsserver. Alle Datenflüsse laufen über einen Server, der zur schwächsten Stelle der Datenflusskette wird. Die Situation verschärft sich, da die eingesetzten Ladeprogramme lediglich auf eine Einzelsatzverarbeitungslogik hin ausgerichtet sind. Parallelisierung kann man nur durch zusätzlichen Aufwand erreichen. Eine vermeintliche Lösung ist ein weiterer Transformationsserver, mit zusätzlichen Kosten- und Wartungsaufwenden. Die Daten - Situation in den Zieldatenbanken (z. B. Vorhandensein von Sätzen, Zustand von Sätzen usw.) kann bei solchen Lösungen nur durch zusätzliche Leseoperationen auf den Zieldatenbanken festgestellt werden. Damit entsteht weiterer Netzverkehr. Zusätzliche Netzlast bei unnötig vielen Servern (z. B. ETL Server) Die Verlagerung des Transformationsprozesses in die Zieldatenbank liefert zwei entscheidende Vorteile: Der Netzverkehr wird erheblich reduziert. Netzverkehr tritt nur noch im Verlauf des Extraktionsschrittes (Lesen von den Quellsystemen) auf. Die Transformationslast kann schon allein durch das Vorhandensein von Datenbankservern auf mehrere Instanzen verteilt werden, ohne dass zusätzliche Server installiert werden müssen. Ein Netzwerk von Datenbanken teilt Transformationsaufgaben unter sich auf. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 47/166 Verringerte Netzlast bei direkter Verarbeitung von Daten in der Datenbank und Minimierung von Servern 4.4.7 Keine versteckten oder geschachtelte Transformationen verwenden Immer wieder findet man in programmierten Ladeprozessen geschachtelte oder versteckte Transformationen. Gerade in graphischen Editoren für Transformationsmappings werden gerne Operatoren nicht separat definiert, sondern Funktionsaufrufe in den Editorfenstern der Operatoren versteckt. Ein Beispiel ist das Mischen von Join- und Where- Anweisungen. Das in der Datenbank laufende SQL unterscheidet hier nicht, allerdings sollte man in den graphischen Editoren für die verschiedenen Transformationsarten wegen der besseren Dokumentation auch verschiedene Operatoren verwenden. Wird mit separaten ETL – Tools gearbeitet, so muss komplexe Logik dann wieder in die Datenbank verlagert werden. Die Dokumentation wird damit unübersichtlich. 4.4.8 Ladeläufe sollten umkehrbar und wiederholbar sein Es kann immer zu Fehlern kommen. Dabei müssen nicht immer technische Gründe vorliegen, wenn fehlerhafte Daten in das Warehouse gelangen: Eine liefernde Instanz kann Daten zweimal liefern. Die Reihenfolge von gelieferten Datenpaketen kann nicht stimmen usw. Daher gehört es zu dem erfolgreichen Management von Ladeläufen, diese umkehrbar und wiederholbar zu machen. Soll ein Ladelauf umkehrbar sein, müssen die Daten wieder entfernt werden können. Hierzu gibt es grundsätzlich drei Verfahren: Einsatz von Partitioning. Kennzeichnung von geladenen Daten Commit - Setzung 4.4.8.1 Einsatz von Partitioning. Hier werden alle geladenen Daten in eine Partition gestellt, die nach Belieben an die Warehouse – Tabellen angehängt aber auch genauso leicht wieder entfernt werden kann. Nachteilig mag der Verwaltungsaufwand sein, weil nicht nur eine Tabelle über das Partition Exchange and Load (PEL) Verfahren bearbeitet wird, sondern mehrere. Hier müssen Scripte geschrieben werden. Wegen des Aufwands wird man nicht alle Tabellen partitionieren. Das bedeutet, dass man sich für einen Teil der Tabellen (oftmals die Stammdaten) ein anderes Verfahren zum Umkehren aussuchen wird, z. B. die Kennzeichnung der geladenen Sätze. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 48/166 4.4.8.2 Kennzeichnung von geladenen Daten Bei diesem Verfahren ergänzt man die geladenen Sätze z. B. durch eine Ladelaufnummer oder eine Version oder einen Timestamp. Über diese Kennzeichnung identifiziert man bei der Umkehrung alle zu löschenden Sätze. [Hierzu mehr in dem separaten Kapitel „Kennzeichnung von Daten“, siehe dort]. Nachteile dieses Verfahrens sind jedoch die erhöhten Laufzeiten, wenn einzelne Deletes auf die Tabellen abgesetzt werden. 4.4.8.3 Commit – Setzung Die Datenbank erlaubt das gezielte Setzen von Commit – Punkten. So lassen sich eine Reihe von logisch zusammenhängenden Daten komplett verarbeiten oder komplett zurücksetzen. Dieses Verfahren ist allerdings nur bei einer überschaubaren Anzahl von Sätzen sinnvoll, z. B. bei der Verarbeitung von Parent / Child – Paaren. Der Vorteil liegt darin, dass mehrere Tabellen gleichzeitig und automatisiert „zurückgerollt“ werden können und die Datenbank übernimmt den Vorgang kontrolliert. Auch die Delete und Update – Änderungen, die sonst nur sehr aufwendig verwaltet werden können, sind über diesen automatisierten Weg leicht steuerbar. Wird dieses Verfahren eingesetzt muss man besonderen Wert auf kleinere Verarbeitungsschritte legen. Die Größe der Verarbeitungsschritte orientiert sich jetzt an der „Rückroll – Logik“. 4.4.8.4 Umkehrung von Updates und Deletes Ein besonders kritischen Fall stellt die Umkehrung von Updates und Deletes dar. Hier hat man keine andere Möglichkeit, als die von Updates oder Deletes betroffenen Sätze vorher „zu retten“, sie also vorher in eine Art Schattentabelle zu speichern. Das führt immer zu einer Verdoppelung der einzelnen Ladeschritte: 1. Prüfen ob DELETE oder UPDATE stattfinden wird, wenn ja dann Schreiben der zu modifizierenden Zielsätze in eine Schattentabelle. 2. Der eigentliche Ladelauf kann erfolgen. 3. Im Fehlerfall müssen die vorher in einer Schattentabelle stehenden Sätze wieder an den Ursprungsort zurückkopiert werden. 4.4.8.5 Wiederholung von Ladeläufen Wiederholung von Ladeläufen sind in der Regel unproblematisch, sofern die Umkehrung des zuvor fehlgeschlagenen Ladelaufes erfolgreich war. Der eigentliche Ladelauf ist wieder zu starten. Die Frage bleibt, ob der Vorgang automatisiert werden sollte. Die Erfahrung zeigt: nein. Denn es handelt sich in der Regel um Ausnahmesituationen, in denen jeder Schritt genauestens kontrolliert ablaufen muss. Das sollte mit großer Konzentration manuell durchgeführt werden. Der Aufwand dieses zu automatisieren, wäre zu hoch. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 49/166 5 Aufbau der Schichten des Data Warehouses 5.1 Aufbau Sammelschicht / Staging Area Die Staging Area ist die Schnittstellenschicht zu den operativen Vorsystemen des Warehouses. Hier sollten alle Prüf- und Konsolidierungsaufgaben erledigt werden, bevor die Daten in endgültiger Form in die Warehouse – Schicht gelangen. Die Staging – Area ist die eigentliche ETL – Schicht. Hier sind z. B. temporäre Arbeitstabellen zu finden, die in der Warehouse – Schicht nur stören würden. Exemplarische Aufgabenstellungen sind: Abgleich zwischen Bewegungs – und Stammdaten (eventuell Dimensionen im Warehouse nutzen). Prüfung auf o Vollständigkeit der Daten und Mengenverhältnisse. o Gültige Wertebereiche. o Vorhandensein von Referenzdaten. o Eindeutigkeit. o Eliminieren von NULL – Werten. Normalisierung / Granularisierung von operativen Datenstrukturen als Vorbereitung für die Warehouse – Schicht. Zusammenführung von vormals in operativen Systemen getrennten Daten und das Bilden neuer Informationsobjekte. Die Daten in der Stage Area sind: Temporär: Sie werden nach dem erfolgreichen Weiterverarbeiten wieder gelöscht. Deltadaten: Die Stage – Daten stellen nur den für die Aktualisierungsperiode des Warehouses benötigten Bestand der seit dem letzten Ladestand veränderten operativen Daten dar. Bezüglich des Lade – und Transformationsprozesses gelten folgende Empfehlungen: Effiziente Extraktion: Bereits während des Extrahierens aus den Quellsystemen sollte gefiltert und transformiert werden, um den Ladeprozess zu beschleunigen und die Anzahl der Ladeschritte zu verringen (Geringhalten der Komplexität). External Tables sind dem SQL Loader vorzuziehen weil hier zusätzliche Jobaufrufe wegfallen und der Ladeprozess sich einfacher gestaltet. Temporäre Tabellen werden mit der Option CTAS ( Create Table As Select ) erzeugt und gelöscht, wenn sie nicht mehr benötigt werden. Indizes oder Constraints werden in der Regel nicht verwendet. 1:1 Ladeaktivitäten sind zu vermeiden. 5.1.1 Orphan Management Bewegungssätze ohne Bezüge zu den Stammdaten (Orphans) werden nicht in das Warehouse übernommen. Sie sind zu isolieren und separat zu bearbeiten. Es gibt Lösungen, in denen diese Sätze dennoch in die Zieltabellen gelangen. Dann ist jedoch eine Markierung („nicht geprüft“) nötig und letztlich ein Update nach erfolgter Validierung. Das ist ein aufwendiges Verfahren, das man am Besten vermeidet. Erfolgreich in die Warehouse – Schicht geladene Sätze sind aus der Stage – Schicht zu löschen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 5.2 50/166 Aufbau Warehouse Schicht Die Warehouse – Schicht beinhaltet sowohl Bewegungs- als auch Stammdaten. Hier ist die Obermenge aller Daten des gesamten Warehouse – Systems enthalten. In der Regel liegen die Informationen in normalisierter Form vor. 5.2.1 Referenzdaten Ein großer Teil der Informationen besteht aus Referenzdaten. Dies sind allgemeine sog. Wissensdaten, die auch operativ nutzbar sind. Dies sind Informationen, die üblicherweise nicht in den operativen Systemen zu finden sind. Es sind oftmals zugekaufte, statistische Daten, Erhebungsergebnisse, Daten der statistischen Landesämter usw. Diese Informationen können als Referenzdatenhierarchien (Stammdatenhierarchien) abgelegt sein. Es sind einzelne Tabellen die nicht notwendiger weisen zu einem Gesamtkontext gehören. Die Tabellen können sich unter einander durch FK/PK – Beziehungen referenzieren (Hierarchien). Es gelten die Empfehlungen: Sie sollten den Warehouse – Benutzern zugänglich gemacht werden. Da sie für Abfragen zur Verfügung stehen können, sind einzelne Indizes sinnvoll. Referenzdaten sollten nicht ausgelagert sein ( z. B. in Form von Flat Files). 5.2.2 Stammdaten Das sind meist Kopien der Stammdaten aus den operativen Vorsystemen, allerdings in einer konsolidierten Form. D. h. es sind Stammdaten aus mehreren Vorsystemen in einem zusammenhängenden, normalisierten Datenmodell abgelegt. Bei einem gut gepflegten unternehmensweiten Warehouse bietet sich hier die einmalige Gelegenheit Abfragen über Stammdaten des gesamten Unternehmens durch zuführen. Auch diese Daten sollten den Endanwendern zur Verfügung stehen. Diese Einmaligkeit hat in manchen Systemen bereits dazu geführt, dass Fachanwender aus den operativen Unternehmensprozessen eher im das Data Warehouse Informationen such, als in den operativen Systemen selbst. Hier wird das Suchen als weniger aufwendig empfunden, weil die Daten zusammenhängend und strukturiert vorliegen. 5.2.3 Bewegungsdaten Bewegungsdaten entsprechen den Transaktionsdaten der operativen Systeme. Bei dem Umgang mit den Bewegungsdaten in der Warehouse - Schicht müssen Kompromisse gefunden werden. Denn es ist nicht immer einsehbar, warum gerade die voluminösen Bewegungsdaten mehrfach verteilt über die gesamte Warehouse – Schicht vorkommen müssen. Es entstehen folgende Fragen: Welche Bewegungsdaten sind vorzuhalten, die von der aktuellen Ladeperiode oder alle Bewegungsdaten des Historisierungszeitraums, also u. U. mehrere Jahre? Werden Daten des gesamten Historisierungszeitraums in der Warehouse – Schicht vorgehalten, dann sind auch die Stammdaten zu historisieren. Was geschieht, wenn eine Historisierung in der Warehouse – Schicht bereits vorgenommen wurde, mit den Data Marts? Weiter unten wird hierzu ein pragmatischer Vorschlag gemacht, wonach in der Warehouse – Schicht nur die aktuelle Ladeperiode vorgehalten und nicht historisiert wird. 5.2.4 Historisierung in der Warehouse – Schicht Da Warehouse – Systeme historische Zustände in den Unternehmen messen, muss auch die Situation der Stammdaten zu unterschiedlichen historischen Zeiten Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 51/166 nachvollzogen werden können. Hierzu gibt es Historisierungsverfahren (Slowly Changing Dimensions), die an dieser Stelle nicht näher beleuchtet werden sollen. Bezüglich der Architektur ist, wie bereits erwähnt, eine Entscheidung zu treffen, wo die Stammdaten historisiert werden. Dies kann in der Warehouse – oder Data Mart – Schicht geschehen. [Siehe hierzu separates Kapitel.] Referenzdaten werden nicht meist nicht historisiert. 5.2.5 Abgrenzung zum Operational Data Store Operational Data Stores bieten einfache, schnelle Datenzugriffe für Mitarbeiter aus den operativen Unternehmensprozessen. Ein solcher Operational Data Store hat jedoch wenig Zweck, wenn bereits die Warehouse – Schicht sehr einfache Zugriffe erlaubt, weil sie z. B. keine Historisierung hat und nur Daten der aktuellen Berichtsperiode enthält. 5.2.6 Auswertungen direkt in der Warehouse - Schicht Die Daten der Warehouse – Schicht sind für Auswertezwecke nicht optimiert (mit der Ausnahme von Indexen), auch wenn sie für Auswertezwecke zur Verfügung stehen können (vgl. Referenzdatenhierarchien). Die Warehouse Schicht ist für Endbenutzer nicht abgeschottet, gerade die vielen Referenz- und Stammdaten sind für Endbenutzer eine ideale Informationsquelle. Die Bereitstellung der Warehouse – Schicht – Daten für Endbenutzer bedeutet ein Mehraufwand an Hilfestellungen und Vorkehrungen. Datenarten in dem 3 Schichtenmodelle Greifen Benutzer auch auf Daten der Warehouse – Schicht zu, ist es besonders wichtig, dass die Benutzer über alle Strukturen des gesamten Systems (mit Ausnahme der Stage – Schicht) informiert werden. Hier wird die Bedeutung der Metadaten deutlich, die über alle Schichten hinweg dokumentieren. Diese Metadaten müssen auch den Fachbenutzern zur Verfügung stehen. Die Metadaten sind in Form von Metadaten – Browsern bereit zustellen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 52/166 5.2.7 Funktionale Bestandteile der Warehouse – Schicht Neben den vorgenannten strukturellen Aufgaben der Warehouse – Schicht (Datenarten und Datenmodelle) hat sie auch funktionale Aufgaben zu übernehmen. Um Aufwende in den Data Marts zu minimieren, sollten redundanten Aufgaben in den Data Marts einmalig in der Warehouse – Schicht realisiert sein. Das sind: Datenbereitstellungen (ETL – Prozesse). Immer wieder muss beobachtet werden, dass ein und dieselben Informationen in den unterschiedlichen Data Marts mit ähnlichen Transformationen hergeleitet werden. Einmalig erstellte und gepflegte Kennzahlen sowie Standardberichte. Das sind z. B. viele Standard - Ranking – Analysen. Betrifft eine Analyse unternehmensweite Daten, so muss sie nicht immer wieder neu in den Data Marts umgesetzt werden. Einmal in der Warehouse – Schicht tut es auch. Anwendungen von Materialized Views. Metadaten steuern Benutzer auch in die Data Warehouse Schicht, in dem sie Listen der zentral vorgehaltenen Informationen bereithalten. 5.2.8 Security – Aspekte in der Warehouse - Schicht Daraus folgt, dass die Data Warehouse - Schicht für Endbenutzer öffentlich sein muss. Das ist ein Dorn in den Augen mancher Warehouse – Administratoren, die am liebsten die Warehouse – Schicht für Endbenutzer verschließen möchten. Zum Schutz der Daten gibt es jedoch andere Möglichkeiten: Die Verwendung von Synonymen und damit Verweis von einem Datenbankschema in ein anderes. Damit werden nur bestimmte Tabellen für Endbenutzer sichtbar. Die Verwendung von Label Security in der Datenbank. Hier wird ein satzbezogener Schutz in die Tabellen eingebaut. So können „gruppenübergreifende Einblicke“ vermieden werden. Eine Art Mandantenfähigkeit entsteht. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 5.3 53/166 Aufbau Auswerteschicht Die Auswerteschicht des Warehouse – Systems (Data Mart) bedient spezifische Endbenutzeranforderungen, für die die Warehouse Schicht nicht flexibel genug bzw. zu schwerfällig ist. Das sind auch bereits die beiden Hauptanforderungen an die Auswerteschicht: Bereitstellung von ausreichender Abfrageperformance. Endbenutzergerechte Bereitstellung der Abfragedaten (übersichtlich und geschäftsobjektbezogen). Beide Anforderungen sind nur in Abhängigkeit von der Art der Speicherung realisierbar. Da unterschiedliche Endbenutzeranforderungen bestehen, muss die Auswerteschicht auch unterschiedliche Speicherungsmöglichkeiten anbieten. Folgende vier Modellvarianten sollten vorhanden sein: Normalisierte Strukturen – sinnvoll für Referenzdaten, die aus pragmatischen Gründen in der Auswerteschicht und nicht in der Warehouse – Schicht liegen. Starschema – Das Auswertemodell für eine große Anzahl von Detaildaten. Würfelstruktur – Das Modell für komplexe Analysen auf verdichteter Ebene. Gezielte denormalisierte Strukturen für besondere Verwendungen (z. B. Data Mining Tabellen, Exporttabellen für nachgelagerte Verarbeitungen usw.) 5.3.1 Allgemeine Empfehlungen Das bevorzugte Datenmodell in der Auswerteschicht ist das Starschema. Die früher häufig anzutreffenden Aggregattabellen können und sollten heute durch Materialized Views ersetzt werden. Der Vorteil liegt in der Vereinfachung des ETL – Prozesses, da sich Materialized Views selbständig aktualisieren. ETL – Schritte fallen weg. Vorhersehbare Auswertungen, sollten bereits innerhalb der Datenbank vorbereitet werden. Das betrifft in der Regel den größten Teil der Standardberichte. Hier ist zu verhindern, dass größere Datenbestände die Datenbank verlassen müssen, um sie außerhalb aufzubereiten. Standardberichte sollte man mit Hilfe von SQL bzw. analytischen Funktionen und Materialized Views vorformulieren. Das Aufbereiten von Standardberichten ist bereits als Bestandteil des Ladeprozesses zu sehen. In der ganzheitlichen Betrachtung des gesamten Informationsgewinnungsprozesses liegen in der Regel mehr Möglichkeiten auch für die Berichtsaufbereitung. Es entsteht Flexibilität, weil zwischen alternativen Lösungswegen gewählt werden kann. Die Dimensionen leiten sich aus den normalisierten Strukturen der Warehouse Schicht ab. Separate Datenhaltungen für spezielle Auswertungen sollten vermieden werden. Alle zur Auswertung benötigten Daten (auch Data Marts) sollten sich physisch an einer Stelle befinden. o Dies bietet die größere Flexibilität weil vielfältigere Möglichkeiten zur Berichtserstellung gegeben sind. o Es garantiert, dass sinnvolle Datenbank – Features auch tatsächlich genutzt werden und nicht brach liegen. o Bzgl. des Gesamtsystems können Synergien genutzt werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 54/166 5.3.2 Durch Granularisierung mehr Informationsvorrat und damit mehr Flexibilität Früher / Heute: Mehr Flexibilität und Informationsvielfalt durch feinere Granularität Die Granularität der Daten in der Faktentabelle hat eine besondere Auswirkung auf die Informationsvielfalt des Starschemas. Aufgrund technischer Beschränkungen von älteren Datenbank – Releasen wurden in der Vergangenheit oftmals für unterschiedliche Abfrage – Level mehrere Faktentabellen gewählt oder sogar Aggregattabellen gebildet. Heute detailliert man Daten wesentlich stärker. In vielen Starschemen liegen die Daten der Faktentabelle auf dem Level operativer Transaktionen. Das spart einerseits aufwendige Aggregationen in dem ETL – Verfahren schafft aber andererseits ein Mehr an Auswertungsflexibilität. Auf ein und dieselbe Faktendatenstruktur können Abfragen mit unterschiedlichen Verdichtungen abgesetzt werden. Um dennoch das Aggregieren nicht zum Abfragezeitpunkt durchführen zu müssen, sind Materialized Views eingerichtet, die die klassischen Summentabellen oder separaten Faktentabellen ersetzen. Können alle Abfragen über eine einzige Faktentabelle erledigt werden, so ist das Starschema wesentlich effizienter. Abfragen können über beliebige Verdichtungsstufen (GROUP BY) auf die selben Objekte formuliert sein. Früher/Heute: Ineffiziente, ältere Strukturen zur Bereitstellung mehrere Granularitätsebenen Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 55/166 Schließlich können mit granularisierten Starschemen mehr Zielgruppen angesprochen werden (siehe dort) ohne dass zusätzlicher Aufwand betrieben werden muss. 5.3.3 Data Mart Die Auswerteschicht kann aus mehreren Data Marts bestehen. Ein Data Mart ist lediglich eine logisch verstandene Zusammenfassung für einen Unternehmensoder Prozessausschnitt. Um die Daten in unterschiedlichen Data Marts synchron zu halten, (gleiche Ergebnisse bei Abfragen in unterschiedlichen Data Marts) können Dimensionen auch Data Mart – übergreifen genutzt werden. Es sollte in unterschiedlichen Data Marts z. B. nicht mit unterschiedlichen Partner- oder Kundenstammdaten gearbeitet werden. Die technische Realisierung dieser Anforderung kann schwierig sein, wenn sich Data Marts in unterschiedlichen Systemen (Servern) befinden. Dies ist häufig bei abteilungsbezogene Data Marts der Fall. Hier zahlt sich der Architekturansatz des zentralen Warehouses aus. Hier gibt es zwar fachbezogene Data Marts. Diese sind physisch jedoch innerhalb der selben Datenbankinstanz eventuell sogar innerhalb desselben Datenbankschemas installiert. Eine Hilfestellung für verteilte Data Marts kann die Bereitstellung von dimensionsähnlichen Strukturen in der Warehouse – Schicht sein: Zusammengehörende Datenstrukturen werden als sog. Tabellenhierarchien in der Warehouse Schicht bereits abgelegt. Sie entsprechen den Referenzdatenhierarchien der Warehouse - Schicht. Die Hierarchielevel sind separate Tabellen. Die Tabellen besitzen aber bereits entsprechend ihrer hierarchischen Anordnung FK/PK – Beziehungen. Die Dimensionen der Data Marts sind nachgelagerte Strukturen, die im Rahmen des ETL – Prozesses zu pflegen sind. Einmalige, normalisierte Tabellen der Warehouse – Schicht versorgen und synchronisieren unterschiedliche Data Marts mit verschiedenen Sichten 5.3.4 Starschema Das bevorzugte Datenmodell in der Auswerteschicht ist das Starschema. Es vereint zwei Vorteile: Es ist eine besonders intuitive (auch visuelle) Darstellung von betriebswirtschaftlichen Fragestellungen (Verwendung von geordneten Geschäftsobjekten über die sich Kennzahlen abfragen lassen). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 56/166 Das sog „Browsen“, also das Navigieren über Attribute und Hierarchielevel hinweg, ist in zusammenhängenden flachen Dimensionstabellen eines einfachen Starschemas leichter, als in den normalisierten Ästen eines Snowflake – Modells. Dies vereinfacht auch die Zugriffe für Abfragewerkzeuge. Das einfach strukturierte Starschema lässt sich von wesentlich mehr Auswertewerkzeugen effizienter und leichter auswerten. Daher gewinnt man bei der Auswahl von Auswertewerkzeugen zusätzliche Freiheiten. Das technische verstandene Datenmodell des Starschemas (die Datenbanktabellen) wird durch die Datenbank besonders vorteilhaft unterstützt. Abfragen laufen schneller. Gründe und Hilfsmittel sind: o Wegfall vielen Joins einer normalisierten Struktur o Besondere Unterstützung des Query Rewrite Verfahrens der Materialized Views durch Dimensional Table Objekte in der Datenbank. Sie werden zusätzlich zu den Dimensionstabellen des Starschemas definiert und geben steuernde Hinweise für den Optimizer für das internen Umschreiben der Abfrage – SELECT – Statements. o Einsatz von Bitmap – Indizierung in Verbindung mit dem internen Verfahren der Star – Transformation. Es wird eine ganz bestimmte Reihenfolge der Join – Auflösungen bei Abfragen auf Starschemen eingehalten. o Partitionierung großer Faktentabellen und Join – Partitioning. Hier wird sowohl die Faktentabelle als auch die zugehörige Dimensionstabelle partitioniert und auf der Ebene der Partitionen gejoint was natürlich bei Abfragen schneller ist. Technische Optimierungen der Datenbank für das Starschema gegenüber dem Snowflake, hier im Beispiel die potentiellen Joins zwischen den Tabellen 5.3.4.1 Empfehlungen für den Aufbau der Dimensionen Auch auf die Gefahr hin sich zu wiederholen: Dimensionen sollten aus nur einer physischen Datenbanktabelle bestehen. Das hat zwei Gründe: o Zum einen fallen Joins weg und Abfragen laufen schneller. o Zum anderen ist es eine Hilfe für Endbenutzer und die Werkzeuge, mit denen die Benutzer auf das Starschema zugreifen, es ist einfacher auch eine Tabelle zuzugreifen, als auf mehrere. Alle Dimensionen sollten Verwaltungsattribute haben wie: o o Zuletzt_geaendert_Am Zuletzt_geaendert_Von Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 57/166 Solche Attribute helfen z. B. bei der möglichen Nachverfolgung von fehlerhaften Einträgen. Dimensionen sollten einfach und überschaubar sein. Damit unterstützt man den Endanwender. Nicht häufig genutzte Attribute sollten entweder komplett aus dem Starschema entfernt oder in eine separate Dimension ausgelagert werden. Auslagern von häufig genutzten Attributen einer Dimension in eine zweite schafft Übersichtlichkeit und u. U. auch eine bessere Abfrageperformance Code – Attribute sollten vermieden und durch sprechendere Attributinhalte ersetzt werden (Beispiel Artikelnummer/Artikelbeschreibung). Codes sind hilfreich für operative Systeme aber nicht für Auswertesysteme. Sprechende Attributnamen und Inhalte unterstützen die Orientierung des Benutzers. Hier ist zu berücksichtigen, dass Auswertewerkzeuge Attributinhalte im Verlauf der Auswertung als Abfragekriterium verwenden und dynamisch anzeigen (Umbenennung von Attributen). Wählt man bereits für die Tabellen in der Datenbank sprechende Attributnamen, so müssen die Auswertewerkzeuge nicht mehr „umcodieren“, auch wenn es ein noch so nettes Feature in den Tools ist. Hierarchielevel innerhalb der Dimensionen sind durch Präfixe zu kennzeichnen. Dies erleichtert die Zuordnung. Auswertewerkzeuge sollten eine eigene graphische Darstellung für Hierarchielevel besitzen, um dem Endbenutzer die Navigation innerhalb der Dimension zu erleichtern. Operativ genutzte Daten sollten in separate Tabellen ausgegliedert werden. Z. B. sollten Adressdaten nicht in Kundendimensionen enthalten sein. Das wäre zu unübersichtlich. Hierfür verbindet man die Dimension über eine 1:1 Beziehung mit der separaten Tabelle. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 58/166 Auslagern von operativ genutzten Attributen (z. B. Adressdaten) in eine von der Dimension abhängigen Tabelle (1:1 Kardinalität) Dimensionen, die nur ein Attribut beinhalten, können auch in die Faktentabelle verlagert werden. Dimensionen sollten bereichserläuternde bzw. zusätzlich qualifizierende Informationen beinhalten. Z. B. Zeitbezüge in der Zeitdimension wie „Letzter Tag im Monat / im Quartal“ oder „zugehoerig zu Hauptverkaufsgebiet“ oder „Produkt Kategorie A“. Solche Informationen vereinfachen die späteren Abfragen der Benutzer. Die Hierarchielevel sollten sich durch eindeutige 1:N Zugehörigkeiten auszeichnen. Die 1:N Kardinalität ist zu prüfen. Parallel Hierarchien, d. h. Hierarchien mit demselben Primary Key – bildenden Attribut, sollten in einer Dimension zusammengefasst sein, anstatt mehrere daraus zu bilden, es sein denn, es ist bewusst so gemacht worden, um die Übersichtlichkeit zu erhöhen. 5.3.4.2 Indizierung und Schlüssel beim Aufbau der Dimensionen Die Struktur des Primary Keys einer Dimension kann sowohl Auswirkungen auf die Abfrageperformance im Starschema haben, als auch die Komplexität des Ladeprozesses beeinflussen. Grundsätzlich muss über einen Primary Key die Eindeutigkeit aller Sätze der Dimension garantiert sein. Nur so ist eine reibungsfreie Zuordnung von Sätzen der Faktentabelle zur Dimension gewährleistet. Aus der klassischen Datenmodellierung können bereits Regeln für den Aufbau von Primary Keys entnommen werden: Kurz und einfach benutzbar (Speicherplatz sparen! Fehler vermeiden!). Nach Möglichkeit nicht zusammengesetzt (lesende Programme, die später über die Schlüssel zugreifen wollen, müssen entsprechende Werte zu allen Schlüsselkomponenten zusammensuchen). Gerade unbedarfte Benutzer, die mit Auswertewerkzeugen auf Dimensionen zugreifen wollen, müssen unnötig viele Informationen parat haben, um zu eindeutigen Abfragekriterien zu gelangen. Es sollten keine Felder gewählt werden, die eventuelle NULL-Werte beinhalten können. NULL - Werten sind nicht mehr eindeutig. Die Column – Werte sollten stabil und nicht ständigen Änderungen unterworfen sein (z.B. ändern sich Nachnamen durch Eheschließung). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 59/166 5.3.4.3 Künstliche und originäre Schlüssel Die einfachste Variante der Primary Key – Bildung ist die Verwendung von künstlichen Schlüsseln. Sie erfüllen am ehesten die vorgenannten Anforderungen und sind schnell im Rahmen des ETL – Prozesses über Sequenz – Datenbankobjekte gebildet. Künstliche Schlüssel neutralisieren zudem die unterschiedlichen Ausprägungen der originären Schlüssel, die in Stammdaten vorkommen können. Ein – und dieselbe Stammdateninformation kann in unterschiedlichen operativen Systemen über unterschiedliche Bezeichner (originäre Schlüssel) identifiziert sein. Das Data Warehouse muss diese synonymen Information zusammenführen und über einen neutralen (künstlichen) Schlüssel neu identifizieren. Der künstliche Schlüssel ist der gemeinsame Nenner. In der Regel ist der Primary Key der Dimensionen ein künstlicher Schlüssel. In den Auswertewerkzeugen sind solche künstlichen Schlüssel vor dem Endbenutzer zu verbergen, da sie keine fachliche Information beinhalten. Die Abfrageperformance ist durch die Wahl von künstlichen Schlüsseln nicht berührt. Künstliche Schlüssel führen allerdings zu Mehraufwand im Ladeprozess. Bewegungsdaten kennen den künstlichen Schlüssel in den Dimensionstabellen nicht. Bei dem Einfügen der Bewegungsdaten in die Faktentabelle muss jeder Satz um den neuen künstlichen Schlüssel aus der entsprechenden Dimensionstabelle ergänzt werden. Hierzu ist eine Leseoperation in die Dimensionstabelle nötig. Die Dimensionstabelle besitzt hierfür korrespondierende Felder über die die Entsprechung von künstlichem zu originärem Schlüssel abfragbar ist. Das sind meist die Originalschlüssel. Das Lesen der künstlichen Schlüssel aus den Dimensionstabellen sollte mittels Join erfolgen (Set Based). Je mehr synonyme Verwendungen in den operativen Systemen stattfinden, um so mehr Vergleichsfelder bzw. künstliche Schlüssel beinhalten die Dimensionstabellen. Liegen einmalige, kaum veränderliche originäre Schlüssel vor, so ist u. U. die Vergabe von künstlichen Schlüsseln nicht nötig. Das vereinfacht das ETL Verfahren. Unterschiedliche Verwendung von Stammdatenschlüsseln in verschiedenen Anwendungen und die Notwendigkeit der Umschlüsselung Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 60/166 5.3.4.4 Verwendung von Btree und Bitmap – Indizes Bei einem Bitmap – Index wird im Gegensatz zu einem Btree – Index für jedes Vorkommen eines Attributinstanzwertes ein „Bit“, also eine 1 verbunden mit dem entsprechenden Pointer gesetzt. D. h. dass Instanzwert ein „Bitstrom“ existiert. Da es sich hier sehr computergerechte Speicherungsform handelt (die inhaltliche Information ist ja bereits auf 1 und 0 heruntergebrochen) handelt es siech hier um einen sehr schnell lesbaren Index, während der Btree – Index ganze „sprechende“ Begriffe indiziert. Nachteil des Bitmap – Index ist die Tatsache, dass je nach Anzahl der unterschiedlichen Instanzen in einem Attribut (Column), es auch viele einzelne Datenströme geben muss. Eine Performanceabhängigkeit von der Menge ist gegeben. Es gelten die Regeln: Auf Columns mit geringer Kardinalität und häufigen Einschränkungen in Where – Klauseln sollten Bitmap – Indizes gelegt werden. Hier gilt ein Wert von 5% Wertvorkommen pro Anzahl Sätze in der Tabelle. Kandidaten für Bitmap – Index im Starschema Dies betrifft meist die Columns der Dimensionen, die am weitesten außen liegen. Sehr stark denormalisierte Strukturen sind Kandidaten für Bitmap Indizes (vorausgesetzt, sie kommen in Abfragen vor). 5.3.4.5 Empfehlungen für den Aufbau der Faktentabelle Granulare Daten. Die heutige Datenbanktechnologie erlaubt das Aufbauen auch von sehr großen Faktentabellen. Deswegen können bei ausreichender Performance auch viele Detaildaten in den Faktentabellen gespeichert werden. Faktentabellen sollten so granular wie möglich aufgebaut sein. Das gibt mehr Spielraum für beliebige Aggregationen entweder zum Abfragezeitraum oder als Materialized Views. Das bedeutet als Konsequenz: o o keine separaten Faktentabellen aufbauen nur um eine zusätzliche Aggregatschicht zu gewinnen keine separaten Faktentabellen aus Performancegründen Separate Faktentabellen sollten erstellt werden, wenn nicht voneinander ableitbare Kennzahlen vorliegen, also keine berechenbare Bezüge herstellbar sind. Unterschiedliche Faktentabellen sollten über gemeinsam genutzte Dimensionstabellen in Bezug zu einander gesetzt werden können, um sogenannte Drill Across – Abfragen zu ermöglichen. Das sind Abfragen die über mehrere Faktentabellen gleichzeitig Daten beziehen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 61/166 Die PK/FK Datenkonsistenz zwischen Fakten- und Dimensionstabellen ist zu prüfen. Diese stellt Hilfsmittel zur Performanceoptimierung für den Datenbank – Optimizer dar. Die Faktentabelle besitzt keinen eigenen Primary Key und entsprechend auch keinen Primary Key – Constraint. Es sind also auch Sätze mit identischen Feldinhalten erlaubt, was bei Bewegungsdaten fachlich nicht falsch sein muss. Alle durch die Dimensionstabellen in die Faktentabelle migrierten Foreign Keys werden einzeln mit einem Bitmap Index belegt. Dies sollte einheitlich erfolgen, d.h. von der Regel sollte auch dann keine Ausnahme gemacht werden, wenn die Kardinalität einzelner Spalten die erwähnte 5 % Grenze überschreitet. Diese Regel ist wichtig, um das Funktionieren der Startransformation zu garantieren. Ohne Bitmapindizierung in der Faktentabelle funktioniert diese nicht. Faktentabellen sind die Hauptkandidaten für Partitionierung. Schlüsselbildung im Starschema 5.3.4.6 Satzübergreifende Konsistenz in der Faktentabelle Die Sätze in der Faktentabelle sollten die gleichen Informationen beinhalten. Vermieden werden sollte die Notwendigkeit mehrere Sätze lesen zu müssen, um alle Informationen zu einem Sachverhalt zu bekommen. Beispiel A: Auf mehrere Sätze verteilte Informationen Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 62/166 In Beispiel A muss die Auswertung zunächst 2 Sätze lesen, bevor die vollständige Information zu Plan- und Ist-Kosten des Arbeitsgangs vorliegen. In Beispiel B ist die Information bereits nach dem lesen eines einzigen Satzes vorhanden. Beispiel B: Alle Informationen sind in einem Satz konzentriert Diese Vorgehensweise minimiert die Aufwände für die Auswertewerkzeuge. In manchen Einsatzfällen kann es vorkommen, dass die vollständige Information zu einem Satz nur über mehrere Ladenläufe hinweg zur Verfügung steht. In diesem Fall müssen die Sätze nach und nach mit Update – bearbeitet werden auch wenn Updates teuer sind. (In dem neuen Datenbank Release 10 g sind Update – Operationen mengenbasiert möglich. Das steigert die Performance.) Eine andere Variante ist das erstellen einer temporären Zwischentabelle. 5.3.5 Einsatz von Materialized Summentabellen Views anstelle von Frühere Warehouse – Systeme bestanden zu einem großen Teil aus Summentabellen. Sie waren oftmals das Herz der Systeme. So war auch eine der häufigsten Erwartungen an die Systeme, dass die wesentlichen Informationen nur in Form von Summentabellen an die Benutzer geliefert werden können. Gedankliche Synonyme „Warehouse = aggregierte Daten = Summentabellen“ waren an der Tagesordnung und wer Daten auf Transaktionslevel ins Warehouse lud, hatte einen methodischen Fehler gemacht. Die Zeit ist vorbei. Längst hat man erkannt, dass der Grad der Granularität wesentlich zur flexiblen und vielfältigen Verwendung der Systeme beiträgt. Die Notwendigkeit Daten zu verdichten, um Informationen in Sekundenschnelle liefern zu können, ist jedoch geblieben auch wenn die Datenbank heute mit wesentlich mehr Daten auf feinerem Level umgehen kann. Für die Oracle Datenbank heißt heute die Empfehlung Materialized Views zu verwenden. Die klassischen Summentabellen haben ausgedient. 5.3.5.1 Vorteile von Materialized Views im Warehouse – Kontext Wegfall eines gesonderten ETL – Schrittes. Die Datenbank aktualisiert die Materialized Views im Hintergrund. Vereinfachung des Workflow / Scheduling, da die Datenbank das Aktualisieren automatisiert übernimmt. Gibt es kein Ladeprogramm, das die Summentabellen aktualisiert, dann muss es auch nicht aufgerufen werden. Transparenter Aufruf. Die Ansteuerung (der Aufruf) geschieht durch den Endbenutzer transparent. Der Benutzer weiß nichts von der Existenz der Materialized Views. Das Datenbanksystem analysiert nur die Informationsanforderung des Benutzers und versucht diese mit dem Informationsangebot des Materialized Views in Deckung zu bringen. Die Notwendigkeit und der Bedarf für eine Materialized View wird durch das System festgestellt. Der Gebrauch wird über Datenbankstatistiken gemessen. Minimierung der Anzahl der Objekte. Die Gesamtanzahl der Objekte wird kleiner. Bei Summentabellen musste für jede verdichtete Abfrage aufgrund der notwendigen textlichen Gleichheit von Abfrage und Tabellendefinition eine separate Summentabelle erstellt werden. Das hat in der Vergangenheit zu dem hohen Anteil von Summentabellen an dem Gesamtsystem von bis zu 50 % geführt. Materialized Views können von mehreren Abfragen mit unterschiedlichem Informationsbedarf gleichzeitig genutzt werden. Denn es Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 63/166 zählt nicht die textliche Gleichheit, sondern die Gleichheit der Information, auch wenn diese nur in Teilen vorhanden ist. Synchronisierung bei Datenänderung. Bei separaten Summentabellen besteht immer die Gefahr, dass die in den Summentabellen gespeicherten Informationen nicht mehr stimmen, weil sie nicht richtig synchronisiert sind. Für die Aktualität der Daten muss das Warehouse – Management mit einer Reihe von Hilfsmitteln sorgen. Dazu gehören regelmäßiges Scheduling und Zeitstempel in den Daten, die besagen wann die Daten zuletzt aktualisiert wurden. Ob sich die Basisdaten geändert haben oder nicht, muss das Warehouse Management dann schon irgendwie wissen. Das Verfahren ist komplex und fehleranfällig. Ein großer Teil der Projektarbeit wurde in der Vergangenheit für die Planung und das Design eines solchen Warehouse Managements verwendet. Bei Materialized Views sorgt die Datenbank für die Synchronität von Basisdaten und Viewdaten. Der Materialized View wird durch das Datenbanksystem als nicht mehr gültig deklariert und kann aktualisiert werden. Wegfall von Summentabellen spart ETL - Schritte und schafft mehr Flexibilität Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 64/166 5.3.6 Bedienen unterschiedlicher Zielgruppen im Unternehmen In Unternehmen entstehen sehr schnell auseinanderdriftende Erwartungen der verschiedenen Benutzergruppen. Fachmitarbeiter brauchen eher Detaildaten während das strategisch handelnde Management verdichtete Informationen benötigt. Aus dieser Situation heraus sollte man jedoch nicht für jede Zielgruppe eine separate Datenhaltung bzw. Datenhaltungsobjekte erstellen. Dies führt zu einem unnötig komplizierten System. Die Datengrundlage sollte für alle Zielgruppen die selbe sein. Schließlich sind es die sehr granularen Faktendaten, mit deren Hilfe unterschiedliche Benutzergruppen ansprechbar sind. Unterschiedlich verdichtete Sichten werden durch granulare Faktendaten erreicht. Sichten auf unterschiedlichen Verdichtungsebenen (verschiedene Verwendungszwecke/Zielgruppen) sollten über sich selbst aktualisierende Materialized Views bereitgestellt werden. Materialized Views können als Schichten angelegt sein. D. h. eine erste Schicht umfasst Abfragen direkt auf den Fakten und Dimensionstabellen. Ein zweite Schicht beinhaltet Materialized Views, die auf der ersten Schicht aufsetzen usw.. Verdichtungen werden also selbst noch einmal verdichtet bzw. , und das ist der Hauptzweck, verdichtetet Daten können neu miteinander kombiniert werden. Sicherheitsrelevante Daten sollten auf Satzebene geschützt werden (Label Security). Security – Anforderungen sollten nicht durch Vermehrung von Tabellen. Hier sieht man, dass das Metadaten Management wichtig wird. Die in den Materialized Views besonders performant abfragbaren Informationen sollten dokumentiert sein. Das sind letztlich die Kennzahlenlisten die über einen Metadaten – Browser anzuzeigen sind. Erstellung von aggregierten Sichten auf der Basis von granularen Faktendaten und Bereitstellung für unterschiedliche Zielgruppen Letztlich geht es immer wieder um ein und dieselben Daten bzw. Informationen. Sie werden für unterschiedliche Benutzergruppen und Anwendungsfälle unterschiedlich verdichtet und aufbereitet. Der Kostenvorteil, der bei dieser Vorgehensweise entsteht, kann nicht oft genug wiederholt werden. Dadurch, dass die Materialized Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 65/166 Views ihre Daten selbst aktualisieren, entsteht für die Bedienung der unterschiedlichen Zielgruppen kein Mehraufwand. Es fallen keine separaten ETL – Schritte an. 5.3.7 Umgang mit großen Faktentabellen Data Mart – und Data Warehouse - Schicht beinhalten redundante Datenmengen. In der Warehouse – Schicht sind nahezu normalisierte Informationen abgelegt, die in den Data Marts als denormalisierte Daten wieder vorkommen. Diese Redundanz ist für die kleineren Dimensionstabelle bzw. Referenz – und Stammdaten unproblematisch. Die Bewegungsdaten in den großen Faktentabellen sollten jedoch nicht doppelt vorgehalten werden. Die Faktentabelle ist die Sammelstelle der historisiert beobachtbaren Bewegungsdaten, also aller Bewegungsdaten eines Betrachtungszeitraums. In einem regelmäßig mit aktuellen Daten beladenen Warehouse wachsen gerade die Faktentabellen kontinuierlich, während alle andere Tabellen kein bzw. wenig Wachstum haben. Die historisierten Bewegungsdaten, also die Daten der Faktentabelle, sollten nur einmal in den jeweiligen Data Marts enthalten sein. Nach Möglichkeit ist die Faktentabelle direkt, ohne viele Zwischenwege, zu befüllen. Die Warehouse – Schicht sollte allenfalls die Bewegungsdaten einer letzten Ladeperiode enthalten. Große Faktentabellen sind im Data Warehouse nur einmal vorhanden Generell ist das Zusammenführen von Datenressourcen zu empfehlen. Siehe hierzu auch den Abschnitt „Mehrfachverwendung von Bereichen und Objekten“. 5.3.8 Die Verwendung multidimensionaler Speichermodelle im Data Mart Mit dem Release 9 der Oracle Datenbank ist die multidimensionale Datenbank Express ein fester Bestandteil der Oracle Datenbank geworden. Damit können zwei physische Speichermodelle mit den gleichen Mitteln innerhalb derselben Umgebung genutzt werden (SQL – Zugriff, analoge Metadaten usw.). Das Mehr an Möglichkeiten erfordert auch Entscheidungskriterien unter welchen Bedingungen welche Technologie am sinnvollsten einzusetzen ist. Bereits sehr früh hat sich bei Business Intelligence Systeme ein physisches Speichermodell am Markt etabliert, das ganz besonders auf die interaktive, breit Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 66/166 angelegte Datenanalyse zugeschnitten war. Dies ist leicht zu erklären, denn die älteren relationalen Datenbanksysteme waren ursprünglich primär für das Speichern großer Datenmengen und das zielgenaue, sehr schnelle Zugreifen und Ändern einzelner Sätze entwickelt worden. Die Datenbanken mussten im Hintergrund von Online – Anwendungen blitzschnell die Daten bereitstellen. Optimale Zugriffspfade für einzelne Informationseinheiten mussten berechnet und optimiert werden. Die Informationen für die Anfrage „Liefern aller Bestellungen des Kunden X“ sind im schlechtesten Fall auf zwei Tabellen verteilt. Mit einer geschickten Indizierung war die Antwort in einem Bruchteil einer Sekunde im Speicher, und musste nur in die Bildschirmmaske kopiert werden. Analytischen Abfragen funktionieren jedoch anders. Es sind nicht einzelne Informationseinheiten, sondern Gruppen von Informationen (Satzmengen). Und auch hier interessieren nicht die einzelnen „Mitglieder“ der Gruppen, sondern die Gruppeneigenschaften als „Kenngröße“ oder Kennzahl. Es interessiert der Gesamtumsatz (eine Summierung als ein Wert) pro Kundengruppe (viele Einzelwerte). Was lag näher, als genau für diese Anforderung ein System zu erstellen. Es entstanden sog. multidimensionale Datenbanken (Würfelsysteme), die den „einen Ergebniswert“ – im Beispiel den aggregierten Gesamtumsatz – in den Mittelpunkt stellten. Die einzelnen Gruppenvertreter (operative Einzelsätze) waren unwichtig (das war die Domäne der operativen Welt), wichtig war die eine Kennzahl als Eigenschaft der Gruppe (aller Einzelsätze). Ein Datenbanksystem, das diese Prämisse in den Vordergrund stellt, kann wesentlich leichter und schneller mit potentiellen und bereits gespeicherten Analyseergebnissen umgehen, als ein System, das die Analyseergebnisse erst noch berechnen muss. Auch im relationalen Speichermodell (z. B. Starschema) gelingt dies, wie wir bereits gesehen haben, mit Hilfe von Materialized Views. Allerdings müssten für alle theoretisch möglichen Abfragen Materialized Views zur Verfügung stehen, was unpraktisch sein kann. Das multidimensionale Modell hält Abfrageergebnisse bereits vor. Auf der Basis dieser Ergebnisse können leicht und flexibel weitere Analyseschritte folgen 5.3.8.1 Sparsity Diese multidimensionale Speichersysteme (MOLAP) halten an den Schnittpunkten der jeweiligen Dimensionsattributwerten bereits deren gültige Ergebnisse vor. Allerdings treten bei komplexen Dimensionen mit vielen Attributen und Attributeinstanzen auch eine Vielzahl Kombinationsmöglichkeiten auf, so dass für eine hohe Zahl von Schnittpunkten kein sinnvoller Ergebniswert zustande kommt. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 67/166 Dieses Phänomen nennt man Sparsity und stellt eine Beschränkung oder zumindest eine besondere Herausforderung der multidimensionalen Datenbanken dar. 5.3.8.2 Multidimensionale Speicherzellen und Materialized Views Aufgrund der besonderen Machart der multidimensionalen Datenbanken, speicherte man an den Schnittpunkten keine Einzelinformationen, sondern bereits aggregierte Informationen. Das reichte für die Zwecke der Analyse auch vollkommen aus, da nur die Eigenschaften von ganzen Gruppen und nicht Einzelinformationen interessierten. Mit der Bedeutung und der Marktrelevanz von Data Warehouse Systemen haben die relationalen Datenbanken wie Oracle, viele Funktionen erhalten, mit denen sie mit großen Datenmengen ebenfalls schnell hantieren können. Letztlich geht es darum gruppenbezogene Informationen (Aggregationen) schnell zu erhalten und diese für eine weitere Bearbeitung (Analyse) dem Benutzer zur Verfügung zu stellen. Wenn relationale Datenbanken mit aggregierten Informationen (Gruppeneigenschaften) so einfach hantieren können wie die multidimensionalen Datenbanken, dann übernehmen sie mehr und mehr die klassischen Aufgaben der MOLAP – Systeme. Um dieses Ziel zu erreichen hat die Oracle Datenbank die Materialized Views eingeführt. Eine Ergebniszeile eines Materialized Views entspricht einer Zelle der multidimensionalen Datenbank. Materialized Views sind physische Speicherungen von zuvor ermittelten Ergebnissen – also Aggregate. Damit hat man Ergebnisse, mit denen man beliebig weiter operieren kann, d. h. also auf deren Basis neue Analysen aufsetzen können. Das Sparcity – Problem der multidimensionalen Datenbanken lösen Materialized Views dabei automatisch, denn bereits bei der Erstellung der Views werden nur solche Sätze in den View aufgenommen, die eine sinnvolle Ergebniskombination darstellen. Allerdings liefern Materialized Views immer nur einen Ausschnitt der in einem Datenmodell angebotenen Informationen, denn man wird immer nur für diejenigen Informationen Materialized View definieren, für die stärkste Nachfrage bei Anwender besteht. Fragen Anwender einen nicht vorbereiteten Informationsbereich ab, so kann eine Abfrage schon mal länger dauern. Das wird bei der multidimensionalen Speicherung nicht geschehen, da dort alle Informationen in dem Definierten Würfelraum fast gleichschnell abfragbar sind. 5.3.8.3 Komplexität von Strukturen und Abfragen Es gibt eine Reihe von Einzelfällen, bei denen sich die multidimensionale Speichertechnik nach wie vor als vorteilhaft erweist. Hier zwei exemplarische Fälle: 5.3.8.3.1 Umgang mit unbalancierten Hierarchien Die Dimensionshierarchien können unterschiedlich strukturiert sein. Aus relationaler Sicht ist eine nach oben gleichmäßig verlaufende n:1 Hierarchisierung am leichtesten abzubilden. D. h. 1 bis n Instanzen eines unteren Hierarchielevels gehören zu genau einer Instanz des darüber liegenden Levels. Für alle übrigen Instanzen des unteren Hierarchielevels lässt sich die gleiche Regel aufstellen. In der realen Welt sind jedoch nicht alle Hierarchien so gleichmäßig strukturiert, wie das folgende Beispiel zu Kostenstellen zeigt. Kostenstellen können an beliebigen Punkten einer Unternehmenshierarchie platziert sein und sie können beliebig viele Hierarchiestufen über sich haben. Ähnliche Beispiele gibt es bei Stücklisten oder Produktgruppenhierarchien. Bei genauer Betrachtung kommen unbalancierte Hierarchien eher häufiger vor, als gleichmäßig strukturierte. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 68/166 Beispiel für eine unbalancierte Hierarchie In der relationalen Speicherung mit Hilfe des Starschemas werden fehlende Lücken in den oberhalb liegenden Hierarchieknoten durch das „Hochkopieren“ der unterliegenden Vertreter ausgefüllt. Ein Verfahren, das nicht zu 100% der Realität entspricht und ein Verfahren, das zusätzlichen ETL – Aufwand bedeutet. Lösungsverfahren von unbalancierten Hierarchien bei der relationalen Speichertechnik (Starschema) In dem multidimensionalen Speichermodell spielt die n:1 Hierarchisierung keine Rolle. Die Struktur kann frei gewählt werden, weil die Instanzen innerhalb der Hierarchie – Stufen lediglich Platzhalter für Adressen der eigentlichen Kennzahlen (Würfelzellen) sind. Wenn es keine übergeordneten Unternehmensstufen zu einer bestimmten Kostenstelle gibt, dann gibt es eben auch keine Werte (Zellen) dafür. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 69/166 Lösungsverfahren von unbalancierten Hierarchien bei der multidimensionalen Speichertechniken (Starschema) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 70/166 5.3.8.3.2 Komplexe Abfragen mit Zwischenergebnissen Abfragen können mehrstufig sein. Die Ergebnisse eines ersten Abfrageteils können die Grundlage für einen zweiten, dritten usw. Teil sein. Gerade bei Zeitreihenanalysen kommt dies häufiger vor. Beispiel: „Wie haben sich die Top 10 Produkte dieses Jahres in den 3 verkaufsbesten Jahren der letzten Dekade entwickelt?“ Diese Abfrage gliedert sich in die folgenden Teilabfragen: 1. Was sind die Top 10 Produkte dieses Jahres. -> Zwischenergebnis A 2. Was sind die Top 3 umsatzstärksten Jahre aus den letzten 10 Jahren. -> Zwischenergebnis B 4. Unterfragen: a. Welchen Anteil hat die diesjährige Top 1 aus Zwischenergebnis A an dem Topjahreswert 1 aus Zwischenergebnis B b. Welchen Anteil hat die diesjährige Top 1 aus Zwischenergebnis A an dem Topjahreswert 2 aus Zwischenergebnis B c. Welchen Anteil hat die diesjährige Top 1 aus Zwischenergebnis A an dem Topjahreswert 3 aus Zwischenergebnis B d. ....... Für das relationale Speichermodell kann man sich vorstellen, dass Rechenfunktionen in die SQL – Abfrage zum Bilden von Materialized Views eingebaut werden. Die neue SQL - Model – Clause (ab Release 10) erleichtert diese Art der Abfrage ebenfalls. Es ist jedoch leicht einsehbar, dass hier Mehraufwand gefordert ist. Selbst ein sehr gutes Auswertewerkzeug kann an seine Grenzen stoßen. Es wird nötig sein, zusätzlichen Programmieraufwand in der Datenbank zu leisten. Bei der multidimensionalen Speicherung kann man leicht zusätzliche Sichten auf die gespeicherten Aggregate bilden, die selbst wieder Grundlage für weitere Abfragen darstellen. Das geht mit der multidimensionalen Speicherung effizienter. Wichtig ist auch, dass ein Benutzer die oben dargestellte Beispielabfrage durch eigenes Zutun und spontan entwickeln kann. Modifiziert er nur einen Ast der Abfrage, so kann er dies „On the Fly“ tun. 5.3.8.4 Gegenüberstellung multidimensionaler und relationaler Datenhaltung Die oben gemachten Unterscheidungen helfen, um die Einsatzgebiete von multidimensionaler und relationaler Datenhaltung besser einschätzen zu können. Hier noch einmal eine Zusammenfassung. Multidimensionale Datenhaltung Relationale Datenhaltung Metadatenbeschreibung und Datenhaltung Quelle und Definition Dimensionen CWM Dimensionen Measures Datenhaltung Cubes Fest gespeicherte Werte. CWM Dimensional Tables Objekte in der Datenbank und echte Tabellen. Fakten Materialized Views oder direkt Tabellenwerte. Charakter der Daten Datenlevel Es machen eher aggregierte Daten Sinn Copyright © 2005 by Oracle Corporation. All rights reserved Granulare Daten, in der Nähe der operativen Bewegungsdaten. Data Warehouse Referenzarchitektur Sparsity Flexibilität des Metamodells Struktur der Dimensionshierarchien Ableitung von Werten 71/166 Muss gesondert behandelt werden. Vorsorge ist notwendig. Tritt nicht auf. Frei wählbar, auch unbalancierte Hierarchien. Geringer Aufwand beim Datenladen. Nur parallele Hierarchien, unbalancierte Hierarchien müssen gesondert behandelt werden. Mehraufwand beim Datenladen. Spalteninhalte können durch eingebettete Funktionen abgeleitet werden. Einschränkungen beim Zusammenspiel mit Materialized Views. Zelleninhalte können „On the Fly“ berechnet werden“. Erleichtert besondere Funktionalität der Planung und der Simulation. Aktualisierung der Daten Muss speziell getriggert werden. Expliziter Ladeschritt nötig. Voll - Load bzw. Teilbereiche. Benutzersicht und Einsatzbereiche Wahlfreie Analyse Innerhalb des bereit gestellten Datenraums (Würfel) uneingeschränkte Auswahl der Datenobjekte. Benutzer mit möglichst hoher Bewegungsfreiheit und einem sehr hohen Anteil an interaktiven, schnellen Analyseschritten. 5.3.8.5 Bei Materialized Views automatisch ohne zusätzliche ETL – Schritte. Inkrementell. Hohe Performance nur bei den entsprechend vorbereiteten Daten. Es kann passieren, dass Benutzer Abfragen formulieren, für die keine Performanceoptimierung (MAV) vorbereitet worden ist. Benutzer mit eher standardisierten und immer wiederkehrenden Abfragearten. Regeln im Umgang mit multidimensionaler und relationaler Datenhaltung Folgende Regeln gelten im Umgang mit multidimensionaler und relationaler Datenhaltung: Unabhängig von der Art der physischen Speicherung sollte immer von nur einem Metadatenmodell ausgegangen werden. Die Metadatenstruktur von beiden Varianten ist gleich. Sie wird am leichtesten mit Oracle Warehouse Builder (OWB) erzeugt. Aus dieser Definition lassen sich sowohl alle Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 72/166 relationalen als auch alle multidimensionalen physischen Objekte sehr leicht herstellen. Bei häufig sich ändernden und ständig nachgeladenen Daten eignet sich eher die relationale Speicherung. Bei sehr granularen Daten und Daten mit operativer Nähe eignet sich eher die relationale Speicherung. Der Grad der Interaktivität und Komplexität der Abfragen ist entscheidend für Wahl zwischen beiden Speichermodellen. Standardberichte oder Informationsabfragen, die im Vorfeld bekannt sind, bedürfen normalerweise keiner multidimensionalen Speicherung. Hierfür stehen genügend relationale Mittel zur Verfügung. Diese Art der Analyse sollte auch bereits in früheren Phasen der Informationsaufbereitung stattfinden (Data Warehouse – Schicht). Abgrenzung Einsatzbereiche multidimensionale und relationale Speicherung Entscheidung leicht gemacht – Schneller Wechsel zwischen den Systemen Die Unterschiede zwischen den beiden Speichersystemen sind bei fortschreitender Entwicklung der Technologien immer marginaler geworden. Es sind spezielle, sich regelmäßig ändernde Anforderungen, die entweder in die eine oder in die andere Richtung tendieren lassen. Ein starres Festhalten an nur einer Speicherungsform führt nur dazu, alle Anforderungen mit den gleichen Mitteln zu lösen. Das kann nicht in allen Fällen passen. Ideal ist daher eine Mischform beider Technologien. Je nach Situation sollte ein Verfahren multidimensionale oder relationale Technologie nutzen können. Allerdings muss der Wechsel zwischen beiden Technologien vertretbar sein und leicht bewerkstelligt werden können. Also das Aufbauen der jeweils anderen Speicherungsform darf nur geringe Aufwende verursachen. Und das sind: Das Definieren des jeweiligen Modells und Die Bereitstellung von Daten innerhalb der neuen Modellform. 5.3.8.6 Die Oracle Warehouse Technologie ist bislang die einzigste Technik mit der beide Speicherungsarten wie „aus einem Guss“ realisierbar sind. Im Detail: Es sind die Metadaten, die nur ein einziges Mal definiert werden müssen. Aus diesen Metadaten wird die jeweilige Struktur generiert, entweder das relationale Starschema oder der multidimensionale Analytical Workspace. Es sind die Daten, die mit der gleichen Technologie entweder in das Starschema oder in den Analytical Workspace geladen werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 73/166 Die Komponente mit der beides gleichzeitig machbar ist, ist der Oracle Warehouse Builder. Das ist gegenwärtig die einzige Technologie am Markt, mit der diese Mischform so elegant praktizierbar ist. Wechselspiel multidimensionale und relationale Auswertemodelle. Einheitliche Steuerung durch Oracle Warehouse Builder (OWB) Das Schema des Referenzmodells muss folglich um die multidimensionale Technik erweitert werden. Die Tatsache, dass es sich um eine eigene Speicherform handelt führt nicht dazu, von einem separaten Data Mart zu reden. Beide Speicherformen können separat nebeneinander mit den gleichen Zugriffsmethoden (SQL) an dem selben Ort innerhalb des Gesamtsystems existieren. Auch hier wieder ein Plus für die Flexibilität, die Endbenutzern geboten werden kann. Auch hierfür gilt das gleichzeitige Ausnutzen von ETL – Schritten und Hardware – Maschinen [Siehe separates Kapitel]. 5.4 Umgang mit Partitions Partitionen sind an mehreren Stellen des Warehouses hilfreich. Sie können keiner bestimmten Warehouse – Schicht zu geordnet werden, da sie letztlich nur ein technisches Datenbank – internes Hilfsmittel darstellen. Allerdings sind sie wichtige Hilfsmittel, um softwaretechnisch Aufgaben zu lösen, die sonst nur durch mehr Hardwareleistung zu leisten sind. Gründe genug, um sich separat damit zu beschäftigen. Der Partitionierung von Tabellen kommen grundsätzlich sechs sehr unterschiedliche Aufgabenbereiche zu: Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 74/166 Schaffung einer besseren Abfrageperformance. Hier nutzt man die Tatsache, dass bei eingeschränkten Abfragen nur ein Teil der Tabellendaten gelesen wird. Leichteres Management von Datenmengen. Hinzufügen und Löschen von Daten eines bestimmten eingrenzbaren Bereiches. Das ist z. B. das Partition Exchange And Load – Verfahren [siehe separates Kapitel]. Leichtere Wartung. Die Index – Strukturen lassen sich leichter aktualisieren, wenn nur der Index von geänderten Partitionen aktualisiert werden muss. Erhöhung der Verfügbarkeit des Warehouses. Partitionen können separat recovered werden, ohne dass die gesamte Tabelle für Benutzerzugriffe gesperrt werden muss. Erleichterung des Backup und Recovery Verfahrens. B&R – Verfahren können sich Partitions zu Nutze machen, indem sie immer nur die jeweils modifizierten Partitionen sichern. Unberührte Partitionen müssen nicht gesichert werden [siehe separates Kapitel]. Intern unterstützt das Partitioning die Parallelisierungsfähigkeit der Datenbank. 5.4.1 Empfehlungen im Umgang mit Partitionen Bei Abfragen sollte man darauf achten, dass sie möglichst einschränkende WHERE – Klauseln besitzen. Oftmals wird oft nur unbewusst ganz pauschal abgefragt während eine Abfrage z. B. auf die aktuelle Zeitperiode genauso hilfreich gewesen wäre (Selektive Abfragen). Die Anzahl der Partitionen sollte eher hoch gewählt werden, als zu niedrig. Mit einer höheren Anzahl ist zum einen die Wirkung bei selektiven Abfragen höher, da noch kleinere Datenmengen zu lesen sind und zum anderen wird die Parallelisierung der Datenbank besser unterstützt. Bei Sub Partioning sollte man vorsichtig sein. Hier sollte man keine sich widersprechenden Partitionierungskriterien wählen. Die in Unterpartitionen zusätzlich gegliederten Sätze sollten auch nur in der einen darüber liegenden Parent -Partition zusammengefasst sein und nicht noch in anderen Parent - Partitionen vorkommen können. Die besten Abfrageperformance - Werte erzielt man mit einfachem Partitioning. D. h. für Sub Partitioning müssen andere Gründe, als die der Performance, sprechen. Partitions können den einzelnen Platten des RAID – Stripe - Verfahrens zugeordnet werden. Damit ist zusätzlich schnelles Lesen möglich. Die Partitions sollten so gewählt sein, dass sie potentiell möglichst gleich viele Datensätze beinhalten. Eine Partitionierung nach Monaten kann hinderlich sein, wenn es Monate mit extrem vielen Geschäftsaktivitäten und Monate mit weniger Aktivitäten gibt. Wenn 50 % aller Sätze in weniger als 10% der Partitionen liegen, dann ist die Wirkung eingeschränkt. Die Steuerungsmittel für die Partitionen sollten gleich sein. Bei einer Monats Partitionierung kann es z. B. hinderlich sein, dass bestimmte Monate weniger Tage haben als andere. Sind Lade und Prüfläufe auf einen Faktor „Anzahl Tage pro Monat“ eingestellt, ist zusätzliche Logik notwendig, um genau die richtige Anzahl Tage pro Monat zu treffen. Eine Alternative dazu sind Wochen mit einer stets konstanten Anzahl Tage. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 75/166 6 Organisation und Aufbau von Ladeläufen und Transformationen 6.1 Spezielle Ladeverfahren für einzelne Warehouse – Bereiche 6.1.1 Informationsbeschaffungsprozess in der Übersicht Die Aufgabenstellungen für das Transformieren von Daten im Verlauf des Warehouse – Prozesses sind in den Schichten unterschiedlich. Es lassen sich vier Schritte unterscheiden Entgegennehmen der Daten (Extraktion aus den Quellsystemen) Prüfen und Konsolidieren Normalisieren Denormalisieren Transformationsaufgaben im Verlauf der verschiednen Phasen des Warehouse Prozesses 6.1.2 Entgegennehmen der Daten Hier sind widersprüchliche Ziele zu vereinbaren: Ziel ist es einerseits die Quellsysteme möglichst wenig belasten, andererseits gilt es den Aufwand für die Datenextraktion so gering wie möglich halten. Folgende Regeln sind festzuhalten: Stabile Datenverbindungen (Netzverbindung, Zugänge). Quellsysteme dürfen nicht behindert werden (Keine Performancebeeinträchtigung). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 76/166 Keine schreibenden Zugriffe auf die Quellsysteme Möglichst kurze Ladezeiten. Die vorgenannten Ziele zwingen oft dazu Quelldaten möglichst 1:1 in die Stage – Schicht zu Laden. Dem entgegen steht das Bestreben Ladeläufe generelle möglichst kurz zu halten und z. B. bereits beim Laden in die Stage – Schicht Verarbeitungsschritte durchzuführen. Zwischen diesen beiden Anforderungen muss man abwägen. Die erste Priorität hat hier die sichere Entgegennahme von Daten aus den operativen Quellsystemen. Sicher bedeutet hier, dass stabile Datenverbindungen bereitstehen 6.1.2.1 Prüfen und Konsolidieren: Das Warehouse führt Daten aus getrennten DV-Verfahren bzw. Unternehmensprozessen zusammen. Der Prüf- bzw. Konsolidierungsvorgang beschränkt sich in dieser Phase auf das Ziel, diese Daten zusammenzuführen, also passend und widerspruchsfrei zu machen. Fehler, die in den operativen Anwendungen entstanden sind, können hier in der Regel nicht korrigiert werden. Es sollte allerdings eine Rückkopplungsfunktion enthalten sein wonach fehlerhafte Eingabeinformationen an die liefernden Prozesse (Stellen) zurückgeschickt werden können. Die Daten sollten hier noch nicht verdichtet oder ‚gejoint’ werden, da das die Prüfverfahren behindern kann. Performance könnte verloren gehen, im Wiederholungsfall könnte schon zu viel Arbeit investiert worden sein, die dann verloren wäre. Zur Prüflogik stehen innerhalb der Datenbank folgende Mittel zur Verfügung: Standard SQL Operatoren (Funktionen, CASE) Regular Expressions Match / Merge Fuzzi Logik Analytische Funktionen Datenbank – Constraints sollte man in dieser Phase aus Performancegründen vermeiden. 6.1.2.2 Prüfen und Protokollieren Das Erstellen von Protokolltabellen ist dem Erstellen von Protokolldateien vorzuziehen, Tabellen sind leichter und schneller zu verarbeiten. Das Erstellen der Protokolltabellen ist durch mengenbasierte Operationen mittels SQL vorzunehmen. Hierzu können auch separate Prüfläufe gestartet werden. Immer wieder ist in bestehenden Warehouse – Installationen zu sehen, wie umständlich Prüfaktivitäten durchgeführt werden. Meist ist das Prüfen die Stelle in den Ladeprozessen, an der die meiste Zeit (Lade – Performance) verloren geht, denn hier wechselt die Verarbeitung oft auf die Satzebene, weil prozedurales Programmier – Denken vorherrscht. Dabei gibt es innerhalb des SQL hervorragende Mittel, um mengenbasiert Prüfungen auch auf Feldebene und mit komplexer Prüflogik zu ermöglichen. Hier ein Beispiel: Es sind alle Felder einer Quelltabelle mit unterschiedlichen Prüfungen zu versehen. Diese Prüfungen können sein: NULL / NOT NULL Numerisch / alphanumerisch Gültiges Datumsfeld Beliebige ‚Regular Expression’ (Spezielle Semantik) Teilstringprüfungen Wertgültig in Abhängigkeit von Werten aus anderen Tabellen Security - Prüfungen ... Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 77/166 Die Beispiele zeigen, wie ausführlich und komplex die Prüfungen sein können. Die Quellsätze sollen in eine Zieltabelle mit gleichem Format überführt werden. Fehlerhafte Sätze sollen vollständig mit Angabe eines Fehlercodes in eine Fehlertabelle geschrieben werden. Bei der Lösung kommt es darauf an, die Prüfung mengenbasiert durchzuführen. Ein wichtiges Hilfsmittel ist die CASE - Anweisung, mit der Ausdrücke auf dem Level von Funktionen (1 Rückgabewert) für jedes einzelne Feld formulierbar sind. Das folgende kuriose Beispiel zeigt die Flexibilität: select case when ((SELECT 1 from DUAL) = 6) then 0 when (0 = 4) then 1 when (sysdate-100 > to_date('31.01.05','DD.MM.YY')) then 2 else 9 end Ergebnis from dual; Die Lösung für die Aufgabenstellung erstellt eine Prüftabelle mit nur zwei Feldern, dem Key – Feld zur Aufnahme des Originalschlüssels (für späteren Join) und einem Flag – Feld in dem ein Fehlercode eingetragen werden kann. Alle vorkommenden Fehler erhalten eine Code – Nr (Fehlertexte werden ausgespart). Über einen Insert wird die Prüftabelle gefüllt. Der Insert bezieht seine Daten aus einem Select, der für jedes Feld eine CASE ... WHEN – Klausel besitzt. In diesem Verfahren wird nur der erste aufgetretene Fehler identifiziert und in die Prüftabelle geschrieben. Das ist ein Kompromiss an die Komplexität des Verfahrens. Es müsste ein zweiter Prüflauf folgen, wenn weitere Fehler gefunden werden sollen. Sollen alle Fehler mit einem einzigen Prüflauf erfasst werden, so muss die Prüftabelle jedes Feld der Quelltabelle enthalten und für jedes Feld ist eine separate CASE – Anweisung aufzunehmen. Auch das ist machbar und verletzt nicht das mengenbasierte Vorgehen des SQL. Ist die Prüftabelle erstellt folgt in einem zweiten Schritt durch einen „Multiple Insert“ das Schreiben entweder in die gültige Zieltabelle oder bei fehlerhaften Quellsätzen in die Fehlertabelle. Gelesen wird über einen Join aus der Original – und der Prüftabelle. Das hört sich komplex an, zumal man eigentlich nicht mehr programmieren will. Aber all diese Konstrukte lassen sich elegant und mit Hilfe eines graphischen Entwurfs mit dem Oracle Warehouse Builder (OWB) erstellen und generieren. (Dies ist kein OWB – Handbuch, daher wird das graphische Verfahren hier nicht dargestellt). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 78/166 Beispielhaftes, mengenbasiertes Prüfverfahren mit CASE 6.1.2.3 Kennzeichnung von Daten Alle gelieferten Informationen (Sätze) sind zu kennzeichnen. Folgende Informationen müssen erkennbar sein: zu welchem Zeitpunkt wurden die Daten extrahiert aus welchem System stammen die Daten welchen Zustand haben die Daten: o geprüft / ungeprüft o bereits in die nächste Schicht geladen oder noch zu laden Diese Informationen helfen bei der Steuerung des Gesamtladevorgangs des Systems: Muss ein Ladelauf wiederholt werden, dann können die bereits in die Warehouse – oder Data Mart – Schicht geladenen Sätze dort wieder gelöscht werden, indem man sie anhand der Kennzeichnung (zuletzt geladen) identifiziert. Wird aufgrund der hohen Datenmenge ein inkrementelles Laden gewählt (Buckets), so kann gesteuert werden, welche Daten bereits verarbeitet wurden und welche noch zu verarbeiten sind. Es kann vorkommen, dass ständig Daten in das Warehouse fließen, also die Ladezeit nicht eindeutig fixiert werden kann. Hier helfen die Statusinformationen bei der Selektion der noch zu bearbeitenden Sätze. Die Kennzeichnung der Sätze sollte nicht durch Update – Vorgänge entstehen, sondern durch zusätzliche Spalten in duplizierten Tabellen. Das Erstellen einer zusätzlichen Tabelle, die zunächst gelöscht und dann mit den neuen geprüften und ergänzten Sätzen gefüllt wird (CTAS – CREATE TABLE AS SELECT) ist die performanteste Methode. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 79/166 Prüf- und Kennzeichnungsverfahren in der Stage - Schicht 6.1.2.4 Deltadatenerkennung Eine Herausforderung bei dem Laden von Daten aus Vorsystemen ist das Erkennen von Änderungsinformationen. Während die Bewegungsdaten regelmäßig fortgeschrieben werden (Daten fließen ergänzend in das Warehouse), müssen oft bei den Stammdaten Änderungen nachvollzogen werden. Viele operative Systeme besitzen zur Kenntlichmachung von Änderungen sogenannte Zeitstempel, also ein „Änderungsdatum“. Hieran erkennt der Ladelauf, dass sich Quellstrukturen geändert haben (Prüfung über eine Where – Klausel). Ist das nicht der Fall, bleibt nur der Weg die Quelldaten mit den vorher geladenen Daten zu vergleichen. Hier hilft die MINUS – Operation. Der neue Zustand der Originaldaten wird im Prinzip von den in der Ladeperiode zuvor geladnen Sätzen abgezogen. Übrig bleiben die Sätze, die sich seit der letzten Ladeperiode änderten. Neue bzw. geänderte Sätze können identifiziert und mit Hilfe der MERGE – Operation in die Zielumgebung geschrieben werden. Üblich sind dann noch Historisierungsverfahren (z. B. Slowly Changing Dimensions). Dies wird separat beschrieben [siehe unten]. Verfahren zur Erkennung von Änderungen Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 80/166 6.1.3 Normalisieren – der Weg in die Warehouse Schicht Um das Warehouse – System gegen Geschäftsprozessänderungen möglichst stabil zu halten, wird in der Warehouse – Schicht normalisiert. Normalisierte Strukturen können später leichter zu neuen Informationsobjekten zusammengefügt werden. Hierzu orientiert man sich an der kleinsten Informationseinheit den Datenelementen innerhalb der Geschäftsobjekte. (Siehe hierzu die Verfahren der Normalisierung 1.,2.,3. – Normalform aus der Datenmodellierung, die hier als bekann vorausgesetzt werden). Sind Entitäten gefunden, die als Child – Informationen zu allen anderen Entitäten funktionieren, so stellen diese Entitäten die Basis der Transformationen dar. Stammdaten sind in der Regel einmalig zu transformieren (distinct). Bewegungsdaten sind so zu laden, wie sie auch in dem operativen System vorkommen. Folgende Vorgehensweise wird bei Transformationen für das Normalisieren einer denormalisierten Struktur gewählt: 1. Distinct - Selektieren der Top – Parent – Information und Speichern in einer separaten Tabelle. Hierbei kann ein neuer künstlicher Schlüssel definiert werden. 2. Distinct – Selektieren der zweithöchsten Parent – Information mit Lookup auf die Top – Parent- Information, um den Primary Key des Parents in die neu entstandene Child - Tabelle einzufügen. 3. Fortsetzen des Verfahrens bis auf die unterste Ebene. Normalisierungsschritt beim Wechsel Stage – Schicht nach Warehouse - Schicht 6.1.4 Denormalisieren – Aufbereiten für die Endbenutzer Bei dem Übergang von der Warehouse – Schicht zu den Data Marts werden die normalisierten Informationsbausteine wieder zu neuen Informationseinheiten zusammengeführt. (Siehe hierzu weiter unten Aufbau von Dimensionen). 6.1.5 Laden von Faktentabellen Faktentabellen können besonders groß werden. Durch die jüngste Hardware- und Datenbankentwicklung begünstigt, bewegen sich Faktendaten heute auf einem wesentlich feineren Detaillevel als früher. Oft überführt man Transaktionen der operativen Systeme direkt in die Faktentabellen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 81/166 Das periodische Füllen der Faktentabellen bedarf besonderer Aufmerksamkeit, da hier mit die größten Ladezeiten entstehen können. Prüfaktivitäten auf Einzelsatzebene sind zu vermeiden. Diese Prüfungen sollten bereits im Vorfeld stattfinden. Das Prüfen von Daten und das Laden von Daten sollte getrennt durchgeführt werden: o Das entzerrt den Ladeprozess, o gibt die Möglichkeit das Laden mengenbasiert durchzuführen, o gibt die Möglichkeit der Einzelsatzverarbeitung im Prüfteil (wenn nötig). o Das eigentliche Laden kann noch verhindert werden, wenn Fehler auftreten. o Prüfroutinen können fachliche Fehler getrennt von technischen und logischen Fehler (z. B. Constraint – Verletzung) behandeln. Daten die fachlich falsch sind, muss man nicht mehr laden. Constraints, Fast Refresh von Materialized Views und das Aktualisieren von Indizes sind zu deaktivieren und erst nach Abschluss des Ladelaufes zu aktualisieren. Updates auf Faktentabellen sollte man vermeiden. Zum einen braucht man zum effektiven Updaten Indizes, die dann wieder bei Inserts stören, zum anderen verursacht das Datenbanksystem zusätzlichen Overhead, der nur für Updates erfolgt. Updates kommen der Einzelsatzverarbeitung nahe. o Können Updates nicht verhindert werden, so sollte man sie in einen separaten Lauf ausgliedern. Lookup – Abgleiche mit den Dimensionstabellen erfolgen über einen Join im Verlauf des Ladevorgangs. Sind Sätze zeitlich oder nach anderen Kriterien geclustert, so hilft das Partitioning der Faktentabelle, indem man neu entstehende Partitionen als temporäre Tabellen vorbereitet und als neue Partition an die Faktentabelle zuschaltet (Exchange Partition). 6.1.6 Laden von Dimensionstabellen Dimensionen eines Starschemas sind als eine einzige Tabelle in der Datenbank abzubilden. Das erfordert einen Denormalisierungsschritt, wenn Daten aus einem normalisierten Modell (Warehouse – Schicht, ODS – Schicht) in ein Starschema überführt werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 82/166 Umwandeln normalisierter Strukturen zu denormalisierten Dimensionen Bei der Überführung werden zwar die Originalschlüssel übernommen. Auf der untersten Ebene wird jedoch ein künstlicher Schlüssel zusätzlich in die Dimension als neuer Primary Key eingeführt (siehe hierzu Umgang mit Schlüsseln weiter unten). Folgende Vorgehensweise ist sinnvoll: 1. Ausgangspunkt ist die unterste Child – Tabelle der normalisierten Struktur. Diese Tabelle wird zum untersten Level der Dimensionstabelle. 2. Ein Sequenz – Objekt liefert beim Laden der Dimensionstabelle den neu zu bildenden Primary Key der neuen Dimensionstabelle. 3. Die weiteren Level der Dimensionstabelle werden als Lookups der Parent Tabellen geladen. In der Regel übernimmt man die Lookup – Schlüssel als neue Level – Schlüssel in der Dimension. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 83/166 Ableitung einer Dimension aus normalisierten Modellen durch Lookups und Generierung von künstlichen Schlüsseln 6.1.7 Das Laden von künstliche Schlüsseln – Das Umschlüsseln Im Warehouse können aus mehreren Gründen nicht die operativen Stammdatenschlüssel verwendet werden, so dass im Verlauf des Ladeprozesses neue zu bilden sind. Das Umschlüsseln von operativen Schlüsseln von Stammdaten zu Schlüssel, die in dem Data Warehouse benutzt werden, wird in der Regel mit Look up – Verfahren innerhalb der Datenbank (Outer – Join) realisiert, es geschieht also mengenbasiert. Heranziehen von Referenzinformationen im SET Based – Verfahren Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 84/166 Zum Laden der künstlichen Schlüsse in die Faktentabelle wird vorgeschlagen: 1. Aufbau der Dimensionstabellen mit Hilfe von Sequenz – Objekten in der Datenbank. Alle Dimensionssätze werden aus den entsprechenden Stammdaten gefüllt und erhalten neben den originären Primary Key Feldern der Stammdaten einen zusätzlichen neuen Primary Key als laufende Nummer über die Sequenz. Diese Dimensionsdaten sind vor jedem Laden der Faktentabelle zu aktualisieren. 2. Laden der Faktentabelle aus den Bewegungssätzen. Im Verlauf des Ladens wird mit einem Outer – Join der neue künstliche Schlüssel aus der Dimensionstabelle entnommen. Dieser ersetzt den originären Schlüssel in der Faktentabelle. 3. In der Faktentabelle ist der Originalschlüssel der Bewegungsdaten nicht mehr zu finden. Bei diesem Verfahren können auch fehlerhafte Sätze geladen werden, deren Originalschlüssel nicht in der Dimensionstabelle zu finden ist. Das Foreign Key Feld bleibt leer. Anschließende Abfragen werden diese Sätze nicht finden, wenn sie über einen Join mit der Dimensionstabelle abgefragt werden. Daher ist dieses Verfahren nur dann zu wählen, wenn man sicher sein kann, dass alle Bewegungsdaten immer einen passenden Satz in der Dimension finden. Hierzu kann man im Vorfeld eine Prüfung einbauen. Siehe auch den folgenden Punkt. 6.1.8 Optimistisches und Pessimistisches Laden Dimensionsdaten in Abhängigkeit von Faktdaten von In den zu ladenden Faktensätzen können Sätze mit Column - Werten enthalten sein, zu denen der Ladeprozess keine Referenzsätze in den Dimensionstabellen findet. a) Im optimistischen Verfahren werden Daten ohne weitergehende Prüfung geladen. Dies ist z. B. mit einem Outer – Join möglich. b) Das pessimistische Verfahren prüft kategorisch und verhindert im Fehlerfall das Laden des falschen Satzes. Der Vorteil liegt darin, dass keine fehlerhaften Sätze in die Faktentabelle gelangen. Der Nachteil ist jedoch, dass fehlerhafte Sätze vollständig verloren gehen und für Auswertungen nicht mehr zur Verfügung stehen. Schlimmer noch: die Ursachen der Fehler werden nicht beseitigt. c) Das dritte Verfahren lädt auch die fehlerhaften Sätze. Es fügt jedoch korrespondierende Sätze in die jeweiligen Dimensionstabellen ein. Das Verfahren besteht aus den folgenden Schritten: 1. Abgleich der zu ladenden Faktensätze mit der Dimensionstabelle mit Hilfe eines Anti – Joins zwischen Faktensätzen und Dimensionsätzen: INSERT INTO Dimension SELECT next.Sequence(PK von Dimension),F.Feld1, F.FeldX from Faktsatztabelle F, Dimension D where F.Originalfeld not equal D.Originalfeld. 2. Insert der so gefundenen Menge in die Dimensionstabelle. 3. Laden der neuen Faktensätze in die Faktentabelle. Der prüfende Join kann jetzt sogar entfallen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 85/166 Zweischritt – Ladeverfahren. 1. Schritt Aktualisieren Dimensionstabelle, 2. Schritt Key Lookup zum Umschlüsseln von Business Key zu künstlichem Schlüssel Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 6.2 86/166 Management des Ladeprozesses (Workflow) Der Aufbau der Datenversorgung des Data Warehouses gliedert sich in zwei Aufgabenstellungen: 1. Entwurf und Erstellung der detaillierten Transformations- und Ladeschritte (Mapping - Techniken). 2. Kombination der Transformations- und Ladeschritte zu einem Lade- und Transformationsprozess (Workflow - Techniken). 6.2.1 Aufgaben des Ladeprozesses Der Ladeprozess ist das äußere Gebilde des ETL -Prozesses, das nach außen das Warehouse System repräsentiert. Auf dieser globalen Ebene findet letztlich die Kapselung der Teilprozesse mit der Detaillogik statt. Die Teilprozesse untergliedern sich wieder. Das geschickte Kapseln und Zusammenfassen von Funktionen führt letztlich zur nötigen Flexibilität. Es gibt keine Regeln die festlegen, was wie zusammengefasst werden sollte. Es gibt nur die eine Anforderung, dass es mindestens vier Gliederungsstufen geben sollte, um ausreichende Flexibilität zu garantieren. 6.2.2 Struktur des Ladeprozesses Durch die mindestens 4-stufige Gestaltungsmöglichkeit liefert der Ladeprozess die Flexibilität, um Ladeläufe je nach Anforderung in mehreren Varianten ablaufen zu lassen. Die vier Stufen sind: 1. Transformationslevel (TL): Wandeln und Laden auf Feldebene. Das sind Funktionen, wie sie z. B. als Datenbankfunktionen bekannt sind (substr,, Expression...) 2. Mappinglevel (ML): Wandeln und Laden auf der Ebene von einer oder mehreren Tabellen. Zusammengefasst werden logisch zusammen gehörende Tabellen (technisch – funktionale Zusammenhänge). Betrachtet werden z. B. alle Quelltabellen, die zum Füllen von ein oder mehreren zusammenhängenden Tabellen ( z. B. Parent / Child – Konfigurationen) nötig sind. Die tabellenbezogene Verarbeitung wird komplett abgeschlossen, beinhaltet also Inserts/Update/Delete - Vorgänge. 3. Prozesslevel I (P1): Mehrere Mappings sind zu Verarbeitungsfolgen zusammengeschlossen. Es entstehen zusätzliche, den Mappings übergeordnete Einheiten. Zusammen gehören z. B. das Füllen aller Dimensionen und Fakten eines Starschemas. 4. Prozesslevel II (P2): Diese Stufe sorgt für die flexible Gestaltung des Gesamtprozesses. Die Verarbeitungsfolgen des Prozesslevel I können hier flexibel kombiniert werden. Auf dieser Ebene ist spontanes Umhängen einzelner Abfolgen mit graphischen Mitteln möglich. Auf diesem Level kann z. B. im Verlauf des Warehouse – Betriebs entschieden werden, ob ein Starschema in einer Ladeperiode gefüllt oder ausgespart wird. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 87/166 4 Ebenen der Datenflusssteuerung im Data Warehouse Von außen betrachten sieht man nur den äußeren Prozessrahmen. Die gesamte Ladelogik ist gekapselt und fügt sich in den IT – Betrieb des Unternehmens ein. Der Gesamtprozess kann zeitgesteuert gestartet werden. Ladeläufe kapseln ihre Logik 6.2.3 Interaktion mit anderen Systemen und Automatisierung Ein Data Warehouse – System sollte vollständig automatisiert mit anderen DV – Systemen im Unternehmen oder Partnerunternehmen kommunizieren können: Es sollten keine manuellen Eingriffe (z. B. manuelles Kopieren von Eingabedaten) nötig sein, um den Betrieb zu garantieren. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 88/166 Kontrollierende Tätigkeiten sind auf ein Minimum zu beschränken. Außergewöhnliche Ereignisse sind durch entsprechende Alarmfunktionen (Mail – Benachrichtigungen) zu lösen. Angeschlossene Systeme (zuliefernde Quellsysteme) dürfen durch die Aktivitäten des Warehouse – Systems nicht beeinträchtigt werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 89/166 7 Mehrfachverwendung von Bereichen und Objekten Die historische Entwicklung von Warehouse Systemen in den Unternehmen hat oft dazu geführt, dass solche Systeme an mehreren Stellen gleichzeitig, aber isoliert von einander, aufgebaut wurden. Dies verursacht nicht nur ein Mehr an Kosten, sondern mindert auch die Qualität der Informationen, wenn fachübergreifende Daten zusammenhängend genutzt werden sollen. Es können drei Szenarien entworfen werden: Szenario 1 (1990 – 2000): Direktes Aufsetzen der Data Marts auf die operativen Systeme. Die in den operativen Systemen oft unterschiedlich verwendeten Daten (z. B. Stammdaten) werden auch unterschiedlich ausgewertet. Direktes Aufsetzen der Data Marts auf die operativen Systeme Szenario 2 (2000 - heute): Einsatz einer zentralen Warehouse Schicht. Dieses Verfahren ist oben bereits besprochen worden. Es bietet die Möglichkeit unterschiedlich genutzte Quelldaten zu konsolidieren und Fehler im Verlauf der Extraktion zu korrigieren. Allerdings können sich bei dem Aufbau der fachspezifischen Data Marts wieder Fehler einschleichen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 90/166 Einsatz einer zentralen Warehouse Schicht Szenario 3 (aufkommende Verfahren): Einsatz einer zentralen Warehouse Schicht und Zusammenfassen der Data Marts. Dieses Verfahren bietet die größte Sicherheit gegenüber potentiellen Fehlern. Das Verfahren hat darüber hinaus den Vorteil, dass Datenbereitstellungs- (ETL-) Kosten über weite Wegstrecken hinweg gemeinsam nutzbar sind. Die Integration der Data Marts kann entweder nur technischer Natur sein, d. h. die Data Marts liegen innerhalb der selben Datenbankumgebung sind aber noch als getrennte Datenmodelle vorhanden oder die Data Marts sind auch als Datenmodelle integriert. Dieses Verfahren ist das mit Abstand effizienteste Verfahren, das die meisten Synergien nutzt, die geringsten Kosten verursacht und die geringste Fehlerquote beinhaltet. Einsatz einer zentralen Warehouse Schicht und Zusammenfassen der Data Marts Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 7.1 91/166 Verteilte (Mehrfach-) Verwendung von Data Mart Strukturen Wenn das vorgenannte 3te Szenario gewählt wird, so können Data Marts nicht mehr isoliert betrachtet werden, auch wenn sie in der Regel auf unterschiedliche und eingegrenzte Themenzusammenhänge bezogen sind. Es ist möglich, Fakten- und Dimensionstabellen einmalig vorzuhalten. Redundanzen werden vermieden. Vorteile sind: Minimierung von Platzverbrauch bei großen Faktentabellen. Gemeinsam genutzte ETL – Bausteine. Minimierung des Aktualisierungsaufwands. Gemeinsame Nutzung von logischen Strukturen führt zur Data Mart (Abteilungs-) – übergreifenden Synchronisierung von Daten und damit Vergleichbarkeit von Auswertungen. Einmaliger Aufwand für Bereitstellung von Hardware und Software – Lizenzen. Einmalige Betriebskosten. Damit ist es auch möglich Data Mart – Grenzen vollständig verschwimmen zu lassen. Dimensionstabellen mit beliebigen Faktentabellen zu kombinieren . Es muss lediglich die Struktur des Foreign Key - Schlüssels stimmen. Welche Dimensionsdaten sinnvoll mit welchen Faktendaten harmonieren, kann nur noch mit Hilfe einer Metadaten – Dokumentation herausgefunden werden. Metadaten – Werkzeuge erlauben eine Data Mart – bezogene Sicht, obwohl die Dimensionen und Fakten nicht mehr nur einem Data Mart zugeordnet werden können. Bei dieser Vorgehensweise, können unterschiedliche Data Marts nicht mehr physisch bzw. räumlich verteilt sein, auch wenn „Eigentümer“ unterschiedliche Fachabteilungen sind. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 92/166 Data Mart - übergreifende Wiederverwendung von Dimensionen und Fakten (unternehmensweit eingesetztes 3 Schichtenmodell) Die Vorgehensweise stellt kein Aufweichen des 3 – Schichten – Modells des Warehouses dar. Das 3 – Schichtenmodell ist ja lediglich eine logische Betrachtung. In der physischen Umsetzung wird hier den beiden konträr angelegten Anforderungen entsprochen: Bereitstellung individuell zugeschnittener Informationen für Fachabteilungen und spezifischen Benutzergruppen. Zentrales kostenschonendes und wiederspruchsfreies Management des Warehouses. Der Nachteil dieser Vorgehensweise ist das Bilden einer gültigen Primary Key / Foreign Key – Verbindung zwischen allen sinnvollen Kombinationen aus Fakten – und Dimensionstabellen. Diese sind aus technischen Gründen für die Star Transformation in der Datenbank nötig. Während des Ladens werden diese Beziehungen aus Performancegründen aufgehoben und müssen dann wieder nach Abschluss des Ladens aktualisiert werden. Das kann zu einer Vergrößerung des Schlüsselbereichs in der Faktentabelle führen. 7.2 Verwaltung gemeinsam genutzter Tabellen Das Konzept der über Fachgrenzen hinweg, mehrfach genutzten Dimensionen und Faktentabellen läuft darauf hinaus, dass Tabellen von unterschiedlichen Nutzerkreisen verwendet werden. Datenbanktechnisch kann die Trennung über Datenbankschemen erfolgen. Innerhalb eines Datenbankschemas können „private“ Daten liegen. Ein Verweis in das Schema in dem alle frei verfügbaren und gemeinsam genutzten Dimensionen liegen, ist möglich. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 93/166 Darstellung der unterschiedlichen Schemata in dem Modell für mehrfach genutzte Dimensionen und Fakten Die technische Voraussetzung für dieses Verfahren ist die Nutzung einer einzigen Datenbank. Hier wird deutlich, wie sinnvoll die Integration bzw. konzentrierte Sammlung von Warehouse - Daten an einer Stelle ist. Hinzu kommt der Vorteil der gemeinsamen Warehouse – Hardware, so dass zusätzlich noch weitere Synergieeffekte genutzt werden können. Stößt man an Hardware – Grenzen, so sollte nicht gleich eine größere Maschine gekauft werden. Die weiter unten erwähnte Real Application Cluster (RAC) Technologie erlaubt es kleine Rechner im Verbund zu betreiben und eine einzige Datenbank über die Rechnergrenzen hinweg skalieren zu lassen. Es treffen mehrere Möglichkeiten zur Nutzenoptimierung zusammen: Integration von Daten führt zu minimiertem Verwaltungsaufwand und Entwicklungsaufwand. Ein geringerer Anteil von Lade – (ETL -) Schritten ist nötig, da mehr Informationen gemeinsam geladen werden und nicht separate, verteilte Data Marts mit Daten versorgt werden müssen. Die Konzentration von Hardware führt zu potentiell weniger Hardware – Einsatz weil Hardware – Ressourcen mehrfach verwendbar sind [siehe separates Kapitel]. 7.2.1 Nutzerübergreifende, organisatorische Abstimmungen Die gemeinsame Nutzung von Ressourcen im Data Warehouse ist nicht nur technologisch oder verfahrenstechnisch zu realisieren. Sie erfordert zusätzliche organisatorische Abstimmungen über die gemeinsam genutzten Ressourcen. Folgende Fragen sind zu beantworten: Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 94/166 Wer nutzt die Ressourcen wie intensiv? Hiervon hängt die Finanzierung der Ressource ab. Wer pflegt die Ressource? Wie sieht die Abstimmung bei Änderungsanforderungen aus? Zur Lösung dieser Fragen ist sicherlich ein ständiger gemeinsamer „Ausschuss“ nötig. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 95/166 8 Metadaten Metadaten sind von ihrer Natur aus beschreibende Daten. Sie beschreiben, dokumentieren etwas anderes. Unabhängig von ihrem Gebrauch haben Metadaten grundsätzliche Eigenschaften, die ihre Eigentümlichkeit ausmachen: Eindeutigkeit: Die Beschreibungen haben den Rang eindeutiger Definitionen, Beschreibungen dürfen nicht mehrfach vorhanden sein. In einem Repository System dürfen Namen z. B. nur einmal vergeben werden. Umgekehrt dürfen nicht unterschiedliche Beschreibungen für ein und dasselbe Objekt existieren. Einmaligkeit: Die Beschreibungen dürfen nicht an mehreren Stellen vorgehalten werden. Semantisches Sprachmittel: Es sind nur beschreibende Mittel, keine Code – Bestandteile. Neutralität: Beliebige Objekte, Sachverhalte müssen sich beschreiben lassen. 8.1 Metadaten im Warehouse - Umfeld Metadaten können im Warehouse Umfeld nach zwei Verwendungsarten unterschieden werden: Metadaten für den Entwicklungsprozess (Design – Time) Metadaten für den Betriebszeitpunkt (Run Time) Diese Unterscheidung entspricht den Praxisanforderungen, denn Entwicklungsaktivitäten könnten den Echtbetrieb stören, wenn konkurrierend auf Metadaten zugegriffen wird. Daneben richten sich Metadaten an unterschiedliche Zielgruppen: Warehouse – Entwickler, Fachanwender des Warehouses, Verantwortliche Betreiber. Folgende Aufgaben werden über das Metadatenmanagement erfüllt: Entwicklungsmedium: Die Warehouse – Entwicklung geschieht am besten mit Hilfe von Modellen (z. B. Datenmodelle, Mappingmodelle usw.). Diese Modelle sind bereits Metadaten aus denen heraus physische Strukturen generiert werden -> („Modellieren / Generieren statt Programmieren und Scripting)“ (z. B. DDL / PL SQL /ABAP / XML - Generierung). Metadaten stellen Strukturen für einzelne Warehouse – Komponenten bereit, z. B. Datenzugriffsstrukturen für Auswertewerkzeuge. Metadaten dokumentieren das Gesamtsystem. Sie liefern technische und fachliche Beschreibungen aller Objekte in dem Warehouse (z. B. Glossars zur fachlichen Begrifflichkeit). Dokumentation der operativen Quellsysteme. Anwenderhilfen: Dokumentation von Abfragepfaden für Endbenutzer (z. B. Drill Down – Wege). Beziehungsabhängigkeiten: Auswirkungs- und Herkunftsanalysen (Impact Analysis und Lineage). Verwaltungsdaten: Sie beschreiben die Gültigkeit von Berichten (letzte Ladeläufe), Verantwortliche für Berichte. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 96/166 Arten und Verwendungen von Metadaten im Data Warehouse 8.1.1 Beispiele für Einsatzfelder der Metadaten Ableitung von Warehouse – Dokumentation aus dem Warehouse – Entwicklungsvorgang 8.1.1.1 Warehouse Handbuch Die Dokumentation zu dem Warehouse – System kann aus den Warehouse – Beschreibungen abgeleitet werden. Dies setzt voraus, dass im Rahmen der Entwicklung entsprechende Beschreibung in Textform den jeweiligen Objekten hinzugefügt worden sind. Die ideale Vorgehensweise ist die komplette Werkzeug – gestützte Dokumentation. Die Erstellung eines Warehouse - Systems erfolgt in der Regel Top Down, d. h. als äußerer Rahmen wird z. B. ein Projekt definiert. Innerhalb der Projekte verläuft die Einteilung entweder entlang der operativen Anwendungssysteme oder entlang von Themengebieten. Über die textlichen Beschreibungen an den jeweiligen Objekten kann ein Rahmengerüst für ein Anwenderhandbuch generiert werden, in dem zumindest ein großer Teil der allgemeinen Beschreibungen zur groben Orientierung für Anwender gegeben ist. Dies entsteht dann einmalig und an einer Stelle. Das ist noch keine Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 97/166 Funktionsbeschreibung von Auswertungsoberflächen. Solche detaillieren Informationen sind noch separat zu erfassen. Im Rahmen der Warehouse – Entwicklungswerkzeuge sind die entsprechenden Möglichkeiten zu nutzen. Diese haben sicherlich keine ausgefeilten Text – Editoren, aber ergänzende Script- und Makrosprachen, können die Textbeschreibungen der vielen Objekte in der richtigen Reihenfolge extrahiert und in einer ersten sinnvollen Form automatisiert aufbereiten werden. Die Betonung liegt auf automatisiert. Der Nutzen entsteht, wenn das Repository die Dokumentation generiert und nicht wenn die Entwickler die Dokumentation zusätzlich manuell bearbeiten müssen. 8.1.1.2 Glossare und Definitionen Glossare sind Sammlungen von fachlichen Definitionen zu Geschäftsobjekten, deren Beziehungen untereinander und Prozessabläufen, in denen die Geschäftsobjekte eine Rolle spielen. Diese Informationen gibt es meist bereits durch die Prozess- bzw. Datenmodellierung. In einigen Unternehmen werden diese Modellierungsschritte mit separaten Werkzeugen durchgeführt. Die Hauptaufgabe dieser Werkzeuge ist auch wieder Dokumentation. Diese Dokumentation sollte man nutzen, indem bestehende Geschäftsobjekt- bzw. Prozessdefinitionen auch hier wieder automatisiert in das Metadaten Repository des Warehouse – Entwicklungswerkzeugs überführt werden. Auch hier helfen Scriptsprachen. Innerhalb der Warehouse – Entwicklungswerkzeuge müssen im Idealfall keine Änderungen gemacht werden. Der generelle Aufwand hierfür sollte sehr gering gehalten werden. Ähnlich wie bei den allgemeinen Beschreibungen sollten Glossars ebenfalls vollständig aus dem Werkzeug heraus mittels Sriptsprache, also automatisiert generiert werden. Textprogramme sollten nur noch graphische Aufbereitungen vornehmen. 8.1.1.3 Betriebshandbuch Analog ist mit dem Betriebshandbuch zu verfahren. In dem Betriebshandbuch ist zum einen der Gesamtablauf des Systems beschrieben, d. h. die zeitliche Reihenfolge der Ladeläufe. Zum anderen sind hier die Anweisungen für den technischen Betrieb des Warehouses durch das Operating zu finden. Diese Informationen stammen aus dem Warehouse – Entwicklungswerkzeug. Dort sind sie an den Prozessund Mappingobjekten hinterlegt. Auch für dieses Handbuch gilt die automatisierte Generierung mittels Scriptsprache. 8.1.1.4 Berichtsverifizierung / Legenden Eine der häufigsten Quellen von Misstrauen in die Richtigkeit von Berichten ist Ungewissheit über deren Herkunft. Daher sollte den Benutzern auch die Möglichkeit der Quellenanalyse zu den Berichten gegeben werden. Da es sich hier um viele Einzelinformationen handelt, sind separate Auswertewerkzeuge notwendig. Und diese sollten sinnvollerweise über einen Webbrowser zur Verfügung stehen. Globale Herkunftsdaten können schließlich auch als festcodierter Text in den Berichten stehen. Hierfür muss weniger Aufwand betrieben werden. 8.1.1.5 Aktualitätsscheck Endanwender benötigen auch eine Information über die Aktualität der Berichte, die sie gerade bearbeiten. Meist ist es die Information über den letzten Ladelauf. Aber auch Informationen über Quelle und Vollständigkeit der Berichtsdaten sind sinnvoll. Diese zur Laufzeit des Warehouses entstehenden Daten sind in den Runtime – Systemen der Warehouse – Werkzeuge enthalten und dokumentiert. Es kann sinnvoll sein, diese Informationen zusätzlich zu extrahieren und separat, z. B. in Form einer Tabelle bereit zu halten. Diese Tabelle kann fachlogisch organisiert sein. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 98/166 Aktualisierungsinformationen im Ladevorgang 8.1.2 Einmaliges, Metadaten zusammenhängendes Speichern von In klassischen Warehouse – Umgebungen fallen Metadaten durch unterschiedliche Werkzeuge und an verschiedenen Stellen der Architektur an. Damit sind die Metadaten nicht mehr zusammenhängend auswertbar. Auswirkungs – und Herkunftsanalysen enden oft an den jeweiligen Werkzeug - Grenzen. Klassische Lösung: Metadaten sind über verschiedene Werkzeuge verteilt Auch wenn Metadaten durch verschiedene Werkzeuge und auch außerhalb der Datenbank entstehen, sollten sie an einer Stelle zusammengefasst gespeichert werden. Herkunfts- und Auswirkungsanalysen sollten den kompletten Informationsfluss im Data Warehouse umfassen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 99/166 Modernes Szenario mit einer einheitlichen Metadaten - Verwaltung 8.1.3 Design – Time Metadaten Metadaten für den Entwicklungsprozess müssen alle Warehouse - Schichten und damit auch alle Modellarten umfassen. Das bedeutet die Metadaten müssen sowohl die relationale Datenwelt, als auch die multidimensionalen Objekte beschreiben können. Mindestens folgende Objekttypen sollten enthalten sein: Tabelle, View ( Columns und alle physischen Eigenschaften und fachlichen Beschreibungen) Dimensionen / Fakten (und Entsprechungen der Würfel) mit allen Beschreibungen Berichte Benutzer / Benutzergruppen Transformationsprogramme (Mappings, Prozeduren, Regeln) Prozesse (Jobs) Anwendungssystem (Einteilung in Module) 8.1.4 Runtime – Metadaten Laufzeitinformationen sind: Letzter Änderungszeitpunkt der Daten im Warehouse Datenmenge der geladenen Dateninkremente Fehlerhafte Daten des letzten Ladelaufes Historie von Ladeläufen Betriebsinformationen Informationen über Ladezyklen und geplante Dauer Handlungsanweisungen für Ausnahmesituationen 8.1.5 Neutralität der Modelle Implementierung gegenüber der physischen In der Warehouse - Praxis haben sich zwei Speichermodelle für die Ablage der Warehouse - Daten etabliert: Speichern der Daten in relationalen Tabellen mit der Möglichkeit von normalisierten und denormalisierten Datenmodellen (ROLAP). Speichern der Daten in multidimensionalen Würfeln, bei denen auf die Speicherorte aller Faktenwerte direkt zugegriffen werden kann (MOLAP). Die Struktur der Informationen beider Speichermodelle ist jedoch gleich. Damit sollten auch die Metadatenbeschreibungen gleich sein. Der multidimensionale Entwurf der Metadaten sollte nur einmal erfolgen. Die Option die Warehouse – Daten entweder relational oder multidimensional zu speichern, sollte die Metadatenbeschreibung nicht berühren. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 8.2 100/166 Erweiterbarkeit des Metadaten - Repositories Idealerweise sollte das Metadaten Repository bzgl. der folgenden Meta - Metatypen flexibel erweiterbar sein: Objekttyp Attributtyp Beziehungstyp Metadatenaustausche mit anderen Komponenten / Tools sollten mittels CWM (Common Warehouse Metamodel – OMG) stattfinden, also auf der Basis von XML. 4 – Ebenenkonzept von “toolneutralen – Metadaten - Repositories“ Die Erweiterbarkeit der Repository – Struktur selbst (also der Meta – Meta – Definition), wie sie das 4 – Ebenenkonzept eines tollneutralen Repositories erlaubt, ist die Voraussetzung dafür, dass auch alle Objekte außerhalb der Warehouse – Prozesse beschrieben werden können. In einem Unternehmen können mehrere unterschiedliche Auswertewerkzeuge eingesetzt werden. Alle diese Werkzeuge, auch wenn sie von unterschiedlichen Herstellern kommen, müssen dokumentiert werden können. Hierzu legt der Entwickler neue Objekttypen und neue Attributtypen in dem Repository an und verbindet die neuen Objekttypen über neu festgelegte Beziehungen mit den bestehenden Objekttypen. Alle Eintragungen zu dem neuen Objekttyp sind jetzt ebenso wie bestehende Objekttypen z. B. über eine Auswirkungs- – oder Herkunftsanalyse abfragbar. Das Metadaten Repository sollte nicht nur über dedizierte Tools modifizierbar bzw. lesbar sein. Auch nicht Tool – gestützte Zugriffe wie z. B. natives SQL sollte möglich sein. 8.3 Automatisiertes Pflegen der Metadaten Die Praxis hat gezeigt, dass Metadaten dann unvollständig (und somit unbrauchbar) werden, wenn sie manuell gepflegt werden. Das Erstellen und Modifizieren der Metadaten sollte daher automatisiert erfolgen. Scripte oder ähnliche Programme sollten immer dann die Metadaten im Hintergrund modifizieren, wenn Entwickler die Struktur des Warehouses verändern. Aus diesem Grund sollte das Metadaten – Repository über eine programmierbare Schnittstelle verfügen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 101/166 8.3.1 Zusätzliche Verwaltungsinformationen Die Einträge in dem Metadaten Repository können zusätzliche Informationen zur leichteren Verwaltung mit sich führen. Diese können sein: Erstellt am Autor / Ersteller Zuletzt geändert am Änderungsautor Version Status Bearbeitungshinweise Description / Beschreibung Die Einträge in diesen Attributen sollten automatisiert gepflegt werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 102/166 9 Operativ genutzte Warehouse – Daten Zu Beginn dieses Textes wurde bereits erwähnt, dass sich die Einsatzgebiete von Data Warehouse – Systemen erweitern. In einigen Fällen schmilzt die Grenze zwischen operativen und dispositiven Daten. Die in der Vergangenheit aufgestellte Regel, beide Datenarten streng zu trennen, wird mittlerweile oft in Frage gestellt. Tatsächlich gibt es heute weniger technologische Gründe für diese Trennung und eine engere Verzahnung beider Datenarten kann praktisch sein. Hier noch einmal zusammengefasst die Gründe für eine Trennung beider Datenarten und für eine Duplizierung der Daten im Data Warehouse: Daten werden aus den operativen Anwendungssystemen in eine separate Datenhaltung kopiert weil: In einem zentralen, einheitlich strukturierten Data Warehouse sind Informationen für viele Benutzergruppen leichter zugänglich, als wenn sie verteilt an vielen Fundstellen liegen würden. Die Datenmodelle sind an analytischen Fragestellungen ausgerichtet und nicht an optimalen Zugriffspfaden, wie das in operativen Datenmodellen der Fall ist. Im Data Warehouse liegen Informationen in historisierter Form vor, anstelle von Momentaufnahmen in operativen Systemen. Entlastung der operativen Systeme durch Verlagerung von aufwendigen Analyse – Abfragen. 9.1 Szenarien und Problembereiche bei operativ genutzten Warehouses Diese Gründe gelten nach wie vor. Allerdings können sie heute um weitere Anforderungen ergänzt werden, denn wenn Daten aus mehreren Quellsystemen zusammengezogen werden, so ist das Mehr an Informationen durchaus auch zur besseren Steuerung operativer Prozesse nutzbar. Auch die Kenntnis über den historischen Kontext von Informationen oder einfach das Wissen, was sich in der Vergangenheit zugetragen hat, kann in der Gegenwart helfen. Es sind die folgenden angenehmen Eigenschaften die das Warehouse System auch für operative Zwecke interessant macht: Durch das Warehouse liegen Daten aus mehreren Systemen in einer integrierten Form vor. Diese Daten können mit einem „historischen Gedächtnis“ versehen werden. Was früher war, ist in den transaktionsorientierten Systemen meist „vergessen“. Die Daten sind leicht zugreifbar. Das Schnittstellenproblem ist meist gelöst. Es sind Standardschnittstellen (SQL, XML) und die Daten liegen in einer sortierten Form vor. Die Folge ist, dass an dispositive Systeme plötzlich Anforderungen gestellt werden, wie man sie sonst nur aus dem operativen Umfeld kennt: Kurze Antwortzeiten im Sekundenbereich für Benutzerzugriffe. Hohe Verfügbarkeit, das bedeutet auch ein schnelles Wiederherstellen im Recovery – Fall. Hohe Aktualität der Daten. Die Daten dürfen kaum älter sein, als wenige Minuten. Es interessieren meist nur Daten aus den jüngsten Zeitperioden. Hier entstehen Konflikte mit den Möglichkeiten bisheriger Warehouse – Systeme: Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 103/166 Kurze Antwortzeiten im Sekundenbereich sind bei großen Datenmengen kaum machbar. Hohe Verfügbarkeit: Große Datenmengen lassen sich nur aufwendig recovern. Hohe Aktualität der Daten, führt zu ständigen Ladeaktivitäten im Warehouse: o Das System kann ständig mit dem Nachladen beschäftigt sein, o es fehlt Rechenleistung für Analysen, o die Informationen sind u. U. nicht konsistent, weil irgendein Teil der Informationen bereits wieder geändert wurde. 9.1.1 Einsatzszenarien operativ genutzter Warehouses Die folgende Einsatzszenarien lassen sich unterscheiden: Die Bereitstellung von operativ nutzbaren Daten für Abfragen von Anwendern aus beliebigen Abteilungen im Unternehmen. Das ist das sog. Operational Data Store (ODS) Konzept. Hier spielt die zeitnahe Verfügbarkeit der Daten noch keine Rolle. Wird ein hoher Anspruch an die Aktualität der Daten gestellt, z. B. wenige Minuten nach Ablauf der operativen Transaktion so findet das Realtime oder Near Realtime Verfahren Anwendung. Werden Warehouse Daten automatisiert in die operativen Prozesse zu dem Zweck der Steuerung zurückgeführt, so wählt man das Loop Back Verfahren. Einordnung der unterschiedlichen Warehouse – Verwendungsarten gegenüber Latenzzeit und Datenart Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 9.2 104/166 Operational Data Store Konzept Sollen Anwender aus beliebigen Abteilungen die oben beschriebenen Vorteile der Warehouse – Technik nutzen können und Warehouse Informationen in ihren operativen Prozessen verwenden, so lässt sich das mit dem Konzept des Operational Data Stores (ODS) lösen. Hierzu wird ein Bereich in dem Data Warehouse geschaffen, in dem zwar bereinigte und konsolidierte Daten enthalten sind (i. d. R. in der 3. Normalform). Diese Daten umfassen jedoch nur einen historisch kurzen Zeitraum. Weil die Datenmenge beschränkt ist, lassen sich performante Abfragen durchführen und für die Daten dieses Ausschnittes kann leicht ein Recovery absolviert werden. Einordnung ODS Die Daten in der ODS – Schicht liegen in granularer Form analog den operativen Transaktionen vor. Es wird ein Zeitraum definiert, für den die Daten vorgehalten werden. Mit dem „Partition Exchange and Load“ – Verfahren können die Daten entweder bereits vor oder nach Ablauf dieses Zeitraums in das eigentliche Warehouse kopiert werden. Das Operational Data Store - Konzept wird in jüngster Zeit immer häufiger eingesetzt, weil sich zum einen die technischen Möglichkeiten verbessert haben und zum anderen aber auch die Bedeutung der operativen Warehouse – Nutzung gewachsen ist. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 105/166 Einführung einer ODS – Schicht zur operativen Nutzung von Warehouse - Daten Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 9.3 106/166 Verfahren für aktivere Rollen des Warehouses (Realtime / Loop Back) Zur Steuerung von granularen Prozesse ziehen Unternehmen zunehmend auch Informationen aus Data Warehouse - Systemen heran. Allerdings nicht als einmalige statisch verstandene Berichte, die in Form von Zahlentabellen Berichtszeiträume referieren, sondern als permanent wirkende, automatisierte Steuerdaten, die unmittelbaren Einfluss auf Entscheidungen auf der taktischen, operativen Unternehmensebene haben. Damit entstehen neue Herausforderungen an die Architektur von modernen Warehouse - Systemen: On-the-Fly - Aktualisierung der Warehouse - Daten (Real Time - Aktualität) Automatisierung der Berichterstellung und des Analyseprozesses (Fast Refresh Summary) Aktive Informationsbereitstellung (durch Automatismen bzw. Events gesteuert) 24/7-Verfügbarkeit Transaktionssicherheit auch in Warehouse – Systemen Die Geschwindigkeit, mit der das Warehouse seine Daten aufbereitet, muss mit der Geschwindigkeit, mit der die Daten in der operativen Welt entstehen, mithalten. Die Daten müssen aus allen Vorsystemen synchron geliefert werden. Sollen Daten aus mehreren Quellsystemen in dem Data Warehouse miteinander verbunden werden, so sind die Lieferzeiten aufeinander abzustimmen. Hier helfen folgende technische Features und Optionen: Verbindungssoftware (Conectors) zu diversen Standardanwendungen (SAP R/3, CRM- Systeme...). Asynchrone Kopplungselemente zur Pufferung von Transaktionen (Queueing). Workflow Technik zur Event - Steuerung. Fast Refresh Aktualisierungstechniken für automatisierte Berechnungen. Streaming -Techniken in denen Daten über eine verkettete Abfolge von Transformationen in Informationen gewandelt werden. In die Datenhaltung integrierte Analyse- und Mining Funktionen mit denen ohne unnötige Datentransporte direkt in der Datenablage auf die Daten automatisiert eingewirkt werden kann. Automatisiertes Korrigieren von Datenfehlern Standardisierte Datenformate wie XML. Durchgängig genutzte Metadatenstandards um Warehouse - Systeme flexibel über Modelle steuern zu können, um sie schnell an die sich ständig ändernden Geschäftsprozessen anzupassen. BPEL (Business Process Execution Language ) Funktionen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 107/166 9.3.1 Der Datenfluss im Real Time / Loopback Warehouse Datendurchlauf Realtime – Verfahren mit Loop Back Der Datenfluss im Realtime Data Warehouse kann wie folgt skizziert werden: 1. Die Datenübernahme aus dem operativen System muss synchronisiert erfolgen. Das nachgelagerte System muss Daten in der Geschwindigkeit weiterverarbeiten, in der diese Daten auch im operativen System entstehen. Dabei darf das operative System nicht behindert werden, weder durch den laufenden Betrieb noch durch eventuelle Ausfallzeiten des nachgelagerten Systems. Um dies zu gewährleisten, wird ein Queue – basierter Sende – Mechanismus zwischen dem operativen und dispositiven System installiert. Die Message – Queue speichert die von dem operativen System gesendeten Sätze im Verlauf einer eventuellen Ausfallzeit des Warehouses. Die Message - Queue sorgt auch für die Quittierung der von dem Warehouse „abgeholten“ Sätze. Der Austausch von Daten zwischen operativem und dispositivem System wird somit als logische Transaktion gesteuert. 2. In dem Eingangsbereich des Warehouses müssen die eingelaufenen Sätze geprüft werden. Das Prüfverfahren muss jedoch so gestaltet sein, dass es im Fehlerfall den Gesamtablauf nicht behindert. Fehlerhafte Sätze werden aussortiert. Diese müssen im korrigierten Zustand nachgeladen werden können. Hierzu sind die jeweils verantwortlichen Stellen zu benachrichtigen. Alle anderen Daten müssen unabhängig von den fehlerhaften Daten stimmig sein. 3. Da die späteren Analyseschritte meist mehrere Informationen (mehrere Sätze) bis hin zu größeren Datenmengen verarbeiten, wird es sinnvoll sein, das Warehouse schubweise mit neuen Daten zu versorgen. D. h. der Aktualisierungsvorgang läuft nicht ständig, sondern periodisch in Zeitintervallen. In den Zwischenzeiträumen kann das System automatisierte Analysen fahren. Um diesen Zustand zu erreichen, wird der ständige Ladefluss der Daten Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 4. 5. 6. 7. 108/166 durch die Queue unterbrochen. Technisch wird die Queue periodisch ausgelesen. Das Ausleseintervall bestimmt dabei die Häufigkeit der Aktualisierung des Warehouses. Die nachgelagerten Analyseschritte können ebenfalls über diese Intervalle gesteuert werden. In einem Konsolidierungsschritt erfolgen jetzt ähnliche Maßnahmen, wie sie auch in einem herkömmlichen Data Warehouse geschehen. Die Aufgabenstellung besteht darin, operative Daten inhaltlich und technisch aufeinander abzustimmen, wenn diese aus unterschiedlichen Vorsystemen stammen. In dem Realtime Warehouse kommt diesem Konsolidierungsschritt sicherlich weniger Bedeutung zu, da in der Kürze der Zeit nicht allzu viele Quelldatenströme konsolidiert werden können. Nach diesem Schritt kann die eigentliche Warehouse – Versorgung vollzogen werden, das bedeutet, dass die geprüften und konsolidierten Daten in die Warehouse – Schichten überführbar sind, je nach dem, ob mit einer ODS – Schicht oder einer Warehouse – Schicht gearbeitet wird. Eine explizite Stage – Schicht gibt es bei dieser Art der Verarbeitung nicht mehr. Diese ist durch die vorgelagerten Puffer- und Prüfschritte ersetzt worden. Im Gegensatz zur klassischen Verwendung eines Data Warehouses liegt der Hauptzweck des Realtime/Loopback – Verfahrens in der automatisierten und zeitnahen Feststellung von Entwicklungen. Es schließt sich also jetzt eine Phase des automatisierten Analysierens an. Das sind Berechnungen, Vergleiche, Aggregationen usw. die man als Batch – Jobs im Hinterrund fährt. Die Analysen verfügen über den vollen historischen Datenvorrat des Warehouses im Hintergrund. Es sind also qualitativ hochwertige Analysen möglich. Der Loopback – Mechanismus ist ein Regelmechanismus, der Steuerinformationen wieder zurück an die operativen Prozesse gibt. Grundlage für diese Steuerinformationen sind natürlich einerseits die Analyseergebnisse des Vorschrittes. Diese Ergebnisse stehen jedoch nicht neutral neben den Geschäftsprozessen, sondern sind vor dem Hintergrund der geschäftlichen Entwicklung der Unternehmen zu bewerten und einzuordnen. Die hierzu nötigen geschäftlichen Regeln stellt das Management als Regeldaten für den Loopback - Prozess bereit. Innerhalb des Loopback – Prozesses entstehen dann als Folge von einfachen Entscheidungsabfragen (if/then/else/case usw.) Impulse für die operativen Prozesse. Im letzten Schritt findet die Kommunikation mit den operativen Prozessen statt, die je nach Geschäftsfall technisch unterschiedlich realisiert sein kann. Hier sind Eingaben in eine Balanced Scorecard ebenso möglich, wie das Modifizieren bestimmter Data Mart – Tabellen, deren Ergebnisse an diversen Stellen eines Portals erscheinen. In anderen Szenarien werden automatisch Emails generiert oder ganz konkret Supportanfragen an eine Servicestelle gerichtet. In einem Produktionsbetrieb können sofort Bestellungen generiert werden, wenn Engpässe zu erwarten sind usw. 9.3.2 Organisatorisch – technische Anforderungen Durch die enge Kopplung des Warehouses an die operativen Systeme ergeben sich neue organisatorisch - technische Anforderungen an die Datenhaltung: Der klassische Rollenwechsel z. B. zwischen Nacht- und Tagbetrieb mit den zur Verfügung stehenden Zeitfenstern zum Laden fällt weg. Damit entfällt auch die Kontrolle des Batchbetriebs durch das Operating oder die mögliche nachgelagerte Korrektur von Batchläufen. Auch Monitoring und Fehlerkorrekturen sind jetzt ständige Aufgaben. Es ist für zwei Notfallsituationen Vorsorge zu treffen: Datenfehler im laufenden Betrieb sind so zu beheben, dass sich den Realtime – Betrieb des Warehouses nicht behindern. Korrekturen sind „On The Fly“ zu erledigen und die bereinigten Daten wieder in den Kreislauf Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 109/166 einzuspielen. Die Aktualität bzw. Richtigkeit der Realtime – Informationen darf unter den fehlerhaften und in Korrektur befindlichen Daten nicht leiden. Ein Totalausfall des Systems hat plötzlich direkten Einfluss auf den operativen Betrieb weil Steuerdaten fehlen. Anders als in den klassischen Warehouse – Verfahren, sind jetzt auch im operativen Betrieb Vorkehrungen für einen Warehouse – Ausfall zu treffen, z. B. kann man mit Default Regeldaten arbeiten, die sich aus den Durchschnittswerten der letzten Tage ergeben. Solche Durchschnittswerte sind natürlich vor einem Ausfall zu ermitteln. 9.3.3 Hochverfügbarkeit von Near Realtime - Systemen Werden Warehouse – Systeme operativ in Richtung Near – Realtime genutzt, so steigt auch deren notwendige Verfügbarkeit aus der Sicht der Anwender. Sie muss zumindest so hoch sein, wie die der operativen Anwendungen mit denen das Warehouse kommuniziert. Das kann bis in den Bereich von 7/24 Stunden reichen. Dies gilt vor allem, wenn Unternehmen international tätig sind und Zeitverschiebungen in den Arbeitszeiten vorkommen. Ist ein Warehouse dann auch noch vernetzt und es arbeiten Warehouse - Komponenten in unterschiedlichen Zeitzonen, gilt dies erst recht. Die Plattensysteme sind durch die RAID – Verfahren mittlerweile sehr gut gegen Ausfälle abgesichert. Mit dem Release 9 hat Oracle das Real Application Cluster (RAC) – Verfahren eingeführt. Hier teilt man die notwendige Gesamtrechnerleistung auf mindesten zwei Rechnerknoten. Bei einem Ausfall eines Knotens übernimmt kurzzeitig der zweite Knoten die Gesamtlast. Das System läuft zwar langsamer, aber fällt nicht aus. Lastübernahme von ausgefallenem Rechnerknoten durch verbleibende Knoten in einem RAC – Clusterverbund Realtime bzw. Near – Realtime Data Warehouse Systeme erhalten gegenwärtig bei einem Neudesign fast immer eine RAC Hardware – Architektur. Einer der Gründe ist die erhöhte Ausfallsicherheit. Eine gute Verfügbarkeit wird auch durch ein entsprechendes Backup und Recovery – Verfahren mitbestimmt. Hier sind es die Sicherungsund Wiederherstellungszeiten, die von Verfahren zu Verfahren verschieden sein können (siehe separates Kapitel hierzu). 9.3.4 Event gesteuertes Warehouse Ein mit operativen Systemen vernetztes Warehouse - System lässt sich nicht mehr über Batch - Mechanismen bzw. über vorbestimmte „geschedulte“ Jobabläufe steuern. Hier übernehmen Events die Kontrolle. Es sind Events wie: Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 110/166 Ändern von Systemzustände, Änderung von Ressourcenverfügbarkeit Auftreten von Fehlern Eintreffen von Daten per FTP Eintreffen von Daten als Email Eintreffen XML Message Eintreffen Queue - Message Veränderung von Tabelleninhalten Feuern von Triggern Hier helfen nicht mehr prozedural ablaufende Ladeprozesse, sondern ein flexibles Netzwerk von gekapselten Prozeduren, die bei Bedarf durch das Auftreten der Events selbständig starten. Meist sind es pollende Routinen, die in Zeitintervallen eine definierte Aktion durchführen (z. B. Prüfe Datei vorhanden -> Starte Aktion). 9.3.4.1 Simulation von Event – gesteuerten Arbeitsphasen Werden wesentliche Teile des Warehouses über Events gestartet, können zwei problematische Situationen auftreten: Es können Ressourcenengpässe entstehen, weil zu viele Schritte parallel laufen, o Maschinenengpässe o Lock – Situationen Datenbank Source – Files Es entstehen Ladefehler, weil eine notwendige Reihenfolge nicht eingehalten wurde. Diese Abläufe sind zu simulieren. Die Wahrscheinlichkeit solcher Vorfälle muss geprüft werden. Hier helfen graphische Workflow – Werkzeuge, deren Monitoring ebenfalls graphisch abrufbar ist. Hier sind ungeplante Wartezustände leicht erkennbar. 9.3.4.2 Testdaten Testdatengeneratoren liefern Zufallswerte, die auch Grenzwertebereiche mit abdecken. Probleme entstehen oft in solchen Grenzbereichen, wenn Vorsysteme Daten oder Konstellationen von Daten liefern, mit denen Entwickler nicht rechnen. Testdatengeneratoren geben die Möglichkeit Datenbereiche festzulegen. Es wird automatisch eine größere Bandbreite an Datenwerten erreicht. 9.3.5 Durch einheitliche Metadaten die Kontrolle bewahren Verteilte Warehouse - Systeme sind einheitlich zu verwaltet und über Systemgrenzen hinweg sind Datenflüsse zu dokumentieren: Impact- bzw. Herkunftsanalyse berichten über Abhängigkeiten. Hier zahlen sich Tool - neutrale Repositories aus. Denn hier können auch Systeme dokumentiert werden, die nicht in klassischen ETL – Prozessen vorkommen. 9.3.6 Datenschutz und nicht Zugriffsschutz Ein solch flexibles und sich fast selbst steuerndes System, braucht besonders effektive Sicherheitsmassnahmen. Die Daten müssen in ihrem Kern geschützt werden. Es reicht nicht, wenn Front End - Werkzeuge ihr Security - System mitbringen. Die Daten sind in der Datenbank auf Satzebene zu schützen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 111/166 Die Daten müssen direkt an der Speicherstelle geschützt sein, nicht in den Frontends 9.3.7 Messagebasiertes Laden versus Batchbetrieb in der Datenbank Um die Zeitnähe von wenigen Minuten zu erreichen sollten operative Daten, bereits unmittelbar nach ihrem Entstehen in das Warehouse gelangen. 1. Ist eine Transaktion im operativen System abgeschlossen, triggert das operative Systeme die geänderten oder neu erstellten Daten in Richtung Data Warehouse. Nachteilig ist hierbei, dass das operative System „angefasst“ werden muss. Es müssen zum einen z. T. Programmänderungen gemacht werden. Zum anderen kann das Triggern der Daten in Richtung Warehouse zu Performanceverlusten führen. Die einfachsten Verfahren hierzu gibt es in einer geschlossenen Oracle – Datenbankwelt, in der z. B. die Log – Dateien des operativen Systems ausgelesen werden können. Da dies eigene Datenbankprozesse sind, leidet die Performance der operativen Prozesse weniger. Eine bequeme Variante stellt die sogenannte „Stand By – Datenbank“ dar. Das Datenbanksystem pflegt über seinen Logbereich ständig eine zweite Schattendatenbank mit. Diese Schattendatenbank kann nach belieben ausgewertet und gelesen werden ohne dass die operative Originaldatenbank Performanceverluste erleidet. 2. Zum Entgegennehmen der Nachrichten aus dem operativen System braucht man passende Konnektoren, das sind meist spezielle Programme, die man selbst kaum programmieren kann. 3. Innerhalb der Warehouse – Datenbank können die eintreffenden Nachrichten nicht sofort weiterverarbeitet werden. Denn das würde zu einem ständigen Lade- und Transformationsfluss im Warehouse führen. Stattdessen sollte man einen klassischen Batch – basierten Lademechanismus erstellen, der in sehr kurzen Zeitabständen wiederholt laufen kann. Die entgegengenommenen Messages werden in einer sog. Message – Queue gepuffert. 4. Alle nach einer kurzen Zeitspanne eingetroffenen Messages liest man dann aus der Message – Queue wieder aus und schickt sie auf die „Batch – Reise“ zur weiteren Aufbereitung durch das Warehouse. Zum Steuern dieses Vorgangs kann man Datenbank – intern eine „pollende“ Prozedur mit DBMS_JOB nutzen. Der Queue – Mechanismus in der Datenbank steuert den Enqueue / Dequeue – Vorgang, so dass eine gesicherte Datenübergabe stattfinden kann. Der gesamte Ladevorgang einer Ladeperiode sollte abgeschlossen sein, wenn der nächste beginnt. Diese Zeiten können variieren. Die Polling – Frequenz sollte flexibel eingestellt werden können. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 112/166 Pollendes Near - Realtime Szenario mit Loop Back Aktion 9.3.8 Entkopplung von ETL und Berichtserstellung Während das Laden und Transformieren der Daten im Realtime – Warehouse ständig (pollend) stattfindet, muss das nicht zwangsläufig auch für die Berichtserstellung der Fall sein. Es gibt sicher Berichte, die nicht ständig aktuell sein müssen. Durch das Realtime – Verfahren können z. B. ODS – Tabellen zeitnah aktuell gehalten werden, dies muss nicht zwangsläufig für Berichte für das Controlling gelten. Das Realtime – Verfahren hat aber Auswirkungen auf die Berichtserstellung wenn parallel Daten aktualisiert werden. Es können fachlich falsche Daten in die Berichte laufen. Hier sind Datenbereiche zu sperren. Der Aktualisierungsmechanismus der Materialized Views kann hier helfen. In klassischen Batch – Lösungen wird die automatische Aktualisierung der Materialized Views nicht genutzt, weil sie Performance kostet. Kommen aber immer wieder kleine Datenmengen, so sind die Performanceverluste nicht so gravierend. Materialized Views als Grundlage von Berichten aktualisieren sich dann selbst im Minutenzyklus. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 113/166 Ausnutzen der Materialized Views mit dem Auslesen der View Logs zum ständigen Aktualisieren der Berichte 9.3.9 Vergleichbarkeit der Berichte (Aktualität) Aufgrund der ständigen Aktualisierung der Warehouse - Daten kann es vor allem bei Ad Hoc – Abfragen zu nicht übereinstimmenden Berichten kommen, wenn Anwender zu unterschiedlichen Zeiten Berichte abfragen. Dieses Problem tritt in klassischen Warehouse - Systemen auch schon auf, wenn der Anwender z. B. bei einem täglichen Updatezyklus Berichte an zwei unterschiedlichen Tagen erstellt. Hier hilft ein organisatorisches Rahmenkonzept, in dem Zeitpunkte für die Berichtserstellung definiert sind. Für automatisierte StandardBerichte ist das Problem damit bereits gelöst. Bei Ad hoc - Abfragen kann eine Aktualisierungsfrequenz der Materialized Views festgesetzt werden, z .B. Aktualisierung immer nach 1 / 3 / 6 Std. usw.. Zur leichteren Verwaltung kann man ein Aktualisierungsschema angelegen: Priogruppe Dringlich keit der Aktualität 0 Aktualisierungszeitpunkt Zweck On Demand (nur auf Anforderung) Summentabellen sollen über einen längeren Zeitraum erhalten bleiben. Berichtsergebnisse lassen sich über einen definierten Zeitraum hinweg vergleichen. Diese Aktualität entspricht den herkömmlichen Batchladeläufen mit täglicher Aktualisierung. Wenig ändernde Transaktionen. Eine Aktualität von max. 2 Std. reicht aus. 1 niedrig Täglich (6 morgens) 2 mittel 3 hoch 4 maximal Zu jeder geraden Stunde ( 8, 10, 12, 14, 16, 18 Uhr) Stündlich (8, 9, 10, 11, 12, 13... Uhr) On Commit (ständig) Copyright © 2005 by Oracle Corporation. All rights reserved Uhr Eine Aktualität von max. 1Std. reicht aus. Realtime-Aktualität. Notwendig, wenn Berichtsergebnisse just-in-Time zur Unterstützung des operativen Geschäfts notwendig sind. Data Warehouse Referenzarchitektur 114/166 9.3.10 Zusammenfassende allgemeine Empfehlungen Hier noch einmal zusammenfassend Empfehlungen für das Verfahren: Der Lade - Prozess ( Extraction Transition Load) ist anders als bei klassischen Systemen kein Batch - Laden mehr, sondern ein „ständiges Holen“ von Daten. In der Art von Real – Time - Systemen wird das Warehouse nach jeder Änderung im operativen System mit angepasst. Die Datenübertragung selbst muss transaktionssicher sein. Nichts darf verloren gehen. Die operativ genutzten Systeme dürfen durch dieses „Abziehen“ der Daten nicht behindert werden (Asynchrone Kopplungen, „OLTP ABS“). Dies gilt sowohl für Performance-Einbussen also auch für Lock-Situationen. Der ETL - Prozess muss extrem einfach gestaltet sein. Komplexität führt nur zu Abbruchrisiken und bringt das automatisierte Verfahren durcheinander. Das Prinzip der Durchgängigkeit der Automatisierung ist zu realisieren mit Hilfe möglichst vieler Standardfunktionen, wenig komplexer Transformationen und ohne unnötige Zwischenspeicher wie hart-codierter Summentabellen. Auswertungsergebnisse (Ad Hoc - Berichte) müssen auch wieder in „Real – Time“ zur Verfügung stehen. Unmittelbar nach einer Änderung, sind die Berichte zu aktualisieren. Eine Aktualität im Minutenbereich ist gefordert, auch wenn Gigabyte große Datenmengen zur Berichtserstellung nötig sind (Real – Time - Ad Hoc - Berichte). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 115/166 10 Wo wird historisiert Nachdem die Konzepte des Schichtenmodells und der unterschiedlichen Verwendungsarten von Warehouse - Daten dargestellt sind, bleibt die Frage nach der Historisierung von Daten offen. Operative Bewegungsdaten erhalten ihren Kontext durch die Stammdaten im Unternehmen. Da die Entwicklung der Bewegungsdaten (Unternehmenskennzahlen) über einen längeren Zeitraum beobachtet werden soll, kann eine Veränderung der Stammdaten nicht ausgeschlossen bleiben. Es treten neue Geschäftsfelder auf, neue Produktgruppen ergänzen den Warenstamm, andere verschwinden, Kunden treten in geänderten Geschäftsbeziehungen zu dem Unternehmen usw. . D. h. die Rahmenbedingungen der Unternehmenskennzahlen ändern sich und das ist zu berücksichtigen, will man Falschaussagen in den Analysen vermeiden. Die Historisierungsverfahren beschränken sich meist auf die Stammdaten. Die Bewegungsdaten werden lediglich periodisch geladen. Dann müssen sie allerdings zu den gültigen Stammdatensätzen passen (Produkte können nur verkauft werden, wenn sie in den Stammdaten richtig erfasst sind usw.). Da die Stammdaten - Informationen im Data Warehouse mindestens an zwei Stellen redundant vorkommen (Warehouse – Schicht und Data Marts), erfordert es eine explizite Entscheidung ob in der Warehouse – oder in der Data Mart – Schicht historisiert werden soll. Im ersten Fall steht der gesamte historisch Kontext in der Warehouse Schicht. Hier wird man nur einen zeitlich begrenzten Ausschnitt in die Data Marts geben. Allerdings müssen Anwender bei Abfragen, die über den gegebenen Zeitrahmen des Data Marts hinaus gehen, auf die zusätzlichen Daten der Warehouse Schicht zugreifen. In vielen Fällen ist das akzeptabel, wenn z. B. Jahresabfragen wesentlich seltener vorkommen als Abfragen in der aktuellen Berichtsperiode. Historisierung in der Warehouse Schicht führt zu vielen Tabellen und einer komplexeren Verwaltung Die Alternative arbeitet genau umgekehrt. Sie historisiert in den Data Marts. Die Warehouse – Schicht beinhaltet nur noch Daten der aktuellen Berichts- bzw. Aktualisierungsperiode. Das bedeutet jedoch einen Mehraufwand bei den Auswertungen, auch bei Auswertungen, die nicht ältere Zeiträume abfragen. In allen Abfragen müssen Zeitkriterien enthalten sein, da sonst die Ergebnisse verfälscht werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 116/166 In diesem Fall sollten Dimensionen unbedingt über Data Mart – Grenzen hinweg nutzbar sein, wie dies in dem Konzept weiter oben vorgestellt wurde, um Aufwand zu vermeiden. Historisierung in der Data Mart Schicht vereinfacht das Gesamtverfahren, mach aber das Lesen für Benutzer schwerer 10.1.1 Historisierungsverfahren Zunächst sollten verschiedene Varianten der Historisierungsverfahren vorgestellt werden: Historisierungsverfahren Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 117/166 1. Die erste Variante ist die einfachste. Hier werden Dimensionsdaten komplett erneuert. Historieninformationen gehen dabei verloren. 2. Bei der zweiten Variante wird ein zusätzlicher Satz mit einem neuen Primary Key eingefügt. Es kann eine Verfälschung bei der Anzahl der Dimensionssätze kommen. Ein Kunde existiert plötzlich zweimal nur weil er umgezogen ist. Ursprungssätze und neue Sätze können nicht als zusammengehörig identifiziert werden. 3. In der dritten Variante führt man ein zweites Feld für die neue bzw. geänderte Information ein und hat die Möglichkeit zumindest den vorletzten gültigen Stand vorzuhalten. 4. Bei der vierten Variante wird bei jeder Änderung ein neuer Satz eingefügt und ein Aktualitätsflag gesetzt. Der Primary Key bleibt erhalten. Zur Unterscheidung der Sätze mit gleichen Primary Keys fügt man eine Versionsnummer ein, die natürlich mit zum Primary Key gehört. Bei Abfragen auf den aktuellen Datenbestand muss jetzt das Aktualitätsflag mit in die Abfrage aufgenommen werden. Außerdem wird der erweiterte Primary Key in die Faktentabelle wandern. Der Primary Key ist unnötig komplex. 5. Die fünfte Variante vereint Nr. 2 und Nr. 4. Man erstellt auch für jeden zusätzlichen Änderungssatz einen neuen Primary Key. Um alle Änderungssätze als zusammengehörig zu kennzeichnen, führt man z.B. eine Kundenummer ein ( diese kann aus dem operativen System übernommen werden). Ein Aktualitätsflag zeigt auf den letzten gültigen Satz. Es kann ein Änderungsdatum mitgepflegt werden, um die Reihenfolge der Änderungen zu dokumentieren 10.1.2 Historisierung in der Warehouse - Schicht Die Historisierung der Stammdaten in der Warehouse – Schicht kommt seltener vor, weil sie nicht immer sinnvoll und praktikabel ist. Folgende Gründe sprechen für die Historisierung in der Warehouse – Schicht: Durch die Historisierung entstehen so große Datenmengen, dass diese nicht in den Data Marts, also sehr nahe an dem performancekritischen Benutzerzugriff, vorgehalten werden können. Durch die Historisierung ist die Komplexität gewachsen. Man will den Benutzern nicht zumuten, ständig Zeit- und Versionsschlüssel in den Abfragen mit zu geben. Die Data Marts bleiben handlich und überschaubar. Zeitreihenanalysen, also Abfragen über längere Zeiträume, werden von Endbenutzern nicht durchgeführt, sondern finden nur automatisiert im Batchverfahren statt. Hierzu passt die Beobachtung, dass Zeitreihenanalysen zwar vorkommen, aber wesentlich seltener als Abfragen aus den jüngsten Zeitperioden. Am häufigsten werden Daten aus den jüngsten Zeitperioden gemacht. Die Data Marts bestehen immer nur eine kurze Zeit und werden für bestimmte Benutzergruppen und Zeiträume gezielt zugeschnitten bzw. neu erstellt. Historische Daten würden bei diesem Verfahren verloren gehen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 118/166 Vorkommen von Berichten mit unterschiedlichen Zeitspannen Folgende Gründe sprechen gegen die Historisierung in der Warehouse – Schicht: Die in der Warehouse – Schicht übliche 3 NF behindert das Historisierungsverfahren und macht es komplex, weil viele Tabellen zu historisieren sind. Benutzer müssen in zwei unterschiedlichen Modellen lesen, wenn sie eine historisierte Abfrage durchführen: aktuelle verdichtetet Daten aus dem Data Mart und die Historiendaten in separaten Tabellen der Warehouse – Schicht. Die Warehouse – Schicht stellt üblicherweise eine Art Vorratsspeicher für neue Informationsbedürfnisse dar. Es ist daher durchaus üblich, dass hier Daten enthalten sind, die noch niemand braucht. Sollen alle diese Informationen historisiert werden. Das wäre zu aufwendig. 10.1.3 Abschließendes Konzept zur Historisierung Die Vorteile für eine Historisierung in der Data Mart Schicht überwiegen in der Regel. Man realisiert die Historisierung dort, wo der Benutzer auch abfragt. Das Mehr an Aufwand, wird durch die größere Informationsvielfalt ausgeglichen. Performanceverluste durch die hohen Datenmengen, können durch die Oracle Datenbanktechniken vermieden werden, z. B. durch das Partitioning. Durch das „Partition Exchange and Load – Verfahren“ wird das Nachladen einer neuen Zeitperiode elegant unterstützt. Hier helfen auch die automatisierten Slowly Changing Dimension – Verfahren, die neuerdings von Oracle Warehouse Builder standardmäßig zur Verfügung gestellt werden. Wird in der Data Mart Schicht historisiert, können in der Warehouse – Schicht die Datenmengen gering gehalten werden. Damit entfallen auch wichtige Gründe für eine ODS – Schicht, die man sich so sparen kann. Es gelten folgende Empfehlungen: Historisierung der Dimensionen in den Starschemen der Data Mart – Schicht. Historisierung durch Einführung von zusätzlichen Versionssätzen unter Beibehaltung der alten Information. Für historisierte Dimensionen sollten künstliche Schlüssel verwendet werden. Wird in der Data Mart Schicht historisiert, entfällt die ODS – Schicht. Deren Aufgabe übernimmt die Warehouse – Schicht. Die Historisierung wird durch Partitionieren von Fakten- und Dimensionstabellen unterstützt. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 119/166 11 Minimieren von Hardware – Aufwenden Grundsätzlich hat die Warehouse – Architektur und die Art der Warehouse – Verwendung, unabhängig von den bereitgestellten Funktionen, Auswirkungen auf die Hardware – Kosten. D. h. bei gleicher Leistung können Systeme unterschiedlich viel Hardware – Ressourcen verbrauchen. Hardware Ressourcen können in folgenden Bereichen reduziert bzw. gering gehalten werden: 1. Die Integration von vielen Funktionsbereichen an zentraler Stelle, z. B. schafft das Verlagern der Data Marts auf die Warehouse Server Maschinen und letztlich in die Data Warehouse – Datenbank Wiederverwendungseffekte. 2. Das Nutzen der Datenbank als Lade - Programm (ETL – Engine) führt zu Wiederverwendungseffekten der Datenbank – Hardware. Diese kann besser ausgenutzt werden. 3. Ladeaktivitäten sollten neben der Datenbank keine zusätzlichen Hardware Server benötigen. Datenbank – und Lade – Server sind identisch. 4. Durch die Verlagerung der Berichtserstellung in die Datenbank hinein und das Vorbereiten der Berichte durch Materialized Views können Hardware Kosten im Bereich der Middle Tier (Application Server) gespart werden. Das Aktualisieren der Materialized Views sollte zu Zeiten erfolgen, in denen kaum Online – Benutzer an der Datenbank angeschlossen sind, und in denen keine Ladeaktivitäten stattfinden. 5. Zusätzliche Datenhaltungen für besondere Auswertezwecke verursachen auch zusätzliche Hardware – Kosten. Daher sollten diese vermieden werden. 6. Gemeinsame Hardware - Nutzung durch operative und dispositive Systeme. 7. Minimierung von Transportaufwenden durch die stärkere Integration der Warehouse – Architektur. 11.1 RAC sinnvolle Voraussetzung für neue Architekturen im Data Warehouse Die Oracle – Datenbank bietet eine Schlüsseltechnologie, mit der die Kosteneffekte für die oben genannten Konzepte besonders leicht zu erreichen sind: Real Application Cluster (RAC). Die Real Application Cluster (RAC) – Technologie erlaubt das Verteilen von Datenbanken über Rechnergrenzen hinweg. Zwei oder mehrere Rechner teilen sich einen zugeteilten Plattenplatz und die darauf gespeicherten Daten. Die Kommunikation über genutzte und ungenutzte Daten findet über das sogenannte Cache Fusion, also dem gegenseitigen Bereitstellen entsprechender Cache – Bereiche, statt. Diese technische Möglichkeit bietet zwei Vorteile: 1. Es können sehr groß ausgelegte Rechner durch kleinere Rechner ersetzt werden. Die Kosten für die kleinen Systeme sind in der Summe meist günstiger als große Systeme, auch wenn es mehr Rechner sind. 2. Der erhöhte Hardware – Aufwand der durch die Integration und die Verlagerung von Daten- und Funktionsbereichen an zentraler Stelle entsteht, wird kostengünstiger und durch die leichtere Skalierung effizienter realisiert. Es ergänzen sich die zentralisiert angelegte Warehouse – Philosophie mit den neuen Möglichkeiten der Hardware – Konfiguration. 11.2 Kostenvorteile durch Verbund kleinerer Systeme Große Systeme sind oft durch die vorgehaltenen Ausbaureserven teuer. Die Option die Leistungsfähigkeit durch zusätzliche CPUs zu erhöhen, muss man meist teuer Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 120/166 bezahlen. Kleine Systeme sind in der Regel für wenige CPUs fertig ausgelegt und daher billiger. Bei Skalierungsanforderungen ist es daher günstiger einen zusätzlichen kleinen Rechner in den RAC – Verbund zu integrieren als nachträglich zusätzliche CPUs in das große System einzubauen. Teuere Ausbaureserven bei großen Rechnersystemen 11.3 Integration von Daten und Funktionsbereichen Neben der Datenintegration auch kostenschonende Hardware – Integration durch RAC Technologie Durch das Real Application Cluster Verfahren kann dezentrale, separate Hardware eingespart und durch den zentralen Cluster - Verbund ersetzt werden. Augenfällig werden die Kostenvorteile durch die gleichzeitige Nutzung aller Hardware Ressourcen durch alle Komponenten des Data Warehouses. Spitzenlasten und Leerlaufzeiten in einzelnen Bereichen können leichter verteilt und gegenseitig ausgeglichen werden. Es gibt keine dedizierten Rechner mehr für spezielle Data Marts oder zentrale Warehouse – Datenbanken. Auch Wartung und Betrieb ist einheitlich und auch nur einmalig zu machen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 121/166 Das Konzept setzt voraus: dass alle Schichten des Warehouses (Stage / DWH / Data Mart usw.) sich in einer einzigen Datenbank befinden und damit die verwendetet Technologie die gleiche ist. Es müssen durchgängig Oracle Datenbanken verwendet werden. Zentralisierte Bereitstellung von geclusterter Hardware für alle Daten- und Funktionsbereiche im Data Warehouse. Real Application Cluster Verbund. 11.4 Integration von Datenhaltungs- und Datenbewegungsaufgaben (Funktionale Integration) Vollkommen unverständlich ist der Umstand, dass zum Laden von Daten in die Warehouse – Datenbank mehr Rechenleistung bereitgestellt werden soll, als für die Datenbank selbst. Eine von zwei Hardware – Einheiten ruht immer, entweder die Datenbank, während der ETL – Server arbeitet, oder umgekehrt der ETL – Server, wenn die Datenbank arbeitet. Das reine Laden in die Datenbank geht in der Regel sehr schnell. Hier werden die Bulk – Load – Mechanismen der Datenbank verwendet. Das ist der einzige Zeitpunkt in dem beide Einheiten arbeiten. Die landläufige aber mittlerweile irrende Vorstellung, ein vollständiges Warehouse müsse über ein eigenständiges ETL – Tool verfügen, setzt sich in dem Hardware – Bereich fort und verursacht neben den Anschaffungskosten für das ETL - Tool auch noch immense Hardwarekosten und weitere Wartungskosten. Verlagert man den ETL – Prozess vollständig in die Datenbank, so wird auch innerhalb der Datenbank Leistung gebraucht. Der ETL – Prozess kann sich die Rechenleistung der Maschinen z. B. mit dem Reporting teilen. Wird dennoch zusätzlich Rechenleistung benötigt, so kann man mit Hilfe der RAC / GRID – Technologie der Oracle Datenbank zusätzliche Rechenleistung effizienter bereitstellen und verteilen. Die gesamte Rechnerkapazität wird über den gesamten Laufzeitraum einheitlicher ausgenutzt. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 122/166 Aufwendige klassische Variante mit separatem ETL – Server und Standalone Engine – Programm. Die Datenbank wird von außen bearbeitet. Heute möglich: Wegfall separater ETL – Server und ETL – Integration in der Datenbank 11.5 Kostenminimierung durch zentralisiertes Analysieren Moderne Warehouse – Umgebungen sind heute webbasiert und besitzen eine 3 teilige Architektur aus Backend - / Frontend – und sog Middle Tier - Komponenten. Die Middle Tier – Komponenten sorgen für den Datentransport über Inter-/Intranet, sie „cachen“ einen Teil der Abfrageergebnisse für die Frontends der einzelnen Benutzer und sie sorgen für das Zustandekommen von Benutzersessions. Auch für die Middle Tier wird Hardware benötigt. Der Hardwarebedarf für die Middle Tier hängt auch von der Datenmenge ab, die zu den Endbenutzern geschickt werden muss. Finden alle Analysevorgänge in den Endbenutzerwerkzeugen statt, so sind alle zu analysierenden Daten auch dort hin zu transportieren. Dies ist besonders ärgerlich, weil oft die meisten Benutzerabfragen ähnlich lauten und auf den selben Datenbestand gehen. Es sind Ranking – Abfragen (Top 10) oder einfache Listings. Das sind üblicherweise auch diejenigen Abfragen, die die breiten Benutzerschichten stellen. Durch Cache – Funktionen in der Middle Tier kann nur ein Teil der Last abgemildert werden. Geschickt wäre es, wenn bei neuen Analysen schon gar nicht so viele Daten angefordert werden würden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 123/166 Aufwendige Aufbereitung von Analysen in den Front Ends Die alternative Vorgehensweise identifiziert möglichst viele Standardabfragen und versucht diese Abfragen bereits im Vorfeld zu beantworten. Hierzu nutzt man in dem Backend – Bereich, also in der Datenbank SQL – Abfragen in Verbindung mit Materialized Views. Die meisten Rankingabfragen (Top 10) bzw. Standardlisten können damit erledigt werden. In der Middle Tier sind dann auch nur noch die Ergebniszeilen der Abfrage zu übermitteln. Entsprechend weniger Hardware wird gebraucht. Sparen von Hardware für die sog. „Middle Tier“ bei Vorbereitung von Standardabfragen innerhalb der Datenbank Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 124/166 11.6 Einsparen von Hardware für separate Auswertelösungen Wenn alle Auswertevarianten innerhalb der Datenbank Platz finden, so besteht kein separater Bedarf nach separaten Servermaschinen. Auch dieses Konzept wurde oben bereits besprochen. Oft ist allerdings sehr viel Diskussionsbedarf vorhanden, weil gerade in Fachabteilungen geglaubt wird, es müsse unbedingt ein besonderes Werkzeug sein, weil nur dieses Werkzeug eine besondere Art der Analyse bereit hält. Nicht bedacht, wird der erneute Hardwarebedarf, weil das separate Auswertewerkzeug noch eine eigene Datenhaltung erfordert. Solche Konstruktionen sind in der Regel bei multidimensionalen Auswertewerkzeugen und im Bereich des Data Mining zu finden in. Besondere Auswertungen müssen heute nicht mehr mit separater Datenhaltung erkauft werden. In der Oracle Datenbank sind multidimensionale - und datamining – spezifische Datenhaltungen integrierbar. Das spart wieder Hardware, weil die Datenbank - Hardware wiederverwendbar ist. Wegfall von separater Hardware für separate Auswerteprogramme 11.7 Gemeinsame Ressourcennutzung Ein weiteres Konzept ist die gemeinsame Nutzung von Hardware – Ressourcen durch operative und dispositive Anwendungen. Dieses Verfahren ermöglicht die Real Application Cluster Technologie. Hier gelingt es Rechner so mit einander zu koppeln, als wären sie ein einziger Rechner. Zum einen können je nach Bedarf Rechner – Ressourcen entweder nur für das dispositive oder das operative System oder für beide in gleichen Teilen bereitgestellt werden. Die Anforderungen der Systeme sind nicht immer gleichbleibend hoch. Durch die flexible Kopplung gewinnt man Freiräume ohne zusätzliche Hardware z. B. für Spitzenzeiten anzuschaffen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 125/166 Ressourcenbereitstellung je nach Bedarf entweder für operative oder dispositive Anwendungen Der zweite Vorteil liegt in der besonderen Nähe der in der Datenbank gespeicherten Daten. Ein Nebeneffekt der RAC – Technologie ist der, dass die Datenbereichen (Datenbank – Schemen) besonders eng aneinander rücken. Das RAC – Verfahren bedient eine logische Datenbank, d. h. alle Objekte können schnell zugegriffen werden. Dabei ist es nicht wichtig, ob es sich um Tabellen von operativen oder dispositiven Anwendungen handelt. Es ist lediglich ein anderes Datenbankschema. Das stellt eine erhebliche Erleichterung des Transports von operativen zu dispositiven Systemen dar. Der sonst übliche Kopierweg von Instanz zu Instanz über Rechnergrenzen hinweg mit DB Links entfällt. SQL Befehle können Daten direkt ohne Performance - Verlust von Schema zu Schema lesen und schreiben. Hier zeigt sich zudem, wie störend sich die Existenz von Engine – basierten ETL – Tools auswirken kann. Deren Existenz machen solche Konzepte zunichte. Ein weiteres Konzept bietet sich an: Es müssen nicht immer Daten zwischen operativen und dispositiven Systemen kopiert werden. Einzelne Tabellen sind jetzt gleichzeitig von beiden Systeme nutzbar. Das ist gerade bei Stammdaten sinnvoll. Stammdaten unterliegen oft weniger häufig Änderungen, daher sind gegenseitige Behinderungen seltener zu erwarten. Setzt man dieses Konzept geschickt ein, so kann das die Problematik der Deltadatenerkennung mildern. Eine Datenbank und zwei Rechner in einem Clusterverbund (RAC) bietet mehr Flexibilität bei der Nutzung operativer und dispositiver Daten. Stammdaten sind gemeinsam nutzbar. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 126/166 Dies sind sicherlich vorerst noch Konzepte, die sich in der Praxis erst noch erwiesen müssen. Die gleichzeitige Nutzung von Datenbanken für operative und dispositive Zwecke führt zu einer stärkeren Abhängigkeit im Wartungsfall. Muss die Datenbank zu Wartungszwecken heruntergefahren werden, so sind operative und dispositive Systeme betroffen. Andererseits entstehen immer mehr Techniken, die das Herunterfahren im Wartungsfall überflüssig machen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 127/166 12 Verfahren für das Backup und Recovery (B+R) im Data Warehouse Backup und Recovery (B+R) ist ein Themenkomplex, der meist als letztes bei der Planung von Warehouse – Systemen bedacht wird (wenn überhaupt). Oftmals überlässt man das Thema den Hardware – Verantwortlichen in den Rechenzentren, die mit mehr oder weniger Aufwand noch jede Platte gesichert haben. In einigen Unternehmen gibt es auch gar kein Konzept hierfür, denn „Warehouse und Backup“ ist für manche schon deswegen keine Frage, weil Warehouse – Systeme zunächst nicht unternehmenskritisch sind. Das Erwachen kommt dann meist, wenn der Ernstfall eintritt. Die B+R – Frage für Warehouse - Systeme ist mit der wachsenden Bedeutung der Systeme und der zunehmenden Operationalisierung des Warehouses sicher heute wichtiger als früher. Das Thema Backup & Recovery sollte man jedoch nicht unabhängig von der Architektur des Warehouses betrachten. Die klassische Herangehensweise, wonach alles was nach Daten aussieht „periodisch zu kopieren ist“, reicht nicht. Man sollte schon betrachten, was wie zu sichern ist. 12.1 Backup und Recovery im Data Warehouse Warum ist Backup und Recovery in einem Data Warehouse anders zu behandeln, als in operativen Systemen? Hierzu gibt es mindestens vier Aspekte: Größere Datenmengen: Data Warehouse – Systeme verwalten ungleich mehr Daten als operative Anwendungen. Und die Datenmengen wachsen. Systeme mit mehr als 5 Terabytes sind keine Seltenheit mehr. Würden wir im Warehouse die gleichen Verfahren anwenden, wie in operativen Systemen, so wären die Kosten kaum noch bezahlbar. Hochverfügbarkeit muss nicht immer sein: Anders als in operativen Systemen, werden in Warehouse – Umgebungen Ausfallzeiten von mehreren Stunden bis hin zu Tagen eher akzeptiert, auch wenn in jüngster Zeit Warehouse – Daten zunehmend auch operative Verwendung finden. Das bedeutet, dass es hier nicht die aufwendigste Spiegelungstechnik sein muss, und ein Recovery – Bestand auch mal auf Band ausgelagert sein kann. Kontrollierte Änderungsvorgänge: Anders als in operativen Anwendungen finden Änderungsvorgänge in einem Data Warehouse kontrolliert statt. In operativen Systemen führen mehrere hundert oder tausend Benutzer Transaktionen gleichzeitig durch. Hier ist die Gefahr von unkontrollierten Aktionen höher. Man denke auch an Aktionen, bei denen z. B. falsche Daten in die Datenbank gelangen. In einem Warehouse – System lassen sich Änderungsvorgänge bezogen auf Zeit und Umfang leicht abgrenzen. Es sind meist einmalige Batch – Läufe. Schlägt ein Änderungsvorgang fehl, so kann er „umgedreht“ und wiederholt werden. Online – Änderungen von Anwendern finden sehr selten statt. So gesehen, muss auch nicht täglich gesichert werden. Man kann das Sichern etwa auf einen Wochenlauf oder Monatslauf beschränken. Man weiß ja in der Regel, was sich seit der letzten Sicherung geändert hat. Historische Daten ändern sich nicht mehr: Ein Warehouse – System enthält historische Daten, die sich meist nur einmal – beim Laden ins Warehouse - ändern. Danach werden sie nur noch lesend angefasst. Etwas was sich nicht mehr verändert, muss man auch nicht mehr sichern werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 128/166 12.2 Was wird alles gesichert? Bei dem Thema Backup denkt jeder automatisch daran die Daten im Data Warehouse zu sichern. Für die Sicherung wichtiger weiterer Komponenten sollte man sich jedoch ebenfalls ein Konzept entwerfen. Das sind: Die Laderoutinen mit denen die Daten erstellt wurden. Die Metadaten zur Definition der Laderoutinen (Design Time Metadaten). Die Datenmodelle und Datenbankstrukturdefinitionen. Die Laufzeitinformationen (Runtime – Metadaten), d. h. wann und unter welchen Bedingungen sind die Daten entstanden. Warum ist dies wichtig: Anders, als bei vielen operativen Anwendungen unterliegen Warehouse Systeme einem ständigen Änderungs- und Weiterentwicklungsprozess. Das ist leicht nachvollziehbar. Die Systeme arbeiten in den Schnittstellen der operativen Anwendungen, sie sind also gleichzeitig von mehreren anderen Verfahren abhängig. Ändert sich irgendwo im Unternehmen ein Verfahren, dann ist die Wahrscheinlichkeit hoch, dass sich auch im Data Warehouse etwas ändert. Werden ältere Datenbestände wiederhergestellt, so müssen auch die Rahmenbedingungen wieder hergestellt werden. Hier zahlt sich aus, dass bei der Oracle Warehouse – Umgebung das Laden von Daten mit Bordmitteln der Datenbank durchgeführt wird, d. h. die Ladeprogramme sind innerhalb der Datenbank vorhanden und fallen automatisch ins Sicherungskonzept. Auch die Metadaten zu den Ladeprogrammen und die Runtime – Informationen liegen als Tabelleninhalte in der Datenbank (OWB /CWM – Repository). Auch diese gehören zu den Objekten, die man sichern sollte. 12.3 Logging / Nologging Um Daten schnell zu bewegen und zu transformieren sollte man Nologging – Operationen wählen. D. H. der Logging – Mechanismus wird ausgeschaltet, um die Aktion zu beschleunigen. Dies ist gerade bei Massendaten immer zu empfehlen. Ist diese Option gewählt, entfallen auch Fragen nach dem ARCHIV - Log oder NOARCHIV - Log - Modus. Der NOARCHIV – LOG MODUS sollte gewählt werden, da ja auch kaum etwas zu loggen ist und auch die Archivierungsprozesse in der Warehouse – Datenbank nicht mehr aktiv sein müssen. 12.3.1 Nach dem Laden sichern – Kein Rollback nach Nolog Aktionen Die mit NOLOG beladenen Tabellen können auch nicht mehr durch eine Rollback – Aktion oder durch ein Zurückladen von Log – Daten in den Zustand vor dem Laden versetzt werden. Das „Zurückholen des Ursprungszustands“ gelingt entweder nur mit DML – Kommandos (DELETES, UPDATES) oder durch das Zurückspielen einer Sicherung (Recovery). Deswegen sollte man das Warehouse, das durch ETL – Prozesse verändert wurde, danach sofort wieder sichern. Backup – Maßnahmen sollten nicht parallel zu ETL Vorgängen laufen. Dies muss immer zeitlich versetzt geschehen und zwar in der Reihenfolge 1. Massenladen im NOLOGGING – Modus, 2. Backup der veränderten Teile im Data Warehouse. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 129/166 12.3.2 RMAN spart viel Arbeit Die jüngste Version von RMAN erlaubt ein bequemes Backup und Recovery. Hier sollen nur noch einmal die Vorteile aufgelistet werden (alle weiteren Informationen im RMAN – Handbuch): Extensives Reporting über alle bestehenden Backups. Leichte Integration mit Media Managers. Inkrementelle Backups, das heißt es muss nicht immer vollständig gesichert werden. Bestehende Backups können inkrementell um die angefallenen Änderungen erweitert werden. Block Media Recovery (BMR). Einzelne korrupte Datenblöcke können z. T. wieder hergestellt werden. Downtime Free Backups. Ein Backup ist im laufenden Betrieb möglich, ohne die Datenbank herunter zu fahren. Archive Log Validierung und Verwaltung von Backups. Backup und Restore Validierung. Corrupt Block Detection. Backup und Restore Optimierung. Trouble Free Backup and Recovery. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 130/166 12.3.3 Read Only Tablespaces Ältere Daten, die sich mit Sicherheit nicht mehr ändern, kann man in einem Read Only Tablespace speichern. Solche Tablespaces müssen nur einmal gesichert werden. Danach nie wieder. Das ist vor allem dann sinnvoll, wenn man die Daten eines Warehouses immer nur „fortschreibt“, also etwa Wochen- / Monatsdaten anfügt. Read-only Tablespaces müssen nicht gesichert werden Dieses Verfahren spart vor allem Backup - nicht aber Recovery – Zeit. Im Recovery – Fall sind alle Daten nach zu laden. 12.3.4 Read Only Tablespaces und Partitioning In Verbindung mit Partitioning kann man das Verfahren noch verbessern. Hier lädt man die durch den periodischen Ladelauf neu hinzukommenden Daten durch das „Partition Exchange and Load“ – Verfahren (PEL) als Partition in das Warehouse. Eine Partition ist gleichzeitig ein Tablespace, der als Ganzes ein neuer Anhang der jeweiligen Warehouse - Tabellen bildet. Vorher kopiert man das dem Tablespace zugeordneter Datafile in den Archivbereich (Platte oder Band). Nachteilig kann der erhöhte Verwaltungsaufwand sein. Read only Tablespaces und Partitioning ergänzen sich Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 131/166 12.4 Beispiele für B+R Szenarien mit ETL Mitteln oder RMAN (NOLOGGING) 12.4.1 Recovery – Strategie mit ETL – Mitteln: Dieses beschriebene Verfahren nutzt Datenbank – eigene ETL – Mittel: 1. Wöchentliches Backup des Warehouses. 2. Jede Nacht Sichern der Änderungsdaten (ETL – Daten), z. B. durch Sichern der Stage – Daten, bevor man diese löscht. Recovery: 1. Zurückladen der wöchentlichen Sicherung. 2. Neudurchführen der täglichen ETL – Schritte Wiedereinspielen der gesicherten Stage – Daten. z. B. durch das Vorteile des Verfahrens: Weniger Aufwand bei der Erstellung der Backups. Nachteile: Manueller Aufwand für Sichern und Wiedereinspielen der ETL – Schritte. Alle Änderungen müssen bekannt sein. 12.4.2 Recovery – Strategie mit RMAN: Dieses Verfahren nutzt RMAN zur Verwaltung der Backup – Vorgänge 1. Wöchentliches Backup des Warehouses. 2. Jede Nacht, inkrementelles Backup von allen modifizierten Tablespaces (nach dem alle nologging Operationen durchgeführt wurden). Recovery: 1. Zurückladen der wöchentlichen Sicherung. 2. Zum Recovern, Restore des wöchentlichen Backups des Data Warehouses, dann Rollforward der nächtlichen inkrementellen Backups. Vorteile des Verfahrens: Kann vollständig durch RMAN verwaltet werden. Einfaches und vollständiges Verwalten von neuen Daten. Nachteile: Nächtliches Backup aller Änderungsdaten im Anschluss an das ETL – Fenster. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 132/166 13 Zusammenfassung Hier noch einmal eine Zusammenfassung der wesentlichen Punkte. Damit wird die Orientierung der Referenzarchitektur noch einmal als Ganzes deutlich. Zusammenfassung der Warehouse Architektur Der wichtigste Leistungsfaktor besteht in der Integration also der Zentralisierung wesentlicher Warehouse – Funktionen. Diese zieht sich wie ein roter Faden durch die gesamte Architektur. o Sie ermöglicht gemeinsame Nutzung von Ressourcen wie Hardware, Laderoutinen (ETL), Analysekomponenten, und Datenmodellen. o Das Informationsmanagement rund um das Data Warehouse wird unternehmensweit schlanker. Um viele unterschiedliche Zielgruppen im Unternehmen möglichst effizient mit Informationen aus einer heterogenen IT – Landschaft zu versorgen, wird das Warehouse logisch in Funktionsbereiche oder Schichten eingeteilt. o Stage- oder Prüfschicht mit dem Ziel der Harmonisierung und Konsolidierung heterogener Quellsysteme. o Warehouse Schicht als Vorratsspeicher für unternehmensweit einmalige Informationen. Fachübergreifendes, Integriertes Datenmodell. Die Warehouse – Schicht hat auch die Aufgabe die nachfolgende Data Mart Schicht von immer wieder gleichen Analyse- und Datenaufbereitungsschritten zu entlasten. o ODS – Schicht (Optional) für schnelle Abfragen die primär der Unterstützung operativer Prozesse dienen. o Data Mart – Schicht: Hier sind fachspezifische Fragestellungen für spezielle Anwendergruppen zusammengefasst. Die Daten sind in einer sehr granularen Form im Data Warehouse gespeichert. Dies gilt durchgängig für alle Schichten. Die Daten in den Schichten sind nicht notwendiger Weise redundant abgelegt. Daten stehen auch schichtenübergreifend zur Verfügung um Ressourcen zu sparen. Die Einteilung in Schichten ist kein Security – Instrument. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 133/166 Die Einteilung in Schichten ist nur logisch zu verstehen. Ideal liegen alle Schichten in einer Datenbank und werden von einem zusammenhängenden Hardware – System (z. B. RAC – System) bedient. Die Data Mart – Schicht ist nicht mehr in einzelne Data Marts unterteilt, sondern besteht nur aus einer Ansammlung von Dimensionen und dazu passenden Faktentabellen. Ziel ist die Wiederverwendung von Strukturen. Verdichtungen für unterschiedliche Zielgruppen werden mit Materialized Views erzeugt. Das bedingt, dass die Daten in der Data Mart – Schicht sich auf einem sehr granularen Level bewegen. Für hochkomplexe Auswertungen kann neben den relationalen Starschemen auch eine multidimensionale Datenhaltungen in das Konzept integriert werden. Der Wechsel zwischen beiden Speichertechniken ist kein Systemwechsel, sondern wird als entweder / oder – Entscheidung aus dem ETL – Prozess heraus innerhalb der Datenbank realisiert. Die Extraktion und Datentransformationen finden ausschließlich mit SQL bzw. Datenbankmitteln statt. o Paradigmenwechsel hin zur mengenbasierten Verarbeitung innerhalb der Datenbank. o Homogenes ETL – Konzept und damit vielfältige Wiederverwendungsoptionen über den gesamten Informationsbeschaffungsprozess hinweg. o Hohe Performance durch Ausnutzen ausgereifter Datenbankfunktionalität und geringerem Datentransportaufkommen. o Flexibilität bei der Realisierung von Transformationen. Die technische Integration von MOLAP und Data Mining in der relationalen Datenbank erlaubt ein freieres Positionieren von ETL – und Analyseschritten. Z. B. sind besondere Analysen nicht mehr durch die technischen Restriktionen einer separaten Datenbank an einen bestimmten Platz im Informationsbeschaffungsprozess gebunden. Die Integration von Daten und Funktionen an zentraler Stelle wird durch die neue kostenschonende Cluster – Technologie der Datenbank zusätzlich unterstützt. Durch diese Integration lohnen sich Hardware – Skalierungen an zentraler Stelle. Durch das zusammenhängende Architekturkonzept wird auch verhindert, dass einfach nur planlos Last in Form von unabhängigen Anwendungen auf die Maschine gepackt wird. Unter der Strich wird weniger Hardware gebraucht: o Keine separate ETL – Hardware o Keine separate Data Mart Hardware o Gemeinsame Nutzung von Hardware durch operative und dispositive Anwendungen. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 134/166 14 Anhang 14.1 Elf vermeidbare Fehler und Tipps für erfolgreiche Data Warehäuser Projekte brauchen einen Nutznießer Ohne jemanden, der die Warehouse – Lösung braucht, braucht man nicht zu starten. Frage erst: Welche Informationen werden gebraucht? Dann kommt Welche Daten muss man dazu haben? Beginne die Betrachtung am Ende des Informationsaufbereitungswegs. Die tollste Transformation nutzt nichts, wenn die falschen Daten transformiert werden. Unterschätze nicht die Aufwände Die meisten Aufwände liegen in der Vorbereitung und Aufbereitung von nicht korrekten Quelldaten. In Warehäusern begegnen sich meist zum ersten Mal Daten aus unterschiedlichen Anwendungen und aus verschiedenen Abteilungen. Verstehe die Daten Das Erstellen des Warehouses ist nicht nur ein technischer Akt. Meist ist betriebswirtschaftliches Fachanwenderwissen nötig, um Daten und Prozesse zu verstehen. Der Techniker im Projektteam allein ist verloren. Es braucht klassische Datenmodellierung Die Wahl und die „Konfiguration“ der richtigen Entitäten ist wichtig. Wo ist die beste Stelle für eine Transformation Den Informationsbeschaffungsweg nicht in Etappen aufteilen, sondern den gesamten Weg der Informationsaufbereitung im Blick haben. Erst die Architektur dann die Tools Die Toolauswahl kommt erst dann, wenn man weiß was man will. Tools ersetzen keine Architektur. Bilde kleine Inkremente Es muss nicht immer die komplette Slowly Shanging oder Update – fähige Lösung implementiert werden. Einige Dinge können auch auf einen späteren Zeitpunkt verschoben werden. Suche den frühen Erfolg Etappenziele für die ersten Erfolge müssen früh gewählt werden. Lieber einen frühen Teilerfolg bevor man das Gesamtziel erst gar nicht erreicht. Einfachheit geht vor Vollständigkeit Warehouse – Systeme können komplex werden und man kann jede Lösung noch perfekter machen. Die einfachste Lösung ist zunächst die stabilste und bringt am ehesten Erfolg, auch wenn es nur eine 80% - Lösung ist. Generieren statt Programmieren So einfach das schnelle Tippen eines Programmierers auch aussehen mag, es endet oft in unvorhersehbarem Aufwand. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 135/166 14.2 Gründe für die Einführung eines Data Warehouses Im wesentlichen lassen sich 4 Hauptgründe zusammenfassen: 1. Informationen stehen in gesammelter Form zentral zur Verfügung und sind von allen Unternehmensstellen her leicht zugänglich. 2. Informationen stehen in einer auswertefähigen und verständlichen Form zur Verfügung. Die Auswertedatenmodelle sind für Benutzerabfragen optimiert. 3. Die Informationen stehen in einem historischen Kontext, sie sind historisiert. Damit sind Trends erkennbar. 4. Durch die Loslösung von den operativen Systemen, werden diese durch Analyseabfragen nicht mehr belastet. 14.2.1 Nutzenpotentiale im Data Warehouse Die Nutzenbetrachtung von Warehouse – Systemen umfasst zwei Bereiche: 1. Leicht messbare Nutzenvorteile. Das sind z. B. Substitutionen von manueller Tätigkeit oder Bereitstellung von zusätzlichen Zeitressourcen für Fachmitarbeiter. 2. Nicht leicht messbare Faktoren wie zusätzlicher Informationsgewinn. Hier kann nicht deutlich vermittelt werden, welchen Nutzen ein Mehr an Informationen beinhaltet. Letztlich ist es die Vermehrung von Handlungsoptionen. Bei entsprechenden Umfragen lassen sich immer wieder die folgenden Nutzenaspekte feststellen: (Die hier genannten Daten entstammen einer Oracle - Umfrage aus dem Jahr 2002) Vereinheitlichung und Strukturierung der Datenbasis (Durch Ladeprozesse können Standardisierungen vorgenommen werden, die in den Quellsystemen aufgrund historischer Begebenheiten und Altlasten nicht möglich sind, 75%) (weder Quantitativ noch subjektiv messbar, da es mit dem Warehouse Informationen gibt, die zuvor einfach nicht da waren. Es kann jetzt lediglich festgestellt werden, was aufgrund neuer Optionen im Unternehmen machbar ist und welchen Nutzen dieses dem Unternehmen bringt. Oft kommt von Anwendern die Aussage, dass ohne das Data Warehouse diese oder jene Informationen nicht da wären. Extreme Aussagen gehen soweit, dass bestimmte Prozesse oder Funktionsbereiche im Unternehmen ohne das Warehouse gar nicht machbar wären. Es bleibt die Frage unbeantwortet, was sein würde, wenn das Warehouse nicht da wäre). Ersetzung von manuellen Tätigkeiten (z. B. händisches Zusammenfügen von Daten, 64%) (Quantitativ messbar. Bei fast allen Data Warehouse – Einsätzen können Einsparungen im Bereich manueller Tätigkeiten festgestellt werden. Dieser Nutzen ist am leichtesten messbar. Z. T. kommt allerdings die Aussage, dass dieser Nutzen alleine die Aufwendungen für das System noch nicht rechtfertigt). Schnellerer und einfacherer Zugriff auf notwendige Informationen (durch integrierte Sichten, graphische Aufbereitung, 62%) (nur z. T. Quantitativ messbar). Erkennen historischer Trends durch Langfristigkeit (Analyse über Zeitreihen, 60%) Bessere Deckung des Informationsbedarfs (über das übliche Reporting hinaus, Erstellung neuer Berichte ist einfach, der Fachanwender kann seinen individuellen Bedürfnissen besser nachkommen, 52%) (subjektiv messbar). Bessere Daten- und Informationsqualität (dadurch dass das Warehouse die einzige Quelle ist , 48%) (subjektiv messbar). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 136/166 Reorganisation und Straffung des bestehenden Berichtsweges (Selbstbedienungseffekt, Wegfall vordefinierter Berichte, Entlastung IT, 48%) (Quantitativ messbar). Aufdecken unbekannter Zusammenhänge (automatisiertes Analysieren lässt ungeahnte Zusammenhänge erkennen, 33%) (subjektiv messbar). Integration externer Daten (in der einheitlichen Datenstruktur des WH lassen sich externe Daten leichter integrieren, 25%) (subjektiv messbar). 14.3 Checkliste zur Optimierung der Warehouse Systeme 14.3.1.1 Platten Einer der wichtigsten Einflussfaktoren für gute Abfrageperformance sind die Plattenzugriffe. Hier gilt: Eher viele kleine Platten als wenige große Platten wählen (Auch wenn größere Platten schneller und im Vergleich billiger sind) Verteilung der verschiedenen Tablespaces auf unterschiedliche Platten mit folgender getrennter Verteilung: Index Users Control File (Control separat sichern) Rollback Segmente zweites Control File Tools System Control File Temp Undo Logs Undo Logs Archive Logs Data Oracle Software RAID 0+1 File und RAID 0+1 RAID 0+1 RAID 0+1 (wenn überhaupt verwendet) RAID 5 oder 3 (je nach Verwendung) - Raid – Verfahren: Hardware based RAID ist bevorzugt vor Software Based RAID zu wählen. Host based RAID (intern) ist bevorzugt vor Bridge Based (extern) RAID zu wählen. Anzahl Platten pro Controller = I-O Bandbreite des Controllers / I-O Bandbreite der einzelnen Platten 14.3.1.2 Partitions Anzahl Partitionen eher hoch wählen Bei Sub Partitioning auf die Stimmigkeit der Gültigkeitsbereiche der Schlüssel achten. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 137/166 14.3.1.3 Materialized Views 14.3.1.3.1 Allgemeine Hinweise ORDER BY Klausel bei der Definition User Defined Functions mit DETERMINISTIC deklariert Einsatz von Partitionierten Materialized Views für Refresh –Performance – Optimierung (Partition Change Tracking PCT ab Oracle 9i) Grouping Sets in Verbindung mit partitionierten Mview für bessere Performance Globalization – Einstellungen Case Sensitivität von Wörtern wie FROM 14.3.1.3.2 Prüfungen auf Zustände Prüfen auf die Einstellparameter von MVIEWS Prüfen auf Vorhandensein und Zustand von Dimensionen select mview_name,REWRITE_ENABLED,STALENESS,REWRITE_C APABILITY from dba_mviews; select* from dba_dimensions; 14.3.1.3.3 Systemparameter Systemparameter die die Rewrite Fähigkeit von Materialized Views beeinflussen query_rewrite_enabled query_rewrite_integrity ENFORCED TRUSTED STALE_TOLERATED Nur wenn Konsistenz garantiert ist STALENESS: Fresh Validierte Constraints Based on prebuild Table CONSIDER FRESH Zusatz Alle Daten Dimensional Tables vorhanden Optimizer_Mode=CHOOSE Definition von Materialized Views mit REWRITE ENABLE STALENESS REWRITE_CAPABILITY Umsetzen Systemparameter alter materialized View dwh.MV_UMSATZ_LAND_ZEIT consider fresh alter system set query_rewrite_integrity=STALE_TOLERATED scope=spfile; alter system set query_rewrite_enabled=TRUE Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 138/166 scope=spfile; Prüfung: Wird ein Query Rewrite stattfinden 1. Schritt: rewrite_table erzeugen 2. Schritt: dbms_mview.explain_re write aufrufen ORAHOME\rdbms\admin\utlxrw.sql DECLARE qrytext VARCHAR2(2000) := 'select sum(f.umsatz), R.Bundesland, Z.Monat from f_umsatz_part f, dim_region R, dim_Zeit Z where z.Zeit_ID_YYYYMMDD = f.Zeit_ID_YYYYMMDD and r.ORT_ID = f.ORT_ID group by R.Bundesland,Z.Monat'; BEGIN dbms_mview.explain_rewrite(qrytext,'DWH.mv_Umsatz_Land_Zeit','1 24'); END; / 3. Schritt: Ergebnis abfragen SELECT message FROM rewrite_table WHERE statement_id = '124' ORDER BY sequence; Größe von MVIEWS berechnen lassen variable num_rows NUMBER; variable num_size NUMBER; exec DBMS_OLAP.ESTIMATE_MVIEW_SIZE( 'simple_store', 'select ' || ' sum(f.umsatz), ' || ' R.Bundesland, ' || ' Z.Monat ' || 'from ' || ' f_umsatz_part f, '|| ' dim_region R, ' || ' dim_Zeit Z ' || 'where '|| ' z.Zeit_ID_YYYYMMDD = f.Zeit_ID_YYYYMMDD ' || ' r.ORT_ID = f.ORT_ID ' || 'group by R.Bundesland,Z.Monat ' || 'order by R.Bundesland,Z.Monat ', :num_rows , :num_size); and print num_rows; print num_size; 14.3.1.3.4 Rewrite Methoden Methoden / Situation Selection Compatibiliy Check Join Compatibility Check Erklärung Selections in Query und MV müssen übereinstimmen WHERE / HAVING Common Joins Query Delta Join MV Delta Join Copyright © 2005 by Oracle Corporation. All rights reserved EInschränkung Die Selections ableitbar sein müssen Stärkere Restriktionen Lossless Informationen Data Warehouse Referenzarchitektur Data Sufficiency Check (Join Back) Grouping Compatibility Check (Rollup) Aggregate Computability Check Query Rewrite with Inline Views Query Rewrite with Views Query Rewrite with Selfjoins 139/166 Zur Vervollständigung der Abfragebedingung (z. B. auf Felder, die nicht in der Select-Liste des Views vorkommen), kann erneut auf eine Basistabelle zurückgegriffen werden. Textgleichheit 14.3.2 Hilfsmittel Datenbankoptimierung Ziel Anzeige Parameterfile Auflisten aller Constraints in einem Schema Erstellen Plantabelle Erstellen Eintrag Plantabelle Anzeigen des letzen Kommandos aus der Plantabelle Abfragen DOP Wie ist die Session eingestellt PX Message Pool SGA - Zustand Verhältnis / Auslastung von Consumer und Producer Aktion Column name format a30 Column value format a30 Column update_comment format a30 select name, value, update_comment from v$spparameter select constraint_name name, constraint_type type,Table_name Tabelle, validated val ,rely from all_constraints where owner ='DWH' C (check constraint on a table) P (primary key) U (unique key) R (referential integrity) V (with check option, on a view) O (with read only, on a view) @$ORACLE_HOME/RDBMS/ADMIN/UTLXPLAN.SQL explain plan for select count(*) from wh_transaktionen; @$ORACLE_HOME/RDBMS/ADMIN/utlxplp.sql oder select * from table(dbms_xplan.display()); select table_name,degree from dba_tables where table_name like 'F_%'; select process,pdml_status,PDDL_Status,PQ_Status, Machine from v$session; select name, sum(bytes) from V$SGASTAT where pool = 'large pool' group by rollup (name); select name, sum(bytes),pool from V$SGASTAT group by name,pool; select dfo_number,tq_id,server_type, process,num_rows from v$PQ_TQSTAT order by dfo_number,tq_id,server_type, Copyright © 2005 by Oracle Corporation. All rights reserved Ergebnis erst nachdem ein Query Kommando Data Warehouse Referenzarchitektur process; Anzahl Prozesse im Parallel Mode Prüfen, ob Prozesse parallel laufen Feststellen ob es seit dem Hochfahren der Datenbank bereits parallele Operationen gegeben hat. Tests auf Erfolg des Steigerns von DOP DBMS_STAT Parametereinst ellungen Prüfen auf Vorhandensein und Zustand von Dimensionen Langläufer Feststellen Platzver-brauch von Tabellen (Extents) Extents Tabelle einer Summe Extents aller Anzahl Blocks einer Tabelle 140/166 abgesetzt wurde select * from V$PQ_TQSTAT; select * from v$PX_process_sysstat; select * from v$PX_process; select name, value from v$sysstat where upper(name) LIKE '%PARALLEL OPERATIONS%' or upper(name) LIKE '%PARALLELIZED%' or upper(name) LIKE '%PX%' Set timing on Select /*+ noparallel(f_Umsatz) */ count(*) from f_Umsatz; Select /*+ parallel(f_Umsatz,2) */ count(*) from f_Umsatz; Select /*+ parallel(f_Umsatz,4) */ count(*) from f_Umsatz; Siehe auch Parameter PARALLEL_AUTOMATIC_TUNING=TRUE exec dbms_stats.gather_table_stats('DWH','f_umsat z',estimate_percent=>20); show parameter star show parameter parallel select* from dba_dimensions Utlbstat Utlestat ->report.txt SELECT substr(segment_name,1,30), extents, tablespace_name, blocks FROM dba_segments WHERE owner = 'DWH'; SELECT extent_id, file_id, block_id, blocks FROM dba_extents WHERE owner='DWH' AND segment_name='F_UMSATZ_PART' SELECT sum(blocks) FROM dba_extents WHERE owner='DWH' AND segment_name='F_UMSATZ_PART' select table_name, Owner, blocks from dba_tables where table_name='F_UMSATZ_PART' and owner = 'DWH' / Copyright © 2005 by Oracle Corporation. All rights reserved Beispiele Data Warehouse Referenzarchitektur Finden der größten Tabellen Check auf High Water Mark Finden von doppelten Indexeinträgen 141/166 select table_name, Owner, blocks from dba_tables where owner = 'DWH' order by blocks Select dba_segments.blocks dba_tables.empty_blocks -1 HWM From dba_segments, dba_tables Where dba_segments.owner = 'DWH' and Dba_segments.segment_name = '&nm' and dba_segments.owner = dba_tables.owner and dba_segments.segment_name = dba_tables.table_name SELECT table_name, index_name FROM dba_indexes a WHERE owner = UPPER('&owner') AND uniqueness <> 'UNIQUE' AND NOT EXISTS (SELECT table_name, column_name, column_position FROM dba_ind_columns b WHERE a.index_name = b.index_name AND a.owner = b.index_owner AND a.owner = b.table_owner AND a.table_name = b.table_name MINUS SELECT table_name, column_name, column_position FROM dba_ind_columns c WHERE a.index_name <> c.index_name AND a.owner = c.index_owner AND a.owner = c.table_owner AND a.table_name = c.table_name) ORDER BY 1 Buffer Cache select round(((1-(sum(decode(name, Hit Rate 'physical reads', value,0))/ (sum(decode(name, 'db block gets', value,0))+ (sum(decode(name, 'consistent gets', value, 0))))))*100),2) || '%' "Buffer Cache Hit Ratio" from v$sysstat; Sollte > 90 % sein Dictionary Hit Rate zum Prüfen der Shared Pool Size SELECT SUM(gets) "data dictionary gets", SUM(getmisses) "data dict. cache get misses", SUM(gets) / (SUM(gets) + SUM(getmisses)) *100 "Dict Hit Rate" FROM v$rowcache Library Hit Rate SELECT SUM(pins "Lib_Cache_hit_ratio" FROM v$librarycache Sollte größer 90 % sein (Wenn nicht dann Shared Pool größer machen) Sollte größer 95 % sein (Wenn nicht Shared Pool größer machen) Wenn mehr als 10 % frei ist, dann kleiner machen Freier Platz im Shared Pool Ungleich- - reloads) / sum(pins)*100 SELECT * FROM v$sgastat WHERE name = 'free memory'; select table_name, index_name, blevel, Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur gewichtige Indexe finden (skewed) decode(blevel,0,'OK BLEVEL',1,'OK BLEVEL', 2,'OK BLEVEL',3,'OK BLEVEL',4,'OK BLEVEL','BLEVEL HIGH') OK from dba_indexes where owner='AIRSRAQS' order by 1,2 Distinctiveness (Unterschiedlic hkeit von Werten Analysieren Indexstrukur (Anzahl Sätze – Anzahl diff. Werte) x 100 / Anzahl Sätze = % Wert Liefert Werte über gelöschte und nicht wieder gefüllte Leaves select DEL_LF_ROWS*100/decode(LF_ROWS, 0, 1, LF_ROWS) PCT_DELETED, (LF_ROWS-DISTINCT_KEYS)*100/ decode(LF_ROWS,0,1,LF_ROWS) DISTINCTIVENESS from index_stats where NAME=Upper('&index_name'); Sort-Vorgänge auf Platte oder im Speicher 142/166 [Wert < 5%: Überlegungen für Bitmap – Index] analyze index “index name” validate structure; SELECT a.sid,a.value,b.name from V$SESSTAT a, V$STATNAME b WHERE a.statistic#=b.statistic# AND b.name LIKE 'sorts %' ORDER BY 1; Wenn PCT_DELETE D > 20%, dann Index neu machen Wenn Sortvorgänge auf der Platte, dann Sort_Area_Size vergrößern. Sollte aber unter 9i durch das Setzen von pga_aggregate _target automatisch geschehen 14.4 Glossar 3 – Schichten Architektur Ad-hoc-Abfragen Logische Aufteilung von Aufgabenbereichen innerhalb des Data Warehouses. Hier vor allem Stage/Data Warehouse/Data Mart. Ad-hoc-Abfragen oder auch spontan formulierte Abfragen. Sie können von dem Endanwender mittels Auswertungstool kreiert werden. Meist sucht sich der Anwender entsprechende Datenstrukturen aus einer angebotenen Liste von Tabellen aus. Sofern möglich, wird er Daten aus unterschiedlichen Tabellen miteinander kombinieren. Zusätzliche Analysetechniken sind -> Drill Down/up -> Slice/Dice -> Pivoting -> Drill Across –Drill to Detail Advanced Queueing (AQ) Aggregation Datenbankkomponente zum – asynchronen Koppeln von Anwendungen. Siehe weiterführende Dokumentation in den Handüchern. Aggregation ist eine Zusammenfassung von Daten in einer neuen Tabelle als eine Art Summentabelle. Beispielsweise Summierung oder Durchschnittsbildung. Aggregationen werden unter anderem zur Performancesteigerung der Abfragen gebildet. Aggregationen werden in modernen Warehouse Systemen immer (Aggregates) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 143/166 weniger verwendet und z. B. durch Materialized Views (Oracle) ersetzt. (WA) Aggregationstabelle Aktualisierungsperiode Alertmanagement Analytical Workspace (AW) Architected Data Marts Asynchrone Kopplung Attribut Auswirkungsanalyse BAM Summentabelle -> Materialized View -> Aggregation (WA) Zeitspanne nach der ein Data Warehouse mit neuen Daten aktualisiert wird. Durchführung von Plausibilitätsprüfungen bzgl. der Gesamtzusammenhänge der Daten. Im Rahmen des Befüllens bzw. Betriebs des Warehouses sind i. d. R. Mechanismen zur Benachrichtigung entsprechender Mitarbeiter implementiert. Z. B. wird ein Email verschickt, wenn Probleme beim Ladeprozess aufgetreten sind. (WM). Speicherkonstruktion für multidimensionale Daten in der Oracle Datenbank. Der Analytical Workspace ist ein Bereich innerhalb der Oracle Datenbank, in dem multidimensionale Daten abgelegt sind. Vor der Integration der multidimensionalen Datenbank Express in die relationale Datenbank Oracle 9i und 10g war der Analytical Workspace ein eigener Speicherbereich innerhalb des Dateinverzeichnisses des jeweiligen Betriebssystems. Nach der Integration ist die Struktur und die Art der Speicherung geblieben aber der Speicherort ist jetzt eine BLOB – Spalte in einer relationalen Tabelle. Ergänzt wurde der Analytical Workspace und ein besonderes API mit dem Zugriffe auch aus dem relationalen Befehlsvorrat möglich sind. Regelung der Abhängigkeiten zwischen Data Marts. Gemeint sind Verfahren mit denen Redundanzen zwischen Data Marts vermieden und die Inhalte synchronisiert werden. Im Gegensatz zur -> synchronen Kopplung werden bei der asynchronen Kopplung Informationen eines Vorsystems mit gewissen zeitlichen Verzögerungen an das nachgelagerte Data Warehouse geschickt. Diese Verzögerungen entstehen, wenn Nachrichten in einer sog. Nachrichten Queue zwischengespeichert und für das zeitlich unabhängige Abholen der Nachricht durch das nachfolgende System vorgehalten werden. Wie bei einem Postbriefkasten wird die Queue nicht sofort geleert. Die Asynchronität kann Vorteile haben, weil die kommunizierenden Systeme nicht durch die Kommunikation in ihrem zeitlichen Verlauf behindert sind. Asynchrone Kopplungsverfahren sind z. B. -> Streams. Kleinste Informationseinheit in einem Datenmodell, die geeignet ist Merkmale eines -> Entities zu benennen. Andere Begriff sind Datenelement. (DM) Metadatenauswertung bei der die Abhängigkeiten bzgl. Ergebnisstabellen bzw. Berichten von Quelltabellen aufgelistet werden. Treten Änderungen in den Quelltabellen auf , muss festgestellt werden, welche abhängigen Tabellen von diesen Änderungen betroffen sind. Diese Analyse erfolgt heute mit graphischen Anzeigewerkzeugen. Business Activity Monitoring. Operational Exception Reporting. Beobachtung und Messung von betriebl. Abläufen mit der Möglichkeit der direkten Korrektur. Messhäufigkeit: Near Realtime bis täglich. BI Business Intelligence, Sammelbegriff für Geschäftsanalysen, zunehmend Synonym für Front-End-Auswerte-Werkzeuge und Anwendungen. Bitmapped Index Für jeden Wert einer Column wird ein 1/0 Bitmuster-Strang zugeordnet, d. h. bei Vorhandensein des Wertes in einem Satz, wird für dieses Satz ein gesetztes Bit (1) aufgenommen wenn nicht eine 0. So sind alle Vorkommnisse einer bestimmten Column über alle Sätze hinweg in dem Index dokumentiert. Da ein Bitmap Index wenig Platz braucht und auch zudem noch komprimiert gespeichert werden kann, ist ein Bitmap-Index bei Columns mit überschaubaren Ausprägungen (Verhältnis 1:25 – 4 %) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur BSC 144/166 günstiger als der klassische Btree-Index. Balanced Score Card Kennzahlensystem für die Kern-Geschäftsbereiche z. B. Finanzen, Kunden, Interne Prozesse und Mitarbeiter: In der BSC werden Ziele mit ihren dazugehörigen Messgrößen definiert und auf einer übersichtlichen Anzeigentafel abgebildet (Scorecard) Business Intelligence Business Objects CDC Change Data Capture Column level validation rule Common Warehouse Metadata -> BI (Geschäftsobjekten) Beschreibbare Gegenstände, die z.B. in einer Datenbank gespeichert werden können. Geschäftsobjekte sind die Objekte, mit denen die Geschäftsprozesse operieren. Beispiele: Kunde, Artikel, Bestellung.. Change Data Capture. Verfahren zum Laden von geänderten Tabelleninhalten in andere Tabellen. - > CDC -> Validation Rule, die sich nur auf eine Column einer Tabelle bezieht. >Constraint-Zusatz auf Columnebene. -> CWM Conforming Dimensions Dimensionen die als Brückenglied zwischen 2 oder mehreren Faktentabellen fungieren. Eine Zeitdimension stellt meist eine solche dar, weil von ihr Foreign Key – Beziehungen in fast alle Starschemen (zu fast allen Faktentabellen) führen. Constraint CPM -> Validation rule Corporate Performance Monitoring. Nach Gartner die Zusammenführung von -> BAM und klassischem -> BI CRM Customer Relation Management CWM Common Warehouse Metadata. Ein sich mehr und mehr durchsetzender Metadaten - Standard der OMG. Das Oracle Warehouse Metadaten Repository (-> OWB) ist nach dem CWM – Standard definiert worden. Data Mart Data Mart ist ein fach- oder themenspezifischer Datenbereich in einem Data Warehouse. Dies bedeutet, die Daten werden auch separat als Auszug im DWH gespeichert. Data Marts haben den Zweck Auswertedaten endbenutzergerecht bereit zu halten. In Data Marts finden sich daher meist besondere Datenmodelle wie -> Star Schema oder -> Snow Flake Schema Isolierte Data Marts. In jüngster Zeit entstanden durch Fertigpakete (z. B: CRM) sog. BI-Add On’s. Tätigkeitsfeld in Unternehmen. Aufgabe ist die inhaltliche, fachliche Strukturierung von Themenbereichen mit Hilfe von Daten. Die Datenadministration bezweckt, die Datenbeschreibungen und -formate sowie die Verantwortlichkeiten derselben einheitlich zu erfassen und zu kontrollieren, um eine anwendungsübergreifende Nutzung der langlebigen Unternehmensdaten zu gewährleisten. Ein Teilgebiet der Datenadministration ist die Datenmodellierung. Gerade in mehr technisch orientierten oder kleineren Unternehmen wird Datenadministration oft mit Datenbankadministration verwechselt. Konzept den ETL – Prozess in die Datenbank zu verlagern um damit die Datenbankressource optimal auszunutzen. Data Mart Silo Datenadministration Datenbankbasiertes Laden Führt in der Regel zu 3 Hauptvorteilen: - Performanter - Flexibler Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Dimension Kostengünstiger Dimensionen sind Bausteine des logisch verstandenen multidimensionalen Datenmodells. In einem multidimensionalen Modell stellen Dimensionen die Äste im Starschema oder die Kanten in dem Würfelmodell dar. Beispiele für Dimensionen sind Transaktionsarten, Produkte, Region, Kostenstellen, Kostenarten oder Zeit. Dimensionen entsprechen den Stammdaten aus den operativen Systemen. Über Einschränkungen (Filter) in den Dimensionstabellen werden die Kennzahlen der Faktentabellen näher bestimmt (eingeschränkt): Umsätze nach Regionen, Umsätze nach Zeit. Regionen und Zeit sind hier die einschränkenden bzw. bestimmenden Kriterien der Faktentabelle. Dimensionen können eine Zusammenfassung von Verdichtungskriterien enthalten die sog. - >Hierarchien. Dimension table Definition Dimensional Table Dimensionstabelle Direct-path load API Dispositive Prozesse Dispositive Systeme DML Drill Across Drill Down 145/166 mehreren Dimension Tables sind eigenständige physische Objekte in der Datenbank. Sie legen die denormalisierte und hierarchisierte Struktur der Spalten einer Tabelle fest, die die Funktion einer Dimension in einem Starschema inne hat. Wie echte Tabellen, so können auch Dimensions mit CREATE in der Datenbank definiert werden. CREATE DIMENSIONAL TABLE.... . Den eigentlichen Zweck erfüllen die Dimensions indem sie dem Optimizer der Datenbank Informationen über mögliche Rewrite - Aktivitäten verschaffen. Logisch repräsentieren sie Geschäftsobjekte aus der Sicht der Fachanwender: die Gegenstandsobjekte der Analysefragen (Kunde, Produkte, Artikel, Zeit...). -> Dimensionstabelle Dimensionstabellen sind die physischen Representanten einer -> Dimension in der Datenbank. Gegensatz zu -> Dimension Table. In der Datenbank existieren zwei Objekteinträge. Zum einen Die Dimensionstabelle und zum weiteren das dimensional Table Objekt zur Steuerung des Optimizers. Anwendungsprogramme können direkt die Loaderfunktionalität von Oracle ansprechen. Hierbei werden zusätzliche Datenbankprüfungen ausgeschaltet. Das Laden ist sehr schnell. Aktivitäten in einem Data Warehouse, die der Aufbereitung von Informationen aus Daten der -> operativen Prozesse dienen. Zusammenfassung aller Softwareanwendungen die einem strategischen, planerischen Zweck im Rahmen der Unternehmenssteuerung dienen. Das sind i. d. R. die Warehouse Anwendungen. Gegenteil -> Operative Systeme. Data Manipulation Language: Kommandosprache mit der die Daten, die in der Datenbank gespeichert sind erstellt oder geändert werden können. Bei relationalen Datenbanken wird SQL genutzt, um die Datenbank zu modifizieren. . Bei SQL unterscheidet man jedoch zwischen den -> DDL katalogmodifizierenden Kommandos und den datenmanipulierenden Kommandos. Im Verlauf einer Auswertung über Tabellengrenzen hinweg springen. In der Regel muss eine Referenzspalte (Column) in beiden Tabellen enthalten sein, über die die Sätze der jeweiligen Spalten zugeordnet werden können. Werden -> Starschemen verwendet, so ist hier der Vorgang gemeint, bei dem man im Verlauf einer Auswertung von einem Starschema in ein anderes (von eine -> Faktentabelle zu einer anderen) springt. Drill Down = „herunterverzweigen“. Der Anwender hat in Auswertewerkezugen die Möglichkeit Daten tiefer zu detaillieren. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 146/166 Beispiel: Er detailliert seine Auswertung z. B. von Artikelgruppe auf Artikel. Drill To Detail Drill Up DWH DWM EAI EDW Entity Entity – Modell Entity - Relationship Methode Entitytyp ERD ETL Im Verlauf einer Auswertung wird von -> aggregierten Daten einer Auswertedatenhaltung auf Detaildaten in anderen Tabellen (u. U. der -> operativen Systeme) verzweigt. Gegenteil von -> Drill Down. Data Warehouse. Das Warehouse ist das zusammenhängende komplette System zu Bereitstellung von Daten für analytische Auswertezwecke. Meist unterteilt man das Data Warehouse in mehrere Schichten: -> Stage, -> ODS, -> Warehouse, -> Data Mart. Oracle Data Warehouse Methode, die Methode beschreibt die Vorgehensweise in einem Data Warehouse Projekt mit ihren Phasen und Prozessen. Enterprise Application Integration, Verfahren zum Message – basierten Austausch von Informationen zwischen operativen Anwendungen. Der Nachrichtigenaustausch bewegt sich meist auf der Ebene der Transaktionen der jeweiligen OLTP Systeme. Embedded Data Warehouse – Data Warehouse Komponente von Oracle Applications. Vollständig vordefiniertes Warehouse. Entities sind Objekte (Sachen, gedachte oder reale), die unter einem gleichen Begriff zusammen gefasst werden können, also auch gleich beschrieben werden können. Zur Beschreibung werden -> Attribute verwendet. Entities unterscheiden sich voneinander, wenn diese mit einer unterschiedlichen menge von Attributen beschrieben werden können. Entities können gedanklich leicht mit den späteren Tabellen einer Datenbank verglichen werden, stellen aber zunächst einmal eine logische Abstraktion dar und sind in der Praxis nicht immer 1:1 in die Datenbankwelt zu überführen. Im Sprachgebrauch wird ein Entity nicht von seiner Typisierung -> Entitiytyp unterschieden (so auch hier) (DM) Entity - Modell, ist die grafische Darstellung von Objekten innerhalb einer Datenbank. Die Entität Kunde könnte beispielsweise wie folgt definiert werden: Der Kunde ist Inhaber eines oder mehrerer Konten. Mehrere Entitäten werden zu einem Modell zusammengefasst. Ein Konzept zur Darstellung von Zusammenhängen aus einem -> Diskursbereich . Beziehungen (-> Relationships) zwischen Objekten (-> Entities) werden beschrieben. Es entsteht ein Plan eines Unternehmens mit seinen Geschäftsobjekten und den Regeln, wie mit diesen -> Geschäftsobjekten umgegangen wird. In der Informatik werden unterschiedliche ERMs eingesetzt. Fast eine Menge gleichartiger -> Entities zusammen. Alle Objekte, die mit der gleichen Menge von Eigenschaften beschrieben werden können. Wird synonym verwendet zu -> Entity. (DM) Entity - Relationship - Diagramm. Eine Methode, um Zusammenhänge der realen Welt graphisch darzustellen. ERD werden z.T. mit unterschiedlichen -> Notationen realisiert -> Entity-Relationship- Methode Extraction Transition Load -> OWB, analoge Begriffe -> ETT Extraktion, Transition, Transform. Allgemeiner Beschreibungsname für die Verfahren nach denen man Daten aus den operativen Vorsystemen des Warehouses in die verschieden Schichten des Warehouses läd, prüft und transformiert. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur ETL - Engine ETT – Werkzeug 147/166 Extraction – Transition – Loade – Engine. Begriff mit dem einige Firmen ihr Data Warehouse – Ladeverwerkzeug benennen. Meist ist es ein eigenständiges Programm, das zusätzliche Hardware Ressourcen benötigt. Im Oracle Data Warehouse wird dieses Programm durch die Datenbank selbst ersetzt. Die Datenbank ist damit die Engine. Damit können auch Hardware – Ressourcen gespart werden. ETT, = Extract Transport und Transform. Bezogen auf ein Data Warehouse würde man mit dem ETT - Werkzeug Daten aus Quellsystemen extrahieren, über das Netz in das Data Warehouse transportieren und dort in die benötigte Datenform transformieren (z.B. wird ein numerischen Feld in ein Datumsfeld umgewandelt). Analog -> ETL Existence - dependent (Existenzabhängig) Ein Child Entity in einer -> identifizierenden Beziehung ist existenzabhängig. Zur eindeutigen Identifizierung einer -> Instanz der Child Entität ist ein migrierter Foreign-Key des Parent - Entities nötig. (Master – Detail – Beziehung) (DM) Fact Table Zentrale Tabelle in einem -> Star Schema. Sie ist n: 1 Beziehungen mit den umgebenden -> Dimensionstabellen verbunden. Ein Teil der Spalten der Faktentabellen sind somit auch die Foreign Keys zu den Dimensionstabellen. Faktentabellen beinhalten die eigentlichen Kennzahlen, die Umsätze, die Mengen. Es ist in der Regel das messbare in den Transaktionen. Während die Dimensionen den Stammdaten entsprechen, enthalten die Faktentabellen die Bewegungsdaten. Factless Facts Faktentabellen müssen nicht immer messbare Werte beinhalten. Sie können auch lediglich aus den Foreign Keys der Dimensionen bestehen. Hier soll z. B. festgehalten werden, ob es überhaupt eine Verkaufsaktivität gegeben hat. Foreign Key Constraint Fremdschlüssel Siehe Referenzielle Integrität Frontend-Software Zeiger bzw. Referenz auf eine andere Tabelle. Der Fremdschlüssel zeigt auf den Primärschlüssel der referenzierten Tabelle. Über Joins werden die Tabellen verknüpft. Frontend-Software, bezeichnet man Software die der Endanwender benutzt. Im Data Warehouse sind dies zum Beispiel Analysetools. Frontend-Software Functional Based Indexes Software, die die direkte Schnittstelle zum Anwender abdeckt Index-Variante. Ein Index kann auf berechnete Werte gesetzt werden. Wird z. B. in WHERE - Klauseln oft auf berechnete Ausdrücke angefragt, so können diese berechneten Ausdrücke indiziert werden. Performancegewinn. Galaxy - Schema Erweitertes Star-Schema, in dem verschiedene Fakt-Tabellen auf gleiche Dimensionstabellen verweisen. Generalisierung Stellt in der Datenmodellierung eine Verallgemeinerung eines Geschäftsobjektes dar. Die Entität KUNDE ist eine Generalisierung von Privatkunde und Firmenkunde. Das Gegenstück ist die Spezialisierung. Technisch unterscheiden sich spezialisierte und generalisierte Entitäten dadurch, dass in der Spezialisierung nur die Attribute aufgenommen sind, die den Spezialisierungscharakter ausmachen. Die generalisierte Entität beinhaltet die Attribute die für alle spezialisierten Entitäten gleichermassen gelten Generatormanagemen Unterstützung des Administrators bei Neustrukturierung und t Weiterentwicklung der Informationsplattform. generic parent (Generalisierungs-Entity) Parent - Entity in einer ->Sub-Category- Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Geschäftsobjekt Granularisieren Granularität der Faktendaten Granularität im Data Warehouse Hash Joins Hash Partitioning Herkunftsanalyse Hierarchical recursion Hierarchie Hierarchie 148/166 Relationship (DM) (Business Objects) Beschreibbare Gegenstände der realen Welt, die z.B. in einer Datenbank gespeichert werden können. Entsprchen den Entitäten aus der Datenmodellierung. Das Pendant zu den Geschäftsobjekten sind die Geschäftsprozesse. Mit den Geschäftsprozessen die Wertschöpfungsketten in den Unternehmen beschrieben. Geschäftsprozessen operieren, modifizieren, erzeugen, bestimmten die Geschäftobjekte. Das Zerteilen von zusammenhängenden Informationen in nicht mehr weiter teilbare Einheiten. Eine Möglichkeit ist die Technik der Normalisierung im Rahmen der Datenmodellierung. Die Art der Detaillierung der Transaktionsdaten (Bewegungsdaten). In jüngster Zeit wird für Faktentabellen eine möglichst detaillierte Sicht gewählt. -> Granularität der Faktendaten Verfahren zum „Verjoinen“ zweier Tabellen indem die Zuordnung der Join-Spalten über einen Hash - Algorithmus festgelegt wird. Verfahren der Datenbank, um Joins zu beschleunigen. Zwischentabellen für Sorts werden vollständig im Speicher durchgeführt ohne Zwischenspeichern auf der Platte. Zufällige Verteilung von Daten um späteres paralleles Lesen leichter zu machen. Werden in Historientabellen Daten sequentiell entsprechend der Zeitreihen geschrieben., so behindert dies die Parallelverarbeitung von Sätzen. Bei dem Hash Partitioning sind die Sätze über die zur Verfügung stehenden physischen Blöcke besser verteilt. Metadatenauswertung bei der die Datenquellen von Ergebnisstabellen bzw. Berichten aufgelistet werden. Diese Analyse erfolgt heute mit graphischen Anzeigewerkzeugen. Eine (->) rekursive Beziehung bei der der Child - Zweig nur einen Parent hat (1:n) (DM) In einer Hierarchie wird dem Umstand Rechnung getragen, dass Geschäftsobjekte (z. B. Artikel) einsprechend gemeinsamer Eigenschaften zu Gruppen von gleichen Geschäftsobjekten zusammengefasst werden können (z. B. Artikelgruppen). Hierarchie, teilt Informations-, Organisations- oder Datenstrukturen in verschiedene Ebenen. Beispiele sind die beiden Hierarchien: Produkt (WKN) zu Produktgruppen (Instrumentenarten) oder Beraterschlüssel zu Abteilungen zu ProfitCenters. Homonyme Begriff aus der -> Datenadministration. Bezeichnet den Umstand dass ein Begriff genutzt wird, um unterschiedliche Dinge zu bezeichnen. Diese Mehrdeutigkeit ist eine Gefahr für stimmige Datenmodelle. Aufgabe der Datenadministration ist es diese zu vermeiden. Gegensatz zu -> Synonyme. Hub and Spoke ETL- Konzept: Zusammenziehen aller Daten auf einen Knoten und Architektur anschließendes Verteilen. Gefahr von Bottlenecks. Alternative sind verteilte Ladeszenarien IDEF1x-Notation Icam DEFinition method1 eXtended Eine vom amerikanischen Militär entwickelte und in den USA sehr stark verbreitete Darstellung (Methode). Beziehungen werden als durchgezogene oder gestrichelte Linien gezeichnet, Kardinalitäten als Punkte/Kreise dargestellt. Identifying relationship (Identifizierende Beziehung) Eine Beziehung zwischen einem ParentEntity und einem Child-Entity wobei der -> Primary Key des ParentEntityies als Primary-Key zum Child-Entities migriert wird. Es entsteht eine sog. Existenzabhängigkeit. ->Instanzen des ChildCopyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur IE-Notation Impact Analyse Informationsplan Initial Load Inline Views insert and replace rules Instance Integrationsmanagem ent IntersectionDimension Inversion Entry Join 149/166 Entities können nur existieren, wenn es auch passende ->Instanzen der Parent-Entität gibt. (DM) Information-Egineering-Darstellung (James Martin): Beziehungen werden als Striche und die -> Kardinalitäten als eine Kombination von 0, 1, nStrichen (Krähenfuß) dargestellt. Hat in Deutschland und den hier eingesetzten Werkezeugen eine große Verbreitung. Wird von Ein Datenmodellierungstool unterstützt. -> Auswirkungsanalyse Auflistung aller Informationen in einem Data Warehouse. Umfasst in der Regel die Datenmodelle. Allerdings ist eine weitere Aufgliederung nach Kennzahlen, Dimensionen, Geschäftsobjekten und Geschäftsprozessen sinnvoll. Der Informationsplan ist wichtig, um zu verhindern, dass Informationen mehrfach modelliert und gewartet werden. Initial Load, erstmaliges Füllen einer Datenbank bzw. eines Data Warehouses mit Daten z.B. aus Vorsystemen. Eine Art Subquery. Eine SELECT - Abfrage nutzt das Ergebnis einer andern SELECT - Abfrage z. B. in der FROM - Klausel. Select a.feld1,b.feld2 from tab1 a, (select distinct feld2 from tab2) b where ….. Beispiele für -> Referentielle Integritätsregel (RI). In einem abhängigen Entity können nicht -> Instanzen eingetragen werden, deren Fremdschlüsselbestandteil nicht mit dem Basisattribut übereinstimmt. (Instanz) Wenn in einer Datenbanktabelle Sätze eingetragen werden, dann sind diese vergleichbar mit den Instanzen einer Entität. Instanzen sind die konkreten Objekte der realen Welt, die über den Begriff des Entities auf einer Abstraktionsebene höher benannt und beschrieben werden. Einbettung eines neuen Systems in die bestehende Systemumgebung. Eine Dimension kann nicht über eine 1:n Beziehung an eine Faktentabelle angeschlossen werden, sondern stellt eigentliche eine n:m Beziehung dar. Statt dessen muss eine Zwischentabelle gebildet werden: die Intersektion – Dimension. Zusätzliches inhaltliches (logisches) Zugriffsattribut auf ein Entity (Tabelle), das aber nicht eindeutig sein muss (not unique). Join, engl. Verknüpfung. Werden zwei oder mehrere Tabellen ausgewertet, benötigt man sogenannte Verknüpfungen (Joins). Die Tabellen werden in Datenbanken über Felder verknüpft, meist Primary Key / Foreign Key Verbindungen. KIM Kunden Informations Management Konstellation Den Gesamtverbund von Faktentabellen über -> Conforming Dimensions nennt man Konstellation (Constallation). Lineage Analyse List Partitioning -> Herkunftsanalyse -> Partitions können entsprechend einer Liste konkreter Werte eines Feldes (Schlüsselwerte) eingerichtet werden. Load Management beschreibt das Verfahren des Datenladens. Eine Hauptkomponente des DWH, die das Einlesen der Daten aus den Quellsystemen regelt. Wann welche Daten zu welchen Zeitpunkt geladen werden und in welcher Abhängigkeit. Wird meist als Workflow realisiert. Hier wird Wert auf Automatisierung gelegt. Load Management Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 150/166 Look Up – Information Look Up – Information ist eine Beschreibung zu einem Feld. Eine Tabelle enthält eine Spalte mit definierten Codewerte. Die Langbeschreibung zu diesen Codewerten ist in eine separate Tabelle ausgelagert. Um die vollständige Information zu erhalten, muss über beide Tabellen ein Join gelegt werden. Look Up Table Look Up Table, eine Tabelle die ergänzende Informationen oder Beschreibungen zu einem Feld einer anderen Tabelle enthält. Loopback Data Warehouse Ein Data Warehouse, dessen Daten zurück in die operativen Ursprungsprozesse fließen. Die zurückfließenden Daten werden als Steuerdaten für operative Prozesse tgenutzt. Im Anhang von Mail-Nachrichten versandte Dokumente. (Muß-Attribut) Gegenteil von ->optional. Wird auch im Zusammenhang von -> nicht identifizierenden Beziehungen benutzt, wenn das Foreign Key Attribut mit Not Null deklariert wurde, womit die Child Entität existenzabhängig wird. Detaillierte Zuweisung von Information aus einer Datenbank/Tabelle an die strukturell gewünschte Stelle einer zweiten Datenbank/Tabelle. Genutzte Methode zur Übernahme von Daten aus Vorsystemen. Mail-Attachment Mandatory Mapping Werden Daten in ein Data Warehouse geladen, schreibt man sie generell in einem dafür vorgesehenen Bereich (Staging Area) herein. Anschließend werden die Daten auf weitere Bereiche verteilt. Das Überführungsobjekt- Programm nennt man Mapping. In ETL – Werkzeugen wird oft auch das was in einem graphischen Editor zusammengefasst werden kann als Mapping bezeichnet (z. B. OWB). Materialized View Physisch gespeicherter View. Dient der Optimierung von Abfragen. Automatische Refresh Funktion. Rewriteverfahren der Datenbank. Enthält verdichtete Daten, die aus detaillierten oder weniger verdichteten Daten gewonnen werden. Der Oracle Cost - Based-Query - Optimizer liest bei geeigneten Abfragen diese Daten anstelle der detaillierten aus. Damit werden diese Abfragen transparent für den Anwender stark beschleunigt. Eine Materialized View aktualisiert sich in der Regel selbständig und muss nicht durch einen Ladeschritt beladen werden. MAV Measures -> Materialized View Fakten, Kennzahlen, anderer Begriff für Faktentabelle Metadaten Daten, die andere Daten beschreiben. Diese werden idealerweise in einem eigenen Datenbankschema (z. B. in einem sog. Repository) gehalten und verwaltet. Metadaten haben in der Warehouse – Technologie zunehmend an Bedeutung gewonnen weil sie die kompletten Warehouse – Strukturen beschreiben. Man unterscheidet zwischen technischen und fachlichen Metadaten. Technische Metadaten sind z. B. Tabellenbeschreibungen. Fachliche Metadaten sind Beschreibungen zur Bedeutung von Entitäten/Geschäftsobjekten im Kontext ihrer betriebswirtschaftlichen Unternehmensprozesse. -> Lineage Analyse (-> Herkunftsanalyse) -> Impact Analyse (-> Auswirkungsanalyse) Multidimensional OnLine Analytical Processing. Werkzeuge, die die zu analysierenden Daten so abspeichern , dass sehr schnell wieder abgegriffen werden können (Würfel). Meist sind die Speicherstellen der jeweiligen Kennzahlen in zusätzlichen Indexbäumen direkt vermerkt. Abfrageeinschränkungen über Dimensionen werden direkt auf die Daten gelenkt. Abfragen in MOLAP – Systemen zeichnen sich durch hohe Performance aus. Allerdings müssen die Daten erst in die sog. Würfel geladen werden. Die Oracle – Technologie hat die Speicherung der MOLAP Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 151/166 Würfel in die relationale Datenbank integriert, so dass zur Verwaltung der Würfel weniger Aufwand anfällt. Monitoring Monitoring, bezugnehmend auf einem Rechner bedeutet es die Überwachung von Aufgaben, Programmen und Prozessen. Das Monitoring wird in der Regel im Rechenzentrum durchgeführt. Die Überwachung von Datenbankprozessen. Aufgaben, Programmen, Rechner- oder MPP MPP =Massive Parallel Processing. Ist eine Steigerung der Parallelisierung. MPP-Systeme sind Rechnersysteme, die für große Mengen von parallelen Transaktionen gebaut werden. Beschreibt große Rechner mit mehreren Knoten(1 Knoten = mehrere Prozessoren). Durch Hinzufügen von beliebig vielen Knoten wird eine fast unbegrenzte Skalierung versprochen. MPP – Systeme werden von mehreren Herstellern angeboten. Haben gegenwärtig sehr stark Konkurrenz erhalten, da die konkurrierende SMP - Rechnerarchitekturen bzgl. der Leistungsfähigkeit sehr stark aufgeholt hat. n-ary relationships N-fache Relationship: mehr als zweifache Beziehung. Diese kommen in der Praxis sehr selten vor, zumal sie schwer zu handhaben sind. N fache Relationships lassen sich immer auflösen in mehrere -> binäre Relationships. (DM) Ein Data Warehouse in das operative Daten in sehr kurzer Zeit fließen. Der Zeitabstand zwischen der Transaktion im operativen System und den analytischen Ergebnissen in dem Data Warehouse ist sehr gering ( < 1 Std.). Dies wird vor allem dort gebraucht, wo Data Warehouse Systemen zur Steuerung operativer Prozesse unmittelbar eingesetzt werden. Eine (->) rekursive Beziehung bei der der Child - Zweig mehrere Parents haben können (n:n) Near Realtime Data Warehouse Network recursion Non-contiguous multiblock read ahead non-identifying relationship Normalisation normalisiert Notation ODS (nicht identifizierende Beziehung) Eine Beziehung zwischen einem Parent - Entity und einem Child - Entity wobei der -> Primary Key des Parent-Entityies lediglich als Foreign- Key zum Child-Entities migriert wird aber nicht in den Primary Key Bereich gelangt. ->Instanzen des Child-Entities können auch existieren, wenn es keine passende ->Instanz der Parent-Entität gibt. Der so entstandene Foreign Key ist nicht notwendig um eine ->Instanz der Child-Entität eindeutig zu Identifizieren. (DM) (Normalisierung ) Verfahren zur Minimierung von Redundanzen im relationalen Datenhaltungssystem. Der Informationsgehalt wird an den Attributen festgemacht, die so den Entitäten zugewiesen werden, dass jede Information nur einmal gespeichert ist und damit auch nur einmal geändert werden muss. Das Verfahren besteht aus ->1./2./3.- Normaform. (DM) Ein nach den Regeln der relationalen Datenspeicherung erstelltes Datenmodell ist normalisiert. Ein wichtiger Aspekt dafür ist die Redundanzfreiheit, d.h. gleiche Daten sind nicht mehrmals im System gespeichert. Man unterscheidet zwischen der 1. 2. 3. Normalform. Das Verfahren der Normalisierung ist ein systematisches, methodisches Vorgehen das zu absolut redundanzfreien Daten führt. Zeichnerische Darstellung von Zusammenhängen zwischen Entität, d.h. Dokumentation einer Beziehung (Ralationship). Beispiele sind ->IDEF1xNotation oder -> IE - Notation. Operational Data Store. Ein (normalisiertes) Datenmodell, das auch für Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur OLAP 152/166 Auswertungen von der operativen Seite her eingesetzt werden. Eine ODS – Schicht in einem Data Warehouse verbindet den Nutzen von Integration, leichter Zugänglichkeit und Fehlerbereinigung den ein Warehouse bietet mit der Notwendigkeit schnell und performant auf Daten zugreifen zu müssen. OLAP = OnLine Analytical Processing. OLAP beschreibt das Analysieren von Daten in einer Datenbank vor dem Hintergrund der dimensionalen Betrachtung. D. h. Fakten werden aus unterschiedlichen Blickwinkeln heraus betrachtet, gemessen und verglichen. Z. B. kann der Umsatz eines Unternehmens nach Regionen gegliedert sein aber auch nach Produktgruppen. Hieraus ergeben sich sehr flexible Analysen. Ein zweiter Aspekt ist der der Interaktion von Benutzern mit dem System. Bei vielen Analysevorgängen wissen die Mitarbeiter im Vorfeld nicht mit welchem Datenmaterial oder mit welcher Abfrage die besten Ergebnisse zu erzielen sind. Daher werden mehrere Analyseschritte nacheinander durchgeführt. OLAP Analysen werden zusätzlich noch nach der Art der Speicherung der Daten unterschieden in -> MOLAP Multidimensional OnLine Analytical Processing und -> ROLAP Relational OnLine Analytical Processing Mit OLAP - Systemen kann der Benutzer direkt Analysen auf Datenbanken durchgeführen. Ein Data Warehouse ist ein OLAP – System mit dem Online analytische Operationen auf Massendaten z.B. Summierung über alle Depots, durchgeführt werden können. OLTP OLTP = OnLine Transaction Processing. Ein OLTP-System (Rechnersystem) ist speziell für die Massenverarbeitung von vordefinierten Operationen kreiert worden. Operational Data Store -> ODS Operationalisierung des Warehouse Operative Systeme Einbindung von Data Warehouse Informationen in operative Unternehmensprozesse. Zusammenfassung aller Softwareanwendungen die die Unternehmensprozesse direkt unterstützen. Das sind i. d. R. die Online – Anwendungen (OLTP). Gegenteil -> Dispositive Systeme. Operative Prozesse Alle Geschäftsprozesse eines Unternehmens, die der Realisierung der Geschäftsidee dienen. Der Begriff wird meist als Abgrenzung zu -> „dispositiven Prozessen“ genutzt. (Optionalität) In einem Feld einer -> Instanz einer Tabelle, die mit einer anderen Tabelle in Beziehung steht dürfen NULL - Werte vorkommen auch dann, wenn dieses Feld das „beziehungsstiftende“ Feld ist, d.h. in der an der Beziehung beteiligten Tabelle das gleiche Feld vorkommt. Gegenteil von : -> mandatory Mit dem Oracle Warehouse Builder (OWB) wird die Struktur des Warehouses und die Datenflüsse des Warehouse - System (-> ETL) mit graphischen Mitteln modelliert. Datenbankobjekte (Tabellen, Indizes, Views, Summentabellen (MV), Starschemen, Partitionen, Funktionen, Prozeduren u.a.) stellt OWB über DDL-Scripte direkt in die Oracle Datenbank. Die Beschreibungen (Metadaten) der OLTP - Quellen sind in das Modell integriert. Auch Warehouse - Endbenutzersichten können mit dem OWB bereits vorbereitet werden. Auf einer Modellebene entsteht ein einheitliches Bild des gesamten Warehouses. In einem „Satz Metadaten“ Optional Oracle Warehouse Builder (OWB) Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Outer Join Outrigger Table OWB Parallel Faktentabelle Parallel Query Parallel query for objects Parallelisierung Partition Exchange And Load (PEL) Partitioning 153/166 ist ein komplettes unternehmensweites Warehouse beginnend bei den Quellen bis hin zu Endbenutzerberichten an einer Stelle dokumentiert! Die Datenbewegung und Transformation übernimmt die Datenbank selbst durch SQL- und PL/SQL-Komponenten, die OWB9i generiert hat – schneller gelingt keine Datentransformation. Spezieller Join, bei dem alle gefundenen Instanzsätze der an dem Join beteiligten Tabellen in das Ergebnisset des Join mit aufgenommen werden, sofern die übrgigen Abfragekriterien erfüllt sind. Eine normalisierte Tabelle als Anhängsel zu einer Dimension. Ein Snwoflake – Schema ist eine Ansammlung von normalisierten Outrigger Tables während das logische Datenmodell aus zusammenhängenden Entitäten besteht. Oracle Warehouse Builder. -> ETL – Tool von Oracle als graphische Oberfläche für die Oracle Datenbank. Generiert Datenbankprogrammcode in Form von PL/SQL mit eingebetteten SQL Kommandos. OWB unterstützt damit die mengenbasierte Vorgehensweise bei dem Laden von Daten durch die Datenbank. Ein Starschema kann durchaus mehrere Faktentabellen beinhalten (auch wenn die Form des Sterns damit nicht mehr gegeben ist). Hier handelt es sich dann meist um Messwerte, die miteinander in Bezug gesetzt werden sollen (Drill-Across-Anforderung). In dem Beispiel ist eine separate Faktentabelle für die Bestellkosten (Lieferkosten, Bezug über Lieferanten) gebildet worden. Zusammenfassung aller Oracle Features mit denen paralleles Arbeiten möglich ist (Mehr-CPU-Maschinen nötig!). Aktivitäten können sein: - Table Scans - Sorts - Such nach eindeutigen Werten - Data Loading - Creation of Summary Tables - Building of indexes - Recovery Festlegung von Objekteigenschaften. Z. B. die Festlegung, dass eine Tabelle im Parallel-Mode der Datenbank gelesen werden darf. Erst wenn der Parallelisierungsgrad einer Tabelle festgelegt wurde, kann das System dieses auch tatsächlich mit mehreren Prozessen parallel bearbeiten. Schlüsselparameter ( z. B. CREATE TABLE ..... PARALLEL 8) Das System kann Defaults wählen. Parallelisierung, werden zwei oder mehrere Operationen auf einem Rechner gleichzeitig ausgeführt, spricht man von einer Parallelisierung. Das Ausführen von mehreren Aufgaben (z. B. Datenbank-Operationen wie INSERT, UPDATE, etc.) zur selben Zeit. Dies ist in Rechnersystemen mit mehreren Prozessoren möglich Oracle - Datenbank – basiertes Verfahren, zum schnellen Laden und Entladen von Daten für partitionierte Tabellen. Eine vorbereitete temporäre Tabelle wird über Partition Exchange als Partiton in die partitionierte Tabelle übernommen. Aufteilung von großen Tabellen auf mehrere Partitionen: Vorteile: - Separates Recovern einzelner Partitions, geringere Ausfallzeiten, nicht alle Daten sind von Aufällen betroffen. - Der Optimizer kann bei Queries relevante Partitions einzeln auffinden und andere überspringen. - Partitions können einzeln reorganisiert werden. - Partitionen können einzeln hinzugefügt oder gelöscht werden. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 154/166 Ein gutes Beispiel ist das Historisieren von DW-Daten. Partitionen entsprechend der Jahrgänge oder Monatsscheiben. Unterscheidung in -> RANGE / HASH / COMPOSIT und LIST Partitioning. Partitioning Option Partition-wise Join PEL Pivoting Primärschlüssel Progress Monitor Query Management Query Rewrite Queue RAC Range Partitioning Real Application Cluster Recursive Relationships Referential integrity (RI) Fähigkeit der Oracle-Datenbank, Tabellen und Indizes physisch in mehreren Teilen und nicht als eine große Einheit zu speichern und zu verwalten. Auf diese Weise können z. B. Umsatzdaten in einer Umsatztabelle nach Monaten aufgeteilt abgespeichert werden. Bei einer Abfrage muss dann nicht auf den gesamten Datenbestand zugegriffen werden. Das bringt deutliche Vorteile für die Verarbeitungsgeschwindigkeit (Performance). Man unterscheidet bei Oracle10g zwischen Range, Hash, Composit und List – Partitioning. Verjoinung der einzelnen Partionen von Fakten – und Dimensionstabellen untereinander. -> Partition Exchange And Load Ändern der horizontalen und vertikalen Platzierung von Dimensionswerten in einer Berichtsanzeigefläche. Spaltenüberschriften werden zu Zeilenbezeichnern und umgekehrt. Tatsächlich wird die Abfrage auf das Datenmaterial anders formuliert. Eine Tabelle enthält genau einen eindeutigen Schlüssel, mit dem jede Zeile identifiziert werden kann. Er kann einer eindeutigen Spalte zugeordnet werden oder aus mehreren Spalten, die zusammen eindeutig sind, bestehen. (Progress monitoring of large running opration) Graphisches Administrator Tool. Der Status von lange laufenden Abfragen kann beobachtet werden. Zugriff über Enterprise Manager Console und Oracle. Eine Hauptkomponente des DWH, die das Verwalten der Auswertungen und Berichte und die Zugriffskontrolle regelt. Internes Umschreiben von Abfragen auf die Datenbank durch den Optimizer. Eines der wichtigsten Hilfsmittel bei der Verwendung von Materialized Views. Warteschlange. Technisches Verfahren in der Oracle Datenbank (-> advanced Queuing), mit dem Nachrichten (Messages) zwischengepuffert werden. Der Empfänger einer Nachricht quittiert bei erfolgreichen Auslesen die Nachricht und löscht diese in der Queue. Damit ist eine gesicherte Nachrichtenübermittlung garantiert. -> Real Application Cluster Partitions können entsprechend der Werte eines Feldes (Schlüsselwerte) eingerichtet werden. Das führt zu einem einfachen Zu- und Abschalten von Partitionen. -> Rolling Window Die Steuerung der Zugehörigkeit zu einer Partition erfolgt über die Inhalte von Keyfeldern. Oracle Datenbank – basiertes Verfahren zu Zusammenschluss von mehreren Rechnern (Knoten) zu einem Rechnerverbund. (Rekursive Beziehen) Ein Entity hat eine rekursive Beziehung zu sich selbst, wenn in einem weiteren Attribut Instanzwerte des eigenen Schlüsselattributes verwendet werden. (-> hierarchical, -> network). Eine solche Beziehung muss non-identifying sein. Hier muss mit -> Rolenames gearbeitet werden. (DM) (Referentielle Integrität) (RI) Ein Set von Regeln, nach denen eine Beziehung zwischen zwei Tabellen in einer Datenbank gesteuert wird. Damit können die Sätze in den Tabellen zu einander in Bezug gesetzt Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 155/166 werden. Die Datenbanksysteme reagieren mit Fehlermeldungen, wenn Regeln im Rahmen der RI verletzt wurden. Die Beziehung zwischen den Tabellen wird üblicherweise durch die „Reference“ - Klausel in dem CREATE TABLE - Statement definiert. Referenzielle Integrität Nach Aktivierung eines „Foreign Key Constraints“ erlaubt die Datenbank nur das Einfügen oder Ändern von Datensätzen, bei denen das referenzierende Attribut in der referenzierten Tabelle existiert. Es wird so sichergestellt, dass keine ungültigen Werte gespeichert werden können. Repository, ist ein zentraler Datenbestand innerhalb einer Datenbank mit Repository Informationen über die verwendeten Daten. Im Repository sind beispielsweise alle fachlichen Objekte des Data Warehouse beschrieben. Optimaler Weise können mehrere Anwender auf ein Repository zugreifen. Aus einem Repository können einheitliche Dokumentationen erzeugt werden. Das Data Warehouse Repository wird mit dem Oracle Tool Designer/2000 verwaltet. restricted ROLAP Prüfung auf Abhängigkeiten im Rahmen der -> Referentiellen Integrität. Im Restricted-Fall wird auf eine mögliche Regel hin geprüft. Delete, insert, update-Kontrolle. Aktivitäten in einer Tabelle werden von Beziehungen zu einer anderen Tabelle abhängig gemacht. Relational OnLine Analytical Processing. Multidimensional OnLine Analytical Processing. Werkzeuge, die die zu analysierenden Daten in relationalen Tabellen abspeichern (Star Schema) Rolename Rolling Window Rollup Row Based RQM Runtime Audit Browser Sample SCD Schlüsselkandidat (Rollenname) Spezifische Verwendung von Fremdschlüsseln (Foreign Key) in abhängigen Entities. Für den Foreign Key wird ein andere Name vergeben um in der Childtabelle einen Namenkonflikt zu vermeiden. (DM) Wird ermöglicht durch das -> Range Partitioning. In großen Tabellen mit Historiendaten können aktuelle Zeiträume (Monate) bequem zugeschaltet werden und veraltete einfach herausgelöscht werden. SQL - Operator. Berechnung der „Subtotals“ einer Dimension bei einem einfachen SQL - Statement. Der Vorteil liegt darin, dass Aufwände auf den Server verlagert werden können. Satzbasiertes Verarbeiten von Daten. Meist langsamste Verarbeitungsvariante. Wird üblicherweise in prozeduralen Programmiersprachen wie PL/SQL verwendet. Risc- und Quality Management Komponente des -> Oracle Warehouse Builders (OWB) in dem System das aus mehreren Tabellen sowie Prozeduren besteht, legen die Laderoutinen (-> ETL - Prozess) (PL/SQL) statistische Informationen ab. Gespeichert werden z. B. - Gelesene Sätze - Geschriebene Sätze - Abgewiesene Sätze - Alle fehlerhaften Sätze - Informationen über bereits gelaufene Job Routinen SAMPLE Operator. Liefert für einen definierten Prozentsatz einer Grundmenge, die angeforderten Ergebnisse. Ist für Schätzwerte hilfreich. „Liefere für 3 % der Kunden den durchschnittlichen Umsatz“. Die 3% werden zufällig zusammengesucht. -> Slowly Changing Dimensions (Candidate key ) Ein Attribut (oder eine Attributgruppe), das zur eindeutigen (!) Identifizierung aller -> Instanzen herangezogen werden kann. Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Self-tuning parallel query Sequential Computations Set Based Set null Slice and Dice 156/166 Candidate Keys können Primärschlüssel werden oder -> Alternate Key sein. -> Alternate-Key (DM) Automatische Verteilung der Last auf zur Verfügung stehende Prozessoren. A kind of fact table that represents the status of accounts at the end of each time period. Daily snapshots and monthly snapshots are common. Mengenbasiertes Verarbeiten von Daten in einer Datenbank. Meist schnellste Verarbeitungsvariante. Das Foreign Key-Feld der abhängigen Tabelle wird mit dem Wert NULL belegt, wenn der Parentsatz gelöscht wird. (RI Regel). Dice engl. Würfel, Über eine Filtersetzung wird nur ein Ausschnitt der Daten betrachtet werden. Slice engl. Scheibe. Über eine Filtersetzung wird nur ein Ausschnitt der Daten betrachtet werden. Slowly Changing Dimensions SMP Snowflake Schema Software-Agenten Star Schema Verfahren zum Historisieren von Dimensionswerten. Stammdaten können sich im Verlauf der Zeit ändern. Weil jedoch in einem Data Warehouse auch „alte“ (historische) Bewegungsdaten vorgehalten werden, müssen die Stammdaten diese in ihrem ursprünglichen Zustand auch wiedergeben. Zu Realisierung gibt es standardiserte Verfahren (nach Kimball). Symmetric Multiprocessing. Ein SMP-Rechner beinhaltet mehrere Prozessoren, die Speicher und Festplattenlaufwerke gemeinsam nutzen. Ein Snowflake Schema (Schneeflocken-Schema) ist eine Erweiterung des Starschemas. Die Dimensionstabellen werden normalisiert. Dadurch entstehen pro Dimension zusätzliche Joins, was das Abfragen innerhalb der Datenbank aufwendiger macht. Oracle empfiehlt daher die Verwendung von reinen Star Schemen. Automatisierte Teilsysteme, die in einem Gesamtsystem, z. B. einem DWH, Teilaufgaben übernehmen. Denormalisiertes Datenmodell, das überwiegend in der Data Mart – Schicht des Warehouses eingesetzt wird. Es werden die Daten zu den Geschäftsobjekten von den zu messenden Kenngrösse (z. B. Umsatz) in mehrere Tabellen getrennt. Die Verbindung zwischen diesen Tabellen stellen 1:n – Beziehungen (Fakten – Dimensionen) dar. Das Star Schema bietet 3 Vorteile: - Es ist flexibel erweiterbar - Es reflektiert die Geschäftsobjketesicht von Fachmitarbeitern - Es ist in relationalen Datenbanken performant abfragbar. Die zentrale Tabelle nennt man Faktentabelle (Facts) die umliegenden Dimensionstabellen (Dimensions). Beide Tabellenarten sind über 1:nBeziehungen miteinander verbunden. Die Foreign Keys sammeln sich in der Faktentabelle. Die Faktentabelle ist lediglich durch diese Foreign Keys bestimmt. Sie hat keinen eigenen Primary Key. Es können also Sätze mehrfach vorkommen. Dimensionstabellen beinhalten beschreibende Informationen zu den Geschäftsobjekten (Textfelder, einmalige Eigenschaften, Stammdateninformationen). Faktentabellen beinhalten Felder, mit denen gerechnet werden kann. Alle mess-/berechenbare Fakten, die sich ereignen (Bewegungsdaten). Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Star Transformation Star-Query Statistiken Streams Sub - CategoryRelationship Sub Partitioning Summary Advisor Summary Management Summary Tables Surrogate Key Synchrone Kopplung Synonyme 157/166 -> Star-Query Spezieller, dem Star - Schema angepasster Zugriffspfad für das Auslesen von Daten im Data Warehouse. Da die Fakt-Tabelle sehr große Datenmengen enthält, die Dimensionstabellen jedoch relativ klein sind, sind die klassischen Join - Verfahren in diesem Fall häufig ineffizient. Der Oracle Cost – Based – Query - Optimizer erkennt Abfragen auf StarSchema - Tabellen und führt dann zuerst ein kartesisches Produkt der Bitmap-Indizes der Dimensionstabellen durch und nutzt dieses zum Join mit der Fakt-Tabelle. Statistiken über die Datennutzung. Werden innerhalb der Oracle – Datenbank mit DBMS_STAT erzeugt. Oracle Datenbank – basiertes Verfahren zu -> asynchronen Koppeln von zwei Datenbank – Anwendungen. Das Verfahren ist auch interessant, weil zum Auslesen der Daten aus möglichen Vorsystemen nur die Logdatei des Vorsystems gelesen werden muss. Zur Kopplung werden Nachrichten von dem Vorsystem zu dem nachfolgenden System über den Datenbank -> Queue – Mechanismus geschickt. Die Nachrichten können zusätzlich über Transformationen modifiziert werden. Damit ist das Verfahren ein logisches Transformationsverfahren und kein rein physisches. Eine Beziehung zwischen einem Entity A und seinen Sub-Entities B und C. In A sind alle Attribute zusammengefasst, die die Entities B und C gemeinsam haben. In B und C sind nur solche Attribute aufgeführt, die nicht gemeinsam und spezifisch für B und C sind. Zwischen A und B sowie A und C besteht eine 1:1 bzw. 1:1,0 Beziehung. Unterteilung einer -> Partition in weitere Unterpartitionen. Es lassen sich RANGE – Partitions z. B. in HASH – Unterpartitions gliedern. Das verstärkt die Selektionsmöglichkeiten bei dem Management der Daten in einer Tabelle. Wizzard zur Analyse von Queries und bestehenden -> Materialized Views. Empfiehlt die Einrichtung von Materialized Views und zeigt die Effizienz bestehender Materialized Views. Kann bei der Vielzahl von möglichen Tabellen Ordnung schaffen. -> Summary Tables (Materialized Views) können transparent im System vorgehalten werden. Der Optimizer der Oracle Datenbank findet automatisch den effektivsten Weg für die Abfrage. Ergebnisse können aus einer Materialized View kommen auch wenn der Benutzer glaubt, die Daten kämen aus der Basistabelle. Gezieltes für den Benutzer transparentes Umschreiben von Abfragen durch das System. Gespeicherte Ergebnisse von häufig gestellten Abfragen. In den jüngeren Versionen von Oracle werden diese zunehmen durch „Materialized Views“ ersetzt die das System selbständig verwalten kann. Künstlicher Primary Key - Ersatzschlüssel, wenn andere Attribute bzw. Foreign Keys als Primary Key nicht gewünscht sind. (DM) Künstlicher Schlüssel. In Oracle können Sequenzen (Sequence) angelegt werden, mit denen es möglich ist, Nummern zu generieren. Da diese pro Sequence eindeutig sind, können diese als Werte für einen Primärschlüssel herangezogen werden. Im Gegensatz zur -> asynchronen Kopplung werden bei der synchronen Kopplung Informationen eines Vorsystems direkt an das nachfolgende System gesendet. Das sendende System steht wartet solange still, bis das Empfängersystem eine Nachricht quittiert hat. Sysnchrone Kopplungen sind z. B. Trigger – basierte Verfahren. Begriff aus der -> Datenadministration. Bezeichnet den Umstand dass Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur Table level validation rule Task Top N/Bottom N Transportable Tablespaces Tuning Unbalancierte Hierarchien Unification Validation rule View VLDB Warehouse Management Zeitreihenanalysen 158/166 mehrere Begriffe genutzt werden, um ein und dasselbe Objekt zu bezeichnen. Synonyme sind oft die einzige Möglichkeit, um gleiche Dinge aus unterschiedlichen Kontexten heraus zu betrachten und zu benennen. Gegensatz zu -> Homonyme. -> Validation Rule, die sich auf mehr als eine Column einer Tabelle bezieht. -> Constraint - Zusatz auf Tabellenebene. Ein einzelner Schritt bzw. eine Aufgabe innerhalb eines Bearbeitungsprozesses. Mehrere Tasks bilden eine Phase. Liefert die N-höchsten, N-niedrigsten Ergebnisse. „Top 10“-Abfragen. Ganze Tablespaces in der Oracle Datenbank können verschoben/kopiert werden ohne die Daten einzeln zu entladen. Hilfreich für Staging Aktivitäten. Die Feinabstimmung von Parametern eines Systems oder Teilsystems zum Zwecke der Optimierung von Abläufen (Programme, Prozesse, etc.). Hier vorwiegend auf Datenbanken bezogen (z. B. Performance Tuning). Dimensionen sind meist nach Hierarchiestufen strukturiert. Bei gleichmäßigen (Balancierte) Hierarchien gibt es auf jeder Hierarchiestufe Instanzwerte. Unbalancierte Hierarchien haben dies nicht. Z. B. gibt es oberhalb der Kostenstellen in einem Unternehmen nicht immer die gleichen Organisationseinheiten. Ein und derselbe Fremdschlüssel wird mehrfach von einem oder mehreren unterschiedlichen Entities übernommen. Soll dies verhindert werden, muss mit -> Rolenames gearbeitet werden (DM). Ein Ausdruck der für eine bestimmte Datenbank festlegt, welche Werte oder Wertebereiche in einer Column gültig sind. (->Column level validation rule/->table level validation rule) Eine View ist eine Sicht auf einen Teilbereich von Daten in einer Datenbank. Eine View kann zum Beispiel die Informationen zu einem Kunden enthalten. Very Large Data Base. Da ein Data Warehouse typischerweise große Datenmengen enthalten kann, muß die zugrundeliegende Datenbank sehr große Datenmengen performant verwalten können. Oracle9i kann Tabellen bis zum PB-Bereich (Peta-Byte) bearbeiten und bietet mit Tabellen-Partitionierung, Bitmap-Indizes und Star-Queries Voraussetzungen, um Data Warehouse Systeme adäquat bedienen zu können. Eine Hauptkomponente und die Schaltzentrale des DWH. Regelt u. a. die Prozesskontrolle, Metadatenmanagement, Archivierung, etc. Berichtsart, bei der Kennzahlen zu verschiedenen Zeitpunkten gemessen und gegenübergestellt werden. (Z. B. Absatzentwicklung Quartal 1,2,3,4 ...) 14.5 Abbildungsverzeichnis Warehouse – Plattform – mehr als nur eine Sammlung von Komponenten ............. 11 Data Warehouse – Architektur – Rückgrat einer effizienten Data Warehouse Lösung ................................................................................................................ 12 Unternehmensprozesse werden nicht mehr nur Top Down sondern auch horizontal auf der unteren ebene gemessen ...................................................................... 16 Bandbreite der Verwendung der Warehouse – Informationen .................................. 17 Prozessunabhängigkeit von Warehouse Strukturen ................................................. 18 Kombinationsmöglichkeiten im multidimensionalen Modell ...................................... 21 Liste von festen Kennzahlen Metadaten gesteuert über Browser dargestellt ........... 22 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 159/166 Architekturen bestehend aus Technologien, Verfahren und Regeln sind standardisierbar und können von Projekt zu Projekt unabhängig von der fachlichen Anforderung wiederverwendet werden. ............................................ 26 Verwendung von Namenskonventionen zur Orientierung bei Auswirkungs- und Herkunftsanalyse über Metadaten ..................................................................... 27 Metadatenmodell (- Ausschnitt) zum Informationsplan im Data Warehouse ............ 29 3 – Schichtenmodell für unternehmensweit eingesetzte Data Warehouse Systeme 30 Die Warehouse – Schicht steht für einmaligen Aufwand und verhindert unkontrolliertes „Werkeln“ in den Data Marts ..................................................... 32 Metadaten kontrollierten die Zusammenhänge in dem 3 Schichtenmodell (Herkünfte und Auswirkungen sind offengelegt) .................................................................. 32 Aufendige historisch gewachsene 4 – Schichten – Lösung ...................................... 33 Freie Wahl von multidimensionaler oder relationaler Datenspeicherung sowohl bei der Definition als auch bei der Datenbefüllung .................................................. 34 Wahlfrei den Ort einer Analyse für Standardberichte festlegen ................................ 34 Einheitliche Sprachmittel standardisieren alle Datenflüsse und Schnittstellen des 3 Schichtenmodells sowohl innerhalb des Systems als auch nach außen ........... 37 Nachteile Engine – basierter ETL – Werkzeuge ....................................................... 39 Schlechtes Beispiel: Hier wird satzweise geladen. Innerhalb einer PL/SQL – Schleife werden zusätzlich SELECT – Aufrufe für Lookups durchgeführt. ...................... 42 Zu bevorzugende Lösung: Alle Lookups werden mengenbasiert durchgeführt und das Ergebnis in eine temporäre Tabelle geschrieben, die anschließend zum Schreiben der korrekten Sätze in die Zieltabelle oder zum Schreiben von falschen Sätzen in eine Fehlertabelle genutzt werden kann. Hierfür nutzt man einen „Multiple Insert“. ........................................................................................ 42 Verfahren Partition Exchange And Load (PEL) ......................................................... 44 Zusätzliche Netzlast bei unnötig vielen Servern (z. B. ETL Server) .......................... 46 Verringerte Netzlast bei direkter Verarbeitung von Daten in der Datenbank und Minimierung von Servern ................................................................................... 47 Datenarten in dem 3 Schichtenmodelle ..................................................................... 51 Früher / Heute: Mehr Flexibilität und Informationsvielfalt durch feinere Granularität 54 Früher/Heute: Ineffiziente, ältere Strukturen zur Bereitstellung mehrere Granularitätsebenen ........................................................................................... 54 Einmalige, normalisierte Tabellen der Warehouse – Schicht versorgen und synchronisieren unterschiedliche Data Marts mit verschiedenen Sichten ......... 55 Technische Optimierungen der Datenbank für das Starschema gegenüber dem Snowflake, hier im Beispiel die potentiellen Joins zwischen den Tabellen ........ 56 Auslagern von häufig genutzten Attributen einer Dimension in eine zweite schafft Übersichtlichkeit und u. U. auch eine bessere Abfrageperformance ................. 57 Auslagern von operativ genutzten Attributen (z. B. Adressdaten) in eine von der Dimension abhängigen Tabelle (1:1 Kardinalität) .............................................. 58 Unterschiedliche Verwendung von Stammdatenschlüsseln in verschiedenen Anwendungen und die Notwendigkeit der Umschlüsselung .............................. 59 Kandidaten für Bitmap – Index im Starschema ......................................................... 60 Schlüsselbildung im Starschema ............................................................................... 61 Auf mehrere Sätze verteilte Informationen ................................................................ 61 Alle Informationen sind in einem Satz konzentriert ................................................... 62 Wegfall von Summentabellen spart ETL - Schritte und schafft mehr Flexibilität ....... 63 Erstellung von aggregierten Sichten auf der Basis von granularen Faktendaten und Bereitstellung für unterschiedliche Zielgruppen ................................................. 64 Große Faktentabellen sind im Data Warehouse nur einmal vorhanden ................... 65 Das multidimensionale Modell hält Abfrageergebnisse bereits vor. Auf der Basis dieser Ergebnisse können leicht und flexibel weitere Analyseschritte folgen .... 66 Beispiel für eine unbalancierte Hierarchie ................................................................. 68 Lösungsverfahren von unbalancierten Hierarchien bei der relationalen Speichertechnik (Starschema) ........................................................................... 68 Lösungsverfahren von unbalancierten Hierarchien bei der multidimensionalen Speichertechniken (Starschema) ....................................................................... 69 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 160/166 Abgrenzung Einsatzbereiche multidimensionale und relationale Speicherung......... 72 Wechselspiel multidimensionale und relationale Auswertemodelle. Einheitliche Steuerung durch Oracle Warehouse Builder (OWB) ......................................... 73 Transformationsaufgaben im Verlauf der verschiednen Phasen des Warehouse Prozesses ........................................................................................................... 75 Beispielhaftes, mengenbasiertes Prüfverfahren mit CASE ....................................... 78 Prüf- und Kennzeichnungsverfahren in der Stage - Schicht ..................................... 79 Verfahren zur Erkennung von Änderungen ............................................................... 79 Normalisierungsschritt beim Wechsel Stage – Schicht nach Warehouse - Schicht . 80 Umwandeln normalisierter Strukturen zu denormalisierten Dimensionen ................ 82 Ableitung einer Dimension aus normalisierten Modellen durch Lookups und Generierung von künstlichen Schlüsseln ........................................................... 83 Heranziehen von Referenzinformationen im SET Based – Verfahren ...................... 83 Zweischritt – Ladeverfahren. 1. Schritt Aktualisieren Dimensionstabelle, 2. Schritt Key Lookup zum Umschlüsseln von Business Key zu künstlichem Schlüssel .. 85 4 Ebenen der Datenflusssteuerung im Data Warehouse .......................................... 87 Ladeläufe kapseln ihre Logik ..................................................................................... 87 Direktes Aufsetzen der Data Marts auf die operativen Systeme ............................... 89 Einsatz einer zentralen Warehouse Schicht .............................................................. 90 Einsatz einer zentralen Warehouse Schicht und Zusammenfassen der Data Marts 90 Data Mart - übergreifende Wiederverwendung von Dimensionen und Fakten (unternehmensweit eingesetztes 3 Schichtenmodell) ........................................ 92 Darstellung der unterschiedlichen Schemata in dem Modell für mehrfach genutzte Dimensionen und Fakten ................................................................................... 93 Arten und Verwendungen von Metadaten im Data Warehouse ................................ 96 Ableitung von Warehouse – Dokumentation aus dem Warehouse – Entwicklungsvorgang ......................................................................................... 96 Aktualisierungsinformationen im Ladevorgang ......................................................... 98 Klassische Lösung: Metadaten sind über verschiedene Werkzeuge verteilt ............ 98 Modernes Szenario mit einer einheitlichen Metadaten - Verwaltung ........................ 99 4 – Ebenenkonzept von “toolneutralen – Metadaten - Repositories“ ...................... 100 Einordnung der unterschiedlichen Warehouse – Verwendungsarten gegenüber Latenzzeit und Datenart ................................................................................... 103 Einordnung ODS ...................................................................................................... 104 Datendurchlauf Realtime – Verfahren mit Loop Back ............................................. 107 Lastübernahme von ausgefallenem Rechnerknoten durch verbleibende Knoten in einem RAC – Clusterverbund ........................................................................... 109 Die Daten müssen direkt an der Speicherstelle geschützt sein, nicht in den Frontends ......................................................................................................... 111 Pollendes Near - Realtime Szenario mit Loop Back Aktion .................................... 112 Ausnutzen der Materialized Views mit dem Auslesen der View Logs zum ständigen Aktualisieren der Berichte ................................................................................ 113 Historisierung in der Warehouse Schicht führt zu vielen Tabellen und einer komplexeren Verwaltung .................................................................................. 115 Historisierung in der Data Mart Schicht vereinfacht das Gesamtverfahren, mach aber das Lesen für Benutzer schwerer ..................................................................... 116 Historisierungsverfahren .......................................................................................... 116 Vorkommen von Berichten mit unterschiedlichen Zeitspannen .............................. 118 Teuere Ausbaureserven bei großen Rechnersystemen .......................................... 120 Neben der Datenintegration auch kostenschonende Hardware – Integration durch RAC Technologie ............................................................................................. 120 Zentralisierte Bereitstellung von geclusterter Hardware für alle Daten- und Funktionsbereiche im Data Warehouse. Real Application Cluster Verbund. ... 121 Aufwendige klassische Variante mit separatem ETL – Server und Standalone Engine – Programm. Die Datenbank wird von außen bearbeitet. .................... 122 Heute möglich: Wegfall separater ETL – Server und ETL – Integration in der Datenbank ........................................................................................................ 122 Aufwendige Aufbereitung von Analysen in den Front Ends .................................... 123 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 161/166 Sparen von Hardware für die sog. „Middle Tier“ bei Vorbereitung von Standardabfragen innerhalb der Datenbank ................................................... 123 Wegfall von separater Hardware für separate Auswerteprogramme ...................... 124 Ressourcenbereitstellung je nach Bedarf entweder für operative oder dispositive Anwendungen................................................................................................... 125 Eine Datenbank und zwei Rechner in einem Clusterverbund (RAC) bietet mehr Flexibilität bei der Nutzung operativer und dispositiver Daten. Stammdaten sind gemeinsam nutzbar. ......................................................................................... 125 Read-only Tablespaces müssen nicht gesichert werden ........................................ 130 Read only Tablespaces und Partitioning ergänzen sich ......................................... 130 Zusammenfassung der Warehouse Architektur ...................................................... 132 Copyright © 2005 by Oracle Corporation. All rights reserved Data Warehouse Referenzarchitektur 162/166 14.6 Index (Herkünfte und Auswirkungen, 33 1:1 Beziehung, 61 1:1 Kardinalität, 62 1:1 Kopiervorgänge, 29 1:1 Ladeaktivitäten, 53 1:1 Laden, 39 1:1 Lesen, 41 1:1 Transformationen, 37 1:N Kardinalität, 62 2. Generation, 40 24/7-Verfügbarkeit, 110 3 – Schichten Architektur, 25 3 – Schichtenarchitektur, 32 3 – Schichtenmodell, 30 Abfrageoptionen, 23 Abfrageperformance, 57, 78 Acta, 40 Adressdaten, 62 Aggregationen, 58 Aggregattabellen, 48 Aktualität der Berichte, 101 Aktualitätscheck, 101 Analysemodell, 25, 26 Analysewerkzeuge, 11 Analytical Workspace, 76 Anwenderhilfen, 99 Anwendungsneutralität, 21 Anzahl an Prozessoren, 48 Application Server, 124 Archive Log, 134 Archive Logs, 141 Ascential, 40 Asynchrone Kopplungselemente, 110 Attributtyp, 104 Auswertemodellen, 23 Auswerteschicht, 59 Auswertewerkzeuge, 61 Auswertewerkzeugen, 63 Automatisierung, 14, 91 Backup, 132, 133 Balanced Scorecard, 11 BAM, 16 Batch, 116 Benutzergruppen, 11 Benutzerstatement, 25 Berichtsschema, 25 Berichtsverifizierung, 101 Berichtszeiten, 14 Betriebshandbuch, 101 Bewegungsdaten, 69 Beziehungstyp, 104 Bitmap – Indizierung, 60 BPEL, 110 Browsen, 60 Bulk – Load – Mechanismen, 126 Copyright © 2005 by Oracle Corporation. All rights reserved Business Activity Monitoring, 16 Cache, 127 CASE, 40, 81 Checkoptionen, 44 Cluster, 42 Clusterverbund, 130 Cobolprogramm, 40 Code – Attribute, 61 Commit, 42, 51, 52 Conectors, 110 Constraintprüfung, 44 Constraints, 53, 85 Corporate Performance Mansagement, 16 Corrupt Block Detection, 134 CPM, 16 CRM – Systeme, 14 CTAS, 44, 82 Cube, 31 Cursor, 44 CWM, 74 Data Mart – Schicht, 137 Data Marts, 59 Data Mining, 17 Data Pump, 47 Database Links, 47 Datafile, 135 Datenadministration, 28 Datenanalyse, 25 Datenänderung, 67 datenbankbasierten Ladens, 21 Datenbanksprache, 38 Datenbeschaffungsprozesses, 34 Datenflussmodell, 25 Datenflusssteuerung, 91 Datenkonsistenz, 65 Datenmanagement, 48 Datenqualität, 25 Datenschutz, 115 Deltadaten, 53 Deltadatenerkennung, 83 Denormalisieren, 79, 84 Denormalisierungsschritt, 85 Denormalisierungsschritte, 31 Dimensional Table, 60 Dimensionshierarchien, 75 Dimensionstabelle, 63 dispositiven Datenbeständen, 31 Distinct, 84 Dokumentation, 25 DOP, 145 Downtime Free Backups, 134 Drill Across, 65 Dynamisches SQL, 44 Einführung, 25 Data Warehouse Referenzarchitektur Einheitliche Sprachmittel, 39 Einzelabfragen, 14 ENFORCED, 142 Engine, 40 Entprivatisierung, 14 Entwicklungsmedium, 99 Entwicklungswerkzeugen, 25 ETL – Aufwende, 37 ETL – Engine, 124 ETL – Integration, 127 ETL – Server, 127 Event, 114 Extents, 145 External Tables, 49, 53 Extraktion, 53 Fachmitarbeiter, 68 Faktentabelle, 58, 65 Fast Refresh, 85, 110 Fehlerprotokollierung, 44 Feste Kennzahlen, 21 FK/PK – Beziehungen, 59 Flexibilität, 24 Flexibilitätsvorteile, 40 Flexible Auswertemodell, 21 FTP, 114 Funktionsbereichen, 31 geschachtelte Transformationen, 51 Glossare, 101 Granulare Daten, 64 granulare Faktendaten, 68 granularen Daten, 17, 76 granularen Faktendaten, 68 Granularisieren, 20 Granularisierung, 53, 58 Granularität, 58 GRID, 126 Gridfähigkeit, 42 Gruppierende Transformationen, 37 Hardware - Nutzung, 124 Hardwarebedarf, 42 Herkunftsanalyse, 28 Hierarchielevel, 61 Historisierungsverfahren, 120 Hochverfügbarkeit, 113, 132 Hub and Spoke, 34, 50 Hub and Spoke – Architektur, 33 Indizes, 45, 53 Informatica, 40 Informationsbausteinen, 20 Informationsbedarf, 25 Informationsbedarfsanalyse, 25, 29 Informationsplan, 29 Informationsversorgungsplan, 25 Join, 37 Join – Partitioning, 60 Kardinalität, 37 Kennzahlen, 23, 29, 60 Kennzahlenlisten, 23 Copyright © 2005 by Oracle Corporation. All rights reserved 163/166 Kennzahlenzugriffskonzept, 26 Kennzeichnung, 82 Komplexe Abfragen, 74 Konsolidieren, 80 Konzept, 25 Kostenfressern, 29 Kostenstellen, 71 Künstliche Schlüssel, 63 Label Security, 56 Ladeprozess, 90 Ladewerkzeugen, 40 LAG, 41 Latency, 14 Latenzzeit, 107 LEAD, 41 Lebensdauer, 20 Lookup, 85, 86 Lookups, 44, 46 Loop Back, 107 Loopback – Mechanismus, 112 Mandantenfähigkeit, 56 manuellen Tätigkeiten, 140 Mappinglevel, 90 Mappingmodell, 25, 26 Materialized Views, 37, 44, 57, 66 Mehrschichtenmodell, 19 Mengen – basierte Transformationen, 44 mengenbasiert, 46 mengenbasiertes Prüfverfahren, 82 Mengenoperationen, 44 MERGE, 83 Merkmale von Geschäftsobjekten, 22 Metadaten, 99 Metadaten Repository, 37, 104 Middle Tier, 128 MINUS, 41 Minutenzyklus, 116 Mission Statement, 25 Modellflexibilität, 21 MOLAP – Systeme, 71 multidimensionale Datenbank, 69 Multidimensionales Modell, 22 multidimensionales Speichern, 34 Namenkonvention, 28 Near Realtime, 107 Netzlast, 50 Neutralität, 99 Nologging, 133 Normalisieren, 79, 84 Normalisierte Strukturen, 57 Normalisierung, 53 Normalisierungs, 31 NOT NULL, 80 NULL, 80 Nutzenpotentiale, 140 Nutzergruppenplan, 26 Objektmodell, 25, 26 Data Warehouse Referenzarchitektur Objekttyp, 104 ODS, 107 ODS – Schicht, 85, 137 OLTP -Systeme, 31 operational Data Store, 31 Operational Data Store, 107 Operational Data Stores, 55 Operationalisierung, 15, 16 Operativ genutzte Daten, 61 Operative Bewegungsdaten, 119 optimistischen Verfahren, 88 Oracle Warehouse Builder, 76, 77 ORDER BY Klausel, 142 Orphans, 53 OUTER JOIN, 41 OWB, 76, 81 Parallel Hierarchien, 62 PARALLEL_AUTOMATIC_TUNING, 48 Parallelisierung, 42 Partionen, 78 Partition Exchange, 47 Partition Exchange and Load, 135 Partition Exchange And Load, 78 Partitionen, 77, 78 Partitionierung, 48, 65 Partitioning, 85 PEL, 47 Performance, 42, 44 pessimistische Verfahren, 88 physisches Speichermodell, 70 PL/SQL – Schleife, 46 Plantabelle, 144 Planung, 18 Platinum, 40 Platten, 47, 141 Primary Keys, 62 Process Reengineering, 15 Produktgruppenhierarchien, 71 Projektaufwand, 13 Projektinkrement, 25 proprietär, 20 proprietären Toolsprachen, 38 Protokollieren, 80 Prozessanalyse, 25 Prozesse, 103 Prozesslevel, 90 Prozesssteuerung, 48 Prozessunabhängigkeit, 18 Prüfen, 80 Prüflogik, 37 Prüfschicht, 137 Pufferschicht, 31 Quellenanalyse, 101 Quellenmodelle, 25 query_rewrite, 142 RAC, 97, 124 RAC – System, 138 Copyright © 2005 by Oracle Corporation. All rights reserved 164/166 RAID, 141 Rankingabfragen, 128 Read Only Tablespace, 135 Real Application Cluster, 97, 124 Real Application Cluster Verbund, 126 Realisierung, 25 Realtime – Verfahren, 116 Recovery, 78, 132, 136 Referenzarchitektur, 8 Referenzdaten, 54 Referenzprüfungen, 44 relationale Speichermodell, 74 relationalen Speichertechnik, 72 Remote – Quellen, 38 Repository, 28 Rewrite, 142 RMAN, 134, 136 ROI, 24, 34 Rollback Segmente, 141 Runtime –Metadaten, 42 Satzübergreifende Konsistenz, 65 Scheduling, 66 Schnittstellenabstimmungen, 15 Scriptsprache, 101 Security, 42 Selektive Abfragen, 78 Semantisches Sprachmittel, 99 Separate Datenhaltungen, 57 Separate Faktentabellen, 65 Serverbasiertes, 16 SET Based, 88 SGA, 145 Sicherheitsmassnahmen, 115 Simulation, 18 Skalierbarkeit, 24 Skalierungsanforderungen, 48 Slowly Changing Dimensions, 55 Sparsity, 71, 75 Split, 37 SQL, 38 SQL Loaders, 49 Staging Area, 31, 53 STALE_TOLERATED, 142 Stammdaten, 53, 54 Stammdatenschlüsseln, 64 Stand By – Datenbank, 115 Standardberichte, 36, 76 Standardberichten, 57 Standardlösungen, 24 Starschema, 21, 31, 57, 59 Steuerung operativer Prozesse, 106 Stored Procedures, 44 Streaming -Techniken, 110 Strukturänderungen, 39 strukturierte Sichten, 21 Stücklisten, 71 Sub Partioning, 78 Data Warehouse Referenzarchitektur Sub Partitioning, 142 Summentabellen, 29, 66 systemfabrik, 40 taktische Ebene, 14 Technik – Neutralität, 21 Teilprozessauswahl, 25 Templates, 28 Temporäre Tabellen, 53 temporären Tabellen, 48 Testdatengenerator, 114 textliche Gleichheit, 67 Transformationen, 32, 37 Transformationslast, 50 Transformationslevel, 90 Transformationsprozesse, 44 Trouble Free Backup, 134 TRUSTED, 142 Umschlüsseln, 87 Umschlüsselung, 64 UNION, 41 Unternehmenshierarchien, 15 Unternehmensreporting, 15 Copyright © 2005 by Oracle Corporation. All rights reserved 165/166 Verbindungssoftware, 110 Verdichtungsstufen, 58 Verwaltungsdaten, 99 Verwaltungsinformationen, 105 Vorhersehbare Auswertungen, 57 Wandlungsflexibilität, 31 Warehouse – Entwicklungswerkzeug, 101 Warehouse – Schicht, 85 Warehouse Handbuch, 100 Warehouse Life Cycle Werkzeug, 25 Warehouse Schicht, 137 Wartung, 25 Wiederverwendung von Dimensionen, 96 Workflow, 48, 66 Würfel, 31 Würfelstruktur, 57 XML –Daten, 41 Zeitdimension, 62 Zielgruppen, 68 Zugriffsschutz, 115 Data Warehouse Referenzarchitektur 166/166 14.7 Kommentare und Ergänzungen: Bitte direkt an den Autor: Alfred Schlaucher Oracle Deutschland GmbH Notkestrasse 15 22607 Hamburg 040 – 89091 - 132 [email protected] Hier auch weitere Informationen zu verschiedenen Data Warehouse Themen und diverse Workshops. Copyright © 2005 by Oracle Corporation. All rights reserved