Datenmodellierung - Beuth Hochschule für Technik Berlin
Werbung

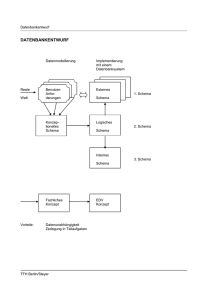
Datenmodellierung Datenmodellierung F. Steyer 1 Datenbanklebenszyklus 2 Datenmodellierung (Datenbankentwurf) einfaches und ausführliches Vorgehen Anforderungsanalyse Konzeptioneller Entwurf Logischer Entwurf Logischer Entwurf mit Oracle Logischer Entwurf mit Access Externer Entwurf Physischer (interner) Entwurf Fallstudie 3 Normalisierung Erste Normalform Zweite Normalform Dritte Normalform 4 Dokumentation Anwenderdokumentation Systemdokumentation 5 UML Klasse, Assoziation, Aggregation, Generalisierung 6 Performance-Massnahmen Hardware, Software, Indizes, Orgware 19.11.2015 Fehler und Wünsche bitte an den Autor. TFH Berlin Datenmodellierung DATENBANKLEBENSZYKLUS Änderung und Anpassung Datenbankentwurf Betrieb und Überwachung Installation Anwendungsprogramme Daten definieren und laden DATENBANKENTWURF - Benutzeranforderungen - konzeptionelles Modell - logisches, externes, internes DB-Schema INSTALLATION - Einlesen des Installationsbandes - Setzen der Umgebung, Initialisierung der Datenbereiche - Hochfahren des Datenbanksystems, Laden der Systemtabellen - Probebetrieb, Sicherung DATEN DEFINIEREN UND LADEN - Laden des Datenbankschemas, Probebetrieb - Laden der Daten mit Sicherungen ANWENDUNGSPROGRAMME - Subsysteme, Pflichtenheft, Tools, Testfälle, Dokumentation - Aus Sicht der Datenbank achten auf Mehrbenutzerproblematik, Datenabsicherung, Datenintegrität, Laufzeit, Blockaden, Sicherung BETRIEB UND ÜBERWACHUNG - Sicherungskonzept, Wiederherstellverfahren - Tagesaktivitäten (interaktiver Betrieb), Nachtaktivitäten ( Stapelläufe, Druck, Sicherungen) - Bedienerausbildung - Monitoring für die Leistungsbewertung (für kritische Bereiche, Lastspitzen) - Notfallplanung (Bereitschaft, Notbetrieb) ÄNDERUNG UND ANPASSUNG - Anpassung an neue Anforderungen (logische Änderungen) - Optimierung (physische Änderungen auf Hardware-, Betriebssystem-, Datenbank- und Programmebene) TFH Berlin/Steyer Datenmodellierung 2 DATENMODELLIERUNG einfaches Vorgehen Ziel: Bearbeitung mit einer Datenbank Vorgehen: in drei Schritten WeltAussschnitt Graph Beschreibung umgangssprachlich, halbformal z.B. Leser leihen Bücher ER-Diagramm dazu mit Entities/Objekten/Substantiven mit Relationships/Beziehungen/Verben mit Attributes/Eigenschaften/Adjektiven Leser Tabellen Grundformen: Tripel Kette/Verlängerung Stern/Verzweigungg Spindel/Parallelisierung Beispiele: Tripel: leihen, buchen, kaufen, lehren Kette/Verlängerung: leihen + Autor, lehren + Zeit/Ort Stern/Verzweigungg: beliefern, lehren + Studiengang Spindel/Parallelisierung: bestellen + beliefern + bezahlen verwalten + bauen + verkaufen TFH Berlin/Steyer leihen Bücher Datenmodellierung DATENMODELLIERUNG ausführliches Vorgehen Reale Welt Datenmodellierung Implementierung mit einem Datenbanksystem BenutzerAnforderungen Externes Konzeptionelles Schema Logisches 1. Schema Schema 2. Schema Schema Internes 3. Schema Schema Fachliches Konzept Vorteile: Datenunabhängigkeit Zerlegung in Teilaufgaben TFH Berlin/Steyer EDV Konzept Datenmodellierung ANFORDERUNGSANALYSE Anforderungen aller potentiellen Benutzer an die Datenbank sammeln (1) Informationsanforderungen (2) Bearbeitungsanforderungen (3) Technische und organisatorische Randbedingungen Ergebnis: (viele) Benutzeranforderungen (Spezifikation) Anmerkungen: Hilfsmittel sind Formblätter, Interviews, Fragebögen, umgangssprachlicher Text. Formale Hilfsmittel gibt es kaum. Diese Phase ist sehr zeitaufwendig, aber auch ausserordentlich notwendig. Eine vollständige konsistente Anforderungsspezifikation ist Voraussetzung für einen sinnvollen Entwurf. Wichtig ist die Identifikation von Organisationseinheiten und Aufgaben. KONZEPTIONELLER ENTWURF Ziel: Formales, integriertes Modell der Informationsstrukturen unabhängig vom Datenbanksystem oder der Hardware (1) Informationsstrukturen aus den Sichten der einzelnen Benutzer herausarbeiten (2) Redundanzen, Inkonsistemzen, Konflikte aufdecken und beseitigen (3) Zusammenfügen der Einzelsichten zu einer globalen Informationsstruktur Ergebnis: Konzeptionelles Schema Anmerkungen: Formale Hilfsmittel: Festlegen der Objekte, Attribute, Beziehungen (Entity Relationship Modell) Objekt: Ein Objekt (Ganzheit, engl. entity) ist etwas, das für ein Unternehmen von Interesse ist. Es muss jeweils einmalige Ausprägungen enthalten. In der Umgangssprache ist es normalerweise ein Substantiv. Beispiele: Maschinen, Konten, Kollegen, Angestellte, Verträge, Kurse. Attribut: Ein Attribut ist eine Eigenschaft eines Objektes. Umgangssprachlich erscheinen die Attribute meist nach 'hat'... Attribute von Kurs sind z.B. Kursnummer, Abteilungsnummer, Name, Semester, Einschreibtermin. Beziehung: Eine Beziehung (engl. relationsship) ist eine Verbindung zwischen zwei oder mehr Objekten. In der Umgangssprache ist es normalerweise ein Verb. Beispiele für Beziehungen zwischen zwei Objekten sind Angestellte ARBEITEN_FÜR Abteilung, Studenten STUDIEREN Fächer, Arbeiter WARTEN Maschinen. TFH Berlin/Steyer Datenmodellierung LOGISCHER ENTWURF Ziel: Schema für das verwendete Datenbanksystem Übersetzung des konzeptionellen Schemas in die Datenstrukturen des Datenbanksystems Ist abhängig von den Modellierungsmöglichkeiten des Datenbanksystems Für das relationale Datenmodell gibt eine Theorie des Entwurfs (Normalformen). Ziele sind Redundanzfreiheit, Anforderungserfüllung, Einfachheit Ergebnis: Logisches Schema mit Zugriffsrechten, Randbedingungen (Constraints) EXTERNER ENTWURF Ziel: Vom gesamten logischen Schema werden entsprechend den Benutzeranforderungen mit der Datenbanksprache formale Benutzersichten für spezielle Benutzer abgeleitet. PHYSISCHER (INTERNER) ENTWURF Ziel: Optimale Weiterentwicklung und Verfeinerung des logischen Entwurfs entsprechend den Gegebenheiten der realen Umwelt Entwicklung des internen Schemas und Festlegen der Systemparameter abhängig von den Anforderungen an die Verarbeitung der Daten Es werden festgelegt: Speicherstrukturen Zugriffsmechanismen Grösse der Datenbank Verteilung auf Platten Grösse des Datenpuffers im Hauptspeicher Datenschutzkonzepte sensibler Daten Datensicherungsverfahren ... Ergebnis: Ladbares Datenbankschema TFH Berlin/Steyer Datenmodellierung SYMBOLE Der Weg zur Datenspeicherung in Tabellen erfolgt über einen graphischen Zwischenschritt. 1) Die verbalen Anwenderanforderungen werden mit drei Konzepten (Objekte, Attribute, Beziehungen) strukturiert und graphisch dargestellt. Objekt/Entity Kunde Objekt/Entity mit Attributen Name Wohnort Kunde Beziehung/Relationship zwischen Objekten/Entities Name Wohnort Kunde Menge bestellt Name Preis Artikel 2) Objekte werden zu Tabellen. Attribute werden zu Tabellenspalten. Beziehungen werden zu wenn 1:1-Beziehung: gleiche Schlüssel in den Objekttabellen wenn n:1-Beziehung: Spalte wenn 1:n-Beziehung: Zwischentabelle wenn n:m-Beziehung: Zwischentabelle Schlüsseleigenschaften: - eindeutig und obligatorisch - einfach oder mehrfach - Attributfeld(er) oder Kunstschlüssel TFH Berlin/Steyer Datenmodellierung ER-TYPEN Tripel Leser leiht Buch Kette Leser leiht Buch Leser leiht Buch Stern Filiale Spindel bestellt Leser leiht gemahnt Buch verfasst von Autor TFH Berlin/Steyer Datenmodellierung ER-MODELL einer FIRMA als Basis für ein System (1) Oberfläche (Formulare) 1 Verkauf 2 Buchhaltung 3 Einkauf Kunde Krechnung Kliefert Kbestellt Artikel Kasse Kunde Krechnung Lieferant Lrechnung Lieferant Lrechnung Lliefert Lbestellt Artikel (2) Prozeduralität (Programme) p1,p2,p3 . . . p4 . . . p5,p6,p7 . . . (3) Daten (Tabellen) Buchhaltung Kasse Kunde Lieferant KRechnung LRechnung Verkauf Einkauf Kliefert Kbestellt Lliefert Artikel Fertigung fertigen Rohstoffe Lbestellt TFH Berlin/Steyer Datenmodellierung ERWEITERUNGEN EINES ERA-ENTWURFES Spaltung der Attribute Adresse PLZ Ort Strasse wird zu Kunde Kunde Verfeinerung der Attribute Wohnort Name Grösse wird zu Kunde Kunde wohnt in Vervielfachen der Beziehungen bestellt Leser Buch leiht Mehrfache Beziehungen Dozent Einsatzplan LV LV Dozent Stundenplan Raum Zeit Ort Land TFH Berlin/Steyer Datenmodellierung 3 NORMALISIERUNG Das Ziel der Normalisierung ist, ein sowohl realitätsnahes als auch ein verarbeitungsgerechtes Datenmodell zu entwickeln. Definition: Normalisierung ist die Verflachung und Teilung einer Datenstruktur in Tabellen, so dass keine Probleme beim Speichern oder Ändern auftreten. Beispiel: Naive Vorform einer Tabelle „Hochschule“ (Studenten machen Kurse und Prüfungen) Snum Sname Znum Telnum Knum Kname Sem 3215 G. Jonas 120DH 2136 3462 A. Schmid 238VH 2344 3567 J. Neider 120DH 2136 4756 K. Alex 345VH 3321 122 120 330 122 122 130 220 230 330 141 389 MAT PHY GRA MAT MAT MAT PSY PHY GRA PHY MUS WS07 SS07 WS07 SS06 WS06 SS06 WS07 SS06 SS07 WS07 WS07 Note 1.3 2.7 3.0 1.3 2.7 1.3 3.7 3.0 2.3 1.3 4.0 Snum Nummer des Studenten. Eine ganze Zahl, die für jeden Studenten einen anderen Wert hat. Sname Name des Studenten. Jeder Student hat nur einen, jedoch können mehrere Studenten mit gleichem Namen existieren. Znum Zimmernummer des Studenten. Jeder hat ein Zimmer, jedoch können mehrere Studenten im selben Zimmer wohnen. Telnum Telefonnummer des Studenten. Jedes Zimmer hat ein Telefon, das sich alle Bewohner des Zimmers teilen. Knum Identifikationsnummer des Kurses, den der Student belegt und abgeschlossen hat. Kname Bezeichnung des Kurses, den der Student belegt und abgeschlossen hat. Sem Semester, in dem ein Student einen Kurs abgeschlossen hat. Der Student kann den Kurs später nochmals belegen. Note Die Note, die ein bestimmter Student in einem bestimmten Semester in einem bestimmten Kurs erreicht hat. Probleme: Leerstellenverarbeitung, Ordnung korrespondierender Werte, komplexe Werte TFH Berlin/Steyer Normalisierung 1. NORMALFORM UND PROBLEME Definition: Jede Relation, die so strukturiert ist, dass jedes Feld nur einen Wert enthält und auch weiterhin enthalten wird, befindet sich in der ersten Normalform (1NF). Eine Relation muss in der ersten Normalform sein, bevor sie geteilt werden kann. Beispiel: Hochschule Snum Sname Znum Telnum Knum Kname Sem Note 3215 3215 3215 3215 3462 3462 3462 3567 3567 3567 4756 120DH 120DH 120DH 120DH 238VH 238VH 238VH 120DH 120DH 120DH 345VH 2136 2136 2136 2136 2344 2344 2344 2136 2136 2136 3321 1.3 2.7 3.0 1.3 2.7 1.3 3.7 3.0 2.3 1.3 4.0 G. Jonas G. Jonas G. Jonas G. Jonas A. Schmid A. Schmid A. Schmid J. Neider J. Neider J. Neider K. Alex 122 120 330 122 122 130 220 230 330 141 389 MAT PHY GRA MAT MAT MAT PSY PHY GRA PHY MUS WS07 SS07 WS07 SS06 WS06 SS06 WS07 SS06 SS07 WS07 WS07 Das ergäbe etwa folgendes Diagramm: Student Snum Sname Znum Telnum Knum Kname Sem Note Eine Tabelle in erster Normalform ist erstmalig mit SQL-Kommandos bearbeitbar, hat jedoch immer noch Probleme: Problem beim Einfügen: Wird ein neuer Student ohne Kurs eingetragen, muss seine Zeile viele Leerfelder bekommen, oder er muss warten, bis er den ersten Kurs beendet hat. Problem beim Ändern: Es existiert eine grosse Zahl offener und versteckter überflüssiger Daten. Offensichtlich kommen Nummer, Name und Telefonnummer mehrfach vor. Versteckt ist, dass für alle Studenten eines Zimmers die Telefonnummer ebenfalls gleich ist. Redundanz hat in jedem Fall die Gefahr von unvollständigen Änderungen. Sie kostet Speicherplatz und Änderungszeit. Problem beim Löschen: Das Verschwinden einer Teilinformation, z.B. Kurs aus einer Zeile müsste zum Löschen der ganzen Zeile führen oder es entsteht das Problem wie beim Einfügen. Die Frage also ist: Welche Einzelinformationen gehören enger zusammen als andere und bilden so eine Einheit ? Das herauszufinden ist Ziel der Normalisierung. Probleme also: Redundanz und Anomalien bei der Verarbeitung TFH Berlin/Steyer Normalisierung FUNKTIONALE ABHÄNGIGKEIT Definition: Schreibweise: Bei zwei gegebenen Attributen A und B ist B funktional abhängig von A, wenn für jeden Wert von A jederzeit genau ein Wert von B existiert, der mit dem Wert von A verbunden ist. A und B können zusammengesetzt sein, d.h. sie können auch Gruppen von mehreren Attributen sein. A -> B A Beispiel: Mathematische Form B Graphische Form/Diagramm Die Nummer der Studenten ist einmalig. Jeder Student hat eine. Mit ihr ist also auch ein Name verbunden: Snum -> Sname. Diese FA kann nicht umgekehrt werden, da ein Name zu mehreren Studenten gehören kann. Jeder Student wohnt in einem Zimmer, aber ein Zimmer kann mehrere Studenten aufnehmen. Es gilt Snum -> Znum, aber nicht Znum -> Snum. Da jedes Zimmer nur ein Telefon hat und jedes Telefon nur eine Nummer, gilt Znum -> Tnum und Tnum -> Znum. Das wird gegenseitige Abhängigkeit genannt und so dargestellt: Znum <-> Tnum. Da es in jedem Zimmer nur ein Telefon gibt, dieses eine einzige Nummer hat und jeder Student nur in einem Zimmer wohnt, gelten: Snum -> Znum und Snum -> Tnum. Die letzte FA besteht darin, dass eine bestimmte Note nur dann festgestellt werden kann, wenn man die Nummer eines Studenten kennt, der in einem bestimmten Semester einen bestimmten Kurs belegt hat, also (Kurs, Seme, Snum) -> Note. Snum Sname Znum Telnum Knum Kname Sem Note SCHLÜSSEL Definition: Wert einer Spalte, der jede Zeile in einer gesamten Tabelle eindeutig identifiziert, Pflichtfeld, Kombination aus mehreren Spaltenwerten ist möglich TFH Berlin/Steyer Normalisierung 2. NORMALFORM Definition: Eine Relation liegt in der zweiten Normalform (2NF) vor, wenn sie in der 1NF ist und jedes Nichtschlüsselattribut voll (nicht teilweise) funktional abhängig vom Primärschlüssel ist. Die zweite Normalform erzwingt damit eine Gruppierung der Attribute in einer Relation nach Sachgebieten und eliminiert dadurch Redundanzen. Die Relation wird deshalb in die folgenden Relationen aufgeteilt: Snum Sname Znum Telnum Knum Kname Seme - Der Informationsgehalt bleibt erhalten. - Die Verbindung dieser Relationen erfolgt durch korrespondierende Attribute. Studentenliste Kursliste Snum Sname Znum Telnum 3215 3462 3567 4756 120DH 238VH 120DH 345VH 2136 2344 2136 3321 Knum Kname 120 122 130 141 220 230 330 389 Prüfungsliste G. Jonas A. Schmid J. Neider K. Alex PHY MAT MAT PHY PSY PHY GRA MUS Snum Knum Sem Note 3215 3215 3215 3215 3462 3462 3462 3567 3567 3567 4756 1.3 2.7 3.0 1.3 2.7 1.3 3.7 3.0 2.3 1.3 4.0 122 120 330 122 122 130 220 230 220 141 389 WS07 SS07 WS07 SS06 WS06 SS06 WS07 SS06 SS07 WS07 WS07 Problem noch: versteckte Abhängigkeiten Note TFH Berlin/Steyer Normalisierung 3. NORMALFORM Definition: Eine Relation ist in 3. Normalform (3NF), wenn sie in der 2NF ist und kein Attribut, das nicht zum Identifikationsschlüssel gehört, transitiv von diesem abhängt. Die dritte Normalform bringt ein weiteres Kriterium zum Auftrennen von Relationen und eliminiert wesentliche beim 2. Normalisierungsschritt verbliebene Redundanzen von Attributen. Unterabhängigkeiten werden herausgenommen. Eine Aufspaltung liefert eine weitere Relation. Snum Sname Znum Telnum Relationen in 3. Normalform (3NF, englisch TNF, third normal form) heissen oft auch nur kurz "normalisiert". In der neuen Relation ist für jeden Studenten die Telefonnummer gespeichert, obwohl sich diese bereits aus der Zimmernummer ergibt. Ändert ein Student seine Zimmernummer, so ändert sich auch die Telefonnummer. Studentenliste Telefonliste Snum Sname Znum 3215 3462 3567 4756 G. Jonas A. Schmid J. Neider K. Alex 120DH 238VH 120DH 345VH Znum Telnum 120DH 2136 238VH 2344 345VH 3321 Kursliste und Prüfungsliste wie oben. TFH Berlin/Steyer Normalisierung Rückblick auf die ursprünglichen Probleme: Problem beim Einfügen: Ein neuer Student kann ohne Kurs eingetragen werden, sobald er ein Zimmer hat (Studentenliste). Problem beim Ändern: Es können nicht mehr die Telefonnummern für eine Person geändert werden, was dann verschiedene Telefonnummern für ein Zimmer zur Folge hätte. Die Telefonnummer ist nun an das Zimmer gekoppelt (Telefonliste). Problem beim Löschen: Wenn eine Kursinformation gelöscht wird, bedeutet das noch nicht das Verschwinden des entsprechenden Studenten (Kursliste). TFH Berlin/Steyer Normalisierung GRENZEN DER NORMALISIERUNG / DENORMALISIERUNG aus Platzgründen Das Spalten von Tabellen bedeutet aber Anhängen der Schlüsselspalte um den Zusammenhang zu rekonstruieren d.h. Speicherbedarf wird langfristig nicht kleiner aus Zeitgründen Joinzugriffe brauchen mehr Zeit und Platz als Einzeltabellenzugriffe, d.h. wenn oft gejoint werden muss, wird das Spalten teuer, denn es muss eine m*n-Doppelschleife durchlaufen werden Numerische Überlegungen 1.NF hat 1 Tabelle mit 11 Zeilen und 8*11 = 88 Werten. ------------------------------------------11 Vergleiche und 88 Werte. 2.NF hat 3 Tabellen mit 4 Zeilen und 4*4 = 16 Werten. 8 Zeilen und 8*2 = 16 Werten. 11 Zeilen und 11*4 = 44 Werten. ------------------------------------------352 Vergleiche und 76 Werte. 3.NF hat 4 Tabellen mit 4 Zeilen und 4*3 = 12 Werten. 3 Zeilen und 3*2 = 6 Werten. 8 Zeilen und 8*2 = 16 Werten. 11 Zeilen und 11*4 = 44 Werten. ------------------------------------------1056 Vergleiche und 78 Werte. Anzahl derZeilenvergleiche (Mass für Zeitdauer) Anzahl der Werte (Mass für Speicherbedarf) 1056 88 78 76 352 11 1.NF 2.NF 3.NF Entscheidung also oft: Logik <-> Performance dabei aufs Anwenderprofil achten 1.NF 2.NF 3.NF TFH Berlin/Steyer Normalisierung METHODE DER NORMALISIERUNG NAME PROBLEME ABHILFE ERGEBNIS VORFORM Lücken Zuordnung ausfüllen 1. Normalform 1. NORMALFORM Redundanz Verarbeitungsanomalien spalten 2. Normalform 2. NORMALFORM versteckte Abhängigkeiten abspalten 3. Normalform 3. NORMALFORM Speicher-/Zeitbedarf denormalisieren 2. Normalform Allgemeine Regeln: Eindeutigkeit herstellen Zusammengehörigkeiten ermitteln Redundanzen beseitigen Unterabhängigkeiten entdecken TFH Berlin/Steyer Dokumentation 4 DOKUMENTATION ANWENDEROKUMENTATION 1. Faltblatt oder Prospekt mit den wichtigen neuen Punkten (möglichst farbig) 2. Übersichtliche Kurzbeschreibung der Funktionsbereiche als detailliertere Einführung, z.B. für Manager 3. zu jeder SW-Komponente: - Benutzerhandbuch Darstellung des Stoffes in sinnvollen Zusammenhängen - Nachschlagehandbuch Lexikon der Kommandos mit Syntaxbeschreibung, Erklärung, Beispiel in alphabetischer Reihenfolge Fehlerliste mit Erläuterung und Benutzerreaktion Beispiele: Handbücher für den interaktiven Benutzer Handbücher für den Programmierer Handbücher für den Administrator 4. Tutorials für wichtige und/oder schwierige Teile, z.B. für SQL oder für die Leistungssteigerung des Systems 5. Faltkarten für Kommandos zum schnellen Nachschlagen der Syntax Bemerkungen: Der Umfang dieser Dokumente ist von der Grösse des Systems abhängig. Sie können auch in einem Buch zusammengefasst werden. Ideal sind die Sprachen deutsch und englisch. Es sollte natürlich ein Textsystem verwendet werden. TFH Berlin/Steyer Dokumentation SYSTEMDOKUMENTATION 1. Verbale übersichtliche Kurzbeschreibung der Funktionsbereiche oder Modulgraph 2. Bedienerführung (Menüstruktur, Zustandsdiagramm mit Übergängen) 3. Maskenbeschreibung (falls Masken vorhanden, mit Verweisen zu 2.) 4. Reportbeschreibung (falls Reports vorhanden, mit Verweisen zu 2.) 5. Daten-(Tabellen-)Beschreibung (mit Verweisen zu 2.) 6. Beschreibung weiterer externer Schnittstellen, z.B. Kommunikation (falls welche vorhanden, mit Verweisen zu 2.) 7. Katalog der Programmmodule (mit Verweisen zu 2.) Aufbau: - Modulbezeichnung - Zweck - Eingabe - Ausgabe/Wirkung - Ablauf in Pseudocode o.ä. - verwendete Untermodule 8. Zahlen, Daten, Fakten, Restriktionen, Hard- und Softwarevoraussetzungen 9. Erweiterungsmöglichkeiten, offene Punkte 10. Programmcode TFH Berlin/Steyer UML 5 UML TFH Berlin/Steyer Performance-Massnahmen 6 Performance-Massnahmen TFH Berlin/Steyer