Datenverarbeitung SS 06
Werbung

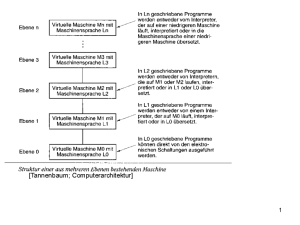
Datenverarbeitung SS 06 Daten sind Buchstaben, Symbole und Ziffern; alle Arten von Nachrichten oder Informationen, die sich maschinell verarbeiten lassen. Nachrichten-Informationen: die abstrakte Information wird durch die konkrete Nachricht mitgeteilt. Information ist Sachverhalt und Vorgang oder Form + Inhalt Daten werden durch Analyse und Aufbereitung (ein Foto) in Information überführt. Informationen sind Angaben über Sachverhalte und Vorgänge. Die Gesamtheit von Informationen und deren Zusammenhänge wird als Wissen bezeichnet. Zur Erinnerung: Daten stellen maschinell verarbeitete Informationen dar. Informationen: Symbole, Ziffern (der PC liefert uns diese Daten und der Mensch interpretiert diese). Nachrist ist der Transport von Daten (Foto). Symbole sind z. B. Pixel beim Foto. Im Großen interpretieren wird das Bild (viele Pixel). In solchen Bildern können auch Codes versteckt sein, welche mit bloßem Auge nicht zu erkennen sind. DV/EDV = Sammelbegriff für die Erfassung und Manipulation von Daten durch elektronische Maschinen (Computer) Verwaltung von Stammdaten: - zustandsorientierte Daten, zur Identifizierung, Klassifizierung und Charakterisierung von Sachverhalten - stehen unverändert über einen längeren Zeitraum hinweg zur Verfügung Verarbeitung von Änderungsdaten (engl.: change data) - abwicklungsorientierte Daten - bewirken fallweise Änderung (Berichtigung, Ergänzung, Löschung) von Stammdaten - auch zur Änderung von Stammdaten (engl.: updating) - Stammdaten (Telefonnummer) Änderungsdaten (gewählte Telefonnummern) Manuelle Informationsverarbeitung (etwas aufschreiben) Rechnergestützte Informationsverarbeitung (durch Drücken der Tasten geben wir dem PC vor, was er machen muss, den Rest macht er selbst – es erscheint auf dem Bildschirm) Hilfsmittel zur Informationsverarbeitung: Manuelle Informationsverarbeitung – durch den Menschen Rechnergestützte Informationsverarbeitung – Rechner führt Informationsverarbeitungsaufgaben weitgehend selbsttätig durch Vorgabe der Anweisungen: Algorithmus: Unter einem Algorithmus versteht man allgemein eine genau definierte Handlungsvorschrift zur Lösung eines Problems oder einer bestimmten Art von Problemen. (Auszug aus Wikipedia) Programm: Eine zur Lösung einer Aufgabe vollständige Anweisung an einen Rechner Programmieren: der Vorgang der Erstellung einer derartigen Anweisung Programmiersprache: einer der Maschine verständlichen Sprache zur Programmierung Bsp: Newton-Algorithmus: (q² = n) q² q=1 1 q=5 25 q = 3,4 11,56 q = 3,0235 9,14 n:q 9 1,8 2,647 2,98 (q + n : q) : 2 5 3,4 3,0235 3,0175 Ein Approximationsalgorithmus ist in der Informatik ein Algorithmus der ein Optimierungsproblem näherungsweise löst. Viele Optimierungsprobleme lassen sich mit exakten Algorithmen nicht effizient lösen. Für solche Probleme kann ist es sinnvoll sein, wenigstens eine Lösung zu finden, die einer optimalen Lösung möglichst nahe kommen. (aus Wikipedia) lesen: Algorithmus Ziel der technischen Informationsverarbeitung: - Rationalisierung - Bewältigung großer Datenmengen - Beschleunigung von Geschäftsprozessen - Verbesserung von Qualität und Service - Unterstützung der Planung, Steuerung und Kontrolle - Umfangreiche, komplizierte Berechnungen (OR) - Ermöglichung neuer Organisationsformen - Groupware (Software, die Zusammenarbeit erleichtern, z. B. email, chat), elektronischer Datenaustausch (EDI) - Strategische Wettbewerbsvorteile Arten von Daten: Bilder, Töne, Text, Zahlen, Video-, Audiostreams Codierung und Speicherung: - Daten werden zur Verarbeitung digitalisiert und codiert - Technisch werden Daten als Zeichen in einer Datei oder als Teil einer Datenbank gespeichert - Datenbank versucht einen Teil der Realität über ein abstrahierendes Datenmodell abzubilden (Realität -> ER-Modell -> relationales Modell -> Access) Begriffe zur Darstellung der Daten im Computer: - Code: Vorschrift zur Abbildung eines Zeichenvorrats in einem anderen Zeichenvorrat (Unter einem Code wird eine Vorschrift verstanden, in der Symbole einer Darstellung in solche einer anderen übertragen werden. = Wikipedia) - Zeichenvorrat: Alphabet, Menge der bei einem Code zur Verfügung stehenden Symbole - Binärcode: Zeichenvorrat mit 2 Werten (Binärcode ist die allgemeine Bezeichnung für einen Code, mit dem Nachrichten durch Sequenzen von zwei verschiedenen Symbolen (zum Beispiel 1/0 oder wahr/falsch) dargestellt werden können (Wikipedia) - Zahlensysteme: Ein Zahlensystem wird zur Darstellung von Zahlen verwendet. Eine Zahl wird dabei nach den Regeln des Zahlensystems als Folge von Ziffern dargestellt. (Wikipedia) Digitale Daten: Buchstaben, Ziffern, Interpunktionszeichen, Steuerzeichen, Farbpunkte von Bildern, akustische Signale Analoge Daten: Thermometer, Rechenschieber, Bildschirm 8 Zeichen = 8 bit = 1 byte Digitalisierung – Codierung Überführung der analogen Darstellung in die digitale Darstellung: Verfahren: - Text: Code verwenden -> 2 Zeichen -> bisher - Bild: Auflösung in Bildpunkte (Attribute: Helligkeit, Farbe, Position) oder Vektoren (Attribute: Startpunkt, Endpunkt, Ausprägung) - Ton: je nach gewünschter Qualität so und sooft pro Sekunde abtasten - Film: Behandelt wie Einzelbilder, zusätzlich Zeitinformation -> DivX – Algorithmus wird immer besser, stark komprimieren, bessere Qualität, weniger Kompressionsartefakte wie früher - Bewegung: Raumkoordination und Zeitkoordinaten Zeichenvorräte und Bits und Bytes Zeichenvorräte: - ASCII, Griechisch, Kyrillisch,… - ASCII (American Standard Code for Information Interchange) ist eine Zeichencodierung. Die Zeichen umfassen das lateinische Alphabet in Großund Kleinschreibung, Ziffern, einige Satzzeichen und Steuerzeichen. Der Zeichensatz entspricht weitgehend der Tastatur einer Schreibmaschine für die englische Sprache. In Computern und anderen elektronischen Geräten, die Text darstellen, wird dieser in der Regel gemäß ASCII codiert. Weiterhin sind die meisten erweiterten Zeichencodierungen kompatibel zu ASCII. (Wikipedia) - Blindenschrift, Morse…. Technische Darstellung: - Binärsystem, also 2 Zeichen - Ein Bit ist die kleinste Info-Einheit - Wortlänge, also wie viele Zeichen fassen wir zu einem Wort zusammen: Byte als ein Wort aus 8 Bit! - Mit einem Bit lassen sich zwei Zustände darstellen: Aus=0 und Ein=L KLAUSUR -> Ausrechnen!!! Die Zahl der abbildbaren Zustände ergibt sich als: Zustände = Zeichenzahl Wortlänge z. B. 64 = 4³ 256 = 28 1.000.000 = 7 Zeichen lesen: Speicherkapazität.pdf! Codeeigenschaften I - Degenerierter Code (braucht mehr Speicherplatz, informationstechnisch nicht möglich), genetischer Code (mehr Sicherheit falls Schreibfehler) - Hamming-Abstand: Das Minimum aller Abstände zwischen den Wörtern innerhalb des gültigen Codes (Mindestabstand jedes sinnvollen Codes = 1) - EDC (Error Detection Code) und ECC (Error Correction Code): Für jeden Code mit Hamming-Distanz h gilt: es können jeweils h-1 Bit Fehler erkannt werden und es können jeweils h-2 bit Fehler korrigiert werden - Entropie: Entropie ist grob gesagt ein Maß für die Menge an Zufallsinformationen, die in einem System oder einer Informationsfolge steckt. lesen: genetischer Code lesen: Hamming-Abstand – Codierung.xls Hamming-Abstand Parität ermitteln: Summe Summe mod 2 (Rest) 010 1 1 101 2 0 111 3 1 Rechenweg 1:2 = 0 Rest 1 2:2 = 1 Rest 0 3:2 = 1 Rest 1 Wenn Übereinstimmung bis 4. Stelle bei Übertragung ist die Übertragung korrekt. Rechenweg ist bekannt bei Empfänger und Sender! Mehr Daten übermitteln, Fehler korrigieren => Datensicherheit erhöht sich. Kanalcodierung: Wie viele Daten müssen „umsonst“ übertragen werden, um Fehler korrigieren zu können? Die Kanalkodierung oder Vorwärtsfehlerkorrektur ist eine Methode in der Nachrichtentechnik, um digitale Daten bei der Speicherung oder bei der Übertragung über gestörte Kanäle gegen Bitfehler zu schützen. In Ergänzung zur Kanalkodierung werden die Verfahren der Quellenkodierung benutzt, um ein Signal so zu komprimieren, dass es möglichst effektiv übertragen werden kann, also eine möglichst geringe Bandbreite benötigt. Die Kodierungstheorie beschäftigt sich mit den mathematischen Grundlagen von Kanalkodierung und untersucht mit algebraischen Methoden die Eigenschaften der Codes. (Wikipedia) Unicode nach ISO: theoretisch 32 bit, es werden aber nur 21 benötigt! SGML (engl. Standard Generalized Markup Language) ist eine Metasprache, mit deren Hilfe man verschiedene Auszeichnungssprachen (engl. markup languages) für Dokumente definieren kann. SGML ist ein ISO-Standard (Wikipedia) lesen: Nyquist-Shannon-Abtasttheorem Code = Vorschrift für die eindeutige Zuordnung eines Zeichenvorrats zu denjenigen eines anderen Zeichenvorrats Probleme: Sonderzeichen, Unterschiedliche Codes je nach Rechnerwelt, Silbenschrift Stichwörter: Unicode, Syntaxprüfungen – Form und Inhalt, Auszeichnungssprachen (html, xml) UTF (Abk. für Unicode Transformation Format) beschreibt Methoden, ein Unicode-Zeichen auf eine Folge von Bytes abzubilden. Für die Repräsentation der Unicode-Zeichen zum Zweck der elektronischen Datenverarbeitung gibt es verschiedene Transformationsformate. In jedem der Formate lassen sich alle 1.114.112 im Unicode-Standard enthaltenen Zeichen (Codepoints) darstellen. Auch lässt sich jedes dieser Formate verlustfrei in ein anderes UTF-Format konvertieren. Die verschiedenen Formate unterscheiden sich hinsichtlich deren Platzbedarf auf Speichermedien (Speichereffizienz), dem Kodierungs- und Dekodierungsaufwand (Laufzeitverhalten) sowie in ihrer Kompatibilität zu anderen (älteren) Kodierungsarten. Während beispielsweise einige Formate sehr effizienten Zugriff (Random Access) auf einzelne Zeichen innerhalb einer Zeichenfolge (String) erlauben, gehen andere sparsam mit Speicherplatz um. Daher ist bei der Auswahl eines bestimmten Unicode-Transformationsformats das für das vorgesehene Anwendungsgebiet geeignetste zu bestimmen. (Wikipedia) Verarbeitungskette: Eingabe: Tastatur, Scanner, Lesegerät Speicherung: Datei Verarbeitung: Textverarbeitung (Word, Lotus, Corel), Editoren (XML-Edit, Notepad) Ausgabe: Drucker, Datei/Datenbank, Bildschirm Zahlen Zahlen sind mit Ziffern (Zeichen) dargestellte Rechengrößen Ganzzahlen – Gebrochene Zahlen – Sonderdarstellungen Ganzzahlen: schnelles Rechnen, Darstellung im Dualzahlsystem (wichtige Sonderformen: Datum, Uhrzeit) Kommazahlen: „genaues Rechnen“, Exponentialdarstellung, hohe Rechenleistung Verarbeitungskette Zahlen: - vergleichbar Verarbeitungskette Text, da i.d.R. Ziffern als Zahldarstellung ein- und ausgegeben werden - Betonung der Zahlinterpretation, z. B. Rechnen in Tabellen, bzwl. Spezialprogramme (z. B. Tabellenkalkulationsprogramme, Statistikprogramme, Buchhaltungsprogramme…) Eingabe: Mikrofon, Mischpult Verarbeitung: Spezialprogramme (Umwandlung, Mischen), Brennprogramme Ausgabe: Lautsprecher, Audioanlage, Datei, Schnittstelle (Synthesizer, Mediengerät) Schall – Ton – Musik Eine Schallwelle wird durch die Amplitude und die Frequenz bestimmt. Das heißt, je höher die Amplitude, desto lauter und je größer die Frequenz, desto höher ist der Ton. FFT – Fast Fourier Transformation: Ziel: n Daten im Zeitbereich auf n Daten im Frequenzbereich abbilden Ohne FFT kein JPEG! KEIM MP3! Die schnelle Fourier-Transformation (englisch fast Fourier transform, daher meist FFT abgekürzt) ist ein Algorithmus zur schnellen Berechnung der Werte einer diskreten Fourier-Transformation (DFT). Die Beschleunigung gegenüber der direkten Berechnung beruht auf der Vermeidung mehrfacher Berechnung sich gegenseitig aufhebender Terme. Der Algorithmus wird James W. Cooley und John W. Tukey zugeschrieben, die ihn 1965 veröffentlichten. Genaugenommen wurde eine Form des Algorithmus jedoch bereits 1805 von Carl Friedrich Gauss entworfen, der ihn zur Berechnung der Flugbahnen der Asteroiden Pallas und Juno verwendete. Darüber hinaus wurden eingeschränkte Formen des Algorithmus noch mehrfach vor Cooley und Tukey entwickelt, so z.B. von Good (1960). Nach Cooley und Tukey hat es darüber hinaus zahlreiche Verbesserungsvorschläge und Variationen gegeben, so etwa von Georg Bruun, C. M. Rader und Leo I. Bluestein. Analog kennt man auch für die diskrete inverse Fourier-Transformation einen schnellen Algorithmus (inverse FFT - iFFT) Es kommen bei der iFFT idente Algorithmen mit anderen Koeffizienten in der Berechnung zur Anwendung. Klassifikation von Bildern: Farbtiefe (Anzahl der Farben in einer Abbildung): schwarz-weiß-/Grauton- und Farbbilder Dimensionen: zweidimensionale und dreidimensionale Bilder Zeitabhängigkeit: feste (statische) und bewegte (dynamische) Bilder Repräsentationsform: Pixelgrafik und Vektorgrafik Gängige Größen: 16 Bit oder 32 Bit /-> Umrechnung 65.536 Farben (216) 8 Bit pro Grundfarbe Darstellung von Festbildern: Pixelgrafik: - Zusammenhängendes Bild, Bildpunkte haben eine bestimmte Größe - Bilder als Matrix von Punkten - Jeder Punkt hat Farb- oder Dichtewert Jeder Punkt kann separat bearbeitet werden Je höher die Auflösung, desto mehr Speicher nötig Es wird ein Ausschnitt vergrößert, unter Verlust der Qualität Rastergrafik, auch Pixelgrafik, englisch Bitmap oder Pixmap, ist eine Methode zur Beschreibung zweidimensionaler Bilder in Form von Daten. Rastergrafiken bestehen aus einer matrixförmigen Anordnung von Pixeln, denen jeweils eine Farbe zugeordnet ist. Die Hauptmerkmale einer Rastergrafik sind daher die Breite und die Höhe in Pixeln, auch Auflösung genannt, sowie die Farbtiefe. Die Bearbeitung, teils auch die Erzeugung, von Rastergrafiken fällt in den Bereich der 2D-Computergrafik. Eine andere Art der Beschreibung von Bildern sind Vektorgrafiken. Anwendungen Zweifarbige Pixelgrafiken/Rastergrafiken eignen sich zur Repräsentation komplexerer Bilder wie Fotos, die nicht mit Vektorgrafiken beschreibbar sind. Rastergrafiken können sowohl aus vorhandenem Material – etwa mit einem Scanner oder einer Digitalkamera – digitalisiert oder mit Bildbearbeitungssoftware erstellt werden. Letztere erlaubt auch Bildbearbeitung. (Wikipedia) Vektorgrafik: - Mathematisch definierte Objekte - Objekte bestehen aus Linien und/oder Kanten und Füllungen - Bildobjekte voneinander unabhängig bearbeiten - Speicherkapazität steigt mit Anzahl von Objekten Eine Vektorgrafik ist ein zwei- oder dreidimensionales Computerbild, das aus grafischen Primitiven wie Linien, Kreisen und Polygonen zusammengesetzt ist. Um beispielsweise das Bild eines Kreises zu speichern, benötigt eine Vektorgrafik zumindest zwei Werte: die Lage des Kreismittelpunkts und den Kreisdurchmesser. Neben den intrinsischen Parametern (Form und Position) der Primitiven werden eventuell auch die Farbe, Strichstärke, diverse Füllmuster und weitere das Aussehen bestimmende Daten angegeben. Vektorgrafiken können im Gegensatz zu Rastergrafiken ohne Qualitätsverlust stufenlos skaliert und verzerrt werden, etwa mittels homogener Koordinaten. Außerdem bleiben bei Vektorgrafiken die Eigenschaften einzelner Linien, Kurven oder Flächen erhalten und können auch nachträglich noch verändert werden. Vektorgrafiken sind ungeeignet für die Darstellung von komplizierten Bildern wie Fotos, da diese sich kaum mathematisch modellieren lassen. Im Extremfall müsste jeder Bildpunkt durch eine Fläche wie etwa ein Quadrat modelliert werden, wodurch der Nutzen der Vektorgrafik verloren ginge. Heutige Bildschirme werden ausschließlich mit Rastergrafiken angesteuert. Daher müssen Vektorgrafiken vor der Ausgabe umgewandelt werden; dies nennt man Rasterung. Ein vektororientiertes Ausgabegerät ist der Plotter. Bewegte Bilder: Aneinanderreihung von Festbildern Maß: Einzelbilder pro Sekunde bzw. frames per second (fps) oder bps = Bildrate Untergrenze 14 Bilder/Sekunde Je höher die Bildrate, desto besser die Qualität Fast immer Kompression erforderlich, da „speicherfressend“ Animation: Anzeige aufeinander Folgender, sich leicht ändernder Bilder erweckt den Eindruck von Leben und Bewegung in Cartoons, Zeichnungen, Gemälden und sonstigen künstlichen Objekten. Darstellung bildlicher Information: - Verarbeitung von Bildern entspricht im grundsätzlichen dem technischen Ablauf der Verarbeitung von Tönen - Eingabegeräte - Ausgabegeräte - Bilddatenstruktur (Darstellungselemente eines Bildes (Punkte, Linien, Kurven) und die Beziehung zwischen diesen) - Hoher Speicher- und Bandbreitenbedarf Verarbeitung von Pixelgrafiken - Bildauflösung: bestimmt erreichbare Feinzeichnung von Details, je mehr Punkte zur Repräsentation eines Bildes verwendet werden, desto höher ist die Auflösung und damit die Klarheit der Darstellung, Maßgröße ppi - Geräteauflösung: Beschreibt die gerätespezifische, fest vorgegebene Eingabe- oder Ausgabequalität, das heißt, wie klein die Punkte sind, die ein Gerät erfassen oder ausgeben kann, Maßgröße bei Scannern und Druckern = dpi Bildauflösung eines Bildschirms: 1000 Bildpunkte pro Zeile = 80 Pixel pro inch Der Drucker hat eine wesentlich höhere Auflösung als der Bildschirm. 1-Bit-Farbtiefe: Jeder Bildpunkt kann nur eine von zwei möglichen Farben haben 8-Bit-Farbtiefe: Jeder Bildpunkt kann eine von 256 Farben haben, die Teil der Palette sind 24-Bit-Farbtiefe: Jeder Bildpunkt wird durch drei Bytes (Rot-, Grün- und BlauWert) repräsentiert. Jeder Bildpunkt kann eine von 16,8 Millionen Farben haben. Multimedia Multimedia-Systeme integrieren mehrere Eingabe- und/oder Ausgabemedien für schriftliche Daten, Ton und Bild, wobei die Speicherung und synchronisierte Ablaufsteuerung auf einem Rechner erfolgen. Vorteile von Multimedia: - Effizienter Informationsfluss und höhere Aufmerksamkeit durch die gleichzeitige Verwendung mehrere Kanäle zur Informationswiedergabe - Möglichkeit, innerhalb einer Informationsbasis ohne nennenswerte Zeitverzögerung beliebig zu navigieren (Hypermedia, Hyperlinks) - Freie Wahl von Ort, Lernrhythmus, Lerngeschwindigkeit bei Schulungssystemen - Kostenreduktion durch teilweisen Ersatz bestehender Dienste bzw. durch neue Dienste an jedem Ort - Neue Bedürfnisse! Aber müssen z. T. erst entwickelt werden Probleme mit Multimedia-Anwendungen: - Entwicklungszeit und –kosten - Hoher Speicher- /Rechenleistungsbedarf - Breitbandanwendung - Evtl. spezielle Endgeräte nötig - Schneller Wechsel in den Standards - „Multimedia Overload“?? - Rechte / Copyright - Software für Entwicklung / Abspielen Kompression Datenkompression kann erreicht werden durch eine Erhöhung der Darstellungsdichte mittels geeigneter Algorithmen wie: - Lauflängencodierung - Codetransformation (Kleinbuchstaben weglassen -> kürzerer Code) - Inhaltsanalyse (z. B. Funktionssysteme) Vorteile: - verkürzt Übertragungszeiten (Modem) - spart Speicherplatz - nutzt gegebene Bandbreiten besser aus (z. B. Bewegtbild über ISDN) Umsetzung: - eigenständige Programme, sog. Packer (WINZIP) - in Programmen eingebaut - In Übertragungsverfahren (GSM, Video-Codecs) Nachteile: - kostet Rechenzeit - macht Programme komplizierter - zusätzlicher Anwendungsschritt Datenkompression Als Datenkompression oder Datenkomprimierung bezeichnet man die Anwendung von Verfahren zur Reduktion des Speicherbedarfs von Daten bzw. zur Vermeidung von Datenaufkommen, bspw. während der Übertragung von Daten. Die Datenmenge wird reduziert, indem eine günstigere Repräsentation bestimmt wird, mit der sich die gleichen Daten in kürzerer Form darstellen lassen. Diesen Vorgang übernimmt ein Kodierer und man bezeichnet den Vorgang als Kompression bzw. Kodierung. Man spricht von einer verlustfreien Kompression (oder verlustfreien Kodierung), wenn die kodierten Daten nach Anwendung der entsprechenden Dekodiervorschrift exakt denen des Originals entsprechen. Die Anwendung der Dekodiervorschrift bezeichnet man als Dekompression oder Dekomprimierung. Wenn man von einer verlustbehafteten Kompression (oder verlustbehafteten Kodierung) spricht, so meint man damit, dass sich die Daten nicht in jedem Fall fehlerfrei rekonstruieren lassen. (Wikipedia) Verlustfreie Kompression Bsp. Huffmann Ziel: Häufige Zeichen mit kurzen Codewörtern, seltene Zeichen mit längeren Codewörtern codieren – oder : durchschnittliche Codewortlänge L minimieren. Durchschnittliche Wortlänge L über einen Text mit n unterschiedlichen Zeichen ist definiert durch: L = Σ pi * li Algorithmus für Ermittlung des „Codierbaums“: 1. Zeichen zählen, nach Häufigkeit und Alphabet sortieren 2. Jeweils die 2 mit kleinsten Häufigkeiten zu einem Knoten vereinen 3. Solange weiter mit 2., bis Endknoten erreicht Komprimierung/Dekomprimierung: 1. Codebaum erstellen 2. Alle Zeichen gemäß Codebaum bzw. Codeliste codieren => fertig 3. codierten Zeichenstrom über Baum oder Codeliste rückwandeln Anmerkung: Dies kommt dem theoretischen Minimum (vgl. Entropie) sehr nahe. SIEHE: Programm Huffmann-Code! Baum müssen wir zeichnen können! Verschlüsselung Verfahren zur Verschlüsselung der Daten (Nachrichten) zur Geheimhaltung und zur Sicherstellung der Urheberschaft (Authentizität). Einfache Verfahren: Schlüssel muss bekannt sein, also zum Empfänger transportiert werden. Heute übliche Verfahren: 2 oder mehr Teilschlüssel: Öffentlicher und privater Schlüssel (kann jedem zur Verfügung gestellt werden) Verschlüsseln: Verschlüsselte Nachricht an mich: mit meinem öffentlichen Schlüssel verschlüsselt, ich entschlüssele mit meinem Privatschlüssel Unterschrift: Ich unterzeichne mit meinem privaten Schlüssel, jeder kann mit meinem öffentlichen nachprüfen, dass die Nachricht von mir ist. Die Verschlüsselungsfunktion ist bekannt, die Entschlüsselungsfunktion kennt nur der Empfänger. Der Schlüssel ist nur mit extrem hohem Rechenaufwand ermittelbar. Basiert z. B. auf großen Primzahlen. Komprimierung ist keine Verschlüsselung! RSA ist ein Verfahren oder Algorithmus zur Verschlüsselung elektronischer Daten, der verschiedene Schlüssel zum Ver- und Entschlüsseln verwendet, wobei der Schlüssel zum Entschlüsseln nicht oder nur mit hohem Aufwand aus dem Schlüssel zum Verschlüsseln berechenbar ist. Der Schlüssel zur Verschlüsselung kann daher veröffentlicht werden. Solche Verfahren werden als asymmetrische oder PublicKey-Verfahren bezeichnet. Er ist nach seinen Erfindern Ronald L. Rivest, Adi Shamir und Leonard Adleman benannt. (Wikipedia) Fragen: Wie stelle ich sicher, dass ein Schlüssel wirklich einer Person gehört - Zertifizierungsstellen - INI-Briefe Weitere Verfahren/Anwendungen: - Steganographie (versteckte Übermittlung von Informationen in einer Sprache) - PIN/TAN-Verfahren - Biologische Merkmale Einwegsfunktions-Verschlüsselung: Es gibt Benutzername und Passwort, wenn das Passwort vergessen wird wir das alte Passwort gelöscht und ein neues erstellt. Auf das alte Passwort kann nicht zugegriffen werden, kennt nur der Benutzer! RSA-Excel-Datei anschauen! Aufbau von Rechnersystemen Genereller Rechneraufbau: Siehe Skript Zentraleinheit: Funktionseinheit innerhalb eines Rechners, die einen oder mehrere Prozessoren und Zentralspeicher umfasst. - der Zentralprozessor (engl.: central processing unit, abgekürzt: CPU) steuert entsprechend den jeweiligen Programmen den Gesamtablauf der Informationsverarbeitung, koordiniert die beteiligten Funktionseinheiten (Leit- oder Steuerwerk) und führt Rechenoperationen aus (Rechenwerk). Ein Ein-Ausgabeprozessor steuert „in seinem Auftrag“ eines oder mehrere Eingabe-, Ausgabe- oder externe Speichergeräte. - Zentralspeicher enthält die auszuführenden Programm und die damit zu verarbeitenden Daten Ein-/Ausgabesystem und Peripherie - Jeder Speicher, der nicht Zentralspeicher ist, wird als externer Speicher (engl.: external storage) bezeichnet - Eine Funktionseinheit innerhalb eines Rechners, die nicht zur Zentraleinheit gehört, wird periphere Einheit (engl.: peripheral unit) genannt Peripheriegeräte sind z. B. Festplatte, Laufwerk, Netzwerkkarte, Grafikkarte, Soundkarte Weitere Komponenten: - Puffer- oder Cache-Speicher - Virtueller Speicher - Busse - BIOS (Basic Input/Output System) - E/A-Kanäle => nachlesen!!! Auch mal ins Skript schauen: Abbildungen Mehrprozessor-Systeme: - eng gekoppelt: gemeinsamer Speicher, rasche Verbindung, beschränkt auf einige Prozessoren (2-16) - lose gekoppelt: jeweils eigene Arbeitsspeicher, Verbindungen langsamer (z. B. LAN, oder Internet -> GRID), nahezu beliebig viele Prozessoren - massiv parallele Rechner: bis zu mehreren tausend Prozessoren, mit jeweils eigenem Arbeitsspeicher, mit individuellen, sehr schnellen Verbindungen - Multiprocessing: SMP (Symetrisches MulitProcessing): Prozesse werden dynamisch auf Prozessoren verteilt, jeder Prozessor kann „alles“; Asymetrisches MultiProcessing: Die Prozessoren haben feste „Zuständigkeitsbereiche“, z. B. P1 – Betriebssystem, P2 Dateisystem… Rechnernetz (engl.: computer network): - räumlich verteiltes System von Rechnern - durch Datenübertragungswege miteinander verbunden - Standards und Protokolle regeln die Kommunikation zwischen den Rechnern auf unterschiedlichen Ebenen - GRID-Computing - CSCW-Computer supported kooperative work - Application support / Terminalcluster, z. B. VNC, metaframe, X-11-Systeme - Fernsteuerung Grid-Computing: bezeichnet alle Methoden, die Rechenleistung vieler Computer innerhalb eines virtuellen Netzwerks so zusammenzufassen, dass über den reinen Datenaustausch hinaus die (zeitlich parallele) Lösung von rechenintensiven Problemen ermöglicht wird (verteiltes Rechnen). Damit kann, zu deutlich geringeren Kosten, sowohl die Kapazität als auch die Rechenleistung heutiger Supercomputer übertroffen werden. Grid-Systeme skalieren sehr gut: durch Hinzufügen von Rechnern zum Netz (oder hierarchisches Zusammenfassen von Grids) erhöht sich die Rechenleistung in entsprechendem Maße, jedoch nicht linear. (Wikipedia) CSCW: Computer Supported Cooperative Work (CSCW) ist die Bezeichnung des Forschungsgebietes, welches auf interdisziplinärer Basis untersucht, wie Individuen in Arbeitsgruppen oder Teams zusammenarbeiten und wie sie dabei durch Informations- und Kommunikationstechnologie unterstützt werden können. Ziel aller Bemühungen im Gebiet CSCW ist es, unter Verwendung aller zur Verfügung stehenden Mittel der Informations- und Kommunikationstechnologie, Gruppenprozesse zu untersuchen und dabei die Effektivität und Effizienz der Gruppenarbeit zu erhöhen. (Wikipedia) VNC: Virtual Network Computing (kurz VNC) ist eine von AT&T entwickelte Software, die den Bildschirminhalt eines entfernten Rechners (auf dem die VNCServer Software läuft) auf einem lokalen Rechner (auf dem die VNC-Viewer Software läuft) anzeigt und im Gegenzug Tastatur- und Mausbewegungen des lokalen Rechners an den entfernten Rechner sendet. Damit kann man auf einem entfernten Rechner arbeiten, als säße man direkt davor. Alternativ ist auch ein Nur- „Lese“-Modus möglich, bei dem also lokale Eingaben keine Auswirkungen auf den entfernten Rechner haben. Neuere Versionen von VNC enthalten einen kleinen Webserver, der ein Java-Applet bereitstellt, so dass ein Zugriff auch ohne installierte Clientsoftware über jeden Java-fähigen Browser möglich wird. Mit VNC ist es beispielsweise möglich, dass der Administrator eines Netzwerkes die Kontrolle über den Computer eines Mitarbeiters übernimmt, um Software zu installieren oder Fehler zu beheben. VNC ist plattformunabhängig nutzbar, für fast alle gängigen Betriebssysteme gibt es mehrere Implementierungen. (Wikipedia) Hardware versus Software: - Hardware: Sammelbegriff für informationstechnische Geräte - Software: Sammelbegriff für Programme - Firmware: Programme, die fest in Geräten gespeichert sind (Read only) Leistungsvermögen – Rechnerleistung im engeren Sinn: Maßzahl der Geschwindigkeit eines Rechners: - durch Benchmarks (Ausrichten von Messwerten auf einem Bezugspunkt) ermittelt: SPEC = Standard Performance Evaluation Corporation - beeinflusst durch die Hardware der Zentraleinheit (Prozessorarchitektur, Befehlsvorrat, Speicherstruktur, Prozessortaktrate, Speicherzugriffszeiten,…) Prozessor-Performance: - Zykluszeit (cycle time) T - Taktfrequenz (clock rate) f = l/T (in MHz) - Anzahl von Zyklen pro Instruktion (cycles per instruction) CPI abhängig vom Befehlssatz und dem Grad der Parallelisierung der Befehlsausführung, typische Werte leistungsstarker Rechner = 3-4 Instruktionen pro Zyklus, daher ¼ <= CPI <= 1/3 - Rechenbeispiel: - Prozessor A: 1 GHz und CPI = 0,33 (1/0,33 -> 3 Instruktionen) gegen Prozessor B: 800 MHz und CPI = 0,25 (0,800/0,25 -> 4 Instruktionen) - Theoretische Prozessorleistung in MIPS (Millionen Instruktionen pro Sekunde) - Prozessor A: 1*109/(0,33*106) = 3030 MIPS Gegen Prozessor B: 800*106/(0,25*106) = 3200 MIPS Leistungsvermögen (Rechnerleistung im weiteren Sinn): Leistung, die im praktischen Einsatz tatsächlich erbracht wird - ermittelt durch alle Komponenten (das heißt durch die Zentraleinheit, die Peripherie, das Betriebssystem und die Anwendungsprogramme) - Maßgrößen sind: - Durchsatz, das heißt die pro Zeiteinheit abgearbeiteten Aufträge (engl. Job) - Antwortzeit (engl. Response time), das Heißt die Reaktionszeit des Rechners auf Eingaben des Benutzers im interaktiven Betrieb. => Wichtig! Leistungssteigerung: - Geschwindigkeit: Probleme: Temperatur, Leitungslängen, Energieverbrauch, Lüftung - Auslagerung auf Spezialprozessoren: Kommunikation/Bandbreite der Busse - Besser Algorithmen, bessere Werkzeuge: z. B. Video, Protokolle, GUI - Durchdringung aller Bereiche mit DV: Infrastruktur gegeben, Ubiquitäres Computing Ubiquitous Computing: WICHTIGER BEGRIFF!! Der Begriff Ubiquitäre Computertechnik (kurz UbiComp) oder englisch Ubiquitous Computing (engl. ubiquitous = allgegenwärtig) bezeichnet die Allgegenwärtigkeit der Informationsverarbeitung im Alltag von Unternehmen und Kunden. In der deutschen Literatur ist auch der synonyme Begriff Rechnerallgegenwart für dieses Paradigma in Gebrauch. Bereits heute steht der PC immer weniger im Mittelpunkt. Das Internet gewinnt an Bedeutung. Der Trend geht hin zu einem mobilen Informationszugang. Nach Ansicht von Friedemann Mattern lässt sich die gegenwärtige Dekade dadurch charakterisieren, dass sich das Internet mit mobilen Anwendungen über seine klassische Domäne hinaus ausbreitet. (vgl. "Ubiquitous Computing - Die Vision von der Informatisierung der Welt") "In the 21st century the technology revolution will move into the everyday, the small and the invisible." ("Im 21. Jahrhundert wird die technologische Revolution das Alltägliche, Kleine und Unsichtbare sein.", Mark Weiser, 1952-1999) Nach der ersten Ära der zentralen Mainframes, die von vielen Wissenschaftlern bedient wurden, sowie der zweiten Ära der PCs, die jedem Nutzer einen eigenen Computer zuordnete, kann UbiComp als die dritte Computer-Ära bezeichnet werden, in der für jede Person viele Computer eingebettet in der Umgebung vernetzt arbeiten und ein "Netz der Dinge" bilden. Probleme ergeben sich damit im Bereich des Datenschutzes, wenn weitgehend unsichtbare Computer mit verschiedenen Sensoren Umgebungsdaten auswerten, austauschen und Aktionen auslösen. Das Bundesministerium für Bildung und Forschung hat deshalb eine Studie zur Technikfolgenabschätzung von UbiComp in Auftrag gegeben, die bis Ende März 2006 vom Institut für Wirtschaftsinformatik an der Humboldt Universität zu Berlin in Kooperation mit dem Unabhängigen Landeszentrum für Datenschutz Schleswig-Holstein (ULD) unter dem Namen "Technikfolgen-Abschätzung: Ubiquitäres Computing und Informationelle Selbstbestimmung" (TAUCIS) durchgeführt wird. Der Abschlußbericht wurde zwischenzeitlich vorgestellt. (Wikipedia) Rechnerklassen: - Mainframe (Großrechner) – Workstations – PCs -> Einteilung nicht mehr so wichtig: - Leistung – Wartungsaufwand (aber Achtung) - Kosten – Sicherheit (Datensicherheit, Ausfallsicherheit und gegenüber Missbrauch) - Terminalsysteme - Spiel/Unterhaltungskonsolen - PDA (Persönliche digitale Assistenten) - Mobiltelefone? / Uhren / MP3-Player - Weareable (Wie kommunizieren die Geräte, wie kommuniziert der Mensch mit Ihnen) Wearables (militärischer Bereich => Forschung) Beispiele: - Jacke mit Elektronik zum Telefonieren - Stimmungserfassung = Sicherheit im Straßenverkehr - Permanent Online - Automatische Identifizierung für z. B. Überwachung an sensibeln Orten Server (wichtig für die Klausur! – 3 Typen von Servern + Begriff!!!) - Server ist ein Programm, das andere Programme (Klienten-Clients) mit Leistungen versorgt - Server ist ein Rechner, auf dem ein Serverprogramm läuft - Einteilung: - Nach Zahl der Nutzer: Arbeitsgruppe, Abteilung, Unternehmen - Nach Plattform: PC-basiert, 64-Bit-RISC unter Unix (z. B. Sunterminalserver) - Nach Einsatzzweck: Infrastruktur (Drucker-, Datei/Daten-, E-Mail-, Webserver…), Datenbankserver, Anwendungsserver (Citrix) - Vorteile: zentrale Verantwortlichkeit, Wartung, Zuständigkeit, Sicherheit - Nachteile: Zentralismus, technische Abhängigkeit, Teamgedanke?, Restriktionen beim Zugriff Ressourcen werden mehrfach genutzt Kosten? Viele teilen wenig -> günstiger, aber: nur bis zu einer bestimmten Anzahl von Benutzern! Aufgaben der Betriebssysteme (MS-DOS, Windows, Linux, Solaris, Mac OS x) - Benutzerführung: Oberflächen oder Kommandozeilen - Laden und Unterbrechung von Programmen: Erzeugen und beenden von Prozessen, Kommunikation zwischen Prozessen - Verwaltung der Prozessorzeit - Verwaltung des Speicherplatzes für Anwendungen: Zuweisung und Überwachung für die Prozesse - Verwaltung der angeschlossenen Geräte und Dateien - Bereitstellung von Dienstprogrammen, z. B. Datei öffnen, Fenster, Explorer (im Unterschied zu Anwendungsprogrammen) - Abstraktion: Verbergen der Komplexität der Maschine vor dem Anwender, Abstraktion des Maschinenbegriffs (nach Coy) - Reale Maschine = Zentraleinheit + Geräte (Hardware) - Abstrakte Maschine = Reale Maschine + Betriebssystem - Benutzermaschine = Abstrakte Maschine + Anwendungsprogramm = Klausur: einige Aufgaben + Beschreibungen! Unterscheidung von Betriebssystemen I: (nach den technischen Eigenschaften der DV-Anlage, die sie benötigen bzw. unterstützen) a) unterstützte Prozessortypen (AMD Athlon) - ursprünglich meist auf die Prozessorfamilie eines Herstellers ausgerichtet (z. B. MS-DOS und Windows auf INTEL) oder herstellerabhängige Betriebssysteme (proprietäre Betriebssysteme) - Kunden verlangen hardwareunabhängige Betriebssysteme (offene Betriebssysteme); kann ggf. von UNIX erfüllt werden (BetriebssystemKern) b) Art und Anzahl der steuerbaren Prozessoren - single-processing – multi-processing c) Größe des verwendbaren Arbeitsspeichers - Diese hängt von der Breite des Adressbusses ab. Ist dieser z. B. 20 Bit breit, so sind 1.048.576 Bits (Adressen) unterscheidbar (vereinfacht) - Erweiterung durch „paging“ etc. d) Kommunikationsmechanismen – intern, extern e) Skalierbarkeit - Anpassbarkeit an aktuelle Leistungs- und Größenerfordernisse Als Paging (englisch page – Speicherseite) oder deutsch Kachelverwaltung bezeichnet man eine Methode der Hauptspeicherverwaltung durch Betriebssysteme. Dabei wird häufig aus Effizienzgründen die sogenannte Memory Management Unit des Prozessors eingesetzt, sofern der Prozessor eine solche bereitstellt. Gelegentlich wird der Begriff Paging synonym mit der gesamten virtuellen Speicherverwaltung gebraucht. Dieser Sprachgebrauch ist jedoch unpräzise, da das Paging nur einen - wenn auch zentralen - Aspekt der virtuellen Speicherverwaltung ausmacht. Zu unterscheiden ist das Paging jedoch deutlich vom Swapping, da letzteres nicht nur einzelne Speicherseiten, sondern praktisch vollständige Prozesse auslagert. Das Paging ist trotz einer häufig unpräzisen Bezeichnung der Auslagerungsdatei als Swap-Datei heute das bei modernen Betriebssystemen vorherrschende Verfahren zur Speicherverwaltung von Prozessen. Unterscheidung von Betriebssytemen II: (nach der Organisation der Auftrags- (Betriebsart), Prozess, und Datenverwaltung) a) Betriebsart (ein oder mehrere Aufgaben gleichzeitig bearbietbar) - single-tasking (nur ein Prozess) – multitasking (mehrere Programmprozesse) - single-programming (ein Programm) – multiprogramming (mehrere Programme) b) Kommunikation zwischen den Anwendungsprogrammen - Zwischenablage, DDE (dynamic data exchange): Programme tauschen Daten aus - OLE (object linking and embedding): Verbindung zwischen Anwendungsprogrammen mittels Objektaustausch - RPC (Remote Procedure Call), ODBC (Open Database Connectivity) c) Anzahl der Nutzer: single-user oder multi-user (= gleichzeitige Nutzung) - nicht so wichtig d) Interaktion zwischen Nutzer / Prozess und DV-Anlage - batch processing (Stapelverarbeitung) (große Datenmengen, nacheinander folgende Projekte die nacheinander abfolgend automatisch erledigt werden -> Videokonvertierung) - conversational processing (Dialogverarbeitung) (Virensuchprogramm: Meldungen auf die man antworten muss – Dialogfenster) - real time processing (Echtzeitverarbeitung; bei technischen Prozessen): zugesicherte Reaktion innerhalb bestimmter Zeit (z. B. Bremsen beim ICE) => Klausur! Nachlesen! Stapelverarbeitung oder auch Batchverarbeitung bezeichnet die Bearbeitung von Aufgaben nacheinander (sequentiell). Dies ist ein Ausdruck aus dem EDVBereich und wird synonym als Batchdatei, Batchfile, Batchprogrammierung, JCL verwendet. Batch-Dateien werden in verschiedenen Betriebssystemen (z. B. DOS, Unix) häufig genutzt. Man spricht heute mehr von Skript-Dateien, vom Konzept her ist es aber dasselbe. Eine Reihe von Befehlen, die die Betriebssystemfunktionen nutzen, werden in einer Datei festgehalten und nach Starten des Skripts abgearbeitet. Vorteile: einfach zu erstellen, Wiederverwendbarkeit, Zeitersparnis (bei der Ausführung) (Wikipedia) Schnittstellen: - Anschluss peripherer Einheiten erfordert Schnittstellen: serielle Schnittstellen, parallele Schnittstellen, Infrarot, Funk - Serielle Schnittstellen: z. B. USB (Daten hintereinander übertragen) - Parallele Schnittstellen: z. B. altes Druckerkabel (Daten gleichzeitig übertragen – BUS) - Infrarot: z. B. Fernbedienung, Sichtkontakt nötig, serieller Lichtstrahl - Bluetooth: Funkvernetzung über kurze Distanz - WLAN/UMTS/WiMax: Netzschnittstellen bzw. Mobiltelefonschnittstellen Datenerfassung – Eingabegeräte: Stichworte: Dokumentenmanagement mit den Zielen: - Einfache Verfügbarkeit und gleichzeitige Archivierung - Hohe Verfügbarkeit (Datenbank) unabhängig vom Arbeitsplatz - Schnellere, gesteuerte und überwachter Workflow („Durchlauf“ auf dem Bearbeitungsweg) - Awareness (Aufmerksamkeit) Mittelung bei Änderung - Intelligente Suchmöglichkeiten (Stichworte, Volltext, Zusatzfelder etc.) Technisches: - Data Capturing als Sammelbegriff für Datenerfassung per Abtaster - Schriftenerkennung als OCR (Optical Character recognition) - Unified Messaging, einheitliche Dokumentenpräsentation und einheitlich Bearbeitung von Papierdokumenten, Email, SMS, Fax Texterkennung oder auch Optische Zeichenerkennung (Abkürzung OCR von englisch Optical Character Recognition, selten auch: OZE) ist ein Begriff aus dem IT-Bereich und beschreibt die automatische Texterkennung von einer gedruckten Vorlage. Ursprünglich wurden zur automatischen Texterkennung eigens entworfene Schriftarten entwickelt, die zum Beispiel für das Bedrucken von Scheckformularen verwendet wurden. Diese Schriftarten waren so gestaltet, dass die einzelnen Zeichen von einem OCR-Lesegerät schnell und ohne großen Rechenaufwand unterschieden werden konnten. So zeichnet sich die Schriftart OCR-A durch einander besonders unähnliche Zeichen, besonders bei den Ziffern, aus. OCR-B ähnelt mehr einer serifenlosen, nicht-proportionalen Schriftart, während OCR-H handgeschriebenen Ziffern und Großbuchstaben nachempfunden wurde. Die gestiegene Leistungsfähigkeit moderner Computer und verbesserte Algorithmen erlauben inzwischen auch die Erkennung von "normalen" Druckerschriftarten bis hin zu Handschriften (z. B. bei der Briefverteilung), wenn jedoch Lesbarkeit durch Menschen nicht vorrangig ist, werden technologisch einfacher handhabbare Strichcodes genutzt. Moderne Texterkennung umfasst auch die Erkennung verschiedener Schriftarten und -größen und des Seitenlayouts zur möglichst originalgetreuen Wiedergabe einer Vorlage. (Wikipedia) Datenspeicherung Kriterien: - Kosten (€ pro bit) und Kosten für Schreib-/Lesegeräte - Zugriffszeit (Zeit von Datenanforderung bis Erhalt) - Lese-, Schreibgeschwindigkeit (Byte pro Sekunde) - Gesamtkapazität - Zuverlässigkeit (lang-, kurzfristig) MTBF = Mean Time Before Failure - Transportfähigkeit, Lagerfähigkeit - Austauschbarkeit, Wiederbeschreibbarkeit - Repräsentationsform (lesbar durch Mensch? - Privatheit der Daten (Verschlüsselung/Zugriffsschutz) Magnetische Speicher Magnetstreifenkarte: 1-3 Spuren (1,2 für lesen, 3 für lesen und schreiben) ca. 1500 Byte Bänder (Archiv): ½“-Technik, Kassetten. QIC (quarter inch cartridge) ; Video(8mm)-Technik, DAT-(4mm)-Technik, MB bis GB, je nach Ausbau, Bestrebungen zur Vereinheitlichung Aufzeichnung: - Serpentinen-Aufzeichnung (Längsspur ------- ------- ) - Helical Scan-Aufzeichnung (Schrägspur / / / / / ) => wichtig! Lineare Aufzeichnung: Das Magnetband wird in Vorwärts- und Rückwärtsrichtung beschrieben. Schrägspuraufzeichnung (Helical Scan): Das Magnetband läuft schräg am Schreibkopf vorbei. (wikipedia) Einsatz: Backup, Austausch Vorteile: automatisierbar, billig, schnell, lange haltbar Nachteile: langsamer Zugriff, empfindlich gegen Staub, Wärme, Feuchte, kein Urbeleg Disketten: - 8“, 5.1/4“, 3.5“, 2“; austauschbar - Programmaustausch, Datenaustausch - Aussterbende Kategorie Jumbodiskette: Zip-Drive, ca. 140 MB, Media-Branche Festplatten: - nicht austauschbar (i.d.R.) - Schnittstellen zwischen Rechnerbus und Festplatte IDE= Integrated drive electronics, SCSI = small computer system interface) bei Umrüstung zu beachten - Zusätzliche Anforderungen für Platten in mobilen Geräten (Laptop) - RAID-Systeme (Redundand Array of inexpensive Disks), Raid 0-5 - Speichernetze (NAS = Network Attached Storage) als Speicherserver oder SAN (Storage Area Network) als Speichernetz - Wechselplatten bzw. transportable Platten (USB) Ein RAID-System dient zur Organisation zweier oder mehrerer physikalischer Festplatten eines Computers zu einem logischen Laufwerk, das eine größere Speicherkapazität und/oder einen größeren Datendurchsatz erlaubt als eine physikalische Platte. Während die meisten in Computer verwendeten Techniken und Anwendungen darauf abzielen Redundanzen (das Vorkommen doppelter Daten) zu vermeiden, werden bei RAID-Systemen redundante Informationen gezielt erzeugt, damit beim Ausfall einzelner Komponenten das RAID als ganzes seine Funktionalität behält. Der Begriff wurde von Patterson, Gibson und Katz an der University of California, Berkeley in dem Papier "A Case for Redundant Array of Inexpensive Disks (RAID)" zum ersten Mal verwendet (frei übersetzt: Redundanter Verbund kostengünstiger Festplatten). Das Papier untersuchte die Möglichkeit kostengünstige Festplatten im Verbund als logisches Laufwerk zu betreiben, um die Kosten für eine große (zum damaligen Zeitpunkt teure) Festplatte einzusparen. Dem gestiegenen Ausfallrisiko im Verbund sollte durch die Speicherung redundanter Daten begegnet werden, die einzelnen Anordnungen wurden als RAID-Level diskutiert. Die weitere Entwicklung des RAID-Konzepts führte zunehmend zum Einsatz in Serveranwendungen, die den erhöhten Datendurchsatz und die Ausfallsicherheit nutzen, der Aspekt der Kostenersparnis wurde dabei aufgegeben. Der Möglichkeit, in einem solchen System einzelne Festplatten im laufenden Betrieb zu wechseln, entspricht die heute gebräuchliche Übersetzung: Redundant Array of Independent Disks (Redundante Anordnung unabhängiger Festplatten). Der Betrieb eines RAID-Systems setzt mindestens zwei Festplatten voraus. Die Festplatten werden gemeinsam betrieben und bilden einen Verbund, der unter mindestens einem Aspekt betrachtet leistungsfähiger ist als die einzelnen Festplatten. Mit RAID-Systemen kann man folgende Vorteile erreichen: Erhöhung der Ausfallsicherheit (Redundanz) Steigerung der Transferraten (Performance) Aufbau großer logischer Laufwerke Austausch von Festplatten und Erhöhung der Speicherkapazität während des Systembetriebes Kostenreduktion durch Einsatz mehrerer preiswerter Festplatten hohe Steigerung der Systemleistungsfähigkeit Die genaue Art des Zusammenwirkens der Festplatten wird durch den RAID-Level spezifiziert. Die gebräuchlichsten RAID-Level sind RAID 0, RAID 1 und RAID 5. Sie werden unten beschrieben. Aus Sicht des Benutzers oder eines Anwendungsprogramms unterscheidet sich ein logisches RAID-Laufwerk nicht von einer einzelnen Festplatte. (Wikipedia) Optische Speicher – DVD: - Größe einer herkömmlichen CD - 4,7 GB/Seite und Layer = 3.200 Disketten = 7 CD-ROMs = 133 min. Film - Doppelseitig bespielbar (1 Layer) => 9,4 GB - Zweischichttechnik 8,5 GB/Seite - Max. Kapazität 17 GB = 8 Stunden MPEG2, 33 Stunden VHS-Standard - 1-fach entspricht ca. 11 Mbit/s, also 1.375 Mbyte/s (= 8 x CD mit 150 kB/s) Defragmentierung: schneller lesen, Festplatten halten länger Unter Defragmentierung versteht man die Neuordnung von Datenblöcken fragmentierter Dateien auf den Spuren und Sektoren der Festplatte, so dass Zugriffe mit optimaler Geschwindigkeit durchgeführt werden können. (Wikipedia) Elektronischer Speicher: Chipkarten, Flash-Speicherkarten, Transponder Bildschirme: Auflösung: Gesamtanzahl der Pixel (= Bildpunkte) die horizontal und vertikal angeordnet sind, üblich etwa 1280 x 1024 als Standard bei 17-Zoll-Schirmen), je mehr Punkte, desto schärfer das Bild Bildwiederholfrequenz (= Vertikalfrequenz = Bilder/s): - Gemessen in Hertz, gibt an, wie oft pro Sekunde das Bild komplett neu aufgebaut wird - Je größer, desto angenehmer fürs Auge, ergonomische Mindestanforderung etwa 75 Hz Kathodenstrahlröhre: CRT (Cathode Ray Tube) – Technik (=Fernseh-Technik) - Technik sehr ausgereift - Maske bestimmt Qualität, richtungsunabhängig, Auflösung umschaltbar aber: - Groß, schwer, flimmern, Strahlung, Verzerrung am Rand - Recycling-Probleme (Größter Anteil am Elektronik-Schrott) - Markt wachsend, Produktion nicht mehr in Europa Flach-Bildschirm: LCD- und TFT-Technik: Liquid Crystal Displays verwenden organische Substanzen (Flüssigkristalle), die zwischen zwei Glasflächen eingeschlossen sind, eine angelegte Spannung ändert die Ausrichtung der Kristalle und die Polarisierung des Lichts Filter ermöglichen die Farbdarstellung. Unterscheidung in: - passive LCD-Bildschirme (nur reflektierend oder Durchlicht) und - aktive (TFT = Thin film transistor) LCD-Bildschirme (einzelne Bildpunkte werden mit aktiven Verstärkern versehen -> schneller, höherer Kontrast, höhere Dicht der Bildpunkte -> höhere Auflösung) Vorteile: Stromverbrauch, Qualität, Farbfähigkeit, Platz sparend, leuchtstark, niedriger Energieverbrauch, flimmerfrei Aber: winkelabhängig, teuer, „langsam“ keine Farbtonveränderung, Qualität auflösungsabhängig, da diese fix ist, geringer Kontrast Plasmabildschirme: - flach, leicht - sehr leuchtstark - bis über 1m Bildschirmgröße möglich - keine Emission - Aber: hoher Preis, hoher Stromverbrauch, niedrige Auflösung, schwer, geringe Bildwiederholfrequenz, Signaleingänge analog – digital (Zwischen zwei Glasplatten befinden sich kleine gasgefüllte Zellen, deren Inhalt „angezündet“ wird) LCD-Bildschirm 1. weißes Licht wird durch einen Polarisationsfilter gelenkt. Dieser lässt nur Licht durch, da in einer Ebene schwingt. 2. Die Flüssigkristalle drehen das Licht nach Anordnung der Moleküle. An der mittleren Zelle liegt hier keine Spannung, dadurch dreht sich die Schwingungsebene des Lichts um 90 Grad. Wird über die Elektroden eine elektrische Spannung angelegt, ordnen sich die Moleküle waagrecht an. Die Höhe der Spannung bestimmt den Drehwinkel. 3. Ein Farbfilter lässt das Licht in den drei Grundfarben austreten 4. Den zweiten Polarisationsfilter kann hier nur der gedrehte Lichtstrahl passieren. Der rote und der blaue Lichtstrahl werden blockiert 5. Der Bildpunkt leuchtet grün. Durch die unterschiedliche Mischung der Grundfarben können alle Farben erzeugt werden 100 % Grün + 100 % Rot + 100 % Blau ergibt weißes Licht Drucker: Kriterien: - Kosten (Gerät und Betrieb) - Geschwindigkeit (Seiten pro Minute) - Qualität (dot per inch) - Farbfähigkeit - Geräuschentwicklung - Entsorgung, Umweltbelastung - Durchschreibfähigkeit / Papierformate / Einzelblatt-Endlospapier - Spezialpapier / Etikettendruck - Lebensdauer (Gesamtleistung in Blatt) 1 Bit = ja/nein 1 Byte = 8 bit = ein Buchstabe 1 kb (KiloByte) ist eine normal bedruckte DIN A4 Seite = 210 = 1024 Byte) 1 MB (MegaByte) = reine Text ohne Gestaltung und ohne Bilder des Buchs EDV-Grundwissen. Er passt auf eine 3,5’’-Diskette = 220 = 1.048.576 Byte 1 GB (GigaByte) = ca. 1,5 Musik-CDs = 230 = 1.073.741.824 Byte 1 TB (TeraByte) = ca. 210 DVDs (SS/SL = 4,9 GB) = 240